Embed Size (px)
DESCRIPTION
Per ogni possibile politica π che l’agente potrebbe adottare, si può definire una funzione di valutazione sull’insieme degli stati Si può provare a far imparare la funzione di valutazione V π ∗ (che si denoter anche V ∗ ) Teorema ˆ Q converge a Q. Si considera il caso di un mondo deterministico dove ogni s, a sia visitato infinite volte
Citation preview

Apprendimento per Rinforzo
Corso di Apprendimento AutomaticoLaurea Magistrale in Informatica
Nicola Fanizzi
Dipartimento di InformaticaUniversità degli Studi di Bari
11 febbraio 2009
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Sommario
Apprendimento del ControlloPolitiche di Controllo che scelgono azioni ottimaliQ-learningConvergenzaEstensioni
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Apprendimento del Controllo I
Si consideri di imparare a scegliere azioni da intraprendere, es.,
Robot che impara a parcheggiare sulla postazione diricarica delle batterie
Imparare a scegliere azioni in modo da ottimizzare laproduzione di una fabbrica
Imparare a giocare a giochi come scacchi, dama,backgammon, ...
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Apprendimento del Controllo II
OsservazioniSi notino diverse caratteristiche del problema rispetto alle altreforme di learning trattate:
Ricompensa differita
Opportunità di esplorazione attiva
Possibilitïà di stati solo parzialmente osservabili
Possibilità di dover apprendere compiti multipli tramite glistessi sensori/effettuatori
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Esempio: TD-Gammon
Obiettivo: Imparare a giocare a Backgammon
Ricompensa immediata+100 se si vince−100 se si perde0 per tutti gli altri stati
Sistema addestrato giocando 1.5M partite contro se stesso
Alla fine il sistema risulta avere approssimativamenteprestazioni paragonabili al miglior giocatore umano
[Tesauro, 1995]
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Problema dell’Apprendimento per Rinforzo
agente
ambiente
ricompensa azionestato
Obiettivo: scegliere le azioni che massimizzino
dove
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Processi di decisione di Markov (MDP)
Si assuma:un insieme di stati S finitoun insieme di azioni Aad ogni istante discreto
l’agente osserva lo stato st ∈ S e sceglie l’azione at ∈ Aquindi riceve una ricompensa immediata rte lo stato corrente diventa st+1
Assunzione di Markov: st+1 = δ(st ,at ) e rt = r(st ,at )
ossia, rt e st+1 dipendono solo dallo stato corrente edall’azione intrapresale funzioni δ e r potrebbe non essere deterministicale funzioni δ e r non sono necessariamente note all’agente
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Compito di apprendimento per l’agente
Si eseguono le azioni nell’ambiente, si osservano i risultati esi impara una politica di azioni π : S → A che massimizzi
E [rt + γrt+1 + γ2rt+2 + . . .]
a partire da qualunque stato di partenza in Squi 0 ≤ γ < 1 è il tasso di sconto per ricompensa future
NovitàFunzione obiettivo π : S → Ama non ci sono esempi di training del tipo 〈s,a〉bensi gli esempi di training sono invece del tipo 〈〈s,a〉, r〉
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Funzione di valutazione
Per cominciare si considerino mondi deterministici ...
Per ogni possibile politica π che l’agente potrebbe adottare, sipuò definire una funzione di valutazione sull’insieme deglistati
Vπ(s) ≡ rt + γrt+1 + γ2rt+2 + ...
≡∞∑
i=0
γ i rt+i
dove le rt , rt+1, . . . sono generate seguendo la politica π apartire dallo stato s
In altri termini,il task consiste nell’apprendere la politica ottimale π∗
π∗ ≡ argmaxπ
Vπ(s) ∀s
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Valori di r(s,a) (ricompensa immediata)
Valori di Q(s,a) Valori di V*(s)
Strategia ottimale
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Cosa imparare
Si può provare a far imparare la funzione di valutazione Vπ∗
(che si denoter anche V ∗)
Si può operare una ricerca in avanti (lookahead) per sceglierela migliore azione a partire da ogni stato s poiché
π∗(s) = argmaxa
[r(s,a) + γV ∗(δ(s,a))]
Problema:Funziona bene se l’agente conosce le funzioniδ : S × A→ S, e r : S × A→ <ma quando questo non accadenon si possono scegliere le azioni in questo modo
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Funzione Q
Si definisce una nuova funzione simile a V ∗
Q(s,a) ≡ r(s,a) + γV ∗(δ(s,a))
Se l’agente impara la funzione Q,si potrà scegliere l’azione ottimale anche senza conoscere δ
π∗(s) = argmaxa
[r(s,a) + γV ∗(δ(s,a))]
π∗(s) = argmaxa
Q(s,a)
Q è la funzione di valutazione che l’agente dovrà imparare
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Regola di training per imparare Q
Si noti che Q e V ∗ sono strettamente legate:
V ∗(s) = maxa′
Q(s,a′)
il che permette di riscrivere Q in modo ricorsivo:
Q(st ,at ) = r(st ,at ) + γV ∗(δ(st ,at )))
= r(st ,at ) + γmaxa′
Q(st+1,a′)
Denotata con Q̂ l’approssimazione corrente si Q, si consideri laregola di training:
Q̂(s,a)← r + γmaxa′
Q̂(s′,a′)
dove s′ è lo stato risultante dall’applicazione dell’azione a nellostato s
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Q-Learning per mondi deterministici
Per ogni s,a inizializzare la cella della tabella: Q̂(s,a)← 0
Sia s lo stato corrente
Ripeti:Selezionare un’azione a ed eseguirlaRicevere la ricompensa immediata rSia s′ il nuovo statoAggiornare l’elemento in tabella Q̂(s,a) come segue:
Q̂(s,a)← r + γmaxa′
Q̂(s′,a′)
s ← s′
Corso di Apprendimento Automatico Apprendimento per Rinforzo
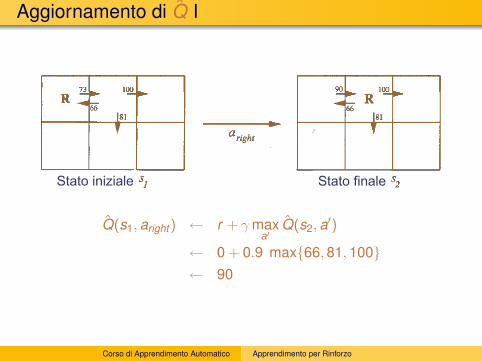
Aggiornamento di Q̂ I
Stato iniziale Stato finale
Q̂(s1,aright ) ← r + γmaxa′
Q̂(s2,a′)
← 0 + 0.9 max{66,81,100}← 90
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Aggiornamento di Q̂ II
Si noti che se le ricompense sono non negative, allora
(∀s,a,n) Q̂n+1(s,a) ≥ Q̂n(s,a)
e(∀s,a,n) 0 ≤ Q̂n(s,a) ≤ Q(s,a)
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Convergenza I
Teorema Q̂ converge a Q.Si considera il caso di un mondo deterministico dove ogni 〈s,a〉sia visitato infinite volte
Dim.:Definire un intervallo pieno durante il quale 〈s,a〉 viene visitato.Durante ogni intervallo pieno l’errore piu’ grande nella tabella Q̂si riduce del fattore γ
Sia Q̂n la tabella ottenuta dopo n aggiornamenti e∆n l’errore massimo in Q̂n; ossia:
∆n = maxs,a|Q̂n(s,a)−Q(s,a)|
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Convergenza II
Per ogni elemento della tabella Q̂n(s,a) aggiornandoall’iterazione n + 1, l’errore nella nuova stima Q̂n+1(s,a) sarà:
|Q̂n+1(s,a)−Q(s,a)| = |(r + γmaxa′
Q̂n(s′,a′))
−(r + γmaxa′
Q(s′,a′))|
= γ|maxa′
Q̂n(s′,a′)−maxa′
Q(s′,a′)|
≤ γmaxa′|Q̂n(s′,a′)−Q(s′,a′)|
≤ γmaxs′′,a′|Q̂n(s′′,a′)−Q(s′′,a′)|
|Q̂n+1(s,a)−Q(s,a)| ≤ γ∆n
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Convergenza III
Si noti che si ricorre alla proprietà seguente:
|maxa
f1(a)−maxa
f2(a)| ≤ maxa|f1(a)− f2(a)|
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Caso non deterministico I
Che succede se la ricompensa e lo stato successivo non sonodeterministici ?
Si ridefiniscono V e Q considerando i valori attesi
Vπ(s) ≡ E [rt + γrt+1 + γ2rt+2 + . . .]
≡ E [∞∑
i=0
γ i rt+i ]
Q(s,a) ≡ E [r(s,a) + γV ∗(δ(s,a))]
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Caso non deterministico II
Il Q-learning si estende a mondi non deterministici
Si modifica la regola di training
Q̂n(s,a)← (1− αn)Q̂n−1(s,a) + αn[r + maxa′
Q̂n−1(s′,a′)]
doveαn =
11 + visitsn(s,a)
Si può comunque provare la convergenza di Q̂ a Q
[Watkins & Dayan, 1992]
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Temporal Difference Learning
Q-learning: ridurre la discrepanza tra stime successive di Q
Differenza di un passo:
Q(1)(st ,at ) ≡ rt + γmaxa
Q̂(st+1,a)
Due passi:
Q(2)(st ,at ) ≡ rt + γrt+1 + γ2 maxa
Q̂(st+2,a)
Per n passi:
Q(n)(st ,at ) ≡ rt + γrt+1 + · · ·+ γ(n−1)rt+n−1 + γn maxa
Q̂(st+n,a)
Mettendo tutto insieme:
Qλ(st ,at ) ≡ (1−λ)[Q(1)(st ,at ) + λQ(2)(st ,at ) + λ2Q(3)(st ,at ) + · · ·
]
Qλ(st ,at ) ≡ (1−λ)[Q(1)(st ,at ) + λQ(2)(st ,at ) + λ2Q(3)(st ,at ) + · · ·
]Espressione equivalente:
Qλ(st ,at ) = rt + γ[ (1− λ) maxa
Q̂(st ,at )
+λ Qλ(st+1,at+1)]
L’algoritmo TD(λ) usa la regola di cui sopraA volte converge più velocemente del Q learningConverge nell’apprendimento di V ∗ per ogni 0 ≤ λ ≤ 1[Dayan, 1992]TD-Gammon di Tesauro usa questo algoritmo
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Particolarità e sviluppi possibili
Cambiare la tabella Q̂ con una rete neurale o altri sistemidi generalizzazioneTrattare il caso di stati solo parzialmente osservabiliProgettare strategie ottime di esplorazioneEstendere al caso di azioni continue (stati continui)Imparare ad usare δ̂ : S × A→ SRelazione con la programmazione dinamica
Corso di Apprendimento Automatico Apprendimento per Rinforzo

Fonti
T. M. Mitchell: Machine Learning, McGraw Hill
Corso di Apprendimento Automatico Apprendimento per Rinforzo








![Apprendimento Automatico: Apprendimento per Rinforzo Roberto Navigli Apprendimento Automatico: Apprendimento per Rinforzo Cap. 13 [Mitchell] Cap. 21 [Russel](https://img.pdfslide.tips/doc/110x75/5542eb4f497959361e8beef6/apprendimento-automatico-apprendimento-per-rinforzo-roberto-navigli-apprendimento-automatico-apprendimento-per-rinforzo-cap-13-mitchell-cap-21-russel.jpg)




















