Embed Size (px)
Citation preview

Statystyka – powtórzenie (II semestr)
©Rafał M. Frąk

TEORIA, OZNACZENIA,
WZORY

Rodzaje miar statystycznych miary położenia
- wyznaczają przeciętna wartość cechy statystycznej miary zróżnicowania (lub zmienności, rozproszenia,
dyspersji)- wyznaczają siłę zróżnicowania wartości cechy statystycznej
miary asymetrii (skośności)- wyznaczają siłę skupienia wartości cechy statystycznej bliżej dolnej lub górnej granicy zbioru wartości
miary spłaszczenia (koncentracji)- wyznaczają siłę skupienia wartości cechy statystycznej wokół wartości przeciętnej

Oznaczenia
}{ neee ,...,, 21
.
n-elementowa zbiorowość statystyczna
X, Y, Z cechy statystyczne
x, y, z wartości cech statystycznych
ix wartość, jaką przyjmuje cecha na i-tym elemencie zbiorowości

Średnia arytmetyczna
∑=
=
=ni
iixnx
1
1 oznacza i–tą obserwację ze zbioru obserwacji indywidualnych.ix
- Dla zbiorowości statystycznej (wartości cechy pogrupowane w przedziały:
- Dla małej zbiorowości statystycznej (bez konieczności grupowania danych w przedziały):
∑=
=
=Kk
kk
o
k xnnx1
1 k
ox
K oznacza ilość wariantów cechy statystycznej
oznacza k–ty wariant cechy lub środek k-tego przedziału.

Średnie pozycyjne - Moda (dominanta)
Moda jest to wartość cechy statystycznej najliczniej reprezentowana w zbiorze obserwacji, czyli wartość występująca z największą częstością.
Moda musi być pojedynczą wartością. Jeśli w zbiorze obserwacji nie istnieje pojedyncza wartość cechy statystycznej występująca najczęściej, to moda nie istnieje w tej zbiorowości.
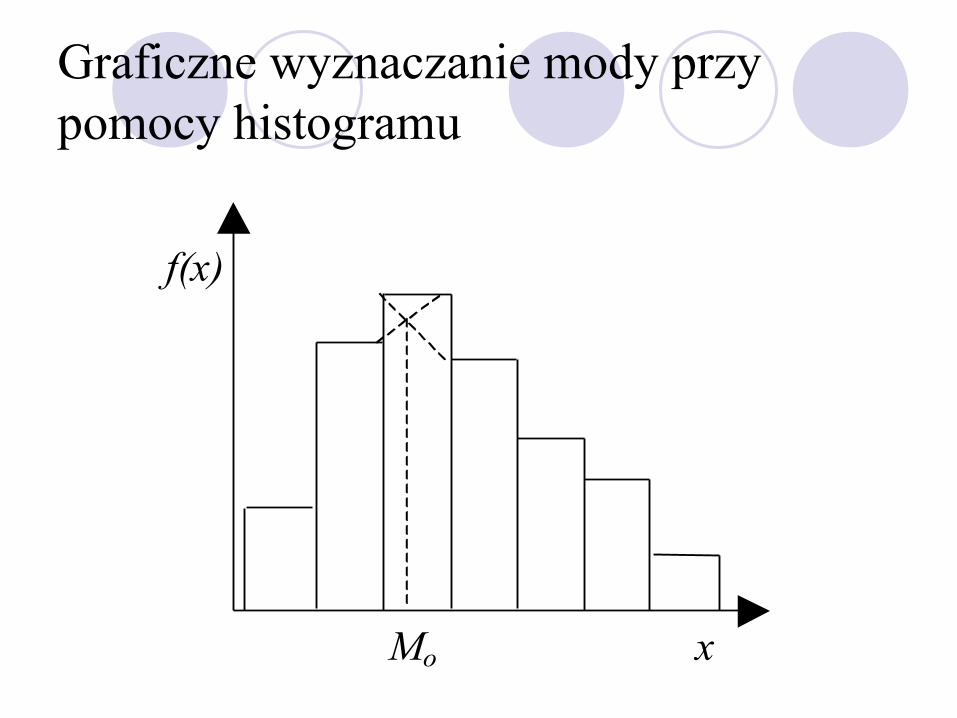
Graficzne wyznaczanie mody przy pomocy histogramu
f(x)
Mo x

Wyznaczanie mody – dla rozkładu ciągłego
( ) ( )
moda z przedzialu dlugosc moda z przedziale
po egonastepujac przedzialu liczebnosc moda z przedzial
acegopoprzedzaj przedzialu liczebnosc moda z przedzialu liczebnosc
moda z przedzialu granica dolna
1
1
11
1
−∆
−
−−−
−+−−∆+≈
+
−
+−
−
d
d
d
d
dddd
dddo
n
nnx
nnnnnnxM

Średnie pozycyjne - Mediana (wartość środkowa)
Mediana jest to wartość cechy statystycznej, dzieląca zbiór obserwacji na 2 liczebnie równe części (zbiór obserwacji o wartościach mniejszych lub równych oraz zbiór obserwacji o wartościach większych lub równych od wartości mediany).

Wyznaczanie mediany – dla rozkładu ciągłego
mediana z przedzialu dlugosc mediana z przedzialu liczebnosc
mediany przedzialacych poprzedzaj
wprzedzialo dla askumulowan liczebnosc
mediana z przedzialu granica dolna 2
1
1
1
1
1
−∆−
−
−
∆
−++≈
∑
∑
−
=
−
=
d
d
kk
d
d
d
kkde
n
n
xn
nnxM

Miary zróżnicowania
miary zróżnicowania zwane również miarami zmienności, rozproszenia lub dyspersji pozwalają określić jakie jest zróżnicowanie wartości cechy statystycznej w zbiorze obserwacji
(jak mocno „rozproszone” są poszczególne obserwacje)

WariancjaMierzy ona średni rozrzut wartości
zmiennej losowej od jej wartości średniej.Intuicyjnie wariancja utożsamiana jest ze
zróżnicowaniem zbiorowości.
22
1
22 )()(1)( xxxxnxsni
ii −== ∑
=
=
− ∑=
=
=ni
iixnx
1
22 1
22
1
22 )()(1)( xxxxnnxsKk
kk
o
k −== ∑=
=
− ∑=
=
=Kk
kk
o
k xnnx1
22 1

Odchylenie
Odchylenie rozumiemy jako różnicę między dwiema wartościami (intuicyjnie oznacza odchylenie jednej wartości od drugiej).
Odchylenie standardowe opisuje rozrzut wartości zmiennej losowej wokół średniej arytmetycznej.
)()( 2 xsxs =

Reguła „trzech sigm”
Regułę trzech sigm rozpatrujemy w oparciu o własności rozkładu normalnego:w przedziale od średnia-3s do średnia+3s
zawiera się około 99% obserwacji,w przedziale od średnia-2s do średnia+2s
zawiera się około 95% obserwacji,w przedziale od średnia-s do średnia+s
zawiera się około 68% obserwacji.

Ilustracja reguły trzech sigm

Typowy obszar zmienności
Typowy obszar zmienności nawiązuje do reguły trzech sigm
Typowy obszar zmienności ma największe zastosowanie w przypadku, gdy dane są wyraźnie skupione wokół wartości średniej
Typowy obszar zmienności ma postać:
)](),([ xsxxsx +−

Pozycyjne miary rozproszeniaWspółczynnik zmienności informuje o sile
rozproszenia.
Klasyczny współczynnik zmienności:
%100)(xxsVs =

Miary asymetriiAsymetria rozkładu cechy statystycznej
oznacza, że elementy zbiorowości statystycznej skupiają się bliżej dolnej albo bliżej górnej granicy tej zbiorowości.
Jeśli jednostki zbiorowości skupiają się bliżej mniejszych wartości cechy, to mówimy, że asymetria jest prawostronna.
Jeśli jednostki zbiorowości skupiają się bliżej większych wartości cechy, to mówimy, że asymetria jest lewostronna.

1 współczynnik asymetrii Pearsona
Współczynnik ten może zostać obliczony tylko wtedy,gdy możliwe jest wyznaczenie mody.
)(1 xsMxW o
s−=

2 współczynnik asymetrii Pearsona
Współczynnik ten jest obliczany przy pomocymediany.
)(2 xsMxW e
s−=

Interpretacja współczynników asymetrii
alewostronn asymetria0naprawostron asymetria0
ysymetryczn rozklad 0
→<→>→=
s
s
s
WWW

Schemat przeprowadzania badania opisowej analizy struktury
1. Planowanie badania2. Uzyskiwanie danych3. Ocena jakości i poprawności danych4. Czyszczenie danych5. Porządkowanie i grupowanie danych6. Prezentacja tabelaryczna danych7. Prezentacja graficzna danych8. Wybór i wyznaczenie miar opisowych9. Wnioski końcowe

Analiza dwuwymiarowa
Analiza dwuwymiarowa rozpatruje parę zmiennych losowych jako integralną całość.
Głównym zadaniem analizy dwuwymiarowej jest wykazanie czy między badanymi zmiennymi istnieje współzależność (związek).

Kierunek współzależności
Kierunek współzależności może być:- dodatniwraz ze wzrostem wartości cechy X rosną też wartości cechy Y (i na odwrót)- ujemnywraz ze wzrostem wartości cechy X maleją wartości cechy Y (i na odwrót)

Rodzaje współzależnościFunkcyjna- zmiana wartości zmiennej X powoduje ściśle określoną zmianę wartości zmiennej YStochastyczna- wraz ze zmianami wartości zmiennej X zmienia się rozkład prawdopodobieństw zmiennej YKorelacyjna- określonym wartościom zmiennej X są przyporządkowane średnie z kilku wartości zmiennej Y

Tablica korelacyjna

Y zmiennej wariantowilosc - m :gdzie
X zmiennej brzegowe iliczebnosc - 1
∑=
=• =
mj
jiji nn
X zmiennej wariantowilosc -r :gdzie
Y zmiennej brzegowe iliczebnosc - 1
∑=
=• =
ri
iijj nn
calkowita liczebnosc - 1 1
∑ ∑=
=
=
=
=ri
i
mj
jijnn
Y) zmiennej wariantu tego-j do oraz X zmiennejwariantu
tego-i donalezy obserwacji (tyle absolutne iliczebnosc - ijn

Tablica korelacyjna - przykład
Y [2000, 3000]
(3000, 4000]
(4000, 5000]
(5000, 6000]
X 2500 3500 4500 5500 ------
[0, 10] 5 12 1 0 0 13
(10, 20] 15 13 17 1 0 31
(20, 30] 25 0 35 8 0 43
(30, 40] 35 0 0 10 3 13
------- 25 53 19 3 100
•in
jn•
j
o
i
oyx \

Rozkłady brzegowe i warunkowe
Rozkład brzegowy prezentuje strukturę wartości jednej zmiennej (X lub Y) bez względu na kształtowanie się wartości drugiej zmiennej. Rozkład warunkowy prezentuje strukturę wartości jednej zmiennej (X lub Y), pod warunkiem, że druga zmienna przyjęła określoną wartość.

Rozkład brzegowy dla zmiennej Y - przykład
Y
2000-3000 2500 25
3000-4000 3500 53
4000-5000 4500 19
5000-6000 5500 3
SUMA ------------- 100
j
oy jn•

Rozkład warunkowy: X | Y= 2500 - przykład
X
0 – 10 5 12
10 – 20 15 13
20 – 30 25 0
30 – 40 35 0
SUMA -----
i
ox 1in
251 =•n

Średnie brzegowe
∑=
=•=
ri
ii
o
i xnnx1
1
∑=
=•=
mj
jj
o
j ynny1
1

Wariancje brzegowe
22
1
22 )(1)( xxxxnn
xsri
ii
o
i −== ∑=
=
−•
∑=
=•=
ri
i
o
ii xnn
x1
22 1

Średnie warunkowe
∑=
=•==
ri
ii
o
ijj
j xnnx1
j1 :yY | X zmiennej Dla
∑=
=•==
mj
jj
o
iji
i ynny1
i1 :xX | Y zmiennej Dla

Tablica korelacyjna – wyznaczanie korelacji
Jeśli wraz ze wzrostem konkretnych wartości jednej zmiennej można zaobserwować wzrost warunkowych średnich drugiej zmiennej, to fakt ten świadczy o istnieniu korelacji (współzależności) DODATNIEJ między tymi zmiennymi.
mjmj
riri
xxxxyyyy
yyyyxxxx
<<<<<→<<<<<
<<<<<→<<<<<
...... ......ALBO
...... ......
2121
2121

Tablica korelacyjna – wyznaczanie korelacji
Jeśli wraz ze wzrostem konkretnych wartości jednej zmiennej można zaobserwować spadek warunkowych średnich drugiej zmiennej, to fakt ten świadczy o istnieniu korelacji UJEMNEJ między tymi zmiennymi.
mjmj
riri
xxxxyyyy
yyyyxxxx
>>>>>→<<<<<
>>>>>→<<<<<
............ALBO
............
2121
2121

Miary siły korelacji
Natomiast do pomiaru siły korelacji służą następujące wielkości:
- Współczynnik zbieżności Czuprowa,- Współczynnik korelacji liniowej Pearsona.

Współczynnik zbieżności Czuprowa
Służy do określenia siły zależności, bądź stwierdzenia jej braku.Niestety NIE można przy jego pomocy wskazać kierunku współzależności.

Współczynnik zbieżności Czuprowa
Jeśli Txy = Tyx = 0, to badane cechy X i Y są stochastycznie niezależne(brak współzależności).
Jeśli Txy = Tyx = 1, to badane cechy X i Y łączy zależność funkcyjna(całkowita współzależność).

Współczynnik korelacji liniowej Pearsona
Jest powszechnie stosowaną miarą siły związku prostoliniowego między dwiema cechami mierzalnymi (zmienne typu ciągłego).Przy jego pomocy możemy wykryć jedynie prostoliniową współzależność między zmiennymi (NIE krzywoliniową).Służy jednocześnie zarówno do określenia siły zależności, jak też do wskazania jej kierunku.

Współczynnik korelacji liniowej Pearsona
)()(),cov(ysxsyxrr yxxy ==
Wyraża się następującym wzorem:
cov(x, y) – tzw. „kowariancja” zmiennych X i Ys(x) – odchylenie standardowe zmiennej X(dla rozkładu brzegowego zmiennej X)s(y) – odchylenie standardowe zmiennej Y(dla rozkładu brzegowego zmiennej Y)

Współczynnik korelacji liniowej Pearsona
Ostatecznie kowariancja zmiennych X i Y określona jest w następujący sposób:
∑ ∑=
=
=
=
⋅−=ri
i
mj
jj
o
i
o
ij yxyxnn
yx1 1
)(1),cov(
Y i Xlosowych zmiennych brzegowe srednie - , yx

Współczynnik korelacji Pearsona
Jeśli rxy = ryx = 0, to badane cechy X i Y są niezależne pod względem liniowości(brak współzależności prostoliniowej, co nie wyklucza istnienia zależności krzywoliniowej).
Jeśli rxy = ryx = 1, to badane cechy X i Y łączy pełna zależność prostoliniowa dodatnia.
Jeśli rxy = ryx = -1, to badane cechy X i Y łączy pełna zależność prostoliniowa ujemna.

Miary krzywoliniowości
Do współczynników mierzących współzależność krzywoliniową należą:
- współczynnik korelacji rang Spearmana- współczynnik Yule'a- współczynnik V Cramera- współczynnik kontyngencji C Pearsona
ϕ

Idea wyznaczania funkcji regresji
Stwierdzenie, że 2 aspekty dotyczące pewnego zjawiska są współzależne i w jakim stopniu, bywa niewystarczające.Zwykle jesteśmy zainteresowani określeniem dokładniejszej postaci zależności między badanymi cechami.Jednym z narzędzi służących do tego celu jest wykorzystanie funkcji regresji.

Idea wyznaczania funkcji regresji
Z drugiej strony, funkcja regresji służy do przybliżenia wartości jednej zmiennej w zależności od wartości drugiej zmiennej.Ogólnie mówiąc, jest to więc sposób predykcji, czyli prognozowania wartości określonej zmiennej losowej w zależności od innych zmiennych losowych.

Regresja empiryczna
Jest to funkcyjne przyporządkowanie średnich warunkowych zmiennej zależnej konkretnym wartościom zmiennej niezależnej.Aby określić średnie warunkowe, potrzebne jest zestawienie danych w tablicy korelacyjnej

Regresja empiryczna
Funkcje regresji empirycznych można przedstawić następująco:- regresja zmiennej Y względem zmiennej X i = 1, 2, …, r - liczba przedziałów zmiennej X
- regresja zmiennej X względem zmiennej Y
j = 1, 2, …, m - liczba przedziałów zmiennej Y
= i
o
i xgy
= j
o
j yfx

Regresja liniowa
W praktyce dość często spotyka się liniową postać współzależności między badanymi cechami.W większości przypadków przybliżenie uzyskane przez zastosowanie funkcji liniowej jest wystarczające.Liniowa funkcja regresji służąca do badania zależności zmiennej Y od zmiennej X ma postać:
yyy XY εβα ++=

Regresja liniowa
W praktyce stosować będziemy linię regresji teoretycznej:
yy bXaY +=ˆ
2
11
2
111
−
−=
∑∑
∑∑∑
==
===
n
ii
n
ii
n
ii
n
ii
n
iii
y
xxn
yxyxna xayb yy −=

Ocena dokładności oszacowania
Oszacowanie wariancji składnika losowego uy
Oszacowanie błędu wyznaczenia parametru aOszacowanie błędu wyznaczenia parametru bObliczenie współczynnika zbieżnościObliczenie współczynnika determinacji

Oszacowania reszt (składnik losowy)
Y zm. wartoscna)(teoretycz estymowana - ˆY zm. wartosca)(empiryczn arzeczywist - y
..., 3, 2, ,1 ;ˆ
i
i
iii
y
niyyu =−=

Błędy oszacowań parametrów strukturalnych
( ) ( ) ( )
( )∑∑==
−=
−=
n
ii
n
ii
y
xx
us
xnx
usas
1
22
1
2
( )( ) ( )
( )∑
∑
∑
∑
=
=
=
=
−=
−
= n
ii
n
ii
n
ii
n
ii
y
xxn
xus
xnxn
xusbs
1
2
1
22
1
22
1
22
( ) ( ) ∑∑== −
=−−
=n
ii
n
iii u
nyy
nus
1
2
1
22
21ˆ
21
( )%100⋅=
y
ya a
asV
( )%100⋅=
y
yb b
bsV

Współczynniki zbieżności i determinacji
( )( )
( )
( )%100
ˆ%100
1
2
1
2
2
22 ⋅
−
−=⋅=
∑
∑
=
=n
ii
n
iii
yy
yy
ysusϕ
( )( )
22
22 11 ϕ−=−=
ysusR
( )( )
( )
( )%100
ˆ%100
ˆ
1
2
1
2
2
222 ⋅
−
−=⋅==
∑
∑
=
=n
ii
n
ii
xy
yy
yy
ysysrR

PRZYKŁADYZADAŃ

ZADANIE 1Przeprowadź analizę statystyczną dla następującej zbiorowości pracowników pod względem cechy X (X – miesięczne wynagrodzenie pracowników w EURO).Wartości cechy uszeregowano w przedziały:[250, 350] – 1 osoba ; [350, 450] – 4 osoby ;[450, 550] – 6 osób ; [550, 650] – 3 osoby.
- Przedstaw powyższą zbiorowość w tabeli roboczej, sporządź histogramy (częstości absolutnych i skumulowanych).
- Oblicz i zinterpretuj następujące miary statystyczne w podanej zbiorowości: - średnia arytmetyczna, moda, mediana - typowy obszar zmienności, klasyczny współcz. zmienności - współczynniki asymetrii Pearsona

ZADANIE 2Przebadano małą zbiorowość pracowników pod kątem
cech statystycznych:X – staż pracy i Y – wynagrodzenie. Rezultat badania
przedstawiono w tablicy korelacyjnej:
Y 1000-1200
1200-1400
1400-1600 SUMA
X ---------
0-2 1 0 1
2-4 0 5 0
4-6 2 0 4
SUMA ----------
j
o
i
oyx \

ZADANIE 2
- Uzupełnij tablicę korelacyjną- Wyznacz rozkład warunkowy zmiennej
X | Y = 1500.- Sprawdź przy pomocy współczynnika
korelacji liniowej Pearsona czy między zmiennymi X i Y zachodzi współzależność. Zinterpretuj otrzymany wynik.

ZADANIE 3
Y [2000, 3000]
(3000, 4000]
(4000, 5000]
X 2500 3500 4500 ------
[0, 10] 5 1 0 8 9
(10, 20] 15 0 5 0 5
(20, 30] 25 5 10 3 18
------- 6 15 11 32
•in
jn•
j
o
i
oyx \

ZADANIE 3
- Wyznacz model regresji empirycznej dla wynagrodzenia (zmienna Y) względem stażu pracy (zmienna X), na podstawie danych zawartych w tablicy korelacyjnej.
- Przedstaw empiryczną funkcję regresji na wykresie.

ZADANIE 4W zamieszczonej tabeli przedstawione zostały dane w postaci obserwacji indywidualnych dotyczące czasu przygotowania do egzaminu testowego (X) i wyników uzyskanych z tego testu (Y) dla grupy 6-ciu studentów.
i ix iy
1 7 42
2 10 55
3 15 67
4 17 74
5 17 70
6 13 59
Razem 79 367

Wykorzystując powyższe dane należy:- sporządzić wykres prezentujący zależność między wynikami egzaminu (Y) oraz czasem przygotowania (X),- jeśli to możliwe i uzasadnione sformułować model regresji liniowej,- oszacować parametry strukturalne modelu regresji liniowej (ay, by),- wyznaczyć i zinterpretować następujące wielkości:błędy oszacowań parametrów strukturalnych, współczynnik zbieżności oraz determinacji.
ZADANIE 4







![WODA Prezentacja [tryb zgodno ci] - pracownik.kul.pl · Woda bezbarwna, bezwonna, pozbawiona smaku i kalorii jest niezbędna do Ŝycia wszystkim organizmom na ziemi. Bez niej nie](https://img.pdfslide.tips/doc/110x75/5c76bbe309d3f29a548b588c/woda-prezentacja-tryb-zgodno-ci-woda-bezbarwna-bezwonna-pozbawiona-smaku.jpg)


















![wiatr [tryb zgodno ci] - pracownik.kul.pl · wplywa na zachowanie si ę i obyczaje zwierz ąt, pokrój i budow ę ... jest ni Ŝsze ni Ŝ na powierzchni l ądu, co powoduje zmian](https://img.pdfslide.tips/doc/110x75/5c793bfb09d3f2fb438c5d9c/wiatr-tryb-zgodno-ci-wplywa-na-zachowanie-si-e-i-obyczaje-zwierz-at-pokroj.jpg)


