Embed Size (px)
Citation preview

Statistics
Chapter 2
Frequency Distributions
次數分配

資料整理
How do we turn “a bunch of numbers” into
something meaningful?
整理資料的第一步驟– 統計表– 統計圖

統計表
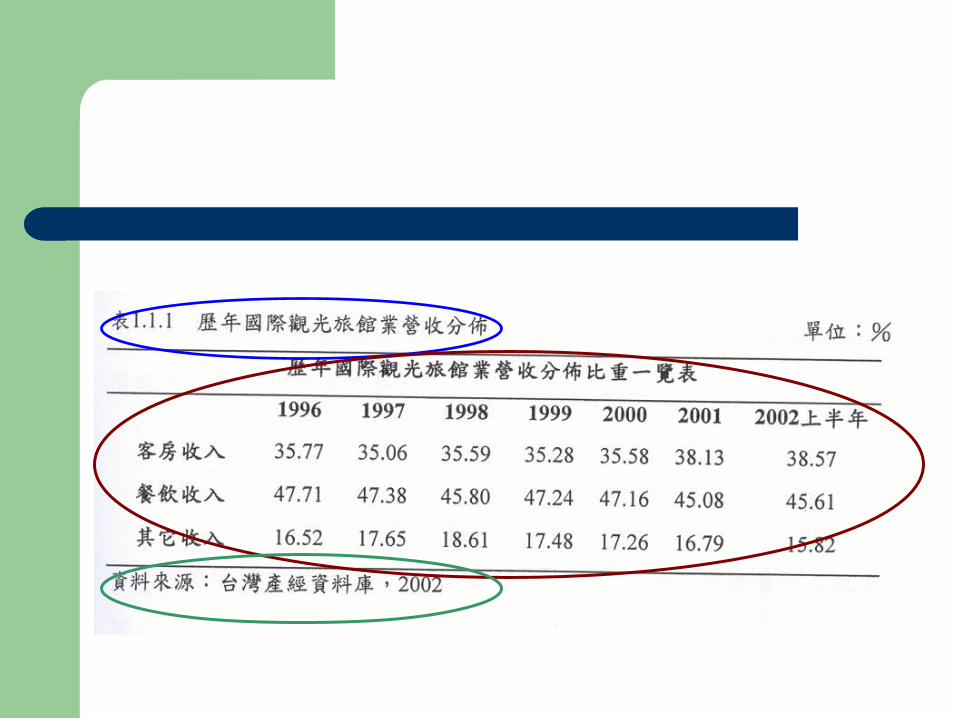
內容– 標題 (Title)– 表身 (Body)– 資料來源及附註

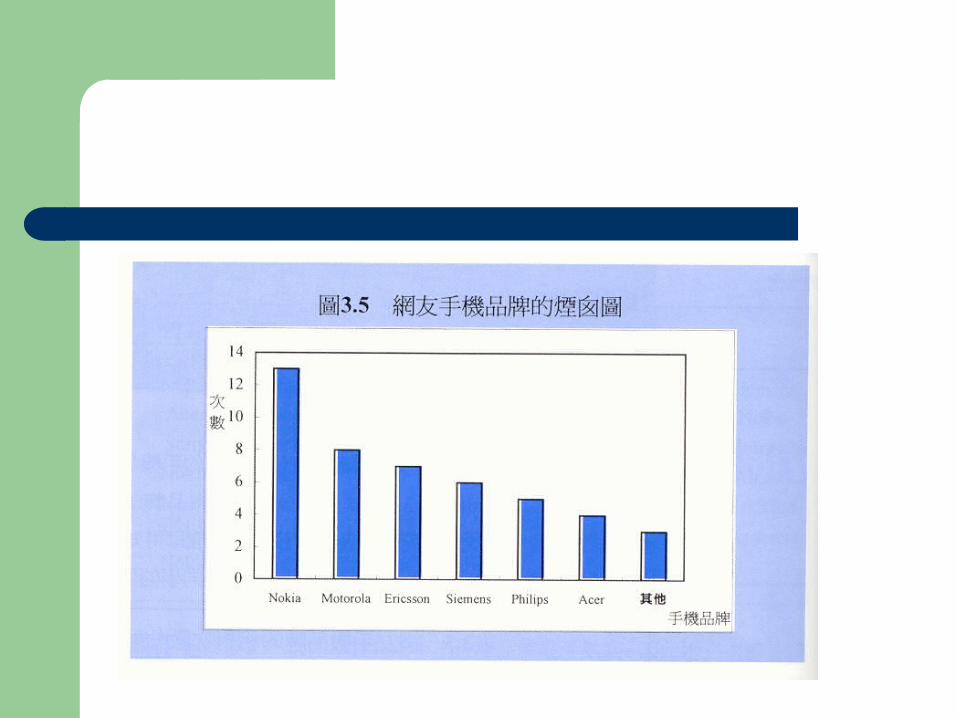
統計圖
種類– 條圖 (bar chart)– 餅圖 (pie chart)– 直方圖 (histogram)– 多邊圖 (polygon)– 枝葉圖 (stem-and-leaf display)

次數分配 Frequency Distributions
最基本的統計方法– 依據資料原始分數按照大小,發生次數予以分類,
以利觀察分析 & 解釋。– Frequency distribution table ( 表 )– Frequency distribution chart ( 圖 )

次數分配 for categorical data
依照類別分類,計算各組次數,顯示資料分佈情形
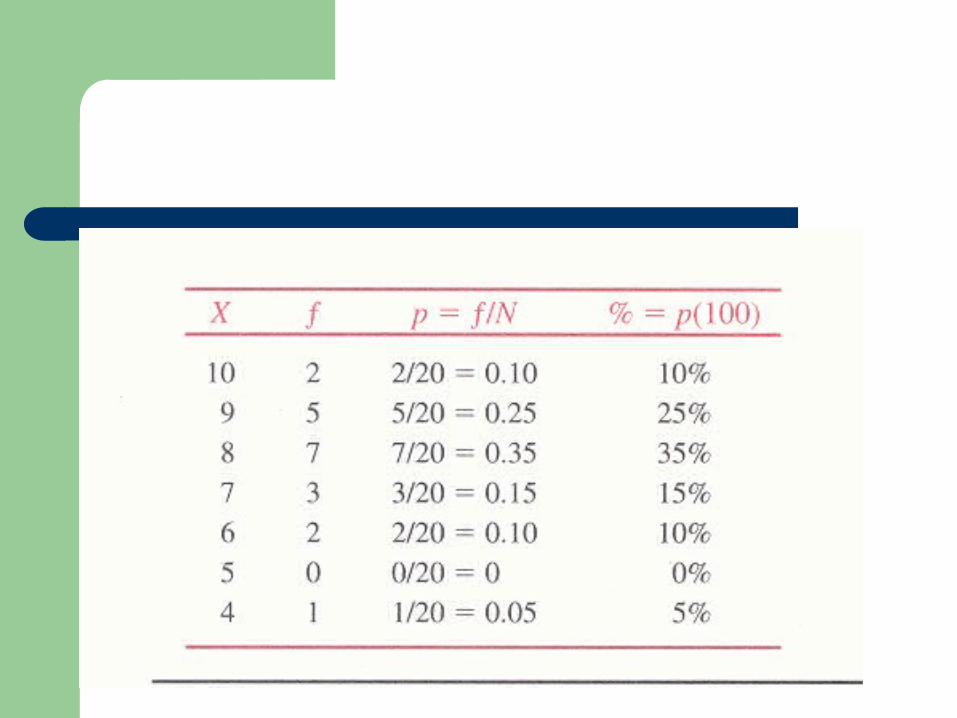
次數分配基本統計值– 類別– 次數 frequency– 相對次數 proportion– 百分比 percentage

Frequency distribution table (cont’)
Table 1 Frequency distribution of the Pilot Study Sample (N=117)
CategoryFrequency (f)
Percentage%
Cumulative Percentage(%)
GenderMaleFemaleSub total
5760117
48.751.3100
48.7100100
Industry experienceYesNoSub total
0710117
91.58.5100
91.5100100
If yes, length of industry experience (n=107)
Less than one year1~ less than 2 years2~ less than 3 yearsmore than 3 yearsSub total
24353810107
22.332.835.59.3100
22.355.190.6100100
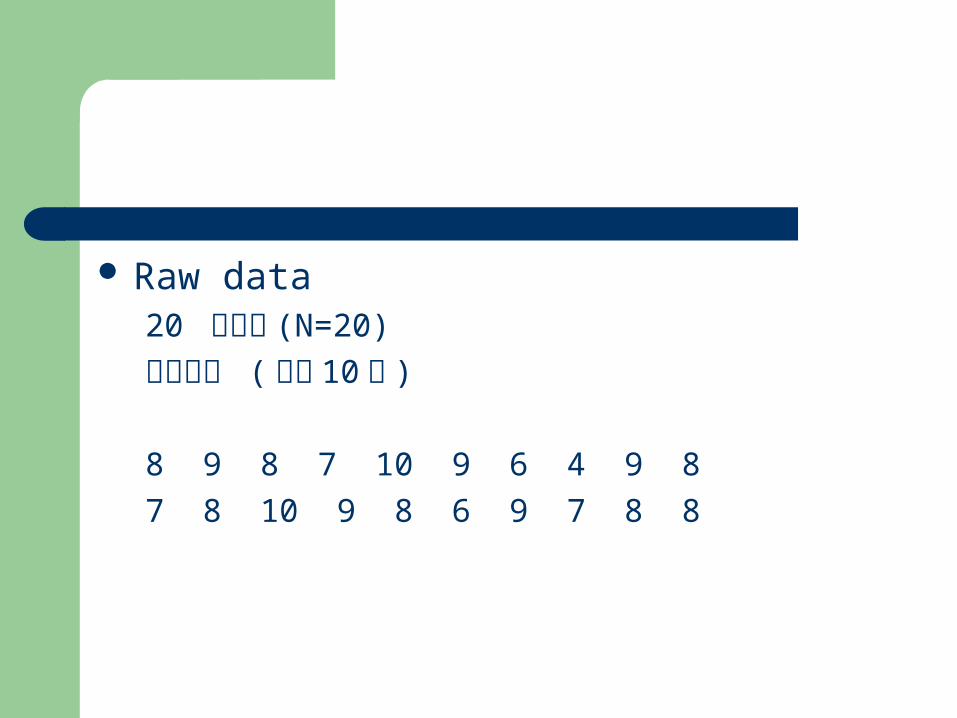
Raw data20 個學生 (N=20)
考試成績 ( 滿分 10 分 )
8 9 8 7 10 9 6 4 9 8
7 8 10 9 8 6 9 7 8 8




次數分配 for continuous data
連續資料的次數分配– 需將資料加以歸類以便讀者能一目了然資料分配狀
況– 將連續資料分成若干組,計算各組次數– 原始組數
rows=highest – lowest + 1
– 將原始組數縮減到較易 manage 的組數 分組原則
– 決定組數 10 組 – 決定組距 (interval width) 大小為 2 , 5 或 10 的倍數– Each interval should start with a score that is a multipl
e of the width– All interval should be the same width
n

排序 全距 (range) 決定組數 (# of interval) 組距 (interval width) = 全距 / 組數 決定組限 (real limit)

Example 2.3
25 位學生成績 (N=25)
82 75 88 93 53 84 87 58 72 94
69 84 61 91 64 87 84 70 76 89
75 80 73 78 60

1. 最低 53 最高 942. 全距 = 94-53=413. 組數 = = 54. 組距 =41/5=8.2 105. 區間組限 X f % 50-60 3 12 61-70 4 16 71-80 7 28 81-90 8 32 91-100 3 12 Total 25 100
1. 排序2. 全距 (range)3. 決定組數 (# of int
erval)4. 組距 (interval widt
h) = 全距 / 組數5. 決定區間組限 (rea
l limit)
25

Continuous variable creates continuous data– Infinite numbers
Real limits 區間組限– 界定出 continuous data 的上下界– Upper real limit – Lower real limit
Real limits vs. Apparent limits
Real limits vs. Apparent limits
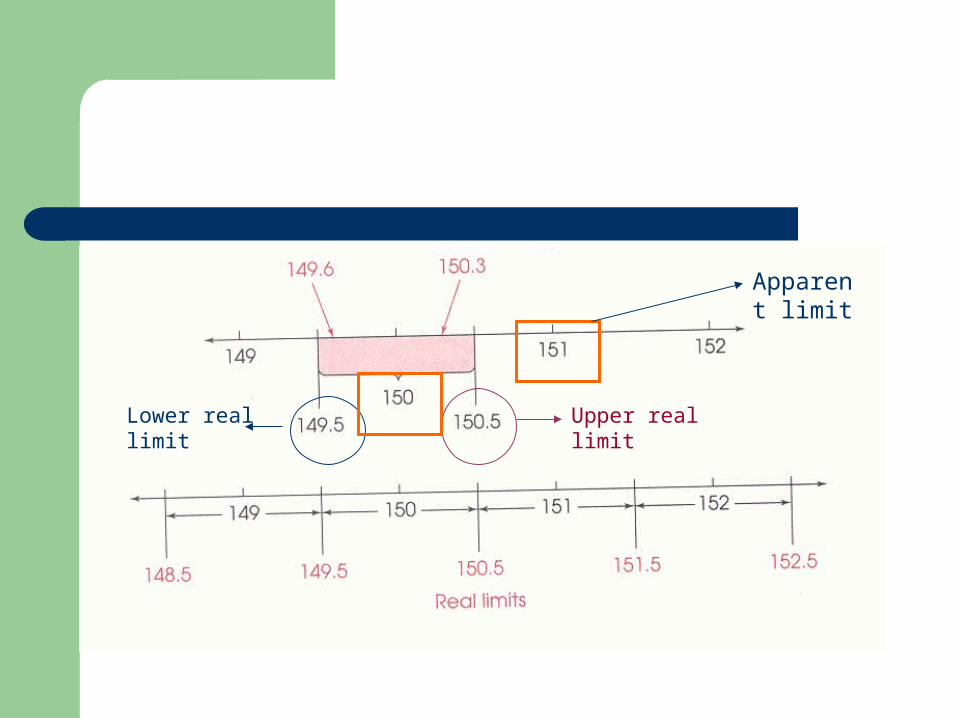
Lower real limit
Upper real limit
Apparent limit

Exercise 30 位學生體重
33 62 47 54 40 51 66 55 48 42
64 71 69 38 61 59 48 55 44 69
35 43 53 46 68 56 54 52 69 73
N=30
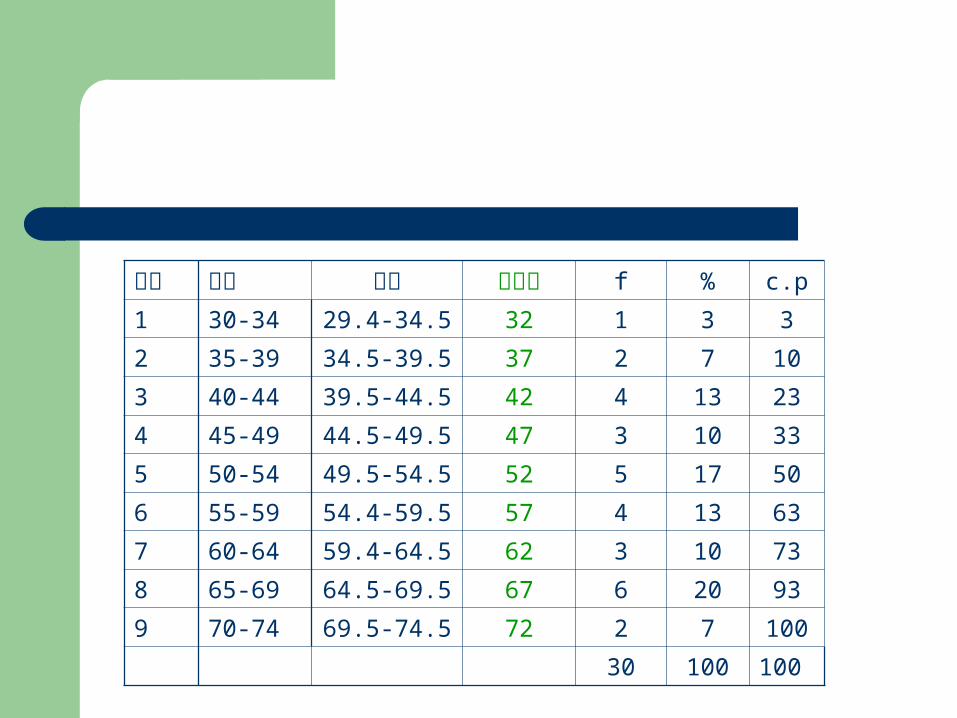
組別 組限 組界 組中點 f % c.p
1 30-34 29.4-34.5 32 1 3 3
2 35-39 34.5-39.5 37 2 7 10
3 40-44 39.5-44.5 42 4 13 23
4 45-49 44.5-49.5 47 3 10 33
5 50-54 49.5-54.5 52 5 17 50
6 55-59 54.4-59.5 57 4 13 63
7 60-64 59.4-64.5 62 3 10 73
8 65-69 64.5-69.5 67 6 20 93
9 70-74 69.5-74.5 72 2 7 100
30 100 100


Histogram 直方圖
適用於 continuous data 以呈現出連續資料的特質
Difference between a bar chart and a histogram: – Bar chart: distances between each bar.– Histogram: no distance among bars.– Bar chart is for categorical data
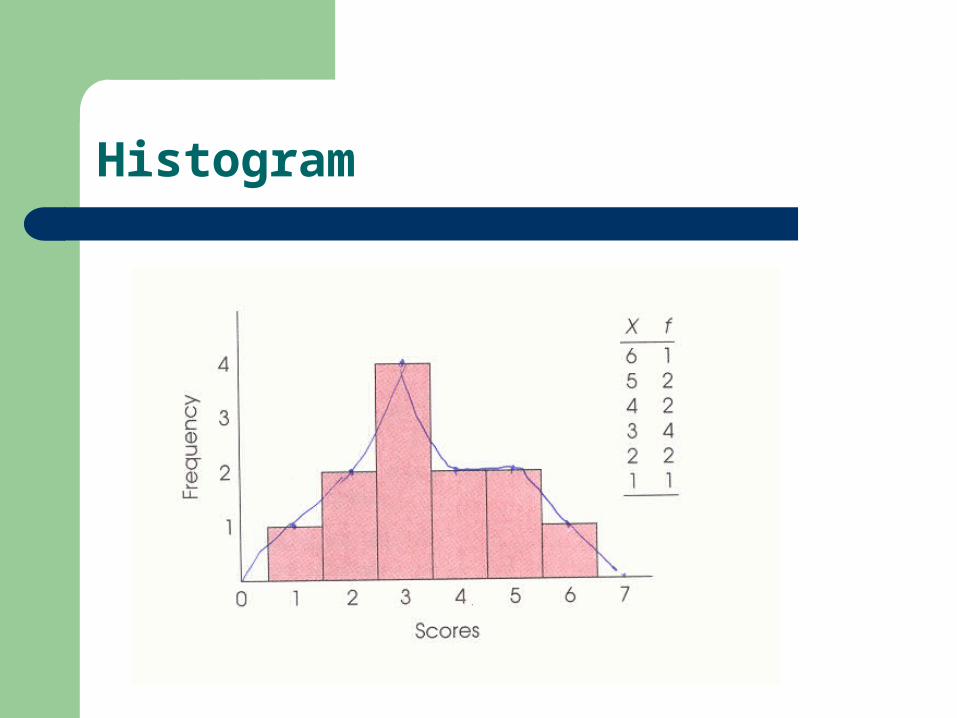
Histogram

多邊圖 polygon

Stem-and-Leaf Displays
An alternative to histograms
Display distributions using actual data values
Advantage is that no information is lost since all values are shown
Stem-first digit of each number Leaf-second digit

Stem-and-leaf example
English test scores:
78 66 98 93 72 83 67 32 77 92
47 79 83 76 74 82 53 89 30 82

3
4
5
6
7
8
9
2 0
7
3
6 7
8 9 7 6 2 4
3 2 3 9 2
8 3 2
3
4
5
6
7
8
9
0 2
7
3
6 7
2 4 6 7 8 9
2 2 3 3 9
2 3 8
重將 leaves
按照次序排好
OK!

3
4
5
6
7
8
9
0 2
7
3
6 7
2 4 6 7 8 9
2 2 3 3 9
2 3 8 3 4 5 6 7 8 9
0 2
7 3 6 7
2 4
6 7
8 9
2 2
3 3
9
2 3
8
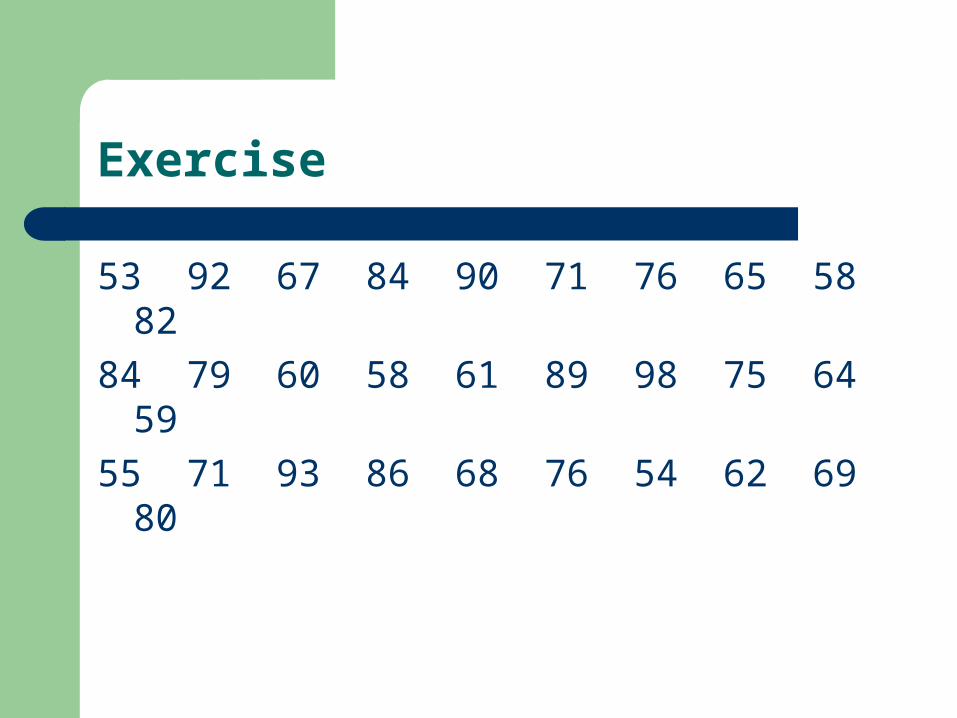
Exercise
53 92 67 84 90 71 76 65 58 82
84 79 60 58 61 89 98 75 64 59
55 71 93 86 68 76 54 62 69 80
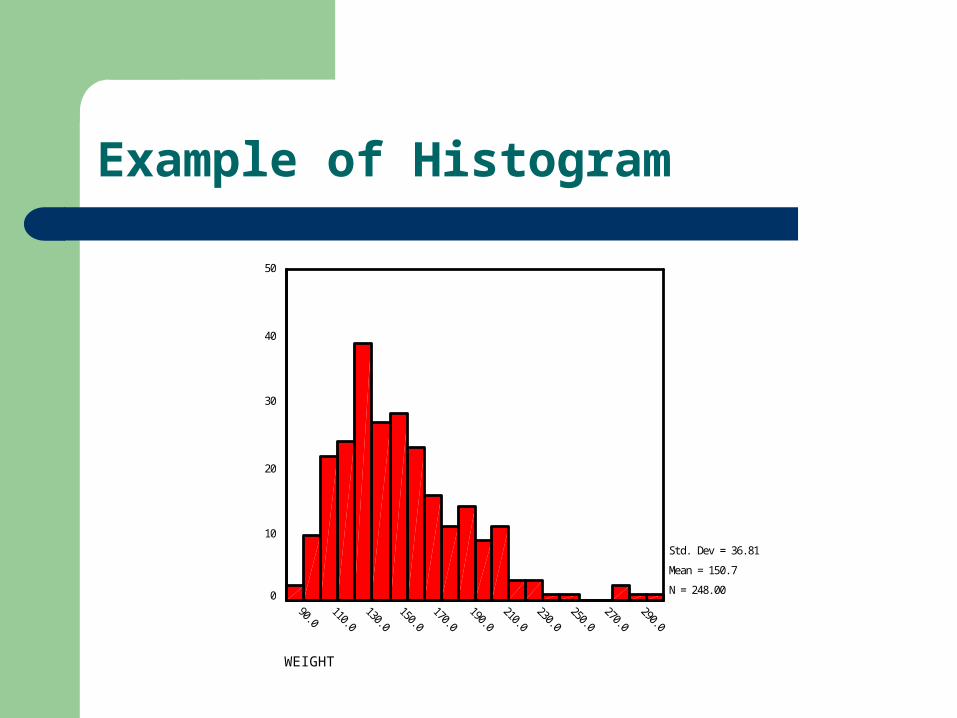
Example of Histogram
WEIGHT
50
40
30
20
10
0
Std. Dev = 36.81
Mean = 150.7
N = 248.00

資料的圖形分佈 Data distribution
資料分佈的三種特質 Shape 資料分佈形狀
– Symmetrical distribution– Skewed distribution
Central tendency 資料集中趨勢– 峰度
Variability 資料散佈狀態

資料形狀
Symmetric distributions 對稱分佈– are similar on both sides of the center
Skewed distributions 不對稱分佈– do not look the same on both sides of the center– Positive skew 右偏– Negative skew 左偏

Degree of skewness displayed by a histogram
WEIGHT
290.0270.0
250.0230.0
210.0190.0
170.0150.0
130.0110.0
90.0
50
40
30
20
10
0
Std. Dev = 36.81
Mean = 150.7
N = 248.00

資料集中趨勢
當次數分配有集中的趨勢 : 峰度 (Modality)– Unimodal distributions 單峰– Multimodal distributions 多峰
峰度高低平坦– Distributions can be described as flat (platykurtic),
peaked (leptokurtic), or normal (mesokurtic)– 常態峰度 mesokurtosis– 高狹峰 leptokurtosis– 低闊峰 platykurtosis

Modality displayed by a histogram
GRAMFAT
100.0
90.0
80.0
70.0
60.0
50.0
40.0
30.0
20.0
10.0
0.0
30
20
10
0
Std. Dev = 24.82
Mean = 54.1
N = 250.00

Distributional Spread
Any distribution of scores can be described in terms of its spread or dispersion
Kurtosis is another term associated with the spread or peakedness of the data
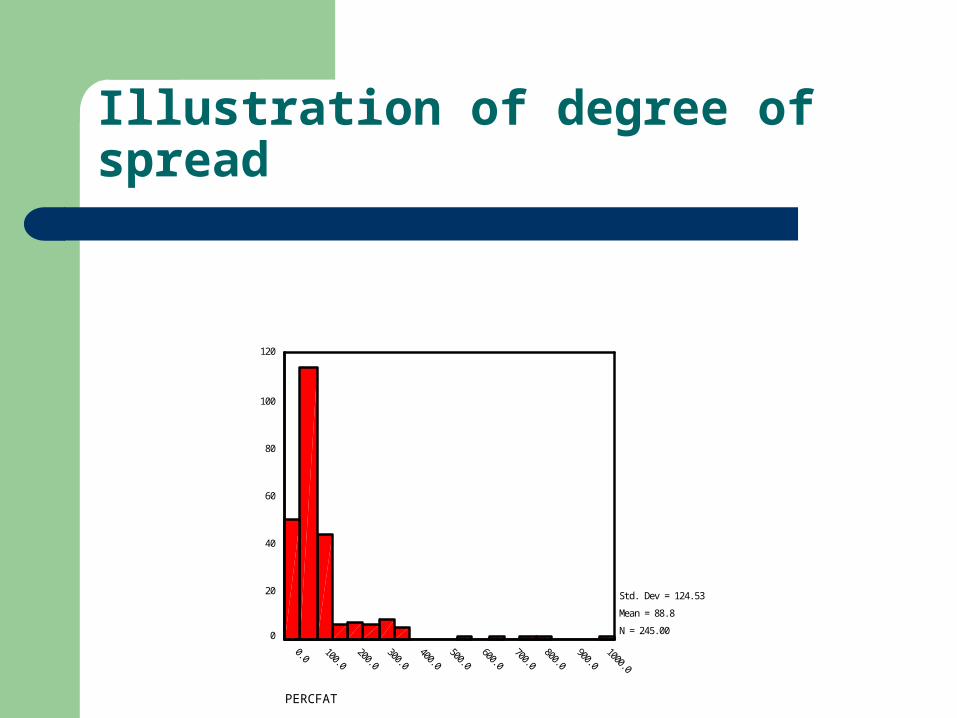
Illustration of degree of spread
PERCFAT
1000.0
900.0800.0
700.0600.0
500.0400.0
300.0200.0
100.00.0
120
100
80
60
40
20
0
Std. Dev = 124.53
Mean = 88.8
N = 245.00