Embed Size (px)
DESCRIPTION
基于广义特征序列的 语义分类体系的自动构建. 陈刚 刘扬 北京大学计算语言学研究所 北京大学计算语言学教育部重点实验室 E-mail: [email protected] [email protected] 2013-05. 提纲. 1 词义的知识表示方式 2 广义特征、序关系、广义特征序列 3 基于广义特征序列, 自动构建语义分类体系 4 实验与数据分析 5 结语. 提纲. 1 词义的知识表示方式 2 广义特征、序关系、广义特征序列 3 基于广义特征序列, 自动构建语义分类体系 4 实验与数据分析 5 结语. - PowerPoint PPT Presentation
Citation preview

基于广义特征序列的语义分类体系的自动构建
陈刚 刘扬
北京大学计算语言学研究所北京大学计算语言学教育部重点实验室
E-mail: [email protected] [email protected]
2013-05 1

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
2

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
3
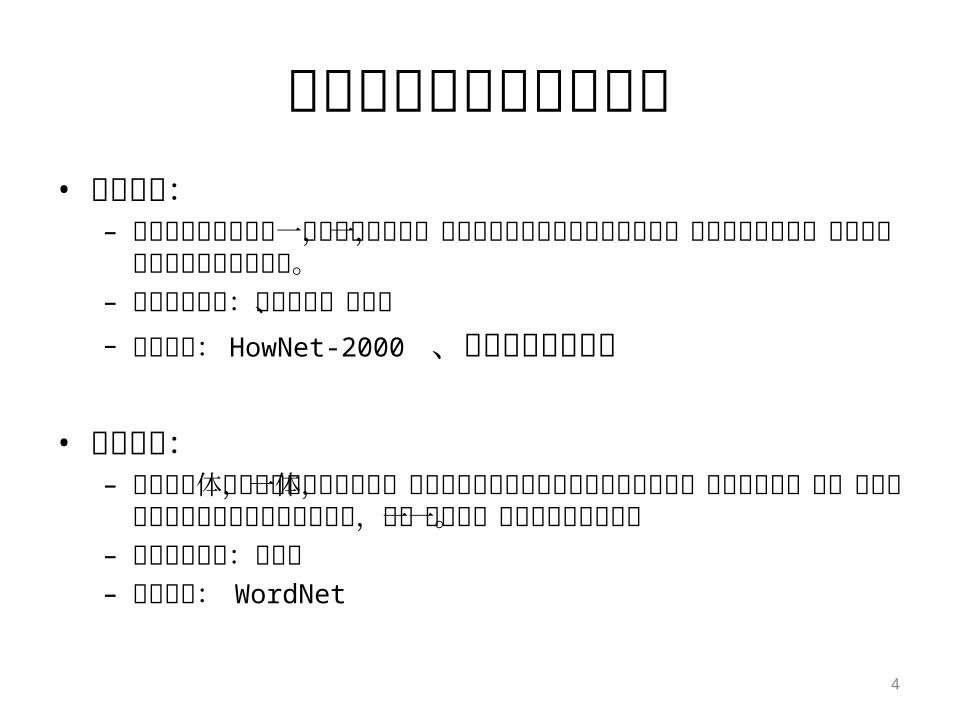
• 属性描述:– 词义知识的属性描述一般采取构造方式,借助义素分析等方法预先
定义出一组基本语义单位,然后组合这些单位形成概念描写。– 典型呈现方式:属性枚举、二维表– 典型系统: HowNet-2000 、现代汉语语义词典
• 分类描述:– 注重对全体概念进行系统性的区分,以上下位关系为主干结构将概
念组织成一个语义分类体系,在此基础上再添加其它类型的语义关系,进一步构成一个复杂的语义网络。
– 典型呈现方式:树结构– 典型系统: WordNet
词义的两种知识表示方式
4

词义的两种知识表示方式• 相互转换:
– 属性描述:强于对概念自身的精细描写、在词义计算中便于实现多样的特征选取;
– 分类描述:强于对系统结构的整体把握、在词义计算中便于在不同粒度上的意义归约。
– 相互转换的可行性与现实状况还未被关注。
• 本文的主要工作:– 在属性描述的基础上,引入广义特征和序关系的概念,自动构建
出一个语义分类体系。完成了从属性描述到分类描述的等价转化。– 基于这种转化所得到的语义分类体系,进行数据分析和实验验证,
帮助语言知识工程进行迭代性的评估与构建。
5

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
6
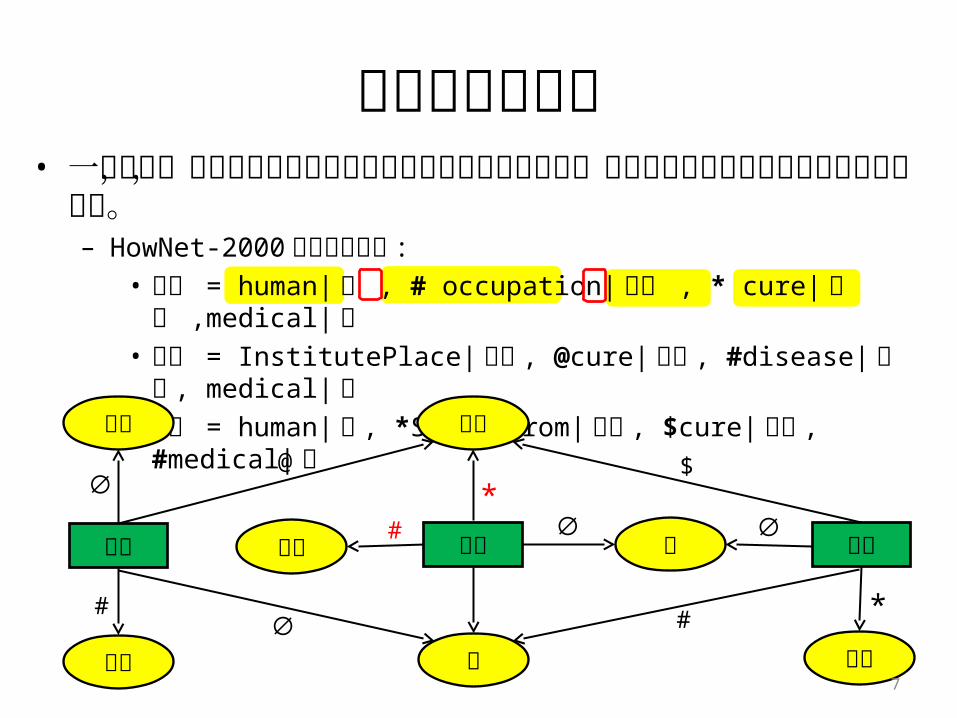
广义特征的背景• 一般而言,属性描述的方式不仅涉及当前概念的多种属性,
也描述它与其它概念之间的多种语义关系。– HowNet-2000 中的概念描述 :
• 医生 = human| 人 , # occupation| 职位 , * cure| 医治 ,medical| 医• 医院 = InstitutePlace| 场所 , @cure| 医治 , #disease| 疾病 ,
medical| 医• 患者 = human| 人 , *SufferFrom| 罹患 , $cure| 医治 , #medical| 医
医治
医
人职位
疾病
场所
罹患
#*
@
# *
$
医院 患者医生
∅ #
∅∅∅
7
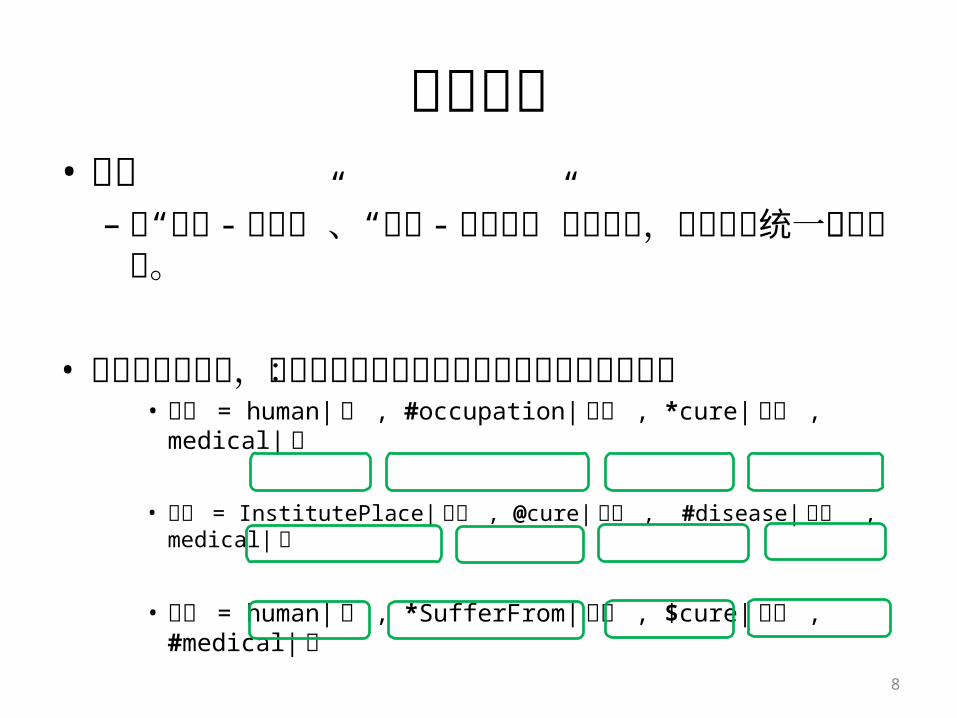
广义特征• 定义
– 把“属性 - 属性值”、“关系 - 目标概念”封装起来,形成简洁统一的广义特征。
• 对于上面的例子,它的所有特征仅仅是多个经过封装的字符串:
• 医生 = human| 人 , #occupation| 职位 , *cure| 医治 , medical| 医
• 医院 = InstitutePlace| 场所 , @cure| 医治 , #disease| 疾病 , medical| 医
• 患者 = human| 人 , *SufferFrom| 罹患 , $cure| 医治 , #medical| 医
8
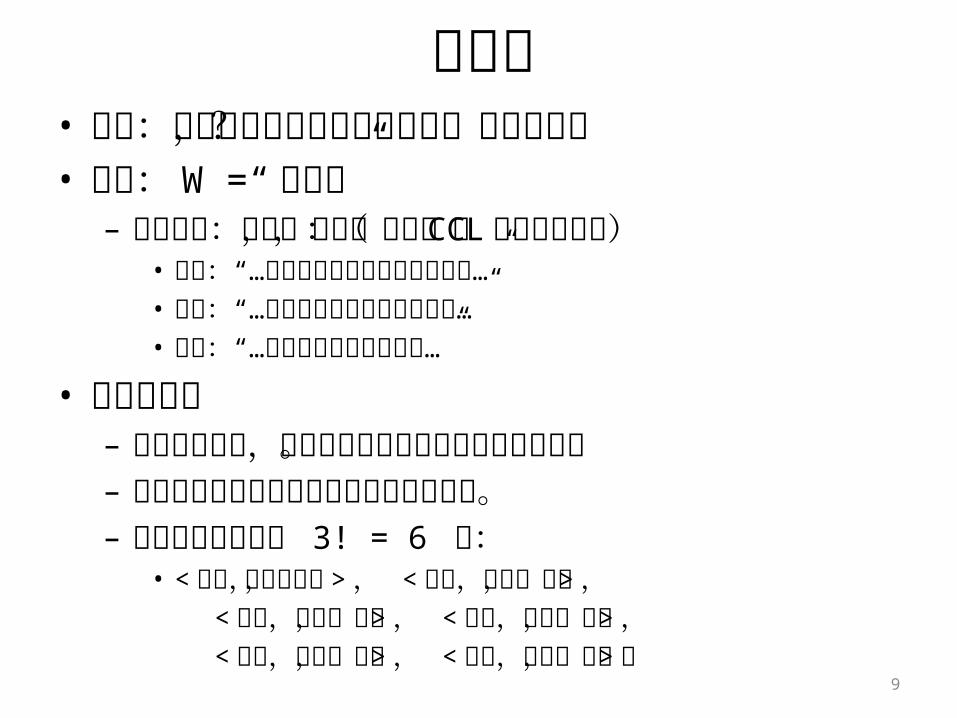
序关系• 问题:词语往往有多个方面的意义,如何兼顾?• 例如: W =“ 中南海”
– 可以表示:地点,机构,人群:( CCL 语料库的例句)• 地点:“…走进了神圣而又神秘的中南海…”• 机构:“…中南海发出的那份红头文件…”• 人群:“…引起中南海的意见分歧…”
• 引入序关系– 根据应用需求,对多个意义方面进行重要性的排序。– 避免在它们之间做出非此即彼的硬性选择。– 可能的特征序列有 3! = 6 种:
• < 地点,机构,人群 > , < 地点,人群,机构 > , < 机构,地点,人群 > , < 机构,人群,地点 > , < 人群,地点,机构 > , < 人群,机构,地点 > 。 9

广义特征序列• 广义特征集合:
– 集合,无序性, W= { F1, F2, … , Fn }
• 广义特征序列:– 在词语 W 的广义特征集合上施加关于多项特征之间的
序关系的认定,则在给定序关系下的排列W = < F′ s1, Fs2, … , Fsn >
称为广义特征序列。– 广义特征集合 + 序关系 = 广义特征序列
• 根据不同的应用需求,实现序关系的“定制”:– 一般领域:
• 医生 = human| 人 ,#occupation| 职位 , *cure| 医治 , medical| 医– 术语研究:
• 医生 = medical| 医 ,#occupation| 职位 , *cure| 医治 , human| 人 10

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
11

广义特征序列前缀• 广义特征序列的意义随着新的广义特征的逐步施加变
得细化而确定。因此,在序列产生的过程中,它的不同长度的前缀,也负载了特殊的意义。
• 例如:– ? = human| 人– ? = human| 人 , #occupation| 职位– ? = human| 人 , #occupation| 职位 , *cure| 医治– 医生 = human| 人 , #occupation| 职位 , *cure| 医治 , medical| 医
• 随着序列前缀的逐步展开,形成了不同的分类层次、构成不同的中间概念,同时自然地模拟了概念涵义从一般到特殊的渐次生成过程。
12

语义分类体系的自动构建• 把广义特征序列的生长过程看做树结构的生长过程。
• 每一项新特征的施加,概念就被约束到一个更小的内涵上去。这个过程模拟、重现了现实分类中的父类、子类关系。
• 这种约束不限于狭义的 kind-of 或 is-a 关系,是一种更为“广义”的上下位关系,也为一般的语义分类实践提供了新的契机。
13

过程演示( 1/3 )• 第一步:形成特征序列
W(1) =<F1, F2, F3>
W(2) =<F1, F2, F4>
W(3) =<F1, F5, F6>
W(4) =<F1, F5>
W(5) =<F1, F2, F4>
14
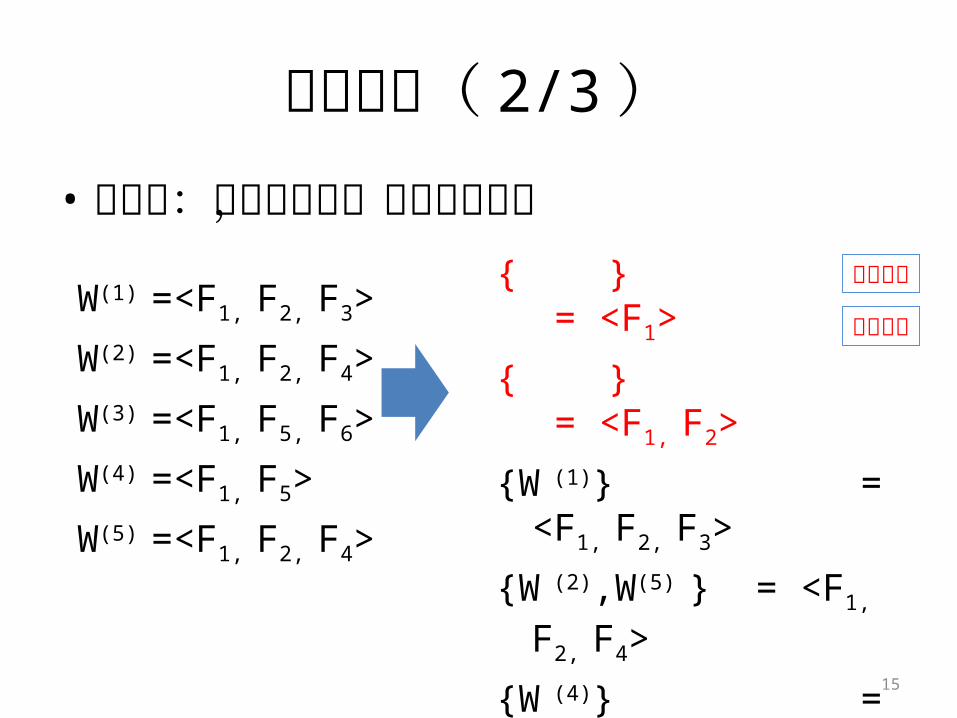
过程演示( 2/3 )• 第二步:合并同义词,提取特征前缀
W(1) =<F1, F2, F3>
W(2) =<F1, F2, F4>
W(3) =<F1, F5, F6>
W(4) =<F1, F5>
W(5) =<F1, F2, F4>
{ } = <F1>
{ } = <F1, F2>
{W (1)} = <F1, F2, F3>
{W (2),W(5) } = <F1, F2, F4>
{W (4)} = <F1, F5>
{W (3)} = <F1, F5, F6>
中间概念
中间概念
15
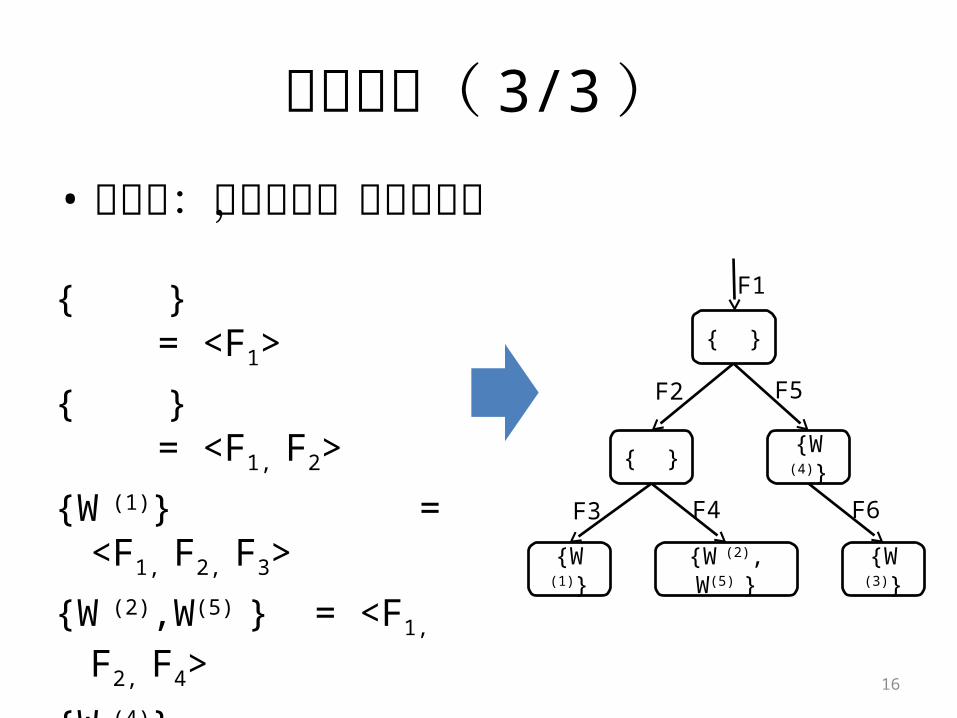
过程演示( 3/3 )• 第三步:纵向收集,形成树结构
{ } = <F1>
{ } = <F1, F2>
{W (1)} = <F1, F2, F3>
{W (2),W(5) } = <F1, F2, F4>
{W (4)} = <F1, F5>
{W (3)} = <F1, F5, F6>
{ }
{ }
{W (1)} {W (2), W(5) }
{W (4)}
{W (3)}
F2 F5
F1
F3 F4 F6
16
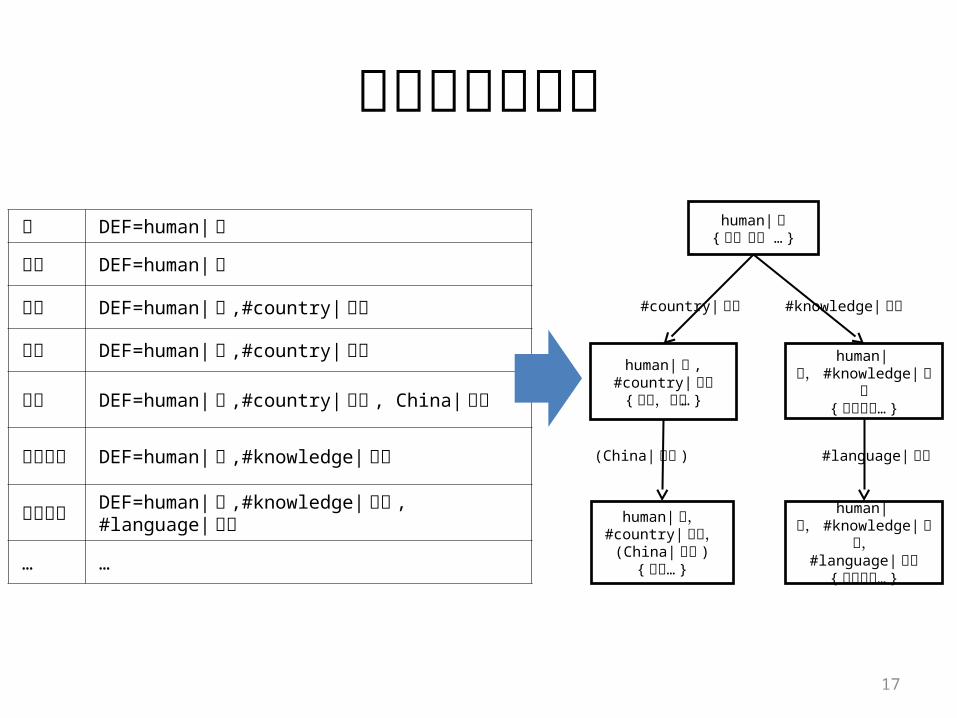
实际数据的例子
人 DEF=human| 人
人物 DEF=human| 人
公民 DEF=human| 人 ,#country|国家
国人 DEF=human| 人 ,#country|国家
华侨 DEF=human| 人 ,#country|国家 , China| 中国
知识分子 DEF=human| 人 ,#knowledge| 知识
语言学家
DEF=human| 人 ,#knowledge|知识 , #language|语言
… …
#country|国家 #knowledge| 知识
(China| 中国 ) #language| 语言
human| 人{ 人,人物 … }
human| 人 , #country|国家
{公民,国人… }
human|人, #knowledge| 知
识{ 知识分子… }
human| 人,#country|国家,
(China| 中国 ){华侨… }
human|人, #knowledge| 知
识,#language| 语言{ 语言学家… }
17
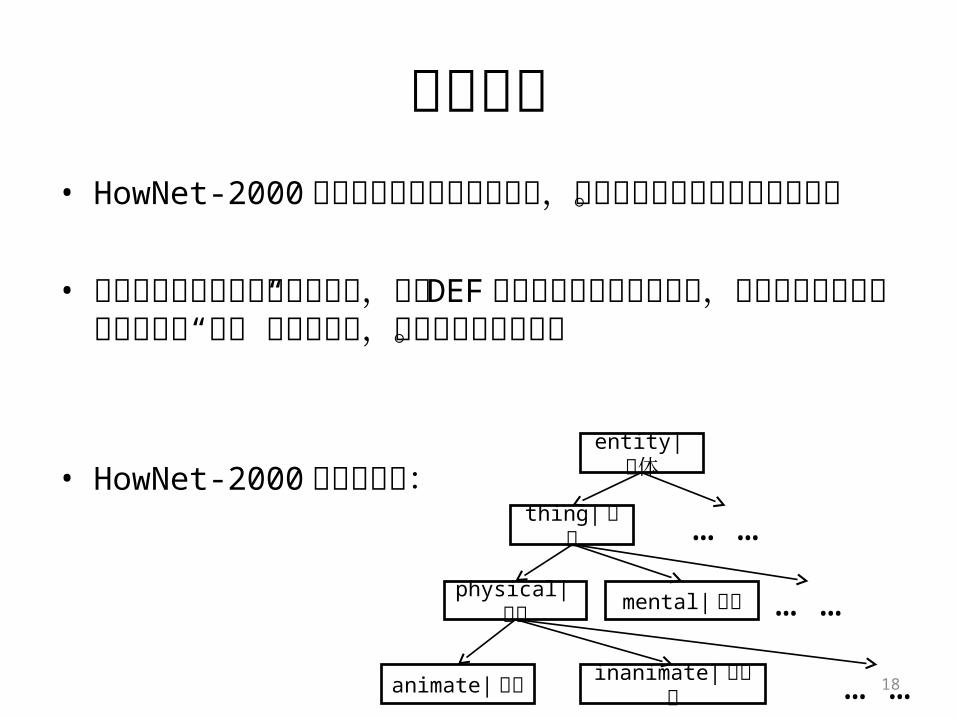
优化方案• HowNet-2000 中的义原已经组织成树结构,且同样可转写
为广义特征序列。
• 这启发我们在自动扩展的基础上,依据 DEF项对应的主要特征的取值,可将此前生成的语义分类直接“拼接”在义原树上,形成层次更深的树。
• HowNet-2000 的义原结构:physical|物质
animate| 生物
entity| 实体
inanimate|无生物 … …
thing|万物 … …
mental| 精神 … …
18
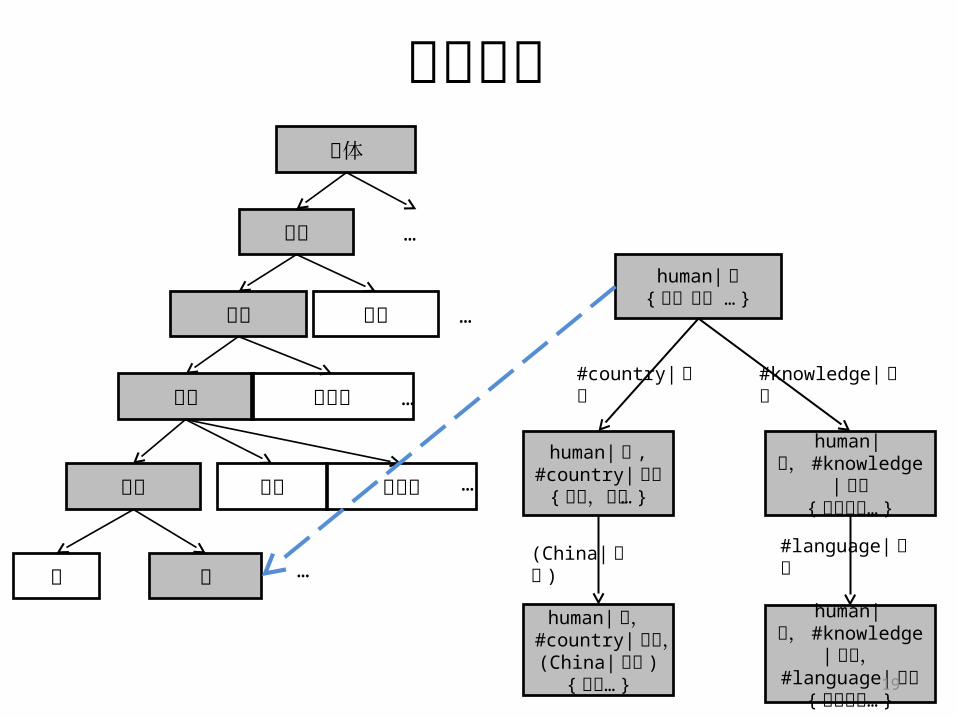
优化方案
物质
生物
动物 植物 微生物
兽 人 …
实体
无生物
万物 …
精神 …
#country|国家
#knowledge| 知识
#language| 语言
human| 人{ 人,人物 … }
human| 人 , #country|国家
{公民,国人… }
human|人, #knowledge|
知识{ 知识分子… }
human| 人,#country|国家,(China| 中国 )
{华侨… }
human|人, #knowledge|
知识,#language| 语言{ 语言学家… }
(China| 中国 )
…
…
19

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
20

概念涵义的扩展与中间概念的生成
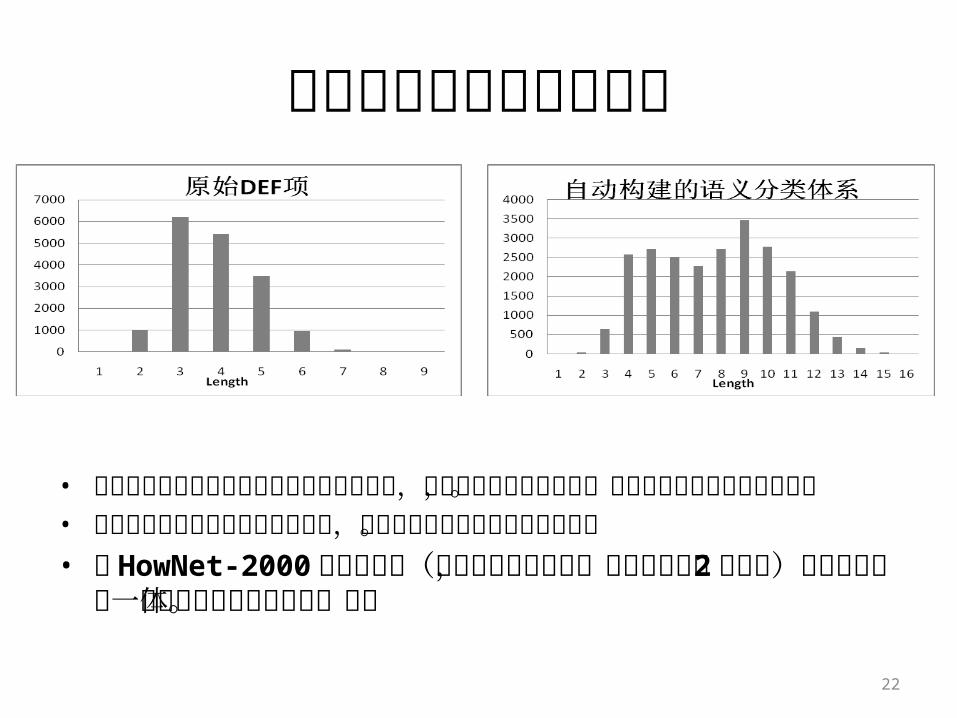
• HowNet-2000原始文件中不重复的 DEF项(即概念定义)的总次数为17216 , DEF项的平均长度为 3.86 。
• 优化方案除覆盖了原始的概念外,同时新生成了 6384 个此前未加定义的中间概念,它们暂时还没有词的实例来承载。这些尚未显性化的中间概念的数量占原有概念数量的 37.08% ,而全体概念数量增长到 23600个, DEF项的平均长度被扩展到约 7.74 。
• 从概念涵义的有意义扩展以及新的中间概念自动生成的角度看,这对语言知识库建设是一个积极的现象。
• 概念描述平均长度的增加,为词义计算供了更多的信息。
不重复的DEF项(概念数目) 平均长度
HowNet-2000原始数据 17216 3.86
自动构建的语义分类体系 23600 (+37.8%)
7.74 (+100.5%)
21
广义特征序列的长度分布
• 将概念的特征序列直接追加到义原分类树上,增加了特征序列的长度,也增强了概念之间的区分性。
• 概念的特征序列长度的分布更均匀,这也有助于确保词义计算的质量。• 在 HowNet-2000的全集规模(覆盖全部原始概念,分类节点数
在 2万以上)上首次给出了一个分布均衡的语义分类体系。
22

揭示属性描述方式下不易察觉的问题
• 核查同一概念节点内不同词的同义性状况:– 亭子 |碑亭 | 垛 |构筑物 |明沟 |窨井
• 概念涵义继承链条的潜在缺失:– DEF=facilities|设施 ,@exercise| 锻练 => “训练场”、“健身中心”…
• 有助于发掘概念涵义继承链条的潜在错误 :– HowNet-2000原始数据中, “冰场”作为“亭子 |碑亭 | 垛 | 构筑物 |明
沟 |窨井”的子孙概念,这是不合理的。– 通过向语义分类体系的转化,问题得以揭示。
DEF=facilities|设施 亭子 |碑亭 | 垛 |构筑物 |明沟 |窨井
DEF=facilities|设施 ,@exercise|锻练 nullDEF=facilities|设施 ,@exercise|锻练 ,#(tennis|网球 ) 网球场DEF=facilities|设施 ,@exercise|锻练 ,#ice|冰 nullDEF=facilities|设施 ,@exercise|锻练 ,#ice| 冰 ,sport|体育 冰场
23

属性描述与分类描述结合的优势• 在属性描述下,针对单个词的属性描述难以对不同的词进
行系统化的横向、纵向比较,在语义分类体系下则可把相关问题清晰呈现出来。
• 反过来,单纯的分类描述缺乏对多种特征的有效认识和把握,在工程实践中也会衍生出许多问题。
• 两种方式的结合有助于发挥综合优势,在语言知识工程上做迭代,以生成高质量的、实用化的词义知识库。
24

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
25
工作小结• 在知识库的构建中,词义知识表示主要依赖属性描述和分类描
述,这两种方式各有所长,但不同表示之间相互转换的可行性与现实状况还未被关注。
• 在属性描述的基础上,本文引入了广义特征、序关系和广义特征序列的概念,以及基于该概念的分类层次展开方法。
• 该方法能够模拟、分析概念涵义从一般到特殊的渐次生成过程,并发掘、记录那些尚未显性化的中间概念,自动构建出一个语义分类体系,实现从属性描述到分类描述的计算性转换。
• 以 HowNet 数据为例,实验表明本方法可以生成一个性质优良、覆盖完全的新的语义分类体系,并反映此前的属性描述在语言知识工程实践中一些不易察觉的问题。
26

应用与展望• 应用:北大“中文概念词典”
– 目前,我们正将基于广义特征序列的概念、方法应用于北大“中文概念词典”的迭代评价和结构重构等方面,希望在语言知识工程上不断演化,生成出高质量的、实用化的词义知识库。
• 反向转化:从分类描述向属性描述的转换
– 从理论和实践上看,广义特征序列的概念、方法具有通用性,在从分类描述向属性描述的转换中同样适用。
– 核心思想:对于语义分类体系中的每个概念节点,持续界定、收集从根节点到该概念节点的路径上的每一处分类的区分性凭证(即区分特征)。若知识库中存在多继承现象和多种其它关系,则需要在序关系上做一些特殊的认定和处理。
27

提纲• 11 词义的知识表示方式词义的知识表示方式• 22 广义特征、序关系、广义特征序列广义特征、序关系、广义特征序列• 33 基于广义特征序列,基于广义特征序列,自动构建语义分类体系自动构建语义分类体系• 44 实验与数据分析实验与数据分析• 55 结语结语
谢谢!28





























