Embed Size (px)
Citation preview

TESIS Maestría en Ingeniería en Sistemas de Información
SISTEMA DISTRIBUIDO DE INTELIGENCIA COLECTIVA
Director: Dr. Eduardo Destéfanis Co-Director: Dr. Mario Groppo
Maestrando: Esp. Ing. Ignacio Cano !!!!
2015! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
2!!
Agradecimientos!
!
Al Dr. Eduardo Destéfanis, por dirigirme en este trabajo, por su paciencia en la espera de resultados, y por su gran colaboración y ayuda para mejorar el presente.
Al Dr. Mario Groppo, por aceptar co-dirigirme en este trabajo, por su constante interés y empuje para que se complete exitosamente, y por sus comentarios siempre tan indicados.
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
3!!
Dedicatoria!
A todos mis seres queridos, especialmente a mi esposa Laura y a mi hija Magdalena, mis grandes amores en esta vida.
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
4!!
Resumen'
!
La competitividad de las empresas depende principalmente del entendimiento y
conocimiento que éstas tienen sobre sus usuarios, si no entienden y conocen las necesidades
de sus clientes, difícilmente serán exitosas en sus rubros.
Crear nuevas oportunidades mediante la utilización de algoritmos que permitan
combinar automáticamente los datos recolectados de diferentes personas, contribuye a
mejorar la competitividad. Dominar este “arte” coloca a las empresas en una posición de
privilegio con respecto a sus competidoras.
El presente trabajo describe el análisis, diseño e implementación de un sistema
distribuido con el fin de asistir a los usuarios finales durante el proceso de toma de
decisiones, permitiéndoles encontrar y elegir productos de su interés entre un conjunto
abrumador de alternativas.
A lo largo del presente, no sólo se introducen conceptos relacionados al campo de la
inteligencia colectiva, los motores de búsquedas, los sistemas de recomendación, las redes
sociales, sino también, se describen las diversas tecnologías necesarias para la creación del
sistema, incluyendo fundamentación de las elegidas para la elaboración del mismo.
En base a los análisis previos, se procede al diseño y construcción de un prototipo, el
cual se integra con diversos clientes. Finalmente, se evalúan los resultados comparando el
sistema con algunas de las soluciones más utilizadas en la actualidad.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
5!!
Índice! !
!
1! Introducción!.................................................................................................................................!12!
1.1! Objetivos!................................................................................................................................!14!
1.1.1! Objetivo!General!.............................................................................................................!14!
1.1.2! Objetivos!Específicos!.......................................................................................................!14!
1.2! Estructura!...............................................................................................................................!15!
2! Marco!Teórico!..............................................................................................................................!17!
2.1! Sistemas!de!Inteligencia!Colectiva!.........................................................................................!17!
2.1.1! Tipos!de!Inteligencia!Colectiva!........................................................................................!18!
2.1.2! Web!2.0!–!Social!Media!...................................................................................................!19!
2.1.3! Ejemplos!en!el!mundo!real!..............................................................................................!20!
2.2! Sistemas!de!Recomendación!..................................................................................................!21!
2.2.1! Algoritmos!de!Recomendación!.......................................................................................!22!
2.2.2! Métodos!de!Evaluación!...................................................................................................!48!
2.2.3! Problema!de!Comienzo!en!Frío!en!Filtros!Colaborativos!................................................!51!
2.3! Motores!de!Búsqueda!............................................................................................................!52!
2.3.1! Elementos!de!los!Buscadores!..........................................................................................!53!
2.3.2! Buscadores!en!la!Actualidad!...........................................................................................!53!
2.4! Redes!Sociales!........................................................................................................................!54!
2.4.1! Importancia!.....................................................................................................................!55!
2.5! Estadísticas!de!Uso!.................................................................................................................!56!
3! Definición!del!Problema!..............................................................................................................!57!
3.1! Importancia!............................................................................................................................!58!
4! Alternativas!de!Solución!..............................................................................................................!60!
5! Diseño!e!Implementación!............................................................................................................!63!
5.1! Diseño!de!Alto!Nivel!...............................................................................................................!63!
5.1.1! Casos!de!Uso!...................................................................................................................!63!
5.1.2! Arquitectura!....................................................................................................................!69!
5.1.3! Servicios!...........................................................................................................................!70!
5.1.4! Módulos!..........................................................................................................................!72!
5.1.5! Diagramas!de!Paquetes!...................................................................................................!74!
5.1.6! Interfaces!de!Programación!de!Aplicaciones!..................................................................!77!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
6!!
5.2! Diseño!de!Bajo!Nivel!...............................................................................................................!89!
5.3! Tecnologías!y!Frameworks!Utilizados!....................................................................................!89!
5.4! Capturas!de!Pantalla!..............................................................................................................!90!
6! Evaluación!de!los!Resultados!......................................................................................................!98!
6.1! Mediciones!para!Filtros!Colaborativos!...................................................................................!98!
6.2! Mediciones!para!Clustering!..................................................................................................!102!
6.3! Comparativas!con!Tecnologías!Actuales!..............................................................................!108!
7! Conclusiones!..............................................................................................................................!116!
8! Trabajos!Futuros!........................................................................................................................!118!
9! Bibliografía!.................................................................................................................................!120!
10! Apéndices!.................................................................................................................................!124!
10.1! Apéndice!A:!Diagramas!de!Clases!.......................................................................................!124!
10.2! Apéndice!B:!Diagramas!de!Secuencia!.................................................................................!126!
10.3! Apéndice!C:!Snippets!de!Código!.........................................................................................!128!
!
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
7!!
Índice!de!Figuras!
!Figura!1:!Diagrama!de!la!Cola!Larga![Jannach!et!al.,!2010]!.................................................................!13!Figura!2:!Tipos!de!Inteligencia![Alag,!2009]!.........................................................................................!19!Figura!3:!Diagrama!de!Líneas!para!cálculo!de!CP!................................................................................!26!Figura!4:!Datos!desestructurados!–!Fuente:!TN!...................................................................................!37!Figura!5:!Ejemplo!de!Clustering!en!plano!xey!......................................................................................!38!Figura!6:!Comparación!entre!Distancia!Euclidiana!y!Distancia!Manhattan!.........................................!42!Figura!7:!Ejemplo!de!ángulo!entre!dos!vectores!.................................................................................!43!Figura!8:!Ejemplo!de!Kemeans!clustering!.............................................................................................!44!Figura!9:!Ejemplo!de!agrupamiento!utilizando!Canopy!.......................................................................!45!Figura!10:!Ejemplo!de!clustering!de!Dirichlet.!Modelo!incorrecto!y!correcto.!....................................!47!Figura!11:!Dirichlet!en!una!distribución!normal!asimétrica!.................................................................!48!Figura!12:!Distancia!interecluster!grande!y!pequeña!...........................................................................!50!Figura!13:!Distancia!intraecluster!grande!y!pequeña!...........................................................................!50!Figura!14:!Diagrama!de!Casos!de!Uso!..................................................................................................!63!Figura!15:!Arquitectura!de!Alto!Nivel!..................................................................................................!70!Figura!16:!Diagrama!de!Servicios!.........................................................................................................!71!Figura!17:!Estructura!Física!del!Prototipo!............................................................................................!72!Figura!18:!Diagrama!de!Paquetes!de!Analytics!....................................................................................!74!Figura!19:!Diagrama!de!Paquetes!de!Catalog!......................................................................................!75!Figura!20:!Diagrama!de!Paquetes!de!Id!...............................................................................................!75!Figura!21:!Diagrama!de!Paquetes!de!Search!.......................................................................................!75!Figura!22:!Diagrama!de!Paquetes!de!Social!.........................................................................................!76!Figura!23:!Diagrama!de!Paquetes!de!Recommender!..........................................................................!76!Figura!24:!Usuario!Anónimo!Sin!Recomendación!en!Intel!AppUp!Center!...........................................!91!Figura!25:!Intel!AppUp!Center!con!Recomendaciones!Personalizadas!...............................................!91!Figura!26:!Recomendación!basada!en!Contenido!para!Usuario!Anónimo!I!en!el!Cliente!X!.................!92!Figura!27:!Recomendación!basada!en!Contenido!para!Usuario!Anónimo!II!en!el!Cliente!X!................!93!Figura!28:!Pantalla!Inicial!de!Cliente!X!sin!Recomendaciones!.............................................................!93!Figura!29:!Pantalla!Inicial!de!Cliente!X!con!Recomendaciones!Personalizadas!...................................!94!Figura!30:!Recomendaciones!Híbridas!para!Usuario!Autenticado!en!el!Cliente!X!...............................!94!Figura!31:!Conexión!con!Redes!Sociales!en!el!Cliente!X!......................................................................!95!Figura!32:!Login!con!Facebook!............................................................................................................!96!Figura!33:!Permisos!Explícitos!de!Acceso!a!Información!de!Facebook!................................................!96!Figura!34:!Usuario!Conectado!a!Facebook!..........................................................................................!97!Figura!35:!Gustos!obtenidos!de!Facebook!...........................................................................................!97!Figura!36:!Jerarquía!AH!......................................................................................................................!109!Figura!37:!Diagrama!de!Clases!de!los!Servicios!de!Catalog!y!Analytics!.............................................!124!Figura!38:!Diagrama!de!Clases!de!los!Servicios!de!Search,!Social!y!Recommender!..........................!125!Figura!39:!Recommender!–!Collaborative!Filtering!...........................................................................!126!Figura!40:!Catalog!–!ItemsByIds!.........................................................................................................!127!Figura!41:!Analytics!e!Rejects!.............................................................................................................!127!Figura!42:!Interfaz!REST!del!Servicio!de!Catalog!................................................................................!128!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
8!!
Figura!43:!Enumeraciones!Polimórficas!utilizadas!en!Recomendaciones!con!Filtros!Colaborativos!.!129!Figura!44:!Objeto!del!Modelo!e!Indexador!del!Motor!de!Búsquedas!...............................................!130!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
9!!
Índice!de!Tablas!
!Tabla!1:!Diferencias!entre!Web!1.0!y!Web!2.0![Rice,!2009]!................................................................!20!Tabla!2:!Fuente!de!Datos!para!cálculo!de!CP!.......................................................................................!26!Tabla!3:!Correlación!de!Pearson!..........................................................................................................!26!Tabla!4:!Distancia!Euclídea!y!Similitud!basada!en!la!DI!.......................................................................!28!Tabla!5:!Preferencias!convertidas!para!cálculo!de!CS!..........................................................................!28!Tabla!6:!Correlación!de!Spearman!.......................................................................................................!29!Tabla!7:!Fuente!de!Datos!para!cálculo!de!CJ!.......................................................................................!30!Tabla!8:!Coeficiente!Jaccard!................................................................................................................!30!Tabla!9:!Fuente!de!Datos!para!cálculo!de!LLR!.....................................................................................!31!Tabla!10:!Eventos!para!cálculo!de!LLR!.................................................................................................!31!Tabla!11:!AeA!para!cálculo!de!LLR!........................................................................................................!32!Tabla!12:!AeB!para!cálculo!de!LLR!........................................................................................................!32!Tabla!13:!AeC!para!cálculo!de!LLR!........................................................................................................!32!Tabla!14:!Valores!de!Similitud!basada!en!LLR!......................................................................................!33!Tabla!15:!Fuente!de!Datos!para!cálculo!de!Diferencias!en!SO!.............................................................!34!Tabla!16:!Promedio!de!diferencias!de!preferencias!entre!pares!de!ítems!para!SO!.............................!34!Tabla!17:!Predicciones!para!distintos!usuarios!con!SO!........................................................................!35!Tabla!18:!Datos!estructurados!.............................................................................................................!36!Tabla!19:!Datos!Semiestructurados!I!...................................................................................................!37!Tabla!20:!Datos!Semiestructurados!II!..................................................................................................!38!Tabla!21:!Escala!de!comparaciones!para!AHP!...................................................................................!109!Tabla!22:!Matriz!de!Arquitectura!.......................................................................................................!110!Tabla!23:!Matriz!de!Anatomía!...........................................................................................................!111!Tabla!24:!Comparativa!de!Facilidad!de!Uso!.......................................................................................!112!Tabla!25:!Matriz!de!Facilidad!de!Uso!.................................................................................................!112!Tabla!26:!Matriz!de!Software!............................................................................................................!112!Tabla!27:!Matriz!de!Costo!..................................................................................................................!113!Tabla!28:!Comparativa!de!Misceláneos!.............................................................................................!113!Tabla!29:!Matriz!de!Misceláneos!.......................................................................................................!113!Tabla!30:!Comparativa!de!Servicios!...................................................................................................!114!Tabla!31:!Matriz!de!Servicios!.............................................................................................................!114!Tabla!32:!Matriz!de!Criterios!.............................................................................................................!114!Tabla!33:!Resultados!finales!AHP!.......................................................................................................!115!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
10!!
Índice!de!Fórmulas!
!Fórmula!1:!Coeficiente!de!Correlación!de!Pearson!.............................................................................!25!Fórmula!2:!Distancia!euclidiana!del!espacio!euclídeo!nedimensional!.................................................!27!Fórmula!3:!Similaridad!basada!en!distancia!Euclidiana!.......................................................................!27!Fórmula!4:!Similitud!basada!en!coeficiente!de!Jaccard!.......................................................................!29!Fórmula!5:!Logelikelihood!Ratio!...........................................................................................................!32!Fórmula!6:!Similitud!basada!en!LLR!.....................................................................................................!32!Fórmula!7:!Peso!tfidf!...........................................................................................................................!40!Fórmula!8:!Distancia!Euclidiana!al!cuadrado!.......................................................................................!41!Fórmula!9:!Distancia!Manhattan!.........................................................................................................!41!Fórmula!10:!Distancia!Cosenoidal!.......................................................................................................!42!Fórmula!11:!Distancia!Tanimoto!..........................................................................................................!43!Fórmula!12:!Grado!de!Asociación!de!Vector!V!a!Cluster!C1!................................................................!46!Fórmula!13:!Error!Cuadrático!Medio!...................................................................................................!48!Fórmula!14:!Precisión!..........................................................................................................................!49!Fórmula!15:!Exhaustividad!..................................................................................................................!49!Fórmula!16:!Prioridad!de!una!alternativa!..........................................................................................!115!
!! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
11!!
!Acrónimos!
!
!AHP* Analytic!Hierarchy!Process!
API* Application!Programming!Interface!
CD* Compact!Disc!CI* Collective!Intelligence!CJ* Coeficiente!de!Jaccard!CP* Correlación!de!Pearson!CRUD* Create!Read!Update!Delete!CS* Correlación!de!Spearman!DI* Distancia!Euclidiana!HTML* HyperText!Markup!Language!HTTP* Hypertext!Transfer!Protocol!ID* Intrusion!Detection!IDF* Inverse!Document!Frecuency!IoC* Inversion!of!Control!JSON* Javascript!Object!Notation!JSP* JavaServer!Pages!LLR* Logelikelihood!Ratio!ML* Machine!Learning!NaN* Not!a!Number!Pymes* Pequeñas!y!Medianas!Empresas!REST* Representational!State!Transfer!RMSE* Root!Mean!Square!Error!RS* Recommender!System!SaaS* Software!as!a!Service!SN* Social!Network!SO* Slope!One!TF* Term!Frecuency!UI* User!Interface!URL* Uniform!Resource!Locator!WAR* Web!Archive!XML* eXtensible!Markup!Language!
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
12!!
1 Introducción!!
En los últimos años ha habido un incremento exponencial en el volumen de
información digital disponible. Dicho aumento trajo aparejado un problema: ¿cómo filtrar y
entregar eficientemente información relevante al usuario? [Ghazanfar, Prugel-Bennett, 2010].
En dicho contexto, se hace imprescindible la existencia de sistemas de extracción de
información que permitan presentar sólo información de interés para los usuarios. Tales
sistemas se denominan “Sistemas de Recomendación” [Patel, Balakrishnan, 2009].
Compañías como Amazon, Facebook, Google, eBay, gozan de gran popularidad
debido a que han sido capaces de proveer información “relevante” basándose en las
interacciones del usuario con el contenido. El factor principal de su éxito es el uso activo de
Inteligencia Colectiva, principalmente, de Sistemas de Recomendación [Nagalakshmi,
Joglekar, 2011].
Anderson propuso el concepto conocido comúnmente como Cola Larga o Long Tail.
El mismo hace referencia a que usualmente pocos eventos suceden muy frecuentemente,
mientras que una gran cantidad de eventos ocurren sólo esporádicamente. Planteó el hecho de
que “hay que olvidarse de exprimir millones de unos pocos grandes éxitos en la cima de las
listas; el futuro está en los millones de nichos de mercado en el extremo bajo de la cadena de
bits”. Una de las reglas que propone Anderson es la utilización de sistemas de
recomendaciones para impulsar la demanda en estos sectores de baja popularidad [Anderson,
2004].

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
13!!
!
Figura(1:(Diagrama(de(la(Cola(Larga([Jannach(et(al.,(2010](
!
De hecho, la distribución de Cola Larga está prácticamente en todos lados, en
palabras y páginas web, en políticos y relaciones públicas, en terremotos y secuencias de
ADN, en partituras musicales y deportes universitarios. En aplicaciones de e-commerce
existe una fuerte demanda de productos desconocidos [Zaier, Godin, Faucher, 2008]. Por
ejemplo, el caso de Rhapsody, donde el 40% de las ventas no provienen de los 39.000 tonos
más vendidos. 21% de las ventas de Netflix provienen de películas que no forman parte de las
3000 más alquiladas. 20% de las ventas de Amazon no provienen de los 130.000 libros más
populares [Anderson, 2006].
El presente trabajo propone el desarrollo de un sistema integral de inteligencia
colectiva, que incluye un motor de búsqueda, un motor de recomendaciones y diferentes
servicios que, por un lado, permiten al usuario contar con información relevante facilitándole
la toma de decisiones (qué ver, qué comprar, qué leer, etc.), y por otro, que permiten
aumentar la demanda en la Long Tail. Se pretende crear valor agregado a través de la
combinación de una arquitectura orientada a servicios. Se hace mayor hincapié en los
servicios de recomendación.
Se realiza también una prueba de concepto integrando algunos servicios con distintas
aplicaciones clientes.
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
14!!
!
1.1 Objetivos!!
1.1.1 Objetivo!General!
Desarrollar un sistema distribuido de inteligencia colectiva que pueda ser utilizado
por diversos clientes, para poder personalizar la información ofrecida, favoreciendo la
experiencia de los usuarios y creando nuevas oportunidades de venta.
1.1.2 Objetivos!Específicos!!
- Analizar el marco teórico sobre Inteligencia Colectiva, Motores de Búsqueda y
Sistemas de Recomendación.
Se estudiará la teoría referida a la inteligencia colectiva, motores de búsqueda y sistemas
de recomendación, sus características principales y usos más frecuentes. Se analizarán los
diferentes algoritmos de recomendación existentes. Se analizará la técnica de
agrupamiento o clustering. Se hará un breve resumen de la terminología básica de la
disciplina junto con los elementos fundamentales que componen los sistemas de
inteligencia colectiva y los motores de búsqueda.
- Describir y Evaluar la factibilidad de la implementación de un sistema con la
tecnología actual.
Se describirán las diversas tecnologías necesarias para la creación de un sistema de
inteligencia colectiva. Se incluirá descripción de las tecnologías elegidas para la
elaboración del sistema.
- Implementar un sistema distribuido de inteligencia colectiva lo suficientemente
genérico que pueda ser reutilizado en distintos proyectos de software.
A partir del análisis de las tecnologías involucradas, se procederá al diseño y concepción
de un sistema orientado a servicios que permitirá buscar y recomendar ítems de interés
para el usuario. Se establecerán métricas de evaluación del framework.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
15!!
- Realizar diferentes pruebas de concepto integrando partes del sistema con diversos
clientes.
A partir del desarrollo del sistema, se procederá a la integración del mismo con diversos
clientes, entre los que se encontrará la tienda virtual de venta de aplicaciones de Intel,
llamado Intel AppUp Center, y se mostrarán algunos resultados. Se realizarán mediciones
con diversos corpus para medir la efectividad de las recomendaciones.
!!
1.2 Estructura!!
Este documento se encuentra organizado del siguiente modo:
- La sección 2 contiene el marco teórico necesario para el desarrollo del presente.
- La sección 2.1 introduce la inteligencia colectiva, los tipos de inteligencia que existen,
sus usos más comunes, etc.
- La sección 2.2 describe los sistemas de recomendación, qué son, los distintos tipos
que existen, los diferentes algoritmos y las métricas para evaluar su efectividad, el
problema del comienzo en frío, técnicas de clustering, etc.!
- La sección 2.3 describe los motores de búsqueda, cómo están compuestos y el
funcionamiento básico. Se enumeran brevemente los más utilizados en la actualidad.!
- La sección 2.4 introduce el concepto de redes sociales como potenciadoras de la
inteligencia colectiva, sus características, impacto y papel que desempeñan en la
actualidad.!
- La sección 2.5 introduce el concepto de estadísticas de uso o analytics, y algunos de
sus usos actuales.!
- La sección 3 define el problema a tratar en este trabajo y destaca su importancia en la
actualidad. !
- La sección 4 plantea diferentes alternativas de solución al problema. Se hace un
análisis de las opciones que existen en la industria. !
- La sección 5 procede a detallar el diseño e implementación del sistema integral de
inteligencia colectiva propuesto como solución al problema planteado en la sección 3. !
- La sección 5.1 presenta el diseño de alto nivel, casos de uso, diagrama de arquitectura,
servicios, diagramas de paquetes, APIs, etc.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
16!!
- La sección 5.2 presenta el diseño de bajo nivel, diagramas de clases, diagramas de
secuencia y algunos pedazos de código.!
- La sección 5.3 enumera las diferentes tecnologías y frameworks que se utilizaron para
el desarrollo del sistema.!
- La sección 6 contiene la evaluación de los resultados.!
- Las secciones 7 y 8 presentan las conclusiones y trabajos futuros respectivamente.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
17!!
2 Marco!Teórico!!
A continuación se define el marco teórico que servirá de respaldo conceptual a la
implementación del prototipo. Cabe destacar que no se pretende realizar un desarrollo
exhaustivo de las disciplinas relacionadas, sino más bien una reducida introducción al marco
de trabajo indispensable para un mejor entendimiento del mismo.
2.1 Sistemas!de!Inteligencia!Colectiva!!
La Inteligencia Colectiva, o CI por sus siglas en inglés, es una forma de inteligencia
que emerge cuando un grupo de individuos realizan cosas en conjunto. El grupo, trabajando
en forma coordinada o colaborativa, es capaz de actuar más inteligentemente que cualquier
individuo miembro [Malone, 2006].
Singh y Gupta definen la CI como la habilidad de un grupo de agentes simples que
trabajan juntos para resolver problemas más grandes y complejos que los que podrían
resolver por separado [Singh, Gupta, 2009].
El conjunto de agentes simples es como un enjambre y la inteligencia emergente de
sus interacciones se la denomina inteligencia de enjambre. Bonabeau, Dorigo and Stutzle,
describen esta inteligencia como cualquier intento de diseñar algoritmos en base al
comportamiento colectivo de colonias de insectos u otras sociedades de animales [Bonabeau,
Dorigo, Stutzle, 1999].
Las personas han utilizado el término Inteligencia Colectiva por décadas, y se ha
vuelto muy importante y popular con la aparición de nuevas tecnologías de comunicación.
Cuando los especialistas usan esta frase, se refieren generalmente a la combinación de
comportamientos, preferencias o ideas de un grupo de personas que permiten obtener nuevos
conocimientos [Segaran, 2007].
Alag define a la Inteligencia Colectiva como el uso efectivo de información provista
por otros para mejorar aplicaciones [Alag, 2009].

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
18!!
Nagalakshmi y Joglekar afirman que las aplicaciones web se encuentran atravesando
un proceso de transformación. Por un lado, las nuevas aplicaciones proveen una experiencia
más rica a los usuarios y reorganizan el contenido dinámicamente basado en lo que conocen
de sus clientes y lo que éstos explícitamente piden. Por otro lado, los usuarios han comenzado
a proveer información de distintas maneras, ya sea compartiendo sus opiniones respecto a un
producto o servicio a través de comentarios y calificaciones, compartiendo contenido,
participando en comunidades online, lo que lleva al problema del “exceso” de información.
Es por esto que resulta cada vez más difícil encontrar la información que se busca
[Nagalakshmi, Joglekar, 2011].
Se necesita convertir toda esta nueva información en inteligencia para las
aplicaciones. El uso de esta inteligencia, conocida como Inteligencia Colectiva, permite
personalizar sitios, mejorando la experiencia de los usuarios. Los sistemas de recomendación
proveen estas funcionalidades [Alag, 2009].
2.1.1 Tipos!de!Inteligencia!Colectiva!!
! La información provista por usuarios de aplicaciones web resulta de tres inteligencias
diferentes: Explícita, Implícita y Derivada [Alag, 2009].!En la Figura 2 se ilustran estos tipos.
- Inteligencia Explícita: se trata de información explícita que el usuario provee, ya sea
por revisiones, comentarios, marcadores, etc.
- Inteligencia Implícita: se trata de información indirecta que el usuario provee, ya sea
simplemente por la colección de estadísticas de uso o por la agregación de contenido
de otras fuentes de información.
- Inteligencia Derivada: se trata de información obtenida de los datos de los usuarios,
tanto explícita como implícitamente.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
19!!
!
Figura(2:(Tipos(de(Inteligencia([Alag,(2009](
En el presente trabajo se abarcan estas tres grandes áreas. Como primer paso se
obtiene información explícita de los usuarios en base a sus calificaciones, revisiones y
estadísticas de uso. Luego se adquiere información implícita de ciertas redes sociales del
usuario. Por último, en base a toda la información recolectada, se hacen búsquedas
inteligentes y se recomienda contenido relevante.
2.1.2 Web!2.0!–!Social!Media!
Durante los últimos años la Web ha experimentado un cambio transformacional
popularmente conocido como Web 2.0. En esencia, este cambio implicó hacer la Web
“participativa”, es decir, poner al usuario en el centro y construir aplicaciones basadas en él
en detrimento del contenido. Singh et al. afirman que el valor agregado que ofrecen las
aplicaciones surge de los datos obtenidos de las interacciones de sus usuarios [Singh et al.,
2009].
En la Tabla 1 Rice Lincoln propone una comparación entre la Web 1.0 y la Web 2.0
para así explicitar ciertas diferencias.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
20!!
!
Tabla(1:(Diferencias(entre(Web(1.0(y(Web(2.0([Rice,(2009](
Es relativamente simple diseñar una aplicación similar a Wikipedia, Amazon, Flickr,
YouTube en términos de interfaz gráfica, pero lo que no se puede replicar fácilmente es la
experiencia de usuario que ofrecen en base a los datos colectados de los billones de usuarios
con los que cuentan. Es justamente ahí donde se encuentra su verdadera fortaleza [Singh et
al., 2009].
Muchas personas consideran ambiguo el término Web 2.0, por ello prefieren utilizar
el concepto de Social Media. Este concepto hace hincapié en las ideas que se crean,
comparten, refinan a través de la colaboración, y no en las ideas que se simplemente se
observan. Social Media acoge la “arquitectura de la participación”. En otras palabras, los
usuarios pueden agregar valor a las aplicaciones que usan [Rice, 2009].
Rice también afirma que la parte más excitante de esta nueva web es el cambio de
mentalidad y filosofía. Propone un nuevo mundo en donde la audiencia, todos nosotros en
vez de una elite, decide qué es lo verdaderamente importante. !
2.1.3 Ejemplos!en!el!mundo!real!
Durante la última década muchas compañías han incluido el concepto de inteligencia
colectiva en sus aplicaciones. Un punto de inflexión en la web fue la introducción de motores
de búsqueda. Google pasó, en menos de 10 años, de ser un startup a ser un jugador dominante
en el sector tecnológico, debido principalmente a su algoritmo de búsqueda, secundado por
otros servicios como Google News, Google Finance [Marmanis, Babenko, 2009].

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
21!!
Amazon fue una de las primeras tiendas virtuales que ofreció recomendaciones a los
usuarios basadas en sus patrones de compras. Ni bien un usuario agrega ítems al carrito de
compras, Amazon le recomienda productos adicionales que de alguna manera están
relacionados con los que seleccionó previamente. Un artículo muy interesante de la agencia
Reuters habla del poder de este gigante. Afirma que Google conoce qué buscan los usuarios,
Facebook conoce qué les gusta a las personas y quiénes son sus amigos, mientras que
Amazon conoce qué zapatos de correr buscó determinado usuario la semana pasada, pero
también sabe que hace un año compró un par. Este tipo de información mantiene en vilo a los
anunciantes [Barr, Saba, 2013].
Otra aplicación web inteligente es Netflix, el más grande servicio de alquiler de
películas online del mundo, el cual ofrece miles de títulos en DVD más una librería de más de
5.000 películas y series de televisión a sus más de 20 millones de suscriptores. Netflix ha sido
galardonado 9 veces por ForeSee Results como el sitio web #1 en satisfacción de usuarios
[NETFLIX, 2012].
Parte del éxito de Netflix se debe a su habilidad para ofrecer a sus usuarios una
manera simple para elegir películas. El núcleo de la plataforma es un sistema de
recomendación denominado Cinematch, cuyo trabajo es predecir los gustos de los usuarios.
Muchos consideran a Netflix como LA aplicación web inteligente. El poder predictivo de
Cinematch es de gran valor para Netflix, a tal punto que en Octubre de 2006 se abrió un
concurso para mejorar sus capacidades en un 10%. Luego de tres años de competencia,
BellKor’s Pragmatic Chaos presentó el algoritmo ganador sólo 24 minutos antes que otro
equipo. Los ganadores se llevaron 1 millón de dólares [Hoffman, 2009].
Last.fm es otra aplicación que incorpora CI. Es un servicio para descubrir nueva
música que ofrece recomendaciones personalizadas basándose en la música que uno escucha
[LASTFM, 2013].
2.2 Sistemas!de!Recomendación!!
Los sistemas de recomendación, o RS por sus siglas en inglés, son aplicaciones de
software que tienen como objetivo apoyar a los usuarios en la toma de decisiones mientras
interactúan con grandes volúmenes de información. Recomiendan artículos de interés a los

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
22!!
usuarios en función de las preferencias que éstos han expresado, ya sea explícita o
implícitamente. El volumen cada vez mayor y la creciente complejidad de la información en
la web, han hecho de estos sistemas herramientas esenciales para los usuarios en actividades
de comercio electrónico y de búsqueda de información [ACM, 2012].
Ricci, Rokach y Shapira afirman que los RS son herramientas y técnicas de software
que proveen sugerencias de ítems útiles para los usuarios. Dichas sugerencias se relacionan
con distintos procesos de toma de decisiones, tales como qué ítems comprar, qué música
escuchar, qué noticias leer, etc. [Ricci, Rokach, Shapira, 2011].
Ítem es el término genérico utilizado para identificar lo que el sistema recomienda a
los usuarios. Un RS normalmente trabaja con un solo tipo de ítem (por ej. CDs, películas,
libros) y están dirigidos a individuos que carecen de suficiente experiencia para evaluar la
enorme cantidad de ítems alternativos que un sitio puede ofrecer [Resnick, Varian, 1997].
! El desarrollo de RS comenzó con una simple observación: a menudo los individuos
confían en las recomendaciones provistas por otros al momento de tomar decisiones diarias.
Por ejemplo, es común leer un libro que alguien nos recomendó, cuando seleccionamos
alguna película para ver, generalmente tendemos a ver las críticas que aparecen en los diarios,
los empleadores se basan fuertemente en las recomendaciones para tomar una decisión de
contratación, etc. [Mahmood, Ricci, 2009].!!
!
2.2.1 Algoritmos!de!Recomendación!!
Generalmente una persona elige un libro en una biblioteca por alguna razón. Una
posibilidad sería porque lo encontró cerca de otros libros que conoce y le sirvieron. Otra,
porque lo vio en la oficina de un compañero de trabajo, el cual comparte su interés por el
tema. O simplemente debido a que se lo recomendaron directamente. Todas estas estrategias
son válidas para descubrir nuevas entidades. Por ejemplo, se podrían observar las cosas que
atraen a personas con gustos similares. También, se podrían buscar qué ítems son parecidos a
los que ya se tienen [Owen et al., 2012].
De hecho, estas son dos categorías de algoritmos de recomendación: basada en
usuarios y basada en ítems. La primera, basada en usuarios, utiliza información personal del
usuario para sugerir buenas recomendaciones. La segunda, basada en ítems, determina qué

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
23!!
ítems están relacionados con un ítem en particular; cuando a un usuario le gusta un ítem, los
relacionados son recomendados [Patel, Balakrishnan, 2009].
Hablando más precisamente, los escenarios precedentes son ejemplos de Filtrado
Colaborativo, más conocido como “Collaborative Filtering”, producen recomendaciones
basadas sólo en las relaciones usuarios-ítems. Existen también otras técnicas, las basadas en
contenido, donde la sugerencia se nutre de algún atributo del ítem, por ejemplo, el autor del
libro, la editorial, etc. [Owen et al., 2012]. Adomavicius y Tuzhilin hacen referencia a una
tercera categoría híbrida que resulta de la mezcla de las dos anteriores [Adomavicius,
Tuzhilin, 2005].
Todo proceso de recomendación requiere la recolección de un set de datos o corpus.
Una vez que se recolectaron estos datos acerca de los gustos de los usuarios, se necesita una
forma para determinar qué tan similares (en cuanto a gustos) son esas personas. Esto se
consigue comparando a los usuarios y calculando un puntaje de similitud entre ellos. Existen
distintas formas para calcular esta similitud, como ser la Correlación de Pearson, la Distancia
Euclidiana [Segaran, 2007], la Correlación de Spearman, la Similitud del Coseno, el
Coeficiente Tanimoto, etc. [Owen et al., 2012].
'
2.2.1.1 Algoritmos'de'Filtrado'Colaborativo'!
Como se mencionó anteriormente, existen dos grandes grupos dentro de esta
categoría, recomendaciones basadas en usuarios o basadas en ítems.
NOTA: Las sub secciones siguientes se basaron en información obtenida del excelente libro “Mahout in Action” (incluido en la bibliografía) a no ser que se indique lo contrario.
2.2.1.1.1 Recomendaciones!Basadas!en!Usuarios!
Consiste en el proceso de recomendar ítems a algún usuario en particular basado en la
similitud entre usuarios. Dicho proceso se muestra a continuación en pseudocódigo.
para cada ítem i que el usuario u aún no emitió preferencia alguna por cada otro usuario v que tiene preferencia por i

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
24!!
computar una similitud s entre u y v incorporar la preferencia de v por i, ponderada por s, en un promedio retornar los top ítems, rankeados por el promedio ponderado Sería muy lento examinar todos los ítems. En realidad, se computa primero un grupo
de usuarios más similares y sólo aquellos ítems conocidos por ese grupo son considerados. El
pseudocódigo actualizado quedaría así:
para cada otro usuario w computar una similitud s entre u y w mantener los usuarios top, rankeados por similitud, en un grupo n para cada ítem i que algún usuario en n emitió una preferencia pero que u aún no calificó para cada otro usuario v en n que tiene una preferencia por i computar una similitud s entre u y v incorporar la preferencia de v por i, ponderada por s, en un promedio retornar los top ítems, rankeados por el promedio ponderado El tiempo de corrida de un algoritmo de recomendación basado en usuarios crece a
medida que el número de usuarios crece.
2.2.1.1.2 Recomendaciones!Basadas!en!Ítems!
! Consiste en el proceso de recomendar ítems a algún usuario en particular basado en la
similitud entre ítems. Dicho proceso se muestra a continuación en pseudocódigo.
para cada ítem i que el usuario u aún no emitió preferencia alguna por cada ítem j que u tiene preferencia por computar una similitud s entre i y j incorporar la preferencia de u por j, ponderada por s, en un promedio retornar los top ítems, rankeados por el promedio ponderado
El tiempo de corrida de un algoritmo de recomendación basado en ítems crece a
medida que el número de ítems crece.
Si el número de ítems es relativamente bajo comparado al número de usuarios, será
mucho más eficiente utilizar una implementación basada en ítems y no en usuarios.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
25!!
2.2.1.1.3 Basadas!en!Ítems!versus!Basadas!en!Usuarios!!
El filtrado basado en ítems es significativamente más rápido que el basado en usuarios
cuando se buscan obtener recomendaciones de un gran set de datos, pero tiene la carga
adicional de tener que mantener una tabla de similitud de ítems [Segaran, 2007].
Segaran también afirma que existe una diferencia en la precisión que depende de qué
tan disperso es el conjunto de datos. Si se tiene un conjunto de datos en donde la mayoría de
los usuarios ha calificado casi todos los ítems, entonces el set de datos se dice que es denso,
caso contrario, se dice que es disperso. El filtrado basado en ítems generalmente tiene mejor
performance que el basado en usuarios en set de datos dispersos. Para set de datos densos,
ambos se desempeñan de manera similar.
Dicho todo esto, también vale la pena mencionar que el filtrado basado en usuarios es
más fácil de implementar, por ende es, usualmente, más apropiado para conjunto de datos
pequeños que cambian con mucha frecuencia [Segaran, 2007].
!
2.2.1.1.4 Métricas!de!Similitud!!
2.2.1.1.4.1 Correlación/de/Pearson/!
! La Correlación de Pearson (CP) es un número entre -1 y 1 que mide la relación lineal
entre dos series de números. Mientras más lineal la relación, más cercano a 1 es el
coeficiente.
Este concepto, muy utilizado en estadística, puede aplicarse a usuarios para medir su
similitud, es decir, medir la tendencia de las preferencias de dos usuarios.
La expresión que permite calcular la correlación de Pearson es la siguiente:
!
Fórmula(1:(Coeficiente(de(Correlación(de(Pearson(
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
26!!
Donde:!
!!:!valor!del!ieésimo!elemento!de!x!!!:!valor!del!ieésimo!elemento!de!y!!:!media!aritmética!de!x((!:!media!aritmética!de!y((!
La Tabla 2, Tabla 3 y Figura 3 muestran un ejemplo, donde los usuarios A, B y C
calificaron los ítems I1, I2, I3, I4 e I5.
!
Tabla(2:(Fuente(de(Datos(para(cálculo(de(CP(
!
Figura(3:(Diagrama(de(Líneas(para(cálculo(de(CP(
!
!
Tabla(3:(Correlación(de(Pearson(
CP es una métrica bastante intuitiva pero tiene algunos problemas. No tiene en cuenta
el número de ítems en que ambos usuarios coincidieron. En otras palabras, dos usuarios que
vieron 200 mismas películas (sin importar si no concuerdan con las calificaciones) son
probablemente más similares que dos usuarios que sólo tienen 2 películas en común.
I1 I2 I3 I4 I5A 4,5 4,5 4 1,5 3B 2 5 2 4 2C 4 4 4 1 3
UsuariosÍtems
Usuarios PearsonA"#"B #0,139A"#"C 0,978B"#"C #0,271A"#"A 1,000

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
27!!
Si dos usuarios se solapan en un solo ítem, no se puede computar la correlación
debido a cómo está definida. Esto puede ser un problema para un conjunto pequeño o
disperso de datos. Aunque también puede ser visto como una ventaja, dos usuarios que se
solapan en un solo ítem, intuitivamente no son similares.
Por último la correlación también sería indefinida si cualquiera de las series de
valores son todos idénticos. En otras palabras, si el usuario B hubiera calificado todos los
ítems con 2, no se hubiera podido computar la correlación entre A y B o B y C o B y B.
2.2.1.1.4.2 Distancia/Euclidiana/!
Esta métrica de similitud se basa en la distancia entre usuarios. Se piensa a los
usuarios como puntos en un espacio n dimensional, donde n es igual al número de ítems y
donde las coordenadas son las preferencias.
La Distancia Euclidiana (DI) por sí sola no constituye una métrica de similaridad
válida debido a que grandes valores significarían mayor distancia, y por lo tanto, usuarios
más disímiles. El valor debería ser más chico a medida que los usuarios son más similares,
siendo uno cuando los usuarios son idénticos.
La expresión que permite calcular la distancia Euclidiana es la siguiente:
!
Fórmula(2:(Distancia(euclidiana(del(espacio(euclídeo(nTdimensional
Donde:!
! = (!",!",… ,!")!! = (!",!",… ,!")!!:!número!de!dimensiones((!!:!punto!p!en!la!ieésima!dimensión((!!:!punto!q!en!la!ieésima!dimensión(
La expresión que permite calcular la similitud basada en la distancia Euclidiana es la
siguiente:
!
Fórmula(3:(Similaridad(basada(en(distancia(Euclidiana
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
28!!
Donde:!
!:!distancia!euclidiana!
En base a los datos de la Tabla 2, la Tabla 4 muestra los resultados de los cómputos
para esta métrica.
!
!
Tabla(4:(Distancia(Euclídea(y(Similitud(basada(en(la(DI((
!
2.2.1.1.4.3 Correlación/de/Spearman/!
La correlación de Spearman (CS) es una variante de la correlación de Pearson. En
lugar de computar una correlación basada en los valores originales de preferencias, Spearman
computa una correlación basada en un ranking relativo de valores de preferencias.
Un ejemplo típico es el siguiente: para cada usuario, el valor del ítem de menor
preferencia se convierte en 1. El valor del siguiente ítem de menor preferencia se convierte en
2 y así sucesivamente. Finalmente se computa la correlación de Pearson para estos nuevos
valores, que en realidad se denomina correlación de Spearman.
A pesar de que preserva el orden de las preferencias, este proceso pierde información.
Para cierto conjunto de datos esto puede ser beneficioso, para otros no.
La Tabla 5 muestra las conversiones del set de datos propuesto en la Tabla 2.
!
Tabla(5:(Preferencias(convertidas(para(cálculo(de(CS(
!
En base a los datos de la!Tabla 5, la Tabla 6!muestra los resultados de los cómputos
para esta métrica.
Usuarios Distancia,Euclideana SimilitudA"#"B 4,213 0,192A"#"C 0,866 0,536B"#"C 4,359 0,187A"#"A 0,000 1,000
I1 I2 I3 I4 I5A 4 4 3 1 2B 1 3 1 2 1C 3 3 3 1 2
UsuariosÍtems

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
29!!
!
Tabla(6:(Correlación(de(Spearman(
Implementar esta métrica de similitud resulta muy costoso en términos
computacionales, requiere de trabajo no trivial para computar y guardar los valores
convertidos de las preferencias.
2.2.1.1.4.4 Coeficiente/Jaccard/!
Esta métrica de similaridad se basa en el coeficiente de Jaccard (CJ). Ignora
completamente los valores de las preferencias de los usuarios, sólo interesa si un usuario
emitió preferencia o no.
Es el número de ítems que dos usuarios han calificado dividido por el número de
ítems que uno u otro ha calificado. En otras palabras, es la razón entre el tamaño de la
intersección y el tamaño de la unión de los ítems calificados.
La expresión que permite calcular la similitud basada en el coeficiente de Jaccard es
la siguiente:
!
!
Fórmula(4:(Similitud(basada(en(coeficiente(de(Jaccard
Donde:!
!!!:!número!de!ítems!que!ambos!usuarios!han!calificado!!!":!número!de!ítems!que!el!primer!usuario!no!calificó!pero!el!segundo!sí.(!!":!número!de!ítems!que!el!primer!usuario!calificó!pero!el!segundo!no.((
La Tabla 7 muestra un ejemplo, donde los usuarios D, E y F calificaron los ítems que
aparecen con una x.
Usuarios SpearmanA"#"B 0,129A"#"C 0,943B"#"C #0,063A"#"A 1,000

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
30!!
!
!
Tabla(7:(Fuente(de(Datos(para(cálculo(de(CJ(
En base a los datos de la!Tabla 7, la Tabla 8 muestra los resultados de los cómputos
para esta métrica.
!
Tabla(8:(Coeficiente(Jaccard
Como ejemplo, se muestra a continuación el cálculo para D-E:
! = !11!01+!10+!11 =
21+ !1+ 2
!
Se utiliza esta métrica si y sólo si los valores de las preferencias de los usuarios son
booleanos. Generalmente se obtienen mejores resultados con una métrica que hace uso de los
valores no booleanos de las preferencias.
!
2.2.1.1.4.5 Cociente/Logarítmico/Probabilístico/!
La similaridad basada en el Cociente Logarítmico Probabilístico, LLR por sus siglas
en inglés, es otra métrica que no tiene en cuenta valores de preferencia individuales. Como el
Coeficiente de Jaccard, se basa en el número de ítems comunes entre dos usuarios. Su valor
es una expresión de que tan poco probable dos usuarios tengan mucho solapamiento.
Para ejemplificar este concepto, se consideran dos fanáticos de películas que vieron y
calificaron muchos largometrajes pero que sólo se solaparon en Forrest Gump y Volver al
I1 I2 I3 I4 I5D x x xE x x xF x x x
UsuariosÍtems
Usuarios JaccardD"E 0,500D"F 0,500E"F 0,333D"D 1,000

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
31!!
Futuro I, es decir, vieron solamente estas dos películas en común. Al haber visto una gran
cantidad de películas y sólo haberse solapado en dos, muy probablemente no son usuarios
similares. En cambio, si ambos hubieran visto pocas películas y ambas películas mencionadas
anteriormente estuvieran en la lista de ambos usuarios, existiría una gran probabilidad de que
ambos usuarios sean similares, el solapamiento sería significativo. Dicho en otras palabras,
dos usuarios similares mostrarán un solapamiento que parecerá muy poco probable que se
deba al azar. Mientras más improbable, más similares.
La Tabla 9!muestra un ejemplo, donde los usuarios A, B y C calificaron los ítems que
aparecen con una x.
!
Tabla(9:(Fuente(de(Datos(para(cálculo(de(LLR
Para computar el valor de similitud entre dos usuarios, replanteamos los valores de la
Tabla 9 en una nueva tabla, cuyas filas y columnas se ilustran en la Tabla 10 [Dunning,
2008].
!
Tabla(10:(Eventos(para(cálculo(de(LLR(
Donde:!
!!!:!número!de!veces!donde!los!dos!eventos!ocurrieron!en!conjunto.!!!":!número!de!veces!donde!ocurrió!el!segundo!evento!SIN!que!ocurra!el!primero.(!!":!número!de!veces!donde!ocurrió!el!primer!evento!SIN!que!ocurra!el!segundo.!!!!:!número!de!veces!donde!ninguno!de!los!dos!eventos!ocurrieron.!!!!
Las tablas que se ilustran a continuación permiten el cálculo de la similitud de los
usuarios A, B y C con el usuario A.
I1 I2 I3 I4 I5 I6 I7A x x xB x x x xC x x x x
UsuariosÍtems
Evento'A No'Evento'AEvento'B k11 k12
No'Evento'B k21 k22

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
32!!
!
Tabla(11:(ATA(para(cálculo(de(LLR(
!
Tabla(12:(ATB(para(cálculo(de(LLR(
!
Tabla(13:(ATC(para(cálculo(de(LLR(
!
La fórmula del Cociente Logarítmico Probabilístico se muestra a continuación:
!
Fórmula(5:(LogTlikelihood(Ratio(
Donde:!
!"#$%&'(#$)*+=!!"#$%&'((!!!,!!!"!,!!!",!!!!)!!"#$%&!"'(=!!"#$%&'((!!!,!!!"!)!+!!"#$%&'((!!",!!!!!)!!"#$%&'&()"*+=!!"#$%&'((!!!,!!!"!)!+!!"#$%&'((!!",!!!!!)!e!"#$%&'(!!,!!!!…!!!)=! !"!
!!! !.!!ln( !")!!!! !e!!!!.!ln !!!e!!!!.!ln !!!e!….!e!!!!.!ln !!!!!
!!
Una vez calculado el LLR, la similitud se computa de la siguiente manera:
!
!
Fórmula(6:(Similitud(basada(en(LLR(
!
Reemplazando la Fórmula 5 y la Fórmula 6 por los valores de la Tabla 11, la Tabla 12
y la Tabla 13 se obtienen los siguientes resultados:
Califica'A No'Califica'ACalifica'A 3 0
No'Califica'A 0 4
Califica'A No'Califica'ACalifica'B 3 1
No'Califica'B 0 3
Califica'A No'Califica'ACalifica'C 2 2
No'Califica'C 1 2

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
33!!
!
Tabla(14:(Valores(de(Similitud(basada(en(LLR
A pesar que es difícil generalizar, esta similaridad suele ser mejor que el Coeficiente
de Jaccard. Es, en esencia, una métrica más “inteligente”.
/
2.2.1.1.5 Pendiente!Uno!/!Slope!One!!
Es un algoritmo de recomendación muy utilizado que estima preferencias para nuevos
ítems basándose en la diferencia promedio del valor de la preferencia entre el nuevo ítem y
los otros ítems que el usuario prefirió.
Para aclarar, supongamos que en promedio, la gente calificó a la película El
Resplandor un punto por encima de la película Atrapado Sin Salida. Y también, que todos, en
promedio, calificaron El Resplandor igual a Mejor Imposible. Ahora bien, aparece un nuevo
usuario que califica a Atrapado Sin Salida con un 2,0 y a Mejor Imposible con 4,0. ¿Cuál
sería una buena estimación para el valor de El Resplandor?
Basado en Atrapado Sin Salida, el valor podría ser 2,0 + 1,0 = 3,0. Basado en Mejor
Imposible, podría ser 4,0 + 0,0 = 4,0. Una mejor aproximación sería el valor promedio de los
dos, 3,5. Esta es la esencia del algoritmo de Slope One (SO).
El nombre del algoritmo proviene del hecho que asume una relación lineal entre las
preferencias de un ítem y otro, es decir, considera válido estimar las preferencias para un ítem
Y basándose en las preferencias del ítem X a través de una función lineal Y = mX + b. Donde
m = 1 (pendiente uno). Queda entonces descubrir b = Y – X, la diferencia en los valores de
las preferencias para cada par de ítems.
El algoritmo tiene una etapa significativa de pre procesamiento, en donde se
computan las mencionadas diferencias.
Usuarios Similitud-basada-en-LLRA4A 0,9A4B 0,84A4C 0,16

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
34!!
para cada ítem i para cada otro ítem j para cada usuario u que calificó tanto a i como a j agregar la diferencia de la preferencia de u por i y j en un promedio
Luego de este pre procesamiento, el pseudocódigo del algoritmo se muestra a
continuación.
para cada ítem i que el usuario u aún no calificó para cada ítem j que el usuario u calificó encontrar la diferencia promedio de las preferencias entre j e i agregar esta diferencia a los valores de preferencia de j del usuario u agregar esto a un promedio retornar los top ítems, rankeados por estos promedios
La Tabla 15 muestra un conjunto de preferencias de los usuarios A, B y C.
!
Tabla(15:(Fuente(de(Datos(para(cálculo(de(Diferencias(en(SO
En base a los valores de la Tabla 15, en la Tabla 16 se muestran las diferencias
necesarias para el cómputo de la predicción basada en SO.
!
Tabla(16:(Promedio(de(diferencias(de(preferencias(entre(pares(de(ítems(para(SO
En este caso, la diferencia promedio de calificaciones entre los ítems I1 e I2 es 0,
entre los ítems I3 e I2 es 0,25, entre los ítems I4 e I2 es 3 y entre I5 e I2 es 1.
I1 I2 I3 I4 I5A 4,5 4,5 4 1,5B 2 2 2C 4 4 3
UsuariosÍtems
Ítems/Ítems I1 I2 I3 I4 I5I1 0,000 0,000 #0,250 #3,000 0,000I2 0,000 0,000 #0,250 #3,000 #1,000I3 0,250 0,250 0,000 #2,500 #0,500I4 3,000 3,000 2,500 0,000 0,000I5 0,000 1,000 0,500 0,000 0,000

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
35!!
Esto significa que el ítem I2 es calificado en promedio 0,25 por arriba del ítem I3, 3
por arriba del ítem I4, 1 por arriba del ítem I5 e igual que el ítem I1.
Si intentamos predecir la calificación del usuario B por el ítem I2 tendríamos las
siguientes opciones, en base a los ítems:
- I1 = 2 + 0 = 2
- I3 = 2 + 0,25 = 2,25
- I4 = 3 + 0 = 3
- I5 = 1 + 2 = 3
Utilizando un promedio ponderado en donde la ponderación se hace en base al
número de usuarios que calificaron ambos ítems, la calificación definitiva del usuario B por
el ítem I2 quedaría así:
!"#2 = !2!. 1!+ !2,25!. 2!+ !3!. 1!+ !3!. 11+ 2+ 1+ 1 = 2,5
La Tabla 17 muestra algunas predicciones de preferencias utilizando Slope One con el
promedio ponderado basado en el número de usuarios que calificaron ambos ítems.
!
Tabla(17:(Predicciones(para(distintos(usuarios(con(SO
!
Este algoritmo resulta atractivo porque la porción online del mismo es muy rápida.
Vale la pena mencionar que los requisitos de memoria para almacenar todas las diferencias de
preferencias entre ítems crecen cuadráticamente con el número de ítems. Doble cantidad de
ítems implica cuatro veces más memoria.
!
!
Usuario Ítem Predicción1Slope1OneC I1 3,563B I2 2,500A I5 3,750

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
36!!
2.2.1.2 Algoritmos'de'Filtrado'basado'en'Contenido'!
Los algoritmos de filtrado basados en contenido permiten recomendar ítems a los
usuarios en base a algún atributo del ítem y al perfil de los usuarios. A pesar de que pueden
ser utilizados en diferentes dominios, los sistemas de recomendación basados en contenido
comparten el hecho de poder describir los ítems, cuentan con algún medio para crear perfiles
de usuario que detallan los tipos de ítems que les interesan, y tienen un medio para comparar
ítems con los perfiles de usuario para determinar qué recomendar. Los perfiles generalmente
son creados y actualizados automáticamente en respuesta a las acciones, opiniones, etc., que
realizan los usuarios [Pazzani, Billsus, 2007].
NOTA: Las sub secciones 2.2.1.2.1 y 2.2.1.2.2.1 se basaron en información obtenida del excelente libro “The Adaptive Web”. El resto de las sub secciones se basaron en el ya citado libro “Mahout in Action”, ambos incluidos en la bibliografía.
2.2.1.2.1 Representación!de!Ítems!
Los ítems que se recomiendan a los usuarios pueden estar representados en forma
estructurada, desestructurada o semiestructurada.
Datos estructurados implica que los ítems tengan un cierto número de atributos, que
cada ítem pueda ser descripto por el mismo conjunto de atributos, y que haya un set de
valores conocidos para cada atributo. La Tabla 18 muestra un ejemplo de datos estructurados.
!!
Tabla(18:(Datos(estructurados
Datos desestructurados implica que no hay atributos con un set de datos predefinidos.
Campos de texto sin restricciones como puede ser un artículo en un periódico es un claro
ejemplo de datos desestructurados. La Figura 4 muestra un ejemplo.
Id Nombre Actor,Principal Director Génerom1 El%Resplandor Jack%Nicholson Stanley%Kubrick Terrorm2 Forrest%Gump Tom%Hanks Robert%Zemeckis Dramam3 Volver%al%Futuro%I Michael%Fox Robert%Zemeckis Ciencia%Ficción
Películas

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
37!!
!
Figura(4:(Datos(desestructurados(–(Fuente:(TN
!
La complejidad inherente del lenguaje natural puede estar presente en estos campos
de texto sin restricciones en forma de palabras polisémicas (la misma palabra pero con
distintos significados), sinónimos (distintas palabras pero con el mismo significado), etc.!!
Muchos dominios son mejor representados con datos semiestructurados, los cuales
tienen algunos atributos con un set de valores restringidos y otros con campos de texto libre.
Un ejemplo de esto sería el mundo de las películas, donde además de tener los atributos
presentes en la Tabla 18, cada película tendría una descripción, una calificación/revisión por
parte de los usuarios, etc. La Tabla 19 y la Tabla 20 ilustran dicha afirmación.
!
Tabla(19:(Datos(Semiestructurados(I(
!
Id Nombre Actor,Principal Director Género Descripción
m1 El%Resplandor Jack%Nicholson Stanley%Kubrick Terror
Relata%la%historia%de%un%hombre%que%empieza%a%sufrir%inquietantes%
trastornos%de%personalidad%a%poco%de%llegar%a%un%solitario%hotel%al%que%se%había%trasladado%con%su%familia...%
m2 Forrest%Gump Tom%Hanks Robert%Zemeckis Drama
La%historia%describe%varias%décadas%de%la%vida%de%Forrest%Gump,%un%
nativo%de%Alabama%que%sufre%de%un%leve%retraso%mental%y%motor.%Ello%
no%le%impide%ser%testigo%privilegiado…
m3 Volver%al%Futuro%I Michael%Fox Robert%Zemeckis Ciencia%Ficción
Relata%las%aventuras%de%Marty%McFly,%un%adolescente%que%es%
enviado%accidentalmente%de%vuelta%en%el%tiempo%de%1985,%su%época,%a%1955.%Tras%alterar%los%sucesos%
ocurridos%en%1955,%específicamente%aquellos%en%los%que%sus%padres%se%
conocieron%y%enamoraron…
Películas

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
38!!
!
Tabla(20:(Datos(Semiestructurados(II(
!
2.2.1.2.2 Clustering!/!Agrupamiento!
!
Clustering es una técnica que se encarga de agrupar ítems de una determinada
colección en grupos de ítems similares. Estos grupos o clústeres pueden ser pensados como
sets de ítems similares entre ellos pero distintos de los ítems que pertenecen a otros clústeres.
La Figura 5 muestra el agrupamiento de puntos en un plano x-y. Cada círculo
representa un clúster que contiene varios puntos. Los círculos son una buena manera de
pensar los clústeres, ya que cada uno de ellos está definido por un punto central y un radio. El
centro del círculo se llama centroide o media del clúster.
!
Figura(5:(Ejemplo(de(Clustering(en(plano(xTy
El agrupamiento de una colección de ítems requiere de al menos tres elementos:
- Un algoritmo de agrupamiento.
- Una medida de similitud / disimilitud.
Id#Película Id#Usuario Calificación Revisión
m1 u1 5Excelente,película,,tiene,todos,los,condimentos,de,un,thriller,de,
terrorm2 u2 4 Apasionante,,única,!!!
m3 u2 4,5Muy,buena,la,actuación,de,Hanks,,
se,roba,la,película.m2 u3 2 Densam3 u3 1
Calificaciones

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
39!!
- Una condición de frenado.
Lo más importante del clustering es encontrar una función que cuantifique la similitud
entre dos puntos/ítems. En el ejemplo de la Figura 5, la medida de similitud que se utilizó fue
la distancia Euclidiana entre los puntos. Pero en el caso que necesitemos por ejemplo agrupar
libros por temas, no existe una medida matemática clara, en cambio, habría que confiar en la
sabiduría del bibliotecario para juzgar la similitud entre los libros.
Una posible métrica podría ser basada en el número de palabras en común que dos
libros contienen en sus respectivos títulos. Por ejemplo, Harry Potter: La Piedra Filosofal y
Harry Potter: El Prisionero de Azkaban contienen dos palabras en común, Harry y Potter.
Desafortunadamente esta métrica no contemplará el caso del libro el Señor de los
Anillos: Las Dos Torres, el cual también es similar a la saga Harry Potter. Habría que alterar
la métrica de similitud para que no sólo se base en los títulos de los libros, sino también en
sus contenidos. Esto es más fácil decirlo que hacerlo. Los libros no sólo contienen miles de
palabras, sino también las características de los distintos lenguajes como ser el español,
inglés, confunden a esta métrica. Existen palabras utilizadas muy frecuentemente como ser el,
la, a, todos, que dicen poco acerca de la similitud entre los libros. Hay varios “trucos” para
combatir estos y otros efectos, el método más utilizado se denomina tfidf, y se explica a
continuación.
2.2.1.2.2.1 Frecuencia/de/Términos/por/Frecuencia/Inversa/de/Documento/[tfidf]/!
Muchos sistemas de personalización que manejan datos desestructurados utilizan una
técnica para crear una representación estructurada de los mismos. En lugar de utilizar
palabras, las formas raíz de las palabras se crean a través de un proceso llamado stemming. El
objetivo de este proceso es crear un término que refleje el significado común de palabras
como “computar”, “computación”, “computadora”, “computadoras”, “cómputos”, etc. El
valor de una variable asociada con un término es un número real que representa su
importancia o relevancia. Este valor se conoce como el peso tfidf.
El peso tfidf de un término t en un documento d se calcula de la siguiente manera:

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
40!!
!
Fórmula(7:(Peso(tfidf
Donde:!
!"!,! =(frecuencia!de!t!en!el!documento!d!!"! =!número!de!documentos!que!contienen!el!término!t((! =!número!de!documentos!en!la!colección!((
A continuación se muestra un ejemplo simplificado de tres pasos para clarificar cómo
se realiza el cálculo:
Paso 1: Calcular la frecuencia de un término en un documento y dividirlo por el número total de palabras en ese documento.
Supongamos que la palabra amor aparece 3 veces en un documento de 612 palabras.
!"!"#$,! = !!!"# = !,!!"#
Paso 2: Calcular la frecuencia inversa de documento. Se divide el número total de documentos por el número de documentos que contienen el término en cuestión, y luego se toma el logaritmo del resultado.
Supongamos que la colección de documentos es 6 y que sólo 1 documento contiene el término amor.
!"#!"#$ = ! !"# !!"!"#$
= !"# !! = !,!!"#
Paso 3: Multiplicar tf por idf para obtener el valor
!"!"#$,!!!!!"#!"#$ = !,!!"#!!!!,!!"# = !,!!"#
La utilización de esta técnica no tiene en cuenta el contexto en que cada palabra es
usada. Una variante de utilizar palabras como términos es la utilización de conjuntos de

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
41!!
palabras contiguas como términos. La utilización del término “amor platónico”, puede
resultar ser más descriptivo que si dichas palabras se trataran como términos individuales.
2.2.1.2.2.2 Métricas/de/Similitud///Distancia/
Las medidas de similitud más comúnmente utilizadas en clustering son las siguientes:
- Distancia Euclidiana: ver sección 2.2.1.1.4.2.
- Distancia Euclidiana al cuadrado: tal como el nombre lo indica, es el cuadrado de la
distancia euclidiana.
!
Fórmula(8:(Distancia(Euclidiana(al(cuadrado
Donde:!
! = !",!",… ,!" =!vector!nedimensional!! = !",!",… ,!" =(vector!nedimensional!!!=!número!de!dimensiones((
- Distancia Manhattan: la distancia entre dos puntos es la suma de las diferencias
absolutas de sus coordenadas.
!
Fórmula(9:(Distancia(Manhattan
Donde:!
! = !",!",… ,!" =!vector!nedimensional!! = !",!",… ,!" =(vector!nedimensional!!!=!número!de!dimensiones((((
La Figura 6 muestra una comparación entre la distancia Euclidiana y la distancia
Manhattan.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
42!!
!
Figura(6:(Comparación(entre(Distancia(Euclidiana(y(Distancia(Manhattan(
!
- Distancia Cosenoidal: esta métrica requiere que pensemos a los puntos como vectores
desde el origen de coordenadas hasta los puntos en sí. !
Dichos vectores forman un ángulo entre ellos. Cuando este ángulo es pequeño, los
vectores apuntan en una dirección similar. El coseno del ángulo es cercano a 1 cuando
el mismo es pequeño y decrece a medida que el ángulo es mayor. La ecuación, por lo
tanto, substrae 1 del valor del coseno para dar una distancia apropiada.
!
Fórmula(10:(Distancia(Cosenoidal
Donde:!
! = !",!",… ,!" =!vector!nedimensional!! = !",!",… ,!" =(vector!nedimensional!!!=!número!de!dimensiones((
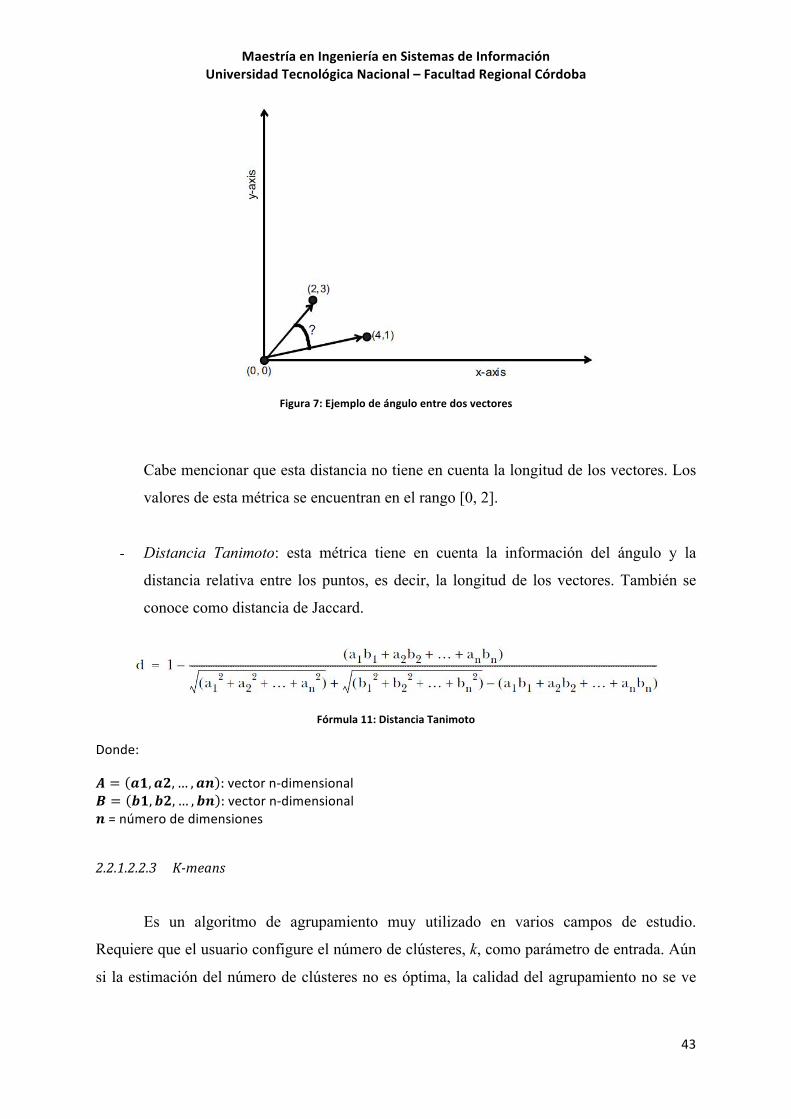
La Figura 7 muestra un ejemplo del ángulo que forman dos vectores.
Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
43!!
!
Figura(7:(Ejemplo(de(ángulo(entre(dos(vectores(
!
Cabe mencionar que esta distancia no tiene en cuenta la longitud de los vectores. Los
valores de esta métrica se encuentran en el rango [0, 2].
- Distancia Tanimoto: esta métrica tiene en cuenta la información del ángulo y la
distancia relativa entre los puntos, es decir, la longitud de los vectores. También se
conoce como distancia de Jaccard. !
!
Fórmula(11:(Distancia(Tanimoto(
Donde:!
! = !",!",… ,!" :!vector!nedimensional!! = !",!",… ,!" :(vector!nedimensional!!!=!número!de!dimensiones!(
2.2.1.2.2.3 KLmeans/!
Es un algoritmo de agrupamiento muy utilizado en varios campos de estudio.
Requiere que el usuario configure el número de clústeres, k, como parámetro de entrada. Aún
si la estimación del número de clústeres no es óptima, la calidad del agrupamiento no se ve

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
44!!
muy afectada. La métrica de similitud utilizada es el factor principal que determina la calidad
de este algoritmo.
La Figura 8 muestra un ejemplo de este algoritmo, en donde n puntos se quieren
agrupar en k=3 clústeres. El algoritmo comienza con k puntos iniciales o centroides, e itera
sucesivamente, refinando la ubicación de los centroides hasta que se llega a un criterio de
corte o hasta que los centroides convergen a un punto fijo.
!Figura(8:(Ejemplo(de(KTmeans(clustering(
!
Hay dos pasos en este algoritmo. El primero es encontrar los puntos que están cerca
de cada centroide y asignarlos a ese clúster específico. El segundo consiste en recalcular el
valor del centroide usando el promedio de las coordenadas de todos los puntos en ese clúster.
2.2.1.2.2.4 Canopy//
Canopy es una técnica clasificada dentro de los llamados algoritmos de aproximación
de clustering, que sirven para estimar el número de clústeres así como también la ubicación
aproximada de los centroides en un determinado set de datos.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
45!!
La estimación de los centroides impacta directamente en la performance de k-means.
Buenas estimaciones ayudan a que el algoritmo converja más rápidamente y haga menos
iteraciones sobre los datos.
Su fortaleza reside en su habilidad de crear clústeres velozmente. Sin embargo, su
fortaleza es también su debilidad. Este algoritmo puede no generar clústeres precisos, pero sí
puede calcular el número óptimo de clústeres.
Divide el conjunto de puntos de entrada en clústeres que se solapan, conocidos como
canopies. Este algoritmo utiliza una métrica rápida de distancia y dos umbrales, T1 y T2,
siendo T1 > T2.
El proceso comienza con un conjunto de puntos y una lista vacía de canopies, luego se
itera sobre el set de datos, creando canopies en el proceso. Durante cada iteración, se remueve
un punto del set de datos y se agrega un canopy a la lista con dicho punto como el centro. Se
itera por el resto de los puntos uno por uno. Para cada uno, se calculan las distancias a todos
los centroides en la lista. Si la distancia entre ese punto y cualquier centroide es menor a T1,
se lo agrega al canopy. Si la distancia es menor a T2, se lo remueve de la lista, previniendo la
formación de un nuevo canopy en las iteraciones siguientes. Se repite el proceso hasta que la
lista queda vacía.
La Figura 9 muestra un ejemplo de agrupamiento utilizando Canopy.
!
Figura(9:(Ejemplo(de(agrupamiento(utilizando(Canopy

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
46!!
2.2.1.2.2.5 KLmeans/Difuso/
En vez del clustering exclusivo que hace k-means, donde cada punto puede pertenecer
solamente a un clúster, k-means difuso trata de generar clústeres solapados. Se dice que k-
means trata de encontrar los clústeres “duros”, mientras que la versión difusa descubre los
clústeres “blandos”. En un clúster “blando”, cualquier punto puede pertenecer a más de un
clúster con un cierto grado de afinidad. Dicha afinidad es proporcional a la distancia entre el
punto y el centroide del clúster.
Este algoritmo tiene un parámetro, m, denominado factor de difusión. Al igual que el
k-means tradicional, la versión difusa itera sobre el conjunto de datos pero en lugar de asignar
vectores a los centroides más cercanos, calcula el grado de asociación del punto con todos los
clústeres. La siguiente fórmula representa el grado de asociación del vector V al primer
clúster C1.
!
Fórmula(12:(Grado(de(Asociación(de(Vector(V(a(Cluster(C1
Donde:!
!",!",… ,!" =(son!las!distancias!a!cada!uno!de!los!centroides!de!los!k*clústeres!! =(factor!de!difusión!(debe!ser!mayor!a!1)!!!
A medida que m se acerca a 1, el algoritmo se comporta más parecido al k-means
tradicional. Si m se incrementa, aumenta la difusión del algoritmo y hay más solapamiento.!
Este algoritmo converge mejor y más rápidamente que el k-means estándar.!
/
2.2.1.2.2.6 Dirichlet/
Para entender mejor la estructura de los datos, a veces se necesita un método diferente
a los algoritmos que se mencionaron anteriormente, hay que entrar en el terreno de los
métodos de clustering basados en modelos. Dirichlet es uno de ellos. Su nombre proviene de

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
47!!
una familia de distribuciones probabilísticas definidas por el matemático alemán Johann
Dirichlet.
Básicamente se comienza con un modelo conocido y se trata de explicar el set de
datos refinando algunos parámetros del modelo para así encajar el mismo con los datos.
Si por ejemplo los datos tienen una distribución ovoide, ni k-means tradicional ni la
versión difusa pueden utilizar esta información para mejorar el agrupamiento. Se debe
recurrir entonces a los algoritmos de agrupamiento basados en modelos, como es el caso de
Dirichlet.
Todo el proceso puede parecer complicado sin tener un profundo conocimiento de las
distribuciones de Dirichlet, pero la idea es simple. Supongamos que uno sabe que sus datos
están concentrados en un área como ser un círculo y que están bien distribuidos dentro del
mismo, y que también se cuenta con un modelo que explica ese comportamiento. Uno podría
probar que los datos encajan en el modelo leyendo los vectores y calculando la probabilidad
de que el modelo se cumpla para esos datos.
Este enfoque puede decir con cierto grado de confianza que cierta concentración de
puntos se adapta mejor a un modelo circular. También puede decir que la región no parece un
triángulo. Si uno encuentra uno que encaje, entonces conoce la estructura de los datos.
La Figura 10 muestra dos modelos. El modelo correcto (el de la derecha) describe
mejor los datos e indica el número de clústeres para ese conjunto de datos.
!
Figura(10:(Ejemplo(de(clustering(de(Dirichlet.(Modelo(incorrecto(y(correcto.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
48!!
La Figura 11!muestra otro ejemplo de clustering utilizando Dirichlet, se trata de una
distribución normal asimétrica. Los clústeres con líneas gruesas son los del estado final, las
líneas más finas son los estados intermedios.
!
Figura(11:(Dirichlet(en(una(distribución(normal(asimétrica(
2.2.2 Métodos!de!Evaluación!!!
2.2.2.1 Sistemas'de'Recomendación'!
Ciordas y Doumen plantean la necesidad de probar qué tan acertados son los
resultados de los sistemas de recomendación [Ciordas, Doumen, 2010]. Para ello, existen
grandes sets de datos que ayudan a los investigadores en la evaluación de los distintos
algoritmos de recomendación (EachMovie, MovieLens, Jester, BookCrossing, Netflix, etc.)
[Herlocker, Konstan, Terveen, 2004].
Usualmente la métrica más utilizada para evaluar estos motores es el Error Cuadrático
Medio o RMSE (ver Fórmula 13), la cual es una técnica simple pero robusta para determinar
la exactitud en las recomendaciones [Harrington, 2012].
!Fórmula(13:(Error(Cuadrático(Medio(
!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
49!!
Donde:!
El!sistema!genera!recomendaciones! !para!un!set!de!datos! !de!pares!usuarioeítem! !para!el!
cual!la!recomendación!real! !es!conocida.!
También se suelen utilizar métricas de Recuperación de Información para evaluar los
sistemas de recomendación, más precisamente precisión y exhaustividad1 [Marmanis,
Babenko, 2009]. La Fórmula 14 muestra la definición de precisión mientras que la Fórmula
15 hace lo propio con exhaustividad.
!Fórmula(14:(Precisión(
!
!Fórmula(15:(Exhaustividad
Donde:!
!!:!Total!de!documentos!relevantes!recuperados.!!":!Total!de!documentos!recuperados.!!":!Total!de!documentos!relevantes.!!
Estos términos se adaptan fácilmente a los motores de recomendación: precisión es la
proporción de recomendaciones principales que son buenas recomendaciones; exhaustividad
es la proporción de buenas recomendaciones que aparecen en las recomendaciones
principales [Owen et al., 2012].!
!
2.2.2.2 Clustering'o'Agrupamiento'!
Los buenos clústeres generalmente se forman alrededor de unos pocos atributos
fuertes, que manejan la noción de similitud entre documentos. Esto significa que elegir los
atributos correctos es tan importante como elegir una métrica de distancia correcta. Para texto
desestructurado, se consigue mejor calidad cuando se extraen mejores atributos. Buen
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!1!Conocidas!comúnmente!por!sus!nombres!en!inglés:!precision!y!recall!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
50!!
clustering requiere que se asigne más peso a los atributos importantes y menos a los no tan
importantes [Owen et al., 2012].
Dos medidas muy utilizadas para determinar la calidad del clustering son las
distancias inter-clúster e intra-clúster. La primera es la distancia entre los centroides de dos
clústeres distintos. La segunda es la distancia entre los miembros de un mismo clúster [Rand,
1971].
Buenos clústeres generalmente tienen mayor distancia inter-clúster y una menor
distancia intra-clúster. La Figura 12 y Figura 13, ambas extraídas del libro de Owen et al.,
muestran ejemplos de ambas distancias.
!
Figura(12:(Distancia(interTcluster(grande(y(pequeña(
!
!
Figura(13:(Distancia(intraTcluster(grande(y(pequeña(

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
51!!
2.2.3 Problema!de!Comienzo!en!Frío!en!Filtros!Colaborativos!!
! Los sistemas de recomendación basados en filtros colaborativos enfrentan el problema
del inicio en frío, también llamado problema de latencia. Cuando un nuevo ítem entra en el
sistema, mientras el número de calificaciones de dicho ítem sea bajo, éste no podrá ser
recomendado a los usuarios. Más específicamente, si ninguno de los vecinos de x calificó el
ítem, el sistema no podrá recomendárselo [Schein et al., 2002].
El mínimo número de calificaciones o ratings requeridos por el sistema para
recomendar un ítem no puede ser definido de antemano. Es más, de acuerdo a quién califica
el ítem, éste puede ser recomendado o no a otros usuarios. Por ejemplo, si los usuarios que
califican un ítem son vecinos de ningún o pocos usuarios, el ítem no podrá ser recomendado a
otros usuarios [Sollenborn, Funk, 2002].
La literatura propone cuatro soluciones para aliviar el problema de comienzo en frío,
filtrado basado en contenido, filtrado basado en ontología, propaganda y modificación de
similaridad. A continuación se presenta un resumen de estas soluciones:
- Filtrado basado en contenido: esta técnica se basa en el análisis del contenido de los
ítems para generar recomendaciones. Un ítem es recomendado a un usuario x si su
contenido es similar al de otro ítem que le gustó a x. Por ejemplo, a un usuario al que
le gustaron varios juegos, se le recomendarán ítems de esa categoría [Pazzani, Billsus,
2007].
Este método no sufre el problema de inicio en frío, un nuevo ítem puede ser
recomendado a cualquier usuario simplemente realizando el análisis de su contenido.
Este tipo de filtrado se suele combinar con el filtrado colaborativo, lo que resulta en
un sistema de recomendación híbrido. En tales sistemas, el algoritmo basado en
contenido ataca el problema de inicio en frío, mientras que el basado en filtros
colaborativos garantiza la introducción de recomendaciones “innovadoras” [Melville,
Mooney, Nagarajan, 2002].
- Filtrado basado en ontología: En este método se utilizan ontologías para crear
automáticamente bases de conocimiento y extraer perfiles semánticos de ítems. De
esta manera, se pueden computar similitudes semánticas entre ítems. El mayor

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
52!!
inconveniente de esta solución es que requiere la existencia de una ontología [Ruiz-
Montiel, Aldana-Montes, 2009].
- Propaganda: Se basa en publicitar nuevos ítems. Por ejemplo, un banner se muestra
en la página inicial de un sitio web, presentando los nuevos ítems; como resultado,
algunos usuarios podrán calificarlos. Sin embargo, algunos usuarios pueden percibir
esta solución como una recomendación a pesar que la inclusión del banner no fue algo
personalizado. Esto puede traer aparejado que ciertos usuarios, a los que no les gustan
los nuevos ítems, se sientan insatisfechos y dejen el sitio [Jones, 2010].
- Modificación de similaridad: Con el objetivo de reducir el problema de inicio en
frío, Ahn propone una nueva medida de similaridad que puede ser computada a partir
de un número reducido de calificaciones. Esta medida explota proximidad, impacto y
popularidad de usuarios, fue pensada para el problema del nuevo usuario, pero puede
aplicarse al problema del nuevo ítem [Ahn, 2008].
! En este trabajo, se propone la creación de un sistema híbrido de recomendaciones
(basado en colaboración y contenido) para solucionar el problema del inicio en frío.
!
2.3 Motores!de!Búsqueda!!
Un motor de búsqueda es un pedazo de software que utiliza diversas aplicaciones para
recolectar información acerca de páginas web, catálogos de productos, entre otras cosas. La
información recolectada consta generalmente de palabras claves o frases que son posibles
indicadores del contenido de una página web, del contenido de un catálogo, etc. Dicha
información es indexada y guardada en una base de datos [Ledford, 2007].
Del lado del usuario, el software cliente generalmente tiene una interfaz gráfica donde
los usuarios ingresan términos de búsqueda, una palabra o frase, para tratar de encontrar
determinada información. Cuando el usuario ejecuta la acción de buscar, un algoritmo
examina la información almacenada en la base de datos y devuelve los resultados que parecen
coincidir con el término buscado por el usuario.
NOTA: La sub sección 2.3.1 se basó en información obtenida del libro “SEO Bible” y la información
de la sub sección 2.3.2 se extrajo del libro “SEO, An Hour a Day”, ambos incluidos en la bibliografía. !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
53!!
!
2.3.1 Elementos!de!los!Buscadores!!
Un motor de búsqueda está constituido por distintas piezas. A continuación
mencionaremos brevemente las fundamentales:
- Interfaz de búsqueda: es el elemento con el que la mayoría de las personas están
familiarizadas. Es básicamente la interfaz gráfica que el usuario ve para ingresar un
término de búsqueda.
- Crawlers, Robots o Arañas: son programas que colectan la información que luego será
indexada para así poder ser buscada por los usuarios.
- Base de Datos: todos los motores de búsqueda contienen o están conectados a un
sistema de base de datos, donde los datos recolectados por los crawlers son
almacenados.
- Algoritmos de Búsqueda: son la parte fundamental de los motores de búsqueda. En
términos generales, un algoritmo de búsqueda es un procedimiento de resolución de
un problema que toma un problema de entrada (el término de búsqueda), evalúa
posibles respuestas (navega por su base de datos) y devuelve una solución (los
documentos).
Existen diferentes algoritmos, entre los que encontramos los de lista, de árbol, SQL,
informada, adversa, etc.
- Recuperación y Ranking: la recuperación de la información es una combinación de las
actividades del crawler, la base de datos y el algoritmo de búsqueda. El ranking de los
resultados es algo en que se suele poner el mayor esfuerzo en descifrar cómo se lo
puede afectar. Diferentes motores usan diferentes criterios de ranking, como ser la
ubicación del término en la página (en el título, en un encabezado, etc.), la frecuencia
con la que el término aparece, los enlaces que tiene, etc.
2.3.2 Buscadores!en!la!Actualidad!!
En la actualidad Google es por lejos el líder en búsquedas. Tiene la mayor cantidad de
tráfico y también ofrece un menú diverso de opciones de búsqueda, incluyendo noticias,
videos, imágenes, blogs, productos, etc.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
54!!
Bing es el motor de búsquedas de Microsoft. Gracias a su alianza con Yahoo, se
calcula que Bing ha incrementado su cuota a un 30% del total del mercado de búsquedas.
Este motor excede en búsquedas de imágenes y video, y ha sido exitoso en crear una
presentación visual más rica de resultados que Google, sin sacrificar la usabilidad.
Yahoo es uno de los más viejos y conocidos motores de búsqueda. A pesar de que
Bing controla la mayoría de los resultados de búsqueda de Yahoo, siguen habiendo áreas en
las que Yahoo continúa ofreciendo resultados derivados de su propio indexado.
!
2.4 Redes!Sociales!!
Las redes sociales, SNs por sus siglas en inglés, son plataformas onlines, sitios,
servicios y herramientas que utilizan los individuos para establecer conexiones y relaciones
con otros usuarios. Las versiones modernas de las redes sociales emergieron en los 90s,
cuando sitios sociales desarrollaron la habilidad de buscar y conectarse con amigos [Dennen,
Myers, 2012].
El concepto de SNs ha estado presente desde siempre. Una red social es simplemente
una estructura que mapea relaciones entre individuos. De una manera u otra, todos
pertenecemos a una gran red social [Rice, 2009].
Schwagereit y Staab definen a una red social como una estructura formada por
entidades sociales, como ser individuos, corporaciones, organizaciones, que están conectadas
por algún tipo de interdependencia, ya sea amistad, intereses comunes, creencias,
intercambios financieros, etc. [Schwagereit, Staab, 2009].
En la actualidad, dos de las SNs más populares son Facebook y Twitter. Facebook
tiene más de 1100 millones de usuarios activos [YAHOONEWS, 2013] y Twitter reporta que
tiene más de 200 millones [TELEGRAPH, 2013].
Boyd y Ellison definen a las redes sociales como servicios basados en la web que
permiten a los individuos 1) contruir un perfil público o semipúblico dentro de un sistema
acotado, 2) manejar una lista de otros usuarios con los que comparten una conexión, 3) ver y
navegar sus listas de conexiones a través del sistema [Boyd, Ellison, 2007].

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
55!!
2.4.1 Importancia!!
Por el año 2008 Li afirmaba que las redes sociales serían como “el aire” [Li, 2008].
Algunas personas discuten acerca de si internet tendrá más impacto que la televisión, radio o
cualquier otro medio de comunicación en la historia de la humanidad. Las SNs están en el
centro de esta revolución y probarán ser las herramientas más poderosas, tanto en el aspecto
social como de negocio, del marketing online [Rice, 2009].
El surgimiento de comunidades web y sitios de redes sociales ha llevado a la
generación de un vasto volumen de datos sociales, en los cuales se encuentran embebidos
enormes conjuntos ricos en conocimiento de las relaciones entre las entidades de dichas
redes. Es así que cobró importancia una nueva rama del conocimiento llamada minería social
de medios, o como se conoce en inglés, social media mining [Guandong, Lin, 2013].
! Esta minería social de medios puede ser considerada como una interacción entre la
minería de datos y la computación social. La minería de datos se refiere a la extracción no
trivial de información implícita, previamente desconocida y potencialmente útil a partir de
ciertos datos. La computación social intercepta el comportamiento social y los sistemas
computacionales en el sentido en que facilita, computacionalmente, los estudios sociales y las
dinámicas humanas en las redes sociales, crea convenciones sociales a través del uso de
software, y diseña tecnologías de la información para manejar el contexto social [Frawley,
Piatetsky-Shapiro, Matheus, 1991].!
La extracción e identificación de información social útil de las relaciones entre las
entidades de las redes sociales está en creciente demanda [Wasserman, Faust, 1994].
En el sistema propuesto, se pretende dejar expuestas interfaces accesibles por distintos
clientes, que extraigan información de distintas redes sociales, como ser Facebook y Twitter,
para que puedan hacer minería social de medios, y obtener mayores réditos en las áreas de
negocio en las que están involucrados.!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
56!!
2.5 Estadísticas!de!Uso!!
Las estadísticas de uso, comúnmente denominadas analytics, son un mecanismo para
medir las interacciones de los usuarios con los sistemas. La capacidad de consumir datos que
llegan cada vez más rápido por parte de las organizaciones, son un diferenciador fundamental
que permiten crear valor a través de analytics [Finch et al., 2014].
El uso de estas estadísticas permite a las empresas actuar con rapidez y precisión. La
amplia variedad de datos recolectados conlleva a la creación de modelos de predicción más
robustos, incrementando la probabilidad de generar un mayor impacto de negocio
[INFORMS, 2015].
En la era de Big Data (grandes cantidades de datos), la agilidad y flexibilidad de la
arquitectura de datos de las empresas juega un rol clave para manejar eficientemente el
volumen, variedad y velocidad de los datos [Finch et al., 2014].
Google Analytics es probablemente el mejor sistema de la actualidad para ejemplificar el
poder de las analytics. Es un software integral que permite la recolección y procesamiento de
datos, y la posterior generación de reportes para facilitar la toma de decisiones.
El sistema aquí propuesto, provee interfaces adecuadas para realizar una recolección y
procesamiento de datos de manera eficiente, dejando para un futuro la posibilidad de integrar
las mismas con diferentes sistemas de reportes.
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
57!!
!
3 Definición!del!Problema!!
Tanto en la introducción como en otras secciones del presente trabajo, se han
mencionado algunas de las tantas implicancias o problemas que acarrea la denominada Era de
la Información en la cual nos encontramos inmersos.
El incremento del volumen de información digital evidencia nuevas dificultades,
como ser, el filtrado y la entrega eficiente de información a los usuarios [Ghazanfar, Prugel-
Bennett, 2010].
Merali y Bennett hablan de una nueva economía, a la cual llaman economía de la
información [Merali, Bennett, 2011], caracterizada principalmente por:
- El rol crítico de la información y el conocimiento.!
- El incremento en el dinamismo, la incertidumbre y la discontinuidad en un contexto
cada vez más competitivo.!
- El aumento de las presiones para la rápida toma de decisiones ante situaciones donde
existe ausencia de información.!
- La importancia del aprendizaje y la innovación para mejorar la flexibilidad y así
poder sobrevivir.
Resnick y Varian plantean la situación actual desde un punto de vista un poco más
personal. Afirman que cada vez es más necesario escoger opciones entre alternativas
desconocidas. En el día a día, necesitamos que otras personas nos recomienden la mejor
opción, ya sea de boca en boca, con cartas de recomendación, con calificaciones de películas
o libros publicadas en periódicos, etc. ¿Qué mejor que tener sistemas inteligentes que hagan
esto automáticamente? [Resnick, Varian, 1997].
Se hace fundamental la existencia de sistemas de extracción de información que
posibiliten entregar información personalizada y de interés a los usuarios [Patel,
Balakrishnan, 2009].

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
58!!
En la actualidad las grandes oportunidades se sitúan en el dominio del manejo de
datos, más precisamente, en cómo se integran estos datos en sistemas de conocimiento para
así poder incorporar inteligencia a los modelos de negocios corporativos [Merali, Bennett,
2011].
Resulta prudente recalcar que a pesar del claro reconocimiento del problema y la
importancia del mismo como tal, su implementación no es trivial.
!
3.1 Importancia!!
Esta sección pretende evidenciar la importancia que tiene hoy en día la problemática
planteada. Para ello, se citan artículos de diferentes periódicos.
Se suelen resaltar ciertos ejemplos típicos para explicar el impacto de los sistemas de
inteligencia colectiva en la actualidad. Uno de ellos es Netflix, la plataforma de video que
ofrece películas y series de televisión a cambio de una cuota de suscripción, la cual utiliza un
sistema sofisticado de recomendaciones basado en filtros colaborativos. De acuerdo al diario
“The Economist”, aproximadamente dos tercios de la selección de películas hechas por los
usuarios provienen de las recomendaciones generadas por dicho sistema [ECON, 2010].
Otro ejemplo atractivo es Amazon, que nació en 1995, y cuya visión sigue siendo ser
la compañía mundial con más foco en los clientes. Conseguir la lealtad de los mismos ha sido
clave en el tremendo éxito de esta empresa. Amazon cuenta que la pieza fundamental que le
permitió alcanzar semejante nivel de ventas fue la inclusión en su sitio de: revisiones y
calificaciones de productos, información detallada de los productos, páginas personalizadas
para preferencias individuales tales como recomendaciones o notificaciones, búsquedas
inteligentes, navegación sencilla a través del catálogo, etc. [Chaffey, 2012].
Ebay es otro caso de estudio en sí mismo. A primera vista parece ser una plataforma
neutral de intercambios comerciales. Sin embargo, realiza ciertos ajustes basados en
información que obtiene de actividades, de comportamientos de subastas, de tendencias en
los precios, de términos de búsqueda, del tiempo que los usuarios miran una página, etc. Cada
producto es tratado como una micro economía. Muchas búsquedas y pocas ventas para un
ítem caro pueden significar demanda insatisfecha [ECON, 2010].

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
59!!
La misión de Google es organizar la información mundial y hacerla universalmente
accesible y útil. Esta corporación cree que la forma más efectiva de cumplir con dicha misión
es poner foco en los usuarios, ofreciéndoles una experiencia personalizada única. Se rigen
bajo el lema “foco en el usuario, el resto vendrá solo” [Chaffey, 2010].
Finalmente, no se puede dejar de mencionar el caso de Facebook. Su misión es
simplemente hacer el mundo más abierto y conectado. Mediante la creación de perfiles de
usuario, la agregación de amigos, la publicación en el muro, etc., permite a los usuarios
expresarse, compartir con amigos, descubrir, aprender y permanecer siempre conectados.
Contar con la información que las personas eligieron publicar, como ser edad, género, lugares
donde estuvieron, intereses, gustos, permite mejorar el valor agregado a los usuarios,
ofreciéndoles una experiencia única que resulta de la combinación de alcance, relevancia y
contexto social [Chaffey, 2013].
Esta información no sólo evidencia a la inteligencia colectiva, los sistemas de
recomendación, las búsquedas, las redes sociales, como booms tecnológicos sino que recalca
su importancia y vigencia como tecnologías innovadoras. Hacer hincapié en los usuarios es
crítico para tener éxito en la industria.
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
60!!
4 Alternativas!de!Solución!!
En esta sección se mencionan algunas de las distintas posibilidades que existen para
proveer una solución al problema planteado. Cabe destacar que no se pretende realizar un
desarrollo exhaustivo, sino más bien una reducida reseña de las posibilidades disponibles en
el mercado actual.
Como se explicó anteriormente, muchas empresas tienen sus sistemas de inteligencia
colectiva funcionando. Sin embargo, resulta difícil encontrar un software out-of-the-box que
provea funcionalidad de recomendaciones, búsquedas, catálogo, colección de analytics y
redes sociales, todo en uno, para la creación de aplicaciones “inteligentes”.
Varias compañías han puesto mucho foco en crear plataformas de Software como un
Servicio, conocidas por sus siglas en inglés como SaaS, ofreciendo distintas capacidades.
Verwoerd publicó en su blog una comparación entre tres soluciones de SaaS para
Aprendizaje de Máquinas (o ML por sus siglas en inglés), BigML2, Prior Knowledge3,
Google Prediction API4. El autor hace una interesante comparación de las tres soluciones en
términos de preparación de datos, qué tanta configuración es requerida para comenzar y qué
tan estricto es el formato de los datos, los modelos, si son de caja negra o caja blanca, la
precisión en las predicciones, la estabilidad de los servicios, los costos, la documentación,
etc. [Verwoerd, 2012].
Existen también soluciones de SaaS para analytics. Entre algunas de las soluciones
reconocidas en el rubro encontramos GoodData5, Easy Insight6, Google Analytics7, entre
otras. Todas ofrecen capacidades de recolección de datos y generación de reportes.
En términos de búsqueda, existen algunas posibilidades para utilizar soluciones de
SaaS. Una muy reconocida es Open Search Server8. Google lanzó recientemente el producto
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!2!https://bigml.com/!3!http://priorknowledge.com/.!Prior!Knowledge!ha!sido!comprada!por!Salesforce!y!lamentablemente!han!cerrado!su!API!pública.!4!https://developers.google.com/prediction/!5!http://www.gooddata.com/!6!http://www.easyeinsight.com/!7!http://www.google.com/analytics/!8!http://www.openesearcheserver.com/!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
61!!
denominado Big Query9, que sin bien no es un servicio de búsquedas per se, permite hacer
consultas a enormes cantidades de datos de manera muy eficiente. Tiene una API para subir
datos, por ejemplo un catálogo, y varias para actualizarlos, consultarlos, etc.
Facebook, Twitter, LinkedIn son también proveedores de SaaS, uno puede acceder a
sus datos a través de interfaces REST con distintas librerías.
En cuanto a librerías para crear una solución de inteligencia colectiva propia,
aparecen muchísimas posibilidades disponibles para distintos lenguajes de programación. El
presente trabajo se enfocará en librerías para Java, dado que es el lenguaje que se utilizará
para realizar la prueba de concepto.
Se encuentran varias opciones para implementar un servidor de búsqueda. Egothor10,
Nutch11, Lucene12, Solr13, Oxyus14, BDDBot15, Compass16, son solo algunos de los
frameworks disponibles.
En cuanto a librerías para implementar algoritmos de recomendación en entornos
distribuidos, una de las más conocidas es Mahout17, que corre sobre Hadoop18, el cual es un
framework de Map Reduce19. También existe Easyrec20, la cual es una aplicación web
fácilmente integrable con un sitio web, que ofrece recomendaciones personalizadas. Por
último, Weka21 es un software para minería de datos muy reconocido en la industria y en la
academia, que corre como una aplicación Java de escritorio y cuenta con una gran cantidad
de algoritmos de Aprendizaje de Máquinas.
También existen diversas opciones para interacción con redes sociales, una es
linkedin-j22, para conectarse a LinkedIn. Facebook y Twitter tienen sus librerías,
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!9!https://developers.google.com/bigquery/!10!http://www.egothor.org/cms/!11!http://nutch.apache.org/!12!http://lucene.apache.org/core/!13!http://lucene.apache.org/solr/!14!http://sourceforge.net/projects/oxyus/!15!http://www.twmacinta.com/bddbot/!16!http://www.compasseproject.org/!17!http://mahout.apache.org/!18!http://hadoop.apache.org/!19!Es!un!modelo!de!programación!y!una!implementación!asociada!para!procesar!y!generar!grandes!sets!de!datos.!Para!más!información!dirigirse!a!http://research.google.com/archive/mapreduce.html!20!http://easyrec.org/!21!http://www.cs.waikato.ac.nz/ml/weka/!22!https://code.google.com/p/linkedinej/!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
62!!
Facebook4J23 y Twitter4J24 respectivamente, ambas no oficiales. Existe también una
extensión de Spring25 para conexión con redes sociales, denominado Spring Social26. Éste
abstrae al desarrollador de las APIs de bajo nivel necesarias para la interacción con redes
sociales.
Resumiendo, existen tres grandes alternativas para encarar el problema propuesto,
utilizar puramente plataformas de SaaS (algunas pagas), implementar un sistema propio o
hacer un sistema híbrido, que tenga ciertas partes integradas con proveedores de SaaS.
El presente trabajo implementa un sistema híbrido, que delega algunas
responsabilidades a proveedores de SaaS, particularmente, la interacción con redes sociales.
La sección 5 detalla en profundidad el diseño del sistema.
! !
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!23!http://facebook4j.org/!24!http://twitter4j.org/!!25!http://www.springsource.org/springeframework!26!http://www.springsource.org/springesocial!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
63!!
5 Diseño!e!Implementación!!
En base a los análisis previos y debido a la falta de una solución integral de
inteligencia colectiva gratuita para clientes, como parte de este trabajo, se procede a la
implementación de un prototipo que incluye distintos servicios implementados con
tecnologías open-source. En las siguientes subsecciones se detalla, con distintos grados de
granularidad, el diseño del sistema.
5.1 Diseño!de!Alto!Nivel!!
5.1.1 Casos!de!Uso!!
! La Figura 14 muestra los principales casos de uso identificados del sistema.
!
Figura(14:(Diagrama(de(Casos(de(Uso(
Usuario Final
Browsear Contenido "Interesante"
Sistema Cliente
CRUD Catálogo de Productos
Recolectar Info de Redes Sociales
Obtener Recomendaciones
Enviar Analytics
Comprar Ítems
Revisar/Calificar Ítems
Conectarse a Redes Sociales

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
64!!
!
!
Nombre:(( Browsear-(Navegar)-Contenido-“Interesante”(
Descripción:(Permite!navegar!por!contenido!de!potencial!interés!para!el!usuario,!determinado!en!base!a!sus!
estadísticas!de!uso,!sus!gustos,!etc.!
Actores:(Usuario!del!sistema.!
Precondiciones:(1e!El!usuario!debe!estar!logueado!en!el!sistema.!
2e!El!servicio!de!search!y!recommender!tienen!que!estar!corriendo!y!ser!accesibles!por!el!sistema!
cliente.!
!
Flujo(Normal:(1e!El!usuario!navega!por!la!pantalla!principal.!
2e!El!sistema!muestra!ítems!de!potencial!interés!para!el!usuario.!
3e!El!usuario!realiza!una!búsqueda!por!texto.!
4e!El!sistema!muestra!los!resultados!de!la!búsqueda!por!texto.!
!
Flujo(Alternativo:(N/A!
Poscondiciones:(El!sistema!muestra!contenido!de!potencial!interés!para!el!usuario.!
Nombre:(( Comprar-Ítems(
Descripción:(Permite!realizar!la!compra!de!algún!ítem!en!particular!que!le!interese!al!usuario.!
Actores:(Usuario!del!sistema.!
Precondiciones:(1e!El!usuario!debe!estar!logueado!en!el!sistema.!
2e!El!servicio!de!analytics!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
!
Flujo(Normal:(1e!El!usuario!navega!por!la!pantalla!principal.!
2e!El!sistema!muestra!ítems!de!potencial!interés!para!el!usuario.!
3e!El!usuario!entra!a!los!detalles!de!algún!ítem!en!particular.!
4e!El!cliente!envía!estadísticas!de!uso!del!usuario.!!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
65!!
!
5e!El!usuario!selecciona!la!opción!de!compra!de!ese!ítem!en!particular.!
6e!El!sistema!procede!a!realizar!la!operación!de!compra.!
7e!El!sistema!envía!estadísticas!de!uso!del!usuario.!
!
Flujo(Alternativo:(5ae!El!ítem!es!pago!y!el!usuario!no!cuenta!con!información!de!tarjeta!de!crédito.!
5be!El!sistema!redirige!al!usuario!para!que!actualice!su!información!de!tarjeta!de!crédito.!
5ce!El!usuario!completa!dicha!información.!
5de!Continúa!en!el!paso!6.!
!
4ae!El!usuario!desiste!de!comprar!ese!ítem.!
4be!El!sistema!no!envía!estadísticas!de!compra.!
4ce!El!usuario!se!dirige!a!la!pantalla!principal.!Vuelve!al!paso!1.!
!!
Poscondiciones:(El!sistema!computa!la!compra!del!ítem!por!parte!del!usuario!y!procede!a!su!descarga!si!así!
correspondiese.!
Nombre:(( Revisar/Calificar-Ítems(
Descripción:(Permite!realizar!la!revisión!o!calificación!de!algún!ítem!en!particular.!
Actores:(Usuario!del!sistema.!
Precondiciones:(1e!El!usuario!debe!estar!logueado!en!el!sistema.!
2e!El!usuario!debe!haber!comprado!el!ítem!que!pretende!revisar/calificar.!
3e!El!servicio!de!analytics!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
!
Flujo(Normal:(1e!El!usuario!ingresa!a!los!detalles!del!ítem!a!revisar/calificar.!!
2e!El!usuario!selecciona!la!opción!de!agregar!una!revisión/calificación.!!
3e!El!usuario!ingresa!una!descripción!en!el!texto!de!la!revisión!y!selecciona!las!estrellas!para!la!
calificación!del!ítem.!
4e!El!usuario!decide!enviar!su!revisión/calificación.!!
5e!El!sistema!envía!estadísticas!de!uso!del!usuario.!
!
Flujo(Alternativo:(3ae!El!usuario!completa!sólo!uno!de!los!dos!campos!(el!texto!de!la!revisión!y!no!selecciona!las!
estrellas,!o!viceversa).!
3be!El!sistema!provee!un!mensaje!de!error,!explicando!que!falta!completar!algún!campo!mandatorio.!
3ce!El!usuario!completa!los!campos!obligatorios!restantes.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
66!!
!
!
3de!Continúa!en!el!paso!4.!
!
Poscondiciones:(El!sistema!computa!la!revisión/calificación!del!ítem!por!parte!del!usuario.!
Nombre:(( Conectarse-a-Redes-Sociales(
Descripción:(Permite!que!un!usuario!pueda!conectarse!a!sus!redes!sociales.!
Actores:(Usuario!del!sistema.!
Precondiciones:(1e!El!usuario!debe!estar!logueado!en!el!sistema.!
2e!El!usuario!debe!tener!al!menos!una!cuenta!en!una!red!social.!
3e!El!administrador!del!sistema!debe!haber!creado!una!aplicación!en!la!red!social!del!usuario.!
4e!El!servicio!de!social!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
!
Flujo(Normal:(1e!El!usuario!selecciona!la!opción!de!conectarse!con!sus!redes!sociales.!!
2e!El!usuario!selecciona!cierta!red!social.!!
3e!El!sistema!redirige!al!usuario!para!que!se!autentique!en!dicha!red!social.!
4e!El!usuario!procede!a!la!autenticación.!
5e!El!usuario!acepta!los!permisos!de!acceso!a!su!información!por!parte!de!la!aplicación!creada!en!la!
red!social.!!
6e!El!sistema!redirecciona!al!usuario!a!la!página!inicial!de!conexión!indicando!que!la!misma!fue!
exitosa.!
!
Flujo(Alternativo:(4ae!El!usuario!ingresa!credenciales!erróneas.!
4be!La!red!social!informa!del!error!y!pide!que!ingrese!credenciales!correctas.!
4ce!El!usuario!ingresa!credenciales!correctas.!
4de!Continúa!en!el!paso!5.!
!
5ae!El!usuario!rechaza!los!permisos!de!acceso!a!su!información.!
5be!El!sistema!redirecciona!al!usuario!a!la!página!inicial!de!conexión!indicando!que!la!misma!fue!
errónea.!
!
Poscondiciones:(El!usuario!unió!su!cuenta!con!la!de!su!red!social.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
67!!
!
Nombre:(( CRUD-Catálogo-de-Productos(
Descripción:(Permite!que!un!sistema!cliente!pueda!realizar!operaciones!de!creación,!lectura,!borrado!y!
actualización!de!ítems!de!un!catálogo.!
NOTA:!en!el!presente!caso!de!uso!se!hace!referencia!sólo!a!las!operaciones!de!creación!y!lectura.!
!
Actores:(Sistema!cliente.!
Precondiciones:(1e!El!servicio!de!catálogo!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
!
Flujo(Normal:(1e!El!sistema!cliente!invoca!a!la!API!de!creación!de!tipo!de!ítems!en!el!servicio!de!catálogo.!!
2e!El!servicio!de!catálogo!responde!exitosamente.!!
3e!El!sistema!cliente!invoca!a!la!API!para!consultar!los!tipos!de!ítems!disponibles!en!el!servicio!de!
catálogo.!!!
4e!El!servicio!de!catálogo!responde!exitosamente!y!como!parte!de!la!respuesta!incluye!el!tipo!de!
ítem!creado!en!el!paso!1.!
5e!El!sistema!cliente!invoca!a!la!API!de!creación!de!ítems!en!el!servicio!de!catálogo.!
6e!El!servicio!de!catálogo!responde!exitosamente.!
7e!El!sistema!cliente!invoca!a!la!API!para!consultar!los!ítems!disponibles!en!el!servicio!de!catálogo.!
8e!El!servicio!de!catálogo!responde!exitosamente!y!como!parte!de!la!respuesta!incluye!los!ítems!
creados!en!el!paso!5.!
!
Flujo(Alternativo:(2ae!El!servicio!de!catálogo!responde!con!un!error.!
2be!El!tipo!de!ítem!no!se!crea!en!el!servicio!de!catálogo.!
!
6ae!El!servicio!de!catálogo!responde!con!un!error.!
6be!Los!ítems!no!se!crean!en!el!servicio!de!catálogo.!
!
Poscondiciones:(El!sistema!cliente!realiza!las!operaciones!de!CRUD!exitosamente!en!el!servicio!de!catálogo.!
Nombre:(( Recolectar-Info-de-Redes-Sociales(
Descripción:(Permite!que!un!sistema!cliente!pueda!recolectar!información!de!redes!sociales.!
!
Actores:(Sistema!cliente.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
68!!
!
!
Precondiciones:(1e!Al!menos!un!usuario!debe!haberse!conectado!a!una!red!social.!Ver!-Conectarse-a-Redes-Sociales.!2e!El!servicio!de!social!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
3e!El!servicio!del!proveedor!de!SaaS!debe!estar!disponible!y!ser!accesible!por!el!servicio!social.!
!
Flujo(Normal:(1e!El!sistema!cliente!invoca!a!las!APIs!de!social!para!obtener!información!de!los!proveedores!de!SaaS!
!como!Facebook,!Twitter,!Linkedin,!Foursquare.!
2e!El!proveedor!de!SaaS!responde!exitosamente!con!gustos,!actividades,!etc.,!de!los!usuarios!en!
cuestión.!!
3e!El!servicio!social!alimenta!a!la!base!de!datos!con!esa!información.!
4e!El!servicio!social!envía!la!respuesta!al!sistema!cliente.!
!
Flujo(Alternativo:(N/A!
!
Poscondiciones:(El!sistema!cliente!obtiene!información!de!usuarios!de!distintas!redes!sociales.!
Nombre:(( Obtener-Recomendaciones(
Descripción:(Permite!que!un!sistema!cliente!pueda!obtener!recomendaciones.!
!
Actores:(Sistema!cliente.!
Precondiciones:(1e!El!servicio!de!recommender!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
!
Flujo(Normal:(1e!El!sistema!cliente!invoca!a!las!APIs!de!recommender!para!obtener!recomendaciones!de!ítems!
similares!a!otros!ítems,!de!ítems!de!usuarios!similares,!etc.!!
2e!El!servicio!de!recommender!responde!exitosamente!con!recomendaciones.!
!
Flujo(Alternativo:(N/A!
!
Poscondiciones:(El!sistema!cliente!obtiene!recomendaciones!para!así!mostrarselas!a!los!usuarios.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
69!!
!
!
5.1.2 Arquitectura!!
La Figura 15 muestra la arquitectura de alto nivel propuesta como parte del desarrollo
del prototipo.
Nombre:(( Enviar-Analytics(
Descripción:(Permite!que!un!sistema!cliente!pueda!enviar!información!de!uso!del!sistema.!
!
Actores:(Sistema!cliente.!
Precondiciones:(1e!El!servicio!de!analytics!tiene!que!estar!corriendo!y!ser!accesible!por!el!sistema!cliente.!
!
Flujo(Normal:(1e!El!sistema!cliente!invoca!a!las!APIs!de!analytics!para!enviar!información!de!uso!del!sistema,!como!
ser:!compras!de!ítems!por!parte!de!ciertos!usuarios,!revisiones!y!calificaciones!de!ítems,!navegación!
por!ciertas!páginas,!etc.!!
2e!El!servicio!de!analytics!responde!exitosamente.!
!
Flujo(Alternativo:(N/A!
!
Poscondiciones:(El!sistema!cliente!envía!información!de!uso!del!sistema.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
70!!
!
Figura(15:(Arquitectura(de(Alto(Nivel(
! Se provee una arquitectura orientada a servicios. La sección 5.1.3 describe más en
profundidad el propósito de cada uno de ellos.
Durante el diseño del sistema, se favoreció la flexibilidad, escalabilidad y
mantenibilidad del mismo. La mayoría de los servicios pueden utilizarse independientemente
uno de otros. Por ejemplo, si Sony ya posee un servicio de recomendaciones pero desea
contratar un servicio de catálogo de productos, esta solución lo permitiría, se proveería sólo el
servicio de catalog con su instancia de base de datos.
! !
5.1.3 Servicios!!
La Figura 16 muestra los distintos servicios disponibles en el prototipo.!
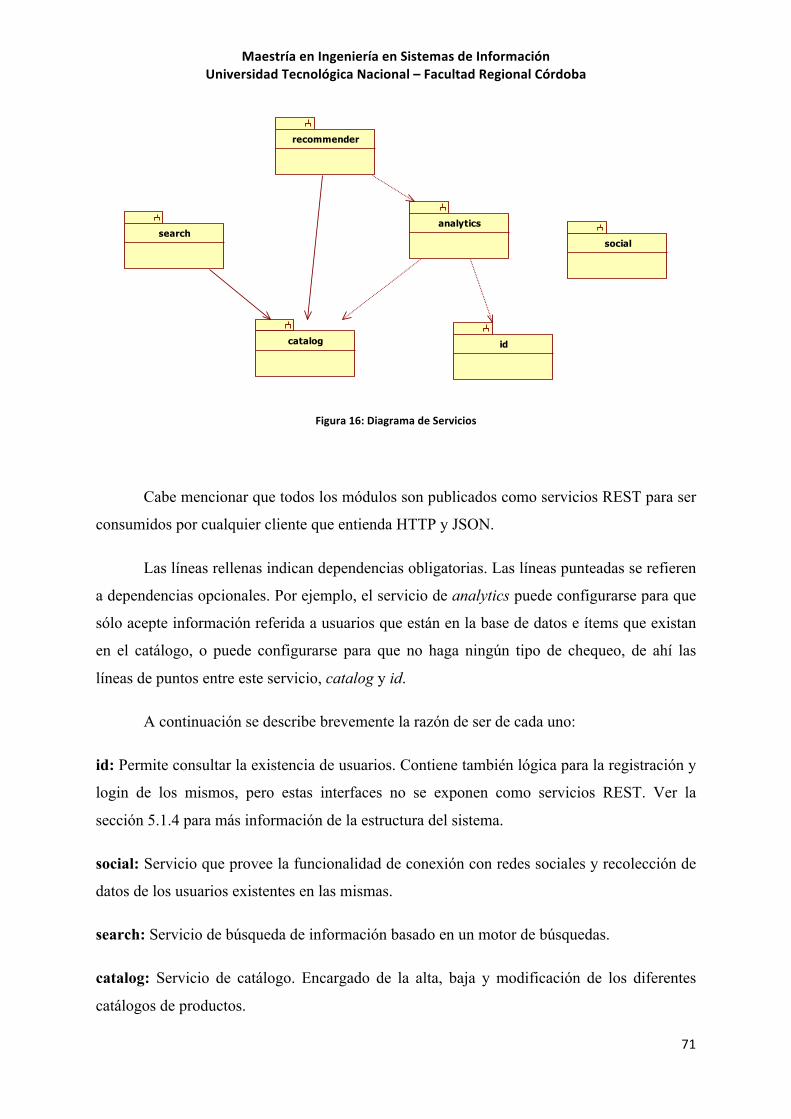
Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
71!!
!
Figura(16:(Diagrama(de(Servicios(
Cabe mencionar que todos los módulos son publicados como servicios REST para ser
consumidos por cualquier cliente que entienda HTTP y JSON.
Las líneas rellenas indican dependencias obligatorias. Las líneas punteadas se refieren
a dependencias opcionales. Por ejemplo, el servicio de analytics puede configurarse para que
sólo acepte información referida a usuarios que están en la base de datos e ítems que existan
en el catálogo, o puede configurarse para que no haga ningún tipo de chequeo, de ahí las
líneas de puntos entre este servicio, catalog y id.
A continuación se describe brevemente la razón de ser de cada uno:
id: Permite consultar la existencia de usuarios. Contiene también lógica para la registración y
login de los mismos, pero estas interfaces no se exponen como servicios REST. Ver la
sección 5.1.4 para más información de la estructura del sistema.
social: Servicio que provee la funcionalidad de conexión con redes sociales y recolección de
datos de los usuarios existentes en las mismas.
search: Servicio de búsqueda de información basado en un motor de búsquedas.
catalog: Servicio de catálogo. Encargado de la alta, baja y modificación de los diferentes
catálogos de productos.
catalog
search
recommender
social
analytics
id

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
72!!
recommender: Servicio de recomendación. Provee la funcionalidad de ofrecer
recomendaciones basadas en filtros colaborativos y basadas en contenido.
analytics: Servicio encargado de recibir y procesar eventos de uso del sistema.
El sistema no fue pensado para ser accedido directamente por un usuario final, sino
que es una herramienta que permitirá a los desarrolladores incorporar fácilmente
“inteligencia” a sus aplicaciones, las cuales sí estarán disponibles para los consumidores
finales. El mismo se podría ofrecer como software de caja blanca o directamente, como un
software de servicios o de caja negra (SaaS), dependiendo de las necesidades del cliente.
5.1.4 Módulos!
La Figura 17!muestra una captura de pantalla de la estructura física del proyecto.
!
Figura(17:(Estructura(Física(del(Prototipo(
!
El proyecto general se llama ci, por Collective Intelligence, el cual consta de
diferentes sub proyectos o módulos. A continuación se describe brevemente la funcionalidad
de cada uno de los sub proyectos de la Figura 17.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
73!!
!
analytics-core: Módulo base para analytics, contiene los modelos de datos necesarios para
hacer analytics, la capa de servicios, la capa de acceso a datos y otras utilidades.
analytics-ws: Módulo de servicios web para analytics. Expone mediante interfaces REST los
servicios disponibles en analytics-core.
catalog-core: Módulo base para manejar catálogos, contiene la capa de servicios y la capa de
acceso a datos.
catalog-ws: Módulo de servicios web para el manejo de catálogos. Expone mediante
interfaces REST los servicios disponibles en catalog-core.
clients: Módulo de clientes REST para diferentes servicios. Utilizado para comunicarse entre
servicios. Contiene clientes para analytics, catalog, social y id.
common: Módulo genérico de utilidades.!
id-core: Módulo base para manejar usuarios, contiene la capa de servicios y la capa de
acceso a datos.
id-ws: Módulo de servicios web para el manejo de usuarios. Expone mediante interfaces
REST algunos de los servicios disponibles en id-core, más precisamente el servicio para
consultar por la existencia de un determinado usuario. No expone los servicios para la
creación ni autenticación de usuarios. Para ello, se requiere utilizar directamente id-core.
models: Módulo que contiene los modelos de datos utilizados por los diferentes sub
proyectos.
recommender-core: Módulo base para hacer recomendaciones, contiene la capa de
servicios, convertidores de datos, filtros, etc.
recommender-ws: Módulo de servicios web que ofrece recomendaciones. Expone mediante
interfaces REST los servicios disponibles en recommender-core.
search-core: Módulo base para las búsquedas, contiene la capa de servicios y las utilidades
necesarias para hacer el indexado de datos en el motor.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
74!!
search-ws: Módulo de servicios web para hacer búsquedas. Expone mediante interfaces
REST los servicios disponibles en search-core.
social-core: Módulo base para la interacción con redes sociales, contiene los modelos de
datos específicos para comunicarse con los proveedores, la capa de servicios, la capa de
acceso a datos y otras utilidades.
social-ws: Módulo de servicios web para utilizar redes sociales. Expone mediante interfaces
REST los servicios disponibles en social-core.!
webapp: Aplicación cliente de ejemplo, que permite registrar y autenticar usuarios, y
también interactuar con redes sociales. Se incluye para demostrar lo simple que resulta la
integración de los módulos del sistema.!
De la lista anterior se desprende una característica muy importante en el diseño del
sistema. Si bien el mismo se pensó como un sistema orientado a servicios, en donde los
diferentes módulos se comunican a través de internet, también se abarcó la posibilidad de
incluir todos los componentes como parte de una sola aplicación, para así evitar problemas de
marshalling27 de datos, de conectividad, etc. Es por ello que se dividió la estructura de los
servicios en core y ws.!
!
5.1.5 Diagramas!de!Paquetes!
5.1.5.1 Analytics'
!Figura(18:(Diagrama(de(Paquetes(de(Analytics(
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!27!También!conocido!como!serialización,!es!el!proceso!de!codificación!de!un!objeto!con!el!fin!de!transmitirlo!a!
través!de!una!conexión!de!red!como!una!serie!de!bytes!o!un!formato!más!legible!como!XML!o!JSON.!
org.tmme.ci.analytics.models
org.tmme.ci.analytics.repository
org.tmme.ci.analytics.repository.populator
org.tmme.ci.analytics.service
org.tmme.ci.analytics.service.impl
org.tmme.ci.clientsorg.tmme.ci.models
org.tmme.ci.analytics.controller
analytics-ws
clients
analytics-core
models
Referencias

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
75!!
5.1.5.2 Catalog'
!
Figura(19:(Diagrama(de(Paquetes(de(Catalog(
'
5.1.5.3 Id'
!
Figura(20:(Diagrama(de(Paquetes(de(Id(
'
5.1.5.4 Search'
!
Figura(21:(Diagrama(de(Paquetes(de(Search
org.tmme.ci.models
catalog-ws
catalog-core
models
Referencias
org.tmme.ci.catalog.repository
org.tmme.ci.catalog.repository.impl
org.tmme.ci.catalog.service
org.tmme.ci.catalog.service.impl
org.tmme.ci.catalog.controller
org.tmme.ci.models
id-ws
id-core
models
Referencias
org.tmme.ci.id.controllerorg.tmme.ci.id.repository
org.tmme.ci.id.service
org.tmme.ci.id.service.impl
org.tmme.ci.models
search-ws
search-core
models
Referencias
org.tmme.ci.search.populator
org.tmme.ci.search.service
org.tmme.ci.search.controller
org.tmme.ci.search.service.impl
org.tmme.ci.common.utils
org.tmme.ci.clients
common
clients

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
76!!
5.1.5.5 Social'
!
Figura(22:(Diagrama(de(Paquetes(de(Social(
!
5.1.5.6 Recommender'!
!
Figura(23:(Diagrama(de(Paquetes(de(Recommender(
!
social-ws
social-core
Referencias
org.tmme.ci.social.service.impl
org.tmme.ci.social.service
org.tmme.ci.social.repository.impl
org.tmme.ci.social.repository
org.tmme.ci.social.controller
org.tmme.ci.social.models
org.springframework.social.connect.web
recommender-ws recommender-core
Referencias
org.tmme.ci.recommender.controllerorg.tmme.ci.recommender.service
org.tmme.ci.recommender.converter
org.tmme.ci.recommender.cf.factory
org.tmme.ci.recommender.cf.factory.impl
org.tmme.ci.recommender.service.impl
org.tmme.ci.recommender.filter
org.tmme.ci.recommender.filter.impl
org.tmme.ci.models
org.tmme.ci.clients
org.tmme.ci.recommender.cb.factory.impl
org.tmme.ci.recommender.cb.factory
org.tmme.ci.recommender.cb.task
org.tmme.ci.recommender.cb.task.impl
org.tmme.ci.recommender.cb.transformer
org.tmme.ci.recommender.cb.utils
org.tmme.ci.recommender.cb.repository.impl
org.tmme.ci.recommender.cb.repository
org.tmme.ci.recommender.cb.model
models clients

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
77!!
5.1.6 Interfaces!de!Programación!de!Aplicaciones!!
En la presente sección se especifican las interfaces que publican los distintos
servicios, conocidas comúnmente como APIs por sus siglas en inglés.!
! !
5.1.6.1 Analytics'!
Revisión/Calificación(de(un(ítem(
Descripción:!Registra!una!revisión!y/o!calificación!de!determinado!ítem!del!catálogo!por!parte!de!un!
usuario.!
URL:!
http://<server_address>:<server_port>/analytics/v1.0/user/<user_id>/review/<item_type_plural>.<
item_id>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/analytics/v1.0/user/[email protected]/review/applications.ABCBVS44A!HTTP/1.1!!Accept:!application/json!!!{!!!!“rate”:!4,!!!!“description”:!“Awesome!application”,!!}!
!Respuesta:*!HTTP/1.1!201!Created!
!
Compra(de(un(ítem(
Descripción:!Registra!la!compra!de!un!ítem!del!catálogo!por!parte!de!un!usuario.!
URL:!
http://<server_address>:<server_port>/analytics/v1.0/user/<user_id>/purchase/<item_type_plural
>.<item_id>!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
78!!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/analytics/v1.0/user/[email protected]/purchase/applications.ABCBVS44523!HTTP/1.1!!Accept:!application/json!!Respuesta:*!HTTP/1.1!201!Created!
(
Visita(de(un(ítem(
Descripción:!Registra!la!visita!a!un!ítem!particular!por!parte!de!un!usuario.!
URL:!
http://<server_address>:<server_port>/analytics/v1.0/user/<user_id>/visit/<item_type_plural>.<ite
m_id>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/analytics/v1.0/user/1234/visit/applications.ABCBVS44523!HTTP/1.1!!Accept:!application/json!!Respuesta:*!HTTP/1.1!201!Created!
!
Aceptación(de(una(recomendación(
Descripción:!Registra!que!el!usuario!acepta!explícitamente!la!recomendación!de!un!ítem.!
URL:!
http://<server_address>:<server_port>/analytics/v1.0/user/<user_id>/accept/<item_type_plural>.<i
tem_id>!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
79!!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/analytics/v1.0/user/[email protected]/accept/applications.ABCBVS44523!HTTP/1.1!!Accept:!application/json!!Respuesta:*!HTTP/1.1!201!Created!
!
Rechazo(de(una(recomendación(
Descripción:!Registra!que!el!usuario!rechaza!explícitamente!la!recomendación!de!un!ítem.!
URL:!
http://<server_address>:<server_port>/analytics/v1.0/user/<user_id>/reject/<item_type_plural>.<it
em_id>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/analytics/v1.0/user/[email protected]/reject/applications.ABCBVS44523!HTTP/1.1!!Accept:!application/json!!Respuesta:*!HTTP/1.1!201!Created!
!
!
!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
80!!
5.1.6.2 Catalog'!
La!siguiente!lista!no!es!exhaustiva,!pero!muestra!a!grandes!rasgos!la!funcionalidad!que!ofrece!la!API.!
(
Crear(un(tipo(de(ítem(
Descripción:!Crea!un!tipo!de!ítem!en!el!catálogo.!
URL:!http://<server_address>:<server_port>/catalog/v1.0/itemtypes/<item_type_plural>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/catalog/v1.0/itemtypes/applications!HTTP/1.1!!Accept:!application/json!!Respuesta:*!HTTP/1.1!201!Created!!!(Crear/Actualizar(un(ítem(
Descripción:!Crea!o!actualiza!un!ítem!en!el!catálogo.!
URL:!http://<server_address>:<server_port>/catalog/v1.0/item/<item_type_plural>!
Formato:!application/json!
Método:!PUT!
Ejemplo:!
Pedido:*!PUT!http://localhost:8080/catalog/v1.0/item/applications!HTTP/1.1!!Accept:!application/json!!{!!“id”:!“ABCGDH43458”,!!“name”:!“Angry!Birds”,!!“description”:!“Video!game!created!by!Finnish!computer…”,!!“publisher”:!“Rovio”!}!!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
81!!
Respuesta:*!HTTP/1.1!201!Created!!
Crear(un(conjunto(de(Ítems(
Descripción:!Crea!un!conjunto!de!ítems!en!el!catálogo.!
URL:!http://<server_address>:<server_port>/catalog/v1.0/items/<item_type_plural>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/catalog/v1.0/items/applications!HTTP/1.1!!Accept:!application/json!![!!!{!!!!“id”:!“ABCGDH43458”,!!!!“name”:!“Angry!Birds”,!!!!“description”:!“Video!game!created!by!Finnish!computer…”,!!!!“publisher”:!“Rovio”!!!},!
!!{!!!!“id”:!“ABCGDH42222”,!!!!“name”:!“Microsoft!Office!2013”,!!!!“description”:!“An!office!suite!of!desktop!applications,!servers!and!services…!”,!!!!“publisher”:!“Microsoft”!!}!]!!Respuesta:*!HTTP/1.1!201!Created!!!Consultar(tipos(de(ítems(
Descripción:!Pedir!los!tipos!de!ítems!disponibles!en!el!catálogo.!
URL:!http://<server_address>:<server_port>/catalog/v1.0/itemtypes!
Formato:!application/json!
Método:!GET!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
82!!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/catalog/v1.0/itemtypes!HTTP/1.1!!Accept:!application/json!!Respuesta:*!
HTTP/1.1!200!OK!
[!"applications",!"books"!]!!!!!!(
Consultar(ítems(
Descripción:!Pedir!los!ítems!de!cierto!tipo!disponibles!en!el!catálogo.!
URL:!http://<server_address>:<server_port>/catalog/v1.0/items/<item_type_plural>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/catalog/v1.0/items/applications!HTTP/1.1!!Accept:!application/json!!Respuesta:*!
HTTP/1.1!200!OK!
[!!!{!!!!“id”:!“ABCGDH43458”,!!!!“name”:!“Angry!Birds”,!!!!“description”:!“Video!game!created!by!Finnish!computer…”,!!!!“publisher”:!“Rovio”!!!},!
!!{!!!!“id”:!“ABCGDH42222”,!!!!“name”:!“Microsoft!Office!2013”,!!!!“description”:!“An!office!suite!of!desktop!applications,!servers!and!services…!”,!!!!“publisher”:!“Microsoft”!!}!]!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
83!!
!
5.1.6.3 Id'!
Consultar(por(usuario(
Descripción:!Consulta!por!la!existencia!de!un!usuario!en!particular.!
URL:!http://<server_address>:<server_port>/id/v1.0?user=<user_id>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/id/[email protected]!HTTP/1.1!Accept:!application/json!!Respuesta:*!HTTP/1.1!200!OK!!{!“id:!“abth53l2312”,!“email”!:!“[email protected]”!}!!
5.1.6.4 Search'!
Búsqueda(por(texto(
Descripción:!Hacer!una!búsqueda!por!texto.!
URL:!http://<server_address>:<server_port>/search/v1.0?q=<text_to_search>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/search/v1.0?q=name:Angry!HTTP/1.1!!Accept:!application/json!!Respuesta:*!
HTTP/1.1!200!OK!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
84!!
[!{!!“id”:!“ABCGDH43458”,!!“name”:!“Angry!Birds”,!!“description”:!“Video!game!created!by!Finnish!computer…”,!!“publisher”:!“Rovio”!},!{!!“id”:!“ABCGDH43888”,!!“name”:!“Angry!Birds!Space”,!!“description”:!“Space!version!of!the!well!known…”,!!“publisher”:!“Rovio”!!}!]!!
5.1.6.5 Social'!
Conectar(a(Red(Social(
Descripción:!Conectarse!a!una!red!social.!Paso!1!
URL:!http://<server_address>:<server_port>/social/v1.0/conn/<provider_id>?user=<user_id>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/social/v1.0/conn/[email protected]!HTTP/1.1!Accept:!application/json!Referer:!<redirect_uri>!!Respuesta:*!
HTTP/1.1!200!OK!
https://graph.facebook.com/oauth/authorize?client_id=<client_id>&response_type=code&redirect_
uri=<redirect_uri>!
eeeeeeee!
Una!vez!que!recibe!esta!URL!de!respuesta,!el!cliente!debe!hacer!un!redirect!a!la!misma.!El!usuario!se!
deberá!autenticar!con!la!correspondiente!red!social!y!luego!ésta!hará!un!callback!a!la!<redirect_uri>!
de! la! respuesta.!En!el!callback!vendrá!un!parámetro! llamado!code! (proveedores!con!Oauth2)!o!un!parámetro!llamado!oauth_token!(proveedores!con!Oauth1).!Cuando!se!ejecuta!el!callback,!el!cliente!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
85!!
debe! invocar! la! siguiente! API! (se! muestra! el! caso! de! que! se! mande! code,! como! es! el! caso! de!
facebook).!
eeeeeeee!
Descripción:!Conectarse!a!una!red!social.!Paso!2!
URL:!http://<server_address>:<server_port>/social/v1.0/conn/<provider_id>?!
user=<user_id>&code=<code>!
Formato:!application/json!
Método:!POST!
Ejemplo:!
Pedido:*!POST!http://localhost:8080/social/v1.0/conn/[email protected]@code=AQCPH7zng4_E!HTTP/1.1!Accept:!application/json!Referer:!<redirect_uri>!!Respuesta:*!
HTTP/1.1!200!OK!
eeeeeeee!
Después!de!este!paso,!el!usuario!se!encuentra!conectado.!Es!momento!pedir!o!subir!información.!
(
Obtener(Gustos(
Descripción:!Pedir!los!“likes”!de!un!usuario!de!determinada!red!social.!
URL:!http://<server_address>:<server_port>/social/v1.0/likes/<provider_id>?user=<user_id>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/social/v1.0/likes/[email protected]!HTTP/1.1!Accept:!application/json!!*

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
86!!
Respuesta:*!
HTTP/1.1!200!OK!
[!“Forrest!Gump”,!“Angry!Birds”,!“Rolling!Stones”!]!
!
Obtener(Actividades(
Descripción:!Pedir!los!“checkein”!de!un!usuario!de!determinada!red!social.!
URL:!http://<server_address>:<server_port>/social/v1.0/checkins/<provider_id>?user=<user_id>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/social/v1.0/checkins/[email protected]!HTTP/1.1!!Accept:!application/json!!Respuesta:*!
HTTP/1.1!200!OK!
[!“UTN!FRC”,!“Patio!Olmos”,!“Aeropuerto!Ezeiza”!]!
!
5.1.6.6 Recommender'!
Recomendación(anónima(
Descripción:!Pedir!una!recomendación!basada!en!similitud!de!ítems,!con!usuario!anónimo.!
URL:!http://<server_address>:<server_port>/recommender/v1.0/<item_type_plural>.<item_id>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/recommender/v1.0/applications.ABCGDH43458!HTTP/1.1!!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
87!!
Accept:!application/json!!Respuesta:*!
HTTP/1.1!200!OK!
[!!!{!!!!“id”:!“ABCGDH433423”,!!!!“name”:!“Angry!Birds!Space”,!!!!“description”:!“the!#1!mobile!game!of!all!time!blasts!off!into!space!…”,!!!!“publisher”:!“Rovio”!!!},!
!!{!!!!“id”:!“ABCGDH411111”,!!!!“name”:!“Angry!Birds!Rio”,!!!!“description”:!“the!#1!mobile!game!of!all!time!blasts!off!into!Rio!de!Janeiro!…!”,!!!!“publisher”:!“Rovio”!!}!]!
!
Recomendación(personal(para(ítems(similares(
Descripción:!Pedir!una!recomendación!personal!para!ítems!similares.!
URL:!
http://<server_address>:<server_port>/recommender/v1.0/user/<user_id>/<item_type_plural>.<ite
m_id>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/recommender/v1.0/user/[email protected]/applications.ABCGDH43458!HTTP/1.1!!Accept:!application/json!!*Respuesta:*!
HTTP/1.1!200!OK!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
88!!
[!!!{!!!!“id”:!“ABCGDH433423”,!!!!“name”:!“Angry!Birds!Space”,!!!!“description”:!“the!#1!mobile!game!of!all!time!blasts!off!into!space!…”,!!!!“publisher”:!“Rovio”!!!},!
!!{!!!!“id”:!“ABSGDH433333”,!!!!“name”:!“Medal!of!Honor”,!!!!“description”:!“written!by!active!US!Tier!1!Operators!while!deployed!overseas!and…!”,!!!!“publisher”:!“Electronic!Arts”!!}!]!
!
Recomendación(personal(
Descripción:!Pedir!una!recomendación!de!ciertos!ítems!para!un!usuario!en!particular.!
URL:!
http://<server_address>:<server_port>/recommender/v1.0/user/<user_id>/<item_type_plural>!
Formato:!application/json!
Método:!GET!
Ejemplo:!
Pedido:*!GET!http://localhost:8080/recommender/v1.0/user/[email protected]/applications!HTTP/1.1!!Accept:!application/json!!Respuesta:*!
HTTP/1.1!200!OK!
[!!!{!!!!“id”:!“ABCGDH433423”,!!!!“name”:!“Angry!Birds!Space”,!!!!“description”:!“the!#1!mobile!game!of!all!time!blasts!off!into!space!…”,!!!!“publisher”:!“Rovio”!!!}!]!!!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
89!!
5.2 Diseño!de!Bajo!Nivel!!
Debido a razones de legibilidad, se incluyen los Diagramas de Clases y de Secuencia
(con diferente formato de página) en los Apéndices A y B respectivamente.
Asimismo, el Apéndice C cuenta con varios snippets de código, que forman parte del
prototipo implementado.
!
5.3 Tecnologías!y!Frameworks!Utilizados!!
A continuación se mencionan algunos de los frameworks, librerías, tecnologías y
herramientas que se utilizaron para el desarrollo de la prueba de concepto:
• Java 7: Lenguaje utilizado para la creación de los componentes.
• C++: Lenguaje utilizado para la extensión del cliente Intel AppUp Center.
• Javascript: Lenguaje utilizado para incluir lógica en la UI de los clientes.
• JSP: Lenguaje utilizado para la capa de la Vista del patrón MVC en la webapp de
muestra.
• HTML5: Lenguaje de marcas utilizado para el maquetado de la UI.
• Spring: Framework de IoC utilizado en el desarrollo de los componentes web.
• Spring MVC: Módulo de Spring utilizado para exponer servicios REST. También se
utilizó para implementar MVC en la webapp de muestra.
• Spring-Social: Extensión de Spring Framework utilizado para la conexión con
proveedores de SaaS como Facebook, Twitter, etc.
• Spring-Data-Mongo: Módulo de Spring-Data para la comunicación con la base de
datos.
• Jackson: Utilizado para el marshalling/unmarshalling de objectos.
• Mahout: Framework de Apache para utilizar algunos de sus algoritmos de
recomendaciones.
• Hadoop: Framework de Apache para procesar grandes sets de datos de manera
distribuida. Utiliza el algoritmo de MapReduce.
• Slf4j: Simple Logging Façade for Java, wrapper de log4j, utilizado para insertar logs
en el código, muy útil para la depuración del mismo.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
90!!
• Boost: Librería utilizada para la conexión del cliente Intel AppUp Center con los
servicios web.
• Apache Solr: Utilizado como motor de búsqueda.
• MongoDB: Base de datos NoSQL, orientada a documentos. Utilizada para persistir
información de catálogo, analytics, etc.
• Tomcat 7: Contenedor utilizado para el deployment de los servicios.
• Maven: Utilizado como herramienta de building de los servicios.
• Ant: Utilizado como herramienta de building de algunos clientes.
• CMake: Utilizado como herramienta de building de Intel AppUp Center.
• Git: Utilizado para el control de configuración de los servicios y del cliente web.
• Mercurial: Utilizado para el control de configuración de Intel AppUp Center.
• Eclipse: Entorno de desarrollo.
5.4 Capturas!de!Pantalla!
En esta sección se incluyen algunas capturas de pantalla de la integración de distintas
partes del sistema con un par de clientes. Se remarcan en rojo las partes importantes de cada
figura.
En la Figura 24 se muestra la pantalla de inicio tradicional de Intel AppUp Center, sin
un usuario autenticado. No se presentan recomendaciones.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
91!!
!
Figura(24:(Usuario(Anónimo(Sin(Recomendación(en(Intel(AppUp(Center(
Sin embargo, en la Figura 25, una vez que el usuario se autentica, aparecen
recomendaciones personalizadas en la pantalla inicial.!
!!
!
Figura(25:(Intel(AppUp(Center(con(Recomendaciones(Personalizadas(
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
92!!
La Figura 26 a la Figura 35 muestran capturas de pantalla de otro cliente, al que
llamaremos Cliente X.
La Figura 26 y la Figura 27 ilustran recomendaciones basadas en contenido,
utilizando las técnicas de clustering explicadas en la sección 2.2.1.2.2. Se pueden apreciar
recomendaciones para las aplicaciones Angry Birds Space y NJam.
La Figura 28 muestra la pantalla inicial para un usuario anónimo, sin
recomendaciones. Allí se pueden visualizar las 6 aplicaciones gratis más requeridas. Una vez
que el usuario se autentica, en la Figura 29, se puede apreciar cómo cambia la pantalla inicial,
y se muestran ahora sólo 3 aplicaciones recomendadas para ese usuario.
!
!
!
Figura(26:(Recomendación(basada(en(Contenido(para(Usuario(Anónimo(I(en(el(Cliente(X(

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
93!!
!!
Figura(27:(Recomendación(basada(en(Contenido(para(Usuario(Anónimo(II(en(el(Cliente(X(
!
Figura(28:(Pantalla(Inicial(de(Cliente(X(sin(Recomendaciones((

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
94!!
!
Figura(29:(Pantalla(Inicial(de(Cliente(X(con(Recomendaciones(Personalizadas(
!
Figura(30:(Recomendaciones(Híbridas(para(Usuario(Autenticado(en(el(Cliente(X(

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
95!!
La Figura 30 muestra la pantalla de detalles de la aplicación Weather App del Cliente
X. A la derecha, se pueden apreciar recomendaciones híbridas, basadas en contenido y en
filtros colaborativos para esa aplicación y ese usuario en particular.
Por último, las siguientes figuras muestran un caso típico de conexión con Facebook y
la posterior obtención de gustos del usuario. En la Figura 31 se ilustra la ventana para
conectarse con diferentes redes sociales del Cliente X.
!
!
Figura(31:(Conexión(con(Redes(Sociales(en(el(Cliente(X(
Una vez que el usuario hace click en el botón verde de Facebook, es redirigido a la
página de dicha red social para autenticarse (Figura 32).

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
96!!
!
Figura(32:(Login(con(Facebook
Ya autenticado, en la Figura 33 se informa al usuario que la aplicación CI quiere
acceder a datos de su perfil, lista de amigos, intereses, gustos, etc.
!
Figura(33:(Permisos(Explícitos(de(Acceso(a(Información(de(Facebook
Cuando el usuario acepta, Facebook hace una redirección a la misma página donde
comenzó todo. En este punto el estado fue actualizado, el usuario aparece como conectado
(Figura 34).

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
97!!
!
Figura(34:(Usuario(Conectado(a(Facebook
Finalmente, la Figura 35 muestra los gustos (remarcados en rojo) que se obtuvieron de
Facebook para ese usuario en particular.
!
Figura(35:(Gustos(obtenidos(de(Facebook
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
98!!
6 Evaluación!de!los!Resultados!!
El desarrollo completo de un sistema requiere la ejecución de una serie de pruebas
que permitan obtener mediciones del mismo.
Con las pruebas se pretende comprobar que, dadas ciertas condiciones de operación,
cada componente cumple debidamente con sus responsabilidades, posibilitando un correcto
funcionamiento integral del mismo.
Si bien se puede invertir mucho esfuerzo en probar, el continuar probando es una
cuestión puramente económica, ya que nunca se puede demostrar que un programa es 100%
correcto. Es por ello que se define la prueba como el proceso de establecer confianza en que
un programa hace lo que se supone que tiene que hacer [DeMendarozqueta, 2007].
Por lo antepuesto, sólo se realizaron mediciones en las partes críticas del sistema. La
siguientes sub secciones muestran los resultados de las pruebas realizadas con el fin de
evaluar los algoritmos de recomendación utilizando algunas de las métricas descriptas en la
sección 2.2.2.
6.1 Mediciones!para!Filtros!Colaborativos!!
Para la realización de pruebas de los algoritmos basados en filtros colaborativos, se
elaboró el pequeño conjunto de datos que se muestra a continuación, al que se referencia
como sample4cf.
userid,itemid,rating!
10,1000,5.0!10,1001,3.0!10,1002,2.5!20,1000,2.0!20,1001,2.5!20,1002,5.0!20,1003,2.0!30,1000,2.5!30,1003,4.0!30,1004,4.5!30,1006,5.0!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
99!!
40,1000,5.0!40,1002,3.0!40,1003,4.5!40,1005,4.0!50,1000,4.0!50,1001,3.0!50,1002,2.0!50,1003,4.0!50,1004,3.5!50,1005,4.0!!
Una forma de evaluar las calificaciones o ratings estimados de un motor de
recomendación es midiendo qué tan cerca el valor estimado está con respecto al valor real.
Como los valores reales no existen, ya que nadie conoce cuánto le gustará a un usuario
determinado ítem en el futuro, se simula separando el corpus en datos de entrenamiento y
datos de prueba. Luego se alimenta al motor sólo con los datos de entrenamiento y se le pide
que estime las preferencias para los datos de prueba. Finalmente estas estimaciones se
comparan con los valores reales del sub set de prueba.
En todas las salidas que se muestran a continuación se utilizó el 70% del set de datos
como conjunto de entrenamiento y el 30% restante como conjunto de prueba. La separación
de datos se dejo librada al framework, el cual garantiza que siempre se elijan los mismos sub
conjuntos. También se muestran resultados tanto para recomendaciones basadas en ítems
como para las basadas en usuarios.
A continuación se aprecia la salida en consola de una corrida del evaluador de
Diferencia Absoluta para el set de datos sample4cf. Un resultado de 1.0 significa, q en
promedio, el recomendador estima una preferencia que se desvía 1.0 del valor real.
!###!Sample4CF!e!AAD!e!User!Based!###!Euclidean!Similarity:!1.0!Pearson!Similarity:!2.5!Jaccard!Similarity:!2.038461685180664!!###!Sample4CF!e!AAD!e!Item!Based!###!Euclidean!Similarity:!1.1479175090789795!Jaccard!Similarity:!1.3458333015441895!LogeLikelihood!Similarity:!1.3490864634513855!
Como siguiente paso, se ejecutaron pruebas con el evaluador de RMSE con el set de
datos sample4cf. Los resultados obtenidos son los siguientes:

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
100!!
!###!Sample4CF!e!RMSE!e!User!Based!###!Euclidean!Similarity:!1.0!Pearson!Similarity:!2.5!Jaccard!Similarity:!2.038461685180664!!###!Sample4CF!e!RMSE!e!Item!Based!###!Euclidean!Similarity:!1.6191675305761162!Jaccard!Similarity:!1.5408555985157832!LogeLikelihood!Similarity:!1.6782930120471817!!! !
A continuación se muestra la salida en consola de una corrida del evaluador de RMSE
para un set de datos movieLens de 100.000 registros28, un corpus más representativo del
verdadero potencial del sistema.
!###!MovieLens!e!RMSE!e!User!Based!###!Euclidean!Similarity:!1.2384180262022733!Pearson!Similarity:!1.244164460784607!Jaccard!Similarity:!1.1278357573960438!LogeLikelihood!Similarity:!1.1491202609316826!!!###!MovieLens!RMSE!e!Item!Based!###!Euclidean!Similarity:!1.0264648042633715!Pearson!Similarity:!1.0921424821523293!Jaccard!Similarity:!1.00921923269968!LogeLikelihood!Similarity:!1.0237779427793616 !!
Se efectuó una corrida del evaluador de Precisión y Exhaustividad para el conjunto de
datos sample4cf. Cabe destacar que la ejecución se realizó considerando los dos resultados
más relevantes, es decir, se ejecutó con precisión y exhaustividad en 2. También se utilizó el
valor promedio de las preferencias del usuario más una desviación estándar como umbral de
decisión para considerar a las recomendaciones como buenas o malas.
Vale la pena aclarar que un valor de precisión de 0.75 significa que en promedio ¾ de
las recomendaciones fueron buenas. Un valor de exhaustividad o recall de 1.0 indica que
todas las buenas recomendaciones que retorna el sistema están entre los resultados relevantes.
!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!28!http://www.grouplens.org/node/73!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
101!!
###!Sample4CF!e!PrecisionRecall!e!User!Based!###!Euclidean!Similarity:!!Precision:!0.5!!Recall:!0.5!Pearson!Similarity:!!Precision:!0.75!!Recall:!1.0!Jaccard!Similarity:!!Precision:!0.75!!Recall:!1.0!Logelikelihood!Similarity:!!Precision:!0.75!!Recall:!1.0!!!###!Sample4CF!e!PrecisionRecall!e!Item!Based!###!Euclidean!Similarity:!!Precision:!0.5!!Recall:!1.0!Pearson!Similarity:!!Precision:!0.75!!Recall:!1.0!Jaccard!Similarity:!!Precision:!0.5!!Recall:!1.0!Logelikelihood!Similarity:!!Precision:!0.25!!Recall:!0.5!!!
! Las características fundamentales de un motor de recomendación es que sea rápido y
produzca buenas recomendaciones. De las dos, siempre es preferible enfocarse primero en la
realización de buenas predicciones, luego en la performance.!
Sin embargo, es casi imposible deducir la implementación correcta con solo ver los
datos. La ejecución de pruebas resulta necesaria. Mediante el análisis de las salidas
anteriores, diferencia absoluta, RMSE, precisión, exhaustividad, se pueden atacar diferentes
aspectos para aumentar la eficiencia del framework.
El sistema posibilita, mediante diferentes configuraciones, que se puedan probar
diversas combinaciones de recomendadores, métricas de similitud y definición de vecindades.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
102!!
6.2 Mediciones!para!Clustering!!
Para la realización de pruebas de los algoritmos de agrupamiento, se elaboró un
pequeño catálogo de películas que se muestra a continuación, al que se referencia como
sample4cb. Se incluye sólo una parte del mismo (posee 21 películas en total) con fines
ilustrativos.
[!!{!"id"!:!"101",!"name"!:!"Forrest!Gump",!"description"! :! "Forrest! Gump! is! a! simple!man!with! a! low! I.Q.! but! good! intentions.! He! is! running!through!childhood!with!his!best!and!only!friend!Jenny.!His!'mama'!teaches!him!the!ways!of!life!and!leaves!him!to!choose!his!destiny.!Forrest!joins!the!army!for!service!in!Vietnam,!finding!new!friends!called!Dan!and!Bubba,!he!wins!medals,!creates!a!famous!shrimp!fishing!fleet,!inspires!people!to!jog,!starts!a!pingepong!craze,!create!the!smiley,!write!bumper!stickers!and!songs,!donating!to!people!and!meeting!the!president!several!times.!However,!this!is!all!irrelevant!to!Forrest!who!can!only!think!of!his! childhood! sweetheart! Jenny! Curran.!Who! has!messed! up! her! life.! Although! in! the! end! all! he!wants!to!prove!is!that!anyone!can!love!anyone.",!"director"!:!"Robert!Zemeckis"!},!{!"id"!:!"102",!"name"!:!"BraveHeart",!"description"! :! "William!Wallace! is!a!Scottish! rebel!who! leads!an!uprising!against! the!cruel!English!ruler!Edward!the!Longshanks,!who!wishes!to!inherit!the!crown!of!Scotland!for!himself.!When!he!was!a!young!boy,!William!Wallace's!father!and!brother,!along!with!many!others,!lost!their!lives!trying!to!free! Scotland.! Once! he! loses! another! of! his! loved! ones,!William!Wallace! begins! his! long! quest! to!make!Scotland!free!once!and!for!all,!along!with!the!assistance!of!Robert!the!Bruce.",!"director":!"Mel!Gibson"!!},!{!"id"!:!"103",!"name"!:!"The!Godfather!I",!"description"! :! "The! story! begins! as! Don! Vito! Corleone,! the! head! of! a! New! York! Mafia! family,!oversees!his!daughter's!wedding!with!his!wife!Wendy.!His!beloved!son!Michael!has!just!come!home!from!the!war,!but!does!not!intend!to!become!part!of!his!father's!business.!Through!Michael's!life!the!nature!of!the!family!business!becomes!clear.!The!business!of!the!family! is! just! like!the!head!of!the!family,! kind! and! benevolent! to! those! who! give! respect,! but! given! to! ruthless! violence! whenever!anything!stands!against!the!good!of!the!family.!Don!Vito!lives!his!life!in!the!way!of!the!old!country,!but!times!are!changing!and!some!don't!want!to!follow!the!old!ways!and!look!out!for!community!and!family.!An!up!and!coming!rival!of!the!Corleone!family!wants!to!start!selling!drugs!in!New!York,!and!needs!the!Don's!influence!to!further!his!plan.!The!clash!of!the!Don's!fading!old!world!values!and!the!new!ways!will!demand!a!terrible!price,!especially!from!Michael,!all!for!the!sake!of!the!family.",!"director":!"Francis!Ford!Coppola"!},!{!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
103!!
"id"!:!"104",!"name"!:!"The!Godfather!II",!"description"! :! "The! continuing! saga! of! the! Corleone! crime! family! tells! the! story! of! a! young! Vito!Corleone!growing!up!in!Sicily!and!in!1910s!New!York;!and!follows!Michael!Corleone!in!the!1950s!as!he!attempts!to!expand!the!family!business!into!Las!Vegas,!Hollywood!and!Cuba.",!"director"!:!"Francis!Ford!Coppola"!},!….!….!….!]!
A continuación se muestran los resultados de correr KMeans con el set de datos
mencionado, sample4cb. El algoritmo se ejecutó con los siguientes parámetros:
- Distancia Euclidiana.!
- k = 3 (número de clústeres)!
- x = 10 (número máximo de iteraciones) !
! Se efectuaron tres iteraciones. La primera muestra la formación de tres clústeres,
llamados CL-13, CL-20 y CL-4, ninguno posee documentos asignados (n=0). También se
muestran las listas de términos más frecuentes.
!:CLe13!{n=0}!Top!Terms:!secrets,!chamber,!voice,!harry,!able,!still,!famous,!hogwarts,!what,!becoming,!warned,!although,!house,!second,!keeps,!knows,!coming,!things,!elf,!true!!:CLe20!{n=0}!Top!Terms:!o'connor,!lapd,!crew,!racing,!toretto,!toretto's,!really,!rival,!high,!sister,!speed,!joins,!finds,!both,!where,!love,!must,!under,!himself,!world!!:CLe4!{n=0}!Top!Terms:!michael,!young,!attempts,!aging,!final,!crime,!don,!corleone,!trilogy,!love,!himself,!must,!back!! En la segunda iteración se asignan documentos a los clústeres (n != 0). A su vez, se
muestra como van cambiando las palabras frecuentes de cada uno. Cabe mencionar que en
este paso se asignaron más documentos (24) que el total (21). Esto implica que varios
documentos se asignaron a más de un clúster, lo que requerirá ejecutar más iteraciones para
evitar el solapamiento.
:CLe13!{n=11}!Top!Terms:!harry,!hogwarts,!has,!school,!what,!potter,!famous,!one,!people,!witchcraft,!wizardry,!year,!have,!dark,!who,!still,!returns,!only,!world,!go!!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
104!!
!:CLe20!{n=5}!Top!Terms:!o'connor,!crew,!lapd,!racing,!toretto,!toretto's,!where,!under,!high,!speed,!finds,!joins,!both,!find,!when,!himself,!really,!rival,!sister,!new!!!:CLe4!{n=8}!Top!Terms:!michael,!corleone,!young,!trilogy,!attempts,!crime,!don,!must,!family,!aging,!himself,!final,!doc,!business,!love,!vito,!york,!marty,!another,!return!!!!!!!!!!!!!!!!
Finalmente se ejecuta una tercera iteración. A continuación se muestran los resultados
finales:
:CLe13!{n=10}!Top!Terms:!harry,!hogwarts,!has,!school,!have,!dark,!one,!potter,!who,!what,!world,!year,!famous,!after,!lord,!people,!witchcraft,!wizardry,!can't,!ring!!:CLe20!{n=4}!Top!Terms:!find,!when,!where,!under,!o'connor,!back,!high,!speed,!rachel,!1944,!allied,!her,!crew,!lapd,!racing,!toretto,!toretto's,!finds,!marty,!joins!!:CLe4!{n=7}!Top!Terms:!corleone,!michael,!young,!family,!trilogy,!attempts,!crime,!must,!doc,!business,!don,!vito,!york,!marty,!another,!aging,!return,!tannen,!traveling,!begins!!! La siguiente salida muestra los documentos que pertenecen a los diferentes clústeres.
Como convención se nombró a los documentos con los ids de los ítems en el catálogo.
!CLe13:![101,!106,!110,!112,!113,!114,!115,!116,!117,!118]!CLe20:![107,!119,!120,!121]!CLe4:![102,!103,!104,!105,!108,!109,!111]!!! El sistema también muestra los resultados de calcular la distancia inter-clúster
máxima, mínima y promedio escalado, por cada iteración.
Iteración!1:!max:!1.4142135623730951!min:!1.3522410114571473!avg(scaled):!0.40624380749579575!!Iteración!2:!max:!0.7360883733251435!min:!0.571882999027159!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
105!!
avg(scaled):!0.644902073186402!!Iteración!3:!max:!0.690796823445148!min:!0.540664593599377!avg(scaled):!0.6559557019126623!!
Como se mencionó en la sección 2.2.2.2, la distancia inter-clúster es una buena
medida de calidad. Buenos clústeres probablemente no tienen centroides cercanos unos de
otros, aunque éste no siempre es el caso. Hay situaciones en que se prefiere que los clústeres
estén cerca, por ejemplo, si se agrupan artículos en donde un clúster contiene las palabras
elección, diputados, primarias, y otro contiene izquierda, oficialismo, candidato.
Comparar distancias inter-clúster entre dos medidas de distancia diferente no tiene
sentido a no ser que estén en la misma escala. El promedio escalado de las distancias inter-
clúster para todos los pares de centroides constituye una mejor medida.
A continuación se muestran los resultados obtenidos de la corrida anterior pero
utilizando la distancia de Coseno. Vale la pena destacar que ejecutar KMeans con esta
distancia requirió sólo 2 iteraciones.
!Iteración!1:!max:!0.9599489032090268!min:!0.8835982740589543!avg(scaled):!0.5281033138167629!!Iteración!2:!max:!0.7836870527258408!min:!0.7029536704341526!avg(scaled):!0.4394374713758605!
El promedio escalado de la distancia inter-clúster utilizando distancia Euclidiana (~
0.66) muestra una mejoría con respecto al calculado con distancia de Coseno (~0.44).
Generalmente un mayor valor indica la creación de clústeres separados más uniformemente.
Una corrida con KMeans Difuso utilizando distancia Euclidiana y factor de difusión
3.0, arroja los siguientes números:
!Iteración!1:!max:!1.3954466385238298!min:!1.28806761101687!avg(scaled):!0.5297393871950239!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
106!!
!Iteración!2:!max:!0.20503178449021023!min:!0.18572408933354426!avg:!0.5473015900259602!!Iteración!3:!max:!0.01444064677370296!min:!0.00985131949854292!avg:!0.732370199403187!!
De la salida anterior se puede apreciar que la distancia inter-clúster mínima es muy
pequeña (~0.0099), lo que indica que al menos 2 clústeres son virtualmente iguales o se
solapan casi completamente.
Por completitud se muestran los términos más frecuentes junto con los documentos
que pertenecen a los clústeres formados con KMeans distancia Cosenoidal y KMeans Difuso
distancia Euclidiana.
KMeans Distancia Cosenoidal !CLe14!{n=13}!Top!Terms:!harry,!have,!has,!up,!hogwarts,!school,!dark,!lord,!potter,!new,!what,!family,!magic,!after,!who,!ring,!corleone,!one,!called,!does!!!!!!!!!!!!!!!!!!!!!!!!CLe19!{n=4}!Top!Terms:!she,!when,!her,!rachel,!old,!under,!who,!trying,!along,!1944,!allied,!biesbosch,!boat,!group,!kuipers,!memories,!netherlands,!resistance,!kowalski,!brother!!CLe6!{n=4}!Top!Terms:!marty,!doc,!time,!must,!trilogy,!delorean,!mcfly,!where,!him,!self,!machine,!together,!speed,!high,!back,!1955,!sports,!younger,!1985,!year,!finds!!!CLe14:![101,!103,!104,!110,!111,!112,!113,!114,!115,!116,!117]!CLe19:![102,!106,!118,!119,!120]!CLe6:![105,!107,!108,!109,!121]!!!
KMeans Difuso Distancia Euclidiana !CLe13!{n=7}!Top!Terms:!harry,!young,!family,!who,!new,!has,!corleone,!year,!back,!hogwarts,!however,!have,!michael,!out,!time,!must,!school,!doc,!world,!when!!!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
107!!
CLe10!{n=6}!Top!Terms:!michael,!harry,!young,!family,!who,!new,!has,!corleone,!have,!year,!back,!however,!hogwarts,!time,!out,!must,!doc,!world,!up,!when!!CLe15!{n=7}!Top!Terms:!harry,!young,!family,!who,!new,!has,!corleone,!year,!doc,!back,!hogwarts,!have,!michael,!out,!time,!world,!must,!when,!school,!however!!!CLe13:![101,!104,!108,!113,!114,!117,!118]!CLe10:![102,!106,!110,!111,!112,!120]!CLe15:![103,!105,!107,!109,!115,!116,!119,!121]!!!
La ejecución de pruebas de este tipo posibilita una mejora en los agrupamientos.
Mediante el análisis de las salidas anteriores, distancias inter-clúster, documentos
pertenecientes a cada clúster, grado de pertenencia de los documentos a los clústeres (no
mostrado anteriormente por razones de legibilidad), etc., se pueden atacar diferentes aspectos
para mejorar la formación de los mismos.
Una de las maneras que permite el sistema es mediante la configuración del
analizador de documentos, el cual posibilita la remoción de “ruido” antes de la generación de
los términos.
Por ejemplo, si se cuenta con un catálogo que contiene atributos con elementos
HTML, como el siguiente:
“description”*:*{*<h1>This*is*the*title.</h1><p>This*is*the*description*of*the*app</p>*}
Se podría configurar un analizador que remueva esos tags, dando como resultando lo
siguiente:
“description”*:*{*This*is*the*title.*This*is*the*description*of*the*app*}
Otra opción sería crear un analizador específico que dé más relevancia a los valores
de los títulos (h1, h2, h3) que a lo de los párrafos (p).
Otra de las maneras de alterar el sistema hasta encontrar un punto aceptable de
funcionamiento es “jugando” con las métricas de distancia. Al igual que con los analizadores,
el prototipo permite configurar las distintas métricas de distancia e incluso crear propias, para
así poder adaptarse aún más a los diversos corpus.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
108!!
6.3 Comparativas!con!Tecnologías!Actuales!!
La sección 4 hace referencia a un análisis comparativo que realizó Verwoerd con
respecto a SaaS para Aprendizaje de Máquinas [Verwoerd, 2012]. Esta sección lo utiliza
como punto de partida para ofrecer algunas comparativas entre los sistemas que existen en la
actualidad y el sistema implementado. No se pretende realizar un tratamiento exhaustivo, sino
más bien elucubrar sólo sobre ciertos aspectos para así poder proceder al desarrollo de las
conclusiones.
NOTA: Como el módulo principal del prototipo es el recommender, se realizarán comparaciones con
sistemas que ofrecen funcionalidades similares al mismo.
Las comparaciones se realizaron en base al método de valoración multicriterio
llamado Proceso de Análisis Jerárquico, o AHP por sus siglas en inglés. Dicho proceso es una
técnica estructurada para organizar y analizar decisiones complejas que consiste de los
siguientes pasos [Saaty, 2008]:
1. Modelar el problema como una jerarquía, la cual contiene una decisión final, las
alternativas para alcanzar dicha decisión, y los criterios para evaluar las diferentes
alternativas. En este caso, decidiremos cuál es el sistema más adecuado entre cuatro
alternativas, BigML, Google Prediction API, Weka y CI, éste último es el nombre que
se le dio al prototipo desarrollado durante este trabajo.
2. Establecer las prioridades de los distintos elementos de la jerarquía haciendo una serie
de juicios basados en comparaciones entre todos los pares de alternativas. La Tabla!21
muestra la escala que utilizaremos en nuestras comparaciones.
3. Combinar los juicios del punto anterior para así obtener un conjunto global de
prioridades para la jerarquía.
4. Chequear la consistencia de los juicios.
5. Tomar la decisión final.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
109!!
!
Tabla(21:(Escala(de(comparaciones(para(AHP
La Figura! 36 ilustra la estructura jerárquica recién mencionada. Las alternativas
BigML, Google Prediction API y Weka fueron escogidas ya que son los sistemas más
utilizados al momento de la realización del presente.
!
Figura(36:(Jerarquía(AH(
Como se puede apreciar, los criterios a considerar son los siguientes:
• Arquitectura: se refiere a si el sistema soporta una arquitectura distribuida (cloud-
based), cliente o híbrida.
• Anatomía: se refiere a si el software es de caja blanca (white-box) o de caja negra
(black-box).
• Facilidad de Uso: abarca distintas características, como ser tiempo de setup, forma de
carga de datos (interfaz gráfica, API o ambas), esquema de datos, documentación,
accesibilidad a usuarios no expertos.
• Software: se refiere a si el sistema es propietario u open-source.
• Costo: se refiere a si el sistema es pago o no.
• Misceláneos: criterio que abarca atributos como seguridad, escalabilidad,
disponibilidad y evaluación.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
110!!
• Servicios: se refiere a los servicios q ofrece el sistema, por ej. servicio de catálogo,
social, recomendaciones, búsquedas, analytics, reportes.
Cabe destacar que se podría haber definido una estructura con más jerarquías. Por
ejemplo, el criterio Facilidad de Uso se podría haber dividido en los subcriterios: tiempo de
setup, forma de carga de datos, esquema de datos, documentación y accesibilidad a usuarios
no expertos, cada uno de ellos con diferentes prioridades. Lo mismo aplicaría a otros
criterios, como Misceláneos o Servicios. Sin embargo, se decidió utilizar la jerarquía plana
que se muestra en la Figura!36 para simplificar los cálculos, es decir, todos los subcriterios de
un criterio en particular contribuyen uniformemente a la prioridad del mismo.
Una vez generado el diagrama de jerarquías, se procede a comparar las distintas
alternativas para cada criterio, de a pares, es decir, se generan |C| matrices cuadradas
∈ ℝ ! !|!|, donde |C| es el número de criterios (en este caso 7) y |A| es el número de
alternativas (en este caso 4). La matriz se denota con la letra M. Para referenciar a un
determinado elemento de la misma, se utiliza la notación Mij, i referencia a la fila, mientras
que j a la columna. Los elementos en la diagonal son iguales a 1, es decir, ∀!! ∶ !!!! = 1.
Asimismo, los elementos transpuestos son recíprocos, es decir, ∀!!:!!!" = ! !!!". Por cada
matriz M, también se calcula el vector de prioridades P, el cual es el vector propio derecho de
M.
NOTA: Sólo se explica cómo interpretar la primera matriz generada. Las restantes siguen la misma
lógica, aunque se omiten por brevedad.
La Tabla 22 muestra la matriz para el criterio Arquitectura y el vector de prioridades. En
este punto CI saca una ventaja con respecto al resto (tiene una mayor prioridad), ya que
debido a su diseño (ver sección 5.1.4) se puede utilizar tanto en un entorno distribuido como
en una aplicación cliente.
!!!!!
Tabla(22:(Matriz(de(Arquitectura

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
111!!
La matriz se puede interpretar de la siguiente manera. BigML vs. Google Prediction
API se consideran iguales (M12 = 1) debido a que ambos sistemas corren en un entorno
distribuido. No es así en el caso de BigML vs. Weka, aquí BigML es superior ya que Weka no
se puede ejecutar de manera distribuida, aspecto fundamental para escalar, por lo que M13 =
7. Lo mismo ocurre con Google Prediction API vs. Weka, y CI vs. Weka. Cuando se compara
CI con las otras alternativas distribuidas (Google Prediction API y BigML), CI saca ventaja
ya que también corre como una aplicación cliente (M41 = 5 y M42 = 5).
El siguiente criterio a considerar es la Anatomía del sistema. La Tabla 23 muestra que
CI fue pensado como un sistema de caja blanca, en donde se da gran poder al usuario
(empresa cliente, desarrollador, etc.), permitiéndole que configure los algoritmos a utilizar,
las métricas de distancia, los analizadores, etc. Weka hace lo propio. Sin embargo, CI también
podría ofrecerse como un sistema black-box, siendo administrado por un tercero que cobre
por sus servicios de proveedor de SaaS (ver sección 5.1.3). BigML y Google Prediction API
sólo soportan el modo black-box.
En este caso, se valoran igual los sistemas black-box y los white-box, pero sí se
favorece al sistema que soporta ambas anatomías (CI).
Tabla(23:(Matriz(de(Anatomía
Otro aspecto a comparar es la Facilidad de Uso de los sistemas. En la Tabla 24 se
puede apreciar que CI carece de ciertas características que lo pondrían más a tono, en este
rubro, con los otros. La versión actual de CI no ofrece una interfaz gráfica para la carga de
datos, sólo ofrece una interfaz REST. Si bien no requiere de un esquema estructurado de
datos, ya que utiliza una clase Item (ver Figura 44) que es básicamente un mapa clave-valor,
la documentación es casi nula.
Requiere de la instalación de diversos productos de software (hadoop, mongodb,
tomcat, mahout, etc.) lo que hace que el tiempo de setup inicial no sea despreciable.
Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
112!!
Tradicionalmente entrar en el mundo de los motores de recomendación, de búsqueda,
ha sido muy complejo debido a una curva de aprendizaje pronunciada. Si bien se mencionó
que CI podría ofrecerse como software de caja negra, es, por defecto, un software de caja
blanca. El hecho de serlo, hace que se necesite de ciertos conocimientos de Machine Learning
para configurarlo correctamente, lo que impide que “cualquier usuario” pueda hacerlo. Si el
mismo fuese ofrecido como SaaS, podría ser accesible por usuarios inexpertos, característica
valiosa de BigML y Google Prediction API.
CI es comparable con Weka, y Google Prediction API con BigML, sin embargo este
último resulta ganador, como se puede apreciar en la Tabla!25.
!
Tabla(24:(Comparativa(de(Facilidad(de(Uso(!
!
Tabla(25:(Matriz(de(Facilidad(de(Uso(
La Tabla 26 ilustra otra atributos importante del sistema, el hecho de ser un software
de código abierto u open-source. Esto abre una infinidad de oportunidades de mejora,
corrección y detección de errores, etc., gracias a la ayuda de miles de desarrolladores
existentes en la comunidad. Esta decisión es un claro ejemplo de favorecer el uso de
inteligencia colectiva.
!
!Tabla(26:(Matriz(de(Software(
Características BigML Google1Prediction1API Weka ciTiempo'de'Setup'Corto x
Interfaz'Gráfica'para'Cargar'Datos x xAPI'para'Cargar'Datos x x x x
Schemaless x x xDocumentación ~ x x
Accesible'para'No'Expertos x x ~
Facilidad1de1Uso

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
113!!
!
Un software propietario no necesariamente es pago. BigML y Google Prediction API,
ofrecen alternativas gratis con ciertas limitaciones de uso. Weka y CI, al ser de código
abierto, se distribuyen gratuitamente (Tabla 27).
!Tabla(27:(Matriz(de(Costo(
!
La seguridad es una materia pendiente en la versión actual de CI, no así para BigML y
Google Prediction API. Durante el diseño de CI se pensó en un sistema escalable y
disponible, para ello se utilizaron frameworks y tecnologías que posibilitan procesar una
enorme cantidad de datos. Como se demostró en las secciones 6.1 y 6.2, CI también ofrece
varias métricas para evaluar y adaptar el funcionamiento del sistema, como se puede ver en la
Tabla 28. En base a los atributos identificados en dicha Tabla, se calcula la matriz de
Misceláneos en la Tabla!29.
!
!Tabla(28:(Comparativa(de(Misceláneos(
!
!Tabla(29:(Matriz(de(Misceláneos(
!
Atributos BigML Google0Prediction0API Weka ciSeguridad x x
Escalabilidad x x xDisponibilidad x x xEvaluación x x x
Misceláneos
Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
114!!
Para finalizar con las comparaciones, resulta conveniente remarcar que CI es un
sistema integral, no sólo ofrece recomendaciones, sino también servicios de catálogo,
servicios sociales, de búsqueda y recolección de estadísticas de uso (analytics). La generación
de reportes en base a éstas últimas es una cuestión pendiente. La Tabla 30! refleja dichos
atributos, y en base a esta Tabla, se calcula la matriz de Servicios en la Tabla!31.
Como se mencionó anteriormente en la sección 4, al momento del presente, no existe
en el mercado un software libre que ofrezca todos estos servicios integrados.
! !!
Tabla(30:(Comparativa(de(Servicios(
!
!
Tabla(31:(Matriz(de(Servicios(
Una vez evaluadas las alternativas con respecto a los diferentes criterios, es turno de
evaluar el peso de los diferentes criterios para tomar la decisión. La Tabla!32 muestra dicha
evaluación. El Costo tiene el mayor peso, seguido de Misc, Servicios y Software.
!
Tabla(32:(Matriz(de(Criterios

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
115!!
Finalmente, calculamos las prioridades de las alternativas con respecto a la decisión. La
prioridad de cada alternativa se define como:
Donde:!
!!:!prioridad!de!la!alternativa!a!!!:!prioridad!del!criterio!c(con!respecto!a!la!decisión!!!,!:!prioridad!de!la!alternativa!a(con!respecto!al!criterio!c!
!
La Tabla! 33 muestra los resultados finales del proceso de análisis jerárquico. Allí se
puede apreciar el aporte de cada alternativa con respecto a los diferentes criterios y a la
decisión final. Los criterios con mayor peso son Costo, Misceláneos y Servicios. CI resulta
ser el mejor sistema, seguido por BigML y Weka.
!!
Tabla(33:(Resultados(finales(AHP
! !
pa =X
c
pc ⇥ pa,c
Fórmula(16:(Prioridad(de(una(alternativa

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
116!!
7 Conclusiones!!
De la colaboración e interacción de muchos individuos surge una nueva forma de
inteligencia, denominada inteligencia colectiva. Dicha inteligencia ha transformado la forma
en que se utiliza internet. La vasta cantidad de contenido digital disponible atrae a mayor
número de usuarios, que a su vez interactúan y aportan sus propios conocimientos,
convirtiendo a la web en una herramienta cada vez más útil e imprescindible. Es así que surge
el interrogante, ¿cómo lograr el filtrado y la entrega de información relevante a los usuarios?
La respuesta a dicha inquietud ha sido el eje principal de este trabajo, el desarrollo de
un sistema! distribuido de inteligencia colectiva que permita mejorar la experiencia de los
usuarios y sirva como disparador de nuevas oportunidades de negocio. En su definición se
reunieron conceptos de sistemas de recomendación, motores de búsqueda, redes sociales y
estadísticas de uso.!
! Los sistemas de recomendación constituyen el núcleo central de los sistemas de
inteligencia colectiva. En este trabajo, se planteó la implementación de un sistema de
recomendación híbrido, basado en filtros colaborativos y en contenido. Dicha decisión se
fundamentó en el problema de comienzo en frío que poseen los sistemas de filtrado
colaborativo.
Como parte del presente, se realizó una amplia descripción de diferentes algoritmos
de recomendación disponibles. Dicho análisis permitió afirmar que la elección del algoritmo
a utilizar no es una tarea trivial, al contrario, es un proceso complejo que requiere de varias
iteraciones de pruebas, con diferentes combinaciones de algoritmos, en donde el conjunto de
datos juega un papel fundamental. !
Si bien se detallaron las métricas de evaluación más comunes de los sistemas de
recomendación y se hicieron pruebas con conjuntos de datos de ejemplo, es imposible
proveer un resultado único para el prototipo implementado. La razón primordial fue
mencionada supra, todo depende del algoritmo y del conjunto de datos utilizado.
La puesta en producción del sistema permitirá la generación de masa crítica de uso, lo
que posibilitará una medición real de la performance del recomendador, a través de la
evaluación de la tendencia de los usuarios de seleccionar los ítems recomendados.

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
117!!
En la actualidad, los motores de búsqueda, indudablemente realizan una excelente
tarea en encontrar información que requieren los usuarios. Por su parte, las redes sociales
constituyen fuentes de información de gran valor.
En el prototipo implementado como parte de este trabajo, se integraron estos tres
grandes componentes, recomendaciones, búsquedas y redes sociales, para proveer un sistema
de inteligencia colectiva, orientado a servicios, que permita no sólo favorecer la experiencia
de los usuarios, sino también, generar nuevas oportunidades de ventas.
Se realizaron comparaciones entre el prototipo y otros sistemas utilizados
comúnmente en la actualidad (BigML, Google Prediction API y Weka) mediante un proceso
de análisis jerárquico, el cual incluyó criterios tales como arquitectura, costo, tipo de
software, facilidad de uso, etc. En base a dichos criterios y a la influencia relativa de los
mismos en la decisión final, resultó ganador el prototipo implementado como parte de este
trabajo. La razón principal de este resultado es que el sistema aquí propuesto tiene buen
rendimiento en los criterios que más influyen en la decisión final (Costo, Misceláneos y
Servicios). El desenlace cambiaría si por ejemplo se hiciese más hincapié en la Facilidad de
Uso, en cuyo caso BigML y Google Prediction API sacarían ventaja.
Resulta irrisorio llamar “competencia” a sistemas desarrollados por Google o BigML,
pero el hecho de realizar un software open-source que empaquete funcionalidad que
implementan, por separado, algunos de los servicios de estas compañías, es una forma de
permitir la inserción de Pymes a un mercado antes impensado, de manera gratuita y sin atarse
a ningún proveedor.
Finalmente, se demostró que las “Aplicaciones Inteligentes” son un claro
diferenciador en la actualidad y lo serán aún más en el futuro. La creciente integración de
aplicaciones actuales con este tipo de tecnologías permitirá ofrecer información cada vez más
relevante a los usuarios y aumentará la demanda de productos de baja popularidad (cola
larga).
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
118!!
8 Trabajos!Futuros!!
Indudablemente, futuros trabajos y mejoras aparecen a partir del presente.
En la implementación actual, cualquier cliente puede llamar a un servicio, éstos no
requieren autenticación ni ningún nivel de autorización. Una mejora sustancial consistiría en
introducir en el componente de id-ws un servicio de manejo de identidades a través de
OAuth2. Habría que crear una interfaz gráfica para que los desarrolladores puedan registrar
sus aplicaciones clientes y obtener las credenciales de acceso. También habría que crear una
UI fácilmente personalizable para cada aplicación cliente, que permita hacer la autenticación
de los usuarios y que requiera la autorización explícita de los mismos para que la aplicación
cliente acceda a sus recursos (similar al ejemplo de Facebook demostrado en la sección 5.4).
La inclusión de un módulo de detección de intrusos sería algo mandatorio si se
pretende poner en producción esta prueba de concepto. Un hacker podría tratar de violar o
engañar al sistema para que realice recomendaciones según más le convenga. Se podría
agregar un servicio de monitoreo basado en comportamiento, es decir, que detectaría
intrusiones observando desviaciones respecto del comportamiento normal o esperado de los
usuarios en el sistema.
Dicho servicio de ID debería imponer mínima sobrecarga sobre el sistema si pretende
ser utilizado. Más aun, debería funcionar continuamente sin supervisión humana, ser tolerante
a fallos y tendría que poder monitorearse a sí mismo para asegurar que no haya sido
perturbado. Es fundamental que sea difícil de engañar.
Debidamente atendidos los aspectos de seguridad, otro punto muy importante a tener
en cuenta son las recomendaciones de distintos tipos de productos, o “cross-domain
recommendations” como se conocen comúnmente en inglés. Por ejemplo, si a un usuario le
gustó el libro de Harry Potter, el motor de recomendaciones debería ser capaz de ofrecerle
las películas del libro homónimo. En la implementación actual, esto no es posible, las
interfaces del componente recommender-ws aceptan sólo un tipo de ítem.
Otro tema no menor es el referido al despliegue de los componentes. El prototipo
implementado es complejo, consta de varios archivos war, utiliza solr como servidor de
búsquedas, hadoop para procesar recomendaciones basadas en contenido, mongo para

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
119!!
persistir datos, etc. Comenzar a experimentar con el sistema requiere de la instalación de
varias piezas de software. Una gran mejora sería la inclusión de algún framework de
deployment que, con sólo un par de clicks, haga un despliegue automático a Amazon.
Resueltos los puntos anteriores, el paso a seguir sería integrar el sistema con algún
mecanismo de generación de reportes. Si bien actualmente el prototipo recolecta estadísticas
de uso, éstas deberían poder exportarse a un formato legible para que, por ejemplo, una
persona de marketing pueda actuar en consecuencia.
Otra cuestión pendiente sería extender el servicio de búsquedas para ofrecer no sólo
búsquedas por texto sino también de distintos tipos. Poder hacer búsquedas por categorías,
por facets, por gustos extraídos de redes sociales, etc., es como se dice en el mundo de la
Ingeniería de Software, “a nice to have”.
Una vez que se pruebe la escalabilidad y estabilidad del sistema, agregar más
proveedores sociales (Last.fm, Flickr, Live, LinkedIn) es un paso necesario para obtener
mayor información de los usuarios, y así poder ofrecerles experiencias aún más ricas.
Ampliar este prototipo, ofreciendo, además, servicios de localización, de contexto,
etc., sería una manera de “cuidar” aún más a los usuarios y hacer que los que ya utilizaron el
sistema, vuelvan a visitarlo.
Por último, pero no menos importante, es necesario agregar pruebas unitarias y
documentación en el código. Al ser una prueba de concepto, no se hizo hincapié en ello, pero
es algo fundamental en proyectos open-source.
! !

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
120!!
9 Bibliografía!!
[ACM,!2012]!Association!for!Computing!Machinery.!(s.f.).!ACM*Conference*on*Recommender*Systems.!Recuperado!el!12!de!Abril!de!2012,!de!http://recsys.acm.org/2011/index.shtml!
[Adomavicius,!Tuzhilin,!2005]!Adomavicius,!G.,!&!Tuzhilin,!A.!(2005).!Toward!the!Next!Generation!of!
Recommender!Systems:!A!Survey!of!the!StateeofetheeArt!and!Possible!Extensions.!IEEE!
TRANSACTIONS!ON!KNOWLEDGE!AND!DATA!ENGINEERING.!
[Ahn,!2008]!Ahn,!H.!J.!(2008).!A!new!similarity!measure!for!collaborative!filtering!to!alleviate!the!new!
user!coldestarting!problem.!Information*Sciences!.!
[Alag,!2009]!Alag,!S.!(2009).!Collective*Intelligence*In*Action.!Manning!Publications.!
[Anderson,!2004]!Anderson,!C.!(2004).!The!Long!Tail.!Wired*Magazine!,*12.!
[Anderson,!2006]!Anderson,!C.!(2006).!The!Long!Tail:!Why!the!Future!of!Business!Is!Selling!Less!of!
More.!Wired*Magazine!.!
[Barr,!Saba,!2013]!Barr,!A.,!&!Saba,!J.!(24!de!Abril!de!2013).!Analysis:*Sleeping*ad*giant*Amazon*finally*stirs.!Recuperado!el!19!de!Mayo!de!2013,!de!Reuters:!
http://www.reuters.com/article/2013/04/24/useamazoneadvertisingeidUSBRE93N06E20130424!
[Bonabeau,!Dorigo,!Stutzle,!1999]!Bonabeau,!B.,!Dorigo,!M.,!&!Stutzle,!T.!(1999).!Swarm!Intelligence:!
From!Natural!to!Artificial!Systems.!
[Boyd,!Ellison,!2007]!Boyd,!D.!M.,!&!Ellison,!N.!B.!(2007).!Social!Network!Sites:!Definition,!history,!and!
scholarship.!ComputerWMediated*Communication!.!
[Chaffey,!2010]!Chaffey,!D.!(16!de!Febrero!de!2010).!Google*Case*Study.!Recuperado!el!08!de!Agosto!de!2013,!de!Smart!Insights:!http://www.smartinsights.com/digitalemarketingestrategy/onlinee
businesserevenueemodels/googleecaseestudy/!
[Chaffey,!2012]!Chaffey,!D.!(16!de!Enero!de!2012).!Amazon.com*Case*Study.!Recuperado!el!09!de!Agosto!de!2013,!de!Smart!Insights:!http://www.smartinsights.com/digitalemarketinge
strategy/onlineebusinesserevenueemodels/amazonecaseestudy/!
[Chaffey,!2013]!Chaffey,!D.!(13!de!Mayo!de!2013).!Facebook*Case*Study.!Recuperado!el!08!de!Agosto!de!2013,!de!Smart!Insights:!http://www.smartinsights.com/socialemediaemarketing/facebooke
marketing/facebookecaseestudy/!
[Ciordas,!Doumen,!2010]!Ciordas,!C.,!&!Doumen,!J.!(2010).!An!Evaluation!Framework!for!Content!
Recommender!Systems!e!The!Industry.!International!Conference!on!Web!Intelligence!and!Intelligent!
Agent!Technology!e!IEEE/WIC/ACM.!
[DeMendarozqueta,!2007]!de!Mendarozqueta,!A.!R.!(2007).!Aseguramiento!de!la!Calidad!de!
Software.!Apuntes*de*la*Cátedra*Ingeniería*de*Software!.!UTN!e!Facultad!Regional!Córdoba.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
121!!
[Dennen,!Myers,!2012]!Dennen,!V.,!&!Myers,!J.!(2012).!Virtual*Professional*Development*and*Informal*Learning*via*Social*Networks.!IGI!Global.!
[Dunning,!2008]!tdunning.blogspot.!(21!de!Marzo!de!2008).!Surprise*and*Coincidence.!Recuperado!el!25!de!Mayo!de!2013,!de!Surprise!and!Coincidence!e!Musings!from!the!Long!Tail:!
http://tdunning.blogspot.com.ar/2008/03/surpriseeandecoincidence.html!
[ECON,!2010]*Clicking*for*Gold.!(25!de!Febrero!de!2010).!Recuperado!el!09!de!Agosto!de!2013,!de!The!Economist:!www.economist.com/node/15557431!
[Finch!et!al.,!2014]!Finch,!G.,!Davidson,!S.,!Kirschniak,!C.,!Weikersheimer,!M.,!Reese,!C.,!&!Shockley,!
R.!(2014).!Analytics:*The*speed*advantage.!IBM!Global!Business!Services.!
[Frawley,!PiatetskyeShapiro,!Matheus,!1991]!Frawley,!W.!J.,!PiatetskyeShapiro,!G.,!&!Matheus,!C.!J.!
(1991).!Knowledge!discovery!in!databases:!An!overview.!En!Knowledge*Discovery*in*Databases.!MIT!
Press.!
[Ghazanfar,!PrugeleBennett,!2010]!Ghazanfar,!M.!A.,!&!PrugeleBennett,!A.!(2010).!A!Scalable,!
Accurate!Hybrid!Recommender!System.!2010!Third!International!Conference!on!Knowledge!
Discovery!and!Data!Mining!e!IEEE.!
[Guandong,!Lin,!2013]!Guandong,!X.,!&!Lin,!L.!(2013).!Social*Media*Mining*and*Social*Network*Analysis:*Emerging*Research.*IGI!Global!Editorial.
[Harrington,!2012]!Harrington,!P.!(2012).!Machine*Learning*in*Action.!Manning!Publications.!
[Herlocker,!Konstan,!Terveen,!2004]!Herlocker,!J.!L.,!Konstan,!J.!A.,!&!Terveen,!L.!G.!(2004).!
Evaluating!collaborative!filtering!recommender.!ACM!Transactions!on!Information!Systems.!
[Hoffman,!2009]!Hoffman,!H.!(21!de!Septiembre!de!2009).!Netflix*awards*$1*million*for*outdoing*Cinematch.!Recuperado!el!21!de!Mayo!de!2013,!de!cnet:!http://news.cnet.com/8301e13515_3e
10357807e26.html!
[INFORMS,!2015]!Informs!Online.!The*Analytics*Value*Proposition.*Recuperado!el!11!de!Marzo!de!
2015,!de!Informs!Online:!https://www.informs.org/Sites/GettingeStartedeWitheAnalytics/Whate
AnalyticseCaneDoeForeYou/TheeAnalyticseValueeProposition.!
[Jannach!et!al.,!2010]!Jannach,!D.,!Zanker,!M.,!Felfernig,!A.,!&!Friedrich,!G.!(2010).!Recommender*Systems:*An*Introduction.!Cambridge!University!Press.!
[Jones,!2010]!Jones,!N.!(2010).!User*Perceived*Qualities*and*Acceptance*of*Recommender*Systems:*The*Role*of*Diversity.!PhD!Thesis!Manuscript.!
[LASTFM,!2013]!Last.fm.!(15!de!Enero!de!2013).!last.fm.!Recuperado!el!21!de!Mayo!de!2013,!de!
www.lastfm.es!
[Ledford,!2007]!Ledford,!J.!L.!(2007).!SEO:*Search*Engine*Optimization*Bible.!John!Wiley!&!Sons.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
122!!
[Li,!2008]!Li,!C.!(6!de!Marzo!de!2008).!The*future*of*social*networks:*Social*networks*will*be*like*air.!Recuperado!el!13!de!Mayo!de!2013,!de!Empowered:!
http://forrester.typepad.com/groundswell/2008/03/theefutureeofes.html!
[Mahmood,!Ricci,!2009]!Mahmood,!T.,!&!Ricci,!F.!(2009).!Improving!recommender!systems!with!
adaptive!conversational!strategies.!Proceedings*of*the*20th*ACM*conference*on*Hypertext*and*hypermedia!(págs.!73e82).!ACM.!
[Malone,!2006]!Malone,!T.!W.!(13!de!Octubre!de!2006).!What*is*Collective*Intelligence*and*what*we*will*do*about*it?!Recuperado!el!20!de!Marzo!de!2012,!de!MIT!Centre!for!Collective!Intelligence:!
http://cci.mit.edu/about/MaloneLaunchRemarks.html!
[Marmanis,!Babenko,!2009]!Marmanis,!H.,!&!Babenko,!D.!(2009).!Algorithms*of*the*Intelligent*Web.!Manning!Publications.!
[Melville,!Mooney,!Nagarajan,!2002]!Melville,!P.,!Mooney,!R.!J.,!&!Nagarajan,!R.!(2002).!Contente
Boosted!Collaborative!Filtering!for!Improved!Recommendations.!Proceedings*of*the*Eighteenth*National*Conference*on*Artificial*Intelligence.!!
[Merali,!Bennett,!2011]!Merali,!Y.,!&!Bennett,!Z.!(2011).!Web!2.0!and!Network!Intelligence.!En!
Context*and*Semantics*for*Knowledge*Management.!SpringereVerlag.!
[Nagalakshmi,!Joglekar,!2011]!Nagalakshmi,!A.,!&!Joglekar,!S.!(2011).!Collective*Intelligence*Applications*W*Algorithms*and*Visualization.!2011!Second!International!Conference!on!Emerging!
Applications!of!Information!Technology!e!IEEE.!
[NETFLIX,!2012]!Netflix.!(2012).!Netflix*Administration.!Recuperado!el!20!de!Mayo!de!2013,!de!
Netflix:!https://signup.netflix.com/Management!
[Owen!et!al.,!2012]!Owen,!S.,!Anil,!R.,!Dunning,!T.,!&!Friedman,!E.!(2012).!Mahout*In*Action.!Manning!
Publications.!
[Patel,!Balakrishnan,!2009]!Patel,!A.,!&!Balakrishnan,!A.!(2009).!Generic!framework!for!
recommendation!system!using!collective!intelligence.!IEEE.!
[Pazzani,!Billsus,!2007]!Pazzani,!M.,!&!Billsus,!D.!(2007).!ContenteBased!Recommendation!Systems.!
En!The*Adaptive*Web.!Springer.!
[Rand,!1971]!Rand,!W.!M.!(1971).!Objective!criteria!for!the!evaluation!of!clustering!methods.!Journal*of*the*American*Statistical*Association.!!
[Resnick,!Varian,!1997]!Resnick,!P.,!&!Varian,!H.!R.!(1997).!Recommender!Systems.!Communications*of*the*ACM!(págs.!56e58).!ACM.!
[Ricci,!Rokach,!Shapira,!2011]!Ricci,!F.,!Rokach,!L.,!&!Shapira,!B.!(2011).!Introduction*to*Recommender*Systems*Handbook.!Springer.!
[Rice,!2009]!Rice!Lincoln,!S.!(2009).!Mastering*Web*2.0.!Kogan!Page.!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
123!!
[RuizeMontiel,!AldanaeMontes,!2009]!RuizeMontiel,!M.,!&!AldanaeMontes,!F.!(2009).!Semantically!
Enhanced!Recommender!Systems.!Proceedings*of*the*OTM*Conference,*Workshop*on*The*Move*To*Meaningful*Internet*Systems.!!
[Saaty,!2008]!Saaty,!T.!L.!(2008).!Decision*making*with*the*analytic*hierarchy*process.!En!Int.!Services!Sciences,!Vol.!1,!No.!1.!
[Schein!et!al.,!2002]!Schein,!A.,!Popescul,!A.,!Ungar,!L.!H.,!&!Pennock,!D.!M.!(2002).!Methods!and!
metrics!for!coldestart!recommendations.!Proceedings*of*the*25th*annual*international*ACM*SIGIR*conference*on*Research*and*Development*in*Information*Retrieval.!ACM.!
[Schwagereit,!Staab,!2009]!Schwagereit,!F.,!&!Staab,!S.!(2009).!Social!networks.!En!Encyclopedia*of*Database*Systems.!Springer.!
[Segaran,!2007]!Segaran,!T.!(2007).!Programming*Collective*Intelligence,*Building*Smart*2.0*Applications.!O'Reilly.!
[Singh,!Gupta,!2009]!Singh,!V.!K.,!&!Gupta,!A.!K.!(2009).!From!Artificial!To!Collective!Intelligence:!
Perspectives!and!Implications.!5th*International*Symposium*on*Applied*Computational*Intelligence*and*Informatics.!!
[Singh!et!al.,!2009]!Singh,!V.!K.,!Jalan,!R.,!Chaturvedi,!S.!K.,!&!Gupta,!A.!K.!(2009).!Collective!
Intelligence!Based!Computational!Approach!to!Web!Intelligence.!International*Conference*on*Web*Information*Systems*and*Mining.!!
[Sollenborn,!Funk,!2002]!Sollenborn,!M.,!&!Funk,!P.!(2002).!Categoryebased!filtering!and!user!
stereotype!cases!to!reduce!the!latency!problem!in!recommender!systems.!Proceedings*of*the*6th*European*Conference*on*Advances*in*CaseWBased*Reasoning.!Springer.!
[TELEGRAPH,!2013]*Twitter*in*numbers.!(21!de!Marzo!de!2013).!Recuperado!el!15!de!Mayo!de!2013,!
de!The!Telegraph:!http://www.telegraph.co.uk/technology/twitter/9945505/Twittereine
numbers.html!
[Verwoerd,!2012]!Verwoerd,!J.!(13!de!Septiembre!de!2012).!Comparing*SaaS*Machine*Learning*Offerings.!Recuperado!el!7!de!Agosto!de!2013,!de!Data!Science!Central:!http://www.datasciencecentral.com/profiles/blogs/comparingesaasemachineelearningeofferings!
[Wasserman,!Faust,!1994]!Wasserman,!S.,!&!Faust,!K.!(1994).!Social*network*analysis:*Methods*and*applications.!Cambridge!University!Press.!
[YAHOONEWS,!2013]*Number*of*active*users*at*Facebook*over*the*years.!(1!de!Mayo!de!2013).!
Recuperado!el!14!de!Mayo!de!2013,!de!Yahoo!NEWS:!http://news.yahoo.com/numbereactiveeuserse
facebookeovere230449748.html!
[Zaier,!Godin,!Faucher,!2008]!Zaier,!Z.,!Godin,!R.,!&!Faucher,!L.!(2008).!Evaluating!Recommender!
Systems.!International!Conference!on!Automated!solutions!for!Cross!Media!Content!and!Multie
channel!Distribution!e!IEEE.!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
124!!
10 #Apéndices#!
10.1 Apéndice#A:#Diagramas#de#Clases#!
A continuación se ilustran algunos diagramas de clases del prototipo. Por razones de legibilidad, se omitieron algunos atributos, métodos y asociaciones entre clases.
La Figura 37 muestra un diagrama de clases de los servicios de Catalog y Analytics. !
!
Figura(37:(Diagrama(de(Clases(de(los(Servicios(de(Catalog(y(Analytics(
!
!
!
CatalogRepository
+getCollectionNames(): Set<String>+createCollection(collectionName: String): void+findItemsByCollectionName(collectionName: String): List<Item>+save(item: Item, collectionName: String): void+save(items: List<Item>, collectionName: String): void+findById(itemId: String, collectionName: String): Item+findItemsByIds(ids: List<String>, collectionName: String): List<Item>
CatalogRepositoryImpl
-mongoTemplate: MongoTemplate-collectionBlackList: List<String>
CatalogService
+createItemType(typeName: String): void+getItemTypes(): Set<String>+createItem(typeName: String, body: String): void+createItems(typeName: String, body: String): void+getItems(typeName: String): List<Item>+getItems(): Map<String, List<Item>>+getItem(typeName: String, itemId: String): Item+getItems(typeName: String, itemIds: List<String>): List<Item>+Operation2()
CatalogServiceImpl
Item
-id: String-values: Map<String, Object>
CatalogController
+createItemType(typeName: String): void+createItem(typeName: String, request: HttpServletRequest): void+createItems(typeName: String, request: HttpServletRequest): void+getItemTypes(): Set<String>+getItem(typeName: String, itemId: String): Item+getItems(typeName: String): List<Item>+getItems(typeName: String, itemIds: List<String>): List<Item>+getAllItems(): Map<String, List<Item>>+handleException(ex: Exception, response: HttpServletResponse)
AnalyticsController
+review(userId: String, typeName: String, itemId: String, review: Review): void+purchase(userId: String, typeName: String, itemId: String): void+visit(userId: String, typeName: String, itemId: String): void+acceptRecommendation(userId: String, typeName: String, itemId: String): void+rejectRecommendation(userId: String, typeName: String, itemId: String): void+rejects(userId: String): List<String>
AcceptRecommendationRepositoryPurchaseRepository
MongoRepository
RejectRecommendationRepository
ReviewRepository
VisitRepository
AnalyticsService
+review(userId: String, typeName: String, itemId: String, review: Review): void+purchase(userId: String, typeName: String, itemId: String): void+visit(userId: String, typeName: String, itemId: String): void+acceptRecommendation(userId: String, typeName: String, itemId: String): void+rejectRecommendation(userId: String, typeName: String, itemId: String): void+getRejects(userId: String): List<String>
AnalyticsServiceImpl
-enableChecks: boolean
CatalogClient
+getItemById(itemId: String, itemType: String): Item+getItemsByIds(itemIds: List<String>, itemType: String): List<Item>+getItems(): Map<String, List<Item>>
CatalogClientImpl
-catalogUrl: String
RestClient
-restTemplate: RestTemplate
+exchange(url: String, requestEntity: HttpEntity<?>, method: HttpMethod, responseType: Class<T>): T+exchange(url: String, requestEntity: HttpEntity<?>, method: HttpMethod, typeRef: ParameterizedTypeReference<T>): T
UserClient
+findByEmail(email: String): User
UserClientImpl
-idUrl: String
User
-id: String-email: String-password: String-roles: List<String>
ReviewPopulator
-enabled: boolean-filename: String
+populate()
AcceptRecommendation
-userId: String-itemId: String
Review
-userId: String-itemId: String-description: String-rate: double-createdAt: Date
Visit
-userId: String-itemId: String
Purchase
-userId: String-itemId: String
RejectRecommendation
-userId: String-itemId: String

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
125!!
!
! La Figura 38 muestra un diagrama de clases de los servicios de Search, Social y Recommender. Las clases/interfaces en naranja no se detallaron debido a las razones de legibilidad mencionadas anteriormente. !
!
Figura(38:(Diagrama(de(Clases(de(los(Servicios(de(Search,(Social(y(Recommender(
!
!
!
SearchController
+search(searchQuery: String): List<Item>
Item
-id: String-values: Map<String, Object>
SearchService
+search(searchQuery: String): List<Item>+updateIndex(json: String): void
SearchServiceImpl
-solrServer: SolrServer-solrRestTemplate: RestTemplate-ignorableFields: Set<String>-solrUpdateUrl: String
SolrIndexer
-oneShot: boolean-notRun: boolean
CatalogClient
SocialController
+likes(userId: String, providerId: String): List<String>+checkins(userId: String, providerId: String): List<String>
LikeService
+getLikes(): List<String>
CheckinService
+getCheckins(): List<String>
FacebookServiceImpl
-connectionRepository: ConnectionRepository
*
1
*
1
ConnectionController
+status(request: NativeWebRequest, userId: String): Map<String, Boolean>+connect(providerId: String, request: NativeWebRequest, userId: String): String+removeConnections(providerId: String, request: HttpServletRequest, response: HttpServletReponse, userId: String): void+oauth2Callback(code: String, userId: String, providerId: String, request: NativeWebRequest): void+oauth1Callback(oauthToken: String, userId: String, providerId: String, request: NativeWebRequest): void
ConnectorService
+connect(providerId: String, request: NativeWebRequest): String+removeConnections(providerId: String, request: NativeWebRequest): void+oauth2Callback(providerId: String, request: NativeWebRequest): void+oauth1Callback(providerId: String, request: NativeWebRequest): void+connectionStatus(request: NativeWebRequest): Map<String, Boolean>
ConnectorServiceImpl
-connectController: ConnectController
SocialConnectionRepository
+findByUsernameAndProviderIdAndProviderUserId(username: String, providerId: String, providerUserId: String): SocialConnection+findByUsernameAndProviderId(username: String, providerId: String): List<SocialConnection>+findByUsername(username: String): List<SocialConnection>+findByProviderIdAndProviderUserId(providerId: String, providerUserId: String): List<SocialConnection>
MongoRepository
SocialUsersConnectionRepository
ConnectionRepository
ConnectionRepositoryImpl
-username: String-textEncryptor: TextEncryptor-connectionFactoryLocator: ConnectionFactoryLocator-connectionMapper: ConnectionMapper
UsersConnectionRepositoryImpl
-textEncryptor: TextEncryptor-connectionFactoryLocator: ConnectionFactoryLocator-mongoTemplate: MongoTemplate
UsersConnectionRepository
SocialConnection
-id: String-providerId: String-providerUserId: String-username: String-displayName: String-profileUrl: String-imageUrl: String-accessToken: String-secret: String-refreshToken: String-expireTime: long
RecommenderController
+contentBased(typeName: String, itemId: String): List<Item>+mixed(userId: String, typeName: String, itemId: String): List<Item>+collaborativeFiltering(userId: String, typeName: String): List<Item>
RecommenderService
+recommend(id: String, type: String, count: int): List<Item>
CollaborativeFilteringRecommenderService
-recommender: Recommender-recommenderItemsConverter: Converter<List<RecommendedItem>, List<String>>-idConverter: Converter<String, Long>
ContentBasedRecommenderServiceHybridRecommenderService
Filter<T>
+filter(elements: List<T>, userId: String): List<T>
RejectRecommendationFilter
-useAnalytics: boolean
AnalyticsClient
+getRejectedRecommendation(userId: String): List<String>
AnalyticsClientImpl
-analyticsUrl: String
RestClient
-restTemplate: RestTemplate
+exchange(url: String, requestEntity: HttpEntity<?>, method: HttpMethod, responseType: Class<T>): T+exchange(url: String, requestEntity: HttpEntity<?>, method: HttpMethod, typeRef: ParameterizedTypeReference<T>): T
RecommenderBuilderFactory
+createRecommenderBuilder(type: RecommenderType, similarity RecommenderSimilarity, dataModel: DataModel): RecommenderBuilder
RecommenderFactory
+createRecommender(type: RecommenderType, similarity: RecommenderSimilarity, dataModel: DataModel): Recommender
RecommenderSimilarity<<enumeration>>
+PEARSON+TANIMOTO+LOG+EUCLIDEAN+NONE
+createNewSimilarity(dataModel: DataModel): Object
RecommenderType<<enumeration>>
+USER+ITEM+SLOPEONE
+createNewRecommender(dataModel: DataModel, similarity: RecommenderSimilarity): Recommender
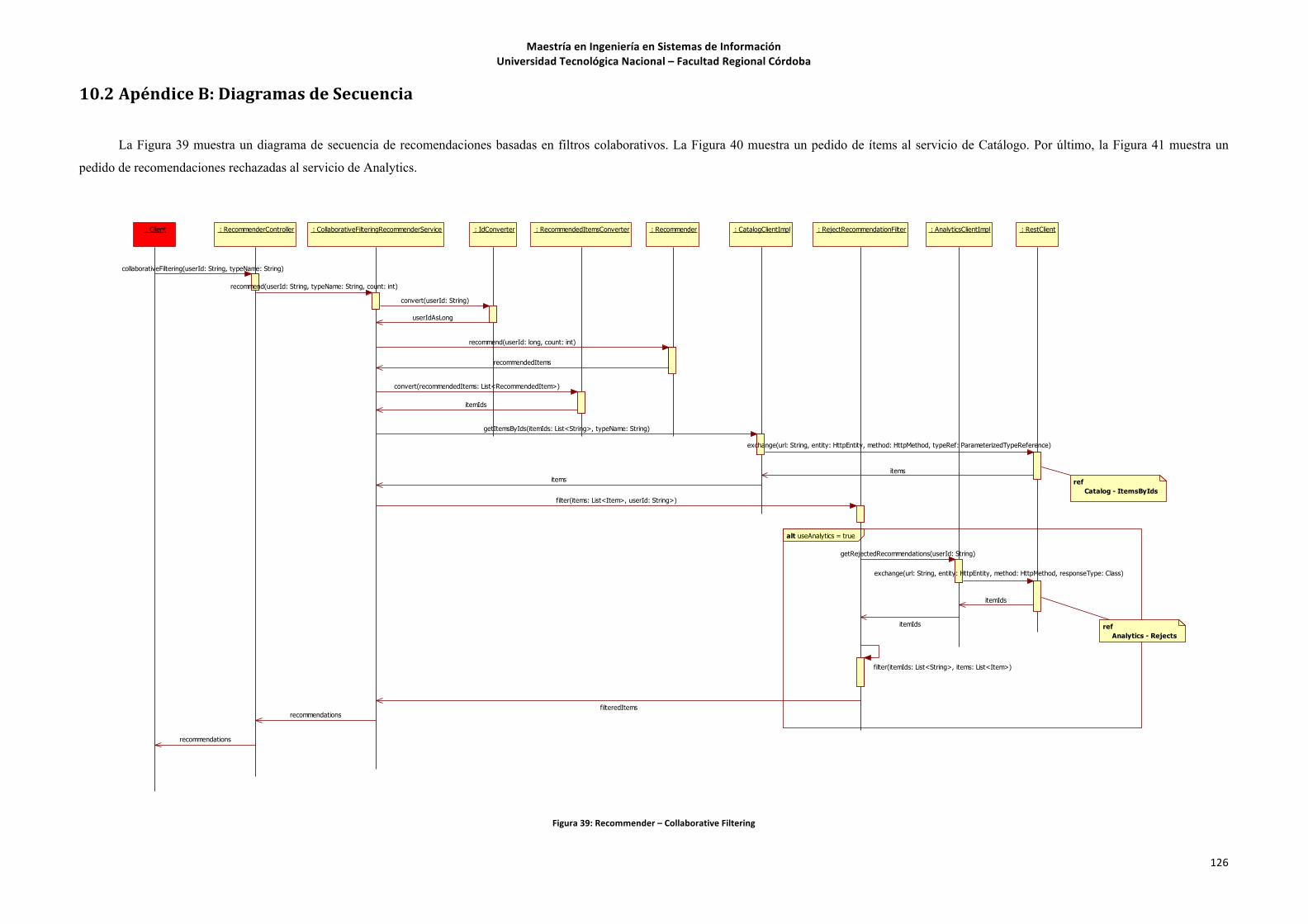
Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
126!!
10.2 Apéndice#B:#Diagramas#de#Secuencia#!
La Figura 39 muestra un diagrama de secuencia de recomendaciones basadas en filtros colaborativos. La Figura 40 muestra un pedido de ítems al servicio de Catálogo. Por último, la Figura 41 muestra un
pedido de recomendaciones rechazadas al servicio de Analytics.
!
!
Figura(39:(Recommender(–(Collaborative(Filtering(
useAnalytics = truealt
: RecommenderController : Client : CollaborativeFilteringRecommenderService : IdConverter : Recommender : RecommendedItemsConverter : CatalogClientImpl : RestClient : RejectRecommendationFilter : AnalyticsClientImpl
collaborativeFiltering(userId: String, typeName: String)
recommend(userId: String, typeName: String, count: int)
convert(userId: String)
userIdAsLong
recommend(userId: long, count: int)
recommendedItems
convert(recommendedItems: List<RecommendedItem>)
itemIds
getItemsByIds(itemIds: List<String>, typeName: String)
exchange(url: String, entity: HttpEntity, method: HttpMethod, typeRef: ParameterizedTypeReference)
itemsitems
filter(items: List<Item>, userId: String>)
getRejectedRecommendations(userId: String)
exchange(url: String, entity: HttpEntity, method: HttpMethod, responseType: Class)
itemIds
itemIds
filter(itemIds: List<String>, items: List<Item>)
filteredItemsrecommendations
recommendations
ref Catalog - ItemsByIds
ref Analytics - Rejects

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
127!!
!
!Figura(40:(Catalog(–(ItemsByIds(
!
!Figura(41:(Analytics(M(Rejects(
: CatalogController : Client : CatalogServiceImpl : CatalogRepositoryImpl : MongoTemplate
: Query
getItems(typeName: String, itemIds: List<String>)
getItems(typeName: String, itemIds: List<String>)
findItemsByIds(itemIds: List<String>, typeName: String)
<<create>>
find(query: Query, entityClass: Class, typeName: String)
items
items
itemsitems
[for each rejection]loop
: Client : AnalyticsController : AnalyticsServiceImpl : RejectRecommendationRepository
: ArrayList<String>
: RejectRecommendation
rejects(userId: String)
getRejects(userId: String)
findByUserId(userId: String)
rejections
<<create>>
itemIds
getItemId()
itemIdadd(itemId: String)
itemIds
itemIds

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
128!!
!
!
10.3 Apéndice#C:#Snippets#de#Código#!
El presente Apéndice ofrece una vista de la interfaz REST disponible en catalog-ws (Figura 42), dos enumeraciones que se utilizan en recommender-core (Figura 43), el objeto Item, disponible en models, y la
clase que indexa, cada cierto tiempo, el motor de búsquedas con información del catálogo, disponible en search-core (Figura 44). Por idénticas razones a los Apéndices anteriores, no se incluyo la totalidad del código.
Si el lector necesita mayor detalle, puede clonarse el repositorio público de github.com. La dirección es la siguiente: https://github.com/nachocano/tmme.git !
!!
!
Figura(42:(Interfaz(REST(del(Servicio(de(Catalog(
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
129!!
!!!
!
Figura(43:(Enumeraciones(Polimórficas(utilizadas(en(Recomendaciones(con(Filtros(Colaborativos(
!
!
!

Maestría(en(Ingeniería(en(Sistemas(de(Información(((((((((((((((((((Universidad(Tecnológica(Nacional(–(Facultad(Regional(Córdoba(
!
130!!
!
!
!
!
Figura(44:(Objeto(del(Modelo(e(Indexador(del(Motor(de(Búsquedas(

























![[262] netflix 빅데이터 플랫폼](https://img.pdfslide.tips/doc/110x75/586fd9281a28ab18428b58a5/262-netflix-.jpg)



