Embed Size (px)
Citation preview

競技プログラミングからみたC++0x
OSC名古屋2011 8/20(土)はじめての競技プログラミング 蛇足
@yak_ex / 新康孝 (CSNagoya)

自己紹介
氏名: 新康孝 (あたらし やすたか)
Twitter ID: yak_ex
Web: http://yak3.myhome.cx:8080/junks
C++ / Perl が主戦場
現在、仕事でコードに触れていないので競技プログラミング(TopCoder、Codeforces)で潤い補充
闇の軍団に憧れるただの C++ 好き

C++0x とは
国際標準化機構 ISO で規格化されている C++ 規格(ISO 14882)の次期版仮称 200x 年代に発行予定だったが間に合わなかったため 0x は 16 進プレフィクスということにhttp://www2.research.att.com/~bs/C++0xFAQ.html
先頃 Final Draft が承認され規格発行を待つ状態であり正式名称 14882:2011 となる予定
小修正だった 14882:2003 とは異なり、言語自体また標準ライブラリに非常に大きな変更が加えられている
本稿では競技プログラミングから見た C++0x の利点について紹介する Codeforces で gcc 4.6 での C++0x 機能が使えるのでそれを基準として説明する

目次
auto
Range-based for
Lambda
tuple
initializer_list
unordered_map / unordered_set
新規アルゴリズム (iota, all_of)
ちょっとした改善 (map::at)
対応微妙(regex / emplace)
auto
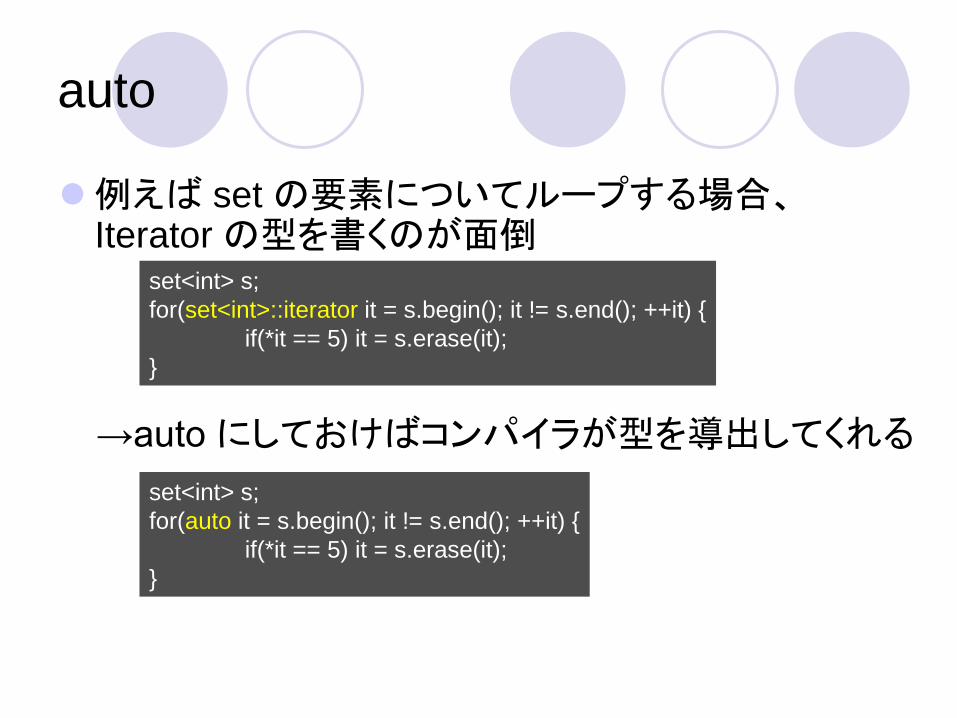
例えば set の要素についてループする場合、Iterator の型を書くのが面倒
set<int> s;
for(set<int>::iterator it = s.begin(); it != s.end(); ++it) {
if(*it == 5) it = s.erase(it);
}
set<int> s;
for(auto it = s.begin(); it != s.end(); ++it) {
if(*it == 5) it = s.erase(it);
}
→auto にしておけばコンパイラが型を導出してくれる

Range-based for ループですっきり
コンテナ s の各要素を v に割り当ててループ
Range-based for
例えば単純に set の要素についてループする場合、C++03では色々と面倒
std::set<int> s;
for(std::set<int>::iterator it = s.begin(); it != s.end(); ++it)
std::cout << *it << std::endl;
std::set<int> s;
for(auto it = s.begin(); it != s.end(); ++it)
std::cout << *it << std::endl;
auto でもやっぱり微妙
set<int> s;
for(auto v : s)
std::cout << v << std::endl;

lambda (無名関数オブジェクト)
<algorithm>は便利だけど関数オブジェクト書くのが面倒でループで書いてしまう
// 関数オブジェクトstruct check2nd
{
check2nd(const int &n) : n(n) {}
bool operator()(const std::pair<int, int> &p) { return p.second == n; }
const int &n;
};
std::vector<std::pair<int, int>> v; int k;
return std::count_if(v.begin(), v.end(), check2nd(k));
// 自前ループstd::vector<std::pair<int, int>> v; int k;
int result = 0;
for(int i=0;i<v.size(); ++i) if(v[i].second == k) ++result;
return result;

lambda (無名関数オブジェクト)
<algorithm>は便利だけど関数オブジェクト書くのが面倒でループで書いてしまう
↓
その場で関数オブジェクトが書けるスコープ内の変数を参照可能
// lambda
vector<std::pair<int, int>> v; int k;
return std::count_if(v.begin(), v.end(),
[&](const std::pair<int, int>& p) { return p.second == k; });
中身が return だけなら戻り値の型を省略可能[&](const std::pair<int, int>& p) -> bool { return p.second == k; }
[&] はスコープ内変数の参照の仕方の指定

lambda (関数内関数風)
ヘルパ関数として切り出したいけど状態渡すのが面倒int count2nd(const std::vector<std::pair<int, int>> &v, int k) {
int result = 0;
for(int i=0;i<v.size(); ++i) if(v[i].second == k) ++result;
return result;
}
std::vector<std::pair<int, int>> v;
if(count2nd(v, 0) == 0 && count2nd(v, 1) == v.size()) /* 適当 */
マクロは C++er として認められないしグローバル変数は未初期化とか上書きの問題がある

lambda (関数内関数風)
ヘルパ関数として切り出したいけど状態渡すのが面倒int count2nd(const std::vector<std::pair<int, int>> &v, int k) {
int result = 0;
for(int i=0;i<v.size(); ++i) if(v[i].second == k) ++result;
return result;
}
std::vector<std::pair<int, int>> v;
if(count2nd(v, 0) == 0 && count2nd(v, 1) == v.size()) /* 適当 */
std::vector<std::pair<int, int>> v;
auto count2nd = [&] (int k) -> int {
int result = 0;
for(int i=0;i<v.size(); ++i) if(v[i].second == k) ++result;
return result;
};
if(count2nd(0) == 0 && count2nd(1) == v.size()) /* 適当 */
関数内関数的にその場でヘルパ関数を定義できる

lambda (関数内関数風)
ヘルパ関数として切り出したいけど状態渡すのが面倒int count2nd(const std::vector<std::pair<int, int>> &v, int k) {
int result = 0;
for(int i=0;i<v.size(); ++i) if(v[i].second == k) ++result;
return result;
}
std::vector<std::pair<int, int>> v;
If(count2nd(v, 0) == 0 && count2nd(v, 1) == v.size()) /* 適当 */
std::vector<std::pair<int, int>> v;
auto count2nd = [&] (int k) {
return count_if(v.begin(), v.end(),
[&] (const std::pair<int, int>&p) { return p.second == k; });
};
if(count2nd(0) == 0 && count2nd(1) == v.size()) /* 適当 */
関数内関数的にその場でヘルパ関数を定義できる※内部でも lambda を使った場合

lambda (関数内関数風)
応用編再帰関数を定義したい→ std::function と組み合わせ
std::vector<std::vector<int>> adj; int goal;
std::vector<bool> visited(adj.size());
// auto dfs = … だとエラーが出るstd::function<bool(int)> dfs = [&](int n) -> bool {
if(n == goal) return true;
visited[n] = true;
for(int i: adj[n]) {
if(!visited[i]) {
bool res = dfs(i);
if(res) return true;
}
}
return false;
};
※std::funciton は関数オブジェクトも持てる関数ポインタ的イメージ

tuple
いちいち構造体を宣言し、かつ比較演算子を用意するのがかったるい
struct data { int level, value, cost; };
bool operator<(const data& d1, const data &d2){
return d1.level < d2.level
|| d1.level == d2.level && d1.value < d2.value
|| d1.level == d2.level && d1.value == d2.value && d1.cost < d2.cost;
}
std::set<data> s;
typedef std::tuple<int, int, int> data; // 辞書式比較演算子定義済みstd::set<data> s;
// こういう用意をしておくてアクセスが分かりやすいかもenum { LEVEL, VALUE, COST };
std::get<LEVEL>(*s.begin());
ref. http://topcoder.g.hatena.ne.jp/cafelier/20110816/1313498443
tuple にお任せ

initializer_list
vector とかの内容を自由に初期化する方法がない
std::vector<int> v(5);
int init[5] = { 1, 3, 2, 5, 4 };
std::copy(init, init + 5, v.begin());
std::vector<int> v({1, 3, 2, 5, 4});
// コンストラクタ呼び出しは () じゃなくて {} でもできるようになったので// 以下も OK
std::vector<int> v{1, 3, 2, 5, 4};
→初期化リスト(initializer_list)をとるコンストラクタを定義できる
map だって初期化できる
std::map<std::string, int> v = {
{ "first", 1 },
{ "second", 2 }
};

initializer_list
応用編min / max
int minimum = std::min(std::min(a, b), std::min(c, d));
int minimum = std::min({a, b, c, d});
min / max は 2 引数だったので複数値の min / max
をとりたい場合は多段で適用する必要があった
→initializer_list を受けられるようになったので一発で OK

initializer_list
応用編固定値のリストでループ
int init[] = { 1, 2, 3, 5, 8, 13, 21 };
for(std::size_t i = 0; i < sizeof(init) / sizeof(init[0]); ++i) {
std::cout << init[i] << std::endl;
}
for(int i : { 1, 2, 3, 5, 8, 13, 21} ) {
std::cout << i << std::endl;
}
固定値を持つ配列を用意して添え字でループ
→Range-based for と initializer_list の組み合わせでこんな簡潔に
unordered_map / unordered_set
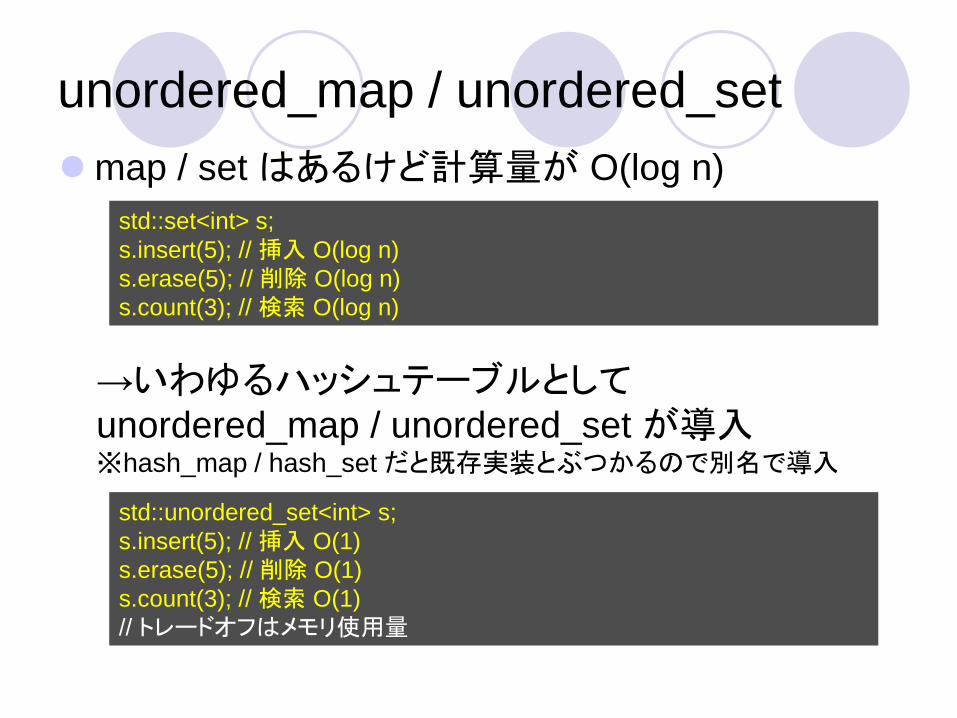
map / set はあるけど計算量が O(log n)
std::set<int> s;
s.insert(5); // 挿入 O(log n)
s.erase(5); // 削除 O(log n)
s.count(3); // 検索 O(log n)
std::unordered_set<int> s;
s.insert(5); // 挿入 O(1)
s.erase(5); // 削除 O(1)
s.count(3); // 検索 O(1)
// トレードオフはメモリ使用量
→いわゆるハッシュテーブルとしてunordered_map / unordered_set が導入※hash_map / hash_set だと既存実装とぶつかるので別名で導入

新規アルゴリズム(iota)
インデックス用配列の初期化めんどいstd::vector<int> vdata;
std::vector<int> index(vdata.size());
for(std::size_t i = 0; i < index.size(); ++i) index[i] = i;
std::sort(index.begin(), index.end(),
[&](int n1, int n2) { return vdata[n1] < vdata[n2]; });
for(int i: index) { std::cout << i << " : " << vdata[i] << std::endl; }
std::vector<int> vdata;
std::vector<int> index(vdata.size());
std::iota(index.begin(), index.end(), 0); // 0 が初期値で 0, 1, 2, …
std::sort(index.begin(), index.end(),
[&](int n1, int n2) { return vdata[n1] < vdata[n2]; });
for(int i: index) { std::cout << i << " : " << vdata[i] << std::endl; }
→地味に仕事をする std::iota
#define RNG(c) (c).begin(), (c).end() でさらに便利

新規アルゴリズム(*_of)
→all_of / any_of / none_of
名前通り
std::vector<int> v;
if(std::all_of(v.begin(), v.end(), [](int n){ return n >= 5; })) {
/* 全要素 5 以上の場合 */
}
if(std::any_of(v.begin(), v.end(), [](int n){ return n >= 5; })) {
/* どれか1要素でも 5 以上の場合 */
}
if(std::none_of(v.begin(), v.end(), [](int n){ return n >= 5; })) {
/* 5 以上の要素がない場合 */
}

ちょっとした改善(map::at)
map::operator[] のせいで const 性の維持が面倒
int get(const std::map<std::string, int> &m, const std::string &s)
{
// map::operator[] に const 版はないのでこう書けない// return m[s];
return m.find(s)->second;
}
int get(const std::map<std::string, int> &m, const std::string &s)
{
return m.at(s);
}
→const 版のある at() で OK

対応微妙(regex, emplace)
→regex(正規表現)で文字列処理が容易に!※でも gcc(libstdc++) は対応微妙
std::vector<pair<std::string, int>> v;
v.push_back(std::make_pair(std::string("hoge"), 5));
→emplace で insert 時等の生成を省略※でも gcc(libstdc++) はコンテナ毎に対応微妙
std::vector<pair<std::string, int>> v;
v.emplace_back("hoge", 5);
※直接、挿入する場所に値を生成するイメージ

まとめ
今なら Codeforces でも C++0x 使用者は尐ないので「同一言語使用者内で世界10位以内(キリッ」とか言える
C++0x は大変便利なので競技プログラミングでもばりばり使うべき

参考文献
競技プログラマのためのC++0xB
http://topcoder.g.hatena.ne.jp/cafelier/201
10816/1313498443
Wikipedia C++0x
http://ja.wikipedia.org/wiki/C%2B%2B0x
cpprefjp
https://sites.google.com/site/cpprefjp/

ご清聴ありがとうございました。



![ULWLN 7HUKDGDS 3HPDKDPDQ 0X ¤DPPDG DO *KD] O ¯ …repository.uinjkt.ac.id/dspace/bitstream/123456789/40384/1/....ulwln 7hukdgds 3hpdkdpdq 0x ¤dppdg do *kd] o ¯ 7hqwdqj £dg ¯](https://img.pdfslide.tips/doc/110x75/5c902f8c09d3f2387d8cf32a/ulwln-7hukdgds-3hpdkdpdq-0x-dppdg-do-kd-o-7hukdgds-3hpdkdpdq-0x-dppdg.jpg)




![DAFTAR KEPUSTAKAAN 0X¶ML]DWXQ :D¶DMDLEXQ …eprints.walisongo.ac.id/1731/7/09311107_Bibliografi.pdf · DAFTAR KEPUSTAKAAN Abdur Rahim, Muhammad, 0X¶ML]DWXQ :D¶DMDLEXQ Minal al-](https://img.pdfslide.tips/doc/110x75/5cc3d19a88c99389538d6546/daftar-kepustakaan-0xmldwxq-ddmdlexq-daftar-kepustakaan-abdur-rahim-muhammad.jpg)



















![[PROGRAMMING COMPETITION SESSION] 21 Maret, 2010angelinaveni.com/wp-content/uploads/2010/04/soalpcs2010.pdf · Ketika anaknya menanyakan panjang ikan tersebut kepadanya ia hanya menjawab](https://img.pdfslide.tips/doc/110x75/5d6266f388c9931f3f8b85e6/programming-competition-session-21-maret-ketika-anaknya-menanyakan-panjang.jpg)