Embed Size (px)
DESCRIPTION
lecture-7-phan-tich-mo-ta-1-bien-lien-tuc
Citation preview

Phân tích mô tả biến liên tục
Nguyễn Văn TuấnViện nghiên cứu Y khoa Garvan
Sydney, Australia

Nội dung
• Phân tích bằng biểu đồ – Kiếm tra outliers – Kiểm tra luật phân phối của dữ liệu – Kiểm tra
• Tóm lược dữ liệu từ một biến • So sánh hai nhóm
– Hai nhóm độc lập– Hai nhóm “kết xứng” hay paired samples

Giả định trong phân tích thống kê
• Số liệu tuân theo luật phân phối chuẩn (Normal distribution)
• Hai nhóm độc lập với nhau, và các số liệu cũng độc lập với nhau.
• Hai nhóm có cùng (hay tương đương) phuơng sai.
• Không có “outliers”
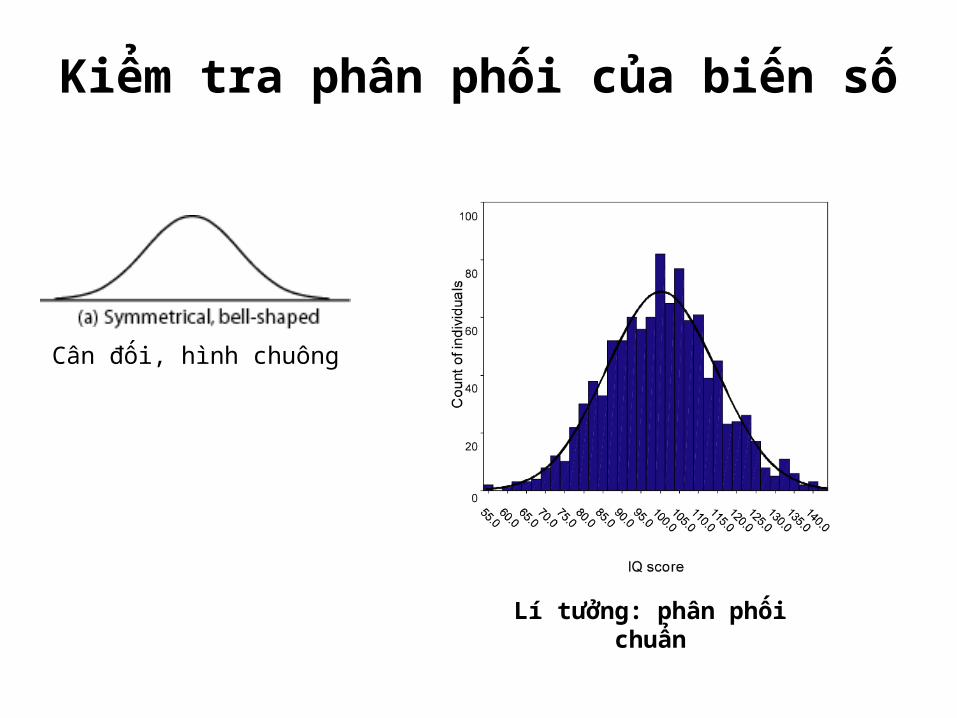
Kiểm tra phân phối của biến số
Lí tưởng: phân phối chuẩn
Cân đối, hình chuông
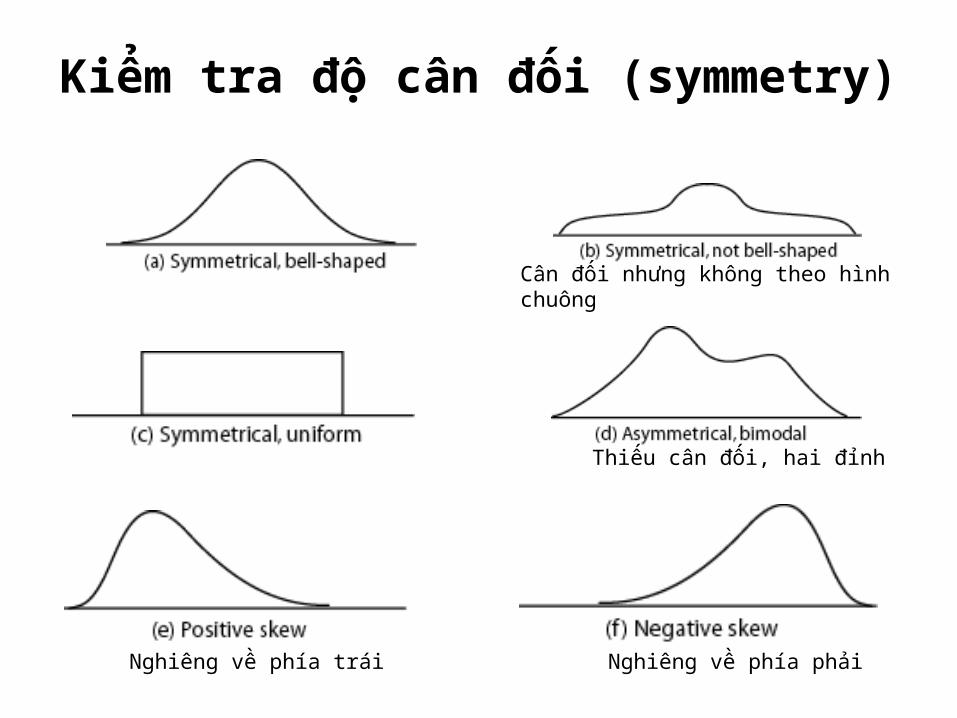
Kiểm tra độ cân đối (symmetry)
Cân đối nhưng không theo hình chuông
Thiếu cân đối, hai đỉnh
Nghiêng về phía phảiNghiêng về phía trái
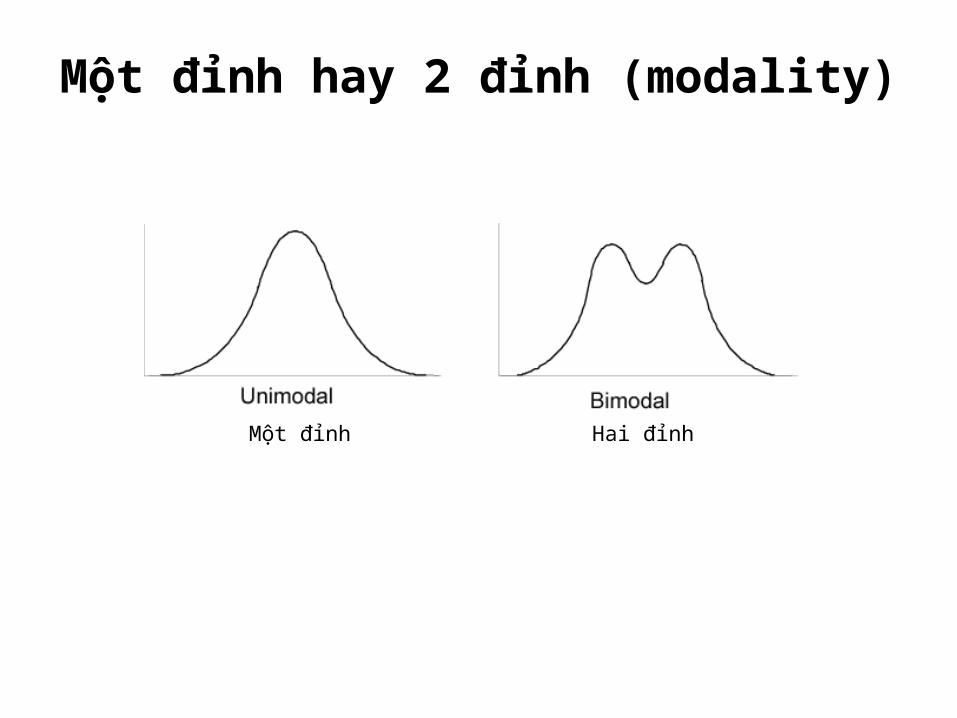
Một đỉnh hay 2 đỉnh (modality)
Hai đỉnhMột đỉnh
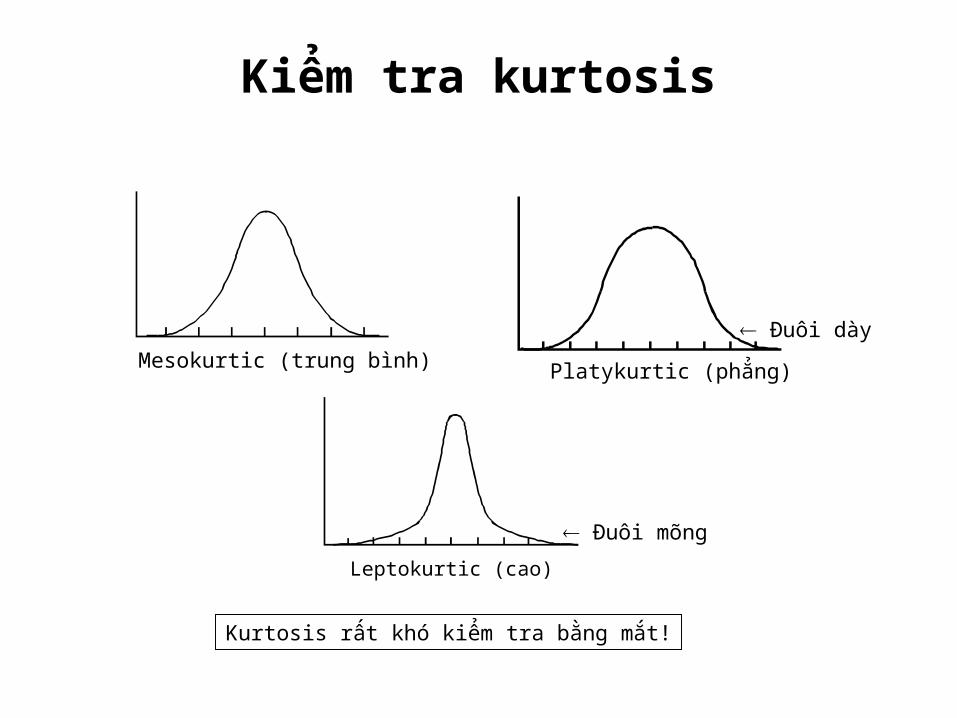
Kiểm tra kurtosis
Mesokurtic (trung bình) Platykurtic (phẳng)
Leptokurtic (cao)
Đuôi mõng
Đuôi dày
Kurtosis rất khó kiểm tra bằng mắt!
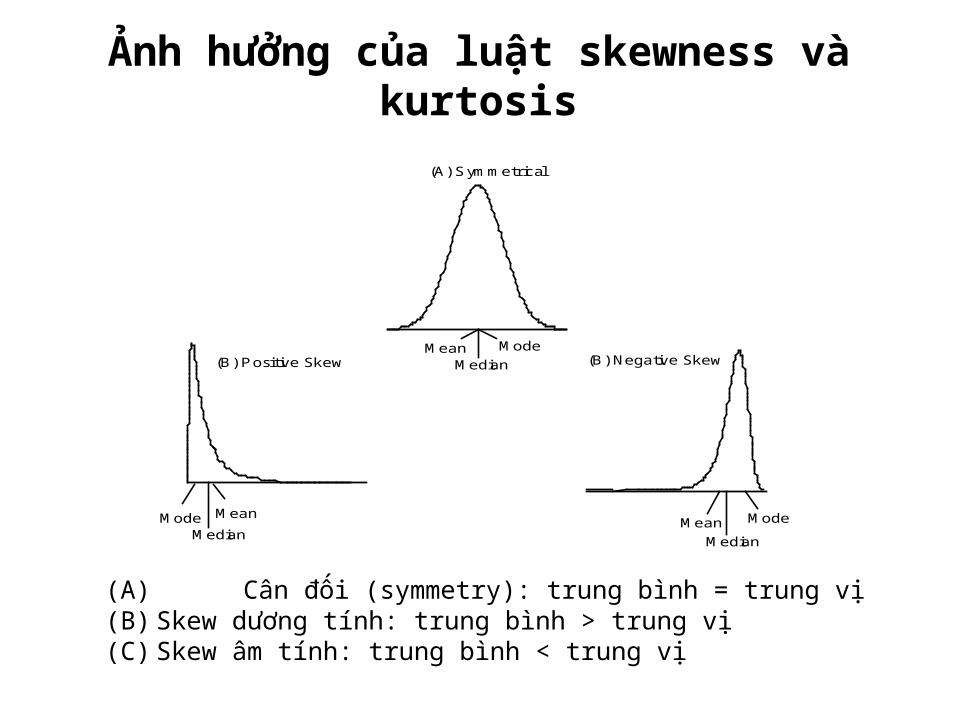
Ảnh hưởng của luật skewness và kurtosis
Mean ModeMedian
(A) Symmetr ical
Mode
MedianMean
Mean
MedianMode
(B) Positive Skew (B) Negative Skew
(A) Cân đối (symmetry): trung bình = trung vị(B) Skew dương tính: trung bình > trung vị(C) Skew âm tính: trung bình < trung vị
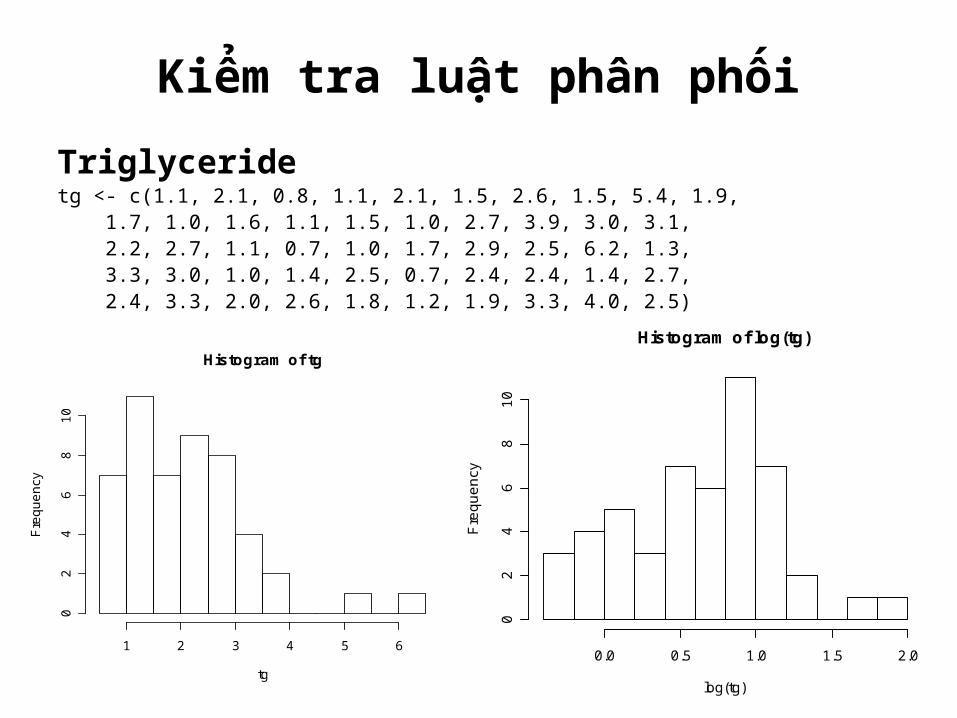
Kiểm tra luật phân phốiTriglyceridetg <- c(1.1, 2.1, 0.8, 1.1, 2.1, 1.5, 2.6, 1.5, 5.4, 1.9, 1.7, 1.0, 1.6, 1.1, 1.5, 1.0, 2.7, 3.9, 3.0, 3.1, 2.2, 2.7, 1.1, 0.7, 1.0, 1.7, 2.9, 2.5, 6.2, 1.3, 3.3, 3.0, 1.0, 1.4, 2.5, 0.7, 2.4, 2.4, 1.4, 2.7, 2.4, 3.3, 2.0, 2.6, 1.8, 1.2, 1.9, 3.3, 4.0, 2.5)
Histogram of tg
tg
Fre
quen
cy
1 2 3 4 5 6
02
46
810
Histogram of log(tg)
log(tg)
Fre
quen
cy
0.0 0.5 1.0 1.5 2.0
02
46
810
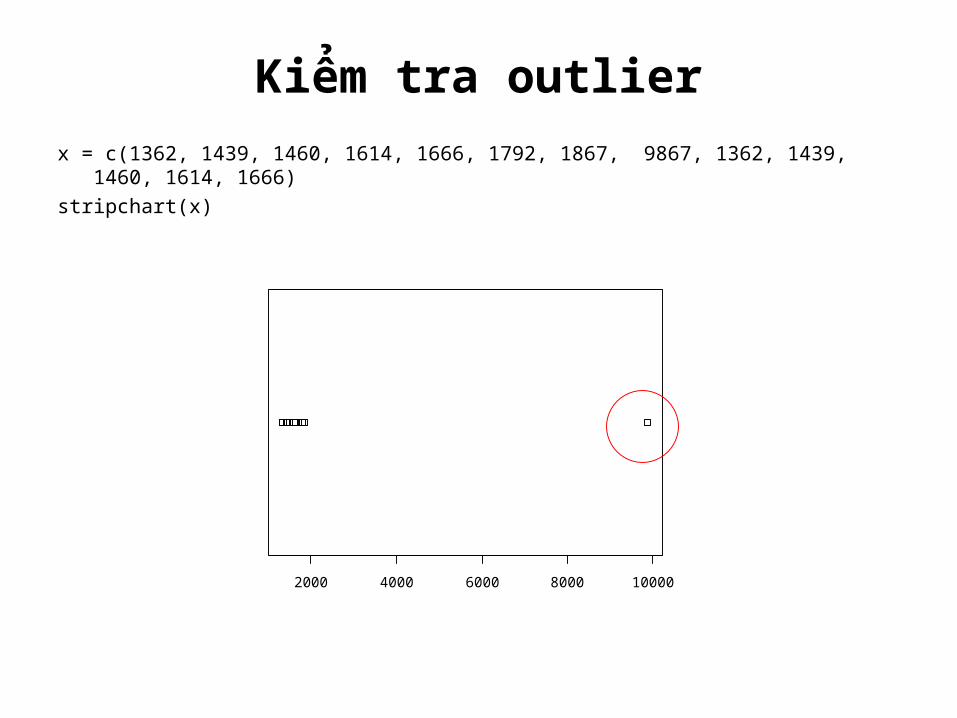
Kiểm tra outlierx = c(1362, 1439, 1460, 1614, 1666, 1792, 1867, 9867, 1362, 1439,
1460, 1614, 1666)stripchart(x)
2000 4000 6000 8000 10000

Tóm lược dữ liệu từ một nhóm

Những chỉ số thống kê thông dụng
• Số lượng mẫu hay đối tượng (n)• Trung bình (mean, average)• Trung vị (median)• Độ lệch chuẩn (standard deviation, SD)
– SD = căn số bậc hai của phương sai (variance)• Percentile
– Trung vị – 25%, 75%– Tối đa (maximum), tối thiểu (minimum)
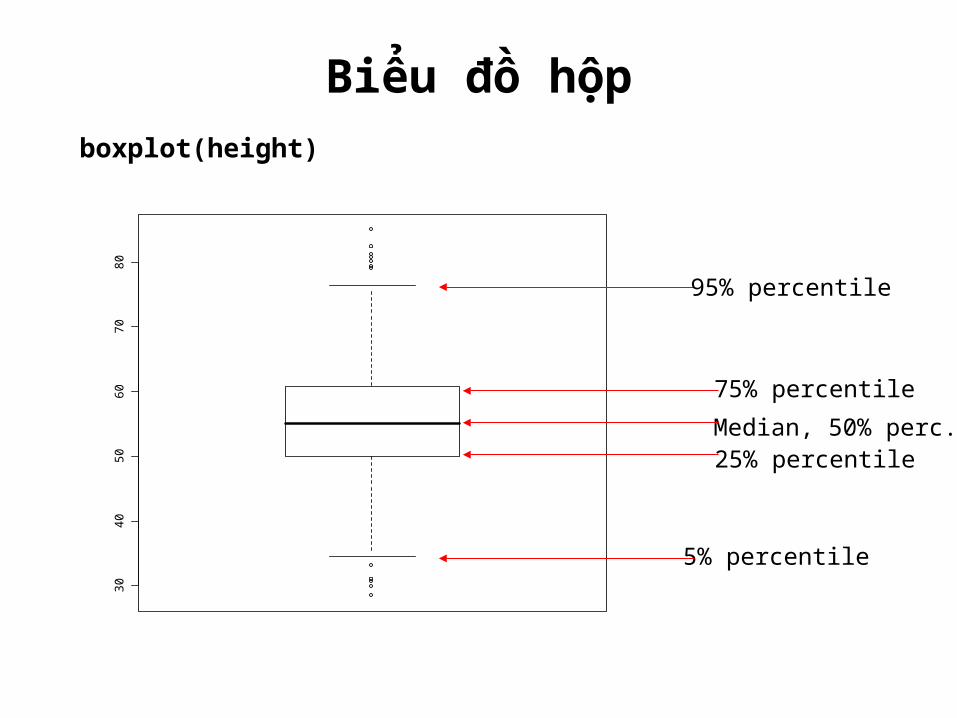
Biểu đồ hộp30
4050
6070
80
boxplot(height)
95% percentile
75% percentile
25% percentile
5% percentile
Median, 50% perc.
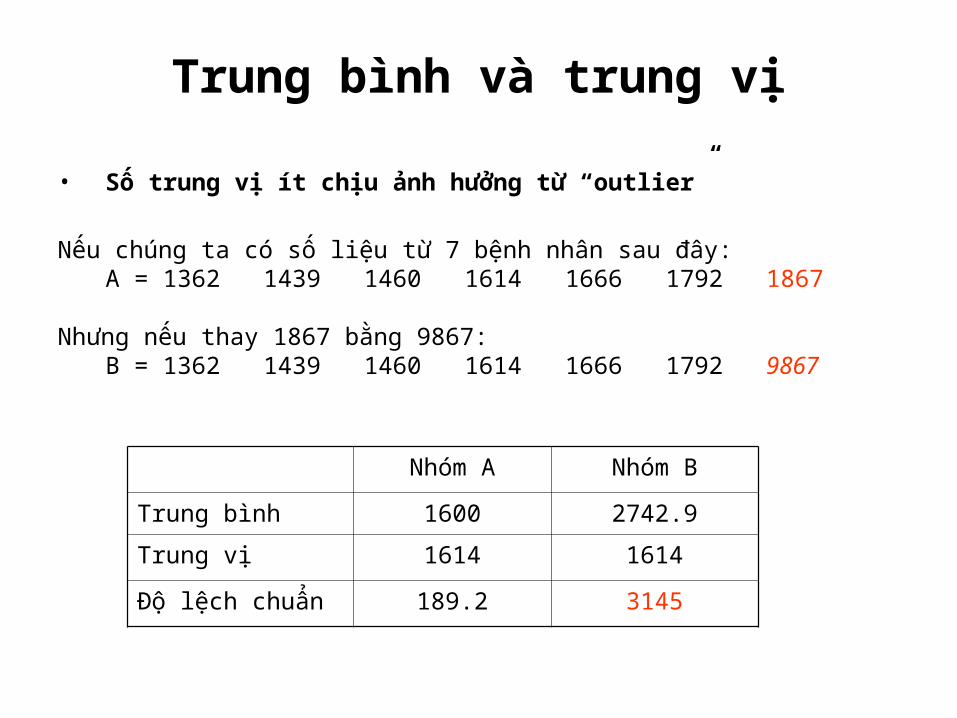
Trung bình và trung vị
• Số trung vị ít chịu ảnh hưởng từ “outlier”
Nếu chúng ta có số liệu từ 7 bệnh nhân sau đây:A = 1362 1439 1460 1614 1666 1792 1867
Nhưng nếu thay 1867 bằng 9867:B = 1362 1439 1460 1614 1666 1792 9867
Nhóm A Nhóm B
Trung bình 1600 2742.9
Trung vị 1614 1614
Độ lệch chuẩn 189.2 3145

So sánh hai nhóm: Biến liên tục

So sánh hai nhóm độc lập: t-test
Fasting cholesterol (mg/dl)
• Nhóm 1 (cá tính A):
233, 291, 312, 250, 246, 197, 268, 224, 239, 239, 254, 276, 234, 181, 248, 252, 202, 218, 212, 325
• Nhóm 2 (cá tính B):
344, 185, 263, 246, 224, 212, 188, 250, 148, 169, 226, 175, 242, 252, 153, 183, 137, 202, 194, 213
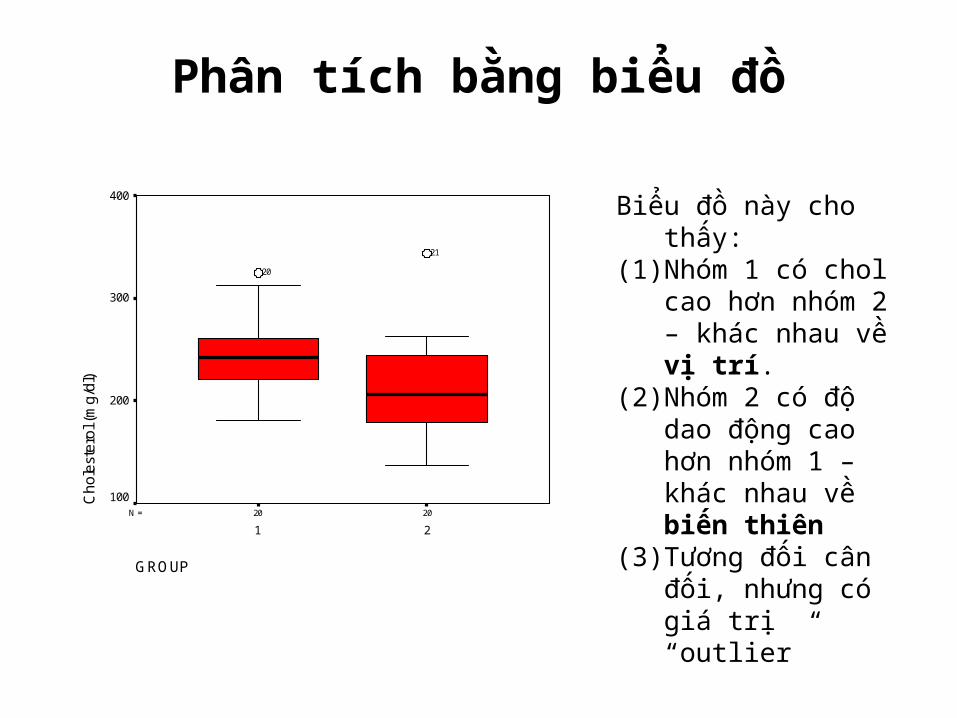
Phân tích bằng biểu đồ
2020N =
GROUP
21
Cho
lest
erol
(m
g/dl
)
400
300
200
100
21
20
Biểu đồ này cho thấy:(1) Nhóm 1 có chol cao
hơn nhóm 2 – khác nhau về vị trí.
(2) Nhóm 2 có độ dao động cao hơn nhóm 1 – khác nhau về biến thiên
(3) Tương đối cân đối, nhưng có giá trị “outlier”
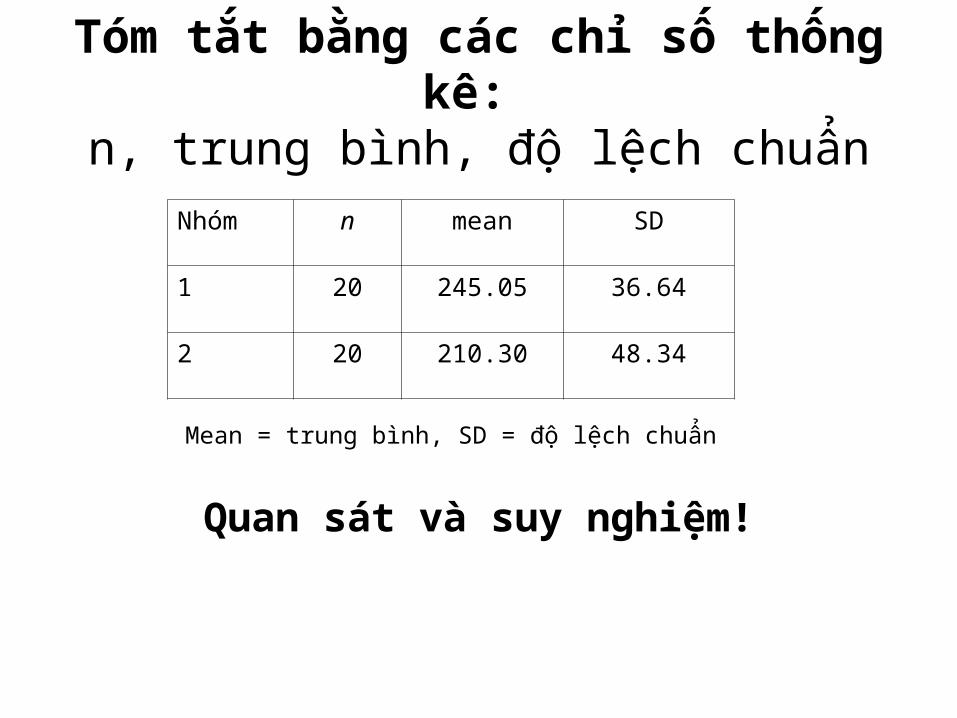
Tóm tắt bằng các chỉ số thống kê: n, trung bình, độ lệch chuẩn
Nhóm n mean SD
1 20 245.05 36.64
2 20 210.30 48.34
Mean = trung bình, SD = độ lệch chuẩn
Quan sát và suy nghiệm!

Vài dòng lí thuyết về t-testThông số (quần thể)
Quần thể 1 N1 µ1 σ1
Quần thể 2 N2 µ2 σ2
Thống kê (mẫu)
Nhóm 1 n1 s1
Nhóm 2 n2 s2
21 xx là ước số (estimate) của 21
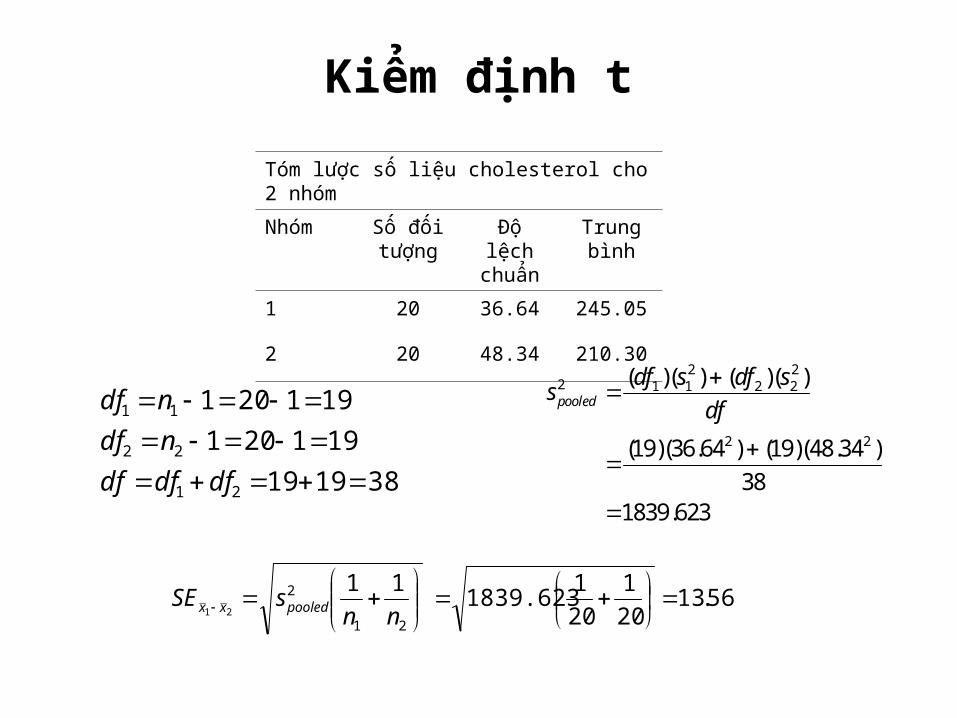
Kiểm định t
Tóm lược số liệu cholesterol cho 2 nhóm
Nhóm Số đối tượng
Độ lệch chuẩn
Trung bình
1 20 36.64 245.05
2 20 48.34 210.30
381919191201191201
21
22
11
dfdfdfndfndf
2 22 1 1 2 2
2 2
( )( ) ( )( )
(19)(36.64 ) (19)(48.34 )38
1839.623
pooleddf s df ss
df
56.13201
2011839.623 11
21
221
nn
sSE pooledxx

Khoảng tin cậy 95% cho µ1 – µ2
)( 21975.0,21 xxdf SEtxx
62.14) (7.36,39.2775.34
)13.56)(02.2()30.21005.245(
))(()(21975,.121
xxn SEtxx
Ví dụ (cholesterol):
Khoảng tin cậy 95% cho µ1 – µ2

Hoán chuyển số liệu không tuân theo luật phân phối chuẩn
• Số liệu dưới đây là lượng lysozyme trong dịch dạ dày của 29 bệnh nhân bị loét dạ dày và của 30 người chứng. Liệu có sự khác nhau về lượng lysozyme trong dịch dạ dày của hai nhóm này không?
Nhóm bệnh: 0.2 0.3 0.4 1.1 2.0 2.1 3.3 3.8 4.5 4.8 4.9 5.0 5.3 7.5 9.8 10.4 10.9 11.3 12.4 16.2 17.6 18.9 20.7 24.0 25.4 40.0 42.2 50.0 60.0
Nhóm chứng: 0.2 0.3 0.4 0.7 1.2 1.5 1.5 1.9 2.0 2.4 2.5 2.8 3.6 4.8 4.8 5.4 5.7 5.8 7.5 8.7 8.8 9.1 10.3 15.6 16.1 16.5 16.7 20.0 20.7 33.0
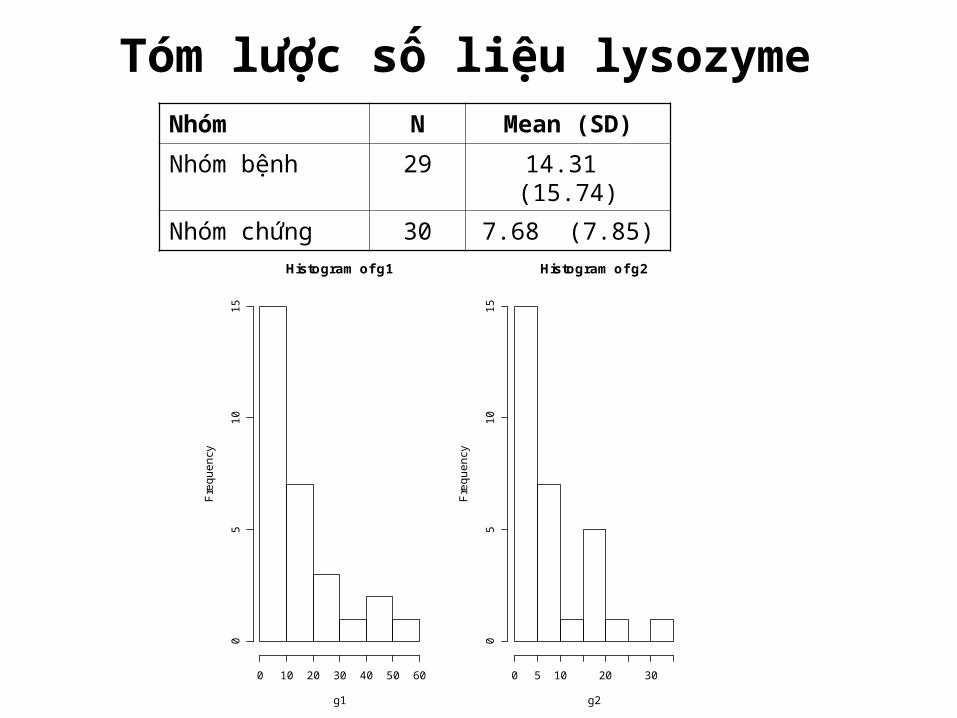
Tóm lược số liệu lysozyme Nhóm N Mean (SD)Nhóm bệnh 29 14.31 (15.74)
Nhóm chứng 30 7.68 (7.85)
Histogram of g1
g1
Fre
quen
cy
0 10 20 30 40 50 60
05
1015
Histogram of g2
g2
Fre
quen
cy
0 5 10 20 30
05
1015

Kiểm định t số liệu lysozymeNhóm N Mean (SD)Nhóm bệnh 29 14.31 (15.74)
Nhóm chứng 30 7.68 (7.85)
15157
85.72974.1528
))(())((
22
222
2112
dfsdfsdfspooled
20.3301
291511 11
21
221
nn
sSE pooledxx
07.220.3
68.731.14
t P = 0.04, có ý nghĩa thống kê

Giả định đằng sau kiểm định t có đáp ứng?
• Hai nhóm độc lập? OK• Phân phối chuẩn? Có vấn đề• Phương sai tương đương? Có vấn đề.

Kiểm định Shapiro-Wilk• Để xem phân phối có tuân theo luật chuẩn hay không.• Giả thuyết là phân phối g1, g2 tuân theo luật chuẩn (p >0.05), nếu kết quả
thu được p <0.05 không tuân theo luật chuẩn.• Cần chú ý: các test này rất nhạy nên cần phải xem xét các yếu tố khác: độ
dốc (skewness) và độ nhọn (kurtosis) của đường cong phân phối đó.
Shapiro.test(g1)Shapiro-Wilk normality testdata: g1 W = 0.8036, p-value = 9.697e-05
shapiro.test(g2)Shapiro-Wilk normality test
data: g2 W = 0.8338, p-value = 0.0002888
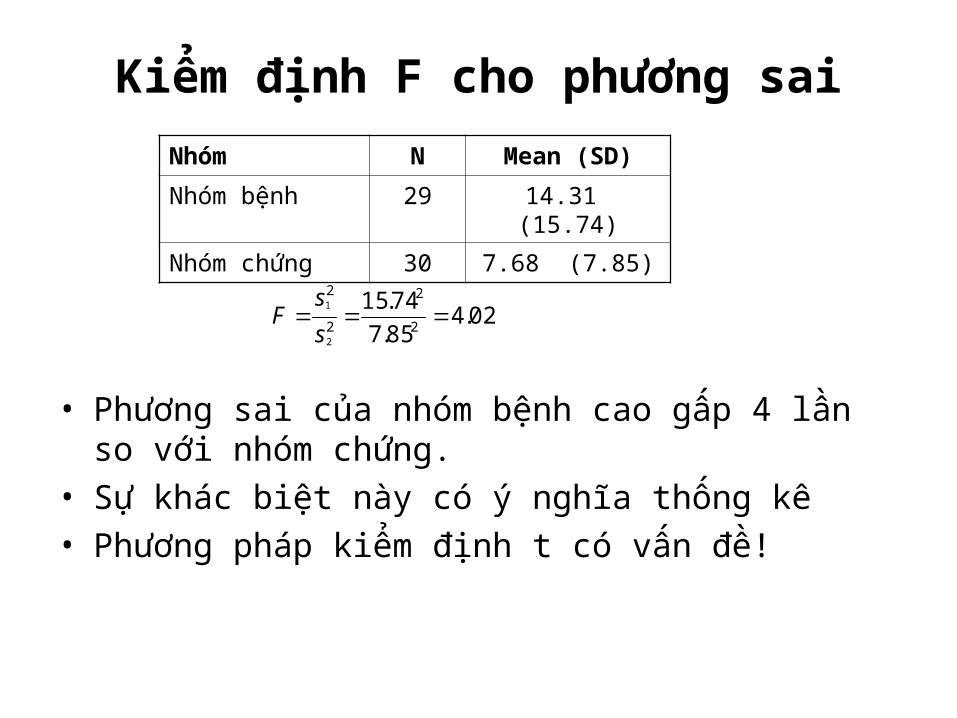
Kiểm định F cho phương sai
• Phương sai của nhóm bệnh cao gấp 4 lần so với nhóm chứng.
• Sự khác biệt này có ý nghĩa thống kê• Phương pháp kiểm định t có vấn đề!
Nhóm N Mean (SD)Nhóm bệnh 29 14.31 (15.74)
Nhóm chứng 30 7.68 (7.85)
02.485.774.15
2
2
2
2
2
1
ss
F
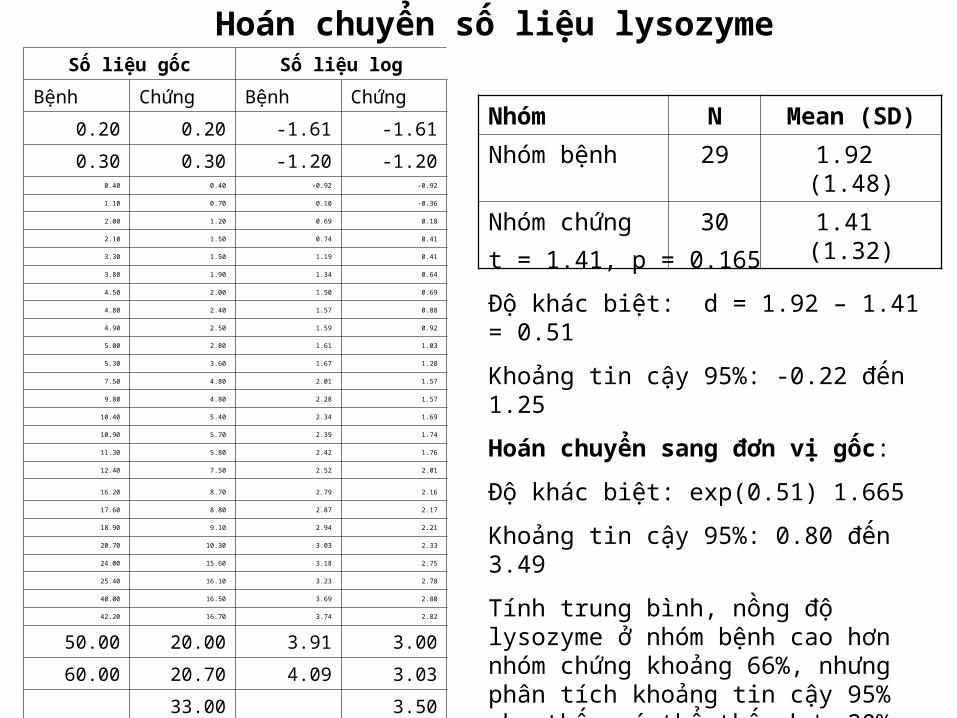
Hoán chuyển số liệu lysozymeSố liệu gốc Số liệu log
Bệnh Chứng Bệnh Chứng
0.20 0.20 -1.61 -1.61
0.30 0.30 -1.20 -1.200.40 0.40 -0.92 -0.92
1.10 0.70 0.10 -0.36
2.00 1.20 0.69 0.18
2.10 1.50 0.74 0.41
3.30 1.50 1.19 0.41
3.80 1.90 1.34 0.64
4.50 2.00 1.50 0.69
4.80 2.40 1.57 0.88
4.90 2.50 1.59 0.92
5.00 2.80 1.61 1.03
5.30 3.60 1.67 1.28
7.50 4.80 2.01 1.57
9.80 4.80 2.28 1.57
10.40 5.40 2.34 1.69
10.90 5.70 2.39 1.74
11.30 5.80 2.42 1.76
12.40 7.50 2.52 2.01
16.20 8.70 2.79 2.16
17.60 8.80 2.87 2.17
18.90 9.10 2.94 2.21
20.70 10.30 3.03 2.33
24.00 15.60 3.18 2.75
25.40 16.10 3.23 2.78
40.00 16.50 3.69 2.80
42.20 16.70 3.74 2.82
50.00 20.00 3.91 3.00
60.00 20.70 4.09 3.03
33.00 3.50
Nhóm N Mean (SD)Nhóm bệnh 29 1.92 (1.48)
Nhóm chứng 30 1.41 (1.32)
t = 1.41, p = 0.165
Độ khác biệt: d = 1.92 – 1.41 = 0.51
Khoảng tin cậy 95%: -0.22 đến 1.25
Hoán chuyển sang đơn vị gốc:
Độ khác biệt: exp(0.51) 1.665
Khoảng tin cậy 95%: 0.80 đến 3.49
Tính trung bình, nồng độ lysozyme ở nhóm bệnh cao hơn nhóm chứng khoảng 66%, nhưng phân tích khoảng tin cậy 95% cho thấy có thể thấp hơn 20% hay cao hơn 2.5 lần.

Phân tích lại số liệu lysozyme
data: log.g1 and log.g2 t = 1.406, df = 55.714, p-value = 0.1653alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.2182472 1.2453165 sample estimates:mean of x mean of y 1.921094 1.407559
exp(1.921-1.407) = 1.67
Trị số lysozyme của nhóm bệnh nhân cao hơn nhóm chứng 1.67 lần hay 67%, tuy nhiên không có ý nghĩa thống kê

Phân tích số liệu 2 nhóm kết xứng (matched case control study)

Matched samples
• Trước / sau• Sinh đôi • Matched case-control
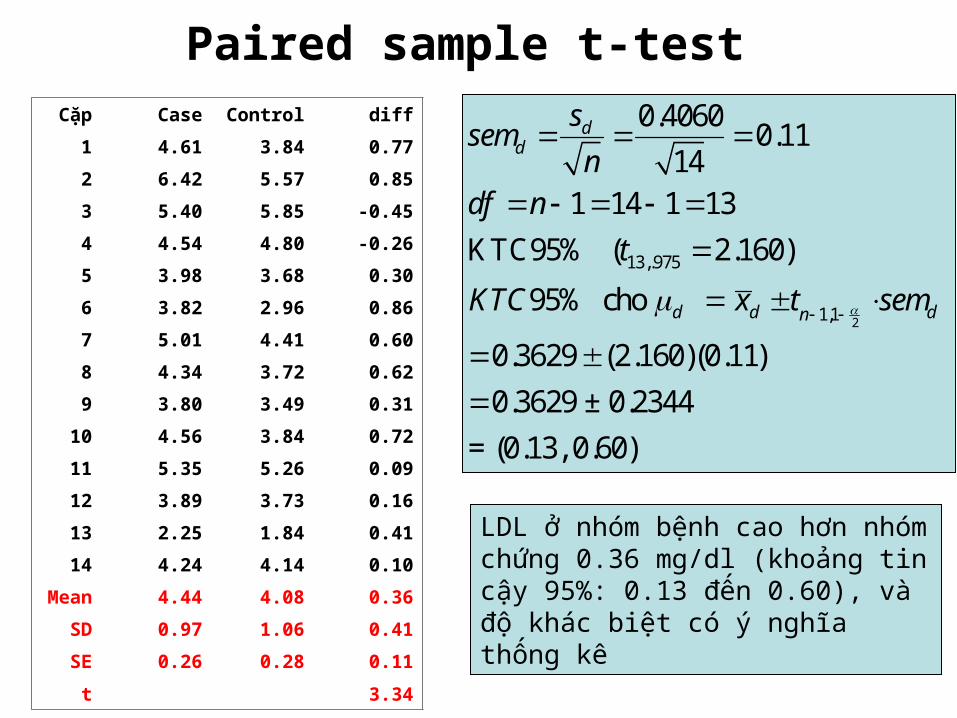
Paired sample t-test Cặp Case Control diff
1 4.61 3.84 0.77
2 6.42 5.57 0.85
3 5.40 5.85 -0.45
4 4.54 4.80 -0.26
5 3.98 3.68 0.30
6 3.82 2.96 0.86
7 5.01 4.41 0.60
8 4.34 3.72 0.62
9 3.80 3.49 0.31
10 4.56 3.84 0.72
11 5.35 5.26 0.09
12 3.89 3.73 0.16
13 2.25 1.84 0.41
14 4.24 4.14 0.10
Mean 4.44 4.08 0.36
SD 0.97 1.06 0.41
SE 0.26 0.28 0.11
t 3.34
2
13,.975
1,1
0.4060 0.1114
1 14 1 13KTC95% ( 2.160)
95% cho
0.3629 (2.160)(0.11)0.3629 ± 0.2344
= (0.13, 0.60)
dd
d d dn
ssem
ndf n
t
KTC x t sem
LDL ở nhóm bệnh cao hơn nhóm chứng 0.36 mg/dl (khoảng tin cậy 95%: 0.13 đến 0.60), và độ khác biệt có ý nghĩa thống kê

Tóm lược
• Cẩn thận với phân phối của số liệu– Sử dụng các thuật phân tích biểu đồ
• Hai nhóm độc lập:– Kiểm định t– Khoảng tin cậy 95%
• Hai nhóm không độc lập:– Kiểm định t





























