Embed Size (px)
Citation preview

Hermenegildo Fernández-Abascal Teira yJosé Luis Rojo García
Universidad de Valladolid
13
C L M . E C O N O M Í A , N º 4 , P r i m e r S e m e s t r e d e 2 0 0 4 . P á g s . 1 3 - 7 5
Predicción de puntos de giroen el ciclo económico.
ResumenComo es conocido, una predicción óptima de la señal cíclica del ciclo económico no implica
que de ella se deduzca un fechado óptimo de sus puntos de giro. Para ello se utilizan métodosespecíficos, orientados a superar la alta volatilidad de los extremos (máximos o mínimos) localesde la señal cíclica.
En este artículo se realiza una revisión de los métodos más actuales y populares, dentro de laliteratura existente sobre el tema, incluyendo un método relacionado con los modelosjerárquicos de Bayes propuesto por los autores.
Este método se ilustra con una aplicación al ciclo de tasas de crecimiento de la economíaespañola, constatándose el grado de habilidad del mismo y sus exigencias en cuanto al manejode los inputs.
Palabras clave: Puntos de giro, análisis de coyuntura, ciclo económico.Clasificación JEL: O47, C53, C13, C11
AbstractIt is well known that an optimal prediction of the Business Cycle doesn’t imply an optimal
prediction of their turning points. Therefore, there exist specific methods, designed to overcomethe high volatility of the local extreme (maximum or minimum) of the cyclical signal.
This paper is a survey of the actual state of the art, mainly oriented to the more recentand/or popular methods arising from the literature, and including a new method proposedby the authors, related with the so called Hierarchical Bayes Models.
We illustrate the proposed method through an application to the Spanish Business Cycle(growth rate cycle), showing their relative ability and the difficulties in the managing of theinput data.
Key words: Turning points, conjunctural analysis, business cycle.JEL Classification: O47, C53, C13, C11


1.- Introducción.La actividad económica presenta fluctuaciones más o menos
regulares, que afectan de manera similar a la producción, al empleo,a los precios, al consumo, a la inversión, etc. Este hecho, del que setiene consciencia desde los albores de la humanidad, es objeto deanálisis desde que en 1860 lo expusiese, de forma razonada ydocumentada, el economista francés Clément Juglar. A partir deentonces, una infinidad de estudios teóricos y empíricos han tratadode definir, explicar y contrastar estadísticamente los denominadosciclos económicos.
En el estudio de los ciclos económicos se han idoconformando dos campos autónomos, cuando no antagónicos:los análisis teóricos y los empíricos. Los análisis empíricos, lo quese ha venido a llamar “medida sin teoría” (Koopmans, 1947), tienen sugermen en los trabajos pioneros de Burns y Mitchell que se reflejanen la casi centenaria actividad del National Bureau of EconomicResearch (NBER).
Este tipo de análisis tiene por objeto conocer la fase cíclica enque se encuentra una economía en un momento determinado ypronosticar la futura evolución de la misma. Para ello es necesarioobtener un ciclo de referencia y un sistema de indicadoresque prevean el comportamiento futuro (indicador adelantado), queevolucionen con el ciclo de referencia (indicador coincidente) yque confirmen a posteriori la evolución cíclica (indicador retrasado).La determinación y la predicción de los puntos de giro, esto es,los períodos en los que la evolución del ciclo cambia el sentido,ocupan un lugar relevante en este tipo de análisis.
En este artículo, tras una breve mención a las distintasconcepciones estadísticas del ciclo económico (ciclos de niveles,ciclos de desviaciones y ciclos de tasas), se hará un recorrido por lasdistintas definiciones de punto de giro y se dará una visión generalde las técnicas más usuales de predicción de punto de giro. En estecontexto, se expondrá un procedimiento bayesiano para predecir laprobabilidad de un punto de giro en la línea del propuesto porZellner, Hong y Min (1991). En concreto, se obtiene el estimador deBayes óptimo de la probabilidad de que el futuro valor de una serie
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
15

de tiempo supere un cierto umbral. El procedimiento se aplica a lapredicción de los puntos de giro de la economía española, enconcreto, al ciclo de crecimiento obtenido a partir del ProductoInterior Bruto, ciclo que se puede explicar por sus propios valoresretardados y por un indicador adelantado complejo, indicadorobtenido agregando un conjunto de indicadores adelantadossimples mediante técnicas de análisis factorial. Para juzgar labondad del procedimiento, se estudia su capacidad predictivasobre puntos de giro históricos.
La aplicación directa del resultado teórico sólo permitepredicciones de punto de giro a un paso. Ahora bien, utilizandociertos procedimientos de simulación se pueden hacerpredicciones en un horizonte más amplio. En concreto, sedesarrollan dos tipos de procedimientos. En primer lugar, unaestimación frecuentista de la probabilidad de punto de giro apartir de muestras obtenidas mediante el muestreo de Gibbs deuna cierta distribución predictiva. En segundo lugar, una estimaciónde dicha probabilidad integrando una estimación Monte Carlo de ladistribución predictiva, estimación realizada a partir de las muestrasde Gibbs. En ambos casos, se obtienen predicciones a 1, 2,…, 6pasos, analizándose la validez de las mismas en la predicción depuntos de giro históricos del ciclo de tasas de la economía española.
2. Ciclos y fluctuacioneseconómicas.
La actividad económica presenta fluctuaciones más o menosregulares, con duración y amplitud variables, que afectan de manerasimilar a la producción, al empleo, a los precios, al consumo, a lainversión, etc. Este hecho da lugar a los ciclos económicos, un tipode variaciones de la actividad económica general producidas pordesequilibrios entre la oferta y la demanda.
Al comienzo de uno de los trabajos pioneros sobre el cicloeconómico, Measuring Business Cycles, los economistas norteame-ricanos Arthur F. Burns y Wesley C. Mitchell daban una definiciónque cincuenta años después sigue siendo válida:
C L M . E C O N O M Í A
16

“Los ciclos económicos son un tipo de fluctuaciones que seencuentran en la actividad económica agregada de las naciones queorganizan su trabajo principalmente en empresas mercantiles. Un cicloconsiste en expansiones que ocurren más o menos a la vez en muchasactividades económicas, seguidas por recesiones generales de manerasimilar, contracciones y recuperaciones que se unen con la fase deexpansión del ciclo siguiente; esta secuencia de cambios es recurrentepero no periódica; la duración de los ciclos económicos varía desde másde un año hasta diez o doce año” (Burns y Mitchell, 1946, pág. 3).
Esta definición ya anticipa alguno de los puntos de interés delestudio de los ciclos:
- Las fluctuaciones se manifiestan en el conjunto de laactividad económica y no sólo en alguna de las variablesrelevantes como puede ser el PIB, si bien es verdad que estavariable, en concreto el PIB en términos reales, es la que seutiliza mayoritariamente como indicador global de laactividad económica agregada.
- Las fluctuaciones tienen un carácter recurrente pero noperiódico, en el sentido de que no existe una regularidad enla amplitud y duración de las mismas, observándose, por unlado, ciclos cortos (de poco más de un año) junto a cicloslargos (de una duración superior a una década) y, por otrolado, ciclos con bruscas caídas en la actividad (depresiones)frente a ciclos donde las caídas en el nivel de la actividadeconómica no presentan consecuencias traumáticas.
Con todo, el ciclo no es una realidad económica directamenteobservable, sino un concepto teórico que parte de la estilización deunos hechos; la complejidad de éstos dificulta la identificación delciclo.
Ahora bien, cuando hablamos de fluctuaciones de la actividadeconómica agregada, ¿nos referimos a los niveles de la misma?,¿o bien a sus tasas de variación? En todo caso, ¿son fluctuacionesen términos absolutos?, ¿o respecto de una situación de equilibrio?El Cuadro 1 describe los tres enfoques más extendidos del cicloeconómico, los denominados ciclos de niveles, de desviaciones y detasas; en el Cuadro 2 se señalan distintos aspectos de la relaciónentre los tres tipos de ciclos.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
17

C L M . E C O N O M Í A
18
Ciclo de niveles (business cycle):
Fluctuaciones en los niveles de la actividad económica en términos absolutos.
Fases:- Expansión (expansion), crecimientos netos en la actividad.- Recesión (recession), inflexión descendente.- Contracción (contraction), decrecimientos netos en la actividad.- Recuperación (revival), inflexión ascendente.
Períodos críticos en los que cambia el sentido del crecimiento:- Pico (peak), paso de la expansión a la contracción.- Valle (trough), paso de la contracción a la expansión.
Concepción predominante hasta 1970: NBER (cronología mensual del ciclo clásico de laeconomía de Estados Unidos desde 1854, más de 30 ciclos completos).
Ciclo de desviaciones (deviation cycle):
Fluctuaciones en las desviaciones de la serie de referencia respecto de su tendencia a largo plazo.
Fases:- Crecimiento alto (high-rate), tasas superiores a las de la tendencia.- Crecimiento bajo (low-rate), tasas inferiores a las de la tendencia.
Los puntos críticos, puntos de giro (turning points), son los períodos en que el crecimiento de la serie coincide con el crecimiento de la tendencia:
- Punto de giro máximo o hacia abajo (downturn), paso de crecimientos altos a crecimientos bajos.
- Punto de giro mínimo o hacia arriba (upturn), paso de crecimientos bajos a crecimientos altos.
Inconvenientes:- Los resultados dependen del método para hallar la tendencia (Canova, 1994, 1999).- Los métodos para eliminar la tendencia pueden inducir ciclos espúreos
(King y Rebello (1993) y Osborn (1995)).
Concepción muy extendida en los últimos 30 años: OCDE (sistema de indicadoresadelantados para predecir a corto plazo la evolución cíclica de las economías de losprincipales países desarrollados).
Ciclo de tasas de crecimiento (growth rate cycle):
Fluctuaciones en la serie de tasas de crecimiento de la serie de referencia.
Fases:- Aceleración (speed up), tasas de crecimiento crecientes.- Desaceleración (slowdown), tasas de crecimiento decrecientes.
Los puntos críticos, puntos de giro (turning points), son los períodos en que cambia el sentido del crecimiento de la serie de tasas de variación:
- Punto de giro máximo o hacia abajo (downturn), paso de la aceleración a la desaceleración.
- Punto de giro mínimo o hacia arriba (upturn), paso de la desaceleración a la aceleración.
Concepción utilizada por el INE en la elaboración de su sistema de indicadores cíclicos.
Cuadro 1Concepciones estadísticas de ciclo económico.

El análisis cíclico desde la perspectiva empiricista tiene comoprimer objetivo determinar el ciclo económico y, a partir de él,describir sus principales características, analizar su relación con otrasvariables de interés y tratar de predecir su evolución futura, sobretodo en qué períodos el ciclo cambiará de sentido. Para alcanzartodos estos objetivos, determinación, medida y predicción, sedispone de un conjunto amplio de técnicas estadísticas.
De entrada, el principal obstáculo en el análisis cíclico loconstituye el hecho de que el ciclo económico, en cualquiera de lasconcepciones, no es una serie observable, sino que es una señal quese oculta en una serie individual (PIB, IPI,…) o en un indicadorcompuesto. La primera tarea del analista es la extracción de unaseñal cíclica de la serie de referencia. Las técnicas de extracción deseñal son numerosas y variadas en cuanto a complejidad yfundamentos. A lo largo de las tres últimas décadas han tenido uncrecimiento espectacular constituyendo uno de los principalestemas de investigación de los métodos cuantitativos aplicados a laeconomía. De esta forma, el interés por los métodos de extracciónse ha trasladado de los más sencillos y empiricistas (métodosaritméticos de descomposición) a los más complejos basados enmodelos.
Una vez se dispone del ciclo económico, el primer paso en elanálisis del mismo lo constituye su descripción a lo largo del tiempoa partir de la determinación de sus puntos de giro, lo que permitirá
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
19
- Fluctuaciones: en los niveles, respecto de la tendencia y en las tasas de crecimiento.
- Necesidad de diferenciar las interpretaciones y la terminología.
- Distintos resultados empíricos: el número de ciclos y el fechado de los puntos críticos no coincide.
- El número de ciclos clásicos es menor que el número de ciclos de desviaciones, y éste menor que el número de ciclos de tasas de crecimiento.
- Los máximos del ciclo de tasas adelantan a los de desviaciones y éstos a los del ciclo clásico.
- Los mínimos del ciclo de tasas adelantan a los del ciclo clásico y éstos a los del ciclo de desviaciones.
- El ciclo de tasas puede considerarse como un indicador adelantado del ciclo de niveles.
Cuadro 2Relación entre las tres concepciones.

evaluar la duración y amplitud de los ciclos, su homogeneidad oheterogeneidad, la simetría o asimetría de sus fases de crecimientoy decrecimiento, etc. El fechado cíclico, esto es, la determinacióndel período en el que la serie cíclica cambia de sentido, requiere deprocedimientos estandarizados, generalmente implementados enprogramas informáticos, que pueden aplicarse de manera mecánicay objetiva a un grupo numeroso de indicadores elementales.
Una vez fechado el ciclo (o previamente a la obtención delciclo cuando éste se construye como agregación de indicadores), elinterés se centra en estudiar su posición en el tiempo respecto deciclos de otros ámbitos (por ejemplo, comparar la relación en eltiempo del ciclo español con el ciclo mundial) o respecto de otrosciclos particulares (por ejemplo, comparar el ciclo de la actividadcon el ciclo del empleo). Este análisis consiste en determinar si, porregla general, los puntos de giro de un ciclo adelantan, coinciden oretrasan respecto de los de otro ciclo. Para poder realizar estaclasificación cíclica se dispone de varias técnicas, desde las mássencillas, basadas en el desfase promedio entre los puntos de giro, alas más complejas, por ejemplo las que tienen en cuenta el espectrode ambos ciclos.
Una pieza fundamental para el seguimiento y predicción delciclo económico es el denominado Sistema de IndicadoresCíclicos. Tres indicadores complejos, uno que adelanta, otro quecoincide y otro que retrasa respecto del ciclo, permiten prever laevolución futura del mismo, conocer con cierta inmediatez susituación actual y confirmarla posteriormente. Para construir elSistema de Indicadores se parte de un conjunto numeroso deindicadores parciales, los cuales se clasifican respecto del ciclo dereferencia. Una selección adecuada de indicadores de cada tipo,adelantados, coincidentes y retrasados, y su composición mediantealguna técnica de agregación, permitirán construir dicho sistema.
Por último, el análisis cíclico no sólo tiene por objetivo describirla evolución histórica de las fluctuaciones de una economía. Suprincipal interés radica en predecir el comportamiento futuro delciclo, en especial la predicción de los puntos de giro. Este interés vamás allá del meramente académico. La información sobre futuroscambios en la marcha de la economía es de suma importancia paratodos los agentes económicos (gobiernos, empresas, familias,…)
C L M . E C O N O M Í A
20

que de este modo pueden diseñar políticas o tomar decisiones queaminoren los efectos negativos, aprovechen al máximo los positivoso, incluso, eviten el cambio predicho.
3. Determinación de puntos de giro.Sea cual sea el concepto de ciclo que se utilice, es de especial
interés el análisis de los puntos de giro, máximos y mínimospronunciados en la señal cíclica, esto es, con una duración y unaamplitud significativa entre máximos y mínimos próximos. Ahorabien, ante la irregularidad de la señal cíclica, se hace necesaria “unadefinición de punto de giro precisa y con significado económico”(Wecker, 1979), definición para la que no existe consenso,enunciándose muchas definiciones, en gran medida sin justificar.
Las distintas definiciones y métodos de determinación de lospuntos de giro se pueden clasificar del siguiente modo:
1. Reglas simples basadas en la evolución local de la señalcíclica, o de su tasa de variación.
2. Procedimientos, aritméticamente más complejos eimplementados habitualmente en programas informáticosad hoc, que permiten la determinación conjunta de lospuntos de giro en toda la serie, introduciendo condicionesde amplitud y duración de los ciclos y de las fases.
3. Procedimientos no objetivos que definen los puntos degiro teniendo en cuenta la evolución de distintosindicadores simples o compuestos que adelantan,coinciden o retrasan con respecto de la señal cíclica.
4. Métodos de definición y predicción de puntos de giro apartir de:
- Reglas simples basadas en la evolución de un indicadorcompuesto adelantado.
- Métodos probabilísticos en el sentido más general.
Describamos brevemente los tres primeros apartados de laanterior clasificación, haciendo hincapié posteriormente en losmétodos de predicción.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
21

3.1. Reglas simples basadas en la evolución localde la señal cíclica.
Se considera un punto de giro en T un máximo (downturn, DT)o un mínimo (upturn, UT) absoluto de la señal cíclica en unentorno del período T; a veces, se añaden otras condiciones paraeliminar puntos de giro episódicos o poco pronunciados.
En general, las reglas difieren por:
- La simetría o asimetría del entorno temporal alrededor de T.- El número de períodos del entorno temporal alrededor de T.- La distinción, o no, entre puntos de giro máximos
y mínimos.- Definir explícitamente los puntos de giro o las fases
de recesión y contracción.- La ubicación del punto de giro, en el máximo o mínimo local
o posteriormente.
Una de las reglas más generalizadas es la siguiente 1:
DT: xT-1 < xT > xT+1 > xT+2 .UT: xT-1 > xT < xT+1 < xT+2
Señalemos brevemente algunos inconvenientes y ventajas deestas reglas:
- Su disparidad dificulta los análisis comparados y lasinterpretaciones, produciéndose cronologías diferentes(Boldin, 1994).
- Son reglas mecánicas de dudoso contenido económico.
- Adolecen de una falta de criterios objetivos relacionadoscon la frecuencia de los datos y con el tipo de cicloanalizado.
C L M . E C O N O M Í A
22
xt
1) Por su interés más alla del análisis cíclico hay que citar la regla incluida en la ley Gramm-Rudman-Hollings,ley aprobada por el Congreso norteamericano en diciembre de 1985, que establece un proceso dereducción gradual del déficit presupuestario federal hasta alcanzar el déficit cero en 1991. La ley dispone de“Procedimientos especiales en caso de recesión” que permiten suspender varias de sus disposiciones parapermitir una mayor inversión pública que aminore y reduzca en el tiempo los efectos de la recesión.Las condiciones que determinan el período de recesión son:
- Dos trimestres consecutivos durante los cuales el crecimiento económico real (crecimiento del PIB real) es menor que cero, según las predicciones de la Congressional Budget Office o de la Office of Management and Budget.
- Una secuencia de al menos dos trimestres con tasas de crecimiento menores que el 1%, según las estimaciones del Department of Commerce.

- Identifican los puntos de giro en una única serie cíclica(habitualmente la obtenida a partir del PIB), asumiendo laslimitaciones del planteamiento univariante (McNees, 1991).
- En muchos casos, estas reglas replican, con un alto grado deacierto, la cronología cíclica de la economía estadounidenseestablecida por el NBER.
3.2. Procedimientos de fechado cíclico.
Los métodos de fechado son procedimientos que permiten elfechado automático de los puntos de giro de una serie bajo lacondición de verificar ciertos requisitos sobre duración y amplitudde fases y ciclos; para facilitar esta tarea de fechado, es habitual quedichos procedimientos estén implementados en algún programainformático ad hoc.
En un sentido amplio, los puntos de giro no son más que losmáximos y mínimos relativos de la serie de referencia (niveles,desviaciones o tasas de crecimiento). Ahora bien, a veces seobservan en las fases de crecimiento de la serie momentáneosperíodos de decrecimiento que no se consolidan, o bien, en lasfases de decrecimiento, períodos de crecimiento igualmentemomentáneos y sin consolidar. No parece razonable considerarestos máximos y mínimos como verdaderos puntos de giro. Eshabitual en los trabajos empíricos de detección de puntos de giroexigir un cierto número mínimo de períodos a cada fase o al ciclocompleto para validar un máximo o mínimo local de la serie comopunto de giro; incluso, aunque está menos extendido, se puedeexigir también una mínima amplitud. Los procedimientos defechado son algoritmos que determinan automáticamente lospuntos de giro a partir de las condiciones impuestas.
En general, estos procedimientos son rápidos, fáciles de aplicary especialmente útiles cuando hay que fechar un númeroconsiderable de series, algo habitual a la hora de construir unsistema de indicadores. De esta forma se evita la tediosa tarea deun fechado por inspección visual, siempre propensa a errores, y seaplica un criterio único para todas las series. En la parte negativa,estos procedimientos no permiten incorporar, en principio, el juiciodel experto, que en muchas ocasiones puede ser más decisivo queel propio criterio automático.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
23

El método de fechado más utilizado, bien sea en su versiónoriginal o en adaptaciones de la misma, es el algoritmo desarrolladopor Bry y Boschan (1971). Otros procedimientos de fechadorelevantes son: el procedimiento de Artis, Kontolemis y Osborn(Artis, Kontolemis y Osborn, 1997), una versión simplificada delprocedimiento de Bry y Boschan, pero introduciendo requisitos deamplitud, el procedimiento <F> (Abad y Quilis, 1995, 1996, 1997),utilizado por el INE (1994) para obtener su sistema de indicadorescíclicos, y el procedimiento Cicle (Fernández Macho, 1991), métodobasado en el análisis armónico y espectral.
3.3. Procedimientos no objetivos que tienen en cuentala evolución de distintos indicadores.
Otro tipo de procedimientos son los que tienen en cuenta laevolución de distintos indicadores, como el utilizado por el NBERpara la determinación de recesiones y expansiones. Así, se considerala recesión como un período entre seis y doce meses de declivegeneral de la actividad, afectando a la mayoría de sectores, concaídas en la producción, en el empleo, en la renta, en el comercio,etc. Un comité de expertos, The Business Cycle Committee,determina los comienzos y los finales de la recesión.
Algunos inconvenientes y ventajas de este procedimientoy otros similares son:
- Demora en la determinación de los puntos de giro: permitehacer “historia” sobre la evolución de la economíanorteamericana, pero no sirven para el “análisis decoyuntura”.
- Ante esta demora y el carácter no objetivo del método, seelaboran procedimientos que tratan de replicar y predecirlas decisiones del comité (método de fechado de Bry yBoschan, método probabilístico de Neftçi,…).
- Amplio consenso sobre la cronología establecida.
C L M . E C O N O M Í A
24

4.- Predicción de puntos de giro.A lo largo del último medio siglo se han utilizado distintas
técnicas para predecir el ciclo económico. En unos casos se trata, sinmás, de predecir los valores futuros del PIB u otro indicador de laactividad; en otros se trata de predecir únicamente los cambios desentido en su evolución. En el primer caso, los métodos a utilizar sonlos habituales en la predicción econométrica, principalmentemodelos ARIMA, modelos de regresión, opinión de expertos,encuesta de expectativas, etc. Por su especificidad en el análisiscíclico, sólo expondremos en este apartado los métodos depredicción de los puntos de giro.
Dentro de estos procedimientos de determinación ypredicción de puntos de giro podemos distinguir dos categorías.Por un lado, procedimientos simples y mecánicos a partir de lainformación proporcionada por un indicador adelantado y, por otrolado, procedimientos más complejos basados en modelosprobabilísticos sobre el comportamiento de la señal cíclica y/o suspuntos de giro. También en este segundo grupo de procedimientosvan a jugar un papel relevante los indicadores adelantados, si bienaquí como una fuente de información del modelo.
4.1. Reglas de predicción a partir del comportamiento de unindicador adelantado.
Los indicadores adelantados, bien sea en sí mismos o bien seacomo elemento fundamental dentro de otros métodos, sonutilizados ampliamente para predecir la evolución futura de unaeconomía.
Cuando se utilizan los indicadores adelantados para lapredicción cíclica “es necesario especificar los datos (habitual-mente un indicador adelantado y/o sus componentes), elobjetivo (todos los cambios en alguna representación de laactividad económica agregada o los puntos de giro en el cicloeconómico o en el agregado seleccionado) y el procedimiento oregla a aplicar (regresiones del indicador coincidente en lasvariables adelantadas o filtrado de la serie adelantada parapredecir picos y valles)” (Zarnowitz, 1992, págs. 339).
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
25

Centrándose en las reglas de filtrado del indicador adelantado,existen distintas propuestas, generalmente a partir del indicadoradelantado del NBER-BEA y para la predicción de los puntos de girodel ciclo de niveles establecido por el NBER para la economíaamericana; de hecho, la validez de estas reglas se mide por el gradode acierto en predecir los picos y valles establecidos por el NBER.
Básicamente existen dos tipos de procedimientos. Por un lado,aquéllos que avisan de un futuro cambio de sentido en la actividadcuando se observa un determinado número de meses de subida ode caída en el indicador adelantado y, a mayores, cuando esassubidas o caídas van más allá de unos límites consideradosnormales. Por otro lado, aquéllos basados en los indicadores depresión.
Dentro del primer tipo de procedimientos, cabe citar laspropuestas de Vaccara y Zarnowitz (1978), Hymans (1973), el sistemade señalización secuencial de Zarnowitz y Moore (1982) yvariaciones del mismo (Deitch, 1985). En cuanto al segundo tipo deprocedimientos, los basados en indicadores de presión, cabe citarlas propuestas de Barnes (1980) y la del Institute for Trend Research.
Todas estas reglas tienen un fuerte contenido empírico muyligado a la predicción del ciclo de niveles y de crecimiento de laeconomía estadounidense y toman como fuente de información elsistema de indicadores cíclicos del NBER-BEA. Cualquier intento detraslación a otro contexto requeriría un cambio en los distintosvalores críticos.
4.2. Métodos probabilísticos de predicción.
En los últimos 20 años, a partir del trabajo pionero de Wecker(1979), se han ido desarrollando distintas técnicas probabilísticas dedeterminación y de predicción de puntos de giro. A continuacióndescribiremos los procedimientos de mayor interés.
4.2.1. Predicción a partir de una extensión del métodode MCO lineal (Wecker).
El procedimiento de Wecker (1979) parte de la constatación deque “los métodos de predicción minimocuadráticos lineales noson directamente aplicables para la predicción de los puntos degiro de una serie de tiempo” (Wecker, 1979, pág. 35), proponiendo
C L M . E C O N O M Í A
26

una solución a partir de la distribución predictiva; esto es, dados nvalores de la serie de tiempo, x1 , x2 ,..., xn , la incertidumbre sobre kfuturos valores, xn+1 , xn+2 ,..., xn+k , queda reflejada en la funciónpredictiva: gn+1,...,n+k ( xn+1 ,..., xn+k | x1 , x2 ,..., xn ).
El conocimiento de esta función permitirá predecir cualquierfunción zt de los valores, observados y futuros, de la serie; porejemplo, predecir los puntos de giro (sea cual sea su definición), laduración de la fase actual, el valor de la serie en el punto de giro, etc.Para simplificar, se asume que zt depende de 2τ+1 valores
de la serie: zt =T ( xt-τ ,..., xt ,..., xt+τ ).
Siguiendo a Box y Jenkins (1976, cap. 5), la distribuciónpredictiva se distribuye como una normal multivariante, en base a locual se plantea un método numérico para estimar la distribuciónpredictiva de zt :
1. Se genera una muestra de valores xn+1 ,..., xn+k de ladistribución de xn+1 ,..., xn+k , esto es, una muestra denúmeros pseudoaleatorios de una normal multivariante.
2. Con la muestra obtenida se computa el valor dezt , zn = T ( xn-τ ,..., xn , xn+1 ,..., xn+τ ).
3. Se repiten sucesivas veces los dos pasos anteriores paraobtener una muestra de zn , zn , zn ,..., zn .
La distribución empírica obtenida convergerá a ladistribución predictiva de zn , fn ,( zn | x1 ,..., xn ).
Kling (1987) propone una extensión del procedimiento deWecker en un doble sentido. En primer lugar, considera un vectorde series de tiempo, Xt , definiendo los puntos de giro en cada unade sus componentes (un máximo o un mínimo en un entorno de±τ períodos). En segundo lugar, se supone que Xt es un vectorautoregresivo (VAR) que se estima bajo distintos supuestos, entreellos el de un modelo bayesiano (BVAR); de esta forma se introduceuna nueva fuente de incertidumbre al considerar los parámetros dela ecuaciones aleatorios. Por otra parte, la simulación de lasdistribuciones predictivas se realiza mediante un sistema depredicción precuencial, extensión del método utilizado por Wecker.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
27
[1] [1]
[1] [1] [1]
[1] [2] [m]

4.2.2. Predicción a partir de una fórmula de probabilidadrecursiva (Neftçi).
Sin duda alguna, el procedimiento probabilístico másextendido de reconocimiento de los puntos de giro es el debido aNeftçi (1982). Este procedimiento parte de la consideración empíricade que “el comportamiento estocástico de los principalesagregados cambia de repente en cuanto la economía entra enun régimen de descenso” (Neftçi, 1982, pág. 225). La soluciónpropuesta se inscribe dentro de los problemas de tiempo de paradade un proceso estocástico y se considera óptima en el sentido dereconocer el punto de giro tan pronto como sea posible yproduciendo un número mínimo de falsas señales.
De entrada, Neftçi argumenta la necesidad de separar elproblema de predicción de puntos de giro del problema másgeneral de predecir el futuro valor de la serie de tiempo. Estanecesidad se justifica a partir de la literatura prekeynesiana del cicloeconómico, que pone de relieve el comportamiento diferenciadode los indicadores económicos antes y después de un punto de giromáximo, y el carácter repentino e inesperado de éste. En concreto,estos indicadores caen rápidamente tras un punto de giro máximomientras que se recuperan más lentamente tras un punto de giromínimo.
El planteamiento teórico del procedimiento se describe acontinuación. Sea Yt la señal cíclica y sea Xt un indicador adelantadode Yt especialmente sensible para recoger sus puntos de giro.Sea ZX una variable aleatoria, con valores enteros ( ZX = 1,2,... ), querepresenta el primer período de tiempo tras producirse un punto degiro en Xt , contando a partir del anterior punto de giro de signocontrario. Dicha variable, no observable, tiene la propiedad de quesi ZX = k la distribución de X k+j , en j = 0,1,... , es diferente de ladistribución de X k- j , para j = 1,2,... Por tanto, si k<t y el punto degiro es un máximo,
p[X0 ≤ x0 ,..., Xk-1 ≤ xk-1 , Xk ≤ xk ,..., Xt ≤ xt ] = F U (x0 ,..., xk-1 ) . F D(xk ,..., xt ),
donde F U y F D son las funciones de distribución de la serie encada uno de los regímenes, expansión y contracción en el
C L M . E C O N O M Í A
28

ciclo de niveles, fase ascendente (upswing) y fase descendente(downswing) en general 2.
Esta caracterización de la distribución de los valores de la serierecoge las dos evidencias empíricas: un distinto comportamientoantes y después del punto de giro (distinta distribución de(X0 ,..., Xk-1) y (Xk ,..., Xt ) y la brusquedad e imprevisibilidad del mismo(independencia entre (X0 ,..., Xk-1) y (Xk ,..., Xt )).
Por otro lado, el modelo asume que los agentes económicosposeen una cierta información histórica sobre la ocurrencia delpróximo punto de giro, información que se recoge en unadistribución de probabilidad a priori.
Con este planteamiento, el problema de predecir un punto degiro se concreta en encontrar un predictor de ZX , que denotaremospor τ . Si τ = t , el predictor señalaría el punto de giro en el períodot, siendo τ - ZX el error de predicción. Los dos posibles errores quese pueden cometer es anunciar un punto de giro antes de que ésteocurra, esto es, una falsa alarma ( τ < ZX ) o predecirlo demasiadotarde ( τ > ZX ). La solución propuesta tendrá en cuenta estos dostipos de errores.
El criterio de optimización fija un límite de error de falsaalarma, p [ τ < ZX ] = α ( 0 ≤ α ≤ 1 ), y busca, entre los estimadoresque lo verifican, aquel que haga mínimo el retraso medio enanunciar el punto de giro demasiado tarde disponiendo deinformación de la serie hasta el período t,
min E [max ( τ - ZX , 0 )].
De acuerdo con esto, la regla óptima de predicción del períodode tiempo en el que se produce el próximo punto de giro está dadapor
τ * = inf { k | πk ≥ A* },
siendo
πk = p [ ZX ≤ k | xk ],
donde xk designa la información disponible hasta el período k,y A* ( 0 < A* < 1 ) una constante que depende de la probabilidadde falsa alarma α .
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
29
τ
k
–
–
2) Para simplificar, hemos considerado el primer punto de giro de la serie y el único hasta el período t.

La aplicación del predictor óptimo requiere del cálculo de πk ,probabilidad de que el punto de giro se produzca en el período k oen alguno anterior con información hasta dicho período. Estaprobabilidad se puede calcular mediante la siguiente fórmularecursiva que, para un punto de giro máximo, resulta 3 :
[πk-1+Γ Uk
. (1-πk-1)] . f D(xk | xk-1)
[πk-1+Γ Uk (1-πk-1)] . f D(xk | xk-1)+(1-π k-1 ) . f U(xk | xk-1) . (1-Γ U
k )
donde Γ Uk es la probabilidad de punto de giro máximo
en k sabiendo que aún no ha ocurrido tras una continua fasede ascenso,
Γ Uk = p [ ZX =k | ZX > k-1],
y f U(xk | xk-1) y f D(xk | xk-1) denotan, para cada régimen,los valores de la función de densidad de Xk condicionada por( X0 = x0 ,..., Xk-1 = xk-1 ) en xk ,
dF U ( xk | xk-1 ) dF D ( xk | xk-1 )
dxk dxk
(Para un punto de giro mínimo, en la formula sólo hay quecambiar entre sí las anteriores funciones de densidadcondicionadas; por otro lado, téngase en cuenta que lasprobabilidades de transición, p [ ZX =k | ZX > k-1], en el primercaso están referidas a una fase ascendente, Γ U
k , y en el segundo auna fase descendente, Γ D
k ).
El primer período en el que la probabilidad πk supera elvalor A* se señala como punto de giro.
Dado que el procedimiento opera sobre el indicadoradelantado Xt , y no sobre la señal cíclica Yt (esto es, se estima ZX
en vez de ZY ), es necesario considerar la relación temporal entreXt e Yt , en concreto el número de períodos de desfase entrelas mismas. Si el estimador señala un punto de giro en k para laserie Xt , ¿cuántos períodos cabe esperar para que éste aparezcaen la serie Yt , serie en la que el punto de giro se define mediantealguna regla simple basada en un determinado número de períodos
C L M . E C O N O M Í A
30
πk = ,-
-
- -- -
- -
-
f U(xk | xk-1) = y f D(xk | xk-1) =
3) Una demostración de la misma se puede ver en Diebold y Rudebusch (1989, págs. 387-390).
.

de crecimiento o decrecimiento? Así, señalado un punto de giroen k, hay que considerar de algún modo un lapso de tiempo ∆ , talque, si antes del período k+∆ no se ha producido el punto de giro,la señal se considere falsa. Este problema, que se relaciona con laclasificación cíclica entre indicadores, no tiene en principio unasolución única. El propio Neftçi (1982, pág. 233) es conscientede la limitación de su procedimiento cuando afirma que “elparámetro ∆ y la correlación entre Xt e Yt no se toman en cuentadurante la obtención de la regla de predicción óptima. Sinembargo, la determinación explícita de reglas de parada queincorporen tales características es una cuestión sin resolver yestá más allá del alcance de este artículo”.
A continuación se describen los 5 pasos a seguir para suaplicación (Niemira, 1991, págs. 93-99 y Niemira y Klein, 1994,págs. 197-198):
1. Determinar las distribuciones de probabilidad condicio-nadas f U(xt | xt-1) y f D(xt | xt-1). Para ello, los valores delindicador adelantado Xt se segmentan en dos distribu-ciones: la distribución de los valores de los períodos deascenso y la de los de descenso. Las muestras de los valoresde Xt en una u otra fase permitirá estimar dos distribucionesteóricas a partir de los histogramas con los incrementosde la serie Xt en cada uno de los regímenes (Neftçi, 1982)o ajustando a una distribución normal (Diebold yRudebusch, 1989).
2. Determinar las probabilidades a priori Γ Ut y Γ D
t , a partirde las frecuencias de las duraciones de fase en el indicadoradelantado del NBER-BEA, unas probabilidades queaumentan en la medida en que se alarga la fase de ascenso(descenso) (Neftçi, 1982). Diebold y Rudebusch (1989, 1991),tras constatar la evidencia de que en el período deposguerra la probabilidad de punto de giro no dependede la duración de la fase, consideran las probabilidades detransición constantes, Γ U
t = Γ U y Γ Dt = Γ D , asignándose
dichas constantes en base a las frecuencias de punto de giroen el indicador adelantado.
3. Aplicar la fórmula recursiva. Dicha fórmula se aplica apartir de un valor inicial π0 , habitualmente cero.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
31
- -

4. Interpretar los resultados. Se anuncia un punto de girocuando la probabilidad acumulada πk supera undeterminado umbral. En Neftçi (1982) se fija un umbralA*=90%, correspondiente a una probabilidad de falsaalarma de α = 0.10.
5. Buscar el próximo punto de giro. Tras detectar el puntode giro y cambiar de régimen, la probabilidad se reajusta acero y vuelve a comenzar el proceso para determinar elsiguiente punto de giro.
4.2.3. Predicción mediante análisis discriminante (Anderson).
El análisis discriminante es una técnica multivariante quepermite clasificar individuos, caracterizados por los valores de unconjunto de variables, en dos o más grupos mutuamenteexcluyentes. En este sentido, un determinado mes T+1 se puedeclasificar como período de expansión o de recesión teniendo encuenta los valores en dicho mes de ciertos indicadores,generalmente adelantados. Si los períodos T-k,...,T, se handeterminado como expansión (contracción) y el período T+1 seclasifica como contracción (expansión), consideraremos que en Tse ha producido un punto de giro. La primera aplicación de estatécnica multivariante para determinar los puntos de giro en elciclo clásico, pero extensible al ciclo de desviaciones y de tasas, sedebe a Anderson (1966). El método consta de las siguientes fases:
1. Obtener la cronología cíclica de la economía a partir de unaserie de referencia y una concepción del ciclo (niveles,desviaciones o tasas), lo que lleva a determinar los períodosde ascenso y descenso.
2. Seleccionar dos muestras, más o menos del mismo tamaño,de períodos de ascenso y de períodos de descenso(muestras de análisis). Los períodos no seleccionadosconstituyen el grupo de validación (ampliación de lamuestra) y se utilizarán para contrastar la eficiencia delprocedimiento.
3. Elegir un conjunto de indicadores, generalmenteadelantados, que cubran en lo posible los distintos aspectosde la actividad.
C L M . E C O N O M Í A
32

P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
33
4. Determinar la distribución de frecuencia de cada uno delos indicadores en los dos regímenes. Para ello se eligenintervalos de clase con el criterio de maximizar las diferenciasentre las distribuciones del indicador en la fase de ascenso yen la de descenso.
5. Establecer la ponderación de los intervalos de claseasignando ponderaciones altas a los intervalos en los que lasdos distribuciones son muy diferentes y asignandoponderaciones bajas a los intervalos en los que dichasdiferencias son pequeñas.
6. Asignar a cada período del grupo de validación lapuntuación resultante de la suma de las ponderacionesestablecidas en el paso anterior, ponderacionescorrespondientes a los intervalos de clase en los que seencuentra cada uno de los valores de los indicadores endicho período.
7. Determinar la puntuación de corte, el umbral que haceque un período se clasifique en uno u otro régimen segúnque la puntuación caiga por encima o por debajo de dichoumbral. Este valor se determina en base al criterio del índicede mayor discriminación. Para ello se tienen en cuenta todaslas puntuaciones del grupo de validación y, para cada una deellas, se determinará el porcentaje de períodos de ascenso yel porcentaje de períodos de descenso con una puntuaciónigual o mayor. Entonces, se elige como punto de corte aquélque maximiza la diferencia entre estos dos porcentajes.
8. Dado un nuevo período, calcular su puntuación y, depen-diendo de que ésta se encuentre por encima o por debajodel punto de corte fijado, clasificar dicho período como fasede ascenso o de descenso. Si el nuevo período cambia suclasificación respecto de los períodos anteriores, quedaríaseñalado un punto de giro.
4.2.4. Predicción a partir del comportamiento probabilísticode un índice de difusión (Chaffin y Talley).
El procedimiento se fundamenta en la idea de que existe uníndice de difusión poblacional, construido a partir de N indicadoresy definido en cada período como la proporción de indicadores que

crecen, Dt . Este indicador guarda conformidad, con L períodos deadelanto, con el nivel de actividad, Bt , en el siguiente sentido:
signo (Bt - Bt - r ) = signo (Dt - L - Dt - L - r ).
Si este índice de difusión poblacional fuese conocidopodríamos prever con exactitud los cambios en el ciclo económicocon L períodos de adelanto. La existencia de tal índice es asumible,no así el conocimiento del mismo, esto es, de los N indicadores quelo forman. Suponemos que en cada período t se puede elegir, pormuestreo sin reemplazamiento, n (n<N) indicadores adelantados,construyéndose el índice de difusión muestral, Dt , estimadorinsesgado del índice de difusión poblacional, Dt (en la práctica, lasmuestras de n indicadores ni son aleatorias ni son independientes).Entonces, Dt - L - Dt - L - r , estimador insesgado de Dt - L - Dt - L - r ,permitirá predecir los cambios en el ciclo económico y, en concreto,permitirá contrastar la existencia de puntos de giro en el índice dedifusión adelantado y, por tanto, en el nivel de la actividad.
Las hipótesis a contrastar son:
H0 : Dt - L - Dt - L - r = 0 ( lo que implica que Bt - Bt - r = 0 )
H1 : Dt - L - Dt - L - r > 0 ( lo que implica que Bt - Bt - r > 0 ).
Así, si se acepta H0 , no existen evidencias suficientes paradeducir que habrá cambios en el ciclo entre los períodos t-r y t.Si se rechaza H0 , se deduce que habrá cambios en el sentido deque el ciclo económico crece en el período t respecto del períodot-r. Igualmente se podría plantear la hipótesis alternativa ensentido contrario.
Estamos interesados en comparar la proporción de indicadoresque crecen en t-L, Dt - L , y los que crecen en t-L-r , Dt - L - r , paraver si dichas proporciones pueden considerarse iguales(hipótesis H0 ) o distintas en uno u otro sentido (hipótesis H1 ). Paraello contamos con la información muestral que proporciona unamuestra apareada de indicadores adelantados (los mismos nindicadores en t-L-r y en t-L ), por lo que se puede aplicar el testde McNemar (1969), un caso particular del test binomial sobre laproporción de individuos que cambian alguna característicadicotómica en dos momentos del tiempo.
C L M . E C O N O M Í A
34
^
^ ^

Este test clasifica a los indicadores según su situación,crecimiento o decrecimiento, en cada uno de los dos períodos,datos que se recogen en el siguiente cuadro de doble entrada:
Período t-L
Período t-L-r Crece Decrece
Crece a b
Decrece c d
n
El análisis se centra en los indicadores que cambian: los sucesos“crece-decrece” y “decrece-crece” se pueden considerar como losdos sucesos complementarios de un experimento de Bernoulli, quedesignaremos como fracaso y éxito, respectivamente. Entonces, lavariable aleatoria D, número de éxitos en los a+d experimentosindependientes de Bernoulli, sigue una distribución binomial deparámetros a+d y p, proporción poblacional de indicadores quedecrecían en t-L-r y crecen en t-L (obsérvese que a+d se considerafijo y sus componentes, a y d, aleatorias).
El contraste de hipótesis se puede reformular en los términosde la proporción p; esto es,
H0 : p = 0,5
H1 : p > 0,5 .
Entonces, el estadístico de la prueba es D, cuya distribuciónbajo H0 es conocida. Calculado el p-valor para un valor muestral d,
p - valor = pH0[ D ≥ d ] = Σ (0,5)i . (0,5)a + d - i = Σ (0,5)a + d ,
si éste es menor que el nivel de significación prefijado rechazamosH0 . De esta forma se acepta que existe un cambio significativoen el índice de difusión poblacional, en concreto un crecimiento( Dt - L - r < Dt - L ), cambio que se producirá en el nivel de la actividadeconómica L períodos más tarde.
Ahora bien, si se venían observando decrecimientoscontinuados en el índice de difusión hasta t-L-r, el hecho deaceptar que hay un crecimiento entre t-L-r y t-L llevaría a aceptarque se ha producido un punto de giro hacia arriba en el indicador
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
35
a + d a + d
i = di = d

adelantado, Dt , punto de giro que se presentará en el nivel deactividad, Bt , L períodos más tarde.
De manera similar se razonaría en el caso de que, al contrastarH0 : p = 0,5 frente H1 : p < 0,5, se rechazara H0 , pudiéndosecontrastar la existencia de un punto de giro hacia abajo.
El punto débil del procedimiento, por otra parte común atodos los procedimientos de predicción de puntos de giro a partirde indicadores adelantados, es el desconocimiento del número deperíodos de adelanto L, valor que se tendrá que estimar de algunamanera.
4.2.5. Predicción mediante un método bayesiano óptimo(Zellner y otros).
En distintos trabajos, Zellner (1986), García-Ferrer, Highfield,Palm y Zellner (1987), Zellner y Hong (1989, 1991), Zellner, Hong yGulati (1990) y Zellner, Hong y Min (1991), se desarrolla unprocedimiento de predicción de puntos de giro en el contexto de lateoría de decisión bayesiana. En concreto, este método bayesianoobtiene predicciones de los puntos de giro óptimas en el sentido deque minimizan la esperanza de una función de pérdida que recogelos costes asociados a los posibles errores: predecir un punto de giroy que éste no se produzca o predecir un no punto de giro y que éstese produzca. El procedimiento se aplica para predecir los puntos degiro en las tasas de crecimiento del PIB de distintos países, variableque se explica por sí misma con uno, dos y tres retardos, y por tresvariables monetarias (precio de las acciones en el país y en elconjunto de países y dinero en circulación).
Describamos a continuación los distintos pasos delprocedimiento:
1. El modelo. Se plantea un modelo autorregresivo de tercerorden con indicadores adelantados (abreviadamente, unmodelo AR(3)LI) para explicar la tasa de crecimiento anual dela actividad agregada de N países; en concreto, para el paísi-ésimo en el año t,
y i t = α i 0 + α i 1 y i t - 1 + α i 2 y i t - 2 + α i 3 y i t - 3 +
+ β i 1 SR i t - 1 + β i 2 SR i t - 2 + β i 3 GM i t - 1 + β i 4 WR t - 1 + ε i 1 ,
C L M . E C O N O M Í A
36

con t=1,2,...,T e i=1,2,...,N, donde yit es la tasa decrecimiento del producto, PIB o PNB real, SRit la tasade crecimiento del precio real de las acciones, GMi t la tasade crecimiento del dinero real, M1 , WRt la mediana del SRit
para todos los países y εi t la perturbación aleatoria, variablesindependientes con distribución normal de media 0 yvarianza σ 2
i .
2. Definición de puntos de giro. Siendo yit la tasa decrecimiento anual del PIB o PNB real en el país i-ésimo,se define un punto de giro hacia abajo (downturn) en T+1como:
DT : yi T-2 , yi T-1 < yi T > yi T+1 ,
y su no ocurrencia como:
NDT : yi T-2 , yi T-1 < yi T ≤ yi T+1 .
Igualmente se define el punto de giro hacia arriba (upturn)y su no ocurrencia.
3. Cálculo de la probabilidad de punto de giro. Una vezdefinidos los puntos de giro, “el problema de predecirlos surgecuando hemos observado yi T-2 , yi T-1 e yi T , siendo yi T+1 unvalor futuro e inobservable. Si se dispone de una distribuciónpredictiva para yi T+1 dados todos los datos pasados, un modeloe información a priori hasta el período T, entonces se puedecalcular la probabilidad de un DT [o de un UT]” (Zellner, Hongy Min, 1991, pág. 280). La función de densidad predictivapara yi T+1 está dada por:
p ( yi T+1 | D ) = ∫ p ( yi T+1 | θ,D ) . p ( θ | D ) dθ ,
donde p ( y i T +1 | θ,D ) es la función de densidad deyi T+1 dados los parámetros del modelo, θ, y los datoshistór icos , D , y p (θ |D ) es la función de dens idad aposter ior i de θ .
Esta distribución predictiva se obtiene para cada país,resultando ser una t de Student descentrada. Conocidala distribución predictiva se puede obtener la probabilidadde punto de giro. Por ejemplo, para un downturn,
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
37
θ

siempre que yi T-2 , yi T-1 < yi T ,
p[ DT ]=p[ yi T+1< yi T |D ]= ∫ p(yi T+1 |D). dyi T+1=p tυT< ,
esto es, la probabilidad de que una t de Student centrada
con υT grados de libertad sea menor que , donde
yi T+1 es la predicción del regresando en T+1 a partir de losvalores de los regresores en dicho período, xi T+1 , es decir,yi T+1 = xi T+1θT, siendo θT la estimación de los parámetros delmodelo con información hasta T; los valores υT , sT y aT sepueden obtener mediante una fórmula recursiva (véaseZellner, Hong y Min (1991, págs. 300-301)).
De igual manera se podría calcular la probabilidad de unupturn.
4. Función de pérdida y regla de decisión. Los errorescometidos al predecir la ocurrencia o no ocurrencia de unpunto de giro conllevan unos costes que se recogen en lafunción de pérdida L. Establecida la función de pérdida sepuede calcular la pérdida esperada al predecir la ocurrenciade un punto de giro y la pérdida esperada al predecir la noocurrencia. El cuadro siguiente, tomada de Zellner, Hong yMin (1991, pág. 281), recoge la función de pérdida y laspérdidas esperadas para un downturn, E [ L | DT ] y E [ L | NDT ].
Resultado
Predicción DT NDT Pérdida esperada
DT 0
NDT 0
Probabilidades
La regla de decisión lleva a predecir el suceso, DT o NDT, quetiene asociada una menor pérdida esperada, es decir,
E [ L | DT ] < E [ L | NDT ] o < se predice DT;
C L M . E C O N O M Í A
38
^
-∞
yi T
sT . aT
yi T - yi T+1
^
sT . aT
yi T - yi T+1
^
^ ^ ^
1-p[DT]
1-p[DT]
p[DT]
p[DT]
c1
c1
c2
c2
c2. p [ DT ]
c1. ( 1-p [ DT ] )

E [ L | DT ] > E [ L | NDT ] o > se predice NDT;
En el caso de una estructura de pérdida simétrica (se valoranpor igual los dos tipos de error), la regla de decisión sesimplifica, prediciéndose un DT si su probabilidad es mayorque 0,5 y un NDT en caso contrario; es decir, se predice elsuceso más probable.
De manera similar se construirá la regla de decisión para unupturn.
4.2.6. Predicción a partir de modelos autorregresivoscon regímenes cambiantes (Hamilton).
Uno de los procedimientos más novedosos y que másrepercusión ha tenido en los últimos años para modelizar el ciclo ypredecir sus puntos de giro es el propuesto por Hamilton (1989) apartir de modelos autorregresivos con cambios markovianos en elrégimen (Markov switching autoregression, MS-AR). La idea consisteen modelizar la señal cíclica mediante un modelo autorregresivoen el que “los parámetros [...] son vistos como el resultado de unproceso de Markov discreto” (Hamilton, 1989, pág. 357).
A continuación expondremos las líneas básicas delprocedimiento siguiendo el trabajo original de Hamilton (1989).Sea yt una serie de tiempo observable que se supone generadapor la composición de una tendencia, nt , y un elementoperturbador, zt ,
yt = nt + zt .
La tendencia responde a un proceso autorregresivo derégimen cambiante,
nt = α1St+ α0 + nt-1 ,
donde St es una variable dicotómica inobservable que indicael estado del sistema: toma el valor 0 si la economía está encontracción y 1 si está en expansión. La transición entre estosdos estados se supone que sigue un proceso de Markov de primerorden, esto es, sus probabilidades de transición son:
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
39
1-p[DT]
p[DT]c1
c2
~ ~
~
~

p [St = 1 | St -1 = 1] = p
p [St = 0 | St -1 = 1] = 1- p
p [St = 0 | St -1 = 0] = q
p [St = 1 | St -1 = 0] = 1- q .
El proceso zt responde a un modelo ARIMA (r, 1, 0) de media 0,
zt - zt -1 = φ1 ( zt -1 - zt -2 ) +...+ φr ( zt - r - zt - r - 1 ) + εt ,
siendo εt variables aleatorias independientes normales demedia 0 y varianza σ 2.
Diferenciando, el modelo también se puede escribir como
yt = α1 St + α 0 + zt
zt = φ1 zt -1 +...+ φr zt - r + εt ,
siendo yt = yt - yt -1 y zt = zt - zt -1 .
Por tanto, el modelo consta de una variable observable,yt , dos inobservables, St y zt, y de r+5 parámetros, α0, α1, p, q,φ1,..., φr y σ, parámetros que se trata de estimar.
En Hamilton (1989) se propone un algoritmo iterativo quepermite obtener
p [ St = st , St-1 = st-1 ,..., St- r +1 = st - r + 1 | yt , yt -1 ,..., y- r +1 ]
a partir de
p [ St-1 = st-1 , St-2 = st-2 ,..., St- r = st - r | yt-1 , yt -2 ,..., y- r +1 ],
y, como subproductos, la distribución de yt condicionadapor los datos históricos,
f ( yt | yt -1, yt -2 ,..., y-r +1 ),
y la probabilidad del estado en que se encuentra el sistemaen t con información hasta dicho período (o, incluso, coninformación hasta t+k ),
p [ St = st | yt , yt -1 ,..., y- r +1 ].
Este algoritmo necesita de una probabilidad condicionada dearranque,
p [ S0 = s0 , S-1 = s-1 ,..., S- r +1 = s- r + 1 | y0 , y-1 ,..., y- r +1 ],
C L M . E C O N O M Í A
40
~ ~ ~ ~
~ ~ ~ ~ ~ ~
~

probabilidad que en Hamilton (1989, págs. 368-369) se sustituyepor la correspondiente probabilidad no condicionada.
A partir de la distribución de yt condicionada por los datoshistóricos se obtiene el logaritmo de la función de verosimilitud,
In f (yT, yT - 1 ,..., y1 | y0 , y - 1 ,..., y- r+1 ) = Σ In f (yt | yt - 1, yt - 2 ,..., y- r+1 ),
obteniéndose mediante una maximización numérica de estafunción las estimaciones máximo verosímiles de los r+5 parámetrosdel modelo, modelo que queda perfectamente identificado alconsiderar que el estado 1 se corresponde con crecimientosrápidos de la tendencia y el estado 0 con crecimientos suaves( α1+α0>α0 o bien α1>0 ).
Aportaciones relevantes al trabajo original de Hamilton son lasde Filardo (1993, 1994), Filardo y Gordon (1998), Lahiri y Wang (1994)y McCulloch y Tsay (1994a, 1994b). Jun y Joo (1993) proponen unprocedimiento para predecir los puntos de giro en el indicadoradelantado que guarda ciertas similitudes con el de Hamilton.Otro procedimiento que guarda relación con el modelo deHamilton se basa en los llamados modelos autorregresivos porumbrales (threshold autoregression, TAR) (Peña, Tiao y Tsay, 2001,págs. 275-282).
5. Procedimiento bayesianopara predecir la probabilidad deun punto de giro en el ciclo de tasasde crecimiento de la economíaespañola.
5.1. Obtención del estimador de Bayes óptimode la probabilidad de que el futuro valor de una serie de tiemposupere un cierto umbral.
Disponemos de T observaciones de una serie de tiempo yt quesuponemos generada por el siguiente modelo:
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
41
T
t =1

yt = θ0 +θ1 yt -1+...+θk yt - k +θk +1 x1, t - l1+...+θk+m xm, t - lm
+εt t = 1,2,...,T ,
donde yt es la variable a explicar, yt -1 ,..., yt - k , x1,t - l1 ,..., xm,t - lm
las variables explicativas, εt las perturbaciones aleatorias yθ0 , θ1 ,..., θk , θk +1 ,..., θk+m los k+m+1 parámetros desconocidos.
En forma matricial:
y = Z . θ +ε .
En T se conocen las observaciones históricas de la variable aexplicar y de los indicadores adelantados, y las condiciones inicialesnecesarias. Todo ello constituyen los datos, D.
Tratamos de estimar, desde un enfoque bayesiano, laprobabilidad de que el nuevo valor de la serie, yT+1 , supere uncierto umbral 4, a : p[ yT+1 > a | ( θ,τ ), D ]. La solución bayesianaal problema consiste en estimar p, buscando el estimador de Bayes,p, aquel que hace mínima la pérdida esperada,
min Ep l D [ L ( p, p ) ] = min ∫ L ( p, p ) . p ( p | D ) dp ,
donde L ( p, p ) = ( p - p )2 es la función de pérdida cuadráticay p ( p | D ) la función de densidad a posteriori de p dados losdatos D.
Para la función de pérdida cuadrática, el estimador de Bayeses la esperanza a posteriori del parámetro,
p = Ep l D ( p | D ) = Ep l D ( p [ yT+1 > a | ( θ,τ ), D ] | D ) = p[ yT+1 > a | D ].
C L M . E C O N O M Í A
42
~
~ ~
~p ~p p
~ ~
~
4) Las soluciones estándar se resumen en:
1. Predecir la evolución de la serie yt . Un modelo de regresión con variables explicativas, un modeloARIMA o un modelo mixto permiten predecir yt en un determinado número de períodos depredicción, comprobando si en esos períodos se verifican, o no, las condiciones de punto de giro.En todo caso, no estimamos la probabilidad de punto de giro sino su presencia, o no, en un futuroinmediato.
2. Predecir directamente la probabilidad de punto de giro. Un modelo de regresión con variabledependiente cualitativa o, en una terminología más extendida que hace referencia a unasdeterminadas soluciones del problema, un modelo Logit-Probit; aquí, el modelo de variablesexplicativas no estima y predice yt , sino la probabilidad de un suceso, por ejemplo, la probabilidaddel suceso [ yT+1 > a ].
Dadas las características de la serie yt , una señal cíclica, y el carácter no lineal del problema (una rupturaen la evolución de la serie), cualquiera de los planteamientos estándar anteriormente citados noproporciona en general soluciones óptimas.

Entonces el problema se concreta en hallar la distribuciónpredictiva de yT+1, p( yT+1 | D ), siendo
yT+1 = ZT+1 θ + εT+1 ,
donde ZT+1 = ( 1 yT ... yT +1- k x1,T + 1 - l1... xm,T +1 - lm ) .
5.1.1. Distribución a priori no informativa.
En principio elegiremos distribuciones que pongan enevidencia la falta de información a priori sobre los parámetros, estoes, distribuciones a priori no informativas e independientes:
p (τ )∝ 1τp (θ )∝ cte.
independientes ,
es decir,
p (θ ,τ) = p (θ ) . p (τ)∝ 1τ = τ -1 .
Por otro lado, dado que y | (θ ,τ)→NT (Zθ ,τ l ), la función deverosimilitud resulta:
l (θ ,τ |D)∝τ . exp - τ2
[ (y -Zθ )’(y -Zθ )] .
De esta forma podemos obtener la distribución a posteriori:
p(θ ,τ |D)=p(θ ,τ ) . l (θ ,τ |D) ∝τ . exp - τ2
[ (y -Zθ )’(y -Zθ )] .
Dado que (y -Zθ )’(y -Zθ )=(θ -θ )’Z ’Z (θ -θ )+e ’e , resulta:
p(τ |D)∝τ . e ,
esto es,
τ |D→ γ ,
y
p(θ |τ ,D)∝τ . exp - τ2
[ (θ -θ )’Z ’Z (θ -θ )] ,
esto es,
θ |(τ ,D)→N k+m+1 (θ ,τ Z ’Z ) .
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
43
}
} }
} }
T2
^
^
^
^ ^
τS C R2
T - k - m -12
T - 22
} }
1
k + m +12
T - k - m -12
, S C R2( (

Por otro lado, dado que yT+1 |((θ ,τ ),D)→N1 (ZT+1θ ,τ ), esto es,
p( yT+1 | (θ ,τ ),D)∝τ . exp - τ2
( yT+1-ZT+1 θ )2 ,
podemos obtener la distribución conjunta de (yT+1 ,θ ,τ ) dado D :
p( yT+1,θ ,τ |D)=p( yT+1|(θ ,τ ),D). p(θ ,τ |D)∝τ .
. exp - τ2
[θ ’Z* ’Z*θ -2( Z* ’y* )’θ +y* ’y*] ,
donde
Z*= e y*= .
Integrando respecto θ y τ se obtiene la distribución predictiva:
p( yT+1|D)=
donde
A = ZT+1 ( Z*’ Z *)-1 Z ’ y
B = 1- ZT+1 ( Z*’ Z *)-1 Z ’T+1
C = y’ [ l - Z ( Z*’ Z *)-1 Z ’ ] y .
Por tanto, yT+1|D→t de Student (Loc, Prec, GI ), una t de Studentdescentrada con los siguientes parámetros de localización,precisión y grados de libertad:
GI =T - k - m - 1 .
C L M . E C O N O M Í A
44
12
T - 12
=(T - k - m -1) [1-ZT+1 ( Z*’ Z *)-1 Z ’T+1 ]2
[1-ZT+1 ( Z*’ Z *)-1 Z ’T+1] y’ [ l - Z ( Z*’ Z *)-1 Z ’ ] y -[ZT+1 ( Z*’ Z *)-1 Z ’ y ]2
AB
Loc = =ZT+1 ( Z*’ Z *)-1 Z ’ y
1-ZT+1 ( Z*’ Z *)-1 Z ’T+1
Prec = =(T - k - m -1)B2
B . C- A2
} }
} }
yyT+1( )Z
ZT+1( )
(T - k - m -1)+12(T - k - m -1)B2(T - k - m -1)B2
T - k - m -11+ .B . C- A2
1
)( 2AB
yT+1 -

5.1.2. Distribución a priori normal-gamma.
De la misma forma, si partimos de una distribución a priorinormal-gamma 5,
p(τ )∝τα -1 . e -τβ
p(θ |τ )∝τ . exp - τ2
[ (θ -µ )’Q (θ -µ )]
esto es,
τ→γ (α,β )
θ |τ→Nk + m+1(µ ,τQ )
Por tanto,
p(θ ,τ )=p(τ ). p(θ |τ )∝τ . exp - τ2
[ (θ -µ )’Q (θ -µ )]+2β ,
De donde obtendríamos la siguiente distribución a posteriori:
p(θ ,τ |D)=p(θ ,τ ). l(θ ,τ |D)∝τ .
. exp - τ2
[θ ’(Q+Z’ Z )θ -2(Qµ+Z’ y )’θ +y ’y+µ ’Qµ+2β ] .
De aquí,
p(τ |D)∝τ .
. exp - τ2
[ y ’y-(Qµ+Z’ y)’(Q+Z’ Z )-1(Qµ+Z’ y )+µ ’Qµ+2β ]
es decir,
y
p(θ |τ ,D)∝τ . exp - τ2
[ (θ -M )’N (θ -M )] ,
con M=(Q+Z’ Z )-1(Qµ+Z’ y ) y N=Q+Z’ Z , es decir,
θ |(τ ,D)→Nk + m+1 ((Q+Z’ Z )-1(Qµ+Z’ y ), τ (Q+Z’ Z )).
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
45
5) Esta hipótesis sobre la distribución a priori no es extraña en el análisis bayesiano (Broemeling, 1985, págs.3 y ss.). El motivo de su utilización es que la familia de distribuciones normal-gamma es conjugada paraverosimilitudes normales: distribución a priori normal-gamma y función de verosimilitud normal dan lugara distribuciones a posteriori también normal-gamma.
} }
} }
} }
} }
} }
}
} k + m +12
k + m +12
k + m +2α -12
T +2α2
-1
T+k + m +2α -12
.
,
,( )y ’y-(Qµ+Z’ y)’(Q+Z’ Z )-1(Qµ+Z’ y )+µ ’Qµ+2βT+2α22
,τ |D→γ

Teniendo en cuenta la distribución de yT+1 dado (θ,τ ) y Dse obtiene la distribución conjunta de ( y T+1, θ, τ ) dado D :
p( y T+1, θ, τ |D)=p( y T+1|(θ, τ ), D) .p(θ, τ |D)∝τ .
. exp - τ2
[θ ’(Q+Z*’ Z *)θ -2(Qµ+Z*’ y* )’θ +y * ’y*+µ ’Qµ+2β ] ,
donde
Z*= e y*= .
De nuevo, integrando respecto de θ y τ se obtiene la distribuciónpredictiva:
p( yT+1|D)=
esto es, yT+1|D→ t de Student (Loc, Prec, GI ) donde
siendo
A = ZT+1 ( Q+Z*’ Z * )-1 ( Qµ+Z ’ y )
B = 1- ZT+1 ( Q+Z*’ Z * )-1 Z ’T+1
C = y’ y - ( Qµ+Z ’ y )’( Q+Z*’ Z * )-1 ( Qµ+Z ’ y )+µ ’Qµ+2β .
Por tanto, en los dos supuestos de distribución a priori, ladistribución predictiva es una t de Student, variando los grados delibertad GL, el parámetro de localización Loc y el parámetro deprecisión Prec. Con todo, se pude ver que las dos solucionesconvergen, hecho que se pone en evidencia en el gráfico 1 querecoge ambas distribuciones predictivas en un período de tiempodeterminado 6.
C L M . E C O N O M Í A
46
T+k + m +2α2
} }
yyT+1( )Z
ZT+1( )
(T +2α )+12(T +2α )B2
T +2α1+ .B . C- A2
1
)( 2AB
yT+1 -
AB
Loc = , Prec = y GI =T + 2α ,(T +2α )B2
B . C- A2
6) Esta convergencia y, por tanto, la similitud de los resultados es extensible a los posterioresprocedimientos de simulación, lo que hace que omitamos en el resto del artículo los resultados obtenidoscon la distribución a priori normal-gamma, dado que no son significativamente distintos a los de ladistribución a priori no informativa.
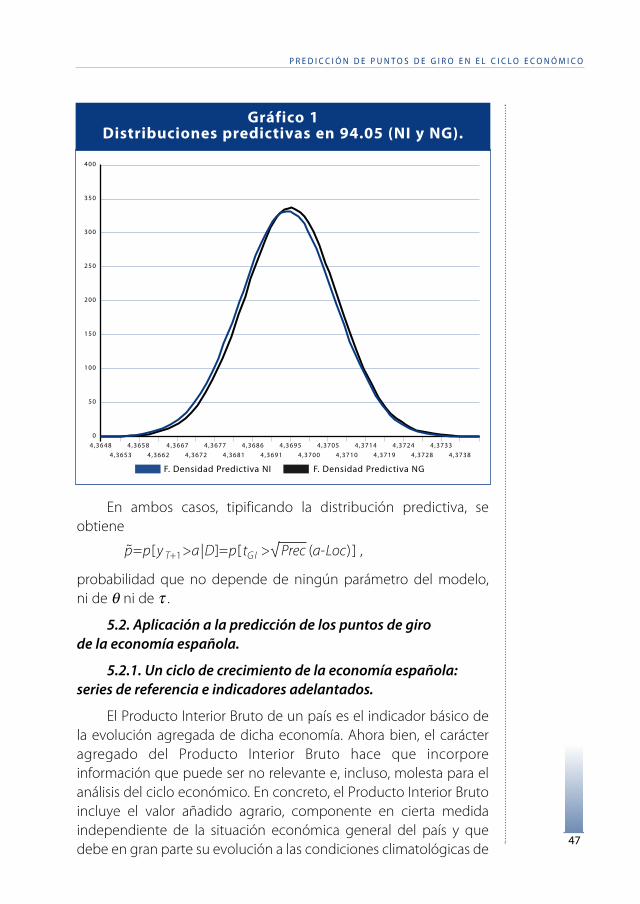
En ambos casos, tipificando la distribución predictiva, seobtiene
p=p[y T+1>a |D]=p[ tG I >√ Prec (a-Loc) ] ,
probabilidad que no depende de ningún parámetro del modelo,ni de θ ni de τ .
5.2. Aplicación a la predicción de los puntos de girode la economía española.
5.2.1. Un ciclo de crecimiento de la economía española:series de referencia e indicadores adelantados.
El Producto Interior Bruto de un país es el indicador básico dela evolución agregada de dicha economía. Ahora bien, el carácteragregado del Producto Interior Bruto hace que incorporeinformación que puede ser no relevante e, incluso, molesta para elanálisis del ciclo económico. En concreto, el Producto Interior Brutoincluye el valor añadido agrario, componente en cierta medidaindependiente de la situación económica general del país y quedebe en gran parte su evolución a las condiciones climatológicas de
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
47
Gráfico 1Distribuciones predictivas en 94.05 (NI y NG).
400
350
300
250
200
150
100
50
0
4,3648 4,3658
4,3653 4,3662 4,3672 4,3681 4,3691 4,3700 4,3710 4,3719 4,3728 4,3738
4,3667 4,3677 4,3686 4,3695 4,3705 4,3714 4,3724 4,3733
F. Densidad Predictiva NI F. Densidad Predictiva NG
~
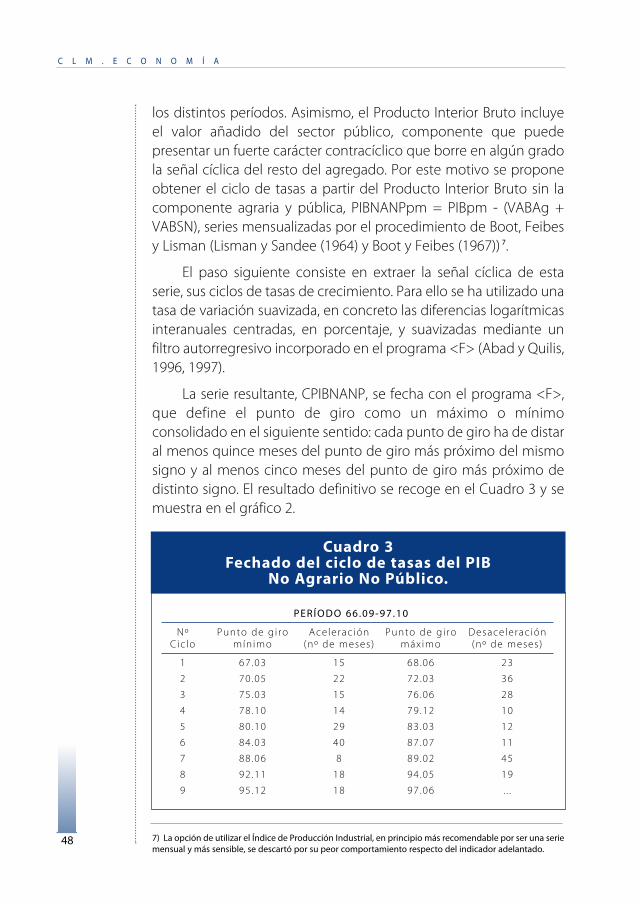
los distintos períodos. Asimismo, el Producto Interior Bruto incluyeel valor añadido del sector público, componente que puedepresentar un fuerte carácter contracíclico que borre en algún gradola señal cíclica del resto del agregado. Por este motivo se proponeobtener el ciclo de tasas a partir del Producto Interior Bruto sin lacomponente agraria y pública, PIBNANPpm = PIBpm - (VABAg +VABSN), series mensualizadas por el procedimiento de Boot, Feibesy Lisman (Lisman y Sandee (1964) y Boot y Feibes (1967)) 7.
El paso siguiente consiste en extraer la señal cíclica de estaserie, sus ciclos de tasas de crecimiento. Para ello se ha utilizado unatasa de variación suavizada, en concreto las diferencias logarítmicasinteranuales centradas, en porcentaje, y suavizadas mediante unfiltro autorregresivo incorporado en el programa <F> (Abad y Quilis,1996, 1997).
La serie resultante, CPIBNANP, se fecha con el programa <F>,que define el punto de giro como un máximo o mínimoconsolidado en el siguiente sentido: cada punto de giro ha de distaral menos quince meses del punto de giro más próximo del mismosigno y al menos cinco meses del punto de giro más próximo dedistinto signo. El resultado definitivo se recoge en el Cuadro 3 y semuestra en el gráfico 2.
C L M . E C O N O M Í A
48 7) La opción de utilizar el Índice de Producción Industrial, en principio más recomendable por ser una seriemensual y más sensible, se descartó por su peor comportamiento respecto del indicador adelantado.
PERÍODO 66.09-97.10
Nº Punto de g i ro Acelerac ión Punto de g i ro Desacelerac iónCic lo mínimo (nº de meses) máximo (nº de meses)
1 67 .03 15 68 .06 23
2 70.05 22 72.03 36
3 75.03 15 76.06 28
4 78.10 14 79.12 10
5 80.10 29 83.03 12
6 84.03 40 87.07 11
7 88.06 8 89.02 45
8 92.11 18 94.05 19
9 95.12 18 97.06 . . .
Cuadro 3Fechado del ciclo de tasas del PIB
No Agrario No Público.
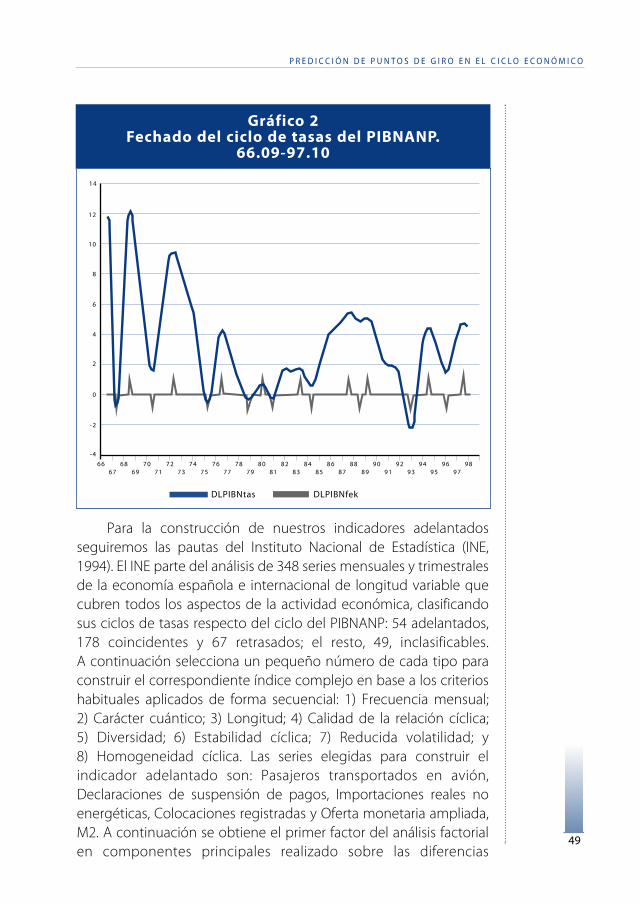
Para la construcción de nuestros indicadores adelantadosseguiremos las pautas del Instituto Nacional de Estadística (INE,1994). El INE parte del análisis de 348 series mensuales y trimestralesde la economía española e internacional de longitud variable quecubren todos los aspectos de la actividad económica, clasificandosus ciclos de tasas respecto del ciclo del PIBNANP: 54 adelantados,178 coincidentes y 67 retrasados; el resto, 49, inclasificables.A continuación selecciona un pequeño número de cada tipo paraconstruir el correspondiente índice complejo en base a los criterioshabituales aplicados de forma secuencial: 1) Frecuencia mensual;2) Carácter cuántico; 3) Longitud; 4) Calidad de la relación cíclica;5) Diversidad; 6) Estabilidad cíclica; 7) Reducida volatilidad; y8) Homogeneidad cíclica. Las series elegidas para construir elindicador adelantado son: Pasajeros transportados en avión,Declaraciones de suspensión de pagos, Importaciones reales noenergéticas, Colocaciones registradas y Oferta monetaria ampliada,M2. A continuación se obtiene el primer factor del análisis factorialen componentes principales realizado sobre las diferencias
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
49
Gráfico 2Fechado del ciclo de tasas del PIBNANP.
66.09-97.10
12
14
10
8
6
4
2
0
-2
-4
6667
6869
7071
7273
7475
7677
7879
8081
8283
8485
8687
8889
9091
9293
9495
9697
98
DLPIBNtas DLPIBNfek

logarítmicas, en porcentaje, centradas y tipificadas, de las cincoseries originales. El indicador adelantado, ADELA, es el resultado desuavizar dicho factor mediante el ya citado filtro autorregresivo. Porúltimo se fecha y se clasifica respecto del ciclo de referencia,resultando un adelanto de 8 meses.
5.2.2. Un modelo ARLI para predecir el ciclo de crecimiento.
A continuación se construye un modelo de regresión queexplique el ciclo del PIBNANP con la misma serie retardada y elindicador adelantado también retardado. El ciclo del PIBNANP seintroduce retardado para recoger el movimiento inercial de la seriey el indicador adelantado, también retardado, para recoger, con uncierto adelanto, la evolución del ciclo, en especial sus puntos degiro. En concreto, la especificación elegida es la siguiente:
yt = θ1 yt -1+θ2 yt -2+θ3 yt -3+θ4 yt -5+θ5 at -6+θ6 at -7+ε t ,
donde yt es el ciclo del PIBNANP (CPIBNANP) y at es el indicadorcompuesto adelantado (ADELA). El Cuadro 4 muestra la estimacióndel modelo. La elección de este modelo no se justifica desde el puntode vista de la regresión mínimo cuadrática: sólo se justifica porqueproduce buenas predicciones de la probabilidad de punto de giro 8.
C L M . E C O N O M Í A
50
Var iable dependiente : CPIBNANPMétodo: Mínimos cuadradosMuestra (a justada) : 1971 :04 1997:10Observaciones inc lu idas : 319 después de a justar los puntos f ina les
8) Sus limitaciones (sobreparametrización, multicolinealidad, heteroscedasticidad, autocorrelación, etc.)no invalidan el modelo para el objetivo buscado: prever el comportamiento de la serie en los puntos de giroa partir de valores de los regresores en períodos pasados.
Cuadro 4Estimación de un modelo ARLI para CPIBNANP.
VARIABLE COEFICIENTE ERROR ESTÁNDAR ESTADÍSTICO t p -VALOR
CPIBNANP(-1) 3 ,672436 0,010436 351,9082 0,0000CPIBNANP(-2) -4 ,839509 0,027227 -177,7443 0,0000CPIBNANP(-3) 2 ,414320 0,020261 119,1637 0,0000CPIBNANP(-5) -0 ,247301 0,003467 -71 ,33509 0,0000ADELA(-6) -0 ,002420 -0 ,000849 -2 ,850299 0,0047ADELA(-7) 0 ,001686 0,000844 1,996525 0,0467
R cuadrado 1,000000 Media de la var iable dependiente 2 ,784441R cuadrado a justado 1,000000 Desviac ión estándar de la var . dep. 2 ,535672Error estándar
de la regres ión 0,001224 Cr i ter io de información de Akaike -10 ,55487Suma de cuadrados
de los res iduos 0 ,000469 Cr i ter io de Schwarz -10 ,48405Logar i tmo de
la veros imi l i tud 1689,502 Estadíst ico F 2 ,73E+08Estadíst ico de
Durbin-Watson 0,203882 p-valor (estadíst ico F) 0 ,000000
5.2.3. Aplicación del procedimiento teórico a un paso.
De entrada, se definen los puntos de giro. Si la serie estádecreciendo, …≥yT-1≥yT , se considera punto de giro hacia arriba(upturn) en T al suceso
UT=[…≥yT-1≥yT <yT+1] ,
y si la serie está creciendo, …≤ yT-1≤yT , punto de giro haciaabajo (downturn) en T a
DT=[…≤yT-1≤ yT > yT+1 ] .
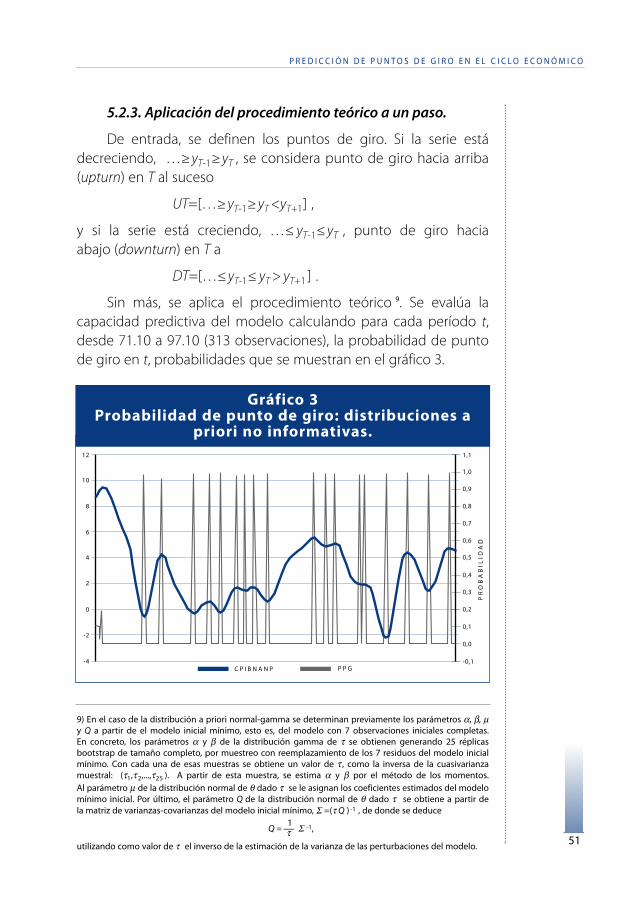
Sin más, se aplica el procedimiento teórico 9. Se evalúa lacapacidad predictiva del modelo calculando para cada período t,desde 71.10 a 97.10 (313 observaciones), la probabilidad de puntode giro en t, probabilidades que se muestran en el gráfico 3.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
51
9) En el caso de la distribución a priori normal-gamma se determinan previamente los parámetros α, β, µy Q a partir de el modelo inicial mínimo, esto es, del modelo con 7 observaciones iniciales completas.En concreto, los parámetros α y β de la distribución gamma de τ se obtienen generando 25 réplicasbootstrap de tamaño completo, por muestreo con reemplazamiento de los 7 residuos del modelo inicialmínimo. Con cada una de esas muestras se obtiene un valor de τ , como la inversa de la cuasivarianzamuestral: (τ1,τ2,...,τ25 ). A partir de esta muestra, se estima α y β por el método de los momentos.Al parámetro µ de la distribución normal de θ dado τ se le asignan los coeficientes estimados del modelomínimo inicial. Por último, el parámetro Q de la distribución normal de θ dado τ se obtiene a partir dela matriz de varianzas-covarianzas del modelo inicial mínimo, Σ =(τ Q ) -1 , de donde se deduce
Q = 1τ Σ -1,
utilizando como valor de τ el inverso de la estimación de la varianza de las perturbaciones del modelo.
Gráfico 3Probabilidad de punto de giro: distribuciones a
priori no informativas.12
10
8
6
4
2
0
-2
-4
1,1
1,0
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0,0
-0,1
PR
OB
AB
ILID
AD
C P I B N A N P P P G

Como se puede observar, la probabilidad de punto de giro seacerca a uno (de hecho vale uno) cuando la serie experimentaefectivamente un punto de giro. En este sentido, bajo ambossupuestos se produce una estimación de la probabilidadexcesivamente rígida: uno en los puntos de giro, cero fuera de ellos.De esta forma el procedimiento no avisaría de la proximidad de unpunto de giro con más de un período de adelanto.
Podemos fijar como criterio de decisión para afirmar que se vaa producir un punto de giro el que la probabilidad supere 0,5:
Si p[UT |D]>0,5 se predice punto de giro hacia arriba (upturn) en t.Si p[DT|D]>0,5 se predice punto de giro hacia arriba (downturn) en t.
El Cuadro 5 analiza los resultados obtenidos. Como se observa,siempre que se predice que no va a haber punto de giro se aciertay sólo 5 veces, para a priori no informativas, y 4 veces, para a priorinormal-gamma, que se predice punto de giro éste no ocurre, si bienestas falsas señales de punto de giro son explicables pues se trata demáximos y mínimos eliminados en el fechado por no serexcesivamente pronunciados.
Aunque el procedimiento no avisa de la proximidad de puntode giro en términos de probabilidad, si lo hace si se considerael t-valor o punto crítico, PCrit=√Prec (yt-Loc):
Si la serie decrece hasta t,p=p[ yt+1>yt |D]=p[ tG I>√Prec (yt-Loc)] ;
Si la serie crece hasta t,p=p[ yt+1< yt |D]=p[ tG I<√Prec (yt-Loc)] .
Como se observa, cuando la serie está decreciendo, el t-valor seva alejando de cero tomando valores positivos, hasta llegar a un
C L M . E C O N O M Í A
52
Cuadro 5Análisis de las predicciones de punto de giro.
DISTRIBUCIONESA priori no informativas A priori normal gamma
Ocurre OcurrePG NPG PG NPG
SE PREDICEPG 14 5 15 4
NPG 0 281 0 281
~
~
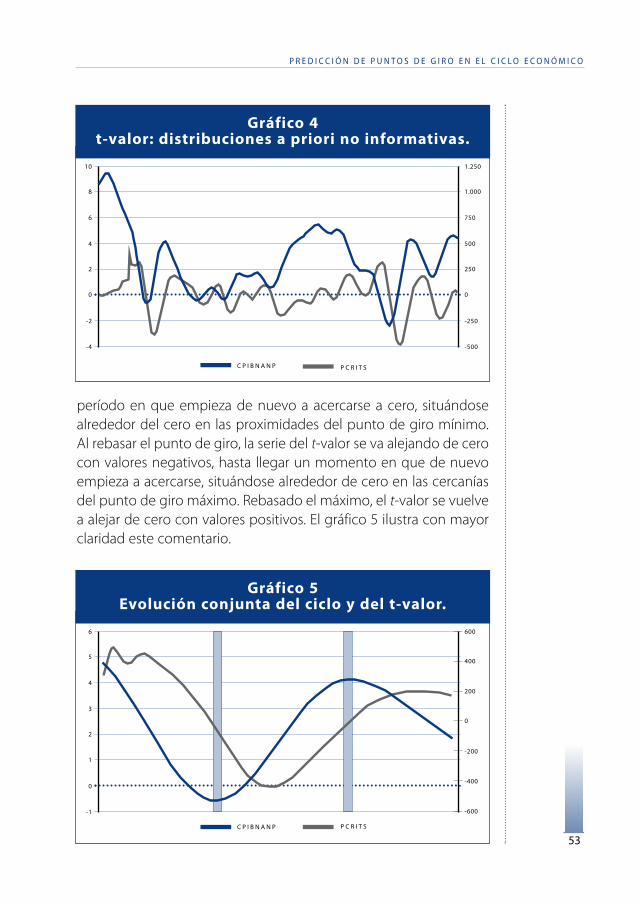
período en que empieza de nuevo a acercarse a cero, situándosealrededor del cero en las proximidades del punto de giro mínimo.Al rebasar el punto de giro, la serie del t-valor se va alejando de cerocon valores negativos, hasta llegar un momento en que de nuevoempieza a acercarse, situándose alrededor de cero en las cercaníasdel punto de giro máximo. Rebasado el máximo, el t-valor se vuelvea alejar de cero con valores positivos. El gráfico 5 ilustra con mayorclaridad este comentario.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
53
Gráfico 5Evolución conjunta del ciclo y del t-valor.
6
5
4
3
2
1
0
-1
600
400
200
0
-200
-400
-600
C P I B N A N P P C R I T S
Gráfico 4t-valor: distribuciones a priori no informativas.
10
8
6
4
2
0
-2
-4
1.250
1.000
750
500
250
0
-250
-500
C P I B N A N P P C R I T S

5.2.4. Aplicación de procedimientos de simulación.
El procedimiento teórico planteado, y resuelto, para lapredicción a un paso podría plantearse a dos o más pasos, pero suresolución requeriría de complicados desarrollos analíticos nosiempre factibles. Para evitar este problema se han ido formalizandoen los últimos años distintos procedimientos de simulación quepermiten obtener una aproximación a ciertas característicasmarginales de una distribución conjunta sin necesidad de dichosdesarrollos analíticos. En concreto, el muestreo de Gibbs y elmuestreo de Gibbs combinado con la integración Monte Carlovan a permitir obtener muestras de la distribución predictiva o elcálculo aproximado de la misma, en este caso, la distribuciónpredictiva de ( yT+1,..., yT+k ), para k =1,2,...,6.
El muestreo de Gibbs “es una técnica para generar variablesaleatorias de una distribución (marginal) de forma indirecta, sin tenerque calcular la densidad” (Casella y George, 1992). Así, dada ladistribución conjunta de ( X,Y ), f ( x,y ), se quiere conocer unacaracterística marginal (la propia distribución, una probabilidad, lamedia, la varianza, ... ). El muestreo de Gibbs genera una muestrapseudoaleatoria de la distribución conjunta, y por tanto de lasmarginales, a partir del conocimiento de las dos distribucionescondicionadas, la de X condicionada por Y=y, f (x | y ), y la de Ycondicionada por X= x, f (y | x ), muestra con la que se podrá estimarla característica deseada. El esquema siguiente ilustra la generaciónde la muestra de Gibbs de (X,Y ):
y0 → f(x| y0) → x0 → f (y | x0) → y1 → f (x| y1) → x1 →→ ............. → ....................... → .......... → ................... → ........... →→ xm -1 → f (y | xm -1) → ym → f (x | ym) → xm →→ ............. → ...................... → .......... → ................... → ........... →→ xm+n-1 → f (y | xm+n-1) → ym+n → f (x | ym+n) → xm+n .
De esta forma se obtiene la siguiente “secuencia Gibbs”:
y0,x0,y1,x1, ...,ym ,xm ,ym+1,xm+1, ...,ym+n ,xm+n .
Bajo condiciones razonables y a partir de un númerosuficientemente grande de iteraciones, m , la muestra
(( xm+1, ym+1),( xm+2, ym+2),...,( xm+n , ym+n )) puede considerarse como
C L M . E C O N O M Í A
54

una muestra a leator ia de tamaño n de (X , Y ) . As imismo(xm+1, xm+2 , ...,xm+n ) se considera una muestra aleatoria de tamañon de X e (ym+1, ym+2 , ...,ym+n ) una muestra aleatoria de tamañon de Y.
El método de Monte Carlo se puede entender “en un sentidoamplio como cualquier técnica para la solución de un modelousando números aleatorios o números pseudo-aleatorios” (Kleijnen,1974). Siguiendo a Kleijnen (1974), las tres principales áreas deaplicación son: 1) La solución de problemas deterministas, como laresolución de integrales definidas; 2) La obtención de la distribucióno de alguno de los parámetros de la distribución de una variablealeatoria; 3) La simulación del comportamiento de un fenómeno apartir de un modelo subyacente al mismo.
Un caso particular del primer tipo de aplicación, la integraciónde Monte Carlo, permite obtener una estimación de una función dedensidad marginal,
fY ( y )=∫ f ( x,y)dx =∫ f ( y | x).fX ( x)dx =EX [ f ( y | x)] ,
con
fY ( y )= 1n Σ f ( y | x( i )) ,
siendo (x (1), x (2) ,..., x (n)) una muestra de X. Por tanto, estimamos laesperanza (media poblacional) de f ( y | x ) con la media muestral.
5.2.4.1. Procedimiento de simulación: muestreo de Gibbs.
El muestreo de Gibbs nos va a proporcionar una muestra pseu-doaleatoria de la distribución predictiva de (yT+1, yT+2 ,...,yT+6 , θ, τ ) y,por tanto, de cualquier subconjunto de estas variables. Los pasos aseguir para construir la “secuencia Gibbs” son:
1. Se conocen las distribuciones condicionadas:
♦ p (τ |D )
♦ p (θ |τ ,D )
♦ p ( yT+1 | (τ ,θ ),D )
♦ p ( yT+2 | yT+1(τ ,θ ),D )
♦ …………………………………
♦ p ( yT+6 | yT+1,...,yT+5, (τ ,θ ),D )
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
55
x
^
x
i =1
n

2. Por la “regla de la multiplicación” de las probabilidades seobtiene distribución conjunta:
p ( yT+1, yT+2,…,yT+6,θ,τ|D )=p (τ|D ) . p (θ|τ ,D ) . p (yT+1| (θ,τ ),D ) .
. p (yT+2|yT+1, (θ,τ ),D )…p (yT+6|yT+1,…,yT+5, (θ,τ ),D ).
3. A partir de la distribución conjunta se obtienen lasdistribuciones de cada una de las 8 variables,θ,τ ,yT+1,…,yT+6 , condicionadas al resto y a los datos D.Así,
p ( τ |yT+1, yT+2,…,yT+6,θ ,D )=
p ( yT+1, yT+2,…,yT+6,θ ,τ |D )
p ( yT+1, yT+2…,yT+6,θ |D )
4. Con estas 8 distribuciones condicionadas se construye la“secuencia Gibbs”:
A partir de esta muestra estimaremos las distintasprobabilidades como frecuencias. Así, si la serie está creciendo,yT-1≤yT ,
- Probabilidad de que siga creciendo al menos hasta el períodoT+k (k=1,2,…,5):
p[yT ≤yT+1≤…≤yT+k |D ]=
- Probabilidad de punto de giro en T+k (k=0,1,…,5):
p[D TT+k |D ]=p[yT ≤yT+1≤…≤yT+k >yT+k+1|D ]=
=
C L M . E C O N O M Í A
56
nº observaciones muestrales l yT ≤yT+1≤…≤yT+k
n.
.
∝p ( yT+1, yT+2,…,yT+6,θ ,τ |D ).=
(0)
(1)
(m)
(m+1)
(m+n)
(0)
(1)
(m)
(m+1)
(m+n)
(0)
(1)
(m)
(m+1)
(m+n)
(0)
(1)
(m)
(m+1)
(m+n)
(0)
(1)
(m)
(m+1)
(m+n)
…
…
…
…
…
…
…
yT+1
yT+1
yT+1
yT+1
yT+1
……
yT+2
yT+2
yT+2
yT+1
yT+2
……
yT+6
yT+6
yT+6
yT+6
yT+6
……
θ
θ
θ
θ
θ
τ
τ
τ
τ
τ
……
……
nº observaciones muestrales l yT ≤yT+1≤…≤yT+k >yT+k+1
n
^
^ ^

- Probabilidad condicionada de punto de giro en T+k (k=0,1,…,5):
pc[D TT+k |D ]=
= p[yT ≤yT+1≤…≤yT+k >yT+k+1|yT ≤yT+1≤…≤yT+k ,D ]=
= =
=
Para probar la bondad del procedimiento realizamospredicciones de puntos de giro en los períodos previos al máximode 94.05. Así, con información hasta el período 93.12, estimaremosla probabilidad, sin condicionar y condicionada, de que haya puntode giro downturn en 93.12 (probabilidad ésta que podemosobtener directamente aplicando el procedimiento teórico), en94.01,..., en 94.05. A continuación, y considerando como últimoperíodo histórico 94.01, se estima la probabilidad de que hayapunto de giro downturn en 94.01,..., en 94.06. De la mismaforma iremos considerando como último período histórico94.02, 94.03,..., 94.04. El Cuadro 6 recoge las distintas probabilidadesestimadas para el supuesto de distribuciones a priori noinformativas. Como se puede observar, en general las estimacionesvan avisando de manera progresiva de la proximidad del punto degiro. Obsérvese que esta probabilidad sigue creciendo tras el puntode giro realmente observado en 94.05: si éste no se hubieraproducido en esa fecha, estaría más obligado a ocurrir en losperíodos sucesivos. La evaluación del procedimiento en otrospuntos de giro históricos ha proporcionado resultados similares.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
57
nº observaciones muestrales l yT ≤yT+1≤…≤yT+k >yT+k+1
nnº observaciones muestrales l yT ≤yT+1≤…≤yT+k
n
.
^
^
^
^
p[yT ≤yT+1≤…≤yT+k >yT+k+1|D ]
p[yT ≤yT+1≤…≤yT+k |D ]
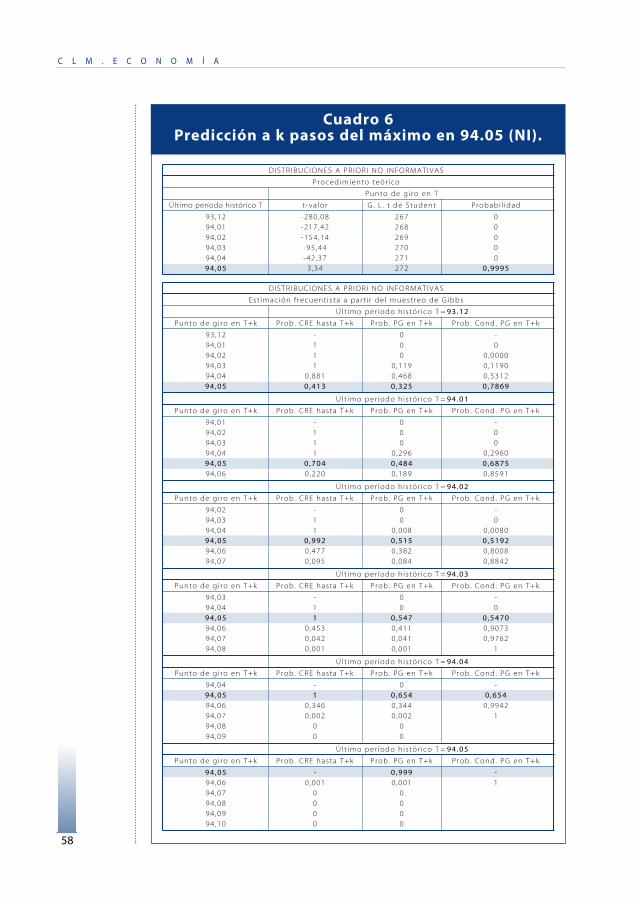
C L M . E C O N O M Í A
58
Cuadro 6Predicción a k pasos del máximo en 94.05 (NI).
DISTRIBUCIONES A PRIORI NO INFORMATIVAS
Procedimiento teór ico
Punto de gi ro en T
Último período histórico T t-va lor G . L . t de Student Probabi l idad
93,12 -280,08 267 094,01 -217,42 268 094,02 -154,14 269 094,03 -95 ,44 270 094,04 -42 ,37 271 094,05 3,34 272 0,9995
DISTRIBUCIONES A PRIORI NO INFORMATIVAS
Est imación f recuent is ta a part i r del muestreo de Gibbs
Últ imo per íodo histór ico T = 93.12
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
93,12 - 0 -94 ,01 1 0 094,02 1 0 0,000094,03 1 0,119 0,119094,04 0 ,881 0,468 0,531294,05 0,413 0,325 0,7869
Últ imo per íodo histór ico T = 94.01
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,01 - 0 -94 ,02 1 0 094,03 1 0 094,04 1 0,296 0,296094,05 0,704 0,484 0,687594,06 0 ,220 0,189 0,8591
Últ imo per íodo histór ico T = 94.02
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,02 - 0 -94 ,03 1 0 094,04 1 0,008 0,008094,05 0,992 0,515 0,519294,06 0 ,477 0,382 0,800894,07 0 ,095 0,084 0,8842
Últ imo per íodo histór ico T = 94.03
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,03 - 0 -94 ,04 1 0 094,05 1 0,547 0,547094,06 0 ,453 0,411 0,907394,07 0 ,042 0,041 0,976294,08 0 ,001 0,001 1
Últ imo per íodo histór ico T = 94.04
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,04 - 0 -94,05 1 0,654 0,65494,06 0 ,346 0,344 0,994294,07 0 ,002 0,002 194,08 0 094,09 0 0
Últ imo per íodo histór ico T = 94.05
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,05 - 0 ,999 -94,06 0 ,001 0,001 194,07 0 094,08 0 094,09 0 094,10 0 0

5.2.4.2. Procedimiento de simulación:estimación Monte Carlo y muestreo de Gibbs.
La distribución predictiva de ( yT+1 ,…,yT+k ) es
p ( yT+1 ,…,yT+k |D )= ∫∫ p ( yT+1 ,…,yT+k ,θ,τ |D )dθdτ=
=∫∫p ( yT+1 ,…,yT+k | (θ,τ ),D ).p(θ,τ )dθdτ =
=E[ p ( yT+1 ,…,yT+k | (θ,τ ),D )],
y la estimación de Monte Carlo en un punto ( yT+1 ,…,yT+k ) ,
p ( yT+1 ,…,yT+k |D )= ,
siendo la distribución condicionada que
podemos hallar y y n valores obtenidos por muestreo de Gibbs.
Si realizamos esta estimación para un conjunto de valores,numerosos y razonables, de ( yT+1 ,…, yT+k ), obtendremos unaaproximación discreta a la distribución predictiva, que permitecalcular la probabilidad de distintos sucesos relativos a la serie yt
en los k primeros períodos de predicción sin más que “integrar” lafunción en el correspondiente recinto S, esto es, calculando elvolumen que queda bajo la función estimada en los puntos queverifican la correspondiente condición. El gráfico 6 ilustra estaestimación para el caso unidimensional.
Así, si la serie crece, yT-1≤ yT ,
- Probabilidad de que siga creciendo al menos hasta el períodoT+k (k=1,2,…,5) :
p[yT ≤yT+1≤…≤yT+k | D ]=∫p[yT+1,…,yT+k |D ]d yT+1…d yT+k ,
siendo S el conjunto de valores ( yT+1,…,yT+k ) que verifican la condición de crecimiento.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
59
θ τ
θ τ
S
θ ( j ) τ ( j )
p yT+1 ,…,yT+k | θ ( j ),τ ( j ) ,D( )( )
n
j =1Σ p yT+1 ,…,yT+k | θ ( j ),τ ( j ) ,D
n
( )( )^
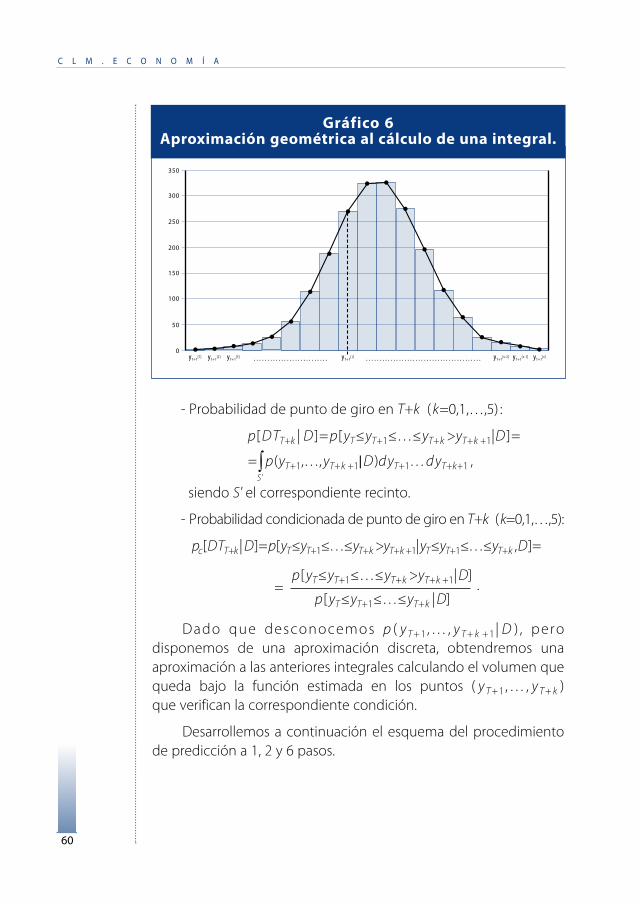
- Probabilidad de punto de giro en T+k (k=0,1,…,5) :
p[D TT+k | D ]=p[yT≤yT+1≤…≤yT+k >yT+k +1|D ]=
=∫p(yT+1,…,yT+k +1|D )d yT+1…d yT+k+1 ,
siendo S' el correspondiente recinto.
- Probabilidad condicionada de punto de giro en T+k (k=0,1,…,5):
pc[DTT+k | D]=p[yT≤yT+1≤…≤yT+k >yT+k +1|yT≤yT+1≤…≤yT+k ,D]=
=
Dado que desconocemos p ( y T +1,…, y T + k +1| D ) , perodisponemos de una aproximación discreta, obtendremos unaaproximación a las anteriores integrales calculando el volumen quequeda bajo la función estimada en los puntos ( y T +1,…, y T + k )que verifican la correspondiente condición.
Desarrollemos a continuación el esquema del procedimientode predicción a 1, 2 y 6 pasos.
C L M . E C O N O M Í A
60
S'
Gráfico 6Aproximación geométrica al cálculo de una integral.
yT+1[1] yT+1
[2] yT+1[3] ……………………… …………………………………… yT+1
[v-2] yT+1[v-1] yT+1
[v]yT+1[ i ]
350
300
250
200
150
100
50
0
p[yT≤yT+1≤…≤yT+k >yT+k +1|D]
p[yT≤yT+1≤…≤yT+k |D].

• Predicción a 1 paso.
Distribución predictiva:
p ( yT+1 |D )= ∫∫ p ( yT+1 ,θ,τ |D )dθdτ=
=∫∫p ( yT+1 | (θ,τ ),D ).p(θ,τ )dθdτ =E[ p ( yT+1 | (θ,τ ),D )].
Estimación de Monte Carlo para un valor yT+1 :
p ( yT+1 |D )= ,
siendo θ ( j ) y τ ( j ) n valores obtenidos por muestreo de Gibbs.
La distribución condicionada p ( yT+1 | (θ,τ ),D ):
yT+1 | (θ,τ ),D →N1(ZT+1θ,τ ),
siendo la media ZT+1θ =θ1yT+θ2 yT-1+θ3yT-2+θ4yT-4+θ5aT-5+θ6aT-6,donde yT es el ciclo del PIBNANP (CPIBNANP) y aT el indicadorcompuesto adelantado (ADELA).
Se realiza la estimación en un conjunto de valores razonablesy más o menos numeroso de yT+1, para lo cual se construyeuna malla:
- Se halla la media, m1 , y la desviación, s1, de la muestra Gibbs de valores de yT+1.
- Se considera el intervalo (a1,b1) donde a1=m1-4s1 y b1=m1+4s1.
- Se determina en este intervalo un número v de valores equidistantes,
a1=yT+1< yT+1< …< yT+1=b1,
siendo
yT+1=a1+( i-1) .
y
l = yT+1- yT+1 = .
- Se estima la distribución predictiva para cada valor de la malla yT+1.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
61
θ τ
θ τ
n
[1]
[ i ]
[ i ]
[ i ]
[i -1]
b1-a1
v-1
[2] [v ]
j =1Σ p yT+1 | θ ( j ),τ ( j ) ,D
n
( )( )
( )
^
b1-a1
v-1

Si la serie crece, yT-1≤yT,
- Probabilidad de punto de giro en T :
p[D TT | D ]=p[yT>yT+1|D ]= ∫ ∫ p(yT+1|D )d yT+1 .
- Estimación de la probabilidad de punto de giro en T:
p[D TT | D ]= Σ l . p(yT+1|D ).
• Predicción a 2 pasos.
Distribución predictiva:
p ( yT+1 , yT+2|D )= ∫∫ p ( yT+1 , yT+2 ,θ,τ |D )dθdτ=
=∫∫p ( yT+1 , yT+2 | (θ,τ ),D ).p(θ,τ )dθdτ =E[ p ( yT+1 , yT+2 | (θ,τ ),D )].
Estimación de Monte Carlo para un par de valores ( yT+1 , yT+2 ):
p ( yT+1 ,yT+2|D )= ,
siendo θ ( j ) y τ ( j ) n valores obtenidos por muestreo de Gibbs.
La distribución condicionada se puede factorizar,
siendo
yT+1 | (θ,τ ),D → N1(ZT+1θ,τ ),
donde ZT+1θ =θ1yT+θ2 yT-1+θ3 yT-2+θ4yT-4+θ5aT-5+θ6aT-6 , e
yT+2 | yT+1 ,(θ,τ ),D →N1(ZT+2θ,τ ),
donde ZT+2θ =θ1yT +1+θ2 yT +θ3 yT-1+θ4 yT-3+θ5 aT- 4+θ6 aT- 5 .
Se realiza la estimación en un conjunto de pares de valoresrazonables y suficientemente numerosos de yT+1, para lo cual seconstruye una malla bidimensional.
C L M . E C O N O M Í A
62
[ yT>yT+1]
yT+1 l yT>yT+1[ ][ i ] [ i ]
[ i ]^^
^
θ τ
θ τ
n
j =1Σ p yT+1 ,yT+2 | θ ( j ),τ ( j ) ,D
n
( )( )
p yT+1 ,yT+2 | θ ( j ),τ ( j ) ,D =( )( ) p yT+2 | yT+1, θ ( j ),τ ( j ) ,D ,( )( )p yT+1 | θ ( j ),τ ( j ) ,D .( )( )
( )
( )

- Se halla la media, mi , y la desviación, si , de la muestra Gibbs de valores de yT+1 para i=1,2.
- Se consideran los intervalos ( ai , bi ) donde ai =mi - 4 si
y bi =mi - 4 si para i=1,2 .
- Se determina en cada intervalo un número v de valores equidistantes,
ai =yT+ i < yT+ i < …< yT+ i =bi ,
siendo
yT+i =ai +(k-1) .
y Rect=l1. l2, donde
li = yT+i - yT+i = ( i=1,2 ) .
- Se estima la distribución predictiva para cada par de valores de la malla yT+1 , yT+2 .
Si la serie crece, yT-1 ≤ yT ,
- Probabilidad de que siga creciendo al menos hasta T+1:
p[yT≤yT+1|D ]= ∫ ∫ p( yT+1,yT+2 |D )d yT+1d yT+2 .
- Estimación de la probabilidad de que siga creciendo al menos hasta T+1:
p[ yT≤yT+1|D ]= Σ Rect . p(yT+1, yT+2 |D ).
- Probabilidad de punto de giro en T+1:
p[D TT+1 | D ]=p[yT≤yT+1>yT+2|D ]=
= ∫ ∫ p(yT+1,yT+2|D )d yT+1d yT+2 .
- Estimación de la probabilidad de punto de giro en T+1:
p[D TT+1 | D ]=p[yT≤yT+1>yT+2|D ]=
= Σ Rect . p(yT+1, yT+2 |D ).
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
63
[1] [2] [v ]
[k ] bi -ai
v-1
bi -ai
v-1[k] [k-1]
[ i ] [ j ]
[ i ] [ k ]
( )
[ yT ≤yT+1]
yT+1 l yT≤yT+1[ ][ i ] [ i ]
^^
^
[ i ] [ k ]^
^
[ yT ≤yT+1>yT+2]
yT+1 , yT+2 l yT ≤yT+1>yT+2[ ( ) ][ i ] [k ] [ i ] [k ]

- Probabilidad condicionada de punto de giro en T+1:
pc [D TT+1 | D ]=p[yT≤yT+1>yT+2| yT≤yT+1 ,D ]=
= ,
estimándose como cociente de las estimaciones del numerador y denominador.
• Predicción a 6 pasos.
Distribución predictiva:
p ( yT+1 , …, yT+6 |D )= ∫∫ p ( yT+1 , …, yT+6 ,θ,τ |D )dθdτ=
=∫∫p ( yT+1 , …, yT+6 | (θ,τ ),D ).p(θ,τ )dθdτ =
=E[ p ( yT+1 , …, yT+6 | (θ,τ ),D )].
Estimación de Monte Carlo en un punto (yT+1 , …, yT+6):
p ( yT+1 , …, yT+6 |D )= ,
siendo θ ( j ) y τ ( j ) n valores obtenidos por muestreo de Gibbs.
La distribución condicionada se puede factorizar,
siendo
yT+k | yT+1 , …, yT+k-1,(θ,τ ),D → N1(ZT+ kθ,τ ),
para k=1,2,…,6, donde
ZT+ kθ =θ1yT+k-1+θ2 yT+k-2+θ3 yT+k-3+θ4 yT+k-5+θ5 aT+k-6+θ6 aT+k-7.
Se estima la distribución predictiva para una malla dedimensión 6 de valores de (yT+1 , …, yT+6).
En este caso, Rect = l1 . l2…l6 , donde
li = yT+i - yT+i = ( i=1,2,…,6 ) .
C L M . E C O N O M Í A
64
p[yT≤yT+1>yT+2 | D ]
p[yT≤yT+1| D ]
θ τ
θ τ
^
n
j =1Σ p yT+1 , …, yT+6 | θ ( j ),τ ( j ) ,D
n
( )( )
p yT+1 , …, yT+6 | θ ( j ),τ ( j ) ,D =( )( )p yT+6 | yT+1 , …, yT+5 θ ( j ),τ ( j ) ,D ,( )( )
p yT+1 | θ ( j ),τ ( j ) ,D .( )( )p yT+2 | yT+1, θ ( j ),τ ( j ) ,D …( )( ).
( )
bi -ai
v-1[k] [k-1]

Si la serie está creciendo, yT -1≤yT,
- Probabilidad de que siga creciendo al menos hasta el período T+k (k=1,2,…,5):
p[yT≤yT+1≤…≤yT+k |D ]=
= ∫ ∫ p(yT+1,…, yT+k |D )d yT+1…d yT+k .
- Probabilidad de punto de giro en T+k (k=0,1,…,5):
p[D TT+k | D ]=p[yT≤yT+1≤…≤yT+k >yT+k +1|D ]=
= ∫ ∫ p(yT+1,…,yT+k +1|D )d yT+1…d yT+k +1 .
- Probabilidad condicionada de punto de giro en T+k (k=0,1,…,5):
pc [D TT+k | D ]=
=p[yT ≤yT+1≤…≤yT+k >yT+k +1| yT≤yT+1 ≤…≤yT+k ,D ]=
= .
Las dos primeras probabilidades se estiman como el volumenbajo la distribución predictiva para los valores de la malla queverifican la correspondiente condición,
p[ S|D ]= Σ…ΣS Rect . p(yT+1 , …,yT+k |D ),
donde
S= yT+1,…, yT+k l yT ≤yT+1 ≤…≤yT+k
o
S= yT+1,…, yT+k , yT+k+1 l yT ≤yT+1 ≤…≤yT+k >yT+k+1 ,
según el caso.
La probabilidad condicionada se obtiene como cociente de lasprobabilidades estimadas que aparecen en el numerador ydenominador de la expresión.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
65
[ yT ≤yT+1≤…≤yT+k]
[ yT ≤yT+1≤…≤yT+k >yT+k+1]
p[yT≤yT+1≤…≤yT+k >yT+k +1| D ]
p[yT≤yT+1≤…≤yT+k | D ]
[ i ] [ l ]
[ i ] [ l ] [ i ] [ l ]
[ i ] [ l ] [ m ] [ i ] [ l ] [ m ]
^^
( )[ ]( )[ ]
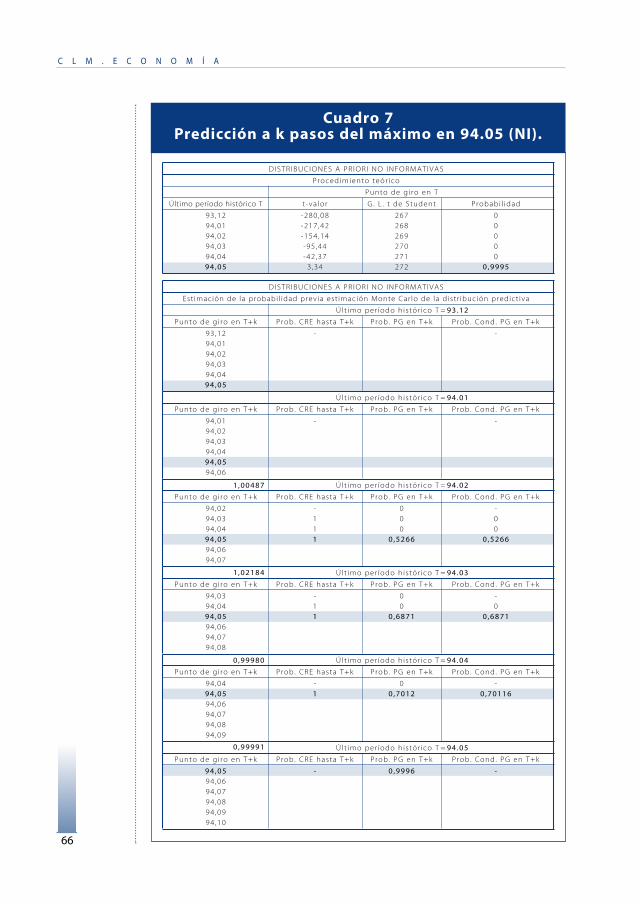
C L M . E C O N O M Í A
66
Cuadro 7Predicción a k pasos del máximo en 94.05 (NI).
DISTRIBUCIONES A PRIORI NO INFORMATIVAS
Procedimiento teór ico
Punto de gi ro en T
Último período histórico T t-va lor G . L . t de Student Probabi l idad
93,12 -280,08 267 094,01 -217,42 268 094,02 -154,14 269 094,03 -95 ,44 270 094,04 -42 ,37 271 094,05 3,34 272 0,9995
DISTRIBUCIONES A PRIORI NO INFORMATIVAS
Est imación de la probabi l idad previa est imación Monte Carlo de la distr ibución predict iva
Últ imo per íodo histór ico T = 93.12
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
93,12 - -94 ,0194,0294,0394,0494,05
Últ imo per íodo histór ico T = 94.01
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,01 - -94 ,0294,0394,0494,0594,06
Últ imo per íodo histór ico T = 94.02
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,02 - 0 -94 ,03 1 0 094,04 1 0 094,05 1 0,5266 0,526694,0694,07
Últ imo per íodo histór ico T = 94.03
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,03 - 0 -94 ,04 1 0 094,05 1 0,6871 0,687194,0694,0794,08
Últ imo per íodo histór ico T = 94.04
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,04 - 0 -94,05 1 0,7012 0,7011694,0694,0794,0894,09
Últ imo per íodo histór ico T = 94.05
Punto de gi ro en T+k Prob. CRE hasta T+k Prob. PG en T+k Prob. Cond. PG en T+k
94,05 - 0 ,9996 -94,0694,0794,0894,0994,10
1,00487
1,02184
0,99980
0,99991

Para evaluar la capacidad predictiva del procedimiento en losdistintos horizontes de predicción, se calculan las probabilidades decrecimiento y de punto de giro a 1, 2,..., 6 pasos en los períodosanteriores al máximo de 94.05, empezando en el período 93.12 parair luego adelantando a 94.01, 94.02,..., hasta 94.05. De la observacióndel Cuadro 7 se deduce la validez del procedimiento para lapredicción. La evaluación del procedimiento en otros puntos degiro históricos ha proporcionado resultados similares.
6. Conclusiones.En este trabajo se abordan dos cuestiones: por un lado, se
proporciona una visión global del estado actual del análisis de lospuntos de giro del ciclo económico, tanto desde la perspectiva desu fechado histórico como desde su predicción. Por otro, sedesarrolla un procedimiento de naturaleza bayesiana, relacionadocon los modelos jerárquicos de Bayes (HB, Hierarchical Bayes), quepermite tanto fechar los puntos de giro históricos como predecirlosa corto plazo.
La primera cuestión intenta ser un recorrido por algunostópicos del análisis cíclico. Así, en el segundo apartado se hanpresentado distintas concepciones del ciclo económico. Suconcepto, fluctuaciones en la actividad agregada de las economíasindustriales, recurrentes pero no periódicas, de una duraciónsuperior al año y que afectan de manera más o menos sincrónica alas distintas ramas, sigue siendo deudor de la definición propuestaen su día por Burns y Mitchell.
Cuando hablamos de fluctuaciones en la economía nospodemos estar refiriendo a fluctuaciones en los niveles (ciclo clásicoo de niveles), a fluctuaciones respecto de una tendencia (ciclo dedesviaciones) o a fluctuaciones de las tasas de crecimiento (ciclo detasas de crecimiento). El interés del análisis cíclico se ha idotrasladando desde los ciclos clásicos hacia los ciclos de tasas decrecimiento. Este deslizamiento en el interés desde uno a otroconcepto (deslizamiento notable en los análisis del ciclo en Europa,no así en Estados Unidos donde la tradición en análisis del cicloclásico sigue siendo manifiesta) se explica por la importancia
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
67

intrínseca asignada al crecimiento económico en el último mediosiglo y a la escasez de evidencias empíricas en relación con los ciclosde niveles.
A continuación, esta revisión se ha orientado a la presentacióny valoración de las distintas formas de definir, determinar y predecirlos puntos de giro: 1) Reglas simples basadas en la evolución localde la señal cíclica; 2) Métodos de fechado; 3) Procedimientos noobjetivos que tienen en cuenta la evolución de indicadoresadelantados; y 4) Métodos de predicción. En cuanto a lasdefiniciones más simples, que consideran puntos de giro losmáximos y mínimos relativos con ciertas condiciones de duración yamplitud, se señalan en el trabajo varias circunstancias: a) Existenmuchas (tal vez habría que decir que demasiadas) definiciones;b) Dichas definiciones no se basan en criterio alguno; c) El hechode que sean puntos de giro de niveles, de desviaciones o de tasasno parece condicionar, al menos explícitamente, dichasdefiniciones, como tampoco la periodicidad de la señal cíclica y sugrado de suavidad; y d) No tienen contenido teórico. Todas estascircunstancias, en cierto modo ya denunciadas por Wecker en eltrabajo pionero de predicción de puntos de giro, son una rémora enla investigación cíclica e impiden frecuentemente la comparaciónde resultados entre países o entre procedimientos. La deuda quetiene el enfoque empírico del análisis cíclico con la metodologíaNBER, tal vez explica esa indefinición de punto de giro: el NBER notiene un criterio establecido, objetivo, reproducible y automáticopara definir el inicio y el fin de una recesión.
Una forma de determinar los puntos de giro, la cronología delciclo, son los métodos de fechado: algoritmos más o menoscomplejos que determinan los máximos y mínimos de la serie quecumplan ciertas condiciones de distancia y, a veces, de amplitud,generalmente automatizados en un programa informático ad hoc.Son deudores del método propuesto por Bry y Boschan parareplicar el fechado realizado de forma no automática por el NBERpara la economía americana. Esto ocurre con el procedimiento deArtis, Kontolemis y Osborn o con el procedimiento <F>, utilizado enla aplicación. Asimismo se referencian otros, como el procedimientoCicle, basado en el análisis de Fourier.
C L M . E C O N O M Í A
68

En los últimos 25 años, a partir del trabajo pionero de Wecker,se han ido desarrollando distintos procedimientos de predicción depuntos de giro, seis de los cuales se describen en el cuarto apartado.Los resultados obtenidos son, según todas las fuentes, satisfactorios(en la literatura se encuentran comparaciones entre algunos deellos; la comparación sistemática de resultados de todos losprocedimientos en distintas situaciones cíclicas sigue siendo unatarea pendiente de gran interés).
Digamos finalmente que todos estos métodos, y el quepresentan los autores, siguen teniendo un lastre fundamental:realmente predicen el pasado. El hecho de que al obtener la señalcíclica (procedimiento de suavizado y/o obtención de tasascentradas) se pierdan bastantes observaciones al principio y al finalde la serie y la conveniencia de éstos y otros métodos de predicciónde no alejar en exceso los horizontes de predicción hace queestemos abocados a predecir hechos ya pasados.
En el apartado quinto se desarrolla la propuesta de los autores,un procedimiento de tipo bayesiano que evalúa la probabilidad deobtener un punto de giro y se aplica a la predicción de los puntosde giro del ciclo de tasas de la economía española. El procedimientoteórico se ha desarrollado siguiendo los siguientes pasos:
1. Planteamiento del problema: estimar la probabilidad de queuna serie de tiempo supere un cierto umbral, estando estaserie generada por un modelo de comportamiento en elque se incluyen como variables la misma serie retardada yuno o más indicadores adelantados.
2. La estimación de dicha probabilidad se hace en un contextobayesiano. Así, y considerando una función de pérdidacuadrática, el estimador de Bayes es la esperanza a posterioride la probabilidad a estimar; dicha esperanza resulta laprobabilidad predictiva de que la serie supere dicho umbral.
3. La obtención de la distribución predictiva se realiza bajo dossupuestos sobre la distribución a priori de los parámetros, loscoeficientes del modelo de regresión y la precisión de susperturbaciones. Bajo estos dos supuestos, distribuciones noinformativas y normal-gamma, la distribución predictiva
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
69

resulta ser una t de Student descentrada, variando losparámetros de la misma, grados de libertad, localización yprecisión.
4. Constatación de que, en cierto sentido, las dos solucionesconvergen, si bien este hecho no se demuestraformalmente.
A continuación, se aplica el resultado para la predicción depuntos de giro a un paso en el ciclo de tasas de la economíaespañola y, mediante técnicas de simulación, se amplía el horizontede predicción a 6 períodos.
Para llevar a cabo esta tarea, se ha estimado un modelo deregresión que genera el ciclo de tasas a partir del mismo ciclo, con1, 2, 3 y 5 retardos, y el indicador compuesto adelantado, con 6 y 7retardos. La dificultad de encontrar un buen modelo desde el puntode vista explicativo, no afecta al modelo elegido, dada la finalidaddel mismo en el procedimiento.
Determinado el modelo de regresión la aplicación se ha hechode tres maneras:
1. Predicción a un paso mediante la aplicación directa delresultado teórico obtenido, procedimiento implementadoen un programa de TSP. La bondad del procedimiento se hatestado viendo su comportamiento en la predicción detodos los períodos históricos. El grado de acierto es óptimopero el procedimiento no avisa de la pronta llegada de unpunto de giro: la probabilidad es igual a 1 cuando ocurre y a0 cuando no ocurre. Con todo, el aviso de la llegadainminente de punto de giro se puede seguir analizando elvalor de la t de Student que determina la probabilidad depunto de giro: dicho valor se acerca a cero, tomando valorespositivos, cuando se avecina un punto de giro “hacia arriba”y se acerca a cero, tomando valores negativos, cuando seavecina un punto de giro “hacia abajo”.
2. Predicción a 1, 2, ..., 6 pasos mediante una estimaciónfrecuentista de la probabilidad de punto de giro en base amuestras de Gibbs de la distribución predictiva. Elprocedimiento está implementado en un programa en Bugs
C L M . E C O N O M Í A
70

y la bondad del método se estudia analizando su respuestaen las proximidades de distintos puntos de giro históricos.
3. Predicción a 1, 2, ..., 6 pasos mediante la integración de ladistribución predictiva estimada por integración de MonteCarlo, esto es, estimación obtenida como la media dedistribuciones condicionadas (se entiende integración de ladistribución predictiva estimada como el cálculo delvolumen bajo dicha distribución en el recinto de valores queverifican la condición de punto de giro). El procedimientoestá implementado en programas TSP y se estudia subondad analizando los resultados obtenidos en lasproximidades de distintos puntos de giro históricos.
Los resultados obtenidos en los tres procedimientos parecensatisfactorios.
La investigación se propone avanzar en el futuro siguiendovarias direcciones. Por un lado, se trataría de mejorar la informaciónestadística que se utiliza en el modelo. En este sentido, se intentaríabuscar un ciclo de referencia más adecuado, que bien pudiera ser elobtenido a partir del Índice de Producción Industrial; aunque sólorecoge directamente un aspecto de la actividad, la producciónindustrial, su periodicidad mensual y su mayor sensibilidad a lacoyuntura, le hacen, en principio, más recomendable. Asimismo, setrataría de buscar indicadores adelantados, simples y complejos,que presenten una mejor relación cíclica con el ciclo de referencia.
Por otro lado, en los aspectos teóricos se trataría de utilizarfunciones de pérdida asimétricas que valoraran de distinto modo lasobreestimación y la subestimación de la probabilidad de punto degiro; asimismo, habría que desarrollar el procedimiento teórico ados o más pasos.
Además, los procedimientos de simulación, desarrollados aquía partir del muestreo de Gibbs, deberían realizarse con otrastécnicas similares (aumento de datos, muestreo de importancia,etc.), comparando los distintos resultados obtenidos.
Por último, otra tarea pendiente sería comparar los resultadosobtenidos en la aplicación de nuestro método (tanto elprocedimiento teórico directo como los procedimientos en base a
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
71

simulaciones) con aquellos que resultan de aplicar losprocedimientos más relevantes (Wecker, Zellner, Neftçi, Hamilton,...).
Terminemos recogiendo una reflexión de Arthur F. Burns quemuestra el camino a seguir: “Harían muy bien los economistas encontinuar investigando a fondo la naturaleza y causas del cicloeconómico, en vigilar con atención cualquier síntoma o posiblefuente de declive de la actividad económica y en buscarcaminos practicables hacia la prosperidad sin inflación” (Burns,1977, pág. 303).
C L M . E C O N O M Í A
72

Bibliografía:ABAD, A.M. y QUILIS, E.M. (1995): “Programas de Análisis Cíclico: <F> y <G> y <FDESC>.
Manual del Usuario”, Documento interno, INE, Madrid.
ABAD, A.M. y QUILIS, E.M. (1996): “<F> y <G>: Dos programas para el análisis cíclico.Aplicación a los agregados monetarios”, Boletín Trimestral de Coyuntura, núm. 62, págs. 63-103, INE.
ABAD, A.M. y QUILIS, E.M. (1997): “Programas de análisis cíclico: <F> y <G> y <FDESC>.Manual del usuario”, Documento interno, INE, Madrid.
ANDERSON, L.C. (1966): “A Method of Using Diffusion Indexes to Indicate the Direction of NationalEconomic Activity”, Proceedings of the American Statistical Association, págs. 424-434.
ARTIS, M.J., KONTOLEMIS, Z.G. y OSBORN, D.R. (1997): “Business Cycles for G7 and European Countries”,Journal of Business, vol. 70, págs. 249-279.
BARNES, L. (1980): “Business Forecasting with Higher Order Indicators-A Neglected Art”,Business Economics, September, págs. 22-31.
BOLDIN, M.D. (1994): “Dating Turning Points in the Business Cycle”, Journal of Business, vol. 67,págs. 97-131.
BOOT, J.C.G. y FEIBES, W. (1967): “On Glejser's derivation of monthly figures from yearly data”,Cahiers Économiques de Bruxelles, núm. 36, págs. 539-546.
BOOT, J.C.G., FEIBES, W. y LISMAN, J.H.C. (1967): “Further Methods of Derivation of Quaterly Figuresfrom Annual Data”, Applied Statistics, vol. 16, págs. 65-75.
BOX, G.E.P. y JENKINS, G.M. (1976): Time Series Analysis: Forecasting and Control, Holden-Day,San Francisco.
BROEMELING, L.D. (1985): Bayesian Analysis of Linear Models, Marcel Dekker, New York.
BRY, G. y BOSCHAN, C. (1971): “Cyclical Analysis of Time Series: Selected Procedures and ComputerPrograms”, Technical Paper, 20, NBER, New York.
BURNS, A.F. y MITCHELL, W.C. (1946): Measuring Business Cycles, NBER, New York.
CANOVA, F. (1994): “Detrending and Turning Points”, European Economic Review, vol. 38, págs. 614-623.
CANOVA, F. (1999): “Does Detrending Matter for the Determination of the Reference Cycle and theSelection of Turning Points?”, The Economic Journal, vol. 109, págs. 126-150.
CASELLA, G. y GEORGE, E.I. (1992): “Explaining the Gibbs Sampler”, The American Statistician, vol. 46,núm. 3, págs. 167-174.
CHAFFIN, W.W. y TALLEY, W.K. (1989): “Diffusion Indexes and a Statistical Test for Predicting TurningPoints in Business Cycles”, International Journal of Forecasting, vol. 5, págs. 29-36.
DEITCH, R.F. (1985): “Anticipating Growth Recessions and Recoveries: a New Sequential SignallingSystem”, Paper presented at the Fifth International Symposium on Forecasting, June 11.
DIEBOLD, F.X. y RUDEBUSCH, G.D. (1989): “Scoring the Leading Indicators”, Journal of Business, vol. 62,núm. 3, págs. 369-391.
DIEBOLD, F.X. y RUDEBUSCH, G.D. (1991): “Forecasting output with the composite leading index:a real-time analysis”, Journal of the American Statistical Association, núm. 86, págs. 603-610.
ESPASA, A. y CANCELO, J.R. (eds.) (1993): Métodos cuantitativos para el análisis de la coyunturaeconómica, Alianza, Madrid.
FERNÁNDEZ MACHO, F.J. (1991): “Indicadores sintéticos de aceleraciones y desaceleracionesen la actividad económica”, Revista Española de Economía, vol. 8, núm. 1, págs. 125-156.
FERNÁNDEZ-ABASCAL, H. (2004): Predicción de puntos de giro en el ciclo de crecimiento de la economíaespañola: un procedimiento bayesiano, Tesis doctoral, Universidad de Valladolid.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
73

FILARDO, A.J. (1993): “The Evolution of U.S. Business Cycle Phases”, Research Working Paper, 93-17,Federal Reserve Bank of Kansas City.
FILARDO, A.J. (1994): “Business Cycle Phases and Their Transition Dynamics”, Journal of Business andEconomic Statistics, núm. 12, págs. 299-308.
FILARDO, A.J. y GORDON S.F. (1998): “Business cycle durations”, Journal of Econometrics, vol. 85, núm. 1,págs. 99-124.
GARCÍA-FERRER, A., HIGHFIELD, R.A., PALM, F. y ZELLNER, A. (1987): “Macroeconomic Forecasting usingPooled International Data”, Journal of Business and Economic Statistics, vol. 5, núm. 1, págs. 53-67.
GELFAND A.E. y SMITH, A.F.M. (1990): “Sampling-Based Approached to Calculating Marginal Densities”,Journal of the American Statistical Association, vol. 85, núm. 410, págs. 398-409.
HAMILTON, J.D. (1989): “A New Approach to the Economic Analysis of Non-stationary Time Seriesand the Business Cycle”, Econometrica, vol. 57, págs. 357-384.
HYMANS, S. (1973): “On the Use of Leading Indicators to Predict Cyclical Turning Points”,Brookings Papers on Economic Activity, vol. 2, págs. 339-384.
INSTITUTO NACIONAL DE ESTADÍSTICA (1993): “Un Sistema de Indicadores Cíclicos para la EconomíaEspañola: índices sintéticos de adelanto, coincidencia y retraso”, Boletín Trimestral de Coyuntura, núm. 50,págs. 51-98, INE.
INSTITUTO NACIONAL DE ESTADÍSTICA (1994): Sistema de Indicadores Cíclicos de la Economía Española.Metodología e índices sintéticos de adelanto, coincidencia y retraso, INE, Madrid.
JUN, D.B. y JOO, Y.J. (1993): “Predicting Turning Points in Business Cycles by Detection of SlopeChanges in the Leading Composite Index”, Journal of Forecasting, vol. 12, págs. 197-213.
KING, R.G. y REBELO, S.T. (1993): “Low Frequency Filtering and Real Business Cycles”,Journal of Economic Dynamics and Control, vol. 17, págs. 207-231.
KLEIJNEN, J.P.C. (1974): Statistical Techniques in Simulation, Part I, Marcel Dekker, New York.
KLING, J.L. (1987): “Predicting the Turning Points of Business an Economic Time Series”,Journal of Business, vol. 60, núm. 2, págs. 201-238.
KOOPMANS, T.C. (1947): “Measurement without theory”, The Review of Economic Statistics, núm. 29,págs. 161-172.
LAHIRI, K. y MOORE, G.H. (eds.) (1991): Leading economic indicators: new approaches and forecastingrecords, Cambridge University Press, Cambridge.
LAHIRI, K. y WANG, J.G. (1994): “Predicting Cyclical Turning Points with Leading Index in a MarkovSwitching Model”, Journal of Forecasting, vol. 13, págs. 245-263.
LISMAN, J.H.C. y SANDEE, J. (1964): “Derivation of quartely figures from annual data”, Applied Statistics,vol. 13, núm. 2, págs. 78-90.
MCCULLOCH, R.E. y TSAY, R.S. (1994a): “Bayesian Analysis of Autoregressive Time Series via the GibbsSampler”, Journal of Time Series Analysis, vol. 15, núm. 2, págs. 235-250.
MCCULLOCH, R.E. y TSAY, R.S. (1994b): “Statistical Analysis of Economic Time Series via MarkovSwitching Models”, Journal of Time Series Analysis, vol. 15, núm. 5, págs. 523-539.
MCNEMAR, Q. (1969): Psychological Statistics, John Wiley & Sons, New York.
MCNESS, S.K. (1991): “Forecasting Cyclical Turning Points: The Record in the Past Three Recessions”,en Lahiri, K. y Moore, G.H. (eds.): Leading Economic Indicators: New Approaches and Forecasting Records,Cambridge University Press, Cambridge, págs. 151-168.
NEFTÇI, S.N. (1982): “Optimal prediction of cyclical downturns”, Journal of Economic Dynamics andControl, núm. 4, págs. 225-241.
NIEMIRA, N.P. (1991): “An International Application of Neftci\'s Probability Approach for SignalingGrowth Recessions and Recoveries Using Turning Points Indicators”, en Lahiri, K. y Moore, G.H. (eds.):Leading Economic Indicators: New Approaches and Forecasting Records, Cambridge University Press,Cambridge, págs. 91-108.
C L M . E C O N O M Í A
74

NIEMIRA, N.P. y KLEIN, PÁG.A. (1994): Forecasting Financial an Economic Cycles, Wiley, New York.
OSBORN, D.R. (1995): “Moving Average Detrending and the Analysis of Business Cycles”, Oxford Bulletinof Economics and Statistics, vol. 57, págs. 547-558.
PEÑA, D., TIAO, G.C. y TSAY, R.S. (eds.) (2001): A Course in Time Series Analysis, John Wiley & Sons, NewYork.
TANNER, M.A. (1996): Tools for Statistical Inference. Methods for the Exploration of Posterior Distributionand Likelihood Functions, Springer-Verlag, New York.
TANNER, M.A. y WONG, W.H. (1987): “The Calculation of Posterior Distributions by DataAugmentation”, Journal of the American Statistical Association, vol. 82, núm. 398, págs. 528-550.
THOMAS, A., SPIEGELHALTER, D.J. y GILKS, W.R. (1992): “BUGS: a Program to Perform Bayesian Inferenceusing Gibbs Sampling”, en Bernardo, J.M, Berger, J.O., Dawid, A.P. y Smith, A.F.M. (eds.): Bayesian Statistics4, Oxford University Press, Oxford, págs. 837-842.
VACCARA, B.N. y ZARNOWITZ, V. (1978): “Forecasting with the Index of Leading Indicators”,Working Paper 284, NBER, New York.
WECKER, W.E. (1979): “Predicting Turning Points of a Time Series”, Journal of Business, vol. 52, núm. 1,págs. 35-50.
ZARNOWITZ, V. (1992): Business Cycles. Theory, History, Indicators, and Forecasting, The Universityof Chicago Press para NBER, Chicago.
ZARNOWITZ, V. y MOORE, G.H. (1982): “Sequential Signals of Recession and Recovery”, Journalof Business, vol. 55, núm. 1, págs. 57-85.
ZELLNER, A. (1971): An Introduction to Bayesian Inference in Econometrics, John Wiley & Sons, New York.
ZELLNER, A. (1986): “Bayesian estimation and prediction using asymmetric loss functions”, Journalof the American Statistical Association, núm. 81, pp 446-451.
ZELLNER, A. y HONG, C. (1989): “Forecasting international growth rates using bayesian shrinkageand other procedures”, Journal of Econometrics, núm. 40, págs. 183-202.
ZELLNER, A. y HONG, C. (1991): “Bayesian Methods for Forecasting Turning Points in EconomicTime Series: Sensitivity of Forecasts to Asimmetry of Loss Structures”, en Lahiri, K. y Moore, G.H. (eds.):Leading Economic Indicators: New Approaches and Forecasting Records, Cambridge University Press,Cambridge, págs. 129-140.
ZELLNER, A., HONG, C. y GULATI, G.M. (1990): “Turning Points in Economic Time Series, LossEstructures and Bayesian Forecasting”, en Geisser, S., Hodges, J.S., Press, S.J. y Zellner, A. (eds.): Bayesianand Likelihood Methods in Statistics and Econometrics. Essays in Honor of George A. Barnard, North-Holland,Amsterdam, págs. 371-393.
ZELLNER, A., HONG, C. y MIN, C. (1991): “Forecasting turning points in international output growthrates using Bayesian exponentially weighted autoregression, time-varying parameter, and poolingtechniques”, Journal of Econometrics, vol. 49, págs. 275-304.
ZELLNER, A. y MIN, C. (1999): “Forecasting turning points in countries' output growth rates: A responseto Milton Friedman”, Journal of Econometrics, vol. 88, págs. 203-206.
P R E D I C C I Ó N D E P U N T O S D E G I R O E N E L C I C L O E C O N Ó M I C O
75