Embed Size (px)
Citation preview

HSA Fundamentals (1)
Henry Wu2014-12-19

Agenda
• Background– Current Gaps
• Introductions to HSA– HSA Features
• References

Agenda
• Background– Current Gaps
• Introductions to HSA– HSA Features
• HSA Programming Model• References

Heterogeneous Parallel Processor
• Trends to leveraging heterogeneous processors– Cell BE[6], DSP, GPU, APU– 50% of top 10 supercomputers use co-
processors[2]– 30% of top 10 supercomputers use NVIDIA GPU[2]
• What are the benefits?– Cost-effectiveness– Energy-efficiency
[2]Toop500.org. (2014). November 2014 | TOP500 Supercomputer Sites. Retrieved December 19, 2014, from http://www.top500.org/lists/2014/11/

Heterogeneous Parallel Programming Models
• Existing programming models– Brook[3], Sh[4], CTM[5]
• Ancient era• Utilize GLSL or HLSL to perform computation on GPU graphic
pipelines
– OpenCL 2.0, CUDA 6, DirectCompute 5• Mainstream programming model
– OpenACC, C++AMP• New high level programming models that aim to lower the
learning curve• Performance optimization is a big challenge• Stacked on mainstream programming models
– And more

Gap1 – long Runtime Latency
• The Mainstream programming model such as OpenCL and CUDA– Has extreme large runtime setup latency
• Device query, context initialization, program compilation, user-space queue setup
• Runtime setup time grows with the number of GPU devices
– The kernel dispatch latency is high• Require the help from traditional driver
• Not an optimal choice for consumer-level applications with small workloads– E.g. Adobe photoshop, spreadsheet functions[7]
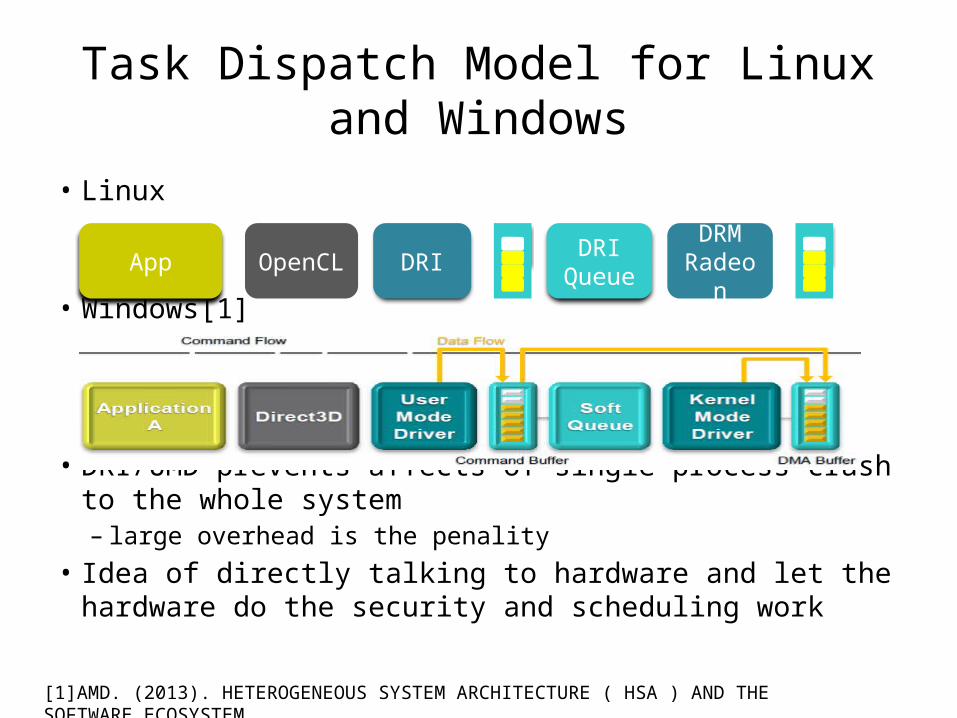
Task Dispatch Model for Linux and Windows
• Linux
• Windows[1]
• DRI/UMD prevents affects of single process crash to the whole system – large overhead is the penality
• Idea of directly talking to hardware and let the hardware do the security and scheduling work
App OpenCL DRI DRI Queue
DRMRadeon
[1]AMD. (2013). HETEROGENEOUS SYSTEM ARCHITECTURE ( HSA ) AND THE SOFTWARE ECOSYSTEM.

Gap2 – Distributed Memory Spaces• Heterogeneous programming model could be used to program
– CPU + discrete GPU or DSP– CPU + fused GPU + discrete GPU– CPU + fused GPU + discrete GPUs + DSP anything …
• With each compute unit has its own memory space– Several copies of same data exist at the same time– Data consistency is a problem
• Memory consistency of various memory spaces in OpenCL is defined by GPU vendor
– Increased complexity of data scheduling• Locality
– Different layout of data may have impact to throughput• The idea is provide a uniformed memory view to all devices
– Require a standard for all hardware devices to follow
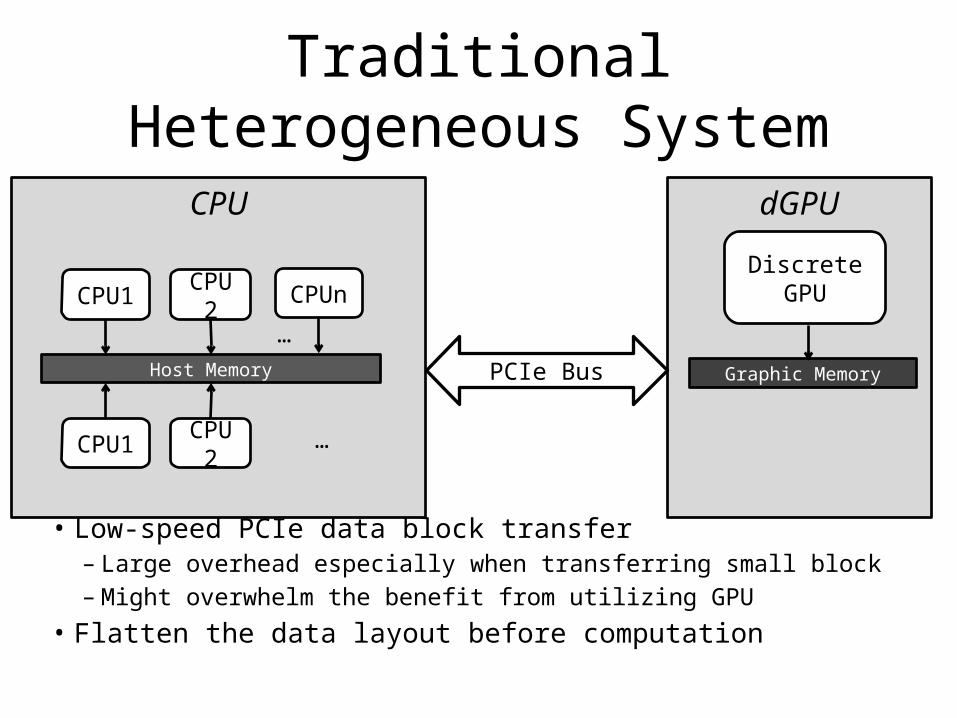
Traditional Heterogeneous System
• Low-speed PCIe data block transfer– Large overhead especially when transferring small block– Might overwhelm the benefit from utilizing GPU
• Flatten the data layout before computation
CPU
Host Memory
…
…
dGPU
Graphic Memory
Discrete GPU
PCIe Bus
CPU1
CPU1
CPU2
CPU2
CPUn
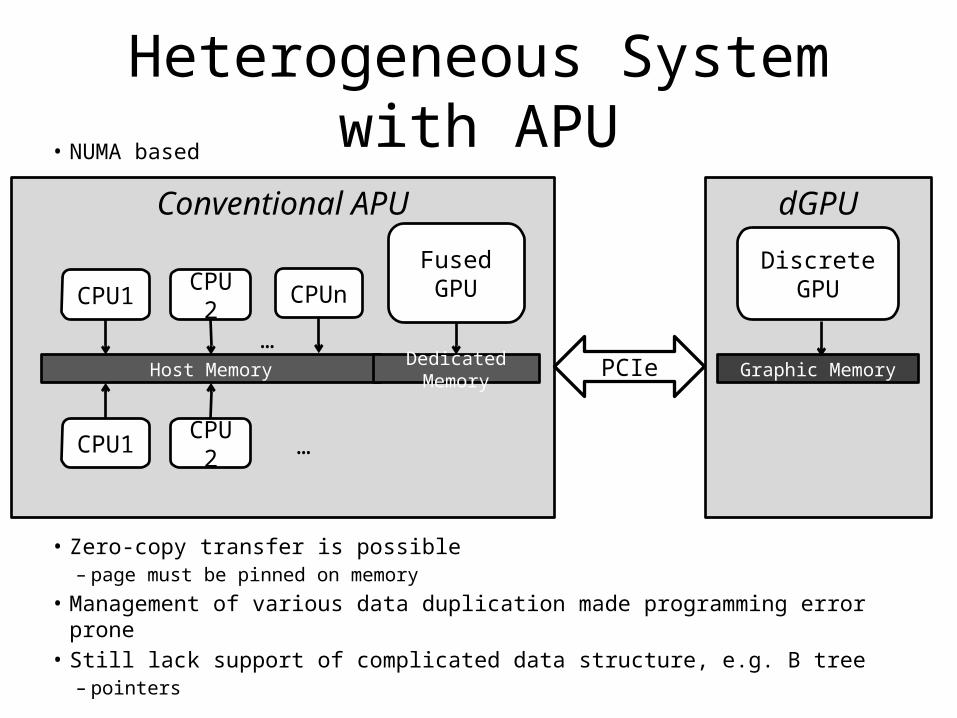
Heterogeneous System with APU• NUMA based
• Zero-copy transfer is possible– page must be pinned on memory
• Management of various data duplication made programming error prone • Still lack support of complicated data structure, e.g. B tree
– pointers
Conventional APU
Host Memory Dedicated Memory
CPU1 CPU2 CPUnFused GPU
CPU1 CPU2
…
…
dGPU
Graphic Memory
Discrete GPU
PCIe

Gap3 – Distributed Memory Spaces and Variety of Architectures
• Heterogeneous programming model could be used to program– CPU + discrete GPU or DSP– CPU + fused GPU + discrete GPU– CPU + fused GPU + discrete GPUs + DSP anything …
• With each compute unit may has its own ISA– Multiple version of kernel binaries needs to compiled on the run – Optimization is time consuming!
• The idea: split compiling– provide an intermediate language
• Low level enough to provide ahead of time optimization
– And Just-in-Time compiler translate to final machine assembly• No compiler optimization to provide fast translation

Background Summary
• HPP is the emerging trend• There exists a lot of HPP models, but learning
curve is high • Complexity of HPP is increasing– Data orchestra– Task scheduling– Multiple versions of kernel codes to run on
various of heterogeneous processors

Agenda – This week
• Background• Introductions to HSA– HSA Features
• HSA Programming Model• References

HSA
• Heterogeneous System Architecture[8]• Not-for-profit industry standard for
programming heterogeneous computing devices• Founders: – AMD– Mobile solutions provider: ARM, MediaTek,
Qualcomm, TI• Developments status:– First version is in provisional phase

HSA Objectives
• A brand new heterogeneous programming experiences– Leads more performance
• Small form factors[1]– Low power & energy efficiency
• HSA is not targeting on replacing mainstream HPP model but provide a solid abstraction layer of underlying heterogeneous resources

High Level HSA features• Computation-focused programming model for heterogeneous
architectures– No need to worry about data movement– Thin runtime
• hUMA, Uniform memory space for all participated CU– Bi-directional coherence– Pageable memory – Pointer support
• hQ, User-mode hardware queue – No more dependence to traditional graphic driver– Negligible dispatch latency
• GPU context switch– QoS scheduling policies
• Assembly-level intermediate language – eliminate processor heterogeneity– HSAIL

HSA-hUMA
• Compute Units include CPUs and GPUs share a uniform memory view
• Memory consistency and coherence are provided
• Pointer is used, no more data block transfer
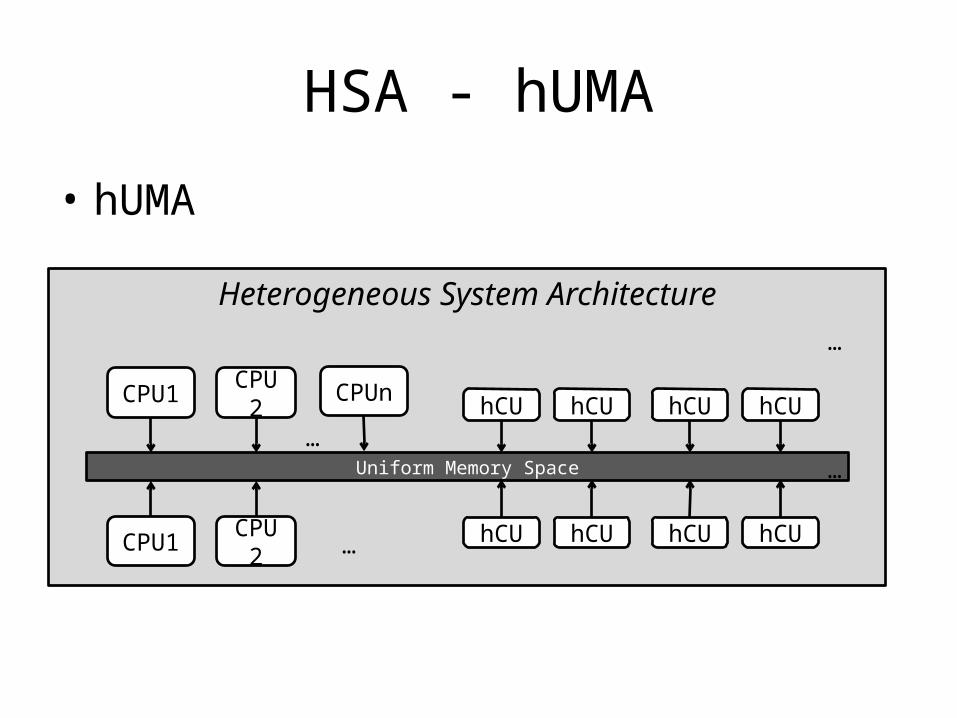
HSA - hUMA
• hUMA
Heterogeneous System Architecture
Uniform Memory Space
CPU1 CPU2 CPUn hCU
CPU1 CPU2
…
…
hCU hCU hCU
hCU hCU hCU hCU
…
…

HSA -hQ• hQ– User-level hardware queue– Hardware receive tasks directly from application
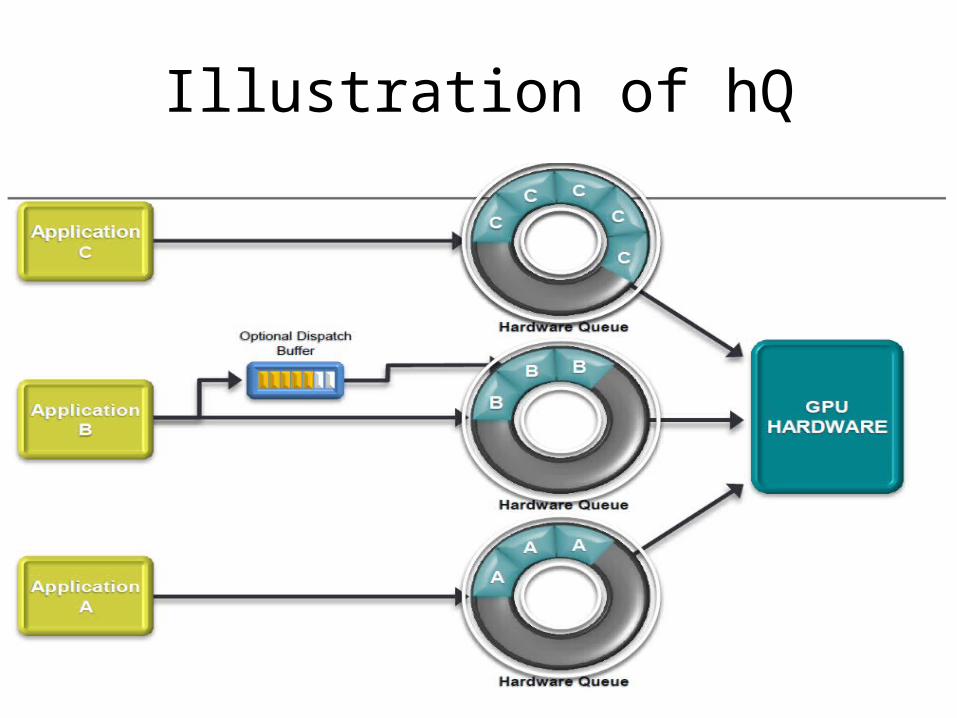
Illustration of hQ
AMD HSA ROADMAPSTEPPE EAGLE KAVERI
Merlin FalconCORRIZO

HSA Limitations
• We observed these limitations from the aspect of implementing HSA on non-AMD platform
• Hardware support[6]– Exception handling
• Floating point• Page fault
– Hardware-based memory coherency• hUMA
– Hardware-based signaling and synchronization• hQ

Agenda
• Background• Introductions to HSA– HSA Features
• References

References• [1] AMD. (2013). HETEROGENEOUS SYSTEM ARCHITECTURE ( HSA ) AND THE
SOFTWARE ECOSYSTEM.• [2] Toop500.org. (2014). November 2014 | TOP500 Supercomputer Sites. Retrieved
December 19, 2014, from http://www.top500.org/lists/2014/11/• [3] Standford. (2003). BrookGPU. Retrieved December 19, 2014, from
http://graphics.stanford.edu/projects/brookgpu/• [4] Intel. (2003). Sh: A high-level metaprogramming language for modern GPUs.
Retrieved December 19, 2014, from http://libsh.org/• [5] AMD. (2007). Clost to the Metal. SIGGRAPH. Retrieved December 19, 2014, from
http://gpgpu.org/static/s2007/slides/07-CTM-overview.pdf• [6] IBM. (2005). Cell Broadband Engine - IBM Microelectronics. Retrieved from
https://www-01.ibm.com/chips/techlib/techlib.nsf/products/Cell_Broadband_Engine• [7] LibreOffice. (2014). Calc: GPU enabling a spreadsheet. FOSDEM. Retrieved
December 17, 2014, from https://archive.fosdem.org/2014/schedule/event/calc_gpu_enabling_a_spreadsheet/
• [8] Foundation, HSA (2014). HSA Foundation. Retrieved December 19, 2014, from http://www.hsafoundation.com/





























