Embed Size (px)
DESCRIPTION
クラシックな機械学習の入門. 5. サポートベクターマシン. SVM の概念 双対化による SVM の定式化 : 線形分離可能な場合 KKT 条件とサポートベクトル 双対化の御利益 ソフトマージン SVM :線形分離できない場合 SVM 実装のためのアルゴリズム(ワーキング集合、 SMO) SVM による回帰 カーネル関数. b y 中川裕志(東京大学). 再掲: 2 乗誤差最小化の線形識別の問題点. この領域に青の境界線が引っ張られることあり。. この領域の判断が困難. - PowerPoint PPT Presentation
Citation preview
5. サポートベクターマシン
SVM の概念双対化による SVM の定式化:線形分離可能な場合
KKT 条件とサポートベクトル双対化の御利益
ソフトマージン SVM :線形分離できない場合SVM 実装のためのアルゴリズム(ワーキング集合、
SMO)
SVM による回帰カーネル関数
クラシックな機械学習の入門
by 中川裕志(東京大学)
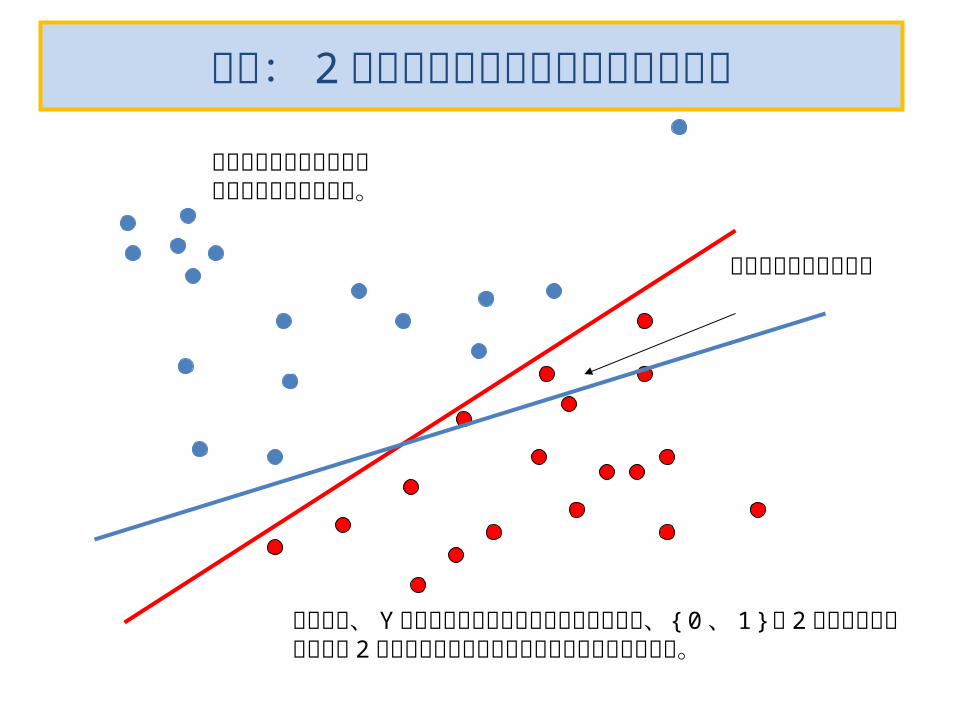
再掲: 2 乗誤差最小化の線形識別の問題点
この領域の判断が困難
この領域に青の境界線が引っ張られることあり。
そもそも、 Y の値は正規分布を想定した理論なのに、{ 0 、 1 }の 2 値しかとらないとして 2 乗誤差最小化を当てはめたところに無理がある。

学習データ:
N 個の入力ベクトル x1,…,xN と
各々に対応するクラス分け結果 y1,….,yN
ただし、 yi は+1(正例)かー1(負例)をとる。新規のデータ x に対して、 y が y(x)>0 なら
正、 y(x)<0 なら負になるようにしたい
0)(
0)(
10)(10)(
,)( 0
yy
yy
yyyy
wy
x
x
xx
xwx
た場合は、当然ながら正しく分類できなかっすなわち、
かつあるいはかつ合は、正しい分類ができた場
SVMの定式化
y(x)=+1
y(x)=0
y(x)=ー1
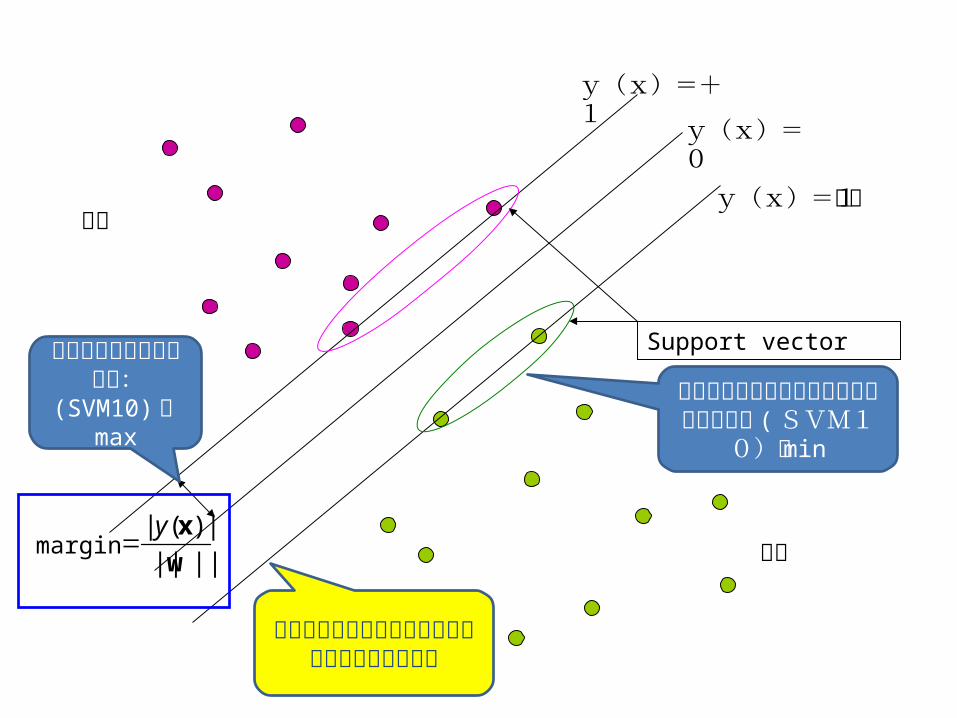
Support vector
正例
負例||||
|)(|
w
xymargin
この図から分かるように対象は線形分離可能な場合
この長さを最大化した
い:(SVM10) の
max
境界面との距離が小さいデータを選びたい ( SVM1
0)の min

マージン最大化SVM の狙いは識別境界面 :y( x )=0 から一番近
いデータ点までの距離(マージン :margin )を最大化すること。以下でその考えを定式化する。
識別境界面 :y( x )=0 からあるxまでの距離は、線形識別の幾何学的解釈で述べたようにy( x )/||w||
我々は正しく識別されたデータ、すなわち yny(xn)>0 のデータにだけ焦点を当てる。
すると、点 xn から境界面までの距離は次式。||||
),(
||||
)( 0
w
xw
w
x wyyy nnnn

したがって、最適な w,w0 を求めることは、境界面までの距離が最小の点の距離( margin) を最大化するという問題に定式化でき、以下の式となる。
この最適化はそのままでは複雑なので、等価な問題に変換する。
)10(),(min||||
1maxarg 0
, 0
SVMwy nnnw
xwww
w を定数倍して cw と変換しても、境界面までの距離
yny(xn)/||w|| の値は分母子で c が相殺するので不変。 よって、境界面に一番近い点で次式が成立して
いるとする。 1),( 0 wy nn xw

双対問題化
Nnwy nn ,,11),( 0 xw
元の問題では、 argmax{ min } という一般的な枠組みの問題なので、内点法などの効率の良い最適化アルゴリズムが良く研究されている「線形制約凸2次計画問題」に変換する方向に進める。参考文献:工系数学講座17「最適化法」(共立出版)
境界面に一番近いデータではしたがって、正しく識別された全てのデータは次式の制約
を満たす。
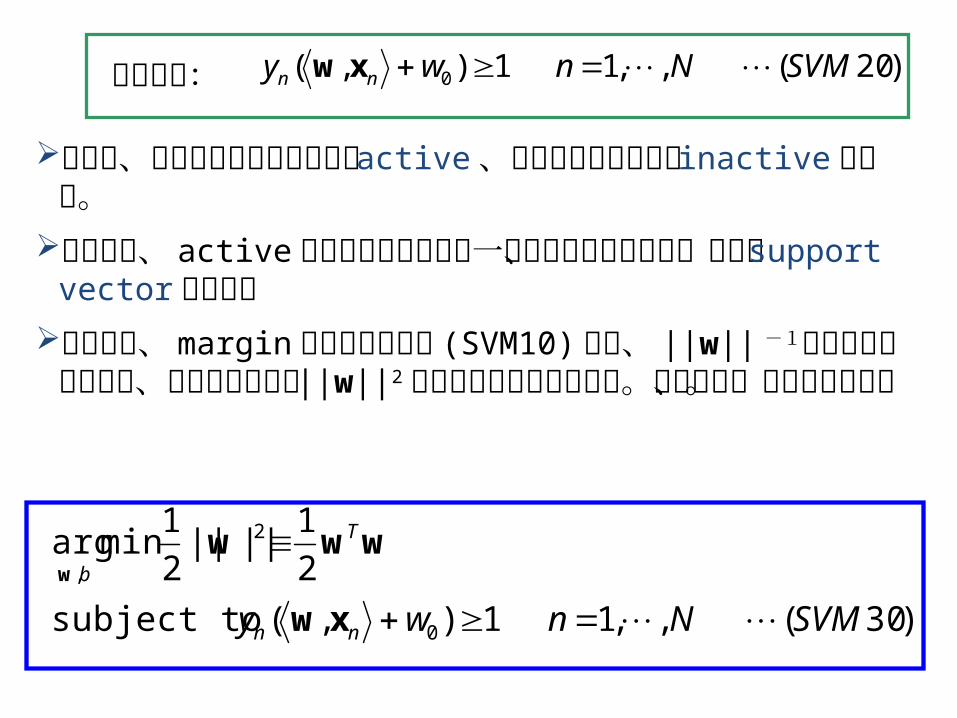
ここで、等号が成り立つデータを active 、そうでないデータを inactive と呼ぶ。
1),( 0 wy nn xw
)30(,,11),(subject to
2
1||||
2
1minarg
0
2
,
SVMNnwy nn
T
b
xw
wwww
ここで、等号が成り立つデータを active 、そうでないデータを inactive と呼ぶ。定義より、 active なデータは境界面に一番近いデータで
あり、これが support vector となる。このとき、 margin を最大化する式 (SVM10) から、 ||w|| -
1を最大化するのだが、これは等価的に ||w||2 を最小化する問題となる。すなわち、以下の定式化。
制約条件:
)20(,,11),( 0 SVMNnwy nn xw

( SVM30) のような不等式制約を持つ最適化問題は、 Lagrange 未定乗数ベクトル a を導入した Lagrange 関数 : L(w, w0,a) を
w,w0 (最小化 )a( 最大化 ) という最適化問題に双対化する
まず、 w, w0 について、 L(w, w0,a) の最適化を行う。
)60(0
)50(
,
)40(),(1||||2
1)),,(
1
1
0
01
20
SVMya
SVMya
w
SVMwyawL
n
N
nn
nn
N
nn
nn
N
nn
xw
w
xwwaw
下の条件が出る。に関して微分すると以
(SVM50)(SVM60) を( SVM40) に代入して、 w と w0 を消すと、次のように双対問題としての定式化が得られる

SVM の双対問題ー境界面で完全に分離できる場合
SVM100))()(
)(
,)(
)90(0
)80(,..,10 subject to
)70()(2
1max)(
~max
01
1
1 1 1
(
で行う対する予測は次式のまた、新規のデータに
wkyay
y
kwhere
SVMya
SVMNna
SVMkyyaaaL
N
nnnn
mnmn
N
nnn
n
N
n
N
n
N
mmnmnmnn
xx,x
x
xxx,x
x,xa
上記 (SVM70,80,90) を解くアルゴリズムは後に説明する。また、(SVM100)で良い理由はカーネルの関する記述で述べる(表現定理)
これがカーネル関数(データ xn,xm の対だけによる)
後で説明する

双対化を最適化の観点から見なおそう
mixg
xf
i ,..,10 subject to
min
最適化問題 P
ラグランジュ関数
双対問題 Q
はベクトルで書く
gxgxf
xgxfxL
T
ii
m
i
,
,1
0 subject to
max
,min
q
xLqx

双対定理弱双対定理最適化問題 P における f の最適値 =f*
双対問題Qにおける q の最適値 =q*
q* ≤ f*
強双対定理目的関数 f が凸で、制約条件が線形の場合は
q* = f* であり、対応するラグランジュ乗数λ* が存在する。
Pは制約条件が線形なので、 f が凸なら強双対定理が成立
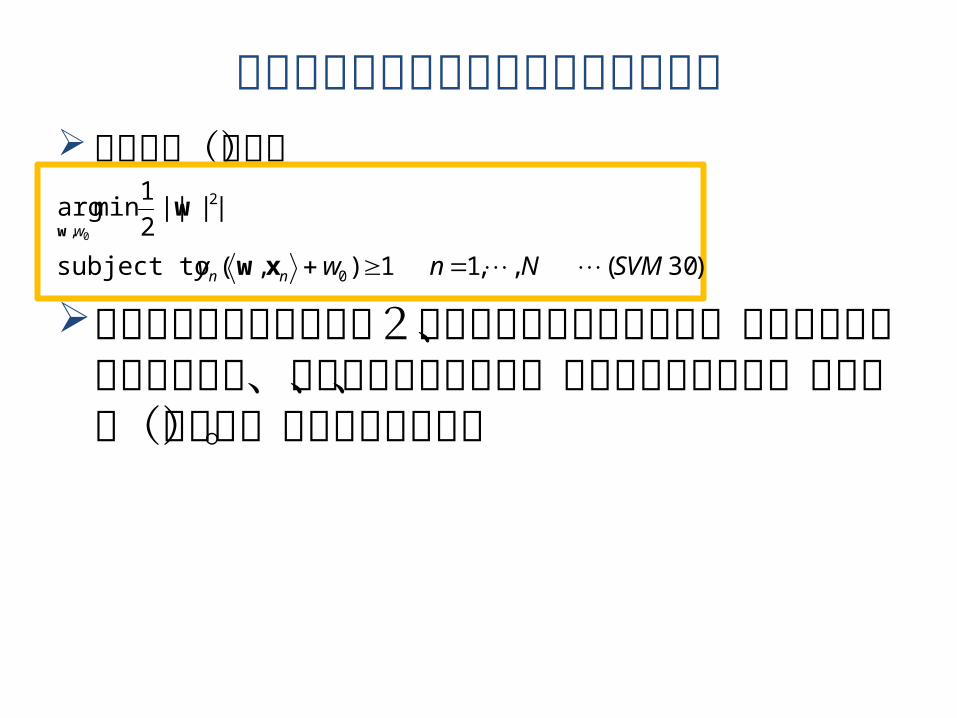
双対化を最適化の観点から見なおそう元の問題(再掲)
この問題では目的関数は2乗ノルムなので凸であり、制約条件が線形な式なので、強双対定理が成立し、双対問題を解けば、この問題(主問題)の解が得られる。
)30(,,11),(subject to
||||2
1minarg
0
2
, 0
SVMNnwy nn
w
xw
ww

鞍点定理からみると元の問題(再掲)
上記の Lagrange 関数 L(w,w0,a) の最小化の意味は次のページの図
)30(,,11),(subject to
||||2
1minarg
0
2
,
SVMNnwy nn
b
xw
ww
)60(0
)50(
,
)40(,1||||2
1),,(
1
1
0
01
20
SVMya
SVMya
w
SVMwyawL
n
N
nn
nn
N
nn
nn
N
nn
xw
w
xwwaw
下の条件が出る。に関して微分すると以
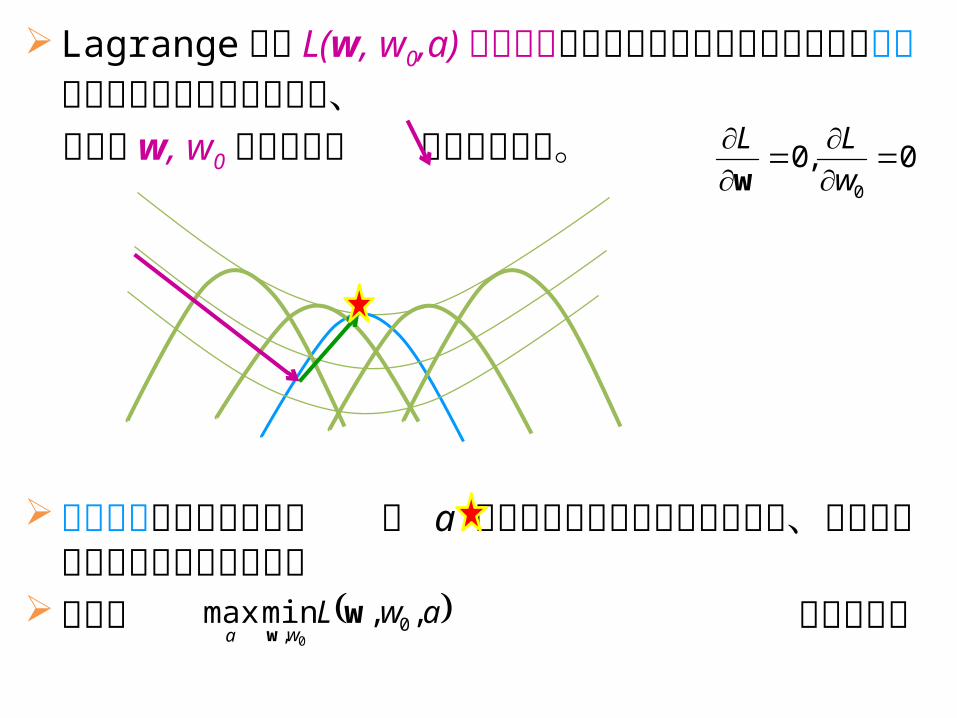
Lagrange 関数 L(w, w0,a) の最小化の意味は下の図で鞍点にかかる曲線に上から近づく処理であり、
となる w, w0 を代入して のように動く。
この曲線に沿って最適点 に a を動かす処理が双対問題であり、図から分かるように最大化となる
つまり という問題
0,00
w
LL
w
awLwa
,,minmax 0, 0
ww

鞍点定理
前のページとの対応は ww0=x, a=λ
は双対問題の解は主問題
**
0
**
0
**
,
,minmax,,maxmin,
x
xLxLxLxxx
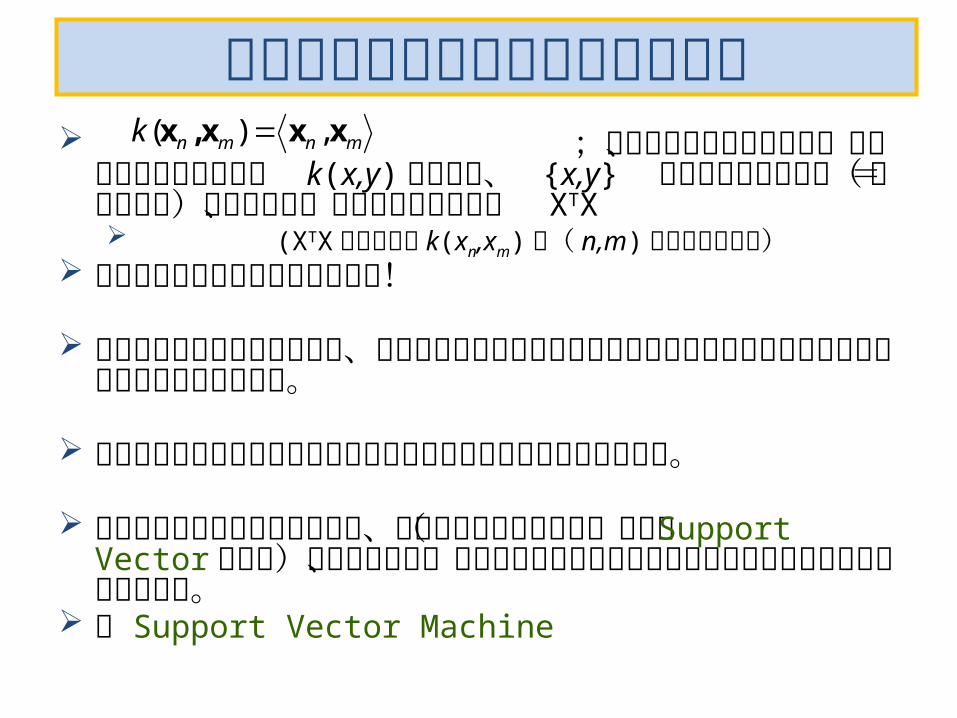
スパースなデータに対する識別器
;カーネル関数を利用して、回帰や識別を行うことは k(x,y) において、 {x,y} のペアの観測データ(=教師データ)が膨大だと、正規方程式に現れた XTX (XTX がちょうど k(xn,xm) を( n,m) 成分とする行列)
の逆行列の計算が計算量的に困難!
すべての観測データを使うと、重要な境界線が観測データの集中的に集まっている部分に強い影響を受けてしまう。
限定された観測データを使って効率よく計算できないものだろうか。
正例データと負例データのうち、両者の境界にあるもの(これを Support Vector という)だけを使えば、つまりスパースなデータによるカーネルならずいぶん楽になる。
Support Vector Machine
mnmnk xxx,x ,)(

KKT条件
を有効な制約と呼ぶ。このような
なので、なら条件と呼ぶ。なおこれを
は
i
ii
ii
i
i
m
iii
m
iii
i
g
gKKT
KKTg
KKT
KKTg
KKTgf
gfLLagrangian
mig
f
0)(0
)4( 0)(
)3( 0
)2( 0)(
)1(0)()(
)()(),(
,..,10)( subject to
)( minimize
1
1
x
x
x
xx
xxx
x
x
を最適化する以下の条件で得られる
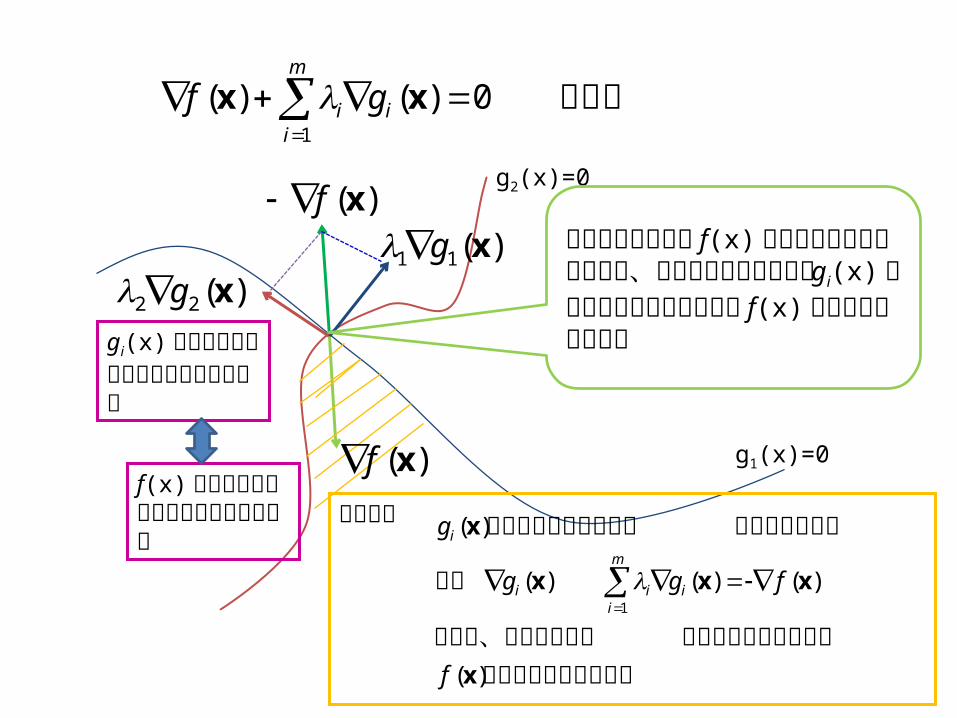
の解釈0)()(1
m
iii gf xx
g2(x)=0
g1(x)=0
)(22 xg )(11 xg
)(xf
)(xf許容領域
許容領域の内部で f(x) が大きくなるということは、その外側へ向う有効な gi(x) たちが作る凸錐の逆方向にf(x) の勾配が向いている
は許容領域の端で最小り込むほど大きいのでなので、許容領域に入
勾配
ほど大きいならが許容領域から離れる
)(
)()()(
)(
1
x
xxx
x
f
fgg
gm
iiii
i
f(x) は許容領域の中に入るほど大きくなる
gi(x) は許容領域から離れるほど大きくなる

である。 この点たちがの点だけ。寄与するのは
に寄与しない。の点はとなる。 かは、よって、全てのデータ
る。条件は以下のようになるなお、この問題におけ
ctor support ve
1)(
)100()(0
1)(0
4)-(KKT0))(1(
3)-(KKT 0
2)-(KKT 0)(1
nn
n
nnn
nnn
n
nn
yy
SVMya
yya
yya
a
yy
KKT
x
x
x
x
x
01
20
1
,1||||2
1),,(
0)()()(),(
wtawL
ggfL
nn
N
nn
i
m
iii
xwwaw
xxxx
式化では、だったが、ここでの定

w0 の求め方
Sm Snnmnnm
Sm
mm
N
nnmnnm
mm
yayS
w
m
w
yy
wyay
yy
x,x
x,x
x
||
1
1
1
1)(nS ctorsupport ve
0
0
2
01
性のためしているのは解の安定だけではなく、なお、1個のる。は以下の式で与えられ
に注意すると、を掛け、両辺に
よって、
においてはに含まれるデータ
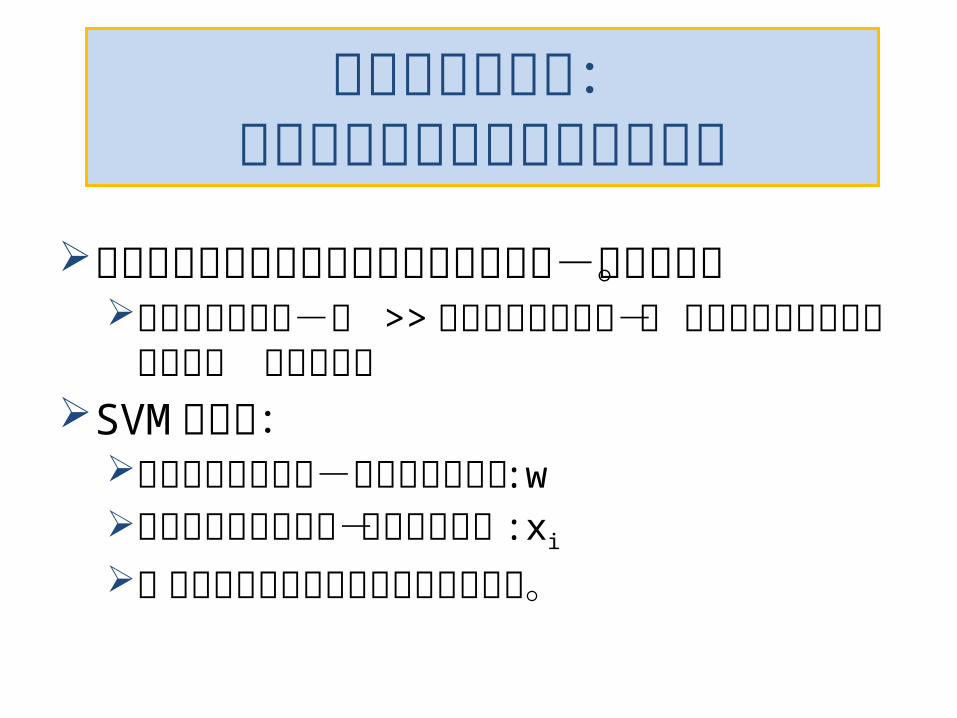
双対化の御利益:教師データアクセスの観点
から主問題と双対問題は最適化するパラメタ
-数が違う。主問題パラメタ-数 >> 双対問題パラメタ-
数 なら双対問題を解くほうが楽 教科書的SVM の場合:主問題のパラメタ-は重みベクトル :w双対問題にパラメタ-は個別データ :xi 必ずしも教科書的なお得感ではない。
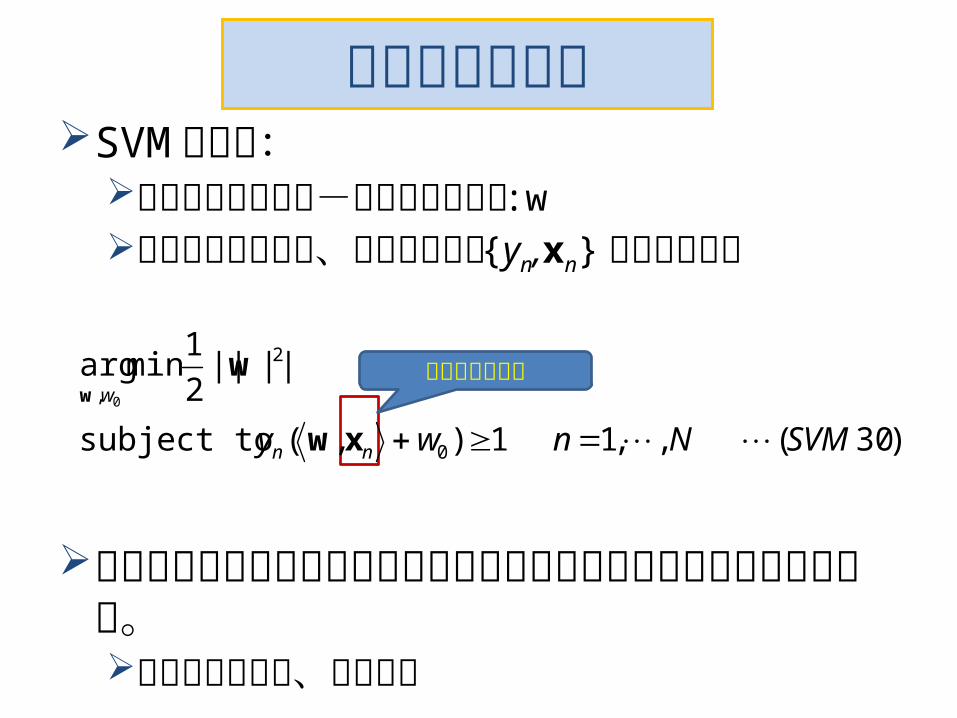
双対化の御利益SVM の場合:主問題のパラメタ-は重みベクトル :w下の定式化なので、全教師データ {yn,xn} が同時に必要
データ量が大きくメモリにロード仕切れない場合に困ったことになる。データ量は最近、増加傾向
)30(,,11),(subject to
||||2
1minarg
0
2
, 0
SVMNnwy nn
w
xw
ww
高次元ベクトル

双対化の御利益 必ずしも教科書的なお得感ではない。
一方、双対問題では入力データ xiyi のと最適化する ai が対応する形で最適化式に現れるので、どのデータを学習で使うか制御しやすい。(下の式参照) 例えば、 ai(i≠j) を固定して、 a jを最適化する操作を j を動か
して繰り返すなど。そのときには だけしか使わない。
とも書く mnmn
N
nnn
n
N
n
N
n
N
mmnmnmnn
kwhereSVMya
SVMNna
SVMyyaaaL
x,xx,x
x,xa
)()90(0
)80(,..,10 subject to
)70(2
1max)(
~max
1
1 1 1
Njk ji ,...,1 , xx
スカラー
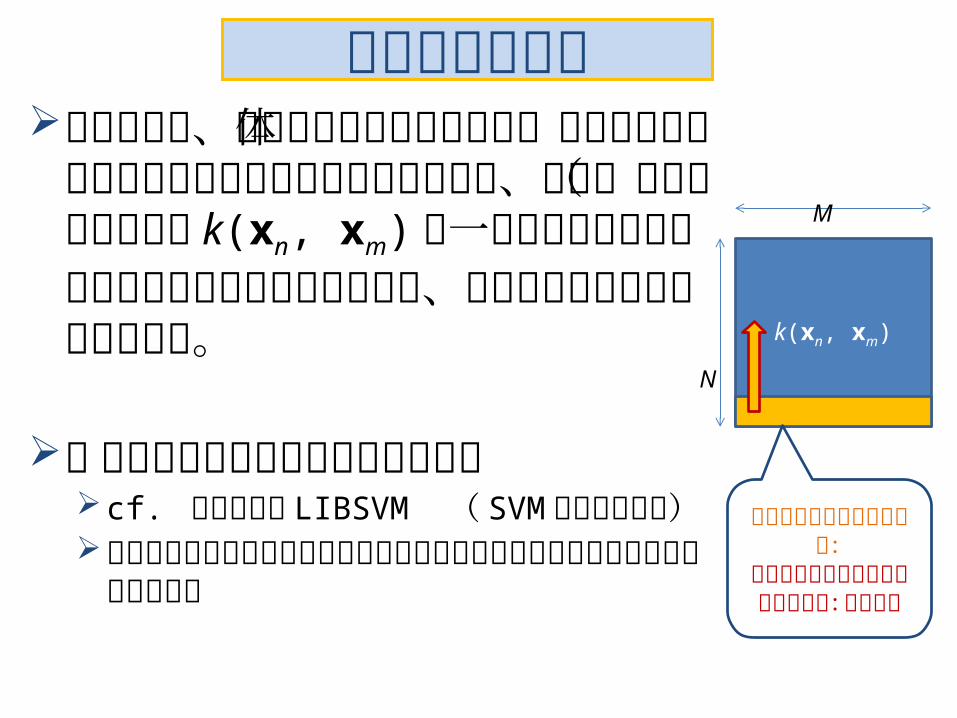
双対化の御利益入力データ、あるいはカーネル行列全体がメモリに乗り切らないビッグデータを扱うために、入力(すなわちカーネル k(xn, xm) の一部を取捨選択してメモリにロードして使う方法が、この双対化で可能になっている。
ビッグデータ時代における御利益cf. 台湾大学の LIBSVM ( SVM の有名
な実装)全データからどのようにメモリにロード
する部分を切り出すかが重要な研究課題
k(xn, xm)
M
N
この部分だけ使って最適化:次に使う部分ロードし直し
て最適化:繰り返す
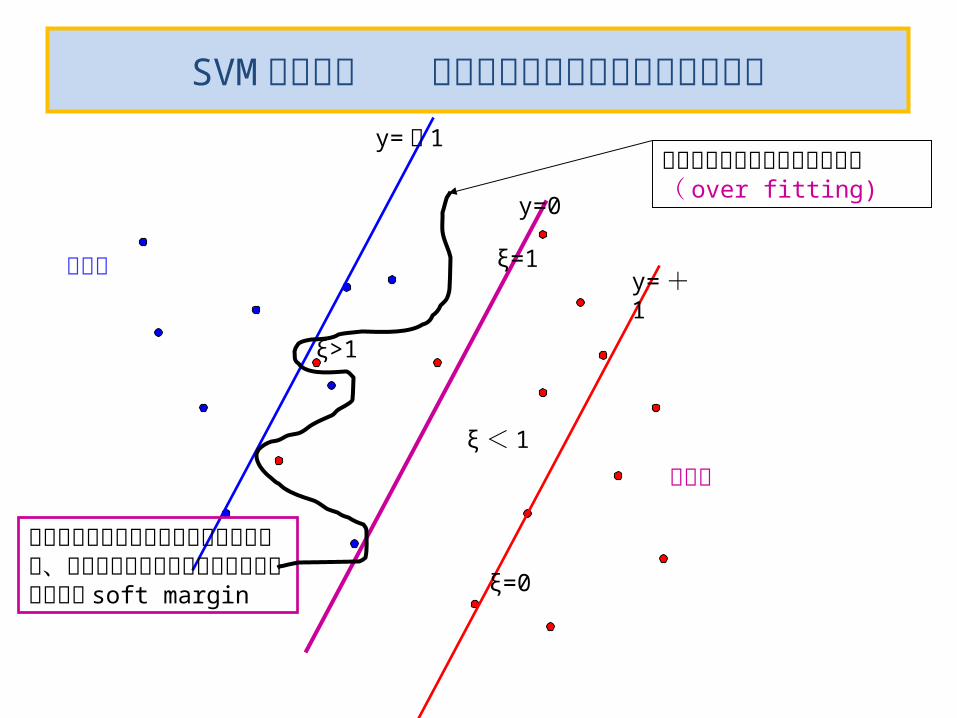
SVM の定式化 境界面で完全に分離できない場合
少々は間違った側に入り込んでもよいが、ゆるい境界面の内側には入るように調整 soft margin
y= ー1
y=0
y= +1
ξ>1
ξ< 1
ξ=0
正例側
負例側
無理やり分離する複雑な境界面( over fitting)
ξ=1

スラック変数 ξ≥0 を導入正しい soft margin の境界面の上ないし内側の点では ξ = 0
その他の点 xn では ξn = |yn-y(xn)|
中央の識別境界面 y(xn)=0 では、 ξn = 1
間違って識別された点は ξn>1
まとめると線形分離できない場合の制約条件の ξ による緩和:
ξn>1 が許容されるが、できるだけ小さく押さえたい!
)10...(00)(1
)(1 0)(1)(1
SFwhereyy
yyyyyy
nnnn
nnnnnnn
x
xxx
最適化は以下のように形式化される。ただし、 C はスラック変数 ξ のペナルティと margin wの按配を制御するパラメター
)20...(0||||2
1
1
2 SFCwhereCminmizeN
nn
w
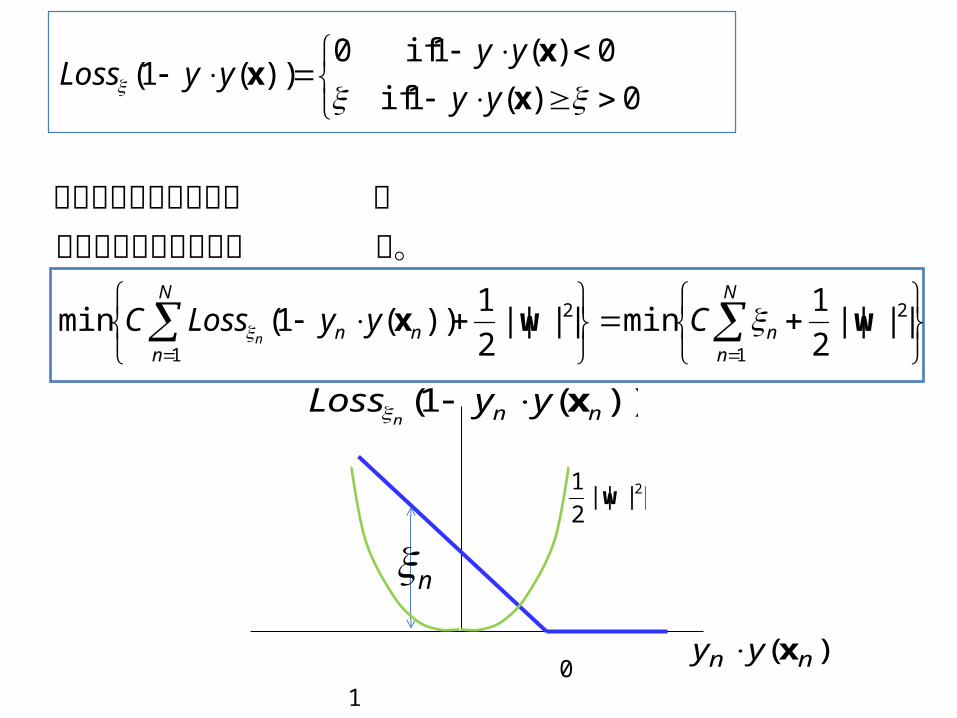
2
1
2
1
||||2
1min||||
2
1))(1(min
0)(1 if
0)(1 if0))(1(
wwx
x
xx
N
nn
N
nnn CyyLossC
yy
yyyyLoss
n
る。関数の最小化問題となのこの関数を用いると次
0 1
))(1( nn yyLossn
x
)( nn yy x
n
2||||2
1w

この最適化問題を解くための Lagrangian は以下のようになる。最後の項は ξ≧0 を表す項。
)30...()(00
)(1||||2
1),,(
0
111
20
SFwyawhere
yyaCwL
nnnn
N
nnn
N
nnnnn
N
nn
xw,x
xwaw
KKT条件は以下の通り。
Nnwhere
yya
yy
a
nn
n
n
nnnn
nnn
n
,...,1
0
0
0
0)(1
0)(1
0
x
x

w、b、 ξ を最適化するために Lagrangian を各々で微分すると右下の結果が得られる。右を Lagrangian に代入す
ると下の双対問題が得られ
線形制約凸2次計画問題
となる。 nnn
n
N
nn
nn
N
nn
CaL
yaw
L
yaL
0
00
0
10
1
xww
N
nnn
n
nnn
mnmn
N
n
N
mmnmnmn
N
nn
ya
Ca
Caa
k
yyaaaL
1
1 11
0
0
00
,,
,2
1)(
~
うになる条件は全体で以下のよ以上をまとめると制約制約条件は
xxxx
xxa

SVM実装上のアルゴリズムの工夫
さて、いよいよ ai を求める段階になった。
SVMは「線形制約を持つ凸 2 次計画問題」なので、標準的な実装方法が使える。
ただし、次元が高い場合には、カーネルの行列をメモリに乗せるだけで大変。
独自の工夫がなされているので、ポイントを紹介
最適解の探索は、素朴な gradient ascent法でも解けるが、効率は良くない。

ワーキング集合法教師データSを分割して部分的に解くことを繰
り返す。
教師データSに対してai0S の適当な部分集合S’を選ぶrepeat
S’ に対する最適化問題を解くKKT条件を満たさないデータから新たな S’ を選択
until 停止条件を満たすreturn {ai}

分解アルゴリズム変数 {ai} の集合全体ではなく、ある大き
さの部分集合(ワーキング集合)のみを更新する。
この更新の後、ワーキング集合に新たな点を加え、他の点は捨てる。
上記の {ai} の選択における極端な方法として、 2 個の ai だけを使って更新する方法を 逐次最小最適化アルゴリズム (Sequential Minimal Optimization algorithm:SMO algorithm) と言う。
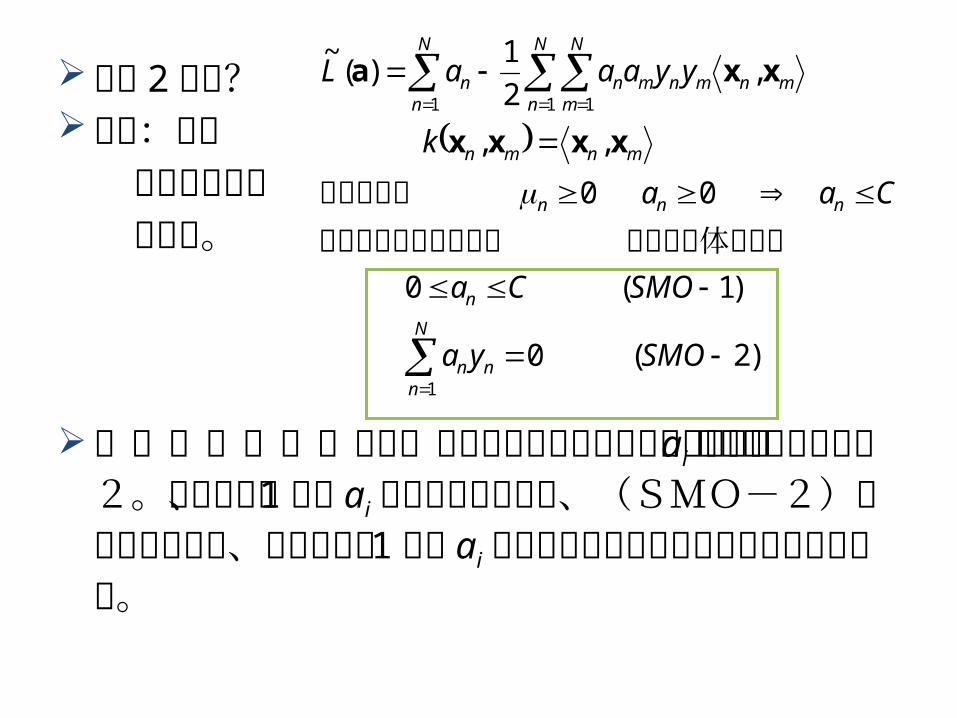
なぜ 2 点か?復習:右の ような最適化 だった。
(SMO-2)より、最適化の各ステップで更新される ai の個数の最小値は2。なぜなら、 1個の ai を更新したときは、(SMO-2)を満たすために、最低でもう 1 個の ai を調整のために更新する必要があるから。
)2(0
)1(0
00
,,
,2
1)(
~
1
1 11
SMOya
SMOCa
Caa
k
yyaaaL
N
nnn
n
nnn
mnmn
N
n
N
mmnmnmn
N
nn
条件は全体で次式以上をまとめると制約制約条件は
xxxx
xxa

S’の 2 点を最適化する更新式
)9()(
)8(2
)()(
2'
222111
122211
2211222
,11
21
SMOaayyaa
SMOKKK
yfyfyaa
fKaykay
S
newoldoldnew
oldnew
ijij
N
jjjij
N
jj
xx
xx,x
x,x とする。点=更新の対象となる

2 点の更新式の導出
対象とする 2 点を a1 、 a2 とする。動かすのが 2 点を a1 、 a2 だけなので次式が成
立
まず、 a2 を a2old から a2
new に変えることにする。
a2 の取る範囲の制約 0≤a2≤C から当然 0≤a2
new≤C
ただし、 (SMO-3) から次の制約が加わる。
)2,1(11
)3(22112211
iy
SMOyayayaya
i
oldoldnewnew
か ただし定数
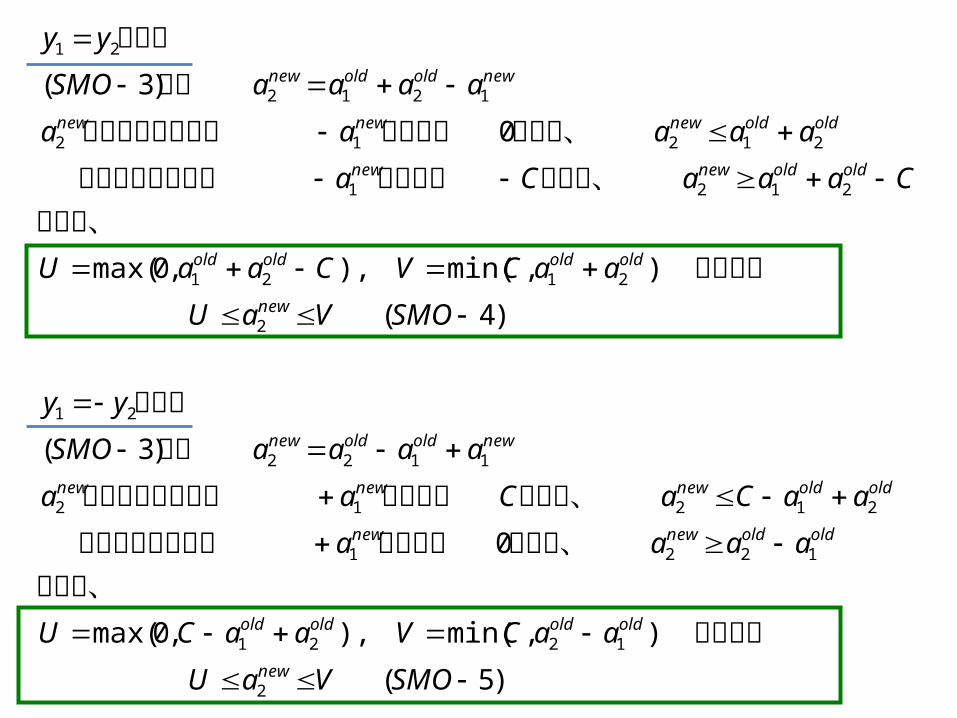
)5(
),min(),,0max(
0
)3(
)4(
),min(),,0max(
0
)3(
2
1221
1221
21212
1122
21
2
2121
2121
21212
1212
21
SMOVaU
aaCVaaCU
aaaa
aaCaCaa
aaaaSMO
yy
SMOVaU
aaCVCaaU
CaaaCa
aaaaa
aaaaSMO
yy
new
oldoldoldold
oldoldnewnew
oldoldnewnewnew
newoldoldnew
new
oldoldoldold
oldoldnewnew
oldoldnewnewnew
newoldoldnew
とおくと
よって、だから、が最小値は最小になっても
だから、が最大値は最大になっても
より
の場合
とおくと
よって、だから、が最小値は最小になっても
だから、が最大値は最大になっても
より
の場合

a2new の更新式の導出
)6(2
1
2
1)(
1
2
1
2
1),(
),(,)70(
2,1
,
)70()(2
1max)(
~max
2221211222
2222
2211222
2121
2121
1221122112211
2221111221212222
21112121
2121
2
13
21
1 1 1
SMOvayvsayKasas
aKsaKasaaW
saasaa
yysy
yyayayayayaya
vayvayKaayyaKaKaaaaW
kK
aaWaaSVM
iforkayfkayv
aa
SVMkyyaaaL
newnew
oldoldnewnew
jiij
jijj
jijij
N
jji
N
n
N
n
N
mmnmnmnn
定数
とおくと上の式はに注意し、
を掛け、の両辺にここで
定数
と略記する。ただし、は次のように書ける。に関連する部分のすると
と定義する。
とにする。注目して最適化するこに関連する部分だけにを、
x,x
x,xxx,x
x,xa

が更新式となる。 上記
は古い値なので、 に入っているここで
であるからが更新されたまたこの式の
に注意。
とおく。で微分しての最大化のために
)7(
,)(
)7(
)(1)2(
1
01
0)(
0)(
21
2
1
2112111122
21212111222112
22
222
112112
2212212212222211
2
2
22
SMO
aaKayfv
SMOvvKKyyyy
vvyKKssKKKa
aa
yyyyyysys
vyvysasKaKaKsasKs
a
aW
aaW
ijjj
jii
new
new
x

)9()(
)5)(4(
)8(2
)()(
2
2)()(
)()(
)()(
)2(
)7(
222111
21221122111
2
2
122211
2211222
2212221122
2112122211222112
2222211112221111121122112112
22112111121
2
2
121
2
111211112
12221122
2
SMOaayyaa
ayyayayayaa
a
SMOSMOa
SMOKKK
yfyfyaa
aaKKKya
KKKKKayffyy
KayKayKayKayKKayayffyy
ayayasyayysaa
KayfKayfKKyyy
KKKya
ySMO
newoldoldnew
newoldoldnewnewnew
new
new
oldnew
oldnew
jjj
jjjj
j
new
によってを掛け、今更新したの両辺には
の更新値とする。ものを の条件で制約した
の値に対して この結果の
としてで割れば、を掛け、の更新式は、両辺に
に注意し書き直すと および
。直して整理してみようを掛け、もう少し書きの両辺に
xx
xx
xx
xx
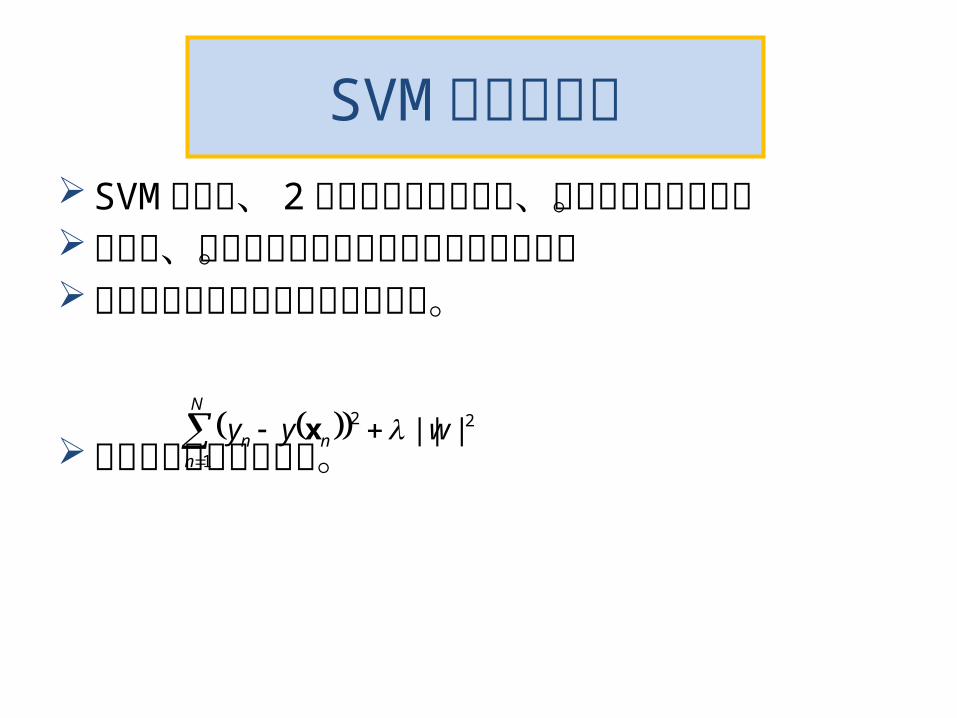
SVM による回帰SVM は本来、 2 クラス分類器であり、識別モ
デルである。しかし、回帰すなわち生成モデルにも使える。線形回帰では次の式を最小化した。
この考え方を拡張する。
2
1
2 |||| wyyN
nnn
x
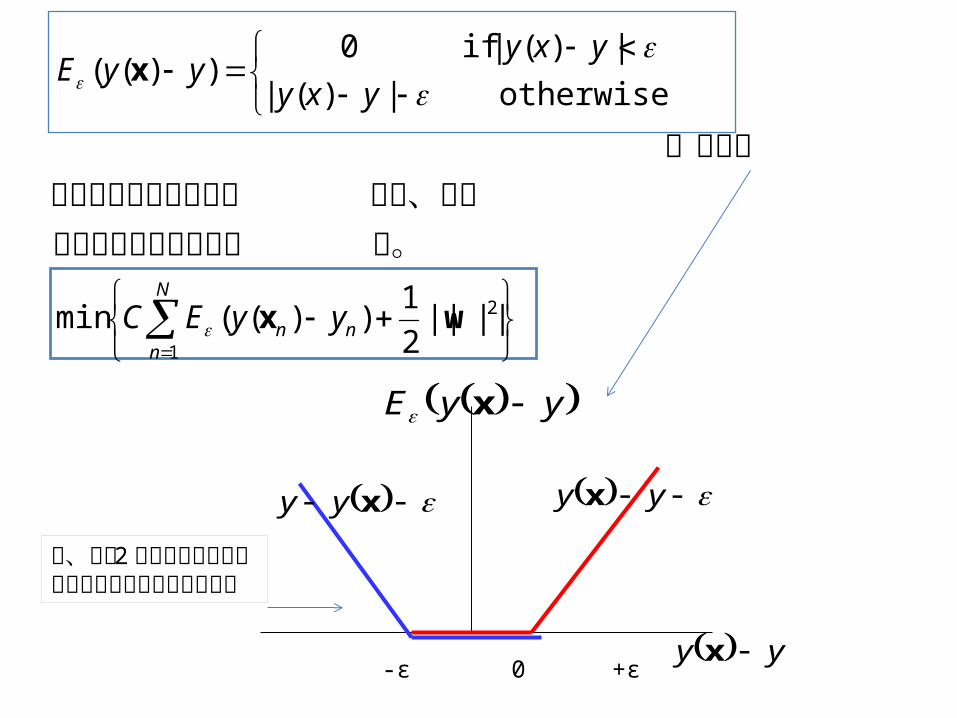
2
1
||||2
1))((min
otherwise|)(|
|)(| if0))((
wx
x
N
nnn yyEC
yxy
yxyyyE
る。関数の最小化問題とな帰は、次のこの関数を用いると回
図参照 下
-ε 0 +ε
yyE x
yy x
yy x xyy
赤、青の 2 個のヒンジ損失の組み合わせであることに注意

y+ε
y
y-ε
)101(ˆ)(
)100()(
0)()(
ˆ
SVMyy
SVMyy
yyy
nnn
nnn
nnn
x
x
xx
という条件は下記。 で0、その外側ですなわち
を導入する。スラック変数青い線の下で正となる
と、ク変数の上で正となるスラッここで、上図の赤い線
ξ>0
0ˆ
)( nn yy x
nn yy )(x

)110(ˆˆ
ˆˆ||||2
1ˆ
Lagrangian
)103(0ˆ
)102(0
)101(ˆ)(
)100()( subject to
||||2
1ˆmin
11
1
2
1
2
1ˆ,,
SVMyyayya
CL
SVM
SVM
SVMyy
SVMyy
C
N
nnnnn
N
nnnnn
N
nnnnn
N
nnn
n
n
nnn
nnn
N
nnn
nn
xx
w
x
x
ww
は
はこうすると最適化問題

で微分その上で
を代入すると
nn
N
nnnnn
N
nnnnn
N
nnnnn
N
nnn
N
nnnnn
N
nnnnn
N
nnnnn
N
nnn
w
wyawya
CL
wy
SVMyyayya
CL
ˆ,,,
,ˆˆ,
ˆˆ||||2
1ˆ
,)(
)110(ˆˆ
ˆˆ||||2
1ˆ
0
10
10
1
2
1
0
11
1
2
1
w
xwxw
w
xwx
xx
w

ージ以降に記述この式の導出は次々ペ
た。を求める問題に帰着しを最適化するこの
とも書く
を求めるとに代入し最大化すべきこの結果を
の最小化のために微分
nn
mnmn
N
nnnn
N
nnn
N
n
N
mmnmmnn
nnn
nnn
N
nnn
n
N
nnn
aaL
k
SVMyaaaa
aaaa,L
LL
CaL
CaL
aaw
L
aaL
L
ˆ,~
,),(
)120( ˆˆ
,ˆˆ2
1)ˆ(
~
~
ˆˆ0ˆ
0
0ˆ0
ˆ0
11
1 1
10
1
xxxx
xxaa
xww

mn
N
mmmn
n
N
nnnnn
nn
N
nnnn
nn
aay
aayw
aaSVM
SVMwaay
CaCa
xx
xwxw
xxx
,ˆ
ˆ,
0ˆ,0110(
)120(,ˆ)(
ˆ00
1
10
01
を代入し
のときは )より
下のようになる。また、回帰モデルは以
制約が得られる。上の導出過程から次の

N
nnnn
N
nnnn
N
nnnnn
N
nnnnn
nnnnnn
N
nnnnn
N
nnnnn
N
nnnnn
N
nnn
nnnnnnnn
nnnnnnnn
nnnn
nnnn
wxyawxya
aCaCaCaC
LLaCaC
wxyawxya
CL
aayyyynot
aCaC
ayya
ayya
KKT
10
10
2
11
10
10
1
2
1
,ˆ,||||2
1
ˆ)ˆ()(ˆ)ˆ()(
0ˆ
ˆˆ
,ˆˆ,
ˆˆ||||2
1ˆ
0ˆ0)ˆ(0)(
0ˆ)ˆ(ˆˆ0)(
)2(0ˆˆ
)1(0
www
ww
w
xx
x
x
かつ
制約条件を消せる。り、導入された変数と条件は以下のようにな
( SVM120 )の導出
ε + ξ>0, ε + ξ^>0

N
nnnn
N
nnn
N
n
N
mmnmmnn
n
N
nnn
N
nnn
N
n
N
mmnmmnn
N
nnn
N
nnnn
N
nnnn
N
nnnn
N
nnnnn
N
nnnnn
yaaaaaaaa
yaaaaaaaa
aaw
Laa
wyawya
aCaCaCaC
111 1
111 1
101
10
10
2
11
ˆˆ,ˆˆ2
1
ˆˆ,ˆˆ2
1
0ˆ0ˆ
,ˆ,||||2
1
ˆ)ˆ()(ˆ)ˆ()(
xx
xx
xw
xwxww
によりと
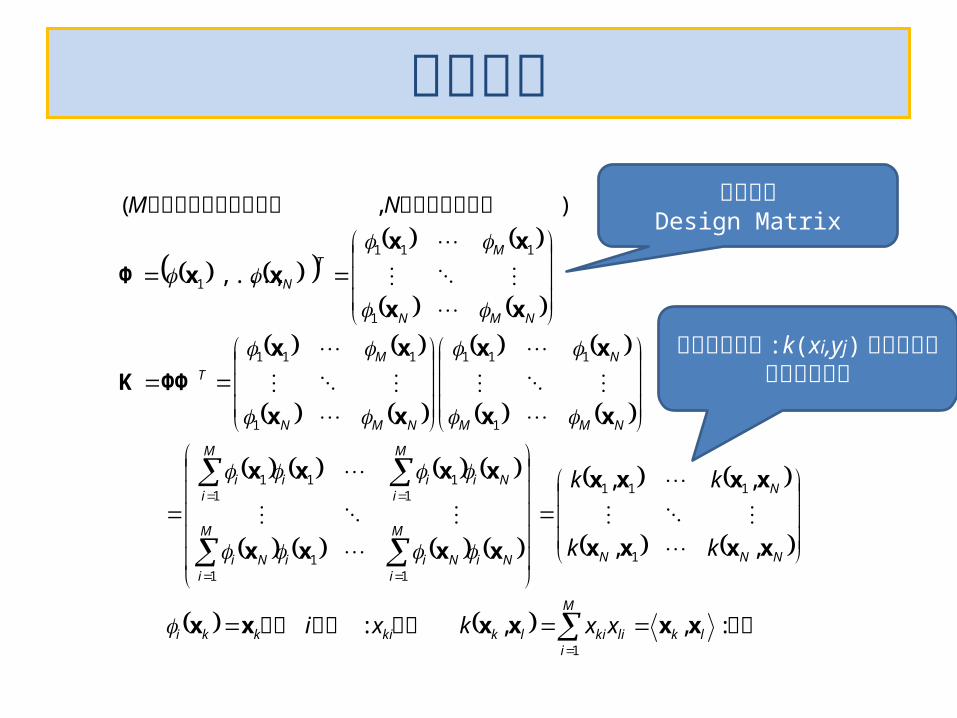
内積 なら成分の第
は教師データ数は教師データの次元数
:,,:
,,
,,
,...,
),(
1
1
111
11
1
111
11
1
111
1
111
1
111
1
lk
M
ilikilkkikki
NNN
N
Ni
M
iNii
M
iNi
Ni
M
iii
M
ii
NMM
N
NMN
MT
NMN
MT
N
xxkxi
kk
kk
NM
xxxxxx
xxxx
xxxx
xxxx
xxxx
xx
xx
xx
xx
ΦΦK
xx
xx
xxΦ
計画行列Design Matrix
カーネル関数 :k(xi,yj) を要素とするグラム行列
カーネル

正定値カーネル: 対称行列 k(xi,xj) が半正定値:グラム行列 :既存のカーネル関数から別のカーネル関数を構成する方法
)10()()()(
)9()()()(
()()(
)8( )(
)7())()(()(
)6()()()(
)5()()()(
)4())(exp()(
)3())(()(
)2()()()()(
)1()()(
21
21
1
21
21
1
1
1
1
kkkk
kkkk
kk
kkk
kkkk
kkkk
kkk
kqkqk
kffkfk
kckk
bbaa
bbaa
baba
T
y,xy,xyx,
y,xy,xyx,
yx,y,yyx,xx
AAyxyx,
y,xyx,
yx,yx,yx,
yx,yx,yx,
yx,yx,
yx,yx,
yyx,xyx,
yx,yx,
のときとも同じ次元に分割)は対称半正定値行列
は係数正の多項式
は任意の関数

カーネルの例
問題の非線形性あるいは高次性を非線形なカーネルで表すことになる
線形カーネル多項式カーネルGaussian カーネル :RBF
以下の分解により Gaussian カーネルがカーネル関数だといえる
by (k-1)(k-2)(k-4)
2
2
2
||||exp)(
,...2,1 )1()(
)(
yx
k
Mk
kMT
T
yx,
yxyx,
yxyx,
)exp()2
exp()2
exp()(
2||||
222
2
yxyyxx
yx,
yxyyxxyxTTT
TTT
k
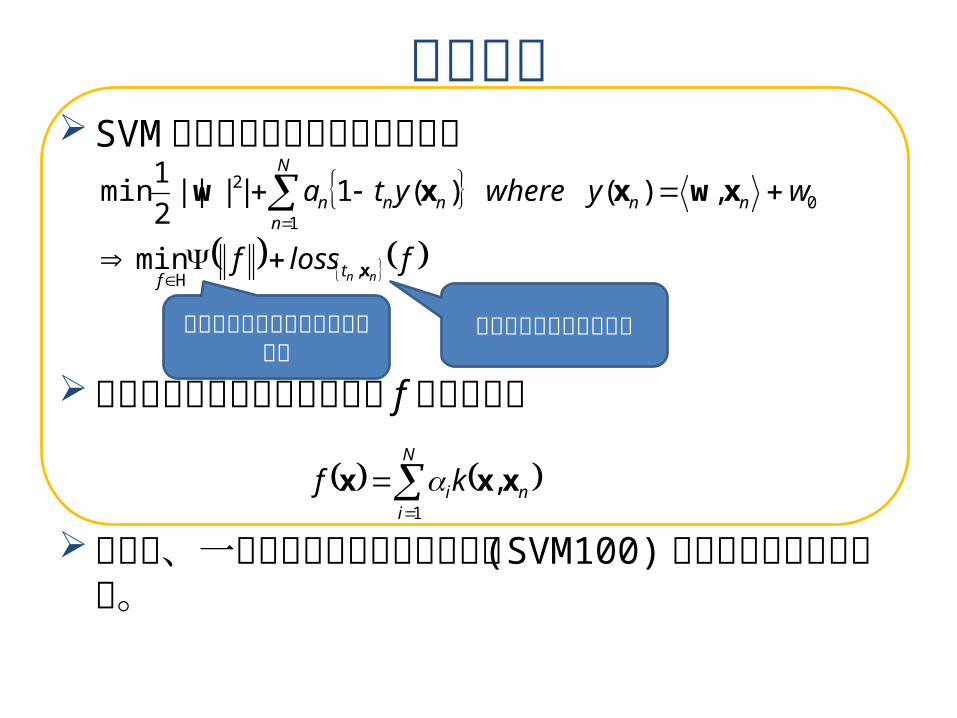
表現定理SVM などの最適化は下のような形
このとき上の最適化問題の解 f は下記の形
よって、一般的なカーネルであっても(SVM100) の形の解を想定できる。
flossf
wywhereyta
nntf
nn
N
nnnn
x
xwxxw
,
01
2
min
,)( )(1||||2
1min
H
正の単調増加関数である正則化項
教師データに対する損失
N
inikf
1
,xxx
よもやま話:スイスロール-1
多様体に写像してから識別境界を切る
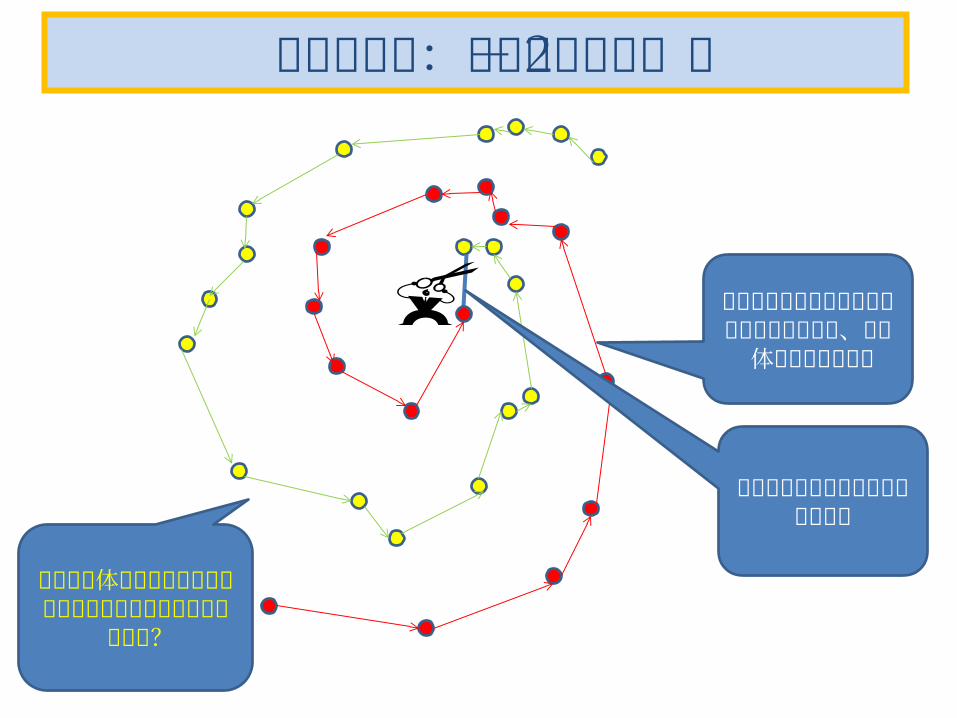
よもやま話:スイスロール-2
同じ色のデータのうち近接するものを繋いで、多様体を近似的
に求め
色が違うデータを繋ぐところで
切るこの多様体による制約を考慮して分類する最適化問題
の定式化は?

捕捉:線形回帰、識別からカーネル関数へ
的に考えてみよう。についてもう少し組織、2乗誤差を考えるときという正規化項つきの
は教師データ数は教師データの次元数
ただし
がとるべき値。は
回帰式に対してという一般化した線形
)(
),
(
)(
)(
)(
)(2
)(2
1)(
)()(
1
2
1
x
x
x
x
xwwwxww
xww
N
M
ttJ
y
nM
n
n
nT
nT
N
nnn
T
T
カーネル関数と呼ばれる で回帰や識別を考え直すことにより、より効率の良い方法が見えてくる。
yxk ,
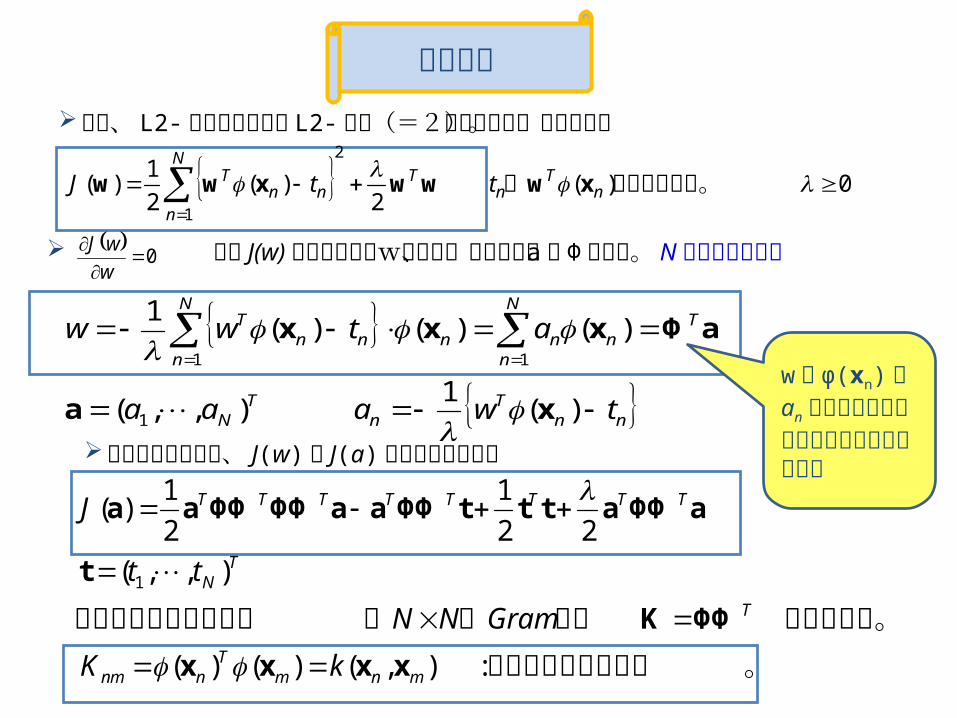
双対表現
まず、 L2- 正規化項つきの L2-損失(=2乗誤差関数)を考える。
0)(2
)(2
1)(
2
1
がとるべき値。は nT
nT
N
nnn
T ttJ xwwwxww
から J(w)を最小化するwを求め、その右辺を a と Φ で表す。 Nは教師データ数
nnT
nT
N
TN
nnnn
N
nnn
T
twaaa
atww
)(1
),,(
)()()(1
1
11
xa
aΦxxx
以上の表記を用い、 J(w) を J(a) として書き直すと
。カーネル関数という
を定義する。 行列のつここで下記の要素を持
:),()()(
),,(
22
1
2
1)(
1
mnmT
nnm
T
TN
TTTTTTTT
kK
GramNN
tt
J
xxxx
ΦΦK
t
aΦΦatttΦΦaaΦΦΦΦaa
0
w
wJ
w が φ(xn)の an を重みとする線形結合で書けることに注目
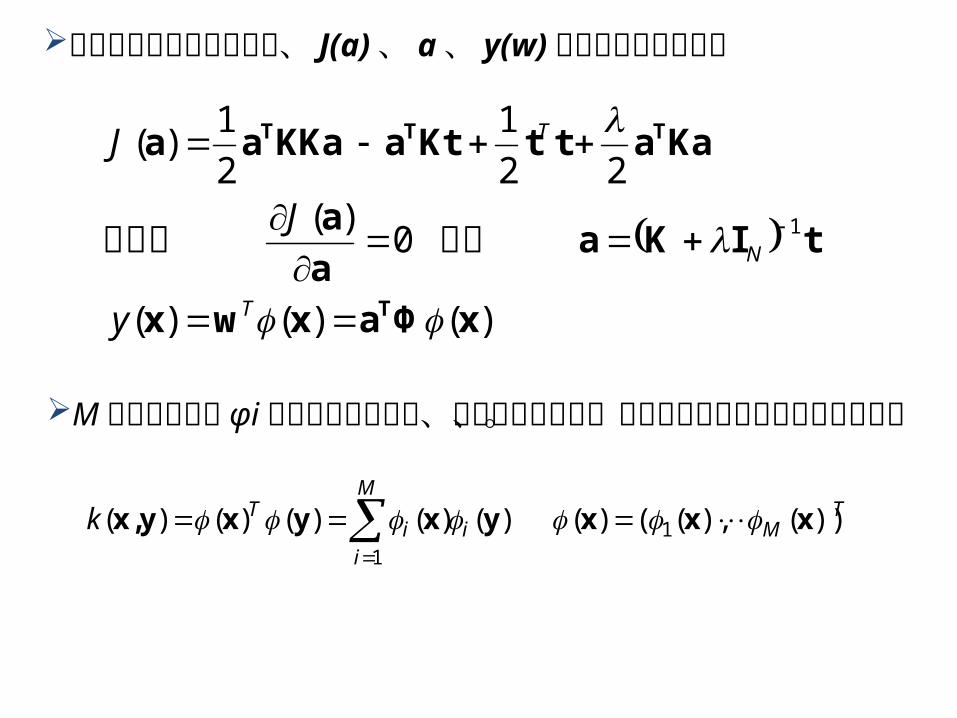
カーネル関数を用いると、 J(a)、 a、 y(w)は次のように書ける
)()()(
0)(
22
1
2
1)(
1
xΦaxwx
tΙKaa
a
KaattKtaKKaaa
T
TTT
T
N
T
y
J
J
よりここで
M 個の基底関数 φi があったとすると、カーネル関数は、内積の形で以下のように書ける。
TM
M
iii
Tk ))(),(()()()()()()( 11
xxxyxyxyx,


![カードゲーム「 3OD]Dnace.main.jp/newsimage/エコシン11月号.pdfエコシン1R ( ) 5 5 5 5 5 5 5 5 5 5 5 É É n ò Ã £ ÿ Ó $ m ¥ q 4 5 â & 5 5 5 5 5 5 a 5 5 5](https://img.pdfslide.tips/doc/110x75/5f7e9255bb31203eeb5bc015/ffffoe-3oddnacemainjpnewsimagef11oepdf-f1r.jpg)


























