Embed Size (px)
Citation preview

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Text-Mining:Clustering
Claes NeuefeindFabian Steeg
15. Juli 2010
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Themen heute
Clustering im TM
Flaches Clustering
Hierarchisches Clustering
Erweiterungen, Labeling
Literatur
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Cluster-Hypothese
“Documents in the same cluster behave similarly with respect torelevance to information needs.”[Manning et al., 2008, S. 322]
I Hypothese ist auch Grundlage der meistenAnwendungen im TM (direkt oder indirekt)
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Anwendungen
I Clustering von Suchergebnissen (z.B. clusty.com)
I Clustering ganzer Sammlungen fur Navigation(z.B. news.google.de)
I Explorative Suche als Alternative zu Keywords
I Verbesserung der Suche:nur in Clustern ahnlich zur Anfrage suchen
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Clustering: Definitionen
I Unterscheidung nach:I Hartes vs. weiches ClusteringI Exhaustiv vs. nicht-exhaustivI Clustering vs. Klassifikation
I Parameter, die das Clustering beeinflussen:I Kardinalitat: Anzahl resultierender ClusterI AhnlichkeitsmaßI Reprasentation der Dokumente
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Clustering-Ansatze
I Flache AlgorithmenI Beginnen i.d.R. mit zufalliger Einteilung der DokumenteI Anschließend iterative Neudefinition der ClusterI Wichtigster Algorithmus: K -Means
I Hierarchische AlgorithmenI Erzeugen hierarchische StrukturenI Bottom-up: Mergen (’agglomerativ’)I Top-down: Teilen (’divisiv’)
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Evaluation
I Interne Kriterien:I Evaluation hinsichtlich KoharenzI ’Intra-’ bzw. ’intercluster’-Ahnlichkeit
I Externe Kriterien:I PurityI Rand IndexI F-MeasureI Normalized Mutual Information
I Evaluation im Kontext von Anwendungen,z.B. durch replizieren eines Gold-Standards
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
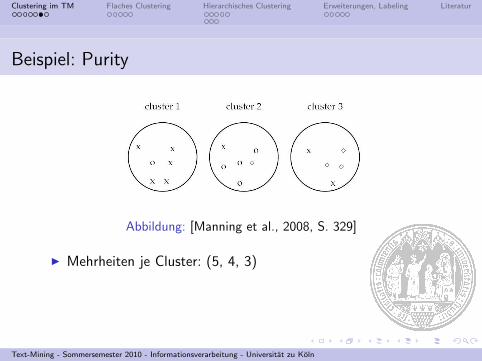
Beispiel: Purity
Abbildung: [Manning et al., 2008, S. 329]
I Mehrheiten je Cluster: (5, 4, 3)
I 17 Elemente insgesamt
I Purity: (1/17)x(5 + 4 + 3) ≈ 0, 71
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Beispiel: Purity
Abbildung: [Manning et al., 2008, S. 329]
I Mehrheiten je Cluster: (5, 4, 3)
I 17 Elemente insgesamt
I Purity: (1/17)x(5 + 4 + 3) ≈ 0, 71
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Beispiel: Purity
Abbildung: [Manning et al., 2008, S. 329]
I Mehrheiten je Cluster: (5, 4, 3)
I 17 Elemente insgesamt
I Purity: (1/17)x(5 + 4 + 3) ≈ 0, 71
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
RI, F-Measure, NMI
I Rand Index (RI), F-measureI Bewertung der Summe aller Cluster-EntscheidungenI RI = Anteil korrekter Entscheidungen (TP+TN)→
”Genauigkeit“
I Flexibler: F-Measure - Gewichtung von “precision” und “recall”
I Normalized mutual information (NMI)I Informationsgehalt bezugl. KlasseneinteilungI Maximale MI fur einelementige ClusterI Deshalb: Normalisierung anhand der Entropie
von Clustern und Klassen
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Charakteristika und Ziele flacher Algorithmen
I Einteilung von N Dokumenten in eine Menge von K Clustern
I Gegeben: N, K
I Gesucht: Einteilung, die das gewahlte Einteilungskriteriumoptimiert→ Clustering ist im Kern ein Suchproblem
I Effektive Heuristik: Der K -means-Algorithmus
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
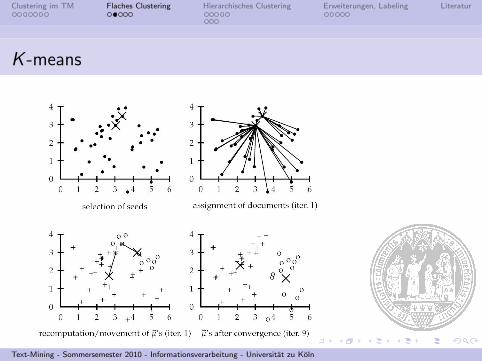
K -means
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
K -means
I Kriterium fur Zuweisung zu einem Cluster ω: Minimierung derdurchschnittlichen quadrierten eukl. Distanz zwischen dem’Schwerpunkt’ ~µ und allen Dokumenten in ω
I Definition des Schwerpunkts:
~µ(ω) =1
|ω|∑~x∈ω
~x
I Minimale Distanz wird iterativ ermittelt:I Neuzuweisung zu nachstliegendem SchwerpunktI Neuberechnung des Schwerpunkts: Durchschnitt
der neu zugewiesenen Vektoren
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Initialisierung: Seed Selection
I Zufallige Auswahl des Seed nur einer von vielen Wegen zurInitialisierung von K -means
I Nicht allzu robust: Fuhrt leicht zu suboptimalem ClusteringI Besser: Seed heuristisch ermitteln
I Teilmenge ermitteln, die den Dokumentenraum gut ’abdeckt’(z.B. mittels hierarchischem Clustering, s.u.)
I ’Ausreißer’ filternI ’Test-Clustern’: i versch. Mengen von Seeds,
jew. K -Means-Clustering durchfuhren,Clustering mit min. durchschnittl. Distanz wahlen
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
K-Means: Kardinalitat
I K kann von externen Faktoren abhangen(z.B. Platzbeschrankung bei Visualisierung)
I Sonst: Ermitteln der Clusterzahl als Teil des ProblemsI Ansatze:
I Auf gut GluckI Strafe fur jedes ClusterI Abwagen zwischen Strafen und durchschnittlicher
Distanz vom SchwerpunktI Wahle K mit bester ’Bilanz’
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Hierarchisches Clustering
I Ziel: Struktur des Datensets, Taxonomien
I Bisher: Ahnlichkeit zwischen Dokumenten
I Jetzt: Ahnlichkeit zwischen Clustern
I Ahnlichkeitsmaß unterscheidet die versch. Algorithmen
I Strategien: top-down vs. bottom-up
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Strategien fur hierarchisches Clustering
I Top-down-Ansatz:I Alle Dokumente bilden ein ClusterI Iterativ aufspaltenI Flaches Clustering als Subroutine→ Divisives hierarchisches Clustering (z.B. Bisecting K -Means)
I Bottom-up-Ansatz:I Zunachst ein eigenes Cluster je DokumentI Iterativ die zwei ahnlichsten mergen
. . . bis nur noch K Cluster ubrig sindI Merge-Verlauf bildet Binarbaum / DendogrammI Hierarchisch Agglomeratives Clustering (HAC)
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
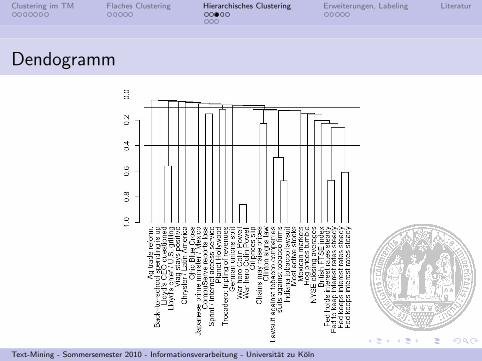
Dendogramm
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Dendogramm: Interpretation
I Merge-Verlauf von unten nach oben ablesbar
I Horizontale Linie jedes Merge gibt Ahnlichkeit an
I ’Schnitt’ ergibt flaches Clustering
I Kriterium z.B. nach Grad der Ahnlichkeit(im Bsp. bei 0.1 und 0.4)
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
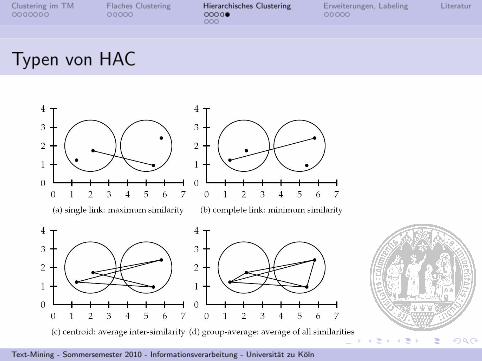
Typen von HAC
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
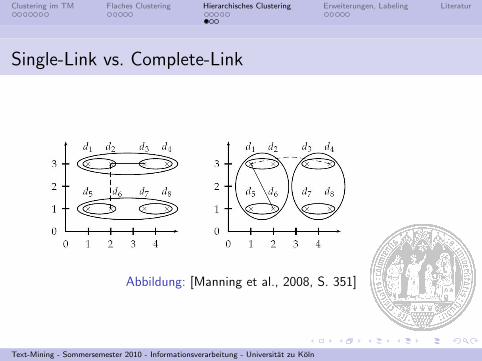
Single-Link vs. Complete-Link
Abbildung: [Manning et al., 2008, S. 351]
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
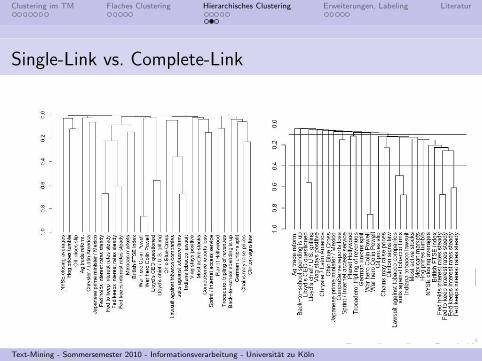
Single-Link vs. Complete-Link
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
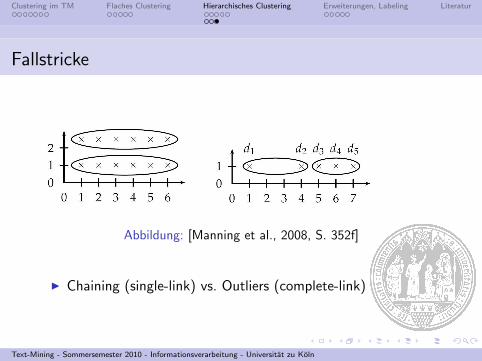
Fallstricke
Abbildung: [Manning et al., 2008, S. 352f]
I Chaining (single-link) vs. Outliers (complete-link)
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Bisecting K -means
I Top-down: Zunachst nur ein Cluster
I Aufteilen mit K -means
I Aus entstandenen Clustern eines wahlen (z.B. großtes),Teilung wiederholen, bis gewunschte Kardinalitat erreicht
I Beispielanwendung:
I 2-Means-Clustering fur ein Korpus mitDokumenten in zwei versch. Sprachen→ Ist keine vollstandige Hierarchie notig, sindTop-down-Ansatze deutlich effizienter als HAC
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Flaches vs. hierarchisches Clustering
I Flache Ansatze fur effizientes Clustering(inkl. Bisecting K -Means)
I HAC fur Hierarchien
I HAC, wenn K vorab nicht ermittelt werden kann(funktioniert auch mit unbekanntem K )
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Welche Labels?
I Wesentliche Teilaufgabe im Clustering:Sprechende Labels zur Beschreibung der Cluster
I Beispiel: Clustering des Suchergebnisses fur “jaguar”:I “Tier”I “Auto”I “Mac OS”
I Vorschlage?
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Labeling
Discriminative labeling
I Vergleiche Cluster ω mit allen anderen ClusternI Finde Terme, die ω von anderen Clustern unterscheidenI Identifikation mittels mutual information, χ2 oder Frequenz
(vgl. Merkmalsauswahl bei Textklassifikation)
Non-discriminative labeling
I Termauswahl ausschließlich anhand von Clusterinternen InformationenI = Terme mit hohem Gewicht im SchwerpunktI Problem: z.T. werden hoherfrequente Terme ausgewahlt,
die nicht zur Unterscheidung beitragen
Titel als Label
I Z.B. Titel von 2-3 Dokumenten, die am nachstenzum Clusterschwerpunkt liegen
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln
Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
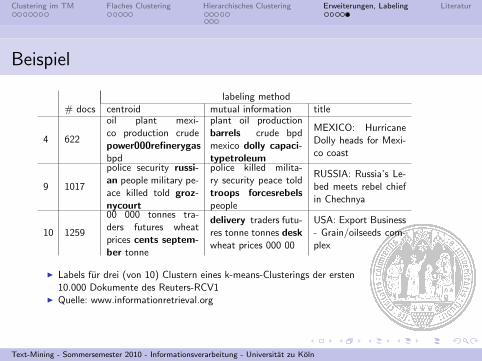
Beispiel
labeling method# docs centroid mutual information title
4 622
oil plant mexi-co production crudepower000refinerygasbpd
plant oil productionbarrels crude bpdmexico dolly capaci-typetroleum
MEXICO: HurricaneDolly heads for Mexi-co coast
9 1017
police security russi-an people military pe-ace killed told groz-nycourt
police killed milita-ry security peace toldtroops forcesrebelspeople
RUSSIA: Russia’s Le-bed meets rebel chiefin Chechnya
10 1259
00 000 tonnes tra-ders futures wheatprices cents septem-ber tonne
delivery traders futu-res tonne tonnes deskwheat prices 000 00
USA: Export Business- Grain/oilseeds com-plex
I Labels fur drei (von 10) Clustern eines k-means-Clusterings der ersten10.000 Dokumente des Reuters-RCV1
I Quelle: www.informationretrieval.org
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln

Clustering im TM Flaches Clustering Hierarchisches Clustering Erweiterungen, Labeling Literatur
Bruckner, T. (2004).Textklassifikation.In Klabunde, R., editor, Computerlinguistik undSprachtechnologie, pages 496–501. Elsevier, Heidelberg.
Manning, C. D., Raghavan, P., and Schutze, H. (2008).Introduction to Information Retrieval.Cambridge University Press.
Text-Mining - Sommersemester 2010 - Informationsverarbeitung - Universitat zu Koln





























