Embed Size (px)
DESCRIPTION
MIPA
Citation preview

BAB III
UKURAN TENDENSI SENTRAL
3.1. Pengantar
Ukuran tendensi sentral atau sering disebut juga ukuran
lokasi merupakan suatu ukuran yang menetapkan letak titik
pemusatan dimana terdapat kecenderungan bagi setiap variabel
untuk mengarah kepadanya. Suatu ukuran tendensi sentral
merupakan suatu bilangan tunggal yang dipergunakan untuk
mewakili suatu kelompok data (Matre & Gilbreath, 1983:28).
Karena kelompok-kelompok data yang berbeda-beda memiliki sifat-
sifat numerical yang berlainan, maka suatu ukuran tendensi sentral
dapat lebih baik dalam menggambarkan sekelompok data tertentu
dari yang lain.
Berikut ini akan diuraikan tentang empat buah ukuran dasar
dari tendensi sentral, yaitu rata-rata hitung, median, mode, dan
rata-rata geometrik.
3.2. Rata-rata hitung (arithmetic mean)
Rata-rata hitung (atau sering disebut dengan rata-rata)
merupakan suatu bilangan tunggal yang dipergunakan untuk
mewakili nilai sentral dari sebuah distribusi. Dalam pemakaian
sehari-hari orang awam lebih mempergunakan istilah rata-rata dari
istilah rata-rata hitung. Bagi sekelompok data, rata-rata adalah nilai
rata-rata dari data itu. Secara teknis dapat dikatakan bahwa rata-
rata dari sekelompok variabel adalah jumlah nilai pengamatan
dibagi dengan banyaknya pengamatan.
Sesuai dengan kondisi datanya, rata-rata hitung dapat
dihitung dengan 4 macam cara, yaitu:

1. Untuk data yang tidak tersusun (ungrouped data) dapat dihitung
dengan:
a. Metode tidak ditimbang (unweighted)
b. Metode ditimbang (weighted)
2. Untuk data yang tersusun (grouped data) dapat dihitung dengan:
a. Metode penunjang (long method)
b. Metode pendek (short cut method)
Perumusan yang lazim dipergunakan untuk menghitung nilai
rata-rata adalah sebagai berikut :
Bentuk dataData yang berasal dari
Populasi Sampel
1. Tidak tersusun
(ungrouped)
a. Tidak ditimbang
b. Ditimbang
2. Tersusun (grouped)
a. Metode panjang
b. Metode pendek
3.2.1.Rata-rata ditimbang
Dalam perhitungan rata-rata tidak ditimbang, setiap variabel
di dalam kelompok diberikan timbangan yang sama. Artinya, tidak
ada perbedaan tingkat kepentingan antara masing-masing variabel.
Dalam kenyataannya tidaklah demikian halnya. Misalkan
keberhasilan seseorang di dalam pekerjaan tentu dipengaruhi oleh
beberapa faktor seperti keterampilan, kemampuan, pengalaman

kerja pada bidangnya, dan lain-lain. karenanya, angka rata-rata
tidak ditimbang sangat kasar (crude) dan lemah.
Untuk mengatasi hal ini setiap perhitungan angka rata-rata
hendaknya disertakan faktor penimbang yang menunjukkan tingkat
kepentingan dari masing-masing variabel. Dengan demikian, hasil
perhitungannya dapat menjadi lebih akurat.
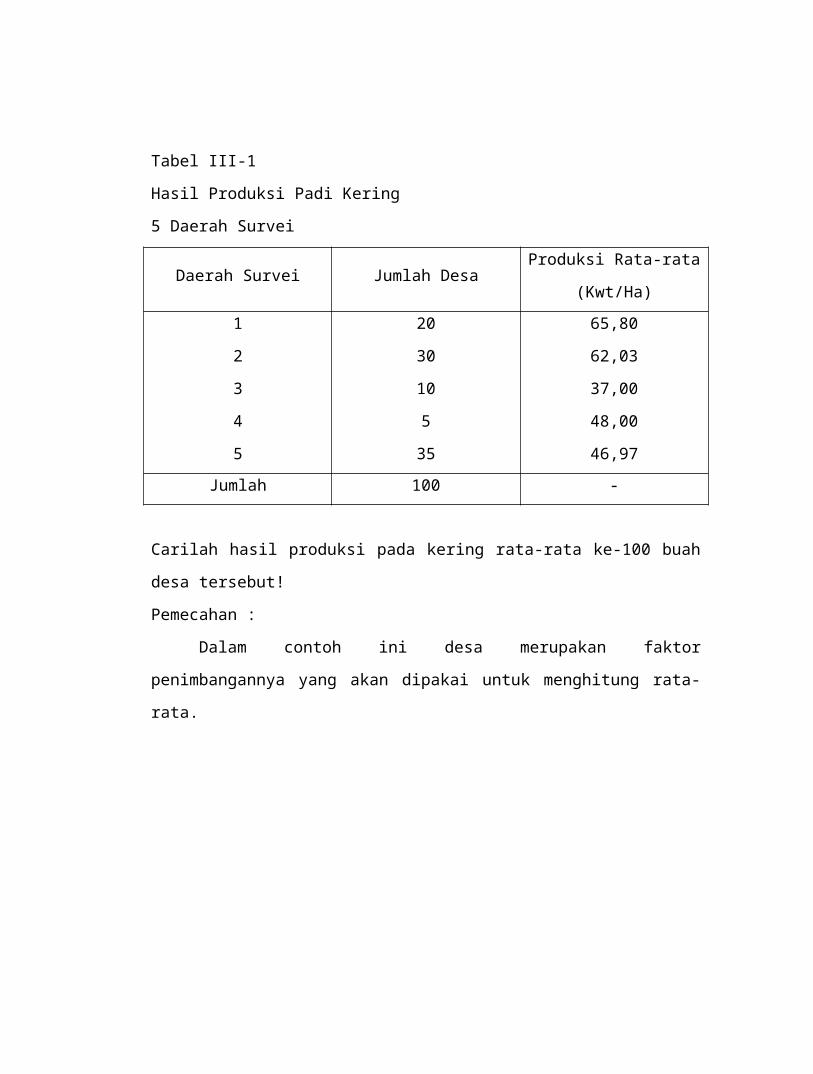
Contoh No. 3
Sebuah penelitian dilakukan disuatu daerah dengan
mengambil 5 daerah survei mengenai hasil produksi rata-rata padi
kering per HA memberikan informasi sebagai berikut :
Tabel III-1
Hasil Produksi Padi Kering
5 Daerah Survei
Daerah Survei Jumlah DesaProduksi Rata-rata
(Kwt/Ha)
1
2
3
4
5
20
30
10
5
35
65,80
62,03
37,00
48,00
46,97
Jumlah 100 -
Carilah hasil produksi pada kering rata-rata ke-100 buah desa
tersebut!
Pemecahan :
Dalam contoh ini desa merupakan faktor penimbangannya
yang akan dipakai untuk menghitung rata-rata.
Daerah Survei Jumlah DesaProduksi Rata-rata
(Kwt/Ha)
65,80
62,03
37,00
48,00
46,97
20
30
10
5
35
1.316,00
1.860,90
370,00
240,00
1.643,95
= 100
. Jadi hasil produksi
pada kering rata-rata untuk ke-100 buah desa tersebut adalah
54,31 Kwt/Ha.
3.2.2.Rata-rata dengan metode panjang
Secara teknis pada dasarnya metode ini tidak ada bedanya
dengan metode rata-rata ditimbang. Yang membedakan keduanya
adalah arti notasi yang dipakai. Pada rata-rata yang ditimbang, X
adalah nilai variabel. Sedangkan pada metode panjang X adalah
nilai tengah dari interval kelas. Faktor penimbang pada rata-rata
ditimbang adalahnilai variabel lain yang mempunyai hubungan
dengan variabel yang dihitung. Sedangkan pada metode panjang
faktor penimbangnya adalah frekuensi dari masing-masing interval
kelas.
Contoh No. 5
Dengan mempergunakan data dalam tabel di bawah,
hitunglah rata-rata waktu yang diperlukan untuk memesan tiket
pesawat oleh 80 orang penumpang di loket pelayanan Blue Bird
Airlines.

Tabel III-3
Waktu pesan Tiket oleh 80 Orang Penumpang pada Blue
Bird Airlines
Waktu
(menit)
Penumpang
(f)
Nilai Tengah
(X)
(fX)
2 - < 6
6 - < 10
10 - < 14
14 - < 18
18 - < 22
22 ke atas
9
15
28
21
6
1*)
4
8
12
16
20
42
36
120
336
336
120
42
Jumlah 80 - 900
*) seorang penumpang memerlukan waktu 42 menit
Pemecahan :
Waktu rata-rata yang diperlukan untuk memesan tiket pesawat
adalah 12,375 menit
3.2.3.Rata-rata dengan metode pendek
Perhitungan rata-rata untuk data tersusun dengan metode
panjang secara teknis akan lebih kompleks bila jumlah interval
kelasnya besar dan frekuensi kelasnya pun besar pula. Ini
disebabkan adanya perkalian langsung antara nilai tengah dengan
nilai frekuensi yang bersangkutan. Guna penyederhanaan
perhitungan dapat dipergunakan metode pendek sebagai gantinya.
Langkah penggunaan metode pendek ini adalah sebagai berikut:
1. Ambillah sembarang nilai tengah untuk dipergunakan sebagai
arbitary origin (A). arbitrary origin dapat diambil dari nilai tengah
yang berada di sembarang tempat. Namun untuk

penyederhanaan perhitungan biasanya dipilih nilai tengah dari
salah satu interval kelas yang terletak di tengah-tengah
distribusi
2. Kemudian dihitungkan simpangan (deviasi, d`) nilai tengah dari
setiap interval kelas dengan arbitrary origin yang dipilih dalam
suatu interval.
Jadi
3. Selanjutnya kalikanlah d` tersebut dengan frekuensi masing-
masing interval kelas
Jadi : f x d` = fd`
Hasilnya kemudian dijumlahkan
Jadi fd`
4. Jumlah tersebut selanjutnya dibagi dengan total frekuensi dan
dikalikan interval
Jadi :
5. Untuk memperoleh angka rata-rata, hasil perhitungan di atas
ditambahkan pada arbitraty origin (A)
3.3. Median
Median merupakan nilai yang membagi serangkaian nilai
variabel (data) sedemikian rupa sehingga setengah dari rangkaian
itu mempunyai nilai yang lebih kecil dari atau sama dengan nilai
media. Sedangkan setengahnya lagi memiliki nilai yang sama
dengan atau lebih besar dari nilai median. Median dapat juga

disebut rata-rata karena yang menjadi dasar adalah letak variabel
bukan nilainya.
3.3.1.Median untuk data tidak tersusun
3.3.1.1. Jumlah variabel
Langkah yang harus dilalui adalah :
1. Susunlah data mentah dalam sebuah array
2. Ambillah nilai variabel yang terletak ditengah sebagai nilai
median
Contoh No. 10
Carilah nilai median dari kelompok nilai variabel 1, 4, 10, 8
dan 10 yang menggambarkan jumlah kilometer yang ditempuh oleh
5 orang mahasiswa.
Pemecahan :
Nilai-nilai tersebut disusun dalam bentuk array sebagai
berikut:
Nomor urut Jarak Tempuh (km)
Nomor Urut Jarak Tempuh (km)
1
2
3
4
5
1
4
8
10
10
Median = 8
Nomor urut ketiga terletak di tengah-tengah, jadi Median = 8
km. median ini membagi kelompok variabel dalam 2 bagian yang
sama, dimana 2 buah variabel (masing-masing no. 1 dan No. 2)
terletak di bawah median, dan 2 buah yang lain (masing-masing No.
4 dan No. 5) terletak di atas median.

3.3.1.2. Jumlah variabel genap
Langkah yang harus dilalui:
1. Susunlah data mentah dalam sebuah array;
2. Ambillah 2 buah nilai variabel yang terletak ditengah;
3. Jumlah kedua nilai tersebut dan bagilah dengan 2
Hasilnya merupakan angka rata-rata dan itu merupakan nilai
median.
Contoh No. 11.
Carilah median dari kelompok nilai berikut (dalam rupiah) 9,
6, 2, 5, 18 dan 12.
Pemecahan
Nomor Urut Jarak Tempuh (km)
1
2
3
4
5
6
2
5
6
9
12
18
Median = Rp. 7.50
Dua buah nilai ditengah adalah Rp. 6,- dan Rp. 9,- (nomor urut
3 dan 4). Kedua angka tersebut dijumlahkan dan hasilnya dibagi 2
sehingga diperoleh median = (Rp. 6,- + Rp. 9,-) 2 + Rp 7,50.
Dari perhitungan tersebut terlihat bahwa median Rp. 7,50
membagi kelompok variabel dalam 2 bagian, dimana 3 bulan
variabel berada di bawah median dengan nilai dibawah nilai
median dan 3 buah variabel lainnya berada di atas median dengan
nilai di atas nilai median.
3.3.2.Median untuk data tersusun

Langkah perhitungan median untuk data yang tersusun dalam
tabel distribusi frekuensi adalah sebagai berikut :
1. Carilah setengah dari total frekuensi (N/2);
2. Jumlahkan frekuensi mulai dari interval kelas pertama dan
seterusnya hingga mencapai jumlah yang mendekati N/2. jumlah
ini merupakan jumlah frekuensi kumulatif dari interval kelas
yang berada di bawah kelas yang berisi median (disebut;
median kelas) (fLMd) fLMd ini harus lebih kecil atau sama dengan
N/2.
3. Bila perhitungan fLMd telah berhenti, maka kelas yang terletak
sesudah kelas terakhir dimana perhitungan fLMd dihentikan
merupakan kelas yang berisi median. Batas bawah dari kelas
tersebut merupakan batas bawah kelas yang berisi median (LmD)
dan frekuensinya merupakan frekuensi kelas yang berisi median
(fmd)
4. Setelah proses (1) sampai dengan (3) selesai, maka median
dapat dicari dengan rumus sebagai berikut:
Contoh No. 12
Bila data pada tabel: III-4 dalam contoh no. 6 dihitung
mediannya, maka prosesnya adalah sebagai berikut :
1. Jumlah frekuensi, N = 80. Jadi N/2 = 80/2 = 40
2. fLmD = 6 + 12 + 19 = 37. Di sini fLMD = 37 < N/2 = 40
3. Dengan sendirinya fmd = 20 dan Lmd = Rp. 2.000,-
4. Dengan interval Rp. 500,-, maka median adalah

3.4. Mode
Mode atau modus adalah nilai variabel (atribut) yang memiliki
frekuensi tertinggi. Mode dapat dipakai terhadap data kuantitatif
dan data kualitatif.
3.4.1.Mode untuk data Tidak tersusun
Contoh No. 14
Carilah mode dari kelompok nilai variabel berikut :
8 12 17 18 21 dan 25
Pemecahan : Di sini masing-masing nilai variabel hanya terdiri dari
1 (satu) frekuensi. Karenanya, disini tidak ada mode atau modenya
nol.
3.4.2.Mode untuk data tersusun
Untuk menentukan besarnya mode bagi data tersusun ikutilah
langkah-langkah berikut ini:
1. Carilah kelas dengan frekuensi yang terbesar (fmo)
2. Tentukan batas bawah dari kelas dengan frekuensi terbesar
(kelas modal) (Lmo)
3. Carilah simpangan (deviasi) antara frekuensi terbesar (fmo)
dengan frekuensi kelas yang ada dibawahnya (f1) dan yang ada
diatasnya (f,);
d1 = fmo – f1 dan d2 = fmo – f2
4. Tentukan besarnya interval (i)
5. Dengan demikian, perumusan untuk menghitung mode adalah;
Mode =

Contoh No. 17

Tabel : III – 9
Rasio Harga Pendapatan untuk 25 Saham Umum
Rasio Saham Umum (f)
5.0 – 8.9
9.0 – 12.9
13.0 – 16.9
17.0 – 20.9
21.0 – 24.9
25.0 – 28.9
3
5
7
6
3
1
Carilah nilai mode dari data di atas!
Pemecahan : fmo = 7; f1 = 5: f2 = 6: Lmo = 13,0
d1 = 7 – 5 = 2 ; d2 = 7 – 6 = 1
jadi Mo = 13,0 + 4,0 = 13,0 + 2,7 = 15.7
3.4.3.Empirical Mode (mg)
Pada umumnya bilamana distribusi sekelompok data itu tidak
simetris tetapi mendekati simetris, diperkirakan median terletak
pada sepertiga jarak antara rata-rata dan mode. Karenanya, bila
telah diketahui besarnya nilai rata-rata dan nilai median, maka
empirical mode dapat dicari dengan perumusan berikut:
Contoh No. 19
Atas dasar informasi berikut, carilah besarnya nilai empirical
mode dengan perumusan di atas!
Diketahui : (a) = 75 dan Md = 70; (b) = 105 dan Md = 120;
Pemecahan : (a) MoE = 75 – 3 (75-70) = 75 - 15 = 60;
(b) MoE = 105 – 3 (105 – 120) = 105 – (-45) = 150
3.5. Hubungan antara rata-rata, median, dan mode

Apabila distribusi dari sekelompok data adalah simetris, maka
rata-rata, median dan mode akan berada pada satu titik dibawah
titik puncak dari kurva. Tetapi bilamana distribusinya menceng
(skewed), negatif atau positif, maka ketiganya akan terpencar.
Mode tetap berada di bawah titik puncak, rata-rata ditarik ke arah
nilai ekstrim, dan median berada diantaranya.
Untuk jelasnya perhatikan gambar berikut:
a. Simetris
b. Asimetris negatif
c. Asimetris positif
Mode jarang diterapkan untuk bisnis disebabkan di dalam
sekelompok data kemungkinan tidak terdapat mode atau terdapat
bi-mode atau multi-mode. Tetapi, mode sering dipergunakan dalam
statistik apabila untuk menggambarkan distribusi frekuensi.
Rata-rata merupakan ukuran tendensi sentral yang sangat
umum dipergunakan karena: (1) sekelompok data selalu memiliki
semata-mata hanya sebuah rata-rata, dan (2) rata-rata memiliki
persyaratan.
Bagi distribusi-distribusi yang menceng (skewed) median
merupakan ukuran tendensi sentral yang lebih baik dari rata-rata,
sebab rata-rata didesak dari wilayah tengah ke arah kemencengan.

Selanjutnya, median memiliki persyaratan 50-50 yang tidak ada
pada rata-rata.
3.6. Rata-rata geometrik
Rata-rata geometrik dari sekelompok nilai n adalah akar ke n
dari hasil kali nilai-nilai dalam kelompok itu. Jika terdapat 2 buah
nilai, akar dari hasil nilai itu merupakan rata-rata geometrik.
3.6.1.Data tidak tersusun
Rata-rata geometrik untuk data tidak tersusun dapat
dinyatakan sebagai berikut:
Rata-rata geometrik (G) =
Misalkan nilai-nilai n dinyatakan dengan X1, X2, X3, …Xa, maka:
(G) =
Jika dipakai logaritma untuk menghitung nilai G, maka rumus
di atas ditulis:
Log G =
Atau kalau disederhanakan menjadi : log G = log X/n. nilai G
merupakan anti – log dari pecahan pada sisi kanan rumus.
3.6.2.Data tersusun
Bila data tersusun dalam sebuah tabel distribusi frekuensi,
maka rumus rata-rata geometrik yang dipakai adalah :
Log G =
Atau singkatnya log G = log X/n
3.6.3.Faktor pertumbuhan (Growth factor)
Faktor pertumbuhan (growth factor) merupakan rasio dari
suatu jumlah pada suatu periode tertentu terhadap jumlah yang
berkaitan pada periode yang terdahulu. Misalnya : tahun 1992

harga satu unit barang ‘X’ adalah Rp. 2000, dan pada tahun 1991
harga barang tersebut hanya Rp. 1.750, faktor pertumbuhan (FP)
harga barang tersebut pada tahun 1992 adalah Rp. 2000,/Rp. 1.750
= 1,14. ini menunjukkan terdapat kenaikan harga barang sebesar 1,
14-1,00 = 0.14 atau 14%
FP dapat juga dicari melalui besarnya persentase perubahan
yang terjadi ditambah dengan 1. misalkan, pada tahun 1992 terjadi
kenaikan harga barang ‘X’ sebesar 35% dari harganya pada tahun
1991. FP atas harga barang tersebut adalah 0,35 + 1.00 = 1.35
Pada tahun 1992 terjadi penurunan harga barang ‘Y" sebesar 5%
dari harga tahun 1991. FP atas harga barang tersebut adalah -0,05
+ 1,00 = 0,95.
Bilamana hendak menghitung rata-rata persentase
perubahan dari waktu ke waktu, maka langkah yang harus
ditempuh adalah :
1. Mengubah persentase perubahan ke faktor pertumbuhan (FP)
2. Mencari rata-rata geometrik dari FP;
3. Mengubah rata-rata geometrik FP ke dalam persentase
perubahan
3.6.4.Perumusan compound – interest
Dari contoh no. 22 diperoleh hasil berikut 2,525436 = 1,2036.
Kalau kedua sisi dipangkatkan dengan 5, maka hasil di atas
berubah menjadi :
2.525436 = (1,2036) atau 2.525436 = (1+0.2036) kalau P5 =
2.525436, Po = 1, dan n = 5, maka perumusan diatas dapat ditulis
sebagai berikut:
P5 = P0 (1+0.2036)
Persamaan di atas dapat ditulis secara umum sebagai berikut:
Pn = P0 (1+r)

Dan ini dikenal dengan nama; perumusan compound-interest
Untuk berbagai tujuan, persamaan tersebut dimanipulasikan
dengan berbagai cara, seperti:
a. r = b.
diketahui bahwa pada tahun 1992 jumlah penduduk suatu
wilayah adalah 200.000 jiwa. Jika tingkat pertumbuhan rata-rata
tahun selama periode 1987 – 1992 sebesar 2,72%, berapakah
perkiraan jumlah penduduk pada tahun 2000?
Pemecahan :
Diketahui r = 2,72% = 0,0272 ; P0 = P1992 = 200.000 jiwa
n = 2000 – 1992 = 8 ; Pn = P. 2.000 = ?
P2000 = P1992 (1+0.0272)8
= 200.000 (1+0.0272)8
= 200.000 (1.2394816)
= 247.896.32
= 247.896
Jadi penduduk tahun 2000 diperkirakan berjumlah 247.896 jiwa.

BAB IV
UKURAN-UKURAN DISPERSE, KEMENCENGAN DAN
PERUNCINGAN
4.1.Pengantar
Ukuran disperse merupakan ukuran tentang derajat
pemencaran (degree of scatter) dimana terdapat kecenderungan
bagi setiap nilai variabel untuk berpencar di sekitar nilai rata-rata.
Disperse merupakan suatu karakteristik yang selalu harus
diperhitungkan di dalam menganalisis data dalam sebuah frekuensi
distribusi. Dengan ukuran disperse dimaksud, untuk mengetahui
apakah pemencaran dari nilai-nilai variabel di sekitar rata-rata itu
sifatnya kompak atau menyebar.
Ukuran kemencengan (skewness) yang diberi notasi “Sk”,
merupakan ukuran tentang derajat kesimetrisan dari sebuah
sebaran (distribusi). Dapat pula dikatakan sebagai ukuran
keseimbangan atau ketidakseimbangan pada kedua sisi nilai
sentral. Keadaan inidisebut juga; asimetris.
Ukuran kemencangan dibedakan antara yang positif dengan
yang negatif. Sebuah sebaran dikatakan menceng positif (positive
skewed) apabila kemencengan itu memberat ke arah kanan, atau
ekornya berada di sebelah kanan. Sebaliknya, sebuah sebaran
dikatakan menceng negatif apabila kemencengan itu memberat ke
arah kiri, atau ekornya terletak di sebelah kiri.
Ukuran peruncingan (Kurtosis), yang diberi notasi “Kt”,
merupakan ukuran tentang derajat peruncingan dari sebuah

sebaran. Dua buah sebaran dapat memiliki rata-rata yang sama,
tetapi yang satu dapat lebih runcing dibandingkan yang lain.
Derajat peruncingan sebuah sebaran dapat dibedakan dalam
3 jenis, yaitu:
1. Leptokurtic; apabila puncak sebaran adalah runcing
2. Mesokutric; apabila puncak sebaran adalah normal
3. Playkurtic; apabila puncak sebaran adalah datar.
4.2.Ukuran Dispersi
Ukuran disperse dibedakan dalam :
1. Ukuran disperse mutlak, yang terdiri dari
a. Simpang rata-rata (mean deviation)
b. Simpang kuartal (quartile deviation)
c. Simpang baku (standard deviation)
2. Ukuran disperse relatif, yang terdiri dari :
Koefisien variasi (coefficient of variation)
Simpang baku dan simpang kuartal lebih umum dipergunakan
sebagai alat pengukur variasi, sedangkan simpang rata-rata
dipergunakan secara insidental.
Masing-masing ukuran memuat suatu konsepsi yang berbeda
satu sama lain dan memberikan hasil yang berbeda-beda.
Akibatnya, setiap ukuran memiliki kegunaan khusus sendiri yang
dapat dimengerti dengan lebih baik setelah metode-metode itu
diuji.
Koefisien variasi biasanya dipergunakan apabila hendak
membandingkan derajat pemencaran dua buah sampel yang

mempunyai satuan ukuran yang berlainan satu sama lain, misalnya
sampel pertama dalam ‘kilogram’ dan sampel kedua ‘meter’.
4.2.1.Simpangan rata-rata
Simpangan rata-rata (mean deviation), dengan notasi “SR”,
biasanya mempergunakan rata-rata hitung atau median sebagai
dasar pengukurannya. Simpang rata-rata dihitung dengan jalan
menjumlahkan simpangan masing-masing nilai variabel dengan
nilai rata-ratanya (atau median) dan kemudian membaginya
dengan jumlah seluruh variabel, tanpa memperhatikan tanda jabar.
Artinya, simpangan-simpangan itu harus dirata-ratakan seolah-olah
kesemuanya itu adalah positif.
Oleh karena, jumlah simpangan-simpangan itu merupakan
suatu minimum bila diambil disekitar median, maka kadang-kadang
simpang rata-rata hitung atas dasar median. Namun dalam praktek
umumnya dipakai rata-rata hitung dan jika rangkaian data itu
simetris, memberikan hasil yang sama.
Simpang rata-rata merupakan sebuah ukuran variabilitas
yang ringkas dan sederhana. Ukuran ini merangkum seluruh
variabel yang ada dan tidak dipengaruhi oleh simpangan-
simpangan ekstrim seperti di dalam simpangan baku.
4.2.2.Simpang kuartal
Simpang kuartal (quartile deviation) dengan notasi ‘SK”
merupakan suatu ukuran disperse yang didasarkan atas nilai
kuartal, yaitu kuartal pertama (K1) dan kuartal ketiga (K3). Ukuran
ini juga disebut; semi interquartile range”, yang berarti setengah
jarak antara kuartal pertama hingga kuartal ketiga. Perumusan
yang dipergunakan adalah :
SK =

Kuartal adalah tiga buah titik yang secara kasar membagi
sebuah urutan atau sebaran frekuensi ke dalam empat bagian
yang sama. Kuartal pertama (K1) memisahkan seperempat pertama
dari sejumlah nilai dengan seperempat kedua; kuartal kedua (K2)
(selamanya disebut; median) memisahkan seperempat kedua
dengan seperempat ketiga; dan kuartal ketiga (K3) memisahkan
seperempat ketiga dengan seperempat keempat. Karenanya,
quartile range K3 – K1, meliputi pertengahan setengah bagian itu.
Simpang kuartal merupakan setengah dari range ini.
4.2.1. Simpang baku
Simpang baku (standar deviation), dengan notasi “s”.
merupakan bentuk simpangan rata-rata yang diperbarui dan juga
merupakan dipergunakan. Dalam kenyataan, simpang baku adalah
demikian pentingnya sehingga menjadi standar ukuran disperse.
Kuadrat dari simpang baku disebut : varian (s)2
4.2.1. Koefisien Variasi
Disperse mutlak seperti yang telah diuraikan umumnya
dinyatakan dalam bentuk satuan original, misalnya; dalam rupiah,
kilogram, liter dan sebagainya. Apabila diinginkan untuk
membandingkan dispersi dari dua buah rangkaian atau lebih
dengan mempergunakan ukuran mutlak akan sulit dilakukan
manakala rangkaian-rangkaian itu memiliki satuan ukuran atau
ukuran rata-rata yang berbeda satu dengan yang lain. misalkan,
kita ingin membandingkan disperse antara gaji pegawai negeri
yang dibayar secara bulanan dengan upah mempunyai ukuran rata-
rata yang berlainan, gaji diukur atas dasar harian. Demikian pula
kita tidak dapat membandingkan secara mutlak disperse antara
gula pasir yang mempunyai satuan pajang meter.

Untuk mengatasi kesulitan ini Karl Pearson (1957-1936) telah
menciptakan ukuran lain yang disebut; Koefisien variasi (V). Ukuran
ini merupakan yang relatif sifatnya karena diperoleh dengan cara
yang tidak langsung. Rumusan yang dipergunakan adalah
V = (s/ ) x 100
4.3.Ukuran Kemencengan
Oleh karena kemencengan itu mempengaruhi letak nilai rata-
rata hitung, median, dan mode, maka untuk dapat mengukur
sampai dimana besarnya derajat kemencengan itu oleh Karl
Pearson dipergunakan ketiga ukuran tendensi tersebut bersama-
sama dengan simpang baku. Di sini terdapat dua buah perumusan
Pearson dan keduanya disebut: Pearson Coefficient of Skewness.
a) b)
rumusan (a) tidak begitu lazim dipergunakan, karena adanya
kenyataan bahwa ada kebanyakan sebaran frekuensi mode
hanyalah merupakan suatu prakiraan. Di samping itu, bila sebaran
sampling bermode dua (bi-mode). Pengukuran mode pada
umumnya dilakukan dengan asumsi-asumsi yang tertentu.
Karenanya rumusan (b) lebih lazim dipergunakan.
Koefisien kemencengan pearson akan positif apabila rata-rata
hitung lebih besar dari median dan mode; dan akan negatif apabila
rata-rata hitung lebih kecil dari median dan mode.
Metode perhitungan berikutnya adalah yang dikemukakan oleh
A.L Bowley yaitu:
1. Koefisien kemencengan Kuartil, dengan perumusan sebagai
berikut :

2. Koefisien kemencengan persentil, dengan perumusan sebagai
berikut:
Nilai P (persentil) dicari dengan perumusan yang sama dengan
yang dipakai untuk menghitung kuartal; hanya saja sekarang N
dibagi dengan 100.
Menurut Bowley bahwa Sk = + 0,10 menggambarkan sebaran
kemencengan tidak berarti (not significant). Sebaliknya, Sk > +
0.30 menggambarkan sebaran yang kemencengannya sangat
berarti (significant)
Sedangkan menurut Croxton & Cowden ukuran kemencengan
bergerak dalam batas-batas + 3. Namun perlu ditambahkan bahwa
besarnya ukuran jarang yang melampaui batas + 1
4.4.Ukuran Peruncingan
Untuk menghitung koefisien peruncingan dapat dipergunakan
perumusan “percentile coefficient of kurtosis” yaitu:
Contoh
Diketahui :
K1 = Rp 6.825,- ; K3 = Rp. 9.075,-
P10 = Rp. 5.812. ; P90 = Rp. 10.100,-

BAB V
ANGKA INDEKS
5.1.Pengantar
Angka indeks merupakan rasio antara dua buah bilangan
yang dinyatakan dalam bentuk persen. Tujuan angka indeks adalah
untuk mengukur perbedaan besaran dari sekelompok variabel yang
saling berhubungan. Perbedaan-perbedaan ini dapat terjadi pada
harga barang-barang, jumlah fisik barang yang diproduksikan,
dipasarkan, atau dikonsumsikan.
Jenis-jenis angka indeks yang lazim dipergunakan antara lain:
indeks harga, indeks jumlah, dan indeks nilai.
Indeks harga bertujuan untuk mengetahui perubahan-
perubahan yang terjadi pada harga atau harga-harga selama dua
periode waktu atau lebih.
Indeks jumlah bertujuan untuk membandingkan perubahan-
perubahan yang terjadi atas sejumlah barang-barang yang
diproduksikan, diperdagangkan, atau dikonsumsikan selama dua
periode waktu atau lebih.
Indeks nilai merupakan hasil perkalian antara indeks harga
dengan indeks jumlah. Tujuannya adalah untuk mengukur
perubahan-perubahan yang terjadi atas nilai sesuatu barang atau
sekelompok barang selama dua periode waktu atau lebih.
Metode perhitungan angka indeks terdiri dari:
1. Metode tidak ditimbang
a. Metode indeks sederhana
b. Metode indeks gabungan sederhana
c. Metode indeks rata-rata relatif sederhana
d. Metode indeks bernilai

2. Metode ditimbang
a. Metode indeks laspeyres
b. Metode indeks paasche
c. Metode indeks fisher
Di dalam menghitung angka indeks data yang dipergunakan
adalah data deret berkala (time series data). Jadi, disini data
terlebih dahulu diklasifikasikan secara kronologi menurut urutan
waktu kejadiannya.
Dalam melakukan perbandingan antara dua periode waktu
atau lebih, terlebih dahulu ditetapkan apa yang disebut; tahun
dasar (base year) atau periode dasar (base period). Sebagai tahun
dasar lazimnya dipilih tahun yang tertua, tahun yang pertama
dalam deretan tahun. Sedangkan sebagai periode dasar dipilih
beberapa tahun pertama dalam deretan perbandingan, yang secara
teknis merupakan penyebut (pembagi). Tahun yang
diperbandingkan disebut tahun tertentu (given year), yang secara
teknis merupakan pembilang (yang dibagi).
5.2.Angka indeks tidak ditimbang
5.2.1. Notasi
= sigma = jumlah, total ; h = harga
0 = tahun dasar atau periode dasar ; j = jumlah (kuantitas)
n= tahun tertentu, dimana ; v =nilai
n=1, 2 . ., k ; I = indeks
I0 = indeks tahun dasar atau indeks periode dasar
I0 = indeks tahun tertentu.
h0 = harga pada tahun dasar atau periode dasar.
hn = harga pada tahun tertentu.
J0 = jumlah pada tahun dasar atau perioe dasar
Jn = jumlah pada tahun tertentu.

Iho = indeks harga pada tahun dasar atau periode dasar.
Ihn = indeks harga pada tahun tertentu.
Ijo = indeks jumlah pada tahun dasar atau periode dasar.
Ijn = indeks jumlah pada tahun tertentu.
Iv0 = indeks nilai pada tahun dasar atau periode dasar.
Ivn = indeks nilai pada tahun tertentu.
5.2.2perumusan
1. Indeks sederhana:
a. Indeksa harga: Iho = (ho/ho) x 100 %
Ihn = (ha/ho) x 100 %
b. Indeks jumlah : Ijo = (jo/jo) x 100 %
Ijn = (ja/jo) x 100 %
c. Indeks Nilai : Ivo = (ho/ho) x 100 %
Ivn = (va/vo) x 100 %
2. Indeks gabungan sederhana
a. Indeks harga: Iho = (ho/ho) x 100 %
Ihn = (ha/ho) x 100 %
b. Indeks jumlah : Ijo = (jo/jo) x 100 %
Ijn = (ja/jo) x 100 %
c. Indeks Nilai : Ivo = (ho/ho) x 100 %
Ivn = (va/vo) x 100 %
3. Indeks rata-rata relatif sederhana
a. Indeks harga: Iho = ((ho/ho) x 100 %) /k
Ihn = ((ha/ho) x 100 % ) /k
b. Indeks jumlah : Ijo = ((jo/jo) x 100 %)/k
Ijn = ((ja/jo) x 100 %)/k
c. Indeks Nilai : Ivo = ((ho/ho) x 100 %)/k
Ivn = ((va/vo) x 100 %/k
4. Indeks Berantai

Perumusan untuk indeks berantai sama dengan
perumusan untuk indeks sederhana, hanya saja tahun dasarnya
bergerak mengikuti gerak tahun tertentu.
5.2.2.Contoh-contoh
Pada tahun 1989 harga beras berkualitas sedang rata-rata Rp.
1.150,- per kg. Pada tahun 1990 untuk beras yang sama harganya
Rp. 1.250 per kg. Dengan dasar harga tahun 1989, carilah indeks
harga besar tahun 1990!
Tentukan pula indeks dasarnya!
Di sini tahun dasarnya adalah tahun 189 dan tahun tertentunya
adalah 1990
h0 = h1998 = Rp. 1.150 dan hn = h1990 = Rp. 1.250
jadi, Ihn = Ih1998 = (Rp. 1.250/Rp. 1.150) x 100% = 108,7%
Ihn = Ih1989 = (Rp. 1.150/Rp. 1.150) x 100% = 100,0%
5.2.3.Angka indeks ditimbang
Dalam bagian ini akan dijelaskan 3 buah metode indeks
ditimbang yang lazim dipergunakan, yaitu: indeks laspeyres,
indeks paasche, dan indeks filter (ideal indeks).
Perumusan yang dipergunakan adalah sebagai berikut:
a. Laspeyres
1. Indeks harga : Lhn = (hojo/hojo) x 100 %
2. Indeks jumlah : Ljn = (joho/joho) x 100 %
3. Indeks harga : Lvn = (hnjn/hnjn) x 100 %
b. Paasche
1. Indeks harga : Phn = (hnjn/hojn) x 100 %
2. Indeks jumlah : Pjn = (jnhn/john) x 100 %
3. Indeks harga : Pvn = (hnjn/hojo) x 100 %

c. Fisher
1. Indeks harga : Fhn = x
100 %
2. Indeks jumlah : Fhn =
3. Indeks harga : Fvhn = (hnjn/hnjn) x 100 %
Catatan :
h = harga ; j = jumlah (kuantitas) ; o = tahun dasar
n = tahun tertentu ; = jumlah (total) ; v = nilai
h0j0 = joho ; hnjo = john
h0jn = jnho ; hnjn = jnhn
Contoh No. 5
Jenis perabot
1989 (0) 1990 (n)
Harga/unit
(Rp. 1000)
(h0)
Jumlah
(unit)
(h0)
Harga/unit
(Rp. 1000)
(hn)
Jumlah
(unit)
(jn)
1. Almari
2. Tempat tidur
3. Sice
470
350
525
10
8
5
485
380
540
15
11
7
Sumber : Hipotesis
Hitunglah : Angka indeks tahun 1990 dengan dasar tahun 1989,
dengan metode-metode Laspeyres, Paasche, dan fisher
Pemecahan :
hojo = [(475x10) + (350x8) + (525x5)] x 1.000 = 10.175.000.
hnjn = [(475x15) + (350x11) + (525x7)] x 1.000 = 14.650.000.
hnjo = [(485x10) + (380x8) + (540x5)] x 1.000 = 10.175.000.
hnjn = [(485x15) + (380x11) + (540x7)] x 1.000 = 15.235.000.
5.2.4.Pemakaian Angka Indeks

Angka indeks dapat dipergunakan untuk berbagai
pengukuran, seperti; indeks perdagangan untuk mengukur hasil
penjualan barang yang riil (nyata), indeks harga konsumen untuk
mengukur taraf hidup (standar of living) dari para penerima
pendapatan tetap melalui pengukuran pendapatan nyata, upah
nyata dan juga untuk mengukur kekuatan beli uang (purchasing
power of money).
Di samping itu, angka indeks memiliki beberapa kegunaan yang
lain, misalnya:
1. Memudahkan, membandingkan dan menganalisis rangkaian
dengan menetapkan suatu periode dasar dan mencakup
berbagai kumpulan angka
2. Merupakan cara yang mudah untuk mengekspresikan suatu
perubahan jumlah dari sekelompok bagian-bagian yang
heterogen
3. Mengubah data menjadi angka indeks juga memudahkan
untuk membandingkan trend dalam suatu rangkaian yang
terdiri dari jumlah-jumlah yang sangat besar
4. Angka indeks merupakan salah satu peralatan statistik yang
ditunjuk guna mengembangkan pengetahuan tentang aspek-
aspek dari perekonomian, seperti; pasar modal, produksi
pertanian, produksi industri, harga konsumen, harga-harga
perdagangan besar, dan perdagangan internasional.
Dari sudut pandangan ini, angka indeks dapat dibanding
sebagai bagian dari statistik deskriptif. Mereka selalu
menggambarkan perubahan-perubahan yang terjadi pada
pasar modal, di dalam sektor produksi dari perekonomian dan
lain-lain.

5.3. Pengujian angka indeks
Untuk mengetahui sampai di mana kebenaran suatu angka
indeks diperlukan adanya suatu pengujian terhadap angka indeks
tersebut. Sebuah angka indeks yang berhasil lolos dari pengujian
dinyatakan sebagai angka indeks yang baik.
Irving Fisher mengemukakan dua buah kriteria untuk menguji
apakah suatu angka indeks itu baik, yaitu; time reversal test dan
factor reversal test.
Sebuah angka indeks dikatakan baik bila ia memenuhi kriteria;
I0n x Ino = I
Dimana
I0n = indeks tahun n dengan dasar tahun o
Ino = indeks tahun o dengan dasar tahun n
Factor Reversal Test
Bila kita ingin menguji kebenaran indeks harga dengan
mempergunakan faktor reversal test, maka perlu adanya
pengetahuan tentang indeks jumlah. Demikian pula sebaliknya. Bila
indeks harga (Ih) memperlihatkan perubahan harga-harga dari
tahun dasar ke tahun n, dan indeks jumlah (Ij) memperlihatkan
perubahan jumlah-jumlah dari tahun dasar ke tahun n, maka
(harga) x (jumlah) = nilai.
Faktor reversal test menghendaki bahwa h x j akan
memperlihatkan perubahan nilai dari tahun dasar ke tahun n.
Jadi,
h x j = hnjn /hojo
dimana hojo memperlihatkan jumlah pengeluaran dalam tahun
dasar dan hnjn memperlihatkan jumlah pengeluaran dalam tahun n.
karena perumusan ini memperlihatkan perubahan nilai, ia disebut
indeks nilai.

5.4. Indeks harga konsumen (IHK)
Masson (1974, 148) mengatakan bahwa ‘indeks harga konsumen
merupakan indeks perubahan harga barang dan jasa yang dibeli
oleh keluarga-keluarga, penerima-penerima upah dan pekerja-
pekerja kantor di kota untuk memelihara tingkat hidup mereka.
Tujuannya adalah untuk mengukur perubahan-perubahan
harga barang dan jasa yang dibeli oleh penerimaan upah dan
pekerja-pekerja kantor di kota selama suatu periode tertentu. Jadi,
bukan peruntukan bagi keluarga petani atau keluarga kaya.
Indeks harga konsumen pada lazimnya selalu mengalami
perubahan dasar perbandingan dikarenakan alasan-alasan berikut
ini:
1. Adanya perubahan secara drastis dari pola konsumsi
Hal ini disebabkan adanya perubahan jenis barang konsumsi,
misalnya penggantian alat-alat transportasi dari sepeda ke
sepeda motor, alat angkut gerobak yang ditarik oleh hewan
diganti dengan mobil gerobak (pick up, truck).
Adanya kebutuhan baru sebagai akibat adanya penemuan-
penemuan baru, seperti TV, Video cassette, dan lain-lain
Perkembangan dunia pendidikan yang begitu pesat, mendorong
pesatnya perubahan pola konsumsi, seperti adanya pengeluaran
tambahan buku-buku, uang SPP, uang ujian, dan lain-lain. orang
akan mengubah pola hidupnya setelah menganyam pendidikan
yang lebih baik.
2. Adanya perubahan kebiasaan berbelanja. Hal ini tampak
beraneka ragamnya jenis pengeluaran keluarga-keluarga.
Komposisi pembagian telah mengalami penggesearan-
penggeseran akibat kemajuan teknologi yang makin meningkat.

indeks harga konsumaen antara dua buah kata atau lebih tidak
dapat di perbandingkan. Sebagai contoh, indeks harga konsumen
sektor makanan tahun 1991 di Jakarta 118,63 dan di Banda Aceh
114,55 dengan dasar April 1977 – Maret 1978 = 100. kita tidak
dapat mengatakan bahwa indeks harga konsumen di Jakarta lebih
tinggi dari pada indeks harga konsumen di Banda Aceh. Yang dapat
dikatakan adalah bahwa di Jakarta terdapat kenaikan indeks
sebesar 18,63% dan di Banda Aceh kenaikan itu sebesar 14,55%.
Ini menunjukkan bahwa kenaikan indeks di Jakarta lebih cepat dari
kenaikan di Banda Aceh.
Kegunaan indeks harga konsumen antara lain untuk
mengukur pendapatan nyata dan kekuatan beli uang, di samping
juga untuk pendeflasian harga uang.
BAB VI
DASAR-DASAR TEORI
KEMUNGKINAN
6.2 Pengantar
Tujuan statistik adalah melakukan penafsiran (inferensif)
mengenai sebuah populasi berdasarkan pada informasi yang
terkandung di dalam sebuah sampel. Karena sampel tersebut
hanya memberikan sebagian informasi mengenai populasi, kita
memerlukan suatu meakanisme yang akan menyelesaikan tujuan
itu.
Kemungkinan (pobality) merupakan mekanisme yang
dimaksud, yang memungkinkan kita mempergunakan sebagian
ainformasi yang terkandung di dalam sekelompok sampel untuk

menaksir sifat dari sekelompok data yang lebih besar, yaitu
populasi.
6.3 Percobaan, peristiwa, dan ruang sampel
data dapat diperoleh baik dengan jalan pengamatan atas
peristiwa-peristiwa alam yang tidak teratasi (uncontrolled events
nature) maupun dengan jalan percobaan yang diawasi di dalam
laboratorium (controlled experimentation).
Percobaan (experiment) merupakan suatu proses di mana
suatu pengamatan (pengukuran) dicatat. Perlu diingat bahwa
pengamatan tidak perlu harus menghasilkan suatu nilai dalam
bentuk angka (numerical value). Beberapa contoh mengenai
percobaan antara lain:
1. Pencatatan mengenai penghasilan seorang pekerja pabrik
2. Mewawancarai seorang pembeli untuk merek kegemaran atas
suatu produk tertentu
3. Pencatatan harga sebuah jaminan pada suatu waktu tertentu.
4. Pemeriksaan suatu jalur perakitan untuk menentukan apakah
telah dihasilkan sejumlah kerusakan yang melebihi jumlah yang
diizinkan.
Setiap percobaan dapat menghasilkan satu hasil (outcome)
atau lebih, yang disebut peristiwa (event) atau peristiwa-peristiwa
(events), dan diberi notasi “E”.
Satu percobaan hanya akan menghasilkan satu peristiwa
sederhana (simple event). Suatu peristiwa sederhana merupakan
suatu peristiwa yang tidak dapat diurai. Simbl dari peristiwa
sederhana adalah huruf E dengan dibubuhi sebuah sub script. Jadi
seperti ini E; untuk setiap peristiwa sederhana dapat ditandai
dengan sebuah titik, yang disebut titik sampel (sample point).

Kumpulan dari beberapa peristiwa sederhana disebut; ruang
sampel (sample space) dan diberi notasi; S. jadi ruang sampel
merupakan himpunan dari seluruh titik sampel bagi suatu
percobaan. Dapat dikatakan bahwa S merupakan totalitas dari
semua titik-titik sampel.
Contoh No. 1.
Sebuah mata uang dilemparkan sebanyak satu kali. Peristiwa-
peristiwa sederhana yang dihasilkan adalah :
Peristiwa E1 = sebuah kepala (head = H) dan
Peristiwa E2 = sebuah ekor (tali = T)
E1 dan E2 merupakan titik-titik cuplikan dalam sebuah ruang sampel
S. perhatikan diagram Venn berikut ini :
6.4 Kemungkinan (probability)
Pada dasarnya kemungkinan (probability) dari suatu peristiwa
merupakan sebuah frekuensi relatif dari banyaknya peristiwa itu
terjadi terhadap seluruh percobaan yang di lakukan. Secara umum
dapat dikatakan bahwa, apabila suatu percobaan (experiment)
diulang-ulang sebanyak N kali dan peristiwa A diamati sebanyak nA
kali, maka kemungkinan terjadi peristiwa A adalah P(A) = nA /N.
Contoh No. 7.
Sebuah mata uang dilempar sebanyak satu kali dan hasilnya
adalah kepala (H) atau ekor (T). disini kita lihat bahwa kemungkinan
hasil yang diperoleh adalah 2, jadi N = 2, yaitu sebuah ekor (T).
disini kita lihat bahwa kemungkinan hasil yang diperoleh adalah 2,
E1
E2
S

jadi N = 2, yaitu sebuah kepala (H) dan sebuah ekor (T). Dengan
demikian bila kita melemparkan sebuah mata uang, kemungkinan
untuk memperoleh kepala adalah ½ atau 0,5 dan kemungkinan
untuk memperoleh ekor juga ½ atau 0,5
Jadi :
Pr(E1) = Pr(H) = nH / N = ½ = 0,5
Pr(E2) = Pr(T) = nT / N = ½ = 0,5
Pr(H) = nH / N = 0,5
Pr(T) = nT / N = 0,5
Nilai kemungkinan berada antara 0 dan 1
Jadi, 0 Pr (E1) 1, untuk semua nilai i.
Pr (E1) = 0. berarti kemungkinan itu hilang atau tidak menjadi
kenyataan.
Pr (E1) = 1 berarti kemungkinan itu berubah menjadi kenyataan.
Kemungkinan dari suatu peristiwa A adalah sama dengan jumlah
kemungkinan dari titik sampel di dalam A itu.
6.5 Penggabungan Peristiwa-peristiwa
Yang dimaksud dengan penggabungan peristiwa-peristiwa
adalah menyatukan beberapa peristiwa gabungan ke dalam suatu
gabungan.
Caranya ada 2 macam, yaitu :
1. Union, dengan notasi : U
2. Intersection, dengan notasi :
Di dalam penggabungan yang mempergunakan cara ‘union’
semua titik sampel yang terdapat didalam peristiwa-peristiwa yang
digabung berubah menjadi titik sampel dari peristiwa baru yang
merupakan hasil penggabungan. Misalkan kita menggabungkan
peristiwa A dengan peristiwa B, maka semua titik sampel, baik yang
ada pada A atau B atau kedua-duanya, merupakan titik-titik sampel

peristiwa gabungan, penulisan cara penggabungan ini adalah
sebagai berikut :
A U B = A atau B = A + B
6.6 Dalil-dalil Kemungkinan
Di muak telah dijelaskan perbedaan antara peristiwa-
peristiwa tidak bebas, dan saling asing. Dengan cara lain peristiwa-
peristiwa tidak bebas dan bebas dapat digolongkan ke dalam
kelompok peristiwa-peristiwa tidak saling asing (non-mutually
exclusive).
Dalil-dalil kemungkinan (probability laws) mengatur dan
membuktikan kebenaran cara pelaksanaan penggabungan itu.
Dalil-dalil tersebut terdiri dari
1. Dalil penjumlahan (additive laws);
Dengan menggabungkan beberapa peristiwa dapat diketahui
apakah hubungan antara satu peristiwa dengan peristiwa yang lain
itu sifatnya saling asing atau bukan saling asing. Kalau sifatnya
saling asing tidak ada masalah lagi, tetapi kalau sifatnya bukan
saling asing masih perlu dipertanyakan apakah hubungan itu bebas
(independent) atau tidak bebas (depend) yang berarti bersyarat
(condisional)
Secara umum dapat dinyatakan bahwa sebagai dalil pertama
dari dalil pertambahan (additive laws)
Bila A dan B adalah saling asing, maka
Pr (A B) = Pr (A) + Pr (B)
2. Dalil perkalian (multiplication laws)
Penggabungan dengan mempergunakan cara intersection ()
hanya dapat dilakukan apabila peristiwa-peristiwa yang akan
digabungkan itu bukan saling asing. Pelaksanaan penggabungan
dipengaruhi oleh kondisi apakah peristiwa-peristiwa yang akan

digabungkan itu merupakan peristiwa-peristiwa bebas (independt).
Bagi peristiwa-peristiwa yang tidak bebas (depent)
penggabunganya akan merupakan yang bersyarat (conditional).
Dalil pertama (dalil khusus) dari dalil perkalian menyatakan
bahwa:
Bila A dan B adalah peristiwa-peristiwa bebas , maka
Pr (A B) = Pr (A) x Pr (B)
6.7 Kemungkinan teoretis dan kemungkinan empiris
Kemungkinan teoretis (kemungkinan matematis) adalah
kemungkinan yang diperoleh dengan menggunakan cara-cara yang
berlainan serta asumsi bahwa semua cara yang mungkin akan
terjadi atas dasar kemungkinan yang sama (equally likely basis).
Apa yang telah diuraikan terdahulu merupakan contoh dari
proses terjadinya kemungkinan teoretis tadi.
Kemungkinan empiris (kemungkinan statistik) adalah
kemungkinan tentang terjadinya suatu peristiwa yang dihitung atas
dasar pengalaman-pengalaman atau percobaan-percobaan tentang
apa yang terjadi pada saat-saat yang sama di masa yang lalu atau
dasar catatan statistik. Karena pengalaman-pengalaman dan hasil
dari berbagai percobaan itu berlainan, maka nilai dari kemungkinan
empiris dari suatu peristiwa dapat berlainan.
Sebagai contoh misalnya, bahwa berdasarkan catatan
statistik 12 orang dari 325 orang yang meninggal pada tahun 1992
dikarenakan sakit jantung. Berapakah kemungkinannya bahwa
seseorang pada tahun 1993 ini akan meninggal karena sakit
jantung? Jawabnya : 12/325 x 100% = 3,69%
6.8 Permutasi
Pengaturan atau penyusunan dari r objek yang diambil dari
suatu set yang terdiri dari n objek, secara matematis dinamakan:

permutasi dari n objek yang diambil sekaligus sebanyak r, di mana r
n. secara simbolis permutasi di atas dinyatakan dengan nPr
Jumlah permutasi dari suatu set yang terdiri dari n objek yang
berjalinan dan yang diambil sekaligus sebanyak r serta tanpa
pengulangan (non repetitive) adalah :
Apabila pengulangan (repetitive) diperbolehkan, maka jumlah
permutasi adalah :
6.9 Kombinasi
Dalam metode statistik, kombinasi mempunyai fungsi yang
lebih penting dari permutasi. Perbedaan antara permutasi dengan
kombinasi terletak pada persoalan urutan atau susunan (order).
Permutasi menekankan pada urutan, sedangkan kombinasi tidak
menghiraukan order, artinya order tidak penting di sini. Jadi, kalau
kita ambil contoh di atas maka urutan AB sama dengan urutan BA.
Sebuah set yang berisi r objek yang dipilih dari suatu set yang
berisi n objek yang berlainan, tanpa menghiraukan susunan
pemilihannya, secara matematis dinamakan kombinasi n objek
yang berlainan dan yang sekaligus diambil sebanyak r objek
dengan ketentuan C<r<n. Secara simbolis dinyatakan dengan: aCr
atau Cnr
Jumlah kombinasi dari n objek yang berlainan dan yang diambil
sebanyak r adalah :
Terdapat 4 macam warna, yaitu: merah, hijau, kuning, dan
biru.

Berapakah jumlah kombinasi yang dapat diperoleh bila setiap
kombinasi terdiri dari 3 warna?
Kombinasi-kombinasi tersebut merah, hijau, kuning merah,
hijau, biru merah, kuning, biru hijau, kuning, biru.
BAB VII
DISTRIBUSI KEMUNGKINAN
7.1. Pengantar
Banyak tipe distribusi kemungkinan yang pada umumnya
dapat digolongkan dalam dua macam bentuk, yaitu:
1. Distribusi kemungkinan diskrit (discrete probability
distribution)
2. Distribusi kemungkinan kontinu (continuous probability
distribution)
Sebuah distribusi kemungkinan merupakan suatu kelompok
(set) nilai yang ditebarkan menurut teori kemungkinan. Nilai-nilai
yang terdapat didalam kelompok merupakan hasil dari seluruh
pendapat (outcomes) yang mungkin dari percobaan-percobaan
yang diulang-ulang di dalam suatu eksperimen dan yang disebut
variabel acak (random variabel).
Kalau nilai-nilai itu merupakan data diskrit, maka distribusinya
disebut; distribusi kemungkinan diskrit. Kalau nilai-nilai itu
merupakan data kontinu, maka distribusinya disebut distribusi
kemungkinan kontinu.

Dalam bab ini akan dijelaskan 2 buah bentuk distribusi diskrit,
yaitu; distribusi binomial dan distribusi poisson; serta sebuah
bentuk distribusi kontinu yaitu; distribusi normal.
7.2. Distribusi binomial
Perumusan mengenai distribusi binomial (disebut juga;
distribusi kemungkinan Bernoulli) ini diketemukan oleh seseorang
tahu matematika bangsa Swiss yang bernama Jacob Bernoulli.
Perumusan yang dikemukakan disebut; fungsi kepadatan
kemungkinan binomial (binomial probablilty density function).
Bentuk perumusan adalah sebagai berikut :
Pr(r/n,P) = aCrPrQn-r
Dalam perumusan diatas dapat dilihat bahwa n merupakan
banyaknya suatu percobaan dilakukan atau diulang. Ini
menunjukkan bahwa suatu percobaan dapat dilakukan lebih dari
sekali. Proses pengulangan tersebut disebut proses Bernoulli dan
memiliki sifat-sifat sebagai berikut :
1. Hanya terdapat dua buah hasil yang mungkin untuk setiap
percobaan;
2. Data yang dikumpulkan di dalam percobaan merupakan hasil
perhitungan dan sebaran kemungkinan Bernouli itu merupakan
sebuah distribusi diskrit;
3. Kemungkinan suatu hasil (sukses) (P) tetap sama untuk setiap
percobaan, demikian juga dengan kemungkinan suatu kegagalan
(Q atau 1-P);
4. Percobaan-percobaan yang dilakukan adalah independen
(bebas) satu sama lain, sehingga tiada suatu pola tertentu
mengenai hasil-hasilnya.
Contoh No. 1.
Dimisalkan N = 8; P = 0,8 Q = 1-P

Hitunglah kemungkinan untuk r = 3 dengan perumusan Binomial!
Pemecahan :
Nilai kemungkinannya dihitung sebagai berikut :
Pr (r = 3/n = 8, P = 0,8) = 8C3. (0,8)3. (0,2)8-3
Pr(r = 3/n=, 8, P = 0,8) = 56 x 0.512 x 0.00032 = 0.00917504 =
0.0092
Atau bila dinyatakan dalam persen = 0,92%
7.3.Menentukan Frekuensi Teoretis
Kemungkinan binomial dapat dipergunakan untuk
menentukan frekuensi teoretis dengan mempergunakan perumusan
:
N x Pr (r)
Perhatikan contoh berikut :
Contoh No. 5
8 buah mata uang dilemparkan sebanyak satu kali. Jika Y
merupakan banyaknya kepala (H) yang diharapkan akan diperoleh
dari hasil pelemparan tersebut, berapakah besarnya nilai
kemungkinan untuk mendapat r = 3? Jika pelemparan dilakukan
sebanyak 250 kali, berapakah jumlah kepala (H) yang dapat
diharapkan akan diperoleh dari seluruh lemparan tersebut?
Pemecahan :
Diketahui : n = 8, r = 3 P = 0,5 N = 250
Pr (r = 3/n = 8, P = 0,5) = 8C3. (0,5)3. (0,5)5 = 56 x 0.125 x 0.03125
= 0.21875 atau 21.88%
Jika lemparan dilakukan sebanyak 250 kali, maka jumlah kepala (H)
yang dapat diharapkan sebanyak 250 x 21,88% = 54,7 = 55 kepala.
Jadi, besarnya frekuensi teoretis = 55.

Perhitungan rata-rata dan simpang baku pada distribusi
kemungkinan binomial
Distribusi kemungkinan binominal juga mempunyai rata-rata
dan simpangan baku. Untuk menghitung rata-rata dan simpang
baku dari sebuah sebaran kemungkinan binomial untuk populasi
tidak terbatas dipergunakan perumusan berikut :
(dari jumlah sukses = np)
(dari jumlah sukses yang ditarik dari sebuah populasi tidak
terbatas) = n PQ
Simbol huruf Yunani (mu) dan (sigma) sering
dipergunakan untuk menyatakan rata-rata hitung dan simpang
baku dari sebuah populasi atau sekelompok data yang lengkap.
7.4.distribusi Poisson
Distribusi Poission dikemukakan oleh seorang ahli matematika
bangsa Perancis Simeon. D. Poisson (1781-1840) pada tahun 1837.
distribusi merupakan bentuk terbatas dari distribusi binomial
dimana kemungkinan dari sukses (P) adalah sangat kecil dan
besaran n adalah besar. Ia merupakan salah satu dari distribusi-
distribusi yang dipergunakan secara lebih luas; antara lain di dalam
statistik pengawasan mutu (quality control statistic) untuk
menghitung jumlah kerusakan di dalam suatu bagian hasil
pekerjaan, atau di dalam ilmu biologi untuk menghitung jumlah
bakteri, atau di dalam ilmu alam untuk menghitung jumlah bakteri,
atau di dalam ilmu alam untuk menghitung partikel-partikel yang
dipancarkan dari sebuah zat radio aktif, atau di dalam masalah-
masalah asuransi untuk menghitung jumlah korban, dan
sebagainya.

Apabila n cukup besar sedangkan P-nya sangat kecil, maka
keadaan demikian tidak dapat didekati dengan menggunakan
distribusi binomial karena distribusi terlalu menceng untuk
mendapatkan hasil yang lebih baik dari distribusi binomial tersebut.
Situasi demikian dapat didekati dengan distribusi poisson, di
mana n tetap tidak berubah, seperti berikut :
7.5.Distribusi Normal
Distribusi normal (normal distribution) merupakan suatu
distribusi kontinu. Beberapa ahli matematika telah membuat
perumusan mengenai sebaran ini. Mereka itu antara lain; Abraham
De Moivre (1667/1754), Pierre S. Laplace (1749-1827), dan Karl
Gauss (1777-1855). Meskipun De Moivre merupakan Penemu
pertama, namun sebaran ini lebih dikenal dengan nama: Gaussian
Distribution.
Ekspresi secara grafik dari distribusi normal ini disebut: kurva
normal atau Gaussian curve.
Ciri-ciri dari kurva normal antara lain :
1. Simetris, berbentuk lonceng tengkurap dan kurvanya
mesokurtik;
2. Nilai rata-rata berada di tengah dan membagi kurva dalam dua
bagian yang sama. Rata-rata, median dan modus berada di satu
tempat;
3. Secara teoritis, kurva melebar kedua jurusan dan secara graduli
makin mendekati sumbu horizontal. Ia melebar dengan tidak
terbatas, tetapi tidak pernah menyinggung sumbu horizontal.
4. Untuk membentuknya diperlukan dan . Karena untuk setiap
dan yang berlainan terdapat sebuah kurva, maka terdapat

banyak kurva normal. Kurva normal dapat dipandang sebagai
sebuah keluarga kurva;
5. Luas daerah di bawah kurva adalah 100%, dengan perincian 50%
berada sebelah kanan rata-rata dan 50% lainnya berada
disebelah kirinya. Hal ini juga memperlihatkan jumlah seluruh
frekuensi dari mana ia ditarik;
6. Umum dikatakan bahwa dalam prakteknya seluruh nilai jatuh di
antara rata-rata plus dan minus tiga simpang baku. Jadi range-
nya adalah 6
Menentukan luas area di bawah kurva Normal
Menentukan luas area antara titik rata-rata (m atau X) dengan
titik ordinat lainmya (X) dapat dilakukan dengan cara berikut:
a. Tentukan nilai z (standar normal deviate) dengan
mempergunakan perumusan :
- untuk populasi
- untuk sampel
b. Kemudian dengan mempergunakan tabel “area di bawah kurva
normal”. Carilah nilai kemungkinannya (Pr(z). nilai kemungkinan
yang ditemukan menunjukkan luas area dalam bentuk ratio.
Biasanya bentuk ini kemudian diubah menjadi bentuk persen.
Misalkan kita memperoleh nilai z = 3,61. Berdasarkan tabel tadi
nilai kemungkinannya Pr(z) = 0,4999. Ini berarti luas area yang
dimaksud sebesar 49,99%
c. Sering pula diminta untuk menentukan besarnya frekuensi pada
luas tersebut. Frekuensi yang diinginkan itu disebut; frekuensi
harapan (expected frequency f), dan ini dicari dengan
mempergunakan perumusan fe = Pr(z) x N.






























