Embed Size (px)
Citation preview

UNIVERZA V MARIBORU FAKULTETA ZA LOGISTIKO
Diplomsko delo magistrskega študija
UPRAVLJANJE Z INCIDENTI V INFORMACIJSKIH SISTEMIH
JAVNE UPRAVE Mentor: izred.prof. dr. Iztok Podbregar Kandidat: Franc Šrok
Celje, junij 2007

ZAHVALA Iskreno se zahvaljujem mentorju dr. Iztoku Podbregarju za strokovno pomoč in koristne napotke pri izdelavi magistrske naloge. Zahvala gre mojim sošolcem, sodelavcem in prijateljem, ki so mi pomagali pri izdelavi magistrske naloge in za podpore med študijem. Hvaležnost pa velja tudi moji družini, ki mi je stala ob strani in mi vlivala voljo in pogum ter podporo v času mojega študija.

POVZETEK Incidenti v informacijskem sistemu so dogodki, ki onemogočajo normalno uporabo sistema. V vsakem informacijskem sistemu se mora organizirati učinkovit sistem upravljanja. V magistrski nalogi je opredeljen problem zagotavljanja učinkovitosti sistema upravljanja z incidenti, ki je narejen po priporočilih ITIL. Na učinkovitost sistema vpliva tudi organizacijska oblika, ki jo organizacija uporablja. V osnovi je lahko sistem upravljanja z incidenti narejen na teritorialnem principu ali po linijsko organizacijski strukturi organizacije. Primerjanje učinkovitosti je narejana na modelih, ki sta narejena na temelju vzorec nastalih incidentov nastalih v opazovanem informacijskem sistemu. S pomočjo sistemske simulacije se oba modela organiziranosti primerjata. Organiziranost sistema upravljanja z incidenti po teritorialnem principu je bolj učinkovita od modela organiziranosti po linijsko organizacijski strukturi.
KLJUČNE BESEDE - Informacijski sistem - Storitev IT - Incident - Sistemska simulacija - ITIL
ABSTRACT Incidents in an information system are all events, which create difficulties and prevent its normal use. Each information system should have its own effective control system. This publication gets down to the problem of providing such a kind of control system, which will effective manage incidents. The system is made in accordance with Information Technology Infrastructure Library (ITIL) requirements. One of the factors that have influence on effective incident management is the form of company organization. Effective control system can be established in two ways: on a territorial principle or in accordance with the organization's line structure. With the use of a systematic stimulation, both of the two organization models are compared, in order to find out their effectiveness in an incident’s managing process. The comparison shows that the incidents control system established on the territorial principle is better that the one organized in accordance with organization's line structure. KEYWORDS
- Information system - IT service - Incident - Systematic simulation - ITIL

KAZALO 1 UVOD..............................................................................................................1
1.1 OPREDELITEV PROBLEMA ......................................................................2 1.2 HIPOTEZA .................................................................................................2 1.3 STRUKTURA NALOGE ..............................................................................2 1.4 METODE DELA.........................................................................................3
1.4.1 UPORABA IN ANALIZA PISNIH IN ELEKTRONSKIH VIROV .............3 1.4.2 METODA TRIANGULACIJE...............................................................3 1.4.3 ZBIRANJE IN ANALIZA PODATKOV.................................................3 1.4.4 SISTEMSKA ANALIZA IN ORGANIZACIJSKA TEORIJA....................3 1.4.5 MATEMATIČNO MODELIRANJE......................................................4 1.4.6 METODA IZKUSTVA...........................................................................4
1.5 OMEJITVE.................................................................................................4 1.6 TEMELJNI POJMI......................................................................................4
2 PRIPOROČILA ITIL IN INCIDENTI V INFORMACIJSKEM SISTEMU................6 2.1 PRIPOROČILA ITIL....................................................................................9
2.1.1 ZAGOTAVLJANJE STORITEV..........................................................11 2.1.2 PODPORA STORITVAM..................................................................13 2.1.3 UPRAVLJANJE INFORMACIJSKO KOMUNIKACIJSKO TEHNOLOŠKE INFRASTRUKTURE..............................................................15 2.1.4 NAČRTOVANJE IMPLEMENTACIJE UPRAVLJANJA STORITEV...17 2.1.5 UPRAVLJANJE APLIKACIJ .............................................................19 2.1.6 POSLOVNA PERSPEKTIVA..............................................................20 2.1.7 UPRAVLJANJE VARNOSTI .............................................................22
2.2 UPRAVLJANJE Z INCIDENTI V INFORMACIJSKIH SISTEMIH ...............24 2.2.1 OSNOVNI KONCEPT ......................................................................26 2.2.2 PREDNOSTI UPRAVLJANJA Z INCIDENTI ......................................33 2.2.3 NAČRTOVANJE IN IMPLEMENTACIJA .........................................34 2.2.4 AKTIVNOSTI PRI UPRAVLJANJU Z INCIDENTI ...............................36 2.2.5 UPRAVLJANJE VEČJIH INCIDENTOV ...........................................44 2.2.6 VLOGE PRI IZVAJANJU UPRAVLJANJA Z INCIDENTI..................44 2.2.7 TEŽAVE PRI DELOVANJU SISTEMA UPRAVLJANJA Z INCIDENTI 45
3 INCIDENTI V INFORMACIJSKIH SISTEMIH JAVNE UPRAVE.......................47 3.1 VZOREC NASTANKOV INCIDENTOV ..................................................49 3.2 VRSTA IN ZNAČILNOSTI INCIDENTOV.................................................52 3.3 REŠEVANJE INCIDENTOV.....................................................................55
4 OBLIKE ORGANIZIRANOSTI ZA UPRAVLJANJE Z INCIDENTI ....................58 4.1 PRINCIPI ORGANIZIRANOSTI ...............................................................60
4.1.1 TERITORIALNI PRINCIP....................................................................60 4.1.2 ORGANIZACIJSKO LINIJSKI PRINCIP............................................61
4.2 KAKOVOST IN UČINKOVITOST SISTEMA ZA UPRAVLJANJA Z INCIDENTI V INFORMACIJSKIH SISTEMIH ..................................................62 4.3 MODELIRANJE ORGANIZACIJSKIH OBLIK..........................................64
4.3.1 MODEL ORGANIZIRANOSTI PO TERITORIALNEM PRINCIPU ......67

4.3.2 MODEL ORGANIZIRANOSTI PO LINIJSKI ORGANIZACIJSKI STRUKTURI .................................................................................................73 4.3.3 SIMULACIJA NA MODELIH............................................................78 4.3.4 REZULTATI SIMULACIJ.....................................................................81
4.4 PRIMERJAVA ORGANIZACIJSKIH OBLIK SISTEMA UPRAVLJANJA Z INCIDENTI.....................................................................................................85 4.5 ZAHTEVE DELOVNIH MEST V SISTEMU UPRAVLJANJA Z INCIDENTI .87
4.5.1 ZAPOSLENI ......................................................................................88 4.5.2 OPREMA IN ORODJA ZA DELOVANJE SISTEMA.........................89
5 ZAKLJUČEK ...................................................................................................90 6 LITERATURA IN VIRI.......................................................................................92 KAZALO SLIK....................................................................................................94 KAZALO TABEL ................................................................................................95 KRATICE IN AKRONIMI ...................................................................................96

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 1
1 UVOD
Sedanjost je v znamenju informacijske tehnologije (ali krajše IT) in je v pravem pomenu poimenovana kot informacijska doba. V preteklih petnajstih letih smo priča fantastičnemu razvoju informacijske tehnologije, ko so računalniki iz znanstveno fantastičnih filmov pripeljani v vsako hišo in so nepogrešljivi inventar na delovnih mestih. Pomemben razvoj je bil dosežen pri informatizaciji delovnih mest: kakor smo pred leti z lahkoto opravljali delovne naloge brez pomoči računalnikov, pa si je dandanes to nemogoče zamisliti. Tako so sedaj računalniki prisotni v avtomobilih, blagajnah, telefonih, delovnih strojih itd. V osnovi sta sestavni del razvoja informacijske tehnologije računalnik in računalniško omrežje. V sodobnih družbah predstavlja informacijska tehnologija ključen pogoj za delovanje vseh pomembnejših družbenih podsistemov, hkrati pa je korenito spremenila delovanje posameznika, družbenih skupin in institucij ter postala cilj in sredstvo za doseganje njihovih interesov (Svete, 2005). Razvoj informacijske tehnologije je s seboj prinesel tudi problem upravljanja s tehnologijo. Obstoječi postopki upravljanja s sistemi, ki so bili v uporabi do pojava informacijske tehnologije, niso več ustrezni. Posledice so manjša učinkovitost uporabe tehnologij s strani uporabnikov, povečanje stroškov za razvoj rešitev, drago vzdrževanje, nepredvidljivo obnašanje IS (informacijskega sistema), itd. Vzroki za to so v naravi informacijske tehnologije, saj ima ta tehnologija karakter »navideznosti« oziroma virtualnosti. Tako lahko težave na strojni opremi (materialna sredstva) uspešno rešujemo s programsko opremo (ne materialna sredstva) ali pa obratno. Istočasno je lokacija virov informacijske tehnologije nepomembna, saj je uporabnikova zaznava informacijskega sistema enaka, če dostopajo do podatkovnih zbirk, ki se nahajajo na računalnikih v njihovih pisarnah ali pa če so ti računalniki nekaj tisoč kilometrov stran. Vsi ti in še drugi novi pojavi so skrbnike informacijske tehnologije pripeljali na novo področje, kjer je bilo potrebno najti nove rešitve. V najkrajšem lahko govorimo o pojavu organizacijskega razkoraka (Vila, 1994). Informacijska tehnologija ni namenjena sama sebi, temveč je na voljo za to, da zadovolji določene potrebe ljudi. Izhajajoč iz osredotočenosti na uporabnika, ki uporablja IT, in njegovo zaznavo tehnologije je nastala ideja o IT storitvah. IT storitev je povezan niz tehničnih rešitev in tehnoloških postopkov, ki uporabnikom rešuje posamezno potrebo. Elektronska pošta je na primer ena od storitev IT. Storitev elektronske pošte pa je sestavljena iz lokalnega računalnika z vsemi potrebnimi lokalnimi programi, ki je povezan v omrežje, samega omrežja,

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 2
strežnikov, itd. Vse te tehnične sisteme pa uporabnik zazna le kot eno storitev, ki mu rešuje potrebo po elektronski pošti.
1.1 OPREDELITEV PROBLEMA
Javna uprava ima na razpolago razvejani IS, ki zagotavlja več različnih IT storitev, od običajnih spletnih storitev in elektronske pošte, do dostopa in koriščenje različnih podatkovnih baz in specializiranih storitev. V takšnem sistemu se iz različnih vzrokov pojavljajo napake, ki imajo svoj vzrok v napakah sistema, neznanju uporabnikov, trenutnih težavah v zagotavljanju delovanja in podobno. Te napake je potrebno odpraviti tako, da bodo lahko uporabniki IS želeno storitev čimprej uporabljali in bodo poslovni procesi v javni upravi čim manj okrnjeni ali moteni. Sistem odpravljanja napak oziroma sistem upravljanja z incidenti mora zadovoljiti večjemu številu kriterijev. Pri tem so učinkovitost, ekonomičnost in varnost bistveni kriterij v IS javne uprave. Upravljanje z incidenti je proces na področju podpore storitvam po priporočilih ITIL. V magistrski nalogi sem razviti model organizacije sistema za upravljanjem z incidenti v IS javne uprave, ki temelji na uveljavljanju in uporabi najboljše prakse oziroma na priporočili ITIL.
1.2 HIPOTEZA
»Organizacija upravljanja z incidenti v informacijskih sistemih javne uprave je po teritorialnem principu bolj učinkovita kot po organizacijsko linijski strukturi .«
1.3 STRUKTURA NALOGE
Na začetku naloge sem opisal osnovna izhodišča, ki opredeljujejo upravljanje z incidenti v modelu procesov ITIL. Posebno težišče sem posvetil procesu podpore storitvam IT in procesu upravljanja z incidenti. V nadaljevanju sem predstavil analizo vzorca incidentov, ki sem jih zbiral o incidentih, ki so se pojavljali v IS dela organa javne uprave. Vzorec za analizo je bil zbran iz IS, ki delujeta v treh vojašnicah Slovenske vojske. Na koncu sem modelirati delovna mesta in organizacijo, ki bi uspešno reševala incidente v IS. Pri tem sem posebno pozornost posvetil številu delovnih mest, ki bi sodelovala v sistemu upravljanja z incidenti, ter opisal osnovne zahteve za delovna mesta. V zaključku sem povzel ugotovitve in potrdil postavljeno hipotezo.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 3
1.4 METODE DELA
Narava problema proučevanja zahteva obsežno teoretično podlago in empirično analizo, pri čemer sem uporabil dedukcijo. Pri proučevanju upravljanja z incidenti v IS sem uporabil naslednje metode:
• Uporaba in analiza pisnih in elektronskih virov, • Metoda triangulacije, • Zbiranje in analiza podatkov, • Sistemska analiza in organizacijska teorija, • Matematično modeliranje, • Izkustvo.
1.4.1 UPORABA IN ANALIZA PISNIH IN ELEKTRONSKIH VIROV
Metodo analize pisnih virov sem uporabljal pri proučevanju že uveljavljenih teorij, spoznanj in ugotovitev. Vanjo sem vključil različna znanstveno-teoretična in strokovna dela, pa tudi poljubna dela s področja proučevanja tematike magistrske naloge. Mediji so bili knjige, strokovni in poljudnoznanstveni članki, različni statistični podatki, internetne strani znanstvenih, strokovnih in drugih institucij iz Slovenije in tujine.
1.4.2 METODA TRIANGULACIJE
Zbrane podatke sem preveril in povzel iz različnih virov. Zaradi aktualnosti problema je večina relevantnih virov objavljenih le na spletu.
1.4.3 ZBIRANJE IN ANALIZA PODATKOV
Zbiranje podatkov sem vodil organizirano z zapisovanjem parametrov o vseh incidentih za določeno število uporabnikov IS v trajanju do 30 dni. Zbiranje podatkov so izvajali operaterji v storitvenem centru po v naprej izdelanih navodilih in so jih vpisovali v naprej pripravljeni obrazec. Tako zbrane podatke sem še preveril na uradni podatkovni bazi podatkov o incidentih.
1.4.4 SISTEMSKA ANALIZA IN ORGANIZACIJSKA TEORIJA
Sistemsko analizo in organizacijsko teorijo sem uporabil, ker na upravljanje z incidenti gledamo kot na sistem in organizacijo.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 4
1.4.5 MATEMATIČNO MODELIRANJE
Na podlagi zbranih podatkov sem poskusil s pomočjo matematičnega modeliranja določiti število delovnih mest, ki so potrebna za uspešno upravljanje z incidenti.
1.4.6 METODA IZKUSTVA
Pri izdelavi naloge sem uporabil izkušnje iz dosedanjega dela na področju informatike in reševanja incidentov.
1.5 OMEJITVE
Pri proučevanju tematike sem uporabil le javno dostopne vire, ki niso označeni s stopnjo tajnosti. Za potrditev teze sem uporabil primer IS, ki bi lahko bil hipotetično organiziran v vojašnici SV. Pri navajanju nazivov enot in lokacij sem uporabil splošne nazive.
1.6 TEMELJNI POJMI
Incident je kateri koli dogodek, ki ni del standardnega delovanja storitve in ki povzroči ali lahko povzroči prekinitev ali zmanjša kakovost te storitve (qSTC, 2006). Informacijska tehnologija (IT) je sposobnost, znanje, spretnost oziroma tehnika, da predvsem z uporabo strojev in naprav, ki omogočajo informacijske dejavnosti, dosežemo želene učinke (Svete, 2005). ITIL (Information Technology Infrastructure Library) je celovita zbirka dokumentov z opisi in napotki za uvajanje in kakovostno upravljanje s storitvami, ki temeljijo na uporabi informacijske tehnologije in izvirajo iz t.i. najboljših praks (best practices) upravljanja s storitvami. Metodologija je rezultat sodelovanja mednarodnih strokovnjakov tako iz javnega kot tudi privatnega sektorja v gospodarstvu. Ti postopki so opredeljeni neodvisno od opreme in so splošna navodila, ki se lahko uporabijo za IT infrastrukturo, za razvoj ali za delovanje (OGC, 2003). Informacijski sistem (IS) obsega računalniško strojno in komunikacijsko opremo ter sistemsko in aplikativno programsko opremo, podatkovne zbirke, računalniške nosilce podatkov, prenos in posredovanje podatkov, identifikacijske in avtorizacijske postopke (Pravilnik o varovanju in zaščiti IS MORS, 1996).

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 5
IT storitev je katerakoli dejavnost v okvirih informacijskega sistema, ki uporabniku omogoča uporabo virov informacijske tehnologije (OGC, 2003). Informacijska varnost (INFOSEC) obsega določanje in uporabo ukrepov za zaščito tajnih podatkov, ki se obdelujejo, shranjujejo in prenašajo s pomočjo komunikacijskih, informacijskih in drugih elektronskih sistemov pred naključno ali namerno izgubo tajnosti, celovitosti ali razpoložljivosti ter ukrepov za preprečevanje izgube celovitosti in razpoložljivosti samih sistemov. Vsebuje ukrepe varovanja tajnosti v računalniških sistemih oziroma računalniško varnost - COMPUSEC (varnost strojne opreme in programske opreme), ukrepe varovanja tajnosti v komunikacijskih sistemih oziroma komunikacijsko varnost – COMSEC, varnost prenosnih sistemov – TRANSEC, varnost kriptografskih metod in naprav – CRYPTOSEC ter varnost pri elektromagnetnem sevanju elektronskih naprav - EMSEC. (Urad vlade za varovanje tajnih podatkov, 2007). Podpora storitvam je ITIL disciplina, ki je usmerjena k uporabniku IT storitev, da mu zagotovi nemoten dostop do primerne storitve, s katero opravlja svojo poslovno funkcijo (OGC, 2003). Sistemska simulacija je način reševanja problemov z metodami eksperimentiranja na računalniških modelih z namenom ugotavljanja funkcioniranja celote ali posameznih delov sistema pri določenih pogojih (Kljajić, 2002). Upravljanje z incidenti IT je vzpostavitev normalnega nivoja delovanja IT storitve v čim krajšem času z minimalnimi neželenimi vplivi na poslovanje, zagotavljanje najboljše možne stopnje kakovosti in razpoložljivosti ter vzdrževanje takšnega stanja. To je en proces znotraj širokih ITIL področji (Rudd, 2006).

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 6
2 PRIPOROČILA ITIL IN INCIDENTI V INFORMACIJSKEM SISTEMU
Sredi osemdesetih letih prejšnjega stoletja so v Veliki Britaniji začeli zbirati najboljše rešitve pri upravljanju z IT storitvami. Tako je nastal ITIL. Metodologijo je začel razvijati britanski OGC (Office of Government Commerce) oziroma Urad za trgovino britanske vlade (prej poznan kot CCTA – Central Computer and Telecommunications Agency), ki je tudi lastnik metodologije ITIL. ITIL sestavlja celovita zbirka dokumentov z opisi in napotki za uvajanje in kakovostno upravljanje s storitvami, ki temeljijo na uporabi informacijske tehnologije in izvirajo iz t.i. najboljših praks (best practices) upravljanja s storitvami. Metodologija je rezultat sodelovanja mednarodnih strokovnjakov tako iz javnega kot tudi privatnega sektorja. Uporabniki ITIL so strokovnjaki za IT, ki se ukvarjajo s storitvami IT in potrebujejo podroben vpogled v procese in postopke upravljanja storitev IT, predvsem s ciljem boljšega upravljanja s storitvami IT. Zaradi nastanka novih procesov, porazdeljenega računalništva in interneta pa se zbirke ITIL stalno posodabljajo. ITIL je danes najbolj razširjen in celoviti pristop, ki se uporablja za zagotavljanje in podporo storitev IT, infrastrukture in razvoj IT. Priporočila ITIL niso formalni standardi. OGC, BSI (British Standard Institute) in itSMF (it Service Management Forum) so skupno razvili uradni britanski standard BS I 5000 – I:2002, ki je podprt in se dopolnjuje z ITIL-om (qSTC, 2006). Standard BS I 5000 je priznan po svetu in je enako zaželen kot standard ISO9000 ter bo verjetno postal del njega. Z uvedbo priporočil ITIL in izboljšavo procesov podprtih z IT lahko podjetja in organizacije dosežejo naslednje (qSTC, 2006):
• Boljšo izkoriščenost virov in sredstev; • Povečanje konkurenčnosti organizacije; • Zmanjšanje obsega ponavljajočega se dela in odpravljanje
odvečnega dela; • Izboljšanje kakovosti projektov in dokončanje projektov v
krajšem času; • Izboljšanje ravni razpoložljivosti, zanesljivosti in varnosti storitev IT,
ki so za poslovanje ključnega pomena; • Utemeljevanje investicij in stroškov zagotavljanja kakovosti
storitev; • Zagotavljanje storitev, ki so po meri organizacije, stranke in
uporabnikov; • Dokumentiranje in posredovanje vlog in odgovornosti pri
zagotavljanju storitev; • Učenje iz minulih izkušenj; • Zagotavljanje uporabnih kazalcev delovanja in zmogljivosti.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 7
Glavni vidik ITIL je izpolnjevanje poslovnih zahtev in zahtev strank in uporabnikov IT storitev. Zagotavljanje kakovostnih storitev strankam se dosega z izpolnjevanjem zahtev in pričakovanj uporabnikov. Osnovne aktivnosti za to so: dogovarjanje in pogajanje z uporabniki, ocenjevanje mnenj, izkušenj in razumevanja strank ter poznavanje ITK infrastrukture. To se lahko dosega le s tesnim sodelovanjem in bližnjim kontaktom s strankami in uporabniki. Uveljavljanje priporočil ITIL zahteva ustrezni nivo napora in vsebuje niz težav. Po odločitvi o uvajanju najboljše prakse se mora v organizacijah izvesti niz ukrepov, ki preprečijo neuspeh sprememb. Vzroki za neuspeh so dejansko enaki, kot so pri vseh projektih v povezavi z informacijsko tehnologijo. Hammer in Chamy (1995) sta vzroke za neuspeh strnila v naslednje razloge:
• Procesi se le popravljajo, namesto, da bi se temeljito spremenili; • Pri uvajanju se vodstvo ne osredotoči na poslovne procese,
temveč se ukvarja z organiziranostjo; • Osredotoča se izključno na preoblikovanje procesov, pri tem pa
se preveč zanemarja ostale vidike delovanja organizacije; • Zanemarjajo se vrednote in prepričanj zaposlenih, ki pa so
dejansko glavni nosilci sprememb; • Preveč hitro se vodstvo zadovolji z malimi uspehi, ki pa dejansko
niso končni; • Vodstvo po prvih neuspehih odneha, ker ni pripravljeno prenesti
naporov sprememb ali pa ni prepričano v uspeh sprememb; • Vnaprej se omeji definicija problema in obsega preurejanja,
čeprav se celotna dimenzija problema in obseg preurejanja pokaže komaj v fazi uvajanja, kar je bilo prej običajno pometeno »pod preprogo«;
• Pri uvajanju se dopušča, da obstoječa kultura in odnos vodstva podjetja prepreči začetek preurejanja, ker je strah pred spremembami prevelik;
• Preurejanje se poskuša izvesti od spodaj navzgor, ker za preurejanjem ne stoji glavno vodstvo organizacije;
• Za vodenje preurejanja se imenujejo osebe, ki preurejanja ne razumejo;
• Za preurejanje se ne nameni dovolj sredstev oziroma se z njimi skopari;
• Preurejanje je organizaciji zadnja skrb, ker se ukvarja s tekočimi zadevami ali sama s seboj;
• Organizacija porazdeli svojo energijo na več projektov preurejanja hkrati, ker ne ve, kje bo težišče preurejanja;
• Organizacija se preurejanja loti, ko glavnemu vodstvu manjkata »le dve leti do upokojitve«, kar pa je za urejanje premalo časa;

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 8
• V podjetju ne razlikujejo preurejanja od drugih programov za izboljšave;
• Energija se usmerja izključno na oblikovanje organizacijske strukture organizacije;
• Preurejanje se poskuša izpeljati tako, da bi bil volk sit in koza cela;
• Organizacija odneha s spremembami, ko se ljude uprejo spremembam;
• Pri preurejanju se preveč zavlačuje pri izpeljavi procesov. Vse to vodi do spoznanja, da je potrebno vse procese povezati v celoto in v njih vgraditi mehanizme za ocenjevanje in izboljšave. Upravljanje z IT zahteva predvsem povezavo štirih elementov, znanih kot štirje P-ji: ljudje (peoples), procesi (processes), izdelki (products) in zunanji izvajalci (partners).
Slika 1: Štirje P-ji
Ti štirje elementi so že dolgo znani, a vseeno se ne izkoriščajo vedno v prid organizacije. Tako je eno od osnovnih načel ITIL, da je potrebno najprej posvetiti pozornost ljudem in procesom, ki jih podpremo s tehnologijo. Torej tehnologija ni sama sebi namen in le v povezavi z ljudmi in procesi oživi v želenem obsegu. Slepo vlaganje v tehnologijo in čakanje na rezultate bo vedno pripeljalo do zloma sistema. Za učinkovit informacijski sistem je potrebno doseči uravnovešen odnos med vsemi štirimi P-ji.
Partnerji (Partners)
Procesi (Processes)
Izdelek (Products)
Ljudje (People)

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 9
2.1 PRIPOROČILA ITIL
Zbirko ITIL sestavljajo usmeritve in napotki za vse vidike celovitega (end-to-end) upravljanja storitev, ki temeljijo na najboljše praksi in zajemajo tako ljudi kot tudi procese, izdelke in sodelovanje partnerjev. Zbirka ITIL in njeni moduli tvorijo enoten in celovit okvir1.
Slika 2: Okvir zbirke ITIL (Rudd, 2006)
Na sliki 2 so prikazani splošno okolje, struktura in vsebina vseh modulov ITIL. Slika prikazuje tudi odnos, ki ga imajo posamezni moduli s poslovanjem in tehnologijo. Iz slike je razvidno, da je modul Poslovna perspektiva bolje usklajen s poslovanjem, modul Upravljanje infrastrukture IKT (informacijsko komunikacijska tehnologija) pa s tehnologijo. Jedro okvira sta modula Zagotavljanje storitev in Podpora storitvam. Vseh sedem modulov skupaj tvori celoto okvirja ITIL. S stalnim dopolnjevanjem posameznih modulov se celotna struktura neprekinjeno izboljšuje in posodablja. Zagotavljanje storitev zajema procese, potrebne za načrtovanje in zagotavljanje kakovostnih storitev IT in se dolgoročno ukvarja s tem, da procesi izboljšujejo kakovost zagotovljenih storitev IT. Podpora storitvam opisuje procese, povezane z vsakodnevnimi dejavnostmi podpore in vzdrževanja v zvezi z zagotavljanjem storitev IT. 1 Poglavje je povzetek gradiva Uvodna predstavitev ITIL pisca Colina Rudda v izdaji qSTC d.o.o., Ljubljana iz leta 2006
P O S L O V A N J E
T E H N O L O G I J A Upravljanje aplikacij
Upravljanje infrastrukture
IKT
Podpora storitvam
Zagotavljanje
storitev
Upravljanje storitev
Načrtovanje implementacije upravljanja storitev
Poslovna perspektiva

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 10
Upravljanje infrastrukture IKT zajema vse vidike upravljanja infrastrukture IKT, od prepoznavanja poslovnih zahtev, razpisnih postopkov do preizkušanja, namestitve, uvajanja in stalnega delovanja ter optimizacije komponent IKT in storitev IT.
Slika 3: Rezultati in posredniki procesov po priporočilih ITIL (qSTC, 2006)
Načrtovanje implementacije upravljanja storitev se ukvarja z vprašanji in opravili načrtovanja, implementacije in izboljševanja procesov upravljanja storitev v organizaciji. Rešuje tudi zadeve v zvezi s kulturnimi in z organizacijskimi spremembami, z razvojem vizije in strategije ter najustreznejšo metodo pristopa.
Poslovni načrt in komunikacije
IKT
Poslovne zahteve
Politika preskrbe Politika dobaviteljev in pogodbe
Vizija in strategija Kultura, ljudje in izobraževalni
načrt
Načrti programov in projektov
Cilji, CSF in KPI
Poslovanje Načrtovanje implementacije SM
Poslovna perspektiva Zagotavljanje storitev
Upravljanje varnosti
Podpora storitvam
Poslovanje strategije in načrt
Ocenjevanje, opredelitev zahtev, povabilo k ponudbi
Načrti neprekinjenosti
poslovanja
Poslovne zahteve Politika poslovanja varnosti
Aplikativna strategija
Zgradba aplikacij
Program razvoja
Politika aplikacij
Upravljanje aplikacij
Zasnova in zgradba IKT
Strategije in načrt IKT
Poslovni primeri, študije
izvedljivosti
Upravljanje infrastrukture IKT
Varnostna politika
Varnostna strategija in
načrt
SIP Načrt kakovosti storitev Finančni načrt
Načrt neprekinjenost poslovanja
Načrt zmogljivosti Načrt razpoložljivost
Načrt konfiguracij, sprememb, izdaj in
drugih storitev podpore

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 11
Upravljanje aplikacij opisuje način upravljanja aplikacij od začetnih poslovnih potreb skozi vse faze življenjskega cikla aplikacije vključno z njeno odstranitvijo. Zelo pomembno je zagotavljanje povezanosti projektov in strategij IT s poslovnimi projekti in strategijami preko celotnega življenjskega cikla aplikacije, kar poslovanju zagotavlja najboljši izkoristek naložbe. Poslovna perspektiva z nasveti in smernicami razlaga osebju IT, kako lahko prispeva k poslovnim ciljem in kako je mogoče vloge in storitve bolje uskladiti in uporabiti, da bi bil prispevek k poslovnim ciljem čim večji. Upravljanje varnosti podrobneje obravnava postopek načrtovanja in upravljanja določene ravni varnosti za informacije in storitve IT, vključno z vsemi vidiki, ki so povezani z odzivi na varnostne incidente. Vključuje tudi ocenjevanje in upravljanje tveganj in ranljivosti ter implementacijo stroškovno upravičenih protiukrepov. Na sliki 3 so prikazane vsebine vseh modulov zbirke ITIL in rezultati posameznih procesov. Puščice med procesi kažejo, na katerih področjih zunaj matičnega procesa se predvsem uporabljajo njegovi rezultati. 2.1.1 ZAGOTAVLJANJE STORITEV
Modul Zagotavljanje storitev (Service Delivery) zajema proaktivne vidike zagotavljanja storitev in je sestavljen iz procesov Upravljanje ravni storitev, Finančno upravljanje za storitve IT, Upravljanje zmogljivosti, Upravljanje neprekinjenosti delovanja storitev IT in Upravljanje razpoložljivosti. Navedeni procesi se nanašajo predvsem na razvoj načrtov za izboljšanje kakovosti dobavljenih storitev IT. Slika 4 prikazuje vlogo upravljanja ravni storitev (SLM – Service level management)) kot glavnega posrednika med poslovanjem in IT ter rezultate posameznih procesov zagotavljanja storitev. Proces SLM obravnava pogajanja, dokumentiranje, usklajevanje in preverjanje potreb po poslovnih storitvah ter njihovih ciljih, opredeljenih v zahtevah po ravni storitev (SLR – Service level requirement) in v dogovorih o ravni storitev (SLA – Service level agreement). Gre predvsem za merjenje, poročanje in preverjanje kakovosti storitev IT, dobavljenih poslovanju. Proces SLM obravnava in usklajuje tudi cilje podpore, kot so opisani v dogovorih o ravni operativne podpore (OLA – Operational level agreement) s skupinami za podporo in v pogodbah o podpori (underpinning contracts) z dobavitelji. Poskrbeti je namreč treba, da so cilji podpore usklajeni s poslovnimi cilji iz SLA.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 12
Slika 4: Procesi zagotavljanja storitev (Rudd, 2006)
V okviru procesa SLM je skrb namenjena tudi izdelavi in vzdrževanju kataloga storitev. Ta vsebuje pomembne podatke ali celotno zbirko zagotovljenih storitev IT. Vloga procesa SLM je tudi razvoj, usklajevanje in upravljanje programa za izboljšanje storitev ali programa za nenehno izboljševanje storitev, ki je celosten načrt za stalno dvigovanje kakovosti storitev IT, zagotovljenih poslovanju. Finančno poslovanje za storitve IT temelji na obravnavanju IT kot poslovne enote ter uvaja zavest o gospodarnem in stroškovno učinkovitem delovanju IT v organizaciji. Glavne dejavnosti so določanje in utemeljevanje stroškov za zagotavljanje vseh storitev IT poslovne enote ter napovedovanje prihodnjih izdatkov v finančnem načrtu IT.
Poslovanje, stranke in uporabniki
Vprašanja Povpraševanje
Komunikacija Posodobitve
Poročila
Zahteve cilji
dosežki
SLA, SLR, OLA, poročila, katalog storitev, SIP ali CSIP, revizijska poročila,
poročila o kršitvah
Upravljanje razpoložljivosti
Načrti razpoložljivosti Kriteriji načrtovanja
Cilji (pragovi) Poročila
Revizijska poročila
Finančni načrt Vrste in modeli
Stroški in obračunavanja
Poročila in napovedi Revizijska poročila Načrt neprekinjenosti
delovanja IT BIA in analiza tveganja
Nadzorni centri Pogodbe DR
Poročila Revizijska poročila
Upravljanje neprekinjenosti
dobave storitev IT
Upravljanje ravni storitve
Finančno upravljanje za
storitev IT
Načrt zmogljivosti Zbirka podatkov o
upravljanju zmogljivosti (CDB)
Cilji Poročila o zmogljivosti Časovni razporedi Revizijska poročila
Upravljanje kapacitete
Opozorila in izjeme Spremembe
Orodja za upravljanje in infrastruktura IT

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 13
Proces upravljanja kapacitet zagotavlja stalno razpoložljivost potrebnih kapacitet, ki so potrebne za delovanje IS, in sicer tako, da poskuša uravnotežiti »zahteve poslovanja s ponudbo IT«. V tem cilju je potrebno redno preverjati načrtovane kapacitete, ki morajo biti tesno povezane s poslovno strategijo. Dejavnosti so upravljanje zmogljivosti, upravljanje delovne obremenitve, upravljanje zahtev in določanje obsežnosti ter modeliranje aplikacije. Neprekinjenost delovanja storitev IT zajema postopke za obnovitev delovanja v primeru večjega incidenta ali v primeru zloma IS. Vsaka organizacija mora predvideti takšne situacije. Namen neprekinjenosti delovanja storitev IT je, da zagotovi organizaciji čim manjšo izgubo zaradi prekinitve poslovanja. Dejavnosti so analiza vplivov ne delovanja IS na poslovanje, analiza tveganja in upravljanje tveganja, izdelava in preskušanjem vseh načrtov obnove. Ključni vidik kakovosti storitev je razpoložljivost. Upravljanje razpoložljivosti pomeni, da razpoložljivost vsake storitve zadošča dogovorjeni razpoložljivosti ter da se nenehno proaktivno izboljšuje. Da bi to dosegli, upravljanje razpoložljivosti spremlja, meri in preverja poglaviten niz metrik vseh storitev in komponent ter poroča o tem, vključno z razpoložljivostjo, zanesljivostjo, vzdržljivostjo, možnostjo servisiranja in varnostjo. 2.1.2 PODPORA STORITVAM
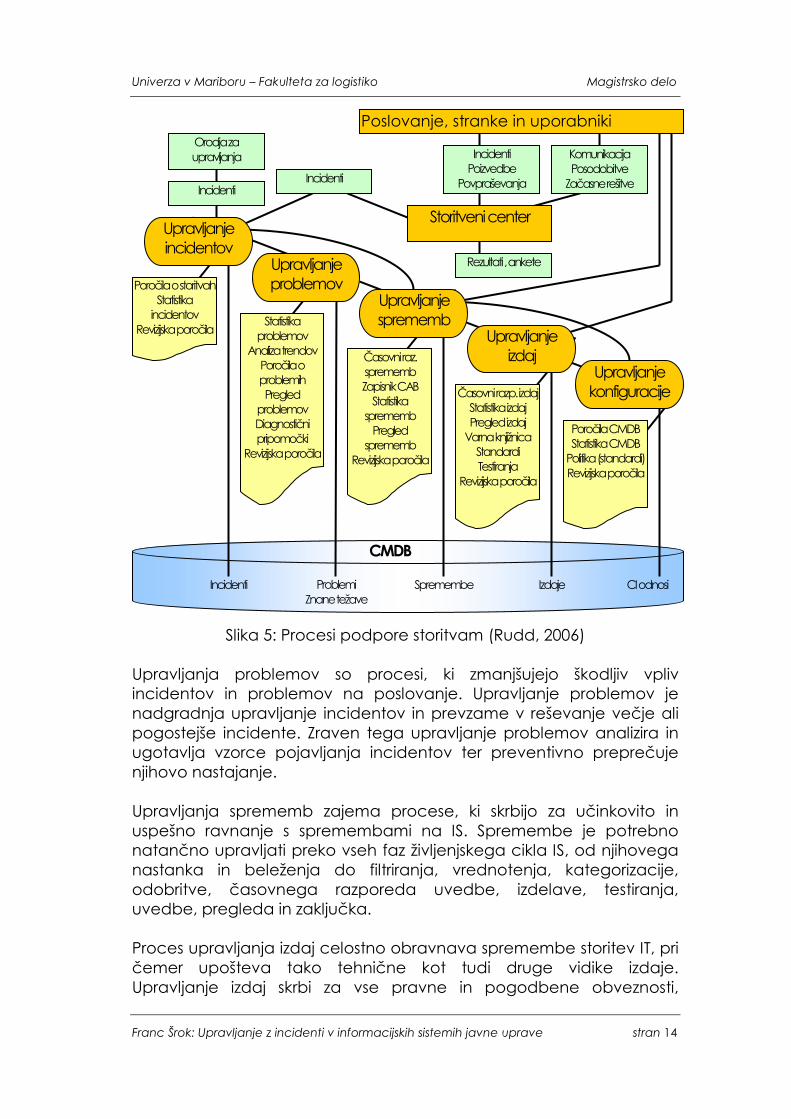
Podpora storitvam (Service Support) so procesi, povezani z vsakodnevno podporo in vzdrževanjem upravljanja incidentov, upravljanja problemov, upravljanja sprememb, upravljanja konfiguracij in upravljanja izdaj ter storitvenega centra. Slika 5 prikazuje vlogo storitvenega centra kot posrednika med poslovanjem in IT ter glavne funkcionalnosti procesov podpore storitvam. Storitveni center je enotna in glavna vstopna točka za vse uporabnike IT v organizaciji, ukvarja pa se z vsemi incidenti, poizvedbami in zahtevami. Poleg tega je posrednik za vse druge procese podpore storitvam. Upravljanje incidentov je proces, ki zaznava, beleži, rešuje in zaključuje vse primere incidentov. Njegov cilj je obnova normalnega delovanja storitve v čim krajšem času in s čim manjšimi motnjami poslovanja.
Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 14
Slika 5: Procesi podpore storitvam (Rudd, 2006)
Upravljanja problemov so procesi, ki zmanjšujejo škodljiv vpliv incidentov in problemov na poslovanje. Upravljanje problemov je nadgradnja upravljanje incidentov in prevzame v reševanje večje ali pogostejše incidente. Zraven tega upravljanje problemov analizira in ugotavlja vzorce pojavljanja incidentov ter preventivno preprečuje njihovo nastajanje. Upravljanja sprememb zajema procese, ki skrbijo za učinkovito in uspešno ravnanje s spremembami na IS. Spremembe je potrebno natančno upravljati preko vseh faz življenjskega cikla IS, od njihovega nastanka in beleženja do filtriranja, vrednotenja, kategorizacije, odobritve, časovnega razporeda uvedbe, izdelave, testiranja, uvedbe, pregleda in zaključka. Proces upravljanja izdaj celostno obravnava spremembe storitev IT, pri čemer upošteva tako tehnične kot tudi druge vidike izdaje. Upravljanje izdaj skrbi za vse pravne in pogodbene obveznosti,
Incidenti Poizvedbe
Povpraševanja
Rezultati , ankete
Statistika problemov
Analiza trendov Poročila o problemih Pregled
problemov Diagnostični pripomočki
Revizijska poročila
Poročila o storitvah Statistika
incidentov Revizijska poročila
Časovni razp. izdaj Statistika izdaj Pregled izdaj
Varna knjižnica Standardi Testiranja
Revizijska poročila
Poročila CMDB Statistika CMDB
Politika (standardi) Revizijska poročila
Upravljanje konfiguracije
Upravljanje problemov
Časovni raz. sprememb Zapisnik CAB
Statistika sprememb
Pregled sprememb
Revizijska poročila
Incidenti
Orodja za upravljanja
Incidenti
Storitveni center
Poslovanje, stranke in uporabniki
Komunikacija Posodobitve
Začasne rešitve
Incidenti Problemi Znane težave
Spremembe Izdaje CI odnosi
CMDB
Upravljanje sprememb
Upravljanje izdaj
Upravljanje incidentov

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 15
povezane z vso strojno in programsko opremo, ki se uporablja v organizaciji. Za doseganje tega cilja in za zaščito sredstev IT upravljanje zdaj vzpostavi shrambo veljavne strojne opreme in knjižnico veljavne programske opreme. Upravljanje konfiguracij je osnova za uspešno upravljanje storitev IT in podpira vse druge procese. Njegov rezultat je podatkovna zbirka upravljanja konfiguracij (CMDB – Configuration management database), ki vsebuje eno ali več integriranih zbirk podatkov z vsemi komponentami infrastrukture IT in druga s tem povezana pomembna sredstva v organizaciji. Prav ta sredstva, znana kot konfiguracijski elementi, so potrebna za zagotavljanje storitev IT. Bistvena sestavina, zaradi katere se CMDB razlikuje od drugih seznamov sredstev, so odnosi ali povezave, ki določajo, kako je vsak element konfiguracije povezan s svojimi sosednjimi elementi in kako je odvisen od njih. Najbolje je, da CMDB vsebuje tudi podrobnosti o incidentih, težavah, znanih napakah in spremembah, povezanih z vsakim elementom konfiguracije. 2.1.3 UPRAVLJANJE INFORMACIJSKO KOMUNIKACIJSKO TEHNOLOŠKE INFRASTRUKTURE
Upravljanje infrastrukture (IM – Infrastructure management) IKT se ukvarja z izzivi, povezanimi z upravljanjem infrastrukture IKT, in zajema celotno upravljanje in administracijo, zasnovo in načrtovanje, tehnično podporo ter uvajanje in delovanje. Procesi upravljanja infrastrukture IKT so tesno povezani z infrastrukturo, ki omogoča delovanje storitev IT. Gre pa predvsem za upravljanje štirih P-jev (ljudje, procesi, izdelki in partnerji). Posebno pomembna so tista področja informacijske tehnologije, ki so najtesneje povezana z dejanskimi orodji in s tehnologijo, kot je prikazano na sliki 6. Procesi upravljanja infrastrukture IKT se ukvarjajo s storitvijo skozi vse faze življenjskega cikla – od zahtev do zasnove, izvedljivosti, razvoja, izgradnje, testiranja, uvajanja, delovanja, optimizacije ter odstranitve storitve. Procesi delovanja IKT skrbijo za delovanje in optimizacijo ter zagotavljajo ustrezen nadzor nad operativnimi dogodki in doseganjem vseh zastavljenih operativnih ciljev storitev. Področji upravljanja in administracije znotraj upravljanja infrastrukture IKT zagotavljata ustvarjanje najprimernejšega okolja z varno infrastrukturo, potrebno za zagotavljanje kakovostnih storitev IT tako zdaj, kot tudi v prihodnosti. Njun cilj je izboljšati učinkovitost in uspešnost infrastrukture IKT ter hkrati vzdrževati raven kakovosti storitev IT.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 16
Slika 6: Glavni posredniki upravljanja infrastrukture IKT (Rudd, 2006)
Funkciji zasnove in načrtovanja se ukvarjata s strateškimi vprašanji, povezanimi z delovanjem funkcije IKT. Ti dve funkciji si morata z upoštevanjem pristopa poslovne perspektive prizadevati tudi za tesno sodelovanje z vsemi poslovnimi vodji in načrtovalci, usmerjevalno skupino IKT, vodji in načrtovalci IT-ja in tako zagotoviti, da so vsi načrti in strategije poslovanja ter IKT med seboj usklajeni, kot je prikazano na sliki 7. Pri procesu postavitve gre za uvajanje novih in spremenjenih rešitev IKT za podporo poslovanju v okviru dogovorjene kakovosti, stroškov in časa. Postavitev načeloma vključuje snovanje in metodologijo projektov, zato da bi ob uvedbi novih rešitev IKT poslovanje potekalo s kar se da minimalnimi prekinitvami in da bi bila uporaba sredstev IKT optimalna. Tehnična podpora zagotavlja potrebne podpore, znanja in sposobnosti, ki so osnova za celotno storitev, ki jo izvaja IKT IM. Vzdržuje poglobljeno strokovno znanje za zagotavljanje informativnih napotkov ter dejanskih virov za raziskovanje in razvoj novih tehnoloških rešitev, poleg tega pa tudi tretje ravni tehnične podpore vsem drugim področjem IT.
Tehnična podpora
Upravljanje varnosti
Poslovna perspektiva
Upravljanje aplikacij
Dobava storitev
Poslovanje Stranke Uporabniki
Podpora storitev
Politika Strategija Načrt Preizkus Uvajanje Deluje Zastarelost
Upravljanje IKT IM in administracija
Poslovne rešitve
Partnerji Tehnologija
Strategija, načrti in potrebe

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 17
Slika 7: Model infrastrukture IKT (Rudd, 2006)
2.1.4 NAČRTOVANJE IMPLEMENTACIJE UPRAVLJANJA STORITEV
Modul za načrtovanje implementacije upravljanja storitev se ukvarja z uvedbo ali izboljševanjem prakse ITIL v organizaciji in upošteva vidike, kot so kje in kdaj začeti, organizacijske spremembe, spremembe v kulturi organizacije, načrtovanje projektov in programov, definicije procesov in izboljševanje uspešnosti delovanja. S pristopom, prikazanim na sliki 8, se najprej oblikuje celotna vizija za IT. Vizija upravljanja storitev IT je izjava o nameri, o kateri se medsebojno sporazumeta vodstvo organizacije in IT. Potem, ko je določena vizija, je potrebno opredeliti trenutno stanje, ki ga je mogoče oceniti tako, da se uporabi model rasti organizacije IT, s katerim se ugotavlja trenutna stopnja zrelosti organizacije IT glede vizije in strategije, smernic, procesov, kadrov, tehnologije in kulture.
3
2 Poslovni proces 1
Poslovna enota A
6
5 Poslovni proces 4
Poslovna enota B
9
8 Poslovni proces 7
Poslovna enota C
Storitev G Storitev F
Storitev E Storitev D
Storitev C Storitev B
Storitev A
SLA
Poslovanje
S/W
Storitev
Komponente
H/W
N/W
D/B
Okolje
(iii) (ii)
Skupina za podporo (i)
Skupine OLA
(iii) (ii)
Dobavitelj (i)
Dobavitelji Pogodbe
Poslovni načrti,
politika in strategija
Politika IKT in strategija
Zasnova in zgradbe
Programski in projektni načrti

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 18
Slika 8: Načrtovanje implementacije upravljanja storitev (Rudd, 2006)
Naslednji korak je dogovor o prihodnji vlogi in značilnostih organizacije IT, da bi določili, kakšno stanje želimo doseči (Kam želimo priti?). Opravi se analiza in izpolni poročilo o oceni razkoraka ter poslovni primer za program nenehnega izboljševanja storitev (CSIP – Countinous service improvement program). Nato je treba izdelati načrt za projekt CSIP, ki se ukvarja z načini doseganja načrtovanih ciljev (Kako priti do želenega cilja?). Pri tem je treba upoštevati kako bomo dosegli spremembe, kje naj začnemo in katere elemente je treba obravnavati v programu CSIP. Z odgovori na ta vprašanja po priporčilih ITIL (Rudd, 2006) določimo pristop, končni obseg in pristojnosti za projekt CSIP. Dogovoriti se je treba o merljivih mejnikih, rezultatih, kritičnih dejavnikih uspeha in ključnih pokazateljih delovanja, da se lahko ocenita napredek in uspešnost projekta CSIP (Kako lahko preverimo, ali so bili mejniki doseženi?). Na koncu cikla se je treba spoprijeti s težjo nalogo, kako pridobljeni zagon ohranjati za nadaljnje izboljševanje storitev (Kako nadaljevati začetni zagon?).
Poslovni cilji na visoki ravni
Ocenjevanje
Merljivi cilji
Kako
nadaljevati začetni zagon?
Kakšna je vizija?
Kje smo zdaj?
Kam želimo priti?
Kako priti do želenega cilja?
Kako preverimo, ali smo dosegli mejnike?
Izboljšave procesov
Merjenja in metrika

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 19
2.1.5 UPRAVLJANJE APLIKACIJ
Upravljanje aplikacij zajema procese, ki so povezani z celotnim življenjskim ciklom aplikacije. Slika 9 prikazuje življenjske cikle aplikacije. Da bi lahko povsem razumeli proces upravljanja aplikacij, ga je treba primerjati z upravljanjem storitev in z razvojem aplikacij:
• Upravljanje aplikacij je zbirka navodil, v kateri je opisano celotno ravnanje oz. upravljanje aplikacije v njenem življenjskem ciklu.
• Razvoj aplikacij se ukvarja z dejavnostmi, ki so potrebne za načrtovanje, oblikovanje in izdelavo aplikacije, ki jo na koncu uporabi del organizacije za izvajanje poslovnih zahtev.
• Upravljanje storitev se osredotoči na dejavnosti, ki se nanašajo na izdajo, dobavo, podporo in optimizacijo aplikacije. Poglavitni cilj je zagotoviti, da bo aplikacija, potem ko je izdelana in uvedena, dosegla dogovorjeno storitveno raven.
Zahteve iz vseh področjih poslovanja organizacije in upravljanja storitev se morajo upoštevati v celotnem življenjskem ciklusu aplikacije. Oblikovanje zahtev in zasnova aplikacije mora biti skupna strategija razvijalcev IT in poslovnega vodstva organizacije, ker se le tako lahko zagotovi, da se IT in poslovanje strinjata glede jasnosti, jedrnatosti in izvedljivosti ciljev.
Slika 9: Življenjski cikel aplikacije (Rudd, 2006)
Pred izdelavo aplikacije mora organizacija oceniti svoje zmožnosti za izdelavo, vzdrževanje in delovanje storitev IT. Z temi ocenami se lahko določi strategija za izdelavo in uvedbo aplikacije, oziroma storitve IT. Upravljanje aplikacij vidi razvoj aplikacij kot neprekinjen krožni proces med delovanjem in optimizacijo aplikacije na vsa področja
Optimizacija
Zahteve
Zasnova
Izdelava
Optimizacija
Delovanje
Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 20
upravljanja storitev, kot medsebojno povezane dele celote, ki jih je treba uskladiti. Posledično morajo enote za razvoj aplikacij, upravljanje storitev in upravljanje infrastrukture IKT tesno sodelovati, če želijo zagotoviti, da bo v posamezni fazi življenjskega cikla ustrezna pozornost posvečena ustvarjanju storitev, uvedbi in operativnosti. Za vsako fazo življenjskega cikla aplikacije je treba razviti nadzorni seznam upravljanja, ki zagotavlja, da so v celoti upoštevani in obravnavani ustrezni vidiki upravljanja storitev ter da se določijo in zasedejo ključne vloge pri upravljanju aplikacij, če želimo, da bodo dejavnosti opravljene v celoti. Bistveno je, da organizacija najde način za merjenje napredka in učinkovitosti glede na doseganje teh ciljev. 2.1.6 POSLOVNA PERSPEKTIVA
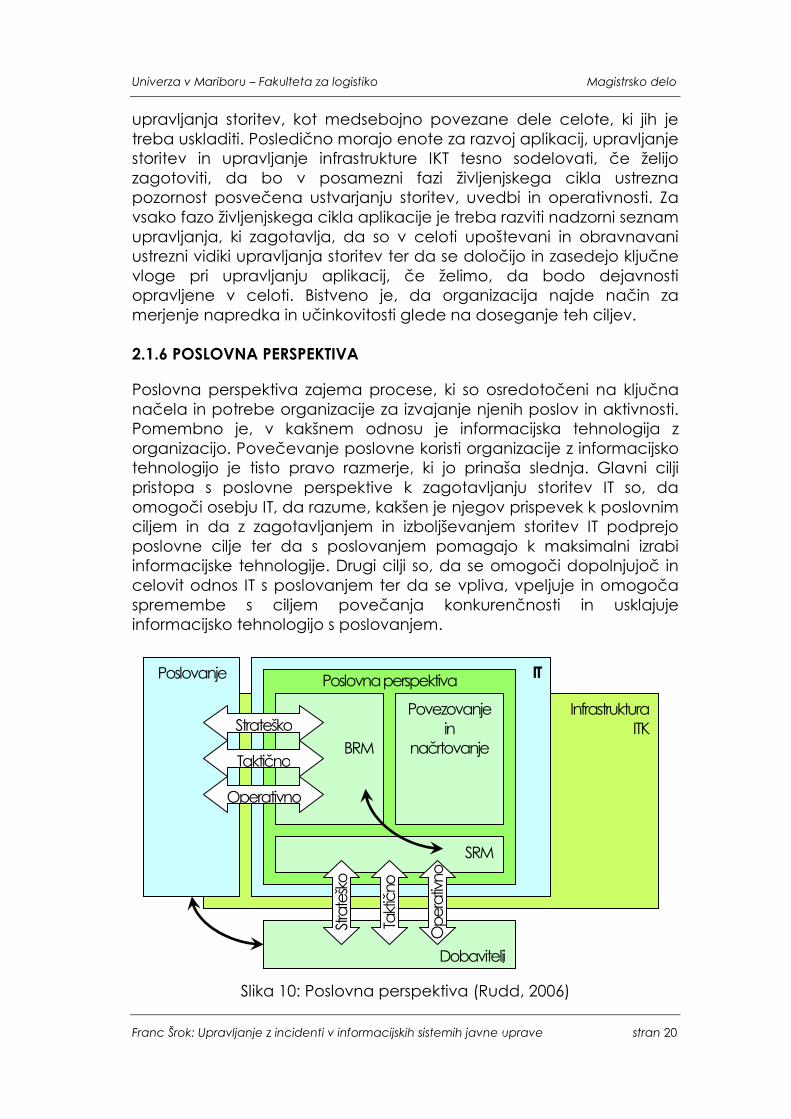
Poslovna perspektiva zajema procese, ki so osredotočeni na ključna načela in potrebe organizacije za izvajanje njenih poslov in aktivnosti. Pomembno je, v kakšnem odnosu je informacijska tehnologija z organizacijo. Povečevanje poslovne koristi organizacije z informacijsko tehnologijo je tisto pravo razmerje, ki jo prinaša slednja. Glavni cilji pristopa s poslovne perspektive k zagotavljanju storitev IT so, da omogoči osebju IT, da razume, kakšen je njegov prispevek k poslovnim ciljem in da z zagotavljanjem in izboljševanjem storitev IT podprejo poslovne cilje ter da s poslovanjem pomagajo k maksimalni izrabi informacijske tehnologije. Drugi cilji so, da se omogoči dopolnjujoč in celovit odnos IT s poslovanjem ter da se vpliva, vpeljuje in omogoča spremembe s ciljem povečanja konkurenčnosti in usklajuje informacijsko tehnologijo s poslovanjem.
Slika 10: Poslovna perspektiva (Rudd, 2006)
Infrastruktura ITK
IT Poslovanje Poslovna perspektiva
BRM
Povezovanje in
načrtovanje
SRM
Dobavitelji
Strateško
Taktično
Operativno
Stra
tešk
o
Takt
ično
Opera
tivno

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 21
Uspešni procesi zagotavljajo, da so storitve IT usklajene z zahtevami poslovanja in da je ta usklajenost podprta tudi z elementi zunanjih dobaviteljev. Zato je pomembno, da se ustvari partnerstvo med informacijsko tehnologijo in poslovanjem ter informacijsko tehnologijo in dobavitelji, ker to omogoča razvoj »poslovno vodene« organizacije IT. Zaradi večje uspešnosti je ta pristop sestavljen iz več procesov, katerih cilj je usklajevanje poslovanja in informacijske tehnologije. Usklajevanje ne pokriva samo trenutnih sistemov IKT in storitev IT, ampak tudi prihodnje. Zato obstaja zahteva po usklajevanju na strateški, taktični in operativni ravni, kot je ponazorjeno na sliki 10. Pri doseganju uskladitve interesov je treba upoštevati več procesnih področij in vlog. Ključni procesi so:
• Upravljanje odnosov s poslovanjem (BRM-Business Relationship Management);
• Upravljanje odnosov z dobavitelji (SRM-Supplier Relationship Management);
• Pregledovanje, načrtovanje in razvoj informacijske tehnologije; • Povezovanje, izobraževanje in obveščanje o IT-ju.
Razvijanje in vzdrževanje odnosov s strankami je vedno pomembno vprašanje v vseh organizacijah. Tudi za ponudnike storitev IT je pomembno, da razvijajo odnose s svojimi strankami in poslovnim vodstvom. Ravno tako je pomembno, da razvijajo odnose s svojimi glavnimi dobavitelji, še posebej tam, kjer je izvajanje celotne storitve vezano na zunanje dobavitelje, ki neposredno vplivajo na kakovost dobavljene storitve strankam in poslovanju. Za doseganje tega je priporočljiva vzpostavitev procesov BRM in SRM. Bistveno je, da osebe, ki delajo znotraj procesa BRM, upoštevajo koristi informacijske tehnologije in njeno vlogo v verigi poslovnih vrednosti in to neprekinjeno propagirajo ter krepijo sporočilo o pomenu uskladitve poslovanja in informacijske tehnologije. Medsebojno morajo sodelovati s poslovnimi enotami in predstavljati njihove poglede preostalim v informacijski tehnologiji. SRM mora zagotoviti, da bodo odnosi z dobavitelji prinašali največjo poslovno prednost. S tem je mišljeno zaznavanje potreb po različnih tipih dobaviteljev skupaj z ustreznimi odnosi z njimi, katalogom dobaviteljev, življenjskim ciklom pogodb, integracijo dobaviteljev v celovite (end-to-end) procese upravljanja storitev in upravljanje poslovanja z dobavitelji.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 22
Uspešni odnosi med poslovanjem in informacijsko tehnologijo ter med informacijsko tehnologijo in dobavitelji na operativni, taktični in strateški ravni lahko pripomorejo tudi k učinkoviti in inovativni uporabi informacijske tehnologije pri povečevanju konkurenčnosti (npr. prepoznavanje novih tehnologij, lažje preoblikovanje poslovanja in zadovoljevanje čedalje večjih in hitro spreminjajočih se poslovnih zahtev). Ključna naloga organizacije IT je, da si prizadeva uskladiti svojo organizacijo, zagotavljanje storitev in kulturo s poslovanjem. Z dobro uskladitvijo je mogoče doseči precejšnje prednosti v poslovanju, predvsem na področjih neprekinjenosti, tveganja, sprememb in dogovorov o ravni storitev, kar prinaša izboljšano zagotavljanje storitev in doseganje ključnih poslovnih ciljev. Usklajevanje s poslovanjem se mora začeti pri vrhu, z uskladitvijo strategij informacijske tehnologije, vodenja in kulture. Vodstvo IT mora oceniti organizacijo in storitve IT ter preveriti in preko programa za nenehno izboljševanje storitev izboljšati usklajenost s poslovanjem. Z vidika upravljanja morata biti uskladitev in vključitev poslovanja upoštevana v vseh procesih upravljanja storitev, tudi na taktični in operativni ravni. Tako bodo zagotovljeni celoviti (end-to-end) integrirani procesi, ki prinašajo dodatne prednosti vzajemnega delovanja in partnerstva v celotni organizaciji. Ta pristop upošteva tudi uporabo kataloga storitev in dogovorov o ravni storitev pri trženju informacijske tehnologije in njenih storitev poslovanja, skupaj s predstavitvijo novih storitev in pričakovanj ter z neprekinjenim izboljševanjem in razvojem organizacijske kulture. Pristop poslovne perspektive se osredotoči tudi na povezovanje med poslovno dejavnostjo in informacijsko tehnologijo, izboljšanje pretoka informacij, načrtovanje poslovnega komuniciranja in še posebej na doslednost pristopa pri koordiniranju dejavnosti BRM in SRM. 2.1.7 UPRAVLJANJE VARNOSTI
Upravljanje varnosti IT je proces upravljanja ustrezne ravni varovanja informacij, storitev IT in infrastrukture. Upravljanje varnosti IT zagotavlja:
• Uvajanje in vzdrževanje varnostnih kontrol, ki nadzirajo spreminjajoče se stanje;
• Upravljanje varnostnih incidentov; • Izvajanje revizije, ustreznostih varnostnih kontrol in drugih
ukrepov; • Izdelavo poročil o stanju varovanja informacij.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 23
Slika 11: Model za varovanje informacij (Rudd, 2006)
Upravljanje varnosti informacijske tehnologije je proces ocenjevanja in upravljanja tveganja in je sestavni del opisa del in nalog vsakega vodje IT. Uprava je odgovorna za sprejemanje ustreznih ukrepov oziroma politike za zmanjševanje možnosti nastajanja varnostnih incidentov na sprejemljivo raven. Ta politika ureja upravljanje varnosti IT. Z varnostno politiko je evidentirana in podkrepljena odločitev podjetja, da vlaga v varovanje informacij in njihovo obdelavo. Vodstvu daje navodila in smernice glede relativne pomembnosti različnih vidikov organizacije in glede tega, kaj je pri uporabi sistemov IKT ter podatkov dovoljeno in kaj ne. Na sliki 11 je prikazan proces varovanja informacij z vidika poslovanja. Pokriva vse stopnje, od določanja politike in začetne ocenitve tveganja, načrtovanja, implementacije in delovanja do ocene in revizije. Na sliki 12 je prikazan ITIL proces za upravljanje varnosti informacijske tehnologije. V procesu je opisana celotna pot, od zbiranja uporabnikovih oziroma strankinih zahtev, načrtovanja, implementacije, ocenjevanja in vzdrževanja – v okviru nadzora – z rednim poročanjem stanja stranki, kar zaključuje zanko. Bistveni elementi vseh dejavnosti znotraj procesa upravljanja varovanja IT so ocenitev tveganja in ranljivosti ter izvajanje stroškovno upravičenih protiukrepov za zmanjšanje ranljivosti in tveganja na raven, sprejemljivo za poslovanje. Te dejavnosti je treba skrbno
Politika
Načrtovanje in implementacija
Analiza tveganja
Ocena in revizija
Delovanje
Poslo
vne p
otre
be
in zu
nanj
i vpliv
i

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 24
uskladiti z drugimi področji upravljanja storitev, še posebej s procesoma upravljanja razpoložljivosti in neprekinjenosti delovanja storitve IT.
Slika 12: Proces upravljanja varovanja informacijske tehnologije (Rudd,
2006)
2.2 UPRAVLJANJE Z INCIDENTI V INFORMACIJSKIH SISTEMIH
Glavni cilj procesa upravljanja z incidenti2 (IMP – incident management process) je v čim krajšem času vzpostavitev in ohranitev normalnega nivoja delovanja storitev z zahtevanim nivojem kvalitete in razpoložljivim delovanjem, da bodo posledice na poslovne procese čim manjše. Normalni nivo delovanja storitve je definiran znotraj meja SLA. V ITIL terminologiji je »incident« definiran kot vsak dogodek, ki ni del standardnega delovanja in je povzročil ali je vzrok za prekinitev ali zmanjšanje kvalitete delovanja posamezne storitve. Zahtevek za novo ali dodatno storitev pogosto ni incident, temveč je to zahtevek za spremembo (RFC – Request for change). V praksi sta pogosto enaka postopka ob zahtevi za storitev in ob napaki v infrastrukturi ter se vključujeta v proces upravljanja z incidenti.
2 Poglavje je povzetek gradiva iz elektronskega vira (CD) Service support : version 2.0 , izdajatelja The Stationery Office : Office of Government Commerce, cop. London izdanega leta 2003
Stranka
SLA
Načrt
Nadzor
Ocena Implementacija
Poročilo
Vzdrževanje

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 25
Na slika 13 je prikazan procese upravljanja z incidenti, kot ga opredeljujejo priporočila ITIL. Vhodi v sistem upravljanja z incidenti so:
• Podatki o vzroku za incidentu, ki ga zabeleži storitveni center o nedelovanju omrežja, računalniške opreme, procesa itd.;
• Podatki o konfiguracijah posameznih računalniških sistemov, storitev, omrežja in podobno, ki so zabeleženi v podatkovnih zbirkah o konfiguraciji IS;
• Podatki o obstoječih rešitvah iz podatkovne zbirke napak ali tako imenovane »baze znanj«;
• Podatki o doseženi stopnji reševanja še nerešenih incidentov; • Podatki o učinkih od RFC, ki se izvajajo v okviru procesa vodenja
incidentov. Izhodi iz sistema za upravljanje z incidenta so:
• Zahtevek za spremembe, ki je bil sprejet v okviru procesa z IMP; • Podatki o reševanju in zaključevanju incidenta. Podatki se
zbirajo v CMDB in bazi znaj; • Komuniciranje z uporabniki, ki poteka preko storitvenega centra; • Poročila o upravljanju sistema, ki so namenjena vodstvu.
Slika 13: Procesi upravljanja z incidenti (OGC,2003)
V procesu upravljanja z incidenti se izvajajo aktivnosti, s katerimi se morajo posamezni incidenti na ustrezen način rešiti. Vse aktivnosti
RFC
Rešitev
Rešitve
Delovni podatki
Vhodni incidenti ali dogodki
Rešitve, delovni
podatki o stopnji
reševanja
Storitveni center
Računalniška oprema
Omrežje
Procesi
Ostali vzroki za incidente
Proces zahtevanja
storitev
Proces upravljanja z incidenti: • Beleženje in spremljanje • Začetna podpora in
klasifikacija • Raziskovanje in diagnostika • Upravljanje reševanja • Reševanje in obnova • Zaključevanje incidentov
CMDB
Proces upravljanja s
spremembami
Podatkovna zbirka napak
Podatki o konfiguracijah
Usmerjanje
Spremljanje

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 26
imajo svoj začetek in konec v storitvenem centru, ki je osrednja točka procesa upravljanja z incidenti. Glavne aktivnosti v procesu so:
• Ugotavljanje in beleženje incidentov, ki so se pojavili v IS; • Klasificiranje in začetno reševanje incidentov; • Začetno raziskovanje in ugotavljanje ter reševanje vzroka za
incident; • Upravljanje reševanja incidenta, kar vključuje določanje
pristojnosti za reševanje (lastništvo), spremljanje in sledenje incidenta ter komuniciranje z vsemi vpletenimi osebami in uporabniki;
• Zapiranje incidenta. 2.2.1 OSNOVNI KONCEPT
V proces upravljanja z incidenti so v večjem ali manjšem obsegu vključeni vsi oddelki in specialisti IT v organizaciji. Storitveni center je odgovoren za spremljanje celotnega poteka reševanja incidentov od registracije do zaključka incidenta in je lastnik vseh incidentov do uporabnika. Proces je v glavnem reakcija na dogodke, ki so naključni. Zmogljivost in učinkovitost reagiranja je možno bistveno povečati z opredelitvijo procedur delovanja, ki so podprte z ustreznimi programskimi orodji. 2.2.1.1. Življenjski ciklus incidenta
Incident, ki se ga v storitvenem centru ne more rešiti ob sprejemu obvestila (začetna podpora ali reševanje incidenta) mora biti predan specialni skupini za nadaljnje reševanje. Dokončna ali improvizirana rešitev incidenta mora biti uporabniku narejena z minimalnim negativnim vplivom na njegovo delo. Če je uporabnik zadovoljen z rešitvijo, se lahko incident zaključi. V primeru improvizirane rešitve se mora primer predati v proces upravljanja s problemi. Na sliki 14 so prikazane aktivnosti med življenjskim ciklusom incidenta. Vsak incident praviloma gre skozi vse stopnje življenjskega cikla oziroma proces reševanja incidenta. Vsaka faza življenjskega ciklusa je enako pomembna. Glede tega, kje se nahaja incident na premici življenjskega cikla, poznamo:
• Nove incidente; • Sprejete incidente; • Razvrščene incidente; • Dodeljene ali poslane posameznemu specialistu; • V delovnem procesu (WIP – work in progress); • V zastoju; • Rešene; • Zaprte.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 27
Slika 14: Življenjski ciklus incidenta (OGC, 2003)
Pomembno je, da incident neprekinjeno potuje skozi proces reševanja incidenta. To morajo upoštevati vsi člani IT ekip in morajo neprekinjeno obnavljati in posodabljati poročila o napredku. Primeri obnavljanja in posodabljanja so:
• Obnavljanje kronoloških podatkov; • Posodabljanje statusa (npr. »Novi« »v delovnem procesu« ali »v
zastoju«); • Spremeniti posledice na poslovne procese ali prioriteto
reševanja; • Vnašanje porabljenega časa in denarja; • Opazovanje eskalacije statusa.
Vzrok za incident se lahko skozi proces reševanja incidenta spremeni. Ne glede na to je pomembno zadržati prvotno prijavljeni vzrok za incident, ker bomo te podatke rabili za analize, komuniciranja z uporabniki in za reševanje eventualnih pritožb. Tako lahko uporabnik prijavi napako na tiskalniku, skozi proces reševanja incidenta pa bo ugotovljeno, da je dejanski vzrok za napako okvara na omrežju. Pri komunikaciji z uporabnikom je v cilju izogiba nesporazuma bolje uporabljati prvotni vzrok napake, kot pa uporabniku pojasnjevati zapletenost delovanja in postopke reševanja tehničnega vzroka za napako.
Lastn
ištvo
, spre
mlja
nje, b
ele
ženj
e in
kom
unic
iranj
e Sprejem in registracija incidenta
Proces zahteve za storitev
Začetna klasifikacija in podpora
Raziskovanje in diagnoza
Ali je zahteva za
spremembo ali nova storitev (RFC)
Da
Ne
Rešitev in obnova
Zaključevanje incidenta

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 28
Zapisovanje podatkov o poteku reševanja incidenta je zelo pomembno pri reševanju sporov, ko se incident ne reši v okvirih SLA. Tako se mora vsak napredek ali zastoj pri reševanju incidenta zabeležiti z naslednjimi podatki:
• Imenom osebe, ki izvaja spremembo poteka reševanja incidenta;
• Datumom in časom nastanka spremembe; • Opisom nastale spremembe; • Vzrokom za spremembo; • Porabljenim časom za izvedbo spremembe.
V primeru reševanja incidenta s strani zunanjega izvajalca, ki nima dostopa do podatkovnih zbirk o reševanju incidentov, mora podatke o spremembah vnašati storitveni center. Na takšen način poskrbimo, da se porabljena sredstva pravilno obračunajo. Vendar je bolje zagotoviti zunanjemu izvajalcu, da sam vnaša podatke o spremembah. Tako je možno imeti neprekinjen in pravočasni vpogled v potek dela pri zunanjem izvajalcu. Enako je možno postopati tudi v primeru, ko lastni izvajalci nimajo možnosti dostopa do podatkovnih zbirk. 2.2.1.2 Prvi, drugi in tretji nivo podpore
V večini primerov so strokovnjaki za reševanje incidentov organizirani in locirani zunaj storitvenega centra. Tako se organizirajo skupine za drugi, tretji ali višji nivo podpore, ki se organizira v skladu z razpoložljivimi strokovnjaki, velikostjo sistema, razpoložljivimi viri in drugimi zahtevami glede reševanja incidentov. Na sliki 15 je prikazan splošni potek reševanja incidenta skozi vse nivoje podpore. Storitveni center je tako prvi nivo podpore. Storitveni center ima po priporočilih ITIL (OGC, 2003) pri vodenju procesa reševanje incidentov pomembno vlogo:
• Vsi incidenti se prijavljajo v storitveni center, tudi tisti, ki se sprožijo samodejno (na primer s pomočjo senzorjev);
• Večina incidentov (tudi do 85% v primeru izkušenega osebja storitvenega centra) bo rešena v storitvenem centru;
• Storitveni center neodvisno opazuje proces reševanja vseh registriranih incidentov.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 29
Slika 15: Prvi, drugi in tretji nivo podpore (OGC, 2003)
Glavne aktivnosti storitvenega centra ob sprejemu incidenta so:
• Zapis osnovnih podatkov o incidentu vključno z opaženimi posledicami;
• V primeru zahtevka za spremembo postopa po ustaljeni proceduri za takšen primer;
• Iz podatkovnih zbirk o konfiguraciji sistema dopolni zapis o incidentu;
• Določi prioriteto reševanja in številko incidenta, ki se potem uporablja v bodoči komunikaciji do uporabnika;
• V primeru, ko je možno, z nasveti pomaga uporabniku, da sam reši incident, pri čemer se uporablja baza znanj;
• V primeru rešitve incidenta se incident zapre in se zapis dopolni z vsemi podrobnosti in statistično obdela;
• Incident se dodeli drugemu nivoju podpore v primeru ne zmožnosti rešitve ali ugotovitve, da je tako bolj primerno.
Prvi nivo podpore Drugi nivo podpore
Tretji nivo podpore
Ugotavljanje in beleženje
Začetna podpora
Proces zahtevanja sprememb
Zahtevek
Rešitev in obnova
Znana rešitev Raziskovanje in diagnostika
Rešitev in obnova
Znana rešitev Raziskovanje in diagnostika
Rešitev in obnova
Znana rešitev
n-nivo podpore
Zapiranje incidenta
NE
NE
NE
DA
DA
Itd.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 30
2.2.1.3 Eskalacija incidenta
Eskalacija incidenta ali stopnjevanje nivoja reševanja incidenta je mehanizem za zagotavljanje pravočasnega reševanja incidentov. S tem mehanizmom se vsakemu incidentu določi mesto in izvajalec v procesu reševanja incidenta. Pošiljanje incidenta iz prvega k drugemu ali višjemu nivoju podpore je osnovni princip eskalacije incidenta in se izvaja takoj, ko izvajalec ugotovi, da nima dovolj znanja ali razpoložljivih virov za rešitev incidenta. Eskalacija incidenta se izvede tudi v primeru predolgega časa oziroma prekoračitvi dogovorjenega časa za reševanje incidenta na nižjem nivoju. Avtomatična eskalacija incidenta mora biti načrtovana pazljivo, da se ne poruši sistem SLA.
Slika 16: Vrste eskalacij incidenta (qSTC, 2006)
Poznamo funkcionalno in hierarhično eskalacijo (qSTC, 2006), obe eskalaciji sta prikazani na sliki 16. Funkcionalna eskalacija vključuje dodatne strokovnjake v proces reševanja incidenta. Hierarhična eskalacija je navpično dvigovanje po liniji upravljanja. Tu gre za posredovanje zahteve vodstvu, da s svojimi pooblastili poišče dodatne vire, ki so potrebni za reševanje incidenta. Eskalacija incidenta se nemudoma izvede v primeru, ko je izvajalec nedvoumno ugotovil, da lahko incident ustrezno reši le višji nivo podore. Eskalacijo incidenta se izvajajo ročno in ga izvaja izvajalec podpore ali storitveni center. Avtomatična eskalacija se izvaja le v primeru preprečitve prekoračitve dogovorjenega časa za reševanje incidenta. Vsaka avtomatična eskalacija incidenta mora biti s strani vodstva pregledana, saj je lahko vzrok za časovno prekoračitev drugačen, kot pa je bilo opredeljeno v politiki delovanja procesa reševanja incidenta in lahko ima za posledico povečanje stroškov delovanja, posebej če je v to vključen zunanji izvajalec.
Storitveni center
Razvoj Delovanje
Upravljanje IKT
Hie
rarh
ična
esk
ala
cija
Funkcionalna eskalacija

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 31
2.2.1.4 Prioriteta
Namen določanja prioritete ali prednost pri reševanju incidentov je ugotavljanje vpliva incidenta na poslovanje in možnosti uporabe nadomestnih rešitev (na primer ali lahko uporabnik v času reševanja incidenta uporablja nadomestno storitev ali ne). Osnovni napotki so opredeljeni v SLA. Za praktično uporabo se morajo posamezni incidenti razvrstiti v različne kategorije. 2.2.1.5 Razmerje med incidenti, težavami, znanimi napakami in RFC
Incident je posledica pomanjkljivosti ali napake znotraj IT infrastrukture. Incident povzroči dejansko ali potencialno odstopanje od načrtovanega režima obratovanja IT storitve. Vzrok za incident je lahko neznan in čez čas izgine, lahko je takšen, da se brez večjih raziskovanj pristopi k popravilu, lahko se najde začasna rešitev ali improvizacija, ali pa se mora pristopiti k spremembi sistema. Kako se bo incident zaključil, je odvisno od uporabnika in razpoložljivega časa. Tako se lahko na primer nekateri incidenti rešijo s ponovnim zagonom osebnega računalnika ali s po-nastavitvijo komunikacijske linije, brez direktnega odkrivanja vzroka za incident. Takšni primeri, ko vzroki za incidente niso ugotovljivi, so osnova za zapis o problemu. Problem je torej neznana napaka znotraj IS ali IT infrastrukture, ki se večkrat ponovi ali je takšne narave, da povzroči večjo škodo, oziroma mora incident biti takšne narave, da upraviči stroške dvigovanje incidenta na nivo problema. Upravičenost stroškov dvigovanja incidenta na nivo problema se bo ocenjevalo pogosto preko vpliva (dejanskega in potencialnega) na poslovne funkcije organizacije in od skupnega deleža števila podobnih incidentov. Uspešno reševanje problemov je tudi iskanje vzrokov za neznane napake, ki tako postanejo znane ter se potem z ustreznimi improvizacijami začasno odpravijo in zatem z RFC postopki dokončno odpravijo. Logični tok od prijave incidente do stopnjevanja na nivo problema ter rešitve je prikazan na sliki 17.
Slika 17: Relacije med incidenti, problemi, znanimi napakami in RFC
(OGC, 2003)
Napaka na IT
infrastrukturi
Incident Problem Znana napaka Sprememba
IT infrastrukture
RFC

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 32
Na podlagi tega se po priporočilih ITIL (OGC, 2003) definira: • Problem je neznan vzrok za en ali več incidentov; • Znana napaka je rešen problem, za katerega je znana
diagnoza in postopek odprave napake ali postopek improvizacije;
• RFC je zahtevek za izvedbo spremembe poljubne komponente IT infrastrukture ali poljubne sestavine IT storitve.
Problem je posledica različnih ali raznovrstnih incidentov in možno je, da se ne bo mogel pravilno opredeliti, dokler se ne bo zgodilo več incidentov v daljšem časovnem obdobju. Upravljanje s problemi je tako drugačno kot upravljanje z incidenti, ki je tako del procesa upravljanja s problemi.
Slika 18: Vodenje procesa reševanja incidenta do začasne in
dokončne rešitve (OGC, 2003) Proces reševanja incidentov poteka tako, da se vzorec incidenta primerja z znanimi incidenti in problemi v podatkovni zbirki napak. V primeru, da se ne najde enakega incidenta, se poskuša postopati kot v najbolj podobnih primerih, če pa je rešitev na razpolago, se incident nemudoma odpravi. Ko se s procesom reševanja incidentov odkrije začasna rešitev, se ta analizira s strani ekip, ki sodelujejo v procesu upravljanja s problemi, in potem posodobijo skupno zbirko znanih problemov in napak (slika 18). Storitveni center bo potem posamezni incident lahko nedvoumno povezal z znanim problemom ali napako, ki bo obstajala v podatkovni zbirki. Možno je, da se pri reševanju določenega problema odkrije začasna ali končna rešitev za en ali več drugih sorodnih incidentov ali problemov. V tem primeru se morajo vsi dosedanji incidenti in
Odkrivanje incidenta
Odkrivanje problemov
Vodenje procesa reševanje incidentov
Vodenje procesa reševanje problemov
Rešitev incidenta
Sistemska rešitev
Začasne rešitve
Problemi in znane napake
Podatkovna zbirka
problemov in napak
Sprejem začasne rešitve
Začasna rešitev Informacija o rešitvi

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 33
problemi spremeniti tako, da bodo povezani k znani napaki. Takoj, ko je incident postal problem, se bo reševal v okvirih reševanja problema. Skozi procese reševanja incidentov se mora še naprej poskušati najti ustrezno rešitev in slediti načinu reševanja problema. Odločilna je komunikacija med ekipami za reševanje incidentov in za reševanje problemov. 2.2.2 PREDNOSTI UPRAVLJANJA Z INCIDENTI
Z uvajanjem upravljanja z incidenti se dosežejo glavne prednosti na področju poslovanja organizacije in na organizaciji IT. Prednosti na področju poslovanja po priporočilih ITIL (OGC, 2003) so:
• Zmanjšanje vpliva incidentov na poslovanje s pravočasnimi in učinkovitejšimi rešitvami;
• Krepitev in izboljšave sistema s predhodnimi ukrepi, ki so rezultat aktivnega spremljanja sistema;
• Usmerjanja vodstva v SLA. Glavne prednosti na področju organizacije IT po priporočilih ITIL (OGC, 2003) so:
• Možnost natančnejšega spremljanja in merjenja izvajanja SLA; • Vodenje IT je možno usmeriti v zagotavljanje kakovosti storitev; • Doseže se večja koristnost in dosega se večjo učinkovitost dela
zaposlenih; • Odpravijo se možnosti za nekorektno in predolgo reševanje
incidentov in zagotavljanje sprememb; • Natančnejša zbirka podatkov o konfiguracijah; • Izboljšanje zadovoljstva uporabnikov.
Z druge strani pa neuspehu implementacije upravljanja z incidenti povzroči po priporočilih ITIL (OGC, 2003) sledeče:
• Nihče ni odgovoren za vodenje in eskalacijo incidenta, zato lahko incident preraste v večjo in bolj škodljivo napako pri zagotavljanju kakovosti IT storitev;
• Stalno se prekinja delo strokovnjakov IT, kar posledično zmanjšuje njihovo učinkovitost;
• Zaposleni se med seboj neprekinjeno motijo, ker si med seboj poskušajo pomagati pri odpravi napak v IS;
• Vedno znova se uporablja čas za ugotavljanje že znanih napak; • Podvajanje dela med strokovnjaki IT; • Izguba, nepravilno ali nekorektno reševanje posameznih
incidentov.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 34
2.2.3 NAČRTOVANJE IN IMPLEMENTACIJA
2.2.3.1. Časovno načrtovanje
Po priporočilih ITIL (OGC, 2003) so za načrtovanje upravljanja z incidenti opredeljena osnovna izhodišča:
• Izdelava načrta za vzpostavitev in delovanja sistema upravljanja z incidenti ne sme potekati izolirano od drugih aktivnosti v IS. Potrebno je v čim večji meri integrirati in vključiti procese iz storitvenega centra, upravljanja s problemi, upravljanja s konfiguracijami, upravljanja s spremembami in upravljanja z izdajami;
• V primeru, ko ni možno hkrati in v celoti implementirati podpore storitev, je najboljše vzpostaviti storitveni center skupaj s sistemom za upravljanje z incidenti. Tako bo dosežen bistven preboj na kvaliteti zagotavljanja IT storitev, posebej gledano s strani uporabnika;
• Vzpostavitev storitvenega centra in procesa upravljanja z incidenti je potrebno izkoristiti čim prej. Vzpostavitev storitvenega centra poteka s postopnim prevzemom novih uporabnikov, ki se vključujejo v proces. Postopek je potrebno nadaljevati, čeprav začetne težave in napake storitvenega centra ne vlivajo zaupanja. Postopoma bo center kvalitetno opravljal vedno več storitev in vključeval vedno več uporabnikov v sistem in tako upravičil svoj obstoj;
• Faza načrtovanja procesa upravljanja z incidenti lahko traja od treh do šest mesecev v primeru visoko razvitega in obširnega IS. Realizacija pa lahko traja od treh mesecev do leta dni, ne glede na to, koliko so bili pretehtani vsi vplivi in dejavniki;
• Čas za zagotavljanje programske in strojne opreme je nekoristen, zato je potrebno izbirni postopek začeti takoj, ko je možno. Podlaga za nabavo je oprema, ki zagotovi podporo ITIL procesom in nudi zadostno prožnost za zagotovitev specifičnih potreb posamezne organizacije;
• Potrebno je povezati vse sisteme v enotno celoto, zlasti pa vključiti sistem za upravljanje s konfiguracijami. Zbirka podatkov o konfiguracijah mora vsebovati podatke o načrtovanem stanju in o obstoječem, oziroma dejanske stanju, ki se izvaja z avtomatskim popisom. V primeru, da ni možno vzpostaviti celovitega sistema, mora biti CMDB del sistema upravljanja z incidenti;
• Storitveni center mora imeti vmesnik do podatkovnih zbirk sistema za upravljanje s problemi, ki osebju omogoča prepoznavanje in dajanje nasvetov na podlagi znanih napak. Če je tovrstni sistem načrtovan za vzpostavitev v poznejši fazi, se začasno uporabljajo papirnati zapisi ali nestandardne

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 35
elektronske rešitve (na primer Excel preglednice) kot začasne rešitve.
2.2.3.2 Kritični faktorji upeha
Za uspešno delovanja sistema upravljanja z incidenti je priporočilih ITIL (OGC, 2003) potrebno posvetiti posebno pozornost osnovnim prvinam sistema:
• Predpogoj je obstoj podatkovne zbirke o konfiguracijah. V primeru, da CMDB ne obstaja, je potrebno podatke o posameznih elementih konfiguracije voditi ročno, kar pa je zamudno, težko in nepregledno;
• Sodobna baza znanj o znanih problemih in napakah je pogoj za hitro in učinkovito iskanje rešitev. To bo zelo pospešilo hitrost reševanja incidentov. Dopolnjevanje baze znaj s tujimi izkušnjami (učenje na tujih napakah) pa omogoča še dodatne koristi;
• Učinkoviti avtomatizirani sistem za upravljanje z incidenti je temelj uspeha storitvenega centra. Ročne podatkovne zbirke niso praktične ali učinkovite. Na tržišču obstajajo dobra in poceni orodja za podporo sistemu za upravljanje z incidenti;
• Zelo pomembno je zagotoviti povezavo z upravljanjem ravni storitev za doseganje odzivnosti sistema upravljanja z incidenti na zahteve uporabnikov. Reševanje incidentov mora biti takšno, da časovno ustreza uporabnikom.
2.2.3.3 Težave pri vzpostavljanju sistema
Pri vzpostavljanju sistema upravljanja z incidenti se priporočilih ITIL (OGC, 2003) pojavljajo nizi težav, podobno kot pri vzpostavljanju vseh sistemov. Te težave so:
• Na razpolago ni ustreznega vodstva in izvedbenega osebja, kar pripelje do ne-razpoložljivosti ostalih virov za realizacijo;
• Pomanjkanje jasne vizije o poslovanju organizacije; • Obstoječa praksa je nepregledna ali je ni; • Slabo opredeljeni cilji storitev, cilji in odgovornosti osebja; • Dogovor o ravni storitve (SLA) ni vzpostavljen; • Pomanjkljivo znanje za reševanje incidentov; • Pomanjkanje primernih tečajev za zaposlene; • Pomanjkljiva integracija z drugimi procesi; • Pomanjkanje finančnih sredstev in orodij za avtomatizacijo
procesov; • Odpor zaposlenih do sprememb.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 36
2.2.4 AKTIVNOSTI PRI UPRAVLJANJU Z INCIDENTI
Aktivnosti pri upravljanju z incidenti po priporočilih ITIL (OGC, 2003) se izvajajo v okvirih šestih dejavnosti:
• Odkrivanje in zapisovanje incidentov; • Razvrščanje in začetno reševanje incidentov; • Raziskovanje in diagnostika; • Reševanje in obnova; • Zapiranje incidentov; • Določanje pristojnosti za reševanje (lastništvo), spremljanje in
sledenje incidenta ter komuniciranje. 2.2.4.1 Odkrivanje in zapisovanje incidentov
Uporabniki napake javljajo v storitveni center, kjer se podatki o napaki oziroma incidentu zabeležijo in opremijo z dodatnimi podatki iz CMDB. Tako zabeleženi podatki so vhod v sistem upravljanja z incidenti. Tako je vhod v ta podsistem zapis o osnovnih podrobnosti incidenta, posredovanje sporočila strokovnjakom za podporo na ustreznem nivoju za ukrepanje in začetek postopka za spremembo. Izhodi iz podsistema pa so posodobljene oziroma dopolnjevane podrobnosti o incidentu, prepoznavanje podobnih napak v CMDB in obveščanje uporabnika o rešitvi oziroma o stopnji reševanja incidenta. Incidenti imajo različni izvor (qSTC, 2006):
• Klic uporabnika; • Sistemska opozorila, ki jih samostojno generirajo orodja; • Notranji incidenti iz operative; • Napake v procedurah, priročnikih in delovnih navodilih.
Najboljša rešitev je takšna sistemska oprema, ki omogoča avtomatski zapis vseh potrebnih podatkov o nastalih incidentih. Skozi proces odkrivanja in zapisovanja incidenta se morajo ugotoviti osnovni indikatorji in posledice incidenta, osnovni vzroki za incident in sorodni incidenti. Vsi ti podatki so potrebni za hitro reševanje incidentov in za uspešno vodenje sistema upravljanja z incidenti na vseh nivojih. V preteklosti je bila praksa, da so se vsa sporočila v storitveni center beležila ročno v podatkovno zbirko. Takšen način ni bil preveč praktičen in ni omogočal podpornim skupinam dopolnjevati podatkov, temveč je nalagal dodatno prepisovanje istih podatkov. Posledično je bila učinkovitost sistema zmanjšana. Z današnjo tehnologijo je možno sporočati incidente na različne načine, vključno z možnostjo direktnega vnosa podatkov v podatkovno bazo s strani uporabnika. Toda temeljna zahteva ostaja, da morajo biti vsi podatki o incidentu dostopni izvajalcem procesa upravljanja z incidenti in da je storitveni center tista točka, preko katere gredo vhodi v sistem in da center spremlja reševanje incidentov ter tudi zadrži odgovornost za

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 37
reševanje incidentov do uporabnika. Posebno pozornost vodstva zahtevajo incidenti, ki povzročijo večjo degradacijo sistema in ko reševanje incidenta zahteva posebno akcijo. Drugače se incidenti rešujejo v skladu s standardi in procedurami, ki so dogovorjeni v okviru upravljanja z ravnijo storitve. 2.2.4.2 Razvrščanje in začetno reševanje incidenta
Vhodi v podsistem razvrščanja in začetnega reševanja incidentov so podatki o podrobnosti incidenta oziroma napake, podatki o podrobnostih o konfiguraciji elementa iz CMDB in podatki o sorodnih incidentih in problemih. Podatki o incidentu se sedaj analizirajo in poskuša se najti vzrok. Incident mora tudi biti razvrščen v ustrezno kategorijo, kar olajša iskanje podobnosti med incidenti. V podsistemu razvrščanja in začetnega reševanja incidentov so glavne aktivnosti klasificiranje incidentov, ugotavljanje podobnosti med znanimi napakami in problemi, dodeljevanje prioritete in nujnosti incidentov za definiranje prednostnega reševanja, ocenjevanje vseh pomembnih nastavitvenih podrobnosti in vseh povezav z drugimi sistemi, seznanjanje skupine za upravljanje s problemi o obstoju novega problema ali ponavljanju starega problema, dajanje začetne podpore reševanja (hitra ocena napake in poskus najti hitre rešitve napake na podlagi znanih napak ali izkušenj) in zapiranje incidenta ali obveščanje strokovnjakov na drugem ali višjem nivoju podpore o incidentu (predaja lastništva nad incidentom). Izhodi v podsistem razvrščanja in začetnega reševanja incidentov so začetek postopka za spremembo konfiguracije, dopolnjevanje podrobnosti o incidentu in postopkih reševanja incidenta ter začasno ali končno rešitev incidenta ali pa dvigovanje nivoja reševanja incidenta. Razvrščanje incidentov je po priporočilih ITIL (OGC, 2003) proces od identifikacije vzroka za incident do določanja poti za reševanje incidenta. Za večino incidentov so poti reševanje dobro znane, ker se ponavljajo. To ni pravilo, vendar se postopki reševanja v večinih primerih ujemajo glede na klasifikacijo incidenta, zato je potrebno, da se klasifikacija spremeni, če je to potrebno. Uspešnost ugotavljanja podobnosti med incidenti bistveno zmanjšuje napore za odkrivanja vzrokov za napake. Razvrščanje incidentov v kategorije oziroma klasifikacija je eden od najbolj pomembnih vidikov v sistemu upravljanja z incidenti. Pravilno razvrščanje pa je tudi najtežji del aktivnosti upravljanja z incidenti.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 38
Razvrščanje v kategorije je uporabno po priporočilih ITIL (OGC, 2003) za:
• Določanje vseh sorodnih storitev, ki so povezane z incidentom; • Določanje relevantnega SLA, ki obravnava reševanje incidenta; • Izbiranje in določanje primernega strokovnjaka ali skupine za
reševanje incidenta; • Identifikacijo prioritete na osnovi vpliva na poslovanje; • Definiranje potreb po dodatnih vprašanjih in informacijah; • Identifikacijo povezav z znanimi napakami in problemi.
Končna razvrstitev incidenta lahko spremeni začetno razvrstitev incidenta, ker uporabnik običajno javlja le vidne posledice incidenta, ne pa vzroke za incident. Natančnost ali nivoji klasifikacij bodo odvisni od potreb posamezne organizacije. Čim več informacij mora biti na voljo, ko se izvaja klasifikacija. Klasifikacija podatkov prispeva k izboljšanju procesa ugotavljanja podobnosti med incidenti, ker:
• Vsebuje podrobnosti o posledicah incidenta; • Je olajšana začetna klasifikacija incidenta; • Daje podatke o pripadajočih konfiguracijskih elementih; • Daje podatke o poslovnem vplivu.
Proces klasifikacije in ujemanja omogoča sistemu upravljanja z incidentih večjo hitrost delovanja in minimalno porabo virov. Ta proces je idealen za uporabo primerne specializirane programske opreme. Storitveni center zbira podatke o konfiguracijskih elementih (CI – Configuration item) ali pa so mu ti podatki na voljo in zato mora zaznati napake, ko se te razlikujejo od podatkov, pridobljenih od uporabnika med prijavljanjem napake (ID številke, itd.). V primeru neujemanja podatkov se mora o tem obvestiti skupino za upravljanje s konfiguracijami. To se lahko naredi avtomatsko preko programske opreme, ki podpira sistem upravljanja z incidenti, ali pa ročno z dnevnim poročilom. Pomemben vidik upravljanja z incidenti je tudi določanje prioritete in prednosti, ki se določa glede na vpliv incidenta na poslovanje. Odgovornost za opredeljevanje prioritet leži na skupini za upravljanje ravni storitve, ki vse potrebne parametre opredeli v dogovoru o nivoju storitve. Zelo pomembno je določiti, koliko naporov in porabe virov je primerno porabiti za reševanje posameznega incidenta, ker bo od tega odvisen način in nivo reševanja incidenta. Prioritete in prednosti za reševanje incidenta so odvisne od:
• Vpliva na poslovanje; • Nujnosti posla, ki ga storitev podpira; • Velikosti, področja in zapletenosti incidenta; • Možnosti uporabe nadomestnih storitev za čas reševanje
incidenta.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 39
Ugotavljanje kritičnega vpliva incidenta ali problema na poslovanje je pogosto ugotavljanje odstopanja delovanja od opredeljene ravni delovanja storitve v SLA. Vpliv se ugotovi s številom prizadetih uporabnikov ali sistemov. Merila za ugotavljanje vpliva je potrebno opredeliti skupaj s poslovodstvom in opredeliti v SLA. Podatki v CMDB nam morajo jasno pokazati, koliko uporabnikov in sistemov je z incidentom prizadetih. Storitveni center mora po priporočilih ITIL (OGC, 2003) imeti dostop do CMDB z orodji, ki omogočajo hitro:
• Ocenjevanje vpliva incidenta na pomembne sisteme za uporabnike;
• Ugotavljanje obsega prizadetih uporabnikov zaradi incidenta; • Ugotavljanje povezav med različnimi incidenti in problemi; • Izdelavo napovedi o trajanju in obsegu dela za reševanje
incidenta; • Alarmiranje drugega ali višjega nivoja podpore.
Nujni ali prednostni so tisti incidenti, ki se morajo rešiti v zelo kratkem času in imajo nedvoumen velik vpliv na poslovanje ali delovanje sistema. Incidenti, ki imajo zelo velik vpliv na poslovanje, se morajo rešiti preko vrste takoj. Na primer: uporabnik z visoko prioriteto ima težave z delovno postajo, ker pa je ne bo koristil zaradi odsotnosti, se mu lahko dodeli nižja prednost. Prioriteta je definirana z naporom, ki se bo vložil v reševanje incidenta. Tako bo incident, ki ima nizek vpliv in povprečno nujnost ter nizki nivo potrebnega vloženega truda, v boljših organizacijah rešen takoj (na primer: po nastavljanje gesla). Začetna podpora, ki jo opravi storitveni center, poveča zadovoljstvo in okrepi zaupanje uporabnika v IT. Rešitve incidentov pri začetni podpori so rezultat delovanja na več področjih:
• Incident je znan in se nahaja v podatkovni zbirki znanih napak; • Osebje storitvenega centra je izkušeno in ima potrebna
ekspertna znanja; • Zaposlenim v storitvenem centru je na razpolago ustrezna
ekspertna oprema (na primer: možnost oddaljenega dostopa, diagnostična orodja itd.).
Začetna podpora v storitvenem centru ne sme trajati predolgo, ker drugače center ne more opravljati svojih osnovnih aktivnosti. V praksi začetna podpora traja le nekaj minut in če se ne najde rešitev, se reševanje preda na drugo raven reševanja.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 40
2.2.4.3 Raziskovanje in diagnostika
Vhoda v podsistem raziskovanje in diagnostika incidentov sta posodobljeni in dopolnjeni podrobnosti o incidentu in podrobnosti o nastavitvah CI iz CMDB. Aktivnosti v podsistemu raziskovanja in diagnostike incidentov so ocenjevanje incidenta, zbiranje in analiza vseh povezanih podatkov z incidentom in reševanje incidenta ter začasne in dokončne rešitve ali pa predaja reševanja incidenta na višji nivo podpore. Izhodi v podsistem raziskovanja in diagnostike incidentov so vnos podatkov o rešitvi incidenta in poročanje. Proces raziskovanja in diagnostike vzrokov za incidente je prikazan na sliki 19. Če je le možno, je potrebno uporabniku zagotoviti nadomestno storitev ali pa obstoječo storitev, ki deluje v omejenem obsegu. Na primer: če ima uporabnik pokvarjen lokalni tiskalnik, se mu v času popravila omogoči tiskanje na skupnem tiskalniku. S takšnimi začasnimi rešitvami ali improvizacijami zmanjšamo negativni vpliv na poslovanje in si zagotovimo ustrezen čas za iskanje kvalitetne rešitve incidenta. Ko je incident predan skupini za podporo na višji ravni, mora potem ta skupina:
• Sprejeti dodeljen incident, določiti čas sprejema (če ni avtomatske registracije) in zagotoviti posodobitev podatkov o incidentu, preko storitvenega centra pa uporabnika obvestiti o napredku pri reševanju incidenta in spreminjanju statusa incidenta;
• Nemudoma svetovati uporabniku (storitvenem centru), da uporabi improvizacijo, če je možna;
• Ponovno pregledati incident in ga primerjati z znanimi napakami, problemi, rešitvami, načrti sprememb in bazo znanj;
• Če je potrebno, posredovati v storitveni center, da ponovno prouči vpliv na poslovanje in prioriteto, ki bo prilagojena nastali situaciji;
• Zapisati vse podrobnosti o izvedenih delih in ugotovitvah pri reševanje incidenta (opis rešitve, ponovno razvrščanje incidenta, posodabljanje podatkov o vseh sorodnih incidentih in če je potrebno, še porabo časa);
• Vrniti incident v storitveni center, da ga zaključi. Preiskovanje in diagnostika lahko postaneta med seboj povezan proces, ki ga začnejo različni specialisti in lahko skozi procese proučevanja incidenta spreminjajo prej postavljene vzroke za ta ali podobne incidente.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 41
Slika 19: Proces raziskovanja in diagnostike vzrokov za incidenta
(OGC, 2003) V proces so lahko vpletene različne skupine za podporo iz različnih nivojev podpore in podporno osebje različnih dobaviteljev opreme. Proces lahko traja neprekinjeno v različnih izmenah tudi ponoči. Takšen proces zahteva strog, discipliniran pristop in izčrpen zapis vseh opravljenih del, kar bo lahko vse vpletene vodilo k rezultatu. Veliko vpletenih oseb v reševanje incidenta na višjih nivojih podpore pogosto zamegli odgovornost za reševanje incidenta. Tukaj se izkaže pomembna vloga storitvenega centra, ki je dejanski lastnik incidenta
Incident
Dodeliti incident reševalcu
Zbiranje osnovnih dejstev
CMDB
Poizvedovanje o podobnih primerih
Incidenti, problemi, baze znanj
Diagnostika Sistemski podatki o odpovedih in dnevniki
Diagnoza DA
NE
Poizkusa rešitev
DA
NE
Dvigovanje ravni podpore
Prekoračitev časovnih
rokov
Kreiran problem ali znane napaka
Zaprti incident
Povzetek reševanja incidenta
Prost besedni format
Kdo, kaj?
● Rezultat?
● Povezave?
● Odpovedi, okvare, itd.!
● Diagnoze in
rešitve, postopki! ●
Kaj, zakaj, kdaj?

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 42
od pojave do zaključka, zato mora storitveni center izvajati koordinacijo med vpletenimi v reševanje incidenta. V primeru prevelikih razhajanj v pristopu k reševanju incidenta je potrebno vključiti še vodstvo sistema za upravljanje s problemi. 2.2.4.4 Reševanje in obnova
Vhodi v podsistem rešitev in obnov so posodobljene in dopolnjene podrobnosti o incidentu, sprememba konfiguracije sistema, ki rešuje en ali več incidentov in izvedena začasna ali dokončna rešitev incidenta. Aktivnosti v podsistemu rešitev in obnov so izvedbe začasne ali dokončne rešitve incidenta, izvedba spremembe sistema, ki je posledica incidenta in izvajanje aktivnosti za obnovo sistema. Izhod iz podsistema rešitev in obnov so RFC za bodoče incidente, rešen incident in obnovljen sistem ter vnos podatkov o rešitvi incidenta in poročanje. Po uspešni odpravi incidenta ali preprečitvi širjenja incidenta bodo strokovnjaki drugega ali tretjega nivoja podpore izvedli ustrezne aktivnosti za obnovo in stabilizacijo sistema. Vodstvo sistema v upravljanju z incidenti mora poskrbeti za pravilno dokumentacijo postopkov. 2.2.4.5 Zapiranje incidentov
Vhoda v podsistem zapiranje incidenta imata posodobljene in dopolnjene podrobnosti o incidentu in rešen incident. Aktivnosti v podsistemu zapiranja incidenta so potrditev rešitve s strani uporabnika in dokončna določitev kategorije incidenta. Izhoda iz podsistema zapiranja incidenta imata dokončno zapisane podrobnosti o incidentu in zaprti incident. Ko je incident dokončno rešen, mora storitveni center zagotoviti:
• Vse podrobnosti o reševanje incidenta morajo biti zapisane v ustrezni obliki (jedrnato, razumljivo, berljivo itd.);
• Razvrstitev incidenta mora biti celovita po dejanskih vzrokih incidenta;
• Stranka mora svoje soglasje, da je izvedena rešitev izpolnila njeno pričakovanje, izraziti na primeren način (verbalno, pisno, e-pošta itd.);
• Vse življenjske faze incidenta in ostale podrobnosti morajo biti zapisane (zadovoljstvo stranke, poraba časa, datumi, izvajalci, itd.).
Ta podsistem je bistven za reševanje sporov med izvajalcem storitve podpore in stranko, ker vsak posamezni uporabnik poda svojo mnenje po zaključku vsakega posameznega incidenta. Tako zaključevanje incidentov ne postane rutina, ki ne preverja ustreznosti rešitev. Vse

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 43
zaključke incidentov mora preveriti vodja sistema za upravljanje z incidenti. Zaključki incidentov se uporabljajo tudi za komuniciranje s skupinami za upravljanje s problemi. Praktično so ti podatki ključni za relevantno oceno problemov v IS. 2.2.4.6 Lastništvo, spremljanje, sledenje in komuniciranje
Vhod v podsistem lastništva, spremljanja, sledenja incidentov in komuniciranja so zapiski in podatki o incidentu. Aktivnosti v podsistemu so spremljanje reševanja incidenta, eskalacija (dvigovanje reševanja na višjo raven podpore) incidenta in seznanjenje uporabnika z izvedenimi aktivnostmi. Izhodi iz podsistema so poročila o napredovanju reševanja incidenta, podatki o eskalaciji incidenta ter poročanje stranki in komunikacija z vpletenimi. Storitveni center je izvirni lastnik vseh incidentov in odgovarja za nadziranje reševanja vseh nerešenih incidentov z naslednjimi postopki:
• Spremljanje napredka pri reševanju vseh incidentov na vseh ravneh podpore;
• Posebno pozornost posveča incidentom, pri katerih lahko pride pri iskanjem rešitev do različnih sporov ali razhajanj med različnimi strokovnjaki podpornih skupin;
• Dajanje večje prioritete in nujnosti incidentom, ki imajo velik vpliv na poslovanje;
• Seznanjenje prizadetih uporabnikov o napredku pri reševanju incidenta;
• Preverjanje podobnih incidentov. Ti postopki bodo pripomogli, da bo vsak posamezen incident rešen čimprej ali pa v dogovorjenih časovnih rokih. Večji storitveni centri morajo imeti v svoji sestavi posebne namenske skupine za spremljanje in sledenje reševanja incidentov. V primeru, ko se ne dosega ustrezni napredek pri reševanju incidenta, mora storitveni center v skladu s politiko reševanja incidentov stopnjevati nivo (eskalacijo) reševanja incidenta. Eskalacija mora potekati s soglasjem vseh vpletenih skupin za podporo. V praksi to pomeni, da se je podporno osebje preveč poosebilo z incidentom, porablja preveč časa za diagnostiko in pri tem pozablja na uporabnikove potrebe, zato je potrebno po izteku dogovorjenih časov za reševanje takoj okrepiti ekipe za reševanje in povečati nadzor nad reševanjem incidenta. Praviloma storitveni center pri porabi 75% časa za reševanje incidenta izvede eskalacijo incidenta, pri 90% porabe časa pa obvešča linijsko vodstvo, da ukrepa.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 44
2.2.5 UPRAVLJANJE VEČJIH INCIDENTOV
Glavni so tisti incidenti, ki imajo zelo veliki vpliv na poslovanje ali na uporabnike. Incidenti, za katere je časovna omejitev reševanja presežena (tudi za mali procent prizadetih uporabnikov), postanejo glavni incidenti. Vodstvo sistema za upravljanje s problemi mora biti o glavnih incidentih obveščeno. V cilju reševanja in informiranja se morajo organizirati redni in posebni sestanki z vsemi zainteresiranimi. Sestankov se morajo udeležiti ključne osebe iz lastne podpore, podpore prodajalca opreme in vodstvo IT z namenom revidiranja napredka in določanja najboljše smeri reševanja. Predstavnik storitvenega centra se udeleži sestankov s ciljem, da se zaključki sestanka dopolnijo v zapiske o incidentih. 2.2.6 VLOGE PRI IZVAJANJU UPRAVLJANJA Z INCIDENTI
Proces upravljanja z incidenti vključuje celotno hierarhijo organizacije. Za vsaki del organizacije ali posameznika je pomembno določiti odgovornosti in pristojnosti, ki jih ima v procesu upravljanja z incidenti. Organiziranost v sistemu je fleksibilna in ima karakter projektne organiziranosti. V večini organizacij so posamezne vloge v sistemu združene z drugimi nalogami, ker se tako prihranijo znatni stroški in doseže večja učinkovitost. Na primer: v organizaciji so vloge upravljanja s spremembami in upravljanje s konfiguracijami združene. Običajno se zaposlenim v storitvenem centru ne dodaja nobenih drugih nalog izven sistema upravljanja z incidenti. Odnosi med posamezniki, ki opravljajo posamezne vloge, so izgrajeni na podlagi avtoritete vloge (pristojnosti in odgovornosti), ki jo ima v posameznem procesu. 2.2.6.1 Vodstvo sistema za upravljanje z incidenti
Vodstvo sistema za upravljanje z incidenti je priporočilih ITIL (OGC, 2003) odgovorno za:
• Učinkovito in uspešno vodenje procesa upravljanja z incidenti; • Izdelava poročil vodstvu organizacije; • Vodenje in nadzor nad prvim in drugim nivojem podpore; • Spremljanje učinkovitosti in predlaganje izboljšav sistema
upravljanja z incidenti; • Razvoj in vzdrževanje sistema za upravljanje z incidenti.
V večini manjših organizacij se vloga vodenja sistema za upravljanje z incidenti združi z vodenjem storitvenega centra. V večjih in zapletenih organizacijah se pa vloga vodenja del nalog prenese na vodjo storitvenega centra, ostanek nalog pa se združi skupaj z vlogo vodje sistema za upravljanje s problemi.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 45
2.2.6.2 Skupine za podporo
Prvi nivo podpore oziroma storitveni center je priporočilih ITIL (OGC, 2003) odgovoren za:
• Registracijo incidentov; • Usmerjanje zahtevka za spremembo k pristojni skupini za
spremembe; • Začetno pomoč uporabniku in klasifikacijo incidenta; • Lastništvo nad incidenti, spremljanje in sledenje reševanje
incidenta in komuniciranje z vsemi vpletenimi v sistemu; • Dodeljevanje reševanje incidenta višji ravni podpore; • Zaključevanje incidenta.
Drugi nivo podpore je sestavljen iz posameznih strokovnjakov ali skupin, ki so lahko organizacijsko sestavni del storitvenega centra (male in enostavne organizacije) ali pa del nekega drugega dela organizacije (večje in dislocirane organizacije). Običajno strokovnjaki iz drugega nivoja nastopajo v različnih vlogah pri procesih, kar je odvisno od politike posamezne organizacije. Drugi nivo podpore oziroma različni specialisti v lokalni podpori so odgovorni za:
• Izvajanje nalog po zahtevkih za reševanje incidentov, ki so jim dodeljeni s strani storitvenega centra;
• Ocenjevanje podatkov o incidentu, vključno z vplivom CI; • Raziskovanje in diagnostika incidenta; • Odkrivanje možnih problemov in dvigovanje incidenta na nivo
problema; • Odkrivanje in izvajanje rešitev in obnova sistema; • Beleženje vseh izvedenih aktivnosti.
Lastništvo nad incidenti, spremljanje in sledenje reševanje incidenta in
komuniciranje zajema spreminjanje statusa incidenta in beleženje napredka pri reševanju odprtih incidentov, seznanjanje uporabnika z napredkom pri reševanju incidenta in eskalacijo incidenta v primeru potrebe. 2.2.7 TEŽAVE PRI DELOVANJU SISTEMA UPRAVLJANJA Z INCIDENTI
Po vzpostavitvi sistema se pri delovanju pojavijo nove težave. Težave lahko strnemo v naslednje oblike (qSTC, 2006):
• Uporabniki in osebje IT se izogibajo proceduram upravljanja incidentov;
• Preveliko število incidentov in njihovo beleženje; • Prehitra eskalacija incidentov; • Katalog storitev ni ažuren; • Pomanjkanje zavzetosti in neustrezna organizacijska kultura.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 46
V primeru, ko uporabniki sami rešijo napako ali se sami neposredno obrnejo na podporno osebje in upoštevajo procedure, se zgodi, da organizacija nima zapisanega rezultata storitev in tudi ne števila napak. Posledično poročila o upravljanju ne vsebujejo ustreznih podatkov. Strokovno osebje se po nepotrebnem obremenjuje z malenkostmi, kar posledično pripelje do neučinkovitosti in preobremenjenosti osebja. Ob pojavi nepričakovanega velikega števila incidentov običajno ni časa, da bi jih vse zapisali. Nepopolni podatki o incidentih lahko upočasnijo proces reševanja in otežujejo usmerjanje incidentov k ustreznim skupinam za podporo. V takšnih primerih je primerno izvesti vertikalno eskalacijo incidentov. Prehitra ali nepotrebna eskalacija ima lahko neugoden učinek na strokovnjake enako kot neupoštevanje procedure, saj jih preveč in po nepotrebnem obremenjuje in jim ne dovoljuje opravljanja rednega dela. SLA je osnovni pogoj za uspešno delovanje sistema. V primeru, da dogovora o ravni delovanja storitve ni ali pa je ta neažuren, je osebje prepuščeno samo sebi in težko določi obseg pomoči uporabniku. Običajno se zatika pri določanju prioritet in eskalaciji incidentov. V tem primeru mora vodstvo IT ukrepati z izdajo dodatnih navodil in z večjim neposrednim vplivom na procese upravljanja z incidenti. Delo v procesni organiziranosti zahteva drugačno zavedanje in organizacijsko kulturo. V primeru neustreznega nivoja zavedanja o posebnosti procesnega organiziranja prihaja neprekinjeno do sporov med strokovnim osebjem, ki se ga poskuša reševati z linijskim vodstvom, le to pa spor rešuje z nepotrebnim birokratizmom in tako običajno zavira procesno organiziranost. Posledica je neučinkovitost sistema. V cilju izogiba temu je potrebno linijsko vodstvo ustrezno usposobiti, da prevzamejo načela ITIL kot osnovo svojega postopanja.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 47
3 INCIDENTI V INFORMACIJSKIH SISTEMIH JAVNE UPRAVE
Incident je vsako delovanje sistema, ki ni del standardnega načina delovanja. Incidenti lahko imajo vzrok v naključni napaki sistema, skriti napaki programske opreme, odpovedi strojne opreme, nepravilni uporabi informacijskega sistema, uporabniški prekoračitvi varnostnih pooblastil in dodeljenih pravic, itd. Incidente lahko zaznamo iz različnih virov. Vsak informacijski sistem ima svojo lastno strukturo incidentov, ki je odvisna od lastnosti in namena sistema, načina upravljanja s sistemom, odnosa uporabnikov in IT osebja do sistema, odnosa vodstva, varnostne politike itd. Za pravočasno izvajanje ukrepov za obvladovanje incidentov mora vsaka organizacija imeti podatke o strukturi incidentov, ki nastajajo v informacijskem sistemu. Strukturo incidentov v informacijskem sistemu je najlažje pridobiti v organizaciji, ki ima vzpostavljen storitveni center po priporočilih ITIL, kjer se beležijo vsi incidenti, ki nastanejo v sistemu. V tem primeru, ki ga obravnava ta naloga, je beleženje incidentov potekalo v storitvenem centru, ki je v začetni fazi formiranja in pokriva uporabnike za sedem organizacijskih enot, razmeščenih na treh lokacijah. Na razpolago sta bili dve zbirki podatkov. Prva je za čas enoletnega preizkusnega delovanje centra za omejeno število uporabnikov in vsebuje podatke o:
• Šifri incidenta; • Datumu nastanka; • Datumu začetka reševanja; • Datum zaključka reševanja incidenta; • Skupnem številu dni za reševanje incidentov.
Druga zbirka podatkov o incidentih pa je nastala z namenom in ciljem, da bodo tako pridobljeni podatki uporabljeni v tej magistrski nalogi. Zajema čas štirih tednov delovanja in vsebuje vse podatke, ki opisujejo pot od nastanka do rešitve. Podatke so zbirali zaposleni v storitvenem centru po vnaprej pripravljenih pisnih navodilih. Z vsemi zaposlenimi je bila narejena tudi priprava za zbiranje podatkov. Nadzor nad zbiranjem podatkov je izvajal vodja storitvenega centra. Del podatkov je sestavni del podatkovne zbirke za podporo delovanja storitvenega centra, del podatkov pa so zaposleni zbirali neposredno od izvajalcev.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 48
Zbirali so se podatki o informacijskem sistemu, ki je bil razvit za 702 uporabnika in razmeščen na treh lokacijah, ki so med seboj oddaljene od 10 do 45 km (Tabela 1). Uporabniki so bili iz 6-ih različnih organizacijskih enot.
Enota LOK1 LOK2 LOK3 Skupaj Delež v %
Enota A 235 - - 235 33,48
Enota B 8 86 - 94 13,39
Enota C 17 17 - 34 4,84
Enota D 18 - - 18 2,56
Enota E - 47 - 47 6,70
Enota F - 14 260 274 39,03
Skupaj 278 164 260 702 100
Delež v % 39,60 23,36 37,04 100,00
Tabela 1: Pregled števila uporabnikov po lokacijah in enotah
V podatkovni zbirki so zbrani podatki o incidentih za:
• Datum prijave napake na sistemu, ki je enak datumu nastanka incidenta, saj je v organizaciji običaj oziroma politika, da uporabnik takoj ob zaznavi napake pokliče storitveni center na splošno znano telefonsko številko;
• Ura nastanka napake se zabeleži na enak način kot datum nastanka in se je vodila na minuto točno;
• Šifra incidenta je bila vzeta iz podatkovne zbirke programa za upravljanja z incidenti. Namen je bil, da se lahko zbrani podatki primerjajo s podatki iz programa;
• Kategorija incidenta, ki opisuje skupino incidentov. Ta podatek je imel vlogo zbrati podobne incidente v logično skupino;
• Opis napake, s katerim se na kratko opiše vsebina napake; • Lokacija nastanka napaka; • Organizacijska enota, kateri prizadeti uporabnik pripada; • Datum, kdaj je bila napaka odpravljena; • Ura, kdaj je bila napaka odpravljena; • Podatek, ali je bila napaka enaka, kot je bila opredeljena ob
prijavi napake; • Čas, ki so ga vsi vpleteni v proces odprave napake dejansko
aktivno (brez časa čakanja) uporabili za odpravo incidenta; • Kdo je napako odpravil (storitveni center, II. nivo, III, nivo itd) • Katera oseba je odpravila incident; • Kdo vse je še sodeloval pri odpravi napake.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 49
Zbrani podatki so bili preverjeni in dopolnjeni v procesu analize, preverjanja in čiščenja podatkov. Ugotovljeno je bilo:
• Da so podatki o dejanski porabi časa nepopolni, saj so zbrani le za eno lokacijo;
• Podatki o incidentih, ki so se zaključili v času klica uporabnika v storitveni center, se niso beležili v podatkovno zbirko in so bili dodani kasneje.
Kljub vsem ugotovljenim pomanjkljivosti in napakah na zbranih podatkih o incidentih je možno zbrane podatke vzeti kot reprezentativni vzorec incidentov, ki nastaja v informacijskem sistemu javne uprave.
3.1 VZOREC NASTANKOV INCIDENTOV
V štirih tednih3 je nastalo 259 incidentov ali povprečno 13,62 incidentov na dan. Oziroma v štirih tednih se je incident povprečno pripetil vsakemu 2,71 uporabniku ali na dan se je en incident pojavil povprečno na 51,2 uporabnika. V primerjavi s podatki iz prve podkovne zbirke so podatki delno primerljivi, saj se je za obdobje enega leta oziroma v 284 delovnih dnevih pojavilo 1751 incidentov za 360 uporabnikov, kar znaša povprečno 6,16 incidenta na dan oziroma na dan se je en incident pojavil povprečno na 58,38 uporabnika. Podatki bi bili popolnoma primerljivi, če bi bilo v prvem primeru le 316 ali za 12,33% manj uporabnikov oziroma bi se pojavilo 224 ali za 13,9% incidentov več. Razlogi za razliko so različni, osnovni razlog pa je v tem, da v času poskusnega delovanja storitvenega centra niso bili vsi incidenti dosledno zabeleženi, ker so se uporabniki občasno obračali neposredno na posameznega specialista IT mimo storitvenega centra. V tabeli 2 so prikazani nastanki incidentov v času štirih tednov po lokacijah in organizacijskih enotah. S hitro primerjavo te tabele s tabelo številka 1 se lahko zaključi, da je število incidentov povezano s številom uporabnikov. Tako je največ incidentov nastalo v enotah A (235 uporabnikov) in F (274 uporabnikov), ki imata največ uporabnikov, najmanj incidentov pa v enoti D, ki ima najmanj uporabnikov (18 uporabnikov). Določena odstopanja je možno pojasniti v intenziteti dela uporabnikov, števila uporabljenih storitev IT, starosti IT, lokaciji in podobno. Tako je enota A bistveno bolj odvisna od komunikacij in podatkovnega omrežja, saj je od omrežnih virov
3 V času od 21.1.1007 do 16.02.2007 je bilo 19 delovnih dni, ker je bil četrtek 08.02.2007 državni praznik

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 50
oddaljena, med tem ko je enota F praktično nameščena na isti lokaciji kot ti viri. Tako je v enoti A zabeleženo 24 težav, povezanih z vstopom v omrežne vire, med tem ko so za enoto F zabeleženi le 4. takšni incidenti v enakem časovnem obdobju.
Enota LOK1 LOK2 LOK3 Skupaj Delež v %
Enota A 120 - - 120 46,33
Enota B 1 23 - 24 9,27
Enota C 6 7 - 13 5,02
Enota D 8 - - 8 3,09
Enota E - 14 - 14 5,41
Enota F - 6 74 80 30,89
Skupaj 135 50 74 259 100
Delež v % 52,12 19,31 28,57 100
Tabela 2: Pregled števila nastalih incidentov po lokacijah in enotah
Z statistično analizo je mogoče ugotoviti, da je pojav števila incidentov odvisen od dneva v tednu. Tako je največ incidentov nastalo v ponedeljek, in sicer povprečno 18,5 incidentov na dan, in najmanj v petek s povprečno 8,5 incidenti na dan. Na drugem mestu po številu pojavljenih incidentov je sreda s povprečno 16,25 incidenti na dan, potem pa četrtek s 13. in torek z 11,75 incidenti na dan. Vsi podatki so prikazani v tabeli 3.
Dan v tednu Skupno število incidentov
Poprečno število incidentov na dan
Delež v %
Ponedeljek 74 18,50 28,57
Torek 47 11,75 18,15
Sreda 65 16,25 25,10
Četrtek 39 13,00 20,08
Petek 34 8,50 13,13
Skupaj 259 64,75 100,00
Tabela 3: Pregled števila nastalih incidentov po dnevu v tednu
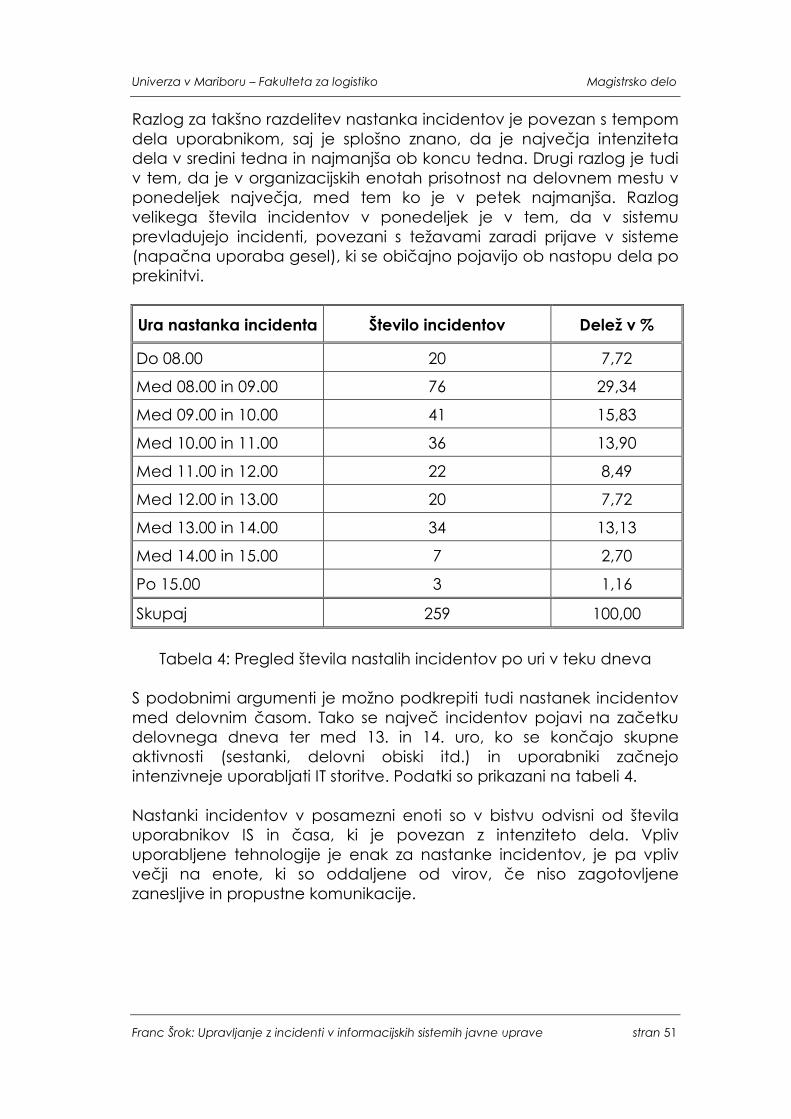
Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 51
Razlog za takšno razdelitev nastanka incidentov je povezan s tempom dela uporabnikom, saj je splošno znano, da je največja intenziteta dela v sredini tedna in najmanjša ob koncu tedna. Drugi razlog je tudi v tem, da je v organizacijskih enotah prisotnost na delovnem mestu v ponedeljek največja, med tem ko je v petek najmanjša. Razlog velikega števila incidentov v ponedeljek je v tem, da v sistemu prevladujejo incidenti, povezani s težavami zaradi prijave v sisteme (napačna uporaba gesel), ki se običajno pojavijo ob nastopu dela po prekinitvi.
Ura nastanka incidenta Število incidentov Delež v %
Do 08.00 20 7,72
Med 08.00 in 09.00 76 29,34
Med 09.00 in 10.00 41 15,83
Med 10.00 in 11.00 36 13,90
Med 11.00 in 12.00 22 8,49
Med 12.00 in 13.00 20 7,72
Med 13.00 in 14.00 34 13,13
Med 14.00 in 15.00 7 2,70
Po 15.00 3 1,16
Skupaj 259 100,00
Tabela 4: Pregled števila nastalih incidentov po uri v teku dneva
S podobnimi argumenti je možno podkrepiti tudi nastanek incidentov med delovnim časom. Tako se največ incidentov pojavi na začetku delovnega dneva ter med 13. in 14. uro, ko se končajo skupne aktivnosti (sestanki, delovni obiski itd.) in uporabniki začnejo intenzivneje uporabljati IT storitve. Podatki so prikazani na tabeli 4. Nastanki incidentov v posamezni enoti so v bistvu odvisni od števila uporabnikov IS in časa, ki je povezan z intenziteto dela. Vpliv uporabljene tehnologije je enak za nastanke incidentov, je pa vpliv večji na enote, ki so oddaljene od virov, če niso zagotovljene zanesljive in propustne komunikacije.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 52
3.2 VRSTA IN ZNAČILNOSTI INCIDENTOV
V tabeli 5 so prikazani podatki o vrsti incidentov. Polovica incidentov je povezanih z uporabo avtorizacijskih podatkov, s težavami pri vstopu v sistem in težavami pri uporabi programov. Incidenti, povezani z napakami na podatkovnih omrežjih, so imeli najbolj negativen učinek, saj je bilo s temi incidenti prizadeto večje število uporabnikov. Incidenti, povezani s popolno odpovedjo programske in strojne opreme, pa so imeli najdaljši čas odprave.
Vrsta incidenta Število
incidentov Delež v %
Težave z avtorizacijskimi podatki (gesla) 49 18,92
Težave pri prijavi v sistem 39 15,06
Pomoč pri uporabi programa 38 14,67
Težave s tiskanjem 25 9,65
Napake namiznega programa 31 11,97
Usluge 14 5,41
RFC 13 5,02
Odpoved periferne opreme 12 4,63
Podatkovno omrežje 11 4,25
Komunikacije 8 3,09
Otežena uporaba IT 7 2,70
Odpoved strojne opreme 6 2,32
Napake skupnih omrežnih virov 3 1,16
Odpoved posameznega IS 2 0,77
Okužba z računalniškim virusom 1 0,39
Tabela 5: Pregled vrste nastalih incidentov
Težave z avtorizacijskimi podatki (gesli) so bile v 49-ih primerih ali v 18,92%. V to kategorijo spadajo incidenti, ko je uporabnik pozabil geslo za vstop v posamezni informacijski sistem, ko je nepravilno uporabil podatke za vstop v sistem in je sistem po nekaj poizkusih preprečil nadaljnje poizkuse vstopanja v sistem ali pa je uporabnik nepravilno ali pa ni pravočasno spremenil gesla. Tako veliko število teh incidentov je iz tega razloga, ker organizacija vodi zelo restriktivno

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 53
varnostno politiko. Incidenti te vrste se najpogosteje pojavljajo v ponedeljek in torek in med 08. in 09. uro. Težav pri prijavi v sistem je bilo zabeleženih 39 ali 15%. V to kategorijo spadajo incidenti, ko uporabniku zaradi odpovedi ali omejenih kapacitet omrežnih virov ni bil omogočen dostop do posamezne IT storitve. Tipična napaka je ne-zmožnost dostopa do podatkovne baze preko terminalnega programa CITRIX, ker ni prostih dostopnih prijavnih mest. Pogosto so vzroki za to težavo tudi porušeni posamezni profili uporabnikov. Večina incidentov s težavo v zvezi s prijavo v sistem se pojavlja skozi ves teden enakomerno in najpogosteje med 08. in 09. uro. Pomoč pri uporabi programa je bilo potrebno izvesti v 38-ih primerih ali v 14,67%. V to kategorijo spadajo incidenti, ko uporabnik napačno uporablja ali pa ne zna uporabljati določenih funkcij namiznih programov. Večino teh napak se reši na nivoju storitvenega centra z dajanjem pojasnil uporabniku. Večina incidentov te vrste se pojavlja enakomerno med tednom in najpogosteje v prvi polovici delovnega dne. Težave s tiskanjem so se pojavile pri 25-ih incidentih ali v 9,65%. V to kategorijo spadajo vsi incidenti, ko uporabnik ni mogel pravočasno ali kvalitetno izvesti tiskanja na lokalnem ali na mrežnem tiskalniku. Vzrok za težave so porušene nastavitve, napaka na tiskalniku ali okvara omrežja. Incidenti v zvezi s tiskanjem se pojavljajo najpogosteje v ponedeljek in sredo med 08. in 10. ter med 13. in 14. uro. Napaka namiznega programa je bila zabeležena v 31-ih primerih ali v 11,97%. V to kategorijo spadajo incidenti, ko se je pojavila napaka na operacijskem sistemu lokalnega računalnika ali pa programa, ki se izvaja v lokalnem okolju. Tipična napaka je, ko uporabnik ne more odpreti določene datoteke ali programa. Večina takšnih incidentov se pojavi v ponedeljek in sredo med 08. in 10. uro. Potrebe po določenih uslugah, ki jih izvaja IT osebje, je bilo potrebno izvesti v 14. primerih ali v 5,41%. V to kategorijo spadajo vse tiste aktivnosti, ki jih uporabnik ne more ali ne zna narediti sam. Politika organizacije je, da ima uporabnik le omejene pravice in možnost za posege v operacijski sistem in programe, zato je poseg IT strokovnjakov potreben in se tudi načrtuje. Tipične aktivnosti pod to kategorijo so izdelave obsežnejših varnostnih kopij lokalnega diska in posodobitve lokalnega programa. Usluge uporabniki najpogosteje rabijo v torek in sredo enakomerno ves čas, med tem ko uslug v petek ne rabijo.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 54
Zahteva za spremembe ali RFC (Request for configuration) je bilo zabeležena v 13-ih primerih ali v 5,02%. Politika podjetja je, da se RFC izvaja po linijski organizaciji in ne preko storitvenega centra. V primeru, da uporabnik poda željo za RFC storitvenemu centru ali pa se ta pojavi za rešitev incidenta, se zahteva preusmeri v sistem za reševanje RFC, ki je opredeljen v organizaciji. Odpoved periferne opreme se je pojavila v 12-ih primerih ali v 4,63%. V to kategorijo spadajo incidenti, ko pride do odpovedi perifernih enot na lokalnem računalniku. Tipični incident pod to kategorijo je odpoved tipkovnice ali miške. Odpovedi perifernih enot se najpogosteje zgodijo v prvi polovici tedna in so enakomerno porazdeljene med delovnim časom. Prekinitev ali moteno delovanje podatkovnega omrežja je bila zabeležena v 11-ih primerih ali v 4,25%. V to kategorijo spadajo incidenti, ko uporabnik ne more uporabljati podatkovnega omrežja zaradi odpovedi segmenta ali določenega dela omrežja. Odpoved celotnega omrežja ni bila zabeležena. Prekinitve in motnje se pojavljajo najpogosteje v torek in sredo ter običajno med 09. in 10. ter med 11. in 13. uro. Napake na komunikaciji so se pojavile v 8-ih primerih ali v 3,09%. Politika organizacije je, da se v storitvenem centru beležijo tudi incidenti na telefonskih klicnih linijah. Izrazitih odstopanj v pojavi napak ni, razen, da takšna vrsta incidenta ni bila zabeležena v petek. Okrnjena ali otežena uporaba IT je bila zabeležena v 7-ih primerih ali v 2,70%. V to kategorijo spadajo incidenti, ko IT deluje s poslabšanimi lastnostmi. Tipična napaka je, da se program ne izvaja z običajno hitrostjo. Ta vrsta incidentov se pojavlja z enakomerno porazdelitvijo ves čas. Odpoved strojne opreme je bila ugotovljena v 6-ih primerih ali v 2,32%. V to kategorijo spadajo okvare v obliki popolne odpovedi posamezne strojne opreme. Tipičen incident je odpoved delovanja lokalne delovne postaje. Napaka skupnih omrežnih virov je bila zabeležena v 3. primerih ali v 1,16%. V to kategorijo spadajo incidenti, ko so skupni omrežni viri nedosegljivi za posameznega uporabnika. Tipična napaka je ne-zmožnost uporabnika, da dostopa do skupnega datotečnega prostora, ki se nahaja na strežniku. Odpoved posameznega IS je bila zabeležena dva krat ali v 0,77%. Tipična napaka je odpoved omrežnega programa.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 55
Okužba z računalniškim virusom se je pojavila enkrat na posebnem računalniku, ki je bil posebej namenjen za spletno deskanje in namenoma ni bil vključen v noben povezan IS v organizaciji. Iz prikaza posameznih značilnosti in vrst zabeleženih incidentov je možno zaključiti, da se ti pojavljajo naključno in običajno v času intenzivnejše uporabe informacijske tehnologije. Kljub posameznim odstopanjem vzorcev nastankov posameznih incidentov je nemogoče narediti posebni vzorec nastajanja incidentov po lokacijah in času, kajti posamezne vrste incidentov se pojavljajo z enakomerno porazdelitvijo.
3.3 REŠEVANJE INCIDENTOV
Vsak zabeležen incident v organizaciji se rešuje v okviru sistema upravljanja z incidenti, ki je organiziran v tri nivoje. Prvi nivo predstavlja storitveni center, kjer se poskuša incident rešiti s pomočjo dajanja dodatnih navodil uporabniku. V primeru, da se incident ne more rešiti na prvem nivoju, se incident rešuje na drugem nivoju oziroma na nivoju lokalne podpore, ki se nahaja razdeljena po enotah. Zadnji nivo reševanja incidentov je tretji nivo, ki je sestavljen iz posameznih specialistov za posamezna področja IT. Politika organizacije predvideva, da se incident rešuje po tem vrstnem redu in ne predvideva možnosti neposredne eskalacije incidenta iz prvega nivoja na tretji nivo. Tabela 6 prikazuje, koliko incidentov je zaključil posamezni nivo. Po zbranih podatkih je največ incidentov zaključil drugi nivo, in to kar 57,53%, najmanj pa tretji nivo oziroma 11,58. Storitveni center pa je rešil le 30,89 %, čeprav posamezni viri, ki obravnavajo področje storitvenega centra (OGC, 2003) predvidevajo, da bi se morali v storitvenem centru zaključiti približno dve tretjini incidentov.
Nivo zaključevanja incidenta Število incidentov Delež v %
1 nivo 80 30,89
2 nivo 149 57,53
3 nivo 30 11,58
Tabela 6: Pregled števila zaključenih incidentov po nivojih podpore

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 56
Razlog manjše učinkovitosti storitvenega centra je v pomanjkanju opreme za oddaljeni dostop operaterja do uporabnikovega računalnika z možnostjo vpogleda ali pa za aktivni prevzem upravljanja. Tako ostane operaterju le možnost glasovne komunikacije in postavitve diagnoze napake na podlagi informacij, ki jih poda uporabnik. Dodatni razlog je še v neizkušenosti operaterjev, saj delo v storitvenem centru opravljajo zelo kratek čas.
Nivo reševanja incidenta
Število incidentov Opombe
1 nivo 6,15 minut
2 nivo 638,52 minut ali ~ 1 delovni dan in 2,5 ure
3 nivo 2129 minut ali ~ 4,5 delovne dni
Povprečni čas reševanja posameznega incidenta je 615,84 minut
Tabela 7: Pregled povprečnega časa reševanja incidentov na
posameznem nivoju podpore Tabela 7 prikazuje povprečne čase reševanja incidentov po nivojih reševanja. Povprečno je bil incident zaključen po 10-ih urah. Skupni čas reševanja vseh incidentov je znašal 2586 ur. Incidenti, ki so se zaključili na nivoju storitvenega centra, so bili rešeni povprečno v 6,15 minute. Drugi nivo je incidente rešil povprečno v 638-ih minutah oziroma je bil incident rešen drugi dan, pri tem pa je bilo 118 ali 79,19% incidentov rešenih isti dan ali v okviru enega delovnega dneva, medtem ko se je le 31 ali 20,80% incidentov reševalo več kot en deloven dan. Povprečno najdaljši čas reševanja incidentov je na tretjem nivoju in znaša 1985 minut ali 4 in pol dni. Takšno dolžino časa je možno razložiti s tem, da so incidenti težje narave in se rešujejo z organizacijo dela specialistov. Z natančnejšo analizo je možno ugotoviti, da je bilo isti dan rešenih 13 incidentov ali 43,33%, drugi, tretji in četrti dan je bilo rešenih 7 primerov ali 23,33% in le v 10-ih primerih ali v 33,33% so se incidenti reševali več kot štiri dni. Povprečni čas je tako dolg zaradi redkih incidentov, ki imajo zelo specifično napako, ki jo je težko odkriti ter odprava vzroka za incident zahteva veliko naporov. Tabela 8 prikazuje povprečne čase reševanja incidentov po posamezni vrsti incidenta. Najdaljše čase reševanja so imeli incidenti povezani s podatkovnimi omrežji in odpovedjo posameznih IS. Najkrajši časi reševanja incidentov so bili zabeleženi v primerih, ko so bili incidenti povezani z oteženo uporabo IT in pomočjo pri uporabi programov ter RFC.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 57
Povprečni čas reševanja incidentov Vrsta incidenta
V minutah V urah
Podatkovno omrežje 1705 28,41
Odpoved posameznega IS 1573 26,21
Okužba z računalniškim virusom 1460 24,33
Usluge 1218 20,31
Težave s tiskanjem 1102 18,37
Odpoved periferne opreme 1007 16,79
Težave pri prijavi v sistem 695 11,58
Napake namiznega programa 603 10,05
Težave z avtorizacijskimi podatki (gesla) 516 8,59
Odpoved strojne opreme 403 6,71
Komunikacije 355 5,92
Napake skupnih omrežnih virov 265 4,42
RFC 146 2,44
Otežena uporaba IT 26 0,44
Pomoč pri uporabi programa 6 0,10
Tabela 8: Pregled povprečnega časa reševanja posameznih vrst
incidentov Največ incidentov reši drugi nivo (lokalna) podpore. Najhitreje se rešujejo incidenti, ki se zaključijo na nivoju storitvenega centra in najdlje incidenti, ki se rešujejo na tretjem nivoju podpore. Povprečne čase reševanja incidentov podaljšujejo maloštevilni specifični incidenti, ki imajo napako, ki jo je težko odkriti ali je način odprave specifičen.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 58
4 OBLIKE ORGANIZIRANOSTI ZA UPRAVLJANJE Z INCIDENTI
Priporočila ITIL organiziranost za upravljanje z incidenti ne opisujejo posebej, temveč le opisujejo procese. Vsaki posamezni organizaciji je prepuščeno, kako bo vzpostavila organizacijsko obliko, da bo sistem upravljanja z incidenti deloval uspešno in učinkovito. V načelu moramo imeti osebje za storitveni center in specialiste IT, ki bodo reševali incidente na višjih stopnjah podpore. Ali bodo specialisti v sestavi storitvenega centra ali posebej organizirani v enem ali v več nivojih je odvisno od različnih dejavnikov. Manjše organizacije ne rabijo nič od naštetega, temveč jim vse procese od storitvenega centra in naprej izvaja zunanji izvajalec (out-sorce). Takšne organizacije tudi nimajo posebej organiziranega IT oddelka ali službe. Večje organizacije, ki imajo nekaj IT strokovnjakov ali že imajo posebej organiziran IT oddelek, morajo razmisliti o smiselnosti vzpostavitve storitvenega centra, ki bo izvajal svojo funkcijo in ima v svoji sestavi vse strokovnjake IT vključno z vodstvom. Organizacije, ki imajo veliko število uporabnikov in so razmeščene na več lokacijah, pa običajno vzpostavijo vse za vsako funkcijo procesa posebno organizacijsko obliko.
Slika 20: Procesna organiziranost IT oddelka za upravljanje z incidenti
Slika 20 prikazuje kakšno organizacijsko obliko bi morala imeti večja organizacija, da lahko uspešno obvladuje upravljanje z incidenti v svoji
Storitveni center (I.nivo pomoči)
Skupine za II.nivo pomoči (Lokalna podpora)
Skupine za III. in višji nivo pomoči (specialisti IT, administratorji IS, delavnice
IT, zunanji izvajalci)
Vodstvo IT
organizacije
Uporabniki
IT oprema
Vodenje in nadzora
Eskalacija
Eskalacija
Komuni-ciranje
Uporaba storitev
SLM, SLA
Vodenje in nadzora
Vodenje in nadzora
Rešitve incidenta
Rešitve incidenta
Rešitve incidenta

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 59
sestavi. Posamezne organizacijske enote imajo lahko različne namene. Storitveni center je ključna in edina organizacijska enota, ki se pretežno ukvarja s procesom upravljanja z incidenti. Centru lahko dodatno dodelimo del nalog povezanih z nadzorom delovanja IS in nalogo zbiranja podatkov o konfiguraciji sistema, ki pa ne smejo biti preobširne. Dodatne naloge v nobenem primeru ne smejo motiti komunikacije z uporabniki, ki je osnovna dejavnost centra in to nalogo mora center izvajati ves čas in neprekinjeno. Vodstvo organizacije se zelo hitro ujame v past, ko določi storitvenemu centru vedno več dodatnih nalog, ker so običajno pri uspešnem centru pokazatelji obremenitve nizki in dodatne naloge v začetni fazi prinašajo naglo povečanje učinkovitosti. Kasneje se zaposleni v storitvenem centru začnejo ukvarjati bolj s temi dodatnimi nalogami in začnejo zapostavljati uporabnike, ki jim postajajo sčasoma samo breme. Lokalna podpora običajno do polovico delovnega časa porabi za naloge iz procesa z incidenti, preostali čas pa sodeluje pri ostalih procesih. Običajno je druga osnovna naloga lokalne podpore sodelovanje pri procesih upravljanja s konfiguracijami in infrastrukture ter administracija lokalnih informacijskih sistemov. Sposobnost lokalne podpore za reševanje posameznih incidentov je zelo različna in je odvisna od značilnosti posameznikov, ki sodelujejo v podpori. Običajno je hitrost reševanje posameznih incidentov povezana z izkušnjami in usposobljenostjo posameznih tehnikov. Praviloma bolj usposobljeno osebje hitreje pridobiva izkušnje in je zato potrebno posvetiti posebno pozornost neprekinjenemu usposabljanju osebja lokalne podpore. Upravljanje z incidenti je lahko organizirano v okvirih linijsko organizacijske strukture ali pa glede na lokacijo razmestitve. V prvem primeru lahko govorimo o linijskem principu organiziranosti, v drugem pa o teritorialnem principu. Značilnost prvega je, da vsaka organizacijska enota samo s svojim osebjem organizira II. nivo podpore na vseh lokacijah, kjer deluje. V drugem pa je II. nivo podpore organiziran tako, da je določena posebna skupina strokovnjakov, ki izvajajo podporo za vse uporabnike na isti in pri njej bližnjih lokacijah. Tretji in višji nivo podpore je običajno organiziran enotno za celotno organizacijo. Določanje organizacijske oblike za upravljanje z incidenti pred odgovorne osebe za izbiro oblike postavlja niz vprašanj, ki zahtevajo ustrezen odgovor. Nobena organizacija skoraj ni tako velika, da bi za upravljanje z incidenti imela posebej organizirano organizacijsko enoto, temveč se izvaja določena kombinacija nalog iz različnih procesov upravljanja z IT. Za srednje velike organizacije, kot je javna uprava, je logično, da ima posebej organiziran storitveni center, med

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 60
tem ko se pri drugem nivoju podpore, ki dejansko rešuje največ incidentov in izvaja tudi največ vsakdanjih nalog iz drugih procesov pri upravljanju z IT organizacije, že postavlja vprašanje, ali ga vezati na posamezne organizacijske enote ali na določeni teritorij. Pri tretjem nivoju pa je samo vprašanje, koliko specialistov je potrebno imeti v svoji sestavi in v kakšnem obsegu se je smiselno nasloniti na zunanje izvajalce. Torej je osnovno vprašanje pri določanju organizacijske oblike pri reševanju incidentov v IS v tem, ali bomo proces reševanje incidentov organizirali po linijski strukturi ali po teritorialnem principu. Obe obliki imata svoje prednosti in slabosti, pri tem pa je pomembno, koliko osebja bomo rabili, da bo sistem deloval optimalno in učinkovito.
4.1 PRINCIPI ORGANIZIRANOSTI
4.1.1 TERITORIALNI PRINCIP
Slika 21: Model teritorialne organiziranosti lokalne podpore
Uporabnik Klici v SC zaradi napake
Storitveni center 3-5 delovnih mest (sprejem klica in začetna podpora)
Storitveni center Razvrščanje in dodeljevanje skupini
2 nivo podpore LOKACIJA 1
2 nivo podpore LOKACIJA 2
2 nivo podpore LOKACIJA 3
enota A – PSSV enota B – BZV enota C – EVOJ enota D – 16.BNZP
3 nivo podpore
Zaključen incident
enota B – BZV enota C – EVOJ enota E – LOGB enota F – GŠ
enota F – GŠ

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 61
Shema organiziranosti po teritorialnem principu je prikazana na sliki 21. V tem primeru vsi incidenti, ki jih storitveni center dobi in jih ne more rešiti, gredo do skupin za drugi nivo podpore, ki so organizirane po lokacijah in izvajajo podporo za vse uporabnike, ki se nahajajo na tisti lokaciji, ne glede na to, v katero organizacijsko enoto spadajo. Naslednja nivoja (3. in 4.) pa sta dejansko ozko specializirani skupini ljudi, ki izvajata podporo za vse uporabnike ne glede na lokacijo in organizacijsko podporo.
4.1.2 ORGANIZACIJSKO LINIJSKI PRINCIP
Slika 22: Model organiziranosti lokalne podpore po organizacijsko
linijskem principu
Uporabnik Klic v SC zaradi napake
Storitveni center 3-5 delovnih mest (sprejem klica in začetna podpora)
Storitveni center Razvrščanje in dodeljevanje skupini
3 nivo podpore
Zaključen incident
2. nivo podpore Enota A
Lokacija 1
2. nivo podpore Enota B
Lokacija 1 Lokacija 2
2. nivo podpore Enota C
Lokacija 1 Lokacija 2
2. nivo podpore Enota D
Lokacija 1
2. nivo podpore Enota E
Lokacija 2
2. nivo podpore Enota F
Lokacija 3

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 62
Z organiziranostjo po organizacijsko linijskem principu storitveni center vse incidente za lokalno podporo pošilja skupini, ki je organizirana pri vsaki organizacijski enoti posebej, in izvaja lokalno podporo za vse uporabnike v organizacijski enoti ne glede na to, na kateri lokaciji se posamezni uporabnik nahaja. Shema organiziranosti po linijskem principu je prikazan na sliki 22. Na prvi pogled je opazno, da je število skupin za lokalno podporo bistveno večje. Naslednja nivoja (3. in 4.) pa sta enaka kot za teritorialno organiziranost.
4.2 KAKOVOST IN UČINKOVITOST SISTEMA ZA UPRAVLJANJA Z INCIDENTI V INFORMACIJSKIH SISTEMIH
Kakovost je težko definirati, zlahka pa jo spoznamo. Kakovost je v splošnem transparentna, takoj jo zaznamo, ko je prisotna, in enako, če je ni. Ko informacijski sistem ne opravlja svojih funkcij v pričakovanem obsegu, preprosto sklepamo, da nima ustreznega nivoja kakovosti. Kakovost bi lahko opredelili kot skupek karakteristik proizvoda, procesa, organizacije, sistema, oseb ipd., ki se nanašajo na njihovo sposobnost, da zadovoljijo izražene in pričakovane potrebe (SIST ISO 8402:1997). Gledano s strani uporabnika bi lahko rekli, da je kakovost informacijskega sistema sestavljena iz več karakteristik (lastnosti), ki zadovoljujejo ali presegajo posredno ali neposredno izraženo potrebo uporabnika. Pivka (1996) je karakteristike, ki vplivajo na kakovost informacijskega sistema, opredelil takole:
• Funkcionalnost (ustreznost, natančnost, kompatibilnost, skladnost, zaščita);
• Zanesljivost (zrelost, toleranca napak, možnost vzpostavitve prejšnjega stanja);
• Uporabnost (razumljivost, zmožnost priučitve, način uporabe); • Učinkovitost (poraba časa, poraba virov); • Vzdrževalnost (sposobnost analize, občutljivost na spremembe,
stabilnost, testabilnost); • Prenosljivost (prilagodljivost, zmožnost inštalacije, skladnost,
zamenljivost). Posamezne karakteristike imajo pri vrednotenju kakovosti različnih informacijskih sistemov različno težo. Težo kriterijev običajno vedno določa končni uporabnik in je odvisna od namena programske opreme oziroma informacijskega sistema. Pri obravnavi pojma kakovosti moramo posebej ločiti vidik kakovosti nastajanja informacijskega sistema in vidik delovanja informacijskega sistema. Sama kakovost nastajanja še ne pomeni, da bo delovanje

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 63
informacijskega sistema tudi temu primerno, čeprav je verjetnost za to delovanje pri kakovostnem informacijskem sistemu bistveno večja kot pa pri nekakovostnem. Vsak sistem za vzpostavitev in delovanje zahteva določene stroške. Pri tem se poraja večno vprašanje, koliko investirati v sistem, da ne bi bilo preveč ali premalo oziroma kako uravnovesiti stroške. Na sliki 23 so pokazani odnosi med stroški, ki nastanejo, če IS ne deluje in stroški, ki ga zahteva sistem za upravljanje z incidenti.
Slika 23: Shema uravnovešenih stroškov sistema (prirejeno po Marolt,
Gomišček, 2005) V javni upravi je zelo težko izračunati stroške nedelovanja sistema, saj končni izdelek ni ocenjen v merljivi vrednosti, temveč ima zelo subjektivno vrednost. Najboljši pokazatelj stroškov nedelovanja sistema v javni upravi je ocena stroškov za plačilo zaposlenih, ko ne opravljajo svojega dela.
V primeru, da se kvaliteta sistema za upravljanje z incidenti v IS povečuje, bo čas izpada vedno krajši, s tem pa bodo tudi manjši stroški za nedelovanja IS. Vendar pa se bodo stroški za delovanje sistema povečali. Na primer, če povečamo število strokovnjakov, bo s tem zagotovljena večja razpoložljivost strokovnjakov in se bo zmanjšal čas čakanja na prostega strokovnjaka in bo čas izpada sistema manjši. Pomembno je tudi vedeti, da samo dvigovanje višine sredstev, vloženih v sistem, še ne pomeni sorazmerno enakega dvigovanja kakovosti, temveč morajo temu slediti tudi vsi ostali ustrezni ukrepi.
Višina stroškov
Kvaliteta sistema upravljanje z incidenti
Stroški nedelovanja
IS
Stroški za reševanje incidenti
Skupni stroški
kakovosti
Optimalni stroškov

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 64
Učinkovitost je v splošnem definirana kot količnik med vložkom v sistem in rezultatom delovanja sistema. V našem primeru lahko rečemo, da je sistem upravljanja z incidenti učinkovitejši, če manjša skupina oseb napravi enako delo kot večja pri enaki kakovosti storitve. V javni upravi lahko učinkovitost sistema upravljanja z incidenti merimo s številom zaposlenih v sistemu upravljanja z incidenti in časom čakanja na reševanje incidentov ter skupnim časom odprave vzroka za incidente. Velikost posameznih parametrov je zelo odvisna od posamezne organizacije in se najlažje opredeli na podlagi izkustva oziroma zatečenega stanja v posamezni organizaciji. Najlažje je ocenjevati obnašanje informacijskega sistema v preteklosti in na podlagi teh izkušenj opredeliti parametre učinkovitosti za naprej.
Priporočila ITIL za presojo učinkovitosti določajo, da morajo biti jasno določeni merljivi parametri delovanja sistema (OGC, 2003). Ti parametri se imenujejo ključni pokazatelji delovanja (KPI – Key Performace Indicators). Priporočila ITIL (OGC, 2003) kot primerne pokazatelje za ocenjevanje učinkovitosti in uspešnosti delovanja sistema za upravljanje z incidenti navajajo:
• Celotno število incidentov; • Minimalni čas za reševanje incidentov po kategorijah; • Odstotek incidentov, obravnavam znotraj odzivnega časa, ki je
opredeljen v SLA; • Povprečna poraba virov (časa, denarja itd.) po incidentu; • Odstotek incidentov, zaprtih znotraj storitvenega centra, brez
posredovanja drugih nivojev podpore; • Odstotek incidentov, ki so bili rešeni na daljavo, brez potrebe za
obisk pri uporabniku. Poročilo o delovanju sistema mora biti narejeno s strani vodje sistema za upravljanje z incidenti, pri katerem sodeluje storitveni center. Poročilo mora biti posredovano vodstvu IT v organizaciji, vsem skupinam za podporo in specialističnim skupinam. V zmanjšanem obsegu mora biti na razpolago tudi uporabnikom in linijskem vodstvu v obliki SLA poročila.
4.3 MODELIRANJE ORGANIZACIJSKIH OBLIK
Model sistema je poenostavljena ponazoritev realnega sistema (Kljajić, 2002). Pri tem morajo te želene značilnosti modela imeti enako obnašanje, kot ga ima realni sistem. To pomeni, da določen vhod v sistem modela na izhodu modela izzove enako obnašanje sistema na izhodu, kot bi ga povzročil realni sistem. Modeliranje je možno

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 65
opredeliti kot postopek, s katerim na podlagi določenih karakteristik realnega sistema izdelamo model. Sistemska simulacija je način reševanja problemov z metodami eksperimentiranja na računalniških modelih z namenom ugotavljanja funkcioniranja celote ali posameznih delov sistema pri določenih pogojih. Kljajić (2002) je simulacijo definiral, kot dinamično ponazoritev obnašanja modela za naslednje namene:
• Opis sistema; • Pojasnitev obnašanja sistema v preteklosti; • Predvidevanje obnašanja sistema v prihodnosti; • Razumevanje delovanja sistema.
Slika 24: Shema procesa sistemske simulacije (Kljajić, 2002)
Postopek sistemske simulacije poteka je sestavljen iz več korakov. Najprej moramo realni sistem opisati in pri tem definirati, kateri problem bomo poskušali osvetliti. V tem koraku moramo opredeliti ravni, cilje in obseg modeliranja obravnavanega problema. Po tem koraku moramo pristopiti k določitvi spremenljivk, povratnih zvez in interakcij med spremenljivkami in med deli obravnavanega sistema. Potem moramo postaviti splošna teoretična izhodišča in okvire, ki vzpostavijo zvezo med konkretnim problemom in konkretnimi rešitvami s splošnega vidika. Na podlagi tega izdelamo model. Model izdelujemo tako, da matematično ločimo posamezne dele sistema ali pa naredimo zapise z ustreznimi enačbami, ki so primerne za simulacijski jezik. Tako narejen model je primeren, da ga z ustreznim orodjem (programski jezik za izdelavo simulacij) spremenimo v računalniško simulacijski program. Potem lahko izvajamo ustrezne eksperimente na modelu. Shema procesa sistemske simulacije je prikazana na sliki 24. Pri večini simulacijskih projektov delo poteka v
Vhodi v sistem
Procesi v realnem sistemu
Odziv sistema
Teorija
Koncept modela
Vhodni podatki
Program za računalnik
Izhodni podatki
Račun
aln
ik

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 66
timih, zaradi tega je potrebno nameniti veliko pozornost tudi predstavitvi in dokumentiranju spoznanj v procesu iskanja rešitev. Metodologija sistemske simulacije za podporo odločanju je prikazana na sliki 25. Iz sheme lahko vidimo, da metodologija vsebuje tri temeljne porazdeljene kroge povratne zveze:
• Vzročni ali povratno zančni krog (feet back), ki predstavlja rezultat poslovanja kot posledico prejšnjih odločitev, je del upravljavčevih izkušenj in zgodovine sistema;
• Aposteriorna informacija o uporabnosti modela in prejšnjih odločitev. Ta krog predstavlja pragmatično validacijo modela. S primerjanjem vnaprejšnje informacije o vplivu izbranega scenarija na obnašanje sistema z dejanskimi doseženimi rezultati omogočimo, da ocenimo vrednost modela in ga izboljšamo;
• Anticipativni ali intelektualni povratni krog, ki omogoča »vnaprejšnjo« informacijo (feet foward) in je pomemben za kreiranje usmeritvene strategije sistema.
Slika 25: Metodologija sistemske simulacije (Kljajić, 2002)
Kroga A in C sta temeljna kroga za pridobivanje znanj in izkušenj za učenje in kvalitetno odločanje. Krog B pa predstavlja pragmatično validacijo modela. Ključni element vseh teh krogov je uporabnik, torej tisti, ki odloča.
Uporabniki
Odločitev Poslovni sistem
Rezultati poslovanja
Rezultati poslovanja
Model
B
C
Želeno obnašanje (feet – foweard)
Povratna informacija (feet – back)
S C
E N
A R
I J
I
A
- +

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 67
V primeru modela upravljanja z incidenti v informacijskem sistemu so splošne značilnosti realnega sistema opisane v drugem poglavju, značilnosti posameznih spremenljivk o incidentih, pa so podane v tretjem poglavju. Na začetku tega poglavja je podan osnovni koncept modela in tudi opredelitev omejitev pri modelu. V osnovi nas zanima, kako s stališča učinkovitosti vpliva na delovanje sistema za upravljanje z incidenti v javni upravi izbrana organizacijska oblika drugega nivoja podpore. Za izdelavo računalniškega simulacijskega programa sem izbral simulacijski jezik GPSS. Simulacijski jezik GPSS (Generale Purpose Simulation System) je med prvimi programskimi jeziki za modeliranje in simbolične jezike. Razvil ga je G. Gordon leta 1961 in je sedaj najbolj popularen in uporabljen simulacijski jezik. Razlog leži v preprostosti projektiranja koncepta transakcij in orientiranosti k procesom na naraven način z vrstami ter uporabo močnih ukazov, da se lahko sistem napiše z malo ukazi (Čerić, 1993). Odločitev za izbiro tega programskega jezika je temeljila na treh temeljih. Najpomembnejše je bilo, da program omogoča izvedbo zahtevanih simulacij. Drugi razlog je bil, da so bile na razpolago izkušnje, torej znanje o samem jeziku in zadnji razlog je, da mi je programski jezik dostopen in na razpolago ter sem ga lahko uporabil brez finančnih vlaganj. 4.3.1 MODEL ORGANIZIRANOSTI PO TERITORIALNEM PRINCIPU
V poglavju 4.1.1. je opisan sistem za upravljanje z incidenti, ki je organiziran po teritorialnem principu. Takšen sistem je primerno predstaviti z diskretnim modelom, kjer je posamezen incident en dogodek. V modelu je zelo pomembno ustrezno generirati incidente, ki so vhodi v sistem. V poglavju 3.1. so opisane vse značilnosti nastajanja incidentov v opisanem sistemu javne uprave. Za izdelavo modela lahko naredimo manjše poenostavitve s ciljem, da model ne bo prevelik in zapleten in da istočasno poenostavitve ne bodo v delovanje modela vnašale popačenj. GPSS blokovni diagram za nastajanje incidentov in sprejeme klicev uporabnikov v storitveni center je prikazan na sliki 26. Incidenti nastajajo povprečno vsakih 35 minut s 35 minutnim odklonom. Ob konici, ki je zgoščena v okvir dveh ur, pa se hitrost nastajanja incidentov poveča. Tako se v enem dnevu pojavi 13,64 incidentov, od tega 7 v konici. Na osnovi tega lahko generiramo običajne incidente, ki nastajajo v času od 0 do 106 minut ali vsakih 53 minut s povprečnim odklonom 53 minut, in pet vrst incidentov, ki

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 68
nastajajo vsak dan (480 minut) s povprečnim odklonom od 20 do 60 minut.
Slika 26: GPSS blokovni diagram za nastajanje incidentov in sprejeme klicev
uporabnikov v SC Vsi nastali incidenti nadaljujejo pot v storitveni center, kjer najprej pridejo v vrsto za sprejem, potem se opravi razgovor z operaterji, ki traja povprečno 6,15 oziroma od 3 do 7 minut (glej tabelo 7), zatem pa se pot nadaljuje v tistem segmentu, v katerem se določa lokacijo izvajanja drugega nivoja podpore. GPSS blokovni diagram za določanje in izvajanje drugega nivoja podpore (lokalna podpora) na treh lokacijah je prikazan na sliki 27. Na podlagi tabele 6 je možno ugotoviti, da storitveni center reši 30% incidentov, zato takšen delež incidentov ne gre na drugi nivo podpore, temveč se takoj napoti na konec programa, kjer se transakcija incidenta zaključi. Ostalih 70% gre na drugi nivo podpore. Na lokaciji 1 se rešuje 52% vseh incidentov. Na lokaciji 2 se reši 19% incidentov, kar znaša 40% od preostalih 48% incidentov, ki ostanejo, ko so incidenti za prvi nivo izdvojeni. Ostali incidenti se rešujejo na lokaciji 3. Na posamezni lokaciji se incidenti rešujejo na podoben način kot v storitvenem centru. Torej gredo najprej v vrsto, da počakajo na
GENERATE 27, 27
TRANSFER, STORCE
Običajni incidenti GENERATE
480, 20
TRANSFER, STORCE
. . .
GENERATE 480, 60
TRANSFER, STORCE
Prvi incidenti v konici . . . Peti incident v konici
QUEQ, SCENTER
STORCE
ENTER, SCENTER
ADVACE, 5, 2
Sprejem klica uporabnika v SC
DEPART, VRSTA
LEAVE, SCENTER
Vrsta za čakanje, da bo operater za sprejem klica prost
Operater se je oglasil
Sprostila se je linija za klic
Operater se pogovarja s stranko, ki traja povprečno 3 do 7 minut
Končan je postopek sprejema prijave in začetnega reševanja incidenta

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 69
prostega tehnika, ki potem rešuje incidente. Tehniki na drugem nivoju incidente rešijo povprečno v času od 15 do 1255 minut, oziroma v času 635 minut z odklonom 620 minut. Po končanem posegu je lahko incident rešen ali pa gre na tretji nivo podpore. Na lokaciji 1 uspejo rešiti 87% incidentov, na lokaciji 2 uspejo rešiti 64%, na lokaciji 3 pa 80% vseh incidentov, medtem ko gredo ostali na tretji nivo podpore.
Slika 27: GPSS blokovni diagram za izvajanje drugega nivoja podpore
GPSS blokovni diagram za izvajanje tretjega nivoja podpore je prikazan na sliki 28. Incidenti, ki pridejo z drugega nivoja podpore, gredo v vrsto, kjer počakajo prostega tehnika. Ko je tehnik sproščen, incident zapusti vrsto in gre v postopek reševanja ter istočasno zapusti vrsto za čakanje. Postopek reševanja incidentov na tretjem nivoju
Izhod incidenta iz storitvenega centra
LOK3
TRANSFER, .7, KONEC, OSTALO TRANSFER,
.48, LOK1, OSTALO1 TRANSFER,
.78, LOK2, LOK3
KONEC
QUEQ, VRSTA3
ENTER, PLOK3
ADVACE, 300, 280
DEPART, VRSTA3
LEAVE, PLOK3
QUEQ, VRSTA2
ENTER, PLOK2
ADVACE, 300, 280
DEPART, VRSTA2
LEAVE, PLOK2
QUEQ, VRSTA1
ENTER, PLOK1
ADVACE, 300, 280
DEPART, VRSTA1
LEAVE, PLOK3
TRANSFER, .8, NTRETJI, KONEC
TRANSFER, .64, NTRETJI, KONEC
TRANSFER, .78, NTRETJI, KONEC
KONEC KONEC KONEC
NTRETJI NTRETJI NTRETJI
LOK3 LOK2 LOK1

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 70
povprečno traja od 120 do 14120 minut, oziroma 2120 minut z odklonom 2000 minut. Po končanem reševanju gre incident brezpogojno na konec transakcije.
Slika 28: GPSS blokovni diagram za izvajanje podpore na tretjem nivoju GPSS blokovni diagram za kontrolo delovanja je prikazan na sliki 29. Vsak incident na zaključku pride v blok »TERMITE«, kjer se transakcija uniči in se števec v bloku »START« zmanjša za ena. Z blokom »START« lahko določimo, koliko incidentov bomo simulirali. V prikazanem primeru na sliki 29 bomo simulirali nastanek 2590 incidentov, kar pomeni, da se bo v bloku za nastajanje incidentov generiralo preko 2590 incidentov; in ko bo 2590-i tako nastali incident pripeljan skozi model do bloka »TEARMITE«, se bo simulacija avtomatsko ustavila oziroma končala. Na takšen način je možno kontrolirati obseg simuliranja. GPSS blokovni diagram za določanje velikosti posameznih elementov je prikazan na sliki 30. V bloku »STORECE« določamo število operaterjev v storitvenem centru, v prikazanem primeru sta to dve osebi. V bloku »PLOK1« določamo število tehnikov za drugi nivo podpore na lokaciji 1, v bloku »PLOK2« določamo število tehnikov za drugi nivo podpore na lokaciji 2, v bloku »PLOK3« določamo število tehnikov za drugi nivo
QUEQ, VRSTANT
ENTER, PLOKNT
ADVACE, 1000, 950
DEPART, VRSTANT
LEAVE, PLOKNT
TRANSFER, , KONEC
KONEC
NTRETJI
Izhod incidenta iz drugega nivoja podpore

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 71
podpore na lokaciji 3 in v bloku »PLOKNT« določamo število tehnikov za tretji nivo podpore.
Slika 29: GPSS blokovni diagram za kontrolo delovanja
Slika 30: GPSS blokovni diagram za izvajanje podpore na tretjem nivoju Na podlagi GPSS blokovnega diagrama je možno napisati program. Končna oblika napisanega program v programskem jeziku GPSS za izvajanje simulacije za model organiziranosti po teritorialnem principu je naslednja: ******************************************************************************** *** MODEL UPRAVLJANJE INCIDENTOV PO TERITORIALNEM PRINCIPU *** ******************************************************************************** * Nastajanje incidentov SIMULATE GENERATE 53,53 Običajno incidenti zunaj špice nastajajo vsakih 52 minut TRANSFER ,STORCE GENERATE 480,20 V špici, ki traja 2 uri vsak dan, nastane 5 incidentov TRANSFER ,STORCE GENERATE 480,30 TRANSFER ,STORCE
STORECE STORAGE 2 V storitvenem centru sta neprekinjeno aktivni dve delovni mesti
PLOK1 STORAGE 5 Na lokaciji 1 neprekinjeno deluje 5 tehnikov
PLOK2 STORAGE 2 Na lokaciji 2 neprekinjeno delujeta 2 tehnika
PLOK3 STORAGE 2 Na lokaciji 3 neprekinjeno delujejo 3 tehniki
PLOKNT STORAGE 10 Na tretjem nivoju podpore deluje neprekinjeno 10 tehnikov
Izhod incidenta iz vseh nivojev podpore
TERMITE 1
START 2590
KONEC
END

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 72
GENERATE 480,40 TRANSFER ,STORCE GENERATE 480,50 TRANSFER ,STORCE GENERATE 480,60 TRANSFER ,STORCE ******************************************************************************* ************************ Velikosti posameznih blokov ********************** SCENTER STORAGE 2 Število zaposlenih v storitvenem centru PLOK1 STORAGE 11 Število zaposlenih v lokalni podpori na LOK 1 PLOK2 STORAGE 3 Število zaposlenih v lokalni podpori na LOK 2 PLOK3 STORAGE 8 Število zaposlenih v lokalni podpori na LOK 3 PLOKNT STORAGE 13 Število zaposlenih na III. nivoju podpore ******************************************************************************** ****************** Sprejem klica v storitvenem centru ********************** STORCE QUEUE VRSTA ENTER SCENTER DEPART VRSTA ADVAVCE 6,2 LEAVE SCENTER ******************************************************************************** ********************** Določanje lokacije za reševanje ******************** * Na nivoju storitvenega centra se reši 30% incidentov, 70% se rešuje na višjih nivojih podpor TRANSFER .3,OSTALO,KONEC * Na lokaciji 1 se reši 52% incidentov OSTALO TRANSFER .52,OSTALO1,LOK1 * Na lokaciji 2 se reši 19% incidentov oziroma 40% od ostanka, ostalo pa na lokaciji 3 OSTALO1 TRANSFER .19,LOK3,LOK2 ******************************************************************************** *********** Izvajanje lokalne podpore na II nivoju po lokacijah ********** * Izvajanje lokalne podpore na 2. nivoju na lokaciji 1 LOK1 QUEUE VRSTA1 ENTER PLOK1 DEPART VRSTA1 ADVAVCE 635,620 LEAVE PLOK1 * Na 2. nivoju se na LOK1 reši 87% dodeljenih incidentov, ostali gredo na višji nivo podpore TRANSFER .87,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju na lokaciji 2 LOK2 QUEUE VRSTA2 ENTER PLOK2 DEPART VRSTA2

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 73
ADVAVCE 635,620 LEAVE PLOK2 * Na 2. nivoju se na LOK2 reši 64% dodeljenih incidentov, ostali gredo na višji nivo podpore TRANSFER .64,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju na lokaciji 3 LOK3 QUEUE VRSTA3 ENTER PLOK3 DEPART VRSTA3 ADVAVCE 635,620 LEAVE PLOK3 * Na 2. nivoju se na LOK3 reši 80% dodeljenih incidentov, ostali gredo na višji nivo podpore TRANSFER .8,NTRETJI,KONEC * Izvajanje podpore na 3. nivoju NTRETJI QUEUE VRSTANT ENTER PLOKNT DEPART VRSTANT ADVAVCE 2120,2000 LEAVE PLOKNT TRANSFER ,KONEC ******************************************************************************** ************************ Zaključevanje simulacije ************************** KONEC TERMINATE 1 START 2590 Izvajanje prve simulacije, generiranih incidentov je 2590 CLEAR START 2590 Izvajanje druge simulacije CLEAR START 2590 Izvajanje tretje simulacije CLEAR END ************************************************************************ V programskem bloku za generiranje se simulacija izvede trikrat. V bloku za kontroliranje velikosti posameznih elementov se vrednosti spreminjajo v skladu z načrtom izvajanja simulacij.
4.3.2 MODEL ORGANIZIRANOSTI PO LINIJSKI ORGANIZACIJSKI STRUKTURI
V poglavju 4.1.2. je opisan sistem upravljanja z incidenti, ki je organiziran po linijski organizacijski strukturi. Sam model je podoben modelu organiziranosti po teritorialnem principu. Razlika je v bloku za določanja in izvajanja drugega nivoja

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 74
podpore. Opazna razlika je v večjem številu skupin za lokalno podporo. Ustrezno se tudi spremenijo elementi v bloku za določanje velikosti posameznih elementov. GPSS blokovni diagram za določanje in izvajanje drugega nivoja podpore (lokalna podpora) v šestih organizacijskih enotah je prikazan na sliki 31. Vsi incidenti, ki pridejo iz storitvenega centra, se ustrezno prerazporejajo v enoto, kjer se bo nadaljevalo reševanje incidentov. Kot je bilo že v prejšnjem modelu, je tudi tu 30% rešenih v storitvenem centru in le ti gredo nato direktno v zadnji blok za zaključek.
Slika 31: GPSS blokovni diagram za izvajanje drugega nivoja podpore
v modelu organiziranosti po linijsko organizacijski strukturi
KONEC
TRANSFER, .3, OSTALO, KONEC
LOKA
OSTALO
TRANSFER, .33, OSTALO1, LOKA
LOKB
TRANSFER, .2, OSTALO2, LOKB
LOKC
OSTALO2
TRANSFER, .07, OSTALO3, LOKC
OSTALO1
LOKD
OSTALO3
TRANSFER, .06, OSTALO4, LOKD
LOKE
TRANSFER, .13, LOKF, LOKE
LOKF
OSTALO4
Incidenti iz storitvenega centra
QUEQ, VRSTAA
ENTER, PLOKA
ADVACE, 635, 620
DEPART, VRSTAA
LEAVE, PLOKA
TRANSFER, .83, NTRETJI, KONEC
NTRETJI
V podoben blok kot je prikazan za LOKA
KONEC

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 75
V enoti A rešijo 33%, v enoti B 13% oziroma 20% ostanka, v enoti C 4% oziroma 7% ostanka, v enoti D 2% oziroma 6% ostanka, v enoti E 6% oziroma 13% ostanka in v enoti F 39% ali 86% ostanka. Reševanje po posameznih enotah je enako, kot v prejšnjem modelu. Za določitev procenta uspešnosti reševanja na drugem nivoju je bolje vzeti vzorec vseh incidentov kot pa posamezne enote, ker bi za manjše enote (C, D, E) bil vzorec nekorekten, ker je premalo vzorčnih primerov. Na podlagi zgornjega GPSS blokovnega diagrama in ugotovitev iz prejšnjega modela je možno napisati program. Končna oblika napisanega program v programskem jeziku GPSS za izvajanje simulacije za model organiziranosti po linijsko organizacijski strukturi je naslednja: ******************************************************************************** **** Model upravljanje incidentov po organizacijsko-linijski strukturi **** ******************************************************************************** * Nastajanje incidentov SIMULATE GENERATE 53,53 Običajno incidenti zunaj špice nastajajo vsakih 52 minut TRANSFER ,STORCE GENERATE 480,20 V špici, ki traja 2 uri vsak dan, nastane 5 incidentov TRANSFER ,STORCE GENERATE 480,30 TRANSFER ,STORCE GENERATE 480,40 TRANSFER ,STORCE GENERATE 480,50 TRANSFER ,STORCE GENERATE 480,60 TRANSFER ,STORCE ******************************************************************************* ********************* Določanje velikosti strežnih mest ******************** SCENTER STORAGE 2 Število zaposlenih v SC PLOKA STORAGE 14 Število zaposlenih v lokalni podpori v enoti A PLOKB STORAGE 3 Število zaposlenih v lokalni podpori v enoti B PLOKC STORAGE 2 Število zaposlenih v lokalni podpori v enoti C PLOKD STORAGE 2 Število zaposlenih v lokalni podpori v enoti D PLOKE STORAGE 2 Število zaposlenih v lokalni podpori v enoti E PLOKF STORAGE 8 Število zaposlenih v lokalni podpori v enotii F PLOKNT STORAGE 13 Število zaposlenih na III. nivoju podpore ******************************************************************************** ********************* Sprejem klica v storitvenem centru *******************

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 76
STORCE QUEUE VRSTA ENTER SCENTER DEPART VRSTA ADVAVCE 6,2 LEAVE SCENTER * Število zaposlenih v storitvenem centru ******************************************************************************* **************** Določanje enote za reševanje incidenta *************** * Na nivoju storitvenega centra se reši 30% incidentov, 70% se rešuje na višjih nivojih podpor TRANSFER .3,OSTALO,KONEC * Na lokaciji A se reši 54% incidentov OSTALO TRANSFER .64,OSTALO1,LOKA * Na lokaciji B se reši 8% incidentov oziroma 17% od ostanka OSTALO1 TRANSFER .17,OSTALO2,LOKB * Na lokaciji C se reši 2% incidentov oziroma 5% od ostanka OSTALO2 TRANSFER .05,OSTALO3,LOKC * Na lokaciji D se reši 3% incidentov oziroma 8% od ostanka OSTALO3 TRANSFER .08,OSTALO4,LOKD * Na lokaciji E se reši 1% incidentov oziroma 3% od ostanka, ostalo na LOKF OSTALO4 TRANSFER .03,LOKF,LOKE ******************************************************************************** *********** Izvajanje lokalne podpore na 2 nivoju po enotah ************ * Izvajanje lokalne podpore na 2. nivoju v enoti A LOKA QUEUE VRSTAA ENTER PLOKA DEPART VRSTAA ADVAVCE 635,620 LEAVE PLOKA * Na 2. nivoju se reši 83% dodeljenih incidentov, ostali gredo na višji nivo podpore TRANSFER .83,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju v enoti B LOKB QUEUE VRSTAB ENTER PLOKB DEPART VRSTAB ADVAVCE 635,620 LEAVE PLOKB TRANSFER .83,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju v enoti C LOKC QUEUE VRSTAC ENTER PLOKC DEPART VRSTAC ADVAVCE 635,620

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 77
LEAVE PLOKC TRANSFER .83,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju v enoti D LOKD QUEUE VRSTAD ENTER PLOKD DEPART VRSTAD ADVAVCE 635,620 LEAVE PLOKD TRANSFER .83,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju v enoti E LOKE QUEUE VRSTAE ENTER PLOKE DEPART VRSTAE ADVAVCE 635,620 LEAVE PLOKE TRANSFER .83,NTRETJI,KONEC * Izvajanje lokalne podpore na 2. nivoju v enoti F LOKF QUEUE VRSTAF ENTER PLOKF DEPART VRSTAF ADVAVCE 635,620 LEAVE PLOKF TRANSFER .83,NTRETJI,KONEC ******************************************************************************** ********************** Izvajanje podpore na 3. nivoju ********************** NTRETJI QUEUE VRSTANT ENTER PLOKNT DEPART VRSTANT ADVAVCE 2120,2000 LEAVE PLOKNT TRANSFER ,KONEC ******************************************************************************** ************************ Zaključevanje simulacije *************************** KONEC TERMINATE 1 START 2590 Izvajanje prve simulacije, število generiranih incidentov je 2590 CLEAR START 2590 Izvajanje druge simulacije CLEAR START 2590 Izvajanje tretje simulacije CLEAR * END ********************************************************************************

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 78
4.3.3 SIMULACIJA NA MODELIH
Osnovni razlog za izdelavo modelov za izvajanje simulacij je možnost raziskovanja delovanja sistema in sprejemanja odločitev v zvezi s sistemom (Čerić, 1993). V našem primeru je bil osnovni razlog za izdelavo modelov raziskovanje učinkovitosti delovanja sistema upravljanja z incidenti v IS. Učinkovitost sistema lahko opredelimo za opazovani sistem kot odnos med časom čakanja na reševanje in številom zaposlenih v sistemu.
Modela sta zgrajena za dve obliki organiziranosti. Za izvajanje simulacij lahko spreminjamo števila delovnih mest po posameznih lokacijah. Tako lahko spreminjamo število zaposlenih v storitvenem centru, na posamezni lokaciji ali enoti izvajanja drugega nivoja podpore in števila zaposlenih na tretjem nivoju podpore.
Možno je tudi spreminjati čas izvajanja simulacije. Odvisno od nastavitev spremenljivk se spreminjajo povprečni časi čakanj posameznih incidentov pred posameznimi bloki v modelu, ki predstavljajo realni del sistema.
Preden začnemo izvajati simulacije, je potrebno preveriti delovanja modela oziroma ga moramo validirati. Preverjanje modela pomeni razvijati smiselni nivo zaupanja v rezultate, ki jih ustvarja model, in videti, če so ti pravilni in primerljivi z realnim sistemom (Čerić, 1993).
Vrednotenje je stopnja zaupanja v model in ni ocenjevanje podobnosti med modelom in sistemom (Shannon v Čeriću, 1993). Razlogi za to so:
• Model je nujna aproksimacija sistema; • Elementi modela, dobljeni z merjenjem na realnem sistemu,
vsebujejo v sebi napako merjenja, kar povzroča posledično netočnost pri rezultatih modela;
• Točnost rezultatov statistične analize izhodov iz modela je odvisna od velikosti opazovanega vzorca, kar pa podraži rezultate pri povečevanju točnosti.
Validacija je filozofija modeliranja (veljavnost, legalizacija). Validacija je primerjanje ustreznosti modela simuliranega sistema z realnim sistemom. Potrdi pozitivno povezavo med vedenjem realnega sistema in modela.
Na sliki 32 je prikazana shema metodologije validacije modela. Ko je model narejen in atestiran, gre v replikativno validacijo. Sledi scenarij in simulacija. Replikativna validacija je statistična metoda, s katero

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 79
preverimo, če so rezultati, dobljeni iz našega modela, podobni tistim iz opazovanega modela. Če dobljeni korelacija ni dovolj velika, moramo model prilagoditi. Oba modela sta bila preverjena. Ustrezno število incidentov se generira v približno enakem časovnem okvirju, v katerem so bili zbrani vzorčni primeri incidentov. Porazdelitev posameznih incidentov po lokacijah oziroma enotah je enaka. Določena odstopanja nastajajo v drugem modelu (model organiziranosti po linijsko organizacijski strukturi) pri enotah, ki imajo manjše število incidentov. To pa zato, ker porazdelitev temelji na verjetnosti in je na razpolago malo število incidentov, ki pa se s povečanjem števila generiranih incidentov zmanjšujejo.
Predikativna validacija je preverjanje ustreznosti modela za napovedovanje sprememb sistema v prihodnosti. Za odločanje o ustreznosti prav tako uporabimo statistične teste. Ta validacija bo predmet nadaljnje obravnave.
Slika 32: Shema metodologije validacije modela (Kljajić, 2002)
Incidente in s tem tudi njihov vzorec nastajanja se je opazovalo 19 delovnih dni ali 9120 minut. V tem času je v realnem sistemu nastalo 259 incidentov. Za opazovanje delovanja modela je smiselno, da simulirani čas delovanja incidentov povečamo za desetkrat. Osnovni razlog je bolj enakomerna verjetnostna porazdelitev za podsisteme, ki imajo v obdelavi manjše število incidentov. Podaljševanje časa simulacije ni več smiselno, ker je porazdelitev ustaljena in se bistveno ne bo spreminjala. Tako bo simulirani čas znašal 190 delovnih dni ali 91.200 minut. V tem času bo nastalo 2590 incidentov.
Tako dobljeni rezultati bodo veljavni za delovanje sistema v načrtovanih okvirjih. Med izvajanje simulacije bomo spreminjali spremenljivke, ki določajo število zaposlenih na drugem nivoju podpore oziroma v lokalni podpori.
Model Replikativna validacija Scenarij in simulacija
Realni sistem Predikativna validacija DA
NE

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 80
Spremenljivke bomo spreminjali tako, da bomo imeli na izhodu tri različne tipe čakalnih vrst za izvajanje drugega nivoja podpore:
• V prvem primeru bomo določili, kolikšno je minimalno število zaposlenih, da se čakalne vrste ne povečujejo, oziroma da model postane smiseln;
• V drugem primeru bomo določili število zaposlenih tako, da se od 80 do 95% incidentov začne reševati takoj oziroma da je povprečni čas čakanja za reševanje na drugem nivoju podpore manj kot 1. uro, maksimalno pa manj kot 5 ur. Za takšen primer lahko nato rečemo, da je optimalen;
• V tretjem primeru bomo določili število zaposlenih tako, da se k reševanju pristopi takoj v več kot 95,01%. Takšno stanje lahko imenujemo idealno.
Število zaposlenih v storitvenem centru in tretjem nivoju podpore bomo določevali posebej. Zaradi omejitve generatorja naključnih števil bomo za vsak posamezni primer izvedli tri simulacije, veljavni rezultat pa bo povprečna vrednost vseh rezultatov izvedenih simulacij.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 81
4.3.4 REZULTATI SIMULACIJ
Rezultati simulacij na modelu organiziranosti po teritorialnem principu so prikazani v tabeli 9. Simulacije so bile izvedene pod pogoji, opisanimi v predhodnem poglavju. Pridobljeni rezultati so takšni zato, ker je število zaposlenih v storitvenem centru in na tretjem nivoju podpore idealno.
Število zaposlenih Opis
Lokacija Število
Simu-lacija
Brez čakanja (%)
Skupni pov. čas
čakanja (min.)
Pov.mak. čas
čakanja (min.)
Pov. šte. inciden. v
delu
S1 39,5 190 314 7,04 S2 39,9 247 412 7,01 S3 56,1 81 185 6,65
LOK1 8
Povp. 45,17 173 304 6,90
S1 48,0 270 521 1,23 S2 64,6 180 510 1,17 S3 63,2 165 450 1,15
LOK2 2
Povp. 58,60 205 494 1,18
S1 10,1 575 685 4,77 S2 10,3 1020 1137 4,81 S3 4,8 2424 2547 4,87
LOK3 5
Povp. 8,40 1340 1456 4,82
Min
ima
lno
šte
vilo
za
po
sle
nih
Skupaj vse 15
S1 91,4 8,0 92 6,75 S2 93,5 8,2 125 6,54 S3 97,0 1,6 53 6,29
LOK 1 11
Povp. 93,97 5,9 90 6,53
S1 86,3 34,7 253 1,33 S2 91,3 31,9 368 1,27 S3 89,6 12,1 116 1,08
LOK 2 3
Povp. 89,07 26,2 246 1,23
S1 82,2 35,3 198 5,17 S2 84,4 20,9 134 5,28 S3 88,9 11,9 53 4,83
LOK 3 8
Povp. 85,17 22,7 128 5,09
Op
tima
lno
šte
vilo
za
po
sle
nih
Skupaj vse 22
S1 97,1 1,7 48 7,01 S2 97,8 1,1 88 6,75 S3 96,7 1,7 100 6,24
LOK 1 12
Povp. 97,20 1,5 78,7 6,67
S1 95,2 6,8 18 1,47 S2 98,7 2,4 152 1,10 S3 98,9 1,2 216 1,36
LOK 2 4
Povp. 97,60 3,5 129 1,31
S1 99,3 0,4 108 4,94 S2 97,5 1,9 132 5,11 S3 98,4 0,9 120 5,16
LOK 3 10
Povp. 98,40 1,1 120 5,07
Ide
aln
o š
tevilo
za
po
sle
nih
Skupaj vse 24
Tabela 9: Rezultati modela organiziranosti po teritorialnem principu

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 82
V tabeli 10, 11 in 12 so prikazani rezultati simulacij na modelu organiziranosti lokalne podpore po organizacijsko linijski strukturi. Pogoji za simulacije so bili enaki kot pri predhodnem modelu.
Število zaposlenih Opis
Lokacija Število
Simu-lacija
Brez čakanja (%)
Skupni pov. čas
čakanja (min.)
Pov.mak. čas
čakanja (min.)
Pov. šte. inciden. v
delu
S1 8,8 1397 1533 7,77 S2 2,1 1908 1949 7,95 S3 8,6 1099 1202 7,81
Enota A 8
Povp. 6,50 1468 1561 7,84
S1 33,6 804 1211 0,73 S2 24,3 644 825 0,77 S3 9,2 2076 2288 0,91
Enota B 1
Povp. 22,37 1175 1441 0,80
S1 64,5 297 837 0,22
S2 84,6 57 374 0,19 S3 70,4 135 458 0,18
Enota C 1
Povp. 73,17 163 556 0,20
S1 67,5 192 591 0,27 S2 75,0 113 452 0,31 S3 61,2 180 465 0,37
Enota D 1
Povp. 67,90 162 503 0,32
S1 100,0 0 0 0,10 S2 80,0 79 396 0,16 S3 90,0 49 491 0,07
Enota E 1
Povp. 90,00 43 296 0,11
S1 30,8 465 672 3,41 S2 40,8 261 441 3,27 S3 27,0 439 602 3,53
Enota F 4
Povp. 32,87 388 572 3,40
Min
ima
lno
šte
vilo
za
po
sle
nih
Skupaj vse
16
Tabela 10: Rezultati modela organiziranosti po organizacijsko linijski
strukturi (minimalna varianta)

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 83
Število zaposlenih Opis
Lokacija Število
Simu-lacija
Brez čakanja (%)
Skupni pov. čas
čakanja (min.)
Pov.mak. čas
čakanja (min.)
Pov. šte. inciden. v
delu
S1 95,2 5,4 113 8,13 S2 91,4 6,5 75 8,52 S3 92,2 8,2 105 8,33
Enota A 13
Povp. 92,93 6,7 98 8,33
S1 97,5 3,2 126 0,90 S2 95,3 12,4 263 0,90 S3 95,0 8,5 167 0,88
Enota B 3
Povp. 95,93 8,0 185 0,89
S1 100,0 0,0 0 0,23 S2 95,0 14,9 299 0,17 S3 100,0 0,0 0 0,24
Enota C 2
Povp. 98,33 5,0 100 0,21
S1 100,0 0,0 0 0,27 S2 100,0 0,0 0 0,21 S3 97,8 3,0 139 0,32
Enota D 2
Povp. 99,27 1,0 46 0,27
S1 95,8 20,0 0 0,17 S2 100,0 0,0 480 0,09 S3 100,0 0,0 0 0,11
Enota E 2
Povp. 98,60 6,7 160 0,12
S1 93,4 12,2 186 3,65 S2 95,6 4,2 94 3,22 S3 93,2 10,1 148 3,52
Enota F 7
Povp. 94,07 8,8 143 3,46
Op
tima
lno
šte
vilo
za
po
sle
nih
Skupaj vse
29
Tabela 11: Rezultati modela organiziranosti po organizacijsko linijski
strukturi (optimalna varianta)

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 84
Število zaposlenih Opis
Lokacija Število
Simu-lacija
Brez čakanja (%)
Skupni pov. čas
čakanja (min.)
Pov.mak. čas
čakanja (min.)
Pov. šte. inciden. v
delu
S1 95,8 6,2 146 8,18 S2 98,8 0,6 64 8,41 S3 98,9 0,7 63 8,08
Enota A 14
Povp. 97,83 2,5 91 8,22
S1 97,6 6,2 255 0,87 S2 97,1 11,4 395 0,75 S3 97,5 2,4 94 0,89
Enota B 3
Povp. 97,40 6,7 248 0,84
S1 100,0 0,0 0 0,17 S2 100,0 0,0 0 0,14 S3 96,3 4,5 122 0,17
Enota C 2
Povp. 98,77 1,5 41 0,16
S1 97,5 16,4 653 0,28 S2 100,0 0,0 0 0,35 S3 97,4 7,3 285 0,28
Enota D 2
Povp. 98,30 7,9 313 0,30
S1 100,0 0,0 0 0,12 S2 100,0 0,0 0 0,07 S3 100,0 0,0 0 0,11
Enota E 2
Povp. 100,00 0,0 0 0,10
S1 99,6 0,1 19 3,20 S2 99,3 0,2 17 3,18 S3 98,9 0,7 68 3,29
Enota F 8
Povp. 99,27 0,3 35 3,22
Ide
aln
o š
tevi
lo z
ap
osle
nih
Skupaj vse
31
Tabela 12: Rezultati modela organiziranosti po organizacijsko linijski
strukturi (idealna varianta) Minimalno, optimalno in idealno število zaposlenih v storitvenem centru in na tretjem nivoju podpore je prikazano v tabeli 13.
Opis Lokacija Število % brez čakanja
% čas čakanja
Storitveni center 1 85,7 0,5 Minimalno število zaposlenih III.nivo podpore 7 3,6 3594
Storitveni center 1 85,7 0,5 Optimalno število zaposlenih III.nivo podpore 12 93,9 13
Storitveni center 2 99,1 0,2 Idealno število zaposlenih III.nivo podore 13 98,1 2
Tabela 13: Rezultati modela organiziranosti po teritorialnem principu

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 85
Pri razlagi rezultatov simulacij moramo imeti v mislih dejstvo, da so prikazana števila delovnih mest idealizirana. To pomeni, da niso upoštevane različne odsotnosti zaposlenih z delovnih nalog oziroma da so vsi zaposleni 100% razpoložljivi za izvajanje nalog v zvezi reševanja incidentov, kar pa v realnem sistemu seveda ne velja.
4.4 PRIMERJAVA ORGANIZACIJSKIH OBLIK SISTEMA UPRAVLJANJA Z INCIDENTI
V tabeli 14 je prikazana razlika števila zaposlenimi pri različnih obsegih delovanja sistema upravljanja z incidentih pri obeh modelih organiziranosti.
Število zaposlenih
Vrsta Po teritorialnem
principu
Po linijsko-organizacijski
strukturi
Opombe
Minimalno število zaposlenih
15 16
Optimalno število zaposlenih
22 29
Idealno število zaposlenih
26 31
Tabela 14: Primerjava števila zaposlenih med modeloma
Oblika organiziranosti po teritorialnem principu zahteva pri minimalnem številom zaposlenih eno osebo manj, pri optimalnem številom zaposlenih pa že 7 manj in pri idealnem številu 5 manj. Model organiziranosti po teritorialnem principu v vseh variantah zahteva manjše število zaposlenih od modela organiziranosti po linijsko organizacijski strukturi. Tako lahko sklepamo, da je model organiziranosti po teritorialnem principu bolj učinkovit. Pri modelu organiziranosti po teritorialnem principu število zaposlenih narašča linearno, med tem pa pri modelu organiziranosti po organizacijsko linijski strukturi število zaposlenih narašča stopničasto, ker je za večino enot (za 50%) število zaposlenih za optimalno in

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 86
idealno varianto enako. Iz tega je možno sklepati, da je model organiziranosti po teritorialnem principu bolj stabilen v primeru izpada (zmanjšanja) števila zaposlenih ali povečanja števila incidentov, ki se pojavljajo v sistemu. Oba modela imata še svoje prednosti in slabosti, ki izhajajo iz specifične oblike vsake posamezne organizacije oblike. V tabeli 15 so prikazane osnovne prednosti in slabosti posamezne organizacijske oblike.
Model organiziranosti po teritorialnem principu
Model organiziranosti po linijsko-organizacijski strukturi
Prednosti
Lažje strokovno vodenje in nadzor dela;
Koncentracija znanja;
Lažje zagotavljanje enotnih standardov dela;
Lažje izvajanje usposabljanja in izobraževanja.
Bližji kontakt IT strokovnjakov z zaposlenimi;
Večja pripadnost organizaciji;
Fleksibilnost in enostavnost pri organizaciji dela;
Lažje usklajevanje med linijskim vodstvom in IT osebjem.
Slabosti
Problemi z linijskim vodstvom;
Težje zagotavljanje specifičnih zahtev za posamezne organizacije;
Težje in kompleksnejše doseganje SLA;
Odtujenost IT strokovnjakov od uporabnikov.
Težje izvajanje strokovnega vodenja in nadzora;
Izvajanje nenamenskih nalog;
Težje zagotavljanje prenosa znanja;
Razlike v kvaliteti opravljenega dela med organizacijskim enotami;
Težje nadomeščanje IT osebja.
Tabela 15: Primerjava prednosti in slabosti med modeloma
Osnovna prednost modela organiziranosti po teritorialnem principu je možnost lažjega strokovnega vodenja in koncentracija zaposlenih, kar olajša izvajanje usposabljanja, standardizacije dela in podobno. Pri drugem modelu pa je osnovna prednost večjega vpliva linijskega vodstva na IT strokovnjake in večja povezanost le teh s samo organizacijo. Slabosti modela organiziranosti po teritorialnem principu pa so težave, ki se pojavljajo v zvezi s spori med linijskim in procesnim vodstvom pri

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 87
zagotavljanju delovanja sistemov. Tako so dogovori o ravni storitve (SLA) bistveno težji in zahtevajo daljši čas za pripravo in usklajevanje. Slabosti modela organiziranosti po organizacijsko linijski strukturi pa sta slabši strokovni nadzor nad izvajanjem nalog in uporaba IT strokovnjakov za izvajanje drugih nalog. Katere prednosti in slabosti modelov imajo večje težo, lahko ocenjujemo zelo subjektivno. Večino slabosti modela organiziranosti po teritorialnem principu je možno z načrtnim in doslednim delovanjem zmanjšati, med tem ko imajo slabosti drugega modela trajno in nepremostljivo omejitev pri delovanju sistema. Na splošno lahko zaključimo, da ima model organiziranosti po teritorialnem principu več prednosti, povezanih s strokovnim delovanjem, in da za uspešno delovanje sistema zahteva manjše število zaposlenih.
4.5 ZAHTEVE DELOVNIH MEST V SISTEMU UPRAVLJANJA Z INCIDENTI
Simulaciji obeh modelov sta narejeni s predpostavko, da so vsa delovna mesta neprekinjeno zasedena z ustreznimi IT strokovnjaki, kar pa v vsakdanjem življenju ne drži. V praksi so delovna mesta zasedena s strokovnjaki, ki imajo različne izkušnje in znanja. Vsi zaposleni tudi ne morejo neprekinjeno izvajati svojih namenskih nalog, saj so iz različnih razlogov odsotni z mesta izvajanja svojih nalog. Te razloge bi lahko zgrnili v dve skupini: v prvi so službeni, v drugi pa osebni razlogi. V prvo skupino spadajo odsotnosti zaradi usposabljanj, izobraževanj, službenih potovanj, sestankov, malic itd., v drugi skupini pa se govori o odsotnosti zaradi letnih dopustov, bolniškega staleža, izredne odsotnosti itd. Za vsako organizacijo se lahko odsotnosti natančno določi s proučevanjem podatkov o odsotnosti v preteklosti. Običajno odsotnost predstavlja od 20 do 30% skupnega delovnega časa. Na podlagi tega je možno zaključiti, da rabimo za dve aktivni delovni mesti približno tri zaposlene osebe. Običajno zaposleni IT strokovnjaki opravljajo naloge iz več procesov, ki se izvajajo v organizaciji s področja IT. Praviloma le zaposleni v storitvenem centru opravljajo naloge, ki so vezane s sistemom upravljanja z incidenti, med tem ko ostali opravljajo še druge naloge. Iz rezultatov simulacij je razvidno, da je povprečna zasedenost zaposlenih z nalogami iz področja upravljanja z incidenti na II. nivoju podpore v primeru optimalnega števila zaposlenih po teritorialnem principu 63,96% in pri organiziranosti po organizacijo linijski strukturi le

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 88
39,36%. Iz tega lahko zaključimo, da lahko zaposleni vsaj tretjino delovnega časa opravljajo naloge iz drugih področjih. Pri tem moramo upoštevati določene omejitve. Naloge ne smejo biti fizično oddaljene od osnovnega delovnega mesta in morajo biti takšne narave, da omogočajo prekinitev izvajanja nalog brez posledic v primeru pojave incidentov. Običajno se zaposlenim v lokalni podpori dodelijo naloge v zvezi RFC (upravljanje s konfiguracijami) in upravljanjem z infrastrukturo. Najlažje je opredeliti naloge tako, da v začetku delovnega dneva zaposleni opravljajo naloge v povezavi z reševanjem incidentov, v drugi polovici delovnega dneva pa se v razpoložljivem času ukvarjajo z drugimi nalogami. Na začetku delovnega časa se pojavlja največ incidentov, prav tako pa se lahko nadaljuje reševanje nerešenih incidentov iz prejšnjega dneva. V tem času lahko predstojniki organizirajo delo za RFC ali kaj podobnega tako, da delo v drugi polovici dneva poteka načrtovano. 4.5.1 ZAPOSLENI
Vsak zaposleni strokovnjak s področja IT mora imeti za svoje delo določene kompetence. Kompetence IT strokovnjakov so specifične in so povezane z njihovo izobrazbo, izkušnjami, področji dosedanjega dela, motiviranostjo za samostojno usposabljanje in izobraževanje, motiviranostjo za samostojno delo itd. Področje IT je zelo široko in posledično zahteva ustrezni nivo specializacije. V praksi je zelo težko zagotoviti ustrezno število strokovnjakov s specialističnim znanjem za vsako področje IT, ki ga potrebujemo, zato je potrebno izgraditi »piramido specialističnega znanja«, kjer na vsakem nivoju nastopajo osebe z različnimi kompetencami in sposobnostmi. V storitvenem centru je potrebno zaposliti IT strokovnjake, ki imajo veliko splošnega znanja o organizaciji, univerzalno znanje s področja IT ter ustrezne komunikacijske sposobnosti. Osnovni pogoj je, da ima operater v centru sposobnost ne-konfliktnega in prijaznega komuniciranja z uporabniki v vseh primerih. Zaželeno je, da je operater sposoben za potrpežljivo delo. Osnovni napaki v večini organizacij sta ti, da v kader v storitvenem centru premalo vlagajo in na ta mesta postavljajo neizkušene osebe. Tehniki na II. nivoju oziroma v lokalni podpori morajo imeti specialistična znanja iz operacijskih sistemov, univerzalna znanja iz namiznih programov in podatkovnih omrežjih. Dobro morajo poznati segment organizacije, ki ga pokrivajo. Zaželeno je, da so motivirani za samostojno usposabljanje in izobraževanje. V praksi je na tem nivoju zelo velik razpon kompetenc, od samih začetnikov do izkušenih

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 89
strokovnjakih IT. Pomembno je, da se na tem nivoju formirajo ekipe, ki vključujejo ljudi z različnimi kompetencami, tako da se zagotovi pretok znanja. Karakteristika tega nivoja je zelo velika fluktuacija kadra. Strokovnjaki na III. in višjem nivoju podpore morajo imeti specifična specialna znanja iz ozkih področjih IT. Večina organizacij si ne more zagotoviti ali privoščiti ustreznega števila oseb iz celotnega spektra oseb s takšnimi znanji, zato je bolj ekonomično, racionalno in učinkovito, da na tem nivoju organizacija izkoristi strokovnjake, ki jih ponujajo zunanji izvajalci IT storitev. 4.5.2 OPREMA IN ORODJA ZA DELOVANJE SISTEMA
Orodja oziroma programska in strojna oprema za podporo delovanju sistema upravljanja z incidenti mora zadovoljiti niz specifičnih zahtev. Priporočila ITIL (OGC,2003) opredeljujejo, da morajo orodja za podporo zadostiti naslednjim osnovnim zahtevam:
• Avtomatično opozarjanje na napake in okvare na IT infrastrukturi (strežniki, omrežna oprema, komunikacije, itd) in posodabljanje zapisov o spremembah (lahko se izvede direktno ali preko vmesnikov);
• Avtomatična eskalacija incidenta v primeru prekoračitve časovnih rokov pri reševanju incidentov;
• Osnovna zahteva je elastično usmerjanje poti reševanja incidentov, ker je osebje lahko razmeščeno na različnih mestih in nalogah tekom dneva;
• Izdelava avtomatičnih izvlečkov podatkov iz CMDB o okvarjeni in soodvisni opremi;
• Idealna programska oprema bi morala zagotoviti hitro in učinkovito delovanje sistema upravljanja z incidenti, ki pa je dejansko odvisna od sposobnosti natančnega klasificiranja incidentov in sposobnosti iskanja podobnih incidentov;
• Možnost avtomatskega registriranja telefonskih številk in imen ter povezava s telefonskim imenikom;
• Navzočnost diagnostičnih orodij, ki pomagajo pri lažjem odkrivanju vzrokov za nastanek incidentov;
• Možnost oddaljenega dostopa do delavnih postaj uporabnikov. Vse te zahteve običajno zagotavljajo razna orodja, ki jih ponujajo komercialni ponudniki programske opreme. Večja težava je v ocenjevanju uporabnosti posamezne opreme, saj lahko oceno ustreznosti opreme strokovnjaki IT v posameznih organizaciji izvedejo le po uvedbi v uporabo. Predhodna ocena ustreznosti orodja pa je nezanesljiva in je pod velikim subjektivnim vplivom. V vsakem primeru pa je pomembno, da IT strokovnjaki to opremo sprejmejo in so motivirani za njeno uporabo.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 90
5 ZAKLJUČEK
Incidenti v informacijskem sistemu so kateri koli dogodek, ki ni del standardnega delovanja storitve in ki povzroči ali lahko povzroči prekinitev ali zmanjša kakovost te storitve. Vsak poslovni sistem mora imeti ustrezni sistem, s katerim obvladuje incidente. Obvladovanje incidentov oziroma upravljanje z incidenti pomeni, da imamo orodja in metode za hitro in učinkovito odkrivanje nastankov incidentov, mehanizme za odpravo vzrokov za incidente, predvidene postopke in načine za odpravo posledic incidentov in sisteme za vodenje, spremljanje in nadzor vseh prej navedenih aktivnosti in postopkov. Če je vse to zaokroženo v delujoč sistem, lahko potem govorimo o sistemu za upravljanje z incidenti v informacijskem sistemu, v katerem poteka proces upravljanja z incidenti. Priporočila ITIL so svetovni »de facto« standard in so najširši model zagotavljanja kakovosti IT storitev, ki temeljijo na uporabi informacijske tehnologije in izvirajo iz t.i. najboljših praks (best practices) upravljanja s storitvami. Priporočila so sestavljena iz celovite zbirke dokumentov z opisi in napotki za uvajanje in kakovostno upravljanje s storitvami. Upravljanje z incidenti je del zbirke dokumentov o storitvah podpore. Upoštevanje priporočil je okvir, ki opredeljuje način pristopa k organizaciji sistema za upravljanje z incidenti in je zelo zanesljiv pogoj kvalitete sistema. Kakovost informacijskega sistema je odločilnega pomena za določanje uporabnikovega odnosa do sistema. V primeru, da uporabnik ne doživlja kakovost informacijskega sistema v pričakovanem obsegu in obliki, ga bo uporabljal z manjšo učinkovitostjo oziroma ga v skrajnem negativnem primeru sploh ne bo. Stabilno in neprekinjeno delovanje sistema je eden pomembnejših kriterijev za ocenjevanje delovanja informacijskega sistema, tako s strani uporabnika kot tudi za poslovodstvo. Prav tu pa pride do izraza kvaliteta procesa upravljanja z incidenti v informacijskim sistemu, ki v primeru kvalitetnega delovanju povečuje ali dopolnjuje kvaliteto obstoječega informacijskega sistema z učinkovitim saniranjem napak, ki so vzrok za nestabilnost ali nedelovanje sistema. Z logičnim sklepanjem lahko ugotovimo, da je lahko kvaliteten proces upravljanja z incidenti v informacijskih sistemih le tisti, ki zagotovi enako ali boljšo kakovostno raven delovanja informacijskega sistema, kot je opredeljena v tehničnih in drugih specifikacijah. Doseženo kakovost procesa upravljanja z incidenti v informacijskem sistemu je potrebno nepretrgoma vzdrževati in izboljševati. Pri tem je

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 91
potrebno imeti v ospredju dejstvi, da je proces upravljanja z incidenti v osnovi storitev, ki je namenjena uporabnikom, in to, da je za oceno kakovosti zelo pomembno, kako uporabniki doživljajo kakovost procesa. Ne glede na učinkovitost, storilnost in uspešnost delovanja tehničnega osebja, ki sodelujejo v procesu, sam proces ne more biti kakovosten, če ga uporabniki kot takšnega ne doživljajo. Pomembno je kvaliteto procesa neprekinjeno preverjati tudi preko zadovoljstva uporabnikov informacijskih sistemov. V primeru razkoraka med pričakovano in zaznavno kakovostjo je potrebno nemudoma ukrepati in razkorak zmanjšati. Vsak sistem je občutljiv na entropijo oziroma s časom postane neurejen, zato je spremljanje kvalitete procesa upravljanja z incidenti v informacijskem sistemu nuja. S stalnim in neprekinjenim spremljanjem kazalcev kvalitete procesa je možno ugotavljati odstopanja v kvaliteti in izvajati ustrezne korektivne ukrepe. Kazalci kvalitete morajo biti jasni in merljivi, ker se bo lahko le tako hitro in učinkovito ugotovilo nedvoumno stanje procesa in pristopilo k sanaciji vzrokov za padec kvalitete ali za odkrivanje dejavnikov za dvig kvalitete. Priporočila ITIL ne opredeljujejo vse podrobnosti pri organizaciji sistema upravljanja z incidenti. Tako ostane odprto vprašanje, katere zmogljivosti moramo razvijati sami in katere moramo prepustiti zunanjemu izvajalcu. Za velike organizacije je smiselno imeti vsaj tri nivoje podpore uporabnikom storitev IT, organiziranih v lastni režiji. Pri tem je v organizaciji z velikim številom enot, ki so geografsko razpršene, potrebno izbrati obliko organiziranosti II. nivoja podpore. Izbiri sta dve. Prva je organiziranost po teritorialnem principu, ko ekipa IT strokovnjakov podpira vse uporabnike storitev, ki gravitirajo k določenem kraju ali pa organizacijsko linijski strukturi, ko je ekipa IT strokovnjakov organizirana po organizacijskih enotah in skrbi le za uporabnike storitev IT iz lastne enote. Organiziranost po teritorialnem principu zahteva manjše število oseb za zagotavljanje enake kakovosti delovanja sistema upravljanja z incidenti v IS. Istočasna organiziranost po teritorialnem principu omogoča boljše strokovno vodenje in nadzor ter boljši strokovni razvoj zaposlenih IT strokovnjakov. Iz teh razlogov je organiziranost upravljanja z incidenti po teritorialnem principu boljša od organiziranosti po organizacijsko linijski strukturi. S tem je teza iz uvodnega dela naloge potrjena.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 92
6 LITERATURA IN VIRI
Knjige:
Rudd, C. (2006), An Introductory Overview of ITIL, itSMF Ltd., Wokingham.
Čerić, V. (993), Simulacijsko modeliranje, Školska knjiga, Zagreb.
Egan, M. (2005), Varovanje informacij – grožnje izzivi in rešitve, Pasadena, Ljubljana 2005.
Hammer, M. in Champy, J. (1995), Preurejanje podjetja, Gospodarski Vestnik, Ljubljana.
Kljajić, M. (2002), Teorija sistemov, Moderna organizacija, Kranj 2002.
Marolt, J. in Gomišček, B. (2005), Management kakovosti, Moderna organizacija, Kranj.
Kokol, P., Hleb Babič, Š., Podgorelec, V. Zorman, M. (2001), Inteligentni sistemi, FERI, Maribor.
Pivka, M. (1996), Kakovost v programskem inženirstvu, DESK, Izola.
Vila, A. (1994), Organizacija in organiziranje, Moderna organizacija, Kranj.
Svete, U. (2005), Varnost informacijske družbe, FDV, Ljubljana.
Članki v reviji:
Ban, J., Prestrukturirati IT oddelek, a kako?, Sistem (str.14-16), Ljubljana 2006.
Florjančič, J., Bernik, M., Bernik, I., Planiranje kadrov, Organizacija in management (str. 11-34), Kranj 2002;
Oražen, B., ITIL in storitveno naravnana organizacijska struktura, INFOSRC, št. 43 (str. 11-13), Ljubljana 2005;
Karlin, P., Upravljanje IT infrastrukture - ITIL in MOF, Uporabna informatika št.4 (str. 200-206), Ljubljana 2003.
Krajnc, T., ITIL - upravljanje IT storitev, Organizacija št.6 (str. 302-308), Kranj 2005;

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 93
Poročila, interni dokumenti:
MORS (1996), Pravilnik o varovanju in zaščiti IS MORS, MORS, Ljubljana1996.
qSTC (2006), Osnove ITIL upravljanja storitev IT : učbenik - slovenska verzija 7.2, qSTC d.o.o., Ljubljana 2006.
OGC (2003), Service support : version 2.0 (Elektronski Vir), The Stationery Office : Office of Government Commerce, cop. London 2003.
Urad RS za standardizacijo in meroslovje (1997), Slovenski standard, SIST EN ISO 8402, Vodenje in zagotavljanje kakovosti, Urad Republike Slovenije za standardizacijo in meroslovje, Ljubljana 1997.
Kolarič, S. (2006), Prednosti uvajanja priporočil ITIL pri upravljanju z incidenti v KIS SV, zaključna naloga, Poljče 2006.
GŠSV (,2006), Projektna dokumentacija skupine za uvajanje ITIL, GŠSV 2006.
Spletne strani:
Urad vlade za varovanje tajnih podatkov, Informacijska varnost.
http://www.uvtp.gov.si/index.php?id=694, 2.12.2006.

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 94
KAZALO SLIK
Slika 1: Štirje P-ji ......................................................................................................8
Slika 2: Okvir zbirke ITIL (Rudd, 2006) ..................................................................9
Slika 3: Rezultati in posredniki procesov po priporočilih ITIL (qSTC, 2006)...10
Slika 4: Procesi zagotavljanja storitev (Rudd, 2006).......................................12
Slika 5: Procesi podpore storitvam (Rudd, 2006)............................................14
Slika 6: Glavni posredniki upravljanja infrastrukture IKT (Rudd, 2006)..........16
Slika 7: Model infrastrukture IKT (Rudd, 2006)..................................................17
Slika 8: Načrtovanje implementacije upravljanja storitev (Rudd, 2006) ...18
Slika 9: Življenjski cikel aplikacije (Rudd, 2006)................................................19
Slika 10: Poslovna perspektiva (Rudd, 2006)...................................................20
Slika 11: Model za varovanje informacij (Rudd, 2006) ..................................23
Slika 12: Proces upravljanja varovanja informacijske tehnologije (Rudd, 2006) .............................................................................................................24
Slika 13: Procesi upravljanja z incidenti (OGC,2003) .....................................25
Slika 14: Življenjski ciklus incidenta (OGC, 2003).............................................27
Slika 15: Prvi, drugi in tretji nivo podpore (OGC, 2003) .................................29
Slika 16: Vrste eskalacij incidenta (qSTC, 2006)..............................................30
Slika 17: Relacije med incidenti, problemi, znanimi napakami in RFC (OGC, 2003).................................................................................................31
Slika 18: Vodenje procesa reševanja incidenta do začasne in dokončne rešitve (OGC, 2003) ....................................................................................32
Slika 19: Proces raziskovanja in diagnostike vzrokov za incidenta (OGC, 2003) .............................................................................................................41
Slika 20: Procesna organiziranost IT oddelka za upravljanje z incidenti .....58
Slika 21: Model teritorialne organiziranosti lokalne podpore .......................60
Slika 22: Model organiziranosti lokalne podpore po organizacijsko linijskem principu ........................................................................................................61
Slika 23: Shema uravnovešenih stroškov sistema (prirejeno po Marolt, Gomišček, 2005)..........................................................................................63
Slika 24: Shema procesa sistemske simulacije (Kljajić, 2002)........................65
Slika 25: Metodologija sistemske simulacije (Kljajić, 2002) ............................66
Slika 26: GPSS blokovni diagram za nastajanje incidentov in sprejeme klicev uporabnikov v SC ............................................................................68
Slika 27: GPSS blokovni diagram za izvajanje drugega nivoja podpore ...69
Slika 28: GPSS blokovni diagram za izvajanje podpore na tretjem nivoju .70
Slika 29: GPSS blokovni diagram za kontrolo delovanja...............................71
Slika 30: GPSS blokovni diagram za izvajanje podpore na tretjem nivoju .71
Slika 31: GPSS blokovni diagram za izvajanje drugega nivoja podpore v modelu organiziranosti po linijsko organizacijski strukturi ......................74
Slika 32: Shema metodologije validacije modela (Kljajić, 2002) .................79

Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 95
KAZALO TABEL
Tabela 1: Pregled števila uporabnikov po lokacijah in enotah .............48 Tabela 2: Pregled števila nastalih incidentov po lokacijah in enotah ..50 Tabela 3: Pregled števila nastalih incidentov po dnevu v tednu ..........50 Tabela 4: Pregled števila nastalih incidentov po uri v teku dneva........51 Tabela 5: Pregled vrste nastalih incidentov ..............................................52 Tabela 6: Pregled števila zaključenih incidentov po nivojih podpore ..55 Tabela 7: Pregled povprečnega časa reševanja incidentov na
posameznem nivoju podpore .............................................................56 Tabela 8: Pregled povprečnega časa reševanja posameznih vrst
incidentov ...............................................................................................57 Tabela 9: Rezultati modela organiziranosti po teritorialnem principu...81 Tabela 10: Rezultati modela organiziranosti po organizacijsko linijski
strukturi (minimalna varianta)...............................................................82 Tabela 11: Rezultati modela organiziranosti po organizacijsko linijski
strukturi (optimalna varianta)...............................................................83 Tabela 12: Rezultati modela organiziranosti po organizacijsko linijski
strukturi (idealna varianta)....................................................................84 Tabela 13: Rezultati modela organiziranosti po teritorialnem principu.84 Tabela 14: Primerjava števila zaposlenih med modeloma.....................85 Tabela 15: Primerjava prednosti in slabosti med modeloma.................86
Univerza v Mariboru – Fakulteta za logistiko Magistrsko delo
Franc Šrok: Upravljanje z incidenti v informacijskih sistemih javne uprave stran 96
KRATICE IN AKRONIMI
BIA: Business impact analysis: Analiza vpliva na poslovanje BRM: Business relationship management: Upravljanje odnosov s
poslovanjem CI: Configuration item: Konfiguracijski elementi CMDB: Configuration management database: Podatkovna zbirka
upravljanja konfiguracij CSF: Critical success factor: Kritični dejavniki uspeha CSIP: Continues service improvement program: Program nenehnega
izboljševanja storitev DHS: Definitive hardware store: Shramba veljavne strojne opreme DSL: Definitive software library: Knjižnica veljavne programske opreme FMITS: Financial management for IT services: Finančno upravljanje za
storitve IT FSC: Forward schedule of change: Časovni razpored sprememb ICT IM: Information communication technology infrastructure
management: Upravljanje infrastrukture IKT ICTO: Information communication technology operations: Delovanje IKT ICTSG: Information communication technology steering group:
Usmerjevalna skupina IKT IKT: Informacijsko komunikacijska tehnologija (ICT) IM: Incident management: Upravljanje incidentov IMP: Incident management process: Procesa upravljanja z incidenti IS: Information system: Informacijski sistem ISM: Information security management: Upravljanje informacijske
varnosti IT: Information technology: Informacijska tehnologija ITIL: IT infrastructure library: Knjižnica IT ITSCM: IT Service continuity management: Upravljanje neprekinjenosti
delovanja storitev IT ITSM: IT service management: Upravljanje storitev IT itSMF: IT service management forum: Forum o upravljanju storitev IT KPI: Key Performance Indicator: Ključni pokazatelji delovanja OGC: Office of government commerce: Urad za trgovino OLA: Operation leave agreement: Raven operativne podpore PISM: Planning to implement service sanagement: Načrtovanje
implementacije upravljanja storitev RCM: Resource capacity management: Upravljanje kapacitet virov RFC: Request for change: Zahtevek za spremembe SAM: Software asset management: Sredstva programske opreme SCM: Service capacity management: Upravljanje kapacitet storitev SRM: Supplier Relationship Management: Upravljanje odnosov z
dobavitelji





























