Embed Size (px)
Citation preview

SPSS – wprowadzenie
SPSS (Statistical Package for the Social Sciences – nazwy tej się już raczej nie używa) to
stworzony w 1968 roku pakiet do analiz statystycznych. Jego autorami są:
Norman H. Nie:
C. Hadlai (Tex) Hull:
oraz Dale H. Bent:
Panowie ci postanowili stworzyć program, który surowe dane statystyczne konwertowałby
przy użyciu łatwego w obsłudze pakietu do postaci, na podstawie której można podejmować decyzje (w założeniu biznesowe).

Program się przyjął i od momentu powstania jest stale rozbudowywany, umożliwiając coraz
wszechstronniejszą i bardziej zaawansowaną analizę danych statystycznych. Teraz SPSS to
prężnie działająca korporacja, która posiada znaczną część rynku oraz której zaufało wielu
dużych klientów (np. American Airlines, a w Polsce: BZ WBK). SPSS doczekał się już swojej szesnastej odsłony, a zapowiadana jest siedemnasta.
Pakiet (podobnie do wielu innych znanych programów do zastosowań statystycznych) składa
się z podstawy (SPSS Base) oraz dodatkowych modułów (SPSS Modules). Moduły to
zestawy narzędzi statystycznych tworzących w ramach modułu pewną tematyczną całość. Przykładem może być moduł ‘Trends’ do analizy szeregów czasowych lub ‘Maps’
pozwalający na prezentację danych na mapach.
Z uwagi na różne wersje SPSSa oraz możliwość rozbudowania go za pomocą modułów, może
się zdarzyć, że prezentowane wydruki nie będą identyczne z uzyskiwanymi przez nas w
trakcie zajęć. Materiały przygotowywane są przy użyciu polskiej wersji SPSS 12.0 (do
niedawna ostatnia osiągalna wersja SPSSa, którą dyspnował WNE), zaś pracujemy na
angielskiej wersji 15.0. Jednak sposób poruszania się w środowisku programu, metody
analizy statystycznej oraz interpretacja wyników pozostaną aktualne.
Dodatkowo, z uwagi na fakt, że w wielu miejscach w Polsce, w których można się potencjalnie spotkać z SPSSem, używana jest polska wersja (najczęściej właśnie 12.0),
sposóby przeprowadzania analiz statystycznych będą prezentowanaye dla wersji polskiej,
jednak bezpośrednio po nich podawane będą również odpowiedniki dla angielskiej wersji
15.0 (w nawiasach).

SPSS – organizacja programu Po uruchomieniu SPSSa wyświetla się główne okno programu (wyświetlać się również może
okno z zadaniami, którymi najczęściej rozpoczynamy pracę w pakiecie statystycznym (typu
‘Otwórz dane’ (‘Open an existing data source’), ‘Uruchom tutorial ’ (‘Run the tutorial’) ), ale
często usuwa się możliwość pojawiania się tego okna przy starcie programu).
Okno główne wygląda tak:
Mamy w nim dwie zakładki: ‘Dane’ (‘Data View’) oraz ‘Zmienne’ (‘Variable View’).
Zakładki te służą do przełączania się odpowiednio pomiędzy edytorem pokazującym wartości
zmiennych (‘Dane’ (‘Data View’)), a edytorem z nazwami zmiennych i ich typem (‘Zmienne’
(‘Variable View’)).
W głównym menu SPSSa mamy do wyboru wiele pozycji (‘Plik’ (‘File’), ‘Edycja’ (‘Edit’),
‘Widok’ (‘View’),…), z których każda posiada dodatkowe rozwijane menu, a niektóre
pozycje tego ostatniego jeszcze dodatkowe menu. Wszystkie elementy tego menu realizują pewne zadania, zaś pozycje głównego menu to uporządkowanie zadań w ten sposób, że
stanowią one zbiory zadań połączonych tematycznie (np. ‘Analiza’ (‘Analyze’) pozwala
przeprowadzać różnego rodzaju wnioskowanie statystyczne).
Do wyników analiz statystycznych otwierane jest dodatkowe okno (‘Raport’ (‘Output’)).
Zapisują się w nim wyniki wszystkich analiz prowadzonych w bieżącej sesji SPSSa.

Wczytywanie / import / eksport danych
Tworzenie własnej bazy danych W SPSSie możemy stworzyć własną bazę danych – przykładowo wpisać w postaci bazy
danych wyniki ankiety, którą zebraliśmy. Powiedzmy, że w ankiecie pytaliśmy studentów o
płeć, wagę, wzrost i wydział i dostaliśmy następujące odpowiedzi:
płeć waga wzrost wydział
K 61 168 WZ
K 52 171 WNE
K ? 170 WZ
M 92 181 WNE
K 48 165 WZ
K 58 173 WNE
M 70 172 WZ
M 84 188 WNE
M 87 195 WZ
K 51 176 WNE
M 95 180 WNE
K ? 177 WZ
M 81 183 WNE
M 75 177 WZ
Taka baza danych, oczywiście w bardziej rozbudowanej postaci, może przykładowo służyć do
porównania wagi i wzrostu studentów (względnie stworzonego na podstawie tych dwóch
współczynnika BMI (body mass index)) pomiędzy kobietami i mężczyznami oraz pomiędzy
wydziałami.
Żeby wprowadzić taką bazę do SPSSa, powinniśmy otworzyć „świeżą” jego sesję, lub wybrać Plik�Nowy�Dane (File�New�Data). Dobrze jest zacząć od zakładki ‘Zmienne’
(‘Variable View’) i w polu ‘Nazwa’ (‘Name’) wpisać nazwy naszych zmiennych.
Przykładowo w pierwsze pole kolumny ‘Nazwa’ (‘Name’) wpiszmy ‘płeć’, klikając
uprzednio na to pole. Po naciśnięciu ‘Enter’ domyślnymi wartościami wypełniają się inne
pola. Możemy oczywiście zmieniać ich wartości. Proszę również zwrócić uwagę, że po
edytorze SPSSa możemy się poruszać podobnie jak po znanym wielu Excelu.
Pozostają do rozwiązania dwa problemy: co robimy z dyskretnymi zmiennymi zbieranymi
jako tekstowe (‘płeć’ i ‘wydział’) oraz jak potraktować braki danych występujące w zmiennej
‘waga’? Pierwszy z problemów standardowo rozwiązuje się przez ustalenie liczb naturalnych,
które będą oznaczały poszczególne kategorie (np. dla zmiennej ‘płeć’ niech 1 oznacza
kobietę, a 2 mężczyznę; dla zmiennej wydział niech 1 oznacza WNE, a 2 - WZ).
Drugi problem to odpowiednie uwzględnienie braków danych. Możemy te braki danych
zakodować jakąś liczbą (np. bardzo dużą 99999999 albo bardzo małą -99999999). Problemem
jest to, że SPSS będzie widział te wartości jako tak samo ważne wartości zmiennych, jak
każde inne, chyba że zdefiniujemy je jako braki danych.

Nasza baza przygotowana do wpisania do SPSSa wygląda więc tak:
płeć waga wzrost wydział
1 61 168 2
1 52 171 1
1 99999999 170 2
2 92 181 1
1 48 165 2
1 58 173 1
2 70 172 2
2 84 188 1
2 87 195 2
1 51 176 1
2 95 180 1
1 99999999 177 2
2 81 183 1
2 75 177 2
Proszę zwrócić uwagę, że po kliknięciu na niektóre komórki, pokazuje się na ich końcu
prostokąt z kropkami lub .
Kliknięcie na prostokąt wyświetla okno opcji, a rozwija dodatkowe menu.
Edycja atrybutów zmiennych W zakładce ‘Zmienne’ (‘Variable View’) możemy jeszcze zmieniać atrybuty zmiennej – od
deklarowania jej typu przez nadawanie jej etykiety, do określania jej skali pomiarowej. W
kolumnie ‘Etykieta’ (‘Label’) możemy opisać zmienne, np. ‘płeć’ jako ‘płeć studenta’. Ważna
jest kolejna kolumna (‘Wartości’ (‘Values’) ), która nadaje etykiety poszczególnym
kategoriom zmiennych dyskretnych (u nas ‘płeć’ i ‘wydział’). Bez nadania tych etykiet, w
wynikach analiz te zmienne będą się pojawiały jako liczby oznaczające ich kategorie (u nas
‘1’ i ‘2’), po ich nadaniu kategorie będą się wyświetlały zgodnie z nadanymi im etykietami.
Nadajmy wartościom ‘1’ zmiennej ‘płeć’ etykietę ‘kobieta’, a ‘2’ mężczyzna. Klikamy na
prostokąt z kropkami w polu ‘Wartości’ (‘Values’) dla zmiennej ‘płeć’ i wypełniamy
wyskakujące okno wpisując wartość zmiennej oraz jej etykietę i klikając ‘Dodaj’ (‘Add’).
Analogicznie zróbmy z wartościami zmiennej ‘wydział’ (‘1’=’WNE’, ‘2’=’WZ’).
Kolejna kolumna to ‘Braki danych’ (‘Missing’). W tej kolumnie wpisujemy wszystkie braki
danych, które wśród zmiennych występują (jeśli nie wpiszemy braku danych to kody tych
braków będą brały udział w analizie – będą w bazie danych istniały osoby ważące
99999999kg..).
Ważna jest również ostatnia kolumna ‘Poziom’ (‘Measure’), przede wszystkim ze względu na
jej wartość informacyjną dla użytkownika, który pierwszy raz widzi bazę danych. W
kolumnie tej możemy ustalić jaka jest skala pomiarowa poszczególnych zmiennych.
Teraz możemy się przenieść do zakładki ‘Dane’ (‘Data View’) i wpisać w nią wartości
zmiennych, dokładnie tak, jakbyśmy to robili w Excelu.

Nasza baza danych powinna więc wyglądać tak:
Zakładka ‘Zmienne’ (‘Variable View’)
Zakładka ‘Dane’ (‘Data View’)
Stworzoną w ten sposób bazę danych możemy zapisać na dysku wybierając Plik�Zapisz
(File�Save) jako i podając nazwę pliku i lokalizację. Proszę to zrobić.
Proszę zwrócić uwagę, że jeśli jesteśmy w zakładce ‘Dane’ (‘Data View’) i klikniemy ikonkę
lub wybierzemy Widok�Etykiety wartości (‘View�Value labels’), to zamiast wartości
dla zmiennych dyskretnych pojawią się ich etykiety (o ile zdefiniowaliśmy je w zakładce
‘Zmienne’ (‘Variable View’)). Ułatwia to czasami wyciąganie wniosków na podstawie
surowych danych.
Korzystanie z istniejących baz danych Wczytać dane możemy wybierając Plik�Otwórz�Dane (File�Open�Data), bądź też
klikając .
Format danych SPSSa to ‘.sav’ i domyślnie SPSS chce otworzyć dane w takim formacie.
Dodatkowo, mamy do wyboru wiele przykładowych baz danych zainstalowanych wraz z
programem. Format ‘.sav’ to nie jedyny format, który SPSS akceptuje. W momencie
otwierania bazy danych, z rozwijanego menu możemy wybrać inne formaty – np. ‘.sas7bdat’
(format SASa), ‘.xls’ (format Excela) i inne (patrz Dodatek).
Spróbujmy najpierw importować bazę danych z pliku ‘data9-12.xls’. W tym celu najpierw
otwórzmy tę bazę pod Excelem i zobaczmy jak ona wygląda. Potem należy zamknąć plik z
bazą (jeśli będzie otwarty, SPSS nie będzie chciał go zaimportować) i w opisany wyżej
sposób proszę go importować do SPSSa.

Żeby zapisać na dysku bazę danych, należy wybrać Plik�Zapisz jako (File�Save as) i
odpowiednio wypełnić wyskakujące okno. Proszę zwrócić uwagę, że opcja ‘Zmienne’
(‘Variables’) pozwala ograniczyć ilość zapisywanych zmiennych.
Na dysku zapisany jest plik w formacie SPSSa, czyli konwertowaliśmy dane z formatu Excela
do formatu SPSSa.
Otwórzmy teraz w SPSSie przykładową bazę danych ‘Absolwenci University of Florida’ –
plik dołączony do materiałów do zajęć (lub ‘University of Florida graduate salaries’). Są to
dane dotyczące charakterystyk absolwentów University of Florida oraz ich początkowych
płac po ukończeniu studiów.
Na koniec eksportujmy tę bazę do formatu Excela. Robi się to dokładnie tak samo, jak
zapisywanie bazy w formacie SPSSa, z tymże przed zapisaniem ustalamy odpowiedni format
z rozwijanego menu. Proszę zapisać tę bazę w znanej lokalizacji, z pominięciem zmiennych
‘degree’ i ‘graduate’ i otworzyć ją pod Excelem w celu weryfikacji.
Wstępna analiza statystyczna Analiza statystyczna odbywa się poprzez wybranie z menu głównego ‘Analiza’ (‘Analyze’)
oraz wybranie pożądanego rodzaju tej analizy. Nie jest również istotne, czy wybór zastanie
dokonany z okna głównego SPSSa (i nieważne, czy będzie to zakładka ‘Dane’ (‘Data View’),
czy ‘Zmienne’ (‘Variable View’)), czy z okna Raportu (Output).
Wstępna analiza statystyczna to bliższe przyjrzenie się zmiennym, z którymi mamy do
czynienia. Oczywiście inaczej będziemy traktować zmienne ilościowe, a inaczej zmienne
porządkowe, czy nominalne. O ile w przypadku pierwszych zasadne jest poznanie statystyk
opisowych tych zmiennych (co pozwoli wnioskować na temat rozkładu zmiennych – średnia,
rozproszenie, skośność, kurtoza), o tyle już niektóre statystyki opisowe nie są liczone dla
zmiennych porządkowych, a już prawie żadne dla zmiennych nominalnych.
Przykładowo:
Z drugiej strony, zmienne nominalne oraz porządkowe zasadne jest prezentować za pomocą częstości występowania ich poszczególnych kategorii. Możemy w ten sposób się dowiedzieć ilu było mężczyzn, a ile kobiet (ile odpowiednio ‘0’ i ‘1’ miała zmienna ‘gender’ – dane
przykładowe ‘Absolwenci University of Florida’). Jest oczywiście nieporozumieniem
wyznaczenie częstości dla zmiennej ‘salary’, gdyż zaprezentujemy w ten sposób ilość wystąpień różnych wartości początkowej płacy, a tych może być bardzo dużo.
Najlepiej się jednak przekonać o wszystkim empirycznie. Wybierzmy Analiza�Opis
statystyczny�Częstości (Analyze�Descriptive statistics�Frequencies), Wyświetli się okno:

Zaznaczamy zmienne, dla których częstości chcemy wyznaczyć i przenosimy do okna
‘Zmienne’ (‘Variable(s)’) za pomocą . Proszę zwrócić uwagę, że każde okno SPSSa
realizujące jakąś funkcję ma dodatkowe opcje. I tak w ‘Częstościach’ (‘Frequencies’)
możemy pokazać lub nie pokazywać tabel częstości (zaznaczenie lub nie odpowiedniego
okienka – ‘display frequency tables’), wybrać wyświetlane statystyki (‘Statystyki’
(‘Statistics’)), rysować wykresy (‘Wykresy’ (‘Charts’)), czy w końcu ustalić format
wyświetlania wyniku (‘Format’), którym może być m.in. powstrzymanie SPSSa od
wyświetlania częstości dla zmiennej ze zbyt dużą ilością kategorii (np. z reguły zmienne
ilościowe).
Zmienne możemy analizować pojedynczo, możemy również od razu wybrać kilka
zmiennych.
Spróbujmy pokazać tabele częstości dla dwóch sensownych zmiennych (‘gender’ i ‘college’)
oraz jednej bez sensu (‘salary’). Zinterpretujmy wynik.
Zajmijmy się teraz statystykami opisowymi: Analiza�Opis statystyczny�Statystyki opisowe
(Analyze�Descriptive statistics�Descriptives). Znowu wybierzmy sensowną i mało
sensowną zmienną: ‘salary’ i ‘college’:
Standardowo wyświetlane są tylko bardzo podstawowe statystyki (liczba obserwacji, średnia,
odchylenie standardowe, minimum i maksimum). Dodajmy do tego rozstęp, skośność (asymetria) i kurtozę (koncentrację). Zinterpretujmy wynik.

Zauważmy, że w ‘Statystykach opisowych’ (‘Descriptives’) brakuje wielu, często
interesujących (np. dominanta (modalna)). Można je było jednak uzyskać przez
Analiza�Opis statystyczny�Częstości (Analyze�Descriptive statistics�Frequencies).
Eksploracja Zmienne możemy eksplorować, czyli wyznaczać ich statystyki opisowe w podpróbkach
wyznaczanych przez zmienną dyskretną. Przykładowo, jeśli interesuje nas kształtowanie się początkowej płacy nie w całej próbie, ale raczej różnice pomiędzy kobietami i mężczyznami
(absolwentkami i absolwentami), to możemy eksplorować zmienną ‘salary’ w podpróbkach
wyznaczanych przez zmienną ‘gender’. Wybierzmy Analiza�Opis
statystyczny�Eksploracje (Analyze�Descriptive statistics�Explore). Pojawia się okno:
Zmienna (zmienne) zależna, to zmienna, której statystyki opisowe chcemy w podpróbkach
poznać. Lista czynników to zmienna, która dzieli próbę na podpróbki. Jeśli nietypowe
obserwacje (np. na wykresie pudełkowym, który generowany jest w ramach ‘Eksploracji’
(‘Explore’)) chcemy opisać nie wartościami zmiennej zależnej, tylko wartościami jeszcze
innej zmiennej, to trzeba ją wstawić do pola ‘Użyj do opisu obserwacji’ (‘Label Cases by’).
Proszę dokonać tej eksploracji i zinterpretować wyniki.
Wykresy w SPSSie Wykresy w SPSSie wykonuje się głównie przy wykorzystaniu opcji ‘Wykresy’ (‘Graphs’) z
głównego menu. Jednak, jak już sami wcześniej widzieliśmy, niektóre wykresy są również opcjonalne przy wykonywaniu analiz statystycznych.
Rzecz jasna, inne wykresy będą nam służyć do przedstawienia zmiennych dyskretnych, inne
do zmiennych ilościowych.
Wykresy dla zmiennych dyskretnych Zacząć możemy od prostych wykresów słupkowych, prezentujących ilość (bądź też procent)
wystąpień poszczególnych wartości zmiennej. Wykresy mogą być zupełnie proste

(pojedyncze słupki wskazujące na ilość/procent wystąpień poszczególnych kategorii
zmiennej) lub też odrobinę bardziej skomplikowane (np. słupki te prezentowane są dla dwóch
rozłącznych podpróbek wydzielonych ze względu na inną zmienną). Wykresy te mogą dalej
prezentować całe kategorie zmiennej dyskretnej lub poszczególne obserwacje.
Oto przykładowe wykresy słupkowe:

Wykresy słupkowe tworzymy wybierając Wykresy�Słupkowy. Przykładowo ostatni
wykresy został uzyskany w wyniku wykonania następujących kroków: Wykresy�Słupkowy,
zaznaczone ‘Zestawiony’ � Definiuj, oś kategorii to ‘gender’ a w polu ‘Definiuj zestawienia
przez:’ stoi zmienna ‘college’.
UWAGA1! Wersja SPSSa 15.0 pozwala wykorzystać tzw. ‘Chart Buildera’ (Graphs�Chart
Builder), który przeprowadza użytkownika przez proces budowy różnego rodzaju wykresów.
Obsługa ‘Chart Buildera’ jest dość intuicyjna – jako mały trening, proszę spróbować otrzymać dwa ostatnie wykresy za pomocą ‘Chart Buildera’.

Gdyby zamienić w polach tego wykresu zmienne ‘gender’ i ‘college’, to otrzymamy:
ZADANIE1. Narysuj wykres słupkowy obrazujący średnie początkowe płace w różnych
grupach wykształcenia. Która grupa średnio zarabiała najwięcej?
Zmodyfikuj ten wykres tak, żeby wprowadzał dodatkowo podział na płeć, zaś słupki niech nie
oznaczają średnich, ale maksymalne zarobki dla danych rodzajów wykształcenia.
Wykresy kołowe. Do graficznego prezentowania zmiennych dyskretnych mogą też służyć wykresy kołowe.
Wywołuje się w analogiczny sposób jak słupkowe (w wersji SPSS 15.0 – za pomocą ‘Chart
Buildera’).
UWAGA2! Wersja SPSSa 15.0 w dość nienaturalny sposób (w kontekście rozwoju
programu), ogranicza funkcjonalność niektórych wykresów. Przykładowo, w wykresach
kołowych ograniczona została możliwość wykorzystania niektórych (wielu) statystyk do
etykietowania ‘slice-ów’ takiego wykresu (np. wykres kołowy pokazujący udział studentów w
podziale na rok zakończenia studiów. Taki wykres mógłby mieć slice-y etykietowane średnim
początkowym wynagrodzeniem dla każdego rocznika absolwentów (co by miało sens
analityczny). Okazuje się, że średnia nie jest już statystyką możliwą do wykorzystania w
takim kołowym wykresie (była w poprzednich wersjach SPSSa). Można np. etykietować slice-y sumą (np. począktowych zarobków), co w przypadku wielu zmiennych nie ma
większego sensu. Taki wykres kołowy można jednak do pewnego stopnia substytuować wykresem słupkowym, który ma większe możliwości).
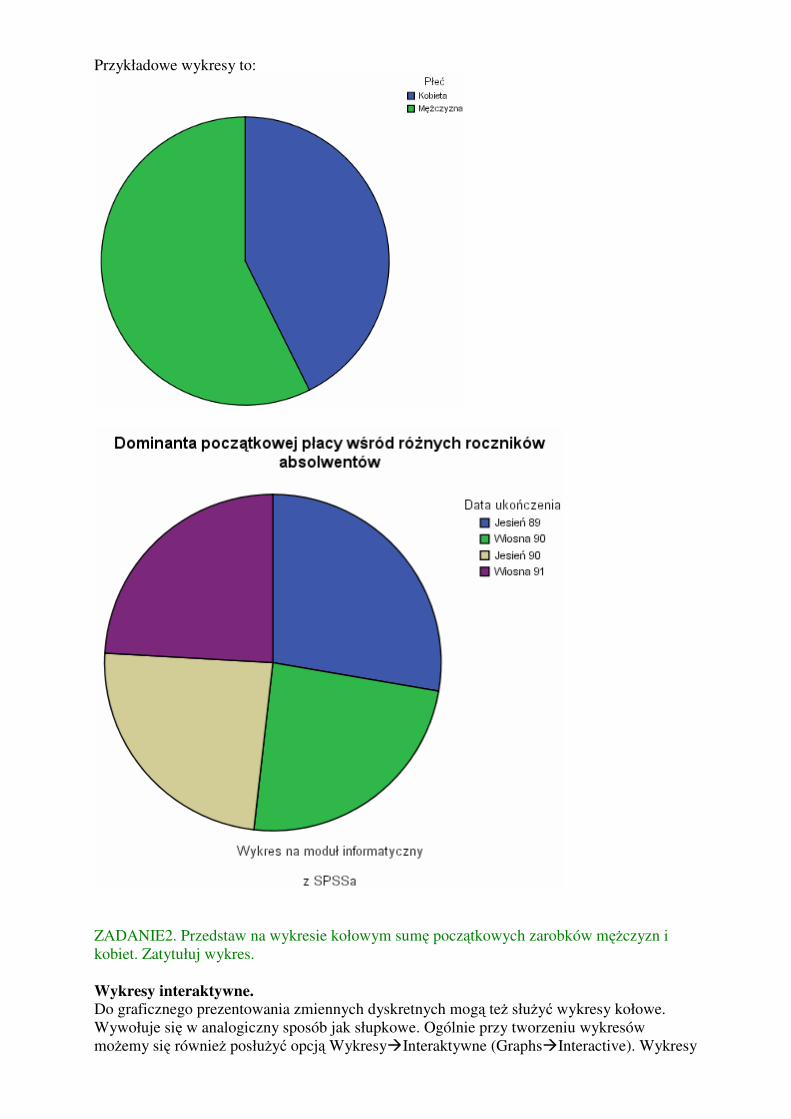
Przykładowe wykresy to:
ZADANIE2. Przedstaw na wykresie kołowym sumę początkowych zarobków mężczyzn i
kobiet. Zatytułuj wykres.
Wykresy interaktywne. Do graficznego prezentowania zmiennych dyskretnych mogą też służyć wykresy kołowe.
Wywołuje się w analogiczny sposób jak słupkowe. Ogólnie przy tworzeniu wykresów
możemy się również posłużyć opcją Wykresy�Interaktywne (Graphs�Interactive). Wykresy

te budujemy ustalając ich parametry (których jest możliwa do ustalenia dość pokaźna ilość) oraz wybierając zmienne (przeciągając je z listy do właściwych pól). Często, korzystając z
opcji wykresów interaktywnych, jesteśmy w stanie wygenerować wykresy łatwiej i do tego
takie, jakich nie byliśmy w stanie stworzyć przy użyciu standardowych funkcji rysujących
wykresy.
Przykładowo, wybierając Wykresy�Interaktywne�Kołowy�Prosty
(Graphs�Interactive�Pie�Simple) i wypełniając pojawiające się okno:
Dostajemy w efekcie:
Interaktywność wykresów polega na możliwości ich późniejszego edytowania i modelowania.
Wykres możemy dowolnie obracać, zmieniać kolory, wyróżniać jego elementy, itp.

Wykresy dla zmiennych ilościowych. Dla zmiennych tych mamy całą gamę wykresów. Zaczynając od wykresów typowo
statystycznych (histogram, wykres pudełkowy), przez wykresy obrazujące zależności z
innymi zmiennymi, kończąc na wykresach szeregów czasowych.
Otwórzmy dane ‘samochody.sav’.
1. Wykresy prezentujące rozkład zmiennej a. Wykresy pudełkowe
Wykres pudełkowy to jedno z narzędzi pozwalające wnioskować rozkładzie
zmiennej:
Standardowa opcja (Wykresy�Skrzynkowy (Graphs�Legacy
Dialogs�Boxplot i ‘Summaries for groups of cases’)) pozwala rysować wykres pudełkowy zmiennej w rozbiciu na podgrupy wydzielone przez inną zmienną. Standardowo nie ma niestety możliwości stworzenia ogólnego (dla
całej próbki) wykresu pudełkowego. Jest to możliwe jedynie przy użyciu opcji
wykresów interaktywnych. W standardowej opcji mamy za to możliwość grupowania wykresów.
Uwaga! W wersji 15.0 można narysować wykres pudełkowy zmiennej bez
rozbijania go na kategorie innej przy wykorzystaniu Graphs�Legacy
Dialogs�Boxplot i wybraniu opcji ‘Summaries of separate variables’.
ZADANIE3
Stwórz ogólny (bez rozbijania na podpróbki) wykres pudełkowy dla zmiennej
‘power’.
ZADANIE4
Korzystając ze standardowego (nie interaktywnego) sposobu tworzenia
wykresów, narysuj wykres pudełkowy masy samochodu (‘mass’) w podziale
na region produkcji i pogrupowany ze względu na ilość cylindrów. Jakie
można wyciągnąć wnioski z tego wykresu?
b. Histogramy Histogram jest bardzo powszechnie używanym narzędziem do wnioskowania o
rodzaju rozkładu zmiennej. Na jego podstawie możemy analizować rozproszenie, skośność, kurtozę rozkładu zmiennej. Możemy też oceniać typowość i jedno- lub wielomodalność rozkładu.
Często istnieje dodatkowa możliwość narysowania w tle histogramu gęstości
rozkładu normalnego, co może dać podstawy do wnioskowania, czy rozkład
zmiennej jest rozkładem normalnym.

Standardowy histogram uzyskamy wybierając Wykresy�Histogram
(Graphs�Legacy Dialogs�Histogram).
Bardziej „wyrafinowane” histogramy uzyskać można z opcji wykresów
interaktywnych. Te ostatnie można dodatkowo dowolnie edytować, uzyskując
pożądanych ich kształt.
ZADANIE5
Narysuj histogram dla zmiennej ‘gas_100’. Niech na wykresie będzie również widoczna gęstość rozkładu normalnego.
ZADANIE6
Stwórz histogramy zmiennej ‘capacity’ w podziale na regiony produkcji. Niech
histogramy prezentują nie liczebność, a procentowy udział każdej klasy
przedziałowej.
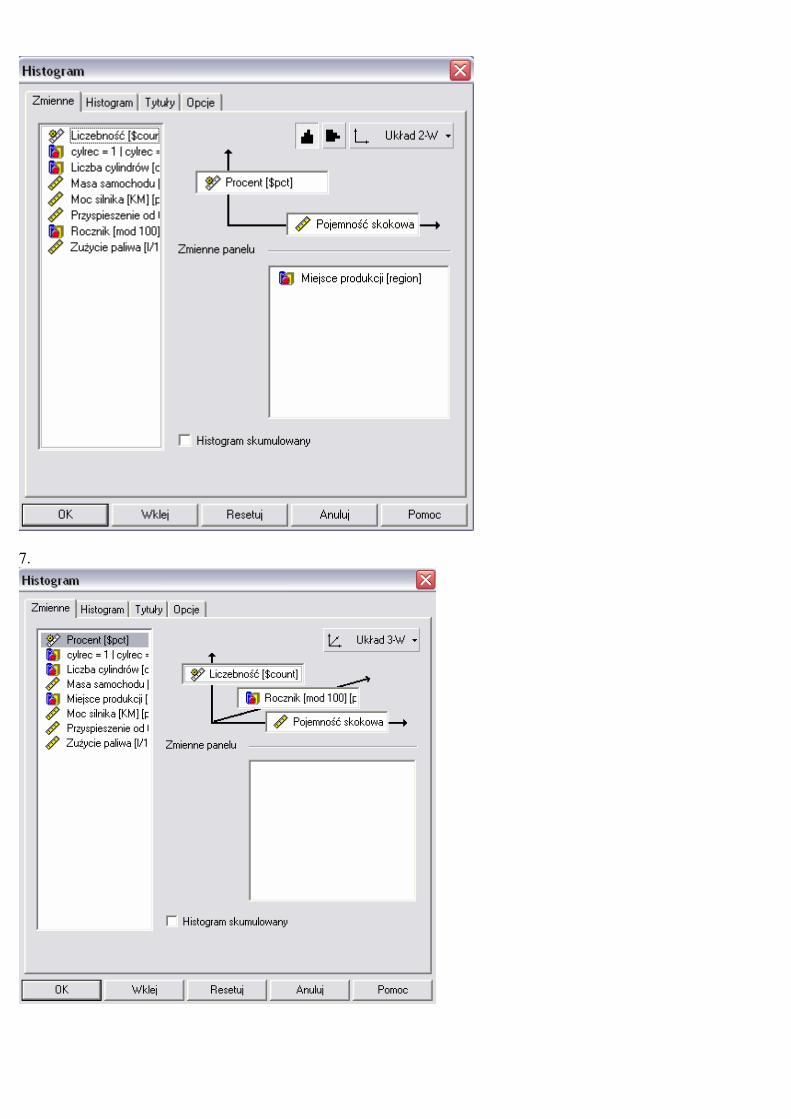
ZADANIE7
Stwórz trójwymiarowy histogram pokazujący rozkłady zmiennej ‘capacity’ w
podziale na rocznik produkcji samochodu. Nie wykonując dodatkowego
wykresu, przerób ten histogram na dwuwymiarowy dla zmiennej ‘capacity’.
c. Wykresy P-P i K-K Wykresy P-P (prawdopodobieństwo-prawdopodobieństwo, P-P: probability-
probability) oraz K-K (kwantyl-kwantyl, Q-Q: quantile-quantile) służą do
graficznego sprawdzenia, czy zmienna pochodzi z jakiegoś znanego rozkładu
teoretycznego.
Wykres K-K jest wynikiem porównywania kwantyli rozkładu empirycznego
zmiennej X (przy wykorzystaniu do tego estymowanej dystrybuanty rozkładu
empirycznego) z odpowiednimi kwantylami rozkładu teoretycznego. Główną ideą wykresu K-K jest posortowanie wartości zmiennej w sposób rosnący, i
wyświetlenie ich na wykresie względem oczekiwanych wartości, jakie zmienna
ta by miała, gdyby rzeczywiście pochodziła z zakładanego rozkładu. Jest
rzeczą jasną, że jeżeli zakładany rozkład teoretyczny jest poprawny, to punkty
wykresu K-K stworzą linię prostą. Odchylenia od tej prostej mówią jak bardzo
rozkład zmiennej różni się od zakładanego.
Różny wygląd wykresów K-K może sugerować różne charakterystyki rozkładu
badanej zmiennej:
Wykres P-P stanowi alternatywę do wykresu K-K i służy podobnemu celowi.
Główną różnicą jest porównywanie dystrybuant rozkładu empirycznego i
teoretycznego, a nie kwantyli tych rozkładów. Sugerowane jest stosowanie
wykresów K-K gdy chcemy porównać rozkład zmiennej do rodziny rozkładów
teoretycznych (np. do rodziny rozkładów normalnych – np. o różnych

średnich), a P-P do gdy chcemy go porównać do konkretnego rozkładu (np.
N(0,1)).
Wykresy K-K i P-P wywołujemy przez Wykresy�P-P lub Wykresy�K-K
(odpowiednio: Analyze�Descriptive statistics�P-P Plots i
Analyze�Descriptive statistics�Q-Q Plots).
ZADANIE8
Narysuj wykres P-P i K-K dla zmiennej ‘acceler’ porównując jej rozkład do
rozkładu normalnego (narysuj sobie wcześniej histogram tej zmiennej z
krzywą gęstości rozkładu normalnego). Czy z graficznej analizy wynika, że
zmienna ta pochodzi z rozkładu normalnego?
ZADANIE9
Narysuj wykres P-P i K-K dla zmiennej ‘gas_100’ porównując jej rozkład do
rozkładu normalnego (narysuj sobie wcześniej histogram tej zmiennej z
krzywą gęstości rozkładu normalnego). Czy z graficznej analizy wynika, że
zmienna ta pochodzi z rozkładu normalnego?
Jeśli nie, to z jakiego może ona rozkładu pochodzić? Zrób wykres P-P i Q-Q
dla tego rozkładu.
2. Wykresy prezentujące zależności pomiędzy zmiennymi
a. Wykresy rozrzutu To wykres prezentujący jak rozkładają się wartości jednej zmiennej względem
wartości innej. W naszym przypadku, możemy przykładowo zobaczyć jak
masa samochodu zależy od pojemności jego silnika. Jeśli wykres będzie
przedstawiał bezkształtną chmurę, to zależność prawdopodobnie nie będzie
występowała. Gdyby jednak chmura nabierała eliptycznego kształtu i była
pochylona w którąś ze stron, to najprawdopodobniej zależność pomiędzy
zmiennymi by występowała.
Wybierzmy Wykres�Rozrzutu (Graphs�Legacy Dialogs�Scatter/Dot),
wybierzmy wykres prosty i wypełnijmy okno:
Proszę zwrócić uwagę, że dwukrotnie klikając nawet na ten (nie interaktywny)
wykres, również możemy go (w ograniczonym stopniu) edytować. Możemy
przykładowo oznaczyć obserwacje nietypowe, podpisując je.
ZADANIE10
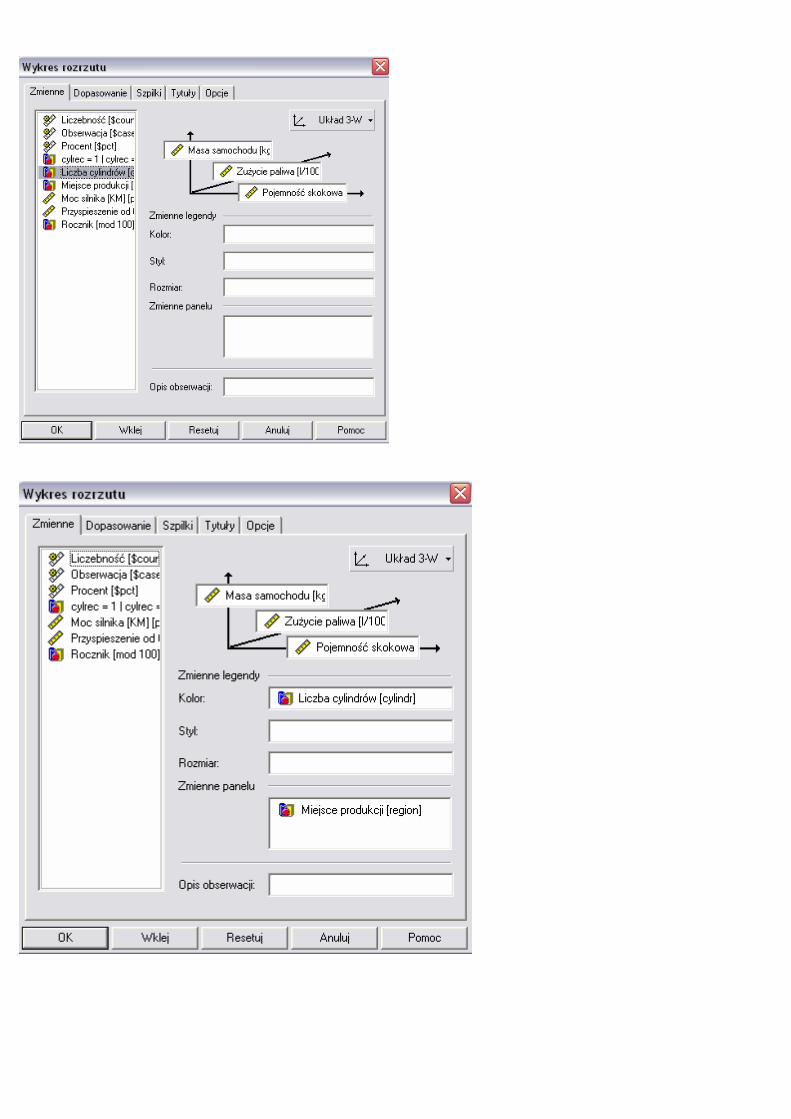
Stwórz interaktywny wykres rozrzutu 3D dla zmiennych: oś OX – zmienna
‘capacity’, oś OY – ‘mass’, oś OZ – ‘gas_100’. W kolejnym kroku stwórz ten
sam wykres, ale w podziale na region produkcji (czyli trzy takie wykresy (bo

trzy regiony produkcji)). Dodatkowo w opcji ‘Kolor’ wstaw zmienną ‘cylindr’
i zobacz jak wpłynie to na wykres.
b. Wykresy szeregów czasowych Proszę otworzyć dane ‘konsumpcja’. W pliku tym znajdują się kwartalne dane
dotyczące zagregowanej konsumpcji i dochodu narodowego USA za okres
1947:1 – 1996:4.
Żeby zdefiniować dane jako szeregi czasowe, należy wybrać Dane�Definiuj
datę i czas (Data�Define Dates) oraz podać SPSSowi z jakimi danymi ma do
czynienia. Nasze dane to dane kwartalne, rozpatrywane w kontekście rocznym,
dlatego wybierzemy ‘Lata, kwartały’ (‘Years, quarters’) oraz podamy datę pierwszej obserwacji (pierwszy kwartał 1947).
Wykres szeregu czasowego (przykładowo dla konsumpcji i dochodu na
jednym wykresie) możemy uzyskać wybierając Wykres�Sekwencyjny
(Analyze�Time series�Sequence Charts lub Graphs�Legacy Dialogs�Line
(‘Simple/Multiple’ z opcją ‘Values of individual cases’)) i wypełniając
wyskakujące okno:
Gdybyśmy chcieli, żeby zmienne przedstawione były na osobnych wykresach,
należałoby dodatkowo zaznaczyć ten kwadracik. Nie podanie etykiety osi
czasu powoduje opisanie jej numerami obserwacji.
Dla szeregów czasowych możemy również robić ich wykresy funkcji
autokorelacji i cząstkowej autokorelacji (ACF i PACF). Przykładowo
Wykresy�Szeregi czasowe�Autokorelacje (Analyze�Time
series�Autocorrelations) oraz:

Można dodatkowo uzyskać wykresy dla różnic lub sezonowych różnic szeregu.

Dodatek. Formaty danych, które SPSS rozumie:
Odpowiedzi do zadań (d użej części do polskiej wersji SPSS 12.0):
1.

2.
3.

4.

5.
6.
7.

8.
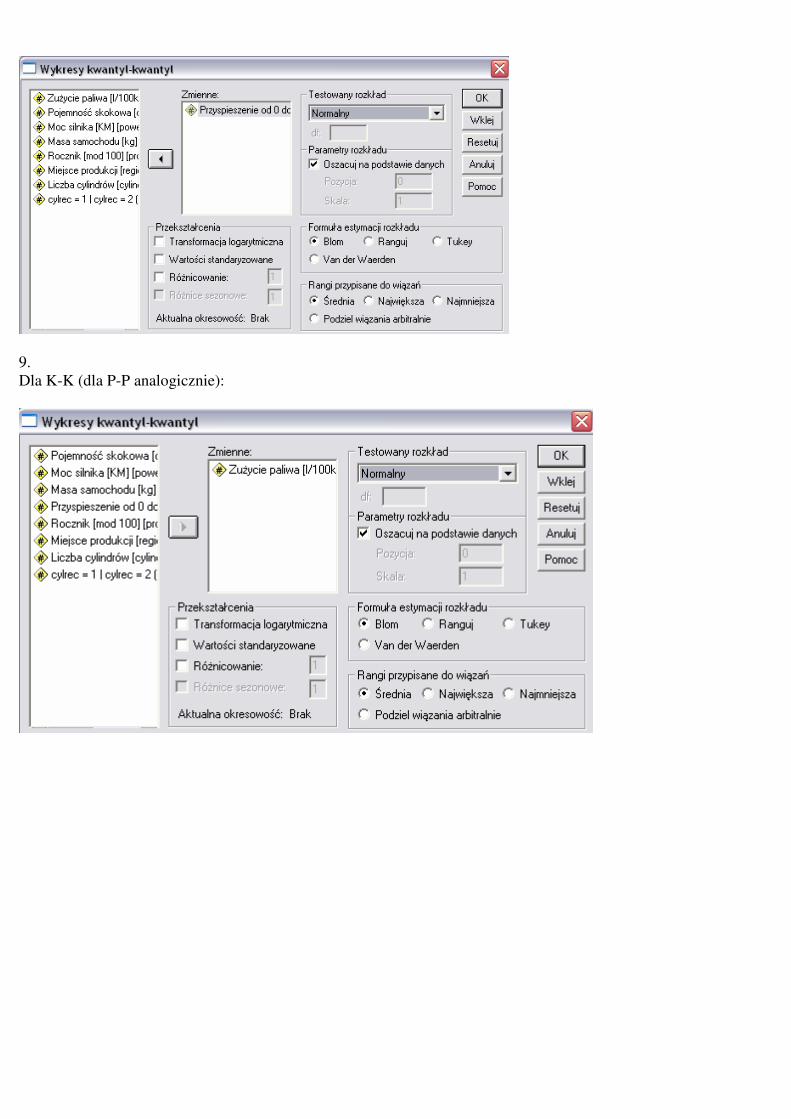
9.
Dla K-K (dla P-P analogicznie):

10.