Embed Size (px)
Citation preview

Machine Learningwith Python
Algorithm chains and Pipelines
1

ContactsHaesun Park
Email : [email protected]
Meetup: https://www.meetup.com/Hongdae-Machine-Learning-Study/
Facebook : https://facebook.com/haesunrpark
Blog : https://tensorflow.blog
2

Book파이썬라이브러리를활용한머신러닝, 박해선.
(Introduction to Machine Learning with Python, Andreas Muller & Sarah Guido의번역서입니다.)
번역서의 1장과 2장은블로그에서무료로읽을수있습니다.
원서에대한프리뷰를온라인에서볼수있습니다.
Github: https://github.com/rickiepark/introduction_to_ml_with_python/
3

Algorithm Chains
4

cancer + MinMaxScaler + SVC
5
𝑥 − 𝑥#$%𝑥#&' − 𝑥#$%
모든특성이0과 1사이에위치
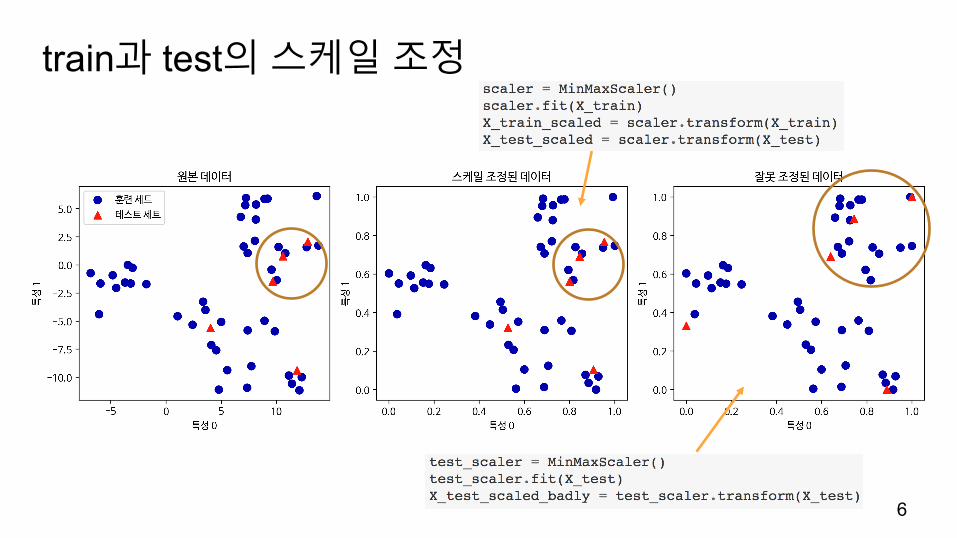
train과 test의스케일조정
6
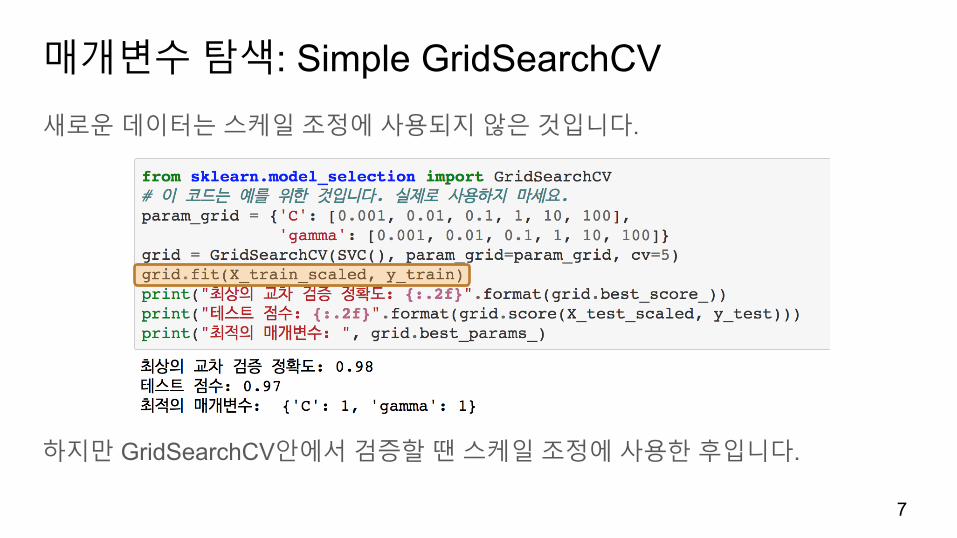
매개변수탐색: Simple GridSearchCV새로운데이터는스케일조정에사용되지않은것입니다.
하지만 GridSearchCV안에서검증할땐스케일조정에사용한후입니다.
7

Validation vs. Predict
8
교차검증
테스트세트예측
검증폴드의정보누설

Simple Pipeline
9
임의문자열(이중밑줄문자만제외)튜플
scaler à svm
scaler à svm
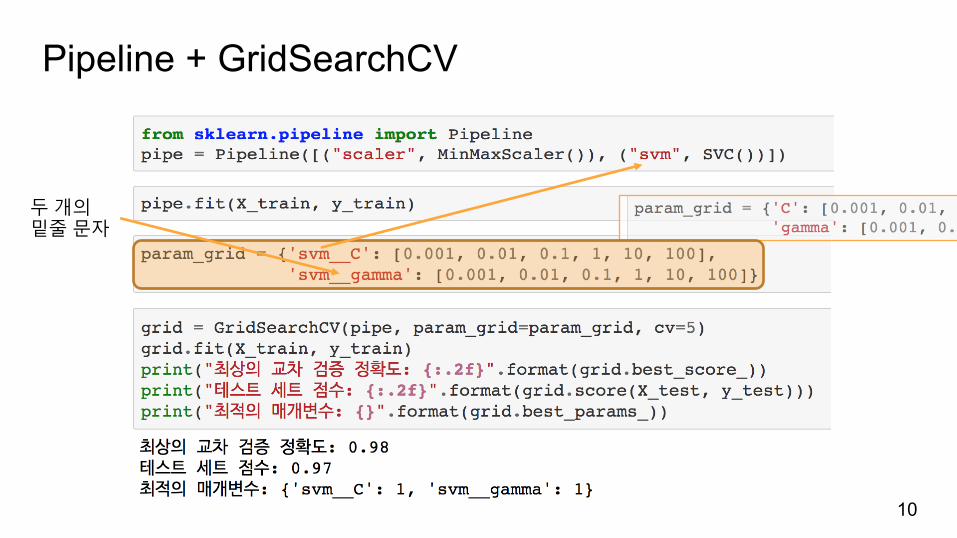
Pipeline + GridSearchCV
10
두개의밑줄문자
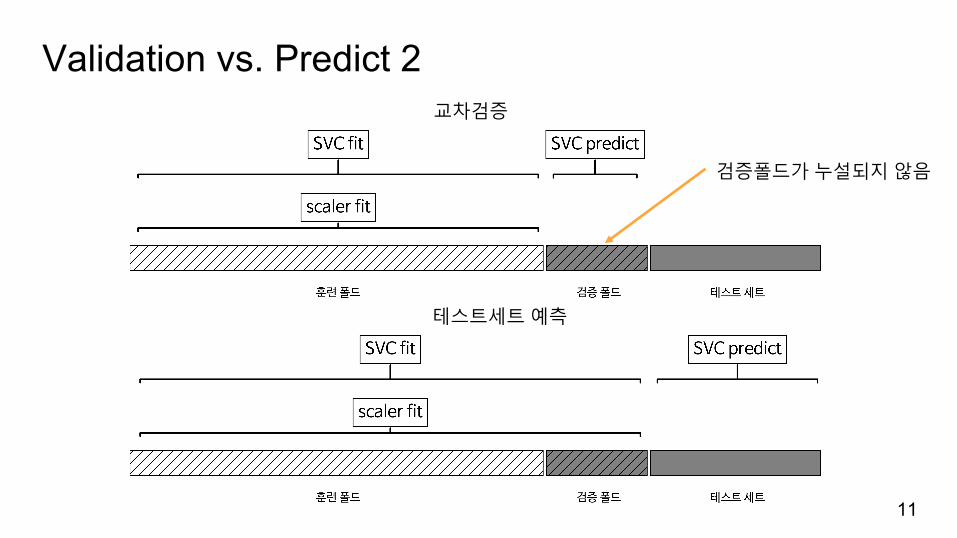
Validation vs. Predict 2
11
교차검증
테스트세트예측
검증폴드가누설되지않음

정보누설의예
헤이스티, 팁시라니, 프리드먼의 ESL에포함된예제
12
1만개의랜덤특성
5%=500개특성선택

Pipeline
13
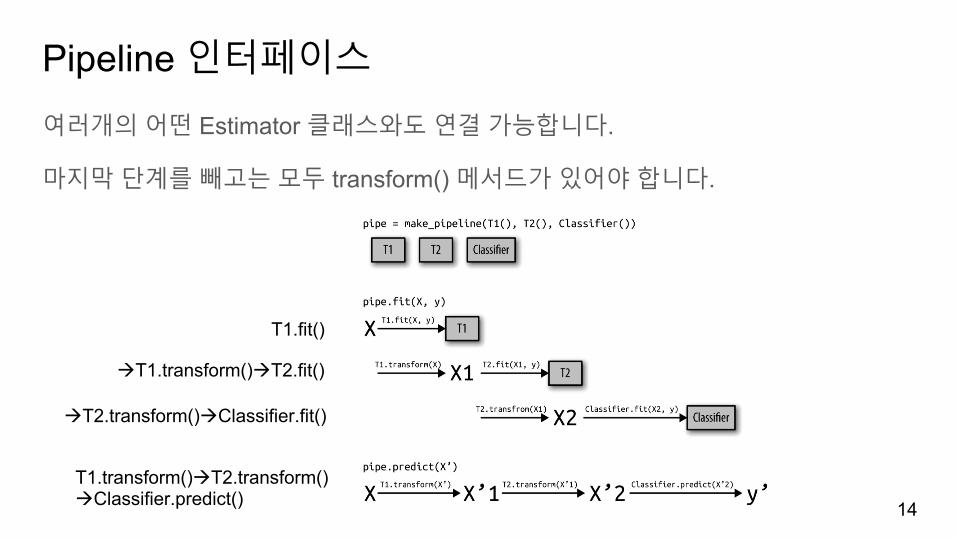
Pipeline 인터페이스
여러개의어떤 Estimator 클래스와도연결가능합니다.
마지막단계를빼고는모두 transform() 메서드가있어야합니다.
14
T1.fit()
àT1.transform()àT2.fit()
àT2.transform()àClassifier.fit()
T1.transform()àT2.transform()àClassifier.predict()

make_pipeline파이프라인단계에자동으로이름을할당합니다.
15
소문자클래스이름
두개이상일때

Pipeline 단계에접근하기
선형모델의계수나 PCA 주성분을확인할때
named_steps 속성에대해단계이름을키로하여접근합니다.
16

그리드서치안의 Pipeline 속성접근하기
17
GridSearchCV의 best_estimator_속성에최적의 Pipeline 모델저장
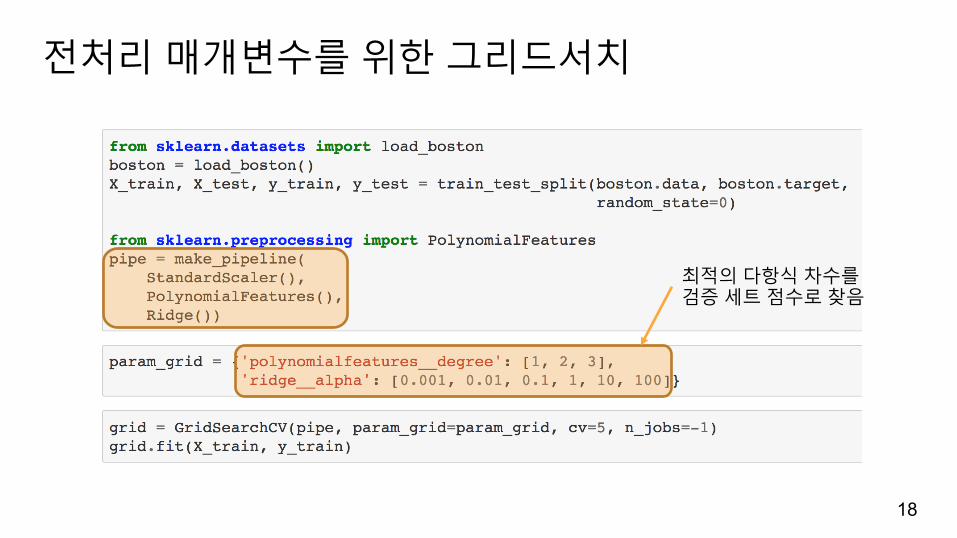
전처리매개변수를위한그리드서치
18
최적의다항식차수를검증세트점수로찾음

선택된다항특성확인
19

모델선택을위한그리드서치
파이프라인의구성단계를탐색대상으로삼을수있습니다.
매개변수그리드리스트를사용합니다.
20
랜덤포레스트는전처리가필요없습니다.

그리드서치로모델선택
21

요약및정리
Pipeline 클래스는여러처리단계를하나의객체로캡슐화합니다.
전처리가있는매개변수선택에서는올바른교차검증을위해필수적입니다.
매개변수와모델등탐색범위가커지면시간이많이걸릴수있습니다.
실험단계에서는처리단계가꼭필요한지검토하고너무복잡하게만들지않습니다.
22

감사합니다.
23





























