Embed Size (px)
Citation preview

文
語
選
ロ
日
ー
ル
カ
日
ロ
ロ
を
文
コ
本
ト
コ
で
コ
、
で
ー
ネ
選
ル
日
ロ
を
ン
で
ル
ネ
ロ
を
カ
の
ん
本
¡
で
¿
¿
文
パ
本
ル
語
で
を
¿
、
ん
ロ
本
ル
文
で
?
ン
語
で
¡
ン
選
カ
ト
日
の
ル
所
¿
ロ
ん
ー
で
ン
を
で
で
ー
語
ん
?
選
¡
、
の
ー
¡
ん
文
の
ト
本
ル
カ
を
ん
¡
字
コ
ン
日
本
ト
で
選
ン
選
¡
で
ル
文
ー
ー
、
ロ
字
字
ル
カ
コ
ロ
?
ン
で
ル
選
ロ
ル
語
を
文
語
語
ー
ネ
を
コ
語
で
ト
ー
の
ロ
で
¡
で
本
、
ト
、
ル
本
¿
文
ー
の
ー
の
¿
語
ル
を
を
¡
ル
の
本
¡
ネ
コ
語
カ
ー
¡
選
ロ
で
ー
ル
で
ん
字
ル
カ
で
の
¿
文
字
ネ
ロ
¿
ン
ロ
で
の
ネ
カ
カ
ロ
¿
の
字
ン
カ
所
で
ル
所
コ
ん
ル
の
¿
パ
¿
¿
ー
コ
語
ン
語
¿
ン
を
ト
ル
ロ
本
ロ
カ
ロ
ト
ル
、
本
ロ
選
ロ
所
選
ー
ネ
本
で
ル
ン
ン
選
選
ル
ロ
ー
ネ
で
の
語
選
日
ン
ル
ル
?
日
字
¡
字
本
選
ん
¿
?
字
ン
の
語
ー
で
ロ
?
字
ル
ル
選
ン
ー
ン
ロ
?
本
で
ネ
本
を
ル
ー
ロ
?
文
で
の
で
文
ル
を
ン
ト
ー
ル
パ
で
?
で
で
ん
語
日
語
日
ル
ん
¿
文
字
字
?
ル
選
ト
語
ー
を
で
?
ロ
ロ
字
¿
カ
語
で
本
ル
コ
字
コ
ネ
ル
ー
ん
ル
所
¿
?
ー
ー
所
ト
を
パ
パ
語
、
で
の
、
パ
?
ル
ん
本
、
ー
ン
ネ
ロ
を
コ
で
を
ロ
ト
語
ネ
の
文
¿
ロ
で
を
で
パ
ン
パ
日
で
ル
で
ト
で
ロ
日
を
ン
ト
、
字
¡
語
ロ
で
、
パ
文
を
ロ
ネ
?
ト
ー
ン
で
パ
パ
ル
ン
ロ
本
語
ン
ロ
字
を
ー
¡
を
で
ネ
で
パ
コ
ん
を
所
コ
字
パ
?
ン
字
日
ん
文
カ
ー
語
で
¡
、
ル
ロ
文
ル
ン
語
ル
所
、
ん
、
ネ
ネ
ト
で
¿
¿
ル
ネ
ト
で
ロ
の
ル
で
で
で
文
パ
ー
選
で
ー
ー
で
、
で
で
パ
ル
日
ネ
¡
ン
で
を
本
ー
ロ
語
ル
で
ル
ン
ル
字
ル
ー
ネ
ン
ン
ー
を
文
¡
¡
パ
ロ
ロ
字
で
コ
で
ん
?
ト
パ
ル
文
カ
、
で
カ
日
¿
ン
¡
の
¿
ー
ロ
カ
ネ
ー
ロ
で
¿
選
ー
語
ン
日
ロ
字
選
で
で
字
選
?
選
を
日
語
カ
ル
日
ロ
ん
ロ
本
を
ト
で
¿
所
¡
所
コ
ル
ん
本
文
ネ
字
で
ん
ロ
の
の
ン
ネ
?
ル
ロ
¡
ル
を
ネ
文
字
ン
ル
日
ー
ン
の
で
日
¡
ん
コ
ル
ネ
?
パ
ネ
字
を
の
ト
ル
ン
所
ロ
¿
語
ル
日
語
ル
ン
所
所
ー
日
ル
選
字
を
語
パ
¡
日
ル
ん
ロ
カ
ン
ル
で
日
カ
ン
選
、
¿
¿
文
ル
を
?
字
ロ
、
ん
ル
ー
で
ル
ロ
カ
ー
¡
を
、
ネ
¡
、
ん
?
¡
の
の
字
ロ
コ
ん
を
ー
ル
ト
パ
を
で
ネ
を
ル
ル
で
で
の
ル
コ
日
を
コ
ー
ロ
語
選
ル
文
ロ
日
ル
ー
ル
所
、
の
字
¡
ロ
パ
ロ
ー
で
ル
日
で
で
¡
ル
¡
選
日
パ
?
で
?
で
パ
で
ト
語
字
カ
¿
字
?
本
選
ネ
パ
語
で
ル
ル
で
ー
?
カ
?
?
選
ー
選
コ
¿
選
で
¡
選
コ
ネ
ロ
本
ル
で
ロ
?
ー
ロ
で
ー
ル
¡
?
本
本
を
語
コ
コ
所
文
カ
の
字
¿
ん
文
ト
日
ロ
カ
ン
ー
ー
¿
選
ル
ネ
ン
字
を
字
ネ
を
所
¡
で
日
ル
文
コ
ロ
選
コ
の
¡
?
ル
ル
ト
ル
ト
字
の
?
ル
パ
文
コ
コ
ロ
¿
、
ル
ル
パ
ル
ー
¡
ん
コ
で
、
の
パ
で
語
で
で
で
ル
の
で
の
ー
、
の
ー
で
ル
ン
を
ト
ン
パ
ロ
で
カ
の
カ
文
選
で
ト
ト
字
ー
ル
字
ト
ロ
ー
ー
¿
コ
本
ん
文
で
ネ
¡
ロ
、
で
ロ
で
ー
ー
ル
?
ル
所
で
コ
ん
コ
ロ
ン
語
ル
ル
本
ル
語
ー
ロ
所
?
ロ
字
字
ー
文
を
文
で
ロ
ロ
の
で
で
を
ー
ル
日
ル
所
文
ー
を
パ
字
所
ロ
ロ
の
文
で
?
カ
ん
ー
文
文
選
選
、
語
ト
で
ー
で
ー
、
選
ル
ロ
ん
ん
¡
選
字
で
¡
ン
?
コ
ネ
日
ロ
ト
本
語
ル
字
で
日
ー
パ
?
で
カ
ト
ル
本
所
所
ル
ん
で
文
ト
文
ン
パ
所
選
?
で
?
を
ん
?
、
語
本
ー
本
日
選
ネ
¿
選
ー
¡
ル
ト
ん
ル
コ
ル
カ
ル
カ
所
選
ル
日
ん
日
¿
¡
字
ー
カ
ネ
パ
コ
所
の
ト
パ
ロ
ロ
ん
ー
の
ネ
を
ル
、
ル
ト
日
ン
文
の
パ
パ
¿
ン
カ
を
で
¡
ロ
パ
ネ
本
を
の
で
文
¡
の
ネ
で
ー
ロ
ル
ル
ル
¡
コ
日
文
カ
ー
で
本
ロ
所
ん
ル
ロ
語
ル
ル
、
を
ト
¿
で
で
所
ル
ん
日
、
ん
選
選
を
で
¿
コ
ル
ル
¡
ネ
で
ー
コ
日
選
選
カ
文
ー
?
で
ル
ン
の
¡
ロ
で
¡
で
、
ロ
日
¡
ル
で
ロ
ロ
¿
?
語
ー
ネ
で
¡
で
ー
で
ー
パ
で
、
¿
で
で
を
ロ
ン
ー
カ
ロ
の
ネ
ト
所
カ
¿
の
字
カ
日
¿
¿
?
ト
語
を
、
選
語
ル
ロ
選
所
所
ネ
ト
カ
本
ロ
日
ト
ロ
コ
¡
で
で
本
ん
ー
を
ン
所
パ
ロ
所
¿
ん
¿
を
ル
カ
カ
ネ
?
¡
¡
文
ト
を
本
ル
を
、
ロ
で
文
ー
コ
所
日
ル
ロ
コ
ネ
ル
日
ル
ル
コ
ネ
選
ル
で
ー
¿
字
ー
コ
ロ
語
ー
で
で
語
文
を
語
¿
ー
所
コ
ネ
ト
語
ル
で
、
で
ル
所
選
ロ
¿
、
で
で
字
ル
¿
ル
ネ
本
ロ
ん
語
字
ー
ー
で
ー
?
ン
ル
¿
日
の
ル
ー
で
で
で
ロ
¿
語
日
カ
で
ん
パ
ロ
ン
カ
カ
カ
ロ
ー
パ
を
ル
ん
ん
本
日
ん
の
ん
コ
ル
日
所
ー
本
ー
ん
¿
ロ
ル
所
ネ
、
¡
パ
字
ン
を
ー
字
ロ
ネ
選
の
ー
ト
で
ロ
¿
選
¡
本
で
ー
ロ
ー
ネ
で
の
日
文
ト
ル
カ
ロ
¿
文
本
所
ー
日
ン
ん
文
ネ
ン
ル
本
ネ
所
日
文
¿
日
ー
ル
、
ー
ー
ー
ル
語
パ
で
ー
語
ル
本
所
ー
ー
の
ん
カ
ー
コ
を
選
で
文
ロ
、
¡
コ
ロ
本
ル
所
で
ン
語
コ
の
?
ル
ネ
ん
選
選
¡
で
カ
¡
語
パ
ン
パ
字
所
コ
字
の
日
日
、
で
本
で
?
語
ル
ネ
本
ん
ー
語
語
ン
ト
の
?
で
ロ
ル
ー
ー
カ
ト
を
ロ
ン
所
ん
ー
¿
ん
?
語
を
ロ
を
ん
ー
選
?
を
で
ネ
ル
で
コ
ん
で
パ
ー
の
、
で
ネ
ロ
ー
¿
ネ
ル
で
ン
ー
語
所
ー
パ
文
の
で
ー
ー
本
字
ル
ー
ロ
本
ル
で
を
で
、
ロ
コ
本
所
の
コ
で
¿
を
字
を
¡
ネ
ト
、
コ
文
選
本
ル
ト
を
パ
字
ル
ル
ン
ー
本
¿
カ
で
¿
ん
を
ン
文
ん
?
¿
字
ネ
ー
パ
所
ー
コ
文
で
選
、
の
ー
ロ
?
文
ロ
、
ー
で
本
ー
で
語
所
ネ
ー
パ
コ
ン
ル
ト
の
字
、
日
ん
ル
¿
カ
?
ン
ン
ン
パ
ネ
¡
文
ル
ル
を
ル
ロ
本
¿
カ
日
文
文
ー
の
本
字
ネ
文
、
?
を
を
で
¡
文
ル
文
ル
?
で
ロ
で
ル
ト
文
で
ロ
語
ル
、
パ
ん
コ
本
、
ル
?
ネ
パ
字
本
カ
¿
パ
ル
の
本
の
、
ル
¡
所
語
?
で
ー
、
で
パ
¿
ル
ー
ん
で
本
ル
ん
ル
ロ
コ
パ
所
語
コ
コ
所
ト
ト
で
の
¡
選
日
で
ん
ー
日
文
本
ル
を
を
ロ
パ
の
語
パ
¡
¿
日
ン
ロ
を
本
文
ロ
本
選
選
ル
ル
文
日
ト
で
選
日
を
ロ
所
ル
コ
ル
ル
で
ト
で
を
ん
で
選
?
ル
字
ん
ネ
ネ
?
で
カ
選
コ
で
の
ネ
ー
ネ
の
ロ
ネ
字
ん
ト
ロ
で
で
ー
の
ロ
ー
ネ
パ
カ
所
¡
?
文
で
で
ン
本
日
の
?
の
ネ
字
の
選
ん
パ
本
で
字
を
字
ル
を
ン
パ
本
ル
ー
語
、
で
文
カ
ロ
で
ー
所
ト
ー
所
ン
ロ
¿
の
ロ
の
ロ
ル
コ
ん
ロ
ル
¿
ん
ル
ロ
カ
ネ
ル
字
で
ン
ン
ロ
日
を
本
の
¿
ル
を
コ
で
字
ト
日
選
文
?
ン
ン
¡
ー
選
ー
ト
で
本
本
日
で
、
ル
本
ン
ネ
で
ロ
¡
ト
語
ル
ー
選
の
ト
ー
¡
字
カ
、
本
選
文
ン
、
の
ル
の
ト
ロ
¡
選
所
で
ト
ル
ル
?
語
¿
カ
文
字
本
字
ロ
、
パ
パ
ロ
で
パ
ル
?
ロ
ル
文
¿
ル
ル
文
カ
を
ル
ル
ン
本
ロ
、
、
ー
で
¡
¡
ん
パ
日
ん
?
ル
ル
?
ん
文
で
文
ン
、
ロ
の
¡
?
ト
語
で
所
ン
で
語
¡
ル
で
で
パ
パ
選
で
ー
ル
で
ン
ん
、
ー
日
ル
で
所
ロ
¡
¿
で
¡
パ
ル
パ
ー
ー
ネ
¡
ん
?
で
を
パ
所
ル
ト
語
の
で
パ
選
日
¿
カ
、
コ
ー
パ
の
¡
文
で
ン
パ
ル
文
選
?
ル
ー
ん
ー
を
日
日
コ
ネ
語
所
文
日
¿
?
¡
ロ
コ
ト
選
ネ
日
パ
ル
¡
ン
コ
ー
ト
ん
ロ
ロ
?
ル
語
ー
選
ル
ー
文
ー
文
ネ
所
、
ネ
ネ
で
、
を
コ
字
ル
ル
の
ル
字
文
ロ
ル
ル
¿
を
ロ
文
選
ロ
ん
ー
を
¿
ん
所
ロ
ー
ル
ト
パ
パ
所
ー
ん
で
で
を
ん
ネ
ト
選
文
パ
所
¡
ー
¿
文
で
の
、
コ
ネ
、
選
で
を
ロ
字
ん
語
¡
パ
で
ン
ロ
を
文
?
本
で
ン
ル
の
日
ル
¿
で
カ
ト
ん
ー
コ
ロ
ん
日
字
、
本
字
ル
で
の
¿
カ
¡
ロ
ル
で
ー
所
で
本
で
ル
¿
ル
日
カ
ー
カ
を
ー
の
語
ン
コ
本
ル
コ
字
本
カ
字
ロ
日
で
ル
語
¡
¿
、
¿
日
¡
語
で
で
日
カ
ン
コ
日
ル
選
語
の
ー
語
を
¡
、
で
文
で
ー
字
、
日
ン
を
ロ
文
ー
カ
ル
選
パ
で
ロ
ト
所
本
コ
ー
¿
字
カ
ネ
で
ロ
コ
選
ネ
¿
で
パ
カ
、
ン
字
コ
字
コ
の
、
を
で
ん
ー
日
¿
語
所
字
で
ネ
ネ
の
ル
の
ネ
本
コ
ル
本
ル
¡
本
を
を
を
ん
パ
で
ん
で
ロ
所
ロ
字
ー
?
ル
コ
ル
ネ
ん
を
所
ル
を
?
ー
ー
パ
パ
ロ
ロ
所
を
文
ロ
¡
ル
カ
字
ロ
パ
字
語
ン
ロ
¿
で
ん
パ
ル
ー
ト
日
の
ネ
パ
で
文
で
ー
の
語
字
カ
で
日
字
文
日
ロ
?
所
で
¿
ネ
パ
字
語
ン
日
ト
ト
ル
コ
語
で
ネ
ル
ー
字
選
文
本
を
で
ル
で
の
ー
ー
を
ロ
ん
語
ー
、
パ
ト
?
の
字
ト
ん
字
ー
日
語
コ
ー
ネ
を
で
ト
ル
選
本
ロ
語
ン
、
ル
ー
、
カ
本
で
?
¿
日
ん
¿
を
ル
選
の
の
ロ
ー
で
¡
所
ー
ん
、
ル
ロ
で
文
で
ロ
ル
字
文
で
¡
ロ
ロ
所
ル
字
ん
?
字
本
ー
¡
ル
所
コ
ル
ネ
ー
字
¡
ル
ル
本
カ
?
、
ン
で
の
?
?
の
語
選
パ
文
ん
ー
字
本
ロ
所
パ
の
本
ん
ル
¡
、
所
¡
ネ
字
¡
、
の
ル
で
で
ン
の
パ
を
ト
日
を
選
で
ん
で
語
で
ン
語
ト
日
で
ル
所
?
の
ん
語
ン
¡
ル
所
ト
ト
コ
パ
所
語
ト
ネ
日
で
ン
で
ト
¡
ロ
ル
ネ
の
ル
日
語
ー
文
ル
ル
コ
本
カ
で
カ
コ
¡
ネ
を
ル
パ
日
所
日
、
で
ロ
選
ー
ん
ル
ロ
ん
コ
本
日
¡
ネ
カ
コ
で
ン
本
パ
で
ト
ル
ト
選
ル
、
ー
ト
¿
本
の
パ
ン
所
で
所
字
ル
ロ
で
日
ン
ル
ネ
ル
?
ル
コ
?
日
日
ト
選
?
日
の
字
の
コ
日
字
で
ル
を
ー
ロ
ん
ト
パ
ル
の
ロ
の
の
で
パ
カ
ん
コ
を
選
コ
ル
で
ル
、
¿
本
ー
本
の
、
文
カ
の
ー
ル
ト
字
ネ
ネ
ロ
ロ
字
ル
の
を
ロ
で
ト
パ
ル
¡
ロ
ロ
、
語
ロ
本
、
文
日
を
語
?
ル
で
本
ロ
¿
ロ
ロ
ー
文
¡
ー
コ
?
ン
?
所
¡
パ
カ
¡
文
ネ
日
字
文
日
語
ロ
ー
文
選
本
ロ
文
?
所
ロ
ロ
¡
カ
ー
文
カ
カ
ー
カ
ネ
で
ー
¡
¡
ー
を
パ
所
で
日
ー
ル
ー
で
日
¿
ル
?
選
、
ル
字
ネ
、
ん
ル
ー
、
で
で
ロ
、
コ
?
の
で
ル
本
で
所
?
ロ
を
語
、
パ
を
ロ
¡
¿
選
ル
文
ル
で
ネ
ト
コ
ん
ル
ロ
語
ル
コ
ン
ル
所
字
本
を
ル
字
語
ネ
¡
、
を
所
ル
ロ
で
日
文
所
選
ル
¡
で
ル
で
ル
文
選
ー
で
パ
¡
ー
語
コ
語
カ
で
ト
ル
カ
ー
日
ロ
?
コ
ロ
コ
日
、
ー
ロ
¡
文
ル
で
で
本
語
カ
ネ
ー
ー
ん
ネ
ネ
ー
で
ネ
日
文
ル
で
ト
所
文
ン
コ
所
パ
の
ト
、
語
ル
選
選
で
パ
字
ロ
ル
ト
¿
で
で
パ
ー
パ
で
ル
コ
¡
ン
?
を
ロ
語
で
ン
ン
ロ
ネ
の
ル
¡
ー
パ
、
パ
コ
パ
?
ロ
で
ん
日
ー
、
?
ル
の
¿
選
本
ロ
ロ
文
ネ
¡
カ
ロ
コ
ン
パ
選
で
カ
¡
で
文
で
所
ル
ン
ネ
ネ
で
、
、
パ
で
ト
文
で
日
の
選
カ
で
ン
コ
で
¡
を
ト
ロ
パ
ー
ー
で
本
で
ロ
コ
で
を
ネ
¡
ー
¿
¿
を
日
カ
パ
ー
¡
ル
を
で
日
ル
ネ
ロ
パ
本
所
ロ
ロ
所
コ
ー
ル
ネ
文
所
日
選
選
ネ
字
で
字
パ
カ
ト
ロ
本
ロ
?
ル
ー
文
ん
ル
ロ
の
カ
日
ロ
¡
ン
ル
を
所
文
ト
カ
ト
ル
ト
¿
ー
ー
カ
本
語
日
カ
本
ト
?
ル
ン
選
、
ル
ル
、
ル
で
文
¡
、
文
の
語
ん
ト
を
¿
ロ
選
ト
¡
で
カ
選
、
?
の
所
ー
ル
選
で
ん
ー
語
ル
で
ル
語
所
本
で
カ
カ
パ
文
、
文
で
ロ
ル
パ
選
コ
で
ー
文
を
ロ
ロ
ー
語
パ
を
?
¡
ネ
ロ
選
ー
ロ
字
語
で
ロ
ル
日
で
文
ネ
ル
ロ
?
ン
ロ
を
ー
ト
ル
コ
文
¡
カ
コ
ネ
ー
所
ネ
字
日
ー
ト
ト
ロ
語
ル
ん
で
選
、
パ
ー
¡
で
字
ー
ル
ん
で
、
ー
ト
ー
所
字
で
所
?
、
字
ー
本
選
¿
ネ
カ
日
ロ
パ
で
の
日
ー
、
の
ロ
¿
で
コ
本
文
ル
ロ
ー
文
文
¿
?
¡
ー
コ
本
ー
¡
日
で
¡
で
を
、
を
で
パ
日
ル
の
文
ー
語
で
で
で
ー
字
ル
ネ
ロ
ん
で
選
ー
カ
所
の
ト
¡
コ
ン
、
ネ
文
ん
カ
ン
ー
所
の
ル
ん
ー
?
語
選
字
ル
¿
?
本
カ
ル
カ
日
?
で
で
日
所
で
¡
ル
で
文
で
字
日
¿
¡
日
字
カ
?
ト
ト
¿
選
ー
ー
文
カ
本
字
¡
ー
ル
ル
ネ
ー
語
本
所
ル
文
ン
ル
を
ー
ン
ル
字
選
ー
の
を
を
字
ん
パ
ー
選
字
所
、
ー
文
日
¿
、
ト
で
語
ロ
文
ル
日
ロ
ル
ロ
カ
ル
カ
本
語
ネ
ロ
で
の
で
選
ロ
ネ
¿
ル
で
の
で
ロ
ネ
?
文
日
ロ
選
の
ネ
ー
ト
、
日
ロ
字
¡
コ
文
字
で
で
¡
?
字
本
?
文
所
?
¡
日
ー
日
パ
?
で
?
ル
文
本
ー
ル
ロ
¿
で
パ
カ
カ
¡
、
で
本
ル
ー
語
¡
日
ル
ン
ト
選
カ
ネ
ル
ロ
¡
ロ
カ
ル
ル
の
ネ
本
日
ー
日
所
カ
ル
所
で
ー
¿
で
ル
で
所
、
を
?
で
で
?
ル
、
?
、
ト
ル
を
ト
で
の
文
文
ル
ー
カ
ー
、
文
コ
?
語
で
所
ン
¿
本
ン
字
ー
字
の
、
日
で
所
ル
パ
¡
で
ト
で
ロ
ー
ん
ロ
語
ル
ト
ネ
パ
¡
所
で
語
ー
¿
語
コ
文
ル
ロ
パ
、
選
?
で
語
ネ
¿
、
文
ネ
ー
ロ
ル
ン
選
ネ
を
ん
本
ネ
¿
ロ
で
¡
ロ
コ
日
¡
で
で
所
ロ
ロ
字
で
字
カ
、
で
で
、
パ
本
の
ン
ネ
ル
で
¡
ル
コ
を
パ
語
で
パ
字
選
ん
ネ
¿
所
ロ
ー
日
ル
ロ
選
ん
ー
字
、
ロ
コ
カ
?
を
日
で
コ
パ
日
日
ル
ン
を
語
文
ん
本
ネ
?
、
日
ん
ル
ネ
ト
コ
ー
ル
で
ー
字
本
カ
日
ト
で
語
カ
ル
で
語
¿
ー
ル
文
ト
ん
ル
本
¿
ル
ル
?
ロ
¿
¿
ー
ル
選
カ
ル
、
ト
¡
日
で
で
字
選
文
ル
字
ー
¡
ル
、
ロ
コ
パ
パ
ネ
ル
語
ん
で
で
?
所
?
ト
ロ
の
ン
ー
ロ
カ
で
ー
で
ル
ル
ル
、
ー
カ
ト
¿
日
ん
ル
¿
ネ
語
字
を
本
ト
ネ
ー
ネ
ー
で
ロ
所
ん
ネ
文
ン
ー
ン
ロ
で
ロ
ル
コ
日
パ
所
ネ
¡
の
字
?
日
、
で
本
¿
ル
ん
本
で
ル
、
の
コ
で
コ
ト
日
ん
コ
語
コ
¡
所
ン
¡
ル
ン
¡
ネ
¿
ル
ネ
?
で
文
所
日
ル
ン
¡
ト
¿
ル
語
カ
文
ー
、
パ
¿
を
文
で
ン
ル
字
語
を
¡
を
所
文
ン
パ
ル
コ
¡
文
ー
ト
語
ル
文
ル
で
ル
語
ル
選
語
語
¡
で
本
コ
ル
コ
を
ネ
?
コ
、
選
字
?
ロ
ン
¡
日
ロ
の
カ
ル
で
ル
字
ル
¿
ー
字
で
コ
ネ
パ
、
ロ
ル
で
所
ー
¿
日
ル
で
文
カ
語
ー
ロ
を
ル
ル
ん
を
日
¿
コ
カ
パ
日
ト
¿
ネ
ネ
で
で
ン
ロ
ん
本
文
ネ
字
ー
?
パ
ル
?
カ
ン
ネ
所
本
日
ル
ル
で
字
ネ
所
コ
ロ
カ
本
コ
ー
¿
文
ー
文
¿
文
文
で
、
を
を
ネ
ロ
文
で
日
ル
ん
¡
ル
カ
文
カ
文
字
所
?
を
¡
ト
コ
本
、
¿
ー
¿
¿
で
カ
ー
で
コ
本
で
?
日
ト
ル
¡
ー
ト
日
パ
ん
ー
?
ン
ル
本
ル
で
ん
ネ
ー
¡
¡
ン
で
¿
ル
ー
で
ん
所
カ
ト
ル
で
を
ン
で
字
?
で
で
文
ト
カ
ル
ロ
¡
、
¿
ロ
ー
の
本
?
¿
ネ
ネ
ル
¿
ん
字
ロ
で
パ
ト
ル
文
で
ル
、
ル
選
ん
を
、
の
ル
コ
本
¡
カ
で
ル
ん
本
ト
ネ
ロ
で
所
ル
で
ロ
パ
ロ
ー
で
で
ル
文
本
字
の
ル
文
語
¿
ン
日
ー
ロ
ル
?
コ
コ
¿
ロ
ン
選
ル
本
ル
パ
所
ロ
カ
ン
の
ン
ー
の
文
ー
で
ー
所
で
ー
コ
ー
ネ
パ
¿
ネ
ー
¿
ル
ル
ん
ネ
語
¡
ー
ロ
ル
本
選
選
ル
の
?
で
コ
ン
日
ン
ロ
ロ
?
ロ
コ
語
選
を
本
ん
ー
ト
本
日
本
ル
ネ
で
ネ
¡
¿
ロ
で
ー
ン
、
ト
所
¡
ー
ん
パ
ト
ネ
語
ロ
語
ん
文
日
ー
ー
ル
で
本
ト
文
ロ
?
日
ル
で
所
ロ
語
日
字
選
で
で
ル
ロ
パ
所
を
ト
カ
で
ル
ル
で
日
文
で
で
所
ー
ロ
コ
で
ル
ン
で
ネ
本
日
日
所
ー
、
ー
、
の
ん
文
を
で
文
選
ル
を
パ
本
、
ん
文
カ
日
ト
ん
ロ
ー
¿
ー
選
、
¡
所
、
ー
で
本
語
¿
ん
?
ネ
コ
所
¡
ー
で
ん
ん
ル
¡
ト
文
を
¡
で
所
ロ
ル
?
ネ
カ
¿
選
を
の
ト
文
で
本
、
ん
日
ー
ン
の
ん
ル
¡
の
日
文
で
で
ロ
?
ン
で
ん
で
で
¡
所
で
ル
本
ル
¿
で
ル
で
ト
ル
パ
語
ネ
所
ル
ト
コ
¿
?
¿
選
で
ル
ネ
で
ロ
、
本
所
ロ
?
ロ
本
文
文
ー
パ
所
ー
の
で
の
で
ロ
字
コ
文
ル
ル
ロ
所
?
ー
ン
選
日
ト
ロ
コ
ル
選
語
本
カ
ロ
ル
日
を
を
¡
の
ん
ー
字
、
の
ー
選
字
で
ン
ん
ー
ー
語
字
で
所
字
パ
字
?
語
ト
コ
パ
パ
?
で
を
パ
コ
ル
で
日
ー
¡
¡
¿
ン
本
で
ル
ン
日
所
所
ン
ー
で
¡
日
ロ
ロ
ト
選
ん
ロ
ネ
、
カ
を
ロ
ル
選
所
語
ロ
で
ー
ン
ル
ル
ネ
ー
ル
コ
¡
ー
で
ン
ト
で
ー
文
語
選
ロ
日
ー
ル
カ
日
ロ
ロ
を
文
コ
本
ト
コ
で
コ
、
で
ー
ネ
選
ル
日
ロ
を
ン
で
ル
ネ
ロ
を
カ
の
ん
本
¡
で
¿
¿
文
パ
本
ル
語
で
を
¿
、
ん
ロ
本
ル
文
で
?
ン
語
で
¡
ン
選
カ
ト
日
の
ル
所
¿
ロ
ん
ー
で
ン
を
で
で
ー
語
ん
?
選
¡
、
の
ー
¡
ん
文
の
ト
本
ル
カ
を
ん
¡
字
コ
ン
日
本
ト
で
選
ン
選
¡
で
ル
文
ー
ー
、
ロ
字
字
ル
カ
コ
ロ
?
ン
で
ル
選
ロ
ル
語
を
文
語
語
ー
ネ
を
コ
語
で
ト
ー
の
ロ
で
¡
で
本
、
ト
、
ル
本
¿
文
ー
の
ー
の
¿
語
ル
を
を
¡
ル
の
本
¡
ネ
コ
語
カ
ー
¡
選
ロ
で
ー
ル
で
ん
字
ル
カ
で
の
¿
文
字
ネ
ロ
¿
ン
ロ
で
の
ネ
カ
カ
ロ
¿
の
字
ン
カ
所
で
ル
所
コ
ん
ル
の
¿
パ
¿
¿
ー
コ
語
ン
語
¿
ン
を
ト
ル
ロ
本
ロ
カ
ロ
ト
ル
、
本
ロ
選
ロ
所
選
ー
ネ
本
で
ル
ン
ン
選
選
ル
ロ
ー
ネ
で
の
語
選
日
ン
ル
ル
?
日
字
¡
字
本
選
ん
¿
?
字
ン
の
語
ー
で
ロ
?
字
ル
ル
選
ン
ー
ン
ロ
?
本
で
ネ
本
を
ル
ー
ロ
?
文
で
の
で
文
ル
を
ン
ト
ー
ル
パ
で
?
で
で
ん
語
日
語
日
ル
ん
¿
文
字
字
?
ル
選
ト
語
ー
を
で
?
ロ
ロ
字
¿
カ
語
で
本
ル
コ
字
コ
ネ
ル
ー
ん
ル
所
¿
?
ー
ー
所
ト
を
パ
パ
語
、
で
の
、
パ
?
ル
ん
本
、
ー
ン
ネ
ロ
を
コ
で
を
ロ
ト
語
ネ
の
文
¿
ロ
で
を
で
パ
ン
パ
日
で
ル
で
ト
で
ロ
日
を
ン
ト
、
字
¡
語
ロ
で
、
パ
文
を
ロ
ネ
?
ト
ー
ン
で
パ
パ
ル
ン
ロ
本
語
ン
ロ
字
を
ー
¡
を
で
ネ
で
パ
コ
ん
を
所
コ
字
パ
?
ン
字
日
ん
文
カ
ー
語
で
¡
、
ル
ロ
文
ル
ン
語
ル
所
、
ん
、
ネ
ネ
ト
で
¿
¿
ル
ネ
ト
で
ロ
の
ル
で
で
で
文
パ
ー
選
で
ー
ー
で
、
で
で
パ
ル
日
ネ
¡
ン
で
を
本
ー
ロ
語
ル
で
ル
ン
ル
字
ル
ー
ネ
ン
ン
ー
を
文
¡
¡
パ
ロ
ロ
字
で
コ
で
ん
?
ト
パ
ル
文
カ
、
で
カ
日
¿
ン
¡
の
¿
ー
ロ
カ
ネ
ー
ロ
で
¿
選
ー
語
ン
日
ロ
字
選
で
で
字
選
?
選
を
日
語
カ
ル
日
ロ
ん
ロ
本
を
ト
で
¿
所
¡
所
コ
ル
ん
本
文
ネ
字
で
ん
ロ
の
の
ン
ネ
?
ル
ロ
¡
ル
を
ネ
文
字
ン
ル
日
ー
ン
の
で
日
¡
ん
コ
ル
ネ
?
パ
ネ
字
を
の
ト
ル
ン
所
ロ
¿
語
ル
日
語
ル
ン
所
所
ー
日
ル
選
字
を
語
パ
¡
日
ル
ん
ロ
カ
ン
ル
で
日
カ
ン
選
、
¿
¿
文
ル
を
?
字
ロ
、
ん
ル
ー
で
ル
ロ
カ
ー
¡
を
、
ネ
¡
、
ん
?
¡
の
の
字
ロ
コ
ん
を
ー
ル
ト
パ
を
で
ネ
を
ル
ル
で
で
の
ル
コ
日
を
コ
ー
ロ
語
選
ル
文
ロ
日
ル
ー
ル
所
、
の
字
¡
ロ
パ
ロ
ー
で
ル
日
で
で
¡
ル
¡
選
日
パ
?
で
?
で
パ
で
ト
語
字
カ
¿
字
?
本
選
ネ
パ
語
で
ル
ル
で
ー
?
カ
?
?
選
ー
選
コ
¿
選
で
¡
選
コ
ネ
ロ
本
ル
で
ロ
?
ー
ロ
で
ー
ル
¡
?
本
本
を
語
コ
コ
所
文
カ
の
字
¿
ん
文
ト
日
ロ
カ
ン
ー
ー
¿
選
ル
ネ
ン
字
を
字
ネ
を
所
¡
で
日
ル
文
コ
ロ
選
コ
の
¡
?
ル
ル
ト
ル
ト
字
の
?
ル
パ
文
コ
コ
ロ
¿
、
ル
ル
パ
ル
ー
¡
ん
コ
で
、
の
パ
で
語
で
で
で
ル
の
で
の
ー
、
の
ー
で
ル
ン
を
ト
ン
パ
ロ
で
カ
の
カ
文
選
で
ト
ト
字
ー
ル
字
ト
ロ
ー
ー
¿
コ
本
ん
文
で
ネ
¡
ロ
、
で
ロ
で
ー
ー
ル
?
ル
所
で
コ
ん
コ
ロ
ン
語
ル
ル
本
ル
語
ー
ロ
所
?
ロ
字
字
ー
文
を
文
で
ロ
ロ
の
で
で
を
ー
ル
日
ル
所
文
ー
を
パ
字
所
ロ
ロ
の
文
で
?
カ
ん
ー
文
文
選
選
、
語
ト
で
ー
で
ー
、
選
ル
ロ
ん
ん
¡
選
字
で
¡
ン
?
コ
ネ
日
ロ
ト
本
語
ル
字
で
日
ー
パ
?
で
カ
ト
ル
本
所
所
ル
ん
で
文
ト
文
ン
パ
所
選
?
で
?
を
ん
?
、
語
本
ー
本
日
選
ネ
¿
選
ー
¡
ル
ト
ん
ル
コ
ル
カ
ル
カ
所
選
ル
日
ん
日
¿
¡
字
ー
カ
ネ
パ
コ
所
の
ト
パ
ロ
ロ
ん
ー
の
ネ
を
ル
、
ル
ト
日
ン
文
の
パ
パ
¿
ン
カ
を
で
¡
ロ
パ
ネ
本
を
の
で
文
¡
の
ネ
で
ー
ロ
ル
ル
ル
¡
コ
日
文
カ
ー
で
本
ロ
所
ん
ル
ロ
語
ル
ル
、
を
ト
¿
で
で
所
ル
ん
日
、
ん
選
選
を
で
¿
コ
ル
ル
¡
ネ
で
ー
コ
日
選
選
カ
文
ー
?
で
ル
ン
の
¡
ロ
で
¡
で
、
ロ
日
¡
ル
で
ロ
ロ
¿
?
語
ー
ネ
で
¡
で
ー
で
ー
パ
で
、
¿
で
で
を
ロ
ン
ー
カ
ロ
の
ネ
ト
所
カ
¿
の
字
カ
日
¿
¿
?
ト
語
を
、
選
語
ル
ロ
選
所
所
ネ
ト
カ
本
ロ
日
ト
ロ
コ
¡
で
で
本
ん
ー
を
ン
所
パ
ロ
所
¿
ん
¿
を
ル
カ
カ
ネ
?
¡
¡
文
ト
を
本
ル
を
、
ロ
で
文
ー
コ
所
日
ル
ロ
コ
ネ
ル
日
ル
ル
コ
ネ
選
ル
で
ー
¿
字
ー
コ
ロ
語
ー
で
で
語
文
を
語
¿
ー
所
コ
ネ
ト
語
ル
で
、
で
ル
所
選
ロ
¿
、
で
で
字
ル
¿
ル
ネ
本
ロ
ん
語
字
ー
ー
で
ー
?
ン
ル
¿
日
の
ル
ー
で
で
で
ロ
¿
語
日
カ
で
ん
パ
ロ
ン
カ
カ
カ
ロ
ー
パ
を
ル
ん
ん
本
日
ん
の
ん
コ
ル
日
所
ー
本
ー
ん
¿
ロ
ル
所
ネ
、
¡
パ
字
ン
を
ー
字
ロ
ネ
選
の
ー
ト
で
ロ
¿
選
¡
本
で
ー
ロ
ー
ネ
で
の
日
文
ト
ル
カ
ロ
¿
文
本
所
ー
日
ン
ん
文
ネ
ン
ル
本
ネ
所
日
文
¿
日
ー
ル
、
ー
ー
ー
ル
語
パ
で
ー
語
ル
本
所
ー
ー
の
ん
カ
ー
コ
を
選
で
文
ロ
、
¡
コ
ロ
本
ル
所
で
ン
語
コ
の
?
ル
ネ
ん
選
選
¡
で
カ
¡
語
パ
ン
パ
字
所
コ
字
の
日
日
、
で
本
で
?
語
ル
ネ
本
ん
ー
語
語
ン
ト
の
?
で
ロ
ル
ー
ー
カ
ト
を
ロ
ン
所
ん
ー
¿
ん
?
語
を
ロ
を
ん
ー
選
?
を
で
ネ
ル
で
コ
ん
で
パ
ー
の
、
で
ネ
ロ
ー
¿
ネ
ル
で
ン
ー
語
所
ー
パ
文
の
で
ー
ー
本
字
ル
ー
ロ
本
ル
で
を
で
、
ロ
コ
本
所
の
コ
で
¿
を
字
を
¡
ネ
ト
、
コ
文
選
本
ル
ト
を
パ
字
ル
ル
ン
ー
本
¿
カ
で
¿
ん
を
ン
文
ん
?
¿
字
ネ
ー
パ
所
ー
コ
文
で
選
、
の
ー
ロ
?
文
ロ
、
ー
で
本
ー
で
語
所
ネ
ー
パ
コ
ン
ル
ト
の
字
、
日
ん
ル
¿
カ
?
ン
ン
ン
パ
ネ
¡
文
ル
ル
を
ル
ロ
本
¿
カ
日
文
文
ー
の
本
字
ネ
文
、
?
を
を
で
¡
文
ル
文
ル
?
で
ロ
で
ル
ト
文
で
ロ
語
ル
、
パ
ん
コ
本
、
ル
?
ネ
パ
字
本
カ
¿
パ
ル
の
本
の
、
ル
¡
所
語
?
で
ー
、
で
パ
¿
ル
ー
ん
で
本
ル
ん
ル
ロ
コ
パ
所
語
コ
コ
所
ト
ト
で
の
¡
選
日
で
ん
ー
日
文
本
ル
を
を
ロ
パ
の
語
パ
¡
¿
日
ン
ロ
を
本
文
ロ
本
選
選
ル
ル
文
日
ト
で
選
日
を
ロ
所
ル
コ
ル
ル
で
ト
で
を
ん
で
選
?
ル
字
ん
ネ
ネ
?
で
カ
選
コ
で
の
ネ
ー
ネ
の
ロ
ネ
字
ん
ト
ロ
で
で
ー
の
ロ
ー
ネ
パ
カ
所
¡
?
文
で
で
ン
本
日
の
?
の
ネ
字
の
選
ん
パ
本
で
字
を
字
ル
を
ン
パ
本
ル
ー
語
、
で
文
カ
ロ
で
ー
所
ト
ー
所
ン
ロ
¿
の
ロ
の
ロ
ル
コ
ん
ロ
ル
¿
ん
ル
ロ
カ
ネ
ル
字
で
ン
ン
ロ
日
を
本
の
¿
ル
を
コ
で
字
ト
日
選
文
?
ン
ン
¡
ー
選
ー
ト
で
本
本
日
で
、
ル
本
ン
ネ
で
ロ
¡
ト
語
ル
ー
選
の
ト
ー
¡
字
カ
、
本
選
文
ン
、
の
ル
の
ト
ロ
¡
選
所
で
ト
ル
ル
?
語
¿
カ
文
字
本
字
ロ
、
パ
パ
ロ
で
パ
ル
?
ロ
ル
文
¿
ル
ル
文
カ
を
ル
ル
ン
本
ロ
、
、
ー
で
¡
¡
ん
パ
日
ん
?
ル
ル
?
ん
文
で
文
ン
、
ロ
の
¡
?
ト
語
で
所
ン
で
語
¡
ル
で
で
パ
パ
選
で
ー
ル
で
ン
ん
、
ー
日
ル
で
所
ロ
¡
¿
で
¡
パ
ル
パ
ー
ー
ネ
¡
ん
?
で
を
パ
所
ル
ト
語
の
で
パ
選
日
¿
カ
、
コ
ー
パ
の
¡
文
で
ン
パ
ル
文
選
?
ル
ー
ん
ー
を
日
日
コ
ネ
語
所
文
日
¿
?
¡
ロ
コ
ト
選
ネ
日
パ
ル
¡
ン
コ
ー
ト
ん
ロ
ロ
?
ル
語
ー
選
ル
ー
文
ー
文
ネ
所
、
ネ
ネ
で
、
を
コ
字
ル
ル
の
ル
字
文
ロ
ル
ル
¿
を
ロ
文
選
ロ
ん
ー
を
¿
ん
所
ロ
ー
ル
ト
パ
パ
所
ー
ん
で
で
を
ん
ネ
ト
選
文
パ
所
¡
ー
¿
文
で
の
、
コ
ネ
、
選
で
を
ロ
字
ん
語
¡
パ
で
ン
ロ
を
文
?
本
で
ン
ル
の
日
ル
¿
で
カ
ト
ん
ー
コ
ロ
ん
日
字
、
本
字
ル
で
の
¿
カ
¡
ロ
ル
で
ー
所
で
本
で
ル
¿
ル
日
カ
ー
カ
を
ー
の
語
ン
コ
本
ル
コ
字
本
カ
字
ロ
日
で
ル
語
¡
¿
、
¿
日
¡
語
で
で
日
カ
ン
コ
日
ル
選
語
の
ー
語
を
¡
、
で
文
で
ー
字
、
日
ン
を
ロ
文
ー
カ
ル
選
パ
で
ロ
ト
所
本
コ
ー
¿
字
カ
ネ
で
ロ
コ
選
ネ
¿
で
パ
カ
、
ン
字
コ
字
コ
の
、
を
で
ん
ー
日
¿
語
所
字
で
ネ
ネ
の
ル
の
ネ
本
コ
ル
本
ル
¡
本
を
を
を
ん
パ
で
ん
で
ロ
所
ロ
字
ー
?
ル
コ
ル
ネ
ん
を
所
ル
を
?
ー
ー
パ
パ
ロ
ロ
所
を
文
ロ
¡
ル
カ
字
ロ
パ
字
語
ン
ロ
¿
で
ん
パ
ル
ー
ト
日
の
ネ
パ
で
文
で
ー
の
語
字
カ
で
日
字
文
日
ロ
?
所
で
¿
ネ
パ
字
語
ン
日
ト
ト
ル
コ
語
で
ネ
ル
ー
字
選
文
本
を
で
ル
で
の
ー
ー
を
ロ
ん
語
ー
、
パ
ト
?
の
字
ト
ん
字
ー
日
語
コ
ー
ネ
を
で
ト
ル
選
本
ロ
語
ン
、
ル
ー
、
カ
本
で
?
¿
日
ん
¿
を
ル
選
の
の
ロ
ー
で
¡
所
ー
ん
、
ル
ロ
で
文
で
ロ
ル
字
文
で
¡
ロ
ロ
所
ル
字
ん
?
字
本
ー
¡
ル
所
コ
ル
ネ
ー
字
¡
ル
ル
本
カ
?
、
ン
で
の
?
?
の
語
選
パ
文
ん
ー
字
本
ロ
所
パ
の
本
ん
ル
¡
、
所
¡
ネ
字
¡
、
の
ル
で
で
ン
の
パ
を
ト
日
を
選
で
ん
で
語
で
ン
語
ト
日
で
ル
所
?
の
ん
語
ン
¡
ル
所
ト
ト
コ
パ
所
語
ト
ネ
日
で
ン
で
ト
¡
ロ
ル
ネ
の
ル
日
語
ー
文
ル
ル
コ
本
カ
で
カ
コ
¡
ネ
を
ル
パ
日
所
日
、
で
ロ
選
ー
ん
ル
ロ
ん
コ
本
日
¡
ネ
カ
コ
で
ン
本
パ
で
ト
ル
ト
選
ル
、
ー
ト
¿
本
の
パ
ン
所
で
所
字
ル
ロ
で
日
ン
ル
ネ
ル
?
ル
コ
?
日
日
ト
選
?
日
の
字
の
コ
日
字
で
ル
を
ー
ロ
ん
ト
パ
ル
の
ロ
の
の
で
パ
カ
ん
コ
を
選
コ
ル
で
ル
、
¿
本
ー
本
の
、
文
カ
の
ー
ル
ト
字
ネ
ネ
ロ
ロ
字
ル
の
を
ロ
で
ト
パ
ル
¡
ロ
ロ
、
語
ロ
本
、
文
日
を
語
?
ル
で
本
ロ
¿
ロ
ロ
ー
文
¡
ー
コ
?
ン
?
所
¡
パ
カ
¡
文
ネ
日
字
文
日
語
ロ
ー
文
選
本
ロ
文
?
所
ロ
ロ
¡
カ
ー
文
カ
カ
ー
カ
ネ
で
ー
¡
¡
ー
を
パ
所
で
日
ー
ル
ー
で
日
¿
ル
?
選
、
ル
字
ネ
、
ん
ル
ー
、
で
で
ロ
、
コ
?
の
で
ル
本
で
所
?
ロ
を
語
、
パ
を
ロ
¡
¿
選
ル
文
ル
で
ネ
ト
コ
ん
ル
ロ
語
ル
コ
ン
ル
所
字
本
を
ル
字
語
ネ
¡
、
を
所
ル
ロ
で
日
文
所
選
ル
¡
で
ル
で
ル
文
選
ー
で
パ
¡
ー
語
コ
語
カ
で
ト
ル
カ
ー
日
ロ
?
コ
ロ
コ
日
、
ー
ロ
¡
文
ル
で
で
本
語
カ
ネ
ー
ー
ん
ネ
ネ
ー
で
ネ
日
文
ル
で
ト
所
文
ン
コ
所
パ
の
ト
、
語
ル
選
選
で
パ
字
ロ
ル
ト
¿
で
で
パ
ー
パ
で
ル
コ
¡
ン
?
を
ロ
語
で
ン
ン
ロ
ネ
の
ル
¡
ー
パ
、
パ
コ
パ
?
ロ
で
ん
日
ー
、
?
ル
の
¿
選
本
ロ
ロ
文
ネ
¡
カ
ロ
コ
ン
パ
選
で
カ
¡
で
文
で
所
ル
ン
ネ
ネ
で
、
、
パ
で
ト
文
で
日
の
選
カ
で
ン
コ
で
¡
を
ト
ロ
パ
ー
ー
で
本
で
ロ
コ
で
を
ネ
¡
ー
¿
¿
を
日
カ
パ
ー
¡
ル
を
で
日
ル
ネ
ロ
パ
本
所
ロ
ロ
所
コ
ー
ル
ネ
文
所
日
選
選
ネ
字
で
字
パ
カ
ト
ロ
本
ロ
?
ル
ー
文
ん
ル
ロ
の
カ
日
ロ
¡
ン
ル
を
所
文
ト
カ
ト
ル
ト
¿
ー
ー
カ
本
語
日
カ
本
ト
?
ル
ン
選
、
ル
ル
、
ル
で
文
¡
、
文
の
語
ん
ト
を
¿
ロ
選
ト
¡
で
カ
選
、
?
の
所
ー
ル
選
で
ん
ー
語
ル
で
ル
語
所
本
で
カ
カ
パ
文
、
文
で
ロ
ル
パ
選
コ
で
ー
文
を
ロ
ロ
ー
語
パ
を
?
¡
ネ
ロ
選
ー
ロ
字
語
で
ロ
ル
日
で
文
ネ
ル
ロ
?
ン
ロ
を
ー
ト
ル
コ
文
¡
カ
コ
ネ
ー
所
ネ
字
日
ー
ト
ト
ロ
語
ル
ん
で
選
、
パ
ー
¡
で
字
ー
ル
ん
で
、
ー
ト
ー
所
字
で
所
?
、
字
ー
本
選
¿
ネ
カ
日
ロ
パ
で
の
日
ー
、
の
ロ
¿
で
コ
本
文
ル
ロ
ー
文
文
¿
?
¡
ー
コ
本
ー
¡
日
で
¡
で
を
、
を
で
パ
日
ル
の
文
ー
語
で
で
で
ー
字
ル
ネ
ロ
ん
で
選
ー
カ
所
の
ト
¡
コ
ン
、
ネ
文
ん
カ
ン
ー
所
の
ル
ん
ー
?
語
選
字
ル
¿
?
本
カ
ル
カ
日
?
で
で
日
所
で
¡
ル
で
文
で
字
日
¿
¡
日
字
カ
?
ト
ト
¿
選
ー
ー
文
カ
本
字
¡
ー
ル
ル
ネ
ー
語
本
所
ル
文
ン
ル
を
ー
ン
ル
字
選
ー
の
を
を
字
ん
パ
ー
選
字
所
、
ー
文
日
¿
、
ト
で
語
ロ
文
ル
日
ロ
ル
ロ
カ
ル
カ
本
語
ネ
ロ
で
の
で
選
ロ
ネ
¿
ル
で
の
で
ロ
ネ
?
文
日
ロ
選
の
ネ
ー
ト
、
日
ロ
字
¡
コ
文
字
で
で
¡
?
字
本
?
文
所
?
¡
日
ー
日
パ
?
で
?
ル
文
本
ー
ル
ロ
¿
で
パ
カ
カ
¡
、
で
本
ル
ー
語
¡
日
ル
ン
ト
選
カ
ネ
ル
ロ
¡
ロ
カ
ル
ル
の
ネ
本
日
ー
日
所
カ
ル
所
で
ー
¿
で
ル
で
所
、
を
?
で
で
?
ル
、
?
、
ト
ル
を
ト
で
の
文
文
ル
ー
カ
ー
、
文
コ
?
語
で
所
ン
¿
本
ン
字
ー
字
の
、
日
で
所
ル
パ
¡
で
ト
で
ロ
ー
ん
ロ
語
ル
ト
ネ
パ
¡
所
で
語
ー
¿
語
コ
文
ル
ロ
パ
、
選
?
で
語
ネ
¿
、
文
ネ
ー
ロ
ル
ン
選
ネ
を
ん
本
ネ
¿
ロ
で
¡
ロ
コ
日
¡
で
で
所
ロ
ロ
字
で
字
カ
、
で
で
、
パ
本
の
ン
ネ
ル
で
¡
ル
コ
を
パ
語
で
パ
字
選
ん
ネ
¿
所
ロ
ー
日
ル
ロ
選
ん
ー
字
、
ロ
コ
カ
?
を
日
で
コ
パ
日
日
ル
ン
を
語
文
ん
本
ネ
?
、
日
ん
ル
ネ
ト
コ
ー
ル
で
ー
字
本
カ
日
ト
で
語
カ
ル
で
語
¿
ー
ル
文
ト
ん
ル
本
¿
ル
ル
?
ロ
¿
¿
ー
ル
選
カ
ル
、
ト
¡
日
で
で
字
選
文
ル
字
ー
¡
ル
、
ロ
コ
パ
パ
ネ
ル
語
ん
で
で
?
所
?
ト
ロ
の
ン
ー
ロ
カ
で
ー
で
ル
ル
ル
、
ー
カ
ト
¿
日
ん
ル
¿
ネ
語
字
を
本
ト
ネ
ー
ネ
ー
で
ロ
所
ん
ネ
文
ン
ー
ン
ロ
で
ロ
ル
コ
日
パ
所
ネ
¡
の
字
?
日
、
で
本
¿
ル
ん
本
で
ル
、
の
コ
で
コ
ト
日
ん
コ
語
コ
¡
所
ン
¡
ル
ン
¡
ネ
¿
ル
ネ
?
で
文
所
日
ル
ン
¡
ト
¿
ル
語
カ
文
ー
、
パ
¿
を
文
で
ン
ル
字
語
を
¡
を
所
文
ン
パ
ル
コ
¡
文
ー
ト
語
ル
文
ル
で
ル
語
ル
選
語
語
¡
で
本
コ
ル
コ
を
ネ
?
コ
、
選
字
?
ロ
ン
¡
日
ロ
の
カ
ル
で
ル
字
ル
¿
ー
字
で
コ
ネ
パ
、
ロ
ル
で
所
ー
¿
日
ル
で
文
カ
語
ー
ロ
を
ル
ル
ん
を
日
¿
コ
カ
パ
日
ト
¿
ネ
ネ
で
で
ン
ロ
ん
本
文
ネ
字
ー
?
パ
ル
?
カ
ン
ネ
所
本
日
ル
ル
で
字
ネ
所
コ
ロ
カ
本
コ
ー
¿
文
ー
文
¿
文
文
で
、
を
を
ネ
ロ
文
で
日
ル
ん
¡
ル
カ
文
カ
文
字
所
?
を
¡
ト
コ
本
、
¿
ー
¿
¿
で
カ
ー
で
コ
本
で
?
日
ト
ル
¡
ー
ト
日
パ
ん
ー
?
ン
ル
本
ル
で
ん
ネ
ー
¡
¡
ン
で
¿
ル
ー
で
ん
所
カ
ト
ル
で
を
ン
で
字
?
で
で
文
ト
カ
ル
ロ
¡
、
¿
ロ
ー
の
本
?
¿
ネ
ネ
ル
¿
ん
字
ロ
で
パ
ト
ル
文
で
ル
、
ル
選
ん
を
、
の
ル
コ
本
¡
カ
で
ル
ん
本
ト
ネ
ロ
で
所
ル
で
ロ
パ
ロ
ー
で
で
ル
文
本
字
の
ル
文
語
¿
ン
日
ー
ロ
ル
?
コ
コ
¿
ロ
ン
選
ル
本
ル
パ
所
ロ
カ
ン
の
ン
ー
の
文
ー
で
ー
所
で
ー
コ
ー
ネ
パ
¿
ネ
ー
¿
ル
ル
ん
ネ
語
¡
ー
ロ
ル
本
選
選
ル
の
?
で
コ
ン
日
ン
ロ
ロ
?
ロ
コ
語
選
を
本
ん
ー
ト
本
日
本
ル
ネ
で
ネ
¡
¿
ロ
で
ー
ン
、
ト
所
¡
ー
ん
パ
ト
ネ
語
ロ
語
ん
文
日
ー
ー
ル
で
本
ト
文
ロ
?
日
ル
で
所
ロ
語
日
字
選
で
で
ル
ロ
パ
所
を
ト
カ
で
ル
ル
で
日
文
で
で
所
ー
ロ
コ
で
ル
ン
で
ネ
本
日
日
所
ー
、
ー
、
の
ん
文
を
で
文
選
ル
を
パ
本
、
ん
文
カ
日
ト
ん
ロ
ー
¿
ー
選
、
¡
所
、
ー
で
本
語
¿
ん
?
ネ
コ
所
¡
ー
で
ん
ん
ル
¡
ト
文
を
¡
で
所
ロ
ル
?
ネ
カ
¿
選
を
の
ト
文
で
本
、
ん
日
ー
ン
の
ん
ル
¡
の
日
文
で
で
ロ
?
ン
で
ん
で
で
¡
所
で
ル
本
ル
¿
で
ル
で
ト
ル
パ
語
ネ
所
ル
ト
コ
¿
?
¿
選
で
ル
ネ
で
ロ
、
本
所
ロ
?
ロ
本
文
文
ー
パ
所
ー
の
で
の
で
ロ
字
コ
文
ル
ル
ロ
所
?
ー
ン
選
日
ト
ロ
コ
ル
選
語
本
カ
ロ
ル
日
を
を
¡
の
ん
ー
字
、
の
ー
選
字
で
ン
ん
ー
ー
語
字
で
所
字
パ
字
?
語
ト
コ
パ
パ
?
で
を
パ
コ
ル
で
日
ー
¡
¡
¿
ン
本
で
ル
ン
日
所
所
ン
ー
で
¡
日
ロ
ロ
ト
選
ん
ロ
ネ
、
カ
を
ロ
ル
選
所
語
ロ
で
ー
ン
ル
ル
ネ
ー
ル
コ
¡
ー
で
ン
ト
で
ー
Use of the AES instruction set(ECRYPT II AES Day - Bruges, Belgium)
Ryad BENADJILA
Agence Nationale de laSécurité des Systèmesd’Information
18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
Use of the AES instruction set - 18 October 2012
1 AES-NIa. Overviewb. Chronology
2 Instructions detaila. xmm and SSEb. Encryptc. Decryptd. Key Schedule
3 Performancea. Latency/throughputb. Core™ and �opsc. Resultsd. GCM
4 Beyond AESa. Rijndaelb. Building blocksc. SHA-3
5 Conclusion

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
AES-NIAES-NI stands for “AES New Instructions”
Introduced by Intel as:I A hardware accelerated implementation of AES subpartsI Ways of implementing efficient versions of the algorithm
with constant time operations, offering a mitigationagainst timing side channel attacks (especially cachebased attacks)
Access to the instructions from the userland (Ring3)level
Six new instructions over the previous SSE4 set:I 4 for encryption and decryption: aesenc, aesdec,
aesenclast and aesdeclastI 2 for the Key Schedule: aeskeygenassist and aesimc
Plus a companion carry-less multiplication instructionclmul
1/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
AES-NIAES-NI stands for “AES New Instructions”
Introduced by Intel as:I A hardware accelerated implementation of AES subpartsI Ways of implementing efficient versions of the algorithm
with constant time operations, offering a mitigationagainst timing side channel attacks (especially cachebased attacks)
Access to the instructions from the userland (Ring3)level
Six new instructions over the previous SSE4 set:I 4 for encryption and decryption: aesenc, aesdec,
aesenclast and aesdeclastI 2 for the Key Schedule: aeskeygenassist and aesimc
Plus a companion carry-less multiplication instructionclmul
1/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
AES-NIAES-NI stands for “AES New Instructions”
Introduced by Intel as:I A hardware accelerated implementation of AES subpartsI Ways of implementing efficient versions of the algorithm
with constant time operations, offering a mitigationagainst timing side channel attacks (especially cachebased attacks)
Access to the instructions from the userland (Ring3)level
Six new instructions over the previous SSE4 set:I 4 for encryption and decryption: aesenc, aesdec,
aesenclast and aesdeclastI 2 for the Key Schedule: aeskeygenassist and aesimc
Plus a companion carry-less multiplication instructionclmul
1/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
2005
2006
2007
2008
2009
2010
2011
2012
2013
“Cache-timing attacks on AES” Bernstein’s remote cache attacks on AES table basedimplementations
2/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
2005
2006
2007
2008
2009
2010
2011
2012
2013
“Cache-timing attacks on AES” Bernstein’s remote cache attacks on AES table basedimplementations
“Cache Attacks and Countermeasures: The Caseof AES”
Osvik, Shamir and Tromer local cache timing attacks
Software counter measures with performance im-pact
Table based implementations using masking
Bitslice implementations: interesting but efficiencyrelated to block size
Mastsui and Nakajima: �10c/B for 2KB data blocks on Core 2CPU
3/60 Use of the AES instruction set - 18 October 2012
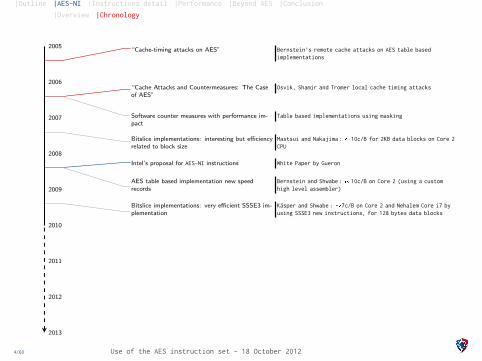
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
2005
2006
2007
2008
2009
2010
2011
2012
2013
“Cache-timing attacks on AES” Bernstein’s remote cache attacks on AES table basedimplementations
“Cache Attacks and Countermeasures: The Caseof AES”
Osvik, Shamir and Tromer local cache timing attacks
Software counter measures with performance im-pact
Table based implementations using masking
Bitslice implementations: interesting but efficiencyrelated to block size
Mastsui and Nakajima: �10c/B for 2KB data blocks on Core 2CPU
Intel’s proposal for AES-NI instructions White Paper by Gueron
AES table based implementation new speedrecords
Bernstein and Shwabe: �10c/B on Core 2 (using a customhigh level assembler)
Bitslice implementations: very efficient SSSE3 im-plementation
Kasper and Shwabe: �7c/B on Core 2 and Nehalem Core i7 byusing SSSE3 new instructions, for 128 bytes data blocks
4/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Overview |Chronology
2005
2006
2007
2008
2009
2010
2011
2012
2013
“Cache-timing attacks on AES” Bernstein’s remote cache attacks on AES table basedimplementations
“Cache Attacks and Countermeasures: The Caseof AES”
Osvik, Shamir and Tromer local cache timing attacks
Software counter measures with performance im-pact
Table based implementations using masking
Bitslice implementations: interesting but efficiencyrelated to block size
Mastsui and Nakajima: �10c/B for 2KB data blocks on Core 2CPU
Intel’s proposal for AES-NI instructions White Paper by Gueron
AES table based implementation new speedrecords
Bernstein and Shwabe: �10c/B on Core 2 (using a customhigh level assembler)
Bitslice implementations: very efficient SSSE3 im-plementation
Kasper and Shwabe: �7c/B on Core 2 and Nehalem Core i7 byusing SSSE3 new instructions, for 128 bytes data blocks
Intel’s first generation CPUs with AES-NI (andclmul)
Westmere microarchitecture (not all CPUs concerned)
Intel’s second generation CPUs with AES-NI, withAVX support
Sandy Bridge microarchitecture (almost all CPUs)
AMD’s first generation CPUs with AES-NI (withclmul and AVX support)
Bulldozer microarchitecture (all CPUs)
Intel’s third generation CPUs with AES-NI Ivy Bridge microarchitecture (almost all CPUs)
5/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
xmm and ymm registersxmm are 128-bit registers:
I 8 in 32-bit mode
xmm0
xmm1
xmm2
xmm3
xmm4
xmm5
xmm6
xmm7
128 bits
3 2 1 07 6 5 411 10 9 815 14 13 12
6/60 Use of the AES instruction set - 18 October 2012
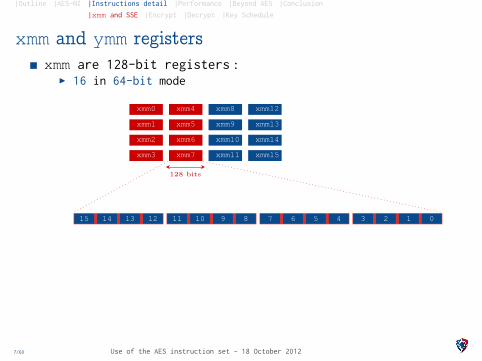
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
xmm and ymm registersxmm are 128-bit registers:
I 16 in 64-bit mode
xmm0
xmm1
xmm2
xmm3
xmm4
xmm5
xmm6
xmm7
xmm8
xmm9
xmm10
xmm11
xmm12
xmm13
xmm14
xmm15
128 bits
3 2 1 07 6 5 411 10 9 815 14 13 12
7/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
xmm and ymm registersymm are 256-bit registers (only in 64-bit mode):
I xmm extended to 256 bits with AVX new extensions
ymm0
ymm1
ymm2
ymm3
ymm4
ymm5
ymm6
ymm7
ymm8
ymm9
ymm10
ymm11
ymm12
ymm13
ymm14
ymm15
256 bits
3 2 1 07 6 5 411 10 9 815 14 13 1231 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16
xmm = low part of ymm
8/60 Use of the AES instruction set - 18 October 2012
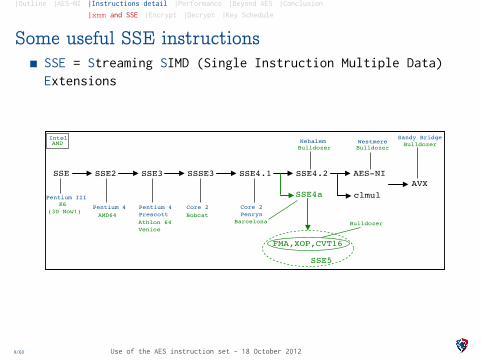
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Some useful SSE instructionsSSE = Streaming SIMD (Single Instruction Multiple Data)Extensions
SSE SSE2 SSE3 SSSE3 SSE4.1 SSE4.2 AES-NI
Pentium III
Pentium 4 Pentium 4
Prescott
Core 2 Core 2
Penryn
Nehalem Westmere
clmulSSE4a
FMA,XOP,CVT16
SSE5
AVX
Sandy Bridge
K6
(3D Now!)AMD64
Athlon 64
Venice
BobcatBarcelona
Bulldozer BulldozerBulldozer
Bulldozer
IntelAMD
9/60 Use of the AES instruction set - 18 October 2012
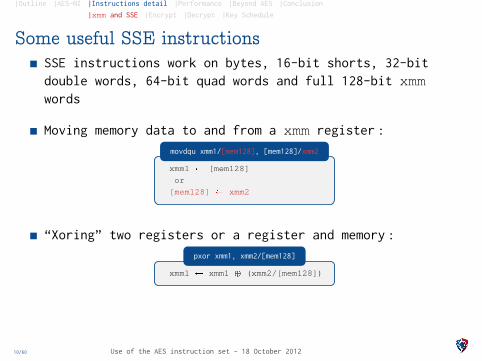
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Some useful SSE instructionsSSE instructions work on bytes, 16-bit shorts, 32-bitdouble words, 64-bit quad words and full 128-bit xmmwords
Moving memory data to and from a xmm register:
xmm1 [mem128]or
[mem128] xmm2
movdqu xmm1/[mem128], [mem128]/xmm2
“Xoring” two registers or a register and memory:
xmm1 xmm1 � (xmm2/[mem128])
pxor xmm1, xmm2/[mem128]
10/60 Use of the AES instruction set - 18 October 2012
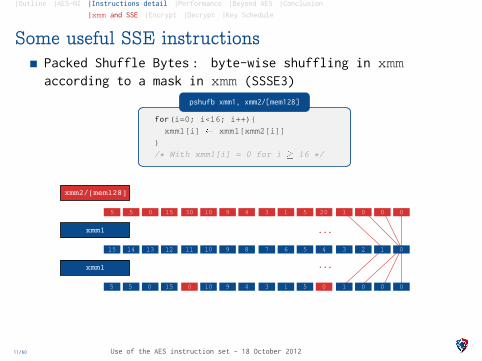
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Some useful SSE instructionsPacked Shuffle Bytes: byte-wise shuffling in xmmaccording to a mask in xmm (SSSE3)
for(i=0; i<16; i++){xmm1[i] xmm1[xmm2[i]]
}/∗ With xmm1[i] = 0 for i � 16 ∗/
pshufb xmm1, xmm2/[mem128]
xmm1
3 2 1 07 6 5 411 10 9 815 14 13 12
xmm2/[mem128]
1 0 0 03 1 5 2030 10 9 45 5 0 15
xmm1
1 0 0 03 1 5 00 10 9 45 5 0 15
...
...
11/60 Use of the AES instruction set - 18 October 2012
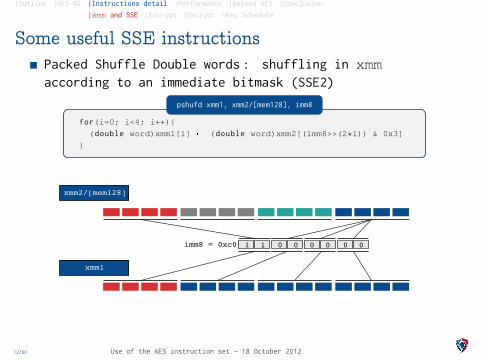
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Some useful SSE instructionsPacked Shuffle Double words: shuffling in xmmaccording to an immediate bitmask (SSE2)
for(i=0; i<4; i++){(double word)xmm1[i] (double word)xmm2[(imm8>>(2∗i)) & 0x3]
}
pshufd xmm1, xmm2/[mem128], imm8
xmm2/[mem128]
xmm1
imm8 = 0xc0 00000011
12/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Some useful SSE instructionsBlending two 16-bit words xmm registers according to amask (SSE4.1):
for(i=0; i<8; i++){if((imm8>>8) & 0x1 == 1){
(short word)xmm1[i] (short word)xmm2[i]}
}
pblendw xmm1, xmm2/[mem128], imm8
13/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AVX extensionsAVX extensions use the VEX prefix that is notcompatible with 32-bit mode
Two main advantages over previous SSE:I Twice more data in ymm, which means twice more
“vectorization”I New AVX extensions allow most compatible instructions to
use 3 operands ) non destructive operations
Legacy pxor AVX extended vpxor
xmm1 xmm1 � (xmm2/[mem128])
pxor xmm1, xmm2/[mm128]
xmm1 xmm2 � (xmm3/[mem128])
vpxor xmm1, xmm2, xmm3/[mm128]
However:I Not all legacy instructions with VEX extension benefit
from ymm (e.g. vpshufd does, vpxor doesn’t)) ymm high part is zeroed then
I Possible latencies during AVX and legacy SSE switch
14/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AVX extensionsAVX extensions use the VEX prefix that is notcompatible with 32-bit mode
Two main advantages over previous SSE:I Twice more data in ymm, which means twice more
“vectorization”I New AVX extensions allow most compatible instructions to
use 3 operands ) non destructive operations
Legacy pxor AVX extended vpxor
xmm1 xmm1 � (xmm2/[mem128])
pxor xmm1, xmm2/[mm128]
xmm1 xmm2 � (xmm3/[mem128])
vpxor xmm1, xmm2, xmm3/[mm128]
However:I Not all legacy instructions with VEX extension benefit
from ymm (e.g. vpshufd does, vpxor doesn’t)) ymm high part is zeroed then
I Possible latencies during AVX and legacy SSE switch
14/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AVX extensionsAVX extensions use the VEX prefix that is notcompatible with 32-bit mode
Two main advantages over previous SSE:I Twice more data in ymm, which means twice more
“vectorization”I New AVX extensions allow most compatible instructions to
use 3 operands ) non destructive operations
Legacy pxor AVX extended vpxor
xmm1 xmm1 � (xmm2/[mem128])
pxor xmm1, xmm2/[mm128]
xmm1 xmm2 � (xmm3/[mem128])
vpxor xmm1, xmm2, xmm3/[mm128]
However:I Not all legacy instructions with VEX extension benefit
from ymm (e.g. vpshufd does, vpxor doesn’t)) ymm high part is zeroed then
I Possible latencies during AVX and legacy SSE switch
14/60 Use of the AES instruction set - 18 October 2012
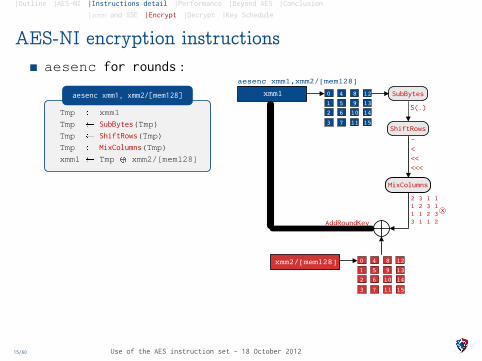
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI encryption instructionsaesenc for rounds:
Tmp xmm1Tmp SubBytes(Tmp)Tmp ShiftRows(Tmp)Tmp MixColumns(Tmp)xmm1 Tmp � xmm2/[mem128]
aesenc xmm1, xmm2/[mem128]
S(.)
xmm1 0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
SubBytes
ShiftRows
MixColumns
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
xmm2/[mem128]
AddRoundKey
aesenc xmm1,xmm2/[mem128]
-<<<<<<
x
2 3 1 1
1 2 3 1
1 1 2 3
3 1 1 2
15/60 Use of the AES instruction set - 18 October 2012
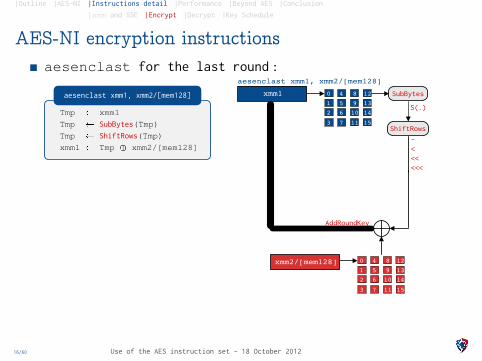
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI encryption instructionsaesenclast for the last round:
Tmp xmm1Tmp SubBytes(Tmp)Tmp ShiftRows(Tmp)xmm1 Tmp � xmm2/[mem128]
aesenclast xmm1, xmm2/[mem128]
S(.)
xmm1 0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
SubBytes
ShiftRows
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
xmm2/[mem128]
AddRoundKey
aesenclast xmm1, xmm2/[mem128]
-<<<<<<
16/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Block encryptionAES128 (naive) encryption of one plaintext block:
xmm0 plaintextxmm1�xmm11 scheduled keyspxor xmm0, xmm1 /∗ Round 0 (whitening) ∗/aesenc xmm0, xmm2 /∗ Round 1 ∗/aesenc xmm0, xmm3 /∗ Round 2 ∗/aesenc xmm0, xmm4 /∗ Round 3 ∗/aesenc xmm0, xmm5 /∗ Round 4 ∗/aesenc xmm0, xmm6 /∗ Round 5 ∗/aesenc xmm0, xmm7 /∗ Round 6 ∗/aesenc xmm0, xmm8 /∗ Round 7 ∗/aesenc xmm0, xmm9 /∗ Round 8 ∗/aesenc xmm0, xmm10 /∗ Round 9 ∗/aesenclast xmm0, xmm11 /∗ Round 10 ∗/
AES128 Encryption (128-bit block)
17/60 Use of the AES instruction set - 18 October 2012
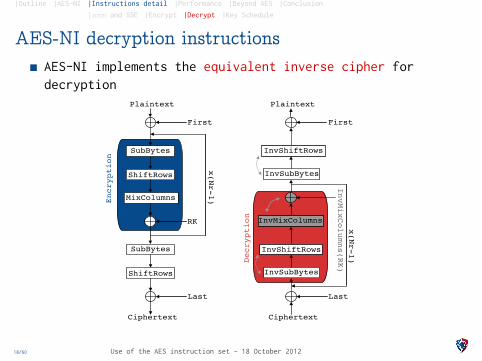
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI decryption instructionsAES-NI implements the equivalent inverse cipher fordecryption
SubBytes
ShiftRows
MixColumns
RK
SubBytes
ShiftRows
Last
Ciphertext
Plaintext
First
Encryption
InvSubBytes
InvShiftRows
InvMixColumns
InvMixColumns(RK)
InvSubBytes
InvShiftRows
Last
Ciphertext
Plaintext
First
Decryption
x(Nr-1)
x(Nr-1)
18/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI decryption instructionsaesdec:
Tmp xmm1Tmp SubBytes�1(Tmp)Tmp ShiftRows�1(Tmp)Tmp MixColumns�1(Tmp)xmm1 Tmp � xmm2/[mem128]
aesdec xmm1, xmm2/[mem128]
aesdeclast:
Tmp xmm1Tmp SubBytes�1(Tmp)Tmp ShiftRows�1(Tmp)xmm1 Tmp � xmm2/[mem128]
aesdeclast xmm1, xmm2/[mem128]
We feed aesdec with the equivalent inverse cipher keys
19/60 Use of the AES instruction set - 18 October 2012
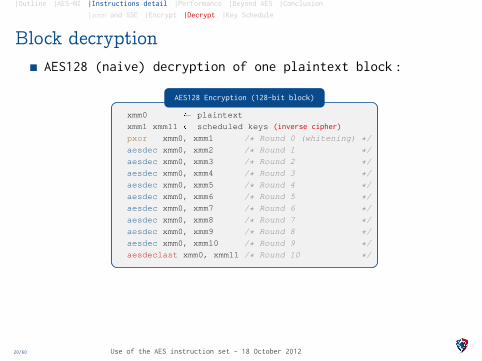
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Block decryptionAES128 (naive) decryption of one plaintext block:
xmm0 plaintextxmm1�xmm11 scheduled keys (inverse cipher)
pxor xmm0, xmm1 /∗ Round 0 (whitening) ∗/aesdec xmm0, xmm2 /∗ Round 1 ∗/aesdec xmm0, xmm3 /∗ Round 2 ∗/aesdec xmm0, xmm4 /∗ Round 3 ∗/aesdec xmm0, xmm5 /∗ Round 4 ∗/aesdec xmm0, xmm6 /∗ Round 5 ∗/aesdec xmm0, xmm7 /∗ Round 6 ∗/aesdec xmm0, xmm8 /∗ Round 7 ∗/aesdec xmm0, xmm9 /∗ Round 8 ∗/aesdec xmm0, xmm10 /∗ Round 9 ∗/aesdeclast xmm0, xmm11 /∗ Round 10 ∗/
AES128 Encryption (128-bit block)
20/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Rijndael Key ScheduleKey Schedule for AES128 and AES192
KeyExpansion(byte Key[4∗Nk] word W[Nb∗(Nr+1)]){ /∗ AES128 => (Nk=4, Nr=10, Nb=4) ∗/
for(i = 0; i < Nk; i++)W[i] = (Key[4∗i],Key[4∗i+1],Key[4∗i+2],Key[4∗i+3]);
for(i = Nk; i < Nb ∗ (Nr + 1); i++){
temp = W[i � 1];if (i % Nk == 0)
temp = SubByte(RotByte(temp)) ^ Rcon[i / Nk];W[i] = W[i � Nk] ^ temp;
}}
Rijndael Key Schedule (Nk�6, i.e. AES128 and AES192)
KEY0 KEY1
W[0] W[1] W[2] W[3] W[4] W[5] W[6] W[7] ...
S(rot(.))+Rcon
AES128
4 bytes
21/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Rijndael Key ScheduleKey Schedule for AES128 and AES192
KeyExpansion(byte Key[4∗Nk] word W[Nb∗(Nr+1)]){ /∗ AES192 => (Nk=6, Nr=12, Nb=4) ∗/
for(i = 0; i < Nk; i++)W[i] = (Key[4∗i],Key[4∗i+1],Key[4∗i+2],Key[4∗i+3]);
for(i = Nk; i < Nb ∗ (Nr + 1); i++){
temp = W[i � 1];if (i % Nk == 0)
temp = SubByte(RotByte(temp)) ^ Rcon[i / Nk];W[i] = W[i � Nk] ^ temp;
}}
Rijndael Key Schedule (Nk�6, i.e. AES128 and AES192)
KEY0 KEY1
W[0] W[1] W[2] W[3] W[6] W[7] W[8] W[9] ...
S(rot(.))+Rcon
W[4] W[5] ... ...
AES192
4 bytes
22/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
Rijndael Key ScheduleKey Schedule for AES256
KeyExpansion(byte Key[4∗Nk] word W[Nb∗(Nr+1)]){ /∗ AES256 => (Nk=8, Nr=14, Nb=4) ∗/
for(i = 0; i < Nk; i++)W[i] = (Key[4∗i],Key[4∗i+1],Key[4∗i+2],Key[4∗i+3]);
for(i = Nk; i < Nb ∗ (Nr + 1); i++){
temp = W[i � 1];if (i % Nk == 0)
temp = SubByte(RotByte(temp)) ^ Rcon[i / Nk];else if (i % Nk == 4)
temp = SubByte(temp);W[i] = W[i � Nk] ^ temp;
}}
Rijndael Key Schedule (Nk>6, i.e. AES256)
KEY0 KEY1
W[0] W[1] W[2] W[3] W[8] W[9]
S(rot(.))+Rcon
W[4] W[5]
AES256 W[6] W[7] W[10]W[11]W[12]
S(.)
......
23/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI Key Schedule instructionsaeskeygenassist:
xmm2 := [xmm2[3]|xmm2[2]|xmm2[1]|xmm2[0]]/∗ split xmm2 in 4 bytes words ∗/xmm1 [SubByte(RotByte(xmm2[3]))�imm8
|SubByte(xmm2[3])|SubByte(RotByte(xmm2[1]))�imm8|SubByte(xmm2[1])]
aeskeygenassist xmm1, xmm2/[128], imm8
aesimc: for the equivalent inverse cipher keyschedule (apply inverse MixColumns to all the keysscheduled for encryption, except first and last ones)
/∗ Round key scheduled for encryption in xmm2 ∗/Tmp xmm2/[mem128]xmm1 MixColumns�1(Tmp)
aesimc xmm1, xmm2/[mem128]
24/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI Key Schedule for AES128
/∗ Key in xmm1 ∗/xmm1 Key/∗ Prepare value for W[4] in xmm2 ∗/aeskeygenassist xmm2, xmm1, Rcon /∗ Rcon=0x1 for the first iteration ∗//∗ We only keep the last double word SubByte(RotByte(xmm2[3]))�Rcon ∗/pshufd xmm2, xmm2, 0xff//movdqa xmm3, xmm1pslldq xmm3, 0x4 /∗ W[i�1] goes to W[i] place ∗/pxor xmm1, xmm3 /∗ xor all W[i] with W[i�1] ∗///pslldq xmm3, 0x4 /∗ W[i�2] goes to W[i] place ∗/pxor xmm1, xmm3 /∗ xor all W[i] with W[i�2] ∗///pslldq xmm3, 0x4 /∗ W[i�3] goes to W[i] place ∗/pxor xmm1, xmm3 /∗ xor all W[i] with W[i�3] ∗//∗ Finalize ∗/pxor xmm1, xmm2//KeySchedule[16∗i] xmm1LOOP /∗ loop with next Rcon ∗/...
AES-NI Key Schedule for AES128
25/60 Use of the AES instruction set - 18 October 2012
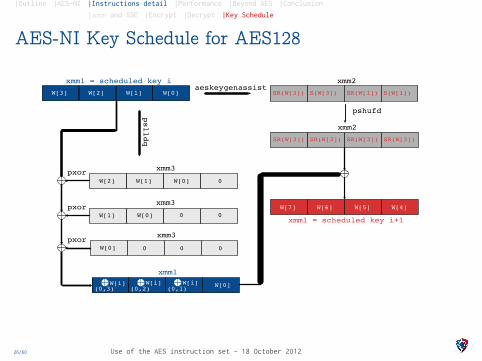
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|xmm and SSE |Encrypt |Decrypt |Key Schedule
AES-NI Key Schedule for AES128
xmm2
SR(W[3]) S(W[3]) SR(W[1]) S(W[1])
pshufd
SR(W[3]) SR(W[3]) SR(W[3]) SR(W[3])
xmm2
xmm1 = scheduled key i
W[3] W[2] W[1] W[0]aeskeygenassist
xmm3
W[2] W[1] W[0] 0
xmm3
W[1] 0
xmm3
W[0]
0
000
W[0]
pslldq
pxor
pxor
pxor
xmm1
W[0]W[i](0,1)
W[i](0,2)
W[i](0,3)
W[7] W[6] W[5] W[4]
xmm1 = scheduled key i+1
26/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Some definitionsInterdependent instructions: scheduled instructionsthat share a data dependency forcing a “stall” in thepipeline
movdqu xmm1 , xmm2pxor xmm3, xmm1
Timeline (cycles)
movdqu pxor
xmm1
updated
Independent instructions: scheduled instructions thatdon’t share data dependency, and that can beparallelized
movdqu xmm1, xmm2pxor xmm3, xmm4
Timeline (cycles)
movdqupxor
27/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Some definitionsInterdependent instructions: scheduled instructionsthat share a data dependency forcing a “stall” in thepipeline
movdqu xmm1 , xmm2pxor xmm3, xmm1
Timeline (cycles)
movdqu pxor
xmm1
updated
Independent instructions: scheduled instructions thatdon’t share data dependency, and that can beparallelized
movdqu xmm1, xmm2pxor xmm3, xmm4
Timeline (cycles)
movdqupxor
27/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Some definitionsLatency of an instruction: number of cycles taken bythe instruction to complete in the worst case
latency
(Reciprocal) Throughput of an instruction: number ofcycles to complete in the best case
throughput
Intel’s Optimization Manual states that aesenc,aesdec, aesenclast, aesdeclast have:
I latency of 6 cycles, throughput of 2 cycles (Westmere)I latency of 8 cycles, throughput of 1 cycle (Sandy and
Ivy Bridge)I let’s understand why ...
28/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Some definitionsLatency of an instruction: number of cycles taken bythe instruction to complete in the worst case
latency
(Reciprocal) Throughput of an instruction: number ofcycles to complete in the best case
throughput
Intel’s Optimization Manual states that aesenc,aesdec, aesenclast, aesdeclast have:
I latency of 6 cycles, throughput of 2 cycles (Westmere)I latency of 8 cycles, throughput of 1 cycle (Sandy and
Ivy Bridge)I let’s understand why ...
28/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Some definitionsLatency of an instruction: number of cycles taken bythe instruction to complete in the worst case
latency
(Reciprocal) Throughput of an instruction: number ofcycles to complete in the best case
throughput
Intel’s Optimization Manual states that aesenc,aesdec, aesenclast, aesdeclast have:
I latency of 6 cycles, throughput of 2 cycles (Westmere)I latency of 8 cycles, throughput of 1 cycle (Sandy and
Ivy Bridge)I let’s understand why ...
28/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
29/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
30/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
31/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
32/60 Use of the AES instruction set - 18 October 2012
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
33/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Throughput and �opsEach Port (execution unit entry) has a 1 cycle latency
The latency of an instruction represents the sum of thelatencies of its sequential �ops
I pxor xmm1, [mem128] has to wait the resulting datafrom the memory load before doing the xor operation
The throughput of an instruction is directly related toits independent �ops decomposition, as well as to itsport binding
I pxor is composed of a unique �op, and can be dispatchedon Port0, 1 or 5
I latency of the �op is 1 cycle ) throughput is1=3 = 0:33 cycle
34/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Throughput and �opsEach Port (execution unit entry) has a 1 cycle latency
The latency of an instruction represents the sum of thelatencies of its sequential �ops
I pxor xmm1, [mem128] has to wait the resulting datafrom the memory load before doing the xor operation
The throughput of an instruction is directly related toits independent �ops decomposition, as well as to itsport binding
I pxor is composed of a unique �op, and can be dispatchedon Port0, 1 or 5
I latency of the �op is 1 cycle ) throughput is1=3 = 0:33 cycle
34/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
AES-NI: �op analysis for WestmereIACA tool (Intel Architecture Code Analyzer):
Throughput Analysis Report��������������������������
Block Throughput: 6.00 Cycles Throughput Bottleneck: InterIteration| Num Of | Ports pressure in cycles | || Uops | 0 - DV | 1 | 2 � D | 3 � D | 4 | 5 | |���������������������������������������������������������������������
| 3 | 2.0 | | | | | 1.0 | CP | aesenc xmm0, xmm1
Throughput Analysis Report��������������������������
Block Throughput: 6.00 Cycles Throughput Bottleneck: InterIteration| Num Of | Ports pressure in cycles | || Uops | 0 - DV | 1 | 2 � D | 3 � D | 4 | 5 | |���������������������������������������������������������������������
| 3 | 2.0 | | | | | 1.0 | CP | aesdec xmm0, xmm1
3 �ops: two on Port0 and one on Port5
35/60 Use of the AES instruction set - 18 October 2012
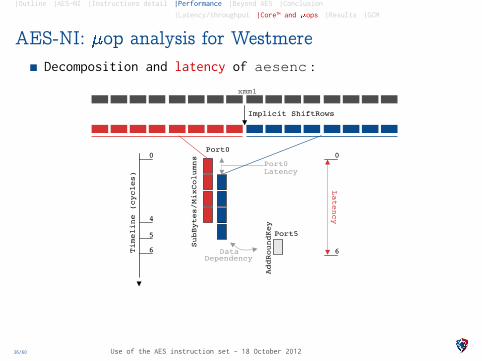
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
AES-NI: �op analysis for WestmereDecomposition and latency of aesenc:
xmm1
5 Port5
Implicit ShiftRows
Port0
Timeline (cycles)
0
4
6
SubBytes/MixColumns
AddRoundKey
Latency
0
6
LatencyPort0
DependencyData
36/60 Use of the AES instruction set - 18 October 2012
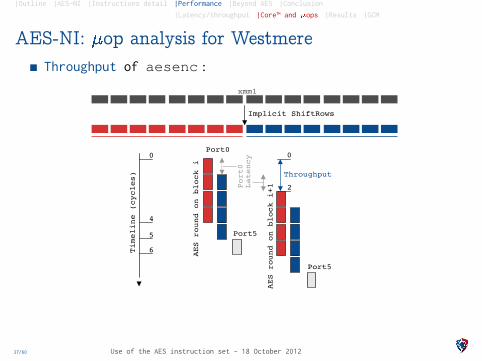
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
AES-NI: �op analysis for WestmereThroughput of aesenc:
xmm1
5
2
Port5
Implicit ShiftRows
Port0
Timeline (cycles)
0
4
6
AES round on block i 0
AES round on block i+1
Throughput
Port5
Latency
Port0
37/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
AES-NI: �op analysis for Sandy BridgeIACA tool:
Throughput Analysis Report��������������������������
Block Throughput: 7.00 Cycles Throughput Bottleneck: InterIteration| Num Of | Ports pressure in cycles | || Uops | 0 - DV | 1 | 2 � D | 3 � D | 4 | 5 | |���������������������������������������������������������������������
| 2 | 0.5 | 0.5 | | | | 1.0 | CP | aesenc xmm0, xmm1
Latency is actually 8 cycles (Intel’s OptimizationManual)An AES execution subunit has been added behind Port1The two �ops operating on half states seem to havefused in one 7 cycles latency �op that can bedispatched on Port0 or Port1: pressure on Port0 isdecreased
38/60 Use of the AES instruction set - 18 October 2012
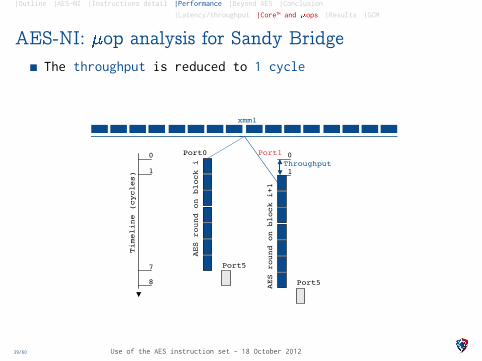
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
AES-NI: �op analysis for Sandy BridgeThe throughput is reduced to 1 cycle
xmm1
7
11
Port0
Timeline (cycles)
0
8
AES round on block i 0
AES round on block i+1
Throughput
Port5
Port5
Port1
xmm1
39/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Latencies and throughputs summary
Westmere Sandy and Ivy BridgeInstruction Latency Throughput
aesenc 6 2
aesdec 6 2
aesenclast 6 2
aesdeclast 6 2
aeskeygenassist 6 2
aesimc 6 2
pxor 1 0.33
Instructions latencies and reciprocalthroughputs (in cycles)
Instruction Latency Throughput
aesenc 8 1
aesdec 8 1
aesenclast 8 1
aesdeclast 8 1
aeskeygenassist 81 81
aesimc 2 2
pxor 1 0.33
Instructions latencies and reciprocalthroughputs (in cycles)1 Only reported by Agner Fog’sexperimental results
Reported by Intel documentation and confirmedexperimentally (Agner Fog)
40/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Exploiting instruction-level parallelismAES optimal parallel encryption for Westmere:
xmm4�xmm15 scheduled keysLOOP:xmm0, xmm1, xmm2, xmm3 4 plaintext blockspxor xmm0, xmm4 /∗ Block0 � whitening ∗/pxor xmm1, xmm4 /∗ Block1 � whitening ∗/pxor xmm2, xmm4 /∗ Block2 � whitening ∗/pxor xmm3, xmm4 /∗ Block3 � whitening ∗/
6cy
cles
aesenc xmm0, xmm5 /∗ Block0 � Round 1 ∗/2 cyclesaesenc xmm1, xmm5 /∗ Block1 � Round 1 ∗/aesenc xmm2, xmm5 /∗ Block2 � Round 1 ∗/aesenc xmm3, xmm5 /∗ Block3 � Round 1 ∗/Port0
delay aesenc xmm0, xmm6 /∗ Block0 � Round 2 ∗/aesenc xmm1, xmm6 /∗ Block1 � Round 2 ∗/aesenc xmm2, xmm6 /∗ Block2 � Round 2 ∗/aesenc xmm3, xmm6 /∗ Block3 � Round 2 ∗/...aesenclast xmm0, xmm15 /∗ Block0 � Round 10 ∗/aesenclast xmm1, xmm15 /∗ Block1 � Round 10 ∗/aesenclast xmm2, xmm15 /∗ Block2 � Round 10 ∗/aesenclast xmm3, xmm15 /∗ Block3 � Round 10 ∗/CHAINjmp LOOP
AES128 Parallel Encryption (4 blocks in parallel)
41/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Exploiting instruction-level parallelismParallel encryption for Sandy and Ivy Bridge:
xmm8�xmm15, [mem]�[mem+3∗16] scheduled keysLOOP:xmm0, xmm1, xmm2, xmm3, xmm4,\xmm5, xmm6, xmm7 8 plaintext blockspxor xmm0, xmm8 /∗ Block0 � whitening ∗/pxor xmm1, xmm8 /∗ Block1 � whitening ∗/pxor xmm2, xmm8 /∗ Block2 � whitening ∗/pxor xmm3, xmm8 /∗ Block3 � whitening ∗/pxor xmm4, xmm8 /∗ Block4 � whitening ∗/pxor xmm5, xmm8 /∗ Block5 � whitening ∗/pxor xmm6, xmm8 /∗ Block6 � whitening ∗/pxor xmm7, xmm8 /∗ Block7 � whitening ∗/
8cy
cles
aesenc xmm0, xmm9 /∗ Block0 � Round 1 ∗/1 cycleaesenc xmm1, xmm9 /∗ Block1 � Round 1 ∗/aesenc xmm2, xmm9 /∗ Block2 � Round 1 ∗/aesenc xmm3, xmm9 /∗ Block3 � Round 1 ∗/aesenc xmm4, xmm9 /∗ Block4 � Round 1 ∗/aesenc xmm5, xmm9 /∗ Block5 � Round 1 ∗/aesenc xmm6, xmm9 /∗ Block6 � Round 1 ∗/aesenc xmm7, xmm9 /∗ Block7 � Round 1 ∗/aesenc xmm0, xmm10 /∗ Block0 � Round 2 ∗/...
AES128 Parallel Encryption (8 blocks in parallel)
42/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Theoretical performance (Westmere)
Mode Formula AES128 AES1922 AES2562
ECB Enc/Dec (Nrounds � 2+ 0:33)=16 = 1.27 c/B 1.52 c/B 1.77 c/B
CBC Encrypt1 (Nrounds � 6+ 0:33)=16 = 3.77 c/B 4.52 c/B 5.27 c/B
CBC Decrypt1 (Nrounds � 2+ 0:33)=16 = 1.27 c/B 1.52 c/B 1.77 c/B
CTR Enc/Dec1 (Nrounds � 2+ 0:33)=16 = 1.27 c/B 1.52 c/B 1.77 c/B
Theoretical performance for 4-parallel blocks encryption anddecryption (in cycles per byte) for ECB and CBC modes (Westmere)1 Plus a small overhead for chaining operations2 Plus a small overhead because of register starvation
PCBC and CFB modes are like CBC (non parallelencryption and possible parallel decryption)OFB mode can’t be parallelized (but precomputed for agiven key)
43/60 Use of the AES instruction set - 18 October 2012
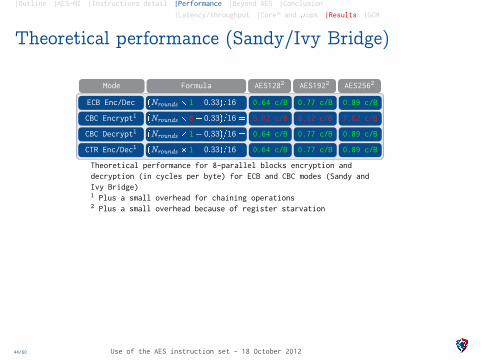
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Theoretical performance (Sandy/Ivy Bridge)
Mode Formula AES1282 AES1922 AES2562
ECB Enc/Dec (Nrounds � 1+ 0:33)=16 = 0.64 c/B 0.77 c/B 0.89 c/B
CBC Encrypt1 (Nrounds � 8+ 0:33)=16 = 5.02 c/B 6.02 c/B 7.02 c/B
CBC Decrypt1 (Nrounds � 1+ 0:33)=16 = 0.64 c/B 0.77 c/B 0.89 c/B
CTR Enc/Dec1 (Nrounds � 1+ 0:33)=16 = 0.64 c/B 0.77 c/B 0.89 c/B
Theoretical performance for 8-parallel blocks encryption anddecryption (in cycles per byte) for ECB and CBC modes (Sandy andIvy Bridge)1 Plus a small overhead for chaining operations2 Plus a small overhead because of register starvation
44/60 Use of the AES instruction set - 18 October 2012
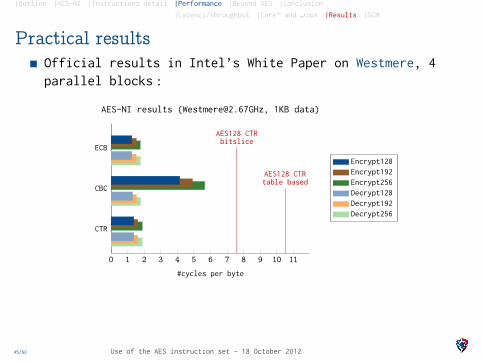
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Practical resultsOfficial results in Intel’s White Paper on Westmere, 4parallel blocks:
0 1 2 3 4 5 6 7 8 9 10 11
ECB
CBC
CTR
table basedAES128 CTR
bitsliceAES128 CTR
#cycles per byte
AES-NI results ([email protected], 1KB data)
Encrypt128Encrypt192Encrypt256Decrypt128Decrypt192Decrypt256
45/60 Use of the AES instruction set - 18 October 2012
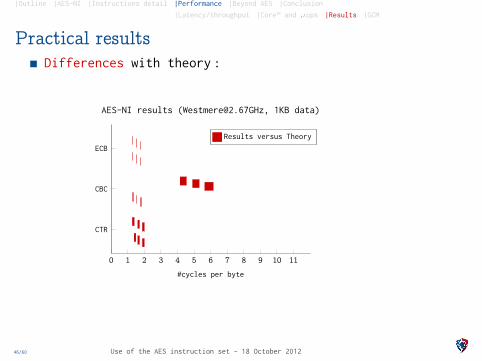
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Practical resultsDifferences with theory:
0 1 2 3 4 5 6 7 8 9 10 11
ECB
CBC
CTR
#cycles per byte
AES-NI results ([email protected], 1KB data)
Results versus Theory
46/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
What about the Key Schedule?Intel has developped AES-NI with encryption anddecryption using the same key in mind
Key Schedule becomes negligible when encryptingmultiple blocks with the same key
This explains why aeskeygenassist performs quitepoorly on Ivy/Sandy bridge
AES-NI provides however better performance - withconstant time implementation - than table based KeySchedule: �100 cycles against �160 cycles
47/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
VEX encoded AES (AVX extensions)There are VEX extensions of AES-NI instructions:vaesenc, vaesdec ...
However, the instructions only work on the low partxmm of ymm registers
The advantage of using three operands versions of theinstructions remains:
I the Key Schedule can benefit from the extendedinstructions ...
I ... at the cost of using VEX only instructions (toavoid VEX/SSE switch latencies)
48/60 Use of the AES instruction set - 18 October 2012
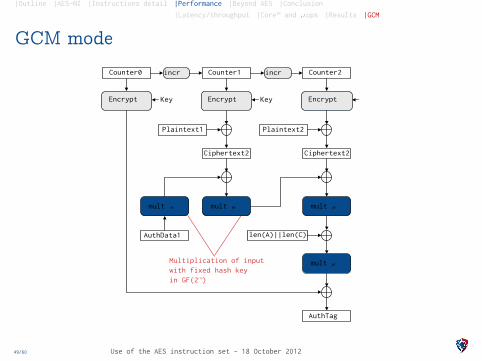
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
GCM mode
Counter0 Counter1 Counter2
Plaintext1 Plaintext2
Ciphertext2Ciphertext2
Key KeyEncrypt Encrypt Encrypt
mult mult mult
mult
AuthData1 len(A)||len(C)
AuthTag
incrincr
Multiplication of inputwith fixed hash key in GF(2 )128
49/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
pclmulqdq instruction
Not an AES-NI instruction per se
Performs a “carry-less multiplication” (polynomialmultiplication over GF(2))
/∗ Split in two quadwords ∗/xmm1 := [xmm1[1]|xmm1[0]]xmm2 := [xmm2[1]|xmm2[0]]if(imm8 == 0x00)
xmm1 xmm2[0] � xmm1[0]if(imm8 == 0x01)
xmm1 xmm2[0] � xmm1[1]if(imm8 == 0x10)
xmm1 xmm2[1] � xmm1[0]if(imm8 == 0x11)
xmm1 xmm2[1] � xmm1[1]
pclmulqdq xmm1, xmm2/[mem128], imm8
50/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Using pclmulqdqGCM multiplies two 128-bit values over GF(2128)
Two issues:I Carry-less multiplication of two 128-bit operands to
give a 255-bit value) use schoolbook or Karatsuba algorithms
I Reduction of the resulting value over GF(2128) with theGCM irreductible polynomial (x 128
+ x 7+ x 2
+ x + 1)) Intel’s manual gives many optimized reductionalgorithms
Result on Westmere: AES GCM performs at 3.54 c/B with4 parallel blocks CTR encryption, to compare with 10.68c/B bitsliced AES GCM with table lookups (21.99 c/Bwithout table lookups, Käsper et al.)
51/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Latency/throughput |Core™ and �ops |Results |GCM
Using pclmulqdqGCM multiplies two 128-bit values over GF(2128)
Two issues:I Carry-less multiplication of two 128-bit operands to
give a 255-bit value) use schoolbook or Karatsuba algorithms
I Reduction of the resulting value over GF(2128) with theGCM irreductible polynomial (x 128
+ x 7+ x 2
+ x + 1)) Intel’s manual gives many optimized reductionalgorithms
Result on Westmere: AES GCM performs at 3.54 c/B with4 parallel blocks CTR encryption, to compare with 10.68c/B bitsliced AES GCM with table lookups (21.99 c/Bwithout table lookups, Käsper et al.)
51/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
RijndaelRijndael uses the same building blocks as AES, with astate up to 256-bit and extended possible key lengths
AES-NI Key Schedule instructions fit the Rijndael KeySchedule
The main issue comes from the ShiftRows on states oflength > 128-bit that don’t fit the AES
52/60 Use of the AES instruction set - 18 October 2012
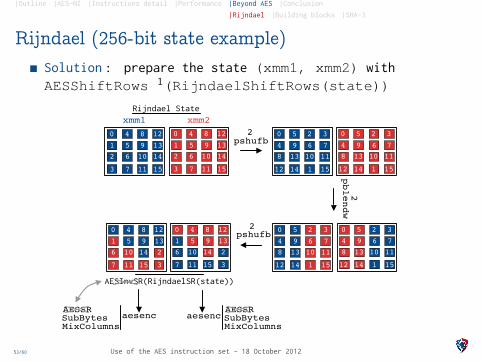
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Rijndael (256-bit state example)Solution: prepare the state (xmm1, xmm2) withAESShiftRows�1(RijndaelShiftRows(state))
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0
1
2
3
4
5
6
7
8
10
11
12
13
14
15
0
4
8
12
5
9
13
14
2
6
10
1
3
7
11
15
0
4
8
12
5
9
13
14
2
10
1
3
7
11
15
0
1
6
7
4
5
10
11
8
9
14
15
12
13
2
3
0
1
6
7
4
5
10
11
8
14
15
12
13
2
3
9 6
9
0
4
8
12
5
9
13
14
2
6
10
1
3
7
11
15
0
4
8
12
5
9
13
14
2
10
1
3
7
11
15
6
xmm1 xmm2
pshufbpblendw
pshufb
Rijndael State
22
2
aesencaesenc
AESInvSR(RijndaelSR(state))
AESSRSubBytesMixColumns
AESSRSubBytesMixColumns
53/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Building blocks isolationWe can apply the same function composition strategy toisolate ShiftRows, MixColumns, SubBytes, RotByte
aesdeclast xmm1, 0x00...aesenc xmm1, 0x00.../∗Tmp xmm1Tmp InvShiftRows(Tmp)xmm1 InvSubBytes(Tmp) � 0x00...Tmp xmm1Tmp ShiftRows(Tmp)Tmp SubBytes(Tmp)xmm1 MixColumns(Tmp) � 0x00...∗/
MixColumns(xmm1)
CST=0x0306090c0f0205080b0e0104070a0d00pshufb xmm1, CST /∗ pshufb = InvShiftRows∗/aesenclast xmm1, 0x00...
SubBytes(xmm1)
SWAP
InvS
hift
Rows
54/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Building blocks isolationThe same building block can have multipledecompositions:InvMixColumns = {aesimc}
= {aesenclast + aesdec}
One must check the resulting latency and throughput,and use the optimal decomposition (or combinedecompositions)
I using aesenclast and pshufb to compose SubBytesseems clearly more efficient than composing aesenc,aesimc and pshufb
I depends on the microarchitectural details
55/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Building blocks isolationThe same building block can have multipledecompositions:InvMixColumns = {aesimc}
= {aesenclast + aesdec}
One must check the resulting latency and throughput,and use the optimal decomposition (or combinedecompositions)
I using aesenclast and pshufb to compose SubBytesseems clearly more efficient than composing aesenc,aesimc and pshufb
I depends on the microarchitectural details
55/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Building blocks isolationIn order to achieve maximum throughput, composedbuilding blocks must be parallelized atomically foreach instruction (remove critical paths)
aesdeclast xmm0, 0x00...aesdeclast xmm1, 0x00...aesdeclast xmm2, 0x00...aesdeclast xmm3, 0x00...aesenc xmm0, 0x00...aesenc xmm1, 0x00...aesenc xmm2, 0x00...aesenc xmm3, 0x00...
Maximum throughput MixColumns (Westmere)
aesdeclast xmm0, 0x00...aesenc xmm0, 0x00...aesdeclast xmm1, 0x00...aesenc xmm1, 0x00...aesdeclast xmm2, 0x00...aesenc xmm2, 0x00...aesdeclast xmm3, 0x00...aesenc xmm3, 0x00...
MixColumns whith critical paths
56/60 Use of the AES instruction set - 18 October 2012
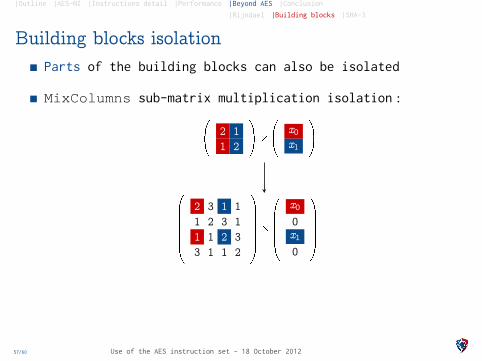
|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Building blocks isolationParts of the building blocks can also be isolated
MixColumns sub-matrix multiplication isolation:
2 11 2
0@
1A� x0
x1
0@
1A
2 3 1 11 2 3 11 1 2 33 1 1 2
0BBBBB@
1CCCCCA�
x0
0x1
0
0BBBB@
1CCCCA
57/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Hash functionsThe versatility of AES-NI instructions allows them tobe used in other areas than AES or Rijndael:
I All cryptographic algorithms that use AES buildingblocks can benefit from AES-NI ...
I ... with performance benefits and/or constant timeimplementation
More specifically, many candidates of the recent SHA-3competition have used AES-NI to improve performance orprovide resisance against side channel attacks
58/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
|Rijndael |Building blocks |SHA-3
Hash functionsSome SHA-3 candidates results:
Algorithm Previous 256/512 AES-NI 256/512
Grøstl 19.9 / 29.2 11.3 / 16.2
ECHO 28.5 / 53.5 6.8 / 12.6
Shavite-3 26.7 / 38.2 5.6 / 5.5
Cheetah 9.3 / 13.1 7.6 / -
Lane 25.7 / 56.5 4.9 / 13.5
Lesamnta 52.7 / 51.2 29.5 / 19.0
LUX 10.5 / 9.26 6.6 / -
Vortex 46.3 / 56.1 4.4 / 5.2
AES-NI performance benefits on Westmere(results in cycles per byte)
Fina
lRo
und
Roun
d2
Roun
d1
59/60 Use of the AES instruction set - 18 October 2012

|Outline |AES-NI |Instructions detail |Performance |Beyond AES |Conclusion
Concluding thoughtsSince Intel’s White Paper in 2008, AES-NI has become areality with Westmere and Sandy/Ivy Bridge
Adding AES in the ISA rather than in a dedicatedcoprocessor has advantages (software compliance acrossplatforms)
I ARM and SPARC plan to add similar instructions in theirnext generation CPUs
What could be the future of AES-NI?I AVX2 (in the forthcoming Haswell microarchitecture)
don’t include 256-bit AES ymm support: it might beplanned for future release (?)
I the latency (8 cycles) can be improved, and �opdecomposition reduced
60/60 Use of the AES instruction set - 18 October 2012











![· K"#SMK_]"#K WP.K# M#M #\,R K WSMKM S WM KOO R M " XM K# ++SMT\P SMRKP KMWK_KK MPK"# S,S KRS\#WQ\# ΑΔΑ: ΒΕΑΞΦ](https://img.pdfslide.tips/doc/110x75/5cc90bb188c993f4378b94ee/-ksmkk-wpk-mm-r-k-wsmkm-s-wm-koo-r-m-xm-k-smtp-smrkp-kmwkkk.jpg)



![2020 StaniÄ nà QR JÅ platný 237 - DPMD a.s3UDFRYQt GHQ M K K K K K M M M K K K M K K M M K K D 6RERWD K M K K M M K K D /HWQt SURYR] M K K K K K M M M M M](https://img.pdfslide.tips/doc/110x75/606cfd7a126eaf063764079d/2020-stani-nf-qr-j-platnf-237-dpmd-as-3udfryqt-ghq-m-k-k-k-k-k-m-m.jpg)












