Embed Size (px)
DESCRIPTION
sadsadsa
Citation preview

7
BAB II
LANDASAN TEORI
2.1 Business Intelligence
Business Intelligence (BI) is an umbrella term that combines architectures,
tools, databases, analytical tools, applications, and methodologies (Turban et al,
2007, p.24). BI meliputi semua proses mengumpulkan dan menganalis data
menggunakan teknologi yang bertujuan untuk mendapatkan informasi yang
membantu sebuah institusi dalam mengambil keputusan (Connoly & Begg, 2010,
p.1195), membantu organisasi mengelola dan menyaring informasi dalam
membuat keputusan yang lebih efektif (Lonnqvist & Pirttimaki, 2006). BI
menyediakan informasi yang bersifat historical, current dan predictive. Adapun
fungsi-fungsi BI antara lain reporting, online analytical processing, analytics,
data mining, process mining, complex event processing, business performance
management, benchmarking, text mining, predictive analytics dan prescriptive
analytics (http://en.wikipedia.org/wiki/Business_intelligence).
2.2 Data Mining
Data mining adalah sebuah istilah yang digunakan untuk menggambarkan
penemuan ilmu pengetahuan dalam bidang database, sebuah bidang analisis
informasi yang mencari pola tersembunyi dalam sekelompok data yang dapat
digunakan untuk memprediksi perilaku masa depan (Turban et al, 2007, p.202).

8
Data mining adalah suatu proses yang menggunakan statistical,
mathematical, artificial intelligence, dan machine-learning techniques untuk
mengekstrak dan mengindentifikasi informasi penting dan subsequent knowledge
dari databases yang besar (Turban et al, 2007, p.305), dimana informasi yang
diektrak digunakan dalam mengambil keputusan bisnis yang cukup krusial
(crucial business decision) (Connoly & Begg, 2010, p.1280).
Data mining juga merupakan proses penemuan pengetahun (knowledge
discovery) dengan mencari pola dan struktur pada sekumpulan data (Kifer at el,
2006, p.730). Data mining adalah teknologi baru yang powerful dengan
kemampuan penemuan useful knowledge, yang semuanya itu diperoleh dari
sumber data yang besar dan cukup kompleks untuk diketahui (Delavari et al,
2008).
Teknik data mining dapat diaplikasikan dalam berbagai bidang bisnis
seperti bidang medicine, statistical analysis, engineering, education, banking,
marketing, sale, etc (ZhaoHui & Maclennan, 2005). Menurut Delavari dkk
(2008), data mining dikenal sebagai teknologi yang sangat tepat dalam
menemukan pengetahuan (insight) bagi entitas lembaga pendidikan seperti
pengetahuan seputar mahasiswa, dosen, karyawan, alumni dan perilaku
managerial.
Pada Gambar 2.1 berikut adalah gambaran dari posisi data mining dalam
konteksi Business Intelligence. Data mining merupakan tahapan data analysis
yang bertujuan pada penemuan pengetahuan (knowledge discovery).

9
Gambar 2.1 Data Mining in the BI Context
(Sumber: http://www.cs.jyu.fi/~mpechen/TIES443)
2.3 Data Mining Function
Data mining memiliki kemampuan cepat dalam melakukan analisis dan
sangat fokus pada variabel-variabel penting. Patterns (pola) dan rules (aturan,
kaidah) yang dapat digunakan dalam membuat keputusan dan forecast
(meramalkan) dampak dari keputusan tersebut. Intelligent data mining meliputi
informasi dalam data warehouse dimana query dan laporan biasa tidak bisa
mengungkapkan informasi secara efektif. Data mining tools mampu menemukan
pola dalam data dan memberi dugaan berupa rules. Dalam bukunya Turban (2007,
p.307), ada tiga metode yang digunakan dalam mengidentifikasi pola dalam data
(Nemati & Barko, 2001), yaitu: simple models (contoh, SQL berbasis query yang
merupakan cara sederhana dalam menarik data, online analytical processing
(OLAP), human judgment); Intermediate models (contoh, regression, decision
trees, clustering); Complex models (contoh, neural networks, other rule

10
induction). Algoritma data mining tradisional juga membagi empat kategori besar,
yakni classification, clustering, association, dan sequence discovery.
Pada Tabel 2.1 di bawah ini mengklasifikasikan model data mining
berdasarkan fungsi dan algoritma yang digunakan.
Tabel 2.1 Data mining Functions, Algorithms, and Application Examples
Data mining function Algorithm Application Examples
Association Statistics, set theory Market basket analysis
Classification Decision trees, neural
networks, control, risk assessment, rules
Target marketing quality
Clustering Neural network, statistics,
optimization, discriminate analysis
Market segmentation
Sequence discovery Statistics, set theory Market basket analysis
over time, customer life cycle analysis
Modeling
Linear and nonlinear regression, curve fitting, neural networks
Sales forecasting, interest rate, prediction, inventory control
Drill-down and aggregate view of data
Visualization, using many different approaches.
Virtually all the preceding application
Sumber: Adapted from J.P. Bigus, Data mining with Neural Networks,
McGraw-Hill, New York, 1996 (Turban et al, 2007, p.309).
2.4 Data Mining Model
Ada berbagai model dalam data mining atau sering disebut teknik data
mining, secara umum model data mining dibagi dalam tiga kelompok berdasarkan
pada tugas atau fungsi yang terdiri dari classification, clustering, dan association.

11
2.4.1 Classification
Classification melakukan analisa pada data historikal yang tersimpan
dalam database dan mengenerate otomatis model yang dapat memprediksi
perilaku masa depan. Dengan melakuan redefined class, model dapat
memprediksi sebuah kelas atau membuat kelas pada rekord-rekord data yang
terklasifikasi. Classification menemukan pola data yang digunakan untuk
mengklasifikasi dalam kategori tertentu (Kifer et al, 2006, p.730), contohnya pada
aplikasi email yang dapat mengklasifikasi email yang bukan spam dan email spam
(http://en.wikipedia.org/wiki/Data_mining#Data_mining). Contoh lain, klasifikasi
antara pelanggan yang membeli produk terbanyak dengan pelanggan yang
membeli produk dalam jumlah sedikit. Informasi ini misalnya bisa digunakan
dalam melakukan iklan, tentu iklan akan difokuskan kepada pelanggan yang
memiliki jumlah pembelian paling banyak, karena besar peluang pelanggan
tersebut untuk membeli kembali. Algoritma yang biasa digunakan dalam
classification adalah neural network, decision trees, naïve bayes dan if-then-else
rules (Turban et al, 2007, p.307).
2.4.1.1 Decision Trees
Decision trees adalah algoritma yang paling banyak digunakan untuk
masalah pengklasifikasian. Decision trees break down problems into increasingly
discrete subsets by working from generalizations to increasingly more specific
information. A decision tree can be define as a root followed by internal nodes
(Turban, 2007, p.313). Pola data yang menggunakan banyak variabel yang sangat
berdampak pada klasifikasi sebuah pola. Variabel ini disebut sebagai atribut dan

12
hasilnya disebut class label. Contoh, ketika mencari pola mahasiswa yang lulus
tidak tepat waktu, klasifikasi yang digunakan seperti lama studi, jumlah SKS dan
GPA, inilah yang disebut atribut. Setiap tree terdiri dari branch dan nodes.
Branch merepresentasikan sebuah hasil dari sebuah test klasifikasi sebuah pola,
berdasarkan pada sebuah test, …a branch represents the outcomes of a test to
classify a pattern on the basis of a test, using an attribute (Turban et al, 2007,
p.315). Leaf node adalah representasi akhir dari sebuah pilihan klasifikasi pada
sebuah pola. Sedangkan intermediate node mereprentasikan test atas suatu atribut.
Decision trees merupakan teknik yang umum digunakan dalam melakukan
prediksi. Berikut adalah contoh dari penerapan decision trees.
Gambar 2.2 Sample Decision Tree For Predicting Academic Failure/Success
(Sumber: Bresfelean, 2009)

13
Dari contoh pada Gambar 2.2 di atas dapat diterjemahkan sebagai berikut:
• “If students’ admittance grade was above 8, then they would pass all their
exams”
• “If students’ admittance grade was in the (7,8] interval, were neutral that
their expectations regarding the present specialization were fulfilled,
believed the financial support from their parents was normal, then they
would fail one or more exams”
• “If students’ admittance grade was in the (7,8] interval, did not agree that
their expectations regarding the present specialization were fulfilled, then
they would fail one or more exams”
2.4.1.2 Neural Network
Suatu representatif dari brain methapor dalam pengolahan informasi,
sebuah model yang secara biologi meniru fungsi kerja otak. Neural network
mengacu kepada metode pengenalan terhadap pola. Sudah banyak digunakan
dalam aplikasi bisnis untuk pattern recognition, forecasting, prediction, dan
classification (Turban et al, 2007, p.346).
Hecht-Nielsend (1988) mendefinisikan Artificial Neural Network (ANN)
atau diterjemahkan menjadi jaringan saraf tiruan adalah suatu struktur pemroses
informasi yang terdistribusi dan bekerja secara paralel, terdiri atas elemen
pemroses (yang memiliki memori lokal dan beroperasi dengan informasi lokal)
yang diinterkoneksi bersama dengan alur sinyal searah yang disebut koneksi.
Setiap elemen pemroses memiliki koneksi keluaran tunggal yang bercabang (fan
out) ke sejumlah koneksi kolateral yang diinginkan (setiap koneksi membawa

14
sinyal yang sama dari keluaran elemen pemroses tersebut). Keluaran dari elemen
pemroses tersebut dapat merupakan sebarang jenis persamaan matematis yang
diinginkan. Seluruh proses yang berlangsung pada setiap elemen pemroses harus
benar-benar dilakukan secara lokal, yaitu keluaran hanya bergantung pada nilai
masukan pada saat itu yang diperoleh melalui koneksi dan nilai yang tersimpan
dalam memori lokal. Sebuah ANN adalah sebuah prosesor yang terdistribusi
paralel dan mempuyai kecenderungan untuk menyimpan pengetahuan yang
didapatkannya dari pengalaman dan membuatnya tetap tersedia untuk digunakan.
Jenis ANN yang paling dikenal adalah ANN multilayer feedforward. Sel-
sel saraf diurutkan berdasarkan pada layer-layer, diawali oleh layer input dan
diakhiri dengan layer output sedangkan di antaranya terdapat layer hidden.
Hubungan dalam ANN jenis ini terjadi hanya satu arah, dari layer input ke layer
hidden pertama lalu ke layer hidden kedua dan seterusnya. Jenis ANN ini bukan
merupakan satu-satunya, namun jenis ANN ini adalah yang paling mudah untuk
dipelajari. Struktur Neural Network dapat dibagi dalam tiga layar seperti pada
Gambar 2.3 berikut.
Gambar 2.3 Neural Network Structure
(Source: SPSS Manual)

15
2.4.1.3 Naive Bayes
Algoritma Naïve Bayes akan mengevaluasi setiap atribut yang
mengkontribusi prediksi pada atribut target. Naïve Bayes tidak memperhitungkan
relasi antar atribut-atribut kontributor prediksi, tidak seperti Decision Tree yang
memperhitungkan relasi antara atribut. Bentuk tugas dasar yang dilakukan oleh
algoritma Naïve Bayes adalah hanyalah klasifikasi (ZhaoHui & MacLennan, 2005,
p.132). Naïve Bayes merupakan teknik data mining dengan pendekatan teori
probabilitas untuk membangun sebuah model klasifikasi berdasarkan pada
kejadian masa lalu yang mempunyai potensi membentuk sebuah objek baru yang
dikategorikan sebagai kelas yang memiliki probabilitas terbaik (Turban et all,
2011, p.220).
Naïve Bayes memiliki kemampuan yang cepat dalam membuat model,
mempunyai kemampuan memprediksi dan juga menyediakan metode baru dalam
mengeksplor dan memahami data. Algoritma Naïve Bayes hanya mendukung pada
atribut yang bertipe data discrete atau discretized, atau tidak mendukung atribut
yang bernilai continuous (numerik) dan semua atribut dapat menjadi independen,
menjadi atribut yang memberi kontribusi kepada atribut yang diprediksi.
Klasifikasi Bayesian adalah klasifikasi statistik yang bisa memprediksi
probabilitas sebuah kelas. Klasifikasi Bayesian ini dihitung berdasarkan Teorema
Bayes berikut ini:
Berdasarkan rumus di atas kejadian H merepresentasikan sebuah kelas dan
X merepresentasikan sebuah atribut. P(H) disebut prior probability H, contoh

16
dalam kasus ini adalah probabilitas kelas yang mendeklarasikan normal. P(X)
merupakan prior probability X, contoh untuk probabilitas sebuah atribut
protocol_type. P(H|X) adalah posterior probability yang merefleksikan
probabilitas munculnya kelas normal terhadap data atribut protocol_type. P(X|H)
menunjukkan kemungkinan munculnya prediktor X (protocol_type) pada kelas
normal. Dan begitu juga seterusnya untuk proses menghitung probabilitas ke-
empat kelas lainnya.
Sebagai contoh kasus Naïve Bayes seperti pada Tabel 2.2. Bertujuan
menemukan pola yang digunakan dalam mendeteksi permohonan kredit yang
beresiko tinggi.
Tabel 2.2 Contoh Data Set Naïve Bayes
Name Debt Income Married? Risk
Joe High High Yes Good Sue Low High Yes Good John Low High No Poor Mary High Low Yes Poor Fred Low Low Yes Poor
1. Membuat model berdasarkan pada kasus
Tabel 2.3 Tabel Perhitungan Contoh Kasus Naïve Bayes
Counts Counts Probabilities Probabilities Independent Variables
Value Good Risk
Poor Risk Good Risk Poor Risk
Debt High 1 1 0.50 0.33 Debt Low 1 2 0.50 0.67 Income High 2 1 1.00 0.33 Income Low 0 2 0.00 0.67 Married Yes 2 2 1.00 0.67 Married No 0 1 0.00 0.33 Total by Risk 2 3
17
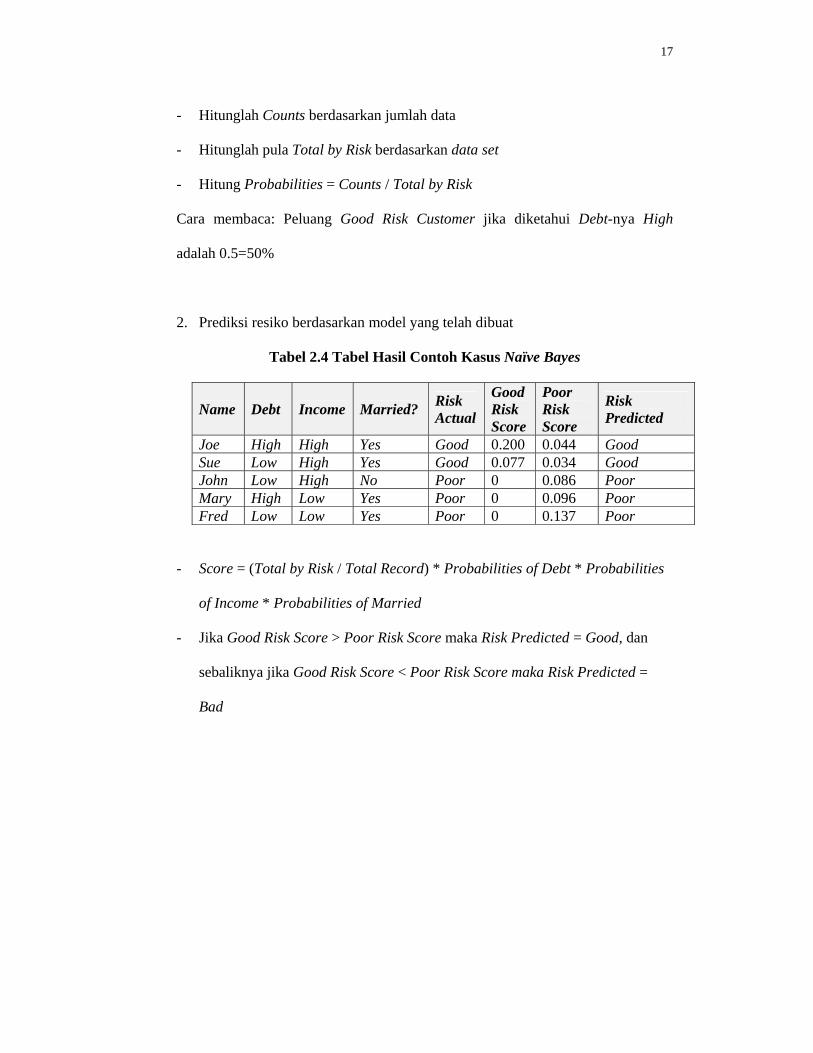
- Hitunglah Counts berdasarkan jumlah data
- Hitunglah pula Total by Risk berdasarkan data set
- Hitung Probabilities = Counts / Total by Risk
Cara membaca: Peluang Good Risk Customer jika diketahui Debt-nya High
adalah 0.5=50%
2. Prediksi resiko berdasarkan model yang telah dibuat
Tabel 2.4 Tabel Hasil Contoh Kasus Naïve Bayes
Name Debt Income Married? Risk Actual
Good Risk Score
Poor Risk Score
Risk Predicted
Joe High High Yes Good 0.200 0.044 Good Sue Low High Yes Good 0.077 0.034 Good John Low High No Poor 0 0.086 Poor Mary High Low Yes Poor 0 0.096 Poor Fred Low Low Yes Poor 0 0.137 Poor
- Score = (Total by Risk / Total Record) * Probabilities of Debt * Probabilities
of Income * Probabilities of Married
- Jika Good Risk Score > Poor Risk Score maka Risk Predicted = Good, dan
sebaliknya jika Good Risk Score < Poor Risk Score maka Risk Predicted =
Bad

18
2.5 Data Mining Dalam Lembaga Pendidikan
Berbagai keuntungan dalam penerapan data mining khususnya dalam
bidang pendidikan seperti increasing student’s promotion rate, retention rate,
transition rate, increasing educational improvement ratio, increasing student’s
success, increasing student’s learning outcome, maximizing educational system
efficiency, decreasing student’s drop-out rate, and reducing the cost of system
processes (Baradwaj & Pal, 2011). Data mining mampu menemukan pola seperti
membuat target mahasiswa yang membutuhkan perhatian khusus, memantau
mahasiswa yang mempunyai nilai tertinggi, memantau kehadiran, kejadian yang
berhubungan dengan kedisiplinan dan berbagai hal yang mempengaruhi kinerja
atau prestasi mahasiswa. Cara seperti ini dapat menghemat waktu, mengurangi
pekerjaan para karyawan dan dapat melakukan perbaikan terhadap layanan
akademik (Jayanthi & Kamna, 2007).
Pengembangan data mining pada lembaga pendidikan lebih kepada
pengembangan model baru dalam menemukan pengetahuan (discover knowledge)
dari database akademik (Galit, 2007; Erdogan & Timor 2005) dan untuk
menganalisa tren dan perilaku akademik mahasiswa. Lembaga pendidikan yang
semakin berkembang, tentu memiliki informasi akademik yang semakin banyak
pula. Potensi data hilang dan tidak tersedianya informasi penting pada saat
dibutuhkan, menjadi hal yang krusial. Salah satu solusi untuk mengatasi masalah
ini adalah dengan menerapkan data mining dalam sistem informasi manajemen di
lembaga pendidikan (Ayesha et al, 2010). Ada berbagai teknik data mining yang
dapat diterapkan dalam lingkungan pendidikan, seperti diuraikan oleh Jayanthi &
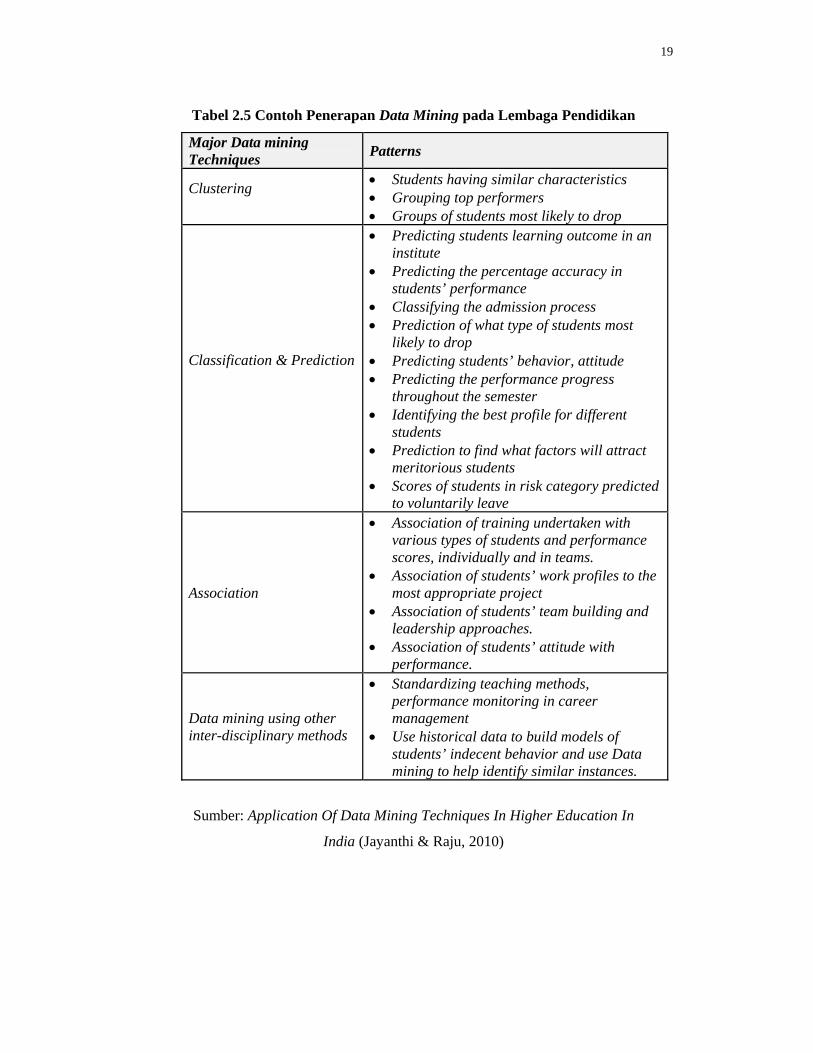
Raju (2010) pada Tabel 2.5 berikut ini.
19
Tabel 2.5 Contoh Penerapan Data Mining pada Lembaga Pendidikan
Major Data mining Techniques Patterns
Clustering
• Students having similar characteristics • Grouping top performers • Groups of students most likely to drop
Classification & Prediction
• Predicting students learning outcome in an institute
• Predicting the percentage accuracy in students’ performance
• Classifying the admission process • Prediction of what type of students most
likely to drop • Predicting students’ behavior, attitude • Predicting the performance progress
throughout the semester • Identifying the best profile for different
students • Prediction to find what factors will attract
meritorious students • Scores of students in risk category predicted
to voluntarily leave
Association
• Association of training undertaken with various types of students and performance scores, individually and in teams.
• Association of students’ work profiles to the most appropriate project
• Association of students’ team building and leadership approaches.
• Association of students’ attitude with performance.
Data mining using other inter-disciplinary methods
• Standardizing teaching methods, performance monitoring in career management
• Use historical data to build models of students’ indecent behavior and use Data mining to help identify similar instances.
Sumber: Application Of Data Mining Techniques In Higher Education In
India (Jayanthi & Raju, 2010)

20
2.6 Data Mining Methodology
CRISP-DM adalah data mining methodology yang pada awalnya
dikembangkan oleh tiga perusahaan, yakni SPSS (ISL by then), NCR, dan
DaimlerChrysler pada tahun 1996 dan baru pada bulan Agustus 2000, version 1.0
CRISP-DM dipublikasikan. Kemudian tahun 2009 CRISP-DM dikenal dengan
SEMMA (sample, explore, modify, model dan assess) yang dikembangkan oleh
SAS Institute, dan CRISP-DM merupakan metodologi data mining yang paling
banyak digunakan (Turban et al, 2011, p214). CRISP-DM merupakan metodologi
yang dikhususkan pada pengembangan data mining, yang terdiri dari enam fase
seperti pada Gambar 2.4 berikut.
Gambar 2.4 Fase CRISP-DM
(Sumber: ZhaoHui & MacLennan, 2005, p.29)

21
Setiap fase dalam CRISP-DM terdiri dari beberapa proses tahapan di
dalamnya, berikut penjelasan setiap fase (Connoly & Begg, 2010, p.1286), yaitu:
1. Business Understanding
Tahapan ini fokus pada tujuan bisnis (business goal) yang ingin dicapai
dan mendefinisikan poin-poin penting yang menjadi kebutuhan bisnis dan
kemudian menerjemahkannya dalam data mining goal.
2. Data Understanding
Mendefinisikan data yang dibutuhkan, keterangan dari setiap data, data
tersebut dapat diambil dari sumber data mana. Kemudian menentukan jenis data
yang dijadikan variabel yang merupakan data yang paling berpengaruh pada
model data mining yang dikembangkan.
3. Data Preparation
Membuat data set yang dapat digunakan dalam modeling. Adapun tugas
dalam tahapan ini yaitu: select data, clean data, construct data, integrated data
dan format data.
4. Modeling
Melakukan proses data mining dengan men-generate struktur data mining
dan kemudian memilih teknik data mining dalam membuat model dan menguji
keakuratan setiap model untuk memperoleh model data mining yang memiliki
akurasi paling tepat.

22
5. Evaluation
Menganalisa hasil dari analisis yang diperoleh dari modelling,
mengevaluasi dan meninjau semua proses untuk memastikan apakah sesuai
dengan tujuan bisnis.
6. Deployment
Tapahan dimana dilakukan implementasi, rencana pengawasan,
pemeliharaan dan laporan akhir.
2.7 Data Mining Tools
2.7.1 ETL
ETL merupakan singkatan dari extract, transform dan load yang berfungsi
melakukan ekstraksi data dari sumber data dan kemudian melakukan transformasi
data, sebelum mengirimkannya ke database tujuan. ETL adalah sebuah alat yang
melakukan 3 fungsi utama data warehouse (Connoly & Begg, 2010, p.1208),
yaitu:
• Extraction. Fase dimana data diektrak dari sumber data yang tersedia baik dari
internal dan external.
• Transformation. Fase cleaning dan transformation yang bertujuan untuk
membersihkan data yang telah diekstrak yang diperoleh dari sumber yang
berbeda, dengan memperbaiki data yang belum inconsistencies, inaccuracies
dan missing value.
• Loading. Fase akhir, dimana setelah data diekstrak dan dipindahkan, data
kemudian dimasukkan ke dalam tabel data warehouse, kemudian data ini
yang digunakan oleh analytics application dan decision support application.

23
2.7.2 Microsoft SQL Server Analysis Services
Microsoft menyediakan tools yang berguna dalam membangun, mengelola
dan menggunakan solusi BI pada suatu perusahaan. Microsoft SQL Server 2008
merupakan platform untuk data warehouse maupun data mart. Ada 3 fitur utama
BI pada SQL Server 2008, yaitu:
1. SQL Server 2008 Integration Services (SSIS)
SQL Server Integration Services adalah tools yang digunakan untuk
melakukan proses ETL (Extract, Transform, Load). Dalam kaitannya dengan
BI, SSIS adalah fitur yang digunakan untuk menarik data dari relational
database, kemudian hasilnya disimpan dalam data warehouse.
2. SQL Server 2008 Analysis Services (SSAS)
SQL Server Analysis Services adalah teknologi untuk OLAP (Online
Analytical Processing) dan data mining. Proses OLAP administration
dilakukan di SQL Server Management Studio berupa viewing data, membuat
Multidimensional Expression (MDX), Data Mining Extension (DMX) dan
XML for Analysis (XML/A) dan mendefenisikan role akses security.
Menurut Connoly (2010, p1101), OLAP adalah perpaduan dinamis, analisis,
dan konsolidasi dari suatu multi-dimensional database yang besar. OLAP
merupakan sebuah istilah yang menggambarkan sebuah teknologi yang
menggunakan sebuah kumpulan data multidimensi untuk menyediakan akses
yang cepat kepada informasi strategi untuk keperluan analisis secara
mendetail. OLAP adalah sebuah kumpulan dari alat-alat yang menganalisa
dan mengumpulkan data untuk menggambarkan kebutuhan bisnis dari suatu
perusahaan (Turban et al, 2006, p423).

24
3. SQL Server 2008 Reporting Services (SSRS)
SQL Server Reporting Services adalah platform laporan berbasis server yang
menyediakan fungsi pembuatan laporan dengan berbagai sumber data. SSRS
terdiri dari kumpulan tools yang digunakan untuk membuat, mengatur dan
mengirim laporan. Dengan SSRS, laporan dapat dibuat dalam bentuk tabular,
grafikal dari sumber data relational (OLTP), multidimensional (OLAP) atau
bahkan XML.
Microsoft SQL Server 2005 Analysis Services (SSAS) menyediakan fungsi
OLAP dan data mining yang digunakan dalam pengembangan aplikasi business
intelligence. Pada aplikasi data mining, SSAS menyediakan berbagai fitur untuk
design, create, visualize model data mining dimana memungkinkan data berasal
dari berbagai sumber data. SSAS memiliki 9 algoritma data mining yaitu: 1.
Microsoft Decision Tree; 2. Microsoft Linear Regression; 3. Microsoft Naïve
Bayes; 4. Microsoft Clustering; 5. Microsoft Association Rules; 6. Microsoft
Sequence Clustering; 7. Microsoft Time Series; 8. Microsoft Neutral Network; dan
9. Microsoft Logistic Regression Algorithm. SSAS ini mempunyai kemampuan
yang luar biasa dalam melakukan identifikasi pola data, memunculkan berbagai
pola yang menjadi informasi penting bagi para pengambil keputusan, mengetahui
apa yang akan terjadi pada masa yang akan datang dan mengapa. Pola inilah yang
disebut insight knowledge yang sangat berguna bagi yang mengambil keputusan.
Menggunakan Analysis Services tidak selalu menggunakan data warehouse, tetapi
cukup dengan tabulasi data yang diambil dari sumber lain seperti file excel dan
proses data mining sudah bisa dilakukan. Bila menggunakan data warehouse atau

25
sumber data berasal dari beberapa sumber data, misalnya dari data mart atau
database operasional, maka Ms SQL Server sudah menyedikan tools BI yang
disebut Integration Services yang berfungsi dalam melakukan proses ETL
(http://msdn.microsoft.com/en-us/library/ms175609%28v=sql.90%29.aspx).
2.7.3 Data Mining Extensions to SQL (DMX)
DMX merupakan suatu query yang digunakan untuk membuat dan
memanipulasi model-model data mining pada SQL Server. Data mining memiliki
bentuk SQL tersendiri yang dinamakan DMX (Data Mining Extension). Lewat
DMX, prediksi dapat dilakukan terhadap algoritma mining model yang tersedia.
2.7.4 Microsoft SQL Server 2005 Data Mining Add-Ins for Office 2007
Microsoft SQL Server 2005 Data Mining Add-Ins for Office 2007 adalah
data mining engine yang disediakan oleh Microsoft, dimana engine ini bisa
dijalankan dalam aplikasi Ms Office 2007. Data mining tools tidak hanya terdapat
pada Ms SQL Server 2005 yang disebut SSAS, dimana di dalamnya tersedia
berbagai fitur data mining. Fitur ini sudah embedded (add-ins) dalam aplikasi
Office. Data mining Add-Ins ini sudah disediakan mulai pada Ms Office versi
2007 ke atas. Data mining Add-Ins khususnya digunakan dalam aplikasi Excel dan
Visio. Lewat Excel, user sangat dimudahkan untuk melakukan proses analisis
dengan menggunakan teknik data mining, tanpa harus memiliki pengetahuan
lebih dalam di dalam penggunaan Analysis Services. Jadi proses data mining bisa
dilakukan oleh siapapun yang sudah terbiasa menggunakan program Ms Office.
Dengan Add-Ins ini sangat memudahkan untuk deploy model di komputer klien

26
manapun, tidak mengharuskan adanya database server, friendly interface dan
memudahkan untuk diakses oleh komputer lain, misalnya dengan menggunakan
web services. Add-Ins ini merupakan aplikasi tambahan, bukan merupakan
program default Ms Office, untuk menggunakannya harus di-install terlebih
dahulu, dimana software ini dapat di-download secara gratis dari situs
http://www.microsoft.com/en-us/download/details.aspx?id=8569. Tersedia tiga
paket yaitu: Table Analysis Tools for Excel, Table Analysis Tools for Excel dan
Data mining Templates for Visio (http://dataminingtools.net/wiki/dm_excel.php).
2.8 Web Application
Web application adalah aplikasi yang dibuat berbasis web dan dapat
diakses melalui jaringan seperti Internet atau intranet. Merupakan suatu aplikasi
perangkat lunak komputer yang dikodekan dalam bahasa yang didukung
penjelajah web (seperti HTML, JavaScript, AJAX, Java, dll). Aplikasi web sangat
populer digunakan dalam pengembangan aplikasi khususnya aplikasi sistem
informasi karena kemudahan dalam mengakses dan kemampuan untuk
memperbarui dan memelihara aplikasi web tanpa harus mendistribusikan di
masing-masing komputer klien.
2.8.1 Apache HTTP Server
Apache HTTP Server adalah web server yang merupakan perangkat lunak
yang menyediakan layanan akses kepada pengguna melalui protokol komunikasi
HTTP atau HTTPS atas dokumen yang terdapat pada situs web dalam layanan ke
pengguna dengan menggunakan aplikasi tertentu seperti web browser. Apache

27
HTTP Server atau server web/www apache merupakan web server yang dapat
dijalankan di berbagai sistem operasi seperti Linux, Windows, dan OS lainnya
yang berguna untuk melayani dan memfungsikan situs web. Apache HTTP Server
merupakan perangkat lunak open source yang dapat digunakan oleh siapapun,
dapat diunduh dari http://www.apache.org.
2.8.2 PHP
PHP: Hypertext Preprocessor adalah bahasa skrip server yang dapat
disisipkan ke dalam halaman HTML. PHP merupakan server client script yang
banyak digunakan dalam pemrograman situs web dinamis, merupakan perangkat
lunak open source yang dapat diunduh dari php.net/downloads.php. Beberapa
kelebihan PHP dari bahasa pemrograman web lainnya
(http://id.wikipedia.org/wiki/PHP), antara lain:
• Bahasa pemrograman PHP adalah sebuah bahasa pemrograman yang tidak
melakukan kompilasi dalam penggunaanya;
• Web Server yang mendukung PHP dapat ditemukan dimana-mana dari apache,
IIS, Lighttpd, hingga Xitami dengan konfigurasi yang relatif mudah;
• Dalam sisi pengembangan lebih mudah, karena banyaknya milis-milis dan
developer yang siap membantu dalam pengembangan;
• Dalam sisi pemahamanan, PHP adalah bahasa pemrograman yang paling
mudah karena memiliki referensi yang banyak;
• PHP adalah bahasa open source yang dapat digunakan di berbagai mesin
(Linux, Unix, Macintosh, Windows) dan dapat dijalankan secara runtime
melalui console serta juga dapat menjalankan perintah-perintah sistem.

28
2.9 Prestasi Akademik Mahasiswa
Lembaga pendidikan pada dasarnya mengutamakan pencapaian prestasi
mahasiswa (student performance) yang setinggi-tingginya. Prestasi atau kinerja
mahasiswa diukur dari berbagai komponen kompetensi akademik. Prestasi
mahasiswa diukur dari nilai akhir pada setiap kelas matakuliah yang diambil dan
secara keseluruhannya dapat diukur dari GPA yang merupakan indeks prestasi
yang diperoleh dari setiap nilai pada tiap komponen kompetensi.
Universitas Bina Nusantara memiliki visi “A World-class university”.
Kualitas pendidikan menjadi hal paling utama dan sudah menjadi tanggungjawab
para manajemen di Universtas Bina Nusantara. Universitas Bina Nusantara
membuat target minimal 90% mahasiswa lulus tepat waktu
(http://binus.ac.id/delivered-ontime-graduation). Improve student’s timely
graduation & high student performance adalah misi Universitas Bina Nusantara
khususnya di program BINUS INTERNATIONAL. Manajemen di BINUS
INTERNATIONAL mempunyai misi untuk mendorong para mahasiswa
mencapai kinerja akademik yang setinggi-tingginya, seperti tertuang pada Dean’s
Goals & Objectives berikut ini:
Goals
To ensure that consistent standards of excellence are applied to and across all
high-achieving students
• To ensure that students who achieve exceptionally high academic
performance are suitably recognized
• To highlight the quality reputation of BINUS INTERNATIONAL

29
Objectives
• To identify all students who achieve an exceptionally high level of
academic performance
• To ensure that those students receive timely recognition of their efforts
and talent
• To enhance the quality reputation of BINUS by identifying and tracking
honour roll students following graduation
BINUS INTERNATIONAL mempunyai syarat kelulusan dan pengukuran
kinerja mahasiswa berdasarkan pada BINUS INTERNATIONAL Student Guideline
– Binusian 2016 6 September 2012.
2.9.1 GPA
BINUS INTERNATIONAL mengukur prestasi mahasiswa dengan GPA
atau grade point average dengan indeks 0,00 sampai 4,00. GPA diperoleh dari
rata-rata poin matakuliah yang diambil. GPA diukur pada setiap semester dan
kumulatif.
• Semestral GPA (GPS) merupakan GPA yang dihitung pada setiap semester
berdasarkan pada nilai akhir dari matakuliah pada semester tersebut.
• Cumulative GPA merupakan GPA yang dihitung dari keseluruhan nilai
matakuliah.
GPA diukur dengan menggunakan formula seperti berikut:

30
Mahasiswa BINUS INTERNATIONAL diwajibkan memiliki GPA
minimum 2,00. Bila GPA mahasiswa di bawah 2,00 berturut-turut selama dua
semester maka mahasiswa tersebut dipertimbangkan untuk diberikan peringatan
yang memungkinkan bisa sampai drop out.
2.9.2 Grade
Untuk nilai akhir setiap matakuliah menggunakan grade seperti Tabel 2.6
berikut. Score merupakan nilai angka yang diberikan oleh dosen untuk satu
matakuliah tertentu. Score ini merupakan kumulatif dari nilai pada setiap bobot
pada matakuliah, setiap matakuliah mempunyai bobot nilai seperti nilai tugas,
nilai ujian tengah semester, nilai akhir semester, dan seterusnya. Nilai dari setiap
bobot dalam matakuliah mempunyai persentase bobot masing-masing sehingga
menghasilkan score akhir. Dari score inilah bisa diperoleh grade berdasarkan
pada score range yang telah ditentukan pada Tabel 2.6. Setiap grade mempunyai
weigth (bobot) yang digunakan dalam perhitungan GPA mahasiswa.

31
Tabel 2.6 Grade Matakuliah
Grade Weight Score A : Excellent A- B+ B : Good B- C+ C : Fair D : Low Pass E : Failed F : Non-attendance
4,00 3,67 3,33 3,00 2,67 2,33 2,00 1,00 0,00 0,00
91 - 100 86 - 90 81 - 85 76 - 80 71 - 75 66 - 70 61 - 65 50 - 60
< 50 0
Adapun yang menjadi syarat akademik kelulusan mahasiswa, antaralain:
• Sudah lulus semua matakuliah pokok minimum grade C
• Sudah lulus matakuliah Characater Building I minimum grade B-
• GPA kumulatif harus lebih besar dari 2,75
Kehadiran mahasiswa pada sesi perkuliahan juga menjadi faktor kelulusan
mahasiswa pada suatu kelas matakuliah. Syarat minimum kehadiran mahasiswa
adalah 80% bila kurang maka tidak layak mengikuti ujian akhir, dimana hal ini
sudah bisa dipastikan mahasiswa yang bersangkutan gagal pada matakuliah
tersebut.
2.10 Literature Review
Penerapan data mining dalam lembaga pendidikan ternyata semakin
banyak dilakukan oleh peneliti saat ini. Data mining merupakan teknologi yang
tepat dalam meningkatkan kualitas pendidikan dan prestasi akademik mahasiswa.
Di bawah ini adalah beberapa penelitian di bidang pendidikan yang bertujuan
untuk melakukan improvement terhadap prestasi akademik mahasiswa.

32
1. Effective Educational Process: A Data-Mining Approach (Jayanthi &
Kamna, 2007)
Dalam studi ini mengembangkan holistic model untuk tujuan pendidikan
menggunakan teknik data mining dengan mengeksplorasi dampak dari perubahan
dalam proses admisi, course delivery dan recruitments. Mengusulkan sebuah
framework proses edukasi yang efektif menggunakan teknik data mining untuk
menemukan tren dan pola. Teknik data mining yang digunakan adalah decision
trees, bayesian models dan forecasting. Studi ini bertujuan untuk melakukan
improvement dalam proses penelitian dan pengambilan keputusan yang
berhubungan dengan akademik melalui penemuan tren dan pola yang
menggunakan kombinasi antara explicit knowledge base, sophisticated analytical
skills dan academic domain knowledge. Dengan harapan kualitas dan prestasi
akademik mahasiswa dapat menjadi lebih baik secara efisien dan efektif.
2. Using Data Mining To Predict Secondary School Student Performance
(Cortez & Silva, 2008)
Studi ini dilakukan di Portugal, dilatarbelakangi oleh tingginya angka
kegagalan para siswa khususnya dalam matapelajaran Matematika dan Bahasa
Portugal. Cortez dan Silva dalam studinya menggunakan data mining dengan
beberapa teknik seperti Decision Tree, Random Forest, Neural Network, dan
Support Vector Machines. Adapun variabel yang digunakan seperti grade
matakuliah siswa, demographic, sosial dan atribut yang berhubungan dengan
akademik siswa itu sendiri. Tujuan studi ini untuk memprediksi grade para siswa
pada periode pertama dan kedua, dalam meningkatkan kualitas pendidikan.

33
3. Data Mining Model for Higher Education System (Ayesha et al, 2010)
Dalam studi ini melakukan analisis terhadap perilaku belajar mahasiswa
(student's learning behaviour). Menganalisa bagaimana perbedaan dampak antar
faktor student's learning behaviour dan performance during academic dengan
menggunakan k-mean dan decision tree. Menggunakan teknik data mining K-
means clustering. Clustering analysis membuat segmen mahasiswa ke dalam
beberapa kelompok berdasarkan karakteristik. Kinerja mahasiswa ditentukan oleh
internal assessment dan external assessment. Internal assessment berdasarkan
pada nilai tugas, kuis, tugas lab, grade kehadiran pada semester sebelumnya, dan
keaktifan pada ekstra kurikulum. Sedangkan external assessment didapatkan dari
nilai ujian akhir. Studi ini bertujuan membantu para dosen untuk mengurangi
jumlah mahasiswa yang drop out secara signifikan dan meningkatkan prestasi
akademik mahasiswa itu sendiri.
4. Use Data Mining To Improve Student Retention In Higher Education – A
Case Study (Kim et al, 2010)
Salah satu tantangan lain pada lembaga pendidikan adalah meningkatkan
student retention (National Audition Office, 2007). Student retention ini sudah
menjadi indikator penting dalam mengukur kinerja lembaga pendidikan. Studi ini
mengembangkan data mining untuk memonitor para siswa, menganalisa perilaku
akademik siswa dan menyediakan informasi penting yang bisa mendukung
strategi yang akan dilakukan untuk tujuan dalam melakukan improvement
terhadap student retention. Informasi yang dibutuhkan antara lain student
enrolment, student result, course/module, learning skills dan student activities.

34
Menggunakan teknik data mining association, classification dan clustering.
Model yang dikembangkan yaitu: Student behavior patterns; Course behavior
patterns; Predict student retention; Predict Course suitability dan Personalized
intervention strategy.
5. Web Usage Mining for Improving Students Performance in Learning
Management Systems (Zafra & Ventura, 2010)
Studi ini bertujuan untuk mendeteksi aktivitas mahasiswa yang sangat
relevan atau mempengaruhi kelulusan mahasiswa pada matakuliahnya,
berdasarkan pada data-data yang diperoleh dari log data pada education web-
based system. Hasil dari penelitian ini adalah memberikan informasi yang
mengklasifikasi mahasiswa dalam dua kelompok:
- high performance: mahasiswa yang mempunyai probabilitas tertinggi akan
lulus
- low performance: mahasiswa memiliki probabilitas tertinggi akan gagal (drop
out).
Secara umum data set yang digunakan yakni: number of students, number
of assignments, number of forums, dan number of quizzes. Beberapa algoritma
yang diuji, MOG3P-MI adalah algorima yang digunakan karena mempunyai
tingkat akurasi model paling tinggi.

35
6. Mining Educational Data to Analyze Students Performance (Baradwaj &
Pal, 2011)
Menurut Baradwaj dan Saurabh Pal dalam studinya, salah satu cara dalam
mencapai kualitas pendidikan terbaik adalah dengan menemukan knowledge yang
dimulai dari enrollment, cara mengajar di kelas, mengetahui siapa yang curang
pada saat ujian online, memprediksi kinerja mahasiswa dan lain sebagainya.
Knowledge ini sudah ada dalam sekumpulan data edukasi yang besar, sehingga
diperlukanlah data mining untuk mengekstrak knowledge tersebut. Dalam studi ini
menggunakan classification model untuk menemukan pola dalam mengevaluasi
kinerja mahasiswa. Teknik yang digunakan antara lain termasuk Decision Trees,
Neural Networks, Naïve Bayes, K- Nearest neighbor, dan lain sebagainya. Studi
ini bertujuan untuk memprediksi prestas akademik seorang mahasiswa pada akhir
semester. Ini sangat membantu dalam mengidentifikasi dengan lebih dini, siapa
siswa yang akan drop out dan mahasiswa yang memerlukan perhatian khusus dan
memungkinkan dosen memberikan konseling secara khusus.
7. A Data Mining Approach To Guide Students Through The Enrollment
Process Based On Academic Performance (Vialardi et al, 2011)
Tujuan dari studi ini adalah membuat model yang memberikan
rekomendasi kepada mahasiswa dalam menentukan matakuliah mana yang lebih
tepat akan diambil. Model data mining dibuat berdasarkan prestasi akademik
mahasiswa itu sendiri. Atribut yang diprediksi pertama adalah matakuliah yang
memiliki tingkat kesulitan yang tinggi dan yang kedua memprediksi kemampuan
atau grade yang akan diperoleh mahasiswa tersebut terhadap matakuliah yang

36
akan diambil. Dalam pengembangan data mining menggunakan CRISP-DM
methodology. Menggunakan teknik C4.5, KNN (K-nearest neighbor), Naïve
Bayes, Bagging dan Boosting. Bagging adalah model yang paling akurat yang
digunakan dalam studi ini.
8. Data Mining: A Prediction For Performance Improvement Using
Classification (Bhardwaj & Pal, 2011).
Tujuan studi ini adalah memprediksi mahasiswa yang memiliki motivasi
belajar yang tinggi dan rendah. Menggunakan teknik Bayesian Classification
dalam memprediksi yang dasarkan pada data setahun sebelumnya.
9. Improving Academic Performance of Students of Defence University Based
on Data Warehousing and Data Mining (Sreenivasarao & Yohannes, 2012)
Studi ini dilakukan oleh Defence University College jurusan Teknik,
berkonsentrasi terhadap faktor-faktor yang mempengaruhi kinerja mahasiswa.
Prestasi akademik mahasiswa jurusan Teknik kebanyakan relatif rendah, diukur
dari GPA setiap mahasiswa. Sehingga manajemen membutuhkan analisis terhadap
pencapaian prestasi mahasiswa. Oleh karena itu, dalam studi ini menerapkan data
mining untuk mengekstrak informasi dan variabel penting yang signifikan
berpengaruh terhadap prestasi akademik mahasiswa. Teknik data mining yang
digunakan adalah k-Means clustering dan Decision tree. Studi ini bertujuan
membantu para guru mengurangi angka mahasiswa yang di drop out dan
memperbaiki prestasi akademik para mahasiswa.

37
10. Mining Educational Data to Improve Students’ Performance: A Case Study
(Tair & El-Halees, 2012)
Dalam studi ini menggunakan data akademik terdiri dari atribut: Gender,
Speciality, City, Matriculation GPA, Secondary School Type dan Grade. Tujuan
studi ini dilakukan untuk meningkatkan prestasi akademik mahasiswa.
Menggunakan teknik data mining association, classification, clustering dan
outlier detection rules untuk memprediksi grade mahasiswa.
11. Educational Data Mining for Improving Educational Quality (Gulati &
Sharma, 2012)
Tujuan dari studi ini adalah meningkatkan kualitas pendidikan berdasarkan
pada aktivitas atau operasional akademik mulai dari jadwal kelas, siswa dan guru.
Bagaimana mengoptimalkan operasional akademik sehingga dapat menjadi faktor
pendukung dalam meningkatkan prestasi mahasiswa. Menggunakan Knowledge
Discovery Database dalam pengembangan data mining. Penerapan data mining
dapat membantu institusi pendidikan dalam mengarahkan mahasiswa, dosen dan
manajemen untuk memperbaiki prestasi institusi. Selain itu dapat membantu para
dosen untuk me-manage kelas dengan baik dan membantu manajemen dalam
membuat aturan akademik dengan baik.
38
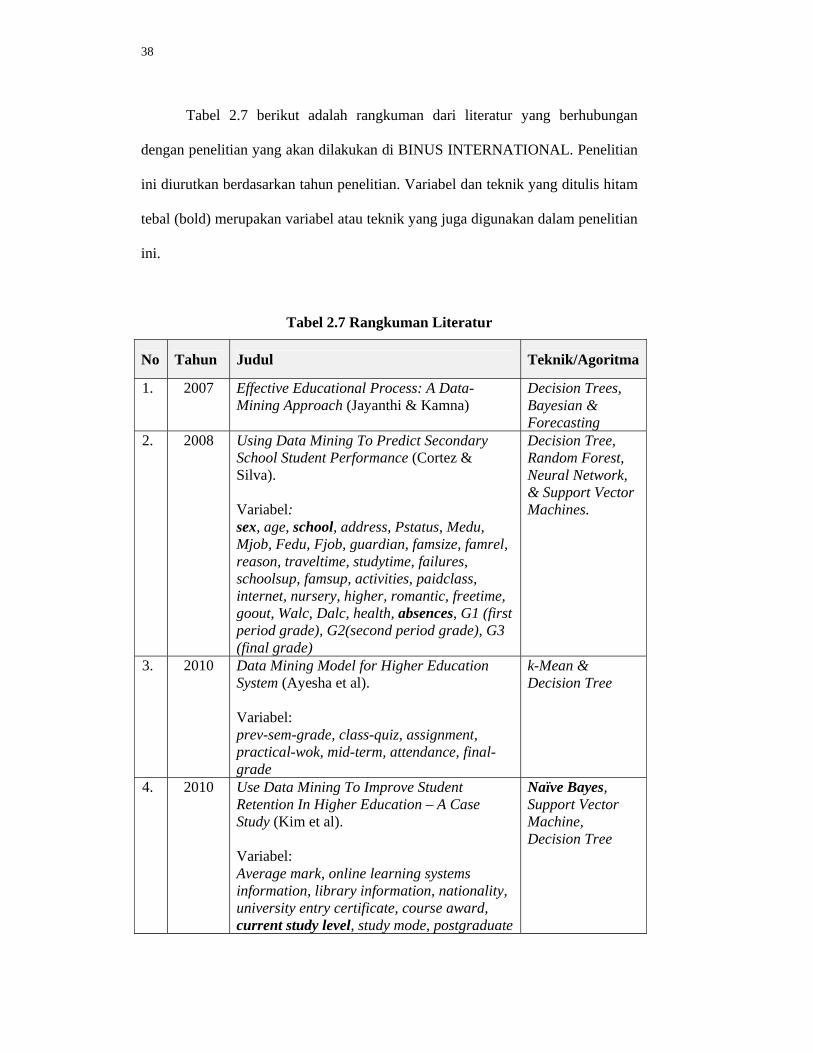
Tabel 2.7 berikut adalah rangkuman dari literatur yang berhubungan
dengan penelitian yang akan dilakukan di BINUS INTERNATIONAL. Penelitian
ini diurutkan berdasarkan tahun penelitian. Variabel dan teknik yang ditulis hitam
tebal (bold) merupakan variabel atau teknik yang juga digunakan dalam penelitian
ini.
Tabel 2.7 Rangkuman Literatur
No Tahun Judul Teknik/Agoritma
1. 2007 Effective Educational Process: A Data-Mining Approach (Jayanthi & Kamna)
Decision Trees, Bayesian & Forecasting
2. 2008 Using Data Mining To Predict Secondary School Student Performance (Cortez & Silva). Variabel: sex, age, school, address, Pstatus, Medu, Mjob, Fedu, Fjob, guardian, famsize, famrel, reason, traveltime, studytime, failures, schoolsup, famsup, activities, paidclass, internet, nursery, higher, romantic, freetime, goout, Walc, Dalc, health, absences, G1 (first period grade), G2(second period grade), G3 (final grade)
Decision Tree, Random Forest, Neural Network, & Support Vector Machines.
3. 2010 Data Mining Model for Higher Education System (Ayesha et al). Variabel: prev-sem-grade, class-quiz, assignment, practical-wok, mid-term, attendance, final-grade
k-Mean & Decision Tree
4. 2010 Use Data Mining To Improve Student Retention In Higher Education – A Case Study (Kim et al). Variabel: Average mark, online learning systems information, library information, nationality, university entry certificate, course award, current study level, study mode, postgraduate
Naïve Bayes, Support Vector Machine, Decision Tree
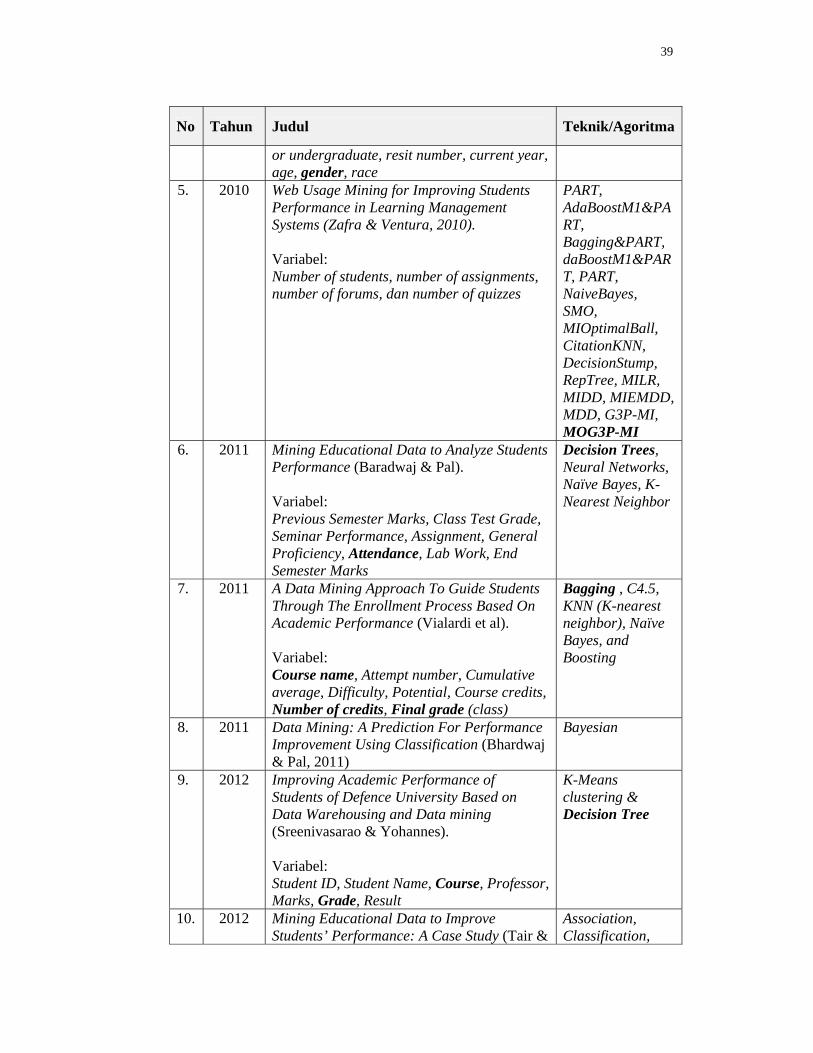
39
No Tahun Judul Teknik/Agoritma
or undergraduate, resit number, current year, age, gender, race
5. 2010 Web Usage Mining for Improving Students Performance in Learning Management Systems (Zafra & Ventura, 2010). Variabel: Number of students, number of assignments, number of forums, dan number of quizzes
PART, AdaBoostM1&PART, Bagging&PART, daBoostM1&PART, PART, NaiveBayes, SMO, MIOptimalBall, CitationKNN, DecisionStump, RepTree, MILR, MIDD, MIEMDD, MDD, G3P-MI, MOG3P-MI
6. 2011 Mining Educational Data to Analyze Students Performance (Baradwaj & Pal). Variabel: Previous Semester Marks, Class Test Grade, Seminar Performance, Assignment, General Proficiency, Attendance, Lab Work, End Semester Marks
Decision Trees, Neural Networks, Naïve Bayes, K- Nearest Neighbor
7. 2011 A Data Mining Approach To Guide Students Through The Enrollment Process Based On Academic Performance (Vialardi et al). Variabel: Course name, Attempt number, Cumulative average, Difficulty, Potential, Course credits, Number of credits, Final grade (class)
Bagging , C4.5, KNN (K-nearest neighbor), Naïve Bayes, and Boosting
8. 2011 Data Mining: A Prediction For Performance Improvement Using Classification (Bhardwaj & Pal, 2011)
Bayesian
9. 2012 Improving Academic Performance of Students of Defence University Based on Data Warehousing and Data mining (Sreenivasarao & Yohannes). Variabel: Student ID, Student Name, Course, Professor, Marks, Grade, Result
K-Means clustering & Decision Tree
10. 2012 Mining Educational Data to Improve Students’ Performance: A Case Study (Tair &
Association, Classification,
40
No Tahun Judul Teknik/Agoritma
El-Halees). Variabel: Student ID, student name, gender, date of birth, place of birth, speciality, enrollment year, graduation year, city, location, address, telephone number, matriculation GPA, secondary school type, matriculation obtained place, matriculation year, college GPA & GPA
Clustering & Outlier Detection Rules
11. 2012 Educational Data Mining for Improving Educational Quality (Gulati & Sharma). Variabel: Menggunakan informasi dari courses assignments, marks, student background
Classification





























