Embed Size (px)
Citation preview

제 13 장 데이터 품질
2015.06
충북대학교 경영정보학과
조 완섭
* 이 장은 “빅데이터 거버넌스“ (홍릉출판사, 조완섭 번역) 제 9장을 요약한 것임

목 차
2015-07-23
• 개요
• 빅데이터 품질 신뢰구간 설정
• 데이터의 품질 향상
• 스트리밍 데이터 품질 향상
• 데이터 관리 주체 지정
충북대학교 조완섭([email protected]) 2

개요
Data quality management
– 데이터에 관한 품질과 무결성을 측정하고, 개선하며, 보증하는 방법
– 엄청난 크기와 속도 및 다양성이라는 빅데이터의 특징으로 인하여 빅데이터 품질은 기존의 데이터 품질 문제와는 다르게 다루어져야 함
기존 데이터와 빅데이터의 품질 관점에서의 차이점
2015-07-23
Dimension Traditional Data Big Data Quality
프로세싱 방식 배치 방식의 프로세싱 실시간,배치 방식의 프로세싱
데이터의 다양성 주로 정규화된 데이터 구조적/반구조적/비구조적 데이터
신뢰수준 분석을 위해서는 미리 데이터 웨어하우스에클렌징된 상태로 데이터가 저장되어있어야만 올바른 분석이 가능함
Noise가 미리 필터링되어 있어야 하지만 데이터는“good enough” 될 필요가 있음 (Poor data 품질이 분석을 지연시킬 수도, 아닐 수도 있다.)
정제 시간 로드하기 전에 데이터 웨어하우스에 클렌징되어 있어야 한다.
중요한 데이터 요소와 데이터들간의 관계를 완벽히 알수 없기에 데이터는 우선 있는 그대로 적재되어야 함-> 빅데이터의 양과 속도는 스트리밍과 인메모리방식의 분석이 요구됨(그러므로 필요한 저장소의 양은 줄어드는 효과를 가져올 수 있다.)
충북대학교 조완섭([email protected]) 3

개 요
기존 데이터와 빅데이터의 품질 관점에서의 차이점
2015-07-23
Dimension Traditional Data Big Data Quality
핵심데이터의 요소
데이터 품질은 고객주소 데이터와 같은 기준이 되는 중요(핵심) 데이터에 의해 평가됨
빅데이터는 그 수가 다양하고 불분명하며때론 더 깊은 탐구가 요구되기 때문에 기준이 되는 핵심 데이터 요소들이 반복적으로 바뀔 수 있음
분석장소 분석할 데이터가 데이터 품질과 분석 엔진으로 이동(데이터 -> 데이터 품질, 분석 엔진)
허용되는 처리 속도와 비용을 줄이기 위해 데이터품질과 분석엔진이 데이터 쪽으로 이동할 필요가있음(데이터 품질, 분석 엔진 -> 데이터)
스튜어 십 관리자는 데이터의 대부분을 관리할 수 있음 빅데이터의 특징인 데이터의 빠른 속도와 많은 양때문에 관리자도 데이터의 일부분만 다룰 수 있는경우가 발생함
충북대학교 조완섭([email protected]) 4

빅데이터 품질 신뢰구간
빅데이터 품질문제– 핵심 데이터 요소를 구분하여 잘 관리해야 하고, 상황에 맞추어 적절
한 품질 수준 (신뢰구간)으로 타협할 필요가 있음
Case Study : Twitter data quality at Acme Corporation
2015-07-23
기준데이터 문제점 데이터 품질의 비즈니스 룰(Rules)
트위터의타임스템프
(timestamp)
표준형식과 다른 트위터의 timestamp의형식은 외부 데이터와 조인을 하는데 있어 많은 오류를 발생시킬 수 있음
★ 모든 양식은 YYYY-MM-DD HH:MM:SS 로재구성한다
사용자 이름(User name)
사용자 이름 중 절반이 실제 이름과 다르지만, 이러한 사용자 이름은 MDM(Mater Data Management)에서 실제 고객 정보와 연결할 수 있는 유용한 요소임
★ 만약 숫자, 부호 문자가 사용자 이름에포함되어 있다면 신뢰수준은 : 0%
★ 만약 성이나, 이름 중 한나만 사용자이름에 포함되어 있다면 신뢰수준은 : 25%
★ 만약 2-3개의 단어가 포함되어있다면
신뢰수준은 : 50 %
★ 만약 사용자 이름이 사전에 등록된것이라면 신뢰수준은 : 99 %
“Best day ever. Went mountain biking today. Will get one for my husband too.” => 여성, 기혼, 자전거타기, 나이 25~55
< Data quality matrix >
충북대학교 조완섭([email protected]) 5

빅데이터 품질 신뢰구간
Data quality matrix
2015-07-23
기준데이터 문제점 데이터 품질의 비즈니스 룰(Rules)
회사의 언급성(Acme)
Acme Corporation 에 대한 트윗인가혹은 필터링 되어야 할 노이즈인가 ?
★ 트윗에 “@Acme” 단어가 포함되어 있다면신뢰수준은 : 99%
★ “Acme”과 Acme 제품의 이름이 포함되어있다면 신뢰수준은 : 75%
★ “Acme”이 포함된 경우 신뢰수준은 : 50%★ 트윗에 “Acme”에 대해 아무 언급이
없으면 신뢰수준은 : 0%
위치(Location)★ 트위터에서 위치 데이터는 매우
중요한 역할을 하고 있음
예) 미국동남부에 위치한 지역 사람들
이 다른 지역에 위치한 사람들보다 불
만스러워하는 이유는 무엇인가?
★ 사용자 프로파일에 거주 도시, 주 이
름 정보가 포함되어 있을 수 있지만 입
증된 것은 아님
★ 사용자의 이름, 장소 데이터를 통해 메타 데
이터에서 사용자가 거주하고 있는 도시와 주
이름을 추출하여 입증하도록 노력함
(이름, 위치 데이터 -> 거주도시, 주 이름 추출)
★ 만약, 장소를 쉽게 알아내기 어렵다면, “알
수 없음”으로 일단 표시해 둠
충북대학교 조완섭([email protected]) 6

빅데이터 품질 신뢰구간
Twitter, 데이터에 대한 신뢰구간의 예
응용에 적합한 수준의 신뢰구간 선택 필요– 고객 감성분석을 하는 부서의 경우 “high” 신뢰구간을 설정
– 콜센터에서는 ‘very high“ 수준을 사용하여 실시간으로 정확한 지원을 할 필요가 있음
2015-07-23
카테고리 신뢰구간
Very high 90%~99%
High 80%~89%
Medium 70%~79%
Low < 69%
충북대학교 조완섭([email protected]) 7
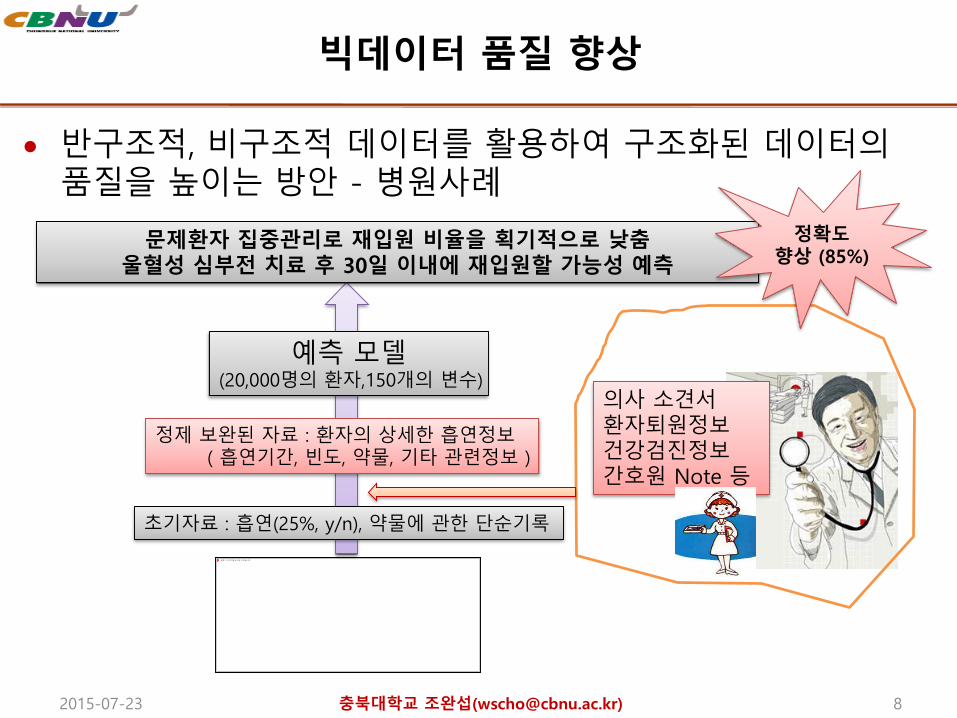
빅데이터 품질 향상
반구조적, 비구조적 데이터를 활용하여 구조화된 데이터의품질을 높이는 방안 - 병원사례
2015-07-23
문제환자 집중관리로 재입원 비율을 획기적으로 낮춤울혈성 심부전 치료 후 30일 이내에 재입원할 가능성 예측
예측 모델(20,000명의 환자,150개의 변수)
초기자료 : 흡연(25%, y/n), 약물에 관한 단순기록
의사 소견서환자퇴원정보건강검진정보간호원 Note 등
정제 보완된 자료 : 환자의 상세한 흡연정보( 흡연기간, 빈도, 약물, 기타 관련정보 )
정확도향상 (85%)
충북대학교 조완섭([email protected]) 8

스트리밍 데이터 품질 향상
2015-07-23
Query Data 분석-결과 Data 분석-결과
데이터를 일단 디스크에 저장한 후, 이를 대상으로 분석함Database, DW가 사용됨주로 정형 데이터 위주
데이터를 수집한 후, 필터링하고, 디스크 저장 없이(메모리에서) 바로 분석함빅데이터 (다양함)기존 컴퓨팅 스트림 컴퓨팅
충북대학교 조완섭([email protected]) 9
(* 한국 IBM 발표자료 참고)

싱크(목적지)스키마
(메타데이터)
스트리밍 데이터 품질 향상
스트리밍 응용에서 데이터에 관해 고려할 사항 2가지
– 소스 스트리밍 응용에 입력되는 데이터를 의미함
소켓연결, 데이터베이스 질의, 자바 메시지 서비스(JMS) topic/queue, 파일 등
각 소스에 관한 정보는 전송 미디어가 상이해도 스키마에 저장하여 관리해야 함
– 싱크 혹은 목적지 스트림 응용에서 생성되는 데이터를 의미하며
소켓 연결, 데이터베이스 테이블, JMS topic/queue, 파일, 혹은 웹서비스 등으로전달되거나 기록됨
스키마에는 목적지에 대한 정보를 저장하여 관리해야 함
2015-07-23
Stream 응용
1. 시간간격 조정 : 데이터 생성주기의 차이극복2. 도착비율 : 연속/폭증여부/gap
충북대학교 조완섭([email protected]) 10

스트리밍 데이터 품질 향상
Case Study
학교 빌딩의 센서를 모니터링 하는 가상적인 스트리밍 응용
2015-07-23
온도센서 (보일러실)
모션센서 (강의실)
60초마다 생성, 전달
30초마다생성, 전달
Hadoop
메모리
온도 데이터가매 10분마다 Hadoop에 저장됨
응용은 다음 상황에서 경고 메시지 발생- 5분 동안 센서 데이터가 발생하지 않거나- 보일러실에서 AM 3:00에 75도 이상이거나- 강의실에서 AM 5:00에 움직임이 감지되면
시간간격조정버퍼
충북대학교 조완섭([email protected]) 11
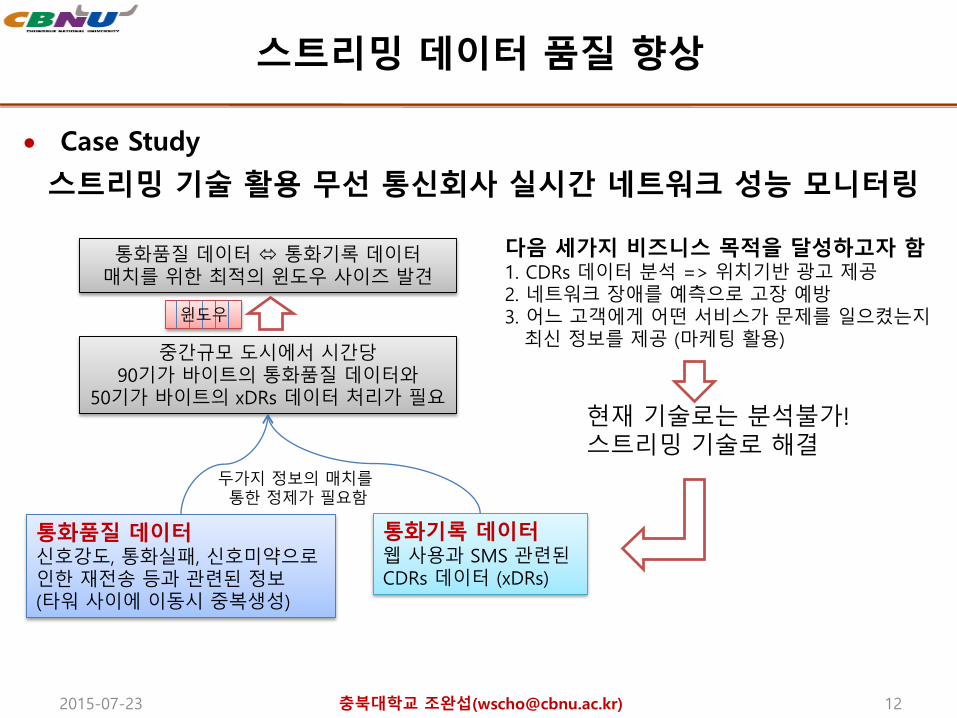
스트리밍 데이터 품질 향상
Case Study
스트리밍 기술 활용 무선 통신회사 실시간 네트워크 성능 모니터링
2015-07-23
통화품질 데이터신호강도, 통화실패, 신호미약으로인한 재전송 등과 관련된 정보(타워 사이에 이동시 중복생성)
통화기록 데이터웹 사용과 SMS 관련된CDRs 데이터 (xDRs)
통화품질 데이터 통화기록 데이터매치를 위한 최적의 윈도우 사이즈 발견
중간규모 도시에서 시간당90기가 바이트의 통화품질 데이터와
50기가 바이트의 xDRs 데이터 처리가 필요
다음 세가지 비즈니스 목적을 달성하고자 함1. CDRs 데이터 분석 => 위치기반 광고 제공2. 네트워크 장애를 예측으로 고장 예방3. 어느 고객에게 어떤 서비스가 문제를 일으켰는지
최신 정보를 제공 (마케팅 활용)
현재 기술로는 분석불가!스트리밍 기술로 해결
두가지 정보의 매치를통한 정제가 필요함
윈도우
충북대학교 조완섭([email protected]) 12

데이터 관리 주체 지정
데이터 품질관리 주체 지정– 빅데이터 거버넌스 프로그램에서는 데이터의 품질에 대하여 책
임지는 관리주체를 지정해야 함
– 품질관리 주체는 다음 세가지 주요 책임을 담당함
1. 빅 데이터 품질에 대한 비즈니스 규칙과 신뢰구간 및 측정방법을 설정하고 개선함- 예: 청구날짜보다 앞선 보험금 지급날짜 발견 규칙
2. 빅 데이터 품질에 대한 이슈를 다루어야 함- 예 : 대량 유입되는 이벤트 데이터의 품질 상태를 자동 인식하여 대처함
3. 빅 데이터의 데이터 품질의 트랜드를 보고해야 한다.- 핵심 데이터 항목에 대한 데이터 품질 동향 (시간 경과에 따른 품질변화)
- 관리권이 요구되는 데이터 품질에 대한 이슈들의 동향
<= 가능한 시각화된 방식으로 보고함
2015-07-23 충북대학교 조완섭([email protected]) 13

요약
빅데이터 품질은 기존의 프로젝트와는 다른 데이터 품질 문제를 가지고 있음
– 빅데이터 품질은 실시간으로 다루어져야 하는 경우도 있으며, 데이터의 품질이 매우 낮은 경우가 많으므로 품질에 대한 신뢰구간을 정하는 것이 필요하다.
– 또한 방대한 볼륨 때문에 전체 데이터 중에서 단지 일부에 대해서만 품질 관리를 할 수 있을 것이다.
2015-07-23 충북대학교 조완섭([email protected]) 14






![비즈니스인텔리전스 - KOCWcontents.kocw.net/KOCW/document/2016/chungbuk/chowanseop/...분석처리시스템(BI) •BusinessIntelligence – [가트너]비즈니스인텔리전스는조직의의사결정과성능을개](https://img.pdfslide.tips/doc/110x75/606d0be9060fc865a46f0bd9/eee-eeoeoebi-abusinessintelligence.jpg)






















