Embed Size (px)
Citation preview

CENTRO FEDERAL DE EDUCAÇÃO TECNOLÓGICA DE MINAS GERAIS
Mestrado em Modelagem Matemática e Computacional
João Paulo Barbosa Nascimento
Um Algoritmo Paralelo para Cálculo de Centralidade
em Grafos Grandes
Orientadora: Profa. Cristina Duarte Murta
Belo Horizonte
Dezembro de 2011

CENTRO FEDERAL DE EDUCAÇÃO TECNOLÓGICA DE MINAS GERAIS
Mestrado em Modelagem Matemática e Computacional
João Paulo Barbosa Nascimento
Um Algoritmo Paralelo para Cálculo de Centralidade
em Grafos Grandes
Dissertação de Mestrado submetida ao Programa de
Pós-Graduação em Modelagem Matemática e Compu-
tacional, como parte dos requisitos exigidos para a ob-
tenção do título de Mestre em Modelagem Matemática
e Computacional.
Orientadora: Profa. Cristina Duarte Murta
Belo Horizonte
Dezembro de 2011


Dedico esse trabalho aos meus pais, Carlos Roberto do Nascimento e
Maria Célia Barbosa Nascimento, a minha esposa Pollyanna de Oliveira
Cattoni Camelo, ao meu irmão Carlos Antônio Barbosa Nascimento e
ao meu sobrinho Carlos Antônio Barbosa Nascimento Júnior.

Agradecimentos
Agradeço primeiramente à minha orientadora Cristina Duarte Murta, pelos ensinamen-
tos e sabedoria transmitidos com maestria, pela dedicação nas orientaçães e por sempre
estar disposta a discutir os assuntos deste trabalho.
Agradeço de maneira especial à minha esposa pela compreensão em minhas faltas aos
eventos familiares, por sempre me apoiar e por me ajudar na conferência dos resultados
deste trabalho.
Aos meus pais por terem me ensinado o caminho.
À minha avó Lúcia pelos ensinamentos sobre a vida.
Ao meu sobrinho Carlos Júnior pelo incentivo.
Aos meus sogros Heráclio e Sandra pela torcida constante.
Ao CEFET-MG, ao DECOM e em especial ao funcionãrio Pedro Ribeiro pela ajuda na
montagem e con�guração do cluster.
Ao amigo Alexandre Wagner pela ajuda nas soluções dos problemas mais difíceis.
À Teca pelo companheirismo nas madrugadas frias em frente ao computador.
Aos professores e colegas do Mestrado em Modelagem Matemática e Computacional
pelo apoio e dicas nas horas difíceis.
A todos que direta ou indiretamente contribuíram com esse trabalho. Este é epenas o
começo.

Resumo
Redes complexas são sistemas grandes e dinâmicos que podem ser modelados por grafos.
Muitos sistemas tecnológicos, sociais ou biológicos são considerados redes complexas, dentre
eles a Internet e a Web, as redes sociais reais ou virtuais e as redes de infraestrutura física,
tais como redes de transporte e de comunicação. A análise destas redes, na forma de
gigantescos grafos, provê informações importantes acerca das características dos sistemas
modelados. No entanto, o processamento sequencial destes grafos pode requerer alto custo
computacional ou mesmo ser inviável, dependendo de seu tamanho e complexidade. Para
solucionar esse problema recorremos ao processamento paralelo e distribuído. Este trabalho
propõe um algoritmo paralelo para encontrar a centralidade de uma rede complexa de
grande porte, medida em termos de seu diâmetro e raio. O algoritmo foi projetado a partir
de um estudo criterioso do modelo MapReduce de programação paralela, aliado a um
planejamento detalhado de experimentos no ambiente Hadoop, que é uma implementação
de código aberto do modelo MapReduce. Os experimentos foram executados em vários
tipos de grafos de diferentes tamanhos. Os testes foram feitos com a parametrização padrão
do Hadoop e também com uma combinação obtida por meio de ajustes de desempenho.
A escalabilidade do algoritmo foi avaliada. Os resultados dos experimentos indicam que o
algoritmo proposto alcança seu objetivo, que é calcular valores exatos de diâmetro e raio
em grafos grandes. Não encontramos na literatura nenhum algoritmo paralelo em Hadoop
para este cálculo.
Palavras-chave: Grafos, programação paralela, redes complexas, MapReduce, Hadoop.

Abstract
Complex networks are large and dynamic systems that can be modeled by graphs. Many
technological, social and biological systems are considered complex networks, including the
Internet and the Web, real-world or virtual social networks, and infrastructure networks,
such as transport and communication systems. Modeled as huge graphs, the network
analysis provides information about the characteristics of the represented systems. Howe-
ver, sequential processing of these graphs may require high computational cost or may be
even unfeasible, depending on their size and complexity. Our proposal is to address this
problem using parallel and distributed programming. In this work, we propose a parallel
algorithm to �nd the centrality of a large complex network, measured in terms of its di-
ameter and radius. The algorithm was designed from a careful study of the MapReduce
framework for parallel programming, combined with a detailed planning of experiments
in Hadoop, which is an open source implementation of the MapReduce framework. Ex-
periments were performed on various types of graphs of di�erent sizes. Tests were done
under the default parameterization of Hadoop and also through an extensive performance
tuning. The scalability of the algorithm was evaluated. The results of the experiments
indicate that the proposed algorithm reaches its goal, which is to calculate exact values of
diameter and radius in large graphs. We have not �nd any parallel algorithm in Hadoop
for this calculation in the technical literature.
Key-words: Graphs, parallel programming, complex networks, MapReduce, Hadoop.

Sumário
Lista de Figuras 11
Lista de Tabelas 13
1 Introdução 16
1.1 Objetivos do Estudo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.2 Resultados e Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.3 Organização do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2 Fundamentação Teórica 21
2.1 A Revolução da Arquitetura Multicore . . . . . . . . . . . . . . . . . . . . . 21
2.2 Comparando Soluções Paralelas e Sequenciais . . . . . . . . . . . . . . . . . 23
2.3 Gestão da Informação em Grandes Volumes de Dados . . . . . . . . . . . . 24
2.4 Modelo MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4.1 Funcionamento do Modelo . . . . . . . . . . . . . . . . . . . . . . . . 26
2.4.2 Fluxo de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5 Hadoop: Uma Implementação do MapReduce . . . . . . . . . . . . . . . . . 30
2.5.1 Componentes do Projeto Hadoop . . . . . . . . . . . . . . . . . . . . 31
2.6 Redes Complexas e Grafos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.6.1 Medidas de Centralidade em Grafos . . . . . . . . . . . . . . . . . . 34
2.7 Problema do Menor Caminho . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.7.1 Menor Caminho a partir de Única Origem . . . . . . . . . . . . . . . 36
2.7.2 Menor Caminho entre Todos os Pares de Vértices . . . . . . . . . . . 36
2.8 Algoritmos Sequenciais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.8.1 Busca em Largura . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.8.2 Algoritmos de Dijkstra . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.8.3 Algoritmo de Floyd-Warshall . . . . . . . . . . . . . . . . . . . . . . 39
2.9 Algoritmos Paralelos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.9.1 HADI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.10 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
8

3 Estado da Arte 45
3.1 MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.2 MapReduce e Banco de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.3 Outras Implementações do MapReduce . . . . . . . . . . . . . . . . . . . . . 49
3.4 Modelagem do MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.5 Avaliação de Desempenho . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.6 MapReduce Aplicado a Algoritmos Genéticos . . . . . . . . . . . . . . . . . 52
3.7 MapReduce na Análise de Dados Cientí�cos . . . . . . . . . . . . . . . . . . 52
3.8 Algoritmos Paralelos para Encontrar o Menor Caminho em Grafos . . . . . 52
3.8.1 Menor Caminho a partir de um Único Vértice Fonte (MCUF) . . . 53
3.8.2 Menor Caminho a partir de Todos os Vértices . . . . . . . . . . . . . 55
3.9 Trabalhos Relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.9.1 HADI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.9.2 Pegasus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.9.3 Pregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.9.4 Outros trabalhos referentes a grafos usando MapReduce . . . . . . . 58
3.9.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4 Algoritmo HEDA 60
4.1 Ideia Principal do Algoritmo HEDA . . . . . . . . . . . . . . . . . . . . . . 60
4.2 Descrição do Algoritmo HEDA . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.2.1 Fluxo Principal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.2.2 Função MAP: Encontrar Menor Caminho . . . . . . . . . . . . . . . 62
4.2.3 Função REDUCE: Encontrar Menor Caminho . . . . . . . . . . . . . 64
4.2.4 Função MAP: Encontrar Centralidade . . . . . . . . . . . . . . . . . 65
4.2.5 Função REDUCE: Encontrar Centralidade . . . . . . . . . . . . . . . 65
4.2.6 O objeto Node . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.3 Formato dos Dados de Entrada . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.4 Exemplo de Execução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5 Projeto dos Experimentos 75
5.1 Ambiente Computacional . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2 Conjuntos de Dados (Grafos) . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2.1 Grafos da Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.2.2 Grafos Sintéticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.2.3 Grafo IMDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.3 Parâmetros para Ajuste de Desempenho . . . . . . . . . . . . . . . . . . . . 78
5.4 Planejamento dos Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.4.1 Comparação com o Algoritmo HADI . . . . . . . . . . . . . . . . . . 81

5.4.2 Comparação com o Algoritmo Sequencial . . . . . . . . . . . . . . . 81
5.4.3 Alterações nos Parâmetros de Desempenho . . . . . . . . . . . . . . 82
5.4.4 Escalabilidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6 Resultados dos Experimentos 83
6.1 Resultados do Algoritmo HEDA . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.1.1 Grafos da Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.1.2 Grafos Sintéticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.1.3 Grafo IMDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6.1.4 Speedup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.1.5 E�ciência . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.1.6 Relação entre o Diâmetro do Grafo e o Tempo de Execução . . . . . 90
6.2 Comparação entre os Algoritmos HEDA e o HADI . . . . . . . . . . . . . . 90
6.2.1 Grafos da Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
6.2.2 Grafos Sintéticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.3 Comparação entre o HEDA e o Algoritmo Sequencial . . . . . . . . . . . . . 93
6.3.1 Grafos da Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
6.3.2 Grafos Sintéticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.4 Alteração nos Parâmetros de Ajuste de Desempenho do Hadoop . . . . . . . 95
6.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
7 Conclusão e Trabalhos Futuros 100
7.1 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
7.2 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
A Tabelas de Resultados de Tempos de Execução 103
Referências Bibliográ�cas 108

Lista de Figuras
2.1 Exemplo de curvas de speedup, baseado em [1] . . . . . . . . . . . . . . . . . 24
2.2 Funcionamento do Modelo MapReduce baseado em [2] . . . . . . . . . . . . 28
2.3 Fluxo de dados do Modelo MapReduce . . . . . . . . . . . . . . . . . . . . . 31
2.4 Subprojetos do Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.5 Exemplo de um grafo com onze vértices e treze arestas . . . . . . . . . . . . 33
2.6 Exemplo de um grafo com cinco vértices e cinco arestas . . . . . . . . . . . 35
4.1 Exemplo de um grafo com cinco vértices e sete arestas . . . . . . . . . . . . 68
4.2 Paralelização do Algoritmo HEDA . . . . . . . . . . . . . . . . . . . . . . . 74
4.3 Fluxo do Algoritmo HEDA . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.1 Resultados do Algoritmo HEDA - Grafos da Internet. . . . . . . . . . . . . . 84
6.2 Resultados HEDA - Grafos Sintéticos - Variação de Arestas. . . . . . . . . . 85
6.3 Resultados HEDA - Grafos Sintéticos - Variação de Vértices e Arestas. . . . 86
6.4 Resultados HEDA - Grafo IMDB. . . . . . . . . . . . . . . . . . . . . . . . . 88
6.5 Resultado HEDA - Speedup. . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.6 Resultado HEDA - E�ciência. . . . . . . . . . . . . . . . . . . . . . . . . . . 90
6.7 Comparação entre os Algoritmos HEDA e HADI - Grafos da Internet. . . . 92
6.8 Comparação entre os Algoritmos HEDA e HADI - Grafos Sintéticos. . . . . 93
6.9 Comparação entre os Algoritmos HEDA e Sequencial - Grafos da Internet. . 94
6.10 Comparação entre os Algoritmos HEDA e Sequencial - Grafos Sintéticos. . . 95
6.11 Resultado dos Ajustes de Parâmetros de Desempenho do Hadoop. . . . . . . 98
11

Lista de Tabelas
4.1 Descrição Detalhada do Arquivo de Arestas . . . . . . . . . . . . . . . . . . 69
4.2 Descrição Detalhada do Arquivo de Distâncias . . . . . . . . . . . . . . . . . 69
5.1 Grafos Reais dos Sistemas Autônomos da Internet . . . . . . . . . . . . . . 76
5.2 Grafos Sintéticos - Variação de Vértices e Arestas . . . . . . . . . . . . . . . 77
5.3 Grafos Sintéticos - Variação de Arestas . . . . . . . . . . . . . . . . . . . . . 77
6.1 Resultado HEDA - Grafos da Internet . . . . . . . . . . . . . . . . . . . . . 84
6.2 Resultados HEDA - Grafos Sintéticos - Variação de Arestas . . . . . . . . . 85
6.3 Resultados HEDA - Grafos Sintéticos - Variação de Vértices e Arestas . . . 86
6.4 Resultados HEDA - Grafos Sintéticos - Variação de Vértices e Arestas -
Análise dos Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.5 Resultados HEDA - Grafos IMDB . . . . . . . . . . . . . . . . . . . . . . . 87
6.6 Conjuntos de Dados para Medida de Speedup . . . . . . . . . . . . . . . . . 88
6.7 Análise de Diâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
6.8 Comparação entre os Algoritmos HEDA e HADI - Grafos da Internet . . . . 91
6.9 Comparação de Resultados entre os Algoritmos HEDA e HADI - Grafos
Sintéticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.10 Resultado HEDA e Sequencial - Grafos da Internet . . . . . . . . . . . . . . 94
6.11 Resultado HEDA - Valores dos Parâmetros de Ajuste de Desempenho . . . 97
A.1 Algoritmo HEDA - Tempo de Execução em Minutos - Grafo da Internet
01/01/2010 sem Ajuste dos Parâmetros de Desempenho . . . . . . . . . . . 103
A.2 Algoritmo HEDA - Tempo de Execução em Minutos - Grafo da Internet
01/01/2010 com Ajustes nos Parâmetros de Desempenho . . . . . . . . . . . 104
A.3 Algoritmo HADI - Tempo de Execução em Minutos - Grafo da Internet
01/01/2010 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
A.4 Algoritmo HEDA - Tempo de Execução em Minutos - Grafo da Internet
01/07/2011 - Speedup e E�ciência . . . . . . . . . . . . . . . . . . . . . . . . 104
A.5 Algoritmo HADI - Tempo de Execução em Minutos - Grafo da Internet
01/07/2011 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
A.6 Algoritmo HEDA - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Arestas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
12

13
A.7 Algoritmo HADI - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Arestas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
A.8 Algoritmo HEDA - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Vértices e Arestas . . . . . . . . . . . . . . . . . . . . . . . . . . 106
A.9 Algoritmo HADI - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Vértices e Arestas . . . . . . . . . . . . . . . . . . . . . . . . . . 106
A.10 Algoritmo HEDA - Tempo de Execução em Minutos - Grafo Sintético -
Speedup e E�ciência . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
A.11 Algoritmo HEDA - Tempo de Execução em Minutos - Grafo Sintético -
Speedup e E�ciência . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
A.12 Algoritmo HEDA - Tempo de Execução em Minutos - Grafo IMDB . . . . . 107
A.13 Algoritmo Sequencial - Tempo de Execução em Minutos . . . . . . . . . . . 107

Lista de Abreviaturas e Siglas
API Application Programming Interface, 45, 53
ASCII American Standard Code for Information Interchange, 24
CSP Communicating Sequential Process, 46
ERP Exponential Rebel Probability , 50
ETL Extract Transform Load , 44
GCC Giant Connected Graph, 50
GFD Graph Fractal Dimension, 50
GFS Google File System, 27
GIM-V Generalized Iterative Matrix Vector multiplication, 52, 53
GPS Global Positioning System, 20
HADI Hadoop-based Diameter Estimator , 37, 51
HDFS Hadoop Distributed File System, 27, 28
JVM Java Virtual Machine, 52
LHC Large Hadron Collider , 48
NDFS Nutch Distributed File System, 27
NUMA Non-Uniform Memory Access, 46
PRAM Parallel Random Access Machine, 49
RWR Random Walk with Restart , 52
SGBD Sistema de Gerenciamento de Banco de Dados, 42�44
14

Lista de Abreviaturas e Siglas 15
SQL Structured Query Language, 28
TPC-H Transaction Processing Performance Council Ad-Hoc, 47
URL Uniform Resource Locator , 21

Capítulo 1
Introdução
Redes complexas, modeladas por grafos grandes, aparecem em diversas áreas do nosso
cotidiano. Literalmente são considerados grafos grandes aqueles que possuem milhares de
vértices e até milhões de arestas. Estudá-los tornou-se algo extremamente útil e importante.
Redes complexas são modeladas para redes sociais (Facebook, Twitter, Orkut, etc), redes de
distribuição (energia, água, telefone, mercadorias), redes de citações de artigos cientí�cos,
roteamento de veículos, serviços de urgência (bombeiros, ambulância, polícia) e a própria
Internet. A tarefa de processar tais redes e encontrar medidas de centralidade tais como
menores caminhos entre todos os pares de vértices, excentricidades dos vértices o raio e
diâmetro de um grafo demanda processamento de alta capacidade e gera grandes volumes
de dados, podendo tornar inviável a solução desses problemas por meio da computação
sequencial.
A computação paralela, ancorada na arquitetura multicore, ressurgiu nos últimos anos
como uma opção para a solução desse tipo de problema. Entretanto, ela requer algumas
habilidades e conhecimentos que a maioria dos atuais desenvolvedores não está acostumada
a lidar. Esses problemas englobam a criação, sincronização e gerenciamento de threads,
bloqueios (locks), gerenciamento de concorrência e mecanismos de tolerância a falhas [3].
Para auxiliar os programadores a projetar programas paralelos considerando os aspectos
da concorrência e, ao mesmo tempo, explorar a evolução contínua da capacidade dos pro-
cessadores, por meio do aumento da quantidade de núcleos, surgiu o modelo MapReduce.
O MapReduce é um modelo baseado em linguagens funcionais e seu principal foco é o
processamento de grandes massas de dados. Os programas projetados nesse modelo são
inerentemente paralelos, permitindo o tratamento e o processamento de grandes massas de
dados de forma paralela e distribuída, por desenvolvedores que não têm intimidade com
programação paralela [4, 5]. O modelo MapReduce foi projetado para fornecer processa-
mento paralelo e distribuído de uma maneira automática, escalável e tolerante a falhas [2].
Todo o gerenciamento do paralelismo �ca a cargo do modelo e, com isso, o desenvolvedor
pode focar seus esforços na solução do problema e não no controle da paralelização [5]. O
MapReduce modela o sistema como um cluster e o Apache Hadoop é a sua principal imple-
mentação livre [2]. O Hadoop, em sua versão atual, contém mais de duzentos parâmetros
con�guráveis para ajuste de seu desempenho [6].
16

17
Um dos principais desa�os da programação no ambiente MapReduce é adequar um
algoritmo sequencial existente para o formato padrão do modelo MapReduce, baseado no
formato de par ordenado chave e valor. Algumas vezes essa adequação torna-se inviável
devido à forma como o MapReduce realiza o processamento paralelo, por meio de combi-
nação de conjuntos chave e valor. O artigo original do MapReduce [5] descreve diversas
aplicações que utilizam o modelo para processar grandes massas de dados, porém não inclui
discussão acerca de algoritmos para grafos. O MapReduce é um modelo habilitado para
processamento de grafos em larga escala. Contudo, parece que o projeto de algoritmos
paralelos em grafos no modelo MapReduce ainda é pouco discutido [7]. Alguns trabalhos
como [8, 9, 10, 11] começam a preencher essa lacuna, ao propor algoritmos para grafos
utilizando o modelo MapReduce.
Alguns trabalhos na literatura apresentam algoritmos para medir a centralidade de gra-
fos utilizando o modelo MapReduce. No entando, nenhum dos trabalhos que encontramos
propõe encontrar medidas exatas para métricas de centralidade. O principal algoritmo
para executar esta tarefa encontrado na literatura é o HADI [8] (Hadoop Diameter and
Radii Estimator). O HADI é um algoritmo de aproximação que trabalha com o conceito
de diâmetro efetivo, de�nido como o número mínimo de saltos em que noventa por cento
de todos os pares de nós conectados podem alcançar uns aos outros. Com isso, o HADI
encontra valores estimados para o raio e diâmetro de um grafo grande.
As métricas exatas de centralidade têm importância fundamental na solução de proble-
mas de localização, ao lidar com a tarefa de escolher um determinado caminho de acordo
com algum critério. Por exemplo, em uma situação de emergência, na maioria das vezes é
necessário minimizar o tempo de deslocamento entre o local da emergência e um hospital,
uma central de polícia ou uma central do corpo de bombeiros. Ao decidir a localização
de um serviço coletivo, tal como uma agência de correios ou uma central de atendimento
de algum serviço público, iremos querer minimizar o tempo total de viagem para todas as
pessoas interessadas nesses serviços. Quando construímos uma ferrovia, um oleoduto ou
uma rodovia nós queremos minimizar a distância da nova estrutura para cada uma das
comunidades a serem servidas. Cada uma dessas situações lida diretamente com o conceito
de centralidade [12].
Diante da inexistência de um algoritmo para cálculo exato de centralidades de gra-
fos grandes, que execute no ambiente paralelo MapReduce/Hadoop, foi criado o HEDA
(Hadoop-based Exact Algorithm). O HEDA é baseado no algoritmo de busca em largura e
realiza o cálculo do menor caminho entre todos os pares de vértices paralelamente. Além
disso, o HEDA encontra as excentricidades de todos os vértices, o raio e o diâmetro exatos
do grafo. Ao �nal de sua execução é possível determinar de forma exata o centro e a
periferia do grafo processado.
A principal diferença entre os algoritmos HADI e HEDA, proposto por esse trabalho,
está na exatidão dos resultados. O algoritmo HADI, por ser um algoritmo de aproximação

1.1. OBJETIVOS DO ESTUDO 18
e estimativa, prejudica a exatidão dos resultados para privilegiar o tempo de processamento
e o espaço ocupado em disco. O HEDA, ao contrário, prejudica o tempo de processamento
e o espaço ocupado em disco para fornecer todos os seus resultados de forma exata.
Geralmente a solução exata das métricas de centralidade é a preferida, a menos que
seu custo seja muito alto. Nesse sentido o HEDA preenche uma lacuna entre o algoritmo
sequencial utilizado nos experimentos deste trabalho, que fornece a solução exata mas não
é capaz de processar uma quantidade muito grande de dados em tempo hábil, e o HADI,
que é capaz de processar quantidades maiores de dados mas não fornece valores exatos.
1.1 Objetivos do Estudo
Esta dissertação apresenta um estudo experimental sobre algoritmos em grafos no am-
biente MapReduce. Para a realização dos experimentos foram utilizados diversos grafos de
redes complexas de diversos tamanhos, como os grafos dos sistemas autônomos da Internet
disponíveis para download diariamente pelo Internet Research Lab (IRL)1 da Universidade
da Califórnia, grafos sintéticos gerados por meio de geradores de grafos e o grafo IMDB
(Internet Movie Database)2, que é um grafo grande e real, representando dados sobre �lmes
e atores.
A seguir são listados os objetivos especí�cos deste estudo:
• Propor um algoritmo para encontrar as medidas exatas de centralidade em grafos
de redes complexas utilizando o modelo MapReduce por meio de sua implementação
Hadoop. Essas medidas de centralidade são excentricidades de um vértice, raio e
diâmetro de um grafo grande e em consequência, o centro e a periferia de um grafo.
• Validar os resultados e comparar o tempo de execução do algoritmo proposto com
um algoritmo sequencial presente na literatura [13].
• Avaliar por medição o tempo de execução do algoritmo proposto em grafos de diversos
tamanhos.
• Comparar os resultados e o tempo de execução do algoritmo proposto com o principal
algoritmo paralelo presente na literatura e que utiliza o modelo MapReduce, o HADI
[8]. Esta comparação é realizada utilizando todos os conjuntos de dados propostos.
• Realizar experimentos alterando os parâmetros de ajuste de desempenho do Hadoop
e analisar os resultados de tempo gasto.
• Veri�car a escalabilidade do algoritmo proposto à medida que máquinas vão sendo
adicionadas ao cluster, por meio da métrica speedup.
• Medir a e�ciência do algoritmo.
1http://irl.cs.ucla.edu/index.html. Acessado em 02 de outubro de 2011.2http://www.imdb.com

1.2. RESULTADOS E CONTRIBUIÇÕES 19
1.2 Resultados e Contribuições
Uma vez que é possível resolver o problema de calcular medidas de centralidade em
grafos grandes com o uso da computação paralela e do modelo MapReduce, a contribuição
principal dessa dissertação está na criação de um novo algoritmo paralelo para encontrar
as medidas de centralidade exata de grafos grandes, utilizando o modelo MapReduce.
Na literatura não foi encontrado nenhum algoritmo com características semelhantes ao
algoritmo proposto por esse trabalho. Esse algoritmo é detalhadamente explicado e um
exemplo de funcionamento é apresentado.
Esse trabalho apresenta também uma ampla revisão bibliográ�ca tanto da área de
algoritmos para centralidade em grafos, quanto da área de algoritmos para o modelo Map-
Reduce, de uma maneira geral.
Além disso, outra contribuição desse trabalho é um estudo experimental sobre os parâ-
metros de ajuste de desempenho do Hadoop. Foram realizados experimentos com diversas
combinações de valores para esses parâmetros. O algoritmo HEDA, para o conjunto de
grafos da Internet, apresentou uma melhora no tempo de processamento total de até 33,6%,
com uma parametrização especí�ca.
O algoritmo proposto teve seus resultados, quanto às métricas calculadas, validados por
um algoritmo sequencial [13] e seus resultados de tempo foram comparados com o algoritmo
HADI [8]. A principal contribuição dessa comparação foi que o algoritmo proposto (HEDA)
apresentou resultados exatos. Por outro lado, o HADI apresentou em todos os testes os
menores tempos de execução.
Quanto à escalabilidade, o HEDA apresenta resultados de speedup superlinear para
alguns tamanhos de grafos experimentados.
1.3 Organização do Trabalho
Este trabalho encontra-se organizado como descrito a seguir. O capítulo 2 apresenta
a fundamentação teórica. Neste capítulo são abordados conceitos fundamentais para as
medidas de centralidade em grafos de redes complexas, tais como os conceitos de excen-
tricidade, diâmetro, raio, periferia e centro de um grafo, o problema do menor caminho a
partir de uma única origem e a partir de todos os pares de vértices. Na parte de progra-
mação paralela é apresentada uma discussão sobre a revolução causada pela arquitetura
multicore e as principais métricas utilizadas para a comparação entre soluções sequenciais
e paralelas, o speedup e a e�ciência. A respeito do modelo MapReduce e de sua imple-
mentação Hadoop, o capítulo 2 discute acerca do impacto das grandes massas de dados
como motivação para o processamento paralelo e faz um apanhado sobre a estrutura do
modelo MapReduce, apresentando seus principais componentes e demonstrando, por meio
de um exemplo prático, seu funcionamento e �uxo de dados. Ao �nal do capítulo, os
principais algoritmos sequenciais e paralelos para solução do menor caminho em grafos são
apresentados.
No capítulo 3 são descritos os trabalhos relacionados. Neste capítulo, são abordados

1.3. ORGANIZAÇÃO DO TRABALHO 20
os trabalhos que utilizam o modelo MapReduce para propor soluções em diversas áreas do
conhecimento, tais como banco de dados, inteligência arti�cial e análise de dados cientí�cos.
Além disso, trabalhos que avaliam o desempenho do modelo MapReduce são apresentados.
O capítulo 3 trata também de trabalhos referentes aos algoritmos paralelos para encontrar
o menor caminho em grafos, mesmo que estes não utilizem o modelo MapReduce. Ao
�nal, diversos trabalhos sobre processamento de grafos utilizando MapReduce/Hadoop são
apresentados, tais como o algoritmo HADI [8] e o modelo Pregel [10].
O capítulo 4 apresenta o algoritmo HEDA (Hadoop-based Exact Diameter Algorithm),
que é o algoritmo proposto por esse trabalho para encontrar a centralidade de grafos gran-
des utilizando o modelo MapReduce. O capítulo inicia-se com uma explicação detalhada
sobre a estrutura do algoritmo, apresentando em seguida a ideia principal do HEDA e
também descrevendo como os resultados do algoritmo foram validados. O funcionamento
do algoritmo é demonstrado, detalhando o modo como o processamento é paralelizado,
aproveitando essa capacidade do modelo MapReduce. Em seguida um exemplo prático é
utilizado para complementar a explicação sobre o funcionamento do HEDA.
No capítulo 5 é descrito o projeto de experimentos. O capítulo descreve o ambiente
computacional para a execução dos experimentos e, em seguida, os conjuntos de dados
de entrada utilizados nos experimentos são detalhados. Os tipos de experimentos e a
forma como estes serão conduzidos são descritos e justi�cados. O capítulo termina com as
considerações �nais sobre o projeto dos experimentos.
O capítulo 6 descreve os resultados dos experimentos. O capítulo realiza o confronto
entre os resultados dos algoritmos HEDA, HADI e sequencial. Os resultados incluem
análises referentes à escalabilidade ao aumentar do número de nós do cluster e speedup.
Finalizando, no capítulo 7 são apresentadas as conclusões e os trabalhos futuros sugeridos.

Capítulo 2
Fundamentação Teórica
2.1 A Revolução da Arquitetura Multicore
A arquitetura multicore surgiu nos últimos anos com o intuito de aumentar considera-
velmente o desempenho de computadores. Nos últimos vinte anos, arquitetos aproveitaram
o aumento de seus orçamentos e o rápido aumento da velocidade dos transistores, que a
tecnologia do silício tornou possível, para duplicar a capacidade de processamento dos pro-
cessadores a cada dezoito meses [3]. O contrato implícito entre hardware e software foi
que enquanto fosse aumentando a quantidade de transistores e a capacidade de dissipação
estivesse em níveis aceitáveis, seria mantida a programação sequencial. Esse contrato levou
a inovações que foram ine�cientes em termos de transistores e capacidade (tais como o pro-
blema de múltiplas instruções, pipelines profundos, execução fora de ordem, execução espe-
culativa e prefetching), mas que aumentaram o desempenho preservando o modelo de pro-
gramação sequencial. A indústria de processadores melhorou a relação custo/desempenho
da computação sequencial por volta de cem bilhões de vezes nos últimos sessenta anos [3].
Esse contrato funcionou bem até atingirmos o limite de capacidade de calor que um
chip pode dissipar [3]. Ao alcançar essa barreira física, esses mesmos arquitetos foram
forçados a encontrar um novo paradigma que sustentasse esse constante aumento de capa-
cidade. Assim, a indústria de hardware decidiu pela única opção viável, que era substituir
um único processador com uma dada capacidade de processamento sem possibilidade de
melhoria, por um processador com muitos núcleos de processamento no mesmo chip. Nesse
momento, toda a indústria de microprocessadores declarou que o futuro estava na compu-
tação paralela, com o aumento do número de núcleos a cada geração da tecnologia, prevista
para cada dois anos [3]. Esse novo processador que passou a ser fabricado �cou rotulado
como processador multicore [1].
Contudo, o salto para o multicore não se baseou, nem foi acompanhado por um avanço
na programação ou na arquitetura. Na verdade, esse avanço é um retrato da difícil ta-
refa que é a construção de processadores com alta capacidade, e�ciência e alta taxa de
processamento [1, 3].
De acordo com [3], o problema da indústria de hardware signi�ca oportunidade para a
comunidade de pesquisadores. Se os pesquisadores enfrentam o desa�o do paralelismo, o
21

2.1. A REVOLUÇÃO DA ARQUITETURA MULTICORE 22
futuro da indústria de hardware será visto com bons olhos, caso contrário, não será. De fato,
o sucesso da empreitada da indústria de hardware dependerá do sucesso da disseminação
da programação paralela.
Em [14], John Hennessy, presidente da Universidade de Stanford, discute sobre o grande
desa�o do paralelismo. Segundo ele, quando iniciou-se a discussão sobre o paralelismo e
a facilidade de uso de computadores verdadeiramente paralelos, falava-se de um problema
que era mais difícil do que qualquer outro que a ciência da computação já tinha enfrentado.
No texto, o autor aponta e discute a grande preocupação que o paralelismo está gerando
na indústria de tecnologia da informação.
Assim, passamos a enfrentar um novo problema que é a forma como desenvolvemos
software. A maioria dos programadores acostumou-se à contínua melhoria de capacidade da
arquitetura sequencial. Agora o panorama é outro. O mais difícil objetivo da programação
paralela não é apenas tornar fácil a escrita de programas e�cientes, portáveis e corretos,
mas sim que esses programas possam ser escaláveis de acordo com o número de núcleos
por processador, que hoje aumenta bianualmente. Os programadores devem encontrar
no ambiente paralelo a mesma facilidade que tinham ao escrever programas sequenciais
[1, 3, 5, 15].
A maioria dos programadores parece não estar preparada para entender os segredos
do software concorrente e do hardware paralelo. Essa di�culdade é devida a tarefas típi-
cas dos ambientes paralelos e distribuídos, tais como bloqueios (locks), gerenciamento de
concorrência, balanceamento de carga e consistência de memória. O desa�o é que pesquisa-
dores desenvolvam tecnologia para que todos os programadores bene�ciem-se da revolução
paralela. [3, 5, 15].
Outros sistemas de computação de fundamental importância, que ainda não evoluíram
satisfatoriamente, e que são resistentes a mudanças, são o sistema operacional e os compi-
ladores [3]. Um grande desa�o existente na área de computação paralela não é melhorar
o desempenho de todo o software já existente. Ao invés disso, será necessário criar aplica-
ções que realmente possam usufruir do aumento do número de núcleos e, ao mesmo tempo,
executar as aplicações antigas com um desempenho aceitável. Para que a indústria de
hardware possa continuar evoluindo satisfatoriamente, pesquisadores precisam demonstrar
um grande valor para o usuário �nal ao aumentar o número de núcleos [3, 1, 16].
Nas duas últimas décadas, a indústria de computadores assistiu a uma grande melhoria
na tecnologia de hardware e software. Mais recentemente, a demanda por mais realismo
em jogos e a indústria do entretenimento fomentou melhorias em software de tempo real,
inteligência arti�cial e efeitos de renderização. Inovação e avanço na comunidade cientí�ca
foram alimentados pela constante melhoria na capacidade do hardware nos últimos qua-
renta anos. Essas novas exigências elegeram a programação concorrente como a próxima
grande revolução da computação [3, 1, 15, 16].

2.2. COMPARANDO SOLUÇÕES PARALELAS E SEQUENCIAIS 23
2.2 Comparando Soluções Paralelas e Sequenciais
A comparação entre versões sequencial e paralela de um algoritmo deve ser realizada
quando houver versões paralela e sequencial do mesmo algoritmo, o que nem sempre ocorre.
Uma vez que um algoritmo foi codi�cado, devemos investigar se a versão paralela do
algoritmo é melhor que a versão do mesmo algoritmo implementado de forma sequencial.
Uma forma trivial de realizar essa comparação é coletar o tempo gasto do início até o �nal
da execução do algoritmo em um ambiente sequencial e em um ambiente paralelo, quando
existir uma implementação do algoritmo para os dois ambientes. Se a versão paralela do
algoritmo tem tempo menor que a versão sequencial, o objetivo dessa nova implementação
foi alcançado. A questão é então saber o quão mais rápido é a versão paralela. Como
representar essa melhoria à medida que recursos são adicionados ao processamento como,
por exemplo, a troca de uma máquina por outra com mais núcleos ou mesmo a inclusão
de um novo nó ao cluster?
Para responder a essa pergunta, podemos aplicar a lei de Amdahl, que estabelece que
o ganho de desempenho a ser obtido usando modos mais rápidos de execução é limitado
pela fração de tempo em que esse modo mais rápido pode ser usado [16].
A lei de Amdahl de�ne o speedup que pode ser obtido usando uma característica par-
ticular. Suponha que seja possível fazer uma modi�cação em um computador que irá
melhorar o desempenho quando ele é usado. O speedup é a seguinte taxa:
S(p) =TempoSemMelhora
TempoComMelhora(2.1)
O speedup nos diz o quão mais rápido uma tarefa irá executar usando um computador com
alguma melhoria em relação ao computador original [16].
Suponha que uma melhoria seja a possibilidade de executar em paralelo. Uma formu-
lação da lei de Amdahl é demonstrada abaixo, onde pctPar é a porcentagem de tempo de
execução que irá executar em paralelo e p é o número de núcleos nos quais a aplicação irá
executar em paralelo [1]:
S(p) =1
(1− pctPar) + pctParp
(2.2)
Observamos que o speedup é proporcional à fração de tempo em que a melhoria pode ser
utilizada e ao número de processadores que executarão essa melhoria.
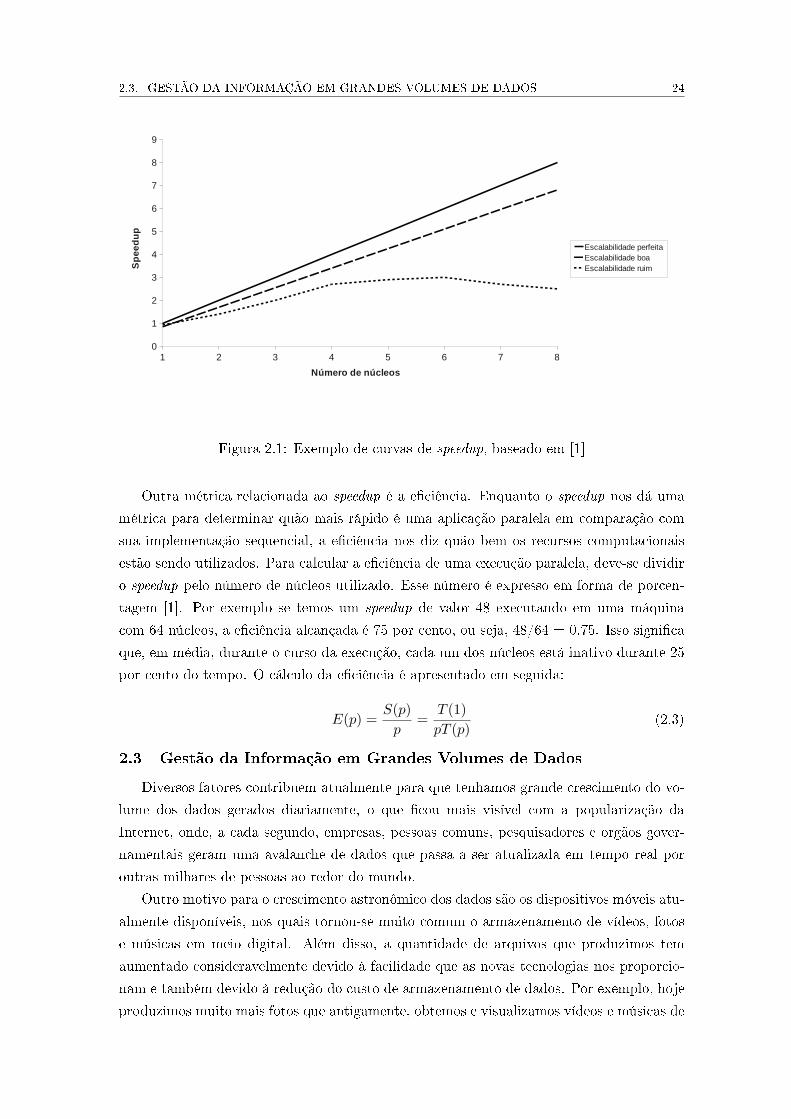
A Figura 2.1 apresenta exemplos de curvas de speedup. O speedup perfeito ocorre
quando o speedup calculado é igual ao número de núcleos (linha sólida). Para uma aplicação
ter uma boa escalabilidade, o speedup deveria aumentar próximo ou na mesma proporção
que novos núcleos são adicionados (linha tracejada), ou seja, se o número de núcleos é
duplicado, o speedup também deve aumentar na mesma proporção. Se o speedup de uma
aplicação não acompanha bem essa proporção (linha pontilhada), dizemos que a aplicação
não escala bem [1].
2.3. GESTÃO DA INFORMAÇÃO EM GRANDES VOLUMES DE DADOS 24
Figura 2.1: Exemplo de curvas de speedup, baseado em [1]
Outra métrica relacionada ao speedup é a e�ciência. Enquanto o speedup nos dá uma
métrica para determinar quão mais rápido é uma aplicação paralela em comparação com
sua implementação sequencial, a e�ciência nos diz quão bem os recursos computacionais
estão sendo utilizados. Para calcular a e�ciência de uma execução paralela, deve-se dividir
o speedup pelo número de núcleos utilizado. Esse número é expresso em forma de porcen-
tagem [1]. Por exemplo se temos um speedup de valor 48 executando em uma máquina
com 64 núcleos, a e�ciência alcançada é 75 por cento, ou seja, 48/64 = 0.75. Isso signi�ca
que, em média, durante o curso da execução, cada um dos núcleos está inativo durante 25
por cento do tempo. O cálculo da e�ciência é apresentado em seguida:
E(p) =S(p)
p=
T (1)pT (p)
(2.3)
2.3 Gestão da Informação em Grandes Volumes de Dados
Diversos fatores contribuem atualmente para que tenhamos grande crescimento do vo-
lume dos dados gerados diariamente, o que �cou mais visível com a popularização da
Internet, onde, a cada segundo, empresas, pessoas comuns, pesquisadores e orgãos gover-
namentais geram uma avalanche de dados que passa a ser atualizada em tempo real por
outras milhares de pessoas ao redor do mundo.
Outro motivo para o crescimento astronômico dos dados são os dispositivos móveis atu-
almente disponíveis, nos quais tornou-se muito comum o armazenamento de vídeos, fotos
e músicas em meio digital. Além disso, a quantidade de arquivos que produzimos tem
aumentado consideravelmente devido à facilidade que as novas tecnologias nos proporcio-
nam e também devido à redução do custo de armazenamento de dados. Por exemplo, hoje
produzimos muito mais fotos que antigamente, obtemos e visualizamos vídeos e músicas de

2.4. MODELO MAPREDUCE 25
forma muito mais fácil, rápida e barata. Isto nos leva a crer que os números e os tamanhos
dos arquivos digitais individuais estão aumentando rapidamente.
Mas, nesse imenso amontoado de dados, não �guram apenas os dados gerados por
pessoas no seu dia-a-dia, mas também os gerados por grandes máquinas, sendo estes os
responsáveis pelo crescimento da massa. Arquivos de logs, redes de sensores, arquivos de
rastreamento de veículos através de GPS e resultados de experimentos cientí�cos �guram
como os maiores produtores de dados [2].
Diante desta realidade, todos os dados produzidos e armazenados precisam ser, de
alguma forma, um dia, processados e disponibilizados, possibilitando a extração de infor-
mações para os mais diversos tipos de usuários. Para isso, precisamos explorar de forma
e�ciente todos os níveis de paralelismo disponíveis, seja através dos processadores multi-
core, não deixando de explorar a arquitetura de redes integradas de alto desempenho em
formato de cluster, até a utilização de grades de processamento, em redes como a Internet.
2.4 Modelo MapReduce
OMapReduce é ummodelo de programação paralela inspirado em linguagens funcionais
e tem como alvo o processamento de grandes massas de dados. Os programas projetados
nesse modelo são inerentemente paralelos, permitindo o tratamento e ou processamento
de grandes massas de dados de forma paralela e distribuída. Os programas podem ser
elaborados por desenvolvedores que não têm intimidade com programação paralela [4, 5].
O modelo MapReduce trabalha primeiramente dividindo o processamento em duas
fases: a primeira fase é a Map e a segunda é a Reduce. O formato dos dados de entrada
é especí�co para cada aplicação e é de�nido pelo programador. O programador especi�ca
um algoritmo usando duas funções: Map e Reduce. A função Map é aplicada aos dados
de entrada e produz uma lista de pares intermediários <chave, valor>. A função Reduce é
aplicada sobre todos os pares intermediários que possuem a mesma chave. Ela tipicamente
executa uma operação para mesclar os dados que possuem a mesma chave e produzir os
pares de saída. Finalmente, os pares de saída são ordenados com base em suas chaves. Na
forma mais simples de criar programas MapReduce, o programador fornece apenas a função
Map. Todas as outras funcionalidades, incluindo o agrupamento de pares intermediários
que possuem a mesma chave e a ordenação �nal, são fornecidas pelo modelo.
O principal benefício desse modelo é a simplicidade. O modelo permite ao programador
desenvolver um algoritmo focando na funcionalidade, e não na paralelização, que é a grande
di�culdade da programação paralela. A parte de paralelização e os detalhes da concorrência
são providos pelo framework.
Uma importante discussão acerca desse modelo é saber o quão amplamente ele pode ser
aplicado, ou seja, quais são os problemas que ele resolve de forma mais e�ciente. Segundo
Dean e Ghemwat [5], diversos exemplos de problemas com grandes massas de dados que
foram codi�cados com sucesso utilizando o modelo MapReduce, tais como:
• Contador de frequência de acessos a uma URL: A função Map processa logs

2.4. MODELO MAPREDUCE 26
de requisições realizadas em páginas Web e tem como saída o par <URL, 1>, onde
URL signi�ca o endereço de um site Web e o número 1 signi�ca um contador de
acesso. A função Reduce agrupa todos os valores da mesma URL e apresenta ao �nal
o seguinte par: <URL, total>, onde o total é o número de vezes que aquela URL foi
acessada.
• Índice invertido: A função Map analisa cada documento e retorna uma sequência
de <palavra, ID documento>. A função Reduce analisa todos esses pares para uma
dada palavra, ordena pelos correspondentes identi�cadores de documentos e retorna
um par <palavra, lista(ID documento)>.
• Multiplicação de matrizes: Cada tarefa Map computa o resultado para um con-
junto de linhas da matriz de saída e retorna a posição (x, y) de cada elemento como
a chave e o resultado da computação como valor <chave, valor>. A tarefa Reduce é
apenas a função identidade.
• Vetor de termos por documento: Um vetor de termos resume as palavras mais
importantes que ocorrem em um documento ou em um conjunto de documentos na
forma de um par <termo, frequência>. A função Map emite um par <documento,
termo> para cada documento de entrada e a função Reduce é executada em todos os
termos do documento. Ela agrupa esses termos, eliminando os não tão frequentes e
então emite um par �nal <documento, vetor de termos>. O documento nesse caso,
pode ser representado pela URL de uma página Web.
Os exemplos aqui apresentados demonstram alguns problemas que podem ser resolvi-
dos utilizando o modelo MapReduce, porém muitos outros tipos de problemas podem ser
representados na forma de <chave, valor> que é o formato padrão dos dados de entrada do
MapReduce. Algoritmos para ordenação, processamento de imagens, aprendizado de má-
quinas e algoritmos para grafos são apenas algumas aplicações que podem ser paralelizadas
e distribuídas pelo modelo MapReduce.
2.4.1 Funcionamento do Modelo
Diversas implementações de MapReduce são conhecidas e novas implementações tam-
bém podem ser feitas, �cando a escolha atrelada ao ambiente de execução e ao problema
envolvido [2]. Uma implementação pode ser adequada para uma pequena máquina de me-
mória compartilhada ou para uma grande máquina com multiprocessadores ou ainda uma
grande rede de computadores.
As chamadas à função Map são distribuídas automaticamente em diversas máquinas
particionando os dados de entrada em M partições. As partições de entrada podem ser
processadas por diferentes máquinas em paralelo. As chamadas à função Reduce são dis-
tribuídas particionando-se as chaves intermediárias em R pedaços, usando uma função de
particionamento (por exemplo, hash(key) mod R). O número de partições (R) e a função

2.4. MODELO MAPREDUCE 27
de particionamento são especi�cados pelo usuário. Quando o programa inicia a execução
de uma tarefa MapReduce, a seguinte sequência de ações ocorre:
1. A biblioteca MapReduce primeiramente divide os arquivos de entrada em M partes,
frequentemente de tamanho 64 Megabytes (MB) por parte. Esse valor é controlado
pelo usuário através de um parâmetro opcional e o valor default é 64 Megabytes.
Esse processo inicia diversas cópias do programa em um cluster de máquinas.
2. Uma das cópias do programa é especial - amaster, que divide o trabalho em M tarefas
Map e R tarefas Reduce. O resto das cópias são workers que recebem trabalhos
atribuídos pelo master. O master escolhe workers inativos e atribui a cada um deles
uma tarefa Map ou uma tarefa Reduce.
3. O worker, a quem o master atribuiu uma tarefa Map, lê o conteúdo da partição de
entrada, analisa o par chave/valor de cada entrada e passa cada par para a função
Map que o usuário de�niu. O par intermediário de chave/valor produzido pela função
Map é armazenado em bu�er. O tamanho desse bu�er também é controlado pelo
usuário por meio de um parâmetro opcional.
4. Periodicamente, os pares armazenados em bu�er são escritos no disco local, partici-
onado em R regiões pela função de particionamento. A localização desses pares em
bu�er no disco local é passada de volta ao master, que é responsável por encaminhar
essas localizações para os workers Reduce.
5. Quando o worker Reduce é noti�cado pelo master sobre essas localizações, ele usa
a chamada a um procedimento remoto para ler os dados em bu�er do disco local
dos workers Map. Quando o worker Reduce ler todos os dados intermediários, ele
ordena esses dados pelas chaves intermediárias, de modo que as mesmas chaves são
agrupadas. A ordenação é necessária porque frequentemente diferentes chaves Map
têm a mesma tarefa Reduce. Se a quantidade de dados intermediários é grande para
caber na memória, uma ordenação externa é usada.
6. O worker Reduce interage sobre os dados intermediários ordenados. Para cada chave
intermediária única encontrada, o worker passa para a função Reduce de�nida pelo
usuário a chave intermediária e o conjunto de valores intermediários correspondentes
à essa chave.
7. Quando todas as tarefas Map e Reduce foram completadas, o master retorna ao
programa que o chamou e que estava em modo de espera.
Depois da execução com sucesso, a saída do MapReduce �ca disponível em R arquivos
de saída, um para cada tarefa Reduce, com nomes especi�cados pelo usuário. Os usuários
não precisam combinar esses R arquivos dentro de um único arquivo, pois eles são frequen-
temente passados como entrada para outra chamada MapReduce e assim sucessivamente

2.4. MODELO MAPREDUCE 28
até que uma situação de parada, de�nida pelo usuário, seja alcançada. A Figura 2.2 ilustra
o funcionamento do modelo MapReduce.
Figura 2.2: Funcionamento do Modelo MapReduce baseado em [2]
2.4.2 Fluxo de Dados
Para facilitar o entendimento do modelo de programação paralela MapReduce, o seu
funcionamento será exempli�cado utilizando uma rede que monitora o nível de CO2 (dió-
xido de carbono) na atmosfera em diversos pontos do globo terrestre. É esperado que, ao
longo do tempo, os dados gerados por essa rede cresçam e as pesquisas �quem inviáveis
do ponto de vista de processamento sequencial. Neste contexto, o modelo MapReduce
torna-se um importante aliado para auxiliar nesse processamento.
Sensores espalhados por pontos estratégicos no mundo fazem a coleta dos dados e os
armazenam em um arquivo em formato texto. Esse problema apresenta-se como um bom
candidato para ser resolvido pelo modelo MapReduce, pois os dados estão estruturados
em posições pré-de�nidas dentro do arquivo texto e estes dados são orientados a registro
(cada medição consiste em uma linha do arquivo).
Iremos usar, apenas a título de exemplo, baseado em [2], alguns dados gerados
e coletados aleatoriamente pelo site de medição de CO2, denominado CO2 Now
(http://www.co2now.org). Os dados são armazenados usando o formato ASCII , e cada
linha corresponde a um registro. Para simpli�car o exemplo, focaremos nos elementos
básicos do conjunto de dados, a saber, data da medição e nível de CO2. Cada linha
a seguir está composta dos seguintes dados: posição 1 até posição 12, data e hora da
medição no seguinte formato: ano (yyyy), mês (mm), dia (dd), hora (hh) e minutos (mm).
Da posição 13 até a posição 17 é o nível de CO2 coletado, representado com duas casas
decimais. Os espaços em branco foram inseridos para facilitar a visualização dos dados e

2.4. MODELO MAPREDUCE 29
sua posição não deve ser contada.
1988 04121402 35707
1988 04251405 35727
1988 05031922 35823
1988 05091357 35719
1987 02231400 35412
1987 03021349 35267
1987 03091400 35350
1987 03161359 35418
1986 01201523 35129
1986 01271518 35520
1986 02031455 35328
1986 02101622 35257
1985 05061943 35234
1985 06241908 35056
1985 07011900 34967
1985 08261528 33733
Suponha que a partir do conjunto de dados apresentado anteriormente, queremos
encontrar o maior nível de CO2 captado por ano pelos sensores e disponível no arquivo
texto. Os dados a serem analisados estão destacados em ano e nível de CO2 apurado.
Primeiramente a função Map recebe as linhas do arquivo e extrai o ano e o nível de CO2
(destacado) e emite os seguintes dados de saída:
(1988, 357.07)
(1988, 357.27)
(1988, 358.23)
(1988, 357.19)
(1987, 354.12)
(1987, 352.67)
(1987, 353.50)
(1987, 354.18)
(1986, 351.29)
(1986, 355.20)
(1986, 353.28)
(1986, 352.57)
(1985, 352.34)
(1985, 350.56)

2.5. HADOOP: UMA IMPLEMENTAÇÃO DO MAPREDUCE 30
(1985, 349.67)
(1985, 337.33)
Em seguida, os dados de saída da função Map são processados pelo framework do
MapReduce antes de serem enviados para a função Reduce. Esse processamento irá
ordenar e agrupar os pares de chave/valor pela chave e ao �nal a função Reduce receberá
o seguinte conjunto de dados:
(1985, [337.33, 349.67, 350.56, 352.34])
(1986, [351.29, 352.57, 353.28, 355.20])
(1987, [352.67, 353.50, 354.12, 354.18])
(1988, [357.07, 357.19, 357.27, 358.23])
Cada ano pode ser processado paralelamente por uma função Reduce e ao �nal será
produzida uma saída composta por ano e seus respectivos níveis de CO2. Cada função
Reduce percorrerá paralelamente todo o vetor de medições e encontrará o maior nível
para cada ano. A saída do processamento será a seguinte:
(1985, 352.34)
(1986, 355.20)
(1987, 354.18)
(1988, 358.23)
Este é um pequeno exemplo prático da maneira como o modelo paraleliza grandes
massas de dados. A Figura 2.3 ilustra o �uxo de dados do modelo MapReduce, a partir
do exemplo explicado acima. Os dados da primeira coluna da função Map (10, 20, 30, ...,
150) são valores de chave gerados automaticamente pelo modelo.
2.5 Hadoop: Uma Implementação do MapReduce
O Hadoop foi criado por Doug Cutting, criador do Apache Lucene, que é uma biblioteca
de busca textual amplamente usada [2]. O Hadoop teve sua origem baseada no Apache
Nutch, um mecanismo de busca na Internet com código fonte aberto. O nome Hadoop
surgiu, segundo o próprio criador, a partir do nome de um elefante amarelo de pelúcia de
seu �lho. Ainda segundo o criador do Hadoop, o nome é curto e relativamente fácil de
soletrar e pronunciar [2].
O Apache Nutch começou a ser desenvolvido em 2002, porém seus desenvolvedores no-
taram que sua arquitetura não poderia armazenar e indexar os bilhões de páginas existentes
na Web. Em 2003, com a publicação do artigo que descreveu a arquitetura do sistema de
arquivos do Google chamado GFS [17], notou-se que o GFS poderia resolver a necessidade
de armazenamento de grandes arquivos gerados pelo processo de indexação das páginas

2.5. HADOOP: UMA IMPLEMENTAÇÃO DO MAPREDUCE 31
Figura 2.3: Fluxo de dados do Modelo MapReduce
Web e economizar tempo que era gasto em tarefas administrativas como o gerenciamento
de nós de armazenamento. Em 2004, foi escrita uma implementação de código aberto, o
Nutch Distributed File System (NDFS).
Ainda em 2004, o Google publicou o artigo que apresentou o modelo MapReduce ao
mundo [5]. Em 2005, os desenvolvedores do Nutch trabalharam em uma implementação do
MapReduce no Nutch e, no meio desse mesmo ano, todos os mais importantes algoritmos
do Nutch foram portados para executar usando o modelo MapReduce e o NDFS.
A partir de então, as implementações do NDFS e do MapReduce no Nutch começaram
a ser aplicadas além da esfera da busca textual. Em fevereiro de 2006 elas foram movidas
para fora do Nutch na forma de um subprojeto independente chamado Hadoop. Ao mesmo
tempo que tudo isso acontecia, Doug Cutting juntou-se ao Yahoo!, que forneceu um time
de desenvolvedores dedicados ao projeto e recursos necessários para transformar o Hadoop
em um sistema que executasse na escala da Web. Em fevereiro de 2008, o Yahoo! anunciou
que produziu índices para pesquisas que foram gerados por um cluster Hadoop com 10.000
núcleos1.
2.5.1 Componentes do Projeto Hadoop
Atualmente, o projeto Hadoop é uma coleção de subprojetos relacionados que se enqua-
dram em uma infraestrutura de computação distribuída. Esses projetos são hospedados
pela Apache Software Foundation, que fornece suporte para um conjunto de projetos de
código aberto. Embora o Hadoop seja a mais conhecida implementação do modelo Map-
Reduce [2] e do sistema de arquivos distribuídos (NDFS renomeado para HDFS - Hadoop
Distributed File System), outros subprojetos fornecem serviços complementares. Esses
1"Yahoo! Launches World's Largest Hadoop Production Application", 19 Fevereiro 2008,
http://developer.yahoo.net/blogs/hadoop/2008/02/yahoo-worlds-largest-production-hadoop.html.

2.6. REDES COMPLEXAS E GRAFOS 32
subprojetos são mostrados na Figura 2.4 e uma breve descrição é apresentada a seguir.
Figura 2.4: Subprojetos do Hadoop
MapReduce: Um modelo de processamento de dados distribuído e um ambi-
ente de execução para grandes clusters.
HDFS: Um sistema de arquivos distribuídos que executa em um grande cluster.
Pig: Uma linguagem de �uxo de dados e um ambiente de execução para ex-
plorar conjuntos de dados muito grandes. Pig executa em clusters HDFS e
MapReduce.
HBase: Um banco de dados orientado a colunas. HBase usa HDFS para o
armazenamento e implementa os estilos em lote usando MapReduce e ponto
de consultas (leitura aleatória).
ZooKeeper: Um serviço coordenado distribuído e altamente disponível. Zoo-
Keeper fornece tarefas primitivas tais como bloqueios distribuídos que po-
dem ser usados para construir aplicações distribuídas.
Hive: Um datawarehouse distribuído. Hive gerencia dados armazenados no
HDFS e fornece uma linguagem de consulta baseada no SQL, a qual é
traduzida em tempo de execução por um mecanismo do MapReduce.
Chukwa: Um sistema de análise de dados distribuídos que coleta dados ar-
mazenados no HDFS e usa o MapReduce para produzir relatórios.
2.6 Redes Complexas e Grafos
Um grafo é um conjunto de itens chamados vértices ou nós, com conexões entre eles
chamadas de arestas [18], conforme ilustra a Figura 2.5. Sistemas baseados em redes
complexas são modelados por meio de grafos. Alguns exemplos de redes são a Internet,
as redes sociais ou alguma outra relação entre indivíduos, redes de distribuição (energia,

2.6. REDES COMPLEXAS E GRAFOS 33
Figura 2.5: Exemplo de um grafo com onze vértices e treze arestas
telefone, entrega de mercadorias, etc), redes de citações entre artigos cientí�cos e muitas
outras.
As redes foram e são amplamente estudadas ao longo dos anos dentro das ciências ma-
temáticas e sociais, na disciplina de teoria de grafos. Modelos em rede permitem solucionar
importantes problemas, tais como a centralidade de um vértice, que de�ne se um vértice
é mais conectado a outros e se possui maior in�uência dentro da rede, e a conectividade,
que de�ne se e como os vértices estão conectados uns aos outros por meio da rede.
Muitas situações do mundo real poderiam ser representadas através de um diagrama
que consiste em um conjunto de pontos e linhas ligando pares desses pontos. Os pontos
poderiam representar pessoas, com linhas ligando pares de amigos, ou os pontos poderiam
ser centros de comunicação, onde as linhas representariam enlaces de comunicação [19].
Estudos recentes em redes complexas têm voltado suas atenções para a análise esta-
tística de propriedades de grandes grafos. Essa nova forma de abordar o estudo de grafos
se deve à disponibilidade atual de computadores e de redes de comunicação de alta capa-
cidade. Atualmente é possível coletar e analisar dados em escala maior, ao contrário de
antigamente quando era comum o estudo de redes sociais com poucas centenas de vértices
ou menos. Hoje em dia é possível encontrar redes com milhões e até bilhões de vértices.
Essa mudança na escala força uma nova abordagem analítica. A maioria dos problemas
e questões que precisavam ser solucionados e respondidos em pequenas redes não são mais
tão úteis em grandes redes [18]. Uma análise em uma rede social precisa responder algumas
importantes questões, por exemplo, qual vértice dessa rede traria mais impacto para a
conectividade da rede se ele fosse removido. Essa remoção de vértice traria um impacto
muito grande se ele estivesse em um pequeno grafo. Em contrapartida, uma questão
razoável em uma grande rede com milhões e até bilhões de vértices seria que percentual de

2.6. REDES COMPLEXAS E GRAFOS 34
vértices precisa ser removido para afetar substancialmente a conectividade da rede.
Um grafo direcionado G é um par (V, A), em que V é um conjunto �nito de vértices e
A é um conjunto de arestas com uma relação binária em V [20]. Em um grafo direcionado,
as arestas só podem ser percorridas em uma única direção. Em grafos direcionados podem
existir arestas de um vértice para si mesmo. Essas arestas são chamadas de self-loops.
Um grafo não direcionado G é um par (V, A), em que o conjunto de arestas A é
constituído de pares de vértices não ordenados. As arestas (u, v) e (v, u) são consideradas
como a mesma aresta. Essa aresta pode ser percorrida nas duas direções. Em grafos não
direcionados, self-loops não são permitidos.
Se (u, v) é uma aresta no grafo G(V, A), o vértice v é adjacente ao vértice u e, se o
grafo é não direcionado, a relação de adjacência é simétrica.
2.6.1 Medidas de Centralidade em Grafos
Na teoria de grafos e na análise de redes complexas, há diversas medidas de centralidade
que determinam a importância de um vértice dentro do grafo. A centralidade de um vértice,
ou a identi�cação de quais vértices são mais centrais que outros, é um problema chave na
análise de redes complexas [21]. Como exemplo de medidas de centralidade podemos citar
a excentricidade de um vértice, o diâmetro e o raio de um grafo [12].
Para identi�car o diâmetro de um grafo é necessário primeiramente descobrir a ex-
centricidade de cada vértice. A excentricidade de um vértice v em um grafo G, denotada
como e(v), é a distância de v para o vértice mais distante de v, utilizando o menor caminho
[22, 12]. Assim, e(v) = max(d(v, x)) ∀ x ∈ V .
Descoberta a excentricidade de todos os vértices do grafo G, podemos denotar o diâ-
metro D(G) como o maior valor dentre as excentricidades dos vértices contidos no grafo G
ou, de forma equivalente, a distância máxima entre dois vértices no grafo G [22]. Assim,
D(G) = max(e(x)) ∀ x ∈ V .
O raio de um grafo G, denotado por R(G), é o menor valor dentre as excentricidades
dos vértices contidos no grafo G [22]. Assim, R(G) = min(e(x)), ∀ x ∈ V .
Um vértice central em um grafo G é o vértice que tem a menor excentricidade, tal
que e(v) = R(G). O centro de um grafo G, denotado por Z(G) é o subgrafo formado pelo
conjunto de vértices centrais do grafo G [22].
A periferia de um grafo é o oposto ao centro. Um vértice periférico v de um grafo G
é um vértice com maior excentricidade, tal que e(v) = D(G). A periferia de um grafo G,
denotado como P(G) é o subgrafo formado pelo conjunto de vértices periféricos [22].
O grau g(v) de um vértice v em um grafo G é o número de arestas de G que incidem
sobre v [19].
A Figura 2.6 apresenta um grafo não dirigido composto de 5 vértices e 5 arestas.
Baseado nas de�nições anteriores, podemos encontrar as seguintes excentricidades: e(1) =
3, e(2) = 3, e(3) = 2, e(4) = 2 e e(5) = 3. De posse de todas as excentricidades, podemos
dizer que D(G) = 3, pois o valor 3 foi a maior excentricidade encontrada e R(G) = 2,

2.7. PROBLEMA DO MENOR CAMINHO 35
Figura 2.6: Exemplo de um grafo com cinco vértices e cinco arestas
pois o valor 2 foi a menor excentricidade encontrada. Além disso, o conjunto de vértices
centrais do grafo G é formado pelos vértices 3, 4 e a periferia é formada pelos vértices 1,
2, 5.
2.7 Problema do Menor Caminho
O problema do menor caminho é um problema fundamental e amplamente estudado em
grafos, com muitas aplicações teóricas e práticas [23]. A solução do problema consiste em
encontrar, partindo de um vértice fonte, os caminhos de menor peso para todos os outros
vértices de um grafo ponderado [24].
O problema do menor caminho tem grande importância na solução de várias métricas de
centralidade, pois por meio da solução desse problema é possível encontrar a excentricidade
de um vértice que nos leva a encontrar o diâmetro, o raio, a periferia e o centro de um
grafo.
Dado um grafo direcionado ponderadoG(V,A), o peso de um caminho c = (v0, v1,...,vk)
é a soma de todos os pesos das arestas do caminho:
p(c) =k∑
i=1
p(vi−1, vi)
O caminho mais curto é de�nido por:
d(u, v) =
{min {p(c) : u→ v}, se existir um caminho de u a v,
∞, caso contrário.
Para grafos não-direcionados e não-ponderados, o peso do menor caminho é a quanti-
dade de arestas que separa o vértice de origem do vértice de destino.
Um caminho mais curto do vértice u ao vértice v pode então ser de�nido como qualquer
caminho c com peso p(c) = d(u, v). O peso das arestas pode ser interpretado também de
outras maneiras, por exemplo tempo, custo, penalidade, perdas ou qualquer quantidade
acumulada no caminho que se deseja minimizar [20].

2.7. PROBLEMA DO MENOR CAMINHO 36
Seja G(V, A) um grafo dirigido onde V representa um conjunto de N vértices e A
representa um conjunto de arestas. A topologia é estática. Cada aresta (i, j) tem um peso
w(i, j) que representa o custo de comunicação através daquela aresta. Um caminho entre
um vértice fonte e um vértice destino é chamado de menor caminho quando a soma de
todos os pesos no caminho entre eles é o menor valor dentre todos os caminhos entre os
dois vértices [25].
O problema do menor caminho ocorre, de forma prática, quando deseja-se obter o cami-
nho mais curto entre duas cidades, utilizando por exemplo, um mapa rodoviário contendo
as distâncias entre cada par de cidades adjacentes. Nesse caso, pode-se modelar o mapa
como um grafo em que vértices representam cidades, arestas representam segmentos de
estradas entre as cidades, e o peso de cada aresta, a distância entre as cidades [20].
2.7.1 Menor Caminho a partir de Única Origem
Para encontrar a rota mais curta entre duas determinadas cidades, basta consultar um
mapa rodoviário em que conste a distância entre cada par de cidades adjacentes, somar
as distâncias em cada rota possível e selecionar a mais curta. Porém, essa operação pode
levar a milhões de possibilidades, dependendo do número de cidades (vértices) e o número
de estradas (arestas) [20].
Em um problema de caminhos mais curtos, temos um grafo orientado ponderado G(V,
A), com funções peso w : E → < mapeando arestas para pesos de valores reais. O peso
do caminho p = (v0, v1,..., vk) é o somatório dos pesos de suas arestas constituintes [26].
w(p) =k∑
i=1
w(vi − 1, vi)
Dado um grafo G(V,A) e um vértice distinto s pertencente a V , chamado de origem,
o problema consiste em encontrar o menor caminho de s para cada um dos outros vértices
pertencentes a G [27].
2.7.2 Menor Caminho entre Todos os Pares de Vértices
O problema de encontrar caminhos mais curtos entre todos os pares de vértices em um
grafo pode surgir, por exemplo, na elaboração de uma tabela de distâncias entre todos os
pares de cidades para um atlas rodoviário.
Pode-se resolver o problema de caminhos mais curtos entre todos os pares de vértices
executando um algoritmo de caminhos mais curtos de única origem |V| vezes, sendo que
a cada execução um vértice assume o papel de origem. Caso o grafo não possua arestas
negativas, uma possibilidade é o uso do algoritmo de Dijkstra. Se o grafo possuir arestas
de peso negativo, o algoritmo de Dijkstra não mais poderá ser usado, em vez disso deve-se
executar o algoritmo de Bellman-Ford, uma vez para cada vértice. O caso de arestas com
peso negativo não será abordado neste trabalho.

2.8. ALGORITMOS SEQUENCIAIS 37
Diferentemente de algoritmos de única origem, que geralmente representam o grafo
em uma lista de adjacências, grande parte dos algoritmos para todos os pares utiliza a
representação de matriz de adjacências para armazenar os dados.
Para solucionar o problema de caminhos mais curtos entre todos os pares de vértices
utilizando uma matriz de adjacências de entrada, precisa-se calcular não apenas os pesos de
caminhos mais curtos, mas também uma matriz predecessora∏
=∏
ij , onde∏
ij é nulo se
i = j ou se não existe nenhum caminho desde i até j e, caso contrário,∏
ij é o predecessor
de j em um caminho mais curto a partir de i [26]. O algoritmo de Floyd-Warshall, que é
descrito em seguida, utiliza essa técnica.
2.8 Algoritmos Sequenciais
Esta seção apresenta os principais algoritmos sequenciais encontrados na literatura
para solução do problema do menor caminho a partir de um único vértice fonte (Busca em
Largura e Dijkstra) e a partir de todos os pares (Floyd-Warshall).
2.8.1 Busca em Largura
A busca em largura é um dos algoritmos mais simples para pesquisar um grafo e é a
base para muitos importantes algoritmos para grafos, como por exemplo o algoritmo de
Dijkstra. Dado um grafo G(V, A) e um vértice de origem distinta s a busca em largura
explora sistematicamente as arestas de G até encontrar cada vértice acessível a partir
de s. O algoritmo calcula as distâncias (menor número de arestas) desde s até todos os
vértices acessíveis. O algoritmo produz uma árvore com raiz s que contém todos os vértices
acessíveis. Para qualquer vértice v acessível a partir de s, o caminho na árvore de s até v
corresponde a um caminho mais curto de s até v em G, ou seja, um caminho que contém
a quantidade mínima de arestas. Esse algoritmo funciona sobre grafos dirigidos e não
dirigidos [26].
A busca em largura recebe esse nome porque expande a fronteira entre vértices desco-
bertos e não descobertos uniformemente ao longo da extensão da fronteira. Com isso, o
algoritmo descobre todos os vértices que estão a uma distância k a partir de s, antes de
descobrir qualquer vértice à distância k + 1.
Para controlar o andamento, a busca em largura pinta cada vértice de branco, cinza
ou preto. No início, todos os vértices são brancos e mais tarde eles podem se tornar cinzas
e depois pretos. Um vértice é descoberto na primeira vez em que é encontrado durante
a pesquisa e nesse momento ele se torna branco. Portanto, vértices em cor cinza e preta
foram descobertos, mas a busca em largura faz distinção entre eles para assegurar que a
pesquisa continuará de maneira a seguir primeiro na extensão. Se (v, v) ∈ A e o vértice u é
preto, então o vértice v é cinza ou preto, isto é, todos os vértices adjacentes a vértices pretos
foram descobertos. Vértices de cor cinza podem ter alguns vértices adjacentes brancos e
eles representam a fronteira entre vértices descobertos e não descobertos.
O Algoritmo 1, que representa a busca em largura, funciona da seguinte maneira. As

2.8. ALGORITMOS SEQUENCIAIS 38
Algoritmo 1: Algoritmo de Busca em Largura, baseado em [26]Entrada: O grafo original G e o vértice fonte s
for cada vértice u ∈ V[G] - {s} do1
cor[u] ← BRANCO2
d[u] ← ∞3
α[u] ← NULL4
endfor5
cor[s] ← CINZA6
d[s] ← 07
α[s] ← NULL8
Q ← 09
ENFILEIRA(Q, s)10
while Q 6= 0 do11
u ← DESENFILEIRA(Q)12
for cada v ← Adj[u] do13
if cor[v] = BRANCO then14
cor[v] ← CINZA15
d[v] ← d[u] + 116
π[v] ← u17
ENFILEIRA(Q, v)18
endif19
cor[u] = PRETO20
endfor21
endw22
linhas 1 a 4 pintam todos os vértices de branco, de�nem d[u] como in�nito para todo vértice
u, e de�nem o pai de todos os vértices como NULL. A linha 6 pinta o vértice de origem
s de cinza, pois ele é considerado descoberto quando o procedimento começa. A linha 7
inicializa d[s] como 0 e a linha 8 de�ne o predecessor da origem como NULL. As linhas 9 e
10 inicializam Q como a �la contendo apenas o vértice s. O laço while das linhas 11 a 21
iterage enquanto continuam a existir vértices cinza, os quais são vértices descobertos que
ainda não tiveram sua lista de adjacências completamente examinada[26].
2.8.2 Algoritmos de Dijkstra
O algoritmo de Dijkstra resolve o problema de caminhos mais curtos de única origem
em um grafo orientado ponderado G(V, A) para o caso no qual todos os pesos de arestas
são não negativos [26].
O algoritmo mantém um conjunto S de vértices cujos pesos �nais de caminhos mais
curtos desde a origem s já foram determinados. O algoritmo seleciona repetidamente o

2.8. ALGORITMOS SEQUENCIAIS 39
vértice {u ≥ V - S} com a estimativa mínima de caminhos mais curtos, adiciona u a S
e relaxa todas as arestas que saem de u. Na implementação apresentada no Algoritmo 2,
mantém-se uma �la de prioridade mínima Q de vértices, tendo como chaves seus valores
de d.
Algoritmo 2: Algoritmo de Dijkstra para encontrar o menor caminhoEntrada: O grafo original G, o peso w e o vértice fonte s
Inicializa-Vertice-Unica-Origem(G, s)1
S ← ∅2
Q ← V[G]3
while Q 6= ∅ do4
u ← Extrai-Min(Q)5
S ← S ∪ u6
for cada_verticev ∈ Adj[u] do7
Relaxa(u, v, w)8
endfor9
endw10
A linha 1 executa a inicialização habitual dos valores de s e a linha 2 inicializa o
conjunto S como o conjunto vazio. O algoritmo mantém o invariante de que Q = V - S no
início de cada iteração do laço while das linhas 4 e 8. A linha 3 inicia a lista de prioridade
mínima Q para conter todos os vértices em V, tendo em vista que S = ∅. Nesse momento,
o invariante é verdadeiro após a linha 3. Em cada passagem pelo laço while das linhas
4 e 8, um vértice u é extraído de Q = V - S e inserido no conjunto S, mantendo assim
o invariante [26]. Em seguida, as linhas 7 e 8 relaxam cada aresta (u, v) que sai de u,
atualizando assim a estimativa d(v), se o caminho mais curto até v pode ser melhorado
mediante a passagem por u.
Pelo fato do algoritmo de Dijkstra sempre escolher o vértice mais próximo, podemos
dizer que ele utiliza uma abordagem gulosa.
2.8.3 Algoritmo de Floyd-Warshall
O algoritmo de Floyd-Warshall é um algoritmo utilizado para encontrar os menores ca-
minhos entre todos os pares de vértices, que executa em tempo Θ(V 3). Como em Bellman-
Ford, arestas de peso negativo poderão estar presentes [26], porém não farão parte do foco
deste trabalho.
A execução do algoritmo trabalha com o conceito de vértices intermediários de um
caminho mais curto, onde um vértice intermediário de um caminho simples p = {v1, v2,
..., vn} é qualquer vértice de p diferente de v1 ou vn, ou seja, qualquer vértice no conjunto
{v2, v3, ..., vn−1}.
Seja V = {v1, v2, ..., vn} o conjunto de vértices de G e seja um subconjunto {k1, k2,

2.8. ALGORITMOS SEQUENCIAIS 40
..., k} de vértices para algum k. Para qualquer par de vértices i, j ∈ V, considere todos
os caminhos desde i até j cujos vértices intermediários são todos traçados a partir de {k1,
k2, ..., k} e seja p um caminho de peso mínimo entre eles. O algoritmo Floyd-Warshall
explora um relacionamento entre o caminho p e os caminhos mais curtos desde i até j com
todos os vértices intermediários no conjunto {k1, k2, ..., k-1}. O relacionamento depende
de k ser ou não um vértice intermediário do caminho p [26].
Se k não é um vértice intermediário do caminho p, então todos os vértices intermediários
do caminho p estão no conjunto {k1, k2, ..., k-1}. Assim, um caminho mais curto desde o
vértice i até o vértice j com todos os vértices intermediários no conjunto {k1, k2, ..., k-1}
também é um caminho mais curto desde i até j com todos os vértices intermediários no
conjunto {v1, v2, ..., k}.
Algoritmo 3: Algoritmo de Floyd-Warshall para encontrar o menor caminho para
todos os pares
if i = j then1
Iij = 02
endif3
if existe aresta e i 6= j then4
Iij = length((vi, vj))5
endif6
else7
Iij = ∞8
endif9
for k = 0 to N - 1 do10
for i = 0 to N - 1 do11
for j = 0 to N - 1 do12
Iij(k + 1) = min( Iij(k), Iik(k) + Ikj(k))13
endfor14
endfor15
endfor16
S = I(N)17
Por outro lado, se k é um vértice intermediário do caminho p, então desmembramos p
em ip1 k
p2 j, P1 é um caminho mais curto desde i até k com todos os vértices intermediários
no conjunto {k1,k2, ..., k}. Como o vértice k não é um vértice intermediário do caminho
p1, podemos observar que p1 é um caminho mais curto desde i até k com todos os vértices
intermediários no conjunto {k1, k2, ..., k-1}. Da mesma forma, p2 é um caminho mais
curto desde o vértice k até o vértice j com todos os vértices intermediários no conjunto
{k1, k2, ..., k-1}.

2.9. ALGORITMOS PARALELOS 41
2.9 Algoritmos Paralelos
Esta seção apresenta o principal algoritmo paralelo encontrado na literatura para solu-
ção do problema do menor caminho entre todos os pares de vértices (HADI).
2.9.1 HADI
O HADI (HAdoop based DIameter estimator) [8] é um algoritmo de aproximação
para cálculo de raio e diâmetro de grandes grafos, ou seja, os resultados apresentados
por esse algoritmo não são exatos. O algoritmo realiza seus cálculos em ambiente Map-
Reduce/Hadoop e utiliza o algoritmo de Flajolet-Martin [28] para gerar os bitstrings ne-
cessários para codi�car todo o conjunto de dados do grafo e para contar o número de
elementos distintos em um conjunto.
O algoritmo HADI foi desenvolvido em duas versões HADI-naive e HADI-plain. A
principal diferença entre as duas versões é um melhoramento feito na versão HADI-plain,
onde apenas os dados estritamente necessários ao processamento (bitstrings) são copiados
entre os reducers, ao contrário da versão HADI-naive que copia os bitstrings para todos os
reducers.
O HADI grava dois arquivos no sistema de arquivos distribuídos do Hadoop (HDFS).
O primeiro arquivo é o de arestas no formato (srcid, dstid) e o outro é o arquivo que
armazena os bitstrings no formato (nodeid, bitstring1, ..., bitstringk).
O algoritmo de Flajolet-Martin mantém um mapa de bits BITMAP[0...L - 1] de tama-
nho L que codi�ca todo o conjunto. Para cada nó adicionado é feito o seguinte:
1. Escolher um índice ∈ [0 ... L - 1] com probabilidade 1/2index+1.
2. Atribuir o BITMAP[index] para 1.
Seja R o índice do bit 0 mais a esquerda no BITMAP. O principal resultado do Flajolet-
Martin é que a estimativa imparcial do tamanho do conjunto é dada por:
1ϕ2
R
onde ϕ = 0.77351. A estimativa mais concentrada pode ser obtida usando múltiplos bits-
trings e a média de R. Se for usado K bitstrings R1 até Rk, o tamanho do conjunto pode
ser estimado por:
1ϕ2
1k
Pkl=1 Rl
Escolher um índice de um item depende de um valor computado por uma função hash
que tem o item como valor de entrada. Assim, juntando os dois conjuntos A e B é sim-
plesmente fazer uma operação OR bit a bit entre os bits dos conjuntos A e B sem se
preocupar com elementos redundantes. O algoritmo de Flajolet-Martin para estimar raio
e diâmetro do grafo mantém K Flajolet-Martin (FM) bitstrings b(h, 1) para cada nó i e o

2.9. ALGORITMOS PARALELOS 42
atual número de saltos h. O b(h, i) codi�ca o número de nós alcançáveis a partir de i em
h saltos e pode ser usado para estimar o raio e diâmetro como será mostrado abaixo. Na
h-ésima iteração, cada nó recebe os bitstrings de seus nós vizinhos e atualiza seus próprios
bitstrings b(h− 1, i).
b(h, i) = b(h− 1, i)BIT −OR{b(h− 1, j)|(i, j) ∈ A}
onde BIT-OR representa a função que realiza a operação OR bit a bit. Depois de h
iterações, um node i tem k bitstrings que codi�cam a função de vizinhança N(h, i) que é o
número de nós dentro de h saltos, a partir do nó i. A função N(h, i) é estimada por meio
de k bitmasks por:
N(h, i) = 10.773512
1k
Pkl=1 bl(i)
onde bl(i) é a posição do bit 0 mais a esquerda do l-ésimo bitstring do node i. As iterações
continuam até que os bitstrings estabilizam e para isso é necessário que a atual iteração
de número h exceda o diâmetro d(G). Depois que as iterações terminam em hmax, será
calculado o efetivo raio de cada nó e o diâmetro do grafo, confome abaixo:
O raio efetivo de i reff (i) é o menor h tal que:
N(h, i) ≥ 0.9 ∗N(hmax, i)
O diâmetro efetivo deff (G) é o menor h tal que:
N(h) =∑
iN(h, i) = 0.9 ∗N(hmax)
Se N(h) > 0.9∗N(hmax) > N(h−1), então deff (G) é linearmente interpolado de N(h)
e N(h− 1), assim:
deff (G) = (h− 1) + 0.9∗N(hmax)−N(h−1)N(h)−N(h−1)
O algoritmo 4 apresenta um resumo do algoritmo descrito acima.

2.9. ALGORITMOS PARALELOS 43
Algoritmo 4: Algoritmo Flajolet-Martin para Calcular o Raio e o DiâmetroEntrada: O grafo G e os inteiros MaxIter e k
Saída: reff (i) de cada nó i e o deff (G)
for i = 1 to n do1
b(0, i) ← NovoFMBitString(n);2
endfor3
for h = 1 to MaxIter do4
Changed ← 0;5
for i = 1 to n do6
for l = 1 to k do7
bl(h, i)← bl(h− 1, i)BIT −OR{bl(h− 1, j)|∀j adjacent de i};8
endfor9
if ∃l s.t. bl(h, i) 6= bl(h− 1, i) then10
aumenta Changed em 1;11
endif12
endfor13
N(h) ←∑
iN(h, i);14
if Changed igual a 0 then15
hmax ← h e sai do loop;16
endif17
endfor18
for i = 1 to n do19
//estima raio efetivo20
reff (i)← menor h′ onde N(h′, i) ≥ 0.9 ∗N(hmax, i);21
endfor22
deff (G)← h′ onde N(h′) = 0.9 ∗N(hmax);23
O raio efetivo reff (i) é determinado na linha 21 e o efetivo diâmetro deff (G) é deter-
minado na linha 23.
Tipicamente, ao parâmetro k é atribuído o valor 32 [28] e ao MaxIter é atribuído o
valor de 256, uma vez que grafos reais têm um diâmetro efetivo relativamente pequeno. A
função NovoFMBitString() gera k FM bitstrings.
O Algoritmo 4 é um algoritmo sequencial e requer espaço da ordem de O(n log n) e
assim não pode manipular grafos extremamente grandes, com bilhões de nós e arestas, o
qual não pode ser processado por uma única máquina.
O HADI segue o �uxo do Algoritmo 4, ou seja, ele utiliza o FM bitstrings e iterati-
vamente atualiza seus bitstrings e os de seus vizinhos. A operação com maior custo no
Algoritmo 4 é a linha 8, onde os bitstrings de cada nó são atualizados.
O �uxo principal da versão HADI-naive, usa o arquivo de bitstrings como um cache

2.10. CONSIDERAÇÕES FINAIS 44
lógico. O HADI-naive interage sobre dois estágios do MapReduce. No primeiro estágio, o
HADI-naive atualiza os bitstrings de cada nó e atribui a situação Changed se pelo menos
um bitstring do nó é diferente do bitstring anterior. O segundo estágio conta o número
de nós Changed e para as iterações quando os bitstrings se estabilizam. Embora simples,
segundo os autores, o HADI-naive é expansivo, pois ele envia todos os bitstrings para todos
os reducers. Para tentar solucionar esse problema foi criado o HADI-plain.
O HADI-plain é melhor que o HADI-naive por copiar apenas os bitstrings necessários
para cada reducer. A ideia principal do HADI-naive é replicar os bitstrings do nó j, x vezes
onde x é o grau do nó j. Os bitstrings replicados do nó j são chamados de bitstring parcial
e representados por bp(h, j). Os bitstrings replicados bp(h, j), são usados para atualizar
b(h, i). O HADI-plain executa iterativamente três estágios do MapReduce até que todos
os bitstrings param de sofrer mudanças.
No primeiro estágio é gerado os pares <chave, valor>, onde a chave é o identi�cador
do nó i e o valor são os bitstrings parciais bp(h, j), onde j varia ao longo da vizinhança
adjacente ao nó i. Para gerar esses pares, os bitstrings do nó j são agrupados com arestas
as quais o dstid é j.
No segundo estágio, os bitstrings do nó i são atualizados combinando os bitstrings
parciais do próprio i e os dos nós adjacentes ao nó i.
No terceiro estágio é calculado o número de nós mudados, os valores dos nós vizinhos
são resumidos e em seguida é calculada a função N(h).
Quando todos os bitstrings de todos os nós convergem, um job MapReduce calcula o
raio efetivo, o diâmetro e em seguida o programa é �nalizado.
2.10 Considerações Finais
Neste capítulo foram apresentados vários conceitos sobre a arquitetura multicore. Em
seguida discutiu-se o modelo MapReduce e sua implementação Hadoop. As redes comple-
xas modeladas por meio de grafos e o problema do menor caminho, a partir de um único
vértice de origem e a partir de todos os pares de vértices também foram abordados. O
capítulo foi �nalizado com a apresentação dos algoritmos sequenciais Busca em Largura,
Dijkstra e Floyd-Warshall e com a apresentação do algoritmo paralelo HADI.

Capítulo 3
Estado da Arte
Este capítulo apresenta alguns trabalhos relacionados que foram importantes no de-
senvolvimento deste trabalho. O capítulo está estruturado conforme descrito a seguir. A
Seção 3.1 apresenta o estado da arte do modelo MapReduce. A Seção 3.2 descreve tra-
balhos que avaliaram o MapReduce em conjunto com tecnologias de banco de dados. Na
Seção 3.3 implementações do MapReduce, diferentes do Hadoop, são apresentadas e seus
princípios de funcionamento são discutidos. Em seguida, a Seção 3.4 apresenta um tra-
balho que criou uma técnica para modelar os processos do MapReduce. Trabalhos sobre
avaliação de desempenho, inteligência arti�cial e aplicações que processam grandes massas
de dados cientí�cos são encontrados nas seções 3.5, 3.6 e 3.7, respectivamente. Na Seção
3.8 é feita uma revisão sobre os trabalhos relacionados a algoritmos paralelos para encon-
trar o menor caminho em grafos, a partir de um único vértice fonte e a partir de todos os
vértices. Na Seção 3.9 são apresentados alguns trabalhos que fazem o processamento de
grafos utilizando o modelo MapReduce, tais como HADI [8], Pegasus [9] e Pregel [10].
3.1 MapReduce
O MapReduce atualmente tem sido usado em diversos trabalhos com o objetivo de
oferecer um modelo de programação paralela para gerar e processar grandes massas de
dados.
Tendo em vista esse novo modelo de processamento, o artigo original do MapReduce [5]
apresentou a estrutura do modelo como um framework simpli�cado para processar grandes
massas de dados em clusters. No trabalho, diversos tipos de programas que podem ser
implementados no modelo são apresentados. Em seguida é realizada uma discussão sobre
o funcionamento do MapReduce, passando pela implementação, execução e tolerância a
falhas. Os autores propõem também diversos re�namentos ao modelo de programação que
eles acreditam serem úteis. Como conclusão do trabalho, os autores atribuem o sucesso
do uso do MapReduce, como por exemplo no Google, à facilidade de uso do modelo uma
vez que programadores sem experiência em programação paralela e sistemas distribuídos
podem implementar facilmente seus programas, deixando os detalhes da paralelização,
da tolerância a falhas e do balanceamento de carga sob responsabilidade do modelo. Os
autores destacam ainda o fato de uma grande variedade de problemas poder ser modelada
45

3.2. MAPREDUCE E BANCO DE DADOS 46
utilizando o MapReduce. Ao �nal, o trabalho aponta que diversas lições foram aprendidas,
como o fato de restringir o modelo de programação torna a paralelização e a computação
distribuída mais tolerável a falhas e ainda, que a largura de banda de rede é um recurso
escasso e, portanto, algumas otimizações no sistema são destinadas a reduzir a quantidade
de dados enviados pela rede. Outra lição aprendida é que otimizações locais permitem ler
dados dos discos locais e escrever uma única cópia dos dados intermediários no disco local,
diminuindo o tráfego de rede. Os autores destacam também que a execução redundante
pode ser usada para reduzir o impacto das máquinas lentas, lidar com falhas de máquinas
e perda de dados.
3.2 MapReduce e Banco de Dados
Outro importante trabalho apresenta uma comparação entre o modelo MapReduce, uti-
lizando a implementação de código aberto Hadoop, e dois sistemas gerenciadores de banco
de dados (SGBD) paralelos, Vertica e DBMS-X [29]. O Vertica é um SGBD paralelo pro-
jetado para armazenar grandes datawarehouses, assim como o DBMS-X. A diferença entre
esses dois SGBDs está na maneira de armazenar os dados. No Vertica, todos os dados são
armazenados em colunas enquanto no DBMS-X os dados são armazenados em linhas. Oos
autores [29] discutem algumas características de cada um dos produtos comparados. Para
essa comparação, foi utilizado um benchmark com o objetivo de avaliar algumas funções
tais como carregamento dos dados, seleção de dados, agregação e junções. Os autores
apresentam uma discussão sobre alguns itens no nível de sistema, tais como inicialização
do sistema, con�guração, otimização, personalização, compressão, layout de dados, estra-
tégias de execução e modelo de controle de falhas. Uma discussão abordando os aspectos
relativos ao uso também é apresentada, considerando facilidade de uso e ferramentas adi-
cionais disponíveis. Alguns pontos da arquitetura dos sistemas avaliados são discutidos e
as seguintes conclusões são apresentadas:
• Indexação: Os autores discutem que, devido à sua simplicidade, o modelo MapRe-
duce não implementa índices embutidos em sua arquitetura, forçando o programador
a desenvolver seus próprios índices, muitas vezes em uma linguagem de baixo nível,
o que torna difícil a utilização desse modelo. Em contrapartida, todos os SGBDs
comparados no trabalho já trazem consigo diversas implementações de índices, cons-
truídos através de tabelas Hash e árvores-B, o que pode diminuir muito o tempo de
acesso aos dados.
• Estratégia de execução: foi discutido que o MapReduce apresenta um problema de
desempenho relacionado à manipulação de dados, na transferência entre as funções
Map e Reduce, devido à necessidade de geração de grandes quantidades de arquivos.
Cada instância de Map produz M arquivos de saída e cada um desses arquivos é
destinado a uma instância Reduce diferente. Assim se tivermos 1000 instâncias da
função Map e M igual a 500, a fase Map do programa produz 500.000 arquivos locais.

3.2. MAPREDUCE E BANCO DE DADOS 47
Por outro lado, os SGBDs paralelos não materializam seus arquivos de forma dividida
levando, em consequência, a um desempenho melhor.
• Tolerância a falhas: neste item, o MapReduce apresenta um modelo mais so�sticado
que os SGBDs avaliados. No MapReduce, se uma unidade falha, então o gerenciador
automaticamente reinicia a tarefa em um nó alternativo; no SGBD, se a execução de
uma grande consulta falha, a consulta inteira precisará ser reiniciada.
Os autores, ao �nal, colheram os resultados do benchmark e foi possível concluir que
os SGBDs Vertica e DBMS-X executaram a maioria das tarefas programadas com um
desempenho signi�cativamente melhor e, consequentemente, consumiram menos energia.
Entretanto, ressalvam que rumores dão conta que a versão MapReduce implementada
pelo Google é mais rápida que a implementação Hadoop, porém não tiveram acesso a
esta implementação e, portanto, não puderam testá-la. Os autores atribuíram o melhor
desempenho dos SGBDs a algumas características dessa tecnologia:
• Índices de árvores-B que são e�cientes em operações de seleção.
• No caso do SGBD paralelo Vertica, o mecanismo de armazenamento não convencional
que, diferentemente dos bancos de dados tradicionais, os registros são armazenados
em colunas ao invés de linhas.
• Técnicas de compressão agressivas com habilidade para operar diretamente sobre os
dados comprimidos.
• So�sticados algoritmos paralelos para consultar grandes conjuntos de dados relacio-
nais.
Em outro trabalho [15], as conclusões apresentadas em [29] são contestadas. Os au-
tores discutem acerca das ferramentas que foram utilizadas na comparação com o Ma-
pReduce/Hadoop. Naquela discussão, o DBMS-X foi classi�cado como um SGBD, porém
este não pode ser reconhecido como um SGBD comercial. Eles dizem ainda que o Vertica
é um SGBD de uma companhia cofundada por um dos autores do artigo. Em seguida,
contestam os problemas apontados em [29], como a discussão sobre índices, argumentando
que a comparação realizada foi incorreta ao concluir que o MapReduce não podia desfrutar
das vantagens da utilização de índices, e que essa conclusão pode ter levado a resultados
distorcidos. Com isso são apresentadas algumas formas de se criar e utilizar índices no mo-
delo MapReduce. Em seguida é contestada a questão do desempenho e os autores sugerem
algumas mudanças que podem melhorar o desempenho do MapReduce frente aos SGBDs
testados. A seguir, apresentam vantagens do MapReduce sobre os SGBDs , tais como:
• O MapReduce é um sistema de armazenamento independente e pode processar dados
sem que estes sejam carregados dentro de um banco de dados, o que reduz o tempo
gasto. O tempo de carregamento dos dados no banco de dados não foi considerado

3.2. MAPREDUCE E BANCO DE DADOS 48
em [29] e este pode ser até cinquenta vezes o tempo necessário para analisar os dados
com o Hadoop.
• Transformações de dados complexas são expressas mais facilmente no modelo Map-
Reduce do que utilizando linguagem SQL.
• O autor cita uma melhoria do modelo MapReduce implementada pelo Google, que
gerou melhoria no tempo gasto com a inicialização dos Workers. Esse problema
foi solucionado mantendo os processos Workers ativos, esperando por uma próxima
chamada ao MapReduce. O Google também melhorou a velocidade de varredura
sequencial que o sistema realiza, usando, para dados estruturados, uma codi�cação
binária mais e�ciente ao invés dos ine�cientes formatos textuais.
Os mesmos autores de [29] escreveram um novo artigo [30] em que mudam um pouco
o discurso de seu artigo anterior e abordam o MapReduce como um modelo que pode
ser utilizado para complementar a utilização de SGBDs paralelos ao invés de concorrer
com eles. Para os autores, o MapReduce pode ser melhor adaptado para situações de
tratamento de dados dos tipos ETL (Extrair-Transformar-Carregar) e pode complementar
essa de�ciência dos SGBDs. Nesse artigo, os autores reconhecem uma falha importante
no primeiro artigo, ao não considerarem o tempo gasto para carregar os dados dentro do
SGBD. Nos experimentos realizados foi observado que os bancos de dados paralelos avali-
ados são substancialmente mais rápidos que o modelo MapReduce, uma vez que os dados
já estão carregados, mas carregar esses dados no banco de dados leva um tempo conside-
rável. Assim, caso os dados sejam processados apenas uma vez, esse carregamento não se
justi�ca e é preferível a utilização do modelo MapReduce que não precisa do carregamento
dos dados e nem de uma de�nição total do esquema dos dados, pois basta uma de�nição
semi-estruturada dos campos chave e valor. Outra vantagem do MapReduce diz respeito
ao seu custo, uma vez que existem diversas implementações de código aberto, enquanto
que os SGBDs paralelos são de arquitetura proprietária e extremamente caros. Ao �nal o
autor sugere a criação de uma interface que possibilite a interação entre o Hadoop e algum
SGBD paralelo.
O trabalho [31] utiliza o mesmo benchmark utilizado em [29] e, por meio de um pro-
fundo estudo do modelo MapReduce, os autores identi�caram quatro fatores que afetam
signi�cativamente o desempenho e investigaram estratégicas alternativas de implementa-
ção para cada um deles. Esses fatores referem-se às características de entrada e saída
de dados, indexação, ordenação e decodi�cação dos registros em tipos apropriados (par-
sing). Ao �nal, os autores avaliaram o desempenho do MapReduce com uma representativa
combinação desses quatro fatores e os resultados dessa avaliação mostraram que, com a
devida aplicação dos fatores, o desempenho do MapReduce pode melhorar de 2,5 até 3,5
vezes, em comparação com bancos de dados paralelos. Os autores concluíram que um sis-
tema que alcança �exibilidade e escalabilidade, como é o caso do MapReduce, não precisa

3.3. OUTRAS IMPLEMENTAÇÕES DO MAPREDUCE 49
necessariamente ter o seu desempenho sacri�cado.
3.3 Outras Implementações do MapReduce
O trabalho apresentado em [4] não utiliza a implementação Hadoop por ter criado sua
própria implementação, chamada Phoenix. Nesse trabalho, diversos testes foram realizados
em ambientes multicore e em ambientes com multiprocessadores e esses testes demandaram
a criação de uma nova ferramenta.
O Phoenix é uma implementação para sistemas de memória compartilhada, baseado no
modelo MapReduce, com uma API de programação própria para as linguagens C e C++
e que permite ao programador manipular a execução do sistema além de permitir que o
mesmo crie suas próprias funções. O Phoenix conta com um e�ciente sistema de execução
[4]. Durante os estudos realizados, o Phoenix foi avaliado em seu potencial de desempenho
e também suas características para recuperação de falhas. Foi feita uma comparação entre
essa implementação do MapReduce e um código escrito em um nível mais baixo, no caso
P-Threads.
Para a avaliação foram criados oito benchmarks, abordando campos chave da computa-
ção tais como computação empresarial (contador de palavras, índice invertido, comparações
de strings), computação cientí�ca (multiplicação de matrizes), inteligência arti�cial (algo-
ritmos KMeans, PCA, regressão linear) e processamento de imagens (histogramas). Foram
usados três conjuntos de dados para cada benchmark. Os testes foram iniciados utilizando
códigos sequenciais e, em seguida, foi desenvolvida uma versão MapReduce utilizando
Phoenix e depois uma versão paralela convencional usando P-Threads. Os autores con-
cluíram que uma vantagem do Phoenix sobre o P-Threads é a �exibilidade proporcionada
ao programador, uma vez que o mesmo pode fornecer uma expressão funcional simples
do algoritmo e a paralelização e controle da concorrência são deixadas para o sistema em
execução, no caso o Phoenix. No trabalho, chegou-se à conclusão que o Phoenix manipula
automaticamente as decisões durante a execução paralela. Ele pode recuperar-se de falhas
momentâneas e também de falhas permanentes, tanto as ocorridas nas funções Map quanto
as ocorridas nas funções Reduce.
Quanto aos resultados de desempenho, concluiu-se que o Phoenix apresenta desempe-
nho similar para a maioria das aplicações testadas. Em alguns casos, como multiplicação
de matrizes, foi observado um speedup superlinear, devido aos efeitos de caching. Em ou-
tros casos foi observado que algumas aplicações sofreram com o balanceamento de carga no
estágio Reduce, como é o caso do contador de palavras. Com um alto número de núcleos,
o sistema multiprocessado frequentemente sofreu com saturação dos barramentos que co-
nectam os processadores (PCA, Histograma). Com esses resultados concluiu-se que podem
existir aplicações que não se adaptam naturalmente ao modelo MapReduce e para as quais
o código P-Threads apresenta desempenho signi�camente melhor. Em cinco aplicações o
Phoenix levou a um speedup similar ou ligeiramente melhor se comparado com P-Threads.
As aplicações que melhor se adaptam ao modelo MapReduce são as que seus dados estão

3.3. OUTRAS IMPLEMENTAÇÕES DO MAPREDUCE 50
sempre associados a chaves como, por exemplo, o contador de palavras. Em contraste,
para aplicações de geração de histogramas, o código P-Threads não utiliza chaves como
formato dos dados e por isso apresenta um melhor resultado.
Ainda no mesmo sentido do trabalho anterior, foi apresentada uma evolução do Phoe-
nix denominada �Renascimento do Phoenix� [32]. Como o próprio título indica, o trabalho
foca na implementação Phoenix do MapReduce, em que os autores identi�caram a neces-
sidade de melhorar a ferramenta no sentido de atender a sistemas de grande escala com
características de acesso à memória não uniforme, na sigla em inglês NUMA (Non-Uniform
Memory Access). Para isso foram reimplementadas com melhoramentos três camadas do
Phoenix: algoritmo, implementação e a interação com o sistema operacional, conforme
descrito a seguir.
• Melhoria do algoritmo: foi necessário realizar melhorias nos algoritmos básicos
do Phoenix tornando-os escaláveis às evoluções do ambiente e sensíveis ao NUMA.
• Melhoria na implementação: para utilizar máquinas de grande escala na tota-
lidade de seus recursos, as aplicações precisam incluir uma grande quantidade de
mecanismos que não são triviais. Os autores implementaram a maioria desses me-
canismos e, mesmo assim, ao �nal, foram identi�cados alguns mecanismos menores
que ainda precisam ser implementados.
• Melhoria da interação com o sistema operacional: uma vez que o algoritmo e
a implementação foram melhorados, o sistema operacional torna-se o próximo candi-
dato a receber a otimização. O Phoenix, segundo os autores, usa mais frequentemente
dois serviços do sistema operacional: alocação de memória e operações de entrada
e saída. Após diversos testes para veri�car as melhorias, foi observado um grande
problema na alocação de memória para as threads e, como solução, foi criado um
pool de threads que permite o reuso dessas threads em diferentes iterações e fases
do MapReduce; assim, foi possível reduzir o número total de chamadas da função
nummap(), que é a função responsável por desalocar a pilha de threads, a um mínimo
estritamente necessário.
Em seguida os autores analisaram os impactos das melhorias realizadas e concluíram o
trabalho dizendo que melhorar o sistema para um ambiente de larga escala, com memória
compartilhada e com característica NUMA, pode ser uma tarefa não trivial devido às com-
plexas interações entre o sistema, os usuários da aplicação e o sistema operacional. Tais
interações podem introduzir sérios problemas de escalabilidade. Contudo, após as otimi-
zações, foi observada uma melhora de duas vezes e meia no speedup médio e uma melhora
de dezenove vezes no pico do speedup. Todas as melhorias realizadas foram publicadas em
http://mapreduce.stanford.edu.

3.4. MODELAGEM DO MAPREDUCE 51
3.4 Modelagem do MapReduce
Uma linha de trabalho diferente da linha dos trabalhos apresentados até aqui pro-
põe um modelo formal para o MapReduce utilizando o método CSP (Communicating
Sequential Process) , que é uma linguagem formal para descrever padrões de interação em
sistemas/processos concorrentes [33]. No decorrer do trabalho, os autores modelaram o
MapReduce em quatro processos ditos cruciais: Mapper, Master, Reducer e FS (File Sys-
tem). Após discutir apenas o processo Master, ao �nal os autores propõem, como trabalho
futuro, analisar e veri�car algumas das propriedades do MapReduce baseado no modelo
construído.
3.5 Avaliação de Desempenho
Para análise de desempenho do Hadoop foi proposta uma ferramenta de monitoramento
dos recursos utilizados por jobs e serviços em um cluster onde o Hadoop está instalado,
baseada em atribuição de recursos. Chamada de Otus, a ferramenta tem o objetivo de
facilitar a análise de desempenho de aplicações distribuídas que processam grandes quanti-
dades de dados [34]. Segundo os autores, Otus coleta e relaciona as métricas de desempenho
de componentes distribuídos e fornece visões que mostram uma série temporal destas mé-
tricas, �ltradas e agrupadas utilizando diversos critérios. Os testes realizados pelos autores
mostraram que essas coletas e relacionamentos de dados não incorrem em um overhead sig-
ni�cativo dos recursos do cluster. A experiência dos autores na utilização do Otus em um
grande cluster de produção mostrou sua utilidade na solução de problemas de desempenho
e no monitoramento do comportamento desse cluster.
Ainda para avaliação de desempenho do modelo MapReduce, outro trabalho apresenta
um benchmark denominado MRBench, que faz uso da implementação Hadoop. Seu foco é
o processamento orientado a consultas, lidando com grandes volumes de dados relacionais
e executando consultas altamente complexas [35]. O benchmark proposto foi baseado no
TPC-H [36] que é um benchmark de suporte a decisões que avalia grandes volumes de dados
e que consiste em um conjunto de consultas aleatórias e de alto grau de complexidade, pro-
jetadas para simular algumas situações de negócios do mundo real. No trabalho, cada uma
das consultas foi convertida em uma tarefa MapReduce e cada tarefa consiste em diversos
passos. Para implementar as consultas SQL com tarefas MapReduce, os autores implemen-
taram as características básicas da linguagem SQL dentro das tarefas MapReduce. Assim,
os dados resultantes de cada passo na execução do modelo MapReduce são tratados como
dados de entrada para o próximo passo do modelo. Isso acontece sucessivamente exceto
no momento de execução do último passo, quando os dados resultantes são coletados, co-
locados dentro de um único arquivo e apresentados como resultado �nal da consulta. Para
validar os resultados encontrados, os autores �zeram uma comparação com os resultados
coletados no benchmark TPC-H do banco de dados Postgresql, veri�cando cada resultado,
utilizando as mesmas variáveis e as mesmas tabelas. Ao �nal, os autores concluíram que o
MRBench é um benchmark para MapReduce que ainda necessita de muitos experimentos

3.6. MAPREDUCE APLICADO A ALGORITMOS GENÉTICOS 52
e atualizações, e observaram também que o MapReduce apresenta características diferen-
tes de desempenho de acordo com a complexidade da carga de trabalho e, por isso, como
trabalho futuro, sugeriram comparar os resultados obtidos com outros conjuntos de testes
já realizados. Além disso, os autores sugeriram ajustar o número de tarefas Map e Reduce
de acordo com o tamanho dos dados para assim tentar conseguir melhores resultados.
3.6 MapReduce Aplicado a Algoritmos Genéticos
O uso do MapReduce na paralelização de algoritmos genéticos é tratado em [37]. Os
autores lembram que muitas aplicações que envolvem algoritmos genéticos não podem ser
executadas de forma precisa no modelo MapReduce devido às suas características especí-
�cas. Alguns problemas de comunicação e sincronização podem acontecer ao executar os
algoritmos genéticos em ambientes distribuídos. Para executar melhor o algoritmo gené-
tico no MapReduce foi necessário realizar uma adaptação no modelo. Esse novo modelo
foi denominado MRPGA (MapReduce for Parallel Genetic Algorithm) e pode paralelizar
automaticamente os algoritmos genéticos. O MRPGA altera as fases do MapReduce de
duas para três, incluindo mais uma fase Reduce na fase de seleção do algoritmo genético,
a saber, Map, Reduce e Reduce. Essa alteração foi realizada na fase em que os dados são
misturados (merge), para tornar possível a inclusão da nova operação Reduce. Ao �nal,
os autores concluem que essa alteração poderá abrir caminho para a fácil paralelização de
outros algoritmos baseados em populações.
3.7 MapReduce na Análise de Dados Cientí�cos
Uma área que demanda a análise de grandes volumes de dados é a cientí�ca em que
muitas vezes podemos coletar dados de diversos tipos de instrumentos, gerando grande
volume a ser processado. Os algoritmos paralelos e concorrentes e os frameworks são a
chave para alcançar melhor escalabilidade e melhor desempenho. Com o intuito de relatar
suas experiências, aplicando o modelo MapReduce para análise desse tipo de dados, os
autores [38] apresentaram um trabalho que aborda a utilização do MapReduce na solução
de problemas que manipulam uma intensa quantidade de dados da área cientí�ca, como
por exemplo, os experimentos do LHC (Large Hadron Collider) que produzem dezenas de
Petabytes de dados anualmente. Na área de astronomia, o Large Synoptic Survey Telescope
que produz por volta de vinte Terabytes de dados em apenas uma noite.
3.8 Algoritmos Paralelos para Encontrar o Menor Caminho em Grafos
Diversos algoritmos sequenciais são usados para processar grandes grafos e encontrar
o menor caminho, tanto a partir de um único vértice fonte quanto a partir de todos os
vértices. Os algoritmos mais conhecidos para essa tarefa são o algoritmo sequencial de
Dijkstra, o algoritmo sequencial Busca em Largura e o algoritmo sequencial de Floyd (ver
Seção 2.8. Muitas implementações paralelas foram propostas ao longo do tempo. Essa
seção apresenta algumas dessas implementações.

3.8. ALGORITMOS PARALELOS PARA ENCONTRAR O MENOR CAMINHO EM GRAFOS 53
3.8.1 Menor Caminho a partir de um Único Vértice Fonte (MCUF)
O problema do menor caminho a partir de um único vértice (MCUF) é um problema
que consiste em encontrar o caminho de menor peso a partir de um determinado vértice
fonte para todos os outros vértices de um grafo dirigido e ponderado [24].
Uma forma de solucionar o problema do MCUF é a divisão do algoritmo sequencial
de Dijkstra em um determinado número de fases, tais que as operações dentro de cada
fase possam ser executadas em paralelo [39, 40, 41]. No trabalho [39], foi apresentado
um algoritmo PRAM (Parallel Random Access Machine) baseado nesses critérios e foi
feita uma análise do desempenho sobre grafos aleatórios, em que os pesos de suas arestas
também são aleatórios e uniformemente distribuídos em [0, 1]. A execução do algoritmo
de Dijkstra foi dividida em três fases: versão OUT, versão IN e versão INOUT que utiliza
em conjunto os critérios aplicados nas duas outras fases.
O desempenho de um algoritmo paralelo para a solução do menor caminho depende de
como os dados são particionados para os processadores disponíveis. Nesse trabalho [39], os
autores investigaram como a decomposição afeta o desempenho do algoritmo e identi�ca-
ram as características de uma boa decomposição. Foram consideradas cinco características
principais de decomposição que são:
• Número de nós de fronteira: nós de fronteira (Boundary Nodes) formam par-
tições separando a rede em sub-redes. A quantidade desses nós afeta o tempo de
comunicação assim como o tempo de processamento. Quanto maior o número de
nós de fronteira, menor o número de nós no interior das sub-redes e assim menor
o número de nós que podem ser atualizados localmente sem comunicação entre os
processadores.
• Número de interfaces: uma interface em uma sub-rede é o grupo de nós que
está em um processador e está compartilhado com outro processador. O número de
interfaces determina o número máximo de mensagens que são enviadas durante uma
iteração do algoritmo de menor caminho.
• Número de nós de fronteira por interface: o número de nós de fronteira por
interface é o número de nós que um processador compartilha com um determinado
vizinho. Esse número determina a quantidade de informação que um processador
recebe em uma determinada mensagem e ajuda a decidir em que processador será
baseado o processamento subsequente.
• Conectividade de sub-rede: um fator que afeta o tempo de processamento de um
algoritmo na maioria das vezes é a conectividade de sub-redes. Se as sub-redes são
um grupo de nós desconectados, o tempo de processamento do algoritmo é maior que
em sub-redes que são totalmente ou quase totalmente conectadas.

3.8. ALGORITMOS PARALELOS PARA ENCONTRAR O MENOR CAMINHO EM GRAFOS 54
• Diamêtro de sub-rede: o diâmetro de uma rede é o maior número de arestas
que separa qualquer dois nós distintos dentro da rede. Para a rede decomposta, o
diâmetro da sub-rede foi de�nido como sendo o maior número de arestas que separa
o nó de fronteira de qualquer outro nó na sub-rede. O diâmetro afeta o número
total de atualizações que pode ser realizado durante a solução do algoritmo de menor
caminho.
Ao �nal, após uma extensa análise estatística das decomposições para redes em grade,
os autores determinaram as características apresentadas acima como sendo características
de uma boa decomposição. Concluíram que uma boa decomposição tem poucas interfaces,
componentes conectados e um pequeno diâmetro, porém um grande número de nós de
fronteira por interface.
Alguns algoritmos utilizam buckets para o processamento do MCUF paralelo [42] e
outros utilizam pilhas [43]. No trabalho [42], foi introduzido um novo algoritmo MCUF
paralelo chamado PIS-SP (Parallel Individual Step-Widths) baseado no PDH-SP (Parallel
Degree Heap) [43]. Ao contrário do PDH-SP que utiliza sempre um passo em largura
comum, o PIS-SP aplica diferentes passos em largura para conjuntos de nós disjuntos ao
mesmo tempo e usa uma nova estrutura de dados em bucket livre de divisões. Assim, a
nova abordagem apresentada pelo artigo não é apenas uma reimplementaçào do PDH-SP
com uma estrutura de bucket especializada mas também apresenta uma nova abordagem
no que diz respeito a seleção de nós.
Em outro trabalho [23], os autores criaram o algoritmo paralelo Delta-stepping para a
solução do problema do menor caminho a partir de um único vértice. O Delta-stepping
divide o algoritmo de Dijkstra em fases, onde cada uma dessas fases pode ser executada
em paralelo. Estudos posteriores do Delta-stepping são relatados em [40]. No trabalho,
os autores demonstraram a capacidade massiva de multithreading para algoritmo de gra-
fos em instâncias altamente desestruturadas, alcançando um desempenho expressivo em
grafos aleatórios com baixo diâmetro. Observou-se também que o tempo de execução da
implementação realizada escala muito bem em relação ao número de processadores para
grafos esparsos com baixo diâmetro.
Na parte de estudos de padrões de comportamento, existe um trabalho [41] em que os
autores estudaram os padrões de comportamento de componentes conectados em grandes
grafos com bilhões de nós e arestas e analisaram as regularidades desses componentes uti-
lizando a ferramenta GFD (Graph Fractal Dimension). Essa ferramenta mede a densidade
dos componentes conectados. Análise realizada mostrou que componentes em grandes gra-
fos Web estáticos têm GFDs constantes em geral. O autor de�ne o raio efetivo de um nó
em um componente como sendo o percentil 90 de todas as distâncias para os outros nós do
componente. Foi mostrado que os componentes desconectados têm um raio máximo efetivo
(maior raio efetivo do componente) relativamente baixo em comparação com o raio efetivo
médio (média dos raios efetivos do componente), devido ao número su�ciente de nós para

3.9. TRABALHOS RELACIONADOS 55
a formação de núcleos. Foi analisada também a probabilidade de rebeldia, por meio do pa-
drão ERP (Exponential Rebel Probability) em que a probabilidade de um nó recém chegado
não se juntar ao GCC (Giant Connected Graph), que é o maior componente desconectado
do grafo, vai decaindo exponencialmente de acordo com o grau do nó recém chegado. Para
explicar o processo de expansão da rede, foi proposto o modelo community connection que
captura o aumento do GFD e também a probabilidade de rebeldia de conjuntos de dados
do mundo real.
3.8.2 Menor Caminho a partir de Todos os Vértices
O problema de encontrar o menor caminho em um grafo é muito importante e é usado
no estudo da comunicação e transporte em redes [44]. Para analisar a escalabilidade de al-
goritmos paralelos e encontrar os menores caminhos entre todos os pares de vértices de um
grafo denso e conectado, foi realizado um trabalho [44] que criou e analisou algoritmos pa-
ralelos baseados a partir dos já bem conhecidos algoritmos seqüenciais de Dijkstra e Floyd.
Para a avaliação, foram feitas diversas previsões de desempenho e para analisar a escala-
bilidade dos algoritmos foi utilizada uma métrica chamada isoe�ciência, que determina o
quão fácil é para um sistema paralelo manter uma e�ciência constante e assim proporci-
onar um aumento do speedup na mesma proporção em que o número de processadores é
aumentado. Funções de isoe�ciência são compactas e úteis para predizer o desempenho
de algoritmos. Se o tamanho do problema precisa aumentar na forma de f(p), onde p é o
número de processadores para manter a e�ciência E, então f(p) é de�nido como a função
de isoe�ciência para a e�ciência E e a plotagem de f(p) no que diz respeito a p é a curva
de isoe�ciência da e�ciência E.
Diversos outros trabalhos baseiam-se na multiplicação de matrizes [45, 9] para encontrar
o menor caminho entre todos os vértices de um grafo dirigido.
3.9 Trabalhos Relacionados
O modelo MapReduce fornece tecnologia para o processamento de grafos em larga es-
cala. No entanto, atualmente, parece haver uma escassez de conhecimento para projetar
algoritmos para grafos escaláveis. A maioria das informações sobre algoritmos para grafos
utilizando a tecnologia MapReduce está dispersa em fontes informais da Internet [7], in-
cluindo alguns slides e vídeos de cursos disponíveis no site do Google1. Alguns trabalhos
abordam a técnica e começam a preencher esse vazio [8] [9] [10]. Esses trabalhos serão
apresentados e discutidos a seguir.
3.9.1 HADI
O HADI (HAdoop based DIameter estimator) é um algoritmo projetado para processar
o diâmetro de grafos na escala de Petabytes [8]. O diâmetro de um grafo G é de�nido a
partir do cálculo da excentricidade de um vértice v, denotado como e(v). A excentricidade
é a distância de v para o vértice mais distânte de v. O diâmetro de um grafo G, denotado
1Disponível em http://code.google.com/edu/parallel - acessado em 16 de agosto de 2011.

3.9. TRABALHOS RELACIONADOS 56
como D(G) é a maior excentricidade entre os vértices de G, ou equivalentemente, a maior
distância entre dois vértices em G [22].
Os valores dos diâmetros são susceptíveis a anomalias e isso levou os autores a utilizar a
de�nição de diâmetro efetivo [Kang and Charalampos [8] apud Palmer and Siganos 2001],
de�nido como sendo o número mínimo de saltos no qual noventa por centro de todos os
pares de nós conectados podem alcançar um aos outros mutuamente. Os autores utilizaram
essa mesma de�nição em outro artigo [41].
Os autores do HADI mostraram como computar o diâmetro de um grande grafo de uma
forma escalável e e�ciente utilizando o modelo MapReduce em sua implementação open-
source Hadoop. A escolha pelo Hadoop foi feita devido a sua livre distribuição e devido a
capacidade e conveniência que ele fornece ao programador. O algoritmo HADI foi testado
em um grande grafo Web com bilhões de arestas demonstrando excelente escalabilidade
[8].
Dado um arquivo de arestas com pares (fonte, destino), o HADI iterativamente calcula
uma função de vizinhança N(h) (h = 1, 2, ..) até uma convergência que é decidida por
um parâmetro α. A função N(h) é a contagem de pares (a, b) tal que a chega até b em h
saltos, sendo esta a operação mais importante do HADI.
O HADI foi criado em duas versões, HADI-naive que é uma implementação mais básica
e o HADI-plain que avança a implementação anterior com algumas melhorias que reduzem
a transferência de dados entre os workers do MapReduce.
Ao �nal os autores concluem que o HADI alcança excelente escalabilidade. O tempo
de execução é linear em relação ao número de arestas do grafo processado. Para os experi-
mentos foi utilizado um grafo com 25GB de dados e 1,9 milhões de arestas e notou-se que
o HADI comportou-se diminuindo o tempo de resposta quase linearmente com o número
de máquinas, até atingir alguns pontos de contenção tais como largura de banda, tempo
de carregamento da JVM (Java Virtual Machine) utilizada pelo Hadoop, quando o tempo
de resposta aumenta. Para os experimentos realizados, o tempo de resposta foi linear em
função do número de máquinas para valores de até 90 máquinas.
3.9.2 Pegasus
O Pegasus tem a mesma �nalidade do HADI e foi criado pelos mesmos autores [9]. A
diferença do Pegasus é que além de computar o diâmetro, ele realiza outras operações de
mineração em grafos tais como classi�cação de páginas (um conhecido algoritmo criado
pelo Google para calcular a relevância de páginas da Internet), Random Walk with restart
(RWR) que é um algoritmo para mensurar a proximidade de nós em um grafo, e busca por
componentes conectados.
A ideia principal do Pegasus é baseada em uma técnica chamada GIM-V (Generalized
Iterative Matrix Vector multiplication), que é essencialmente uma repetida sequência de
multiplicações matriz-vetor. O GIM-V executa três operações principais, considerando M
como uma matriz n × n e v um vetor de tamanho n. Assim:

3.9. TRABALHOS RELACIONADOS 57
m × v = v′ onde v′j =∑n
j=1 mi,j , vi
As operações são:
• combine2: multiplica-se mi,j por vj .
• combineAll: soma-se os n resultados de multiplicações para o nó i.
• assign: reescreve o valor anterior de vi com um novo resultado para fazer v′i.
A palavra Iterative no nome GIM-V denota que as três operações acima são aplicadas
até que uma convergência especí�ca do algoritmo é alcançada. O Pegasus também é
baseado no modelo MapReduce e construído utilizando o Hadoop.
O GIM-V foi implementado com algumas variações sem perder o paralelismo, tais como
GIM-V Base multiplicação simples, GIM-V BL multiplicação em blocos, GIM-V CL arestas
agrupadas e GIM-V DI iteração por blocos diagonais.
Os resultados mostraram que o GIM-V altamente melhorado alcança boa escalabilidade
sobre o número de máquinas disponíveis, executa em tempo linear sobre o número de
arestas e tem o desempenho cerca de cinco vezes mais rápido que a versão não otimizada
do GIM-V.
3.9.3 Pregel
Um outro modelo de computação foi criado para auxiliar o processamento distribuído
de grafos grandes. Para implementar esse modelo foi criado o Pregel, uma implementação
escalável, tolerante a falhas e com uma expressiva e �exível API [10]. O modelo do Pregel
é baseado no modelo Valiant's Bulk Synchronous Parallel e, diferentemente do modelo
MapReduce, o Pregel mantém os vértices e arestas do grafo na máquina que executa o
processamento e usa a rede apenas para trafegar mensagens. O modelo MapReduce é
essencialmente funcional e requer trafegar o grafo inteiro ao trocar de um estado anterior
para um próximo estado, necessitando em geral de muito mais tráfego de dados.
O processamento do Pregel consiste em uma sequência de iterações, chamadas superpas-
sos. Durante os superpassos, para cada vértice, o framework invoca uma função chamada
Compute() que é implementada pelo usuário e executada em paralelo. A biblioteca do
Pregel divide o grafo em partições, cada uma consistindo de um conjunto de vértices e
todos esses vértices com arestas de saída. A atribuição de um vértice para uma partição
depende apenas de um identi�cador do vértice, o qual implica na possibilidade de conhecer
a qual partição cada vértice pertence.
Foram desenvolvidos no trabalho quatro exemplos, que são versões simpli�cadas de al-
goritmos para resolver problemas reais, tais como menor caminho, classi�cação de páginas,
Bipartite Matching e um algoritmo de Semi-Clustering. Para os experimentos foi utilizado
apenas o algoritmo do menor caminho.
Os experimentos foram conduzidos em uma implementação do MCUF (Menor Caminho
a partir de um Único Vértice Fonte). Foram reportadas execuções para árvores binárias

3.9. TRABALHOS RELACIONADOS 58
(para estudar as propriedades de escalabilidade) e grafos aleatórios com distribuição log-
normal (para estudar o desempenho em um cenário mais real) usando grafos de vários
tamanhos e com pesos nas arestas iguais a um. Todos os resultados apresentados mostra-
ram que o Pregel escala bem com o aumento do tamanho do grafo. No entanto, o código
fonte do Pregel não está disponível para testes2.
3.9.4 Outros trabalhos referentes a grafos usando MapReduce
Um trabalho muito relevante e relacionado a este foi apresentado em [7]. Por meio
de três padrões de projeto para algoritmos de grafos que utilizam MapReduce os autores
conseguiram reduzir o tempo de processamento de seus experimentos ao implementar e
executar o algoritmo PageRank em um grafo com 1,4 bilhões de vértices. Estes padrões
abordam as de�ciências das implementações básicas. São eles:
• In-Mapper Combining: custos associados com a materialização intermediária de
pares chave/valor ao utilizar funções combiner.
• Schimmy: custos associados com o embaralhamento da estrutura dos grafos ao
enviar os dados da função Map para a função Reduce.
• Assign: custos associados com as funções hash que particionam os vértices.
Outro trabalho de grande relevância, apresentado por [11], discute a aplicação do mo-
delo MapReduce em algoritmos de grafos, mostrando que, apesar de algumas soluções
usualmente envolverem melhorias na complexidade do algoritmo, em algum ponto a acomo-
dação do grafo em memória se tornará impraticável e proibitivamente cara. O autor propõe
a distribuição do processamento em uma nuvem (cloud computing) onde os nós são conec-
tados por uma rede e possuem seu próprio disco. Sobre essa nuvem existe um hardware
com uma infraestrutura que suporta a distribuição de dados e tarefas e um componente
robusto que possa manipular as falhas. MapReduce surge como uma solução interessante
para esse tipo de problema. Contudo, apesar do forte interesse na tecnologia, poucos pes-
quisadores têm publicado trabalhos (mesmo em websites informais) com algoritmos para
grafos em MapReduce. Em particular, algoritmos de grafos usando o MapReduce quase
não aparecem na literatura, com exceção de um simpli�cado cálculo de PageRank e uma
implementação simples para encontrar distâncias de um nó especí�co [11]. Ao longo desse
trabalho, o autor apresenta alguns processos para construção de algoritmos para grafos
utilizando MapReduce, discutindo sua implementação passo a passo e sua complexidade.
Ao �nal o autor conclui que implementações de operações úteis para grafos são possíveis
e podem ser bastante simples. Além disso implementações desses algoritmos utilizando o
modelo MapReduce não são análogas à implementação de algoritmos padrão para grafos.
Essa implementação requer que o problema seja repensado.
2"Conforme relatado pelo autor do artigo [10] por email enviado em 08 de novembro de 2010.

3.9. TRABALHOS RELACIONADOS 59
3.9.5 Considerações Finais
Neste capítulo foi realizado um estudo sobre o estado da arte do modelo MapReduce
e suas aplicações. Após a revisão dos trabalhos existentes concluímos que o MapReduce
é um modelo que está sendo amplamente utilizado com sucesso para solução de diversos
tipos de problemas tais como análise de grandes massas de dados em banco de dados,
análise de dados cientí�cos, inteligência arti�cial e principalmente algoritmos para grafos.
Na área de algoritmos para grafos, que é o foco deste trabalho, encontramos diversos
algoritmos já implementados (HADI, Pegasus e Pregel). Trabalhos que propõem padrões
para o desenvolvimento de novos algoritmos para grafos utilizando o MapReduce foram
publicados e fornecem boas práticas para a criação de novos algoritmos.

Capítulo 4
Algoritmo HEDA
Neste capítulo apresentamos e discutimos os detalhes da implementação de um al-
goritmo para o cálculo exato da centralidade de grafos grandes proposto neste trabalho,
utilizando a tecnologia MapReduce.
O MapReduce permite o processamento de grandes grafos, porém não há ainda material
bibliográ�co que mostre de maneira sistemática as possibilidades do modelo. A maior
parte das informações sobre algoritmos em grafos utilizando MapReduce está dispersa em
fontes informais da Internet, incluíndo slides e vídeos gravados para cursos de MapReduce
patrocinados pelo Google [7].
O artigo original do MapReduce [5] descreve diversos problemas que envolvem grandes
massas de dados e que podem usar o modelo, porém não discute algoritmos para grafos.
A primeira demonstração de um algoritmo para grafos utilizando o modelo MapReduce,
pode ser encontrada em [46]. A ideia principal do algoritmo foi publicada na Internet pelo
Google no ano de 2007 por meio de slides e vídeos explicativos. Esse material descreve a
implementação do algoritmo para busca em largura paralelo utilizando MapReduce [7].
Diante da falta de um algoritmo exato para o cálculo da centralidade de grandes grafos
em ambiente MapReduce, foi criado o HEDA. O algoritmo HEDA se baseia no algoritmo
de busca em largura para o modelo MapReduce proposto em [46]. A principal diferença é
que o HEDA calcula o menor caminho a partir de todos os vértices para todos os outros
vértices do grafo, ao contrário do trabalho apresentado em [46], onde é calculado o menor
caminho a partir de um único vértice para todos os outros vértices do grafo.
Esse capítulo está organizado da seguinte forma. A Seção 4.1 descreve a ideia principal
do HEDA e apresenta a forma como a validação dos resultados foi realizada. A Seção 4.2
apresenta uma explicação detalhada do algoritmo, incluíndo todas as suas fases. A Seção
4.3 detalha o formato dos dados de entrada suportado pelo HEDA. Em seguida, a Seção 4.4
apresenta um exemplo prático para um melhor entendimento do algoritmo. Finalizando o
capítulo, a Seção 4.5 apresenta as considerações �nais.
4.1 Ideia Principal do Algoritmo HEDA
O algoritmo proposto foi denominado HEDA, que signi�ca Hadoop-based Exact Diame-
ter Algorithm, ou seja, um algoritmo para cálculo exato do diâmetro baseado em Hadoop.
60

4.2. DESCRIÇÃO DO ALGORITMO HEDA 61
O HEDA é um algoritmo cuidadosamente desenvolvido e aperfeiçoado para calcular o raio e
o diâmetro de grafos médios e grandes. O HEDA executa no ambiente MapReduce/Hadoop
e apresenta boa escalabilidade à medida que novos recursos são adicionados ao cluster.
A ideia principal do algoritmo é baseada na proposta apresentada em [46]. Nessa
proposta o algoritmo de busca em largura é executado a partir de um único vértice fonte.
O algoritmo HEDA faz o cálculo do menor caminho paralelamente, a partir de todos os
vértices para todos os outros vértices do grafo, utilizando também o algoritmo de busca
em largura; ao �nal, encontra o diâmetro e o raio do grafo. Além disso, as informações
�nais geradas pelo algoritmo auxiliam a determinação do centro e da periferia do grafo
processado. Todas as métricas que o HEDA fornece são exatas.
Durante a criação e desenvolvimento do algoritmo HEDA, seus resultados de excentri-
cidade, diâmetro e raio foram validados com os resultados produzidos por um algoritmo
sequencial [13], com o objetivo de comprovar sua exatidão. Durante esses testes prelimi-
nares, grafos de diversos tamanhos foram comparados. Todos os resultados comparados
foram idênticos.
4.2 Descrição do Algoritmo HEDA
A execução de cálculos exatos em uma estrutura de grafos requer que todos os vértices
pertencentes a essa estrutura sejam processados. No caso de nossa proposta, que é encon-
trar a centralidade do grafo por meio das medidas de diâmetro e raio, a excentricidade de
cada vértice tem papel fundamental no valor �nal de cada uma das métricas.
4.2.1 Fluxo Principal
O Algoritmo 5 apresenta o �uxo principal do algoritmo HEDA.
Algoritmo 5: Algoritmo HEDA - Fluxo PrincipalEntrada: Caminho do Arquivo de Arestas, Arquivo de Distâncias, Caminho do
Arquivo de saída
iteracao ← 1;1
vetorArestas ← arquivoArestas;2
while PossuiVerticesAProcessar() do3
caminhoSaída ← caminhoSaída + iteracao;4
EncontrarMenorCaminho(vetorArestas, arquivoDistancias, caminhoSaída);5
iteracao ← iteracao + 1;6
endw7
EncontrarCentralidade();8
O �uxo principal do algoritmo HEDA recebe como parâmetros de entrada o endereço
do arquivo de arestas, o arquivo de distâncias e o endereço no HDFS para gravação dos
dados de saída. Na linha 1 a variável que controla o número da iteração é iniciada. Na
linha 2, o �uxo principal transforma todo o arquivo de arestas em um único vetor, cujo

4.2. DESCRIÇÃO DO ALGORITMO HEDA 62
índice i indica o vértice de origem da aresta e o conteúdo da posição i do vetor armazena
os vértices de destino da aresta, separados por vírgula. Na linha 3, o algoritmo realiza
um laço e, por meio da função PossuiVerticesAProcessar(), decide se será chamada a
função EncontrarMenorCaminho() ou se o algoritmo encerrará sua execução chamando
a função EncontrarCentralidade(). A função EncontrarMenorCaminho implementa uma
função Map e uma função Reduce que atuarão sobre os dados a cada iteração do algoritmo.
Após todos os vértices serem processados, a função PossuiVerticesAProcessar() retorna
um valor falso e o �uxo principal continua sua execução calculando as excentricidades dos
vértices, o raio e diâmetro do grafo por meio da função EncontrarCentralidade(). A cada
iteração do algoritmo, a variável que controla as iterações é incrementada (linha 6).
4.2.2 Função MAP: Encontrar Menor Caminho
O Algoritmo 6 descreve o método Map da função EncontrarMenorCaminho que encon-
tra o menor caminho entre todos os pares de vértices do grafo G. A função Map recebe
como parâmetros de entrada, enviados pelo �uxo principal, um vetor com todas as arestas
do grafo, o arquivo de distâncias e um diretório do HDFS no qual os dados de saída serão
gravados. O arquivo de distâncias é a base da função Map, pois ele de�ne quantas vezes
a função Map será executada, de acordo com o número de linhas do arquivo. No parâme-
tro chave, encontra-se uma chave gerada automaticamente pelo Hadoop e no parâmetro
valor encontra-se a linha completa do arquivo, composta de vértice fonte, vértice destino,
distância e estado atual.
Antes de entrar no método Map, o método Inicial é executado. No Hadoop, seu nome
é con�gure. Nessa função, na linha 3, o HEDA atribui a um vetor global da classe Mapper
chamado ARESTAS, o vetor de arestas que foi passado por parâmetro e que não é visível
para toda a classe Mapper. Dessa forma, o vetor de arestas poderá ser acessado tanto
no método Inicial quanto no método Map. Em seguida, na linha 4, é criado um segundo
vetor de tipo booleano que controla se o vértice, representado no índice i do vetor, já
foi processado. Esse vetor implementa o padrão de projeto para algoritmos em grafos
utilizando MapReduce, In-Mapper Combining, apresentado no trabalho [7]. O padrão In-
Mapper Combining tem o objetivo de eliminar a função Combine do algoritmo, fazendo
essa operação dentro da própria fase Map. A função Combine é um mini-reducer e tem o
propósito de reduzir o volume de dados que precisa ser enviado para um Reducer por meio
de uma tarefa Map, resumindo registros de saída que possuem a mesma chave. Cada nó
executa sua função Combine dentro do próprio nó, antes de devolver os dados pela rede
[47].

4.2. DESCRIÇÃO DO ALGORITMO HEDA 63
Algoritmo 6: Algoritmo HEDA - Função MAP EncontrarMenorCaminho
Entrada: Caminho do arquivo de arestas, Arquivo de Distâncias, Caminho do
arquivo de saida
classe MAPPER1
método INICIAL (Array arestas)2
ARESTAS ← new array(arestas);3
VISITADOS ← ARRAYASSOCIATIVO;4
método MAP (chave, valor)5
Node n1 ← new Node( id chave, valor, ARESTAS[chave] );6
if n1.estado = 2 then7
VISITADOS[n1.verticeDestino] ← true;8
SAÍDA( n1.verticeDestino, n1.dados )9
else10
forall ( id a ∈ n1.listaArestas ) faça11
if a = n1.verticeDestino ou VISITADOS[ a ] = true then12
continue;13
Node n2 ← new Node(a);14
n2.atribuiDistancia( n1.distancia + 1);15
n2.atribuiEstado(1);16
SAÍDA( n2.verticeDestino, n2.dados );17
VISITADOS[ a ] ← true;18
endfor19
n.atribuiEstado(2);20
endif21
VISITADOS[ n.verticeDestino ] ← true;22
SAÍDA( n.verticeDestino, n.dados);23
A linha 6 do algoritmo cria uma instância do objeto de tipo Node, chamada n1. Esse
objeto representa um vértice. O Algoritmo 10 da seção 4.2.6 apresenta as propriedades e
métodos desse objeto.
Na linha 7 é feito um teste do estado do vértice. Caso ele esteja no estado 2, que indica
que já foi processado, o vetor que identi�ca os vértices já processados é marcado e o vértice
é diretamente enviado para a fase Reduce, por meio do comando SAÍDA (output.collect do
Hadoop). Caso o estado do vértice seja 1 (em processamento), o HEDA recupera todas as
arestas do vértice destino na linha 11 e inicia um laço percorrendo aresta por aresta.
Na linha 12 é testado se o vértice n1 é igual ao vértice encontrado no laço de arestas
ou se o vértice encontrado no laço de arestas já foi processado. Caso uma dessas condições
seja verdadeira, o algoritmo salta para um novo vértice no laço de arestas; caso contrário,
um novo objeto Node é instanciado e esse novo Node é chamado n2.

4.2. DESCRIÇÃO DO ALGORITMO HEDA 64
Esse novo vértice que foi instanciado, n2, recebe a distância acumulada no vértice n1
acrescido de 1, seu estado é atribuído para 1 (em processamento), ele é enviado para a fase
Reduce por meio do comando SAÍDA e o vértice é marcado no vetor de vértices visitados.
Após o laço de arestas passar por todas as arestas, o vértice n1 tem seu estado atribuído
para 2 (já processado), na linha 20. Ao �nal, o vértice n1 é marcado no vetor de visitados
e o vértice é enviado para a fase Reduce, na linha 23.
Ao �nal da execução do Algoritmo 6, os dados processados são enviados para a fase
Reduce.
4.2.3 Função REDUCE: Encontrar Menor Caminho
O algoritmo 7 descreve o método Reduce da função EncontrarMenorCaminho. O algo-
ritmo inicia atribuindo valores iniciais para as variáveis distancia e estado. Para a variável
distancia é atribuído um valor relativamente alto, e aqui utilizamos o maior valor suportado
por uma variável do tipo int. Para a variável estado é atribuído o valor zero.
Algoritmo 7: Algoritmo HEDA - Função REDUCE: EncontrarMenorCaminho
Entrada: Dados de saída da função Map
classe REDUCER1
método REDUCE(id chave, P[p1, p2, ..., pn] )2
distancia ← INT-MAX;3
estado ← 0;4
while(P.lêPróximo()) faça5
valor ← P.próximo();6
Node n1 ← new Node(chave, valor);7
if n1.distancia < distancia then8
distancia ← n1.distancia;9
if n1.estado > estado then10
estado ← n1.estado;11
endw12
Node n2 ← new Node(chave);13
n2.atribuiDistancia(distancia);14
n2.atribuiEstado(estado);15
SAÍDA(n2.id, n2.dados);16
O Hadoop agrupa automaticamente os valores de uma mesma chave. Esses valores são
agrupados em uma lista e essa lista �ca disponível no parâmetro P.
Em seguida, na linha 5 é criado um laço para percorrer todos os valores das chaves.
Esses valores, a cada iteração, são armazenados na variável valor. O conteúdo da variável
valor é utilizado para instanciar um objeto do tipo Node, chamado de n1 (linha 7). O
laço vai percorrendo todos os vértices de uma mesma chave e ao �nal encontra a maior

4.2. DESCRIÇÃO DO ALGORITMO HEDA 65
distância e a maior situação de uma determinada chave.
Quando o laço termina, um novo objeto Node é instanciado (n2 ) para armazenar a
maior distância (linha 14) e o maior estado (linha 15). Em seguida, os dados são gravados
no HDFS (linha 16).
4.2.4 Função MAP: Encontrar Centralidade
Algoritmo 8: Algoritmo HEDA - Função MAP: EncontrarCentralidade
classe MAPPER1
método MAP (chave, valor)2
chaveTransformada ← Copia posições anteriores ao TAB;3
valorTransformado ← Copia posições posteriores ao TAB;4
SAÍDA(chaveTransformada, valorTransformado);5
A função Map do EncontrarCentralidade tem um trabalho bem simples em comparação
aos outros algoritmos do HEDA. Sua tarefa é buscar no HDFS os dados da última iteração
da fase EncontrarMenorCaminho e repassá-los para a fase Reduce, transformando as linhas
que são buscadas no arquivo em pares chave/valor. Por exemplo, no arquivo de distâncias
a linha que representa a conexão do vértice fonte 1 para o vértice destino 2 é representada
na seguinte forma:
1.2TAB5|2
Analisando esta sequência de caracteres, o Algoritmo 8 armazenará na variável chave-
Transformada os caracteres que estão antes do TAB (linha 3 do algoritmo), ou seja, 1.2.
A variável valorTransformado armazenará os valores referentes à distância e estado, sepa-
rados pelo caracter `|', ou seja, 5|2 (linha 4 do algoritmo). Após essa operação os dados
são enviados para a fase Reduce (linha 5).
4.2.5 Função REDUCE: Encontrar Centralidade
A função Inicial do Algoritmo 9 tem o objetivo de atribuir o valor zero para a variável
global diametro e um alto valor para a variável raio (2048). Os grafos que processamos
em nossos experimentos e os grafos da Internet têm a característica de possuírem valores
de raio não muito altos. Assim, esse valor (2048) é su�cientemente alto e é um valor
que também foi utilizado pelo algoritmo HADI [8] para atribuir um número alto para o
máximo de iterações do algoritmo, lembrando que o número de iterações corresponde ao
diâmetro calculado pelo algoritmo HADI. Ao �m da execução, as variáveis diametro e raio
armazenarão os valores de diâmetro e o raio do grafo, respectivamente.

4.2. DESCRIÇÃO DO ALGORITMO HEDA 66
Algoritmo 9: Algoritmo HEDA - Função REDUCE EncontrarCentralidade
classe REDUCER1
método INICIAL()2
diametro ← 0;3
raio ← 2048;4
método REDUCE (id chave, P[p1, p2, ..., pn)5
excentricidade ← 0;6
while(P.lêPróximo()) faça7
valor ← P.próximo();8
if valor > excentricidade then9
excentricidade ← valor;10
endw11
if excentricidade > diametro then12
diametro ← excentricidade;13
if excentricidade < raio then14
raio ← excentricidade;15
SAÍDA(chave, excentricidade);16
método FINALIZA()17
SAÍDA(�D(G) = �, diametro);18
SAÍDA(�R(G) = �, raio);19
A função Reduce inicia o processo atribuindo valor zero à variável excentricidade para
cada nova chave processada (linha 6). Em seguida é criado um laço que percorrerá to-
dos os valores de uma determinada chave, veri�cando se o valor corrente é maior que a
maior excentricidade já encontrada (linha 9). Se essa condição for verdadeira, a variável
excentricidade recebe o conteúdo da variável valor. O código na linha 12 veri�ca se a ex-
centricidade apurada até o momento é maior que o maior diâmetro já encontrado; se for, a
variável diâmetro assume o valor da variável excentricidade. O teste na linha 14 veri�ca se
a excentricidade é menor que o menor raio já apurado; se for, a variável raio recebe o valor
da variável excentricidade. A cada conjunto de chaves processado é gravado no HDFS o
identi�cador do vértice fonte, o vértice destino e o valor da excentricidade.
A função Finaliza grava no HDFS o valor de diâmetro D(G) e raio R(G).
4.2.6 O objeto Node
O objeto do tipo Node foi de�nido para representar um vértice e fornecer todas as
propriedades e métodos necessários para essa representação. Para isso, o objeto implementa
as seguintes propriedades:
• verticeFonte: Se estamos processando um grafo e no momento de instanciar o
objeto estamos calculando a distância do vértice fonte i para o vértice destino j, essa

4.2. DESCRIÇÃO DO ALGORITMO HEDA 67
propriedade irá armazenar o identi�cador do vértice i.
• verticeDestino: essa propriedade tem o objetivo de identi�car o vértice destino, no
exemplo acima o vértice j.
• distância: essa propriedade armazena a distância acumulada do vértice fonte até o
vértice destino.
• arestas: uma lista onde constam todas as arestas do vértice destino.
• estado: essa propriedade armazena a situação atual do vértice destino. As situações
são: em processamento (1) e já processado (2).
Os seguintes métodos são implementados para o objeto:
• Construtor Node: o construtor da classe recebe como parâmetro as variáveis chave,
valor e arestas. Com base nesses valores as propriedades verticeFonte, verticeDestino,
distância, e estado são extraídas e atribuídas.
• atribuiDistancia: esse método permite atribuir um novo valor de distância para o
vértice. Recebe como parâmetro a nova distância a ser atribuída.
• atribuiEstado: esse método permite atribuir um novo valor de estado para o vértice.
Recebe como parâmetro o novo estado a ser atribuído.
• dados: esse método retorna os dados do vértice no formato previsto no arquivo de
distâncias (verticeFonte.verticeDestino TAB distância|estado).
• listaArestas: retorna uma lista com todas as arestas para o vértice destino.
O Algoritmo 10 apresenta as principais propriedades e métodos da classe Node.
Algoritmo 10: Algoritmo HEDA - Objeto Node
classe NODE1
Property verticeFonte;2
Property verticeDestino;3
Property distancia;4
Property arestas;5
Property estado;6
Construtor Node(chave, valor, arestas)7
Método atribuiDistancia(distancia)8
Método atribuiEstado(estado)9
Método dados()10
Método listaArestas()11
A seguir será apresentado um exemplo de execução do algoritmo HEDA.

4.3. FORMATO DOS DADOS DE ENTRADA 68
4.3 Formato dos Dados de Entrada
Para padronizar a entrada de dados para o HEDA, foi necessário criar um padrão de
dados para a representação de um grafo. Para processar um grafo e encontrar o menor
caminho entre todos os pares de vértices, dois arquivos são criados. O primeiro arquivo
armazena todas as informações referentes às arestas. Esse arquivo não sofre alterações
durante todo o processamento do grafo. O segundo arquivo armazena informações referen-
tes às distâncias já encontradas e esse arquivo sofre alterações à medida que o algoritmo
vai percorrendo os vértices, pois nesse arquivo �cam armazenadas as informações sobre as
distâncias de cada vértice para todos os outros vértices do grafo, além da situação atual
de cada vértice.
Para exempli�car o formato de dados criado, apresentamos o grafo da Figura 4.1.
Figura 4.1: Exemplo de um grafo com cinco vértices e sete arestas
Para esse grafo o primeiro arquivo, de arestas, terá o seguinte formato:
1TAB2,5
2TAB1,3,4,5
3TAB2,4
4TAB2,3,5
5TAB1,2,4
A Tabela 4.1 exibe a descrição detalhada das posições do arquivo de arestas, usando
como exemplo a primeira linha do arquivo representado acima.
O segundo arquivo, que armazena as distâncias e a situação dos vértices para o mesmo
grafo, terá o seguinte formato no início da execução.
1.1TAB0|1
2.2TAB0|1
3.3TAB0|1
4.4TAB0|1

4.4. EXEMPLO DE EXECUÇÃO 69
Posição Exemplo Signi�cado
0 até TAB 1 Vértice de origem da aresta
Caracteres após o TAB 2, 5 Vértices de destino da aresta separados por vír-
gula
Tabela 4.1: Descrição Detalhada do Arquivo de Arestas
5.5TAB0|1
Cada uma das linhas representa um ponto de partida do algoritmo para o processamento
do grafo. Como o processamento é paralelo, o algoritmo partirá de cada um dos vértices
na primeira iteração e irá expandindo o processamento à medida que novos vértices são
alcançados. Para calcular a distância do vértice 1 para todos os outros vértices do grafo,
o ponto de partida será 1.1; do vértice 2 para todos os outros, o ponto de partida será 2.2
até chegar ao vértice n onde o ponto de partida será n.n, sendo n o maior identi�cador dos
vértices. Assim na primeira iteração, o algoritmo partirá de n pontos paralelamente.
A Tabela 4.2 exibe a descrição detalhada das posições do arquivo de distâncias, tendo
como exemplo a primeira linha.
Posição Exemplo Signi�cado
0 até 2 1.1 Vértice origem concatenado com ponto e o vér-
tice de destino
3 até 3 TAB Separa o vértice origem/destino do resto dos da-
dos
4 até o primeiro | 0 Distância acumulada de um vértice até o outro
Primeiro | | Caractere utilizado para separar a distância acu-
mulada e o indicativo de status do vértice
Do primeiro | até o �nal 1 Indica se o vértice já foi processado, com dois
valores possíveis: 1 (em processamento) e 2 (já
processado)
Tabela 4.2: Descrição Detalhada do Arquivo de Distâncias
4.4 Exemplo de Execução
Nesta seção apresentamos um exemplo prático do algoritmo HEDA para o grafo da
Figura 4.1.
A entrada de dados do algoritmo, inclui o arquivo de arestas no seguinte formato:
1TAB2,5
2TAB1,3,4,5

4.4. EXEMPLO DE EXECUÇÃO 70
3TAB2,4
4TAB2,3,5
5TAB1,2,4
No arquivo de distâncias, teremos o seguinte formato:
1.1TAB0|1
2.2TAB0|1
3.3TAB0|1
4.4TAB0|1
5.5TAB0|1
O algoritmo inicia sua execução pelo �uxo principal (Algoritmo 5), transformando o
arquivo de arestas em um vetor de arestas. Em seguida, o algoritmo veri�ca se existe algum
par de vértices com o estado 1 (em processamento) no arquivo de distâncias. Como estamos
iniciando o processo, todos os pares de vértices estão com o estado em processamento.
Como existem pares de vértices para serem processados, o �uxo principal inicia o pro-
cesso de encontrar os menores caminhos na primeira iteração do algoritmo. Após a primeira
iteração, o arquivo de distâncias �cará com o seguinte formato:
1.1TAB0|2
1.2TAB1|1
1.5TAB1|1
2.2TAB0|2
2.1TAB1|1
2.3TAB1|1
2.4TAB1|1
2.5TAB1|1
3.3TAB0|2
3.2TAB1|1
3.4TAB1|1
4.4TAB0|2
4.2TAB1|1
4.3TAB1|1
4.5TAB1|1
5.5TAB0|2
5.1TAB1|1
5.2TAB1|1
5.4TAB1|1
Na primeira iteração do algoritmo, as linhas dos pares de vértices 1.1, 2.2, 3.3, 4.4 e
5.5 foram expandidas paralelamente.

4.4. EXEMPLO DE EXECUÇÃO 71
No caso do par de vértices 1.1, como o vértice destino 1 possui arestas para os vértices
2 e 5, criou-se os registros 1.2 e 1.5, ambos com estado 1 (em processamento) e a distância
que foi atribuída para esses novos pares de vértices criados foi a distância do par de vértices
que estava sendo expandido acrescida de um. Sendo assim, esses novos pares de vértices
receberam a distância 1, pois o vértice que foi expandido tinha a distância zero. Em
seguida, ao par de vértices 1.1, que foi expandido, atribuiu-se o estado 2 (�já processado�).
O mesmo foi feito paralelamente para o par de vértices 2.2, criando os registros 2.1, 2.3,
2.4 e 2.5, uma vez que o vértice destino 2 possui arestas para os vértices 1, 3, 4 e 5. Os
pares de vértices 3.3, 4.4 e 5.5 também foram expandidos da mesma forma.
Após a primeira iteração, o HEDA veri�ca novamente se existem pares de vértices a
serem processados e, como é o caso, o �uxo principal inicia uma nova busca pelos menores
caminhos, iniciando a segunda iteração. Novamente os pares de vértices com o estado
�em processamento� serão expandidos e novos registros serão criados de acordo com suas
arestas. Pares de vértices que possuem o estado �já processado� são simplesmente enviados
para a próxima iteração sem nenhuma operação sobre os seus dados. Após a execução da
segunda iteração, o arquivo de distâncias terá o seguinte conteúdo:
1.1TAB0|2
1.2TAB1|2
1.3TAB2|1
1.4TAB2|1
1.5TAB1|2
2.2TAB0|2
2.1TAB1|2
2.3TAB1|2
2.4TAB1|2
2.5TAB1|2
3.3TAB0|2
3.1TAB2|1
3.2TAB1|2
3.4TAB1|2
3.5TAB2|1
4.4TAB0|2
4.1TAB2|1
4.2TAB1|2
4.3TAB1|2
4.5TAB1|2
5.5TAB0|2
5.1TAB1|2
5.2TAB1|2

4.4. EXEMPLO DE EXECUÇÃO 72
5.3TAB2|1
5.4TAB1|2
Seguindo a mesma ideia da iteração anterior, o HEDA vai expandindo os pares de
vértices que possuem o estado 1, atuando sobre os dados que estão no arquivo de distância
da iteração anterior. Assim, o par de vértices 1.1 é enviado sem alterações para a próxima
iteração devido ao seu estado 2 e o par de vértices 1.2 será expandido devido ao seu estado
1. Ao realizar essa expansão, o HEDA cria os registros 1.3 e 1.4, porém esses novos registros
são criados com distância 2, pois o par de vértices 1.2 tinha a distância 1.
A expansão do par de vértices 1.5 deveria gerar os registros 1.1, 1.2 e 1.4. Esses registros
não foram gerados, pois no par de vértices 1.1, o vértice de origem é igual ao vértice destino.
Essa situação é tratada na linha 12 do Algoritmo 6. Esse tratamento tem o objetivo de
evitar a geração de registros duplicados e, consequentemente, a queda de desempenho do
algoritmo. Os registros 1.2 e 1.4 também não foram gerados, pois esses registros já existem
no arquivo de distâncias e essa duplicidade é tratada pelo padrão In-Mapper Combining,
conforme descrito na seção 4.2.2 e implementado no algoritmo 6, linha 12.
Para esse pequeno grafo do exemplo, o HEDA encontra os menores caminhos a partir
de todos os vértices já na terceira iteração do algoritmo e o resultado �nal é apresentado
abaixo:
1.1TABI|2
1.2TAB1|2
1.3TAB2|2
1.4TAB2|2
1.5TAB1|2
2.1TAB1|2
2.2TABI|2
2.3TAB1|2
2.4TAB1|2
2.5TAB1|2
3.1TAB2|2
3.2TAB1|2
3.3TABI|2
3.4TAB1|2
3.5TAB2|2
4.1TAB2|2
4.2TAB1|2
4.3TAB1|2
4.4TABI|2
4.5TAB1|2

4.5. CONSIDERAÇÕES FINAIS 73
5.1TAB1|2
5.2TAB1|2
5.3TAB2|2
5.4TAB1|2
5.5TABI|2
Após a terceira iteração, o HEDA irá novamente veri�car se existe algum par de vértices
para ser processado. Como nesse exemplo não existem mais pares vértices para serem
processados, o HEDA irá passar para a fase que encontra a excentricidade do grafo.
Para essa nova fase, o arquivo de distâncias da última iteração é utilizado como entrada
e as excentricidades dos vértices são encontradas. Além disso, ao �nal o raio e diâmetro
do grafo são encontrados e escritos no arquivo �nal.
e(1) = 2
e(2) = 1
e(3) = 2
e(4) = 2
e(5) = 2
D(G) = 2
R(G) = 1
A Figura 4.2 demonstra como o algoritmo HEDA realiza a paralelização por meio do
modelo MapReduce. O �uxo principal do algoritmo é executado sequencialmente apenas
no nó master do cluster e é a parte do algoritmo que gasta menos tempo. As funções
EncontrarMenorCaminho e EncontrarCentralidade são as funções que gastam o maior
tempo de execução e são as funções que são paralelizadas por meio das funções Map e
Reduce do modelo MapReduce. Essas funções paralelizáveis são distribuídas e processadas
tanto pelo nó master quanto pelos nós slaves.
A Figura 4.3 apresenta o �uxo de cada uma das fases do algoritmo HEDA. Os blocos das
fases 1 EncontrarMenorCaminho e 2 EncontrarCentralidade são processados paralelamente
pelo modelo MapReduce. A função que veri�ca a existência de vértices a processar é
executada de maneira sequencial.
4.5 Considerações Finais
Nesse capítulo descrevemos a ideia principal e toda a estrutura do algoritmo HEDA.
A validação do algoritmo foi também discutida e, ao �nal, por meio de um exemplo de-
monstramos o funcionamento do algoritmo passo a passo. Criado em fases, o algoritmo
HEDA tem o objetivo de aproveitar o máximo possível do paralelismo oferecido pelo modelo
MapReduce.
Em seguida, no capítulo 5, iremos apresentar o planejamento de experimentos que será
utilizado para avaliar o algoritmo proposto. Após, no capítulo 6, os experimentos serão
realizados e no capítulo seguinte os resultados dos experimentos serão apresentados.
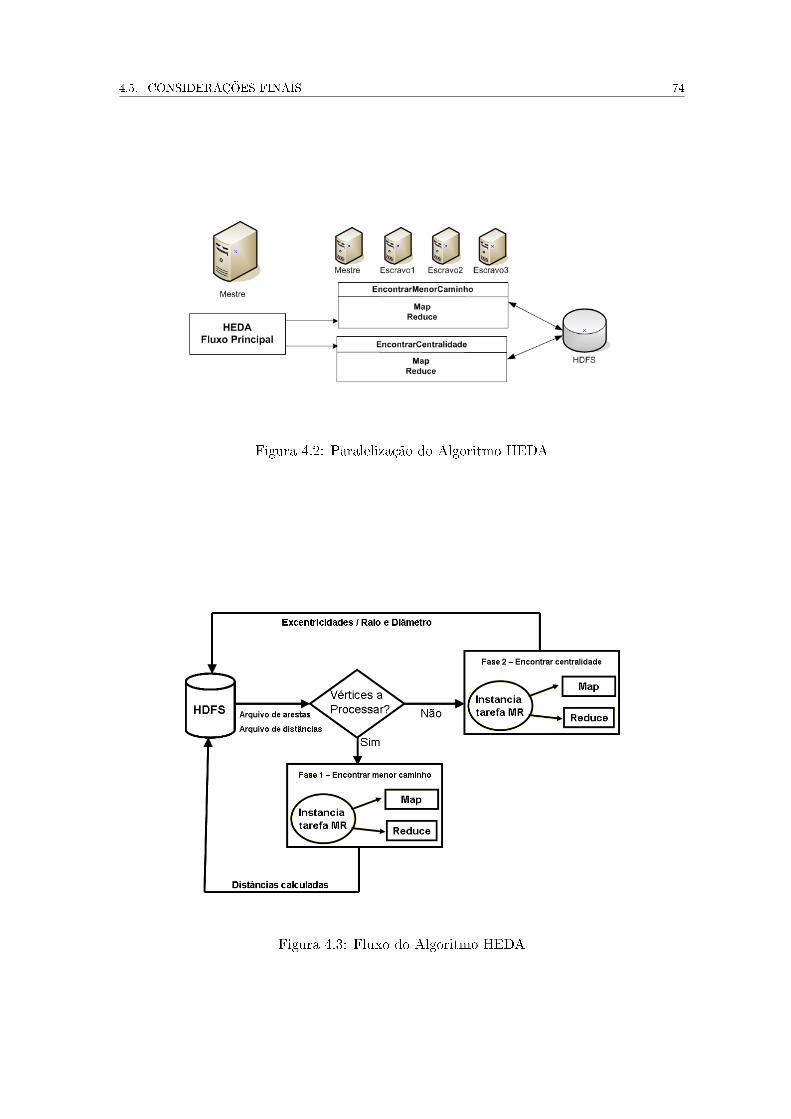
4.5. CONSIDERAÇÕES FINAIS 74
Figura 4.2: Paralelização do Algoritmo HEDA
Figura 4.3: Fluxo do Algoritmo HEDA

Capítulo 5
Projeto dos Experimentos
Nesse capítulo apresentaremos a metodologia e o planejamento dos experimentos para
avaliação do algoritmo proposto nesse trabalho. Na Seção 5.1 é apresentado o ambiente
computacional utilizado para executar os experimentos. A Seção 5.2 descreve os conjuntos
de dados (grafos) que foram utilizados para execução dos experimentos e o formato adotado
para esses dados. A Seção 5.3 trata dos parâmetros con�guráveis para ajuste de desempe-
nho do Hadoop, que podem impactar nos resultados �nais desses experimentos. A Seção
5.4 apresenta a descrição do planejamento dos experimentos realizados nesse trabalho e a
metodologia utilizada para comparar resultados do algoritmo HEDA, o algoritmo HADI
[8] e uma implementação sequencial [13], bem como uma discussão acerca da medição de
escalabilidade do algoritmo.
5.1 Ambiente Computacional
Para os experimentos deste trabalho foram utilizadas seis máquinas do cluster locali-
zado no Departamento de Computação, Campus II, do CEFET-MG. Cada uma das máqui-
nas contém dois processadores QuadCore Intel Xeon E5620 2.4GHz, totalizando 8 núcleos.
Cada máquina tem 32 Gigabytes de memória RAM, 320 Gigabytes de espaço em disco e
estão ligadas em rede por meio de um switch Gigabit.
O sistema operacional utilizado em cada um dos nós é o Linux Ubuntu Server 64-Bit
versão 10.04. A JVM (Java Virtual Machine) é a OpenJDK 64-Bit Server 1.6.0.20 (build
19.0-b09, mixed mode) e a versão do Hadoop é a 0.20.2.
Nosso ambiente computacional apresenta limitações em comparação ao ambiente uti-
lizado pelo trabalho HADI. A equipe do HADI executa seus experimentos em um cluster
que é um dos maiores supercomputadores do mundo, o M45 pertencente ao Yahoo. O
M45 possui 480 nós e cada nó é composto por 2 processadores quad-core, atingindo o total
de 4.000 núcleos. O M45 possui ainda três Terabytes de memória RAM agregada e 1.5
Petabytes de espaço em disco [48].
5.2 Conjuntos de Dados (Grafos)
Para a avaliação de desempenho do nosso algoritmo no ambiente Hadoop foram utiliza-
dos diversos conjuntos de dados, de dois tipos básicos: grafos obtidos a partir de sistemas
reais e grafos gerados sinteticamente. Os grafos reais são grafos da topologia dos sistemas
75

5.2. CONJUNTOS DE DADOS (GRAFOS) 76
autônomos da Internet e o grafo IMDB. Os grafos sintéticos são grafos gerados aleatoria-
mente pelo modelo de Erdös-Rényi [49]. O principal trabalho da literatura, o HADI [8],
também utiliza esse modelo de Erdös-Rényi em seus experimentos.
Os grafos reais nem sempre são facilmente encontrados com a quantidade de vértices
e arestas que gostaríamos para determinado tipo de experimento. Por isso, os grafos
sintéticos foram utilizados, devido à �exibilidade que esse tipo de grafo fornece ao podermos
adicionar ou retirar vértices e arestas de acordo com a necessidade do experimento.
5.2.1 Grafos da Internet
Os dados reais da topologia da Internet foram coletados e tratados pelo Internet Rese-
arch Lab (IRL)1 da Universidade da Califórnia (UCLA). O IRL faz pesquisa em diversas
áreas como tolerância a falhas em sistemas distribuídos de larga escala, infraestrutura de
roteamento da Internet, roteamento de domínios da Internet dentre outros. Nesse grafo,
cada vértice é um sistema autônomo da Internet e as arestas representam rotas entre eles.
Essa fonte de dados foi escolhida para fazer parte desse trabalho por representar uma
rede complexa real e fundamental na sociedade atual, além de ser atualizada diariamente
e por estar disponível para download sem custos na Internet. Para os experimentos foram
utilizados dois grafos, coletados em dias diferentes, conforme apresentado na Figura 5.1:
Data Arestas Vértices
01/01/2010 570.570 42.089
01/07/2011 718.768 47.224
Tabela 5.1: Grafos Reais dos Sistemas Autônomos da Internet
Para o cálculo do menor caminho foram considerados apenas os vértices que possuem
grau maior que zero. O grau g(v) de um vértice v em um grafo G é o número de arestas
de G que incidem sobre v, conforme descrito na Seção 2.6.1.
5.2.2 Grafos Sintéticos
Os geradores de grafos constrõem grafos aleatoriamente. Partindo de um grafo vazio, o
gerador vai adicionando progressivamente vértices e arestas até obter um grafo do tamanho
que o usuário deseja [13].
Nesse trabalho utilizamos um gerador de grafos [8] disponível na Web2, baseado no
modelo de Erdös-Rényi [49]. Foram gerados grafos variando o número de vértices, partindo
de 25 mil e terminando em 400 mil, incluindo em cada grafo uma quantidade de arestas
que é o triplo do número de vértices, conforme apresentado na Tabela 5.2.
Esse formato de grafos aleatórios foi escolhido para possibilitar a análise do comporta-
mento do algoritmo no que diz respeito ao tempo e espaço, à medida que aumentamos a
1http://irl.cs.ucla.edu/index.html. Acessado em 02 de outubro de 2011.2http://www.cs.cmu.edu/ukang/HADI/
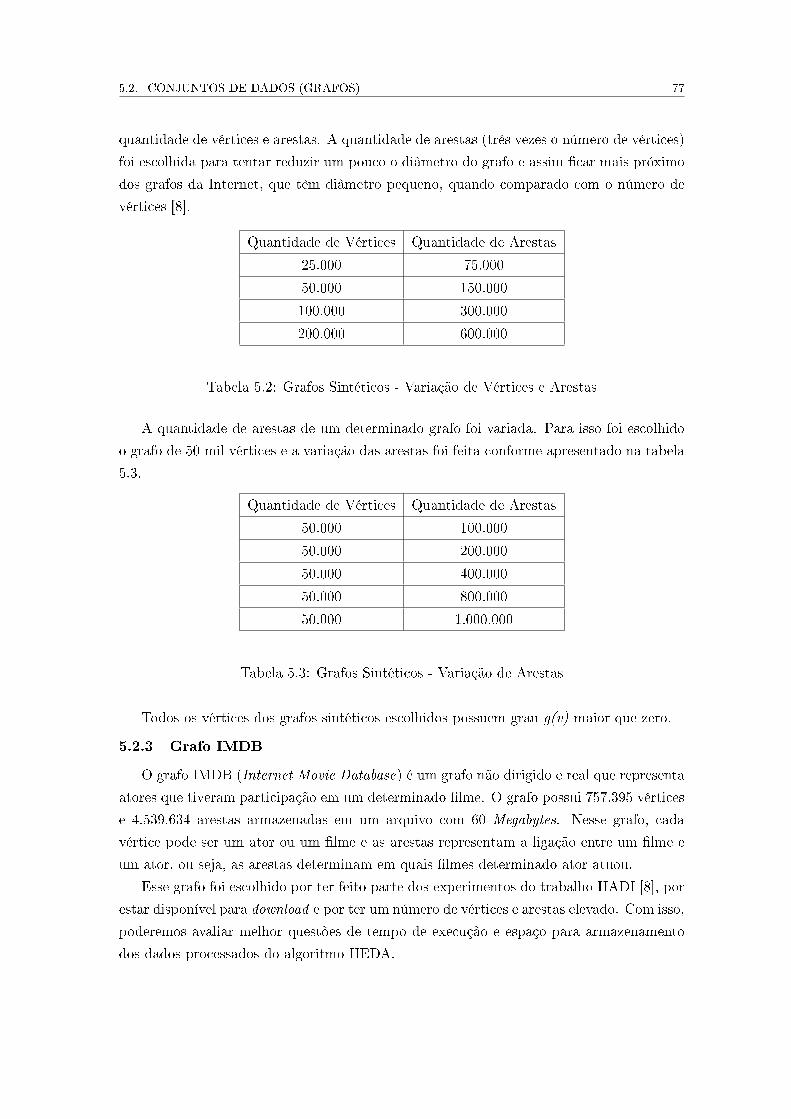
5.2. CONJUNTOS DE DADOS (GRAFOS) 77
quantidade de vértices e arestas. A quantidade de arestas (três vezes o número de vértices)
foi escolhida para tentar reduzir um pouco o diâmetro do grafo e assim �car mais próximo
dos grafos da Internet, que têm diâmetro pequeno, quando comparado com o número de
vértices [8].
Quantidade de Vértices Quantidade de Arestas
25.000 75.000
50.000 150.000
100.000 300.000
200.000 600.000
Tabela 5.2: Grafos Sintéticos - Variação de Vértices e Arestas
A quantidade de arestas de um determinado grafo foi variada. Para isso foi escolhido
o grafo de 50 mil vértices e a variação das arestas foi feita conforme apresentado na tabela
5.3.
Quantidade de Vértices Quantidade de Arestas
50.000 100.000
50.000 200.000
50.000 400.000
50.000 800.000
50.000 1.000.000
Tabela 5.3: Grafos Sintéticos - Variação de Arestas
Todos os vértices dos grafos sintéticos escolhidos possuem grau g(v) maior que zero.
5.2.3 Grafo IMDB
O grafo IMDB (Internet Movie Database) é um grafo não dirigido e real que representa
atores que tiveram participação em um determinado �lme. O grafo possui 757.395 vértices
e 4.539.634 arestas armazenadas em um arquivo com 60 Megabytes. Nesse grafo, cada
vértice pode ser um ator ou um �lme e as arestas representam a ligação entre um �lme e
um ator, ou seja, as arestas determinam em quais �lmes determinado ator atuou.
Esse grafo foi escolhido por ter feito parte dos experimentos do trabalho HADI [8], por
estar disponível para download e por ter um número de vértices e arestas elevado. Com isso,
poderemos avaliar melhor questões de tempo de execução e espaço para armazenamento
dos dados processados do algoritmo HEDA.

5.3. PARÂMETROS PARA AJUSTE DE DESEMPENHO 78
5.3 Parâmetros para Ajuste de Desempenho
Ferramentas para construção de aplicações que manipulam dados em larga escala, como
o Hadoop, têm ganhado grande popularidade. Entender todos os recursos de desempenho
oferecidos por elas é uma tarefa útil, porém pode ser um tanto difícil devido às diversas
combinações que podem ser elaboradas alterando seus parâmetros de ajuste de desempe-
nho [34]. Neste tópico apresentamos e discutimos alguns dos parâmetros con�guráveis do
Hadoop, com ênfase para os que mais impactaram o desempenho de nossa aplicação.
O Hadoop, em sua versão 0.20, possui mais de 200 parâmetros ajustáveis e que podem
alterar o desempenho de um determinado trabalho. Porém, ajustar esses parâmetros em
um cluster é uma atividade bem diferente de ajustá-los em um nó individual e esse trabalho
deve ser planejado adequadamente [50]. Um mesmo parâmetro pode apresentar ganho ou
perda de desempenho, quando aplicado a dois conjuntos de dados diferentes.
Existem parâmetros que precisam ser observados em separado ao ajustar o cluster
inteiro. Dentre esses parâmetros estão o número de jobs em execução, o volume de dados a
ser processado, a quantidade dos dados a ser replicada, o número de réplicas desses dados,
o tamanho do bu�er para ordenação dos dados e o controle de utilização dos recursos
disponíveis no cluster Hadoop.
A manipulação dos parâmetros do Hadoop em busca de um melhor desempenho é um
processo muito trabalhoso [50], devido à quantidade de parâmetros, acrescida pelo número
de opções para cada um. Geralmente esse processo ocorre em ciclos e esses ciclos são
compostos por fases, sendo elas: determinar os parâmetros a serem alterados, realizar um
benchmark com os parâmetros atuais, alterar os parâmetros selecionados, realizar um ben-
chmark com os novos parâmetros e �nalmente comparar os resultados decidindo em seguida
se serão mantidos os parâmetros antigos ou se serão aproveitados os novos parâmetros.
A seguir estão listados os principais parâmetros da ferramenta Hadoop com uma breve
descrição sobre cada um deles, assim como a apresentação de seus valores padrão.
• mapred.tasktracker.map/reduce.tasks.maximum - Esse parâmetro de�ne a quantidade
máxima de tarefas Map e de tarefas Reduce que executarão simultaneamente em um
nó escravo (TaskTracker). O Hadoop considera o valor de duas tarefas para a função
Map e duas tarefas para a função Reduce como valores default.
• mapred.child.java.opts - Além das otimizações normais do código Java, a quantidade
de memória atribuída à JVM, para cada tarefa, também afeta o desempenho. O
parâmetro mapred.child.java.opts pode ser utilizado para alterar várias caracterís-
ticas da JVM e, no caso da memória, o valor a ser atribuído é -XmxYYYm, onde
YYY corresponde a quantidade de memória RAM que deseja-se atribuir à JVM e os
caracteres -Xmx signi�cam que estamos querendo alterar o tamanho do Heap Size
da JVM. O caracter m, ao �nal, signi�ca que o valor atribuído ao parâmetro está em
Megabytes. Por padrão o Hadoop já considera o valor de 200 Megabytes. O efetivo

5.3. PARÂMETROS PARA AJUSTE DE DESEMPENHO 79
uso da memória RAM disponível é muito importante para um melhor aproveitamento
dos recursos do hardware [6].
• io.sort.mb - Esse parâmetro de con�guração é utilizado para de�nir o tamanho do
bu�er de memória usado pelas tarefas Map para ordenar seus dados de saída e
que serão enviados à função Reduce. O valor padrão para essa propriedade é de
100 Megabytes. Para trabalhos de grande escala e que possuem funções Map que
produzem grandes quantidades de dados, esse valor deve ser aumentado, levando em
conta que isso aumentará também a quantidade de memória necessária para processar
cada tarefa Map; portanto, o aumento desse parâmetro deve estar de acordo com a
memória disponível no nó.
• io.sort.spill.percent - Esse parâmetro deverá ser utilizado em conjunto com o parâ-
metro io.sort.mb pois ele de�ne o momento em que os dados que estão armazenados
no bu�er deverão ser descarregados em disco. Essa tarefa é executada por meio de
uma thread que é disparada no momento que o bu�er atinge o valor de�nido no
parâmetro. Esse valor é de�nido em formato de percentual e seu valor padrão é 0.80
ou 80 por cento. Enquanto os dados estão sendo descarregados em disco, as tarefas
Map podem continuar a escrever novos dados no bu�er.
• mapred.local.dir - Quando os dados do bu�er atingem o valor de�nido em
io.sort.spill.percent eles precisam ser descarregados em disco e o caminho onde esses
dados serão descarregados pelo nó (TaskTracker) está de�nido nesse parâmetro. Esse
valor pode ser apenas um endereço de diretório ou uma lista de endereços separados
por vírgula. Todos os dados armazenados aqui são eliminados quando o job termina
sua execução.
• io.sort.factor - Antes de uma determinada tarefa Map terminar, os arquivos referentes
a essa tarefa precisam ser mesclados em um único arquivo ordenado de saída. Esse
parâmetro controla o número máximo de streams que será utilizado por vez para
mesclar os dados de diversos arquivos em apenas um único arquivo. O valor padrão
é 10.
• mapred.reduce.parallel.copies - Os dados de saída de uma função Map são copiados
para as funções Reduce no momento em que uma tarefa Map termina sua execução.
As tarefas Reduce têm uma quantidade de�nida de threads que tem o objetivo de
buscar os dados em paralelo. Essa quantidade de threads é de�nida no parâmetro
mapred.reduce.parallel.copies e tem o valor padrão de 5 threads.
• tasktracker.http.threads - Esse parâmetro de�ne o número de threads que executam
no servidor HTTP em cada nó (Tasktracker). O servidor HTTP é utilizado pelas
tarefas Reduce para buscar os dados intermediários liberados pelas funções Map. O
valor padrão desse parâmetro é 50.

5.4. PLANEJAMENTO DOS EXPERIMENTOS 80
• mapred.compress.map.output - Os dados de saída das funções Map podem ser com-
primidos antes de serem escritos no disco com o objetivo de agilizar a escrita desses
dados, diminuir a ocupação do disco e diminuir também a quantidade de dados que
são transferidos para a função Reduce. No formato padrão esse parâmetro tem o
valor falso, ou seja, é desabilitado. Deve ser considerado que, ao utilizar esse parâ-
metro os dados são comprimidos na função Map e descomprimidos na função Reduce
e isso pode acarretar um aumento no tempo de processamento. A utilização deve ser
avaliada de acordo com o tamanho do cluster e o tamanho da massa de dados a ser
processada.
• io.�le.bu�er.size - O Hadoop utiliza um bu�er de 4 kb de tamanho para suas ope-
rações de entrada e saída. Esse valor é muito conservador levando-se em conta a
disponibilidade de hardware e sistemas operacionais que temos atualmente [2]. A
propriedade io.�le.bu�er.size é utilizada para controlar o tamanho desse bu�er e
tem como valor padrão 4096 (4kb).
Além dos parâmetros apresentados, o Hadoop possui diversos outros que devem ser
avaliados e testados cuidadosamente de acordo com as características do trabalho a ser
executado [2]. Con�gurações do sistema operacional, como a quantidade de arquivos que
podem ser abertos simultaneamente, podem afetar diretamente o desempenho de um de-
terminado trabalho. Outros fatores que também têm maior in�uência são a velocidade da
rede, versão da máquina virtual do Java e aspectos de programação, como a reutilização
de objetos, que facilita o trabalho do coletor de lixo (Garbage Collector) do Java.
5.4 Planejamento dos Experimentos
Experimentos são uma parte natural dos processos de tomada de decisão em engenharia
e em ciência. Para um determinado problema, um experimento pode consistir em utilizar
diversos métodos para a solução desse problema. Os dados desse experimento poderiam
ser usados para determinar qual método deveria ser usado para fornecer a melhor solução
dentre todas experimentadas. Um experimento pode ser somente um teste ou uma série
de testes. Experimentos são feitos em todas as disciplinas cientí�cas e de engenharia
e constituem uma importante parte da maneira de aprendermos sobre como sistemas e
processos funcionam. Consequentemente, o planejamento dos experimentos tem papel
principal na solução futura do problema que inicialmente motivou o experimento [51]. O
objetivo principal de um projeto de experimentos é obter o máximo de informação com
um número mínimo de experimentos [52].
A análise de experimentos ajuda na separação dos efeitos de vários fatores que afe-
tam o desempenho, permitindo determinar se um fator teve um efeito signi�cativo ou se
a diferença observada é simplesmente devido a variações aleatórias causadas por medidas
errôneas e parâmetros que não são controlados. Usando planejamento de experimentos, os
engenheiros podem determinar que subconjunto das variáveis de processos tem a maior in-

5.4. PLANEJAMENTO DOS EXPERIMENTOS 81
�uência no desempenho do processo. Para este trabalho, o planejamento de experimentos
tem extrema importância, pois os resultados dos experimentos podem conduzir a um me-
lhor rendimento do processo de avaliação, redução na variabilidade dos resultados e melhor
obediência aos requisitos do projeto, assim como desenvolvimento, redução nos tempos do
projeto e redução nos custos de execução [51].
Vários tipos de projetos de experimentos são descritos na literatura. Os mais utiliza-
dos são projetos simples, projetos fatoriais completos e projetos fatoriais fracionados [51].
Devido ao grande número de combinações que teríamos ao utilizar o projeto fatorial com-
pleto, optamos pela utilização do projeto simples. Por meio de um projeto e análise de
experimentos, esperamos obter resultados sobre o comportamento de algoritmos paralelos
ao processarem grandes massas de dados. O planejamento de experimentos tem importân-
cia fundamental sobre as seguintes etapas do trabalho: execução dos experimentos, análise
dos resultados, análise de complexidade, comparação e conclusões.
As Seções 5.4.1 e 5.4.2 apresentam o planejamento de experimentos para comparação do
algoritmo HEDA com outros algoritmos existentes na literatura. A Seção 5.4.3 apresenta
o planejamento de experimentos para avaliação do impacto do ajuste dos parâmetros de
desempenho no tempo de execução do algoritmo. A Seção 5.4.4 apresenta o experimento
planejado para medir a escalabilidade do HEDA.
5.4.1 Comparação com o Algoritmo HADI
Os resultados do algoritmo HEDA serão comparados com o principal trabalho presente
na literatura, o HADI, que utiliza um algoritmo de aproximação para o cálculo do raio e
diâmetro de um grafo grande [8].
O alvo principal dessa comparação é demonstrar que o algoritmo HEDA produz resul-
tados exatos, referentes às distâncias entre todos os pares de vértices, às excentricidades
de todos os vértices, o diâmetro e o raio do grafo.
Os experimentos são executados e, por meio de uma criteriosa coleta de dados, os
resultados de diâmetro e raio apresentados pelos dois algoritmos são confrontados, bem
como seus tempos de execução e suas escalabilidades. Cada experimento foi executado
três vezes e ao �nal foi feita a média dos tempos de execução.
5.4.2 Comparação com o Algoritmo Sequencial
Durante o desenvolvimento do algoritmo HEDA, seus resultados de diâmetro e raio
foram comparados com o algoritmo descrito no trabalho [13], com o intuito de validar a
exatidão dos resultados apresentados pelo algoritmo.
Nem todos os tamanhos de grafos propostos por esse trabalho puderam ser executados
no algoritmo sequencial devido ao grande espaço ocupado por grandes grafos e pelo exces-
sivo uso de memória RAM. Assim, apenas os grafos da Internet e alguns grafos sintéticos
foram processados no algoritmo sequencial.
Todos os experimentos foram executados três vezes e os tempos de execução do HEDA

5.5. CONSIDERAÇÕES FINAIS 82
foram comparados com o tempo de execução do algoritmo sequencial.
5.4.3 Alterações nos Parâmetros de Desempenho
Para os experimentos realizados com os grafos da Internet (Seção 5.2.1), primeiramente
foram executados no algoritmo HEDA no ambiente Hadoop sem qualquer alteração nos
parâmetros de ajuste de desempenho. Esses experimentos foram executados três vezes
para cada grafo da Internet e os resultados de diâmetro e raio foram coletados, assim como
o tempo de execução. Ao �nal uma média dos tempos de execução foi calculada.
Em seguida, realizamos diversas alterações nos parâmetros de ajustes de desempenho
e novamente os resultados foram coletados e os tempos de execução foram comparados
com os tempos coletados na execução sem alteração dos parâmetros. Os parâmetros de
ajuste de desempenho que foram alterados estão detalhadamente explicados na descrição
dos resultados (Capítulo 6).
5.4.4 Escalabilidade
A escalabilidade de um algoritmo paralelo, em uma arquitetura paralela, é a medida
da capacidade da utilização efetiva dos recursos pelo algoritmo, ao aumentar o número
de processadores. A análise da escalabilidade de uma combinação algoritmo-arquitetura
pode ser usada para uma variedade de propósitos como, por exemplo, selecionar a melhor
combinação entre o algoritmo e a arquitetura para a solução de um determinado problema
que tenha várias restrições quanto ao aumento do tamanho desse problema e do número
de processadores.
A escalabilidade pode ser usada também para predizer o desempenho de um algoritmo
paralelo e uma arquitetura paralela para um grande número de processadores, por meio
do desempenho conhecido em um ambiente com poucos processadores [53]. Uma baixa
escalabilidade pode resultar em um sistema com baixo desempenho, necessitando de uma
reengenharia ou mesmo da duplicação dos sistemas [54].
Nossos experimentos avaliaram a escalabilidade do algoritmo HEDA à medida que
máquinas são adicionadas ao cluster. Iniciamos os testes executando os grafos da Internet
três vezes, partindo de uma máquina e chegando até seis máquinas. De posse dos tempos
de execução avaliamos a escalabilidade do algoritmo HEDA veri�cando seus valores de
speedup e e�ciência. Esse teste também foi executado com o algoritmo HADI.
5.5 Considerações Finais
Neste capítulo foi discutida a metodologia dos experimentos executados. Foi apresen-
tado o ambiente computacional em que os experimentos foram executados, os conjuntos de
dados utilizados, todo o planejamento de experimentos e discutiu-se sobre os parâmetros
para ajuste de desempenho do Hadoop.

Capítulo 6
Resultados dos Experimentos
Neste capítulo são apresentados os resultados dos experimentos executados em cluster
utilizando Hadoop. Este capítulo está estruturado conforme descrito a seguir. Na Seção
6.1 os resultados dos experimentos realizados com o HEDA são apresentados e discutidos.
Esta seção engloba subseções que tratam especi�camente de cada tipo de grafo (Internet,
Sintéticos e IMDB), uma seção que apresenta os resultados de speedup e outra que trata
da e�ciência do algoritmo HEDA.
Na Seção 6.2 os resultados dos algoritmos HEDA e HADI [8] foram comparados. Para
esta comparação foram utilizados o tempo de processamento e os resultados das métricas
de centralidade, como o diâmetro e o raio do grafo processado. Neste experimento, todos
os grafos da Internet, todos os grafos sintéticos e o grafo IMDB foram avaliados.
Na Seção 6.3 são apresentados os resultados da comparação entre o algoritmo HEDA,
proposto por esse trabalho, e um algoritmo sequencial presente na literatura [13]. Essa
comparação foi realizada utilizando como dados de entrada os grafos da Internet e alguns
grafos sintéticos.
Na Seção 6.4, diversos parâmetros de ajuste de desempenho do Hadoop foram alterados
e ajustados com o objetivo de avaliar o impacto dessas alterações no tempo de processa-
mento do grafo proposto. Para esses experimentos, apenas o grafo da Internet foi utilizado.
Ao �nal do capítulo, as considerações �nais são apresentadas.
6.1 Resultados do Algoritmo HEDA
Esta seção apresenta os resultados do algoritmo HEDA obtidos no processamento de
cada um dos grafos propostos: Internet (Seção 6.1.1), Sintéticos (Seção 6.1.2) e o grafo
IMDB (Seção 6.1.3).
6.1.1 Grafos da Internet
Para cada grafo da Internet, o algoritmo HEDA foi executado três vezes e o tempo
médio de execução foi calculado. Os grafos da Internet são identi�cados pela data de
coleta dos dados.
A Tabela 6.1 apresenta os dados numéricos referentes aos grafos da Internet, com
quantidade de vértices e de arestas e os resultados de diâmetro D(G) e raio R(G) de cada
um dos grafos processados pelo algoritmo HEDA.
83

6.1. RESULTADOS DO ALGORITMO HEDA 84
Data Arestas Vértices D(G) R(G)
01/01/2010 570.570 42.089 10 7
01/07/2011 718.768 47.224 10 7
Tabela 6.1: Resultado HEDA - Grafos da Internet
Os grá�cos da Figura 6.1 apresentam os resultados de tempo de execução de cada
um dos grafos em relação ao número de máquinas disponíveis no cluster, partindo de
uma máquina (8 núcleos) e adicionando máquina por máquina até chegar ao total de seis
máquinas (48 núcleos).
0
200
400
600
800
1000
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Grafo 01/01/2010
HEDA
0
300
600
900
1200
1500
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Grafo 01/07/2011
HEDA
Figura 6.1: Resultados do Algoritmo HEDA - Grafos da Internet.
Nesses grá�cos, pode-se notar que o tempo de execução dos experimentos vai dimi-
nuindo à medida que mais máquinas são adicionadas ao cluster. Observamos que, apa-
rentemente, o tempo pode continuar decrescente se acrescentarmos mais máquinas. No
entanto, o experimento foi limitado a seis máquinas devido a questões operacionais.
O grafo da Internet do dia 01/07/2011 possui 25,9% mais arestas, 12,20% mais vértices e
gastou 37,41% mais tempo em sua execução, em comparação ao grafo do dia 01/01/2010.
Esses resultados indicam que o algoritmo HEDA, para os grafos da Internet avaliados,
apresenta tempo de execução proporcional ao aumento do tamanho do grafo.
6.1.2 Grafos Sintéticos
Assim como nos grafos da Internet, o HEDA foi executado três vezes para cada um dos
grafos sintéticos e os tempos médios das execuções foram calculados.
Para criação dos grafos sintéticos deste trabalho, utilizamos o gerador de grafos criado
por [8] e disponível na web1, baseado no modelo de Erdös-Rényi [49]. Foram gerados dois
tipos de grafos sintéticos. No primeiro tipo, apenas o número de arestas sofre variação, ou
seja, o número de vértices é �xo. No segundo tipo, o número de vértices e o número de
arestas são variáveis.1http://www.cs.cmu.edu/ukang/HADI/

6.1. RESULTADOS DO ALGORITMO HEDA 85
A Tabela 6.2 apresenta os dados numéricos referentes aos grafos sintéticos, em que as
arestas têm quantidades variadas, iniciando em cem mil e chegando até a um milhão de
arestas. A quantidade de vértices é �xa em 50.000. A tabela exibe ainda os resultados de
diâmetro D(G), raio R(G), o tempo de execução em minutos, a variação da quantidade de
arestas e a variação do tempo, ambos em comparação ao grafo da linha anterior.
Arestas D(G) R(G) Tempo (minutos) Variação Arestas Variação Tempo
100.000 31 22 141 - -
200.000 16 13 159 2X 1,13X
400.000 10 8 181 4X 1,28X
800.000 6 5 315 8X 2,23X
1.000.000 6 5 479 10X 3,39X
Tabela 6.2: Resultados HEDA - Grafos Sintéticos - Variação de Arestas
O grá�co da Figura 6.2 apresenta os resultados de tempo de execução para os grafos
sintéticos com variação de arestas. Podemos concluir, com base nos resultados, que o
algoritmo HEDA é escalável em relação à quantidade de arestas. Podemos observar que,
ao duplicar a quantidade de arestas de 100.000 para 200.000, o HEDA apresentou tempo
de execução apenas 0,13 vezes maior. Ao compararmos o grafo de 100.000 arestas com o
grafo com 1.000.000 arestas temos 10 vezes mais arestas e o tempo de execução 2,39 vezes
maior. Se compararmos o grafo de 400.000 arestas com o grafo de 800.000 arestas temos o
dobro de arestas e 0,74 vezes mais tempo de execução.
0
100
200
300
400
500
0 200 400 600 800 1000
Tem
po (
em m
inut
os)
Quantidade de Arestas (em milhares)
Variação de Arestas
HEDA
Figura 6.2: Resultados HEDA - Grafos Sintéticos - Variação de Arestas.
A Tabela 6.3 apresenta os dados numéricos referentes aos grafos sintéticos gerados
com quantidades de vértices e arestas variáveis, exibindo o identi�cador de cada grafo, a
quantidade de vértices, a quantidade de arestas e os resultados de diâmetro e raio de cada
um dos grafos, calculados pelo HEDA.
A Tabela 6.4 apresenta, para cada um dos grafos que variam a quantidade de arestas e

6.1. RESULTADOS DO ALGORITMO HEDA 86
Grafo Vértices Arestas D(G) R(G)
1 25.000 75.000 22 15
2 50.000 150.000 23 16
3 100.000 300.000 22 16
4 200.000 600.000 26 20
Tabela 6.3: Resultados HEDA - Grafos Sintéticos - Variação de Vértices e Arestas
a quantidade de vértices, uma coluna com a soma dos vértices e arestas (V + A), o tempo
de execução em minutos, a variação da quantidade de vértices e arestas e a variação do
tempo, ambos em comparação ao grafo da linha anterior.
Grafo V + A Tempo (minutos) Variação Grafo Variação Tempo
1 100.000 62 - -
2 200.000 209 2X 3,37X
3 400.000 974 4X 15,70X
4 800.000 1967 8X 31,72X
Tabela 6.4: Resultados HEDA - Grafos Sintéticos - Variação de Vértices e Arestas - Análise
dos Resultados
O grá�co da Figura 6.3 apresenta os resultados de tempo de execução dos grafos sinté-
ticos com variação de vértices e arestas.
0
400
800
1200
1600
2000
0 1 2 3 4
Tem
po (
em m
inut
os)
Identificador
Variação de Vértices e Arestas
HEDA
Figura 6.3: Resultados HEDA - Grafos Sintéticos - Variação de Vértices e Arestas.
Os resultados apresentados na Tabela 6.4 demonstraram que a comparação entre os
grafos com identi�cadores 1 e 2 apresentou aumento de duas vezes no número de vértices e
de arestas e 2,37 vezes no tempo de execução. Em comparação com o grafo 3, o aumento
do número de vértices e arestas foi de quatro vezes enquanto o aumento do tempo foi de
14,70 vezes. A comparação com o grafo 4 foi ainda maior; aumento do número de vértices e

6.1. RESULTADOS DO ALGORITMO HEDA 87
arestas �cou em 8 vezes cada e o aumento do tempo �cou em 30,72 vezes. Esse aumento no
tempo foi menor na comparação entre os grafos 1 e 2 devido ao overhead inicial do sistema.
Ao compararamos os grafos 3 e 4 é possível notar que houve aumento de duas vezes na
quantidade de vértices e arestas e o tempo de execução aumentou 2,02 vezes, indicando
que essa proporcionalidade no crescimento em grafos já grandes, elimina o problema do
overhead inicial.
6.1.3 Grafo IMDB
O grafo IMDB (Internet Movie Database) é um grafo não dirigido e real que representa
atores que tiveram participação em um determinado �lme. O grafo possui 757.395 vértices
e 4.539.634 arestas armazenadas em um arquivo com 60 Megabytes. Devido a limitações
do ambiente de teste como, por exemplo, o espaço em disco nos nós do cluster, não foi
possível processar o grafo em sua completude, ou seja, processar o grafo a partir de todos
os vértices para todos os outros vértices do grafo. Sendo assim, foi feito o processamento
partindo do primeiro vértice para todos os outros e dos 10, 100, 1.000 e 10.000 primeiros
vértices para todos os outros vértices do grafo.
A Tabela 6.5 apresenta os dados numéricos referentes ao grafo IMDB. A tabela exibe
a quantidade de vértices de partida, a variação da quantidade desses vértices de partida e
a variação do tempo de execução.
Vértices de Partida Tempo (em minutos) Variação Tempo
1 25 -
10 26 1,04X
100 32 1,28X
1.000 122 4,88X
10.000 1352 54,08X
Tabela 6.5: Resultados HEDA - Grafos IMDB
A Figura 6.4 apresenta os resultados para o grafo IMDB, processado pelo algoritmo
HEDA.
Os resultados apresentados pela Tabela 6.5 apresentam evidência da escalabilidade do
algoritmo quanto à sua principal tarefa: o cálculo das distâncias entre os vértices. Na
execução a partir de 1 vértice em comparação a execução a partir de 10 vértices, a variação
foi de apenas 0,04 vezes no tempo de execução enquanto a quantidade de vértices de partida
aumentou em 10 vezes. Na execução a partir de 1 vértice em comparação com a execução
a partir de 100 vértices, a variação no tempo foi de 0,28 vezes enquanto a quantidade
de vértices de partida aumentou em 100 vezes. Na execução a partir de 1 vértice em
comparação com a execução a partir de 1.000 vértices, a variação de tempo foi de 3,88
vezes enquanto a quantidade de vértices de partida aumentou em 1.000 vezes. Na execução
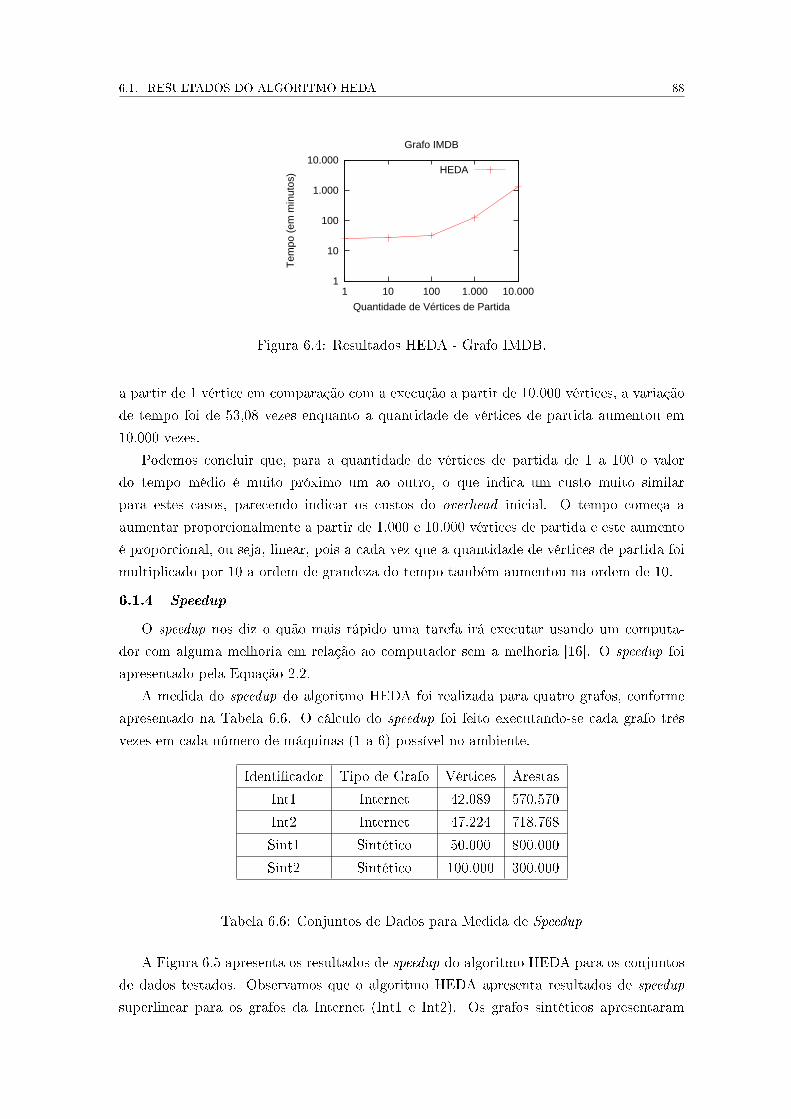
6.1. RESULTADOS DO ALGORITMO HEDA 88
1
10
100
1.000
10.000
1 10 100 1.000 10.000T
empo
(em
min
utos
)
Quantidade de Vértices de Partida
Grafo IMDB
HEDA
Figura 6.4: Resultados HEDA - Grafo IMDB.
a partir de 1 vértice em comparação com a execução a partir de 10.000 vértices, a variação
de tempo foi de 53,08 vezes enquanto a quantidade de vértices de partida aumentou em
10.000 vezes.
Podemos concluir que, para a quantidade de vértices de partida de 1 a 100 o valor
do tempo médio é muito próximo um ao outro, o que indica um custo muito similar
para estes casos, parecendo indicar os custos do overhead inicial. O tempo começa a
aumentar proporcionalmente a partir de 1.000 e 10.000 vértices de partida e este aumento
é proporcional, ou seja, linear, pois a cada vez que a quantidade de vértices de partida foi
multiplicado por 10 a ordem de grandeza do tempo também aumentou na ordem de 10.
6.1.4 Speedup
O speedup nos diz o quão mais rápido uma tarefa irá executar usando um computa-
dor com alguma melhoria em relação ao computador sem a melhoria [16]. O speedup foi
apresentado pela Equação 2.2.
A medida do speedup do algoritmo HEDA foi realizada para quatro grafos, conforme
apresentado na Tabela 6.6. O cálculo do speedup foi feito executando-se cada grafo três
vezes em cada número de máquinas (1 a 6) possível no ambiente.
Identi�cador Tipo de Grafo Vértices Arestas
Int1 Internet 42.089 570.570
Int2 Internet 47.224 718.768
Sint1 Sintético 50.000 800.000
Sint2 Sintético 100.000 300.000
Tabela 6.6: Conjuntos de Dados para Medida de Speedup
A Figura 6.5 apresenta os resultados de speedup do algoritmo HEDA para os conjuntos
de dados testados. Observamos que o algoritmo HEDA apresenta resultados de speedup
superlinear para os grafos da Internet (Int1 e Int2). Os grafos sintéticos apresentaram

6.1. RESULTADOS DO ALGORITMO HEDA 89
resultados de speedup bem próximos à linearidade.
1
2
3
4
5
6
1 2 3 4 5 6
Spe
edup
Quantidade de Máquinas
Medidas de Speedup do Algoritmo HEDA
Int1Int2
Sint1Sint2
Linear
Figura 6.5: Resultado HEDA - Speedup.
Resultados de speedup superlinear são relatados na literatura [16, 52]. Uma possível
causa pode ser o efeito de caching ao adicionar novos recursos. O tamanho total do cache
aumenta à medida que processadores são adicionados, resultando em menor número de
acessos à memória, reduzindo consideravelmente o tempo de acesso [55].
Alguns trabalhos que utilizam o modelo MapReduce e a ferramenta Hadoop apresen-
taram speedup superlinear [4, 56, 57]. O trabalho [4] atribui esse resultado ao efeito de
caching. Outra justi�cativa dada é que grande parte do tempo de execução é gasto nas
fases de intercalação e ordenação os dados de saída da função Map. Ao adicionar mais
núcleos ao processamento, o uso de caches reduz o overhead.
6.1.5 E�ciência
A e�ciência é uma métrica diretamente relacionada ao speedup e determina quão bem
utilizados estão os recursos computacionais. Para calcular a e�ciência de uma execução
paralela, deve-se calcular o speedup e dividí-lo pelo número de máquinas utilizadas. O
número é expresso em percentagem. Seja S(p) o speedup, p o número de máquinas, T (1)
o tempo de execução do algoritmo em apenas uma máquina do cluster e T (p) o tempo de
execução em p máquinas, a e�ciência E(p) é dada pela Equação 2.3.
A Figura 6.6 apresenta os percentuais de e�ciência para os grafos que tiveram o spe-
edup calculado na Seção 6.1.4. Alguns grafos como Int1, Int2 apresentaram percentual
de e�ciência máxima acima de 1. Isso se deve ao fato desses grafos apresentarem speedup
superlinear. O grafo Sint1 apresentou taxa de e�ciência máxima de 1. Já o grafo Sint2
apresentou taxa de e�ciência máxima de 0,88.
Dentre todos os grafos analisados, a maior taxa de e�ciência foi do grafo Int1 com
5 máquinas que apresentou e�ciência 1,06. A pior e�ciência foi apresentada pelo grafo
Sint1, com a taxa de 0,76. Todos os resultados de tempo de execução, speedup e taxas de
e�ciência dos grafos podem ser visualizadas nas tabelas do Apêndice A.

6.2. COMPARAÇÃO ENTRE OS ALGORITMOS HEDA E O HADI 90
0.6
0.8
1
1.2
1.4
1.6
1 2 3 4 5 6E
ficiê
ncia
Quantidade de Máquinas
Medidas de Eficiência do Algoritmo HEDA
Int1Int2
Sint1Sint2
Figura 6.6: Resultado HEDA - E�ciência.
6.1.6 Relação entre o Diâmetro do Grafo e o Tempo de Execução
O diâmetro do grafo também tem in�uência direta no tempo de execução do algoritmo
HEDA. Esse resultado por ser avaliado a partir dos dados apresentados na Tabela 6.7, para
os grafos sintéticos.
Vértices Arestas Tempo Diâmetro
50.000 150.000 209 23
50.000 200.000 159 16
Tabela 6.7: Análise de Diâmetros
A Tabela 6.7 apresenta o grafo com 50.000 vértices e 200.000 arestas com tempo de
execução menor que o grafo com 50.000 vértices e 150.000 arestas. Os dois grafos possuem
a mesma quantidade de vértices, porém o segundo grafo possui 33,34% a mais de arestas
e o tempo de execução do segundo grafo é 31,44% menor, em relação ao primeiro.
Isso acontece devido ao fato do algoritmo HEDA ser dividido em fases, onde o número
de fases é igual ao valor do diâmetro do grafo. Para o primeiro grafo o HEDA executa 23
fases e para o segundo grafo apenas 16. Portanto, o tempo de execução do algoritmo é
in�uenciado pelo diâmetro do grafo.
6.2 Comparação entre os Algoritmos HEDA e o HADI
Esta seção tem o objetivo de comparar o algoritmo HEDA com outro algoritmo da
literatura e o algoritmo escolhido para esta comparação foi o HADI [8] por ser um algoritmo
paralelo que tem diversas características similares ao HEDA. Dentre essas características
destaca-se o fato de o HADI ser baseado no modelo MapReduce e por encontrar medidas
de centralidade de grafos grandes, tais como o diâmetro e o raio.
A Seção 6.2.1 realiza a comparação dos algoritmos HEDA e HADI utilizando os grafos
da Internet como entrada de dados. Na Seção 6.2.2 todos os grafos sintéticos também são
utilizados para a comparação.
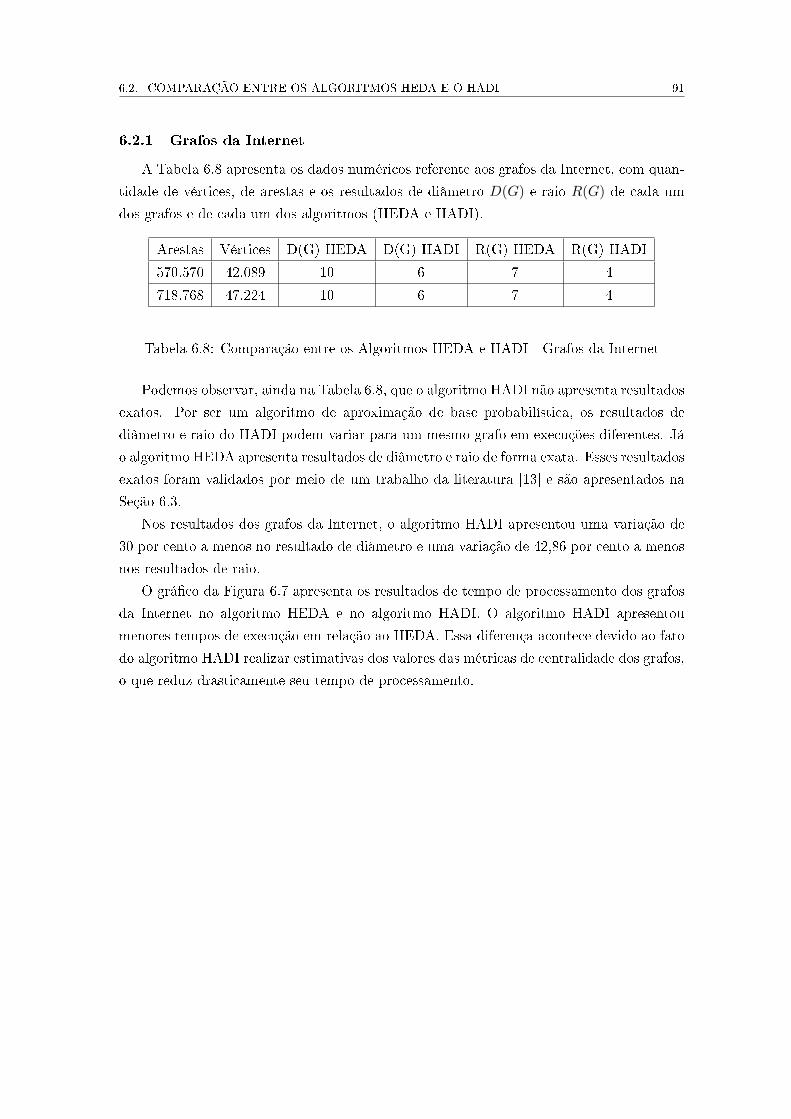
6.2. COMPARAÇÃO ENTRE OS ALGORITMOS HEDA E O HADI 91
6.2.1 Grafos da Internet
A Tabela 6.8 apresenta os dados numéricos referente aos grafos da Internet, com quan-
tidade de vértices, de arestas e os resultados de diâmetro D(G) e raio R(G) de cada um
dos grafos e de cada um dos algoritmos (HEDA e HADI).
Arestas Vértices D(G) HEDA D(G) HADI R(G) HEDA R(G) HADI
570.570 42.089 10 6 7 4
718.768 47.224 10 6 7 4
Tabela 6.8: Comparação entre os Algoritmos HEDA e HADI - Grafos da Internet
Podemos observar, ainda na Tabela 6.8, que o algoritmo HADI não apresenta resultados
exatos. Por ser um algoritmo de aproximação de base probabilística, os resultados de
diâmetro e raio do HADI podem variar para um mesmo grafo em execuções diferentes. Já
o algoritmo HEDA apresenta resultados de diâmetro e raio de forma exata. Esses resultados
exatos foram validados por meio de um trabalho da literatura [13] e são apresentados na
Seção 6.3.
Nos resultados dos grafos da Internet, o algoritmo HADI apresentou uma variação de
30 por cento a menos no resultado de diâmetro e uma variação de 42,86 por cento a menos
nos resultados de raio.
O grá�co da Figura 6.7 apresenta os resultados de tempo de processamento dos grafos
da Internet no algoritmo HEDA e no algoritmo HADI. O algoritmo HADI apresentou
menores tempos de execução em relação ao HEDA. Essa diferença acontece devido ao fato
do algoritmo HADI realizar estimativas dos valores das métricas de centralidade dos grafos,
o que reduz drasticamente seu tempo de processamento.
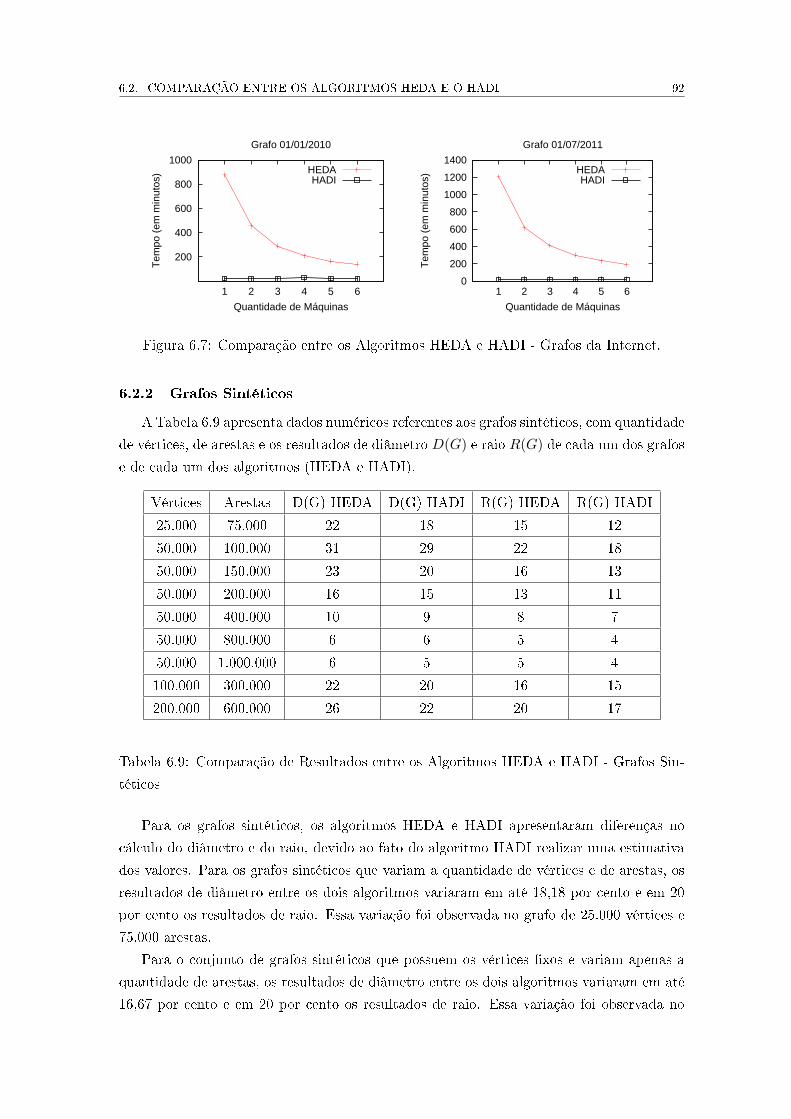
6.2. COMPARAÇÃO ENTRE OS ALGORITMOS HEDA E O HADI 92
200
400
600
800
1000
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Grafo 01/01/2010
HEDAHADI
0
200
400
600
800
1000
1200
1400
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Grafo 01/07/2011
HEDAHADI
Figura 6.7: Comparação entre os Algoritmos HEDA e HADI - Grafos da Internet.
6.2.2 Grafos Sintéticos
A Tabela 6.9 apresenta dados numéricos referentes aos grafos sintéticos, com quantidade
de vértices, de arestas e os resultados de diâmetro D(G) e raio R(G) de cada um dos grafos
e de cada um dos algoritmos (HEDA e HADI).
Vértices Arestas D(G) HEDA D(G) HADI R(G) HEDA R(G) HADI
25.000 75.000 22 18 15 12
50.000 100.000 31 29 22 18
50.000 150.000 23 20 16 13
50.000 200.000 16 15 13 11
50.000 400.000 10 9 8 7
50.000 800.000 6 6 5 4
50.000 1.000.000 6 5 5 4
100.000 300.000 22 20 16 15
200.000 600.000 26 22 20 17
Tabela 6.9: Comparação de Resultados entre os Algoritmos HEDA e HADI - Grafos Sin-
téticos
Para os grafos sintéticos, os algoritmos HEDA e HADI apresentaram diferenças no
cálculo do diâmetro e do raio, devido ao fato do algoritmo HADI realizar uma estimativa
dos valores. Para os grafos sintéticos que variam a quantidade de vértices e de arestas, os
resultados de diâmetro entre os dois algoritmos variaram em até 18,18 por cento e em 20
por cento os resultados de raio. Essa variação foi observada no grafo de 25.000 vértices e
75.000 arestas.
Para o conjunto de grafos sintéticos que possuem os vértices �xos e variam apenas a
quantidade de arestas, os resultados de diâmetro entre os dois algoritmos variaram em até
16,67 por cento e em 20 por cento os resultados de raio. Essa variação foi observada no
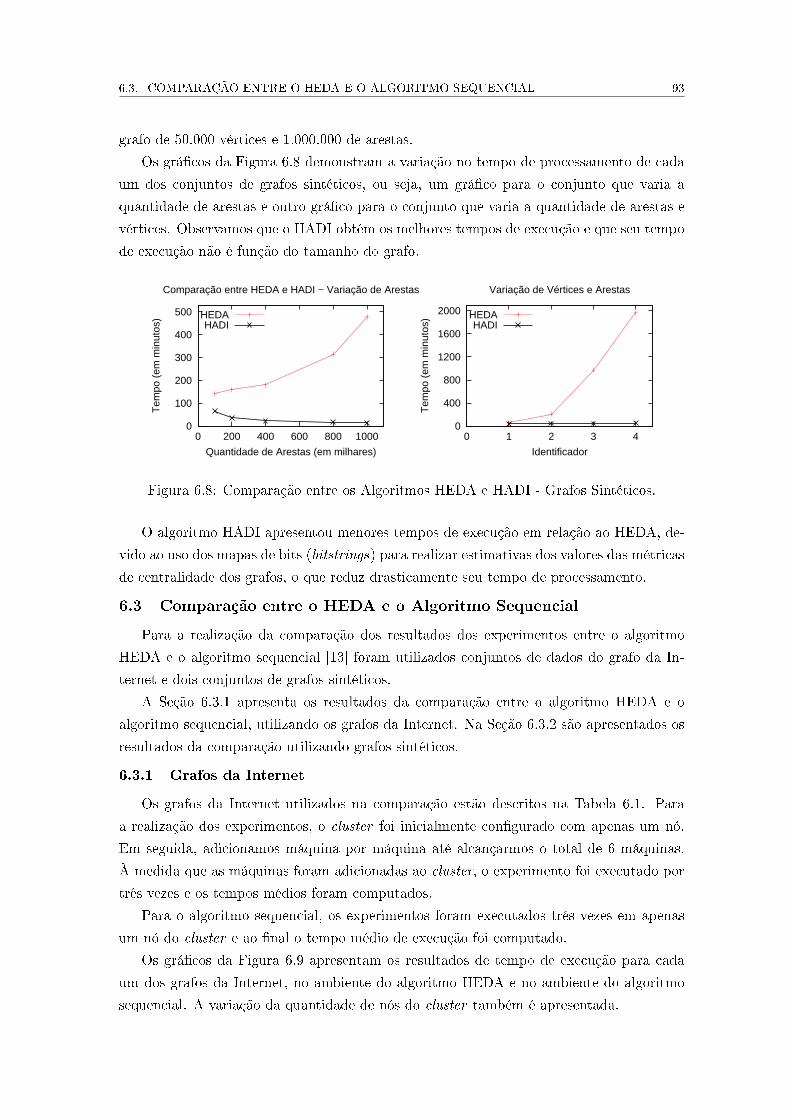
6.3. COMPARAÇÃO ENTRE O HEDA E O ALGORITMO SEQUENCIAL 93
grafo de 50.000 vértices e 1.000.000 de arestas.
Os grá�cos da Figura 6.8 demonstram a variação no tempo de processamento de cada
um dos conjuntos de grafos sintéticos, ou seja, um grá�co para o conjunto que varia a
quantidade de arestas e outro grá�co para o conjunto que varia a quantidade de arestas e
vértices. Observamos que o HADI obtém os melhores tempos de execução e que seu tempo
de execução não é função do tamanho do grafo.
0
100
200
300
400
500
0 200 400 600 800 1000
Tem
po (
em m
inut
os)
Quantidade de Arestas (em milhares)
Comparação entre HEDA e HADI − Variação de Arestas
HEDAHADI
0
400
800
1200
1600
2000
0 1 2 3 4T
empo
(em
min
utos
)
Identificador
Variação de Vértices e Arestas
HEDAHADI
Figura 6.8: Comparação entre os Algoritmos HEDA e HADI - Grafos Sintéticos.
O algoritmo HADI apresentou menores tempos de execução em relação ao HEDA, de-
vido ao uso dos mapas de bits (bitstrings) para realizar estimativas dos valores das métricas
de centralidade dos grafos, o que reduz drasticamente seu tempo de processamento.
6.3 Comparação entre o HEDA e o Algoritmo Sequencial
Para a realização da comparação dos resultados dos experimentos entre o algoritmo
HEDA e o algoritmo sequencial [13] foram utilizados conjuntos de dados do grafo da In-
ternet e dois conjuntos de grafos sintéticos.
A Seção 6.3.1 apresenta os resultados da comparação entre o algoritmo HEDA e o
algoritmo sequencial, utilizando os grafos da Internet. Na Seção 6.3.2 são apresentados os
resultados da comparação utilizando grafos sintéticos.
6.3.1 Grafos da Internet
Os grafos da Internet utilizados na comparação estão descritos na Tabela 6.1. Para
a realização dos experimentos, o cluster foi inicialmente con�gurado com apenas um nó.
Em seguida, adicionamos máquina por máquina até alcançarmos o total de 6 máquinas.
À medida que as máquinas foram adicionadas ao cluster, o experimento foi executado por
três vezes e os tempos médios foram computados.
Para o algoritmo sequencial, os experimentos foram executados três vezes em apenas
um nó do cluster e ao �nal o tempo médio de execução foi computado.
Os grá�cos da Figura 6.9 apresentam os resultados de tempo de execução para cada
um dos grafos da Internet, no ambiente do algoritmo HEDA e no ambiente do algoritmo
sequencial. A variação da quantidade de nós do cluster também é apresentada.
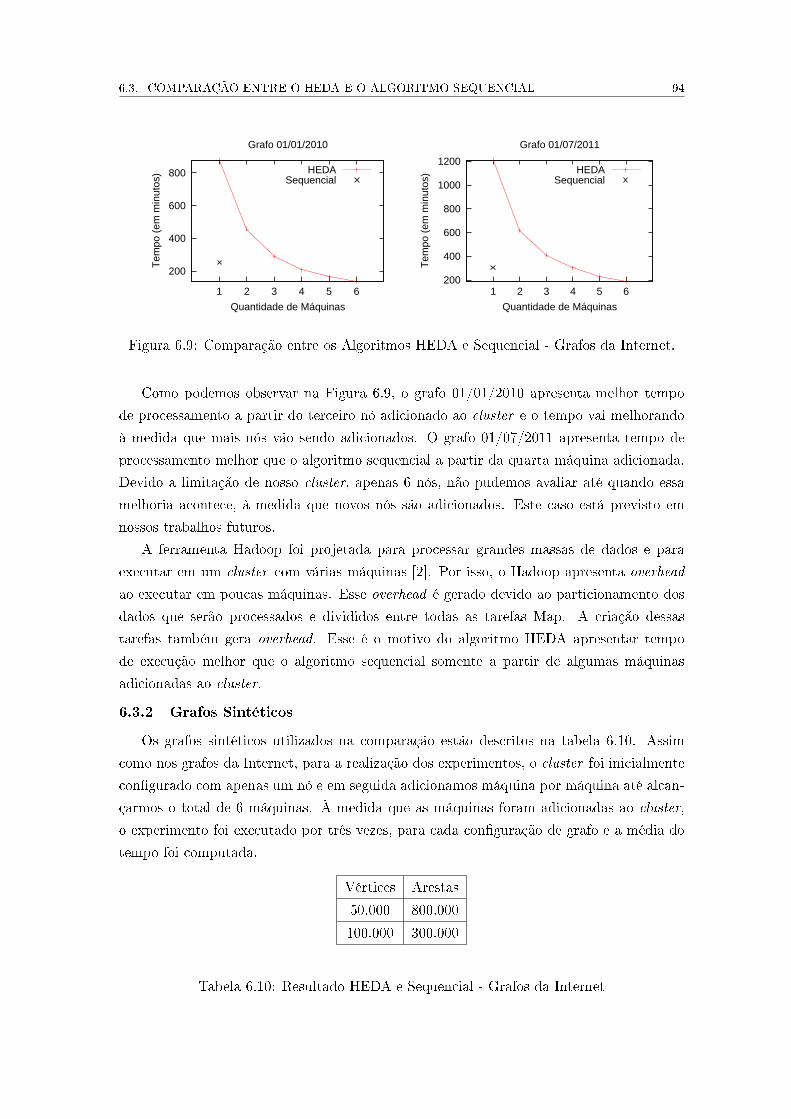
6.3. COMPARAÇÃO ENTRE O HEDA E O ALGORITMO SEQUENCIAL 94
200
400
600
800
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Grafo 01/01/2010
HEDASequencial
200
400
600
800
1000
1200
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Grafo 01/07/2011
HEDASequencial
Figura 6.9: Comparação entre os Algoritmos HEDA e Sequencial - Grafos da Internet.
Como podemos observar na Figura 6.9, o grafo 01/01/2010 apresenta melhor tempo
de processamento a partir do terceiro nó adicionado ao cluster e o tempo vai melhorando
à medida que mais nós vão sendo adicionados. O grafo 01/07/2011 apresenta tempo de
processamento melhor que o algoritmo sequencial a partir da quarta máquina adicionada.
Devido a limitação de nosso cluster, apenas 6 nós, não pudemos avaliar até quando essa
melhoria acontece, à medida que novos nós são adicionados. Este caso está previsto em
nossos trabalhos futuros.
A ferramenta Hadoop foi projetada para processar grandes massas de dados e para
executar em um cluster com várias máquinas [2]. Por isso, o Hadoop apresenta overhead
ao executar em poucas máquinas. Esse overhead é gerado devido ao particionamento dos
dados que serão processados e divididos entre todas as tarefas Map. A criação dessas
tarefas também gera overhead. Esse é o motivo do algoritmo HEDA apresentar tempo
de execução melhor que o algoritmo sequencial somente a partir de algumas máquinas
adicionadas ao cluster.
6.3.2 Grafos Sintéticos
Os grafos sintéticos utilizados na comparação estão descritos na tabela 6.10. Assim
como nos grafos da Internet, para a realização dos experimentos, o cluster foi inicialmente
con�gurado com apenas um nó e em seguida adicionamos máquina por máquina até alcan-
çarmos o total de 6 máquinas. À medida que as máquinas foram adicionadas ao cluster,
o experimento foi executado por três vezes, para cada con�guração de grafo e a média do
tempo foi computada.
Vértices Arestas
50.000 800.000
100.000 300.000
Tabela 6.10: Resultado HEDA e Sequencial - Grafos da Internet
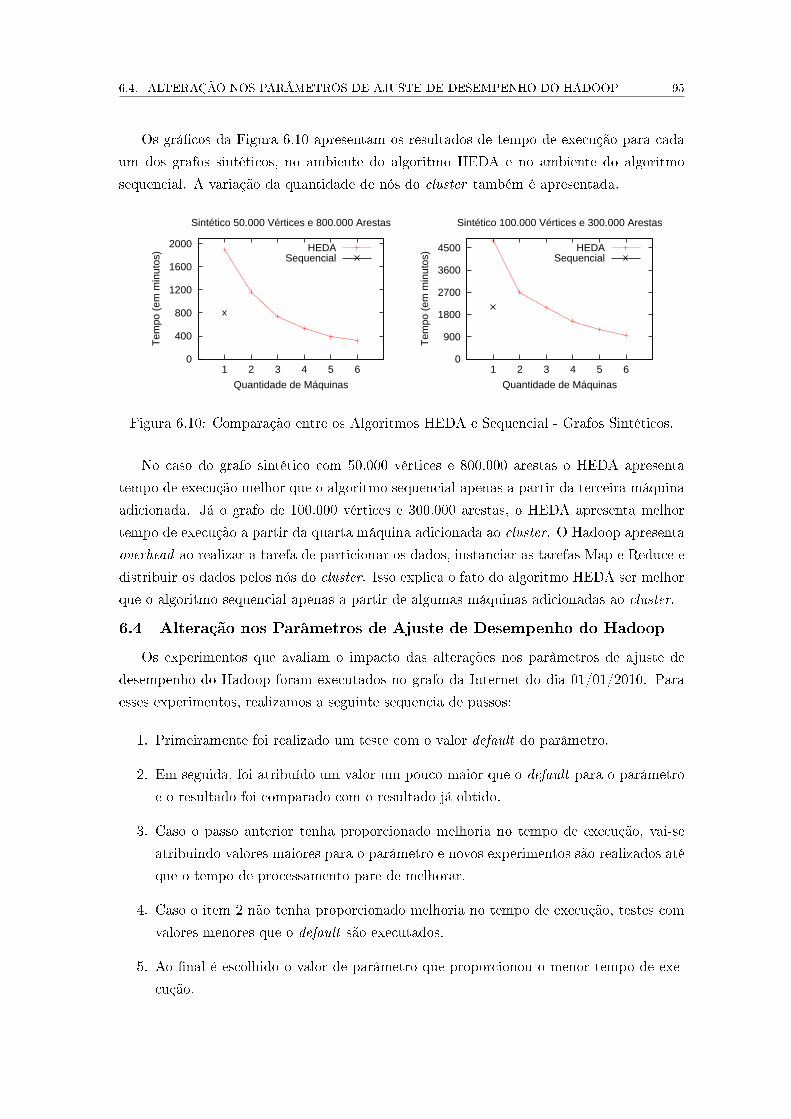
6.4. ALTERAÇÃO NOS PARÂMETROS DE AJUSTE DE DESEMPENHO DO HADOOP 95
Os grá�cos da Figura 6.10 apresentam os resultados de tempo de execução para cada
um dos grafos sintéticos, no ambiente do algoritmo HEDA e no ambiente do algoritmo
sequencial. A variação da quantidade de nós do cluster também é apresentada.
0
400
800
1200
1600
2000
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Sintético 50.000 Vértices e 800.000 Arestas
HEDASequencial
0
900
1800
2700
3600
4500
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Sintético 100.000 Vértices e 300.000 Arestas
HEDASequencial
Figura 6.10: Comparação entre os Algoritmos HEDA e Sequencial - Grafos Sintéticos.
No caso do grafo sintético com 50.000 vértices e 800.000 arestas o HEDA apresenta
tempo de execução melhor que o algoritmo sequencial apenas a partir da terceira máquina
adicionada. Já o grafo de 100.000 vértices e 300.000 arestas, o HEDA apresenta melhor
tempo de execução a partir da quarta máquina adicionada ao cluster. O Hadoop apresenta
overhead ao realizar a tarefa de particionar os dados, instanciar as tarefas Map e Reduce e
distribuir os dados pelos nós do cluster. Isso explica o fato do algoritmo HEDA ser melhor
que o algoritmo sequencial apenas a partir de algumas máquinas adicionadas ao cluster.
6.4 Alteração nos Parâmetros de Ajuste de Desempenho do Hadoop
Os experimentos que avaliam o impacto das alterações nos parâmetros de ajuste de
desempenho do Hadoop foram executados no grafo da Internet do dia 01/01/2010. Para
esses experimentos, realizamos a seguinte sequência de passos:
1. Primeiramente foi realizado um teste com o valor default do parâmetro.
2. Em seguida, foi atribuído um valor um pouco maior que o default para o parâmetro
e o resultado foi comparado com o resultado já obtido.
3. Caso o passo anterior tenha proporcionado melhoria no tempo de execução, vai-se
atribuindo valores maiores para o parâmetro e novos experimentos são realizados até
que o tempo de processamento pare de melhorar.
4. Caso o item 2 não tenha proporcionado melhoria no tempo de execução, testes com
valores menores que o default são executados.
5. Ao �nal é escolhido o valor de parâmetro que proporcionou o menor tempo de exe-
cução.

6.4. ALTERAÇÃO NOS PARÂMETROS DE AJUSTE DE DESEMPENHO DO HADOOP 96
Os nomes e valores dos parâmetros que foram alterados e que resultaram em diminui-
ção no tempo de processamento são apresentados abaixo. Além disso, uma justi�cativa
para cada alteração é apresentada. A descrição sobre o funcionamento de cada um dos
parâmetros pode ser encontrada na seção 5.3.
• mapred.child.java.opts: Veri�camos que para grafos grandes é necessário aumen-
tar o tamanho da pilha para a máquina virtual do Java (JVM). O valor padrão para
esse parâmetro é 200 Megabytes. Iniciamos os testes aumentando esse valor de 200
em 200 Megabytes até que o tempo de processamento parou de melhorar ao atingir
1000 Megabytes. Ao chegar nesse valor, reduzimos o valor do parâmetro em 100
Megabytes, chegando a 900 Megabytes. Nesse momento o valor de 900 Megabytes
foi o melhor valor, pois apresentou tempo de processamento melhor que o valor de
800 e melhor que o valor de 1000 Megabytes.
• mapred.tasktracker.map/reduce.tasks.maximum: Para esses parâmetro o Ha-
doop considera o valor padrão 2. Iniciamos os experimentos atribuindo o valor de
8 para o parâmetro, que é o valor total de núcleos de cada nó do cluster. Nesse
momento houve melhora no tempo de processamento, porém ao atribuir o valor de 9,
esse tempo piorou. Em seguida atribuimos o valor 7 e o resultado foi melhor que 8.
Atribuímos então o valor 6 e novamente o tempo de processamento piorou. Ao �nal,
decidimos considerar o valor 7 como o melhor valor para esse parâmetro, levando em
conta o grafo processado.
• tasktracker.http.threads: O Hadoop considera o valor default de 50 threads. Ini-
ciamos os experimentos atribuindo o valor de 60 e houve melhora no tempo de pro-
cessamento. Em seguida elevamos o valor do parâmetro para 70 e o tempo de pro-
cessamento piorou. Decidimos então considerar o valor de 60 como o melhor valor
para esse parâmetro, levando em conta o grafo processado.
• io.sort.factor: Para este parâmetro o Hadoop considera o valor default 10. Inicia-
mos os testes elevando esse valor de 10 em 10 unidades e o tempo de processamento
foi melhorando até atingir o valor de 120. A partir desse valor, ao chegar em 130,
o tempo de processamento piorou. Sendo assim, consideramos o valor 120 como o
melhor valor para esse parâmetro, levando em consideração o grafo processado.
• mapred.reduce.parallel.copies: O Hadoop considera o valor 5 como default para
esse parametro. Assim decidimos elevar o valor desse parâmetro em 2 em 2 unida-
des. O tempo de processamento foi melhorando até atingir o valor 9. Quando foi
atribuído o valor 11, o tempo de processamento piorou. Assim, decidiu-se realizar o
processamento do grafo com o valor 10 e ainda assim houve melhora em relação ao
valor 9. Consideramos então como o melhor valor para esse parâmetro, levando em
conta o grafo processado, o valor 10.

6.4. ALTERAÇÃO NOS PARÂMETROS DE AJUSTE DE DESEMPENHO DO HADOOP 97
• io.�le.bu�er.size: O valor default desse parâmetro atribuído pelo Hadoop é 4096
ou 4KB. Iniciamos os testes aumentando o valor do parâmetro de 4096 em 4096.
O tempo de processamento apresentou melhorias até atingirmos o valor de 98304
ou 96KB. Ao elevarmos o valor do parâmetro para 102400 ou 100KB o tempo de
processamento começou a piorar. Assim decidimos manter o valor de 98304 como o
melhor valor para esse parâmetro, levando em conta o grafo processado.
• io.sort.mb: O Hadoop atribui o valor default 100 Megabytes para esse parâmetro.
Iniciamos a avaliação do impacto desse parâmetro no tempo de processamento ele-
vando o valor de 100 em 100 Megabytes. O tempo de processamento apresentou
melhoria até atingirmos o valor de 400 Megabytes. Ao elevar o valor do parâmetro
para 500 Megabytes, o tempo de processamento apresentou piora. Assim, o valor de
400 Megabytes foi considerado como o melhor valor para esse parâmetro, levando em
consideração o grafo processado.
• Arquivos Abertos pelo Sistema Operacional: Como o Hadoop trabalha com
grandes quantidades de arquivos abertos, foi necessário aumentar a quantidade de
arquivos abertos simultaneamente pelo sistema operacional. O padrão é de 1024 ar-
quivos abertos por processo. Assim iniciamos a alteração desse parâmetro atribuindo
o valor de 8192. Ao realizar essa alteração o tempo de execução melhorou. Em se-
guida atribuimos o valor 12288 e o tempo de execução continuou melhorando. Após
foi atribuído o valor de 16384 e ainda houve melhora no tempo de processamento.
Em seguida, atribuímos o valor de 24576 e o tempo de processamento piorou. Assim
decidimos manter o valor de 16384 para esse parâmetro.
A tabela 6.11 apresenta o resumo dos parâmetros de ajuste de desempenho que sofre-
ram alterações, assim como seus valores default e os melhores valores atribuídos por este
trabalho.
Nome do Parâmetro Valor default Melhor Valor
mapred.child.java.opts 200 900
mapred.tasktracker.map/reduce.tasks.maximum 2 2
tasktracker.http.threads 50 60
io.sort.factor 10 120
mapred.reduce.parallel.copies 5 10
io.�le.bu�er.size 4096 98304
io.sort.mb 100 400
Arquivos abertos 1024 16384
Tabela 6.11: Resultado HEDA - Valores dos Parâmetros de Ajuste de Desempenho
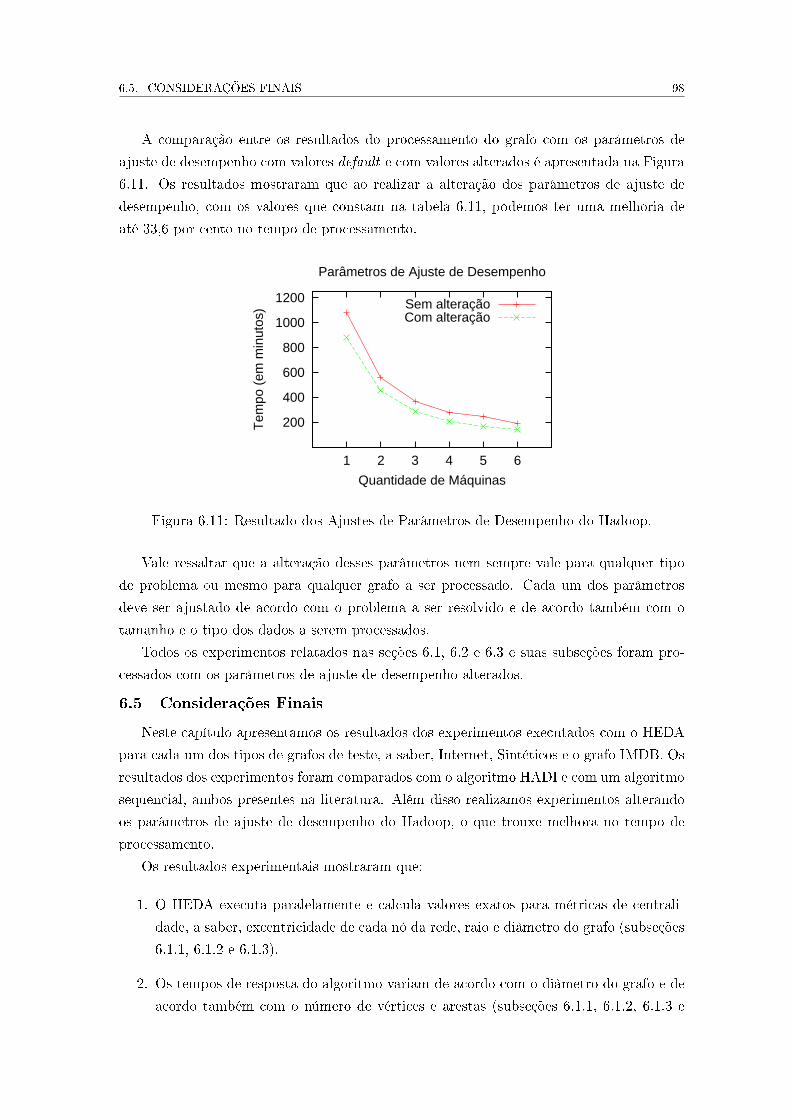
6.5. CONSIDERAÇÕES FINAIS 98
A comparação entre os resultados do processamento do grafo com os parâmetros de
ajuste de desempenho com valores default e com valores alterados é apresentada na Figura
6.11. Os resultados mostraram que ao realizar a alteração dos parâmetros de ajuste de
desempenho, com os valores que constam na tabela 6.11, podemos ter uma melhoria de
até 33,6 por cento no tempo de processamento.
200
400
600
800
1000
1200
1 2 3 4 5 6
Tem
po (
em m
inut
os)
Quantidade de Máquinas
Parâmetros de Ajuste de Desempenho
Sem alteraçãoCom alteração
Figura 6.11: Resultado dos Ajustes de Parâmetros de Desempenho do Hadoop.
Vale ressaltar que a alteração desses parâmetros nem sempre vale para qualquer tipo
de problema ou mesmo para qualquer grafo a ser processado. Cada um dos parâmetros
deve ser ajustado de acordo com o problema a ser resolvido e de acordo também com o
tamanho e o tipo dos dados a serem processados.
Todos os experimentos relatados nas seções 6.1, 6.2 e 6.3 e suas subseções foram pro-
cessados com os parâmetros de ajuste de desempenho alterados.
6.5 Considerações Finais
Neste capítulo apresentamos os resultados dos experimentos executados com o HEDA
para cada um dos tipos de grafos de teste, a saber, Internet, Sintéticos e o grafo IMDB. Os
resultados dos experimentos foram comparados com o algoritmo HADI e com um algoritmo
sequencial, ambos presentes na literatura. Além disso realizamos experimentos alterando
os parâmetros de ajuste de desempenho do Hadoop, o que trouxe melhora no tempo de
processamento.
Os resultados experimentais mostraram que:
1. O HEDA executa paralelamente e calcula valores exatos para métricas de centrali-
dade, a saber, excentricidade de cada nó da rede, raio e diâmetro do grafo (subseções
6.1.1, 6.1.2 e 6.1.3).
2. Os tempos de resposta do algoritmo variam de acordo com o diâmetro do grafo e de
acordo também com o número de vértices e arestas (subseções 6.1.1, 6.1.2, 6.1.3 e

6.5. CONSIDERAÇÕES FINAIS 99
6.1.6).
3. O speedup do algoritmo é próximo ao linear (subseção 6.1.4).
4. A e�ciência do algoritmo varia de 0,76 até 1,06 (subseção 6.1.5). A e�ciência acima
de 1 foi encontrada em grafos que possuem speedup superlinear.
5. O algoritmo é projetado para executar grafos de tamanhos medianos; grafos pequenos
podem apresentar tempos de execução menores em algoritmos não paralelos. O Ha-
doop tem um custo inicial referente à instância das tarefas, gerenciamento dos nós do
cluster e distribuição dos trabalhos. Esse overhead pode inviabilizar o processamento
desses grafos.
O próximo capítulo apresenta as conclusões deste trabalho e os trabalhos futuros.

Capítulo 7
Conclusão e Trabalhos Futuros
A programação paralela esteve sempre presente nos estudos da computação. No en-
tanto, a ampla disponibilidade de máquinas paralelas está sendo experimentada pela pri-
meira vez na história da computação. Neste contexto, a programação paralela tem um
apelo sem precedentes. Este trabalho se insere nesse contexto.
Neste trabalho, apresentamos um algoritmo paralelo baseado no modelo MapReduce,
denominado HEDA (Hadoop-based Exact Diameter Algorithm), para calcular valores exatos
para métricas de centralidade em grafos grandes. As métricas calculadas pelo algoritmo
são o menor caminho a partir de todos os vértices para todos os outros vértices do grafo,
as excentricidades de cada um dos vértices, o diâmetro, raio, centro e periferia do grafo.
A exatidão das métricas calculadas pelo algoritmo HEDA foi validada com a execução de
um algoritmo relatado na literatura.
O algoritmo HEDA foi projetado no modelo de programação paralela MapReduce e
programado em Hadoop. Para demonstrar sua correção e desempenho, diversos experi-
mentos foram planejados e executados. Foram utilizados, para testar o algoritmo, três
tipos de grafos, sendo eles os grafos dos sistemas autônomos da Internet, grafos sintéticos
gerados por meio de geradores de grafos e o grafo IMDB, que é um grafo real com milha-
res de vértices e milhões de arestas. O algoritmo paralelo HEDA atingiu o seu principal
objetivo que é encontrar medidas exatas para métricas de centralidade em grafos de redes
complexas.
Para avaliação do algoritmo HEDA, utilizamos o tempo de processamento dos expe-
rimentos e o cálculo de seu speedup e e�ciência. Os resultados foram comparados com o
principal trabalho da literatura, o HADI, que é um algoritmo de aproximação que também
calcula métricas de centralidade de grafos grandes, porém seus resultados são estimados.
O Hadoop fornece diversos parâmetros para ajuste de desempenho e foi realizado diversas
combinações para veri�car o impacto da alteração dos valores desses parâmetros no tempo
de execução do algoritmo HEDA.
Os resultados dos experimentos executados com os grafos da topologia da Internet de-
monstraram que após o overhead inicial do Hadoop, o tempo de execução do HEDA vai
diminuindo à medida que mais máquinas vão sendo adicionadas ao cluster. Observamos
que os grafos que possuem variação de arestas apresentam melhor proporcionalidade no
100

7.1. TRABALHOS FUTUROS 101
tempo de execução em comparação aos grafos que possuem variação de arestas e vértices.
Além disso, observamos que o diâmetro do grafo tem grande in�uência no tempo de exe-
cução devido à arquitetura em fases do algoritmo HEDA. O tempo de execução do HEDA
comparado com o tempo de execução do algoritmo sequencial foi melhor à medida que
máquinas foram sendo adicionadas ao cluster.
Os resultados de tempo de execução do algoritmo HEDA foram comparados com o prin-
cipal algoritmo paralelo para redes complexas modeladas por grafos que utiliza o modelo
MapReduce, o algoritmo HADI. Nessa comparação concluímos que o HADI apresentou
tempos de execução mais rápidos que o HEDA; porém, conforme esperado, os resultados
das medidas de centralidade não foram iguais. Essas medidas apresentaram diferenças de
até 30% a menos no resultado de diâmetro e variação de até 33,33% a menos no resultado
de raio. O algoritmo HADI dá maior prioridade à exatidão do resultado das métricas de
centralidade, apresentando resultados estimados, para privilegiar o tempo de execução. O
algoritmo HEDA, por outro lado, privilegia o resultado exato das métricas de centralidade
e para isso, compromete o tempo de execução.
Quanto aos parâmetros de ajuste de desempenho disponíveis na ferramenta Hadoop,
podemos concluir que estes têm participação importante na melhoria do tempo de proces-
samento. Nesse trabalho, com conjuntos de dados especí�cos, foi possível conseguir uma
melhoria de até 33,6% no tempo de execução ao ajustar os parâmetros.
O algoritmo HEDA apresentou speedup superlinear para alguns grafos utilizados nos
experimentos, como é o caso dos grafos dos sistemas autônomos da Internet. Outros grafos,
tais como os grafos sintéticos, apresentaram valores de speedup próximos à linearidade.
Esse speedup superlinear pode ser atribuído ao efeito de caching. Foram observados valores
de e�ciência superior a 1 em alguns experimentos e esse valor ocorreu em grafos que
apresentaram speedup superlinear.
7.1 Trabalhos Futuros
Devemos ressaltar que os experimentos realizados nesse trabalho foram processados em
um pequeno cluster em comparação aos experimentos realizados por outros trabalhos da
literatura. É preciso futuramente executar os mesmos experimentos em um cluster maior,
com o objetivo de veri�car o comportamento do algoritmo quanto ao tempo de execução,
à medida que mais máquinas são adicionadas ao cluster.
Para processamento de grafos ainda maiores àqueles que foram processados nesse traba-
lho, são necessárias máquinas com mais espaço em disco pois, como sabemos, os algoritmos
paralelos para calcular as métricas de centralidade de redes complexas geram grandes mas-
sas de dados.
Sugerimos ainda, como trabalho futuro, algumas melhorias no próprio algoritmo HEDA.
A experiência da programação e execução do algoritmo nos permitiu ver que existem mui-
tas formas de realizar essas melhorias. A principal delas é não repassar as informações de
vértices já totalmente processados para fases posteriores. Se as distâncias de um deter-

7.2. CONSIDERAÇÕES FINAIS 102
minado vértice para todos os outros vértices do grafo já foram encontradas, estas deverão
ser armazenadas em um arquivo diferente do arquivo de distâncias, no HDFS, para não
sobrecarregar os discos dos nós. Com essas distâncias encontradas, é possível calcular as
excentricidades dos vértices com funções intermediárias que encontram as métricas de cen-
tralidade e, em seguida, eliminar os dados referentes aos menores caminhos, já que estes
dados ocupam muito espaço e causam maior tráfego na rede. Para veri�car se todas as
distâncias de determinado vértice já foram calculadas, pode-se utilizar apenas uma função
Map sem Reduce. Essa técnica é mais rápida, pois assim o modelo não realiza a opera-
ção mais custosa do MapReduce que é a ordenação dos dados. A ordenação dos dados é
processada ao mudar de uma fase Map para uma fase Reduce.
Outra alteração no algoritmo que deve ser realizada é a utilização de combiners para
eliminar dados duplicados entre as fases Map e Reduce e assim reduzir o tráfego de rede.
Outro trabalho que pode ser desenvolvido e trazer grandes benefícios é a criação de uma
ferramenta para a con�guração e manipulação das funcionalidades do Hadoop. Por meio
dessa ferramenta será possível manipular os diversos parâmetros de ajuste de desempenho,
iniciar e parar os serviços, gerenciar e formatar o HDFS, visualizar logs e acompanhar a
execução dos processos da ferramenta Hadoop. Tudo isso por meio de uma interface grá�ca,
onde todas as funcionalidades estariam ao alcance do usuário, evitando a necessidade de
longas linhas de comando.
7.2 Considerações Finais
Esse trabalho foi nossa primeira experiência com programação paralela, principalmente
com o modelo MapReduce e o ambiente Hadoop. O ambiente de cluster, exigido pelo
modelo, é um ambiente que tem uma con�guração não trivial e que demanda muito tempo
para esse �m. Em comparação com outros trabalhos da literatura já consolidados, tais
como o HADI e o Pregel, nosso trabalho contou com o ambiente computacional, a equipe
de pesquisadores e o tempo de desenvolvimento bastante restritos. No entanto, mesmo
frente à estas restrições, consideramos que o objetivo foi alcançado e os resultados foram
satisfatórios.
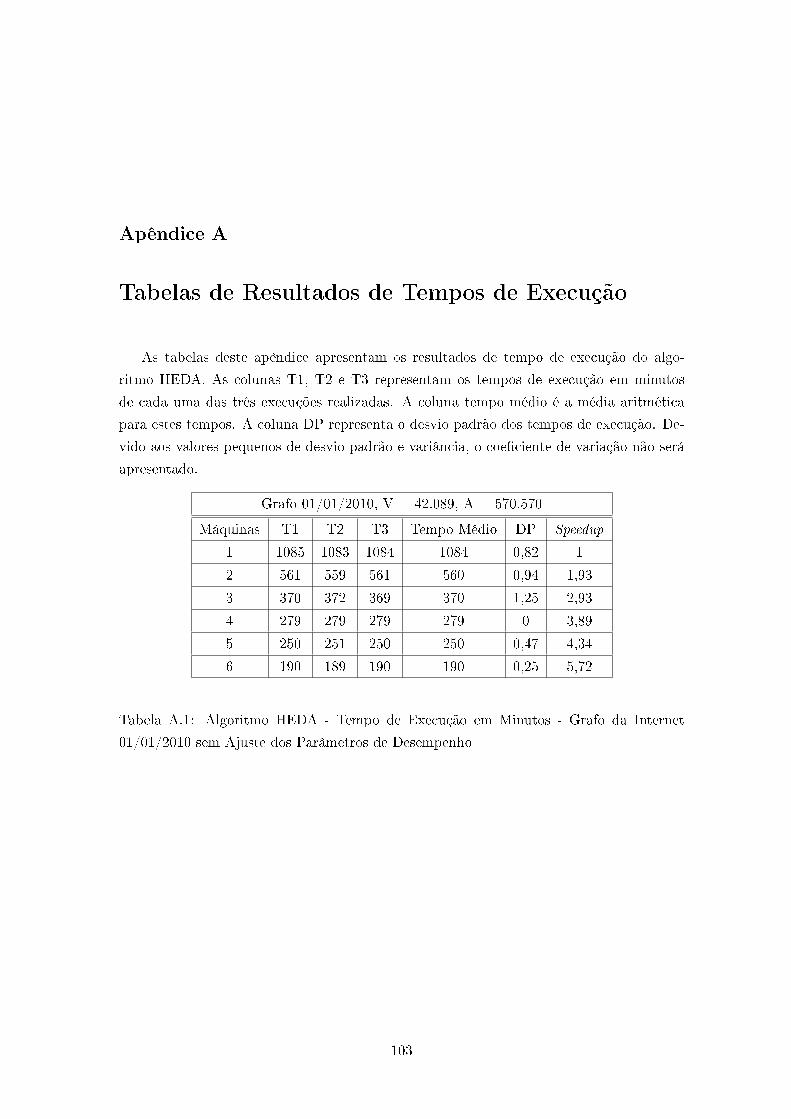
Apêndice A
Tabelas de Resultados de Tempos de Execução
As tabelas deste apêndice apresentam os resultados de tempo de execução do algo-
ritmo HEDA. As colunas T1, T2 e T3 representam os tempos de execução em minutos
de cada uma das três execuções realizadas. A coluna tempo médio é a média aritmética
para estes tempos. A coluna DP representa o desvio padrão dos tempos de execução. De-
vido aos valores pequenos de desvio padrão e variância, o coe�ciente de variação não será
apresentado.
Grafo 01/01/2010, V = 42.089, A = 570.570
Máquinas T1 T2 T3 Tempo Médio DP Speedup
1 1085 1083 1084 1084 0,82 1
2 561 559 561 560 0,94 1,93
3 370 372 369 370 1,25 2,93
4 279 279 279 279 0 3,89
5 250 251 250 250 0,47 4,34
6 190 189 190 190 0,25 5,72
Tabela A.1: Algoritmo HEDA - Tempo de Execução em Minutos - Grafo da Internet
01/01/2010 sem Ajuste dos Parâmetros de Desempenho
103
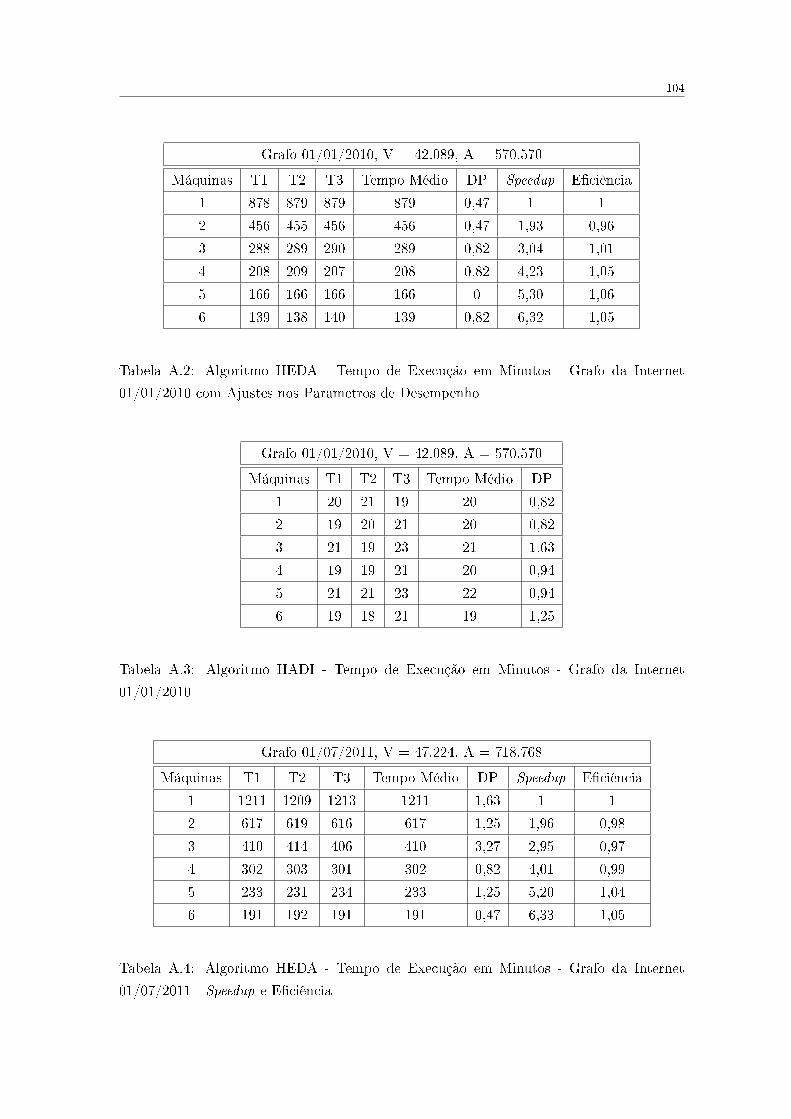
104
Grafo 01/01/2010, V = 42.089, A = 570.570
Máquinas T1 T2 T3 Tempo Médio DP Speedup E�ciência
1 878 879 879 879 0,47 1 1
2 456 455 456 456 0,47 1,93 0,96
3 288 289 290 289 0,82 3,04 1,01
4 208 209 207 208 0,82 4,23 1,05
5 166 166 166 166 0 5,30 1,06
6 139 138 140 139 0,82 6,32 1,05
Tabela A.2: Algoritmo HEDA - Tempo de Execução em Minutos - Grafo da Internet
01/01/2010 com Ajustes nos Parâmetros de Desempenho
Grafo 01/01/2010, V = 42.089, A = 570.570
Máquinas T1 T2 T3 Tempo Médio DP
1 20 21 19 20 0,82
2 19 20 21 20 0,82
3 21 19 23 21 1,63
4 19 19 21 20 0,94
5 21 21 23 22 0,94
6 19 18 21 19 1,25
Tabela A.3: Algoritmo HADI - Tempo de Execução em Minutos - Grafo da Internet
01/01/2010
Grafo 01/07/2011, V = 47.224, A = 718.768
Máquinas T1 T2 T3 Tempo Médio DP Speedup E�ciência
1 1211 1209 1213 1211 1,63 1 1
2 617 619 616 617 1,25 1,96 0,98
3 410 414 406 410 3,27 2,95 0,97
4 302 303 301 302 0,82 4,01 0,99
5 233 231 234 233 1,25 5,20 1,04
6 191 192 191 191 0,47 6,33 1,05
Tabela A.4: Algoritmo HEDA - Tempo de Execução em Minutos - Grafo da Internet
01/07/2011 - Speedup e E�ciência
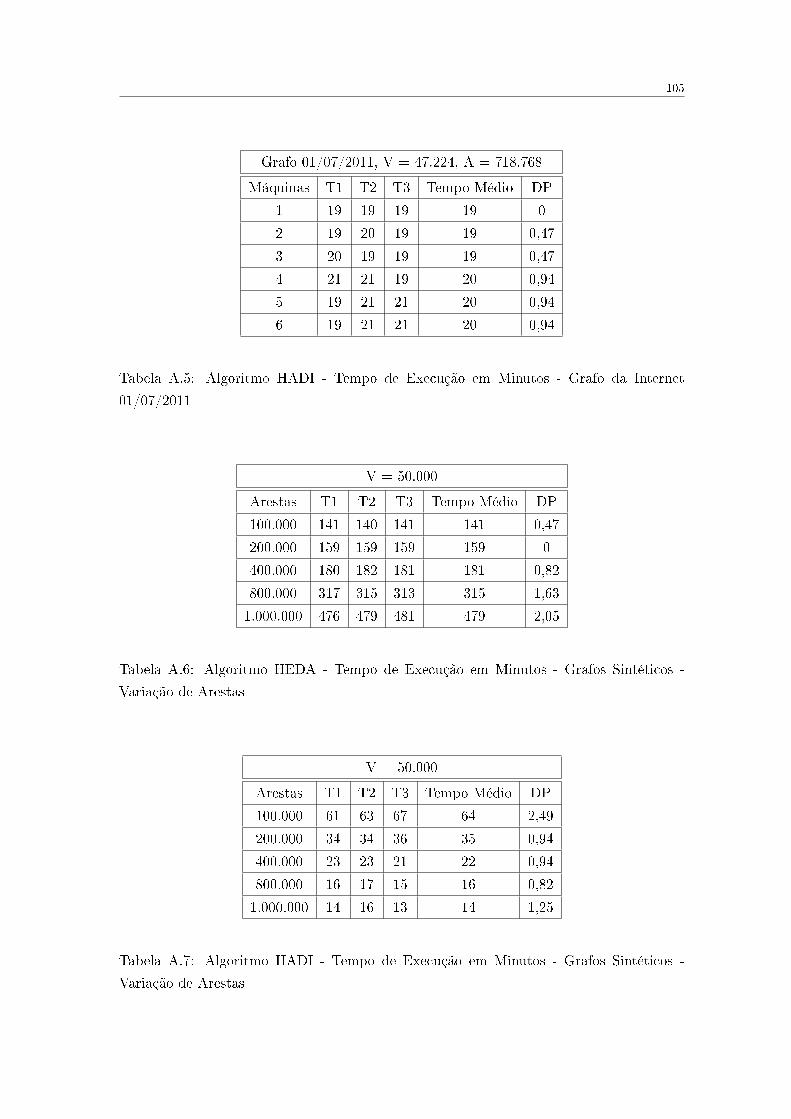
105
Grafo 01/07/2011, V = 47.224, A = 718.768
Máquinas T1 T2 T3 Tempo Médio DP
1 19 19 19 19 0
2 19 20 19 19 0,47
3 20 19 19 19 0,47
4 21 21 19 20 0,94
5 19 21 21 20 0,94
6 19 21 21 20 0,94
Tabela A.5: Algoritmo HADI - Tempo de Execução em Minutos - Grafo da Internet
01/07/2011
V = 50.000
Arestas T1 T2 T3 Tempo Médio DP
100.000 141 140 141 141 0,47
200.000 159 159 159 159 0
400.000 180 182 181 181 0,82
800.000 317 315 313 315 1,63
1.000.000 476 479 481 479 2,05
Tabela A.6: Algoritmo HEDA - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Arestas
V = 50.000
Arestas T1 T2 T3 Tempo Médio DP
100.000 61 63 67 64 2,49
200.000 34 34 36 35 0,94
400.000 23 23 21 22 0,94
800.000 16 17 15 16 0,82
1.000.000 14 16 13 14 1,25
Tabela A.7: Algoritmo HADI - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Arestas
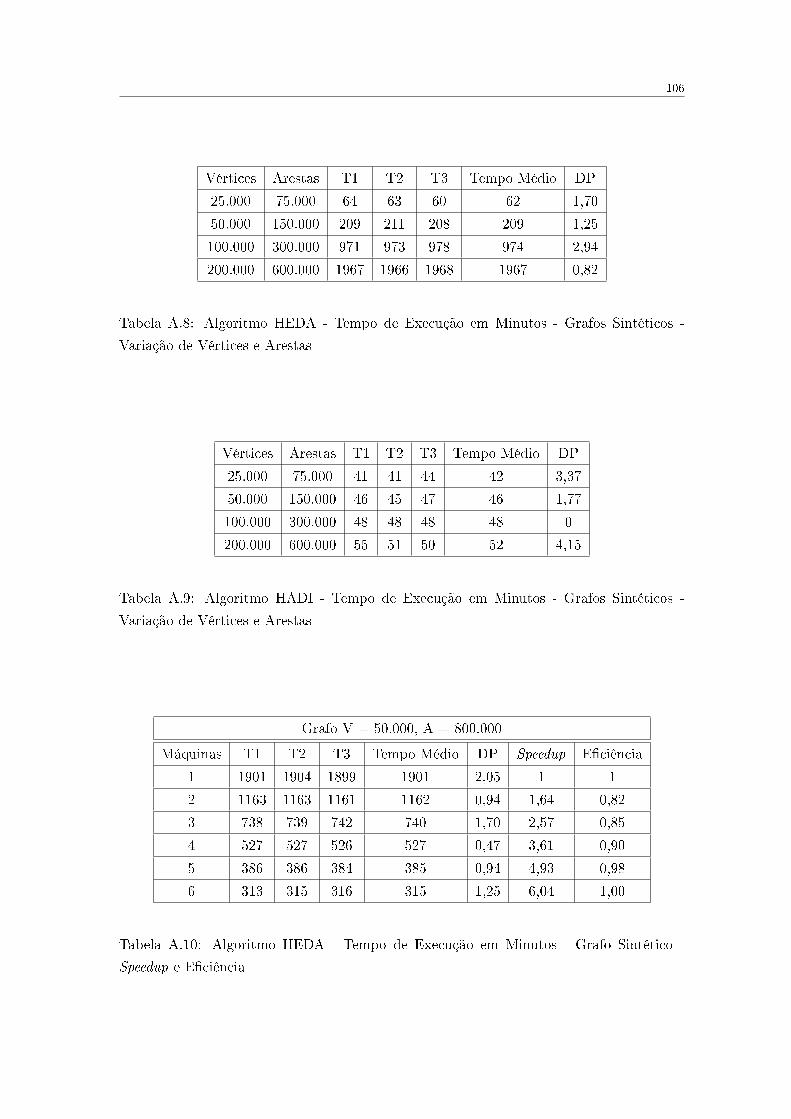
106
Vértices Arestas T1 T2 T3 Tempo Médio DP
25.000 75.000 64 63 60 62 1,70
50.000 150.000 209 211 208 209 1,25
100.000 300.000 971 973 978 974 2,94
200.000 600.000 1967 1966 1968 1967 0,82
Tabela A.8: Algoritmo HEDA - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Vértices e Arestas
Vértices Arestas T1 T2 T3 Tempo Médio DP
25.000 75.000 41 41 44 42 3,37
50.000 150.000 46 45 47 46 1,77
100.000 300.000 48 48 48 48 0
200.000 600.000 55 51 50 52 4,15
Tabela A.9: Algoritmo HADI - Tempo de Execução em Minutos - Grafos Sintéticos -
Variação de Vértices e Arestas
Grafo V = 50.000, A = 800.000
Máquinas T1 T2 T3 Tempo Médio DP Speedup E�ciência
1 1901 1904 1899 1901 2,05 1 1
2 1163 1163 1161 1162 0,94 1,64 0,82
3 738 739 742 740 1,70 2,57 0,85
4 527 527 526 527 0,47 3,61 0,90
5 386 386 384 385 0,94 4,93 0,98
6 313 315 316 315 1,25 6,04 1,00
Tabela A.10: Algoritmo HEDA - Tempo de Execução em Minutos - Grafo Sintético -
Speedup e E�ciência
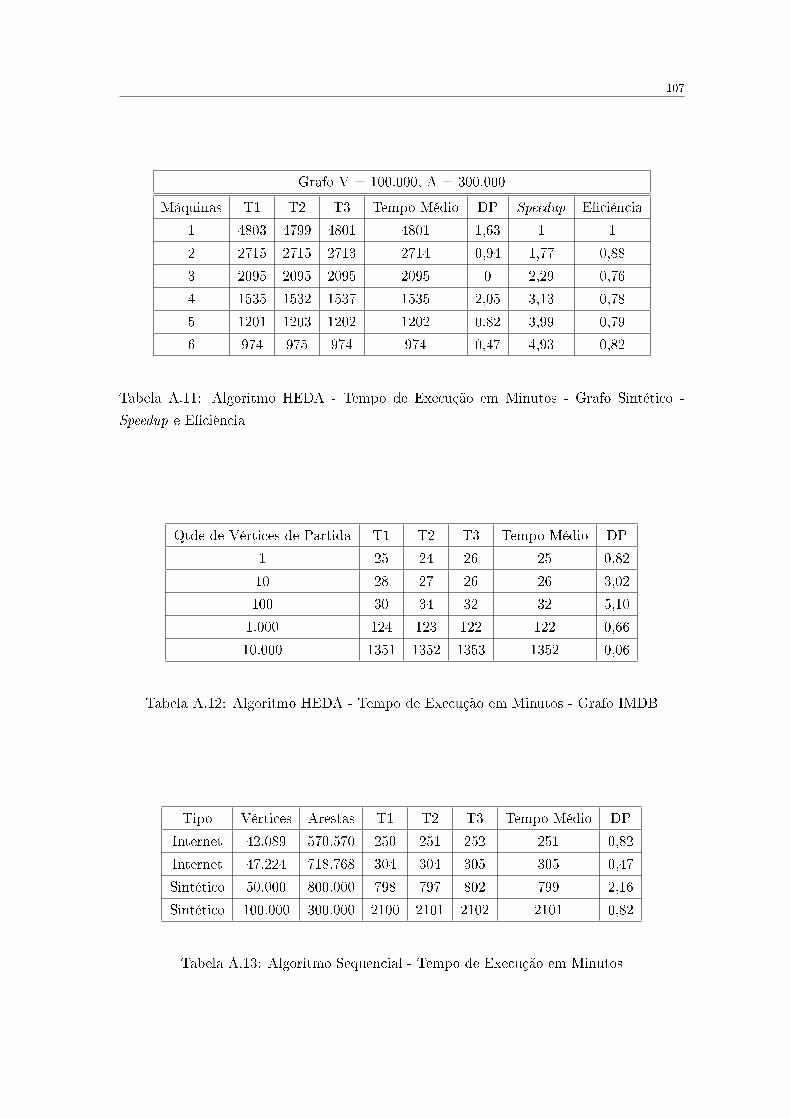
107
Grafo V = 100.000, A = 300.000
Máquinas T1 T2 T3 Tempo Médio DP Speedup E�ciência
1 4803 4799 4801 4801 1,63 1 1
2 2715 2715 2713 2714 0,94 1,77 0,88
3 2095 2095 2095 2095 0 2,29 0,76
4 1535 1532 1537 1535 2,05 3,13 0,78
5 1201 1203 1202 1202 0,82 3,99 0,79
6 974 975 974 974 0,47 4,93 0,82
Tabela A.11: Algoritmo HEDA - Tempo de Execução em Minutos - Grafo Sintético -
Speedup e E�ciência
Qtde de Vértices de Partida T1 T2 T3 Tempo Médio DP
1 25 24 26 25 0,82
10 28 27 26 26 3,02
100 30 34 32 32 5,10
1.000 124 123 122 122 0,66
10.000 1351 1352 1353 1352 0,06
Tabela A.12: Algoritmo HEDA - Tempo de Execução em Minutos - Grafo IMDB
Tipo Vértices Arestas T1 T2 T3 Tempo Médio DP
Internet 42.089 570.570 250 251 252 251 0,82
Internet 47.224 718.768 304 304 305 305 0,47
Sintético 50.000 800.000 798 797 802 799 2,16
Sintético 100.000 300.000 2100 2101 2102 2101 0,82
Tabela A.13: Algoritmo Sequencial - Tempo de Execução em Minutos

Referências Bibliográ�cas
[1] BRESHEARS, C. The Art of Concurrency. San Francisco, CA, USA: O'Reilly, 2009.
[2] WHITE, T. Hadoop: The De�nitive Guide. Primeira edição. [S.l.]: O'Reilly, 2009.
[3] ASANOVIC, K. et al. A View of the Parallel Computing Landscape. Commun. ACM,
ACM, New York, NY, USA, v. 52, p. 56�67, Outubro 2009.
[4] RANGER, C. et al. Evaluating MapReduce for Multi-core and Multiprocessor Systems.
In: Proceedings of the 2007 IEEE 13th International Symposium on High Performance
Computer Architecture. Washington, DC, USA: IEEE Computer Society, 2007. p. 13�24.
[5] DEAN, J.; GHEMAWAT, S. MapReduce: Simpli�ed Data Processing on Large Clus-
ters. Commun. ACM, ACM, New York, NY, USA, v. 51, p. 107�113, January 2008.
[6] INC., I. T. Hadoop Performance Tuning - White Paper - Impetus Technologies Inc.
[S.l.], outubro 2009.
[7] LIN, J.; SCHATZ, M. Design patterns for e�cient graph algorithms in MapReduce. In:
Proceedings of the Eighth Workshop on Mining and Learning with Graphs. New York,
NY, USA: ACM, 2010. (MLG '10), p. 78�85.
[8] KANG, U. et al. HADI: Mining Radii of Large Graphs. ACM Trans. Knowl. Discov.
Data, ACM, New York, NY, USA, v. 5, p. 8:1�8:24, February 2011.
[9] KANG, U.; TSOURAKAKIS, C. E.; FALOUTSOS, C. PEGASUS: A Peta-Scale Graph
Mining System Implementation and Observations. In: Proceedings of the 2009 Ninth
IEEE International Conference on Data Mining. Washington, DC, USA: IEEE Compu-
ter Society, 2009. (ICDM '09), p. 229�238.
[10] MALEWICZ, G. et al. Pregel: a system for large-scale graph processing. In: Proce-
edings of the 2010 International Conference on Management of Data. New York, NY,
USA: ACM, 2010. (SIGMOD '10), p. 135�146.
[11] COHEN, J. Graph Twiddling in a MapReduce World. Computing in Science and
Engineering, IEEE Computer Society, Los Alamitos, CA, USA, v. 11, p. 29�41, 2009.
[12] BUCKLEY, F. H. F. Distance in Graphs. Primeira edição. [S.l.]: Perseus Books, 1990.
108

REFERÊNCIAS BIBLIOGRÁFICAS 109
[13] GONÇALVES, M. R. S.; MACIEL, J. N; MURTA, C. D. Geração de Topologias
da Internet por Redução do Grafo Original. XXVIII Simpósio Brasileiro de Redes de
Computadores e Sistemas Distribuídos (SBRC), Gramado, Brasil, p. 959�972, 2010.
[14] O'HANLON, C. A Conversation with John Hennessy and David Patterson. Queue,
ACM, New York, NY, USA, v. 4, p. 14�22, Dezembro 2006.
[15] DEAN, J.; GHEMAWAT, S. MapReduce: a Flexible Data Processing Tool. Commun.
ACM, ACM, New York, NY, USA, v. 53, p. 72�77, Janeiro 2010.
[16] PATTERSON, D. A.; HENNESSY, J. L. Computer Architecture: a quantitative ap-
proach. Fourth edition. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.,
2007.
[17] GHEMAWAT, S.; GOBIOFF, H.; LEUNG, S.-T. The Google File System. SIGOPS
Oper. Syst. Rev., ACM, New York, NY, USA, v. 37, p. 29�43, Outubro 2003.
[18] NEWMAN, M. E. J. The Structure and Function of Complex Networks. SIAM Review,
SIAM, v. 45, n. 2, p. 167�256, 2003.
[19] BONDY, J. A. Graph Theory With Applications. [S.l.]: Elsevier Science Ltd, 1976.
[20] ZIVIANI, N. Projeto de Algoritmos com Implementações em Java e C++. Primeira
edição. [S.l.]: Thomson, 2007.
[21] OPSAHL, T.; AGNEESSENS, F.; SKVORETZ, J. Node centrality in weighted
networks: Generalizing degree and shortest paths. Social Networks, Elsevier, v. 32, n. 3,
p. 245 � 251, 2010.
[22] GROSS, J.; YELLEN, J. Graph theory and its applications. Boca Raton, FL, USA:
CRC Press, Inc., 1999.
[23] MEYER, U.; SANDERS, P. Delta-stepping: a parallelizable shortest path algorithm.
J. Algorithms, Academic Press, Inc., Duluth, MN, USA, v. 49, p. 114�152, October 2003.
[24] TRÄFF, J. L. An experimental comparison of two distributed single-source shortest
path algorithms. Parallel Comput., Elsevier Science Publishers B. V., Amsterdam, The
Netherlands, The Netherlands, v. 21, p. 1505�1532, September 1995.
[25] GHOSH, S. Distributed Systems: An Algorithmic Approach. [S.l.]: Chapman &
Hall/CRC, 2006.
[26] CORMEN, T. H. et al. Introduction to Algorithms. [S.l.]: MIT Press, 2001.
[27] TRÄFF, J. L.; ZAROLIAGIS, C. D. A Simple Parallel Algorithm for the Single-Source
Shortest Path Problem on Planar Digraphs. In: Proceedings of the Third Internatio-
nal Workshop on Parallel Algorithms for Irregularly Structured Problems. London, UK:
Springer-Verlag, 1996. (IRREGULAR '96), p. 183�194.

REFERÊNCIAS BIBLIOGRÁFICAS 110
[28] FLAJOLET, P.; MARTIN, G. N. Probabilistic counting algorithms for data base
applications. J. Comput. Syst. Sci., Academic Press, Inc., Orlando, FL, USA, v. 31, p.
182�209, September 1985.
[29] PAVLO, A. et al. A comparison of approaches to large-scale data analysis. In: Pro-
ceedings of the 35th SIGMOD International Conference on Management of Data. New
York, NY, USA: ACM, 2009. (SIGMOD '09), p. 165�178.
[30] STONEBRAKER, M. et al. MapReduce and Parallel DBMSs: friends or foes? Com-
mun. ACM, ACM, New York, NY, USA, v. 53, p. 64�71, Janeiro 2010.
[31] JIANG, D. et al. The Performance of MapReduce: an in-depth study. Proc. VLDB
Endow., VLDB Endowment, v. 3, p. 472�483, September 2010. ISSN 2150-8097.
[32] YOO, R. M.; ROMANO, A.; KOZYRAKIS, C. Phoenix Rebirth: Scalable MapReduce
on a large-scale shared-memory system. In: Proceedings of the 2009 IEEE Internatio-
nal Symposium on Workload Characterization (IISWC). Washington, DC, USA: IEEE
Computer Society, 2009. (IISWC '09), p. 198�207.
[33] SU, W. et al. Modeling MapReduce with CSP. In: Proceedings of the 2009 Third IEEE
International Symposium on Theoretical Aspects of Software Engineering. Washington,
DC, USA: IEEE Computer Society, 2009. p. 301�302.
[34] REN, K.; LóPEZ, J.; GIBSON, G. Otus: resource attribution in data-intensive clus-
ters. In: Proceedings of the Second International Workshop on MapReduce and its appli-
cations. New York, NY, USA: ACM, 2011. (MapReduce '11), p. 1�8. ISBN 978-1-4503-
0700-0.
[35] KIM, K. et al. MRBench: A Benchmark for MapReduce Framework. In: Proceedings
of the 2008 14th IEEE International Conference on Parallel and Distributed Systems.
Washington, DC, USA: IEEE Computer Society, 2008. p. 11�18.
[36] TPC-H Benchmark. http://www.tpc.org/tpch/. Acesso em novembro de 2010.
[37] JIN, C.; VECCHIOLA, C.; BUYYA, R. MRPGA: An Extension of MapReduce for
Parallelizing Genetic Algorithms. In: Proceedings of the 2008 Fourth IEEE International
Conference on eScience. Washington, DC, USA: IEEE Computer Society, 2008. p. 214�
221.
[38] EKANAYAKE, J.; PALLICKARA, S.; FOX, G. MapReduce for Data Intensive Sci-
enti�c Analysis. In: Proceedings of the 2008 Fourth IEEE International Conference on
eScience. Washington, DC, USA: IEEE Computer Society, 2008. p. 277�284.
[39] CRAUSER, A. et al. A parallelization of Dijkstra's shortest path algorithm. In: BRIM,
L.; GRUSKA, J.; ZLATUSKA, J. (Ed.).Mathematical Foundations of Computer Science
1998. [S.l.]: Springer Berlin / Heidelberg, 1998. v. 1450, p. 722�731.

REFERÊNCIAS BIBLIOGRÁFICAS 111
[40] MADDURI, K. et al. An Experimental Study of A Parallel Shortest Path Algorithm
for Solving Large-Scale Graph Instances. In: Proc. 9th Workshop on Algorithm Engine-
ering and Experiments (ALENEX 2007). [S.l.: s.n.], 2007.
[41] KANG, U. et al. Patterns on the connected components of terabyte-scale graphs.
IEEE International Conference on Data Mining, 2010.
[42] MEYER, U. Buckets strike back: Improved Parallel Shortest-Paths. In: Proc. 16th
Intl. Par. Distr. Process. Symp. (IPDPS). [S.l.]: IEEE Computer Society, 2002. p. 1�8.
[43] MEYER, U. Heaps Are Better than Buckets: Parallel Shortest Paths on Unbalanced
Graphs. In: Proceedings of the 7th International Euro-Par Conference Manchester on
Parallel Processing. London, UK: Springer-Verlag, 2001. (Euro-Par '01), p. 343�351.
[44] KUMAR, V.; SINGH, V. Scalability of parallel algorithms for the all-pairs shortest-
path problem. J. Parallel Distrib. Comput., Academic Press, Inc., Orlando, FL, USA,
v. 13, p. 124�138, October 1991.
[45] HAN, Y.; PAN, V.; REIF, J. E�cient parallel algorithms for computing all pair
shortest paths in directed graphs. In: Proceedings of the fourth annual ACM Symposium
on Parallel Algorithms and Architectures. New York, NY, USA: ACM, 1992. (SPAA '92),
p. 353�362.
[46] Google Developers, Lecture 5: Parallel Graph Algorithms with MapReduce - 28
Aug. 2007; http://www.slideshare.net/jhammerb/lec5-pagerank - Acesso em setembro
de 2011.
[47] VENNER, J. Pro Hadoop. 1st. ed. Berkeley, CA, USA: Apress, 2009.
[48] Yahoo Research; http://research.yahoo.com/node/1884 - Acesso em novembro de
2011.
[49] ERDöS, P.; RéNYI, A. On random graphs, I. Publicationes Mathematicae (Debrecen),
v. 6, 1959.
[50] JABLONSKI, J. Hadoop in the Enterprise - A Dell Technical White Paper. [S.l.], 2011.
[51] MONTGOMERY, D. C.; RUNGER, G. C. Estatística Aplicada e Probabilidade para
Engenheiros. Rio de Janeiro, RJ: LTC Livros Técnicos e Cientí�cos Editora S. A., 2007.
[52] JAIN, R. The Art of Computer Systems Performance Analysis: Techniques for Expe-
rimental Design, Measurement, Simulation and Modeling. New York, USA: John Wiley
and Sons, 1991.
[53] KUMAR, V.; GUPTA, A. Analysis of scalability of parallel algorithms and architec-
tures: a survey. In: Proceedings of the 5th Iternational Conference on Supercomputing.
New York, NY, USA: ACM, 1991. (ICS '91), p. 396�405.

REFERÊNCIAS BIBLIOGRÁFICAS 112
[54] BONDI, A. B. Characteristics of scalability and their impact on performance. In:
Proceedings of the 2nd International Workshop on Software and Performance. New York,
NY, USA: ACM, 2000. p. 195�203.
[55] GRAMA, A. et al. Introduction to Parallel Computing (2nd Edition). 2. ed. [S.l.]:
Addison Wesley, 2003. Hardcover.
[56] URBANI, J.; MAASSEN, J.; BAL, H. Massive Semantic Web data compression with
MapReduce. In: Proceedings of the 19th ACM International Symposium on High Per-
formance Distributed Computing. New York, NY, USA: ACM, 2010. (HPDC '10), p.
795�802.
[57] SCHATZ, M. C. Cloud Burst: highly sensitive read mapping with MapReduce. In: .
[S.l.]: Bioinformatics Original Paper, 2009. v. 25, n. 11, p. 1363�1369.







![Implementação do do Algoritmo Paralelo para o Problema ... · simples fluxo, adotamos o método Simplex Convexo apresentado por Kennington [KEN80]. Nesta implementação paralela](https://img.pdfslide.tips/doc/110x75/5e2d583fcccb267bcf626bce/implementao-do-do-algoritmo-paralelo-para-o-problema-simples-fluxo-adotamos.jpg)





















