Embed Size (px)
Citation preview

1
Тема 1. Парная линейная регрессия Цель и задачи Цель контента темы 1 — дать представление об эконометрическом моделировании, познакомить с моделью парной линейной регрессии. Задачи контента темы 1:
• Ввести понятие эконометрической модели, сформулировать ос-новные этапы эконометрического моделирования;
• Ввести понятие парной линейной регрессии, дать спецификацию этой модели;
• Познакомить с методом наименьших квадратов (МНК), вывести оценки параметров парной линейной регрессии по МНК, дать им экономическую интерпретацию;
• Сформулировать основные предположения регрессионного ана-лиза и статистические свойства оценок;
• Обсудить критерии качества парной регрессии, сформулировать критерии проверки статистической значимости (оценок по от-дельности и регрессии в целом), построить доверительные ин-тервалы и прогнозы с помощью парной линейной регрессии.
Оглавление. § 1.1. Введение. § 1.2. Основные элементы эконометрической модели. § 1.3 Спецификация модели парной линейной регрессии. § 1.4 Оценка параметров. Метод наименьших квадратов. Экономиче-
ская интерпретация. § 1.5. Основные предположения регрессионного анализа. § 1.6. Статистические свойства оценок. Теорема Гаусса-Маркова. § 1.7. Показатели качества регрессии. Коэффициент детерминации.
Коэффициент парной корреляции. § 1.8. Проверка статистической значимости в парной линейной рег-
рессии. § 1.9. Доверительные интервалы.
§ 1.1 Введение Математические модели широко используются в экономике, в
финансах, в общественных науках. Обычно модели строятся и вери-фицируются на основе имеющихся наблюдений изучаемого показате-ля и, так называемых, объясняющих факторов. Язык экономики все больше становится математическим, а саму экономику все чаще упо-минают как одну из наиболее математизированных наук. В течение

2
последних десятилетий математические и, в частности, статистиче-ские методы в экономике стремительно развиваются. Свидетельством признания эконометрики является присуждение за наиболее выдаю-щиеся работы в этой области Нобелевских премий по экономике: Р. Фришу и Я. Тинбергу (1969) за разработку математических методов анализа экономических процессов, Л. Клейну (1980) за создание эко-нометрических моделей и их применение к анализу экономических ко-лебаний и экономической политике, Т. Хаавельмо (1989) за работы в области вероятностных основ эконометрики и анализ одновременных экономических структур, Дж. Хекману и Д. Макфаддену (2000) за раз-витие методов анализа селективных выборок и моделей дискретного выбора.
Вряд ли возможно в настоящее время дать единое общеприня-тое определение эконометрики. Термин «эконометрика» был предло-жен в 1926 г. норвежским ученым Р. Фришем и дословно означает «эконометрические измерения». Более узкое значение этого термина подразумевает набор математико-статистических методов, исполь-зуемых в приложениях математики в экономике. Ниже приводятся не-сколько определений известных ученых — экономистов, математиков, позволяющих получить представление о содержании эконометрики.
«Эконометрика — это раздел математики, занимающийся разра-боткой и применением статистических методов для измерений взаи-мосвязей между экономическими переменными» (С. Фишер).
«Основная задача эконометрики — наполнить эмпирическим со-держанием априорные экономические рассуждения» (Л. Клейн).
«Цель эконометрики — эмпирический вывод экономических за-конов» (Э. Маленво).
«Эконометрика есть единство трех составляющих — статистики, экономической теории и математики» (Р. Фриш).
Не будет преувеличением сказать, что эконометрика объединяет совокупность методов и моделей, позволяющих на базе экономиче-ской теории, экономической статистики и математико-статистического инструментария придавать количественные выражения качественным зависимостям. Успешное освоение и применение эконометрических методов анализа экономических явлений требует знания основных разделов теории вероятностей и, в особенности, математической ста-тистики (см., например, вопросы для самопроверки №№1–9).
Часто говорят, что современное экономическое образование ос-новывается на макроэкономике, микроэкономике и эконометрике. Можно указать следующие взаимосвязи между этими элементами:
• Основные результаты экономической теории носят качест-венный характер, а эконометрика вносит в них эмпирическое содержание;

3
• Математическая экономика выражает экономические законы в виде математических соотношений, а эконометрика осущест-вляет опытную проверку этих законов;
• Экономическая статистика дает информационное обеспече-ние исследуемых явлений в виде исходных статистических данных и экономических показателей, а эконометрика прово-дит анализ количественных взаимосвязей между этими пока-зателями.
Несмотря на то, что многие эконометрические результаты явля-ются, по сути и форме, математическими (имеют, например, вид тео-рем), именно экономическая теория определяет постановку задач и исходные предпосылки, а полученные результаты представляют ин-терес лишь тогда, когда удается их экономическая интерпретация.
§ 1.2. Основные элементы эконометрической модели В рамках эконометрического анализа обычно ставится задача
определения некоторой величины (показателя), значение которой формируется под воздействием некоторых факторов. Так, цена на по-держанный автомобиль может зависеть от года выпуска, пробега, мощности двигателя и т.п. Такие показатели, как например цена, обычно называют зависимыми (объясняемыми) переменными, а фак-торы, от которых они зависят — объясняющими переменными (фак-торами). Нас обычно интересует среднее или ожидаемое значение зависимой переменной при заданных значениях объясняющих пере-менных.
Конкретное значение зависимой переменной (наблюдаемое зна-чение) обычно зависит и от случайных явлений. В примере с автомо-билем случайным может быть состоянием рынка, характер продавца и т.д. Для экономики типична такая форма связи между переменными величинами, когда каждому значению одной переменной соответству-ет не какое-то определенное значение другой переменной, а множест-во возможных значений (более точно — некоторое условное распре-деление) другой переменной. Такая зависимость называется стати-стической (стохастической, вероятностной). Стохастическая фор-ма связи обуславливается тем, что зависимая переменная подверже-на влиянию ряда неконтролируемых или неучтенных факторов, а так-же тем, что измерение значений переменных обычно сопровождается некоторыми случайными ошибками.
Таким образом, зависимая переменная является случайной ве-личиной, имеющей при заданных значениях факторов некоторое рас-пределение. В любой эконометрической модели зависимая перемен-ная обычно разбивается на две части: объясненную и случайную. В общем виде задача эконометрического моделирования состоит в следующем:

4
На основании экспериментальных данных определить (оце-нить) объясненную часть зависимой переменной и, рассматривая случайную составляющую как случайную величину, получить оценки параметров ее распределения.
Обозначим зависимую переменную через y , ее объясненную часть, зависящую от значений объясняющих переменных
1 2( , , , )kx x x=X K через ( )f X (т.е. объясненная часть представляет со-бой функцию от значений факторов), а случайную составляющую (на-зываемую также возмущением или ошибкой) — через ε . Тогда в об-щем виде эконометрическая модель имеет вид: ( )y f ε= +X . (1.2.1)
В качестве объясненной части ( )f X случайной величины y ес-тественно выбрать ее среднее (ожидаемое) значение при заданных значениях X — иными словами, условное математическое ожидание
( )E yX , полученное при данном значении объясняющих переменных 1 2( , , , )kx x x=X K :
( ) ( )E y f=X X . (1.2.2) Это уравнение (зависимость) называется теоретическим уравнением регрессии, функция ( )f X — теоретической функцией регрессии, а уравнение ( )y E y ε= +X , (1.2.3) уравнением регрессионной модели.
В силу своего определения регрессионная модель обладает особыми свойствами. Так, взяв от обеих частей равенства математи-ческое ожидание при заданном наборе значений объясняющих пере-менных, получаем, что
( ) 0E ε =X , а значит, что и ( ) 0E ε = — т.е. в регрессионной модели среднее значе-ний случайной ошибки равно нулю. Это свойство оказывается весьма существенным условием, влияющим на статистические свойства по-лучаемых результатов.
Исходной точкой любого эконометрического исследования явля-ется выборка наблюдений зависимой переменной y и объясняющих переменных , 1,jx j k= K . Такие выборки представляют собой наборы значений 1 2( , , , , )i i ik ix x x yK , где 1, ,i n= K — номер наблюдения, k — ко-личество объясняющих переменных (факторов). Обычно выделяются два типа выборочных данных:
• Пространственная выборка (cross-sectional data) — набор экономических показателей, полученных в некоторый момент времени (или в относительно небольшом промежутке време-ни), т.е. набор независимых выборочных данных из некоторой генеральной совокупности (так как практически независимость

5
случайных величин проверить трудно, то обычно за незави-симые принимаются величины, не связанные причинно);
• Временной (динамический) ряд (time-series data) — выборка, в которой важны не только сами наблюдаемые значения, но и порядок их следования друг за другом. Чаще всего данные представляют собой наблюдения одной и той же величины в последовательные моменты времени.
Необходимо, однако, заметить, что такое разделение во многом условно и определяется целью и содержанием исследования.
После того, как определен набор объясняющих переменных, по-лучены эмпирические (выборочные) данные, для точного описания уравнения регрессии необходимо найти объясненную часть зависи-мой переменной y , обозначенную нами через ( )f X (как указывалось выше, представляющую собой условное математическое ожидание). Однако на практике точное ее определение, как правило, невозможно, поэтому можно говорить только об оценке (приближенном выражении, аппроксимации) теоретической функции регрессии по выборке. Стан-дартная процедура оценивания состоит в следующем:
Шаг 1. Выбирается вид функции ( )f X (точнее — параметриче-ское семейство, к которому принадлежит искомая функ-ция, рассматриваемая как функция от значений объяс-няющих переменных X );
Шаг 2. С помощью методов математической статистики находят-ся оценки параметров этой функции.
Важно иметь в виду, что в общем случае не существует фор-мальных способов выбора наилучшего семейства функций ( )f X на шаге 1. Очень часто выбирается семейство линейных функций. Выбор линейной модели, кроме вполне очевидного преимущества — просто-ты, имеет ряд существенных математических оснований, оправды-вающих этот выбор.
В целом формулировку исходных предпосылок и ограничений, выбор структуры уравнения модели, представление в математической форме обнаруженных взаимосвязей и соотношений, установление со-става объясняющих переменных называют спецификацией модели. От того, насколько удачно решена проблема спецификации, в значи-тельной степени зависит успех всего процесса эконометрического мо-делирования.
Оценку теоретической функции регрессии, построенную по эм-пирическим данным, обозначим через y) . Уравнение ( , )y f= X B
)) , (1.2.4) полученное по выборке, где y) — оценка условной средней перемен-ной y при значениях переменных 1 2( , , , )kx x x=X K , B — вектор пара-метров функции f
) (которая является аппроксимацией функции f ),

6
называется выборочным (эмпирическим) уравнением регрессии (мо-дельной функцией регрессии).
Итак, можно выделить несколько основных этапов эконометри-ческого моделирования и анализа:
Этап 1. Постановочный — формируется цель исследования (анализ экономического объекта, прогноз его показате-лей, имитация развития, выработка управленческих ре-шений), теоретическое обоснование выбора перемен-ных;
Этап 2. Априорный — анализ сущности изучаемого объекта, формирование и формализация имеющейся информа-ции;
Этап 3. Параметризация — выбор вида модели (вида функции ( )f X ), анализ взаимосвязей и спецификация модели;
Этап 4. Информационный — сбор необходимой статистической информации — наблюдаемых значений переменных;
Этап 5. Идентификация модели — статистический анализ мо-дели и оценка ее параметров;
Этап 6. Верификация модели — проверка адекватности, стати-стической значимости модели.
§ 1.3. Спецификация модели парной линейной регрессии В случае парной регрессии рассматривается один объясняющий
фактор: через y обозначим изучаемый эконометрический показатель; через x — объясняющий фактор. Эконометрическая модель, приво-дящая к парной регрессии, имеет следующий вид ( )y f x ε= + , (1.3.1) где ( )f x — неизвестная функциональная зависимость (теоретическая регрессия); ε — возмущение, случайное слагаемое, представляющее собой совокупное действие не включенных в модель факторов, по-грешностей.
Основная задача эконометрического моделирования — построе-ние по выборке эмпирической модели, выборочной парной регрессии
( )f x)
, являющейся оценкой теоретической регрессии (функции ( )f x ): ( )y f x=
)) , (1.3.2) здесь ( )f x
) — эмпирическая (выборочная) регрессия, описывающая
усредненную по x зависимость между изучаемым показателем и объ-ясняющим фактором. После построения выборочной регрессии обыч-но производится верификация модели — проверка статистической значимости и адекватности построенной парной регрессии имеющим-ся эмпирическим данным.
7
Экспериментальная основа построения парной эмпирической регрессии — двумерная выборка: 1 1( , ), , ( , )n nx y x yK , где n — объем вы-борки (объем массива экспериментальных данных).
Основная задача спецификации модели — выбор вида функцио-нальной зависимости. В случае парной регрессии обычно рассматри-ваются функциональные зависимости следующего вида
( )f x xα β= + — линейная; (1.3.3) 2
1 2( )f x x xα β β= + + — параболическая; (1.3.4)
( )f xxβ
α= + — гиперболическая; (1.3.5)
( ) e xf x βα= — показательная; (1.3.6) ( )f x xβα= — степенная, (1.3.7)
а так же некоторые другие. Заметим, что функциональные зависимо-сти 1.3.3, 1.3.4 и 1.3.5 линейны по своим параметрам α и β .
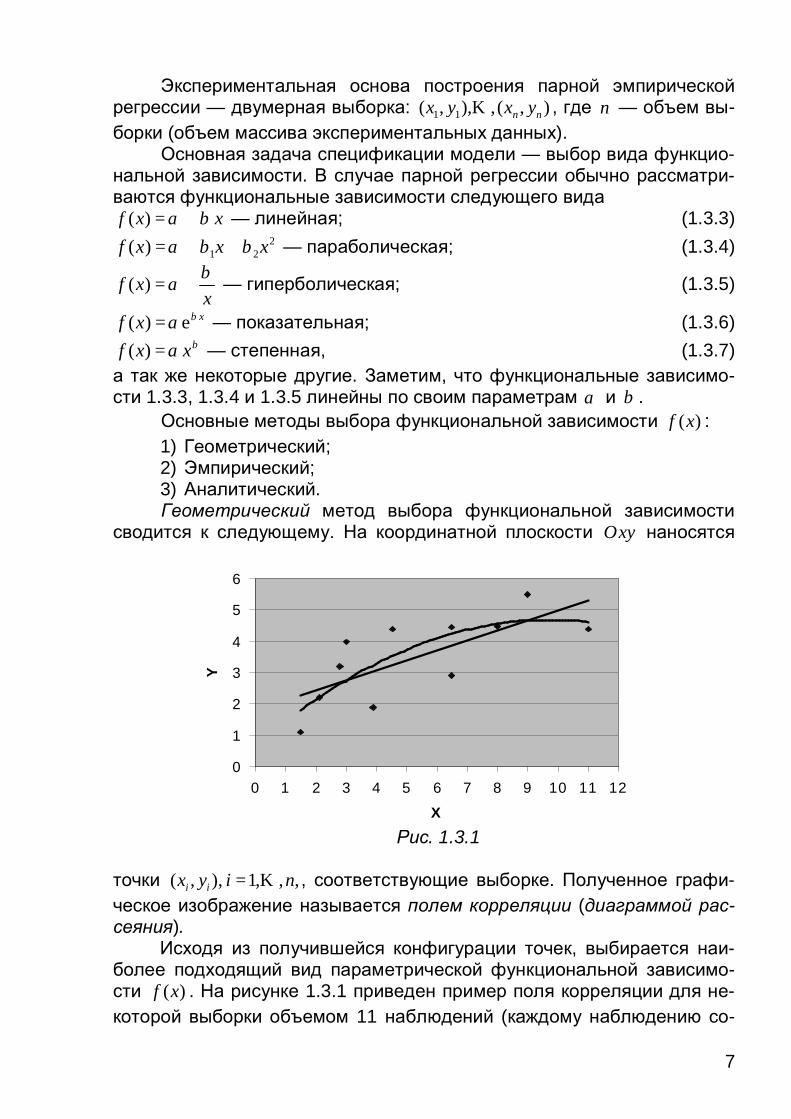
Основные методы выбора функциональной зависимости ( )f x : 1) Геометрический; 2) Эмпирический; 3) Аналитический. Геометрический метод выбора функциональной зависимости
сводится к следующему. На координатной плоскости Oxy наносятся
точки ( , ), 1, , ,i ix y i n= K , соответствующие выборке. Полученное графи-ческое изображение называется полем корреляции (диаграммой рас-сеяния).
Исходя из получившейся конфигурации точек, выбирается наи-более подходящий вид параметрической функциональной зависимо-сти ( )f x . На рисунке 1.3.1 приведен пример поля корреляции для не-которой выборки объемом 11 наблюдений (каждому наблюдению со-
0
1
2
3
4
5
6
0 1 2 3 4 5 6 7 8 9 10 11 12
X
Y
Рис. 1.3.1

8
ответствует одна точка) с графиками двух функциональных зависимо-стей — линейной функции и параболы.
Эмпирический метод состоит в следующем. Выбирается некото-рая параметрическая функциональная зависимость ( )f x (см., напри-мер, 1.3.3–1.3.7). Для построения по выборке оценки ( )f x
) этой зави-
симости чаще всего используется метод наименьших квадратов (МНК).
Согласно методу наименьших квадратов значения параметров функции ( )f x
) (будем обозначать их через a , b ) выбираются таким
образом, чтобы сумма квадратов отклонений выборочных значений iy от значений ( )if x
) была минимальной
( )2
,1
( ) minn
i i a bi
y f x=
− →∑)
, (1.3.8)
минимум ищется по параметрам a b , которые входят в зависимость ( )f x
). Найденные значения параметров, которые минимизируют ука-
занную сумму квадратов разностей, называются оценками неизвест-ных параметров регрессии по методу наименьших квадратов (оцен-ками МНК). Выборочная регрессия ( )y f x=
)) (или ( ), 1, ,i iy f x i n= =)) K ), в
которую подставлены найденные значения, уже не содержит неиз-вестных параметров и является оценкой теоретической регрессии. Именно эту зависимость ( )f x
) будем рассматривать как эмпирическую
усредненную зависимость изучаемого показателя от объясняющего фактора.
После нахождения эмпирического уравнения регрессии вычис-ляются значения ( )i iy f x=
)) и остатки i i ie y y= − ) , 1,i n= . По величине
остаточной суммы квадратов 2
1
( )n
i ii
y y=
−∑ ) можно судить о качестве со-
ответствия эмпирической функции ( )f x)
имеющимся в наличии стати-стическим наблюдениям. Перебирая разные функциональные зависи-мости и, каждый раз, действуя подобным образом можно практически подобрать наиболее подходящую функцию для описания имеющихся данных.
Аналитический метод сводится к попытке выяснения содержа-тельного смысла зависимости изучаемого показателя от объясняюще-го фактора и последующего выбора на этой основе соответствующей функциональной зависимости. Так, если y — расходы фирмы, x — объем выпущенной продукции за месяц, то нетрудно получить сле-дующую модель зависимости расходов от объема выпущенной про-дукции:

9
y xα β ε= + + , где α — условно-постоянные расходы, xβ — условно-переменные расходы.
В практике эконометрического анализа часто используют линей-ную парную регрессию. В модели парной линейной регрессии зависи-мость 1.3.1 между переменными представляется в виде y xα β ε= + + , (1.3.9) т.е. теоретическая регрессия имеет вид 1.3.3.
На основе выборочных наблюдений оценка теоретической рег-рессии — выборочная (эмпирическая) регрессия y) строится в виде: y a bx= +) , (1.3.10) где a , b являются оценками параметров α , β теоретической регрес-сии.
§ 1.4. Оценка параметров. Метод наименьших квадратов. Экономическая интерпретация
Рассматривается модель парной линейной регрессии , 1,i i iy x i nα β ε= + + = .
На основе эмпирических наблюдений построим оценку теорети-ческой регрессии — найдем выборочное уравнение регрессии , 1,i iy a bx i n= + =) .
Оценки a , b параметров α , β определяются по методу наи-меньших квадратов из соотношения:
( )22,
1 1
( ) ( ) minn n
i i i i a bi i
y y y a bx= =
− = − + →∑ ∑) , (1.4.1)
т.е. a , b выбираются таким образом, чтобы минимизировать сумму квадратов отклонений выборочных (эмпирических) значений показа-теля iy от расчетных iy) .
Вычисляя производные по параметрам a , b и приравнивая их к нулю, приходим к следующей системе из двух уравнений (т.н. систе-ма нормальных уравнений):
1 1
2
1 1 1
n n
i ii i
n n n
i i i ii i i
an b x y
a x b x x y
= =
= = =
+ = + =
∑ ∑
∑ ∑ ∑. (1.4.2)
Решение этой системы уравнений называется оценкой неиз-вестных параметров по методу наименьших квадратов, его можно найти по формулам:
2 2
, ,xy xyb a y bxx x
−= = −
− (1.4.3)
где

10
1
1 n
ii
y yn =
= ∑ , 1
1 n
ii
x xn =
= ∑ , 1
1 n
i ii
xy x yn =
= ∑ , 2 2
1
1 n
ii
x xn =
= ∑ .
Таким образом, парная эмпирическая линейная регрессия имеет вид: ( )y a bx y b x x= + = + −) , (1.4.4) где коэффициенты a и b определяются по формуле 1.4.3.
Коэффициенту b при объясняющем факторе x в парной линей-ной регрессии можно дать естественную экономическую интерпрета-цию. Коэффициент b показывает, на какую величину изменяется в среднем изучаемый эконометрический показатель при увеличении объясняющего фактора на одну единицу.
Нетрудно найти значения показателя, рассчитанные по выбо-рочной линейной регрессии для тех значений объясняющего фактора, которые содержатся в выборке: ( )i i iy a bx y b x x= + = + −) , 1, ,i n= K . (1.4.5)
Особое значение для проверки статистической значимости пар-ной линейной регрессии имеют остатки (разности между истинными значениями показателя и значениями, вычисленными по уравнению линейной регрессии): i i ie y y= − ) , 1, ,i n= K . (1.4.6)
§ 1.5. Основные предположения регрессионного анализа Основные предположения регрессионного анализа относятся к
случайной компоненте ε и имеют решающее значение для правиль-ного и обоснованного применения регрессионного анализа в эконо-метрических исследованиях.
В классической модели регрессионного анализа предполагаются выполненными следующие предположения (условия Гаусса-Маркова):
Условие 1.5.1. Величины iε являются случайными. Условие 1.5.2. Математическое ожидание возмущений равно ну-
лю: ( ) 0iE ε = . Условие 1.5.3. Возмущения iε и jε некоррелированы: ( ) 0i jE ε ε = ,
i j≠ . Условие 1.5.4. Дисперсия возмущения iε постоянна для каждого
i : 2( )iD ε σ= . Это условие называется условием гомоскедастичности. Нарушение этого условия называется гетероскедастичностью.
Условие 1.5.5. Величины iε взаимно независимы со значениями объясняющих переменных.
Здесь, во всех условиях 1,2, ,i n= K .

11
Эти предположения образуют первую группу предположений, необходимых для проведения регрессионного анализа в рамках клас-сической модели.
Вторая группа предположений дает достаточные условия для обоснованного проведения проверки статистической значимости эм-пирических регрессий:
Условие 1.5.6. Совместное распределение случайных величин 1, , nε εK является нормальным.
При выполнении предположений первой и второй групп случай-ные величины 1, , nε εK оказываются взаимно независимыми, одинако-во распределенными случайными величинами, подчиняющимися нор-мальному распределению с нулевым математическим ожиданием и дисперсией 2σ .
§ 1.6. Статистические свойства оценок. Теорема Гаусса-Маркова
При выполнении предположений первой группы справедлива Теорема 1.6.1. (Гаусса-Маркова) Если регрессионная модель
y xα β ε= + + удовлетворяет условиям 1.5.1–1.5.5, то оценки МНК a и b (1.4.3) име-ют наименьшую дисперсию в классе всех линейных несмещенных оценок.
Заметим, что после построения уравнения выборочной регрес-сии, наблюдаемые значения iy можно представить в виде , 1,i i iy y e i n= + =) , (1.6.1) где , 1,i iy a bx i n= + =) , коэффициенты a , b определяются по формуле 1.4.3. Остатки ie являются, в отличие от возмущений iε , наблюдае-мыми величинами, с помощью которых можно оценить воздействие неучтенных факторов и ошибок наблюдений. Говорят, что ie является выборочной оценкой возмущения iε .
Можно показать, что статистика (выборочная остаточная дис-персия), определяемая с помощью остатков ie (см. 1.4.6):
2
2 1 1( )
2 2
n n
i i ii i
ост
y y eS
n n= =
−= =
− −
∑ ∑)
(1.6.2)
является несмещенной оценкой дисперсии 2σ — дисперсии возмуще-ний (теоретической остаточной дисперсии).
При выполнении условий Гаусса-Маркова первой и второй групп (1.5.1–1.5.6) справедливы утверждения:

12
Утверждение 1.6.1. Статистика a
am
α− распределена по закону
Стьюдента с 2n − степенями свободы, здесь
2
1
n
ii
a остx
xm S
s n==∑
, (1.6.3)
представляет собой стандартную ошибку коэффициента a , 2 2
1
1 ( )n
x ii
s x xn =
= −∑ — выборочная дисперсия x .
Утверждение 1.6.2. Статистика b
bm
β− распределена по закону
Стьюдента с 2n − степенями свободы, здесь
остb
x
Sms n
= , (1.6.4)
представляет собой стандартную ошибку коэффициента b , 2 2
1
1 ( )n
x ii
s x xn =
= −∑ — выборочная дисперсия x .
Утверждение 1.6.3. Если y и x некоррелированы, то статистика
2
21
xyr
xy
rt n
r= −
− (1.6.5)
распределена по закону Стьюдента с 2−n степенями свободы. Здесь ( , )y xρ — теоретический коэффициент парной корреляции, xyr — вы-
борочный коэффициент парной корреляции:
1
1 ( )( )n
i ii
xyx y
y y x xnr
s s=
− −=
∑, (1.6.6)
где 2 2
1
1 ( )n
x ii
s x xn =
= −∑ , 2 2
1
1 ( )n
y ii
s y yn =
= −∑ — выборочные дисперсии x и y ,
соответственно.
§ 1.7. Показатели качества регрессии. Коэффициент де-терминации. Коэффициент парной корреляции
Коэффициент детерминации является одной из наиболее эф-фективных оценок адекватности регрессионной модели, т.е. мерой ка-чества уравнения регрессии (соответствия регрессионной модели эм-пирическим данным).
После построения выборочного уравнения регрессии, как уже указывалось выше в 1.6.1, значение зависимой переменной y в каж-дом наблюдении можно разложить на две составляющие:

13
, 1,i i iy y e i n= + =) , здесь остаток ie представляет собой ту часть зависимой переменной y , которую невозможно «объяснить» с помощью выборочной регрес-сии. Можно показать, что дисперсия y может быть представлена в виде суммы: ( ) ( ) ( )D y D y D e= +) , (1.7.1) в которой первое слагаемое представляет собой часть, «объяснен-ную» регрессионным уравнением (или обусловленную регрессией), а второе — «необъясненную» часть, характеризующую влияние неуч-тенных факторов и т.п. Необходимо заметить, что такое разложение справедливо только в том случае, когда в уравнение регрессии вклю-чена константа a .
Разложение 1.7.1 часто записываю в следующем виде:
2 2 2
1 1 1
( ) ( ) ( )n n n
i i i ii i i
y y y y y y= = =
− = − + −∑ ∑ ∑) ) , (1.7.2)
где 2
1
( )n
ii
y y=
−∑ представляет собой общую сумму квадратов отклоне-
ний зависимой переменной от средней, 2
1
( )n
ii
y y=
−∑ ) есть сумма квадра-
тов отклонений, обусловленная регрессией, а 2
1
( )n
i ii
y y=
−∑ ) — остаточ-
ная сумма квадратов. Коэффициент детерминации определяется по формуле:
2 2
2 1 1
2 2
1 1
( ) ( )1
( ) ( )
n n
i i ii in n
i ii i
y y y yR
y y y y
= =
= =
− −= = −
− −
∑ ∑
∑ ∑
) )
. (1.7.3)
Величина 2R , как видно из формул 1.7.2 и 1.7.3, представляет собой часть (долю) вариации (разброса, дисперсии) зависимой пере-менной обусловленную («объясненную») уравнением регрессии (ино-гда говорят — обусловленную вариацией объясняющей переменной).
Свойства коэффициента детерминации: Свойство 1.7.1 20 1R≤ ≤ ; Свойство 1.7.2. Чем ближе 2R к единице, тем лучше регрессия
аппроксимирует эмпирические данные, т.е. эмпирические наблюдения ближе к линии выборочной регрессии. Если 2 1R = , то между y и x есть линейная функциональная зависимость, в этом случае все эмпи-рические точки наблюдений лежат на прямой регрессии;

14
Свойство 1.7.3. Если 2 0R = , то в этом случае вариация зависи-мой переменной полностью обусловлена случайными воздействиями и линия выборочной регрессии параллельна оси Ox .
Заметим, что коэффициент детерминации 2R имеет смысл рас-сматривать только при наличии свободного члена в уравнении регрес-сии, так как лишь в этом случае справедливо равенство 1.7.2.
Оценка качества соответствия выборочного равнения регрессии наблюдаемым данным может производиться и с помощью средней ошибки аппроксимации регрессии по формуле:
1
1 100%n
i i
i i
y yA
n y=
−= ∑
). (1.7.4)
Как указывают некоторые авторы, в практических исследованиях значение этой ошибки в пределах 5-7% свидетельствует о хорошем соответствии модели эмпирическим данным.
Коэффициент регрессии b , как уже отмечалось выше, показыва-ет, на сколько единиц в среднем изменяется значение показателя y , когда фактор x увеличивается на одну единицу — поэтому он также может служить мерой тесноты связи между y и x . Однако b зависит от единиц измерения переменных. Именно поэтому удобно использовать некоторую «стандартную» систему единиц измерения тесноты связи, в которой различные данные были бы сравнимы между собой. В качест-ве единиц измерения такой системы используется среднее квадрати-ческое отклонение переменных, а показателем тесноты связи служит коэффициент корреляции.
Действительно, используя понятия выборочных дисперсий, ко-вариации и корреляции, оценки МНК можно записать специальным образом:
yxy
x
sa y r x
s= − , y
xyx
sb r
s= , (1.7.5)
где 1
1 n
ii
y yn =
= ∑ , 1
1 n
ii
x xn =
= ∑ — выборочные средние, 2 2
1
1 ( )n
y ii
s y yn =
= −∑ ,
2 2
1
1 ( )n
x ii
s x xn =
= −∑ — выборочные дисперсии, xyr — выборочный коэф-
фициент корреляции (см. 1.6.5). Следовательно, парная эмпирическая линейная регрессия мо-
жет быть записана в виде:
( )yxy
x
sy a bx y r x x
s= + = + −) . (1.7.6)
Таким образом, величина
xxy
y
sr bs
= (1.7.7)

15
показывает, на сколько величин ys изменится (в среднем) y , если x увеличится на одно xs , поэтому выборочный коэффициент корреля-ции xyr также является показателем тесноты связи (более точно — ха-рактеризует тесноту линейной зависимости) между переменными.
Выборочный коэффициент корреляции является безразмерной величиной и обладает следующими свойствами:
Свойство 1.7.4. 1 1xyr− ≤ ≤ ; Свойство 1.7.5. При 1xyr = ± корреляционная зависимость пред-ставляет собой линейную функциональную зависимость (все на-блюдаемые значения располагаются на прямой линии регрес-сии); Свойство 1.7.6. При 0xyr = линейная корреляционная связь от-сутствует (линия регрессии параллельна оси Ox ). Заметим, что выборочный коэффициент корреляции xyr полно-
стью оценивает тесноту связи только в случае совместного нормаль-ного распределения случайных величин y и x , в других случаях вы-борочный коэффициент корреляции является оценкой меры только линейной зависимости.
Практически наиболее удобна следующая формула вычисления xyr (которая непосредственно может быть получена из определения):
1 1 12 2
2 2
1 1 1 1
n n n
i i i ii i i
xyn n n n
i i i ii i i i
n x y x yr
n x x n y y
= = =
= = = =
−=
− ⋅ −
∑ ∑ ∑
∑ ∑ ∑ ∑. (1.7.8)
В случае парной линейной регрессии между коэффициентом де-терминации 2R и коэффициентом корреляции xyr существует следую-щая связь: 2 2
xyR r= . (1.7.9)
§ 1.8. Проверка статистической значимости в парной ли-нейной регрессии
Проверка значимости (статистической) уравнения регрессии оз-начает проверку соответствия модели, выражающей зависимость ме-жду переменными, экспериментальным данным, а также проверку до-статочности включенных в уравнение объясняющих переменных для описания зависимой переменной.
Правило проверки статистической значимости оценок a и b ос-новывается на статистических свойствах оценок МНК (§ 1.6) и провер-ке статистических гипотез 0 1: 0, : 0H Hα α= ≠ и 0 1: 0, : 0H Hβ β= ≠ . Не-возможность отклонения какой-либо из гипотез означает статистиче-

16
скую незначимость соответствующего коэффициента и наоборот, от-клонение какой-либо из гипотез означает, что соответствующий ко-эффициент статистически значим.
Как всегда, проверка статистических гипотез осуществляется при некотором уровне значимости. В практических эконометрических ис-следованиях наиболее часто используются 5% и 1% уровни значимо-сти. Выбор того или иного уровня значимости определяется исследо-вателем.
Напомним, что если нулевая гипотеза отклоняется при 1%-ном уровне значимости, то она автоматически отклоняется и при 5%-ном уровне.
Если нулевая гипотеза принимается при 5%-ном уровне значи-мости, то она принимается и при 1%-ном уровне.
Если же при 5%-ном уровне значимости нулевая гипотеза откло-няется, то необходимо проверить ее при 1%-ном уровне и, если при этом уровне она принимается, то результаты проверки гипотезы при-водятся для двух уровней значимости.
1.8.1. Правило проверки значимости коэффициента b :
Статистика bb
btm
= при выполнении гипотезы 0 : 0H β = распреде-
лена по закону Стьюдента с 2n − степенями свободы. Из таблицы распределения Стьюдента с 2n − степенями свобо-
ды по заданному уровню значимости выбирается значение таблt как критическая точка, соответствующая двусторонней области. Тогда:
1) Если b таблt t≥ , то гипотезу 0 : 0H β = следует отклонить и, сле-довательно, признать коэффициент b статистически значимым,
2) Если b таблt t< , то гипотезу 0 : 0H β = следует принять и, следо-вательно, признать коэффициент b статистически незначимым.
1.8.2. Правило проверки значимости коэффициента a :
Статистика aa
atm
= при выполнении гипотезы 0 : 0H α = распреде-
лена по закону Стьюдента с 2n − степенями свободы. Из таблицы распределения Стьюдента с 2n − степенями свобо-
ды по заданному уровню значимости выбирается значение таблt как критическая точка, соответствующая двусторонней области. Тогда:
1) Если a таблt t≥ , то гипотезу 0 : 0H α = следует отклонить и, сле-довательно, признать коэффициент a статистически значимым,
2) Если a таблt t< , то гипотезу 0 : 0H α = следует принять и, следо-вательно, признать коэффициент a статистически незначимым.

17
1.8.3. Правило проверки значимости коэффициента корреляции xyr :
Статистика 2
21
xyr
xy
rt n
r= −
− при выполнении гипотезы 0 : 0yxH ρ =
(т.е. при отсутствии корреляционной связи, здесь ρ — генеральный коэффициент корреляции) распределена по закону Стьюдента с 2n − степенями свободы.
Из таблицы распределения Стьюдента с 2n − степенями свобо-ды по заданному уровню значимости выбирается значение таблt как критическая точка, соответствующая двусторонней области. Тогда:
1) Если r таблt t≥ , то гипотезу 0 : 0yxH ρ = следует отклонить и, следовательно, признать коэффициент xyr статистически значимым,
2) Если r таблt t< , то гипотезу 0 : 0yxH ρ = следует принять и, сле-довательно, признать коэффициент xyr статистически незначимым.
Проверка значимости коэффициента b одновременно является проверкой значимости парной линейной регрессии в целом. Еще один способ проверки значимости парной линейной регрессии основан на коэффициенте детерминации 2R и статистике, распределенной по за-кону Фишера с числом степеней свободы числителя равном 1 и чис-лом степеней свободы знаменателя равном 2n − . 1.8.4. Правило проверки значимости линейной регрессии в целом (гипотезы 0 : 0H β = ) с использованием F статистики:
Если выполнены предположения регрессионного анализа, то при выполнении гипотезы 0 : 0H β = (что означает отсутствие взаимосвязи между x и y , а так же статистическую незначимость построенной пар-
ной регрессии) статистика 2
2 ( 2)1
RF nR
= −−
распределена по закону
Фишера с числом степеней свободы числителя равном 1 и числом степеней свободы знаменателя равном 2n − .
По таблице распределения Фишера-Снедекора при заданном уровне значимости определяется значение таблF как критическая точка при числе степеней свободы числителя равном 1 и числе степеней свободы знаменателя равном 2n − . Тогда:
1) Если таблF F≥ , то гипотезу 0 : 0H β = следует отклонить и, сле-довательно, признать построенное уравнение линейной регрессии статистически значимым,
2) Если таблF F< , то гипотезу 0 : 0H β = следует принять и, следо-вательно, признать построенное уравнение статистически незначи-мым.

18
1.8.5. Взаимосвязь критериев
В случае парного регрессионного анализа оба способа проверки статистической значимости (использование t -критерия проверки зна-чимости коэффициента b и F -критерия проверки значимости уравне-ния в целом) равносильны, так как можно показать, что соответст-вующие статистики связаны между собой следующим образом 2 2
b rt t F= = . Кроме того, критическое значение таблF равно квадрату таблt .
§ 1.9. Доверительные интервалы 1.9.1. Доверительные интервалы для параметров регрессии
Учитывая статистические свойства оценок МНК, можно постро-ить доверительные интервалы для параметров α и β с заданным уровнем доверия, в качестве которого на практике обычно выбирают вероятность 0,95 (соответствующую уровню значимости 5%).
По таблицам распределения Стьюдента с 2n − степенями сво-боды определяется таблt — критическое значение для заданного уров-ня значимости и числа степеней свободы 2n − , тогда ( ; )a табл a таблa m t a m t− + (1.9.1) есть доверительный интервал для α с заданным уровнем доверия,
здесь
2
1
n
ii
a остx
xm S
s n==∑
— стандартная ошибка коэффициента a (см.
1.6.2). Аналогично для коэффициента β :
( ; )b табл b таблb m t b m t− + (1.9.2) есть доверительный интервал для β с заданным уровнем доверия,
здесь остb
x
Sms n
= — стандартная ошибка коэффициента b (см. 1.6.3).
1.9.2. Доверительный интервал прогноза для парной линейной регрессии
Точечный прогноз py значения показателя y согласно линейной парной регрессии для px x= вычисляется по формуле
( )yp p xy p
x
sy a bx y r x x
s= + = + − . (1.9.3)
Интервальный прогноз (доверительный интервал прогноза) для px x= вычисляется аналогично доверительному интервалу для пара-
метров регрессии.

19
По таблицам распределения Стьюдента с 2n − степенями сво-боды определяется таблt — критическое значение для заданного уров-ня значимости и числа степеней свободы 2−n , тогда ( ; )p y табл p y таблy m t y m t− + (1.9.4) есть доверительный интервал прогноза индивидуального значения показателя py в точке px x= с заданным уровнем доверия, где стан-дартная ошибка индивидуального прогноза определяется следующим образом:
2
2
1
( )11( )
py ост n
ii
x xm S
n x x=
−= + +
−∑. (1.9.5)
Нетрудно видеть, что чем дальше px от x , тем шире доверительный интервал прогноза, или, другими словами, тем выше погрешность про-гноза. Выводы
• Эконометрика — это наука, в рамках которой на базе реальных статистических данных строятся, анализируются и совершенст-вуются математические модели экономических явлений. Эконо-метрика позволяет найти количественное подтверждение либо опровержение экономического закона, либо гипотезы. Одним из важнейших направлений эконометрики является построение прогнозов по различным экономическим показателям.
• Модель парной линейной регрессии является наиболее распро-страненным (и простым) уравнением зависимости между эконо-мическими переменными. Метод наименьших квадратов дает наилучшие (в определенном смысле) оценки параметров регрес-сии. Решающее значение для правильного и обоснованного применения регрессионного анализа в эконометрических иссле-дованиях имеет выполнение условий Гаусса–Маркова.
• Необходимым элементом эконометрического анализа является проверка статистической значимости полученных оценок коэф-фициентов, а также всего уравнения регрессии в целом. В каче-стве показателя качества регрессии может использоваться ко-эффициент детерминации.
• При использовании парной линейной регрессии для построения прогнозов необходимо учитывать доверительные интервалы прогноза и параметров регрессии.
Вопросы для самопроверки
1. Что такое генеральная совокупность и выборка?

20
2. Как вычисляются основные выборочные числовые характери-стики: выборочные среднее, дисперсия, среднее квадратиче-ское отклонение?
3. Как вычисляется выборочный коэффициент корреляции? 4. Приведите основные свойства выборочного коэффициента кор-
реляции. 5. В чем различие между точечными и интервальными оценками? 6. Дайте определения эффективности, несмещенности и состоя-
тельности оценок. 7. В чем состоит общая схема проверки статистической гипотезы?
Какова ее цель? 8. Что такое уровень значимости? 9. Как определяются распределения Стьюдента, Фишера, хи-
квадрат? 10. Каковы основные этапы эконометрического моделирования? 11. Опишите эконометрическую модель, приводящую к парной ли-
нейной регрессии. 12. Какова эмпирическая основа построения эмпирической парной
регрессии? 13. Назовите основные причины присутствия в регрессионной мо-
дели случайного члена. 14. Что понимается под спецификацией модели, и как она осуще-
ствляется? 15. Приведите примеры функциональных зависимостей, исполь-
зуемых в парных регрессиях. 16. В чем состоит отличие теоретического и эмпирического урав-
нений регрессии? 17. В чем состоит суть МНК? 18. Докажите справедливость формул вычисления МНК оценок па-
раметров парной линейной регрессии. 19. Почему регрессию (в частности парную линейную) называют
усредненной эмпирической зависимостью? 20. Дайте интерпретацию уравнению регрессии 3 2y x= + , где y —
объем продукции (в млн. руб), x — объем инвестиций в ИТ тех-нологии (в сотнях тыс. долларов).
21. Чем отличаются возмущения iε от остатков ie ? 22. В чем состоят основные предположения регрессионного анали-
за? 23. Как связаны коэффициенты линейной регрессии с выборочным
коэффициентом корреляции? 24. Докажите формулы 1.7.3. 25. Как определяются стандартные ошибки регрессии и коэффици-
ентов регрессии?

21
26. Что является несмещенной оценкой дисперсии возмущений? Приведите формулу.
27. Укажите статистики, распределенные по закону Стьюдента в парной линейной регрессии.
28. Каким образом можно оценить качество уравнения регрессии? 29. Как связаны между собой коэффициент парной корреляции и
коэффициент детерминации? 30. Является ли значимым коэффициент выборочный корреляции
0,8r = , если он получен по выборке объемом 6n = ? 31. В чем суть статистической значимости коэффициентов регрес-
сии? Сформулируйте правило проверки статистической значи-мости коэффициентов парной линейной регрессии.
32. В чем состоит идея проверки статистической значимости урав-нения регрессии в целом? Сформулируйте правило проверки.
33. Как связаны между собой критерии проверки статистической значимости в парном регрессионном анализе?
Библиография
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. — М.: ЮНИТИ, 1998. — 650 с.
2. Буре В.М.. Евсеев Е.А. Основы эконометрики: Учеб. Пособие. — СПб.: Изд-во С.-Петерб. ун-та, 2004.— 72 с.
3. Валландер С.С. Заметки по эконометрике. — СПб.: Европ. ун-т, 2001. — 46 с.
4. Доугерти К. Введение в эконометрику: учебник. 2-е изд. М.: ИНФРА-М, 2004.— 432 с.
5. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов.— М.: ЮНИТИ-ДАНА, 2004.— 311 с.
6. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. На-чальный курс. — М.: Дело, 2000. — 400 с.
7. Эконометрика: Учебник / Под ред. И.И.Елисеевой. — М.: Фи-нансы и статистика, 2001. — 344 с.


![Скачать ГОСТ Р 55633-2013 Внутренний водный ...[ГОСТ 26069-86, статья 85] 3.23 кнехт: Металлическая парная тумба](https://img.pdfslide.tips/doc/110x75/5f560672d2b27d40a04de327/oe-55633-2013-f-.jpg)


![Скачать ГОСТ Р 55633-2013 Внутренний водный ... · 2019-12-19 · [ГОСТ 26069-86, статья 85] 3.23 кнехт: Металлическая парная](https://img.pdfslide.tips/doc/110x75/5f3bf785bfaace336928c8bd/oe-55633-2013-f-2019-12-19.jpg)























