Embed Size (px)
DESCRIPTION
Une présentation concernant l'outil splunk
Citation preview

Présentation Sur Splunk Réalisée par: MR IHSINE Najib Le 20/5/2013

Splunk est considérée comme étant l’une des plus puissante plate-forme d’analyse des données machine, des données que génèrent les machines en grande quantité mais qui sont rarement utilisé de façon efficace.
En effet les données machine (Machine data) sont déjà d’une importance capitale dans le domaine de la technologie et ne cesse de gagner de l’influence dans le monde des affaires (intelligence opérationnel).
Introduction

IntroductionLa meilleure façon de prendre conscience de la puissance ainsi que de la polyvalence de splunk est de se pencher sur les deux scénarios qui suivent :1-le premier étant dans ‘’Data center ’’2-le second étant dans le département marketing

Splunk à la rescousse dans un Datacenter :
Imaginant le cas de figure suivant : il est 2h du matin. Le téléphone sonne, votre patron appelle, pour vous informer que le site web de la compagnie est tombé en panne, et là instantanément un torrent de question vient vous harceler l’esprit .

vous avez déployé splunk au préalable, il suffit juste de le lancer de votre emplacement en se connectant à votre serveur splunk, et d’effectuer des recherches sur vos fichiers log rediriger depuis vos serveurs : web, base de données, firewall, routeurs, etc.
Splunk à la rescousse dans un Datacenter : (suite)

Vous travaillez au sein du service de promotion d’une grande compagnie, La semaine dernière, les gars du Datacenter ont installé un nouveau tableau de bord Splunk qui montre (pour la dernière heure, le jour et semaine) tous les termes de recherche utilisés pour trouver le site web de la société.
Splunk Dans Le Département Marketing:
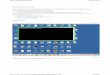
Vue qu’on utilise splunk pour réponde à un certain nombre de questions, qui dépondent principalement de notre contexte professionnel on peut rapidement se rendre compte que cette tache peut se deviser en trois phases distinctes voir le graphe :
Premièrement, identifier les
données qui peuvent répondre à votre
question.
Deuxièmement, transformer les
données en résultats qui
peuvent répondre à vos
question.
Troisièmement, afficher la réponse dans un rapport,
tableau interactif, ou graphique pour la
rendre intelligible à un grand nombre de
gens.
Le fonctionnement de splunk

Le cœur de métier de splunk est de rendre les données machines utile pour les gens.
En effet le gens qui ont créé les systèmes tel que : (Serveur web, load balencers, plateformes de médias sociaux, etc...),ils ont aussi spécifié les informations que ces derniers doivent écrire au sein des fichiers log quand il sont au en train de s’exécutées.
Exemple (d’output dans un fichier log) :
Le fonctionnement de splunk
Action: ticked s:57, m:05, h:10, d:23, mo:03, y:2011Action: ticked s:58, m:05, h:10, d:23, mo:03, y:2011Action: ticked s:59, m:05, h:10, d:23, mo:03, y:2011Action: ticked s:00, m:06, h:10, d:23, mo:03, y:2011

Mais comment splunk conçoit-il les données machines?
-Réponse:
Le fonctionnement de splunk
Splunk divise les données machine brutes en morceaux d'information discrets connu sous le nom ‘’événements’’.
en effet Lorsque vous effectuez une recherche simple, Splunk
récupère lesévénements qui correspondent
à vos termes de recherche.

Le fonctionnement de splunk
Le fonctionnement de splunk
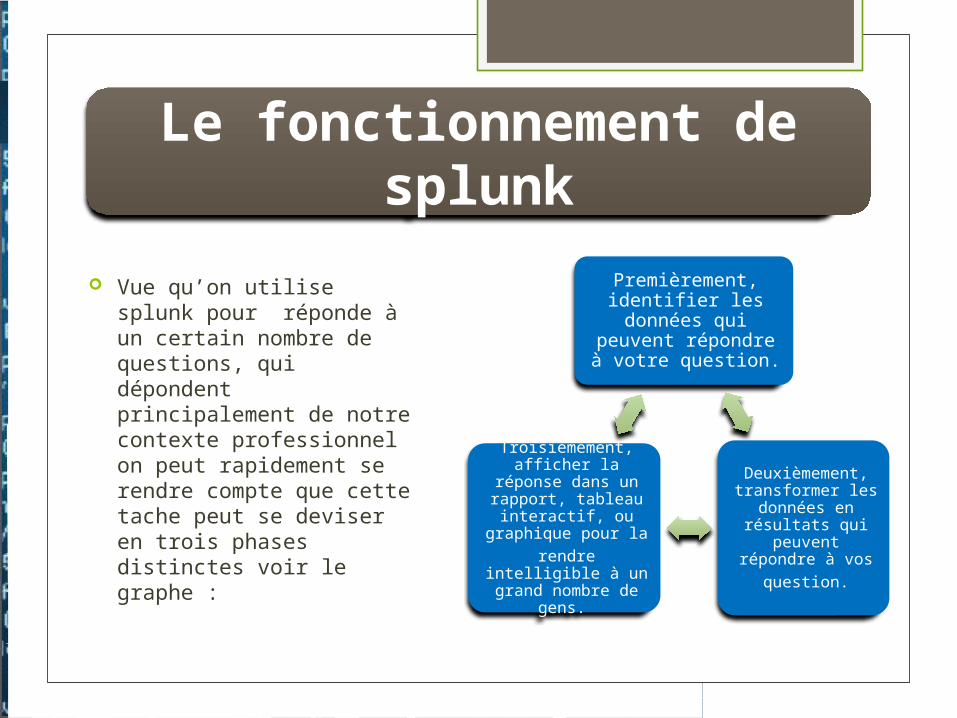
La seule exigence concernant les données machine est le faite qu’elles soient textuel et non pas binaire, par exemple les fichiers images et son sont des exemples courant de données binaires, toutefois certains types de fichiers binaire comme le core dump qui ce produit lorsque un programme crashe peut être convertie en format texte. Splunk offre la possibilité de faire appelle à nos scripts afin de pouvoir réaliser ce type de conversion avant l'indexation des données
Durant l’indexation Splunk peut lire les données à partir de plusieurs sources parmi on site : (les plus commune)
Les fichiers
Le réseau
Les scripts d’entrée
Le fonctionnement de splunk
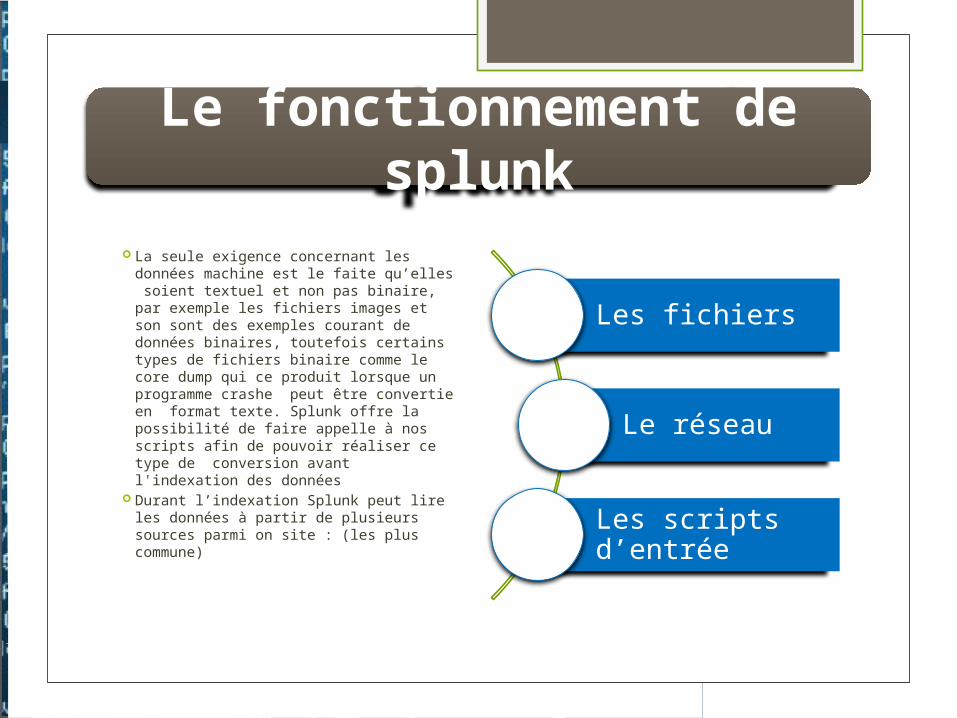
1-Splunk Commence par indexer les données
Ce qui signifie que Splunk collecte les données de différents endroits et les combine puis il les stocke dans un index centralisé, avant les administrateur système devait se logger dans différentes machines afin d’avoir accès au données
2-utilisation des indexes pour optimiser les recherches
L’utilisation des indexes confère à Splunk un grand degré de rapidité lors des recherches de sources de problèmes dans les fichiers log
3-filtrage des résultats
Splunk mais à disposition de l’utilisateur plusieurs outils permettant de filtrer les résultats ce qui implique par voie de conséquence une détection plus rapide de la racine du problème
Comment Splunk traite les données machine au sein d’un Datacenter ?

Le fonctionnement de splunkRemarque :Le Champ Timestamp (_time ) est considéré comme étant spécial dû au fait que les indexeurs l’utilise pour ordonner les évènements , il permet aussi à Splunk de rechercher efficacement des évènements appartenant un intervalle temporelle bien précis .le schéma qui suit montre de façon détaillée le processus d’indexage de Splunk.

Le fonctionnement de splunkLes données que Splunk prend en Input sont appelées les données brut. Splunk les indexe on créant une map de mots basée sur le temps.Ce qu’il faut bien retenir c’est que ce processus ce déroule sans que les données ne soient modifiées .
En effet l’indexe que construit Splunk est similaire aux indexes qui existent au dos des manuels scolaires, et qui pointent vers des pages en utilisant des mots spécifiques .cependant en Splunk les « pages » sont appelés événements
Chaque évènement en Splunk dispose d’au moins quatre champs par défaut et qui sont fournis dans le schéma qui suit :
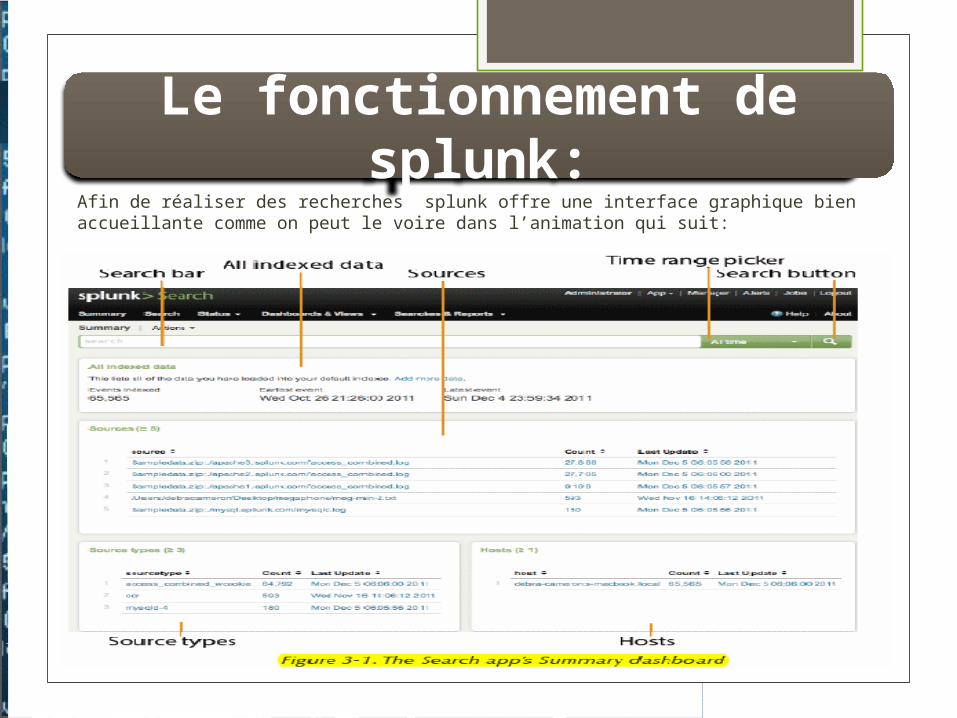
Le fonctionnement de splunk:Afin de réaliser des recherches splunk offre une interface graphique bien accueillante comme on peut le voire dans l’animation qui suit:

SPL : (Search Processing Language)Splunk offre une aide précieuse puisque il permet de tamiser les données provenant de plusieurs indexes de grandes taille pour ne conserver à la fin que les données utiles permettant ainsi de répondre à nos questions que sa soit d’un point de vue technologique (administration réseau ,sécurité informatique ) ou bien d’un point de vue intelligence opérationnelle (exemple : examiner les données utilisateurs de notre afin de déceler quelles sont les tendances futur ).
En effet Splunk offre un outil très performant qui permet de réaliser des recherches d’une précision d’orfèvre, cet outil n’est rien d’autre que le langage SPL.
Définition:SPL ou Search Processing Language est un langage de programmation à usage spécial conçu par Splunk, afin de gérer, la big data généré par un réseau de machine. A L'origine SPL est basé sur Unix Piping et SQL, son champ d'application comprend les données de recherche, de filtrage, de modification, de manipulation, d'insertion et de suppression.
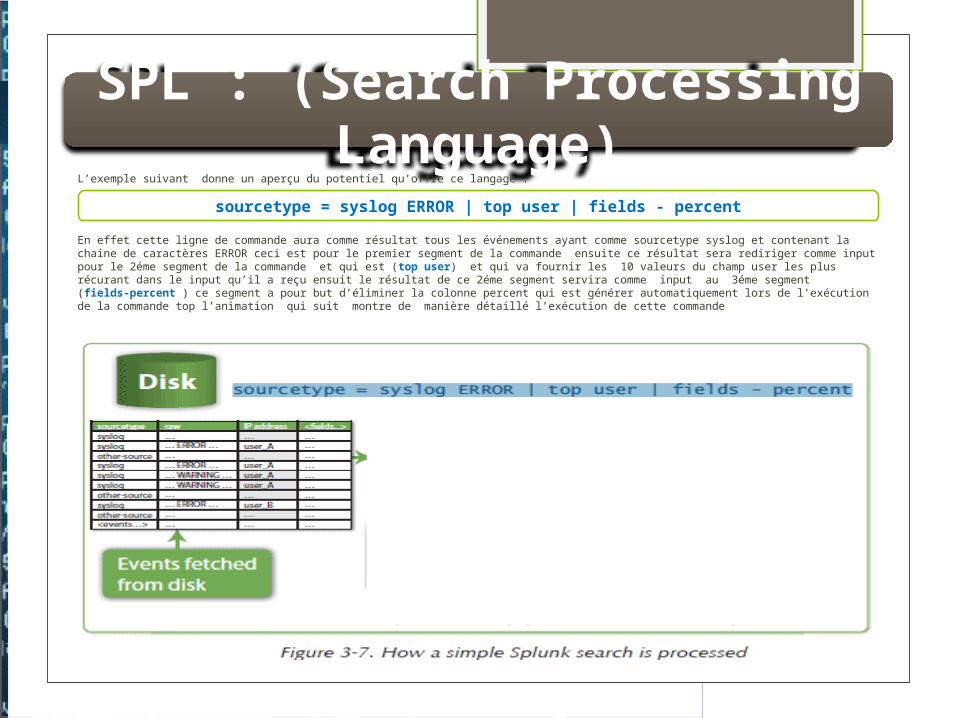
SPL : (Search Processing Language)L’exemple suivant donne un aperçu du potentiel qu’offre ce langage :
En effet cette ligne de commande aura comme résultat tous les événements ayant comme sourcetype syslog et contenant la chaine de caractères ERROR ceci est pour le premier segment de la commande ensuite ce résultat sera rediriger comme input pour le 2éme segment de la commande et qui est (top user) et qui va fournir les 10 valeurs du champ user les plus récurant dans le input qu’il a reçu ensuit le résultat de ce 2éme segment servira comme input au 3éme segment (fields-percent ) ce segment a pour but d’éliminer la colonne percent qui est générer automatiquement lors de l’exécution de la commande top l’animation qui suit montre de manière détaillé l’exécution de cette commande
sourcetype = syslog ERROR | top user | fields - percent
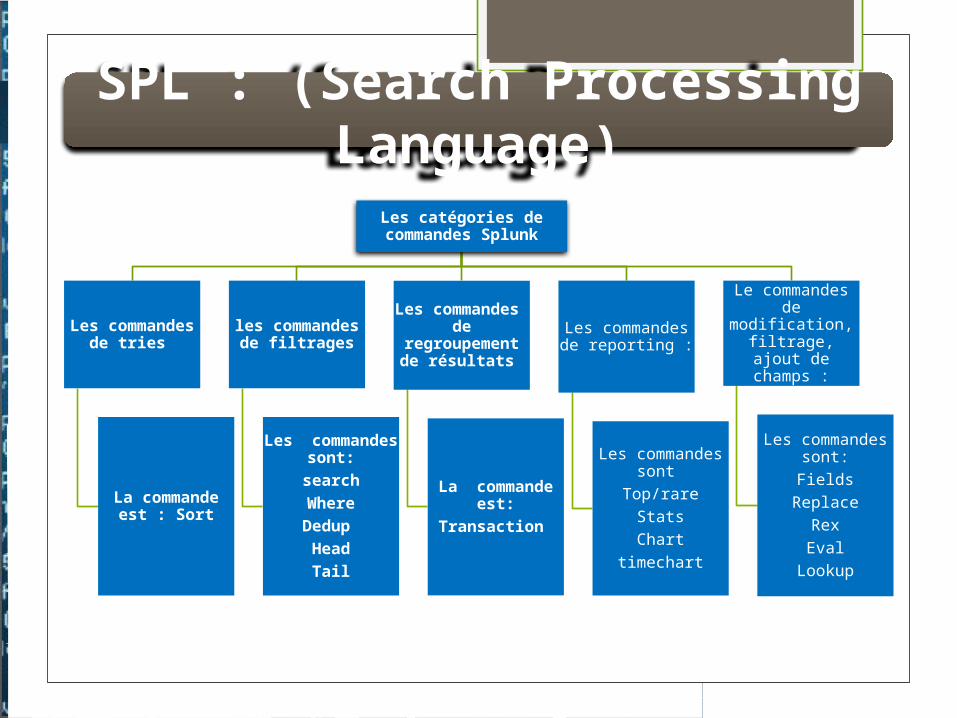
SPL : (Search Processing Language)
Les catégories de commandes Splunk
Les commandes de tries
La commande est : Sort
les commandes de filtrages
Les commandes sont:
searchWhereDedup HeadTail
Les commandes de regroupement de
résultats
La commande est:Transaction
Les commandes de reporting :
Les commandes sont
Top/rareStatsChart
timechart
Le commandes de modification,
filtrage, ajout de champs :
Les commandes sont:Fields
ReplaceRexEval
Lookup
SPL : (Search Processing Language) Explication de l’Arborescence :
1- la commande sort : est une commande ayant pour but d’ordonner les résultats d’une recherche et de limiter de manière optionnel le nombre de résultats.
2- les commandes qui suivent sont des commandes de filtrages en autres termes se sont des commandes qui vont prendre un ensemble d’évènements ou de résultats comme entrée afin qu’ils subissent une opération de filtrage ayant comme objectif de fournir une sortie d’une dimension moindre que celle de l’entrée et qui ne conserve que les informations nécessaire : (search, where, dedup, head, tail).
3-la commande transaction est une commande de type Grouping Results comme le nom du type de la commande l’indique cette dernière a pour but de regrouper les évènements de façon à mettre en lumière des tendances (très apprécié dans le domaine de l’intelligence opérationnel ).
4- les commandes classifier dans la catégorie Reporting sont des commandes dont le cœur de métier est de générer des résumer pour les rapports en prenant comme entrée les résultats de recherche. Parmi ces commandes on site : (top/rare, stats, chart, timechart).
5-les commandes de type modification, filtrage, ajout de champs : ce sont des commandes ayant comme rôle de filtrer (supprimer) certains champs afin de ne se focaliser que sur les champs qui nous intéresse, ou bien modifier ou ajouter des champs pour enrichir nos résultats on site : (fields, replace, rex, eval, lookup).
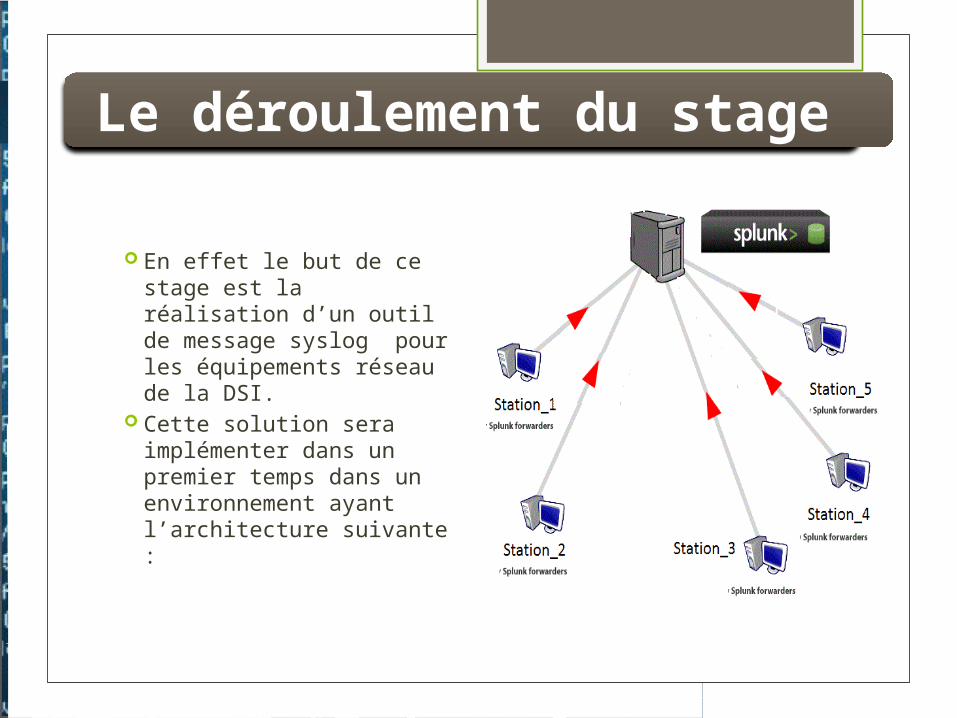
Le déroulement du stage
En effet le but de ce stage est la réalisation d’un outil de message syslog pour les équipements réseau de la DSI.
Cette solution sera implémenter dans un premier temps dans un environnement ayant l’architecture suivante :

Le déroulement du stage La première phase a été d’établir une étude afin de
déterminer les caractéristiques technique de l’environnement hardware sur lequel splunk devrait être déployé, ces derniers sont cité dans ce qui suit:
les caractéristiques Hardware
1-le processeur : une puce Intel d'architecture x86 64bit.2- 2 CPUs 4cores pour chacune d'ente elle soit un total de 8
cores , un minimum de 2.5 GHz pour chacun des cores 3-La mémoire vive : une RAM d'une taille de 8 GB.
4-la carte réseau : une carte de 1 Gb Ethernet , (optionnelle) une deuxième carte réseau Ethernet du même type pour la
gestion du réseau

Le déroulement du stage Effectivement l’environnement matériel qui a été choisi est
le suivant:1-un serveur IBM System x3650 (offrant les caractéristiques technique vue précédemment) 2-Installation de la distribution centos 6.3 64 bits sur ce dernier

Le déroulement du stage Sur le site web de la compagnie splunk : il n’existe aucune procédure d’installation spécifique à une distribution centos, cependant vue que centos est un équivalent open source de RHEL on adoptera la même procédure d’installation spécifiée pour ce dernier :
Pour installer splunk dans le répertoire par défaut /opt/Splunk rpm -i splunk_package_name.rpm
./splunk start --accept-license
./splunk enable boot-start

Les SDK de Splunk sont écrits au-dessus de la APIs REST Splunk. est de nous fournir une large couverture de l'API REST dans un mode spécifique au langage utilisé. Afin de faciliter votre accès à notre moteur de recherche Splunk.
Les différentes SDKs fournis par splunk sont es suivantes:
Possibilité à exploiter
Python
Java
JavaScript
PHP
Ruby
C#

tout ce qu’on vient de cité est intéressant, Cependant qu’elles sont les possibilités qu’offre de telle SDKs pouvant être exploitées afin de répondre au mieux à notre besoin:
Possibilité à exploiter
L’intégration avec d’autres outils de reporting
Se connecter directement à splunk
Intégrer les résultats de recherche de Splunk dans nos applications
Extraire des données pour l'archivage
Construire une interface utilisateur adopter à nos besoins en se basant
sur la pile web existante
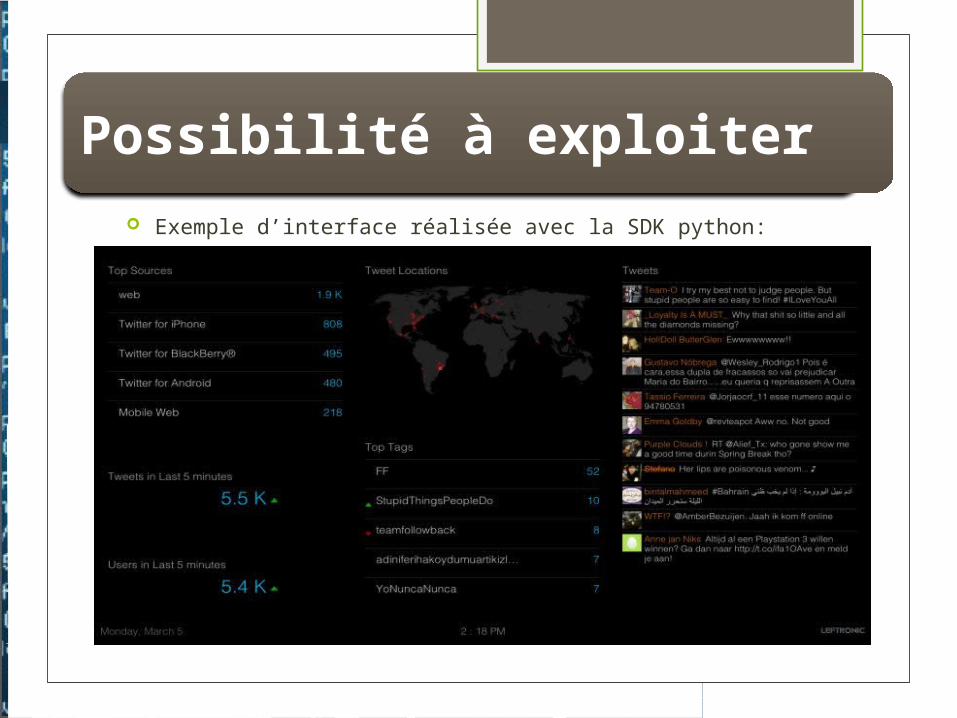
Exemple d’interface réalisée avec la SDK python:
Possibilité à exploiter

fin