Embed Size (px)
Citation preview

<Insert Picture Here>
トラブルシューティングのポイント解説
日本オラクル株式会社2011年06月29日
第62回 夜な夜な! なにわオラクル塾

Copyright© 2011, Oracle. All rights reserved. 2
以下の事項は、弊社の一般的な製品の方向性に関する概要を説明するものです。また、情報提供を唯一の目的とするものであり、いかなる契約にも組み込むことはできません。以下の事項は、マテリアルやコード、機能を提供することをコミットメント(確約)するものではないため、購買決定を行う際の判断材料になさらないで下さい。オラクル製品に関して記載されている機能の開発、リリースおよび時期については、弊社の裁量により決定されます。
OracleとJavaは、Oracle Corporation 及びその子会社、関連会社の米国及びその他の国における登録商標です。文中の社名、商品名等は各社の商標または登録商標である場合があります。

Copyright© 2011, Oracle. All rights reserved.
内容
• パフォーマンス問題の原因調査とチューニング
• パフォーマンス問題の原因
• パフォーマンス問題へのアプローチ
• 原因調査に有効な取得情報
• よくあるパフォーマンス問題の原因例
• 内部エラーのトラブルシューティング
• 内部エラーの概要
• 現場で可能なトラブルシューティング
• 効率的に オラクル カスタマ・サポートと連携する方法
• RAC環境のインスタンスダウンやノードダウンの原因調査と予防
• RAC環境における可用性の管理
• RAC環境における考慮事項
3

Copyright© 2011, Oracle. All rights reserved. 4
パフォーマンス問題の原因調査とチューニング
<Insert Picture Here>

Copyright© 2011, Oracle. All rights reserved.
パフォーマンス問題が発生
5
原因は決していつも同じではありませんそのため、恒常的に有効な解決策はありません
データベースのレスポンスが急に低下してしまった。早急に対処しなければいけないのでいち早く対処策を確認したい!!
Oracle Database システム利用者
DBA
パフォーマンスが悪い!応答が返らない!
データベースのパフォーマンス問題を解決する方法は?
Application Server

Copyright© 2011, Oracle. All rights reserved.
パフォーマンス問題の原因の例
6
OSやハードウェア :
OS負荷が高い、メモリ不足、ディスクIOが遅い
アプリケーション :
アプリケーション側のコーディングミス、SQL文の効率が悪い
ネットワーク :
ネットワーク負荷が高い
データベース :
不適切なパラメータ設定、データ量の増加、不適切な実行計画
まずは根本的な問題点を特定した上で、その原因に合わせて
適切な対処を施す必要があります

Copyright© 2011, Oracle. All rights reserved.
パフォーマンス問題解決への流れ
7
時系列での事象の把握と整理
状況に合わせた資料取得
取得情報の分析と原因の特定
実装した対処の有効性確認
原因に合わせた対処策の検討と実装
実装した対処が不適切?
別の問題が発生?
チューニング成功

Copyright© 2011, Oracle. All rights reserved.
問題発生時の状況把握
8
• 何が発生したのか?
(特定処理のみが遅延しているのか、データベース全体で遅いのか)
• いつからいつまで発生したのか?
• 問題は既に解消したのか?どうやって問題が解消したのか?
• 問題を検知した方法は?
• 再現性はあるのか?
• 遅延しているのか、全く応答がないのかの判断はできているか?
パフォーマンス問題の原因特定の第一歩として、発生した事象を正確に整理することが必要
確認するべきポイントとは?
誰が、何を実行して、いつ、どのような問題が発生したのか

Copyright© 2011, Oracle. All rights reserved.
状況に合わせた資料の取得
9
取得する情報の種類によって、確認できるポイントや調査項目は大きく変わります。
したがって、いつも同じ情報だけを取得するのではなく、発生時の状況に応じて適切な情報を取得することが重要です。
データベースのパフォーマンス問題のパターンとは?
パフォーマンス問題は主に2つのパターンに分けられます
• 特定の処理のみが遅くなっている場合
• データベース全体、あるいは複数の処理が遅くなっている場合
Copyright© 2011, Oracle. All rights reserved.
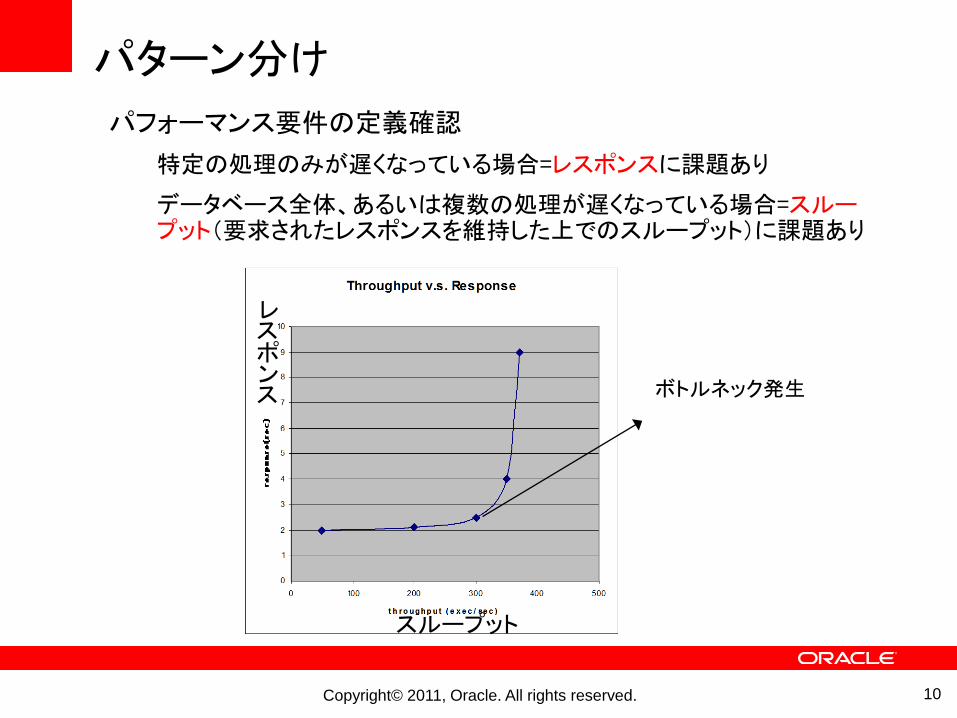
パターン分け
10
パフォーマンス要件の定義確認
特定の処理のみが遅くなっている場合=レスポンスに課題あり
データベース全体、あるいは複数の処理が遅くなっている場合=スループット(要求されたレスポンスを維持した上でのスループット)に課題あり
ボトルネック発生
スループット
レスポンス

Copyright© 2011, Oracle. All rights reserved.
パターン別の取得情報
11
特定の処理のみが遅くなっている場合
データベース全体、あるいは複数の処理が遅くなっている場合
セッション単位で処理状況が確認できる情報
データベース全体のパフォーマンス状況が確認できる情報
• SQLトレース
• V$SESSION / V$SESSION_WAIT 等のビュー
• ASH (Active Session Hitory)、AWR reportのSQL statistics
• 問題がなかったときのAWR reportとの比較
• ボトルネックがなにかをみつける
• V$SESSION / V$SESSION_WAIT 等のビュー
• ps / top / vmstat / sar などOSのリソース使用状況が分かる情報
• STATSPACKレポート/AWRレポート/ASH (Active Session History)
• スループットが低いとき / 問題がない時との比較

Copyright© 2011, Oracle. All rights reserved.
SQLトレースとは
12
出力される情報例
• CPU時間/経過時間
• 実行された回数
• 待機イベントの発生回数、待機時間
• ディスクから読み込んだブロック数
• バッファキャッシュから読み込んだブロック数
任意のSQLに対して、実行計画や処理時間、待機イベント
など詳細なパフォーマンス情報をトレースファイルに出力
TKPROFを使用して見やすい出力に整形し、その結果を診断

Copyright© 2011, Oracle. All rights reserved.
SQLトレースの出力例 – 処理時間
13
call count cpu elapsed disk query current rows
------- ------ ------ ------- ------ ------ ------- --------
Parse 1 0.00 0.00 4 4 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 838862 45.63 76.75 41101 84 360 1000000
------- ------ ------ ------- ------ ------ ------- --------
total 838864 45.63 76.75 41105 88 360 1000000
count :実行された回数cpu :CPU時間elapsed :待機イベントも含めた経過時間disk :ディスクから読み込んだブロック数query + current :バッファ・キャッシュ上でアクセスしたデータブロック数rows :処理された行数
• CPU時間よりもElapsedが非常に大きくなっている
待機イベントがボトルネックとなっている → 待機イベントをチェック
• CPU時間自体が大きい
バッファキャッシュへのアクセスが多い → 実行計画をチェック

Copyright© 2011, Oracle. All rights reserved.
V$SESSION/V$SESSION_WAITとは
14
現在のセッション情報を出力するビュー
V$SESSION / V$SESSION_WAITの列の例
SID : セッションの SID
EVENT : 待機イベント名
STATE : セッションの状態
• WAITING セッションは待機イベントで待機中
• WAITED / WAITED_xxx_TIME
EVENT列に表示されている待機イベントで
待機し終えた後CPUを使用して処理を実行中
BLOCKING_SESSION : リソースを保持しているセッションID
SECONDS_IN_WAIT : 待機した時間 (秒)
• 何かの処理をしているのか、待機イベントで待機しているのか
• 特定の待機イベントで待機し続けているのか、遷移しているのか
セッション単位での待機状況、遷移をチェック
Copyright© 2011, Oracle. All rights reserved.
ASH (Active Session History)とは
15
アクティブな状態のセッション情報を、SGA上で 1秒毎に
収集。さらにSGA上の情報はAWRのスナップショットの
取得時にサンプリングされて保存
• V$ACTIVE_SESSION_HISTORYビュー
SGA上で収集されたアクティブセッションの情報
• DBA_HIST_ACTIVE_SESS_HISTORYビュー
サンプリングして保存されたアクティブセッションの情報
• ASHレポート
保存された 情報を元に、指定された期間の
パフォーマンス状況をレポート化
V$SESSIONと同じくセッション単位での処理や
待機イベントの遷移をチェック
Diag Pack

Copyright© 2011, Oracle. All rights reserved.
ASHで出力される情報例
16
DBA_HIST_ACTIVE_SESS_HISTORY ビューの列の例
INSTANCE_NUMBER
SAMPLE_TIME
SESSION_ID
SQL_ID
EVENT
P1, P2, P3
SESSION_STATE
BLOCKING_SESSION
:インスタンス番号
:サンプルの時間
:セッションID
: SQL_ID
:待機イベント
:待機イベントの引数
:セッションの状態 (WAITING/ON CPU)
:ロック等のリソースをブロックしているセッションID
• 一回の検索だけで特定セッションの遷移を確認可能
• 過去の情報を一定期間(Oracle Database 11gR1以降は8日間)
保存
• 現象の解消後も情報を取得可能
Diag Pack

Copyright© 2011, Oracle. All rights reserved.
AWRレポートとは
17
出力される情報例
• 待機イベントの発生回数や合計の待機時間
• 負荷の高い上位SQL文
• SGAやPGAのメモリ使用状況
任意の2時点で取得したスナップショットに基づき、データ
ベースパフォーマンスに関連した統計をレポート形式で出力
スナップショット スナップショット
12:00 13:00
1時間分のデータベースの状況をレポート化
データベース全体のアクティビティやアプリケーションの傾向、
待機イベントの発生状況などの負荷状況をチェック
Diag Pack

Copyright© 2011, Oracle. All rights reserved.
AWRレポートの出力例Top 5 Timed Foreground Events
18
Top 5 Timed Events Avg %Total
~~~~~~~~~~~~~~~~~~ wait Call
Event Waits Time (s) (ms) Time
-------------------------- ------------ ----------- ------ ------
db file sequential read 2,599,951 21,568 8 53.5
CPU time 8,529 21.2
gc cr multi block request 687,139 1,765 3 4.4
db file scattered read 63,925 1,667 26 4.1
gc cr grant 2-way 1,918,674 1,615 1 4.0
アイドルイベント以外の上位待機イベントやCPU時間を出力
• 処理が多数実行されている状況で、一番ボトルネックになって
いる待機イベントを特定
• 待機イベントのタイプに合わせてチューニングポイントを検討
CPU time: データベース内の処理でCPUを使用していた時間
Diag Pack

Copyright© 2011, Oracle. All rights reserved.
よくあるパフォーマンス問題の原因
19
例:特定のSQLのパフォーマンスダウン
いつもは数秒程度で完了する特定の処理が、突然時間を
要するようになってしまった。
• 最新の統計情報が取得されていないため、不適切な実行計画が
選択された
• SQLで処理されるデータ量が増加した
(EXISTS句、IN句+副問い合わせを含むSQL 等)
• 他のセッションで実行されているSQLとのリソース競合が発生した
• アプリケーションからのSQLの実行回数が増加した
• バッファキャッシュ上に対象のデータがないためにディスクIOが発生した
• WHERE句の条件にバインド変数を使用して同じSQL文を繰り返して
実行しているために、ソフトパースにより実行計画が変化していない
よくある原因例

Copyright© 2011, Oracle. All rights reserved.
調査アプローチ
20
• 正常時と遅延時のSQLトレース処理に要した時間、待機イベントの発生回数や待機時間、処理された行数、実行計画の違いをチェックまた、ハードパースで実行されているかどうかもチェック可能
• 現象が発生した時間を含むV$ビュー / ASHの情報対象セッションでの待機イベントの遷移状況、ロックやラッチなどのリソースをブロックしているセッションの特定
• 表のデータ量、データ内容の変化の度合い急に処理されるデータが増加していないかどうかを確認
• 表、索引、列、パーティションに対するDBAビューの情報統計情報の取得状況やオブジェクトの状態などをチェック(統計情報の取得時刻はLAST_ANALYZED列から、
オブジェクトの状態はSTATUS列より判断可能)

Copyright© 2011, Oracle. All rights reserved.21
パフォーマンス問題の原因調査とチューニング
• パフォーマンス問題へのアプローチ発生した問題について詳細に整理した上で、問題のタイプにあわせて適切な資料の取得と解析が重要
• 取得資料のバリエーション取得可能な情報は様々な種類があるが、状況にあわせて取得するべき資料、確認するべきポイントが異なる
• パフォーマンス問題の傾向お問い合わせがあるパフォーマンス問題には陥りがちな傾向がある
パフォーマンス問題の発生を極力抑制
予期せぬ問題が発生した場合にも、より素早い解決を実現

Copyright© 2011, Oracle. All rights reserved. 22
内部エラーのトラブルシューティング
<Insert Picture Here>

Copyright© 2011, Oracle. All rights reserved. 23
内部エラーとは?
ORA-00600: 内部エラー・コード,
引数: [string], [string], [string] ...
原因: これは、Oracleプログラムの例外に対する一括内部エラー番
号です。プロセスで例外条件が検出されたことを示します。
処置: このエラーをバグとして報告してください。最初の引数は内
部エラー番号です。

Copyright© 2011, Oracle. All rights reserved. 24
Oracle® Database Error Messages
11g Release 2 (11.2) の ORA-600 の対処
Action: Visit My Oracle Support to access the ORA-00600
Lookup tool (reference Note 600.1) for more information
regarding the specific ORA-00600 error encountered. An
Incident has been created for this error in the Automatic
Diagnostic Repository (ADR). When logging a service request,
use the Incident Packaging Service (IPS) from the Support
Workbench or the ADR Command Interpreter (ADRCI) to
automatically package the relevant trace information
(reference My Oracle Support Note 411.1).
My Oracle Support で Notes#600.1 を確認
ADRを確認、SR登録時にはインシデント・パッケージを活用:参照 Notes#411.1

Copyright© 2011, Oracle. All rights reserved. 25
ORA-600とは?
• Oracle Database の一般的な内部例外を示すエラーコード
• 値の整合性チェックで 問題を検出する等、内部的な不整合
を検知したことを示す
• 検知したプロセスは診断情報を出力して、影響を最小限に抑
える為、検知した処理を終了する
• ソースコードの様々な箇所で定義されていて、エラー発生時
の引数により発生箇所の絞込みを行う
If Block_type != Data_Blockthen
ORA-600[4519]
End if
ブロックのタイプがデータブロックと異なる
Check

Copyright© 2011, Oracle. All rights reserved. 26
ORA-7445とは?
• 不正なメモリ参照により SIGSEGV や SIGBUS シグナル
を受け取る等、オペレーティングシステムの例外を受け取
った場合に発生するエラー
• 検知したプロセスは core と基本的な診断情報を出力して
処理を終了する
• ソースコードで定義されているエラーでないため、理論上
はどの関数内でも発生する可能性がある。
• クライアントには ORA-3113 等のサーバーとのセッション
が切断されたエラーが返る

Copyright© 2011, Oracle. All rights reserved. 27
Oracle Database 11g R1 から細分化した内部エラー
• ORA-700 :ソフト内部エラー
• ORA-600 として取り扱っていたエラーのうち、処理を停止させる
必要のないエラーを ORA-700 として検知
• ORA-700 を検知した処理は継続する。
• ORA-3137 : TTCプロトコル内部エラー
• クライアントから受信したパケットの整合性チェックで不整合を検
知したことを示す
• パラメータにより、エラー検知時の動作を制御可能
• SEC_PROTOCOL_ERROR_FURTHER_ACTION
• SEC_PROTOCOL_ERROR_TRACE_ACTION

Copyright© 2011, Oracle. All rights reserved. 28
内部エラーの一般的な原因
• ハードウェアの問題
• オペレーティング・システムやコンパイラの問題
• Oracle Database の問題や制限
• ユーザー・アプリケーションの問題

Copyright© 2011, Oracle. All rights reserved. 29
内部エラーの代表的な影響
• SQL解析時や実行時の動作に起因した例外
• SQLの実行が異常終了する
• ORA-7445 の場合、プロセスが異常終了する。
• 同じ SQL を実行した時に再現性が見られる可能性が高い。
• SGA や PGA 上のメモリに格納されている値の例外
• プロセスが異常終了する。
• バックグラウンドプロセスなどで検知した場合、インスタンスがダウンする
可能性がある。
• データベース構成ファイルに格納されている値や管理情報の例外
• 関連するデータへのアクセスが不可能になる。
• インスタンスを再起動しても解消せず、リカバリが必要になる。

Copyright© 2011, Oracle. All rights reserved. 30
問題の確認と影響の把握
• サーバー側の状況把握
• アラートログ
• トレースファイル
• プロセスやサービスの稼動状況や負荷状況
• シスログや イベントログ
• クライアント側の状況把握
• 問題が確認された日時
• 問題を検知した端末とアプリケーション
• 発生した問題の詳細、エラーコードとエラーメッセージ
ログや画面のハードコピー等のエラーの発生が確認できる資料
• 問題の発生を検知したジョブやオペレーション、SQL

Copyright© 2011, Oracle. All rights reserved. 31
アラートログの確認点
• エラーメッセージ
• エラーの発生頻度
• エラーの発生プロセス
• 出力されているトレースファイル名
• Oracle Database のバージョン
• インスタンス起動時に認識されている初期化パラメータ
• パラメータの変更履歴

Copyright© 2011, Oracle. All rights reserved. 32
トレースファイルの確認点
• エラーを検知した SQL の情報
• Call Stack Trace の情報
• エラーを検知したクライアントの情報
• 実行計画の情報

Copyright© 2011, Oracle. All rights reserved.
• 特定の SQL 実行時のみ再現性がみられる(Y/N)
• オプティマイザによる SQL解析時の問題の可能性がある。
• 特定の表や索引、データにアクセスすると発生する(Y/N)
• 特定の表や索引が破損している可能性がある。
• 表の整合性チェックでエラーを検知する(Y/N)
• SQL> ANALYZE TABLE <表名> VALIDATE STRUCTURE
• SQL> ANALYZE TABLE <表名> VALIDATE STRUCTURE CASCADE
• 特定の表や索引が破損している可能性がある。
• インスタンス再起動後も発生する(Y/N)
• 表や索引を格納するデータベースファイル自体に
問題が発生している可能性が高い。
33
影響の切り分けのための確認点
SQL
Disk
それ以外メモリ関連

Copyright© 2011, Oracle. All rights reserved.
• My Oracle Support のナレッジ検索
• NOTE:153788.1 ORA-600/ORA-7445 Error Lookup
Tool を使用した検索
• ナレッジ・ベースの検索より ORA-600 と第一引数を
入力した検索
• KROWN キーワード検索
• KROWNディレクトリ・サービスの検索
• KROWN:145899 の参照情報の欄から
関連コンテンツの確認
34
サポートサイトのナレッジベースを利用した調査

Copyright© 2011, Oracle. All rights reserved.
KROWNとは
• KROWNとは35,000タイトル以上の技術情報を公開している知識ベース
• お好みの方法で情報にアクセス可能KROWN文書はディレクトリをたどるだけでなく、キーワードまたは文書番号で検索することが可能
• お問い合わせいただくよりも早く問題が解決することも!
• 調べながら関連情報も得られます!
• 24時間いつでも簡単に調べられます!
35

Copyright© 2011, Oracle. All rights reserved.
KROWNディレクトリサービス
36
• 分類された技術情報だから「したいこと」が探しやすい
A
B
C
A:ブラウズ製品、カテゴリに分類し、ツリー表示でたどることが可能
B:必見カテゴリ最初に表示されているのは、サポート・エンジニアによるおすすめのカテゴリ群
C:関連文書サポート以外からの物も含め、オラクル製品の各カテゴリに関する技術情報を紹介

Copyright© 2011, Oracle. All rights reserved. 37
オラクル カスタマ・サポートとの協業
• 現場の役割
• 問題の実際の影響の把握
• 問題を発生時の一連のオペレーションの把握
• 問題の発生に関係するオブジェクトやデータ情報の把握
• 問題発生時の特徴的な状況の把握
• 対処方法の実装の検討
• サポートの役割
• 検知した例外の把握
• 問題が潜在的に与える影響の調査
• 問題への対処方法の調査
• 問題の原因調査

Copyright© 2011, Oracle. All rights reserved.
オラクル カスタマ・サポートへのお問い合わせ時に送付いただきたい資料
• インシデント・パッケージ
• アラートログ
• トレースファイル
• 適用パッチの情報
• オペレーティングシステムのログ
• クライアントアプリケーションのログ
• OS Watcher などのオペレーティング・システムのリソースの使用状況
• Remote Diagnostic Agent による情報取得
• 問題の再現性。再現性がある場合は具体的な再現手順
• 最近行ったシステムの構成変更の情報
38

Copyright© 2011, Oracle. All rights reserved.
インシデント・パッケージとは?
• Oracle Database 11g R1以降の障害診断インフラストラクチャの診断データのパッケージング形式
• 問題の1回の発生を1インシデントとして管理し、インシデント単位で診断データのパッケージングを行う• 自動診断リポジトリ(ADR) でインシデントが生成されるエラー番号
• KROWN#126440(11.1)/KROWN#140871(11.2)
• オラクル カスタマ・サポートへの資料提供の標準• Webから or KROWN#135295を参考にパッケージを作成
39
自動診断リポジトリ (ADR)
診断データ取得
自動情報取得障害
インシデント・パッケージ
情報のパッケージング
インシデント
トレース/アラート
診断ログ

Copyright© 2011, Oracle. All rights reserved.
• オペレーティング・システムのリソース情報を取得するツール
• 以下のコマンドの実行結果を取得(Linux の例)
• vmstat
• iostat
• mpstat
• netstat
• ps
• top
• traceroute
• NOTE:301137.1 より無料でダウンロードして利用可能
OS Watcher (OSW) とは?
40

Copyright© 2011, Oracle. All rights reserved.
Remote Diagnostic Agent (RDA) とは?
• 問題解析のための診断資料を効率よく取得するため診断ツール
• Oracle Database だけでなく、Oracle WebLogic やOracle E-Business Suite 等、多くの製品にも対応
• My Oracle Support の NOTE:314422.1 より無料でダウンロードして利用可能
• KROWN#106485 Remote Diagnostic Agent 4.x (RDA 4.x) について
41
DBサーバ
APサーバ

Copyright© 2011, Oracle. All rights reserved.
Remote Diagnostic Agent
• 取得可能な情報の例
RDBMS設定・統計情報RDBMSログ・トレース情報パフォーマンス統計情報OSのセットアップ情報ネットワーク情報DBコントロール情報インストール関連情報システムのオーバービュー
• KROWN#106485
Remote Diagnostic Agent 4.x (RDA 4.x) について
42

Copyright© 2011, Oracle. All rights reserved.
• 内部エラーの対応は現場での迅速な初期対応と情報取得が重要です。現場だから確認できる情報が重要になることがあります。
• 内部エラーが発生する以前より、取得可能な情報については取得の仕組みを実装しておきましょう。
• サポート・サイトのナレッジベースを有効活用しましょう。日頃よりナレッジベースに慣れることで、トラブルへの対処時以外にも有効な情報を得ることができます。
内部エラーのトラブルシューティング
43

Copyright© 2011, Oracle. All rights reserved. 44
RAC環境のインスタンスダウンやノードダウンの原因調査と予防
<Insert Picture Here>
Copyright© 2011, Oracle. All rights reserved.
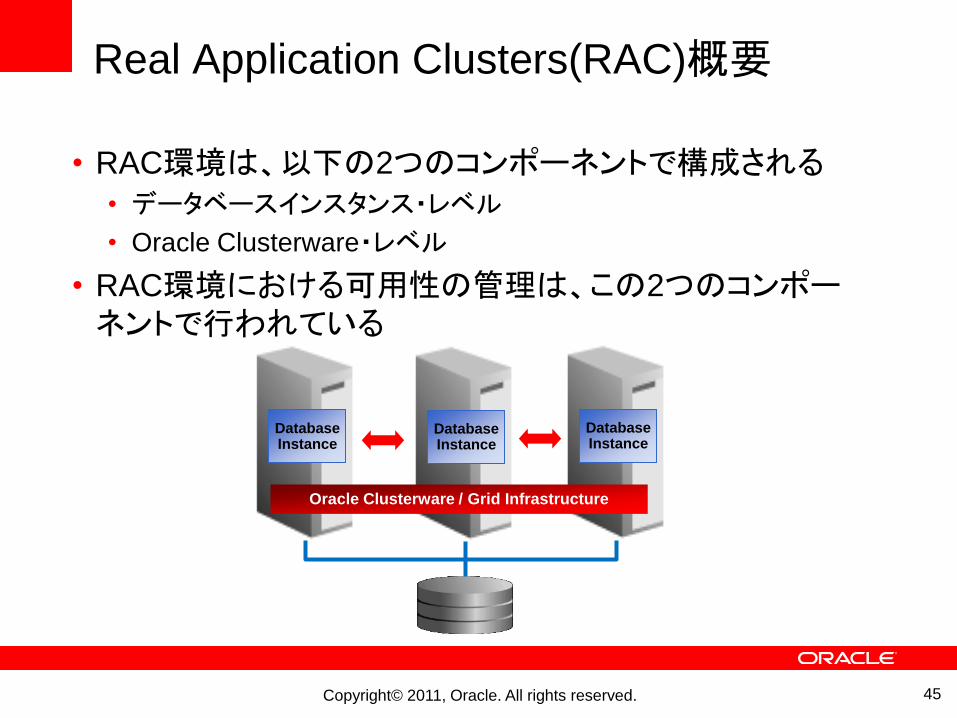
Real Application Clusters(RAC)概要
• RAC環境は、以下の2つのコンポーネントで構成される• データベースインスタンス・レベル
• Oracle Clusterware・レベル
• RAC環境における可用性の管理は、この2つのコンポーネントで行われている
45
DatabaseInstance
DatabaseInstance
DatabaseInstance
Oracle Clusterware / Grid Infrastructure

Copyright© 2011, Oracle. All rights reserved.
インスタンス監視の仕組み
生存を監視するハートビート機能
• lmon同士がネットワーク通信を介して他インスタンスの生存を確認
• ckpt同士が制御ファイルへの書き込みを介して他インスタンスの生存を確認
46
ckptが制御ファイルへ書込む
lmon同士がネットワーク通信lmon
ckpt
制御ファイル
lmon
ckpt
Oracle Clusterware Oracle Clusterware
Database Instance Database Instance

Copyright© 2011, Oracle. All rights reserved.
インスタンス排除の仕組み
IMR (Instance Membership Recovery)
による障害の検出と対処
• ハートビートの障害や、プロセスのノード間通信で障害を検知
• 制御ファイルを用いた投票で、生存インスタンスの確認と排除インスタンスの決定
• ORA-29740を出力し、lmonがインスタンスを停止
47
制御ファイル
生存排除
ORA-29740
lmon lmon
ハートビート
プロセスの
ノード間通信インスタンス1 インスタンス2
プロセス プロセス
排除インスタンスのアラートログ
Thu Nov 1 15:19:54 2010
ORA-29740: evicted by member 0, group incarnation 54
Thu Nov 1 15:19:54 2010
LMON: terminating instance due to error 29740
補足:Clusterware が自動的にインスタンスを再起動KROWN#56123 RAC 環境における ORA-29740 のトラブルシューティングガイド

Copyright© 2011, Oracle. All rights reserved.
インスタンス排除の原因調査で有効な情報
48
原因調査で有効な情報が確認できるファイル
•アラートログ、 LMONのトレース
•生存インスタンスと障害インスタンスを比較し、全体の流れを把握
•投票の結果や Reason など、IMRの詳細な状況を確認
•IPC Send timeout が発生したプロセスのトレース
•通信障害の詳細を確認
•OS側ログ(syslog、messages)
•ハードウェアやOSなどの障害の有無を確認
採取しておきたい情報
•OS負荷、リソース使用状況、プロセスの一覧、ネットワークの統計
•sar や vmstat、ps –elf や top、netstat など OS Watcherの利用も検討
•ネットワーク障害だけではなく、プロセスハング、OSリソース不足などを確認することができる
ファイルの場所
•アラートログ、トレース:(10g) background_dump_dest、user_dump_dest、(11g)<diagnostic_dest>/diag/rdbms/<db_unique_name>/<SID>/trace/
•OSログ:/var/adm/syslog、/var/log/

Copyright© 2011, Oracle. All rights reserved.
IMRにおける問題点
49
•IMRによるインスタンス停止処理が lmonのハングなどが原因で長引くと、インスタンス再構成(※)を開始できず、全インスタンスでSQL処理がハングしてしまう可能性がある。
•IMR によるインスタンス排除フェーズまで、最大でおよそ20分間の障害検出時間がある。
インスタンス再構成を開始できない
生存インスタンス 排除インスタンス
バッファ
キャッシュ
バッファ
キャッシュ
インスタンス停止が完了しない
※一般的に、RAC環境でインスタンスを停止(正常停止を含む)するとインスタンス再構成(バッファキャッシュの整合性などを再構成する処理)が起動中のインスタンスで実行される。

Copyright© 2011, Oracle. All rights reserved.
インスタンスの可用性に関する機能拡張(1)
50
oclskd
kill
プロセスの終了によりインスタンス強制停止
DBインスタンス1
oclskd による可用性の確保 (Oracle Database 11g R1)•oclskd は Clusterware 側のデーモン•oclskd が排除インスタンスのプロセスをkillしてインスタンス強制停止
•oclskd ログ : $ORA_CRS_HOME/log/<nodename>/client/oclskd.log
•プロセスのkillでも対処できない場合はノード再起動へ
Oracle Clusterware
早く終了して欲しい
DBインスタンス2
[ OCLSKD][3086743232]clsskdKillMembers: Member kill requested. Number of pids: 11[ OCLSKD][3086743232]clsskdKillMembers: kill status 0 pid 15932 [ OCLSKD][3086743232]clsskdKillMembers: kill status 0 pid 15973[ OCLSKD][3086743232]clsskdKillMembers: kill status 0 pid 15989...[ OCLSKD][3086743232]clsskdKillMembers: kill status 0 pid 18309[ OCLSKD][3086743232]clsskdeventhndlr: Kill daemon instructed to exit. Exiting …
oclskd.log
対象のプロセスをkill

Copyright© 2011, Oracle. All rights reserved.
インスタンスの可用性に関する機能拡張(2)
51
Thu Nov 1 12:34:30 2010
Errors in file
/u01/app/oracle/diag/rdbms/sid/sid4/trace/sid4_lmhb_18291.trc (incident=243417):
ORA-29770: global enqueue process LMON (OSID 18272) is hung for more than 70 seconds
Incident details in:
/u01/app/oracle/diag/rdbms/sid/sid4/incident/incdir_243417/sid4_lmhb_18291_i243417.trc
ERROR: Some process(s) is not making progress.
LMHB (ospid: 18291) is terminating the instance.
Please check LMHB trace file for more details.
Please also check the CPU load, I/O load and other system properties for anomalous behavior
ERROR: Some process(s) is not making progress.
LMHB (ospid: 18291): terminating the instance due to error 29770
Thu Nov 1 12:34:43 2010
Instance terminated by LMHB, pid = 18291
Instance
ハング状態
Node
LMS
LMON LMD
LMHB
ハング検知
ORA-29770
Oracle Clusterware
LCK
LMHBプロセスによるインスタンス停止
•RAC固有の重要プロセス(LMS LMD LMON LCK)を監視し、より早くハング(インスタンス障害)を検知
•ハングを検知するとLMHBプロセスがインスタンスを停止
LMHBがインスタンス停止
LMONハングを検知

Copyright© 2011, Oracle. All rights reserved.
Oracle Clusterwareによる監視の仕組み
52
ネットワーク通信のハートビート
投票ディスクのハートビート
CSS
oprocdOS負荷を監視
Oracle Clusterware Oracle Clusterware
CSSの状態を監視
oclsomon
CSS(Cluster Synchronization Services )
•メンバーシップを管理
•他ノード生存を監視
•投票ディスクのハートビート
•ネットワーク通信のハートビート
CSS
oprocd
OS負荷を監視
oclsomon
oclsomon
•CSSを監視し、ハングを検知
oprocd
•OS負荷を監視し、カーネルレベルのハングを検知
投票ディスク

Copyright© 2011, Oracle. All rights reserved.
CSSによる監視
53
設定値を確認するコマンド
$ crsctl get css disktimeout
200
$ crsctl get css misscount
60
•ハートビートを通じた監視
•投票ディスクのタイムアウト:disktimeout (秒)
•ネットワーク通信のタイムアウト:misscount (秒)
•ハートビートの監視がタイムアウトすると、ノード排除処理へ進む
CSSのログ
•$ORA_CRS_HOME/log/< hostname>/cssd/配下
(10gR1: $ORA_CRS_HOME/css/log/配下)
Clusterwareのアラートログ
•$ORA_CRS_HOME/log/<hostname>/alert<hostname>.log
確認した結果(200秒)
確認した結果(60秒)

Copyright© 2011, Oracle. All rights reserved.
排除するノードの決定
54
1 2
3 4
各ノードからノード1への通信が障害
ノード2~4は互いを認識、最大のサブクラスタを形成
→ノード1を排除
ノード1と3、ノード2と4のそれぞれがサブクラスタ
ノード1が最も若い
→ノード2、4を排除
1 2
3 4
1 2
相手ノードへの通信に障害
ノード1が最も若い
→ノード2を排除
•投票ディスクを通じて、サブクラスタを把握
•ノード数が最大のサブクラスタに属するノードが生存、属さないノードが排除
•サブクラスタに属するノード数が同じ場合は、ノード番号が若いノードが属するサブクラスタが生存、それ以外が排除
障害 障
害
障害

Copyright© 2011, Oracle. All rights reserved.
oprocdによるOS負荷監視
55
| INF | monitoring started with timeout(1000), margin(500), skewTimeout(125)
| INF | fatal mode startup, setting process to fatal mode
| ERR | AlarmHandler: timeout(3500) exceeds interval(1000)+margin(500)
| ERR | *** Terminating process in FATAL mode ***
oprocd OS負荷を監視
•定期的に自ノードのOSの動作状況を監視
•高負荷などでOS処理遅延があると障害として検知
•oprocdがノードを再起動
•/var/opt/oracle/oprocd 配下または /etc/oracle/oprocd 配下の<nodename>.oprocd.log.<date-time>
処理が遅延して監視がタイムアウトに達している

Copyright© 2011, Oracle. All rights reserved.
oclsomonによるCSSの監視
56
ネットワークのハートビート
投票ディスクのハートビート
CSSoclsomon
CSSの状態を監視
CSS
•CSS の動作状態を監視
•CSS障害を検知するとノードを再起動
•$ORA_CRS_HOME/log/<hostname>/cssd/oclsomon/oclsomon.log
2010-11-09 14:44:13.085: clsc_connect: (0x98b3a28) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=OCSSD_LL_node1_))
Reconfig event. (12/2/2)
clssomon: Timeout waiting for CSS response.
CSSからの応答がなく、監視がタイムアウトに達している

Copyright© 2011, Oracle. All rights reserved.
ノード排除の原因調査で有効な情報
57
原因調査で有効な情報が確認できるファイル
ocssd.log、Clusterwareのアラートログ
生存ノードと障害ノードを比較し、全体の流れを把握
ハートビートのエラーや投票の結果など、詳細な状況を確認
oprocd.log、oclsomon.log
CSSのハートビート以外の要因でノード再起動となっているかを確認
OS側ログ(syslog、messages)
ハードウェアやOSなどの障害の有無を確認
採取しておきたい情報
OS負荷、リソース使用状況、プロセスの一覧、ネットワークの統計
sar や vmstat、ps –elf や top、netstat など。 OS Watcherの利用も。
ネットワーク障害だけではなく、プロセスハング、OSリソース不足などを確認することができる
ファイルの場所
Clusterware : $ORA_CRS_HOME/<hostname>/log 配下
oprocd : /var/opt/oracle/oprocd 配下または /etc/oracle/oprocd 配下
OSログ : /var/adm/syslog、/var/log/

Copyright© 2011, Oracle. All rights reserved.
ノード再起動が発生した場合の調査手順
58
1.いつ、どのノードで何が発生し、どのノードが排除されたのかを調べる
•messagesなどOSログ、ocssd.log
•記録が途切れた箇所、OSやCSSが起動を開始した記録を探す
2.どのプロセスが排除処理を行ったのかを調べる
•ocssd.log、oprocd.log、oclskd.log、oclsomon.log
※注意
あるノードが突然OS停止のとき、他のノードでは通信ハートビートのエラーが検知され、ocssd.logに記録される。
•Eviction startedも記録される。CSSが管理するメンバーシップ情報の更新。
•OS停止のほうが先か、OS側ログやocssd.logの記録のタイムスタンプ等から判断する。
3.必要に応じ、負荷やリソース使用状況、ネットワークや投票ディスクの状況を調べる
•CPUやメモリ使用、RUNキュー、ページイン/アウト、など
•NIC、スイッチ、ストレージ装置、ストレージへのパス、など

Copyright© 2011, Oracle. All rights reserved.
インスタンス/ノードの再起動のまとめ
• データ保護のためインスタンスやノードを再起動させる(排除)
• インスタンス
• 監視:LMONはネットワーク通信、CKPTは制御ファイル
• ORA-29740
• ノード
• CSSによる監視:投票ディスク、ネットワーク通信
• oprocd による監視:OS負荷
• oclsomon による監視:CSSの障害
• 調査方法
• いつ、どのプロセスで障害があって、だれがダウンさせたのかを把握
59

Copyright© 2011, Oracle. All rights reserved.
排除後の対応と注意
60
• 排除後を想定した処理能力を用意
• 運用開始後も負荷状況の変化を把握
接続要求や処理要求が生存インスタンスへ集まる
•CPUやメモリを要する
•排除直後は短時間に集中する
•生存ノードが高負荷になる
DBインスタンスへのセッションが切断されている
•再接続が必要
• FCF、TAFを設定
• アプリ側で再接続を実装
被害拡大の可能性を最小化するためには
•排除後に再接続するよう設定
•排除後、生存ノードでの負荷・処理能力を確認

Copyright© 2011, Oracle. All rights reserved.
生存ノードの負荷に関して設計や考え方のヒント
61
余裕のある設計・運用を心がけてください
100
1つのノードの最大処理能力を100とし、
ノード数減少後に各ノードが100の処理を行うことになったと想定
ノード数減少
正常時は各ノードで66の要求まで処理
正常時 再構成後
ノード数減少
正常時は各ノードで50の要求まで処理
100
1005050
66 66 66

Copyright© 2011, Oracle. All rights reserved.
RAC環境のインスタンスダウンやノードダウンの原因調査と予防
監視と排除の仕組み• データ保護のため
• 監視・排除の仕組み
ダウン後の対応と注意• ダウン後の対応も考慮することが必要
• 生存インスタンスでの負荷に備えてリソースの用意
• 余裕のある設計とテストを行うことが必要
62

Copyright© 2011, Oracle. All rights reserved.
まとめ
• パフォーマンス問題の原因調査とチューニング
• パフォーマンス問題の原因
• パフォーマンス問題へのアプローチ
• 原因調査に有効な取得情報
• よくあるパフォーマンス問題の原因例
• 内部エラーのトラブルシューティング
• 内部エラーの概要
• 現場で可能なトラブルシューティング
• 効率的に オラクル カスタマ・サポートと連携する方法
• RAC環境のインスタンスダウンやノードダウンの原因調査と予防
• RAC環境における可用性の管理
• RAC環境における考慮事項
63

Copyright© 2011, Oracle. All rights reserved. 64
Appendix
<Insert Picture Here>

Copyright© 2011, Oracle. All rights reserved.
参考文献
• SQLトレース(TKPROF) / AWR / ASH の使用方法• Oracle Databaseパフォーマンス・チューニング・ガイド 11gリリース2(11.2)• Oracle Databaseパフォーマンス・チューニング・ガイド 11gリリース1(11.1)
21 アプリケーション・トレース・ツールの使用方法5 自動パフォーマンス統計
• V$ビューやDBAビュー定義• Oracle Databaseリファレンス11g リリース2(11.2)• Oracle Databaseリファレンス11g リリース1(11.1)
• AWR / ASHの使用にかかわるライセンス情報• Oracle Databaseライセンス情報11gリリース2(11.2)
Oracle Databaseライセンス情報11gリリース1(11.1)
• DBMS_MONITORパッケージの定義• Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス11g リリース2(11.2)• Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス11g リリース1(11.1)
65

Copyright© 2011, Oracle. All rights reserved.
• KROWN : 109185 Oracle 10g トレース機能 (DBMS_MONITOR)
• KROWN : 137157 SQL トレースを使用したSQLチューニング
• KROWN : 136531 AWR レポートリファレンス - 目次
• KROWN : 127934 Active Session History(ASH) 情報の取得方法
• KROWN : 66559 ハング時に取得する情報およびその取得方法 (Oracle9i以降対応版 シングルインスタンス対応)
• KROWN :140563 OS Watcher (OSW) を使用してオペレーティング・システムに関する情報を取得する方法
• KROWN:145899 内部エラー(ORA-600/ORA-7445/ORA-700)のトラブルシューティング・ガイド
• KROWN:147414 内部エラーのトレースファイル解析入門
• KROWN:135295 インシデント調査の SR 登録時にアップロードするパッケージの作成手順について
• KROWN:140563 OS Watcher (OSW) を使用してオペレーティング・システムに関する情報を取得する方法
• KROWN:106485 Remote Diagnostic Agent 4.x (RDA 4.x) について
参考文献
66

Copyright© 2011, Oracle. All rights reserved.
参考文献
67
KROWN:55682 Real Application Clustersにおける、Instance Membership Recoveryについて
KROWN:56123 RAC 環境における ORA-29740 のトラブルシューティングガイド
NOTE:219361.1 Troubleshooting ORA-29740 in a RAC Environment
KROWN:91896 10g RAC : CSS による投票ディスクへの I/O タイムアウトについて
KROWN:108257 10gR2 RAC : CSS による投票ディスクへの I/O タイムアウトについて (10.2.0)
KROWN:140599 11gRAC : CSS による投票ディスクへの I/O タイムアウトについて (11g)
KROWN:126323 10gR2 RAC : 10.2.0.3 以降の diskLongTimeout について
KROWN:100830 10g RAC : 10.1.0.3 からの CSS タイムアウト算出 および CSS MISSCOUNT の変更方法
KROWN:93150 10g RAC : Cluster Synchronization Services (CSS) の MISSCOUNT の意味について
KROWN:129170 Oracle Database 11g 以降のトレースファイルの出力ディレクトリについて
KROWN:133097 [ADR] 自動診断レポジトリと rdbms, listener, clients 配下のファイルについて
KROWN:140563 OS Watcher (OSW) を使用してオペレーティング・システムに関する情報を取得する方法

Copyright© 2011, Oracle. All rights reserved.
• NOTE:1092832.1
• Master Note for Diagnosing ORA-600
• NOTE:1092855.1
• Master Note for Diagnosing ORA-7445
• NOTE:153788.1
• Troubleshoot an ORA-600 or ORA-7445 Error Using the Error Lookup Tool
• NOTE:175982.1
• ORA-600 Lookup Error Categories
• NOTE:146580.1
• What is an ORA-600 Internal Error?
• NOTE:211909.1
• Customer Introduction to ORA-7445 Errors
• NOTE 559339.1
• Diagnostic Tools Catalog
• NOTE:301137.1
• OS Watcher User Guide
• NOTE:314422.1
• Remote Diagnostic Agent (RDA) 4 - Getting Started
参考文献
68

Copyright© 2011, Oracle. All rights reserved. 69
アラートログの出力例
2010-09-24 15:19:26.251000 +09:00
Starting ORACLE instance (normal)
:
Starting up:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options.
Using parameter settings in server-side spfile
/home/ora11201/app/oracle/product/11.2.0.1/db_1/dbs/spfileora11201.ora
System parameters with non-default values:
sga_max_size = 800M
sga_target = 520M
:
2010-09-25 15:21:48.265000 +09:00
ALTER SYSTEM SET sga_target='720M' SCOPE=BOTH;
2010-09-26 08:44:28.802000 +09:00
Errors in file /home/ora11201/app/oracle/product/11.2.0.1/diag/rdbms/ora11201/ora11201/trace/ora11201_ora_29001.trc
(incident=670218):
ORA-00600: internal error code, arguments: [kdsgrp1], [], [], [], [], [], [], [], [], [], [], []
Incident details in:
/home/ora11201/app/oracle/product/11.2.0.1/diag/rdbms/ora11201/ora11201/incident/incdir_670218/ora11201_ora_2900
1_i670218.trc
バージョン情報
初期化パラメータの情報
変更パラメータの情報
ORA-600 とその引数
診断情報が出力された
トレースファイル名の情報

Copyright© 2011, Oracle. All rights reserved.
• ORA-600[17059] の発生
• サポートサイトのナレッジベースよりエラーの意味を調査
• ライブラリキャッシュにロードされている特定の親カーソルで管理される子カーソルの数が最大数に達したことを示す。
• 共有プールの flush により子カーソルを消去する事で対処
トラブルシューティング例(1)共有プールの flush による対処
70
行1でエラーが発生しました。:
ORA-00600: 内部エラー・コード, 引数: [17059], [0x11CACBB00], [0x11CACB4C8], [0x11CACBFC8], [], [], [], [], [], [], [], []
SQL> alter system flush shared_pool;
システムが変更されました。
共有プールのフラッシュにより子カーソルの情報を消去

Copyright© 2011, Oracle. All rights reserved.
トラブルシューティング例(2)統計情報の制御による対処
• ORA-600[19004] の発生
• サポートサイトのナレッジベースよりエラーの意味を調査• オプティマイザによる SQL の解析時において予期しない統計情
報の値を検知したこと示す。
• 統計情報の削除や過去の統計情報のリストアにて対処• DBMS_STATS.DELETE_TABLE_STATS
• DBMS_STATS.RESTORE_TABLE_STATS
71

Copyright© 2011, Oracle. All rights reserved.
トラブルシューティング例(3)オブジェクト破損への対処
• ORA-600[12700] 発生
• サポートサイトのナレッジベースよりエラーの意味を調査
• 表と索引の間の不整合を検知
• 破損箇所の切り分けを実施
• ANALYZE TABLE <表名> VALIDATE STRUCTURE CASCADE
• ANALYZE TABLE <表名> VALIDATE STRUCTURE
• 破損への対処
• 索引の破損の場合、破損した索引の再作成にて対処
• 表の破損の場合、過去のバックアップのリストアによる対処
72

Copyright© 2011, Oracle. All rights reserved.
• ORA-600[12333](11.1 以後は ORA-3137[12333])
• 受信したパケットの特定レイヤの不整合を検知
• ORA-600[723] , ORA-600[729]
• ログオフ時に PGA や UGA のメモリリークを検知
• ORA-600[170xx]
• ライブラリ・キャッシュ上の処理で問題を検知
• ORA-600[171xx]
• ヒープの破損を検知
73
問合せの多い ORA-600 の例
Copyright© 2011, Oracle. All rights reserved.
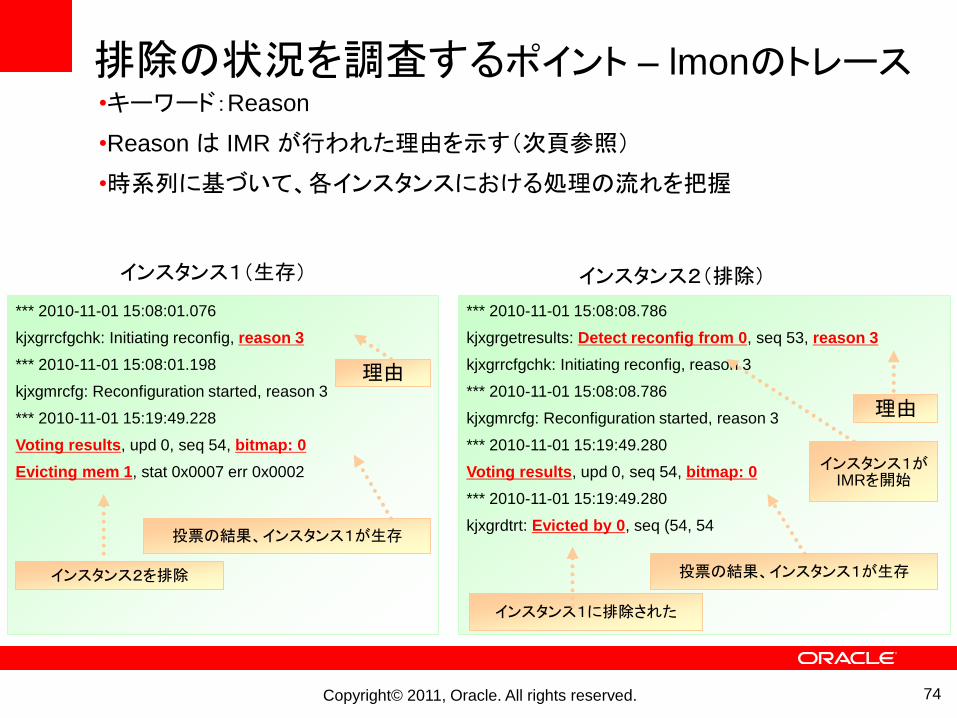
排除の状況を調査するポイント – lmonのトレース
74
*** 2010-11-01 15:08:08.786
kjxgrgetresults: Detect reconfig from 0, seq 53, reason 3
kjxgrrcfgchk: Initiating reconfig, reason 3
*** 2010-11-01 15:08:08.786
kjxgmrcfg: Reconfiguration started, reason 3
*** 2010-11-01 15:19:49.280
Voting results, upd 0, seq 54, bitmap: 0
*** 2010-11-01 15:19:49.280
kjxgrdtrt: Evicted by 0, seq (54, 54
*** 2010-11-01 15:08:01.076
kjxgrrcfgchk: Initiating reconfig, reason 3
*** 2010-11-01 15:08:01.198
kjxgmrcfg: Reconfiguration started, reason 3
*** 2010-11-01 15:19:49.228
Voting results, upd 0, seq 54, bitmap: 0
Evicting mem 1, stat 0x0007 err 0x0002
インスタンス1(生存) インスタンス2(排除)
•キーワード:Reason
•Reason は IMR が行われた理由を示す(次頁参照)
•時系列に基づいて、各インスタンスにおける処理の流れを把握
理由
理由
インスタンス1がIMRを開始
投票の結果、インスタンス1が生存
インスタンス1に排除された
投票の結果、インスタンス1が生存インスタンス2を排除

Copyright© 2011, Oracle. All rights reserved.
Reasonの意味
75
I/O障害、ネットワーク障害
ネットワーク障害
プロセスのスピン、ハング
ノード高負荷によるOSハング、OSリソース不足
クラスタウェアが障害を検知し、ノードを排除した場合
Reason 2:インスタンスダウンの検知による再構成
•例 他インスタンスの監視で、制御ファイルから生存を確認できなくなった
Reason 1:ノードモニター(クラスタのレイヤ)からの通知
•例 クラスタウェアがノードを排除したためインスタンスも排除された
Reason 3:ノード間通信での障害による再構成
•例 LMON によるハートビートが途絶えた
•例 フォアグラウンド、バックグラウンドプロセスの通信に障害

Copyright© 2011, Oracle. All rights reserved.
投票ディスクのハートビート障害
76
WARNING: clssnmvDiskCheck: voting device hang at 50% fatal, termination in 99370 ms, disk (0//voting/1106_voting1)
WARNING: clssnmvDiskCheck: voting device hang at 50% fatal, termination in 99330 ms, disk (2//voting/1106_voting3)
WARNING: clssnmvDiskCheck: voting device hang at 75% fatal, termination in 49280 ms, disk (0//voting/1106_voting1)
WARNING: clssnmvDiskCheck: voting device hang at 75% fatal, termination in 49240 ms, disk (2//voting/1106_voting3)
...
WARNING: clssnmvDiskCheck: voting device hang at 90% fatal, termination in 150 ms, disk (2//voting/1106_voting3)
WARNING: clssnmvDiskCheck: voting device hang at 90% fatal, termination in 20 ms, disk (0//voting/1106_voting1)
TRACE: clssnmvDiskCheck: stale disk (200020 ms) (2//voting/1106_voting3)
TRACE: clssnmvDiskCheck: stale disk (200010 ms) (0//voting/1106_voting1)
ERROR: clssnmDiskPMT: Aborting, 2 of 3 voting disks unavailable
ERROR: ###################################
ERROR: clssscExit: CSSD aborting from thread clssnmvDiskPingMonitorThread
ERROR: ###################################
•障害を検知したノードの ocssd.log に記録
•過半数の投票ディスクへのハートビート障害が発生するとCSSが終了し、ノード再起動
投票ディスクのハートビート
例:投票ディスクが3つある環境
2つ
の投
票デ
ィス
クの
ハー
トビ
ート
の失
敗
3つの投票ディスクのうち2つが利用不可

Copyright© 2011, Oracle. All rights reserved.
ネットワーク通信のハートビート障害
77
WARNING: clssnmPollingThread: node node2 (2) at 50% heartbeat fatal, eviction in 14.236 seconds
WARNING: clssnmPollingThread: node node2 (2) at 75% heartbeat fatal, eviction in 7.236 seconds
WARNING: clssnmPollingThread: node node2 (2) at 90% heartbeat fatal, eviction in 2.236 seconds
WARNING: clssnmPollingThread: node node2 (2) at 90% heartbeat fatal, eviction in 0.236 seconds
…
TRACE: clssnmPollingThread: Eviction started for node node2 (2), flags 0x000d, state 3, wt4c 0
補足:10.2.0.2までWARNING: clssnmPollingThread: node(2) missed(4) checkin(s)
WARNING: clssnmPollingThread: node(2) missed(5) checkin(s)
WARNING: clssnmPollingThread: node(2) missed(6) checkin(s)
...
WARNING: clssnmPollingThread: node(2) missed(29) checkin(s)
…
TRACE: clssnmPollingThread: Eviction started for node node2 (2), flags 0x000d, state 3, wt4c 0
•ハートビート障害を検知したノードの ocssd.log に記録
•タイムアウトすると排除ノード決定処理へ進む(即排除ではない)
•ハートビート障害を検知した秒数がmisscount の何%かを記録
ネットワーク通信のハートビート
misscount:30秒
排除ノード決定処理に進む
排除ノード決定処理に進む
排除ノード決定処理まで約14秒
ハートビート障害がmisscountの50%続いた
ハートビート障害が29秒続いた

Copyright© 2011, Oracle. All rights reserved.
排除されるノードにおけるログ出力例
78
ERROR: clssnmCheckDskInfo: Aborting local node to avoid splitbrain.
…
ERROR: ###################################
ERROR: clssscExit: CSSD aborting
ERROR: ###################################
補足:正常停止時のログWARNING: clssgmClientShutdown: graceful shutdown completed.
USER: Copyright 2010, Oracle version 11.1.0.7.0
USER: CSS daemon log for node node1, number 1, in cluster ddd2010
TRACE: clssgmHandleDataInvalid: grock HB+ASM, member 1 node 1, birth 1
TRACE: clssgmDispatchCMXMSG: msg type(3) src(4) dest(3) size(420) tag(07b90036) incarnation(168309989)
TRACE: clssgmHandleMasterAdd(): src(3) dest(3) size(420)
USER: Copyright 2010, Oracle version 11.1.0.7.0
USER: CSS daemon log for node node1, number 1, in cluster ddd2010
•投票ディスクから投票結果を確認
•排除が決定したノードのCSSが終了し、ノード再起動へ
•CSS終了のログが残らない場合がある
CSSのshutdown(停止)が正常に完了した
ノード1に排除されていることを投票結果から把握している
shutdownの記録がなく、突然起動している
CSSが起動を開始

Copyright© 2011, Oracle. All rights reserved.
調査の例1 ノード間通信の障害
79
高負荷
ノード1 ocssd.logでは、 11/9 12:01:15 ごろからネットワークのハートビートのエラーを記録[ CSSD]2010-11-09 12:01:15.861 [18] >WARNING: clssnmPollingThread: node node2 (2) at 50% heartbeat fatal, eviction in 14.236 seconds
[ CSSD]2010-11-09 12:01:22.861 [18] >WARNING: clssnmPollingThread: node node2 (2) at 75% heartbeat fatal, eviction in 7.236 seconds
[ CSSD]2010-11-09 12:01:29.861 [18] >WARNING: clssnmPollingThread: node node2 (2) at 90% heartbeat fatal, eviction in 0.236 seconds
…
[ CSSD]2010-11-09 12:01:30.097 [18] > TRACE: clssnmPollingThread: Eviction started for node node2 (2), flags 0x000d, state 3, wt4c 0
…
[ CSSD]2010-11-09 12:01:30.615 [18] >TRACE: clssnmReadDskHeartbeat: node 2, node2, has a disk HB, but no network HB, DHB has rcfg 91536673, 30 wrtcnt, 12233830, LATS 250279884, lastSeqNo 12233830, timestamp 1236578848/4294395390
ノード2 ocssd.logでも 11/9 12:01:15 ごろからハートビートのエラーを記録、最終的にabortしている[ CSSD]2010-11-09 12:01:15.731 [18] >WARNING: clssnmPollingThread: node node1 (1) at 50% heartbeat fatal, eviction in 14.236 seconds
[ CSSD]2010-11-09 12:01:22.731 [18] >WARNING: clssnmPollingThread: node node1 (1) at 75% heartbeat fatal, eviction in 7.236 seconds
[ CSSD]2010-11-09 12:01:29.731 [18] >WARNING: clssnmPollingThread: node node1 (1) at 90% heartbeat fatal, eviction in 0.236 seconds
…
[ CSSD]2010-11-09 12:01:29.967 [18] > TRACE: clssnmPollingThread: Eviction started for node node1 (1), flags 0x000d, state 3, wt4c 0
…
[ CSSD]2010-11-09 12:01:30.088 [18] > ERROR: clssnmCheckDskInfo: Aborting local node to avoid splitbrain.
…
[ CSSD]2010-11-09 12:01:30.088 [18] > ERROR: ###################################
[ CSSD]2010-11-09 12:01:30.088 [18] > ERROR: clssscExit: CSSD aborting
[ CSSD]2010-11-09 12:01:30.088 [18] > ERROR: ###################################
1.いつ、どのノードで何が発生し、どのノードが排除されたか
misscount:30秒、2ノードRAC

Copyright© 2011, Oracle. All rights reserved.
調査の例1 ノード間通信の障害
80
ノード間のネットワーク通信で用いているスイッチが故障していた
ノード2 ocssd.log より、ノード1から排除されている。CSSによる排除。[ CSSD]2010-11-09 12:01:30.088 [18] > ERROR: clssnmCheckDskInfo: Aborting local node to avoid splitbrain.
2.どのプロセスが排除したのか
3.ネットワークの状況
総合的に考え、ノード間ネットワーク通信の障害

Copyright© 2011, Oracle. All rights reserved.
調査の例2 OS高負荷でoprocdが障害を検知
81
ノード1 ocssd.logでは、 11/9 12:01:15 ごろからハートビートのエラーを記録[ CSSD]2010-11-09 12:01:15.861 [18] >WARNING: clssnmPollingThread: node node2 (2) at 50% heartbeat fatal, eviction in 14.236 seconds
[ CSSD]2010-11-09 12:01:22.861 [18] >WARNING: clssnmPollingThread: node node2 (2) at 75% heartbeat fatal, eviction in 7.236 seconds
[ CSSD]2010-11-09 12:01:29.861 [18] >WARNING: clssnmPollingThread: node node2 (2) at 90% heartbeat fatal, eviction in 0.236 seconds
…
[ CSSD]2010-11-09 12:01:30.097 [18] > TRACE: clssnmPollingThread: Eviction started for node node2 (2), flags 0x000d, state 3, wt4c 0
ノード2 ocssd.log では、11/9 12:02:00 ごろ、突然、CSS起動の記録がはじまっていた[ CSSD]2010-11-09 12:00:50.000 >TRACE: clssgmExecuteClientRequest: GRKEXIT recvd from client 1567
[ CSSD]2010-11-09 12:02:00.000 >USER: Copyright 2010, Oracle version 11.1.0.7.0
1.いつ、どのノードで何が発生し、どのノードが排除されたか
?
Node#1 Node#2

Copyright© 2011, Oracle. All rights reserved.
調査の例2 OS高負荷でoprocdが障害を検知
82
高負荷
ノード2の各種ログを調査したところ oprocd.log に以下の記録
Nov 09 12:01:00.000| ERR | AlarmHandler: timeout(3500) exceeds interval(1000)+margin(500)
Nov 09 12:01:00.000| ERR | *** Terminating process in FATAL mode ***
ノード再起動したノードの sar などを見ると、負荷が高い
負荷の情報採取のスケジュールが遅れている(例:12:00:00の予定が12:01:30に採取されていた)
CPUのアイドルが数%しかない状態が続いていた、RUNキューが多い、ページイン・アウトが多い
0
100
もしも負荷・リソース使用の情報採取が無かった場合、ログからはoprocdが再起動を発生させ、負荷が高かった状況である可能性の推測までは可能。どのような負荷が高かったことまでは言及が難しい(裏付けられない)。
負荷の情報があると高負荷の状況の詳細まで調査・判断できる。
2.どのプロセスが排除したのか
3.負荷の状況
総合的に考え、高負荷が原因で oprocd が排除したと考えられる

Copyright© 2011, Oracle. All rights reserved.

Copyright© 2011, Oracle. All rights reserved. 84


![アシスト #44 - Oracle...2015/10/28 · 夜な夜な! なにわオラクル塾 Presented By アシスト #44 [初中級編] 90分で分かる! Oracle](https://img.pdfslide.tips/doc/110x75/60b471b8e5b9a47b38046047/f-44-oracle-20151028-oeoe-ff.jpg)

![Redefining Business Ownership. [2]CONFIDENTIAL Insert Your Picture Here Insert your Picture Here Insert Your Picture Here You must have Microsoft Powerpoint](https://img.pdfslide.tips/doc/110x75/56649e0e5503460f94af8f27/redefining-business-ownership-2confidential-insert-your-picture-here-insert.jpg)
























