Embed Size (px)
Citation preview

Факторизационные модели врекомендательных системах
Петр Ромов
15 октября 2013 г.
1

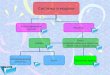
План
Факторизационные моделиМодель SVDСложные модели предпочтенияFactorization Machines
2

Outline
Факторизационные моделиМодель SVDСложные модели предпочтенияFactorization Machines
3

Коллаборативная фильтрация
Имеются сведения вида: (u, i, rui)(u,i)∈R,I u — пользователь,I i — предмет,I rui — оценки, отклик (feedback) пользователя u на
предмет i,I R — множество пар пользователь/предмет, для которых
оценка известна,I R(u) = i : (u, i) ∈ R
Хотим:I предсказывать rui ≈ rui,I рекомендовать i? = arg maxi rui,I оценивать похожесть предметов: sim(i1, i2),I обосновывать рекомендацию/предсказание
4

Модель SVD
rui = µ+ bu + bi︸ ︷︷ ︸biases
+ 〈pu, qi〉︸ ︷︷ ︸personal
I µ — общее смещение оценок, bu, bi — индивидуальныесмещения пользователей и предметов;
I pu ∈ Rd — латентный вектор (профиль) пользователя u;I qi ∈ Rd — латентный вектор (профиль) предмета i;I d — ранг модели, длина латентных векторов.
Параметры модели: Θ = pu, qi, bu, bi
5

Обучение модели SVD
J(Θ) =∑
(u,i)∈R
l(rui(Θui)) + Ω(Θui)→ minΘ
I МНК:J(Θ) =
∑
(u,i)∈R
(rui − rui)2 + Ω(Θ)
I МНК с нелинейным преобразованием:
J(Θ) =∑
(u,i)∈R
(rui − σ(rui))2 + Ω(Θ)
I Классификация, ordinal regression, pairwise-ранжирование...
Регуляризация:
Ω(Θ) = λbias
(∑
u
b2u +∑
i
b2i
)+λuser
∑
u
‖pu‖2 +λitem∑
i
‖qi‖2
6

Визуализация профилей SVD в 2DПрофили треков/жанров из SVD для набора Yahoo! Music dataset
Linkin Park
Green Day
Nelly
Red Hot Chili Peppers
Missy Elliott Beyoncé
50 Cent
Mariah Carey
Aerosmith
Snoop Dogg
Jay-Z
U2
Metallica
Mary J. Blige
Coldplay
Janet Jackson
AC/DC
Madonna
Nirvana
Led Zeppelin
The Doors
Avril Lavigne
Bob Marley
Nine Inch Nails
Busta Rhymes
Pop
R&B
Rock
Soul
Adult Alternative
Classic Rock
Soft Pop
Rock Moderno
Latin
Electronic/Dance
Mainstream
Rap
Mainstream Pop
R&B Moderno
Hip-Hop
Jazz
Rap
Disco
-1.5
-0.5
0.5
1.5
2.5
3.5
4.5
5.5
-4.2 -3.2 -2.2 -1.2 -0.2 0.8
Artists
Genres
Figure 1: The most popular musical tracks and gen-res in the Yahoo! Music dataset are embedded intoa 2-dimensional. The open cone suggests the regionof highly preferred items for the user (her logo isat the center of the cone). Note how the learnedembedding separates Rock and similar items fromHip-Hop and similar items. The low dimensional-ity (which is required for a visualization), causes asmall number of items to be wrongly folded near lessrelated items (e.g., Bob Marley).
loss of accuracy. If the item vectors were normalized, theRoR problem would have been reduced to the well studiednearest neighbor search (as explained in section 3). How-ever, such a normalization will introduce a distortion on thebalance between the original item trait vector and the itembias which constitute the concatenated vector qi. This wouldevidently result in an incorrect solution.
Denoting the concatenated user and item vectors as pu
and qi respectively, and the e!ective rating for the task ofretrieval as rui, RoR reduces to the following task: Given auser query pu, we want to find an item qi ! S such that:
p!u qi = max
q"Sp!
u q (6)
Hence the RoR task is equivalent to the problem of findingthe best-match for a query in a set of points with respect tothe dot-product (described in equation 1). A very simplisticvisualization of this task is depicted in Figure 1. For thegiven user, the best recommendations (in this case songs) liewithin the open cone around the user vector (maximizing thecos (!pu,qi) term) and are as far as possible from the origin(maximizing the "qi" term).
3. ALGORITHMS FORFINDING BEST-MATCHES
E"ciently finding the best match using the dot-product(equation 6) appears to be very similar to much existingwork in the literature. Finding the best match with re-spect to the Euclidean (or more generally Lp) distance isthe widely studied problem of nearest-neighbor search inmetric spaces [4]. The nearest-neighbor search problem (inmetric space) can be solved approximately with the popular
Locality-sensitive hashing (LSH) method [9]. LSH has beenextended to other forms of similarity functions (as opposedto the distance as a dissimilarity function) like the cosinesimilarity [3]. In this section, we show that the problemstated in equation 6 is di!erent from these existing prob-lems.
Nearest-neighbor Search in Metric Space.The problem of finding the nearest-neighbor in this setting
is to find a point qi ! S for a query pu such that:
qi = arg minq"S"pu # q"2 = arg max
q"S
!p!
u q # "q"2 /2"
$= arg maxq"S
p!u q (unless "q"2 = const % q ! S).
If all the points in S are normalized to the same length, thenthe problem of finding the best match with respect to thedot-product is equivalent to the problem of nearest-neighborsearch in any metric space. However, without this restric-tion, the two problems can yield very di!erent answers.
Cosine similarity.Finding the best match with respect to the cosine simi-
larity is to find a point qi ! S for a query pu such that
qi = arg maxq"S
p!u q/("pu" "q") = arg max
q"Sp!
u q/ "q"
$= arg maxq"S
p!u q (unless "q" = const % q ! S).
As in the previous case, the best match with cosine similar-ity is the best match with dot-products if all the points inthe set S are normalized to the same length. Under gen-eral conditions, the best matches with these two similarityfunctions can be very di!erent.
Locality-sensitive Hashing.LSH involves constructing hashing functions h which sat-
isfy the following for any pair of points q, p ! RD:
Pr[h(q) = h(p)] = sim(q, p), (7)
where sim(q, p) ! [0, 1] is the similarity function of inter-est. For our situation, we can scale our dataset such that% q ! S, "q" & 1 and assume that the data is in the firstquadrant (such as in non-negative matrix factorization mod-els [19]). In that case, sim(q, p) = q!p ! [0, 1] is our simi-larity function of interest.
For any similarity function to admit a locality sensitivehash function family (as defined in equation 7), the distancefunction d(q, p) = 1 # sim(q, p) must satisfy the triangleinequality (Lemma 1 in [3]). However, the distance functiond(q, p) = 1 # q!p does not satisfy the triangle inequality.Hence LSH cannot be applied to the dot-product similarityfunction even in restricted domains (the first quadrant).
3.1 Why is finding the maximum dot-productsharder?
Unlike the distance functions in metric space, dot-productsdo not induce any form of triangle inequality (even undersome assumptions as mentioned in the previous section).Moreover, this lack of any induced triangle inequality causesthe similarity function induced by the dot-products to haveno admissible family of locality sensitive hashing functions.Any modification to the similarity function to conform towidely used similarity functions (like Euclidean distance orCosine-similarity) will create inaccurate results.
7

Низкоранговое представление матрицы
Пусть R ∈ Rn×m,I Если rank(R) = k, то найдутся X ∈ Rn×k,Y ∈ Rm×k, что
R = XY T
I Если rank(R) > k, то низкоранговое приближение:
R ≈XY T
I ‖R−XY T ‖F → minX,Y — матричное SVD разложение
I Матрица R не известна полностью — взвешенноенизкоранговое приближение:
∑
i,j
wij(rij − xTi yj)2 = ‖W (R−XY T )‖ → min
X,Y
8

Низкоранговое представление матрицы
Пусть R ∈ Rn×m,I Если rank(R) = k, то найдутся X ∈ Rn×k,Y ∈ Rm×k, что
R = XY T
I Если rank(R) > k, то низкоранговое приближение:
R ≈XY T
I ‖R−XY T ‖F → minX,Y — матричное SVD разложениеI Матрица R не известна полностью — взвешенное
низкоранговое приближение:∑
i,j
wij(rij − xTi yj)2 = ‖W (R−XY T )‖ → min
X,Y
8

Проблемы низкорангового представления
I Неоднозначность разложения матрицыДля произвольной невырожденной матрицы A ∈ Rk×k:
R = XY T = XAA−1Y T = (XA)(Y A−T )T
I Сложность взвешенного SVD1
I rank(W ) = 1 ⇒ любой локальный оптимум являетсяглобальным
I rank(W ) > 1 ⇒ много плохих локальных оптимумов
1srebro2003weighted.9

Мотивация низкоранговых приближений
I Коллаборативная фильтрация — задача заполненияматрицы (matrix completion)
I Пусть имеется матрица M = (mij), известны некоторыеэлементы mij(i,j)∈Ω, известен ранг матрицы rankM = r.
TheoremЕсли Ω (известные элементы матрицы) взяты наугад,выполняется
m ≥ Cn5/4r log n
где m = |Ω|, то с вероятностью 1− cn−3 log n все значенияматрицы M можно восстановить в точности и единственнымобразом.2
2candes2009exact.10

Оптимизация модели: SGD
J(u,i)(Θui) = l(rui(Θui)) + Ωui(Θui)
Алгоритм:I Совершать проходы по выборке (эпохи) до сходимости
I Для каждого (u, i) ∈ RI Вычислить предсказание rui при текущих параметрах Θui
I Пересчитать параметры:pnewu = pu − η ·
(l′(rui)
∂rui∂pu
(Θui) + ∂Ωui∂pu
)
qnewi = qi − η ·
(l′(rui)
∂rui∂qi
(Θui) + ∂Ωui∂qi
)
аналогично остальные параметры
I Важен порядок элементов, поправка регуляризатора накаждом шаге, много других «тюнингов» алгоритма....
11

Оптимизация модели: SGD
J(u,i)(bu, bi,pu,pi) = (rui−rui)+λbias(b2u+b2i )+λuser‖pu‖2+λitem‖qi‖2
rui(bu, bi,pu,pi) = µ+ bu + bi + 〈pu, qi〉
Алгоритм:I Совершать проходы по выборке (эпохи) до сходимости
I Для каждого (u, i) ∈ RI Вычислить предсказание rui при текущих параметрах Θui
I Пересчитать параметры:eui = rui − ruipnewu = pu − η · (euiqi + λuserpu + λbiasbu)
qnewi = qi − η · (euipu + λitemqi + λbiasbi)
аналогично остальные параметры
I Важен порядок элементов, поправка регуляризатора накаждом шаге, много других «тюнингов» алгоритма....
11

Оптимизация модели: SGD
I ОсобенностиI Работает с любыми дифференцируемыми потерямиI Можно делать нелинейное преобразование модели:
обучать rui = f(µ+ bu + bi + 〈pu, qi〉)I Сходится за небольшое количество эпох (проходов по
обучающей выборки)I Техники обучения нейронных сетей3
I МасштабированиеI Задача не параллелится ⇒ мощная лошадка с большим
количеством памятиI Vowpal Wabbit4 умеет параллелить SGD и обучать SVD
3bottou-91c.4https://github.com/JohnLangford/vowpal_wabbit
12

Оптимизация модели: ALS
Смещения (biases) опущены для наглядности.
∑
(u,i)∈R
(rui − pTuqi)2 + λ
(∑
u
‖pu‖2 +∑
i
‖qi‖2)→ min
Θ
Зафиксируем qi, тогда оптимизация распадется нанезависимые по пользователям задачи линейной регрессии:
∑
u
∑
i∈R(u)
(rui − pTuqi)2 + λ‖pu‖2
→ min
pu
I Настройка параметров путем последовательнойоптимизации по pu и qi
I Хорошо масштабируется, даже на MapReduce
13

Выражение для обновления pu
Пусть зафиксированы профили предметов qi. Выражениедля оптимального вектора pu с точки зрения имеющейсяинформации:
p?u = (QTuQu + λI)−1
︸ ︷︷ ︸W u
QTuru︸ ︷︷ ︸du
= W udu =∑
j∈R(u)
W uqjruj
Qu — матрица из qi таких что i ∈ R(u), ru — векторсоответствующих оценок.
I Способ быстро обновить / создать вектор профиляпользователя.
I Способ объяснить предсказание.
14

Объяснение предсказаний в SVD
rui = qTi p?u =
∑
j∈R(u)
qTi W uqjruj =∑
j∈R(u)
ruj〈qi, qj〉W u
Матрица W u положительна, допускает разложение Холецкого:W u = V T
uV u. Перепишем в виде:
rui =∑
j∈R(u)
ruj〈V uqi,V uqj〉
I simu(i, j) = 〈qi, qj〉W u — персонализованная мерасхожести предметов;
I V u — оператор предпочтения пользователя.
15

Неперсонализованная схожесть предметовПусть в нашей модели rui = 1 означает положительный отклик.Представим пользователя, который оценил единственныйобъект i: ri = 1. Оптимальный профиль такого пользователя:
p? = (qTi qi + λI)−1qi
Выразим предсказание оценки для нового предмета j:
rj = qTj (qiqTi + λI)−1qi = Sherman–Morrison formula =
=1
λ
(1− ‖qi‖2
λ+ ‖qi‖2)〈qj , qi〉
I sim(i, j) ∝ 〈qj , qi〉I Интерпретация sim(i, j): аффинность профилей предметов
пропорциональна предсказанию оценки пользователя,поставившего только одну оценку.
16

Implicit SVD
∑
u
∑
i
cui(rui − rui)2 + Ω(Θ)→ minΘ
Предположение:I cui = 1 и rui = 0, если (u, i) 6∈ R
Эффективная оптимизация методом ALS:I p?u = (QTCuQ + λI)−1QTCuruI QTCuQ = QTQ + QT (Cu − I)Q
I QTQ предпосчитываетсяI (Cu − I) содержит не более |R(u)| ненулевых элементовI Curu содержит не более |R(u)| ненулевых элементов
Профит:I Работа не с оценками, а степенями уверенности:
I полагаем rui = 0 — dislike, rui = 1 — like;I если (u, i) 6∈ R, считаем что dislike с малой уверенностью
17

Быстрое построение списков рекомендаций
Задача Max Inner-product
fixed u : i? arg maxi〈qi,pu〉
I неравенство треугольника не выполняется ни в какойформе;
I методы поиска ближайшего соседа не работаютI arg minr∈S ‖p− r‖22 = arg maxr∈S
(〈p, r〉 − 1
2‖r‖22)
I arg maxr∈S〈q,r〉
‖q‖‖r‖ = arg maxr∈S〈q,r〉‖r‖
I стандартные LSH не работают с приемлемой точностью;
18

Быстрое построение списков рекомендацийЗадача Max Inner-product
fixed u : i? arg maxi〈qi,pu〉
Есть надежда: cone-trees5
I аналог KD-tree для поиска max-inner;I branch-and-bound алгоритм, приближенная версия;
Replacing !p and !q with "p and "q by using the aforementioned equalities (similar to the techniques inproof for theorem 3.1), we have:
!q!, p!" = !q0, p0" + rprq cos(# # ("p + "q)) + rp $q0$ cos(# # "p) + rq $p0$ cos(# # "q)
% maxrp,rq,!p,!q
!q0, p0" + rprq cos(# # ("p + "q)) + rp $q0$ cos(# # "p) + rq $p0$ cos(# # "q)
% maxrp,rq
!q0, p0" + rprq + rq $p0$ + rp $q0$ (since cos(·) % 1), (11)
% !q0, p0" + RpRq + Rq $p0$ + Rp $q0$ , (12)
where the first inequality comes from the definition of max and the final inequality comes from the fact thatrp % Rp, rq % Rq.
For the dual-tree search algorithm (Alg. 6), the maximum-possible inner-product between two tree nodesQ and T is set as
MIP(Q, T ) = !q0, p0" + RpRq + Rq $p0$ + Rp $q0$ .
It is interesting to note that this upper bound bound reduces to the bound in theorem 3.1 when the ballcontaining the queries is reduced to a single point, implying Rq = 0.
Ox
y
Figure 8: Cone-tree: These cones are open cones and only the angle made at the origin with the axis ofthe cone is bounded for every point in the cone. The norms of the queries are not bounded at all.
4.3 Cone-trees for Queries
An interesting fact is that in equation 1, the point p, where the maximum is achieved, is independent of thenorm ||q|| of the query q. Let "q,r be the angle between the q and r at the origin, then the task of searchingfor the maximum inner-product is equivalent to search for a point p & S such that:
p = arg maxr"S
$r$ cos "q,r. (13)
This implies that we only care about the direction of the queries irrespective of their norms. For this reason,we propose the indexing of the queries on the basis of their direction (from the origin) to form a cone-tree (figure 8). The queries are hierarchically indexed as (possibly overlapping) open cones. Each cone isrepresented by a vector, which corresponds to its axis, and an angle, which corresponds to the maximumangle made by any point within the cone with the axis at the origin.
12
5ram2012maximum.18

Вероятностные методы обучения SVDI Probabilistic Matrix Factorization (максимум правдоподобия)I Bayesian PMF (иерархический прайор)
I MCMC оптимизаци, «стохастический ALS»I Matchbox
I EP, VB и другие байесовские аппроксимации, реализованоисключительно в Infer.NET
I Профит: автоматическая подстройка гиперпараметров
UVj i
Rij
j=1,...,Mi=1,...,N
Vσ Uσ
σ
iY
Vj
Rij
j=1,...,M
U i iI
i=1,...,N
Vσ
Uσ
W
k=1,...,M
k
Wσ
σ
Figure 1: The left panel shows the graphical model for Probabilistic Matrix Factorization (PMF). The rightpanel shows the graphical model for constrained PMF.
Many of the collaborative filtering algorithms mentioned above have been applied to modellinguser ratings on the Netflix Prize dataset that contains 480,189 users, 17,770 movies, and over 100million observations (user/movie/rating triples). However, none of these methods have proved tobe particularly successful for two reasons. First, none of the above-mentioned approaches, exceptfor the matrix-factorization-based ones, scale well to large datasets. Second, most of the existingalgorithms have troublemaking accurate predictions for users who have very few ratings. A commonpractice in the collaborative filtering community is to remove all users with fewer than someminimalnumber of ratings. Consequently, the results reported on the standard datasets, such as MovieLensand EachMovie, then seem impressive because the most difficult cases have been removed. Forexample, the Netflix dataset is very imbalanced, with “infrequent” users rating less than 5 movies,while “frequent” users rating over 10,000 movies. However, since the standardized test set includesthe complete range of users, the Netflix dataset provides a much more realistic and useful benchmarkfor collaborative filtering algorithms.
The goal of this paper is to present probabilistic algorithms that scale linearly with the number ofobservations and perform well on very sparse and imbalanced datasets, such as the Netflix dataset.In Section 2 we present the Probabilistic Matrix Factorization (PMF) model that models the userpreference matrix as a product of two lower-rank user and movie matrices. In Section 3, we extendthe PMF model to include adaptive priors over the movie and user feature vectors and show howthese priors can be used to control model complexity automatically. In Section 4 we introduce aconstrained version of the PMF model that is based on the assumption that users who rate similarsets of movies have similar preferences. In Section 5 we report the experimental results that showthat PMF considerably outperforms standard SVD models. We also show that constrained PMF andPMF with learnable priors improve model performance significantly. Our results demonstrate thatconstrained PMF is especially effective at making better predictions for users with few ratings.
2 Probabilistic Matrix Factorization (PMF)
Suppose we have M movies, N users, and integer rating values from 1 to K1. Let Rij representthe rating of user i for movie j, U ! RD!N and V ! RD!M be latent user and movie featurematrices, with column vectorsUi and Vj representing user-specific and movie-specific latent featurevectors respectively. Since model performance is measured by computing the root mean squarederror (RMSE) on the test set we first adopt a probabilistic linear model with Gaussian observationnoise (see fig. 1, left panel). We define the conditional distribution over the observed ratings as
p(R|U, V, !2) =N!
i=1
M!
j=1
"N (Rij |UT
i Vj , !2)
#Iij
, (1)
where N (x|µ, !2) is the probability density function of the Gaussian distribution with mean µ andvariance !2, and Iij is the indicator function that is equal to 1 if user i rated movie j and equal to
1Real-valued ratings can be handled just as easily by the models described in this paper.
2
Bayesian Probabilistic Matrix Factorization using MCMC
UVj i
Rij
j=1,...,Mi=1,...,N
V U
α
α α
j
Rij
j=1,...,Mi=1,...,N
Vµ µ Ui
ΛU
µU
0ν , W0
µ0V0
VΛ
, W00ν
α
Figure 1. The left panel shows the graphical model for Probabilistic Matrix Factorization (PMF). The right panel showsthe graphical model for Bayesian PMF.
tors are assumed to be Gaussian:
p(U |µU , !U ) =N!
i=1
N (Ui|µU , !!1U ), (5)
p(V |µV , !V ) =
M!
i=1
N (Vi|µV , !!1V ). (6)
We further place Gaussian-Wishart priors on the userand movie hyperparameters "U = µU , !U and"V = µV , !V :
p("U |"0) = p(µU |!U )p(!U )
= N (µU |µ0, (!0!U )!1)W(!U |W0, "0), (7)
p("V |"0) = p(µV |!V )p(!V )
= N (µV |µ0, (!0!V )!1)W(!V |W0, "0). (8)
Here W is the Wishart distribution with "0 degrees offreedom and a D ! D scale matrix W0:
W(!|W0, "0) =1
C|!|(!0!D!1)/2 exp ("1
2Tr(W!1
0 !)),
where C is the normalizing constant. For conveniencewe also define "0 = µ0, "0, W0. In our experimentswe also set "0 = D and W0 to the identity matrixfor both user and movie hyperparameters and chooseµ0 = 0 by symmetry.
3.2. Predictions
The predictive distribution of the rating value R"ij for
user i and query movie j is obtained by marginalizing
over model parameters and hyperparameters:
p(R"ij |R, "0) =
""p(R"
ij |Ui, Vj)p(U, V |R, "U , "V )
p("U , "V |"0)dU, V d"U , "V . (9)
Since exact evaluation of this predictive distributionis analytically intractable due to the complexity of theposterior we need to resort to approximate inference.
One choice would be to use variational methods (Hin-ton & van Camp, 1993; Jordan et al., 1999) that pro-vide deterministic approximation schemes for posteri-ors. In particular, we could approximate the true pos-terior p(U, V, "U , "V |R) by a distribution that factors,with each factor having a specific parametric form suchas a Gaussian distribution. This approximate poste-rior would allow us to approximate the integrals inEq. 9. Variational methods have become the method-ology of choice, since they typically scale well to largeapplications. However, they can produce inaccurateresults because they tend to involve overly simple ap-proximations to the posterior.
MCMC-based methods (Neal, 1993), on the otherhand, use the Monte Carlo approximation to the pre-dictive distribution of Eq. 9 given by:
p(R"ij |R, "0) # 1
K
K#
k=1
p(R"ij |U (k)
i , V(k)j ). (10)
The samples U(k)i , V
(k)j are generated by running
a Markov chain whose stationary distribution is theposterior distribution over the model parameters andhyperparameters U, V, "U , "V . The advantage of
19

Outline
Факторизационные моделиМодель SVDСложные модели предпочтенияFactorization Machines
20

Учет тегов в SVD
Пусть предметы имеют теги:
i 7→ T (i) = t1, t2, ... ⊆ T
Учет тегов в модели: введем латентные вектора теговt 7→ xt ∈ Rd.
rui = µ+ bu + bi + bt + 〈pu, qi +∑
t∈T (i)
xt〉
I Теперь не просто разложение матрицы, а продвинутаямодель данных.
I Профили тегов берут на себя информацию, свойственнуюгруппам предметов (имеющих один тег) ⇒ емкость моделибольше расходуется на извлечение индивидуальныхособенностей предметов.
21

Модель параметрического соседства
I Parametric Neighborhood6
По аналогии с Item-based rui =∑
j∈Iu sim(i, j)(ruj − rj):
rui = bui +∑
j∈R(u)
wij(ruj − buj)
I Asymmetric-SVDПредставим W = XTY , т.е. wij = 〈xi,yj〉
rui = bui + xTi
∑
j∈R(u)
(ruj − buj)yj
6koren2008factorization.22

Модель параметрического соседства
I Parametric Neighborhood6
По аналогии с Item-based rui =∑
j∈Iu sim(i, j)(ruj − rj):
rui = bui +∑
j∈R(u)
wij(ruj − buj)
I Asymmetric-SVDПредставим W = XTY , т.е. wij = 〈xi,yj〉
rui = bui + xTi
∑
j∈R(u)
(ruj − buj)yj
6koren2008factorization.22

SVD++ и соседство
I SVD++7
rui = bui + qTi
pu +
∑
j∈R(u)
(ruj − buj)yj
I Integrated model
rui = bui + qTi
pu +
∑
j∈R(u)
(ruj − buj)yj
+
∑
j∈Rk(i;u)
wij(ruj − buj)
Rk(i;u) = Rk(i) ∩R(u), где Rk(i) — k наиболее похожихна i предмета, относительно внешней меры похожести.
7Шаманские нормировочные коэффициенты перед суммами опущены23

Integrated model with implicit feedback
Обозначим N(u) — множество предметов, с которымивзаимодействовал пользователь u, но не поставил оценку.
rui = µ+ bu + bj+
qTi
pu +
∑
j∈R(u)
(ruj − buj)yj +∑
j∈N(u)
xj
+
∑
j∈Rk(i;u)
wij(ruj − buj) +∑
j∈Nk(i;u)
cij
I Модель, которая «выиграла» Netflix Prize8.
8bell2008bellkor.24

Таксономия в SVD
Рассмотрим задачу рекомендации музыкальных треков,альбомов и исполнителей9.
I Треки, альбомы и артисты являются предметами в моделиI type(i) ∈ track, album, artistI album(i) — предмет, являющийся альбомом предмета iI artist(i) — предмет, являющийся артистом предмета iI bui = µ+ bu + bu,type(i) + bi + balbum(i) + bartist(i)I qi = qi + qalbum(i) + qartist(i)
rui = bui + 〈pu, qi〉
9koenigstein2011yahoo.25

Пользовательские сессииПредположение: поведение пользователя слегка меняется вовремя различных посещений.
I s — номер сессииI bu = bu + bu,s
I pu = pu + pu,s
26

Учет таксономии + сессий
Совместим модель сессий пользователей и таксономии впредметах. Для наглядности опустим смещения.
rui = 〈pu + pu,s, qi + qalbum(i) + qartist(i)〉
rui = 〈pu, qi〉+ 〈pu, qalbum(i)〉+ 〈pu, qartist(i)〉+〈pu,s, qi〉+ 〈pu,s, qalbum(i)〉+ 〈pu,s, qartist(i)〉
I Больше специфичных задачI Больше накруток моделиI Меньше работы
27

Учет таксономии + сессий
Совместим модель сессий пользователей и таксономии впредметах. Для наглядности опустим смещения.
rui = 〈pu + pu,s, qi + qalbum(i) + qartist(i)〉
rui = 〈pu, qi〉+ 〈pu, qalbum(i)〉+ 〈pu, qartist(i)〉+〈pu,s, qi〉+ 〈pu,s, qalbum(i)〉+ 〈pu,s, qartist(i)〉
I Больше специфичных задачI Больше накруток моделиI Меньше работы
27

Outline
Факторизационные моделиМодель SVDСложные модели предпочтенияFactorization Machines
28

Factorization Machines
Факторизационные машины10 предложены как универсальнаямодель предсказания, иммитирующая многие из известныхмоделей коллаборативной фильтрации.
y(x) = w0 +
p∑
j=1
wjxj +
p∑
j=1
p∑
j′=j+1
xjxj′〈vj ,vj′〉
I x ∈ Rp — вектор-признак объектаI y(x) — предсказаниеI w0,w,V = (v1, . . . ,vp) — параметры модели
10rendle2012factorization.29

Factorization Machines: SVD
(u, i) 7→ x, y(x) = w0 + wu + wi + 〈vu,vi〉Tensor Factorization Time-aware Factorization Models Factorization Machines
Application to Large Categorical Domains
User Movie RatingAlice Titanic 5Alice Notting Hill 3Alice Star Wars 1Bob Star Wars 4Bob Star Trek 5Charlie Titanic 1Charlie Star Wars 5. . . . . . . . .
1 0 0 ...
1 0 0 ...
0 1 0 ...
0 1 0 ...
0 0 1 ...
1
0
0
0
1
0
1
0
0
0
0
0
1
0
0
0
0
0
1
0
...
...
...
...
...
0 0 1 ... 0 0 1 0 ...A B C ... TI NH SW ST ...
x(1)
x(2)
x(4)
x(5)
x(6)
x(7)
Feature vector x
User Movie
1 0 0 ... 0 0 1 0 ...x(3)
5
3
4
5
1
5
Target y
y(1)
y(2)
y(4)
y(5)
y(6)
y(7)
1 y(3)
Applying regression models to this data leads to:
Linear regression: y(x) = w0 + wu + wi
Polynomial regression: y(x) = w0 + wu + wi + wu,i
Matrix factorization (with biases): y(u, i) = w0 + wu + hi + hwu,hi i
Ste↵en Rendle 48 / 75 Social Network Analysis, University of Konstanz
30

Factorization Machines: Feature Engineering
Factorization Machines with libFM 57:3
Fig. 1. Example (from Rendle [2010]) for representing a recommender problem with real valued featurevectors x. Every row represents a feature vector xi with its corresponding target yi. For easier interpreta-tion, the features are grouped into indicators for the active user (blue), active item (red), other movies ratedby the same user (orange), the time in months (green), and the last movie rated (brown).
where k is the dimensionality of the factorization and the model parameters ! =w0, w1, . . . , wp, v1,1, . . . vp,k are
w0 ! R, w ! Rp, V ! Rp"k. (2)
The first part of the FM model contains the unary interactions of each input variablex j with the target—exactly as in a linear regression model. The second part with thetwo nested sums contains all pairwise interactions of input variables, that is, x j x j # .The important difference to standard polynomial regression is that the effect of theinteraction is not modeled by an independent parameter wj, j but with a factorizedparametrization wj, j $ %v j, v j # & =
!kf=1 v j, f v j #, f which corresponds to the assumption
that the effect of pairwise interactions has a low rank. This allows FMs to estimate re-liable parameters even in highly sparse data where standard models fail. The relationof FMs to standard machine-learning models is discussed in more detail in Section 4.3.
In Section 4, it will also be shown how FMs can mimic other well known factoriza-tion models, including matrix factorization, SVD++, FPMC, timeSVD, etc.
Complexity. Let Nz be the number of nonzero elements in a matrix X or vector x.
Nz(X ) :="
i
"
j
"(xi, j '= 0), (3)
where " is the indicator function
"(b ) :=#
1, if b is true0, if b is false
. (4)
The FM model in Equation (1) can be computed in O(k Nz(x)) because it is equivalent[Rendle 2010] to
y(x) = w0 +p"
j=1
w j x j +12
k"
f=1
$
%&
'
(p"
j=1
v j, f x j
)
*2
(p"
j=1
v2j, f x2
j
+
,- . (5)
The number of model parameters |!| of an FM is 1 + p + k p and thus linear in thenumber of predictor variables (= size of the input feature vector) and linear in the sizeof the factorization k.
ACM Transactions on Intelligent Systems and Technology, Vol. 3, No. 3, Article 57, Publication date: May 2012.
31

Factorization Machines: иммитация SVD++
y(x) = y(u, i, l1, . . . , lm) =
SVD++︷ ︸︸ ︷
w0 + wu + wi + 〈vu,vi〉+1
m
m∑
j=1
〈vi,vlj 〉︸ ︷︷ ︸
FPMC
+
+1
m
m∑
j=1
wlj +1
m
m∑
j=1
〈vu,vlj 〉+1
m2
m∑
i=1
m∑
j′>j
〈vlj ,vlj′ 〉
32

Какие модели может иммитировать FM
I SVDI Pairwise interaction tensor factorizationI SVD++, FPMCI BPTS, TimeSVDI NNI SVM with Polynomial kernelI Attribute-aware models
Однако, иммитация FM как правило содержат слагаемые,которых нет в оригинальных моделях.
33

Свойства
I Мультилинеарность по параметрам
y(x; θ) = gθ(x) + θhθ(x)
I Выражение для быстрого подсчета y(x):
y(x; Θ) = w0 + wTx +1
2
K∑
k=1
(
p∑
i=1
vikxi
)2
−p∑
i=1
v2ikx
2i
34

High-order Factorization Machines
d-order factorization machine:
y(x) = w0 +
p∑
j=1
wjxj +
p∑
j=1
p∑
j′=j+1
xjxj′〈vj ,vj′〉+
+
d∑
l=2
p∑
j1=1
· · ·p∑
jd=jd−1
(l∏
i=1
xjl
)kl∑
f=1
l∏
i=1
vjl,f
I Зависимости между 3, 4... видами сущностейI FM в режиме d > 2 никто не использовалI Для моделирования зависимостей между 3, 4... видами
сущностей используют низкоранговые тензорныеразложения
35

Оптимизация FM
I SGDI ALSI ALS1 + кэширование ошибкиI MCMC (стохастическая версия ALS)I SGD, ALS1 для блочной структуры данных
Реализация: libFM (http://libfm.org/)
36

Блочная структура данных
Данные часто имеют реляционную структуру
!
"
#
# $
!
%&
'(&
&"%&
!
Figure 1: Example database from a movie commu-nity.
2. RELATIONALPREDICTIVEMODELINGIn the following, first the standard feature based approach
of predictive modeling is shortly recapitulated. Then thelimitations of this approach for scaling to data with rela-tional structure are described.
2.1 Predictive ModelingThe most common approach to predictive modeling is to
select a set of variables that are assumed to be predictivefor a task. Throughout this work, for illustration, the taskof predicting rating scores for users on movies is used. E.g.for the data in Figure 1, a data analyst might assume thatthe user ID, movie ID, date, gender, age, the set of moviegenres, the set of friends of a user and the set of all themovies a user has ever watched are predictive for estimatingthe rating score5. The task of machine learning is to learnthe functional dependency of the predictor variables on thetarget (Figure 2(a)).
Learning is based on observed samples of the functionaldependency – called training data. Each sample can be writ-ten as a vector of variable assignments for the predictor vari-ables and the target. Each row in Figure 2(b) shows one ofthe observed combinations of predictor variable values andthe observed target value. E.g. the first row represents thatAlice who is a 30 year old female has watched Titanic, Not-ting Hill and Star Wars and has Eve and Charlie as friendsrated Titanic which is an Action and Romance movie with 5stars. A variable assignment of predictor variables is calleda feature vector. The process of selecting and generatingpredictor variables is called feature engineering.
The process sketched so far is a very generic one and is fol-lowed by most of the standard machine learning approaches,incl. linear regression, support vector machines (SVM), de-cision trees, etc. The di!erence between the machine learn-ing methods lies in the type of functional dependency thatis assumed (e.g. for a linear regression a linear dependencyis assumed and for SVMs a linear dependency in a projectedspace is assumed), optimization aspects such as regulariza-tion and the particular learning algorithms.
So far, there is no restriction on the domain (e.g. numeri-cal, categorical, string, graph) of each variable in the featurevector. For a generic formalization, many machine learning
5Note that the selected variables are not limited to explicitlystated columns in the original data, but can also be derived.
methods rely on a numeric vector representation of the vari-ables (either explicitly or implicitly). Also in the remainderof this work, it is assumed that there are p numeric predic-tor variables, i.e. each case can be represented as a vectorx ! Rp. E.g. for encoding a categorical/nominal variablewith m levels, the standard approach is to map the variableto m numerical variables and use a binary encoding. Figure2(c) shows one possibility of how to represent the trainingdata of 2(b) with numeric variables. In total, the n caseseach represented by a feature vector x ! Rp can be seenas a matrix X ! Rn!p which is typically called design ma-trix. The n prediction targets can be represented as an ndimensional vector y ! Rn for regression (or y ! ", +n
for binary classification).In general, a highly desirable property of a learning al-
gorithm is a linear runtime complexity in the size of thedesign matrix X. Often the data is sparse, i.e. containsmany 0 values. Let NZ(X) denote the number of non-zerosin a matrix X. Sparse learning algorithms can make use ofthe non-zeros in the training data and a desirable propertyis a runtime complexity linear in NZ(X). In the following,it is discussed that in relational data even a linear runtimecomplexity in NZ(X) can be infeasible.
2.2 Relational Predictive ModelingThe standard approach of predictive modeling to select
predictor variables and to learn the dependency on a tar-get is also reasonable for predictive problems on relationaldata. Actually, the example presented in Figure 2 involvesrelational data. This means the concepts of feature engineer-ing, feature vectors and design matrices are also applied hereand any standard machine learning method can be used.
However, relational data can lead to very large featurevectors/ design matrices with redundant information. Fig-ure 3(a) illustrates this on the running example. Investigat-ing the first case (first row), one can see that parts of thefeature vector are repeated in other rows. E.g. the partshighlighted in red reappear in the second and third case.The parts highlighted in blue appear also in the 6th case.It is clear that these repeating patterns stem from the re-lational structure of the predictor variables: The red blockcorresponds to the variables describing user Alice, the blueblock from variables describing movie Titanic. Whenevera case uses predictor variables describing Alice, the featurevector will include all of Alice’s descriptors including age,gender, friends, etc. Regarding the predictive model, thisis correct as the case depends on all the predictor variables(no matter from where they come from). However, the de-sign matrix X can get very large and intractable. E.g. insocial networks each user often has hundreds of friends, us-ing these friends as predictor variable for the taste of theuser is reasonable but will result in a long predictor vec-tor with many non-zero entries (for each friend a non-zerovariable) for describing the case. In the evaluation, exam-ples of the size NZ(X) for a selection of predictor variablesin real-world datasets are shown (Figure 5, Table 1). Forany machine learning method that relies on feature vectors/design matrices – which are most ML methods – relationaldatasets can result in very large design matrices that areinfeasible for standard algorithms, even if the algorithm hasa linear runtime complexity in NZ(X). The contributionof this work are new learning algorithms that make use ofrepeating patterns to speed up learning.
338
37

Блочная структура данных
Figure 3: (a) In relational domains, design matrices X have large blocks of repeating patterns (example fromFigure 2). (b) Repeating patterns in X can be formalized by a block notation (see section 2.3) which stemsdirectly from the relational structure of the original data. Machine learning methods have to make use ofrepeating patterns in X to scale to large relational datasets.
to process feature vectors in the original space, i.e. by con-catenating the vectors (eq. 1) – not even on-the-fly. On-the-fly concatenating would reduce the memory complexity toO(NZ(B)) but not the runtime complexity. In analogy tocompression: if B is regarded as a compression of X, thena linear runtime complexity in B means that the algorithmshave to do all calculations without decompressing the dataat all (not even on-the-fly or partially).
3. SCALING LINEAR REGRESSIONTo highlight the basic ideas of scaling learning algorithms,
the well-known linear regression model is discussed first.
3.1 Standard Linear RegressionThe linear regression (LR) model for the i-th row/ feature
vector xi of an n! p design matrix X is
y(xi) = w0 +
p!
j=1
wj xi,j
where ! = w0, w1, . . . , wp are the model parameters. Pre-dicting all n cases can be implemented in O(NZ(X)) by re-garding only the non-zero elements in the design matrix.
There are several ways to learn a LR model. The tradi-tional one for least-squares regression is based on solving ap ! p system of linear equations (typically in O(p3) time).Iterative approaches scale better to a large number of pre-dictor variables p and coordinate descent (CD) [2] is one ofthe most e"cient iterative algorithms. The CD algorithmstarts with an initial (random) guess of !, then iterates overeach model parameter wl " ! and performs an update
wl #wl
"ni=1 x2
i,l +"n
i=1 xi,l ei"ni=1 x2
i,l + !l(3)
where !l " R+ is a predefined regularization constant for thel-th model parameter and ei = yi$ y(xi) is the i-th residual(i " 1, . . . , n) which should be precomputed and has to beupdated during learning. After a parameter changes fromwl to w!
l (let #l = wl $w!l be the di$erence), each residual
changes and can be updated in constant time ei # ei+#l xl.This process of updating each model parameter wl (and
updating precomputed residuals) is iterated over all modelparameters until convergence. The runtime of CD is domi-nated (see eq. (3)) by computing the two quantities:
n!
i=1
x2i,l,
n!
i=1
xi,l ei. (4)
By caching residuals e, each full iteration (i.e. over all !)of CD can be implemented e"ciently in O(NZ(X)).
Whereas CD is a point estimator, i.e. the result is a sin-gle value for each parameter wl, Bayesian inference can in-clude uncertainty into the model. Bayesian inference typi-cally improves the prediction quality and also allows to inferregularization values automatically. Bayesian inference withMarkov chain Monte Carlo (MCMC), here Gibbs samplingwith block size of one, is related to CD. In this case, theGibbs sampler updates the model parameters by drawingwl from its conditional posterior distribution:
wl % N#
" wl
"ni=1 x2
i,l + ""n
i=1 xi,l ei + µl !l
""n
i=1 x2i,l + !l
,
1
""n
i=1 x2i,l + !l
$(5)
where " is the precision of the likelihood and µl is the meanand !l the precision of the normal prior distribution overwl. These three hyperparameters are found automaticallyby Gibbs sampling – see [13] for details. As it can be seen, for
340
Figure 3: (a) In relational domains, design matrices X have large blocks of repeating patterns (example fromFigure 2). (b) Repeating patterns in X can be formalized by a block notation (see section 2.3) which stemsdirectly from the relational structure of the original data. Machine learning methods have to make use ofrepeating patterns in X to scale to large relational datasets.
to process feature vectors in the original space, i.e. by con-catenating the vectors (eq. 1) – not even on-the-fly. On-the-fly concatenating would reduce the memory complexity toO(NZ(B)) but not the runtime complexity. In analogy tocompression: if B is regarded as a compression of X, thena linear runtime complexity in B means that the algorithmshave to do all calculations without decompressing the dataat all (not even on-the-fly or partially).
3. SCALING LINEAR REGRESSIONTo highlight the basic ideas of scaling learning algorithms,
the well-known linear regression model is discussed first.
3.1 Standard Linear RegressionThe linear regression (LR) model for the i-th row/ feature
vector xi of an n! p design matrix X is
y(xi) = w0 +
p!
j=1
wj xi,j
where ! = w0, w1, . . . , wp are the model parameters. Pre-dicting all n cases can be implemented in O(NZ(X)) by re-garding only the non-zero elements in the design matrix.
There are several ways to learn a LR model. The tradi-tional one for least-squares regression is based on solving ap ! p system of linear equations (typically in O(p3) time).Iterative approaches scale better to a large number of pre-dictor variables p and coordinate descent (CD) [2] is one ofthe most e"cient iterative algorithms. The CD algorithmstarts with an initial (random) guess of !, then iterates overeach model parameter wl " ! and performs an update
wl #wl
"ni=1 x2
i,l +"n
i=1 xi,l ei"ni=1 x2
i,l + !l(3)
where !l " R+ is a predefined regularization constant for thel-th model parameter and ei = yi$ y(xi) is the i-th residual(i " 1, . . . , n) which should be precomputed and has to beupdated during learning. After a parameter changes fromwl to w!
l (let #l = wl $w!l be the di$erence), each residual
changes and can be updated in constant time ei # ei+#l xl.This process of updating each model parameter wl (and
updating precomputed residuals) is iterated over all modelparameters until convergence. The runtime of CD is domi-nated (see eq. (3)) by computing the two quantities:
n!
i=1
x2i,l,
n!
i=1
xi,l ei. (4)
By caching residuals e, each full iteration (i.e. over all !)of CD can be implemented e"ciently in O(NZ(X)).
Whereas CD is a point estimator, i.e. the result is a sin-gle value for each parameter wl, Bayesian inference can in-clude uncertainty into the model. Bayesian inference typi-cally improves the prediction quality and also allows to inferregularization values automatically. Bayesian inference withMarkov chain Monte Carlo (MCMC), here Gibbs samplingwith block size of one, is related to CD. In this case, theGibbs sampler updates the model parameters by drawingwl from its conditional posterior distribution:
wl % N#
" wl
"ni=1 x2
i,l + ""n
i=1 xi,l ei + µl !l
""n
i=1 x2i,l + !l
,
1
""n
i=1 x2i,l + !l
$(5)
where " is the precision of the likelihood and µl is the meanand !l the precision of the normal prior distribution overwl. These three hyperparameters are found automaticallyby Gibbs sampling – see [13] for details. As it can be seen, for
340
37