
Mapping Early Modern News Networks: Digital Methods and New Perspectives
Giovanni Colavizza (EPFL, Lausanne) Mario Infelise (Ca’ Foscari, Venice)
Renaissance Society Conference, Berlin 2015

Subject: our topic
Elements of a definition: 1. Information as a commodity 2. Impersonal customer base 3. Periodical issues
1+2: e.g. pamphlets. 1+3: e.g. avvisi segreti or “private informers”. 1+2+3: gazettes.
NB news were exchanged in many other ways!

Subject: the European news flow
Hypothesis: a system of news exchange through Europe, developed during first-half of XVII.
Favouring factors: raise in demand during 30y War, regular postal service.
Key traits of this information system: • multi-media (handwritten long and short range, more
flexible on demand; printed short range and broader public)
• adaptive “hub and spoke” network • multi-language

How gazettes look

Our questions and general aims
How to:
1. explore the extent of the flow 2. reconstruct its fine-grained dynamic cartography 3. study the problem of information supply and exchange:
media interactions
Initial approach: assume no significant editorial interventions and detect plain text reuse.We start by developing robust methods for printed gazettes.
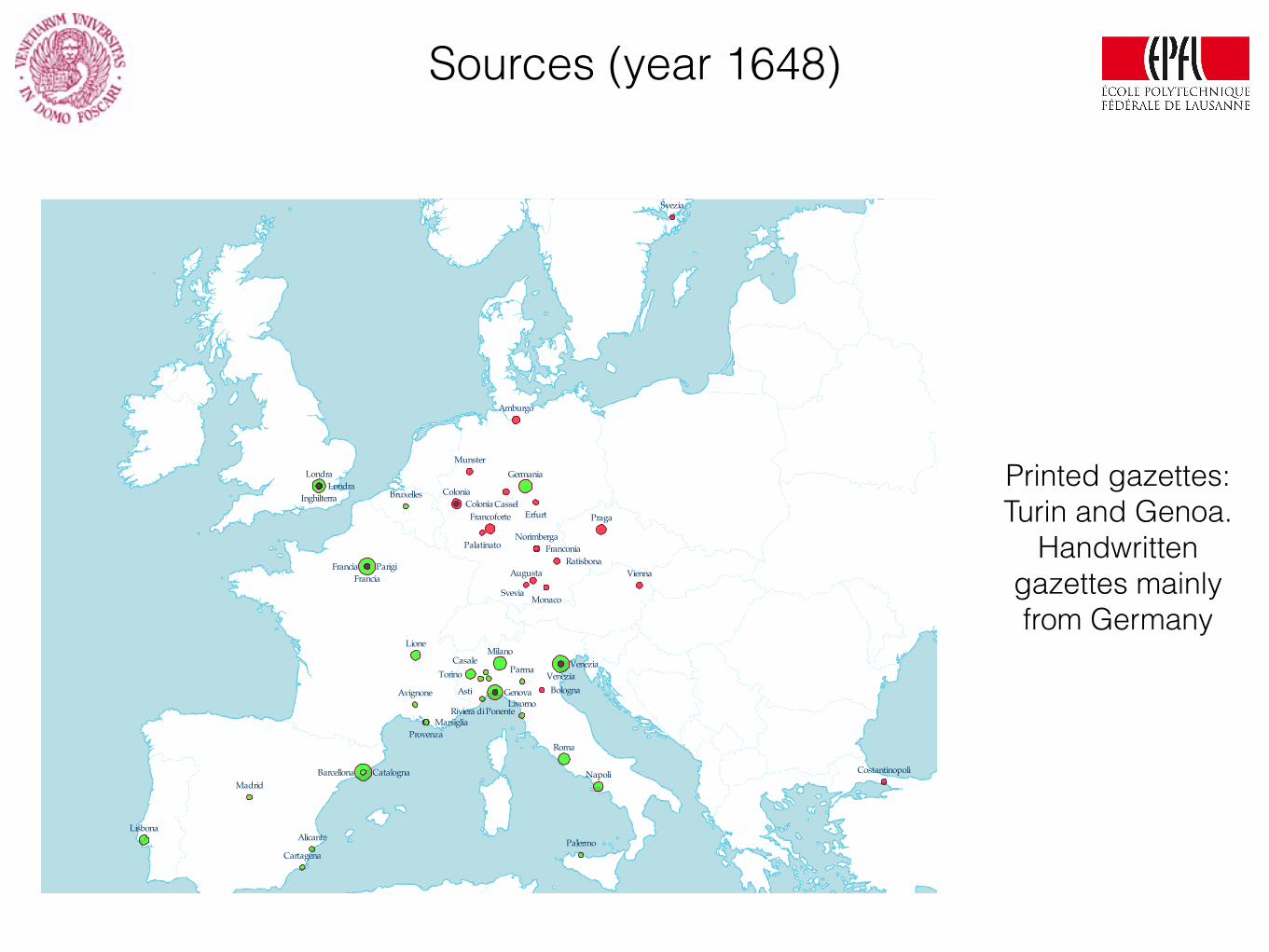
Sources (year 1648)
Asti
Cartagena
Francia
Catalogna
Provenza
Livorno
Alicante
CasaleParma
Bruxelles
Avignone
Colonia
Palermo
Riviera diPonente
Madrid
Marsiglia
Inghilterra
Lione
Torino
Napoli
Lisbona
Roma
Londra Germania
Milano
Genova
Barcellona
Parigi
VeneziaBologna
Francia
Svezia
Augusta
Palatinato
Costantinopoli
Monaco
Erfurt
Norimberga
Londra
Franconia
Cassel
Venezia
Vienna
Svevia
Munster
Ratisbona
Amburgo
Francoforte PragaColonia
Printed gazettes: Turin and Genoa.
Handwritten gazettes mainly from Germany

Part I: printed gazettes

Methods: data preparation
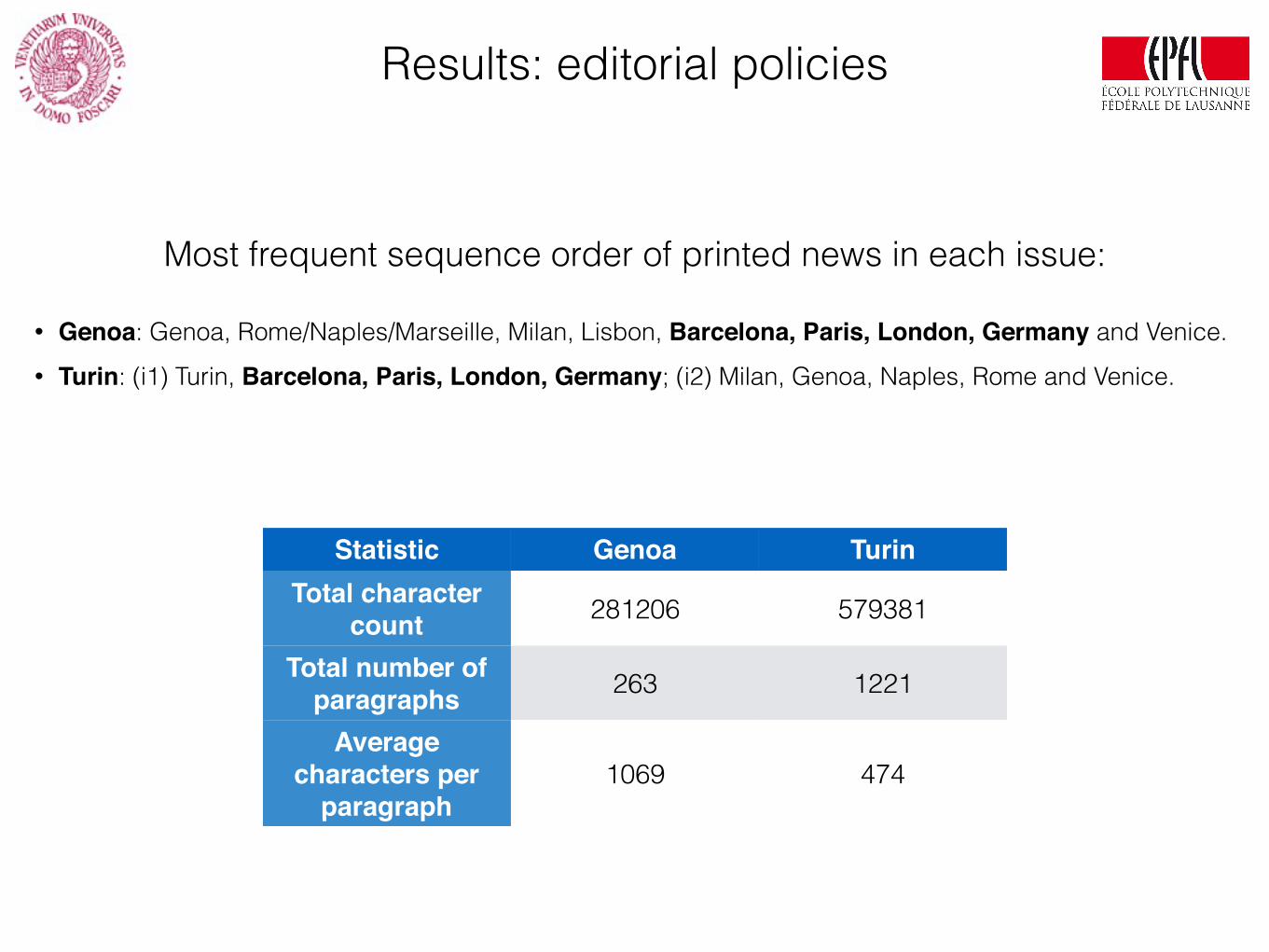
Results: editorial policies
Most frequent sequence order of printed news in each issue:
• Genoa: Genoa, Rome/Naples/Marseille, Milan, Lisbon, Barcelona, Paris, London, Germany and Venice. • Turin: (i1) Turin, Barcelona, Paris, London, Germany; (i2) Milan, Genoa, Naples, Rome and Venice.
Statistic Genoa TurinTotal character
count 281206 579381
Total number of paragraphs 263 1221
Average characters per
paragraph1069 474
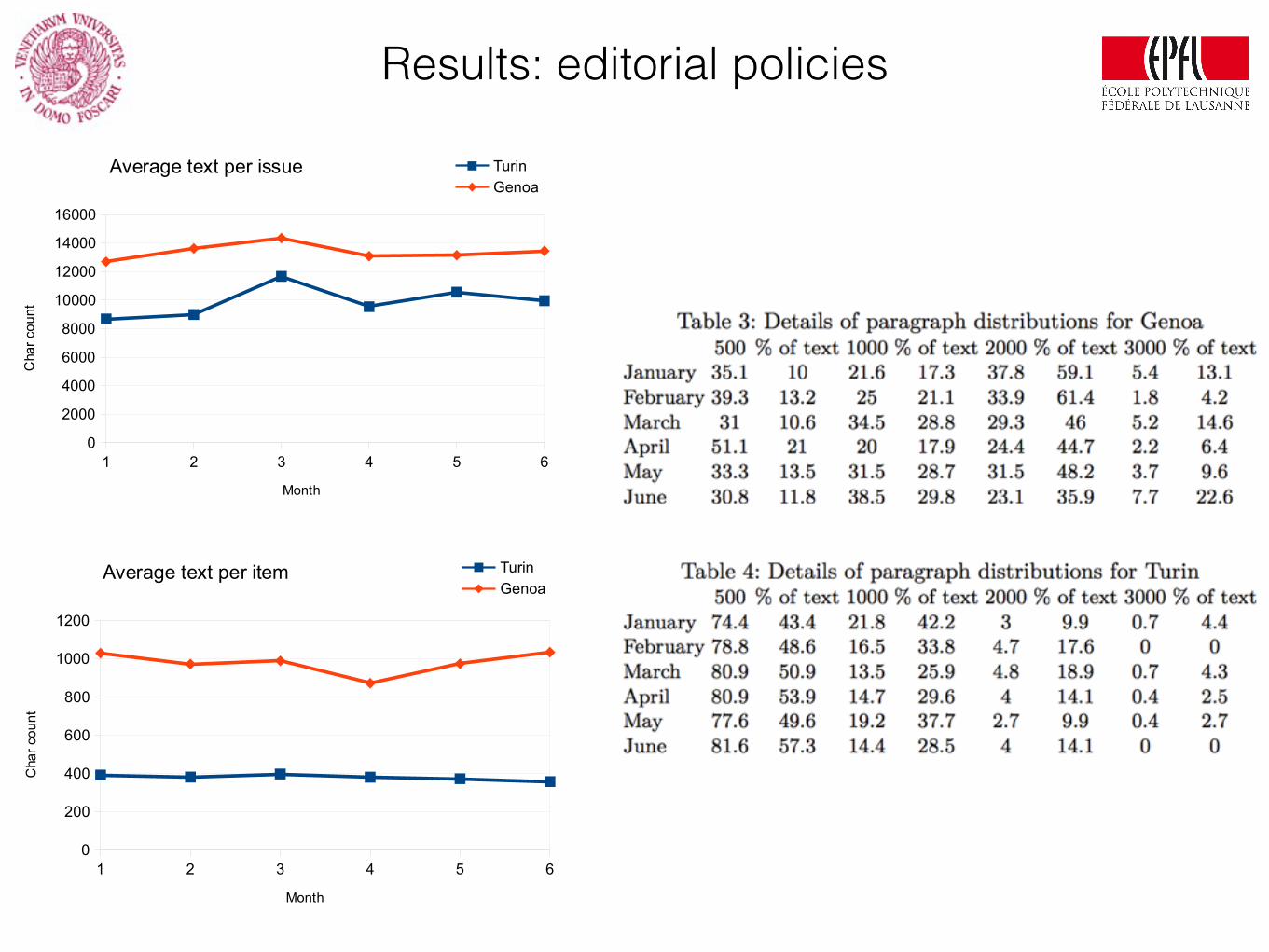
Results: editorial policiesSheet1
Page 1
1 2 3 4 5 6
0
200
400
600
800
1000
1200
Average text per item per month Turin
Genoa
Month
Cha
r co
unt
1 2 3 4 5 6
0
2000
4000
6000
8000
10000
12000
14000
16000
Average text per issue Turin
Genoa
Month
Cha
r co
unt
Sheet1
Page 1
1 2 3 4 5 6
0
200
400
600
800
1000
1200
Average text per item Turin
Genoa
Month
Cha
r co
unt
1 2 3 4 5 6
0
2000
4000
6000
8000
10000
12000
14000
16000
Average text per issue Turin
Genoa
Month
Cha
r co
unt

Results: editorial policies
• Strong regular overlap of provenances • Similar publication order (by provenance) • Different use of paragraphs: 1 per provenance
(Genoa) or 1 per news (Turin)
Preliminary conclusions: 1. Provenance overlap and publication order might hint
at reception order (regular postal system) 2. Different editorial policies: group by provenance
(Genoa, to save space?), compose “as is” for Turin

Methods: matching algorithms I
4 Colavizza G., Infelise M., Kaplan, F.
3 Method
The internal structure of printed gazettes is very regular. Each gazette is aunique sheet folded once (in-folio), resulting in 4 pages of text. Most often newsare organized in paragraphs, by place of origin and date. It is this informationidentifying groups of news within each issue that allows scholars to reconstructnews flows. Our method implies the comparison of paragraphs to detect textborrowings or similarities, which allows us to know when two di�erent issueshad the same source of information, the extent of the overlap, and if therewas a di�erent editorial policy according to text formatting. We refrain fromproviding a clear definition of what we consider a text reuse and what not sincewe do not want to limit ourselves to strictly verbatim borrowings. An a posteriori
classification of borrowings will be instead proposed below.Our pipeline is as follows: from images we extract the text of news in digital
form by OCR. This text is then manually annotated with the necessary meta-data and normalized. Finally, each paragraph of each news is compared with allparagraphs of all other news from di�erent gazettes within a time window ofone month ahead and backwards of the issue date. Each positive result above agiven threshold is submitted to the user for direct evaluation and classification.
3.1 Text extraction, annotation and pre-processing
All OCR has been done with ABBYY Fine Reader 11, Corporate Edition.5We trained the software on a random sample of 10% of the pages for bothgazettes, expanding the character training set and the verification vocabularies.Results varied greatly according to the print and conservation quality of theoriginal documents, therefore we do not report error rates for the OCR process,and threat all texts as bad quality. We then manually annotated OCRed textswith xml metadata on issue place and date, source date and place of origin,and paragraph division. Lastly, in a normalization step we removed all stop-words, punctuation, words shorter than 2 characters, whitespace, and we broughteverything to lowercase.
An example of text after OCR is:Daumarelatsonc defaeficltdell^^ 1 p.siriedrà quantoforfogilitosin à qual^ giorno,;à Che aggipngOno qiielle de Rome dalli 23 . che PArmata Fran-cese partita da Portolcsigone alli r 4oseguitatada’5 . Vasselli di Portu-gallochen’ehe n.altriFranCrsifossero rimastitnLiuornoànstàrCiesogiòn-
Which after pre-processing becomes (in yellow the most relevant informa-tions retained, despite the loss of word segmentation):
daumarelatsoncdefaeficltdell1psiriedràquantoforfogilitosinqualgiornocheaggipngonoqiielleromedalli23parmatafrancesepartitaportolcsigoneallir4oseguitatada5vasselliportugallochenehenaltrifrancrsifosserorimastitnliuornoànstàrciesogiòn5 finereader.abbyy.com.
4 Colavizza G., Infelise M., Kaplan, F.
3 Method
The internal structure of printed gazettes is very regular. Each gazette is aunique sheet folded once (in-folio), resulting in 4 pages of text. Most often newsare organized in paragraphs, by place of origin and date. It is this informationidentifying groups of news within each issue that allows scholars to reconstructnews flows. Our method implies the comparison of paragraphs to detect textborrowings or similarities, which allows us to know when two di�erent issueshad the same source of information, the extent of the overlap, and if therewas a di�erent editorial policy according to text formatting. We refrain fromproviding a clear definition of what we consider a text reuse and what not sincewe do not want to limit ourselves to strictly verbatim borrowings. An a posteriori
classification of borrowings will be instead proposed below.Our pipeline is as follows: from images we extract the text of news in digital
form by OCR. This text is then manually annotated with the necessary meta-data and normalized. Finally, each paragraph of each news is compared with allparagraphs of all other news from di�erent gazettes within a time window ofone month ahead and backwards of the issue date. Each positive result above agiven threshold is submitted to the user for direct evaluation and classification.
3.1 Text extraction, annotation and pre-processing
All OCR has been done with ABBYY Fine Reader 11, Corporate Edition.5We trained the software on a random sample of 10% of the pages for bothgazettes, expanding the character training set and the verification vocabularies.Results varied greatly according to the print and conservation quality of theoriginal documents, therefore we do not report error rates for the OCR process,and threat all texts as bad quality. We then manually annotated OCRed textswith xml metadata on issue place and date, source date and place of origin,and paragraph division. Lastly, in a normalization step we removed all stop-words, punctuation, words shorter than 2 characters, whitespace, and we broughteverything to lowercase.
An example of text after OCR is:Daumarelatsonc defaeficltdell^^ 1 p.siriedrà quantoforfogilitosin à qual^ giorno,;à Che aggipngOno qiielle de Rome dalli 23 . che PArmata Fran-cese partita da Portolcsigone alli r 4oseguitatada’5 . Vasselli di Portu-gallochen’ehe n.altriFranCrsifossero rimastitnLiuornoànstàrCiesogiòn-
Which after pre-processing becomes (in yellow the most relevant informa-tions retained, despite the loss of word segmentation):
daumarelatsoncdefaeficltdell1psiriedràquantoforfogilitosinqualgiornocheaggipngonoqiielleromedalli23parmatafrancesepartitaportolcsigoneallir4oseguitatada5vasselliportugallochenehenaltrifrancrsifosserorimastitnliuornoànstàrciesogiòn5 finereader.abbyy.com.

Methods: matching algorithms II
4 Colavizza G., Infelise M., Kaplan, F.
3 Method
The internal structure of printed gazettes is very regular. Each gazette is aunique sheet folded once (in-folio), resulting in 4 pages of text. Most often newsare organized in paragraphs, by place of origin and date. It is this informationidentifying groups of news within each issue that allows scholars to reconstructnews flows. Our method implies the comparison of paragraphs to detect textborrowings or similarities, which allows us to know when two di�erent issueshad the same source of information, the extent of the overlap, and if therewas a di�erent editorial policy according to text formatting. We refrain fromproviding a clear definition of what we consider a text reuse and what not sincewe do not want to limit ourselves to strictly verbatim borrowings. An a posteriori
classification of borrowings will be instead proposed below.Our pipeline is as follows: from images we extract the text of news in digital
form by OCR. This text is then manually annotated with the necessary meta-data and normalized. Finally, each paragraph of each news is compared with allparagraphs of all other news from di�erent gazettes within a time window ofone month ahead and backwards of the issue date. Each positive result above agiven threshold is submitted to the user for direct evaluation and classification.
3.1 Text extraction, annotation and pre-processing
All OCR has been done with ABBYY Fine Reader 11, Corporate Edition.5We trained the software on a random sample of 10% of the pages for bothgazettes, expanding the character training set and the verification vocabularies.Results varied greatly according to the print and conservation quality of theoriginal documents, therefore we do not report error rates for the OCR process,and threat all texts as bad quality. We then manually annotated OCRed textswith xml metadata on issue place and date, source date and place of origin,and paragraph division. Lastly, in a normalization step we removed all stop-words, punctuation, words shorter than 2 characters, whitespace, and we broughteverything to lowercase.
An example of text after OCR is:Daumarelatsonc defaeficltdell^^ 1 p.siriedrà quantoforfogilitosin à qual^ giorno,;à Che aggipngOno qiielle de Rome dalli 23 . che PArmata Fran-cese partita da Portolcsigone alli r 4oseguitatada’5 . Vasselli di Portu-gallochen’ehe n.altriFranCrsifossero rimastitnLiuornoànstàrCiesogiòn-
Which after pre-processing becomes (in yellow the most relevant informa-tions retained, despite the loss of word segmentation):
daumarelatsoncdefaeficltdell1psiriedràquantoforfogilitosinqualgiornocheaggipngonoqiielleromedalli23parmatafrancesepartitaportolcsigoneallir4oseguitatada5vasselliportugallochenehenaltrifrancrsifosserorimastitnliuornoànstàrciesogiòn5 finereader.abbyy.com.

Methods: on String Kernels
Ft(s) =1
�k
X
g2St
�length(g)
More on String Kernels: • feature space for each text is the score vector of all
(possibly non-)contiguous k-mers • exponentially decaying factor over length of non-
contiguity • lambda controls decaying factor
E.g. a single document with the word “war” is represented by a vector of 2-mers as (1,1,0.5) for
“wa”, “ar” and “wr” respectively, with lambda = 0.5.
I used 5-mers with lambda = 0.5

Methods: matching procedure
Strategy: compare paragraphs (units of formatting/reading but also meaning)
Global match: SubString Kernels (similarity of sequences of non-contiguous characters) Local alignment: Smith-Waterman (finds local matching passages) Threshold filtering and manual evaluation of 2 highest scoring matches
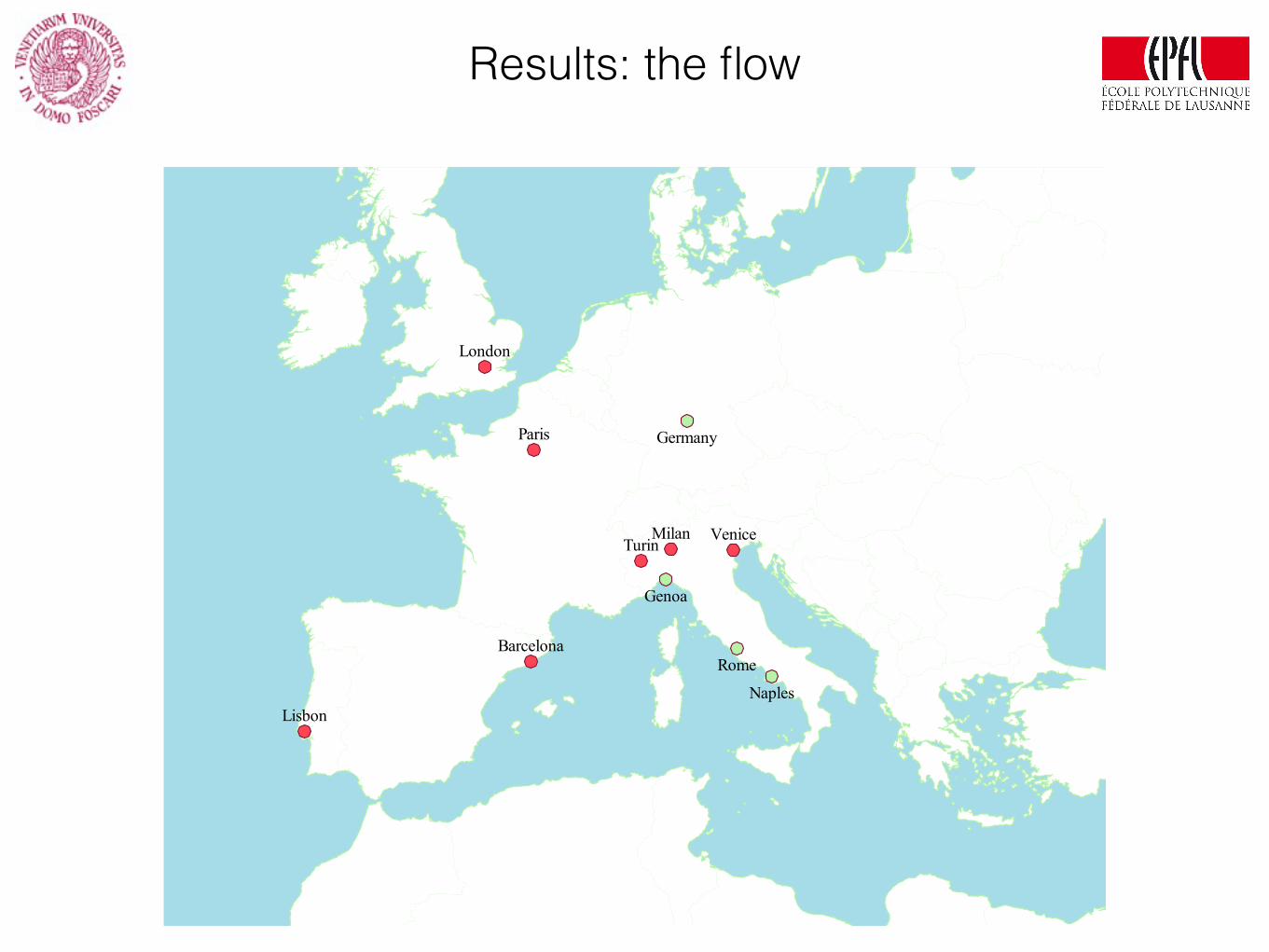
Results: the flow
Turin
Paris
Barcelona
Lisbon
Milan Venice
London
Naples
Rome
Genoa
Germany

Results: comparisons
Categories: 1. verbatim copy of a whole paragraph or parts of it 2. paraphrasing or translations of the same source 3. same news from different sources 4. same topic but different news
Results: 1 and 3 <1%2 circa 30% 4 circa 43%
Evaluation: precision by hand recall “intractable”

Results: the flow
A tricky example:

Part II: handwritten gazettes

Methods: data preparation
Plenipotentiario di Spagna (keyword)
Re di Spagna (name_of_person)
Conte d'Avò (name_of_person)
spagnoli (quantity)
Ambasciatore di Portogallo (keyword)
Perera (name_of_person)
Hassi (keyword)
Cassel (name_of_place)
Plenipotentiario di Franza (keyword)
Sua Maestà Cesarea (name_of_person)
Landgraviessa d'Assia (name_of_person)
Osnapruch (name_of_place)
trattato dell'Imperio (keyword)
Lantgravio di Darmstat (name_of_person)
Amnistia nello stati hereditarij (keyword)
anni (quantity)
Pinorada (name_of_person)
Svedesi (keyword)
Provincia d'Utrecht (name_of_place)
pace (keyword)
Spagna (name_of_place)
Olanda (name_of_place)
Zelanda (name_of_place)
Provinzie Basse (name_of_place)
Francia (name_of_place)

Methods: matching algorithms
Strategy: compare paragraphs
Typed canonicalisation: similar words are grouped into typed categories (Jaro-Winkler distance) Paragraph comparison: Tf-idf vectors, cosine distance Manual evaluation of 2 highest scoring matches
Too limited and skewed corpus for now..

Results: matchings
Munster 24 April 1648:
Cologne 19 April 1648:
High score, same topic, different news. Different news-sheets

Open questions and conclusions
1. How to assess results? The problem of scalable recall and precision evaluation
2. How to get a larger corpus? 1) lack of data 2) cost of data preparation
3. How to compare printed and handwritten news? 4. What to focus on? Variations are as interesting as verbatim
copies to study the interaction of different medias and types of gazettes
For a start: • We can still do something with noisy OCR • The flow is there

Mapping Early Modern News Networks: Digital Methods and New Perspectives
Thank you
Giovanni Colavizza (EPFL, Lausanne) Mario Infelise (Ca’ Foscari, Venice)
Renaissance Society Conference, Berlin 2015
Recommended

















