Embed Size (px)
Citation preview

TAIPEI | SEP. 21-22, 2016
Shun-Fang Yang, Ph.D, 9/21/2016
Telecommunication Laboratories, Chunghwa Telecom Co., Ltd
以深度學習加速語音及影像辨識應用發展

2
AGENDA
深度學習DNN
深度學習應用於語音辨識
深度學習應用於影音場景偵測
深度學習應用於車牌辨識

3
深度學習DNN

4
ARTIFICIAL NEURAL NETWORK
Each neuron is a function
A Neuron for Machine
z
1w
2w
Nw
…
1x
2x
Nx
+
b
( )zs ( )zs
zbias
a
( ) zez -+=11s
Sigmoid function
Activation function
ANN is one type of machine learning that's loosely based on how neurons work in the brain, though “the actual similarity is very minor”.

5
DEEP LEARNING (DEEP NEURAL NETWORK)
Each layer is a simple function in the production
Cascading the neurons to form a neural network
2006年「A fast learning algorithm for deep belief nets」論文,如果類神經網路神經元權重不是以隨機方式指派,可以大幅縮短神經網路的計算時間,類似非監督式學習來做為神經網路初始權重的指派
6
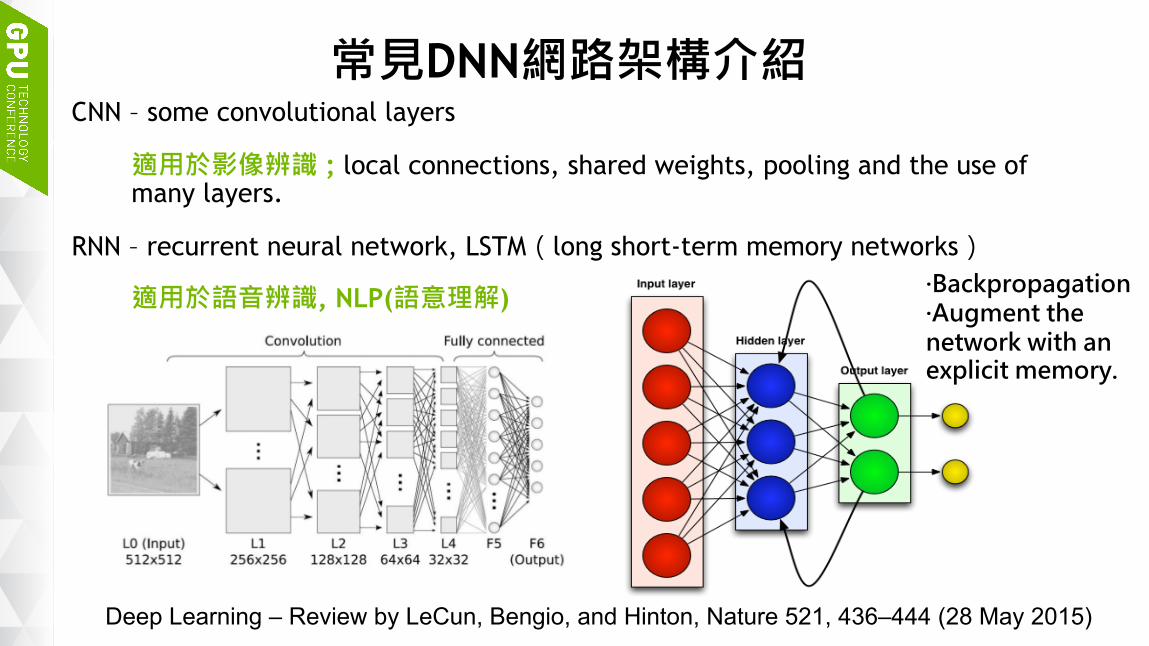
常見DNN網路架構介紹CNN – some convolutional layers
適用於影像辨識 ; local connections, shared weights, pooling and the use of many layers.
RNN – recurrent neural network, LSTM(long short-term memory networks)
適用於語音辨識, NLP(語意理解) ·Backpropagation·Augment the network with anexplicit memory.
Deep Learning – Review by LeCun, Bengio, and Hinton, Nature 521, 436–444 (28 May 2015)

7
訓練深度學習MODEL之TOOLKIT項目 用途 授權方式 備註
Kaldi 語音辨識 Apache 2.0 Open Source Project
Caffe 影像辨識 BSD license Berkeley
Torch 影像辨識, 語音辨識, 自然語言 BSD license Facebook
Theano 語音辨識, 自然語言 BSD license Universite de Montreal
Tensorflow 語音辨識, 影像辨識, 自然語言 Apache 2.0 Google
CNTK 影像辨識, 語音辨識, 自然語言 微軟自己的授權合約 Microsoft
項目 用途 備註
CUDA 平行運算架構 NVIDIA
cuDNN 為深層神經網路設計的 GPU 加速原式函式庫(Caffe, TensorFlow, Theano,Torch and CNTK都有使用)
NVIDIA
DIGITS 整合現有的開發工具(Caffe,Torch),實現DNN設計、訓練和可視化等任務變得簡單化。
NVIDIA

8
深度學習框架比較
8/39+20
Caffe CNTK TensorFlow Theano Torch
模型涵蓋性 ★★★ ★★ ★★★★☆ ★★★★☆ ★★★★★
佈署性 ★★★★★ ★★★★☆ ★★★★☆ ★★★ ★★★
架構修改性 ★★★ - ★★★★★ ★★★ ★★★★★
介面易用性 ★★★C++/CMDPython/Matlab
★★☆CMD/C++Python/.NET
★★★★☆PythonC++
★★★★Python
★★★★Lua/LuaJITC
原開發語言 C++/Python C++ C++/Python Python C/Lua
支援分散式 No Yes Yes No No
授權 BSD 2-Clause Free Apache 2.0 BSD BSD
支持廠商/原創者
Berkeley Microsoft Google Université de Montréal
FacebookTwitterGoogle(before)
https://en.wikipedia.org/wiki/Comparison_of_deep_learning_softwarehttps://github.com/zer0n/deepframeworks
n TensorFlow在模型涵蓋性及佈署皆有不錯的表現,受Google支持,社群/學習資源快速起步n Torch/Theano成熟度高,已有豐富的網路分享資源供學習;Caffe有相當多影像領域的使用者

9
深度學習應用於語音辨識

10
104查號台
語音搜尋
AppStore GooglePlay

11
語音辨識
笑一個
Voice Text
GMM-HMM
MFCCMel-frequency cepstra
Gaussian Mixture ModelHidden Markov Model

12
DNN-HMM
深度學習(Deep Learning)為目前機器學習 熱門研究領域之一,有別於以往傳統機器學習技術
深度學習提供了有效率的end-to-end學習架構,近年來很多文獻證明其辨識率遠高於傳統的GMM-HMM
n shallow structure vs. deep learning
n limited data vs. big data
n unstable performance vs. noise robust
目前使用Kaldi toolkit來訓練DNN-HMM
n C++ , Linux shell scripts, LVCSR

13
GMM-HMM VS. DNN-HMM
GMM-HMMHand-crafted feature extraction is needed. Each box is a simple function in the production line,only GMM is learned from data.
Construct very large Context-Dependent output units in DNNMake decoding of such huge networks highly efficient using HMM technology

14
語音辨識訓練目前訓練語料約126小時
Feature
nMFCC 39 維
Acoustic model
nHMM, 414 音節 , 8 states
Language model
nFree syllable grammar,即任一音節可自由相接
Decoder
nKaldi tooolkit

15
中文FREE SYLLABLE辨識結果
DNN network:
n6 layers, 1024 hidden node
測試語料:
n104ASR4000句short spontaneous speech
相對提升了25%
測試語料 GMM-HMM DNN-HMM
104Asr 69.27% 76.96%

16
小結
持續增加訓練語料
n 1000-2000小時
實驗不同的network
n LSTM-RNN, CNN, Combination Networks
中英台多語言DNN

17
深度學習應用於影音場景偵測

18
問題與挑戰
如何在中華電信影視平台上提供相關商品推薦/多螢互動內容?
n內容由供應商提供(無法掌握)
n請廣告頻道商自製(耗時費力)
影音內容分析辨識
n借助深度學習技術,自動分析影片內容出現的事物 阿羅街夜市
馬來西亞芒果汁
互動內容 購買推薦
如何產生?

19
技術架構• 發展機器學習技術
– 辨識影音內容– 產生描述資訊
位置資訊(例:平鎮)
相關推薦技術
合作店家
影像/聲音描述資訊
阿羅街夜市、馬來西亞、果汁
• 基於描述資訊提供相關推薦服務─ 藉由影音內容辨識技術自動產生
描述資訊(metadata),作為購買推薦/互動內容依據
托斯卡尼尼-平鎮店
影音內容辨識技術影像/聲音描述資訊
(例:庭園、義大利麵)

20
場景辨識資料/模型
• 訓練資料nPlaces365 Dataset
365類
Standard(1.8m)
Challenge(8m)
• 類神經模型(辨識器)– AlexNet(8層)– VGGNet(16層)
Input
Conv
Pool
FC
Softmax
Conv
Conv
Conv
Conv
Conv
Conv
Pool
Pool
Conv
Conv
Conv
Pool
Conv
Conv
Conv
Pool
FC
FC
Input
Conv
FC
Softmax
Conv
Conv
Pool
Pool
FC
Pool
Conv
Conv
FC
AlexNet
VGGNet

21
場景辨識訓練效果評估
測試資料/模型
nPlaces365 Validation Set
nVGG(16層)
辨試時間(每張圖片)
nGPU: 27.7ms (NVIDIA K80)
nCPU: 1.6s (Intel Xeon E5-2698 v3@ 2.30GHz)
辨識正確率
nTop1: 52.26%
nTop5: 83.03%

22
電影場景辨識
辨識資料
n院線電影
處理流程
n影片轉檔(H.264, mp4)
n換幕偵測/擷取代表畫面
n場景辨識
產生資訊
n第幾幕、時間、長度、場景、信心度
例:第1312幕、時間: 01:05:40.728、長度: 2.34秒、衣物間、0.99

23
電影場景辨識結果

24
小結
多數錯誤並非辨識器能力不足
n畫面模糊
n不在定義類別中
n畫面非場景(例:人)

25
深度學習應用於車牌辨識

26
車牌辨識流程
輸入影像
n車牌偵測
n字元切割與辨識 (字元辨識)
輸出車牌號碼

27
問題 / 挑戰
n光線 n 角度 n 大小

28
以 CNN 解決問題
輸入影像
n車牌偵測 ( CNN 車牌偵測)
n字元切割與辨識 (CNN 字元辨識)
輸出車牌號碼

29
CNN 車牌偵測網路架構
You Only Look Once: Unified, Real-Time Object Detection (CVPR 2016)

30
CNN 字元辨識網路架構
以 Caffe 實作

31
CNN 車牌偵測
資料庫 單純環境 複雜環境
張數 5,981 6,737
車牌偵測率 92.3%® 97.7% 74.9%® 92.3%
CPU / GPU 執行效能比較 CPU ([email protected]) 0.08 FPSGPU (NVIDIA Quadro M5000) 12 FPS
利用 CUDA 進行開發,充分應用 GPU 的運算能力
GPU 訓練效能比較 GPU (T7600) 11,410 分鐘GPU (K80) 4,305 分鐘
GPU 效能對深度學習訓練階段有很大的影響
32
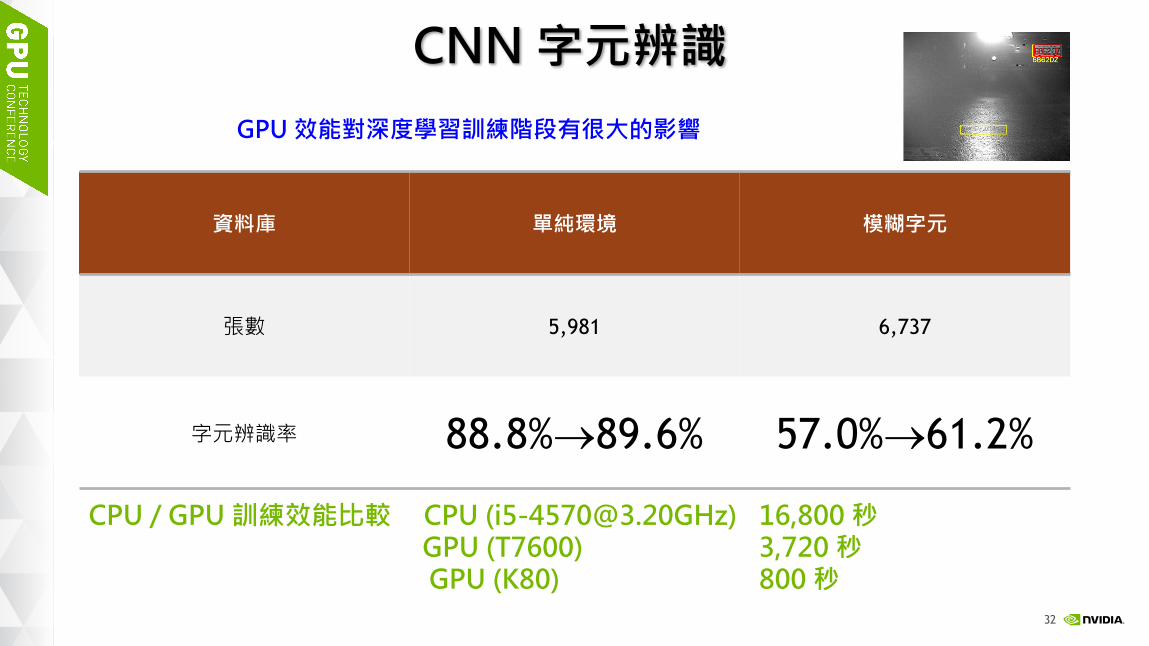
CNN 字元辨識
資料庫 單純環境 模糊字元
張數 5,981 6,737
字元辨識率 88.8%®89.6% 57.0%®61.2%
CPU / GPU 訓練效能比較 CPU ([email protected]) 16,800 秒GPU (T7600) 3,720 秒GPU (K80) 800 秒
GPU 效能對深度學習訓練階段有很大的影響

33
CNN 車牌辨識
資料庫 單純環境 複雜環境
張數 5,981 6,737
車牌辨識率 88.8%®93.7% 57.0%®67.8%

34導入 CNN 讓車牌辨識系統更為穩定
CNN 車牌辨識
上圖:原始車牌辨識,下圖:CNN 車牌辨識(籃框為原始車牌偵測,紅框為 CNN 車牌偵測,淺藍字串為辨識結果)
上圖:原始車牌辨識,下圖:CNN 車牌辨識

35
小結
從深度學習的應用發展趨勢來看,許多研究單位常先將一個問題各部分替換為 DNN,當一個問題的各部分都可以 DNN 解決時, 終將朝向整合為一個完整的網路架構,這樣的好處是從輸入一路接到結果 (End-to-End) 可以讓 DNN 針對問題的學習更為精確,在執行階段也避免了一些重複計算,可以更有效率
目前僅將車牌辨識中的部分模組由 CNN 取代,後續將其整合為一個完整的車牌辨識網路是值得嘗試的研發方向

36
結論
深度學習技術突破的關鍵因素:
n資料:Amount of available (big) data from people, sensors and devices.
n人才:Improvement in algorithms and combination of algorithms.
n設備:Specialized hardware (GPU/FPGA/ASIC HPC)
車牌及語音辨識各模組逐步替換為DNN方式
影音場景偵測持續往物件、事件偵測及Visual Question Answering等目標努力

TAIPEI | SEP. 21-22, 2016
THANK YOU