Embed Size (px)
DESCRIPTION
klssñlasssa
Citation preview

EYP1113 - Probabilidad y EstadısticaCapıtulo 8: Analisis de Regresion (Otro Enfoque)
Ricardo Aravena C. Ricardo Olea O.
Departamento de EstadısticaPontificia Universidad Catolica de Chile
Primer Semestre 2015
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 1 / 30

Contenido I
1 El Modelo de Regresion MultipleEspecificacion del ModeloDesarrollo del ModeloGraficos Tridimensionales
2 Estimacion de CoeficientesMetodos de Mınimos Cuadrados
3 Poder Explicativo de una Ecuacion de Regresion Multiple
4 Intervalos de Confianza y Contraste de HipotesisIntervalos de ConfianzaContraste de Hipotesis
5 Contraste de Coeficientes de RegresionContraste de todos los CoeficientesContraste de un conjunto de Coeficientes
6 Prediccion
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 2 / 30

El Modelo de Regresion Multiple Especificacion del Modelo
El Modelo de Regresion MultipleEspecificacion del Modelo
La regresion lineal multiple permite obtener dos importantes resultados:
1. Una ecuacion lineal estimada que predice la variable dependiente, Y , enfuncion de K variables independientes observadas, xj , donde j = 1, . . . ,K.
yi = b0 + b1 xi 1 + b2 xi 2 + · · ·+ bK xiK
donde i = 1, . . . , n observaciones.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 3 / 30

El Modelo de Regresion Multiple Especificacion del Modelo
El Modelo de Regresion MultipleEspecificacion del Modelo
2. La variacion marginal de la variable dependiente, Y , provocada por lasvariaciones de las variables independientes, que se estima por medio de loscoeficientes, b′j . En la regresion multiple, estos coeficientes dependen deque otras variables se incluyan en el modelo.
El coeficiente bj indica la variacion de Y , dada una variacion unitaria dexj , descontando al mismo tiempo el efecto simultaneo de las demasvariables independientes.
En algunos problemas, ambos resultados son igual de importantes. Sinembargo, normalmente predomina uno de ellos.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 4 / 30

El Modelo de Regresion Multiple Desarrollo del Modelo
El Modelo de Regresion MultipleDesarrollo del Modelo
El modelo de regresion multiple define la relacion entre una variabledependiente o endogena, Y , y un conjunto de variables independientes oexogenas, xj , donde j = 1, . . . ,K. Se supone que las xj i son numerosfijos; Y es una variable aleatoria definida para cada observacion, i, dondei = 1, . . . , n, y n es el numero de observaciones.
El modelo se define de la forma siguiente:
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi
donde las βj son coeficientes constantes y las ε son variables aleatorias demedia 0 y varianza σ2.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 5 / 30

El Modelo de Regresion Multiple Graficos Tridimensionales
El Modelo de Regresion MultipleGraficos Tridimensionales
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 6 / 30

El Modelo de Regresion Multiple Graficos Tridimensionales
El Modelo de Regresion MultipleDatos Ejemplo
Ejemplo: Datos sobre ahorro y credito inmobiliario.
La siguiente tabla proporciona el margen anual de beneficios (Y ), ingresosanuales netos por dolar depositado (X1), y el numero de oficinasexistentes ese ano (X2).
Tabla : Datos sobre ahorro y credito inmobiliario
Ano Ingresos Oficinas Beneficio Ano Ingresos Oficinas Beneficio1 3.92 7298 0.75 14 3.78 6672 0.842 3.61 6855 0.71 15 3.82 6890 0.793 3.32 6636 0.66 16 3.97 7115 0.704 3.07 6506 0.61 17 4.07 7327 0.685 3.06 6450 0.70 18 4.25 7546 0.726 3.11 6402 0.72 19 4.41 7931 0.557 3.21 6368 0.77 20 4.49 8097 0.638 3.26 6340 0.74 21 4.70 8468 0.569 3.42 6349 0.90 22 4.58 8717 0.41
10 3.42 6352 0.82 23 4.69 8991 0.5111 3.45 6361 0.75 24 4.71 9179 0.4712 3.58 6369 0.77 25 4.78 9318 0.3213 3.66 6546 0.78
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 7 / 30

Estimacion de Coeficientes
Estimacion de Coeficientes
El modelo de regresion poblacional multiple es
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi
y suponemos que se dispone de n conjuntos de observaciones. Se postulanlos siguientes supuestos habituales para el modelo.
Las xi j son o bien numeros fijos, o bien realizaciones de variablesaleatorias, Xj , que son independientes de los terminos del error, ε. Enel segundo caso, la inferencia se realiza condicionada a los valoresobservados de las xi j .
El valor esperado de la variable aleatoria Y es una funcion lineal delas variables independientes X’s.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 8 / 30

Estimacion de Coeficientes
Estimacion de Coeficientes
Los terminos de error son variables aleatorias cuya media es cero yque tienen la misma varianza, σ2. Este ultimo supuesto se denominahomocedasticidad o varianza uniforme.
E(εi) = 0 y E(ε2i ) = σ2,
para i = 1, . . . , n.
Los terminos de error aleatorio, εi, no estan correlacionados entre sı,por lo que
E(εi · εj) = 0 ∀i 6= j
No es posible hallar un conjunto de numeros que no sean iguales acero, c0, c1,. . . , cK , tal que
c0 + c1 xi 1 + · · ·+ cK xiK = 0
Esta es la propiedad de la ausencia de relacion lineal entre las Xj .
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 9 / 30

Estimacion de Coeficientes Metodos de Mınimos Cuadrados
Estimacion de CoeficientesMetodos de Mınimos Cuadrados
Para una muestra de n observaciones (x1 i, x2 i,. . . , xK i, Yi, dondei = 1, . . . , n) medidas para u proceso cuyo modelo de regresionpoblacional multiple es
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi
Las estimaciones por mınimos cuadrados de los coeficientes β1, β2,. . . , βKson los valores b0, b1,. . . , bK para los que la suma de los cuadrados de lasdesviaciones
SCE =
n∑i=1
(yi − b0 − b1 xi 1 − b2 xi 2 − · · · − bK xiK)2
es la menor posible.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 10 / 30
Estimacion de Coeficientes Metodos de Mınimos Cuadrados
Estimacion de CoeficientesMetodos de Mınimos Cuadrados
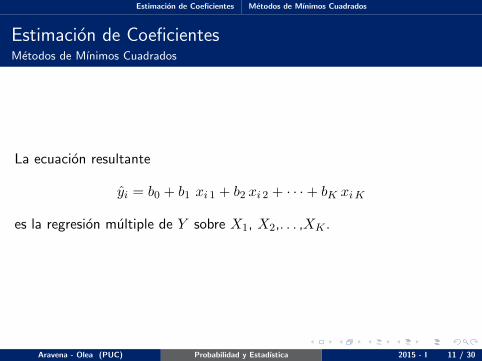
La ecuacion resultante
yi = b0 + b1 xi 1 + b2 xi 2 + · · ·+ bK xiK
es la regresion multiple de Y sobre X1, X2,. . . ,XK .
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 11 / 30

Estimacion de Coeficientes Metodos de Mınimos Cuadrados
Estimacion de CoeficientesMetodos de Mınimos Cuadrados
Ejemplo Consideremos el caso con dos variables de prediccion
yi = b0 + b1 xi 1 + b2 xi 2
Los estimadores de los coeficientes pueden resolverse utilizando las formassiguientes:
b1 =sy(rx1 y − rx1 x2
rx2 y)
sx1(1− r2x1 x2
)
b2 =sy(rx2 y − rx1 x2
rx1 y)
sx2(1− r2x1 x2
)
b0 = y − b1 x1 − b2 x2
donde r es la correlacion muestral y s es la desviacion tıpica muestral.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 12 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Descomposicion Suma de Cuadrados
Comenzamos con el modelo de regresion multiple ajustado mediantemınimos cuadrados
yi = b0 + b1 xi 1 + b2 xi 2 + · · ·+ bK xiK + ei = yi + ei
donde las bj son las estimaciones por mınimos cuadrados de loscoeficientes del modelo de regresion poblacional y las e son los residuos delmodelos de regresion estimado.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 13 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Descomposicion Suma de Cuadrados
La variabilidad del modelo puede dividirse en los componentes
SCT = SCR + SCE
las que se definen de la siguiente manera
STC =
n∑i=1
(yi − y)2
=
n∑i=1
(yi − y)2 +n∑i=1
(yi − yi)2
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 14 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Descomposicion Suma de Cuadrados
Esta descomposicion puede interpretarse como
Variabilidad Muestral Total = Variabilidad Explicada + Variabilidad No Explicada
El coeficiente de determinacion, R2, de la regresion ajustada es laproporcion de la variabilidad muestral total explicada por la regresion
R2 =SCR
SCT= 1− SCE
SCT
y se deduce que0 ≤ R2 ≤ 1
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 15 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Estimacion de la Varianza de los Errores
Dado el modelo de regresion poblacional multiple
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi
y los supuestos habituales de la regresion, sea σ2 la varianza comun deltermino de error, εi. Entonces, una estimacion insesgada de esta varianzaes
s2e =1
n−K − 1
n∑i=1
e2i =SCE
n−K − 1
donde K es el numero de variables independientes en el modelo deregresion. La raız cuadrada de la varianza, se, tambien se llama errortıpico de la estimacion.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 16 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Coeficiente de Determinacion Ajustado
El coeficiente de determinacion ajustado, R2, se define de la forma
siguiente:
R2= 1− SCE/(n−K − 1)
SCT/(n− 1)
Utilizamos esta medida para tener en cuenta el hecho de que las variablesindependientes irrelevantes provocan una pequena reduccion de la suma delos cuadrados de los errores.
Por lo tanto, el R2
ajustado permite comparara mejor los modelos deregresion multiple que tienen diferentes numeros de variablesindependientes.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 17 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Coeficiente de Correlacion Multiple
El coeficiente de correlacion multiple es la correlacion entre el valorpredicho y el valor observado de la variable dependiente.
R = r(y, y) =√R2
y es igual a la raız cuadrada del coeficiente multiple de determinacion.Utilizamos R como otra medida de la fuerza de la relacion entre variabledependiente y las variables independientes.
Por lo tanto, es comparable a la correlacion entre Y y X en la regresionsimple.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 18 / 30

Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Salida R
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 19 / 30
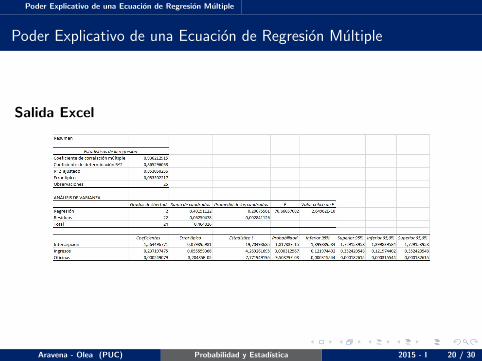
Poder Explicativo de una Ecuacion de Regresion Multiple
Poder Explicativo de una Ecuacion de Regresion Multiple
Salida Excel
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 20 / 30

Intervalos de Confianza y Contraste de Hipotesis
Intervalos de Confianza y Contraste de Hipotesis
Base para Inferencia
Sea el modelo de regresion poblacional
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi
Sean b0, b1, . . . , bK las estimaciones por mınimos cuadrados de losparametros poblacionales y sb0 , sb1 , . . . , sbK las desviaciones tıpicas de losestimadores de mınimos cuadrados.
Entonces, si se cumplen los supuestos habituales de la regresion y si losterminos de error, εi, siguen una distribucion normal, entonces
Tbj =bj − βjsbj
, j = 1, 2, . . . ,K
sigue una distribucion t-student(n−K − 1).
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 21 / 30

Intervalos de Confianza y Contraste de Hipotesis Intervalos de Confianza
Intervalos de Confianza y Contraste de HipotesisIntervalos de Confianza
Si lo errores de la regresion poblacional, εi, siguen una distribucion normaly se cumplen los supuestos habituales de la regresion, los intervalos deconfianza bilaterales al (1−α)× 100% de los coeficientes de regresion, βj ,son
bj − t1−α/2(n−K − 1) · sbj < βj < bj + t1−α/2(n−K − 1) · sbj
donde t1−α/2(n−K − 1) corresponde al percentil (1− α/2)× 100% deuna variable aleatoria t-Student(n−K − 1).
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 22 / 30

Intervalos de Confianza y Contraste de Hipotesis Contraste de Hipotesis
Intervalos de Confianza y Contraste de HipotesisContraste de Hipotesis
Si los errores de la regresion, εi, siguen una distribucion normal y secumplen los supuestos habituales del analisis de regresion, los siguientescontrastes de hipotesis tienen el nivel de significacion α:
Para contrastar cualquiera de las dos hipotesis nulas
H0 : βj = β∗j o H0 : βj ≤ β∗j
frente a la hipotesis alternativa
Ha : βj > β∗j
Se rechaza H0 sibj − β∗jsbj
> t1−α(n− k − 1)
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 23 / 30

Intervalos de Confianza y Contraste de Hipotesis Contraste de Hipotesis
Intervalos de Confianza y Contraste de HipotesisContraste de Hipotesis
Para contrastar cualquiera de las dos hipotesis nulas
H0 : βj = β∗j o H0 : βj ≥ β∗j
frente a la hipotesis alternativa
Ha : βj < β∗j
Se rechaza H0 sibj − β∗jsbj
< tα(n− k − 1)
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 24 / 30

Intervalos de Confianza y Contraste de Hipotesis Contraste de Hipotesis
Intervalos de Confianza y Contraste de HipotesisContraste de Hipotesis
Para contrastar la hipotesis nula
H0 : βj = β∗j
frente a la hipotesis alternativa
Ha : βj 6= β∗j
Se rechaza H0 si ∣∣∣∣bj − β∗jsbj
∣∣∣∣ > t1−α/2(n− k − 1)
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 25 / 30

Contraste de Coeficientes de Regresion Contraste de todos los Coeficientes
Contraste de Coeficientes de RegresionContraste de todos los Coeficientes
Consideremos el modelo de regresion multiple
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi
Para contrastar la hipotesis nula
H0 : β1 = β2 = · · · = βK = 0
Frente a la hipotesis alternativa
Ha : Al menos un βj 6= 0
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 26 / 30

Contraste de Coeficientes de Regresion Contraste de todos los Coeficientes
Contraste de Coeficientes de RegresionContraste de todos los Coeficientes
A un nivel de significacion α, utilizamos la regla de decision:
Rechazar H0 siCMR
s2e> F1−α(K, n−K − 1)
donde F1−α(K, n−K − 1) es el percentil (1− α)× 100% de una variablealeatoria Fisher(K, n−K − 1).
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 27 / 30

Contraste de Coeficientes de Regresion Contraste de un conjunto de Coeficientes
Contraste de Coeficientes de RegresionContraste de un conjunto de Coeficientes
Dado un modelo de regresion con la descomposicion de las variablesindependientes en los subconjuntos X y Z,
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + α1 zi 1 + · · ·+ αr zi r + εi
Para contrastar la hipotesis nula
H0 : α1 = α2 = · · · = αr = 0
de que los parametros de regresion de un subconjunto sonsimultaneamente iguales a cero, frente a la hipotesis alternativa
Ha : Al menos un αj 6= 0, j = 1, . . . , r
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 28 / 30

Contraste de Coeficientes de Regresion Contraste de un conjunto de Coeficientes
Contraste de Coeficientes de RegresionContraste de un conjunto de Coeficientes
Comparamos la suma de los cuadrados de los errores del modelo completocon la suma de los cuadrados de los errores del modelo restringido.
Se rechaza H0 si
(SCE(r)− SCE)/r
s2e> F1−α(r, n−K − r − 1)
con r el numero de variables eliminadas y s2e la varianza estimada del errordel modelo completo, es decir, con los K + r regresores.
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 29 / 30

Prediccion
Prediccion
Dado que se cumple el modelo de regresion poblacional
yi = β0 + β1 xi 1 + β2 xi 2 + · · ·+ βK xiK + εi, i = 1, . . . , n
y que los supuestos habituales del analisis de regresion son validos, seanb0, b1, . . . , bK las estimaciones por mınimos cuadrados de los coeficientesdel modelo, βj , siendo j = 1, . . . ,K, basados en los puntos de datosx1 i, x2 i, . . . , xK i, (i = 1, . . . , n).
En tal caso, dada una nueva observacion de un punto de datosx1, n+1, x2, n+1, . . . , xK,n+1, la mejor prediccion lineal insesgada de yn+1 es
yn+1 = b0 + b1 xn+1 ,1 + b2 xn+1 ,2 + · · ·+ bK xn+1 ,K
Aravena - Olea (PUC) Probabilidad y Estadıstica 2015 - I 30 / 30

















![[CCF]DanMachi, Novela 01, Capítulo 01](https://img.pdfslide.tips/doc/110x75/55cf8a9155034654898bcead/ccfdanmachi-novela-01-capitulo-01.jpg)










