Embed Size (px)
DESCRIPTION
In deze presentatie gaan we wat dieper in op de Cuda-programmeeromgeving en de Tesla-architectuur van Nvidia.
Citation preview

Ervaring met parallel computing van CudaKasper Van RemoortereNils Lamot1ste Bachelor Informatica

Inhoudstafel
•Situatieschets•GeForce 8800•Programmeertaal: CUDA•Architectuur: Tesla•Applicatie voorbeeld•Conclusies
2
Kasper Van Remoortere - Nils Lamot

Situatieschets
•Kloksnelheid verhogen Parallel geschakelde processors
•Efficiënt gebruik?
•GPU’s al langer parallel real-time graphics
3
Kasper Van Remoortere - Nils Lamot

•Tesla architectuur▫Rechtstreeks programmeerbare GPU’s
•CUDA programmeermodel (= extensie van C)▫Makkelijk voor programmeurs▫Versnelt het rekenproces
4
Kasper Van Remoortere - Nils Lamot
GeForce 8800

Programmeertaal - CUDA
•Programmeeromgeving van Nvidia
•Doelen:▫Uitbreiding C/C++
uitdrukking parallellisme vereenvoudigen▫Code goed verdelen over threads
Vb.: Huidige GPU’s - 30 720 threads
5
Kasper Van Remoortere - Nils Lamot

Programmeertaal - onderdelen
6
Parallelle Threads
Rooster van blokken

7
Programmeertaal - geheugen
HS gedeeld geheugen
Globaal geheugen
Data-parallel > Task-parallel

Architectuur - Tesla
•Doel: programma’s in CUDA optimaal uitvoeren▫Aanmaak, planning, resource management
In hardware opgenomen Tijd creëren/verwijderen = verwaarloosbaar
▫Geoptimaliseerd in het verwerken van opeenvolgende, gelijkende patronen
8
Kasper Van Remoortere - Nils Lamot

9
Kasper Van Remoortere - Nils Lamot
Architectuur - structuurSM Multi-threaded Processor•Communicatie threads in blok•SIMT: blok thread =
warp van 32 threads
SP cores: toegang tot assortiment instructies
Multithreading: grote cache overbodig

10
Applicaties
•Moleculaire bewegingen
•Numerieke lineaire algebra
•Medische sector
•Beweging van vloeistoffen
•Seismologie

Applicatie – Numerieke lineaire algebraMatrixvermenigvuldiging•Berekeningen verdeelbaar in blokken
11
Hoe matrices vermenigvuldigen:A x B = Ca1,1 x b1,1 + a1,2 x b2,1 +… = c1,1
Kasper Van Remoortere - Nils Lamot

12
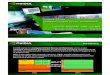
Applicatie – Numerieke lineaire algebraAlgoritme Volkov en Demmel vs. MKL
GeForce 8800 GTX - V&D Core2 Quad - MKL0
50
100
150
200
250
Rekenkracht in Gflops
Kasper Van Remoortere - Nils Lamot

Applicatie – Numerieke lineaire algebraVerklaring snelheid algoritme V&D
•Data-blocks opgeslagen in GPU-registers register = groot tijdelijke opslag berekeningen
•Blokken elementen /thread 1/thread
•Software prefetching wachttijd geheugen
13
Kasper Van Remoortere - Nils Lamot

Applicatie – Numerieke lineaire algebraMatrix factorisatie
•Matrix naar eenvoudigste vorm omzetten
•Oplossen stelsels
•Factorisatiemethodes: ▫LU ▫Cholesky ▫QR factorisatie
14
Kasper Van Remoortere - Nils Lamot

15
Kasper Van Remoortere - Nils Lamot

Conclusies•Cuda bruikbaar voor data-parallel programmeren
•Cuda voor groot publiek beschikbaar
16
Kasper Van Remoortere - Nils Lamot





![Программно-аппаратная архитектура CUDA, осень 2015 [Открытое прочтение]: Программная модель CUDA](https://img.pdfslide.tips/doc/110x75/588468ba1a28abbd308b6965/-cuda--591390cfeebd1.jpg)