Embed Size (px)
Citation preview

ULM-1
Understanding Language
by MachinesThe Borders of Ambiguity
Ruben Izquierdo
http://rubenizquierdobevia.com

Structure Part I
The ULM-1 project
Part II Error analysis on WSD
Part III Using Background Information to Perform WSD
Part IV What is next?
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 2

Who am I? Ruben Izquierdo Bevia
Computer Science, Alicante, Spain 2004
2004-2011 researcher at the University of Alicante
September 2010, Alicante
Phd. Thesis: An approach to Word Sense Disambiguation based on Supervised Machine Learning and Semantic Classes
Sept 2011 Sept 2012
DutchSemCor project (Tilburg and VU universities, NL)
Sept 2012 Sept 2014
Opener project (VU University, NL)
Sept 2014
ULM1 Spinoza project
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 3

Part I
Understanding Language by
Machines
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 4

Understanding Languages by
Machines
NWO (Netherlands Organization for Scientific
Research)
Spinoza Price
Highest Dutch award in science for top researchers with
international reputation
Piek Vossen was one of the three winners in 2013
Some money for research 4 ULM projects
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 5

Understanding Languages by
Machines
Develop computer models that assign deeper meaning
to language and approximates human understanding
Use the models to automatically read and understand
texts
Words and texts are highly ambiguous
Get a better understanding of the scope and complexity
of this ambiguity
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 6

Understanding Languages by
Machines ULM-1: The borders of ambiguity
Word relations and ambiguity
Define the problem and find an optimal solution
ULM-2: Word, Concept, Perception and Brain
Relate words and meanings to perceptual data and brain activation patterns
ULM-3: From timelines to storylines
Interpretation of words and our way of interacting with the changing world
Structure these changes as stories along explanatory motivations
ULM-4: A quantum model of text understanding
Technical model
Move from pipeline approaches which take early decisions to a model there the final interpretation is carried out by high-order semantic and contextual models
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 7

Understanding Languages by
Machines ULM-1: The borders of ambiguity
Word relations and ambiguity
Define the problem and find an optimal solution
ULM-2: Word, Concept, Perception and Brain
Relate words and meanings to perceptual data and brain activation patterns
ULM-3: From timelines to storylines
Interpretation of words and our way of interacting with the changing world
Structure these changes as stories along explanatory motivations
ULM-4: A quantum model of text understanding
Technical model
Move from pipeline approaches which take early decisions to a model there the final interpretation is carried out by high-order semantic and contextual models
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 8

ULM-1: The Borders of
Ambiguity
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 9
Piek Vossen Marten Postma Ruben Izquierdo

Word Sense DisambiguationWSD “The problem of computationally determining which ‘sense’ of a word is activated by the use of that word in a particular context” (Agirre & Edmonds, 2006)
Our1 project14 looks14 into1 breaking60 the1 borders10 of1ambiguity1, for1 which1 the1 queen12 piece18 is13 an1 example1
1.981.324.800 interpretations !!!
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 10

Classical Approaches Supervised approaches
Require annotated data
Problems with domain adaptation
Knowledge based
Dependent on the resources
Unsupervised approaches
Low performance
Require large amount of data
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 11

Still UnsolvedWSD is still considered to be “unsolved”
Competition Year Type Baseline Best F1
SensEval2 2001 all-words 57.0 69.0 (Sup)
SensEval3 2004 All-words 60.9 65.1 (Sup)
SemEval1 2007 All-words (task 17) 51.4 59.1 (Sup)
SemEval2 2010 All-words on specific
domain
50.5 56.2 (Kb)
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 12

General Trends Look at WSD as a purely classification problem
Focus more on the low level algorithm than on the WSD problem itself
Poor representation of the context
Following the idea: “the more features, the better performance”
Usually Bag-of-words features
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 13

… but … what about the
discourse and background
information?
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 14

Discourse and Background
Knowledge
The winner will walk away with $1.5 million
source: http://www.southafrica.info/news/sport/golf- nedbank-
210613.htm#.VEAWkYusVW8
Creation time: 21 June 2013
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 15

Discourse and Background
Knowledge
The winner will walk away with $1.5 million
source: http://www.southafrica.info/news/sport/golf- nedbank-
210613.htm#.VEAWkYusVW8
Creation time: 21 June 2013
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 16
Winner the contestant who wins the contest (wordnet
synset ENG30-10782940-n)

Discourse and Background
KnowledgeThe winner will walk away with $1.5 million
source: http://www.southafrica.info/news/sport/golf- nedbank-
210613.htm#.VEAWkYusVW8
Creation time: 21 June 2013
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 17
The winner won the Nedbank
Golf Challengue

Discourse and Background
KnowledgeThe winner will walk away with $1.5 million
source: http://www.southafrica.info/news/sport/golf- nedbank-
210613.htm#.VEAWkYusVW8
Creation time: 21 June 2013
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 18
The winner was Thomas Bjørn
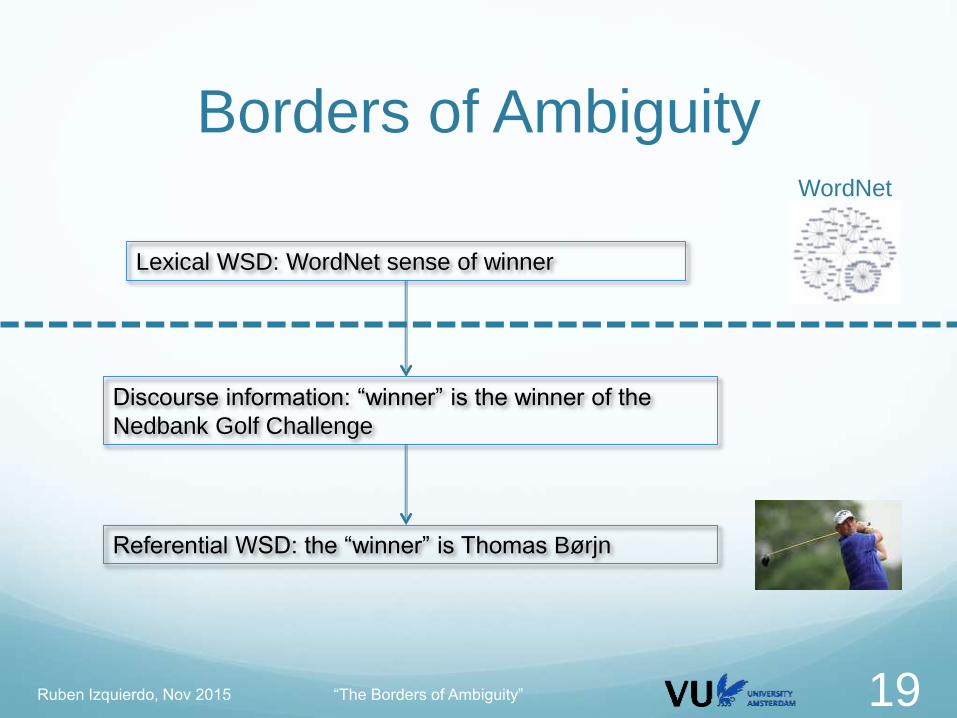
Borders of Ambiguity
Lexical WSD: WordNet sense of winner
Discourse information: “winner” is the winner of the
Nedbank Golf Challenge
Referential WSD: the “winner” is Thomas Børjn
WordNet
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 19

The Role of Background
knowledge
“One of the best moves by Gary Kasparov which includes a queen sacrifice…”
Source: http://www.chess.com/forum/view/chess-players/kasparov-queen-sacrifice
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 20

The Role of Background
knowledge
“One of the best moves by Gary Kasparov which includes a queen sacrifice…”
Source: http://www.chess.com/forum/view/chess-players/kasparov-queen-sacrifice
STATE OF THE ART SYSTEM
It-makes-sense WSD system (Zhong and Ng, 2010)
• 36% queen.n.1: the only fertile female in a colony of social insects such
as bees, ants or termites.
• 34% queen.n.2: a female sovereign ruler
• 30% queen.n.3: the wife or widow of a king
• …..
• 0% queen.n.6: the most powerful chess piece
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 21

The Role of Background
knowledge A very naïve approach
Find “Gary Kasparov” as an entity and link it to Wikipedia
Compare textual overlapping of:
Wikipage Queen_chessWikipage Gary_Kasparov
170 overlapping types
Wikipage Queen_regnantWikipage Gary_Kasparov
88 overlapping types
Examples of matching words Queen_chess – G. Kasparov
board opening matches game press championship rules
chess player king queen
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 22
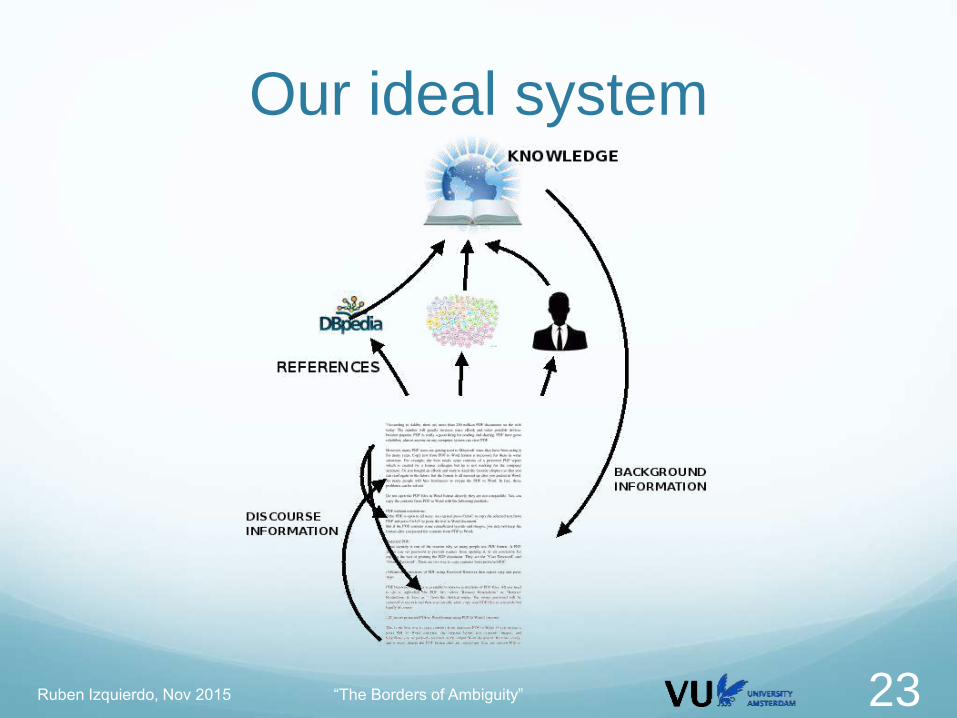
Our ideal system
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 23

Part II
Error Analysis of WSD
systems
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 24
Piek Vossen Marten Postma Ruben Izquierdo
MotivationWord Sense Disambiguation is still an unsolved problem
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 25

Hypothesis Little attention has been paid to the problem
WSD as just 1 problem
The context is not being exploited properly
Systems rely too much on the Most Frequent Sense
It is indeed the baseline, very hard to overcome
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 26

Goal of the Analysis Perform error analysis of the participant systems on
previous WSD evaluations to prove our hypothesis
Senseval-2: all-words task
Senseval-3: all-words task
Semeval2007: all-words task (#17)
Semeval2010: all-words on specific domain (#17)
Semeval2013: multilingual all-words WSD and entity
linking (#12)
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 27

Analysis Calculate the performance of the systems according to
different criteria of the gold data
Monosemous / polysemous
Part-of-speech
Most Frequent Sense vs. Non MFS
Polysemy class
Frequency class
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 28
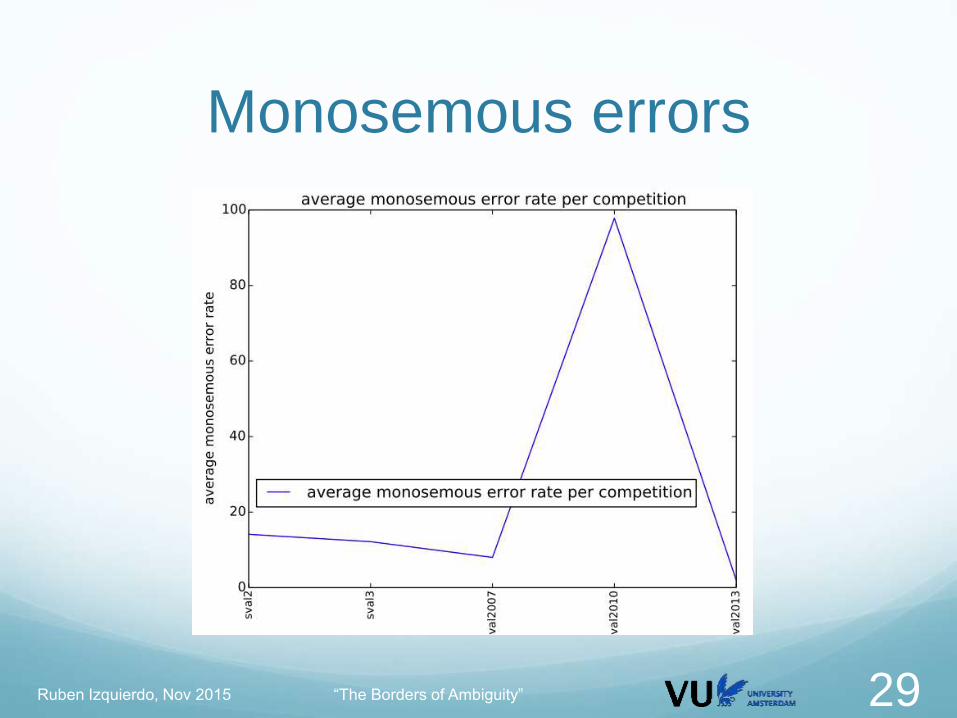
Monosemous errors
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 29

Monosemous Errors
Competition Monosemou
s
Wrong Examples
Senseval2 499 (20.9%) 37.5% gene.n (suppressor_gene.n), chance.a
(chance.n) next.r (next.a)
Senseval3 334 (16.6%) 44.1% Datum.n (data.n) making.n (make.v)
out_of_sight (sight)
Semeval2007 25 (5.5%) 11.1% get_stuck.v, lack.v, write_about.v
Semeval2010 31 (2.2%) 97.9% Tidal_zone.n pine_marten.n roe_deer.n
cordgrass.n
Semeval2013
(lemmas)
348 (21.1%) 1.9% Private_enterprise, developing_country,
narrow_margin
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 30
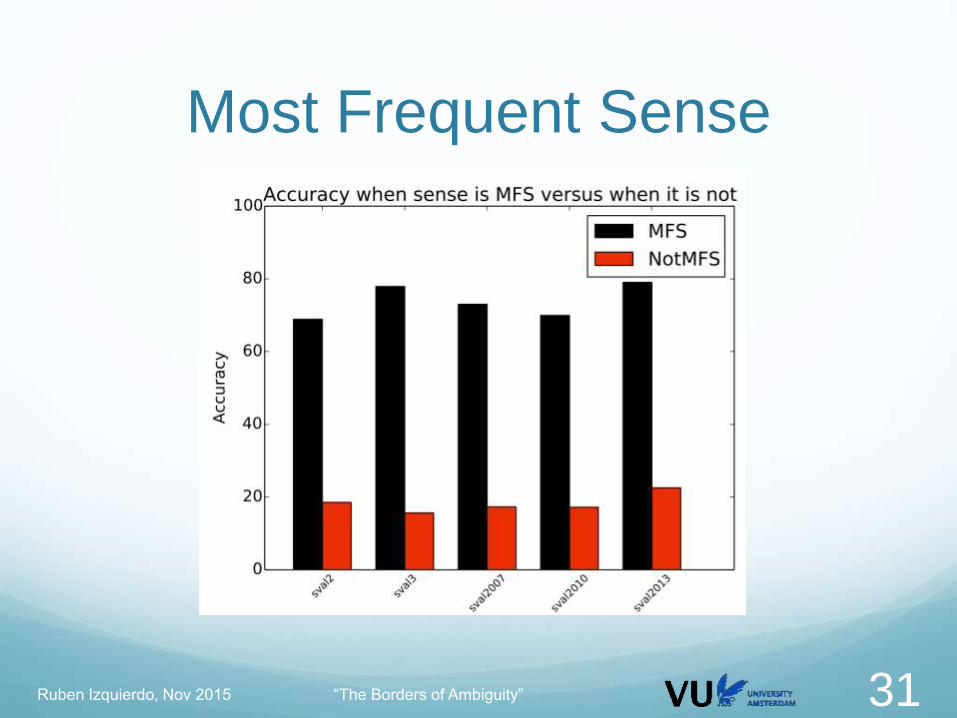
Most Frequent Sense
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 31

Most Frequent Sense When the correct sense is NOT the most frequent
sense
Systems still assign mostly the MFS
Senseval2
799 tokens are not MFS
84% systems still assign the MFS
Most “failed” words due to MFS bias
Senseval2, senseval3
Say.v find.v take.v have.v cell.n church.n
Semeval2010
Area.n nature.n connection.n water.n population.n
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 32
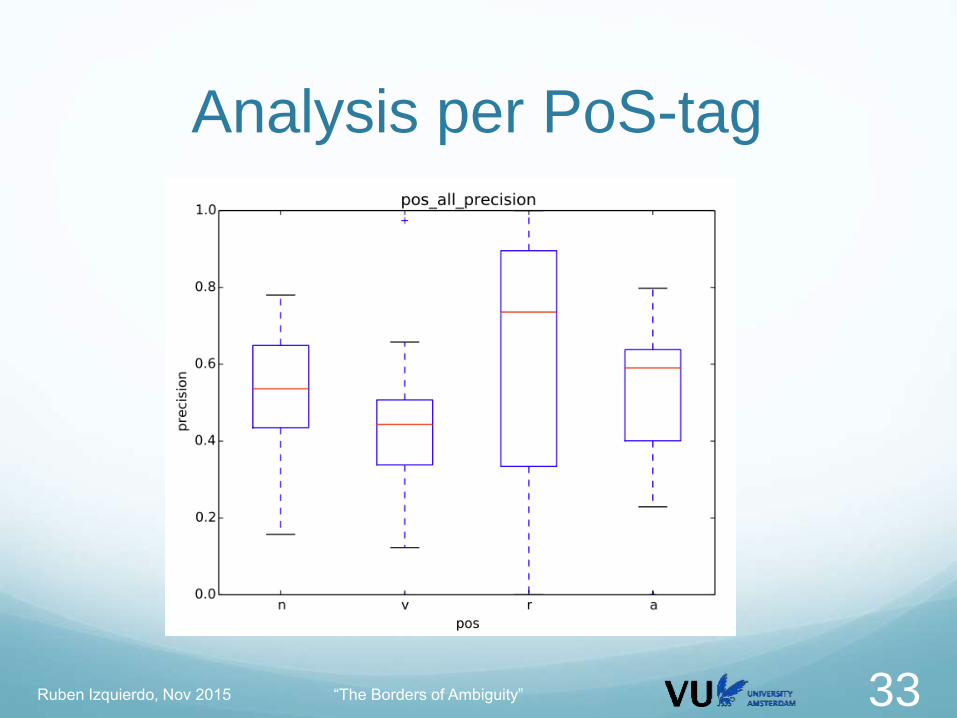
Analysis per PoS-tag
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 33
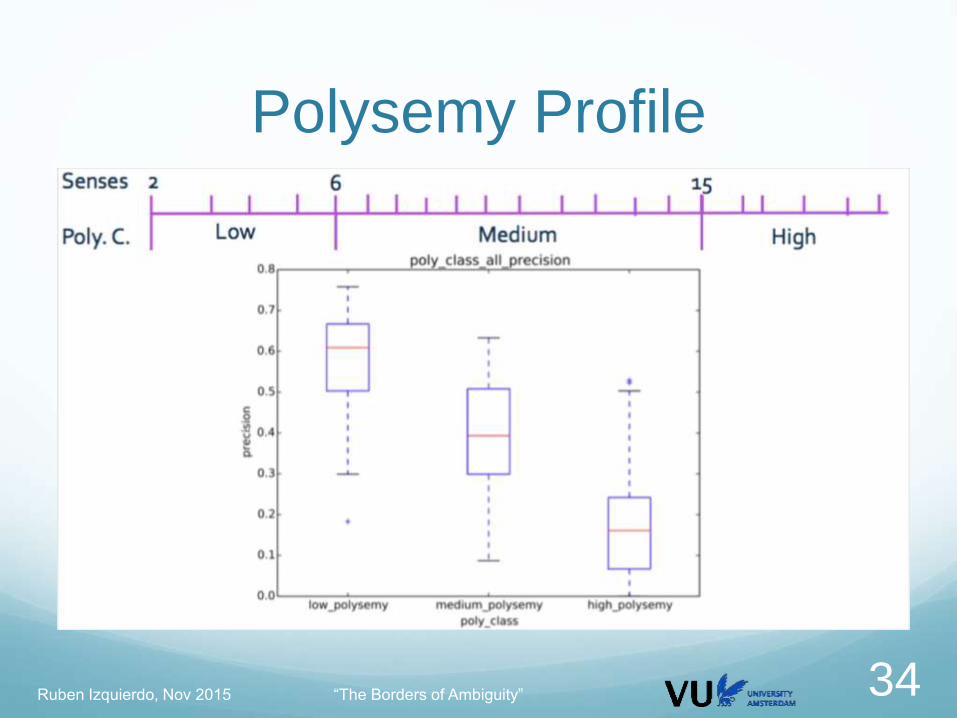
Polysemy Profile
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 34

Frequency Class
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 35

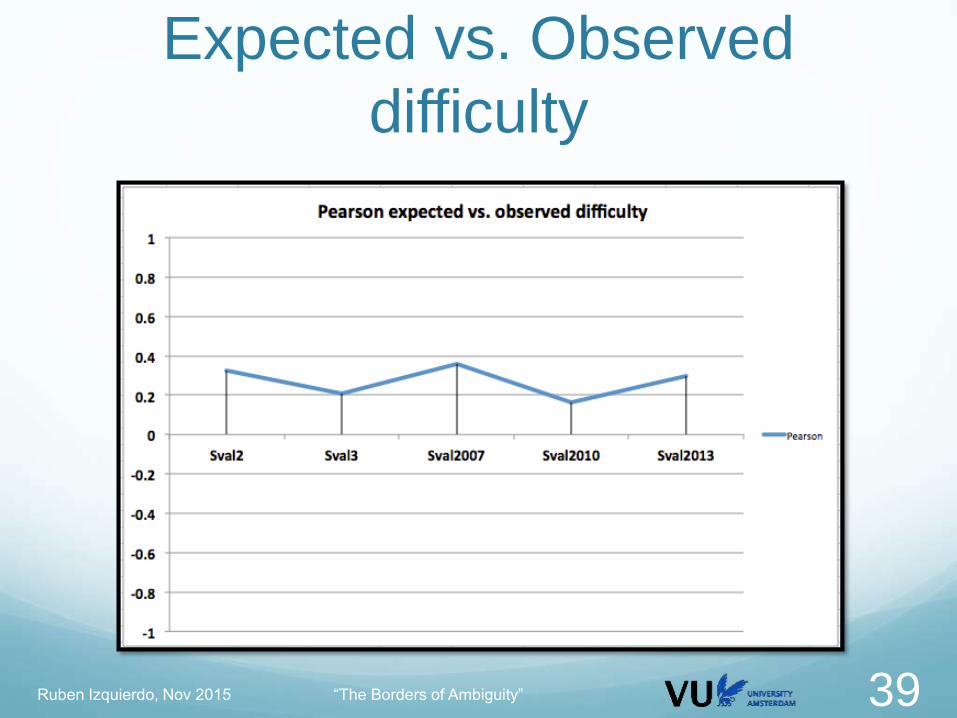
Expected vs. Observed
difficulty Calculate per sentence
The “expected” difficulty
Average polysemy, sentence length, average word length
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 36
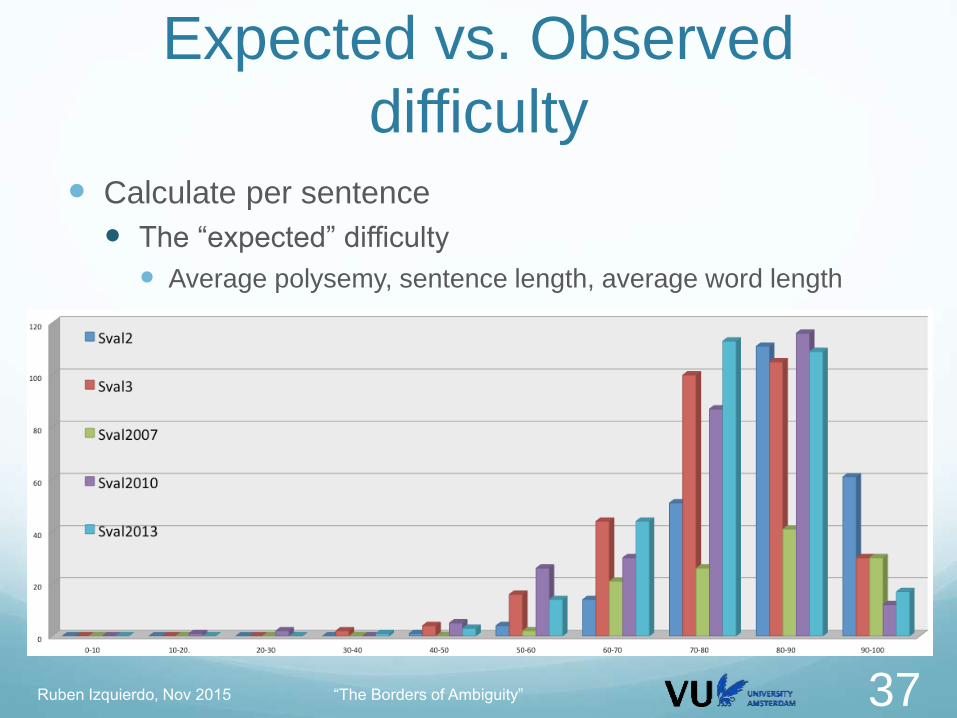
Expected vs. Observed
difficulty Calculate per sentence
The “expected” difficulty
Average polysemy, sentence length, average word length
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 37

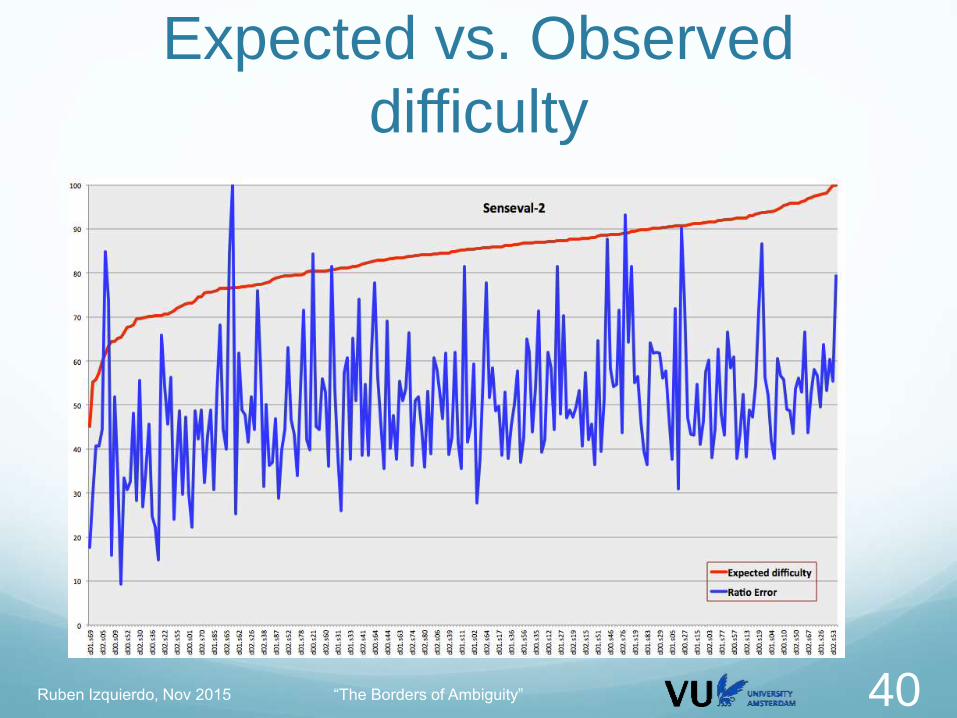
Expected vs. Observed
difficulty Calculate per sentence
The “expected” difficulty
Average polysemy, sentence length, average wor length
The “observed” difficulty
From the real participant outputs, average error rate
We could expect:
harder sentences higher error rate
easier sentences lower error rate
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 38
Expected vs. Observed
difficulty
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 39
Expected vs. Observed
difficulty
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 40
Expected vs. Observed
difficulty
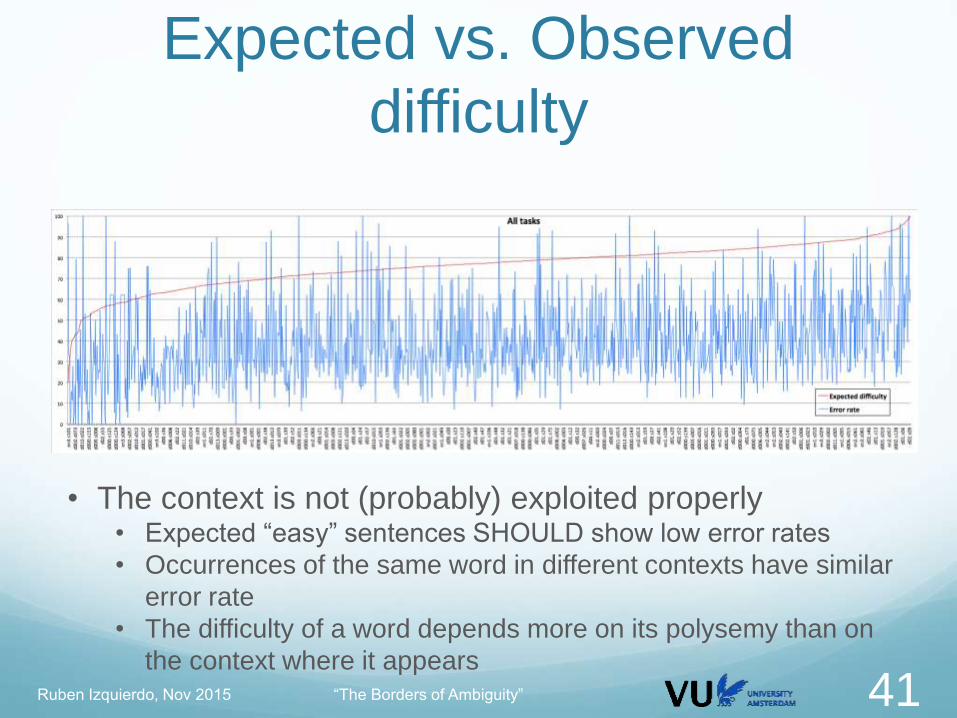
• The context is not (probably) exploited properly • Expected “easy” sentences SHOULD show low error rates
• Occurrences of the same word in different contexts have similar
error rate
• The difficulty of a word depends more on its polysemy than on
the context where it appearsRuben Izquierdo, Nov 2015 “The Borders of Ambiguity” 41
WSD Corpora http://github.com/rubenIzquierdo/wsd_corpora
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 42
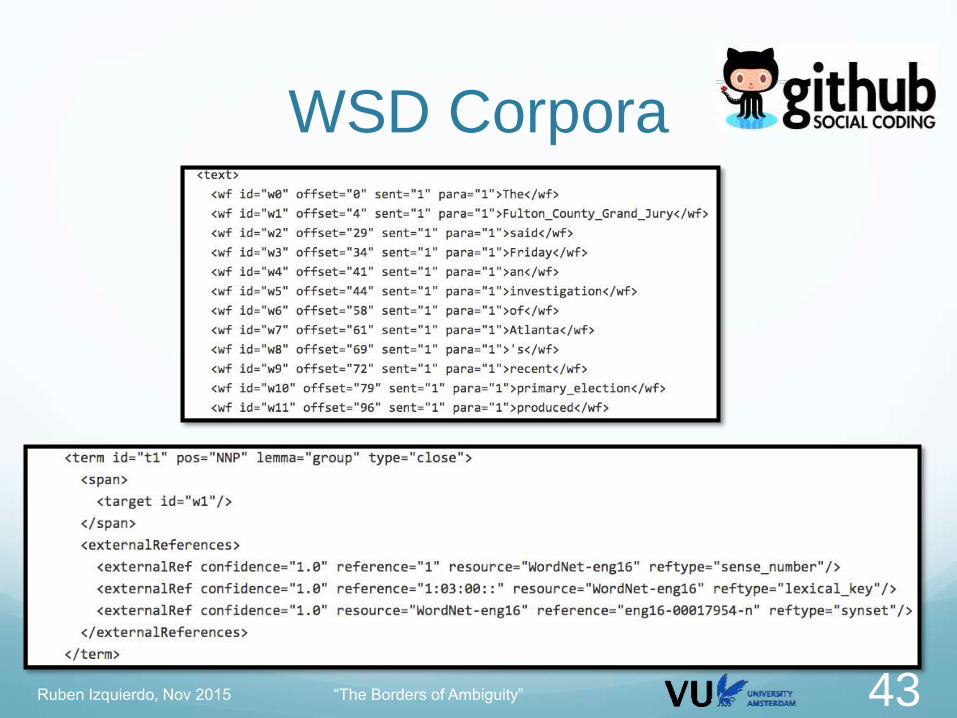
WSD Corpora
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 43
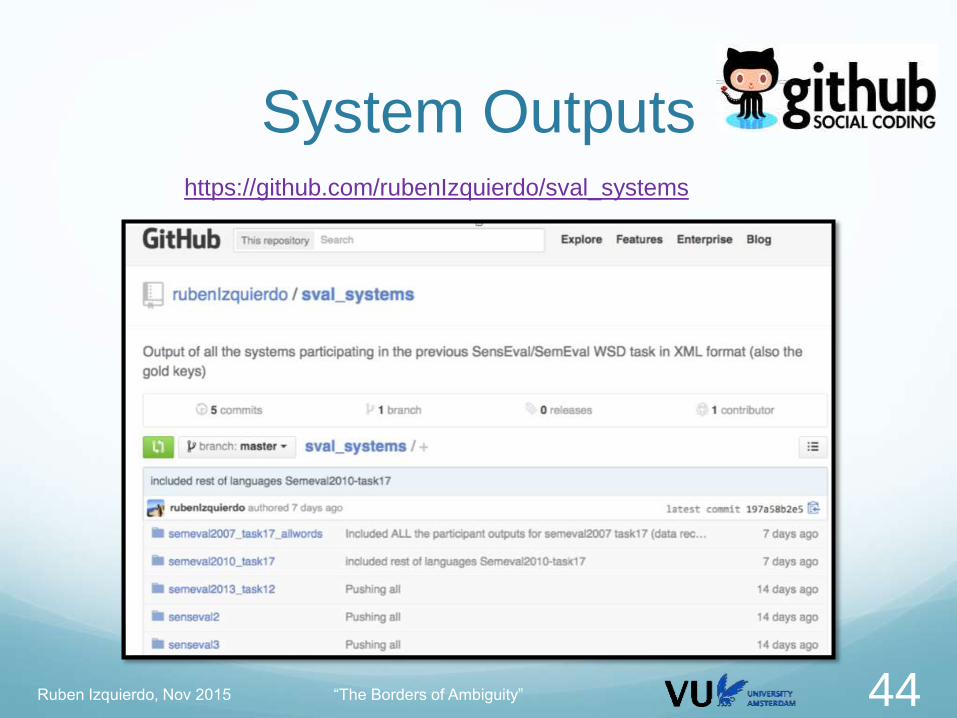
System Outputshttps://github.com/rubenIzquierdo/sval_systems
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 44

System Outputs
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 45

Part III
When to Use Background
Information to Perform WSD
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 46
Piek Vossen Marten Postma Ruben Izquierdo

SemEval-2015 Task #13 Multilingual All-Words Sense Disambiguation and Entity
Linking
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 47

SemEval-2015 Task #13
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 48

Motivation From the previous error analysis
MFS bias is a big problem
For both supervised and unsupervised approaches
Specially when there is domain shift
Our approach
1. Determine the predominant sense for every lemma in the specific domain (unsupervised)
2. Apply a state-of-the-art WSD system
3. Define an heuristic to determine when to apply 1) or 2)
4. We focused on WSD in English only
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 49
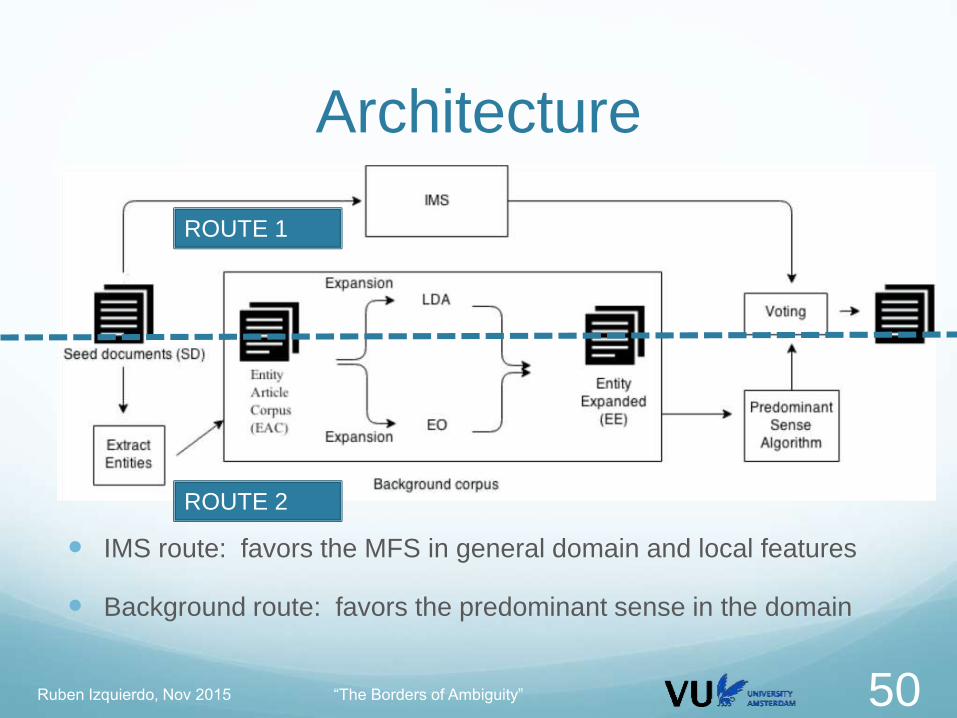
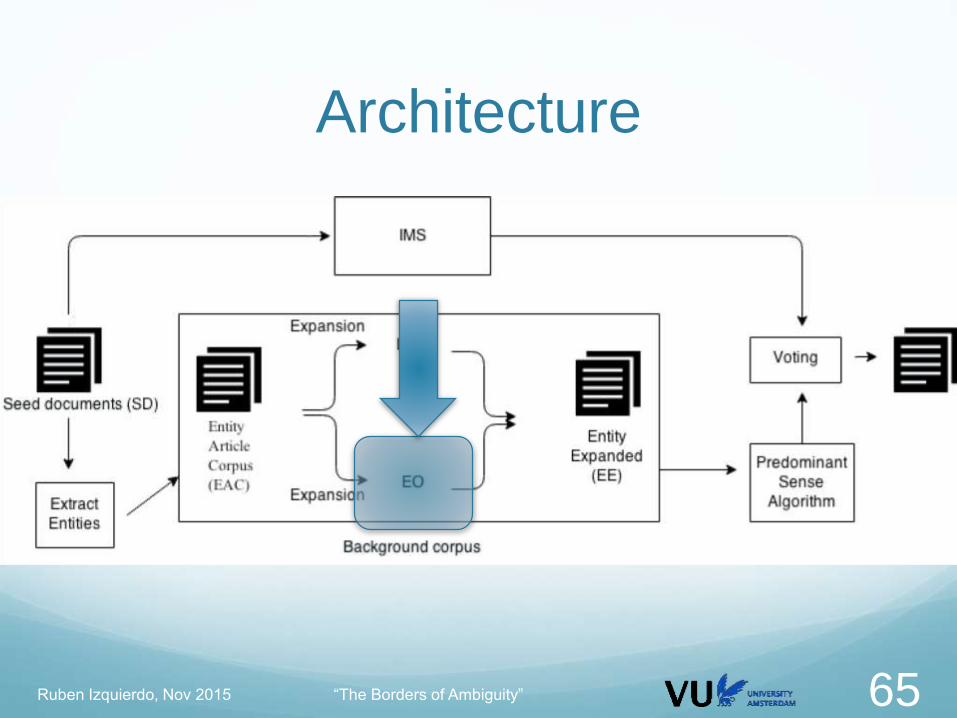
Architecture
IMS route: favors the MFS in general domain and local features
Background route: favors the predominant sense in the domain
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 50
ROUTE 1
ROUTE 2

Architecture
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 51

Architecture
Two different approaches
Online approach
The SemEval test documents (4 documents)
Offline approach
Precompiled documents for the target domain
Documents from biomedical domain
Converted to NAF
Tokens, Lemmas and PoS tags
Seed documents SD
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 52
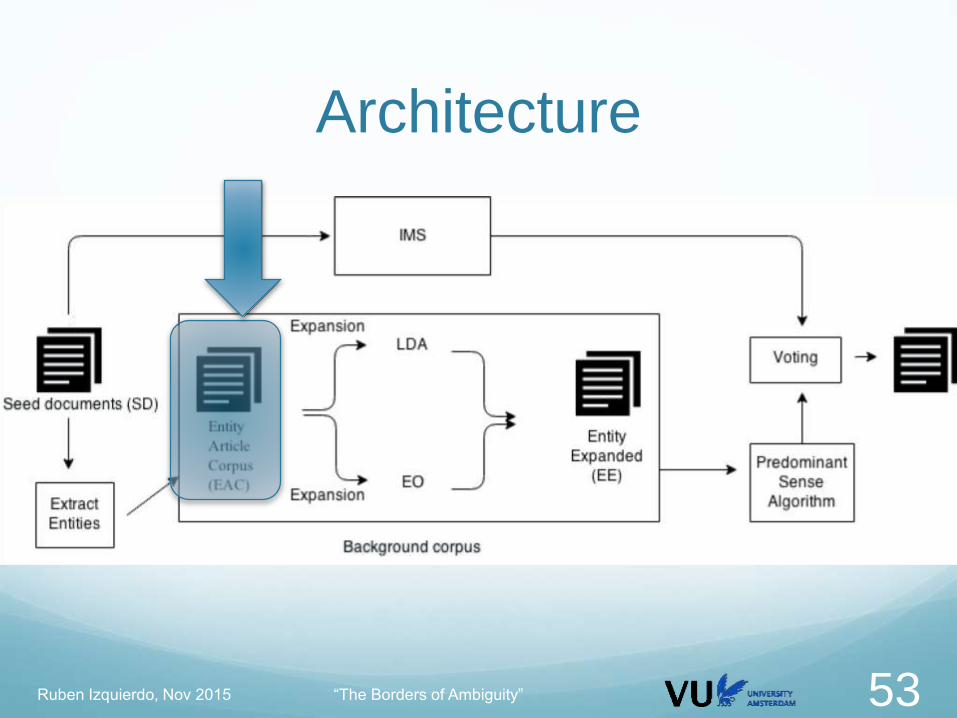
Architecture
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 53

Architecture
DBpedia spotlight is applied to the seed documents
Entities and links to DBpedia are extracted
Wikipedia pages from DBpedia links
Filter:
Consider only DBpedia links with a ontological type which is a leaf on the ontology
Better results without filter
All the wikipedia pages compile the EAC corpus
Entity Article Corpus EAC
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 54

Architecture
Entity Article Corpus EAC
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 55

Architecture
Entity Article Corpus EAC
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 56
Architecture
Entity Article Corpus EAC
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 57
Architecture
Entity Article Corpus EAC
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 58
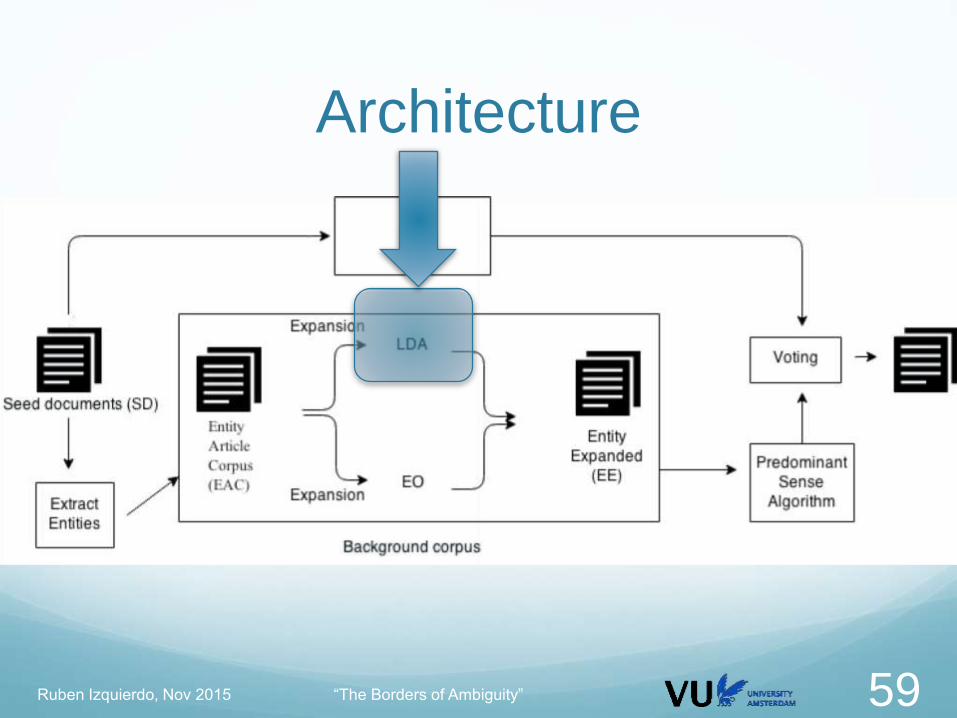
Architecture
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 59

Architecture
Targets high recall and low precision/quality
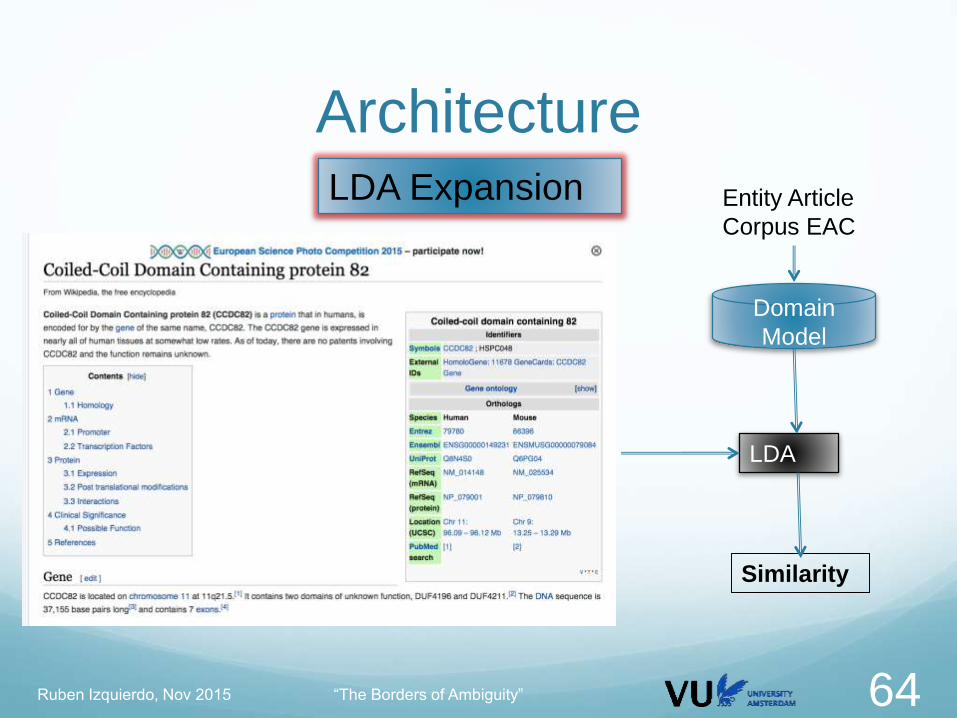
Entity Article Corpus EAC LDA Domain Model DM
For every document DEAC in EAC
Obtain the DBpedia type T
Obtain the set of DBpedia entities S from DBpedia which belong to
T
For every document DS in S:
Compute the similarity of DS against the model DM
If similarity >= THRESHOLD select document for the Entity expanded
corpus
LDA Expansion
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 60
ArchitectureLDA Expansion
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 61

ArchitectureLDA Expansion
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 62

ArchitectureLDA Expansion
http://dbpedia.org/ontology/HumanGene
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 63
ArchitectureLDA Expansion
Domain
Model
LDA
Similarity
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 64
Entity Article
Corpus EAC
Architecture
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 65

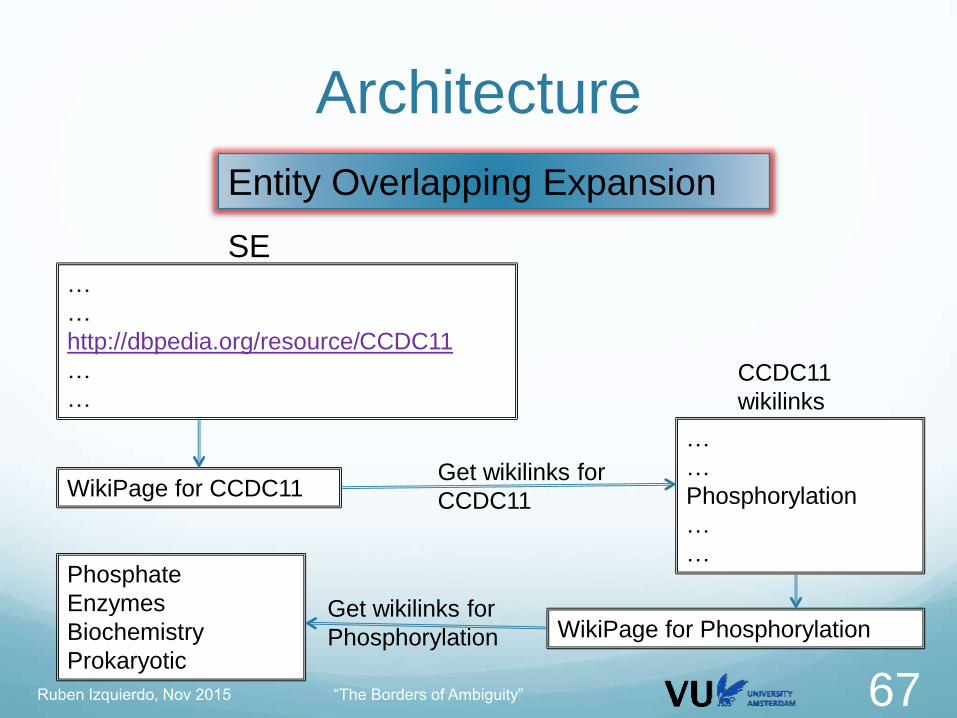
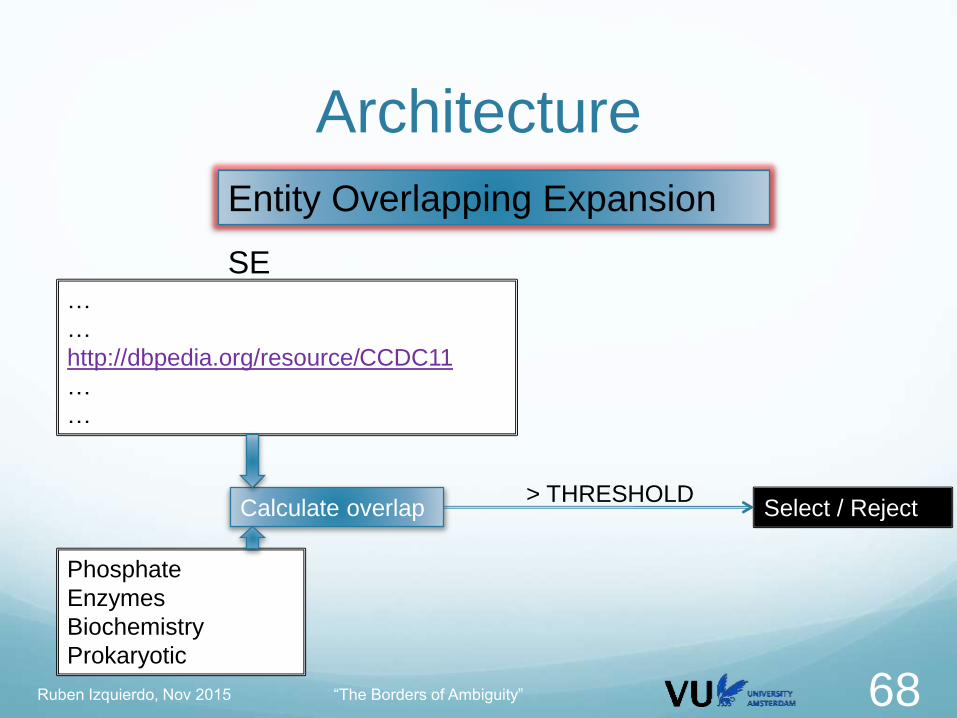
ArchitectureEntity Overlapping Expansion
Targets high quality and medium recall
Entity Article Corpus EAC
Extract all the set of entities: SE
For every entity E in SE:
Obtain all the wikilinks in E: W
For every Ew in W
Obtain all the wikilinks Wew in Ew SW
Compute the overlap SE and SW
Filter by threshold
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 66
Architecture
Entity Overlapping Expansion
…
…
http://dbpedia.org/resource/CCDC11
…
…
SE
WikiPage for CCDC11Get wikilinks for
CCDC11
…
…
Phosphorylation
…
…
WikiPage for PhosphorylationGet wikilinks for
Phosphorylation
Phosphate
Enzymes
Biochemistry
Prokaryotic
CCDC11
wikilinks
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 67
Architecture
Entity Overlapping Expansion
…
…
http://dbpedia.org/resource/CCDC11
…
…
SE
Phosphate
Enzymes
Biochemistry
Prokaryotic
Calculate overlap> THRESHOLD
Select / Reject
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 68
Architecture
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 69

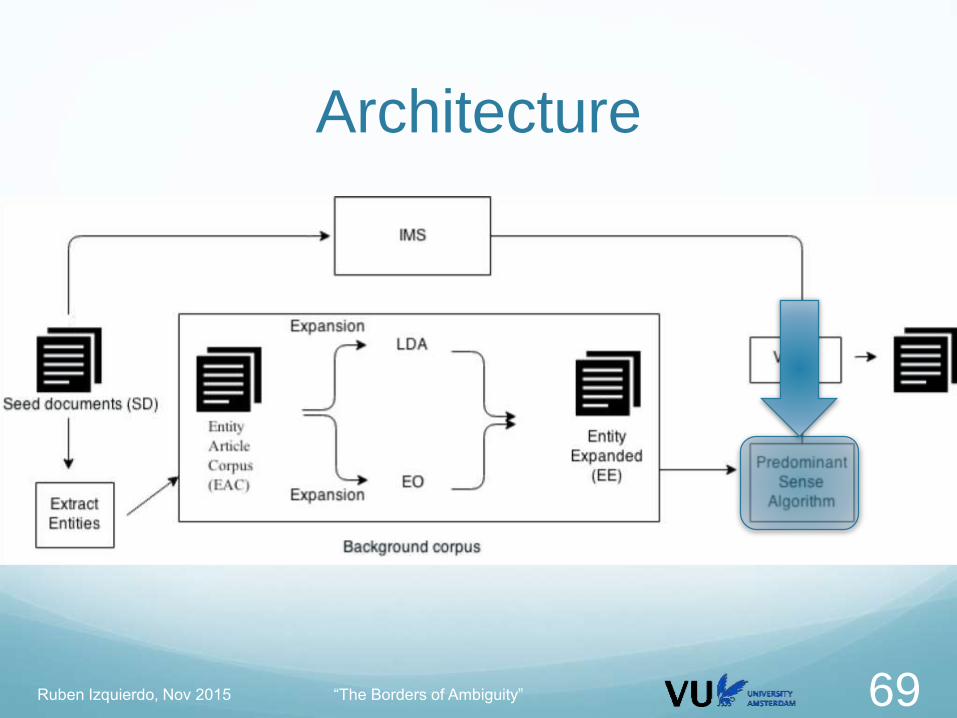
ArchitecturePredominant Sense Algorithm
Background corpus BC: EAC + EE
For every lemma L in BC:
Extract all sentences containing L
If there are more than 100 sentences
Word sense induction with Hierarchical Dirichlet Processes
(Lau et al., 2012)
Induce senses using Topic Modeling
Output: list of senses with confidences per lemma
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 70
Architecture
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 71

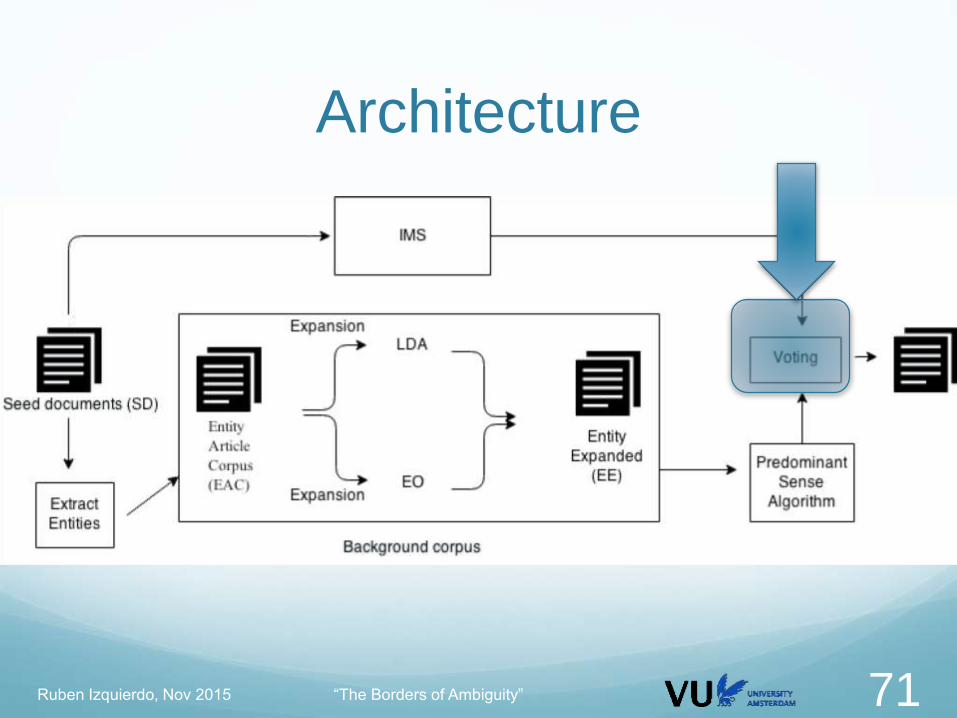
ArchitectureVoting
For a new instance for a given lemma
Obtain sense ranking of Predominant Sense (PS)
Only if first 2 senses agglomerate 85% of confidence (avoid
skewedness)
Mix both sense rankings
PS and ItMakesSense
Select the sense with highest confidence
If there is no Predominant Sense information
Use ItMakesSense best sense
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 72
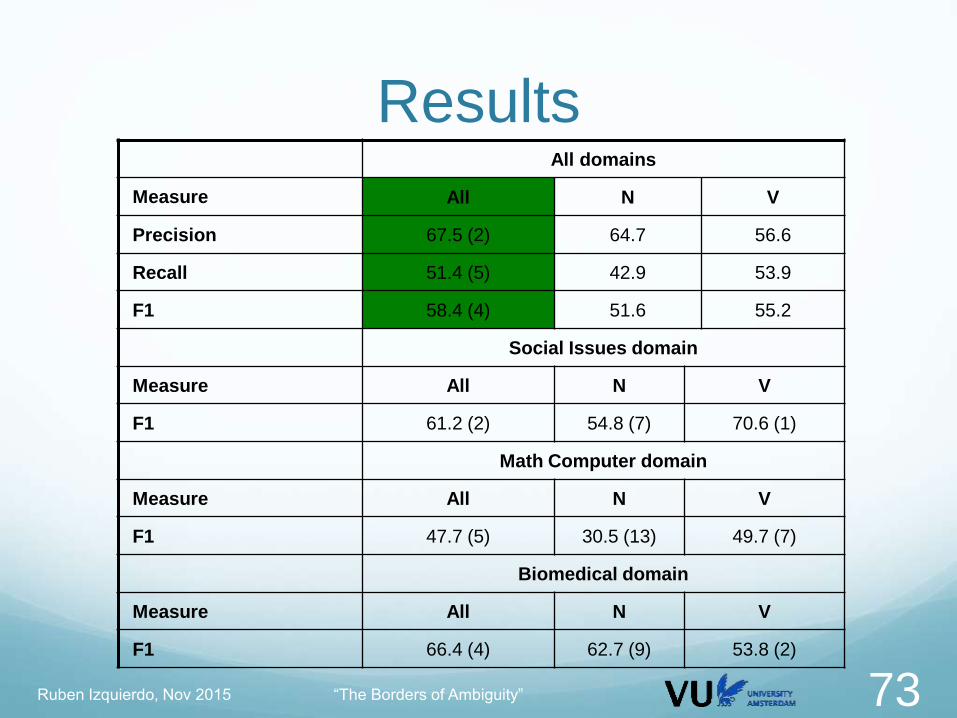
ResultsAll domains
Measure All N V
Precision 67.5 (2) 64.7 56.6
Recall 51.4 (5) 42.9 53.9
F1 58.4 (4) 51.6 55.2
Social Issues domain
Measure All N V
F1 61.2 (2) 54.8 (7) 70.6 (1)
Math Computer domain
Measure All N V
F1 47.7 (5) 30.5 (13) 49.7 (7)
Biomedical domain
Measure All N V
F1 66.4 (4) 62.7 (9) 53.8 (2)
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 73

Discussion The domain was not just biomedical, but mixed
We couldn’t use offline approach
Online approach: small size of seed documents
We used WN1.7.1 while gold was WN3.0 Some test instances were not annotated
Only the predominant sense output Precision nouns improved 64.7% 69.1%
Precision verbs improved 56.6% 64.6%
… but…
Recall nouns 42.9% 20.1%
Recall verbs 53.9% 17.7%
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 74
GitHub Codehttps://github.com/cltl/vua-wsd-sem2015
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 75

Part IV
What is next?
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 76

Current and Future Most Frequent Sense Classifier
Decide when MFS apply or not
Based on the output of 2 WSD systems
UKB
IMS
Random Forest algorithm
Features
Confidence of the MFS by systems
Sense ranking entropy
WordNet Domains / SuperSense for the MFS
…
Voting for selecting the MFS
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 77

Current and Future Unsupervised learning for MFS / LFS
Distributional semantics and word2vec for detecting the
MFS
Vectors for representing MFS cases
Vectors for representing LFS cases
Operate with vectors
V(‘Paris’) – V(‘France’) + V(‘Italy’) => V(‘Rome’)
V(‘king’) – V(‘man’) + V(‘woman’) V(‘queen’)
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 78

ULM-1
Understanding Language
by Machines
The Borders of Ambiguity
THANKS
Ruben Izquierdo
http://rubenizquierdobevia.com
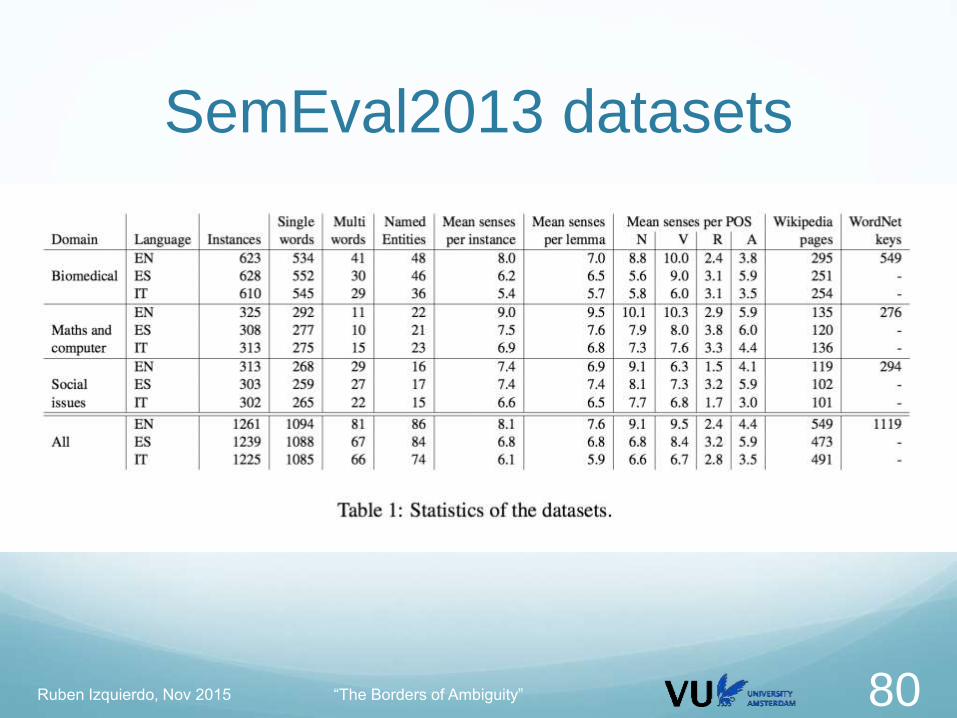
SemEval2013 datasets
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 80
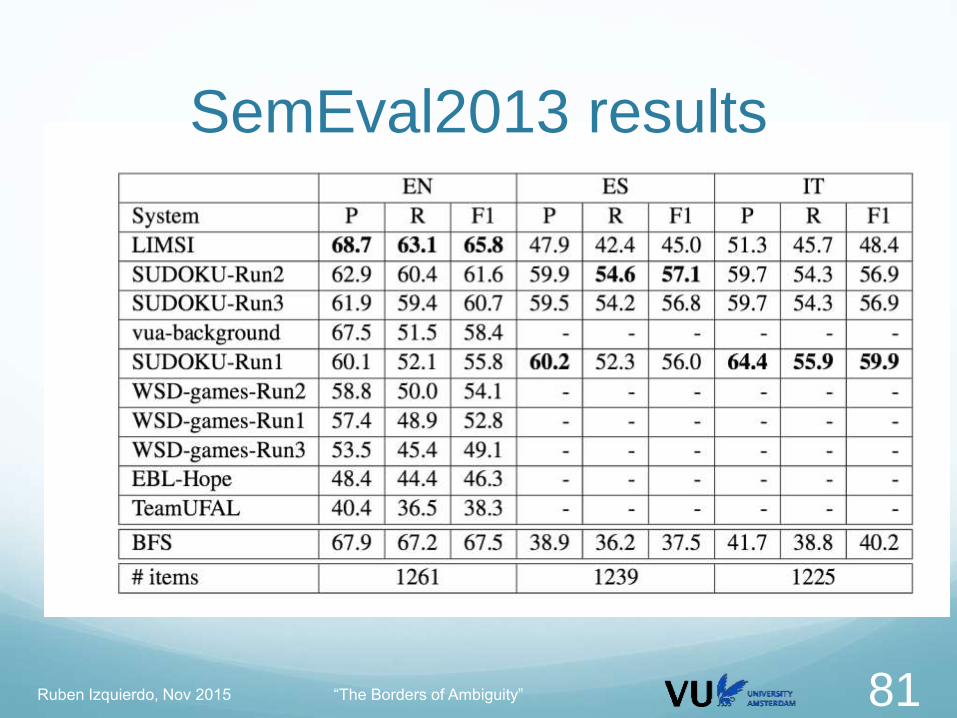
SemEval2013 results
Ruben Izquierdo, Nov 2015 “The Borders of Ambiguity” 81





























