Embed Size (px)
Citation preview

Temporal Difference Learning
• Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung imReinforcement Lernen.
• Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Pro-grammierung (DP) Methoden kombiniert.
• Im TD Lernen wird wie beim MC Lernen aus Erfahrung ohne Kenntnisseines Modells gelernt, d.h. dieses wird aus Daten/Beispielen gelernt.
• Wie beim DP werden Schätzungen für Funktionswerte durchgeführt(V π(s) oder Qπ(s, a)), die wiederum auf Schätzungen basieren (nämlichdie Schätzungen V π(s′) nachfolgender Zustände).
• Wir beginnen mit der Evaluation von Policies π, d.h. mit der Berechnungder Wertefunktionen V π bzw. Qπ.
F. Schwenker Reinforcement Learning 85

TD Evaluation
• TD und MC Methoden nutzen Erfahrung aus Beispiele um V π bzw. Qπ füreine Policy π zu lernen.
• Ist st der Zustand zur Zeit t in einer Episode, dann basiert die Schätzungvon V (st) auf den beobachteten Return Rt nach Besuch des Zustand st
• In MC Methoden wird nun der Return Rt bis zum Ende der Episode be-stimmt und dieser Schätzwert für V (st) angesetzt.
• Eine einfache Lernregel nach der Every Visit MC Methode hat dann diefolgende Gestalt:
V (st) := V (st) + α [Rt − V (st)] mit α > 0
• In den einfachen 1-Schritt TD Methoden nur der nächste Zustandsüber-gang s → s′ abgewartet und der unmittelbar erzielte Reward zusammenmit V (s′) benutzt.
F. Schwenker Reinforcement Learning 86

• Ein 1-Schritt TD Algorithmus, der sog. TD(0) Algorithmushat die Lernregel
V (st) := V (st) + α [rt+1 + γV (st+1) − V (st)] α > 0, γ ∈ (0, 1]
• Zur Erinnerung– es gilt
V π(s) = Eπ
{
Rt | st = s}
= Eπ
{
∞∑
k=0
γkrt+1+k | st = s}
= Eπ
{
rt+1 + γ
∞∑
k=0
γkrt+2+k | st = s
}
= Eπ {rt+1 + γV π(st+1) | st = s}
• Sollwert beim MC Lernen : Rt
• Sollwert beim TD Lernen : rt+1 + γV π(st+1)
F. Schwenker Reinforcement Learning 87
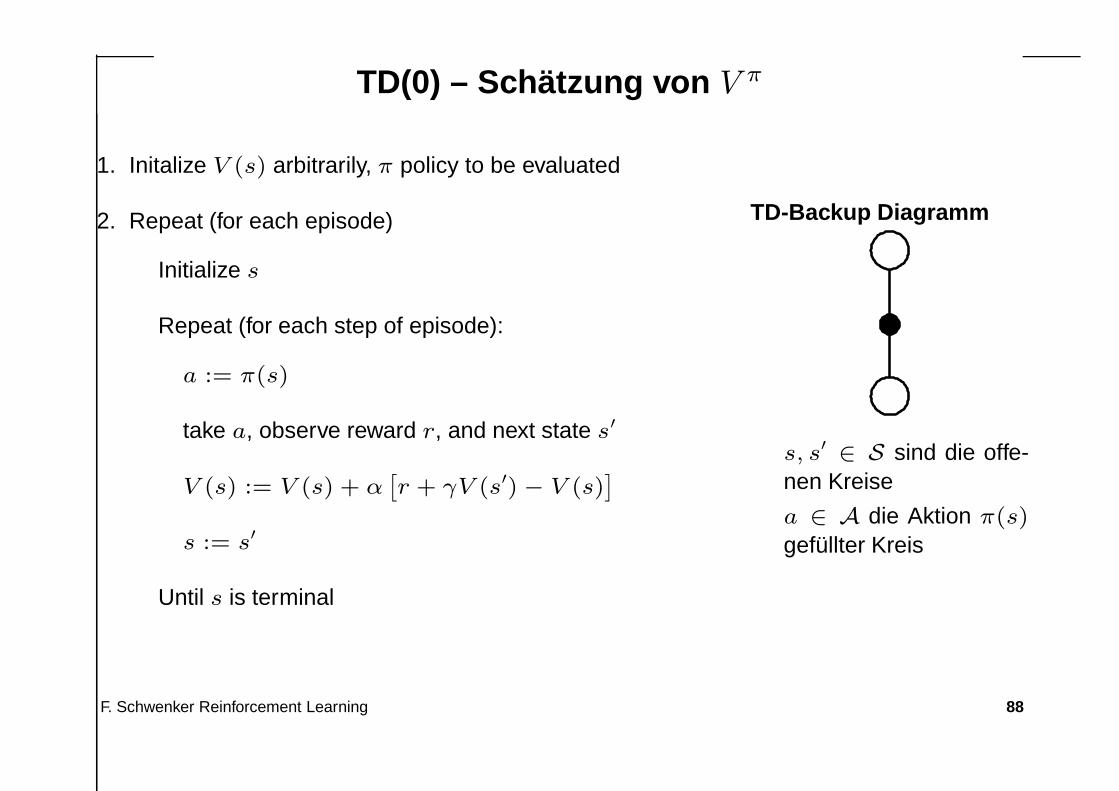
TD(0) – Schätzung von V π
1. Initalize V (s) arbitrarily, π policy to be evaluated
2. Repeat (for each episode)
Initialize s
Repeat (for each step of episode):
a := π(s)
take a, observe reward r, and next state s′
V (s) := V (s) + α[
r + γV (s′) − V (s)]
s := s′
Until s is terminal
TD-Backup Diagramm
s, s′∈ S sind die offe-
nen Kreise
a ∈ A die Aktion π(s)
gefüllter Kreis
F. Schwenker Reinforcement Learning 88
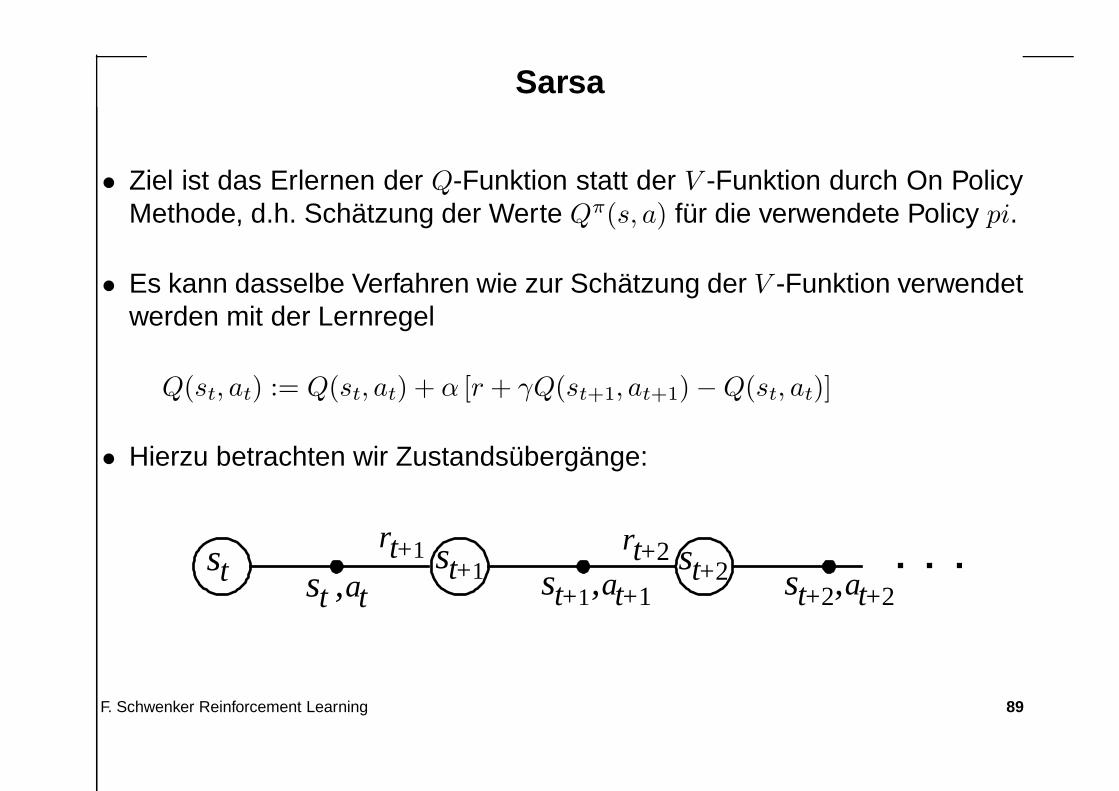
Sarsa
• Ziel ist das Erlernen der Q-Funktion statt der V -Funktion durch On PolicyMethode, d.h. Schätzung der Werte Qπ(s, a) für die verwendete Policy pi.
• Es kann dasselbe Verfahren wie zur Schätzung der V -Funktion verwendetwerden mit der Lernregel
Q(st, at) := Q(st, at) + α [r + γQ(st+1, at+1) − Q(st, at)]
• Hierzu betrachten wir Zustandsübergänge:
st+2,at+2st+1,at+1
rt+2rt+1st st+1st ,atst+2
F. Schwenker Reinforcement Learning 89

Sarsa: Algorithmus
1. Initalize Q(s, a) arbitrarily,
2. Repeat (for each episode)
Initialize s
Choose a from s using policy derived from Q (e.g. ε-greedy)
Repeat (for each step of episode):
Take a, observe reward r, and next state s′
Choose a′ from s′ using policy derived from Q (e.g. ε-greedy)
Q(s, a) := Q(s, a) + α[
r + γQ(s′, a′) − Q(s, a)]
s := s′; a := a′
Until s is terminal
F. Schwenker Reinforcement Learning 90

Q-Learning
Q-Lernen ist das wichtigste Verfahren im Bereich des Reinforcement Ler-nens, es wurde von Watkins 1989 entwickelt.
Ist ein Off Policy TD Lernverfahren definiert durch die Lernregel
Q(st, at) := Q(st, at) + α[
r + γ maxa
Q(st+1, a − Q(st, at)]
Q konvergiert direkt gegen Q∗ (vereinfacht die Analyse des Verfahrens).
Policy π legt die Aktion fest, und somit wird durch π die Folge von (st, at)festgelegt, die in der Episode vorkommen (und damit auch die Stellen anden die Q-Funktion gelernt wird).
F. Schwenker Reinforcement Learning 91
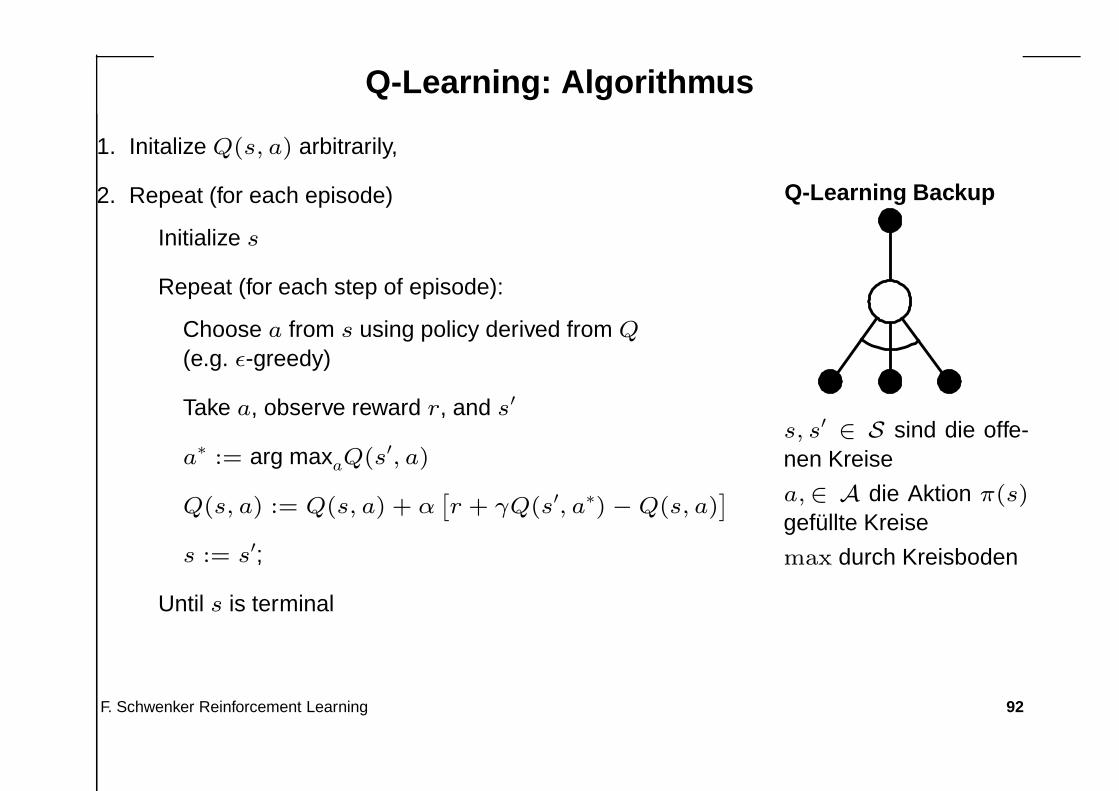
Q-Learning: Algorithmus
1. Initalize Q(s, a) arbitrarily,
2. Repeat (for each episode)
Initialize s
Repeat (for each step of episode):
Choose a from s using policy derived from Q
(e.g. ε-greedy)
Take a, observe reward r, and s′
a∗ := arg maxaQ(s′, a)
Q(s, a) := Q(s, a) + α[
r + γQ(s′, a∗) − Q(s, a)]
s := s′;
Until s is terminal
Q-Learning Backup
s, s′∈ S sind die offe-
nen Kreise
a,∈ A die Aktion π(s)
gefüllte Kreise
max durch Kreisboden
F. Schwenker Reinforcement Learning 92

TD n-step Methoden
• Die bisher vorgestellten TD Lernverfahren verwenden den unmittelbar fol-genden Reward (k = 1-Schritt) rt+1.
• Idee bei den Mehrschritt Methoden ist es, auch die nächsten k = 2, 3, . . . nerzielten Rewards rt+k einzubeziehen.
• Dazu betrachten wir die Zustands-Reward-Folge
st, rt+1, st+1, rt+2, . . . , rT , sT
sT der Endzustand.
• MC Methoden verwenden zum Backup von V π(st) den Return
Rt = rt+1 + γrt+2 + γ2rt+3 + . . . γT−t−1rT
Rt ist das Lehrersignal (Sollwert) für die MC Lernverfahren.
F. Schwenker Reinforcement Learning 93

• Für 1-Schritt TD Methoden ist das Lehrersignal
R(1)t = rt+1 + γVt(st+1)
hier dient γVt(st+1) als Näherung für
γrt+2 + γ2rt+3 + . . . γT−t−1rT
• Bei einem 2-Schritt-TD Verfahren ist der Sollwert
R(2)t = rt+1 + γrt+2 + γ2Vt(st+2)
wobei jetzt γ2Vt(st+2) die Näherung ist für
γ2rt+3 + γ3rt+4 + . . . + γT−t−1rT
• Allgemein ist der n-Schritt-Return R(n)t zur Zeit t gegeben durch
R(n)t = rt+1 + γrt+2 + γ2rt+3 + γn−1rt+n + γnVt(st+n)
F. Schwenker Reinforcement Learning 94
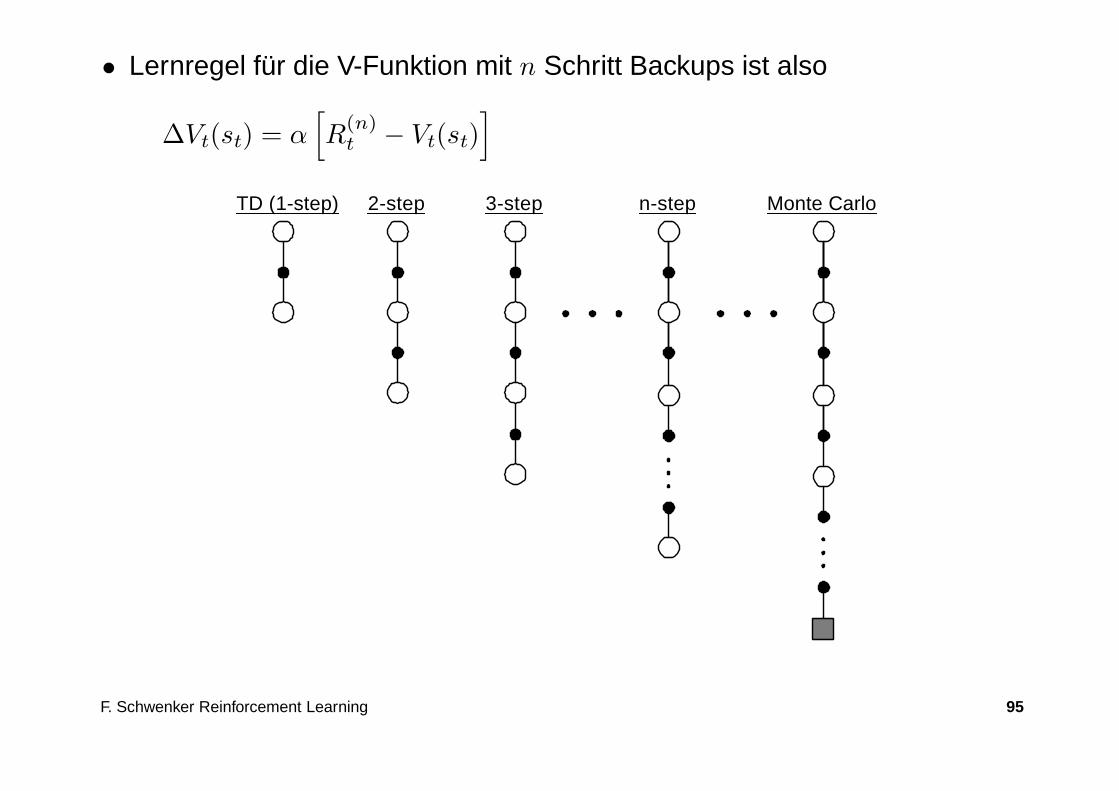
• Lernregel für die V-Funktion mit n Schritt Backups ist also
∆Vt(st) = α[
R(n)t − Vt(st)
]
TD (1-step) 2-step 3-step n-step Monte Carlo
F. Schwenker Reinforcement Learning 95

TD(λ)-Verfahren
• Backups können nicht nur auf der Basis von n-Schritt Returns R(n)t ,
sondern durch Mittelung verschiedener n-Schritt Returns erfolgen, z.B.Mittelwert eines 2− und 4− Schritt Returns
Ravet =
1
2R
(2)t +
1
2R
(4)
• Allgemeine Mittelungen sind möglich. Nur die Gewichte sollten nicht-negativ sein und sich zu 1 summieren.
• Dies führt auf die TD(λ) Verfahren, hier werden alle n-Schritt Returnsgewichtet.
• Mit einem Nomalisierungsfaktor 1−λ (stellt sicher das die Summe derGewichte = 1 ist) definieren wir den λ-Return durch
Rλt = (1 − λ)
∞∑
n=1
λn−1
R(n)t = (1 − λ)
T−t−1∑
n=1
λn−1
R(n)t + λ
T−t−1Rt
1
2
1
2
F. Schwenker Reinforcement Learning 96
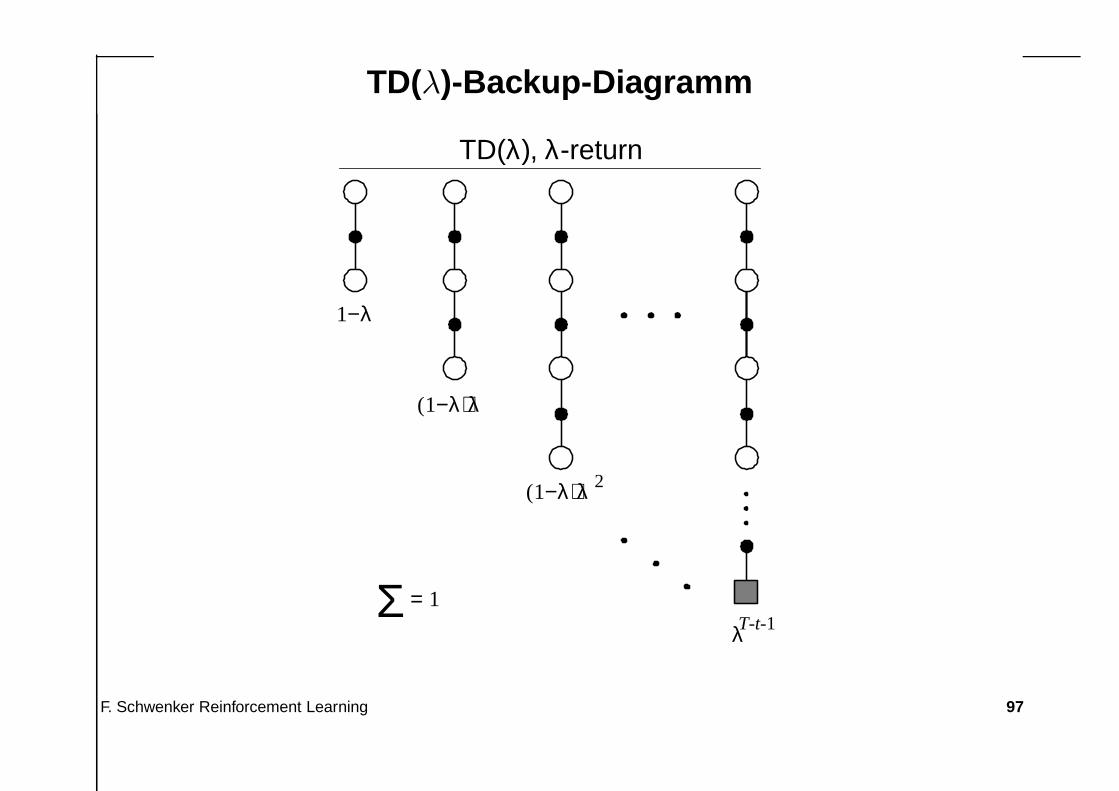
TD(λ)-Backup-Diagramm
1−λ
(1−λ) λ
(1−λ) λ2
Σ = 1
TD(λ), λ-return
λT-t-1
F. Schwenker Reinforcement Learning 97
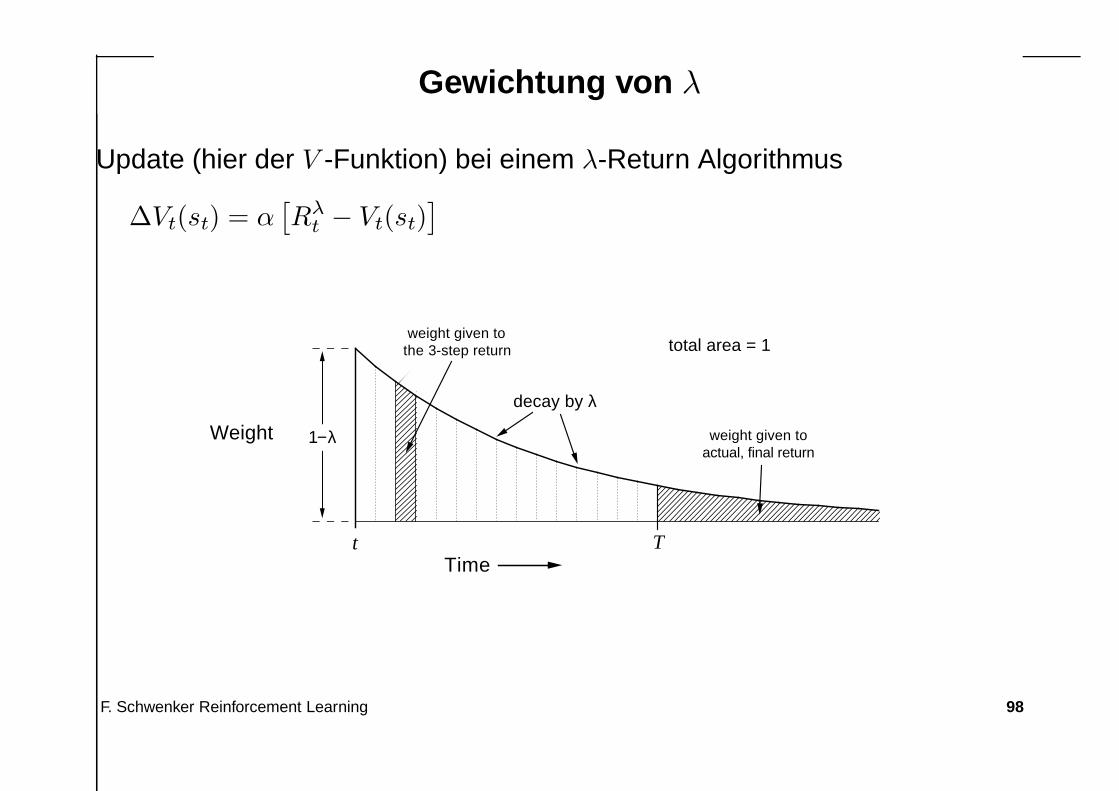
Gewichtung von λ
Update (hier der V -Funktion) bei einem λ-Return Algorithmus
∆Vt(st) = α[
Rλt − Vt(st)
]
1−λ
weight given tothe 3-step return
decay by λ
weight given toactual, final return
t TTime
Weight
total area = 1
F. Schwenker Reinforcement Learning 98
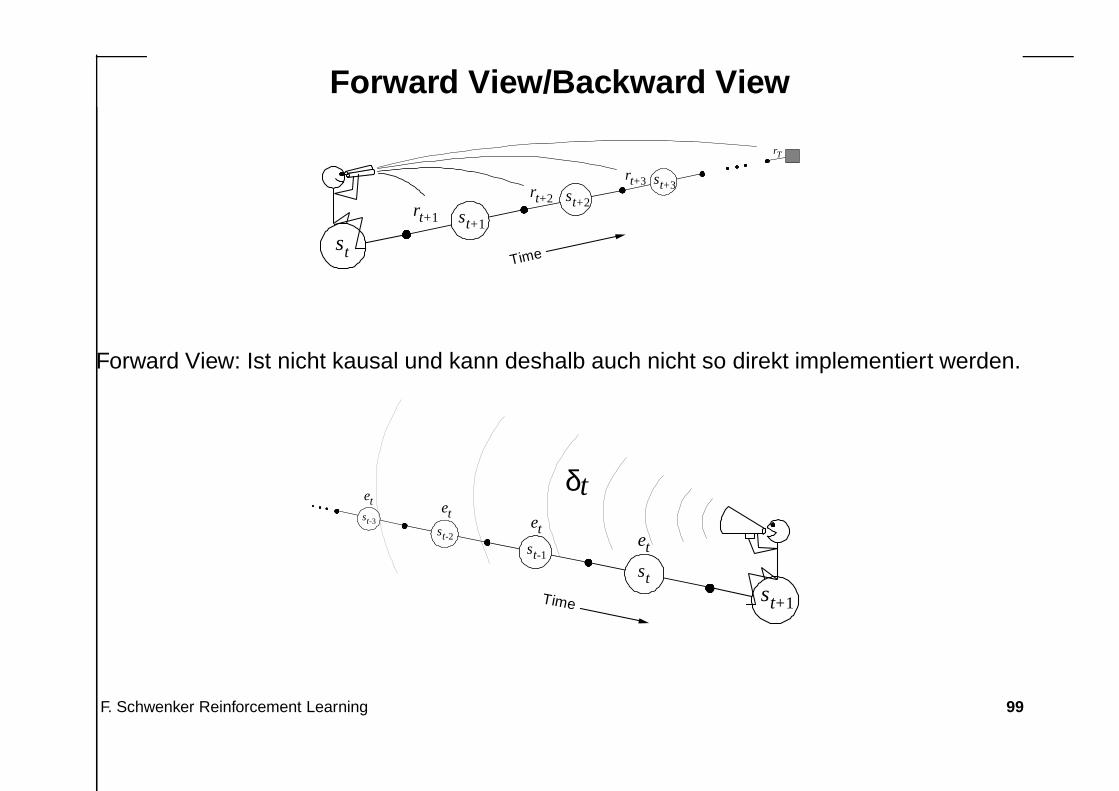
Forward View/Backward View
Time
rt+3rt+2
rt+1
rT
st+1
st+2
st+3
st
Forward View: Ist nicht kausal und kann deshalb auch nicht so direkt implementiert werden.
δtet etet
et
Time
stst+1
st-1
st-2
st-3
F. Schwenker Reinforcement Learning 99
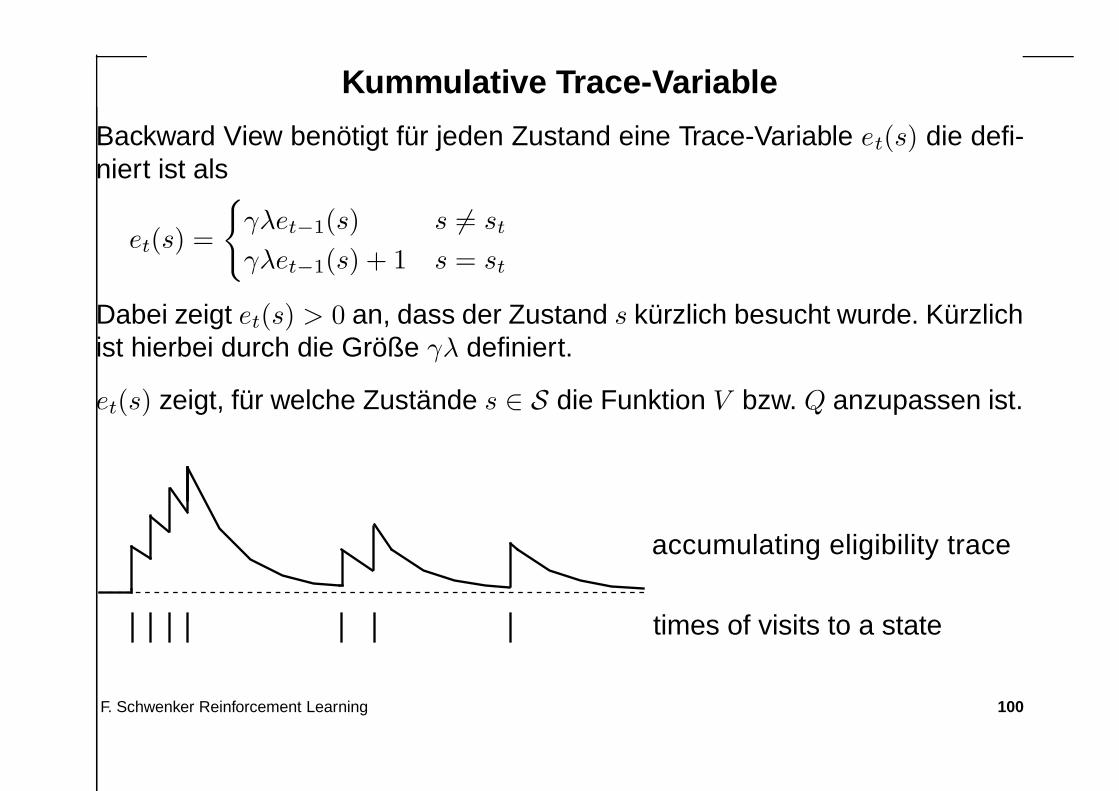
Kummulative Trace-Variable
Backward View benötigt für jeden Zustand eine Trace-Variable et(s) die defi-niert ist als
et(s) =
{
γλet−1(s) s 6= st
γλet−1(s) + 1 s = st
Dabei zeigt et(s) > 0 an, dass der Zustand s kürzlich besucht wurde. Kürzlichist hierbei durch die Größe γλ definiert.
et(s) zeigt, für welche Zustände s ∈ S die Funktion V bzw. Q anzupassen ist.
accumulating eligibility trace
times of visits to a state
F. Schwenker Reinforcement Learning 100

Die Fehlersignale sind (hier für V -Funktion):
δt = rt+1 + γVt(st+1) − Vt(st)
Alle kürzlich besuchten Zustände s werden damit adaptiert (wieder für V )
∆Vt(st) = αδtet(s) für alle s ∈ S
Hierbei ist wieder γ ∈ (0, 1] der Diskontierungsfaktor und α > 0 eine konstan-te Lernrate.
F. Schwenker Reinforcement Learning 101

TD(λ)
1. Initalize V (s) arbitrarily and e(s) = 0; π policy to be evaluated
2. Repeat (for each episode)
Initialize s
Repeat (for each step of episode):
a := π(s)
take a, observe reward r, and next state s′
δ := r + γV (s′) − V (s)
e(s) := e(s) + 1;
For all s:
V (s) := V (s) + αδe(s)
e(s) := γλe(s)
s := s′
Until s is terminal
F. Schwenker Reinforcement Learning 102

Äquivalenz der beiden Methoden
Wir zeigen nun, das die Updates von V der Vorwärts- und Rückwärtssicht fürdas Off-line-Lernen äquivalent sind.
• Es sei∆V λt (st) die Änderung von V (st) zur Zeit t nach der λ-Return Me-
thode (Vorwärtssicht).
• Es sei ∆V TDt (s) die Änderung von V (s) zur Zeit t von Zustand s nach dem
TD(0) Algorithmus (Rückwärtssicht).
Ziel ist es also zu zeigen
T−1∑
t=0
∆V λt (st)1[s=st] =
T−1∑
t=0
∆V TDt (s) für alle s ∈ S
F. Schwenker Reinforcement Learning 103

es ist 1[s=st] gleich 1 genau dann wenn s = st ist. Wir untersuchen eineneinzelnen Update ∆V λ
t (st) = α[
Rλt − Vt(st)
]
.
1
α∆V λ
t (st) = −Vt(st) +
(1 − λ)λ0 [rt+1 + γVt(st+1)] +
(1 − λ)λ1[
rt+1 + γrt+2 + γ2Vt(st+2)]
+
(1 − λ)λ2[
rt+1 + γrt+2 + γ2rt+3 + γ3Vt(st+3)]
+
(1 − λ)λ2[
rt+1 + γrt+2 + γ2rt+3 + γ3rt+4 + γ4Vt(st+4)]
+
. . . . . . . . .
Summation spaltenweise nach den Rewards rt+k durchführen , dh. zuerstdie rt+1 mit den Gewichten (1 − λ)λk über k = 0, 1, . . . summieren ergibt denWert 1 (geometrische Reihe), dann rt+2 mit den Gewichten (1 − λ)γλk überk = 1, 2, 3, . . . ergibt den Wert γλ, usw. mit rt+k für k ≥ 3, 4, . . ..
F. Schwenker Reinforcement Learning 104

1
α∆V λ
t (st) = −Vt(st) + (γλ)0[rt+1 + (1 − λ) γVt(st+1)] +
(γλ)1 [rt+2 + (1 − λ) γVt(st+2)] +
(γλ)2[rt+3 + (1 − λ) γVt(st+3)] +
(γλ)3 [rt+4 + (1 − λ) γVt(st+4)] +
. . . . . . . . .
= (γλ)0 [rt+1 + γVt(st+1) − Vt(st)] +
(γλ)1[rt+2 + γVt(st+2) − Vt(st+1)] +
(γλ)2[rt+3 + γVt(st+3) − Vt(st+2)] +
(γλ)3 [rt+4 + γVt(st+4) − Vt(st+3)] +
. . . . . . . . .
=∞∑
k=t
(γλ)k−t
δk =T−1∑
k=t
(γλ)k−t
δk
F. Schwenker Reinforcement Learning 105

Wir können somit für die Summe der Updates durch λ-Return schreiben:
T−1∑
t=0
∆V TDt (s)1[s=st] = α
T−1∑
t=0
(
T−1∑
k=t
(γλ)k−t
δk
)
1[s=st]
= α
T−1∑
t=0
1[s=st]
T−1∑
k=t
(γλ)k−t
δk.
F. Schwenker Reinforcement Learning 106

Nun die Updates des TD(0) Verfahrens: Zunächst gilt
et(s) =
t∑
k=0
(γλ)t−k
1[s=sk]
Einsetzen liefert nunT−1∑
t=0
∆V TDt (s) =
T−1∑
t=0
αδt
t∑
k=0
(γλ)t−k1[s=sk]
= α
T−1∑
k=0
k∑
t=0
(γλ)k−t
1[s=st]δk
= α
T−1∑
t=0
T−1∑
k=t
(γλ)k−t
1[s=st]δk
= α
T−1∑
t=0
1[s=st]
T−1∑
k=t
(γλ)k−tδk
F. Schwenker Reinforcement Learning 107

Sarsa(λ)
• Idee von Sarsa(λ) ist, den Sarsa-Algorithmus zum Erlernen der Q-Funktion mit der TD(λ) Methoden zu kombinieren.
• Statt der Variablen et(s) für alle s ∈ S brauchen wir Variablen et(s, a) füralle (s, a) ∈ S × A.
• Dann ersetzen wir V (s) durch Q(s, a) und et(s) durch et(s, a). Also
Qt+1(s, a) = Qt(s, a) + αδtet(s, a) für alle s ∈ S, a ∈ A
δt = rt+1 + γQt(st+1, at+1) − Qt(st, at)
und
et(s, a) =
{
γλet−1(s) + 1 falls st = s und at = a
γλet−1(s) sonst
F. Schwenker Reinforcement Learning 108
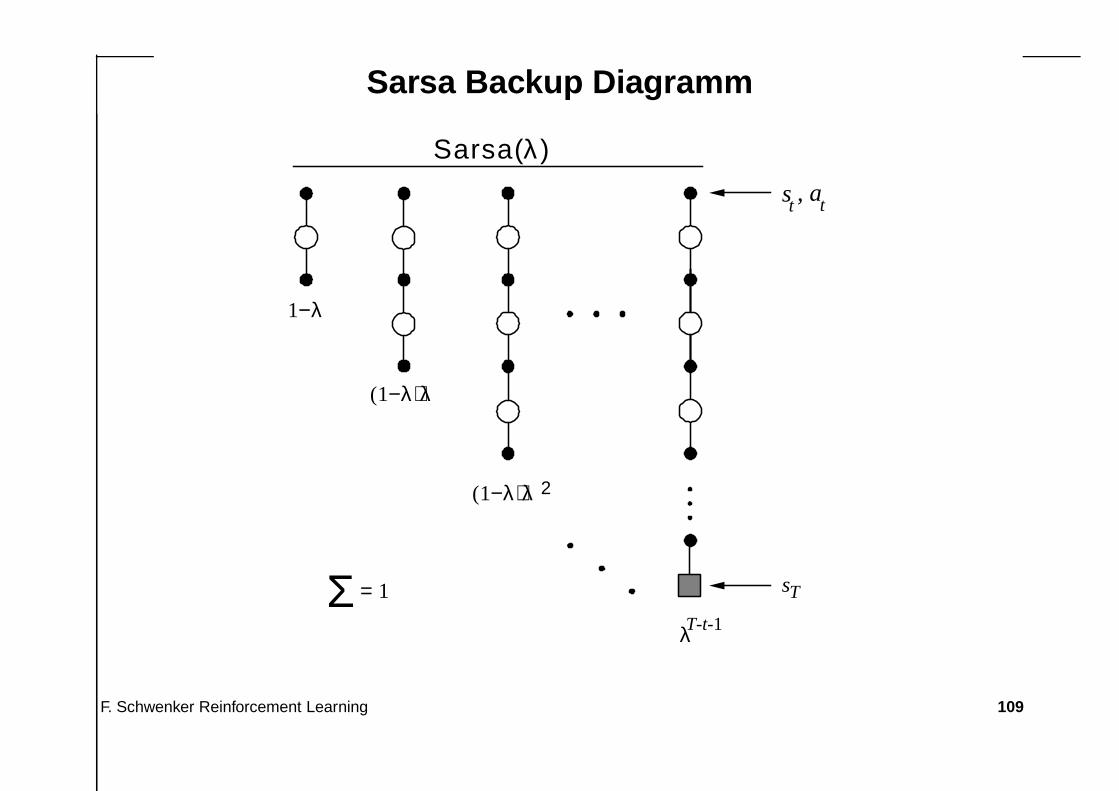
Sarsa Backup Diagramm
λT-t-1
s , at
1−λ
(1−λ) λ
(1−λ) λ2
Σ = 1
t
sT
Sarsa(λ)
F. Schwenker Reinforcement Learning 109

Sarsa Algorithmus (Q als Tabelle)
1. Initalize Q(s, a) arbitrarily and e(s, a) = 0 all s, a
2. Repeat (for each episode)Initialize s, a
Repeat (for each step of episode):
Take a, observe reward r, and next state s′
Choose a′ from s′ using policy derived from Q (e.g. ε-greedy)
δ := r + γQ(s′, a′) − Q(s, a)
e(s, a) := e(s, a) + 1
For all s, a:
Q(s, a) := Q(s, a) + αδe(s, a)
e(s, a) := λγe(s, a)
s := s′; a := a′
Until s is terminal
F. Schwenker Reinforcement Learning 110

Q(λ)-Lernverfahren
• Es gibt 2 Varianten: Watkin’s Q(λ) und Peng’s Q(λ) Verfahren (Letzterer istschwerer implementierbar, deshalb hier nur Watkin’s Q-Lernverfahren).
• Q-Lernen ist ein Off-Policy Verfahren.
• Beim Q-Lernen folgt der Agent einer explorativen Policy (z.B. ε-GreedyVerfahren bzgl. der Q-Funktion) und adaptiert die Q-Funktion nach derGreedy-Policy (bzgl. der Q-Funktion).
• Hier muss in Betracht gezogen werden, dass der Agent explorative Aktio-nen durchführt, die keine Greedy Aktionen sind.
• Zum Erlernen der zur Greedy Policy gehörenden Q-Funktionen dürfen die-se explorativen Aktionen nicht berücksichtigt werden.
• Deshalb werden die n-step Returns beim Q(λ) Verfahren auch nur bis zumAuftreten der nächsten explorativen Aktion berücksichtigt, und nicht stetsbis zum Ende einer Episode.
F. Schwenker Reinforcement Learning 111
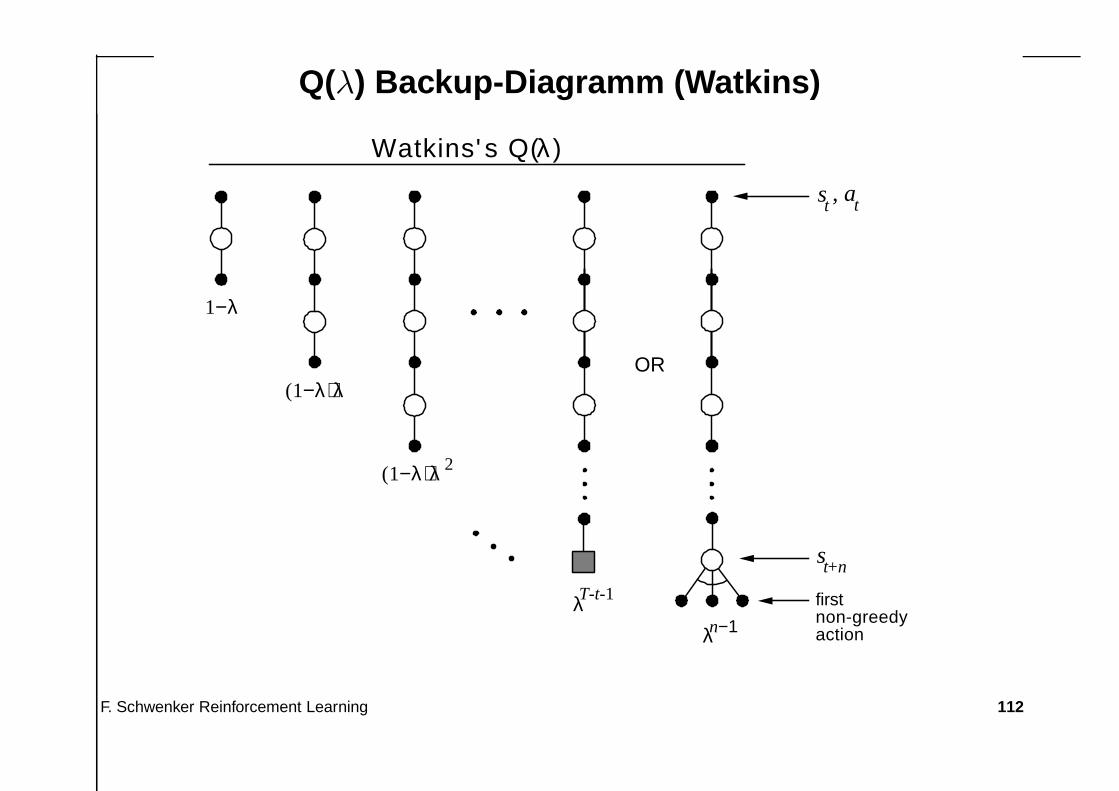
Q(λ) Backup-Diagramm (Watkins)
1−λ
(1−λ) λ
(1−λ) λ2
Watkins's Q(λ)
OR
firstnon-greedyactionλn−1
s , at t
st+n
λT-t-1
F. Schwenker Reinforcement Learning 112

Q(λ)-Algorithmus (Q als Tabelle)
1. Initalize Q(s, a) arbitrarily and e(s, a) = 0 all s, a
2. Repeat (for each episode)Initialize s, a
Repeat (for each step of episode):Take a, observe reward r, and next state s′
Choose a′ from s′ using policy derived from Q (e.g. ε-greedy)
a∗ := arg maxbQ(s′, b) (if a′ ties for the max, then a∗ := a′).
δ := r + γQ(s′, a∗) − Q(s, a)
e(s, a) := e(s, a) + 1
For all s, a:Q(s, a) := Q(s, a) + αδe(s, a)
if a′ = a∗ then e(s, a) := λγe(s, a) else e(s, a) := 0
s := s′; a := a′
Until s is terminal
F. Schwenker Reinforcement Learning 113