Embed Size (px)
Citation preview

Repaso para el segundo parcial
Dr. Pastore, Juan Ignacio Profesor Adjunto.

Algunas Distribuciones Estadísticas Teóricas
Distribución Continuas:
a) Distribución Uniforme
b) Distribución de Exponencial
c) Relación entre la Distribuciones de Poisson y Exponencial.
d) Distribución Normal

Distribución Uniforme
Se dice que la variable aleatoria X se distribuye uniformemente en el intervalo [a,b] si
su función de densidad de probabilidades (f.d.p) está dada por:
Esperanza
Varianza
2
b aE X
2
12
b aV X
1
( ) -
0
si a x bf x b a
en otro casof(x)
1
b a
fdp
x a b

0 si x < a
F(x)= si a x b
1 si x > b
x a
b a
Distribución Uniforme
Si X es una variable aleatoria distribuida uniformemente en el intervalo [a,b] su
función de distribución acumulativa (FDA) está dada por:
x
FDA
a b

f(x)
1
b a
fdp
x x
FDA F(x)
1
a b a b
Distribución Uniforme

0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0
0 1 2 3 4 5 6 7 8
2.0
Se dice que X, que toma todos los valores no negativos, tiene una
distribución exponencial, con parámetro , si su fdp está dada por: 0
- si x 0f(x)
0 si x < 0
xe
(en la distribución de Poisson)
1.0
0.5
Distribución Exponencial

Esta distribución: suele ser el modelo de aquellos fenómenos
aleatorios que miden el tiempo que transcurre entre la ocurrencia de
dos sucesos.
Demostrar las características numéricas de la función exponencial:
2
1 1( ) V(x)=E x
Distribución Exponencial

La FDA está dada por:
1 si x 0F(x)
0 si x<0
xe
F(x)
1
x
Distribución Exponencial
Sea X una v.a distribuida exponencialmente, con parámetro , su
función de distribución acumulativa (FDA) está dada por:
0

La probabilidad de que el elemento falle en una hora (o en un día, o en segundo) no depende del tiempo que lleve funcionando.
( ) ( ) ( )( / )
( ) 1 ( )
P s x s t F s t F sP x s t x s
P x s F s
( )1 1 ( 1)
1 (1 )
s t s as t s s t
s s s
e e e e e e e
e e e
1 ( ) ( )te F t P x t
Propiedad fundamental de la Distribuciones Exponencial
La distribución exponencial no tiene memoria :
P( x< s + t / x> s ) = P( x< t )

Relación entre la Distribuciones de Poisson y Exponencial
La v.a X que es igual a la distancia entre conteos sucesivos de un proceso
de Poisson con media tiene una distribución exponencial con
parámetro :
0 0
Sea X una variable de Poisson que mide el número de ocurrencias de un determinado suceso en un período t. Entonces: La probabilidad de que no haya ocurrencias en el período de tiempo t está dado por:
La variable T : tiempo transcurrido hasta la primera ocurrencia de Poisson en el período t es una variable exponencial de parámetro λ. Entonces la probabilidad de que la variable aleatoria T exceda el tiempo t está dada por
0
00!
t
te t
P X e
0tP T t e P X

: º 1min
.( )
!
30.10.5 ( 2)01 ( 2) 1 ( 0) ( 1
60
1 0,91 0,09
k
X n de partìculas en
eP X k
k
P X P X P X P X
Sea X el número de partículas emitidas por una fuente radioactiva. Si se sabe que
el número esperado de demisiones en una hora es de 30 partículas: ¿Cuál es la
probabilidad de que sean emitidas al menos 2 partículas en un lapso de 1 minuto?
Solución/
Relación entre la Distribuciones de Poisson y Exponencial

Sea X el número de partículas emitidas por una fuente radioactiva. Si se
sabe que el número esperado de demisiones en una hora es de 30
partículas: Cuál es la probabilidad de que el tiempo entre emisiones
sucesivas sea mayor a 3 minutos?
Solución/
0 1.5
: (min) ,
30.3: 3min, 1.5
60
(1.5) .( 3) ( 0) 0.22
0!
T tiempo hasta que ocurre la prox emision
Y partìculas emitidas en
eP T P Y
Relación entre la Distribuciones de Poisson y Exponencial

Sin duda la distribución de
probabilidad continua más
importante, por la frecuencia con
que se encuentra y por sus
aplicaciones teóricas, es la
distribución normal, gaussiana o de
Laplace - Gauss. Fue publicada por
primera vez en 1733 por De Moivre.
A la misma llegaron, de forma
independiente, Laplace (1812) y
Gauss (1809), en relación con la
teoría de los errores de observación
astronómica y física .
Pierre Simon de Laplace (1749-1827)
Karl F. Gauss (1777-1855)
Distribución Normal

Se dice que X que toma todos los valores reales, tiene una distribución normal, si su
fdp está dada por:
21
21f(x) con - < x <
2
x
e
Distribución Normal
2( ) ( )E x y V x
La función depende de únicamente de dos parámetros, μ y σ, su media y
desviación estándar, respectivamente. Una vez que se especifican μ y σ, la
curva normal queda determinada por completo.

Distribución Normal: Principales Características:
1.La función tiene un máximo en x = .
2.La curva es simétrica alrededor del eje vertical x=μ, donde coinciden la
mediana (Me) y la moda (Mo ).
3.Los puntos de inflexión tienen como abscisas los valores en x=μ ± σ, es
cóncava hacia abajo si μ-σ<X< μ+σ, y es cóncava hacia arriba en cualquier
otro punto.
4.La curva normal se aproxima al eje horizontal de manera asintótica
conforme nos alejamos de la media en cualquier dirección, es decir Para x
tendiendo a , el límite f(x) =0.
5.El área total bajo la curva y sobre el eje horizontal es igual a 1.
6.Los parámetros μ y σ son realmente la media y la desviación estándar de
la distribución normal.

+ - +
Puntos de
inflexión
=Mo=Me
Distribución Normal: Principales Características:

Distribución normal con =0 para varios valores
0
0.4
0.8
1.2
1.6
-2.50 -1.50 -0.50 0.50 1.50 2.50
0.25
0.5
1
p(x)

20 30 40 50 60 70 80 90 100 110 120
5 5
10
Distribución normal con distintas medias y dispersión
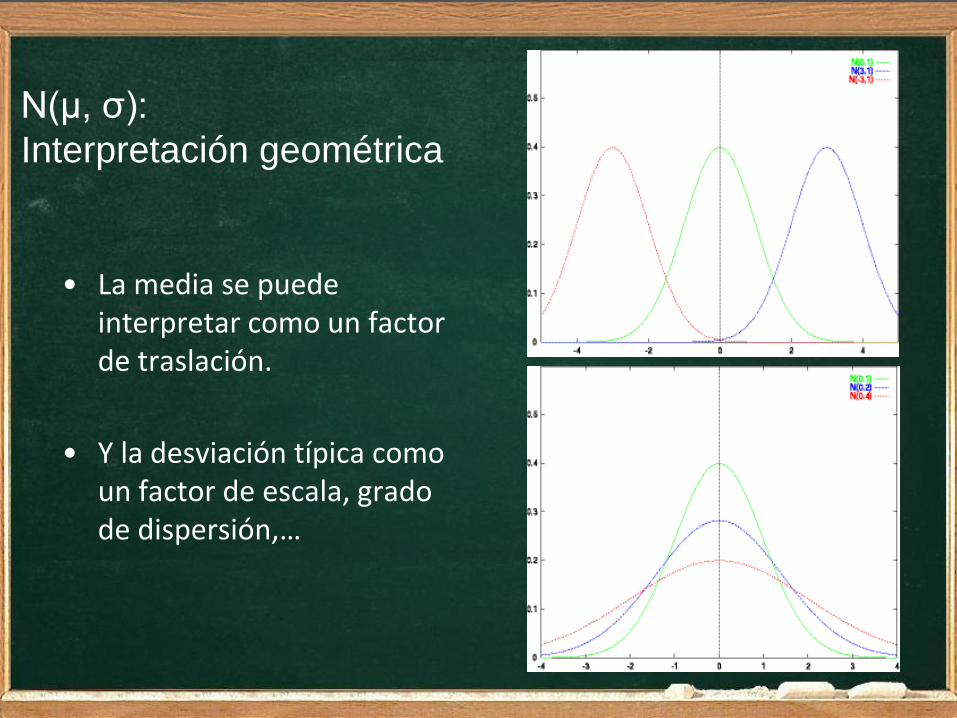
N(μ, σ):
Interpretación geométrica
• La media se puede interpretar como un factor de traslación.
• Y la desviación típica como un factor de escala, grado de dispersión,…

Estandarización de la Distribución Normal
Dada la dificultad que se encuentra al resolver las integrales de una
funciones densidades de probabilidades asociada a una v.a. normal, es
necesario contar con una tabulación de las áreas de la curva normal para
una referencia rápida. Sin embargo, sería una tarea difícil intentar
establecer tablas separadas para cada valor de μ y σ.
Afortunadamente, podemos transformar todas las observaciones de
cualquier v.a. normal X a un nuevo conjunto de observaciones de una
variable normal Z con media 0 y desviación estándar 1.
2Si X N , Z= , Z N 0,1
x

2
21
2
tz
P Z z z e dt
Sea X una v.a su función de distribución acumulativa (FDA)
está dada por: 0,1X N
P(Z<z)
Estandarización de la Distribución Normal

P P
a x ba x b
P
a b b aZ
2Si X N , y Z= N 0,1
xZ
Estandarización de la Distribución Normal

2Si X N ,
P P Px x x
1
2 1
Cálculo de la probabilidad de desviación prefijada. P x

Regla de las tres sigmas
Es un caso particular de desviación prefijada.
Si = 3 P 3 P 3 3 P 3 3x x x
3 33 3
3 1 3 2. 3 1 0,9974
Esto significa que el suceso 3x
Es prácticamente un suceso cierto, o que el suceso contrario es poco probable y
puede considerarse prácticamente imposible.

3 0,9974P x
Regla de las tres sigmas: Su esencia.
Si una variable aleatoria está distribuida normalmente, entonces la desviación respecto de la esperanza matemática, en valor absoluto, no es mayor que el triple de la dispersión.

Para ilustrar el uso de las Tablas, calculemos la probabilidad de que Z sea menor
que 1.64. Primero localizamos un valor de z igual a 1.6 en la primera columna
(izquierda), después nos “movemos” a lo largo de la fila hasta encontrar la columna
correspondiente a 0.04, donde leemos 0.9594. Por lo tanto P(Z<1.64)=0.9495.

Para encontrar un valor de z que corresponda a una probabilidad dada, el proceso se
invierte. Po ejemplo, el valor de z que deja un área de 0.9 bajo la curva a la izquierda
de z es de 1.28.

LEY DE LOS GRANDES NÚMEROS
Cuando el número de repeticiones de un experimento aleatorio aumenta, la
frecuencia relativa del suceso A converge en sentido probabilístico a la
probabilidad teórica.
Ley de los grandes números
( ) para Af P A n

Desigualdad de Tchebyshev
Esta desigualdad brinda un medio para entender cómo la varianza mide la
variabilidad alrededor de la esperanza matemática de la variable.
Si la esperanza y la varianza de la variable X son finitas, para cualquier número
positivo k, la probabilidad de que la variable aleatoria X esté en el intervalo
2
1; es mayor o igual que 1- es decirk k
k
2
11-P X k
k

Teorema de Bernoulli Generalizado
En toda sucesión de pruebas de Bernoulli, la frecuencia relativa converge en sentido probabilístico a p.
1 0lím An
P f p
0 0lim An
P f p

Población y Muestra
Una variable aleatoria X con E(x) = µ y V(x) =σ2 puede pensarse como cualquier característica medible de los individuos de una población. El conjunto de todas las mediciones de dicha variable es la Población o Universo.
1 2 3, , ,..... Nx x x x
Muestra es un subconjunto de la población al que tenemos acceso y sobre el
que realmente hacemos las mediciones

Estas variables forman una muestra aleatoria de tamaño n si:
•Las Xi son variables aleatorias independientes.
•Cada variable Xi tiene la misma distribución de probabilidad que la
distribución de la población con su misma esperanza µ y varianza σ2., es
decir E(xi) = µ y V(xi) = σ2
Población y Muestra

Teorema de Bernoulli Generalizado
Dada una m.a.s., es decir: una sucesión 1 2 3, , ,..... nx x x x
dos a dos independientes, con una misma distribución de probabilidad y con esperanza y varianza entonces
0
El límite, en probabilidad, de la media muestral para n
es igual a la media de la población de la que se extrajo la muestra
1 0n n
P x ó P xlím lím
2

Suma de Variables Aleatorias
El teorema afirma que, con ciertas restricciones leves, la distribución de la suma de un gran número de variables aleatorias, tiene aproximadamente una distribución normal.
El valor de este teorema es que no requiere condiciones para las distribuciones de las
variables aleatorias individuales que se suman para n tendiendo a infinito.

Suma de Variables Aleatorias
entonces, bajo ciertas condiciones, la función de densidad de probabilidad de la variable aleatoria X se distribuye aproximadamente en forma norma, para n tendiendo a infinito.
1
( )n
i
i
E X
2
1
( )n
i
i
X
Observación:Esta generalización es válida cuando las variables aleatorias
individuales sólo hacen una contribución relativamente pequeña a la suma
total
1
2
1
~ 0,1
n
i
i
n
i
i
X
z N
1
n
i
i
X x
1 2 3, , ,..... nx x x x
Si X es la suma de un gran número de variables aleatorias independientes
Es decir, entonces
donde

En particular, si las xi están idénticamente distribuidas, es decir, tienen la
misma media y la misma varianza de la población de la que fueron extraídas
1 1
( ) .
i
n n
i i
i i
E x
E X E x E x n
2
2
1 1
( ) .
i
n n
i i
i i
V x
V X V x V x n
Entonces el teorema afirma que la fdp de la variable S se distribuye normalmente
Luego
~ 0,1
.
X nz N
n
Suma de Variables Aleatorias

Parámetro: Es una cantidad numérica calculada sobre la población.
Estimación: Es el valor numérico que toma un estimador.
Estadístico o estimador : Es cualquier operación que se hace con la
muestra. Por eso es una función de las observaciones contenidas en una
muestra.
Ejemplos: la media muestral, la proporción muestral y la varianza muestral.
Los estimadores son variables aleatorias, por lo tanto tienen su distribución
de probabilidades que se conocen como distribuciones de muestreo.
Parámetros y Estimadores

Estimación puntual: Es un número calculado con los datos de la muestra, del cual se
espera que estime un parámetro poblacional.
Si X es una variable aleatoria con distribución de probabilidades f(x), caracterizada por
el parámetro desconocido y si es una muestra aleatoria de tamaño
n, entonces 1 2, ,....., nx x x
1 2ˆ ( , ,..... )nh x x x
Es un estimador puntual de
Estimación de Parámetros

• Propiedad de insesgadura:
• Propiedad de eficiencia
• Propiedad de suficiencia: Un estimador es suficiente si utiliza toda la información de la muestra.
Propiedades de los Estimadores

Debemos hallar los estadísticos L y U tales que
( ) 1P L U
Coeficiente de confianza
Intervalo de confianza para la media poblacional conociendo la 2
/2 /2( ) 1P z Z z
2
,X Nn
0,1
xz N
n
Estimación por intervalo
Dada una m.a.s., extraída de una población con distribución normal. 2,X N
/2 /2x z x z
n n

Nivel de confianza y precisión de la estimación
Cuanto más alto es el nivel de confianza, mayor amplitud tiene el intervalo y menor es la precisión de la estimación.
Elección del tamaño de la muestra
La precisión del intervalo de confianza es el radio del intervalo
2
zn
Esto significa que al usar la media muestral para estimar la media poblacional , el
error que se comete es:
2
x zn

Sean variables aleatorias distribuidas normal e independientemente
con media 0 y varianza 1. Entonces la variable aleatoria:
2 2 2 2 2
1 2 3 ..... nx x x x
Tiene distribución Ji-Cuadrado con n grados de libertad. Con media y varianza
2 2n n
Distribución Ji-cuadrado
1 2 3, , ,..... nx x x x

2
2
12 2
2
Función de densidadde
1( ) . . 0
.22
v x
vf x x e x
v
Es no negativa y asimétrica hacia la derecha. Si n aumenta, se aproxima a la normal
Distribución Ji-cuadrado

Los puntos porcentuales de la distribución se dan en la tabla correspondiente
22,
2 2
,n
n nP f x dx
Distribución Ji-cuadrado

2
2 2
12
1n
n S
2SSi es la varianza de una muestra aleatoria de tamaño n tomada de una población
normal que tiene una varianza 2
Entonces la variable aleatoria definida por
Se distribuye como
2
1n
Distribución muestral de la varianza

Extremos del intervalo para la varianza poblacional
2 2 2
1 /2; 1 /2; 11
n nP
2
2 2
1 /2; 1 /2; 12
11
n n
n SP
2 2
2
2 2
/2; 1 1 /2; 1
1 11
n n
n S n SP
2 2
2
2 2
/2; 1 1 /2; 1
1 1
n n
n S n S

Si Z es una variable aleatoria con distribución N(0,1), V una variable aleatoria
con distribución Ji-Cuadrado con n grados de libertad y además Z y V son
variables aleatorias independientes, entonces la variable aleatoria definida
por:
Z
TV
n
Tiene una distribución t de Student con n gradis de libertad con la siguiente fdp:
Los puntos porcentuales están dados por la tabla correspondiente
1 /22
1 / 2 1( ) .
/ 1.2
n
nf t t
n t nn
Distribución t de Student

,
;n
n tP T t f t dt
Distribución de la media muestral con varianza poblacional desconocida
•Si n >30, podemos utilizar la distribución normal y S en reemplazo de
•Si n<30 y proviene de una distribución normal, entonces
1
/n
xT t
S n
Distribución t de Student
Los puntos porcentuales están dados por la tabla correspondiente

Intervalo de confianza para la media con varianza
poblacional desconocida y n<30
Si la población base es normal, la varianza es desconocida y el tamaño de la
muestra menor que 30, la media muestral tiene distribución T con n-1 grados de
libertad
/2, 1 /2, 1( ) 1
n nP t T t
/2, 1 /2, 1( ) 1
n n
xP t t
S
n
/2, 1 /2, 1( ) 1
n n
S SP x t x t
n n
/2, 1 /2, 1n n
S Sx t x t
n n

Intervalo de confianza sobre una proporción
Si se ha tomado una muestra aleatoria de tamaño n de una gran población (posiblemente infinita), donde X observaciones en esta muestra pertenecen a la clase de interés.
ˆX
pn
Es el estimador puntual de la proporción poblacional.
X una v.a. binomial, de parámetros n y p
La distribución de muestreo de es aproximadamente normal con
esperanza p y varianza con p no cerca de 0 y 1.
p̂ 1p p
n

Una prueba de hipótesis es una técnica de Inferencia Estadística que permite
comprobar si la información que proporciona una muestra observada
concuerda (o no) con la hipótesis estadística formulada y, por lo tanto, decidir si
se debe rechazar o no rechazar dicha hipótesis.
Prueba de Hipótesis

Hipótesis Estadística es cualquier afirmación o conjetura sobre una o varias características
de interés de la población.
Paramétrica
No Paramétrica
:
Es una afirmación sobre
alguna característica
estadística de la población
en estudio.
Por ejemplo, las
observaciones son
independientes, la
distribución de la variable en
estudio es normal, la
distribución es simétrica, etc.
Es una afirmación sobre los valores de
los parámetros poblacionales
desconocidos.
Simple
la hipótesis
asigna valores
únicos a los
parámetros
Compuesta
la hipótesis
asigna un rango
de valores a los
parámetros

Identificación de las Hipótesis Estadísticas Paramétricas
Hipótesis nula Ho – Se plantea con el parámetro de
interés usando alguno de los símbolos
– La probabilidad de rechazar Ho
es muy baja, y se llama nivel de significación porque Ho es la hipótesis que se considera
cierta.
Hipótesis Alternativa H1
– Es contraria a la hipótesis nula.
(Niega a H0). Se plantea usando
según el caso respectivo al planteo
de Ho. – Está muy relacionada con la
hipótesis de investigación, es coherente con los resultados
obtenidos en la muestra.
, , , >,<

• Cualquier decisión estará basada sobre información parcial de una
población, contenida en una muestra, por lo que habrá siempre una posibilidad de una decisión incorrecta.
• La siguiente tabla resume cuatro posibles situaciones que pueden surgir en un test de hipótesis.
Verdadero estado de la población
Decisión posible H0 es cierta H1 es cierta
Se rechazo H0 Error de tipo I Decisión correcta
No se rechaza H0
Decisión correcta Error de tipo II
Tipos de error

Esquema para realizar una prueba de hipótesis
Etapas: 1) Enunciado de la hipótesis nula y alternativa 2) Selección del estadístico de prueba (Considerar el parámetro
poblacional utilizado en 1) y los datos del problema). 3)Gráfico de la distribución del estadístico de prueba para la
determinación de la región crítica con el alfa dado y la búsqueda en tabla del valor crítico.
4) Cálculo del valor observado a partir del estadístico. 5) Comparación de valores. 6) Exposición de las conclusiones

La posición de la región crítica depende de la hipótesis alternativa
Unilateral Unilateral
Bilateral
H1: <20 H1: >20
H1: 20
20
20 20
Prueba de hipótesis: unilateral y bilateral

Prueba para la media poblacional no se conoce la dispersión poblacional
Si la muestra proviene de una población normal
Cuando se desconoce σ, se observa el tamaño de la muestra n
Si n <30 Si n ≥30
La media muestral se distribuye normalmente, porque S es una
mejor estimación de σ
1~
/n
xT t
S n
xz
S
n
La media muestral tiene distribución T, porque S
no es una buena estimación de σ

Prueba para la comparación de medias
Cuando se conocen las varianzas, La diferencia de medias muestrales se distribuye normalmente. Se usa el estadístico Z
Cuando se desconocen las varianzas pero son iguales, se observa el tamaño de cada muestra indep, que provienen de poblaciones normales
Si n1 +n2 -2 <30 Si n1 +n2 -2 ≥30
La diferencia de medias muestrales se distribuye normalmente. Se usa el estadístico Z
1 2 1 2
2 2
1 2
1 2
ob
x xz
n n
1 2 1 2
2 2
1 1 2 2
1 2 1 2
1 1 1 1
2
ob
x xt
n S n S
n n n n
La diferencia de medias muestrales se distribuye según T. Se usa el estadístico T
1 2 1 2
2 2
1 2
1 2
ob
x xz
S S
n n

Análisis de Regresión y Correlación Lineal
Si se trata de predecir o explicar el comportamiento de una variable Y, a la que se denomina dependiente o variable respuesta, en función de otra variable X denominada independiente o regresora, Y =f(X), estamos frente a un problema de análisis de regresión simple; pero si deseamos investigar el grado de asociación entre las variables X e Y estamos frente a un problema de análisis de correlación. Es decir, Nos va a interesar estudiar la relación que existen entre ellas y de qué forma se asocian. Para esto analizaremos dos técnicas: la de regresión y la de correlación.
Frecuentemente se nos formulan las siguientes preguntas: ¿El peso de las personas está relacionado con la estatura? ¿El peso y la presión arterial se relacionan? ¿La presión de una masa de gas depende de su volumen y de su temperatura?, etc.

Tipos de relación entre variables Dos variables pueden estar relacionadas por una dependencia funcional, por una dependencia estadística o pueden ser independientes. Raramente se determina una dependencia funcional rigurosa ya que ambas variables o una de ellas, están expuestas a factores aleatorios, surge entonces una dependencia estadística. La dependencia se llama estadística cuando la variación de una de las variables da lugar a la alteración de la distribución de la otra. La dependencia estadística se manifiesta en que, al variar una de las variables se altera el valor medio de la otra, en este caso se llama dependencia de correlación. Estadísticamente nos interesa analizar la relación entre dos o más variables, siempre que se tenga un indicio de que entre ellas existe por lo menos cierto grado de dependencia o asociación. Lo importante es medir y expresar funcionalmente esta relación mediante una función o modelo matemático.

Análisis de regresión simple entre dos variables X e Y Consideremos el problema de tratar de hallar la relación funcional existente entre dos variables aleatorias X e Y. Supongamos que en n experimentos las variables asumieron pares de valores {(xi,yi):i=1,…,n}, podemos inicialmente observar su comportamiento graficando dichos pares de valores sobre un sistema de coordenadas ortogonales. Dicho gráfico, llamado diagrama de dispersión a menudo permite discernir si existe alguna tendencia hacia algún tipo de interrelación entre ambas variables, y, si es posible, la naturaleza de dicho tipo de interrelación.

XY1x1y2x 2y3x 3ynx ny
Correlación positiva Correlación negativa
No hay correlación
X X
X X
Y Y
Y Y
Diagrama de Dispersión
Observación: Solo nos ocuparemos del caso lineal en esta unidad.

Ajuste de una función de regresión: Método de mínimos cuadrados Ajustar una función de regresión significa encontrar, la función que exprese con mayor precisión la relación entre las variables X e Y. Gráficamente será aquella función que mejor se adecue a la nube de puntos. En este sentido, es recomendable como primer paso construir el diagrama de dispersión o diagrama de nube de puntos para, luego de analizar su forma, decidir por el tipo de función matemática (modelo) o la ecuación de regresión que exprese la relación entre las variables X e Y. Luego, se estiman los parámetros del modelo, para lo cual existen varios métodos, siendo el más usado el método de mínimos cuadrados.
El problema queda ahora reducido a encontrar los coeficientes de un tipo de curva C que hagan mínimo el valor D. Una vez determinados estos valores, a la curva correspondiente se la llamará curva de regresión de Y sobre X.
2 2 2 2
1 2 1n nD d d d d

Análisis de regresión lineal simple Es frecuente suponer que existe entre las variables observadas una relación proximadamente lineal:
i iy ax b
La recta y=ax+bxes una recta de regresión. El parámetro a es la pendiente de la recta e indica cómo cambia la variable respuesta o dependiente cuando el incremento de x es una unidad. El parámetro b es el término independiente de la recta e indica el valor de Y cuando X = 0.
Problema estadístico: Estimar los parámetros a y b a partir de los datos , de una muestra.

Determinación de las rectas de regresión por el método e mínimos cuadrados
y ax b yxa
donde
2
*
i i
i
D y y
2 2
*
i i yx i i
i i
D y y x b y
1
2
1
2 00
2 00
n
yx i i i
i i i
ni i yx i yx i
yx i i
i
DDX b y x
y bn x
x y x xDDX b y
bb
1 1 1
2
2
1 1
n n n
i i i i
i i ixy
n n
i i
i i
n x y x y
n x x
1 1
n n
i i
i iyx
y x
bn n
Resolviendo el sistema obtenemos:
,
Ecuación muestral de regresión de Y en X
yxxy x b

INFERENCIA EN REGRESION La recta de regresión nos permite, basándonos en los datos de la muestra, estimar un valor de la variable Y, correspondiente a un valor dado xi de la variable X. Para ello es suficiente reemplazar el valor de xi en la recta de regresión y encontrar el correspondiente valor estimado. La obtención de los coeficientes de la recta de regresión muestral puede considerarse también como un proceso de estimación puntual de los coeficientes poblacionales.

X: representa el tiempo de recalentamiento
Y: los espesores de óxido de cierta pieza
X
(min)
20 30 40 60 70 90 100 120 150 180
Y
(Ang)
3,5 7,4 7,1 15,6 11,1 14,9 23,5 27,1 22,1 32,9
18469i ix y 860ix 165,2iy
2 98800ix 0,17 1,76 0,17 1,76yx xa y x
Ejemplo: Determinar la recta de regresión lineal
yxxy x b
1 1 1
2
2
1 1
n n n
i i i i
i i ixy
n n
i i
i i
n x y x y
n x x
1 1
n n
i i
i i
y x
bn n

Coeficiente de correlación de Pearson
LA COVARIANZA COMO MEDIDA DE ASOCIACIÓN LINEAL Definiremos como covarianza de dos variables X e Y, y denotaremos por SXY, el estadístico que nos permite analizar la variación conjunta de dos variables. Viene dado por la siguiente expresión: Esto nos lleva a utilizar la covarianza como una medida de la asociación lineal entre las variables, de modo que si ésta es positiva, nos indica una relación directa entre ellas y si es negativa, nos indica una relación inversa. Si las variables son independientes, entonces la covarianza es aproximadamente 0.
,i i
XY
x x y yCov X Y S
n

EL COEFICIENTE DE CORRELACIÓN LINEAL Algunas veces es deseable tener un indicador del grado de intensidad o fuerza de la relación lineal entre dos variables X e Y que sea independiente de sus respectivas escalas de medición. A este indicador se le denomina coeficiente de correlación lineal entre X e Y. El estadígrafo comúnmente utilizado se llama coeficiente de correlación del producto momento de Pearson. Definición. Sea (X, Y) una variable aleatoria bidimensional, definimos r el coeficiente de correlación muestral entre X e Y como sigue:
2 2 2 2
,i i
X Yi i
x x y y Cov X Yr
x x y y
x
xy
y
rNotar que si σx=σy
xyr

INTERPRETACIÓN El coeficiente de correlación lineal de Pearson (r): -Está acotado entre -1 y 1. -Un valor positivo se interpreta como indicador de una relación directa: A medida que aumentan los valores de una variable aumentan los valores de la otra. -Un valor negativo se interpreta como indicador de una relación inversa : A medida que aumentan los valores de una variable disminuyen los valores de la otra. -El valor absoluto se interpreta como el grado de relación lineal existente entre las variables, que será mayor cuanto más cercano sea a 1. -Si el valor del coeficiente de correlación muestral, en valor absoluto, es mayor de 0,93 se considera buena la estimación que se realiza con la recta de regresión.
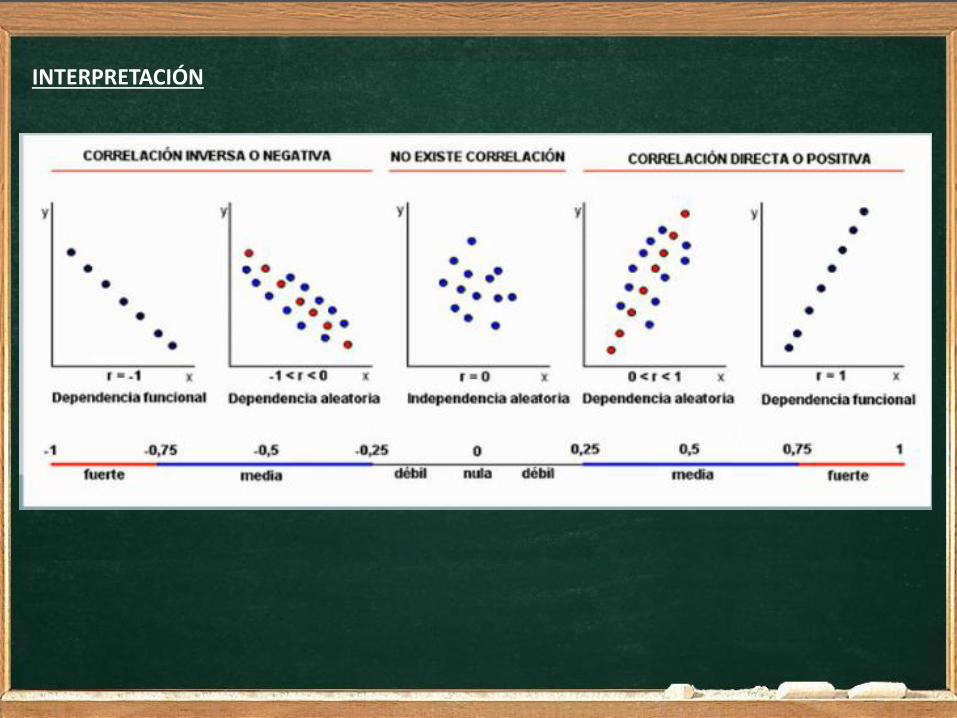
INTERPRETACIÓN


























