Embed Size (px)
Citation preview

ここから始める情報処理~機械学習(とその周辺)編~
Toshihiko Yamasaki
Associate Professor,Department of Information and Communication Engineering,
Graduate School of Information Science and Technology,The University of Tokyo

Today’s agenda
How can we start?
Which algorithm should you choose?
How can you find real data?
SVMを使い倒す
4

Today’s agenda
How can we start?
Which algorithm should you choose?
How can you find real data?
SVMを使い倒す
5

Tools: Python
6
http://scikit-learn.org/
Tools: MATLAB
7
http://jp.mathworks.com/products/statistics/

MATLAB Student Suite
8
http://jp.mathworks.com/academia/student_version/

Tools: R
9https://www.r-project.org/http://www.kdnuggets.com/2015/06/top-20-r-machine-learning-packages.html

Tools: Weka
10

No available PC? Use cloud computers
Such as Amazon EC2, Microsoft Azure, etc…
Virtualized PC on the Internet
「ゼロから始めるクラウドコンピューティング」
11http://aws.amazon.com/jp/ec2/https://azure.microsoft.com/ja-jp/

Today’s agenda
How can we start?
Which algorithm should you choose?
How can you find real data?
SVMを使い倒す
12

Which ML algorithm is better?
13
[Caruana, ICML06]

In short
BST-DT > RF > BAG-DT > SVMs > ANN > KNN > BST-STMP > DT > LOGREG > NB
Boosted Trees:
RF + boosting technique
Note!!
Feature dims. were 10-100.
RF usually requires 10xdim vectors for training
14
[Caruana, ICML06]

Random Forests and Boosted Trees
15
www.habe-lab.org/habe/RFtutorial/SSII2013_RFtutorial_Slides.pdfhttp://www.slideshare.net/HitoshiHabe/ss-58784309
https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
RF
Boosted Trees
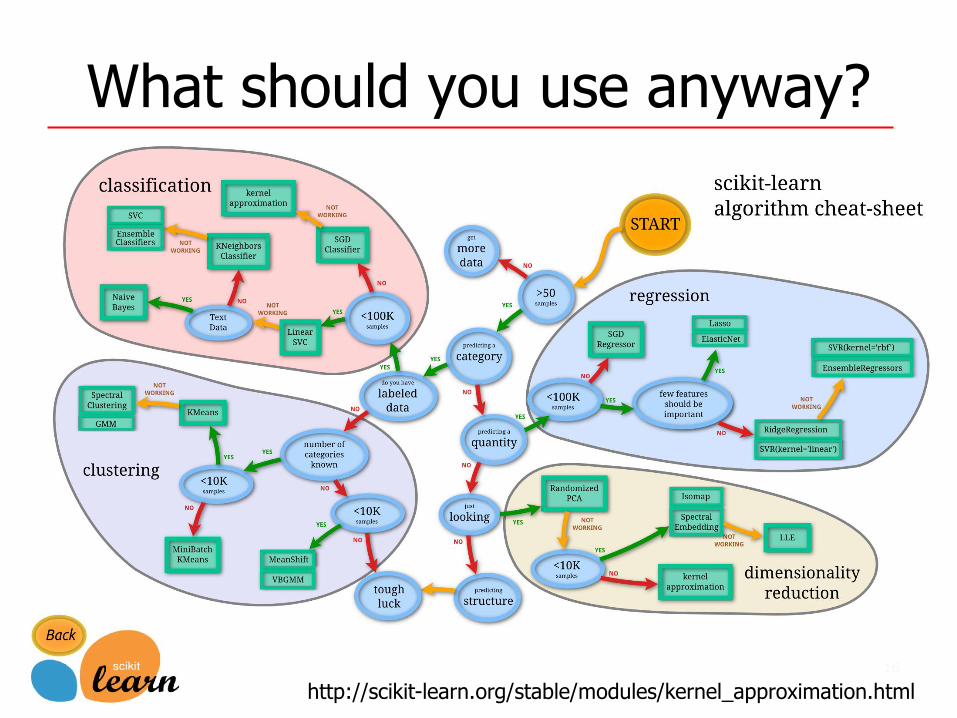
What should you use anyway?
16
http://scikit-learn.org/stable/modules/kernel_approximation.html

Today’s agenda
How can we start?
Which algorithm should you choose?
How can you find real data?
SVMを使い倒す
17
If you want real data to play with
18
https://www.kaggle.com/

Today’s agenda
How can we start?
Which algorithm should you choose?
How can you find real data?
SVMを使い倒す
19

How do you usually use SVM?
Through Python/Matlab/R/…
In many cases, you are using libSVM
By downloading binary code
Why don’t we download a source code?
20http://www.csie.ntu.edu.tw/~cjlin/libsvm/

Which kernel you should use?
Gaussian kernel is the best in many cases
But it takes a lot of time
Linear kernel performs as well as Gaussian
When the data size is large
When the feature dimension is large
You may also consider using liblinear
What else?
You can use your own kernel
21

Scale the data
22http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f407
Sometimes scaling helps

Optimize the parameters
For binary or MATLAB, use grid.py/grid.m
It tries to optimize C and g for Gaussian kernel
You should check the source code
Use n-cross validation
Sometimes, make train, validation, test data
23http://www.csie.ntu.edu.tw/~cjlin/libsvm/

Scikit-learn is easier
24
http://qiita.com/SE96UoC5AfUt7uY/items/c81f7cea72a44a7bfd3a

Unbalanced data
25http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f410
What if you have unbalance data?
For example, +1: 1,000 items, -1: 10,000 items
SVM can achieve 91% accuracy just by saying “-1”

Non numerical data
libSVM can handle only numerical data
× Sun:0, Mon: 1, Tue: 2(There is no meaning in magnitude relation)
Change to Categorical/one-hot
Sun: (1, 0, 0, 0…)
Mon: (0, 1, 0, 0…)
Tue: (0, 0, 1, 0…)
26

Missing data?
There is no golden rule
Eliminate such vectors
Use average or median value
Use the most frequently appearing value
27

Use OpenMP
28http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f432
As I introduced in my first lecture, it is very easy

SVM (except for linear kernel) is slow
29
http://mklab.iti.gr/project/GPU-LIBSVM

30*If you do not have GPUs, just use cloud computers

Decision value
31http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f415

You can know probability
You can be probability instead ofobtaining +1/-1 labels or continuous values
Use “–b 1” option
It is useful for further processing
32

Look at the model file
When using a linear kernel or liblinear
Weight vector w will be saved
You can also know support vectors
33
http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f433

You can use your own kernel
34README in libSVM
In some cases, using other kernels is recommended
c2, histogram intersection, etc…





























