Embed Size (px)
Citation preview

Finite Automata vs
Regular Expressions,
Non-Regular Languages
CS 154

Deterministic Finite Automata
Computation with finite memory

Non-Deterministic Finite Automata
Computation with finite memory
and “guessing”

Regular Languages are closed
under all of the following operations:
Union: A ∪∪∪∪ B = { w | w ∈∈∈∈ A or w ∈∈∈∈ B }
Intersection: A ∩∩∩∩ B = { w | w ∈∈∈∈ A and w ∈∈∈∈ B }
Complement: ¬¬¬¬A = { w ∈ Σ* | w ∉∉∉∉ A }
Reverse: AR = { w1 …wk | wk …w1 ∈∈∈∈ A }
Concatenation: A ⋅⋅⋅⋅ B = { vw | v ∈∈∈∈ A and w ∈∈∈∈ B }
Star: A* = { w1 …wk | k ≥ 0 and each wi ∈∈∈∈ A }

Regular Expressions
Computation as simple, logical description
A totally different way of thinking about computation:
What is the complexity of
describing the strings in the language?

Inductive Definition of Regexp
For all σσσσ ∊∊∊∊ Σ, σσσσ is a regexp
ε is a regexp
∅∅∅∅ is a regexp
If R1 and R2 are both regexps, then
(R1R2), (R1 + R2), and (R1)* are regexps
Let Σ be an alphabet. We define the regular
expressions over Σ inductively:
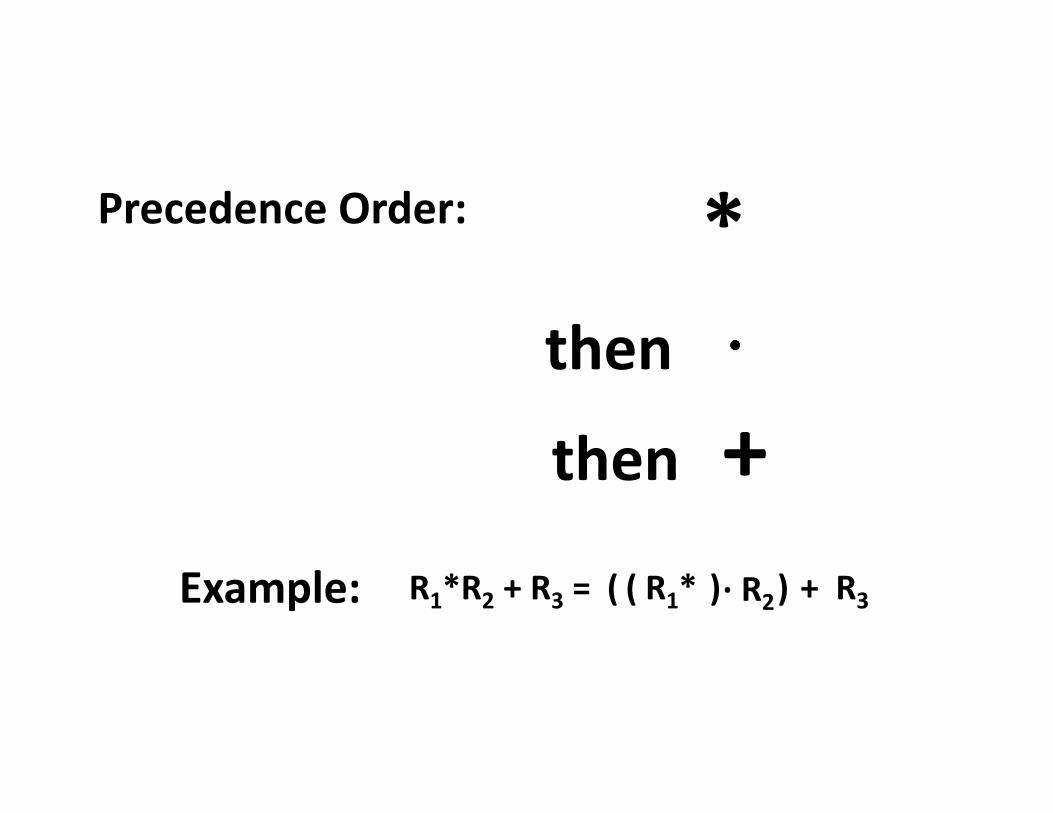
Precedence Order: *
then ⋅⋅⋅⋅
then +
· R2R1*(Example: R1*R2 + R3 = ( ) ) + R3

Definition: Regexps Represent Languages
The regexp σσσσ ∊∊∊∊ Σ represents the language {σσσσ}
The regexp ε represents {ε}
The regexp ∅∅∅∅ represents ∅∅∅∅
If R1 and R2 are regular expressions
representing L1 and L2 then:
(R1R2) represents L1 ⋅⋅⋅⋅ L2
(R1 + R2) represents L1 ∪∪∪∪ L2
(R1)* represents L1*
Example: (10 + 0*1) represents {0k1 | k ≥ 0} ∪∪∪∪ {10}

Regexps Represent Languages
For every regexp R, define L(R) to be the
language that R represents
A string w ∊∊∊∊ Σ* is accepted by R
(or, w matches R) if w ∊ ∊ ∊ ∊ L(R)
Example: 01010 matches the regexp (01)*0

{ w | w has exactly a single 1 }
0*10*
Assume Σ = {0,1}
{ w | w contains 001 }
(0+1)*001(0+1)*
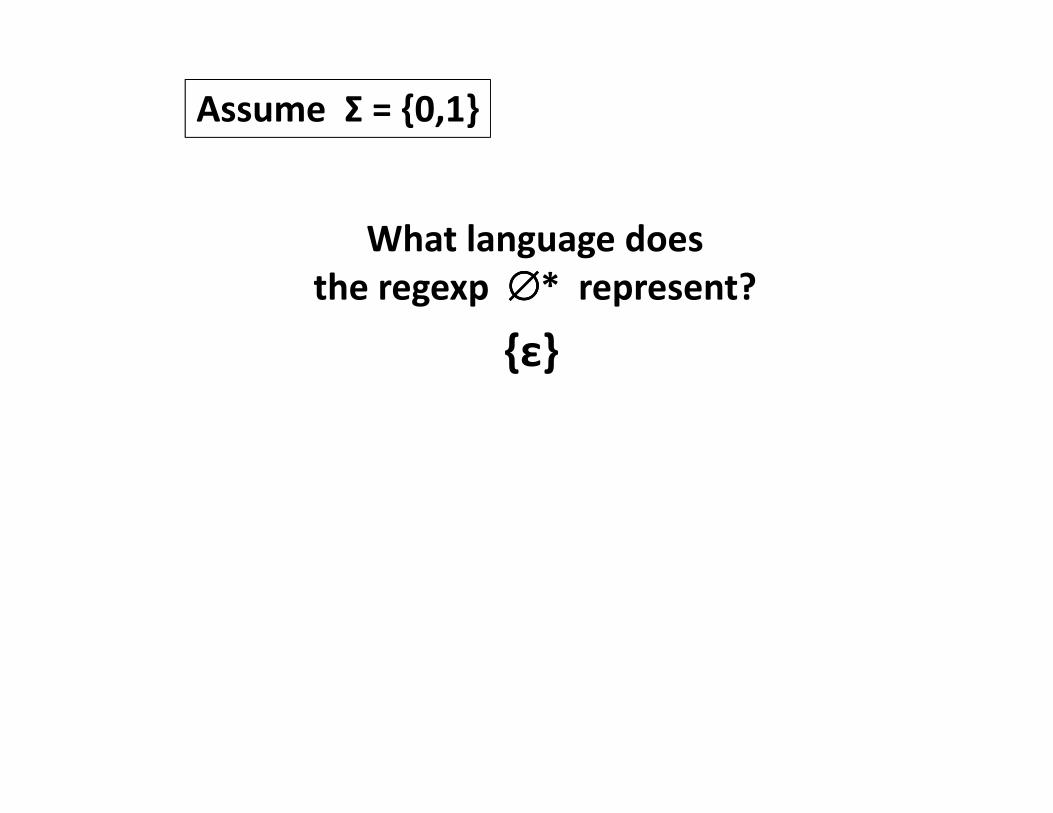
What language does
the regexp ∅∅∅∅* represent?
{ε}
Assume Σ = {0,1}

{ w | w has length ≥ 3 and its 3rd symbol is 0 }
(0+1)(0+1)0(0+1)*
Assume Σ = {0,1}

{ w | every odd position in w is a 1 }
(1(0 + 1))*(1 + ε)
Assume Σ = {0,1}

L can be represented by some regexp
⇔⇔⇔⇔ L is regular
DFAs ≡ NFAs ≡ Regular Expressions!

L can be represented by some regexp
⇒⇒⇒⇒ L is regular
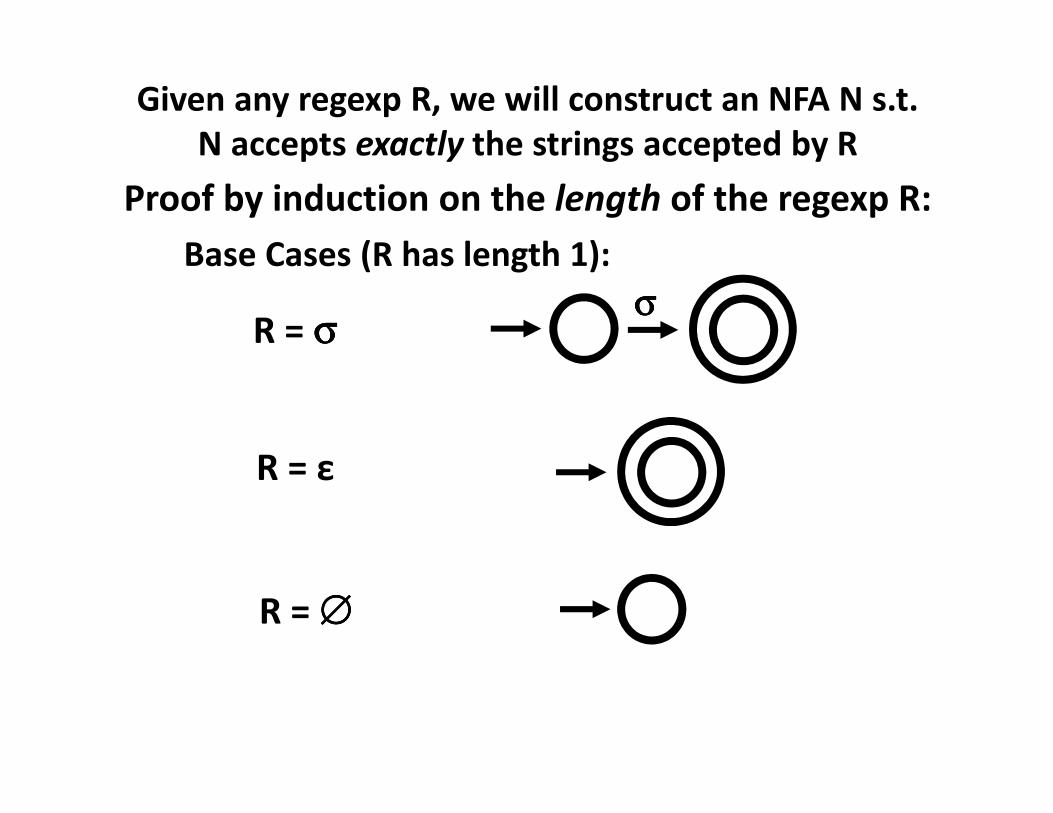
Given any regexp R, we will construct an NFA N s.t.
N accepts exactly the strings accepted by R
Proof by induction on the length of the regexp R:
Base Cases (R has length 1):
R = σσσσσσσσ
R = ε
R = ∅∅∅∅

Induction Step: Suppose every regexp of length < k
represents some regular language.
Three possibilities for R:
R = R1 + R2
R = R1 R2
R = (R1)*
Consider a regexp R of length k > 1

Induction Step: Suppose every regexp of length < k
represents some regular language.
Three possibilities for R:
R = R1 + R2
R = R1 R2
R = (R1)*
Consider a regexp R of length k > 1
By induction, R1 and R2 represent
some regular languages, L1 and L2
But L(R) = L(R1 + R2) = L1 ∪∪∪∪ L2
so L(R) is regular, by the union theorem!

Induction Step: Suppose every regexp of length < k
represents some regular language.
Three possibilities for R:
R = R1 + R2
R = R1 R2
R = (R1)*
Consider a regexp R of length k > 1
By induction, R1 and R2 represent
some regular languages, L1 and L2
But L(R) = L(R1····R2) = L1····L2
so L(R) is regular by the concatenation
theorem

Induction Step: Suppose every regexp of length < k
represents some regular language.
Three possibilities for R:
R = R1 + R2
R = R1 R2
R = (R1)*
Consider a regexp R of length k > 1
By induction, R1 and R2 represent
some regular languages, L1 and L2
But L(R) = L(R1*) = L1*
so L(R) is regular, by the star theorem

Induction Step: Suppose every regexp of length < k
represents some regular language.
Three possibilities for R:
R = R1 + R2
R = R1 R2
R = (R1)*
Consider a regexp R of length k > 1
By induction, R1 and R2 represent
some regular languages, L1 and L2
But L(R) = L(R1*) = L1*
so L(R) is regular, by the star theorem
Therefore: If L is represented by a regexp,
then L is regular
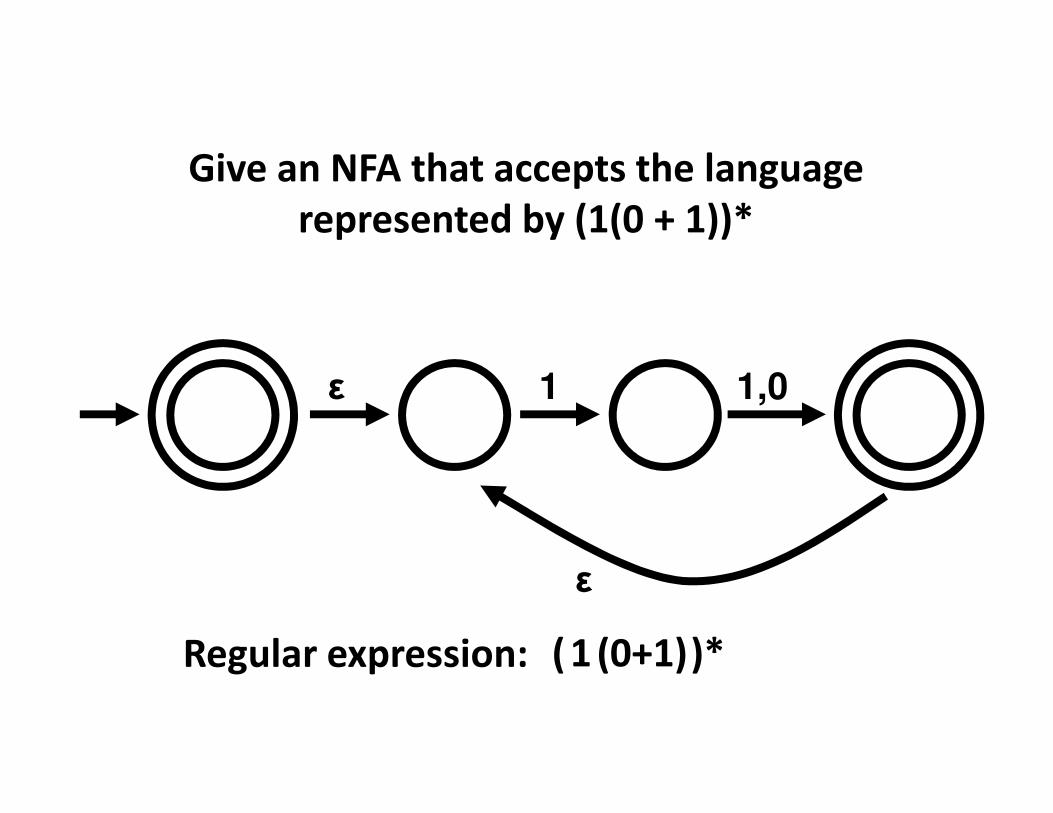
Give an NFA that accepts the language
represented by (1(0 + 1))*
1ε 1,0
ε
1 (0+1)( )*Regular expression:

L can be represented by a regexp
⇒⇒⇒⇒
L is a regular language
⇐⇐⇐⇐
Idea: Transform an NFA for L into a regular
expression by removing states and
re-labeling the arcs with regular expressions
Generalized NFAs (GNFA)
Rather than reading in just 0 or 1 letters from the
string on a step, we can read in entire substrings

Q, Σ are states and alphabet
R : (Q-{qaccept}) ×××× (Q-{qstart}) → RRRR
is the transition function
qstart ∈∈∈∈ Q is the start state
R R R R = set of all regular expressions over Σ
A GNFA is a 5-tuple G = (Q, Σ, R, qstart, qaccept)
qaccept ∈∈∈∈ Q is the (unique) accept state

Let w ∈ Σ* and let G be a GNFA.
G accepts w if w can be written as w = w1 LLLL wk
where wi ∈∈∈∈ Σ* and there is a sequence
r0, r1, ..., rk ∈∈∈∈ Q such that
• r0 = qstart
• wi matches R(ri-1, ri) for all i = 1, ..., k, and
• rk ==== qaccept
A GNFA is a 5-tuple G = (Q, Σ, R, qstart, qaccept)
L(G) = set of all strings that G accepts
= “the language recognized by G”
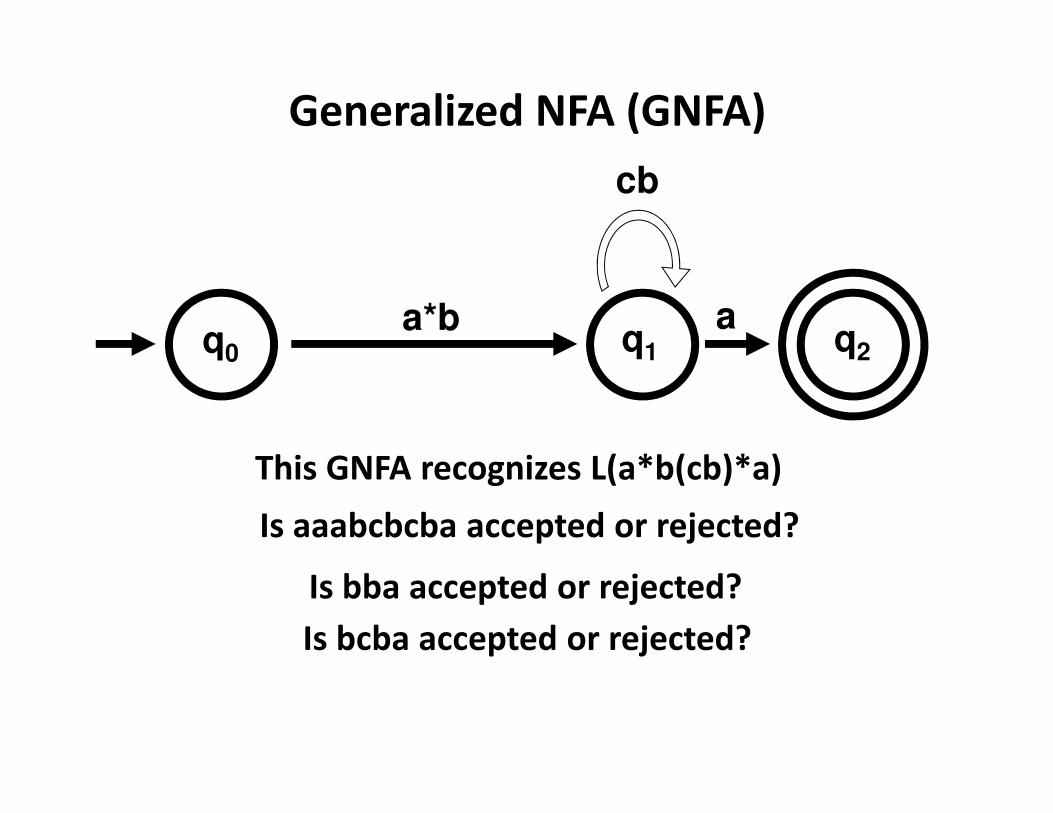
q1
cb
aa*bq0 q2
This GNFA recognizes L(a*b(cb)*a)
Is aaabcbcba accepted or rejected?
Is bba accepted or rejected?
Is bcba accepted or rejected?
Generalized NFA (GNFA)
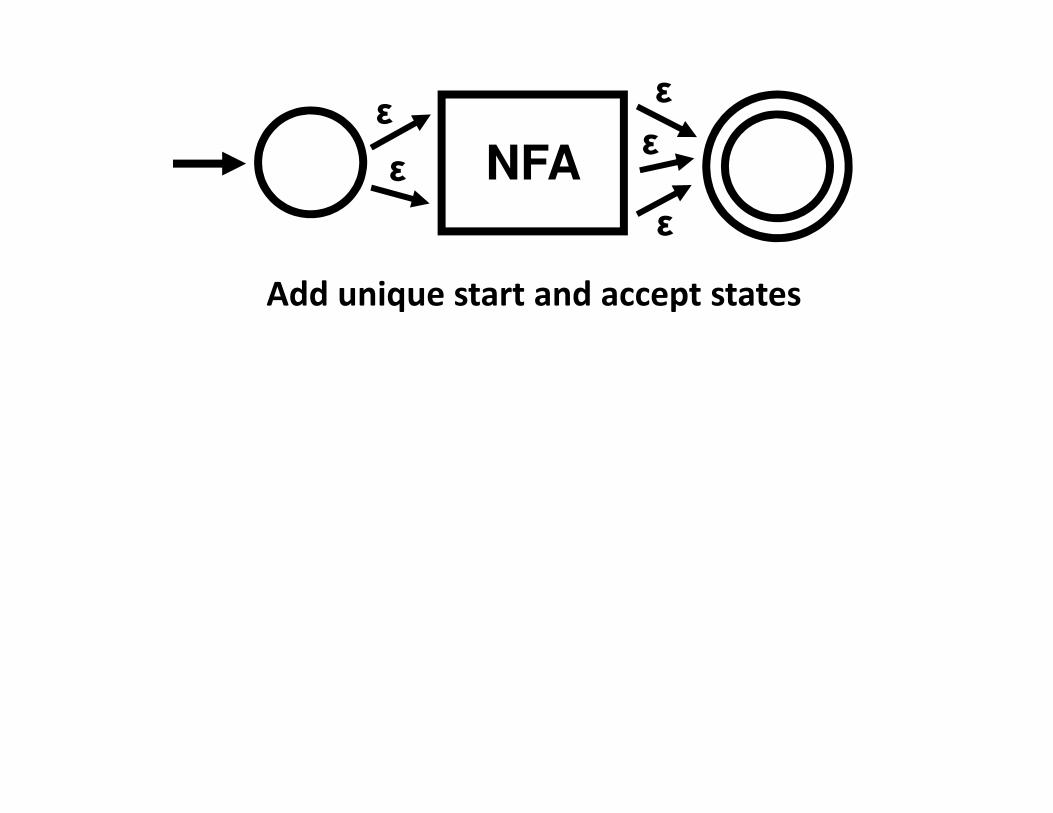
NFAε
ε
ε
ε
ε
Add unique start and accept states
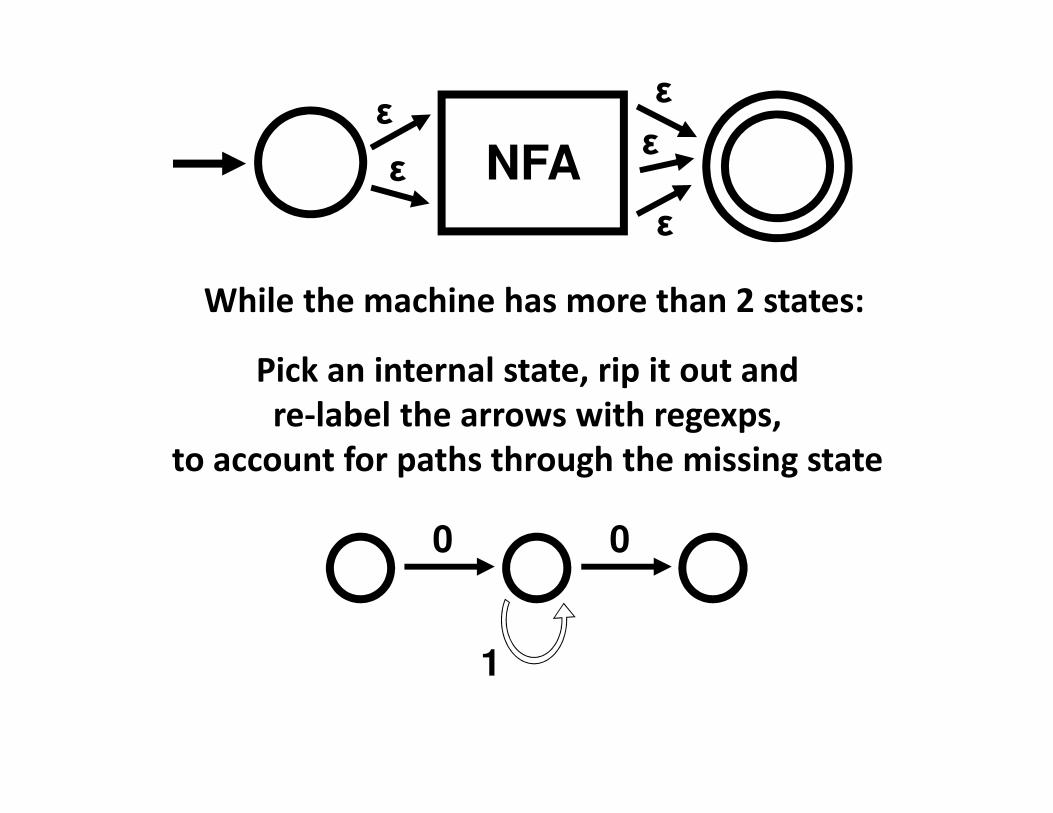
NFAε
ε
ε
ε
ε
While the machine has more than 2 states:
Pick an internal state, rip it out and
re-label the arrows with regexps,
to account for paths through the missing state
0
1
0
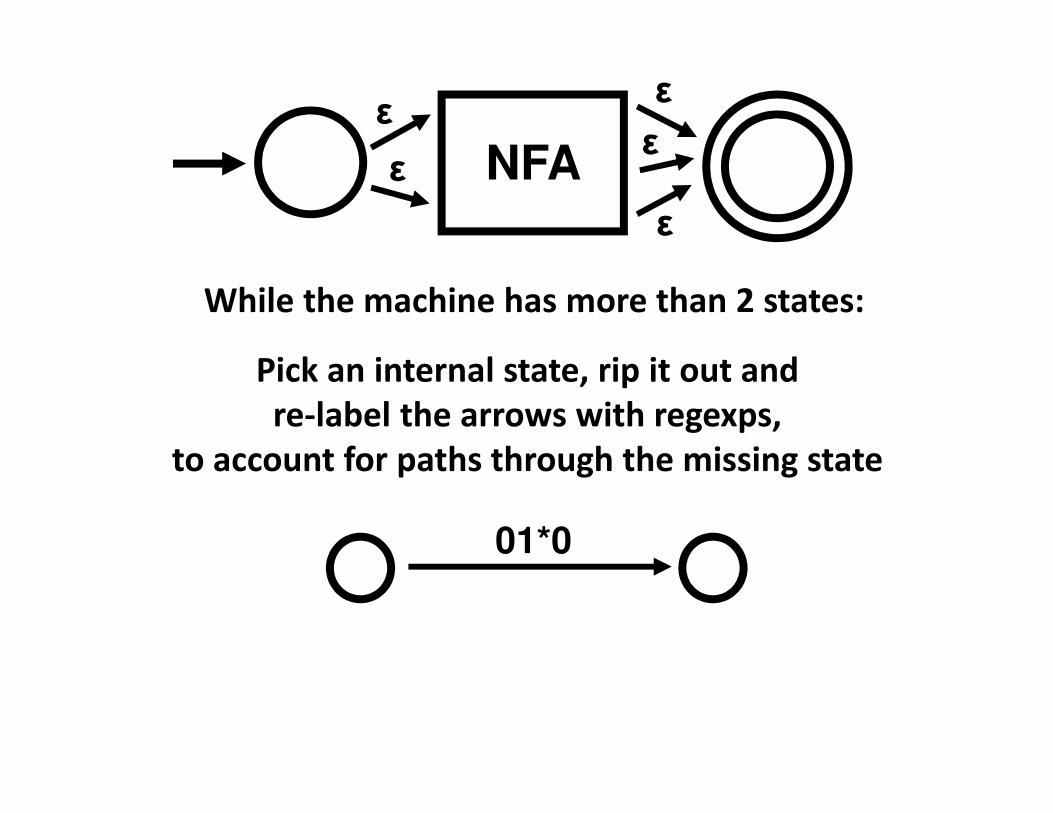
NFAε
ε
ε
ε
ε
While the machine has more than 2 states:
Pick an internal state, rip it out and
re-label the arrows with regexps,
to account for paths through the missing state
01*0
NFAε
ε
ε
ε
ε
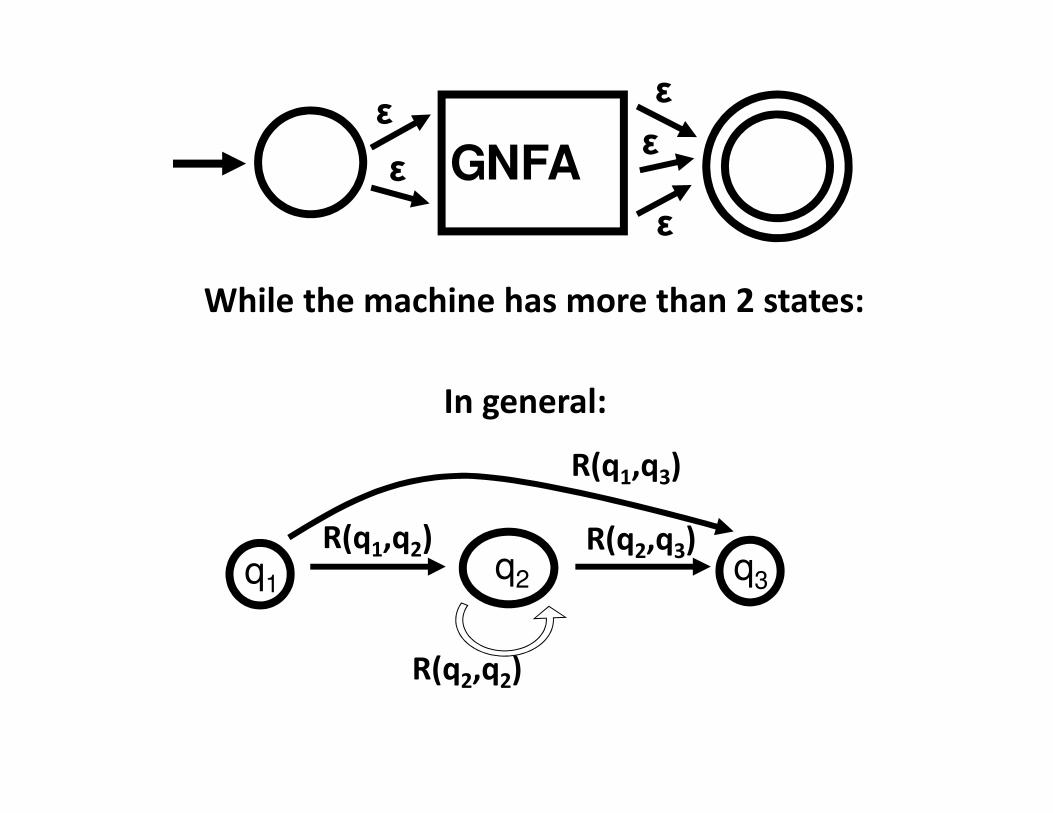
In general:
R(q1,q2)
R(q2,q2)
R(q2,q3)q1
q2 q3
G
R(q1,q3)
While the machine has more than 2 states:
NFAε
ε
ε
ε
ε
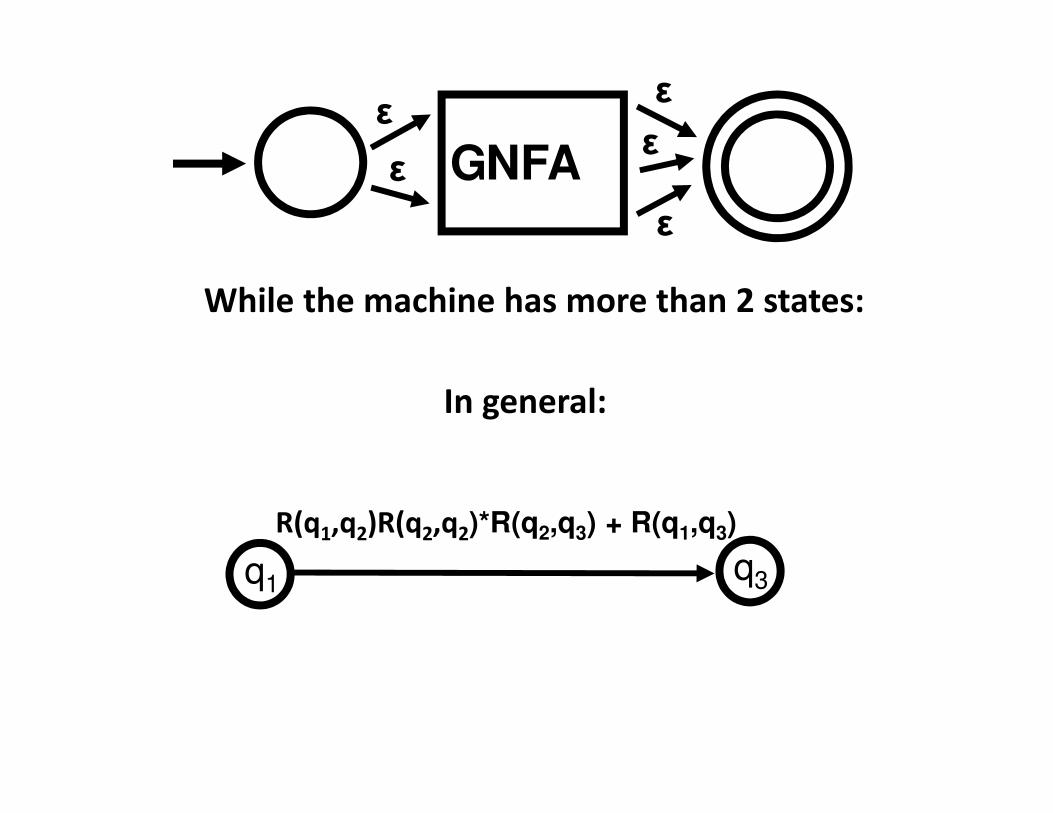
In general:
R(q1,q2)R(q2,q2)*R(q2,q3) + R(q1,q3)
q1q3
G
While the machine has more than 2 states:
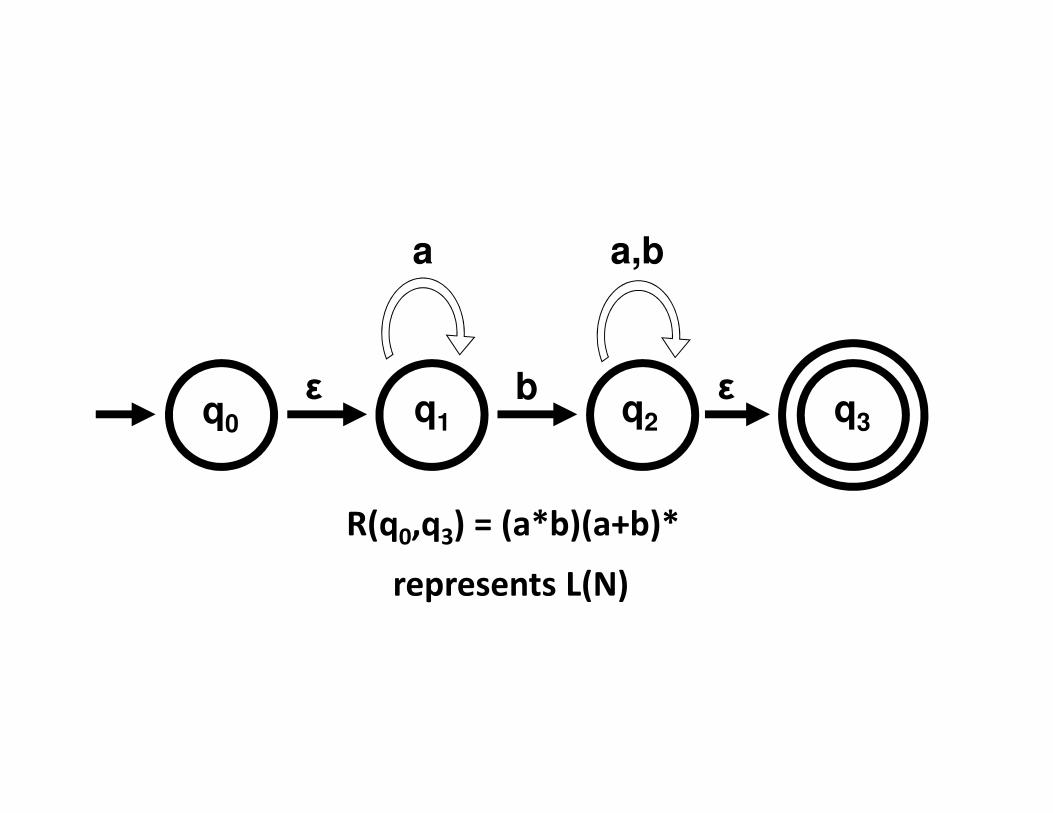
q1
b
a
εq2
a,b
εq0 q3
R(q0,q3) = (a*b)(a+b)*
represents L(N)

q2
a,b
εa*bq0 q3
R(q0,q3) = (a*b)(a+b)*
represents L(N)
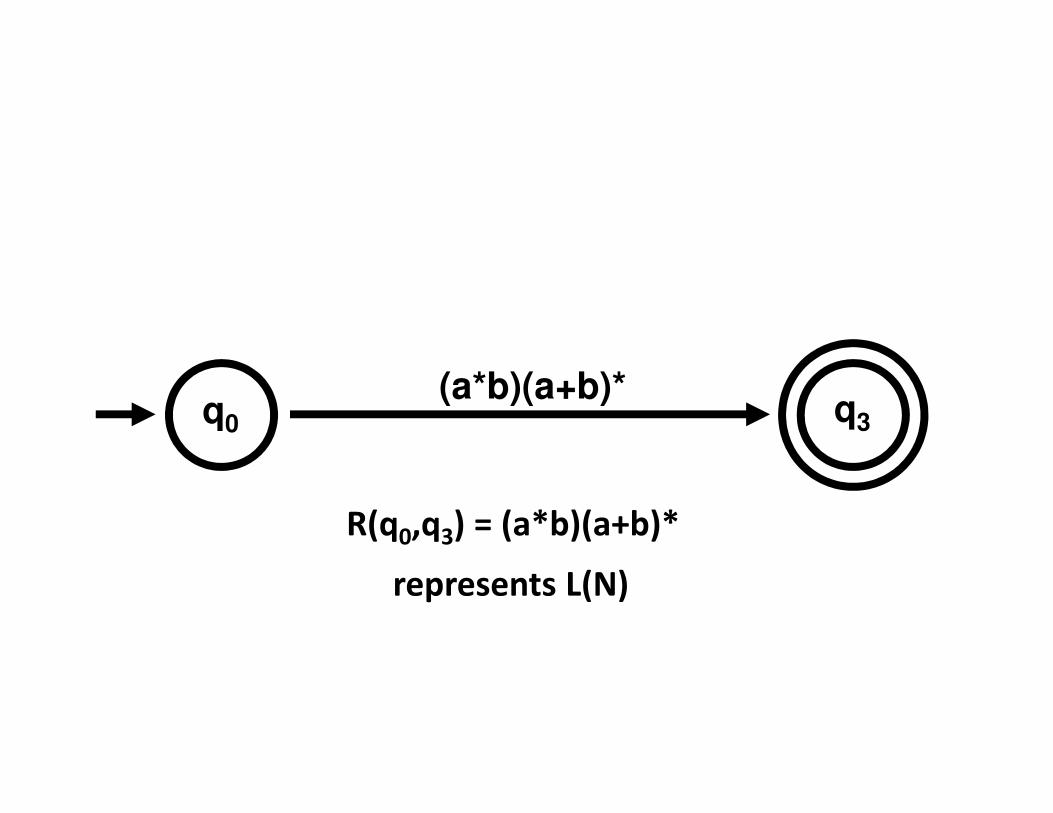
(a*b)(a+b)*q0 q3
R(q0,q3) = (a*b)(a+b)*
represents L(N)

Formally: Given a DFA, add qstart and qacc to create G
CONVERT(G): (Takes a GNFA, outputs a regexp)
If #states = 2 return R(qstart, qacc)
If #states > 2
select qrip∈∈∈∈Q different from qstart and qacc
define Q′′′′ = Q – {qrip} defines a
new GNFA G′′′′define R′′′′ on Q’-{qacc} x Q’-{qstart} as:
R′′′′(qi,qj) = R(qi,qrip)R(qrip,qrip)*R(qrip,qj) + R(qi,qj)
For all q,q’, define R(q,q’) to be σ if δ(q,σ) = q’, else ∅
return CONVERT(G′′′′) Claim:
L(G’) = L(G)

Theorem: Let R = CONVERT(G). Then L(R) = L(G).
Proof by induction on k, the number of states in G
Base Case: k = 2
Inductive Step:
Assume theorem is true for k-1 state GNFAs
Let G have k states. Let G’ be the k-1 state GNFA
obtained by ripping out a state.
CONVERT outputs R(qstart, qacc) �
G’ has k-1 states, so by induction,
L(G′′′′) = L(CONVERT(G’)) = L(R)
Therefore L(R)=L(G). QED
We already claimed L(G) = L(G′′′′) [Sipser, p.73--74]
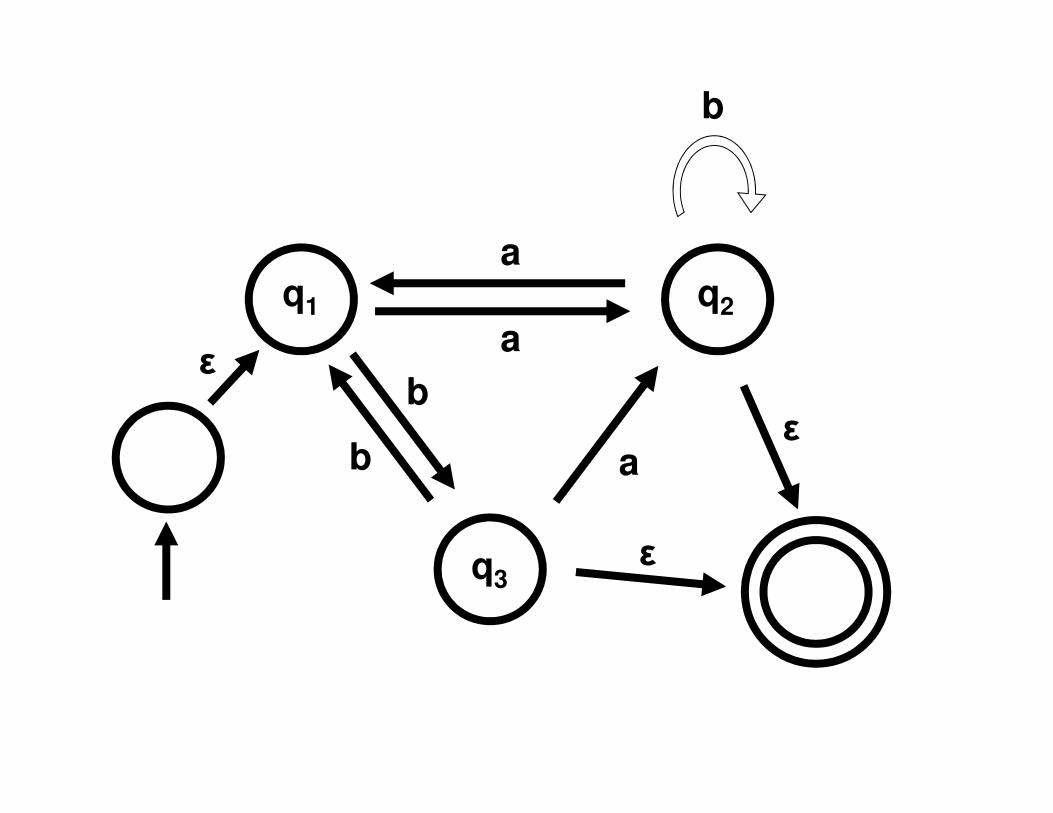
q3
q2
b
a
b
q1
b
a
a
ε
ε
ε

q2
b
b
q1
a
ε
ε
bb
a + ba
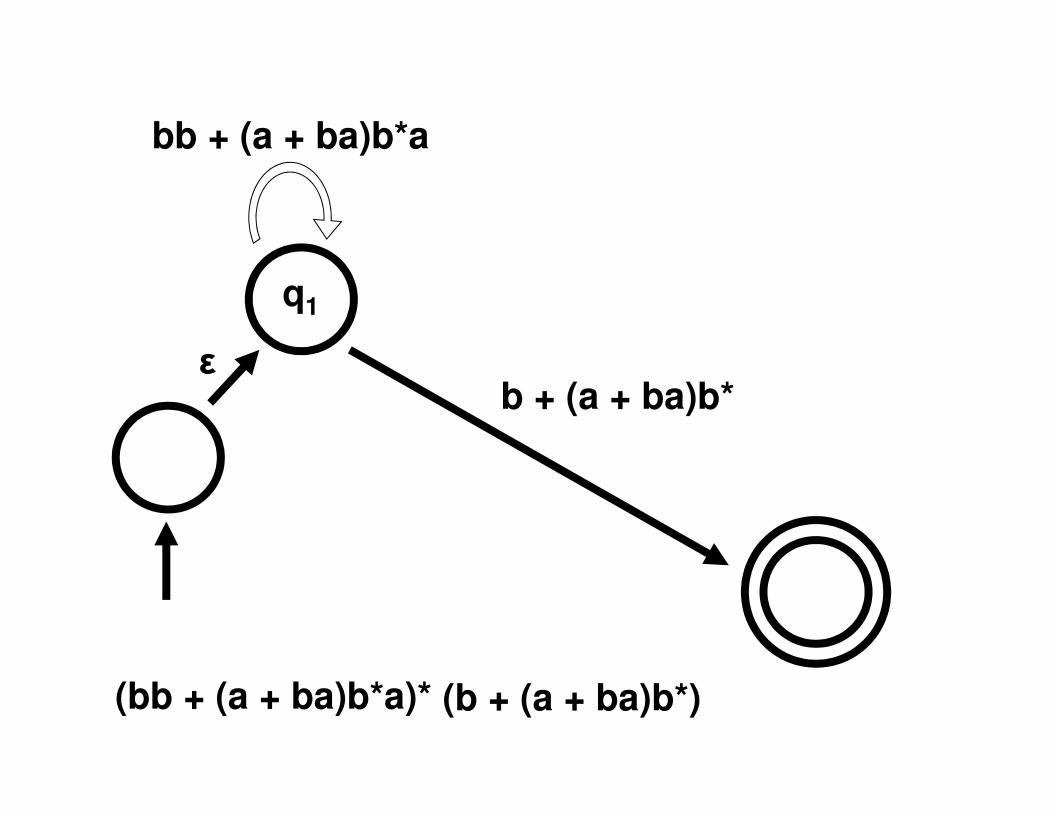
bb + (a + ba)b*a
q1
ε
b + (a + ba)b*
(bb + (a + ba)b*a)* (b + (a + ba)b*)

Convert the NFA to a regular expression
q3
q2
b
bq1
a
a, b
b
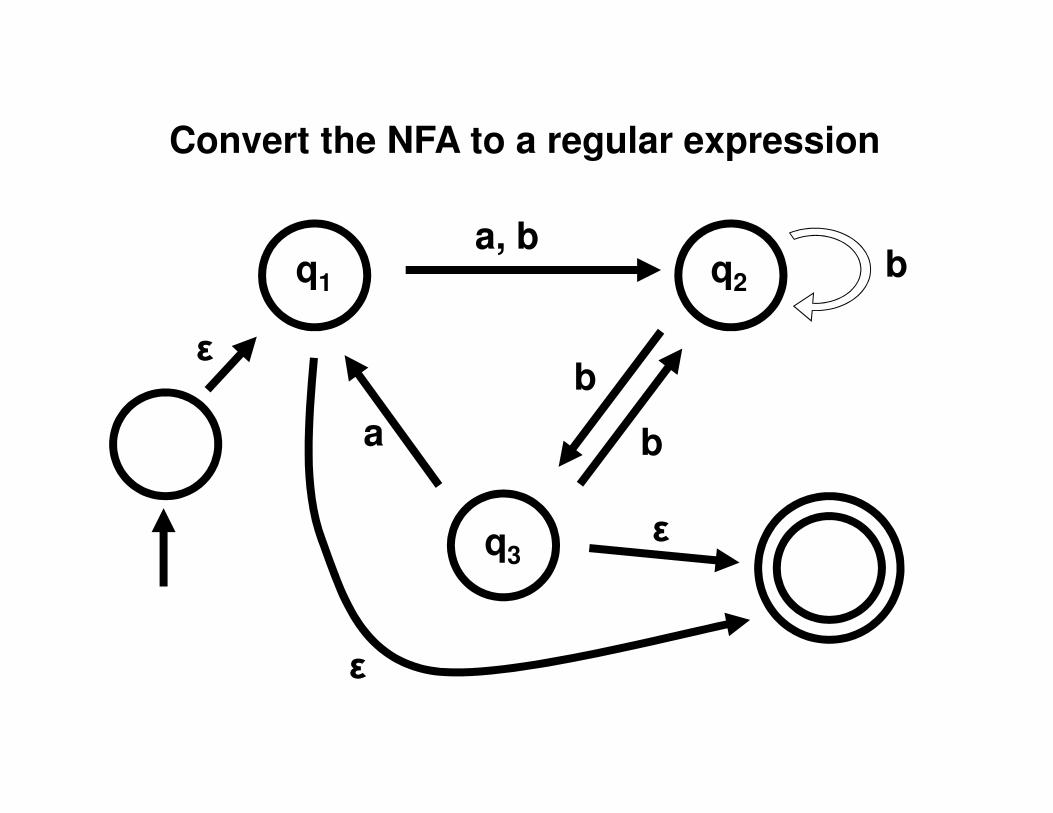
Convert the NFA to a regular expression
q3
q2
b
bq1
a
a, b
ε
ε
εb
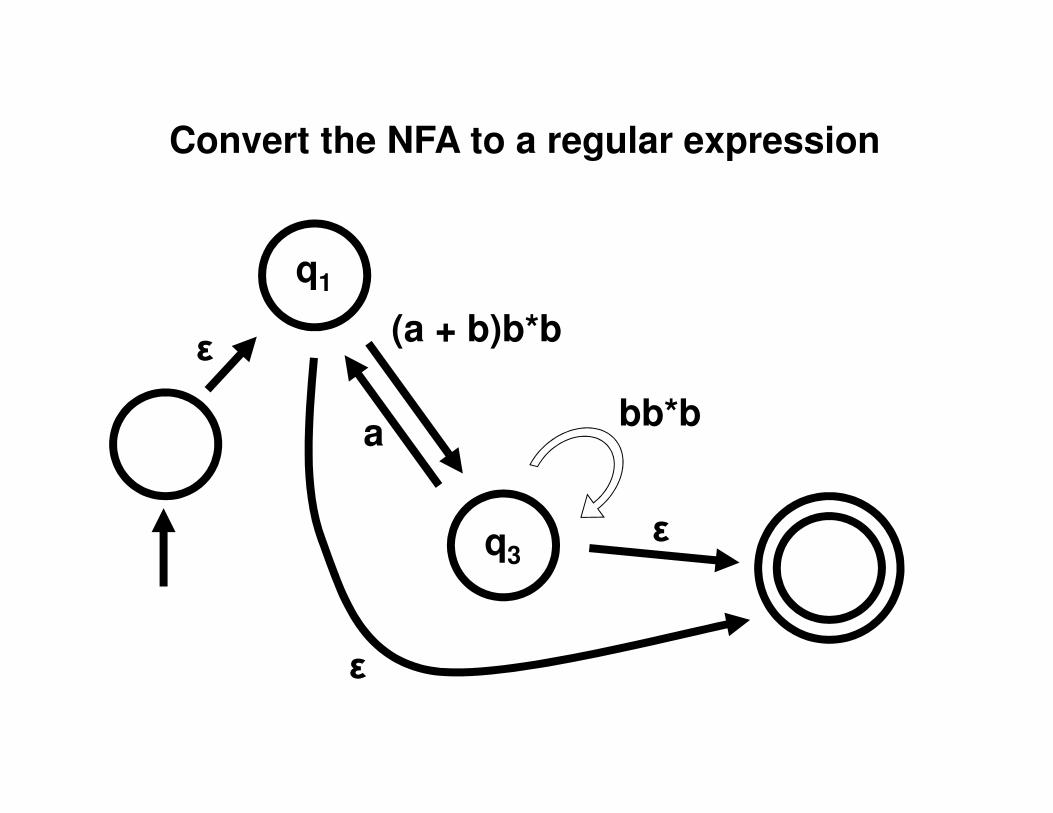
Convert the NFA to a regular expression
q3
q1
a
ε
ε
ε(a + b)b*b
bb*b
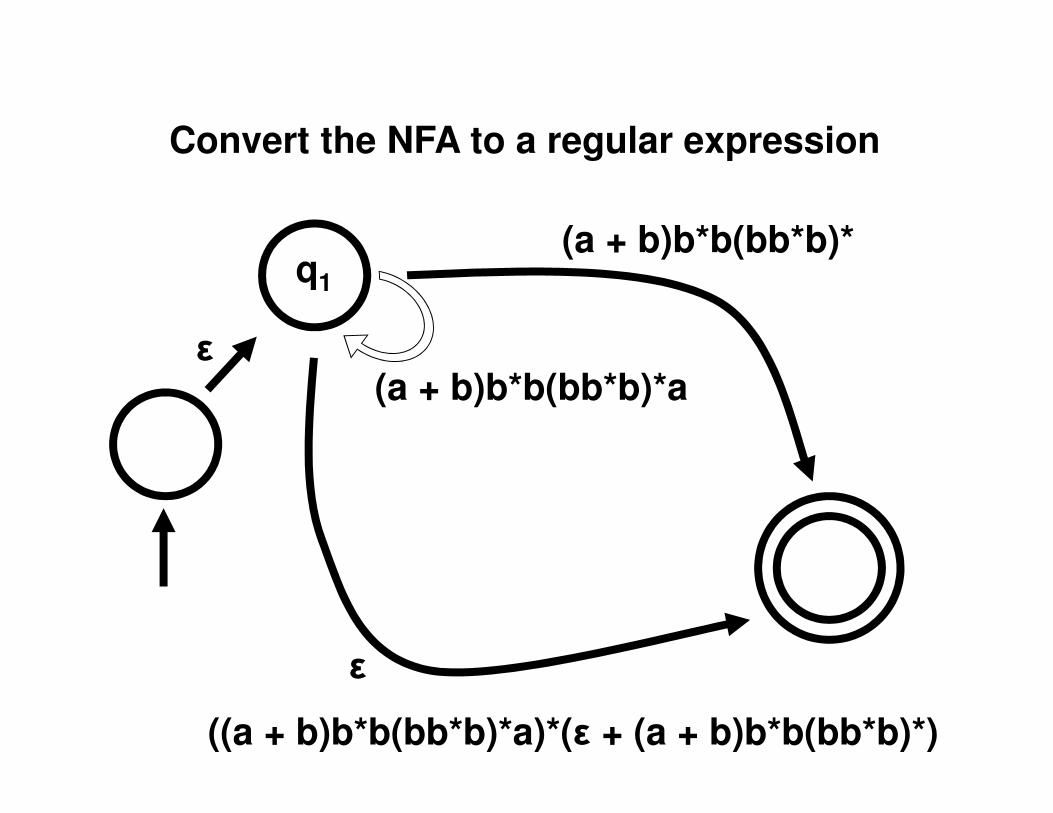
Convert the NFA to a regular expression
q1
ε
ε
(a + b)b*b(bb*b)*
(a + b)b*b(bb*b)*a
((a + b)b*b(bb*b)*a)*(ε + (a + b)b*b(bb*b)*)
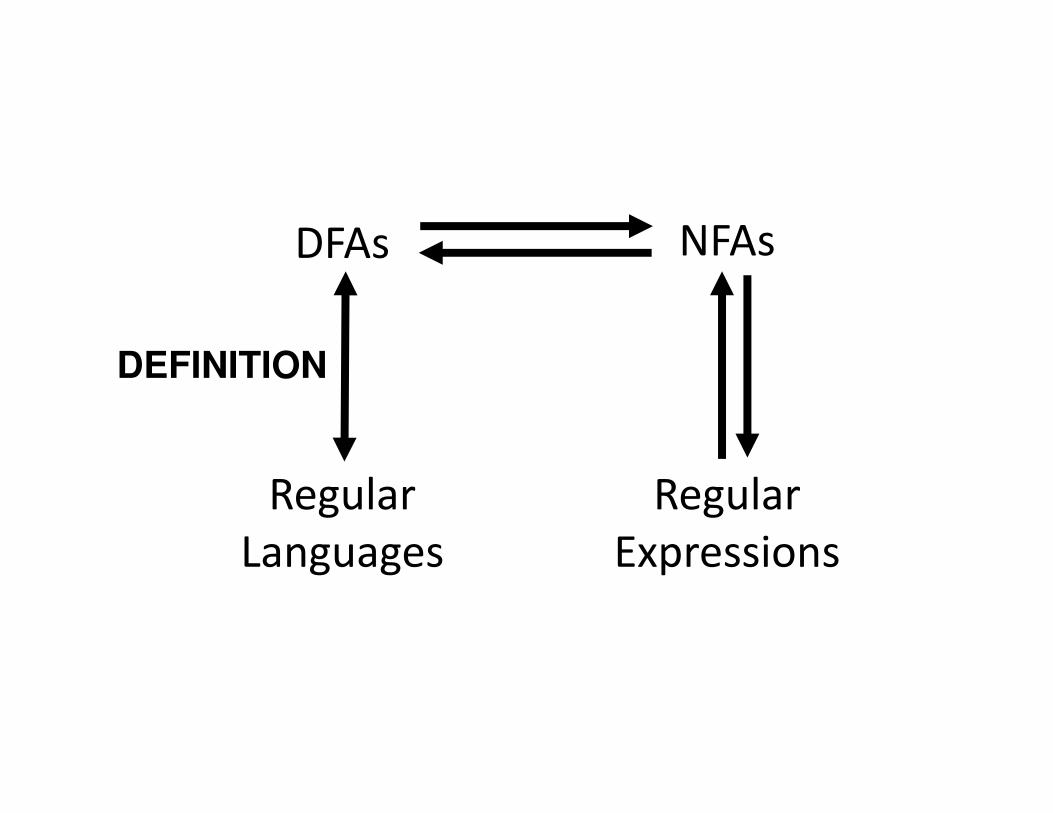
DFAs NFAs
Regular
Languages
Regular
Expressions
DEFINITION

Some Languages Are Not Regular:
Limitations on DFAs

Regular or Not?
C = { w | w has equal number of 1s and 0s}
D = { w | w has equal number of
occurrences of 01 and 10 }
NOT REGULAR!
REGULAR!

1 + 0 + ε + 0(0+1)*0 + 1(0+1)*1
{ w | w has equal number of
occurrences of 01 and 10}
= { w | w = 1, w = 0, or w = ε, or
w starts with a 0 and ends with a 0, or
w starts with a 1 and ends with a 1 }
Claim:
A string w has equal occurrences of 01 and 10
� w starts and ends with the same bit.

The Pumping Lemma:
Structure in Regular Languages
Let L be a regular language
Then there is a positive integer P s.t.
1. |y| > 0 (that is, y ≠≠≠≠ ε)
2. |xy| ≤ P
3. For all i ≥ 0, xyiz ∈∈∈∈ L
for all strings w ∈∈∈∈ L with |w| ≥ P
there is a way to write w = xyz, where:
Why is it called the pumping lemma? The word w gets
pumped into longer and longer strings…
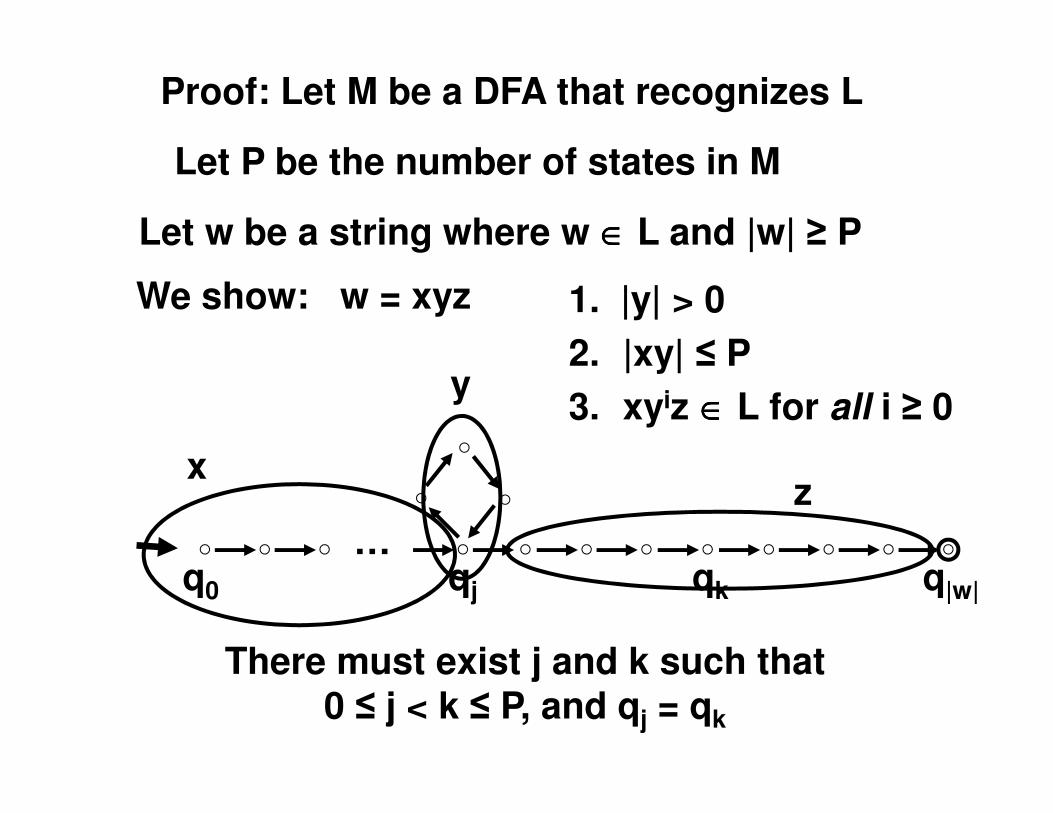
z
Let P be the number of states in M
Let w be a string where w ∈∈∈∈ L and |w| ≥ P
q0 qj qk q|w|
…
There must exist j and k such that
0 ≤ j < k ≤ P, and qj = qk
Proof: Let M be a DFA that recognizes L
1. |y| > 0
2. |xy| ≤ P
3. xyiz ∈∈∈∈ L for all i ≥ 0
We show: w = xyz
x
y
![Reduksi DFA [Deterministic Finite Automata] · PDF file[Deterministic Finite Automata] ... FSA dengan jumlah state yang lebih sedikit merupakan FSA yang paling efisien](https://img.pdfslide.tips/doc/110x75/5a9650b37f8b9a30358cf790/reduksi-dfa-deterministic-finite-automata-deterministic-finite-automata-fsa.jpg)


















![Title Regular Frequency Computations (Algebraic Systems, … · 2016-06-16 · frequency computation has been [4] extendedby Kinber to deterministic finite automata, which leads](https://img.pdfslide.tips/doc/110x75/5f2858e1f5387e2a6c28ed27/title-regular-frequency-computations-algebraic-systems-2016-06-16-frequency.jpg)









