
Informatik I
Informatik I
Unterlagen zur Vorlesung
Stand: WS 07/08
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik
Informatik I
Gliederung
1 – Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 – Theorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
1 – Mengen . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2 – Halbgruppen, Monoide, Worter . . . . . . . . . . . . . 33
3 – Relationen und Graphen . . . . . . . . . . . . . . . . 38
4 – Halbordnungen, Verbande . . . . . . . . . . . . . . . 62
5 – Aussagenlogik . . . . . . . . . . . . . . . . . . . . . . 70
6 – Formale Systeme . . . . . . . . . . . . . . . . . . . .103
7 – Grammatiken und Automaten . . . . . . . . . . . . . .118
8 – Aufwand von Algorithmen . . . . . . . . . . . . . . . .163
3 – Programmierung . . . . . . . . . . . . . . . . . . . . . . .178
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik
Informatik I
1 – Elementare Datentypen . . . . . . . . . . . . . . . . .179
2 – Funktionen . . . . . . . . . . . . . . . . . . . . . . . .183
3 – Pradikate und bedingte Ausducke . . . . . . . . . . .200
4 – Rekursion . . . . . . . . . . . . . . . . . . . . . . . .204
5 – Elementare Listenoperationen . . . . . . . . . . . . .216
6 – Iteration . . . . . . . . . . . . . . . . . . . . . . . . . .227
7 – Lokale Variable und Konstanten . . . . . . . . . . . .242
8 – Fu. als Argumente und Werte; reine Funktionen . . .244
9 – Operationen mit Listen . . . . . . . . . . . . . . . . .262
10 – Muster . . . . . . . . . . . . . . . . . . . . . . . . . .289
11 – Objekte mit Zustanden . . . . . . . . . . . . . . . . .306
4 – Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . .319
1 – Datenabstraktion . . . . . . . . . . . . . . . . . . . . .320
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik
Informatik I
2 – Binarbaume: Suche . . . . . . . . . . . . . . . . . . .331
3 – Binarbaume: Arithmetische Ausdrucke . . . . . . . .342
4 – Binarbaume: Huffman-Code . . . . . . . . . . . . . .346
5 – Heaps, Heap-Sort . . . . . . . . . . . . . . . . . . . .369
5 – Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . .381
1 – Tiefen- und Breitensuche (Backtracking) . . . . . . .382
2 – Binare Suche . . . . . . . . . . . . . . . . . . . . . . .401
3 – Sortieren . . . . . . . . . . . . . . . . . . . . . . . . .405
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik
Informatik I 1 Einfuhrung
1 – Einfuhrung
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 4
Informatik I 1 Einfuhrung
Motivation
Maschinen (Computer) verarbeiten heutzutage alle moglichen Datenund Informationen. Sie
• simulieren Crash-Tests,
• steuern Flugzeuge,
• verwalten Unternehmensdaten,
• schauen in den menschlichen Korper,
• usw.
Was bedeutet Daten- und Informationsverarbeitung?
Der Computer versteht keine naturliche Sprache.Was bedeutet es einen Computer zu programmieren?
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 5
Informatik I 1 Einfuhrung
Signale, Datum, Information
Physik, Elektro-, Nachrichtentechnik:Kontinuierliche Welt: Sensoren → Signale → Nachrichten
Informatik:Diskrete Welt: Nachrichten → Interpretation → Information
Die Bedeutung einer Nachricht hangt vom jeweiligen Kontext ab. Auchund besonders die Interpretation von Nachrichten in unserer naturlichenSprache ist sehr kontextabhangig.
Ich sah den Stern mit dem Fernglas.Ich sah den Polizisten mit der Pistole.
Daten = Nachrichten und zugehoriger Kontext.
Beispiel. Nachricht x2: Zeichen x mit oberen Index 2, Polynom mitder Unbekannten x, Vorschrift “Quadriere x”, das Quadrat von x.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 6
Informatik I 1 Einfuhrung
Wissen
• Deklaratives Wissen: Information gegebener Daten (“Was istder Fall”).
• Prozedurales Wissen: Vermogen der Interpretation gegebenerDaten (“Wie geht etwas”).
Datenstrukturen dienen zur Darstellung von Wissen. Informations-verarbeitung verknupft Daten, um neue Informationen zu gewinnen(z.B. Filterung, Pradiktion).
Informatik ist die Wissenschaft
– der Modellierung,
– der Analyse,
– des Entwurfs, und
– der Realisierung
von Systemen zur Informationsverarbeitung.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 7

Informatik I 1 Einfuhrung
Wirklichkeit und Modelle
Wirklichkeit:
– Dinge
– Personen
– Beziehungen (Relationen)zwischen Dingen und zwi-schen Personen (Fakten)
– Veranderungen mit derZeit.
Modell:
– Begriffe von Dingen
– Begriffe von Personen
– Formale Beziehungen zwi-schen Begriffen (moglicheSachverhalte)
– Veranderungen mit der(fiktiven) Zeit.
Informationsverarbeitung dient der Konstruktion von Modellen, um Aus-sagen uber die Wirklichkeit machen zu konnen.
Modellierung ist eine zentrale Aufgabe der Informatik.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 8
Informatik I 1 Einfuhrung
Systeme
Systeme sind Mengen von Dingen oder Personen (Systemkompo-nenten ), zusammen mit Beziehungen zwischen diesen Objekten.
Die Systemkomponenten und deren Beziehungen fur einen festenZeitpunkt nennt man Zustand . Die Veranderung des Systemzustandsmit der Zeit machen das Systemverhalten aus.
Jedes System ist in eine Umgebung eingebettet. Die Grenze zur Um-gebung heißt Schnittstelle . Sie definiert den Nachrichtenaustauschund Beziehungen mit der Umgebung.
Systemkomponenten konnen selbst Systeme sein. Man spricht voneinem schwarzen Kasten (black box ), wenn Details des innerenAufbaus und der Struktur einer Systemkomponente fur das Verstandnisdes Gesamtsystems unwesentlich sind, also nur der Zustand des Teil-systems relevant ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 9
Informatik I 1 Einfuhrung
Systeme (Forts.)
Systeme konnen diskret, kontinuierlich, statisch, dynamisch, determi-nistisch und indeterministisch sein. Auch Mischformen treten haufigauf.
Reaktive Systeme verarbeiten kontinuierlich Daten der Umgebung,gewinnen Informationen, und beeinflussen die Umwelt durch eigeneAktionen (Beispiele: Regelung eines Prozesses, autonomer Roboter).
Man spricht von eingebetteten Systemen , wenn das informations-verarbeitende System Komponente eines umfassenderen Systemsist, dessen Teilkomponenten nicht der Datenverarbeitung dienen (Bei-spiel: Sensordatenverarbeitung im Auto).
Adaptive Systeme sind in der Lage, sich Veranderungen der Um-gebung anzupassen, insbesondere solchen, die es selbst bewirkt hat(lernende Systeme ).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 10
Informatik I 1 Einfuhrung
Validierung und Verifikation
Unter Validierung versteht man die Uberprufung des “Wahrheitsge-haltes” eines Modells, indem man einen Prototyp des entworfenenSystems implementiert und das Systemverhalten in der Wirklichkeittestet. Diese Prufung kann nicht vollstandig sein.
Validierung heißt Verifikation , wenn das Systemverhalten anhand ei-ner Spezifikation uberpruft wird, d.h. einer hinreichend formalen Be-schreibung der geforderten Systemleistung. Diese Uberprufung er-folgt dann ebenfalls mit formalen Methoden, d.h. man strebt an zubeweisen, dass das Systemverhalten der Spezifikation genugt.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 11

Informatik I 1 Einfuhrung
Algorithmen
Die elementarste Aufgabe eines informationsverarbeitenden Systemsist die Realisierung einer Funktion f : A→ B, das heißt fur zulassigeEingaben a aus einer Menge A das zugehorige Ergebnis b = f(a)
zu ermitteln. Jedes komplexere Systemverhalten baut auf Funktionenauf.
Der Computer ermittelt das Ergebnis schrittweise, so wie wir bei-spielsweise eine Bedienungsanleitung fur irgendein Gerat befolgen.Diese Anleitung, hinreichend prazise in einer fur den Computer ver-standlichen Programmiersprache als Programm formuliert, nenntman Algorithmus .
Bezuglich des Ablauf eines Algorithmus unterscheidet man:
• Sequentielle Ausfuhrung: Teilschritte hangen voneinander ab,z.B. durch Weiterverwendung von Teilergebnissen.
• Parallele Ausfuhrung: Teilschritte hangen nicht voneinander ab.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 12
Informatik I 1 Einfuhrung
• Bedingte Ausfuhrung: Der Ablauf wird durch eine Bedingunggesteuert: Ist sie erfullt, dann fuhre den Teilschritt aus. Optionalkann als Alternative ein anderer Teilschritt ausgefuhrt werden.
• Ausfuhrung in einer Schleife: Solange eine Bedingung nichterfullt ist, fuhre einen Teilschritt aus. Oder: Fuhre einen Teilschrittaus, bis eine Bedingung erfullt ist.
• Ausfuhrung eines Unterprogramms: Fuhre einen Teilschritt, der– weil er oft benotigt wird – woanders separat beschrieben ist,aus, und verwende das Ergebnis weiter.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 13
Informatik I 1 Einfuhrung
Programmiersprachen
Man unterscheidet folgende Programmiersprachen zum Formulie-ren eines Algorithmus als Programm:
Funktionale Programmiersprachen formulieren Funktionsdefinitio-nen. Konkrete Eingabewerte werden in die Definition an den ent-sprechenden Stellen eingesetzt (substituiert). Anschließend wirdder resultierende Ausdruck zur Berechnung des Ergebnisses aus-gewertet.
Funktionen konnen andere Funktionen “aufrufen”, d.h. uber diesedefiniert sein.
Gemaß der Eindeutigkeit des Ergebnisses einer Funktion sprichtman von Verarbeitung ohne Nebenwirkungen .
Deklarative oder logische Programmiersprachen formulieren Fak-tenwissen uber Pradikate (vgl. Logeleien in Zeitschriften) und prufen,ob ein bestimmtes Pradikat fur eine vorliegende Eingabe richtigist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 14
Informatik I 1 Einfuhrung
• Imperative und objektorientierte Programmiersprachen bilden– analog zu einem System als Modell der Wirklichkeit – Datenob-jekte, deren Zustande durch Anweisungen verandert werden. An-ders als funktionalen Sprachen verursacht die Programmausfuhrunghier Nebenwirkungen oder Seiteneffekte .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 15
Informatik I 1 Einfuhrung
von-Neumann Rechner
Algorithmen werden auf Rechnern implementiert (realisiert). Die gangigevon-Neumann Rechnerarchitektur besteht aus
• dem Rechnerkern oder Zentralprozessor , der das Programmausfuhrt,
• dem Arbeitsspeicher , der Programme und Daten enthalt,
• der Peripherie (Plattenspeicher, Tastatur, Maus, Bildschirm, Drucker,Scanner, etc., die uber Ein-/Ausgabeprozessoren mit dem Rech-nerkern und dem Arbeitsspeicher kommunizieren,
• Busse (Verbindungswege), die alle Rechnerkomponenten mit-einander verbinden und Befehle, Speicheradressen, Daten undSteuersignale ubertragen.
Die technischen Komponenten eines Rechners nennt man Hardware ,Programme und Dokumentationen nennt man Software .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 16
Informatik I 1 Einfuhrung
Anweisungen fur den Prozessor sind in einer primitiven Maschinen-sprache formuliert. Diese resultiert durch Ubersetzung des in der ei-gentlichen Programmiersprache formulierten Programms. Program-me, welche dies leisten, heißen Compiler .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 17
Informatik I 1 Einfuhrung
Abstraktionsebenen fur den Entwurf von Informatiksystem en
Problem
Spezifikation
Algorithmen
Programm
Maschine
Lösung
Validierung
Verifikation
Test
Ausführung
Übersetzung
Programmierung
Algorithmenentwurf
Problemanalyse
Programmieren erfordert kritische Kommunikation, analytisches Den-ken, kreative Entwurfe, Selbstdisziplin.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 18
Informatik I 1 Einfuhrung
Teilgebiete der Informatik
Theoretische InformatikAutomatentheorie und formale Sprachen, Berechenbarkeitstheo-rie, Komplexitatstheorie; Aussagen sind gultig und unabhangigvon einer Realisierung.
Praktische InformatikSoftwaretechnik, grundlegende Konzepte zur Losung konkreterAufgaben der Informationsverarbeitung (Betriebsysteme, Daten-banktechnologie, Ubersetzerbau, Rechnernetze, grundlegende Al-gorithmen, usw.)
Technische InformatikHardwaretechnische Grundlagen der Informatik (Mikroprozesso-ren, Speicherkomponenten, Bussysteme, Spezialrechnerbau), flie-ßender Ubergang zur Elektrotechnik (Schaltungstechnik).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 19

Informatik I 1 Einfuhrung
Teilgebiete der Informatik (Fortsetzung)
Angewandte InformatikAnwendung von Soft- und Hardwaretechnik sowie Entwurf spezi-eller Programmiersprachen und algorithmischer Verfahren in an-deren Wissenschaftszweigen: Mathematik, Physik, Chemie, Bio-logie, Umweltwissenschaften, Wirtschaftswissenschaften, Medi-zin, usw. (Bindestrich-Informatik).
Zahlreiche Wissenschaftsdisziplinen (Robotik, Sprachverarbeitung,Bildverarbeitung, Mustererkennung, Computergrafik, ...), deren Ak-tivitaten sich oft, aber nicht ausschließlich, der Informatik zuord-nen lassen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 20
Informatik I 1 Einfuhrung
Lernziel und Gliederung der Vorlesung
Lernziel:
Elementare Konzepte der Programmierung undAlgorithmik (“Programmieren im Kleinen”)
Die Vorlesung pendelt zwischen vier Themenbereichen hin und her(vgl. Link zur Vorlesung im Netz):
• Mathematische Grundlagen, Begriffe der Theorie
• Konzepte der Programmierung
• Abstrakte Datenstrukturen
• Algorithmen
Zu all diesen Themenbereichen gibt es vertiefende Vorlesungen (z.B. “Al-gorithmen und Datenstrukturen”).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 21
Informatik I 1 Einfuhrung
Das Lernziel ist Teil des umfassenderen Themengebietes
Software-Entwicklung und -Engineering:
• Definition der Anforderungen (Systemanalyse)
• Entwurf des Software-Systems (“Programmieren im Großen”)
• Programmieren der Software-Komponenten (“Programmierenim Kleinen”)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 22
Informatik I 1 Einfuhrung
Programmiersprachen
imperativ Fortran, Algol, Cobol, Pascal, C, Ada, Modula,
(Mathematica), ...
objektorientiert C++, Java, Smalltalk, Eiffel, Oberon,
(Mathematica), ...
funktional Lisp, Scheme, Miranda, Gofer, Haskell,
Mathematica, ...
deklarativ Prolog, (Mathematica)
Jede Programmiersprache unterstutzt bestimmte Konzepte der Pro-grammierung gut, und andere weniger gut.
Verschiedene Probleme erfordern die Anwendung verschiedener, pro-blemangepasster Programmierkonzepte.
⇒ Lernen von Programmierkonzepten ohne Einengung durch dasKorsett einer bestimmten Programmiersprache!
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 23

Informatik I 1 Einfuhrung
Programmiersprache dieser Vorlesung
Mathematica, und C++ in den Ubungen.
Eigenschaften:
• Wenig Ballast (Plattforabhangigkeit, Installationsproblem, aufwen-dig zu bedienende Programmierumgebung, ...).
• Unterstutzt die Einubung verschiedener Programmierstile.
• Sehr einfache Syntax.
• Enorme Funktionalitat, sehr gute Dokumentation.
Das Lernen einer konkreten Programmiersprache fallt leichter auf derBasis eingeubter Konzepte. Diesen Weg beschreiten Informatiker ihrganzes Berufsleben. Der umgekehrte Weg ist schwieriger.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 24
Informatik I 1 Einfuhrung
Mathematica
Kurze Beschreibung (RZ RWTH Aachen):
Mathematica, von Wolfram Research Inc., ist ein allgemeinesSystem fur numerische, symbolische und grafische Berech-nungen, eingesetzt sowohl als interaktives Berechnungstool,als Simulationswerkzeug und als Programmiersprache. Dienumerischen Fahigkeiten beinhalten beliebig genaue Fließ-kommaarithmetik und Matrizenmanipulation. Mathematica er-moglicht die vollstandige Entwicklung, Berechnung und Dar-stellung von technischen Problemstellungen in einer integrier-ten Umgebung, die sich außerst flexibel und zuverlassig demWissenschaftler gegenuber darstellt. Optimierung, Anpassungund Anderung sind aufgrund der voll-assoziativen Programm-struktur in Stunden statt in Tagen durchzufuhren.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 25
Informatik I 1 Einfuhrung
Mathematica
Kurze Beschreibung (Fortsetzung):
Neu ist die konsequente Integration von 64-Bit und MultiCore-Unterstutzung, JAVA, .Net, Web Services, DatabaseLink zurwebgestutzten Programmierung und Datenbankanbindung. Ma-thematica ist eine, “vom ersten Gedanken” bis zur Entwick-lung durchgehend integrierte Losung fur Problemstellungenmit technischen Berechnungen, 2D-und 3D-Visualisierung, Mo-dellierung und Simulation, bis hin zum Einsatz als Dynamisches-Geometrie-System. Aufgrund der vielfaltigen Einsatzmoglichkeitenwird Mathematica auch als das System fur Technical Compu-ting und Publishing bezeichnet.
Wir lernen Mathematica einigermaßen gut kennen – aber die Vorle-sung ist kein Mathematica-Kurs. Im Vordergrund steht die Vermittlungvon Programmierkonzepten und Algorithmen mit Mathematica.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 26
Informatik I 1 Einfuhrung
Literatur
• G. Goos, W. Zimmermann: Vorlesungen uber Informatik,Band 1 und 2, Springer, 2006.
• M. Felleisen, R.B. Findler, M. Flatt, S. Krishnamurthi:How to Design Programs, MIT Press, 2001.Neuauflage: http://www.htdp.org/2003-09-26/Book/086034898
• T.H. Cormen, C.E. Leiserson, R.L. Rivest:Introduction to Algorithms, MIT Press, 2000.
• U. Schoning: Theoretische Informatik – kurzgefaßt,Spektrum Akademischer Verlag, 2001.
• U. Schoning: Logik fur Informatiker,Spektrum Akademischer Verlag, 2000.
• M. Aigner: Diskrete Mathematik, Vieweg, 2006.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 27

Informatik I 1 Einfuhrung
Hinweise und Erwartungen meinerseits an Sie
• Die Vorkenntnisse der Horer sind sehr unterschiedlich.⇒ Nehmen Sie Rucksicht auf andere. Dinge, die Ihnen trivial
erscheinen, sind es fur viele andere nicht.
• Das Tempo der Vorlesung ist anfangs gemachlich, um alle Anfangermitzunehmen. Danach nimmt das Tempo zu.
• Fragen Sie rechtzeitig, aber nicht ohne vorher selbst nachgedachtzu haben.
• Uben Sie! Eine notwendige Voraussetzung fur das Lernen vonProgrammieren ist, dass man es tut.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 28
Informatik I 1 Einfuhrung
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 29
Informatik I 2 Theorie
2 – Theorie
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 29
Informatik I 2 Theorie
2.1 – Mengen
Elementare Notation
a ∈M a ist Element der Menge M .
a 6∈M a ist kein Element von M .
∅ leere Menge
|M | Anzahl der Elemente einer endlichen Menge M .
M = ... Definition einer Menge durch Angabe ihrer Elemente.
M =a∣∣ ...
Definition einer Menge durch die Eigenschaft ihrer
Elemente: M ist die Menge aller a fur die gilt ...
Beispiele Z Menge der ganzen Zahlen
N Menge der naturlichen Zahlen
N = 0, 1, 2, ...N =
z ∈ Z
∣∣ z ≥ 0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 30

Informatik I 2 Theorie
Mengenoperationen
M ∪N Vereinigung
M ∩N Schnittmenge
M ⊂ N Teilmenge
M ⊆ N echte Teilmenge
M \N =x∣∣ x ∈M und x 6∈ N
Differenz
M und N heißen disjunkt , wenn M ∩N = ∅.
Wenn U ⊆M , dann heißt M \ U Komplement von U bezuglich M .
Notation: U oder ∁U
Eine Aufteilung M = U1 ∪ U2 ∪ · · · ∪ Un =⋃n
i=1 Ui heißt Zerlegungoder Partition von M , wenn die Teilmengen Ui , i = 1, . . . , n, disjunktsind.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 31
Informatik I 2 Theorie
Die Menge aller Teilmengen einer Menge M heißt Potenzmenge .
Notation: 2M oder P(M)
Beispiel
2a,b,c =, a, b, c, a, b, a, c, b, c, a, b, c
Die MengeM ×N =
(x, y)
∣∣ x ∈M , y ∈ N
heißt das kartesische oder direkte Produkt der Mengen M und N .Ihre Elemente sind die geordneten Paare (x, y).
Die Elemente (x1, x2, . . . , xn) des Produktes mehrerer Mengen
M1 ×M2 × · · · ×Mn =n∏
i=1
Mi
heißen n-Tupel . Wir schreiben Mn =∏n
i=1 M und M0 = ∅.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 32
Informatik I 2 Theorie
2.2 – Halbgruppen, Monoide, W orter
In der Informatik spielen Zeichenreihen einen große Rolle. Dieser Ab-schnitt stellt notwendige Begriffe und Operationen bereit.
Eine nicht-leere Menge H zusammen mit einer assoziativen inne-ren Verknupfung heißt Halbgruppe (H, ). Die Verknupfung bildetzwei Elemente a, b ∈ H auf ein Element aus H ab:
H ∋ a, b → a b ∈ H .
Dabei gilt das Assoziativgesetz
(a b) c = a (b c) , fur alle a, b, c ∈ H .
Beispiele: (N, +), (N, ·), (P(M),∪), (P(M),∩).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 33
Informatik I 2 Theorie
U ⊆ H heißt Unterhalbgruppe , wenn U bezuglich der Operation algebraisch abgeschlossen ist:
u1 u2 ∈ U , falls u1, u2 ∈ U .
Fur Teilmengen U1, U2 ⊆ H definieren wir ein Produkt durch
U1 U2 =u1 u2
∣∣ u1 ∈ U1 , u2 ∈ U2
.
Mit diesem Produkt ausgestattet wird die Potenzmenge P(H) eineHalbgruppe
(P(H),
).
Ein Monoid ist eine Halbgruppe (H, ) zusammen mit einem neutra-len Element ε:
ε h = h , h ε = h , fur alle h ∈ H .
Beispiele: Die Halbgruppen (N, +), (N, ·), (P(M),∪), (P(M),∩)
und(P(H),
)sind Monoide mit neutralen Elementen 0, 1, ∅, M, ε.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 34

Informatik I 2 Theorie
Beispiel
Zwei Monoide, jeweils gegeben durch die Verknupfungstabelle.
0 1 viele
0 0 1 viele
1 1 viele viele
viele viele viele viele
0 1 viele
0 0 1 viele
1 1 1 1
viele viele viele viele
Im linken Beispiel gilt das Kommutativgesetz
a b = b a .
Man nennt das Monoid dann kommutativ oder abelsch .a
Das Monoid des rechten Beispiels ist nicht kommutativ.
aNiels Henrik Abel (1802-1829).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 35
Informatik I 2 Theorie
Mittels des oben eingefuhrten Produktes von Teilmengen setzen wirfur M ⊆ H
M0 = ε , M1 = M , Mn+1 = M Mn ,
M+ =⋃
i≥1
M i , M∗ =⋃
i≥0
M i = M0 ∪M+ .
Beispiel: Fur das Monoid (N, +) gilt 1+ = N \ 0 und 1∗ = N.
Wir betrachten nun einen endliche, nicht-leere Menge Σ von Zeichenoder Symbolen . Σ wird auch Alphabet genannt. Σ ist zusammen mitder Verkettung (Konkatenation ) von Zeichen und dem leeren Wortε, das aus null Zeichen besteht, ein Monoid.
Die Verkettung von Zeichen ist nicht kommutativ.
Wir schreiben in diesem Zusammenhang ab anstelle von a b.
Die Elemente von Σ∗ heißen Worter uber Σ, und Σ+ = Σ∗ \ ε.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 36
Informatik I 2 Theorie
Wir setzen fur eine Wort w ∈ Σ∗
wn = www · · ·w︸ ︷︷ ︸
n mal
, w0 = ε ,
und |w| gleich der Lange von w.
BeispielFur Σ = a, b ist die Menge aller Worter w der Lange |w| ≤ 4
, a, b, aa, ab, ba, bb, aaa, aab, aba, abb, baa, bab,
bba, bbb, aaaa, aaab, aaba, aabb, abaa, abab, abba,
abbb, baaa, baab, baba, babb, bbaa, bbab, bbba, bbbb
Teilmengen A, B ⊆ Σ∗ nennt man Sprachen . Die Menge aller Spra-chen uber Σ ist P(Σ∗).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 37
Informatik I 2 Theorie
2.3 – Relationen und Graphen
Eine (zweistellige homogene) Relation R auf einer Menge V isteine Teilmenge des kartesischen Produkts V 2:
R ⊆ V × V
Zwei Elemente x, y ∈ V stehen in Relation zueinander, wenn
(x, y) ∈ R .
Bei zweistelligen Relation schreibt man auch xRy.
n-stellige Relationen sind entsprechend definiert:
(x1, . . . , xn) ∈ R , R ⊆ V n .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 38

Informatik I 2 Theorie
Beispiele
0.5 1 1.5 2x
0.5
1
1.5
2y
0.5 1 1.5 2x
0.5
1
1.5
2y
R =(x, y) ∈ R
2∣∣ 0 ≤ y ≤ x
V = 1, 2, 3, 4, 5
R =(a, b) ∈ V 2
∣∣ a teilt b
=(1, 1), (1, 2), (1, 3), (1, 4), (1, 5),
(2, 2), (2, 4), (3, 3), (4, 4), (5, 5)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 39
Informatik I 2 Theorie
Reprasentation von Relationen auf endlichen Mengen:Tabellen, Adjazenzmatrix oder Boolesche Matrix , Adjazenzlisten .
1 2 3 4 5
1 × × × × ×2 × ×3 ×4 ×5 ×
1 1 1 1 1
0 1 0 1 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
1, 2, 3, 4, 52, 4345
Zwei spezielle Relationen sind die Identit at und die Nicht-Identit at
I =(x, y)
∣∣ x = y
⊆ V × V ,
I =(x, y)
∣∣ x 6= y
⊆ V × V .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 40
Informatik I 2 Theorie
Eigenschaften zweistelliger Relationen R:
reflexiv Es gilt xRx fur alle x ∈ V .
irreflexiv Es gilt xRx fur kein x ∈ V .
symmetrisch Aus xRy folgt yRx fur alle x, y ∈ V .
antisymmetrisch Aus xRy und yRx folgt x = y, fur alle x, y ∈ V .
asymmetrisch Aus xRy folgt yRx gilt nicht, fur alle x, y ∈ V .
transitiv Aus xRy und yRz folgt xRz fur alle x, y, z ∈ V .
alternativ Entweder xRy oder yRx gilt, fur alle x, y ∈ V .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 41
Informatik I 2 Theorie
Eine zweistellige Relation R ⊆ V 2 heißt
Quasiordnung (Praordnung ),wenn sie reflexiv und transitiv ist.
Ordnungsrelation , partielle Ordnung , oder Halbordnung ,wenn sie reflexiv, antisymmetrisch und transitiv ist.
strenge Halbordnung ,wenn sie irreflexiv und transitiv ist.
totale oder lineare Ordnung ,wenn sie eine alternative Halbordnung ist.
Aquivalenzrelation ,wenn sie reflexiv, symmetrisch und transitiv ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 42

Informatik I 2 Theorie
Beispiele
• Wir definieren fur n-Tupel x = (x1, . . . , xn), y = (y1, . . . , yn), x, y ∈R
n, die Quasiordnung
x ≤ y wenn maxx1, . . . , xn
≤ max
y1, . . . , yn
.
Diese Relation ist weder symmetrisch, noch antisymmetrisch.
• Eine antisymmetrische Quasiordnung ist eine Halbordnung. Ele-mente, die in beiden Richtungen zueinander in Beziehung stehen,mussen gleich sein.
Wir definieren fur x, y ∈ Rn die Halbordnung
x ≤ y wenn xi ≤ yi fur i = 1, 2, . . . , n .
Man beachte, dass es Elemente gibt, die nicht vergleichbar sind(nicht alternativ).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 43
Informatik I 2 Theorie
Beispiele
• Die Relation < auf R definiert eine totalgeordnete Menge (R, <).
• Die Relation x ≤ y,
wenn x1 < y1
oder x1 = y1 und x2 < y2
oder x1 = y1, x2 = y2 und x3 < y3
oder . . .
oder x1 = y1, . . . , xn−1 = yn−1 und xn < yn
oder x = y
ist eine totale Ordnung, die sog. lexikographische Ordnung desR
n.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 44
Informatik I 2 Theorie
Eine symmetrische Quasiordnung ist eine Aquivalenzrelation.
R =(x, y)
∣∣ x + y ist gerade
⊆ N2
1 2 3 4 5
1 × × ×2 × ×3 × × ×4 × ×5 × × ×
Jede Aquivalenzrelation R zerlegt die zugrundeliegende Menge V inAquivalenzklassen
[x]R =y ∈ V
∣∣ (x, y) ∈ R
.
x heißt Reprasentant der Klasse [x]R.
Beispiel (vgl. oben)
1, 2, 3, 4, 5 = [1]R ∪ [2]R = 1, 3, 5 ∪ 2, 4 .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 45
Informatik I 2 Theorie
Wir definieren die Transposition einer Relation R
R⊤ =(x, y)
∣∣ (y, x) ∈ R
,
und die Verknupfung (Produkt ) von Relationen R, S
R S =(x, z) ∈ V × V
∣∣ es gibt ein y ∈ V mit xRy und ySz
.
Wir schreiben einfacher RS statt R S und setzen
R0 = I , R1 = R , R2 = RR , Rn+1 = R Rn , usw.,
sowie analog zu den Definitionen auf Seite 36
R+ =⋃
i≥1
Ri , R∗ =⋃
i≥0
Ri = R0 ∪R+ .
Die Menge aller Relationen P(V ×V ) ist zusammen mit dem Produkt und dem neutralen Element I ein Monoid.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 46

Informatik I 2 Theorie
Beispiel
V = a, b, c, d, e , R =(a, c), (b, c), (c, c), (c, d), (d, e), (e, a)
R2 =(a, c), (a, d), (b, c), (b, d), (c, c), (c, d), (c, e), (d, a), (e, c)
R =
0 0 1 0 0
0 0 1 0 0
0 0 1 1 0
0 0 0 0 1
1 0 0 0 0
, R2 =
0 0 1 1 0
0 0 1 1 0
0 0 1 1 1
1 0 0 0 0
0 0 1 0 0
Es gilt beispielsweise cR2e, weil es ein Element d gibt mit cRd unddRe.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 47
Informatik I 2 Theorie
R+ ist die sog. transitive Hulle von R, d.h. die kleinste transitive Re-lation S, die R umfaßt: R ⊆ R+ ⊆ S.
R∗ ist die sog. transitive, reflexive Hulle von R, d.h. die kleinstetransitive und reflexive Relation S, die R umfaßt: R ⊆ R∗ ⊆ S.
Roy-Warshall Algorithmus zur Berechnung der transitiven Hulle R+
von R (Reprasentation: Boolesche Matrizen; n = |V |):
Fur i = 1, 2, . . . , n,
fur j = 1, 2, . . . , n,
falls Rji = 1, dann
fur k = 1, 2, . . . , n,
Rjk = maxRjk, Rik.
Rji bedeutet den Eintrag in der j-ten Zeile und i-ten Spalte der Boo-leschen Matrix, welche die Relati-on R reprasentiert.
Rji = 1 bedeutet, dass fur das i-teElement xi und das j-te Elementxj aus V gilt: xjRxi.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 48
Informatik I 2 Theorie
Beispiel
R =
0 0 1 0 0
0 0 1 0 0
0 0 1 1 0
0 0 0 0 1
1 0 0 0 0
, R+ =
1 0 1 1 1
1 0 1 1 1
1 0 1 1 1
1 0 1 1 1
1 0 1 1 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 49
Informatik I 2 Theorie
Heterogene Relationen sind Teilmengen des kartesischen Produk-tes verschiedener Mengen:
R ⊂M ×N .
R definiert eine Transformation R : M → N ,
M ∋ x → R(M) =y ∈ N
∣∣ es gibt ein x ∈M mit xRy
⊆ N ,
die jedem x ∈ M die korrespondierenden Elemente R(M) ⊆ N zu-ordnet. In der Informatik reprasentieren solche Transformationen in-deterministische Zuordnungen eines beliebigen Elementes y ∈ R(M)
zu x.
Fur eine Transformation R : M → N transformieren wir den Definiti-onsbereich
Def(R) =x ∈M
∣∣ es gibt ein y ∈ N mit xRy
⊆M ,
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 50

Informatik I 2 Theorie
und das Bild
Bild(R) = R(M) =y ∈ N
∣∣ es gibt ein x ∈M mit xRy
⊆ N .
Beispiel: Def(R) und Bild(R) einer Relation R ⊂ R2.
Fur K ⊆ N heißt die Menge
R−1(K) =x ∈M
∣∣ es gibt ein y ∈ K mit xRy
⊆M
das Urbild von K bezuglich der Transformation R. Falls K = y nurein Element hat, so schreiben wir einfacher R−1(y) statt R−1(y).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 51
Informatik I 2 Theorie
Eine Abbildung oder Funktion f : M → N ist eine Relation f ⊂M ×N , die jedem x ∈M eindeutig ein y ∈ N zuordnet:
Aus (x, y) ∈ f und (x, z) ∈ f folgt y = z .
Anstelle von (x, y) ∈ f oder xfy schreibt man in der Regel y = f(x).
Die Abbildung f heißt partiell , wenn Def(f) 6= M , d.h. es gibt x ∈M
fur die f(x) nicht definiert ist. Andernfalls heißt f total .
Die Menge aller Paare (x, y) ∈ f ⊆ M × N heißt der Graph derFunktion f .
Eine Abbildung f : M → N heißt
surjektiv , wenn f(M) = N ;
injektiv , wenn fur y ∈ Bild(f) das Urbild f−1(y) = x eindeutig ist;
bijektiv , wenn f sowohl surjektiv als auch injektiv ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 52
Informatik I 2 Theorie
Beispiele
Wir reprasentieren Abbildungen f : M → N durch Listenf(m1), f(m2), . . . ,
der Bilder f(m) ∈ N , m ∈M .
Die surjektiven Abbildungen f : 1, 2, 3 → a, b sind
a, a, b, a, b, a, a, b, b, b, a, a, b, a, b, b, b, a
Die injektiven Abbildungen f : 1, 2 → a, b, c sind
a, b, a, c, b, a, b, c, c, a, c, b
Die bijektiven Abbildungen f : 1, 2, 3 → a, b, c sind
a, b, c, a, c, b, b, a, c, b, c, a, c, a, b, c, b, a
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 53
Informatik I 2 Theorie
Die Verknupfung (Verkettung ) von Relationen gilt auch fur Funktio-nen f : L→M , g : M → N , allerdings wird der Ausdruck g f in derumgekehrten Reihenfolge interpretiert:
(g f
)(x) = g
(f(x)
)(“g nach f ”) .
Entsprechend der Gleichheitsrelation I definieren wir die Identit atsfunktionidM , idM (x) = x fur alle x ∈M , und setzen
f0 = idM , f1 = f , f2 = f f , fn+1 = f fn , usw.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 54

Informatik I 2 Theorie
Graphen
Hom. zweist. Relationen E ⊂ V 2 werden anschaulich durch gerich-tete Graphen D = (V, E) reprasentiert (directed graph, digraph ).
Die Elemente von
– V heißen Knoten oder Ecken (vertices , nodes ),
– E heißen (gerichtete) Kanten (edges ).
BeispielDie Relation “teilt” auf der Menge
V = 1, 2, 3, 4, 5 .
1
2
3
4
5
Der genaue geometrische Verlauf der Pfeile ist unerheblich.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 55
Informatik I 2 Theorie
Fur einen Knoten v ∈ V nennt man die Zahl der eintreffenden bzw. ab-gehenden Kanten den Eingangsgrad d+(v) bzw. den Ausgangs-grad d−(v).
Eine Folge v0, v1, . . . , vn von Knoten bzw. (v0, v1), (v1, v2), . . . , (vn−1, vn)von Kanten heißt ein Weg oder Pfad der Lange n, oder auch einfachv0 → vn Pfad.
Ein Weg der Lange n ≥ 1 heißt Zyklus oder (gerichteter ) Kreis ,wenn v0 = vn. Ein gerichteter Graph ohne Zyklen heißt azyklisch(directed acyclic graph (DAG) ).
12
3
4 5
6
12
3
4 5
6
12
3
4 5
6
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 56
Informatik I 2 Theorie
Symmetrische Relationen reprasentieren wir durch ungerichtete Gra-phen G = (V, E).
BeispielDie Relation “x + y ist gerade” aufder Menge
V = 1, 2, 3, 4, 5 .
1
2
3
4
5
Die Nachbarn N(v) eines Knotens v ∈ V sind alle Knoten v 6= w ∈ V
mit (v, w) = (w, v) ∈ E. Der Grad eines Knoten v ist d(v) = |N(v)|.Ein Graph heißt zusammenh angend , wenn jedes Knotenpaar ubereinen Pfad miteinander verbunden ist. Eine gerichteter Graph mit die-ser Eigenschaft heißt stark zusammenh angend bzw. schwach zu-sammenh angend , wenn dies nur fur den zugrundeliegenden unge-richteten Graph gilt.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 57
Informatik I 2 Theorie
Beispiel
Der Graph oben zerfallt in zwei (Zusammenhangs- ) Komponenten ,den beiden Aquivalenzklassen entsprechend.
Ein Graph heißt vollst andig , wenn fur alle Knotenpaare (v1, v2) ∈ V
gilt (v1, v2) ∈ E.
Beispiel Die vollstandigen Graphen mit |V | ∈ 3, 5, 11.1
2
3
1
2
3
4
5
1
234
5
6
78 9
10
11
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 58

Informatik I 2 Theorie
Eine Graph G′(V ′, E′) heißt Untergraph von G(V, E), wenn V ′ ⊆ V
und E ⊆ E.
Enthalt G′ alle Kanten aus E zwischen Knoten aus V ′, dann heißt G′
der durch V ′ induzierte Untergraph
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
2
4
5
6
8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 59
Informatik I 2 Theorie
Ein ungerichteter Graph ohne Kreise heißt ein Wald oder, falls er zu-sammenhangend ist, ein Baum (tree ) T (V, E).
Die folgenden Bedingungen sind aquivalent:
• T ist ein Baum.
• Je zwei Knoten in T sind durch genau einen Weg verbunden.
• T ist zusammenhangend, und es gilt |E| = |V | − 1.
Ein Knoten v mit d(v) = 1 heißt Blatt . Ein Untergraph T eines Gra-phen G, der ein Baum ist mit der gleichen Knotenmenge V , heißtaufspannender Baum oder Spannbaum .
1
23
4
5
6
7
81
2
3
1
23
4
5
6
7
81
2
3
1
23
4
5
6
7
81
2
3
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 60
Informatik I 2 Theorie
Graphen mit einer Zerlegung V = V1 ∪ V2 der Knotenmenge undKanten ausschließlich der Form (v1, v2) ∈ E, v1 ∈ V1, v2 ∈ V2, heißenbipartit .
Sie dienen (unter anderem) der Reprasentation heterogener Rela-tionen R ⊆ X × Y , also von Teilmengen des kartesischen Produktesverschiedener Mengen.
Beispiel
AnnaBeate
Julia
Susi
KarlRalf
Thomas
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 61
Informatik I 2 Theorie
2.4 – Halbordnungen, Verb ande
Wir betrachten nochmals die Ordnungsrelation “teilt” auf V = 1, 2, 3, 4, 5.Diese Relation definiert eine geordneteMenge (V,≤) (partially ordered set, poset )mit (v, w) ∈ E ⊂ V × V (bzw. v ≤ w, v → w),wenn “v teilt w” gilt.Wir schreiben v ≺ w, wenn v < w und es keinu gibt mit v < u < w.
Das Hasse-Diagramm ist der gerichtete azy-klische Graph D(V,≺) zur Visualisierunghalbgeordneter Mengen. “Transitive Kanten”der Halbordnung ≤ werden dabei weggelas-sen.Da alle Pfeile von unten nach oben verlaufen,laßt man sie ublicherweise weg.
1
2
3
4
5
1
2 3
4
5
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 62
Informatik I 2 Theorie
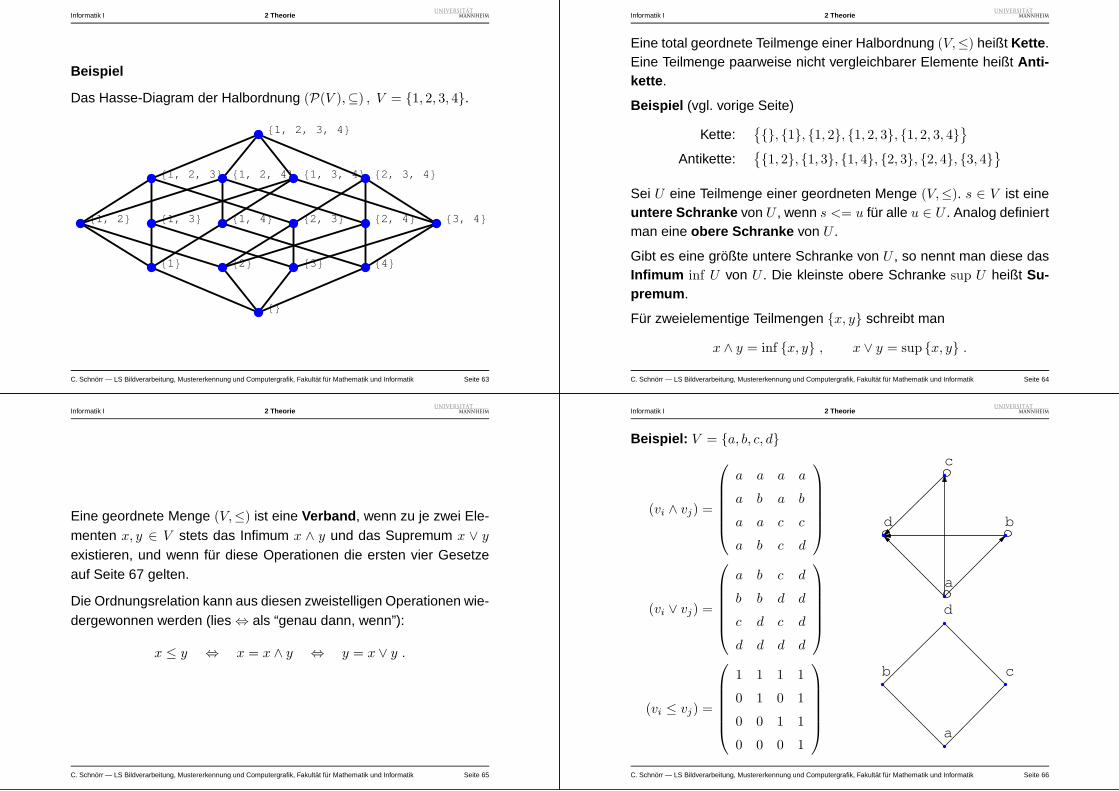
Beispiel
Das Hasse-Diagram der Halbordnung (P(V ),⊆) , V = 1, 2, 3, 4.
8<
81< 82< 83< 84<
81, 2 < 81, 3 < 81, 4 < 82, 3 < 82, 4 < 83, 4 <
81, 2, 3 < 81, 2, 4 < 81, 3, 4 < 82, 3, 4 <
81, 2, 3, 4 <
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 63
Informatik I 2 Theorie
Eine total geordnete Teilmenge einer Halbordnung (V,≤) heißt Kette .Eine Teilmenge paarweise nicht vergleichbarer Elemente heißt Anti-kette .
Beispiel (vgl. vorige Seite)
Kette:, 1, 1, 2, 1, 2, 3, 1, 2, 3, 4
Antikette:1, 2, 1, 3, 1, 4, 2, 3, 2, 4, 3, 4
Sei U eine Teilmenge einer geordneten Menge (V,≤). s ∈ V ist eineuntere Schranke von U , wenn s <= u fur alle u ∈ U . Analog definiertman eine obere Schranke von U .
Gibt es eine großte untere Schranke von U , so nennt man diese dasInfimum inf U von U . Die kleinste obere Schranke sup U heißt Su-premum .
Fur zweielementige Teilmengen x, y schreibt man
x ∧ y = inf x, y , x ∨ y = sup x, y .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 64
Informatik I 2 Theorie
Eine geordnete Menge (V,≤) ist eine Verband , wenn zu je zwei Ele-menten x, y ∈ V stets das Infimum x ∧ y und das Supremum x ∨ y
existieren, und wenn fur diese Operationen die ersten vier Gesetzeauf Seite 67 gelten.
Die Ordnungsrelation kann aus diesen zweistelligen Operationen wie-dergewonnen werden (lies⇔ als “genau dann, wenn”):
x ≤ y ⇔ x = x ∧ y ⇔ y = x ∨ y .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 65
Informatik I 2 Theorie
Beispiel: V = a, b, c, d
(vi ∧ vj) =
a a a a
a b a b
a a c c
a b c d
(vi ∨ vj) =
a b c d
b b d d
c d c d
d d d d
(vi ≤ vj) =
1 1 1 1
0 1 0 1
0 0 1 1
0 0 0 1
a
b
c
d
a
b c
d
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 66

Informatik I 2 Theorie
In einem Verband gelten die Gesetze:
Assoziativitat (x ∧ y) ∧ z = x ∧ (y ∧ z)
(x ∨ y) ∨ z = x ∨ (y ∨ z)
Kommutativitat x ∧ y = y ∧ x
x ∨ y = y ∨ x
Idempotenz x ∧ x = x
x ∨ x = x
Absorption (x ∨ y) ∧ x = x
(x ∧ y) ∨ x = x
In einem distributiven Verband gilt
Distributivitat x ∨ (y ∧ z) = (x ∨ y) ∧ (x ∨ z)
x ∧ (y ∨ z) = (x ∧ y) ∨ (x ∧ z)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 67
Informatik I 2 Theorie
Der Verband heißt vollst andig , falls zu jeder Teilmenge U ⊂ V dasInfimum inf U und das Supremum sup U existieren. Es gibt dann einkleinstes und gr oßtes Element
⊥ = inf V , ⊤ = sup V .
Endliche Verbande sind stets vollstandig.
Neutrale Elemente x ∧ ⊥= ⊥ , x ∨ ⊥ = x
x ∧ ⊤= x , x ∨ ⊤ = ⊤
Ein Verband heißt komplement ar, wenn er vollstandig ist und zu je-dem Element genau ein Komplement existiert.
Komplement x ∧ ∁x = ⊥ , x ∨ ∁x = ⊤
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 68
Informatik I 2 Theorie
Ein vollstandiger, komplementarer, distributiver Verband heißt boole-scher Verband oder boolesche Algebra . Fur diese gelten
Involution ∁(∁x) = x
De Morgan ∁(x ∧ y) = ∁x ∨ ∁y
∁(x ∨ y) = ∁x ∧ ∁y
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 69
Informatik I 2 Theorie
2.5 – Aussagenlogik
Wir betrachten die Menge B(n) aller 0/1-Worter der Lange n
x = (x1, x2, . . . , xn) ∈ 0, 1n
und identifizieren Elemente x ∈ B(n) mit den charakteristische Vekto-ren (oder Indikatorvektoren) der Teilmengen Sx ⊂ S,S = 1, 2, . . . , n,gemaß
i ∈ Sx ⇔ xi = 1 .(B(n),≤
)mit der Ordnungsrelation
x ≤ y ⇔ Sx ⊆ Sy
ist ein Boolescher Verband. Fur das Infimum und das Supremumzweier Elemente gilt
x∧ y = infx, y ↔ Sx ∩Sy , x∨ y = supx, y ↔ Sx ∪Sy ,
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 70
Informatik I 2 Theorie
wobei elementeweise
(x ∧ y)i = xi ∧ yi , (x ∨ y)i = xi ∨ yi
gilt mit
xi yi xi ∧ yi
0 0 0
0 1 0
1 0 0
1 1 1
xi yi xi ∨ yi
0 0 0
0 1 1
1 0 1
1 1 1
Das Komplement ist gegeben durch x = (x1, x2, . . . , xn) ⇔ S \ Sx
undxi xi
0 1
1 0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 71
Informatik I 2 Theorie
Ausgangspunkt der Logik sind Boolesche Variable
A1, A2, . . . ∈ 0, 1 oder A, B, . . . ∈ 0, 1 ,
die atomare Formeln oder atomare Aussagen heißen. Die Elemen-te 0, 1 heißen in diesem Zusammenhang Wahrheitswerte . Der Werteiner Variablen druckt aus, ob die Aussage wahr oder falsch ist.
Beispiele
A: “Es regnet.”
B: “Die Straße ist naß.”
Atomare Aussagen (Formeln) werden durch die einfachen Operatio-nen “und” (∧), “oder” (∨) und “nicht” (¬) verknupft.a In der Logik unter-sucht man den Wahrheitsgehalt zusammengesetzter Ausdrucke (For-meln), abhangig von den Wahrheitswerten der atomaren Formeln.
aStatt ∁A oder A schreibt man in der Logik haufig ¬A.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 72
Informatik I 2 Theorie
Syntax der Aussagenlogik (Definition: Formel)
• Alle atomaren Formeln sind Formeln.
• Fur alle Formeln F und G gilt: F ∧G und F ∨G sind Formeln.
• Fur jede Formel F gilt: ¬F ist eine Formel.
F ∧G heißt Konjunktion von F und G, F ∨G heißt Disjunktion vonF und G, ¬F heißt Negation von F .
Beispiel
F = ¬((A∧B)∨¬C)
Not
Or
And
A B
Not
C
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 73
Informatik I 2 Theorie
Abkurzende Schreibweise:
F1 ⇒ F2 statt ¬F1 ∨ F2 (“impliziert”, “daraus folgt”, “wenn dann”)
F1 ⇔ F2 statt (F1 ∧ F2) ∨ (¬F1 ∧ ¬F2) (“genau dann, wenn”)
F1 F2 ¬F1 ¬F2 F1 ⇒ F2 F1 ∧ F2 ¬F1 ∧ ¬F2 F1 ⇔ F2
0 0 1 1 1 0 1 1
0 1 1 0 1 0 0 0
1 0 0 1 0 0 0 0
1 1 0 0 1 1 0 1
Die Operatoren ¬, ∧, ∨,⇒,⇔ heißen Junktoren .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 74

Informatik I 2 Theorie
Semantik der Aussagenlogik
Sei Fa die Menge aller atomaren Formeln und F die Menge aller For-meln, die aus solchen aufgebaut sind. SeiM : Fa → 0, 1 eine Funk-tion, genannt Belegung , die jeder atomaren Formel einen Wahrheits-wert zuweist. Dann gelte die folgende Erweiterung M : F → 0, 1vonM auf F :
M((F ∧G)
)=
1 wennM(F ) = 1 undM(G) = 1 ,
0 sonst.
M((F ∨G)
)=
1 wennM(F ) = 1 oderM(G) = 1 ,
0 sonst.
M(¬F ) =
1 wennM(F ) = 0 ,
0 sonst.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 75
Informatik I 2 Theorie
Beispiel
SeiM(A) = 1,M(B) = 1,M(C) = 1 und
F = ¬((A ∧B) ∨ ¬C) .
Dann ist
M(F ) = ¬(( A︸︷︷︸
1
∧ B︸︷︷︸
1
)
︸ ︷︷ ︸
1
∨¬ C︸︷︷︸
1︸ ︷︷ ︸
0︸ ︷︷ ︸
1
) = 0 .
Bemerkung. Assoziiert man atomare Formeln mit Aussagen, dannspiegelt der Wahrheitsgehalt einer Formel nicht notwendigerweise un-sere eigene kontextabhangige naturlichsprachliche Interpretation wi-der. Man betrachte etwa die Aussagen (A ∧B) und (B ∧ A) fur
A: “Otto wird krank.”
B: “Der Arzt verschreibt Otto eine Medizin.”
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 76
Informatik I 2 Theorie
Modell, erfullbar, allgemeingultig (Tautologie)
Ist M(F ) = 1, so nennt man die Belegung M ein Modell fur dieFormel F (“F gilt unter der BelegungM”), und schreibt
M |= F .
IstM(F ) = 0, alsoM kein Modell fur F , so schreiben wirM 6|= F .
Eine Formel F heißt erfullbar , wenn F mindestens ein Modell be-sitzt. Andernfalls heißt F unerfullbar . Eine Menge von Formeln heißterfullbar, wenn eine (feste) Belegung existiert, die fur jede Formel derMenge ein Modell ist.Eine unerfullbare Formel heißt Kontradiktion oder Widerspruch .
Eine Formel F heißt allgemeingultig oder Tautologie , falls jede Be-legung von F ein Modell fur F ist. Wir schreiben
|= F .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 77
Informatik I 2 Theorie
Beispiel
Die FormelF =
((¬A) ⇒ (A⇒ B)
)
ist eine Tautologie.
A B ¬A A⇒ B (¬A)⇒ (A⇒ B)
0 0 1 1 1
0 1 1 1 1
1 0 0 0 1
1 1 0 1 1
Ist F eine Tautologie, dann ist jede BelegungM von F kein Modell fur¬F ,M(¬F ) = 0, d.h. ¬F ist unerfullbar. Ist umgekehrt ¬F unerfullbar,so ist jede BelegungM ein Modell fur F .
Eine Formel F ist eine Tautologie genau dann, wenn ¬F
unerfullbar ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 78

Informatik I 2 Theorie
Eine Formel G heißt Folgerung der Formeln F = F1, F2, . . . , Fk,wenn gilt: IstM ein Modell von F , dann istM auch ein Modell fur G.
Aufgrund dieser Definition kann nicht gleichzeitig M(F) = 1 undM(G) = 0 sein. Also ist der Sachverhalt “G folgt aus F” aquivalent zu
((k∧
i=1
Fi
)⇒ G
)
ist eine Tautologie.
Zwei Formeln F und G heißen (semantisch) aquivalent , wenn furalle BelegungenM gilt:M(F ) =M(G). Wir schreiben dafur
F ≡ G .
Sei F ≡ G und F eine Teilformel von H. Ersetzt man F durch G in H
und nennt die resultierende Formel H ′, dann gilt H ≡ H ′.
Ersetzt man in den Gesetzen eines Booleschen Verbands (Seiten67..69) = durch ≡, ∁ durch ¬, ⊤ durch 1 und ⊥ durch 0, dann sinddie entstehenden aussagenlogischen Formeln allgemeingultig.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 79
Informatik I 2 Theorie
Beispiel
Absorptionsgesetz
F ≡ (F ∧ (F ∨G))
Uberprufung mittels der Wahrheitstabelle:
F G F ∨G F ∧ (F ∨G) F ⇔ (F ∧ (F ∨G))
0 0 0 0 1
0 1 1 0 1
1 0 1 1 1
1 1 1 1 1
Fur alle Belegungen stehen in der ersten und in der vorletzten Spal-te die gleichen Werte. Mit anderen Worten: F ⇔ (F ∧ (F ∨ G)) istallgemeingultig (Tautologie), siehe letzte Spalte.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 80
Informatik I 2 Theorie
Beispiel
Bedeuten die Aussagen
“Es regnet, und wenn es regnet, dann ist die Straße naß.”
und
“Es regnet und die Straße ist naß.”
dasselbe? Wir setzen
F : Es regnet.
G: Die Straße ist naß.
und formen aquivalent um:
F ∧ (F ⇒ G) ≡ F ∧ (¬F ∨G) (Distributivgesetz)
≡ (F ∧ ¬F ) ∨ (F ∧G) (Komplement)
≡ 0 ∨ (F ∧G) (Neutrales Element)
≡ F ∧G
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 81
Informatik I 2 Theorie
Beispiel((
A ∨ (B ∨ C))∧ (C ∨ ¬A)
)
≡((B ∧ ¬A) ∨ C
)
Wir formen die linke Seite aquivalent um.((
A∨ (B ∨ C))∧ (C ∨ ¬A)
)
≡((
(A ∨B) ∨ C)∧ (C ∨ ¬A)
)
(Assoziativitat)
≡((
(A ∨B) ∨ C)∧ (¬A ∨ C)
)
(Kommutativitat)
≡((
(A ∨B) ∧ ¬A)∨ C
)
(Distributivitat)
≡((
(A ∧ ¬A) ∨ (B ∧ ¬A))∨ C
)
(Distributivitat)
≡((
0 ∨ (B ∧ ¬A))∨ C
)
(Komplement)
≡((B ∧ ¬A) ∨ C
)(Neutrales Element)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 82

Informatik I 2 Theorie
Beispiel (Logelei)
Die Diatregeln eines 100-jahrigen lauten:
Wenn ich kein Bier zu einer Mahlzeit trinke, dann habe ich im-mer Fisch. Immer wenn ich Fisch und Bier zur selben Mahl-zeit habe, verzichte ich auf Eiscreme. Wenn ich Eiscreme ha-be oder Bier meide, dann ruhre ich Fisch nicht an.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 83
Informatik I 2 Theorie
Zur Vereinfachung setzen wir B: Bier, F : Fisch, E: Eiscreme.
(¬B ⇒ F ) ∧((F ∧B)⇒ ¬E
)∧((E ∨ ¬B)⇒ ¬F
)
≡ (B ∨ F ) ∧(¬(F ∧B) ∨ ¬E
)∧(¬(E ∨ ¬B) ∨ ¬F
)
≡ (B ∨ F ) ∧ (¬F ∨ ¬B ∨ ¬E) ∧((¬E ∧B) ∨ ¬F
)
≡ (B ∨ F ) ∧ (¬F ∨ ¬B ∨ ¬E) ∧ (¬E ∨ ¬F ) ∧ (B ∨ ¬F )
≡ (B ∨ F ) ∧ (B ∨ ¬F )︸ ︷︷ ︸
B∨(F∧¬F )≡B
∧ (¬B ∨ ¬E ∨ ¬F ) ∧ (¬E ∨ ¬F )︸ ︷︷ ︸
¬E∨¬F
≡ B ∧ (¬E ∨ ¬F )
≡ B ∧ ¬(E ∧ F )
Die vereinfachte Diatvorschrift lautet also: “Ich trinke immer Bier undesse niemals Eiscreme zusammen mit Fisch.”
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 84
Informatik I 2 Theorie
Gemaß Seite 79 ist der Sachverhalt “Formel G folgt aus der Formel-
menge F” gleichbedeutend mit((∧k
i=1 Fi
)⇒ G
)
ist eine Tautologie.
Die ist genau dann der Fall, wenn die Negation dieser Bedingung un-erfullbar ist (Seite 78). Anwendung der Gesetze von De Morgan undder Involution (doppelte Verneinung) liefert
¬((
k∧
i=1
Fi
)⇒ G
)
≡ ¬(
¬(
k∧
i=1
Fi
)∨G
)
≡(
¬[
¬(
k∧
i=1
Fi
)]
∧ ¬G)
≡((
k∧
i=1
Fi
)∧ ¬G
)
Formel G ist eine Folgerung der Formeln F = F1, . . . , Fkgenau dann, wenn
((k∧
i=1
Fi
)∧ ¬G
)
unerfullbar ist. Wir schreiben: F |= G.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 85
Informatik I 2 Theorie
Schlußregel: modus ponens
Schlußregel: Unter Annahme der linken Seite kann die rechte Seitegefolgert werden.
F, F ⇒ G |= G
F G F ⇒ G(F ∧ (F ⇒ G)
)⇒ G
(F ∧ (F ⇒ G)
)∧ ¬G
0 0 1 1 0
0 1 1 1 0
1 0 0 1 0
1 1 1 1 0
Alternativer Nachweis durch Aquivalenzumformungen:
F ∧ (F ⇒ G) ∧ ¬G ≡ F ∧ (¬F ∨G) ∧ ¬G (Kommutativitat)
≡ F ∧ ¬G ∧ (¬F ∨G) (De Morgan)
≡ (F ∧ ¬G) ∧ ¬(F ∧ ¬G) (Komplement)
≡ 0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 86
Informatik I 2 Theorie
Weitere Schlußregeln
¬F, G⇒ F |= ¬G (modus tollens )
¬F ⇒ G, ¬F ⇒ ¬G |= F (reductio ad absurdum )
¬G⇒ ¬F |= (F ⇒ G) (Kontraposition )
Beispiel (reductio ad absurdum, indirekter Beweis durch Widerspruch)
F : Es gibt unendlich viele Primzahlen (Satz von Euklid).
¬F : Es gibt endlich viele Primzahlen.
¬F ⇒ G: Es gibt eine großte Primzahl x.
¬G: Es gibt eine Primzahl großer als x.
Um F zu zeigen, folgern wir ¬G aus ¬F . Wir betrachten dazu dieZahl y = 2 · 3 · 5 . . . x + 1, die großer als x ist, deshalb keine Primzahlist (Annahme) und in Primfaktoren aus X = 2, . . . , x zerfallt. Keinedieser Faktoren teilt jedoch y. Deshalb existiert ein weiterer Primfaktornicht aus X , der folglich großer als x ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 87
Informatik I 2 Theorie
Beispiel (Kontraposition)
Behauptung: Es gibt keine Primzahl n außer 3, sodass n + 1 eineQuadratzahl ist (d.h. n + 1 = m2 , m ∈ N).
F : n 6= 3 ist Primzahl.
G: n + 1 ist keine Quadratzahl.
Wir folgern F ⇒ G indem wir ¬G⇒ ¬F zeigen.
¬F : n 6= 3 ist keine Primzahl.
¬G: n + 1 ist eine Quadratzahl.
Aus n + 1 = m2 folgt n = m2 − 1 = (m + 1)(m − 1). Dies ist keinePrimzahl fur m− 1 > 1. m = 2 kann nicht sein, da n 6= 3 = m2 − 1.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 88
Informatik I 2 Theorie
Boolesche Funktionen, Schaltfunktionen
Jeder Formel mit n Variablen definiert eine Funktion
f : B(n)→ 0, 1 ,
eine sog. Boolesche Funktion oder – im Zusammenhang mit digita-ler Schaltungstechnik – Schaltfunktion .
Da es 2n Belegungen von n Variablen gibt und jeweils zwei moglicheFunktionswerte 0, 1, gibt es insgesamt 22n
Funktionen.
Die 221
= 4 moglichen Funktionen mit einer Variable sind:
F 0 F ¬F 1
0 0 0 1 1
1 0 1 0 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 89
Informatik I 2 Theorie
Die 222
= 16 Funktionen mit 2 Variablen sind
F G 0 F ∧ G ¬(F ⇒ G) F ¬(G ⇒ F ) G F ⊕ G F ∨ G
0 0 0 0 0 0 0 0 0 0
0 1 0 0 0 0 1 1 1 1
1 0 0 0 1 1 0 0 1 1
1 1 0 1 0 1 0 1 0 1
F G ¬(F ∨ G) F ⇔ G ¬G G ⇒ F ¬F F ⇒ G ¬(F ∧ G) 1
0 0 1 1 1 1 1 1 1 1
0 1 0 0 0 0 1 1 1 1
1 0 0 0 1 1 0 0 1 1
1 1 0 1 0 1 0 1 0 1
Die Funktionen F ⊕G, ¬(F ∨G), und ¬(F ∧G) nennt man auch Xor-(exklusives entweder-oder), Nor- und Nand-Funktion.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 90

Informatik I 2 Theorie
Ubung a
Des Professors Festplatte ist geloscht worden. Er hat acht Verdachtigeim Visier und befragt einen nach dem anderen:
Simon: Wenn Detlev an der Aktion beteiligt war, dann auch Rolf.
Michel: Wenn Friedl mitgemacht hat, dann hat Detlev nichts mit derSache zu tun.
Detlev: Das hat Simon angezettelt.
Tobias: Klaus hat nichts mit der Sache zu tun.
Friedl: Wenn Tobias unschuldig ist, dann war Michel daran beteiligt.
Klaus: Wenn Rolf dabei war, dann auch Simon.
Rolf: Torsten war es.
Torsten: Soweit ich weiß, war Klaus einer von denen.aFrei nach einer Logelei im ZEITmagazin 48/07.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 91
Informatik I 2 Theorie
Der Professor muß sich um seine kaputte Festplatte kummern undbittet um Ihre Mithilfe.
Stellen Sie eine Formel auf, welche den geschilderten Sachverhaltbeschreibt. Der oder die unbekannten Tater haben gelogen, die Un-beteiligten nicht. Jeder kommt als Tater in Frage.
Vereinfachen Sie die Formel mit der Mathematica-Funktion Simplify.
Wer war es?
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 92
Informatik I 2 Theorie
Normalformen von Formeln
Ein Literal ist eine atomare Formel F oder ihre Negation ¬F .
Eine Formel F der Gestalt
F =n∨
i=1
( mi∧
j=1
Li,j
)
, Li,j ∈ F1, F2, . . . ∪ ¬F1,¬F2, . . . ,
ist in Disjunktiver Normalform (DNF).
Eine Formel F der Gestalt
F =
n∧
i=1
( mi∨
j=1
Li,j
)
, Li,j ∈ F1, F2, . . . ∪ ¬F1,¬F2, . . . ,
ist in Konjunktiver Normalform (KNF).
Zu jeder Formel gibt es eine aquivalente Formel in DNF undeine aquivalente Formel in KNF.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 93
Informatik I 2 Theorie
Berechnung der DNF einer Formel F mittels der Wahrheitstabelle
Wir wahlen separat die Literale der einzelnen Konkunktionsterme so,dass sie gleich 1 fur Belegungen mitM(F ) = 1 sind.
F1 F2 F = F1 ⊕ F2
0 0 0
0 1 1
1 0 1
1 1 0
Im Beispiel links ergeben die 2. und die3. Zeile zwei Konjunktionsterme,
¬F1 ∧ F2 und F1 ∧ ¬F2 .
Akkumulation mit ∨ ergibt M(F ) = 1 fur genau diese Belegungen,undM(F ) = 0 sonst.
F1 ⊕ F2 ≡ (¬F1 ∧ F2) ∨ (F1 ∧ ¬F2)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 94

Informatik I 2 Theorie
Berechnung der KNF einer Formel F mittels der Wahrheitstabelle
Wir formen die KNF in die DNF um.
F = ¬¬[ n∧
i=1
( mi∨
j=1
Li,j
)]
≡ ¬[ n∨
i=1
¬( mi∨
j=1
Li,j
)]
≡ ¬[ n∨
i=1
( mi∧
j=1
¬Li,j
)]
Aufgrund der Uberlegungen fur die DNF lesen wir an dem letztenTerm ab, dass wir die Literale fur die Disjunktionsterme der KNF ne-giert einsetzen, und dies fur alle Belegungen mitM(F ) = 0.
F1 F2 F = F1 ⊕ F2
0 0 0
0 1 1
1 0 1
1 1 0
Im Beispiel links ergeben die 1. und die4. Zeile zwei Disjunktionsterme,
F1 ∨ F2 und ¬F1 ∨ ¬F2 .
Die KNF lautet somit
F1 ⊕ F2 ≡ (F1 ∨ F2) ∧ (¬F1 ∨ ¬F2)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 95
Informatik I 2 Theorie
Beispiel
Ein digitales Schaltwerk soll fur drei binare Eingange das Paritatsbitberechnen. Wie lautet eine Formel F , welche diese Boolesche Funk-tion f realisiert?
F1 F2 F3 f(F1, F2, F3)
0 0 0 1
0 0 1 0
0 1 0 0
0 1 1 1
1 0 0 0
1 0 1 1
1 1 0 1
1 1 1 0
Die DNF lautet
F = (¬F1 ∧ ¬F2 ∧ ¬F3) ∨ (¬F1 ∧ F2 ∧ F3)∨(F1 ∧ ¬F2 ∧ F3) ∨ (F1 ∧ F2 ∧ ¬F3)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 96
Informatik I 2 Theorie
Die Realisierung Boolescher Funktionen mit einer minimalen Anzahlan Termen (Schaltungsaufwand) ist Gegenstand der Digitalen Schal-tungstechnik (Informatik-II).
Das Boolesche Erfullbarkeitsproblem (SAT Problem , satisfiabi-lity problem ) betrifft die Entscheidung, ob eine gegebene Formelerfullbar ist. Durchprobieren aller Belegungen der entsprechendenWahrheitstabelle ist keine zufriedenstellende Losung, da der Aufwandexponentiell von der Zahl der Variablen abhangt.
Das SAT Problem ist ein zentrales Thema der Algorithmen- und Kom-plexitatstheorie.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 97
Informatik I 2 Theorie
Hornformeln und logisches Programmieren
Eine Formel F ist eine Hornformel , wenn sie in KNF ist, und wennjeder Disjunktionsterm hochstens ein positives Literal enthalt.
Beispiel
F = (A ∨ ¬B) ∧ (¬C ∨ ¬A ∨D) ∧ (¬A ∨ ¬B) ∧D ∧ ¬E
Wir konnen alle Terme als Implikationen schreiben, z.B. fur D und ¬E
D ≡ (0 ∨D) ≡ (¬1 ∨D) ≡ (1⇒ D) , ¬E ≡ (¬E ∨ 0) ≡ (E ⇒ 0) .
Hornformeln sind also Konjunktionen von Implikationen:
F = (B ⇒ A) ∧ (C ∧A⇒ D) ∧ (A ∧B ⇒ 0) ∧ (1⇒ D) ∧ (E ⇒ 0)
Gegenbeispiel
G = (A ∨ ¬B) ∧ (C ∨ ¬A ∨D)
Der hintere Disjunktionsterm enthalt zwei positive Literale.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 98

Informatik I 2 Theorie
Erfullbarkeitstest fur Hornformeln
Eingabe: Hornformel F .
1. Markiere alle atomaren Formeln A in Teilformeln derGestalt (1⇒ A).
2. Solange es in F Teilformeln G der Form
(a) (A1 ∧ · · · ∧An ⇒ B) , n ≥ 1 , oder
(b) (A1 ∧ · · · ∧An ⇒ 0) , n ≥ 1
gibt, in denen die atomaren Formeln A1, . . . , An bereits markiertsind, nicht jedoch B:
Hat G die Form (a), dann markiere jeweils B.Hat G die Form (b), dann gib “unerfullbar” aus und stoppe.
3. Gib “erfullbar” aus und stoppe.
Ist F erfullbar, so gilt fur die erfullende Belegung M(Ai) = 1 genaudann, wenn Ai markiert ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 99
Informatik I 2 Theorie
Ist n die Anzahl der atomaren Formeln in F , dann stoppt der Erfullbar-keitstest immer nach spatestens n Markierungsschritten. Er ist alsoeffizient.
Beispiel
Wir wollen die Schlussregel modus tollens ¬F, G ⇒ F |= ¬G zei-gen. Die Annahme lauten als Hornformel
(F ⇒ 0) ∧ (G⇒ F )
Um zu zeigen, dass ¬G folgt, fugen wir diese Anfrage negiert hinzu,(F ⇒ 0) ∧ (G⇒ F ) ∧G, und prufen auf Unerfullbarkeit (vgl. S.85).
Atomare Formeln werden mit einer Box markiert.
(F ⇒ 0) ∧ ( G ⇒ F ) ∧ (1⇒ G )
( F ⇒ 0) ∧ ( G ⇒ F ) ∧ (1⇒ G )
→ unerfullbar, womit die Schlußregel gezeigt ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 100
Informatik I 2 Theorie
Beispiel
Angenommen, einem Labor stunden Apparate zur Verfugung, um diefolgenden chemischen Reaktionen durchzufuhren:
MgO + H2 → Mg + H20
C + O2 → CO2
H2O + CO2 → H2CO3
Weiter seien als Grundstoffe verfugbar: MgO, H2, O2, C. Kann dasLabor H2CO3 herstellen?
Wir stellen Fakten und negierte Anfrage durch eine Hornformel dar,
(MgO ∧H2 ⇒Mg) ∧ (MgO ∧H2 ⇒ H20) ∧ (C ∧O2 ⇒ CO2)∧(H2O ∧ CO2 ⇒ H2CO3) ∧ (1⇒MgO) ∧ (1⇒ H2) ∧ (1⇒ O2)∧
(1⇒ C) ∧ (H2CO3 ⇒ 0) ,
und wenden den Markierungsalgorithmus an:
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 101
Informatik I 2 Theorie
( MgO ∧ H2 ⇒Mg) ∧ ( MgO ∧ H2 ⇒ H20) ∧ ( C ∧ O2 ⇒ CO2)∧
(H2O ∧ CO2 ⇒ H2CO3) ∧ (1⇒ MgO ) ∧ (1⇒ H2 ) ∧ (1⇒ O2 )∧
(1⇒ C ) ∧ (H2CO3 ⇒ 0)
( MgO ∧ H2 ⇒ Mg ) ∧ ( MgO ∧ H2 ⇒ H20 ) ∧ ( C ∧ O2 ⇒ CO2 )∧
( H2O ∧ CO2 ⇒ H2CO3) ∧ (1⇒ MgO ) ∧ (1⇒ H2 ) ∧ (1⇒ O2 )∧
(1⇒ C ) ∧ (H2CO3 ⇒ 0)
( MgO ∧ H2 ⇒ Mg ) ∧ ( MgO ∧ H2 ⇒ H20 ) ∧ ( C ∧ O2 ⇒ CO2 )∧
( H2O ∧ CO2 ⇒ H2CO3 ) ∧ (1⇒ MgO ) ∧ (1⇒ H2 ) ∧ (1⇒ O2 )∧
(1⇒ C ) ∧ ( H2CO3 ⇒ 0)
→ unerfullbar, womit die Anfrage positiv beantwortet ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 102

Informatik I 2 Theorie
2.6 – Formale Systeme
Gleichungen und “Gleichheit” sind nicht nur in der Mathematik wich-tig. Es ist eine große Unterstutzung bei Computeranwendungen, wennein System aquivalente Ausdrucke als solche erkennt.
Anwendung von Mathematica auf Beispiele aus der Mathematik:
Sin[0] == Sin[6 Pi] --> True
Simplify[3(1 + x) + x^2] --> 3 + 3x + x2
Simplify[2 + x + (1 + x)^2] --> 3 + 3x + x2
Simplify[Cos[(x - y)/2] - Cos[(x + y)/2]]
--> 2 sin(
x2
)sin(
y2
)
Das System wendet Regeln an, um Ausdrucke durch Ersetzen vonTeilausdrucken auf eine Normalform zu bringen und zu vergleichen.Die Normalform ist die Bedeutung des Ausdrucks.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 103
Informatik I 2 Theorie
Solche Systemfahigkeiten spielen eine wichtige Rolle in der Informa-tik und bei Computeranwendungen wie symbolisches Rechnen, au-tomatisches Beweisen, Programmverifikation und -spezifikation und“high-level” Programmiersprachen (wie z.B. Mathematica).
In diesem Abschnitt lernen wir einige elementare Begriffe kennen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 104
Informatik I 2 Theorie
Textersetzungssystem (Semi-Thue-System)
Wir betrachten einen Zeichenvorrat Σ = I, + und entsprechendeWorter aus Σ∗:
III+II , +I+IIIIIIIIIIII+II , etc.
Eine Regel ist ein geordnetes Paar von Ausdrucken (p, q). Wir notie-ren sie mit p→ q.
Regeln kann man als gerichtete Gleichungen auffassen: Die linke Sei-te kann durch die rechte Seite ersetzt werden.
Gegeben seien zwei Regeln
+I → I+
+ → ε
fur das Ersetzen von Teilwortern.
ε bezeichnet wie schon bekannt das leere Wort.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 105
Informatik I 2 Theorie
Wir transformieren das Wort II+III und geben schrittweise die Ergeb-nisse aller anwendbaren Regeln an:
II+IIIIII+II, IIIIIIIII+I, IIIII, IIIII+, IIIII, , IIIII, , ,
Dies ist ein Beispiel eines Algorith-mus , d.h. eine Folge von Operationenangewendet auf eine Eingabe. Der Al-gorithmus terminiert (oder halt ) beiEintritt einer Bedingung (hier: keineRegel ist anwendbar).
Der Algorithmus ist indeterministisch , da eine beliebige Regel an-wendbar bzw. die Transformation mehrdeutig ist.
Das Endergebnis hangt davon offenbar nicht ab. Bei Eintritt der Ter-minierungsbedingung – oben wird erzeugt – steht auf der linken Seiteder (beliebigen) anzuwendenden Regel immer der gleiche Ausdruck.
Die Normalform (und damit Bedeutung) des Ausdrucks II+III ist IIIII.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 106

Informatik I 2 Theorie
Wir betrachten als ein weiteres Beispiel das “Entfernen von Kaffee-bohnen”a aus einer Dose.
Die Regeln lauten
black white→ black
white black→ black
black black→ white
Wir stellen den Doseninhalt als Worter uber Σ = b, w dar.
bbwbwwb, bbb, bbbwb, wb, bw, wb, bwb, b, b, b, b
aDas Beispiel wird C.S. Scholten zugeschrieben in Gries (1981), The Science ofProgramming.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 107
Informatik I 2 Theorie
Wir transformieren ein anderes Wort:
wwbwwbw, wbw, wwbbw, wb, bw, wb, wb, wbb, b, b, b, b, b
Aus den Regeln kann man ablesen, dass fur irgendeinen Ausdruckmit einer ungeraden Anzahl schwarzer Bohnen immer eine schwarzeBohne ubrig bleibt.
Probieren wir einen anderen Ausdruck:
bwbwbbw, bbw, bwbww, bb, ww, bb, bb, bb, w, , w, w, w
Das Ergebnis hangt vonder Reihenfolge der ange-wendeten Regeln ab!
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 108
Informatik I 2 Theorie
Noch ein weiterer Versuch:
wwwbbwwbb, wwwwwbb, www, bb, ww, , w, , ,
Wiederum Mehrdeutigkeit!
Wann ist eine Normalform eindeutig? Wie hangt diese Eigenschaftvon den Regeln ab?
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 109
Informatik I 2 Theorie
Wir nennen die Transformation eines Ausdrucks l nach r durch An-wendung einer Regel p → q eine direkte Ableitung und notieren siemit l ⇒ r.
Wir schreiben l+⇒ r, wenn r aus l durch sukzessive Ableitung gewon-
nen werden kann, und l∗⇒ r, wenn entweder l
+⇒ r oder l = r. Um-gekehrt sagt man, dass r auf l reduziert werden kann, wenn l
∗⇒ r.
Eine Menge T = p→ q von Regeln zusammen mit Metaregeln zurAnwendung der Ersetzungen,
• wenn a · · · b → c · · · d anwendbar ist, dann ersetze das Teilworta · · · b von x durch c · · · d,
• wenn a · · · b mehrfach vorkommt oder mehrere Regeln anwendbarsind, dann wahle das Teilwort bzw. die Regel beliebig,
• wiederhole die Anwendung von Regeln beliebig oft,
heißt ein Textersetzungssystem (string-rewriting system ) oder Semi-Thue System (Axel Thue (1863-1922)).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 110

Informatik I 2 Theorie
Die Menge r | l ∗⇒ r heißt die formale Sprache L(T , l).
Uberfuhrt ein Semi-Thue System T ein Wort x in y = T (x), x∗⇒ y,
dann heißt y Normalform von x.
Fur die Vereinfachung und den Vergleich von Ausdrucken ist die Ein-deutigkeit der Normalform wunschenswert, aber ohne weitere Ein-schrankungen allgemein nicht gegeben.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 111
Informatik I 2 Theorie
Formale Systeme
Wir nennen (U,⇒) ein formales System , wenn
• U eine endliche oder abzahlbar unendliche Menge ist,
• ⇒⊆ U × U eine Relation ist,
• es einen Algorithmus gibt, der jedes r ∈ U mit l ⇒ r, l ∈ U , inendlichen vielen Schritten aus l berechnen kann (r ist effektivberechenbar ).
Beispiele: Eine Menge von Wortern U = Σ∗ zusammen mit der Ablei-tungsrelation⇒ eines Textersetzungssystems. U = Z×Z zusammenmit der Addition (m, n)⇒ (m + n, 0).
Gegenbeispiel: U = R, da uberabzahlbar.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 112
Informatik I 2 Theorie
Mit (U,⇒) ist auch (U,∗⇒) ein formales System. Fur ein gegebenen
Ausdruck r ist aber nicht klar, ob dieser effektiv berechenbar ist.
Ein formales System heißt entscheidbar , wenn fur beliebige l, r ∈ U
effektiv festgestellt werden kann, ob l∗⇒ r gilt oder nicht.
Ein formales System (U,⇒) heißt ein Kalkul , wenn die Relation ⇒durch eine endliche Menge p→ q von Regeln zusammen mit einerendlichen Menge von Meta- oder Kalkulregeln definiert ist.
Beispiel: Ein Semi-Thue System.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 113
Informatik I 2 Theorie
Normalformen und Konfluenz
Wir setzen im folgenden voraus, dass Ableitungen der Form x∗⇒ y
∗⇒x nicht vorkommen. Die Relation ∗⇒ ist dann eine Halbordnung unddie uber ein Semi-Thue-System definierte Menge (Σ∗,
∗⇒) geordnet.
Die Relation⇒ heißt terminierend oder noethersch a, wenn es keineendlosen Ketten x ⇒ y1 ⇒ y2 ⇒ · · · gibt. Genau dann definiert dasSemi-Thue-System einen Algorithmus.
Lesen wir⇒ als≤, dann sind Normalformen die maximalen Elemen-te. Ist die Relation ⇒ noethersch, dann gibt es zu jedem Ausdruckmindestens eine Normalform.
Eine Relation R heißt konfluent , wenn aus xR∗y1
und xR∗y2 die Existenz eines Elementes z folgt mity1R
∗z und y2R∗z.
R*R*
R*R*
x
y1 y2
z
aEmmy Noether (1882-1935)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 114
Informatik I 2 Theorie
Die algebraische Bedingung fur Konfluenz von R ist
(R⊤)∗ R∗ ⊆ R∗ (R⊤)∗ .
Eine noethersche Halbordnung R, und damit speziell auch eine noether-sche Ableitungsrelation ⇒ ist genau dann konfluent, wenn fur jedesx ∈ U eine eindeutige Normalform existiert.
Eine Relation R heißt lokal konfluent , wenn ausxRy1 und xRy2 die Existenz eines Elementes z folgtmit y1R
∗z und y2R∗z.
RR
R*R*
x
y1 y2
z
Diamantenlemma (Newton 1942): Eine noethersche Halbordnungist genau dann konfluent, wenn sie lokal konfluent ist.
Die Eigenschaften “terminierend (noethersch)” und “(lokal) konfluent”verhindern also Sackgassen bei regelbasierten Ableitungen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 115
Informatik I 2 Theorie
Beispiel
Wir betrachten nochmals die Regeln zum Leeren einer Kaffeedoseund ein mehrdeutiges Ergebnis.
black white→ black
white black→ black
black black→ white
bwbwbbw, bbw, bwbww, bb, ww, bb, bb, bb, w, , w, w, w
Die vorletzte Zeile legt nahe, die Regel white white → white zuerganzen.
Die Relation ⇒ ist sicher ter-mierend, da jede Regel einWort verkurzt. Und die herge-stellte Konfluenz sorgt nun furEindeutigkeit.
bwbwbbw, bbw, bwbww, bb, ww, bb, bb, bbw, w, w, w, w, w
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 116
Informatik I 2 Theorie
Wir transformieren den Term des zweite Beispiel von oben mit mehr-deutigem Ergebnis. Auch hier ergibt sich nun eine eindeutige Normal-form.
wwwbbwwbb, wwbb, wwbb, wwwwwbb, wbb, www, wbb, wbb, www, wbb, wbb, wwwwww, www, wwwbb, ww, bb, ww, ww, ww, bb, ww, bb, ww, ww, wwbb, ww, bb, ww, ww, ww, ww, ww, ww, ww, ww, www, w, w, w, w, w, w, w, w, ww, w, w, w, w, w, w, ww, w, w, w, w, w
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 117
Informatik I 2 Theorie
2.7 – Grammatiken und Automaten
Formale Sprachen L ⊂ Σ∗ sind unendliche Objekte. Fur den algo-rithmischen Umgang benotigen wir endliche Beschreibungen solcherObjekte. Dazu dienen Grammatiken und Automaten.
Grammatiken sind Mechanismen zum Erzeugen einer formalen Spra-che. Automaten modellieren Systeme mit einer endlichen Zahl inter-ner Zustande. Sie akzeptieren Eingaben und erkennen Worter einerformalen Sprache.
Anwendungsbeispiele: Steuereinheit eines Fahrstuhls, digitale Schalt-kreise, syntaktische Analyse (Compiler), Texteditoren, ...
Dieser Abschnitt fuhrt den Begriff “Grammatik” ein und behandelt dieAquivalenz von Grammatiken der einfachsten Klasse und entspre-chenden Automaten.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 118

Informatik I 2 Theorie
Beispiel
Die nachfolgenden Regeln, Produktionen genannt, definieren eineGrammatik. Syntaktische Einheiten, reprasentiert durch Variable aufder linken Seite, konnen jeweils durch die rechte Seite ersetzt werden.Ausgehend von der Startvariable 〈Satz〉 wird die formale Sprache auf-gebaut.
〈Satz〉 → 〈Subjekt〉〈Pradikat〉〈Objekt〉〈Subjekt〉 → 〈Artikel〉〈Attribut〉〈Substantiv〉〈Artikel〉 → ε
〈Artikel〉 → der
〈Artikel〉 → die
〈Artikel〉 → das
〈Attribut〉 → ε
〈Attribut〉 → 〈Adjektiv〉
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 119
Informatik I 2 Theorie
〈Attribut〉 → 〈Adjektiv〉〈Attribut〉〈Adjektiv〉 → kleine
〈Adjektiv〉 → bissige
〈Adjektiv〉 → große
〈Substantiv〉 → Hund
〈Substantiv〉 → Katze
〈Pradikat〉 → jagt
〈Objekt〉 → 〈Artikel〉〈Attribut〉〈Substantiv〉
Mittels dieser Regeln kann z.B. der Satz
der kleine bissige Hund jagt die große Katze
abgeleitet werden. Dieser Vorgang wird durch den Syntax- oder Ab-leitungsbaum auf der folgenden Seite beschrieben.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 120
Informatik I 2 Theorie
Beispiel (Forts.)
Satz
Subj
Art
der
Attr
Adj
kleine
Attr
Adj
bissige
Subs
Hund
Praed
jagt
Obj
Art
die
Attr
Adj
grosse
Subs
Katze
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 121
Informatik I 2 Theorie
Definition (Grammatik)
Eine Grammatik G = (V, Σ, P, S) ist definiert durch
– eine endliche Menge V von Variablen ,
– ein endliches Terminalalphabet Σ mit V ∩ Σ = ∅,
– eine endliche Menge P ⊂ (V ∪ Σ)+ × (V ∪ Σ)∗ von Regeln oderProduktionen , und
– eine Startvariable S ∈ V .
Die Produktionen definieren eine Relation⇒ auf der Menge (V ∪Σ)∗.a
Fur u, v ∈ (V ∪ Σ)∗ gilt u⇒ v, wenn
u = xyz , v = xy′z , x, z ∈ (V ∪ Σ)∗ ,
und y → y′ eine Regel in P ist.
aHierbei wird immer eine konkrete, gegebene Grammatik vorausgesetzt.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 122

Informatik I 2 Theorie
Die von G reprasentierte (erzeugte) formale Sprache ist
L(G) =w ∈ Σ∗ ∣∣S ⇒∗ w
Eine Folge von Wortern S = w0 ⇒ w1 ⇒ · · · ⇒ wn heißt Ableitungvon wn. Ein Wort wi ∈ (V ∪ Σ)∗, das (noch) Variablen enthalt, heißtSatzform .
Beispiel: Die Grammatik G =(S, T, F, (,),a,*,+, P, S
)mit
P = S → T
S → S + T
T → F
T → T ∗ F
F → a
F → (S)
stellt korrekt geklammerte arithmetische Ausdrucke dar.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 123
Informatik I 2 Theorie
Beispiel (Forts.) Der Ableitungsbaum zu a ∗ a ∗ (a + a) + a ∈ L(G).
S
S
T
T
T
F
a
* F
a
* F
H S
S
T
F
a
+ T
F
a
L
+ T
F
a
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 124
Informatik I 2 Theorie
Die Ableitung ist im allgemeinen kein eindeutiger, deterministischerProzeß, d.h. die Relation⇒ ist keine Funktion.
Zwei Ableitungen ...
S ⇒ T ⇒ T ∗ F ⇒ F ∗ F ⇒ a ∗ F ⇒ a ∗ a
S ⇒ T ⇒ T ∗ F ⇒ T ∗ a⇒ F ∗ a⇒ a ∗ a
... mit dem gleichen Syntaxbaum (rechts).
S
T
T
F
a
* F
a
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 125
Informatik I 2 Theorie
Chomsky-Sprachhierarchie
Gemaß Noam Chomsky klassifiziert man Grammatiken und die durchsie erzeugten formalen Sprachen:
Typ 0: Alle (endlichen) Grammatiken. Die Regeln unterliegen keinenEinschrankungen.
Typ 1: Kontextsensitive Grammatiken; fur jede Regel w1 → w2 inP gilt |w1| ≤ |w2|.
Typ 2: Kontextfreie Grammatiken; fur alle Regeln in P ist zusatzlichdie linke Seite eine einzelne Variable w1 ∈ V .
Typ 3: Regul are Grammatiken; fur alle Regeln in P ist zusatzlich dierechte Seite w2 ∈ Σ∪ΣV entweder ein einzelnes Terminalsymbol,oder ein solches gefolgt von einer Variable.
Eine formale Sprache L(G) heißt vom Typ 0 (Typ 1, Typ 2, Typ 3),wenn die sie erzeugende Grammatik G vom Typ 0 (Typ 1, Typ 2, Typ3) ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 126

Informatik I 2 Theorie
Es gibt Sprachen, die nicht durch Grammatiken (endliche Objekte)beschreibbar sind. Damit ergibt sich folgende Hierarchie:
Menge aller Sprachen
Typ 0 - Sprachen oder
rek. aufz. Sprachen
entscheidbare Sprachen
kontextsensitive oder
-Sprachen + Typ
kontextfreie oder
Typ-2 Sprachen
reguläre oder
Typ-3 Sprachen
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 127
Informatik I 2 Theorie
Beispiele
Die Grammatik auf Seite 123 ist vom Typ 2.
Die Sprache L(G) =anbncn
∣∣n ≥ 1
ist vom Typ 1 und wird durch
die Grammatik G =(S, B, C, a, b, c, P, S
)erzeugt mit
P = S → aSBC, S → aBC, CB → BC,
aB → ab, bB → bb, bC → bc, cC → cc
Satz
Das Wortproblem ist fur Typ 1 Sprachen entscheidbar. D.h.:Es gibt einen Algorithmus, der bei Eingabe einer kontext-sensitivenGrammatik G und eines Worte w ∈ Σ∗ in endlicher Zeit ent-scheidet, ob w ∈ L(G) oder w 6∈ L(G).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 128
Informatik I 2 Theorie
Mathematica
Wir schreiben fur kontextfreie Grammatiken ein einfaches Programm,um ein Eingabewort w durch “Invertierung” der Produktionen zu ana-lysieren. Die Ausgabe ist ein Ausdruck, der sich als Ableitungsbaumvisualisieren laßt, oder die leere Menge (w 6∈ L(G)).
Gegeben sei G =(S, A, B, a, b, c, P, S
)mit
P = S → aB, S → Ac, A→ ab, B → bc
Wir reprasentieren ein Eingabewort, zum Beispiel abc,durch eine Liste a, b, c, und benutzen die in Mathematica vor-handene Funktion
ReplaceList[expr, rules]
attempts to transform the entire expression expr by
applying a rule or list of rules in all possible ways,
and returns a list of the results obtained.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 129
Informatik I 2 Theorie
Beispiel
ReplaceList[a, b, c, d, e, f, x__, y__ -> x, y]
--> a, b, c, d, e, f, a, b, c, d, e, f,
a, b, c, d, e, f, a, b, c, d, e, f,
a, b, c, d, e, f
Anwendung auf unser zu analysierendes Wort:
ReplaceList[a, b, c, rules]
--> , , A[a, b], c, a, B[b, c]
Nicht-anwendbare Regeln ergeben . Wir filtern diese Falle heraus.
TransformWord[word_, rules_] :=
With[transformed = ReplaceList[word, rules],
Join @@ Select[transformed, (Length[#] > 0 &)]]
TransformWord[a, b, c, rules]
--> A[a, b], c, a, B[b, c]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 130

Informatik I 2 Theorie
Dieses Ergebnis wird iterative weitertransformiert, bis eine Reduktionauf das Startsymbol erfolgt ist.
Map[TransformWord[#, rules] &, %]
--> S[A[a, b], c], S[a, B[b, c]]
In unserem einfachen Beispiel sind wir also nach diesem weiterenSchritt schon am Ziel.
In weniger einfachen Fallen (vgl. die Syntaxbaume auf den vorigenSeiten) iterieren wir die Transformation bis die Liste der resultierendenAusdrucke leer ist, und selektieren nach jedem Iterationsschritt sichergebende Ableitungen mit dem Pradikat
recognizedQ[word_] := MatchQ[word, _S]
parseWord[word_, rules_] := Module[result, transformed,
transformed = TransformWord[word, rules];
result = Select[transformed, recognizedQ];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 131
Informatik I 2 Theorie
(Fortsetzung)
While[Length[transformed] > 0,
transformed =
Union[Join @@
Map[TransformWord[#, rules] &, transformed]];
result = Join[result,
Select[transformed, recognizedQ]]
];
If[Length[result] == 0,
Print["Unknown word!"],
result
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 132
Informatik I 2 Theorie
parseWord[a, b, c, rules]
--> S[a, B[b, c]], S[A[a, b], c]
Es gibt zwei verschiedene, offensichtlicheAbleitungen. Wir visualisieren diese ver-schachtelten Ausdrucke:Flatten[%] // TreeForm
List
S
a B
b c
S
A
a b
c
parseWord[a, c, b, rules] --> Unknown word!
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 133
Informatik I 2 Theorie
Backus-Naur Form (BNF) a
Syntaktisch korrekte Programme in gangigen Programmiersprachenlassen sich durch kontextfreie Grammatiken beschreiben. In diesemZusammenhang notiert man die Produktionen auch anders, z.B.:
< Ausdruck > ::= < Ausdruck > + < Ausdruck > |< Ausdruck > ∗ < Ausdruck > |(< Ausdruck >) | bez
Eine einfacher zu lesende Alternative sind Syntaxdiagramme :Ausdruck Ausdruck
AusdruckAusdruck
+
*
( Ausdruck )
Bezeichner
Jeder Weg von links nachrechts ist zulassig.
aJ. Backus, P. Naur, im Zusammenhang mit der Einfuhrung der ProgrammierspracheAlgol 60.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 134
Informatik I 2 Theorie
Regul are Grammatiken
Eine regulare Grammatik heißt recht-linear , wenn die Produktionendie Form haben:
A→ wB , A→ w
Eine regulare Grammatik heißt links-linear , wenn die Produktionendie Form haben:
A→ Bw , A→ w
Beispiel
Die Sprache 0(10)∗ wird von der rechts-linearen Grammatik
S → 0 | 0AA→ 1B
B → 0 | 0A
erzeugt.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 135
Informatik I 2 Theorie
Endliche Automaten
Ein deterministischer, endlicher Automat (DFA) M = (Z, Σ, δ, z0, E)
ist definiert durch
Z die Menge der Zust ande ,
Σ das Eingabealphabet , Z ∩ Σ = ∅,δ : Z × Σ→ Z die Uberfuhrungsfunktion ,
z0 ∈ Z den Startzustand,
E ⊆ Z die Menge der Endzust ande .
Wir veranschaulichen DFAs durch ihren Zustandsgraphen , einen ge-richteten Graphen mit den Zustanden als Knoten.
Kanten werden gemaß der Definition der Uberfuhrungsfunktion be-schriftet, d.h. die Kante von z1 nach z2 mit a ∈ Σ, wenn δ(z1, a) = z2.Ebenso werden der Startzustand und die Endzustande kenntlich ge-macht.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 136
Informatik I 2 Theorie
Beispiel
M =(z0, z1, z2, z3, 0, 1, δ, z0, z0
)
0
1
0
1
0
1
0
1
z0z2
z1z3
δ wird durch eine Tabelle fur dieZustandsubergange definiert:
0 1
z0 z2 z1
z1 z3 z0
z2 z0 z3
z3 z1 z2
z0 ist hier sowohl Startzustand (schwarzer Rahmen) als auch einzigerEndzustand (grauer Hintergrund).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 137
Informatik I 2 Theorie
Wir definieren mittels der Ubergangsfunktion δ : Z × Σ→ Z dieauf Worter erweiterte Ubergangsfunktion δ : Z × Σ∗ → Z:
δ(z, ε) = z
δ(z, aw) = δ(δ(z, a), w
), z ∈ Z , a ∈ Σ , w ∈ Σ∗ .
Beispiel (Forts.)
δ(z0, 1) = δ(δ(z0, 1), ε
)= δ(z1, ε) = z1
δ(z0, 11) = δ(δ(z0, 1), 1
)= δ(
δ(δ(z0, 1), 1
), ε)
= z0
δ(z0, 110) = δ(δ(z0, 1), 10
)= δ(
δ(δ(z0, 1), 1,
), 0)
= δ
(
δ(
δ(δ(z0, 1), 1
), 0)
, ε
)
= z2
Die von M akzeptierte Sprache ist
T (M) =w ∈ Σ∗ ∣∣ δ(z0, w) ∈ E
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 138

Informatik I 2 Theorie
Satz
Jede durch einen endlichen Automaten M erkennbare Spra-che T (M) ist regular (Typ 3).
Wir geben fur einen gegebenen DFA M eine regulare Grammatik G =
(V, Σ, P, S) zu mit L(G) = T (M).
Es ist V = Z und S = z0. P besteht aus den folgenden Regeln:Jeder Zustandsubergang
δ(z1, a) = z2
ergibt eine Regel
z1 → az2 ∈ P ,
sowie, falls z2 ∈ E, zusatzlich die Regel
z1 → a ∈ P .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 139
Informatik I 2 Theorie
Beispiel (Forts.)
z0 → 0z2 z0 → 1z1
z1 → 0z3 z1 → 1z0
z1 → 1
z2 → 0z0 z2 → 1z3
z2 → 0
z3 → 0z1 z3 → 1z2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 140
Informatik I 2 Theorie
Endliche Automaten mit Ausgabe
Bei einer Moore-Automat M = (Z, Σ, ∆, δ, λ, z0) sind Z, Σ, δ und z0
wie bei einem DFA definiert. ∆ ist das Ausgabealphabet , und
λ : Z → ∆
die Ausgabefunktion. Eine Eingabe w1w2 . . . wn erzeugt die Ausgabeλ(z0)λ(z1) . . . λ(zn), wenn z0 . . . zn die Zustandsfolge mit δ(zi−1, wi) =
zi , i = 1, . . . , n, ist. Die leere Eingabe ε erzeugt die Ausgabe λ(z0).
Ein Melay-Automat unterscheidet sich von dem Moore-Automat nurdurch die Definition
λ : Z × Σ→ ∆
der Ausgabefunktion. Eine Eingabe w1 . . . wn erzeugt die Ausgabeλ(z0, w1) . . . λ(zn−1, wn). Die leere Eingabe ε erzeugt die Ausgabe ε.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 141
Informatik I 2 Theorie
Beispiel (Moore-Automat)
M soll eine binare Zeichenketten w als Eingabe akzeptieren und nachjedem Zeichen den Rest ausgeben, den man bei Division durch 3 der-jenigen ganzen Zahl x erhalt, welche durch die bisher eingelesenenZeichen reprasentiert wird.
Sei w1w2 . . . wi die Binardarstellung von x. Dann gilt w1w2 . . . wi0 =
2x und w1w2 . . . wi1 = 2x + 1.
Ist r = xmod 3, dann gilt (2x) mod 3 = (2r) mod 3 bzw. (2x+1) mod 3 =
(2r + 1) mod 3. Dies ergibt die Ubergange und den Automat
r/wi+1 0 1
0 0 1
1 2 0
2 1 2
10
1
0
01z0 z1 z2
λ(zr) = r , r = 0, 1, 2 .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 142

Informatik I 2 Theorie
Nichtdeterministische Automaten (NFA)
Bei einem NFA kann es bei der gleichen Eingabe Ubergange zu meh-reren Zustanden geben.
a az1z2 z3
Erfolgt die Eingabe a, so kann der Automat sowohl in den Zustand z2
oder z3 ubergehen.
Ein Wort w ∈ Σ∗ wird erkannt, wenn eine Zustandsfolge existiert, dieauf einen Endzustand fuhrt.
Gegenuber dem DFA wird eine Menge von Startzustanden zugelas-sen.
Beispiel: Der NFA akzeptiert das Wort w = 0 und alle 0/1-Worter, diemit 00 enden.
0È1 0 0z0 z1 z2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 143
Informatik I 2 Theorie
Ein nichtdeterministischer, endlicher Automat (NFA)M = (Z, Σ, δ, S, E) ist definiert durch
Z die Menge der Zust ande ,
Σ das Eingabealphabet , Z ∩ Σ = ∅,δ : Z × Σ→ P(Z) die Uberfuhrungsfunktion ,
S ⊆ Z die Menge der Startzustande,
E ⊆ Z die Menge der Endzust ande .
Analog zum DFA mittels der Ubergangsfunktion δ : Z × Σ → P(Z)
eine Funktion δ : P(Z)× Σ∗ → P(Z) definiert werden:
δ(Z ′, ε) = Z ′ , δ(Z ′, aw) =⋃
z∈Z′
δ(δ(z, a), w
), fur alle Z ′ ⊆ Z .
Die von M akzeptierte Sprache ist
T (M) =w ∈ Σ∗ ∣∣ δ(S, w) ∩ E 6= ∅
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 144
Informatik I 2 Theorie
Satz
Jede von einem NFA akzeptierbare Sprache ist auch durcheinen DFA akzeptierbar.
Wir konstruieren fur einen geg. NFA M = (Z, Σ, δ, S, E) einen DFA
M ′ = (Z, Σ, δ′, z′0, E′),
der T (M) akzeptiert.
Z = P(Z) ,
δ′(Z ′, a) = δ(Z ′, a) =⋃
z∈Z′
δ(z, a) ,
z′0 = S ,
E′ =Z ′ ∈ Z
∣∣Z ′ ∩ E 6= ∅
.
Wir betrachten alle Teilmen-gen von Zustanden als Ein-zelzustande. δ wurde auf Sei-te 138 definiert. Die Teilmen-ge der Startzustande (NFA) de-finiert den Startzustand (DFA).E′ ergibt sich aus der Definitionvon T (M).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 145
Informatik I 2 Theorie
Viele Zustande aus Z konnen von z′0 aus nicht erreicht und deshalbentfernt werden.
Beispiel
NFA:
0È1 0 0z0 z1 z2
DFA:
10 0
11
0
z0 z1
z0z0 z1 z2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 146

Informatik I 2 Theorie
Satz
Fur jede regulare Grammatik G gibt es einen NFA M mitL(G) = T (M).
Fur gegebene Grammatik G = (V, Σ, P, S) ist ein NFA M = (Z, Σ, δ, S′, E)
mit den geforderten Eigenschaften (X ist ein zusatzlich eingefuhrterZustand):
Z = V ∪ X ,
S′ = S ,
E = X ,
B ∈ δ(A, a) falls A→ aB ∈ P , ∀A, B ∈ V , ∀a ∈ Σ ,
X ∈ δ(A, a) falls A→ a ∈ P ∀A ∈ V , ∀a ∈ Σ .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 147
Informatik I 2 Theorie
Beispiel
Fur die Grammatik von Seite 135 erhalten wir
Z = S, A, B, X , δ(S, 0) = A, X , δ(S, 1) = ∅ ,
δ(A, 0) = ∅ , δ(A, 1) = B , δ(B, 0) = A, X , δ(B, 1) = ∅ .
0
0 10
0
S A
X B
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 148
Informatik I 2 Theorie
Minimale Automaten
Einer gegebene Sprache L ⊆ Σ∗ ordnen wir eine AquivalenzrelationRL ⊆ Σ∗ × Σ∗ zu.
xRLy ⇔(
∀z ∈ Σ∗ , xz ∈ L ⇔ yz ∈ L)
Wegen z = ε gilt insbesondere x ∈ L ⇔ y ∈ L.
Beispiel
L sei die Sprache (0|1)∗00. Beliebige Worter x, y ∈ L, also alle 0/1-Worter, die mit 00 enden, sind aquivalent, da x0, y0 ∈ L und x1, y1 6∈L, und sie sich bezuglich der Mitgiedschaft in L gleich verhalten beiVerkettung mit beliebigen Wortern z ∈ Σ∗. Wir bezeichnen dieseAquivalenzklasse mit dem einfachsten Reprasentaten (vgl. Seite 45)
[00]RL
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 149
Informatik I 2 Theorie
Worter x, y 6∈ L enden mit 01, 10 oder 11. Davon sind Worter, die mit01 und 11 enden, aquivalent, nicht jedoch Worter, die mit 01 bzw. 10
enden: 010 6∈ L, 100 ∈ L. Es gibt also zwei weitere Aquivalenzklassen
[ε]RL= [01]RL
= [11]RLund [10]RL
.
Wir ordnen L eine weitere Aquivalenzrelation RM zu.Sei M = (Z, 0, 1, δ, z0, E) der L erkennende DFA: L = T (M). Danngelte (vgl. Seite 138)
xRMy ⇔ δ(z0, x) = δ(z0, y) ,
d.h. Worter x, y sind aquivalent, wenn sie als Eingabe M in den glei-chen Zustand uberfuhren.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 150

Informatik I 2 Theorie
Sei nun z ∈ Σ∗ beliebig und xRMy. Dann folgt
xz ∈ L⇔ δ(z0, xz) ∈ E
⇔ δ(δ(z0, x), z
)∈ E
⇔ δ(δ(z0, y), z
)∈ E (Annahme)
⇔ δ(z0, yz) ∈ E
⇔ yz ∈ L
Diese Beziehungen gelten auch, wenn wir ∈ durch 6∈ ersetzen. AusxRMy folgt also xRLy, d.h. RM ⊆ RL: Die durch RL definierte Zerle-gung von Σ∗ ist grober als diejenige von RM . Folglich ist die Anzahlder Aquivalenzklassen bzgl. RL kleiner als diejenige bzgl. RM , unddamit insbesondere endlich.
Satz
Eine Sprache L ist genau dann regular, wenn der Index vonRL (Anzahl der Aquivalenzklassen) endlich ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 151
Informatik I 2 Theorie
Wir konstruieren einen DFA ML = (Z, Σ, δ, z0, E), der L erkennt. Sei-en [x1], [x2], . . . , [xI ] die Aquivalenzklassen (wir lassen den Index RL
weg), und [x] bezeichne irgendein Element dieser Menge.
Z =[ε], [x1], . . . , [xk]
, δ
([x], a
)= [xa] ,
z0 = [ε] , E =[x] ∈ Z
∣∣x ∈ L
.
Da RM ⊆ RL = RML, hat RML
die minimale Anzahl von Zustanden.
Beispiel (Forts.)Wir erhalten die Zustandsubergange
0 1
[ε] [10] [ε]
[10] [00] [ε]
[00] [00] [ε]
1
01
0
0
1
@ΕD
@10D@00D
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 152
Informatik I 2 Theorie
Minimierung der Zust ande
Da RM ⊆ RL, ist ein L erkennender DFA M nicht unbedingt minimal.
Beispiel
0 1
01
1
00È1
01 z0
z1
z2
z4
z3 Seien x, y ∈ Σ∗
Worter mit δ(z0, x) =
z1 und δ(z0, y) = z3.Dann gilt beispiels-weise nicht xRMy,wohl aber xRLy.
Wir konnen diese beiden Aquivalenzklassen (bzgl. RM ) vereinigen,da fur beliebige w ∈ Σ∗ gilt
δ(z1, w) ∈ E ⇔ δ(z3, w) ∈ E ,
wegen der RL-Aquivalenz von x, y.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 153
Informatik I 2 Theorie
Algorithmus zur Minimierung der Zahl der Zustande eines DFA(Illustration am obigen Beispiel).
(1) Stelle eine Tabelle allerverschiedener Zustandspaareauf (obere oder untere Drei-eckshalfte; der Rest wird igno-riert).
z0 z1 z2 z3 z4
z0 –
z1 – –
z2 – – –
z3 – – – –
z4 – – – – –
(2) Markiere alle Paare (z, z′)
mit z ∈ E, z′ 6∈ E odermit z 6∈ E, z′ ∈ E.
z0 z1 z2 z3 z4
z0 – ×
z1 – – ×
z2 – – – ×
z3 – – – – ×
z4 – – – – –
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 154
Informatik I 2 Theorie
(3) Markiere alle unmarkiertenPaare (z, z′) fur die ein Zeichena ∈ Σ existiert, sodass das Zu-standspaar
(δ(z, a), δ(z′, a)
)
markiert ist.
z0 z1 z2 z3 z4
z0 – × × ×
z1 – – × ×
z2 – – – × ×
z3 – – – – ×
z4 – – – – –
(4) Iteriere den vorigen Schritt,bis sich nichts mehr andert.
z0 z1 z2 z3 z4
z0 – × × ×
z1 – – × ×
z2 – – – × ×
z3 – – – – ×
z4 – – – – –
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 155
Informatik I 2 Theorie
(5) Alle unmarkierten Paare konnen zu jeweils zu einem Zustandvereinigt werden.
10
10 0È1z0 z2 z1 z3 z4
Dieser minimale DFA erkennt die Sprache (0|1)∗00(0|1)∗. Die Zustandeentsprechen den Aquivalenzklassen [ε], [0], [00].
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 156
Informatik I 2 Theorie
Regul are Ausdrucke
Regulare Ausdrucke sind spezielle Formeln zur Beschreibung regularerSprachen. Definition:
• ∅, ε und jedes a ∈ Σ sind regulare Ausdrucke.
• Sind α, β regulare Ausdrucke, so auch αβ, (α|β) und (α)∗.
Regularen Ausdrucken sind eindeutig formale Sprachen zugeordnet.
Regularer Ausdruck γ Sprache L(γ)
γ = ∅ L(γ) = ∅γ = ε L(γ) = εγ = a L(γ) = a
γ = αβ L(γ) = L(α)L(β)
γ = (α|β) L(γ) = L(α) ∪ L(β)
γ = (α)∗ L(γ) = L(α)∗
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 157
Informatik I 2 Theorie
Beispiele
(0|1)∗ Alle 0/1-Worter.
(0|1)∗00(0|1)∗ Alle 0/1-Worter, die mindestens zwei aufeinander-
folgende Nullen enthalten.
(1|10)(1|10)∗ Alle 0/1-Worter, die mit einer Eins beginnen und
keine zwei aufeinanderfolgende Nullen enthalten.
(0|ε)(1|10)∗ Alle 0/1-Worter, die keine zwei aufeinanderfolgende
Nullen enthalten.
0∗1∗2∗ Verkettung einer jeweils beliebigen Anzahl von Nullen,
Einsen und Zweien.
00∗11∗22∗ Wie voriges Beispiel, aber jedes Zeichen muss
mindestens einmal vorkommen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 158

Informatik I 2 Theorie
Analog zur Definition regularer Ausdrucke konstruieren wir endlichenicht-deterministische Automaten (NFAs), welche die zugeordnetenSprachen erkennen.
• Dem Ausdruck ∅ entspricht ein DFA mit einem Startzustand z0
und einem isolierten Endzustand z1, der nicht erreicht werdenkann.
• Dem Ausdruck ε entspricht ein DFA mit einem einzigen Startzu-stand, der gleichzeitig Endzustand ist.
• Dem Ausdruck a entspricht der DFA z0a−→ z1 .
Sei γ = αβ und Mα, Mβ die NFAs mit T (Mα) = L(α), T (Mβ) = L(β).
• Mγ hat die Startzustande von Mα und die Endzustande von Mβ .
• Ist ε ∈ L(α), so sind auch die Startzustande von Mβ Startzustandevon Mγ .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 159
Informatik I 2 Theorie
• Alle Zustande von Mα, die in einen Endzustand von Mα ubergehenkonnen, erhalten zusatzlich die gleich markierte Kanten zu denStartzustanden von Mβ .
Beispiel γ = αβ , α = (0|1)∗ , β = 00. NFAs und result. DFA:
0È1 z0
0 0z0 z1 z2
0È1 0È1 0 0z0 z1 z2 z3
0
1
0
1
0
1
z0 z1
z0 z1 z2z0 z1 z2 z3
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 160
Informatik I 2 Theorie
Sei γ = (α|β). Dann ist
Mγ =(Zα ∪ Zβ, Σ, δα ∪ δβ , Sα ∪ Sβ , Eα ∪ Eβ
)
Sei γ = (α)∗.
• Ist ε 6∈ L(α), dann fuge einen neuen isolierten Zustand hinzu,der zugleich Start- und Endzustand ist. Dadurch wird zusatzlich ε
erkannt.
• Mγ hat die gleichen Start- und Endzustande wie Mα, Fuge furjeden Zustandsknoten, der in einen der (ursprunglichen) End-zustande ubergehen kann, die gleich markierte Kante zu jedemStartzustand hinzu.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 161
Informatik I 2 Theorie
Beispiel
γ = 01∗|1.
Parallelschaltung (Vereinigung) zweier NFAs ...
01 z0z1
1 z2z3
... und resultierender DFA.
0 11 z0 z2z1 z3
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 162

Informatik I 2 Theorie
2.8 – Aufwand von Algorithmen
Unabhangig von der technischen Entwicklung stoßen anspruchsvolleComputeranwendungen in der Wissenschaft und in der Industrie oftan die Grenzen der verfugbaren Rechen- und Speicherkapazitat, dersog. Ressourcen .
In diesem Zusammenhang unterscheidet man
• die Große n eines Problems abhangig von der Eingabe,
• den Aufwand T (n) eines Algorithmus, ausdruckt durch die An-zahl der Zeit- und Speichereinheiten, als Funktion der Problem-große.
Beispiele fur Eingabegroßen:
Sortieralgorithmus: Anzahl der zu ordnenden Elemente
Graphalgorithmus: Anzahl der Knoten und Kanten
Fibonaccizahl F (n): Wert von n
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 163
Informatik I 2 Theorie
Beispiel
Der Aufwand des Algorithmus
mySum[term_, a_, b_] :=
If[a > b, 0, term[a] + mySum[term, a + 1, b]]
ist unter der Annahme, dass term[ ] in konstanter Zeit ausgewertetwerden kann, mit n = b− a + 1 gleich
T (n) = c1n + c2 , c1, c2 konstant .
Man sagt, der Aufwand ist linear .
Der Zeitaufwand T (n) wird bis auf konstante Faktoren untersucht, umvon unterschiedlichen Rechner, Implementierungen einer Program-miersprache, usw. zu abstrahieren.
Die Komplexit at eines Problems ist der geringstmogliche Aufwandmit dem man das Problem algorithmisch losen kann. Diese Schrankegilt also fur jeden Algorithmus.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 164
Informatik I 2 Theorie
Man unterscheidet den gunstigsten Aufwand (best case), den mitt-leren oder erwarteten Aufwand (average case), und den ungunst-igsten Aufwand (worst case).
Der erwartete Aufwand eines Algorithmus, gemittelt uber alle Einga-ben gleicher Große, ist oft deutlich besser als der ungunstigste Auf-wand, und insbesondere bei schwierigen kombinatorischen Proble-men praktisch relevant.
Der asymptotische Aufwand ist die Abhangigkeit des Aufwands furn → ∞. Dieser ist gewohnlich gemeint, wenn man von “Aufwand”spricht.
Wir beschranken uns im folgenden auf den Zeitaufwand T (n).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 165
Informatik I 2 Theorie
Die wesentlichen Komplexitatsklassen:
T (n) Beispiel
log n binare Suche
n lineare Suche
n log n effizientes Sortieren
n2 naives Sortieren
n3 allg. lineares Gleichungssystem losen
2n alle Teilmengen
n! alle Permutationen
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 166
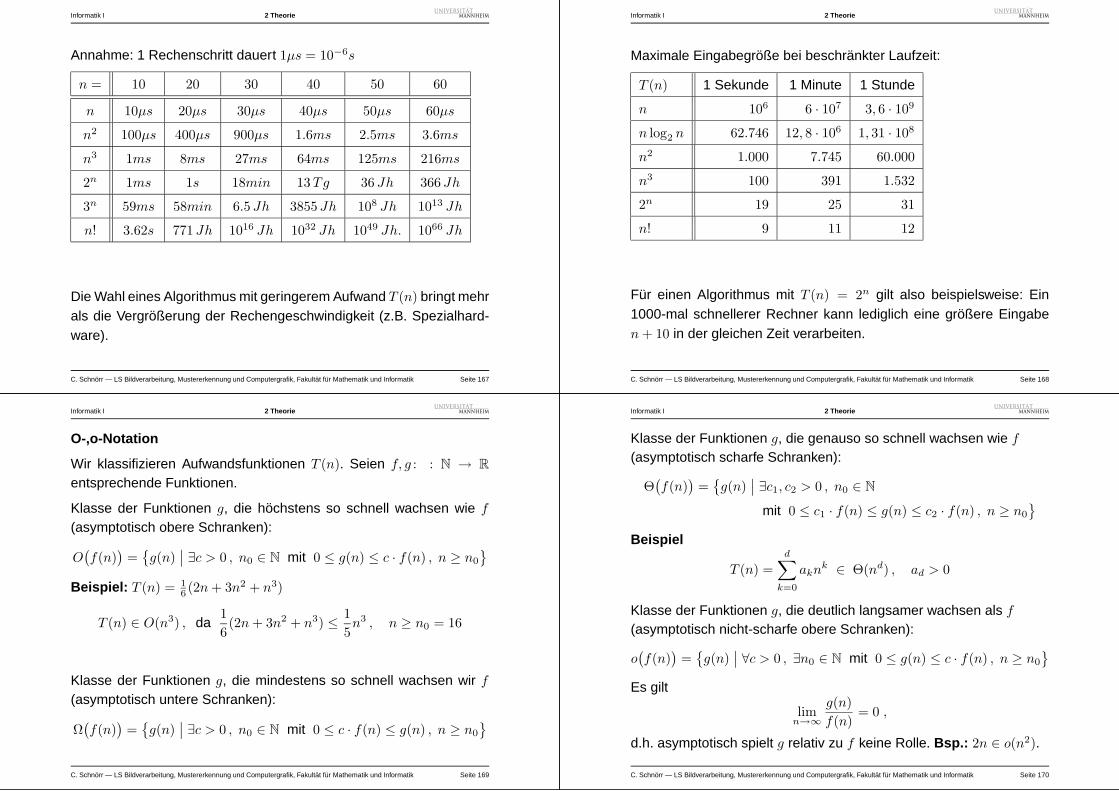
Informatik I 2 Theorie
Annahme: 1 Rechenschritt dauert 1µs = 10−6s
n = 10 20 30 40 50 60
n 10µs 20µs 30µs 40µs 50µs 60µs
n2 100µs 400µs 900µs 1.6ms 2.5ms 3.6ms
n3 1ms 8ms 27ms 64ms 125ms 216ms
2n 1ms 1s 18min 13 Tg 36 Jh 366 Jh
3n 59ms 58min 6.5 Jh 3855 Jh 108 Jh 1013 Jh
n! 3.62s 771 Jh 1016 Jh 1032 Jh 1049 Jh. 1066 Jh
Die Wahl eines Algorithmus mit geringerem Aufwand T (n) bringt mehrals die Vergroßerung der Rechengeschwindigkeit (z.B. Spezialhard-ware).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 167
Informatik I 2 Theorie
Maximale Eingabegroße bei beschrankter Laufzeit:
T (n) 1 Sekunde 1 Minute 1 Stunde
n 106 6 · 107 3, 6 · 109
n log2 n 62.746 12, 8 · 106 1, 31 · 108
n2 1.000 7.745 60.000
n3 100 391 1.532
2n 19 25 31
n! 9 11 12
Fur einen Algorithmus mit T (n) = 2n gilt also beispielsweise: Ein1000-mal schnellerer Rechner kann lediglich eine großere Eingaben + 10 in der gleichen Zeit verarbeiten.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 168
Informatik I 2 Theorie
O-,o-Notation
Wir klassifizieren Aufwandsfunktionen T (n). Seien f, g : : N → R
entsprechende Funktionen.
Klasse der Funktionen g, die hochstens so schnell wachsen wie f
(asymptotisch obere Schranken):
O(f(n)
)=g(n)
∣∣ ∃c > 0 , n0 ∈ N mit 0 ≤ g(n) ≤ c · f(n) , n ≥ n0
Beispiel: T (n) = 16 (2n + 3n2 + n3)
T (n) ∈ O(n3) , da1
6(2n + 3n2 + n3) ≤ 1
5n3 , n ≥ n0 = 16
Klasse der Funktionen g, die mindestens so schnell wachsen wir f
(asymptotisch untere Schranken):
Ω(f(n)
)=g(n)
∣∣ ∃c > 0 , n0 ∈ N mit 0 ≤ c · f(n) ≤ g(n) , n ≥ n0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 169
Informatik I 2 Theorie
Klasse der Funktionen g, die genauso so schnell wachsen wie f
(asymptotisch scharfe Schranken):
Θ(f(n)
)=g(n)
∣∣ ∃c1, c2 > 0 , n0 ∈ N
mit 0 ≤ c1 · f(n) ≤ g(n) ≤ c2 · f(n) , n ≥ n0
Beispiel
T (n) =d∑
k=0
aknk ∈ Θ(nd) , ad > 0
Klasse der Funktionen g, die deutlich langsamer wachsen als f
(asymptotisch nicht-scharfe obere Schranken):
o(f(n)
)=g(n)
∣∣ ∀c > 0 , ∃n0 ∈ N mit 0 ≤ g(n) ≤ c · f(n) , n ≥ n0
Es gilt
limn→∞
g(n)
f(n)= 0 ,
d.h. asymptotisch spielt g relativ zu f keine Rolle. Bsp.: 2n ∈ o(n2).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 170
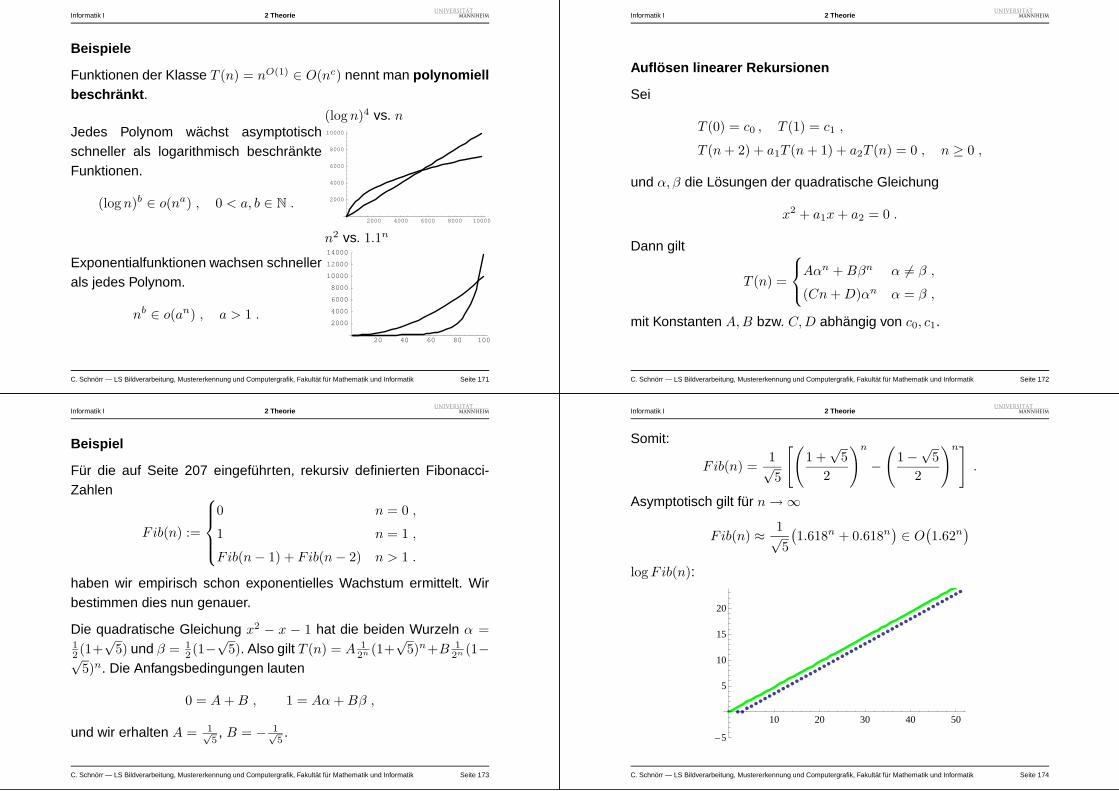
Informatik I 2 Theorie
Beispiele
Funktionen der Klasse T (n) = nO(1) ∈ O(nc) nennt man polynomiellbeschr ankt .
Jedes Polynom wachst asymptotischschneller als logarithmisch beschrankteFunktionen.
(log n)b ∈ o(na) , 0 < a, b ∈ N .
(log n)4 vs. n
2000 4000 6000 8000 10000
2000
4000
6000
8000
10000
Exponentialfunktionen wachsen schnellerals jedes Polynom.
nb ∈ o(an) , a > 1 .
n2 vs. 1.1n
20 40 60 80 100
2000
4000
6000
8000
10000
12000
14000
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 171
Informatik I 2 Theorie
Aufl osen linearer Rekursionen
Sei
T (0) = c0 , T (1) = c1 ,
T (n + 2) + a1T (n + 1) + a2T (n) = 0 , n ≥ 0 ,
und α, β die Losungen der quadratische Gleichung
x2 + a1x + a2 = 0 .
Dann gilt
T (n) =
Aαn + Bβn α 6= β ,
(Cn + D)αn α = β ,
mit Konstanten A, B bzw. C, D abhangig von c0, c1.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 172
Informatik I 2 Theorie
Beispiel
Fur die auf Seite 207 eingefuhrten, rekursiv definierten Fibonacci-Zahlen
Fib(n) :=
0 n = 0 ,
1 n = 1 ,
F ib(n− 1) + Fib(n− 2) n > 1 .
haben wir empirisch schon exponentielles Wachstum ermittelt. Wirbestimmen dies nun genauer.
Die quadratische Gleichung x2 − x − 1 hat die beiden Wurzeln α =12 (1+
√5) und β = 1
2 (1−√
5). Also gilt T (n) = A 12n (1+
√5)n+B 1
2n (1−√5)n. Die Anfangsbedingungen lauten
0 = A + B , 1 = Aα + Bβ ,
und wir erhalten A = 1√5, B = − 1√
5.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 173
Informatik I 2 Theorie
Somit:
Fib(n) =1√5
[(
1 +√
5
2
)n
−(
1−√
5
2
)n]
.
Asymptotisch gilt fur n→∞
Fib(n) ≈ 1√5
(1.618n + 0.618n
)∈ O
(1.62n
)
log Fib(n):
10 20 30 40 50
-5
5
10
15
20
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 174
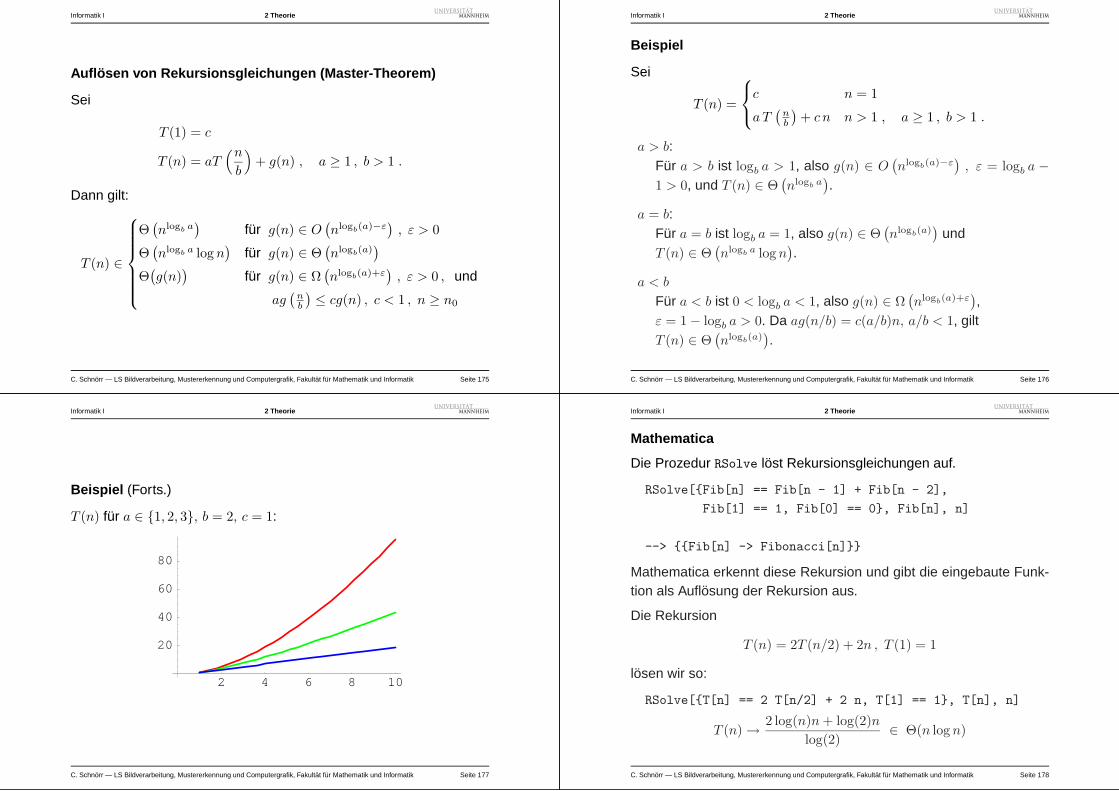
Informatik I 2 Theorie
Aufl osen von Rekursionsgleichungen (Master-Theorem)
Sei
T (1) = c
T (n) = aT(n
b
)
+ g(n) , a ≥ 1 , b > 1 .
Dann gilt:
T (n) ∈
Θ(nlog
ba)
fur g(n) ∈ O(nlog
b(a)−ε
), ε > 0
Θ(nlog
ba log n
)fur g(n) ∈ Θ
(nlog
b(a))
Θ(g(n)
)fur g(n) ∈ Ω
(nlog
b(a)+ε
), ε > 0 , und
ag(
nb
)≤ cg(n) , c < 1 , n ≥ n0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 175
Informatik I 2 Theorie
Beispiel
Sei
T (n) =
c n = 1
a T(
nb
)+ c n n > 1 , a ≥ 1 , b > 1 .
a > b:Fur a > b ist logb a > 1, also g(n) ∈ O
(nlog
b(a)−ε
), ε = logb a −
1 > 0, und T (n) ∈ Θ(nlog
ba).
a = b:Fur a = b ist logb a = 1, also g(n) ∈ Θ
(nlog
b(a))
undT (n) ∈ Θ
(nlog
ba log n
).
a < b
Fur a < b ist 0 < logb a < 1, also g(n) ∈ Ω(nlog
b(a)+ε
),
ε = 1− logb a > 0. Da ag(n/b) = c(a/b)n, a/b < 1, giltT (n) ∈ Θ
(nlog
b(a)).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 176
Informatik I 2 Theorie
Beispiel (Forts.)
T (n) fur a ∈ 1, 2, 3, b = 2, c = 1:
2 4 6 8 10
20
40
60
80
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 177
Informatik I 2 Theorie
Mathematica
Die Prozedur RSolve lost Rekursionsgleichungen auf.
RSolve[Fib[n] == Fib[n - 1] + Fib[n - 2],
Fib[1] == 1, Fib[0] == 0, Fib[n], n]
--> Fib[n] -> Fibonacci[n]
Mathematica erkennt diese Rekursion und gibt die eingebaute Funk-tion als Auflosung der Rekursion aus.
Die Rekursion
T (n) = 2T (n/2) + 2n , T (1) = 1
losen wir so:
RSolve[T[n] == 2 T[n/2] + 2 n, T[1] == 1, T[n], n]
T (n)→ 2 log(n)n + log(2)n
log(2)∈ Θ(n log n)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 178
Informatik I 3 Programmierung
3 – Programmierung
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 178
Informatik I 3 Programmierung
3.1 – Elementare Datentypen
In Mathematica gibt es atomare und zusammengesetzte Ausducke.
Atomare Ausdrucke:
• Symbole : a, radius, XY, ...
• Zeichenketten (strings), eingeschlossen durch doppelte Hoch-kommatas: “ccccc”, “Heidelberg”, ...
• Zahlen des Typs
– Integer: ganze Zahlen; Eingabe z.B. 1, 312, -79346
– Real: Gleitkomma-Zahlen; Eingabe z.B. 5.3, 10.^-2, -8.34^-1
– Rational: rationale Zahlen; Eingabe z.B. 3/5, 9/(35+2)
– Complex: komplexe Zahlen; Eingabe z.B. 3+5I, 5/(I+3)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 179
Informatik I 3 Programmierung
Jeder korrekte Term (Ausdruck ) in Mathematica hat die Form
h[a, b, ...]
wobei h und a, b, ... wiederum Terme sind. h ist der Kopf (Head ) desAusdrucks. Er wird mit der Funktion Head[〈Ausdruck〉] bestimmt.
Ubliche Notation Mathematica
1 1 , Head[1] → Integer
1.25 1.25 , Head[1.25] → Real
35 Rational[3, 5]
3 + 5i Complex[3, 5]
a + b Plus[a, b]
a == b Equal[a, b]
Der Kopf eines Terms kann ein Operator, ein Symbol, und allgemeinein beliebiger Ausdruck sein.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 180
Informatik I 3 Programmierung
Mathematica erlaubt meistens die Eingabe von Termen in der ublichenForm, wie z.B. 3/5, 3 + 5I, a + b, usw.
Achtung: a == b ist die bequemere Eingabeform von Equal[a, b],nicht a = b (Benennung, Zuweisung).
Ausdrucke konnen mit geschweiften Klammern zu einer Liste zusam-mengefasst werden:
Eingabe Interne Reprasentation
a, b, c List[a, b, c]
“Heidelberg′′, Sqrt[2] List[”Heidelberg”, Power[2, Rational[1, 2]]]
Listen sind also korrekte Ausdrucke mit dem Kopf List.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 181

Informatik I 3 Programmierung
Weitere Beispiele zusammengesetzter (nicht-atomarer) Ausdrucke:
Eingabe Interne Reprasentation
(a + b) ∗ c + d Plus[Times[Plus[a, b], c], d]
−a ∗ b2 + c ∗ (a + d) Plus[Times[−1, a, Power[b, 2]], Times[c, Plus[a, d]]]
a, b, c, d, e2 List[a, b, List[c, d], Power[e, 2]]
Auch dies ist ein korrekter Ausdruck: Derivative[1][d][x]
Derivative︸ ︷︷ ︸
Kopf
[ 1︸︷︷︸
Argument
]
︸ ︷︷ ︸
Kopf
[ f︸︷︷︸
Argument
]
︸ ︷︷ ︸
Kopf
[ x︸︷︷︸
Argument
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 182
Informatik I 3 Programmierung
3.2 – Funktionen
Atomare Ausdrucke sind die kleinsten Einheiten der Programmier-sprache.
Wir haben bereits arithmetische Ausdrucke kennengelernt, welcheatomare Ausdrucke kombinieren, z.B. Plus[a,b]
Das Symbol Plus bezeichnet hier die Funktion, welche die Sum-me der Argumente – hier a und b – ergibt. Diese Bedeutung ist inMathematica, wie die vieler anderer Funktionen, schon “eingebaut”.(Zusatzlich erlaubt Mathematica die bequemere Eingabe des Aus-drucks: a + b).
Wir lernen in diesem Abschnitt eigene Funktionen zu definieren.
Abstraktion durch Benennung einer Kombination von Ausdrucken,welche dann als Einheit verwendet werden kann, ist ein wesentlichesMerkmal der Programmierung.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 183
Informatik I 3 Programmierung
Definition von Funktionen
Wir beginnen mit einem Beispiel und definieren eine Funktion, welcheeine beliebige Zahl quadriert.
quadrat[x_] := x^2
Argumente werden mit einem nach dem Bezeichner angegeben.
Mathematica kennt nun das Symbol quadrat und seine Bedeutung inder globalen Umgebung.
?quadrat
Global‘quadrat
quadrat[x_] := x^2
Wir wenden die Funktion an und lassen Mathematica die Evaluierungdes Ausdrucks ausgeben:
quadrat[5]
quadrat::trace: quadrat[5] --> 52
25
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 184
Informatik I 3 Programmierung
In der Definition von quadrat ist x ein lokaler Name, der das Argument(Operand) bezeichnet. x ist ein Platzhalter fur beliebige Werte, aufwelche die Operation quadrat angewendet werden kann.
Beim Aufruf der Funktion wird x durch den Wert des Arguments er-setzt (substituiert). Anschließend wird der resultierende Ausdruck aus-gewertet.
Der lokale Name x wird nicht mit dem Namen x eines Ausdrucks inder globalen Umgebung verwechselt.
x = "Heidelberg"
quadrat[16]
256
? x
Global‘x
x = Heidelberg
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 185

Informatik I 3 Programmierung
Mathematica weiß, dass quadrat ein Argument hat.quadrat[3, 4]
quadrat[3, 4]
Mathematica wertet Funktionen bei fehlerhafter Ein-gabe (Anzahl oder – spater – Typ der Argumente)nicht aus.
Die Funktion quadrat kann auf einen beliebigen Ausdruck angewen-det und mit beliebigen Ausdrucken kombiniert werden.
quadrat[a] --> a2
quadrat[b^3] --> b6
quadrat[2]*quadrat[3] --> 36
quadrat[quadrat[3]] --> 81
quadrat[quadrat[a] + quadrat[5]] --> (25 + a2)2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 186
Informatik I 3 Programmierung
Die Funktion quadrat kann als Baustein in weiteren Definition ver-wendet werden.
quadratsumme[a_, b_] := quadrat[a] + quadrat[b]
quadratsumme[2 + 3, 4]
quadratsumme::trace: quadratsumme[2 + 3, 4]
--> quadratsumme[5,4]
quadratsumme::trace: quadratsumme[5, 4]
--> quadrat[5]+quadrat[4]
41
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 187
Informatik I 3 Programmierung
Mit Clear “loschen” wir Definitionen.Clear [quadrat, quadratsumme]
?quadrat
Global‘quadrat
Mit Remove “loschen” wir Definitionen samt Namen.Remove[quadrat, quadratsumme]
?quadrat
Information::notfound: Symbol quadrat not found.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 188
Informatik I 3 Programmierung
Allgemeine Form der Funktionsdefinition
<Name>[ <Argumente> ] := <Rumpf>
Der Name ist mit der Definition in der Umgebung verknupft.
Die Argumente werden als Platzhalter im Rumpf zur Definition der mitName bezeichneten Operation benutzt.
Rumpf ist ein Ausdruck zur Berechnung der Funktionswertes, sobaldfur die Argumente die entsprechenden Werte des Funktionsaufrufssubstituiert worden sind.
Name und Argumente werden auch als Kopf der Funktionsdefinitionbezeichnet.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 189

Informatik I 3 Programmierung
Tipps fur den Programmentwurf
Wir gehen einige Punkte anhand der folgenden einfachen Aufgabedurch:
Entwerfen Sie ein Programm, das die Flache einer ringformigenKreisscheibe mit gegeben innerem und außerem Radius be-rechnet.
• Verstehen Sie zuerst genau den Anwendungszweck des Programms.Was sind die Eingangsdaten? Welche Daten werden produziert?
• Legen Sie einen sinnvollen Namen fest. Beginnen Sie mit ei-nem kleinen Buchstaben zur Vermeidung von Kollisionen mit vor-handenen Definitionen in Mathematica. Benutzen Sie aber auchGroßbuchstaben zur besseren Lesbarkeit, z.B.
ringFlaeche
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 190
Informatik I 3 Programmierung
• Legen Sie den Funktionskopf fest. Wahlen Sie sinnvolle Namenfur die Argumente gemaß den zu verarbeitenden Eingangsdaten.
ringFlaeche[radiusAussen_, radiusInnen_] := ...
• Fugen Sie eine Kurzbeschreibung des Programms hinzu (Anwen-dungshintergrund und -zweck).
ringflaeche berechnet die Flaeche einer Kreisringscheibe
mit den Radien radiusAussen und radiusInnen.
In Mathematica konnen diese Beschreibung direkt als Text in dasNotebook eingeben. In C++ wird die Beschreibung als Kommen-tar in die Quelltextdatei eingefugt und muß als solcher mit Son-derzeichen am Zeilenanfang gekennzeichnet werden, damit derCompiler ihn als syntaktisch korrekten Ausdruck erkennen kann.
// Kommentartext ...
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 191
Informatik I 3 Programmierung
• Geben Sie Anwendungsbeispiele an.
Beispiel: ringFlaeche[2, 1] --> 3 Pi
Es ist sinnvoll, dies vor dem eigentlichen Schreiben des Pro-gramms zu tun.
• Fullen Sie den Rumpf der Funktionsdefinition aus. Schreiben Sieeinen Ausdruck, welcher die Ausgangsdaten aus den Eingangs-daten berechnet.
Verwenden Sie schon definierte Funktionen und definieren Sieggfs. eigene Hilfsfunktionen. Dies verbessert in der Regel dieLesbarkeit des Programms.
Sparen Sie nicht mit Kommentaren.
• Geben Sie Tests an zur Detektion von Laufzeitfehlern (z.B. Sub-stitution der Argumentwerte ergibt einen inkorrekten Ausdruck)und von logischen Fehlern (das Programm tut nicht was es soll).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 192
Informatik I 3 Programmierung
ringFlaeche[radiusAussen_, radiusInnen_] :=
kreisFlaeche[radiusAussen] - kreisFlaeche[radiusInnen]
kreisFlaeche[radius_] := Pi*radius^2
Anmerkung: Die Konstante Pi ist in Mathematica schon definiert.
Anwendung:
ringFlaeche[2, 1]
ringFlaeche::trace: ringFlaeche[2, 1]
--> kreisFlaeche[2] - kreisFlaeche[1]
kreisFlaeche::trace: kreisFlaeche[2] --> π 22
kreisFlaeche::trace: kreisFlaeche[1] --> π 12
3π
Anmerkung: Wie in der Mathematik ublich kann die Multiplikation * inMathematica einfach durch das Leerzeichen ersetzt werden.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 193

Informatik I 3 Programmierung
Beispiel: Problemzerlegung und Kombination von Funktionen
Ein Kinobesitzer stellt fest, dass bei einem Eintrittspreis von5,- Euro (im Mittel) 120 Besucher eine Vorstellung besuchen.Verringert er den Preis um 10 Cent, dann kommen (im Mittel)15 Besucher mehr. Eine Vorstellung verursacht 180,- EuroFixkosten. Jeder Besucher verursacht 0.04 Euro Unkosten.
Entwerfen Sie ein Programm, welches den Gewinn fur denBesitzer als Funktion des Eintrittspreises einer Vorstellungberechnet.
Wir analysieren zunachst den Sachverhalt.
• Der Gewinn resultiert aus dem Umsatz abzuglich der Kosten.
• Der Umsatz ist Eintrittspreis mal Anzahl der Besucher.
• Die Kosten belaufen sich auf 180,- plus einem Betrag, der von derAnzahl der Besucher abhangt.
• Die Anzahl der Besucher hangt von dem Eintrittspreis ab.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 194
Informatik I 3 Programmierung
Wir definieren diese funktionalen Zusammenhange.
gewinn[eintrittsPreis_] :=
umsatz[eintrittsPreis] - kosten[eintrittsPreis]
umsatz[eintrittsPreis_] :=
besucherZahl[eintrittsPreis] * eintrittsPreis
kosten[eintrittsPreis_] :=
180 + 0.04 * besucherZahl[eintrittsPreis]
besucherZahl[eintrittsPreis_] :=
120 + 15 * (5 - eintrittsPreis)/0.1
Dieses Programm ist wesentlich lesbarer und einfacher zu warten alsdas folgende, ebenfalls korrekte Programm:
gewinn[e_] :=
-180 - 0.04 (120 + 150. (5 - e)) + (120 + 150. (5 - e)) e
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 195
Informatik I 3 Programmierung
gewinn[1] --> 511.2
gewinn[2] --> 937.2
gewinn[3] --> 1063.2
gewinn[4] --> 889.2
gewinn[5] --> 415.2
Der maximale Gewinn 1064.16 Euro wird bei einem Eintrittspreis von2, 92 Euro erzielt.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 196
Informatik I 3 Programmierung
Debugging
On[symbol1,symbol2,...] schaltet eine Trace-Funktion ein, welcheschrittweise die Auswertung der mit den Argumenten benannten Aus-drucke ausgibt.
On[gewinn, umsatz, kosten, besucherZahl]
gewinn[3]
gewinn::trace: gewinn[3] --> umsatz[3]-kosten[3]
umsatz::trace: umsatz[3] --> besucherZahl[3] 3
besucherZahl::trace: besucherZahl[3] --> 120 + 15(5−3)0.1
kosten::trace: kosten[3] --> 180+0.04 besucherZahl[3]
besucherZahl::trace: besucherZahl[3] --> 120 + 15(5−3)0.1
1063.2
Abschalten der Trace-Funktion: Off[symbol1,symbol2,...].
Die Ausgabe solch ausfuhrlicher Informationen ist nur bei einfachenProgrammen sinnvoll.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 197

Informatik I 3 Programmierung
Die FunktionTrace[ausdruck, symbol]
ermoglicht eine spezifischere Filterung. Sie wertet den Ausdruck ausdruckaus und gibt nur Transformationen im Zusammenhang mit dem Sym-bol symbol aus.
Trace[gewinn[3], kosten]
kosten[3], 180 + 0.04 besucherZahl[3]
Spater in der Vorlesung werden wir den Gebrauch von Mustern inMathematica kennenlernen, mittels derer Trace noch selektiver ein-gesetzt werden kann.
Funktionen liefern einen Funktionswert zuruck. In der Entwurfs- undTestphase interessieren auch die Werte von Ausdrucken, die “unter-wegs” berechnet werden. Solche Werte konnen mit
Sow[ausdruck]
markiert und mit der umschliessenden Funktion
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 198
Informatik I 3 Programmierung
Reap[ ... ]
“eingesammelt” werden.
BeispielWir modifizieren zwei der obigen Funktionen
gewinn[eintrittsPreis_] :=
umsatz[eintrittsPreis] - Sow[kosten[eintrittsPreis]]
kosten[eintrittsPreis_] :=
180 + 0.04*Sow[besucherZahl[eintrittsPreis]]
und erhalten neben dem Gewinn auch in der Reihenfolge der Auswer-tungen die besucherZahl und die kosten
Reap[gewinn[3]]
1063.2, 420., 196.8
Wie Trace konnen auch Sow und Reap sehr flexibel eingesetzt werden.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 199
Informatik I 3 Programmierung
3.3 – Pradikate und bedingte Ausducke
Pradikate sind Ausdrucke mit dem WertebereichTrue, False
Diese beiden Symbole bezeichnen in Mathematica dieBoolschen Wahrheitswerte .
Schreibweise im folgenden:Operator[a,b,...] oder a Kurzform b Kurzform ...
Tests (Operator(Kurzform))
Equal(==), Unequal(!=), SameQ(===), UnsameQ(=!=)
1.0 == 1 -> True bzw. Equal[1.0,1] -> True
1.0 === 1 -> False
Less(<), LessEqual(<=), Greater(>), GreaterEqual(>=)
3 <= -1 -> False
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 200
Informatik I 3 Programmierung
NumberQ, IntegerQ
NumberQ[6.151] -> True IntegerQ[6.151] -> False
und viele weitere Pradikate mehr ...
Logische Operationen
Not(!), And(&&), Or(||)
False || !False -> True
(1 < 2) && !(4 < 2) -> True
Bedingte Ausdrucke
If[predicate, t] Werte t aus, falls predicate True ergibt.If[8 > 7, x] -> x
If[7 > 8, x] -> Null
If[predicate, t, f] ... sonst fIf[7 > 8, x, y] -> y
If[predicate, t, f, u] ... u falls weder True noch False
If[x == y, a, b, c] -> c
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 201
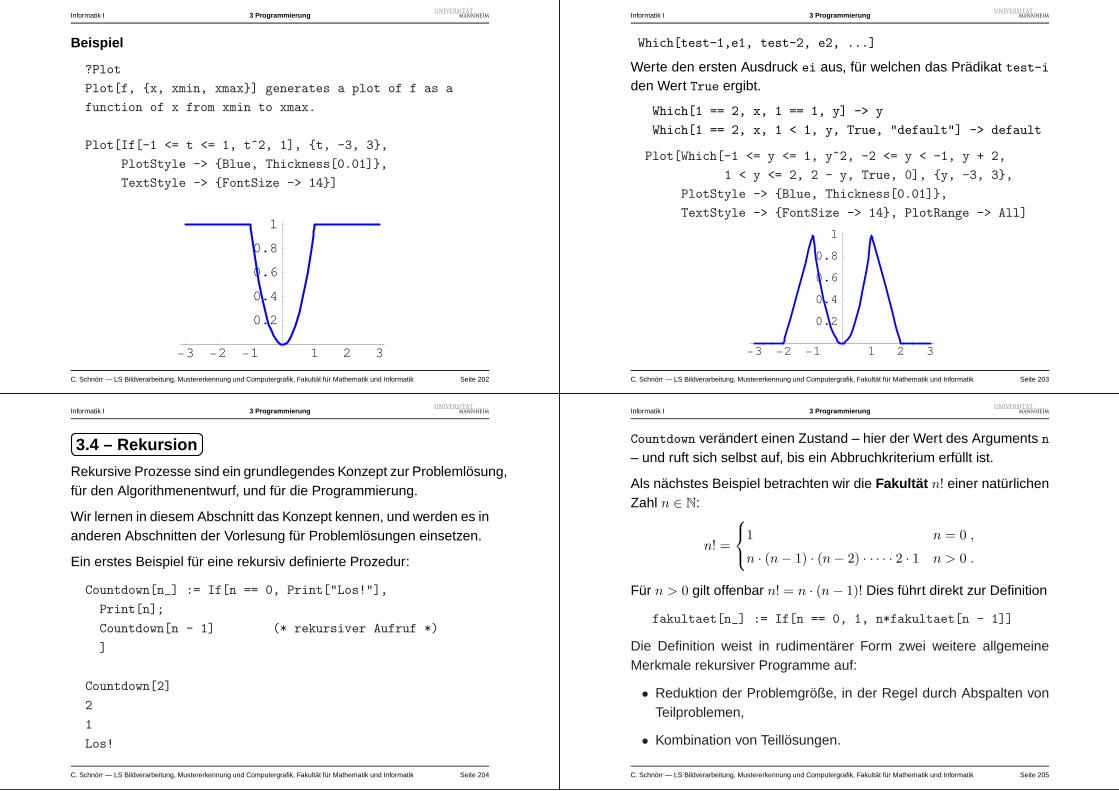
Informatik I 3 Programmierung
Beispiel
?Plot
Plot[f, x, xmin, xmax] generates a plot of f as a
function of x from xmin to xmax.
Plot[If[-1 <= t <= 1, t^2, 1], t, -3, 3,
PlotStyle -> Blue, Thickness[0.01],
TextStyle -> FontSize -> 14]
-3 -2 -1 1 2 3
0.2
0.4
0.6
0.8
1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 202
Informatik I 3 Programmierung
Which[test-1,e1, test-2, e2, ...]
Werte den ersten Ausdruck ei aus, fur welchen das Pradikat test-iden Wert True ergibt.
Which[1 == 2, x, 1 == 1, y] -> y
Which[1 == 2, x, 1 < 1, y, True, "default"] -> default
Plot[Which[-1 <= y <= 1, y^2, -2 <= y < -1, y + 2,
1 < y <= 2, 2 - y, True, 0], y, -3, 3,
PlotStyle -> Blue, Thickness[0.01],
TextStyle -> FontSize -> 14, PlotRange -> All]
-3 -2 -1 1 2 3
0.2
0.4
0.6
0.8
1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 203
Informatik I 3 Programmierung
3.4 – Rekursion
Rekursive Prozesse sind ein grundlegendes Konzept zur Problemlosung,fur den Algorithmenentwurf, und fur die Programmierung.
Wir lernen in diesem Abschnitt das Konzept kennen, und werden es inanderen Abschnitten der Vorlesung fur Problemlosungen einsetzen.
Ein erstes Beispiel fur eine rekursiv definierte Prozedur:
Countdown[n_] := If[n == 0, Print["Los!"],
Print[n];
Countdown[n - 1] (* rekursiver Aufruf *)
]
Countdown[2]
2
1
Los!
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 204
Informatik I 3 Programmierung
Countdown verandert einen Zustand – hier der Wert des Arguments n
– und ruft sich selbst auf, bis ein Abbruchkriterium erfullt ist.
Als nachstes Beispiel betrachten wir die Fakult at n! einer naturlichenZahl n ∈ N:
n! =
1 n = 0 ,
n · (n− 1) · (n− 2) · · · · · 2 · 1 n > 0 .
Fur n > 0 gilt offenbar n! = n · (n− 1)! Dies fuhrt direkt zur Definition
fakultaet[n_] := If[n == 0, 1, n*fakultaet[n - 1]]
Die Definition weist in rudimentarer Form zwei weitere allgemeineMerkmale rekursiver Programme auf:
• Reduktion der Problemgroße, in der Regel durch Abspalten vonTeilproblemen,
• Kombination von Teillosungen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 205
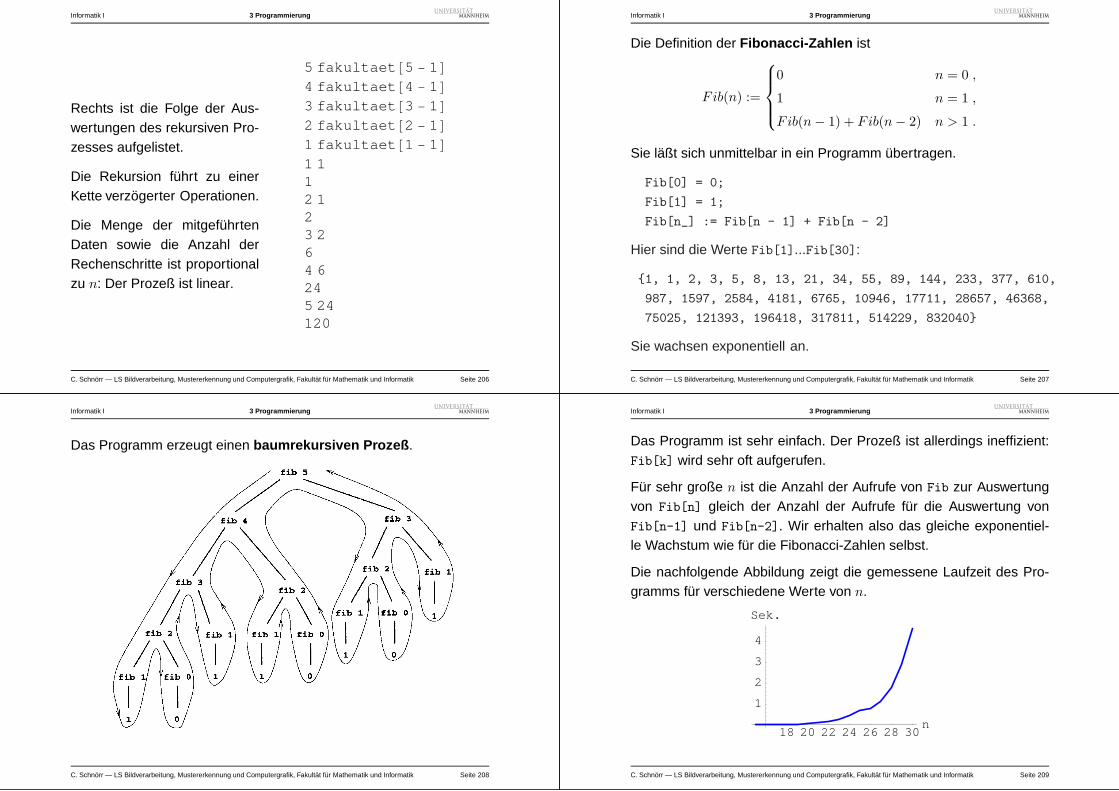
Informatik I 3 Programmierung
Rechts ist die Folge der Aus-wertungen des rekursiven Pro-zesses aufgelistet.
Die Rekursion fuhrt zu einerKette verzogerter Operationen.
Die Menge der mitgefuhrtenDaten sowie die Anzahl derRechenschritte ist proportionalzu n: Der Prozeß ist linear.
5 fakultaet @5 - 1D4 fakultaet @4 - 1D3 fakultaet @3 - 1D2 fakultaet @2 - 1D1 fakultaet @1 - 1D1 112 123 264 6245 24120
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 206
Informatik I 3 Programmierung
Die Definition der Fibonacci-Zahlen ist
Fib(n) :=
0 n = 0 ,
1 n = 1 ,
F ib(n− 1) + Fib(n− 2) n > 1 .
Sie laßt sich unmittelbar in ein Programm ubertragen.
Fib[0] = 0;
Fib[1] = 1;
Fib[n_] := Fib[n - 1] + Fib[n - 2]
Hier sind die Werte Fib[1]...Fib[30]:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610,
987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368,
75025, 121393, 196418, 317811, 514229, 832040
Sie wachsen exponentiell an.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 207
Informatik I 3 Programmierung
Das Programm erzeugt einen baumrekursiven Prozeß .
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 208
Informatik I 3 Programmierung
Das Programm ist sehr einfach. Der Prozeß ist allerdings ineffizient:Fib[k] wird sehr oft aufgerufen.
Fur sehr große n ist die Anzahl der Aufrufe von Fib zur Auswertungvon Fib[n] gleich der Anzahl der Aufrufe fur die Auswertung vonFib[n-1] und Fib[n-2]. Wir erhalten also das gleiche exponentiel-le Wachstum wie fur die Fibonacci-Zahlen selbst.
Die nachfolgende Abbildung zeigt die gemessene Laufzeit des Pro-gramms fur verschiedene Werte von n.
18 20 22 24 26 28 30n
1
2
3
4
Sek.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 209

Informatik I 3 Programmierung
Rekursive Prozesse losen oft in einfacher Weise Probleme, bei deneneine iterative Berechnung nicht unmittelbar auf der Hand liegt.
Die Turme von Hanoin Scheiben sind von einemStartstapel (links) auf einenZielstapel (rechts) umzu-stecken.Dabei darf ein Hilfsstapel (Mitte) verwendet werden, um die folgendenRegeln einzuhalten:
• Die Scheiben sollen am Ziel in der gleichen Reihenfolge sein.
• Die Scheiben sollen einzeln bewegt werden.
• Es darf niemals eine großere Scheibe auf eine kleinere zu liegenkommen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 210
Informatik I 3 Programmierung
Wir zerlegen die Aufgabe in Teilprobleme:
• Bewege n − 1 Scheiben vom Start zum Hilfsort. Dabei wird Zielals Hilfsstapel verwendet.
• Bewege eine Scheibe vom Start zum Ziel.
• Bewege n − 1 Scheiben vom Hilfsort zum Ziel. Dabei wird Startals Hilfsstapel verwendet.
bewegeTurm[scheibe_, start_, ziel_, hilfsort_] :=
If[scheibe == 1, bewegeScheibe[1, start, ziel],
bewegeTurm[scheibe - 1, start, hilfsort, ziel];
bewegeScheibe[scheibe, start, ziel];
bewegeTurm[scheibe - 1, hilfsort, ziel, start]
]
bewegeScheibe[scheibe_, start_, ziel_] :=
Print["Scheibe ", scheibe, " von ", start, " nach ", ziel]
Man beachte, dass immer nur eine Scheibe bewegt wird.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 211
Informatik I 3 Programmierung
bewegeTurm@2, "Start", "Ziel", "Hilfsort" D
Scheibe 1 von Start nach Hilfsort
Scheibe 2 von Start nach Ziel
Scheibe 1 von Hilfsort nach Ziel
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 212
Informatik I 3 Programmierung
bewegeTurm@3, "Start", "Ziel", "Hilfsort" D
Scheibe 1 von Start nach Ziel
Scheibe 2 von Start nach Hilfsort
Scheibe 1 von Ziel nach Hilfsort
Scheibe 3 von Start nach Ziel
Scheibe 1 von Hilfsort nach Start
Scheibe 2 von Hilfsort nach Ziel
Scheibe 1 von Start nach Ziel
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 213

Informatik I 3 Programmierung
Die Belegung von Start, Hilfsort und Ziel fur einen Stapel mit vierScheiben:
i
k
jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj
84, 3, 2, 1 < 8< 8<84, 3, 2 < 81< 8<84, 3 < 81< 82<84, 3 < 8< 82, 1 <84< 83< 82, 1 <84, 1 < 83< 82<84, 1 < 83, 2 < 8<84< 83, 2, 1 < 8<8< 83, 2, 1 < 84<8< 83, 2 < 84, 1 <82< 83< 84, 1 <82, 1 < 83< 84<82, 1 < 8< 84, 3 <82< 81< 84, 3 <8< 81< 84, 3, 2 <8< 8< 84, 3, 2, 1 <
y
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 214
Informatik I 3 Programmierung
Animation
Out[54]=
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 215
Informatik I 3 Programmierung
3.5 – Elementare Listenoperationen
Listen sind Kollektionen beliebiger Ausdrucke, die in der Ein- und Aus-gabe mit geschweiften Klammern zusammengefaßt werden.
a, b, "liste", 5.2
Listen sind Ausducke mit dem Kopf List.List[a, b, "liste", 5.2]
Ausgangspunkt fur die Konstruktion von Listenoperationen sind dreielementare, vordefinierte Funktionen:
Prepend[a,b,c,d,x] --> x,a,b,c,d
First[a,b,c,d] --> a
Rest[a,b,c,d] --> b,c,d
In Mathematica beginnen Listen mit dem 1. Element,in manchen anderen Sprachen mit dem 0. Element!
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 216
Informatik I 3 Programmierung
Bemerkung
Mathematica stellt viele Listenoperationen zur Verfugung.
Das Studium der Konstruktion von Listenoperationen ist trotzdem sinn-voll, da einige andere Programmiersprachen diese nicht bereitstellen,und als Programmierubung.
Im weiteren Verlauf der Vorlesung benotigen wir weitergehende Li-stenoperationen. Wir greifen dann auf vorhandene Listenoperationenvon Mathematica, die wir nachfolgend vorgestellen und implementie-ren, zuruck.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 217

Informatik I 3 Programmierung
Lange einer Liste
Addiere 1 bis die Restliste leer ist.
myLength[] = 0;
myLength[lst_] := 1 + myLength[Rest[lst]]
myLength[a, b, c, d] --> 4
Mathematica:
Length[a, b, c, d] --> 4
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 218
Informatik I 3 Programmierung
Letztes Element
Entferne das erste Element bis die Restliste leer ist.
myLast[] = "Die Liste ist leer";
myLast[lst_] := If[Rest[lst] == , First[lst],
myLast[Rest[lst]]
]
myLast[a, b, c, d] --> d
Mathematica:
Last[a, b, c, d] --> d
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 219
Informatik I 3 Programmierung
n-tes Element
Rekursive Konstruktion:
• Wenn n = 1, dann liefert First das Ergebnis.
• Wenn n > 1, dann berechne das (n−1)-te Element der Restliste.
myPart[lst_, 1] := First[lst]
myPart[lst_, n_] := myPart[Rest[lst], n - 1]
myPart[a, b, c, d, 3] --> c
Mathematica:
Part[a, b, c, d, 3] --> c
a, b, c, d[[3]] --> c
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 220
Informatik I 3 Programmierung
Die ersten n Elemente
Ist n = 0, dann gib die leere Liste aus.
Andernfalls fuge das erste Element in die Liste der ersten n − 1 Ele-mente der Restliste ein.
myTake[lst_, 0] :=
myTake[lst_, n_] := Prepend[myTake[Rest[lst], n - 1],
First[lst]]
myTake[a, b, c, d, e, 3] --> a,b,c
Mathematica:
Take[a, b, c, d, e, 3] --> a,b,c
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 221

Informatik I 3 Programmierung
Anh angen eines Elements
Ist die Liste leer, dann ist die ein-elementige Liste mit dem Elementdas Ergebnis.
Andernfalls fuge das erste Element ein in Restliste mit angehangtemElement.
myAppend[, el_] := el
myAppend[lst_, el_] := Prepend[myAppend[Rest[lst], el],
First[lst]]
myAppend[a, b, c, d, x] --> a, b, c, d, x
Mathematica:
Append[a, b, c, d, x] --> a, b, c, d, x
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 222
Informatik I 3 Programmierung
Verketten zweier Listen
Gib die zweite Liste aus, falls die erste leer ist.
Andernfalls fuge das erste Element der ersten Liste ein in die Verket-tung der ersten Restliste und der zweiten Liste.
myJoin[, lst_] := lst
myJoin[lst1_, lst2_] := Prepend[myJoin[Rest[lst1], lst2],
First[lst1]]
myJoin[a, b, c, d, e] --> a, b, c, d, e
Mathematica:
Join[a, b, c, d, e] --> a, b, c, d, e
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 223
Informatik I 3 Programmierung
Entfernen des letzten Elements
Rekursive Konstruktion dieser Kopfliste :
Hat die Liste ein Element, dann gebe die leere Liste aus.
Andernfalls fuge das erste Element in den Kopf der Restliste ein.
myMost[] = "Die Liste ist leer!";
myMost[lst_] := If[Rest[lst] == ,
,
Prepend[myMost[Rest[lst]], First[lst]]
]
myMost[a, b, c, d] --> a,b,c
Mathematica:
Most[a, b, c, d] --> a,b,c
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 224
Informatik I 3 Programmierung
Entfernen der ersten n Elemente
Ist n = 0, dann gebe die Liste aus.
Andernfalls entferne die ersten n− 1 Elemente der Restliste.
myDrop[lst_, 0] := lst
myDrop[lst_, n_] := myDrop[Rest[lst], n - 1]
myDrop[a, b, c, d, e, 3] --> d,e
Mathematica:
Drop[a, b, c, d, e, 3] --> d,e
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 225

Informatik I 3 Programmierung
Umkehren einer Liste
Ist die Liste leer, so ist nichts zu tun.
Andernfalls hange das letzte Element an die umgekehrte, verbleiben-de Liste (ohne letztes Element) an.
Wir benutzen die Funktionen Most und Last.
myReverse[] = ;
myReverse[lst_] := Prepend[myReverse[Most[lst]],
Last[lst]]
myReverse[a, b, c, d] --> d, c, b, a
Mathematica:
Reverse[a, b, c, d] --> d, c, b, a
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 226
Informatik I 3 Programmierung
3.6 – Iteration
Wir wollen wieder ein Programm zur Berechnung der Fakultat n! schrei-ben. Alternativ zur Rekursion beschreiben wir den Zustand vollstandig
• durch einen Zahler: 1, 2, 3, ...
• durch eine weitere Variable, welche das Ergebnis durch Multipli-kation der Zahlerwerte akkumuliert.
fakultaet[n_] := fakIteration[1, 1, n]
fakIteration[produkt_, zaehler_, zaehlerMaximum_] :=
If[zaehler > zaehlerMaximum, produkt,
fakIteration[zaehler*produkt, zaehler + 1, zaehlerMaximum]
]
Die Prozeßablauf auf der folgenden Seite zeigt,
• dass bei der Iteration die Auswertungen sofort erfolgen,
• dass der Prozeß wiederum linear ist.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 227
Informatik I 3 Programmierung
Auswertung von fakultaet[4]:
fakIteration @1, 1, 4 DIf @1 > 4, 1, fakIteration @1 1, 1 + 1, 4 DDfakIteration @1 1, 1 + 1, 4 DfakIteration @1, 2, 4 DIf @2 > 4, 1, fakIteration @2 1, 2 + 1, 4 DDfakIteration @2 1, 2 + 1, 4 DfakIteration @2, 3, 4 DIf @3 > 4, 2, fakIteration @3 2, 3 + 1, 4 DDfakIteration @3 2, 3 + 1, 4 DfakIteration @6, 4, 4 DIf @4 > 4, 6, fakIteration @4 6, 4 + 1, 4 DDfakIteration @4 6, 4 + 1, 4 DfakIteration @24, 5, 4 DIf @5 > 4, 24, fakIteration @5 24, 5 + 1, 4 DD
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 228
Informatik I 3 Programmierung
Wir berechnen die Fibonacci-Zahlen iterativ :
Fib(0) = 0
Fib(1) = 1
Fib(2) = Fib(1) + Fib(0)
Fib(3) = Fib(2) + Fib(1)
. . .
Fib(n) = Fib(n− 1) + Fib(n− 2)
Offensichtlich brauchen wir zwei Zustandsvariable.
Fib[0] = 0;
Fib[1] = 1;
Fib[n_] := FibIteration[1, 0, n - 1]
FibIteration[letzter_, vorletzter_, zaehler_] :=
If[zaehler == 1, letzter + vorletzter,
FibIteration[letzter + vorletzter, letzter, zaehler - 1]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 229

Informatik I 3 Programmierung
Auswertung von Fib[10] (--> 55)
FibIteration @1, 0, 9 DFibIteration @1, 1, 8 DFibIteration @2, 1, 7 DFibIteration @3, 2, 6 DFibIteration @5, 3, 5 DFibIteration @8, 5, 4 DFibIteration @13, 8, 3 DFibIteration @21, 13, 2 DFibIteration @34, 21, 1 D
Dieser Prozeß ist wesentlich effizienter als die Baumrekursion.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 230
Informatik I 3 Programmierung
Iterative Berechnung von y =√
x (Newtonverfahren)
Fur einen gegebenen festen Wert x wollen iterativ den Wert fur y
berechnen, fur den die Gleichung
g(y) = y2 − x = 0
erfullt ist. Wahlen wir als Beispiel x = 2, dann liegt der gesuchte Wertzwischen 1 und 2, da
g(1) = −1 ≤ 0 ≤ 2 = g(2) .
Wir konnen somit einen ersten Naherungswert als Startwert y0 derIteration wahlen, z.B. y0 = 1. Die tiefgestellte Zahl 0 zeigt den Iterati-onsschritt an.
Wir wollen den Startwert y0 verbessern, indem wir eine bis jetzt un-bekannte Zahl δ0 als Korrekturterm addieren.
y1 = y0 + δ0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 231
Informatik I 3 Programmierung
Der optimale Korrekturterm δ0 ist die Zahl, fur welche der verbesserteNaherungswert y1 = y0 + δ0 die Gleichung g(y) = 0 erfullt. Da unsdie direkte Auflosung dieser Gleichung zu schwierig ist, ersetzen wirsie durch eine lineare Naherung um den aktuellen Wert y0 fur dasunbekannte y:
g(y1) = g(y0 + δ0) ≈ g(y0) + g′(y0)δ0!= 0 .
Wir losen nach δ0 auf
δ0 = − g(y0)
g′(y0)= −y2
0 − x
2y0= −1
2y0 +
1
2
x
y0
und erhalten als verbesserte Naherung
y1 = y0 + δ0 =1
2
(
y0 +x
y0
)
.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 232
Informatik I 3 Programmierung
Wir iterieren diese Verbesserung
yk+1 =1
2
(
yk +x
yk
)
bis die Nullstelle der Gleichung hinreichend genau bestimmt ist:
∣∣g(yk)
∣∣ ≤ ε .
Programm:
wurzel[x_] := wurzelIteration[1, x]
wurzelIteration[naeherung_, x_] :=
If[naeherungIstOK[naeherung, x], naeherung,
wurzelIteration[bessereNaeherung[naeherung, x], x]
]
bessereNaeherung[naeherung_, x_] := (naeherung + x/naeherung)/2
naeherungIstOK[naeherung_, x_] := Abs[naeherung^2 - x] < 0.001
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 233

Informatik I 3 Programmierung
Trace[wurzel[2.0], wurzelIteration[_, _]]
wurzelIteration[1, 2.],
wurzelIteration[bessereNaeherung[1, 2.], 2.],
wurzelIteration[1.5, 2.],
wurzelIteration[bessereNaeherung[1.5, 2.], 2.],
wurzelIteration[1.41667, 2.],
wurzelIteration[bessereNaeherung[1.41667, 2.], 2.],
wurzelIteration[1.41422, 2.]
Abs[wurzel[2.0] - Sqrt[2]]
2.1239× 10−6
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 234
Informatik I 3 Programmierung
Schleifenanweisung: Do
Do[expr, imax] wertet expr imax mal aus.
Do[Print["hallo"], 2]
hallo
hallo
Do[expr, i, imax] beinhaltet eine Laufvariable.
Do[Print["i = ", k], k, 2]
i = 1
i = 2
Angabe einer unteren und oberen Schranke imin und imax, sowieeiner Schrittweite di
Do[expr, i, imin, imax]
Do[expr, i, imin, imax, di]
Do[Print[y^2],y,2,6,2] --> 4 16 36
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 235
Informatik I 3 Programmierung
Verschachtelte Iteration:
Do[expr, i, imin, imax, j, jmin, jmax, ... ] evaluates
expr looping over different values of j, etc. for each i.
Do[Print["i = ", k, ", j = ", l], k,2, l,3]
i = 1, j = 1
i = 1, j = 2
i = 1, j = 3
i = 2, j = 1
i = 2, j = 2
i = 2, j = 3
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 236
Informatik I 3 Programmierung
Schleifenanweisung: While
While[test, body]
wertet test aus und dann wiederholt body, solange bis test den WertFalse ergibt.
Achtung: Im Gegensatz zu C++ erfolgt die Trennung der An-weisungsteile durch Kommatas, und die Trennung der Anwei-sungen innerhalb eines Anweisungsteils durch Strichpunkte.
i=1; qsum=0;
While[i<=3, qsum+=i^2; i++]
qsum --> 14
Mathematica akzeptiert C++ - typische Schreibweisen:
i++ ist eine Kurzform fur i = i+1
qsum+=i^2 ist eine Kurzform fur qsum = qsum + i^2
analog: ++i, i--, --i, -=, *=, /=
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 237

Informatik I 3 Programmierung
Nochmals die Newton-Iteration zur Berechnung der Quadratwurzel:
bessereNaeherung[naeherung_,x_] := (naeherung+x/naeherung)/2
naeherungIstOK[naeherung_,x_] := Abs[naeherung^2-x] < 10.^-6
naeherung=1.0; x=2.0;
While[ !naeherungIstOK[naeherung, x],
naeherung = bessereNaeherung[naeherung, x]
]
Abs[naeherung - Sqrt[2]] --> 1.59472× 10−12
Beachte: Iterationen durch Schleifenanweisungen implementieren kei-ne Funktionen, sondern manipulieren externe Variable. Solche Wert-zuweisungen erzeugen Seiteneffekte und konnen schwer zu detek-tierende Fehler erzeugen.
Funktionen, die globale Variable manipulieren, kennzeichneneinen schlechten Programmierstil.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 238
Informatik I 3 Programmierung
Der gr oßte gemeinsame Teiler (ggt) der naturlichen Zahlen a = 15
und b = 25 ist ggt(a, b) = 5. Allgemein gilt
a = ca · ggt(a, b) , b = cb · ggt(a, b) .
In unserem Beispiel ist ca = 3, cb = 5. Schon Euklid hat festgestellt,dass der Rest der ganzzahligen Division Mod(a, b) von a durch b undb den gleichen ggt haben,
ggt(a, b) = ggt(b, Mod(a, b)
),
denn Mod(a, b) = ca ·ggt(a, b) oder Mod(a, b) = cb′ ·ggt(a, b), cb′ < cb,je nachdem ob a < b oder a > b.
Ersetzen wir also
a′ ← b , b′ ← Mod(a, b) ,
dann gilt b′ < b und ggt(a′, b′) = ggt(a, b).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 239
Informatik I 3 Programmierung
Iteration fuhrt irgendwann zu b′ = 0 und
ggt(a′, 0) = a′ = ggt(a, b) .
ggt[a0_, b0_] := Module[a = a0, b = b0,
While[b > 0, a, b = b, Mod[a, b]];
a
]
ggt[15, 25] --> 5
Beachte: Die Zuweisungen zu a und b erfolgen gleichzeitig.Inspektion mit Reap and Sow:
ggt[a0_, b0_] := Module[a = a0, b = b0,
While[b > 0, Sow[a, b = b, Mod[a, b]]];
a
]
Reap[ggt[15, 25]]
5, 25, 15, 15, 10, 10, 5, 5, 0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 240
Informatik I 3 Programmierung
Schleifenanweisung: For
For[start, test, incr, body]
wertet den Ausdruck start aus und anschließend wiederholend body
und incr, solange bis test den Wert False ergibt.
For[qsum=0; i=1, i<=3, i++, qsum+=i^2]
qsum --> 14;
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 241

Informatik I 3 Programmierung
3.7 – Lokale Variable und Konstanten
Die Verwendung lokaler Variable hilft unerwunschte Seiteneffekte zuvermeiden.
Module[x, y, ... , body]
Module[x = x0, ... , body] (* mit Initialisierung *)
Wir belegen global eine Variablev = "hallo"
und definieren eine Funktion.f[x_] := Module[v=(1+x^2), v^2]
f[2] --> 25
x ist lediglich der Bezeichner des Operanden und in der globalen Um-gebung nicht definiert.
x --> x
Die lokale Variable hat auf die globale Umgebung keinen Einfluß.v --> hallo
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 242
Informatik I 3 Programmierung
Merke: Zuweisungen zu Argumenten einer Funktion sind nichtzulassig. Namen von Argumenten sind lediglich Bezeichner,die im Funktionsrumpf durch die Werte der Operanden beimFunktionsaufruf ersetzt werden.
g[x_] := Module[v=1, x=v]
g[2] --> Set::setraw: Cannot assign to raw object 2.
Der Zahl 2 kann man nichts zuweisen.
Die AnweisungWith[x = x0, y = y0, ... , expr]
definiert lokale Konstanten x, y, ... mit denen sich expr ubersichtlicherformulieren laßt. Zum Beispiel konnte
x(1 + xy)2 + y(1− y) + (1 + xy)(1− y)
so implementiert werden:
With[a = 1 + x y, b = 1 - y, x a^2 + y b + a b]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 243
Informatik I 3 Programmierung
3.8 – Fu. als Argumente und Werte; reine Funktionen
Funktionen als Argumente . Die Ausdrucke
a + (a + 1) + (a + 2) + · · ·+ (b− 1) + b =b∑
i=a
i
(2a− 1) +(2(a + 1)− 1
)+ · · ·+ (2b− 1) =
b∑
i=a
(2i− 1)
a2 + (a + 1)2 + · · ·+ b2 =b∑
i=a
i2
haben die gleiche Struktur. Sie unterscheiden sich nur in den Termen,die addiert werden.
Wir wollen von diesem Unterschied abstrahieren, indem wir einer Funk-tion, welche Summen dieser Art auswertet, eine Funktion als Argu-ment ubergeben, welche den Term reprasentiert.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 244
Informatik I 3 Programmierung
mySum[term_, a_, b_] := If[a > b, 0,
term[a] + mySum[term, a + 1, b]]
t1[n_] := n
t2[n_] := 2 n - 1
t3[n_] := n^2
mySum[t1, 1, 10] --> 55
mySum[t2, 1, 10] --> 100
mySum[t3, 1, 10] --> 385
Mathematica:
mySum[term_, a_, b_] := Sum[term[i], i, a, b]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 245

Informatik I 3 Programmierung
Um den Ausdruck
π
8=
1
1 · 3 +1
5 · 7 +1
9 · 11 + · · ·
auszuwerten, erweitern wir unsere Summationsfunktion und eine Funk-tion, welche den nachsten Wert der Summationsvariablen berechnet.Wir schreiben
π
8≈
b∑
i=0
1
(2 + 4 · i− 1)(2 + 4 · i + 1)
und definieren als Naherung fur π
mySum[term_, a_, incr_, b_] :=
If[a > b, 0, term[a] + mySum[term, incr[a], incr, b]]
term[n_] := 1/((n - 1)(n + 1))
plusFour[n_] := n + 4
8 * mySum[term, 2.0, plusFour, 1000] --> 3.13959
Mma: mySum[term,a_,incr_,b_] := Sum[term[i],i,a,b,incr]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 246
Informatik I 3 Programmierung
Zur Auswertung des Ausdrucks
π
4=
2 · 4 · 4 · 6 · 6 · 8 · · ·3 · 3 · 5 · 5 · 7 · 7 · · ·
mussen wir den Operator Plus, welcher die einzelnen Terme akku-muliert, durch Times ersetzen. Wir schreiben
π
4≈
b∏
i=2
ii+1 falls i gerade ,
i+1i falls i ungerade ,
und definieren
myAccumulate[combine_,neutralValue_,term_,a_,incr_,b_] :=
If[a > b, neutralValue,
combine[term[a],
myAccumulate[combine, neutralValue,
term, incr[a], incr, b]
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 247
Informatik I 3 Programmierung
Den Term implementieren wir mittels des vorhandenen PradikatesEvenQ fur ganze Zahlen.
term[n_] := N[If[EvenQ[n], n/(n + 1), (n + 1)/n]]
Zur numerischen Akkumulation umschließen wir mit N[...]
Mit dem Ausdruck
plusOne[n_] := n + 1
werten wir als Naherung fur π aus:
4 * myAccumulate[Times, 1, term, 2, plusOne, 10000]
3.14144
Die Folge konvergiert sehr langsam. Mathematica gibt das Ergebnismit der entsprechend geringen Genauigkeit aus.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 248
Informatik I 3 Programmierung
Wir implementieren die lange Rekursion des vorigen Beispiels alter-nativ als iterativen Prozeß.
Eine lokal definierte Funktion akkumuliert die Teilergebnisse:
myAccumulate[combine_,neutralValue_,term_,a_,incr_,b_] :=
Module[iterate,
iterate[i_, result_] :=
If[i > b, result,
iterate[incr[i], combine[term[i], result]]
];
iterate[a, neutralValue]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 249

Informatik I 3 Programmierung
Eine alternative Implementierung mittels einer While-Schleife:
myAccumulate[combine_,neutralValue_,term_,a_,incr_,b_] :=
Module[i = a, result = neutralValue,
While[i <= b,
result = combine[term[i], result];
i = incr[i]
];
result
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 250
Informatik I 3 Programmierung
Iteration mittels einer Do-Schleife funktioniert nur fur ein konstantesInkrement der Iterationsvariablen.
myAccumulate[combine_,neutralValue_,term_,a_,incr_,b_] :=
Module[result = neutralValue,
Do[
result = combine[term[i], result],
i, a, b, incr
];
result
]
4 * myAccumulate[Times, 1, term, 2, 1, 10000]
3.14144
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 251
Informatik I 3 Programmierung
Reine Funktionen
Wir haben Abstraktion durch die Ubergabe von Funktionen als Argu-mente an Funktionen kennengelernt. Etwas umstandlich ist jedoch,dass alle zu ubergebenden Funktionen, wie verschiedene zu akku-mulierende Terme oder Inkremente von Schleifenvariablen, explizitdefiniert werden mußten.
Ausdrucke der Form
Function[body]
Function[x, body]
Function[x1, x2, ... , body]
definieren sog. reine Funktionen mit einem Argument # oder x, odermit mehreren Argumenten #1, #2, ... oder x1, x2, ....
Reine Funktionen sind nicht benannt. Sie konnen “aus dem Stehgreif”erzeugt werden, was die Flexibilitat beim Programmieren erhoht.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 252
Informatik I 3 Programmierung
Das Symbol f benennt eine Quadratfunktion.
f[x_] := x^2
Hier die reine Quadratfunktion angewendet auf 5:
Function[#^2][5] --> 25
Wie bisher wird der Platzhalter # durch den Wert des Arguments beider Anwendung der Funktion 5 ersetzt, gefolgt von der Auswertungdes Funktionsrumpfes.
Hier die gleiche Funktion mit beliebig benanntem Argument:
Function[z,z^2][5] --> 25
Eine reine Funktion ist ein korrekter Ausdruck in Mathematica mit demKopf Function. Er kann beliebig benannt und angewendet werden.
FullForm[Function[#^2]] --> Function[Power[Slot[1], 2]]
q = Function[#^2];
q[5] --> 25
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 253

Informatik I 3 Programmierung
Kurzform reiner Funktionen
Reine Funktionen konnen fur eine kompaktere Schreibweise auch inKurzform notiert werden. Dabei wird Function[body] durch body &
ersetzt.
Die Kurzform der reinen Quadratfunktion angewendet auf 5 lautet
#^2 &[5] --> 25
Hier eine reine Funktion mit zwei Argumente:
#1^2 + #2^2 & [4,5]
#1 wird durch das erste Argument ersetzt, #2 durch das zweite.
Wir wenden als Beispiel die Summationsfunktion auf Seite 245 an,ohne den Term explizit definieren und benennen zu mussen.
mySum[# &, 1, 10] --> 55
mySum[2#-1 &,1, 10] --> 100
mySum[#^2 &, 1, 10] --> 385
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 254
Informatik I 3 Programmierung
Der Aufruf der erweiterten Funktion eine Seite spater konnte lauten
8 * mySum[((# - 1)(# + 1))^-1 &, 2.0, # + 4 &, 1000]
3.13959
Wir wenden uns noch einmal der Newton-Iteration zur Berechnungder Quadratwurzel y =
√x auf Seite 231 zu. Ausgehend von einer
Naherung y0 wurde ein Korrekturterm
δ0 = − g(y0)
g′(y0)
berechnet und iteriert,
yk+1 = yk + δk , k = 0, 1, . . . ,
bis |g(yk)| < ε. Wir wollen diese Fixpunktiteration fur eine beliebigeGleichung g(y) = 0 implementieren.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 255
Informatik I 3 Programmierung
myFixedpoint[g_, gDerivative_, y_, threshold_] :=
With[ynext = y - g[y]/gDerivative[y],
If[Abs[g[ynext]] < threshold, ynext,
myFixedpoint[g, gDerivative, ynext, threshold]
]
]
Zur Berechnung der Quadratwurzel benotigen wir
g(y) = y2 − x ,
g′(y) = 2y .
Wir ubergeben reine Funktionen als Argumente.
myFixedpoint[#^2 - 2.0 &, 2 # &, 1.0, 0.001]
1.41422
Abs[% - Sqrt[2]] --> 2.1239× 10−6
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 256
Informatik I 3 Programmierung
Funktionen als Werte
Funktionen konnen Argumente auch auf eine Funktion abbilden.
Die Funktion plusFunction gibt eine Funktion mit einem Argumentzuruck, die das Argument, mit dem plusFunction aufgerufen wird,addiert.
plusFunction[x_] := # + x &
plusFunction[3][2] --> 5
pF7 = plusFunction[7];
pF7[1] --> 8
pF2 = plusFunction[2];
pF2[pF7[1]] --> 10
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 257
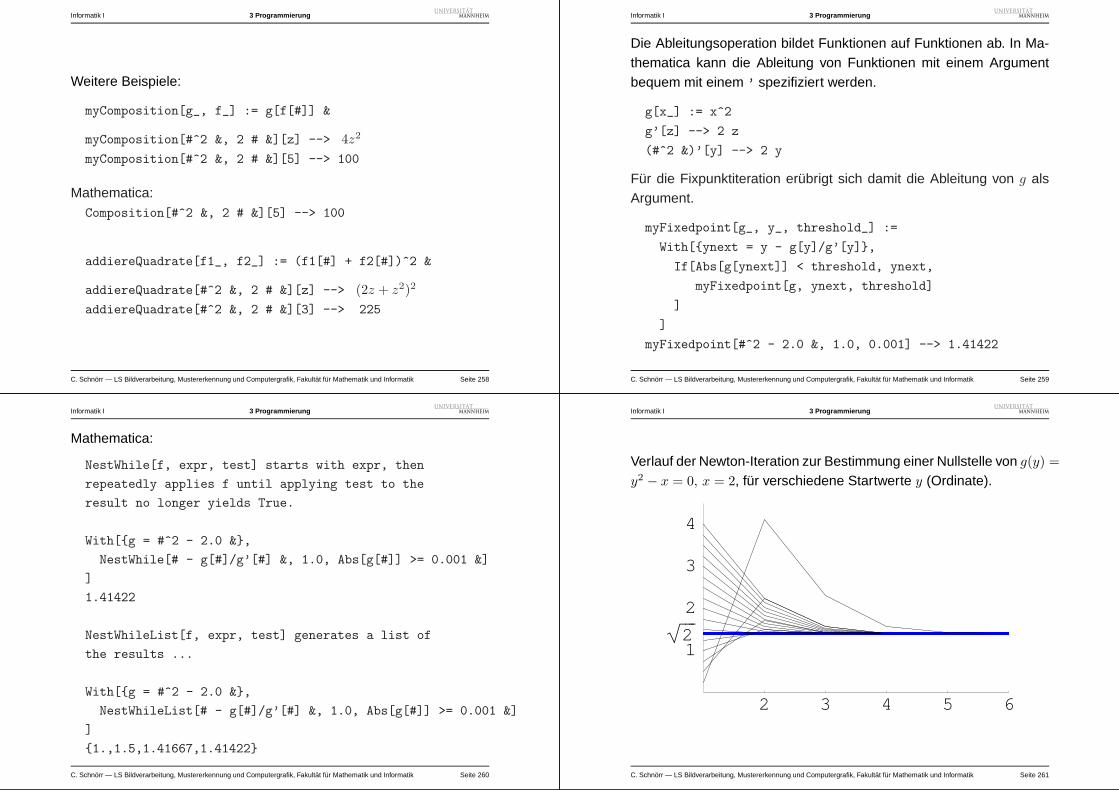
Informatik I 3 Programmierung
Weitere Beispiele:
myComposition[g_, f_] := g[f[#]] &
myComposition[#^2 &, 2 # &][z] --> 4z2
myComposition[#^2 &, 2 # &][5] --> 100
Mathematica:Composition[#^2 &, 2 # &][5] --> 100
addiereQuadrate[f1_, f2_] := (f1[#] + f2[#])^2 &
addiereQuadrate[#^2 &, 2 # &][z] --> (2z + z2)2
addiereQuadrate[#^2 &, 2 # &][3] --> 225
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 258
Informatik I 3 Programmierung
Die Ableitungsoperation bildet Funktionen auf Funktionen ab. In Ma-thematica kann die Ableitung von Funktionen mit einem Argumentbequem mit einem ’ spezifiziert werden.
g[x_] := x^2
g’[z] --> 2 z
(#^2 &)’[y] --> 2 y
Fur die Fixpunktiteration erubrigt sich damit die Ableitung von g alsArgument.
myFixedpoint[g_, y_, threshold_] :=
With[ynext = y - g[y]/g’[y],
If[Abs[g[ynext]] < threshold, ynext,
myFixedpoint[g, ynext, threshold]
]
]
myFixedpoint[#^2 - 2.0 &, 1.0, 0.001] --> 1.41422
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 259
Informatik I 3 Programmierung
Mathematica:
NestWhile[f, expr, test] starts with expr, then
repeatedly applies f until applying test to the
result no longer yields True.
With[g = #^2 - 2.0 &,
NestWhile[# - g[#]/g’[#] &, 1.0, Abs[g[#]] >= 0.001 &]
]
1.41422
NestWhileList[f, expr, test] generates a list of
the results ...
With[g = #^2 - 2.0 &,
NestWhileList[# - g[#]/g’[#] &, 1.0, Abs[g[#]] >= 0.001 &]
]
1.,1.5,1.41667,1.41422
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 260
Informatik I 3 Programmierung
Verlauf der Newton-Iteration zur Bestimmung einer Nullstelle von g(y) =
y2 − x = 0, x = 2, fur verschiedene Startwerte y (Ordinate).
2 3 4 5 6
1
!!!!22
3
4
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 261

Informatik I 3 Programmierung
3.9 – Operationen mit Listen
Konstruktion von Listen
Die explizite Konstruktion einer Liste mittels geschweifter Klammernist uns schon bekannt.
3, v, liste, abc, 5.78
Listen sind korrekte Ausdrucke mit dem Kopf List
FullForm[%] --> List[3, v, "liste", abc, 5.78]
Haufig werden Listen mit naturlichen Zahlen benotigt. Diese mochtenwir nicht eintippen mussen.
myRange[0] = ;
myRange[n_] := Append[myRange[n - 1], n]
myRange[5] --> 1, 2, 3, 4, 5
Mathematica: Range[5] --> 1, 2, 3, 4, 5
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 262
Informatik I 3 Programmierung
Als Verallgemeinerung konstruieren wir eine Liste mit Funktionswer-ten naturlicher Zahlen.
myArray[f_, 0] :=
myArray[f_, n_] := Append[myArray[f, n - 1], f[n]]
myArray[#^2 &, 5] --> 1,4,9,16,25
Mathematica:
Array[f, n] generates a list of length n, with
elements f[i].
Array[#^2 &, 5] --> 1,4,9,16,25
Table[expr, i, imax] generates a list of the values of
expr when i runs from 1 to imax.
Table[k^2, k,5] --> 1,4,9,16,25
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 263
Informatik I 3 Programmierung
Abbildungen uber Listen
Eine haufige Operation ist die Abbildung aller Elemente einer Liste.
myMap[f_, ] :=
myMap[f_, lst_] := Prepend[ myMap[f, Rest[lst]],
f[First[lst]] ]
myMap[#^2 &, 1, 2, 3, 4, 5]
1, 4, 9, 16, 25
Mathematica:
Map[#^2 &, 1, 2, 3, 4, 5]
1, 4, 9, 16, 25
#^2 & /@ 1, 2, 3, 4, 5 (* Kurzform von Map *)
1, 4, 9, 16, 25
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 264
Informatik I 3 Programmierung
In Mathematica haben viele Operationen das Attribut Listable, wiebeispielweise die Addition.
Attributes[Plus]
Flat, Listable, NumericFunction, OneIdentity, ...
Operatoren mit dieser Eigenschaft werden automatisch uber Listen“verteilt”.
Weitere Beispiele:
1, 2, 3 + a --> 1 + a, 2 + a, 3 + a
1, 2, 3 + a, b, c --> 1 + a, 2 + b, 3 + c
1, 2, 3 / faktor →
1faktor ,
2faktor ,
3faktor
Abs[-1, 3, 5.6, -14] --> 1, 3, Abs[a], 14
Sin[Pi 1/6, 1/4, 1/3, 1/2] →
12 , 1√
2,√
32 , 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 265

Informatik I 3 Programmierung
Akkumulieren von Listen
Auf Seite 247 hatten wir schon Folgen beliebiger Terme akkumuliert.Listen sind endliche Folgen von Termen. In diesem Zusammenhangnennen wir die Operation Fold.
myFold[combine_, lst_] :=
If[Rest[lst] == , First[lst],
combine[First[lst], myFold[combine, Rest[lst]]]
]
myFold[f, a, b, c, d] --> f[a, f[b, f[c, d]]]
myFold[Plus, 1, 2, 3, 4] --> 10
myFold[Times, 1, 2, 3, 4] --> 24
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 266
Informatik I 3 Programmierung
Diese Version akkumuliert “von vorne”:
myFold[combine_, lst_] :=
If[Most[lst] == , Last[lst],
combine[myFold[combine, Most[lst]], Last[lst]]
]
myFold[f, a, b, c, d] --> f[f[f[a, b], c], d]
Wir verallgemeinern die Funktion und berucksichtigen einen beliebi-gen Ausdruck x.
myFold[combine_, x_, ] := x
myFold[combine_, x_, lst_] :=
combine[myFold[combine, x, Most[lst]], Last[lst]]
myFold[f, x, a, b, c, d] --> f[f[f[f[x, a], b], c], d]
myFold[Plus, 1, 2, 3, 4] --> 10
Wahlen wir fur x das neutrale Element bezuglich combine, so erhaltenwir die vorige Funktion.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 267
Informatik I 3 Programmierung
Mathematica:
Fold[op, z, a, b, c] --> op[op[op[z, a], b], c]
Fold[Plus, 1, 2, 3, 4] --> 10
Substitution des Kopfes von Ausdrucken
Wir wissen, dass Listen a,b,c,... Ausdrucke der Form
List[a, b, c, ...]
sind. Ersetzt man den Kopf durch einen Operator mit einer entspre-chenden Anzahl an Argumenten, so erhalt man als resultierendenAusdruck den Wert der Anwendung des Operators. Diese Substitu-tion leistet die Mathematica-Funktion Apply. Kurzform: @@
Apply[op, a, b, c] --> op[a, b, c] (* op @@ a,b,c *)
Akkumulation einer Liste mit Plus oder Times ergibt sich nun direkt.
Apply[Plus, 1, 2, 3, 4] --> 10 (* Plus @@ 1,2,3,4 *)
Apply[Times, 1, 2, 3, 4] --> 24 (* Times @@ 1,2,3,4 *)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 268
Informatik I 3 Programmierung
Wir verallgemeinern die Map-Funktion auf beliebig viele Listen undOperationen mit ebenso vielen Argumenten.
myMapThread[f, a1, a2, a3, b1, b2, b3, c1, c2, c3]
f[a1, b1, c1], f[a2, b2, c2], f[a3, b3, c3]
myMapThread[f_, manyLists_] :=
If[EmptyQ[manyLists], ,
Prepend[myMapThread[f, Map[Rest, manyLists]],
Apply[f, Map[First, manyLists]]
]
]
EmptyQ[lsts_] := 0 == Apply[Plus, Map[Length, lsts]]
EmptyQ[, , ] --> True
myMapThread[Plus, 1, 2, 3, 10, 20, 30, 100, 200, 300]
111, 222, 333
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 269

Informatik I 3 Programmierung
Mathematica:
MapThread[f, a1, a2, a3, b1, b2, b3, c1, c2, c3]
f[a1, b1, c1], f[a2, b2, c2], f[a3, b3, c3]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 270
Informatik I 3 Programmierung
Filtern von Listen
Wir wahlen Elemente einer Liste mit einem Pradikat aus.
mySelect[, test_] :=
mySelect[lst_, test_] :=
If[test[First[lst]],
Prepend[mySelect[Rest[lst], test], First[lst]],
mySelect[Rest[lst], test]
]
mySelect[1, 2, 3, 4, 5, EvenQ] --> 2, 4
ls = Array[Random[Integer, 1, 10] &, 10]
5, 1, 1, 5, 1, 1, 2, 6, 9, 4
Select[ls, # > 5 &] --> 6, 9
Mathematica:
Select[1, 2, 3, 4, 5, EvenQ] --> 2, 4
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 271
Informatik I 3 Programmierung
Vektoren und Matrizen
Vektoren sind geordnete Listen. Die Position eines Elements hat eineanwendungsspezifische Bedeutung (Dimension, Merkmal, etc.).
In der Mathematik wird mit Indizes auf dieElemente der Liste, die sog. Komponen-ten eines Vektors v, verwiesen.
v =
v1
v2
...
vn
Das Innen- oder Skalarprodukt zweier Vektoren u, v ist
u · v = u1v1 + · · ·+ unvn =n∑
i=1
uivi .
So stehen z.B. u und v senkrecht aufeinander, u ⊥ v, wenn u · v = 0.
myInner[u_, v_] := Apply[Plus, MapThread[Times, u, v]]
myInner[2, 3, 4, a, b, c] --> 2 a + 3 b + 4 c
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 272
Informatik I 3 Programmierung
In Mathematica kann diese grundlegende Operation kurzer ausge-druckt
Apply[Plus, 2, 3, 4*a, b, c] --> 2 a + 3 b + 4 c
und auch direkt eingegeben werden:
2, 3, 4.a, b, c --> 2 a + 3 b + 4 c;
Matrizen sind zweidimensionale Anordnungen von Zahlen.
1 2 3 4
5 6 7 8
9 10 11 12
In einer Mathematik-Vorlesung werden Sie lernen, dass sie lineareAbbildungen zwischen Vektorraumen darstellen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 273

Informatik I 3 Programmierung
Wir reprasentieren Matrizen als Listen von Zeilenvektoren:
M = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
In Mathematica erfolgt die Ausgabe in mathematischer Schreibweisemittels MatrixForm.
MatrixForm[M] oder M // MatrixForm
Fur den Zugriff auf ein Matrixelement , d.h. auf ein Element dieserListe von Listen, benutzen wir die Funktion Part von Seite 220.
Part[Part[M, 2], 3] --> 7
Die entsprechende mathematische Schreibweise ist
M23 = 7
Analog ermoglicht Mathematica eine kurzere Eingabe.
M[[2, 3]] --> 7
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 274
Informatik I 3 Programmierung
Mehrdimensionale Listen, und damit auch Matrizen konnen bequemmit Array oder Table erzeugt werden.
Array[#1 * #2 &, 3, 4] // MatrixForm
1 2 3 4
2 4 6 8
3 6 9 12
Table[Random[], i, 3, j, 4] // MatrixForm
0.875 0.475 0.024 0.136
0.667 0.055 0.592 0.303
0.007 0.457 0.261 0.686
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 275
Informatik I 3 Programmierung
Die Multiplikation einer Matrix M mit einem Vektor v ergibt den Vek-tor
Mv =
M11v1 + M12v2 + · · ·+ M1nvn
M11v1 + M12v2 + · · ·+ M1nvn
. . .
Mm1v1 + Mm2v2 + · · ·+ Mmnvn
,
(Mv)i =n∑
j=1
Mijvj , i = 1, . . . , m .
Jede Komponente des Ergebnisvektors ist das Innenprodukt des ent-sprechenden Zeilenvektors von M mit v.
Map[myInner[#, 1, 2, 3, 4] &, M] --> 30, 70, 110
Kurzform in Mathematica:
M.1, 2, 3, 4 --> 30, 70, 110
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 276
Informatik I 3 Programmierung
Die Transposition einer Matrix M ergibt die Matrix M⊤ durch Ver-tauschen der Zeilen und Spalten von M .
myTranspose[M_] := MapThread[List, M]
1 5 9
2 6 10
3 7 11
4 8 12
Mathematica: Transpose[M]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 277

Informatik I 3 Programmierung
Die Multiplikation zweier Matrizen A und B ergibt die Matrix
C = AB , Cij =∑
k
AikBkj
Das ij-te Element der Ergebnismatrix ist das Innenprodukt des i-tenZeilenvektors von A mit dem j-ten Spaltenvektor von B.
Der j-te Spaltenvektor der Ergebnismatrix ist A multipliziert mit demj-ten Spaltenvektor von B.
myMatMult[M1_, M2_] := Transpose[Map[M1.# &, Transpose[M2]]]
Der i-te Zeilenvektor der Ergebnismatrix ist der i-te Zeilenvektor vonA multipliziert mit B.
myMatMult[M1_, M2_] := Map[#.M2 &, M1]
Mathematica: M1.M2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 278
Informatik I 3 Programmierung
A = Array[#1 * #2 &, 2, 3];
B = Array[#1 / #2 &, 3, 2];
A =
1 2 3
2 4 6
, B =
1 12
2 1
3 32
, C =
14 7
28 14
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 279
Informatik I 3 Programmierung
Ubung: Julia-Mengen
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 280
Informatik I 3 Programmierung
Verschachtelte Listen
Wir haben bereits zusammengesetzte Ausdrucke und ihre Reprasentationdurch (auf den Kopf gestellte) Baume kennengelernt. Beispiele hierfursind veschachtelte Listen.
Der Ausdruck
1, 2, 3, 4
besteht aus zwei verschachteltenListen als Knoten des Baumes
1, 2, 3, 4
1, 2
sowie aus atomaren Ausdruckenals Bl atter .
1, 2, 3, 4
List
List
1 2
3 4
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 281

Informatik I 3 Programmierung
Ein zweites Beispiel: 1, 2, 3, 4, 5, 6, 7
1, 2, 3, 4, 5, 6, 7
2, 3, 4, 5
3, 4
6, 7
1, 2, 3, 4, 5, 6, 7
List
List
List
List 1
2
3 4
5 6 7
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 282
Informatik I 3 Programmierung
Wir schreiben eine Prozedur, welche die Blattelemente ausgibt. Furden rekursiven Prozeß brauchen wir ein Pradikat, welches erkennt,ob eine Liste oder eine anderer Ausdruck vorliegt.
? UnsameQ
lhs =!= rhs yields True if the expression lhs is not
identical to rhs, and yields False otherwise.
Head[1, 2, 4, 5] =!= List --> False
Head[] =!= List --> False
Head[4] =!= List --> True
countLeaves[] = 0;
countLeaves[lst_] :=
If[Head[lst] =!= List, 1,
countLeaves[First[lst]] +
countLeaves[Rest[lst]]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 283
Informatik I 3 Programmierung
Anwendung und Prozeß:
ls = 1, 2, 3, 4;
countLeaves[ls]
4
countLeaves[1,2]
countLeaves[1]
countLeaves[2]
countLeaves[2]
countLeaves[]
countLeaves[3,4]
countLeaves[3]
countLeaves[4]
countLeaves[4]
countLeaves[]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 284
Informatik I 3 Programmierung
Zweites Beispiel:
ls = 1, 2, 3, 4, 5, 6, 7;
countLeaves[ls]
7
countLeaves[1]countLeaves[2]countLeaves[3, 4]countLeaves[3]countLeaves[4]countLeaves[4]countLeaves[]countLeaves[5]countLeaves[5]countLeaves[]countLeaves[6, 7]countLeaves[6]countLeaves[7]countLeaves[7]countLeaves[]countLeaves[]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 285

Informatik I 3 Programmierung
Wir nutzen den gleichen Prozeß, um die Map-Funktion auf verschach-telte Listen zu verallgemeinern.
mapTree[op_, ] :=
mapTree[op_, lst_] :=
If[Head[lst] =!= List, op[lst],
Prepend[mapTree[op, Rest[lst]],
mapTree[op, First[lst]]]
]
ls = 1, 2, 3, 4;
mapTree[#^2 &, ls] --> 1, 4, 9, 16
ls = 1, 2, 3, 4, 5, 6, 7;
mapTree[#^2 &, ls] --> 1, 4, 9, 16, 25, 36, 49
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 286
Informatik I 3 Programmierung
Ein weiteres Beispiel:
M = Table[i*j, i, 3, j, 4];
M =
1 2 3 4
2 4 6 8
3 6 9 12
mapTree[EvenQ, M] // MatrixForm
False True False True
True True True True
False True False True
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 287
Informatik I 3 Programmierung
Die folgende Map-Version akkumuliert die transformierten Blattelemen-te in einer gewohnlichen “flachen” Liste.
mapFlat[op_, ] :=
mapFlat[op_, lst_] :=
If[Head[lst] =!= List, op[lst],
Join[mapFlat[op, First[lst]],
mapFlat[op, Rest[lst]]]
]
ls = 1, 2, 3, 4, 5, 6, 7;
mapFlat[#^2 &, ls] --> 1, 4, 9, 16, 25, 36, 49
Die Anwendung der Identitat zahlt lediglich die Blattelemente auf.
mapFlat[# &, ls] --> 1, 2, 3, 4, 5, 6, 7
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 288
Informatik I 3 Programmierung
3.10 – Muster
Das allgemeinste Muster
Muster reprasentieren Klassen von Ausdrucken. Operationen mit die-sen Klassen sind die Grundlage wichtiger Konzepte der Programmie-rung mit vielen Anwendungen.
Die Klasse aller Ausdrucke wird durch das Muster _ reprasentiert. Dieinterne Reprasentation dieses Ausdrucks lautet
FullForm[_] --> Blank[]
Benennung von Mustern
Mit einem beliebigen Symbol konnen wir Muster benennen und erhal-ten Ausdrucke mit dem Kopf Pattern.
FullForm[n_] --> Pattern[n, Blank[]]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 289

Informatik I 3 Programmierung
Analog benennen wir spezielle Muster, die nur auf Ausdrucke mit ei-ner bestimmten Struktur passen, sowie Teilausdrucke:
x:<spezielles Muster>. Beispiel: x:a_+b_
Das letzte Muster reprasentiert die Klasse aller Ausdrucke, welchedie Summe zweier Ausdrucke sind, mit der Benennung x, a, b.
Abgleich von Mustern und Ausdrucken .
Zum Test, ob ein Ausdruck zu einem Muster paßt, benutzen wir dievorhandene Funktion
?MatchQ
MatchQ[expr, form] returns True if the pattern form
matches expr, and returns False otherwise.
Da das Muster _ alle Ausdrucke reprasentiert, liefertMatchQ[<Ausdruck>, _] immer True.
MatchQ["passt das?", _] --> True
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 290
Informatik I 3 Programmierung
Beispiele
f[n_] f mit irgendeinem (einzelnen) Argument, mit Namen n.
MatchQ[f["hallo"], f[n_]] --> True
MatchQ[f[a, b], f[n_]] --> False
f[n_,m_] f mit zwei benannten Argumenten.
MatchQ[f[a, b], f[n_, m_]] --> True
x^n_ x mit einem Exponenten namens n
MatchQ[x^"hallo", x^n_] --> True
MatchQ[y^2, x^n_] --> False
x_^n_ Irgendein potenzierter Ausdruck
MatchQ[y^2, x_^n_] --> True
a_+b_ Summe zweier Ausdrucke
MatchQ[(3 x + y)^2 + Sqrt[24 a b], a_+b_] --> True
MatchQ[1 + 2 + 3, a_+b_] --> False
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 291
Informatik I 3 Programmierung
Beispiele (Forts.)
a_,b_ Eine Liste mit zwei Ausdrucken
MatchQ["ABC", 88, ABC, a_, b_] --> True
MatchQ[, , ,, a_, b_] --> False
f[n_,n_] f mit zwei identischen Argumenten
MatchQ[f["ABC", "ABC"], f[n_, n_]] --> True
MatchQ[f[(a + b)^2, a^2 + 2 a b + b^2], f[n_, n_]]
--> False
Beachte: Mathematisch aquivalente Ausdrucke konnen von unter-schiedlicher Struktur sein und deshalb nicht zu demselben Musterpassen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 292
Informatik I 3 Programmierung
Mathematica gleicht Muster ausschließlich mit der Struktur der inter-nen Reprasentation eines Ausdrucks ab.
FullForm[1/x] --> Power[x, -1]
FullForm[a_/b_]
--> Times[Pattern[a, Blank[]], Power[Pattern[b, Blank[]], -1]]
MatchQ[1/x, a_/b_] --> False
MatchQ[1/x, Power[_, _]] --> True
Anwendung
Muster ermoglichen die prazisere Definition von Funktionen. Soll bei-spielsweise eine Funktion Punkte v =
(v1v2
)∈ R
2 als Argument haben,dann ist die Definition
f[v1_, v2_] := ...
sinnvoller alsf[v1_,v2_] := ...
Zudem sind die Komponenten der Punkte schon benannt und ermoglichenden direkten Zugriff im Rumpf der Funktion.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 293

Informatik I 3 Programmierung
Spezifikation des Typs eines Ausdrucks
Das Muster_Head oder in benannter Form x_Head
reprasentiert alle Ausdrucke mit Kopf Head.
Beispiele
x_Integer, x_Real, x_Complex, x_List, x_Symbol, usw.
Damit laßt sich der Typ eines Ausdrucks prufen. Dies gilt insbesonde-re (spater) fur Datentypen, die wir selbst konstruieren.
AnwendungIn dem obigen Beispiel wissen wir, dass das Argument v ∈ R
2 eineListe zweier reeller Zahlen ist. Also definieren wir noch genauer:
f[v1_Real, v2_Real] := ...
f[1, 4.5] --> f[1, 4.5] (wird nicht ausgewertet)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 294
Informatik I 3 Programmierung
Testen von Mustern
Ausdrucke der FormMuster?Test
reprasentieren jeweils eine Klasse von Ausdrucken, die auf ein Musterpassen und zudem einen Test erfullen.
Map[MatchQ[#, _?Positive] &, -1.0, -1, 1.0, 1]
--> False, False, True, True
Map[MatchQ[#, _Integer?Positive] &, -1.0, -1, 1.0, 1]
--> False, False, False, True
Anwendung
Soll die Funktion des obigen Beispiels nur auf Vektoren v ∈ R2+ ange-
wendet werden, dann konnten wir die Definition nochmals prazisieren:
f[v1_Real?Positive, v2_Real?Positive] := ...
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 295
Informatik I 3 Programmierung
Nochmals Testen von Mustern
Allgemeinere Tests sind Ausdrucke der FormMuster/;Bedingung
Lies: Ausdrucke der Form Muster fur die gilt, dass ... (Bedingung)
Im Bedingungsteil kann das benannte Muster, oder benannte Teilaus-drucke des Musters, verwendet werden, um die Bedingung zu formu-lieren.
Map[MatchQ[#, _, l_ /; NumberQ[l] && Positive[l]] &,
1, 1, 1, -1, 1, a, 1, 2, 3, "hallo", 1]
--> True, False, False, False, True
Map[MatchQ[#, a_^b_Integer /; And[a==x || a==y, b > 2]] &,
x^5, y^2, z^2, y^10, x^3.1]
--> True, False, False, True, False
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 296
Informatik I 3 Programmierung
Weitere Beispiele fur Musterausdrucke
expr.. a pattern or expression repeated one or more times
expr... a pattern or expression repeated zero or more times
Analog dazu Muster fur Sequenzen von Ausdrucken:__ und __Head , bzw. ___ und ___Head .
x_List or x:___ a list
x_List/;VectorQ[x] a vector containing no sublists
x_List/;VectorQ[x,NumberQ] a vector of numbers
x:___List or x:___... a list of lists
x_List/;MatrixQ[x] a matrix containing no sublists
x_List/;MatrixQ[x,NumberQ] a matrix of numbers
x:_,_... a list of pairs
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 297

Informatik I 3 Programmierung
Funktionen zum Musterabgleich
Einige Beispiele:
• MatchQ[expr,form]
test whether an expression matches a pattern
Diese Funktion wurde oben schon eingefuhrt und angewendet.
• FreeQ[expr,form]
test if an expression is free of a pattern
FreeQ[1, -300, x^2, a + b^2, _Real] --> True
FreeQ[1, -300, x^2, a + b^2, _Integer] --> False
FreeQ[1, -300, x^2, a + b^2, _^_] --> False
FreeQ[1, -300, a + b^2, _^_] --> False
• MemberQ[list,form]
test if any member of a list matches a pattern
MemberQ[1, 4, 6, 8, 10, _?PrimeQ] --> False
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 298
Informatik I 3 Programmierung
• Except[c]
is a pattern object which represents any expression
except one that matches c.
Map[MatchQ[#, Except[_Integer + _Symbol]] &,
2, x + 1, a + 6 + c, 400 - z]
--> True, False, True, True
• Select[list, criterion]
picks out all elements of list for which criterion is True.
Select[Range[20] - 10, Negative]
--> -9, -8, -7, -6, -5, -4, -3, -2, -1
Select[Range[20] - 10, Positive[#] && OddQ[#] &]
--> 1, 3, 5, 7, 9
• Cases[list, pattern]
return a list of elements matching a pattern
Cases[Range[100], _?(Mod[#, 15] == 0 &)]
--> 15, 30, 45, 60, 75, 90
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 299
Informatik I 3 Programmierung
• Count[list, pattern]
a count of occurrences of a pattern
Count[Range[1000], _?PrimeQ] --> 168
• Pick[list, select, pattern]
picks out those elements of list for which the
corresponding element of select matches pattern.
Pick[Anna, Beate, Dirk, Karl, Uwe,
1, 2, 3, 4, 5, _?EvenQ]
--> Beate, Karl
Neben weiteren Funktionen stellt Mathematica eine Menge von Funk-tionen bereit, die analog zu oben Muster von Zeichenketten ( StringPatterns ) verarbeiten.
Anstelle einer – notwendig unvollstandigen – weiteren Aufzahlung be-trachten wir lieber ein kleines Anwendungsbeispiel.
Weitere Informationen → Tutorial im Help-Menu.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 300
Informatik I 3 Programmierung
Anwendungsbeispiel
Wir wollen von der Webseite www.bundesliga.de/de/liga/tabelle/
die Logos der Bundesligaclubs herausfiltern und herunterladen.
Zuerst importieren wir die ganze Webseite als sog. XMLObject.
website =
Import["http://www.bundesliga.de/de/liga/tabelle/",
"XMLObject"];
Mathematica erzeugt einen strukturierten komplexen Ausdruck, ent-sprechend den Strukturelementen dieser Auszeichnungssprache (Mar-kup Language). Wir ignorieren diesen Kontext und suchen direkt nachden Bildchen.
Wir selektieren aus dem Ausdruck alle Zeichenketten, unter deneneinige die gesuchten Pfade der Bilddateien angeben.
strings = Cases[website, _String, Infinity];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 301

Informatik I 3 Programmierung
Das Argument Infinity weist Cases an, im Falle eines hierarchi-schen Ausdrucks (typischerweise ein Baum) bei der Suche beliebigoft “hinabzusteigen”.
Wir prufen, ob auch wirklich nur Zeichenketten extrahiert wurden.
Equal[Map[Head, strings]] --> True
Wir haben jetzt viele Zeichenketten, unter denen uns nur wenige in-teressieren.
Length[strings] --> 1815
Take[strings, 10]
"Version", "1.0", "Standalone", "yes", "html",
"version", "-//W3C//DTD HTML 4.01 Transitional//EN",
"lang", "en", "http://www.w3.org/XML/1998/namespace"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 302
Informatik I 3 Programmierung
Wir selektieren weiter alle Zeichenketten, die mit .gif abschließen.~~ bedeutet Verkettung mit Mustern.
Take[Select[strings,
(Length[StringCases[#, __ ~~ ".gif"]] > 0 &)],
10] // TableForm
"/pics/icon_rss.gif",
"/pics/_header/gra_logo.gif",
"/pics/_header/txt_offizielle_website.gif",
"/pics/_buttons/btn_login.gif",
"this.src=’/pics/_buttons/btn_login.gif’",
"this.src=’/pics/_buttons/btn_login_mo.gif’",
"/media/images/vereinsleiste/stuttgart_28x28.gif",
"/media/images/vereinsleiste/schalke_28x28.gif",
"/media/images/bundesliga/werderlogo28x28.gif",
"/media/images/vereinsleiste/bayern_muenchen_28x28.gif"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 303
Informatik I 3 Programmierung
Nun konnen wir gezielter suchen. pattern, pattern, ... oderpattern | pattern | ... bedeutet eine alternative Auswahl an Mu-stern (“oder”: irgendeines der Muster soll passen).
Durch die Verwendung des vorhandenen Symbols StartOfLine igno-rieren wir Zeichenketten, bei denen /media/... nicht am Anfang steht.
imageSources = Select[strings,
(Length[
StringCases[#,
StartOfLine ~~ "/media/images/vereinsleiste/"
~~ __ ~~ ".gif",
StartOfLine ~~ "/media/images/bundesliga/"
~~ __ ~~ ".gif"
]
] > 0 &)
];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 304
Informatik I 3 Programmierung
Wir erganzen die Links zu absoluten Adressen und importieren dieBilder (Mathematica importiert eine Menge gangiger Dateiformate).<> bedeutet die Verkettung von Zeichenketten.
With[str = "http://www.bundsliga.de/",
images = Map[Import[str <> #] &, imageSources]];
GraphicsGrid[Partition[images, 6]]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 305

Informatik I 3 Programmierung
3.11 – Objekte mit Zust anden
Wir definieren eine Variable, die den Stand eines Kontos darstellenbalance = 100;
soll, sowie eine Prozedur zum Geldabheben.
withDraw[amount_] := If[balance >= amount,
balance = balance - amount;
"Balance = " <> ToString[balance], (* display balance *)
"Balance " <> ToString[balance] <> (* else error message *)
" is insufficient for withdrawal of "
<> ToString[amount] <> "!"]
withDraw[25] --> "Balance = 75"
withDraw[25] --> "Balance = 50"
withDraw[60] --> "Balance 50 is insufficient for
withdrawal of 60!"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 306
Informatik I 3 Programmierung
Eine globale Variable als Kontostand ist weder guter Programmierstil,noch eine gute Idee. Jede Prozedur kann den Kontostand andern.
Die folgende Funktion speichert den Kontostand in einer lokalen Va-riablen und gibt die obige Abhebe-Funktion zuruck, welche den loka-len Kontostand wie gewunscht andert.
makeWithdraw[yourMoney_] :=
Module[balance = yourMoney, (* lokale Variable setzen *)
Function[amount, (* Abhebe-Funktion als Wert *)
If[balance >= amount,
balance = balance - amount;
"Balance = " <> ToString[balance],
"Balance " <> ToString[balance] <> " is insufficient
for withdrawal of " <> ToString[amount] <> "!"]]]
Der Wert von makeWithdraw verhalt sich wie ein Objekt mit eigenemZustand, dem Kontostand balance.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 307
Informatik I 3 Programmierung
W1 = makeWithdraw[100];
W1[10] --> "Balance = 90"
W1[20] --> "Balance = 70"
W1[71] --> "Balance 70 is insufficient for withdrawal of 71!"
W1[70] --> "Balance = 0"
W2 = makeWithdraw[100];
W2[50] --> "Balance = 50"
W2 = W1;
W2[1] --> Balance 0 is insufficient for withdrawal of 1!
Wir wollen auf diese Weise eine Funktion makeAccount definieren,welche ein Bankkonto-Objekt erzeugt, von dem man abheben bzw. aufdas man einzahlen kann.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 308
Informatik I 3 Programmierung
Wir gehen die Definition von makeAccount abschnittsweise durch.
Als Argumente ubergeben wir neben einem Geldbetrag fur die Konto-eroffnung auch den Namen des Kontoeigentumers.
makeAccount[yourMoney_, name_] := Module[
Als lokale Variable definieren wir die Zust ande des Kontoobjektes
balance = yourMoney, owner = name,
und Funktionen, in diesem Kontext Methoden genannt, mit denenman Zustande inspizieren und verandern kann.
PrintBalance, PrintInsufficientBalance, Withdraw, Deposit,
PrintBalance hat kein Argument und gibt einfach den aktuellen Kon-tostand aus.
PrintBalance =
Function[,
owner <> "’s account: balance = " <> ToString[balance]];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 309

Informatik I 3 Programmierung
PrintInsufficientBalance ist eine Fehlermeldung.
PrintInsufficientBalance =
Function[,
"Balance " <> ToString[balance] <> " is insufficient
for withdrawal of " <> ToString[amount] <> "!"];
Die Abhebe-Routine wurde oben schon eingefuhrt.
Withdraw = Function[amount,
If[balance >= amount,
balance = balance - amount; PrintBalance[],
PrintInsufficientBalance[]
]
];
Analog definieren wir eine Methode zum Einzahlen.
Deposit = Function[amount,
balance = balance + amount; PrintBalance[]];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 310
Informatik I 3 Programmierung
Der Wert von makeAccount ist eine (reine) Funktion mit einem Argu-ment method, welche abhangig vom Wert von method die entspre-chende, fur den Benutzer bestimmte Methode zuruckgibt.
Function[method, Switch[method,
"Withdraw", Withdraw,
"Deposit", Deposit,
_, Function[amount,
"ERROR (unknown method: " <> ToString[method] <> ")"]
] (* Switch *)
] (* Function *)
] (* Module makeAccount *)
Wir erproben diese vorlaufige Version von makeAccount.
a1 = makeAccount[100, "Christoph"];
a1["Withdraw"][50]
--> "Christoph’s account: balance = 50"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 311
Informatik I 3 Programmierung
a1["Withdraw"][40]
--> "Christoph’s account: balance = 10"
a1["Withdraw"][50]
--> "Balance 10 is insufficient for withdrawal of amount!"
a1["Deposit"][30]
--> "Christoph’s account: balance = 40"
a1[Hallo][40]
--> "ERROR (unknown method: Hallo)"
Einerseits funktioniert das wie beabsichtigt, andererseits ist das For-mat zum Aufrufen einer Methode mittels einer Zeichenkette
<object>["<Methodenname>"][Argument der Methode]
gewohnungsbedurftig. Rufen wir eine Methode falsch auf und verges-sen dabei das Argument, so gibt es zudem noch eine unbeabsichtigteAntwort (unevaluierte Funktion als Wert von a1).
a1[Hallo] --> Function[amount$,
"ERROR (unknown method: " <> ToString[Hallo] <> ")"]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 312
Informatik I 3 Programmierung
Wir versehen aus diesem Grund des Ruckgabewert von makeAccount
mit einem Kopf Account
Clear[makeAccount]
makeAccount[ ...
...
Account[Function[method,
Switch[method,
"Withdraw", Withdraw,
"Deposit", Deposit
]]]
und verbergen die obigen Methodenaufrufe hinter gewohnlichen Funk-tionsdefinitionen, welche zudem nur dann eine Methode aufrufen, wennauch ein Objekt des Typs Account ubergeben wird.
WithDraw[Account[a_], amount_] := a["Withdraw"][amount]
Deposit[Account[a_], amount_] := a["Deposit"][amount]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 313

Informatik I 3 Programmierung
Methodenaufrufe und Fehlerreaktionen erfolgen nun wie gewohnt.
a1 = makeAccount[100, "Christoph"];
WithDraw[a1, 99]
--> "Christoph’s account: balance = 1"
Deposit[a1, 98]
--> "Christoph’s account: balance = 99"
WithDraw[hallo, 5]
--> WithDraw[hallo, 5] (* unevaluiert *)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 314
Informatik I 3 Programmierung
Anwendungsbeispiel
Wir wollen den Ablauf einer Ampelschaltung graphisch simulieren.Dazu definieren wir ein Ampelobjekt, das unter anderem uber eineMethode verfugt sich selbst zu zeichnen. Diesen Ausdruck ubergebenwir der Mathematica-Funktion
Dynamics[expr]
represents an object that displays as the dynamically
updated current value of expr.
Wann immer sich der Zustand der Ampel andert, wird also automa-tisch die Methode aufgerufen und der neue Zustand visualisiert.
Beim Erzeugen einer neuen Ampel ubergeben wir den initalen Zu-stand und setzen den internen Zustand entsprechend.
newStoplight[initialState_] := Module[
currentState = initialState,
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 315
Informatik I 3 Programmierung
In einer weiteren lokalen Variablen speichern wir die Folge moglicherZustande.
states = Red, White, White, Red, Yellow, White,
White, White, Green, White, Yellow, White,
Jede Ampel verfugt uber zwei Methoden.
Draw, nextState ,
Das Bild einer Ampel sind drei Scheiben in einem Rahmen.GraphicsColumn[
Graphics /@
Red, Disk[],
Yellow, Disk[],
Green, Disk[]
,
Frame -> True, FrameStyle -> Thickness[0.05]]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 316
Informatik I 3 Programmierung
Entsprechend lautet die Method Draw
Draw = Function[,
GraphicsColumn[
Graphics /@ Map[List[#, Disk[]] &, states[[currentState]]],
Frame -> True, FrameStyle -> Thickness[0.05]]
];
Die Funktion der Methode nextState ist klar.
nextState =
Function[,
currentState =
If[currentState == Length[states], 1, currentState + 1];
];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 317

Informatik I 3 Programmierung
Wir definieren der Wert von newStoplight,
Stoplight[Function[method,
Switch[method,
"Draw", Draw,
"nextState", nextState]]]
]
sowie Funktionen fur die Anwendung dieser beiden Methoden.
Draw[Stoplight[s_]] := s["Draw"][]
nextState[Stoplight[s_]] := s["nextState"][]
Wir erzeugen zwei Ampeln.
ersteAmpel = newStoplight[1];
zweiteAmpel = newStoplight[3];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 318
Informatik I 3 Programmierung
Aufruf von
Dynamic[GraphicsRow[Draw[ersteAmpel], Draw[zweiteAmpel]]]
erzeugt das vorige Bild, das automatisch neu ausgefuhrt wird, sobaldsich Zustand einer Ampel, z.B. aufgrund der Anweisung
nextState[ersteAmpel]; nextState[zweiteAmpel]
andert.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 319
Informatik I 4 Datenstrukturen
4 – Datenstrukturen
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 319
Informatik I 4 Datenstrukturen
4.1 – Datenabstraktion
Bisheriger Schwerpunkt der Vorlesung: Prozedurale Abstraktion .Abstraktion von elementaren Operation durch Kombination von Funk-tionen.
Beispiel aus dem Abschnitt “Muster”.
myFunction[v1_Integer?Positive, v2_Integer?Positive] :=
Module[ <lokale Variable> ,
... Funktionsrumpf ...
]/;Bedingung[...]
Vorteil der Abstraktion: Der Benutzer muß lediglich die Spezifikationder Funktion kennen, d.h. Funktionsname, Typen der Argumente undMenge der zulassigen Eingabewerte.
Die Implementierung der Funktion (Funktionsrumpf, interne Namen,Hilfsvariablen), sind fur den Benutzer irrelevant. Dies erleichtert War-tung und Optimierung der Software.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 320
Informatik I 4 Datenstrukturen
Thema dieses Abschnitts: Datenabstraktion .
Abstraktion von elementaren Daten durch Konstruktion zusammen-gesetzter Datenobjekte.
Die Implementierung eines neuen Datentyps basiert auf den elemen-taren Datentypen. Wie bei der prozeduralen Abstraktion ist auch beider Datenabstraktion fur den Benutzer nur die Spezifikation des Da-tentyps relevant, die als Abstraktionsbarriere (“Benutzerschnittstelle”)Details der konkreten Implementierung verbirgt.
Vorteile:
• Klarheit und mehr Sicherheit bei Umgang mit Daten des spezifi-zierten Typs,
• leichtere Wartbarkeit der Software.
Beispiel: Mathematica selbst (≈ 106 Zeilen Code).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 321
Informatik I 4 Datenstrukturen
Spezifikation eines Datentyps
Die Spezifikation besteht aus Funkionen zur Erzeugung von Datenob-jekten des spezifizierten Typs, sowie zur Definition von Operationenzum Umgang mit diesen Daten.
Konstruktoren erzeugen Daten des spezifizierten Typs.
Selektoren ermoglichen den Zugriff auf die Daten oder auf Kom-ponenten eines (typischerweise zusammengesetzten) Datenob-jekts.
Pradikate stellen Tests bereit.
Gleichungen beschreiben Beziehungen zwischen den voranstehen-den Operationen und damit ihre Eigenschaften, die eine korrekteImplementierung zu erfullen hat.
Ein Datentyp, der auf diese Weise ohne Bezug zu einer konkretenImplementierung spezifiziert ist, nennt man abstrakter Datentypen(ADT).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 322
Informatik I 4 Datenstrukturen
Aspekte der Implementierung eines ADTs
• Reprasentation der Datenelemente.
• Definition der Operationen (Konstruktoren, Selektoren, Pradikate).
• Regeln fur die Reduktion von Ausdrucken auf eine Normalform.Dies gewahrleistet die Vergleichbarkeit verschiedener Daten glei-chen Typs.
• Unterstutzung der Eingabe von Daten des spezifizierten Typs.
• Gut lesbares Ausgabeformat fur die Inspektion von Daten.
• Uberladen von Standardoperatoren, um Daten des Typs entspre-chend kombinieren zu konnen.
• Automatische Typkonversion (Beispiel: Daten jedes numerischenTyps sind als Argument des Konstruktors zulassig).
• Speicher- und Laufzeiteffizienz, Rucksicht auf spezielle Rechner-architekturen, ...
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 323
Informatik I 4 Datenstrukturen
Beispiel
Wir wollen einen Datentyp Rat zum Umgang mit rationalen Zahlenspezifizieren und implementieren (wir ignorieren vorubergehend denin MMa vorhandenen Zahlentyp Rational).
Konstruktor
makeRat: Integer× Integer→ Rat
Selektoren
numerator : Rat→ Integer
denominator: Rat→ Integer
Beziehungen zwischen diesen Operationen scheinen offensichtlich:
makeRat[numerator[r], denominator[r]] == r
numerator[makeRat[n, d]] == n (korrekt?)
denominator[makeRat[n, d]] == d (korrekt?)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 324

Informatik I 4 Datenstrukturen
Pradikat fur den Vergleich zweier Zahlen:
equal : Rat→ Booleans
Standardoperationen (Plus, Minus, ...), Ausgabeformat, ...
Eine naheliegende Implementierung des Konstruktors ist
makeRat[n_Integer, d_Integer] := Rat[n, d]
makeRat[3, 2] --> Rat[3, 2]
Der Kopf Rat kennzeichnet Daten dieses Typs und kann bei der Defi-nition von Funktionen gepruft werden.
f[r_Rat] := ...
Die Implementierung hat aber noch Mangel:
makeRat[-3, 2], makeRat[3, -2], makeRat[-3, -2],
makeRat[6, 4], makeRat[1, 0]
--> Rat[-3, 2], Rat[3, -2], Rat[-3, -2], Rat[6, 4],
Rat[1, 0]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 325
Informatik I 4 Datenstrukturen
Wir definieren eine Normalform von Ausdrucken des Typs Rat durchfolgende Regeln.
• Der Nenner ist immer positiv, d.h. der Zahler reprasentiert (auch)das Vorzeichen der rationalen Zahl.
• Zahler und Nenner werden gekurzt.
Die erste Regel kann man mittels If und dem Pradikat Positive im-plementieren, oder noch einfacher mit
Sign[x]
gives -1, 0 or 1 depending on whether x is negative,
zero, or positiv.
Kurzung erfolgt durch ganzzahlige Division mit dem ggt (MMa: GCD).
GCD[6, 4], GCD[4, 6], GCD[-6, 4], GCD[6, -4]
--> 2, 2, 2, 2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 326
Informatik I 4 Datenstrukturen
Die Reduktion auf Normalform erfolgt direkt durch den Konstruktor.
makeRat[n_Integer, d_Integer] :=
With[factor = GCD[n, d],
Rat[Sign[d] Quotient[n, factor],
Quotient[Abs[d], factor]
]
] /; d != 0
makeRat[-3, 2], makeRat[3, -2], makeRat[-3, -2],
makeRat[6, 4], makeRat[1, 0]
--> Rat[-3, 2], Rat[-3, 2], Rat[3, 2], Rat[3, 2],
makeRat[1, 0]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 327
Informatik I 4 Datenstrukturen
Implementierung der Selektoren.
numerator[Rat[n_, d_]] := n
denominator[Rat[n_, d_]] := d
Das Pradikat:
equal[r1_Rat, r2_Rat] :=
numerator[r1] == numerator[r2] &&
denominator[r1] == denominator[r2]
equal[makeRat[3, -2], makeRat[-12, 8]]
--> True
Dies funktioniert, da wir auf Normalform reduzieren.
Die Regeln der Addition rationaler Zahlen sind bekannt.
n1
d1+
n2
d2=
n1 · d2 + n2 · d1
d1 · d2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 328

Informatik I 4 Datenstrukturen
Entsprechende Implementierung:
add[r1_Rat, r2_Rat] :=
makeRat[numerator[r1]*denominator[r2] +
numerator[r2]*denominator[r1],
denominator[r1]*denominator[r2]
]
add[makeRat[2, 3], makeRat[1, 6]] --> Rat[5, 6]
add[makeRat[2, 3], makeRat[1, -6]] --> Rat[1, 2]
Mathematica (fur Interessierte)Eleganter als die Definition eigener Funktionen fur Standardoperatio-nen ist die Moglichkeit MMa “mitzuteilen”, was bei vorhandenen Ope-ratoren mit Datenobjekten des Typs Rat getan werden soll.
Rat /: r1_Rat + r2_Rat :=
makeRat[numerator[r1]*denominator[r2] +
numerator[r2]*denominator[r1],
denominator[r1]*denominator[r2] ]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 329
Informatik I 4 Datenstrukturen
Wann immer MMa in einem Ausdruck Plus[...] auf Daten des TypsRat trifft, werden diese Regeln angewendet. Dies erlaubt eine schonereEingabe und berucksichtigt die Assoziativitat der Addition gleich mit.
makeRat[2, 3] + makeRat[1, 6] --> Rat[5, 6]
makeRat[2, 3] + makeRat[1, -6] --> Rat[1, 2]
makeRat[2, 3] + makeRat[1, -6] + makeRat[-1, 8] --> Rat[3, 8]
Man kann diese Definition auf zwei Arten interpretieren:
– Uberladen des Operators Plus fur Objekte des Typs Rat,
– Verfugbar machen der Methode Plus fur Objekte des Typs Rat.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 330
Informatik I 4 Datenstrukturen
4.2 – Bin arbaume: Suche
Ein bin arer Suchbaum ist eine einfache dynamische Datenstruktur,die das effiziente Einfugen und Wiederfinden von Datenelementenunterstutzt.
Wir beschranken uns auf ganze, eindeutige, positive Zahlen als Da-tenelemente, stellvertretend fur Schlussel beliebiger Datensatze.
Ein Binarbaum besteht aus ei-nem Schlusselelement sowie ei-nem linken und einem rechtenBin arbaum .
Alle Schlussel des linken (rech-ten) Binarbaumes sind kleiner(großer ) als der Schlussel desBinarbaumes.
4
2 6
1 3 5 7
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 331
Informatik I 4 Datenstrukturen
Definition des ADT
Symbol zur Reprasentation des leeren Binarbaumes:emptyTree
Konstruktor:makeBinaryTree[key_, left_, right_] :=
bTree[key, left, right]
Selektoren:getKey[bTree[key_, _, _]] := key
leftTree[bTree[_, left_, _]] := left
rightTree[bTree[_, _, right_]] := right
Pradikate:emptyQ[emptyTree] = True;
emptyQ[tree_bTree] := False
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 332

Informatik I 4 Datenstrukturen
Einfugen eines Schlussels
Gibt es keinen Baum, dann erzeugen wie einen solchen bestehendaus dem Schlussel und zwei leeren Teilbaumen.
insertTree[emptyTree, key_] :=
makeBinaryTree[key, emptyTree, emptyTree]
b = insertTree[emptyTree, 5]
--> bTree[5, emptyTree, emptyTree]
getKey[b] --> 5
rightTree[b] --> emptyTree
emptyQ[b] --> False
emptyQ[leftTree[b]] --> True
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 333
Informatik I 4 Datenstrukturen
Ist der Baum nicht-leer, dann
– geben wir lediglich den Baum zuruck, falls der einzufugende Schlusselgleich dem vorhandenen ist,
– fugen wir den Schlussel je nach Großenvergleich mit dem vor-handenen Schlussel in den linken bzw. rechten Teilbaum ein –rekursiver Aufruf!
insertTree[tree_bTree, key_Integer?Positive] := Which[
key == getKey[tree], tree,
key < getKey[tree],
makeBinaryTree[getKey[tree],
insertTree[leftTree[tree], key], rightTree[tree]],
key > getKey[tree],
makeBinaryTree[getKey[tree], leftTree[tree],
insertTree[rightTree[tree], key]]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 334
Informatik I 4 Datenstrukturen
b = insertTree[b, 3]
--> bTree[5, bTree[3, emptyTree, emptyTree], emptyTree]
5
3
bTree
5 bTree
3 emptyTree emptyTree
emptyTree
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 335
Informatik I 4 Datenstrukturen
b = insertTree[b, 7]
--> bTree[5, bTree[3, emptyTree, emptyTree],
bTree[7, emptyTree, emptyTree]]
5
3 7
bTree
5 bTree
3 emptyTree emptyTree
bTree
7 emptyTree emptyTree
Ist ein Schlussel schon vorhanden, dann passiert nichts.
insertTree[b, 5]
--> bTree[5, bTree[3, emptyTree, emptyTree],
bTree[7, emptyTree, emptyTree]]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 336

Informatik I 4 Datenstrukturen
Zur Eingabe aller Schlussel falten wir die Liste mit insertTree.
Zur Erinnerung:Fold[f, x, 1, 2, 3] --> f[f[f[x, 1], 2], 3]
data = 4, 2, 1, 3, 6, 5, 7
b = Fold[insertTree, emptyTree, data]
4
2
4
2
1
4
2
1 3
4
2 6
1 3
4
2 6
1 3 5
4
2 6
1 3 5 7
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 337
Informatik I 4 Datenstrukturen
Suchen eines Schlussels
Mittels Vergleich und rekursiven Aufrufs durchlaufen wir den linkenbzw. den rechten Teilbaum, bis wir den Schlussel gefunden habenoder auf einen leeren Teilbaum stoßen (Schlussel nicht vorhanden).
searchTree[emptyTree, key_] := False
searchTree[tree_bTree, key_] := Which[
key == getKey[tree], True,
key < getKey[tree], searchTree[leftTree[tree], key],
key > getKey[tree], searchTree[rightTree[tree], key]
]
data = RandomSample[Range[20], 10]
--> 10, 15, 19, 2, 13, 7, 16, 17, 8, 3
searchTree[b, 16] --> True
searchTree[b, 18] --> False
Der Auswand ist durch die Hohe H desBaumes bestimmt: T (n) ∈ O(H).
10
2 15
7
3 8
13 19
16
17
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 338
Informatik I 4 Datenstrukturen
Traversieren des Baumes
Wir spezifizieren drei Durchlaufstrategien, um die Schlussel einesBaumes linear auszugeben.
inOrder[emptyTree] = ;
inOrder[tree_bTree] := Join[
inOrder[leftTree[tree]],
getKey[tree],
inOrder[rightTree[tree]]
]
8
4 12
2 6
1 3 5 7
10 14
9 11 13 15
inOrder[b]
--> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 339
Informatik I 4 Datenstrukturen
preOrder[emptyTree] = ;
preOrder[tree_bTree] :=
Join[
getKey[tree],
preOrder[leftTree[tree]],
preOrder[rightTree[tree]]
]
postOrder[emptyTree] = ;
postOrder[tree_bTree] :=
Join[
postOrder[leftTree[tree]],
postOrder[rightTree[tree]],
getKey[tree]
]
preOrder[b]
--> 8, 4, 2, 1, 3, 6, 5, 7, 12, 10, 9, 11, 14, 13, 15
postOrder[b]
--> 1, 3, 2, 5, 7, 6, 4, 9, 11, 10, 13, 15, 14, 12, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 340

Informatik I 4 Datenstrukturen
Weiterfuhrende Themen
• Entfernen von Schlusseln
• Im ungunstigsten Fall der Eingabe einer ge-ordneten Liste ist die Hohe des SuchbaumesH = n− 1!
→ Strategien, um ausgeglichene Baume zuerhalten.
1
2
3
4
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 341
Informatik I 4 Datenstrukturen
4.3 – Bin arbaume: Arithmetische Ausdrucke
Als Variation des Themas des vorigen Abschnitts konstruieren wirBinarbaume zur Verarbeitung arithmetischer Ausdrucke unter der Vor-aussetzung, dass alle Operatoren zweistellig sind.
Nehmen wir an, der Term
term = a*(((b + c)*d) - e)
werde in der folgenden Form eingegeben:
Times[a,Plus[Times[Plus[b,c],d],Times[-1,e]]]
Dies ist dies ein hierarchischer Ausdruck nach dem Muster
h_[x_, y_]
mit einem Operator h als Kopf und Operanden x, y, die entweder einAusdruck nach dem gleichen Muster sind, oder aber einfache Ope-randen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 342
Informatik I 4 Datenstrukturen
Entsprechend schreiben wir anstelle von insertTree eine Funktion,welche rekursiv einen Binarbaum nach dem obigen Muster aufbaut.
Ist ein Operand ein Operatorausdruck, so erfolgt ein rekursiver Ausruf.
makeBExprTree[h_[x_, y_]] :=
With[xOp = MatchQ[x, _[_, _]], yOp = MatchQ[y, _[_, _]],
Which[
xOp && yOp,
makeBinaryTree[h, makeBExprTree[x], makeBExprTree[y]],
xOp && !yOp,
makeBinaryTree[h, makeBExprTree[x], y],
!xOp && yOp,
makeBinaryTree[h, x, makeBExprTree[y]],
!xOp && !yOp, makeBinaryTree[h, x, y]
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 343
Informatik I 4 Datenstrukturen
termTree = makeBExprTree[term]
--> bTree[Times, a, bTree[Plus, bTree[Times,
bTree[Plus, b, c], d], bTree[Times, -1, e]]]
Links der Kantorowitsch-Baum , rechts seine Darstellung als Binarbaum.
Times
a Plus
Times
Plus
b c
d
Times
-1 e
bTree
Times a bTree
Plus bTree
Times bTree
Plus b c
d
bTree
Times -1 e
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 344

Informatik I 4 Datenstrukturen
Fur einen Postorder-Durchlauf mussen wir die Routinen des vorigenAbschnitts zur Terminierung der Rekursion modifizieren, da an dieStelle leerer Baume emptyTree nun einfache Operanden getreten sind.
postOrder[x_Symbol] := x
postOrder[x_?NumberQ] := x
postOrder[termTree]
--> a, b, c, Plus, d, Times, -1, e, Times, Plus, Times
Der Vergleich mit
term = a*(((b + c)*d) - e)
Times[a,Plus[Times[Plus[b,c],d],Times[-1,e]]]
zeigt, dass der Ausdruck ohne Klammerung korrekt ausgewertet kann:Sobald ein Operator in dieser linearen Sequenz (Liste) auftritt, kanner auf die beiden voranstehenden einfachen Operanden angewendetwerden.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 345
Informatik I 4 Datenstrukturen
4.4 – Bin arbaume: Huffman-Code
Ein Code ist eine injektive Abbildung f : A→ Σ∗ von Elementen einerZeichenmenge auf (Code-)Worter eines Alphabets.
Beispiel: Dezimaldarstellung der binaren ASCII-Codierung einigerBuchstaben, Ziffern und Sonderzeichen.
!33
"34
ð35
$36
%37
&38
’39
H40
L41
*42
+43
,44 -45
.4647
048
149
250
351
452
553
654
755
856
957
:58
;59
<60
=61
>62
?63
64
A65
B66
C67
D68
E69
F70
G71
H72
I73
J74
K75
L76
M77
N78
O79
P80
Q81
R82
S83
T84
U85
V86
W87
X88
Y89
Z90
@91
\92
D93
^94
_95 ‘96
a97
b98
c99
d100
e101
f102
g103
h104
i105
j106
k107
l108
m109
n110
o111
p112
q113
r114
s115
t116
u117
v118
w119
x120
y121
z122
8123
È124
<125
~126
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 346
Informatik I 4 Datenstrukturen
Gegeben sei ein Text einer nicht weiter bekannten Nachrichtenquelle.
text = "BACADAEAFABBAAAGAH"
uber der Zeichenmenge
zeichenMenge = Union[Characters[text]]
--> "A", "B", "C", "D", "E", "F", "G", "H"
Wir betrachten die Aufgabe, diesen Textbinar zu kodieren.
Da |zeichenMenge| = 8 = 23, besteht einoffensichtlicher Ansatz darin, die Zeichenmit 3 Bits durchzuzahlen und die entspre-chenden Codeworter uber Σ = 0, 1 zubilden.
"A" -> "000",
"B" -> "001",
"C" -> "010",
"D" -> "011",
"E" -> "100",
"F" -> "101",
"G" -> "110",
"H" -> "111"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 347
Informatik I 4 Datenstrukturen
Der kodierte Text benotigt 54 Bits.
StringReplace[text, rules]
--> 001000010000011000100000101000001001000000000110000111
StringLength[%] --> 54
Allerdings braucht der folgende Code weniger Zeichen:
rules = Sort[huffmanEncodeRules[ht]]
"A" -> "0", "B" -> "111", "C" -> "1000", "D" -> "1001",
"E" -> "1101", "F" -> "1100", "G" -> "1011", "H" -> "1010"
StringReplace[text, rules]
--> 111010000100101101011000111111000101101010
StringLength[%] --> 42
Das ist eine Einsparung der Nachrichtenmenge um ≈ 22%!
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 348

Informatik I 4 Datenstrukturen
Der vorige Code orientiert sich an der relativen Haufigkeit, mit der dieZeichen in Nachrichten vorkommen.
Characters[text]
--> "B", "A", "C", "A", "D", "A", "E", "A", "F", "A",
"B", "B", "A", "A", "A", "G", "A", "H"
Union[%] --> "A", "B", "C", "D", "E", "F", "G", "H"
characterFrequencies[text_String] :=
Module[charSequence, symbols,
charSequence = Characters[text];
symbols = Union[charSequence];
Thread[List[Map[Count[charSequence, #] &, symbols],
symbols]]
]
data = characterFrequencies[text]
--> 9, "A", 3, "B", 1, "C", 1, "D", 1, "E",
1, "F", 1, "G", 1, "H"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 349
Informatik I 4 Datenstrukturen
Normieren wir die Haufigkeiten, so erhalten wir die empirische Wahr-scheinlichkeitsverteilung
p(x) ≥ 0 ,∑
x∈X
p(x) = 1 , x ∈ X = A, B, C, D, E, F, G, H
des Auftretens eines Zeichens in Nachrichten der gegebenen Quelle.
With[frequencies = Map[First, data],
frequencies/Total[frequencies]]
→
1
2,1
6,
1
18,
1
18,
1
18,
1
18,
1
18,
1
18
Haufig auftretende Zeichen erhalten kurze Codeworter, z.B. "A" -> "0",seltenere Zeichen erhalten langere Codeworter, z.B. "D" -> "1001".
Dieses Ausnutzen der Zeichenstatistik (Entfernen von Redundanz) ei-ner Nachrichtenquelle nennt man Quellenkodierung , im Unterschiedzur Kanalcodierung (Hinzufugen von Redundanz) zur Detektion undKorrektur von Ubertragungsfehlern.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 350
Informatik I 4 Datenstrukturen
Ein Code C ⊆ Σ∗ heißt Prafix-Code (prefix code , instantaneouscode ), wenn kein Wort aus C Prafix eines anderen Wortes aus C ist.
Dadurch ist es moglich, eine codierte Zeichenkette von links nachrechts zu lesen und unmittelbar zu dekodieren.
Problem (Quellenkodierung)
Gegeben eine Menge X = x1, x2, . . . , xn und eine Wahr-scheinlichkeitverteilung pi = p(xi) , i = 1, . . . , n. Konstruiereeinen Prafix-Code c : X → Σ∗, wi = c(xi), mit
L(C) =n∑
i=1
pi|wi| ist minimal.
L(C) ist die durchschnittliche (erwartete) Lange der Codeworteraus C = w1, . . . , wn.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 351
Informatik I 4 Datenstrukturen
Binare Prafix-Codes konnen bijektiv auf Binarbaume abgebildet wer-den, mit den Codewortern als Blatter. Der Weg zu einem Codewortergibt die 0/1-Folge, je nachdem ob wir links oder rechts an einemKnoten weiterlaufen. Wenn kein Codewort durch einen inneren Kno-ten reprasentiert wird, kann keines Prafix eines anderen Wortes sein.
Wir konstruieren diesenHuffman-Baum mit den Ori-ginalzeichen als Blatter. FurA ergibt sich das Codewort 0
(einmal nach links laufen), fur D
das Wort 1001 (recht-links–links-rechts).Die inneren Knoten zeigen dieSumme der nicht-normiertenHaufigkeiten aller Zeichen(Blatter) des zugehorigen Teil-baumes.
181
A 92
45 53
27 26
C D H G
24 B
F E
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 352

Informatik I 4 Datenstrukturen
Auskunft uber die Existenz eines Baumes (bzw. Prafix-Codes) in Ab-hangigkeit der Wortlangen l1 = |w1|, . . . , ln = |wn| gibt die
Kraftsche Ungleichung
Sei T ein Binarbaum mit den Weglangen l1, . . . , ln der Blatter.Dann gilt
∑ni=1
12li≤ 1 und Gleichheit genau dann, wenn T
vollstandig ist, d.h. wenn jeder innere Knoten zwei Teilbaume(ggfs. Blatter) hat.
Seien umgekehrt l1 = |w1|, . . . , ln = |wn| gegeben und dieobige Ungleichung erfullt, dann existiert ein Binarbaum mit n
Blattern und den Weglangen l1, . . . , ln.
Im obigen Beispiel gilt
rules = "A"->"0", "B"->"111", "C"->"1000", "D"->"1001",
"E"->"1101", "F"->"1100", "G"->"1011", "H"->"1010"
Map[StringLength[Last[#]] &, rules] --> 1,3,4,4,4,4,4,4
Total[Map[2^(-#) &, %]] --> 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 353
Informatik I 4 Datenstrukturen
Der nachfolgende beruhmte Satz der Informationstheorie gibt eineuntere Schranke an fur die minimale mittlere Wortlange L eines Pradix-Codes.
Satz (Shannon)
Sei p = p1, . . . , pn eine Wahrscheinlichkeitsverteilung aufden Blattern eins Binarbaumes T . Dann gilt
H(p) ≤ L ≤ H(p) + 1 ,
mit der Entropie H(p) = −∑ni=1 pi log2 pi der Verteilung p.
In unserem Beispiel gilt
p =
1
2,1
6,
1
18,
1
18,
1
18,
1
18,
1
18,
1
18
wordLengths = 1, 3, 4, 4, 4, 4, 4, 4
N[-Sum[p[[i]] Log[2, p[[i]]], i, Length[p]]] --> 2.3208
p.wordLengths --> 7/3
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 354
Informatik I 4 Datenstrukturen
Algorithmus von Huffman
Der Algorithmus von Huffman ist ein Greedy-Algorithmus zur Berech-nung eines Codes mit einer mittleren Wortlange gemaß des Satzesvon Shannon.
Ausgehend von den Daten
data = 9, "A", 3, "B", 1, "C", 1, "D", 1, "E",
1, "F", 1, "G", 1, "H";
fassen wir iterativ zwei Elemente mit der niedrigsten Haufigkeit zu-sammen und akkumulieren deren Haufigkeit.
9, "A", 3, "B", 1, "C", 1, "D", 1, "E",
1, "F", 1, "G", 1, "H",
2, 1, "H", 1, "G", 1, "F", 1, "E", 1, "D",
1, "C", 3, "B", 9, "A",
2, 1, "C", 1, "D", 1, "E", 1, "F",
2, 1, "H", 1, "G", 3, "B", 9, "A", ...
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 355
Informatik I 4 Datenstrukturen
Programm. Zum Sortieren der Daten nach der Haufigkeit ubergebenwir der eingebauten Funktion Sort eine Vergleichsfunktion.
sortNodes[nodes : _Integer?Positive, _ ..] :=
Sort[nodes, First[#1] < First[#2] &]
Zusammenfassen zweier Elemente: Gibt es nur noch ein Element,dann tun wir nichts.
mergeNodes[nodes : _Integer?Positive, _] := nodes
Andernfalls, sortiere die Daten und fasse zwei Elemente zusammen.
mergeNodes[nodes : _Integer?Positive, _ ..] :=
Module[sorted = sortNodes[nodes], n1, n2,
n1, n2 = Take[sorted, 2];
Prepend[Drop[sorted, 2],
First[n1] + First[n2], n1, n2]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 356

Informatik I 4 Datenstrukturen
Der Greedy-Algorithmus zum Aufbau der hierarchischen Liste laßtsich nun als Fixpunktiteration schreiben.
FixedPoint[mergeNodes, data] -->
18, 9, "A", 9, 4, 2, 1, "C", 1, "D",
2, 1, "H", 1, "G", 5, 2, 1, "F",
1, "E", 3, "B"
Wir bauen nun dar-aus in umgekehrterRichtung rekursiveinen Binarbaum,den sog. Huffman-Baum , auf.
181
A 92
45 53
27 26
C D H G
24 B
F E
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 357
Informatik I 4 Datenstrukturen
Die einzelnen, zu kodierenden Zeichen sind die Blatter.
makeLeaf[s_String] := insertTree[emptyTree, s]
Die gleichformig aufgebauten Elemente der hierarchischen Liste losenwir rekursiv auf.
makeHuffmanTree[parent_, child1_, child2_] :=
Switch[child1, child2,
_Integer, _String, _Integer, _String,
makeBinaryTree[parent, makeLeaf[Last[child1]],
makeLeaf[Last[child2]]],
_Integer, _String, _,
makeBinaryTree[parent, makeLeaf[Last[child1]],
makeHuffmanTree[child2]],
_, _Integer, _String,
makeBinaryTree[parent, makeHuffmanTree[child1],
makeLeaf[Last[child2]]],
...
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 358
Informatik I 4 Datenstrukturen
...
_, _,
makeBinaryTree[parent, makeHuffmanTree[child1],
makeHuffmanTree[child2]]
]
Der Huffman-Baum resultiert aus der Anwendung der vorigen Funkti-on auf das außerste (erste) Element der hierarchischen Liste.
huffmanTree[data : _Integer?Positive, _String ..] :=
Module[nodeTree = FixedPoint[mergeNodes, data],
makeHuffmanTree[First[nodeTree]]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 359
Informatik I 4 Datenstrukturen
Wir wenden nun den Huffman-Baum zum Kodieren eines Textes an.Dazu extrahieren wir aus dem Baum die Zeichencodes
rules =
"A" -> "0",
"B" -> "111",
"C" -> "1000",
"D" -> "1001",
"E" -> "1101",
"F" -> "1100",
"G" -> "1011",
"H" -> "1010"
181
A 92
45 53
27 26
C D H G
24 B
F E
und ersetzen mit diesen Regeln den Text.
text = "BACADAEAFABBAAAGAH"
StringReplace[text, rules]
--> 111010000100101101011000111111000101101010
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 360

Informatik I 4 Datenstrukturen
Programm . Wir benotigen zunachst eine Funktion zum Extrahierender Symbole eines (Teil-)Baumes.
getSymbols[emptyTree] = ;
getSymbols[tree_bTree] :=
If[StringQ[getKey[tree]],
Join[getKey[tree],
getSymbols[leftTree[tree]],
getSymbols[rightTree[tree]]],
Join[ getSymbols[leftTree[tree]],
getSymbols[rightTree[tree]]]
]
ht = huffmanTree[data];
getSymbols[ht] --> "A","C","D","H","G","F","E","B"
getSymbols[leftTree[ht]] --> "A"
getSymbols[rightTree[rightTree[ht]]] --> "F","E","B"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 361
Informatik I 4 Datenstrukturen
Der Code eines Zeichens ergibt sich durch Akkumulieren der 0-enund 1-en beim Durchlaufen des Baumes.
huffmanEncodeSymbol[tree_bTree, symb_String] :=
Switch[getKey[tree],
_Integer,
If[MemberQ[getSymbols[leftTree[tree]], symb],
Join[0, huffmanEncodeSymbol[leftTree[tree], symb]],
Join[1, huffmanEncodeSymbol[rightTree[tree], symb]]
],
_String, ,
_, Print["Error!"]
]
huffmanEncodeSymbol[ht, "D"] --> 1, 0, 0, 1
Mittels vorhandener Funktionen erhalten wir eine 0/1-Zeichenkette.
binaryListToString[lst_] := IntegerString[FromDigits[lst, 2], 2]
binaryListToString[1, 1, 1] --> "111"
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 362
Informatik I 4 Datenstrukturen
Aus der Liste der gespeicherten Zeichen und der Liste ihrer Binarcodesbilden wir Transformationsregeln fur die Kodierung des Textes.
huffmanEncodeRules[tree_bTree] :=
Thread[
Rule[getSymbols[tree],
Map[binaryListToString[
huffmanEncodeSymbol[tree, #]] &,
getSymbols[tree]
]
]
]
rules = Sort[huffmanEncodeRules[ht]]
--> "A" -> "0", "B" -> "111", "C" -> "1000", "D" -> "1001",
"E" -> "1101", "F" -> "1100", "G" -> "1011", "H" -> "1010"
StringReplace["BACADAEAFABBAAAGAH", rules]
--> 111010000100101101011000111111000101101010
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 363
Informatik I 4 Datenstrukturen
Wir fassen zusammen:
huffmanEncode[tree_bTree, text_String] :=
StringReplace[text, huffmanEncodeRules[tree]]
huffmanEncode[ht, text]
--> "111010000100101101011000111111000101101010"
Wir wenden uns dem Dekodieren zu.
huffmanDecode[ht, huffmanEncode[ht, text]]
--> "BACADAEAFABBAAAGAH"
Da es sich um einen Prafix-Code handelt, mussen wir lediglich an-hand der gegebenen 0/1-Zeichenkette links bzw. rechts (Null bzw. Eins)den Huffman-Baum durchlaufen und an den Blattern die dekodiertenZeichen auslesen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 364

Informatik I 4 Datenstrukturen
Wir benotigen zunachst eine Gegenstuck zu binaryListToString.
binaryStringToList[s_String] :=
Map[FromDigits[#, 2] &, Characters[s]]
binaryStringToList[huffmanEncode[ht, text]]
--> 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0,
1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1,
0, 1, 1, 0, 1, 0, 1, 0
Die Dekodierfunktion transformiert die 0/1-Zeichenkette und ruft eineHilfsfunktion auf.
huffmanDecode[tree_bTree, code_String] :=
huffmanDecodeString[tree, tree, binaryStringToList[code]]
Die Hilfsfunktion hat bei leerer Eingabe nichts zu dekodieren.
huffmanDecodeString[tree_bTree, subtree_bTree, ] := ""
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 365
Informatik I 4 Datenstrukturen
Im allg. Fall werden der Baum durchlaufen, Zeichen gelesen (PradikatStringQ), akkumuliert (StringJoin), und rekursiv aufgerufen.
huffmanDecodeString[tree_bTree, subtree_bTree, code_List] :=
Switch[First[code],
0,
If[StringQ[getKey[leftTree[subtree]]],
StringJoin[getKey[leftTree[subtree]],
huffmanDecodeString[tree, tree, Rest[code]]],
huffmanDecodeString[tree, leftTree[subtree], Rest[code]]
],
1,
If[StringQ[getKey[rightTree[subtree]]],
StringJoin[getKey[rightTree[subtree]],
huffmanDecodeString[tree, tree, Rest[code]]],
huffmanDecodeString[tree, rightTree[subtree], Rest[code]]
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 366
Informatik I 4 Datenstrukturen
Empirische Auftrittswahrscheinlichkeiten von Buchstaben in deutsch-sprachigen Texten.a
e 0.1470 n 0.0884 r 0.0686 i 0.0638 s 0.0539
t 0.0473 d 0.0439 h 0.0436 a 0.0433 u 0.0319
l 0.0293 c 0.0267 g 0.0267 m 0.0213 o 0.0177
b 0.0160 z 0.0142 w 0.0142 f 0.0136 k 0.0096
v 0.0074 ü 0.0058 p 0.0050 ä 0.0049 ö 0.0025
j 0.0016 y 0.0002 q 0.0001 x 0.0001
aQuelle: Goos (vgl. Literaturverzeichnis)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 367
Informatik I 4 Datenstrukturen
Huffman-Baum:
84861
342713 50592
163116 179614
76218 86917
34522 41719
16823 o
v 9424
4525 ä
2026 ö
427 j
y 228
x q
20420 m
k 10821
p ü
a h
n 91215
d t
22655 27943
107311 11926
53412 s
g c
5719 6217
27810 l
f w
3028 u
z b
13244 e
i r
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 368
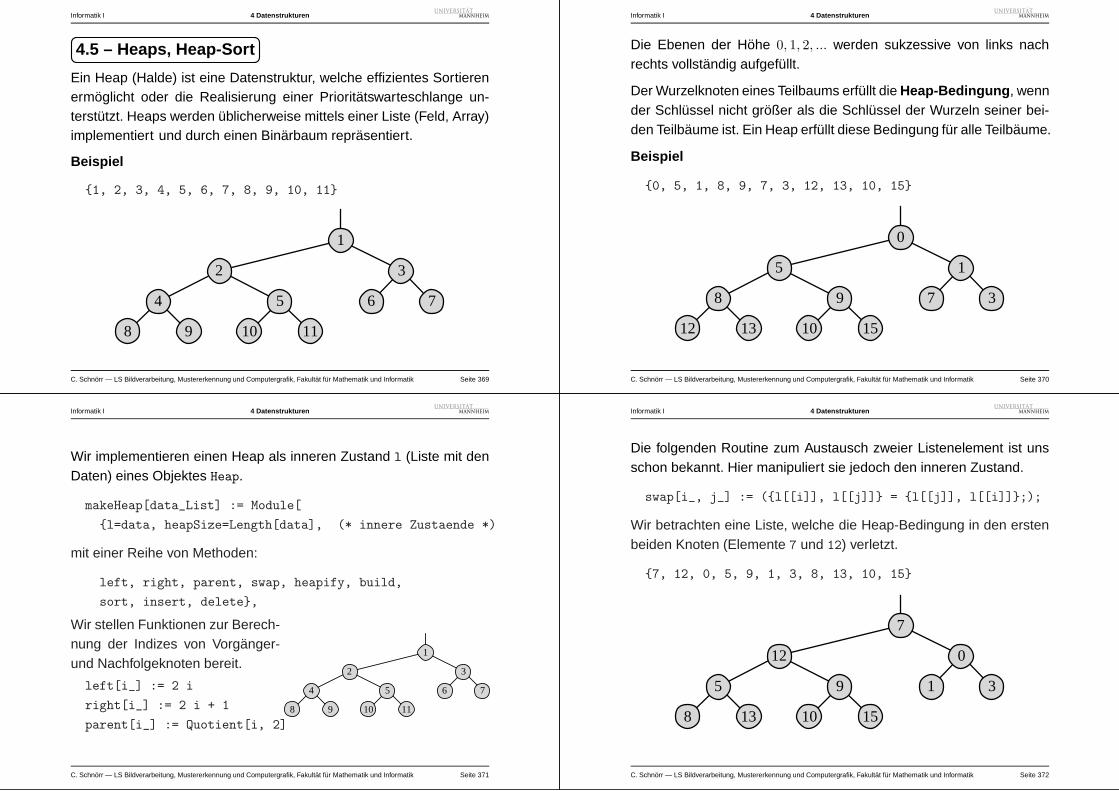
Informatik I 4 Datenstrukturen
4.5 – Heaps, Heap-Sort
Ein Heap (Halde) ist eine Datenstruktur, welche effizientes Sortierenermoglicht oder die Realisierung einer Prioritatswarteschlange un-terstutzt. Heaps werden ublicherweise mittels einer Liste (Feld, Array)implementiert und durch einen Binarbaum reprasentiert.
Beispiel
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
8 9
4
10 11
5
2
6 7
3
1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 369
Informatik I 4 Datenstrukturen
Die Ebenen der Hohe 0, 1, 2, ... werden sukzessive von links nachrechts vollstandig aufgefullt.
Der Wurzelknoten eines Teilbaums erfullt die Heap-Bedingung , wennder Schlussel nicht großer als die Schlussel der Wurzeln seiner bei-den Teilbaume ist. Ein Heap erfullt diese Bedingung fur alle Teilbaume.
Beispiel
0, 5, 1, 8, 9, 7, 3, 12, 13, 10, 15
12 13
8
10 15
9
5
7 3
1
0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 370
Informatik I 4 Datenstrukturen
Wir implementieren einen Heap als inneren Zustand l (Liste mit denDaten) eines Objektes Heap.
makeHeap[data_List] := Module[
l=data, heapSize=Length[data], (* innere Zustaende *)
mit einer Reihe von Methoden:
left, right, parent, swap, heapify, build,
sort, insert, delete,
Wir stellen Funktionen zur Berech-nung der Indizes von Vorganger-und Nachfolgeknoten bereit.
left[i_] := 2 i
right[i_] := 2 i + 1
parent[i_] := Quotient[i, 2]
8 9
4
10 11
5
2
6 7
3
1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 371
Informatik I 4 Datenstrukturen
Die folgenden Routine zum Austausch zweier Listenelement ist unsschon bekannt. Hier manipuliert sie jedoch den inneren Zustand.
swap[i_, j_] := (l[[i]], l[[j]] = l[[j]], l[[i]];);
Wir betrachten eine Liste, welche die Heap-Bedingung in den erstenbeiden Knoten (Elemente 7 und 12) verletzt.
7, 12, 0, 5, 9, 1, 3, 8, 13, 10, 15
8 13
5
10 15
9
12
1 3
0
7
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 372

Informatik I 4 Datenstrukturen
Zur “Reparatur” eines Knotens (Erfullen der Heap-Bedingung) tau-schen wir den Schlussel mit dem kleineren Schlussel der beiden Teilbaume,gefolgt von einem rekursiven Aufruf.
heapify[node_, size_] := Module[
ln = left[node], rn = right[node],
If[ln <= size && rn > size, (* kein rechter Teilbaum *)
If[l[[ln]] < l[[node]], swap[node, ln]]];
If[rn <= size, (* beide Teilbaeume vorhanden *)
With[son = If[l[[ln]] < l[[rn]], ln, rn],
If[l[[son]] < l[[node]],
swap[node, son];
heapify[son, size] (* rekursiver Aufruf *)
]]]
];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 373
Informatik I 4 Datenstrukturen
Reparatur des ersten Knoten (Element 12) und danach der Wurzel:
8 13
5
10 15
9
12
1 3
0
7
12 13
8
10 15
9
5
1 3
0
7
12 13
8
10 15
9
5
7 3
1
0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 374
Informatik I 4 Datenstrukturen
Aus einer beliebigen Datenliste bauen wir einen Heap auf, indem furalle Teilbaume – “von hinten nach vorne” – die Heap-Bedingung her-gestellt wird.
build[size_] := Do[heapify[i, size],
i, parent[size], 1, -1];
Mittels dieser Method konnen wir eine weitere definieren, welche einenneuen Schlussel in den Heap einfugt.
insert = Function[datum,
l = Append[l, datum]; heapSize++; build[heapSize]];
Beispiel: Nachste Seite.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 375
Informatik I 4 Datenstrukturen
Sukzessives Einfugen neuer Schlussel in einen Heap.
7, 12, 0, 5, 9, 1, 3, 8, 13, 10, 15
12 7
0
12
5 7
0
12 9
5 7
0
12 9
5
7
1
0
12 9
5
7 3
1
0
12
8 9
5
7 3
1
0
12 13
8 9
5
7 3
1
0
12 13
8
10
9
5
7 3
1
0
12 13
8
10 15
9
5
7 3
1
0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 376

Informatik I 4 Datenstrukturen
Die Operation delete gibt das Wurzelelement zuruck und entfernt esaus dem Heap durch Tausch mit dem letzten Element, Verkleinerndes Heaps um 1, und durch nachfolgende Reparatur des Wurzelkno-tens.
delete = Function[,
If[heapSize > 0, With[root = First[l],
swap[1, heapSize]; l = Most[l]; heapSize--;
heapify[1, heapSize]; root]]];
Beispiel: Nachste Seite.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 377
Informatik I 4 Datenstrukturen
Zweimalige Anwendung von delete.
12 13
8
10 15
9
5
7 3
1
0
12 13
8
10
9
5
7 15
3
1
12 13
8 9
5
10 15
7
3
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 378
Informatik I 4 Datenstrukturen
Heap-SortAus der Heap-Bedingung folgt, dass das kleinste Element immer das-jenige der Wurzel ist. Wir konnen also Daten sortieren (hier in derReihenfolge von groß nach klein), indem wir
• einen Heap aufbauen,
• und anschließend sukzessive das erste und das letzte Elementtauschen, den Heap um 1 verkleinern und den Wurzelknoten re-parieren.
sort = Function[, build[heapSize];
Do[
swap[1, heapSize - (i - 1)];
heapify[1, heapSize - i],
i, 1, heapSize - 1
]];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 379
Informatik I 4 Datenstrukturen
Wie groß ist der Aufwand?
• Die Funktion heapify[k,n] fuhrt jeweils 2 Vergleiche fur die Ebe-nen ⌊log2(k)⌋, ⌊log2(k) + 1⌋, . . . , ⌊log2(n) − 1⌋ aus. Wir erhaltennaherungsweise
2(log2 n− log2 k) = 2 log2(n/k)
Zum Aufbau des Heaps wird diese Funktion aufgerufen fur k =
1 . . . n/2.
• Anschließend wird die Funktion heapify[k,l] aufgerufen fur dieWerte k = 1 und l = 1 . . . n− 1.
Wir erhalten somit
2
n/2∑
k=1
log2(n/k) + 2n−1∑
l=1
log2 l
Beide Summen haben weniger als n Terme, jeweils der Große kleinerlog2 n. Es folgt T (n) ∈ O(n log n).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 380

Informatik I 4 Datenstrukturen
Wir fugen noch Funktionen zur Inspektion des Heaps hinzu,
show = Function[, l];
length = Function[, heapSize];
bauen den Heap intern auf, als Teil des Konstruktors makeHeap
build[heapSize];
und machen die Methoden – wie im Abschnitt “Objekte mit Zustanden”eingefuhrt – verfugbar.
Heap[Function[method,
Switch[method,
"insert", insert,
"delete", delete,
"sort", sort,
"show", show,
"length", length
]]] ]
HeapInsert[Heap[h_],
datum_Integer?Positive]
:= h["insert"][datum]
HeapDelete[Heap[h_]] := h["delete"][]
HeapSort[Heap[h_]] := h["sort"][]
HeapShow[Heap[h_]] := h["show"][]
HeapLength[Heap[h_]] := h["length"][]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 381
Informatik I 5 Algorithmen
5 – Algorithmen
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 381
Informatik I 5 Algorithmen
5.1 – Tiefen- und Breitensuche (Backtracking)
Backtracking ist ein allgemein anwendbarer Suchalgorithmus zur com-putergestutzten Problemlosung. Tiefen- bzw. Breitensuche sind zweiverschiedene Suchstrategien mit Backtracking.
Ausgangspunkt ist die Reprasentation eines Problems als Graph unddie Bestimmung einer Losung des Problems als Pfad in diesem Gra-phen. Es kann vorkommen, dass keine, genau eine, oder viele Losungenexistieren. Backtracking berechnet (irgend)eine Losung, sofern dieseexistiert, oder eine Meldung, falls keine Losung existiert.
Wir konzentrieren uns zunachst unabhangig von einer Anwendungauf den Algorithmus und dessen Implementierung, indem wir direkteinen Graphen angeben.
Anschließend wenden wir das Programm an.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 382
Informatik I 5 Algorithmen
Gegeben sei der Graph
s
a b c
d e t
Knoten s reprasentiert eine Startkonfiguration, Knoten t eine Pro-blemlosung.
Das Problem ist einen Pfad von s nach t zu suchen. Bei der Anwen-dung bedeutet dies die Bestimmung einer Problemlosung.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 383

Informatik I 5 Algorithmen
Wir reprasentieren den Graphen als Adjazenzliste
s, a, d, a, s, b, d, b, a, c, e,
c, b, d, s, a, e, e, b, d, t, t, e,
und Pfade als geordnete Listen der Knotensymbole. Der Losungspfadist s, a, b, e, t.
Wir stellen ein Pradikat bereit, welches eine Losung erkennt.
SolutionQ[path_] := Last[path] === t
Weiter benotigen wir eine Routine, welche die Nachbarn eines Knotenermittelt.
Neighbors[v_, ] :=
Neighbors[v_, adjList_] :=
If[First[First[adjList]] === v, Last[First[adjList]],
Neighbors[v, Rest[adjList]]]
Neighbors[a, adjList] --> s, b, d
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 384
Informatik I 5 Algorithmen
Wir benutzen die Routine Neighbors, um Teillosungen zu vervollstand-igen. Die Funktion Extend hangt an einen Teilpfad alle Nachbarn desletzten Knotens an.
Extend[path_, adjList_] :=
Map[Append[path, #] &, Neighbors[Last[path], adjList]]
Extend[s, a, adjList]
--> s, a, s, s, a, b, s, a, d
Extend[s, d, e, b, adjList]
--> s, d, e, b, a, s, d, e, b, c, s, d, e, b, e
Offenbar werden so jedoch zyklische Pfade erzeugt. Wir vermeidendas, indem wir aus den erzeugten Pfaden diejenigen auswahlen, beidenen der zugefugte letzte Knoten nicht schon einmal vorkommt. AlsTest benutzen wir das Pradikat MemberQ
?MemberQ
MemberQ[list, form] returns True if an element of list
matches form, and False otherwise.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 385
Informatik I 5 Algorithmen
Wir erganzen die Funktion Extend entsprechend.
Extend[path_, adjList_] :=
With[extendedPaths =
Map[Append[path, #] &,
Neighbors[Last[path], adjList]],
Select[extendedPaths, ! MemberQ[Most[#], Last[#]] &]
]
Extend[s,a, adjList]
s, a, b, s, a, d
Extend[s,d,e,b, adjList]
s, d, e, b, a, s, d, e, b, c
Eine Sackgasse kann nicht erweitert werden.
Extend[s,a,b,c, adjList] -->
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 386
Informatik I 5 Algorithmen
Backtracking: Tiefensuche
Die Tiefensuche vervollstandigt rekursiv alle Teillosungen einer Liste,bis eine Losung gefunden ist. Neue erweiterte Teillosungen werdenam Anfang der Liste eingefugt. Sackgassen werden eliminiert.
DepthFirst[, Extend_, SolutionQ_] :=
Print["Keine Loesung!"]
DepthFirst[queue_, Extend_, SolutionQ_] :=
If[SolutionQ[First[queue]], First[queue],
DepthFirst[
Join[Extend[First[queue]], Rest[queue]],
Extend, SolutionQ]
]
Wir rufen die Funktion mit einer einzelnen Teillosung auf.
DepthFirst[s, Extend[#, adjList]&, SolutionQ]
s, a, b, e, t
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 387

Informatik I 5 Algorithmen
Inspektion mit Sow und Reap:
Extend[path_,adjList_]:=
With[extendedPaths =
Map[Append[path,#]&,
Neighbors[Last[path],adjList]],
Sow[path]; (* <-- eingefuegt *)
Select[extendedPaths,!MemberQ[Most[#],Last[#]]&]
]
Reap[DepthFirst[s, Extend[#, adjList] &,
SolutionQ]]
s, a, b, e, t,
s, s, a, s, a, b, s, a, b, c, s, a, b, e,
s, a, b, e, d
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 388
Informatik I 5 Algorithmen
Backtracking: Breitensuche
Die Breitensuche fugt erweiterte Teillosungen am Ende der Liste ein.
BreadthFirst[queue_, Extend_, SolutionQ_] :=
If[SolutionQ[First[queue]], First[queue],
BreadthFirst[
Join[Rest[queue], Extend[First[queue]]],
Extend, SolutionQ]
]
Reap[BreadthFirst[s, Extend[#, adjList] &,
SolutionQ]]
s, d, e, t,
s, s, a, s, d, s, a, b, s, a, d, s, d, a,
s, d, e, s, a, b, c, s, a, b, e, s, a, d, e,
s, d, a, b, s, d, e, b
Es wird in der Tat “breiter” gesucht und eine andere Losung gefunden.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 389
Informatik I 5 Algorithmen
Um Backtracking anwenden zu konnen, mussen die folgenden Vor-aussetzungen erfullt sein:
• Eine erste Teillosung s ist bekannt.
• Fur jede Teillosung konnen alle zulassigen Erweiterungen ermit-telt oder aber festgestellt werden, dass keine existieren.
Beachte: Der Graph, welcher das Problem reprasentiert, mussnicht explizit konstruiert werden. Lediglich ein Algorithmus zurBerechnung der Nachbarn eines Knotens (Erweiterung einer Teil-losung) ist notwendig.
• Eine vollstandige Losung wird erkannt.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 390
Informatik I 5 Algorithmen
Anwendung: Das Damenproblem
Auf einem Schachbrett sollen acht Damen so positioniert werden,dass keine Dame durch irgendeine andere bedroht wird.
Eine Dame, die beispielsweise in der 4. Zeile (von unten) und 3. Spal-te (von links) sitzt, bedroht die rot markierte Felder.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 391

Informatik I 5 Algorithmen
Eine Dame auf Position z1,s1 bedroht eine andere auf Positionz2,s1 (und umgekehrt), wenn
– entweder die Damen in der gleiche Zeile oder Spalte sitzen, oder
– der Differenzvektor betragsmassig gleiche Komponenten hat.
threatsQ[pos1_, pos2_] :=
With[diff = pos1 - pos2,
MemberQ[diff, 0] || Equal @@ Abs[diff]]
threatsQ[1, 1, 5, 5] --> True
threatsQ[1, 1, 2, 3] --> False
Wir erweitern dies zu einer Funktion, die ermittelt, ob eine Dame aufPosition pos keine der anderen Damen in posList bedroht.
threatsNoneQ[pos_, posList_] :=
Not[Or @@ Map[threatsQ[pos, #] &, posList]]
threatsNoneQ[1, 1, 2, 3, 5, 5, 7, 8] --> False
threatsNoneQ[1, 1, 2, 3, 5, 2, 7, 8] --> True
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 392
Informatik I 5 Algorithmen
Die Konstruktion einer ersten Teillosung ist trivial. Wir beginnen mitirgendeiner einzelnen Position 1,x, 1 ≤ x ≤ size, in der erstenZeile.
Nachbarknoten sind alle Positionen in der nachsten Zeile.
Neighbors[pos_, size_] :=
Map[List[First[pos] + 1, #] &, Range[size]]
Neighbors[2, 3, size]
3, 1, 3, 2, 3, 3, 3, 4, 3, 5, 3, 6,
3, 7, 3, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 393
Informatik I 5 Algorithmen
Teillosungen werden durch Nachbarn, die keine schon positionierteDame bedrohen, erweitert.
Extend[path_, size_] :=
With[extendedPaths =
Map[Append[path, #] &,
Neighbors[Last[path], size]],
Select[extendedPaths, threatsNoneQ[Last[#], path] &]
]
Extend[1, 1, size]
1, 1, 2, 3, 1, 1, 2, 4, 1, 1, 2, 5,
1, 1, 2, 6, 1, 1, 2, 7, 1, 1, 2, 8
Extend[1, 1, 2, 5, size]
1, 1, 2, 5, 3, 2, 1, 1, 2, 5, 3, 7,
1, 1, 2, 5, 3, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 394
Informatik I 5 Algorithmen
Eine vollstandige Losung kann leicht erkannt werden.
SolutionQ[path_, size_] := First[Last[path]] == size
Wir wenden die Tiefensuche an.
DepthFirst[1, 2, Extend[#, size] &,
SolutionQ[#, size] &]
1, 2, 2, 4, 3, 6, 4, 8, 5, 3, 6, 1,
7, 7, 8, 5
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 395
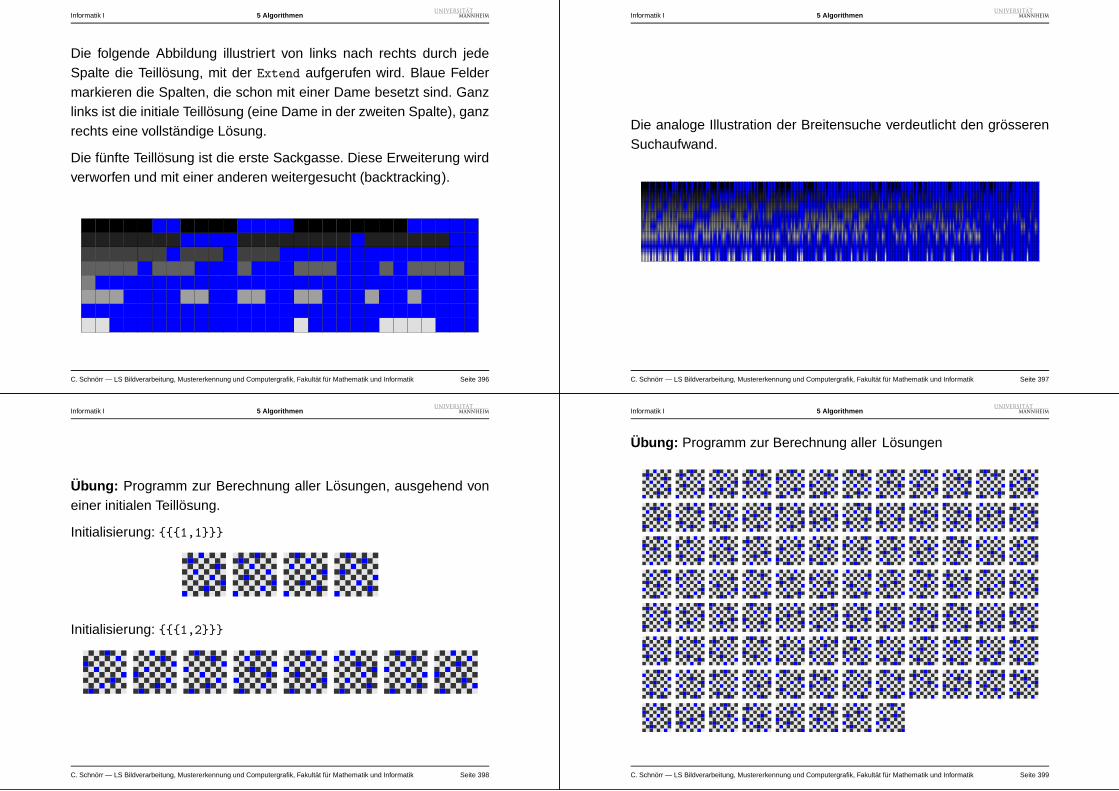
Informatik I 5 Algorithmen
Die folgende Abbildung illustriert von links nach rechts durch jedeSpalte die Teillosung, mit der Extend aufgerufen wird. Blaue Feldermarkieren die Spalten, die schon mit einer Dame besetzt sind. Ganzlinks ist die initiale Teillosung (eine Dame in der zweiten Spalte), ganzrechts eine vollstandige Losung.
Die funfte Teillosung ist die erste Sackgasse. Diese Erweiterung wirdverworfen und mit einer anderen weitergesucht (backtracking).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 396
Informatik I 5 Algorithmen
Die analoge Illustration der Breitensuche verdeutlicht den grosserenSuchaufwand.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 397
Informatik I 5 Algorithmen
Ubung: Programm zur Berechnung aller Losungen, ausgehend voneiner initialen Teillosung.
Initialisierung: 1,1
Initialisierung: 1,2
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 398
Informatik I 5 Algorithmen
Ubung: Programm zur Berechnung aller Losungen
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 399

Informatik I 5 Algorithmen
Ubung: Sudoku
1 7 9
5 4 1 3
4 5 2 8
2 1 6 8
9 5
3 8 1 9
3 1 5 9
1 9 7 4
7 4 1
1 8 2 6 7 3 4 5 9
6 5 9 4 8 1 7 3 2
3 7 4 5 9 2 8 1 6
5 2 1 7 3 9 6 8 4
9 6 7 8 1 4 3 2 5
4 3 8 2 5 6 1 9 7
2 4 3 1 6 5 9 7 8
8 1 6 9 2 7 5 4 3
7 9 5 3 4 8 2 6 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 400
Informatik I 5 Algorithmen
5.2 – Bin are Suche
Der Index eines Elements elem in einer sortierten Liste soll bestimmtwerden. Ist das Element nicht vorhanden, dann soll 0 ausgegebenwerden.
Beispiel
BinarySearch[1, 3, 5, 7, 9, 11, 9] --> 5
BinarySearch[1, 3, 5, 7, 9, 11, 8] --> 0
Eine naive Suche wurde die Liste list durchlaufen, bis entweder dasElement gefunden ist, list[[i]] == elem, oder bis erkannt ist, dassdas Element nicht vorhanden ist, list[[i]] < elem < list[[i+1]].
Eine effizienteres Verfahren halbiert sukzessive den Datensatz, undsucht aufgrund eines Vergleichs mit dem Grenzelement entweder inder Halfte der kleineren oder der grosseren Elemente weiter.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 401
Informatik I 5 Algorithmen
Wir fangen zunachst den Trivialfall ab. Das Argument offset ist op-tional mit Vorgabewert 0. Wir benutzen es zur Rekonstruktion des ab-soluten Index, da diese Information durch das “Wegwerfen” der Li-stenhalften verloren geht.
BinarySearch[, elem_, offset_: 0] := 0;
BinarySearch[list_, elem_, offset_: 0] :=
With[split = Floor[(1 + Length[list])/2],
If[list[[split]] == elem, offset + split, (* found *)
(* otherwise continue *)
If[list[[split]] < elem,
BinarySearch[Drop[list, split], elem, offset + split],
BinarySearch[Take[list, split - 1], elem, offset]
]
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 402
Informatik I 5 Algorithmen
Wir suchen das Element 98 in allen ungeraden Zahlen in [1, 2000]
BinarySearch[Cases[Range[2000], _?OddQ], 98]
und inspizieren die Indizes der erzeugten Teillisten.
1, 1000,
1, 499,
1, 249,
1, 124,
1, 61,
32, 61,
47, 61,
47, 53,
47, 49,
49, 490 200 400 600 800 1000
Der Algorithmus braucht 10 ≈ log2(2000/2) Schritte. Der Aufwand istallgemein T (1) = c1 , T (n) = T (n/2) + c2, d.h. T (n) ∈ Θ(log n).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 403

Informatik I 5 Algorithmen
Wir programmieren die Binarsuche ebenfalls imperativ. Die Funkti-on Return terminiert sofort die umgebende Kontrollstruktur (While-Schleife) und gibt das Argument zuruck.
BinarySearch[list_, elem_] :=
Module[left = 1, right = Length[list], split,
While[left <= right,
split = Floor[(left + right)/2]; (* bisect *)
If[list[[split]] == elem, Return[split]]; (* found *)
If[list[[split]] < elem, (* continue *)
left = split + 1,
right = split - 1
]
];
0 (* not found *)
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 404
Informatik I 5 Algorithmen
5.3 – Sortieren
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 405
Informatik I 5 Algorithmen
Sortieren durch Austauschen ( Bubble-Sort )
Ein einfacher Algorithmus:
Durchlaufe die Daten und vertausche aufeinanderfolgendeElemente, die in der falschen Reihenfolge sind. Wiederholeden Durchlauf bis die Daten sortiert sind.
Nach dem ersten Durchlauf konnen wir sicher sein, das das großteElement am richtigen Platz ist; nach dem zweiten Durchlauf das zweit-großte Element ...
BubbleSort[list_] := Module[l = list,
Do[
Do[
If[l[[i]] > l[[i + 1]], l = swap[l, i, i + 1]],
i, Length[l] - j],
j, Length[l] - 1];
l
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 406
Informatik I 5 Algorithmen
Das Unterprogramm zum Vertauschen zweier Elemente:
swap[list_, i_, j_] := Module[l = list,
l[[i]], l[[j]] = l[[j]], l[[i]];
l
]
Beispiel
BubbleSort[4, 7, 3, 1, 5, 8, 2, 6]
4 3 1 5 7 2 6 83 1 4 5 2 6 7 8
1 3 4 2 5 6 7 8
1 3 2 4 5 6 7 8
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 407

Informatik I 5 Algorithmen
In der j-ten Schleife erfolgen n− j Vergleiche.
T (n) =n−1∑
j=1
n− j = (n− 1) + (n− 2) + · · ·+ 2 + 1
=1
2n(n− 1) ∈ O(n2) .
Zusatzlich zu den Vergleichen mussen die Daten im schlechtestenFall, wenn sie genau umgekehrt geordnet sind, mit ebenfalls quadra-tischem Aufwand O(n2) umsortiert werden.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 408
Informatik I 5 Algorithmen
Sortieren durch Einfugen
Ein intuitives, einfaches Verfahren. Wir entnehmen nacheinander einElement der Datenliste (rechts) und fugen es in eine Ergebnisliste(links) an der richtigen Stelle ein:
4, 7, 3, 1, 5, 8, 2, 6
,4,7,3,1,5,8,2,6
4,7,3,1,5,8,2,6
4,7,3,1,5,8,2,6
3,4,7,1,5,8,2,6
1,3,4,7,5,8,2,6
1,3,4,5,7,8,2,6
1,3,4,5,7,8,2,6
1,2,3,4,5,7,8,6
1, 2, 3, 4, 5, 6, 7, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 409
Informatik I 5 Algorithmen
Entsprechend beginnt die Hauptroutine mit einer leeren Ergebnisliste
InsertionSort[data_] := InsertionSort[, data]
Wir sortieren das erste Element ein und fahren fort mit den Restdaten:
InsertionSort[sorted_, data_] :=
InsertionSort[InsertDatum[sorted, First[data]],
Rest[data]]
Ist die Datenliste leer, dann haben wir das Ergebnis.
InsertionSort[sorted_, ] := sorted
Alternativ konnte wir programmieren:
InsertionSort[data_] :=
Fold[InsertDatum[#1, #2] &, , data]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 410
Informatik I 5 Algorithmen
Fur das Einfugen eines Elementes in eine Liste benutzen wir die vor-handene Funktion
Insert[list, elem, n] inserts elem at position n in list
Beispiele
Insert[1, 2, 3, x, 1] --> x, 1, 2, 3
Insert[1, 2, 3, x, 3] --> 1, 2, x, 3
Insert[1, 2, 3, x, 4] --> 1, 2, 3, x
Damit formulieren wir unsere Unterroutine
InsertDatum[sorted_, datum_] :=
Insert[sorted, datum, InsertPosition[sorted, datum]]
Es verbleibt die einzufugende Position zu ermitteln.Zu Beginn ist diese klar:
InsertPosition[, datum_] := 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 411

Informatik I 5 Algorithmen
Ansonsten prufen wir die aktuelle Position, geben diese zuruck, soferneingefugt werden soll, oder fahren mit der nachsten Position fort(position ist ein optionales Argument mit Vorgabewert 1).
InsertPosition[sorted_, datum_, position_: 1] :=
If[position > Length[sorted], position,
If[datum < sorted[[position]], position,
InsertPosition[sorted, datum, position + 1]
]
]
Wie groß ist der Suchaufwand? Das i-te Element wird i − 1 Verglei-chen unterzogen. Daraus folgt
1 + 2 + · · ·+ (n− 2) + (n− 1) =1
2n(n− 1) ∈ O(n2)
Dieser Aufwand laßt sich reduzieren, wenn man berucksichtigt, dassdie (partielle) Ergebnisliste schon sortiert ist, nicht jedoch der Auf-wand des “Verschiebens” der Elemente durch das Einfugen.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 412
Informatik I 5 Algorithmen
Untere Schranke fur den Aufwand
Wir wollen abschatzen, wie effizient ein Sortieralgorithmus uberhauptsein kann.
Die unsortierten Dateni1, i2, . . . , in entsprechenirgendeiner Permutati-on der sortierten Daten1, 2, . . . , n.Sortieren entspricht der Su-che dieser Permutation an-hand paarweiser Verglei-che.Wir beschreiben dies durcheinen binaren Entschei-dungsbaum T (V, E).
Beispiel: n = 3
ja nein
ja nein ja nein
ja nein ja nein
i1 < i2
i1 < i3 i1 < i3
i2 < i3 83, 1, 2< 82, 1, 3< i2 < i3
81, 2, 3< 81, 3, 2< 82, 3, 1< 83, 2, 1<
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 413
Informatik I 5 Algorithmen
Die inneren Knoten (gelb) des Entscheidungsbaumes entsprechenden Tests, die Blatter (blau) den Losungen des Suchproblems.
Die Hohe H(T ) des Baumes ist die maximale Lange h(v) eines Wegesvon der Wurzel (oberster Knoten) zu einem Knoten v:
H(T ) = maxv∈V
h(v) .
Im Beispiel oben ist H(T ) = 3. Diese Hohe bestimmt den Suchauf-wand.
Ein Baum der Hohe H = 0 hat 1 = 20 Blatt, namlich gerade dieWurzel. Ein Baum der Hohe H = 1 hat maximal 2 = 21 Blatter. Wennwir voraussetzen, dass ein Baum der Hohe H maximal 2H Blatter hat,dann folgt durch Induktion, dass ein Baum der Hohe H + 1 maximaldie Summe der Blatter der beiden Baume der Hohe H hat, welcheman durch Loschen der Wurzel erhalt: 2 · 2H = 2H+1. Also gilt dieseSchranke fur beliebige H ≥ 0.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 414
Informatik I 5 Algorithmen
Aus 2H ≥ l (l: Anzahl der Blatter) erhalten wir die untere Schranke:
Satz: Die Hohe H eines binaren Baumes mit l Blattern ist mindestens
H ≥ log2 l .
Das Beispiel oben zeigt, dass das Sortierproblem fur einen 3-elementigenDatensatz auf einen binaren Entscheidungsbaum T mit 3! = 6 Blatternfuhrt. Die Hohe ist somit mindestens gleich H = 3 ≥ log2 6 ≈ 2.6.
Im allgemeinen Fall gilt H ≥ log2 n! und
log2(n− 1)!
= log2 1 + log2 2 + · · ·+ log2(n− 1)
<
∫ n
1
log2 x dx = n log2 n− n− 1
log 2
< log2 n! 2 3 4 5 6 7 8
0.5
1.0
1.5
2.0
2.5
3.0
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 415

Informatik I 5 Algorithmen
Asymptotisch erhalten wir aus der linken Ungleichung
log2 n!
n log2 n<
1
n log2 n
(
(n + 1) log2(n + 1)− 1
log 2n)
=n log2(n + 1)
n log2 n+
1
n
log2(n + 1)
log2 n− 1
log 2 log2 nn→+∞−−−−−→ 1 ,
und aus der rechten Ungleichung
log2 n!
n log2 n> 1− n− 1
log 2 · n log2 n
n→+∞−−−−−→ 1 ,
also insgesamt log2 n! = Θ(n log2 n). Dies ist eine untere Schrankefur den Aufwand des Sortierens eines n-elementigen Datensatzes.
Anmerkung: Da n = elog n = elog 2 log n
log 2 = 2log n
log 2 , folgt log2 n = log nlog 2 ,
d.h. die Basis des Logarithmus spielt bei asymptotischen Betrachtun-gen keine Rolle.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 416
Informatik I 5 Algorithmen
Sortieren durch Mischen ( Merge-Sort )
Teile-und-Herrsche Strategie (divide-and-conquer ):
– Halbiere den Datensatz (teilen),
– sortiere (rekursiver Aufruf!) beide Teildatensatze (herrschen),
– fuge die beiden sortierten Datensatze zusammen (mischen).
Wir uberfuhren diese Schritte direkt in ein Programm.
Den Index zum Teilen einer Datenliste list berechnen wir durch ganz-zahlige Division:
Quotient[Length[list], 2]
Eine Alternative fur andere Programmiersprachen ist die normale Di-vision und Rundung des Ergebnisses:
Floor[Length[list]/2]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 417
Informatik I 5 Algorithmen
Eine ein-elementige Liste ist schon sortiert.MergeSort[i_Integer] := i
Im allgemeinen Fall gehen wir wie oben beschrieben vor.
MergeSort[list_] :=
Module[index = Quotient[Length[list], 2],
Merge[
MergeSort[Take[list, index]],
MergeSort[Drop[list, index]]
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 418
Informatik I 5 Algorithmen
Fur das Zusammenfugen (mischen) zweier sortierter Datensatze fan-gen wir zunachst die Trivialfalle ab:
Merge[, list_] := list
Merge[list_, ] := list
Zusammenfugen zweier nicht-leerer Datensatze:
Merge[list1_, list2_] :=
With[l1 = First[list1], l2 = First[list2],
If[l1 < l2,
Prepend[Merge[Rest[list1], list2], l1],
Prepend[Merge[list1, Rest[list2]], l2]
]
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 419

Informatik I 5 Algorithmen
Beispiel
MergeSort[4,7,3,1,5,8,2,6]
4,7,3,1,5,8,2,6 --> 4,7,3,1 , 5,8,2,6
4,7,3,1 --> 4,7 , 3,1
4,7 --> 4 , 7
Merge: 4 , 7
3,1 --> 3 , 1
Merge: 3 , 1
Merge: 4,7 , 1,3
5,8,2,6 --> 5,8 , 2,6
5,8 --> 5 , 8
Merge: 5 , 8
2,6 --> 2 , 6
Merge: 2 , 6
Merge: 5,8 , 2,6
Merge: 1,3,4,7 , 2,5,6,8 --> 1, 2, 3, 4, 5, 6, 7, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 420
Informatik I 5 Algorithmen
Aufwand fur Sortieren durch Teilen und Mischen:
T (n) = 2T(n
2
)
+ Θ(n) .
Da Θ(n) = Θ(nlog2 2) folgt T (n) ∈ Θ(n log n) (vgl. S. 175).
Sortieren durch Mischen ist asymptotisch optimal.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 421
Informatik I 5 Algorithmen
Zufallsgesteuerter Algorithmus: Quick-Sort
Merge-Sort:
– Halbiere den Datensatz (unsortiert),
– sortiere (rekursiver Aufruf!) beide Teildatensatze,
– fuge beide sortierten Datensatze zusammen (mischen).
Quick-Sort:
– Teile den Datensatz in kleinere und großere Elemente auf,
– sortiere (rekursiver Aufruf!) beide Teildatensatze,
– fuge beide sortierten Datensatze zusammen (Verkettung).
Den linearen Aufwand des dritten Schritts von Merge-Sort benotigtQuick-Sort im ersten Schritt: Großenvergleich mit einem Element.Dafur ist der dritte Schritt trivial.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 422
Informatik I 5 Algorithmen
Fur die Datenl = 4, 7, 3, 1, 5, 8, 2, 6;
verlauft Quick-Sort wie folgt.
Wir bestimmen zufallig ein Element der Liste, hier die 5, und teilen dieDaten durch Großenvergleich auf.
5, 4, 3, 1, 2, 7, 8, 6
Durch rekursiven Aufruf verfahren wir analog
mit der einen Teilliste,
1, , 4, 3, 2
3, 2, 4
2, ,
4, ,
und mit der anderen Teilliste.
8, 7, 6,
7, 6,
6, ,
Zwei Teillisten mussen jeweils nur noch verkettet werden, mit demaufgewahlten Element dazwischen.
--> 1, 2, 3, 4, 5, 6, 7, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 423

Informatik I 5 Algorithmen
Programm:
QuickSort[] = ;
QuickSort[i_] := i
QuickSort[list_] := Module[
lessThan, pivot, greaterThan,
lessThan, pivot, greaterThan = splitList[list];
Join @@
QuickSort[lessThan], pivot, QuickSort[greaterThan]
]
In der Funktion splitList wahlen wir zufallig ein Element aus ...
splitList[list_] := Module[
element, lessThan = , greaterThan = , index, pivot,
index = RandomInteger[1, Length[list]];
pivot = list[[index]];
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 424
Informatik I 5 Algorithmen
... und teilen die Daten durch Großenvergleich auf.
Do[
If[k != index,
With[element = list[[k]],
If[element <= pivot,
AppendTo[lessThan, element],
AppendTo[greaterThan, element]]]],
k, 1, Length[list]];
lessThan, pivot, greaterThan
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 425
Informatik I 5 Algorithmen
Wie groß ist der Aufwand?
Worst caseWaren die Daten schon sortiert, und wurden wir immer das kleinste(erste) Element auswahlen, dann ware der Aufwand O(n2).
Best caseWurden wir immer dasjenige Element wahlen, das zu einer Teilungder Daten in gleichgroße Halften fuhrt, dann ware der Aufwand T (n) ≤2T (n/2) + c n ∈ O(n log n). Allerdings kennen wir dieses Elementnicht.
Wir wenden uns dem average case zu, also den erwarteten Kosten.Ein zufallig bestimmtes Element wird i.d.R. zu ungleichen Halftenfuhren.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 426
Informatik I 5 Algorithmen
Wir reprasentieren jeden zufallsgesteuertenSortierprozeß gemaß Quick-Sort durch einenzufalligen Binarbaum. Jede Wurzel eines(Teil-) Baumes ist das Element, das die Auf-teilung der Liste durch Großenvergleich be-stimmt → linker bzw. rechter Teilbaum.
Zum Beispiel lautete die erste Unterteilungoben 5, 4, 3, 1, 2, 7, 8, 6
5
1 8
3
2 4
7
6
Um den erwarteten Aufwand zu bestimmen, mussen wir die Anzahlder Vergleiche abschatzen, die in der zweiten Zeile von Quick-Sort(splitList) durchgefuhrt werden.
Das obige Experiment und der abgebildete Baum machen klar: Nurdiejenigen Elemente li, lj werden verglichen, die in einer “Vorganger-Nachkomme” Beziehung zueinander stehen. Keine Vergleiche erfol-gen zwischen Elementen verschiedener Teilbaume, z.B. 1 und 8.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 427

Informatik I 5 Algorithmen
Bezeichne l(1), l(2), . . . , l(n) die geordnete Liste.
Im obigen Beispiel istl = 4, 7, 3, 1, 5, 8, 2, 6;
und 1 = l4 = l(1) und 8 = l6 = l(8).
Ob zwei Elemente l(i) und l(j) beim Sortieren der Liste verglichenwerden oder nicht, hangt vom Zufall ab. Wir reprasentieren diesesEreignis durch eine Zufallsvariable xij , welche die entsprechendenWerte xij = 1 oder xij = 0 annimmt.
Die Anzahl aller Vergleiche ist somit
n−1∑
i=1
n∑
j=i+1
xij ,
und der erwartete Aufwand gleich dem Erwartungswert dieser zufalligenAnzahl. Ware immer xij = 1, so hatten wir quadratischen AufwandT (n) = 1
2n(n− 1) ∈ O(n2) (worst case).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 428
Informatik I 5 Algorithmen
In der Wahrscheinlichkeitstheorie wird gezeigt, dass der Erwartungs-wert einer linearen Funktion von Zufallsvariablen gleich der linearenFunktion der Erwartungswerte dieser Variablen ist. Somit erhalten wir
E
n−1∑
i=1
n∑
j=i+1
xij
=n−1∑
i=1
n∑
j=i+1
E[xij ] .
Der Erwartungswert der binaren Zufallsvariablen xij ist
E[xij ] = 1 · Pr(xij = 1) + 0 · Pr(xij = 0)
= Pr(xij = 1) =: pij .
Um den erwarteten Aufwand abzuschatzen, mussen wir diese Wahr-scheinlichkeiten pij bestimmen und dann die obige Summe auswer-ten.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 429
Informatik I 5 Algorithmen
Wir betrachten den Vergleich zweier Elemente l(i) < l(j) , i < j.
– Sie werden nicht verglichen, xij = 0, wenn Sie unterschiedlichenTeilbaumen zugewiesen werden. Dies ist genau dann der Fall,wenn zufallig ein Element l(k) mit l(i) < l(k) < l(j) fur das Aufteileneiner Liste durch Großenvergleich bestimmt wird.
– Ist l(k) = l(i) oder l(k) = l(j), dann erfolgt ein Vergleich: xij = 1.
– Die Falle l(k) < l(i) und l(k) > l(j) sind irrelevant, da l(i), l(j) in dergleichen Teilliste landen und keine Entscheidung erfolgt.
pij ist somit gleich der Wahrscheinlichkeit, dass bei der zufalligenBestimmung eines Elementes l(k) aus der Menge l(i), . . . , l(j) derzweite obige Fall gilt:
pij =2
∣∣l(i), . . . , l(j)
∣∣
=2
j − i + 1
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 430
Informatik I 5 Algorithmen
Wir schatzen der erwarteten Aufwand ab.
n−1∑
i=1
n∑
j=i+1
pij =
n−1∑
i=1
n∑
j=i+1
2
j − i + 1=
n−1∑
i=1
n−i+1∑
k=2
2
k
≤ 2n∑
i=1
n∑
k=1
1
k︸ ︷︷ ︸
=Hn
= 2nHn
Hn sind die Glieder der Harmoni-schen Reihe. Es gilt
Hn ∈ Θ(log n) .
10 20 30 40 50 60 70
2
3
4
5
Somit ist der erwartete Aufwand fur Quick-Sort gleich O(n log n).
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 431

Informatik I 5 Algorithmen
Alternative Implementierung (C-Stil)
Wir implementieren Quick-Sort mittels in-place Operationen direkt aufder Datenliste. Die Call-by-Reference Ubergabe von Argumenten wirdin Mathematica durch setzen des Attributs HoldFirst realisiert.
BeispielDie Funktion swap zum Austausch zweier Listenelemente wurde oben(Abschnitt Bubble-Sort) wie folgt definiert:
swap[list_, i_, j_] := Module[l = list,
l[[i]], l[[j]] = l[[j]], l[[i]]; l ]
Hier wird die ganze Liste nach l kopiert (Call-by-Value).
Im Gegensatz dazu (Call-by-Reference):
SetAttributes[swap, HoldFirst]
swap[l_Symbol, i_, j_] :=
(l[[i]], l[[j]] = l[[j]], l[[i]];)
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 432
Informatik I 5 Algorithmen
Anwendung:
l = 4, 7, 3, 1, 5, 8, 2, 6; (* global definiert *)
swap[l, 2, 5]
l
--> 4, 5, 3, 1, 7, 8, 2, 6
Die folgende Implementierung von Quick-Sort beruht auf der Annah-me, dass die Anordnung der zu sortierenden Daten zufallig ist. Wirwahlen deshalb willkurlich das erste Element aus, unterteilen die Li-ste durch n−1 Vergleiche und rufen Quick-Sort rekursiv fur die beidenTeillisten auf.
Zum Unterteilen der Liste setzen wir “Zeiger” i und j an das untereund obere Ende der Liste, tauschen ggfs. das erste Element aufgrundeines Großenvergleichs, und zahlen die Zeiger hinauf bzw. herunter.
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 433
Informatik I 5 Algorithmen
SetAttributes[QSort, HoldFirst]
QSort[l_Symbol, start_, end_] /; start >= end := l
QSort[l_Symbol, start_, end_] :=
Module[i = start, j = end, left = True,
Do[
If[l[[i]] > l[[j]],
swap[l, i, j];
If[left, i++; left = False, j--; left = True],
If[left, j--, i++]
], end - start];
QSort[l, start, i - 1]; (* rekursiver Aufruf *)
QSort[l, i + 1, end] (* rekursiver Aufruf *)
]
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 434
Informatik I 5 Algorithmen
l = 4, 7, 3, 1, 5, 8, 2, 6;
Der Aufruf
QSort[l, 1, Length[l]]
fuhrt zu folgenden in-place Vertauschungen:
2, 7, 3, 1, 5, 8, 4, 6,
2, 4, 3, 1, 5, 8, 7, 6,
2, 1, 3, 4, 5, 8, 7, 6,
1, 2, 3, 4, 5, 8, 7, 6,
1, 2, 3, 4, 5, 6, 7, 8
C. Schnorr — LS Bildverarbeitung, Mustererkennung und Computergrafik, Fakultat fur Mathematik und Informatik Seite 435
Recommended
![edikatè ayisyen gen “malis kache nan kè yo? [] Timalis an ...ufdcimages.uflib.ufl.edu/.../02007_HAI_2201_Dejean_Study_Notes.pdf · 2 Konnen li konnen se kreyòl sèlman yo konnen](https://img.pdfslide.tips/doc/110x75/5c1012d409d3f23e618bffdf/edikate-ayisyen-gen-malis-kache-nan-ke-yo-timalis-an-2-konnen-li.jpg)
















