Embed Size (px)
Citation preview

제4장 디지털 정보 구축 | 1
제4장 디지털 정보 구축
정보를 디지털로 변환하여 자료로 구축할 때, 자료를 어떻게 입수하여, 어떤 파일 형식으로 제작할지 결정해야 한다. 디지털 정보 입수방법은 여러 가지가 있다. 어떤 경우에는 텍스트가 이미 전자 텍스트 형태로 되어 있는 경우도 있다. 또는 디지털 텍스트를 일반 회사나 학술기관으로부터 사거나 무료로 구할 수도 있다. 이런 경우, 사용하는 컴퓨터 하드웨어와 소프트웨어에 맞게 자료를 수정하거나 변환시키는 작업이 필요할 수 있다. 이와는 달리 어떤 경우에는 텍스트가 인쇄물 또는 사본 형태로만 존재하기도 한다. 이럴 경우 아날로그 텍스트 형식을 디지털 텍스트 형식으로 변환해야 한다.
1. 디지털 자료 활용
디지털 자료를 구축하기 가장 손쉬운 방법은 인터넷 자료를 활용하는 것이다. 요즈음 모든 자료가 웹 형식으로 제공되고 있어 필요한 자료를 얻을 수만 있다면, 인터넷을 활용하는 것이 좋다. 인터넷에서 원하는 자

2 | 프랑스어와 컴퓨터
료를 찾을 수 없다면, 오프라인 형태의 디지털 자료를 활용할 수 있다.
가장 일반적인 형태가 CD/DVD-ROM이다. 최근 저장 매체가 발전하여 이를 활용하는 빈도가 낮아지기는 했지만, 이전에 만들어진 자료가 상당히 많다. 인터넷이나 CD/DVD-ROM에서 원하는 자료를 구할 수 없다면,
특정 프로그램에서만 읽을 수 있는 비표준 디지털 자료를 활용할 수도 있다.
1.1. 인터넷을 활용한 자료 수집
주요 국제 학술기관과 상용 컴퓨터 사이트를 연결해주는 네트워크 체계가 구축된 경우가 많은데, 이를 활용해 전자우편이나 다른 형태의 파일전송 방식으로 정보교환이 가능해졌다. 이 국제적 네트워크 시스템은 현재 일반적으로 인터넷(Internet)으로 알려졌다. 지난 몇 년간 이 시스템은 엄청나게 확장됐고, 또 사용이 쉽고 편하게 발전했다. 인터넷으로 거의 모든 컴퓨터에 접속할 수 있게 되었다.
학술용 컴퓨터 시스템에 접속할 수 있다면 대개는 인터넷에 연결할 수 있는데, 대부분 쉽게 필요한 자료를 얻을 수 있다. 만일, 이러한 컴퓨터 시스템에 접속할 수 없을 때는 접속 가능성을 모색하거나 하드웨어와 소프트웨어의 연계 문제에 대해 고민해야 한다.
인터넷에 접속하면 편리한 점이 많지만, 가장 큰 장점 중의 하나는 많은 텍스트 보관소가 인터넷에 연결되어 있어서 필요한 텍스트 중의 일부라도 인터넷을 통해서 입수할 수 있다는 것이다. 어떤 경우에는 사전준비 작업 없이 또는 무료로 인터넷을 통해서 자료를 구할 수 있는데,
이렇게 하면 보통 최소 노력과 최소 비용 또는 무료로 자료 보관소에

제4장 디지털 정보 구축 | 3
보관된 다양한 텍스트를 얻을 수 있어 코퍼스 구축에 도움이 된다. 이런 방식으로 입수된 텍스트에는 대개 몇 가지 이용조건이 붙는다. 그러나 이 조건은 주로 텍스트를 상용으로 이용할 때에만 적용되며, 학술연구용으로 이용할 때에는 거의 영향을 받지 않는다.
파일전송 시설은 인터넷 시스템의 필수적인 부분인데, 일단 적당한 사이트를 발견하게 되면 표준 파일전송 소프트웨어를 사용하여 필요한 텍스트를 개인 컴퓨터로 전송할 수 있다. 사용하는 소프트웨어의 기능이 기관에 따라 다르지만, 컴퓨터 사용자는 표준화와 단순화라는 두 가지 목적을 추구하려고 노력하고 있다. 따라서 대부분의 학술용 사이트에 보관 중인 파일은 일반 문서작성 프로그램보다도 사용하기 쉬운 프로그램으로 제작된 것이다.
어떤 경우 특정 사이트에 있는 텍스트가 다른 컴퓨터로는 전송되지 않을 수도 있는데, 이런 경우에는 연구를 위해 특정 사이트에 개별적으로 연락해야 한다. 대부분 코퍼스에 일반인 자격으로 접속하는 것이 보통인데, 호스트 사이트에서 사용할 수 있는 소프트웨어를 통해서만 텍스트를 보고 분석할 수 있는 경우가 있다. 이럴 경우 텍스트 분석 작업에 제약이 따를 수 있다.
텍스트 말고도 다양한 소프트웨어를 인터넷 사이트에서 구할 수 있는데, 이 경우에는 인터넷 사이트가 전국적, 혹은 국제적 소프트웨어 보관소 역할을 하는 셈이다. 구할 수 있는 소프트웨어는 컴퓨터 사용자의 다양한 요구에 부응할 수 있는 것으로서 어떤 것은 언어분석 목적으로 유용하게 사용할 수 있다. 각각의 소프트웨어마다 다른 사용조건이 붙기도 한다. 대개는 범용 소프트웨어가 많아서 무료로 사용할 수 있다. 어떤 경우에는 공유 소프트웨어(shareware)로 제공되기도 한다. 이 경우 소프

4 | 프랑스어와 컴퓨터
트웨어가 사용자의 필요에 부합하면 무료로 제공되지만, 소프트웨어 마다 등록비를 지급해야 하거나 까다로운 사용조건이 따르기도 한다.
이렇게 사이트에서 구할 수 있는 소프트웨어나 그 소프트웨어 사용 설명서가 표준 규격을 따르지 않는 것도 있으므로, 사용 전에 연구목적에 적합한지 정밀하게 분석해야 한다. 또한, 컴퓨터에 설치하기 전에 그 소프트웨어가 바이러스에 감염되어 있는지, 또는 다른 문제를 포함하고 있지 않은지 분명히 확인해야 하는데, 그렇게 하기 위해서는 가까이 있는 전문가의 도움을 받아야 할 경우도 있다. 여러 가지 잠재적인 문제가 있음에도 불구하고 공개된 사이트에서 구할 수 있는 소프트웨어는 분석 도구로서 아주 유용하게 사용할 수 있어서 적어도 연구목적을 충족시킬 수는 있다.
1.2. CD/DVD-ROM을 활용한 자료 수집
필요한 자료가 CD/DVD-ROM에 수록되어 제공되는 경우가 있는데,
이런 경우에는 원하는 소프트웨어를 이용하여 자료를 분석할 수 있다.
저렴한 대용량 저장매체라는 특징이 있어 CD/DVD-ROM은 다양한 컴퓨터 게임이나, 백과사전 그리고 기타 참고도서 등과 같은 멀티미디어 응용프로그램의 저장매체로 채택되었다. 일반적으로 큰 용량의 텍스트와 함께 시각 영상, 짤막한 비디오 자료와 음향 등이 여기에 저장될 수 있다.
보통 650MB 정도로 알려진 CD-ROM 저장용량을 전적으로 텍스트만 저장하는 데에 사용한다면 엄청난 양의 텍스트를 저장할 수 있다. 최근 고용량 DVD-ROM 드라이브가 점점 더 널리 보급됨에 따라서 전자출판

제4장 디지털 정보 구축 | 5
계의 발전도 가속화되었고, 이 때문에 CD/DVD- ROM에 많은 텍스트를 저장하여 출판하게 되었다. 이들 중에는 언어연구 프로젝트에 유용하게 사용할 수 있는 것도 많다.1)
CD/DVD-ROM으로 입수할 수 있는 텍스트의 최대 단점은 텍스트 저장형태라고 할 수 있다. 한 장의 CD/DVD-ROM에 들어갈 수 있는 비교적 대규모의 저장용량에도 불구하고 텍스트가 너무 방대하면 주어진 공간 안에 자료를 모두 저장하기 위해 그 자료를 압축해야 한다.
CD/DVD-ROM에 따라오는 소프트웨어는 이렇게 압축된 텍스트를 풀 수 있게 해주긴 하지만 그 텍스트를 표준 소프트웨어를 사용하여 분석하기 위해 또 다른 저장매체에 복사하지 못하게 하는 경우가 있다. 복사할 수 있다고 해도 사용 계약서에 언급된 판권보호를 목적으로 복사 횟수를 제한하는 경우도 있다. 프로젝트를 수행할 때, 어떤 제약이 있는지 미리 파악할 필요가 있다.
1.3. 특정 경로로 자료 수집
특정 출판물은 특정 문서작성 프로그램이나 탁상출판 소프트웨어로 작성되기 때문에, 이것을 읽으려면 특정 프로그램이 필요하다. 최근 판매가 급증하고 있는 E-Book이 여기에 해당한다. 비록 출판업자가 텍스
1) 보관소에 저장된 많은 텍스트가 이러한 CD/DVD-ROM 모음집, 그것도 한 장의 CD/DVD-ROM에 저장되어 배포되는 경우가 많은데, 이 텍스트가 일반에게 공개된 출처에서 입수한 것이기 때문이다. 그러나 이러한 추세는 변화하고 있어서 출판업자의 전자출판과 컴퓨터로 읽을 수 있는 텍스트의 잠재적 시장성에 대한 인식은 점점 더 증가하고 있다. 특히, 정기간행물 출판업자는 정기적으로 텍스트를 CD/DVD-ROM으로 출판하고 있는데 이 때문에 신문이나 잡지의 전문을 쉽게 구매하여 분석용으로 사용할 수 있게 되었다.

6 | 프랑스어와 컴퓨터
트 사용에 일정한 제약을 가하고, 또 사용료를 받으려고 하긴 하겠지만 어떤 경우에는 자료를 무료로 구할 수 있다. 자료를 구하는 가장 좋은 방법은 출판사 담당자와 직접 연락하여 연구 성격을 설명하고, 판권보호를 약속하는 것이다. 연구 성격, 출판사에 돌아갈 이점 그리고 텍스트에서 얻어지는 자료의 잠재적인 상업적 용도 등에 대하여 지속적으로 협의할 수 있다.
어떤 경우에는 저작권자가 출판업자가 아닐 수 있다. 만일 학술적인 연구를 하는 경우라면 학술기관 내에서 문서작성 프로그램으로 편집된 다량의 텍스트를 구할 수 있는데, 연구 목적으로 텍스트 사본을 기증받을 수 있다. 이런 경우라 해도 텍스트 사용자는 저작권자의 권리를 지키려고 노력해야 한다.
컴퓨터 기반 텍스트 활용 가능성이 커지면서, 문서작성 프로그램으로 작성된 텍스트 형태가 다양해지고 있다. 업무용 통신, 전자우편 메시지 그리고 교육 과정에 쓰인 교재 등 다양한 자료를 구할 수 있다. 각각의 텍스트는 수집방법과 포맷 형식이 달라서 연구자에게 어려움을 줄 수 있다. 그러나 출판업자에게 요구했던 것처럼 개인이나 단체에 연구자가 직접 연락하여 연구목적을 설명하는 것이 가장 좋은 방법이다. 이런 방법으로 필요한 자료를 구할 수 없다면, 인쇄매체를 활용할 수밖에 없다.
이럴 경우 아날로그 텍스트 형식을 디지털 텍스트 형식으로 변형시켜야 하는 부담이 있다.
2. 아날로그 자료 활용

제4장 디지털 정보 구축 | 7
웹에 검색했는데도 불구하고 연구에 필요한 텍스트를 찾지 못했다면,
필요한 텍스트를 어떻게 디지털 텍스트로 변환할 것인지를 고민해야 한다. 인쇄된 텍스트를 스캐닝하거나 키보드로 입력하여 디지털 텍스트로 변환시킬 수 있고, 음성 자료를 STT(Speech To Text) 프로그램을 활용하여 텍스트 파일로 변환시킬 수 있다. 그러나 어떤 방법을 사용할 것인지를 결정하기 전에, 텍스트 저작권 문제를 염두에 두어야 한다. 지적 재산권 관계 법령은 복잡하고 국가마다 상당히 다르다. 그러나 기본적으로 텍스트를 디지털 텍스트로 변환하기 전에 저작권 소유자의 허락을 받아야 한다.
2.1. 스캐닝(Scanning)
텍스트 자료를 컴퓨터에 불러들여 분석하려면, 자료를 특정 텍스트 파일로 변환시킨 뒤, 이동식 디스크나 하드 디스크 같은 저장매체에 저장해야 한다. 만일 텍스트가 인쇄되어 있다거나, 또는 필사본 형태로 되어 있다면 이 자료를 디지털 자료로 변환하여야 한다. 왜냐하면, 컴퓨터는 종이에 인쇄되어 있거나 필사본으로 되어 있는 글은 처리하지 못하기 때문이다.
인쇄된 텍스트를 스캐닝하고 그것을 이미지로 저장하여 그 이미지를 문자로 인식하는 일은 아주 복잡하고 느리며, 또 실수가 자주 생긴다.
이 때문에 텍스트 스캐닝은 보통 자료입력과는 별도로 수행되며, 그 결과가 컴퓨터 파일로 저장되기 때문에 분석하기 전에 정확히 변환되었는지 확인해야 한다. 텍스트를 스캐닝하고 인식하는 과정에는 특수한 하드웨어, 즉, 스캐닝 장비 그리고 이 장비와 같이 사용할 수 있는 문자 인식

8 | 프랑스어와 컴퓨터
소프트웨어가 필요하다.
소형이라서 손에 들고 사용할 수 있는 형태를 포함해서 A4 크기의 탁상 스캐너 그리고 대형 스캐너 등 다양한 하드웨어가 있다. 손에 들고 사용할 수 있는 스캐너는 가격이 저렴하지만 비교적 좁은 범위의 텍스트만을 스캔할 수 있고, 흔히 A4 용지 한 장을 스캐닝하기 위해서는 한 페이지를 두세 번에 나누어서 사용해야 하며, 언어자료 관련 구축용으로는 너무 느리고 정확성이 떨어진다.
반면, 대형 스캐너는 대용량 텍스트를 빠르고 정확하게 처리할 수 있지만 비싼 가격과 크기 때문에 지속적으로 대용량 텍스트 스캐닝을 하는 대형기관이나 주요 연구 프로젝트에 제한적으로 사용된다. 탁상 평면 스캐너는 스캐닝 하드웨어 중에서 중간 계층에 속하는 것으로서 주종을 이루는데, 비교적 사용이 쉽고 상당히 많은 양의 텍스트를 꽤 빠르고 정확하게 스캔할 수 있다. 요즈음은 프린터가 스캐너 기능을 갖추고 있어 이것을 활용하면, 필요한 자료를 손쉽게 스캔할 수 있다.
스캔 된 이미지를 텍스트로 변환하기 위해서는 그것을 문자로 인식할 수 있는 소프트웨어가 필요한데, 이러한 소프트웨어를 흔히 OCR(Optical Character Recognition) 소프트웨어라고 부른다. 이 소프트웨어 또한 인식 가능한 텍스트의 복잡성이나 다양성 정도에 따라 다양한 종류로 나뉘는데, 레이저 프린터로 완벽하게 인쇄한 자료를 제외한 다른 텍스트를 스캔할 때는 정확도를 유지하기 위해 고급 평면 스캐너와 상당히 비싼 문자인식 소프트웨어가 필요하다.
그러나 연구가 끝난 뒤에는 계속 사용할 가능성이 없는데도 불구하고 소규모 연구에 사용할 목적으로 고급 스캐너와 문자 인식 소프트웨어(OCR) 구매에 과다한 비용을 지출하는 것은 합리적인 프로젝트 수행

제4장 디지털 정보 구축 | 9
방법이 아니다. 다행히 몇몇 회사에서 다양한 스캐닝 서비스를 제공하고 있는데, 이 회사를 통해서 비교적 저렴한 가격으로 인쇄된 텍스트를 전자 텍스트 파일로 변환할 수 있다. 한국어와 영어 인식 프로그램인 ‘아르미(ARMI)’는 스캐너를 구매하면서 함께 얻을 수 있다. 프랑스어와 영어 인식 프로그램으로는 ‘옴니페이지(OmniPage)’가 있는데 저렴한 비용으로 구할 수 있다.
스캐너 사용에서 가장 주된 문제는 문자 인식과정에서 인식실수가 발생할 수 있다는 것이다. 인쇄된 원본 텍스트가 상당히 낡은 경우, 이 낡은 원본을 보호하기 위해 복사하여 그 복사본을 스캔할 수 있다. 또 아무리 스캐닝이 잘 되었다고 하더라도 약간의 실수는 불가피하며 스캔 된 텍스트를 연구에 적절하게 사용할 수 있도록 만들기 위해서는 상당한 교정 작업과 수작업이 필요하다. 스캔할 때 파일 변환 형식을 이미지 형태나 텍스트 형태로 선택할 수 있다. 도서관 장서 가운데 원문을 이미지 형태로만 변환한 경우가 많을 것이다. 텍스트 파일을 구할 수 있다면 텍스트를 적절한 디지털 형태로 저장하고, 그렇지 않으면 이미지 형태로 저장한 후, 디지털 텍스트 형태로 변환시켜야 한다.
원본을 스캔하여 이미지 형태로 변환할 경우 텍스트 형태보다 파일의 크기가 크고 구축비용이 많이 들고, 내용을 검색할 수 없는 단점이 있다.
그러나 저작권이 보호될 수 있고, 원문의 모습을 그대로 전하기 때문에 인용하기 쉽고, 범용성이 뛰어나다.
이미지를 저장하는 압축방식에 따라 파일 형식이 정해지는데, 일반적으로 JPG와 TIFF 형식이 많이 사용된다. JPG는 JPEG(Joint Photographic
Experts Group)라고도 하는데, 문헌을 스캐닝하면 페이지 수만큼의 파일을 생성한다. 이 경우 한 타이틀을 구성하는 많은 파일을 관리해야 하는

10 | 프랑스어와 컴퓨터
단점이 있지만 웹 브라우저 상에서 직접 볼 수 있는 장점이 있다.2)
이미지 파일의 범용성을 높이기 위하여 TIFF 파일을 PDF(Portable
Document Format) 형식으로 변환하는 방법도 있다. PDF는 텍스트 파일뿐만 아니라 이미지 파일을 수용하고, 마크업 기능 등의 편집이 가능하므로 널리 사용되고 있다.
최근 제작되는 자료는 컴퓨터상에서 작업이 이루어지는 경우가 많아 내용을 특정 파일 형식으로 내려 받아 텍스트 형태로 변환시킬 수 있다.
내용의 수정, 조작 가능성이 있으므로 내용의 완전성이 보장되어야 한다. 이 경우 인쇄본의 모습을 완벽하게 재현하지 못할 수 있다. 이런 문제는 화면으로 디스플레이하는 과정과 텍스트의 편집 과정에서 생긴다.
이미지 형태처럼 원본 형식을 그대로 제시하지 못하는 경우가 많다.
이러한 단점에도 불구하고 그림 형태를 텍스트 형태로 변환하면 활용하기 쉽다는 장점이 있다. 텍스트 형태의 데이터는 변환비용이 상대적으로 저렴하고, 파일 저장용량이 적고 이미지 파일보다 전송 속도가 빠르다. 그리고 내용 전체를 대상으로 검색할 수 있다는 점이 가장 큰 장점이다. 텍스트 형태로 구축하면, 형식을 변환할 수 있는 가용성이 커진다.
어떤 파일 형식이든 전문이 확보되어 있다면, 필요에 따라 파일을 변환하여 서비스 방법을 개선할 수 있다.
인터넷상에서 가장 널리 통용되는 파일 형식은 HTML이다. 웹 브라우저 자체가 지원하는 파일 형식은 HTML(HyperText Markup Language)과 2) TIFF(Tagged Image File Format) 형식에는 JPG처럼 한 페이지를 각각 파일로 저장
하는 Single TIFF와 전체 페이지를 하나의 파일에 저장하는 Multi TIFF가 있다. Multi TIFF는 이미지 정보에 목차, Page Matching 정보 등의 표시가 가능하며, 이미지 원문에서 처리하기가 불가능한 목차정보를 텍스트로 처리할 수 있다. 따라서 이미지 형태로 구축하는 데 있어서 Multi TIFF 방식이 선호되고 있다. TIFF 방식의 데이터는 웹 브라우저상에서 직접 볼 수 없으므로 전용 뷰어를 별도로 제공해야 한다.

제4장 디지털 정보 구축 | 11
TXT인데, 우리가 웹 브라우저로 보는 것은 대부분 HTML 파일 형식으로 제작된다. 워드프로세서 파일을 HTML이나 TXT 파일 형식으로 변환하면 원문의 모습을 완벽하게 재현하지 못하기 때문에, 인터넷상에서 원문의 모습을 잘 나타내도록 지원하는 파일 형식으로 변환시켜줘야 한다. SGML(표준범용표시언어 Standard Generalized Markup Language)
형식이 여기에 해당한다. 텍스트 파일을 표준 규정에 따라 편집할 때 SGML를 주로 활용한다.
SGML은 ISO에서 정한 문서 표현 기준으로 제정된 것으로 DTD
(Document Type Definition)에 따라 문서의 구조를 지정하는 마크업 언어이다. 웹 브라우저가 사용하는 HTML은 SGML을 기반으로 한 언어의 일종이다. 그러나 SGML 파일로 변환하는 데에는 변환결과를 검증하는 시간과 노력이 많이 필요하다. 따라서 원문을 완벽하게 재현하는 SGML
자동변환기가 개발되기 전에는 많은 양의 자료를 전문 DB로 구축하기는 현실적으로 어렵다. SGML의 대안으로 SGML과 HTML의 중간 성격을 가진 XML 방식을 고려할 만하다.
XML(확장생성언어 eXtensible Markup Language) 형식은 인터넷(internet), 인트라넷(intranet) 등에서 데이터를 공유할 목적으로 활용된다. 현재 웹 컨소시엄에서 웹의 유용성을 높이기 위하여 XML 형식을 권하고 있다. XML은 문헌이나 파일을 기술하는 마크업 기호를 포함하기 때문에 HTML 언어와 유사하다. 그런데 HTML이 웹 페이지의 내용(문장과 그림의 배열, 관계)을 기술하는 데 비해, XML은 데이터가 기술되는 용어로 내용을 기술한다. XML이 SGML과 HTML의 단점을 극복하기 위하여 개발되었으므로 이에 대한 기대감은 높지만 아직은 국내 한글 환경에서 널리 사용되지 않는다.

12 | 프랑스어와 컴퓨터
XML은 데이터의 형식 정보를 기술하기 위해 설계된 언어로 스타일 시트(style sheet)를 정의할 수 있도록 개선된 것이다. XML은 W3C(World Wide Web Consortium)의 후원을 받아 개발되었다. XML은 문서의 형식 의미, 문서의 마크업 언어(markup language), 태그 세트(tag
set) 등을 정의한 SGML과 문서처리를 위한 DSSSL(표준규격기술언어 Document Style Semantics and Specification Language)이 결합된 형태라고 볼 수 있다.
XSL(외형정보언어 eXtensible Stylesheet Language)는 표준규격 기술언어와 CSS(연속형 문서양식 Cascading Style Sheet) 표준에 기반을 두고 확장되었다. 표준규격기술언어는 복잡해서 인터넷에 적용하기 어렵다. 그러나 XSL은 SGML과 같은 기능이 있으면서도 인터넷에서 활용이 쉽고 간편한 형태로 개발되었다.3)
근래 급속히 보급되고 있는 파일 형식인 PDF는 모든 컴퓨터 시스템 환경에서도 전송과 읽기가 가능하도록 지원되는 포맷이다. PDF는 페이지 포맷정보, 이미지를 포함하기 때문에 텍스트 파일과 이미지 파일 모두를 PDF 파일로 변환할 수 있다. 북마크, 하이퍼링크, 전문의 내용 검색 등이 가능하다.
앞에서 지적했듯이 한글이나 영문 텍스트는 ‘아르미’ 문자 인식 소프트웨어를 활용하면, [그림 1]과 같이 95% 이상의 인식률을 보인다. 원본의 상태에 따라 인식률이 달라지기는 하지만, 스캔 옵션을 잘만 조절하3) HTML의 스타일 지원을 위해 개발된 연속형 문서양식은 간단한 구조의 XML 문서
를 표시할 수 있다. 반면, XSL은 더 강력하며, 전문화되고 상세한 구조를 지닌 XML 문서의 표시가 가능하다. XSL은 텍스트와 그래픽이 아닌 식별된 장소에 데이터를 저장한다. 이를 통해 개발자가 XML 파일 안에 있는 데이터 저장장소를 어느 위치에 어떻게 표시할지 정확하게 지정하도록 돕는다. 또 다른 스타일 시트 언어처럼 하나의 XML 문서를 위한 스타일 정의를 만드는 데도 사용된다.

제4장 디지털 정보 구축 | 13
면, 성공률을 높일 수 있다.
[그림 1] 아르미로 한글 텍스트를 인식한 예
텍스트 저장 방식도 다양하여, *.RTF, *.HWP, *.TXT, *.DOC 등 다양한 형식으로 저장할 수 있다.
[그림 2] 아르미로 인식한 한글 텍스트 저장 방법
한글 윈도우즈에서 프랑스어 텍스트를 인식하는 방법은 크게 두 가지

14 | 프랑스어와 컴퓨터
로 나누어 생각해 볼 수 있다. 한글 윈도우즈에서는 프랑스어 특수문자가 깨지기 때문에 아르미를 사용해 *.TIFF나 *.JPG와 같은 그림 파일로 저장한 다음 ‘옴니페이지’를 실행하여 그림 파일을 불러들이면, 프랑스어 텍스트를 인식할 수 있다.
[그림 3] 한국어 시스템에서 아르미로 스캔한 예(프랑스어)
[그림 4] 한국어 시스템에서 아르미로 스캔하여 그림으로 저장

제4장 디지털 정보 구축 | 15
[그림 5] 한국어 시스템에서 프랑스어 문서를 OmniPage로 스캔한 예
이런 과정이 번거롭다면, 앞 장에서 언급한 것처럼 한국어 시스템을 프랑스어 시스템으로 변경하고 나서 컴퓨터를 다시 작동시킨 다음 'OmniPage'로 직접 스캔하여 프랑스어 문서를 작성하면 된다.
[그림 6] 프랑스어(프랑스) 시스템으로 변경

16 | 프랑스어와 컴퓨터
[그림 7] 프랑스어 시스템으로 변경 후 OmmiPage로 스캐닝한 예
2.2. 키보드 입력
스캔은 원본 텍스트가 소프트웨어로 인식할 수 있을 정도로 분명하게 인쇄되어 있으면 아주 유용하고 효과적인 방법이다. 텍스트의 형태나 상태가 스캐닝에 부적합한 경우에는 텍스트를 직접 손으로 타이핑할 수밖에 없다. 타이핑을 할 경우, 스캐너와 그에 필요한 문자 인식 소프트웨어가 필요 없지만, 전문 타이피스트가 문서 내용을 컴퓨터에 입력해야 한다.
타이피스트가 뛰어난 타이핑 능력이 있고 관련 텍스트에 대한 충분한 지식이 있다면 그 결과는 스캔한 경우보다 더 정확하다. 그러나 시간이 많이 걸릴 수 있다. 그리고 연구자가 직접 자료를 타이핑하여 입력하는 대신에 일반 타이피스트를 고용한다면 그 입력비용이 아주 비싸질 수 있다. 그러나 어떤 경우에는 선택의 여지가 없는 경우도 있다. 문자 인식 소프트웨어는 인쇄품질이 좋은 텍스트 원본을 상당히 잘 인식한다. 그러나 텍스트 형태가 상당히 복잡하거나 인쇄되어 있지 않은 필사본일 경우

제4장 디지털 정보 구축 | 17
소프트웨어가 내용을 제대로 인식할 수 없다.
타이피스트를 고용하면, 비용이 들지만 입력된 자료의 정확도를 높일 수 있다. 그러나 키보드 입력실수로 야기된 오타를 찾아내 교정하기 위해서 전체 자료를 다시 검증하는 과정이 필요하다. 정확도 증진도 증진이지만 키보드로 자료를 직접 입력할 때는 추가로 자료를 보충할 수 있어 내용 보강이라는 장점이 있다.
2.3. 발화언어의 활용
지금까지 텍스트 스캐닝과 키보드 입력을 논의하면서 우리는 연구자료 원본이 인쇄되어 있거나 필사본인 것으로 가정했다. 발화 언어자료는 소리 형태로 되어있는 정보를 컴퓨터에 입력시키기 전에 문자 형태로 변환하는 사전 처리단계가 필요하다는 점에서 좀 더 복잡하다. 만일 발화 언어자료의 대본이 있다면, 이는 이미 글로 된 형태이므로 앞에서 언급한 방식으로 디지털 자료를 만들 수 있다. 그렇지 않다면 궁극적으로 컴퓨터로 분석하고 처리할 수 있는 자료형태로 변환시키기 위해서 어떤 방식으로든 대본제작에 필요한 절차를 거쳐야 한다.
물론 컴퓨터에 발화 자료를 입력하여 직접 처리하게 하거나, 또는 자동으로 그것을 문자 형태로 변환할 수 있다면 훨씬 더 편리할 것이다.
이를 위해서는 OCR에 해당하는 음성언어인식 소프트웨어를 개발해야 한다. 비록 음성인식 분야에 STT(Speech To Text) 프로그램 개발에 약간의 진전이 있기는 하지만, 아직 음성을 텍스트로 변환시켜주는 완벽한 프로그램은 없다.

18 | 프랑스어와 컴퓨터
2.4. 사용할 수 있는 텍스트
앞 장에서 언급했듯이, 텍스트를 컴퓨터로 처리할 수 있는 형태로 변환시키려 할 때, 연구대상으로 선택한 텍스트를 합법적으로 사용할 수 있어야 한다. 수작업으로 데이터를 구축할 경우는 크게 문제가 되지 않는다. 왜냐하면, 학술 출판물의 경우 텍스트 검색 결과로 얻어진 내용을 적절하게 인용할 수 있기 때문이다.
컴퓨터를 이용함으로써 야기되는 어려운 문제는 텍스트를 디지털 형식으로 저장해야 한다는 것이다. 이것은 출판물에 포함된 출판사 소유 저작권 규정에서 구체적으로 금지하고 있어서 만일 텍스트를 디지털 형식으로 저장하게 되면, 국가마다 다르게 규정해 놓은 복잡한 지적 재산권 관련 법규를 위반하게 될 수도 있다. 그러나 이런 복잡한 문제를 피할 수 있는 방법은 있다.
확실히 해둘 것은 텍스트의 저작권에 대한 정확한 사항을 확인해보는 것이다. 만일 사용하려고 하는 텍스트가 꽤 오래전에 출판되었다면 저작권 시효가 지났는지도 모른다. 정확한 시효기간은 국가마다 다르므로 확인해 보아야 한다. 오래된 작품이라고 해도 새 판본이 출판된 경우에는 저작권이 갱신되었을 경우가 있다는 것을 잊지 말아야 한다. 이런 사항은 디지털 텍스트로 출판된 경우에도 적용된다. 일단 저작권자가 확인되면 공식적으로 그 텍스트를 연구목적으로 사용할 수 있도록 허가해 달라고 요청해야 한다.
여기서 연구 성격, 텍스트를 어떤 저장매체에 저장할 것인지 그리고 그것을 이용해서 어떤 형태로 출판하게 되고, 또 허가해줄 경우에 어떤 식으로 답례할 것인지에 대해 구체적으로 설명해야 한다. 일반적으로

제4장 디지털 정보 구축 | 19
텍스트를 제시할 때 텍스트 보관소에서 저작권과 사용 조건을 공지하는데, 사용자가 조건에 동의해야 필요한 텍스트를 내려 받을 수 있다.
2.5. 기타 사항
텍스트를 입수하거나 적합한 방법을 통하여 입력하였다 해도, 그 텍스트를 수정할 필요가 있다. 자료의 형식이 사용하려고 하는 하드웨어나 소프트웨어에 적합하지 않거나, 또는 텍스트에 아주 중대한 실수가 있을 가능성이 있다. 모든 것이 완벽한 텍스트라고 해도 필요에 따라 다른 사항을 추가해야 하는 경우도 있다. 본 장에서는 가장 문제가 될 수 있는 부분을 살펴보고 어려움을 극복할 수 있는 방법에 대해 알아보기로 한다.
컴퓨터로 처리할 수 있는 텍스트는 CD/DVD-ROM이나 특정 형태로 인터넷 사이트에서 받을 수 있지만, 자신이 사용하는 하드웨어나 소프트웨어에 호환되지 않으면 사용하지 못할 수도 있다. 그 이유는 보통 텍스트 형태나 텍스트 논리적 형태와 관련이 있다. 이 두 가지 모두 자신의 하드웨어나 소프트웨어와 호환성이 없거나 적절한 변환과정을 거치지 않으면 자료를 사용할 수 없다.
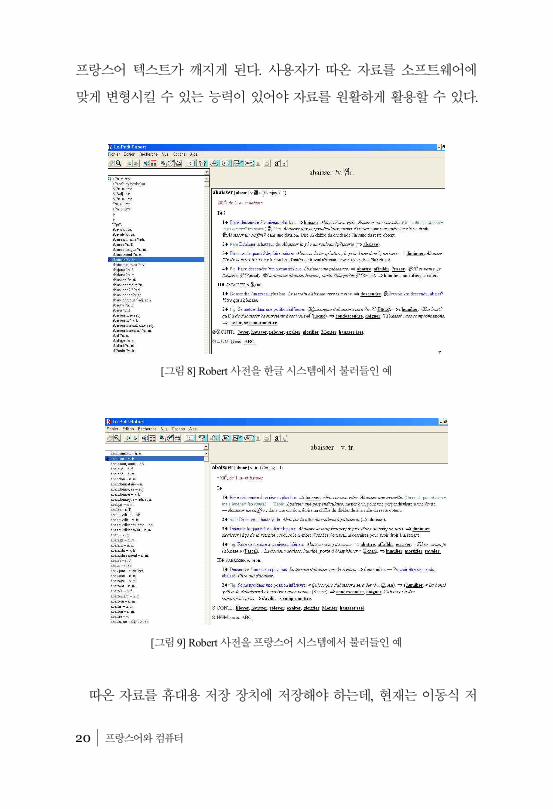
간단한 예를 들면, 프랑스에서 산 CD/DVD-ROM 자료를 한글 윈도우즈에서 구동시키면, [그림 8]과 같이 프랑스어가 모두 깨져 나온다. 이 문제를 해결하려면, 한글 윈도우즈에서 언어 시스템을 프랑스어로 바꿔 컴퓨터를 다시 작동시키면, [그림 9]와 같이 프랑스어 텍스트를 제대로 볼 수 있다. 가끔 프로그램에 따라 텍스트 전체를 복사하지 못하게 하는 경우도 있다. 또 프로그램의 특성에 따라 문자 코드를 잘 맞추지 않으면,
20 | 프랑스어와 컴퓨터
프랑스어 텍스트가 깨지게 된다. 사용자가 따온 자료를 소프트웨어에 맞게 변형시킬 수 있는 능력이 있어야 자료를 원활하게 활용할 수 있다.
[그림 8] Robert 사전을 한글 시스템에서 불러들인 예
[그림 9] Robert 사전을 프랑스어 시스템에서 불러들인 예
따온 자료를 휴대용 저장 장치에 저장해야 하는데, 현재는 이동식 저

제4장 디지털 정보 구축 | 21
장매체(USB)나 웹 하드를 많이 사용한다. 연구용 텍스트를 사용하려면 하드웨어와 운용 체계에 호환되고 또 적정규격 저장매체에 저장하여 조건에 맞게 사용해야 한다. 개별 자료마다 있을지 모르는 문제를 해결하기 위한 가장 좋은 방법은 다른 컴퓨터에서 사용 가능한 표준 방식을 따르는 것이다.
만일 파일형식을 완전히 다른 유형의 컴퓨터에서 사용할 수 있는 형식으로 변환해야 한다거나, 적절한 유형의 드라이브를 갖춘 컴퓨터가 없다면 자료를 한 컴퓨터에서 다른 컴퓨터로 직접 전송하는 방법이 있다. 이렇게 하려면 두 컴퓨터를 연결하는 특수 케이블을 사용하거나, 인터넷을 통해서 자료를 보관소가 있는 사이트로 전송해야 한다.
일단 텍스트 파일을 적합한 저장매체에 적절한 크기와 정확한 형식으로 변환하여 컴퓨터로 읽어 들일 수 있는 파일로 변환한 후에 그 파일이 논리적으로도 적절한 형식을 갖추게 해야 한다. 흔히 원본에서 특수문자로 표기된 텍스트를 컴퓨터로 처리하기 위해서는 문자 변환 프로그램을 사용할 필요가 있다. 만일 소프트웨어로 이를 적절하게 처리할 수 없다면, 텍스트 파일을 꼼꼼하게 수정하여 분석결과가 잘못 나오는 일이 없도록 해야 한다.
텍스트가 처음부터 표준 형식을 지원하지 않는 문서작성 프로그램이나 탁상출판 프로그램을 사용하여 작성된 텍스트일 경우에는 텍스트 포맷팅(text formatting), 페이지 형태, 텍스트에 포함된 도표나 그림 등과 같은 추가 정보를 포함하고 있을 가능성이 있다. 이런 추가 정보 때문에 표준 형식 파일과는 크게 다를 수 있는데, 선택한 소프트웨어로 파일을 처리하기 전에 그 파일을 적절하게 변환시켜야 한다. 대부분의 문서작성 프로그램이나 탁상출판 프로그램에서는 파일형식 변환기능이 포함되어

22 | 프랑스어와 컴퓨터
있는데, 문자코드 표준에 대해 항상 염두에 두어야 한다. 텍스트 변환을 하면 문자체, 크기, 문단 들여쓰기 등과 같은 정보가 모두 사라진다는 사실에 주의해야 한다.
텍스트를 어떻게 입수하였든지, 텍스트에는 실수가 포함되어 있기 마련이다. 스캔하는 과정에서의 부정확한 문자인식에 의한 오타, 텍스트 입력 시 혹은 원본자료 작성 시의 오타 또는 텍스트의 일부분이 생략,
중복되었거나, 틀린 위치에 오는 것 등이 이런 실수에 포함된다. 입력과정에서 실수를 최소화해야 하는데 아무리 꼼꼼하게 살펴본다고 해도 항상 약간의 실수는 있기 마련이다.
실수 교정은 연구에 사용할 자료를 준비하는 데 있어서 중요하지만,
시간과 비용이 많이 소요되는 작업이다. 그래서 실수교정을 어떻게 할 것인가를 결정하기 전에 적정 실수율을 결정해야 한다. 결과에 중대한 영향을 미치지 않는 실수는 교정할 필요가 없다. 그리고 대개는 자료가 얼마나 정확한지 알아보기 위해 예비연구를 시행하는 것이 좋다.
일단 실수 발견 방법과 적절한 실수교정 정도를 결정한 뒤에는 보조적으로 컴퓨터를 이용하거나 아예 전적으로 컴퓨터를 이용할 수도 있다.
그러나 그 실수가 일관되게 반복되고 또 그것을 정확하게 찾아낼 수 있을 때라야만 컴퓨터를 사용할 수 있다. 예를 들어, 하이픈으로 잘린 단어의 경우에 행간 하이픈을 찾아서 다음 행 앞에 오는 나머지 문자와 연결해주는 간단한 프로그램을 만들었다고 하자. 그런 프로그램은 하이픈을 일반 대시(dash)와 구분할 수 있어야 하고, 또 단어의 끝을 인식할 수 있어야 한다. 요즘은 OCR 프로그램의 성능이 향상되어 하이픈과 일반 대시를 구별하여 자동으로 문자를 인식하기도 한다.
이와 비슷하게 만일 한 단어가 스캐닝 과정이나 타이피스트의 실수로

일관되게 잘못 입력되었다면 틀린 부분을 자동으로 교정할 수 있다. 물론 이 작업을 실행하기 전에 그 실수가 일관성이 있고 또 그 실수 중의 어떤 것도 다른 단어가 될 가능성이 없음을 확인해야 한다. 조금이라도 의심된다면 ‘바꾸기(replace)’ 기능을 실행하기 전에 문서작성 소프트웨어의 ‘찾아 바꾸기(search and replace)’ 기능을 사용할 수 있다.
문학 텍스트에서 흔히 볼 수 있듯이 원본 텍스트에 행 번호가 붙어 있으면 컴퓨터를 이용해서 신속하게 행 숫자를 세어서 전체 행 숫자와 대조하며 확인할 수 있지만, 생략되거나 중복된 부분을 찾기 위해 컴퓨터를 이용하기는 힘들다. 만일 텍스트의 일부가 단순히 틀린 위치에 놓여 있다면 이런 방법으로 실수를 찾기 힘들다.





























