Embed Size (px)
Citation preview

定理証明における機械学習の応用
定理証明 + 機械学習 = ?
Preferred Networks八幡 啓祐 @skyrunner_01酒井 政裕 @masahiro_sakai
片岡 俊基 @toslunar
Proof Summit 2017
2017/7/23(Sun)東京都中央区築地1丁目13−1 ADK松竹スクエア

八幡啓祐
Twitter : @skyrunner_01数学科出身(修士卒)
6年間 数学科コンピュータサイエンス、数理論理学に関してはまだまだ勉強中
2

本日の発表内容
①機械学習の応用例② AlphaGoの紹介
3
③自動証明と囲碁AIの違い④既存研究の紹介
⑤考察・課題

• 画像認識 (深層学習)• 自動運転 (強化学習+深層学習)
• 画像の自動生成(深層学習)
• 囲碁、将棋、チェスのAI (強化学習+深層学習)
• 自動証明?(強化学習+深層学習??)
機械学習の応用例
4

5
• 2016年スタート
• AI + ATPの国際会議

囲碁AI
AlphaGoの紹介
6

について
• 2015年10月人間プロ相手に(ハンデなしで)初勝利した 囲碁AI
• Google DeepMind社 によって開発• 人間が理解できない 手を選択し続けた
V.S
4勝1敗
7
Deep Learning(深層学習)
人類最強クラス

囲碁AI は難しい!
8

囲碁AIの難しさ(その1)
19
1919 ×19 = 361通り
360!通り
9

10
将棋 ⇒ 1069くらい
囲碁 ⇒ 10172もある!
状態数(考えられる盤面の総数)

探索空間がとにかく広い!
11

囲碁AIの難しさ(その2)
≧
>??
石は石。
12
なんとなくわかる

13
どっちが良い??

14
人力での各盤面の評価が難しい!
機械学習を使いましょう

かるく まとめ
15

1. 全探索は ムリ!→ ある程度 選択肢 幅を絞る必要がある
2. ある程度人間を模倣させた上で 探索したい!→ 畳み込みニューラルネットワーク(深層学習)
3.(探索手法には)モンテカルロ探索→ アマチュアレベルには これだけでも勝てる
4. 模倣させたAI同士で対決させて洗練!→ 強化学習
16
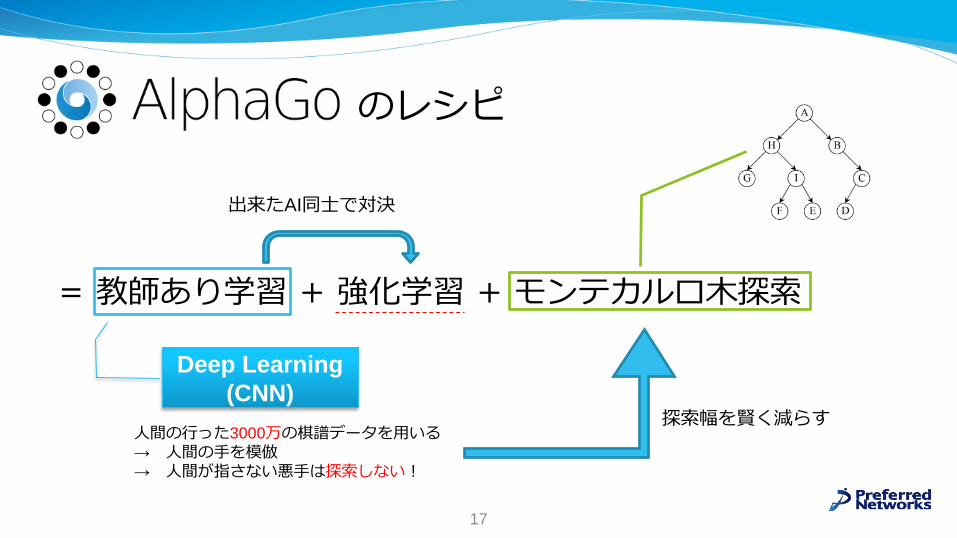
のレシピ
=教師あり学習+強化学習+モンテカルロ木探索
Deep Learning
(CNN)
人間の行った3000万の棋譜データを用いる→ 人間の手を模倣→ 人間が指さない悪手は探索しない!
探索幅を賢く減らす
出来たAI同士で対決
17

定理証明も、同じようなアイディアでできるのでは?
18

①深層学習で人間の証明テクニックを模倣
②正しい証明図となるような木探索(①で探索の選択肢を絞る)
③できあがった人間模倣のモデルを強化学習させる
19

※そんな単純じゃない
20

• 教師データはどうやってあつめるの?→MMLとか?Metamathの公式ライブラリset.mmとか?→フォーマットの統一はどうやって?
• ボードゲームと違って、モンテカルロ木探索が単純じゃない!ボードゲームの場合 → 一定数以内に勝敗が決まる定理証明の場合 → そういう保証はない
(というより主張が真か偽かすらわからない)
• そもそも探索空間の大きさが囲碁以上に広い→適用可能な公理図式やタクティックは有限であっても、パラメータを含めて考えると無限
21

※工夫が必要!
22

既存研究の紹介
23

定理証明に機械学習を応用するアプローチ
• アプローチ– 探索の効率化– より直接的な証明の生成
• 構成要素例– 論理式の表現学習 (c.f word2vec)
– 用いられる公理の予測– 適用すべき公理・タクティックの予測/ランキング
• 探索順の制御 (c.f. AlphaGo, Ponanza Chainer)
– 強化学習的な探索– ……
24

自動定理証明器をガイドして効率化
• 自動定理証明器:
• 自動定理証明器のつらさ…… すぐに組合せ爆発!
• → うまくガイドすることで爆発を避けたい
自動定理証明の紹介
〜Proof Summit〜 2011-09-25
酒井 政裕
対話的定理証明vs 自動定理証明
対話的定理証明 自動定理証明
ツール Coq, Agda, … E, SPASS, Otter, …
自動化 人間が証明を書き、それをツールが検査。
ツールが証明を探索。人間はそれをガイド
古典論理? 直観主義論理 古典論理
⾼階/一階 ⾼階 一階
25

自動定理証明器をガイドして効率化
• 公理の選択 (Premise Selection)
– 証明に必要な公理を予測、不要な公理を捨てて問題サイズを縮小
– 例: Miz𝔸ℝ 40, Deep Math
• 中間ゴールの予測、次に処理すべき節の選択
– 例: Deep Network Guided Proof Search, HolStep
26
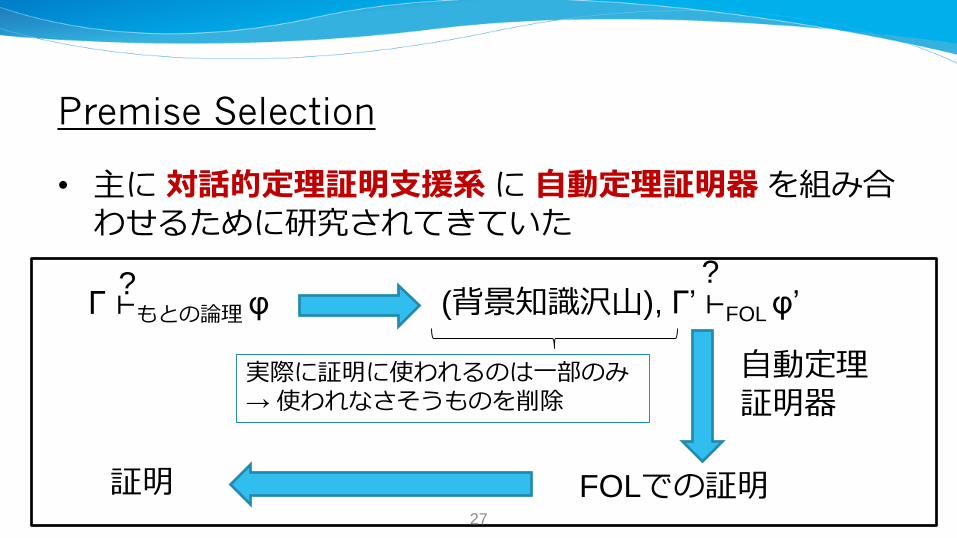
Premise Selection
• 主に対話的定理証明支援系に自動定理証明器を組み合わせるために研究されてきていた
Γ ⊢もとの論理φ (背景知識沢山), Γ’ ⊢FOL φ’ ? ?
FOLでの証明
自動定理証明器
証明
実際に証明に使われるのは一部のみ→ 使われなさそうものを削除
27

MizAR 40 for Mizar 40
• [Cezary Kaliszyk and Josef Urban, 2015]
• Mizar で MML 4.181.1147に含まれる 57897 の定理などを対象に、
• ナイーブベイズやk-NNといった古典的なモデル(+ TF-IDFやLSI、アンサンブルやブースティング)でそれぞれの公理が必要かを予測
• 予測スコアの⾼い公理 n 個に限定して自動定理証明器(Vampire, E, Z3) を呼び出す
• 単一手法(モデル+証明器)で最⾼27.3%、複数手法で40%以上証明できたなど
28

DeepMath
• DeepMath - Deep Sequence Models for Premise Selection [arXiv:1606.04442]
• 同じくMizarとMMLを対象に、モデルを深層学習っぽいモデルにすることを試みた論文
• 自動定理証明器には E を使用
• 複数のモデルを試しており、テスト用の 2,742 個の定理中、単一モデルで最⾼62.95%、複数モデルで77%ほど証明できた!
29

DeepMath のアーキテクチャ
1. conjectureとaxiomをNN(CNNもしくはRNN)で固定長のベクトル(embedding)に変換
2. それらを連結
3. 使われるかどうかを予測
https://arxiv.org/abs/1606.04442より引用
30

DeepMath のアーキテクチャ
• 論理式のembeddingへの変換に、2層のCNNを用いる場合のイメージ
https://arxiv.org/abs/1606.04442より引用
31

DeepMath の再現の試み: データセット
C fof(l100_finseq_1, axiom, r2_hidden(7, k2_finseq_1(7))).
+ fof(cc8_ordinal1, axiom, (! [A] : (m1_subset_1(A, k4_ordinal1) => v7_ordinal1(A)) ) ).
+ fof(redefinition_k5_numbers, axiom, k5_numbers=k4_ordinal1).
+ fof(rqLessOrEqual__r1_xxreal_0__r1_r7, axiom, r1_xxreal_0(1, 7)).
+ fof(rqLessOrEqual__r1_xxreal_0__r7_r7, axiom, r1_xxreal_0(7, 7)).
+ fof(spc7_numerals, axiom, ( (v2_xxreal_0(7) & m2_subset_1(7, k1_numbers, k5_numbers)) & (m1_subset_1(7, k5_numbers) & m1_subset_
+ fof(t1_finseq_1, axiom, (! [A] : (v7_ordinal1(A) => (! [B] : (v7_ordinal1(B) => (r2_hidden(A, k2_finseq_1(B)) <=> (r1_xxreal_0(1
- fof(l98_finseq_1, axiom, (r2_hidden(3, k2_finseq_1(7)) & r2_hidden(4, k2_finseq_1(7))) ).
- fof(l99_finseq_1, axiom, (r2_hidden(5, k2_finseq_1(7)) & r2_hidden(6, k2_finseq_1(7))) ).
- fof(l97_finseq_1, axiom, (r2_hidden(1, k2_finseq_1(7)) & r2_hidden(2, k2_finseq_1(7))) ).
- fof(t5_finseq_1, axiom, (! [A] : (v7_ordinal1(A) => (! [B] : (v7_ordinal1(B) => (r1_xxreal_0(A, B) <=> r1_tarski(k2_finseq_1(A),
- fof(d3_tarski, axiom, (! [A] : (! [B] : (r1_tarski(A, B) <=> (! [C] : (r2_hidden(C, A) => r2_hidden(C, B)) ) ) ) ) ).
データセット https://github.com/JUrban/deepmath
例: nndata/l100_finseq_1
必要だった公理
不要な公理
証明したい命題
32
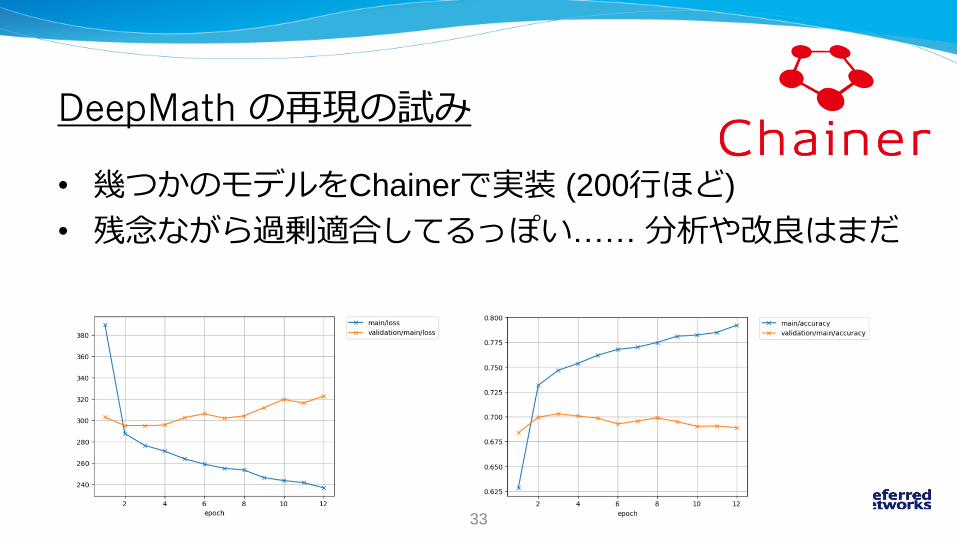
DeepMath の再現の試み
• 幾つかのモデルをChainerで実装 (200行ほど)
• 残念ながら過剰適合してるっぽい…… 分析や改良はまだ
33

次に処理すべき節の選択への適用:
Deep Network Guided Proof Search
• [arXiv:1701.06972]• DeepMathがEに与える前提を絞るのにNNを使っていたのに対し、
• 自動定理証明器(E Prover)中に次に処理すべき節の選択のために、ある節が証明中で使われるか否かを予測するNNを学習し、そのスコアの⾼い節から処理。
• 探索手のランキングにNNを使うAlphaGo, Ponanza Chainerとも類似
• 対象は同じくMizarとMML
• アーキテクチャはDeepMathと同様34
https://arxiv.org/abs/1701.06972より引用

中間ゴールの予測: HolStep
• HolStep: A Machine Learning Dataset for Higher-Order
Logic Theorem Proving
• [arXiv:1703.00426]
• (前提の集合、証明したい定理の主張)
→ 使えそうな中間ステップを予測する問題
35

HolStep データの例 train/00010:
N REAL_IMP_CNJ
C |- (!z. ((real z) ==> ((cnj z) = z)))
T c==> creal f0 c= ccnj f0 f0
D TRUTH
A |- T
T cT
D REAL_CNJ
A |- (!z. ((real z) = ((cnj z) = z)))
T c= creal f0 c= ccnj f0 f0
+ |- ((t ==> t) = T)
T c= c==> f0 f0 cT
- |- (((x = x) ==> p) = p)
T c= c==> c= f0 f0 f1 f1
+ |- ((!z. t) = t)
T c= ! f0 f0
- |- ((x = x) = T)
T c= c= f0 f0 cT
証明したい
前提①
前提②
(実際に)
使われたもの
使われなかったもの
36

既存研究例:Holophrasm
• [arXiv:1608.02644]
• 完全な証明を書きだすところまでやる
• payoff network: 探索の優先順を決める
• relevance network: 適用する定理の選択
• generative network: 代入の生成
37
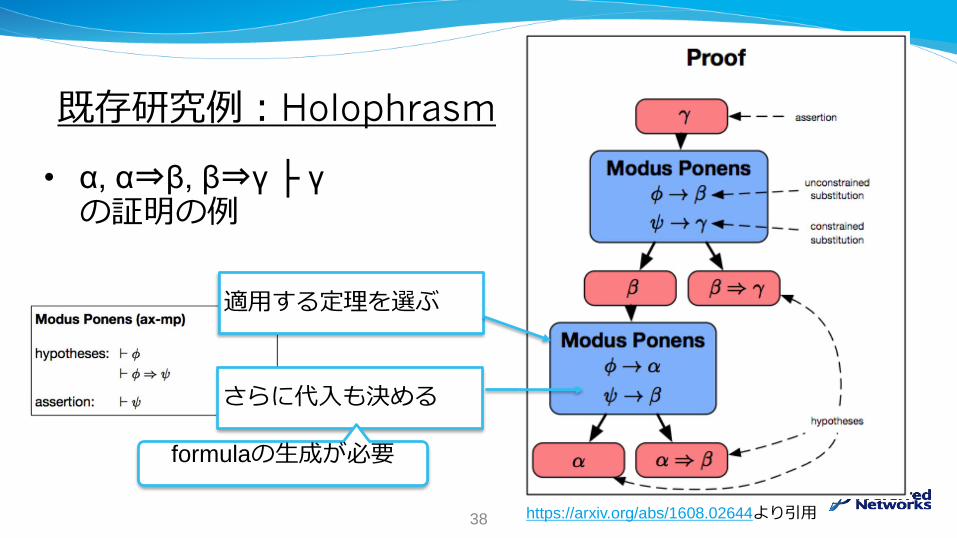
既存研究例:Holophrasm
• α, α⇒β, β⇒γ ├ γの証明の例
適用する定理を選ぶ
さらに代入も決める
formulaの生成が必要
38 https://arxiv.org/abs/1608.02644より引用

既存研究例:Holophrasm
• 証明探索時は,定理適用のノードを生成していく
• 示すべき補題のノードが仮定したものになれば証明成功
39 https://arxiv.org/abs/1608.02644より引用

既存研究例:Holophrasm
• 証明探索時は,定理適用のノードを生成していく
• 示すべき補題のノードが仮定したものになれば証明成功
φ, ψ ├ χ の証明
χ
ψ
φ
φ ψ
40

既存研究例:Holophrasm
• どのノードの探索を進めるか:基本的にモンテカルロ木探索
• 青ノードの探索順はrelevance network を利用
• least promising childについての値を payoff とする
φ, ψ ├ χ の証明
χ
ψ
φ
φ ψ
41

既存研究例:Holophrasm
• どのノードの探索を進めるか:基本的にモンテカルロ木探索
• 赤ノードの initial payoff の生成を学習する
• その補題を「証明できそうか」
φ, ψ ├ χ の証明
χ
ψ
φ
φ ψ
42

既存研究の比較論理 タスク
DeepMath Mizar を
FOL(一階述語論理)
に変換
Premise Selection
Deep Network
Guided Proof
Search
探索のガイド
HolStep HOL 探索のガイド
Holophrasm FOL 証明の生成、探索のガイド、代入生成
DeepProlog
Tim Rocktäschel
et al. ‘17
FOL - 関数記号 帰納論理プログラミング
[arxiv.1706.06462]
Sekiyama et al. ‘17
命題論理 証明の生成
43

我々の考える課題
• より適切な表現学習
• 正しい盤面評価の方法
• 取り得るアクションの数の多さ
44

課題: より適切な表現の学習
• 画像はピクセルの配列、自然言語は文字やトークンの列、と比較的単純な構造を扱っていた。
• 一方で、論理式や証明はより複雑な構造を持つ
• CNN / RNN で論理式や証明の複雑な構造を捉えられるのか?
• → Recursive NN や Tree LSTM などで、文字列・トークン列ではなく、構文木を直接扱う?
45

課題: 非常に疎な報酬
• 探索問題として考えて強化学習的なアプローチで扱おうとすると、探索途上ではまったく報酬がなく、最後に証明成功したときにだけ報酬が発生する
• 碁や将棋では、先読みやMCTS(モンテカルロ木探索)による勝率などでノードの価値を評価できるが、証明ではそれができない
– そもそも先読みや play out で正の報酬にたどり着けていれば、それで証明終了
– 深さに全く制限がないので、終局まで play out しようがない
46

課題: 取り得るアクションの数の多さ
• 適用可能な公理図式やタクティックは有限であっても、パラメータを含めて考えると無限
– 数学的帰納法を使うときの述語 P の候補は無数P(0) ∧ (∀x. P(x) → P(x+1)) →∀x. P(x)
– ゴール αに対して Modus Ponens を適用して β→αと βに変形するとき、論理式 βを推測する必要。しかし候補は無数
• 候補をランキングするのでは不十分
– Holophrasmの generative network のようにそれらを生成するネットワークが必要
– しかし、複雑な構造を直接生成するのは、より難しい
47

論文紹介は以上です
48

References
• C. Kaliszyk and J. Urban, "MizAR 40 for Mizar 40," In Journal of Automated Reasoning, vol. 55, no. 3, pp. 245-256, 2015. http://link.springer.com/article/10.1007/s10817-015-9330-8
• A. A. Alemi, F. Chollet, G. Irving, C. Szegedy, and J. Urban, "DeepMath - deep sequence models for premise selection," Jun. 2016. http://arxiv.org/abs/1606.04442
• S. Loos, G. Irving, C. Szegedy, and C. Kaliszyk, "Deep network guided proof search," Jan. 2017. [Online]. Available: http://arxiv.org/abs/1701.06972
• C. Kaliszyk, F. Chollet, and C. Szegedy, "HolStep: A machine learning dataset for higher-order logic theorem proving," Mar. 2017. http://arxiv.org/abs/1703.00426
• D. Whalen, "Holophrasm: a neural automated theorem prover for higher-order logic," Aug. 2016. http://arxiv.org/abs/1608.02644
• T. Rocktäschel and S. Riedel, "End-to-end differentiable proving," May 2017. http://arxiv.org/abs/1705.11040
• T. Sekiyama, A. Imanishi, and K. Suenaga, "Towards proof synthesis guided by neural machine translation for intuitionistic propositional logic," Jun. 2017. http://arxiv.org/abs/1706.06462
49

References
• D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V.
Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K.
Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of go with deep neural networks and tree search,” Nature,
vol. 529, no. 7587, pp. 484-489, Jan. 2016
https://www.nature.com/nature/journal/v529/n7587/abs/nature16961.html?lang=en
• 山本一成, 下山晃, 齋藤真樹, 藤田康博, 秋葉拓哉, 土井裕介, 菊池悠太, 奥田遼介, 須藤武文 and 大川和仁, “第27回世界コンピュータ将棋選手権 Ponanza Chainerアピール文章,” 2017.
http://www2.computer-shogi.org/wcsc27/appeal/Ponanza_Chainer/Ponanza_Chainer.pdf
50

Links
• AITPの公式サイト
http://aitp-conference.org/2017/
• 酒井政裕, “自動定理証明の紹介,” Proof Summit 2011, Sep. 2011.
http://www.slideshare.net/sakai/ss-9413447
51

定理証明などに関して取り組むと面白そうなチャレンジ求む!
52

53

ご清聴ありがとうございました。
54









![BtoB b2b b 2 b summit 2015 interview stéphane munier slideshare (1)[1]](https://img.pdfslide.tips/doc/110x75/58a4b1ba1a28ab2d688b45d9/btob-b2b-b-2-b-summit-2015-interview-stephane-munier-slideshare-11.jpg)



















