Embed Size (px)
Citation preview

DL research trendsbased on AAAI 2016 proceedings

Attention & Memory
Ilya Sutskever, Research Director at OpenAI
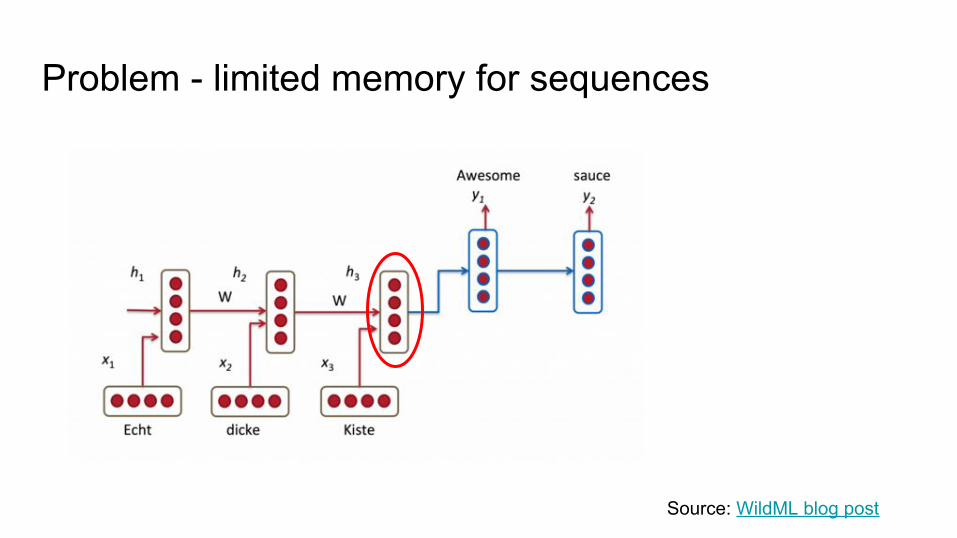
Problem - limited memory for sequences
Source: WildML blog post
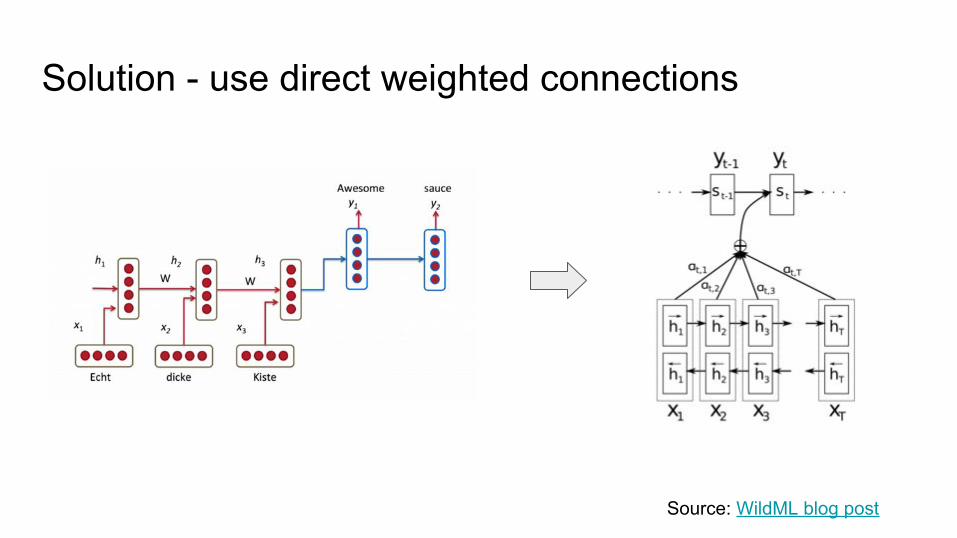
Solution - use direct weighted connections
Source: WildML blog post
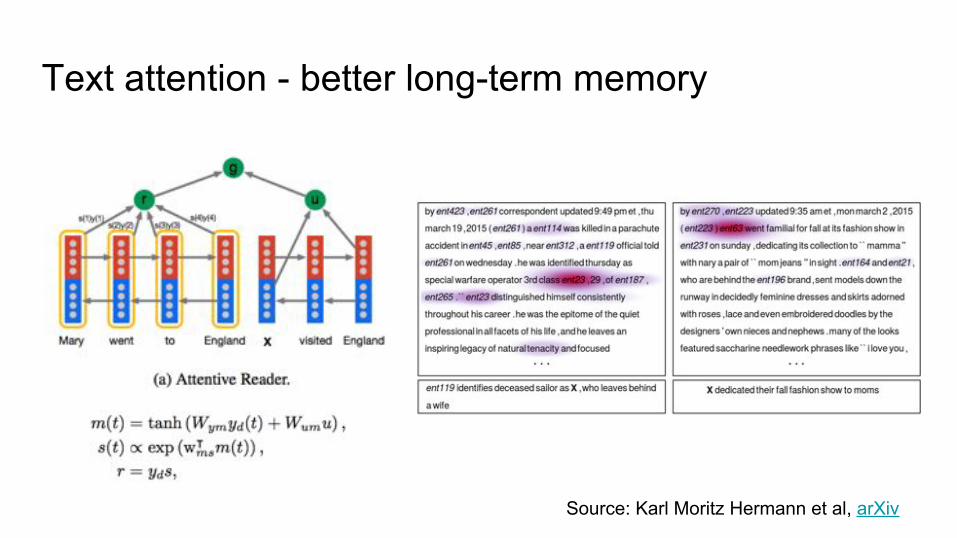
Text attention - better long-term memory
Source: Karl Moritz Hermann et al, arXiv
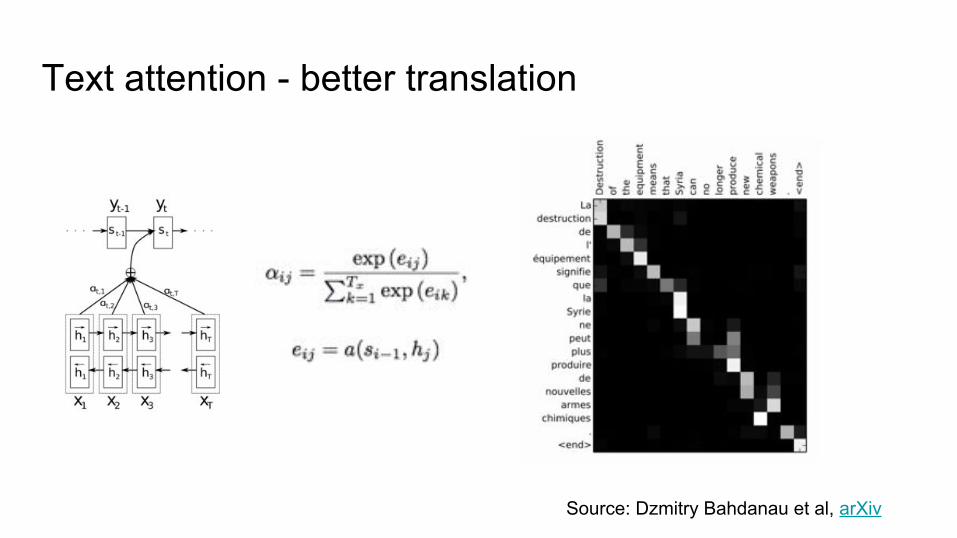
Text attention - better translation
Source: Dzmitry Bahdanau et al, arXiv
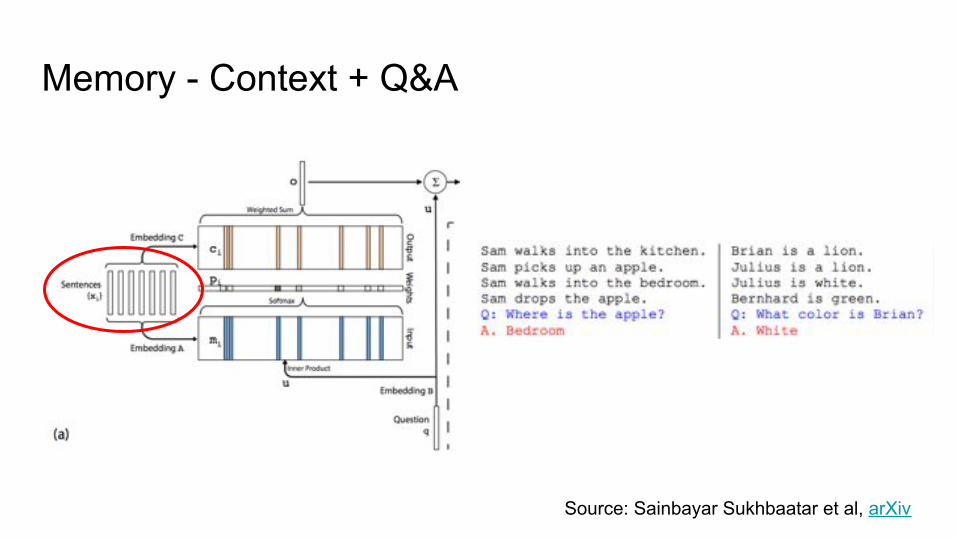
Memory - Context + Q&A
Source: Sainbayar Sukhbaatar et al, arXiv

Visual Attention - better cap generation
Source: Kelvin Xu et al, arXiv

Adversarial Networks

Problem - MCMC-based sampling is hard● Backprop is good, but it requires direct feedback / gradient● Hard to train anything non-backprop
Source: Deep Learning Book

Solution - 2-players game
Sources: Torch blog post
1. Take samples from original distribution
2. Generative model tries to create new images
3. Discriminative model tries to distinguish between them
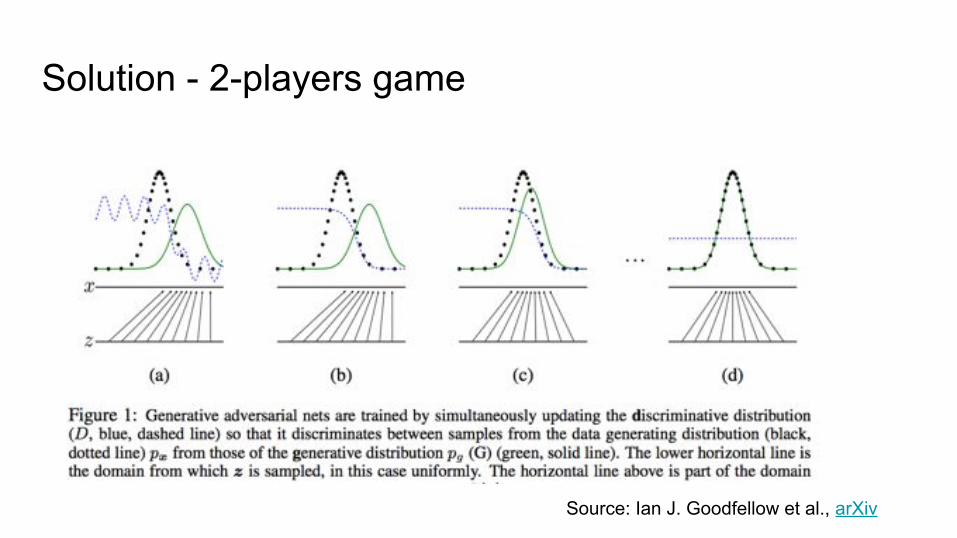
Solution - 2-players game
Source: Ian J. Goodfellow et al., arXiv

Smooth transitions in latent space
Sources: Torch blog post
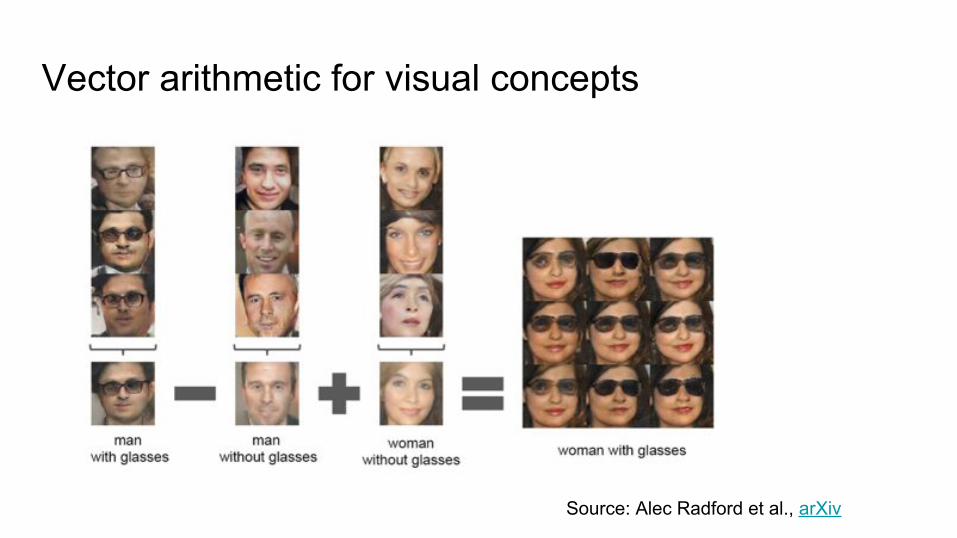
Vector arithmetic for visual concepts
Source: Alec Radford et al., arXiv
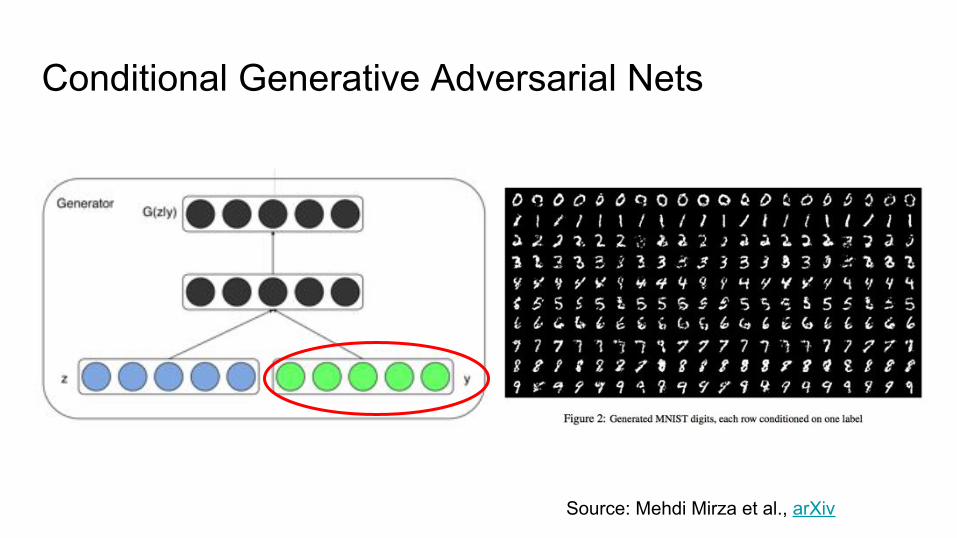
Conditional Generative Adversarial Nets
Source: Mehdi Mirza et al., arXiv

Char-level text comprehension

Problem - word-level models ignores chars
● Word-level models cannot gracefully deal with new words
● Every new form of word is a new embedding to learn (unless stemmed or lemmatized)
● Char-level LSTMs are having difficulties learning high-level features (sentences, meaning, etc)
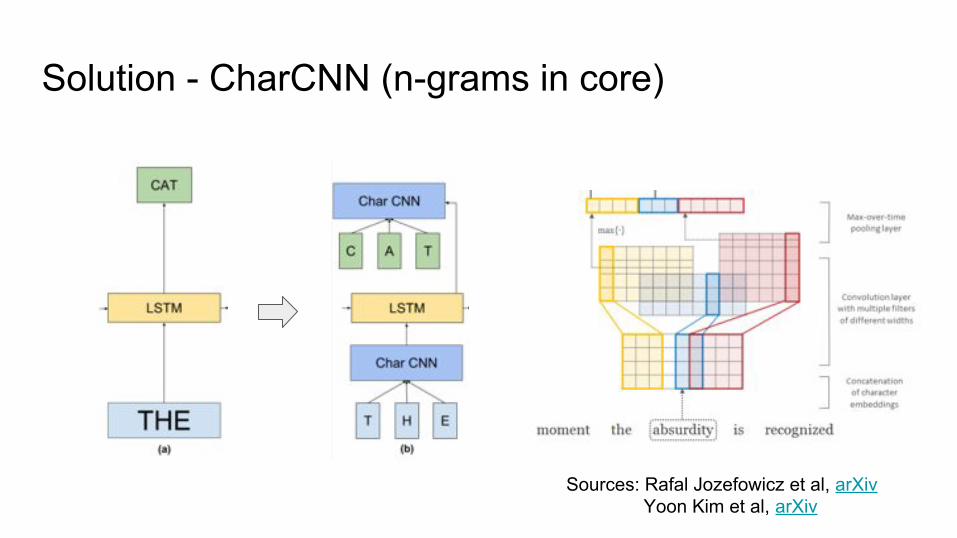
Solution - CharCNN (n-grams in core)
Sources: Rafal Jozefowicz et al, arXiv Yoon Kim et al, arXiv

Char-level text comprehensionOn 7th of February 2016 Google sets a new record in language modeling, beating the previous best result by 41.5% in terms of perplexity
Key tricks:● Very large network● Importance Sampling● Char-level CNNs
Source: Rafal Jozefowicz et al, arXiv

Why perplexity matters?
Perplexity is a technical metric used to evaluate general language modeling algorithms.
But it influences all language tasks:● Better grammar checking● Better machine translation● Better text-generation from chatbot● Better document compression
Source: Coursera, Stanford NLP

Questions?

































