Embed Size (px)
Citation preview

Лекция n2Softmax слой
Ограниченная машина Больцмана
Нестеров Павел
11 декабря 2014 г.

План лекции
Вспоминаем прошлую лекцию
Softmax слой
Обучение без учителя
Ограниченная машина Больцмана
Алгоритм contrastive divergence
Заметки про RBM
1 / 60
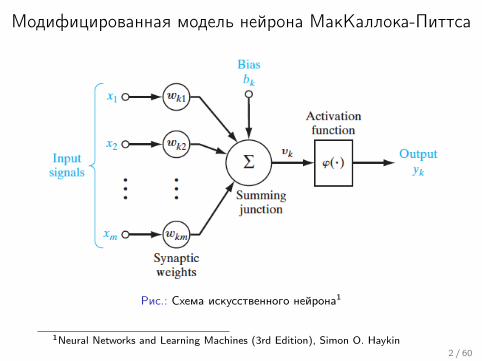
Модифицированная модель нейрона МакКаллока-Питтса
Рис.: Схема искусственного нейрона1
1Neural Networks and Learning Machines (3rd Edition), Simon O. Haykin2 / 60
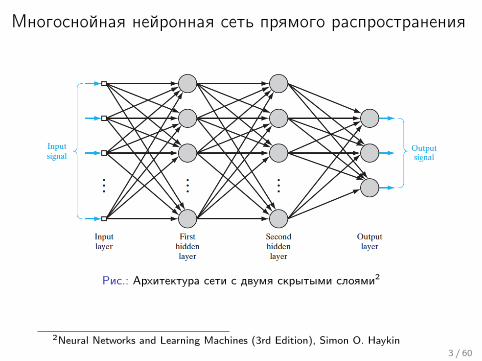
Многоснойная нейронная сеть прямого распространения
Рис.: Архитектура сети с двумя скрытыми слоями2
2Neural Networks and Learning Machines (3rd Edition), Simon O. Haykin3 / 60
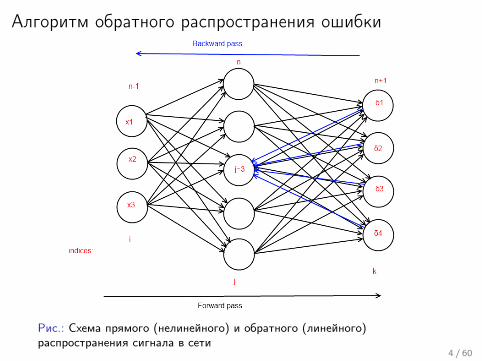
Алгоритм обратного распространения ошибки
Рис.: Схема прямого (нелинейного) и обратного (линейного)распространения сигнала в сети
4 / 60

Некоторые функции стоимости
Среднеквадратичная ошибка:
I E =1
2
∑i∈output (ti − yi )
2
I∂E
∂yi= yi − ti
Логарифм правдоподобия Бернулли:I E = −
∑i∈output (ti log yi + (1− ti ) log (1− yi ))
I∂E
∂yi=
tiyi− 1− ti
1− yiДля каких задач машинного обучения удобны эти функции?
5 / 60

Вспоминаем логистическую регрессию, два класса
I D = {(xi , yi )}i=1...m ,∀xi ∈ Rn,∀yi ∈ {0, 1}
P(y = 1, x) =P(x |y) · P(y)
P(x |y) · P(y) + P(x |y) · P(y)
=1
1 + exp(
P(x|y)·P(y)P(x|y)·P(y)
)=
1
1 + e−a= σ(a)
где y это y = 0, а так же P(y = 0) = 1− P(y = 1), a : h(w) = wT · xI H(p, q) = −
∑i pi · log qi = −y · log y − (1− y) · log(1− y)
I какое распределение?
6 / 60

Логистическая регрессия, обобщение на N классов
I D = {(xi , yi )}i=1...m ,∀xi ∈ Rn,∀yi ∈ {0, 1, . . . ,N}I P(y = 1|x) = 1
1+e−a = e−a
e−a+1 = 1Z · e
−a = 1Z · e
wT ·x
I Z - некоторая нормализирующая константаI P(x) = 1
Z · e−E(x) - распределение Больцмана-Гиббса (почти)
Введем для каждого класса свой вектор весов, получим:
P(y = c |x) =1
Z· ew
Tc ·x =
ewTc ·x∑
i ewT
i ·x(1)
I∑
c P(y = c |x) =∑
c1Z · e
wTc ·x = Z
Z = 1
I как представить в виде нейросети?
7 / 60
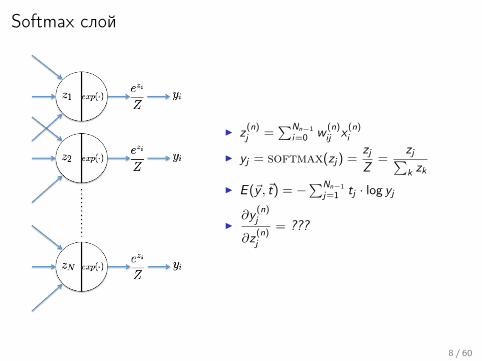
Softmax слой
I z(n)j =
∑Nn−1
i=0 w(n)ij x
(n)i
I yj = softmax(zj) =zjZ
=zj∑k zk
I E (~y , ~t) = −∑Nn−1
j=1 tj · log yj
I∂y
(n)j
∂z(n)j
= ???
8 / 60

Дифференцирование softmax функции
∂y(n)j
∂z(n)j
=∂
∂zj
ezj
Z
=1
Z 2·(∂ezj
∂zj· Z − ezj · ∂Z
∂zj
)=
1
Z 2·(ezjZ − ezj
∂ezj
∂zj
)=
ezjZ − (ezj )2
Z 2=
ezj
Z−(ezj
Z
)2
= yj − y2j
= yj · (1− yj)
9 / 60

Вспомним backprop
I∂E
∂w(n)ij
=∂E
∂z(n)j
∂z(n)j
∂w(n)ij
I∂z
(n)j
∂w(n)ij
=∑
i
∂w(n)ij x
(n−1)i
∂w(n)ij
= x(n−1)i
В итоге получим:∂E
∂w(n)ij
= x(n−1)i
∂E
∂z(n)j
(2)
Продолжим с этого момента, с учетом того, что функциейстоимости является перекрестная энтропия (опустим индекс слоядля наглядности):
I E (~y (~z) , ~t) = −∑Nn−1
j=1 tj · log yj(zj)
I∂E
∂zj= ???
10 / 60

Дифференцирование перекрестной энтропии, #1
Раньше было так (для выходного слоя):
∂E
∂zj=∂E
∂yj
∂yj∂zj
Теперь стало так:
∂E
∂zj=
Nn∑i=1
∂E
∂yi· ∂yi∂zj
I почему так?
11 / 60

Дифференцирование перекрестной энтропии, #2
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi???
12 / 60

Дифференцирование перекрестной энтропии, #2
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
∂E
∂yi= − ∂
∂yi
(Nn∑k
tk · log yk
)
= − ∂
∂yi(ti · log yi )
= − tiyi
13 / 60

Дифференцирование перекрестной энтропии, #3
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi= − ti
yi
I∂yi∂zj
???
14 / 60

Дифференцирование перекрестной энтропии, #4
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi= − ti
yi
∂yi∂zj
=
{yj (1− yj) , i = j
???, i 6= j
15 / 60

Дифференцирование перекрестной энтропии, #5
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi= − ti
yi
I∂yi∂zj
={
yj (1−yj ),i=j???,i 6=j
∂y(n)i
∂z(n)j
=1
Z 2·(∂ezi
∂zj· Z − ezi · ∂Z
∂zj
)=
1
Z 2(0− ezi · ezj )
= −yi · yj
16 / 60

Дифференцирование перекрестной энтропии, #6
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi= − ti
yi
I∂yi∂zj
={
yj (1−yj ),i=j−yiyj ,i 6=j
I∂E
∂yi· ∂yi∂zj
={−tj (1−yj ),i=j
yj ti ,i 6=j
I собираем все вместе
17 / 60

Дифференцирование перекрестной энтропии, #7
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi· ∂yi∂zj
={−tj (1−yj ),i=j
yj ti ,i 6=j
∂E
∂zj= −tj (1− yj) +
Nn∑i=1,i 6=j
yj ti
= −tj + tjyj + yj ·Nn∑
i=1,i 6=j
ti
= −tj + yj
tj + ·Nn∑
i=1,i 6=j
ti
= ???
18 / 60

Дифференцирование перекрестной энтропии, #8
I∂E
∂zj=∑Nn
i=1
∂E
∂yi· ∂yi∂zj
I∂E
∂yi· ∂yi∂zj
={−tj (1−yj ),i=j
yj ti ,i 6=j
∂E
∂zj= −tj (1− yj) +
Nn∑i=1,i 6=j
yj ti
= −tj + tjyj + yj ·Nn∑
i=1,i 6=j
ti
= −tj + yj
tj + ·Nn∑
i=1,i 6=j
ti
= yj − tj
19 / 60
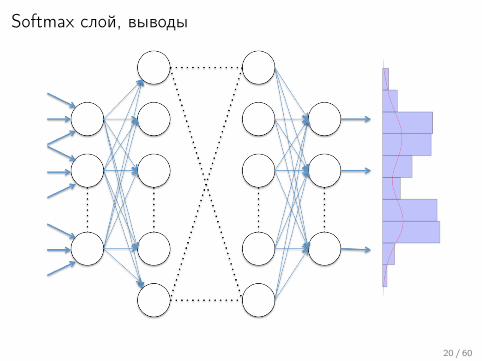
Softmax слой, выводы
20 / 60

Обучение без учителя
When we’re learning to see, nobody’s telling us what the right answersare — we just look. Every so often, your mother says “that’s a dog”, butthat’s very little information. You’d be lucky if you got a few bits ofinformation — even one bit per second — that way. The brain’s visualsystem has 1014 neural connections. And you only live for 109 seconds.So it’s no use learning one bit per second. You need more like 105 bitsper second. And there’s only one place you can get that muchinformation: from the input itself.3
3Geoffrey Hinton, 1996 (quoted in (Gorder 2006))21 / 60

Статистическая механика, #1Представим некоторую физическую систему с множеством степенейсвободы, которая может находится в одном из множества состоянийс некоторой вероятностью, а каждому такому состоянию состояниюсоответствует некоторая энергия всей системы:
I pi ≥ 0 - вероятность состояния iI∑
i pi = 1I Ei - энергия системы в состоянии i
Тогда вероятность состояния i будет описываться распределениемБольцмана-Гиббса, при условии термодинамического равновесиямежду системой и окружающей средой:
pi =1
Zexp
(− Ei
kB · T
)(3)
гдеI T - абсолютная температура (К)I kB - константа Больцмана (Дж/К)
I Z =∑
i exp(− Ei
kB ·T
)- нормализирующая константа (partition
function, Zustadsumme, статсумма)22 / 60

Статистическая механика, #2
Два важных вывода:1. состояния с низкой энергией имеют больше шансов возникнуть
чем состояния с высокой энергией;2. при понижении температуры, чаще всего будут возникать
состояния из небольшого подмножества состояний с низкойэнергией.
23 / 60
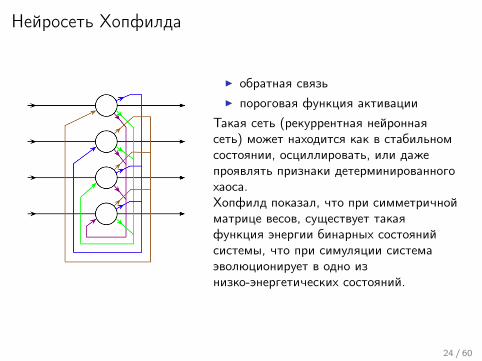
Нейросеть Хопфилда
I обратная связьI пороговая функция активации
Такая сеть (рекуррентная нейроннаясеть) может находится как в стабильномсостоянии, осциллировать, или дажепроявлять признаки детерминированногохаоса.Хопфилд показал, что при симметричнойматрице весов, существует такаяфункция энергии бинарных состоянийсистемы, что при симуляции системаэволюционирует в одно изнизко-энергетических состояний.
24 / 60
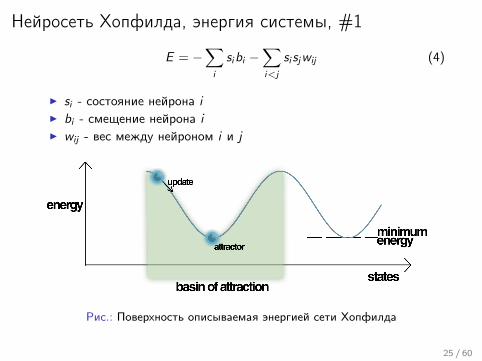
Нейросеть Хопфилда, энергия системы, #1
E = −∑i
sibi −∑i<j
si sjwij (4)
I si - состояние нейрона iI bi - смещение нейрона iI wij - вес между нейроном i и j
Рис.: Поверхность описываемая энергией сети Хопфилда
25 / 60

Нейросеть Хопфилда, энергия системы, #2
Рис.: Поверхность описываемая энергией сети Хопфилда, два стабильныхсостояния4
4Neural Networks and Learning Machines (3rd Edition), Simon O. Haykin26 / 60
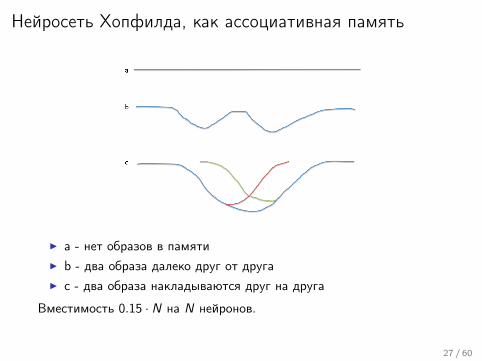
Нейросеть Хопфилда, как ассоциативная память
I a - нет образов в памятиI b - два образа далеко друг от другаI c - два образа накладываются друг на друга
Вместимость 0.15 · N на N нейронов.
27 / 60

Нейросеть Хопфилда, алгоритм обучения
Обучение сети Хопфилда происходит в один прогон по множествуданных по следующему правилу:
∆wij =1
n
n∑i=1
si sj ,∀k : sk ∈ {−1, 1} (5)
Это в точности первое правило Хебба:I если два нейрона по разные стороны от синапсов активируются
синхронно, то "вес"синапса слегка возрастает
28 / 60
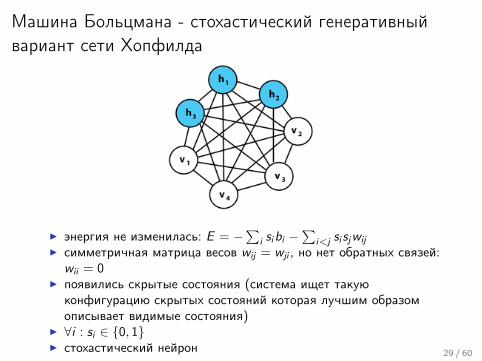
Машина Больцмана - стохастический генеративныйвариант сети Хопфилда
I энергия не изменилась: E = −∑
i sibi −∑
i<j si sjwij
I симметричная матрица весов wij = wji , но нет обратных связей:wii = 0
I появились скрытые состояния (система ищет такуюконфигурацию скрытых состояний которая лучшим образомописывает видимые состояния)
I ∀i : si ∈ {0, 1}I стохастический нейрон 29 / 60
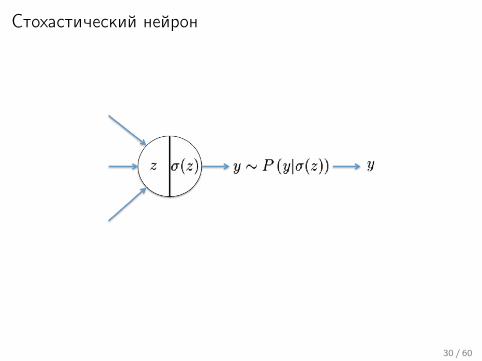
Стохастический нейрон
30 / 60

Имитация отжига, идея, #1
31 / 60

Имитация отжига, идея, #2
Рис.: Влияние температуры на вероятности переходов5
I SimulatedAnnealing.gif5https://class.coursera.org/neuralnets-2012-001/lecture
32 / 60

Имитация отжигаI ∆Ei = bi +
∑j wijsj
I pi = 1Z exp
(− Ei
kB ·T
)pi=1
pi=0= exp
(−Ei=0 − Ei=1
kBT
)= exp
(∆Ei
kBT
)⇒
∆Ei
T= ln(pi=1)− ln(pi=0) = ln(pi=1)− ln(1− pi=1)
= ln
(pi=1
1− pi=1
)⇒
−∆Ei
T= ln
(1− pi=1
pi=1
)= ln
(1
pi=1− 1
)⇒
exp
(−∆Ei
T
)=
1
pi=1− 1⇒
pi=1 =1
1 + exp(−∆Ei
T
)33 / 60
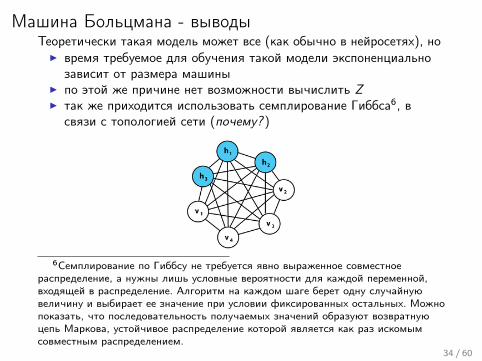
Машина Больцмана - выводыТеоретически такая модель может все (как обычно в нейросетях), но
I время требуемое для обучения такой модели экспоненциальнозависит от размера машины
I по этой же причине нет возможности вычислить ZI так же приходится использовать семплирование Гиббса6, в
связи с топологией сети (почему? )
6Семплирование по Гиббсу не требуется явно выраженное совместноераспределение, а нужны лишь условные вероятности для каждой переменной,входящей в распределение. Алгоритм на каждом шаге берет одну случайнуювеличину и выбирает ее значение при условии фиксированных остальных. Можнопоказать, что последовательность получаемых значений образуют возвратнуюцепь Маркова, устойчивое распределение которой является как раз искомымсовместным распределением.
34 / 60
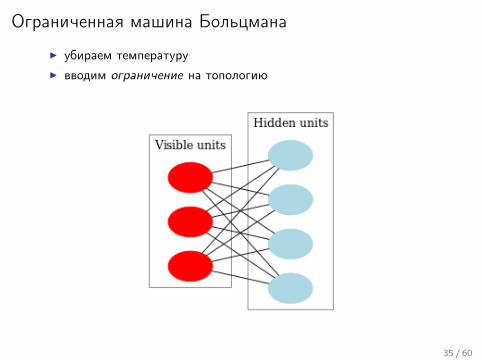
Ограниченная машина Больцмана
I убираем температуруI вводим ограничение на топологию
35 / 60

Виды RBM
В зависимости от априрного распределения ассоциированного свидимым и скрытым слоями, различают несколько видов RBM:
I Bernoulli-Bernoulli (binary-binary)I Gaussian-BernoulliI Gaussian-GaussianI Poisson-BernoulliI и т.д.
Бинарные (Bernoulli-Bernoulli, binary-binary) RBM играют важнуюроль в глубоком обучении, по аналогии с выводом алгоритмаобучения для бинарной ограниченной машины Больцмана, можновывести аналогичные правила для остальных типов моделей.
36 / 60

RBM, обозначения
I D = {~xi}i=1...N - множество данных;
I ~v , ~h - значения видимых и скрытых нейронов;I ~a, ~b,W - смещения видимых и скрытых нейронов, и матрица
весов;I n,m - количество видимых и скрытых нейронов;I E (~v , ~h) = −
∑ni=1 aivi −
∑mj=1 bjhj −
∑ni=1
∑mj=1 wijvihj =
−~vT~a− ~hT~b − ~vTW ~b
I p(~v , ~h) = 1Z e−E(~v ,~h)
I Z =∑N
r
∑Mt e−E(~v (r),~h(t))
I P(~v) =∑M
t P(~v , ~h(t)) = 1Z
∑Mt e−E(~v ,~h(t))
Далее значки вектора ~x будут опускаться для простоты.
37 / 60

RBM, функция активации
Аналогично обычной машине Больцмана, рассмотрим только дляскрытого слоя:
P(hk = 1|v) =e−E1
e−E1 + e−E0
=1
1 + eE1−E0
=1
1 + e−bk−∑n
i viwik
= σ
(bk +
n∑i=1
viwik
)
Вопрос:I P(h|v) = ???
38 / 60
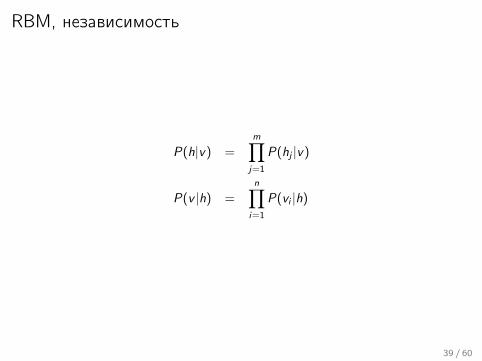
RBM, независимость
P(h|v) =m∏j=1
P(hj |v)
P(v |h) =n∏
i=1
P(vi |h)
39 / 60

RBM, целевая функция
E (~v , ~h) = −n∑
i=1
aivi −m∑j=1
bjhj −n∑
i=1
m∑j=1
wijvihj (6)
P(~v) =1
Z
M∑t
e−E(~v ,~h(t)) (7)
I максимизировать вероятность данных при заданнойгенеративной модели
I что будем делать?
40 / 60

RBM, дифференцирование P(v), #1
E (~v , ~h) = −n∑
i=1
aivi −m∑j=1
bjhj −n∑
i=1
m∑j=1
wijvihj
∂E (v , h)
∂wij= ?
∂E (v , h)
∂ai= ?
∂E (v , h)
∂bj= ?
∂e−E(v ,h)
∂wij= ?
∂e−E(v ,h)
∂ai= ?
∂e−E(v ,h)
∂bj= ?
41 / 60

RBM, дифференцирование P(v), #2
E (~v , ~h) = −n∑
i=1
aivi −m∑j=1
bjhj −n∑
i=1
m∑j=1
wijvihj
∂E (v , h)
∂wij= −vihj
∂E (v , h)
∂ai= −vi
∂E (v , h)
∂bj= −hj
∂e−E(v ,h)
∂wij= vihje
−E(v ,h)
∂e−E(v ,h)
∂ai= vie
−E(v ,h)
∂e−E(v ,h)
∂bj= hje
−E(v ,h)
42 / 60

RBM, дифференцирование P(v), #3
Z =N∑r
M∑t
e−E(~v (r),~h(t))
∂Z
∂wij= ?
∂Z
∂ai= ?
∂Z
∂bj= ?
43 / 60

RBM, дифференцирование P(v), #4
Z =N∑r
M∑t
e−E(~v (r),~h(t))
∂Z
∂wij=
N∑r
M∑t
v(r)i h
(t)j e−E(v (r),h(t))
∂Z
∂ai=
N∑r
M∑t
v(r)i e−E(v (r),h(t))
∂Z
∂bj=
N∑r
M∑t
h(t)j e−E(v (r),h(t))
44 / 60

RBM, дифференцирование P(v), #5
∂P(v (k)
)∂wij
=1
Z 2
(Z
(M∑t
v(k)i h
(k)j e−E(v (r),h(t))
)
−
(M∑t
e−E(v (r),h(t))
)(N∑r
M∑t
v(r)i h
(t)j e−E(v (r),h(t))
))∂ lnP
(v (k)
)∂wij
=1
P(v (k)
) ∂P (v (k))
∂wij
45 / 60

RBM, дифференцирование P(v), #6
∂ lnP(v (k)
)∂wij
= v(k)i
M∑t
h(t)j P
(h(t)|v (k)
)−
N∑r
M∑t
v(r)i h
(t)j P
(h(t), v (k)
)= ???
46 / 60

RBM, дифференцирование P(v), #7
∂ lnP(v (k)
)∂wij
=M∑t
v(k)i h
(t)j P
(h(t)|v (k)
)−
N∑r
M∑t
v(r)i h
(t)j P
(h(t), v (k)
)= M
[v
(k)i hj
]data−M [vihj ]model
∂ lnP(v (k)
)∂ai
= v(k)i −M [vi ]model
∂ lnP(v (k)
)∂bj
= M [hj ]data −M [hj ]model
47 / 60

RBM, правила обновления
∆wij = η(M[v
(k)i hj
]data−M [vihj ]model
)∆ai = η
(v
(k)i −M [vi ]model
)∆bj = η
(M [hj ]data −M [hj ]model
)
48 / 60
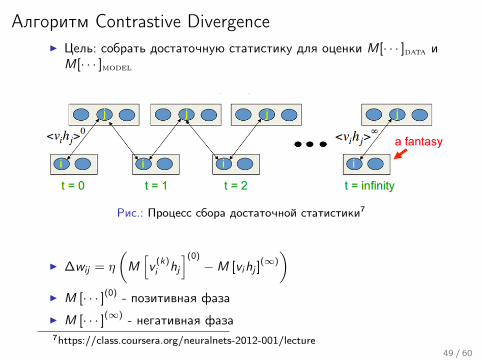
Алгоритм Contrastive DivergenceI Цель: собрать достаточную статистику для оценки M[· · · ]data и
M[· · · ]model
Рис.: Процесс сбора достаточной статистики7
I ∆wij = η
(M[v
(k)i hj
](0)
−M [vihj ](∞)
)I M [· · · ](0) - позитивная фаза
I M [· · · ](∞) - негативная фаза7https://class.coursera.org/neuralnets-2012-001/lecture
49 / 60

Практические советы
I не семплировать видимый слой (семплирование замедляетсходимость, но математически это более корректно);
I не семплировать значения скрытого слоя при выводе извосстановленного образа;
I CD-k , уже при k = 1 качество не сильно уступает большимзначениям, но выигрыш в скорости значительный;
I размер минибатча 10-100 экземпляров (почему? );I кроссвалидаци восстановленных образов;I использование момента сказывается крайне положительно на
скорости сходимости;I http://www.cs.toronto.edu/ hinton/absps/guideTR.pdf
50 / 60

Визуализация восстановленных образов
51 / 60

Визуализация признаков, #1
52 / 60

Визуализация признаков, #2
Рис.: Признаки на множестве рукописных цифр MNIST8
8http://deeplearning.net/53 / 60

Визуализация признаков, #3
54 / 60

Визуализация признаков, #4
Рис.: RBM как базис9
9http://cs.stanford.edu/55 / 60

Регуляризация в RBM, #1
(a) RBM, no reg (b) RBM, L2 reg
Рис.: Иллюстрация эффекта регуляризации
56 / 60

Регуляризация в RBM, #2
(a) RBM, L2 reg (b) RBM, L1 reg
Рис.: Иллюстрация эффекта регуляризации
57 / 60
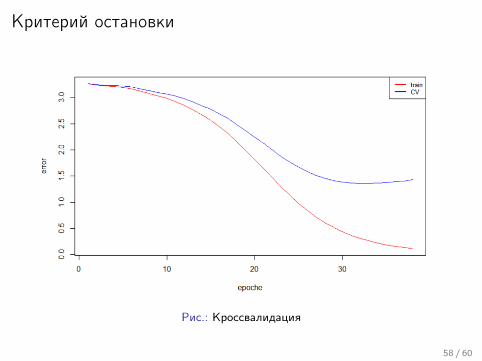
Критерий остановки
Рис.: Кроссвалидация
58 / 60
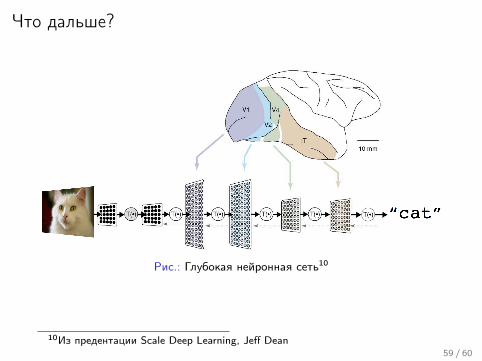
Что дальше?
Рис.: Глубокая нейронная сеть10
10Из предентации Scale Deep Learning, Jeff Dean59 / 60

Вопросы





























