Embed Size (px)
Citation preview

UNIVERSITE DE LAUSANNE
ECOLE DES HAUTES ETUDES COMMERCIALES
Sécurité des biens dans une entreprise de grande distribution :
Méthodologie et conception d’un système à base de
connaissances pour la formation et la gestion
Mémoire présenté par Paoly Philippe
en vue de l’obtention du
Diplôme postgrade en informatique et organisation
Année académique 1999-2000
devant le jury composé de :
Professeur A.R. Probst, directeur du mémoire
Marcel Giller, chef sécurité auprès de COOP Vaud Chablais valaisan
CONFIDENTIEL

Paoly Philippe Diplôme postgrade en informatique et organisation Page 2/80
Année académique 1999-2000
Table des matières
Partie I – Introduction
1 - Définition du sujet………………………………………………………………. Page 4
2 - L’entreprise……………………………………………………………………… Page 6
3 - Confidentialité, contraintes et cadre de travail…………………………………. Page 8
4 – Contexte………………………………………………………………………… Page 10
5 - Hypothèses et postulats…………………………………………………………. Page 12
6 - Politique de l’entreprise………………………………………………………… Page 13
Partie II – Méthodologie
7 - Importance d’une méthodologie……………………………………………..….. Page 14
8 - Définition d’une méthodologie…………………………………………………. Page 14
Partie III – Méta connaissances
9 - Besoins de connaissances………………………………………………………. Page 16
10 - Acquisition de connaissances…………………………………………………. Page 23
11 - Choix d’une stratégie de gestion des connaissances………………………….. Page 25
12 - Expression des connaissances………………………………………………… Page 27
Partie IV – Conception et modélisation du business
13 - Outil de modélisation………………………………………………………….. Page 37
14 - Diagramme de classe………………………………………………………….. Page 39
15 - Use case……………………………………………………………………….. Page 40
16 – Séquences…………………………………………………………………….. Page 42
17 - Diagramme de composant……………………………………………………. Page 43
18 - Diagramme de déploiement………………………………………………….. Page 44

Paoly Philippe Diplôme postgrade en informatique et organisation Page 3/80
Année académique 1999-2000
Partie V – Moteur d’inférence
19 - Définition des besoins d’inférence……………………………………………. Page 45
20 - Choix des moteurs d’inférence……………………………………………….. Page 47
21 - Modélisation des moteurs d’inférence………………………………………... Page 48
Partie VI – Le prototype
22 - Choix des outils de développement…………………………………………... Page 56
23 - Limites du développement…………………………………………………… Page 56
24 - Fonctionnalités de l’application……………………………………………… Page 57
25 – Modélisation Entité-Association et relationnelle……………………………. Page 58
26 - Implémentation des moteurs d’inférences……………………………………. Page 61
27 - Définition de l’interface………………………………………………………. Page 62
Partie VII – Conclusion
28 - Critiques et difficultés………………………………………………………… Page 72
29 - Proposition d’améliorations……...…………………………………………… Page 73
30 - Conclusion générale………………………………………………………….. Page 76
31 – Remerciements………………………………………………………………. Page 76
32 - Bibliographie et références…………………………………………………… Page 77
Partie VIII – Annexes …………………………………………………………… Page 78

Paoly Philippe Diplôme postgrade en informatique et organisation Page 4/80
Année académique 1999-2000
Partie I – Introduction
1. Définition du sujet
La gestion des connaissances est un problème important permettant la capitalisation et la valorisation de
connaissances et de compétences [Dieng 00]. De plus, apprendre c’est trouver une réponse à une
question préalablement posée, mais aussi mettre en pratique le savoir acquis [HBR 00]. Ceci étant dit,
intéressons-nous au sujet même du présent mémoire.
« Sécurité des biens dans une entreprise de distribution : méthodologie et conception d’un
système à base de connaissances1 pour la formation et la gestion ». Ce titre recouvre divers
éléments qui se doivent d’être précisés. La sécurité des biens recouvre l’ensemble des atteintes à la
propriété. Nous verrons dans les chapitres qui suivent que cette notion sera limitée d’une part
géographiquement, d’autre part fonctionnellement.
Par méthodologie, nous entendons la définition d’une méthode de travail, méthode qui se veut
généraliste, en ce sens qu’elle doit être capable de devenir un pattern2 et donc être appliquée à d’autres
cas de modélisation d’un système à base de connaissances notamment dans un rôle « d’aide mémoire »,
et s’appliquer de manière inchangée à la conceptualisation de systèmes équivalents à celui qui est
justement le sujet du présent travail.
La conception sous-entend la création d’un modèle théorique mais également la concrétisation de ce
modèle au travers d’un prototype d’application. La réalisation d’un prototype signifie donc qu’il s’agit
de l’implémentation des diverses fonctionnalités définies. L’application ainsi réalisée n’a pas l’ambition
de la perfection, mais se veut être une illustration du domaine du possible et montrer, sous les
contraintes imposées naturellement comme le temps par exemple, les difficultés qui peuvent se présenter
lors d’un travail équivalent.
Concernant la gestion et la formation, ces termes ont une portée interne à l’entreprise. Le chapitre
concernant les hypothèses et postulats définit les objectifs principaux et permettra d’éclaircir ces deux
concepts. En terme de gestion, nous verrons qu’il s’agit moins d’une gestion opérationnelle et précise
1 Par connaissances, nous entendons le savoir et l’expérience 2 Modèle générique réutilisable lors de travaux équivalents

Paoly Philippe Diplôme postgrade en informatique et organisation Page 5/80
Année académique 1999-2000
qu’une gestion d’indices offrant des « directions » ou des suggestions. Sur le plan de la formation, celle-
ci s’adresse aux divers intervenants faisant partie du personnel de l’entreprise. A ce propos précisons
encore que le présent mémoire est réalisé en collaboration avec COOP Vaud-Chablais valaisan.
En résumé, l’objectif est de concevoir un système de gestion des connaissances, de présenter une
méthodologie et de la suivre dans notre développement, puis pour terminer, de réaliser le prototype
d’une application informatique reflétant le système conçu.
Afin d’aider le lecteur à suivre de manière optimale les pages qui suivent, je crois nécessaire de
présenter dès le départ, de manière succincte, l’approche utilisée.
L’idée de base est de créer un Case-Based Reasoning3 (CBR). Ceci suppose trois éléments :
• Trouver les données essentielles d’un cas
• Trouver comment exprimer ces données
• Trouver comment exploiter ces données
La partie III tente de définir les données nécessaires et comment les exprimer. La partie V tente de
montrer comment exploiter ces données.
La partie IV est importante. Elle permet deux choses essentielles :
• D’une part de se faire une idée du business, du « travail » de la sécurité et d’en avoir une bonne
compréhension
• D’autre part de situer notre système dans ce cadre d’activité.
Ces deux éléments permettent non seulement de voir plus facilement les besoins d’informations (et donc
influe sur la partie V), mais également de cerner les objectifs et contraintes de notre prototype (et donc
influe sur la partie VI).
3 Raisonnement à partir d’une base de cas

Paoly Philippe Diplôme postgrade en informatique et organisation Page 6/80
Année académique 1999-2000
2. L’entreprise
COOP Vaud Chablais valaisan est une des coopératives du groupe COOP4. Chaque coopérative est
une unité indépendante et la coordination de toutes les coopératives est assurée par COOP Suisse. En
août 1999, l’ensemble des coopératives a décidé de fusionner en une seule unité : COOPForte, fusion
qui deviendra opérationnelle en 2001. Le présent travail prend donc place dans un environnement en
mutation, sans pour autant remettre en cause la problématique générale. Cependant, il est important de
préciser que les chiffres qui suivent ainsi que les organigrammes ont une réalité qui est sur le point de
disparaître, d’être modifiée ou de perdre en représentativité, puisqu’ils se basent sur l’entreprise COOP
Vaud Chablais valaisan, entreprise en train de disparaître en tant qu’unité indépendante.
Fondée en 1895, COOP Vaud Chablais valaisan est une société coopérative dont le nombre de
sociétaires s’élevait, en fin 1999, à 121'428. Elle possédait en fin de cette période 58 magasins, 4
Brico-Bâti-Loisirs, 13 restaurants (ou assimilés) pour une surface de vente totale de près de 61'000 m2.
Toujours fin 1999, l’entreprise employait 2'058 personnes et réalisait un chiffre d’affaires net de près de
562 millions de francs, et ce pour un résultat d’exercice de 2,2 millions.
Le graphique suivant permet de se faire une idée sur l’évolution du chiffre d’affaires depuis 1996 :
4 Site web : http://www.coop.ch
510520530540550560570
CA net en millions
1996 1997 1998 1999
Années
Evolution du chiffre d'affaires
Paoly Philippe Diplôme postgrade en informatique et organisation Page 7/80
Année académique 1999-2000
Figure 1 : CA de COOP Vaud Chablais valaisan
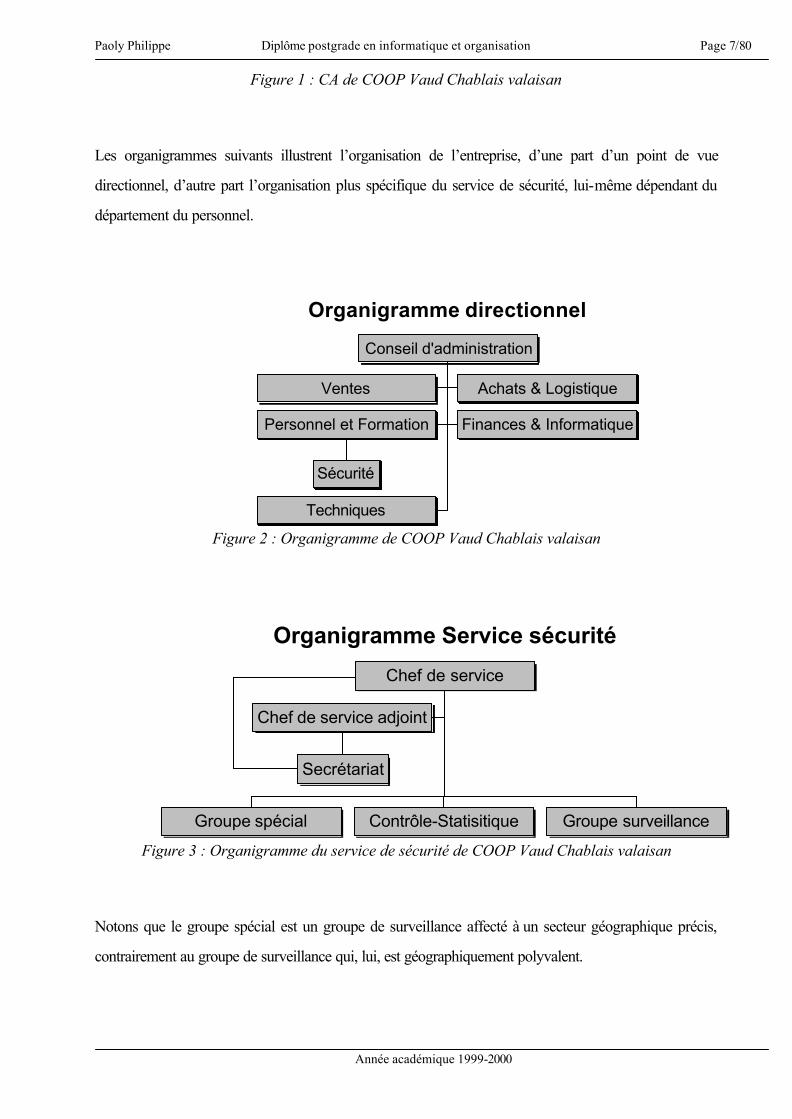
Les organigrammes suivants illustrent l’organisation de l’entreprise, d’une part d’un point de vue
directionnel, d’autre part l’organisation plus spécifique du service de sécurité, lui-même dépendant du
département du personnel.
Figure 2 : Organigramme de COOP Vaud Chablais valaisan
Figure 3 : Organigramme du service de sécurité de COOP Vaud Chablais valaisan
Notons que le groupe spécial est un groupe de surveillance affecté à un secteur géographique précis,
contrairement au groupe de surveillance qui, lui, est géographiquement polyvalent.
Organigramme directionnel
Ventes Achats & Logistique
Sécurité
Personnel et Formation Finances & Informatique
Techniques
Conseil d'administration
Organigramme Service sécurité
Secrétariat
Chef de service adjoint
Groupe spécial Contrôle-Statisitique Groupe surveillance
Chef de service

Paoly Philippe Diplôme postgrade en informatique et organisation Page 8/80
Année académique 1999-2000
3. Confidentialité, contraintes et cadre de travail
3.1. Confidentialité
Diverses clauses de confidentialité ont été imposées, soit pour des raisons légales soit pour des raisons
propres à la sécurité de l’entreprise. Parmi ces clauses, nous pouvons notamment relever :
• Les données nominatives existantes des délits, dans le cadre de la loi fédérale sur la protection
des données. Ces données seront donc anonymes.
• L’inventaire physique des moyens de surveillance.
• Les noms des surveillants et autres intervenants.
• Le détail des procédures internes de traitement et de décision.
• Les plans et stratégies de surveillance.
• L’inventaire physique des moyens de protection.
• Toutes données stratégiques, par exemples le nom des possesseurs de clé d’accès aux magasins
ou l’organisation des transferts de fonds.
Les données confidentielles existent dans les annexes, mais également dans le texte au travers de chiffres
ou d’indications diverses. En conséquence, l’ensemble du mémoire est touché par la clause de
confidentialité.
3.2. Contraintes
Diverses contraintes ont été imposées par l’entreprise alors que d’autres relèvent du cadre même du
mémoire. On peut citer notamment :
• La non-utilisation du matériel de l’entreprise.
• Le contrôle des interviews du personnel de l’entreprise par le responsable de la sécurité.
• Le contrôle des sorties de documents de l’entreprise par le responsable de la sécurité.
• Les contraintes de responsabilité (civile) lors d’observations sur le terrain.
• Les contraintes d’échéance et les obligations académiques.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 9/80
Année académique 1999-2000
Ces contraintes peuvent avoir un impact sur l’orientation du travail et sur son organisation.
3.3. Cadre de travail
Dans le chapitre concernant la définition du sujet, il est précisé que l’objet du travail regroupe
l’ensemble des atteintes à la propriété, mais que cette notion est limitée géographiquement et
fonctionnellement. De plus, l’orientation de la gestion et de la formation est résolument interne à
l’entreprise. Le cadre de travail se limite donc à l’interne de l’entreprise, en intégrant les contraintes
légales auxquelles l’entreprise doit faire face.
La limite géographique comprend l’ensemble des magasins COOP sous l’autorité de COOP Vaud-
Chablais valaisan, sans tenir compte d’éventuelles sociétés détenues en participations.
De plus, la limite fonctionnelle définit la frontière entre les atteintes à la propriété dont nous tiendrons
compte et celles ignorées. Cette limite comprend deux axes :
• La surface de vente à l’intérieur du magasin et tout ce qu’elle contient, y compris les caisses et
les entrepôts.
• Le type de délit : l’appropriation illégale d’un bien ou d’argent liquide, qu’il s’agisse de vol à
l’étalage, de fausse monnaie ou d’arnaque.
Ces limites excluent donc les délits de type vandalisme, espionnage ou sabotage. Précisons en outre
qu’elles sont posées de manière arbitraire, pour les besoins du mémoire.
Paoly Philippe Diplôme postgrade en informatique et organisation Page 10/80
Année académique 1999-2000
4. Contexte
4.1. En général
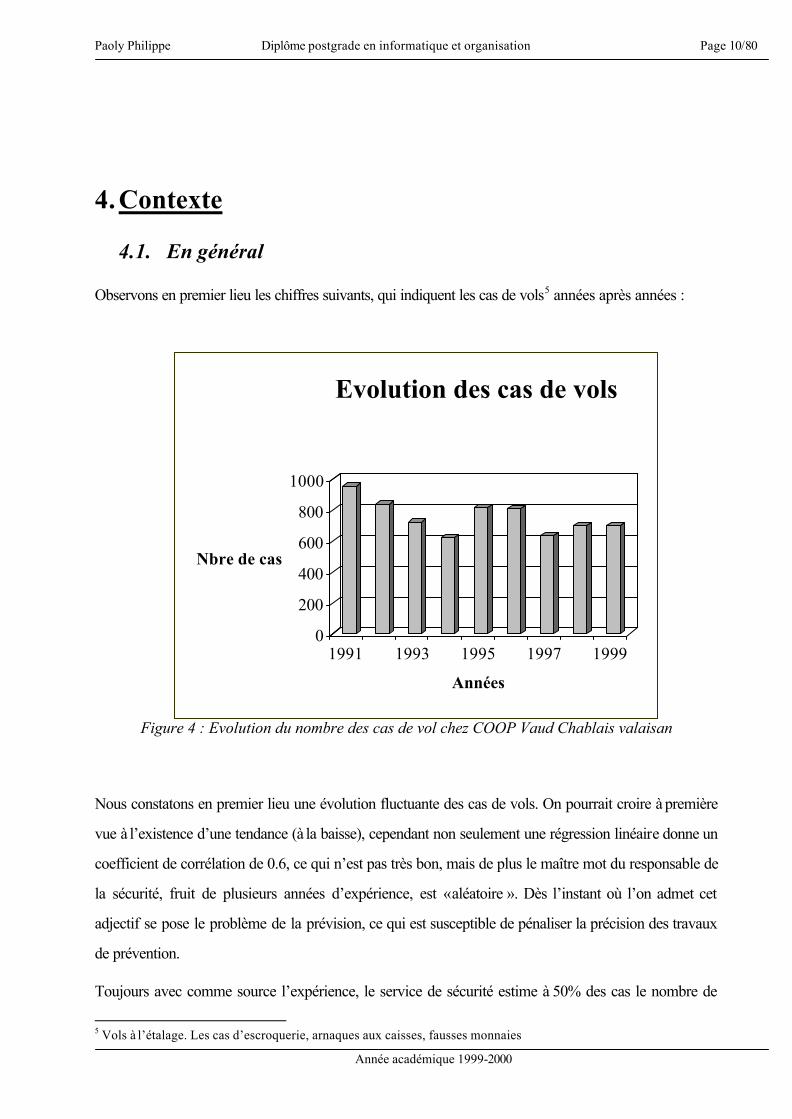
Observons en premier lieu les chiffres suivants, qui indiquent les cas de vols5 années après années :
Figure 4 : Evolution du nombre des cas de vol chez COOP Vaud Chablais valaisan
Nous constatons en premier lieu une évolution fluctuante des cas de vols. On pourrait croire à première
vue à l’existence d’une tendance (à la baisse), cependant non seulement une régression linéaire donne un
coefficient de corrélation de 0.6, ce qui n’est pas très bon, mais de plus le maître mot du responsable de
la sécurité, fruit de plusieurs années d’expérience, est « aléatoire ». Dès l’instant où l’on admet cet
adjectif se pose le problème de la prévision, ce qui est susceptible de pénaliser la précision des travaux
de prévention.
Toujours avec comme source l’expérience, le service de sécurité estime à 50% des cas le nombre de
5 Vols à l’étalage. Les cas d’escroquerie, arnaques aux caisses, fausses monnaies
0
200
400
600
800
1000
Nbre de cas
1991 1993 1995 1997 1999
Années
Evolution des cas de vols

Paoly Philippe Diplôme postgrade en informatique et organisation Page 11/80
Année académique 1999-2000
vols commis par des récidivistes. En résumé, un voleur sur deux est connu de l’entreprise comme tel. Il
n’est malheureusement pas possible d’estimer actuellement le nombre de récidives moyen (récidive ou
multi-récidive). De plus, 20% environ des vols sont commis par le personnel de l’entreprise.
Relevons également l’incertitude concernant le montant moyen d’un vol, outre le nombre de ces vols. A
titre d’exemple, les 700 cas de 1999 ont représenté un montant de 38'450.-, soit un montant moyen de
55.- environ, alors que les 956 cas de 1991 représentaient près de 100'000.- , soit environ 105.-. On
constate donc des variations d’au moins du simple au double.
Un élément à noter également est le nombre d’escroqueries et d’arnaques aux caisses. Ces cas ne sont
pas compris dans le graphique représenté à la figure 4. En l’absence de statistiques, ils sont estimés à une
cinquantaine de cas annuellement.
4.2. La formation
Un élément important est l’aspect de la formation. Lorsqu’un nouveau surveillant arrive dans le service
de sécurité, ce dernier est envoyé sur le terrain accompagné par des collaborateurs d’expérience. Le
savoir se transmet donc de manière orale en fonction des cas rencontrés. Une autre méthode de
formation est l’organisation de cours de formation, soit par des personnes internes, soit externes, sur des
sujets généraux ou plus précis. De plus, il existe des procédures écrites permettant une acquisition du
savoir par la lecture.
Concernant le personnel en magasin, la formation concerne principalement les gérants qui d’une part
possèdent le manuel du gérant, recueil de procédures, et d’autre part suivent divers cours de formation.
En outre, chaque gérant passe au moment de sa nomination une journée sur le terrain avec une équipe
du service de sécurité. Concernant la formation du reste du personnel de magasin, il faut constater
qu’elle est inexistante vu l’absence de programme de cours ciblé. En effet, ces collaborateurs ne sont
pas censés intervenir dans un cas de vol, bien que leur intervention soit constatée sur le terrain.
En bref, on peut retenir 4 éléments principaux :
• L’imprévisibilité des cas de vol (quantité et montants).
• Le nombre important de récidives.
• L’importance des vols de la part du personnel.
• La formation sur deux axes principaux : manuels et tutorat.
ne sont pas compris dans les chiffres.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 12/80
Année académique 1999-2000
5. Hypothèses et postulats
Vu ce qui a été dit précédemment, notre système devrait remplacer ou appuyer la formation, offrir des
réponses efficaces à diverses questions, proposer des fonctionnalités de traitement statistique ou
d’exploration, de la simple régression aux méthodes plus évoluées telles que l’analyse factorielle ou
discriminante.
En bref, les fonctionnalités de base devraient être :
• Interpréter une requête en langage structuré : comprendre et traiter une question.
• Proposer une réponse pertinente : analyser les données existantes et générer une réponse.
• Apprendre et évoluer : assimilation des nouvelles données dans les traitements.
• Générer des scénarii : proposer des cas.
• Décrire diverses situations : mettre en évidence les caractéristiques de la situation, selon des
critères définis ou non.
• Illustrer une problématique : donner des exemples selon une problématique donnée.
• Tester divers comportements/réactions : tester la pertinence d’une action et générer la réaction
probable.
• Générer des profils.
• Déceler des problèmes sous-jacents : attirer l’attention sur des éléments probables.
• Traiter des indices : générer des probabilités suivant divers éléments.
• Traiter des données : divers types de traitements statistiques.
• Offrir une bibliothèque de cas : permettre la gestion des documents papiers.
• Gérer les procédures : indiquer les règles d’action existantes, proposer des règles d’action.
Ces fonctionnalités paraissent à priori essentielles dans les réponses aux besoins de l’entreprise. Elles
permettent d’offrir un soutien autant dans la formation que dans la gestion.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 13/80
Année académique 1999-2000
6. Politique de l’entreprise
La politique de COOP Vaud Chablais valaisan en matière de vol est la suivante :
« S’assurer que la marchandise soit payée. A priori le client est honnête. C’est donc la marchandise qui
est surveillée, non le client lui-même, ou le personnel le cas échéant ».
Cette politique influe sur les investissements en moyen de surveillance et sur les méthodes de
surveillance. Par exemple, la surveillance des WC par caméra est exclue, puisque cela supposerait une
surveillance des individus et non plus des produits. De plus, la surveillance s’exerce selon deux moyens
principaux : la surveillance par caméra (surveillance de produits ou de rayonnages) et la surveillance
directe par des professionnels, également sur des secteurs de vente ou des rayonnages. Rappelons en
outre qu’une personne peut remplir ses poches de marchandises. Sa seule obligation est de payer ces
marchandises à la caisse.
Une surveillance de personnes peut cependant exister. Par exemple si l’on constate des erreurs de
caisse trop fréquentes et que les soupçons portent sur une caissière en particulier, une surveillance sera
mise en place spécifiquement sur ce poste de travail au moment où cette caissière sera en activité. Mais
même dans ce cas, on relève que la surveillance initiale concernait l’argent, ou du moins son mouvement,
et que c’est uniquement lorsqu’un problème est décelé à une étape quelconque qu’une surveillance de
personne est éventuellement mise en place.
Cette politique de l’entreprise devra rester à l’esprit tout au long de la réflexion qui va suivre.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 14/80
Année académique 1999-2000
Partie II – Méthodologie
7. Importance d’une méthodologie
La méthodologie est un élément essentiel, sinon l’élément essentiel des méta-connaissances6. En effet, la
méthodologie fait totalement partie de la création d’un pattern réutilisable tel quel ou sous réserve
d’adaptations. Elle offre non seulement un cadre de réflexion mais également une méthode de travail et
de développement. La question « Comment faire ? » est importante car sa réponse conditionne
l’ensemble des travaux et l’ensemble des réflexions. La méthodologie développée ici concerne aussi
bien la réflexion intellectuelle que la modélisation du business ou la conception du prototype, mais
l’accent principal est mis sur les deux premiers éléments, dans un souci de respect du cadre
académique.
8. Définition d’une méthodologie
La méthodologie utilisée est axée sur trois piliers fondamentaux :
• Les méta-connaissances: il s’agit ici des connaissances sur les connaissances, principalement la
définition des besoins, des méthodes d’acquisition ou des sources, les stratégies de gestion et
l’expression des connaissances.
• La conception et la modélisation du business : il s’agit ici de représenter les processus et les
méthodes de fonctionnement dans le cadre de notre problématique. Nous cherchons à obtenir
une représentation fidèle de la réalité, de ce qui se passe concrètement dans le quotidien.
• La conception du moteur d’inférence 7: il s’agit de définir les besoins d’inférence, le choix d’un
modèle d’inférence et de modéliser le moteur d’inférence choisit. L’opération logique de
déduction ou d’induction peut prendre diverses formes et cette opération est essentielle dans la
modélisation du prototype.
6 Connaissances sur les connaissances 7 Moteur permettant d’automatiser une opération logique permettant d’admettre une proposition en vertu de sa liaison avec d’autres propositions tenues pour vraies

Paoly Philippe Diplôme postgrade en informatique et organisation Page 15/80
Année académique 1999-2000
Ces trois piliers permettrons la conception et la réalisation du prototype : il s’agit ici de modéliser et de
créer un prototype d’application informatique permettant d’offrir les fonctionnalités, ou du moins les plus
importantes puisqu’il ne s’agit que d’un prototype, définies dans les opérations précédentes.
La définition de la méthodologie peut être schématisée de la manière suivante :
Figure 4 : Les 3 piliers de la méthodologie
Insistons sur l’objectif de cette méthodologie qui reste la réalisation d’un prototype d’application.
METHODOLOGIE
Mét
a-co
nnai
ssan
ces
Mét
a-co
nnai
ssan
ces
Con
cept
ion
bus
ines
sC
once
ptio
n b
usin
ess
Mot
eur
d’in
fére
nce
Mot
eur
d’in
fére
nce
Paoly Philippe Diplôme postgrade en informatique et organisation Page 16/80
Année académique 1999-2000
Partie III – Méta connaissances
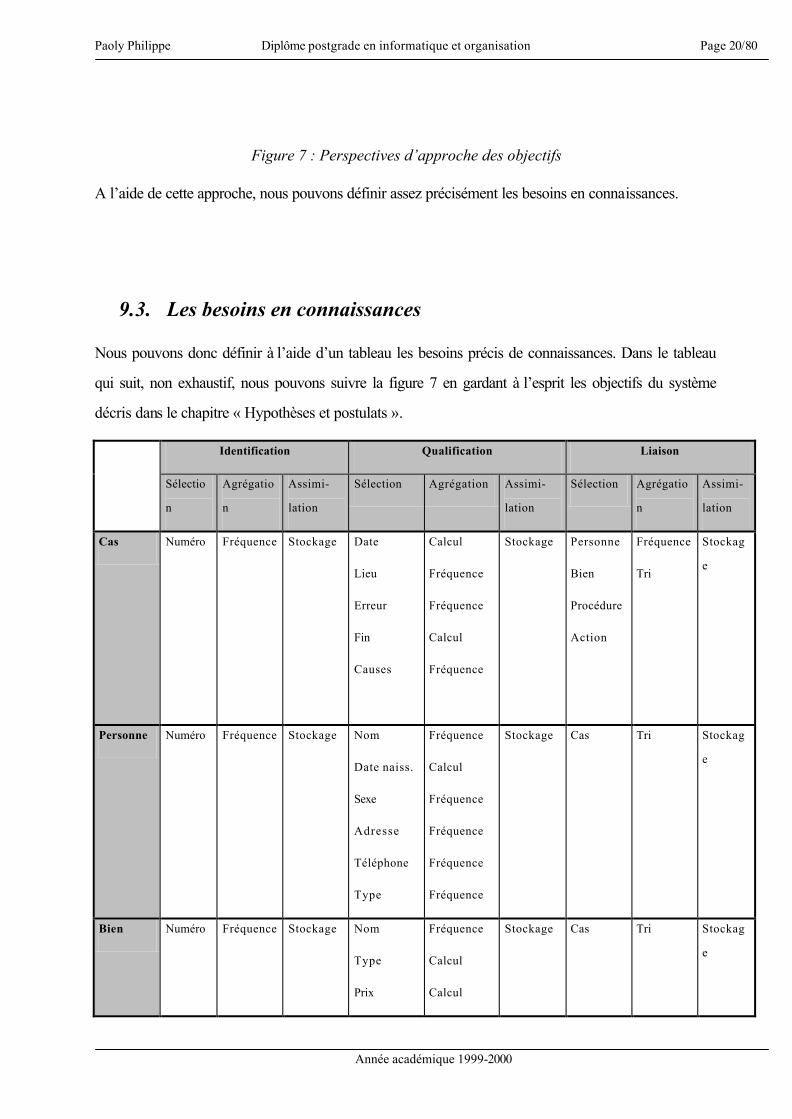
9. Besoins de connaissances
Nous pouvons reprendre certains éléments décrit dans le chapitre « Hypothèses et postulats » comme
base de travail et définir pour chacun d’eux un type de raisonnement ou d’approche de manière à cerner
plus précisément les besoins en connaissances. Le tableau suivant donne l’association entre chaque
objectif du système et un type de raisonnement :
Objectifs du système Types de raisonnement
Interpréter une requête Codage
Proposer une réponse Méthode de sélection
Apprendre et évoluer Méthode d’assimilation
Générer des scénarii Méthode de sélection
Décrire diverses situations Méthode d’agrégation
Déceler des problèmes sous-jacents Méthode de sélection
Traiter des indices Méthode de sélection
Traiter des données Méthode d’agrégation
Illustrer une problématique Méthode d’agrégation
Générer des profils Méthode d’agrégation
Offrir une bibliothèque de cas Méthode de sélection
Gérer les procédures Méthode de sélection
Tester divers comportements/réactions Méthode de sélection
Figure 5 : Objectifs et types de raisonnement
A partir de ce tableau, il est possible de travailler sur deux bases :
• Les données elles-mêmes (et les objets auxquels elles se rattachent)

Paoly Philippe Diplôme postgrade en informatique et organisation Page 17/80
Année académique 1999-2000
• Les types de raisonnement
9.1. Les types de données et les objets
9.1.1. Les données
Par rapport à un cas précis, il est possible de définir trois types de données :
• Les données d’identification : par exemple un numéro identifiant une personne.
• Les données descriptives : par exemple le nom, l’adresse, etc. pour une personne.
• Les données de liaison : par exemple le vol lie une personne et un bien.
Les besoins en données sont définis par des objets, objets qui doivent être également définis.
9.1.2. Les objets
La définition des objets nous oblige à réfléchir sur la définition même d’un cas de vol dans le cadre de
tout ce qui à été dit précédemment . A partir de la définition du Petit Robert, qui nous dit : « Vol : action
qui consiste à soustraire frauduleusement le bien d’autrui », nous pouvons constater que nous avons
d’ores et déjà deux objets principaux :
• Un objet « Personne ».
• Un objet « Bien ».
Cependant, pour nous, cette définition n’est pas suffisante. Nous ne nous intéressons pas seulement au
vol, mais au « cas » de vol, ce qui englobe tout ce qui tourne autour du vol à proprement parler, qu’il
s’agisse de l’interpellation, de la surveillance, etc…
« Un cas de vol est un vol ainsi que toutes les interactions ou actions en rapport avec ce vol ».
En bref, nous pouvons ici définir un nouvel objet :
• Un objet « Action »
Toutefois, notre liste n’est pas encore complète. En effet une des tâches de notre système est la gestion
des procédures. Nous pouvons définir une procédure comme une règle obligatoire, c’est à dire une suite
ou un enchaînement d’actions obligatoires. L’objet « Action » défini ci-dessus n’est pas suffisant,
puisque ce qui nous intéresse ici n’est pas une action en particulier, mais l’enchaînement en tant que tel.
Nous définissons donc un objet supplémentaire :

Paoly Philippe Diplôme postgrade en informatique et organisation Page 18/80
Année académique 1999-2000
• Un objet « Procédure »
En résumé, nous avons ici quatre objets fondamentaux, complété de l’objet principal de l’étude qu’est
le cas en lui-même, enchaînement ou ensemble d’objets :
• Personne
• Bien
• Action
• Procédure
• Cas
Les besoins en connaissances concernent donc ces cinq objets, qu’il s’agira d’identifier, de décrire (et
de qualifier en répondant éventuellement aux questions où, comment, pourquoi, quand, etc..) et de lier le
cas échéant. Naturellement, en fonction des besoins, ces objets peuvent être déclinés en « sous-
objets ».
9.2. Les types de raisonnement
Les types de raisonnement listés dans la figure 5 sont les suivants :
• Sélection
• Assimilation
• Agrégation8
La méthode de codage n’est pas essentielle ici, puisqu’elle dépend des outils utilisés, non du système
lui-même (en terme de conception).
A ce niveau il est nécessaire de répondre à deux questions, soit :
• Quoi : que faut-il sélectionner, agréger ou assimiler ?
• Comment : comment sélectionner, agréger ou assimiler ?
Il est possible d’apporter un premier élément de réponse à l’aide du tableau suivant :
8 Ou toute fonction de regroupement

Paoly Philippe Diplôme postgrade en informatique et organisation Page 19/80
Année académique 1999-2000
Quoi ? Comment ?
Sélectionner Tout Définition de critères
Agréger Tout Définition de fonction
Assimiler Tout Stocker
Figure 6: Quoi et comment agréger, sélectionner et assimiler?
Le tableau ci-dessus montre que toutes les données doivent pouvoir être :
• Sélectionnées : en fonction de critères que l’utilisateur devra choisir parmi les diverses
occurrences possibles associées et éventuellement un opérateur de comparaison.
• Agrégées : à l’aide de fonctions pré-définies ou selon une formule insérée par l’utilisateur. Il est
nécessaire ici de faire la distinction entre les données qualitatives et les données quantitatives. En
effet, pour les données qualitatives, seule une fonction de définition de fréquence est possible,
même si d’autres fonctions de calcul sont possibles dans un deuxième temps sur les fréquences
elles-même.
• Assimilées : à l’aide d’une fonctionnalité de stockage, chaque donnée doit pouvoir être
enregistrée. En fonction du moteur d’inférence choisi, il sera possible dans un deuxième temps
d’automatiser certaines fonctions d’agrégation qui pourraient être vues comme une assimilation.
Mais ces fonctions sont effectuées dans un deuxième temps.
En résumé, nous pouvons aborder la perspective des objectifs du système décrit dans le chapitre
« Hypothèses et postulats » selon trois axes qui sont :
• Le type de données
• Le type de raisonnement
• Les objets
selon le schéma suivant :
Objets
Typ
es d
e do
nnée
s
Paoly Philippe Diplôme postgrade en informatique et organisation Page 20/80
Année académique 1999-2000
Figure 7 : Perspectives d’approche des objectifs
A l’aide de cette approche, nous pouvons définir assez précisément les besoins en connaissances.
9.3. Les besoins en connaissances
Nous pouvons donc définir à l’aide d’un tableau les besoins précis de connaissances. Dans le tableau
qui suit, non exhaustif, nous pouvons suivre la figure 7 en gardant à l’esprit les objectifs du système
décris dans le chapitre « Hypothèses et postulats ».
Identification Qualification Liaison
Sélectio
n
Agrégatio
n
Assimi-
lation
Sélection Agrégation Assimi-
lation
Sélection Agrégatio
n
Assimi-
lation
Cas Numéro Fréquence Stockage Date
Lieu
Erreur
Fin
Causes
Calcul
Fréquence
Fréquence
Calcul
Fréquence
Stockage Personne
Bien
Procédure
Action
Fréquence
Tri
Stockag
e
Personne Numéro Fréquence Stockage Nom
Date naiss.
Sexe
Adresse
Téléphone
Type
Fréquence
Calcul
Fréquence
Fréquence
Fréquence
Fréquence
Stockage Cas Tri Stockag
e
Bien Numéro Fréquence
Stockage Nom
Type
Prix
Fréquence
Calcul
Calcul
Stockage Cas Tri Stockag
e

Paoly Philippe Diplôme postgrade en informatique et organisation Page 21/80
Année académique 1999-2000
Procédure Numéro Fréquence
Stockage Objet 1
Donnée 1
Valeur 1
Objet 2
Donnée 2
Valeur 2
Fréquence
Fréquence
Calcul
Fréquence
Fréquence
Calcul
Stockage Action
Cas
Stockag
e
Action Numéro Fréquence
Stockage Nom
Circonstanc
es
Lieu
Fréquence
Fréquence
Stockage Cas
Procédure
Stockag
e
Figure 8 : Application de la figure 7
9.3.1. Remarques
Relevons que trois méthodes d’agrégation sont possibles :
• Le tri
• Le calcul de fréquences
• Le calcul
Ces méthodes sont liées par une hiérarchie ou une inclusion. En effet, nous avons :
Tri ⊂ Calcul de fréquence ⊂ Calcul .
En effet, partout où les fonctions de calcul sont possibles, nous pouvons calculer une fréquence,
et partout où le calcul d’une fréquence est possible nous pouvons effectuer un tri. L’inverse
n’est pas vrai. Pour simplifier la lecture, seule est indiquée la fonction la plus large.
Concernant les types de données, chaque objet est identifié par un numéro qui a une fonction
d’identification. Pour les données de type descriptif, quelques précisions s’imposent, à l’aide du
tableau de définition (figure 9).
Pour les données de liaison, le tableau (figure 8) indique seulement les objets directement liés. Il
est évident que des liaisons indirectes sont possibles. De plus, le lien entre deux objets entraîne
obligatoirement un lien entre les données relatives à ces objets.
Concernant les procédures, les données qualificatives reprennent une structure « si…alors… ».
En effet, l’idée est de formaliser une procédure comme suit : si la donnée 1 appartenant à l’objet

Paoly Philippe Diplôme postgrade en informatique et organisation Page 22/80
Année académique 1999-2000
1 prend la valeur 1, alors la donnée 2 appartenant à l’objet 2 prend la valeur 2.
Objets Données Définitions
Date Date du cas
Lieu Lieu de déroulement du cas
Erreur Y-a-t-il eu vol ou s’agit-il d’une erreur ?
Fin Indice de terminaison (violence, collaboration, etc..).
Cas
Cause Causes, circonstances ou contexte du cas
Nom Nom et prénom
Date de naissance Date de naissance et âge (par calcul)
Sexe Sexe de la personne
Adresse Rue, numéro postal, ville et pays
Téléphone Le numéro de téléphone de la personne
Personne
Type Client, service de sécurité, personnel
Nom Désignation du bien
Prix Prix ou valeur du bien Bien
Type Type de bien (appartenance à un rayon)

Paoly Philippe Diplôme postgrade en informatique et organisation Page 23/80
Année académique 1999-2000
Objet 1 Objet imposant la procédure
Donnée 1 Donnée imposant la procédure
Valeur 1 Valeur imposant la procédure (ou critère)
Objet 2 Objet sur lequel porte la procédure
Donnée 2 Donnée sur laquelle porte la procédure
Procédure
Valeur 2 Valeur résultant de la procédure
Nom Désignation de l’action
Circonstances Circonstances, causes de l’action Action
Lieu Lieu de déroulement de l’action
Figure 9 : Précisions et définitions des données
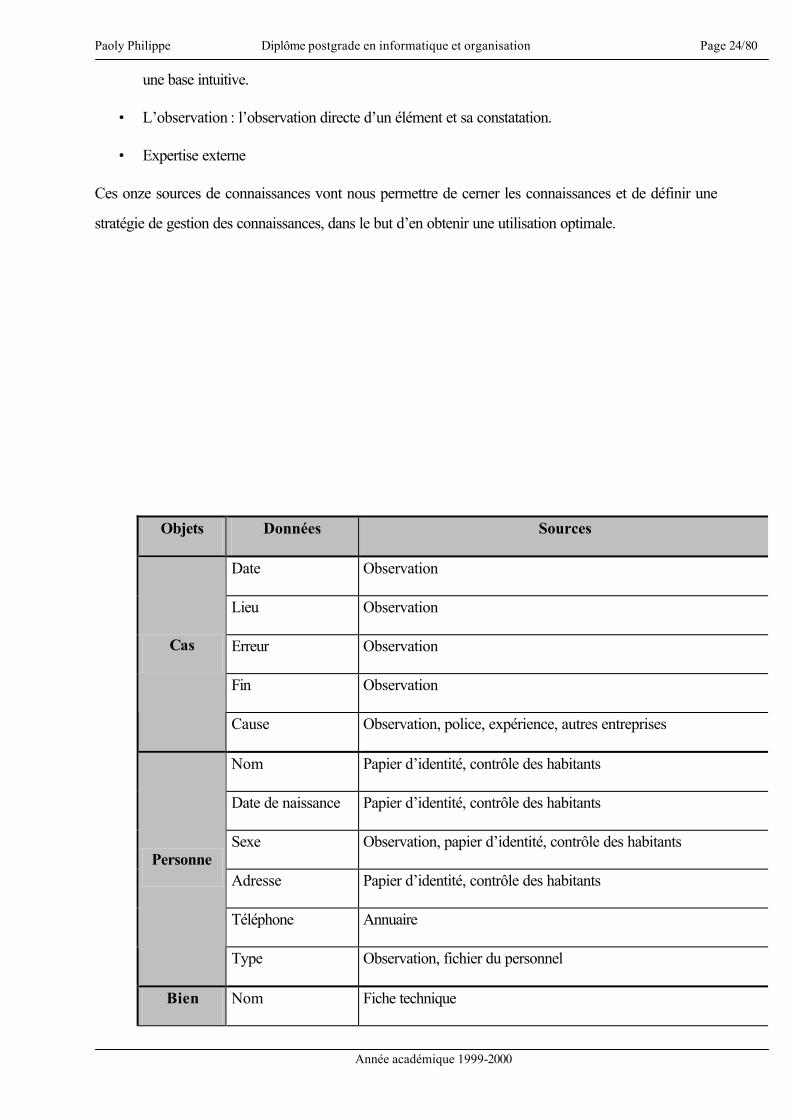
10. Acquisition de connaissances
L’acquisition des connaissances pose le problème des sources de connaissances. Ces sources peuvent
être internes à l’entreprise ou externes. Pour schématiser les sources de connaissances, nous pouvons
utiliser en partie la figure 9 pour créer un tableau des sources (figure 10).
Ce tableau nous donne les sources de connaissances concernant les données. Nous pouvons lister ces
sources, en ajoutant l’expertise externe :
• La police : donne des indices, des avertissements (risque de vol) ou des règles à suivre.
• Le manuel du gérant : ensemble de procédures à l’attention des gérants de magasin.
• Règlements internes : ensemble de règles et de procédures définies par l’entreprise.
• La presse (et médias) : donne des éléments d’information (manifestations, évènements, etc.).
• Autres entreprises : donnent des informations sur des risques particuliers (fausses monnaies,
etc.).
• La loi : référence aux règles légales impératives (obligations et interdictions).
• Le contrôle des habitants : toutes les informations de base concernant les individus.
• Les fiches techniques : toutes les informations relatives aux biens.
• L’expérience : toute l’information provenant des gérants, des surveillants ou du personnel sur
Paoly Philippe Diplôme postgrade en informatique et organisation Page 24/80
Année académique 1999-2000
une base intuitive.
• L’observation : l’observation directe d’un élément et sa constatation.
• Expertise externe
Ces onze sources de connaissances vont nous permettre de cerner les connaissances et de définir une
stratégie de gestion des connaissances, dans le but d’en obtenir une utilisation optimale.
Objets Données Sources
Date Observation
Lieu Observation
Erreur Observation
Fin Observation
Cas
Cause Observation, police, expérience, autres entreprises
Nom Papier d’identité, contrôle des habitants
Date de naissance Papier d’identité, contrôle des habitants
Sexe Observation, papier d’identité, contrôle des habitants
Adresse Papier d’identité, contrôle des habitants
Téléphone Annuaire
Personne
Type Observation, fichier du personnel
Bien Nom Fiche technique
Paoly Philippe Diplôme postgrade en informatique et organisation Page 25/80
Année académique 1999-2000
Prix Fiche technique
Type Fiche technique
Objet 1 Police, loi, manuel du gérant, règlements internes
Donnée 1 Police, loi, manuel du gérant, règlements internes
Valeur 1 Police, loi, manuel du gérant, règlements internes
Objet 2 Police, loi, manuel du gérant, règlements internes
Donnée 2 Police, loi, manuel du gérant, règlements internes
Procédure
Valeur 2 Police, loi, manuel du gérant, règlements internes
Nom Observation
Circonstances Observation, presse, police, autres entreprises Action
Lieu Observation
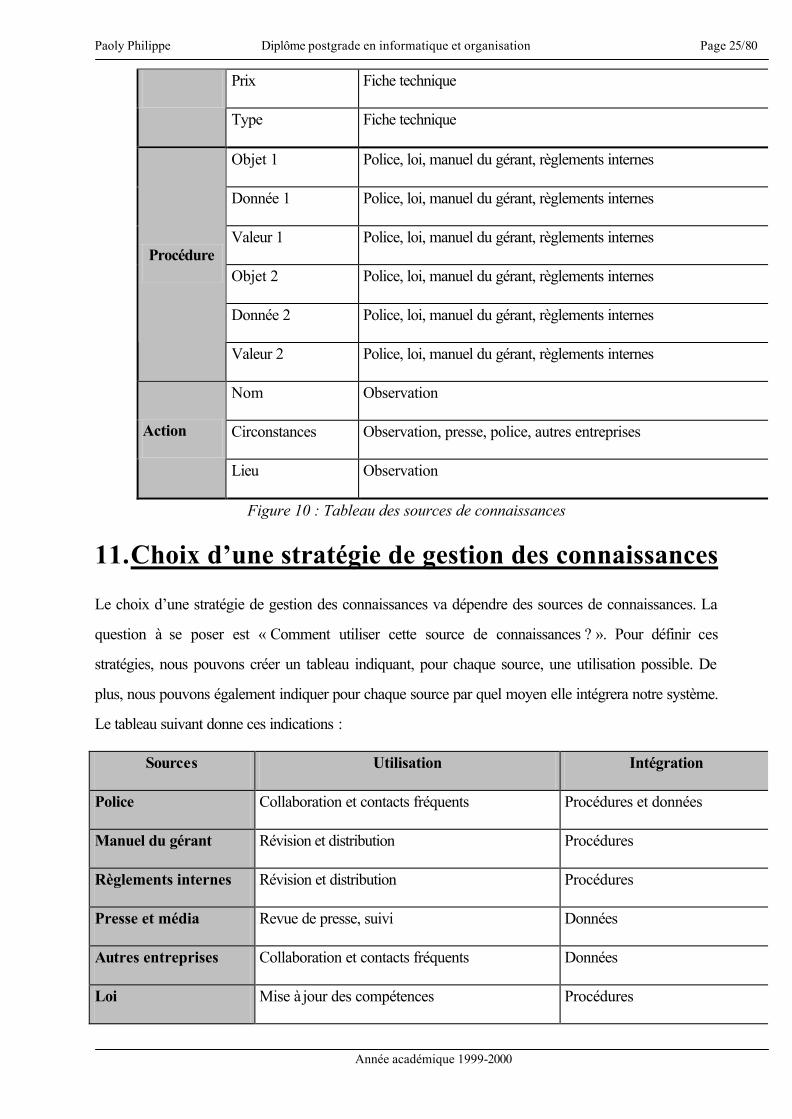
Figure 10 : Tableau des sources de connaissances
11. Choix d’une stratégie de gestion des connaissances
Le choix d’une stratégie de gestion des connaissances va dépendre des sources de connaissances. La
question à se poser est « Comment utiliser cette source de connaissances ? ». Pour définir ces
stratégies, nous pouvons créer un tableau indiquant, pour chaque source, une utilisation possible. De
plus, nous pouvons également indiquer pour chaque source par quel moyen elle intégrera notre système.
Le tableau suivant donne ces indications :
Sources Utilisation Intégration
Police Collaboration et contacts fréquents Procédures et données
Manuel du gérant Révision et distribution Procédures
Règlements internes Révision et distribution Procédures
Presse et média Revue de presse, suivi Données
Autres entreprises Collaboration et contacts fréquents Données
Loi Mise à jour des compétences Procédures

Paoly Philippe Diplôme postgrade en informatique et organisation Page 26/80
Année académique 1999-2000
Contrôle des habitants Par téléphone si besoin -
Fiches techniques Révision et distribution Données
Expérience Intégration et analyse, cours et séminaires Données
Observation Intégration et analyse Données
Expertise externe Cours et séminaires -
Figure 11 : Utilisation et intégration des sources de connaissances
Précisons encore que par « intégration et analyse », il est entendu une intégration, au travers de la saisie des données et de la conception même du système des éléments d’expérience et d’observation. L’aspect de la conception sera abordé plus loin.
11.1. Précisions
La figure 11 indique comment gérer les sources de connaissances. Cependant elle offre également une
information quant à la gestion des connaissances elles-mêmes. En effet, nous constatons qu’excepté
l’expertise externe et les fichiers du contrôle des habitants, toutes les connaissances peuvent être
intégrées dans le système, soit au travers des procédures, soit au travers des données. Nous constatons
cependant que toutes les sources de connaissances offrent comme information soit un fait constaté, soit
une règle à suivre. Deux exceptions à cette constatation : l’expertise externe et l’expérience.
L’expérience n’est rien d’autre qu’une expertise interne. Cette expertise, qu’elle soit externe ou interne,
transmet donc un savoir théorique et une expérience de terrain. Si le savoir théorique peut être transmis
par des cours ou des séminaires, l’expérience est plus intuitive. Comment transmettre une manière de
faire non formelle, intuitive et qui concerne une problématique où les rapports humains et la subjectivité
jouent un rôle important, puisqu’il s’agit de cerner un ensemble d’interactions humaines ? C’est le
chapitre suivant, concernant l’expression des connaissances qui nous offre la réponse. Cependant, nous
pouvons d’ores et déjà signaler que nous aurons une stratégie de gestion des connaissances basée une
caractéristique des connaissances, caractéristique qui peut prendre deux valeurs :
• Objective (ou qui peut être raisonnée)
• Subjective (ou instinctive)
Par une connaissance objective, il est entendu une connaissance qui découle d’une règle ou d’un fait qui
peut être défini par réflexion. A titre d’exemple, une règle de procédure, une observation ou un texte de
loi sont des données objectives. Par donnée subjective, il est entendu une connaissance intuitive. A titre
d’exemple, la réaction face à un voleur agressif est un comportement intuitif ou instinctif qui ne peut, la

Paoly Philippe Diplôme postgrade en informatique et organisation Page 27/80
Année académique 1999-2000
plupart du temps, être cerné qu’au moment où il se produit. Si nous demandons à quelqu’un ce qu’il
ferait dans ce cas, nous aurons certainement une réponse intéressante, mais biaisée par divers éléments
extérieurs et surtout une part de réflexion. Mais pour connaître véritablement ce que cette personne
ferait, seule l’observation donne une réponse sans appel car elle permet le constat pur et simple. Or
l’expérience est de ce type. L’expérience relève du réflexe plus que de la réflexion. Le Petit Robert
donne comme synonymes de l’expérience, entre autres, « routine » et « habitude », deux termes qui
généralement excluent la réflexion. Agir par habitude, c’est agir machinalement.
Nous pouvons donc définir une stratégie de gestion des connaissances basée sur trois piliers, dont le
principal est certainement le premier :
• Saisie et traitement par le système
• La gestion de documents
• La transmission orale (cours, etc)
Dès maintenant, ce qui va nous intéresser est la saisie et le traitement par le système. La transmission
orale (cours, tutorat, etc) ainsi que la gestion de documents ne seront plus abordés excepté, pour ce
dernier point, l’accès automatique éventuel aux procès verbaux.
12. Expression des connaissances
L’expression des connaissances concerne ici les moyens et méthodes pour formaliser et coder les
connaissances dans notre système. La figure 11 nous a donné les sources de connaissances, comment
en tirer l’information (la connaissance brute) et comment intégrer cette information dans notre système.
Notons que pour l’observation et l’expérience, l’utilisation de la source de connaissances suppose une
intégration et une analyse au travers de notre système, alors que les autres sources peuvent être gérées
indépendamment de celui-ci. Dans tous les cas (excepté l’expertise externe et le contrôle des habitants),
toutes les informations peuvent être saisies sous forme de données, y compris l’expérience et
l’observation. La particularité de ces deux sources de connaissances est que l’expression de la
connaissance ne se contente pas d’une simple saisie de données, mais est totale à condition de mettre en
place une structure de données. Nous avons donc deux outils d’expression des connaissances :
• Les données en tant que tel
• La structure des données
La structure est un élément essentiel de cette expression, comme la syntaxe peut être essentielle à la

Paoly Philippe Diplôme postgrade en informatique et organisation Page 28/80
Année académique 1999-2000
langue. Dans une langue, nous avons en effet des listes de mots, mais c’est la syntaxe qui est l’élément
essentiel du sens, au-delà de la sémantique. En effet, chaque mot à un sens intrinsèque, mais c’est
l’enchaînement lui-même qui donne un sens global à une proposition.
Or si nous reprenons la définition d’un cas de vol donnée précédemment :
« Un cas de vol est un vol ainsi que toutes les interactions ou action en rapport avec ce vol »
Nous constatons que nous avons bien affaire à un enchaînement d’actions ou d’interactions, et que si
l’action est importante intrinsèquement, l’enchaînement et l’ordre d’enchaînement sont les éléments
porteurs et générateurs de connaissances nouvelles, et que l’expérience dans la manière de traiter un cas
sera exprimée principalement par l’enchaînement plutôt que par une liste d’actions.
En conséquence, nous allons tenter de définir un nouveau langage avec comme base de référence la
langue française, mais en créant une nouvelle grammaire nous permettant de répondre à notre
problématique. L’avantage de cette approche est que la nouvelle grammaire définie peut être
rapprochée de toutes les langues de base latine ou germanique (pour le moins).
12.1. Création du langage
Pour la création de notre langage, nous allons, tout en gardant le vocabulaire de la langue française, nous
intéresser à la morphologie9 et à la syntaxe10 de ce langage.
En terme de syntaxe, il est nécessaire de garder à l’esprit l’objectif cherché : enregistrer l’expérience (en
plus des données brutes). Nous avons précisé plus haut que c’est l’enchaînement d’actions ou
d’interactions qui était important. En conséquence, il est nécessaire de définir une structure unitaire la
plus simple possible, de manière à obtenir une précision optimale au niveau de l’ensemble. Nous
pouvons définir d’ores et déjà l’action comme un élément de cette structure unitaire. Cependant, l’action
ne suffit pas. L’intérêt porte également sur la source de l’action, et sur l’objet de l’action. La structure
unitaire est donc la suivante :
Source + Action + Objet
Cependant, cette structure de base n’est pas tout à fait suffisante. Dire « le surveillant attrape le voleur »
est intéressant, mais l’information permettant de répondre aux questions « Où ? », « Avec quoi ? »,
9 La morphologie englobe les catégories de mots, la déclinaison et la conjugaison

Paoly Philippe Diplôme postgrade en informatique et organisation Page 29/80
Année académique 1999-2000
« Pourquoi ? », etc. (et parfois « Combien ? ») est également intéressante. Il est donc nécessaire
d’intégrer la notion de « circonstance » dans notre structure unitaire, ainsi qu’une qualification numérique
de l’objet de l’action.
Nous avons donc en final la structure suivante :
Source + Action + Qualification numérique + Objet + circonstances
En linguistique, notre structure correspond à :
Sujet + Prédicat11 + numéral + COD12 + Compléments circonstanciels
Notons que pour respecter la structure unitaire, non seulement le numéral ne peut concerner que des
objets inanimés mais qu’il est impératif d’empêcher l’utilisation de groupe verbal, de groupe nominal,
etc. En conséquence, notre structure se limite à l’échelle de la proposition13, rendant impossible la
phrase. De plus, par souci de simplification, seule une action directe est admise (« le voleur est interpellé
par un surveillant » est interdit. Seul est autorisé « le surveillant interpelle le voleur »). Pour simplifier la
formule, nous imposons que le sujet est obligatoirement une personne.
Cependant, s’arrêter à l’aspect syntaxique n’est pas suffisant pour préserver l’aspect unitaire de cette
structure. Il nous faut se pencher sur l’aspect morphologique pour donner des règles d’expression qui
garantissent cette nécessité.
En conséquence, le langage créé ne comporte que trois catégories morphologiques :
• Les substantifs.
• Les verbes.
• Les numéros.
Ceci nous permet principalement de supprimer :
• Les adverbes et les adjectifs qui risquent d’amener une subjectivité supplémentaire (en effet, la
valeur de « rapidement » ou « rapide » est relative).
• Les pronoms qui peuvent être remplacés par des substantifs.
• Les conjonctions, rendues inutiles par l’imposition d’une structure limitée à la proposition.
• Les prépositions puisque qu’elles sont remplacées par une qualification des compléments
10 La syntaxe défini les règles d’enchaînement des mots ou des propositions 11 Le prédicat est une catégorie syntaxique : qui concerne le sujet 12 Complément d’objet direct

Paoly Philippe Diplôme postgrade en informatique et organisation Page 30/80
Année académique 1999-2000
circonstanciels au sein même de notre système.
• Les articles : l’information quant au genre, au cas et au nombre n’est pas utile dans notre
problématique. De plus, seul le singulier caractérise nos substantifs, puisque chaque substantif
est nominalisé.
Notre langage ne comporte ni conjugaison, ni déclinaison. En effet, l’absence de conjugaison est rendue
possible par l’imposition de l’infinitif pour tous les verbes14 exprimant le prédicat de notre structure.
L’absence de déclinaison est possible en imposant les règles suivantes :
• Impossibilité d’avoir un COI15 dans notre structure, ce qui élimine le datif (dû à l’imposition de
l’action directe).
• Impossibilité d’avoir un attribut du sujet, ce qui élimine le génitif (dû à notre structure unitaire).
• L’imposition de l’infinitif exclu le mode16 impératif, ce qui élimine le vocatif.
• Le nominatif est inutile puisque déduit de notre structure même. En effet, le sujet appelle le
nominatif et le sujet précède obligatoirement le prédicat.
• L’accusatif est inutile puisque définit par déduction dans notre structure. Par défaut, tout ce qui
suit le prédicat est accusatif.
De plus, tous les compléments sont également des substantifs.
Ajoutons que certains compléments circonstanciels sont abandonnés, notamment les compléments :
• De but (ex : afin de…) : la notion du futur n’est pas essentielle.
• De condition (ex : en cas de…) : inutiles puisqu’une action est un constat (s’est produite).
• De concession (ex : malgré…) : apportent une nuance non essentielle.
• D’association (ex : avec…): ne respectent pas la structure unitaire.
• Cumulatifs (ex : ensemble) : ne respectent pas la structure unitaire.
• De mode (ex : rapide) : impliquent une subjectivité dans l’interprétation ou apporte une nuance
non essentielle.
• Consécutifs ( ex : jolie à croquer) : ne respectent pas la structure unitaire.
13 En grammaire, unité syntaxique élémentaire de la phrase, généralement construite autour d’un verbe 14 Un verbe est une catégorie morphologique : mot exprimant une action ou un ensemble d’action 15 Complément d’objet indirect 16 Le mode est la forme verbale qui exprime la manière dont l’action est présentée (infinitif, impératif, conditionnel, etc.)

Paoly Philippe Diplôme postgrade en informatique et organisation Page 31/80
Année académique 1999-2000
• Fréquentatifs (ex : toujours) : ne respectent pas la structure unitaire.
• D’agent : (ex : il est arrêté par …) : supposent une action passive.
• Comparatifs (ex : plus petit que …) : ne respectent pas la structure unitaire.
• D’exclusion (ex : sans moi) : ne respectent pas la structure unitaire.
• D’opposition : ne concernent que les phrases.
• Restriction : ne concerne que les phrases.
Restent les compléments de :
• De temps : qui permettent de répondre à la question « quand » se déroule l’action.
• De lieu : qui permettent de répondre à la question « où » se déroule l’action
• De cause : qui permettent de répondre à la question de « l’origine » de l’action
• Instrumentaux : qui permettent de répondre à la question « à l’aide de quels moyens » se déroule
l’action
En résumé, les connaissances sont exprimées selon un langage suivant les règles suivantes :
• Unité d’une proposition.
• Le sujet est une personne.
• Que des substantifs et des verbes.
• Un seul mode : l’infinitif.
• Une structure imposée : sujet + prédicat + numéral + COD + compléments circonstanciels.
• Pas de conjugaison.
• Pas de déclinaison.
• Numéral uniquement pour les substantifs inanimés.
• Compléments circonstanciels limités aux compléments :
o De lieu.
o De temps.
o De cause.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 32/80
Année académique 1999-2000
o Instrumentaux.
12.2. Remarques
Quelques remarques s’imposent sur notre langage. Notre structure est ici une structure logique
linguistique. Il est évident que le système informatique derrière cette structure sera adapté pour une
optimisation de traitement. La vue présentée ici en terme d’expression des connaissances s’adresse
donc principalement à l’utilisateur. Le problème du codage en arrière plan n’est pas abordé dans ce
chapitre.
De plus, en ce qui concerne les personnes, voir les objets, il est important de relativiser le terme
« substantif ». Le COD, le sujet et les compléments circonstanciels sont obligatoirement des substantifs
dans notre langage. Là aussi se cache une abstraction. En effet, pour exprimer le fait que M. Dupond
vole trois pains, une structure comme suit :
Dupond / voler / 3 / pain
Il est évident qu’en arrière plan, Dupond sera qualifié par un prénom, une adresse, etc. De même, pain
sera qualifié par un type, un prix, etc.
En bref, notre langage donne une manière formelle d’exprimer les connaissances sur papier (rappelons
que la connaissance que nous cherchons à exprimer par ce langage est une connaissance
d’enchaînement des actions, une structure). Ce sera à notre système, dans un deuxième temps,
d’identifier « Dupond » et « pain ». La qualification de ces deux substantifs ne fait plus partie du
problème structurel du langage, mais de l’identification des besoins de connaissances et de leur
expression sous forme de données brutes.
12.3. Enchaînements et combinaison du langage
Nous avons défini un langage permettant de formaliser le problème de structure. Ce langage nous
permet d’exprimer une action élémentaire dans une structure unitaire.
Cependant l’expérience et l’observation découlent comme dit précédemment d’un enchaînement
d’actions ou d’interactions. Reste donc la question de l’expression de cet enchaînement. Cette
expression peut être réalisée par défaut en utilisant le complément circonstanciel de temps. Non
seulement ce complément nous offre une information sur les circonstances de l’action, mais, de plus, il
nous offre une information sur l’ordre chronologique du déroulement de l’ensemble des actions.
Or la chronologie peut être vue de deux manières différentes. Soit deux actions A et B ayant lieu dans

Paoly Philippe Diplôme postgrade en informatique et organisation Page 33/80
Année académique 1999-2000
cet ordre. Nous pouvons dire soit « A précède B » soit « B suit A ».
Les deux approches sont équivalentes. Un choix arbitraire est fait pour privilégier la première. Ceci
signifie que nous posons comme ordre de lien un ordre « Amont-Aval » et non l’inverse.
Cependant le lien chronologique n’est pas suffisant. En effet, si l’on se réfère à la définition du cas de vol
donnée précédemment, soit « un cas de vol est un vol ainsi que toutes les interactions ou actions en
rapport avec ce vol », on constate que l’ordre chronologique ne donne pas nécessairement le lien
d’interaction.
Mais il est possible de combiner les deux aspects, ordre chronologique et lien d’interaction, dans une
approche « stimulus-réponse ». L’idée est que puisque nous avons des actions unitaires ou
élémentaires, il est possible de faire l’hypothèse que pour chaque intervenant dans un cas de vol, une
action entraîne obligatoirement une réaction d’un autre intervenant, et qu’une action est elle-même une
réaction. En effet, même l’absence de réaction est une réaction en soi. Ceci connaît pourtant une
exception : « l’initialisation ». En effet, il est évident qu’il doit exister au moins une première action,
comme il existe nécessairement une dernière action. Puisque le lien d’interaction se fait dans le sens
« Amont-Aval », il existe une première valeur nulle pour l’aval, soit le début de l’enchaînement. Ceci
peut être résolu par l’existence d’un complément de cause. Nous pouvons donc poser une règle
supplémentaire :
• Un ensemble d’interactions est un enchaînement d’actions où chacune d’elle est une réaction à
la précédente, excepté pour la première action qui est dépendante d’une cause extérieure à cet
enchaînement.
Cette règle, basée sur le principe stimulus-réponse, peut être représentée de la manière suivante :
Figure 12 : Schéma de Stimulus-Réponse
Action RéactionCause

Paoly Philippe Diplôme postgrade en informatique et organisation Page 34/80
Année académique 1999-2000
12.4. Langage complet
L’expression des connaissances définie ici prend comme assise les sources de connaissances existantes.
Outre l’expertise externe, le contrôle des habitants et une partie de l’expertise interne, toutes les
connaissances utiles s’appuient donc sur trois piliers principaux :
• Des données
• Une structure
• Une règle d’enchaînement
Ceci permet de définir un principe général d’expression des connaissances. L’implantation de ce
principe pourra bien sûr être adapté, puisque se posera la question de savoir où commence
l’enchaînement.
Nous avons donc le système général suivant :
Figure 13 : Schéma du langage
Relevons que les données relatives au cas (ainsi que les procédures - voir ci-dessous) ne sont pas
intégrées dans notre structure. En effet une telle intégration n’est pas nécessaire ni utile, puisque ces
données ne sont que des descriptions générales du cas. Ces données ne sont donc pas concernées par
les règles de grammaire décrites précédemment.
12.5. Les procédures
On constate dans la figure précédente que les données relatives aux procédures sont à part. En effet,
une procédure (en tant que donnée) n’est pas soumise aux règles de structure ou d’enchaînement. En
effet, si l’on s’intéresse à la structure de la procédure telle qu’elle est définie dans le chapitre
Cas
Sujet + Prédicat + numéral + COD + Compléments circonstanciels
Cause Action RéactionCause Action Réaction
PersonneActionBien ProcédureDonnées:
Structure:
Enchaînement:

Paoly Philippe Diplôme postgrade en informatique et organisation Page 35/80
Année académique 1999-2000
« Acquisition des connaissances », soit :
Objet 1 + Donnée 1 + Valeur 1 + Objet 2 + Donnée 2 + Valeur 2
où la valeur peut également être un critère, le principe est que si la valeur 1 associée à la donnée 1
relative à l’objet 1 est vraie, alors la valeur 2 doit être associée à la donnée 2 relative à l’objet 2. Il s’agit
ici du principe des règles de procédures selon le concept :
Si Condition Vrai, alors Résultat
La condition est l’ensemble Objet 1 + Donnée 1 + Valeur 1 et le résultat par l’ensemble Objet 2 +
Donnée 2 + Valeur 2.
La procédure n’entre pas dans le cadre de la structure ou de l’enchaînement définis à la figure 13, mais
influe sur l’enchaînement en imposant des actions ou des valeurs aux différents éléments de la structure
syntaxique.
Toutes les procédures devront donc être exprimées sur ce principe. L’intégration des procédures dans
le schéma général présenté à la figure 13 se fait selon le schéma de la figure 14.
L’expression des connaissances, utilise donc, en plus des données, structures et des règles
d’enchaînement des règles de définition de valeur.
12.6. Les procédures obligatoires et non obligatoires
Il est une distinction importante à faire au sein même des procédures. Cette distinction est la notion
d’obligation. En effet, certaines procédures sont impératives, pour des causes légales ou internes à
l’entreprise, alors que d’autres offrent la possibilité aux intervenants de s’adapter aux conséquences, le
plus souvent lorsque des procédures sont contradictoires ou susceptibles de l’être. A titre d’exemple,
les règlements internes donnent comme règle un appel aux forces de l’ordre lorsqu’un cas de récidive se
présente. Cependant, une autre règle conseillant une grande diplomatie envers les personnes âgées, les
femmes enceintes, etc.. laisse aux intervenants une marge de manœuvre. D’autre part, en pratique,
l’appel aux forces de l’ordre se fait principalement en cas de multi-récidive.
Nous avons ici un exemple concret d’une procédure qui en fait n’est qu’une recommandation.
L’intégration des procédures dans le schéma général, comme décrit dans la figure 14 doit être
relativisée. Ce schéma s’impose en effet uniquement pour les procédures obligatoires.
Les procédures assimilées à des recommandations sont intégrées avec une modification importante :
suite à la phase de test, la procédure ne définit pas une donnée de notre structure, mais une donnée d’un
Paoly Philippe Diplôme postgrade en informatique et organisation Page 36/80
Année académique 1999-2000
autre objet nommé « indication » (cf. le prototype) qui définira simplement le contenu de boîtes de
dialogue.
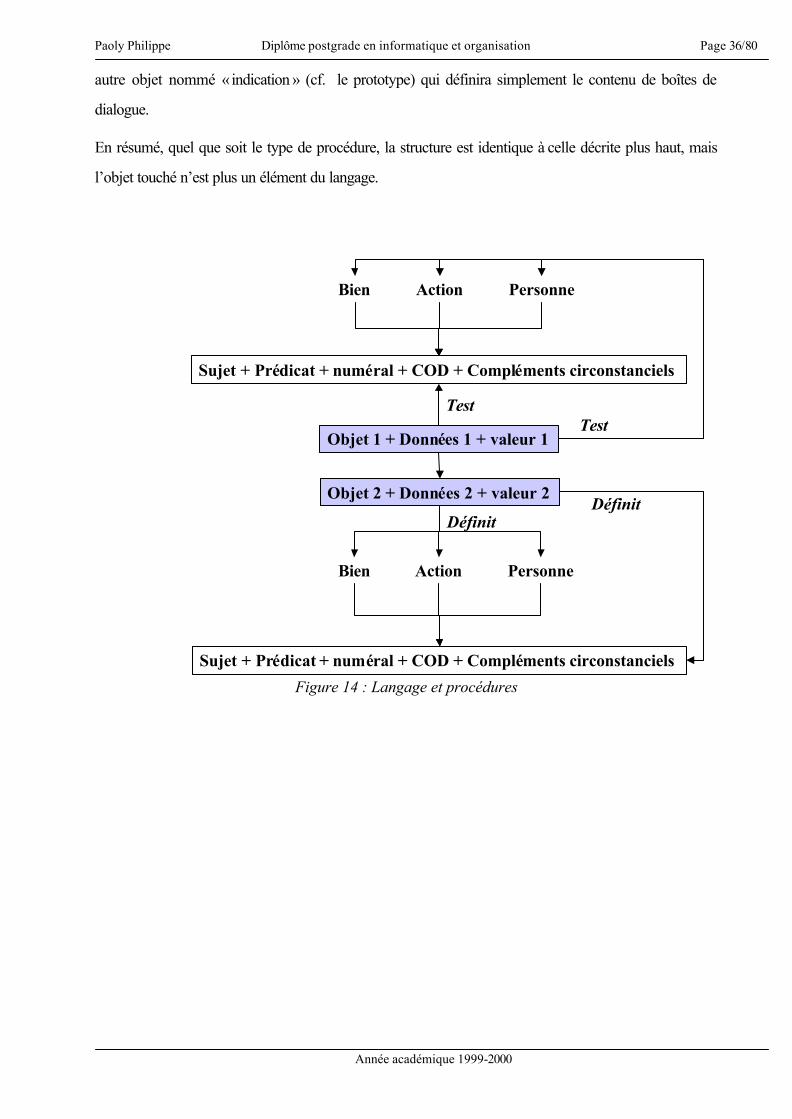
En résumé, quel que soit le type de procédure, la structure est identique à celle décrite plus haut, mais
l’objet touché n’est plus un élément du langage.
Figure 14 : Langage et procédures
Sujet + Prédicat + numéral + COD + Compléments circonstanciels
PersonneActionBien
Objet 2 + Données 2 + valeur 2
Objet 1 + Données 1 + valeur 1
Sujet + Prédicat + numéral + COD + Compléments circonstanciels
PersonneActionBien
TestTest
DéfinitDéfinit

Paoly Philippe Diplôme postgrade en informatique et organisation Page 37/80
Année académique 1999-2000
Partie IV – Conception et modélisation du business
13. Outil de modélisation
Maintenant que nous avons défini la méthodologie, les besoins de connaissances, la stratégie de gestion
des connaissances, l’acquisition et l’expression des connaissances, il nous faut comprendre et modéliser
le business, autrement dit la problématique générale de la sécurité dans l’entreprise COOP Vaud
Chablais valaisan dans le cadre que nous avons défini. Pour ce faire, nous allons utiliser le langage de
modélisation UML17 dans une approche orientée objet.
UML se base sur quatre vues, selon le schéma suivant développé par [Muller 97] :
Figure 15 : approche 4+1 vues
Outre ces 4+1 vues, UML propose de manière transversale un total de neuf diagrammes, soit :
• Diagramme des cas d’utilisation (use-case)
• Diagramme d’objet
• Diagramme de collaboration
17 Unified Modeling Language
VueLogique
Vue desprocessus
Vue dedéploiement
Vue descomposants
Vues des cas d’utilisation

Paoly Philippe Diplôme postgrade en informatique et organisation Page 38/80
Année académique 1999-2000
• Diagramme de séquence
• Diagramme de classe
• Diagramme d’état transition
• Diagramme d’activité
• Diagramme de composants
• Diagramme de déploiement
Cependant, N.Kettani [Kettani 98] explique l’importance de la dimension métier d’un système
d’information. Il définit la modélisation du métier comme l’ensemble des étapes suivantes :
• L’étude du périmètre des intervenants extérieurs à l’entreprise
• L’étude des processus de l’entreprise
• L’étude des travailleurs et des entités de l’entreprise
• L’étude des workflows des processus
• L’étude des structures organisationnelles
Le tout suppose d’intégrer les processus de développement du système informatique dans le processus
d’ingénierie de métier, de construire le système informatique dont le métier a besoin (et non l’inverse) et
d’utiliser les mêmes concepts pour un métier et pour son système.
Dans le cadre du présent mémoire, l’objectif n’est pas la réalisation complète d’un système
d’information opérationnel, mais de définir une méthode de conception et de créer un prototype. Ajouté
à la contrainte temporelle, il est évident qu’il n’est pas possible de réaliser une modélisation complète
selon les deux composantes que sont les vues et les diagrammes.
De plus, nous ne cherchons pas à modéliser une entreprise mais une activité seulement de celle-ci,
modélisation dont la difficulté est due à l’existence d’un système compliqué mais non complexe (au sens
systémique). En conséquence, certains diagrammes ne sont pas essentiels. Dans notre cas, le diagramme
d’état transition n’apporte aucun élément utile, puisque les objets définis précédemment ne subissent
aucun changement d’état lors des processus. En outre, le diagramme d’objet n’est pas ici utile, puisque
le diagramme de classe apporte la même information (en plus détaillé). Ajoutons que le diagramme
d’activité n’apporte pas non plus d’information essentielle puisque que celle-ci peut se voir dans le
diagramme des cas d’utilisation et que le détail des activités est justement l’inconnu que nous cherchons
à saisir.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 39/80
Année académique 1999-2000
D’autre part, nous ne sommes pas dans un service ayant une activité industrielle. Les processus sont des
ensembles de relations humaines, ce qui entraîne logiquement une communion des concepts de
processus et de collaboration. Un diagramme de séquence englobe donc l’information contenue dans un
diagramme de collaboration ou d’activité.
Ceci étant dit, nous pouvons déduire que seuls cinq diagrammes sur neuf sont utiles pour nous. Ceux-ci
sont :
• Le diagramme de classe
• Le use case (diagramme des cas d’utilisation)
• Le diagramme de séquences
• Le diagramme de composant
• Le diagramme de déploiement
Naturellement, même dans le cadre restrictif de ces cinq diagrammes, toutes les situations ne peuvent
être abordées, faute de temps. Nous allons donc présenter ces cinq diagrammes dans une forme non
exhaustive et à titre principal d’illustration.
14. Diagramme de classe
Concernant le diagramme de classe, nous pouvons ici nous baser sur les objets, du moins dans un
premier temps, définis dans le chapitre « besoin de connaissances ».
Ces objets sont :
• Les cas : l’objet cas est un objet englobant données et enchaînement
• Les personnes : l’objet personne peut se décliner en divers types selon les besoins
• Les biens : l’objet bien peut se décliner en divers types selon les besoins
• Les procédures : l’objet procédure peut se décliner en procédure obligatoire et non obligatoire
• Les actions : l’action de base, unitaire
Il est possible de rajouter certains objets, de manière à simplifier l’approche et la compréhension du
business. Ceci peut bien sûr apporter quelques modifications à la liste du chapitre « Besoin de

Paoly Philippe Diplôme postgrade en informatique et organisation Page 40/80
Année académique 1999-2000
connaissances », liste rappelons-le qui n’est pas exhaustive d’une part, et qui prend place dans une
réflexion plus large que la modélisation d’autre part. Notamment, nous pouvons définir 5 classes
d’objets supplémentaires :
• Le lieu : le lieu où se déroule un cas ou une action
• Les moyens : les moyens d’action mis en œuvre
• Les processus : le processus sous-jacent à l’action
• Les causes : la cause d’une action
• Le contexte : le contexte général du cas
A l’aide de ces classes, nous pouvons construire le diagramme de classe :
Figure 16 : Diagramme de classe
Ce diagramme nous montre les diverses classes d’objets et leurs relations entre elles.
15. Use case
Le use case possède ici un rôle important, puisqu’il pose le problème de l’utilisation de notre système.
Nous commençons en premier lieu à définir les acteurs du métier, qui sont ici :
• Le client
• Le surveillant
Cas
Personnes
Biens
Procédures
Actions
Lieu
Cause
Moyens
Processus
Contexte
Prédicat
englobe 1..*
produit 1..*
sélectionne 1..*
définit 1..* est 1-1
Prend place dans 1-1
utilise 1..*
appartient à 1-1
utilise 1..*
implique 1..*définit 1..*
utilise 1-1
Cas
Personnes
Biens
Procédures
Actions
Lieu
Cause
Moyens
Processus
Contexte
Prédicat
englobe 1..*
produit 1..*
sélectionne 1..*
définit 1..* est 1-1
Prend place dans 1-1
utilise 1..*
appartient à 1-1
utilise 1..*
implique 1..*définit 1..*
utilise 1-1

Paoly Philippe Diplôme postgrade en informatique et organisation Page 41/80
Année académique 1999-2000
• L’interpellant
• Le personnel du magasin
• Le chef de la sécurité
• Les tiers
Une fois ceci fait, il est important de définir les acteurs de notre système, qui sont les mêmes personnes,
mais dans une approche de fonction. Ici, le même acteur du métier peut endosser plusieurs vestes
différentes comme acteur du système.
Ceux-ci sont, en rappelant que notre objectif principal, dans l’utilisation de notre système, est la gestion
et la formation :
• Le gestionnaire : le gestionnaire du système
• L’élève : en formation
• Le formateur : celui qui a la charge de la formation
• Le surveillant : celui qui effectue la surveillance
• L’interpellant : celui qui interpelle l’auteur du délit
• L’administrateur : s’occupe des problèmes administratifs (saisies, etc…)
Nous pouvons dès lors construire un use case. Ici nous en présentons un, où le gestionnaire du système
n’apparaît pas, dans le but d’en faciliter la compréhension, de même que l’administrateur. Le rôle du
gestionnaire se définit comme un rôle de modérateur, de contrôle des entrées dans le système, de
maintien de la cohérence et un rôle général de supervision. Le rôle de l’administrateur est une notion de
fonction, rôle remplit ici par tous les intervenants excepté l’élève.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 42/80
Année académique 1999-2000
Figure 17 : Use case
La liste des tâches effectuées par le système n’est bien sûr pas complète, mais donne ici une idée des
possibilités offertes.
16. Séquences
Surveillant
Calcule des risques
Gestion d'indices
Génère des profils
Interpellant
Traite les requêtes
Elève
Indique des procédures
Indique les cas délicats
Formateur
Surveillant
Calcule des risques
Gestion d'indices
Génère des profils
Interpellant
Traite les requêtes
Elève
Indique des procédures
Indique les cas délicats
Formateur

Paoly Philippe Diplôme postgrade en informatique et organisation Page 43/80
Année académique 1999-2000
Le diagramme de séquences montre les interactions, entre les objets, arrangées en séquences dans le
temps. En particulier, il montre les objets participant dans l’interaction par leur « ligne de vie » et les
messages qu’ils échangent ordonnancés dans le temps. Il ne montre pas les associations entre objets
[Kettani 98]. Cette définition est illustrée ici par un diagramme présentant le déroulement d’un cas de
vol.
Figure 18 : Diagramme de séquence
Bien évidemment, le diagramme ci-dessus n’est qu’une illustration permettant de voir, de manière
simplifiée, le déroulement d’un cas de vol. Il est important de préciser encore que les objets présentés
sont des personnes, définies par leurs fonctions. L’interpellant et le surveillant, par exemple, sont le plus
souvent une seule et même personne.
17. Diagramme de composants
Surveillant Personnesoupçonée
Interpellant Administrateur Gestionnaire
Remarquer
Hesiter
Rechercher
Avertitr et Informer
Arreter
Reagir ou collaborer
Appeler
Verifier BD
Assister
Poser des questions
Repondre
Demander informationssuplem.
Fournir justification
Decider
Expliquer la décision
Payer, restituer ou Réfuser
Remplir les formulaires
Transmettre les informations
Modifier BD
Donner des instructions
Surveillant Personnesoupçonée
Interpellant Administrateur Gestionnaire
Remarquer
Hesiter
Rechercher
Avertitr et Informer
Arreter
Reagir ou collaborer
Appeler
Verifier BD
Assister
Poser des questions
Repondre
Demander informationssuplem.
Fournir justification
Decider
Expliquer la décision
Payer, restituer ou Réfuser
Remplir les formulaires
Transmettre les informations
Modifier BD
Donner des instructions
Paoly Philippe Diplôme postgrade en informatique et organisation Page 44/80
Année académique 1999-2000
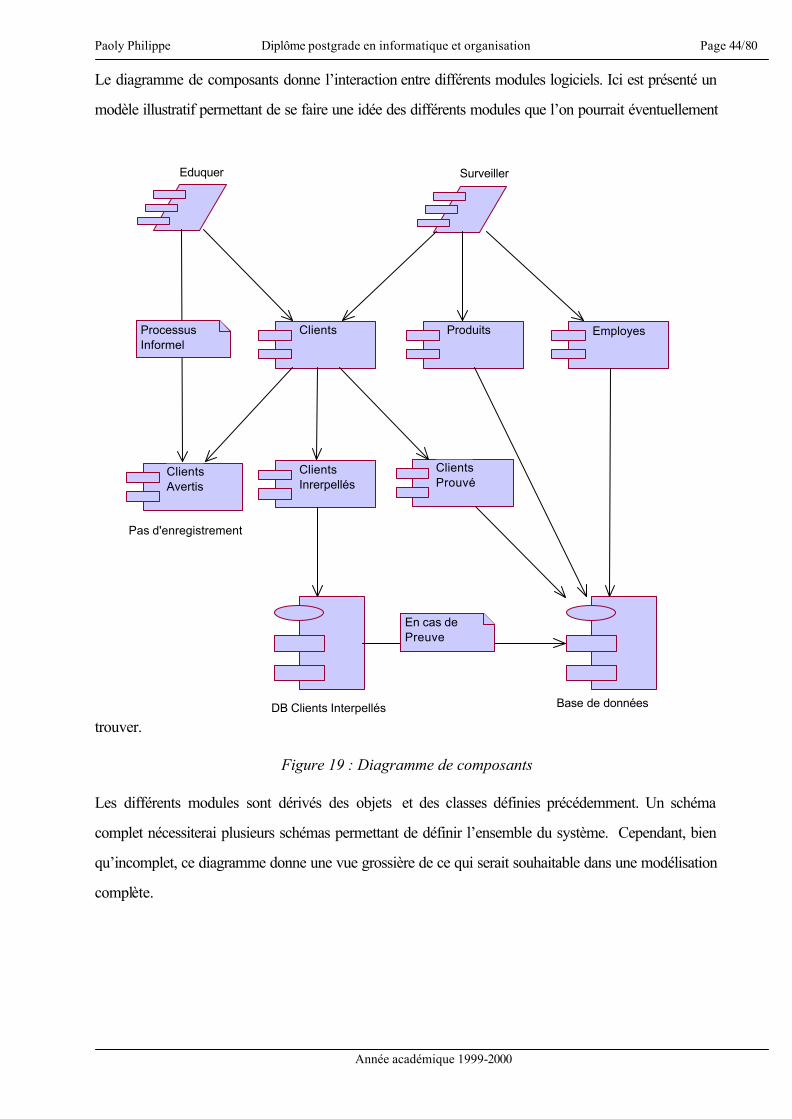
Le diagramme de composants donne l’interaction entre différents modules logiciels. Ici est présenté un
modèle illustratif permettant de se faire une idée des différents modules que l’on pourrait éventuellement
trouver.
Figure 19 : Diagramme de composants
Les différents modules sont dérivés des objets et des classes définies précédemment. Un schéma
complet nécessiterai plusieurs schémas permettant de définir l’ensemble du système. Cependant, bien
qu’incomplet, ce diagramme donne une vue grossière de ce qui serait souhaitable dans une modélisation
complète.
Clients Produits Employes
Base de données
ClientsAvertis
ClientsInrerpellés
ClientsProuvé
En cas de Preuve
Eduquer Surveiller
ProcessusInformel
Pas d'enregistrement
DB Clients Interpellés

Paoly Philippe Diplôme postgrade en informatique et organisation Page 45/80
Année académique 1999-2000
18. Diagramme de déploiement
Le dernier diagramme présenté est le diagramme de déploiement. Il donne une idée de l’architecture
générale que devrait avoir l’implémentation du système. Là aussi, il ne s’agit qu’une représentation
illustrative, donnant une idée d’une implantation possible.
Figure 20 : Diagramme de déploiement
On constate que la proposition est ici de lier entre elles les différentes coopératives régionales. Au sein
de chaque coopérative régionale, il existe des relations informatiques avec les magasins et les centres de
formation. Le tout étant relié à un serveur central, permettant une agrégation des données au niveau
national.
Naturellement, à chaque niveau, il est possible d’intégrer des périphériques, comme un serveur
d’impression par exemple. De plus, l’utilisation d’Internet permet des liens avec divers serveurs, internes
ou externes à l’entreprise. Non seulement il est facile d’imaginer des liens avec d’autres services de
l’entreprise, comme les achats par exemple (dans le but d’une modification directe de certaines
données), mais aussi avec d’autres partenaires ou entreprises, parfois concurrentes mais partenaires
dans le domaine de la sécurité.
ServeurGeneve
Serveur central
Serveurweb
Poste acheteur
Serveurd'impres
SGBD
Internet
Consulter marché
ServeurVaud
Serveur magasin
Serveur C.format
SGBD régional
SGBD local
SGBD local
SGBD local
Consulter historique
Serveurmagasin
Serveurmagasin
ServeurC.format
Serveurmagasin
SGBD local
SGBD local
SGBD local SGBD régional
Consulter historiqueConsulter historique

Paoly Philippe Diplôme postgrade en informatique et organisation Page 46/80
Année académique 1999-2000
Partie V – Moteur d’inférence
19. Définition des besoins d’inférence
Il est important dans cette définition de garder à l’esprit les objectifs du système et principalement de se
souvenir des fonctionnalités de base définies dans le chapitre « Hypothèses et postulats ». Ces
fonctionnalités étaient (et restent) celles-ci :
• Interpréter une requête en langage structuré
• Proposer une réponse pertinente
• Apprendre et évoluer
• Générer des scénarii
• Décrire diverses situations
• Illustrer une problématique
• Tester divers comportements/réactions
• Générer des profils
• Déceler des problèmes sous-jacents : attirer l’attention sur des éléments probables
• Traiter des indices : générer des probabilités suivant divers éléments
• Traiter des données : divers types de traitements statistiques
• Offrir une bibliothèque de cas : permettre la gestion des documents papiers
• Gérer les procédures : indiquer les règles d’action existantes, proposer des règles d’action
Ces fonctionnalités paraissent à priori essentielles dans les réponses aux besoins de l’entreprise. Elles
permettent d’offrir un soutien autant dans la formation que dans la gestion.
Nous pouvons définir trois groupes de fonctions à partir de ces hypothèses :
• Fonctions d’extraction suite à une question : ces fonctions permettent non seulement de
répondre à une question, mais également d’illustrer une certaine problématique
• Fonctions d’extraction en vue d’un traitement statistique : ces fonctions doivent préparer les
données extraites en vue d’un traitement quelconque.
• Fonctions de génération de scénarii (ou de test) : doivent permettre de générer des scénarii dans

Paoly Philippe Diplôme postgrade en informatique et organisation Page 47/80
Année académique 1999-2000
le but de simuler des jeux de rôle, en cohérence avec la réalité.
La bonne marche de ces groupes de fonctions dépend naturellement des types de raisonnement définis
dans le chapitre « besoin de connaissances ». Ces types étaient :
• Sélection
• Assimilation
• Agrégation
La réflexion concernant la modélisation du moteur d’inférence doit donc s’appuyer sur une matrice à
deux dimensions qui permet de définir la méthode qui nous permettra de répondre aux deux objectifs.
Le chapitre « modélisation des moteurs d’inférence » détaillera cette matrice qui est la suivante :
Extraction :question Extraction : statistique Extraction :scénarii Sélection Critères Critères Probabilité Assimilation - - Probabilité Agrégation Probabilité et proximité Calcul ou néant Probabilité
Figure 21 : Matrice de réflexion du moteur d’inférence On distingue à partir de cette matrice quatre type de méthodes :
• L’utilisation de critères de recherche
• L’utilisation des probabilités
• L’utilisation de la notion de proximité
• L’utilisation de fonctions de calculs
Ces types de méthodes vont définir les choix des moteurs d’inférence. Mais le choix des moteurs d’inférence
influence également l’utilisation des ces types de méthodes. Il y a ici un raisonnement itératif.
En outre, les fonctions de calculs ne sont pas vraiment un élément d’inférence, de même que l’utilisation de
critères. Ces deux derniers éléments ne correspondent pas ici à la définition d’un moteur d’inférence (permettant
d’automatiser une opération logique permettant d’admettre une proposition en vertu de sa liaison avec d’autres
propositions tenues pour vraies). Reste donc deux méthodes utiles pour les moteurs d’inférence, l’utilisation de la
proximité et des probabilités. L’utilisation de critères et les fonctions de calcul n’ont pas d’utilité ici, dans la
conception du moteur d’inférence, mais en auront naturellement dans la conception du prototype, puisque
qu’elles correspondent à des fonctionnalités prévues pour l’utilisateur.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 48/80
Année académique 1999-2000
20. Choix des moteurs d’inférence
Quels moteurs d’inférence allons choisir, ou plutôt quels types de moteur d’inférence. La principale
question est de choisir entre deux types principaux :
• Moteur basé sur des règles de procédures
• Moteur basé sur des stéréotypes
Puisque nous avons des procédures, aurons-nous naturellement un moteur d’inférence basé sur les
règles de procédures ?
Il est essentiel de se souvenir que dans notre système, les procédures sont là pour guider l’enchaînement
d’actions, non pour générer une opération logique de lien. De plus, il ne faut pas perdre de vue que
l’élément essentiel à intégrer dans notre système est l’expérience. Il s’agit d’un enchaînement variable
d’actions unitaires variables. L’utilisation de règles de procédure est ici irréaliste. En effet, il est
impossible de définir une règle de procédure liant l’action d’un individu (par exemple l’interpellation) et
la réaction d’un autre individu (par exemple la collaboration). En cas d’interpellation, les possibilités de
réaction sont à priori aussi nombreuses qu’il y a d’individu sur la planète.
Par contre, la notion de stéréotype est ici pertinente. Il possible de dire, s’il s’agit de ce qui est observé
le plus souvent dans la réalité, que s’il y a interpellation, il y a généralement une réaction de
collaboration.
En bref, compte tenu de certains éléments connus à l’origine, il est possible, par analogie, de définir un
cas probable qui, pour notre problématique, devient un stéréotype associé à une probabilité.
Nous aurons donc un moteur d’inférence basé sur la notion de stéréotype. De plus, les stéréotypes
seront basés sur l’utilisation des probabilités d’apparition.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 49/80
Année académique 1999-2000
21. Modélisation des moteurs d’inférence
La modélisation des moteurs d’inférence n’est pas présentée de manière complète. Elle illustre
l’utilisation de la notion de distance et des probabilités. Comme illustration, nous allons aborder trois
fonctionnalités que doit remplir notre moteur, soit :
• La sélection d’un stéréotype
• La génération de scénarii
• Interpréter une requête en langage structuré
Mais il est important de commencer par le commencement, soit par la méthode d’assimilation, puisque
sans une assimilation correcte, une sélection et une agrégation seraient impossibles.
Notons également que la modélisation est également limitée, toujours dans un but illustratif, à
l’enchaînement d’actions uniquement définies par le prédicat. Le principe d’utilisation des probabilités et
de distances reste identique pour les autres éléments de notre langage.
21.1. L’assimilation
21.1.1. Rappels sur les probabilités
Précédemment nous avons défini l’assimilation comme le résultat de l’utilisation des probabilités. En
faisant appel aux principes de base de l’utilisation des probabilités, principalement à la notion de « OU »
et à la notion de « ET » et à leurs significations dans la théorie des ensembles (intersection et union),
nous nous souvenons que le « OU » entraîne l’addition des probabilités associées et le « ET » entraîne
la multiplication des probabilités.
A titre d’exemple, si dans un sac se trouvent dix boules de couleurs différentes, trois rouges, trois
bleues, deux blanches et deux noires, et que nous pratiquons un tirage avec remise, la probabilité de
tirer une boule blanche est, à chaque tirage, de 1/5, alors que la probabilité de tirer une boule rouge est
de 3/10.
La probabilité, avec un tirage, de tirer une boule blanche OU une rouge est de 1/2. Nous constatons
que ce chiffre peut être obtenu en additionnant 1/5 et 3/10.
La probabilité, avec deux tirages, de tirer une boule blanche ET une rouge est de 3/50. Nous constatons
que ce chiffre peut être obtenu en multipliant 1/5 et 3/10.
La probabilité, avec deux tirages, de tirer deux boules blanches est de 1/25. Nous constatons que ce
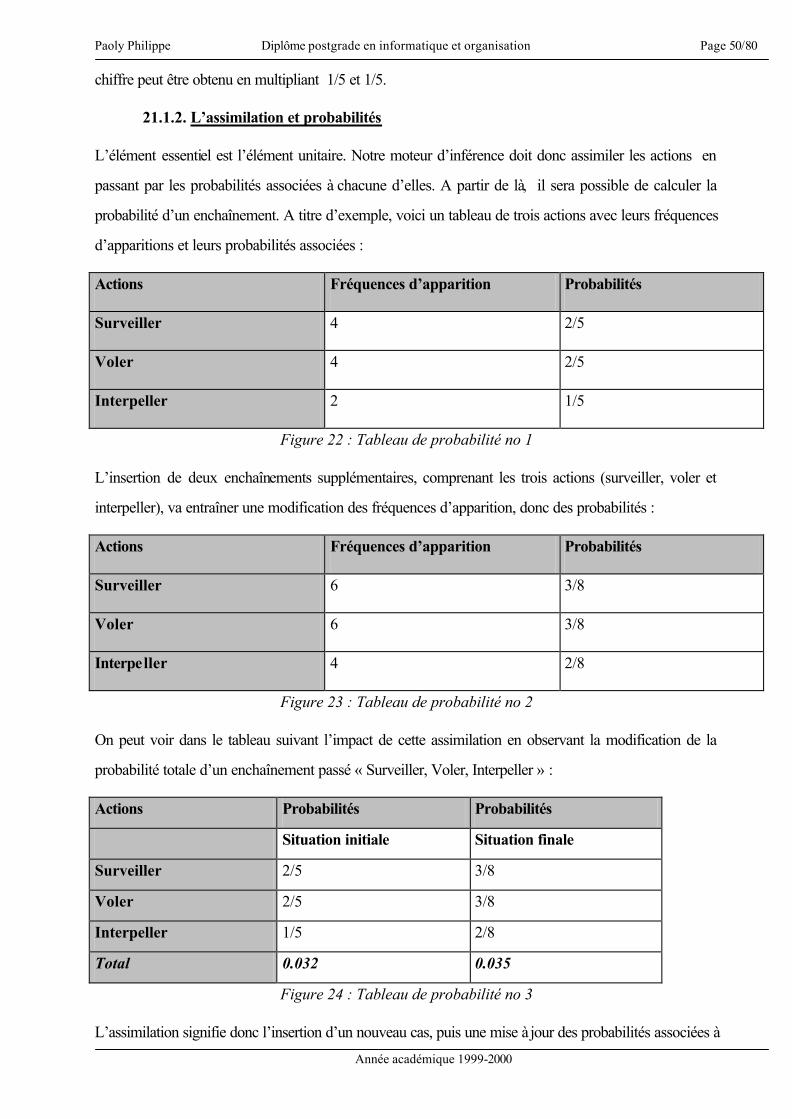
Paoly Philippe Diplôme postgrade en informatique et organisation Page 50/80
Année académique 1999-2000
chiffre peut être obtenu en multipliant 1/5 et 1/5.
21.1.2. L’assimilation et probabilités
L’élément essentiel est l’élément unitaire. Notre moteur d’inférence doit donc assimiler les actions en
passant par les probabilités associées à chacune d’elles. A partir de là, il sera possible de calculer la
probabilité d’un enchaînement. A titre d’exemple, voici un tableau de trois actions avec leurs fréquences
d’apparitions et leurs probabilités associées :
Actions Fréquences d’apparition Probabilités
Surveiller 4 2/5
Voler 4 2/5
Interpeller 2 1/5
Figure 22 : Tableau de probabilité no 1
L’insertion de deux enchaînements supplémentaires, comprenant les trois actions (surveiller, voler et
interpeller), va entraîner une modification des fréquences d’apparition, donc des probabilités :
Actions Fréquences d’apparition Probabilités
Surveiller 6 3/8
Voler 6 3/8
Interpeller 4 2/8
Figure 23 : Tableau de probabilité no 2
On peut voir dans le tableau suivant l’impact de cette assimilation en observant la modification de la
probabilité totale d’un enchaînement passé « Surveiller, Voler, Interpeller » :
Actions Probabilités Probabilités
Situation initiale Situation finale
Surveiller 2/5 3/8
Voler 2/5 3/8
Interpeller 1/5 2/8
Total 0.032 0.035
Figure 24 : Tableau de probabilité no 3
L’assimilation signifie donc l’insertion d’un nouveau cas, puis une mise à jour des probabilités associées à

Paoly Philippe Diplôme postgrade en informatique et organisation Page 51/80
Année académique 1999-2000
chaque action puis enfin une mise à jour des probabilités de chaque cas déjà inséré.
21.2. La sélection d’un stéréotype
La sélection d’un stéréotype se base également sur les probabilités, mais en intégrant une notion
supplémentaire, celle de distance. En se référant à l’assimilation, le travail repose sur l’analyse des
enchaînements.
L’idée est qu’en proposant un enchaînement d’actions, le moteur d’inférence recherche le cas le plus
probable comportant cet enchaînement. Deux cas de figure peuvent apparaître : soit l’enchaînement
existe dans la base de données, soit l’enchaînement n’existe pas. Parallèlement à cela, deux options sont
possibles : soit l’ordre d’apparition des actions dans l’enchaînement compte, soit il ne compte pas.
Nous n’illustrerons ici que l’option où l’ordre compte, cette option étant la plus complète et surtout la
plus logique dans notre problématique.
21.2.1. Si l’enchaînement existe
Lorsque l’enchaînement existe dans la base de données, l’idée est de trouver le cas le plus probable
comprenant cet enchaînement. Prenons par exemple une base de données comportant six cas différents,
combinant dix actions différentes (voir la figure 25) :
• Enchaînement no 1 : actions 1, 2, 4 et 7
• Enchaînement no 2 : actions 1, 2, 4 et 5
• Enchaînement no 3 : actions 1, 2, 5 et 8
• Enchaînement no 4 : actions 1, 2, 5 et 9
• Enchaînement no 5 : actions 1, 3, 5 et 10
• Enchaînement no 1 : actions 1, 3, 6 et 10
Imaginons que nous recherchons l’enchaînement comprenant les actions no 1, 2 et 4, ce qui correspond
aux cas no 1 et 2 (les enchaînements dans lesquels se retrouvent les actions).
Hors, grâce à l’assimilation, nous avons pu définir une probabilité pour chaque action (voir la figure 26),
ce qui nous permet d’associer une probabilité à chaque cas (voir la figure 27). Cette association nous
permet de donner un rang à chaque cas. Ici notre problématique est la recherche d’un cas existant, les
cas no 1 et 2. La figure 27 permet de choisir entre les deux, soit ici celui qui à la probabilité (ou le rang)
la plus élevée, soit le cas no 1. Lorsque nous avons une recherche donnant comme résultat deux cas
ayant la même probabilité, soit le moteur travaille sur la proximité à partir des cas sélectionnés, dans
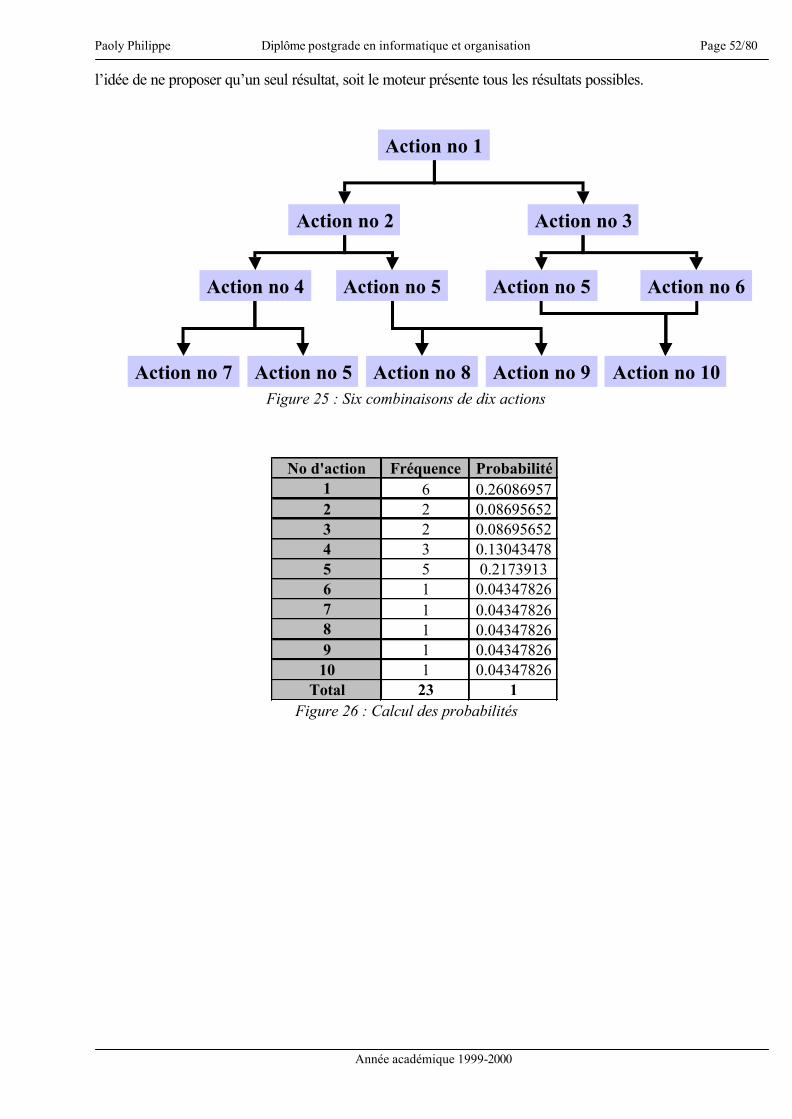
Paoly Philippe Diplôme postgrade en informatique et organisation Page 52/80
Année académique 1999-2000
l’idée de ne proposer qu’un seul résultat, soit le moteur présente tous les résultats possibles.
Figure 25 : Six combinaisons de dix actions
Figure 26 : Calcul des probabilités
Action no 1
Action no 3Action no 2
Action no 6Action no 4 Action no 5Action no 5
Action no 9Action no 8Action no 5Action no 7 Action no 10
No d'action Fréquence Probabilité1 6 0.260869572 2 0.086956523 2 0.086956524 3 0.130434785 5 0.21739136 1 0.043478267 1 0.043478268 1 0.043478269 1 0.0434782610 1 0.04347826
Total 23 1

Paoly Philippe Diplôme postgrade en informatique et organisation Page 53/80
Année académique 1999-2000
Figure 27 : choix des cas
L’intégration de la notion d’ordre est ici très simple à effectuer. En effet il suffit d’associer à chaque
action de l’enchaînement recherché un numéro d’ordre, et de ne sélectionner que les cas où
l’enchaînement correspond à ces numéros d’ordre, en travaillant sur la notion de plus grand ou plus
petit. Ceci est d’autant plus facile qu’au moment de la saisie des informations, l’ordre d’enchaînement
des actions est intégré dans la structure et devient donc disponible.
A titre d’exemple, en recherchant par exemple l’enchaînement des actions no 2 et 1, dans l’ordre, nous
n’avons aucun résultat disponible.
21.2.2. Si l’enchaînement n’existe pas
Lorsque l’enchaînement n’existe pas dans la base de données, l’idée de base est de trouver le cas dont
la probabilité est la plus élevée et dont la proximité avec l’enchaînement donné est la plus haute. La
méthode est décomposée en trois étapes :
• Recherche des cas comportant le maximum des actions de l’enchaînement recherché
• Recherche du cas le plus probable
• Recherche du cas dont la proximité avec l’enchaînement recherché est la plus élevée
A titre d’exemple (en continuant à nous baser sur l’exemple précédent), si nous recherchons
l’enchaînement comportant les actions no 1, 8, 9 et 10, nous nous rendons compte, en nous basant sur
la figure 25, que cet enchaînement n’existe pas. Par contre, une première recherche permet de
sélectionner les cas no 3, 4 et 5, selon la figure suivante :
No d'action/cas 1 2 3 4 5 61 0.26086957 0.26086957 0.26086957 0.26086957 0.26086957 0.2608695652 0.08695652 0.08695652 0.08695652 0.08695652 1 13 1 1 1 1 0.08695652 0.0869565224 0.13043478 0.13043478 1 1 1 15 1 0.2173913 0.2173913 0.2173913 0.2173913 16 1 1 1 1 1 0.0434782617 0.04347826 1 1 1 1 18 1 1 0.04347826 1 1 19 1 1 1 0.04347826 1 1
10 1 1 1 1 0.04347826 0.043478261Total 0.00012864 0.00064322 0.00021441 0.00021441 0.00021441 4.28815E-05Rang 4 3 2 2 2 1
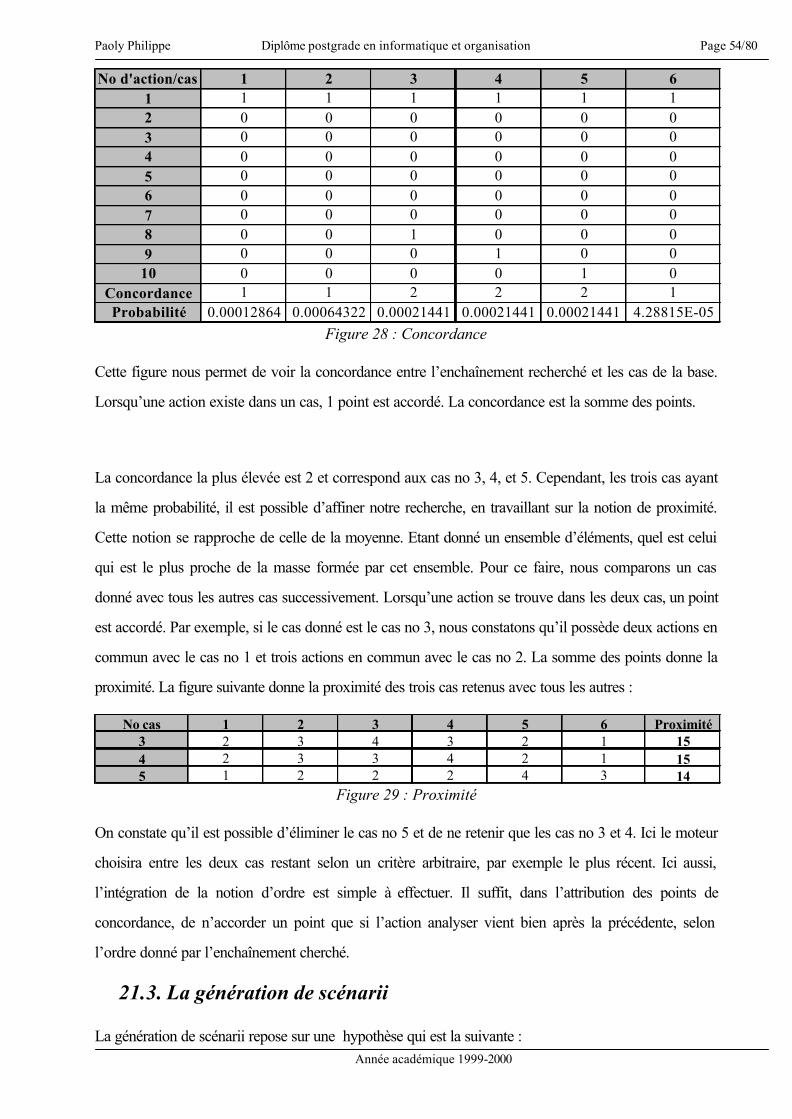
Paoly Philippe Diplôme postgrade en informatique et organisation Page 54/80
Année académique 1999-2000
Figure 28 : Concordance
Cette figure nous permet de voir la concordance entre l’enchaînement recherché et les cas de la base.
Lorsqu’une action existe dans un cas, 1 point est accordé. La concordance est la somme des points.
La concordance la plus élevée est 2 et correspond aux cas no 3, 4, et 5. Cependant, les trois cas ayant
la même probabilité, il est possible d’affiner notre recherche, en travaillant sur la notion de proximité.
Cette notion se rapproche de celle de la moyenne. Etant donné un ensemble d’éléments, quel est celui
qui est le plus proche de la masse formée par cet ensemble. Pour ce faire, nous comparons un cas
donné avec tous les autres cas successivement. Lorsqu’une action se trouve dans les deux cas, un point
est accordé. Par exemple, si le cas donné est le cas no 3, nous constatons qu’il possède deux actions en
commun avec le cas no 1 et trois actions en commun avec le cas no 2. La somme des points donne la
proximité. La figure suivante donne la proximité des trois cas retenus avec tous les autres :
Figure 29 : Proximité
On constate qu’il est possible d’éliminer le cas no 5 et de ne retenir que les cas no 3 et 4. Ici le moteur
choisira entre les deux cas restant selon un critère arbitraire, par exemple le plus récent. Ici aussi,
l’intégration de la notion d’ordre est simple à effectuer. Il suffit, dans l’attribution des points de
concordance, de n’accorder un point que si l’action analyser vient bien après la précédente, selon
l’ordre donné par l’enchaînement cherché.
21.3. La génération de scénarii
La génération de scénarii repose sur une hypothèse qui est la suivante :
No d'action/cas 1 2 3 4 5 61 1 1 1 1 1 12 0 0 0 0 0 03 0 0 0 0 0 04 0 0 0 0 0 05 0 0 0 0 0 06 0 0 0 0 0 07 0 0 0 0 0 08 0 0 1 0 0 09 0 0 0 1 0 0
10 0 0 0 0 1 0Concordance 1 1 2 2 2 1Probabilité 0.00012864 0.00064322 0.00021441 0.00021441 0.00021441 4.28815E-05
No cas 1 2 3 4 5 6 Proximité3 2 3 4 3 2 1 154 2 3 3 4 2 1 155 1 2 2 2 4 3 14

Paoly Philippe Diplôme postgrade en informatique et organisation Page 55/80
Année académique 1999-2000
Les probabilités associées aux cas suivent une distribution normale.
Ceci permet donc d’utiliser les probabilités associées et la loi normale pour générer un scénario. Le
principe est le suivant, décomposé en trois étapes :
• Génération par le moteur d’un nombre aléatoire suivant une distribution normale.
• Multiplication de ce nombre par la probabilité maximum associée à un cas.
• Choix du cas ayant la probabilité la plus proche du produit précédent.
A titre d’exemple, en prenant comme référence les chiffres de la figure 28, voyons ce qui se passerait en
générant un nombre aléatoire égal à 0.56.
En multipliant ce nombre par la probabilité maximum associée à un cas, soit 0.00012864, nous obtenons
0.000072016. La probabilité associée la plus proche est alors de 0.0000428815, soit le cas no 6.
Puisqu’un nombre aléatoire est toujours compris entre 1 et 0, nous avons, en multipliant ce nombre à la
probabilité maximum associée à un cas, une borne supérieure (le cas ayant la plus forte probabilité) et
une borne inférieure (le zéro). Tous les cas sont donc couverts.
Cette approche permet de travailler sur des cas en copiant leur fréquence d’apparition dans la réalité.
Mais elle peut-être étendue dans une vue action-réaction, reproduisant la structure de notre langage. En
effet, il est possible d’attribuer un rôle à une personne en formation, par exemple le rôle de l’interpellant,
et d’attribuer un rôle différent au moteur. Lorsque la personne choisit une action, le moteur choisit une
réaction de manière aléatoire, selon le même principe. A cette réaction, la personne choisit une action en
réponse. Le moteur peut analyser alors, selon les méthodes décrites dans le chapitre concernant le test
de comportement, quelles sont les implications de cet enchaînement.
21.4. Interpréter une requête en langage structuré
L’interprétation d’une requête en langage structuré repose sur le langage développé dans ce travail.
Nous avons développé un langage avec sa propre morphologie et grammaire. Ce sont ces règles qui
représentent la structure de la requête.
Le but de la requête est ici la recherche précise d’un cas.
La requête s’appuiera donc sur la figure 13, où l’utilisateur définira une donnée associée à un élément de
structure. L’ordre d’enchaînement des propositions sera défini par l’ordre de saisie.
Outre cette recherche basée sur le langage défini précédemment, la recherche peut naturellement porter
sur l’ensemble des objets et attributs définis dans les chapitres précédents. A chaque attribut, l’utilisateur

Paoly Philippe Diplôme postgrade en informatique et organisation Page 56/80
Année académique 1999-2000
pourra définir une valeur de référence, éventuellement un ordre de grandeur (plus grand et plus petit),
valeur sur laquelle portera la recherche.
Naturellement, la transcription entre les valeurs de recherche définies par l’utilisateur et le langage SQL
devra être automatique et non visible.
Outre la définition de valeur, l’utilisateur devra pouvoir donner des indications de sélection, notamment
deux fonctions primordiales, le OU et le ET.
En résumé, l’utilisateur doit pouvoir faire une recherche répondant à trois questions :
• Quoi ? (Quel objet ou quelle valeur)
• Comment ? (Et/Ou)
• Quand ? (Sous quelles conditions )
La structure du langage est reprise de la figure 13 dans le but de conjuguer saisie et recherche et permet
d’introduire un élément supplémentaire dans la recherche : la notion d’ordre.
Naturellement, deux approches sont possibles dès l’instant où les paramètres de recherche sont définis :
• La sélection d’un cas précis, en indiquant l’absence de cas si les paramètres ne sont pas
absolument respectés
• La sélection d’un cas précis, puis la sélection du cas le plus probable en cas d’inexistence, ce
qui revient à générer un stéréotype.
L’utilisateur doit donc avoir le choix entre les deux options.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 57/80
Année académique 1999-2000
Partie VI – Le prototype
22. Choix des outils de développement
Le choix des outils de développement du prototype repose sur deux piliers principaux :
• L’aspect pratique et la disponibilité de l’outil
• Le souci de l’utilisateur, soit l’emploi d’un outil qu’il connaît
Dans notre cas, cinq outils principaux sont utilisés, d’une part en termes de modélisation du prototype,
d’autre part en termes d’implémentation du modèle. Ces outils sont les suivants :
• Le modèle Entité-Association : permet une première modélisation de la base de données
• Le modèle relationnel : permet une modélisation de l’implantation de la base de données
• DB-main : outil logiciel permettant les deux modélisations précédentes
• MS-Access : outil logiciel permettant l’implantation des modèles précédents
• VBA : langage de programmation associé à MS-Access [Callahan 00]
L’utilisation de DB-main s’explique par sa disponibilité, sa gratuité et son efficacité. L’utilisation de MS-
Access s’explique par le fait que l’entreprise utilise déjà ce logiciel, notamment au service de sécurité.
MS-Access utilise VBA comme langage de programmation, ce qui explique ce choix du langage, qui est
d’ailleurs plus une contrainte qu’un choix.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 58/80
Année académique 1999-2000
23. Limites du développement
Comme pour de nombreux éléments de ce travail, le temps est une contrainte essentielle. Il est
impossible de développer notre prototype avec autant d’ouverture qu’il faudrait. L’objectif est ici de
montrer un potentiel, de montrer une petite partie de ce qu’il est possible de faire. Un autre objectif est
de faire le lien entre tout ce qui a été dit précédemment et la réalisation d’une implantation concrète. En
effet, l’intérêt est pour nous de passer d’une problématique théorique, avec la création d’un langage
d’expression des connaissances, la définition de classes et d’objet, puis de passer à un modèle
relationnel et une application effective.
24. Fonctionnalités de l’application
Les fonctionnalités de notre prototype sont le résultat d’un choix arbitraire. Il serait bien sûr possible
d’effectuer autant de fonctionnalités qu’il existe de besoins. Nous en retenons deux :
• La saisie d’un cas • La recherche selon un langage structuré, avec la recherche d’un cas précis
Ces deux fonctionnalités sont naturellement complétées par les utilitaires du système, principalement :
• L’intégration des procédures • L’intégration du langage défini
De plus, la saisie d’un cas peut entraîner des fonctions de mise à jour de la base données. Deux fonctions de mise à jour sont réalisées à titre illustratif :
• L’insertion d’une nouvelle personne • L’insertion d’une description de personne, lorsque celle-ci est inconnue
Les fonctions de programmation en VBA ne sont pas ici détaillées ni définies, l’objectif n’étant pas pour nous de
présenter ou de concevoir une structure d’application informatique. Cependant, il est évident que le prototype
nécessite un travail de programmation, autant au niveau de la gestion de l’interface qu’au niveau du
fonctionnement du système. D’ailleurs, ajoutons à ce propos que la gestion de l’interface repose implicitement sur
certaines procédures. Par exemple, lorsqu’une personne commet un délit et que sa fuite empêche une
identification, il est nécessaire d’en faire une description. La gestion de l’interface prend en compte cette règle.
Les règles de procédure définies précédemment restent valables, mais l’interface devient elle-même un objet.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 59/80
Année académique 1999-2000
25. Modélisation Entité-Association et relationnelle
La réalisation du prototype passe par la modélisation en schéma E-A de la problématique générale
décrite dans les pages précédentes puis dans la transformation de ce schéma en un schéma relationnel.
Pour ce faire nous allons naturellement nous baser sur toutes les réflexions précédentes.
25.1. Le schéma Entité-Association
Nous pouvons définir douze entités différentes :
• Le cas : le cas de vol
• La proposition : la proposition unitaire de notre langage
• Le processus : les principales étapes d’un cas de vol (surveillance, interpellation, vol et
traitement)
• La personne : tout individu intervenant dans un cas
• Les inanimés : tout substantif n’étant pas une personne
• Les types de complément : les types définis lors de l’élaboration de notre langage
• Les procédures : l’ensemble des procédures
• Les verbes : les verbes qui serviront de prédicat
• Les messages : indication lorsqu’une procédure n’est pas obligatoire
• Les terminaisons : définition de la fin d’un cas
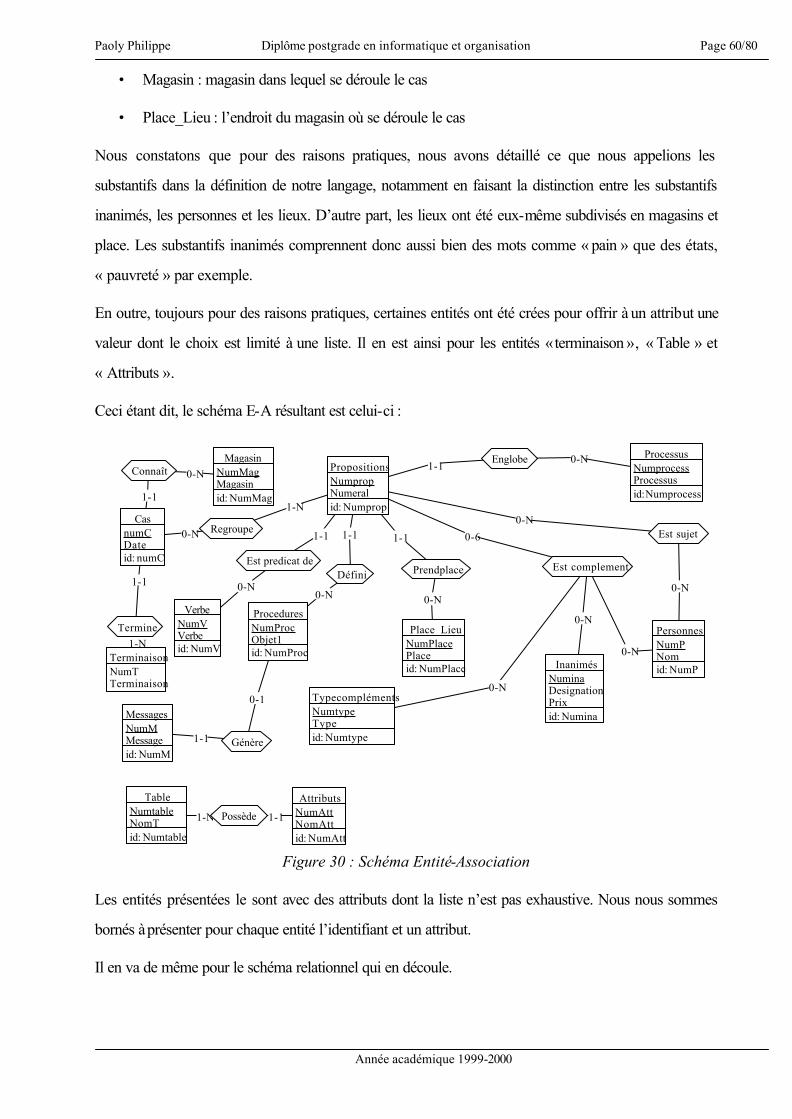
Paoly Philippe Diplôme postgrade en informatique et organisation Page 60/80
Année académique 1999-2000
• Magasin : magasin dans lequel se déroule le cas
• Place_Lieu : l’endroit du magasin où se déroule le cas
Nous constatons que pour des raisons pratiques, nous avons détaillé ce que nous appelions les
substantifs dans la définition de notre langage, notamment en faisant la distinction entre les substantifs
inanimés, les personnes et les lieux. D’autre part, les lieux ont été eux-même subdivisés en magasins et
place. Les substantifs inanimés comprennent donc aussi bien des mots comme « pain » que des états,
« pauvreté » par exemple.
En outre, toujours pour des raisons pratiques, certaines entités ont été crées pour offrir à un attribut une
valeur dont le choix est limité à une liste. Il en est ainsi pour les entités « terminaison », « Table » et
« Attributs ».
Ceci étant dit, le schéma E-A résultant est celui-ci :
Figure 30 : Schéma Entité-Association
Les entités présentées le sont avec des attributs dont la liste n’est pas exhaustive. Nous nous sommes
bornés à présenter pour chaque entité l’identifiant et un attribut.
Il en va de même pour le schéma relationnel qui en découle.
1-1
1-N
Termine
0-N
1-N
Regroupe
1-11-N Possède
1-1
0-N
Prendplace
1-1
0-1
Génère
0-N
0-N
Est sujet 1-1
0-N
Est predicat de
0-N
0-N
0-6
0-N
Est complement
1-10-NEnglobe
1-1
0-N
Défini
0-N
1-1
Connaît
VerbeNumVVerbeid: NumV
TypecomplémentsNumtypeTypeid: Numtype
TerminaisonNumTTerminaison
PropositionsNumpropNumeralid: Numprop
ProcessusNumprocessProcessusid: Numprocess
ProceduresNumProcObjet1id: NumProc
Place_LieuNumPlacePlaceid: NumPlace
PersonnesNumPNomid: NumP
MessagesNumMMessageid: NumM
MagasinNumMagMagasinid: NumMag
InanimésNuminaDesignationPrixid: Numina
AttributsNumAttNomAttid: NumAtt
TableNumtableNomTid: Numtable
CasnumCDateid: numC

Paoly Philippe Diplôme postgrade en informatique et organisation Page 61/80
Année académique 1999-2000
25.2. Le schéma relationnel
Le schéma relationnel découlant du schéma E-A est le suivant :

Paoly Philippe Diplôme postgrade en informatique et organisation Page 62/80
Année académique 1999-2000
Figure 31 : Schéma relationnel
Nous dénombrons quinze tables au complet pour faire fonctionner notre application. Outre les douze
tables découlant des entités définies, nous voyons l’apparition de trois tables supplémentaires, provenant
des associations définies précédemment, soit :
• Est complément : lie un objet inanimé, une personne, une proposition et un type de complément.
Cette association de quatre éléments nous donne un complément de notre langage. En effet, un
complément possède un certain type, concerne une proposition, et peut être soit un objet
inanimé soit une personne.
• Regroupe : lie un cas et les propositions
• Est sujet : Lie une personne et une proposition. Cette association de deux éléments donne le
sujet de notre langage. En effet, un sujet est une personne et est lié à une proposition.
Reste maintenant à implémenter ces tables.
26. Implémentation des moteurs d’inférences
L’implémentation du moteur d’inférence passe par le calcul des probabilités associées à chaque action,
NVP =
VerbeNumVVerbeid: NumV
acc
TypecomplémentsNumtypeTypeid: Numtype
acc
TerminaisonnumCNumTTerminaisonid: numC
equ acc
RegroupenumCNumpropid: numC
Numpropacc
equ: Numpropacc
ref: numCacc
PropositionsNumpropNumeralNumPlaceNumVNumprocessNumProcid: Numprop
acc ref: NumPlace
acc ref: NumV
acc ref: Numprocess
acc ref: NumProc
acc
ProcessusNumprocessProcessusid: Numprocess
acc ProceduresNumProcObjet1id: NumProc
acc
Place_LieuNumPlacePlaceid: NumPlace
acc
PersonnesNumPNomid: NumP
acc
MessagesNumMNumProcMessageid: NumM
acc id': NumProc
ref acc
MagasinNumMagMagasinid: NumMag
acc
InanimésNuminaDesignationPrixid: Numina
acc
Est sujet NumPNumpropid: Numprop
NumPacc
ref: Numpropacc
ref: NumPacc
Est complement NuminaNumPNumpropNumtypeid: Numtype
NumPNumpropNuminaacc
ref: Numtypeacc
ref: Numpropacc
ref: NumPacc
ref: Numinaacc
AttributsNumAttNomAttNumtableid: NumAtt
acc equ: Numtable
acc
TableNumtableNomTid: Numtable
acc
CasnumCDateNumMagid: numC
acc ref: NumMag
acc

Paoly Philippe Diplôme postgrade en informatique et organisation Page 63/80
Année académique 1999-2000
ici à chaque verbe. Pour cela, il suffit de compter le nombre de propositions, puisque dans chaque
proposition il y a un prédicat défini par un verbe. Puis ce nombre, nommé NTP, devient le dénominateur
d’une fraction dont le numérateur est le nombre d’apparitions totales de chaque verbe, nombre nommé
NV. En conséquence, cette probabilité est, pour chaque verbe, calculée de la manière suivante :
A partir de ce résultat, nous pouvons, pour chaque cas, remplacer chaque proposition par la probabilité
associée à son prédicat et faire le produit de ces probabilités. Ceci nous donne la probabilité associée à
chaque cas.
L’utilisation des requêtes dans MS-Access permet une implémentation simplifiée de cette règle, mais
l’utilisation d’un algorithme codé reste nécessaire. Concernant la notion de proximité, cette approche
n’est pas implémentée puisque qu’elle n’est pas nécessaire dans les fonctionnalités choisies pour le
prototype. Cependant, une recherche basée sur cette notion ne poserait pas de problème particulier.
Encore une fois, l’utilisation de requêtes successives dans MS-Access simplifie le problème, même si le
codage en SQL n’est pas très complexe. Le principe de base est d’accorder 1 point lorsqu’il y a
correspondance, aucun point dans le cas contraire. Il suffit alors de choisir le cas où le nombre de point
est le plus grand. La notion d’ordre est une simple condition supplémentaire pour accorder un point
dans la correspondance
Avec C un cas, PT un point, V la valeur d’un attribut d’un cas, Vr la valeur d’un attribut recherchée et i
un indice lié au cas, nous avons alors deux formules successives :
Naturellement, il est possible d’additionner divers attributs de recherche. Pour chaque attribut
recherché, il faudrait alors calculer PT et en faire la somme, ce qui nous donnerait un PTtotal. Ce dernier
remplacerai PT dans la deuxième formule.
27. Définition de l’interface
0Pelse1PthenVrVifPT ====
( )∑= iPTMAXChoix
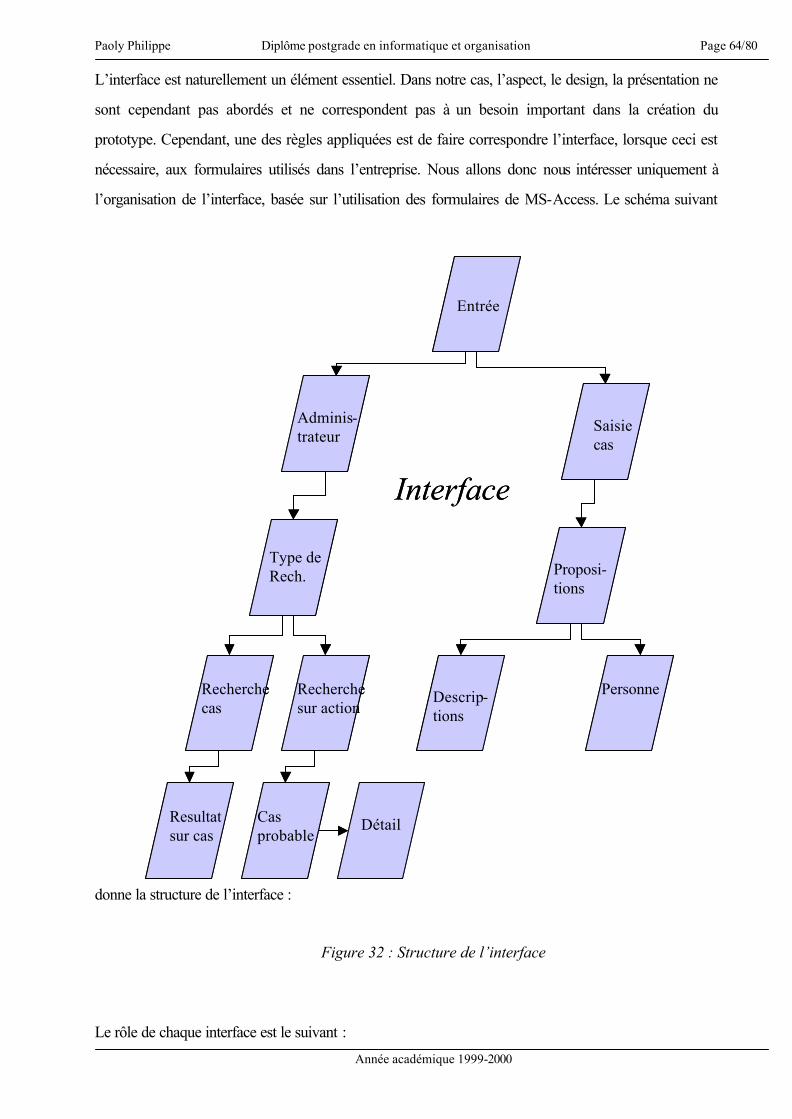
Paoly Philippe Diplôme postgrade en informatique et organisation Page 64/80
Année académique 1999-2000
L’interface est naturellement un élément essentiel. Dans notre cas, l’aspect, le design, la présentation ne
sont cependant pas abordés et ne correspondent pas à un besoin important dans la création du
prototype. Cependant, une des règles appliquées est de faire correspondre l’interface, lorsque ceci est
nécessaire, aux formulaires utilisés dans l’entreprise. Nous allons donc nous intéresser uniquement à
l’organisation de l’interface, basée sur l’utilisation des formulaires de MS-Access. Le schéma suivant
donne la structure de l’interface :
Figure 32 : Structure de l’interface
Le rôle de chaque interface est le suivant :
Saisiecas
Type deRech.
Détail
Proposi-tions
PersonneDescrip-tions
Recherchecas
Recherchesur action
Resultatsur cas
Cas probable
Entrée
Adminis-trateur
Interface
Saisiecas
Type deRech.
Détail
Proposi-tions
PersonneDescrip-tions
Recherchecas
Recherchesur action
Resultatsur cas
Cas probable
Entrée
Adminis-trateur
Interface

Paoly Philippe Diplôme postgrade en informatique et organisation Page 65/80
Année académique 1999-2000
• Entrée : interface de départ permettant un choix d’activité • Saisie cas : interface de saisie d’un cas • Administrateur : interface administrateur avec accès codé • Propositions : interface de saisie des enchaînements • Description : interface de saisie lorsqu’un voleur a pris la fuite • Personne : interface de saisie d’une nouvelle personne • Type de recherche : interface de choix d’une recherche sur cas ou sur action • Recherche cas : interface de saisie des paramètres de recherche du cas • Recherche sur action : interface de saisie des paramètres de recherche sur une action • Résultat sur cas : interface de présentation des résultats de recherche sur cas • Cas probable : interface de présentation du cas le plus probable, selon l’action prédéfinie • Détail : détail des enchaînements lié au cas le plus probable, suite à la recherche sur action
27.1. Entrée Cette interface est la suivante :
Figure 33 : Interface d’entrée L’utilisateur peut choisir entre les fonctions réservées à l’administrateur, quitter l’application ou saisir un nouveau cas.
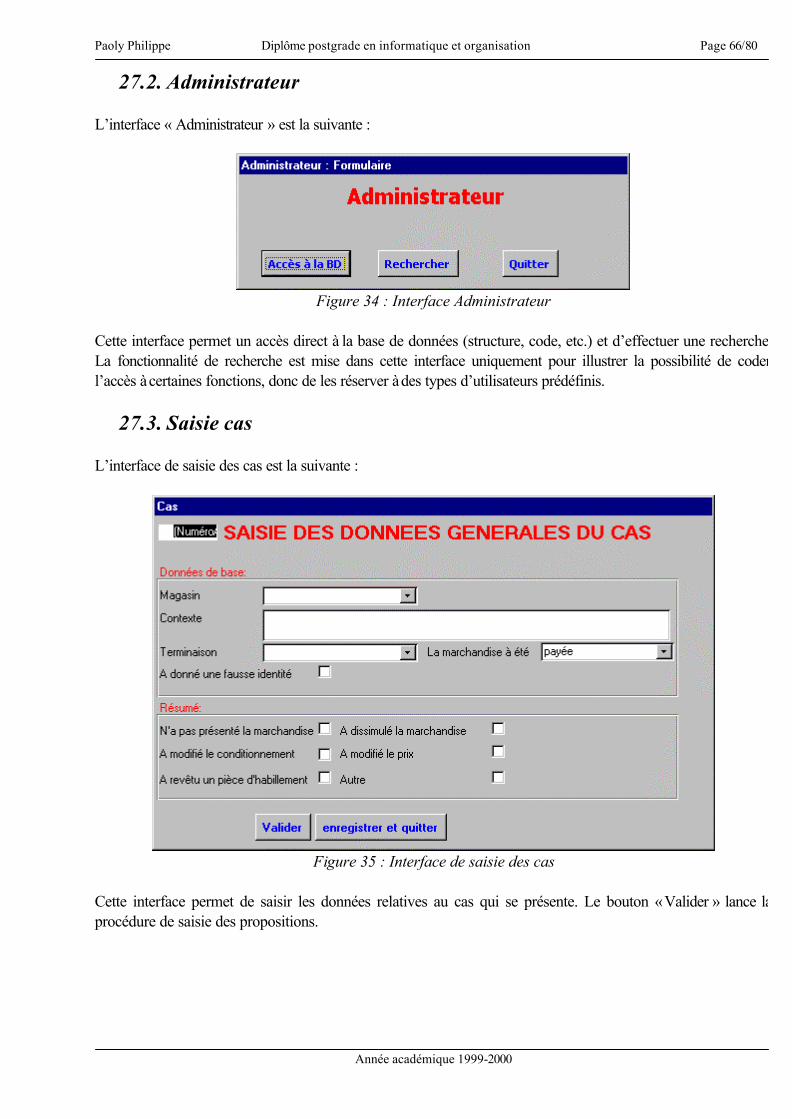
Paoly Philippe Diplôme postgrade en informatique et organisation Page 66/80
Année académique 1999-2000
27.2. Administrateur L’interface « Administrateur » est la suivante :
Figure 34 : Interface Administrateur
Cette interface permet un accès direct à la base de données (structure, code, etc.) et d’effectuer une recherche. La fonctionnalité de recherche est mise dans cette interface uniquement pour illustrer la possibilité de coder l’accès à certaines fonctions, donc de les réserver à des types d’utilisateurs prédéfinis.
27.3. Saisie cas L’interface de saisie des cas est la suivante :
Figure 35 : Interface de saisie des cas
Cette interface permet de saisir les données relatives au cas qui se présente. Le bouton « Valider » lance la procédure de saisie des propositions.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 67/80
Année académique 1999-2000
27.4. Propositions L’interface permettant la saisie des propositions, donc des enchaînements d’actions, est la suivante :
Figure 36 : Interface propositions Cette interface varie également en fonction des actes de l’utilisateur. Elle permet de saisir une proposition en respectant la structure du langage définit dans le paragraphe correspondant. La validation entraîne en arrière plan, à l’aide du code VBA, une mise à jour complète des tables.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 68/80
Année académique 1999-2000
27.5. Description L’interface permettant de décrire une personne inconnue est la suivante :
Figure 37 : interface description Cette interface reprend exactement le formulaire utilisé dans l’entreprise. Elle permet, lorsqu’une personne prend la fuite par exemple, d’en donner une description la plus détaillée possible, en offrant à la personne saisissant les données un aide mémoire visuel. De plus, elle suit également, implicitement, une procédure qui est de donner une description lorsqu’une personne ne peut pas être identifiée.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 69/80
Année académique 1999-2000
27.6. Personne L’interface permettant la saisie de nouvelles personnes est la suivante :
Figure 38 : interface personne
Cette interface reprend exactement le formulaire utilisé dans l’entreprise. Elle est utilisée lorsque l’interface proposition est ouverte. En effet, au moment de saisir le sujet par exemple, il est possible que la personne en question ne soit pas dans la base de données. Il est possible alors de saisir une nouvelle personne. Une fois cette interface fermée, l’interface « proposition » est actualisée.
27.7. Type de recherche L’interface permettant le choix des types de recherches est le suivant :
Figure 39 : interface type de recherche
Le choix offre deux possibilités : la recherche d’un cas suivant des paramètres liés à ce cas et la recherche du cas le plus probable étant donnée une suite d’actions.
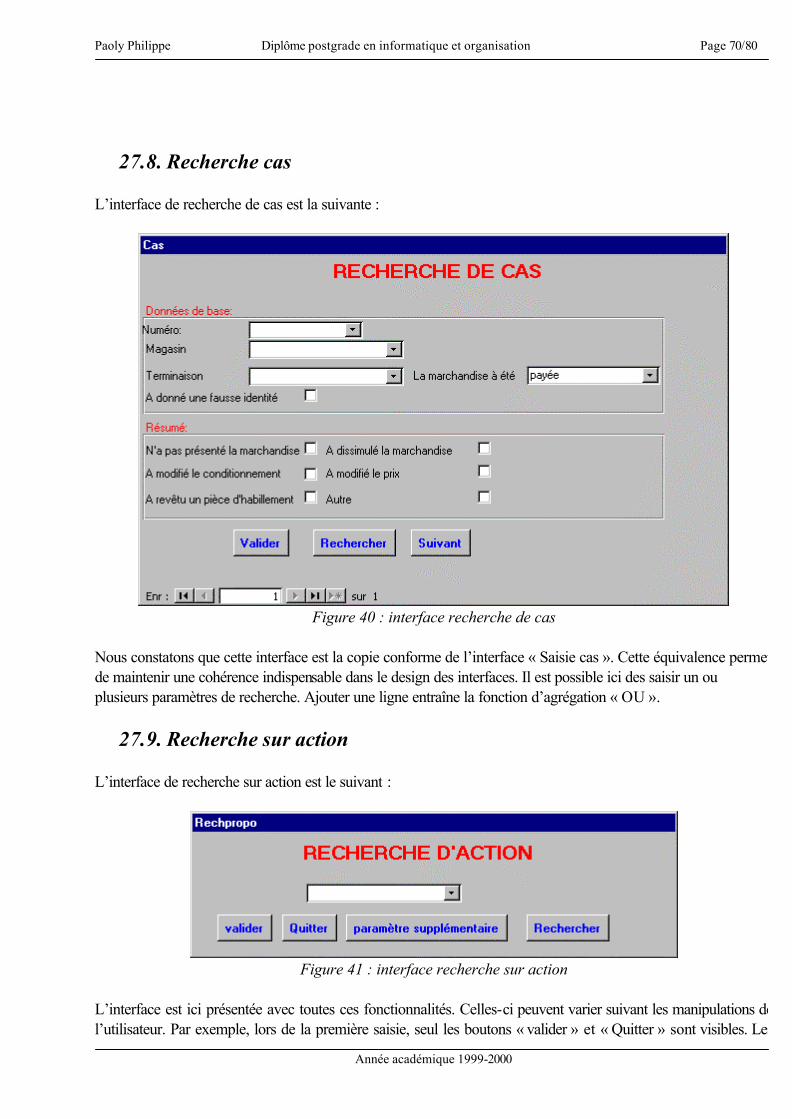
Paoly Philippe Diplôme postgrade en informatique et organisation Page 70/80
Année académique 1999-2000
27.8. Recherche cas L’interface de recherche de cas est la suivante :
Figure 40 : interface recherche de cas
Nous constatons que cette interface est la copie conforme de l’interface « Saisie cas ». Cette équivalence permet de maintenir une cohérence indispensable dans le design des interfaces. Il est possible ici des saisir un ou plusieurs paramètres de recherche. Ajouter une ligne entraîne la fonction d’agrégation « OU ».
27.9. Recherche sur action L’interface de recherche sur action est le suivant :
Figure 41 : interface recherche sur action
L’interface est ici présentée avec toutes ces fonctionnalités. Celles-ci peuvent varier suivant les manipulations de l’utilisateur. Par exemple, lors de la première saisie, seul les boutons « valider » et « Quitter » sont visibles. Les
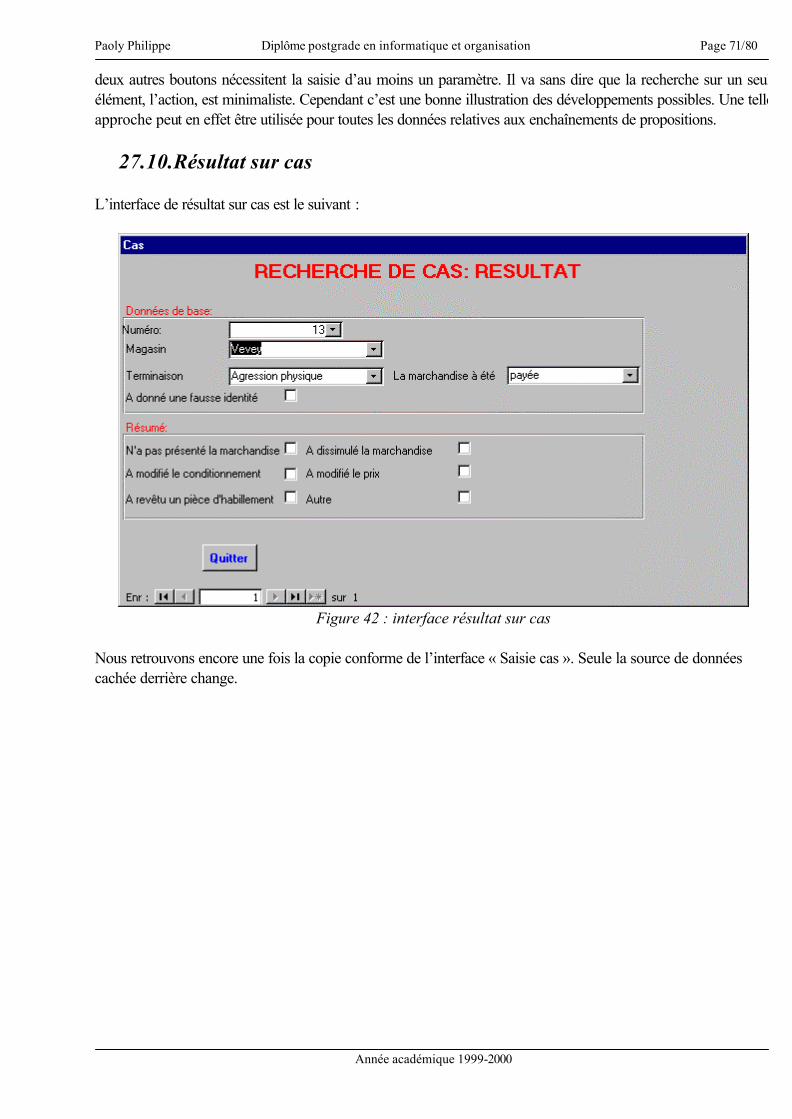
Paoly Philippe Diplôme postgrade en informatique et organisation Page 71/80
Année académique 1999-2000
deux autres boutons nécessitent la saisie d’au moins un paramètre. Il va sans dire que la recherche sur un seul élément, l’action, est minimaliste. Cependant c’est une bonne illustration des développements possibles. Une telle approche peut en effet être utilisée pour toutes les données relatives aux enchaînements de propositions.
27.10. Résultat sur cas L’interface de résultat sur cas est le suivant :
Figure 42 : interface résultat sur cas
Nous retrouvons encore une fois la copie conforme de l’interface « Saisie cas ». Seule la source de données cachée derrière change.
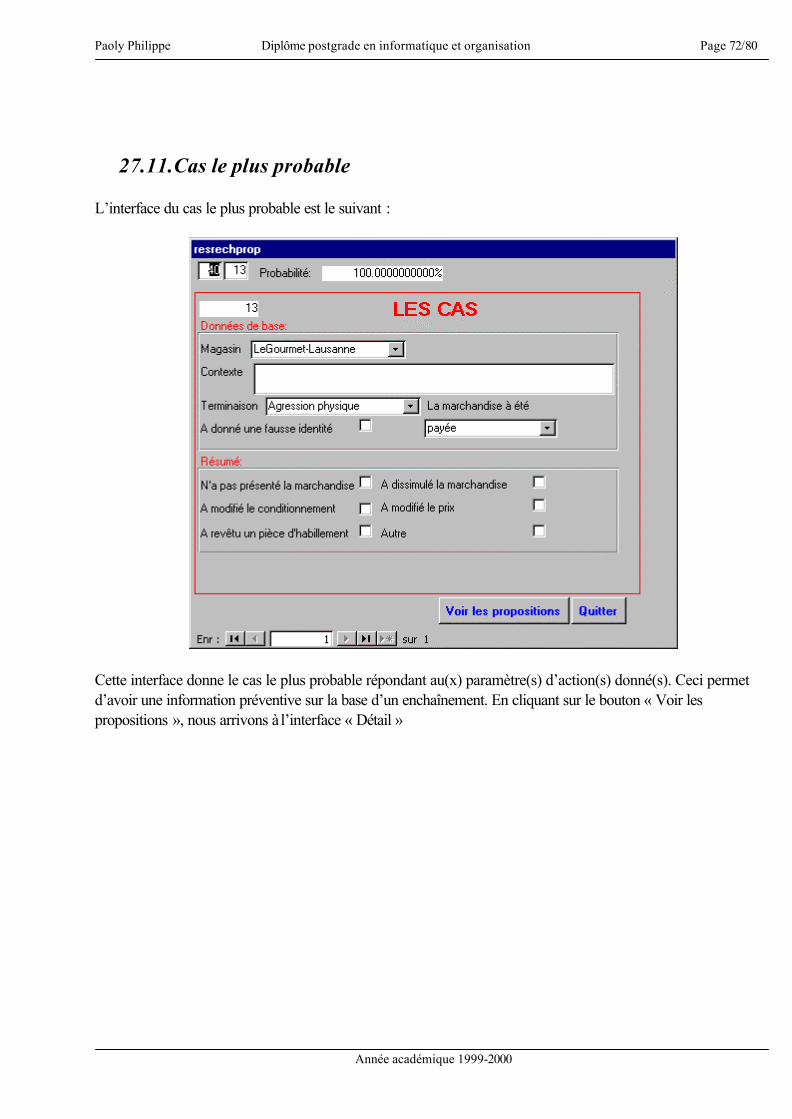
Paoly Philippe Diplôme postgrade en informatique et organisation Page 72/80
Année académique 1999-2000
27.11. Cas le plus probable L’interface du cas le plus probable est le suivant :
Cette interface donne le cas le plus probable répondant au(x) paramètre(s) d’action(s) donné(s). Ceci permet d’avoir une information préventive sur la base d’un enchaînement. En cliquant sur le bouton « Voir les propositions », nous arrivons à l’interface « Détail »

Paoly Philippe Diplôme postgrade en informatique et organisation Page 73/80
Année académique 1999-2000
.
27.12. Détail L’interface Détail est la suivante :
Cette interface présente tous les enchaînements de propositions liés au cas. Dans la partie supérieure, nous retrouvons le processus auquel appartient la proposition et le lieu de déroulement, ainsi que les trois premiers éléments de notre langage. La partie inférieure (ici vide) présente la totalité des compléments, en donnant le substantif et le type de complément auquel il appartient.
27.13. Remarques Naturellement, l’interface devrait être davantage développée. Par exemple, la recherche d’action devrait englober l’action et également tous ses composants. De plus, la totalité des tables devraient pouvoir être mise à jour directement depuis une interface prévue à cet effet. En outre, la même interface peut prendre successivement des formes différentes. Par exemple, les éléments affichés sur l’interface de saisie peuvent varier au cours de la saisie. Ajoutons également l’utilisation des boites de messages au cours des étapes successives. Ces boites de messages ne sont pas indiquées ici car elles sont générées par du code. Précisons pour terminer que la figure 32 présente les formulaires MS-Access utilisés successivement, chacun d’eux étant en soi une interface pour un objectif donné et partie de l’ensemble que représente l’interface dans son sens général.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 74/80
Année académique 1999-2000
Partie VII – Conclusion
28. Critiques et difficultés
Les difficultés lors de la rédaction de ce mémoire furent nombreuses. Principalement le manque de
temps n’a pas permis une exploration totale de toutes les possibilités. Plus d’une fois, il fut nécessaire de
se limiter à des illustrations ou des présentations partielles. D’autre part, certaines contraintes matérielles
ont empêché l’utilisation d’outils peut-être plus polyvalents.
Le temps, outre sa responsabilité dans une exploration seulement partielle, a un impact également dans
la réalisation du prototype. Le choix de réaliser deux fonctionnalités seulement, la saisie et la recherche,
mais également une recherche limitée, est dû à cette contrainte. L’objectif est alors de favoriser l’élément
illustratif, au détriment de l’élément qualitatif d’un point de vue technique. La recherche d’un cas
correspondant exactement aux paramètres de recherche évite un travail de programmation, travail qui
peut être réalisé en manipulant les requêtes et en limitant la difficulté à l’intégration de formules
algébriques. La programmation est alors limitée à la gestion de l’interface, ce qui, bien sûr, peut être
réalisé dans un délai raisonnable. Notons toutefois que ce travail de programmation englobe également
un autre élément essentiel, la mise à jour. Si la mise à jour d’une table source est facilitée par l’utilisation
d’un formulaire, il en va autrement lorsqu’une table fait office de jointure. Dans ce cas, le code est
apparu comme un avantage. De plus, l’implémentation du moteur d’inférence ne peut que passer par
une utilisation intensive du code. Ceci explique que le moteur d’inférence implémenté dans le prototype
est resté très sommaire.
Une autre difficulté fut de trouver un moyen de modélisation de la problématique. L’idée de base étant
de modéliser la rencontre de deux ou plusieurs comportements, la première étape fut de penser à un
processus de stimulus-réponse, qui déboucha sur le principe action-réaction, reflétant le constat que
dans le traitement d’un cas de vol, chacun réagit en fonction de l’autre. D’où l’idée de l’enchaînement
d’actions. La deuxième étape, tout aussi problématique, était de trouver un moyen d’exprimer une
action, et de l’exprimer de la manière la plus complète possible. Or il existe un modèle connu de tous
pour exprimer une action, modèle parfaitement structuré depuis des siècles : la langue. D’où l’idée de

Paoly Philippe Diplôme postgrade en informatique et organisation Page 75/80
Année académique 1999-2000
reproduire la structure de la langue (la réflexion s’est basée sur le latin, dont la structure est la plus
complète des langues occidentales). L’aide et les conseils d’un linguiste s’est alors révélé nécessaire. La
distinction entre la structure et la sémantique fut parfois problématique, mais la conclusion de la réflexion
est que l’interprétation sémantique est laissée à l’utilisateur.
29. Proposition d’améliorations
De nombreuses améliorations sont bien sûr possibles. Premièrement, en ce qui concerne l’expression
d’une action, nous avons supprimé par exemple les adverbes, les adjectifs, les compléments de mode,
etc.. avec comme justification une interprétation relative. En effet, comment interpréter des mots tel que
« rapidement », « violemment », voire des adjectifs comme « bleu », « grand » ou encore des
expressions comme « avec force » ? En effet, « rapidement » peut avoir un sens différent selon la
situation ou la personne qui l’utilise. « Grand » pose le même problème. Lorsqu’on mesure 165 cm, on
est grand pour celui qui mesure 130 cm, petit pour celui qui mesure 180 cm. La problématique est ici
l’interprétation des nuances, comme pour les couleurs. En prenant par exemple du bleu et en ajoutant
progressivement un pourcentage de jaune, nous allons finir par atteindre la couleur verte. Mais la
frontière entre les deux couleurs n’est pas clairement définie. Cependant il est possible de résoudre ce
problème à l’aide de la logique floue. La logique floue permet justement de résoudre ce genre de
problème, car elle permet d’appréhender l’imprécision et la subjectivité [Godjevac 99]. Je suis
persuadé (à priori) que l’intégration, au niveau du moteur d’inférence, d’un processus de fuzzification18
et d’un processus de defuzzification19, permettrait de modéliser la structure complète (ou d’une grande
partie) de la langue, peut-être avec quelques aménagements, notamment lorsque deux formes
permettent l’expression d’une seule et même chose (par exemple les pronoms peuvent être remplacés
par des substantifs ; une seule forme peut être alors imposée).
En élargissant la réflexion concernant les problèmes d’expression, nous nous rendons compte,
notamment vu les difficultés liées à la programmation, qu’une notion supplémentaire devrait être ajoutée à
notre langage : la notion de champ lexical20. Une liste de substantifs comme nous trouvons
principalement dans le prototype et également dans la structure du langage, en terme de concept et en
terme de source, est utilisable tel quel sans difficultés techniques, mais il semble évident que l’utilisation
de champs lexicaux permettrait une amélioration sensible d’une part de la compréhension générale du
système, d’autre part de l’efficacité du travail de programmation. En effet, l’utilisation de champs
18 Transformation des entrées précises en degrés d’appartenance 19 Transformation des résultats flous en sorties précises 20 Ensemble structuré d’unités lexicales. Par exemple, la couleur est un champ lexical regroupant bleu, vert, rouge, etc.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 76/80
Année académique 1999-2000
lexicaux offre un critère supplémentaire de tri, un ciblage plus précis des termes en fonction des besoins
de saisie ou de recherche et un travail qui peut être basé sur des ensembles et non plus des valeurs.
Une autre amélioration évidente est la séparation entre l’interface et la base de données. Une base de
données sur un serveur avec une application au niveau des postes clients permettrait une mise en
commun plus aisée et plus efficace du système complet. L’élaboration des requêtes et certaines
opérations de calcul serait alors à la charge du poste client, permettant ainsi le soulagement du serveur
central.
En liaison avec ceci, une autre amélioration possible serait d’utiliser une approche objet, autant pour la
création de la base de donnée que pour l’interface. L’utilisation de l’approche objet sur les deux
éléments permettrait la conjugaison de la base de donnée avec les fonctionnalités de programmation
d’un logiciel comme JAVA par exemple. Rappelons en outre que JAVA permet la création et la
gestion de base de données sous forme de matrice au format texte. Ce genre d’approche, avec l’idée
de séparer la base de données de l’interface permettrait d’utiliser Internet comme support réseau.
Une autre amélioration évidente est bien sûr l’interface. Rudimentaire ici dans la création du prototype,
l’interface devrait naturellement coller aux habitudes des utilisateurs et également simplifier le travail de
saisie et de recherche.
Ajoutons également une notion qui n’a pas été traitée, soit la notion d’oubli. En effet, il est essentiel de
reprendre la base de données régulièrement afin de l’épurer. Par exemple, nous pouvons nous
demander si des données vieilles de plusieurs années sont non seulement d’actualité, mais aussi
apportent une information ou une connaissance marginale suffisante. Si la réponse est non, il est
important de définir un âge limite des données et de procéder à leur élimination.
De plus, la gestion de la base nécessite un modérateur. En effet, le principe développé ici est que
l’intervenant effectue lui-même la saisie. Or la langue connaît des synonymes. Il serait donc souhaitable
d’avoir un modérateur qui contrôle régulièrement les éléments saisis, notamment en cas de mise à jour
(ajout de nouveaux verbes, etc), afin d’éviter d’avoir deux valeurs différentes pour une même
signification sémantique. La sémantique est un problème qui reste ici à la charge de l’utilisateur.
Pour terminer, notons qu’une formation préalable à l’utilisation du système ainsi que la mise en place
d’incitations semble essentielle. En effet, comprendre l’application et son maniement assure une
utilisation efficace. D’autre part, les incitations poussent l’utilisateur à faire preuve de rigueur et de
précision au moment de la saisie principalement. Notre système est basé sur une relation action-
réaction. Sa précision et son intérêt sont proportionnels au niveau de détail choisi pour décrire une

Paoly Philippe Diplôme postgrade en informatique et organisation Page 77/80
Année académique 1999-2000
action. Il est important que celui qui effectue la saisie prenne le temps de chercher à chaque fois l’action
unitaire la plus petite possible. Or cette recherche peut prendre parfois du temps, temps que l’utilisateur
souhaite peut-être minimiser. Ajoutons également que certaines résistances peuvent apparaître, celui
possédant l’expérience ne souhaitant pas forcément la partager, cette expérience pouvant lui assurer une
sorte de « monopole » au sein de l’entreprise.
En bref, les principales améliorations (ou les principaux développements) envisageables sont :
• Utilisation de la logique floue
• Elargissement des catégories morphologiques
• Utilisation des champs lexicaux
• Séparation de l’interface et de la base de données
• Utiliser la programmation objet
• Créer la conjugaison entre l’interface et l’utilisateur
• Implémenter la notion d’oubli à l’aide de procédures d’épurement
• Intégrer un modérateur dans le fonctionnement général du système
• Intégrer un système d’incitations poussant l’utilisateur à un maximum de détail et de méticulosité
dans la saisie
Nous voyons que les améliorations sont nombreuses et touchent des domaines variés, autant en terme
d’outil, d’approche, d’interface ou de gestion.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 78/80
Année académique 1999-2000
30. Conclusion générale
Ce mémoire fut extrêmement intéressant et stimulant sur l’aspect de la réflexion. Les discussions avec le
responsable de la sécurité chez COOP Vaud Chablais valaisan, avec des intervenants et la visualisation
de cas réel de vol ont permis d’avoir une bonne vue d’ensemble des problèmes de vol en particulier, de
sécurité en général. L’approche linguistique à également permis de développer des connaissances dans
ce domaine et a montré les possibilités liant informatique et langage. Dans le même temps, le sentiment
d’une frustration est réel lorsqu’on compare le travail réalisé et le travail réalisable. En effet, le sujet
devient vite passionnant et la contrainte du temps, qui oblige à limiter non seulement l’exploration dans le
raisonnement mais également la mise en œuvre des fonctionnalités au niveau du prototype, devient vite
pesante.
Il serait intéressant de développer l’approche en intégrant la logique floue et en développant non
seulement l’approche linguistique, mais également en élargissant la problématique à l’ensemble des
problèmes de sécurité. De plus, il serait passionnant de développer la totalité des fonctionnalités utiles au
niveau du prototype, voire de réaliser une application opérationnelle. Ceci supposerait cependant le
cumul de diverses compétences, notamment en termes de linguistique, en termes de sécurité, en termes
de modélisation et bien sûr en termes de programmation.
Ceci dit, il semble évident que les possibilités offertes par les systèmes à base de connaissances, en tous
cas dans le domaine de la sécurité, voire dans la gestion des comportements (en effet, la modélisation
action-réaction pourrait s’appliquer à d’autres domaines, comme le déroulement d’une vente par
exemple) sont extrêmement larges.
Pour terminer sur une note personnelle, je dirais que ce travail m’a non seulement permis de
comprendre de manière plus approfondie les buts et le développement des systèmes à base de
connaissance, mais également éveillé un intérêt très vif pour la logique floue, élément qui n’a
malheureusement pas pu être intégré faute de temps.
31. Remerciements
Je remercie tout particulièrement le professeur A.R Probst, pour son soutien et son enthousiasme
communicatif. Je remercie également M. Giller, responsable de la sécurité chez COOP Vaud Chablais

Paoly Philippe Diplôme postgrade en informatique et organisation Page 79/80
Année académique 1999-2000
valaisan pour sa disponibilité et les informations remises, ainsi que tous ses collaborateurs m’ayant
accordé du temps et ayant répondu à mes nombreuses questions. Je remercie également Mlle
Gradinaru, linguiste, pour ses conseils et son apport de compétences.
32. Bibliographie et références
[Kettani 98] Nasser Kettani, Dominique Mignet, Pascal Paré, Camille Rosenthal-Sabroux
« De Merise à UML », Eyrolles, 1998.
[Godjevac 99] Jelena Godjevac « Idées nettes sur la logique floue », Presses polytechniques et
universitaires romandes, 1999.
[Muller 97] P.A Muller « Modélisation objet avec UML », Eyrolles, 1997
[HBR 00] Harvard Business Revue « le Knowledge management », Editions d’Organisation,
2000.
[Dieng 00] Rose Dieng, Olivier Corby, Alain Giboin, Joanna Golebioska, Nada Matta,
Myriam Ribière, « Méthodes et outils pour la gestion des connaissances », Dunod,
2000.
[Callahan 99] Evan Callahan, « Microsoft Access2000, Visual Basic Edition Applications, étape
par étape », Microsoft Press.

Paoly Philippe Diplôme postgrade en informatique et organisation Page 80/80
Année académique 1999-2000
Partie VIII – Annexes
• Exemples d’instructions et procédures :
o Vol à l’étalage de clients
o Agression, menace, chantage, attentat, enlèvement
• Formulaires internes :
o Déclaration de vol à l’étalage
o Fiche signalétique
• Graphiques et chiffres concernant le vol du personnel
o 1996-1997
o 1997-1998
o 1998-1999

























![La sécurité informatique dans la petite entreprise []](https://img.pdfslide.tips/doc/110x75/5571fbf049795991699623e2/la-securite-informatique-dans-la-petite-entreprise-wwwvideos-formationorg.jpg)



