Embed Size (px)
DESCRIPTION
主題六、相關、迴歸與預測. 主講人 陳陸輝 特聘研究員兼主任 政治大學選舉研究中心 美國密西根州立大學博士. 講授主題. 一、預測與變數之間的關係 二、最小平方迴歸線 三、預測的誤差 四、 OLS 的特性 五、迴歸模型中的適合度檢定. 迴歸的使用時機. 當我們的依變數是 數字資料 ,自變數是 類別 或是 數字 資料,可以使用迴歸分析。 以模型中的自變數的變化情況,來解釋或是預測依變數的變化情況。. 線性函數的例子一. 圖 7.1. 線性函數. 自變數 依變數 截距 斜率 X 軸 Y 軸. 斜率與回歸線方向. 一、李登輝與國民黨. - PowerPoint PPT Presentation
Citation preview

112/04/20 政治學研究方法班1
主題六、相關、迴歸與預測
主講人 陳陸輝 特聘研究員兼主任政治大學選舉研究中心美國密西根州立大學博士

112/04/20政治學研究方法班2
講授主題
一、預測與變數之間的關係
二、最小平方迴歸線
三、預測的誤差
四、 OLS的特性
五、迴歸模型中的適合度檢定

112/04/20政治學研究方法班3
迴歸的使用時機
當我們的依變數是數字資料,自變數是類別或是數字資料,可以使用迴歸分析。
以模型中的自變數的變化情況,來解釋或是預測依變數的變化情況。
112/04/20政治學研究方法班4
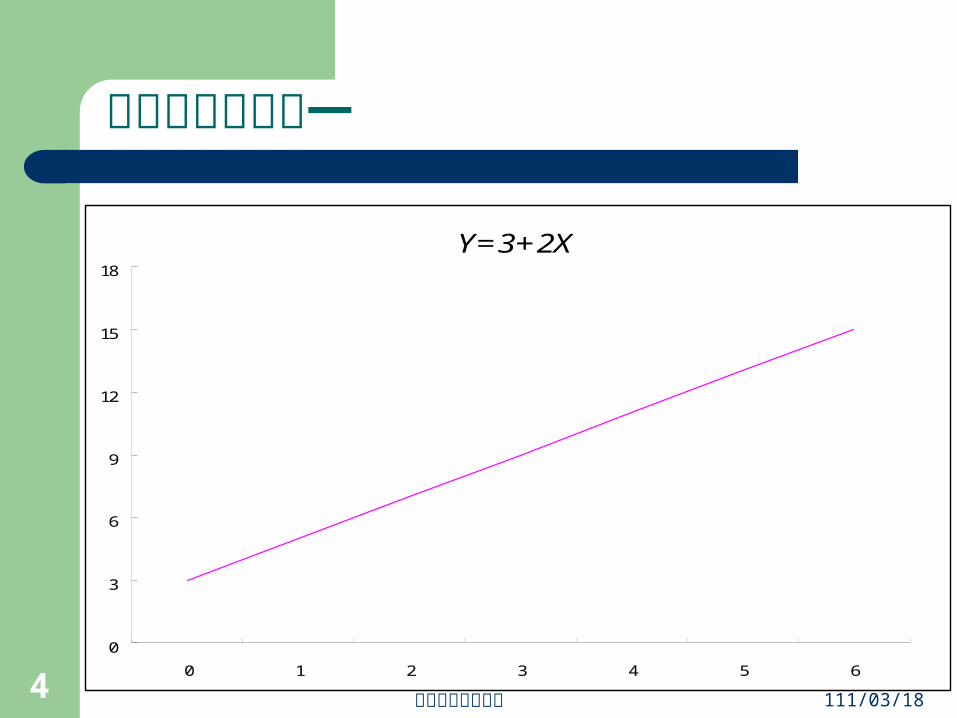
線性函數的例子一
Y=3+2X
0
3
6
9
12
15
18
0 1 2 3 4 5 6
Y
X
112/04/20政治學研究方法班5
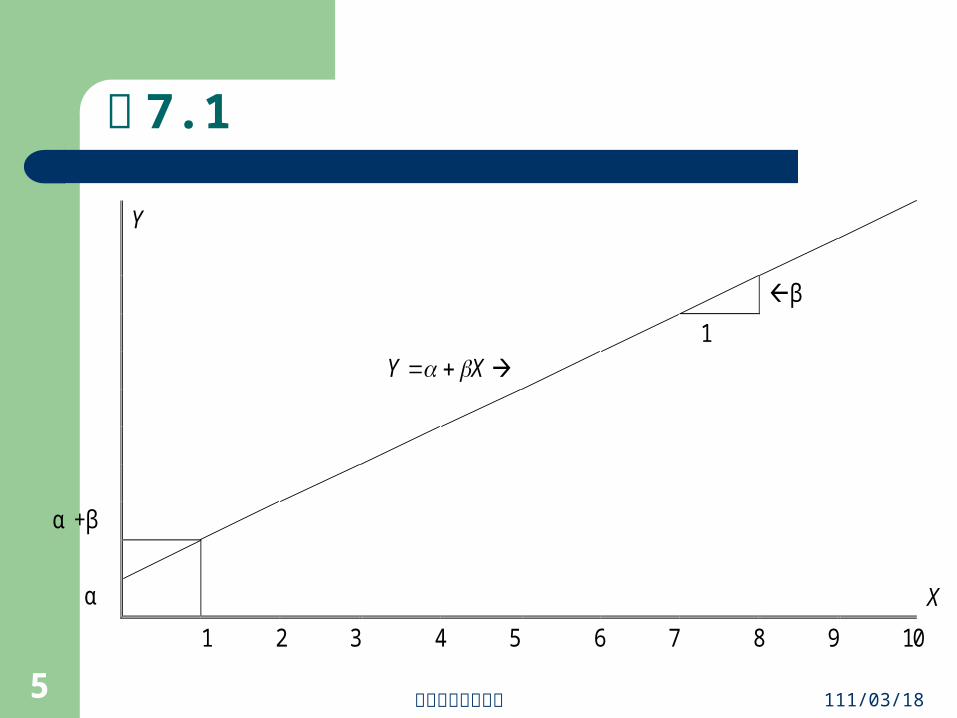
圖 7.1
Y
β
1
XY
α +β
α X
1 2 3 4 5 6 7 8 9 10
112/04/20政治學研究方法班6
線性函數
自變數依變數截距斜率X 軸Y 軸
112/04/20政治學研究方法班7
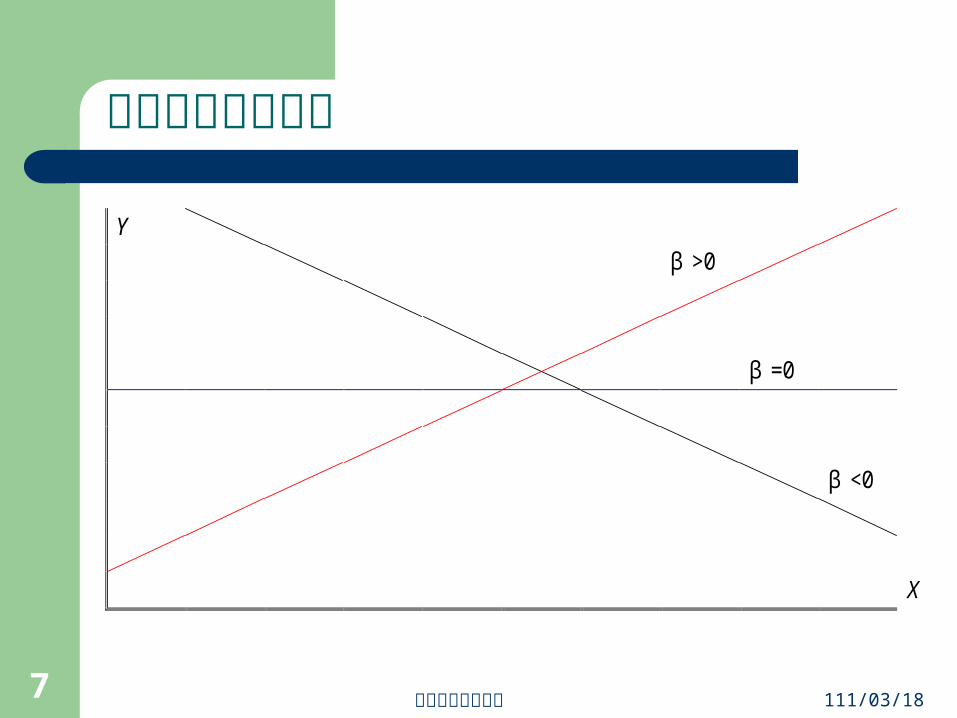
斜率與回歸線方向
Y
β >0
β =0
β <0
X

112/04/20政治學研究方法班8
一、李登輝與國民黨
民眾對李登輝( X )與國民黨( Y )評價之關聯性:
r = 22 yx
xy
(8.20)
= n XY X Y
n X X n Y Y
( )( )
[ ( ) ][ ( ) ]2 2 2 2 (8.21)
=654 / 8361304 =0.626
112/04/20政治學研究方法班9
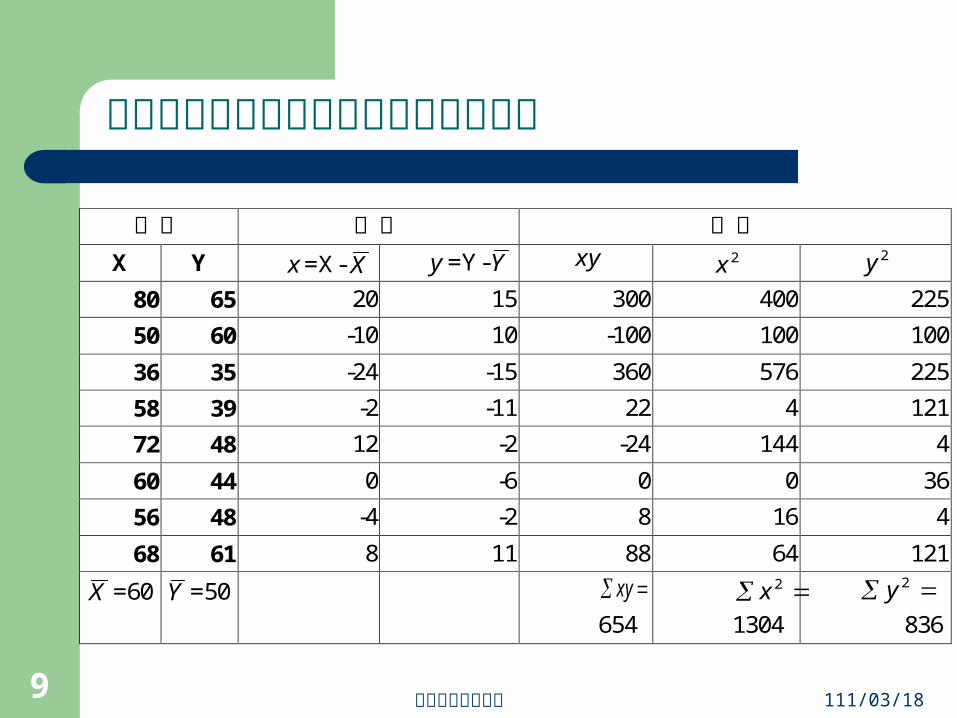
皮爾森積差相關係數的計算與解釋實例
資料 均差 乘積
X Y x =X- X y =Y-Y xy 2x 2y
80 65 20 15 300 400 225
50 60 -10 10 -100 100 100
36 35 -24 -15 360 576 225
58 39 -2 -11 22 4 121
72 48 12 -2 -24 144 4
60 44 0 -6 0 0 36
56 48 -4 -2 8 16 4
68 61 8 11 88 64 121
X =60 Y =50 xy
654
2x
1304
2y
836
112/04/20政治學研究方法班10
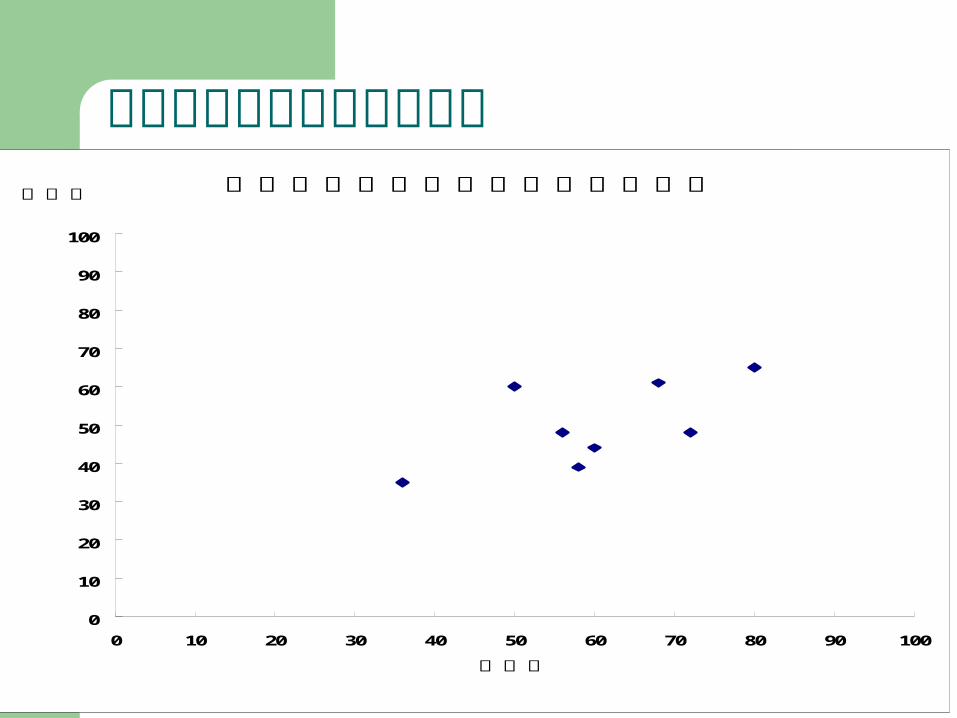
以圖形表示變數之間的關係
民眾對李登輝( X )與國民黨( Y )評價之關聯性的散佈圖:
對李登輝與對國民黨評價的散佈圖
0
10
20
30
40
50
60
70
80
90
100
0 10 20 30 40 50 60 70 80 90 100
李登輝
國民黨

112/04/20政治學研究方法班11
幾種圖形的可能
1.一直線2.一團線3.其他情況4.方向5.強弱6.關聯性與預測
112/04/20政治學研究方法班12
迴歸分析基本邏輯
以模型中的自變數(對李登輝評價_ X )的變化情況,來解釋或是預測依變數(對國民黨評價_ Y )的變化情況。
我們想找到一條預測的迴歸線,將我們觀察值與對國民黨評價的預測值之間的誤差平方,降到最低。則這一條就是所謂的最小平方迴歸線( least-squares regression line ),這種估計方法,就是所謂的普通最小平方法( ordinary least squares method, OLS method )。

112/04/20政治學研究方法班13
二、最小平方迴歸線
Y 是我們的依變數,對李登輝總統的評價。 X1是我們的自變數或是解釋變數,是一個用來解釋影響李登
輝先生評價的因素。 β0是迴歸方程式中的常數項,它的定義是當我們把其他解釋
變數的值設定為 0 時,依變數, Y ,的平均值。 β 1是解釋變數 X1的係數,他表示當 X1每變動 1 單位時, Y
變動的量。 ε 則是我們模型中的誤差項,當誤差愈小,表示我們的模型
愈能夠正確地預測我們的依變數。
110 XY (8.26) ( 10.1 )

112/04/20政治學研究方法班14
預測的方程式
xy
2)(
))(*)((
xx
yyxx
xy

112/04/20政治學研究方法班15
迴歸估計結果
1502.088.19ˆ XY (10.7)
2R =0.392 (10.8)

112/04/20政治學研究方法班16
迴歸的解釋與預測之實例 當民眾對李登輝的評價為 0 的時候,我們預測他對國民黨的評價為 19.88 分
當民眾對李登輝的評價每增加 1 分,他的對國民黨的評價就會增加 0.502 分
當一個民眾對李登輝的評價是 60 分的時候,我們預測他對國民黨的評價分數就是 50 分

112/04/20政治學研究方法班17
迴歸模型的適合度— R-Square
其分佈介於 0 到 1 之間,被稱之為模型解釋變異量。
2R =2
2
)(
)(̂
YY
YY (10.10)

112/04/20政治學研究方法班18
R-Square 的定義
1.(樣本的)決定係數2.模型解釋變異量(百分比)3.自變數對依變數的影響力4.(測量)誤差量
112/04/20政治學研究方法班19
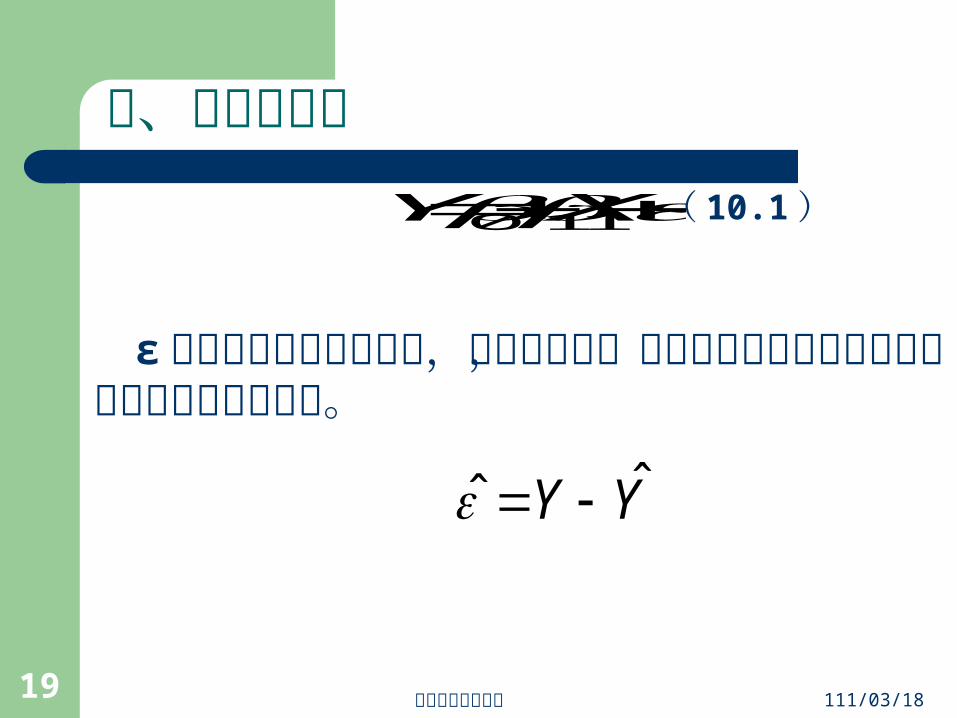
三、預測的誤差
ε 是我們模型中的誤差項,當誤差愈小,表示我們的模型愈能夠正確地預測我們的依變數。
110 XY (8.26) ( 10.1 )
YY ˆˆ

112/04/20政治學研究方法班20
迴歸估計的標準誤 S.E.E.
2))(
(2
)ˆ(
2
ˆˆ
2
22
22
N
x
xyy
N
YY
N
112/04/20政治學研究方法班21
估計的標準誤的使用
S.E.E. 告訴我們模型預測的精確程度,當它愈小,代表我們做的預測更精確,也讓我們更有信心。
Achen (1982: 62) 認為,因為 S.E.E. 不受解釋變數的變異程度大小而影響且它的單位與依變數相同,所以,是一個比較好的模型適合度的判斷標準。

112/04/20政治學研究方法班22
四、 OLS的特性
當 OLS 對是最佳線性無偏估計 (Best Linear Unbiased Estimator, BLUE) ,它具有以下幾個特性:
它對一個隨機變數是具有線性關係 它是一個無偏估計。 它的變異數最小-是最有效率的估計量。

112/04/20政治學研究方法班23
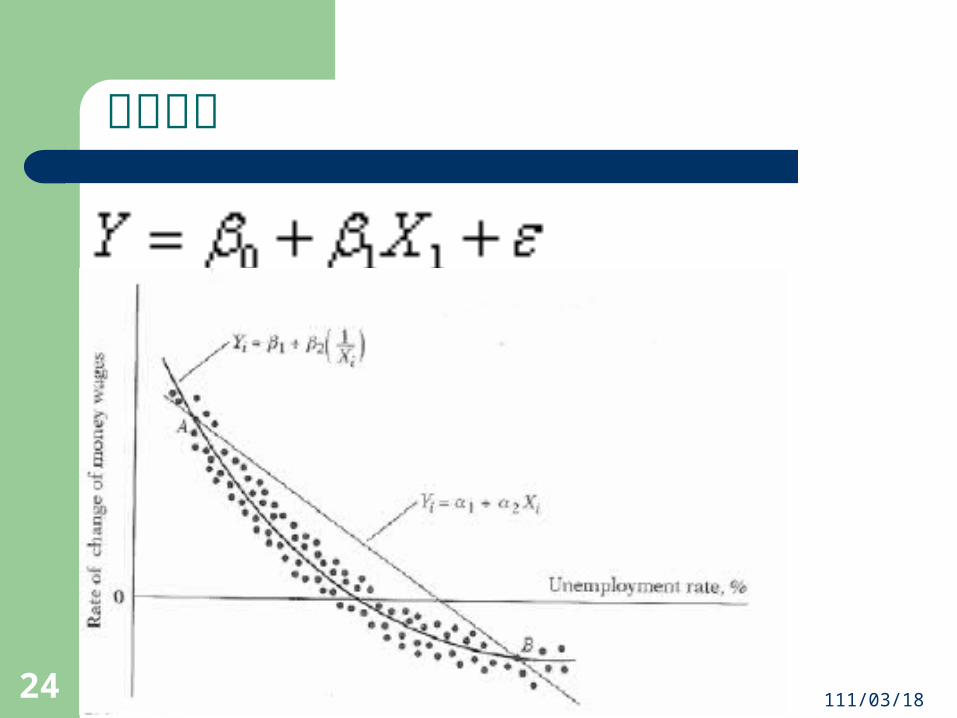
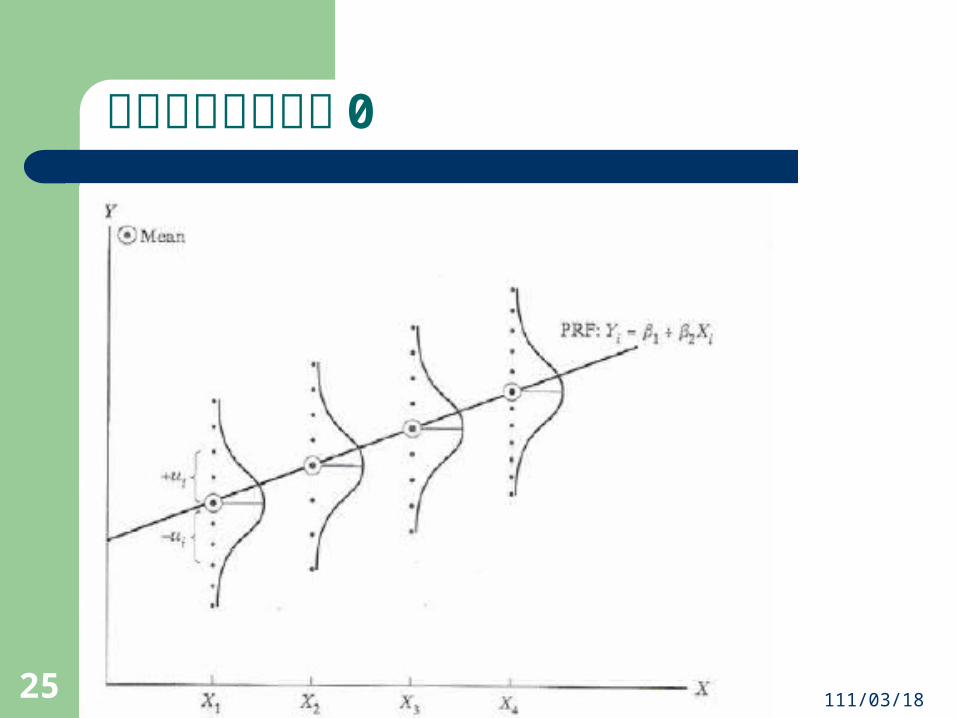
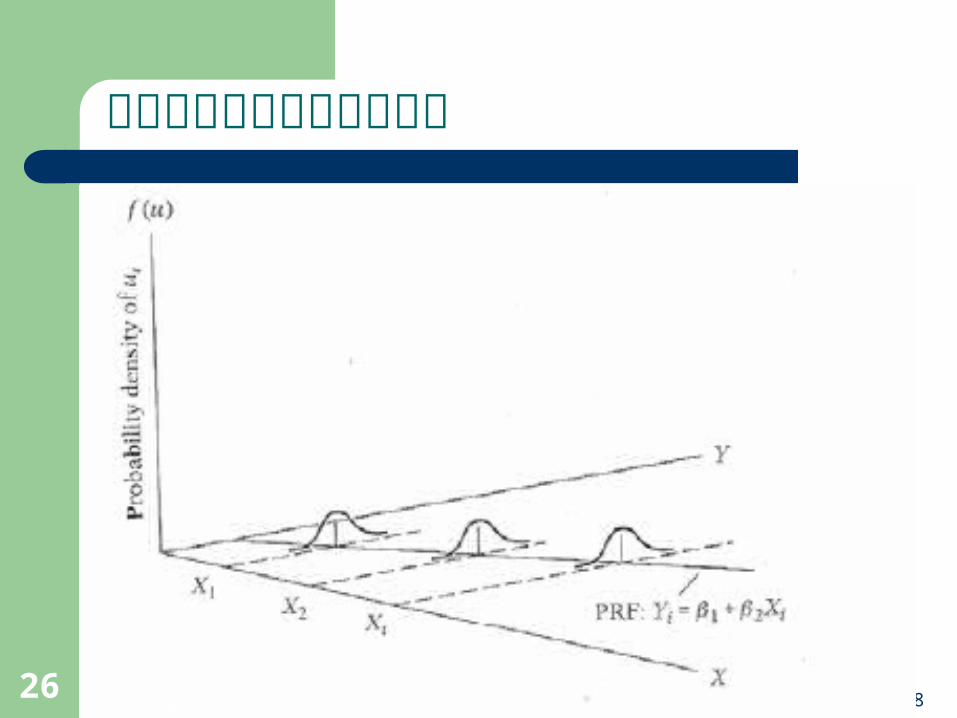
OLS重要的假設1. 依變數與解釋變數之間的關係是線性關係。 2. 誤差項的期望值為 0-- 0)( E 。 3. 誤差項的條件變異數均相同,具變異數齊一性(homoskedasticity)﹔誤差項之間彼此獨立,無「自我相關」(autocorrelation):
4. 自變數為重複抽樣中固定的(fixed in repeated samples)觀察值,而依變數為隨機變數。
5. 自變數之間彼此無線性關係。 6. 樣本數(n)大於自變數(k): n>=k+1。 7. 解釋變數須不為常數。
迴歸的模型設定(model specification)必須正確。
112/04/20政治學研究方法班24
線性關係
112/04/20政治學研究方法班25
誤差項的期望值為 0
112/04/20政治學研究方法班26
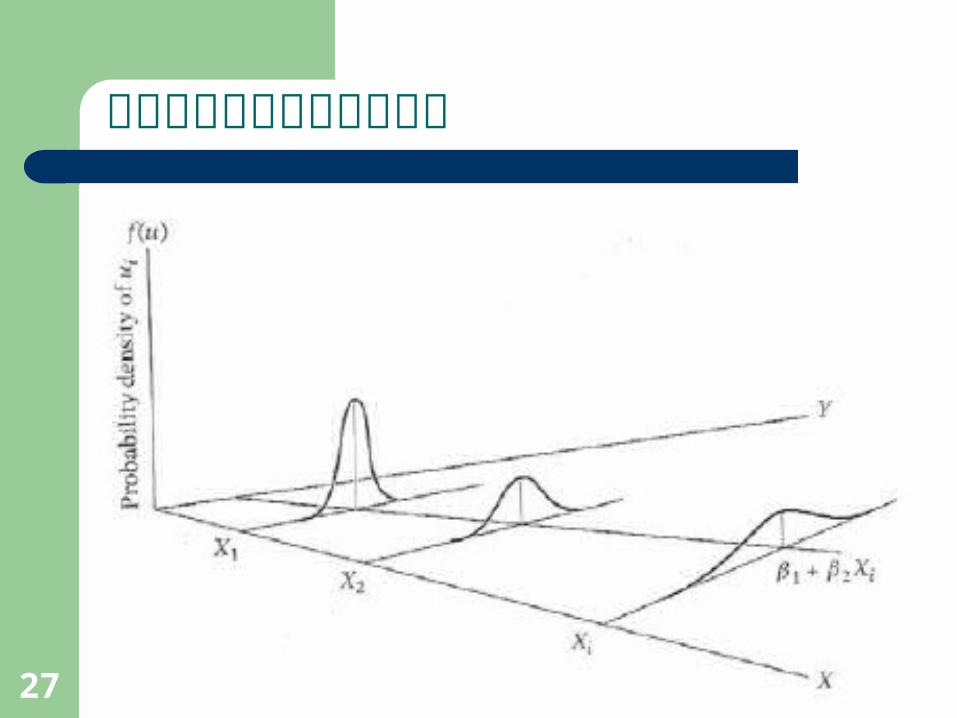
誤差項的條件變異數均相同
112/04/20政治學研究方法班27
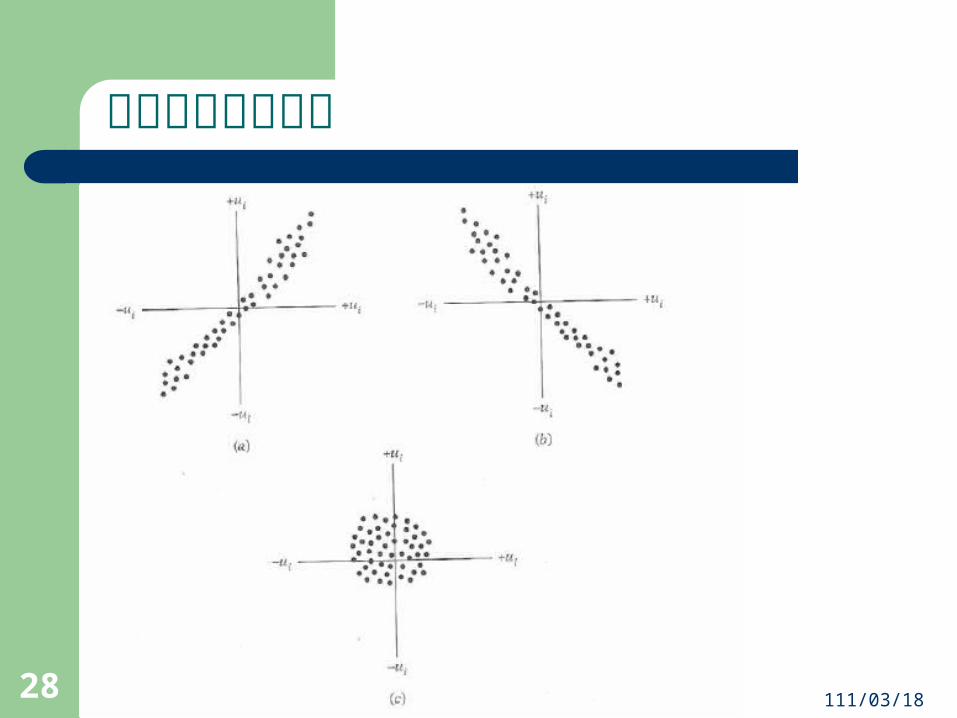
誤差項的條件變異數不相同
112/04/20政治學研究方法班28
誤差項無自我相關
112/04/20政治學研究方法班29
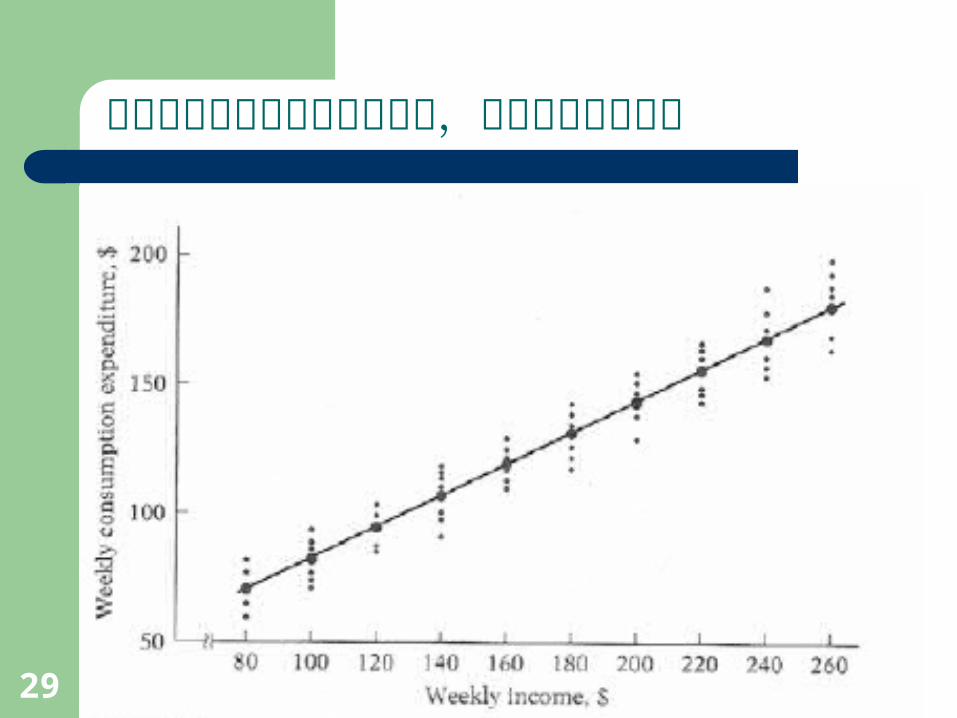
自變數為重複抽樣固定觀察值,依變數為隨機變數
112/04/20政治學研究方法班30
自變數之間彼此無線性關係
下次將會詳細說明

112/04/20政治學研究方法班31
樣本數 (n) 大於自變數 (k): n>=k+1
不然如何解釋
112/04/20政治學研究方法班32
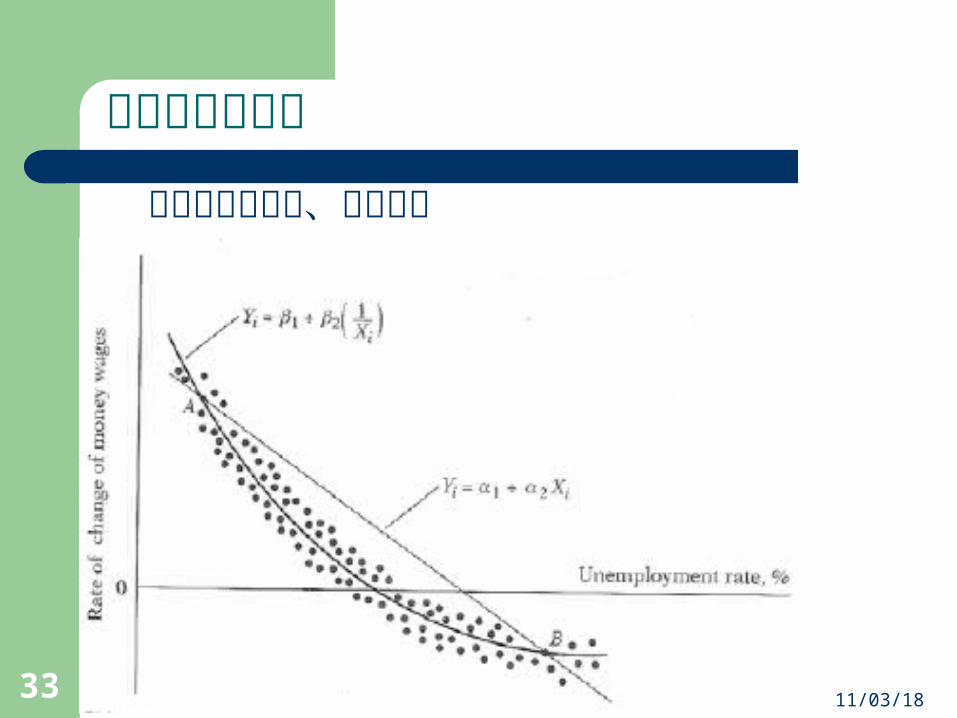
解釋變數須不為常數
常數當然無法解釋變數
112/04/20政治學研究方法班33
模型經適當設定
不忽略重要變數、函數正確

112/04/20政治學研究方法班34
五、迴歸模型中的適合度檢定
1.我們要看迴歸方程式中,單一解釋變數,是否顯著,則用 t 檢定。所以,該變數的估計係數與該估計係數的標準誤,決定 t 檢定的結果。
2.如果我們要考慮加入一個或是一組新變數,對於模型的解釋力有沒有「顯著」提升,此時,可以用 F 檢定。
3.如果要同時考慮好幾個變數,則個別變數顯著與否,可以參考 t 檢定,整組變數(整個模型)是某顯著,則可參考 F 檢定。

112/04/20政治學研究方法班35
迴歸模型的各種資訊
1.R-Square/Adjuested R-Square
2. F -test
3.SEE (Standard Error of Estimator)
4. B /(S.E.)/t -value
5. Standardized B (Beta)

112/04/20政治學研究方法班36
SPSS的簡單迴歸模型操作
基本問題:政治信任是人民對於政府的信念( faith ),影響的因素可以從三個角度討論。首先是個人政治社會化的過程、其次是政府或是政治人物的表現,第三個因素則是制度安排。本研究針對民眾對國民黨的喜好程度以及對於馬英九的喜好度,檢視政治社會化以及對政治人物好惡,是否影響其政治信任。

112/04/20政治學研究方法班37
指標建構本研究運用以上資料建構一個政治信任的指標,數值愈大,表示信任程度愈高。數值經過重新編碼,每一題以 1 表示信任感相當低, 4 表示信任感極高,四個題目取其平均值,新的數值分佈介於 1到 3.5之間,平均數為 2.17 標準差為 0.44 ,內在一致信的信度檢定結果( Cronbach’s α )為 0.60 。

112/04/20政治學研究方法班38
自變數對執政黨的喜好程度:N2—0~10
J6C—0~10
其他數值改為系統遺漏值( system missing )

112/04/20政治學研究方法班39
迴歸模型的操作Analyze Regression Linear
先放入依變數: D7NS4
自變數: N2N

112/04/20政治學研究方法班40
對執政黨好惡與政治信任研究假設:從政治社會化的角度出發,本研究認為:民眾對於執政黨的好惡,會影響其政治信任。
統計虛無假設:
統計對立假設:
112/04/20政治學研究方法班41
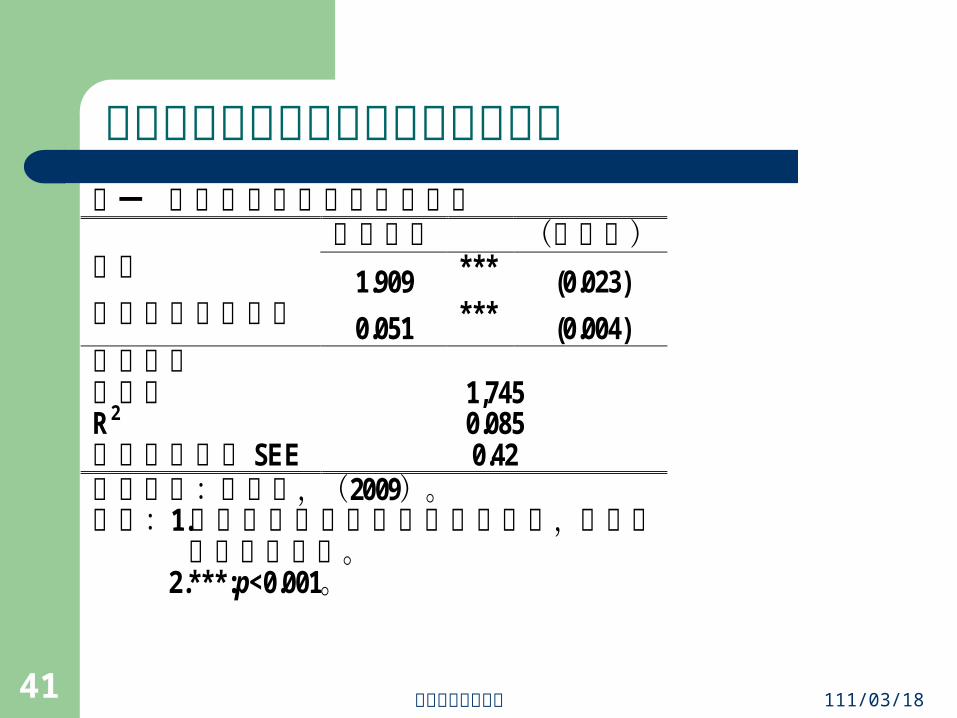
對執政黨好惡與政治信任的估計結果表一 對國民黨喜好度與政治信任 估計係數 (標準誤) 常數 1.909 *** (0.023) 對國民黨喜歡程度 0.051 *** (0.004) 模型資訊 樣本數 1,745 R2 0.085 估計的標準誤 SEE 0.42 資料來源:游清鑫,(2009)。 說明:1.政治信任係由四個變數建構而成,詳細情
況請參閱附錄。 2.***:p<0.001。

112/04/20政治學研究方法班42
對執政黨好惡與政治信任的模型解釋
統計解釋:從表一中可以發現:民眾對國民黨的喜好程度,對其政治信任具有顯著影響力。

112/04/20政治學研究方法班43
對執政黨好惡與政治信任的模型解釋
研究論文:本研究運用四個變數建構的政治信任量表,並進一步分析民眾對於執政黨的好惡情況會不會影響其政治信任。表一中發現:民眾對國民黨的喜好程度,對於民眾政治信任具有顯著影響。民眾對國民黨的好惡程度愈高,其政治信任愈高。當民眾對國民黨的喜好程度每增加一個單位,其政治信任就增加 0.051單位。

112/04/20政治學研究方法班44
迴歸模型的操作Analyze Regression Linear
先放入依變數: D7NS4
自變數: J6C

112/04/20政治學研究方法班45
對執政黨好惡與政治信任研究假設:從政治究責( accountability )出發,本研究認為:民眾對於執政者的好惡,會影響其政治信任。
統計虛無假設:
統計對立假設:
112/04/20政治學研究方法班46
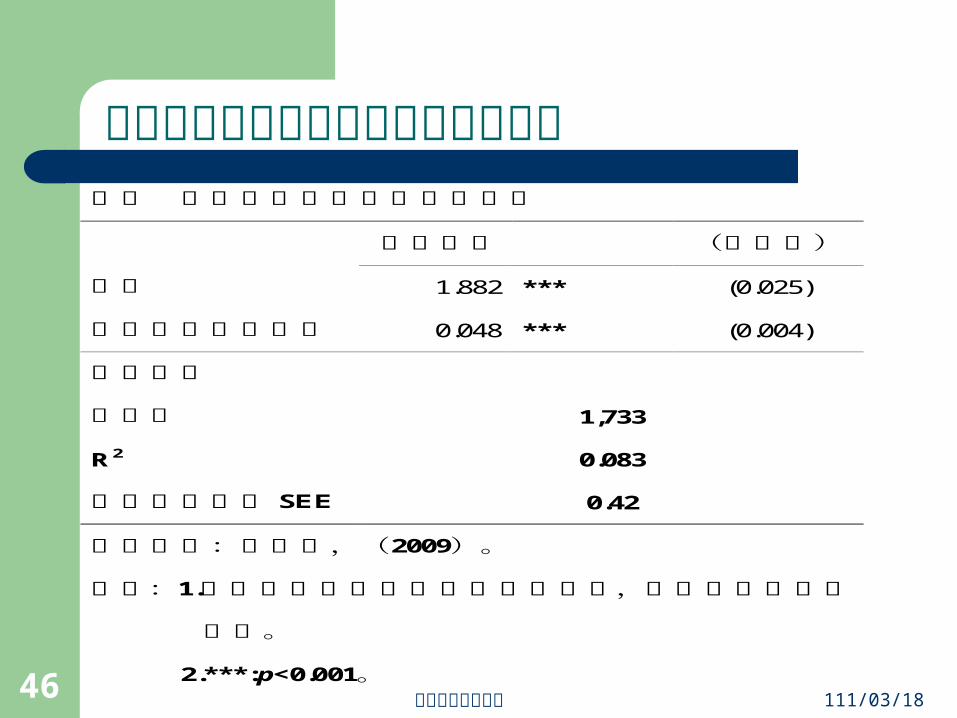
對馬英九好惡與政治信任的估計結果表二 對馬英九喜好度與政治信任
估計係數 (標準誤)
常數 1.882 *** (0.025)
對馬英九喜歡程度 0.048 *** (0.004)
模型資訊
樣本數 1,733
R2 0.083
估計的標準誤 SEE 0.42
資料來源:游清鑫,(2009)。
說明:1.政治信任係由四個變數建構而成,詳細情況請參閱
附錄。
2.***:p<0.001。

112/04/20政治學研究方法班47
對馬英九好惡與政治信任的模型解釋
統計解釋:從表一中可以發現:民眾對馬英九的好惡程度,對其政治信任具有顯著影響力。
112/04/20政治學研究方法班48
對執政黨好惡與政治信任的模型解釋
研究論文:本研究運用四個變數建構的政治信任量表,並進一步分析民眾對於執政黨的好惡情況會不會影響其政治信任。表二中發現:民眾對馬英九的喜好程度,對於民眾政治信任具有顯著影響。民眾對馬英九的喜好程度愈高,其政治信任愈高。當民眾對馬英九的喜好程度每增加一個單位,其政治信任就增加 0.048單位。
112/04/20政治學研究方法班49
尋找研究問題政治信任
政治支持
影響因素(起源)
政治重要(後果)





























