Embed Size (px)
Citation preview

Deep Directed Generative Models with Energy-Based Probability Estimation
米岡 大輔

概要
• 世にはenergy functionを用いて生成プロセスを定義するモデル(生成モデル)が沢山ある
• しかし,それらは一般的に分配関数の計算が難しい
• MCMCなどの方法があるが,それも時間やコストがかかる
• GANのアイディアを援用し,classifierと同時にenergy functionをdeep learningで学習することで,MCMCを使わない方法を提案

Introduction
• LeCun(1998)は画像分類において,予測誤差最小の基準 の代わりにエネルギー関数 を定義すること提案– エネルギーの大小とrandom variableを結びつけて考えることができる– Boltzmann machine, Restricted Boltzmann machine, Hopfield modelなんかを 同一の枠組みで捉えられる
• しかし,エネルギーを用いたモデルの最尤法は分配関数の計算が困難
– ガウス分布やベルヌーイ分布などの単純な分布を使う– MCMCを使う
• 多峰すぎると困難

提案手法の概要
• MCMCの計算を避けるため(というか,分配関数の陽な計算を避けるため)に以下(の2つの見方)を導入
• エネルギー関数
– 尤度関数(の勾配)をサンプルにより経験的に学習– マルコフ連鎖からのサンプルではなく,生成モデルからのサンプルと 考える
• 生成関数 (generator)– GANと同じような枠組みで学習
• Discriminator (識別関数)がエネルギー関数としてみなせる• Low energy = real data• High energy = fake data
– Discriminatorはエネルギー関数なので勾配も計算可能

Energy-Based model
• 低いエネルギーほど確率としては起こりやすい
• Product of Experts (PoE)– ボルツマン分布(ギブス分布とも呼ばれる)
– Expertsは
• エネルギーを最適化するということは,分配関数を考えなくても良いということ

GANのアイディア• まずはなんかすごい画像を見てください
• Deep Convolutional GAN [Randford+, ‘16]
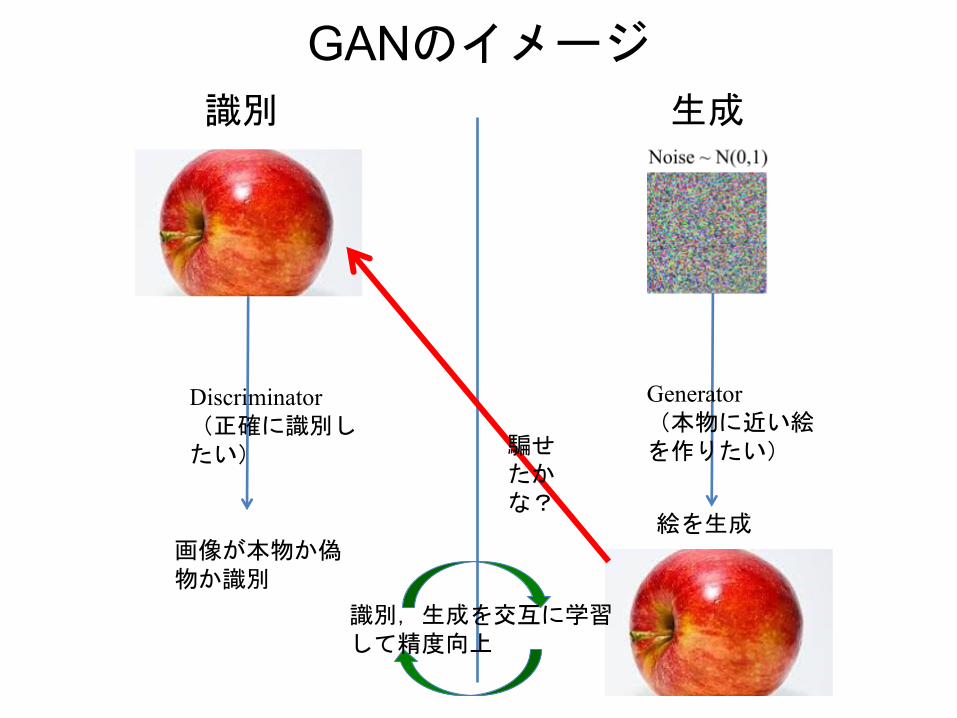
GANのイメージ
画像が本物か偽物か識別
Discriminator(正確に識別したい)
Generator(本物に近い絵を作りたい)
絵を生成
騙せたかな?
識別 生成
識別,生成を交互に学習して精度向上
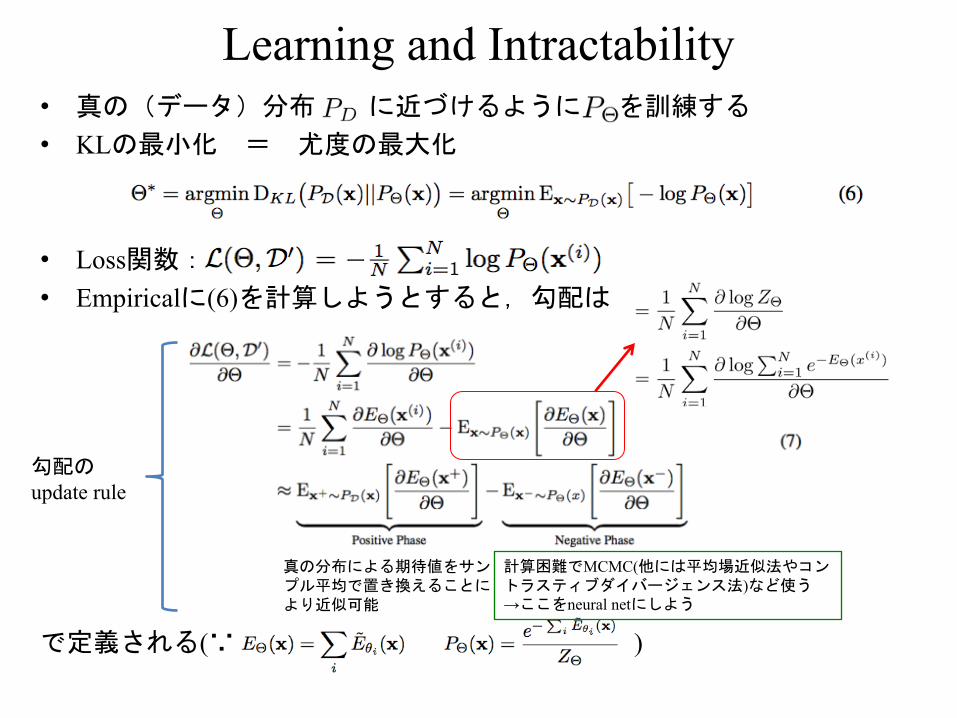
Learning and Intractability• 真の(データ)分布 に近づけるように を訓練する• KLの最小化 = 尤度の最大化
• Loss関数:• Empiricalに(6)を計算しようとすると,勾配は
で定義される(∵ )
真の分布による期待値をサンプル平均で置き換えることにより近似可能
計算困難でMCMC(他には平均場近似法やコントラスティブダイバージェンス法)など使う→ここをneural netにしよう
勾配のupdate rule

Training models as a classification problem• [Bengio, ’09] [Hinton, ’99] は前スライドの勾配のupdate ruleはclassifierの学習である,と提案
• yを用意して
• Classifierはシグモイド関数σを用いて• 簡単のために
• Ψの学習は
←(7)と同じupdate ruleになる
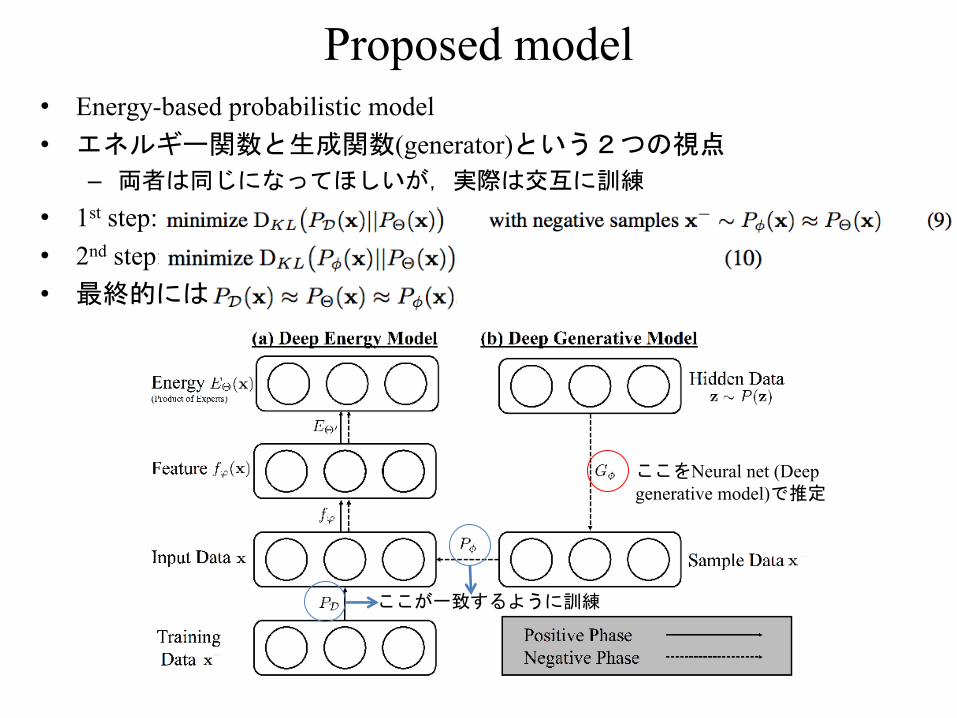
Proposed model• Energy-based probabilistic model• エネルギー関数と生成関数(generator)という2つの視点
– 両者は同じになってほしいが,実際は交互に訓練• 1st step:• 2nd step:• 最終的には
ここをNeural net (Deep generative model)で推定
ここが一致するように訓練
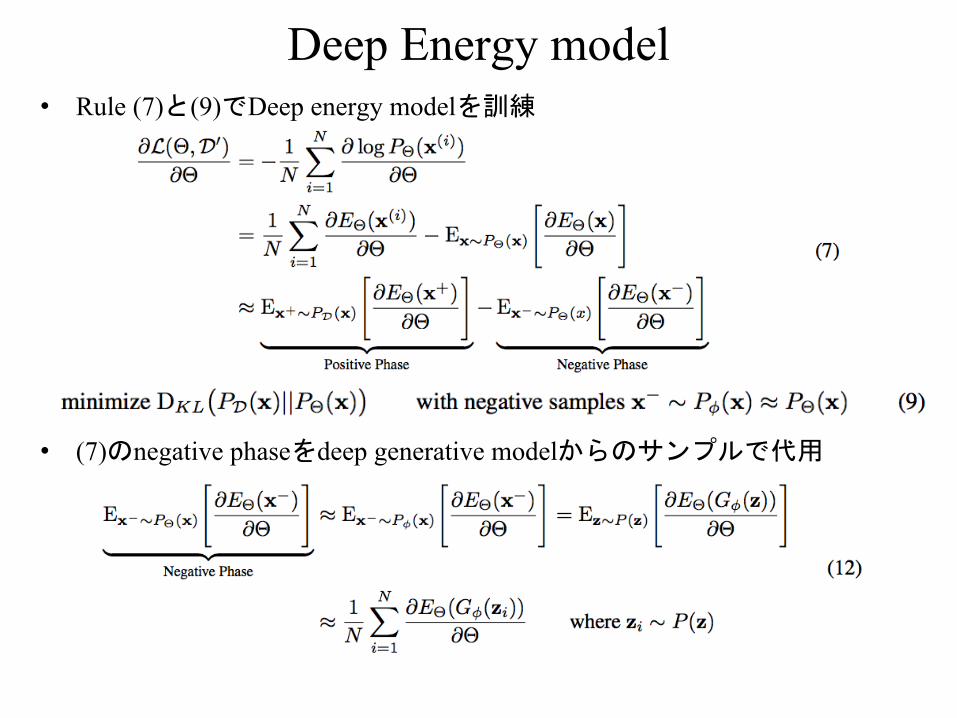
Deep Energy model• Rule (7)と(9)でDeep energy modelを訓練
• (7)のnegative phaseをdeep generative modelからのサンプルで代用

Deep Generative model• このモデルの目的
1. 効率的(non-iterative)なサンプルの生成2. Deep energy modelのnegative phaseを近似するためのサンプル生成
• サンプル生成は普通の伝承サンプル
1. からzをサンプル2. zを (deep generative model)に放り込んで変換3. で を構成
• KLを最小化することでモデル を訓練
– 第一項
– 第二項Back-propagationで計算可能らしい
↓正則化項(エントロピー)として働く
↑Batch処理にしている

Relation to GAN
• GANはdiscriminatorとgeneratorという2つのモデルを同時に訓練するというアイディア
• 今回はdiscriminatorがenergy-functionであるモデルを提案
• 相違点
– GANのdiscriminatorはconstant outputに収束しがち• 結果として,どんなinputを入力しても,D=0.5を出しがち
– GANは最初の方にどのような学習をしていたかを記憶していない– 提案手法はdiscriminatorはサンプルがtraining dataから来たものなのか,それともこれまでのgeneratorのいずれかから来たものなのかを判定する
• GANのdiscriminatorはサンプルがtrainingか今現在のgeneratorから来たものなのかを判定する
• 結果として,GANのdiscriminatorはtrivialな判別器を作ってしまいがちだが,提案手法はこれを避けられる
![konkrete fotografie generative fotografie · 2014. 10. 10. · spielens des Physischen in das Metaphysische. [2] 9 Was ist Generative Fotografie? Gottfried Jäger Eine Generative](https://img.pdfslide.tips/doc/110x75/5fe57c308ff1c3750d37f320/konkrete-fotografie-generative-fotografie-2014-10-10-spielens-des-physischen.jpg)




























