Embed Size (px)
Citation preview

MODELLI PARAMETRICI E PSD
La PSD non parametrica è data dalla trasformata di Fourier della sequenza infinita dell’AC.
I modelli parametrici consentono una risoluzione migliore nella PSD, utilizzando l’informazione disponibile anche fuori della finestra di analisi ed evitando l’uso di finestre.
La PSD parametrica è una funzione dei parametri del modello e della varianza del rumore, che si ottengono dall’AC o direttamente dai dati. In quest’ultimo caso, la difficoltà sta nel scegliere (stimare) il modello “migliore” per i dati, cioè quello che meglio approssima i dati.
Vedremo sia metodi di stima dei parametri del modello basati sulla conoscenza dell’AC sia metodi che stimano i parametri direttamente dai dati (identificazione parametrica).

MODELLI PARAMETRICI
Modello ARMA (AutoRegressive
Moving Average):
x(n)=uscita; u(n)=ingresso
h(n)=risposta impulsiva
Abbiamo visto che la funzione di trasferimento di un sistema lineare è:
con:
AR MA

MODELLI MA E AR
Modello MA (p=0)
Modello AR (q=0)
Dato un modello ARMA, AR o MA è possibile esprimerlo secondo uno degli altri
due modelli. Un processo ARMA o MA è rappresentabile tramite un modello
AR di ordine infinito (finito, di ordine sufficientemente elevato). Lo stesso per un
modello MA. Per i modelli AR esistono algoritmi di risoluzione
particolarmente efficienti.

MODELLO AR Data la AC per lag 0,..,p, i parametri AR si possono ottenere risolvendo il
sistema di equazioni normali di Yule-Walker:
Matrice di AC:
Toeplitz ed
Hermitiana
La AC per lag 0,…,p descrive in maniera univoca il processo AR di ordine
p, poiché i lag per |m|>p si ottengono ricorsivamente da:
i valori non noti di rxx possono essere “estrapolati” da questa relazione
La sequenza di autocorrelazione però non è in genere nota. Alcune proprietà dei
processi AR consentono di sviluppare algoritmi di stima dei parametri AR
utilizzando direttamente i dati (identificazione parametrica).
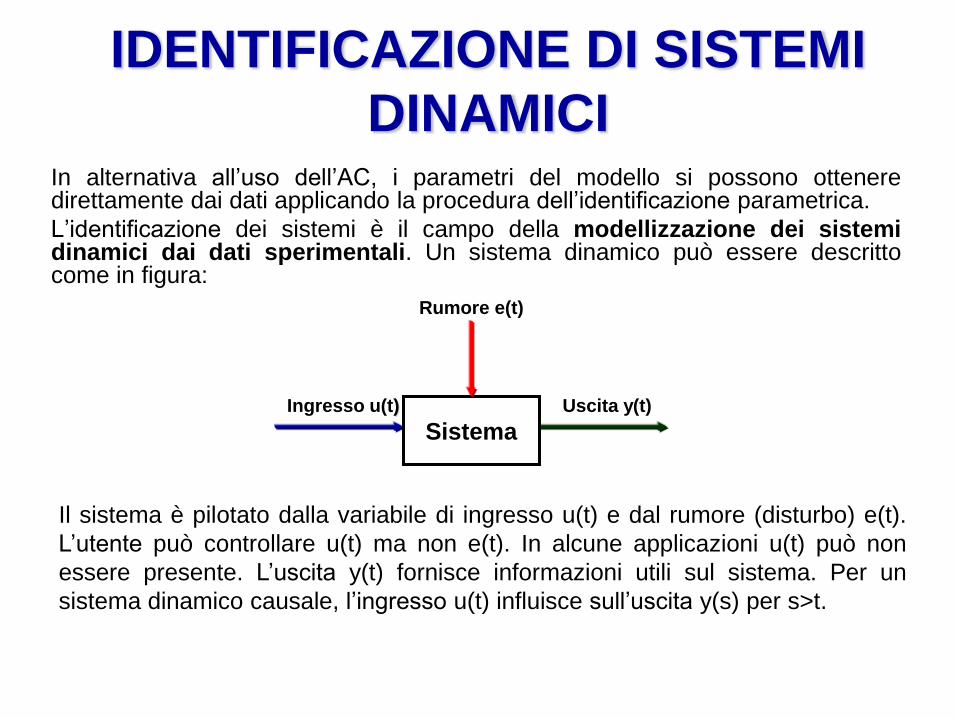
IDENTIFICAZIONE DI SISTEMI
DINAMICI In alternativa all’uso dell’AC, i parametri del modello si possono ottenere direttamente dai dati applicando la procedura dell’identificazione parametrica.
L’identificazione dei sistemi è il campo della modellizzazione dei sistemi dinamici dai dati sperimentali. Un sistema dinamico può essere descritto come in figura:
Sistema Ingresso u(t) Uscita y(t)
Rumore e(t)
Il sistema è pilotato dalla variabile di ingresso u(t) e dal rumore (disturbo) e(t).
L’utente può controllare u(t) ma non e(t). In alcune applicazioni u(t) può non
essere presente. L’uscita y(t) fornisce informazioni utili sul sistema. Per un
sistema dinamico causale, l’ingresso u(t) influisce sull’uscita y(s) per s>t.

LA PROCEDURA
DELL’
IDENTIFICAZIONE
PARAMETRICA 1. Si progettano esperimenti sul sistema (non
sempre è possibile);
2. Si eseguono gli esperimenti e si raccolgono
i dati (spesso si dispone di un’unica
realizzazione del processo);
3. Si sceglie la struttura più appropriata per il
modello (AR, MA, ARMA, con
considerazioni teoriche ed empiriche);
4. Si sceglie un metodo di stima dei parametri
e si calcolano le stime (esistono metodi
ricorsivi e non);
5. Si eseguono test per determinare
l’accuratezza del modello (analisi dei residui
ecc.);
6. Se il risultato non è corretto, si ripete la
procedura, modificando il/i punti inadeguati.

IDENTIFICAZIONE PARAMETRICA
Quando è possibile, si eseguono vari esperimenti sul sistema allo studio, applicando opportune funzioni di ingresso ed osservando ingressi ed uscite per un certo periodo di tempo. Altrimenti, si fanno ipotesi sulla validità del modello.
Lo scopo è di ottenere il modello (equazione differenziale o alle differenze, in genere lineare) che descrive i dati nel modo migliore possibile, con opportuna scelta dei suoi parametri.
Di solito, si ipotizzano vari ordini per il modello e si calcola il modello migliore tramite criteri di scelta dell’ ordine ottimo. In genere, il criterio è quello di scegliere il modello il cui ordine e parametri minimizzano, nel senso dei Minimi Quadrati, la varianza dell’errore di stima ρ2.
Un ordine troppo basso per il modello comporta una stima troppo “smussata”. Viceversa, un ordine troppo elevato aumenta la risoluzione ed introduce dettagli spuri nel modello.
La scelta dell’ordine del modello costituisce quindi un trade-off fra aumento della risoluzione e minimizzazione della varianza dell’errore.

METODI DI STIMA PARAMETRICA
Esistono due tipi di algoritmi per il calcolo dei parametri dei modelli AR: i
metodi a “blocchi” e i metodi “ricorsivi”.
Metodi a blocchi: viene elaborato un intero blocco di dati di dimensioni
adeguate. L’ordine del modello non è noto, ed è stimato ipotizzando ordini
crescenti e determinando quello che approssima il sistema nel modo
“migliore”. Fra i metodi a blocchi consideriamo:
- Il metodo di Yule-Walker: stima l’AC, e da essa i parametri AR;
- I metodi basati sulle stime ai Minimi Quadrati (Least Squares, LS)
a Predizione Lineare (Linear Prediction, LP): si distinguono in
metodi a Predizione “in avanti”, “indietro” e “misti”, a seconda del
tipo di LP usato.
Metodi ricorsivi: i dati sono elaborati sequenzialmente, via via che un
nuovo dato è disponibile. L’ordine del modello AR è fissato. Sono metodi
adatti per segnali lentamente variabili nel tempo.

STIMA A BLOCCHI
Abbiamo visto i modelli ARMA e AR:
ARMA AR
Che possiamo esprimere con la struttura generale:
Dove T(t) = [-y(n-1), -y(n-2), …, -y(n-P), x(n), x(n-1), …, x(n-Q) ] (ARMA)
oppure T(t) = [-x(n-1), -x(n-2), …,-x(n-p) ] (AR)
= vettore dei (P+Q) parametri incogniti a(k), b(k) (ARMA) oppure p parametri a(k) (AR).
Il metodo di stima più semplice è quello detto ai Minimi Quadrati (Least Squares, LS)

REGRESSIONE LINEARE
Minimi Quadrati (Least Squares LS)
La struttura del modello (parametrico) è:
Dove:
y(t) = uscita misurabile
T(t) = [(t-1) (t-1) … (t-n)] vettore n-dimensionale di quantità note (regressori)
= vettore n-dimensionale di parametri incogniti ( =(a1, …, an)) .
Problema: stimare da y(1), …, y(N), (1), …, (N). Date le misure, si ottiene un
sistema di equazioni lineari:
in notazione
matriciale: Con:
Vettore
Nx1
Matrice
Nxn

LS (cont.)
Se N=n, è una matrice quadrata e non singolare il sistema:
Si risolve facilmente: = -1Y.
In genere però, il rumore sul segnale, gli errori di modello ed i disturbi
consigliano di scegliere N>n per ottenere una stima migliore. Il sistema è
quindi sovradimensionato e non esiste una soluzione unica.
e si costruisce il vettore
Si definisce l’errore di equazione (residuo):
Da:

LS (cont.)
La stima LS di è definita come il vettore ̂ che minimizza la funzione (quadrato
dell’errore):
Dove ||.|| indica la norma euclidea. La soluzione è:
ed il corrispondente valore minimo di V() è:

LS (cont.)
Infatti, da: = Y -
poiché V()=ε2/2, si ha:
Moltiplicando per
I=(T )-1 (T ):
Il 2° termine non dipende da . Il minimo di V() si ottiene uguagliando a 0 la
derivata rispetto a oppure per tale che il primo termine sia = 0), cioè:
Questo è il valore ottimo dei parametri cercato. Sono dette: Equazioni Normali

MINIMI QUADRATI Il metodo LS, visto per modelli lineari deterministici (regressione lineare), può essere
esteso al caso di sistemi dinamici stocastici. Il modello è (qz):
con:
che si può scrivere come:
con:
che è la forma già vista. Il vettore dei parametri che
minimizza l’errore quadratico VN() (varianza del rumore
errore di stima nel caso deterministico):
è quindi

METODI DI STIMA DELL’ORDINE p
Per la scelta dell’ordine ottimo p per un modello AR, si definisce un criterio di “errore”
che indichi qual è l’ordine “ottimo” per quel modello.
L’approccio più semplice è quello di costruire modelli AR di ordine via via crescente,
fino ad ottenere un minimo nella funzione di errore, data dalla varianza dell’errore di
predizione. Per i metodi visti, però, la varianza decresce monotonicamente al crescere
di p.
Sono stati definiti numerosi criteri basati su funzioni non monotone decrescenti, che
raggiungono un valore minimo per qualche valore di p per poi crescere nuovamente.
Il principio è quello di inserire nel criterio un termine “penalizzante”, funzione di
p: infatti, il “principio di parsimonia” afferma che l’ordine del modello deve
essere il più basso possibile.
Vediamo i criteri più noti.
Ricordiamo comunque che la conoscenza delle caratteristiche del segnale allo studio e
del/dei parametri che vogliamo estrarre da esso è di fondamentale importanza per la
definizione di un range ammissibile di valori entro cui stimare p.

CRITERI DI STIMA DELL’ORDINE
OTTIMO
Final Prediction Error
Spesso sottostima l’ordine ottimo.
Akaike Information Criterion
Tende a sovrastimare p per N grande
Minimum Description Length
Non presenta il problema dell’AIC
Criterion Autoregressive Transfer
Analogo al precedente
N=n. di dati, p= varianza dell’errore (decresce al crescere di N)

CONFRONTO METODI
p=3?
p=3 p=3
p=3
ES.: I dati (simulati) provengono da un sistema di equazioni alle differenze del 3° ordine (modello AR, p=3 ) V
ari
an
za
de
ll’e
rro
re d
i s
tim
a

ES: MODELLO DELLA PRODUZIONE
DELLA VOCE
Con opportuna scelta dei modelli di G e L (sperimentali), V si ottiene da:
y(n)=a1y(n-1)+a2y(n-2)+…+apy(n-p)+e(n)
(modello lineare AutoRegressivo (AR))
y(n)
e(n)
T
T
L
G V
N
0k
1k
0zz
1 L(z)
21cT )ze1(
1)z(G
u(n)
?
V
e(n)=impulsi di periodo T
(suoni vocalici)
e(n)=rumore bianco
(consonanti)

METODI DI STIMA DI F0
• Nel tempo: AC del segnale, AC dell’errore di stima di opportuno modello, zero-crossing, AMDF.
• In frequenza: 1a armonica, distanza media fra le armoniche.
1 2 3 4 5 6 7 8 9 10 11
x 10-3
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
/a/ post-surgical
Time [s]
No
rma
lis
ed
am
pli
tud
e [
arb
.un
its
]
1a armonica
Si cerca la periodicità del segnale
in uscita alle labbra. Esistono
numerose tecniche che sfruttano
questa caratteristica:
• In altri domini: cepstrum, wavelets.
• Si utilizzano pre-filtraggi per
smussare il segnale e eliminare le
frequenze indesiderate (clipping,
filtri passa-basso, ecc).

Le cavità si comportano da risonatori, rinforzando le armoniche la cui frequenza di vibrazione corrisponde alla loro frequenza di risonanza. Più grande è la cavità, più bassa è la frequenza di risonanza, e viceversa.
MODELLO DEL TRATTO VOCALE L’aria in vibrazione in uscita dalla glottide incontra una serie di cavità, fra cui le principali sono la cavità faringea e quella orale. Forma e dimensioni non sono nettamente determinate e sono variabili, a causa dei movimenti degli articolatori (lingua, labbra, denti, ecc.).
Modello TC:
equazioni differenziali
Modello TD: equazioni alle
differenze (modelli AR)

ESEMPIO: MODELLO A TUBI DEL
TRATTO VOCALE
Modello “discreto”: p tubi coassiali
di uguale lunghezza l e sezione
variabile. Si studia con equazioni
alle differenze (modelli AR).
Il numero di sezioni
corrisponde all’ordine p del
modello AR.
Se c 340m/s è velocità di propagazione del suono nell’aria e 2 = l/c è tempo necessario per percorrere una sezione di lunghezza l, allora:
T = 4 = 2l/c è tempo necessario per il percorso di andata e ritorno in una sezione di lunghezza l. Quindi
2p = pl/c=pT/2
è il tempo necessario ad un’onda acustica per propagarsi dalla glottide alle labbra.
l
L=l x p

RELAZIONE FRA FS E p
Fs =1/T = frequenza di campionamento; L = pl = lunghezza del tratto vocale.
Poiché T = 2l/c = 2pl/pc = 2L/pc,
Si ha:
Fs = pc/2L
Oppure:
p = 2LFs/c
1. Maschi adulti: L17cm p1 Fs/1000
2. Femmine adulte: L 14cm p2 0.8Fs/1000;
3. Neonati: L 8.5cm p3 0.5Fs/1000.
Es.: con Fs = 44 kHz, si ha:
p1=44; p2=35; p3=22.
N.B:.Se Fs è troppo bassa, questa relazione non è più affidabile.

MODELLI AR E PREDIZIONE
LINEARE - LP
Abbiamo visto che i parametri di un modello AR e la successione dei valori di
AC sono legati da relazioni lineari.
L’AC può però non essere nota, o è nota solo su un intervallo finito.
La stima parametrica basata sulla procedura dell’identificazione parametrica,
consente di superare questa limitazione: i parametri del modello AR si
ottengono direttamente dai dati.
Gli studi su questo argomento sono molto vasti ed hanno dato luogo a
denominazioni alternative per l’analisi (spettrale) basata su modelli AR.
In particolare si parla di “Predizione Lineare” (Linear Prediction, LP): un
modello AR può essere visto come una relazione lineare che consente di
“predire” il valore x(n) del segnale sulla base di p valori passati:
p
1k
p )kn(x)k(a)n(x̂ )n(e)n(x)n(x̂p
L’errore di stima e(n) è dovuto al fatto che utilizzo un numero finito p di
campioni passati di x(n) invece di un numero infinito.

MODELLI A PREDIZIONE LINEARE (LP)
xp(n) = x(n)+e(n) = a1x(n-1)+a2x(n-2)+…+apx(n-p)+e(n)
xp(n)x(n)
x(n-p)
E’ un
modello AR
x(n-1)
x(n-2)
Campioni passati

PREDIZIONE LINEARE LP (cont.)
I parametri ai e l’ordine p del modello A(z) si ottengono direttamente dal
segnale, con un metodo di stima ai Minimi Quadrati, applicato ad e(n).
L’ordine p è tanto maggiore quanto più il segnale è complesso.
L’ordine p dipende anche dalla lunghezza M della sequenza di dati a
disposizione. Spesso è bene scegliere M/3<p<M/2.
La scelta è inoltre legata alla frequenza di campionamento Fs (in kHz). In
molte applicazioni (analisi segnale vocale):
e(n) = x(n)-xp(n) = errore di predizione
errore che si commette nell’utilizzare un numero finito p di campioni
passati per stimare x(n)
ss FpF3
1

PREDIZIONE “IN AVANTI” - FLP Il modello LP visto è:
Definiamo la stima di predizione lineare “in avanti” (Forward Linear Prediction, flp):
p
1k
ff
p )kn(x)k(a)n(x̂
del campione x(n), dove af(k) è il coefficiente flp all’istante k. La predizione è detta
“in avanti” nel senso che la stima all’istante n è basata su p campioni ad
istanti precedenti. L’errore di predizione in avanti è:
)n(x̂)n(x)n(e f
p
f
p
L’ espressione è identica a quella che descrive un modello AR(p). Qui però ef(n)
non è in genere un rumore bianco. Per utilizzare i metodi di stima parametrica
AR, si fa l’ipotesi (vera sotto opportune condizioni) che ef(n) sia un rumore
bianco.
p
1k
p )kn(x)k(a)n(x̂

p
1k
ff
p )kn(x)k(a)n(x̂FLP
xfp(n)x(n)
af(1) x(n-1)
af(2) x(n-2)
af(p)x(n-p)
Campioni passati

In modo analogo, si può definire la predizione lineare “all’ indietro” (Backward Linear Prediction, blp):
p
1k
bb
p )kn(x)k(a)n(x̂
Dove ab(k) = blp coefficiente all’istante k. La predizione è “all’indietro” nel
senso che la stima all’istante n è basata su p campioni ad istanti successivi.
L’errore di predizione blp è:
)n(x̂)n(x)n(e b
p
b
p .
Si dimostra che la varianza dell’errore in avanti e quella all’indietro
coincidono. I coefficienti dell’errore blp sono i complessi coniugati di quelli flp se i
modelli di predizione in avanti e all’indietro sono della stessa lunghezza p.
I parametri LP si possono quindi ottenere definendo e risolvendo due problemi
diversi ma simili, la Predizione Lineare in Avanti (FLP) e quella all’indietro (BLP).
Entrambi sono rappresentabili tramite un modello lineare AutoRegressivo (AR) e
forniscono la stessa soluzione.
PREDIZIONE “INDIETRO” - BLP

1 2 3 4 5 6 7 8 9 10 11
x 10-3
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
/a/ post-surgical
Time [s]
No
rma
lis
ed
am
pli
tud
e [
arb
.un
its
]
p
1k
bb
p )kn(x)k(a)n(x̂
ab(1)x(n+1)
ab(2)x(n+2)
ab(p)x(n+p)
BLP
xbp(n)x(n)
Campioni futuri

COVARIANZA MODIFICATA
FLP + BLP Abbiamo visto due metodi:
Il primo utilizza la predizione lineare “in avanti” (flp), l’altro quella “all’indietro” (blp),
separatamente.
Esiste un metodo più robusto, basato su una combinazione delle due tecniche flp
e blp, detto metodo della Covarianza Modificata. Si minimizza la media degli
errori di predizione flp e blp:
Questo metodo fornisce in genere risultati migliori dei precedenti, in
quanto utilizza un numero di dati maggiore (doppio).

1 2 3 4 5 6 7 8 9 10 11
x 10-3
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
/a/ post-surgical
Time [s]
No
rma
lis
ed
am
pli
tud
e [
arb
.un
its
]
ab(1)x(n+1)
ab(2)x(n+2)
ab(p)x(n+p)
FLP+BLP
xbp(n)x(n) xf
m(n)
Campioni futuri
af(1)x(n-1)
af(2)x(n-2)
af(m)x(n-m)
Campioni passati

STIMA LS RICORSIVA (RLS)
RLS = Recursive Least Squares. E’ detta anche stima parametrica “on line”: i
parametri all’istante t sono stimati sulla base di quelli ottenuti all’istante t-1.
Caratteristiche:
• Alla base dei sistemi di controllo adattativo
(es: dosaggio farmaci)
• Occupazione di memoria modesta
• Utili per il tracking dei parametri tempo-
varianti, e per individuarne cambiamenti
significativi (es: diagnosi di
malfunzionamento).

MINIMI QUADRATI RICORSIVI Con il metodo LS abbiamo visto
che i parametri (t) si ottengono
da:
Definiamo Da cui:
Sostituendo nella (1):
e dalla (2a) per t-1
(1)
Che possiamo scrivere
come:
(t) = errore di
predizione
(2b)
Il calcolo di P(t) implica un’inversione di matrice ad ogni iterazione (numericamente
poco efficiente).
(3)
t
1s
)s(y)s()t(P)t(̂dalla (1): (2a)

RLS (cont.) Utilizzando il lemma di inversione di matrici (v. sotto), con: AP-1, Bφ, C I, D φT,
da (2b): P(t)=(P-1(t)+ φ(t)IφT(t))-1, la ricorsione si può scrivere come segue:
Divisione per
scalare invece di
inversione di
matrice Da cui nella (3):
LEMMA DI INVERSIONE DI MATRICI
Dimostrazione:

RLS CON FORGETTING FACTOR
Modifica del metodo RLS visto, per il tracking dei parametri nel caso di sistema
tempo-variante.
Si modifica il funzionale da minimizzare tramite un fattore (forgetting factor):
1. Minore è , più velocemente vengono “dimenticate” le misure passate. La
“memoria” è data da: 1/1- . Es.: =0.99 1/1- =100; =0.95 1/1- =20.
La formulazione del metodo generale è quindi (caso precedente: =1):
Condizioni iniziali:

IDENTIFICAZIONE PARAMETRICA:
ASPETTI PRATICI • Scelta del segnale di ingresso (raramente possibile per segnali biomedici!): deve avere
PSD>0 nel range di frequenze di interesse.
• Presenza di valor medio non nullo: genera una continua non desiderata e crea una
polarizzazione delle stime. Si può eliminare il valor medio prima delle elaborazioni o
lavorare sul segnale differenziato: y(t)=y(t)-y(t-1).
• Scelta della frequenza di campionamento: bassa perdita di informazione alle alte
frequenze; alta esaltazione del contributo delle componenti alle alte frequenze (può
essere solo rumore, non sempre è di interesse).
• Prefiltraggio per ridurre il rumore: solo se l’obbiettivo non è proprio quello di stimare il
rumore!
• Scelta del modello e dell’ordine: dipende dalla disponibilità o meno di ingressi misurabili
e dal tipo di analisi che si vuole effettuare. Vale il principio di parsimonia = utilizzare il
modello ottimo di ordine minimo possibile, anche tramite i metodi visti (AIC, MDL, ecc.).
• Convalida del modello: analisi statistica degli errori di predizione (dovrebbero essere
scorrelati con l’ingresso e fra di loro).
• Buon senso e conoscenza del problema: documentarsi sulle caratteristiche del
segnale, sugli obbiettivi, osservare i dati, osservare i risultati, ecc.
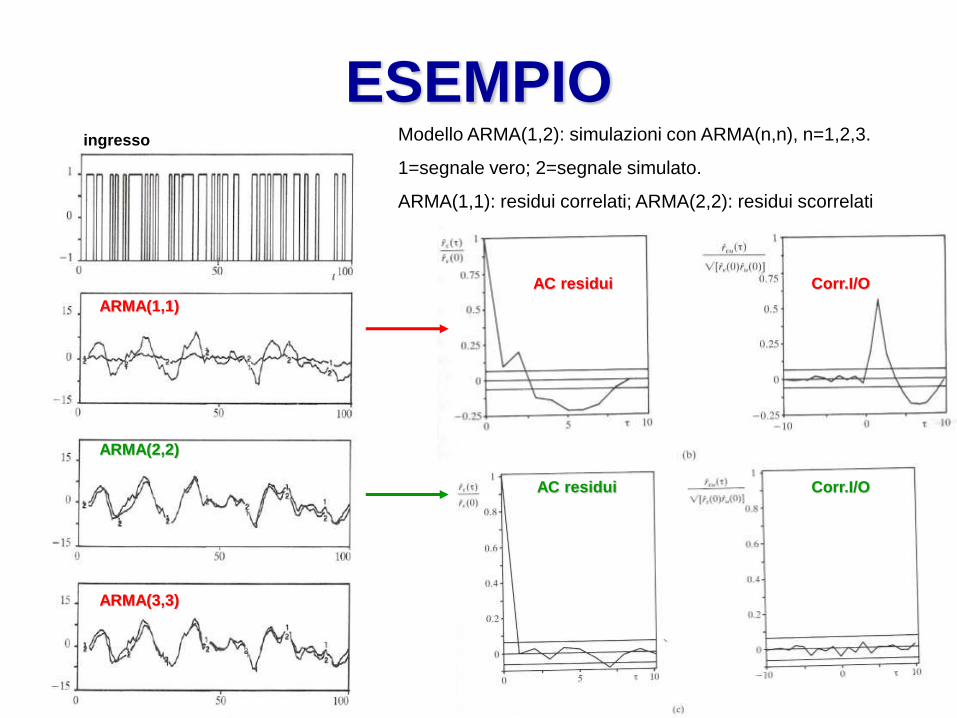
ESEMPIO Modello ARMA(1,2): simulazioni con ARMA(n,n), n=1,2,3.
1=segnale vero; 2=segnale simulato.
ARMA(1,1): residui correlati; ARMA(2,2): residui scorrelati
ingresso
ARMA(2,2)
ARMA(1,1)
ARMA(3,3)
AC residui
AC residui
Corr.I/O
Corr.I/O





























