
• 海量存储空间
• 高效的数据访问:高并发、低延迟
• 高可扩展性
• 高可用性:7x24
• 安全性和可靠性
• 功能和接口丰富、简单易用
• 有效应对系统(数据、模式、环境)变更和升级
• 易维护:管理便捷,自动化程度高
• 控制成本
互联网应用的数据存储需求

•设计目标:
为博客、相册、邮箱、网盘、IM等各类大型互联网应
用提供一种通用的用户数据存储和管理解决方案。
•实现方案:分布式数据库+分布式文件系统
–分布式数据库(DDB):基于关系数据库集群解决结构
化数据的海量存储和高效访问。
–分布式文件系统(DFS):以文件为存储单位的非结构化
数据分布式存储解决方案。
网易海量数据存储平台简介

• 基于Sharding的Scale Out。
• 多平台和多语言环境下的通用SQL访问接口。
• 支持常用的RDBMS功能:
–DDL:支持大多数语句,union和嵌套查询除外
–DML:表、视图、存储过程、触发器等
–用户管理和权限控制
–全局ID分配
• 事务支持:节点内、跨节点、跨DDB。
• 支持MySQL和Oracle混合使用。
• 命令行和图形化管理工具。
DDB的功能特点
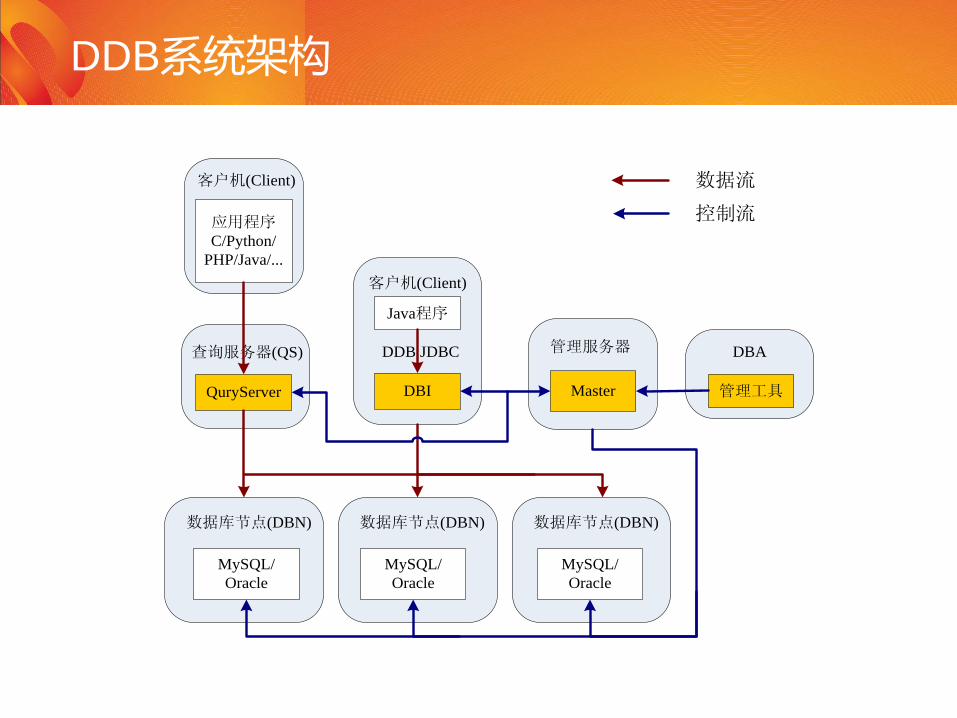
DDB系统架构
管理服务器
Master
DBA
管理工具
客户机(Client)
Java程序
DBI
查询服务器(QS) DDB JDBC
QuryServer
客户机(Client)
应用程序C/Python/
PHP/Java/...
数据库节点(DBN)
MySQL/
Oracle
数据库节点(DBN)
MySQL/
Oracle
数据库节点(DBN)
MySQL/
Oracle
控制流
数据流
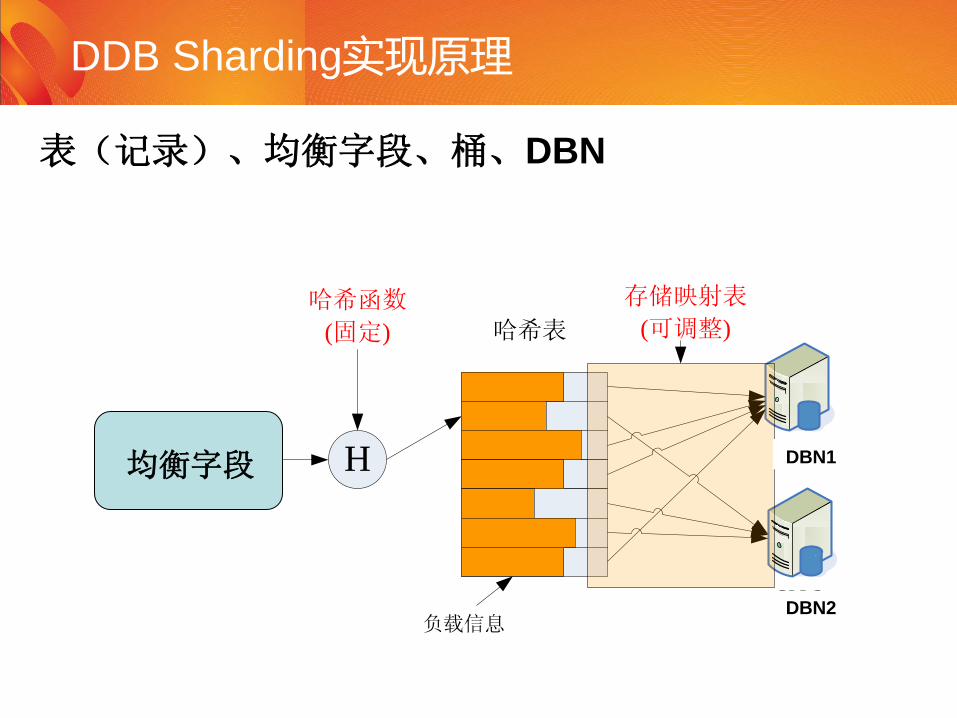
DDB Sharding实现原理
逻辑ID H SN 1
SN 2
哈希函数
(固定) 哈希表
存储映射表
(可调整)
负载信息
DBN1
DBN2
表(记录)、均衡字段、桶、DBN
均衡字段

•优化访问性能
•安全性问题
•监控和故障处理
•系统更新和升级
•系统扩容
需要解决的问题

• 去中心化,Client通过DBI直接访问DBN
• DBI Cache
–Meta Data Cache
–DBN Connection Pool
–DBN PreparedStatement Cache
–SQL Syntax Tree Cache
• 优化排序操作:Merge Sort优先
• 支持游标
• 基于Master-Slave的读写分离和读负载均衡
DDB访问性能优化——系统设计优化

• 优化索引和SQL
• 尽量使用绑定变量(PreparedStatement)
• 尽量控制事务范围和执行时间
• 避免limit或offset值过大
• 获取大结果集时使用游标
• 为表选择合适的均衡策略(均衡字段、均衡函数、桶到
DBN的映射)
• 查询条件中尽量使用均衡字段等值条件
• 开销大的查询在Slave节点执行
DDB访问性能优化——开发DBA

• SQL Explain:分析DDB SQL执行计划
• SQL执行统计
–计算SQL签名:select * from T where a=? And b=#
–DDB SQL统计:tables, dbns, clients, count,time, avg_time,
mysql_count, mysql_time, dbn_count, rows
–MySQL SQL统计:handler_read_first, handler_read_key,
hander_read_next, handler_read_rnd, hander_read_next, explain
• DBI资源状态监视
–DBN连接池状态,占用连接的线程堆栈
–资源对象:Connection/Statement/PreparedStatement
访问异常排除和性能优化——工具支持

• 访问认证
–用户名、口令认证和IP地址检查
–DDB认证+DBN(RDBMS)认证
• 权限管理
–区分普通用户和管理员用户
–权限控制粒度:用户对表的读、写和授权
–用户访问配额控制
–管理员权限细分:Schema配置、维护、监控统计、用户管理
–管理员操作日志
• 其他:
–口令加密传输和保存
–只允许内网访问
DDB系统安全

• DBN状态监视:By Master
–心跳监视和报警,故障时切换到Standby Node。
–Session自动监视、统计和报警
–Slow Log自动监视、统计和报警
–复制延迟和异常自动监视和报警
• Query Server监视:By Master
–心跳监视和报警,动态调整和广播可用的QueryServer列表。
–负载监视,动态调整和广播可用的QueryServer访问权值。
• Master监视:By Monitor or Zookeeper
–采用主从模式,故障时自动切换
–Meta Data复制
DDB状态监视和故障处理

• 系统变更:
产品升级、硬件升级、系统软件升级、DDB版本升级
• 技术挑战:
降低影响、避免误操作、时间可控、自动化、可回退
• 应对策略
–硬件和系统软件升级:主备切换,逐步替换
–测试环境 -> 线上环境:正确性验证和实施时间评估
–管理操作支持命令行方式执行,降低重复操作中的误操作
–计划任务:支持多任务、多模式、异常处理、详细日志和执行结果通知
–数据备份:Mirror + backup(snapshot) + Binlog
– DDB版本升级:Master和DBI升级,通信协议向下兼容
应对系统变更和升级
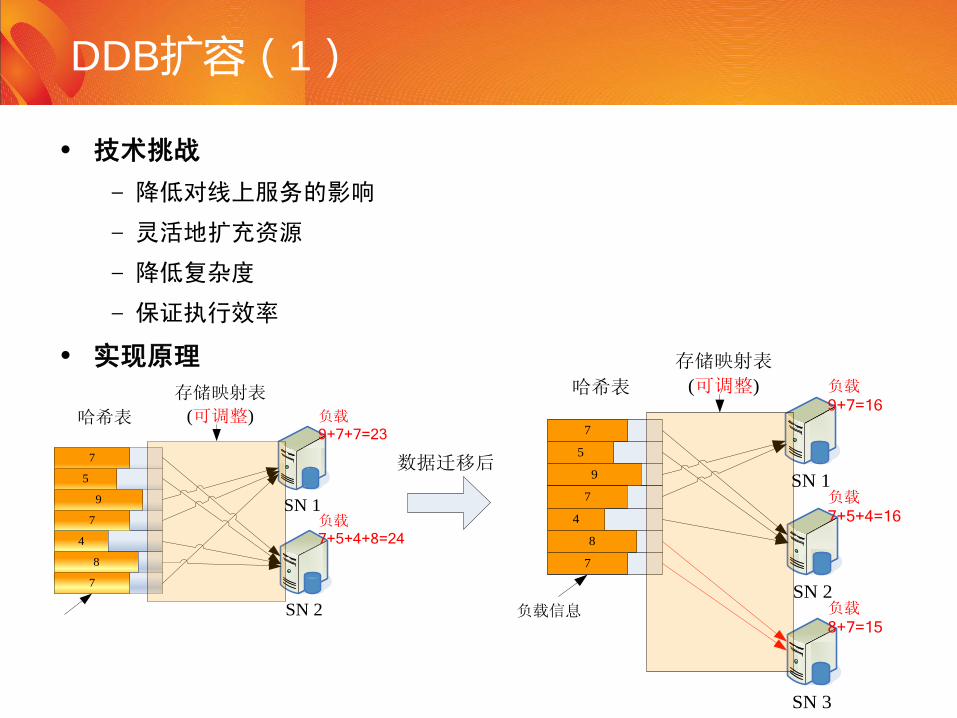
• 技术挑战
–降低对线上服务的影响
–灵活地扩充资源
–降低复杂度
–保证执行效率
• 实现原理
DDB扩容(1)
SN 1
SN 2
哈希表
存储映射表
(可调整)
7
5
9
7
4
8
7
负载9+7+7=23
负载7+5+4+8=24
SN 3
SN 1
SN 2
哈希表
存储映射表
(可调整)
7
5
9
7
4
8
7
负载信息
负载9+7=16
负载7+5+4=16
负载8+7=15
数据迁移后

实现方案
• 方案一:DBN间数据导出导入
–优点:迁移效率较好,实现较简单,灵活性好
–缺点:停服时间长,容易导致数据不一致,删除数据的负面影响
• 方案二:基于事务的批量数据迁移
–优点:不用停服,应用透明,灵活性好
–缺点:实现复杂,迁移效率低,对线上访问有一定影响。
• 方案三:基于复制的数据扩容
–优点:对应用透明,不需停服,效率高,对线上访问基本无影响。
–缺点:操作较为复杂,只能实现成倍扩容,灵活性较差。
DDB扩容(2)

• 面向海量的非结构化用户数据存取
• 支持大量的高并发数据操作
• 支持动态扩展,存储量和处理能力线性增加。
• 高可靠性,避免数据丢失和单点故障
• 负载均衡,可控性好
• 存储成本可控
DFS的设计目标

• 数据访问去中心化
– 文件读取和写入不经过中心节点,提高访问效率
– 通过ID(64bit)标识和定位文件
– 文件元信息:不支持目录、文件名、权限信息,支持SIZE,UpdateTime,MD5。
• 访问接口:
– 不支持POSIX文件接口
– 面向Java/C++的API:read,insert,delete,append,update等
– HTTP文件读取接口
• 支持多副本
• 支持数据在集群中复制和迁移
• 支持文件级别的数据去重
• 定制硬件降低成本
DFS的功能特点
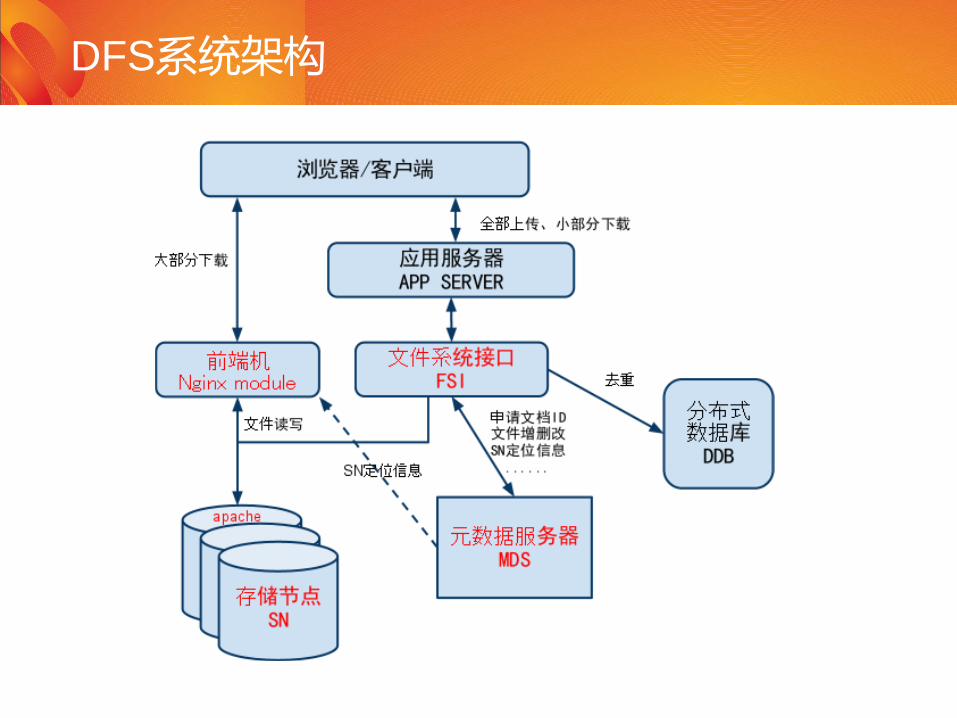
DFS系统架构
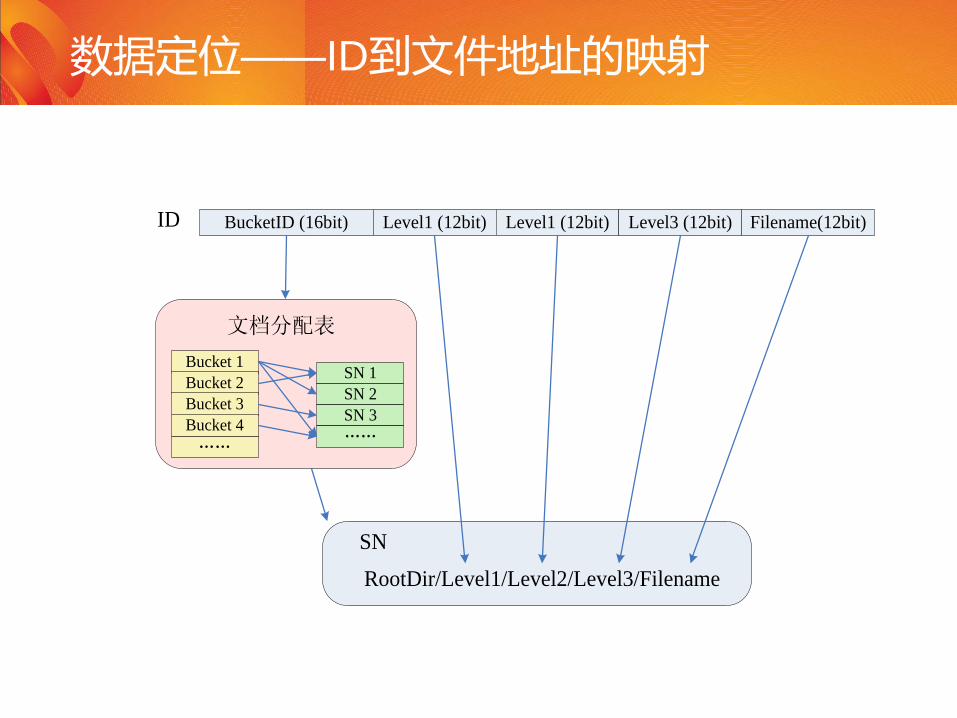
数据定位——ID到文件地址的映射
BucketID (16bit) Level1 (12bit) Level1 (12bit) Level3 (12bit) Filename(12bit)
Bucket 1
Bucket 2
Bucket 3
Bucket 4
……
SN 1
SN 2
SN 3
……
文档分配表
SN
RootDir/Level1/Level2/Level3/Filename
ID

• 以Bucket为单位进行配置和管理
• 将Bucket映射到不同SN的不同磁盘上
• FSI负责多副本的同步写
• FSI和前端机随机挑选副本读取数据
• SN故障处理:
1.MDS检查到SN心跳失效
2.MDS通知所有FSI和前端机停止对故障SN的访问
3.MDS通知其他副本所在SN将桶数据复制到空闲SN上
4.MDS修改数据映射表
多副本管理

• 应用场景:
–SN异常恢复,恢复或增加副本
–SN系统软硬件更换或升级,服务器搬迁
–跨数据中心数据灾备
–均衡负载
• 实现策略:
–以桶为单位进行复制和迁移。
–源SN上记录操作日志
–将源SN上的桶数据拷贝到目标SN后通过redo操作日志来保证源
和目标SN的同步。
–完成最后的数据同步瞬间源SN设为只读。
数据复制和迁移

• 定制存储服务器
–配备桌面级SATA硬盘 24x2T
–电源管理功管理磁盘上下电状态
• DFS对定制服务器的支持
–通过多副本减少磁盘故障的影响。
–控制SN的读写。
–对只读或只有少量写操作的多副本磁盘组轮流上下电,通过定期
Redo操作日志保证数据一致。
• 带来的好处:
–降低硬件采购的成本
–降低功耗
–延长磁盘寿命
DFS定制存储服务器

• DDB在保持了RDBMS的特性和功能的基础上支持高吞吐、
高可用、高扩展,适合传统的基于RDBMS的应用开发。
• DFS在DDB的基础上提供大对象存储,提供了更好的扩展性
。
• DDB弥补了DFS在元数据管理方面的不足。
• DDB与DFS的结合可以满足大多数互联网应用的快速开发要
求。
• 基于廉价服务器的分布式解决方案降低了存储系统的成本。
• 功能强大的管理工具弥补分布式集群带来的管理复杂性。
总结

• 使用平台的产品
– 网易博客
– 网易微博
– 网易相册
– 网易企业邮箱
– 邮箱网盘和超大附件
– 网易POPO(即时通信)
– 社区类游戏
• DDB存储节点数量 400+
• DDB总数据量 60TB
• DFS存储节点数量 1200+
• DFS总数据量 4PB
存储平台应用情况

感谢您的关注!
Q&A
Recommended


















