Embed Size (px)
DESCRIPTION
PyCon 2014の発表資料です。 CRMやマーケティングに活用できる実践的なデータ分析とはどのようなものなのか、データ分析の実例を交えつつ、データ分析関連のPythonのライブラリ(NumPy, pandas, SciPy, scikit-learn など)をダイジェストで紹介します。
Citation preview


2

3

4
5

6

7

8

9

10

11

12

13

14

15

16

17
PlayStation 3
PlayStation 4

18

19

20

21

22

23

24

25

26

27

28

29

30

31

32

33

34

35
分析対象 分析手法例
顧客ユーザークラスタリング
RFM分析・ロイヤルカスタマー分析商圏 商圏・出店分析
商品商品間アソシエーション分析時系列分析 / 需要・売上予測
季節性分析
広告マイクロコンバージョン分析 クリエイティブ最適化アトリビューション分析

36

37

38

39

from itertools import permutations !
d = ['A', 'B', 'C'] !
for v in permutations(d) print(v)
40

from collections import Counter !
d = ['A', 'A', 'A', 'B', 'B', 'C'] !
for w, c in Counter(d).items() print('{0}が{1}個'.format(w, c))
41

42

43

44

45

46

47

48
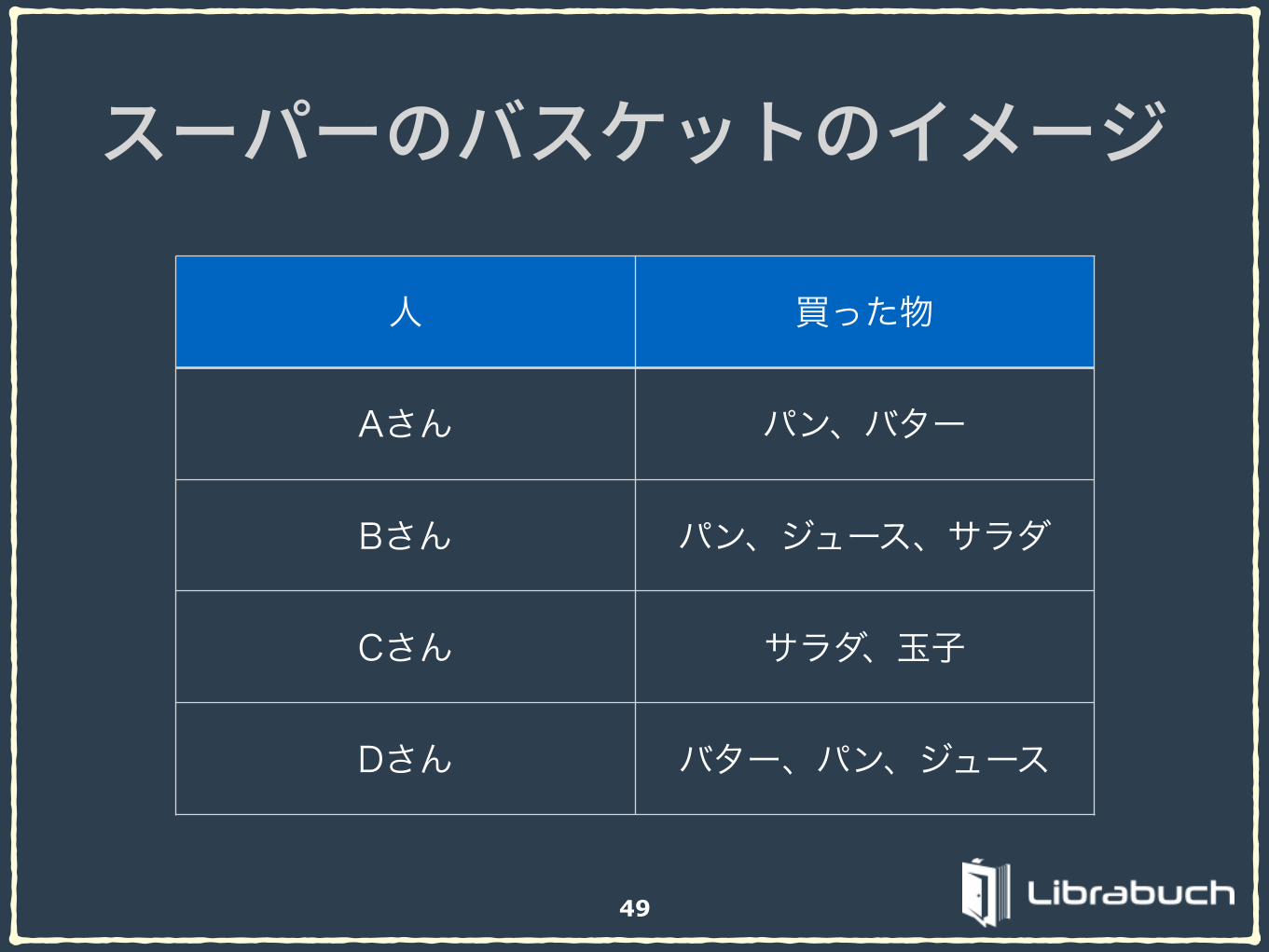
49
!
人 買った物
Aさん パン、バター
Bさん パン、ジュース、サラダ
Cさん サラダ、玉子
Dさん バター、パン、ジュース

50
人 買った物
Aさん パン、バター
Bさん パン、ジュース、サラダ
Cさん サラダ、玉子
Dさん バター、パン、ジュース
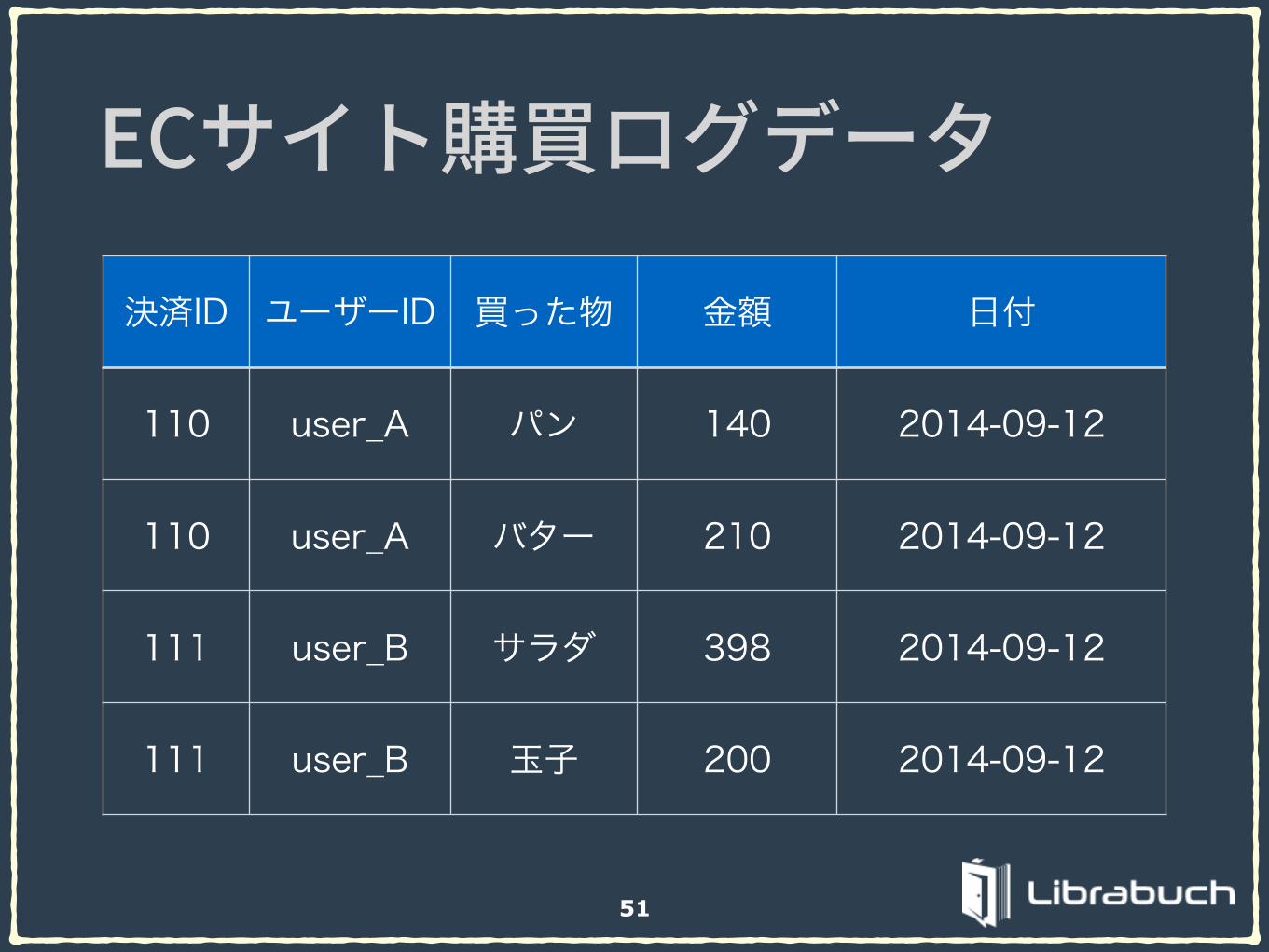
51
!
決済ID ユーザーID 買った物 金額 日付
110 user_A パン 140 2014-09-12
110 user_A バター 210 2014-09-12
111 user_B サラダ 398 2014-09-12
111 user_B 玉子 200 2014-09-12

52

53
|X \ Y |
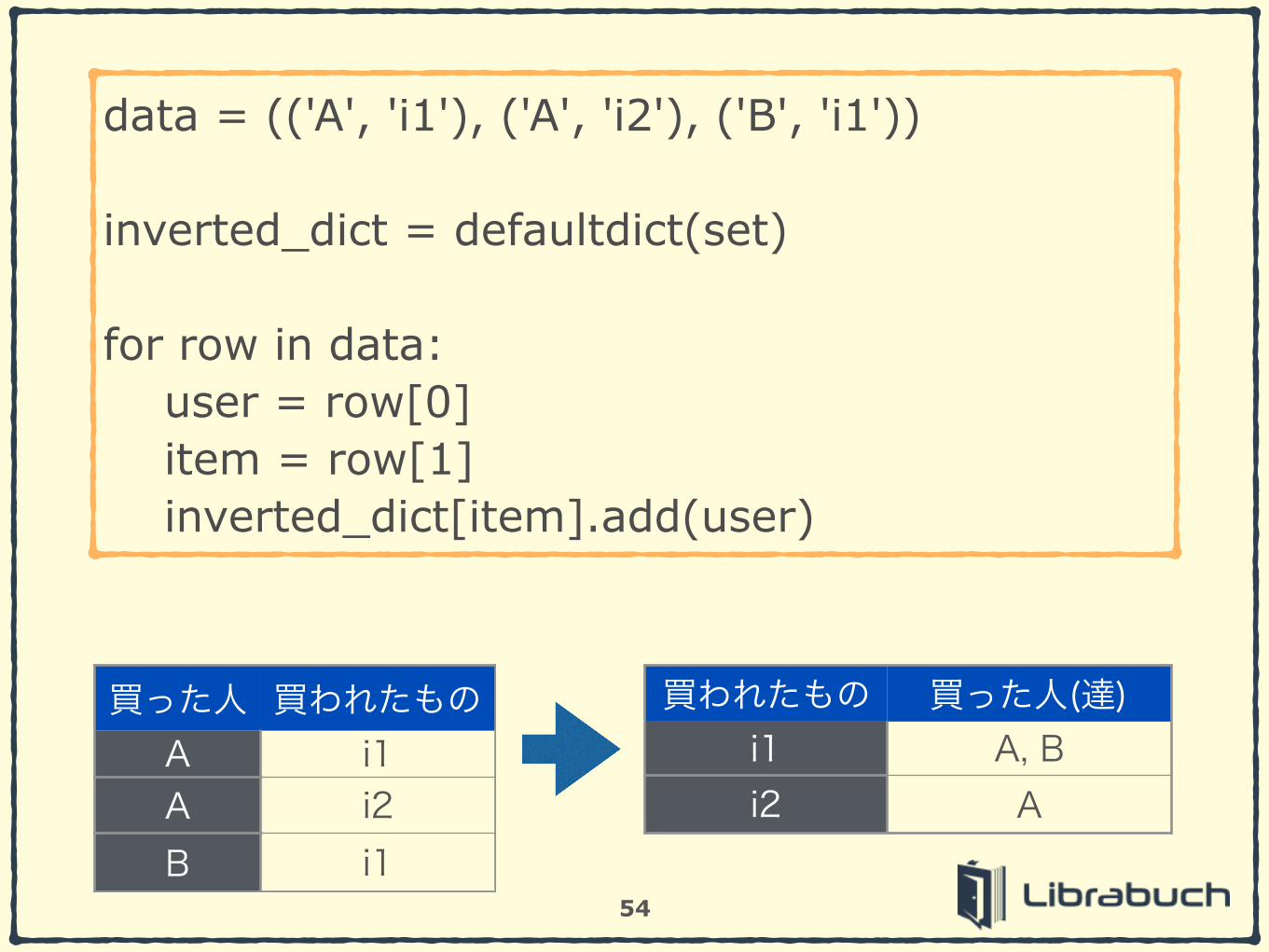
data = (('A', 'i1'), ('A', 'i2'), ('B', 'i1')) !
inverted_dict = defaultdict(set) !
for row in data: user = row[0] item = row[1] inverted_dict[item].add(user)
54
買った人 買われたものA i1A i2B i1
買われたもの 買った人(達)i1 A, Bi2 A
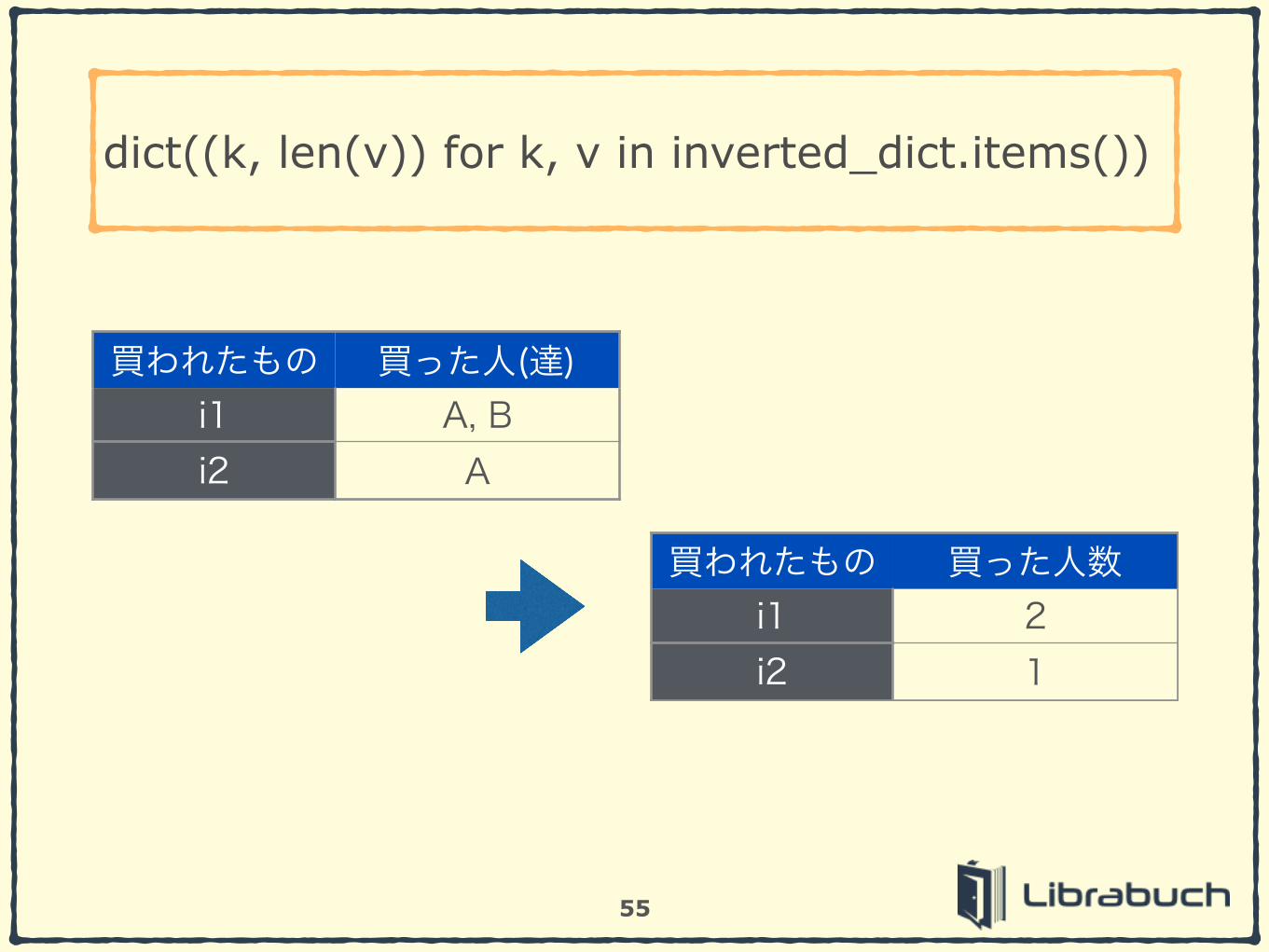
dict((k, len(v)) for k, v in inverted_dict.items())
55
買われたもの 買った人(達)i1 A, Bi2 A
買われたもの 買った人数i1 2i2 1

len(x.intersection(y))
56
買われたもの 買った人(達)i1 A, Bi2 A
一緒に買われたもの 人数
i1とi2 1
|X \ Y |

57
Dice =2⇥ |X \ Y ||X|+ |Y |
Jaccard =|X \ Y ||X [ Y |
Simpson =|X \ Y |
min (|X| , |Y |)

58

59
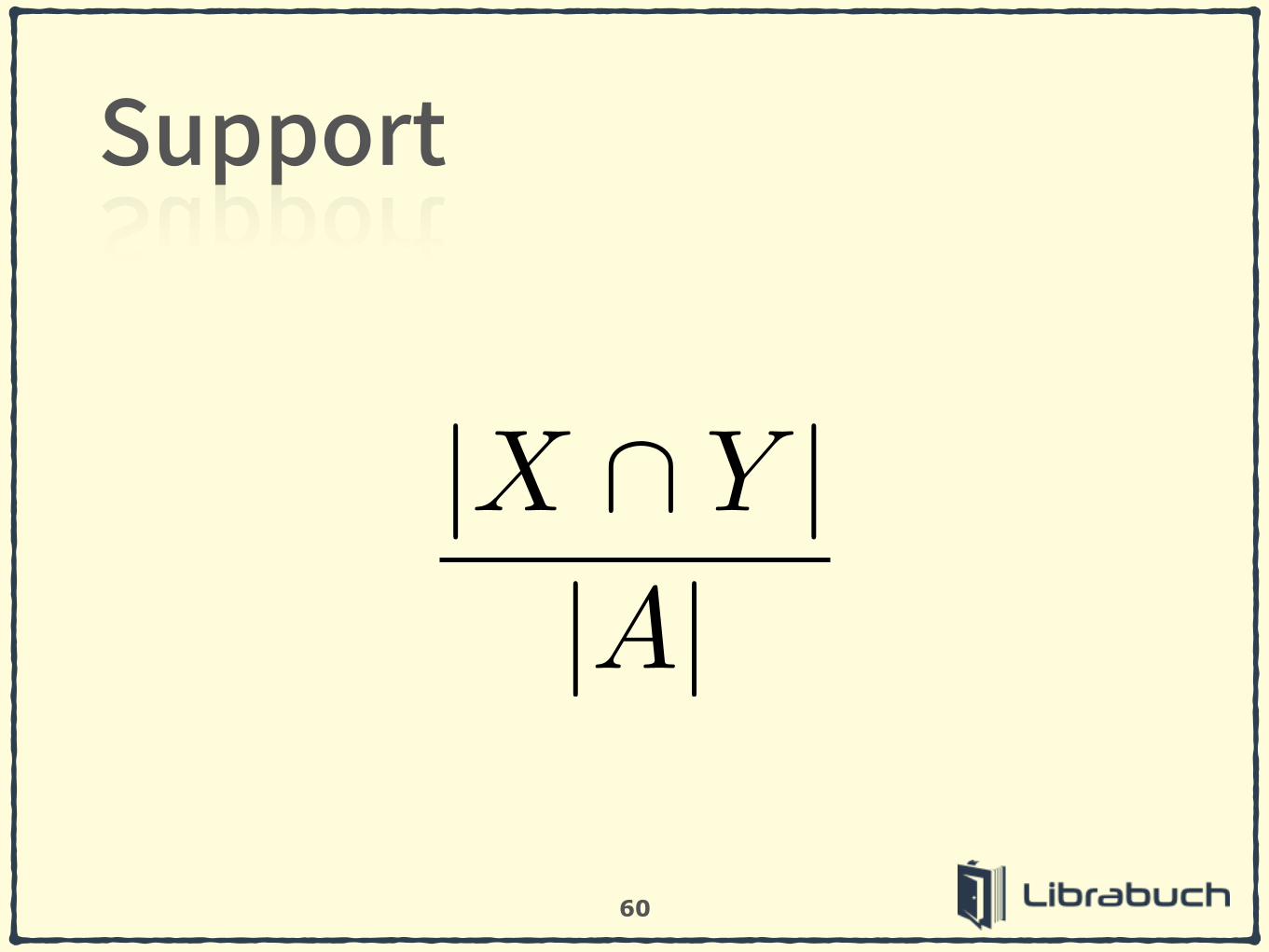
60

61
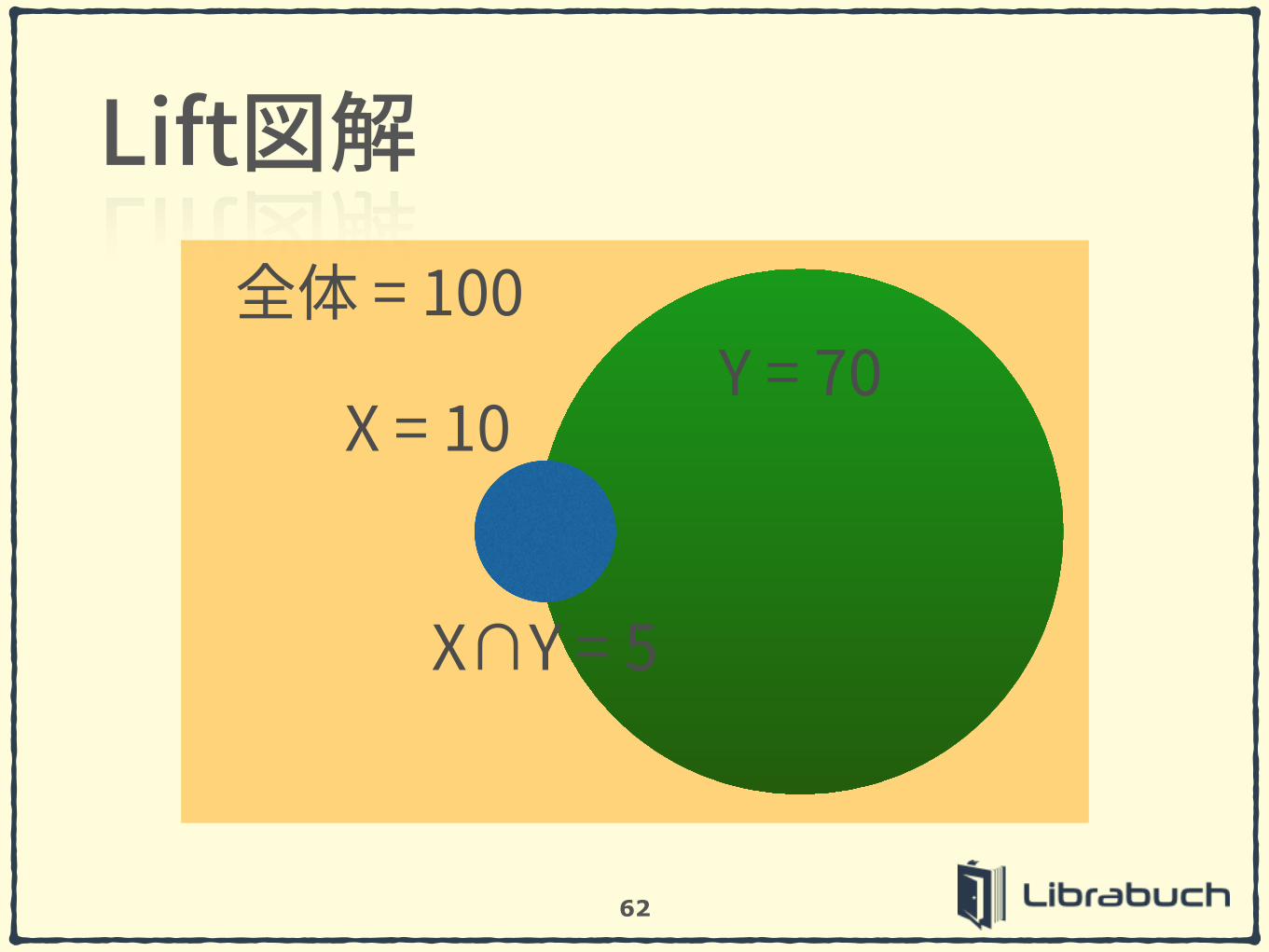
62
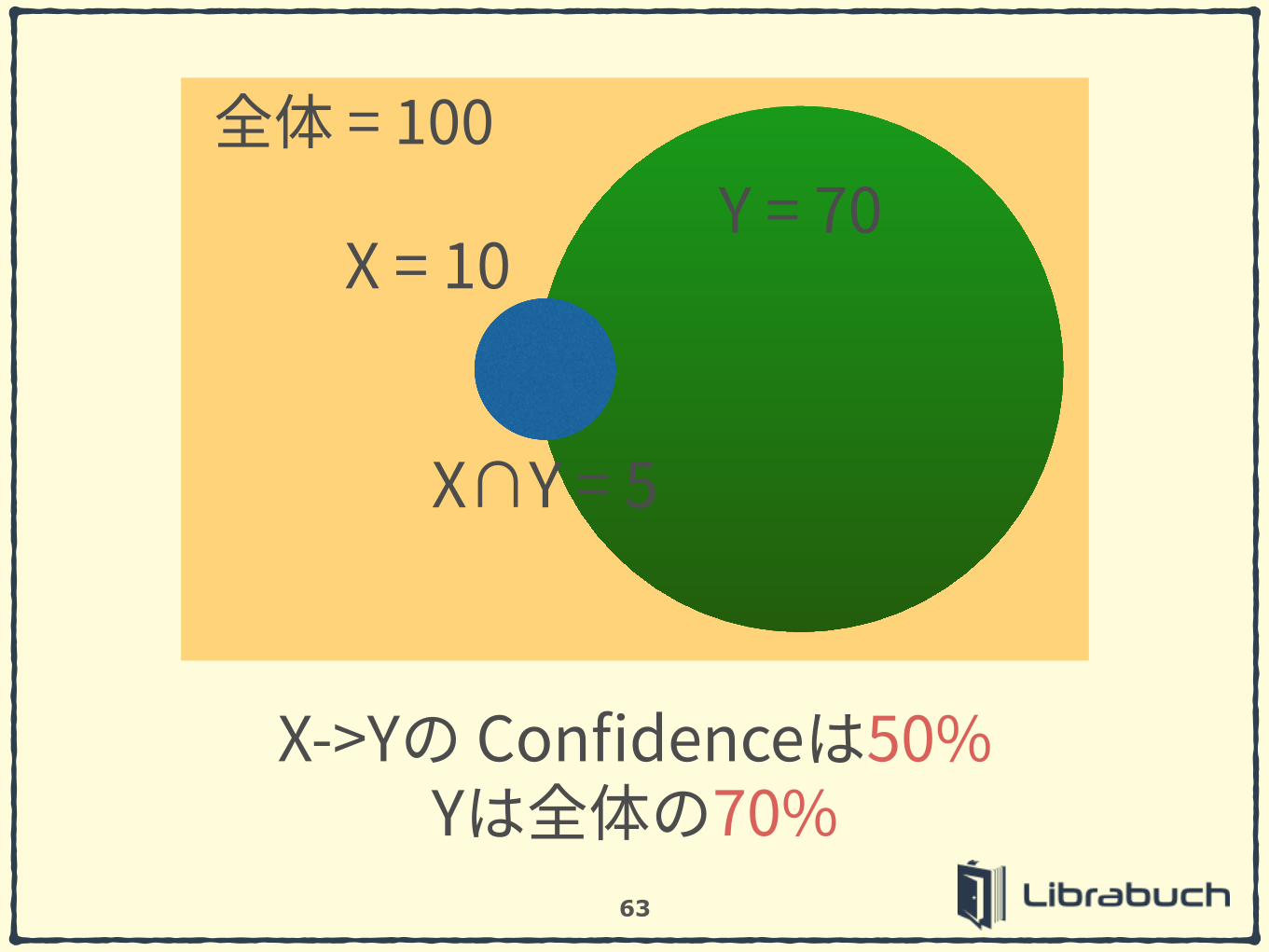
63

64

65

66

67

68

69

import numpy !
data = numpy.array([[0, 1], [1, 0]])
70

71

72

73

import numpy as np !
x = np.array([[1, 2], [1, 3]]) y = np.array([[3, 2], [2, 1]]) !
x + y
74

import numpy as np !
x = np.array([[1, 2], [1, 3]]) y = np.array([[3, 2], [2, 1]]) !
x.dot(y)
75

import numpy as np !
x = np.array([[1, 2], [1, 3]]) !
x * 3
76

import numpy as np !
x = np.array([[1, 2], [1, 3]]) !
x.T
77

78

# 要点のみ抜粋
50 + 10 * (score - np.average(a)) / np.std(a)
79

80

81

82

import pandas !# CSVファイルの読み込み df = pandas.read_csv('../sample3.csv') !# 先頭から3行 df.head(3) !# 末尾から2行 df.tail(2)
83

from pandas import DataFrame !x = [1, 2, 4, 4, 5, 10] df = DataFrame(x) df.describe()
84

85

86

87

88

89
90

91
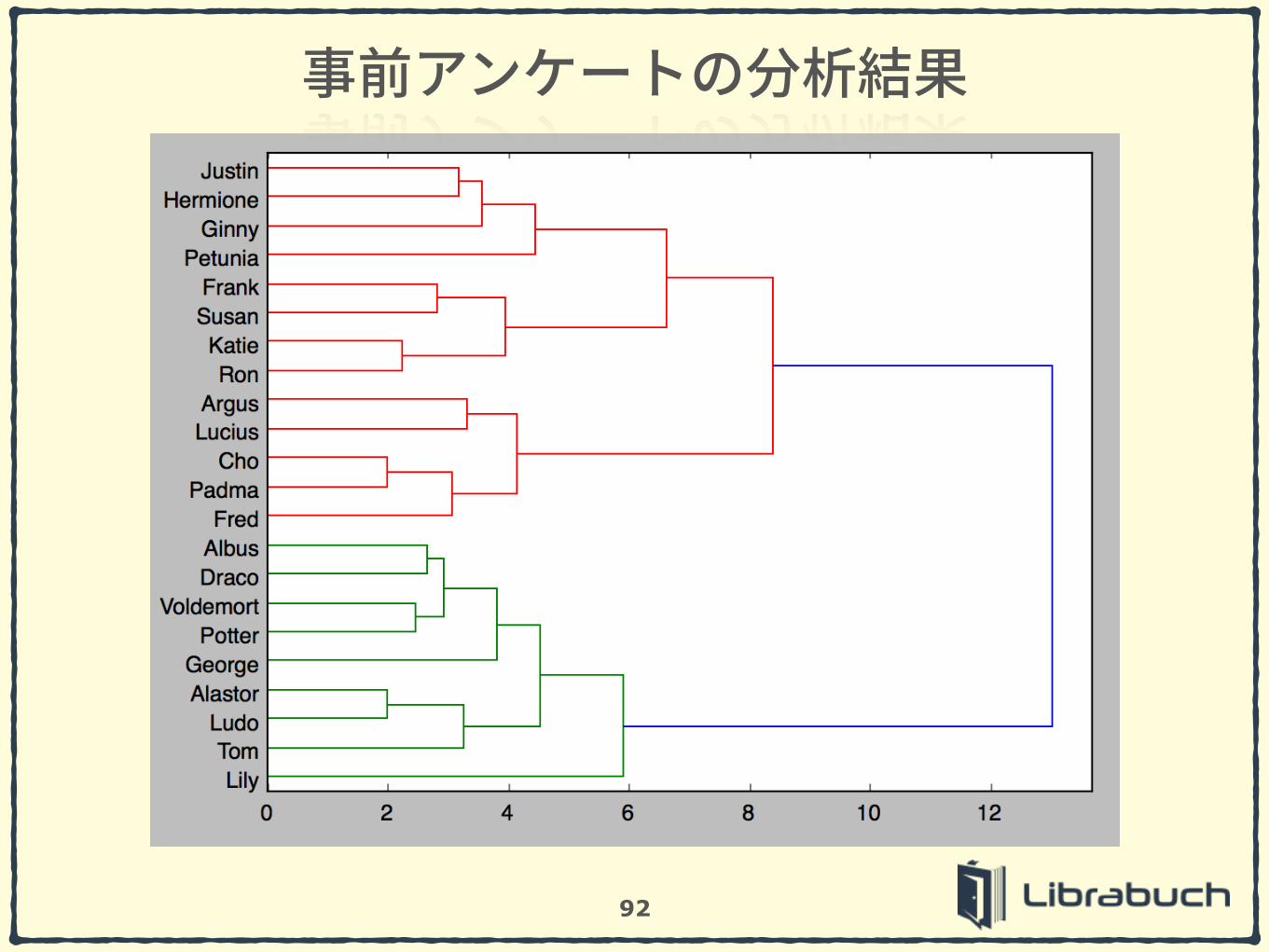
92

93

94
!

95

96

97
手法の例 適応できる分析の例
SVM 時系列分析/需要予測
クラスタリング 顧客分析、商品カテゴリ分析
決定木 ロイヤルカスタマー分析
ロジスティック回帰 商圏・出店分析季節性分析

!
98

99

100

101
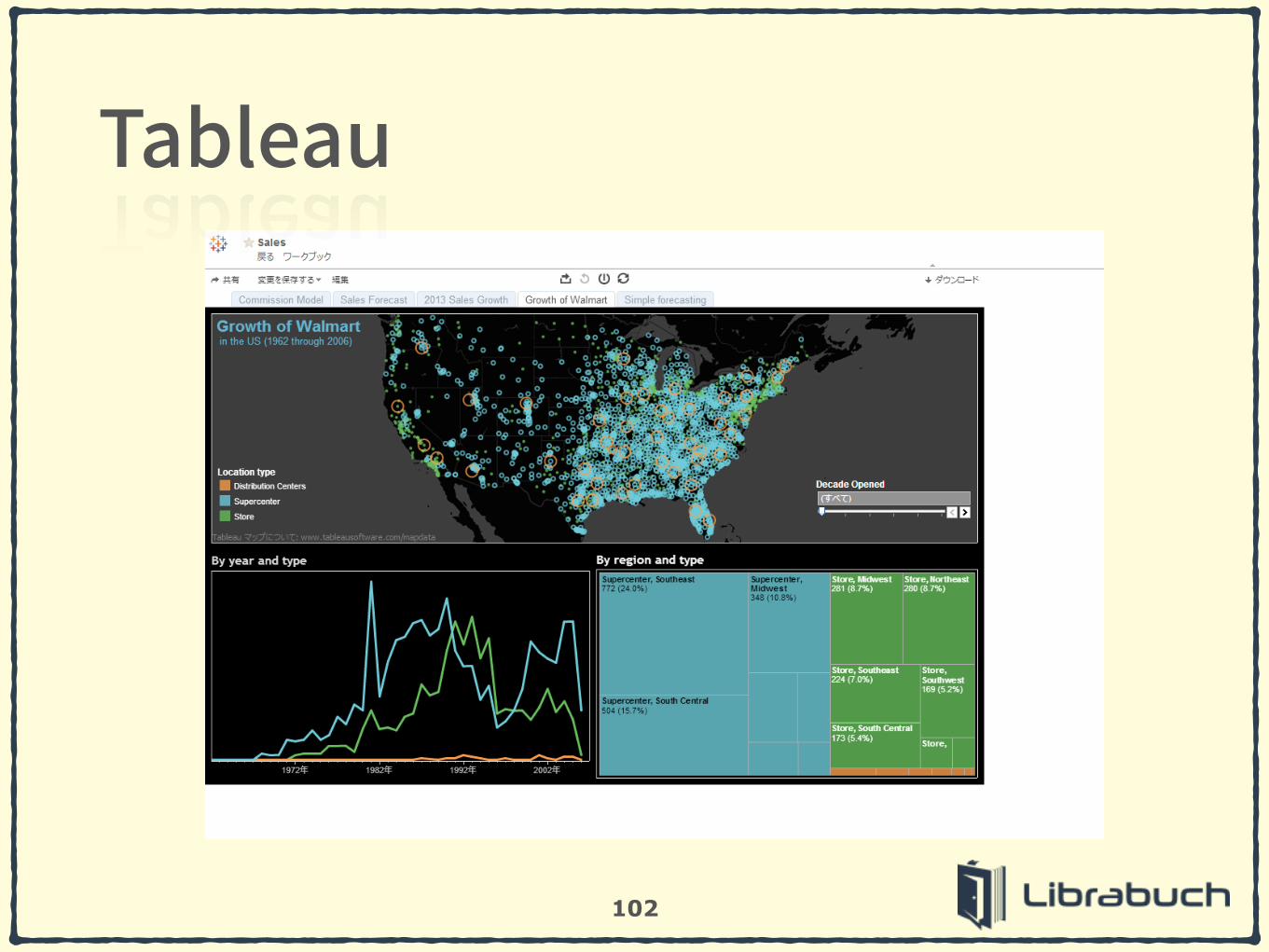
102

103

104

105

106

107

108

!
109