Embed Size (px)
Citation preview

YaCy Módulo IMECANISMO DE BUSCA OPEN SOURCE
Mestrando Julio Della Flora – Tutor
Prof. Dr. Benjamin Luiz Franklin - Coordenador
Vinculado ao Projeto Uel - LabFree
Projeto LabFree

Introdução aos Buscadores
A preocupação em desenvolver ferramentas que
facilitem a busca por informação cresce à medida
que a rede mundial de computadores aumenta.
Para Cendón (2001) os diretórios foram ofertados
como primeira alternativa para organizar e
localizar conteúdo na Web, precedendo o modelo
atual, baseado em motores de busca.
Oportuno salientar que aquele modelo foi
introduzido quando a quantidade de informaçãodisponível na internet ainda era pequeno.

Introdução aos Buscadores
Os diretórios possuíam como método a
divisão do conteúdo eletrônico por
categorias, que, por sua vez, poderiam se
desdobrar em subcategorias.
Em contrapartida, os motores de busca
não se organizam consoante o método
retro enunciado. Em seu lugar está a
abrangência de conteúdo na sua base de
dados, podendo-se alcançar bilhões de
itens, os quais são localizáveis mediante
busca através de palavras-chave.

Introdução aos Buscadores
Monteiro (2009), em sua bibliografia, descreve a anatomia das máquinas de busca
em três processos principais:
Crawling
Indexing
Searching
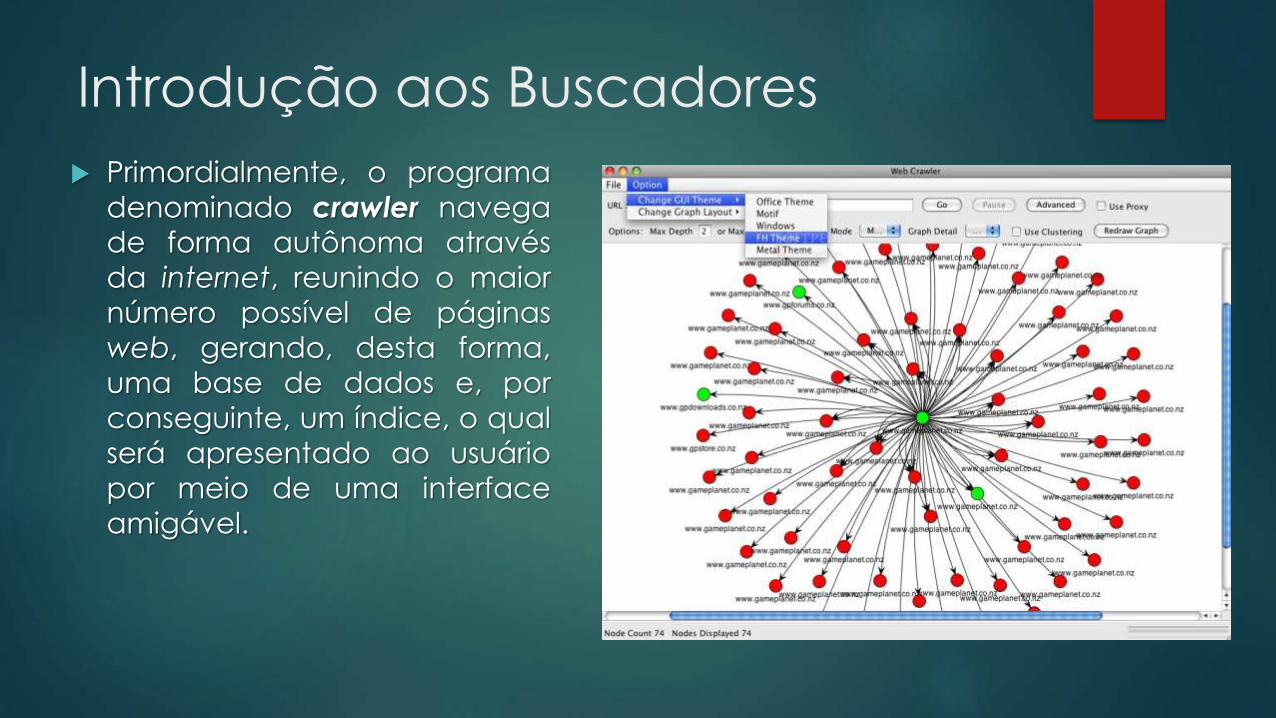
Introdução aos Buscadores
Primordialmente, o programa
denominado crawler navegade forma autônoma através
da internet, reunindo o maior
número possível de páginas
web, gerando, desta forma,
uma base de dados e, por
conseguinte, um índice, o qual
será apresentado ao usuário
por meio de uma interface
amigável.

Introdução aos Buscadores
Subsequentemente, a geração do
índice (Indexing) associa as palavras
presentes na página web ao
endereço URL (Uniform Resouce
Locator), gerando metadados que
serão tratados de acordo com o
algoritmo implementado no motor
de busca. Conforme a Battelle
(2006), o índice representa uma
enorme base de dados onde
encontram-se informações
importantes a respeito de diversos
sites na Web.
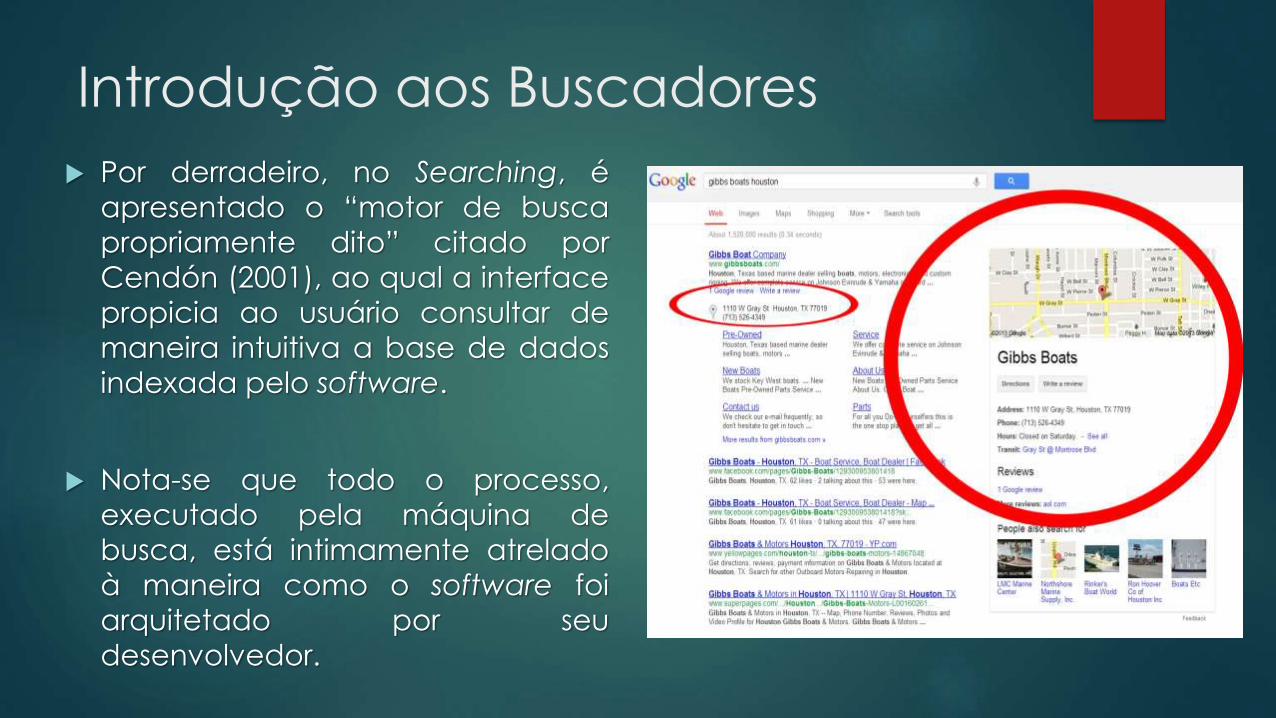
Introdução aos Buscadores
Por derradeiro, no Searching, é
apresentado o “motor de busca
propriamente dito” citado por
Cendón (2001), ao qual a interface
propicia ao usuário consultar de
maneira intuitiva a base de dados
indexada pelo software.
Nota-se que todo o processo,
executado pela máquina de
busca, está intimamente atrelado
à maneira como o software foi
arquitetado por seu
desenvolvedor.

Modelo e Problemática
Atualmente as ferramentas de busca são tratadas como deidades do
ciberespaço, detentoras e difusoras de todo o conhecimento, em sua
maioria oferecidos por grandes companhias como o Google, Yahoo e
Microsoft.
Cujos sistemas são
essencialmente
fechados, resultando
em uma tecnologia
de indexação e
classificação deveras
nebulosa aos usuários
deste serviço.

Modelo e Problemática
Ao utilizar buscadores
privados, não se pode
arguir quanta informação
será censurada,
bloqueada ou removida
do resultado, ficando este
à critério apenas da
entidade detentora do
software.
Caso o detentor da página web queira indexá-la por meio de um mecanismo
de busca, deverá aceitar as suas regras e termos de uso, assim como a sua
insubordinação, acarretará em punições severas ao website em questão, ou
seja, sua não indexação.

Modelo e Problemática
“Buscas efetuadas mediante mecanismos
privados são, fundamentalmente, tendenciosas,
seja por políticas organizacionais, privilégios a
patrocinadores do serviço ou determinações
judiciais”
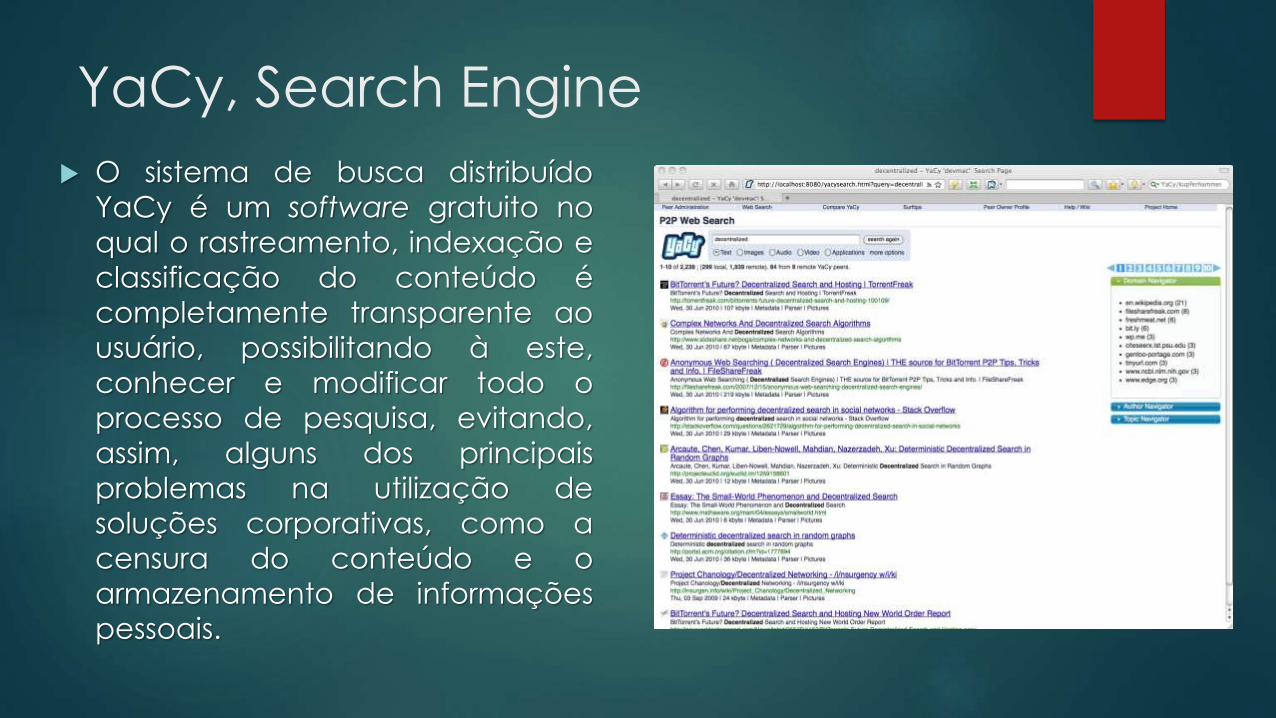
YaCy, Search Engine
O sistema de busca distribuído
YaCy é um software gratuito no
qual o rastreamento, indexação e
classificação do conteúdo é
completamente transparente ao
usuário, possibilitando à este,
conhecer e modificar todo o
processo de pesquisa, evitando,
assim, alguns dos principais
problemas na utilização de
soluções corporativas, como a
censura do conteúdo e o
armazenamento de informações
pessoais.

YaCy, Search Engine
Para os desenvolvedores do
projeto (YaCy, 2011), este
software possui como diferencial a
utilização de um modelo baseado
na tecnologia par-a-par (P2P)
para transferência de arquivos.
Modelos de transmissão
fundamentados na tecnologia de
redes P2P proporcionam uma
capacidade híbrida, em que
cada nó (usuário) poderá atuar
tanto como cliente, quanto como
servidor.

YaCy, Search Engine
É notável a semelhança entre a arquitetura citada e o rizoma de Deleuze.
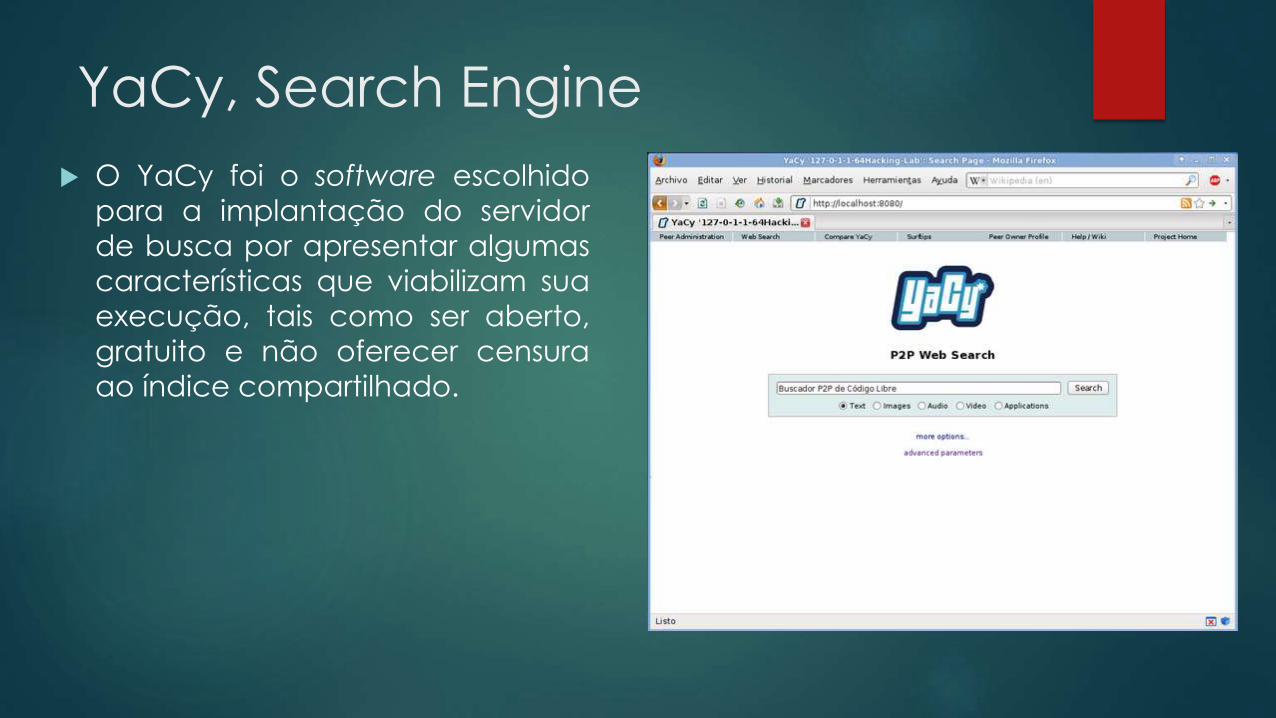
YaCy, Search Engine
O YaCy foi o software escolhido
para a implantação do servidor
de busca por apresentar algumas
características que viabilizam sua
execução, tais como ser aberto,
gratuito e não oferecer censura
ao índice compartilhado.

YaCy, Search Engine
Trata-se de um mecanismo de
busca com a funcionalidade de
crawler, o que proporciona a
capacidade de obter todas as
páginas web publicadas pela
revista apontada.
Entretanto, para que essa função
trabalhe de maneira apropriada
são necessárias configurações
específicas no software.

YaCy, Search Engine
Para usufruir dos
benefícios do software
são necessárias
algumas configurações,
conforme descrito a
seguir.
Inicialmente é
necessário escolher o
perfil de operação do
software

YaCy, Search Engine
O propósito de uso do software é fator determinante nessa escolha, que
apresenta 3 opções principais de funcionamento, conforme segue:
Community-based web search: insere o servidor YaCy recém criado em uma rede
global livre de censura denominada freeworld, replicando seu índice e
disponibilizando-o para consultas futuras;
Search portal for your own web pages: apresenta em sua base de dados apenas
conteúdo indexado pelo usuário, cujo funcionamento ocorre de maneira
independente à rede de busca global (freeworld). É comumente utilizado na criação
de portais de busca orientados por assunto;
Intranet Indexing: empregado na concepção de buscadores para intranet, podetrabalhar de maneira integrada com servidores de troca de arquivo, o que beneficia
organizações que possuam grande quantidade de documentos dispostos de maneira
não estruturada.

YaCy, Search Engine
Admite-se também a possibilidade de
modificar a ordem dos resultados
buscados, conferindo ênfase
diferenciada às palavras com
ocorrência em trechos distintos de
um documento.
A figura ao lado, apresenta o sistema
de ranking, no qual é possível
observar uma atribuição numérica
em seus campos. Cada opção possui
influência direta na ordenação do
resultado pesquisado.

Apache Solr
Solr é um projeto Open
Source de um servidor de
buscas de alta performance
do projeto Apache Lucene. É
desenvolvido em Java e
utiliza o Lucene Core como
base para indexação e
busca, além de fornecer APIs
baseadas em REST o que lhe
permite ser integrado a
praticamente qualquer
linguagem de programação.

Apache Solr

Apache Solr
Buscas podem ser
executadas através de
query’s XML através do
próprio YaCy.
Essa Opção pode ser
acessada na aba “Solr
Default Core”
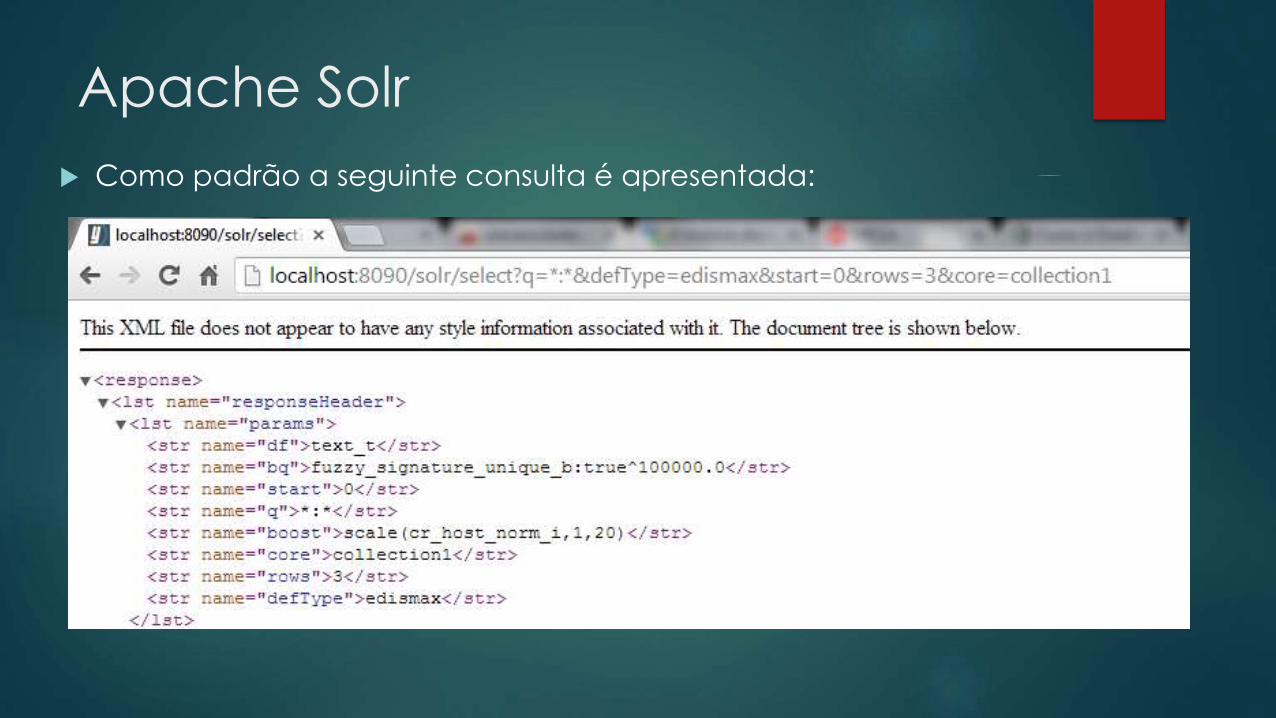
Apache Solr
Como padrão a seguinte consulta é apresentada:
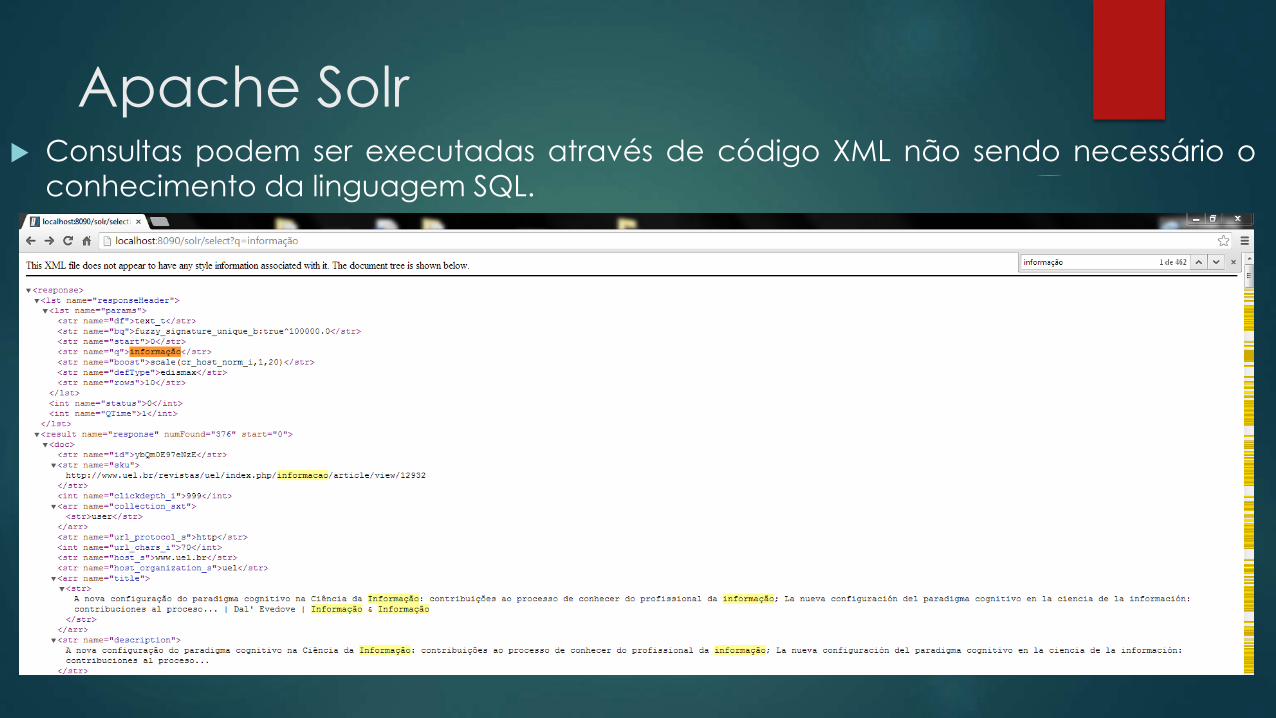
Apache Solr Consultas podem ser executadas através de código XML não sendo necessário o
conhecimento da linguagem SQL.

Atividade PráticaInteração com a ferramenta YaCy
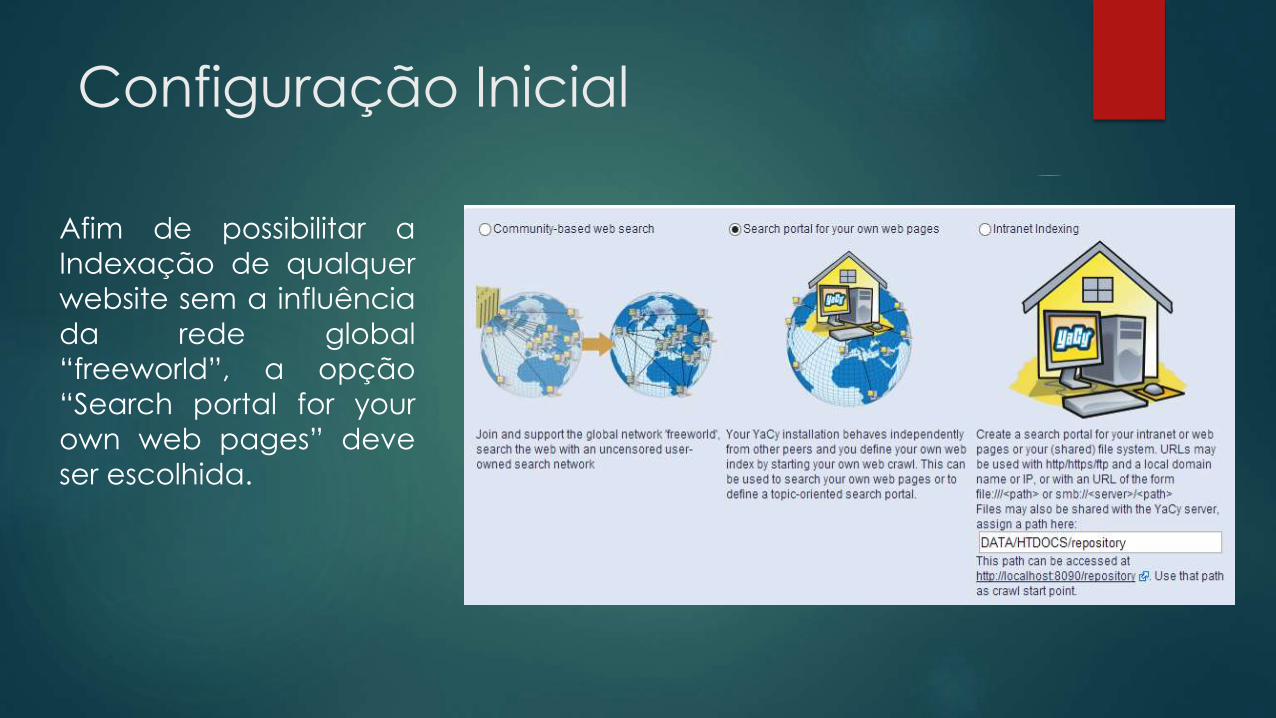
Configuração Inicial
Afim de possibilitar a
Indexação de qualquer
website sem a influência
da rede global
“freeworld”, a opção
“Search portal for your
own web pages” deve
ser escolhida.
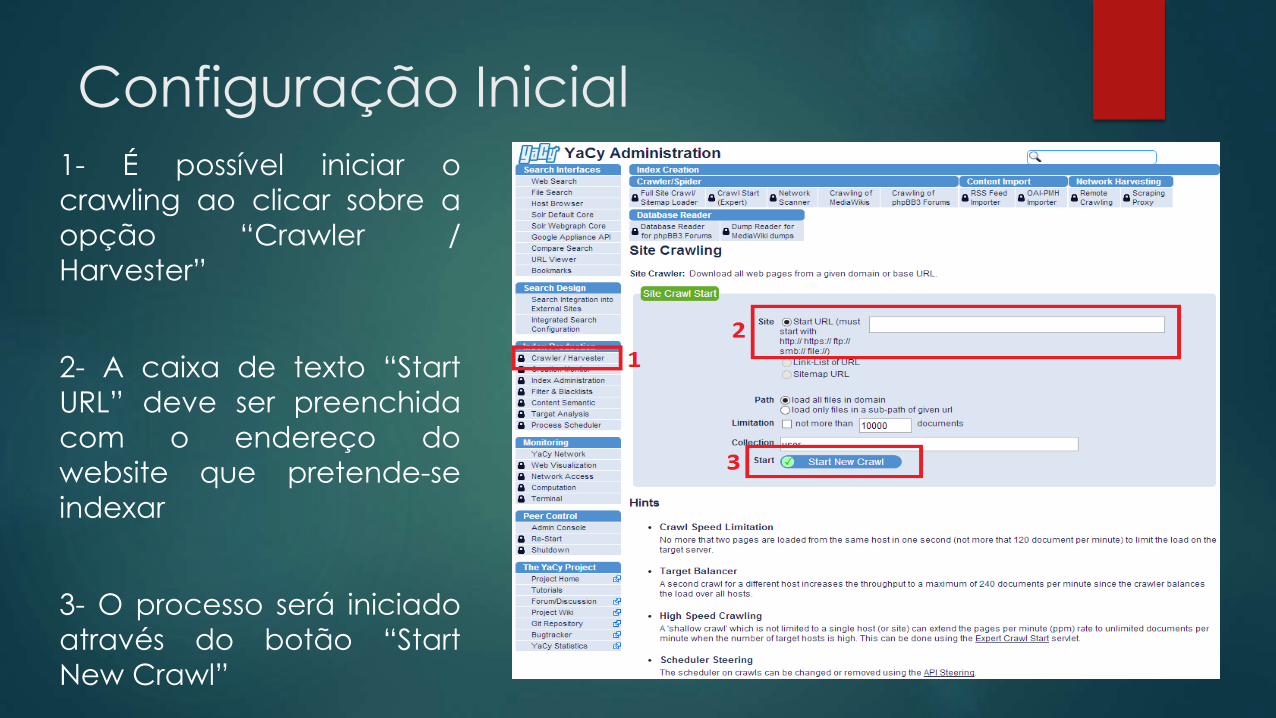
Configuração Inicial
1- É possível iniciar o
crawling ao clicar sobre a
opção “Crawler /
Harvester”
2- A caixa de texto “Start
URL” deve ser preenchida
com o endereço do
website que pretende-se
indexar
3- O processo será iniciado
através do botão “Start
New Crawl”
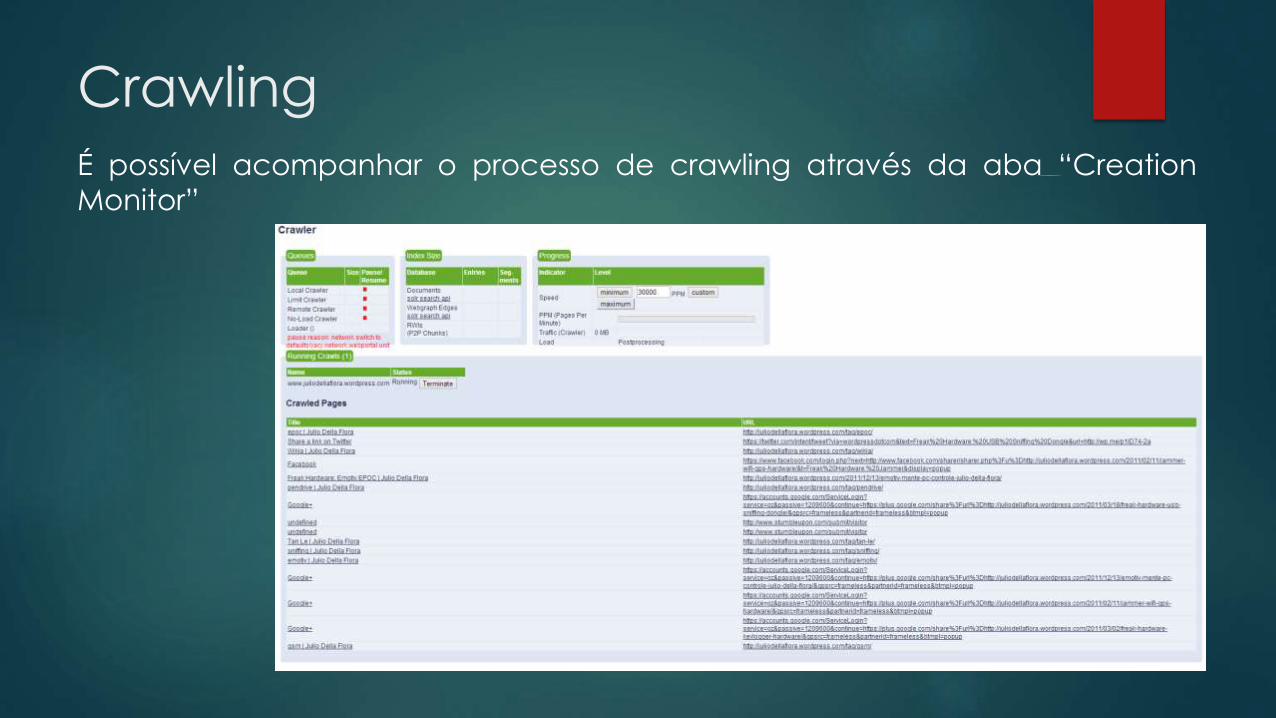
Crawling
É possível acompanhar o processo de crawling através da aba “Creation
Monitor”
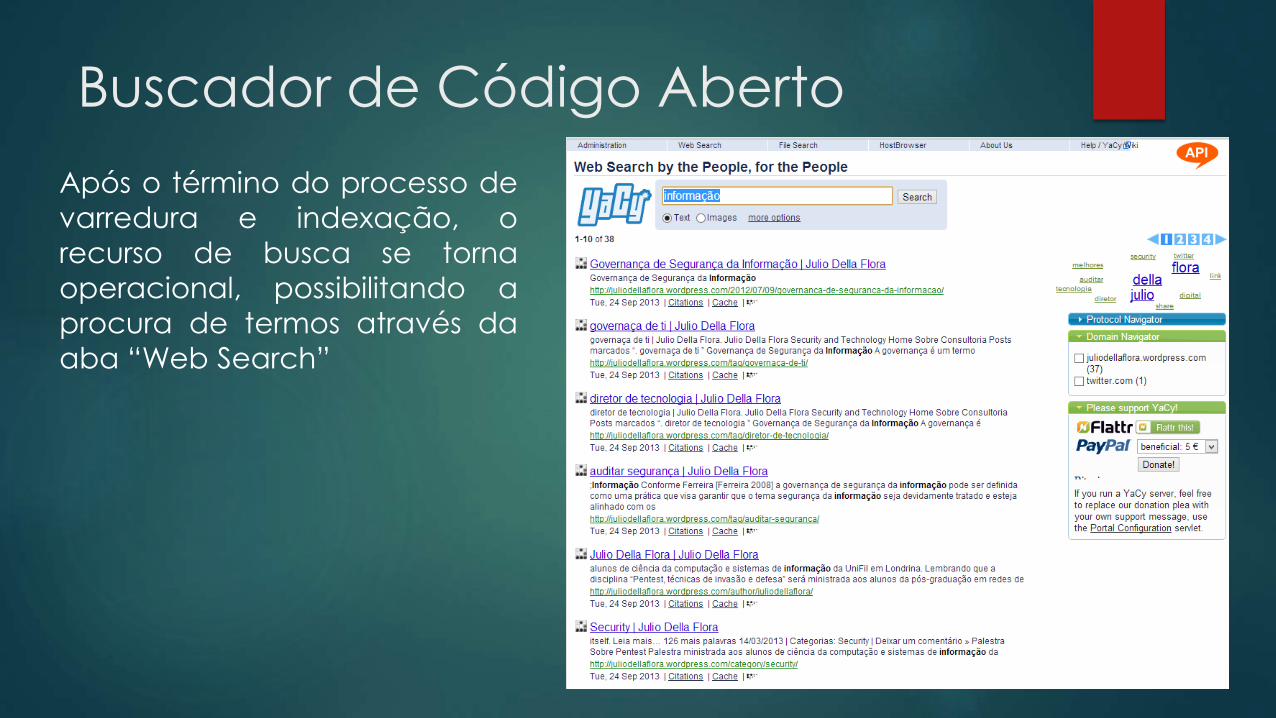
Buscador de Código Aberto
Após o término do processo de
varredura e indexação, o
recurso de busca se torna
operacional, possibilitando a
procura de termos através da
aba “Web Search”
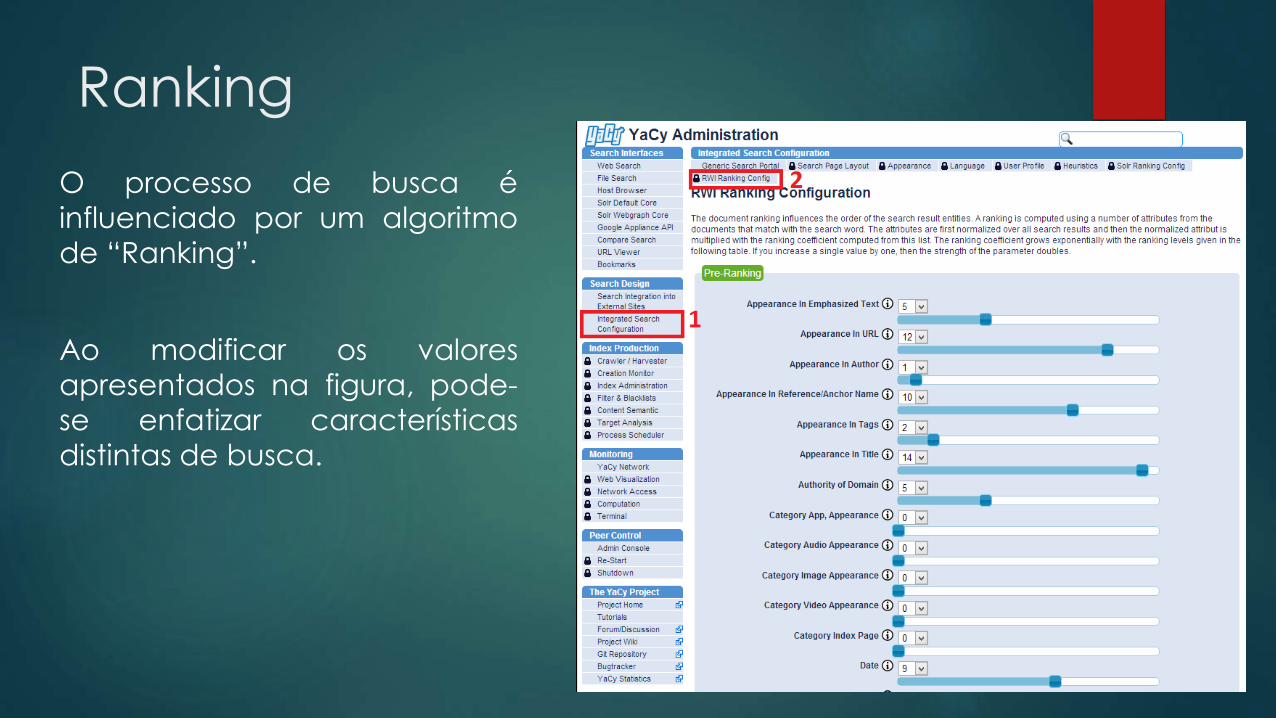
Ranking
O processo de busca é
influenciado por um algoritmo
de “Ranking”.
Ao modificar os valores
apresentados na figura, pode-
se enfatizar características
distintas de busca.
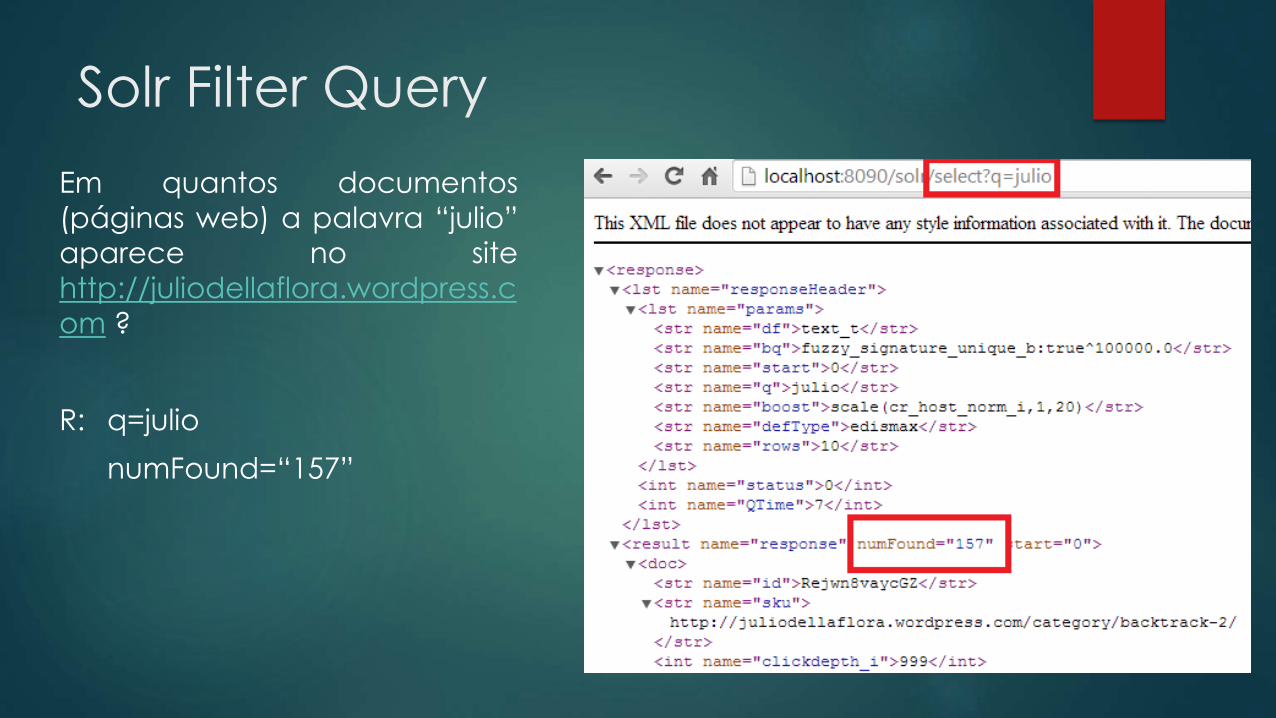
Solr Filter Query
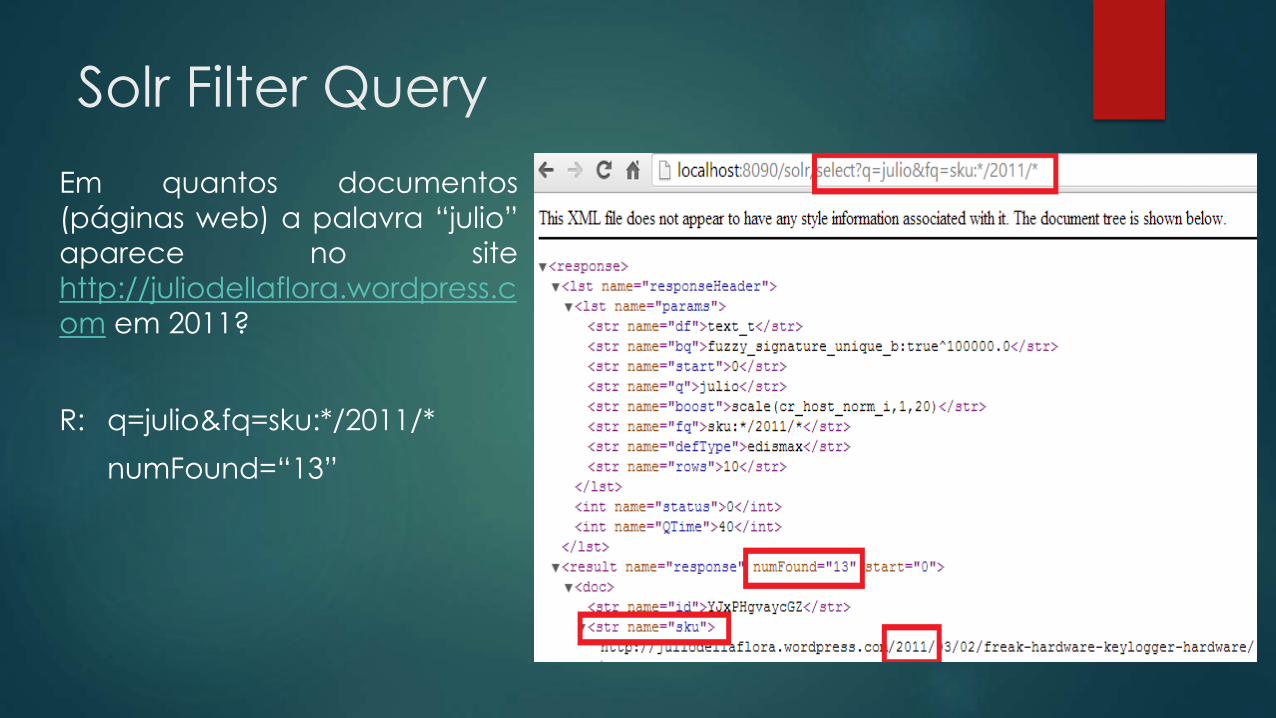
Em quantos documentos
(páginas web) a palavra “julio”
aparece no site
http://juliodellaflora.wordpress.c
om ?
R: q=julio
numFound=“157”
Solr Filter Query
Em quantos documentos
(páginas web) a palavra “julio”
aparece no site
http://juliodellaflora.wordpress.c
om em 2011?
R: q=julio&fq=sku:*/2011/*
numFound=“13”
Solr Filter Query
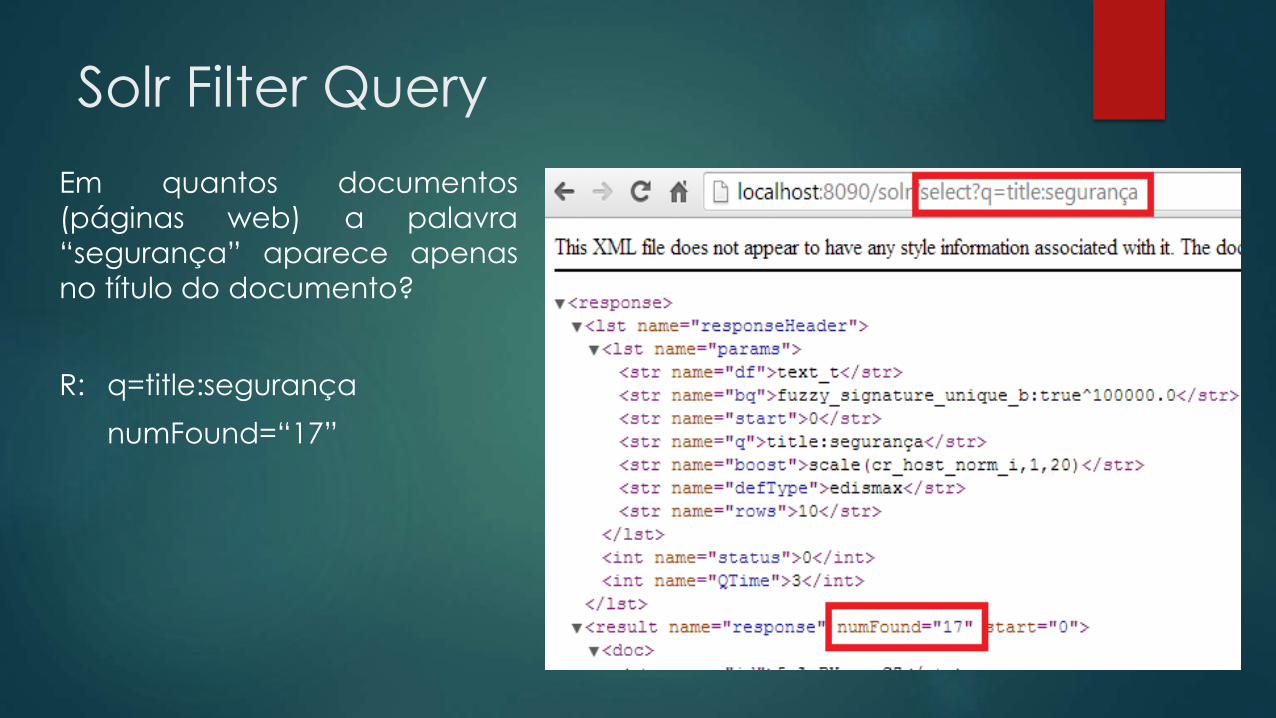
Em quantos documentos
(páginas web) a palavra
“segurança” aparece apenas
no título do documento?
R: q=title:segurança
numFound=“17”
Solr Filter Query
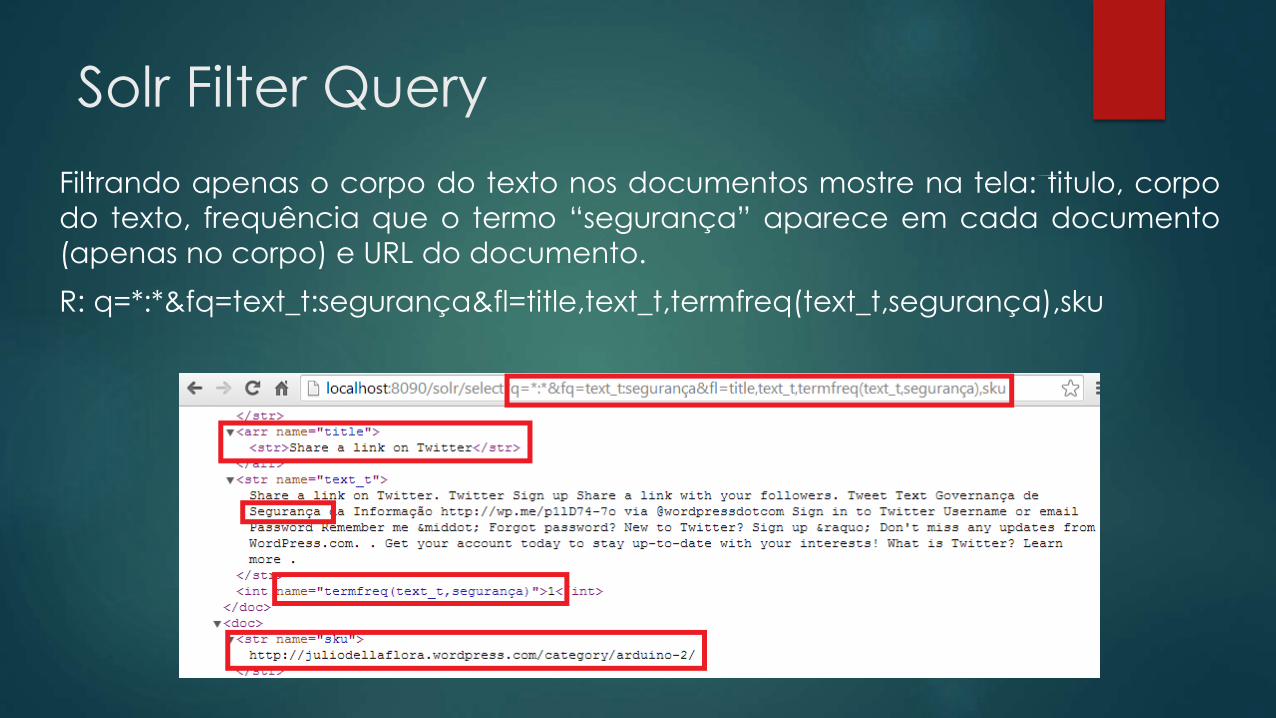
Filtrando apenas o corpo do texto nos documentos mostre na tela: titulo, corpo
do texto, frequência que o termo “segurança” aparece em cada documento
(apenas no corpo) e URL do documento.
R: q=*:*&fq=text_t:segurança&fl=title,text_t,termfreq(text_t,segurança),sku
![[PPT]Organização como sistemas abertospaginas.fe.up.pt/~ci03051/Homepage/Bib. Barcelos.ppt · Web viewSistema Aberto/Sistema Fechado Sistema aberto Mecanismo de feedback que permite](https://img.pdfslide.tips/doc/110x75/5c17677209d3f2564e8bfa54/pptorganizacao-como-sistemas-ci03051homepagebib-barcelosppt-web-viewsistema.jpg)















![Dialogo Aberto[1]](https://img.pdfslide.tips/doc/110x75/5571f83749795991698ce91a/dialogo-aberto1.jpg)













