Embed Size (px)
Citation preview

Romero, Adriana, et al. "Diet Networks: Thin
Parameters for Fat Genomic." arXiv preprint
arXiv:1611.09340 (2016).
@St_Hakky

本論文の概要
• Bengio先生の研究グループによる研究。
• ICLR 2017で採択された
• 「変数の数>>データ数」によるDeep Learningの学習パラメーターの数が大きくなる問題を解決した
– 遺伝子関係のデータではよくある状況
– SNPから遺伝的系統をDeepLearningを用いて予測するのは初めての試み
– 今回の研究対象はバイオであり、 SNPを扱う

Deep Learningのバイオデータでの活躍
• Deep Learningを生物データに適用させて成功した研究は既にある– Using Convolutional Neural Networks (CNNs) to learn the functional activity of DNA sequences
(Basset package, Kelley et al. (2016)
– Predicting effects of noncoding DNA (DeepSEA, Zhou & Troyanskaya (2015))
– Investigating the regulatory role of RNA binding proteins in alternative splicing (Alipanahi et al.,
2015)
• こういった研究はシーケンスデータ対象であり、CNNやRNNが適用しやすい

SNPとは
• SNPは、DNAの中の1つの塩基が別の塩基に置き換わったもの– 人間の遺伝的変異を表す
– 個々人の病気や体質の違いを生む要因と言われている
– ヒトゲノムでは約300~500万個あると言われている
• このSNPデータにDeep Learningを適用することで、個々人の薬のリスク等を特定する
– しかし、 SNPは遺伝的変異に着目しているため、シーケンスなコンテキストを利用できない、高次元なデータである

SNPデータの問題点
• シーケンスでないデータはCNNなどの手法は利用できない
• 変数の数≫データ数
– 患者特有の特徴を捉える時に高次元の変数を使いたい時がある
– この時、過学習の問題はもちろんのこと、学習をうまく行うこと自体が難しい
– このようなデータに対して、Deep Learningを使う時、パラメーター数が多くなり、問題になる

Problem
目的 • SNPから個々人の遺伝的系統を予測することを行いたい
問題点
• シーケンスデータでないので、CNNなどの手法が使えない• 「変数の数 ≫データ数」な時のNeural Networkにおける問題点• 第一層目のパラメーターの数が異常なまでに多くなる• 学習するパラメータ数が多すぎて過学習が発生する上に、学習速度も遅くなる
提案手法• Diet Networksを用いて、パラメーター数を圧倒的に削減する

Method:Diet Network
• 入力が超高次元で且つデータ数よりも次元のオーダーが大きい場合に、パラメーターの数を劇的に減らし学習する方法を提案
記号 意味
𝑁 サンプル数
𝑁𝑑 次元数
𝑁 ≪ 𝑁𝑑 サンプル数が次元数よりも圧倒的に小さい
𝑋 ∈ 𝑅𝑁×𝑁𝑑 データ
𝑌 予測した値(出力)
𝑋 次元圧縮後、復元した値

Fat Hidden/Reconstruction Layer
• 高次元のデータの場合、最初の隠れ層と最後の隠れ層のパラメーター数が非常に大きくなる
– 例:𝑁𝑑 = 300𝐾で、最初の層のノード数が100だと、パラメーター数は30M
– 最初の隠れ層をFat Hidden Layerと言う
– 最後の隠れ層をFat Reconstruction Layerと言う
この重みが非常に大きくなる。

Modelの工夫点
• Fat Hidden/Reconstruction Layerのパラメーター数を減らすためにModelを工夫する
– 工夫点1:重み学習する補助Networkを導入
– 工夫点2:入力を転置
– 工夫点3:Embedding表現
– 工夫点4:目的関数の工夫
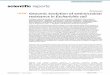
工夫点1:Base Network / Auxiliary Network
• パラメーター数を減らすため、次の2つのNetworkを導入する
– Base Network(図:a)
– Auxiliary(補助) Network (図:b, c)
MLP:Multi Layer Perceptron

工夫点1:Base Network / Auxiliary Network
• (b)のネットワークは最初の隠れ層のパラメーターを予測するNetwork
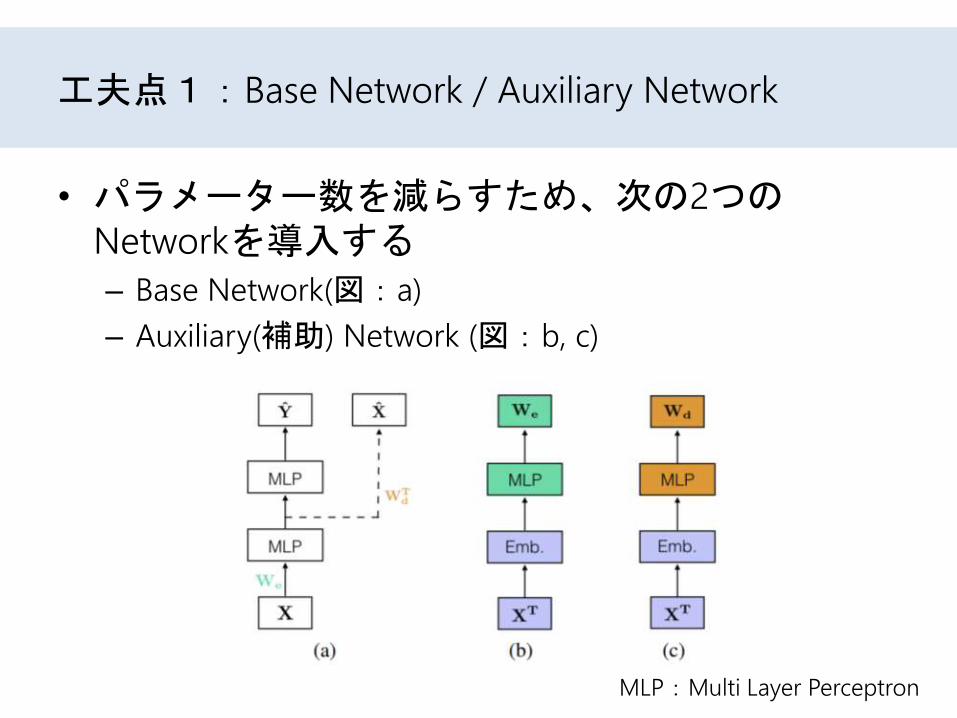
工夫点1:Base Network / Auxiliary Network
• (c)のネットワークはデータの復元を行う層のパラメーターを予測するNetwork
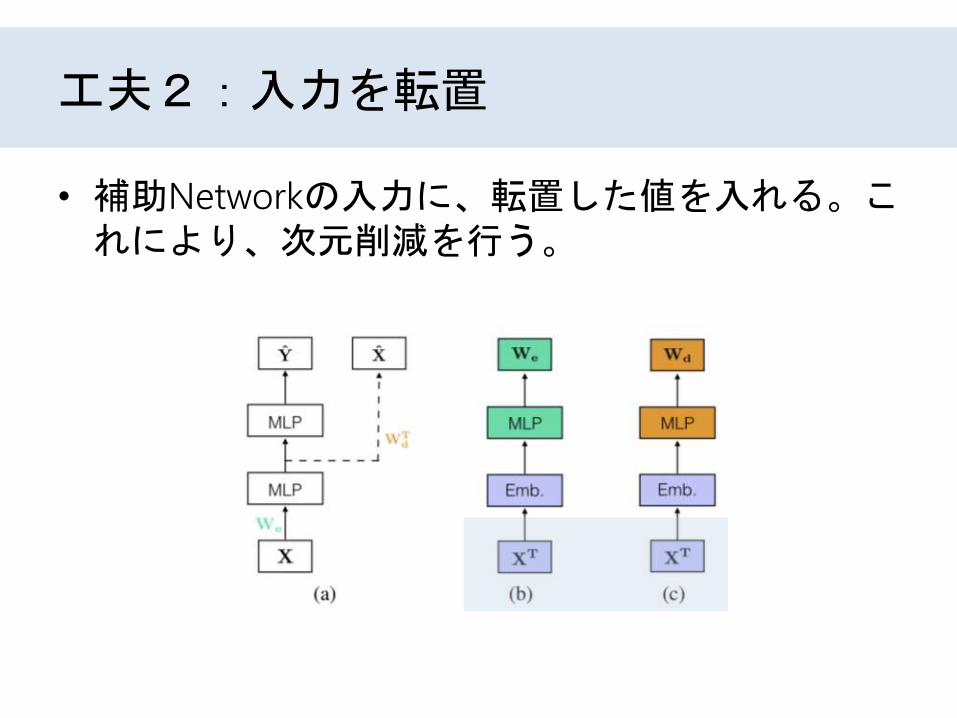
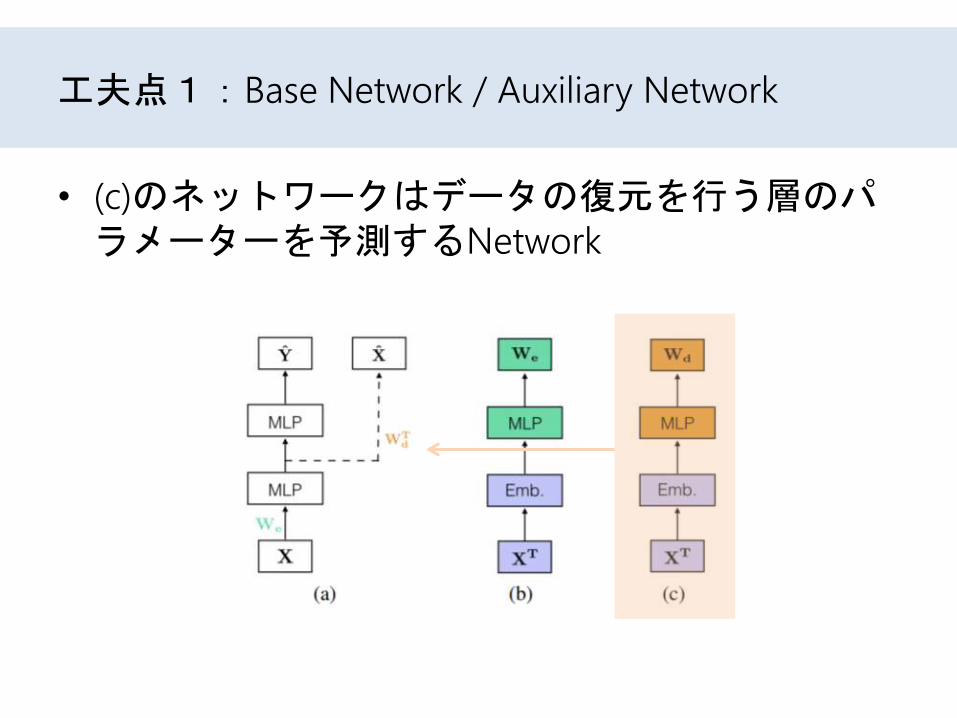
工夫2:入力を転置
• 補助Networkの入力に、転置した値を入れる。これにより、次元削減を行う。

工夫3:Embedding表現
• 特徴のEmbedding(埋め込み)を学習する

工夫3:Embedding表現
• 補助ネットワークで使われるEmbeddingは、事前に計算しておくかオフラインで学習が出来る
• 理論上はどのような種類のEmbeddingを用いても良い
– もちろん、当初の目的であるパラメーターを削減するということを忘れなければ大丈夫

Embeddingの種類
• 次の4種類が論文では紹介されていた。
– Random projection
– Per class histogram
– SNPtoVec
– Embedding learnt end-to-end from raw data

Random projection
• MLPを使用
– ただし、学習するわけではなくて、ランダムに初期化したものをそのまま使用する• 学習すると、それはそれでまたパラメーターが増えるので
– 普通にデータをそのまま利用するよりは、Random
Projectionでもまだ扱えるレベルの次元に落とす

Per class histogram
• SNPデータに対して、ヒストグラムを作成
• 正規化した後、SNPは3つの値に割り振られる
– しかし、この方法では粗すぎることがわかった
• 代わりに、今回使用する1000 Genome datasetでは、26のクラスを考え、それぞれで3つの値に分けるようにした
– そのため、各特徴量は78次元にまで落とせる
– 𝑋𝑇の次元が、𝑁𝑑 × 78まで落とせる(凄い)

SNPtoVec
• Mikolovらの研究(2013)により、Neural Networkによる単語の分脈の再現を精度良く可能にした単語の特徴の埋め込み方法が提案された
• SNPは文章ほど良い位置的な分脈を持たない– SNPはほぼ独立な位置関係
• そのため、𝑋から学習したDenoising AutoEncoder(DAE)
を用いて特徴の埋め込みを獲得することにした– DAEの一つの特徴のInputによるautoencoderの隠れ層の表現が補助ネットワークのEmbeddingとして用いられる

Embedding learnt end-to-end from raw data
• 普通にMLPを使用するというもの
• これは補助ネットワークのMLPと完全に同一のものになる

工夫点4:目的関数の工夫
目的関数
目的関数にReconstruction Errorを入れる

工夫点4:目的関数の工夫
目的関数
目的関数にReconstruction Errorを入れる
クロスエントロピー Reconstruction Error
𝛾はハイパーパラメーター

Modelの工夫点のまとめ
• 以上のような工夫を行い、高次元の入力によるパラメーター数の増加に対応する。
– 工夫点1:重み学習する補助Networkを導入
– 工夫点2:入力を転置
– 工夫点3:Embedding表現
– 工夫点4:目的関数の工夫

Data : The 1000 Genomes Project
• 1000 Genomes Projectは世界中の人種の、多くの人のシーケンスデータを集めるプロジェクト
– 人間の遺伝的変異のカタログの中では最も大きいパブリックデータを生み出した
– 26人種、5地域からのデータを取得
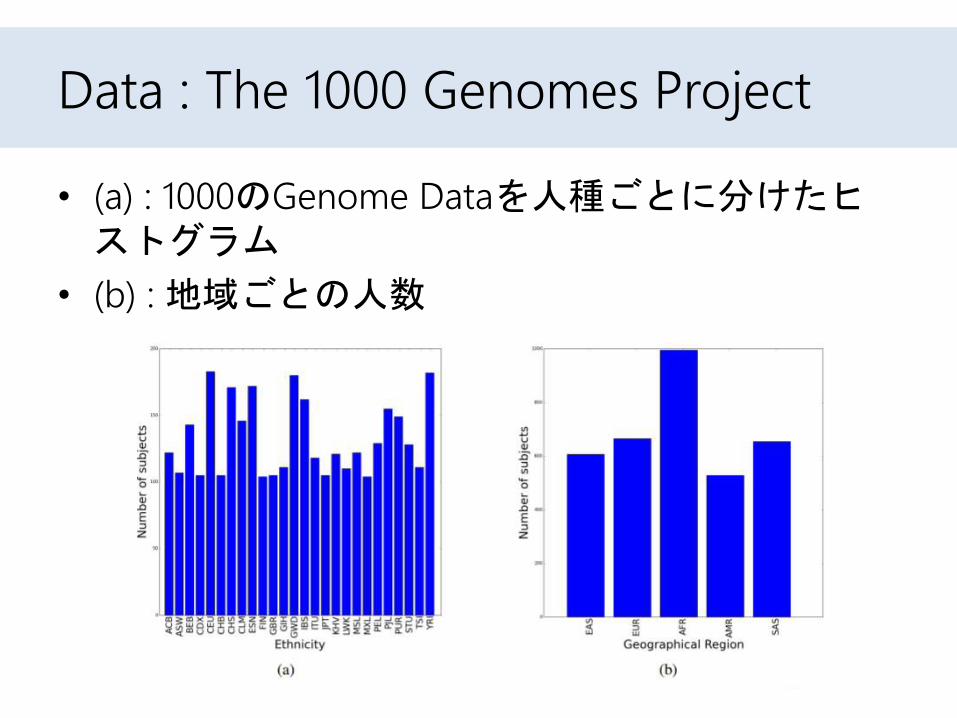
Data : The 1000 Genomes Project
• (a) : 1000のGenome Dataを人種ごとに分けたヒストグラム
• (b) : 地域ごとの人数

Experiments
• 今回はこのデータセットを用いてSNPから人種や地域を分類分けする問題を解く

Model Architecture
• 基本のNetwork– 隠れ層2つ– 活性化関数はsoftmax
• 補助ネットワーク– 紹介したEmbeddingを用いつつ、MLPをその上に載せる形– 中間層のノード数は100
• 実験における学習– 補助ネットワークありとなしの両方で学習– Adaptive learning rate ありのSGDで勾配更新– 𝛾 : 0,10
– Dropoutを使用– 1に重みを正規化 and/or 重み減衰を使用

実験方法
• 5-foldクロスバリデーション適用
– 1つはテスト用
– 3つは学習用
– 1つはバリデーション用
• 5回繰り返し、平均と標準偏差を取得した
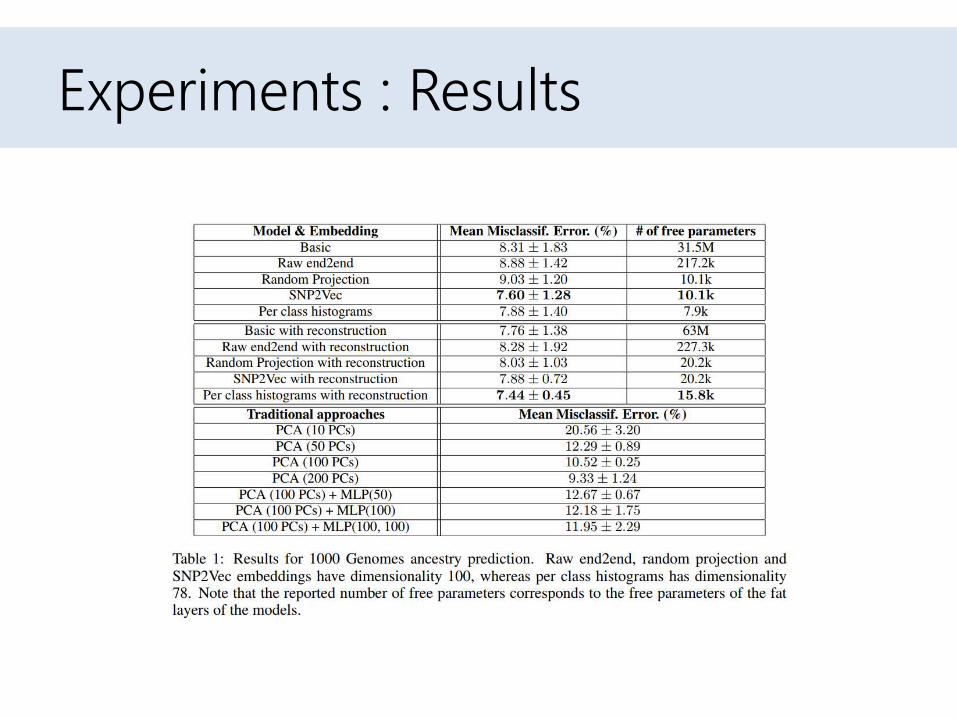
Experiments : Results

• Reconstruction Errorを入れたほうが精度が良い• 平均はもちろん、標準偏差の値を小さい傾向がある
• ロバストな結果を得れていることがわかる

• Reconstruction Errorを入れたほうが精度が良い• 平均はもちろん、標準偏差の値を小さい傾向がある
• ロバストな結果を得れていることがわかる
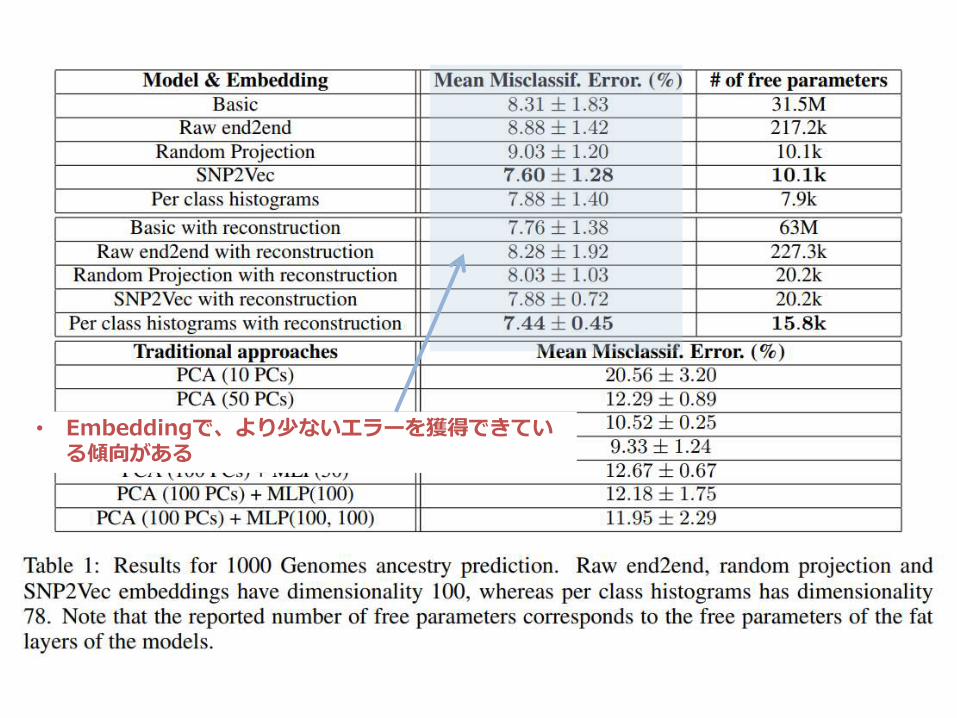
• Embeddingで、より少ないエラーを獲得できている傾向がある
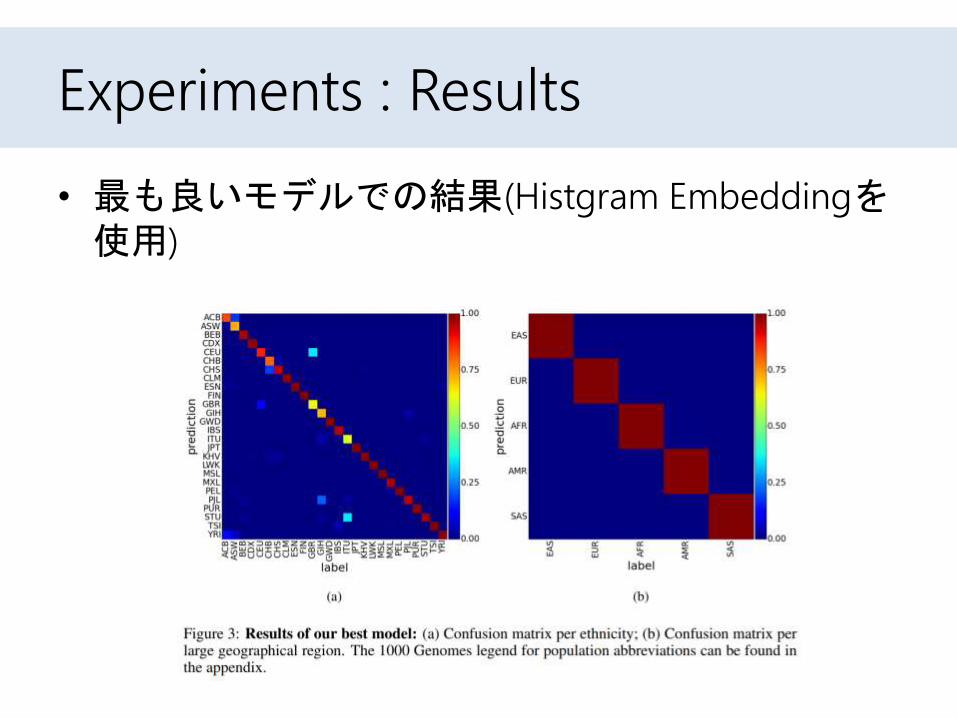
Experiments : Results
• 最も良いモデルでの結果(Histgram Embeddingを使用)

Experiments : Results
• 今回の実験結果をまとめる– Reconstruction Errorを入れたほうが精度が良い
• 平均はもちろん、標準偏差の値を小さい傾向がある– これから、ロバストな結果を得れていることがわかる
– Embeddingで、より少ないエラーを獲得できている傾向がある• これにより、パラメーター数も少なくなっている• また、Random projectionが良い結果を示している
– これは学習するパラメータの数が少ない形で住むことを示している
• SNP2Vecは、SNP間の類似度や共起性を抽出することを学習する– これはrandom projectionよりも少し性能が良い– Reconstruction Errorをいれることで平均的な精度はかわっていないが、標準偏差が低くなっている
• Reconstruction Error込みのPer class histogram encodingが単純でありながら、良い精度を出している
– これがもっとも自由パラメーターとしては少ない– 誤りを起こしているところも似たような民族性を持つところが多い
» BritishはEngland,やScotlandから来ている人が多いなど– 5つの地域的な分類を行うときはほぼ100%の精度を出している
– PCAとも比較した• Linear classifierを主成分のトップ10と50, 100, 200のそれぞれで学習した

Conclusion
• 今回、Diet Networkというものを提案した
• 圧倒的にパラメーターを削減できた
• Embeddingというのが良い効果をもたらす

Fin