Embed Size (px)
DESCRIPTION
Alignment. 陳致嘉. Questions. Question 1: 假設現在有 1 條未知的蛋白質 , 我們要如何得知它和何種生物較親近 ? Ans:build a protein database,but … . Question 2: 怎麼定義 2 條蛋白質的相似度 ? Ans: Alignment techniques. Alignment. 蛋白質是由胺基酸組成的 , 所以蛋白質又可稱為胺基酸序列 序列排序 (A lignment) 的定義為分析 2 條胺基酸序列的相似度 Pairwise Alignment - PowerPoint PPT Presentation
Citation preview

AlignmentAlignment
陳致嘉陳致嘉

QuestionsQuestions
Question 1:Question 1: 假設現在有假設現在有 11 條未知的蛋白質條未知的蛋白質 ,,我們要如何得知它和何種生物較親近我們要如何得知它和何種生物較親近 ?? Ans:build a protein database,but….Ans:build a protein database,but….
Question 2:Question 2: 怎麼定義怎麼定義 22 條蛋白質的相似度條蛋白質的相似度 ?? Ans: Alignment Ans: Alignment techniquestechniques

AlignmentAlignment
蛋白質是由胺基酸組成的蛋白質是由胺基酸組成的 ,, 所以蛋白所以蛋白質又可稱為胺基酸序列質又可稱為胺基酸序列
序列排序序列排序 (Alignment)(Alignment) 的定義為分析的定義為分析 22條胺基酸序列的相似度條胺基酸序列的相似度 Pairwise AlignmentPairwise Alignment Multiple sequence AlignmentMultiple sequence Alignment

Compare two sequenceCompare two sequence
垂直的線段” 垂直的線段” | ”| ” 表示相同的胺基酸殘基表示相同的胺基酸殘基 ,, 插入缺插入缺洞洞 (gap)(gap) 而使不等長的而使不等長的 22 條序列能上下對齊條序列能上下對齊
A simple exampleA simple example
SEQUENSE 1 (query) AGGVLTTQVG | | | | | | | | |
SEQUENSE 2 (sebject) AGGVL--TQVG
SEQUENSE 1 (query) AGGVLTTQVG | | | | | |
SEQUENSE 2 (sebject) AGGVLTQVG

Compare two sequenceCompare two sequence
簡單的評分方法簡單的評分方法 [1][1] 相同的胺基酸殘基分數相同的胺基酸殘基分數 +1+1
[2]gap[2]gap 分數分數 -1-1
[3]extension gap get extension penalty[3]extension gap get extension penalty
[4][4] 用演算法找出分數最高的組合用演算法找出分數最高的組合
定義此分數為定義此分數為 edit distanceedit distance

Pairwise alignment techniquesPairwise alignment techniques
QuestionQuestion:: 如果我們並不想比較整條蛋白質如果我們並不想比較整條蛋白質的相似度的相似度 ,, 只想看一小段的功能呢只想看一小段的功能呢 ?? Global alignmentGlobal alignment
Local alignmentLocal alignment
Use matrixUse matrix
Question:Question: 在比較在比較 22 條蛋白質時條蛋白質時 ,, 有時有時 22個不同的胺基酸殘基發生突變使得原個不同的胺基酸殘基發生突變使得原本不同的胺基酸變成相同本不同的胺基酸變成相同 ,, 該怎麼辦該怎麼辦 ??
Ans:Ans: 生物資訊上使用矩陣來分析突生物資訊上使用矩陣來分析突變的可能性變的可能性
Use matrixUse matrix
The Dayhoff Mutation Data MatrixThe Dayhoff Mutation Data Matrix [2[2 條蛋白質有條蛋白質有 85%85% 以上胺基酸相等時使以上胺基酸相等時使
用用 ]]
The BLOSUM matricesThe BLOSUM matrices [2[2 條蛋白質有條蛋白質有 85%85% 以下胺基酸相等時使以下胺基酸相等時使
用用 ]]
The Dayhoff Mutation Data MatrixThe Dayhoff Mutation Data Matrix
為一種相關機率(為一種相關機率( relatedness oddsrelatedness odds )矩)矩陣陣
矩陣中值大於矩陣中值大於 00 的元素所對應的兩個殘基的元素所對應的兩個殘基之間發生突變的可能性較大之間發生突變的可能性較大
值小於值小於 00 的元素所對應的兩個殘基之間發的元素所對應的兩個殘基之間發生突變的可能性較小生突變的可能性較小

The Dayhoff Mutation Data MatrixThe Dayhoff Mutation Data Matrix

The Dayhoff Mutation Data MatrixThe Dayhoff Mutation Data Matrix

The BLOSUM matrices?The BLOSUM matrices?
The The technique is almost the same!technique is almost the same!

Use AlgorithmUse Algorithm
為求簡單為求簡單 ,, 先不考慮突變的可能性先不考慮突變的可能性 ,, 使使用演算法計算用演算法計算 22 條蛋白質間的相似度條蛋白質間的相似度
Global alignmentGlobal alignment
Needleman-Wunsch algorithmNeedleman-Wunsch algorithm Local alignmentLocal alignment
Smith-Waterman algorithmSmith-Waterman algorithm
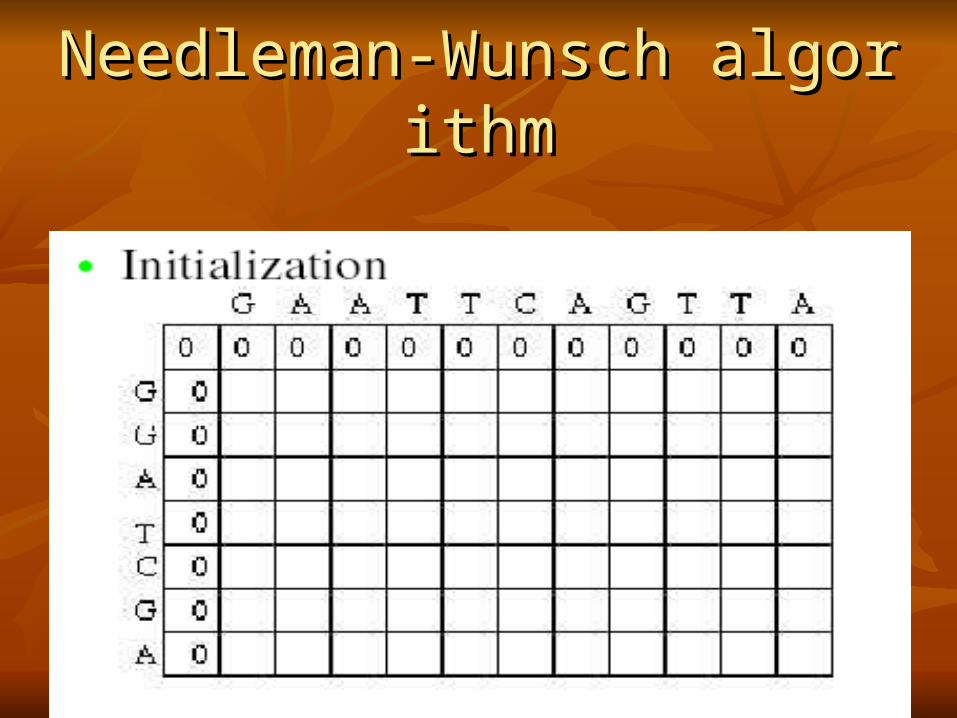
Needleman-Wunsch algorithmNeedleman-Wunsch algorithm

Needleman-Wunsch algorithmNeedleman-Wunsch algorithm

Needleman-Wunsch algorithmNeedleman-Wunsch algorithm

Needleman-Wunsch algorithmNeedleman-Wunsch algorithm

Needleman-Wunsch algorithmNeedleman-Wunsch algorithm

Smith-Waterman algorithmSmith-Waterman algorithm
SoftwareSoftware
FastAFastA 系列系列 :: 靈敏、但是靈敏、但是速度速度較慢較慢
BlastBlast 系列系列 :: 搜尋速度很快,但在序列相似搜尋速度很快,但在序列相似性較低時會有失誤性較低時會有失誤

Multiple sequence AlignmentMultiple sequence Alignment
多序列排序多序列排序 (Multiple sequence Align(Multiple sequence Alignment)ment) 是對一個或多個蛋白質進行分析是對一個或多個蛋白質進行分析並將之歸類於某個基因家族並將之歸類於某個基因家族
作蛋白質演化分析作蛋白質演化分析 是建立是建立 protein databaseprotein database 的基礎的基礎
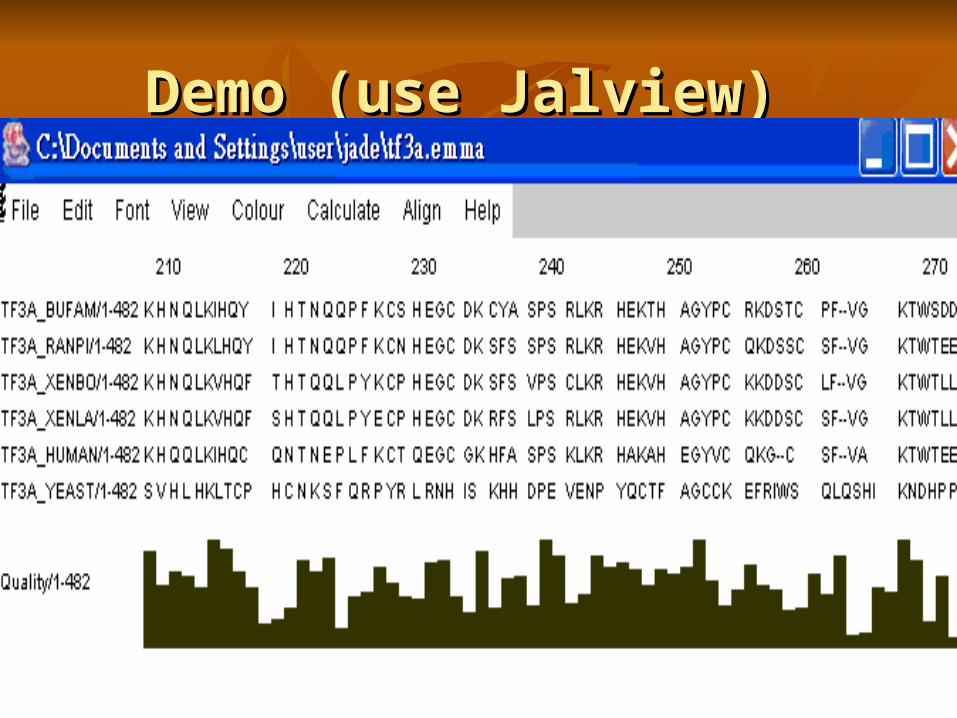
Demo (use Jalview) Demo (use Jalview)

ReferenceReference
Introduction to bioinformation Introduction to bioinformation
(Teresa K Attwood/David J.Parry-Smith(Teresa K Attwood/David J.Parry-Smith 著著 )) http://www.cs.fiu.edu /~giri/teach http://www.cs.fiu.edu /~giri/teach http:// www.chinagenenet.com/commInfo http:// www.chinagenenet.com/commInfo





























