Embed Size (px)
Citation preview

Hå sÜ ®µm (Chñ biªn) ®ç ®øc ®«ng – lª minh hoµng – nguyÔn thanh hïng
tµi liÖu gi¸o khoa
cchhuuyyªªnn ttiinn quyÓn 2
Nhµ xuÊt b¶n gi¸o dôc viÖt nam

2
C«ng ty Cæ phÇn dÞch vô xuÊt b¶n Gi¸o dôc Hµ Néi - Nhµ xuÊt b¶n Gi¸o dôc ViÖt Nam gi÷ quyÒn c«ng bè t¸c phÈm.
349-2009/CXB/43-644/GD M4 sè : 8I746H9

3
LỜI NÓI ðẦU
Bộ Giáo dục và ðào tạo ñã ban hành chương trình chuyên tin học cho các lớp chuyên 10, 11, 12. Dựa theo các chuyên ñề chuyên sâu trong chương trình nói trên, các tác giả biên soạn bộ sách chuyên tin học, bao gồm các vấn ñề cơ bản nhất về cấu trúc dữ liệu, thuật toán và cài ñặt chương trình.
Bộ sách gồm ba quyển, quyển 1, 2 và 3. Cấu trúc mỗi quyển bao gồm: phần lí thuyết, giới thiệu các khái niệm cơ bản, cần thiết trực tiếp, thường dùng nhất; phần áp dụng, trình bày các bài toán thường gặp, cách giải và cài ñặt chương trình; cuối cùng là các bài tập. Các chuyên ñề trong bộ sách ñược lựa chọn mang tính hệ thống từ cơ bản ñến chuyên sâu.
Với trải nghiệm nhiều năm tham gia giảng dạy, bồi dưỡng học sinh chuyên tin học của các trường chuyên có truyền thống và uy tín, các tác giả ñã lựa chọn, biên soạn các nội dung cơ bản, thiết yếu nhất mà mình ñã sử dụng ñể dạy học với mong muốn bộ sách phục vụ không chỉ cho giáo viên và học sinh chuyên PTTH mà cả cho giáo viên, học sinh chuyên tin học THCS làm tài liệu tham khảo cho việc dạy và học của mình.
Với kinh nghiệm nhiều năm tham gia bồi dưỡng học sinh, sinh viên tham gia các kì thi học sinh giỏi Quốc gia, Quốc tế Hội thi Tin học trẻ Toàn quốc, Olympiad Sinh viên Tin học Toàn quốc, Kì thi lập trình viên Quốc tế khu vực ðông Nam Á, các tác giả ñã lựa chọn giới thiệu các bài tập, lời giải có ñịnh hướng phục vụ cho không chỉ học sinh mà cả sinh viên làm tài liệu tham khảo khi tham gia các kì thi trên.
Lần ñầu tập sách ñược biên soạn, thời gian và trình ñộ có hạn chế nên chắc chắn còn nhiều thiếu sót, các tác giả mong nhận ñược ý kiến ñóng góp của bạn ñọc, các ñồng nghiệp, sinh viên và học sinh ñể bộ sách ñược ngày càng hoàn thiện hơn .
Các tác giả

4

5
Chuyên ñề 6
KIỂU DỮ LIỆU TRỪU TƯỢNG
VÀ CẤU TRÚC DỮ LIỆU
Kiểu dữ liệu trừu tượng là một mô hình toán học với những thao tác ñịnh nghĩa
trên mô hình ñó. Kiểu dữ liệu trừu tượng có thể không tồn tại trong ngôn ngữ lập trình mà chỉ dùng ñể tổng quát hóa hoặc tóm lược những thao tác sẽ ñược
thực hiện trên dữ liệu. Kiểu dữ liệu trừu tượng ñược cài ñặt trên máy tính bằng
các cấu trúc dữ liệu: Trong kỹ thuật lập trình cấu trúc (Structural
Programming), cấu trúc dữ liệu là các biến cùng với các thủ tục và hàm thao
tác trên các biến ñó. Trong kỹ thuật lập trình hướng ñối tượng (Object-
Oriented Programming), cấu trúc dữ liệu là kiến trúc thứ bậc của các lớp, các
thuộc tính và phương thức tác ñộng lên chính ñối tượng hay một vài thuộc tính
của ñối tượng.
Trong chương này, chúng ta sẽ khảo sát một vài kiểu dữ liệu trừu tượng cũng
như cách cài ñặt chúng bằng các cấu trúc dữ liệu. Những kiểu dữ liệu trừu
tượng phức tạp hơn sẽ ñược mô tả chi tiết trong từng thuật toán mỗi khi thấy
cần thiết.
1. Danh sách
1.1. Khái niệm danh sách
Danh sách là một tập sắp thứ tự các phần tử cùng một kiểu. ðối với danh sách, người ta có một số thao tác: Tìm một phần tử trong danh sách, chèn một phần tử vào danh sách, xóa một phần tử khỏi danh sách, sắp xếp lại các phần tử trong danh sách theo một trật tự nào ñó v.v…
Việc cài ñặt một danh sách trong máy tính tức là tìm một cấu trúc dữ liệu cụ thể mà máy tính hiểu ñược ñể lưu các phần tử của danh sách ñồng thời viết các ñoạn chương trình con mô tả các thao tác cần thiết ñối với danh sách.

6
Vì danh sách là một tập sắp thứ tự các phần tử cùng kiểu, ta ký hiệu ��������
là kiểu dữ liệu của các phần tử trong danh sách, khi cài ñặt cụ thể, �������� có thể là bất cứ kiểu dữ liệu nào ñược chương trình dịch chấp nhận (Số nguyên, số thực, ký tự, …).
1.2. Biểu diễn danh sách bằng mảng
Khi cài ñặt danh sách bằng mảng một chiều , ta cần có một biến nguyên � lưu số phần tử hiện có trong danh sách. Nếu mảng ñược ñánh số bắt ñầu từ 1 thì các phần tử trong danh sách ñược cất giữ trong mảng bằng các phần tử ñược ñánh số
từ 1 tới �: � �� �� a) a) a) a) Truy cTruy cTruy cTruy cp php php php ph����n tn tn tn t���� trong mtrong mtrong mtrong m����ngngngng
Việc truy cập một phần tử ở vị trí � trong mảng có thể thực hiện rất dễ dàng qua
phần tử �. Vì các phần tử của mảng có kích thước bằng nhau và ñược lưu trữ
liên tục trong bộ nhớ, việc truy cập một phần tử ñược thực hiện bằng một phép toán tính ñịa chỉ phần tử có thời gian tính toán là hằng số. Vì vậy nếu cài ñặt bằng mảng, việc truy cập một phần tử trong danh sách ở vị trí bất kỳ có ñộ phức
tạp là ����.
b) b) b) b) Chèn phChèn phChèn phChèn ph����n tn tn tn t���� vào mvào mvào mvào m����ngngngng
ðể chèn một phần tử � vào mảng tại vị trí �, trước hết ta dồn tất cả các phần tử
từ vị trí � tới tới vị trí � về sau một vị trí (tạo ra “chỗ trống” tại vị trí �), ñặt giá
trị � vào vị trí �, và tăng số phần tử của mảng lên 1.
procedure Insert(p: Integer; const v: TElement);
//Thủ tục chèn phần tử v vào vị trí p var i: Integer;
begin
for i := n downto p do a[i + 1] := a[i];
a[p] := v;
n := n + 1;
end;
Trường hợp tốt nhất, vị trí chèn nằm sau phần tử cuối cùng của danh sách
(� � � �), khi ñó thời gian thực hiện của phép chèn là ����. Trường hợp xấu
nhất, ta cần chèn tại vị trí 1, khi ñó thời gian thực hiện của phép chèn là ����.

7
Cũng dễ dàng chứng minh ñược rằng thời gian thực hiện trung bình của phép
chèn là ����.
c) c) c) c) Xóa phXóa phXóa phXóa ph����n tn tn tn t���� khkhkhkh����i mi mi mi m����ngngngng
ðể xóa một phần tử tại vị trí � của mảng mà vẫn giữ nguyên thứ tự các phần tử
còn lại: Trước hết ta phải dồn tất cả các phần tử từ vị trí � � � tới � lên trước
một vị trí (thông tin của phần tử thứ � bị ghi ñè), sau ñó giảm số phần tử của
mảng (�) ñi .
procedure Delete(p: Integer); //Thủ tục xóa phần tử tại vị trí p
var i: Integer;
begin
for i := p to n - 1 do a[i] := a[i + 1];
n := n - 1;
end;
Trường hợp tốt nhất, vị trí xóa nằm cuối danh sách (� ��, khi ñó thời gian
thực hiện của phép xóa là ����. Trường hợp xấu nhất, ta cần xóa tại vị trí 1, khi
ñó thời gian thực hiện của phép xóa là ����. Cũng dễ dàng chứng minh ñược
rằng thời gian thực hiện trung bình của phép xóa là ����.
Trong trường hợp cần xóa một phần tử mà không cần duy trì thứ tự của các phần tử khác, ta chỉ cần ñưa giá trị phần tử cuối cùng vào vị trí cần xóa rồi giảm số
phần tử của mảng (�) ñi 1. Khi ñó thời gian thực hiện của phép xóa chỉ là ����.
1.3. Biểu diễn danh sách bằng danh sách nối ñơn
Danh sách nối ñơn (Singly-linked list) gồm các nút ñược nối với nhau theo một chiều. Mỗi nút là một bản ghi (record) gồm hai trường:
� Trường ���� chứa giá trị lưu trong nút ñó
� Trường ���� chứa liên kết (con trỏ) tới nút kế tiếp, tức là chứa một thông tin ñủ ñể biết nút kế tiếp nút ñó trong danh sách là nút nào, trong trường hợp là nút cuối cùng (không có nút kế tiếp), trường liên kết này
ñược gán một giá trị ñặc biệt, chẳng hạn con trỏ ���. type
PNode = ^TNode; //Kiểu con trỏ tới một nút TNode = record; //Kiểu biến ñộng chứa thông tin trong một nút
���� ����

8
info: TElement;
link: PNode;
end;
Nút ñầu tiên trong danh sách (���) ñóng vai trò quan trọng trong danh sách nối ñơn. ðể duyệt danh sách nối ñơn, ta bắt ñầu từ nút ñầu tiên, dựa vào trường liên kết ñể ñi sang nút kế tiếp, ñến khi gặp giá trị ñặc biệt (duyệt qua nút cuối) thì dừng lại
Hình 1.1. Danh sách nối ñơn
aaaa) ) ) ) Truy cTruy cTruy cTruy cp php php php ph����n tn tn tn t���� trong danh sách ntrong danh sách ntrong danh sách ntrong danh sách n!!!!i "#ni "#ni "#ni "#n
Bản thân danh sách nối ñơn ñã là một kiểu dữ liệu trừu tượng. ðể cài ñặt kiểu
dữ liệu trừu tượng này, chúng ta có thể dùng mảng các nút (trường ���� chứa chỉ
số của nút kế tiếp) hoặc biến cấp phát ñộng (trường ���� chứa con trỏ tới nút kế
tiếp). Tuy nhiên vì cấu trúc nối ñơn, việc xác ñịnh phần tử ñứng thứ � trong
danh sách bắt buộc phải duyệt từ ñầu danh sách qua � nút, việc này mất thời
gian trung bình ����, và tỏ ra không hiệu quả như thao tác trên mảng. Nói cách khác, danh sách nối ñơn tiện lợi cho việc truy cập tuần tự nhưng không hiệu quả nếu chúng ta thực hiện nhiều phép truy cập ngẫu nhiên.
bbbb) ) ) ) Chèn phChèn phChèn phChèn ph����n tn tn tn t���� vào danh sách nvào danh sách nvào danh sách nvào danh sách n!!!!i "#ni "#ni "#ni "#n
ðể chèn thêm một nút chứa giá trị � vào vị trí của nút � trong danh sách nối
ñơn, trước hết ta tạo ra một nút mới ������� chứa giá trị � và cho nút này liên
kết tới �. Nếu � ñang là nút ñầu tiên của danh sách (���) thì cập nhật lại ���
bằng �������, còn nếu � không phải nút ñầu tiên của danh sách, ta tìm nút �
là nút ñứng liền trước nút � và chỉnh lại liên kết: � liên kết tới ������� thay vì
liên kết tới thẳng � (h.1.2).
���
a b c d e

9
Hình 1.2. Chèn phần tử vào danh sách nối ñơn
procedure Insert(p: PNode; const v: TElement);
//Thủ tục chèn phần tử v vào vị trí nút p var NewNode, q: PNode;
begin
New(NewNode);
NewNode^.info := v;
NewNode^.link := p;
if head = p then head := NewNode
else
begin
q := head;
while q^.link ≠ p do q := q^.link;
q^.link := NewNode;
end;
end;
Việc chỉnh lại liên kết trong phép chèn phần tử vào danh sách nối ñơn mất thời
gian ����, tuy nhiên việc tìm nút ñứng liền trước nút � yêu cầu phải duyệt từ
ñầu danh sách, việc này mất thời gian trung bình ����. Vậy phép chèn một phần
tử vào danh sách nối ñơn mất thời gian trung bình ���� ñể thực hiện.
cccc) ) ) ) Xóa phXóa phXóa phXóa ph����n tn tn tn t���� khkhkhkh����i danh sách ni danh sách ni danh sách ni danh sách n!!!!i "#n:i "#n:i "#n:i "#n:
ðể xóa nút � khỏi danh sách nối ñơn, gọi �� � là nút ñứng liền sau � trong danh sách. Xét hai trường hợp:
� Nếu � là nút ñầu tiên trong danh sách ��� � thì ta ñặt lại ��� bằng �� �.
a b c d e
� � ���
a b c d e
� � ��� � �������

10
� Nếu � không phải nút ñầu tiên trong danh sách, tìm nút � là nút ñứng liền
trước nút � và chỉnh lại liên kết: � liên kết tới �� � thay vì liên kết tới � (h.1.3)
Việc cuối cùng là huỷ nút �.
procedure Delete(p: PNode); //Thủ tục xóa nút p của danh sách nối ñơn
var next, q: PNode;
begin
next := p^.link;
if p = head then head := next
else
begin
q := head;
while q^.link <> p do q := q^.link;
q^.link := next;
end;
Dispose(p);
end;
Hình 1.3. Xóa phần tử khỏi danh sách nối ñơn
Cũng giống như phép chèn, phép xóa một phần tử khỏi danh sách nối ñơn cũng
mất thời gian trung bình ���� ñể thực hiện.
Trên ñây mô tả các thao tác với danh sách biểu diễn dưới dạng danh sách nối ñơn các biến ñộng. Chúng ta có thể cài ñặt danh sách nối ñơn bằng một mảng,
mỗi nút chứa trong một phần tử của mảng và trường liên kết ���� chính là chỉ số của nút kế tiếp. Khi ñó mọi thao tác chèn/xóa phần tử cũng ñược thực hiện tương tự như trên:
const max = ...; //Số phần tử cực ñại
type
TNode = record
a b c d e
� � ��� �� �
a b d e
� ��� �� �

11
info: TElement;
link: Integer;
end;
TList = array[1..max] of TNode;
var
Nodes: TList;
head: Integer;
1.4. Biểu diễn danh sách bằng danh sách nối kép
Việc xác ñịnh nút ñứng liền trước một nút � trong danh sách nối ñơn bắt buộc
phải duyệt từ ñầu danh sách, thao tác này mất thời gian trung bình ���� ñể thực hiện và ảnh hưởng trực tiếp tới thời gian thực hiện thao tác chèn/xóa phần tử. ðể khắc phục nhược ñiểm này, người ta sử dụng danh sách nối kép.
Danh sách nối kép gồm các nút ñược nối với nhau theo hai chiều. Mỗi nút là một bản ghi (record) gồm ba trường:
� Trường info chứa giá trị lưu trong nút ñó.
� Trường �� � chứa liên kết (con trỏ) tới nút kế tiếp, tức là chứa một thông tin ñủ ñể biết nút kế tiếp nút ñó là nút nào, trong trường hợp nút ñứng cuối cùng trong danh sách (không có nút kế tiếp), trường liên kết này ñược gán
một giá trị ñặc biệt (chẳng hạn con trỏ ���) � Trường �!�� chứa liên kết (con trỏ) tới nút liền trước, tức là chứa một
thông tin ñủ ñể biết nút liền trước nút ñó là nút nào, trong trường hợp nút ñứng ñầu tiên trong danh sách (không có nút liền trước), trường liên kết này ñược gán một giá trị
ñặc biệt (chẳng hạn con trỏ ���) type
PNode = ^TNode; //Kiểu con trỏ tới một nút
TNode = record; //Kiểu biến ñộng chứa thông tin trong một nút
info: TElement;
next, prev: PNode;
end;
Khác với danh sách nối ñơn, trong danh sách nối kép ta quan tâm tới hai nút:
Nút ñầu tiên (��!"�) và phần tử cuối cùng (�"�). Có hai cách duyệt danh sách
nối kép: Hoặc bắt ñầu từ ��!"�, dựa vào liên kết �� � ñể ñi sang nút kế tiếp, ñến
���� �� � �!��

12
khi gặp giá trị ñặc biệt (duyệt qua �"�) thì dừng lại. Hoặc bắt ñầu từ �"�, dựa
vào liên kết �!�� ñể ñi sang nút liền trước, ñến khi gặp giá trị ñặc biệt (duyệt
qua ��!"�) thì dừng lại
Hình 1.4. Danh sách nối kép
Giống như danh sách nối ñơn, việc chèn/xóa nút trong danh sách nối kép cũng ñơn giản chỉ là kỹ thuật chỉnh lại các mối liên kết giữa các nút cho hợp lý. Tuy nhiên ta có thể xác ñịnh ñược dễ dàng nút ñứng liền trước/liền sau của một nút
trong thời gian ����, nên các thao tác chèn/xóa trên danh sách nối kép chỉ mất
thời gian ����, tốt hơn so với cài ñặt bằng mảng hay danh sách nối ñơn.
1.5. Biểu diễn danh sách bằng danh sách nối vòng ñơn
Trong danh sách nối ñơn, phần tử cuối cùng trong danh sách có trường liên kết
ñược gán một giá trị ñặc biệt (thường sử dụng nhất là giá trị ���). Nếu ta cho trường liên kết của phần tử cuối cùng trỏ thẳng về phần tử ñầu tiên của danh sách thì ta sẽ ñược một kiểu danh sách mới gọi là danh sách nối vòng ñơn.
Hình 1.5. Danh sách nối vòng ñơn
ðối với danh sách nối vòng ñơn, ta chỉ cần biết một nút bất kỳ của danh sách là ta có thể duyệt ñược hết các nút trong danh sách bằng cách ñi theo hướng liên kết. Chính vì lý do này, khi chèn/xóa vào danh sách nối vòng ñơn, ta không phải xử lý các trường hợp riêng khi nút ñứng ñầu danh sách. Mặc dù vậy, danh sách
nối vòng ñơn vẫn cần thời gian trung bình ���� ñể thực hiện thao tác chèn/xóa vì việc xác ñịnh nút ñứng liền trước một nút cho trước cũng gặp trở ngại như với danh sách nối ñơn.
a b c d e
a b c d e
�"�
��!"�

13
1.6. Biểu diễn danh sách bằng danh sách nối vòng kép
Danh sách nối vòng ñơn chỉ cho ta duyệt các nút của danh sách theo một chiều, nếu cài ñặt bằng danh sách nối vòng kép thì ta có thể duyệt các nút của danh sách cả theo chiều ngược lại nữa. Danh sách nối vòng kép có thể tạo thành từ
danh sách nối kép nếu ta cho trường �!�� của nút ��!"� trỏ tới nút #"� còn
trường �� � của nút �"� thì trỏ tới nút ��!"�.
Tương tự như danh sách nối kép, danh sách nối vòng kép cho phép thao tác
chèn/xóa phần tử có thể thực hiện trong thời gian ����.
Hình 1.6. Danh sách nối vòng kép
1.7. Biểu diễn danh sách bằng cây
Có nhiều thao tác trên danh sách, nhưng những thao tác phổ biến nhất là truy cập phần tử, chèn và xóa phần tử. Ta ñã khảo sát cách cài ñặt danh sách bằng mảng hoặc danh sách liên kết, nếu như mảng cho phép thao tác truy cập ngẫu nhiên tốt hơn danh sách liên kết, thì thao tác chèn/xóa phần tử trên mảng lại mất khá nhiều thời gian.
Dưới ñây là bảng so sánh thời gian thực hiện các thao tác trên danh sách.
Phương pháp Truy cập ngẫu nhiên Chèn Xóa
Mảng Θ��� Θ��� Θ���
Danh sách nối ñơn Θ��� Θ��� Θ���
Danh sách nối kép Θ��� Θ��� Θ���
Danh sách nối vòng ñơn Θ��� Θ��� Θ���
Danh sách nối vòng kép Θ��� Θ��� Θ���
Cây là một kiểu dữ liệu trừu tượng mà trong một số trường hợp có thể gián tiếp dùng ñể biểu diễn danh sách. Với một cách ñánh số thứ tự cho các nút của cây (duyệt theo thứ tự giữa), mỗi phép truy cập ngẫu nhiên, chèn, xóa phần tử trên
a b c d e

14
danh sách có thể thực hiện trong thời gian $�%&' ��. Chúng ta sẽ tiếp tục chủ ñề này trong một bài riêng.
Bài tập
1.1. Viết chương trình thực hiện các phép chèn, xóa, và tìm kiếm một phần tử trong danh sách các số nguyên ñã sắp xếp theo thứ tự tăng dần biểu diễn bởi:
� Mảng � Danh sách nối ñơn � Danh sách nối kép
1.2. Viết chương trình nối hai danh sách số nguyên ñã sắp xếp, tổng quát hơn,
viết chương trình nối � danh sách số nguyên ñã sắp xếp ñể ñược một danh sách gồm tất cả các phần tử.
1.3. Giả sử chúng ta biểu diễn một ña thức �� � ( )* � + ), � - �. )/, trong ñó 0( 1 0+ 1 - 1 0. dưới dạng một danh sách nối ñơn mà
nút thứ � của danh sách chứa hệ số 2, số mũ 02 và con trỏ tới nút kế tiếp
(nút � � �). Hãy tìm thuật toán cộng và nhân hai ña thức theo các biểu diễn này.
1.4. Một số nhị phân ..3( 4 , trong ñó 2 5 678�9 có giá trị bằng : 2;2.2<4 . Người ta biểu diễn số nhị phân này bằng một danh sách nối ñơn
gồm � nút, có nút ñầu danh sách chứa giá trị ., mỗi nút trong danh sách
chứa một chữ số nhị phân 2 và con trỏ tới nút kế tiếp là nút chứa chữ số
nhị phân 23(. Hãy lập chương trình thực hiện phép toán “cộng 1” trên số nhị phân ñã cho và ñưa ra biểu diễn nhị phân của kết quả.
Gợi ý: Sử dụng phép ñệ quy
2. Ngăn xếp và hàng ñợi Ngăn xếp và hàng ñợi là hai kiểu dữ liệu trừu tượng rất quan trọng và ñược sử dụng nhiều trong thiết kế thuật toán. Về bản chất, ngăn xếp và hàng ñợi là danh sách tức là một tập hợp các phần tử cùng kiểu có tính thứ tự.

15
Trong phần này chúng ta sẽ tìm hiểu hoạt ñộng của ngăn xếp và hàng ñợi và cách cài ñặt chúng bằng các cấu trúc dữ liệu. Tương tự như danh sách, ta gọi
kiểu dữ liệu của các phần tử sẽ chứa trong ngăn xếp và hàng ñợi là ��������.
Khi cài ñặt chương trình cụ thể, kiểu �������� có thể là kiểu số nguyên, số thực, ký tự, hay bất kỳ kiểu dữ liệu nào ñược chương trình dịch chấp nhận.
2.1. Ngăn xếp
Ngăn xếp (Stack) là một kiểu danh sách mà việc bổ sung một phần tử và loại bỏ một phần tử ñược thực hiện ở cuối danh sách.
Có thể hình dung ngăn xếp như một chồng ñĩa, ñĩa nào ñược ñặt vào chồng sau cùng sẽ nằm trên tất cả các ñĩa khác và sẽ ñược lấy ra ñầu tiên. Vì nguyên tắc “vào sau ra trước”, ngăn xếp còn có tên gọi là danh sách kiểu LIFO (Last In First Out). Vị trí cuối danh sách ñược gọi là ñỉnh (top) của ngăn xếp.
ðối với ngăn xếp có sáu thao tác cơ bản:
� =���: Khởi tạo một ngăn xếp rỗng
� ="����>: Cho biến ngăn xếp có rỗng không?
� ="?@��: Cho biết ngăn xếp có ñầy không?
� A��: ðọc giá trị phần tử ở ñỉnh ngăn xếp
� B@"�: ðẩy một phần tử vào ngăn xếp
� B��: Lấy ra một phần tử từ ngăn xếp
a) a) a) a) BiBiBiBi&&&&u diu diu diu di''''n ng(n xn ng(n xn ng(n xn ng(n x****p bp bp bp b++++ng mng mng mng m����ngngngng
Cách biểu diễn ngăn xếp bằng mảng cần có một mảng =���" ñể lưu các phần tử
trong ngăn xếp và một biến nguyên ��� ñể lưu chỉ số của phần tử tại ñỉnh ngăn xếp. Ví dụ:
const max = ...; //Dung lượng cực ñại của ngăn xếp
type
TStack = record
items: array[1..max] of TElement;
top: Integer;
end;
var Stack: TStack;
Sáu thao tác cơ bản của ngăn xếp có thể viết như sau:

16
//Khởi tạo ngăn xếp rỗng
procedure Init;
begin
Stack.top := 0;
end;
//Hàm kiểm tra ngăn xếp có rỗng không?
function IsEmpty: Boolean;
begin
Result := Stack.top = 0;
end;
//Hàm kiểm tra ngăn xếp có ñầy không?
function IsFull: Boolean;
begin
Result := Stack.top = max;
end;
//ðọc giá trị phần tử ở ñỉnh ngăn xếp
function Get: TElement;
begin
if IsEmpty then
Error ← "Stack is Empty" //Báo lỗi ngăn xếp rỗng
else
with Stack do Result := items[top];
//Trả về phần tử ở ñỉnh ngăn xếp
end;
//ðẩy một phần tử x vào ngăn xếp
procedure Push(const x: TElement);
begin
if IsFull then
Error ← "Stack is Full" //Báo lỗi ngăn xếp ñầy
else
with Stack do
begin
top := top + 1; //Tăng chỉ số ñỉnh Stack
items[top] := x; //ðặt x vào vị trí ñỉnh Stack
end;
end;
//Lấy một phần tử ra khỏi ngăn xếp
function Pop: TElement;
begin

17
if IsEmpty then
Error ← "Stack is Empty" //Báo lỗi ngăn xếp rỗng
else
with Stack do
begin
Result := items[top]; //Trả về phần tử ở ñỉnh ngăn xếp
top := top - 1; //Giảm chỉ số ñỉnh ngăn xếp
end;
end;
b) b) b) b) BiBiBiBi&&&&u diu diu diu di''''n ng(n xn ng(n xn ng(n xn ng(n x****p bp bp bp b++++ng danh sách nng danh sách nng danh sách nng danh sách n!!!!i "#n kii "#n kii "#n kii "#n ki&&&&u LIFOu LIFOu LIFOu LIFO
Ta sẽ trình bày cách cài ñặt ngăn xếp bằng danh sách nối ñơn các biến ñộng và con trỏ. Trong cách cài ñặt này, ngăn xếp sẽ bị ñầy nếu như vùng không gian nhớ dùng cho các biến ñộng không còn ñủ ñể thêm một phần tử mới. Tuy nhiên, việc kiểm tra ñiều này phụ thuộc vào máy tính, chương trình dịch và ngôn ngữ lập trình. Mặt khác, không gian bộ nhớ dùng cho các biến ñộng thường rất lớn
nên ta sẽ không viết mã cho hàm ="?@��: Kiểm tra ngăn xếp tràn.
Các khai báo dữ liệu:
type
PNode = ^TNode; //Kiểu con trỏ liên kết giữa các nút TNode = record //Kiểu dữ liệu cho một nút info: TElement;
link: PNode;
end;
var top: PNode; //Con trỏ tới phần tử ñỉnh ngăn xếp
Các thao tác trên ngăn xếp:
//Khởi tạo ngăn xếp rỗng
procedure Init;
begin
top := nil;
end;
//Kiểm tra ngăn xếp có rỗng không
function IsEmpty: Boolean;
begin
Result := top = nil;
end;

18
//ðọc giá trị phần tử ở ñỉnh ngăn xếp
function Get: TElement;
begin
if IsEmpty then
Error ← "Stack is Empty" //Báo lỗi ngăn xếp rỗng
else
Result := top^.info;
end;
//ðẩy một phần tử x vào ngăn xếp
procedure Push(const x: TElement);
var p: PNode;
begin
New(p); //Tạo nút mới
p^.info := x;
p^.link := top; //Nối vào danh sách liên kết
top := p; //Dịch con trỏ ñỉnh ngăn xếp
end;
//Lấy một phần tử khỏi ngăn xếp
function Pop: TElement;
var p: PNode;
begin
if IsEmpty then
Error ← "Stack is Empty" //Báo lỗi ngăn xếp rỗng
else
begin
Result := top^.info; //Lấy phần tử tại con trỏ top
p := top^.link;
Dispose(top); //Giải phóng bộ nhớ
top := P; //Dịch con trỏ ñỉnh ngăn xếp
end;
end;
2.2. Hàng ñợi
Hàng ñợi (Queue) là một kiểu danh sách mà việc bổ sung một phần tử ñược thực hiện ở cuối danh sách và việc loại bỏ một phần tử ñược thực hiện ở ñầu danh sách.

19
Khi cài ñặt hàng ñợi, có hai vị trí quan trọng là vị trí ñầu danh sách (�!���), nơi
các phần tử ñược lấy ra, và vị trí cuối danh sách (!�!), nơi phần tử cuối cùng ñược ñưa vào.
Có thể hình dung hàng ñợi như một ñoàn người xếp hàng mua vé: Người nào xếp hàng trước sẽ ñược mua vé trước. Vì nguyên tắc “vào trước ra trước”, hàng ñợi còn có tên gọi là danh sách kiểu FIFO (First In First Out).
Tương tự như ngăn xếp, có sáu thao tác cơ bản trên hàng ñợi:
� =���: Khởi tạo một hàng ñợi rỗng
� ="����>: Cho biến hàng ñợi có rỗng không?
� ="?@��: Cho biết hàng ñợi có ñầy không?
� A��: ðọc giá trị phần tử ở ñầu hàng ñợi
� B@"�: ðẩy một phần tử vào hàng ñợi
� B��: Lấy ra một phần tử từ hàng ñợi
aaaa) ) ) ) BiBiBiBi&&&&u diu diu diu di''''n hàng "n hàng "n hàng "n hàng "0000i bi bi bi b++++ng mng mng mng m����ngngngng
Ta có thể biểu diễn hàng ñợi bằng một mảng ����" ñể lưu các phần tử trong
hàng ñợi, một biến nguyêf!��� ñể lưu chỉ số phần tử ñầu hàng ñợi và một biến
nguyên !�! ñể lưu chỉ số phần tử cuối hàng ñợi. Chỉ một phần của mảng ����"
từ vị trí �!��� tới !�! ñược sử dụng lưu trữ các phần tử trong hàng ñợi. Ví dụ:
const max = ...; //Dung lượng cực ñại
type
TQueue = record
items: array[1..max] of TElement;
front, rear: Integer;
end;
var Queue: TQueue;
Sáu thao tác cơ bản trên hàng ñợi có thể viết như sau:
//Khởi tạo hàng ñợi rỗng
procedure Init;
begin
Queue.front := 1;
Queue.rear := 0;
end;
//Kiểm tra hàng ñợi có rỗng không

20
function IsEmpty: Boolean;
begin
Result := Queue.front > Queue.rear;
end;
//Kiểm tra hàng ñợi có ñầy không
function IsFull: Boolean;
begin
Result := Queue.rear = max;
end;
//ðọc giá trị phần tử ñầu hàng ñợi
function Get: TElement;
begin
if IsEmpty then
Error ← "Queue is Empty" //Báo lỗi hàng ñợi rỗng
else
with Queue do Result := items[front];
end;
//ðẩy một phần tử x vào hàng ñợi
procedure Push(const x: TElement);
begin
if IsFull then
Error ← "Queue is Full" //Báo lỗi hàng ñợi ñầy
else
with Queue do
begin
rear := rear + 1;
items[rear] := x;
end;
end;
//Lấy một phần tử khỏi hàng ñợi
function Pop: TElement;
begin
if IsEmpty then
Error ← "Queue is Empty" //Báo lỗi hàng ñợi rỗng
else
with Queue do
begin
Result := items[front];

21
front := front + 1;
end;
end;
bbbb) ) ) ) BiBiBiBi&&&&u diu diu diu di''''n hàng "n hàng "n hàng "n hàng "0000i bi bi bi b++++ng danh sách vòngng danh sách vòngng danh sách vòngng danh sách vòng
Xét việc biểu diễn ngăn xếp và hàng ñợi bằng mảng, giả sử mảng có tối ña 10
phần tử, ta thấy rằng nếu như làm 6 lần thao tác B@"�, rồi 4 lần thao tác B��, rồi
tiếp tục 8 lần thao tác B@"� nữa thì không có vấn ñề gì xảy ra cả. Lý do là vì chỉ
số ��� lưu ñỉnh của ngăn xếp sẽ ñược tăng lên 6000, rồi giảm về 2000, sau ñó lại tăng trở lại lên 10000 (chưa vượt quá chỉ số mảng). Nhưng nếu ta thực hiện các thao tác ñó ñối với cách cài ñặt hàng ñợi như trên thì sẽ gặp thông báo lỗi
tràn mảng, bởi mỗi lần ñẩy phần tử vào ngăn xếp, chỉ số cuối hàng ñợi !�! luôn tăng lên và không bao giờ bị giảm ñi cả. ðó chính là nhược ñiểm mà ta nói
tới khi cài ñặt: Chỉ có các phần tử từ vị trí �!��� tới !�! là thuộc hàng ñợi, các
phần tử từ vị trí 1 tới �!��� C � là vô nghĩa.
ðể khắc phục ñiều này, ta có thể biểu diễn hàng ñợi bằng một danh sách vòng (dùng mảng hoặc danh sách nối vòng ñơn): coi như các phần tử của hàng ñợi ñược xếp quanh vòng tròn theo một chiều nào ñó (chẳng hạn chiều kim ñồng
hồ). Các phần tử nằm trên phần cung tròn từ vị trí �!��� tới vị trí !�! là các
phần tử của hàng ñợi. Có thêm một biến � lưu số phần tử trong hàng ñợi. Việc
ñẩy thêm một phần tử vào hàng ñợi tương ñương với việc ta dịch chỉ số ��! theo chiều vòng một vị trí rồi ñặt giá trị mới vào ñó. Việc lấy ra một phần tử
trong hàng ñợi tương ñương với việc lấy ra phần tử tại vị trí �!��� rồi dịch chỉ
số �!��� theo chiều vòng. (h.1.7)

22
Hình 1.7. Dùng danh sách vòng mô tả hàng ñợi
ðể tiện cho việc dịch chỉ số theo vòng, khi cài ñặt danh sách vòng bằng mảng, người ta thường dùng cách ñánh chỉ số từ 0 ñể tiện sử dụng phép chia lấy dư (modulus - mod).
const max = ...; //Dung lượng cực ñại type
TQueue = record
items: array[0..max - 1] of TElement;
n, front, rear: Integer;
end;
var Queue: TQueue;
Sáu thao tác cơ bản trên hàng ñợi cài ñặt trên danh sách vòng ñược viết dưới dạng giả mã như sau:
//Khởi tạo hàng ñợi rỗng
procedure Init;
begin
with Queue do
begin
front := 0;
rear := max - 1;
n := 0;
end;
end;
//Kiểm tra hàng ñợi có rỗng không
function IsEmpty: Boolean;
0
1 2
3
4
56
7
�!���
!�!

23
begin
Result := Queue.n = 0;
end;
//Kiểm tra hàng ñợi có ñầy không
function IsFull: Boolean;
begin
Result := Queue.n = max;
end;
//ðọc giá trị phần tử ñầu hàng ñợi
function Get: TElement;
begin
if IsEmpty then
Error ← "Queue is Empty" //Báo lỗi hàng ñợi rỗng
else
with Queue do Result := items[front];
end;
//ðẩy một phần tử vào hàng ñợi
procedure Push(const x: TElement);
begin
if IsFull then
Error ← "Queue is Full" //Báo lỗi hàng ñợi ñầy
else
with Queue do
begin
rear := (rear + 1) mod max;
items[rear] := x;
Inc(n);
end;
end;
//Lấy một phần tử ra khỏi hàng ñợi
function Pop: TElement;
begin
if IsEmpty then
Error ← "Queue is Empty" //Báo lỗi hàng ñợi rỗng
else
with Queue do
begin
Result := items[front];

24
front := (front + 1) mod max;
Dec(n);
end;
end;
cccc) ) ) ) BiBiBiBi&&&&u diu diu diu di''''n hàng "n hàng "n hàng "n hàng "0000i bi bi bi b++++ng danh sách nng danh sách nng danh sách nng danh sách n!!!!i "#n kii "#n kii "#n kii "#n ki&&&&u FIFOu FIFOu FIFOu FIFO
Tương tự như cài ñặt ngăn xếp bằng biến ñộng và con trỏ trong một danh sách
nối ñơn, ta cũng không viết hàm ="?@�� ñể kiểm tra hàng ñợi ñầy.
Các khai báo dữ liệu:
type
PNode = ^TNode; //Kiểu con trỏ liên kết giữa các nút TNode = record //Kiểu dữ liệu cho một nút info: TElement;
link: PNode;
end;
var front, rear: PNode; //Con trỏ tới phần tử ñầu và cuối hàng ñợi
Các thao tác trên hàng ñợi:
//Khởi tạo hàng ñợi rỗng
procedure Init;
begin
front := nil;
end;
//Kiểm tra hàng ñợi có rỗng không
function IsEmpty: Boolean;
begin
Result := front = nil;
end;
//ðọc giá trị phần tử ñầu hàng ñợi
function Get: TElement;
begin
if IsEmpty then
Error ← "Queue is Empty" //Báo lỗi hàng ñợi rỗng else
Result := front^.info;
end;
//ðẩy một phần tử x vào hàng ñợi
procedure Push(const x: TElement);

25
var p: PNode;
begin
New(p); //Tạo một nút mới p^.info := x;
p^.link := nil; //Nối nút ñó vào danh sách
if front = nil then front := p
else rear^.link := p;
rear := p; //Dịch con trỏ rear end;
//Lấy một phần tử ra khỏi hàng ñợi
function Pop: TElement;
var P: PNode;
begin
if IsEmpty then
Error ← "Queue is Empty" //Báo lỗi hàng ñợi rỗng
else
begin
Result := front^.info; //Lấy phần tử tại con trỏ front
P := front^.link;
Dispose(front); //Giải phóng bộ nhớ
front := p; //Dịch con trỏ front
end;
end;
2.3. Một số chú ý về kỹ thuật cài ñặt
Ngăn xếp và hàng ñợi là hai kiểu dữ liệu trừu tượng tương ñối dễ cài ñặt, các thủ tục và hàm mô phỏng các thao tác có thể viết rất ngắn. Tuy vậy trong các chương trình dài, các thao tác vẫn nên ñược tách biệt ra thành chương trình con ñể dễ dàng gỡ rối hoặc thay ñổi cách cài ñặt (ví dụ ñổi từ cài ñặt bằng mảng sang cài ñặt bằng danh sách nối ñơn). ðiều này còn giúp ích cho lập trình viên trong trường hợp muốn biểu diễn các kiểu dữ liệu trừu tượng bằng các lớp và ñối tượng. Nếu có băn khoăn rằng việc gọi thực hiện chương trình con sẽ làm chương trình chạy chậm hơn việc viết trực tiếp, bạn có thể ñặt các thao tác ñó dưới dạng inline functions.

26
Bài tập
1.5. Hàng ñợi hai ñầu (doubled-ended queue) là một danh sách ñược trang bị bốn thao tác:
B@"�?���: ðẩy phần tử � vào ñầu danh sách
B@"�D���: ðẩy phần tử � vào cuối danh sách
B��?: Loại bỏ phần tử ñầu danh sách
B��D: Loại bỏ phần tử cuối danh sách
Hãy tìm cấu trúc dữ liệu thích hợp ñể cài ñặt kiểu dữ liệu trừu tượng hàng ñợi hai ñầu.
1.6. Có hai sơ ñồ ñường ray xe lửa bố trí như hình sau:
Ban ñầu có � toa tàu xếp theo thứ tự từ 1 tới � từ phải qua trái trên ñường
ray �. Người ta muốn xếp lại các toa tàu theo thứ tự mới từ phải qua trái ��(8 �+8 E 8 �.� lên ñường ray F theo nguyên tắc: Các toa tàu không ñược
“vượt nhau” trên ray, mỗi lần chỉ ñược chuyển một toa tàu từ � G H, � G H hoặc � G F. Hãy cho biết ñiều ñó có thể thực hiện ñược trên sơ ñồ ñường ray nào trong hai sơ ñồ trên.
3 2 1
� H
F I
3 2 1
�
H
F II

27
3. Cây
3.1. ðịnh nghĩa
Cây là một kiểu dữ liệu trừu tượng gồm một tập hữu hạn các nút, giữa các nút có một quan hệ phân cấp gọi là quan hệ “cha-con”. Có một nút ñặc biệt gọi là gốc (root).
Có thể ñịnh nghĩa cây bằng cách ñệ quy như sau:
� Một nút là một cây, nút ñó cũng là gốc của cây ấy
� Nếu ! là một nút và !(8 !+8 8 !I lần lượt là gốc của các cây �(8 �+8 8 �I, thì
ta có thể xây dựng một cây mới � bằng cách cho nút ! trở thành cha của các
nút !(8 !+8 8 !I. Cây � này nút gốc là ! còn các cây �(8 �+8 8 �I trở thành các cây con hay nhánh con (subtree) của nút gốc.
ðể tiện, người ta còn cho phép tồn tại một cây không có nút nào mà ta gọi là cây
rỗng (null tree), ký hiệu J.
Một vài hình ảnh của cấu trúc cây:
� Mục lục của một cuốn sách với phần, chương, bài, mục v.v… có cấu trúc của cây
� Cấu trúc thư mục trên ñĩa cũng có cấu trúc cây, thư mục gốc có thể coi là gốc của cây ñó với các cây con là các thư mục con (sub-directories) và tệp (files) nằm trên thư mục gốc.
� Gia phả của một họ tộc cũng có cấu trúc cây. � Một biểu thức số học gồm các phép toán cộng, trừ, nhân, chia cũng có thể
lưu trữ trong một cây mà các toán hạng ñược lưu trữ ở các nút lá, các toán tử ñược lưu trữ ở các nút nhánh, mỗi nhánh là một biểu thức con (h.1.8).
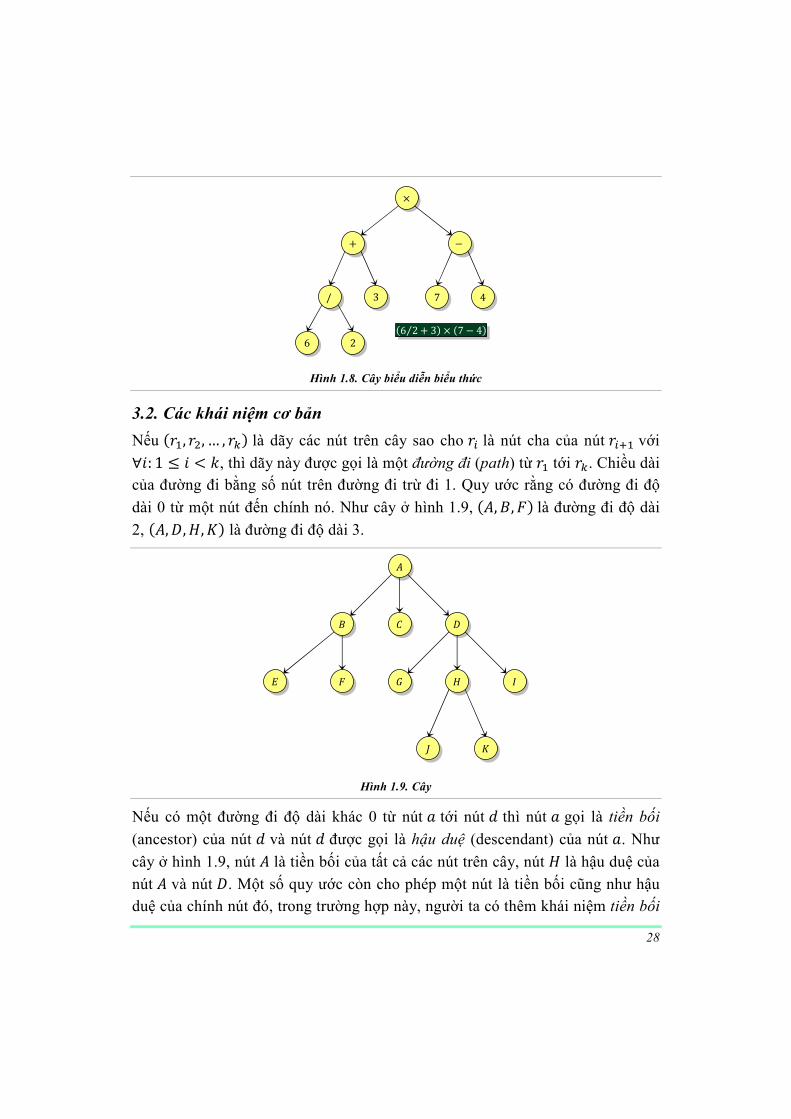
28
Hình 1.8. Cây biểu diễn biểu thức
3.2. Các khái niệm cơ bản
Nếu �!(8 !+8 8 !I� là dãy các nút trên cây sao cho !2 là nút cha của nút !2K( với L�M � N � O �, thì dãy này ñược gọi là một ñường ñi (path) từ !( tới !I. Chiều dài của ñường ñi bằng số nút trên ñường ñi trừ ñi 1. Quy ước rằng có ñường ñi ñộ
dài 0 từ một nút ñến chính nó. Như cây ở hình 1.9, ��8 H8 ?� là ñường ñi ñộ dài
2, ��8 P8 Q8 R� là ñường ñi ñộ dài 3.
Hình 1.9. Cây
Nếu có một ñường ñi ñộ dài khác 0 từ nút tới nút � thì nút gọi là tiền bối
(ancestor) của nút � và nút � ñược gọi là hậu duệ (descendant) của nút . Như
cây ở hình 1.9, nút � là tiền bối của tất cả các nút trên cây, nút Q là hậu duệ của
nút � và nút P. Một số quy ước còn cho phép một nút là tiền bối cũng như hậu duệ của chính nút ñó, trong trường hợp này, người ta có thêm khái niệm tiền bối
�
F H P
A ? � = Q
S R
T ;
U V
�
W X
C Y
�T ;Z � V� Y �W C X�

29
thực sự (proper ancestor) và hậu duệ ñích thực (proper descendant) trùng với khái niệm tiền bối và hậu duệ mà ta ñã ñịnh nghĩa.
Trong cây, chỉ duy nhất một nút không có tiền bối là nút gốc. Một nút không có hậu duệ gọi là nút lá (leaf) của cây, các nút không phải lá ñược gọi là nút nhánh
(branch). Như cây ở hình 1.9, các nút F8 �8 ?8 A8 =8 S8 R là các nút lá.
ðộ cao của một nút là ñộ dài ñường ñi dài nhất từ nút ñó tới một nút lá hậu duệ của nó, ñộ cao của nút gốc gọi là chiều cao (height) của cây. Như cây ở hình 1.9,
cây có chiều cao là 3 (ñường ñi ��8 P8 Q8 S�).
ðộ sâu (depth) của một nút là ñộ dài ñường ñi duy nhất từ nút gốc tới nút ñó.
Như cây ở hình 1.9, nút � có ñộ sâu là 0, nút H8 F8 P có ñộ sâu là 1, nút �8 ?8 A8 Q8 = có ñộ sâu là 2, và nút S8 R có ñộ sâu là 3. Có thể ñịnh nghĩa chiều cao của cây là ñộ sâu lớn nhất của các nút trong cây.
Một tập hợp các cây ñôi một không có nút chung ñược gọi là rừng (forest), có thể coi tập các cây con của một nút là một rừng.
Những nút con của cùng một nút ñược gọi là anh em (sibling). Với một cây, nếu chúng ta có tính ñến thứ tự anh em thì cây ñó gọi là cây có thứ tự (ordered tree), còn nếu chúng ta không quan tâm tới thứ tự anh em thì cây ñó gọi là cây không có thứ tự (unordered tree).
3.3. Biểu diễn cây tổng quát
Trong thực tế, có một số ứng dụng ñòi hỏi một cấu trúc dữ liệu dạng cây nhưng không có ràng buộc gì về số con của một nút trên cây, ví dụ như cấu trúc thư mục trên ñĩa hay hệ thống ñề mục của một cuốn sách. Khi ñó, ta phải tìm cách
mô tả một cách khoa học cấu trúc dữ liệu dạng cây tổng quát. Giả sử �������� là kiểu dữ liệu của các phần tử chứa trong mỗi nút của cây, khi ñó ta có thể biểu diễn cây bằng một trong các cấu trúc dữ liệu sau:
a) a) a) a) BiBiBiBi&&&&u diu diu diu di''''n bn bn bn b++++ng liên kng liên kng liên kng liên k****t tt tt tt t4444i nút chai nút chai nút chai nút cha
Với � là một cây, trong ñó các nút ñược ñánh số từ 1 tới �, khi ñó ta có thể gán
cho mỗi nút � một nhãn �!������ là số hiệu nút cha của nút �. Nếu nút � là nút
gốc, thì �!������ ñược gán giá trị 0. Cách biểu diễn này có thể cài ñặt bằng một

30
mảng các nút, mỗi nút là một bản ghi bên trong chứa giá trị lưu tại nút (����� và
nhãn �!���.
const max = ...; //Dung lượng cực ñại
type
TNode = record
info: TElement;
parent: Integer;
end;
TTree = array[1..max] of TNode;
var Tree: TTree;
Trong cách biểu diễn này, nếu chúng ta cần biết nút cha của một nút thì chỉ cần truy xuất trường parent của nút ñó. Tuy nhiên nếu ta cần liệt kê tất cả các nút con của một nút thì không có cách nào khác là phải duyệt toàn bộ danh sách nút
và kiểm tra trường parent. Thực hiện việc này mất thời gian ���� với mỗi nút.
b) b) b) b) BiBiBiBi&&&&u diu diu diu di''''n bn bn bn b++++ng cng cng cng c6666u trúc liên ku trúc liên ku trúc liên ku trúc liên k****tttt
Trong cách biểu diễn này, ta sắp xếp các nút con của mỗi nút theo một thứ tự nào ñó. Mỗi nút của cây là một bản ghi gồm 4 trường:
� Trường ����: Chứa giá trị lưu trong nút
� Trường �!���: Chứa con trỏ liên kết tới nút cha, tức là chứa một thông tin ñủ ñể biết nút cha của nút ñang xét là nút nào. Trong trường hợp nút ñang
xét là gốc (không có nút cha), trường �!��� ñược gán một giá trị ñặc biệt
(���). � Trường ��!"�: Chứa liên kết (con trỏ) tới nút con ñầu tiên (con cả) của nút
ñang xét, trong trường hợp nút ñang xét là nút lá (không có nút con), trường
này ñược gán một giá trị ñặc biệt (���). � Trường "�0���[: Chứa liên kết (con trỏ) tới nút em kế cận (nút cùng cha với
nút ñang xét, khi sắp thứ tự các nút con thì nút "�0���[ ñứng liền sau nút ñang xét). Trong trường hợp nút ñang xét không có nút em, trường này
ñược gán một giá trị ñặc biệt (���). type
PNode = ^TNode;
TNode = record
info: TElement;
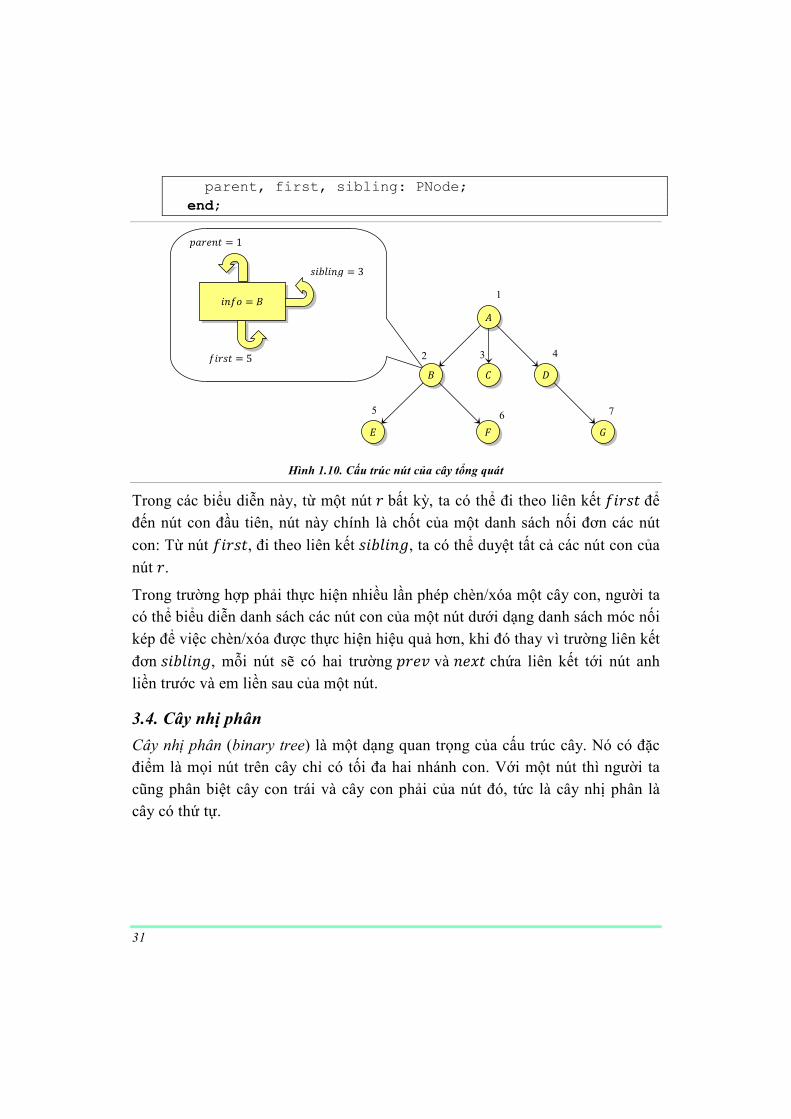
31
parent, first, sibling: PNode;
end;
Hình 1.10. Cấu trúc nút của cây tổng quát
Trong các biểu diễn này, từ một nút ! bất kỳ, ta có thể ñi theo liên kết ��!"� ñể ñến nút con ñầu tiên, nút này chính là chốt của một danh sách nối ñơn các nút
con: Từ nút ��!"�, ñi theo liên kết "�0���[, ta có thể duyệt tất cả các nút con của
nút !.
Trong trường hợp phải thực hiện nhiều lần phép chèn/xóa một cây con, người ta có thể biểu diễn danh sách các nút con của một nút dưới dạng danh sách móc nối kép ñể việc chèn/xóa ñược thực hiện hiệu quả hơn, khi ñó thay vì trường liên kết
ñơn "�0���[, mỗi nút sẽ có hai trường �!�� và �� � chứa liên kết tới nút anh liền trước và em liền sau của một nút.
3.4. Cây nhị phân
Cây nhị phân (binary tree) là một dạng quan trọng của cấu trúc cây. Nó có ñặc ñiểm là mọi nút trên cây chỉ có tối ña hai nhánh con. Với một nút thì người ta cũng phân biệt cây con trái và cây con phải của nút ñó, tức là cây nhị phân là cây có thứ tự.
�
F H P
� ? A
1
2 3 4
5 6 7
���� H
��!"� \
�!��� � "�0���[ V

32
a) a) a) a) MMMM8888t st st st s!!!! dddd9999ng "ng "ng "ng "::::c bic bic bic bi;;;;t ct ct ct c<<<<a cây nha cây nha cây nha cây nh>>>> phânphânphânphân
Hình 1.11. Cây nhị phân suy biến
Các cây nhị phân trong hình 1.11 ñược gọi là cây nhị phân suy biến (degenerate binary tree), trong cây nhị phân suy biến, các nút không phải lá chỉ có ñúng một cây con. Cây a) ñược gọi là cây lệch phải, cây b) ñược gọi là cây lệch trái, cây c) và d) ñược gọi là cây zíc-zắc.
Hình 1.11. Cây nhị phân hoàn chỉnh
Cây trong hình 1.11 ñược gọi là cây nhị phân hoàn chỉnh (complete binary tree). Cây nhị phân hoàn chỉnh có mọi nút lá nằm ở cùng một ñộ sâu và mọi nút nhánh
ñều có hai nhánh con. Số nút ở ñộ sâu � của cây nhị phân hoàn chỉnh là ;].
Tổng số nút của cây nhị phân hoàn chỉnh ñộ cao � là ;]K( C �
a) b) c d)

33
Hình 1.12. Cây nhị phân gần hoàn chỉnh
Cây trong hình 1.12 ñược gọi là cây nhị phân gần hoàn chỉnh (nearly complete
binary tree). Một cây nhị phân ñộ cao � ñược gọi là cây nhị phân gần hoàn
chỉnh nếu ta bỏ ñi mọi nút ở ñộ sâu � thì ñược một cây nhị phân hoàn chỉnh. Cây nhị phân hoàn chỉnh hiển nhiên là cây nhị phân gần hoàn chỉnh.
Hình 1.13. Cây nhị phân ñầy ñủ
Cây trong hình 1.13 ñược gọi là cây nhị phân ñầy ñủ (full binary tree). Cây nhị phân ñầy ñủ là cây nhị phân mà mọi nút nhánh của nó ñều có hai nút con.
Dễ dàng chứng minh ñược những tính chất sau:
� Trong các cây nhị phân có cùng số lượng nút như nhau thì cây nhị phân suy biến có chiều cao lớn nhất, còn cây nhị phân gần hoàn chỉnh thì có chiều cao nhỏ nhất.
� Số lượng tối ña các nút ở ñộ sâu � của cây nhị phân là ;^
� Số lượng tối ña các nút trên một cây nhị phân có chiều cao � là ;]K( C �
� Cây nhị phân gần hoàn chỉnh có � nút thì chiều cao của nó là _%' �`.

34
b) b) b) b) BiBiBiBi&&&&u diu diu diu di''''n cây nhn cây nhn cây nhn cây nh>>>> phânphânphânphân
Rõ ràng có thể sử dụng các cách biểu diễn cây tổng quát ñể biểu diễn cây nhị phân, nhưng dựa vào những ñặc ñiểm riêng của cây nhị phân, chúng ta có thể có những cách biểu diễn hiệu quả hơn. Trong phần này chúng ta xét một số cách biểu diễn ñặc thù cho cây nhị phân, tương tự như với ñối với cây tổng quát, ta
gọi �������� là kiểu dữ liệu của các phần tử chứa trong các nút của cây nhị phân.
� Biểu diễn bằng mảng
Một cây nhị phân hoàn chỉnh có � nút thì có chiều cao là _%' �`, tức là các nút sẽ
nằm ở các ñộ sâu từ 0 tới _%' �`, Khi ñó ta có thể liệt kê tất cả các nút từ ñộ sâu 0
(nút gốc) tới ñộ sâu _%' �`, sao cho với các nút cùng ñộ sâu thì thứ tự liệt kê là từ
trái qua phải. Thứ tự liệt kê cho phép ta ñánh số các nút từ 1 tới � (h.1.14).
Hình 1.14. ðánh số các nút của cây nhị phân hoàn chỉnh ñể biểu diễn bằng mảng
Với cách ñánh số này, hai con của nút thứ � sẽ là các nút thứ ;� và ;� � �. Cha
của nút thứ � là nút thứ _� ;Z `. Ta có thể lưu trữ cây bằng một mảng ���� trong
ñó phần tử chứa trong nút thứ � của cây ñược lưu trữ trong mảng bởi �������. Với cây nhị phân ở hình 1.14, ta có thể dùng mảng ���� ��8 H8 �8 F8 P8 �8 A� ñể chứa các giá trị trên cây.
Trong trường hợp cây nhị phân không hoàn chỉnh, ta có thể thêm vào một số nút giả ñể ñược cây nhị phân hoàn chỉnh. Khi biểu diễn bằng mảng thì những phần tử tương ứng với các nút giả sẽ ñược gán một giá trị ñặc biệt. Chính vì lý do này nên việc biểu diễn cây nhị phân không hoàn chỉnh bằng mảng sẽ rất lãng phí bộ nhớ trong trường hợp phải thêm vào nhiều nút giả. Ví dụ ta cần tới một mảng 15 phần tử ñể lưu trữ cây nhị phân lệch phải chỉ gồm 4 nút (h.1.15).
A
B
C D
E
F G
1
2 3
4 5 6 7
A B E C D F
1 2 3 4 5 6
G
7

35
Hình 1.15. Nhược ñiểm của phương pháp biểu diễn cây nhị phân bằng mảng
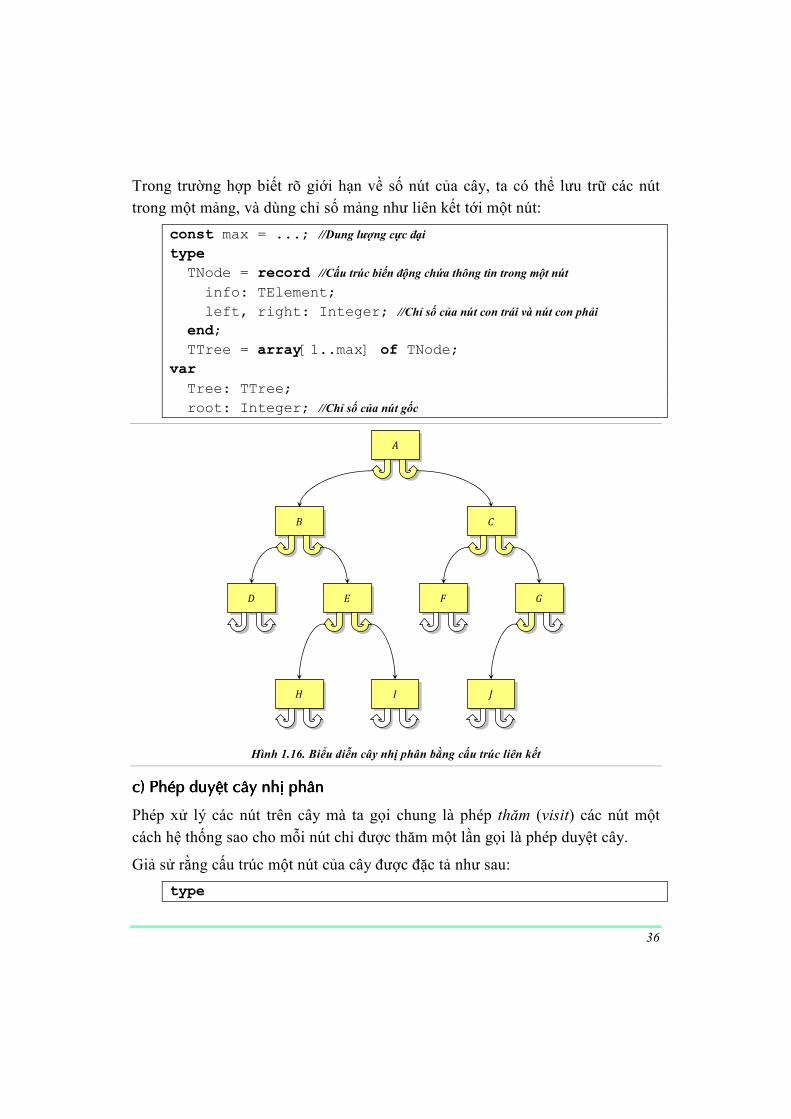
� Biểu diễn bằng cấu trúc liên kết.
Khi biểu diễn cây nhị phân bằng cấu trúc liên kết, mỗi nút của cây là một bản ghi (record) gồm 4 trường:
� Trường ����: Chứa giá trị lưu tại nút ñó
� Trường �!���: Chứa liên kết (con trỏ) tới nút cha, tức là chứa một thông tin ñủ ñể biết nút cha của nút ñó là nút nào, ñối với nút gốc, trường này
ñược gán một giá trị ñặc biệt (���). � Trường ����: Chứa liên kết (con trỏ) tới nút con trái, tức là chứa một thông
tin ñủ ñể biết nút con trái của nút ñó là nút nào, trong trường hợp không có
nút con trái, trường này ñược gán một giá trị ñặc biệt (���). � Trường !�[��: Chứa liên kết (con trỏ) tới nút con phải, tức là chứa một
thông tin ñủ ñể biết nút con phải của nút ñó là nút nào, trong trường hợp không có nút con phải, trường này ñược
gán một giá trị ñặc biệt (���). ðối với cây ta chỉ cần phải quan tâm giữ lại nút gốc (!���),
bởi từ nút gốc, ñi theo các hướng liên kết ����, !�[�� ta có thể duyệt mọi nút khác.
type
PNode = ^TNode; //Kiểu con trỏ tới một nút
TNode = record //Cấu trúc biến ñộng chứa thông tin trong một nút
info: TElement;
left, right: PNode
end;
var root: PNode; //Con trỏ tới nút gốc
A
B
C
D
A
1 2
B
3
4
5
6
C
7
8
9
10
11
12
13
14
D
15
!�[������
����
�!���
36
Trong trường hợp biết rõ giới hạn về số nút của cây, ta có thể lưu trữ các nút trong một mảng, và dùng chỉ số mảng như liên kết tới một nút:
const max = ...; //Dung lượng cực ñại type
TNode = record //Cấu trúc biến ñộng chứa thông tin trong một nút
info: TElement;
left, right: Integer; //Chỉ số của nút con trái và nút con phải
end;
TTree = array[1..max] of TNode;
var
Tree: TTree;
root: Integer; //Chỉ số của nút gốc
Hình 1.16. Biểu diễn cây nhị phân bằng cấu trúc liên kết
cccc) ) ) ) Phép duyPhép duyPhép duyPhép duy;;;;t cây nht cây nht cây nht cây nh>>>> phânphânphânphân
Phép xử lý các nút trên cây mà ta gọi chung là phép thăm (visit) các nút một cách hệ thống sao cho mỗi nút chỉ ñược thăm một lần gọi là phép duyệt cây.
Giả sử rằng cấu trúc một nút của cây ñược ñặc tả như sau:
type
H
P �
F
? A
�
Q = S

37
PNode = ^TNode; //Kiểu con trỏ tới một nút
TNode = record //Cấu trúc biến ñộng chứa thông tin trong một nút
info: TElement;
left, right: PNode
end;
var root: PNode; //Con trỏ tới nút gốc
Quy ước rằng nếu như một nút không có nút con trái (hoặc nút con phải) thì liên
kết ���� (!�[��) của nút ñó ñược liên kết thẳng tới một nút ñặc biệt mà ta gọi là ���, nếu cây rỗng thì nút gốc của cây ñó cũng ñược gán bằng ���. Khi ñó có ba cách duyệt cây hay ñược sử dụng:
� Duyệt theo thứ tự trước
Trong phép duyệt theo thứ tự trước (preorder traversal) thì giá trị trong mỗi nút bất kỳ sẽ ñược liệt kê trước tất cả các giá trị lưu trong hai nhánh con của nó, có thể mô tả bằng thủ tục ñệ quy sau:
procedure Visit(node: PNode); //Duyệt nhánh cây gốc node^
begin
if node ≠ nil then
begin
Output ← node^.info;
Visit(node^.left);
Visit(node^.right);
end;
end;
Quá trình duyệt theo thứ tự trước bắt ñầu bằng lời gọi a�"���D����.

38
Hình 1.17
Hình 1.17 là một cây nhị phân có 9 nút. Nếu ta duyệt cây này theo thứ tự trước thì quá trình duyệt theo thứ tự trước sẽ lần lượt liệt kê các giá trị: ?8 P8 H8 �8 F8 �8 Q8 A8 =
� Duyệt theo thứ tự giữa
Trong phép duyệt theo thứ tự giữa (inorder traversal) thì giá trị trong mỗi nút bất kỳ sẽ ñược liệt kê sau tất cả các giá trị lưu ở nút con trái và ñược liệt kê trước tất cả các giá trị lưu ở nút con phải của nút ñó, có thể mô tả bằng thủ tục ñệ quy sau:
procedure Visit(node: PNode); //Duyệt nhánh cây gốc node^
begin
if node ≠ nil then
begin
Visit(node^.left);
Output ← node^.info;
Visit(node^.right);
end;
end;
Quá trình duyệt theo thứ tự giữa cũng bắt ñầu bằng lời gọi a�"���D����.
Nếu ta duyệt cây ở hình 1.17 theo thứ tự giữa thì quá trình duyệt sẽ liệt kê lần lượt các giá trị: �8 H8 F8 P8 �8 ?8 A8 Q8 =
� F
H �
P
A =
Q
?

39
� Duyệt theo thứ tự sau
Trong phép duyệt theo thứ tự sau thì giá trị trong mỗi nút bất kỳ sẽ ñược liệt kê sau tất cả các giá trị lưu trong hai nhánh con của nó, có thể mô tả bằng thủ tục ñệ quy sau:
procedure Visit(node: PNode); //Duyệt nhánh cây gốc node^
begin
if node ≠ nil then
begin
Visit(node^.left);
Visit(node^.right);
Output ← node^.info;
end;
end;
Quá trình duyệt theo thứ tự sau cũng bắt ñầu bằng lời gọi a�"���D����.
Cũng với cây ở hình 1.17, nếu ta duyệt theo thứ tự sau thì các giá trị sẽ lần lượt ñược liệt kê theo thứ tự: �8 F8 H8 �8 P8 A8 =8 Q8 ?
3.5. Cây k-phân
Cây �-phân là một dạng cấu trúc cây mà mỗi nút trên cây có tối ña � nút con (có tính ñến thứ tự của các nút con).
Cũng tương tự như việc biểu diễn cây nhị phân, người ta có thể thêm vào cây �-
phân một số nút giả ñể cho mỗi nút nhánh của cây �-phân ñều có ñúng � nút
con, các nút con ñược xếp thứ tự từ nút con thứ nhất tới nút con thứ �, sau ñó
ñánh số các nút trên cây �-phân bắt ñầu từ 0 trở ñi, bắt ñầu từ mức 1, hết mức này ñến mức khác và từ “trái qua phải” ở mỗi mức.
Theo cách ñánh số này, nút con thứ b của nút � sẽ là: �� � b. Nếu � không phải là
nút gốc (� 1 7) thì nút cha của nút i là nút _�� C �� �Z `. Ta có thể dùng một mảng =��� ñánh số từ 0 ñể lưu các giá trị trên các nút: Giá trị tại nút thứ � ñược lưu trữ
ở phần tử =������. ðây là cơ chế biểu diễn cây �-phân bằng mảng.
Cây �-phân cũng có thể biểu diễn bằng cấu trúc liên kết với cấu trúc dữ liệu cho mỗi nút của cây là một bản ghi (record) gồm 3 trường:

40
� Trường ����: Chứa giá trị lưu trong nút ñó.
� Trường �!���: Chứa liên kết (con trỏ) tới nút cha, tức là chứa một thông tin ñủ ñể biết nút cha của nút ñó là nút nào, ñối với nút gốc, trường này
ñược gán một giá trị ñặc biệt (���). � Trường ����": Là một mảng gồm � phần tử, phần tử thứ � chứa liên kết (con
trỏ) tới nút con thứ �, trong trường hợp không có nút con thứ � thì ����"��� ñược gán một giá trị ñặc biệt (���).
ðối với cây �-phân, ta cũng chỉ cần giữ lại nút gốc, bởi từ nút gốc, ñi theo các hướng liên kết có thể ñi tới mọi nút khác.
Bài tập
1.7. Xét hai nút 8 > trên một cây nhị phân, ta nói nút nằm bên trái nút > (nút > nằm bên phải nút ) nếu:
� Hoặc nút nằm trong nhánh con trái của nút >
� Hoặc nút > nằm trong nhánh con phải của nút
� Hoặc tồn tại một nút c sao cho nằm trong nhánh con trái và > nằm trong
nhánh con phải của nút c
Chỉ ra rằng với hai nút 8 > bất kỳ trên một cây nhị phân ( d >) chỉ có ñúng một trong bốn mệnh ñề sau là ñúng:
� nằm bên trái >
� nằm bên phải >
� là tiền bối thực sự của >
� > là tiền bối thực sự của
1.8. Với mỗi nút trên cây nhị phân �, giả sử rằng ta biết ñược các giá trị B!��!��!� �, =��!��!� � và B�"��!��!� � lần lượt là thứ tự duyệt trước,
giữa, sau của . Tìm cách chỉ dựa vào các giá trị này ñể kiểm tra hai nút có quan hệ tiền bối-hậu duệ hay không.
1.9. Bậc (degree) của một nút là số nút con của nó. Chứng minh rằng trên cây nhị phân, số lá nhiều hơn số nút bậc 2 ñúng một nút.

41
1.10. Chỉ ra rằng cấu trúc của một cây nhị phân có thể khôi phục một cách ñơn ñịnh nếu ta biết ñược thứ tự duyệt trước và giữa của các nút. Tương tự như vậy, cấu trúc cây có thể khôi phục nếu ta biết ñược thứ tự duyệt sau và giữa của các nút.
1.11. Tìm ví dụ về hai cây nhị phân khác nhau nhưng có thứ tự trước của các nút giống nhau và thứ tự sau của các nút cũng giống nhau trên hai cây.
4. Ký pháp tiền tố, trung tố và hậu tố ðể kết thúc chương này, chúng ta nói tới một ứng dụng của ngăn xếp và cây nhị phân: Bài toán phân tích và tính giá trị biểu thức.
4.1. Biểu thức dưới dạng cây nhị phân
Chúng ta có thể biểu diễn các biểu thức số học gồm các phép toán cộng, trừ, nhân, chia bằng một cây nhị phân ñầy ñủ, trong ñó các nút lá biểu thị các toán hạng (hằng, biến), các nút không phải là lá biểu thị các toán tử (phép toán số học chẳng hạn). Mỗi phép toán trong một nút sẽ tác ñộng lên hai biểu thức con nằm
ở cây con bên trái và cây con bên phải của nút ñó. Ví dụ: Biểu thức �T ;Z �X� Y �e C V� ñược biểu diễn trong cây ở hình 1.18.
Hình 1.18. Cây biểu diễn biểu thức
4.2. Các ký pháp cho cùng một biểu thức
Với cây nhị phân biểu diễn biểu thức trong hình 4.1,
T ;
U X
�
e V
C
Y
�T ;Z � X� Y �e C V�

42
� Nếu duyệt theo thứ tự trước, ta sẽ ñược Y � U T ; X C e V, ñây là dạng tiền tố (prefix) của biểu thức. Trong ký pháp này, toán tử ñược viết trước hai toán hạng tương ứng, người ta còn gọi ký pháp này là ký pháp Ba lan.
� Nếu duyệt theo thứ tự giữa, ta sẽ ñược T U ; � X Y e C V . Ký pháp này bị nhập nhằng vì thiếu dấu ngoặc. Nếu thêm vào thủ tục duyệt một cơ chế bổ sung các cặp dấu ngoặc vào mỗi biểu thức con, ta sẽ thu ñược biểu thức fg�TU;� � Xh Y �e C V�i. Ký pháp này gọi là dạng trung tố (infix) của một
biểu thức (Thực ra chỉ cần thêm các dấu ngoặc ñủ ñể tránh sự mập mờ mà thôi, không nhất thiết phải thêm vào ñầy ñủ các cặp dấu ngoặc).
� Nếu duyệt theo thứ tự sau, ta sẽ ñược T ; U X � e V C Y , ñây là dạng hậu tố (postfix) của biểu thức. Trong ký pháp này toán tử ñược viết sau hai toán hạng, người ta còn gọi ký pháp này là ký pháp nghịch ñảo Balan (Reverse Polish Notation - RPN)
Chỉ có dạng trung tố mới cần có dấu ngoặc, dạng tiền tố và hậu tố không cần phải có dấu ngoặc. Chúng ta sẽ thảo luận về tính ñơn ñịnh của dạng tiền tố và hậu tố trong phần sau.
4.3. Cách tính giá trị biểu thức
Có một vấn ñề cần lưu ý là khi máy tính giá trị một biểu thức số học gồm các
toán tử hai ngôi (toán tử gồm hai toán hạng như �8 C8Y8U) thì máy chỉ thực hiện ñược phép toán ñó với hai toán hạng. Nếu biểu thức phức tạp thì máy phải chia nhỏ và tính riêng từng biểu thức trung gian, sau ñó mới lấy giá trị tìm ñược ñể
tính tiếp*. Ví dụ như biểu thức � � ; � X máy sẽ phải tính � � ; trước ñược kết quả là 3 sau ñó mới ñem 3 cộng với 4 chứ không thể thực hiện phép cộng một lúc ba số ñược.
Khi lưu trữ biểu thức dưới dạng cây nhị phân thì ta có thể coi mỗi nhánh con của cây ñó biểu diễn một biểu thức trung gian mà máy cần tính trước khi tính biểu
thức lớn. Như ví dụ trên, máy sẽ phải tính hai biểu thức TU; � X và e C V trước
* Thực ra ñây là việc của trình dịch ngôn ngữ bậc cao, còn máy chỉ tính các phép toán với hai toán hạng
theo trình tự của các lệnh ñược phân tích ra.

43
khi làm phép tính nhân cuối cùng. ðể tính biểu thức TU; � X thì máy lại phải
tính biểu thức TU; trước khi ñem cộng với X.
Vậy ñể tính một biểu thức lưu trữ trong một nhánh cây nhị phân gốc !, máy sẽ làm giống như hàm ñệ quy sau:
function Calculate(r: Nút): Giá trị;
//Tính biểu thức con trong nhánh cây gốc r begin
if «nút r chứa một toán hạng» then
Result := «Giá trị chứa trong nút r»
else //Nút r chứa một toán tử ♦
begin
x := Calculate(nút con trái của r);
y := Calculate(nút con phải của r);
Result := x ♦ y;
end;
end;
(Trong trường hợp lập trình trên các hệ thống song song, việc tính giá trị biểu thức ở cây con trái và cây con phải có thể tiến hành ñồng thời làm giảm ñáng kể thời gian tính toán biểu thức).
4.4. Tính giá trị biểu thức hậu tố
ðể ý rằng khi tính toán biểu thức, máy sẽ phải quan tâm tới việc tính biểu thức ở hai nhánh con trước, rồi mới xét ñến toán tử ở nút gốc. ðiều ñó làm ta nghĩ tới phép duyệt cây theo thứ tự sau và ký pháp hậu tố. Năm 1920, nhà lô-gic học người Balan Jan Łukasiewicz ñã chứng minh rằng biểu thức hậu tố không cần phải có dấu ngoặc vẫn có thể tính ñược một cách ñúng ñắn bằng cách ñọc lần lượt biểu thức từ trái qua phải và dùng một Stack ñể lưu các kết quả trung gian:
� Bước 1: Khởi tạo một ngăn xếp rỗng � Bước 2: ðọc lần lượt các phần tử của biểu thức RPN từ trái qua phải (phần
tử này có thể là hằng, biến hay toán tử) với mỗi phần tử ñó: � Nếu phần tử này là một toán hạng thì ñẩy giá trị của nó vào ngăn xếp.
� Nếu phần tử này là một toán tử j, ta lấy từ ngăn xếp ra hai giá trị (> và ) sau ñó áp dụng toán tử j ñó vào hai giá trị vừa lấy ra, ñẩy kết quả
tìm ñược ( j>) vào ngăn xếp (ra hai vào một).

44
� Bước 3: Sau khi kết thúc bước 2 thì toàn bộ biểu thức ñã ñược ñọc xong, trong ngăn xếp chỉ còn duy nhất một phần tử, phần tử ñó chính là giá trị của biểu thức.
Ví dụ: Tính biểu thức T ; U X � e V C Y tương ứng với biểu thức trung tố �TU; � X� Y �e C V�
ðọc Xử lý Ngăn xếp
6 ðẩy vào 6 6
2 ðẩy vào 2 6, 2
/ Lấy ra 2 và 6, ñẩy vào TU; V 3
4 ðẩy vào 4 3, 4
+ Lấy ra 4 và 3, ñẩy vào V � X W 7
8 ðẩy vào 8 7, 8
3 ðẩy vào 3 7, 8, 3
- Lấy ra 3 và 8, ñẩy vào e C V \ 7, 5
× Lấy ra 5 và 7, ñẩy vào W Y \ V\ 35
Ta ñược kết quả là 35
Dưới ñây ta sẽ viết một chương trình ñơn giản tính giá trị biểu thức RPN.
Input
Biểu thức số học RPN, hai toán hạng liền nhau ñược phân tách bởi dấu cách. Các toán hạng là số thực, các toán tử là +, -, * hoặc /.
Output
Kết quả biểu thức
Sample Input Sample Output
6 2 / 4 + 8 3 - * 35.0000
ðể ñơn giản, chương trình không kiểm tra lỗi viết sai biểu thức RPN, việc ñó chỉ là thao tác tỉ mỉ chứ không phức tạp lắm, chỉ cần xem lại thuật toán và cài thêm các lệnh bắt lỗi tại mỗi bước.
� RPNCALC.PAS � Tính giá trị biểu thức RPN
{$MODE OBJFPC}
program CalculatingRPNExpression;
type

45
TStackNode = record
// Ngăn xếp ñược cài ñặt bằng danh sách móc nối kiểu LIFO
value: Real;
link: Pointer;
end;
PStackNode = ^TStackNode;
var
RPN: AnsiString;
top: PStackNode;
procedure Push(const v: Real);
//ðẩy một toán hạng là số thực v vào ngăn xếp var p: PStackNode;
begin
New(p);
p^.value := v;
p^.link := top;
top := p;
end;
function Pop: Real; //Lấy một toán hạng ra khỏi ngăn xếp
var p: PStackNode;
begin
Result := top^.value;
p := top^.link;
Dispose(top);
top := p;
end;
procedure ProcessToken(const token: AnsiString);
//Xử lý một phần tử trong biểu thức RPN var
x, y: Real;
err: Integer;
begin
if token[1] in ['+', '-', '*', '/'] then
//Nếu phần tử token là toán tử begin //Lấy ra hai phần tử khỏi ngăn xếp, thực hiện toán tử và ñẩy giá trị vào ngăn xếp
y := Pop;
x := Pop;
case token[1] of
'+': Push(x + y);

46
'-': Push(x - y);
'*': Push(x * y);
'/': Push(x / y);
end;
end
else //Nếu phần tử token là toán hạng thì ñẩy giá trị của nó vào ngăn xếp
begin
Val(token, x, err);
Push(x);
end;
end;
procedure Parsing; //Xử lý biểu thức RPN
var i, j: Integer;
begin
j := 0; //j là vị trí ñã xử lý xong
for i := 1 to Length(RPN) do //Quét biểu thức từ trái sang phải
if RPN[i] in [' ', '+', '-', '*', '/'] then
//Nếu gặp toán tử hoặc dấu phân cách toán hạng begin
if i > j + 1 then //Trước vị trí i có một toán hạng chưa xử lý
ProcessToken(Copy(RPN, j + 1, i - j - 1));
//Xử lý toán hạng ñó if RPN[i] in ['+', '-', '*', '/'] then
//Nếu vị trí i chứa toán tử
ProcessToken(RPN[i]); //Xử lý toán tử ñó
j := i; //ðã xử lý xong ñến vị trí i
end;
if j < Length(RPN) then
//Trường hợp có một toán hạng còn sót lại (biểu thức chỉ có 1 toán hạng)
ProcessToken(Copy(RPN, j + 1, Length(RPN) - j));
//Xử lý nốt end;
begin
ReadLn(RPN); //ðọc biểu thức
top := nil; //Khởi tạo ngăn xếp rỗng,
Parsing; //Xử lý
Write(Pop:0:4); //Lấy ra phần tử duy nhất còn lại trong ngăn xếp và in ra kết quả.
end.

47
4.5. Chuyển từ dạng trung tố sang hậu tố
Có thể nói rằng việc tính toán biểu thức viết bằng ký pháp nghịch ñảo Balan là khoa học hơn, máy móc và ñơn giản hơn việc tính toán biểu thức viết bằng ký pháp trung tố. Chỉ riêng việc không phải xử lý dấu ngoặc ñã cho ta thấy ưu ñiểm của ký pháp RPN. Chính vì lý do này, các chương trình dịch vẫn cho phép lập trình viên viết biểu thức trên ký pháp trung tố theo thói quen, nhưng trước khi dịch ra các lệnh máy thì tất cả các biểu thức ñều ñược chuyển về dạng RPN. Vấn ñề ñặt ra là phải có một thuật toán chuyển biểu thức dưới dạng trung tố về dạng RPN một cách hiệu quả, dưới ñây ta trình bày thuật toán ñó:
Thuật toán sử dụng một ngăn xếp k�l� ñể chứa các toán tử và dấu ngoặc mở.
Thủ tục B@"���� ñể ñẩy một phần tử vào k�l�, hàm B�� ñể lấy ra một phần tử
từ k�l�, hàm A�� ñể ñọc giá trị phần tử nằm ở ñỉnh k�l� mà không lấy phần tử ñó ra. Ngoài ra mức ñộ ưu tiên của các toán tử ñược quy ñịnh bằng hàm B!��!��>: Ưu tiên cao nhất là dấu nhân (*) và dấu chia (/) với mức ưu tiên là 2, tiếp theo là dấu cộng (+) dấu (-) với mức ưu tiên là 1, ưu tiên thấp nhất là dấu ngoặc mở với mức ưu tiên là 0.
Stack := Ø;
for «phần tử token ñọc ñược từ biểu thức trung tố» do
case token of
//token có thể là toán hạng, toán tử, hoặc dấu ngoặc ñược ñọc lần lượt theo thứ tự từ trái qua phải
'(': Push(token); //Gặp dấu ngoặc mở thì ñẩy vào ngăn xếp
')':
//Gặp dấu ngoặc ñóng thì lấy ra và hiển thị các phần tử trong ngăn xếp cho tới khi lấy tới dấu ngoặc mở repeat
x := Pop;
if x ≠ '(' then Output ← x;
until x = '(';
'+', '-', '*', '/': //Gặp toán tử
begin
//Chừng nào ñỉnh ngăn xếp có phần tử với mức ưu tiên lớn hơn hay bằng token, lấy phần tử ñó ra và hiển thị
while (Stack ≠ Ø)
and (Priority(token) ≤ Priority(Get)) do
Output ← Pop;
Push(token); //ðẩy toán tử token vào ngăn xếp
48
end;
else //Gặp toán hạng thì hiển thị luôn
Output ← token;
end;
//Khi ñọc xong biểu thức, lấy ra và hiển thị tất cả các phần tử còn lại trong ngăn xếp
while Stack ≠ Ø do
Output ← Pop
Ví dụ với biểu thức trung tố �TU; � X� Y �e C V�
ðọc Xử lý Ngăn xếp Output Chú thích
( ðẩy “(” vào ngăn xếp (
6 Hiển thị ( 6
/ ðẩy “/” vào ngăn xếp (/ 6 “/” > “(”
2 Hiển thị (/ 6 2
+ Lấy “/” khỏi ngăn xếp và hiển thị, ñẩy “+” vào ngăn xếp
(+ 6 2 / “(” < “+” < “/”
4 Hiển thị (+ 6 2 / 4
) Lấy “+” và “(” khỏi ngăn xếp, hiển thị “+”
Ø 6 2 / 4 +
× ðẩy “×” vào ngăn xếp × 6 2 / 4 +
( ðẩy “(” vào ngăn xếp ×( 6 2 / 4 +
8 Hiển thị ×( 6 2 / 4 + 8
- ðẩy “-” vào ngăn xếp ×(- 6 2 / 4 + 8 “-” > “)”
3 Hiển thị ×(- 6 2 / 4 + 8 3
) Lấy “-” và “(” khỏi ngăn xếp, hiển thị “-”
× 6 2 / 4 + 8 3 -
Hết Lấy nốt “×” ra và hiển thị Ø 6 2 / 4 + 8 3 - ×
Thuật toán này có tên là thuật toán “xếp toa tàu” (shunting yards) do Edsger Dijkstra ñề xuất năm 1960. Tên gọi này xuất phát từ mô hình ñường ray tàu hỏa:

49
Hình 1.19. Mô hình “xếp toa tàu” của thuật toán chuyển từ dạng trung tố sang hậu tố
Trong hình 1.19, mỗi toa tàu tương ứng với một phần tử trong biểu thức trung tố
nằm ở “ñường ray” =��� . Có ba phép chuyển toa tàu: Từ ñường ray =��� sang
thẳng ñường ray DB�, từ ñường ray =��� xuống ñường ray k�l� , hoặc từ
ñường ray k�l� lên ñường ray DB�. Thuật toán chỉ ñơn thuần dựa trên các luật chuyển mà theo các luật ñó ta sẽ chuyển ñược tất cả các toa tàu sang ñường ray DB� ñể ñược một thứ tự tương ứng với biểu thức hậu tố* (ví dụ toán hạng ở =��� sẽ ñược chuyển thẳng sang DB� hay dấu “(” ở =��� sẽ ñược chuyển
thẳng xuống k�l�).
Dưới ñây là chương trình chuyển biểu thức viết ở dạng trung tố sang dạng RPN:
Input
Biểu thức trung tố
Output
Biểu thức hậu tố
Sample Input Sample Output
(6 / 2 + 4) * (8 - 3) 6 2 / 4 + 8 3 - *
� INFIX2RPN.PAS � Chuyển từ dạng trung tố sang hậu tố
{$MODE OBJFPC}
* Thực ra thì còn thao tác loại bỏ các dấu ngoặc trong biểu thức RPN nữa, nhưng ñiều này không quan
trọng, dấu ngoặc là thừa trong biểu thức RPN vì như ñã nói về phương pháp tính: biểu thức RPN có thể
tính ñơn ñịnh mà không cần các dấu ngoặc.
DB�
k�l�
=��� �TU; � X� Y �e C V�

50
program ConvertInfixToRPN;
type
TStackNode = record
// Ngăn xếp ñược cài ñặt bằng danh sách móc nối kiểu LIFO
value: AnsiChar;
link: Pointer;
end;
PStackNode = ^TStackNode;
var
Infix: AnsiString;
top: PStackNode;
procedure Push(const c: AnsiChar); //ðẩy một phần tử v vào ngăn xếp
var p: PStackNode;
begin
New(p);
p^.value := c;
p^.link := top;
top := p;
end;
function Pop: AnsiChar; //Lấy một phần tử ra khỏi ngăn xếp
var p: PStackNode;
begin
Result := top^.value;
p := top^.link;
Dispose(top);
top := p;
end;
function Get: AnsiChar; //ðọc phần tử ở ñỉnh ngăn xếp
begin
Result := top^.value;
end;
function Priority(c: Char): Integer; //Mức ưu tiên của các toán tử
begin
case c of
'*', '/': Result := 2;
'+', '-': Result := 1;
'(': Result := 0;
end;

51
end;
//Xử lý một phần tử ñọc ñược từ biểu thức trung tố
procedure ProcessToken(const token: AnsiString);
var
x: AnsiChar;
Opt: AnsiChar;
begin
Opt := token[1];
case Opt of
'(': Push(Opt); //token là dấu ngoặc mở ')': //token là dấu ngoặc ñóng
repeat
x := Pop;
if x <> '(' then Write(x, ' ')
else Break;
until False;
'+', '-', '*', '/': //token là toán tử
begin
while (top <> nil)
and (Priority(Opt) <= Priority(Get)) do
Write(Pop, ' ');
Push(Opt);
end;
else //token là toán hạng
Write(token, ' ');
end;
end;
procedure Parsing;
const Operators = ['(', ')', '+', '-', '*', '/'];
var i, j: Integer;
begin
j := 0; //j là vị trí ñã xử lý xong
for i := 1 to Length(Infix) do
if Infix[i] in Operators + [' '] then
//Nếu gặp dấu ngoặc, toán tử hoặc dấu cách begin
if i > j + 1 then //Trước vị trí i có một toán hạng chưa xử lý
ProcessToken(Copy(Infix, j + 1, i - j - 1));
//xử lý toán hạng ñó

52
if Infix[i] in Operators then
//Nếu vị trí i chứa toán tử hoặc dấu ngoặc
ProcessToken(Infix[i]); //Xử lý ký tự ñó
j := i; //Cập nhật, ñã xử lý xong ñến vị trí i
end;
if j < Length(Infix) then //Xử lý nốt toán hạng còn sót lại
ProcessToken(Copy(Infix, j + 1, Length(Infix) - j));
//ðọc hết biểu thức trung tố, lấy nốt các phần tử trong ngăn xếp ra và hiển thị while top <> nil do
Write(Pop, ' ');
WriteLn;
end;
begin
ReadLn(Infix); //Nhập dữ liệu
top := nil; //Khởi tạo ngăn xếp rỗng
Parsing; //ðọc biểu thức trung tố và chuyển thành dạng RPN
end.
4.6. Xây dựng cây nhị phân biểu diễn biểu thức
Ngay trong phần ñầu tiên, chúng ta ñã biết rằng các dạng biểu thức trung tố, tiền tố và hậu tố ñều có thể ñược hình thành bằng cách duyệt cây nhị phân biểu diễn biểu thức ñó theo các trật tự khác nhau. Vậy tại sao không xây dựng ngay cây nhị phân biểu diễn biểu thức ñó rồi thực hiện các công việc tính toán ngay trên cây?. Khó khăn gặp phải chính là thuật toán xây dựng cây nhị phân trực tiếp từ dạng trung tố có thể kém hiệu quả, trong khi ñó từ dạng hậu tố lại có thể khôi phục lại cây nhị phân biểu diễn biểu thức một cách rất ñơn giản, gần giống như quá trình tính toán biểu thức hậu tố:
� Bước 1: Khởi tạo một ngăn xếp rỗng dùng ñể chứa các nút trên cây � Bước 2: ðọc lần lượt các phần tử của biểu thức RPN từ trái qua phải (phần
tử này có thể là hằng, biến hay toán tử) với mỗi phần tử ñó:
� Tạo ra một nút mới c chứa phần tử mới ñọc ñược � Nếu phần tử này là một toán tử, lấy từ ngăn xếp ra hai nút (theo thứ tự
là > và ), cho trở thành con trái và > trở thành con phải của nút c
� ðẩy nút c vào ngăn xếp

53
� Bước 3: Sau khi kết thúc bước 2 thì toàn bộ biểu thức ñã ñược ñọc xong, trong ngăn xếp chỉ còn duy nhất một phần tử, phần tử ñó chính là gốc của cây nhị phân biểu diễn biểu thức.
Bài tập
1.12. Biểu thức có thể có dạng phức tạp hơn, chẳng hạn biểu thức bao gồm cả
phép lấy số ñối (C ), phép tính lũy thừa ( m), hàm số với một hay nhiều biến số. Chúng ta có thể biểu diễn những biểu thức dạng này bằng một cây tổng quát và từ ñó có thể chuyển biểu thức về dạng RPN ñể thực hiện tính toán. Hãy xây dựng thuật toán ñể chuyển biểu thức số học (dạng phức tạp) về dạng RPN và thuật toán tính giá trị biểu thức ñó.
1.13. Viết chương trình chuyển biểu thức logic dạng trung tố sang dạng RPN. Ví
dụ chuyển: nop 0 &q l nop � thành: 0 nop l � nop &q.
1.14. Chuyển các biểu thức sau ñây ra dạng RPN
a) � Y �H � F�
b) � � �HUF� � P
c) � Y �H � CF�
d) � C �H � F�rUs
e) �� &q H� nop gF &q �P &q o&t ��h f) �� H� &q �F P�
1.15. Với một ảnh ñen trắng hình vuông kích thước ;. Y ;. , người ta dùng phương pháp sau ñể mã hóa ảnh:
� Nếu ảnh chỉ gồm toàn ñiểm ñen thì ảnh ñó có thể ñược mã hóa bằng xâu chỉ gồm một ký tự ‘B’
� Nếu ảnh chỉ gồm toàn ñiểm trắng thì ảnh ñó có thể ñược mã hóa bằng xâu chỉ gồm một ký tự ‘W’
� Nếu B8 u8 D8 k lần lượt là xâu mã hóa của bốn ảnh vuông kích thước bằng
nhau thì vBuDk là xâu mã hóa của ảnh vuông tạo thành bằng cách ñặt 4 ảnh vuông ban ñầu theo sơ ñồ:

54
B uk D
Ví dụ “&B&BWWBW&BWBW” và
“&&BBBB&BWWBW&BWBW” là hai xâu mã hóa của cùng một ảnh bên:
Bài toán ñặt ra là cho số nguyên dương � và hai xâu mã hóa
của hai ảnh kích thước ;. Y ;.. Hãy cho biết hai ảnh ñó có khác nhau không và nếu chúng khác nhau hãy chỉ ra một vị trí có màu khác nhau trên hai ảnh.
5. Cây nhị phân tìm kiếm
5.1. Cấu trúc chung của cây nhị phân tìm kiếm
Cây nhị phân tìm kiếm (binary search tree-BST) là một cây nhị phân, trong ñó mỗi nút chứa một phần tử (khóa). Khóa chứa trong mỗi nút phải lớn hơn hay bằng mọi khóa trong nhánh con trái và nhỏ hơn hay bằng mọi khóa trong nhánh con phải.
Ở ñây chúng ta giả sử rằng các khóa lưu trữ trong cây ñược lấy từ một tập hợp k có quan hệ thứ tự toàn phần.
Hình 1.20. Cây nhị phân tìm kiếm
Có thể có nhiều cây nhị phân tìm kiếm biểu diễn cùng một bộ khóa. Hình 1.20 là
ví dụ về hai cây nhị phân tìm kiếm biểu diễn cùng một bộ khóa ��8;8V8X8\8T�.
2
1 3
4
5
6
1
2
5
4 6
3

55
ðịnh lý 5.1
Nếu duyệt cây nhị phân tìm kiếm theo thứ tự giữa, các khóa trên cây sẽ ñược liệt kê theo thứ tự không giảm (tăng dần).
Chứng minh
Ta chứng minh ñịnh lý bằng quy nạp: Rõ ràng ñịnh lý ñúng với BST chỉ có một nút. Giả sử
ñịnh lý ñúng với mọi BST có ít hơn � nút, xét một BST bất kỳ gồm � nút, và ở nút gốc
chứa khóa �, thuật toán duyệt cây theo thứ tự giữa trước hết sẽ liệt kê tất cả các khóa trong
nhánh con trái theo thứ tự không giảm (giả thiết quy nạp), các khóa này ñều N � (tính chất
của cây nhị phân tìm kiếm). Tiếp theo thuật toán sẽ liệt kê khóa � của nút gốc, cuối cùng,
lại theo giả thiết quy nạp, thuật toán sẽ liệt kê tất cả các khóa trong nhánh con phải theo thứ
tự không giảm, tương tự như trên, các khóa trong nhánh con phải ñều w �. Vậy tất cả �
khóa trên BST sẽ ñược liệt kê theo thứ tự không giảm, ñịnh lý ñúng với mọi BST gồm �
nút. ðPCM.
5.2. Các thao tác trên cây nhị phân tìm kiếm
a) a) a) a) CCCC6666u trúc nútu trúc nútu trúc nútu trúc nút
Chúng ta sẽ biểu diễn BST bằng một cấu trúc liên kết các nút ñộng và con trỏ liên kết. Mỗi nút trên BST sẽ là một bản ghi gồm 3 trường:
� Trường ��>: Chứa khóa lưu trong nút.
� Trường �!���M Chứa liên kết (con trỏ) tới nút cha, nếu là nút gốc (không
có nút cha) thì trường �!��� ñược ñặt bằng một con trỏ ñặc biệt, ký hiệu ����.
� Trường ����: Chứa liên kết (con trỏ) tới nút con trái, nếu nút không có
nhánh con trái thì trường ���� ñược ñặt bằng ����.
� Trường !�[��: Chứa liên kết (con trỏ) tới nút con phải, nếu nút không có
nhánh con phải thì trường !�[�� ñược ñặt bằng ����.
Nếu các khóa chứa trong nút có kiểu �R�> thì cấu trúc nút của BST có thể ñược khai báo như sau:
type
PNode = ^TNode; //Kiểu con trỏ tới một nút
TNode = record
key: TKey;
parent, left, right: PNode;
end;
var

56
sentinel: TNode;
nilT: PNode; //Con trỏ tới nút ñặt biệt
root: PNode; //Con trỏ tới nút gốc
begin
nilT := @sentinel;
...
end.
Các ngôn ngữ lập trình bậc cao thường cung cấp hằng con trỏ ��� (hay �@��) ñể
gán cho các liên kết không tồn tại trong cấu trúc dữ liệu. Hằng con trỏ ��� chỉ ñược sử dụng ñể so sánh với các con trỏ khác, không ñược phép truy cập biến
ñộng ���x.
Trong cài ñặt BST, chúng ta sử dụng con trỏ ���� có công cụng tương tự như
con trỏ ���: gán cho những liên kết không có thực. Chỉ có khác là con trỏ ����
trỏ tới một biến "������� có thực, chỉ có ñiều các trường của ����x là vô nghĩa
mà thôi. Chúng ta hy sinh một ô nhớ cho biến "������� ����x ñể ñơn giản hóa các thao tác trên BST*.
b) b) b) b) KhKhKhKhBBBBi ti ti ti t9999o cây ro cây ro cây ro cây rCCCCngngngng
Trong cấu trúc BST khai báo ở trên, ta quy ước một cây rỗng là cây có gốc D��� ����, phép khởi tạo một BST rỗng chỉ ñơn giản là:
procedure MakeNull;
begin
root := nilT;
end;
c) c) c) c) Tìm khóa lTìm khóa lTìm khóa lTìm khóa l4444n nhn nhn nhn nh6666t và nht và nht và nht và nh���� nhnhnhnh6666tttt
Theo ðịnh lí 5.1, khóa nhỏ nhất trên BST nằm trong nút ñược thăm ñầu tiên và khóa lớn nhất của BST nằm trong nút ñược thăm cuối cùng nếu ta duyệt cây theo thứ tự giữa. Như vậy nút chứa khóa nhỏ nhất (lớn nhất) của BST chính là
nút cực trái (cực phải) của BST. Hàm y����@� và y ��@� dưới ñây lần
* Mục ñích của biến này là ñể bớt ñi thao tác kiểm tra con trỏ � d ��� trước khi truy cập nút �x.

57
lượt trả về nút chứa khóa nhỏ nhất và lớn nhất trong nhánh cây BST gốc (ở
ñây ta giả thiết rằng nhánh BST gốc khác rỗng: d ����)
function Minimum(x: PNode): PNode; //Khóa nhỏ nhất nằm ở nút cực trái
begin
while x^.left ≠ nilT do //ði sang nút con trái chừng nào vẫn còn ñi ñược
x := x^.left;
Result := x;
end;
function Maximum(x: PNode): PNode; //Khóa lớn nhất nằm ở nút cực phải
begin
while x^.right ≠ nilT do //ði sang nút con phải chừng nào vẫn còn ñi ñược
x := x^.right;
Result := x;
end;
d) d) d) d) Tìm nút liTìm nút liTìm nút liTìm nút liEEEEn trFn trFn trFn trF4444c và nút lic và nút lic và nút lic và nút liEEEEn saun saun saun sau
ðôi khi chúng ta phải tìm nút ñứng liền trước và liền sau của một nút nếu
duyệt cây BST theo thứ tự giữa. Trước hết ta xét viết hàm B!���l�""�!� � trả
về nút ñứng liền trước nút , xét hai trường hợp:
� Nếu có nhánh con trái thì trả về nút cực phải của nhánh con trái: D�"@�� z y ��@�� xE #���� . � Nếu không có nhánh con trái thì từ , ta ñi dần lên phía gốc cây cho tới
khi gặp một nút chứa trong nhánh con phải thì dừng lại và trả về nút ñó.
function Predecessor(x: PNode): PNode;
begin
if x^.left ≠ nilT then //x có nhánh con trái
Result := Maximum(x^.left) //Trả về nút cực phải của cây con trái
else
repeat
Result := x^.parent;
//Nếu x là gốc hoặc x là nhánh con phải thì thoát ngay if (Result = nilT)
or (x = Result^.right) then Break;
x := Result; //Nếu không thì ñi tiếp lên phía gốc
until False;
end;

58
Hàm k@ll�""�!� � trả về nút liền sau nút có cách làm tương tự nếu ta ñổi vai
trò #��� và D�[��, y����@� và y ��@�:
function Successor(x: PNode): PNode;
begin
if x^.right ≠ nilT then //x có nhánh con phải
Result := Minimum(x^.right) //Trả về nút cực trái của cây con phải
else
repeat
Result := x^.parent;
//Nếu x là gốc hoặc x là nhánh con trái thì thoát ngay if (Result = nilT)
or (x = Result^.left) then Break;
x := Result; //ði tiếp lên phía gốc
until False;
end;
eeee) ) ) ) Tìm kiTìm kiTìm kiTìm ki****mmmm
Phép tìm kiếm nhận vào một nút và một khóa �. Nếu khóa � có trong nhánh
BST gốc thì trả về một nút chứa khóa �, nếu không trả về ����.
Phép tìm kiếm trên BST có thể cài ñặt bằng hàm k�!l�, hàm này ñược xây
dựng dựa trên nguyên lý chia ñể trị: Nếu nút chứa khóa � thì hàm ñơn giản
trả về nút , nếu không thì việc tìm kiếm sẽ ñược tiến hành tương tự trên cây
con trái hoặc cây con phải tùy theo nút chứa khóa nhỏ hơn hay lớn hơn �:
//Hàm Search trả về nút chứa khóa k, trả về nilT nếu không tìm thấy khóa k trong nhánh gốc x
function Search(x: PNode; const k: TKey): PNode;
begin
while (x ≠ nilT) and (x^.key ≠ k) do //Chừng nào chưa tìm thấy
if k < x^.key then x := x^.left
//k chắc chắn không nằm trong cây con phải, tìm trong cây con trái else x := x^.right;
//k chắc chắn không nằm trong cây con trái, tìm trong cây con phải
Result := x;
end;

59
ffff) ) ) ) ChènChènChènChèn
Chèn một khóa � vào BST tức là thêm một nút mới chứa khóa � trên BST và móc nối nút ñó vào BST sao cho vẫn ñảm bảo cấu trúc của một BST. Phép chèn
cũng ñược thực hiện dựa trên nguyên lý chia ñể trị: Bài toán chèn � vào cây
BST sẽ ñược quy về bài toán chèn � vào cây con trái hay cây con phải, tùy theo
khóa � nhỏ hơn hay lớn hơn hoặc bằng khóa chứa trong nút gốc. Trường hợp cơ
sở là � ñược chèn vào một nhánh cây rỗng, khi ñó ta chỉ việc tạo nút mới, móc
nối nút mới vào nhánh rỗng này và ñặt khóa � vào nút mới ñó.
Hình 1.11. Cây nhị phân tìm kiếm trước và sau khi chèn khóa { | Trước tiên ta viết một thủ tục k��#����B!�������8 F��������8 =�#���� ñể
chỉnh lại các liên kết sao cho nút F�������� trở thành nút con của nút B!�������:
procedure SetLink(ParentNode, ChildNode: PNode;
InLeft: Boolean);
begin
ChildNode^.parent := ParentNode;
if InLeft then ParentNode^.left := ChildNode
//InLeft = True: Cho ChildNode thành nút con trái của ParentNode else ParentNode^.right := ChildNode;
//InLeft = False: Cho ChildNode thành nút con phải của ParentNode end;
Khi ñó thủ tục chèn một nút �������x vào BST có thể viết như sau
//Chèn k vào BST, trả về nút mới chứa k
3
7
5 8
4
3
7
5 8
4 6

60
function Insert(k: TKey): PNode;
var x, y: PNode;
begin
y := nilT;
x := root; //Bắt ñầu từ gốc
while x ≠ nilT do
begin
y := x;
if k < x^.key then x := x^.left //Chèn vào nhánh trái
else x := x^.right; //Chèn vào nhánh phải
end;
New(x); //Tạo nút mới chứa k
x^.key := k;
x^.left := nilT;
x^.right := nilT;
SetLink(y, x, k < y^.key); //Móc nối vào BST
if root = nilT then root := x;
//Cập nhật lại gốc nếu là nút ñầu tiên ñược chèn vào Result := x;
end;
gggg) ) ) ) XóaXóaXóaXóa
Việc xóa một nút trong BST thực chất là xóa ñi khóa chứa trong nút . Phép xóa ñược thực hiện như sau:
� Nếu có ít hơn hai nhánh con, ta lấy nút con (nếu có) của lên thay cho
và xóa nút .
� Nếu có hai nhánh con, ta xác ñịnh nút > là nút cực phải của nhánh con trái
(hoặc nút cực trái của cây con phải), ñưa khóa chứa trong nút > lên nút rồi
xóa nút >. Chú ý rằng nút > chắc chắn không có ñủ hai nút con, việc xóa quy về trường hợp trên. (h.1.22)

61
Hình 1.22. Xóa nút khỏi BST
procedure Delete(x: PNode);
var y, z: PNode;
begin
if (x^.left ≠ nilT) and (x^.right ≠ nilT) then
//x có hai nhánh con begin
y := Maximum(x^.left); //Tìm nút cực phải của cây con trái
x^.key := y^.key; //ðưa khóa của nút y lên nút x
x := y;
end;
//Vấn ñề bây giờ là xóa nút x có nhiều nhất một nhánh con, xác ñịnh y là nút con (nếu có) của x
if x^.left ≠ nilT then y := x^.left
else y := x^.right;
z := x^.parent; //z là cha của x //cho y làm con của z thay cho x
SetLink(z, y, z^.left = x);
if x = root then root := y;
//Trường hợp nút x bị hủy là gốc thì cập nhật lại gốc là y
Dispose(x); //Giải phóng bộ nhớ cấp cho nút x
end;
hhhh) ) ) ) PhépPhépPhépPhép quay câyquay câyquay câyquay cây
Phép quay cây là một phép chỉnh lại cấu trúc liên kết trên BST, có hai loại: quay trái (left rotation) và quay phải (right rotation).
Khi ta thực hiện phép quay trái trên nút , chúng ta giả thiết rằng nút con phải
của là > d ���. Trên cây con gốc , phép quay trái sẽ ñưa > lên làm gốc mới,
5
2 6
1 7 4
3
4
2 6
1 7
3
4
2 6
1 7 3
>
>

62
trở thành nút con trái của > và nút con trái của > trở thành nút con phải của .
Phép quay này còn gọi là quay theo liên kết }G >.
Ngược lại, phép quay phải thực hiện trên những cây con gốc > mà nút con trái
của > là d ����. Sau phép quay phải, sẽ ñược ñưa lên làm gốc nhánh, > trở
thành nút con phải của và nút con phải của > trở thành nút con trái của . Phép
quay này còn gọi là quay theo liên kết > ~G .
Dễ thấy rằng sau phép quay, ràng buộc về quan hệ thứ tự của các khóa chứa trong cây vẫn ñảm bảo cho cây mới là một BST.
Hình 5.4 mô tả hai phép quay trên cây nhị phân tìm kiếm.
Hình 1.23. Phép quay cây
Các thuật toán quay trái và quay phải có thể viết như sau:
procedure RotateLeft(x: PNode);
var y, z, branch: PNode;
begin
y := x^.right;
z := x^.parent;
branch := y^.left;
SetLink(x, branch, False); //Cho branch trở thành con phải của x
SetLink(y, x, True); //Cho x trở thành con trái của y
SetLink(z, y, (z^.left = x)); //Móc nối y vào làm con của z thay cho x
if root = x then root := y; //Cập nhật lại gốc cây nếu trước ñây x là gốc
end;
>
� �
�
Quay phải
Quay trái
c
> �
� �
c

63
procedure RotateRight(y: PNode);
var x, z, branch: PNode;
begin
x := y^.left;
z := y^.parent;
branch := x^.right;
SetLink(y, branch, True); //Cho branch trở thành con trái của y
SetLink(x, y, False); //Cho y trở thành con phải của x
SetLink(z, x, z^.left = y); //Móc nối x vào làm con của z thay cho y
if root = y then root := x; //Cập nhật lại gốc cây nếu trước ñây y là gốc
end;
Dễ thấy rằng một BST sau phép quay vẫn là BST. Chúng ta có thể viết một thao
tác ���!��� � tổng quát hơn: Với d !��� , và > xE �!��� , phép ���!��� � sẽ quay theo liên kết > � ñể ñẩy nút lên phía gốc cây (ñộ sâu
của giảm 1) và kéo nút > xuống sâu hơn một mức làm con nút .
procedure UpTree(x: PNode);
var y, z, branch: PNode;
begin
y := x^.parent; //y^ là nút cha của x^
z := y^.parent; //z^ là nút cha của y^
if x = y^.left then //Quay phải
begin
branch := x^.right;
SetLink(y, branch, True);
//Chuyển nhánh gốc branch^ của x^ sang làm con trái y^
SetLink(x, y, False); //Cho y^ làm con phải x^
end
else //Quay trái
begin
branch := x^.left;
SetLink(y, branch, False);
//Chuyển nhánh gốc branch^ của x^ sang làm con phải y^
SetLink(x, y, True); //Cho y^ làm con trái x^
end;
SetLink(z, x, z^.left = y); //Móc nối x^ vào làm con z^ thay cho y^
if root = y then root := x;
//Cập nhật lại gốc BST nếu trước ñât y^ là gốc

64
end;
5.3. Hiệu lực của các thao tác trên cây nhị phân tìm kiếm
Có thể chứng minh ñược rằng các thao tác y����@� , y ��@� , B!���l�""�!, k@ll�""�!, k�!l�, =�"�!� ñều có thời gian thực hiện $��� với � là chiều cao của cây nhị phân tìm kiếm. Hơn nữa, trong trường hợp xấu nhất,
các thao tác này ñều có thời gian thực hiện ����.
Vậy khi lưu trữ � khóa bằng cây nhị phân tìm kiếm thì cấu trúc BST tốt nhất là
cấu trúc cây nhị phân gần hoàn chỉnh (có chiều cao thấp nhất: � _%' �`) còn cấu trúc BST tồi nhất ñể biểu diễn là cấu trúc cây nhị phân suy biến (có chiều
cao � � C �).
5.4. Cây nhị phân tìm kiếm tự cân bằng
a) a) a) a) Tính cân bTính cân bTính cân bTính cân b++++ngngngng
ðể tăng tính hiệu quả của các thao tác cơ bản trên BST, cách chung nhất là cố
gắng giảm chiều cao của cây. Với một BST gồm � nút, dĩ nhiên giải pháp lý
tưởng là giảm ñược chiều cao xuống còn _%' �` (cây nhị phân gần hoàn chỉnh) nhưng ñiều này thường làm ảnh hưởng nhiều tới thời gian thực hiện giải thuật. Người ta nhận thấy rằng muốn một cây nhị phân thấp thì phải cố gắng giữ ñược sự cân bằng (về chiều cao và số nút) giữa hai nhánh con của một nút bất kỳ. Chính vì vậy những ý tưởng ban ñầu ñể giảm chiều cao của BST xuất phát từ những kỹ thuật cân bằng cây, từ ñó người ta xây dựng các cấu trúc dữ liệu cây nhị phân tìm kiếm có khả năng tự cân bằng (self-balancing binary search tree)
với mong muốn giữ ñược chiều cao của BST luôn là một ñại lượng $�%' ��.
b) b) b) b) MMMM8888t st st st s!!!! dddd9999ng BST tng BST tng BST tng BST tLLLL cân bcân bcân bcân b++++ngngngng
� Cây AVL
Một trong những phát kiến ñầu tiên về cấu trúc BST tự cân bằng là cây AVL
[1]. Trong mỗi nhánh cây AVL, chiều cao của nhánh con trái và nhánh con phải hơn kém nhau không quá 1. Mỗi nút của cây AVL chứa thêm một thông tin về hệ số cân bằng (ñộ lệch chiều cao giữa nhánh con trái và nhánh con phải). Ngay sau mỗi phép chèn/xóa, hệ số cân bằng của một số nút ñược cập nhật lại và nếu

65
phát hiện một nút có hệ số cân bằng w ;, phép quay cây sẽ ñược thực hiện ñể cân bằng ñộ cao giữa hai nhánh con của nút ñó.
Một cây AVL có ñộ cao � thì có không ít hơn ��� � V� C � nút. Ở ñây ��� � V�
là số fibonacci thứ � � V. Các tác giả cũng chứng minh ñược rằng chiều cao của
cây AVL có � nút trong là một ñại lượng � �EXX7X %'�� � ;� C 7EV;e.
� Cây ñỏ ñen
Một dạng khác của BST tự cân bằng là cây ñỏ ñen (Red-Black tree) [4]. Mỗi nút của cây ñỏ ñen chứa thêm một bit màu (ñỏ hoặc ñen). Ngoài các tính chất của BST, cây ñỏ ñen thỏa mãn 5 tính chất sau ñây:
� Mọi nút ñều ñược tô màu (ñỏ hoặc ñen)
� Nút gốc !���x có màu ñen
� Nút ����x có màu ñen � Nếu một nút ñược tô màu ñỏ thì cả hai nút con của nó phải ñược tô màu ñen � Với mỗi nút, tất cả các ñường ñi từ nút ñó ñến các nút lá hậu duệ có cùng
một số lượng nút ñen.
Tương tự như cây AVL, ñi kèm với các phép chèn/xóa trên cây ñỏ ñen là những thao tác tô màu và cân bằng cây. Người ta chứng minh ñược rằng chiều cao của
cây ñỏ ñen có � nút trong không vượt quá ; %'�� � ��. Trên thực tế cây ñỏ ñen nhanh hơn cây AVL ở phép chèn và xóa nhưng chậm hơn ở phép tìm kiếm.
� Cây Splay
Còn rất nhiều dạng BST tự cân bằng khác nhưng một trong những ý tưởng thú vị
nhất là cây Splay [35]. Cây Splay duy trì sự cân bằng mà không cần thêm một thông tin phụ trợ nào ở mỗi nút. Phép “làm bẹp” cây ñược thực hiện mỗi khi có lệnh truy cập, những nút thường xuyên ñược truy cập sẽ ñược ñẩy dần lên gần gốc cây ñể có tốc ñộ truy cập nhanh hơn. Các phép tìm kiếm, chèn và xóa trên
cây Splay cũng ñược thực hiện trong thời gian $�%' �� (ñánh giá bù trừ). Trong trường hợp tần suất thực hiện phép tìm kiếm trên một khóa hay một cụm khóa cao hơn hẳn so với những khóa khác, cây splay sẽ phát huy ñược ưu thế về mặt tốc ñộ.

66
c) c) c) c) VVVV6666n "n "n "n "EEEE chchchchNNNNng minh lý thuyng minh lý thuyng minh lý thuyng minh lý thuy****t và cài "t và cài "t và cài "t và cài "::::tttt
Cây AVL và cây ñỏ ñen thường ñược ñưa vào giảng dạy trong các giáo trình cấu trúc dữ liệu vì các tính chất của hai cấu trúc dữ liệu khá dễ dàng trong chứng minh lý thuyết. Cây Splay thường ñược sử dụng trong các phần mềm ứng dụng vì tốc ñộ nhanh và tính chất “nhanh hơn nếu truy cập lại” (quick to access again). Ba loại cây này khá phổ biến trong các thư viện hỗ trợ của các môi trường phát triển cao cấp ñể viết các phần mềm ứng dụng. Lập trình viên có thể tùy chọn loại cây thích hợp nhất ñể cài ñặt giải quyết vấn ñề của mình.
Trong trường hợp bạn lập trình trong thời gian hạn hẹp mà không có thư viện hỗ trợ (chẳng hạn trong các kỳ thi lập trình), phải nói rằng việc cài ñặt các loại cây kể trên không hề ñơn giản và dễ nhầm lẫn (bạn có thể tham khảo trong các tài liệu khác về cơ sở lý thuyết và kỹ thuật cài ñặt các loại cây kể trên). Nếu bạn cần sử dụng các cấu trúc dữ liệu này trong phần mềm, theo tôi các bạn nên sử dụng các thư viện sẵn có hoặc viết một thư viện lớp mẫu (class template) thật cẩn thận ñể sử dụng lại.
Tôi sẽ không ñi vào chi tiết các loại cây này. ðiều bạn phải nhớ chỉ là có tồn tại những cấu trúc như vậy, ñể khi ñánh giá một thuật toán có sử dụng BST, có thể
coi các thao tác cơ bản trên BST ñược thực hiện trong thời gian $�%' ��.
Trong bài sau tôi sẽ giới thiệu một cấu trúc BST khác dễ cài ñặt hơn, dễ tùy biến hơn, và tốc ñộ cũng không hề thua kém trên thực tế: Cấu trúc Treap.
Bài tập
1.16. Quá trình tìm kiếm trên BST có thể coi như một ñường ñi xuất phát từ nút gốc. Giáo sư X phát hiện ra một tính chất thú vị: Nếu ñường ñi trong quá
trình tìm kiếm kết thúc ở một nút lá, ký hiệu # là tập các giá trị chứa trong
các nút nằm bên trái ñường ñi và D là tập các giá trị chứa trong các nút
nằm bên phải ñường ñi. Khi ñó L 5 #8 > 5 D, ta có N >. Chứng minh phát hiện của giáo sư X là ñúng hoặc chỉ ra một phản ví dụ.
1.17. Cho BST gồm � nút, bắt ñầu từ nút y����@�x , người ta gọi hàm k@ll�""�! ñể ñi sang nút liền sau cho tới khi duyệt qua nút y ��@�x.

67
Chứng minh rằng thời gian thực hiện giải thuật này có thời gian thực hiện $���. Gợi ý: Thực hiện � lời gọi k@ll�""�! lên tiếp ñơn giản chỉ là duyệt qua
các liên kết cha/con trên BST mỗi liên kết tối ña 2 lần. ðiều tương tự có
thể chứng minh ñược nếu ta bắt ñầu từ nút y ��@�x và gọi liên tiếp
hàm B!���l�""�! ñể ñi sang nút liền trước.
1.18. Cho BST có chiều cao �, bắt ñầu từ một nút �(, người ta tìm nút �+ là nút
liền sau �(: �+ z k@ll�""�!��(�, tiếp theo lại tìm nút �� là nút liền sau �+,… Chứng minh rằng thời gian thực hiện � lần phép k@ll�""�! như vậy
chỉ mất thời gian $�� � ��.
1.19. (tree Sort) Người ta có thể thực hiện việc sắp xếp một dãy khóa bằng cây nhị phân tìm kiếm: Chèn lần lượt các giá trị khóa vào một cây nhị phân tìm kiếm sau ñó duyệt cây theo thứ tự giữa. ðánh giá thời gian thực hiện giải thuật trong trường hợp tốt nhất, xấu nhất và trung bình. Cài ñặt thuật toán tree Sort.
1.20. Viết thuật toán k�!l�#���� ñể tìm nút chứa khóa lớn nhất N � trong BST.
1.21. Viết thuật toán k�!l�A���� ñể tìm nút chứa khóa nhỏ nhất w � trong BST.
1.22. Viết thủ tục y�����D������ nhận vào nút � và dùng các phép quay ñể
chuyển nút � thành gốc của cây BST.
1.23. Viết thủ tục y�����#����� nhận vào nút � và dùng các phép quay ñể
chuyển nút � thành một nút lá của cây BST.
1.24. Radix tree (cây tìm kiếm cơ số) là một cây nhị phân trong ñó mỗi nút có thể chứa hoặc không chứa giá trị khóa, (người ta thường dùng một giá trị ñặc biệt tương ứng với nút không chứa giá trị khóa hoặc sử dụng thêm một bit ñánh dấu những nút không chứa giá trị khóa)
Các giá trị khóa lưu trữ trên Radix tree là các dãy nhị phân, hay tổng quát hơn là một kiểu dữ liệu nào ñó có thể mã hóa bằng các dãy nhị phân. Phép chèn một khóa vào Radix tree ñược thực hiện như sau: Bắt ñầu từ nút gốc ta duyệt biểu diễn nhị phân của khóa, gặp bit 0 ñi sang nút con trái và gặp

68
bit 1 ñi sang nhánh con phải, mỗi khi không ñi ñược nữa (ñi vào liên kết ����), ta tạo ra một nút và nối nó vào cây ở chỗ liên kết ���� vừa rẽ sang rồi ñi tiếp. Cuối cùng ta ñặt khóa vào nút cuối cùng trên ñường ñi. Hình dưới ñây là Radix tree sau khi chèn các giá trị 1011, 10, 100, 0, 011. Các nút tô ñậm không chứa khóa
Gọi k là tập chứa các khóa là các dãy nhị phân, tổng ñộ dài các dãy nhị
phân trong k là �. Chỉ ra rằng chúng ta chỉ cần mất thời gian ���� ñể xây
dựng Radix tree chứa các phần tử của k , mất thời gian ���� ñể duyệt
Radix tree theo thứ tự giữa và liệt kê các phần tử của k theo thứ tự từ ñiển.
1.25. Cho BST tạo thành từ � khóa ñược chèn vào theo một trật tự ngẫu nhiên,
gọi Gọi � là biến ngẫu nhiên cho chiều cao của BST. Chứng minh rằng kỳ
vọng ���� $�%' ��.
1.26. Cho BST tạo thành từ � khóa ñược chèn vào theo một trật tự ngẫu nhiên,
gọi Gọi � là biến ngẫu nhiên cho ñộ sâu của một nút. Chứng minh rằng kỳ
vọng ���� $�%' ��.
1.27. Gọi 0��� là số lượng các cây nhị phân tìm kiếm chứa � khóa hoàn toàn phân biệt.
� Chứng minh rằng 0�7� � và 0��� : 0I0.3(3I.3(I<4
011
0
10
100
1011
0 1
1
1 1
1
0
0

69
� Chứng minh rằng 0��� (.K( g+.. h (số catalan thứ �). Từ ñó suy ra xác suất
ñể BST là cây nhị phân gần hoàn chỉnh (hoặc cây nhị phân suy biến) nếu � khóa ñược chèn vào theo thứ tự ngẫu nhiên.
� Chứng minh công thức xấp xỉ 0��� �/��.�U, g� � $��U��h
6. Cây nhị phân tìm kiếm ngẫu nhiên
6.1. ðộ cao trung bình của BST
Trong bài trước ta ñã biết rằng các thao tác cơ bản của BST ñược thực hiện
trong thời gian $��� với � là chiều cao của cây. Nếu � khóa ñược chèn vào một
BST rỗng, ta sẽ ñược một BST gồm � nút. Chiều cao của BST có thể là một số
nguyên nào ñó nằm trong phạm vi từ _�[�` tới � C �. Nếu thay ñổi thứ tự chèn � khóa vào cây, ta có thể thu ñược một cấu trúc BST khác.
ðiều chúng ta muốn biết là nếu chèn � khóa vào BST theo các trật tự khác nhau thì ñộ cao trung bình của BST thu ñược là bao nhiêu. Hay nói chính xác hơn,
chúng ta cần biết giá trị kỳ vọng của ñộ cao một BST khi chèn � khóa vào theo một trật tự ngẫu nhiên.
Thực ra trong các thao tác cơ bản của BST, ñộ sâu trung bình của các nút mới là
yếu tố quyết ñịnh hiệu suất chứ không phải ñộ cao của cây. ðộ sâu của nút � chính là số phép so sánh cần thực hiện ñể chèn nút � vào BST. Tổng số phép so
sánh ñể chèn toàn bộ � nút vào BST có thể ñánh giá tương tự như QuickSort,
bằng $�� %' ��. Vậy ñộ sâu trung bình của mỗi nút là (. $�� %' �� $�%' ��.
Người ta còn chứng minh ñược một kết quả mạnh hơn: ðộ cao trung bình của
BST là một ñại lượng $�%' ��. Cụ thể là ���� N V %' � � $��� với ���� là giá trị
kỳ vọng của ñộ cao và � là số nút trong BST. Chứng minh này khá phức tạp, bạn có thể tham khảo trong các tài liệu khác .

70
6.2. Treap
Chúng ta có thể tránh trường hợp suy biến của BST bằng cách chèn các nút vào cây theo một trật tự ngẫu nhiên*. Tuy nhiên trên thực tế rất ít khi chúng ta ñảm bảo ñược các nút ñược chèn/xóa trên BST theo trật tự ngẫu nhiên, bởi các thao tác trên BST thường do một tiến trình khác thực hiện và thứ tự chèn/xóa hoàn toàn do tiến trình ñó quyết ñịnh.
Trong mục này chúng ta quan tâm tới một dạng BST mà cấu trúc của nó không phụ thuộc vào thứ tự chèn/xóa: Treap.
Cho mỗi nút của BST thêm một thông tin �!��!��> gọi là “ñộ ưu tiên”. ðộ ưu
tiên của mỗi nút là một số dương. Khi ñó Treap† [33] ñược ñịnh nghĩa là một BST thỏa mãn tính chất của Heap. Cụ thể là:
� Nếu nút > nằm trong nhánh con trái của nút thì >E ��> N E ��>.
� Nếu nút > nằm trong nhánh con phải của nút thì >E ��> w E ��>.
� Nếu nút > là hậu duệ của nút thì >E �!��!��> N E �!��!��> Hai tính chất ñầu tiên là tính chất của BST, tính chất thứ ba là tính chất của Heap. Nút gốc của Treap có ñộ ưu tiên lớn nhất. ðể tiện trong cài ñặt, ta quy
ñịnh nút giả ����x có ñộ ưu tiên bằng 0.
ðịnh lý 6-1
Xét một tập các nút, mỗi nút chứa khóa và ñộ ưu tiên, khi ñó tồn tại cấu trúc Treap chứa các nút trên.
Chứng minh
Khởi tạo một BST rỗng và chèn lần lượt các nút vào BST theo thứ tự từ nút ưu
tiên cao nhất tới nút ưu tiên thấp nhất. Hai ràng buộc ñầu tiên ñược thỏa mãn vì ta
sử dụng phép chèn của BST. Hơn nữa phép chèn của BST luôn chèn nút mới vào
thành nút lá nên sau mỗi bước chèn, nút lá mới chèn vào không thể mang ñộ ưu
tiên lớn hơn các nút tiền bối của nó ñược. ðiều này chỉ ra rằng BST tạo thành là
một Treap.
* Từ “tránh” ở ñây không chính xác, trên thực tế phương pháp này không tránh ñược trường hợp xấu. Có
ñiều là xác suất xảy ra trường hợp xấu quá nhỏ và rất khó ñể “cố tình” chỉ ra cụ thể trường hợp xấu (giống
như Randomized QuickSort). † Tên gọi Treap là ghép của hai từ: “tree” và “Heap”

71
ðịnh lý 6-2
Xét một tập các nút, mỗi nút chứa khóa và ñộ ưu tiên. Nếu các khóa cũng như ñộ ưu tiên của các nút hoàn toàn phân biệt thì tồn tại duy nhất cấu trúc Treap chứa các nút trên.
Chứng minh
Sự tồn tại của cấu trúc Treap ñã ñược chỉ ra trong chứng minh trong ðịnh lí 6.1. Tính duy nhất của cấu trúc Treap này có thể chứng minh bằng quy nạp: Rõ ràng
ñịnh lý ñúng với tập gồm 0 nút (Treap rỗng). Xét tập gồm w � nút, khi ñó nút có
ñộ ưu tiên lớn nhất chắc chắn sẽ phải là gốc Treap, những nút mang khóa nhỏ hơn
khóa của nút gốc phải nằm trong nhánh con trái và những nút mang khóa lớn hơn
khóa của nút gốc phải nằm trong nhánh con phải. Sự duy nhất về cấu trúc của
nhánh con trái và nhánh con phải ñược suy ra từ giả thiết quy nạp. ðPCM.
Trong cài ñặt thông thường của Treap, ñộ ưu tiên �!��!��> của mỗi nút thường ñược gán bằng một số ngẫu nhiên ñể vô hiệu hóa những tiến trình “cố tình” làm cây suy biến: Cho dù các nút ñược chèn/xóa trên Treap theo thứ tự nào, cấu trúc của Treap sẽ luôn giống như khi chúng ta chèn các nút còn lại vào theo thứ tự
giảm dần của B!��!��> (tức là thứ tự ngẫu nhiên). Hơn nữa nếu biết trước ñược
tập các nút sẽ chèn vào Treap, ta còn có thể gán ñộ ưu tiên �!��!��> cho các nút một cách hợp lý ñể “ép” Treap thành cây nhị phân gần hoàn chỉnh (trung vị của tập các khóa sẽ ñược gán ñộ ưu tiên cao nhất ñể trở thành gốc cây, tương tự với nhánh trái và nhánh phải…). Ngoài ra nếu biết trước tần suất truy cập nút ta có thể gán ñộ ưu tiên của mỗi nút bằng tần suất này ñể các nút bị truy cập thường xuyên sẽ ở gần gốc cây, ñạt tốc ñộ truy cập nhanh hơn.
6.3.Các thao tác trên Treap
a) a) a) a) CCCC6666u trúc nútu trúc nútu trúc nútu trúc nút
Tương tự như BST, cấu trúc nút của Treap chỉ có thêm một trường �!��!��> ñể lưu ñộ ưu tiên của nút
type
PNode = ^TNode; //Kiểu con trỏ tới một nút
TNode = record
key: TKey;
parent, left, right: PNode;
priority: Integer;

72
end;
var
sentinel: TNode;
nilT: PNode; //Con trỏ tới nút ñặt biệt
root: PNode; //Con trỏ tới nút gốc
begin
sentinel.priority := 0;
nilT := @sentinel;
...
end.
Trên lý thuyết người ta thường cho các giá trị B!��!��> là số thực ngẫu nhiên,
khi cài ñặt ta có thể cho B!��!��> số nguyên dương lấy ngẫu nhiên trong một
phạm vi ñủ rộng. Ký hiệu DB là hàm trả về một số dương ngẫu nhiên, bạn có thể cài ñặt hàm này bằng bất kỳ một thuật toán tạo số ngẫu nhiên nào. Ví dụ:
function RP: Integer;
begin
Result := 1 + Random(MaxInt - 1); //Lấy ngẫu nhiên từ 1 tới MaxInt - 1 end;
Các phép khởi tạo cây rỗng, tìm phần tử lớn nhất, nhỏ nhất, tìm phần tử liền trước, liền sau trên Treap không khác gì so với trên BST thông thường. Phép quay không ñược thực hiện tùy tiện trên Treap vì nó sẽ phá vỡ ràng buộc thứ tự Heap, thay vào ñó chỉ có thao tác UpTree ñược nhúng vào trong mỗi phép chèn (Insert) và xóa (Delete) ñể hiệu chỉnh cấu trúc Treap.
Nhắc lại về thao tác ���!��� �
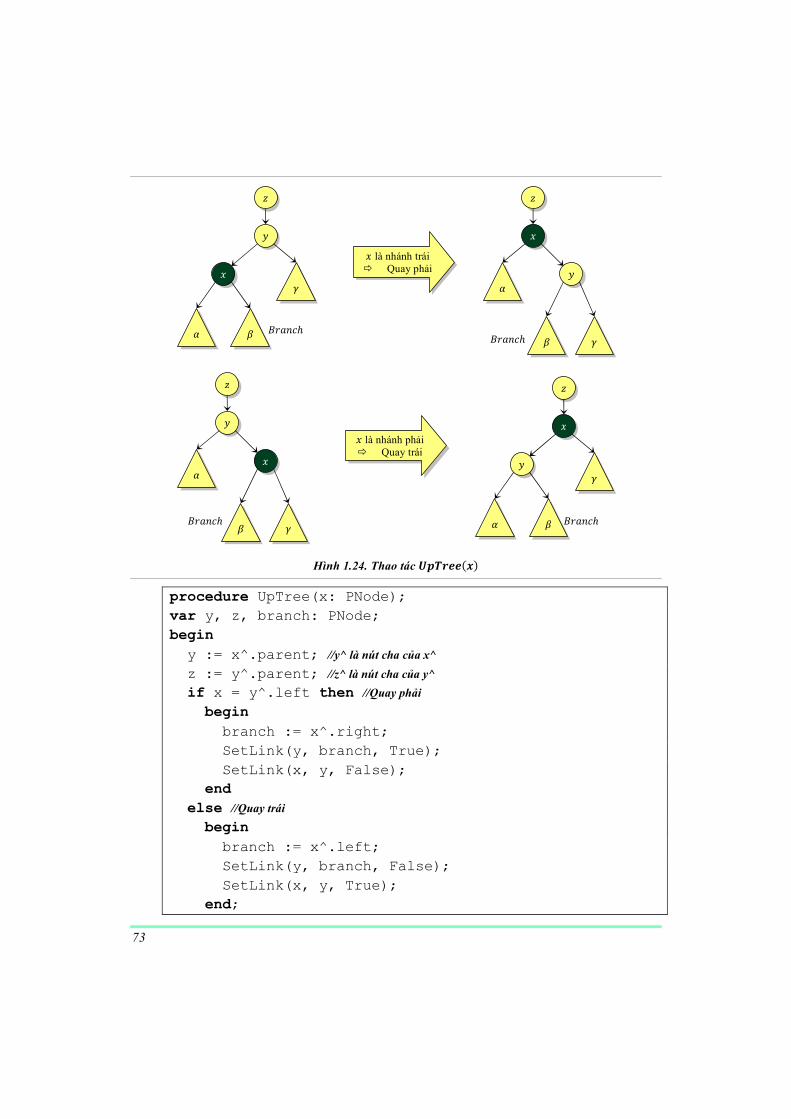
73
Hình 1.24. Thao tác ��������� procedure UpTree(x: PNode);
var y, z, branch: PNode;
begin
y := x^.parent; //y^ là nút cha của x^
z := y^.parent; //z^ là nút cha của y^
if x = y^.left then //Quay phải
begin
branch := x^.right;
SetLink(y, branch, True);
SetLink(x, y, False);
end
else //Quay trái
begin
branch := x^.left;
SetLink(y, branch, False);
SetLink(x, y, True);
end;
>
� � �
là nhánh trái � Quay phải
c
> �
� �
c
> �
� �
c
là nhánh phải � Quay trái
>
� � �
c
H!�l� H!�l�
H!�l� H!�l�

74
SetLink(z, x, z^.left = y); //Móc nối x^ vào làm con z^ thay cho y^
if root = y then root := x;
//Cập nhật lại gốc BST nếu trước ñât y^ là gốc end;
b) b) b) b) ChènChènChènChèn
Phép chèn trên Treap trước hết thực hiện như phép chèn trên BST ñể chèn khóa
vào một nút lá. Nút lá x mới chèn vào sẽ ñược gán một ñộ ưu tiên ngẫu nhiên.
Tiếp theo là phép hiệu chỉnh Treap: Gọi >x là nút cha của x, chừng nào thấy x mang ñộ ưu tiên lớn hơn >x (vi phạm thứ tự Heap) ta thực hiện lệnh ���!��� � ñể ñẩy nút x lên làm cha nút >x và kéo nút >x xuống làm con nút x.
//Chèn khóa k vào Treap, trả về con trỏ tới nút chứa k
function Insert(k: TKey): PNode;
var x, y: PNode;
begin
//Thực hiện phép chèn như trên BST
y := nilT;
x := root;
while x ≠ nilT do
begin
y := x;
if k < x^.key then x := x^.left
else x := x^.right;
end;
New(x);
x^.key := k;
x^.left := nilT;
x^.right := nilT;
SetLink(y, x, k < y^.key);
if root = nilT then root := x;
//Chỉnh Treap
x^.priority := RP; //Gán ñộ ưu tiên ngẫu nhiên
repeat
y := x^.parent;
if (y ≠ nilT)
and (x^.priority > y^.priority) then UpTree(x)

75
else Break;
until False;
Result := x;
end;
Ví dụ chúng ta có một Treap chứa các khóa A, B, E, G, H, K với ñộ ưu tiên là A:1, B:5, E:2, G:7, H:4, K:3 và chèn một nút khóa chứa khóa I và ñộ ưu tiên 6 vào Treap, trước hết thuật toán chèn trên BST ñược thực hiện như trong hình 1.25.
Hình 1.15. Phép chèn trên Treap trước hết thực hiện như trong BST
Tiếp theo là hai phép ���!�� ñể chuyển nút I:6 về vị trí ñúng trên Treap (h.1.26)
Hình 1.26. Sau phép chèn BST là các phép UpTree ñể chỉnh lại Treap
Số phép ���!�� cần thực hiện phụ thuộc vị trí và ñộ ưu tiên của nút mới chèn
vào (Có thể là số nào ñó từ 0 tới � với � là ñộ cao của Treap), nhưng người ta ñã chứng minh ñược ñịnh lý sau:
ðịnh lý 6.3
Trung bình số phép ���!�� cần thực hiện trong phép chèn =�"�!� là 2.
G:7
A:1 E:2
B:5
K:3
H:4
I:6
G:7
A:1 E:2
B:5
I:6
H:4
K:3
G:7
A:1 E:2
B:5
K:3
I:6
H:4
G:7
A:1 E:2
B:5
K:3
H:4
G:7
A:1 E:2
B:5
K:3
H:4
I:6

76
c) c) c) c) XóaXóaXóaXóa
Phép xóa nút x trên Treap ñược thực hiện như sau:
� Nếu x có ít hơn hai nhánh con, ta lấy nút con (nếu có) của x lên thay cho x và xóa nút x.
� Nếu x có ñúng hai nhánh con, gọi >x là nút con mang ñộ ưu tiên lớn hơn
trong hai nút con, thực hiện phép ���!���>� ñể kéo nút x xuống sâu phía
dưới lá và lặp lại cho tới khi x chỉ còn một nút con. Việc xóa quy về trường hợp trên
procedure Delete(x: PNode);
var y, z: PNode;
begin
while (x^.left ≠ nilT) and (x^.right ≠ nilT) do
//Chừng nào x^ có 2 nút con begin
//Xác ñịnh y^ là nút con mang ñộ ưu tiên lớn hơn
y := x^.left;
if y^.priority < x^.right^.priority then
y := x^.right;
UpTree(y); //ðẩy y lên phía gốc, kéo x xuống phía lá
end;
//Bây giờ x^ chỉ có tối ña một nút con, xác ñịnh y^ là nút con (nếu có) của x if x^.left <> nilT then y := x^.left
else y := x^.right;
z := x^.parent; //z^ là nút cha của x^
SetLink(z, y, z^.left = x); //Cho y^ làm con của z^ thay cho x^
if x = root then root := y; //Cập nhật lại gốc
Dispose(x); //Giải phóng bộ nhớ
end;
Ví dụ chúng ta có một Treap chứa các khóa A, B, E, G, H, I, K với ñộ ưu tiên là
A:1, B:5, E:2, G:7, H:4, I:6, K:3 và xóa nút chứa khóa G. Ba phép ���!�� (quay) sẽ ñược thực hiện trước khi xóa nút chứa khóa G

77
Hình 1.27. Thực hiện các phép quay ñẩy dần nút cần xóa xuống dưới lá, khi nút cần xóa còn ít hơn 1
nhánh con thì xóa trực tiếp.
Tương tự như phép chèn, số phép ���!�� cần thực hiện phụ thuộc vị trí và ñộ ưu tiên của nút bị xóa, nhưng người ta ñã chứng minh ñược ñịnh lý sau ñây.
ðịnh lý 6-4
Trung bình số phép ���!�� cần thực hiện trong phép xóa P����� là 2.
Bài tập
1.28. Thứ tự thống kê: Cho một Treap, hãy xây dựng thuật toán tìm khóa ñứng
thứ � khi sắp thứ tự. Ngược lại cho một nút, hãy tìm số thứ tự của nút ñó khi duyệt Treap theo thứ tự giữa.
1.29. Treap biểu diễn tập hợp
Khi dùng Treap � biểu diễn tập hợp các giá trị khóa, (tức là các khóa trong
Treap hoàn toàn phân biệt), phép thử � 5 � có thể ñược thực hiện thông
G:7
E:2
B:5
K:3
I:6
H:4 A:1
G:7
E:2
B:5
K:3
I:6
A:1
H:4
B:5
E:2
A:1
K:3
I:6
G:7
H:4
B:5
G:7
A:1
K:3
I:6
H:4
E:2
B:5
E:2
A:1
K:3
I:6
H:4

78
qua hàm k�!l�. Việc thêm một phần tử vào tập hợp có thể thực hiện
thông qua một sửa ñổi của hàm =�"�!� (Chỉ chèn nếu khóa chưa có trong Treap). Việc xóa một phần tử khỏi tập hợp cũng ñược thực hiện thông qua
việc sửa ñổi thủ tục P����� (tìm phần tử trong Treap, nếu tìm thấy thì thực hiện phép xóa). Ngoài ra còn có nhiều thao tác khác ñược thực hiện rất hiệu quả với cấu trúc Treap, hãy cài ñặt các thao tác sau ñây trên Treap:
Phép tách (Split): Với một giá trị �4, tách các khóa O �4 và các khóa 1 �4 ra hai Treap biểu diễn hai tập hợp riêng rẽ.
Gợi ý: Tìm nút chứa phần tử �4 trong Treap, nếu không thấy thì chèn �4
vào một nút mới. ðặt ñộ ưu tiên của nút này bằng ��. Theo nguyên lý của cấu trúc Treap, nút này sẽ ñược ñẩy lên thành gốc cây. Ngoài ra theo nguyên lý của cấu trúc BST, nhánh con trái của gốc cây sẽ chứa tất cả các
khóa O �4 và nhánh con phải của gốc cây sẽ chứa tất cả các khóa 1 �4.
Phép hợp (Union): Cho hai Treap chứa hai tập khóa, xây dựng Treap mới chứa tất cả các khóa của hai Treap ban ñầu
Phép giao (Intersection): Cho hai Treap chứa hai tập khóa, xây dựng Treap mới chứa tất cả các khóa có mặt trong cả hai Treap ban ñầu
Phép lấy hiệu (Difference): Cho hai Treap �8 H chứa hai tập khóa, xây
dựng Treap mới chứa các khóa thuộc � nhưng không thuộc H.
7. Một số ứng dụng của cây nhị phân tìm kiếm Ngoài ứng dụng ñể biểu diễn tập hợp (Bài tập 6.2), cây nhị phân tìm kiếm còn có nhiều ứng dụng quan trọng khác nữa. Trong bài này chúng ta sẽ khảo sát một vài ứng dụng khác của cấu trúc BST.
Cấu trúc BST thông thường có thể dùng ñể cài ñặt chương trình giải quyết những vấn ñề trong bài, tuy nhiên bạn nên sử dụng một dạng BST tự cân bằng hoặc Treap ñể tránh trường hợp xấu của BST.
7.1. Cây biểu diễn danh sách
Chúng ta ñã biết những cách cơ bản ñể biểu diễn danh sách là sử dụng mảng hoặc danh sách móc nối. Sử dụng mảng có tốc ñộ tốt với phép truy cập ngẫu nhiên nhưng sẽ bị chậm nếu danh sách luôn bị biến ñộng bởi các phép chèn/xóa.

79
Trong khi ñó, sử dụng danh sách móc nối có thể thuận tiện hơn trong các phép chèn/xóa thì lại gặp nhược ñiểm trong phép truy cập ngẫu nhiên.
Trong mục này chúng ta sẽ trình bày một phương pháp biểu diễn danh sách bằng cây nhị phân mà các trên ñó, phép truy cập ngẫu nhiên, chèn, xóa ñều ñược thực
hiện trong thời gian $�%' ��. Ta sẽ phát biểu một bài toán cụ thể và cài ñặt chương trình giải bài toán ñó.
a) a) a) a) Bài toánBài toánBài toánBài toán
Cho một danh sách # ñể chứa các số nguyên. Ký hiệu #��[���#� là số phần tử trong danh sách. Xét các thao tác căn bản trên danh sách:
� Phép chèn =�"�!���8 ��: Nếu � N � N #��[���#� � �, thao tác này chèn một
số � vào vị trí � của danh sách, nếu không thao tác này không có hiệu lực.
(Trường hợp � #��[���#� � � thì a�@� sẽ ñược thêm vào cuối danh sách).
� Phép xóa P��������: Nếu � N � N #��[���#�, thao tác này xóa phần tử thứ � trong danh sách, nếu không thao tác này không có hiệu lực.
Cho danh sách # � và � thao tác thuộc một trong hai loại, hãy in ra các phần tử theo ñúng thứ tự trong danh sách cuối cùng.
Input
� Dòng 1 chứa số nguyên dương � N �7�
� � dòng tiếp, mỗi dòng cho thông tin về một thao tác. Mỗi dòng bắt ñầu bởi
một ký tự 5 6=8 P9. Nếu ký tự ñầu dòng là “I” thì tiếp theo là hai số nguyên �8 � tương ứng với phép chèn =�"�!���8 ��, nếu ký tự ñầu dòng là P thì tiếp
theo là số nguyên � tương ứng với phép xóa P��������. Các giá trị �8 � là số nguyên Integer.
Output
Các phần tử trong danh sách cuối cùng theo ñúng thứ tự.

80
Sample Input Sample Output
8
I 5 1
I 6 1
I 7 1
I 8 3
I 1 2
D 4
I 9 2
D 1
9 1 6 5
b) b) b) b) GiGiGiGi����i thui thui thui thut và tt và tt và tt và tQQQQ chchchchNNNNc dc dc dc dRRRR lililili;;;;uuuu
Chúng ta sẽ lưu trữ các phần tử của danh sách # trong một cấu trúc Treap sao
cho nếu duyệt Treap theo thứ tự giữa thì các phần tử của # sẽ ñược liệt kê theo ñúng thứ tự trong danh sách.
� Nút cầm canh cuối danh sách
ðộ ưu tiên của các nút là một số nguyên dương ngẫu nhiên nhỏ hơn hằng số
MaxInt. ðể tiện cài ñặt, ta thêm vào danh sách # một phần tử giả ñứng cuối danh sách và gán ñộ ưu tiên MaxInt ñể phần tử này trở thành nút gốc của Treap. Phần tử giả này có hai công dụng:
� Mọi phép chèn hiệu lực ñều có một phần tử của danh sách nằm tại vị trí chèn, ta bớt ñi ñược các phép xử lý trường hợp riêng khi chèn vào cuối danh sách.
� Nút gốc !���x của Treap không bao giờ bị thay ñổi, ta không cần phải kiểm tra và cập nhật lại gốc sau các phép chèn hoặc xóa.
Theo cách xây dựng Treap như vậy, toàn bộ các phần tử của danh sách # sẽ nằm trong nhánh con trái của nút gốc Treap. Ta chỉ cần duyệt nhánh con trái của nút gốc Treap theo thứ tự giữa là liệt kê ñược tất cả các phần tử theo ñúng thứ tự.
� Quản lý số nút
Trong mỗi nút !x của Treap, ta lưu trữ !xE "�c� là số lượng nút nằm trong nhánh
Treap gốc !x. Trường "�c� của các nút sẽ ñược cập nhật mỗi khi có sự thay ñổi

81
cấu trúc Treap. Công dụng của trường "�c� là ñể quản lý số nút trong một nhánh Treap, phục vụ cho phép truy cập ngẫu nhiên.
� Truy cập ngẫu nhiên
Cả hai phép chèn và xóa ñều có một tham số vị trí �. Việc chèn/xóa trên danh
sách trừu tượng # sẽ quy về việc chèn/xóa trên Treap sao cho duy trì ñược sự
thống nhất giữa Treap và danh sách # như ñã ñịnh. Vậy việc ñầu tiên chính là
xác ñịnh nút tương ứng với vị trí � là nút nào trong Treap. Theo nguyên lý của phép duyệt cây theo thứ tự giữa (duyệt nhánh trái, duyệt nút gốc, sau ñó duyệt
nhánh phải), thuật toán xác ñịnh nút tương ứng với vị trí � có thể diễn tả như
sau: Xét bài toán tìm nút thứ � trong nhánh Treap gốc !x:
� Nếu � !xE ����xE "�c� � � thì nút cần tìm chính là nút !.
� Nếu � O !xE ����xE "�c� � � thì quy về tìm nút thứ � trong nhánh con trái của !.
� Nếu � 1 !xE ����xE "�c� � � thì quy về tìm nút thứ � C !xE ����xE "�c� C �
trong nhánh con phải của !x.
Số bước lặp ñể tìm nút tương ứng với vị trí � có thể tính bằng ñộ sâu của nút kết
quả (cộng thêm 1). Phép truy cập ngẫu nhiên ñược cài ñặt bằng hàm ���������:
Nhận vào một số nguyên � và trả về nút tương ứng với vị trí ñó trên Treap.
� Chèn
ðể chèn một giá trị � vào vị trí �, trước hết ta tạo nút x chứa giá trị �, xác ñịnh
nút >x là nút hiện ñang ñứng thứ �. Nếu >x không có nhánh trái thì móc nối x
vào thành nút con trái của >x. Nếu không ta ñi sang nhánh trái của >x và móc
nối x vào thành nút cực phải của nhánh trái này.
Tiếp theo là phải cập nhật số nút, nút x chèn vào sẽ trở thành nút lá và có xE "�c� �, trường "�c� trong tất cả các nút tiền bối của x cũng ñược tăng lên 1 ñể giữ tính ñồng bộ.
Cuối cùng, ta gán cho xE �!��!��> một ñộ ưu tiên ngẫu nhiên và thực hiện các
phép ���!��� � ñể ñẩy x lên vị trí ñúng. Chú ý là trong phép ���!��, ngoài
những thao tác xử lý cơ bản trên Treap, ta phải cập nhật lại trường "�c� của hai nút chịu ảnh hưởng qua phép quay.

82
� Xóa
ðể xóa phần tử tại vị trí �, ta xác ñịnh nút x nằm tại vị trí � và tiến hành xóa nút x. Phép xóa ñược thực hiện như trên Treap: Chừng nào x còn hai nút con, ta
xác ñịnh >x là nút con mang ñộ ưu tiên lớn hơn và thực hiện ���!���>� ñể kéo x sâu xuống dưới lá. Khi x còn ít hơn hai nút con, ta ñưa nhánh con gốc >x
(nếu có) của x vào thế chỗ và xóa nút x. Sau khi xóa thì toàn bộ trường k�c�
trong các nút tiền bối của x phải giảm ñi 1 ñể giữ tính ñồng bộ.
c) c) c) c) Cài "Cài "Cài "Cài "::::tttt
� DYNLIST.PAS � Cây biểu diễn danh sách
{$MODE OBJFPC}
program DynamicList;
type
PNode = ^TNode; //Kiểu con trỏ tới một nút
TNode = record //Kiểu nút Treap
value: Integer;
priority: Integer;
size: Integer;
left, right, parent: PNode;
end;
var
sentinel: TNode; //Lính canh (= nilT^)
nilT, root: PNode;
n: Integer; //Số thao tác
function NewNode: PNode; //Hàm tạo nút mới, trả về con trỏ tới nút mới
begin
New(Result); //Cấp phát bộ nhớ
with Result^ do //Khởi tạo các trường trong nút mới tạo ra
begin
priority := Random(MaxInt - 1) + 1;
//Gán ñộ ưu tiên ngẫu nhiên
size := 1; //Nút ñứng ñơn ñộc, size = 1
parent := nilT;
left := nilT;
right := nilT; //Các trường liên kết ñược gán = nilT
end;

83
end;
procedure InitTreap; //Khởi tạo Treap
begin
sentinel.priority := 0;
sentinel.size := 0;
nilT := @sentinel; //ðem con trỏ nilT trỏ tới sentinel
root := NewNode;
root^.priority := MaxInt; //root^ ñược gán ñộ ưu tiên cực ñại
end;
//Móc nối ChildNode thành con của ParentNode
procedure SetLink(ParentNode, ChildNode: PNode;
InLeft: Boolean);
begin
ChildNode^.parent := ParentNode;
if InLeft then ParentNode^.left := ChildNode
else ParentNode^.right := ChildNode;
end;
function NodeAt(i: Integer): PNode; //Truy cập ngẫu nhiên
begin
Result := root; //Bắt ñầu từ gốc Treap
repeat
if i = Result^.left^.size + 1 then Break;
//Nếu nút này ñứng thứ i thì dừng if i <= Result^.left^.size then //Lặp lại, tìm trong nhánh con trái
Result := Result^.left
else //Lặp lại, tìm trong nhánh con phải
begin
Dec(i, Result^.left^.size + 1);
Result := Result^.right;
end;
until False;
end;
procedure UpTree(x: PNode); //ðẩy x^ lên phía gốc Treap bằng phép quay
var y, z, branch: PNode;
begin
y := x^.parent;
z := y^.parent;
if x = y^.left then //Quay phải

84
begin
branch := x^.right;
SetLink(y, branch, True);
SetLink(x, y, False);
end
else //Quay trái
begin
branch := x^.left;
SetLink(y, branch, False);
SetLink(x, y, True);
end;
SetLink(z, x, z^.left = y); //Cẩn thận, phải cập nhật y^.size trước khi cập nhật x^.size with y^ do size := left^.size + right^.size + 1;
with x^ do size := left^.size + right^.size + 1;
end;
procedure Insert(v, i: Integer); //Chèn
var x, y: PNode;
begin
if (i < 1) or (i > root^.size) then Exit;
//Phép chèn vô hiệu, bỏ qua x := NewNode;
x^.value := v; //Tạo nút x^ chứa value
y := NodeAt(i); //Xác ñịnh nút y^ cần chèn x^ vào trước
if y^.left = nilT then SetLink(y, x, True)
//y^ không có nhánh trái, cho x^ làm nhánh trái else
begin
y := y^.left; //ði sang nhánh trái
while y^.right <> nilT do y := y^.right;
//Tới nút cực phải SetLink(y, x, False); //Móc nối x^ vào làm nút cực phải
end;
//y = x^.parent, cập nhật trường size của các nút từ y lên gốc while y <> nilT do
begin
Inc(y^.size);
y := y^.parent;
end;

85
//Chỉnh Treap bằng phép UpTree while x^.priority > x^.parent^.priority do
//Chừng nào x^ ưu tiên hơn nút cha UpTree(x); //ðẩy x^ lên phía gốc end;
procedure Delete(i: Integer); //Xóa var x, y, z: PNode;
begin
if (i < 1) or (i >= root^.size) then Exit;
//Phép xóa vô hiệu, bỏ qua x := NodeAt(i); //Xác ñịnh nút cần xóa x^ while (x^.left <> nilT) and (x^.right <> nilT) do
//x^ có hai nút con begin //Xác ñịnh y^ là nút con mang ñộ ưu tiên lớn hơn
if x^.left^.priority > x^.right^.priority then
y := x^.left
else y := x^.right;
UpTree(y); //Kéo x^ xuống sâu phía dưới lá
end;
//x^ chỉ còn tối ña 1 nút con, xác ñịnh y^ là nút con nếu có của x^ if x^.left <> nilT then y := x^.left
else y := x^.right;
z := x^.parent; //z^ là cha của x^ SetLink(z, y, z^.left = x); //Cho y^ vào làm con z^ thay cho x^ Dispose(x); //Giải phóng bộ nhớ while z <> nilT do //Cập nhật trường size của các nút từ z^ lên gốc begin
Dec(z^.size);
z := z^.parent;
end;
end;
procedure ReadOperators;
//ðọc dữ liệu, gặp thao tác nào thực hiện ngay thao tác ñó var
k, v, i: Integer;
op: AnsiChar;
begin
ReadLn(n);
for k := 1 to n do

86
begin
Read(op);
case op of
'I': begin
ReadLn(v, i);
Insert(v, i);
end;
'D': begin
ReadLn(i);
Delete(i);
end;
end;
end;
end;
procedure PrintResult; //In kết quả procedure InOrderTraversal(x: PNode); //Duyệt cây theo thứ tự giữa
begin
if x = nilT then Exit;
InOrderTraversal(x^.left); //Duyệt nhánh trái Write(x^.value, ' '); //In ra giá trị trong nút
InOrderTraversal(x^.right); //Duyệt nhánh phải Dispose(x); //Duyệt xong thì giải phóng bộ nhớ luôn
end;
begin
InOrderTraversal(root^.left);
//Toàn bộ danh sách trừu tượng L nằm trong nhánh trái của gốc
Dispose(root); //Giải phóng luôn nút gốc
WriteLn;
end;
begin
InitTreap;
ReadOperators;
PrintResult;
end.

87
cccc) ) ) ) Hoán vHoán vHoán vHoán v>>>> JosephusJosephusJosephusJosephus
� Bài toán tìm hoán vị Josephus
Bài toán lấy tên của Flavius Josephus, một sử gia Do Thái vào thế kỷ thứ nhất. Tương truyền rằng Josephus và 40 chiến sĩ bị người La Mã bao vây trong một hang ñộng. Họ quyết ñịnh tự vẫn chứ không chịu bị bắt. 41 chiến sĩ ñứng thành vòng tròn và bắt ñầu ñếm theo một chiều vòng tròn, cứ người nào ñếm ñến 3 thì phải tự vẫn và người kế tiếp bắt ñầu ñếm lại từ 1. Josephus không muốn chết và ñã chọn ñược một vị trí mà ông ta cũng với một người nữa là hai người sống sót cuối cùng theo luật này. Hai người sống sót sau ñó ñã ñầu hàng và gia nhập quân La Mã (Josephus sau ñó chỉ nói rằng ñó là sự may mắn, hay “bàn tay của Chúa” mới giúp ông và người kia sống sót).
Có rất nhiều truyền thuyết và tên gọi khác nhau về bài toán Josephus, trong toán
học người ta phát biểu bài toán dưới dạng một trò chơi: Cho � người ñứng
quanh vòng tròn theo chiều kim ñồng hồ ñánh số từ 1 tới �. Họ bắt ñầu ñếm từ
người thứ nhất theo chiều kim ñồng hồ, người nào ñếm ñến � thì bị loại khỏi vòng và người kế tiếp bắt ñầu ñếm lại từ 1. Trò chơi tiếp diễn cho tới khi vòng
tròn không còn lại người nào. Nếu ta xếp số hiệu của � người theo thứ tự họ bị
loại khỏi vòng thì sẽ ñược một hoán vị �b(8 b+8 8 b.� của dãy số ��8;8 8 �� gọi là
hoán vị Josephus ��8 �� . Ví dụ với � W8 � V , hoán vị Josephus sẽ là �V8T8;8W8\8�8X�. Bài toán ñặt ra là cho trước hai số �8 � hãy xác ñịnh hoán vị
Josephus ��8 ��.
� Thuật toán
Bài toán tìm hoán vị Josephus ��8 �� có thể giải quyết dễ dàng nếu sử dụng
danh sách ñộng (Mục 0): Danh sách ñược xây dựng có � phần tử tương ứng với � người. Việc xác ñịnh người sẽ phải ra khỏi vòng sau ñó xóa người ñó khỏi danh sách ñơn giản chỉ là phép truy cập ngẫu nhiên và xóa một phần tử khỏi danh sách ñộng.
Nhận xét: Nếu sau một lượt nào ñó, người vừa bị loại là người thứ � và danh
sách còn lại � người. Khi ñó người kế tiếp bị loại là người ñứng thứ: �� � � C;� �&p � � � trong danh sách.

88
Tuy bài toán khá ñơn giản nhưng liên quan tới một kỹ thuật cài ñặt quan trọng
nên ta sẽ cài ñặt cụ thể chương trình tìm hoán vị Josephus ��8 ��.
Input
Hai số nguyên dương �8 � N �7�
Output
Hoán vị Josephus ��8 ��
Sample Input Sample Output
7 3 3 6 2 7 5 1 4
Xây dựng danh sách gồm � phần tử, ban ñầu các phần tử ñều chưa ñánh dấu
(chưa bị xóa). Thuật toán sẽ tiến hành � bước, mỗi bước sẽ ñánh dấu một phần tử tương ứng với một người bị loại.
Có thể quan sát rằng nếu biểu diễn danh sách này bằng cây nhị phân gồm � nút, thì chúng ta chỉ cần cài ñặt hai thao tác:
� Truy cập ngẫu nhiên: Nhận vào một số thứ tự � và trả về nút ñứng thứ � trong số các nút chưa ñánh dấu (theo thứ tự giữa)
� ðánh dấu: ðánh dấu một nút tương ứng với một người bị loại
Vậy có thể biểu diễn danh sách bằng một cây nhị phân gần hoàn chỉnh dựng sẵn. Cụ thể là chúng ta tổ chức dữ liệu trong các mảng sau:
� Mảng �!���� �� ñể biểu diễn cây nhị phân gồm � nút có gốc là nút 1, ta
quy ñịnh nút thứ � có nút con trái là ;� và nút con phải là ;� � �, nút cha của
nút b là nút _bU;`. Cây này ban ñầu sẽ ñược duyệt theo thứ tự giữa và các
phần tử �8;8 8 � sẽ ñược ñiền lần lượt vào cây (mảng �!��) theo thứ tự giữa.
� Mảng y!����� �� ñể ñánh dấu, trong ñó y!������ �!@� nếu nút
thứ � ñã bị ñánh dấu, ban ñầu mảng y!����� �� ñược khởi tạo bằng
toàn giá trị ?�"�.
� Mảng k�c��� �� trong ñó k�c���� là số nút chưa bị ñánh dấu trong nhánh
cây gốc �. Mảng k�c��� �� cũng ñược khởi tạo ngay trong quá trình dựng cây.

89
Phép truy cập ngẫu nhiên - nhận vào một số thứ tự � và trả về chỉ số nút ñứng
thứ � chưa bị ñánh dấu theo thứ tự giữa - sẽ ñược thực hiện như sau: Bắt ñầu từ
nút gốc �, gọi #���k�c� là số nút chưa ñánh dấu trong cây con trái của .
Nếu nút chưa bị ñánh dấu và � #���k�c� � � thì trả về ngay nút và dừng
ngay, nếu không thì quá trình tìm kiếm sẽ tiếp tục trên cây con trái (� N#���k�c�) hoặc cây con phải của (� 1 #���k�c�).
Phép ñánh dấu một nút chỉ ñơn thuần gán y!���� � z �!@� , sau ñó ñi
ngược từ lên gốc cây, ñi qua nút > nào thì giảm k�c��>� ñi 1 ñể giữ tính ñồng bộ.
� Cài ñặt
� JOSEPHUS.PAS � Tìm hoán vị Josephus
{$MODE OBJFPC}
program JosephusPermutation;
const max = 100000;
var
n, m: Integer;
tree: array[1..max] of Integer;
Marked: array[1..max] of Boolean;
size: array[1..max] of Integer;
procedure BuildTree; //Dựng sẵn cây nhị phân gần hoàn chỉnh gồm n nút
var Person: Integer;
procedure InOrderTraversal(Node: Integer);
//Duyệt cây theo thứ tự giữa begin
if Node > n then Exit;
InOrderTraversal(Node * 2); //Duyệt nhánh trái
Inc(Person);
tree[Node] := Person; //ðiền phần tử kế tiếp vào nút
InOrderTraversal(Node * 2 + 1); //Duyệt nhánh phải //Xây dựng xong nhánh trái và nhánh phải thì bắt ñầu tính trường size
size[Node] := 1;
if Node * 2 <= n then
Inc(size[Node], size[Node * 2]);
if Node * 2 + 1 <= n then
Inc(size[Node], size[Node * 2 + 1]);

90
end;
begin
Person := 0;
InOrderTraversal(1);
FillChar(Marked, SizeOf(Marked), False); //Tất cả các nút ñều chưa ñánh dấu end;
//Truy cập ngẫu nhiên, nhận vào số thứ tự p, trả về nút ñứng thứ p trong số các nút chưa ñánh dấu function NodeAt(p: Integer): Integer;
var LeftSize: Integer;
begin
Result := 1; //Bắt ñầu từ gốc
repeat
//Tính số nút trong nhánh con trái if Result * 2 <= n then
LeftSize := size[Result * 2]
else LeftSize := 0;
if not Marked[Result] and (LeftSize + 1 = p) then
Break; //Nút Result chính là nút thứ p, dừng
if LeftSize >= p then
Result := Result * 2 //Tìm tiếp trong nhánh trái
else
begin
Dec(p, LeftSize);
//Trước hết tính lại số thứ tự tương ứng trong nhánh phải if not Marked[Result] then Dec(p);
Result := Result * 2 + 1; //Tìm tiếp trong nhánh phải
end;
until False;
end;
procedure SetMark(Node: Integer); //ðánh dấu một nút
begin
Marked[Node] := True; //ðánh dấu
while Node > 0 do //ðồng bộ hóa trường size của các nút tiền bối
begin
Dec(size[Node]);
Node := Node div 2; //ði lên nút cha
end;

91
end;
procedure FindJosephusPermutation;
var Node, p, k: Integer;
begin
p := 1;
for k := n downto 1 do
begin //Danh sách có k người
p := (p + m - 2) mod k + 1; //Xác ñịnh số thứ tự của người bị loại
Node := NodeAt(p); //Tìm nút chứa người bị loại
Write(tree[Node], ' '); //In ra số hiệu người bị loại
SetMark(Node); //ðánh dấu nút tương ứng trên cây
end;
end;
begin
Readln(n, m);
BuildTree;
FindJosephusPermutation;
WriteLn;
end.
� Tìm người cuối cùng còn lại ����
Một bài toán khác liên quan tới bài toán Josephus là cho trước hai số nguyên
dương �8 �, hãy tìm người cuối cùng bị loại. Ta có thể sử dụng thuật toán tìm hoán vị Josephus và in ra phần tử cuối cùng trong hoán vị. Tuy nhiên có thuật toán quy hoạch ñộng hiệu quả hơn ñể tìm người cuối cùng bị loại. Thuật toán dựa trên công thức truy hồi sau:
���� ��8 oế� � ����� C �� C � � �� �&p � � �8 oế� � 1 �� (7.1)
Trong ñó ���� là chỉ số người bị loại cuối cùng trong trò chơi với trò chơi gồm � người. Công thức truy hồi (7.2) có thể giải trong thời gian ���� bằng một ñoạn chương trình ñơn giản.
Input → n, m;
f := 1;
for i := 2 to n do
f := (f - 1 + m) mod i + 1;

92
Output ← f;
7.2. Thứ tự thống kê ñộng
Nhắc lại: Bài toán thứ tự thống kê: Cho một tập k gồm � ñối tượng, mỗi ñối
tượng có một khóa sắp xếp. Hãy cho biết nếu sắp xếp � ñối tượng theo thứ tự
tăng dần của khóa thì ñối tượng thứ � là ñối tượng nào?.
Chúng ta ñã biết thuật toán tìm thứ tự thống kê trong thời gian $���. Tuy nhiên
trong trường hợp tập k liên tục có những sự thay ñổi phần tử (thêm vào hay bớt ñi một ñối tượng), ñồng thời có rất nhiều truy vấn về thứ tự thống kê ñi kèm với những sự thay ñổi ñó thì thuật toán này tỏ ra không hiệu quả. Chúng ta cần có phương pháp tốt hơn ñối với bài toán thứ tự thống kê ñộng (Dynamic Order Statistics).
Cây tìm kiếm nhị phân là một cách ñể giải quyết hiệu quả vấn ñề này. Chúng ta
lưu trữ các ñối tượng của k trong một BST, mỗi nút chứa một ñối tượng với khóa so sánh chính là khóa của ñối tượng chứa trong.
Mỗi ñối tượng � ñược gắn với một con trỏ ��!��� tới nút tương ứng trên BST, con trỏ này ñược cập nhật mỗi khi có phép thêm/bớt ñối tượng. Tại mỗi nút ta
duy trì số nút trong nhánh con ñó bằng trường "�c�, trường này ñược cập nhật mỗi khi cấu trúc BST bị thay ñổi (chèn/xóa/quay). Khi ñó phép thêm và bớt ñối
tượng ñược thực hiện tự nhiên bằng phép chèn và xóa trên BST �$�%' ��. Dựa
vào trường "�c� mỗi nút, mỗi truy vấn về thứ tự thống kê ñược trả lời trong thời
gian $�%' �� (Xem lại mục 0 về cách sử dụng trường k�c�).
7.3. Interval tree
Cây chứa khoảng (Interval tree) là một cấu trúc dữ liệu ñể lưu trữ một tập các khoảng trên trục số.
Có ba loại khoảng trên trục số: khoảng ñóng (closed interval), khoảng mở (open interval) và khoảng nửa mở. �"8 �� 6 5 �M " N N �9 �"8 �� 6 5 �M " O O �9 �"8 �� 6 5 �M " N O �9 �"8 �� 6 5 �M " O N �9

93
Khoảng ñóng còn có tên gọi là ñoạn. Ở những vấn ñề trong phần này chúng ta quan tâm tới khoảng ñóng, nếu muốn làm việc với khoảng mở hoặc khoảng nửa mở cần có một số sửa ñổi nhỏ. Chúng ta quy ñịnh thêm là với một khoảng ñóng �"8 �� bất kỳ thì " N �.
ðịnh lý 7-1
Với hai ñoạn �( �"(8 �(� và �+ �"+8 �+�, ñúng một trong ba mệnh ñề dưới ñây thỏa mãn (interval trichotomy):
� �( và �+ gối nhau (overlap), tức là hai ñoạn �( và �+ có ñiểm chung
� �( nằm bên trái �+: �( O "+
� �( nằm bên phải �+: �+ O "(
Interval tree bản chất là một BST, mỗi nút chứa một ñoạn và khóa so sánh là ñầu mút trái của mỗi ñoạn. Tức là nếu duyệt cây theo thứ tự giữa ta sẽ liệt kê ñược tất cả các ñoạn theo thứ tự tăng dần của ñầu mút trái.
Tại mỗi nút , ta lưu trữ thêm một trường !�[���"�: Giá trị lớn nhất của các
ñầu mút phải của các ñoạn nằm trong nhánh cây gốc . Nút giả ����x có trường !�[����"� C�. Hình 1.28 là ví dụ về cây chứa 10 ñoạn: ��T8;��� �e8��� �;\8V7�� �\8e�� ��\8;V�� ��W8���� �;T8;T�� �78V�� �T8�7�� ���8;7�
Hình 1.28. Interval tree
Cấu trúc nút của Interval tree có thể ñặc tả như sau:
type
PNode = ^TNode;
TNode = record
s, f: Real; //s: ñầu mút trái, f: ñầu mút phải
�78V� V
�T8�7� �7
�\8e� �7
��\8;V� ;V
�e8�� ;V
���8;7� ;7
��W8��� ;7
�;T8;T� ;T
�;\8V7� V7
��T8;�� V7
����!��!�[����"�

94
rightmost: Real; //Thông tin phụ trợ
parent, left, right: PNode;
end;
var
sentinel: TNode;
nilT, root: PNode;
begin
sentinel.rightmost := -∞;
nilT := @sentinel;
root := nilT;
...
end.
Trường !�[����"� của mỗi nút x ñược tính theo công thức truy hồi:
xE !�[����"� z �n� � xE ����xE !�[����"� xE � xE !�[��xE !�[����"�� (7.2)
Khi một nút x ñược chèn vào thành một nút lá hay bị xóa khỏi BST, tất cả các
trường !�[����"� trong x và các nút tiền bối của x phải ñược cập nhật lại. Nếu bạn cài ñặt Interval tree bằng Treap hay một dạng cây nhị phân tìm kiếm tự
cân bằng, cần chú ý cập nhật lại trường !�[����"� sau phép quay cây
(���!��). a) a) a) a) Tìm Tìm Tìm Tìm "o"o"o"o9999n có giao vn có giao vn có giao vn có giao v4444i mi mi mi m8888t "ot "ot "ot "o9999n cho trFn cho trFn cho trFn cho trF4444cccc
Bài toán ñặt ra là cho một tập k gồm � ñoạn. Cho một ñoạn �8 0�, hãy chỉ ra
một ñoạn của k có giao với (hay gối lên) ñoạn �8 0�. Một dạng truy vấn cụ thể
hơn là hãy chỉ ra một ñoạn của k chứa một ñiểm cho trước. Bài toán này có
thể quy về bài toán tổng quát với �8 0� � 8 � Dĩ nhiên ta có thể trả lời truy vấn này trong thời gian $���: Duyệt tất cả các
ñoạn của k và sử dụng hàm ���!����� dưới ñây ñể tìm cũng như liệt kê các
ñoạn gối lên ñoạn ��. Hàm ���!����� nhận vào 2 ñoạn �"(8 �(�8 �"+8 �+� và trả
về giá trị �!@� nếu hai ñoạn gối nhau:
function Overlapped(s1, f1, s2, f2: Real): Boolean;
begin
Result := (s1 ≤ f2) and (s2 ≤ f1);

95
end;
Tuy vậy nếu tập k liên tục có sự biến ñộng (thêm/bớt) các ñoạn thì phương pháp này tỏ ra không hiệu quả. Sử dụng Interval tree cho phép thực hiện thêm/bớt ñoạn và trả lời truy vấn này hiệu quả hơn.
Xây dựng Interval tree chứa tất cả các ñoạn của tập k. Bắt ñầu từ nút x !���x , nếu ñoạn trong x có giao với �8 0� thì xong. Ngược lại, nếu xE ����xE !�[����"� w , ta quy về tìm trong nhánh con trái của x, nếu không
ta quy về tìm trong nhánh con phải của x:
//Trả về nút chứa ñoạn giao với [a, b], trả về nilT nếu không thấy
function IntervalSearch(a, b: Real): PNode;
begin
Result := root; //Bắt ñầu từ gốc
while (Result ≠ nilT) and
not Overlapped(Result^.s, Result^.f, a, b) do
//Result chứa ñoạn không giao với [a, b]
if (Result^.left^.rightmost ≥ a) then
Result := Result^.left //Sang trái
else Result := Result^.right; //Sang phải
end; Tính ñúng ñắn của thuật toán ñược chỉ ra trong hai nhận xét sau:
� Nếu xE ����xE !�[����"� w thì chỉ cần tìm trong nhánh con trái của x
là ñủ, bởi nếu tìm trong nhánh con trái của x không thấy thì chắc chắn tìm trong nhánh con phải cũng thất bại.
� Nếu xE ����xE !�[����"� O thì nhánh con trái của x chắc chắn không
chứa ñoạn nào có giao với �8 0�. Thời gian thực hiện giải thuật =���!��k�!l� là $��� với � là chiều cao của
Interval tree. Các phép thêm/bớt ñoạn trong tập k ñược xử lý như trên BST, sau
ñó cập nhật các trường !�[����"�, cũng có thời gian thực hiện $��� ( $�%' �� nếu sử dụng một dạng BST tự cân bằng). b) b) b) b) Tìm Tìm Tìm Tìm "o"o"o"o9999n "n "n "n "����u tiên có giao vu tiên có giao vu tiên có giao vu tiên có giao v4444i mi mi mi m8888t "ot "ot "ot "o9999n cho trFn cho trFn cho trFn cho trF4444cccc
Trong một số trường hợp chúng ta cần tìm nút ñầu tiên trên Interval tree (theo
thứ tự giữa) chứa ñoạn có giao với ñoạn �8 0�. ðiều này ñược thực hiện dựa trên
một hàm ñệ quy ?�!"�=���!��k�!l� như sau:

96
//Tìm ñoạn ñầu tiên giao với [a, b] trong nhánh cây gốc x^
function FirstIntervalSearch(x: PNode;
a, b: Real): PNode;
begin
Result := nilT;
if x = nilT then Exit; //Nhánh rỗng thì trả về nilT
if x^.left^.rightmost ≥ a then //Nếu có thì phải có trong nhánh trái
Result := FirstIntervalSearch(x^.left, a, b);
else //Nhánh trái chắc chắn không có
if Overlapped(x^.s, x^.f, a, b) then
//ðoạn trong x^ có giao với [a, b]
Result := x
else //Nếu có thì chỉ có trong nhánh phải
Result := FirstIntervalSearch(x^.right, a, b);
end;
c) c) c) c) LiLiLiLi;;;;t kê các "ot kê các "ot kê các "ot kê các "o9999n có giao vn có giao vn có giao vn có giao v4444i mi mi mi m8888t "ot "ot "ot "o9999n cho n cho n cho n cho trFtrFtrFtrF4444cccc
Bài toán ñặt ra là cho tập k gồm � ñoạn, hãy liệt kê các ñoạn có giao với ñoạn �8 0� cho trước. Dĩ nhiên chúng ta có thể duyệt tất cả các ñoạn của k và dùng
hàm ���!����� ñể liệt kê các ñoạn thỏa mãn trong thời gian ����, trên thực tế không có thuật toán nào tốt hơn trong trường hợp xấu nhất: Tất cả các ñoạn của k ñều có giao với �8 0�. Tuy nhiên chúng ta có thể tìm một thuật toán khác mà thời gian thực hiện giải
thuật phụ thuộc vào số ñoạn ñược liệt kê và ít phụ thuộc vào giá trị của �.
Trước hết ta xây dựng Interval tree chứa các ñoạn của k. Sau ñó sử dụng thủ tục #�"�=���!��"�D���8 8 0� ñể liệt kê. Thủ tục #�"�=���!��" ñược cài ñặt như sau:
//Liệt kê các ñoạn có giao với [a, b] trong nhánh cây gốc x^
procedure ListIntervals(x: PNode; a, b: Real);
begin
if x = nilT then Exit;
if x^.left^.rightmost >= a then //Trong nhánh con trái có thể có
ListIntervals(x^.left); //Liệt kê trong nhánh con trái
if Overlapped(x^.s, x^.f, a, b) then //ðoạn chứa trong x^ có giao
Output ← [x^.s, x^.f]; //Liệt kê
if x^.s <= b then //Trong nhánh con phải có thể có

97
ListIntervals(x^.right); //Liệt kê trong nhánh con phải
end;
Thời gian thực hiện giải thuật là $�%' � � �� với � là số nút ñược liệt kê
7.4. Tóm tắt về kỹ thuật cài ñặt
Còn rất nhiều ứng dụng khác liên quan tới cấu trúc cây nhị phân, nhưng chỉ với một số ứng dụng kể trên, ta có thể thấy rằng cây nhị phân là một cấu trúc dữ liệu tốt ñể biểu diễn danh sách: Bằng cơ chế ñánh số nút theo thứ tự giữa, chúng ta có hình ảnh một danh sách với các nút ñược sắp thứ tự, qua ñó có thể cài ñặt các phép chèn/xóa và truy cập ngẫu nhiên rất hiệu quả.
Tại sao lại là thứ tự giữa mà không phải thứ tự trước hay thứ tự sau? Mặc dù các thao tác cơ bản này vẫn có thể cài ñặt nếu các nút của cây ñược ñánh số theo thứ tự trước (hoặc sau), nhưng chúng ta sẽ gặp phải khó khăn khi thực hiện thao tác cân bằng cây. Hiện tại hầu hết các kỹ thuật cân bằng cây nhị phân (trên cây AVL, cây ñỏ ñen, cây Splay hay Treap) ñều dựa vào phép quay, mà phép quay thì không bảo toàn thứ tự trước và thứ tự sau của các nút. Nếu như chúng ta không cần sử dụng phép quay (như bài toán tìm hoán vị Josephus) thì hoàn toàn có thể ñánh số các nút trên cây theo thứ tự trước hoặc thứ tự sau.
Một chú ý quan trọng nữa là cơ chế lưu trữ và ñồng bộ hóa thông tin phụ trợ. Thông thường ñối với các bài toán sử dụng cây nhị phân, mỗi nút sẽ có chứa một thông tin ñể hỗ trợ quá trình tìm kiếm trên cây (tại mỗi bước thì ñi tiếp sang nhánh trái hay nhánh phải). Như ở ví dụ cây biểu diễn danh sách chúng ta sử
dụng trường "�c� chứa số nút trong một nhánh cây, hay ở ví dụ Interval tree,
chúng ta sử dụng trường !�[����"� ñể chứa ñầu mút phải lớn nhất của một ñoạn nằm trong nhánh cây. Thông tin phụ trợ sẽ ñược cập nhật mỗi khi có sự thay ñổi cấu trúc ñể giữ tính ñồng bộ. Có hai nguyên lý chọn thông tin phụ trợ: Thứ nhất, thông tin phụ trợ ở mỗi nút phải là thông tin tổng hợp từ tất cả các nút trong nhánh ñó, thứ hai, tuy là sự tổng hợp thông tin từ tất cả các nút trong nhánh nhưng thông tin phụ trợ có thể tính ñược chỉ bằng thông tin ở gốc nhánh và hai nút con.
Những ràng buộc như vậy ñảm bảo cho quá trình ñồng bộ thông tin phụ trợ không làm tăng cấp phức tạp của thời gian thực hiện giải thuật. Việc thay ñổi

98
thông tin phụ trợ ở một nút chỉ kéo theo việc cập nhật lại thông tin phụ trợ ở những nút tiền bối mà thôi*.
Chú ý cuối cùng là nếu như biết trước cây nhị phân sẽ chỉ chứa các phần tử
trong một tập hữu hạn k, ñồng thời có cách nào ñó tránh không phải cài ñặt phép
chèn và xóa thì có thể dựng sẵn một cây nhị phân gần hoàn chỉnh gồm �k� nút. Khi ñó chúng ta loại bỏ ñược các con trỏ liên kết và không cần thực hiện các phép cân bằng cây – hai thứ dễ gây nhầm lẫn nhất trong việc cài ñặt cây nhị phân.
Ta xét một ví dụ cuối cùng trước khi kết thúc bài.
7.5. ðiểm giao nhiều nhất
a) a) a) a) TrFTrFTrFTrFUUUUng hng hng hng h0000p mp mp mp m8888t chit chit chit chiEEEEuuuu
Bài toán tìm ñiểm giao nhiều nhất (point of Maximum Overlap – POM) (một
chiều) phát biểu như sau: Cho � khoảng ñóng trên trục số, khoảng ñóng thứ � là �"28 �2� ("2 N �2), hãy tìm một ñiểm trên trục số thuộc nhiều khoảng nhất trong số � khoảng ñã cho.
Thuật toán ñể giải quyết bài toán POM một chiều khá ñơn giản: Với một khoảng
ñóng �"28 �2�, ta gọi "2 là ñầu mút mở và �2 là ñầu mút ñóng. Sắp xếp ;� ñầu mút của các khoảng ñã cho từ trái qua phải (từ nhỏ ñến lớn), nếu nhiều ñầu mút ở cùng tọa ñộ thì tất cả ñầu mút mở tại vị trí ñó ñược xếp các ñầu mút ñóng. Khởi tạo một biến ñếm bằng 0 và duyệt các ñầu mút theo thứ tự ñã sắp xếp, gặp ñầu mút mở thì biến ñếm tăng 1 còn gặp ñầu mút ñóng thì biến ñếm giảm 1. Quá trình kết thúc, biến ñếm trở lại thành 0, nơi biến ñếm ñạt cực ñại chính là ñiểm cần tìm. Giá trị cực ñại của bộ ñếm ñạt ñược chính là số khoảng ñóng phủ qua ñiểm ñó.
Tuy vậy, thuật toán trên không thực sự hiệu quả nếu tập các khoảng ñóng liên tục biến ñộng ñi kèm với những truy vấn về POM. Chúng ta cần xây dựng cấu
* Có những bài toán cụ thể sử dụng cây nhị phân mà thông tin phụ trợ không tuân theo hai nguyên lý này,
nhưng cần ñến một cơ chế ñồng bộ hóa ñặc biệt.

99
trúc dữ liệu ñể hỗ trợ các phép thêm/bớt khoảng và trả lời các truy vấn về ñiểm giao nhiều nhất hiệu quả hơn.
Giải pháp là ta lưu trữ các ñầu mút trong một BST sao cho nếu duyệt BST theo thứ tự giữa thì ta sẽ ñược thứ tự sắp xếp nói trên (ñầu mút nhỏ hơn xếp trước và ñầu mút mở ñược xếp trước ñầu mút ñóng nếu ở cùng vị trí trên trục số).
Thông tin phụ trợ thứ nhất trong mỗi nút x là nhãn "�[�. Ở ñây xE "�[� ��
nếu nút chứa ñầu mút mở và xE "�[� C� nếu nút chứa ñầu mút ñóng.
Thông tin phụ trợ thứ hai trong mỗi nút x là trường "@�: Tổng của tất cả các
nhãn trong các nút nằm trong nhánh cây gốc x. Trường "@� ñược tính theo công thức:
xE "@� z xE ����xE "@� � xE "�[� � xE !�[��xE "@� (7.3)
Thông tin phụ trợ thứ ba trong mỗi nút x là trường � "@�: Cho biết nếu ta
duyệt nhánh cây gốc x theo thứ tự giữa và cộng dồn lần lượt các trường "�[� ở mỗi nút thì giá trị lớn nhất ñạt ñược trong quá trình cộng là bao nhiêu. Trường � "@� ñược tính theo công thức:
xE � "@�z �n� � xE ����xE � "@� xE ����xE "@� � xE "�[� xE #���xE "@� � xE "�[� � xE !�[��xE � "@�� (7.4)
Công thức truy hồi (7.3) khá dễ hiểu, ta sẽ phân tích tính ñúng ñắn của công
thức truy hồi (7.4). Rõ ràng trong quá trình cộng dồn các trường "�[� ở mỗi nút vào một biến ñếm, giá trị cực ñại của biến ñếm này có thể bằng:
� Giá trị lớn nhất ñạt ñược khi cộng xong nhánh con trái, khi ñó xE � "@� xE ����x� "@�.
� Giá trị ñạt ñược khi cộng tới nút x , khi ñó xE � "@� xE ����xE "@� � xE "�[� � Giá trị ñạt ñược khi cộng tới một nút nào ñó ở nhánh con phải, khi ñó xE � "@� xE ����xE "@� � xE "�[� � xE !�[��xE � "@�
Vậy ta có thể lấy giá trị lớn nhất trong ba khả năng này ñể gán cho xE � "@�.

100
ðể tiện hơn trong việc trả lời truy vấn POM, tại mỗi nút ta lưu trữ một trường B�y chứa ñiểm mà tại ñó quá trình cộng dồn các trường "�[� ñạt cực ñại (bằng � "@�). Phép cập nhật B�y ñược thực hiện song song với quá trình tính � "@�: Tùy theo � "@� ñạt tại nhánh trái, chính nút x hay nhánh phải, ta
sẽ cập nhật lại trường B�y của x.
Có thể nhận thấy rằng trường "@� và � "@� tuy là thông tin tổng hợp từ tất cả các nút trong một nhánh, nhưng có thể tính ñược chỉ dựa vào thông tin trong nút gốc và hai nút con. Tức là ta có thể duy trì và ñồng bộ thông tin phụ trợ trong mỗi nút sau mỗi phép chèn/xóa mà không làm tăng cấp phức tạp của thời gian thực hiện giải thuật.
Vậy thì nếu � là số nút trên BST,
� Chèn một ñoạn �"8 �� vào tập trừu tượng các khoảng ñóng tương ứng với
chèn một ñầu mút " với "�[� � vào BST và chèn một ñầu mút � với "�[� C� vào BST. Thời gian $�%' ��.
� Xóa một ñoạn �"8 �� tương ứng với xóa ñi ñầu mút " và ñầu mút � khỏi
BST. Thời gian $�%' ��.
� Trả lời truy vấn POM, chỉ cần truy xuất !���xE B�y. Thời gian $���. b) b) b) b) TrFTrFTrFTrFUUUUng hng hng hng h0000p hai chip hai chip hai chip hai chiEEEEuuuu
Bài toán tìm ñiểm giao nhiều nhất (hai chiều) ñược phát biểu như sau: Cho �
hình chữ nhật ñánh số từ 1 tới � trong mặt phẳng trực giao $ >. Các hình chữ nhật có cạnh song song với các trục tọa ñộ. Mỗi hình chữ nhật ñược cho bởi 4
tọa ñộ (8 >(8 +8 >+ trong ñó � (8 >(� là tọa ñộ góc trái dưới và � +8 >+� là tọa ñộ
góc phải trên ( ( O +8 >( O >+). Hãy tìm một ñiểm trên mặt phẳng thuộc nhiều hình chữ nhật nhất trong số các hình chữ nhật ñã cho (ñiểm nằm trên cạnh một hình chữ nhật vẫn tính là thuộc hình chữ nhật ñó).
Bài toán POM hai chiều là một trong những ví dụ hay về kỹ thuật cài ñặt, chúng ta sẽ viết chương trình ñầy ñủ giải bài toán POM hai chiều với khuôn dạng Input/Output như sau.
Input
� Dòng 1 chứa số nguyên dương � N �7�.

101
� � dòng tiếp theo, dòng thứ � chứa 4 số nguyên dương (8 >(8 +8 >+. �C�7 N ( O + N �7 � C�7 N >( O >+ N �7 �. Output
ðiểm giao nhiều nhất và số hình chữ nhật chứa ñiểm giao nhiều nhất.
Sample Input Sample Output
4
1 3 5 7
3 1 6 4
4 2 8 5
6 5 8 7
point of Maximum Overlap: (4, 3)
Number of Rectangles: 3
� Biến ñổi tọa ñộ
Mỗi hình chữ nhật tương ứng với hai cạnh ngang (cạnh ñáy và cạnh ñỉnh) và hai
cạnh dọc (cạnh trái và cạnh phải). Như vậy có tất cả ;� cạnh ngang và ;� cạnh dọc. Sắp xếp hai dãy tọa ñộ này theo quy tắc sau:
� Dãy ;� cạnh dọc ñược xếp theo thứ tự tăng dần theo hoành ñộ (trái qua phải), nếu nhiều cạnh dọc ở cùng hoành ñộ thì những cạnh trái ñược xếp trước những cạnh phải.
� Dãy ;� cạnh ngang ñược xếp theo thứ tự tăng dần theo tung ñộ (dưới lên trên), nếu nhiều cạnh ngang ở cùng tung ñộ thì những cạnh ñáy ñược xếp trước những cạnh ñỉnh.
1 2 3 4 5 6 7 8 0
1
2
3
4
5
6
7

102
Sau ñó ta ánh xạ hoành ñộ mỗi cạnh ngang cũng như tung ñộ mỗi cạnh dọc thành chỉ số của nó trong hai dãy ñã sắp xếp.
Tọa ñộ những hình chữ nhật ban ñầu sẽ bị biến ñổi qua ánh xạ này, tuy nhiên ta có thể tìm POM trong tập các hình chữ nhật mới và ánh xạ ngược tọa ñộ POM thành tọa ñộ ban ñầu. Ví dụ:
Hình 1.19. Phép ánh xạ tọa ñộ
Phép biến ñổi này có những công dụng:
� Tất cả các hoành ñộ của cạnh dọc cũng như tất cả các tung ñộ của cạnh
ngang trở thành ;� số nguyên hoàn toàn phân biệt. � Cho dù tọa ñộ của các hình chữ nhật ban ñầu có thể rất lớn, hoặc là số thực,
qua ánh xạ này chúng ta sẽ chỉ xử lý các tọa ñộ nguyên �8;8 8;�. � Tọa ñộ POM có thể ánh xạ ngược lại dễ dàng. Bởi khi xác ñịnh ñược ñiểm
giao nhiều nhất nằm trên ñường ngang thứ mấy và ñường dọc thứ mấy, ta có thể chiếu vào hai dãy tọa ñộ ban ñầu ñể tìm tọa ñộ trước khi ánh xạ.
Bạn có thể thắc mắc rằng POM có thể không nằm trên ñường ngang cũng như
ñường dọc nào (như ví dụ trên có thể ta tìm ñược POM là �VE\8VE\� trên bản ñồ ánh xạ). Khi ñó ta có thể xác ñịnh POM nằm giữa hai ñường ngang liên tiếp nào và nằm giữa hai ñường dọc liên tiếp nào, sau ñó ánh xạ ngược lại. Tuy nhiên không cần phải rắc rối như vậy, thuật toán mà chúng ta sẽ trình bày luôn tìm ñược POM nằm trên giao của một ñường ngang và một ñường dọc.
1 2 3 4 5 6 7 8 0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 0
1
2
3
4
5
6
7
8

103
� ðường quét ngang
G ñiểm giao nhiều nhất có tọa ñộ �8 0�, khi ñó nếu ta xét ñường thẳng > 0, nó sẽ cắt ngang qua một số hình chữ nhật. Giao của các hình chữ nhật với ñường
thẳng > 0 tạo thành các khoảng ñóng trên ñường thẳng ñó. Khi ñó tọa ñộ chính là ñiểm giao nhiều nhất của các khoảng ñóng (một chiều).
Ví dụ như với bản ñồ trên, ta xét ñường thẳng > V, nó sẽ cắt ngang qua 3 hình
chữ nhật tạo thành 3 khoảng ñóng: ��8X�� �;8T�� �V8e�. ðiểm giao nhiều nhất của 3
khoảng ñóng này là ñiểm V (hay bất cứ ñiểm nào nằm trong ñoạn �V8X�). Vậy POM tương ứng có tọa ñộ �V8V�. Thuật toán tìm POM hai chiều có thể trình bày như sau: Xét tất cả các ñường
thẳng nằm ngang có phương trình > 0, với mỗi ñường ñó ta xét các giao với các hình chữ nhật ñã cho và tìm ñiểm giao nhiều nhất, ghi nhận lại ñiểm giao
nhiều nhất trên tất cả các giá trị 0 ñã thử.
Chúng ta sẽ phải thử với bao nhiêu ñường thẳng dạng > 0?, có thể nhận thấy
rằng chỉ cần thử với lần lượt các giá trị 0 �8;8 8;� là ñủ.
Rõ ràng với 0 7, tập các khoảng ñóng tạo ra trên ñường thẳng > 7 là rỗng.
Sau khi xét xong mỗi ñường thẳng > 0, xét tiếp ñến ñường thẳng > 0 � �, có hai khả năng xảy ra:
� Nếu ñường > 0 � � là một cạnh ñáy của hình chữ nhật � (8 >(8 +8 >+�
( >( 0 � � ), ta bổ sung � (8 +� vào tập các khoảng ñóng (thời gian $�%' ��) và tìm POM ($���).
1 2 3 4 5 6 7 8 0
1
2
3
4
5
6
7
8
> V

104
� Nếu ñường > 0 � � là một cạnh ñỉnh của hình chữ nhật � (8 >(8 +8 >+�
( >+ 0 � � ), ta loại bỏ � (8 +� khỏi tập các khoảng ñóng (thời gian $�%' ��). � Dựng sẵn BST
Nhắc lại trong kỹ thuật cài ñặt bài toán tìm POM một chiều, ta sử dụng BST chứa các ñầu mút của các khoảng ñóng. Tuy nhiên do các ñầu mút là các số
nguyên hoàn toàn phân biệt trong phạm vi �8;8 8;�, nên ta có thể dựng sẵn cây
nhị phân chứa ;� nút, mỗi nút sẽ chứa một ñầu mút với nhãn k�[� �� nếu ñó
là ñầu mút mở, k�[� C� nếu ñó là ñầu mút ñóng và k�[� 7 ñể ñánh dấu ñầu mút ñó không có hiệu lực (do khoảng ñóng tương ứng chưa ñược xét ñến
hoặc ñã bị loại bỏ). Có thể thấy rằng cách gán giá trị k�[� 7 này không làm ảnh hưởng ñến tính ñúng ñắn của công thức (7.3) và (7.4).
Cây nhị phân dựng sẵn ñược biểu diễn bởi một mảng �!���0 ;��, mỗi phần tử
là một bản ghi chứa các trường ����� : tọa ñộ ñiểm, "�[� : Nhãn ñầu mút 5 6C�878 ��9, "@�, � "@� và B�y. Ý nghĩa của các trường ñược giải thích
như trên. Nút gốc của cây là �!�����. Nút � có con trái là ;� và con phải là ;� � �. Hai hàm ���� và !�[�� dưới ñây trả về nút con trái và con phải của một
nút, (trả về 0 trong trường hợp nút � không có con trái hoặc con phải)
function valid(x: Integer): Boolean;
begin
Result := x <= 2 * n;
end;
function left(x: Integer): Integer;
begin
if IsNode(x * 2) then Result := x * 2
else Result := 0;
end;
function right(x: Integer): Integer;
begin
if IsNode(x * 2 + 1) then Result := x * 2 + 1
else Result := 0;
end;
Vì nếu nút không có con trái (phải) thì hàm ���� (!�[��) trả về 0, ta sẽ gán các
trường "@� và � "@� của �!���7� bằng 0 cho tiện cài ñặt.

105
� Cài ñặt
� POM.PAS � ðiểm giao nhiều nhất
{$MODE OBJFPC}
program PointOfMaximumOverlap;
const max = 100000;
type
TEndPointType = (eptOpen, eptClose);
TEndPoint = record //Kiểu ñầu mút của khoảng ñóng
value: Integer; //Tọa ñộ
ept: TEndPointType; //Loại: ñầu mút mở hay ñầu mút ñóng
rid: Integer; //Chỉ số hình chữ nhật tương ứng
end;
TRect = record //Kiểu hình chữ nhật
x1, y1, x2, y2: Integer; //(x1, y1): Trái Dưới, (x2, y2): Phải Trên
end;
TEndPointArray = array[1..2 * max] of TEndPoint;
//Kiểu danh sách các ñầu mút TNode = record //Thông tin nút của cây nhị phân
point: Integer;
sign: Integer;
sum, maxsum: Integer;
POM: Integer;
end;
var
x, y: TEndPointArray;
r: array[1..max] of TRect;
tree: array[0..2 * max] of TNode;
ptr: array[1..2 * max] of Integer;
n, ResX, ResY, m: Integer;
procedure Enter; //Nhập dữ liệu var i, j: Integer;
begin
ReadLn(n);
for i := 1 to n do //ðọc 2n tọa ñộ x và 2n tọa ñộ y
begin
j := 2 * n + 1 - i;
Read(x[i].value);

106
x[i].Ept := eptOpen;
x[i].rid := i;
Read(y[i].value);
y[i].Ept := eptOpen;
y[i].rid := i;
Read(x[j].value);
x[j].Ept := eptClose;
x[j].rid := i;
Read(y[j].value);
y[j].Ept := eptClose;
y[j].rid := i;
end;
end;
operator < (const p, q: TEndPoint): Boolean;
//p sẽ ñược xếp trước q nếu... begin
Result := (p.value < q.value) or
(p.value = q.value) and (p.Ept < q.Ept);
//Open < Close end;
procedure Sort(var k: TEndPointArray);
//Sắp xếp danh sách các ñầu mút procedure Partition(L, H: Integer);
var
i, j: Integer;
Pivot: TEndPoint;
begin
if L >= H then Exit;
i := L + Random(H - L + 1);
Pivot := k[i];
k[i] := k[L];
i := L;
j := H;
repeat
while (Pivot < k[j]) and (i < j) do Dec(j);
if i < j then
begin
k[i] := k[j];
Inc(i);

107
end
else Break;
while (k[i] < Pivot) and (i < j) do Inc(i);
if i < j then
begin
k[j] := k[i];
Dec(j);
end
else Break;
until i = j;
k[i] := Pivot;
Partition(L, i - 1);
Partition(i + 1, H);
end;
begin
Partition(1, 2 * n);
end;
procedure RefineRects; //Ánh xạ tọa ñộ
var i: Integer;
begin
for i := 1 to 2 * n do
begin
with x[i] do
if ept = eptOpen then r[rid].x1 := i
else r[rid].x2 := i;
with y[i] do
if ept = eptOpen then r[rid].y1 := i
else r[rid].y2 := i;
end;
end;
function valid(x: Integer): Boolean; //Nút có hợp lệ không
begin
Result := x <= 2 * n;
end;
function left(x: Integer): Integer; //Tìm nút con trái của Node
begin
if valid(x * 2) then Result := x * 2 //Nút con trái hợp lệ
else Result := 0; //Nếu không trả về 0

108
end;
function right(x: Integer): Integer; //Tìm nút con phải của Node
begin
if valid(x * 2 + 1) then Result := x * 2 + 1
//Nút con phải hợp lệ else Result := 0; //Nếu không trả về 0 end;
procedure BuildTree; //Dựng sẵn BST gồm 2n nút var
i: Integer;
procedure InOrderTraversal(x: Integer);
//Duyệt cây theo thứ tự giữa begin
if not valid(x) then Exit;
InOrderTraversal(x * 2);
Inc(i);
tree[x].point := i; //ðưa ñiểm i vào nút Node ptr[i] := x; //ptr[i]: Nút chứa ñiểm tọa ñộ i trong BST
InOrderTraversal(x * 2 + 1);
end;
begin
FillByte(tree, SizeOf(tree), 0); //sum, maxsum := 0 i := 0;
InOrderTraversal(1);
end;
//target := Max(a, b, c)
function ChooseMax3(var target: Integer;
a, b, c: Integer): Integer;
begin
target := a;
Result := 1; //Trả về 1 nếu Max ñạt tại a
if target < b then
begin
target := b;
Result := 2; //Trả về 2 nếu Max ñạt tại b
end;
if target < c then
begin
target := c;

109
Result := 3; //Trả về 3 nếu Max đạt tại c
end;
end;
//Đặt nhãn sign = s cho nút mang tọa độ p trong BST
procedure SetPoint(p: Integer; s: Integer);
var
Node, L, r, Choice: Integer;
begin
Node := ptr[p]; //Xác định nút chứa điểm p
tree[Node].sign := s; //Đặt nhãn sign
repeat //Cập nhật thông tin phụ trợ từ Node lên gốc 1
L := left(Node);
r := right(Node); //L: Con trái; r: Con phải
//Tính trường sum
tree[Node].sum := tree[Node].sign + tree[L].sum
+ tree[r].sum;
//Tính trường maxsum
Choice := ChooseMax3(tree[Node].maxsum,
tree[L].maxsum,
tree[L].sum + tree[Node].sign,
tree[L].sum + tree[Node].sign
+ tree[r].maxsum);
case Choice of //Tính POM tùy theo maxsum đạt tại đâu
1: tree[Node].POM := tree[L].POM; //Đạt tại nhánh trái
2: tree[Node].POM := tree[Node].point;
//ðạt tại chính Node 3: tree[Node].POM := tree[r].POM; //Đạt tại nhánh phải
end;
Node := Node div 2; //Đi lên nút cha
until Node = 0;
end;
//Thêm một đoạn [x1, x2] vào tập cần tìm POM
procedure InsertInterval(x1, x2: Integer);
begin
SetPoint(x1, +1); //Đặt nhãn đầu mút mở là +1
SetPoint(x2, -1); //Đặt nhãn đầu mút đóng là -1
end;
//Loại một đoạn [x1, x2] khỏi tập cần tìm POM (đặt nhãn của hai đầu mút thành 0)
procedure DeleteInterval(x1, x2: Integer);

110
begin
SetPoint(x1, 0);
SetPoint(x2, 0);
end;
procedure Sweep; //Sử dụng các dòng quét ngang để tìm POM
var
sweepY, POM: Integer;
begin
BuildTree;
m := 0;
for sweepY := 1 to 2 * n do //Xét các đường quét y = 1, 2, ..., 2n
with y[sweepY] do
if ept = eptOpen then //Quét vào một cạnh đáy
begin
InsertInterval(r[rid].x1, r[rid].x2);
//Thêm một đoạn vào tập tìm POM if tree[1].maxsum > m then
//POM mới là giao của nhiều hình chữ nhật hơn POM cũ begin
m := tree[1].maxsum;
POM := tree[1].POM;
//Ánh xạ ngược lại, tìm tọa độ
ResX := x[POM].value;
ResY := y[sweepY].value;
end;
end
else //Quét vào một cạnh đỉnh
DeleteInterval(r[rid].x1, r[rid].x2);
end;
procedure PrintResult;
begin
WriteLn('Point of Maximum Overlap:
(', ResX, ', ', ResY, ')');
WriteLn('Number of Rectangles: ', m);
end;
begin
Enter; //Nhập dữ liệu
Sort(x);

111
Sort(y); //Sắp xếp hai dãy tọa độ
RefineRects; //Ánh xạ sang tọa độ mới
Sweep; //Sử dụng đường quét ngang để tìm POM
PrintResult; //In kết quả
end.
Thời gian thực hiện giải thuật tìm ñiểm giao nhiều nhất của � hình chữ nhật là $�� %' ��.
Bài tập
1.30. Cho một BST chứa � khóa, và hai khóa 8 0. Người ta muốn liệt kê tất cả
các khóa � của BST thỏa mãn N � N 0. Hãy tìm thuật toán $�� � %' ��
ñể trả lời truy vấn này (� là số khóa ñược liệt kê).
1.31. Cho � là một số nguyên dương và � (8 +8 8 .� là một hoán vị của
dãy số ��8;8 8 ��. Với L�M � N � N �, gọi �2 là số phần tử ñứng trước giá
trị � mà lớn hơn � trong dãy . Khi ñó dãy � ��(8 �+8 8 �.� ñược gọi là
dãy nghịch thế của dãy � (8 +8 8 .�.
Ví dụ với � T , dãy �V8;8�8T8X8\� thì dãy nghịch thế của nó là � �;8�878�8�87�
Xây dựng thuật toán $�� %' �� tìm dãy nghịch thế từ dãy hoán vị cho trước
và thuật toán $�� %' �� ñể tìm dãy hoán vị từ dãy nghịch thế cho trước.
1.32. Trên mặt phẳng với hệ tọa ñộ trực giao $ > cho � hình chữ nhật có cạnh
song song với các trục tọa ñộ. Hãy tìm thuật toán $�� %' �� ñể tính diện
tích phần mặt phẳng bị � hình chữ nhật ñó chiếm chỗ.
1.33. Cho � dây cung của một hình tròn, không có hai dây cung nào chung ñầu
mút. Tìm thuật toán $�� %' �� xác ñịnh số cặp dây cung cắt nhau bên trong
hình tròn. (Ví dụ nếu � dây cung ñều là ñường kính thì số cặp là g.+h).
1.35. Trên trục số cho � ñoạn ñóng, ñoạn thứ � là �28 02�, �28 02 5 ¡�. Hãy chọn
trên trục số một số ít nhất các ñiểm nguyên phân biệt sao cho có ít nhất l2 ñiểm ñược chọn thuộc vào ñoạn thứ �. �� N � N �7�� 7 N 2 8 028 l2 N �7��.

112
1.36. Bản ñồ một khu ñất hình chữ nhật kích thước � Y � ñược chia thành lưới
ô vuông ñơn vị. Trên ñó có ñánh dấu � ô trồng cây ��8 �8 � N �7��. Người ta muốn giải phóng một mặt bằng nằm trong khu ñất này. Bản ñồ mặt bằng có các ràng buộc sau:
� Cạnh mặt bằng là số nguyên � Mặt bằng chiếm trọn một số ô trên bản ñồ � Cạnh mặt bằng song song với cạnh bản ñồ
Hãy trả lời hai câu hỏi:
� Nếu muốn xây dựng mặt bằng với cạnh là P thì phải giải phóng ít nhất bao nhiêu ô trồng cây?
� Nếu không muốn giải phóng ô trồng cây nào thì có thể xây dựng ñược mặt bằng với cạnh lớn nhất là bao nhiêu?
1.37. Một bộ � N �7� lá bài ñược xếp thành tập và mỗi lá bài ñược ghi số thứ tự
ban ñầu của lá bài ñó trong tập bài (vị trí các lá bài ñược ñánh số từ 1 tới � từ trên xuống dưới).
Xét phép tráo ký hiệu bởi k��8 b�: rút ra lá bài thứ � và chèn lên trên lá bài
thứ b trong số � C � lá bài còn lại �� N �8 b N ��, quy ước rằng nếu b �
thì lá bài thứ � sẽ ñược ñặt vào vị trí dưới cùng của tập bài.
Ví dụ với � T
g�8 ; 8 V8X8\8Th ¢�+8��£¤¤¥ g�8V8 ; 8 X8\8Th g � 8 V8;8X8\8Th ¢�(8+�£¤¤¥ gV8 � 8 ;8X8\8Th gV8�8;8 X 8 \8Th ¢��8��£¤¤¥ gV8�8;8\8 X 8 Th
g V 8 �8;8\8X8Th ¢�(8��£¤¤¥ g�8;8\8X8T8 V h Người ta tráo bộ bài bằng phép tráo ( N �7�). Bạn ñược cho biết phép tráo ñó, hãy sử dụng thêm ít nhất các phép tráo nữa ñể ñưa các lá bài về vị trí ban ñầu. Như ở ví dụ trên, chúng ta cần sử dụng thêm 2 phép tráo k�T8V� và k�\8X�.

113
Chuyên ñề 7
ðỒ THỊ
1. ðường ñi ngắn nhất
1.1. ðồ thị có trọng số
Trong các ứng dụng thực tế, chẳng hạn trong mạng lưới giao thông, người ta không chỉ quan tâm ñến việc tìm ñường ñi giữa hai ñịa ñiểm mà còn phải lựa chọn một hành trình tiết kiệm nhất (theo tiêu chuẩn không gian, thời gian hay một ñại lượng mà chúng ta cần giảm thiểu theo hành trình). Khi ñó người ta gán cho mỗi cạnh của ñồ thị một giá trị phản ánh chi phí ñi qua cạnh ñó và cố gắng tìm một con ñường mà tổng chi phí các cạnh ñi qua là nhỏ nhất.
ðồ thị có trọng số là một bộ ba A �a8 �8 �� trong ñó A �a8 �� là một ñồ thị, � là hàm trọng số: �M � � � � ¦ ���� Hàm trọng số gán cho mỗi cạnh � của ñồ thị một số thực ���� gọi là trọng số
(weight) của cạnh. Nếu cạnh � �@8 �� thì ta cũng ký hiệu ��@8 �� ����. Tương tự như ñồ thị không trọng số, có nhiều cách biểu diễn ñồ thị có trọng số trong máy tính. Nếu ta sử dụng danh sách cạnh, danh sách kề hay danh sách liên thuộc, mỗi phần tử của danh sách sẽ chứa thêm một thông tin về trọng số của
cạnh tương ứng. Trường hợp biểu diễn ñơn ñồ thị gồm � ñỉnh, ta còn có thể sử
dụng ma trận trọng số § 6�¨©9.Y. trong ñó �¨© là trọng số của cạnh �@8 ��.
Trong trường hợp �@8 �� ª � thì tùy bài toán cụ thể, �¨© sẽ ñược gán một giá trị
ñặc biệt ñể nhận biết �@8 �� không phải là cạnh (chẳng hạn có thể gán bằng ��,
0 hay C�).
ðường ñi, chu trình trong ñồ thị có trọng số cũng ñược ñịnh nghĩa giống như trong trường hợp không trọng số, chỉ có khác là ñộ dài ñường ñi không tính

114
bằng số cạnh ñi qua, mà ñược tính bằng tổng trọng số của các cạnh ñi qua. ðộ
dài của một ñường ñi B ñược ký hiệu là ��B�.
1.2. ðường ñi ngắn nhất xuất phát từ một ñỉnh
Bài toán tìm ñường ñi ngắn nhất xuất phát từ một ñỉnh (single-source shortest
path) ñược phát biểu như sau: Cho ñồ thị có trọng số A �a8 �8 ��, hãy tìm các
ñường ñi ngắn nhất từ ñỉnh xuất phát " 5 a ñến tất cả các ñỉnh còn lại của ñồ
thị. ðộ dài của ñường ñi từ ñỉnh " tới ñỉnh �, ký hiệu «�"8 ��, gọi là khoảng cách
(distance) từ " ñến �. Nếu như không tồn tại ñường ñi từ " tới � thì ta sẽ ñặt
khoảng cách ñó bằng ��. Có một vài biến ñổi khác của bài toán tìm ñường ñi ngắn nhất xuất phát từ một ñỉnh:
� Tìm các con ñường ngắn nhất từ mọi ñỉnh tới một ñỉnh � cho trước. Bằng cách ñảo chiều các cung của ñồ thị, chúng ta có thể quy về bài toán tìm
ñường ñi ngắn nhất xuất phát từ �.
� Tìm ñường ñi ngắn nhất từ ñỉnh " tới ñỉnh � cho trước. Dĩ nhiên nếu ta tìm
ñược ñường ñi ngắn nhất từ " tới mọi ñỉnh khác thì bài toán tìm ñường ñi
ngắn nhất từ " tới � cũng sẽ ñược giải quyết. Hơn nữa, vẫn chưa có một
thuật toán nào tìm ñường ñi ngắn nhất từ " tới � mà không cần quy về bài
toán tìm ñường ñi ngắn nhất từ " tới mọi ñỉnh khác. � Tìm ñường ñi ngắn nhất giữa mọi cặp ñỉnh của ñồ thị: Mặc dù có những
thuật toán ñơn giản và hiệu quả ñể tìm ñường ñi ngắn nhất giữa mọi cặp ñỉnh, chúng ta vẫn có thể giải quyết bằng cách thực hiện thuật toán tìm ñường ñi ngắn nhất xuất phát từ một ñỉnh với mọi cách chọn ñỉnh xuất phát.
a) a) a) a) CCCC6666u trúc bài toán con tu trúc bài toán con tu trúc bài toán con tu trúc bài toán con t!!!!i Fui Fui Fui Fu
Các thuật toán tìm ñường ñi ngắn nhất mà chúng ta sẽ khảo sát ñều dựa vào một ñặc tính chung: Mỗi ñoạn ñường trên ñường ñi ngắn nhất phải là một ñường ñi ngắn nhất.
ðịnh lý 1-1
Cho ñồ thị có trọng số A �a8 �8 ��, gọi B ¬�(8 �+8 8 �I là một ñường ñi
ngắn nhất từ �( tới �I , khi ñó với mọi �8 bM � N � N b N � , ñoạn ñường B2® ¬�2 8 �2K(8 8 �® là một ñường ñi ngắn nhất từ �2 tới �® .

115
Chúng ta sẽ thấy rằng hầu hết các thuật toán tìm ñường ñi ngắn nhất ñều là thuật toán quy hoạch ñộng (ví dụ thuật toán Floyd) hoặc tham lam (ví dụ thuật toán Dijkstra) bởi tính chất bài toán con tối ưu nêu ra trong ðịnh lý 1-1.
Nếu như ñồ thị có chu trình âm (chu trình với ñộ dài âm) thì khoảng cách giữa một số cặp ñỉnh nào ñó có thể không xác ñịnh, bởi vì bằng cách ñi vòng theo chu trình này một số lần ñủ lớn, ta có thể chỉ ra ñường ñi giữa hai ñỉnh nào ñó trong chu trình này nhỏ hơn bất kỳ một số cho trước nào. Trong trường hợp như vậy, có thể ñặt vấn ñề tìm ñường ñi ñơn ngắn nhất. Vấn ñề ñó lại là một bài toán NP-ñầy ñủ, hiện chưa ai chứng minh ñược sự tồn tại hay không một thuật toán ña thức tìm ñường ñi ñơn ngắn nhất trên ñồ thị có chu trình âm.
b) b) b) b) Quy vQuy vQuy vQuy vEEEE bài toán "o khobài toán "o khobài toán "o khobài toán "o kho����ng cáchng cáchng cáchng cách
Nếu như ñồ thị không có chu trình âm thì có thể chứng minh ñược rằng một trong những ñường ñi ngắn nhất là ñường ñi ñơn. Khi ñó chỉ cần biết ñược
khoảng cách từ " tới tất cả những ñỉnh khác thì ñường ñi ngắn nhất từ " tới � có thể tìm ñược một cách dễ dàng qua thuật toán sau:
Trước tiên ta tìm ñỉnh �( d � ñể «�"8 �� «�"8 �(� � l��(8 ��. Dễ thấy rằng luôn
tồn tại ñỉnh �( như vậy và ñỉnh ñó sẽ là ñỉnh ñứng liền trước � trên ñường ñi
ngắn nhất từ " tới �. Nếu �( " thì ñường ñi ngắn nhất là ñường ñi trực tiếp
theo cung �"8 ��. Nếu không thì vấn ñề trở thành tìm ñường ñi ngắn nhất từ " tới �( . Và ta lại tìm ñược một ñỉnh �+ ª 6�8 �(9 ñể «�"8 �(� «�"8 �+� �l��+8 ��…Cứ tiếp tục như vậy sau một số hữu hạn bước cho tới khi xét tới ñỉnh �I ", Ta có dãy � �48 �(8 �+8 �I " không chứa ñỉnh lặp lại. Lật ngược
thứ tự dãy cho ta ñường ñi ngắn nhất từ " tới �.
c) c) c) c) Nhãn khoNhãn khoNhãn khoNhãn kho����ng cách và phép cong cách và phép cong cách và phép cong cách và phép co
Tất cả những thuật toán chúng ta sẽ khảo sát ñể tìm ñường ñi ngắn nhất xuất phát từ một ñỉnh ñều sử dụng kỹ thuật gán nhãn khoảng cách: Với mỗi ñỉnh � 5 a, nhãn khoảng cách ���� là ñộ dài một ñường ñi nào ñó từ " tới �. Trong
"
�+
�(
�

116
trường hợp chúng ta chưa xác ñịnh ñược ñường ñi nào từ " tới �, nhãn ���� ñược gán giá trị ��. Ban ñầu chúng ta chưa xác ñịnh ñược bất kỳ ñường ñi nào từ " tới các ñỉnh khác
nên các ���� ñược gán giá trị khởi tạo là:
���� ¯78 nếu � "��8 nếu � d "� �� �8;8 8 �� (1.1)
procedure Init;
begin
for Lv 5 V do d[v] := +∞; d[s] := 0;
end;
Do tính chất của nhãn khoảng cách, ta có ���� w «�"8 ��8 L� 5 a. Các thuật toán
tìm ñường ñi ngắn nhất sẽ cực tiểu hóa dần các nhãn ��E � cho tới khi ���� «�"8 ��8 L� 5 a. Trong các thuật toán mà chúng ta sẽ khảo sát, việc cực tiểu hóa các nhãn khoảng cách ñược thực hiện bởi các phép co. Phép co theo cạnh �@8 �� 5 �, gọi tắt là phép co �@8 �� ñược thực hiện như sau:
Giả sử chúng ta ñã xác ñịnh ñược ��@� là ñộ dài một ñường ñi từ " tới @, ta nối
thêm cạnh �@8 �� ñể ñược một ñường ñi từ " tới � với ñộ dài ��@� � ��@8 ��.
Nếu ñường ñi này có ñộ dài ngắn hơn ����, ta ghi nhận lại ���� bằng ��@� ���@8 �� . ðiều này có nghĩa là nếu " ° @ nối thêm cạnh �@8 �� lại ngắn hơn
ñường ñi " ° � ñang có, thì ta hủy bỏ ñường ñi " ° � hiện tại và ghi nhận lại
ñường ñi " ° � mới là ñường ñi " ° @ G �.
Hình 2.1. Phép co
Có thể hình dung hoạt ñộng của phép co như sau: Căng một ñoạn dây ñàn hồi
dọc theo ñường ñi " tới �, ñoạn dây sẽ dãn ra tới ñộ dài ����. Tiếp theo ta thử
lấy ñoạn dây ñó căng dọc theo ñường ñi từ " tới @ rồi nối tiếp ñến �. Nếu ñoạn dây bị chùng xuống (co lại) hơn so với cách căng cũ, ta ghi nhận ñường ñi tương
" @
� ����
��@� l�@8 ��

117
ứng với cách căng mới, nếu ñoạn dây không chùng xuống (hoặc căng thêm) thì ta vẫn giữ ñoạn dây ñó căng theo ñường cũ. Chính vì phép co không làm “dài”
thêm ����, ta nói rằng ���� bị cực tiểu hóa qua phép co �@8 ��. Phép co �@8 �� ñược thực hiện bởi hàm D�� , hàm nhận vào cạnh �@8 �� và trả
về True nếu nhãn ���� bị giảm ñi qua phép co �@8 ��: function Relax(e = (u,v)5 E): Boolean; begin
Result := d[v] > d[u] + w(e);
if Result then
begin
d[v] := d[u] + w(e); //cực tiểu hóa nhãn d[v]
trace[v] := u; //Lưu vết ñường ñi
end
end;
Mỗi khi ���� bị giảm xuống sau phép co �@8 ��, ta lưu lại vết �!l���� z @ với
ý nghĩa ñường ñi ngắn nhất từ " tới � cho tới thời ñiểm ñược ghi nhận sẽ là
ñường ñi qua @ trước rồi ñi tiếp theo cung �@8 ��, vết này ñược sử dụng ñể truy vết tìm ñường ñi khi thuật toán kết thúc. dddd) ) ) ) MMMM8888t st st st s!!!! tính chtính chtính chtính ch6666t và quy Ft và quy Ft và quy Ft và quy F4444cccc
Các tính chất sau ñây tuy ñơn giản nhưng quan trọng ñể chứng minh tính ñúng ñắn của các thuật toán trong bài:
� Bất ñẳng thức tam giác (triangle inequality): Với một cạnh �@8 �� 5 �, ta có «�"8 �� N «�"8 @� � ��@8 ��.
� Cận dưới (lower bound) và sự hội tụ (convergence): Các ���� sau một loạt
phép co sẽ giảm dần nhưng không bao giờ nhỏ hơn khoảng cách «�"8 ��.
Tức là khi ���� «�"8 �� (���� ñạt cận dưới) thì không một phép co nào
làm giảm ���� ñi ñược nữa.
� Cây ñường ñi ngắn nhất (shortest-path tree): Nếu ta khởi tạo các ���� và
thực hiện các phép co cho tới khi ���� bằng khoảng cách từ " tới � (L� 5a) thì chúng ta cũng xây dựng ñược một cây gốc " trong ñó nút � là con của
nút �!l����. ðường ñi trên cây từ nút gốc " tới một nút � chính là ñường ñi ngắn nhất.

118
� Sự không tồn tại ñường ñi (no path): Nếu không tồn tại ñường ñi từ " tới �
thì cho dù chúng ta co như thế nào chăng nữa, ���� luôn bằng ��. ðể tiện trong trình bày thuật toán, ta ñưa vào một quy ước khi cộng giá trị � với
hằng số F. Bởi trong máy tính không có khái niệm �, các chương trình cài ñặt thường sử dụng một hằng số ñặc biệt ñể thay thế, nhưng có thể phải ñi kèm với vài sửa ñổi ñể hợp lý hóa các phép toán: F � ���� ���� � F �� F � �C�� �C�� � F C�
Dưới ñây ta sẽ xét một số thuật toán tìm ñường ñi ngắn nhất từ ñỉnh " tới ñỉnh �
trên ñồ thị có hướng A �a8 �� có � ñỉnh và � cung, các ñỉnh ñược ñánh số từ
1 tới �. Trong trường hợp ñồ thị vô hướng với trọng số không âm, bài toán tìm ñường ñi ngắn nhất có thể quy dẫn về bài toán tìm ñường ñi ngắn nhất trên phiên bản có hướng của ñồ thị.
Input
� Dòng 1 chứa số ñỉnh � N �7�, số cung � N �7� của ñồ thị, ñỉnh xuất phát ", ñỉnh ñích �.
� � dòng tiếp theo, mỗi dòng có dạng ba số @, �, �, cho biết �@8 �� là một
cung 5 � và trọng số của cung ñó là � (� là số nguyên có giá trị tuyệt ñối N �7�)
Output
ðường ñi ngắn nhất từ " tới � và ñộ dài ñường ñi ñó.

119
Sample Input Sample Output
6 7 1 4
1 2 1
1 6 10
2 3 2
3 4 20
3 6 3
5 4 5
6 5 4
Distance from 1 to 4: 15
4<-5<-6<-3<-2<-1
eeee) ) ) ) ThuThuThuThut toán Bellmant toán Bellmant toán Bellmant toán Bellman----FordFordFordFord
� Thuật toán
Thuật toán Bellman-Ford[5][14] có thể sử dụng ñể tìm ñường ñi ngắn nhất xuất
phát từ một ñỉnh " 5 a trong trường hợp ñồ thị ± �²8 ³8 ´� không có chu trình âm. Thuật toán này khá ñơn giản: Khởi tạo các nhãn khoảng cách ��"� z 7 và ���� z ��8 L� d ", sau ñó thực hiện phép co theo mọi cạnh của ñồ thị. Cứ lặp lại như vậy ñến khi không thể cực tiểu hóa thêm bất kỳ một nhãn ���� nào nữa.
Init;
repeat
Stop := True;
for Le 5 E do if Relax(e) then Stop := False;
until Stop;
� Tính ñúng và tính dừng
Gọi «I�"8 �� là ñộ dài ngắn nhất của một ñường ñi từ " tới � qua ñúng � cạnh,
nếu không tồn tại ñường ñi từ " tới � qua � cạnh thì «I�"8 �� ��.
Ta chứng minh rằng sau mỗi lần lặp thứ � của vòng lặp repeat…until thì
���� N «I�"8 ��8 L� 5 a (1.2)
Tại bước khởi tạo, rõ ràng ���� «4�"8 �� . Giả sử bất ñẳng thức (1.2) ñúng
trước lần lặp thứ �, ta chứng minh rằng bất ñẳng thức vẫn ñúng sau lần lặp thứ �. Thật vậy, ñường ñi ngắn nhất từ " tới � qua � cạnh sẽ phải thành lập bằng
1
2 3
4
5 6
1
2
3
4
5
20
10

120
cách lấy một ñường ñi ngắn nhất từ " tới một ñỉnh @ nào ñó qua � C � cạnh rồi
ñi tiếp tới � bằng cung �@8 ��: " ° @ G �. Vì thế «I�"8 �� có thể ñược tính bằng công thức truy hồi:
«I�"8 �� �µo¨5¶�¨8©�5s6«I3(�"8 @� � ��@8 ��9
w �µo¨5¶�¨8©�5s6��@� � ��@8 ��9
w ���� (1.3)
Bất ñẳng thức thứ nhất ñúng do giả thiết quy nạp và các phép co không bao giờ
làm tăng ��@�. Bất ñẳng thức thứ hai ñúng vì sau khi căng theo tất cả các cạnh � 8 �� thì không thể tồn tại @ ñể ���� 1 ��@� � ��@8 �� ñược nữa. Trong các ñường ñi ngắn nhất từ " tới �, sẽ có một ñường ñi ñơn (qua không quá � C � cạnh). Tức là «�"8 �� �µoIM(·I·.3( «I�"8 �� . Sau � C � bước lặp của
vòng lặp repeat…until, ta thu ñược các ���� thỏa mãn ���� N «I�"8 �� với mọi � 5 a và mọi số � �8;8 8 � C �. ðiều này chỉ ra rằng: ���� N «�"8 ��8 L� 5a. Mặt khác ���� w «�"8 �� (tính bị chặn dưới), vậy L� 5 aM ���� «�"8 �� sau � C � bước lặp repeat…until, ñiều này cũng cho thấy thuật toán Bellman-Ford
sẽ kết thúc sau không quá � C � bước lặp repeat…until.
� Cài ñặt
Cách biểu diễn ñồ thị tốt nhất ñể cài ñặt thuật toán Bellman-Ford là sử dụng
danh sách cạnh. Danh sách cạnh của ñồ thị ñược lưu trữ trong mảng ��� ��, mỗi phần tử của mảng là một bản ghi chứa chỉ số hai ñỉnh ñầu mút @8 � và trọng
số � tương ứng với một cạnh � BELLMANFORD.PAS � Thuật toán Bellman-Ford
{$MODE OBJFPC}
program BellmanFordShortestPath;
const
maxN = 10000;
maxM = 100000;
maxW = 100000;
maxD = maxN * maxW;
type

121
TEdge = record //Cấu trúc biểu diễn cung
x, y: Integer; //Đỉnh đầu và đỉnh cuối
w: Integer; //Trọng số
end;
var
e: array[1..maxM] of TEdge; //Danh sách cung
d: array[1..maxN] of Integer; //Nhãn trọng số
trace: array[1..maxN] of Integer; //Vết
n, m, s, t: Integer;
procedure Enter; //Nhập dữ liệu
var i: Integer;
begin
ReadLn(n, m, s, t);
for i := 1 to m do
with e[i] do ReadLn(x, y, w);
end;
procedure Init; //Khởi tạo
var v: Integer;
begin
for v := 1 to n do d[v] := MaxD; //Các nhãn d[v] := +∞
d[s] := 0; //Ngoại trừ d[s] = 0
end;
function Relax(const e: TEdge): Boolean; //Phép co theo cạnh e
begin
with e do
begin
Result := (d[x] < maxD) and (d[y] > d[x] + w);
if Result then //Co được
begin
d[y] := d[x] + w; //Cực tiểu hóa nhãn d[v]
trace[y] := x; //Lưu vết
end;
end;
end;
procedure BellmanFord;
var
Stop: Boolean;
i, CountLoop: Integer;

122
begin
for CountLoop := 1 to n - 1 do //Lặp tối đa n – 1 lần
begin
Stop := True; //Chưa có sự thay đổi nhãn nào
for i := 1 to m do
if Relax(e[i]) then Stop := False;
if Stop then Break; //Không nhãn nào thay đổi, dừng
end;
end;
procedure PrintResult; //In kết quả
begin
if d[t] = maxD then //d[t] = +∞, không có đường
WriteLn('There is no path from ', s, ' to ', t)
else
begin
WriteLn('Distance from ', s, ' to ', t, ':
', d[t]);
while t <> s do //Truy vết từ t
begin
Write(t, '<-');
t := trace[t];
end;
WriteLn(s);
end;
end;
begin
Enter;
Init;
BellmanFord;
PrintResult;
end.
Dễ thấy rằng thời gian thực hiện giải thuật Bellman-Ford trên ñồ thị A�a8 �8 ��
là $��a�����.

123
ffff) ) ) ) ThuThuThuThut toán Dijkstrat toán Dijkstrat toán Dijkstrat toán Dijkstra
� Thuật toán
Trong trường hợp ñồ thị ± �²8 ³8 ´� có trọng số trên các cung không âm,
thuật toán do Dijkstra [8] ñề xuất dưới ñây hoạt ñộng hiệu quả hơn nhiều so với thuật toán Bellman-Ford bởi quá trình sửa nhãn sẽ chỉ xét mỗi cạnh tối ña một
lần. Tại mỗi bước, thuật toán ñi tìm ñỉnh @ mà nhãn ��@� ñã ñạt cận dưới bằng «�"8 @�. Nhãn ��@� chắc chắn không thể cực tiểu hóa ñược nữa, khi ñó thuật toán
mới tiến hành cực tiểu hóa các nhãn ���� khác bằng các phép sửa nhãn theo
cạnh �@8 ��. Các bước cụ thể ñược tiến hành như sau: Bước 1: Khởi tạo
Gọi thủ tục Init ñể khởi tạo các nhãn khoảng cách ��"� z 7 và ���� z��8 L� d ". Một nhãn ���� gọi là cố ñịnh nếu ta biết chắc ���� «�"8 �� và
không thể cực tiểu hóa ���� thêm nữa bằng phép co, ngược lại nhãn ���� gọi là
tự do. Ta sẽ ñánh dấu trạng thái nhãn bằng mảng �����E E �� trong ñó ������ ¸q�¹ nếu nhãn ���� còn tự do. Ban ñầu tất cả các nhãn ñều tự do. Bước 2: Lặp, bước lặp gồm có hai thao tác:
� Cố ñịnh nhãn: Chọn trong các ñỉnh có nhãn tự do, lấy ra ñỉnh @ là ñỉnh có ��@� nhỏ nhất, ñánh dấu cố ñịnh nhãn ñỉnh @ (����@� z ºn%»¹).
� Sửa nhãn: Dùng ñỉnh @, xét tất cả những ñỉnh � nối từ @ và thực hiện phép
co theo cung �@8 �� ñể cực tiểu hóa nhãn ����. Bước lặp sẽ kết thúc khi mà ñỉnh ñích � ñược cố ñịnh nhãn (tìm ñược ñường ñi
ngắn nhất từ " tới �); hoặc tại thao tác cố ñịnh nhãn, tất cả các ñỉnh tự do ñều có
nhãn là �� (không tồn tại ñường ñi).
Tại lần lặp ñầu tiên, ñỉnh " có ��"� nhỏ nhất (bằng 0) sẽ ñược cố ñịnh nhãn. Có
thể ñặt câu hỏi tại sao ñỉnh @ có nhãn tự do nhỏ nhất ñược cố ñịnh nhãn tại từng
bước, giả sử ��@� còn có thể làm nhỏ hơn nữa thì tất phải có một ñỉnh mang
nhãn tự do sao cho ��@� 1 �� � � �� 8 @�. Do trọng số �� 8 @� không âm nên ��@� 1 �� �, trái với cách chọn ��@� nhỏ nhất.
Bước 3: Truy vết

124
Kết hợp với việc lưu vết ñường ñi trên từng bước sửa nhãn, thông báo ñường ñi ngắn nhất tìm ñược hoặc cho biết không tồn tại ñường ñi.
� Cài ñặt
Thuật toán Dijkstra hoạt ñộng tốt nhất nếu ñồ thị ñược biểu diễn bằng danh sách kề dạng forward star. Cấu trúc danh sách kề ñược khai báo như sau:
type
TAdjNode = record //Cấu trúc nút của danh sách kề
v: Integer; //Đỉnh kề
w: Integer; //Trọng số cạnh tương ứng
end;
var
adj: array[1..maxM] of TAdjNode; //Mảng các nút
head: array[1..maxN] of Integer;
//head[u]: Chỉ số nút ñầu tiên của danh sách kề u link: array[1..maxM] of Integer;
//link[i]: Chỉ số nút kế tiếp nút adj[i] trong cùng một danh sách kề
Mỗi ñỉnh @ sẽ tương ứng với một danh sách các nút, mỗi nút chứa một ñỉnh � và
trọng số � của một cung �@8 �� . Tất cả các nút ñược lưu trữ trong mảng �b�� �� và mỗi nút sẽ thuộc ñúng một danh sách kề. Các nút thuộc danh
sách kề của ñỉnh @ là �b��(�8 �b��+�8 �b���� , trong ñó �( ����@�� �+ ������(�� �� ������+� ðây chính là cấu trúc dữ liệu biểu diễn danh sách móc nối ñơn, nhưng khác với những phép cài ñặt truyền thống, ta sử dụng mảng các nút thay cho cơ chế cấp phát biến ñộng và sử dụng chỉ số với vai trò như con trỏ.
� DIJKSTRA.PAS �
{$MODE OBJFPC}
program DijkstraShortestPath;
const
maxN = 10000;
maxM = 100000;
maxW = 100000;
maxD = maxN * maxW;
type
TAdjNode = record //Cấu trúc nút của danh sách kề
v: Integer; //Đỉnh kề
w: Integer; //Trọng số cung tương ứng

125
link: Integer; //Chỉ số nút kế tiếp trong cùng danh sách kề
end;
var
adj: array[1..maxM] of TAdjNode; //Mảng chứa tất cả các nút
head: array[1..maxN] of Integer;
//head[u]: Chỉ số nút đứng đầu danh sách kề của u d: array[0..maxN] of Integer; //Nhãn khoảng cách
avail: array[1..maxN] of Boolean; //Đánh dấu tự do/cố định
trace: array[1..maxN] of Integer; //Vết đường đi
n, m, s, t: Integer;
procedure Enter; //Nhập dữ liệu
var i, u: Integer;
begin
ReadLn(n, m, s, t);
FillChar(head[1], n * SizeOf(head[1]), 0);
//Khởi tạo các danh sách kề rỗng for i := 1 to m do
begin
ReadLn(u, adj[i].v, adj[i].w);
//Đọc một cung (u, v) trọng số w, đưa v và w vào trong nút adj[i]
adj[i].link := head[u]; //Chèn nút adj[i] vào ñầu danh sách kề của u head[u] := i; //Cập nhật chỉ số nút đứng đầu danh sách kề của u
end;
end;
procedure Init; //Khởi tạo
var v: Integer;
begin
for v := 0 to n do d[v] := MaxD;
//Các nhãn d[v] := +∞, d[0]: phần tử cầm canh
d[s] := 0; //Ngoại trừ d[s] = 0
FillChar(avail[1], n * SizeOf(avail[1]), True);
//Các nhãn đều tự do end;
procedure Relax(u, v: Integer; w: Integer);
//Phép co theo cung (u, v) trọng số w begin
if d[v] > d[u] + w then
begin
d[v] := d[u] + w;

126
trace[v] := u;
end;
end;
procedure Dijkstra; //Thuật toán Dijkstra
var u, v, i: Integer;
begin
repeat
//Tìm đỉnh u có nhãn tự do nhỏ nhất
u := 0;
for v := 1 to n do
if avail[v] and (d[v] < d[u]) then
u := v;
if (u = 0) or (u = t) then Break;
//u = 0: không tồn tại đường đi, u = t, xong
avail[u] := False; //Cố định nhãn đỉnh u
//Co theo các cung nối từ u
i := head[u]; //Duyệt từ đầu danh sách kề
while i <> 0 do
begin
Relax(u, adj[i].v, adj[i].w); //Thực hiện phép co
i := adj[i].link; //Chuyển sang nút kế tiếp trong danh sách kề
end;
until False;
end;
procedure PrintResult; //In kết quả
begin
if d[t] = maxD then
WriteLn('There is no path from ', s, ' to ', t)
else
begin
WriteLn('Distance from ', s, ' to ', t, ':
', d[t]);
while t <> s do
begin
Write(t, '<-');
t := trace[t];
end;
WriteLn(s);

127
end;
end;
begin
Enter;
Init;
Dijkstra;
PrintResult;
end.
Mỗi lượt của vòng lặp repeat…until sẽ có một ñỉnh mang nhãn tự do bị cố ñịnh
nhãn, suy ra số lượt lặp của vòng lặp repeat…until là $��a��. Việc tìm ñỉnh @ có
nhãn tự do nhỏ nhất ñược thực hiện trong thời gian $��a��, vậy nên xét trên toàn
thuật toán, tổng thời gian thực hiện của các pha cố ñịnh nhãn là $��a�+�. Mỗi lượt của vòng lặp repeat…until khi cố ñịnh nhãn ñỉnh @ sẽ phải duyệt danh
sách các ñỉnh nối từ @ ñể thực hiện pha sửa nhãn. Vì vậy xét trên toàn thuật
toán, tổng thời gian thực hiện của các pha sửa nhãn là $�: p¹'K�@�¨5¶ � $�����.
Vậy thủ tục Dijkstra thực hiện trong thời gian $��a�+ � ����.
� Kết hợp với hàng ñợi ưu tiên
ðể thuật toán Dijkstra làm việc hiệu quả hơn, người ta thường kết hợp với một
cấu trúc dữ liệu hàng ñợi ưu tiên chứa các ñỉnh tự do có nhãn d �� ñể thuận tiện trong việc lấy ra ñỉnh có nhãn nhỏ nhất cũng như cập nhật lại nhãn của các ñỉnh. Hàng ñợi ưu tiên cần hỗ trợ các thao tác sau:
� � �!l�M Lấy ra một ñỉnh ưu tiên nhất (ñỉnh @ có ��@� nhỏ nhất) khỏi hàng ñợi ưu tiên.
� ��������: Thao tác này báo cho hàng ñợi ưu tiên biết rằng nhãn ���� ñã
bị giảm ñi, cần tổ chức lại (thêm � vào hàng ñợi ưu tiên nếu � ñang nằm ngoài).
Khi ñó thuật toán Dijkstra có thể viết theo mô hình mới sử dụng hàng ñợi ưu tiên:
Init;
PQ := (s); //Hàng đợi ưu tiên được khởi tạo chỉ gồm đỉnh xuất phát
repeat
u := Extract; //Lấy ra ñỉnh u có d[u] nhỏ nhất

128
if u = t then Break;
for L(u, v) 5 E do if Relax(u, v) then Update(v);
until PQ = �; if d[t] = +∞ then
Output ← Không có ñường
else
«Truy vết tìm ñường ñi từ s tới t»
Vòng lặp repeat…until mỗi lần sẽ lấy một ñỉnh khỏi hàng ñợi ưu tiên và ñỉnh lấy ra sẽ không bao giờ bị ñẩy vào hàng ñợi ưu tiên lại nữa. Vòng lặp for bên trong
xét trong tổng thể cả chương trình sẽ duyệt qua tất cả các cung �@8 �� của ñồ thị.
Vậy thuật toán Dijkstra cần thực hiện không quá � phép � �!l� và � phép ����� với � là số ñỉnh và � là số cung của ñồ thị.
Trong chương trình cài ñặt thuật toán Dijkstra dưới ñây tôi sử dụng Binary Heap ñể biểu diễn hàng ñợi ưu tiên, khi ñó thời gian thực hiện giải thuật sẽ là $�� %' � � � %' ��. Ngoài cấu trúc Binary Heap, người ta cũng ñã nghiên cứu nhiều cấu trúc dữ liệu hiệu quả hơn ñể biểu diễn hàng ñợi ưu tiên, chẳng hạn
Fibonacci Heap[17], Relaxed Heap[11], 2-3 Heap[39], v.v… Những cấu trúc
dữ liệu này cho phép cài ñặt thuật toán Dijkstra chạy trong thời gian $�� %' � ���. Tuy nhiên việc cài ñặt các cấu trúc dữ liệu này khá phức tạp, các bạn có thể tham khảo trong những tài liệu khác.
� DIJKSTRAHEAP.PAS � Thuật toán Dijkstra và cấu trúc Heap
{$MODE OBJFPC}
program DijkstraShortestPathUsingHeap;
const
maxN = 10000;
maxM = 100000;
maxW = 100000;
maxD = maxN * maxW;
type
TAdjNode = record //Cấu trúc nút của danh sách kề
v: Integer; //Đỉnh kề
w: Integer; //Trọng số cung tương ứng
link: Integer; //Chỉ số nút kế tiếp trong cùng danh sách kề

129
end;
THeap = record //Cấu trúc Heap
Items: array[1..maxN] of Integer; //Các phần tử chứa trong
nItems: Integer; //Số phần tử chứa trong
Pos: array[1..maxN] of Integer;
//Pos[v] = vị trí của ñỉnh v trong Heap end;
var
adj: array[1..maxM] of TAdjNode; //Mảng chứa tất cả các nút
head: array[1..maxN] of Integer;
//head[u]: Chỉ số nút đứng đầu danh sách kề của u d: array[1..maxN] of Integer;
trace: array[1..maxN] of Integer;
n, m, s, t: Integer;
Heap: THeap;
procedure Enter; //Nhập dữ liệu
var i, u: Integer;
begin
ReadLn(n, m, s, t);
FillChar(head[1], n * SizeOf(head[1]), 0);
//Khởi tạo các danh sách kề rỗng for i := 1 to m do
begin
ReadLn(u, adj[i].v, adj[i].w);
//Đọc một cung (u, v) trọng số w, đưa v và w vào trong nút adj[i]
adj[i].link := head[u]; //Chèn nút adj[i] vào ñầu danh sách kề của u head[u] := i; //Cập nhật chỉ số nút đứng đầu danh sách kề của u
end;
end;
procedure Init;
var v: Integer;
begin
for v := 1 to n do d[v] := MaxD;
d[s] := 0;
with Heap do //Khởi tạo Heap chỉ chứa mỗi phần tử s
begin
FillChar(Pos[1], n * SizeOf(Pos[1]), 0);
Items[1] := s;
Pos[s] := 1;

130
nItems := 1;
end;
end;
function Extract: Integer; //Lấy ñỉnh u có nhãn d[u] nhỏ nhất ra khỏi Heap var p, c, v: Integer;
begin
with Heap do
begin
Result := Items[1]; //Trả về đỉnh ở gốc Heap
v := Items[nItems]; //Vun lại Heap bằng phép Down-Heap
Dec(nItems);
p := 1; //Bắt đầu từ gốc
repeat
//Tìm c là nút con chứa ñỉnh mang nhãn khoảng cách nhỏ hơn trong hai nút con c := p * 2;
if (c < nItems)
and (d[Items[c + 1]] < d[Items[c]]) then
Inc(c);
if (c > nItems)
or (d[v] <= d[Items[c]]) then Break;
Items[p] := Items[c]; //Chuyển đỉnh từ c lên p
Pos[Items[p]] := p; //Cập nhật vị trí
p := c; //Đi xuống nút con
until False;
Items[p] := v; //Đặt đỉnh v vào nút p của Heap
Pos[v] := p; //Cập nhật vị trí
end;
end;
procedure Update(v: Integer); //d[v] vừa bị cực tiểu hóa, tổ chức lại Heap
var p, c: Integer;
begin
with Heap do
begin
c := Pos[v]; //c là vị trí của đỉnh v trong Heap
if c = 0 then //Nếu v chưa có trong Heap
begin
Inc(nItems);
c := nItems; //Cho v vào Heap ở vị trí một nút lá

131
end;
repeat //Thực hiện Up-Heap
p := c div 2; //Xét nút cha của c
if (p = 0) or (d[Items[p]] <= d[v]) then Break;
//Dừng nếu đã xét lên gốc hoặc gặp vị trí đúng
Items[c] := Items[p]; //Kéo đỉnh từ nút cha xuống nút con
Pos[Items[c]] := c; //Cập nhật vị trí
c := p; //Đi lên nút cha
until False;
Items[c] := v; //Đặt v vào nút c
Pos[v] := c; //Cập nhật vị trí
end;
end;
function Relax(u, v: Integer; w: Integer): Boolean; //Phép co theo cạnh (u, v) trọng số w begin
Result := d[v] > d[u] + w;
if Result then
begin
d[v] := d[u] + w;
trace[v] := u;
end;
end;
procedure Dijkstra; //Thuật toán Dijkstra
var u, i: Integer;
begin
repeat
u := Extract; //Lấy ra đỉnh u có d[u] nhỏ nhất
if (u = 0) or (u = t) then Break;
i := head[u]; //Duyệt từ đầu danh sách kề của u
while i <> 0 do
begin
if Relax(u, adj[i].v, adj[i].w) then
//Nếu thực hiện được phép co
Update(adj[i].v); //Tổ chức lại Heap
i := adj[i].link; //Chuyển sang nút kế tiếp trong danh sách kề
end;
until Heap.nItems = 0;
end;

132
procedure PrintResult; //In kết quả
begin
if d[t] = maxD then
WriteLn('There is no path from ', s, ' to ', t)
else
begin
WriteLn('Distance from ', s, ' to ', t, ':
', d[t]);
while t <> s do
begin
Write(t, '<-');
t := trace[t];
end;
WriteLn(s);
end;
end;
begin
Enter;
Init;
Dijkstra;
PrintResult;
end.
gggg) ) ) ) \F\F\F\FUUUUng "i ngng "i ngng "i ngng "i ng]]]]n nhn nhn nhn nh6666t trên "t trên "t trên "t trên "^̂̂̂ thththth>>>> không có chu trìnhkhông có chu trìnhkhông có chu trìnhkhông có chu trình
� Thuật toán
Xét trường hợp ñồ thị có hướng, không có chu trình (Directed Acyclic Graph - DAG), có một thuật toán hiệu quả ñể tìm ñường ñi ngắn nhất dựa trên kỹ thuật sắp xếp Tô pô (Topological Sorting), cơ sở của thuật toán dựa vào ñịnh lý: Nếu A �a8 �� là một DAG thì các ñỉnh của nó có thể ñánh số sao cho mỗi cung của A chỉ nối từ ñỉnh có chỉ số nhỏ hơn ñến ñỉnh có chỉ số lớn hơn.

133
Hình 2.2. Phép ñánh chỉ số lại theo thứ tự tô pô
Phép ñánh số theo thứ tự tô pô ñã ñược trình bày trong thuật toán Kosaraju-Sharir (Error! Reference source not found., Mục Error! Reference source not found.): Dùng thuật toán tìm kiếm theo chiều sâu trên ñồ thị ñảo chiều và ñánh số các ñỉnh theo thứ tự duyệt xong (Finish).
procedure TopoSort;
procedure DFSVisit(v5V); //Thuật toán tìm kiếm theo chiều sâu từ đỉnh v trên đồ thị đảo chiều
begin
avail[v] := False; //avail[v] = False ⇔⇔⇔⇔ v ñã thăm
for ∀u 5 V:(u, v)5 E do //Duyệt mọi ñỉnh v chưa thăm nối ñến u if avail[u] then
DFSVisit(u); //Gọi ñệ quy ñể tìm kiếm theo chiều sâu từ ñỉnh u
«ðánh số v»; //ðánh số v theo thứ tự duyệt xong
end;
begin
for ∀v 5 V do avail[v] := True; //ðánh dấu mọi ñỉnh ñều chưa thăm
for ∀v 5 V do if avail[v] then DFSVisit(v);
end.
Một cách khác ñể ñánh số theo thứ tự tô pô là sử dụng thuật toán tìm kiếm theo
chiều rộng: Với mỗi ñỉnh � ta tính và lưu trữ p¹'3��� là bán bậc vào của nó. Sử dụng một hàng ñợi chứa các ñỉnh có bán bậc vào bằng 0 (ñỉnh không có cung ñi
vào). Sau ñó cứ lấy một ñỉnh @ khỏi hàng ñợi, ñánh số cho ñỉnh @ ñó và xóa
ñỉnh @ khỏi ñồ thị. Việc xóa ñỉnh @ khỏi ñồ thị tương ñương với việc giảm tất cả
các p¹'3��� của những ñỉnh � nối từ @ ñi 1, nếu p¹'3��� bị giảm về 0 thì ñẩy � vào hàng ñợi ñể chờ…Quá trình ñánh số sẽ kết thúc khi hàng ñợi rỗng (tất cả
6 7
3
4 2
5
1
2 6
3
1 5
4
7

134
các ñỉnh ñều ñã ñược ñánh số thứ tự mới). Phương pháp này tuy cài ñặt có dài dòng hơn và chậm hơn một chút nhưng không cần sử dụng ñệ quy.
Nếu các ñỉnh ñược ñánh số sao cho mỗi cung phải nối từ một ñỉnh tới một ñỉnh khác mang chỉ số lớn hơn thì thuật toán tìm ñường ñi ngắn nhất có thể thực hiện khá ñơn giản:
Init;
for v := s + 1 to t do
for Lu:(u, v) 5 E do Relax(u, v); //Co theo các cung nối tới v
Có thể thấy rằng sau mỗi bước lặp với ñỉnh �, nhãn ���� không thể co thêm
ñược nữa (��@� «�"8 @�).
� Cài ñặt
Vì mục tiêu của chúng ta chỉ cần tìm ñường ñi từ " tới �, vì thế chúng ta chỉ cần
ñánh số thứ tự tô pô cho những ñỉnh ñến ñược � bằng lời gọi P?ka�"�����,
những ñỉnh ñến ñược từ � (có thứ tự tô pô lớn hơn �) sẽ bị bỏ qua.
Cách cài ñặt thông thường nhất ñể tìm ñường ñi ngắn nhất trên ñồ thị không có chu trình là tách biệt hai pha: Sắp xếp tô pô và tối ưu nhãn. Pha sắp xếp tô pô trước hết thực hiện tìm kiếm theo chiều sâu trên ñồ thị ñảo chiều bằng lời gọi P?ka�"�����. Mỗi khi một ñỉnh ñược duyệt xong (ñánh số thứ tự tô pô), nó sẽ ñược ñẩy vào một hàng ñợi. Pha tối ưu nhãn lần lượt lấy các ñỉnh ra khỏi hàng ñợi (theo ñúng thứ tự tô pô) và thực hiện phép co theo tất cả các cung nối tới ñỉnh vừa lấy ra. Cách cài ñặt này có ưu ñiểm là khá sáng sủa, trong trường hợp mà ta bỏ qua ñược khâu sắp xếp tô pô hoặc có thể xác ñịnh thứ tự tô pô bằng một cách ñơn giản hơn, chương trình trở nên rất gọn.
Tuy nhiên nếu ta phải giải quyết bài toán tổng quát bao gồm cả hai pha sắp xếp tô pô và tối ưu nhãn thì có thể khéo léo lồng pha tối ưu nhãn vào pha sắp xếp tô
pô: Trước khi ñỉnh � ñược ñánh số (duyệt xong), ta thực hiện tất cả các phép co
theo các cung �@8 �� với mọi ñỉnh @ nối ñến �.
� SHORTESTPATHDAG.PAS � ðường ñi ngắn nhất trên DAG
{$MODE OBJFPC}
program DAGShortestPath;
const
maxN = 10000;

135
maxM = 100000;
maxW = 100000;
maxD = maxN * maxW;
type
TAdjNode = record //Cấu trúc nút của danh sách kề dạng reverse star
u: Integer; //Đỉnh kề
w: Integer; //Trọng số cung tương ứng
link: Integer; //Chỉ số nút kế tiếp trong cùng danh sách kề
end;
var
adj: array[1..maxM] of TAdjNode; //Mảng chứa tất cả các nút
head: array[1..maxN] of Integer;
//head[u]: Chỉ số nút đứng đầu danh sách kề của u d: array[1..maxN] of Integer; //Nhãn khoảng cách
trace: array[1..maxN] of Integer; //Vết
avail: array[1..maxN] of Boolean;
n, m, s, t: Integer;
procedure Enter; //Nhập dữ liệu
var i, v: Integer;
begin
ReadLn(n, m, s, t);
FillChar(head[1], n * SizeOf(head[1]), 0);
for i := 1 to m do
begin
ReadLn(adj[i].u, v, adj[i].w);
//Đọc một cung (u, v) trọng số w, đưa u và w vào trong nút adj[i]
adj[i].link := head[v]; //Chèn nút adj[i] vào ñầu danh sách kề của v head[v] := i; //Cập nhật chỉ số nút đứng đầu danh sách kề của v
end;
end;
procedure Init;
var v: Integer;
begin
FillChar(avail[1], n * SizeOf(avail[1]), True);
for v := 1 to n do d[v] := maxD;
d[s] := 0;
end;
procedure Relax(u, v: Integer; w: Integer);

136
begin
if (d[u] < maxD) and (d[v] > d[u] + w) then
begin
d[v] := d[u] + w;
trace[v] := u;
end;
end;
procedure DFSVisit(v: Integer); //DFS trên đồ thị đảo chiều
var i: Integer;
begin
avail[v] := False;
i := head[v];
while i <> 0 do //Duyệt danh sách các đỉnh nối đến v
begin
if avail[adj[i].u] then
//adj[i].u là một đỉnh nối đến v, nếu adj[i].u chưa thăm thì đi thăm,
DFSVisit(adj[i].u); //sau lời gọi này d[adj[i].u] sẽ bằng δ(s, adj[i].u) Relax(adj[i].u, v, adj[i].w); //Thực hiện luôn phép co (adj[i].u, v) i := adj[i].link; //Nhảy sang nút kế tiếp trong danh sách kề
end;
end; //Khi thủ tục kết thúc, d[v] sẽ bằng δ(s,v) procedure PrintResult; //In kết quả
begin
if d[t] = maxD then
WriteLn('There is no path from ', s, ' to ', t)
else
begin
WriteLn('Distance from ', s, ' to ', t, ':
', d[t]);
while t <> s do
begin
Write(t, '<-');
t := trace[t];
end;
WriteLn(s);
end;
end;

137
begin
Enter;
Init;
DFSVisit(t);
PrintResult;
end.
Thời gian thực hiện giải có thể ñánh giá qua thời gian thực hiện giải thuật DFS,
tức là bằng $����� khi ñồ thị ñược biểu diễn bởi danh sách kề. 1.3. ðường ñi ngắn nhất giữa mọi cặp ñỉnh
Trong một số ứng dụng thực tế, ñôi khi người ta ta có nhu cầu tính sẵn ñường ñi ngắn nhất giữa mọi cặp ñỉnh của ñồ thị (all-pairs shortest paths) ñể trả lời nhanh những truy vấn tìm ñường ñi ngắn nhất mà không cần thực hiện lại thuật toán. Rõ ràng ta có thể áp dụng thuật toán tìm ñường ñi ngắn nhất xuất phát từ
một ñỉnh với � lượt chọn ñỉnh xuất phát, nhưng những thuật toán trong mục này có thể thực hiện nhanh hơn và ñơn giản hơn nhiều.
a) a) a) a) ThuThuThuThut toán Floydt toán Floydt toán Floydt toán Floyd
Cho ñơn ñồ thị có hướng, có trọng số A �a8 �� với � ñỉnh và � cung. Thuật
toán Floyd tính tất cả các phần tử của ma trận khoảng cách P 6�¨©9.Y., trong
ñó ��@8 �� là khoảng cách từ @ tới �. Cách làm tương tự như thuật toán Warshall
ñể tìm bao ñóng ñồ thị: từ ma trận trọng số § 6��@8 ��9.Y. , trong ñó ���8 �� 78 L� 5 a, thuật toán Floyd tính lại các ��@8 �� thành ñộ dài ñường ñi
ngắn nhất từ @ tới � theo cách sau: Với L� 5 a ñược xét theo thứ tự từ 1 tới �,
thuật toán xét mọi cặp ñỉnh @8 � và cực tiểu hóa ��@8 �� theo công thức:
��@8 ����� z �µo6��@8 ��cũ8 ��@8 �� � ���8 ��9 (1.4)
Tức là nếu như ñường ñi từ @ tới � ñang có lại dài hơn ñường ñi từ @ tới � cộng
với ñường ñi từ � tới � thì ta huỷ bỏ ñường ñi từ @ tới � hiện thời và coi ñường
ñi từ @ tới � sẽ là nối của hai ñường ñi từ @ tới � rồi từ � tới �:
for k := 1 to n do
for u := 1 to n do
for v := 1 to n do
w[u, v] := min(w[u, v], w[u, k] + w[k, v]);

138
� Tính ñúng của thuật toán
Gọi «I�@8 �� là ñộ dài ñường ñi ngắn nhất từ @ tới � mà chỉ ñi qua các ñỉnh
trung gian thuộc tập 6�8;8 8 �9 . Rõ ràng khi � 7 thì «4�@8 �� ��@8 �� (ñường ñi ngắn nhất là ñường ñi trực tiếp không qua ñỉnh trung gian nào). Nếu ñường ñi ngắn nhất từ @ tới � mà chỉ qua các ñỉnh trung gian thuộc tập 6�8;8 8 �9 lại:
� Không ñi qua ñỉnh � , tức là chỉ qua các ñỉnh trung gian thuộc tập 6�8;8 8 � C �9 thì «I�@8 �� «I3(�@8 ��. � Có ñi qua ñỉnh �, thì ñường ñi ñó sẽ là nối của một ñường ñi ngắn nhất từ @
tới � và một ñường ñi ngắn nhất từ � tới �, hai ñường ñi này chỉ ñi qua các
ñỉnh trung gian thuộc tập 6�8;8 8 � C �9 , vậy «I�@8 �� «I3(�@8 �� �«I3(��8 ��E Vì ta muốn «I�@8 �� nhỏ nhất nên suy ra:
«I�@8 �� �µo6«I3(�@8 ��8 «I3(�@8 �� � «I3(��8 ��9 (1.5)
Cuối cùng ta quan tâm tới các «.�@8 ��: ðộ dài ñường ñi ngắn nhất từ @ tới � mà
chỉ ñi qua các ñỉnh trung gian thuộc tập 6�8;8 8 �9, tức là khoảng cách giữa @ và �: «�@8 ��. Ta sẽ chứng minh rằng sau mỗi bước lặp của vòng lặp “for k…”, thì:
��@8 �� N «I�@8 �� (1.6)
Phép chứng minh ñược thực hiện quy nạp theo �. Ký hiệu �I�@8 �� là giá trị ��@8 �� sau vòng lặp thứ � , khi � 7 thì như ñã chỉ ra ở trên, �4�@8 �� «4�@8 �� . Giả sử bất ñẳng thức ñúng với � C � , trước hết dễ thấy rằng các ��@8 �� sẽ ñược tối ưu hóa giảm dần theo từng bước. Từ công thức (1.5), ta có:
«I�@8 �� �µo ¼«I3(�@8 ��½¾¾¿¾¾ÀÁÂÃÄ*�¨8©� 8 «I3(�@8 ��½¾¾¿¾¾ÀÁÂÃÄ*�¨8I� � «I3(��8 ��½¾¾¿¾¾ÀÁÂÃÄ*�I8©� Å w �I�@8 ��
Mặt khác có thể thấy thuật toán Floyd tìm ñược �.�@8 �� là ñộ dài của một
ñường ñi từ @ tới �. Tức là �.�@8 �� w «.�@8 ��. Từ những kết quả trên suy ra

139
khi kết thúc thuật toán, �.�@8 �� «.�@8 �� «�@8 �� là ñộ dài ñường ñi ngắn
nhất từ @ tới �.
� Cài ñặt
Ta sẽ cài ñặt thuật toán Floyd trên ñồ thị có hướng gồm � ñỉnh, � cung với khuôn dạng Input/Output như sau:
Input
� Dòng 1 chứa số ñỉnh � N �7�, số cung � N �7� của ñồ thị, ñỉnh xuất phát ", ñỉnh cần ñến �.
� � dòng tiếp theo, mỗi dòng có dạng ba số @, �, �, cho biết �@8 �� là một
cung 5 � và trọng số của cung ñó là � (� là số nguyên có giá trị tuyệt ñối N �7�)
Output
ðường ñi ngắn nhất từ " tới � và ñộ dài ñường ñi ñó.
Sample Input Sample Output
6 7 1 4
1 2 1
1 6 10
2 3 2
3 4 20
3 6 3
5 4 5
6 5 4
Distance from 1 to 4: 15
1->2->3->6->5->4
Thuật toán Floyd chỉ cần thực hiện một lần trên ñồ thị và khi cần tìm ñường ñi ngắn nhất giữa một cặp ñỉnh khác, ta chỉ cần dò ñường dựa trên ma trận khoảng cách mà thôi. Trên thực tế người ta thường kết hợp với một cơ chế lưu vết ñể trả
lời nhanh nhiều truy vấn về ñường ñi ngắn nhất: Gọi �!l��@8 �� là ñỉnh ñứng
liền sau @ trên ñường ñi ngắn nhất từ @ tới � . Sau mỗi phép cực tiểu hóa l�@8 �� z l�@8 �� � l��8 �� (ñường ñi ngắn nhất từ @ tới � phải ñi vòng qua �), ta
cập nhật lại vết �!l��@8 �� z �!l��@8 ��.
1
2 3
4
5 6
1
2
3
4
5
20
10

140
� FLOYD.PAS � Thuật toán Floyd
{$MODE OBJFPC}
program FloydAllPairsShortestPaths;
const
maxN = 1000;
maxW = 1000;
maxD = maxN * maxW;
var
w: array[1..maxN, 1..maxN] of Integer; //Ma trận trọng số
trace: array[1..maxN, 1..maxN] of Integer; //Vết
n, m, s, t: Integer;
procedure Enter; //Nhập dữ liệu, các cạnh không có được gán trọng số +∞
var
i, u, v, weight: Integer;
begin
ReadLn(n, m, s, t);
for u := 1 to n do
for v := 1 to n do
if u = v then w[u, v] := 0
else w[u, v] := maxD;
for i := 1 to m do
begin
ReadLn(u, v, weight);
if w[u, v] > weight then
//Phòng trường hợp nhiều cung nối từ u tới v (ña ñồ thị) w[u, v] := weight; //Chỉ ghi nhận cung trọng số nhỏ nhất
end;
end;
procedure Floyd;
var k, u, v: Integer;
begin
for u := 1 to n do
for v := 1 to n do trace[u, v] := v;
//Khởi tạo đường đi ngắn nhất là đường đi trực tiếp for k := 1 to n do
for u := 1 to n do
if w[u, k] < maxD then
for v := 1 to n do

141
if (w[k, v] < maxD)
and (w[u, v] > w[u, k] + w[k, v]) then
begin //Cực tiểu hóa c[u, v]
w[u, v] := w[u, k] + w[k, v];
//Ghi nhận ñường ñi vòng qua k trace[u, v] := trace[u, k]; //Lưu vết
end;
end;
procedure PrintResult; //In kết quả
begin
if w[s, t] = maxD then
WriteLn('There is no path from ', s, ' to ', t)
else
begin
WriteLn('Distance from ', s, ' to ', t, ':
', w[s, t]);
while s <> t do
begin
Write(s, '->');
s := trace[s, t];
end;
WriteLn(t);
end;
end;
begin
Enter;
Floyd;
PrintResult;
end.
Dễ thấy rằng thời gian thực hiện giải thuật Floyd là ����� và chi phí bộ nhớ là ���+�.
b) b) b) b) ThuThuThuThut toán Johnsont toán Johnsont toán Johnsont toán Johnson
Trong trường hợp A �a8 �� là ñồ thị thưa gồm � ñỉnh và � cạnh: � Æ �+ , thuật toán Johnson tìm ñường ñi ngắn nhất giữa mọi cặp ñỉnh hoạt ñộng hiệu quả hơn thuật toán Floyd. Bản chất của thuật toán Johnson là thực hiện thuật

142
toán Bellman-Ford ñể gán lại trọng số và thực hiện tiếp thuật toán Dijkstra ñể tìm ñường ñi ngắn nhất.
Nếu ñồ thị không có cạnh trọng số âm, ta có thể thực hiện thuật toán Dijkstra �
lần với cách chọn lần lượt � ñỉnh làm ñỉnh xuất phát. Bằng cách kết hợp với một hàng ñợi ưu tiên ñược tổ chức dưới dạng Fibonacci Heap, thời gian thực hiện
một lần thuật toán Dijkstra là $�� %' � � ��, và như vậy ta có thể tìm ñường ñi
ngắn nhất giữa mọi cặp ñỉnh trong thời gian $��+ %' � � ���.
Nếu ñồ thị có cạnh trọng số âm nhưng không có chu trình âm, thuật toán Johnson thực hiện một kỹ thuật gọi là gán lại trọng số (re-weighting). Tức là
trọng số �M � G � sẽ ñược biến ñổi thành trọng số �ÇM � G � thỏa mãn hai ñiều kiện sau ñây:
� Với mọi cặp ñỉnh @8 � 5 a, ñường ñi B là ñường ñi ngắn nhất từ @ tới � ứng
với trọng số � nếu và chỉ nếu B cũng là ñường ñi ngắn nhất từ @ tới � ứng
với trọng số �Ç
� Với mọi cạnh � 5 �, trọng số �Ç��� là một số không âm
ðịnh lý 1-2
Cho ñồ thị A �a8 �� với trọng số �M � G �. Gọi �M a G � là một hàm gán cho
mỗi ñỉnh � một số thực ����. Xét trọng số �ÇM � G � ñịnh nghĩa bởi: �Ç�@8 �� ��@8 �� � ��@� C ����
Xét � ¬�48 �(8 8 �I là một ñường ñi từ �4 tới �I, khi ñó � là ñường ñi ngắn
nhất từ �4 tới �I với trọng số � nếu và chỉ nếu � là ñường ñi ngắn nhất từ �4 tới �I với trọng số �Ç . Hơn nữa A có chu trình âm tương ứng với trọng số � nếu và
chỉ nếu A có chu trình âm với trọng số �Ç .
Chứng minh
Ký hiệu ���� và �Ç��� lần lượt là ñộ dài ñường ñi � với trọng số � và �Ç . Ta có
�Ç��� È �Ç��23(8 �2�I2<(
Èg���23(8 �2� � ���23(� C ����hI2<(

143
ÉÈ ���23(8 �2�I2<( Ê � ���4� C ���I�
���� � ���4� C ���I�
Vậy qua phép biến ñổi trọng số, ñộ dài mọi ñường ñi từ �4 tới �I sẽ ñược cộng
thêm một lượng ���4� C ���I�. Hay nói cách khác, ñường ñi nào ngắn nhất với
trọng số � cũng là ñường ñi ngắn nhất với trọng số �Ç .
Nếu � là một chu trình, �4 �I, ta suy ra �Ç��� ����. ðộ dài của chu trình
ñược bảo toàn qua phép biến ñổi trọng số, tức là A có chu trình âm với trọng số �
nếu và chỉ nếu A có chu trình âm với trọng số �Ç .
Mục tiêu tiếp theo là chỉ ra một phép gán trọng số mới cho ñồ thị A ñể ñảm bảo
các trọng số không âm. Nếu A không có chu trình âm ta thêm vào ñồ thị một ñỉnh
giả " và các cung nối từ ñỉnh " tới tất cả các ñỉnh còn lại của ñồ thị, trọng số của
các cung này ñược ñặt bằng 0. Do ñỉnh " không có cung ñi vào, ñồ thị mới tạo
thành cũng không có chu trình âm. Thực hiện thuật toán Bellman-Ford trên ñồ thị
mới với ñỉnh xuất phát " ñể xác ñịnh các ���� «�"8 �� là ñộ dài ñường ñi ngắn
nhất từ " tới � tương ứng với trọng số l.
ðịnh lý 1-3
Trọng số �ÇM � G � xác ñịnh bởi �Ç�@8 �� ��@8 �� � ��@� C ���� là một hàm trọng số không âm.
Chứng minh
Khi thuật toán Bellman-Ford kết thúc, sẽ không tồn tại một cạnh �@8 �� nào mà ���� 1 ��@� � ��@8 ��
hay nói cách khác, với mọi cạnh �@8 �� của ñồ thị, ta có ��@8 �� � ��@� C ���� w 7
Các nhận xét kể trên, ñặc biệt là ðịnh lý 1-2 và ðịnh lý 1-3, cho ta mô hình cài ñặt thuật toán Johnson:
� Thêm vào ñồ thị một ñỉnh " và các cung trọng số 0 nối từ " tới tất cả các
ñỉnh khác, dùng thuật toán Bellman-Ford tính các ���� là ñộ dài ñường ñi
ngắn nhất từ " tới �. Thời gian thực hiện giải thuật $���� � Loại bỏ " và các cung mới thêm vào khỏi ñồ thị, gán lại trọng số
cạnh �Ç�@8 �� z ��@8 �� � ��@� C ���� với mọi cạnh �@8 �� 5 �. Thời gian
thực hiện giải thuật ����

144
� Lần lượt lấy các ñỉnh � 5 a làm ñỉnh xuất phát, thực hiện thuật toán
Dijkstra ñể tìm ñường ñi ngắn nhất từ � tới tất cả các ñỉnh khác. Thời gian
thực hiện giải thuật $��+ %' � � ��� nếu sử dụng Fibonacci Heap
Vậy thuật toán Johnson tìm ñường ñi ngắn nhất giữa mọi cặp ñỉnh có thể thực
hiện trong thời gian $��+ %' � � ���. Thuật toán dựa trên hai thuật toán ñã biết ñể tìm ñường ñi ngắn nhất xuất phát từ một ñỉnh, việc cài ñặt xin dành cho bạn ñọc.
1.4. Một số chú ý
Ở một số chương trình trong bài, ñôi khi ta sử dụng ma trận trọng số và ñem
trọng số �� gán cho những cạnh không có trong ñồ thị ban ñầu, hay khi khởi
tạo các nhãn khoảng cách, chúng ta thường gán ���� z �� và cực tiểu hóa dần
các nhãn ñó. Trên máy tính thì không có khái niệm trừu tượng �� nên ta sẽ
phải chọn một số dương � P ñủ lớn ñể thay. Như thế nào là ñủ lớn?. Số ñó phải ñủ lớn hơn tất cả trọng số của các ñường ñi ñơn ñể cho dù ñường ñi thật có tồi tệ ñến ñâu vẫn tốt hơn ñường ñi trực tiếp theo cạnh tưởng tượng ra ñó.
Trong trường hợp ñồ thị có cạnh trọng số âm, cần cẩn thận với phép cộng trọng
số: Nếu một trong hai hạng tử là � P, ta coi như tổng bằng � P (F � � �) và không cần cộng nữa. Lý do thứ nhất là ñể hạn chế lỗi tràn số khi hằng số � P trong bài toán cụ thể quá lớn, lý do thứ hai là ñể không bị tính sai khi
cộng � P với một số âm ñược kết quả O � P , khi ñó rất có thể ���� O� P mặc dù không tồn tại ñường ñi từ " tới �. Những thuật toán tìm ñường ñi ngắn nhất bộc lộ rất rõ ưu, nhược ñiểm trong từng trường hợp cụ thể (Ví dụ như số ñỉnh của ñồ thị quá lớn làm cho không thể biểu diễn bằng ma trận trọng số thì thuật toán Floyd sẽ gặp khó khăn, hay thuật toán Ford-Bellman làm việc khá chậm). Vì vậy cần phải hiểu bản chất và thành thạo trong việc cài ñặt tất cả các thuật toán trên ñể có thể sử dụng chúng một cách uyển chuyển trong từng bài toán thực tế.

145
Bài tập
2.1. Cho ñồ thị có hướng A �a8 �� không có chu trình âm, hãy tìm thuật toán $��a����� ñể tính tất cả các «Ë�@� �µo©5¶6«�@8 ��9 2.2. Cho ñồ thị có hướng A �a8 �� gồm � ñỉnh và � cung, hãy tìm thuật toán $���� ñể xác ñịnh ñồ thị có chu trình âm hay không và chỉ ra một chu
trình âm nếu có.
Gợi ý: Thực hiện thuật toán Bellman-Ford (tối ña � C � lần quét danh sách cạnh và thực hiện phép co), sau ñó ta quét lại danh sách cạnh xem có thể thực hiện ñược phép co nào nữa hay không. Nếu còn có thể co theo cạnh �@8 �� nào ñó, ta kết luận ñồ thị có chu trình âm và thực hiện phép co này,
sau ñó lần ngược vết ñường ñi từ ñỉnh �, nếu quá trình lần vết ñi lặp lại
một ñỉnh nào ñó, ta có một chu trình bắt ñầu và kết thúc ở ñỉnh .
2.3. Hệ ràng buộc: Cho (8 +8 8 . là các biến số, cho � ràng buộc, mỗi ràng buộc có dạng: ® C 2 N �2®8 g�2® 5 �h
Vấn ñề ñặt ra là hãy tìm cách gán giá trị cho các biến (8 +8 8 . thỏa mãn tất cả các ràng buộc ñã cho.
Gợi ý: Có nhiều ví dụ về hệ ràng buộc trên thực tế, chẳng hạn một công
trình xây dựng có � công ñoạn. Vì lý do kỹ thuật, một công ñoạn ® không
ñược bắt ñầu muộn hơn �2® thời gian so với công ñoạn 2. Ràng buộc này
có thể viết dưới dạng ® C 2 N �2® . Một dạng ràng buộc khác là công
ñoạn ® phải bắt ñầu sau khi công ñoạn 2 bắt ñầu ñược ít nhất �2® thời
gian, ràng buộc này cũng có thể viết dưới dạng ® C 2 w �2® hay 2 C ® N C�2®.
Coi mỗi biến là một ñỉnh của ñồ thị, mỗi ràng buộc ® C 2 N �2® cho
tương ứng với một cạnh g 2 8 ®h có trọng số �2®. Khi ñó nếu ñồ thị có chu
trình âm thì không tồn tại giải pháp. Thật vậy, giả sử tồn tại chu trình âm,
không giảm tính tổng quát, giả sử chu trình âm ñó là F ¬ (8 +8 8 I8 (, ta có + C ( N �(+

146
� C + N �+� ( C I N �I( Tổng vế trái của các bất ñẳng thức trên bằng 0 và tổng vế phải chính là
trọng số của chu trình (âm), bất ñẳng thức 7 N ��l� O 7 không thể ñược thỏa mãn.
Nếu ñồ thị không có chu trình âm, ta thêm vào một ñỉnh " và các cung nối
trọng số 0 từ " tới mọi ñỉnh khác. Dùng thuật toán Bellman-Ford ñể tìm
ñường ñi ngắn nhất từ ", khi ñó các nhãn �� 2� «�"8 2� chính là một cách gán giá trị thỏa mãn tất cả các ràng buộc. Hơn nữa cách này còn làm khoảng giá trị gán cho các biến là hẹp nhất: �n�(·2·.6 29 C �µo(·®·.Ì ®Í G �µo
2.4. (Cải tiến của Yen cho thuật toán Bellman-Ford) Với ñồ thị có hướng A �a8 �� gồm � ñỉnh, ta ñánh số các ñỉnh từ 1 tới �, chia tập cạnh � làm
hai tập con: �( gồm các cung nối từ ñỉnh có chỉ số nhỏ tới ñỉnh có chỉ số
lớn và �+ gồm các cung nối từ ñỉnh có chỉ số lớn tới ñỉnh có chỉ số nhỏ.
ðặt A( �a8 �(� và A+ �a8 �+�, hai ñồ thị này là ñồ thị có hướng không có chu trình ñược biểu diễn bằng danh sách kề.
Thuật toán Bellman-Ford sau ñó ñược thực hiện như sau:
Init;
repeat
Stop := True;
for u := 1 to n - 1 do
for Lv: (u, v)5 E1 do if Relax(u, v) then Stop := False;
for u := n downto 2 do
for Lv: (u, v)5 E2 do if Relax(u, v) then Stop := False;
until Stop;
Bên trong vòng lặp repeat…until là hai pha tối ưu nhãn: pha thứ nhất xét các ñỉnh theo thứ tự tăng dần còn pha thứ hai xét các ñỉnh theo thứ tự giảm dần của chỉ số. Mỗi khi một ñỉnh ñược xét và thực hiện phép co theo tất cả

147
các cung ñi ra khỏi @, mỗi pha thực hiện tương tự như thuật toán tìm ñường ñi ngắn nhất trên ñồ thị không có chu trình.
Chỉ ra rằng vòng lặp repeat…until trong cải tiến của Yen lặp không quá Î�U;Ï lần. Cài ñặt thuật toán và so sánh với cách cài ñặt chuẩn của thuật toán Bellman-Ford.
2.5. Arbitrage là một cách sử dụng sự bất hợp lý trong hối ñoái tiền tệ ñể kiếm lời. Ví dụ nếu 1$ mua ñược 0.7£, 1£ mua ñược 190¥, 1¥ mua ñược 0.009$ thì từ 1$, ta có thể ñổi sang 0.7£, sau ñó sang 0.7x190=133¥, rồi ñổi lại sang 133x0.009=1.197$. Kiếm ñược 0.197$ lãi.
Giả sử rằng có � loại tiền tệ ñánh số từ 1 tới �. Bảng D Ì!2®Í.Y. cho biết
tỉ lệ hối ñoái: một ñơn vị tiền � ñổi ñược !2® ñơn vị tiền b. Hãy tìm thuật
toán ñể xác ñịnh xem có thể kiếm lời từ bảng tỉ giá hối ñoái này bằng phương pháp arbitrage hay không? Nếu có thể sử dụng arbitrage, hãy chỉ ra một cách kiếm lời.
2.6. (Thuật toán Karp tìm chu trình có trung bình trọng số nhỏ nhất) Cho ñồ thị
có hướng A �a8 �� gồm � ñỉnh, hàm trọng số �M � G �. Ta ñịnh nghĩa
trung bình trọng số của một chu trình F gồm các cạnh ¬�(8 �+8 8 �I là:
Ð�F� �� È ���2�I2<(
ðặt ÐË �µoÑ 6Ð�F�9 Khi ñó chu trình F có Ð�F� ÐË gọi là chu trình có trung bình trọng số
nhỏ nhất (minimum mean-weight cycle). Chu trình có trung bình trọng số nhỏ nhất có nhiều ý nghĩa trong các thuật toán tìm luồng với chi phí cực tiểu.
Không giảm tính tổng quát, giả sử mọi ñỉnh � 5 a ñều ñến ñược từ một
ñỉnh " 5 a (Ta có thể thêm một ñỉnh giả " và cung trọng số 0 nối từ " tới
mọi ñỉnh khác, " không nằm trên chu trình ñơn nào nên không ảnh hưởng
tới tính ñúng ñắn của thuật toán). ðặt «��� là ñộ dài ñường ñi ngắn nhất từ " tới �. ðặt «I��� là ñộ dài ñường ñi ngắn nhất trong số các ñường ñi từ "

148
tới � qua ñúng � cạnh (ta có thể thêm vào các cung trọng số ñủ lớn ñể với
mọi cặp ñỉnh @8 � luôn tồn tại cung �@8 �� và ��8 @�, việc tìm chu trình trung bình trọng số nhỏ nhất không bị ảnh hưởng bởi những cung thêm
vào và «I��� luôn là giá trị hữu hạn).
a) Chứng minh rằng nếu ÐË 7, ñồ thị A không có chu trình âm và: «��� �µo4·I·.3(6«I���9 8 L� 5 a
b) Chứng minh rằng nếu ÐË 7 thì
�n�4·I·.3(«.��� C «I���� C � w 7 8 L� 5 a
(Gợi ý: Sử dụng kết quả câu a)
c) Gọi F là một chu trình trọng số 0, @8 � là hai ñỉnh nằm trên F, giả sử ÐË 7 và là ñộ dài ñường ñi từ @ tới � dọc theo chu trình F . Chứng minh rằng «��� «�@� �
d) Chứng minh rằng nếu ÐË 7 thì trên mỗi chu trình trọng số 0 sẽ tồn tại
một ñỉnh � sao cho:
�n�4·I·.3(«.��� C «I���� C � 7
e) Chứng minh rằng nếu ÐË 7 thì
�µo©5¶ �n�4·I·.3(«.��� C «I���� C � 7
f) Chỉ ra rằng nếu chúng ta cộng thêm một hằng số Ò vào tất cả các trọng
số cạnh thì ÐË tăng lên Ò. Sử dụng tính chất này ñể chứng minh rằng
ÐË �µo©5¶ �n�4·I·.3(«.��� C «I���� C �
g) Tìm thuật toán $���a����� và lập chương trình ñể tính ÐË và chỉ ra một chu trình có trung bình trọng số nhỏ nhất.
2.7. Trên mặt phẳng cho � ñường tròn, ñường tròn thứ � ñược cho bởi bộ ba số
thực � 28 >28 !2�, � 28 >2� là toạ ñộ tâm và !2 là bán kính. Chi phí di chuyển trên mỗi ñường tròn bằng 0. Chi phí di chuyển giữa hai ñường tròn bằng

149
khoảng cách giữa chúng. Hãy tìm phương án di chuyển giữa hai ñường
tròn "8 � cho trước với chi phí ít nhất.
2.8. Thuật toán Dijkstra có thể sai nếu ñồ thị có cạnh trọng số âm, hãy chỉ ra một ví dụ.
2.9. Cho ñồ thị vô hướng A �a8 �� có � ñỉnh và � cạnh, các cạnh có trọng số
là số nguyên trong phạm vi từ 0 tới �. Hãy thay ñổi thuật toán Dijkstra ñể
ñược thuật toán $��� � �� tìm ñường ñi ngắn nhất xuất phát từ một ñỉnh " 5 a.
Gợi ý: ðể ý rằng nếu một nhãn ���� O �� thì nhãn này phải là số nguyên
nằm trong khoảng �7 �� C �� Y ��, ñồng thời nếu xét nhãn khoảng cách của các ñỉnh lấy ra khỏi hàng ñợi ưu tiên thì các nhãn khoảng cách này ñược sắp xếp theo thứ tự không giảm. Ta tổ chức hàng ñợi ưu tiên dưới
dạng bảng băm: ��7 �� C �� Y �� trong ñó �� � là chốt của một danh
sách móc nối chứa các ñỉnh � mà ���� . Khi ñó các phép chèn, cập
nhật trên hàng ñợi ưu tiên chỉ mất thời gian $���. Phép lấy ra một phần tử
trong hàng ñợi ưu tiên tính tổng thể mất thời gian $����.
2.10. Tương tự như Bài tập 2.9 nhưng hãy tìm một thuật toán $g�� � �� %&' �h
Gợi ý: ðể ý rằng tại mỗi bước của thuật toán Dijkstra, có tối ña � � ; giá
trị khác nhau của các nhãn ���� trong hàng ñợi ưu tiên. Mỗi giá trị sẽ
cho tương ứng với một danh sách móc các nút � mà ���� , các chốt của danh sách móc nối ñược lưu trữ trong một Binary Heap, khi ñó các phép ñẩy vào, lấy ra, co nhãn khoảng cách ñược thực hiện trong thời gian $�%&' ��.
2.11. (Thuật toán Gabow) Xét ñồ thị A �a8 �� có các trọng số cạnh là số tự
nhiên: �M � G ¡. Giả sử rằng từ ñỉnh xuất phát " có ñường ñi tới mọi ñỉnh
khác. Gọi � là trọng số lớn nhất của các cạnh trong �. Gọi c Î%'�� ���Ï, khi ñó trọng số mỗi cạnh có thể ñược biểu diễn bằng một dãy c bit.
Với mỗi cạnh � 5 � mang trọng số ����, ta ký hiệu �2��� là số tạo thành
bằng � bit ñầu tiên của ����, tức là: �2��� ���� pµÓ ;Ô328 �L� �8;8 8 c�E Ví dụ c \ và ���� �� 7�7���+�. Ta có:

150
�(��� 7�+� 7 �+��� 7��+� � ����� 7�7�+� ; ����� 7�7��+� \ ����� 7�7���+� ��
ðịnh nghĩa «2�"8 �� là ñộ dài ñường ñi ngắn nhất từ " tới � trên ñồ thị A
với hàm trọng số �2 . Rõ ràng �Ô��� ���� nên «Ô�"8 �� «�"8 �� với L� 5 a.
a) Giả sử rằng «�"8 �� N ��� với mọi ñỉnh � có ñường ñi từ ", tìm thuật
toán $����� ñể xác ñịnh tất cả các «�"8 ��. (Gợi ý: Sử dụng hàng ñợi ưu tiên như trong Error! Reference source not found.).
b) Chứng minh rằng các «(�"8 �� có thể tính ñược trong thời gian $�����.
(Gợi ý: Chú ý rằng các trọng số �(��� 5 678�9). c) Chỉ ra rằng với mọi � ;8V8 8 c : �2��� ;E �23(��� hoặc �2��� ;E �23(��� � �E Từ ñó chứng minh rằng: ;E «23(�"8 �� N «2�"8 �� O ;E «23(�"8 �� � �a� (Gợi ý: ðộ dài ñường ñi ngắn nhất từ " tới � sẽ nhân ñôi nếu ta nhân ñôi
các trọng số cạnh)
d) Với mọi cạnh � �@8 �� 5 �, ñịnh nghĩa: �Ç2��� �Ç2�@8 �� �2�@8 �� � ;E «23(�"8 @� C ;E «23(�"8 ��
Chứng minh rằng với mọi ñường ñi �M @ ° �, ta có: �Ç2��� �2��� � ;E «23(�"8 @� C ;E «23(�"8 ��
e) ðịnh nghĩa «Õ2�"8 �� là ñộ dài ñường ñi ngắn nhất từ " tới � trên ñồ thị A
với hàm trọng số �Ç2. Chứng minh rằng với � ;8V8 8 c và L� 5 a:
«Õ2�"8 �� «2�"8 �� C ;E «23(�"8 �� N ��� f) Tìm thuật toán tính các «2�"8 �� từ các «23(�"8 �� trong thời gian $�����.
Từ ñó chứng minh rằng có thể tìm ñường ñi ngắn nhất trên ñồ thị A trong
thời gian $����E c� $���� %' ��.

151
2.12. Cho một bảng các số tự nhiên kích thước � Y � . Từ một ô có thể di
chuyển sang một ô kề cạnh với nó. Hãy tìm một cách ñi từ ô � 8 >� ra một ô biên sao cho tổng các số ghi trên các ô ñi qua là nhỏ nhất.
2.13. Cho một dãy số nguyên � �(8 +8 8 .�. Hãy tìm một dãy con gồm nhiều nhất các phần tử của dãy ñã cho mà tổng của hai phần tử liên tiếp là số nguyên tố.
2.14. Một công trình lớn ñược chia làm � công ñoạn. Công ñoạn � phải thực
hiện mất thời gian �2 . Quan hệ giữa các công ñoạn ñược cho bởi bảng � Ì2®Í.Y. trong ñó 2® � nếu công ñoạn b chỉ ñược bắt ñầu khi mà
công ñoạn � ñã hoàn thành và 2® 7 trong trường hợp ngược lại. Mỗi
công ñoạn khi bắt ñầu cần thực hiện liên tục cho tới khi hoàn thành, hai công ñoạn ñộc lập nhau có thể tiến hành song song, hãy bố trí lịch thực hiện các công ñoạn sao cho thời gian hoàn thành cả công trình là sớm nhất, cho biết thời gian sớm nhất ñó.
Gợi ý: Dựng ñồ thị có hướng A �a8 ��, mỗi ñỉnh tương ứng với một
công ñoạn, ñỉnh @ có cung nối tới ñỉnh � nếu công ñoạn @ phải hoàn thành
trước khi công ñoạn � bắt ñầu. Thêm vào A một ñỉnh " và cung nối từ " tới
tất cả các ñỉnh còn lại. Gán trọng số mỗi cung �@8 �� của ñồ thị bằng �©.
Nếu ñồ thị có chu trình, không thể có cách xếp lịch, nếu ñồ thị không có
chu trình (DAG) tìm ñường ñi dài nhất xuất phát từ " tới tất cả các ñỉnh
của ñồ thị, khi ñó nhãn khoảng cách ���� chính là thời ñiểm hoàn thành
công ñoạn �, ta chỉ cần xếp lịch ñể công ñoạn � ñược bắt ñầu vào thời
ñiểm ���� C �© là xong. 2.15. Cho ñồ thị A �a8 ��, các cạnh ñược gán trọng số không âm. Tìm thuật
toán và viết chương trình tìm một chu trình có ñộ dài ngắn nhất trên A. 2. Cây khung nhỏ nhất Cho A �a8 �8 �� là ñồ thị vô hướng liên thông có trọng số. Với một cây khung � của A, ta gọi trọng số của cây �, ký hiệu ����, là tổng trọng số các cạnh trong �. Bài toán ñặt ra là trong số các cây khung của A, chỉ ra cây khung có trọng số nhỏ nhất, cây khung như vậy ñược gọi là cây khung nhỏ nhất (minimum

152
spanning tree) của ñồ thị. Sau ñây ta sẽ xét hai thuật toán thông dụng ñể giải bài toán cây khung nhỏ nhất của ñơn ñồ thị vô hướng có trọng số, cả hai thuật toán này ñều là thuật toán tham lam.
2.1. Phương pháp chung
Xét ñồ thị vô hướng liên thông có trọng số A �a8 �8 ��. Cả hai thuật toán ñể tìm cây khung ngắn nhất ñều dựa trên một cách làm chung: Nở dần cây khung.
Cách làm này ñược mô tả như sau: Thuật toán quản lý một tập các cạnh � Ö � và cố gắng duy trì tính chất sau (tính bất biến vòng lặp): × luôn nằm trong tập cạnh của một cây khung nhỏ nhất.
Tại mỗi bước lặp, thuật toán tìm một cạnh �@8 �� ñể thêm vào tập � sao cho tính
bất biến vòng lặp ñược duy trì, tức là � Ø �@8 �� phải nằm trong tập cạnh của
một cây khung nhỏ nhất. Ta nói những cạnh �@8 �� như vậy là an toàn (safe) ñối
với tập �.
procedure FindMST; //Tìm cây khung ngắn nhất
begin
A := �; while «A chưa phải cây khung» do
begin
«Tìm cạnh an toàn (u, v) ñối với A»;
A := A Ø {(u, v)}; //Bổ sung (u, v) vào A end;
end;
Vấn ñề còn lại là tìm một thuật toán hiệu quả ñể tìm cạnh an toàn ñối với tập �. Chúng ta cần một số khái niệm ñể giải thích tính ñúng ñắn của những thuật toán sau này.
Một lát cắt (cut) trên ñồ thị là một cách phân hoạch tập ñỉnh a thành hai tập rời
nhau �8 Ù: � Ø Ù a� � Ú Ù �. Ta nói một lát cắt a � Ø Ù tương thích với
tập � nếu không có cạnh nào của � nối giữa một ñỉnh thuộc � và một ñỉnh thuộc Ù. Trong những cạnh nối � với Ù, ta gọi những cạnh có trọng số nhỏ nhất là
những cạnh nhẹ (light edge) của lát cắt a � Ø Ù.

153
Hình 2.3. Lát cắt và cạnh nhẹ
ðịnh lý 2-1
Cho ñồ thị vô hướng liên thông có trọng số A �a8 �8 ��. Gọi � là một tập con
của tập cạnh của một cây khung nhỏ nhất và a � Ø Ù là một lát cắt tương
thích với �. Khi ñó mỗi cạnh nhẹ của lát cắt a � Ø Ù ñều là cạnh an toàn ñối
với �.
Chứng minh
Gọi �@8 �� là một cạnh nhẹ của lát cắt a � Ø Ù, gọi � là cây khung nhỏ nhất
chứa tất cả các cạnh của �. Nếu � chứa cạnh �@8 ��, ta có ñiều phải chứng minh.
Nếu � không chứa cạnh �@8 ��, ta thêm cạnh �@8 �� vào � sẽ ñược một chu trình,
trên chu trình này có ñỉnh thuộc � và cũng có ñỉnh thuộc Ù, vì vậy sẽ phải có ít
nhất hai cạnh trên chu trình nối � với Ù. Ngoài cạnh �@8 �� nối � với Ù, ta gọi �@Û8 �Û� là một cạnh khác nối � với Ù trên chu trình, theo giả thiết �@8 �� là cạnh
nhẹ nên ��@8 �� N ��@Û8 �Û�. Ngoài ra do lát cắt a � Ø Ù tương thích với � nên �@Û8 �Û� ª �.
Cắt bỏ cạnh �@Û8 �Û� khỏi cây �, cây sẽ bị tách rời làm hai thành phần liên thông,
sau ñó thêm cạnh �@8 �� vào cây nối lại hai thành phần liên thông ñó ñể ñược cây �Û. Ta có ���Û� ���� C ��@Û8 �Û� � ��@8 �� N ���� Do � là cây khung nhỏ nhất, �Û cũng phải là cây khung nhỏ nhất. Ngoài ra cây �Û chứa cạnh �@8 �� và tất cả các cạnh của �. Ta có ñiều phải chứng minh.
Hệ quả
Cho ñồ thị vô hướng liên thông có trọng số A �a8 �8 ��. Gọi � là một tập con
của tập cạnh của một cây khung nhỏ nhất. Gọi F là tập các ñỉnh của một thành
phần liên thông trên ñồ thị AÜ �a8 ��. Khi ñó nếu �@8 �� 5 � là cạnh trọng số
� Ù 3
5
1
1
1
22
Lát cắt

154
nhỏ nhất nối từ F tới một thành phần liên thông khác thì �@8 �� là cạnh an toàn
ñối với �.
Chứng minh
Xét lát cắt a F Ø �a C F�, lát cắt này tương thích với � và cạnh �@8 �� là cạnh
nhẹ của lát cắt này. Theo ðịnh lý 3-17, �@8 �� an toàn ñối với �.
Chúng ta sẽ trình bày hai thuật toán tìm cây khung nhỏ nhất trên ñơn ñồ thị vô hướng và cài ñặt chương trình với khuôn dạng Input/Output như sau:
Input
� Dòng 1 chứa số ñỉnh � N �777 và số cạnh � của ñồ thị
� � dòng tiếp theo, mỗi dòng chứa chỉ số hai ñỉnh ñầu mút và trọng số của một cạnh. Trọng số cạnh là số nguyên có giá trị tuyệt ñối không quá 1000.
Output
Cây khung nhỏ nhất của ñồ thị
Sample Input Sample Output
6 8
1 2 3
1 3 3
2 4 3
2 5 3
3 5 4
4 5 2
4 6 2
5 6 1
Minimum Spanning Tree:
(5, 6) = 1
(4, 5) = 2
(1, 2) = 3
(2, 5) = 3
(1, 3) = 3
Weight = 12
2.2. Thuật toán Kruskal
Thuật toán Kruskal [27] dựa trên mô hình xây dựng cây khung bằng thuật toán hợp nhất, chỉ có ñiều thuật toán không phải xét các cạnh với thứ tự tuỳ ý mà xét
các cạnh theo thứ tự ñã sắp xếp: ðể tìm cây khung ngắn nhất của ñồ thị A �a8 �8 ��, thuật toán khởi tạo cây � ban ñầu không có cạnh nào. Duyệt danh sách cạnh của ñồ thị từ cạnh có trọng số nhỏ ñến cạnh có trọng số lớn, mỗi khi xét tới
một cạnh và việc thêm cạnh ñó vào � không tạo thành chu trình ñơn trong � thì
kết nạp thêm cạnh ñó vào �… Cứ làm như vậy cho tới khi:
1
2
3
4
5
6
3
3
3
3
4
2
2
1

155
� Hoặc ñã kết nạp ñược �a� C � cạnh vào trong � thì ta ñược � là cây khung nhỏ nhất
� Hoặc khi duyệt hết danh sách cạnh mà vẫn chưa kết nạp ñủ �a� C � cạnh.
Trong trường hợp này ñồ thị A là không liên thông, việc tìm kiếm cây khung thất bại.
Như vậy cần làm rõ hai thao tác sau khi cài ñặt thuật toán Kruskal:
� Làm thế nào ñể xét ñược các cạnh từ cạnh có trọng số nhỏ tới cạnh có trọng số lớn.
� Làm thế nào kiểm tra xem việc thêm một cạnh có tạo thành chu trình ñơn trong T hay không.
a) a) a) a) DuyDuyDuyDuy;;;;t danh sách ct danh sách ct danh sách ct danh sách c9999nhnhnhnh
Vì các cạnh của ñồ thị phải ñược xét từ cạnh có trọng số nhỏ tới cạnh có trọng số lớn. Ta có thể thực hiện một thuật toán sắp xếp danh sách cạnh rồi sau ñó duyệt lại danh sách ñã sắp xếp. Tuy nhiên khi cài ñặt cụ thể, ta có thể khéo léo lồng thuật toán Kruskal vào QuickSort hoặc HeapSort ñể ñạt hiệu quả cao hơn. Chẳng hạn với QuickSort, ý tưởng là sau khi phân ñoạn danh sách cạnh bằng
một cạnh chốt B����, ta ñược ba phân ñoạn: ðoạn ñầu gồm các cạnh có trọng số N ��B����� , tiếp theo là cạnh B���� , ñoạn sau gồm các cạnh có trọng số w ��B�����. Ta gọi ñệ quy ñể sắp xếp và xử lý các cạnh thuộc ñoạn ñầu, tiếp
theo xử lý cạnh B����, cuối cùng lại gọi ñệ quy ñể sắp xếp và xử lý các cạnh thuộc ñoạn sau. Dễ thấy rằng thứ tự xử lý các cạnh như vậy ñúng theo thứ tự
tăng dần của trọng số. Ngoài ra khi thấy ñã có ñủ � C � cạnh ñược kết nạp vào cây khung, ta có thể ngưng ngay QuickSort mà không cần xử lý tiếp nữa.
b) b) b) b) KKKK****t nt nt nt n9999p cp cp cp c9999nh và hnh và hnh và hnh và h0000p câyp câyp câyp cây
Trong quá trình xây dựng cây khung, các cạnh trong � ở các bước sẽ tạo thành một rừng (ñồ thị không có chu trình ñơn), mỗi thành phần liên thông của rừng
này là một cây khung. Muốn thêm một cạnh �@8 �� vào � mà không tạo thành
chu trình ñơn thì �@8 �� phải nối hai cây khác nhau của rừng �. ðiều này làm chúng ta nghĩ ñến cấu trúc dữ liệu biểu diễn các tập rời nhau: Ban ñầu ta khởi
tạo � tập k(8 k+8 8 k., mỗi tập chứa ñúng một ñỉnh của ñồ thị. Khi xét tới cạnh

156
�@8 ��, nếu @ và � thuộc hai tập khác nhau k¨8 k© thì ta hợp nhất k¨8 k© lại thành một tập.
Vậy có hai thao tác cần phải cài ñặt hiệu quả trong thuật toán Kruskal: phép kiểm tra hai ñỉnh có thuộc hai tập khác nhau hay không và phép hợp nhất hai tập. Một trong những cấu trúc dữ liệu hiệu quả ñể cài ñặt những thao tác này là rừng các tập rời nhau (disjoint-set forest). Cấu trúc dữ liệu này ñược cài ñặt như sau:
Mỗi tập k�E � ñược biểu diễn bởi một cây, trong ñó mỗi ñỉnh trong tập tương ứng
với một nút trên cây. Cây ñược biểu diễn bởi mảng con trỏ tới nút cha: �0��� là
nút cha của nút �. Trong trường hợp � là nút gốc của cây, ta ñặt: �0��� z Chạng của cây Hạng (rank) của một cây là một số nguyên không nhỏ hơn ñộ cao của cây. Ban
ñầu mỗi tập k�E � chỉ gồm một ñỉnh, nên họ các tập k(8 k+8 8 k. ñược khởi tạo
với các nhãn �0��� z 7, L� 5 a tương ứng với một rừng gồm � cây ñộ cao 0.
ðể xác ñịnh hai ñỉnh @8 � có thuộc 2 tập khác nhau hay không, ta chỉ cần xác
ñịnh xem gốc của cây chứa @ và gốc của cây chứa � có khác nhau hay không.
Việc xác ñịnh gốc của cây chứa @ ñược thực hiện bởi hàm ?���k���@�: ði từ @
lên nút cha, ñến khi gặp nút gốc (nút ! có �0�!� N 7) thì dừng lại. ði kèm với
hàm ?���k���@� là phép nén ñường (path compression): Dọc trên ñường ñi từ @
tới nút gốc !, ñi qua ñỉnh nào ta cho luôn ñỉnh ñó làm con của !:
function FindSet(u: Integer): Integer;
//Xác ñịnh gốc cây chứa ñỉnh u begin
if lab[u] <= 0 then Result := u
//u là gốc của một tập S[.] nào ñó, trả về chính u else //u không phải gốc
begin
Result := FindSet(lab[u]); //Gọi ñệ quy tìm gốc
lab[u] := Result; //Nén ñường, cho u làm con của nút gốc luôn
end;
end;

157
Việc hợp nhất hai tập tức là xây dựng cây mới chứa tất cả các phần tử trong hai
cây ban ñầu. Giả sử ! và " là gốc của hai cây tương ứng với hai tập cần hợp nhất. Khi ñó:
� Nếu cây gốc ! có hạng cao hơn cây gốc ", ta cho " làm con của !, hạng của
cây gốc ! không thay ñổi, tương tự cho trường hợp cây gốc ! thấp hơn cây
gốc ".
� Nếu hai cây ban ñầu có cùng hạng, ta cho cây gốc ! làm con của gốc " khi
ñó cây gốc " có thể sẽ bị tăng ñộ cao, do vậy ñể hợp lý hóa ta tăng hạng của " lên 1, tương ñương với việc giảm �0�"� ñi 1. procedure Union(r, s: Integer); //Hợp nhất hai tập r và s
begin
if lab[r] < lab[s] then //hạng của r lớn hơn
lab[s] := r //cho s làm con của r
else
begin
if lab[r] = lab[s] then Dec(lab[s]);
//Nếu hai tập bằng hạng, tăng hạng của s lab[r] := s; //Cho r làm con của s
end;
end;
Hình 2.4 mô tả hai cây biểu diễn hai tập rời nhau, sau khi xét tới một cạnh �@8 �� nối giữa hai tập, hai cây ñược hợp nhất lại bằng cách cho một cây làm cây con của gốc cây kia.
Hình 2.4. Hai tập rời nhau ñược hợp nhất lại khi xét tới một cạnh nối một ñỉnh của tập này với một
ñỉnh của tập kia
� KRUSKAL.PAS � Thuật toán Kruskal
{$MODE OBJFPC}
program MinimumSpanningTree;
! "
@
�
!
"
@ �

158
const
maxN = 1000;
maxM = maxN * (maxN - 1) div 2;
type
TEdge = record //Cấu trúc cạnh
x, y: Integer; //Hai đỉnh đầu mút
w: Integer; //Trọng số
Selected: Boolean; //Đánh dấu chọn/không chọn vào cây khung
end;
var
lab: array[1..maxN] of Integer; //Nhãn của disjoint set forest
e: array[1..maxM] of TEdge; //Danh sách cạnh
n, m, k: Integer;
procedure Enter; //Nhập dữ liệu
var i: Integer;
begin
ReadLn(n, m);
for i := 1 to m do
with e[i] do
begin
ReadLn(x, y, w);
Selected := False; //Chưa chọn cạnh nào
end;
for i := 1 to n do lab[i] := 0;
//Khởi tạo n tập rời nhau hạng của mỗi tập bằng 0 k := 0; //Biến đếm số cạnh được kết nạp vào cây khung
end;
function FindSet(u: Integer): Integer; //Xác định tập chứa đỉnh u
begin
if lab[u] <= 0 then Result := u //u là gốc của một tập S[.] nào đó
else //u không phải gốc
begin
Result := FindSet(lab[u]); //Gọi đệ quy tìm gốc
lab[u] := Result; //Nén đường
end;
end;
procedure Union(r, s: Integer); //Hợp nhất hai tập r và s
begin

159
if lab[r] < lab[s] then //hạng của r lớn hơn
lab[s] := r //cho s làm con của r
else
begin
if lab[r] = lab[s] then Dec(lab[s]);
//Nếu hai tập bằng hạng, tăng hạng của s
lab[r] := s; //Cho r làm con của s
end;
end;
procedure ProcessEdge(var e: TEdge); //Xử lý một cạnh e
var r, s: Integer;
begin
with e do
begin
r := FindSet(x);
s := FindSet(y); //Xác định 2 tập tương ứng với 2 đầu mút
if r <> s then //Hai đầu mút thuộc hai tập khác nhau
begin
Selected := True; //Cạnh e sẽ ñược chọn vào cây khung nhỏ nhất Inc(k); //Tăng biến đếm số cạnh được kết nạp
Union(r, s); //Hợp nhất hai tập thành một
end;
end;
end;
procedure QuickSort(L, H: Integer); //Xử lý danh sách cạnh e[L...H]
var
i, j: Integer;
pivot: TEdge;
begin
//Nếu cây đã có đủ k cạnh hoặc danh sách cạnh rỗng thì thoát luôn
if (L > H) or (k = n - 1) then Exit;
//Chú ý L > H, không phải L ≥ H như trong QuickSort
i := L + Random(H - L + 1);
pivot := e[i];
e[i] := e[L];
i := L;
j := H;
repeat

160
while (e[j].w > pivot.w) and (i < j) do Dec(j);
if i < j then
begin
e[i] := e[j];
Inc(i);
end
else Break;
while (e[i].w < pivot.w) and (i < j) do Inc(i);
if i < j then
begin
e[j] := e[i];
Dec(j);
end
else Break;
until i = j;
QuickSort(L, i - 1); //Các cạnh e[L...i – 1] có trọng số ≤ Pivot.w, gọi ñệ quy xử lý trước e[i] := Pivot;
if k < n - 1 then ProcessEdge(e[i]); //Xử lý tiếp cạnh e[i] = Pivot QuickSort(i + 1, H); //Các cạnh e[i + 1...H] có trọng số ≥ Pivot.w, gọi ñệ quy xử lý sau end;
procedure PrintResult;
var
i, Weight: Integer;
begin
if k < n - 1 then //Không kết nạp đủ n – 1 cạnh, đồ thị không liên thông
WriteLn('Graph is not connected!')
else //In ra cây khung nhỏ nhất
begin
WriteLn('Minimum Spanning Tree:');
Weight := 0;
for i := 1 to m do
with e[i] do
if Selected then //In ra cách cạnh được đánh dấu chọn
begin
WriteLn('(', x, ', ', y, ') = ', w);
Inc(Weight, w);

161
end;
WriteLn('Weight = ', Weight);
end;
end;
begin
Enter;
QuickSort(1, m); //Lồng thuật toán Kruskal vào QuickSort
PrintResult;
end.
Tính ñúng ñắn của thuật toán Kruskal ñược suy ra từ ðịnh lý 3-17: ðể ý rằng các cạnh ñược kết nạp vào cây khung sau mỗi bước sẽ tạo thành một rừng (ñồ
thị không có chu trình ñơn). Mỗi khi cạnh �@8 �� ñược xét ñến, nó sẽ chỉ ñược
kết nạp vào cây khung nếu như @ và � thuộc hai cây (hai thành phần liên thông) �̈ 8 �© khác nhau. Ký hiệu � là tập cạnh của �̈ , khi ñó lát cắt a �̈ Ø �a C �̈ �
là tương thích với tập �, �@8 �� là cạnh nhẹ của lát cắt nên �@8 �� cũng phải là một cạnh trên một cây khung nhỏ nhất.
c) c) c) c) ThThThThUUUUi gian thi gian thi gian thi gian thLLLLc hic hic hic hi;;;;n gin gin gin gi����i thui thui thui thutttt
Với hai số tự nhiên �8 �, hàm Ackermann ���8 �� ñược ñịnh nghĩa như sau:
���8 �� �� � �8 nếu � 7��� C �8��8 nếu � 1 7 và � 7�g� C �8 ���8 � C ��h8 nếu � 1 7 và � 1 7� Dưới ñây là bảng một số giá trị hàm Ackermann:

162
�: �:
0 1 2 3 4
0 1 2 3 4 5
1 2 3 4 5 6
2 3 5 7 9 11
3 5 13 29 61 125
4 13 65533 ;����� C V ;+ÝÞÞ�Ý C V ;+,ÝÞÞ�Ý C V
Hàm ���8 �� là một hàm tăng rất nhanh theo ñối số �. Có thể chứng minh ñược ��78 �� � � � ���8 �� � � ; ��;8 �� ;� � V ��V8 �� ;.K� C V ��X8 �� ;+ ,ß.K� lũy thừa
C V
Chẳng hạn ��X8;� là một số có 19729 chữ số, ��X8X� là một số mà số chữ số của nó lớn hơn cả số nguyên tử trong phần vũ trụ mà con người biết ñến.
Khi � 1 7, xét hàm ���8 ��, gọi là nghịch ñảo của hàm Ackerman, ñịnh nghĩa như sau:
���8 �� �µo à� w �M � f�8 á�� âi w %' �ã
Người ta ñã chứng minh ñược rằng với cấu trúc dữ liệu rừng các tập rời nhau,
việc thực hiện � thao tác ?���k�� và ����� mất thời gian $g����8 ��h. Ở ñây ���8 �� là một hằng số rất nhỏ (trên tất cả các dữ liệu thực thế, không bao giờ ���8 �� vượt quá 4). ðiều ñó chỉ ra rằng ngoại trừ việc sắp xếp danh sách cạnh,
thuật toán Kruskal ở trên có thời gian thực hiện $g��������8 �a��h.
Tuy nhiên nếu phải thực hiện sắp xếp danh sách cạnh, chúng ta cần cộng thêm
thời gian thực hiện giải thuật sắp xếp $���� %'���� nữa.

163
2.3. Thuật toán Prim
a) a) a) a) TF tFTF tFTF tFTF tFBBBBng cng cng cng c<<<<a thua thua thua thut toánt toánt toánt toán
Trong trường hợp ñồ thị dày (có nhiều cạnh), có một thuật toán hiệu quả hơn ñể
tìm cây khung ngắn nhất là thuật toán Prim [32]. Với một cây khung � và một
ñỉnh � ª �, ta gọi khoảng cách từ � tới �, ký hiệu ����, là trọng số nhỏ nhất của
một cạnh nối � với một ñỉnh nằm trong �: ���� �µo¨5ä 6��@8 ��9 Tư tưởng của thuật toán có thể trình bày như sau: Ban ñầu khởi tạo một cây �
chỉ gồm 1 ñỉnh bất kỳ của ñồ thị, sau ñó ta cứ tìm ñỉnh gần � nhất (có khoảng
cách tới � ngắn nhất) kết nạp vào � và kết nạp luôn cạnh tạo ra khoảng cách gần nhất ñó, cứ làm như vậy cho tới khi:
� Hoặc ñã kết nạp ñủ � ñỉnh vào �, ta có một cây khung ngắn nhất.
� Hoặc chưa kết nạp ñủ � ñỉnh nhưng không còn cạnh nào nối một ñỉnh trong � với một ñỉnh ngoài �. Ta kết luận ñồ thị không liên thông và không thể tồn tại cây khung.
b) b) b) b) KKKK`̀̀̀ thuthuthuthut cài "t cài "t cài "t cài "::::tttt
Khi cài ñặt thuật toán Prim, ta sử dụng các nhãn khoảng cách ���� ñể lưu
khoảng cách từ � tới � tại mỗi bước. Mỗi khi cây � bổ sung thêm một ñỉnh @, ta tính lại các nhãn khoảng cách theo công thức sau: ����mới z �µo 6����cũ8 ��@8 ��9 Tính ñúng ñắn của công thức có thể hình dung như sau: ���� là khoảng cách từ � tới cây �, theo ñịnh nghĩa là trọng số nhỏ nhất trong số các cạnh nối � với một
ñỉnh nằm trong �. Khi cây � “nở” ra thêm ñỉnh @ nữa mà ñỉnh @ này lại gần �
hơn tất cả các ñỉnh khác trong �, ta ghi nhận khoảng cách mới ���� là trọng số
cạnh �@8 ��, nếu không ta vẫn giữ khoảng cách cũ.

164
Hình 2.5. Cơ chế cập nhật nhãn khoảng cách
Tại mỗi bước, ñỉnh ngoài cây có nhãn khoảng cách nhỏ nhất sẽ ñược kết nạp vào cây, sau ñó các nhãn khoảng cách ñược cập nhật và lặp lại. Mô hình cài ñặt của thuật toán có thể viết như sau:
u := «Một ñỉnh bất kỳ»;
T := {u};
for Lv ∉ T do d[v] := +∞; //Các ñỉnh ngoài T ñược khởi tạo nhãn khoảng cách +∞ for i := 1 to n - 1 do //Làm n – 1 lần
begin
for (Lv ∉ T:(u, v) 5 E) do d[v] := min{d[v], w(u, v)};
//Cập nhật nhãn khoảng cách của các ñỉnh kề u nằm ngoài T
u := arg min{d[v]:v ∉ T}; //Chọn u là ñỉnh có nhãn khoảng cách nhỏ nhất trong số các ñỉnh nằm ngoài T if d[u] = +∞ then //ðồ thị không liên thông
begin
Output ← "Không tồn tại cây khung";
Break;
end;
T := T ∪ {u}; //Bổ sung u vào T
end;
Output ← T;
Cài ñặt dưới ñây sử dụng ma trận trọng số ñể biểu diễn ñồ thị. Kỹ thuật ñánh
dấu ñược sử dụng ñể biết một ñỉnh � ñang nằm ngoài (�@�"������ �!@�) hay
nằm trong cây � (�@�"������ ?�"�). Ngoài ra ñể tiện lợi hơn trong việc chỉ
ra cây khung nhỏ nhất, với mỗi ñỉnh � nằm ngoài � ta lưu lại �!l���� là ñỉnh @
nằm trong � mà cạnh �@8 �� tạo ra khoảng cách gần nhất từ � tới �: ��@8 ��
@
�
����cũ
��@8 �� �

165
���� . Khi thuật toán kết thúc, các cạnh trong cây khung là những cạnh ��!l����8 ��.
� PRIM.PAS � Thuật toán Prim
{$MODE OBJFPC}
program MinimumSpanningTree;
const
maxN = 1000;
maxW = 1000;
var
w: array[1..maxN, 1..maxN] of Integer; //Ma trận trọng số
d: array[1..maxN] of Integer; //Các nhãn khoảng cách
outside: array[1..maxN] of Boolean; //ðánh dấu các ñỉnh ngoài cây
trace: array[1..maxN] of Integer; //Vết
n: Integer;
procedure Enter;
var
i, m, u, v: Integer;
begin
ReadLn(n, m);
for u := 1 to n do
for v := 1 to n do w[u, v] := maxW + 1;
//Khởi tạo ma trận trọng số với các phần tử +∞ for i := 1 to m do
begin
ReadLn(u, v, w[u, v]);
//Chú ý: ðơn ñồ thị mới có thể ñọc dữ liệu thế này w[v, u] := w[u, v]; //ðồ thị vô hướng
end;
end;
function Prim: Boolean; //Thuật toán Prim, trả về True nếu tìm ñược cây khung
var
u, v, dmin, i: Integer;
begin
u := 1; //Cây ban ñầu chỉ gồm ñỉnh 1
for v := 2 to n do d[v] := maxW + 1;
//Nhãn khoảng cách cho các ñỉnh ngoài cây khởi tạo bằng +∞
FillChar(outside[2],

166
(n - 1) * SizeOf(outside[2]),
True); //ðánh dấu các ñỉnh 2...n nằm ngoài cây
outside[1] := False; //ðỉnh 1 nằm trong cây
for i := 1 to n - 1 do //Làm n – 1 lần
begin
//Trước hết tính lại các nhãn khoảng cách for v := 1 to n do
if outside[v] and (d[v] > w[u, v]) then
//Cạnh (u, v) tạo khoảng cách ngắn hơn khoảng cách cũ begin
d[v] := w[u, v]; //Cập nhật nhãn khoảng cách
trace[v] := u; //Lưu vết
end;
//Tìm ñỉnh u ngoài cây có nhãn khoảng cách nhỏ nhất
dmin := maxW + 1;
u := 0;
for v := 1 to n do
if outside[v] and (d[v] < dmin) then
begin
dmin := d[v];
u := v;
end;
if u = 0 then Exit(False);
//Cây không có cạnh nào nối ra ngoài, ñồ thị không liên thông, thoát
outside[u] := False; //Kết nạp u vào cây
end;
Result := True;
end;
procedure PrintResult; //In kết quả trong trường hợp tìm ra cây khung nhỏ nhất
var
v, Weight: Integer;
begin
WriteLn('Minimum Spanning Tree:');
Weight := 0;
for v := 2 to n do
begin
WriteLn('(', trace[v], ', ', v, ') = ',
w[trace[v], v]);
Inc(Weight, w[trace[v], v]);

167
end;
WriteLn('Weight = ', Weight);
end;
begin
Enter;
if Prim then PrintResult
else WriteLn('Graph is not connected!');
end.
Tính ñúng ñắn của thuật toán Prim cũng dễ dàng suy ra ñược từ ðịnh lý 3-17:
Gọi � là tập cạnh của cây � tại mỗi bước, xét lát cắt tách tập ñỉnh a làm 2 tập
rời nhau, một tập gồm các ñỉnh 5 � và tập còn lại gồm các ñỉnh ª �. ðỉnh �
ñược kết nạp vào cây � tại mỗi bước tương ứng với cạnh ��!l����8 �� là cạnh
nhẹ của lát cắt nên nó là an toàn với tập �, việc bổ sung cạnh này vào � vẫn ñảm
bảo � là tập con của tập cạnh một cây khung ngắn nhất.
c) c) c) c) ThThThThUUUUi gian thi gian thi gian thi gian thLLLLc hic hic hic hi;;;;n gin gin gin gi����i thui thui thui thutttt
Chương trình cài ñặt thuật toán Prim ở trên có thời gian thực hiện ���+�, hiệu quả hơn thuật toán Kruskal trong trường hợp ñồ thị dày nhưng lại kém hơn nếu ñồ thị thưa. Trong trường hợp ñồ thị thưa, ta có thể cải tiến mô hình cài ñặt thuật toán Prim bằng cách kết hợp với một hàng ñợi ưu tiên chứa các ñỉnh ngoài cây
có nhãn khoảng cách O ��. Hàng ñợi ưu tiên cần hỗ trợ các thao tác sau:
� � �!l�M Lấy ra một ñỉnh ưu tiên nhất (ñỉnh @ có ��@� nhỏ nhất) khỏi hàng ñợi ưu tiên.
� ��������: Thao tác này báo cho hàng ñợi ưu tiên biết rằng nhãn ���� ñã
bị giảm ñi, cần tổ chức lại (thêm � vào hàng ñợi ưu tiên nếu � ñang nằm ngoài).
Khi ñó thuật toán Prim có thể viết theo mô hình mới:
T := {Một ñỉnh bất kỳ u};
for Lv ª T do d[v] := +∞; //Các ñỉnh ngoài T ñược khởi tạo nhãn khoảng cách +∞
PQ := �; //Hàng ñợi ưu tiên ñược khởi tạo rỗng for i := 1 to |V| - 1 do //Làm n – 1 lần
begin
for (Lv 5 V:(u, v)5 E) do //Cập nhật nhãn các ñỉnh ngoài cây kề với u

168
if (v ª T) and (d[v] > w(u, v)) then begin
d[v] := w(u, v);
Update(v);
end;
if PQ = � then //ðồ thị không liên thông begin
Output ← "Không tồn tại cây khung";
Break;
end;
u := Extract;
//Chọn u là ñỉnh có nhãn khoảng cách nhỏ nhất trong số các ñỉnh nằm ngoài T
T := T Ø {u}; //Bổ sung u vào T end;
Thời gian thực hiện giải thuật có thể ước lượng theo số lời gọi ����� và � �!l�. Tương tự như thuật toán Dijkstra, có thể thấy rằng chúng ta cần sử
dụng không quá � C � lời gọi � �!l� và không quá � lời gọi ����� với � là
số ñỉnh và � là số cạnh của ñồ thị.
Một số cấu trúc dữ liệu biểu diễn hàng ñợi ưu tiên có thể sử dụng ñể cải thiện tốc ñộ thuật toán Prim trong trường hợp ñồ thị thưa. Chẳng hạn nếu sử dụng Fibonacci Heap làm hàng ñợi ưu tiên, thời gian thực hiện giải thuật là $��a� %'�a� � ����. Mặc dù vậy cần nhấn mạnh rằng trong các ứng dụng thực tế
mà danh sách cạnh có thể ñược sắp xếp trong thời gian $����� (chẳng hạn dùng các thuật toán sắp xếp cơ số hoặc ñếm phân phối), thuật toán Kruskal luôn là sự lựa chọn hợp lý hơn cả vì nó có thể tìm ñược cây khun trong thời gian $g��������8 �a��h.
Bài tập
2.16. Cho � là cây khung nhỏ nhất của ñồ thị A và �@8 �� là một cạnh trong �.
Chứng minh rằng nếu ta trừ trọng số cạnh �@8 �� ñi một số dương thì � vẫn
là cây khung nhỏ nhất của ñồ thị A.

169
2.17. Cho A là một ñồ thị vô hướng liên thông, F là một chu trình trên A và � là
cạnh trọng số lớn nhất của F. Chứng minh rằng nếu ta loại bỏ cạnh � khỏi ñồ thị thì không ảnh hưởng tới trọng số của cây khung nhỏ nhất.
2.18. Chứng minh rằng ñồ thị có duy nhất một cây khung nhỏ nhất nếu với mọi lát cắt của ñồ thị, có duy nhất một cạnh nhẹ nối hai tập của lát cắt. Cho một ví dụ ñể chỉ ra rằng ñiều ngược lại không ñúng.
2.19. Gọi � là một cây khung nhỏ nhất của ñồ thị vô hướng liên thông A, ta
giảm trọng số của một cạnh không nằm trong cây �, hãy tìm một thuật toán ñơn giản ñể tìm cây khung của ñồ thị mới.
Gợi ý: Gọi cạnh bị giảm trọng số là �@8 ��, thêm �@8 �� vào � ta sẽ ñược ñúng một chu trình ñơn, loại bỏ cạnh trọng số lớn nhất trên chu trình ñơn này sẽ ñược cây khung nhỏ nhất của ñồ thị mới.
2.20. Giả sử rằng ñồ thị vô hướng liên thông A có cây khung nhỏ nhất �, người ta thêm vào ñồ thị một ñỉnh mới và một số cạnh liên thuộc với ñỉnh ñó. Tìm thuật toán xác ñịnh cây khung nhỏ nhất của ñồ thị mới.
2.21. Giáo sư X ñề xuất một thuật toán tìm cây khung ngắn nhất dựa trên ý
tưởng chia ñể trị: Với ñồ thị vô hướng liên thông A �a8 ��, phân hoạch
tập ñỉnh a làm hai tập rời nhau a(8 a+ mà lực lượng của hai tập này hơn
kém nhau không quá 1. Gọi �( là tập các cạnh chỉ liên thuộc với các ñỉnh 5 a( và �+ là tập các cạnh chỉ liên thuộc với các ñỉnh 5 a+. Tìm cây khung
nhỏ nhất trên ñồ thị A( �a(8 �(� và A+ �a+8 �+� bằng thuật toán ñệ quy,
sau ñó chọn cạnh trọng số nhỏ nhất nối a( với a+ ñể nối hai cây khung tìm ñược thành một cây. Chứng minh tính ñúng ñắn của thuật toán hoặc chỉ ra một phản ví dụ cho thấy thuật toán sai.
2.22. (Cây khung nhỏ thứ nhì) Cho A �a8 �8 �� là ñồ thị vô hướng liên thông
có trọng số, giả sử rằng ��� w �a� và các trọng số cạnh là hoàn toàn phân
biệt (� là ñơn ánh). Gọi å là tập tất cả các cây khung của A và � là cây
khung nhỏ nhất của A, khi ñó cây khung nhỏ thứ nhì ñược ñịnh nghĩa là
cây khung H 5 å thỏa mãn: ��H� �µoä5å36Ü96����9

170
� Chỉ ra rằng ñồ thị A có duy nhất một cây khung nhỏ nhất là �, nhưng có thể có nhiều cây khung nhỏ thứ nhì.
� Chứng minh rằng luôn tồn tại một cạnh �@8 �� 5 � và � 8 >� ª � ñể nếu ta
loại bỏ cạnh �@8 �� khỏi � rồi thêm cạnh � 8 >� vào � thì sẽ ñược cây khung nhỏ thứ nhì.
� Với L@8 � 5 a, gọi ��@8 �� là cạnh mang trọng số lớn nhất trên ñường ñi duy
nhất từ @ tới � trên cây �. Tìm thuật toán $��a�+� ñể tính tất cả các ��@8 ��, L@8 � 5 a. � Tìm thuật toán hiệu quả ñể tìm cây khung nhỏ thứ nhì của ñồ thị. 2.23. Cho " và � là hai ñỉnh của một ñồ thị vô hướng có trọng số A �a8 �8 ��.
Tìm một ñường ñi từ " tới � thỏa mãn: Trọng số cạnh lớn nhất ñi qua trên ñường ñi là nhỏ nhất có thể.
Gợi ý: Có rất nhiều cách làm: Kết hợp một thuật toán tìm kiếm trên ñồ thị với thuật toán tìm kiếm nhị phân, hoặc sửa ñổi thuật toán Dijkstra, hoặc sử dụng thuật toán tìm cây khung ngắn nhất.
2.24. (Euclidean Minimum Spanning Tree) Trong trường hợp các ñỉnh của ñồ thị ñầy ñủ ñược ñặt trên mặt phẳng trực chuẩn và trọng số cạnh nối giữa hai ñỉnh chính là khoảng cách hình học giữa chúng. Người ta có một phép tiền xử lý ñể giảm bớt số cạnh của ñồ thị bằng thuật toán tam giác phân
Delaunay ($�� %' ��), ñồ thị sau phép tam giác phân Delaunay sẽ còn
không quá V� cạnh, do ñó sẽ làm các thuật toán tìm cây khung nhỏ nhất hoạt ñộng hiệu quả hơn. Hãy tự tìm hiểu về phép tam giác phân Delaunay và cài ñặt chương trình ñể tìm cây khung nhỏ nhất.
2.25. Trên một nền phẳng với hệ toạ ñộ trực chuẩn ñặt � máy tính, máy tính thứ � ñược ñặt ở toạ ñộ � 28 >2�. ðã có sẵn một số dây cáp mạng nối giữa một số cặp máy tính. Cho phép nối thêm các dây cáp mạng nối giữa từng cặp máy tính. Chi phí nối một dây cáp mạng tỉ lệ thuận với khoảng cách giữa hai máy cần nối. Hãy tìm cách nối thêm các dây cáp mạng ñể cho các máy tính trong toàn mạng là liên thông và chi phí nối mạng là nhỏ nhất.
2.26. Hệ thống ñiện trong thành phố ñược cho bởi � trạm biến thế và các ñường
dây ñiện nối giữa các cặp trạm biến thế. Mỗi ñường dây ñiện � có ñộ an
toàn là ���� 5 �78��. ðộ an toàn của cả lưới ñiện là tích ñộ an toàn trên các

171
ñường dây. Hãy tìm cách bỏ ñi một số dây ñiện ñể cho các trạm biến thế vẫn liên thông và ñộ an toàn của mạng là lớn nhất có thể.
Gợi ý: Bằng kỹ thuật lấy logarithm, ñộ an toàn trên lưới ñiện trở thành tổng ñộ an toàn trên các ñường dây.
3. Luồng cực ñại trên mạng
3.1. Các khái niệm và bài toán
a) a) a) a) MMMM9999ngngngng
Mạng (flow network) là một bộ năm A �a8 �8 l8 "8 ��, trong ñó: a và � lần lượt là tập ñỉnh và tập cung của một ñồ thị có hướng không có khuyên (cung nối từ một ñỉnh ñến chính nó). " và � là hai ñỉnh phân biệt thuộc a, " gọi là ñỉnh phát (source) và � gọi là ñỉnh thu (sink). l là một hàm xác ñịnh trên tập cung �M lM � � �78 ��� � ¦ l���
gán cho mỗi cung � 5 � một số không âm gọi là sức chứa (capacity)* l��� w 7.
Bằng cách thêm vào mạng một số cung có sức chứa 0, ta có thể giả thiết rằng
mỗi cung � �@8 �� 5 � luôn có tương ứng duy nhất một cung ngược chiều, ký
hiệu – � ��8 @� 5 �, gọi là cung ñối của cung �, ta cũng coi � là cung ñối của
cung C� (tức là – �C�� ��. Có thể thấy rằng số cung cần thêm vào mạng là
một ñại lượng $���.
Chú ý rằng mạng là một ña ñồ thị, tức là giữa hai ñỉnh có thể có nhiều cung nối.
ðể thuận tiện cho việc trình bày, ta quy ước các ký hiệu sau:
* Từ này còn có thể dịch là “khả năng thông qua” hay “lưu lượng”

172
Với �8 Ù là hai tập con của tập ñỉnh a và �M � G � là một hàm xác ñịnh trên tập
cạnh �:
Ký hiệu 6� G Ù9 là tập các cung nối một từ một ñỉnh thuộc � tới một ñỉnh thuộc Ù: 6� G Ù9 6� �@8 �� 5 �M @ 5 �8 > 5 Ù9 Ký hiệu ���8 Ù� là tổng các giá trị hàm � trên các cung � 5 6� G Ù9:
���8 Ù� È ����ç5èGé
b) b) b) b) LuLuLuLu^̂̂̂ngngngng
Luồng (flow) trên mạng A là một hàm: �M � � � � ¦ ����
gán cho mỗi cung � một số thực ����, gọi là luồng trên cung �, thỏa mãn ba ràng buộc sau ñây:
� Ràng buộc về sức chứa (Capacity constraint): Luồng trên mỗi cung không
ñược vượt quá sức chứa của cung ñó: L� 5 �M ���� N l���.
� Ràng buộc về tính ñối xứng lệch (Skew symmetry): Với L� 5 �, luồng trên
cung � và luồng trên cung ñối C� có cùng giá trị tuyệt ñối nhưng trái dấu
nhau: L� 5 �M ���� C��C��.
� Ràng buộc về tính bảo tồn (Flow conservation): Với mỗi ñỉnh � không phải ñỉnh phát và cũng không phải ñỉnh thu, tổng luồng trên các cung ñi ra khỏi � bằng 0: L� 5 a C 6"8 �9M ��6�98 a� 7.
Từ ràng buộc về tính ñối xứng lệch và tính bảo tồn, ta suy ra ñược: Với mọi ñỉnh � 5 a C 6"8 �9, tổng luồng trên các cung ñi vào � bằng 0: ��a8 6�9� 7.
Giá trị của luồng � trên mạng A ñược ñịnh nghĩa bằng tổng luồng trên các cung ñi ra khỏi ñỉnh phát:
��� ��6"98 a� (3.1)

173
Bài toán luồng cực ñại trên mạng (maximum-flow problem): Cho một mạng A
với ñỉnh phát " và ñỉnh thu �, hàm sức chứa l, hãy tìm một luồng có giá trị lớn
nhất trên mạng A.
c) c) c) c) LuLuLuLu^̂̂̂ng dF#ngng dF#ngng dF#ngng dF#ng
Luồng dương (positive flow) trên mạng A là một hàm êM � � �78 ��� � ¦ ê��� gán cho mỗi cung � một số thực không âm ê��� gọi là luồng dương trên cung � thỏa mãn hai ràng buộc sau ñây:
� Ràng buộc về sức chứa (Capacity constraint): Luồng dương trên mỗi cung
không ñược vượt quá sức chứa của cung ñó: L� 5 �M 7 N ê��� N l���. � Ràng buộc về tính bảo tồn (Flow conservation): Với mỗi ñỉnh � không phải
ñỉnh phát và cũng không phải ñỉnh thu, tổng luồng dương trên các cung ñi
vào � bằng tổng luồng dương trên các cung ñi ra khỏi �: L� 5 a C 6"8 �9: ê�a8 6�9� ê�6�98 a�.
Giá trị của một luồng dương ñược ñịnh nghĩa bằng tổng luồng dương trên các cung ñi ra khỏi ñỉnh phát trừ ñi tổng luồng dương trên các cung ñi vào ñỉnh phát*:
�ê� ê�6"98 a� C ê�a8 6"9� (3.2)
Hình 2.6. Mạng với các sức chứa trên cung (1 phát, 6 thu) và một luồng dương với giá trị 7
* Một số tài liệu khác ñưa vào thêm ràng buộc: ñỉnh phát " không có cung ñi vào và ñỉnh thu � không có
cung ñi ra. Khi ñó giá trị luồng dương bằng tổng luồng dương trên các cung ñi ra khỏi ñỉnh phát. Cách
hiểu này có thể quy về một trường hợp riêng của ñịnh nghĩa.
1
2
3
4
5
6
5
5
6
3
3
1
6
6
1
2
3
4
5
6
5
2
5
1
0
1
6
1

174
d) d) d) d) MMMM!!!!i quan hi quan hi quan hi quan h;;;; gigigigiRRRRa lua lua lua lu^̂̂̂ng và lung và lung và lung và lu^̂̂̂ng dF#ngng dF#ngng dF#ngng dF#ng
Bổ ñề 3-1
Cho êM � G � là một luồng dương trên mạng A �a8 �8 l8 "8 ��. Khi ñó hàm �M � � � � ¦ ���� ê��� C ê�C�� là một luồng trên mạng A và ��� �ê�
Chứng minh
Trước hết ta chứng minh � thỏa mãn tất cả các ràng buộc về luồng:
Ràng buộc về sức chứa: Với L� 5 �: ���� ê��� C ê�C��½¿ÀÁ4 N ê��� N l�@8 �� Ràng buộc về tính ñối xứng lệch: Với L� 5 � ���� ê��� C ê�C�� Cgê�C�� C ê���h C��C�� Ràng buộc về tính bảo tồn: L� 5 a, ta có:
��6�98 a� È gê��� C ê�C��hç5Ì6©9G¶Í
ë È ê���
ç5Ì6©9G¶Íì C ë È ê�C��
ç5Ì6©9G¶Íì
ë È ê���ç5Ì6©9G¶Í
ì C ë È ê�C��3ç5̶G6©9Í
ì ê�6�98 a� C ê�a8 6�9�
Nếu � d " và � d �, ta có: ��6�98 a� ê�6�98 a� C ê�a8 6�9� 7 (Do tổng luồng dương ñi ra khỏi � bằng tổng luồng dương ñi vào �)
Nếu � ", xét giá trị luồng � ��� ��6"98 a� ê��6"98 a� C ê�a8 6"9� �ê� Bổ ñề 3-2
Cho �M � G � là một luồng trên mạng A �a8 �8 l8 "8 ��. Khi ñó hàm:

175
êM � � �78 ��
� ¦ ê��� �n�6����8 79 �����8 nếu ���� w 778 nếu ���� O 7 � là một luồng dương trên mạng và �ê� ���
Chứng minh
Trước hết ta chứng minh ê thỏa mãn các ràng buộc về luồng dương:
Ràng buộc về sức chứa: L� 5 � , rõ ràng ê��� là số không âm và ê��� �n�6����8 79 N l���.
Ràng buộc về tính bảo tồn: L� 5 a, tổng luồng dương ra khỏi � trừ tổng luồng
dương ñi vào � bằng:
ê�6�98 a� C ê6a8 6�9� È ����ç5Ì6©9G¶Íí�ç�Á4
C È ����ç5̶G6©9Íí�ç�î4
È ����
ç5Ì6©9G¶Íí�ç�Á4� È ��C��
3ç5Ì6©9G¶Íí�3ç�ï4 ��6�98 a�
Nếu � d " và � d �, ��6�98 a� 7 nên luồng dương ñi vào � (ê�6�98 a)) ñược bảo
tồn khi ñi ra khỏi � (ê�a8 6�9�).
Nếu � ", ta có: �ê� ê�6"98 a� C ê�a8 6"9� ��6"98 a� ��� Bổ ñề 3-1 và Bổ ñề 3-2 cho ta một mối tương quan giữa luồng và luồng dương. Khái niệm về luồng dương dễ hình dung hơn so với khái niệm luồng, tuy nhiên những ñịnh nghĩa về luồng tổng quát lại thích hợp hơn cho việc trình bày và chứng minh các thuật toán trong bài. Ta sẽ sử dụng luồng dương trong các
hình vẽ và output (chỉ quan tâm tới các giá trị luồng dương ê���), còn các khái niệm về luồng sẽ ñược dùng ñể diễn giải các thuật toán trong bài.
Trong quá trình cài ñặt thuật toán, các hàm l và � sẽ ñược xác ñịnh bởi tập các
giá trị 6l���9ç5s và 6����9ç5s nên ta có thể dùng lẫn các ký hiệu l���8 ���� (nếu
muốn ñề cập tới giá trị hàm) hoặc l���8 ���� (nếu muốn ñề cập tới các biến số). e) e) e) e) MMMM8888t st st st s!!!! tính chtính chtính chtính ch6666t c# bt c# bt c# bt c# b����nnnn
Cho mạng A �a8 �8 l8 "8 �� và một luồng � trên A. Gọi l��8 Ù� là lưu lượng từ � sang Ù và ���8 Ù� là giá trị luồng từ � sang Ù.

176
ðịnh lý 3-3
Cho � là một luồng trên mạng A �a8 �8 l8 "8 ��, khi ñó:
a) L� Ö a, ta có ���8 �� 7.
b) L�8 Ù Ö a, ta có ���8 Ù� C��Ù8 ��.
c) L�8 Ù8 ð Ö a và � Ú Ù �, ta có ���8 ð� � ��Ù8 ð� ?�� Ø Ù8 ð�.
d) L� Ö a C 6"8 �9, ta có ���8 a� 7.
Chứng minh
a) L� Ö a, ta có:
���8 �� È ����ç56èGè9
như vậy ���� xuất hiện trong tổng nếu và chỉ nếu ��C�� cũng xuất hiện trong
tổng. Theo tính ñối xứng lệch của luồng: ���� C��C��, ta có ���8 �� 7.
b) L�8 Ù Ö a, ta có :
���8 Ù� È ����ç56èGé9 C È ��C��3ç56éGè9 C��Ù8 ��
c) L�8 Ù8 ð Ö a và � Ú Ù �, ta có:
��� Ø Ù8 ð� È ����ç56èØéGñ9
È ����ç56èGñ9½¾¾¾¿¾¾¾Àí�è8ñ�
� È ����ç56éGñ9½¾¾¾¿¾¾¾Àí�é8ñ�
d) L� Ö a C 6"8 �9, do
� ò6@9¨5è
Nên theo chứng minh phần c):
���8 a� È ��6@98 a�¨5è
Mỗi hạng tử của tổng: ��6@98 a� chính là tổng luồng trên các cung ñi ra khỏi ñỉnh @, do tính bảo tồn luồng và @ không phải ñỉnh phát cũng không phải ñỉnh thu,
hạng tử này phải bằng 0, suy ra ���8 a� 7. Từ chứng minh phần b), ta còn suy
ra ��a8 �� 7 nữa.

177
ðịnh lý 3-4
Giá trị luồng trên mạng bằng tổng luồng trên các cung ñi vào ñỉnh thu
Chứng minh
Giả sử � là một luồng trên mạng A �a8 �8 l8 "8 ��, ta có: ��� ��6"98 a� ��a8 a� C ��a C 6"98 a� C��a C 6"98 a� ��a8 a C 6"9� ��a8 6�9� � ��a8 a C 6"8 �9� ��a8 6�9� Hệ quả
Giá trị luồng dương trên mạng bằng tổng luồng dương ñi vào ñỉnh thu trừ tổng luồng dương ra khỏi ñỉnh thu.
f) f) f) f) MMMM9999ng thng thng thng th::::ng dFng dFng dFng dF
Với � là một luồng trên mạng A �a8 �8 l8 "8 ��. Ta xét mạng Aí cũng là mạng A
nhưng với hàm sức chứa mới cho bởi:
líM � � �78 ��� � ¦ lí��� l��� C ���� (3.3)
Mạng Aí xây dựng như vậy ñược gọi là mạng thặng dư (residual network) của
mạng A sinh ra bởi luồng �. Sức chứa của cung ��� trên Aí thực chất là lượng
luồng tối ña chúng ta có thể ñẩy thêm vào luồng ���� mà không làm vượt quá
sức chứa l���.
Một cung trên A gọi là cung bão hòa (saturated edge) nếu luồng trên cung ñó ñúng bằng sức chứa, ngược lại cung ñó gọi là cung thặng dư (residual edge). Ký
hiệu �í là tập các cung thặng dư trên mạng thặng dư Aí. Một ñường ñi chỉ qua
các cung thặng dư trên Aí gọi là ñường thặng dư (residual path).
Cung bão hòa của mạng A trên mạng thặng dư sẽ có sức chứa 0, cung này ít có ý
nghĩa trong thuật toán nên chúng ta sẽ chỉ vẽ các cung thặng dư (5 �í) trong các
hình vẽ.

178
Hình 2.7. Một luồng trên mạng (số ghi trên các cung là: sức chứa:luồng dương) và mạng thặng dư
tương ứng.
Hình 2.7 là một ví dụ về mạng thặng dư. Như ñã quy ước, chúng ta chỉ vẽ các
luồng dương. ðồ thị có cung �;8X� với sức chứa l�;8X� T, tức là phải có cung
ñối �X8;� với l�X8;� 7. Luồng dương trên cung �;8X� là ê�;8X� ��;8X� \,
ñiều này cũng cho biết luồng trên cung �X8;� là ��X8;� C\ theo tính ñối xứng
lệch. Vậy trên mạng thặng dư, ta có cung �;8X� với sức chứa l�;8X� C ��;8X� T C \ � ñồng thời có cung �X8;� với sức chứa l�X8;� C ��X8;� 7 C �C\� \.
ðịnh lý 3-5
Cho � là một luồng trên mạng A �a8 �8 l8 "8 ��. Khi ñó nếu �Û là một luồng trên Aí thì hàm:
� � �óM � � � � ¦ �� � �ó���� ���� � �ó��� là một luồng trên mạng A với giá trị luồng �� � �Û� ��� � ��Û�.
Chứng minh
Ta chứng minh �� � �Û� thỏa mãn ba tính chất của luồng:
Ràng buộc về sức chứa: Với L� 5 �: �� � �Û���� ���� � �Û��� N ���� � gl��� C ����h l���
Tính ñối xứng lệch: Với L� 5 �: �� � �Û���� ���� � �Û��� C��C�� C �Û�C��
1
2
3
4
5
6
5:5
5:2
6:5
3:1
3:0
1:1
6:6
6:1
1
2
3
4
5
6
5
5
1
6
15
23
1
3
2
1

179
Cg��C�� � ��C��h C�� � ���C��
Tính bảo tồn: Với L@ 5 a, tổng luồng � � �Û ñi ra khỏi @ bằng:
�� � �ó��6@98 a� È g���� � �ó���hç5Ì6¨9G¶Í
È ����
ç5Ì6¨9G¶Í� È �ó���
ç5Ì6¨9G¶Í
��6@98 a� � �ó�6@98 a� Nếu @ d " và @ d �, ta có �� � �ó��6@98 a� ��6@98 a� � �ó�6@98 a� 7. Thay @ ", ta có �� � �ó� �� � �ó��6"98 a� ��6"98 a� � �ó�6"98 a� ��� � ��ó�
ðịnh lý 3-6
Cho � và �ó là hai luồng trên mạng A �a8 �8 l8 "8 �� khi ñó hàm: �ó C �M � � � � ¦ ��ó C ����� �ó��� C ���� là một luồng trên mạng thặng dư Aí với giá trị luồng ��ó C �� ��ó� C ���.
Chứng minh
Ta chứng minh rằng �ó C � thỏa mãn ba tính chất của luồng
Ràng buộc về sức chứa: Với L� 5 �: ��ó C ����� �ó��� C ���� N l��� C ���� lí���
Tính ñối xứng lệch: Với L� 5 �: ��ó C ����� �ó��� C ���� Cg�ó�C�� C ��C��h C��ó C ���C��
Tính bảo tồn: Với L� 5 a
��ó C ���6�98 a� È g�ó��� C ����hç5Ì6©9G¶Í
È �ó���
ç5Ì6©9G¶ÍC È ����
ç5Ì6©9G¶Í
�ó�6�98 a� C ��6�98 a�

180
Nếu @ d " và @ d �, ta có ��ó C ���6�98 a� �ó�6�98 a� C ��6�98 a� 7. Thay @ ", ta có ��ó C �� ��ó C ���6"98 a� �ó�6"98 a� C ��6"98 a� ��ó� C ���
3.2. Thuật toán Ford-Fulkerson
a) a) a) a) \F\F\F\FUUUUng t(ng lung t(ng lung t(ng lung t(ng lu^̂̂̂ngngngng
Với � là một luồng trên mạng A �a8 �8 l8 "8 ��. Gọi B là một ñường ñi ñơn từ "
tới � trên mạng thặng dư Aí. Giá trị thặng dư (residual capacity) của ñường B,
ký hiệu Òô , ñược ñịnh nghĩa bằng sức chứa nhỏ nhất của các cung dọc trên
ñường B (xét trên Aí):
Òô �µoÌlí���M ��� nằm trên BÍ Vì các sức chứa lí��� là số không âm nên Òô luôn là số không âm. Nếu Òô 1 7
tức là ñường ñi B là một ñường thặng dư, khi ñó ñường ñi B gọi là một ñường
tăng luồng (augmenting path) tương ứng với luồng �. ðịnh lý 3-7
Cho � là một luồng trên mạng A �a8 �8 l8 "8 ��, B là một ñường tăng luồng trên Aí. Khi ñó hàm �ôM � G � ñịnh nghĩa như sau:
�ô��� ��∆ô 8 nếu � 5 BC∆�8 nếu C � 5 B78 trường hợp khác
� (3.4)
là một luồng trên Aí với giá trị luồng ��ô� Òô 1 7.
Chứng minh
Chúng ta sẽ không chứng minh cụ thể vì việc kiểm chứng �ô thỏa mãn ba tính chất
của luồng khá dễ dàng. Bản chất của luồng �ô là ñẩy một giá trị luồng Òô từ " tới �
dọc theo các cung trên ñường B, ñồng thời kéo một giá trị luồng – Òô từ � về "
theo hướng ngược lại*.
* Có thể hình dung cơ chế này như một quá trình ñiện phân: Bao nhiêu ion dương (cation) chuyển ñến cực
âm (catot) � thì cũng phải có bấy nhiêu ion âm (anion) chuyển ñến cực dương (anot) ".

181
ðịnh lý 3-5 và ðịnh lý 3-7 cho ta một hệ quả sau:
Hệ quả 3-8
Cho � là một luồng trên mạng A �a8 �8 l8 "8 �� và B là một ñường tăng luồng
trên Aí, gọi �ô là luồng trên Aí ñịnh nghĩa như trong công thức (3.4). Khi ñó � � �ô là một luồng mới trên A với giá trị �� � �ô� ��� � ��ô� ��� � Òô.
Hình 2.8. Tăng luồng dọc ñường tăng luồng.
Hình 2.8 là ví dụ về cơ chế tăng luồng trên mạng với ñỉnh phát 1, ñỉnh thu 6 và
luồng � giá trị 7 (hình a) (chú ý rằng ta chỉ vẽ các luồng dương cho ñỡ rối). Với
mạng thặng dư Aí (hình b), giả sử ta chọn ñường ñi B ¬�8V8X8;8\8T làm ñường
tăng luồng, giá trị thặng dư của B bằng Òô ; (sức chứa của cung �V8X�).
Luồng �ô trên Aí sẽ có các giá trị sau:
�ô��8V� �ô�V8X� �ô�X8;� �ô�;8\� �ô�\8T� ; �ô�V8�� �ô�X8V� �ô�;8X� �ô�\8;� �ô�T8\� C;
Cộng các giá trị này vào luồng � ñang có, ta sẽ ñược một luồng mới trên A với giá trị 9 (hình c).
Cơ chế cộng luồng �ô vào luồng � hiện có gọi là tăng luồng dọc theo ñường
tăng luồng B.
1
2
3
4
5
6
5:5
5:2
6:5
3:1
3:0
1:1
6:6
6:1
1
2
3
4
5
6
5
1
6
121
1
5
53 3
2
1
2
3
4
5
6
5:5
5:4
6:3
3:3
3:2
1:1
6:6
6:3
a)
b)
c

182
b) b) b) b) ThuThuThuThut toán Fordt toán Fordt toán Fordt toán Ford----FulkersonFulkersonFulkersonFulkerson
Thuật toán Ford-Fulkerson [14] ñể tìm luồng cực ñại trên mạng dựa trên cơ chế
tăng luồng dọc theo ñường tăng luồng. Bắt ñầu từ một luồng � bất kỳ trên mạng
(chẳng hạn luồng trên mọi cung ñều bằng 0), thuật toán tìm ñường tăng luồng B
trên mạng thặng dư, gán � z � � �ô ñể tăng giá trị luồng � và lặp lại cho tới khi không tìm ñược ñường tăng luồng nữa.
f := «Một luồng bất kỳ»;
while «Tìm ñược ñường tăng luồng P» do
f := f + fP;
Output ← f;
c) c) c) c) Cài "Cài "Cài "Cài "::::tttt
Chúng ta sẽ cái ñặt thuật toán Ford-Fulkerson ñể tìm luồng cực ñại trên mạng với khuôn dạng Input/Output như sau: Input
� Dòng 1 chứa số ñỉnh � N �7� , số cung � N �7� của mạng, ñỉnh phát ",
ñỉnh thu �.
� � dòng tiếp theo, mỗi dòng chứa ba số nguyên dương @8 �8 l tương ứng với
một cung nối từ @ tới � với sức chứa l N �7�.
Output
Luồng cực ñại trên mạng (như ñã quy ước, chỉ ñưa ra các luồng dương trên các cung).

183
Sample Input Sample Output
6 8 1 6
5 6 6
4 6 6
3 5 1
3 4 3
2 5 3
2 4 6
1 3 5
1 2 5
Maximum flow:
e[1] = (5, 6): c = 6, f = 3
e[2] = (4, 6): c = 6, f = 6
e[3] = (3, 5): c = 1, f = 1
e[4] = (3, 4): c = 3, f = 3
e[5] = (2, 5): c = 3, f = 2
e[6] = (2, 4): c = 6, f = 3
e[7] = (1, 3): c = 5, f = 4
e[8] = (1, 2): c = 5, f = 5
Value of flow: 9
ðể cài ñặt thuật toán ñược hiệu quả cần có một cơ chế tổ chức dữ liệu hợp lý.
Chúng ta cần lưu trữ luồng � trên các cung, tìm ñường tăng luồng B trên Aí và
cộng luồng �ô vào luồng � hiện có. Việc tìm ñường tăng luồng B trên Aí sẽ ñược
thực hiện bằng một thuật toán tìm kiếm trên ñồ thị còn việc tăng luồng dọc trên
ñường B ñòi hỏi phải tăng giá trị luồng trên các cung dọc trên ñường ñi ñồng thời giảm giá trị luồng trên các cung ñối. Vậy cấu trúc dữ liệu cần tổ chức ñể tạo ñiều kiện thuận lợi cho thuật toán tìm ñường tăng luồng cũng như dễ dàng chỉ ra cung ñối của một cung cho trước.
ðồ thị ñược biểu diễn bởi danh sách liên thuộc. Tất cả � cung của mạng ñược
chứa trong danh sách ��� ��. Ngoài ra ta thêm � cung ñối của chúng với sức
chứa 0. Các cung ñối này ñược lưu trữ trong danh sách ��C� C ��, cung ñối
của cung ���� là cung ��C��, cung ��7� ñược sử dụng với vai trò phần tử cầm canh và không ñược tính ñến.
Mỗi phần tử của danh sách � là một bản ghi gồm 4 trường � 8 >8 l8 �� trong ñó , > là ñỉnh ñầu và ñỉnh cuối của cung, l là sức chứa và � là luồng trên cung. Danh
1
2
3
4
5
6
5:5
5:4
6:3
3:3
3:2
1:1
6:6
6:3

184
sách liên thuộc ñược xây dựng bởi hai mảng ����� �� và �����C� ��, trong ñó:
� ����@� là chỉ số cung ñầu tiên trong danh sách liên thuộc các cung ñi ra
khỏi @, trường hợp @ không có cung ñi ra, ����@� ñược gán bằng 0.
� ������� là chỉ số cung kế tiếp cung ���� trong cùng danh sách liên thuộc các
cung ñi ra khỏi một ñỉnh. Trường hợp ���� là cung cuối cùng của một danh
sách liên thuộc, ������� ñược gán bằng 0
Việc duyệt các cung ñi ra khỏi ñỉnh @ sẽ ñược thực hiện theo cách sau:
i := head[u]; //i là chỉ số cung ñầu tiên trong danh sách liên thuộc các cung ra khỏi u
while i ≠ 0 do //Chừng nào chưa duyệt qua cung cuối danh sách liên thuộc
begin
«Xử lý cung e[i]»;
i := link[i]; //Nhảy sang xét cung kế tiếp trong danh sách liên thuộc
end;
Tại mỗi bước, ta dùng thuật toán BFS ñể tìm ñường ñi từ " tới � trên Aí, mỗi
ñỉnh � trên ñường ñi ñược lưu vết �!l���� là chỉ số cung ñi vào � trên ñường ñi B tìm ñược. Dựa vào vết này, ta sẽ liệt kê ñược tất cả các cung trên ñường ñi,
tăng luồng trên các cung này lên Òô ñồng thời giảm luồng trên các cung ñối ñi Òô.
Edmonds và Karp [12] ñã ñề xuất mô hình cài ñặt thuật toán Ford-Fulkerson trong ñó thuật toán BFS ñược sử dụng ñể tìm ñường tăng luồng nên người ta còn gọi thuật toán Ford-Fulkerson với kỹ thuật sử dụng BFS tìm ñường tăng luồng là thuật toán Edmonds-Karp.
� EDMONDSKARP.PAS � Thuật toán Edmonds-Karp
{$MODE OBJFPC}
program MaximumFlow;
const
maxN = 1000;
maxM = 100000;
maxC = 10000;
type
TEdge = record //Cấu trúc một cung
x, y: Integer; //Hai đỉnh đầu mút

185
c, f: Integer; //Sức chứa và luồng
end;
TQueue = record //Hàng đợi dùng cho BFS
items: array[1..maxN] of Integer;
front, rear: Integer;
end;
var
e: array[-maxM..maxM] of TEdge; //Danh sách các cung
link: array[-maxM..maxM] of Integer;
//Móc nối trong danh sách liên thuộc head: array[1..maxN] of Integer;
//head[u]: Chỉ số cung đầu tiên trong danh sách liên thuộc các cung ra khỏi u trace: array[1..maxN] of Integer; //Vết đường đi
n, m, s, t: Integer;
FlowValue: Integer;
Queue: TQueue;
procedure Enter; //Nhập dữ liệu
var i, u, v, capacity: Integer;
begin
ReadLn(n, m, s, t);
FillChar(head[1], n * SizeOf(head[1]), 0);
for i := 1 to m do
begin
ReadLn(u, v, capacity);
with e[i] do //Thêm cung e[i] = (u, v) vào danh sách liên thuộc của u
begin
x := u;
y := v;
c := capacity;
link[i] := head[u];
head[u] := i;
end;
with e[-i] do //Thêm cung e[-i] = (v, u) vào danh sách liên thuộc của v
begin
x := v;
y := u;
c := 0;
link[-i] := head[v];

186
head[v] := -i;
end;
end;
end;
procedure InitZeroFlow; //Khởi tạo luồng 0
var i: Integer;
begin
for i := -m to m do e[i].f := 0;
FlowValue := 0;
end;
function FindPath: Boolean; //Tìm đường tăng luồng bằng BFS
var u, v, i: Integer;
begin
FillChar(trace[1], n * SizeOf(trace[1]), 0);
trace[s] := 1; //trace[s] ≠ 0: ñỉnh ñã thăm, có thể dùng bất cứ hằng số nào khác 0 with Queue do
begin
items[1] := s;
front := 1;
rear := 1; //Hàng đợi chỉ gồm đỉnh s
repeat
u := items[front];
Inc(front); //Lấy một đỉnh u khỏi hàng đợi
i := head[u];
while i <> 0 do //Duyệt danh sách liên thuộc của u
begin
v := e[i].y; //nút e[i] chứe một cung đi từ u tới v
if (trace[v] = 0)
and (e[i].f < e[i].c) then
//v chưa thăm và e[i] là cung thặng dư begin
trace[v] := i; //Lưu vết
if v = t then Exit(True);
//Tìm thấy đường tăng luồng, thoát
Inc(rear);
items[rear] := v; //Đẩy v vào hàng đợi
end;
i := link[i]; //Nhảy sang nút kế tiếp trong danh sách liên thuộc

187
end;
until front > rear;
Result := False; //Không tìm thấy đường tăng luồng
end;
end;
procedure AugmentFlow; //Tăng luồng dọc đường một tăng luồng
var Delta, v, i: Integer;
begin
//Trước hết xác định Delta bằng sức chứa nhỏ nhất của các cung trên đường tăng luồng
v := t; //Bắt đầu từ t
Delta := maxC;
repeat
i := trace[v];
// e[i] là một cung trên ñường tăng luồng với sức chứe e[i].c - e[i].f if e[i].c - e[i].f < Delta then
Delta := e[i].c - e[i].f;
v := e[i].x; //Đi dần về s
until v = s;
//Tăng luồng thêm Delta
v := t; //Bắt đầu từ t
repeat
i := trace[v]; // e[i] là một cung trên đường tăng luồng
Inc(e[i].f, Delta); //Tăng luồng trên e[i] lên Delta
Dec(e[-i].f, Delta); //Giảm luồng trên cung đối tương ứng đi Delta
v := e[i].x; //Đi dần về s
until v = s;
Inc(FlowValue, Delta); //Giá trị luồng f được tăng lên Delta
end;
procedure PrintResult; //In kết quả
var i: Integer;
begin
WriteLn('Maximum flow: ');
for i := 1 to m do
with e[i] do
if f > 0 then //Chỉ cần in ra các cung có luồng > 0
WriteLn('e[', i, '] = (', x, ', ', y, '): c
= ', c, ', f = ', f);
WriteLn('Value of flow: ', FlowValue);
end;

188
begin
Enter; //Nhập dữ liệu
InitZeroFlow; //Khởi tạo luồng 0
while FindPath do //Thuật toán Ford-Fulkerson
AugmentFlow;
PrintResult; //In kết quả
end.
d) d) d) d) Tính "úng cTính "úng cTính "úng cTính "úng c<<<<a thua thua thua thut toánt toánt toánt toán
Trước hết dễ thấy rằng thuật toán Ford-Fulkerson trả về một luồng, tức là kết quả mà thuật toán trả về thỏa mãn các tính chất của luồng. Việc chứng minh luồng ñó là cực ñại ñã xây dựng một ñịnh lý quan trọng về mối quan hệ giữa luồng cực ñại và lát cắt hẹp nhất.
Ta gọi một lát cắt ��8 Ù� là một cách phân hoạch tập ñỉnh a làm hai tập rời nhau: � Ú Ù � và � Ø Ù a. Lát cắt có " 5 � và � 5 Ù ñược gọi là một lát cắt " C�.
Lưu lượng từ � sang Ù (l��8 Ù�) và luồng từ � sang Ù (���8 Ù�) ñược gọi là lưu lượng và luồng thông qua lát cắt.
Bổ ñề 3-9
Với � là một luồng trên mạng A �a8 �8 l8 "8 ��. Khi ñó luồng thông qua một lát
cắt " C � bất kỳ bằng ���. Chứng minh
Với a � Ø Ù là một lát cắt " C � bất kỳ, theo ðịnh lý 3-3
���8 � ���8 a� C ���8 a C � ���8 a� C ���8 �� ���8 a�
Cũng theo ñịnh lý này ta có: ���8 a� ��"8 a� � ��� C 6"98 a�½¾¾¾¿¾¾¾À4 ��"8 a� ��� Bổ ñề 3-10
Với � là một luồng trên mạng A �a8 �8 l8 "8 ��. Khi ñó luồng thông qua một lát
cắt " C � bất kỳ không vượt quá lưu lượng của lát cắt ñó.
Chứng minh
Với a � Ø Ù là một lát cắt " C � bất kỳ ta có

189
���8 Ù� È ����ç56èGé9 N È l���
ç56èGé9 l��8 Ù�
ðịnh lý 3-11 (mối quan hệ giữa luồng cực ñại, ñường tăng luồng và lát cắt hẹp nhất)
Nếu � là một luồng trên mạng A �a8 �8 l8 "8 ��, khi ñó ba mệnh ñề sau là tương ñương:
a) � là luồng cực ñại trên mạng A.
b) Mạng thặng dư Aí không có ñường tăng luồng.
c) Tồn tại a � Ø Ù là một lát cắt " C � ñể ���8 Ù� l��8 Ù�
Chứng minh
“a⇒b”
Giả sử phản chứng rằng mạng thặng dư Aí có ñường tăng luồng B thì � � �ô cũng
là một luồng trên A với giá trị luồng lớn hơn �, trái giả thiết � là luồng cực ñại
trên mạng.
“b⇒c”
Nếu Aí không tồn tại ñường tăng luồng thì ta ñặt � là tập các ñỉnh ñến ñược từ "
bằng một ñường thặng dư và Ù là tập các ñỉnh còn lại: � 6�M õ ñường thặng dư " ° � 9� Ù a C �
Rõ ràng � Ú Ù �, � Ø Ù a và " 5 � , � 5 Ù (� không thể ñến ñược từ " bởi
một ñường thặng dư bởi nếu không thì ñường ñi ñó sẽ là một ñường tăng luồng).
Các cung � 5 6� G Ù9 chắc chắn phải là cung bão hòa, bởi nếu có cung thặng dư � �@8 �� 5 6� G Ù9 thì từ " sẽ tới ñược � bằng một ñường thặng dư. Tức là � 5 �, trái với cách xây dựng lát cắt. Từ ���� l��� với L� 5 6� G Ù9, ta có
���8 Ù� È ����ç56èGé9 È l���
ç56èGé9 l��8 Ù� “c⇒a”
Bổ ñề 16.9 và ðịnh lí 16.17 cho thấy giá trị của một luồng trên mạng không thể
vượt quá lưu lượng của một lát cắt " C � bất kỳ. Nếu tồn tại một lát cắt " C � mà
luồng thông qua lát cắt ñúng bằng lưu lượng thì luồng ñó chắc chắn phải là luồng
cực ñại.
Lát cắt " C � có lưu lượng nhỏ nhất (bằng giá trị luồng cực ñại trên mạng) gọi là
Lát cắt hẹp nhất của mạng A.

190
e) e) e) e) Tính dTính dTính dTính daaaang cng cng cng c<<<<a thua thua thua thut toánt toánt toánt toán
Thuật toán Ford-Fulkerson có thời gian thực hiện phụ thuộc vào thuật toán tìm ñường tăng luồng tại mỗi bước. Có thể chỉ ra ñược ví dụ mà nếu dùng DFS ñể tìm ñường tăng luồng thì thời gian thực hiện giải thuật không bị chặn bởi một
hàm ña thức của số ñỉnh và số cạnh. Thêm nữa, nếu sức chứa của các cung là số thực, người ta còn chỉ ra ñược ví dụ mà với thuật toán tìm ñường tăng luồng không tốt, giá trị luồng sau mỗi bước vẫn tăng nhưng không bao giờ ñạt luồng cực ñại. Tức là nếu có thể cài ñặt chương trình tính toán số thực với ñộ chính xác tuyệt ñối, thuật toán sẽ chạy mãi không dừng.
Hình 2.8. Mạng với 4 ñỉnh (1 phát, 4 thu), thuật toán Ford-Fulkerson có thể mất 2 tỉ lần tìm ñường
tăng luồng nếu luân phiên chọn hai ñường ¬ö8 ÷8 ø8 ù và ¬ö8 ø8 ÷8 ù làm ñường tăng luồng, mỗi lần tăng giá trị luồng lên 1 ñơn vị.
Chính vì vậy nên trong một số tài liệu người ta gọi là “phương pháp Ford-Fulkerson” ñể chỉ một cách tiếp cận chung, còn từ “thuật toán” ñược dùng ñể chỉ một cách cài ñặt phương pháp Ford-Fulkerson trên một cấu trúc dữ liệu cụ thể, với một thuật toán tìm ñường tăng luồng cụ thể. Ví dụ phương pháp Ford-Fulkerson cài ñặt với thuật toán tìm ñường tăng luồng bằng BFS như trên ñược gọi là thuật toán Edmonds-Karp. Tính dừng của thuật toán Edmonds-Karp sẽ ñược chỉ ra khi chúng ta ñánh giá thời gian thực hiện giải thuật.
Xét Aí là mạng thặng dư của một mạng A ứng với luồng � nào ñó, ta gán trọng
số 1 cho các cung thặng dư của Aí và gán trọng số �� cho các cung bão hòa
của Aí. Dễ thấy rằng thuật toán tìm ñường tăng luồng bằng BFS sẽ trả về một
ñường ñi ngắn nhất từ " tới � tương ứng với hàm trọng số ñã cho. Ký hiệu «í�@8 �� là ñộ dài ñường ñi ngắn nhất từ @ tới � (khoảng cách từ @ tới �) trên
mạng thặng dư.
1
2
3
4 1
�7 �7
�7 �7

191
Bổ ñề 3-12
Nếu ta khởi tạo luồng 0 và thực hiện thuật toán Edmonds-Karp trên mạng A �a8 �� có ñỉnh phát " và ñỉnh thu �. Khi ñó với mọi ñỉnh � 5 a , khoảng
cách từ " tới � trên mạng thặng dư không giảm sau mỗi bước tăng luồng.
Chứng minh
Khi � ", rõ ràng khoảng cách từ " tới chính nó luôn bằng 0 từ khi bắt ñầu tới
khi kết thúc thuật toán. Ta chỉ cần chứng minh bổ ñề ñúng với những ñỉnh � d ".
Giả sử phản chứng rằng tồn tại một ñỉnh � 5 a C 6"9 mà khi thuật toán Edmonds-
Karp tăng luồng � lên thành �ó sẽ làm cho «íú�"8 �� nhỏ hơn «í�"8 �� . Nếu có
nhiều ñỉnh � như vậy ta chọn ñỉnh � có «íú�"8 �� nhỏ nhất. Gọi B " ° @ G � là
ñường ñi ngắn nhất từ " tới � trên Aíú, ta có �@8 �� là cung thặng dư trên Aíú và
«íú�"8 @� «íú�"8 �� C �
Bởi cách chọn ñỉnh �, ñộ dài ñường ñi ngắn nhất từ " tới @ không thể bị giảm ñi
sau phép tăng luồng, tức là «íú�"8 @� w «í�"8 @�
Ta chứng minh rằng �@8 �� phải là cung bão hòa trên Aí. Thật vậy, nếu �@8 �� là
cung thặng dư (có trọng số 1) trên Aí thì:
«í�"8 �� N «í�"8 @� � � (bất ñẳng thức tam giác) N «íú�"8 @� � � (khoảng cách từ " tới @ không giảm) «íú�"8 �� Trái với giả thiết rằng khoảng cách từ " tới � phải giảm ñi sau phép tăng luồng.
Làm thế nào ñể �@8 �� là cung bão hòa trên Aí nhưng lại là cung thặng dư trên Aíú? Câu trả lời duy nhất là do phép tăng luồng từ � lên �Û làm giảm luồng trên
cung �@8 ��, tức là cung ñối ��8 @� phải là một cung trên ñường tăng luồng tìm
ñược. Vì ñường tăng luồng tại mỗi bước luôn là ñường ñi ngắn nhất nên ��8 @�
phải là cung cuối cùng trên ñường ñi ngắn nhất từ " tới @ của Aí. Từ ñó suy ra:
«í�"8 �� «í�"8 @� C � N «íú�"8 @� C � (khoảng cách từ " tới @ không giảm) «íú�"8 �� C ; (theo cách chọn @ và �) Mâu thuẫn với giả thuyết khoảng cách từ " tới � phải giảm ñi sau khi tăng luồng.
Ta có ñiều phải chứng minh: Với L� 5 a, khoảng cách từ " tới � trên mạng thặng
dư không giảm sau mỗi bước tăng luồng.

192
Bổ ñề 3-13
Nếu thuật toán Edmonds-Karp thực hiện trên mạng A �a8 �8 l8 "8 �� với luồng khởi tạo là luồng 0 thì số lượt tăng luồng ñược sử dụng trong thuật toán là $��a�����E
Chứng minh
Ta chia quá trình thực hiện thuật toán Edmonds-Karp thành các pha. Mỗi pha tìm
một ñường tăng luồng B và tăng luồng thêm một giá trị thặng dư Òô. Giá trị thặng
dư này theo ñịnh nghĩa sẽ phải bằng sức chứa của một cung thặng dư � nào ñó
trên ñường B: õ� 5 BM Òô l��� C ���� Khi tăng luồng dọc trên ñược B thì cung � sẽ trở thành bão hòa. Những cung
thặng dư trở nên bão hòa sau khi tăng luồng gọi là cung tới hạn (critical edge) tại
mỗi pha. Mỗi pha có ít nhất một cung tới hạn.
Ta ñánh giá xem mỗi cung của mạng có thể trở thành cung tới hạn bao nhiêu lần.
Với một cung � �@8 ��, ta xét pha � ñầu tiên làm � trở thành cung tới hạn và �Ü
là luồng khi bắt ñầu pha �. Do � nằm trên ñường tăng luồng ngắn nhất trên Aíû
nên khi pha này bắt ñầu: «íû�"8 @� � � «íÜ�"8 ��
Pha � sau khi tăng luồng sẽ làm cung � sẽ trở nên bão hòa.
ðể � có thể trở thành cung tới hạn một lần nữa thì tiếp theo pha � phải có một pha H giảm luồng trên cung � ñể biến � thành cung thặng dư, tức là cung – � ��8 @�
phải là một cung trên ñường tăng luồng của pha H. Gọi �ü là luồng khi pha H bắt
ñầu, cũng vì tính chất của ñường ñi ngắn nhất, ta có «íü�"8 �� � � «íü�"8 @�
Bổ ñề 16.12 ñã chứng minh rằng khoảng cách từ " tới � trên mạng thặng dư không
giảm ñi sau mỗi pha, nên «íý�"8 �� w «íû�"8 ��. Suy ra:
«íý�"8 @� «íý�"8 �� � � w «íû�"8 �� � � «íû�"8 @� � ;
Như vậy nếu một cung �@8 �� là cung tới hạn trong � pha thì khi pha thứ � bắt
ñầu, khoảng cách từ " tới @ trên mạng thặng dư ñã tăng lên ít nhất ;�� C �� ñơn vị
so với thời ñiểm trước pha thứ nhất. Khoảng cách «í�"8 @� ban ñầu là số không âm
và chừng nào còn ñường thặng dư ñi từ " tới @, khoảng cách «í�"8 @� không thể
vượt quá �a� C �. ðiều ñó cho thấy � N �¶�K(+ $��a��.

193
Tổng hợp lại, ta có:
� Mạng có tất cả ��� cung.
� Mỗi pha có ít nhất một cung tới hạn
� Một cung có thể trở thành tới hạn trong $��a�� pha
Vậy tổng số pha ñược thực hiện trong thuật toán Edmonds-Karp là một ñại lượng $��a�����
ðịnh lý 3-14
Có thể cài ñặt thuật toán Edmonds-Karp ñể tìm luồng cực ñại trên mạng A �a8 �8 l8 "8 �� trong thời gian $��a����+�.
Chứng minh
Bổ ñề 3-15 ñã chứng minh rằng thuật toán Edmonds-Karp cần thực hiện $��a����� lượt tăng luồng. Tại mỗi lượt thuật toán tìm ñường tăng luồng bằng
BFS và tăng luồng dọc ñường này có thời gian thực hiện $�����. Suy ra thời gian
thực hiện giải thuật Edmonds-Karp là $��a����+�.
Nếu khả năng thông qua trên các cung của mạng là số nguyên thì còn có một cách ñánh giá khác dựa trên giá trị luồng cực ñại, nếu ta khởi tạo luồng 0 thì sau mỗi lượt tăng luồng, giá trị luồng ñược tăng lên ít nhất 1 ñơn vị. Suy ra thời gian
thực hiện giải thuật khi ñó là $�������� với ��� là giá trị luồng cực ñại.
3.3. Thuật toán ñẩy tiền luồng
Thuật toán Ford-Fulkerson không những là một cách tiếp cận thông minh mà việc chứng minh tính ñúng ñắn của nó cho ta nhiều kết quả thú vị về mối liên hệ giữa luồng cực ñại và lát cắt hẹp nhất. Tuy vậy với những ñồ thị kích thước rất lớn thì tốc ñộ của chương trình tương ñối chậm.
Trong phần này ta sẽ trình bày một lớp các thuật toán nhanh nhất cho tới nay ñể giải bài toán luồng cực ñại, tên chung của các thuật toán này là thuật toán ñẩy tiền luồng (preflow-push).
Hãy hình dung mạng như một hệ thống ñường ống dẫn nước từ với ñiểm phát "
tới ñiểm thu �, các cung là các ñường ống, sức chứa là lưu lượng ñường ống có thể tải. Nước chảy theo nguyên tắc từ chỗ cao về chỗ thấp. Với một lượng nước
lớn phát ra từ " tới một ñỉnh �, nếu có cách chuyển lượng nước ñó sang ñịa ñiểm
khác thì không có vấn ñề gì, nếu không thì có hiện tượng “tràn” xảy ra tại �, ta
“dâng cao” ñiểm � ñể lượng nước ñó ñổ sang ñiểm khác (có thể ñổ ngược về ").

194
Cứ tiếp tục quá trình như vậy cho tới khi không còn hiện tượng tràn ở bất cứ ñiểm nào. Cách tiếp cận này hoàn toàn khác với thuật toán Ford-Fulkerson: thuật
toán Ford-Fulkerson cố gắng tìm một dòng chảy phụ từ " tới � và thêm dòng chảy này vào luồng hiện có ñến khi không còn dòng chảy phụ nữa.
a) a) a) a) TiTiTiTiEEEEn lun lun lun lu^̂̂̂ngngngng
Cho một mạng A �a8 �8 l8 "8 ��. Một tiền luồng (preflow) trên A là một hàm: �M � � � � ¦ ����
gán cho mỗi cung � 5 � một số thực ���� thỏa mãn ba ràng buộc:
� Ràng buộc về sức chứa (capacity constraint): tiền luồng trên mỗi cung
không ñược vượt quá sức chứa của cung ñó: L� 5 �: ���� N l���. � Ràng buộc về tính ñối xứng lệch (skew symmetry): Với L� 5 �, tiền luồng
trên cung � và cung ñối – � có cùng giá trị tuyệt ñối nhưng trái dấu nhau: ���� C��C��. � Ràng buộc về tính dư: Với mọi ñỉnh không phải ñỉnh phát, tổng tiền luồng
trên các cung ñi vào ñỉnh ñó là số không âm: L� 5 a C 6"9: ��a8 6�9� : ����ç5̶G6©9Í w 7.
Với L� 5 a, ta gọi lượng tràn tại �, ký hiệu � l�""���, là tổng tiền luồng trên
các cung ñi vào ñỉnh �:
� l�""��� ��a8 6�9� È ����ç5̶G6©9Í
ðỉnh � 5 a C 6"8 �9 gọi là ñỉnh tràn (overflowing vertex) nếu � l�""��� 1 7 . Khái niệm ñỉnh tràn chỉ có nghĩa với các ñỉnh không phải ñỉnh phát cũng không phải ñỉnh thu.
function Overflow(v5V): Boolean; begin
Result := (v ≠ s) and (v ≠ t) and (excess[u] > 0);
end;

195
ðịnh nghĩa về tiền luồng tương tự như ñịnh nghĩa luồng, chỉ khác nhau ở ràng buộc thứ ba. Vì vậy chúng ta cũng có khái niệm mạng thặng dư, cung thặng dư, ñường thặng dư… ứng với tiền luồng tương tự như ñối với luồng.
b) b) b) b) KhKhKhKhBBBBi ti ti ti t9999oooo
Cho � là một tiền luồng trên mạng A �a8 �8 l8 "8 ��. Ta gọi �M a G ¡ là một
hàm ñộ cao ứng với � nếu � gán cho mỗi ñỉnh � 5 a một số tự nhiên ���� thỏa mãn ba ñiều kiện:
� ��"� �a�. � ���� 7.
� ��@� N ���� � � với mọi cung thặng dư �@8 ��.
Những ràng buộc này gọi là ràng buộc ñộ cao.
Hàm ñộ cao � khi cài ñặt sẽ ñược xác ñịnh bởi tập các giá trị 6����9©5¶ nên tùy
theo từng trường hợp, ta có thể sử dụng ký hiệu ���� (nếu muốn nói tới giá trị
hàm) hoặc ���� (nếu muốn nói tới một biến số). Thao tác khởi tạo =��� chịu trách nhiệm khởi tạo một tiền luồng và một hàm ñộ
cao tương ứng. Một cách khởi tạo là ñặt tiền luồng trên mỗi cung � ñi ra khỏi "
ñúng bằng sức chứa l��� của cung ñó (dĩ nhiên sẽ phải ñặt cả tiền luồng trên
cung ñối – � bằng – l��� ñể thỏa mãn tính ñối xứng lệch), còn tiền luồng trên
các cung khác bằng 0. Khi ñó tất cả các cung ñi ra khỏi " là bão hòa.
���� �l���8 nếu � 5 �K�"�Cl���8 nếu C � 5 �K�"�78 trường hợp khác
� Ta khởi tạo hàm ñộ cao �M a G ¡ như sau:
���� ��a�8 oế� � "78 oế� � ��8 nếu � d 6"8 �9� Rõ ràng mọi cung thặng dư �@8 �� không thể là cung ñi ra khỏi " (@ d ") nên ta
có ��@� N � N ���� � �. Hàm ñộ cao trên là thích ứng với tiền luồng �.
Việc cuối cùng là khởi tạo các giá trị � l�""�E � ứng với tiền luồng �.
procedure Init;

196
begin
//Khởi tạo tiền luồng
for Le 5 E do f[e] := 0; for Lv 5 V do excess[v] := 0; for Le =(s,v)5 E+(s) do begin
f[e] := c(e);
f[-e] := -c(e);
excess[v] := excess[v] + c(e);
end;
//Khởi tạo hàm ñộ cao
for Lv 5 V do h[v] := 1; h[s] := |V|;
h[t] := 0;
end;
c) c) c) c) Phép "Phép "Phép "Phép "bbbby luy luy luy lu^̂̂̂ngngngng
Phép ñẩy luồng B@"���� có thể thực hiện trên cung � �@8 �� nếu các ñiều kiện sau ñược thỏa mãn:
� @ là ñỉnh tràn: @ 5 a C 6"8 �9 và � l�""�@� 1 7
� � là cung thặng dư trên Aí: lí��� l��� C ���� 1 7
� @ cao hơn �: ��@� 1 ����
Ràng buộc ��@� 1 ���� kết hợp với ràng buộc ñộ cao: ��@� N ���� � � có thể
viết thành ��@� ���� � �.
Phép B@"�g� �@8 ��h sẽ tính lượng luồng tối ña có thể thêm vào theo cung �: Ò �µoÌ� l�""�@�8 lí���Í, thêm lượng luồng này vào cung � và bớt một lượng
luồng Ò từ � về @ theo cung – � ñể giữ tính ñối xứng lệch của tiền luồng. Việc
cuối cùng là cập nhật lại � l�""�@� và � l�""��� theo tiền luồng mới. Bản chất
của phép B@"�g� �@8 ��h là chuyển một lượng luồng tràn Ò từ ñỉnh @ sang
ñỉnh �. Dễ thấy rằng các tính chất của tiền luồng vẫn ñược duy trì sau phép B@"�:
procedure Push(e = (u,v));
begin
∆ := min(excess[u], cf(u, v)); //Tính lượng luồng tối ña có thể ñẩy

197
f[e] := f[e] + ∆; f[-e] := f[-e] – ∆; //ðẩy luồng
excess[u] := excess[u] – ∆;
excess[v] := excess[v] + ∆; //Cập nhật mức tràn
end;
Phép B@"� bảo tồn tính chất của hàm ñộ cao. Thật vậy, khi thao tác B@"�g� �@8 ��h ñược thực hiện, nó chỉ có thể sinh ra thêm một cung thặng dư C� ��8 @� mà thôi. Phép B@"� không làm thay ñổi các ñộ cao, tức là trước khi B@"�, ��@� 1 ���� thì sau khi B@"�, ���� vẫn nhỏ hơn ��@�, tức là ràng buộc ñộ cao ���� N ��@� � � vẫn ñược duy trì trên cung thặng dư C� ��8 @�.
Phép B@"�g� �@8 ��h ñẩy một lượng luồng Ò �µoÌ� l�""�@�8 lí���Í tràn từ @ sang �. Nếu Ò ñúng bằng lí��� l��� C ���� có nghĩa là khi phép B@"� tăng ���� lên Ò thì cung � sẽ bão hòa và không còn là cung thặng dư trên Aí nữa, ta
gọi phép ñẩy luồng này là ñẩy bão hòa (saturating push), ngược lại phép ñẩy luồng ñó gọi là ñẩy không bão hòa (non-saturating push), sau phép ñẩy không
bão hòa thì � l�""�@� 7, tức là @ không còn là ñỉnh tràn nữa. d) d) d) d) Phép nângPhép nângPhép nângPhép nâng
Phép nâng #����@� thực hiện trên ñỉnh @ nếu các ñiều kiện sau ñược thỏa mãn:
� @ là ñỉnh tràn: �@ d "�, �@ d �� và � l�""�@� 1 7.
� @ không chuyển ñược luồng xuống nơi nào thấp hơn: Với mọi cung thặng
dư � �@8 �� 5 �í: ��@� N ����. Khi ñó phép #����@� nâng ñỉnh @ lên bằng cách ñặt ��@� bằng ñộ cao thấp nhất
của một ñỉnh � nó có thể chuyển tải sang cộng thêm 1: ��@� z �µoÌ����M õ�@8 �� 5 �íÍ � � procedure Lift(u5V); begin
minH := +∞;
for Lv:(u,v)5 Ef do if h[v] < minH then minH := h[v];
h[u] := minH + 1;
end;

198
Nếu @ là ñỉnh tràn thì ít nhất phải có một cung thặng dư ñi ra khỏi @, ñiều này
ñảm bảo cho phép lấy �µoÌ����M �@8 �� 5 �íÍ ñược thực hiện trên một tập khác
rỗng. Thật vậy, do @ là ñỉnh tràn, ta có � l�""�@� : ����ç5̶G6¨9Í 1 7 tức là ít
nhất có một cung � 5 Ìa G 6@9Í ñể ���� 1 7. Cung ñối – � chắc chắn là một
cung thặng dư ñi ra khỏi @ bởi: lí�C�� l�C�� C ��C�� l�C�� � ���� 1 7
Phép #��� không ñộng chạm gì ñến tiền luồng �. Ngoài ra phép #��� chỉ tăng ñộ cao của một ñỉnh và bảo tồn ràng buộc ñộ cao: Với một cung thặng dư ��8 @� ñi vào @, ràng buộc ñộ cao ���� N ��@� � � không bị vi phạm nếu ta
nâng ñộ cao ��@� của ñỉnh @. Mặt khác, với một cung thặng dư �@8 �� ñi ra khỏi @ thì việc ñặt ��@� z �µoÌ����M õ�@8 �� 5 �íÍ � � cũng ñảm bảo rằng ��@� N���� � �. e) e) e) e) Mô hình chung và thuMô hình chung và thuMô hình chung và thuMô hình chung và thut toán FIFO Preflowt toán FIFO Preflowt toán FIFO Preflowt toán FIFO Preflow----PushPushPushPush
� Mô hình chung
Thuật toán ñẩy tiền luồng có mô hình cài ñặt chung khá ñơn giản: Khởi tạo tiền
luồng � và hàm ñộ cao, sau ñó nếu thấy phép nâng (#���) hay ñẩy luồng (B@"�) nào thực hiện ñược thì thực hiện nga… Cho tới khi không còn phép nâng hay
ñẩy nào có thể thực hiện ñược nữa thì tiền luồng � sẽ trở thành luồng cực ñại trên mạng.
Chính vì thứ tự các phép B@"� và #��� ñược thực hiện không ảnh hưởng tới tính ñúng ñắng của thuật toán nên người ta ñã ñề xuất rất nhiều cơ chế chọn thứ tự thực hiện nhằm giảm thời gian thực hiện giải thuật.
Bổ ñề 3-15
Cho mạng A �a8 �8 l8 "8 �� có tiền luồng � và hàm ñộ cao �. Với một ñỉnh tràn @, luôn có thể thực hiện ñược thao tác B@"���� trên một cung � ñi ra khỏi @
hoặc thực hiện ñược thao tác #����@�
Chứng minh
Nếu thao tác B@"� không thể áp dụng ñược cho cung thặng dư nào ñi ra khỏi @
tức là với mọi cung thặng dư �@8 �� 5 �í , ��@� không cao hơn ����, ñiều ñó chính
là ñiều kiện hợp lệ ñể thực hiện thao tác #����@�.

199
� Thuật toán FIFO Preflow-Push
ðịnh lý 3-17 là cơ sở cho thuật toán FIFO Preflow-Push. Thuật toán ñược
Goldberg ñề xuất [18] dựa trên cơ chế xử lý ñỉnh tràn lấy ra từ một hàng ñợi.
Tại thao tác khởi tạo, các ñỉnh tràn sẽ ñược lưu trữ trong một hàng ñợi u@�@�
hỗ trợ hai thao tác: B@"���u@�@���� ñể ñẩy một ñỉnh tràn � vào hàng ñợi và B��?!��u@�@� ñể lấy một ñỉnh tràn khỏi hàng ñợi. Thuật toán sẽ xử lý từng
ñỉnh tràn c lấy ra khỏi hàng ñợi theo cách sau: Trước hết cố gắng ñẩy luồng trên
các cung thặng dư ñi ra khỏi c bằng phép B@"�. Nếu ñẩy ñược hết lượng tràn
(� l�""�c� 7) thì xong, nếu không ta dâng cao ñỉnh c bằng phép #����c� và
ñẩy lại c vào hàng ñợi chờ xử lý sau. Thuật toán sẽ tiếp tục với ñỉnh tràn tiếp theo trong hàng ñợi và kết thúc khi hàng ñợi rỗng, bởi khi mạng không còn ñỉnh
tràn thì không còn thao tác B@"� hay #��� nào có thể thực hiện ñược nữa.
Giả sử rằng chúng ta có một ñỉnh tràn @ và một cung � �@8 �� không thể ñẩy luồng ñược, tức là ít nhất một trong hai ñiều kiện sau ñây ñược thỏa mãn:
� �@8 �� là cung bão hòa l��� ����.
� @ không cao hơn �: ��@� N ����.
Khi ñó:
� Sau bất kỳ phép B@"� nào, chúng ta vẫn không thể ñẩy luồng ñược trên
cung � �@8 ��. Thật vậy, nếu @ không cao hơn �, phép B@"� không làm
thay ñổi hàm ñộ cao nên sau phép B@"� thì @ vẫn không cao hơn �. Nếu @
cao hơn � thì � phải là cung bão hòa, lệnh B@"� duy nhất có thể biến nó
thành cung thặng dư là lệnh B@"��C�� làm giảm ���� . Nhưng lệnh B@"��C�� không thể thực hiện ñược vì cung – � ��8 @� có � thấp hơn @.
� Sau bất kỳ phép #��� nào ngoại trừ #����@�, chúng ta cũng không thể ñẩy
luồng ñược trên cung � �@8 ��. Bởi phép #��� không làm thay ñổi tiền luồng trên các cung, tính bão hòa hay thặng dư của các cung ñược giữ
nguyên. Như vậy nếu �@8 �� ñang bão hòa thì sau phép #��� nó vẫn bão hòa
và không thể ñẩy luồng ñược. Nếu �@8 �� là cung thặng dư thì @ ñang không
cao hơn �, lệnh #��� duy nhất có thể khiến @ cao hơn � là lệnh #����@�.
Hai nhận ñịnh trên cho phép ta xây dựng một cấu trúc dữ liệu hiệu quả ñể cài ñặt thuật toán:

200
Tương tự như chương trình cài ñặt thuật toán Edmonds-Karp, ta sử dụng mảng ��C� �� chứa các cung, mảng ������ �� chứa móc nối trong danh sách
liên thuộc và mảng ����� �� chứa chỉ số cung ñầu tiên của các danh sách
liên thuộc. Ngoài ra thuật toán duy trì một mảng chỉ số l@!!����� ��, ở ñây l@!!������ là chỉ số của một cung nào ñó trong danh sách liên thuộc các cung
ñi ra khỏi �, ban ñầu l@!!������ ñược gán bằng ������ với mọi ñỉnh � 5 a.
type
TEdge = record //Cấu trúc một cung
x, y: Integer; //Hai đỉnh đầu mút
c, f: Integer; //Sức chứa và luồng
end;
var
e: array[-maxM..maxM] of TEdge; //Danh sách các cung
link: array[-maxM..maxM] of Integer;
//Móc nối trong danh sách liên thuộc head, current: array[1..maxN] of Integer;
Trên cấu trúc dữ liệu này, danh sách móc nối các nút chứa các cung ñi ra khỏi c là: ���(�8 ���+�8 �����8 Trong ñó �( ����c�, �+ ������(�, �� ������+�,…
Thuật toán FIFO Preflow-Push sẽ xử lý lần lượt từng ñỉnh tràn lấy ra khỏi hàng
ñợi. Với mỗi ñỉnh tràn c lấy khỏi hàng ñợi, cung �þl@!!����c�� là một cung ñi
ra khỏi c, giả sử cung ñó là �c8 ��. Nếu phép ñẩy luồng (B@"�) trên cung ñó có
thể thực hiện ñược thì thực hiện ngay, ñồng thời ñẩy � vào hàng ñợi nếu � chưa
có trong hàng ñợi. Nếu phép ñẩy luồng này làm c hết tràn thì chuyển sang xử lý
ñỉnh tràn kế tiếp trong hàng ñợi, ngược lại nếu c vẫn còn là ñỉnh tràn (tức là
không thể ñẩy luồng trên cung �þl@!!����c�� nữa), ta dịch chỉ số l@!!����c� sang cung kế tiếp trong danh sách liên thuộc (l@!!����c� z ����þl@!!����c��) ñể chuyển sang xét một cung khác…Khi dịch chỉ số l@!!����c� ñến hết danh
sách liên thuộc mà c vẫn tràn, ñỉnh c sẽ ñược nâng lên bằng phép #����c�, chỉ số l@!!���� � ñược ñặt trở lại bằng ����c� ñể nó trỏ lại về ñầu danh sách liên
thuộc. ðỉnh c sau ñó ñược ñẩy lại vào hàng ñợi chờ xử lý sau…

201
Tính hợp lý của thuật toán nằm ở chỗ : khi ñỉnh tràn c bắt ñầu ñược xử lý, tất cả
những cung ñứng trước cung �þl@!!����c�� ñều không thể ñẩy luồng ñược. Tức
là nếu muốn ñẩy luồng ra khỏi c thì chỉ cần xét các cung từ �þl@!!����c�� trở ñi
là ñủ, không cần duyệt từ ñầu danh sách liên thuộc.
procedure FIFOPreflowPush;
begin
Init; //Khởi tạo tiền luồng, ñộ cao, hàng ñợi Queue chứa các ñỉnh tràn
while Queue ≠ � do begin
z := PopFromQueue; //Xử lý ñỉnh tràn x lấy ra từ hàng ñợi
while current[z] <> 0 do //Cố gắng đẩy luồng khỏi z
begin //Xét cung (z, v) chứa trong nút e[current[z]]
v := e[current[z]].y;
if «Có thể ñẩy luồng trên cung (z, v)» then
begin
NeedQueue := (v ≠ s) and (v ≠ t)
and (excess[v] = 0);
Push(z, v); //ðẩy luồng
if NeedQueue then
//Sau phép ñẩy, v ñang không tràn trở thành tràn
PushToQueue(v); //ðẩy v vào hàng ñợi chờ xử lý
if excess[z] = 0 then Break;
//Sau phép ñẩy mà z hết tràn thì dừng ñẩy end;
current[z] := link[current[z]];
//z chưa hết tràn, chuyển sang xét cung liên thuộc tiếp theo end;
if excess[z] > 0 then //Duyệt hết danh sách liên thuộc mà x vẫn tràn
begin
Lift(z); //Dâng cao z
current[z] := head[z]; //ðặt lại chỉ số current[z] về nút ñầu danh sách liên thuộc
PushToQueue(z); //ðẩy z vào hàng ñợi chờ xử lý sau
end;
end;
end;

202
Từ nhận xét trên, có thể nhận thấy rằng những phép B@"� và #��� trong mô hình cài ñặt ñảm bảo ñược gọi tại những thời ñiểm mà những ñiều kiện cần ñể thực thi chúng ñược thỏa mãn. ffff) ) ) ) Tính "úng cTính "úng cTính "úng cTính "úng c<<<<a thua thua thua thut toánt toánt toánt toán
Sau mỗi bước của vòng lặp chính, hàng ñợi u@�@� luôn chứa danh sách các ñỉnh tràn và thuật toán sẽ kết thúc khi không còn ñỉnh tràn nào trên mạng. Với L� 5 a C 6"8 �9, ta có: ��6�98 a� C��a8 6�9� C� l�""��� 7
Tức là với L� 5 a C 6"8 �9 thì tổng luồng trên các cung ñi ra khỏi � bằng 0, ñiều này chỉ ra rằng khi thuật toán kết thúc, tiền luồng chúng ta duy trì trên mạng trở thành một luồng. ðịnh lý 3-16
Cho � là một tiền luồng trên mạng A �a8 �8 l8 "8 ��, nếu tồn tại một hàm ñộ cao �M a G ¡ ứng với � thì mạng thặng dư Aí không có ñường tăng luồng.
Chứng minh
Nhắc lại về ràng buộc ñộ cao: ��"� �a�, ���� 7 và với mọi cung thặng dư �@8 �� thì ��@� N ���� � �. Giả sử phản chứng rằng có ñường tăng luồng ¬" �48 �(8 8 �I � trên mạng thặng dư Aí ñi qua � cung thặng dư. Khi ñó:
���4� N ���(� � � N ���+� � ; N - N ���I� � � hay
��"�ß�¶� N ����ß4 � �
Ta có �a� N �, nhưng ñường tăng luồng phải là ñường ñi ñơn, tức là qua không
quá �a� C � cạnh, vậy � N �a� C �. ðiều này mâu thuẫn, nghĩa là không thể tồn tại
ñường tăng luồng trên Aí.
ðịnh lý 3-17 và ðịnh lý 3-11 (mối quan hệ giữa luồng cực ñại, ñường tăng luồng và lát cắt hẹp nhất) chỉ ra rằng: thuật toán ñẩy tiền luồng trả về một luồng và một hàm ñộ cao ứng với luồng ñó nên luồng trả về chắc chắn là luồng cực ñại.

203
g) g) g) g) Tính dTính dTính dTính daaaang cng cng cng c<<<<aaaa thuthuthuthut toánt toánt toánt toán
Tính dừng của thuật toán ñẩy tiền luồng ở trên sẽ ñược suy ra khi chúng ta phân tích thời gian thực hiện giải thuật. Tương tự như thuật toán Ford-Fulkerson, chúng ta sẽ không phân tích thời gian thực hiện trên mô hình tổng quát mà chỉ phân tích thời gian thực hiện giải thuật FIFO Preflow-Push mà thôi.
ðịnh lý 3-17
Cho � là một tiền luồng trên mạng A �a8 �8 l8 "8 ��, khi ñó với mọi ñỉnh tràn @,
tồn tại một ñường thặng dư ñi từ @ tới ".
Chứng minh
Với một ñỉnh tràn @ bất kỳ, xét tập � là tập các ñỉnh có thể ñến ñược từ @ bằng
một ñường thặng dư. ðặt Ù a C � là tập những ñỉnh nằm ngoài �. Trước hết ta
chỉ ra rằng tiền luồng trên các cung thuộc 6Ù G �9 không thể là số dương. Thật
vậy nếu có � 5 6Ù G �9 mà ���� 1 7 thì – � 5 6� G Ù9 và ��C�� O 7. Suy ra có
cung thặng dư – � nối một ñỉnh thuộc � với một ñỉnh > nào ñó thuộc Ù. Theo cách
xây dựng tập �, > sẽ phải là ñỉnh thuộc �. Mâu thuẫn.
Tiền luồng trên các cung thuộc 6Ù G �9 không thể là số dương thì ��Ù8 �� N 7.
Ta xét tổng mức tràn của các ñỉnh 5 �: � l�""��� ��a8 �� ���8 ��½¾¿¾À4 � ��Ù8 ��½¾¿¾À·4 N 7
Lượng tràn tại mỗi ñỉnh không phải ñỉnh phát ñều là số không âm, ngoài ra @ là
ñỉnh tràn 5 � nên � l�""�@� 1 7, ñiều này cho thấy chắc chắn ñỉnh phát " phải
thuộc � ñể � l�""��� N 7. Nói cách khác từ @ ñến ñược " bằng một ñường thặng
dư.
Hệ quả
Cho mạng A �a8 �8 l8 "8 ��. Giả sử chúng ta thực hiện thuật toán ñẩy tiền luồng
với hàm ñộ cao �M a G ¡ thì ñộ cao của các ñỉnh trong quá trình thực hiện giải
thuật không vượt quá ;�a� C �.
Chứng minh
Mạng phải có ít nhất một ñỉnh phát và một ñỉnh thu nên �a� w ; . Ban ñầu, ��"� �a�, ���� 7 và ���� �8 L� ª 6"8 �9 nên ñộ cao của các ñỉnh ñều nhỏ
hơn ;�a� C �.
ðộ cao của " và � không bao giờ bị thay ñổi và với mỗi ñỉnh @ 5 a C 6"8 �9 thì chỉ
phép #����@� có thể làm tăng ñộ cao của ñỉnh @. ðiều kiện ñể thực hiện phép

204
#����@� là @ phải là ñỉnh tràn. Phép #��� không thay ñổi tiền luồng nên sau phép #����@� thì @ vẫn tràn. Áp dụng kết quả của ðịnh lý 3-17, tồn tại ñường ñi ñơn
từ @ tới " ¬@ �48 �(8 8 �I " chỉ ñi qua � cung thặng dư ��48 �(�,��(8 �+�,…,��I3(8 �I�. Từ ràng buộc ñộ cao ta có: ��@� ���4� N ���(� � � N ���+� � ; N - N ���I� � � N �a� � � ðường ñi ñơn thì không qua nhiều hơn �a� C � cạnh nên ta có � N �a� C �, kết
hợp lại có ��@� N ;�a� C �. ðPCM.
ðịnh lý 3-18 (thời gian thực hiện giải thuật FIFO Preflow-Push)
Có thể cài ñặt giải thuật FIFO Preflow-Push ñể tìm luồng cực ñại trên mạng A �a8 �8 l8 "8 �� trong thời gian $��a�� � �a�����.
Chứng minh
Ta sẽ chứng minh mô hình cài ñặt thuật toán FIFO Preflow-Push ở trên có thời
gian thực hiện là $��a�� � �a�����. Vòng lặp chính của thuật toán mỗi lượt lấy
một ñỉnh tràn c khỏi hàng ñợi và cố gắng tháo luồng cho ñỉnh c bằng các
phép B@"� theo các cung ñi ra khỏi c. Nếu c chưa hết tràn thì thực hiện phép #����c� và ñẩy lại c vào hàng ñợi. Như vậy thuật toán FIFO Preflow-Push sẽ thực
hiện một dãy các phép #��� và B@"�: #����E �8 B@"��E �8 B@"��E � 8 B@"��E �8 #����E �8 B@"��E �8
Trước hết ta chứng minh rằng số phép #��� trong dãy thao tác trên là $��a�+� và
tổng thời gian thực hiện chúng là $��a�����. Thật vậy, Mỗi phép #��� sẽ nâng ñộ
cao của một ñỉnh lên ít nhất 1, ngoài ra ñộ cao của mỗi ñỉnh không vượt quá ;�a� C � (theo hệ quả của ñịnh lý ðịnh lý 3-17). Cứ cho là mọi ñỉnh 5 a C6"8 �9 khi kết thúc thuật toán ñều có ñộ cao ;�a� C � ñi nữa thì do chúng ñược khởi
tạo bằng 1, tổng số phép #��� cần thực hiện cũng không vượt quá: ��a� C ;��;�a� C ;� $��a�+�
Mỗi cung �@8 �� sẽ ñược xét ñến ñúng một lần trong phép #����@�, phép #����@�
lại ñược gọi không quá ;�a� C ; lần. Vậy tổng cộng trong tất cả các phép #��� thì
mỗi cung sẽ ñược xét không quá ;�a� C ; lần, mạng có ��� cung suy ra tổng thời
gian thực hiện của các phép #��� trong giải thuật là ����;�a� C ;� $��a�����.
Tiếp theo ta chứng minh rằng số phép ñẩy bão hòa cũng như tổng thời gian thực
hiện chúng là $��a�����. Sau phép ñẩy bão hòa B@"����, nếu muốn thực hiện tiếp
phép ñẩy B@"���� nữa thì trước ñó chắc chắn phải có phép ñẩy B@"��C�� ñể làm
giảm ���� và biến � trở lại thành cung thặng dư. Giả sử � �@8 �� và – � ��8 @�
thì ñể thực hiện phép B@"����, ta phải có ��@� 1 ����. ðể thực hiện B@"��C��,
ta phải có ���� 1 ��@� và ñể thực hiện tiếp B@"���� nữa ta lại phải có ��@� 1

205
����. Bởi ñộ cao của các ñỉnh không bao giờ giảm ñi nên sau phép B@"���� thứ
hai, ñộ cao ��@� lớn hơn ít nhất 2 ñơn vị so với ��@� ở phép B@"���� thứ nhất.
Vậy nếu một cung � �@8 �� của mạng ñược ñẩy bão hòa � lần thì ñộ cao của
ñỉnh @ sẽ tăng lên ít nhất là ;�� C ��. Vì ñộ cao của các ñỉnh không vượt quá ;�a� C � nên số phép ñẩy bão hòa trên mỗi cung � là � N �a�. Mạng có ��� cung
và thời gian thực hiện phép B@"� là $��� nên số phép ñẩy bão hòa là $��a����� và
thời gian thực hiện chúng cũng là $��a�����.
ðối với các phép ñẩy không bão hòa, việc ñánh giá thời gian thực hiện giải thuật ñược thực hiện bằng hàm tiềm năng (potential function). ðịnh nghĩa hàm tiềm
năng � là ñộ cao lớn nhất của các ñỉnh tràn:
� �n�6����M � là ñỉnh tràn9
Trong trường hợp mạng không còn ñỉnh tràn thì ta quy ước � 7. Vậy � N � khi
khởi tạo tiền luồng và trở lại bằng 0 khi thuật toán kết thúc.
Chia dãy các thao tác #��� và B@"� làm các pha liên tiếp. Pha thứ nhất bắt ñầu khi
hàng ñợi ñược khởi tạo gồm các ñỉnh tràn và kết thúc khi tất cả các ñỉnh ñó (và
chỉ những ñỉnh ñó thôi) ñã ñược lấy ra khỏi hàng ñợi và xử lý. Pha thứ hai tiếp tục
với hàng ñợi gồm những ñỉnh ñược ñẩy vào trong pha thứ nhất và kết thúc khi tất
cả các ñỉnh này ñược lấy ra khỏi hàng ñợi và xử lý, pha thứ ba, thứ tư… ñược chia
ra theo cách tương tự như vậy.
Nhận xét rằng phép B@"� chỉ ñẩy luồng từ ñỉnh cao xuống ñỉnh thấp, vậy nên
những ñỉnh ñược ñẩy vào hàng ñợi sau phép B@"� luôn thấp hơn ñỉnh ñang xét
vừa lấy ra khỏi hàng ñợi. Suy ra nếu một pha chỉ chứa phép B@"� thì giá trị hàm
tiềm năng � sau pha ñó giảm ñi ít nhất 1 ñơn vị.
Giá trị hàm tiềm năng � chỉ có thể tăng lên sau một pha nếu pha ñó có chứa phép #��� và giá trị � tăng lên phải bằng một ñộ cao của một ñỉnh � nào ñó sau phép #������ trong pha. Xét mức tăng của � sau pha ñang xét:
�mới C �cũ �����ớµ C �cũ N �����ớµ C ����cũ Tức là sau mỗi pha làm � tăng lên, luôn tồn tại một ñỉnh � mà mức tăng ñộ cao
của � lớn hơn mức tăng của �. Xét trên toàn bộ giải thuật, ñộ cao của mỗi ñỉnh � 5 a C 6"8 �9 ñược khởi tạo bằng 0 và ñược nâng lên tối ña bằng ;�a� C � nên
tổng toàn bộ mức tăng của các ñỉnh không vượt quá ��a� C ;��;�a� C �� $��a�+�.
Vậy nếu ta xét các pha làm � tăng thì tổng mức tăng của � trên các pha này là $��a�+�, tức là số các pha làm � giảm cũng phải là $��a�+�. Nói cách khác, sẽ chỉ
có $��a�+� pha có chứa phép #��� và $��a�+� pha không chứa phép #���. Cộng lại
ta có số pha cần thực hiện trong toàn bộ giải thuật là $��a�+�.

206
Một pha sẽ phải lấy khỏi hàng ñợi tối ña �a� C ; ñỉnh ñể xử lý. Với mỗi ñỉnh lấy
từ hàng ñợi, việc tháo luồng sẽ chỉ sử dụng tối ña 1 phép ñẩy không bão hòa vì
sau phép ñẩy này thì ñỉnh sẽ hết tràn và quá trình xử lý sẽ chuyển sang ñỉnh tiếp
theo trong hàng ñợi. Vậy trong mỗi pha có không quá �a� C ; phép ñẩy không bão
hòa. Vì tổng số pha là $��a�+�, ta có số phép ñẩy không bão hòa trong cả giải
thuật là $��a��� và tổng thời gian thực hiện chúng cũng là $��a���.
Cuối cùng, ta ñánh giá thời gian thực hiện những thao tác duyệt danh sách liên
thuộc bằng các chỉ số l@!!����E � trong thuật toán FIFO Preflow-Push. Với mỗi
ñỉnh c, chỉ số l@!!����c� ban ñầu sẽ ứng với nút ñầu danh sách liên thuộc và
chuyển dần ñến hết danh sách gồm p¹'K�c� nút. Khi duyệt hết danh sách liên
thuộc mà c vẫn tràn thì sẽ có một phép #����c� và con trỏ l@!!����c� ñược ñặt lại
về ñầu danh sách liên thuộc. Số phép #����c� trong toàn bộ giải thuật không vượt
quá ;�a� C �, nên số lượt dịch chỉ số l@!!����c� không vượt quá ;�a� p¹'K�c�.
Suy ra nếu xét tổng thể, số phép dịch các chỉ số l@!!����E � trên tất cả các danh
sách liên thuộc phải nhỏ hơn:
�;�a�� È p¹'K�c�Ô5¶ ;�a���� $��a�����
Kết luận:
Tổng thời gian thực hiện các phép nâng: $��a�����.
Tổng thời gian thực hiện các phép ñẩy bão hòa: $��a�����.
Tổng thời gian thực hiện các phép ñẩy không bão hòa: $��a���.
Tổng thời gian thực hiện các phép duyệt danh sách liên thuộc bằng chỉ số l@!!����E �: $��a�����.
Thời gian thực hiện giải thuật FIFO Preflow-Push: $��a�� � �a�����.
h) h) h) h) MMMM8888t st st st s!!!! kkkk`̀̀̀ thuthuthuthut t(ng tt t(ng tt t(ng tt t(ng t!!!!c "c "c "c "8888 gigigigi����i thui thui thui thutttt
Ta ñã chứng minh rằng thuật toán Edmonds-Karp có thời gian thực hiện $��a����+� và thuật toán FIFO Preflow-Push có thời gian thực hiện $��a�� ��a�����. Những ñại lượng này thoạt nhìn làm chúng ta có cảm giác như thuật toán FIFO Preflow-Push thực hiện nhanh hơn thuật toán Edmonds-Karp, ñặc
biệt trong trường hợp ñồ thị dày (��� � �a�). Tuy vậy, những ñánh giá này chỉ là cận trên của thời gian thực hiện giải thuật trong trường hợp xấu nhất. Hiện tại chưa có các ñánh giá chặt về cận trên và cận dưới trong trường hợp trung bình. Những thử nghiệm bằng chương trình cụ thể cũng cho thấy rằng các thuật toán ñẩy tiền luồng như FIFO Preflow-Push, Lift-

207
to-Front Preflow-Push, Highest-Label Preflow-Push… không có có cải thiện gì về tốc ñộ so với thuật toán Edmonds-Karp (thậm chí còn chậm hơn) nếu không sử dụng những mẹo cài ñặt (heuristics).
Chưa có ñánh giá lý thuyết chặt chẽ nào về tác ñộng của những mẹo cài ñặt lên thời gian thực hiện giải thuật nhưng hầu hết các thử nghiệm ñều cho thấy việc sử dụng những mẹo cài ñặt trên thực tế gần như là bắt buộc ñối với các thuật toán ñẩy tiền luồng.
� Bản chất của hàm ñộ cao
Nhắc lại về ràng buộc ñộ cao: Xét một tiền luồng � trên mạng A �a8 �8 l8 "8 ��,
hàm ñộ cao �M a G ¡ gọi là tương ứng với tiền luồng � nếu ��"� �a� ; ���� 7; và với mọi cung thặng dư �@8 �� thì ��@� N ���� � �.
Nếu ta gán trọng số cho các cung của mạng thặng dư Aí theo quy tắc: Cung
thặng dư có trọng số 1 và cung bão hòa có trọng số ��. Ký hiệu «í�@8 �� là ñộ
dài ñường ñi ngắn nhất từ @ tới � trên Aí với cách gán trọng số này. Khi ñó
không khó khăn kiểm chứng ñược rằng với L� 5 a C 6"8 �9: � ���� N «í��8 ��, tức là ���� luôn là cận dưới của ñộ dài ñường ñi ngắn nhất
từ � tới ñỉnh thu.
� Trong trường hợp ���� 1 �a�, từ � chắc chắn không có ñường thặng dư ñi
tới � và ���� C �a� N «í��8 "�, tức là ���� C �a� trong trường hợp này là
cận dưới của ñộ dài ñường ñi ngắn nhất từ � về ñỉnh phát.
Những mẹo cài ñặt dưới ñây nhằm ñẩy nhanh các ñộ cao ���� trong tiến trình thực hiện giải thuật dựa vào những nhận xét trên.
� Gán nhãn lại toàn bộ
Nội dung của phương pháp gán nhãn lại toàn bộ (global relabeling heuristic)
ñược tóm tắt như sau: Xét lát cắt chia tập a làm hai tập rời nhau � và Ù: Tập Ù
gồm những ñỉnh ñến ñược � bằng một ñường thặng dư và tập � gồm những ñỉnh
còn lại. Chắc chắn không có cung thặng dư nối từ � sang Ù, ta có " 5 �8 � 5 Ù. Phép gán nhãn lại toàn bộ sẽ ñặt:
� Với L� 5 Ù, ta gán lại ñộ cao ���� z «í��8 ��.
� Với L@ 5 � và «í�@8 "� O ��, ta gán lại ñộ cao ��@� z �a� � «í�@8 "�

208
� Với L@ 5 � và «í�@8 "� ��, ta gán lại ñộ cao ��@� z ;�a� C � Không khó khăn ñể kiểm chứng tính hợp lý của hàm ñộ cao mới. Có thể thấy rằng các ñộ cao mới ít ra là không thấp hơn các ñộ cao cũ. Các giá trị «í��8 �� cũng như «í�@8 "� có thể ñược xác ñịnh bằng hai lượt thực
hiện thuật toán BFS từ � và ". Bởi ta cần thời gian $����� cho hai lượt BFS và gán lại các ñộ cao, nên phép gán nhãn lại toàn bộ thường ñược gọi thực hiện sau
một loạt chỉ thị sơ cấp ñể không làm ảnh hưởng tới ñánh giá $ lớn của thời gian
thực hiện giải thuật (chẳng hạn sau mỗi �a� phép #���). Chú ý là khi nâng ñộ cao ��c� của một ñỉnh c nào ñó, cần cập nhật lại l@!!����c� z ����c�. � ðẩy nhãn theo khe
Phép ñẩy nhãn theo khe (gap heuristic) ñược thực hiện nhờ quan sát sau:
Giả sử ta có một số nguyên 7 O [� O �a� mà không ñỉnh nào có ñộ cao [�
(số nguyên [� này ñược gọi là “khe”), khi ñó mọi ñỉnh c có ��c� 1 [� ñều
không có ñường thặng dư ñi ñến �.
Nhận ñịnh trên có thể chứng minh bằng phản chứng: Giả sử từ c có ñường thặng
dư ñi ñến �, với một cung �@8 �� trên ñường ñi ta có ��@� N ���� � �, tức là trên
ñường ñi này, từ một ñỉnh @ ta chỉ có thể ñi sang một ñỉnh � không thấp hơn
hoặc thấp hơn @ ñúng một ñơn vị. Từ ��c� 1 [� 1 7 và ���� 7, chắc chắn
trên ñường thặng dư từ tới � phải có một ñỉnh ñộ cao [�. Mâu thuẫn với giả thuyết phản chứng.
Phép ñẩy nhãn theo khe nếu phát hiện khe 7 O [� O �a� sẽ xét tất cả những
ñỉnh c 5 a C 6"9 có [� O ��c� N �a� và ñặt lại ��c� z �a� � �.
Ta sẽ chỉ ra rằng phép ñẩy ñộ cao này vẫn ñảm bảo ràng buộc ñộ cao của hàm �.
ðộ cao của ñỉnh phát và ñỉnh thu không bị ñộng chạm ñến, tức là ��"� �a� và ���� 7. Trước khi thực hiện phép ñẩy theo khe, ta chia tập ñỉnh a thành hai
tập rời nhau: Tập � gồm những ñỉnh cao hơn [� và tập Ù gồm những ñỉnh thấp
hơn [�. Do ràng buộc ñộ cao ��@� N ���� � � với mọi cung thặng dư �@8 ��,
không tồn tại cung thặng dư nối từ � tới Ù. Phép ñẩy theo khe chỉ tăng ñộ cao
của một vài ñỉnh 5 � và như vậy ràng buộc ñộ cao nếu bị vi phạm thì chỉ bị vi
phạm trên những cung thặng dư ñi ra khỏi . Như lập luận trên, cung thặng dư ñi

209
ra khỏi chắc chắn phải ñi vào một ñỉnh Û 5 � có ñộ cao ít nhất là �a� sau phép
ñẩy theo khe. Từ �� � �a� � � ta có �� � N �� ó� � �.
Phép ñẩy nhãn theo khe sử dụng mảng l�@���7 ;�a� C �� ñể ñếm l�@����� là
số ñỉnh có ñộ cao �. Mỗi khi có sự thay ñổi ñộ cao, ta phải ñồng bộ lại mảng l�@�� theo tình trạng hàm ñộ cao mới. Sau mỗi phép #����@�, ñộ cao cũ của
ñỉnh @ ñược lưu trữ lại trong biến ���Q và phép #��� thực hiện như bình
thường. Sau ñó nếu 7 O ���Q O �a� và l�@������Q� 7, phép ñẩy theo khe ���Q sẽ ñược gọi và thực hiện trong thời gian $��a��. Bởi số phép #��� cần
thực hiện trong toàn bộ giải thuật là $��a�+�, tổng thời gian thực hiện các phép
ñẩy theo khe sẽ là $��a��� nên không ảnh hưởng tới ñánh giá $-lớn của thời gian thực hiện giải thuật FIFO Preflow-Push.
Dưới ñây là bảng so sánh tốc ñộ của các chương trình cài ñặt cụ thể trên một số
bộ dữ liệu. Với một cặp số �8 �, 100 ñồ thị với � ñỉnh, � cung ñược sinh ngẫu
nhiên với sức chứa là số nguyên trong khoảng từ 0 tới �7�. Có 4 chương trình ñược thử nghiệm: A: Thuật toán Edmonds-Karp, B: thuật toán FIFO Preflow-Push, C: thuật toán FIFO Preflow-Push với phép gán nhãn lại toàn bộ và D: thuật toán FIFO Preflow-Push với phép ñẩy nhãn theo khe. Mỗi chương trình ñược thử trên cả 100 ñồ thị và ño thời gian thực hiện trung bình (tính bằng giây):
� �77 � �7777 � ;77 � V7777 � \77 � X7777
� e77 � �7777 � �777 � �77777
A 0.0688 0.5925 0.6598 1.7158 2.7629
B 0.0983 0.7395 3.4377 9.9014 25.0723
C 0.0313 0.0624 0.0857 0.1809 0.2433
D 0.0282 0.0577 0.0828 0.1575 0.1889
� Cài ñặt
Dưới ñây là chương trình cài ñặt thuật toán FIFO Preflow-Push kết hợp với kỹ thuật ñẩy nhãn theo khe, việc cài ñặt và ñánh giá hiệu suất của phép gán nhãn lại toàn bộ chúng ta coi như bài tập. Các bạn có thể thử cài ñặt kết hợp cả hai kỹ thuật tăng tốc này ñể xác ñịnh xem việc ñó có thực sự cần thiết không.

210
Input/Output có khuôn dạng giống như ở chương trình cài ñặt thuật toán Edmonds-Karp. Hàng ñợi chứa các ñỉnh tràn ñược tổ chức dưới dạng danh sách vòng: Các chỉ số ñầu/cuối hàng ñợi sẽ chạy xuôi trong một mảng và khi chạy ñến hết mảng sẽ tự ñộng quay về ñầu mảng.
� FIFOPREFLOWPUSH.PAS � Thuật toán FIFO Preflow-Push
{$MODE OBJFPC}
program MaximumFlow;
const
maxN = 1000;
maxM = 100000;
maxC = 10000;
type
TEdge = record //Cấu trúc một cung
x, y: Integer; //Hai đỉnh đầu mút
c, f: Integer; //Sức chứa và luồng
end;
TQueue = record //Cấu trúc hàng đợi
items: array[0..maxN - 1] of Integer; //Danh sách vòng
front, rear, nItems: Integer;
end;
var
e: array[-maxM..maxM] of TEdge; //Mảng chứa các cung
link: array[-maxM..maxM] of Integer;
//Móc nối trong danh sách liên thuộc head, current: array[1..maxN] of Integer;
//con trỏ tới đầu và vị trí hiện tại của danh sách liên thuộc excess: array[1..maxN] of Integer; //mức tràn của các đỉnh
h: array[1..maxN] of Integer; //hàm độ cao
count: array[0..2 * maxN - 1] of Integer;
//count[k] = số đỉnh có độ cao k
Queue: TQueue; //Hàng đợi chứa các đỉnh tràn
n, m, s, t: Integer;
FlowValue: Integer;
procedure Enter; //Nhập dữ liệu
var
i, u, v, capacity: Integer;
begin

211
ReadLn(n, m, s, t);
FillChar(head[1], n * SizeOf(head[1]), 0);
for i := 1 to m do
begin
ReadLn(u, v, capacity);
with e[i] do //Thêm cung e[i] = (u, v) vào danh sách liên thuộc của u
begin
x := u;
y := v;
c := capacity;
link[i] := head[u];
head[u] := i;
end;
with e[-i] do //Thêm cung e[-i] = (v, u) vào danh sách liên thuộc của v
begin
x := v;
y := u;
c := 0;
link[-i] := head[v];
head[v] := -i;
end;
end;
for v := 1 to n do current[v] := head[v];
end;
procedure PushToQueue(v: Integer); //Đẩy một đỉnh v vào hàng đợi
begin
with Queue do
begin
rear := (rear + 1) mod maxN;
//Dịch chỉ số cuối hàng đợi, rear = maxN - 1 sẽ trở lại thành 0
items[rear] := v; //Đặt v vào vị trí cuối hàng đợi
Inc(nItems); //Tăng biến đếm số phần tử trong hàng đợi
end;
end;
function PopFromQueue: Integer; //Lấy một đỉnh khỏi hàng đợi
begin
with Queue do
begin

212
Result := items[front]; //Trả về phần tử ở đầu hàng đợi
front := (front + 1) mod maxN;
//Dịch chỉ số đầu hàng đợi, front = maxN - 1 sẽ trở lại thành 0
Dec(nItems); //Giảm biến đếm số phần tử trong hàng đợi
end;
end;
procedure Init; //Khởi tạo
var v, sf, i: Integer;
begin
//Khởi tạo tiền luồng
for i := -m to m do e[i].f := 0;
FillChar(excess[1], n * SizeOf(excess[1]), 0);
i := head[s];
while i <> 0 do
//Duyệt các cung ñi ra khỏi ñỉnh phát và ñẩy bão hòa các cung ñó, cập nhật các mức tràn excess[.] begin
sf := e[i].c;
e[i].f := sf;
e[-i].f := -sf;
Inc(excess[e[i].y], sf);
Dec(excess[s], sf);
i := link[i];
end;
//Khởi tạo hàm độ cao
for v := 1 to n do h[v] := 1;
h[s] := n;
h[t] := 0;
//Khởi tạo các biến đếm: count[k] là số đỉnh có độ cao k
FillChar(count[0], (2 * n) * SizeOf(count[0]), 0);
count[n] := 1;
count[0] := 1;
count[1] := n - 2;
//Khởi tạo hàng đợi chứa các đỉnh tràn
Queue.front := 0;
Queue.rear := -1;
Queue.nItems := 0; //Hàng đợi rỗng
for v := 1 to n do //Duyệt tập đỉnh
if (v <> s) and (v <> t) and (excess[v] > 0) then
//v tràn

213
PushToQueue(v); //đẩy v vào hàng đợi
end;
procedure Push(i: Integer); //Phép đẩy luồng theo cung e[i]
var Delta: Integer;
begin
with e[i] do
if excess[x] < c - f then Delta := excess[x]
else Delta := c - f;
Inc(e[i].f, Delta);
Dec(e[-i].f, Delta);
with e[i] do
begin
Dec(excess[x], Delta);
Inc(excess[y], Delta);
end;
end;
procedure SetH(u: Integer; NewH: Integer);
//Đặt độ cao của u thành NewH, đồng bộ hóa mảng count begin
Dec(count[h[u]]);
h[u] := NewH;
Inc(count[NewH]);
end;
procedure PerformGapHeuristic(gap: Integer);
//Đẩy nhãn theo khe gap var v: Integer;
begin
if (0 < gap) and (gap < n) and (count[gap] = 0) then
//gap đúng là khe thật for v := 1 to n do
if (v <> s) and (gap < h[v]) and (h[v] <= n) then
begin
SetH(v, n + 1);
current[v] := head[v];
//Nâng độ cao của v cần phải cập nhật lại con trỏ current[v] end;
end;
procedure Lift(u: Integer); //Phép nâng đỉnh u
var minH, OldH, i: Integer;

214
begin
minH := 2 * maxN;
i := head[u];
while i <> 0 do //Duyệt các cung đi ra khỏi u
begin
with e[i] do
if (c > f) and (h[y] < minH) then
//Gặp cung thặng dư (u, v), ghi nhận đỉnh v thấp nhát
minH := h[y];
i := link[i];
end;
OldH := h[u]; //Nhớ lại h[u] cũ
SetH(u, minH + 1); //nâng cao đỉnh u
PerformGapHeuristic(OldH); //Có thể tạo ra khe OldH, đẩy nhãn theo khe
end;
procedure FIFOPreflowPush; //Thuật toán FIFO Preflow-Push
var
NeedQueue: Boolean;
z: Integer;
begin
while Queue.nItems > 0 do //Chừng nào hàng đợi vẫn còn đỉnh tràn
begin
z := PopFromQueue; //Lấy một đỉnh tràn x khỏi hàng đợi
while current[z] <> 0 do //Xét một cung đi ra khỏi x
begin
with e[current[z]] do
begin
if (c > f) and (h[x] > h[y]) then
//Nếu có thể đẩy luồng được theo cung (u, v) begin
NeedQueue := (y <> s) and (y <> t)
and (excess[y] = 0);
Push(current[z]); //Đẩy luồng luôn
if NeedQueue then
//v đang không tràn sau phép đẩy trở thành tràn
PushToQueue(y); //Đẩy v vào hàng đợi
if excess[z] = 0 then Break;
//x hết tràn thì chuyển qua xét đỉnh khác ngay end;

215
end;
current[z] := link[current[z]];
//x chưa hết tràn thì chuyển sang xét cung liên thuộc tiếp theo end;
if excess[z] > 0 then //Duyệt hết danh sách liên thuộc mà x vẫn tràn begin
Lift(z); //Nâng cao x
current[z] := head[z];
//Đặt con trỏ current[x] trỏ lại về đầu danh sách liên thuộc
PushToQueue(z); //Đẩy lại x vào hàng đợi chờ xử lý sau
end;
end;
FlowValue := excess[t];
//Thuật toán kết thúc, giá trị luồng bằng tổng luồng đi vào đỉnh thu (= - excess[s]) end;
procedure PrintResult; //In kết quả
var i: Integer;
begin
WriteLn('Maximum flow: ');
for i := 1 to m do
with e[i] do
if f > 0 then //Chỉ cần in ra các cung có luồng > 0
WriteLn('e[', i, '] = (', x, ', ', y, '): c
= ', c, ', f = ', f);
WriteLn('Value of flow: ', FlowValue);
end;
begin
Enter; //Nhập dữ liệu
Init; //Khởi tạo
FIFOPreflowPush; //Thực hiện thuật toán đẩy tiền luồng
PrintResult; //In kết quả
end.
ðịnh lý 3-19 (ñịnh lý về tính nguyên)
Nếu tất cả các sức chứa là số nguyên thì thuật toán Ford-Fulkerson cũng như thuật toán ñẩy tiền luồng luôn tìm ñược luồng cực ñại với luồng trên cung là các số nguyên.

216
Chứng minh
ðối với thuật toán Ford-Fulkerson, ban ñầu ta khởi tạo luồng 0 thì luồng trên các
cung là nguyên. Mỗi lần tăng luồng dọc theo ñường tăng luồng B, luồng trên mỗi
cung hoặc giữ nguyên, hoặc tăng/giảm một lượng Òô cũng là số nguyên. Vậy nên
cuối cùng luồng cực ñại phải có giá trị nguyên trên tất cả các cung.
ðối với thuật toán ñẩy tiền luồng, ban ñầu ta khởi tạo một tiền luồng trên các cung
là số nguyên. Phép #��� và B@"� không làm thay ñổi tính nguyên của tiền luồng
trên các cung. Vậy nên khi thuật toán kết thúc, tiền luồng trở thành luồng cực ñại
với giá trị luồng trên các cung là số nguyên.
3.4. Một số mở rộng và ứng dụng của luồng
a) a) a) a) MMMM9999ng vng vng vng v4444i nhii nhii nhii nhiEEEEu "u "u "u "ddddnh phát và nhinh phát và nhinh phát và nhinh phát và nhiEEEEu "u "u "u "ddddnh thunh thunh thunh thu
Ta mở rộng khái niệm mạng bằng cách cho phép mạng A có � ñỉnh phát: "(8 "+8 8 "� và � ñỉnh thu �(8 �+8 8 ��, các ñỉnh phát và các ñỉnh thu hoàn toàn
phân biệt. Hàm sức chứa và luồng trên mạng ñược ñịnh nghĩa tương tự như trong trường hợp mạng có một ñỉnh phát và một ñỉnh thu. Giá trị của luồng ñược ñịnh nghĩa bằng tổng luồng trên các cung ñi ra khỏi các ñỉnh phát. Bài toán ñặt ra là tìm luồng cực ñại trên mạng có nhiều ñỉnh phát và nhiều ñỉnh thu.
Thêm vào mạng hai ñỉnh: một siêu ñỉnh phát " và siêu ñỉnh thu �. Thêm các
cung nối từ " tới các ñỉnh "2 có sức chứa ��, thêm các cung nối từ các ñỉnh �®
tới � với sức chứa ��. Ta ñược một mạng mới Aó �a8 �ó� (h.2.9).
Hình 2.9. Mạng với nhiều ñỉnh phát và nhiều ñỉnh thu
Có thể thấy rằng nếu � là một luồng cực ñại trên AÛ, thì � hạn chế trên A cũng là
luồng cực ñại trên A. Vậy ñể tìm luồng cực ñại trên A, ta sẽ tìm luồng cực ñại
"
"( "+ "�
�( �+ ��
� ��
����
��
����
��
��

217
trên Aó rồi loại bỏ siêu ñỉnh phát ", siêu ñỉnh thu � và tất cả những cung giả mới thêm vào.
Một cách khác có thể thực hiện ñể tìm luồng trên mạng có nhiều ñỉnh phát và nhiều ñỉnh thu là loại bỏ tất các các cung ñi vào các ñỉnh phát cũng như các
cung ñi ra khỏi các ñỉnh thu. Chập tất cả các ñỉnh phát thành một siêu ñỉnh " và
chập tất cả các ñỉnh thu lại thành một siêu ñỉnh thu �, mạng không còn các ñỉnh "(8 "+8 E E 8 "� và �(8 �+8 8 �� nữa mà chỉ có thêm ñỉnh phát " và ñỉnh thu �. Trên
mạng ban ñầu, mỗi cung ñi vào/ra "2 ñược chỉnh lại ñầu mút ñể nó ñi vào/ra ñỉnh ", mỗi cung ñi vào/ra �® cũng ñược chỉnh lại ñầu mút ñể nó ñi vào/ra ñỉnh �, ta
ñược một mạng mới Aóó. Khi ñó ta ta có thể tìm � là một luồng cực ñại trên Aóó và khôi phục lại ñầu mút
của các cung như cũ ñể � trở thành luồng cực ñại trên A.
b) b) b) b) MMMM9999ng vng vng vng v4444i si si si sNNNNc chc chc chc chNNNNa trên ca trên ca trên ca trên c���� các "các "các "các "ddddnh và các cungnh và các cungnh và các cungnh và các cung
Cho mạng A �a8 �8 l8 "8 ��, mỗi ñỉnh � 5 a C 6"8 �9 ñược gán một số không âm ���� gọi là sức chứa của ñỉnh ñó. Luồng dương ê trên mạng này ñược ñịnh nghĩa với tất cả các ràng buộc của luồng dương và thêm một ñiều kiện: Tổng
luồng dương trên các cung ñi vào mỗi ñỉnh � 5 a C 6"8 �9 không ñược vượt quá ����: : ê���ç5sÄ�©� N ����. Bài toán ñặt ra là tìm luồng dương cực ñại trên
mạng có ràng buộc sức chứa trên cả các ñỉnh và các cung. Tách mỗi ñỉnh 5 a C 6"8 �9 thành 2 ñỉnh mới 2.8 �¨� và một cung � 2.8 �¨��
với sức chứa �� �. Các cung ñi vào ñược chỉnh lại ñầu mút ñể ñi vào 2. và
các cung ñi ra khỏi ñược chỉnh lại ñầu mút ñể ñi ra khỏi �¨� (h.2.10). Ta xây
dựng ñược mạng Aó �aó8 �ó� với ñỉnh phát " và ñỉnh thu �.
Hình 2.10. Tách ñỉnh
�¨� 2. �� �
�� �

218
Khi ñó việc tìm luồng dương cực ñại trên mạng A có thể thực hiện bằng cách
tìm luồng dương cực ñại trên mạng Aó, sau ñó chập tất cả các cặp � 2.8 �¨�� trở
lại thành ñỉnh (L 5 a C 6"8 �9) ñể khôi phục lại mạng A ban ñầu.
c) c) c) c) MMMM9999ng vng vng vng v4444i ràng bui ràng bui ràng bui ràng bu8888c luc luc luc lu^̂̂̂ngngngng dF#ng bdF#ng bdF#ng bdF#ng b>>>> chchchch::::n hai phían hai phían hai phían hai phía
Cho mạng A �a8 �8 l8 "8 �� trong ñó mỗi cung � 5 � ngoài sức chứa (lưu
lượng) tối ña l��� còn ñược gán một số không âm ���� N l��� gọi là lưu lượng
tối thiểu. Một luồng dương tương thích ê trên A ñược ñịnh nghĩa với tất cả các ràng buộc của luồng dương và thêm một ñiều kiện: Luồng dương trên mỗi cung � 5 � không ñược nhỏ hơn sức chứa tối thiểu của cung ñó: ���� N ê��� N l���
Bài toán ñặt ra là kiểm chứng sự tồn tại của luồng dương tương thích trên mạng với ràng buộc luồng dương bị chặn hai phía.
Xây dựng một mạng Aó �aó8 �ó� từ mạng A theo quy tắc:
� Tập ñỉnh aÛ có ñược từ tập a thêm vào ñỉnh phát giả "ó và ñỉnh thu giả �ó: aó a � 6"ó8 �ó9. � Mỗi cung � �@8 �� 5 � sẽ tương ứng với ba cung trên �ó: cung �( �@8 ��
có sức chứa l��� C ����, cung �+ �"ó8 �� và cung �� �@8 �ó� có sức chứa ����. Ngoài ra thêm vào cung ��8 "� 5 �ó với sức chứa ��
Hình 2.11.
Gọi P : ����ç5s là tổng sức chứa tối thiểu của các cung trên mạng A. Khi ñó
trên mạng Aó, tổng sức chứa các cung ñi ra khỏi "ó cũng như tổng sức chứa các
cung ñi vào �ó bằng P. Vì vậy với mọi luồng dương trên Aó thì giá trị luồng ñó
không thể vượt quá P.
" @ � �
"ó �ó
l��� C �������� ����
��

219
Từ ñó suy ra rằng nếu tồn tại một luồng dương êó trên Aó có giá trị luồng �êó� P thì êó bắt buộc là luồng dương cực ñại trên Aó. Bổ ñề 3-20 cho phép ta kiểm chứng sự tồn tại luồng dương tương thích trên A
bằng việc ño giá trị luồng cực ñại trên Aó. Bổ ñề 3-20
ðiều kiện cần và ñủ ñể tồn tại luồng dương tương thích ê trên mạng A là tồn tại
luồng dương cực ñại êó trên Aó với giá trị luồng �êó� PE Chứng minh
Giả sử luồng dương cực ñại êó trên Aó có �ê� P : ����ç5s . Ta xây dựng
luồng ê trên A bằng cách cộng thêm vào luồng êÛ trên mỗi cung � một lượng ����: êM � G �78 ��� � G ê��� êó��� � ���� Khi ñó có thể dễ dàng kiếm chứng ñược ê thỏa mãn tất cả các ràng buộc của
luồng dương tương thích trên mạng A.
Ngược lại nếu ê là một luồng dương tương thích trên A . Ta xây dựng luồng
dương êó trên Aó bằng cách trừ luồng ê trên mỗi cung � ñi một lượng ����, ñồng
thời ñặt luồng êó trên các cung ñi ra khỏi "ó cũng như trên các cung ñi vào �ó ñúng
bằng sức chứa của cung ñó. Khi ñó cũng dễ dàng kiểm chứng ñược êó là luồng
dương cực ñại và �ê� P.
d) d) d) d) MMMM9999ng vng vng vng v4444i si si si sNNNNc chc chc chc chNNNNa âma âma âma âm
Cho mạng A �a8 �8 l8 �8 "8 �� trong ñó ta mở rộng khái niệm sức chứa bằng cách cho phép cả những sức chứa âm trên một số cung. Khái niệm luồng ñược ñịnh nghĩa như bình thường.
Nếu như có thể khởi tạo ñược một luồng thì thuật toán Ford-Fulkerson vẫn hoạt ñộng ñúng ñể tìm luồng cực ñại trên mạng có sức chứa âm. Vấn ñề khởi tạo một luồng bất kỳ trên mạng không phải ñơn giản vì chúng ta không thể khởi tạo bằng luồng 0, bởi nếu như vậy, ràng buộc sức chứa tối ña sẽ bị vi phạm trên các cung có sức chứa âm.
Giả sử một cung � 5 � có sức chứa l��� O 7. Theo tính ñối xứng lệch của luồng ���� C��C�� và ràng buộc sức chứa tối ña ���� N l���, ta có:

220
��C�� C���� w Cl��� 1 7 (3.5)
Như vậy ràng buộc sức chứa tối ña ���� N l��� tương ñương với ràng buộc về
sức chứa tối thiểu – l��� trên cung ñối – �. Việc chỉ ra một luồng bất kỳ trên A có thể thực hiện bằng cách tìm luồng dương trên mạng với ràng buộc luồng dương bị chặn hai phía sau ñó biến ñổi luồng dương này thành luồng cần tìm.
e) e) e) e) Lát cLát cLát cLát c]]]]t ht ht ht heeeep nhp nhp nhp nh6666tttt
Ta quan tâm tới ñồ thị vô hướng liên thông A �a8 �� với hàm trọng số (hay
lưu lượng) lM � G �78 ���. Giả sử �a� w ;, người ta muốn bỏ ñi một số cạnh ñể ñồ thị mất tính liên thông và yêu cầu tìm phương án sao cho tổng trọng số các cạnh bị loại bỏ là nhỏ nhất.
Bài toán cũng có thể phát biểu dưới dạng: hãy phân hoạch tập ñỉnh a thành hai
tập khác rỗng rời nhau � và Ù sao cho tổng lưu lượng các cạnh nối giữa � và Ù
là nhỏ nhất có thể. Cách phân hoạch này gọi là lát cắt tổng quát hẹp nhất của A,
ký hiệu y��F@��A�. l��8 Ù� G min � d �� Ù d �� � Ú Ù �� � Ø Ù a� Một cách tệ nhất có thể thực hiện là thử tất cả các cặp ñỉnh "8 �. Với mỗi lần thử
ta cho " làm ñỉnh phát và � làm ñỉnh thu trên mạng A, sau ñó tìm luồng cực ñại
và lát cắt " C � hẹp nhất. Cuối cùng là chọn lát cắt " C � có lưu lượng nhỏ nhất
trong tất cả các lần thử. Phương pháp này cần f�;i .Y�.3(�+ lần tìm luồng cực
ñại, có tốc ñộ chậm và không khả thi với dữ liệu lớn.
Bổ ñề 3-21
Với " và � là hai ñỉnh bất kỳ. Từ ñồ thị A, ta xây dựng ñồ thị A�� bằng cách chập
hai ñỉnh " và � thành một ñỉnh duy nhất, ký hiệu "�, các cạnh nối " với � bị hủy
bỏ, các cạnh liên thuộc với chỉ " hoặc � ñược chỉnh lại ñầu mút ñể trở thành
cạnh liên thuộc với "�. Khi ñó y��F@��A� có thể thu ñược bằng lấy lát cắt có lưu lượng nhỏ nhất trong hai lát cắt:

221
� Lát cắt " C � hẹp nhất: Coi " là ñỉnh phát và � là ñỉnh thu, lát cắt " C � hẹp nhất có thể xác ñịnh bằng việc giải quyết bài toán luồng cực ñại trên mạng A.
� Lát cắt tổng quát hẹp nhất trên A��: y��F@��A���.
Chứng minh
Xét lát cắt tổng quát hẹp nhất trên A có thể ñưa " và � vào hai thành phần liên
thông khác nhau hoặc ñưa chúng vào cùng một thành phần liên thông. Trong
trường hợp thứ nhất, y��F@��A� là lát cắt " C � hẹp nhất. Trong trường hợp thứ
hai, y��F@��A� là y��F@��A���.
Bổ ñề 3-21 cho phép chúng ta xây dựng một thuật toán tốt hơn: Nếu ñồ thị chỉ gồm 2 ñỉnh thì chỉ việc cắt rời hai ñỉnh vào hai tập. Nếu không, ta chọn hai ñỉnh
bất kỳ "8 � làm ñỉnh phát và ñỉnh thu, tìm luồng cực ñại và ghi nhận lát cắt " C �
hẹp nhất. Tiếp theo ta chập hai ñỉnh "8 � thành một ñỉnh "� và lặp lại với ñồ thị A��… Cuối cùng là chỉ ra lát cắt " C � hẹp nhất trong số tất cả các lát cắt ñược
ghi nhận. Phương pháp này ñòi hỏi phải thực hiện �a� C � lần tìm luồng cực ñại, tuy ñã có sự cải thiện về tốc ñộ nhưng chưa phải thật tốt.
Nhận xét rằng tại mỗi bước của cách giải trên, chúng ta có thể chọn hai ñỉnh "8 �
bất kỳ miễn sao " d �. Vì vậy người ta muốn tìm một cách chọn cặp ñỉnh "8 �
một cách hợp lý tại mỗi bước ñể có thể chỉ ra ngay lát cắt " C � hẹp nhất mà
không cần tìm luồng cực ñại. Thuật toán dưới ñây [37] là một trong những thuật toán hiệu quả dựa trên ý tưởng ñó.
Với � là một tập con của tập ñỉnh a và là một ñỉnh không thuộc �. ðịnh nghĩa
lực hút của � ñối với là tổng trọng số các cạnh nối với các ñỉnh thuộc �:
l��8 6 9� È l���ç<��8m�5sm5Ü
Bổ ñề 3-22
Bắt ñầu từ tập � chỉ gồm một ñỉnh bất kỳ 5 a, ta cứ tìm một ñỉnh bị � hút
chặt nhất kết nạp thêm vào � cho tới khi � a. Gọi " và � là hai ñỉnh ñược kết
nạp cuối cùng theo cách này. Khi ñó lát cắt �a C 6�98 6�9� là lát cắt " C � hẹp nhất.

222
Chứng minh
Xét một lát cắt " C � bất kỳ , ta sẽ chứng minh rằng lưu lượng của lát cắt �a C 6�98 6�9� không lớn hơn lưu lượng của lát cắt . Một ñỉnh � ñược gọi là ñỉnh hoạt tính nếu � và ñỉnh ñược ñưa vào � liền trước �
bị rơi vào hai phía của lát cắt . Gọi �© là tập các ñỉnh ñược kết nạp vào � trước
ñỉnh � , © là lát cắt hạn chế trên �© Ø 6�9 (Lát cắt © dùng ñúng cách phân
hoạch của lát cắt nhưng chỉ quan tâm tới tập ñỉnh �© Ø 6�9). Gọi l�� là lưu
lượng của lát cắt , l�©� là lưu lượng của lát cắt ©.
Trước hết ta sử dụng phép quy nạp ñể chỉ ra rằng nếu @ là ñỉnh hoạt tính thì:
l��¨8 6@9� N l�¨� (3.6)
Nếu @ là ñỉnh hoạt tính ñầu tiên ñược kết nạp vào � , lát cắt ¨ sẽ chia tập �¨ Ø 6@9 làm hai tập, một tập là �¨ và một tập là 6@9, khi ñó ta có l��¨8 6@9� cũng
chính là l�¨�. Giả thiết rằng bất ñẳng thức (3.6) ñúng với ñỉnh hoạt tính @, ta sẽ
chứng nó cũng ñúng với những ñỉnh hoạt tính � ñược kết nạp vào � sau @. Thật
vậy,
l��© 8 6�9� l��¨8 6�9� � l��© C �¨ 8 6�9� (3.7)
Do �¨ phải hút @ mạnh hơn �, kết hợp với giả thiết quy nạp, ta có: l��¨8 6�9� N l��¨8 6@9� N l�¨� Hạng tử l��© C �¨8 6�9� là tổng trọng số các cạnh nối giữa � và �© C �¨. Do @ và � là hai ñỉnh hoạt tính liên tiếp, các cạnh này sẽ nối giữa hai phía của lát cắt © và
có ñóng góp trong phép tính l�©�, mặt khác do � ª �¨ Ø 6@9 nên những cạnh này
không ñóng góp trong phép tính l�¨�. Vậy từ công thức (3.7), ta suy ra:
l��©8 6�9� l��¨ 8 6�9� � l��© C �¨8 6�9� N l�¨� � l��© C �¨8 6�9� N l�©� (3.8)
Vì là một lát cắt " C � nên chắc chắn " và � nằm ở hai phía khác nhau của lát cắt
, hay nói cách khác, � là ñỉnh hoạt tính. Bất ñẳng thức (3.6) chứng minh ở trên
cho ta kết quả:
l�a C 6�98 6�9� l��� 8 6�9� N l��� l�� (3.9)
Ta chứng minh ñược lát cắt �a C 6�98 6�9� là lát cắt " C � hẹp nhất.

223
ðịnh lý 3-23
Việc tìm lát cắt tổng quát trên ñồ thị vô hướng liên thông với hàm trọng số
không âm có thể ñược thực hiện bằng thuật toán trong thời gian $��a�+ %&'�a� ��a�����. Chứng minh
Bắt ñầu từ tập � chỉ gồm một ñỉnh bất kỳ, ta mở rộng � bằng cách lần lượt kết nạp
vào � ñỉnh bị hút chặt nhất cho tới khi � a. Việc này ñược thực hiện với kỹ
thuật tương tự như thuật toán Prim: với L� ª �, ta ký hiệu nhãn ���� là lực hút
của � ñối với ñỉnh �. khi � ñược kết nạp thêm một @ thì các nhãn lực hút của
những ñỉnh � khác sẽ ñược cập nhật lại theo công thức: �����ớµ z ����� � l�@8 ��8 L�@8 �� 5 �
Bằng việc tổ chức các ñỉnh ngoài � trong một hàng ñợi ưu tiên dạng Fibonacci
Heap, việc mở rộng tập � cho tới khi � a ñược thực hiện trong thời gian $��a� %&'�a� � ����. Trong quá trình ñó, " và � là hai ñỉnh cuối cùng ñược kết nạp
vào � cũng ñược xác ñịnh và y��F@��A� ñược cập nhật theo lát cắt " C � hẹp
nhất. Sau ñó hai ñỉnh "8 � ñược chập vào và thuật toán lặp lại với ñồ thị A��. Tổng
cộng ta có �a� C � lần lặp, suy ra lát cắt tổng quát hẹp nhất có thể tìm ñược trong
thời gian $��a�+ %&'�a� � �a�����.
Mặc dù tính ñúng ñắng của thuật toán ñược chứng minh dựa vào lý thuyết về luồng cực ñại và lát cắt hẹp nhất, việc cài ñặt thuật toán lại khá ñơn giản và không
ñộng chạm gì ñến luồng cực ñại.
Bài tập
2.27. Cho �( và �+ là hai luồng trên mạng A �a8 �8 l8 "8 �� và � là một số thực
nằm trong ñoạn �78��. Xét ánh xạ: ��M � G � � ����� ��(��� � �� C ���+���
Chứng minh rằng �� cũng là một luồng trên mạng A với giá trị luồng: ���� ���(� � �� C ����+� 2.28. Cho � là một luồng trên mạng A �a8 �8 l8 "8 �� , chứng minh rằng với L� 5 �, ta có:

224
lí��� � lí�C�� l��� � l�C��
2.29. Cho � là luồng cực ñại trên mạng A �a8 �8 l8 "8 ��, gọi Ù là tập các ñỉnh
ñến ñược � bằng một ñường thặng dư trên Aí và � a C Ù. Chứng minh
rằng ��8 Ù� là lát cắt " C � hẹp nhất của mạng A. 2.30. Viết chương trình nhận vào một ñồ thị có hướng A �a8 �� với hai ñỉnh
phân biệt " và � và tìm một tập gồm nhiều ñường ñi nhất từ " tới � sao cho các ñường ñi trong tập này ñôi một không có cạnh chung.
Gợi ý
Coi " là ñỉnh phát và � là ñỉnh thu, các cung ñều có sức chứa 1. Tìm luồng cực ñại trên mạng bằng thuật toán Ford-Fulkerson, theo ðịnh lý 3-19 (ñịnh lý về tính nguyên), luồng trên các cung chỉ có thể là 0 hoặc 1. Loại bỏ các cung có luồng 0 và chỉ giữ lại các cung có luồng 1. Tiếp theo ta tìm một
ñường ñi từ " tới �, chọn ñường ñi này vào tập hợp, loại bỏ tất cả các cung dọc trên ñường ñi này khỏi ñồ thị và lặp lại…, thuật toán sẽ kết thúc khi ñồ
thị không còn cạnh nào (không còn ñường ñi từ " tới �).
Về kỹ thuật cài ñặt, ta có thể tìm một ñường ñi từ " tới � trên ñồ thị A, ñảo chiều tất cả các cung trên ñường ñi này và lặp lại cho tới khi không còn
ñường ñi từ " tới � nữa. Có thể thấy rằng ñồ thị A tại mỗi bước chính là ñồ thị các cung thặng dư và ñường ñi tìm ñược ở mỗi bước chính là ñường tăng luồng.
ðồ thị A giờ ñây không còn ñường ñi từ " tới �, ta tìm một ñường ñi từ �
về ", kết nạp ñường ñi theo chiều ngược lại (từ " tới �) vào tập hợp, xóa bỏ tất cả các cung trên ñường ñi và cứ tiếp tục như vậy cho tới khi không còn
ñường ñi từ � về " nữa.
2.31. Tương tự như Bài tập 2.29 nhưng yêu cầu thực hiện trên ñồ thị vô hướng.
2.32. (Hệ ñại diện phân biệt) Một lớp học có � bạn nam và � bạn nữ. Nhân ngày
8/3, lớp có mua � món quà ñể các bạn nam tặng các bạn nữ. Mỗi món quà có thể thuộc sở thích của một số bạn trong lớp.
Hãy lập chương trình tìm cách phân công tặng quà thỏa mãn:

225
� Mỗi bạn nam phải tặng quà cho ñúng một bạn nữ và mỗi bạn nữ phải nhận quà của ñúng một bạn nam. Món quà ñược tặng phải thuộc sở thích của cả hai người.
� Món quà nào ñã ñược một bạn nam chọn ñể tặng thì bạn nam khác không ñược chọn nữa.
Gợi ý: Xây dựng một mạng trong ñó tập ñỉnh a gồm 3 lớp ñỉnh k, � và �:
� Lớp ñỉnh phát k 6"(8 "+8 8 ".9, mỗi ñỉnh tương ứng với một bạn nam.
� Lớp ñỉnh � � (8 +8 8 .� mỗi ñỉnh tương ứng với một món quà.
� Lớp ñỉnh thu � 6�(8 �+8 8 �.9 mỗi ñỉnh tương ứng với một bạn nữ. Nếu bạn nam � thích món quà �, ta cho cung nối từ "2 tới I, nếu bạn nữ b
thích món quà �, ta cho cung nối từ I tới �®. Sức chứa của các cung ñặt
bằng 1 và sức chứa của các ñỉnh �(8 �+8 8 �. cũng ñặt bằng 1. Tìm luồng
nguyên cực ñại trên mạng A có � ñỉnh phát, � ñỉnh thu, ñồng thời có cả ràng buộc sức chứa trên các ñỉnh, những cung có luồng 1 sẽ nối giữa một món quà và người tặng/nhận tương ứng.
2.33. Cho mạng ñiện gồm � Y � ñiểm nằm trên một lưới �
hàng, � cột. Một số ñiểm nằm trên biên của lưới là nguồn ñiện, một số ñiểm trên lưới là các thiết bị sử dụng ñiện. Người ta chỉ cho phép nối dây ñiện giữa hai ñiểm nằm cùng hàng hoặc cùng cột. Hãy tìm cách ñặt các dây ñiện nối các thiết bị sử dụng ñiện với nguồn ñiện sao cho hai ñường dây bất kỳ nối hai thiết bị sử dụng ñiện với nguồn ñiện tương ứng của chúng không ñược có ñiểm chung.
2.34. (Kỹ thuật giãn sức chứa) Cho mạng A �a8 �8 l8 �8 "8 �� với sức chứa
nguyên: lM � G ¡. Gọi F z �n�ç5s l���.
a) Chứng minh rằng lát cắt " C � hẹp nhất của A có lưu lượng không vượt
quá F��� b) Với một số nguyên �, tìm thuật toán xác ñịnh ñường tăng luồng có giá
trị thặng dư w � trong thời gian $�����.
c) Chứng minh rằng thuật toán sau ñây tìm ñược luồng cực ñại trên mạng A:

226
procedure MaxFlowByScaling;
begin
f := «Luồng 0»;
k := C; //k là sức chứa lớn nhất của một cung trong E
while k ≥ 1 do
begin
while «Tìm ñược ñường tăng luồng P
có giá trị thặng dư ≥ k» do
«Tăng luồng dọc theo ñường P»;
k := k div 2;
end;
end;
d) Chứng minh rằng khi bước vào mỗi lượt lặp của vòng lặp:
while k ≥ 1 do...
Lưu lượng của lát cắt hẹp nhất trên mạng thặng dư Aí không vượt quá ;����. e) Chứng minh rằng trong mỗi lượt lặp của vòng lặp:
while k ≥ 1 do...
Vòng lặp while bên trong thực hiện $��� lần với mỗi giá trị của �.
f) Chứng minh rằng thuật toán trên (maximum flow by scaling) có thể cài
ñặt ñể tìm luồng cực ñại trên A trong thời gian $����+ %&' F�.
4. Bộ ghép cực ñại trên ñồ thị hai phía
4.1. ðồ thị hai phía
ðồ thị vô hướng A �a8 �� ñược gọi là ñồ thị hai phía nếu tập ñỉnh a của nó có
thể chia làm hai tập con rời nhau: � và Ù sao cho mọi cạnh của ñồ thị ñều nối
một ñỉnh thuộc � với một ñỉnh thuộc Ù . Khi ñó người ta còn ký hiệu A �� Ø Ù8 ��. ðể thuận tiên trong trình bày, ta gọi các ñỉnh thuộc � là các �_ñỉnh
và các ñỉnh thuộc Ù là các Ù_ñỉnh.

227
Hình 2.12. ðồ thị hai phía
Một ñồ thị vô hướng là ñồ thị hai phía nếu và chỉ nếu từng thành phần liên thông của nó là ñồ thị hai phía. ðể kiểm tra một ñồ thị vô hướng liên thông có phải ñồ thị hai phía hay không, ta có thể sử dụng một thuật toán tìm kiếm trên ñồ thị
(BFS hoặc DFS) bắt ñầu từ một ñỉnh " bất kỳ. ðặt: � z Ìtập các ñỉnh ñến ñược từ " qua một số chẵn cạnhÍ Ù z Ìtập các ñỉnh ñến ñược từ " qua một số lẻ cạnhÍ Nếu tồn tại cạnh của ñồ thị nối hai ñỉnh 5 � hoặc hai ñỉnh 5 Ù thì ñồ thị ñã cho không phải ñồ thị hai phía, ngược lại ñồ thị ñã cho là ñồ thị hai phía với cách
phân hoạch tập ñỉnh thành hai tập �8 Ù ở trên.
ðồ thị hai phía gặp rất nhiều mô hình trong thực tế. Chẳng hạn quan hệ hôn nhân giữa tập những người ñàn ông và tập những người ñàn bà, việc sinh viên chọn trường, thầy giáo chọn tiết dạy trong thời khoá biểu v.v…
4.2. Bài toán tìm bộ ghép cực ñại trên ñồ thị hai phía
Cho ñồ thị hai phía A �� Ø Ù8 ��. Một bộ ghép (matching) của A là một tập các cạnh ñôi một không có ñỉnh chung. Có thể coi một bộ ghép là một tập y Ö � sao cho trên ñồ thị �� Ø Ù8 y�, mỗi ñỉnh có bậc không quá 1.
Vấn ñề ñặt ra là tìm một bộ ghép lớn nhất (maximum matching) (có nhiều cạnh nhất) trên ñồ thị hai phía cho trước.
4.3. Mô hình luồng
ðịnh hướng các cạnh của A thành cung từ � sang Ù. Thêm vào ñỉnh phát giả "
và các cung nối từ " tới các �_ñỉnh, thêm vào ñỉnh thu giả � và các cung nối từ
� Ù

228
các Ù_ñỉnh tới �. Sức chứa của tất cả các cung ñược ñặt bằng 1, ta ñược mạng Aó. Xét một luồng trên mạng Aó có luồng trên các cung là số nguyên, khi ñó có
thể thấy rằng những cung có luồng bằng 1 từ � sang Ù sẽ tương ứng với một bộ
ghép trên A. Bài toán tìm bộ ghép cực ñại trên A có thể giải quyết bằng cách tìm
luồng nguyên cực ñại trên Aó.
Hình 2.13. Mô hình luồng của bài toán tìm bộ ghép cực ñại trên ñồ thị hai phía.
Chúng ta sẽ phân tích một số ñặc ñiểm của ñường tăng luồng trong trường hợp này ñể tìm ra một cách cài ñặt ñơn giản hơn.
Xét ñồ thị hai phía A �� Ø Ù8 �� và một bộ ghép y trên A.
� Những ñỉnh thuộc y gọi là những ñỉnh ñã ghép (matched vertices), những
ñỉnh không thuộc y gọi là những ñỉnh chưa ghép (unmached vertices).
� Những cạnh thuộc y gọi là những cạnh ñã ghép, những cạnh không thuộc y ñược gọi là những cạnh chưa ghép. � Nếu ñịnh hướng lại những cạnh của ñồ thị thành cung: Những cạnh chưa
ghép ñịnh hướng từ � sang Ù, những cạnh ñã ghép ñịnh hướng ngược lại từ Ù về �. Trên ñồ thị ñịnh hướng ñó, một ñường ñi ñược gọi là ñường pha
(alternating path) và một ñường ñi từ một � _ñỉnh chưa ghép tới một Ù_ñỉnh chưa ghép gọi là một ñường mở (augmenting path).
Dọc trên một ñường pha, các cạnh ñã ghép và chưa ghép xen kẽ nhau. ðường mở cũng là một ñường pha, ñi qua một số lẻ cạnh, trong ñó số cạnh chưa ghép nhiều hơn số cạnh ñã ghép ñúng một cạnh.
Ví dụ với ñồ thị hai phía trong hình 2.14 và một bộ ghép 6� (8 >(�8 � +8 >+�9.
ðường ñi ¬ �8 >+8 +8 >( là một ñường pha, ñường ñi ¬ �8 >+8 +8 >(8 (8 >� là một
ñường mở.
1
2
3
1
2
3
� Ù
" �

229
Hình 2.14. ðồ thị hai phía và các cạnh ñược ñịnh hướng theo một bộ ghép
ðường mở thực chất là ñường tăng luồng với giá trị thặng dư 1 trên mô hình luồng. ðịnh lý 3-11 (mối quan hệ giữa luồng cực ñại, ñường tăng luồng và lát
cắt hẹp nhất) ñã chỉ ra rằng ñiều kiện cần và ñủ ñể một bộ ghép y là bộ ghép
cực ñại là không tồn tại ñường mở ứng với y.
Nếu tồn tại ñường mở B ứng với bộ ghép y, ta mở rộng bộ ghép bằng cách: dọc
trên ñường B loại bỏ những cạnh ñã ghép khỏi y và thêm những cạnh chưa
ghép vào y. Bộ ghép mới thu ñược sẽ có lực lượng nhiều hơn bộ ghép cũ ñúng
một cạnh. ðây thực chất là phép tăng luồng dọc trên ñường B trên mô hình luồng.
4.4. Thuật toán ñường mở
Từ mô hình luồng của bài toán, chúng ta có thể xây dựng ñược thuật toán tìm bộ ghép cực ñại dựa trên cơ chế tìm ñường mở và tăng cặp: Thuật toán khởi tạo một bộ ghép bất kỳ trước khi bước vào vòng lặp chính. Tại mỗi bước lặp, ñường
mở (thực chất là một ñường ñi từ một �_ñỉnh chưa ghép tới một Ù_ñỉnh chưa ghép) ñược tìm bằng BFS hoặc DFS và bộ ghép sẽ ñược mở rộng dựa trên ñường mở tìm ñược.
M := «Một bộ ghép bất kỳ, chẳng hạn: �»; while «Tìm ñược ñường mở P» do
begin
«Dọc trên ñường P:
- Loại bỏ những cạnh ñã ghép khỏi M
- Thêm những cạnh chưa ghép vào M
»
end;
1
� Ù
1
2
3
2
3

230
Ví dụ với ñồ thị trong hình 2.14 và bộ ghép y 6� (8 >(�8 � +8 >+�9, thuật toán sẽ
tìm ñược ñường mở: � � >+ G�5� + � >( G�5� ( � >�
Dọc trên ñường mở này, ta loại bỏ hai cạnh �>+8 +� và �>(8 (� khỏi bộ ghép và
thêm vào bộ ghép ba cạnh � �8 >+�, � +8 >(�, � (8 >��, ñược bộ ghép mới 3 cạnh.
ðồ thị với bộ ghép mới không còn ñỉnh chưa ghép (không còn ñường mở) nên ñây
chính là bộ ghép cực ñại (h.2.15).
Hình 2.15. Mở rộng bộ ghép
4.5. Cài ñặt
Chúng ta sẽ cài ñặt thuật toán tìm bộ ghép cực ñại trên ñồ thị hai phía A �� Ø Ù8 ��, trong ñó ��� �, �Ù� � và ��� �. Các �_ñỉnh ñược ñánh số từ
1 tới � và các Ù_ñỉnh ñược ñánh số từ 1 tới �. Khuôn dạng Input/Output như sau:
Input
� Dòng 1 chứa ba số nguyên dương �8 �8 � lần lượt là số �_ñỉnh, số Ù_ñỉnh
và số cạnh của ñồ thị hai phía. ��8 � N �7�� � N �7��.
� � dòng tiếp theo, mỗi dòng chứa hai số nguyên dương �8 b tương ứng với
một cạnh g 28 >®h của ñồ thị.
Output
Bộ ghép cực ñại trên ñồ thị.
1
� Ù
1
2
3
2
3
1
� Ù
1
2
3
2
3

231
Sample Input Sample Output
3 3 5
3 2
2 2
2 1
1 3
1 1
1: x[2] - y[1]
2: x[3] - y[2]
3: x[1] - y[3]
a) a) a) a) BiBiBiBi&&&&u diu diu diu di''''n "n "n "n "^̂̂̂ thththth>>>> hai phía và bhai phía và bhai phía và bhai phía và b8888 ghépghépghépghép
ðồ thị hai phía A �� Ø Ù8 �� sẽ ñược biểu diễn bằng cách danh sách kề của
các �_ñỉnh. Cụ thể là ta sẽ sử dụng mảng ����� �� với các phần tử ban ñầu
ñược khởi tạo bằng 0, mảng �b�� �� và mảng ������ ��. Danh sách kề ñược xây dựng ngay trong quá trình ñọc danh sách cạnh: mỗi khi ñọc một cạnh �2 � 8 >� ta gán �b��� z > , ñặt ������� z ���� � sau ñó cập nhật lại ���� � z �. Khi ñọc xong danh sách cạnh thì danh sách kề cũng ñược xây
dựng xong, khi ñó ñể duyệt các Ù_ñỉnh kề với một ñỉnh 5 �, ta có thể sử dụng thuật toán sau:
i := head[x]; //Từ ñầu danh sách móc nối các ñỉnh kề x
while i ≠ 0 do
begin
«Xử lý ñỉnh adj[i]»;
i := link[i]; //Nhảy sang phần tử kế tiếp trong danh sách móc nối
end;
Bộ ghép trên ñồ thị hai phía ñược biểu diễn bởi mảng ��l��� �>�, trong ñó ��l��b� là chỉ số của �_ñỉnh ghép với ñỉnh >®. Nếu >® là ñỉnh chưa ghép, ta
gán ��l��b� z 7. b) b) b) b) Tìm Tìm Tìm Tìm "F"F"F"FBBBBng mng mng mng mBBBB
ðường mở thực chất là một ñường ñi từ một �_ñỉnh chưa ghép tới một Ù_ñỉnh chưa ghép trên ñồ thị ñịnh hướng. Ta sẽ tìm ñường mở tại mỗi bước bằng thuật toán DFS:
1
� Ù
1
2
3
2
3

232
Bắt ñầu từ một ñỉnh 5 � chưa ghép, trước hết ta ñánh dấu các Ù_ñỉnh bằng
mảng ����� �� trong ñó ����b� ¸q�¹ nếu ñỉnh >® 5 Ù chưa thăm và ����b� ºn%»¹ nếu ñỉnh >® 5 Ù ñã thăm (chỉ cần ñánh dấu các Ù_ñỉnh).
Thuật toán DFS ñể tìm ñường mở xuất phát từ ñược thực hiện bằng một thủ
tục ñệ quy a�"��� �, thủ tục này sẽ quét tất cả những ñỉnh > 5 Ù chưa thăm nối
từ � (dĩ nhiên qua một cạnh chưa ghép), với mỗi khi xét ñến một ñỉnh > 5 Ù,
trước hết ta ñánh dấu thăm >. Sau ñó:
� Nếu > ñã ghép, dựa vào sự kiện từ > chỉ ñi ñến ñược ��l��>� qua một
cạnh ñã ghép hướng từ Ù về �, lời gọi ñệ quy a�"�����l��>�� ñược thực
hiện ñể thăm luôn ñỉnh ��l��>� 5 � (thăm liền hai bước).
� Ngược lại nếu > chưa ghép, tức là thuật toán DFS tìm ñược ñường mở kết
thúc ở >, ta thoát khỏi dây chuyền ñệ quy. Quá trình thoát dây chuyền ñệ quy thực chất là lần ngược ñường mở, ta sẽ lợi dụng quá trình này ñể mở rộng bộ ghép dựa trên ñường mở.
ðể thuật toán hoạt ñộng hiệu quả hơn, ta sử dụng liên tiếp các pha xử lý lô: Ký
hiệu �Ë là tập các �_ñỉnh chưa ghép, mỗi pha sẽ cố gắng mở rộng bộ ghép dựa trên không chỉ một mà nhiều ñường mở không có ñỉnh chung xuất phát từ các
ñỉnh khác nhau thuộc �Ë . Cụ thể là một pha sẽ khởi tạo mảng ñánh dấu ����� �� bởi giá trị ¸q�¹, sau ñó quét tất cả những ñỉnh 5 �Ë , thử tìm
ñường mở xuất phát từ và mở rộng bộ ghép nếu tìm ra ñường mở. Trong một
pha có thể có nhiều �_ñỉnh ñược ghép thêm.
procedure Visit(x 5X); //Thuật toán DFS
begin
for Ly: (x, y)5 E do //Quét các Y_đỉnh kề x
if avail[y] then //y chưa thăm, chú ý (x, y) chắc chắn là cạnh chưa ghép
begin
avail[y] := False; //Đánh dấu thăm y
if match[y] = 0 then Found := True
//y chưa ghép, dựng cờ báo tìm thấy đường mở else Visit(match[y]); //y đã ghép, gọi đệ quy tiếp tục DFS
if Found then // Ngay khi đường mở được tìm thấy
begin
match[y] := x; //Chỉnh lại bộ ghép theo đường mở

233
Exit; //Thoát luôn, lệnh Exit đặt ở đây sẽ thoát cả dây chuyền đệ quy
end;
end;
end;
begin //Thuật toán tìm bộ ghép cực đại trên đồ thị hai phía
«Khởi tạo một bộ ghép bất kỳ, chẳng hạn �»; X* := «Tập các ñỉnh chưa ghép»;
repeat //Lặp các pha xử lý theo lô
Old := |X*|; //Lưu số đỉnh chưa ghép khi bắt đầu pha
for Ly 5 Y do avail[y] := True; //ðánh dấu mọi Y_ñỉnh chưa thăm
for Lx 5 X* do begin
Found := False; //Cờ báo chưa tìm thấy đường mở
Visit(x); //Tìm đường mở bằng DFS
if Found then X* := X* - {x};
//x ñã ñược ghép, loại bỏ x khỏi X* end;
until |X*| = Old; //Lặp cho tới khi không thể ghép thêm
end;
� BMATCH.PAS � Tìm bộ ghép cực ñại trên ñồ thị hai phía
{$MODE OBJFPC}
program MaximumBipartiteMatching;
const
maxN = 10000;
maxM = 1000000;
var
p, q, m: Integer;
adj: array[1..maxM] of Integer;
link: array[1..maxM] of Integer;
head: array[1..maxN + 1] of Integer;
match: array[1..maxN] of Integer;
avail: array[1..maxN] of Boolean;
List: array[1..maxN] of Integer;
nList: Integer;
procedure Enter; //Nhập dữ liệu
var i, x, y: Integer;
begin

234
ReadLn(p, q, m);
FillChar(head[1], p * SizeOf(head[1]), 0);
for i := 1 to m do
begin
ReadLn(x, y); //Đọc một cạnh (x, y), đưa y vào danh sách kề của x
adj[i] := y;
link[i] := head[x];
head[x] := i;
end;
end;
procedure Init; //Khởi tạo bộ ghép rỗng
var i: Integer;
begin
FillChar(match[1], q * SizeOf(match[1]), 0);
for i := 1 to p do List[i] := i;
//Mảng List chứa nList X_ñỉnh chưa ghép nList := p;
end;
procedure SuccessiveAugmentingPaths;
var
Found: Boolean;
Old, i: Integer;
procedure Visit(x: Integer); //Thuật toán DFS từ x∈∈∈∈X
var i, y: Integer;
begin
i := head[x]; //Từ đầu danh sách kề của x
while i <> 0 do
begin
y := adj[i]; //Xét một đỉnh y∈∈∈∈Y kề x
if avail[y] then //y chưa thăm, hiển nhiên (x, y) là cạnh chưa ghép
begin
avail[y] := False; //Đánh dấu thăm y
if match[y] = 0 then Found := True
//y chưa ghép thì báo hiệu tìm thấy đường mở else Visit(match[y]);
//Thăm luôn match[y]∈∈∈∈X (thăm liền 2 bước) if Found then //Tìm thấy đường mở
begin
match[y] := x; //Chỉnh lại bộ ghép

235
Exit; //Thoát dây chuyền đệ quy
end;
end;
i := link[i]; //Chuyển sang ñỉnh kế tiếp trong danh sách các ñỉnh kề x end;
end;
begin
repeat
Old := nList; //Lưu lại số X_đỉnh chưa ghép
FillChar(avail[1], q * SizeOf(avail[1]), True);
for i := nList downto 1 do
begin
Found := False;
Visit(List[i]); //Cố ghép List[i]
if Found then //Nếu ghép được
begin //Xóa List[i] khỏi danh sách các X_đỉnh chưa ghép
List[i] := List[nList];
Dec(nList);
end;
end;
until Old = nList; //Không thể ghép thêm X_đỉnh nào nữa
end;
procedure PrintResult; //In kết quả
var j, k: Integer;
begin
k := 0;
for j := 1 to q do
if match[j] <> 0 then
begin
Inc(k);
WriteLn(k, ': x[', match[j], '] - y[', j, ']');
end;
end;
begin
Enter;
Init;
SuccessiveAugmentingPath;
PrintResult;

236
end.
Nếu ñồ thị có � ñỉnh (� � � �) và � cạnh, do mảng ñánh dấu ����� �� chỉ ñược khởi tạo một lần trong pha, thời gian thực hiện của một pha sẽ bằng $�� � �� (suy ra từ thời gian thực hiện giải thuật của DFS).
Các pha sẽ ñược thực hiện lặp cho tới khi �Ë � hoặc khi một pha thực hiện
xong mà không ghép thêm ñược ñỉnh nào. Thuật toán cần không quá � lần thực hiện pha xử lý lô, nên thời gian thực hiện giải thuật tìm bộ ghép cực ñại trên ñồ
thị hai phía là $��+ � ��� trong trường hợp xấu nhất. Còn trong trường hợp tốt nhất, ta có thể tìm ñược bộ ghép cực ñại chỉ qua một lượt thực hiện pha xử lý lô, tức là bằng thời gian thực hiện giải thuật DFS. Cần lưu ý rằng ñây chỉ là những
ñánh giá $ lớn về cận trên của thời gian thực hiện. Thuật toán này chạy rất nhanh trên thực tế nhưng hiện tại chưa có ñánh giá nào chặt hơn.
Ý tưởng tìm một lúc nhiều ñường mở không có ñỉnh chung ñã ñược nghiên cứu
trong bài toán luồng cực ñại bởi Dinic[10]. Dựa trên ý tưởng này, Hopcroft và
Karp[21] ñã tìm ra thuật toán tìm bộ ghép cực ñại trên ñồ thị hai phía trong thời
gian $ f��a����i. Thuật toán Hopcroft-Karp trước hết sử dụng BFS ñể phân lớp
các ñỉnh theo ñộ dài ñường ñi ngắn nhất sau ñó mới sử dụng DFS trên rừng các cây BFS ñể xử lý lô tương tự như cách làm của chúng ta ở trên.
Bài tập
2.35. Có � thợ và � việc. Mỗi thợ cho biết mình có thể làm ñược những việc nào, và mỗi việc khi giao cho một thợ thực hiện sẽ ñược hoàn thành xong trong ñúng 1 ñơn vị thời gian. Tại một thời ñiểm, mỗi thợ chỉ thực hiện không quá một việc.
Hãy phân công các thợ làm các công việc sao cho:
� Mỗi việc chỉ giao cho ñúng một thợ thực hiện. � Thời gian hoàn thành tất cả các công việc là nhỏ nhất. Chú ý là các thợ có
thể thực hiện song song các công việc ñược giao, việc của ai người nấy làm, không ảnh hưởng tới người khác.

237
3.36. Một bộ ghép y trên ñồ thị hai phía gọi là tối ñại nếu việc bổ sung thêm bất
cứ cạnh nào vào y sẽ làm cho y không còn là bộ ghép nữa.
a) Chỉ ra một ví dụ về bộ ghép tối ñại nhưng không là bộ ghép cực ñại trên ñồ thị hai phía
b) Tìm thuật toán $����� ñể xác ñịnh một bộ ghép tối ñại trên ñồ thị hai phía
c) Chứng minh rằng nếu � và H là hai bộ ghép tối ñại trên cùng một ñồ thị
hai phía thì ��� N ;�H� và �H� N ;���. Từ ñó chỉ ra rằng nếu thuật toán ñường mở ñược khởi tạo bằng một bộ ghép tối ñại thì số lượt tìm ñường mở giảm ñi ít nhất một nửa so với việc khởi tạo bằng bộ ghép rỗng.
3.37. (Phủ ñỉnh – Vertex Cover) Cho ñồ thị hai phía A �� Ø Ù8 ��. Bài toán
ñặt ra là hãy chọn ra một tập F gồm ít nhất các ñỉnh sao cho mọi cạnh 5 �
ñều liên thuộc với ít nhất một ñỉnh thuộc F.
Bài toán tìm phủ ñỉnh nhỏ nhất trên ñồ thị tổng quát là NP-ñầy ñủ, hiện tại chưa có thuật toán ña thức ñể giải quyết. Tuy vậy trên ñồ thị hai phía, phủ ñỉnh nhỏ nhất có thể tìm ñược dựa trên bộ ghép cực ñại.
Dựa vào mô hình luồng của bài toán bộ ghép cực ñại, giả sử các cung ��8 Ù� có sức chứa ��, các cung �"8 �� và �Ù8 �� có sức chứa 1. Gọi �k8 ��
là lát cắt hẹp nhất của mạng. ðặt F 6 5 �9 Ø 6> 5 k9. a) Chứng minh rằng F là một phủ ñỉnh
b) Chứng minh rằng F là phủ ñỉnh nhỏ nhất
c) Giả sử ta tìm ñược y là bộ ghép cực ñại trên ñồ thị hai phía, khi ñó chắc
chắn không còn tồn tại ñường mở tương ứng với bộ ghép y. ðặt: ÙË Ì> 5 ÙM õ 5 � chưa ghép8 ñến ñược > qua một ñường phaÍ �Ë 6 5 �M ñã ghép và ñỉnh ghép với không thuộc ÙË9 Chứng minh rằng ��Ë8 ÙË� là lát cắt hẹp nhất.
d) Xây dựng thuật toán tìm phủ ñỉnh nhỏ nhất trên ñồ thị hai phía dựa trên thuật toán tìm bộ ghép cực ñại.
3.38. Cho y là một bộ ghép trên ñồ thị hai phía A �� Ø Ù8 ��. Gọi � là số �_ñỉnh chưa ghép. Chứng minh rằng ba mệnh ñề sau ñây là tương ñương:

238
� y là bộ ghép cực ñại.
� A không có ñường mở tương ứng với bộ ghép y.
� Tồn tại một tập con � của � sao cho ������ ��� C �. Ở ñây ���� là tập
các Ù_ñỉnh kề với một ñỉnh nào ñó trong � (Gợi ý: Chọn � là tập các �_ñỉnh ñến ñược từ một �_ñỉnh chưa ghép bằng một ñường pha)
2.39. (ðịnh lý Hall) Cho A �� Ø Ù8 �� là ñồ thị hai phía có ��� �Ù�. Chứng
minh rằng A có bộ ghép ñầy ñủ (bộ ghép mà mọi ñỉnh ñều ñược ghép) nếu
và chỉ nếu ��� N ������ với mọi tập � Ö �.
2.40. (Phủ ñường tối thiểu) Cho A �a8 �� là ñồ thị có hướng không có chu
trình. Một phủ ñường (path cover) là một tập B các ñường ñi trên A thỏa
mãn: Với mọi ñỉnh � 5 a, tồn tại duy nhất một ñường ñi trong B chứa �. ðường ñi có thể bắt ñầu và kết thúc ở bất cứ ñâu, tính cả ñường ñi ñộ dài 0 (chỉ gồm một ñỉnh). Bài toán ñặt ra là tìm phủ ñường tối thiểu (minimum path cover): Phủ ñường gồm ít ñường ñi nhất.
Gọi � là số ñỉnh của ñồ thị, ta ñánh số các ñỉnh thuộc a từ 1 tới �. Xây
dựng ñồ thị hai phía Aó �� Ø Ù8 �ó� trong ñó: � 6 (8 +8 .9 Ù 6>(8 >+8 >.9 Tập cạnh �ó ñược xây dựng như sau: Với mỗi cung ��8 b� 5 �, ta thêm vào
một cạnh g 2 8 >®h 5 �ó (h.2.16)

239
Hình 2.16. Bài toán tìm phủ ñường tối thiểu trên DAG có thể quy về bài toán bộ ghép cực ñại trên ñồ
thị hai phía.
Gọi y là một bộ ghép trên Aó. Khởi tạo B là tập � ñường ñi, mỗi ñường ñi
chỉ gồm một ñỉnh trong A, khi ñó B là một phủ ñường. Xét lần lượt các
cạnh của bộ ghép, mỗi khi xét tới cạnh g 2 8 >®h ta ñặt cạnh ��8 b� nối hai
ñường ñi trong B thành một ñường…Khi thuật toán kết thúc, B vẫn là một phủ ñường.
a) Chứng minh tính bất biến vòng lặp: Tại mỗi bước khi xét tới cạnh g 2 8 >®h 5 y, cạnh ��8 b� 5 � chắc chắn sẽ nối hai ñường ñi trong B: một
ñường ñi kết thúc ở � và một ñường ñi khác bắt ñầu ở b. Từ ñó chỉ ra tính
ñúng ñắn của thuật toán. (Gợi ý: mỗi khi xét tới cạnh g 28 >®h 5 y và ñặt
cạnh ��8 b� nối hai ñường ñi của B thành một ñường thì �B� giảm 1. Vậy khi
thuật toán trên kết thúc, �B� � C �y� , tức là muốn �B� G �µo thì �y� G �n�).
b) Viết chương trình tìm phủ ñường cực tiểu trên ñồ thị có hướng không có chu trình.
c) Chỉ ra ví dụ ñể thấy rằng thuật toán trên không ñúng trong trường hợp A có chu trình.
d) Chứng minh rằng nếu tìm ñược thuật toán giải bài toán tìm phủ ñường cực tiểu trên ñồ thị tổng quát trong thời gian ña thức thì có thể tìm ñược ñường ñi Hamilton trên ñồ thị ñó (nếu có) trong thời gian ña thức. (Lý
�
V
\
;
X
T
(
+
�
�
�
�
>(
>+
>�
>�
>�
>�
B( ¬�8V8\ B+ ¬;8X8T

240
thuyết về ñộ phức tạp tính toán ñã chứng minh ñược rằng trên ñồ thị tổng quát, bài toán tìm ñường ñi Hamilton là NP-ñầy ñủ và bài toán tìm phủ ñường cực tiểu là NP-khó. Có nghĩa là một thuật toán với ñộ phức tạp ña thức ñể giải quyết bài toán phủ ñường cực tiểu trên ñồ thị tổng quát sẽ là một phát minh lớn và ñáng ngạc nhiên).
2.41. Tự tìm hiểu về thuật toán Hopcroft-Karp. Cài ñặt và so sánh tốc ñộ thực tế với thuật toán trong bài.
2.42. (Bộ ghép cực ñại trên ñồ thị chính quy hai phía) Một ñồ thị vô hướng A �a8 �� gọi là ñồ thị chính quy bậc � (�-regular graph) nếu bậc của
mọi ñỉnh ñều bằng �. ðồ thị chính quy bậc 0 là ñồ thị không có cạnh nào, ñồ thị chính quy bậc 1 thì các cạnh tạo thành bộ ghép ñầy ñủ, ñồ thị chính quy bậc 2 có các thành phần liên thông là các chu trình ñơn.
a) Chứng minh rằng ñồ thị hai phía A �� Ø Ù8 �� là ñồ thị chính quy thì ��� �Ù�. b) Chứng minh rằng luôn tồn tại bộ ghép ñầy ñủ trên ñồ thị hai phía chính
quy bậc � (� w ��.
c) Tìm thuật toán $���� %&'���� ñể tìm một bộ ghép ñầy ñủ trên ñồ thị
chính quy bậc � w �.














![TIN HỌC ĐẠI CƯƠNG Bài 8. Mảng và xâu kí tự · 2014-07-10 · • Mảng một chiều và mảng nhiều chiều ... – int b[3][4][5]; // mảng 3 chiều 7 8.1.2](https://img.pdfslide.tips/doc/110x75/5b448f557f8b9a2d328c09c2/tin-hoc-dai-cuong-bai-8-mang-va-xau-ki-tu-2014-07-10-.jpg)














