Embed Size (px)
Citation preview

MODELO PARA LA OBTENCION DE CONOCIMIENTO ESTRUCTURADO
DESDE BASES DE DATOS EN UNA EMPRESA DE TRANSPORTE COLECTIVO
JHON ALEXANDER VERGARA LOAIZA
CRISTIAN ARBEY JARAMILLO POSADA
UNIVERSIDAD DE SAN BUENAVENTURA SECCIONAL MEDELLÍN
FACULTAD DE INGENIERÍAS
ESPECIALIZACIÓN EN GESTIÓN DE INFORMACIÓN Y BASES DE DATOS
MEDELLIN
2014

MODELO PARA LA OBTENCION DE CONOCIMIENTO ESTRUCTURADO
DESDE BASES DE DATOS EN UNA EMPRESA DE TRANSPORTE COLECTIVO
JHON ALEXANDER VERGARA LOAIZA
CRISTIAN ARBEY JARAMILLO POSADA
Proyecto presentado para optar al título de Especialista en Gestión de Información
y Bases de Datos
Asesor
Fray León Osorio Rivera, Ph.D. en Ingeniería de Software
UNIVERSIDAD DE SAN BUENAVENTURA SECCIONAL MEDELLÍN
FACULTAD DE INGENIERÍAS
ESPECIALIZACIÓN EN GESTIÓN DE INFORMACIÓN Y BASES DE DATOS
MEDELLIN
2014

CONTENIDO
1. JUSTIFICACIÓN .................................................................................................................................5
2. PLANTEAMIENTO DEL PROBLEMA ...................................................................................................7
3. OBJETIVO GENERAL ..........................................................................................................................9
4. OBJETIVOS ESPECÍFICOS ...................................................................................................................9
5. MARCO REFERENCIAL ................................................................................................................... 10
5.1 de los datos a la información y de la información al conocimiento ....................................... 11
5.2 Avances tecnológicos en la gestión comercial ........................................................................ 12
5.3 Calidad en la atención al cliente ............................................................................................. 14
5.4 DATA WAREHOUSE: una plataforma para la gestión de la información ................................ 15
5.5 Justificación del data warehouse en la gestión comercial ...................................................... 16
5.6 Logros del data warehose en la gestión comercial ................................................................. 19
5.7 Técnicas más usadas en la minería de datos .......................................................................... 22
5.7.2 Árboles de decisión .......................................................................................................... 24
5.7.3 Algoritmos genéticos ....................................................................................................... 24
5.7.4 Sistemas basados en conocimiento y sistemas expertos ................................................ 25
5.7.5 Modelos de regresión lineal............................................................................................. 25
5.7.6 Agrupamiento o clustering .............................................................................................. 25
5.7.7 Aprendizaje automático ................................................................................................... 26
5.7.8 CRISP-DM (Cross Industry Standard Process For Data Mining) ....................................... 27
5.8 ALGORITMOS EN MINERÍA DE DATOS .................................................................................... 27
5.8.1 El algoritmo K-means ....................................................................................................... 27
5.8.2 El algoritmo A priori ......................................................................................................... 27
5.8.3 El algoritmo EM ................................................................................................................ 28
5.8.4 Algoritmo PageRank ......................................................................................................... 28
5.8.5 Algoritmo AdaBoost ......................................................................................................... 28
5.8.6 Naive Baye ........................................................................................................................ 28
5.8.7 Algoritmo CART ................................................................................................................ 29
5.8.8 Algoritmo del vecino k más cercano ................................................................................ 29

5.8.9 Máquinas de vectores de soporte ................................................................................... 29
5.9 MODELOS DE OPTIMIZACIÓN DE TRANSPORTE EXISTENTES ................................................. 29
5.9.1 Modelo de Ceder y Wilson ............................................................................................... 30
5.9.2 Modelo de Baaj y Mahmassani ........................................................................................ 30
5.9.3 Modelo de Israeli y ceder ................................................................................................. 31
5.9.4 Modelo de Krishna Rao Et Al ............................................................................................ 31
5.9.5 Modelo de Gruttner Et Al ................................................................................................. 31
5.9.6 Modelo de Ngamchai y Lovell .......................................................................................... 32
5.9.7 Modelo de Tom y Mohan ................................................................................................. 32
5.9.8 Modelo de Fan y Machemehl .......................................................................................... 32
5.10 PRÁCTICAS UTILIZADAS EN LA CIUDAD DE MEDELLÍN .......................................................... 32
5.11 NORMATIVIDAD DEL TRANSITO DE MEDELLIN ..................................................................... 34
5.12 IMPORTANCIA DE LA MEDICIÓN ........................................................................................... 41
5.13 Qué es un indicador .............................................................................................................. 42
5.14 Características de los indicadores ......................................................................................... 43
6. METODOLOGIA ............................................................................................................................. 45
6.1 Enfoque para la extracción de conocimiento como: la calidad en la gestión empresarial, la
orientación hacia el cliente y optimización de los servicios en empresas de transporte público
colectivo en la ciudad de Medellín. .............................................................................................. 47
6.2 Componentes del modelo para la extracción de conocimiento para empresas de transporte
público colectivo ........................................................................................................................... 47
6.2.1 Análisis de desarrollo para extracción ................................................................................. 47
6.2.2 FASES .................................................................................................................................... 49
6.2.3 Propuesta de modelo de extracción según metodología CRIPS-DM ................................... 50
7. CONCLUSIONES ............................................................................................................................. 70
8. REFERENCIAS BIBLIOGRAFICAS ..................................................................................................... 71

Pág. 5
1. JUSTIFICACIÓN
La forma de entender y de incorporar los modelos de extracción de conocimiento
de la información que se genera en la gestión empresarial; va evolucionando con
el tiempo. Las experiencias, conocimientos y necesidades actuales han permitido
desarrollar nuevos modelos. Los modelos son esquemas teóricos que nos facilitan
la comprensión y el estudio del comportamiento de la realidad.
El trabajo comprende el estudio de las características, componentes, restricciones
y modo de operación actual del funcionamiento de las empresas de transporte
colectivo, para lograr su caracterización.
La investigación tecnológica, busca establecer una idea clara del estado y de las
opciones tecnológicas que se encuentran en este mercado específico y que
pueden dar solución satisfactoria al problema en estudio. Seguidamente, se
formula el modelo que describe la esencia del sistema y caracteriza sus variables.
Teniendo el modelo inicial que describe el problema es necesario entonces
escoger la técnica de solución que nos permite encontrar los valores de las
diferentes variables controlables del sistema para dar solución al problema
planteado. Existen dos alternativas básicas para enfrentar la solución de
problemas de optimización: herramientas basadas en los principios de la
programación matemática y herramientas fundamentadas en la lógica, la imitación
de sistemas y el buen racionamiento. Luego se implementa la solución
computacional (prototipo) y se aplica al caso concreto y obtener un modelo final
que arroje resultados confiables.
Al realizar un sondeo al sector accesible a nuestra propuesta de trabajo de grado,
hay muy poca información sobre el proceso de aprovechamiento de información y
extracción de conocimiento, ya que todo se hace en forma empírica y aunque se

Pág. 6
han desarrollado modelos de optimización para transporte público colectivo en
otros sectores mas productivos, se hace difícil adaptarlos a las condiciones de
operación del Transporte Público en la ciudad.
En el Transporte Público intervienen procesos de planeación, diseño, operación,
administración y control, pero unos de los más descuidados, son los procesos de
planeación, de los cuales, la programación de rutas o itinerarios, la capacidad y la
regulación de los vehículos, los tiempos de los viajes, la comodidad y la calidad de
la prestación de los servicios de transporte entre otros, forman parte importante.
La realización eficiente de estos estos procesos, aunque no es la solución a todos
los problemas del transporte, puede contribuir en gran manera a que se tenga un
servicio eficiente, moderno y organizado. Por lo tanto, la problemática que se
aborda en esta propuesta, es el desarrollo de un modelo que permita la extracción
de conocimiento que a su vez apunte a la optimización de los diversos entornos de
la información que se genera en las empresas de Transporte Público Colectivo.
Para dicha optimización se hace necesario explorar diversas técnicas, que sean
capaces de realizar procesos de optimización, sobre problemas con varios
objetivos conflictivos entre sí.
Por esto es importante; ya que los resultados de la elaboración de esta propuesta
y su aportación seguramente enriquecerá y promoverá un cambio en la forma que
se opera el transporte colectivo.

Pág. 7
2. PLANTEAMIENTO DEL PROBLEMA
Es manifiesto que el transporte público colectivo en una ciudad de un país en vía
de desarrollo, es muy diferente del transporte en los países desarrollados, tanto en
su infraestructura, operación, políticas, estructura interna, como en su filosofía. En
la ciudad de Medellín (Colombia) también se observa, que el transporte público
colectivo urbano, es un servicio público en manos de particulares con fuertes
intereses económicos.
Los dueños de los vehículos los afilian a empresas de transporte y los conductores
son contratados directamente por los dueños para trabajar en muchos casos, por
porcentaje. Así que es un sistema complejo en el cual intervienen muchos actores
con intereses que pueden ser conflictivos entre sí.
La mayoría de las empresas de Transporte Público Colectivo no son en realidad
empresas transportadoras, ya que no son propietarias de los vehículos, sino más
bien son afiliadoras o cooperativas que agrupan a una gran multitud de
propietarios de vehículos que se afilian a una empresa en particular, para poder
operar sus vehículos en las rutas de dicha empresa.
La empresa afiliadora simplemente cobra al dueño del vehículo una cuota única de
afiliación denominada “cupo” y una cuota mensual de administración. Con esos
dineros proporciona la infraestructura para el despacho y control de la operación
en cada una de sus rutas. Sin embargo, dado que la empresa tiene garantizados
sus ingresos por concepto de afiliación y administración, no se interesa mucho
porque la operación sea eficiente y sus mecanismos de control son demasiado
ineficaces. De tal forma que para la empresa es mucho más importante aumentar
la cantidad de vehículos afiliados que la calidad del servicio, el cumplimiento de
los itinerarios, la optimización de los recursos y la gestión del recurso humano
disponible para la operación.

Pág. 8
Conocida la situación descrita anteriormente, se evidencian los problemas que se
intentan atender con la propuesta de investigación; estos problemas se
categorizan en los siguientes grupos:
Causas estructurales: capacidad institucional deficiente, regulación
inadecuada.
Problemas de la oferta en los servicios: sobreoferta, rutas y operación
inadecuadas, vehículos y equipos obsoletos.
Problemas de la oferta en la infraestructura: subutilizada, deficiencia en la
calidad, insostenible, inequitativa.
Impactos negativos sobre el usuario: tiempo del viaje, seguridad, comodidad,
confiabilidad, tarifa.
Externalidades negativas: accidentalidad, medio ambiente, consumo
energético, congestión, desarrollo humano.
La pregunta de la investigación es la siguiente: ¿Cual es la mejor manera que se
puede atender la demanda de la prestación del servicio de transporte colectivo,
mediante procesos de análisis y evaluación de información?
La falta de aprovechamiento de la información que se genera en la gestión
empresarial y de la prestación del servicio a los clientes, no permite la
optimización de los recursos físicos y el talento humano con el que cuenta la
empresa. Aunque la solución de este problema no acaba con toda la problemática
del transporte, si puede representar muchas mejoras para todos los actores
involucrados e incluso hacer más rentable y eficiente el servicio de transporte
público colectivo, convirtiéndolo en una alternativa más atractiva para la
comunidad. Hay otros problemas relacionados con el Transporte Público, cuya
solución implica inversiones muy altas y cambios estructurales, que tal vez sean
mucho más difíciles de implementar.

Pág. 9
3. OBJETIVO GENERAL
Diseñar un modelo de optimización para el aprovechamiento de la información
desde una base de datos, para una empresa de transporte público colectivo en la
ciudad de Medellín.
4. OBJETIVOS ESPECÍFICOS
Estudiar distintos enfoques para la extracción de conocimiento como: la calidad
en la gestión empresarial, la orientación hacia el cliente y optimización de los
servicios en empresas de transporte público colectivo en la ciudad de Medellín.
Definir los componentes del modelo para la extracción de conocimiento para
empresas de transporte público colectivo
Diseñar un modelo conceptual para la extracción de conocimiento para
empresas de transporte público colectivo

Pág. 10
5. MARCO REFERENCIAL
El ambiente en el cual se desenvolverá el modelo de extracción de conocimiento
que se propone, está directamente vinculado a temas como la minería de datos,
la extracción del conocimiento y la creación de herramientas para extraer
conocimiento.
A continuación se relaciona la información que enmarca el entorno de la
propuesta.
En el ámbito de las organizaciones, tecnologías de la información tales como las
bases de datos y los almacenes de datos o Data Warehouse (DW) han soportado,
en primera instancia, el almacenamiento de ítems de información proveniente de
la automatización de los procesos de carácter típicamente repetitivo o
administrativo.
Pero en la actualidad se ha de señalar que también se puede contar con dichas
tecnologías para dar apoyo en aquellas actividades donde la aplicación del
conocimiento, la experiencia y la propia coordinación juegan un papel fundamental
en la eficiencia y productividad. Especialmente en los procesos para mejorar la
calidad en la atención y satisfacción de los clientes, hecho que sin duda redunda
en la eficacia comercial de las empresas.
En este trabajo, en primer lugar se incide en la importancia que tiene para la
empresa el proceso de transformación de los datos operacionales en información
y conocimiento.
Posteriormente, se indican cuales han sido los esfuerzos de las empresas por
incorporar soluciones que mejoren sus procesos comerciales, a través de un
tratamiento adecuado de la información. Pasando a comentar más en detalle una
de las soluciones, el Data Warehouse, que permite la captura, recolección, filtrado,

Pág. 11
consolidación, y establecimiento de relaciones de la información organizacional.
Posteriormente, se exponen varias razones que justifican la creación del DW para
obtener la información necesaria en los procesos de gestión comercial, en lugar de
obtener esa información directamente de las bases de datos de las aplicaciones
operacionales. Finalmente, se ilustra cómo el DW puede dar respuesta al reto
actual de las corporaciones de reenfocar su atención a la relación con el cliente.
5.1 de los datos a la información y de la información al conocimiento
El nivel competitivo alcanzado en las empresas, les exige desarrollar nuevas
estrategias de gestión de uno de sus recursos más valiosos, el de la información.
En la actualidad las organizaciones, en sus bases de datos, almacenan
electrónicamente datos tanto internos como externos de clientes, productos,
servicios, estructura organizativa, canales de distribución, operaciones, personal,
proveedores, competencia, mercado, coyuntura socioeconómica, encuestas, etc.
Sin embargo, esta enorme y creciente cantidad de datos no se suele corresponder
con una mayor accesibilidad a la información de utilidad en la gestión comercial.
Para entender esta aparente contradicción es necesario aclarar qué es dato, qué
es información y qué es conocimiento.
Los datos hacen referencia a los hechos que son capturados y guardados en el
entorno empresarial, pero que no necesariamente tienen que ser útiles, ya que a
priori carecen del contexto en el que aplicarlos. Tradicionalmente los datos se
encuentran dispersos a través de la organización e infrautilizados en muchas
ocasiones.
La información, en cambio, relaciona datos en un contexto conocido y por tanto es
de utilidad para que el analista extraiga conclusiones.

Pág. 12
Subiendo un peldaño más es este proceso se encuentra el conocimiento, que
implica que las tendencias observadas en la información se conocen y pueden ser
institucionalizadas y embebidas en algún proceso de negocio de la empresa. Por
tanto, con los datos, la empresa almacena eventos que tienen lugar en la misma,
con la información responde a los eventos y con el conocimiento puede anticiparse
a los mismos.
En este sentido, el esfuerzo de las organizaciones debe estar en convertir la
enorme cantidad de datos, que posee en sus bases de datos corporativas, en
información útil, para finalmente extraer el mayor conocimiento posible.
Manifestándose así el verdadero poder de la información en la gestión de los
recursos disponibles, en general, y el poder estratégico de ésta en la gestión
comercial. Ya que, el proceso de gestión comercial es una actividad que implica el
procesamiento de grandes cantidades de datos para extraer relativamente pocas
cantidades de información y/o conocimiento.
La información y el conocimiento obtenido facilitarán una estrategia de negocio
centrada en anticipar, conocer y satisfacer las necesidades y los deseos presentes
y previsibles de los clientes.
5.2 Avances tecnológicos en la gestión comercial
En un principio en la mayor parte de las empresas, esta necesaria capitalización
de la información comercial ha venido de la mano de la incorporación de bases de
datos relacionales. El modelo relacional tiene entre sus objetivos guardar la
integridad de los datos obtenidos en los procesos transaccionales automatizados
(OLTP: Procesamiento Transaccional en Línea). Sin embargo, este modelo no se
corresponde con la forma en la que el usuario percibe la gestión del conocimiento
de un negocio, en general, y la gestión del conocimiento comercial, en particular.
De hecho, aunque los sistemas de gestión de bases de datos relacionales, han

Pág. 13
sido muy beneficiosos para los usuarios, nunca han sido diseñados para
proporcionar funciones potentes de síntesis, análisis y consolidación de los datos.
Teniendo presente ese hecho y el hecho de que la economía actual está centrada
en el cliente, las corporaciones deben impulsar diversos esfuerzos técnicos y
metodológicos para intentar acometer el objetivo de reenfocar su atención a la
relación con el cliente.
Como parte de dichos esfuerzos se deben crear una serie de indicadores nuevos
que permitan conocer aspectos tales como la satisfacción del cliente, fidelidad,
ciclo de vida del cliente, etc., así como indicadores sobre el desempeño del equipo
comercial y de los departamentos de servicio al cliente cuando existen. Sin
embargo, esta es una información que en muchas ocasiones no procede, o no con
tanto detalle, las bases de datos de los sistemas transaccionales que las
empresas utilizan para la operación diaria. Por ello, muchas empresas deciden
introducir o desarrollar soluciones CRM (Customer Relationship Management) que
les permiten automatizar la actividad comercial, dar soporte a campañas
orientadas a segmentos de clientes y una serie de funcionalidades más que les
brindan la información necesaria para construir indicadores sobre la actividad
comercial y características de la relación del cliente con la corporación, además de
poder detectar necesidades de sus clientes.
Este esfuerzo puede constituir un primer paso para comenzar a obtener
información o mejorar la calidad de ésta y dar seguimiento a una parte
importantísima de la operativa de la empresa, que es la gestión comercial.
Un segundo paso, no necesariamente posterior al primero, consiste en la creación
de un repositorio histórico de información cuyas unidades principales son el
cliente, el producto y la organización.
Se introduce así el término Data Warehouse, para referirse al repositorio, y
datawarehousing para referirse a la captura, recolección, filtrado, reconciliación,
limpieza, depuración, carga, consolidación y establecimiento de relaciones entre la

Pág. 14
información proveniente de distintas fuentes, sobre la base de un modelo de
información al servicio del negocio.
El objetivo de conformar este repositorio es el de tener acceso a una visión
histórica y sobre distintos aspectos de los clientes con el objetivo de crear
indicadores de gestión y suministrar información para mejorar los procesos de
marketing y de rentabilidad y control de riesgos. Por ello, a continuación veremos
con un poco más de detalle las claves de este proceso.
5.3 Calidad en la atención al cliente
J. Harrington define a los clientes como:
Las personas más importantes para cualquier empresa.
No son una interrupción en nuestro trabajo, son un fundamento.
Son personas que llegan a nosotros con sus necesidades y deseos y
nuestro trabajo consiste en satisfacerlos.
Merecen que le demos el trato más atento y cortés que podamos.
Representan el fluido para este negocio o cualquier otro, sin ellos nos
veríamos forzados a cerrar.
Los clientes de las empresas de transporte público colectivo se sienten
defraudados y desalentados, no por sus precios, sino por la apatía, la indiferencia
y la falta de atención de sus empleados.
Los clientes conforman un universo sumamente heterogéneo, y por eso es que la
investigación del mercado es una de las herramientas fundamentales para
conocer en forma directa la opinión y características de los clientes. La utilización
de esta herramienta permite llevar a cabo una variedad de acciones, como las
siguientes:

Pág. 15
Mejorar la calidad de servicio al cliente.
Analizar problemáticas específicas, técnicas y comerciales.
5.4 DATA WAREHOUSE: una plataforma para la gestión de la información
A partir de mediados de los ochenta, en el entorno empresarial, ha cobrado
importancia el concepto Data Warehouse o almacén-factoría de datos, entendido
como la plataforma que concentra toda la información de interés para la
organización, sus fuentes de información son tanto las bases de datos
corporativas, como otras fuentes externas (por ejemplo, actualmente Internet se
ha convertido en la fuente más importante de suministro de datos).
Con el Data Warehouse se integra y se facilita el acceso a la información,
eliminando aquellos datos que obstaculizan la labor de análisis de información y
entregando la información que se requiere en la forma más apropiada.
La estructura básica de la arquitectura DW incluye:
Datos operacionales: fuente de datos para el componente de
almacenamiento físico.
Extracción de Datos: selección sistemática de datos operacionales usados
para poblar el componente de almacenamiento físico.
Transformación de datos: Procesos para sumarizar y realizar otros cambios
en los datos operacionales y para reunir los objetivos de orientación a temas e
integración.
Carga de Datos: inserción sistemática de datos en el componente de
almacenamiento físico.
Data Warehouse: almacenamiento físico de datos de la arquitectura DW.
Herramientas de Acceso al componente de almacenamiento físico DW:
herramientas que proveen acceso a los datos.

Pág. 16
Hay que señalar que el diseño del Data Warehouse no es un proceso trivial, se
debe elegir, en base a la información que se desea explotar, los datos que se
guardarán, la unidad mínima de éstos, la estructura de las entidades de
información, las dimensiones que se estudiarán, estadísticos intermedios que se
deben conservar y muchos aspectos más para que el diseño responda a las
necesidades de información de distintos departamentos o áreas y niveles
jerárquicos de la empresa, así como la eficiencia en la provisión operacional de
dicha información.
En este sentido, las bases de datos que conforman el componente de
almacenamiento físico del DW se caracterizan por los siguientes aspectos:
Integradas: deben constituir un conjunto de datos y metadatos perfectamente
integrados con respecto al nombre de las variables, formatos de los distintos
campos, medida de los atributos, codificación, etc.
Temáticas: las bases de datos deben conformarse hacia materias o temas,
como clientes, productos, campañas, etc., a diferencia de las bases de datos
de los sistemas operacionales, más orientadas a procesos administrativos.
Históricas: éste es un factor clave en la toma de decisiones, contar con
información histórica para comparar datos en distintos períodos e identificar
tendencias. El tiempo debe estar en todos y cada uno de los registros del DW,
de manera que, cuando un dato entra en el DW se sepa en qué momento tenía
ese valor.
No Volátiles: la información una vez incorporada al DW debe mantenerse, en
general, invariable, cargándose una vez en el tiempo y no permitiendo
actualizaciones de los datos.
5.5 Justificación del data warehouse en la gestión comercial
Existen varias razones que justifican la creación del Data Warehouse para obtener
la información necesaria en los procesos de gestión comercial, en lugar de obtener

Pág. 17
esa información directamente de las bases de datos de las aplicaciones
operacionales:
Rendimiento: se tarda mucho menos en acceder a los datos del repositorio del
Data Warehouse que en hacer una consulta a varias bases de datos distintas.
Además hacer consultas complicadas a las bases de datos de los sistemas
operacionales puede empeorar el tiempo de respuesta de estos sistemas para
otros usuarios. Múltiples orígenes de datos: combinar los datos de distintas
fuentes suele ser una tarea bastante complicada para las personas encargadas de
tomar decisiones con esa información. Normalmente hay que homogenizar los
datos de una forma u otra. Por ejemplo, es probable que no se utilicen los mismos
criterios de almacenamiento (nombres de las entidades, atributos considerados,
tipos etc.) en las bases de datos de distintos departamentos. Sin embargo, en el
DW los datos se homogenizan durante el proceso de carga.
Limpieza de los datos: las empresas no siempre cuentan con aplicaciones
únicas para cada parte de la operativa del negocio, sino que pueden poseer
replicaciones y distintos sistemas para atender un mismo conjunto de
operaciones, y en esos caso es probable que las bases de datos de los
sistemas operacionales contengan datos duplicados, a veces erróneos,
superfluos o incompletos. Estos datos se corrigen durante el proceso de carga
al Data Warehouse.
Ajustes: en ocasiones se hace necesario un ajuste de los datos para posibles
comparaciones. Por ejemplo si se está combinando información financiera de
distintos países habrá que ajustar toda esta información conforme a una única
norma contable para hacerla comparable. Esos ajustes ya se realizan en el DW
durante el proceso de carga mencionado.
Periodicidad: La periodicidad de los datos en las distintas bases de datos
puede ser distinta diaria, semanal, mensual etc..Como en los casos anteriores

Pág. 18
para posibles comparaciones es necesaria la homogeneización ya realizada en
el DW.
Datos históricos: Los datos históricos no se suelen guardar en los sistemas
operacionales, pero son un elemento esencial de cualquier análisis. El Data
Warehouse es el lugar adecuado para estos datos.
Agregados: Muchas veces para tomar decisiones, no es necesario entrar en la
línea de mas detalle durante el análisis, en este sentido, en el Data Warehouse
se suelen guardar sólo los agregados necesarios (por ejemplo el importe total
de ventas trimestralmente en cada punto de venta, el tipo de publicidad más
efectivo en función de la edad del público objetivo etc.).
Por tanto, la plataforma Data Warehouse lejos de ser un punto final en la cadena
de automatización de la actividad y gestión del conocimiento de la organización,
se ha convertido en la puerta hacia una nueva dimensión en la concepción de las
corporaciones.
El Data Warehouse junto con una nueva serie de herramientas, enmarcadas bajo
la denominación de Data Mining- (minería de datos) permiten, no sólo, el análisis
de la información, sino también, y esto es lo realmente importante y diferencial, el
planteamiento y descubrimiento automático de hechos e hipótesis (patrones,
reglas, grupos, funciones, modelos, secuencias, relaciones, correlaciones...) que
pueden desembocar:
En importantes descubrimientos para la gestión comercial de información y/o
conocimiento no visibles a partir de los grandes volúmenes de datos
almacenados en las bases de datos de los sistemas operacionales de las
corporaciones.

Pág. 19
En un aumento de la eficacia y productividad para las empresas en el terreno
comercial.
5.6 Logros del data warehose en la gestión comercial
El proceso de remodelación de las empresas, para adaptarse a los nuevos
escenarios comerciales y a las necesidades del cliente, tiene entre sus principales
retos:
El enfoque al cliente: el centro de la economía actual ya no es el producto
sino el cliente.
Inteligencia de clientes: Se necesita tener conocimiento sobre el cliente para
poder desarrollar productos/servicios enfocados a sus expectativas.
Interactividad: El proceso de comunicación debe pasar de un monólogo (de la
empresa al cliente) a un diálogo (entre la empresa y el cliente).
Fidelización de clientes: Es mucho mejor y más rentable (del orden de seis
veces menor) fidelizar a los clientes que adquirir clientes nuevos.
El eje de la comunicación es el marketing directo enfocado a clientes
individuales en lugar de en medios "masivos" (TV, prensa, radio etc.).
Personalización: Cada cliente quiere comunicaciones y ofertas
personalizadas
Por tanto, el reto actual de las corporaciones es conseguir conocer a los clientes y
actuar en consonancia, cuando en lugar de tener unos pocos cientos clientes,
como se tenía antes de la globalización de mercados, se pueden llegar a tener
millones.
En ese sentido, el reto es tecnológicamente posible con soluciones basadas en el
uso de DW y bases de datos combinadas con otras tecnologías de la información
y la comunicación, tales como técnicas estadísticas y de minería de datos,
sistemas de información geográfica, uso de intranet, extranet e Internet, etc. A

Pág. 20
través de dichas soluciones se puede dar respuesta a los retos indicados
anteriormente:
Enfoque al cliente: las bases de datos ahora son temáticas y entre sus temas o
materias de interés se encuentran los clientes, además de otros como productos,
campañas, ventas, competencia, etc.
Inteligencia de clientes: se pueden crear y tener acceso a una serie de
indicadores que permitan conocer aspectos tales como:
Quiénes son para la corporación los clientes fieles, ocasionales, potenciales o
cuáles reportan la mayor parte de los ingresos, por ejemplo a través de la
segmentación por modelos estadísticos de la base de datos.
Cuál es la tipología de disposición al consumo, los hábitos de consumo, la
rentabilidad, por ejemplo mediante técnicas de análisis de los datos.
Cuáles son áreas dónde se concentran los clientes actuales y los potenciales,
cuáles son las áreas de cobertura, en definitiva, el geomarketing es posible con
la combinación de los datos almacenados y los GIS (Sistemas de Información
Geográfica).
Interactividad: la combinación DW con Internet/Intranet está dando lugar a un
nuevo concepto los cyberwarehose que posibilitan una nueva comunicación on-
line entre la empresa y el cliente que dilata el tiempo (24h al día) y agiliza y
aumenta la disponibilidad de comunicación.
Fidelización de clientes: un mejor conocimiento del cliente permite que se
mejoren constantemente las características de las ofertas, el enfoque de las
mismas y los servicios consiguiendo “atrapar al cliente”. Además, con nuevos
datos provenientes de proveedores externos se puede ampliar la base de datos
con la incorporación selectiva de potenciales y la selección de áreas con mayor
presencia de potenciales.

Pág. 21
Marketing directo: se pasa a desarrollar campañas basadas en perfiles con
productos, ofertas y mensajes dirigidos específicamente a ciertos tipos de clientes,
en lugar de emplear medios masivos con mensajes no diferenciados.
Con el análisis de los clientes se puede conocer cómo dirigirse a ellos
posibilitando una comunicación diferenciada, basada en el conocimiento de
éste (sexo, nivel de estudios, tamaño del hogar, etc.).
Con la incorporación de datos de las campañas, con el seguimiento de la
consecución de objetivos, etc. se dispone de un soporte para valorar la
efectividad de las acciones de marketing, permitiendo además la optimización
de campañas futuras.
Personalización: a través de segmentación de clientes y de los patrones de
comportamiento que se pueden anticipar con técnicas de Data Mining sobre el
repositorio, se puede llegar a la personalización del mensaje, en fondo y en forma,
hecho que le permite a la empresa aumentar drásticamente la eficacia de sus
acciones de comunicación. Con el marketing one to one en última instancia, se
están consiguiendo eficacias comerciales del 87% al 92%.
En la actualidad son ya numerosas las organizaciones, de diferentes sectores de
la economía, que han implantado soluciones basadas en DW, por ejemplo:
Bacardí Martini (distribución de bebidas) utiliza la información de ventas existente
en el DW para optimizar la utilización de recursos con el fin de lograr el máximo de
ventas con un coste preestablecido de antemano.
Pierre Fabré Ibérica (laboratorio multinacional cosmético y farmacéutico) utiliza un
DW comercial para el seguimiento de ventas por zona geográfica, organización
comercial, por producto, cliente, cadena y campaña etc., integrado en la aplicación
de red de ventas, produce también un extenso informe mensual requerido por la
casa matriz francesa.
Pastas La Familia (producción y distribución de alimentos) cuenta con un DW
comercial que se destaca por la integración de la información presupuestaria en el

Pág. 22
ámbito de familia de producto y cadena, genera hojas electrónicas con información
real del año en curso, sobre las cuales el departamento correspondiente calcula
los presupuestos del próximo año.
SEUR (empresa de mensajería y transporte de paquetes) posee un DW de más
de 80 millones de registros para seguimiento estadístico de los movimientos
operativos, que permite realizar unos análisis mucho más detallados y precisos de
envíos por ejemplo por origen y destino, por volumen, peso o precios de envío.
El diario El Mundo cuenta con un DW cuyo objetivo es obtener información
completa sobre la contratación de publicidad en sus medios.
Las organizaciones comentadas a título de ejemplo están utilizando
estratégicamente la información y el conocimiento obtenido del DW en diversos
procesos de su gestión comercial.
5.7 Técnicas más usadas en la minería de datos
Las técnicas que más disponen de información y que se describirán a
continuación son:
Redes neuronales
Árboles de decisión
Algoritmos genéticos
Modelos Lineales
Sistemas basados en conocimiento y sistemas expertos
Clustering

Pág. 23
Aprendizaje automático
CRISP-DM (Cross Industry Standard Process for Data Mining)
5.7.1 Redes neuronales
Inspirados en la anatomía y fisiología del cerebro humano, las Redes Neuronales
Artificiales (RNA) son modelos matemáticos que permiten hacer computación
inteligente y llevar a cabo tareas que las computadoras seriales no pueden
realizar: reconocimiento de patrones, memorias y aprendizaje asociativo, control
adaptivo, predicción de series de tiempo, clasificación de señales y clustering,
entre otras.
En una computadora neuronal el procesamiento es distribuido a toda una red de
procesadores denominados “neuronas” que realizan el cómputo en paralelo. La
propiedad de distribución y la capacidad de paralelizar los procesos determinan
las nuevas capacidades implicadas en el paradigma neuronal. Desde el punto de
vista de la minería de datos, el procesamiento paralelo y distribuido es muy
importante porque permite que las redes neuronales sean capaces de llevar a
cabo el procesamiento de datos a una escala masiva.
Una de las principales características de las redes neuronales, es que son
capaces de trabajar con datos incompletos e incluso paradójicos, que
dependiendo del problema puede resultar una ventaja o un inconveniente.
Además esta técnica posee dos formas de aprendizaje: supervisado y no
supervisado.
Esta técnica de inteligencia artificial, en los últimos años se ha convertido en uno
de los instrumentos de uso frecuente para detectar categorías comunes en los
datos, debido a que son capaces de detectar y aprender complejos patrones, y
características de los datos.

Pág. 24
5.7.2 Árboles de decisión
Está técnica se encuentra dentro de una metodología de aprendizaje supervisado.
Su representación es en forma de árbol en donde cada nodo es una decisión, los
cuales a su vez generan reglas para la clasificación de un conjunto de datos.
Los árboles de decisión son fáciles de usar, admiten atributos discretos y
continuos, tratan bien los atributos no significativos y los valores faltantes. Su
principal ventaja es la facilidad de interpretación.
Los algoritmos de árbol de decisión consisten en organizar los datos en elecciones
que compiten formando ramas de influencia después de una decisión inicial. El
tronco del árbol representa la decisión inicial, y empieza con una pregunta de sí o
no, como tomar o no desayuno. Tomar desayuno y no tomar desayuno serían las
dos ramas divergentes del árbol, y cada elección posterior tendría sus propias
ramas divergentes que llevan a un punto final.
5.7.3 Algoritmos genéticos
Los algoritmos genéticos, herramienta utilizada en esta investigación, son una
técnica matemática de búsqueda y optimización que encuentra soluciones a un
problema basándose en los principios que rigen la evolución de las especies a
nivel genético molecular. Estos algoritmos requieren de un conjunto de datos para
realizar su proceso de aprendizaje.
Los algoritmos genéticos imitan la evolución de las especies mediante la mutación,
reproducción y selección, como también proporcionan programas y optimizaciones
que pueden ser usadas en la construcción y entrenamiento de otras estructuras

Pág. 25
como es el caso de las redes neuronales. Además los algoritmos genéticos son
inspirados en el principio de la supervivencia de los más aptos.
Esta herramienta se usa en las primeras fases de la minería y después se aplica
redes neuronales o regresión logística.
5.7.4 Sistemas basados en conocimiento y sistemas expertos
Permiten la formalización de árboles y reglas de decisión, extraídas del
conocimiento de expertos. Poseen motores de inferencia, que gestionan las
preguntas. De esta forma el proceso de decisión es eficiente y rápido.
5.7.5 Modelos de regresión lineal
Es la más utilizada para formar relaciones entre datos. Rápida y eficaz pero
insuficiente en espacios multidimensionales donde puedan relacionarse más de 2
variables.
5.7.6 Agrupamiento o clustering
Es un procedimiento de agrupación de una serie de vectores según criterios
habitualmente de distancia; se tratará de disponer los vectores de entrada de
forma que estén más cercanos aquellos que tengan características comunes.
Agrupan datos dentro de un número de clases preestablecidas o no, partiendo de
criterios de distancia o similitud, de manera que las clases sean similares entre sí
y distintas con las otras clases. Su utilización ha proporcionado significativos
resultados en lo que respecta a los clasificadores o reconocedores de patrones,

Pág. 26
como en el modelado de sistemas. Este método debido a su naturaleza flexible se
puede combinar fácilmente con otro tipo de técnica de minería de datos, dando
como resultado un sistema híbrido.
Un problema relacionado con el análisis de cluster es la selección de factores en
tareas de clasificación, debido a que no todas las variables tienen la misma
importancia a la hora de agrupar los objetos. Otro problema de gran importancia y
que actualmente despierta un gran interés es la fusión de conocimiento, ya que
existen múltiples fuentes de información sobre un mismo tema, los cuales no
utilizan una categorización homogénea de los objetos. Para poder solucionar estos
inconvenientes es necesario fusionar la información a la hora de recopilar,
comparar o resumir los datos.
5.7.7 Aprendizaje automático
Esta técnica de inteligencia artificial es utilizada para inferir conocimiento del
resultado de la aplicación de alguna de las otras técnicas antes mencionadas.
Las técnicas de aprendizaje automático son una alternativa para clasificar y
predecir acciones futuras en el sistema. En algunos enfoques de sistemas
recomendadores, durante el proceso de recomendación se opta por modelar las
referencias de los usuarios mediante técnicas de aprendizaje automático, tales
como: redes neuronales, árboles de decisión, redes bayesianas, etc.
Estos algoritmos de clasificación supervisada se utilizan comúnmente como parte
de las técnicas de minería de datos justamente cuando se cuenta con una enorme
cantidad de datos que necesitan ser clasificados y analizados.

Pág. 27
5.7.8 CRISP-DM (Cross Industry Standard Process For Data Mining)
Incluye descripciones de las fases normales de un proyecto, las tareas necesarias
en cada fase y una explicación de las relaciones entre las tareas.
Como modelo de proceso, ofrece un resumen del ciclo vital de minería de datos
La metodología esta descrita en términos de un modelo jerárquico, que consiste
en conjunto de tareas dividida en cuatro niveles de abstracción, de lo general a lo
específico, los niveles son: fases, tareas genéricas, tareas especializadas y las
instancias de proceso.
5.8 ALGORITMOS EN MINERÍA DE DATOS
La funcionalidad de los algoritmos es encontrar patrones de datos y relaciones en
grandes conjuntos de información; estos son conjuntos de reglas para resolver un
problema mediante una serie de pasos concretos. A continuación se presentan
algunos de los más utilizados:
5.8.1 El algoritmo K-means
El algoritmo K-means se basa en el análisis de grupos. Trata de dividir los datos
recogidos en "bloques" (clusters) separados agrupados por características
comunes.
5.8.2 El algoritmo A priori
El algoritmo Apriori normalmente controla los datos de transacciones. Por ejemplo,
en una tienda de ropa, el algoritmo podría controlar qué camisas suelen comprar
juntas los clientes.

Pág. 28
5.8.3 El algoritmo EM
Este algoritmo define parámetro analizando los datos y predice la posibilidad de
una salida futura o evento aleatorio dentro de los parámetros de datos. Por
ejemplo, el algoritmo EM podría intentar predecir el momento de una siguiente
erupción de un géiser según los datos de tiempo de erupciones pasadas.
5.8.4 Algoritmo PageRank
El algoritmo PageRank es un algoritmo base para los motores de búsqueda.
Puntúa y estima la relevancia de un trozo determinado de datos dentro de un gran
conjunto, como un único sitio web dentro de un conjunto mayor de todos los sitios
web de Internet.
5.8.5 Algoritmo AdaBoost
El algoritmo AdaBoost funciona dentro de otros algoritmos de aprendizaje que
anticipan un comportamiento según los datos observados para que sean sensibles
a extremos estadísticos. Aunque el algoritmo EM puede sesgarse debido a un
géiser que tiene dos erupciones en menos de un minuto cuando normalmente
tiene una erupción una vez al día, el algoritmo AdaBoost modificaría la salida del
algoritmo EM analizando la relevancia del extremo.
5.8.6 Naive Baye
El algoritmo Naive Baye predice la salida de una identidad basándose en los datos
de observaciones conocidas. Por ejemplo, si una persona tiene una altura de 6
pies y 6 pulgadas (1,97 m) y lleva una talla 14 de zapatos, el algoritmo Naive Baye
podría predecir con una determinada probabilidad que la persona es un hombre.

Pág. 29
5.8.7 Algoritmo CART
"CART" significa análisis de clasificación y árbol regresivo "Classification and
Regressive Tree". Al igual que los análisis de árboles de decisión, organiza los
datos según opciones que compiten, como si una persona ha sobrevivido a un
terremoto. Al contrario que los algoritmos de árboles de decisión, que sólo pueden
clasificar una salida o una salida numérica basada en regresión, el algoritmo
CART puede usar los dos para predecir la probabilidad de un evento.
5.8.8 Algoritmo del vecino k más cercano
Este algoritmo reconoce patrones en la ubicación de los datos y los asocia a los
datos con un identificador mayor. Por ejemplo, si quieres asignar una oficina postal
a cada ubicación geográfica del hogar y tienes un conjunto de datos para cada
ubicación geográfica del hogar, el algoritmo del vecino k más cercano asignará las
casas a la oficina postal más cercana según su proximidad.
5.8.9 Máquinas de vectores de soporte
Los algoritmos de máquinas de vectores de soporte toman datos de entrada y
predicen cuál de las dos posibles categorías incluye los datos de entrada. Un
ejemplo sería recoger los códigos postales de un grupo de votantes e intentar
predecir si un votante es demócrata o republicano.
5.9 MODELOS DE OPTIMIZACIÓN DE TRANSPORTE EXISTENTES
Se consideraran aquellos más actuales (últimos 20 años), dado que son los más
utilizados en el gremio del transporte desde que el tema se viene tratando.
Estos modelos presentan las siguientes características:

Pág. 30
Tienen como variables de decisión, los trazados de los recorridos y las
frecuencias.
Modelan los intereses de los usuarios y los operadores.
Toman en cuenta los datos de la demanda, la estructura y los costos de la red.
5.9.1 Modelo de Ceder y Wilson
Los autores presentan en un modelo de dos fases, cuya formulación está ligada
estrechamente con su estrategia de resolución. En la primera fase se determinan
los recorridos y en la segunda las frecuencias.
En la primera fase, se reflejan únicamente los objetivos de los usuarios,
minimizando las diferencias entre tiempos de viaje en vehículos efectivos y
óptimos, y los tiempos de transbordo si este existiera. En la segunda fase se
introducen las frecuencias de los recorridos como variables de decisión, lo que
permite calcular: los tiempos de espera y el tamaño de la flota necesaria para
cubrir los servicios.
5.9.2 Modelo de Baaj y Mahmassani
Este modelo propone minimizar una combinación de objetivos de usuarios y
operadores. El objetivo de los usuarios se representa como la minimización de los
tiempos de viaje (espera, en vehículo y trasbordo), los tiempos están ponderados
por las demandas en la función objetivo de los usuarios, así estos tendrán más
chance de ser transportados, utilizando caminos más cortos y mayores
frecuencias en la solución óptima. Los objetivos de los operadores están
representados por la cantidad de vehículos necesarios para cubrir todos los
recorridos con sus respectivas frecuencias.
Este modelo maneja una restricción que establece un máximo valor de ocupación
de los vehículos por sobre su capacidad de pasajeros sentados; esta restricción

Pág. 31
modela un determinado aspecto del nivel de confort de los pasajeros. El modelo
de asignación considera diferentes líneas para pasajeros que comparten el mismo
par origen-destino, utilizando como criterio principal, la minimización de los
trasbordos y el tiempo de viaje en los vehículos.
5.9.3 Modelo de Israeli y ceder
En este modelo, se incluye la utilización de los vehículos de interés tanto para
usuarios (si el vehículo viaja excedido en su capacidad se reduce el confort) como
para operadores (si el vehículo viaja con muchos asientos vacíos durante mucho
tiempo, la rentabilidad del recorrido disminuye). En este modelo se considera la
importancia de los costos de viaje, la espera y la importancia de la desocupación
de los vehículos.
5.9.4 Modelo de Krishna Rao Et Al
Se utilizan dos modelos de asignación diferentes. Para la fase uno, se considera
que los pasajeros viajando de un lugar a otro, seleccionan el recorrido más corto
en la red (quien los transporta con un menor tiempo de viaje), en caso de tener
más de una opción. Para la fase dos, se utiliza el modelo de asignación de Baaj y
Mahmassani.
5.9.5 Modelo de Gruttner Et Al
El modelo presentado difiere de los anteriores en la formulación de la función
objetivo, la que resume intereses de usuarios y operadores, expresando estos
últimos en términos de su rentabilidad. El modelo de asignación utiliza un modelo
logit para hallar las proporciones de demanda que utilizan cada línea.
Este modelo considera la demanda elástica, y modela la sensibilidad de esta
frente a una determinada solución utilizando el modelo logit.

Pág. 32
5.9.6 Modelo de Ngamchai y Lovell
Los autores proponen un modelo mediante el cual asumiendo simplificaciones en
el modelo de asignación, se puede derivar de forma analítica las frecuencias
óptimas para una determinada configuración de recorridos.
5.9.7 Modelo de Tom y Mohan
El modelo de estos autores es prácticamente el mismo que el de Baaj y
Mahmassani. En su formulación se incluye un término en la función objetivo, que
penaliza la demanda no satisfecha.
5.9.8 Modelo de Fan y Machemehl
El modelo de estos autores se basa en el de Baaj y Mahmassani, y agrega el
término de demanda no satisfecha a la función objetivo. Además se agregan
algunas restricciones adicionales: frecuencia máxima, mínima y máxima duración
de recorridos, y máxima cantidad de recorridos.
5.10 PRÁCTICAS UTILIZADAS EN LA CIUDAD DE MEDELLÍN
Las prácticas utilizadas en la ciudad de Medellín para la planeación, asignación y
administración de las rutas de las empresas de transporte colectivo, tienen una
estructura similar a los modelos presentados, con las siguientes características:
Tienen como variables de decisión los trazados de los recorridos y las frecuencias
de operación en su formulación.
En la función objetivo se representan los intereses de los usuarios y operadores.
Para los usuarios, generalmente se considera la minimización de los tiempos de
viaje entre todos los nodos de la red que componen un recorrido; estos tiempos

Pág. 33
generalmente incluyen tiempos de viaje en vehículo, de espera en la parada, y
penalización por trasbordo. Para la expresión de los objetivos de los operadores,
generalmente se considera el tamaño de la flota requerida (que representa los
costos de operación de los servicios). En el caso de la ciudad de Medellín los
modelos mencionados, no son detallados en la inclusión de la recaudación como
parte de la función objetivo de los operadores; esto se debe a que la cuantificación
de los ingresos no solo depende de la afluencia, sino de la política impuesta por
las autoridades que las regulan en otros países.
Las restricciones más comunes son las que acortan las frecuencias, el tamaño de
flota, las duraciones de los recorridos y el factor de ocupación de los vehículos.
Las diferencias estructurales más importantes entre los modelos, se presentan en
los siguientes niveles:
Una o dos fases: la mayoría de los modelos presentan la totalidad de su
formulación en una sola fase. Sin embargo algunos, principalmente a efectos de
su resolución, presentan formulaciones en dos fases, separando el tratamiento de
las variables de decisión (trazados de recorridos y frecuencias).
Objetivo único y multiobjetivo: la gran mayoría de los modelos presentados
resumen en su formulación los intereses de los usuarios y operadores en una sola
expresión, para lo cual se deben introducir coeficientes, que cumplen dos
funciones: realizar la conversión entre diferentes unidades y reflejar la importancia
relativa de los objetivos contrapuestos. El único modelo de optimización
multiobjetivo en sentido estricto, es el de Israelí y Ceder donde además se
presenta una metodología para seleccionar una solución no dominada particular.
Modelo de asignación: la solución óptima de un modelo depende fuertemente del
modelo de asignación. La complejidad de expresar el modelo de asignación en
términos de las variables de decisión del problema en el contexto del modelo de
optimización, hace que generalmente se exprese en forma implícita. De esta

Pág. 34
forma, valores como los tiempos de viaje en vehículo y tiempos de espera para
una determinada solución serán conocidos una vez aplicado el modelo de
asignación.
5.11 NORMATIVIDAD DEL TRANSITO DE MEDELLIN
Para el desarrollo de la investigación, se indagó sobre la normatividad que rige el
sector de transporte público colectivo en la ciudad de Medellín y que a
continuación se mencionan:
LEYES:
Ley 1310 del 26 de junio de 2009, mediante el cual se unifican normas sobre
agentes de transito y transporte y grupos de control vial de las entidades
territoriales y se dictan otras disposiciones.
Ley 769 del 6 de julio de 2002, Por la cual se expide el Código Nacional de
tránsito Terrestre y se dictan otras disposiciones.
Ley 105 del 30 de diciembre de 1993, Por la cual se dictan disposiciones básicas
sobre el transporte, se redistribuyen competencias y recursos entre la Nación y las
Entidades Territoriales, se reglamenta la planeación en el sector transporte y se
dictan otras disposiciones.
Ley 906 del 31 de agosto de 2004, por la cual se expide el Código de
Procedimiento Penal.
Ley 1005 del 19 de enero de 2006, por la cual se adiciona y modifica el Código
Nacional de Tránsito Terrestre, Ley 769 de 2002.

Pág. 35
Ley 1083 31/07/2006: por medio de la cual se establecen algunas normas sobre
planeación urbana sostenible y se dictan otras disposiciones.
Capítulo I: movilidad sostenible en distritos y municipios con planes de
ordenamiento territorial.
Artículo 2°: c) Reorganizar las rutas de transporte público y tráfico sobre
ejes viales que permitan incrementar la movilidad y bajar los niveles de
contaminación.
Ley 105 de 1993: por la cual se dictan disposiciones básicas sobre el transporte,
se redistribuyen competencias y recursos entre la Nación y las entidades
territoriales, se reglamenta la planeación en el sector transporte y se dictan otras
disposiciones.
Capítulo II: principios rectores del transporte.
Artículo 3°, principios del transporte público: el transporte publico es
una industria encaminada a garantizar la movilización de personas o cosas
por medio de vehículos apropiados a cada una de las infraestructuras del
sector, en condiciones de libertad de acceso, calidad y seguridad de los
usuarios sujeto a una contraprestación económica y se regirá por los
siguientes principios: acceso al transporte, el carácter del servicio público
del transporte, la colaboración entre entidades, la participación ciudadana,
las rutas para el servicio público de transporte de pasajeros, la libertad de
empresa, los permisos o contratos de concesión, transporte intermodal y los
subsidios a determinados usuarios.
Capítulo III: regulación del transporte y el tránsito.
Artículo 6°, reposición del parque automotor del servicio de pasajeros
y/o mixto: la vida útil máxima de los vehículos terrestres de servicio público
colectivo de pasajeros y/o mixto será de veinte (20) años. Se excluyen de
esta reposición el parque automotor de servicio público colectivo de

Pág. 36
pasajeros y/o mixto (camperos, chivas) de servicio público colectivo de
pasajeros y/o mixto del sector rural, siempre y cuando reúnan los requisitos
técnicos de seguridad exigidos por las normas y con la certificación
establecida por ellas.
La vida útil máxima de los vehículos terrestres de servicio público colectivo
de pasajeros y/o mixto será de veinte (20) años. El ministerio de transporte
exigirá la reposición del parque automotor, garantizando que se sustituyan
por nuevos los vehículos que hayan cumplido su ciclo de vida util.
Artículo 7°, programa de reposición del parque automotor: las
empresas de carácter colectivo de pasajeros y/o mixto, y las organizaciones
de carácter cooperativo y solidario de la industria del transporte. Están
obligadas a ofrecerle a los propietarios de vehículos, programas periódicos
de reposición y a establecer y reglamentar fondos que garanticen la
reposición gradual del parque automotor, establecida en el artículo anterior
(6).
Ley 336 20 de diciembre 1996: estatuto general de transporte.
Capítulo I: disposiciones generales para los modos de transporte.
Artículo 3°: para los efectos pertinentes, en la regulación del transporte
público las autoridades competentes exigirán y verificaran las condiciones
de seguridad, comodidad y accesibilidad requerida para garantizarle a los
habitantes la eficiente prestación del servicio básico y de los demás niveles
que se establezcan el interior de cada Modo, dándole prioridad a la
utilización de medios de transporte masivo. En todo caso, el estado
regulara y vigilara la industria del transporte en los términos previstos en los
artículos 333 y 334 de la constitución política.

Pág. 37
Capitulo III: creación y funcionamiento de las empresas de transporte
público.
Artículo 11°: las empresas interesadas en prestar el servicio público de
transporte o constituidas para tal fin, deberá solicitar y obtener habilitación
para operar.
La habilitación, para efectos de esta ley, es la autorización expedida por la
autoridad competente en cada modo de transporte para la prestación del
servicio público de transporte.
El gobierno nacional fijara las condiciones para el otorgamiento de la
habilitación, en materia de organización y capacidad económica y étnica,
igualmente, señalara los requisitos que deberán acreditar los operadores,
tales como estados financieros debidamente certificados, demostración de
la existencia del capital suscrito y pagado, y patrimonio bruto, comprobación
del origen del capital, aportado por los socios, propietarios o accionistas,
propiedad, posesión o vinculación de equipos de transporte, factores de
seguridad, ámbito de operación y necesidades del servicio.
Capitulo IV: de la prestación del servicio.
Artículo 17°: el permiso para la prestación del servicio en áreas de
operación, rutas y horarios o frecuencias de despacho, estará sometido a
las condiciones de regulación o de libertad que para su prestación se
establezcan en los reglamentos correspondientes. En el transporte de
pasajeros existente o potencial, según el caso para adoptar las medidas
conducentes a satisfacer las necesidades de movilización.
Artículo 18°: el permiso para la prestación del servicio publico de
transporte es revocable e intransferible, y obliga a su beneficiario a cumplir
lo autorizado bajo las condiciones en él establecidas.
Artículo 19°: el permiso para la prestación del servicio publico de
transporte se otorgara mediante concurso en el que garanticen la libre
concurrencia y la iniciativa privada sobre creación de nuevas empresas,

Pág. 38
según lo determina la reglamentación que expida el gobierno nacional.
Cuando el servicio a prestar no esté sujeto a rutas y horarios
predeterminados el permiso se podrá otorgar directamente junto con la
habilitación para operar como empresa de transporte.
DECRETOS:
Decreto 007 de 2010, por el cual se adopta el plan estratégico de movilidad para
Medellín, y se dictan otras disposiciones.
Decreto 3422 de 2009, por el cual se reglamentan los sistemas de transporte
públicos (SETP) de conformidad con la ley 1151de 2007.
Decreto 0099 de 2010, por el cual se autoriza la implementación de subsistemas
de transporte para el mejoramiento en la prestación del servicio publico colectivo
de pasajeros en la ciudad de Medellín.
Decreto 170 de 2001, Por el cual se reglamenta el Servicio Público de Transporte
Terrestre Automotor Colectivo Metropolitano, Distrital y Municipal de Pasajeros.
Decreto 1881 de 2010, Por el cual se establecen las condiciones de presentación
de planes de rodamiento por parte de las empresas de transporte publico colectivo
del radio de acción municipal
Decreto 1449 de 2011, Por el cual se adoptan medidas para aplicar la
reglamentación del transporte público colectivo urbano accesible, con radio de
acción municipal.
Decreto 0560 de 2002, Por medio del cual se toman medidas sobre las rutas de
transporte público colectivo de la ciudad.

Pág. 39
Decreto 1739 de 2004, Por medio del cual se implementa el sistema de caja única
para todas las rutas que operan en la ciudad de Medellín.
Decreto 0373 de 2008, Por medio del cual se fijan las tarifas para el servicio
público de transporte municipal colectivo de las rutas urbanas, corregimientos e
integradoras a las estaciones del metro de la ciudad de Medellín.
Decreto 0428 de 2004, Por medio del cual se fija la tarifa para el servicio de
transporte público colectivo de los estudiantes de estratos 1,2 y 3 que cumplan
con los requisitos que establezca el programa “tiquete estudiantil”.
Decreto 0624 de 1989, Por el cual se expide el Estatuto Tributario de los
impuestos administrados por la Dirección General de Impuesto Nacionales.
Decreto 1698 de 2011, Por medio del cual se dictan normas para el recaudo
tarifario en el servicio público de transporte colectivo de las rutas urbanas y
corregimientos de la ciudad de Medellín.
Decreto 0288 de 2011, Por el cual se establecen los parqueaderos autorizados
para vehículos de transporte público colectivo, y se dictan otras disposiciones.
Decreto 0311 de 2002, Por el cual se crea “La mesa de trabajo sobre transporte,
tránsito y medio ambiente saludable”.
Decreto 0473 de 2002, Por el cual se exige el uso de equipos de control de
contaminación a las fuentes móviles automotores de mas de tres ruedas,
matriculados o que circulen en Medellín.
Decreto 0019 de 2012, Por el cual se establecen los criterios para la aplicación
del decreto: Medidas de inmediata aplicación, medidas que requieren
reglamentación o implementación de herramientas administrativas.

Pág. 40
Decreto 1760 de 2009, Por el cual se establecen reglas generales para la
administración de los inmuebles propiedad del municipio de Medellín y se dictan
otras disposiciones.
RESOLUCIONES:
Resolución 3027 de 2010, se describen el valor de las infracciones.
Resolución número 297 de 2010, Por medio de la cual se extiende el horario de
servicio y se establecen frecuencias de despacho en las horas de la noche para
algunas rutas de transporte público colectivo.
Resolución 479 de 2010(febrero 22)
Por la cual se expide el reglamento técnico para vehículos de servicio público
colectivo y especial de pasajeros con capacidad entre 10 y 79 pasajeros, no
incluido el conductor, y dictan otras disposiciones.
Resolución número 849 de 2007(octubre 08)
Por medio de la cual se fija la capacidad transportadora y se determinan las
frecuencias de despacho a una empresa de transporte público colectivo.
Resolución número 1182 de 2010(agosto 23)
Por medio del cual se establece un procedimiento para seleccionar los vehículos
de transporte público colectivo del radio de acción municipal, cuyas tarjetas de
operación o trámites de transporte han de ser suspendidos temporalmente hasta
que las empresas ajusten su capacidad transportadora a la autorizada por esta
secretaria en virtud de la sobre-oferta establecida en estudios técnicos.
Resolución número 1500 de 2010(0ctubre 06)
Por medio de la cual se autoriza el ajuste de capacidad a una empresa de
transporte público colectivo.

Pág. 41
Resolución número 004775 de 2009(octubre 10)
Por la cual se establece el manual de trámites para el registro o matrícula de
vehículos automotores y no automotores en todo el territorio nacional y se dictan
otras disposiciones.
5.12 IMPORTANCIA DE LA MEDICIÓN
La medición permite comparar una magnitud con un patrón preestablecido, lo que
permite observar el grado en que se alcanzan las actividades propuestas dentro
de un proceso específico.
Los resultados obtenidos a través de la medición permiten mejorar la planificación,
dado que es posible observar hechos en tiempo real, logrando tomar decisiones
con mayor certeza y confiabilidad.
Una adecuada medición requiere ser PERTINENTE, esto significa que las
mediciones que se lleven a cabo deberán ser relevantes y útiles para facilitar las
decisiones que serán tomadas sobre la base de sus resultados; PRECISA, debe
reflejar fielmente el comportamiento de las variables de medición, en este punto
interviene la adecuada elección del instrumento de medición; OPORTUNA, que
los resultados de la medición estén disponibles en el tiempo en que la información
es importante y relevante para la toma de decisiones, tanto para corregir como
para prevenir y ECONÓMICA, debe existir una proporcionalidad y racionalidad
entre los costos incurridos en la medición y los beneficios o la relevancia de la
información suministrada.

Pág. 42
5.13 Qué es un indicador
Un indicador es una expresión cualitativa o cuantitativa observable, que permite
describir características, comportamientos o fenómenos de la realidad a través de
la evolución de una variable o el establecimiento de una relación entre variables, la
que comparada con periodos anteriores o bien frente a una meta o compromiso,
permite evaluar el desempeño y su evolución en el tiempo.
Los indicadores sirven para establecer el logro y el cumplimiento de la misión,
objetivos, metas, programas o políticas de un determinado proceso o estrategia,
por esto podemos decir que son ante todo, que es la información que agrega valor
y no simplemente un dato, ya que los datos corresponden a unidades de
información que pueden incluir números, observaciones o cifras, pero si no están
ligadas a contextos para su análisis carecen de sentido. Por su parte la
información es un conjunto organizado de datos, que al ser procesados, pueden
mostrar un fenómeno y dan sentido a una situación en particular.
Los Indicadores permiten evidenciar el nivel de cumplimiento acerca de lo que
está haciendo la organización y sobre los efectos de sus actividades, a través de
la medición de aspectos tales como:
Recursos: Como talento humano, presupuesto, planta y equipos.
Cargas de Trabajo: Como estadísticas y metas que se tengan para un período
de tiempo determinado y el tiempo y número de personas requeridas para
realizar una actividad.
Resultados: Como ciudadanos atendidos, oficios respondidos, ejecución del
cronograma, niños vacunados, kilómetros construidos, etc.
Impacto: De los productos y/o servicios, tales como enfermedades prevenidas,
impuestos recolectados, niveles de seguridad laboral alcanzados.

Pág. 43
Productividad: Como casos atendidos por profesionales, solicitudes
procesadas por persona, llamadas de emergencia atendidas.
Satisfacción del Usuario: Como el número de quejas recibidas, resultados de
las encuestas, utilización de procesos participativos, visitas a los clientes.
Calidad y Oportunidad del Producto y/o Servicio: Como tiempos de
respuesta al usuario, capacidad para acceder a una instancia, racionalización
de trámites.
5.14 Características de los indicadores
Los indicadores deben cumplir con unos requisitos y elementos para poder apoyar
la gestión en el cumplimiento de los objetivos institucionales. Las características
más relevantes son las siguientes:
Oportunidad: Deben permitir obtener información en tiempo real, de forma
adecuada y oportuna, medir con un grado aceptable de precisión los resultados
alcanzados y los desfases con respecto a los objetivos propuestos, que permitan
la toma de decisiones para corregir y reorientar la gestión antes de que las
consecuencias afecten significativamente los resultados o estos sean irreversibles.
Excluyentes: cada indicador evalúa un aspecto específico único de la realidad,
una dimensión particular de la gestión. Si bien la realidad en la que se actúa es
multidimensional, un indicador puede considerar alguna de tales dimensiones
(económica, social, cultural, política u otras), pero no puede abarcarlas todas.
Prácticos: Que se facilite su recolección y procesamiento.
Claros: Ser comprensible tanto para quienes lo desarrollen como para quienes lo
estudien o lo tomen como referencia.
Por tanto, un indicador complejo o de difícil interpretación que sólo lo entienden
quienes lo construyen debe ser replanteado.

Pág. 44
Explícitos: Definir de manera clara las variables con respecto a las cuales se
analizará para evitar interpretaciones ambiguas.
Sensibles: Reflejar el cambio de la variable en el tiempo.
Transparente/Verificable: Su cálculo debe estar adecuadamente soportado y ser
documentado para su seguimiento y trazabilidad.

Pág. 45
6. METODOLOGIA
La calidad del servicio es vital dentro de una organización, para que esta se
mantenga en el mercado, por consiguiente una empresa que tiene baja calidad de
servicio es muy probable que desaparezca.
En el marco actual de las empresas que prestan servicio público colectivo, la
confluencia de nuevas infraestructuras de comunicación con potentes y flexibles
herramientas de tratamiento de información (bases de datos, Dta Warehouse,
Data Mining) mejoran la calidad, cantidad y eficiencia de los datos, así como el
análisis, procesamiento y comunicación de los mismos. En otras palabras, pueden
aportar a estas empresas las bases necesarias para afrontar los nuevos retos de
la situación actual y las perspectivas de futuro de la gestión comercial. De ahí, que
en este trabajo, se resalte el hecho de que las bases de datos y el DW permiten
en primera instancia el almacenamiento adecuado de los datos obtenidos de las
actividades habituales de estas empresas, producción, control de gestión,
planificación estratégica, etc. Pero además se incide en otro hecho, que es el que
a través de dichas herramientas estas empresas pueden extraer de dichos datos,
la información y el conocimiento que necesitan para identificar y responder
estratégicamente a las necesidades de su actividad comercial. Permitiendo un
mejor conocimiento del cliente para poder desarrollar estrategias y/o servicios
enfocados a sus expectativas. Ayudando a desarrollar ofertas y mensajes dirigidos
específicamente a ciertos tipos de clientes teniendo en cuenta que todos los
clientes no utilizan el servicio público colectivo. Como resultado se mejora el
proceso de gestión de información entre la empresa, los clientes y los directivos de
la empresa, hecho que redunda en la fidelización de los clientes y en el aumento
drástico de la eficacia en la gestión del conocimiento.

Pág. 46
OBJETIVO ACTIVIDADES TECNICAS FUENTES
Estudiar distintos enfoques para la
extracción de conocimiento como: la
calidad en la gestión empresarial, la
orientación hacia el cliente y
optimización de los servicios en
empresas de transporte público
colectivo en la ciudad de Medellín.
Conocimiento sobre: calidad en la gestión empresarial, orientación hacia el cliente y optimización de los servicios en empresas de transporte público colectivo
Conocimientos en empresas de transporte público colectivo.
Adecuación de los servicios para la estabilidad y comodidad de los clientes.
Marketing.
Orientación hacia la toma de decisiones.
Revisión documental Libros
Revistas
Artículos
Publicaciones web
Encuestas
Buzón de sugerencias
Definir los componentes del modelo
para la extracción de conocimiento
para empresas de transporte
público colectivo
Integración y recopilación.
Selección, limpieza y transformación.
Minería de datos.
Evaluación e interpretación
Difusión y uso
Diseñar un modelo conceptual para
la extracción de conocimiento para
empresas de transporte público
colectivo
Creación de una base de datos.
Interpretación de un modelo entidad relación.
Conocimiento en Analisys Services.
Conocimiento en SQL server.
Funcionalidad de una minería de datos.

Pág. 47
6.1 Enfoque para la extracción de conocimiento como: la calidad en la gestión
empresarial, la orientación hacia el cliente y optimización de los servicios en
empresas de transporte público colectivo en la ciudad de Medellín.
6.2 Componentes del modelo para la extracción de conocimiento para empresas
de transporte público colectivo
Los pasos a seguir para la realización de un proyecto de extracción de datos son
siempre los mismos, independientemente de la técnica específica de extracción de
conocimiento usada.
6.2.1 Análisis de desarrollo para extracción
Para el planteamiento teórico de la extracción de conocimiento del trabajo propuesto,
se toma como referente la aplicación de la metodología CRISP-DM, la cual se define a
partir de experiencias consultadas y tomando lo mejor de los procedimientos más
exitosos o populares.
Esta metodología incluye un modelo y una guía, estructurados en seis fases:
A continuación veremos cada fase de CRISP-DM con sus tareas respectivas:
1. Comprensión del Negocio:
- Determinar objetivos del negocio.
- Valoración de la situación.
- Determinar los objetivos de DM.

Pág. 48
- Realizar el plan del proyecto.
2. Comprensión de los Datos:
- Recolectar los datos iniciales.
- Descripción de los datos.
- Exploración de los datos.
- Verificar la calidad de los datos.
3. Preparación de Datos:
- Seleccionar los datos.
- Limpiar los datos.
- Estructurar los datos.
- Integrar los datos.
- Formateo de los datos.
4. Modelado:
- Seleccionar técnica de modelado.
- Generar el plan de prueba.
- Construir el modelo.
- Evaluar el modelo.
5. Evaluación:
- Evaluar los resultados.
- Revisión del proceso.
- Determinar próximos pasos.
6. Implementación:
- Plan de implantación.
- Plan de monitoreo y mantención.
- Informe final.
- Revisión del proyecto

Pág. 49
6.2.2 FASES
Las fases de la metodología CRISP-DM son las siguientes:
Las flechas indican las relaciones más habituales entre las fases, aunque se pueden
establecer relaciones entre cualquier fase. El círculo exterior simboliza la naturaleza
cíclica del proceso de modelado.
Comprensión
del Negocio
Comprensión
de los Datos
Preparación de
Datos
Modelado
Evaluación
Implementación
Datos

Pág. 50
6.2.3 Propuesta de modelo de extracción según metodología CRIPS-DM
Para el desarrollo de la propuesta de extracción de conocimiento en una empresa de
transporte público colectivo en la ciudad de Medellín a partir de una base de datos se
tienen en consideración la implementación de las siguientes fases:
1. Comprensión del negocio: la empresa de transporte público colectivo, busca
mejorar los ejes temáticos de calidad de la gestión empresarial, calidad de
atención al cliente y optimización de los servicios, por medio de la generación
de indicadores para hacer un seguimiento de su frecuencia previamente
definida que a su vez apoyen a la toma de decisiones a las directivas de la
empresa. Estos indicadores no existen o complementan los manejados en esta.
Para la construcción se parte de una base de datos elaborada en SQL Server
2008 y para la implementación de los indicadores se utiliza la herramienta
Analysis Server de la misma.
2. Comprensión de los datos: los datos seleccionados para realizar la extracción
del conocimiento corresponden a la información del personal vinculado a la
empresa, los vehículos, los horarios, los insumos, las rutas, los recorridos y las
averias, con el fin de tener el mayor aprovechamiento de los datos relacionados
con los ejes temáticos de calidad de la gestión empresarial, atención al cliente y
optimización de los servicios.
3. Preparación de los datos: Toda la información necesaria para realizar el
desarrollo del proyecto propuesto se encuentra en una única base de datos y
no se hace necesario integrar otros orígenes. Los atributos seleccionados para
realizar la extracción de conocimiento en la base de datos de transporte público
colectivo corresponden a indicadores que buscan analizar resultados,
productividad, recursos, satisfacción del usuario, y cargas de trabajo. El objetivo
es asociar en una sola tabla las dimensiones necesarias (lugar, fecha y hecho)
para la elaboración de los cubos.

Pág. 51
4. Modelado: para la realización de este paso se utilizaron las técnicas de minería
de datos del SQL Server 2008, utilizando la herramienta SQL Server Business
Intelligence Development Studio, específicamente SQL Server Analysis
Services (SSAS). A continuación se relacionan los indicadores a obtener con
este modelado:
Calidad en la gestión empresarial
Tipo de
Indicador
Nombre de
indicador
Formula del
indicador
Escala de
medición
Periodicidad
del indicador
Resultados
Porcentaje rutas
cumplidas
correctamente
(Total de rutas
despachadas /
total de rutas
cumplidas) x 100
% mensual
Productividad
Porcentaje de
averías por ruta
(Total de averías
por ruta / total de
averías) x 100
% mensual
Productividad
Porcentaje de
averías por
vehículo
(Total averías por
vehículo / total de
averías) x 100
% mensual
Resultados
Porcentaje
facturado por ruta
(Total facturado
por ruta / total
facturado) x 100
% mensual
Resultados
Porcentaje
facturado por
vehículo
(Total facturado
por (vehículo /
total facturado) x
100
% mensual
Productividad Costo de
operación por
(costo real del
vehículo - costo
Total Mensual

Pág. 52
vehículo presupuestado)
Productividad Ganancia de
operación por ruta
(valor de las
ventas totales por
ruta - costo
logístico total por
ruta)
Total Mensual
Productividad
Costo de
operación por
conductor
(costo total de
transporte /
número de
conductores)
Total Mensual
Productividad
Costo de
operación por
usuario
transportado
(costo total de
operación /
número de
usuarios
transportados)
Total Mensual
Productividad
Total de usuarios
transportados por
vehículo
Sumatoria de
usuarios
transportados por
vehículo
Total Mensual
Productividad
Porcentaje de
usuarios
transportados por
vehículo
(Total de usuarios
transportados por
vehículo / Total
de usuarios
transportados) x
100
% Mensual
Productividad Total de usuarios
transportados por
Sumatoria de
usuarios
transportados por
Total Mensual

Pág. 53
ruta ruta
Recursos Valor total de los
activos de logística
Sumatoria de
Valores de los
activos de
logística
Total Mensual
Recursos
Porcentaje de
proveedores
Certificados
(proveedores
certificados / total
de proveedores)x
100
% Mensual
Recursos Volumen de
compra
Sumatoria de
valor de compras Total Mensual
Recursos Gastos de
servicios públicos
Sumatoria de
valor de compras Total Mensual
Recursos Porcentaje de
Vejez de vehículos
(unidades
obsoletas /
unidades
disponibles) x
100
% Mensual
Recursos
Costo
almacenamiento
logística
(costo
almacenamiento /
número de
unidades
almacenadas)
Total Mensual
Productividad
Porcentaje de
productividad por
ruta
(valor real de
producción / valor
de producción
esperado) x100
% Mensual

Pág. 54
Productividad
Porcentaje de
productividad por
vehículo
(valor real de
producción / valor
de producción
esperado) x 100
% Mensual
Recursos Área de parqueo
(parqueaderos
disponible -
parqueadero
utilizado)
Total Mensual
Recursos
Porcentaje de
mantenimiento de
vehículos
(vehículos en
mantenimiento /
total de vehículos
disponibles) x
100
% Mensual
Recursos Cantidad Rotación
de vehículos
(fecha actual -
año modelo
vehículo)
Total Mensual
Calidad en la atención al cliente
Tipo de
Indicador
Nombre de
indicador
Formula del
indicador
Escala de
medición
Periodicidad
del indicador
Satisfacción
del Usuario
Atención al cliente
(horas
dedicadas a
responder
reclamos / horas
disponibles)
Total Mensual
Satisfacción
del Usuario
Porcentaje de
atención de
reclamos
(Reclamos
atendidos / total
de los reclamos)
% Mensual

Pág. 55
Optimización de los servicios
Tipo de
Indicador
Nombre de
indicador
Formula del
indicador
Escala de
medición
Periodicidad
del indicador
Resultados
Porcentaje de tiempo
de ruta
(Rutas a tiempo /
total de las rutas
despachadas) x
100
% Mensual
Resultados
Promedio de tiempo
por ruta
Se obtiene
dividiendo la
suma de estas
cantidades entre
el número de
ellas
% Mensual
Resultados
Promedio de tiempo
por vehículo
Se obtiene
dividiendo la
suma de estas
cantidades entre
el número de
ellas
% Mensual
Resultados Rendimiento de
vehículo
(número de
usuarios
transportados /
capacidad max
del vehículo) x
100
% Mensual
Resultados Comparativo costo
de transporte
(costo de
transporte propio
x unidad / costo
contratar
transporte x
Total Mensual

Pág. 56
unidad)
Resultados Porcentaje de
rendimiento por ruta
(total usuarios
reales / total de
usuarios
esperados) x 100
% Mensual
Resultados
Porcentaje de
rendimiento por
vehículo
(total usuarios
reales / total de
usuarios
esperados) x 100
% Mensual
Cargas de
Trabajo
Porcentaje de horas
por vehículos
(Horas de
vehículo
utilizadas / horas
disponibles) x
100
% Mensual
Cargas de
Trabajo
Disponibilidad
servicio por vehículo
(Número de días
por mes en
servicio por
vehículo / días
disponible por
mes)
Total Mensual
Cargas de
Trabajo
Disponibilidad
servicio por
conductor
(Número de días
por mes en
servicio por
conductor / días
disponible por
mes)
Total Mensual
Resultados
Diferencia periódica
de recorrido en una
ruta
(distancia real
recorrida –
distancia
estándar
Total Mensual

Pág. 57
recorrida)
Resultados Rendimiento de
combustible por ruta
(uso real de
combustible –
uso estándar de
combustible)
Total Mensual
Resultados Rendimiento de
horas por ruta
(hora real por
ruta – horas
estándar por
ruta)
Total Mensual
Cargas de
Trabajo
Porcentaje de
actividad por
conductor
(horas
trabajadas /
horas
esperadas) x 100
% Mensual
Cargas de
Trabajo
Porcentaje de
inactividad por
conductor
(100 – (horas
trabajadas /
horas
esperadas))
% Mensual

Pág. 58
5. Evaluación: en esta fase se evalúa el modelo escogido, y si cumple o no
cumple con los objetivos propuestos para la extracción del conocimiento. Se
revisa el proceso teniendo en cuenta los resultados obtenidos para repetir
alguna fase en caso que se hayan cometido errores.
6. Despliegue: los modelos y reglas obtenidos podrán ser utilizados por una
empresa de transporte público colectivo como modelo de extracción de
conocimiento y así podrán trazar estrategias que le permitan elevar la calidad
en la gestión empresarial, la calidad en la atención al cliente y la optimización
de los servicios.

Pág. 59
6.3 Modelo conceptual para la extracción de conocimiento para empresas de
transporte público colectivo
ESTRUCTURACIÓN Y ADMISNITRACIÓN DE LOS DATOS
Tablas con sus respectivos campos
TABLA COLUMNA DESCRIPCIÓN TIPO TAMAÑO NULLEABLE PRIMARY/FOREIGN
KEY
Conductor
idConductor Identificador único del conductor bigint NO PRIMARY KEY
apellidos Apellidos del conductor varchar 50 SI
direccion Direccion de la vivienda del conductor varchar 50 SI
edad Edad del conductor int SI
idGenero Referencia tabla genero bigint SI FK: tabla Genero
nombres nombre del conductor varchar 50 SI
telefono Telefonos de contacto del conductor int SI
Genero
idGenero Identificador unico del genero bigint NO PRIMARY KEY
esActivo Informa si el genero esta activo (True) o inactivo (False) bit 1 NO
inicial La sigla o letra inicial del nombre del genero varchar 5 NO
tipoGenero
Indica el tipo de genero, los generos son: Masculino, Femenino e Indefinido varchar 50 NO
Horario
idHorario Identificador unico del horario bigint NO PRIMARY KEY
esActivo Informa si el horario esta activo (True) o inactivo (False) bit 1 NO
horaDesde Hora de inicio del horario varchar 10 SI
horaHasta Hora final del horario varchar 10 SI
idTipoHorario Referencia tabla TipoHorario bigint SI FK: tabla TipoHorario
nombreHorario Nombre del horario varchar 50 SI
Insumos
idInsumo Identificador unico de insumo bigint NO PRIMARY KEY
esActivo Informa si el insumo esta activo (True) o inactivo (False) bit 1 NO
nombreInsumo Nombre del insumo varchar 50 NO
valorUnitario Valor unitario del insumo int NO
Insumos_Recorrido
idInsumo_Recorrido Identificador unico de insumo recorrido bigint NO PRIMARY KEY
cantidadInsumo Cantidad de insumos en un recorrido int SI
idInsumo Referencia tabla Insumo bigint NO FK: tabla Insumo
idRecorrido Referencia tabla Recorrido bigint NO FK: tabla Recorrido
Marca idMarca Identificador unico de la marca bigint NO PRIMARY KEY
nombre Nombre de la marca varchar 50 SI
Recorrido idRecorrido Identificador unico del recorrido bigint NO PRIMARY KEY

Pág. 60
idTipoFrecuencia Referencia tabla TipoFrecuencia bigint SI FK: tabla TipoFrecuencia
kilometros Numero de kilómetros int NO
NombreRecorrido nombre del recorrido varchar 200 NO
Recorrido_Horario idRecorridoHorario
Identificador unico del recorrido horario bigint NO PRIMARY KEY
idHorario Referencia tabla Horario bigint NO FK: tabla Horario
idRecorrido Referencia tabla Recorrido bigint NO FK: tabla Recorrido
Ruta
idRuta Identificador unico de la ruta bigint NO PRIMARY KEY
idRecorridoHorario Referencia tabla Recorrido_Horario bigint NO FK: tabla Recorrido_Horario
idTipoAveria Referencia tabla TipoAveria bigint SI FK: tabla TipoAveria
idValorRuta Referencia tabla ValorRuta bigint NO FK: tabla ValorRuta
idVehiculo Referencia tabla Vehículo bigint NO FK: tabla Vehículo
idVelocidad Referencia tabla Velocidad bigint NO FK: tabla Velocidad
TipoAveria
idTipoAveria Identificador unico de las averias bigint NO PRIMARY KEY
esActivo Informa si el tipo de averia esta activo (True) o inactivo (False) bit 1 NO
nombreAveria
Indica los tipos de averias que pueden ser por: Chasis, Direccion, Motor, Carroceria Externa, Carroceria Interna, Sistema de frenos, Fallos electronicos, Barra estabilizadora, Bombillas Fundidas, Brazos de Suspensión, Fuga de Aceite, Radiador, Sistema de Rodamiento varchar 50 NO
TipoFrecuencia
idTipoFrecuencia Identificador unico de las frecuencias bigint NO PRIMARY KEY
esActivo Informa si el tipo de frecuencia esta activo (True) o inactivo (False) bit 1 NO
TipoFrecuencia
Indica los tipos de frecuencias que pueden ser: Nunca, Siempre, Medianamente, Semanal, Quincenal, Mensual, Trimestral, Semestral, Anual varchar 50 NO
TipoHorario
idTipoHorario Identificador unico del horario bigint NO PRIMARY KEY
esActivo Informa si el tipo de horario esta activo (True) o inactivo (False) bit 1 NO
tipoHorario Indica los tipos de horario que son: Nocturno, Diurno varchar 50 NO
TipoVehiculo
idTipoVehiculo Identificador unico del tipo de vehículo bigint NO PRIMARY KEY
esActivo Informa si el tipo de vehiculo esta activo (True) o inactivo (False) bit 1 NO
tipoVehiculo
Indica los tipo de vehículo que se tiene, son: Bus, Buseta, Micro Bus, Mini Bus, Minivan varchar 50 NO
ValorRuta
idValorRuta Identificador unico del valor de la ruta bigint NO PRIMARY KEY
esActivo Informa si el valor de la ruta esta activo (True) o inactivo (False) bit 1 NO
valor Valor monetario de la ruta int NO
Vehiculo idVehiculo Identificador unico del vehículo bigint NO PRIMARY KEY
idMarca Referencia tabla Marca bigint NO FK: tabla Marca

Pág. 61
idTipoVehiculo Referencia tabla TipoVehiculo bigint NO FK: tabla TipoVehiculo
Vehiculos_Conductor idVehiCond
Identificador unico del vehículo conductor bigint NO PRIMARY KEY
idConductor Referencia tabla Conductor bigint NO FK: tabla Conductor
idVehiculo Referencia tabla Vehículo bigint NO FK: tabla Vehículo
Velocidad
idVelocidad Identificador unico de la velocidad bigint NO PRIMARY KEY
inicial_km/h Valor inicial del rango de velocidad int SI
Final_km/h Valor final del rango de velocidad int SI
nombreVelocidad Nombre de la velocidad varchar 50 NO

Pág. 62
Reglas de transformación
Campo Antes Después
Genero Masculino M
Femenino F
EstadoCivil Soltero SO
Casado CA
Separado SE
Union Libre UL
Viudo VI
nombreVelocidad Alta A
Media M
Baja B
Fechas 19/01/2012 19-01-2012
Reglas de depuración
1. Reglas de integridad
Los Id en cada una de las dimensiones no se deben repetir, deben ser de
tipo identidad.
No deben haber conductores programados en dos rutas diferentes el
mismo día y a la misma hora.
Un conductor dolo puede tener una identificación.
Cada uno de los vehículos solo debe tener una placa.
2. Reglas de validación
Si el conductor tiene varias rutas asignadas, la identificación debe ser
igual.
La regla NOT NULL se debe cumplir en todas las dimensiones.
Se debe tener en cuenta el tipo de dato en el momento de la carga

Pág. 63
Reglas de carga
1. Método de carga
La carga de información se desarrolla de la siguiente manera:
Extracción de la información desde las fuentes.
Transformación de la información.
Transporte de la información
Validación de la información
Carga de la bodega de datos
Extracción Carga
OLTP ETL
(Transacción del proceso en línea) (Extracción, transformación y
carga)
BD
Temp
DM

Pág. 64
Técnicas de almacenamiento
Teniendo en cuenta la estructura de los datos se empleara la técnica de
almacenamiento denominada OLAP. A diferencia del OLTP, OLAP describe una clase
de tecnologías diseñadas para mantener específicamente el análisis y acceso a datos.
Mientras el procesamiento transaccional generalmente confía solamente en las bases
de datos relacionales, OLAP viene a ser un sinónimo con vistas multidimensionales de
los datos del negocio. Estas vistas multidimensionales se apoyan en la tecnología de
bases de datos multidimensionales. Estas vistas multidimensionales proporcionan la
base técnica para cálculos y análisis requeridos por las Aplicaciones del Negocio
Inteligente.
Las aplicaciones OLAP son usadas por analistas y gerentes que frecuentemente
quieren una vista de datos de nivel superior. Las bases de datos OLAP normalmente
se actualizan en lote, a menudo de múltiples fuentes, y proporcionan un back-end
analítico poderoso a las aplicaciones de múltiples usuarios. Por tanto, las bases de
datos OLAP se perfeccionan para el análisis.
Esta herramienta OLAP tiene tres principales características:
Un modelo multidimensional de la información para el análisis interactivo.
Un motor OLAP que procesa las consultas multidimensionales sobre los datos.
Un mecanismo de almacenamiento para guardar los datos.
Técnicas de presentación de los datos
Para la presentación de los datos lo podemos hacer en diferentes herramientas, en
este caso se escogió Excel.
Excel puede mostrar datos OLAP solo como informe de tabla dinámica o informe de
gráfico dinámico o en una función de hoja de cálculo convertida a partir de un informe
de tabla dinámica, pero no como intervalo de datos externo. Puede guardar los
informes de las tablas dinámicas y de los gráficos dinámicos OLAP en plantillas de
informes. Además, puede crear archivos de conexión de datos de Office (ODC, Office

Pág. 65
Data Connection) (.odc) para conectarse a bases de datos OLAP con el fin de efectuar
consultas OLAP. Al abrir un archivo ODC, Excel muestra un informe de tabla dinámica,
que ya está listo para que lo diseñe.
Recuperación de los datos
Un servidor OLAP devuelve nuevos datos a Microsoft Excel cada vez que se cambia el
diseño del informe. Con otros tipos de datos de origen externo, se consultan todos los
datos la vez, o se pueden establecer opciones para que la consulta se realice
solamente cuando se muestren elementos de campo de página (campo de página:
campo asignado a una orientación de página en un informe de tabla dinámica o de
gráfico dinámico. Puede mostrarse un resumen de todos los elementos de un campo
de página o bien un elemento cada vez que filtre los datos para los demás elementos.)
Diferentes. También están disponibles otras opciones para actualizar (actualizar:
renovar el contenido de un informe de tabla dinámica o gráfico dinámico para reflejar
los cambios realizados en el origen de datos subyacente. Si el informe está basado en
datos externos, la actualización ejecuta la consulta subyacente para recuperar los
datos nuevos o modificados.) El informe.
En informes basados en datos de origen OLAP, no está disponible la configuración del
campo de página (campo de página: campo asignado a una orientación de página en
un informe de tabla dinámica o de gráfico dinámico. Puede mostrarse un resumen de
todos los elementos de un campo de página o bien un elemento cada vez que filtre los
datos para los demás elementos.), la consulta en segundo plano ni la optimización de
la memoria.

Pág. 66
Diagrama del OLTP
Vehiculo
idVehiculo bigint
idTipoVehiculo bigint
idMarca bigint
Column Name Data Type Allow Nulls
TipoVehiculo
idTipoVehiculo bigint
tipoVehiculo varchar(50)
esActivo bit
Column Name Data Type Allow Nulls
Conductor
idConductor bigint
nombres varchar(50)
apellidos varchar(50)
telefono int
edad int
idGenero bigint
direccion varchar(50)
Column Name Data Type Allow Nulls
Ruta
idRuta bigint
idRecorridoHorario bigint
idVehiculo bigint
idTipoAveria bigint
idVelocidad bigint
idValorRuta bigint
Column Name Data Type Allow Nulls
Horario
idHorario bigint
nombreHorario varchar(50)
horaDesde varchar(10)
horaHasta varchar(10)
idTipoHorario bigint
esActivo bit
Column Name Data Type Allow Nulls
Recorrido
idRecorrido bigint
NombreRecorrido varchar(200)
kilometros int
idTipoFrecuencia bigint
Column Name Data Type Allow Nulls
TipoAveria
idTipoAveria bigint
nombreAveria varchar(50)
esActivo bit
Column Name Data Type Allow Nulls
FK_V ehiculo_TipoV ehiculo
FK_Ruta_V ehiculo
Vehiculos_Conductor
idVehiCond bigint
idVehiculo bigint
idConductor bigint
Column Name Data Type Allow Nulls
FK_V ehiculos_C onductor_C onductor
FK_V ehiculos_C onductor_V ehiculo
FK_Ruta_TipoA v eria
Recorrido_Horario
idRecorridoHorario bigint
idRecorrido bigint
idHorario bigint
Column Name Data Type Allow N...
FK_Recorrido_Horario_Horario
FK_Recorrido_Horario_Recorrido
FK_Ruta_Recorrido_Horario
Marca
idMarca bigint
nombre varchar(50)
Column Name Data Type Allow N...
FK_V ehiculo_Marca
Velocidad
idVelocidad bigint
nombreVelocidad varchar(50)
[inicial_km/h] int
[Final_km/h] int
Column Name Data Type Allow N...
FK_Ruta_V elocidad
Insumos
idInsumo bigint
nombreInsumo varchar(50)
valorUnitario int
esActivo bit
Column Name Data Type Allow Nulls
Insumos_Recorrido
idInsumo_Recorrido bigint
idInsumo bigint
idRecorrido bigint
cantidadInsumo int
Column Name Data Type Allow Nulls
FK_Insumos_Recorrido_Insumos
FK_Insumos_Recorrido_Recorrido
ValorRuta
idValorRuta bigint
valor int
esActivo bit
Column Name Data Type Allow Nulls
FK_Ruta_V alorRuta
TipoHorario
idTipoHorario bigint
tipoHorario varchar(50)
esActivo bit
Column Name Data Type Allow Nulls
FK_Horario_TipoHorario
TipoFrecuencia
idTipoFrecuencia bigint
TipoFrecuencia varchar(50)
esActivo bit
Column Name Data Type Allow Nulls
FK_Recorrido_TipoF recuencia
Genero
idGenero bigint
tipoGenero varchar(50)
inicial varchar(5)
esActivo bit
Column Name Data Type Allow Nulls
FK_C onductor_Genero

Pág. 67
Construcción del cubo (SQL server business intelligence Development Studio)

Pág. 68

Pág. 69

Pág. 70
7. CONCLUSIONES
El ejercicio investigativo permitió conocer las necesidades implícitas que se
convierten en falencias y una oportunidad para fortalecer las competencias en
las diversas áreas de la empresa que se basan en la consolidación de
información para la toma decisiones.
El modelo permite cualificar algunos procesos de la empresa para administrar
sus diferentes escalas jerárquicas, como un aporte del nivel operativo y del
comportamiento de la población que hace uso del servicio, al nivel
administrativo.
El ejercicio investigativo de campo, permitió confirmar el hermetismo que tiene
el sector de transporte público colectivo hacia la seguridad de la información
operativa del negocio y evidencia la falta de sistemas de captura, consolidación
y transformación de datos para el aprovechamiento en la misma. Estas
prácticas se observan claramente en el uso actual de planillas, talonarios y
registros manuales para el seguimiento de rutas, conductores y vehículos.
El modelo plantea estrategias de mejoramiento y calidad para comprender y
reconocer el aprovechamiento del recurso disponible relacionado con la
actividad del negocio, sus beneficios administrativos y económicos.
El modelo pone a consideración la inclusión de buenas prácticas en la empresa
para el seguimiento continuo de los procesos productivos de esta y la idea de
mejoramiento en el pensamiento de quienes trabajan en la organización.

Pág. 71
8. REFERENCIAS BIBLIOGRAFICAS
MOLINERO M., A. SANCHEZ A., I. (1998). Transporte Público: Planeación, Diseño,
Operación y Administración. 3ª Edición. México: Fundación ICA.
REVISTA CAMBIO (2004). Primera Estación. En: Revista Cambio, Agosto de 2004,
Colombia
MAUTTONE, A. et al. (2004). Diseño y Optimización de Rutas y Frecuencias en el
Transporte Colectivo Urbano, Modelos y Algoritmos. Universidad de la República
Uruguay. Tesis de Maestría.
MELO G., L. (2004). Los pecados del Transporte Público. En: Periódico El País,
Colombia, mayo 14 de 2001, p. 1B.
MOLLER, R. (2001) Una Propuesta de Mejoramiento del Transporte Público Colectivo
Urbano en Santiago de Cali. En: Ingeniería y Competitividad. Universidad del valle.
Volumen 3. No.1. Junio de 2001. Pags. 19-34.
http://gamoreno.wordpress.com/2007/10/03/tecnicas-mas-usadas-en-la-mineria-
de-datos/
http://anibalgoicochea.com/2009/08/11/crisp-dm-una-metodologia-para-proyectos-
de-mineria-de-datos/
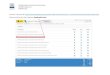























![Modelo continuidad del conocimiento[1]](https://img.pdfslide.tips/doc/110x75/55b31b2cbb61ebca088b4662/modelo-continuidad-del-conocimiento1.jpg)




