Embed Size (px)
Citation preview

Strona 1 z 51
Architektury i technologie
integracji danych
Materiały laboratoryjne
Edycja 2018/19
Wersja dla konfiguracji „Wirtualnego Laboratorium”
Bartosz Bębel
Politechnika Poznańska, Instytut Informatyki

Strona 2 z 51
Wprowadzenie do ć wićzenia
Niniejsze ćwiczenie ma za zadanie zademonstrować słuchaczowi szereg technik, umożliwiających
utworzenie środowiska integrującego dane zarówno heterogeniczne (różne formaty danych,
oprogramowanie różnych producentów) jak i dane homogeniczne. W ćwiczeniu zamodelujemy
działanie systemu informatycznego wyższej Wirtualnej Uczelni. Uczelnia składa się z następujących
jednostek organizacyjnych:
Dziekanat – przechowuje dane osobowe studentów oraz dane o ocenach i zaliczeniach,
Dział Stypendiów – przechowuje informacje o przyznanych studentom świadczeniach,
Dział Zarządzania Akademikami – przechowuje dane o akademikach i zakwaterowanych w
nich studentach,
Studium Języków Obcych – przechowuje dane o zdobytych przez studentów ocenach i
zaliczeniach z lektoratów,
Dział Kształcenia – jednostka zajmująca się sprawozdawczością.
Naszym celem będzie umożliwienie pracownikom Działu Kształcenia przygotowania szeregu
raportów, pokazujących różne aspekty działania Wirtualnej Uczelni.
Uwaga! Przy kopiowaniu umieszczonych w dokumencie zawartości plików konfiguracyjnych zwróć uwagę na możliwość wystąpienia niezgodności w kodowaniu znaków końca linii pomiędzy tekstem w dokumencie a tekstem w systemie Linux. Może to powodować błędną interpretację parametrów konfiguracyjnych. Dlatego w tekście skopiowanym z dokumentu do plików w systemie Linux usuń znaki końców linii i wstaw je ponownie.
Strona 3 z 51
Środowisko ćwiczeniowe
W tym ćwiczeniu będziesz pracował/a na komputerze symulującym działanie serwera
bazodanowego. Serwer będzie działał pod kontrolą systemu operacyjnego CentOS 6 (jest to jedna z
dystrybucji systemu Linux). System operacyjny został przygotowany do instalacji systemów
zarządzania bazami danych różnych producentów (m.in. Oracle, IBM). W środowisku sieciowym nasz
serwer będzie identyfikowany pod nazwą integracja_mw.
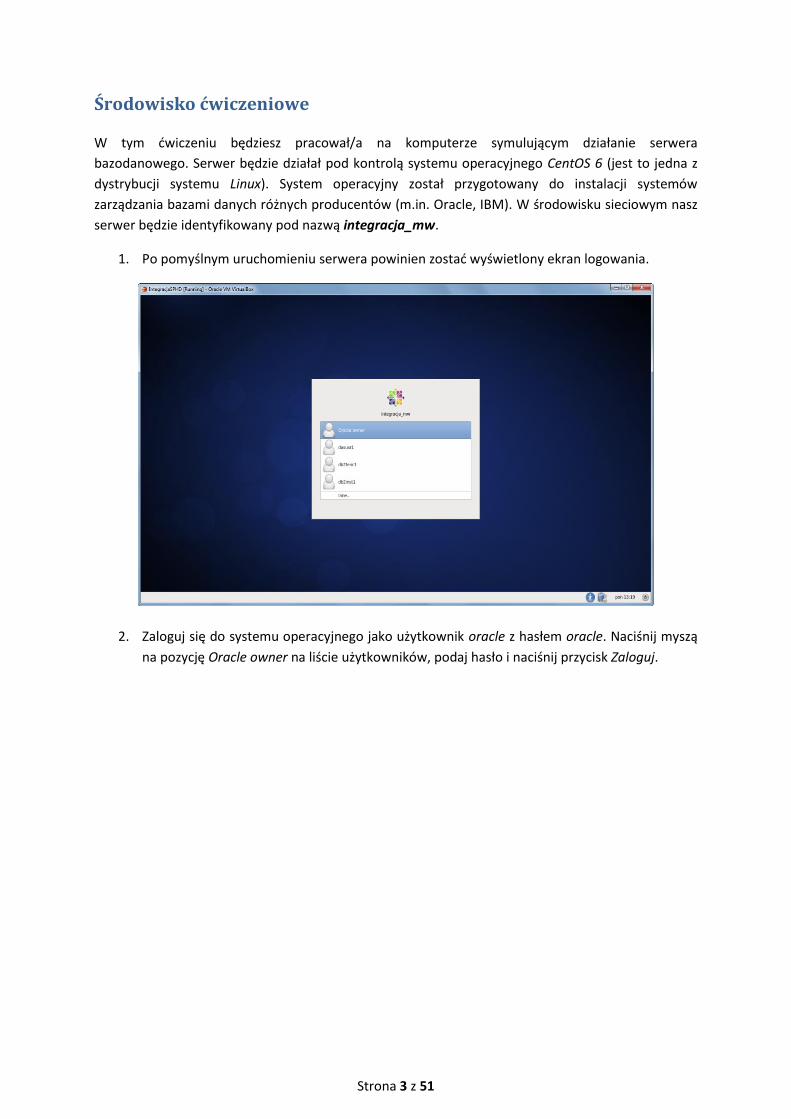
1. Po pomyślnym uruchomieniu serwera powinien zostać wyświetlony ekran logowania.
2. Zaloguj się do systemu operacyjnego jako użytkownik oracle z hasłem oracle. Naciśnij myszą
na pozycję Oracle owner na liście użytkowników, podaj hasło i naciśnij przycisk Zaloguj.
Strona 4 z 51
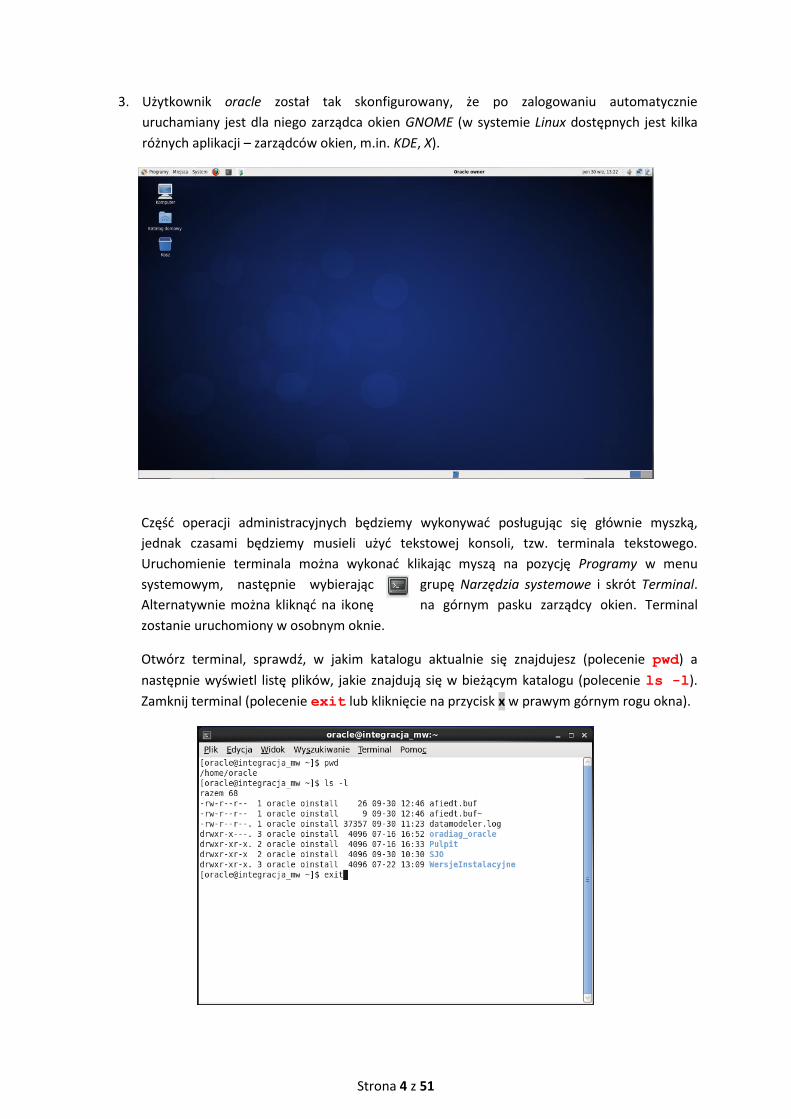
3. Użytkownik oracle został tak skonfigurowany, że po zalogowaniu automatycznie
uruchamiany jest dla niego zarządca okien GNOME (w systemie Linux dostępnych jest kilka
różnych aplikacji – zarządców okien, m.in. KDE, X).
Część operacji administracyjnych będziemy wykonywać posługując się głównie myszką,
jednak czasami będziemy musieli użyć tekstowej konsoli, tzw. terminala tekstowego.
Uruchomienie terminala można wykonać klikając myszą na pozycję Programy w menu
systemowym, następnie wybierając grupę Narzędzia systemowe i skrót Terminal.
Alternatywnie można kliknąć na ikonę na górnym pasku zarządcy okien. Terminal
zostanie uruchomiony w osobnym oknie.
Otwórz terminal, sprawdź, w jakim katalogu aktualnie się znajdujesz (polecenie pwd) a
następnie wyświetl listę plików, jakie znajdują się w bieżącym katalogu (polecenie ls -l).
Zamknij terminal (polecenie exit lub kliknięcie na przycisk x w prawym górnym rogu okna).

Strona 5 z 51
Ć wićzenie 1.
Celem niniejszego ćwiczenia jest utworzenie heterogenicznego środowiska baz danych.
Wykorzystamy do tego celu zainstalowane już na komputerze serwery baz danych IBM DB2 Oracle.
Serwer DB2 zawiera bazę danych FINANSE, z której korzysta Dział Stypendiów naszej Wirtualnej
Uczelni. W bazie FINANSE znajdują się dwie tabele:
RODZAJE_SWIADCZEN – przechowuje informacje o rodzajach przyznawanych studentom
świadczeń,
SWIADCZENIA – przechowuje informacje o świadczeniach przyznanych studentom.
Z kolei serwer bazy danych Oracle jest wykorzystywany przez Dział Kształcenia Wirtualnej Uczelni.
Naszym zadaniem będzie umożliwienie odczytu danych z serwera bazy danych DB2, wykorzystywanej
przez Dział Stypendiów, przez pracowników Działu Kształcenia, będących użytkownikami bazy danych
Oracle.
Wprowadzenie do środowiska DB2
Na początek spróbujesz przyłączyć się do bazy DB2, obejrzeć jej zawartość i wykonać kilka
przykładowych operacji.
1. Jeśli tego dotąd nie zrobiłaś/eś, uruchom serwer a następnie zaloguj się jako użytkownik
oracle.
2. Uruchom nowy terminal, następnie w terminalu przyłącz się jako użytkownik db2inst1 z
hasłem db2. Użyj polecenia su – db2inst1. Po pomyślnym przyłączeniu się jako
użytkownik db2inst1, nazwa tego użytkownika powinna zostać wyświetlona w znaku zachęty
(ang. prompt).
3. Aby móc przyłączyć się do bazy danych IBM DB2, konieczne jest uruchomienie Menedżera
Bazy Danych DB2. Uruchom menedżera bazy danych, wykonując polecenie db2start.
(możesz otrzymać komunikat: "Menedżer baz danych jest już aktywny", oznacza to, że
narzędzie już działa). Następnie uruchom procesor wiersza komend dla DB2 poleceniem db2.
Po uruchomieniu procesora wiersza znak zachęty powinien zmienić się na db2 =>.

Strona 6 z 51
4. Sprawdź, jakie bazy danych zostały zdefiniowane w DB2. W tym celu w procesorze komend
dla DB2 wykonaj polecenie list db directory.

Strona 7 z 51
5. Baza danych, w której znajdują się interesujące nas dane, nosi nazwę FINANSE. Przyłącz się
do bazy FINANSE wykonując polecenie connect to finanse.
db2 => connect to finanse
Informacje o połączeniach bazy danych
Serwer baz danych = DB2/LINUX 10.5.0
ID autoryzowanego użytkownika SQL = DB2INST1
Alias lokalnej bazy danych = FINANSE
6. Odczytaj nazwy tabel, jakie istnieją w bazie danych FINANSE. W tym celu wykonaj polecenie
list tables.
db2 => list tables
Tabela/Widok Schemat Typ Czas utworzenia
------------------------------- --------------- ----- -----------------------
---
RODZAJE_SWIADCZEN DB2INST1 T 2013-07-05-
12.37.19.598124
SWIADCZENIA DB2INST1 T 2013-07-04-
14.39.22.529645
Wybrano rekordów: 2.
7. Zapoznaj się ze strukturą tabel w bazie danych FINANSE. Polecenie wyświetlające schemat
tabeli to describe table <nazwa_tabeli>.
db2 => describe table rodzaje_swiadczen
Schemat Długość
Nazwa kolumny typu danych Nazwa typu danych kolumny
Skala NULL
------------------------------- --------- ------------------- ---------- ----
- ------
SYMBOL SYSIBM VARCHAR 2
0 Nie
NAZWA SYSIBM VARCHAR 50
0 Tak
Wybrano rekordów: 2.
db2 => describe table swiadczenia
...

Strona 8 z 51
8. Wyświetl zawartość tabel z bazy danych FINANSE, wykonując odpowiednie polecenia języka
SQL.
db2 => SELECT * FROM rodzaje_swiadczen
SYMBOL NAZWA
------ --------------------------------------------------
SN stypendium za wyniki w nauce
SS stypendium socjalne
SP stypendium sportowe
Wybrano rekordów: 3.
db2 => SELECT * FROM swiadczenia
...
9. Zakończ pracę z menedżerem bazy danych DB2 poleceniem quit. Zamknięcie menedżera
bazy danych DB2 automatycznie odłącza użytkownika od przyłączonej bazy danych (możesz
również ręcznie odłączyć się od bazy danych poleceniem disconnect <baza danych>,
np. disconnect finanse). Zamknij również sesję użytkownika db2inst1 (polecenie
exit) i terminal (kolejne polecenie exit).

Strona 9 z 51
Konfiguracja połączenia Oracle – DB2
Przystąpimy teraz do skonfigurowania połączenia między bazą danych Oracle a bazą IBM DB2.
Połączenie umożliwi nam wymianę danych między połączonymi bazami. Zasymuluje to sytuację
pobrania danych przez Dział Kształcenia (baza danych Oracle) z bazy Działu Stypendiów (baza danych
DB2). Połączenie będzie realizowane przez dedykowane oprogramowanie o nazwie brama
(ang. gateway).
1. Proces konfiguracji środowiska rozpoczniemy od zainstalowania oprogramowania Oracle
Database Gateway, pozwalającego na dostęp z SZBD Oracle do informacji w bazach danych
innych producentów. Wersja instalacyjna tego oprogramowania została już pobrana ze
strony producenta (adres: http://oracle.com) i umieszczona w odpowiednim katalogu
serwera.
2. Otwórz terminal jako użytkownik oracle. Następnie przejdź do katalogu
WersjeInstalacyjne/gateways (polecenie cd WersjeInstalacyjne/gateways) i
uruchom plik runInstaller (polecenie ./runInstaller).
Strona 10 z 51
3. Na ekranie powitalnym instalatora naciśnij przycisk Next.
4. Pozostaw niezmienione opcje określające nazwę i lokalizację katalogu domowego
oprogramowania Oracle. Naciśnij przycisk Next.
Strona 11 z 51
5. Instalator dokonuje teraz weryfikacji zgodności zainstalowanego już oprogramowania Oracle
z oprogramowaniem, które chcemy zainstalować. Nie powinno być żadnych niezgodności
(Status: Succeeded). Naciśnij przycisk Next.
6. Na ekranie wyboru oprogramowania zaznacz pozycję Oracle Database Gateway for DRDA
11.2.0.3.0 i naciśnij przycisk Next.

Strona 12 z 51
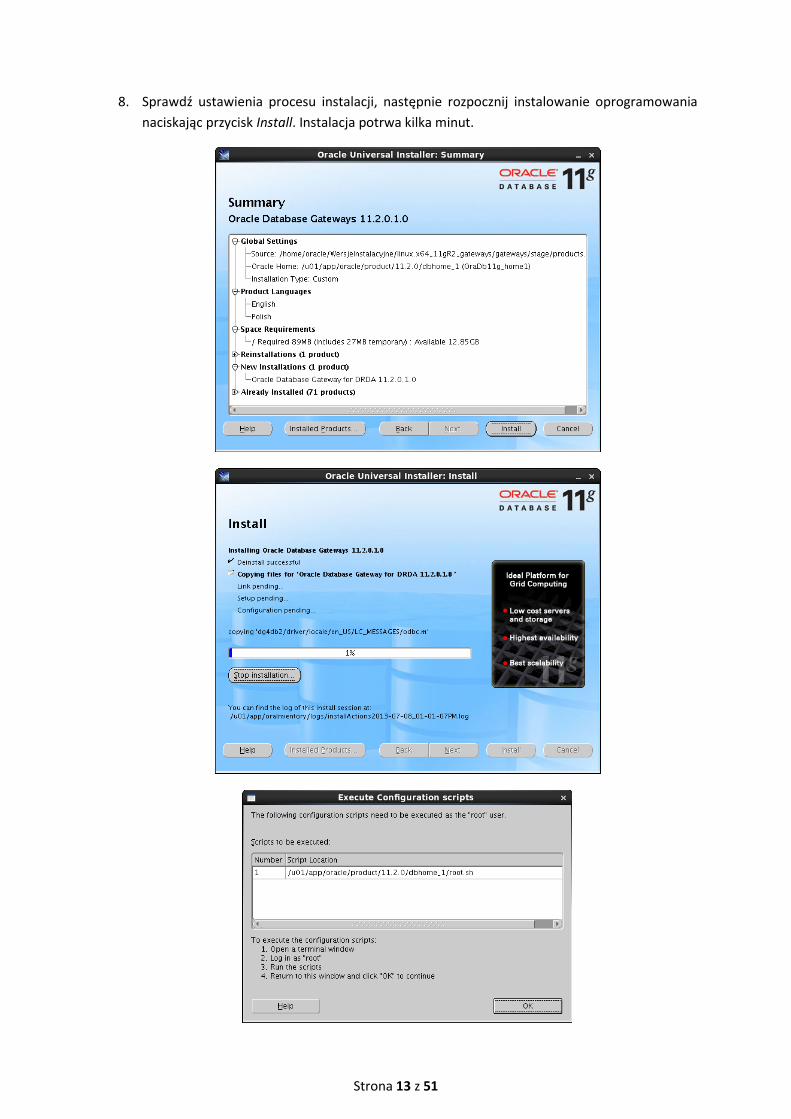
7. Zdefiniuj parametry serwera DB2, do którego dostęp będzie umożliwiało instalowane
oprogramowanie:
lokalizacja serwera DB2: integracja_mw (czyli nasz serwer)
port procesu nasłuchu serwera DB2: 50000
nazwa bazy danych DB2: FINANSE
typ serwera DB2: LUW
Następnie naciśnij przycisk Next.
Strona 13 z 51
8. Sprawdź ustawienia procesu instalacji, następnie rozpocznij instalowanie oprogramowania
naciskając przycisk Install. Instalacja potrwa kilka minut.
Strona 14 z 51
9. Teraz konieczne jest ręczne uruchomienie skryptu, przeprowadzającego dodatkowe
czynności konfiguracyjne instalowanego oprogramowania. W tym celu uruchom nowy
terminal i przyłącz się w nim jako użytkownik root z hasłem root. Użyj do tego celu polecenia
su – root. Następnie przejdź do katalogu /u01/app/oracle/product/11.2.0/dbhome_1/
(polecenie cd …) i uruchom plik root.sh. Przy odpowiedzi na wszystkie pytania, jakie zostaną
zadane podczas uruchomienia skryptu, udziel odpowiedzi domyślnych (naciśnij klawisz
Enter). Po zakończeniu działania skryptu zamknij terminal (dwukrotnie polecenie exit) a w
oknie dialogowym naciśnij przycisk OK.
10. Instalacja zostaje zakończona i oprogramowanie jest gotowe do działania. Naciśnij przycisk
Exit i potwierdź chęć zamknięcia instalatora przyciskiem Yes. Terminal pozostaw aktywny –
wykorzystamy go do skonfigurowania zainstalowanego właśnie oprogramowania Oracle
Gateway.

Strona 15 z 51
11. Przystąpimy teraz do skonfigurowania poszczególnych elementów serwera bazodanowego, z
którego korzysta Dział Kształcenia. Na początek uruchomimy serwer bazy danych Oracle oraz
proces nasłuchu Oracle Listener (odpowiada za obsługę żądań klientów przyłączających się do
bazy danych). W tym celu w terminalu, będąc zalogowanym jako użytkownik oracle:
aby uruchomić proces nasłuchu Oracle Listener wykonaj lsnrctl start
aby uruchomić serwer bazy danych w programie SQL*Plus uwierzytelnij się jako
użytkownik administracyjny SZBD Oracle poleceniem sqlplus "/as sysdba",
po pomyślnym uwierzytelnieniu wykonaj polecenie startup,
po uruchomieniu serwera zamknij program SQL*Plus poleceniem exit.

Strona 16 z 51
12. Pozostań w terminalu. Przejdź do katalogu
/u01/app/oracle/product/11.2.0/dbhome_1/dg4db2/admin/ (możesz posłużyć się zmienną
środowiskową ORACLE_HOME, w której zapisana jest ścieżka do katalogu oprogramowania
Oracle, wykonując polecenie cd $ORACLE_HOME/dg4db2/admin/).
13. Otwórz plik initdg4db2.ora. (możesz do tego celu użyć edytora systemowego gedit i
polecenia gedit initdg4db2.ora), przechowujący parametry konfiguracyjne bramy
(ang. gateway), umożliwiającej dostęp z serwera Oracle do serwera DB2. Sprawdź zawartość
pliku, zwróć uwagę na wartość parametru HS_FDS_CONNECT_INFO – zawiera on parametry
docelowego serwera DB2 oraz nazwę bazy danych, które zostały podane podczas instalacji
oprogramowania Oracle Gateway. Nie zmieniaj zawartości tego pliku! Zamknij edytor.
14. Aby móc wykonywać dostęp z serwera Oracle do serwera DB2, procesu nasłuchu Oracle
Listener musi zostać odpowiednio skonfigurowany. Przejdź do katalogu
$ORACLE_HOME/network/admin i otwórz do edycji plik listener.ora. Dodaj na końcu pliku
następujący wpis:
SID_LIST_LISTENER=
(SID_LIST=
(SID_DESC=
(SID_NAME=dg4db2)
(ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1)
(PROGRAM=dg4db2)
)
)
15. Zapisz plik i zamknij edytor. Następnie, aby wprowadzone w poprzednim punkcie zmiany
weszły w życie, dokonaj restartu procesu nasłuchu bazy danych Oracle wykonując polecenia
lsnrctl stop a następnie lsnrctl start. Poleceniem lsnrctl status
możesz wyświetlić stan procesu nasłuchu. Zwróć uwagę na komunikat Instancja "dg4db2",

Strona 17 z 51
stan …. Oznacza on, że proces nasłuchu został poprawnie skonfigurowany do dostępu do
zewnętrznej bazy danych przez bramę.
16. Kolejny krok to zdefiniowanie nazwy, pod którą użytkownik bazy danych Oracle będzie
odwoływał się do zdalnej bazy DB2. W tym celu otwórz do edycji plik tnsnames.ora (znajduje
się w tym samym katalogu co plik listener.ora) a następnie dodaj na końcu pliku wpis:
db2finanse =
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=integracja_mw)(PORT=1521))
(CONNECT_DATA=(SID=dg4db2))
(HS=OK)
)
Powyższy wpis określa, że adresując obiekty w bazie danych FINANSE serwera DB2
użytkownik serwera Oracle będzie posługiwał się nazwą db2finanse. Zapisz zmiany i zakończ
edycję pliku.

Strona 18 z 51
17. Możesz przetestować poprawność dokonanego w poprzednim punkcie wpisu, wykonując
polecenie tnsping db2finanse. Jeśli otrzymałaś/eś komunikat "OK", oznacza to sukces
w nawiązaniu kontaktu ze zdalną (w stosunku do serwera bazy Oracle) bazą danych DB2.
Następnie zamknij terminal.
Strona 19 z 51
Testowanie komunikacji Oracle – DB2
Przetestujemy teraz, czy wykonane dotąd czynności konfiguracyjne odniosły skutek – czy możemy z
Działu Stypendiów (baza DB2) pobrać dane do Działu Kształcenia (baza Oracle).
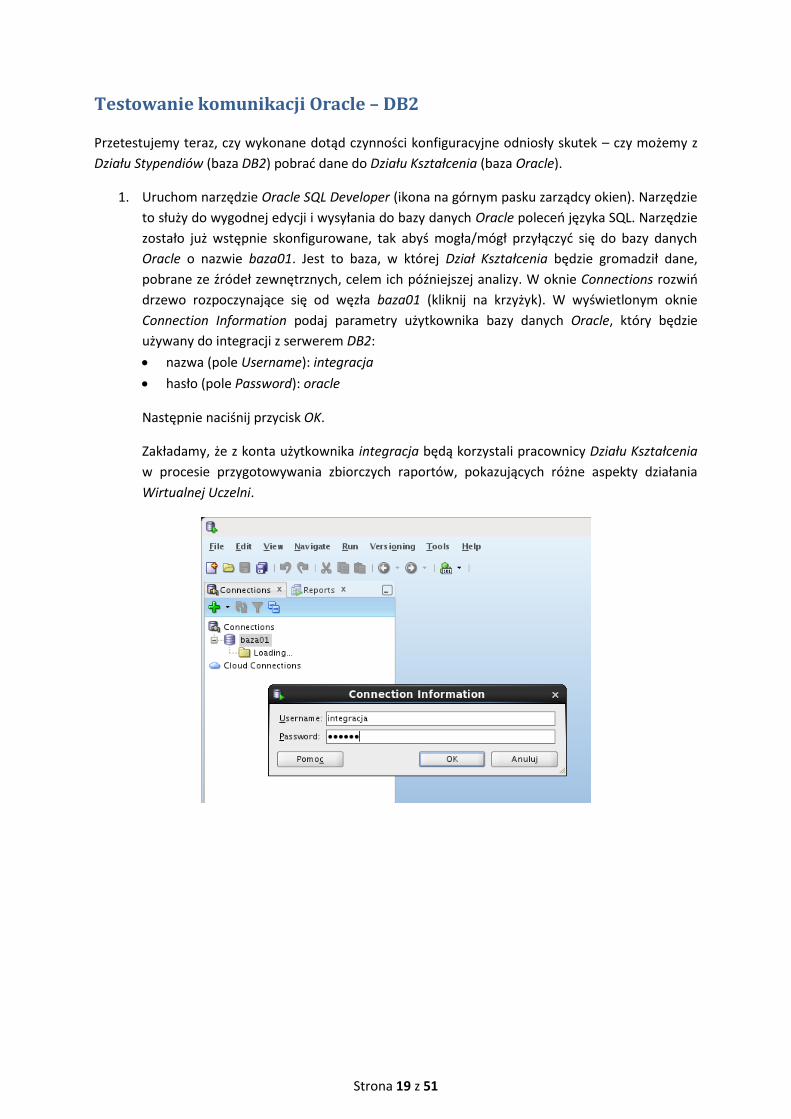
1. Uruchom narzędzie Oracle SQL Developer (ikona na górnym pasku zarządcy okien). Narzędzie
to służy do wygodnej edycji i wysyłania do bazy danych Oracle poleceń języka SQL. Narzędzie
zostało już wstępnie skonfigurowane, tak abyś mogła/mógł przyłączyć się do bazy danych
Oracle o nazwie baza01. Jest to baza, w której Dział Kształcenia będzie gromadził dane,
pobrane ze źródeł zewnętrznych, celem ich późniejszej analizy. W oknie Connections rozwiń
drzewo rozpoczynające się od węzła baza01 (kliknij na krzyżyk). W wyświetlonym oknie
Connection Information podaj parametry użytkownika bazy danych Oracle, który będzie
używany do integracji z serwerem DB2:
nazwa (pole Username): integracja
hasło (pole Password): oracle
Następnie naciśnij przycisk OK.
Zakładamy, że z konta użytkownika integracja będą korzystali pracownicy Działu Kształcenia
w procesie przygotowywania zbiorczych raportów, pokazujących różne aspekty działania
Wirtualnej Uczelni.

Strona 20 z 51
2. Użytkownik integracja na razie nie posiada żadnych obiektów, możesz to sprawdzić
poleceniem
SELECT * FROM user_objects; (wpisz polecenie do okna Worksheet, wykonaj je
naciskając klawisze Ctrl+Enter lub przycisk Run Statement w pasku narzędziowym).
3. Do komunikacji ze zdalnym serwerem (w naszym przypadku będzie to serwer bazy danych
DB2 Działu Stypendiów) konieczne jest utworzenie tzw. łącza bazodanowego. Do utworzenia
łącza wykorzystujemy następujące polecenie:
CREATE DATABASE LINK <nazwa łącza>
CONNECT TO <nazwa użytkownika w zdalnej bazie danych>
IDENTIFIED BY <hasło użytkownika w zdalnej bazie danych>
USING '<nazwa identyfikująca zdalną bazę danych>';
W naszym przypadku parametry łącza są następujące:
nazwa łącza: db2finanse,
nazwa użytkownika w bazie danych DB2: db2inst1,
hasło użytkownika w bazie danych DB2: db2,
wskazanie zdalnej bazy danych: db2finanse (przypomnijmy: ta nazwa została
zdefiniowana przez nas w pliku tnsnames.ora).
Łącze wykorzystuje do komunikacji z serwerem DB2 wcześniej zainstalowane przez nas
oprogramowanie Oracle Gateways.
4. Sprawdź działanie utworzonego łącza bazodanowego. Spróbuj odczytać dane z tabel
umieszczonych w bazie danych DB2 wykonując w Oracle SQL Developer następujące
polecenia:
SELECT * FROM rodzaje_swiadczen@db2finanse;
SELECT * FROM swiadczenia@db2finanse;
5. Utwórz w schemacie użytkownika integracja w bazie danych Oracle dwie perspektywy, które
ułatwią korzystanie z danych pobieranych z serwera DB2 (użytkownik bazy Oracle będzie
„widział” zdalne dane w taki sam sposób jak dane lokalne):
perspektywa RODZAJE_SWIADCZEN_V, która będzie udostępniać wszystkie dane z tabeli
RODZAJE_SWIADCZEN z bazy DB2,
perspektywa SWIADCZENIA_V, która będzie udostępniać połączone dane z tabel
RODZAJE_SWIADCZEN i SWIADCZENIA, umieszczonych w bazie danych DB2 (zbuduj
warunek połączeniowy wykorzystując atrybuty: rodzaj_swiadczenia z tabeli
SWIADCZENIA i symbol z tabeli RODZAJE_SWIADCZEN).
Następnie sprawdź działanie obu perspektyw.

Strona 21 z 51
CREATE VIEW rodzaje_swiadczen_v AS
SELECT * FROM rodzaje_swiadczen@db2finanse;
SELECT * FROM rodzaje_swiadczen_v;
SYMBOL NAZWA
------ ------------------------------
SN stypendium za wyniki w nauce
SS stypendium socjalne
SP stypendium sportowe
CREATE VIEW swiadczenia_v AS
…
SELECT student, semestr, nazwa, kwota, data_przyznania
FROM swiadczenia_v ORDER BY student;
STUDENT SEMESTR NAZWA KWOTA
DATA_PRZYZNANIA
------ -------------------- ---------------------------- ----- --------------
--
365 2001/02 zimowy stypendium za wyniki w nauce 750 01/10/01
365 2001/02 letni stypendium za wyniki w nauce 750 02/03/01
365 2000/01 zimowy stypendium za wyniki w nauce 750 00/10/01
365 2000/01 letni stypendium za wyniki w nauce 1000 01/03/01
366 2000/01 zimowy stypendium socjalne 196 00/10/01
366 2001/02 zimowy stypendium za wyniki w nauce 1000 01/10/01
366 2000/01 zimowy stypendium za wyniki w nauce 1000 00/10/01
366 2000/01 letni stypendium za wyniki w nauce 1000 01/03/01
366 2001/02 letni stypendium za wyniki w nauce 1000 02/03/01
367 2001/02 zimowy stypendium socjalne 153 01/10/01
...
6. Spróbuj za pomocą perspektywy RODZAJE_SWIADCZEN_V dodać nowy rodzaj świadczenia o
nazwie „stypendium ministerialne” i symbolu „SM”.
INSERT INTO rodzaje_swiadczen_v(symbol, nazwa)
VALUES ('SM', 'stypendium ministerialne');
SELECT * FROM rodzaje_swiadczen_v;
SYMBOL NAZWA
------ ----------------------------
SN stypendium za wyniki w nauce
SS stypendium socjalne
SP stypendium sportowe
SM stypendium ministerialne
7. Otwórz nowy terminal i przyłącz się jako użytkownik db2inst1. Następnie przyłącz się do bazy
danych FINANSE serwera DB2 i sprawdź zawartość tabeli RODZAJE_SWIADCZEN. Czy wynik
zapytania zawiera dodany w poprzednim punkcie (w bazie danych Oracle) rodzaj
świadczenia?
db2 => SELECT * FROM rodzaje_swiadczen
???
Wybrano rekordów: ???.

Strona 22 z 51
8. Wróć do Oracle SQL Developer i zatwierdź bieżącą transakcję poleceniem commit.
Ponownie sprawdź zawartość tabeli RODZAJE_SWIADCZEN w bazie FINANSE serwera DB2.
db2 => SELECT * FROM rodzaje_swiadczen
SYMBOL NAZWA
------ --------------------------------------------------
SN stypendium za wyniki w nauce
SS stypendium socjalne
SP stypendium sportowe
SM stypendium ministerialne
Wybrano rekordów: 4.
Punkty dodatkowe (9. – 14.) – do wykonania jeśli pozostał jeszcze czas.
9. Tym razem dodaj nowy rodzaj świadczenia o nazwie „dodatek do DS” i symbolu „DS” do
tabeli RODZAJE_SWIADCZEN w bazie FINANSE serwera DB2. Sprawdź w Oracle SQL Developer
jaka jest bieżąca zawartość perspektywy RODZAJE_SWIADCZEN_V.
db2 => INSERT INTO rodzaje_swiadczen VALUES('DS','dodatek do DS')
DB20000I Wykonanie komendy SQL zakończyło się pomyślnie.
Oracle SQL Developer:
SELECT * FROM rodzaje_swiadczen_v;
Widzisz różnicę w obsłudze transakcji pomiędzy Oracle i DB2?
10. Sprawdź tryb zatwierdzania transakcji w DB2. W tym celu wykonaj polecenie LIST
COMMAND OPTIONS.
db2 => LIST COMMAND OPTIONS
Ustawienia opcji procesora wiersza komend
Czas oczek. procesu od strony serwera (s) (DB2BQTIME) = 1
Liczba prób połączeń od strony serwera (DB2BQTRY) = 60
Czas oczekiwania w kolejce żądań (s) (DB2RQTIME) = 5
Czas oczekiwania w kol. wejściowej (s) (DB2IQTIME) = 5
Opcje komend (DB2OPTIONS) =
Opcja Opis Bieżące ustaw.
------ ---------------------------------------- ---------------
-a Wyświetlaj obszar komunikacyjny SQL OFF
-b Wykonaj automatyczne wiązanie ON
-c Zatwierdzaj automatycznie ON
-d Pobieraj i wyświetlaj deklaracje XML OFF
...
Zwróć uwagę na pozycję Zatwierdzaj automatycznie.

Strona 23 z 51
11. Wyłącz w DB2 automatyczne zatwierdzanie transakcji poleceniem UPDATE COMMAND
OPTIONS USING c OFF, sprawdź ponownie tryb zatwierdzania transakcji.
db2 => UPDATE COMMAND OPTIONS USING c OFF
DB20000I Wykonanie komendy UPDATE COMMAND OPTIONS zakończyło się
pomyślnie.
db2 => LIST COMMAND OPTIONS
Ustawienia opcji procesora wiersza komend
Czas oczek. procesu od strony serwera (s) (DB2BQTIME) = 1
Liczba prób połączeń od strony serwera (DB2BQTRY) = 60
Czas oczekiwania w kolejce żądań (s) (DB2RQTIME) = 5
Czas oczekiwania w kol. wejściowej (s) (DB2IQTIME) = 5
Opcje komend (DB2OPTIONS) =
Opcja Opis Bieżące ustaw.
------ ---------------------------------------- ---------------
-a Wyświetlaj obszar komunikacyjny SQL OFF
-b Wykonaj automatyczne wiązanie ON
-c Zatwierdzaj automatycznie OFF
-d Pobieraj i wyświetlaj deklaracje XML OFF
...
12. W DB2 usuń dodany uprzednio rodzaj świadczenia o symbolu „DS”. Sprawdź w Oracle SQL
Developer jaka jest bieżąca zawartość perspektywy RODZAJE_SWIADCZEN_V.
db2 => DELETE rodzaje_swiadczen WHERE symbol = 'DS'
DB20000I Wykonanie komendy SQL zakończyło się pomyślnie.
db2 => SELECT * FROM rodzaje_swiadczen
SYMBOL NAZWA
------ --------------------------------------------------
SN stypendium za wyniki w nauce
SS stypendium socjalne
SP stypendium sportowe
SM stypendium ministerialne
Wybrano rekordów: 4.
Oracle SQL Developer:
SELECT * FROM rodzaje_swiadczen_v;
13. Zatwierdź w DB2 bieżącą transakcję poleceniem commit. W Oracle SQL Developer sprawdź
ponownie zawartość perspektywy RODZAJE_SWIADCZEN_V.
14. Zadanie samodzielne. Dodaj do perspektywy RODZAJE_SWIADCZEN_V nowy rodzaj
świadczenia, pozostaw aktywną (niezatwierdzoną) transakcję. Następnie dodaj w DB2 do
tabeli RODZAJE_SWIADCZEN ten sam rodzaj świadczenia. Zatwierdź transakcję w Oracle SQL
Developer. Co obserwujesz w DB2? Wykonaj analogiczną operację, tym razem jako pierwszy
dodaj nowy rodzaj świadczenia do DB2.
Koniec punktów dodatkowych

Strona 24 z 51
15. Po zakończeniu ćwiczenia odłącz się od bazy danych DB2 i zamknij terminal. Następnie
zamknij narzędzie Oracle SQL Developer.

Strona 25 z 51
Ć wićzenie 2.
W bieżącym ćwiczeniu spróbujemy połączyć system zarządzania bazą danych Oracle ze źródłem
danych za pomocą interfejsu ODBC (ang. Open Database Connectivity). Interfejs ODBC, z racji
zaimplementowania dla niego wielu sterowników do różnorakich typów źródeł danych, jest często
wykorzystywany przy dostępie do danych w niewspieranych już, spadkowych formatach. W naszym
środowisku integracji wykorzystamy ten interfejs do dostępu do danych udostępnianych przez
serwer bazy danych MySQL. Przechowywane tam są dane systemu, wykorzystywanego przez Dział
Zarządzania Akademikami naszej Wirtualnej Uczelni. Baza danych nosi nazwę AKADEMIKI, zawiera
dwie tabele:
DOMY_STUDENCKIE – przechowuje informacje o akademikach, w których mieszkają studenci
wirtualnej uczelni,
PRZYZNANE_MIEJSCA – zawiera dane o miejscach w akademikach, przyznanych studentom w
poszczególnych semestrach akademickich.
Naszym zadaniem będzie umożliwienie dostępu z serwera bazy danych Oracle (Dział Kształcenia) do
danych z bazy AKADEMIKI serwera MySQL.
Konfiguracja źródła danych ODBC
W bieżącym punkcie skonfigurujemy nasz system, aby móc wykonywać dostęp do danych w bazie
AKADEMIKI serwera MySQL przy pomocy interfejsu ODBC.
1. Uruchom terminal jako użytkownik oracle. W terminalu wykonaj polecenie odbcinst -j,
które pokaże aktualny stan interfejsu ODBC w systemie.

Strona 26 z 51
Znaczenie poszczególnych pozycji jest następujące:
DRIVERS – lokalizacja pliku przechowującego definicje zainstalowanych w systemie
sterowników dla różnych typów źródeł danych,
SYSTEM DATA SOURCES – lokalizacja pliku przechowującego definicje systemowych
źródeł danych (źródeł dostępnych dla wszystkich użytkowników systemu),
FILE DATA SOURCES – lokalizacja pliku przechowującego definicje źródeł danych
dostępnych dla wszystkich użytkowników systemu,
USER DATA SOURCES – lokalizacja pliku przechowującego definicje prywatnych źródeł
danych (źródeł dostępnych tylko dla konkretnego użytkownika, w tym wypadku
użytkownika oracle),
pozostałe wpisy określają dodatkowe parametry ODBC.
2. Sprawdź, jakie sterowniki i źródła danych są aktualnie zdefiniowane w systemie (obejrzyj
zawartość plików, wskazywanych przez wynik działania polecenia odbcinst).
3. Zainstalujemy teraz sterownik ODBC dla bazy danych MySQL. W tym celu w terminalu
przyłącz się jako użytkownik root z hasłem root (polecenie su – root). Następnie przejdź
do katalogu /home/oracle/WersjeInstalacyjne. Umieszczono tam plik mysql-connector-odbc-
5.1.12-1.el6.i686.rpm z oprogramowaniem instalującym sterownik ODBC umożliwiający
dostęp do serwera MySQL. Proces instalacji uruchamia polecenie rpm –ihv mysql-
connector-odbc-5.1.12-1.el6.i686.rpm.
Po chwili proces instalacji powinien ulec zakończeniu (jednym z efektów instalacji jest
umieszczenie w katalogu /usr/lib pliku sterownika o nazwie libmyodbc5.so, sprawdź, czy taki
plik został utworzony). Zakończ sesję użytkownika root (polecenie exit), pozostań
zalogowanym w terminalu jako użytkownik oracle.

Strona 27 z 51
4. Zdefiniujemy teraz źródło danych dla użytkownika oracle, pozwalające na dostęp do danych
serwera MySQL. W tym celu otwórz plik .odbc.ini z katalogu /home/oracle (lub utwórz nowy
jeśli taki plik jeszcze nie istnieje) poleceniem gedit /home/oracle/.odbc.ini (zwróć
uwagę na kropkę przed odbc). Parametry nowego źródła danych ODBC będą następujące:
nazwa źródła: mysql
lokalizacja pliku sterownika (Driver): /usr/lib/libmyodbc5.so
opis (Description): Serwer MySQL
lokalizacja serwera (Server): integracja_mw
nazwa bazy danych (Database): Akademiki
lokalizacja gniazda dostępu do serwera (Socket): /var/lib/mysql/mysql.sock
Zawartość pliku .odbc.ini przedstawiono poniżej.
[mysql]
Driver=/usr/lib/libmyodbc5.so
Description=Serwer MySQL
Server=integracja_mw
Database=akademiki
Socket=/var/lib/mysql/mysql.sock
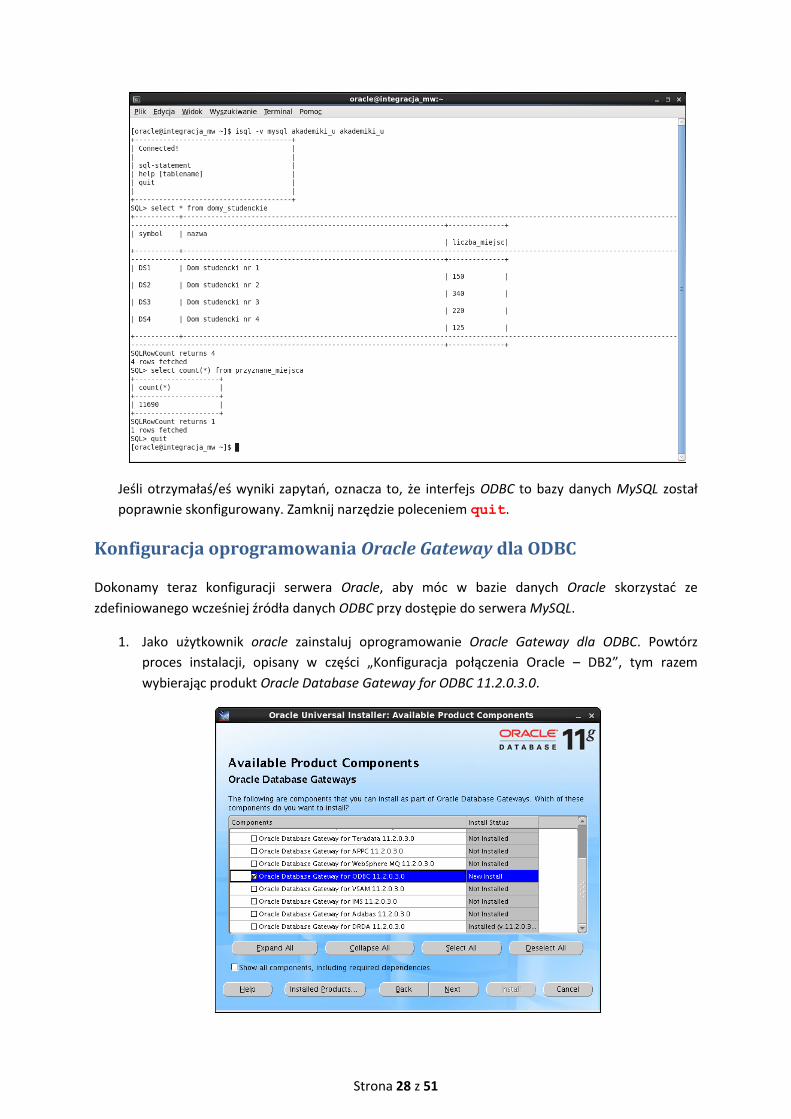
5. Przetestuj działanie definicji źródła mysql. W tym celu uruchom program isql, przy pomocy
którego wykonasz zapytanie do plikowego źródła danych (program jest instalowany razem z
zarządcą interfejsu ODBC). Polecenie uruchamiające program to isql –v <nazwa
źrodła> <nazwa użytkownika bd> <hasło>, gdzie: <nazwa źródła> – nazwa
zdefiniowana w pliku .odbc.ini (w naszym przypadku: mysql), <nazwa użytkownika bd> to
nazwa użytkownika w bazie danych, a <hasło> to hasło użytkownika w bazie danych. W bazie
AKADEMIKI serwera MySQL istnieje użytkownik akademiki_u z hasłem akademiki_u, mający
dostęp do danych. Użyj tego użytkownika przy podłączeniu się do uprzednio zdefiniowane
źródła danych. Następnie wykonaj zapytania do dwóch tabel z bazy danych AKADEMIKI
(DOMY_STUDENCKIE i PRZYZNANE_MIEJSCA). Zamknij narzędzie poleceniem quit.
Strona 28 z 51
Jeśli otrzymałaś/eś wyniki zapytań, oznacza to, że interfejs ODBC to bazy danych MySQL został
poprawnie skonfigurowany. Zamknij narzędzie poleceniem quit.
Konfiguracja oprogramowania Oracle Gateway dla ODBC
Dokonamy teraz konfiguracji serwera Oracle, aby móc w bazie danych Oracle skorzystać ze
zdefiniowanego wcześniej źródła danych ODBC przy dostępie do serwera MySQL.
1. Jako użytkownik oracle zainstaluj oprogramowanie Oracle Gateway dla ODBC. Powtórz
proces instalacji, opisany w części „Konfiguracja połączenia Oracle – DB2”, tym razem
wybierając produkt Oracle Database Gateway for ODBC 11.2.0.3.0.

Strona 29 z 51
2. W terminalu, gdzie jesteś zalogowana/y jako użytkownik oracle, przejdź do katalogu
$ORACLE_HOME/hs/admin. Jest to katalog, w którym znajdują się pliki konfiguracyjne Oracle
Gateway for ODBC. Następnie otwórz do edycji nowy plik o nazwie initmysqlodbc.ora (użyj
polecenia gedit initmysqlodbc.ora). Plik ten posłuży nam do skonfigurowania
połączenia bazy danych Oracle z bazą MySQL za pomocą interfejsu ODBC.
3. W pliku initmysqlodbc.ora wpisz następujące pozycje:
HS_FDS_CONNECT_INFO = mysql
HS_FDS_TRACE_LEVEL = off
HS_FDS_SHAREABLE_NAME = /usr/lib/libmyodbc5.so
HS_LANGUAGE=polish_poland.ee8iso8859P2
set ODBCINI=/home/oracle/.odbc.ini
set
LD_LIBRARY_PATH=/usr/lib:/u01/app/oracle/product/11.2.0/dbhome_1/lib
Znaczenie poszczególnych pozycji jest następujące:
HS_FDS_CONNECT_INFO – nazwa źródła danych ODBC,
HS_FDS_TRACE_LEVEL – poziom śledzenia informacji o połączeniu ze źródłem,
HS_FDS_SHAREABLE_NAME – lokalizacja sterownika ODBC dla źródła,
HS_LANGUAGE – standard kodowania w źródle,
set ODBCINI – wskazanie lokalizacji pliku z definicją źródła,
set LD_LIBRARY_PATH – ustawienie ścieżki przeszukiwania bibliotek.
Zapisz plik i zamknij edytor.

Strona 30 z 51
4. Dokonamy teraz rekonfiguracji procesu nasłuchu Oracle Listener, aby współpracował ze
źródłem danych ODBC za pośrednictwem Oracle Gateways. Przejdź do katalogu
$ORACLE_HOME/network/admin i otwórz do edycji plik listener.ora. W sekcji
SID_LIST_LISTENER dodaj kolejną podsekcję SID_DESC (istniejąca sekcja SID_DESC o
nazwie dg4db2 odpowiada za komunikację z DB2 – nie zmieniaj jej!). Zawartość pliku po
zmianach przedstawiono poniżej (kolorem czerwonym zaznaczono nową sekcję).
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = integracja_mw)(PORT = 1521))
)
)
SID_LIST_LISTENER=
(SID_LIST=
(SID_DESC=
(SID_NAME=dg4db2)
(ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1)
(PROGRAM=dg4db2)
)
(SID_DESC=
(SID_NAME=mysqlodbc)
(ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1)
(ENVS="LD_LIBRARY_PATH=/usr/lib:/u01/app/oracle/product/11.2.0/dbhome_1/lib")
(PROGRAM=dg4odbc)
)
)
ADR_BASE_LISTENER = /u01/app/oracle
5. Dokonaj restartu procesu nasłuchu Oracle Listener poleceniami lsnrctl stop
i lsnrctl start , następnie sprawdź status usług, jakie aktualnie Oracle Listener
zapewnia (polecenie lsnrctl status). Zwróć uwagę na komunikat Instancja
"mysqlodbc" ….
6. Teraz zdefiniujemy nazwę, pod którą użytkownik systemu Oracle będzie odwoływał się do
źródła danych w postaci serwera MySQL. W tym celu otwórz do edycji plik tnsnames.ora (z
tego samego katalogu co plik listener.ora) a następnie dodaj do pliku wpis:
mysqlakademiki =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = tcp)(HOST = integracja_mw)(PORT = 1521))
(CONNECT_DATA = (SID = mysqlodbc))
(HS = OK)
)
Powyższy wpis określa, że adresując obiekty w serwerze MySQL użytkownik serwera Oracle
będzie posługiwał się nazwą mysqlakademiki. Zapisz zmiany i zakończ edycję pliku. Sprawdź
poprawność dokonanego wpisu poleceniem tnsping mysqlakademiki.
7. Uruchom narzędzie Oracle SQL Developer, następnie przyłącz się do bazy baza01 jako
użytkownik integracja z hasłem oracle.

Strona 31 z 51
8. Podobnie jak w ćwiczeniu z DB2, do komunikacji ze zdalnym serwerem przy pomocy ODBC
konieczne jest utworzenie łącza bazodanowego. Parametry łącza są następujące:
nazwa łącza: mysqlakademiki,
nazwa użytkownika w bazie danych MySQL: „akademiki_u” (nazwa użytkownika w
cudzysłowie!),
hasło użytkownika w bazie danych DB2: „akademiki_u” (hasło w cudzysłowie!),
wskazanie zdalnej bazy danych: mysqlakademiki.
Utwórz to łącze.
9. Sprawdź działanie utworzonego łącza bazodanowego. Spróbuj odczytać dane z tabel
umieszczonych w bazie danych MySQL wykonując w Oracle SQL Developer następujące
polecenia:
SELECT * FROM "domy_studenckie"@mysqlakademiki;
SELECT * FROM "przyznane_miejsca"@mysqlakademiki;
Zwróć uwagę na nazwy tabel w cudzysłowie. Również przy odwołaniu w zapytaniu do
poszczególnych kolumn tabel z bazy AKADEMIKI ich nazwy również należy otoczyć
cudzysłowem, np.:
SELECT "nazwa" FROM "domy_studenckie"@mysqlakademiki;
10. Utwórz dwie perspektywy o nazwach DOMY_STUDENCKIE_V i PRZYZNANE_MIEJSCA_V, które
ułatwią nam późniejsze operacje na danych z serwera MySQL.
CREATE VIEW domy_studenckie_v AS
SELECT "symbol" AS SYMBOL, "nazwa" AS NAZWA, "liczba_miejsc" AS LICZBA_MIEJSC
FROM"domy_studenckie"@mysqlakademiki;
CREATE VIEW przyznane_miejsca_v AS
…
Perspektywy powinny umożliwić odwołanie do poszczególnych kolumn tabel bez
konieczności ujmowania ich w cudzysłów, np.:
SELECT nazwa FROM domy_studenckie_v;
SELECT student, rok_akademicki FROM przyznane_miejsca_v;

Strona 32 z 51
Punkty dodatkowe (11. – 13.) – do wykonania jeśli pozostał jeszcze czas.
11. Spróbuj w Oracle SQL Developer za pomocą perspektywy DOMY_STUDENCKIE_V dodać nowy
dom studencki o symbolu DS5, nazwie Dom studencki nr 5 i liczbie miejsc równej 200.
Następnie sprawdź zawartość tabeli DOMY_STUDENCKIE przy pomocy narzędzia isql.
Zatwierdź transakcję (polecenie commit) w Oracle SQL Developer. Wykonaj ponownie
zapytanie w isql.
12. Wykonaj w isql polecenie (delete from), które usunie z tabeli DOMY_STUDENCKIE
uprzednio dodany rekord. Zaraz po wykonaniu operacji odczytaj w Oracle SQL Developer
zawartość perspektywy DOMY_STUDENCKIE_V.
13. Wykonaj w isql dwa polecenia, definiujące w tabeli DOMY_STUDENCKIE dwa nowe
akademiki, DS6 i DS7, jako jedną transakcję. Początek transakcji oznacz poleceniem begin,
następnie wykonaj dwa polecenia insert. Sprawdź w Oracle SQL Developer zawartość
perspektywy DOMY_STUDENCKIE_V. Czy widzisz dodane akademiki? Zakończ w isql bieżącą
transakcję poleceniem commit. Ponownie odczytaj zawartość perspektywy
DOMY_STUDENCKIE_V, następnie usuń przy jej pomocy akademiki o symbolach DS6 i DS7.
Koniec punktów dodatkowych
14. Wyjdź z programu isql, zamknij terminal i Oracle SQL Developer.

Strona 33 z 51
Ć wićzenie 3.
Kolejne ćwiczenie pokaże możliwość dostępu z systemu zarządzania bazą danych Oracle do danych,
przechowywanych w plikach płaskich. Studium Języków Obcych naszej Wirtualnej Uczelni dostarcza
do dziekanatu oceny, jakie studenci zdobyli w poszczególnych semestrach akademickich z lektoratów
języków obcych, w postaci tekstowego pliku płaskiego o następującej strukturze:
identyfikator studenta, który zdobył ocenę – liczba,
określenie semestru akademickiego, w którym została wystawiona ocena – ciąg znaków w
postaci „<numer roku> <skrót rodzaju semestru>”, np. „2009/10 z” dla semestru zimowego w
roku 2009/10,
numer semestru studiów studenta – liczba,
nazwa przedmiotu – ciąg znaków,
zdobyta ocena – ciąg znaków (ocena wyrażona słownie lub liczbowo).
Przykładowa część zawartości pliku została przedstawiona poniżej:
2888;2004/05 l;6;Język angielski;dobry
2888;2004/05 l;6;Język niemiecki;2
2686;2004/05 l;6;Język angielski;bardzo dobry
2686;2004/05 l;6;J. niemiecki;4
3004;2004/05 l;6;J. angielski;dostateczny
3004;2004/05 l;6;J. niemiecki;5
3083;2004/05 l;6;Język angielski;bardzo dobry
2937;2005/06 l;8;Język angielski;niedostateczny
3087;2004/05 l;6;Język angielski;bardzo dobry
3087;2004/05 l;6;J. niemiecki;5
Uwaga! Nazwy przedmiotów mogą być w postaci zarówno „Język angielski” jak i „J. angielski”,
natomiast oceny mogą być podane zarówno w formie liczbowej jak i opisowej.
Plik z danymi nosi nazwę oceny_lektorat.txt, został umieszczony na serwerze w katalogu
/home/oracle/SJO i zawiera dokładnie 14 688 ocen z lektoratów z języków: angielskiego,
niemieckiego i francuskiego. Chcemy, aby pracownicy Działu Kształcenia mieli dostęp do danych z
tego pliku za pośrednictwem bazy danych Oracle.
1. Otwórz terminal jako użytkownik oracle, przejdź do wskazanego katalogu i obejrzyj zawartość
pliku z ocenami.
2. Uruchom narzędzie Oracle SQL Developer, przyłącz się do bazy baza01 jako użytkownik
integracja z hasłem oracle.
3. Dostęp do katalogów w systemie plików serwera bazodanowego Oracle jest realizowany za
pośrednictwem obiektu o nazwie katalog (ang. directory). Polecenie tworzenia katalogu
przedstawiono poniżej:
CREATE DIRECTORY <nazwa obiektu> AS 'ścieżka do katalogu w systemie plików
serwera';

Strona 34 z 51
4. Sprawdź w perspektywie systemowej ALL_DIRECTORIES, czy w Twoim schemacie istnieje
obiekt katalog (ang. directory) o nazwie SJO. Obiekt powinien wskazywać na katalog
/home/oracle/SJO w systemie plików serwera bazy danych. Jeśli obiekt katalog nie istnieje,
utwórz go.
SELECT * FROM all_directories WHERE directory_name = 'SJO';
nie wybrano żadnych wierszy
CREATE DIRECTORY ...
Katalog został utworzony.
SELECT * FROM all_directories WHERE directory_name = 'SJO';
OWNER DIRECTORY_NAME DIRECTORY_PATH
---------- ------------------- ------------ -------------------------
SYS SJO /home/oracle/SJO
5. W dalszej części ćwiczenia utworzymy tabelę zewnętrzną, przy pomocy której będziemy
wykonywać dostęp do danych z pliku oceny_lektorat.txt, przy użyciu katalogu SJO.
Źródłem danych dla tabeli zewnętrznej jest plik, zlokalizowany w systemie plików serwera
bazy danych. Użycie tabeli zewnętrznej jest identyczne jak zwykłej tabeli (zapytania SQL,
możliwość użycia w programach PL/SQL, itd.). W momencie wykonywania zapytania do tabeli
zewnętrznej wywoływane jest odpowiednie oprogramowanie: Oracle SQL*Loader lub Oracle
Data Pump (zależnie od typu tabeli), które realizuje operacje na przyłączonym do tabeli pliku.
Operacje, jakie można wykonać na tabeli zewnętrznej, zależą od jej typu oraz typu pliku:
plik tekstowy – możliwy tylko odczyt (typ tabeli ORACLE_LOADER),
plik binarny w formacie backup-u SZBD Oracle – możliwe jednokrotne przesłanie danych
z bazy danych do pliku (przy tworzeniu tabeli), potem tylko odczyt (typ tabeli
ORACLE_DATAPUMP).
Polecenie tworzące tabelę zewnętrzną przedstawiono poniżej:
CREATE TABLE <nazwa_tabeli> (<definicja atrybutów tabeli>)
ORGANIZATION EXTERNAL // tabela będzie pobierać dane z pliku
(type [oracle_loader | oracle_datapump] // typ oprogram. wczytującego dane
default directory <obiekt DIRECTORY> // katalog z plikiem danych
access parameters
(records delimited by newline // rekordy w osobnych liniach pliku
badfile <[obiekt DIRECTORY>:]'<nazwa pliku błędów>' // plik - log błędów
logfile <[obiektu DIRECTORY>:]'<nazwa pliku logu>' // plik - log operacji
skip <liczba> // ile początkowych linii pliku pominąć przy wczytywaniu
fields terminated by '<znak oddzielający wartości w rekordzie>'
fields (<definicja pól>) // opcjonalna definicja pól pliku
missing field values are null) // czy pola bez wartości pozostaną puste
location ([obiekt DIRECTORY:]'<nazwa pliku danych>'))
reject limit [0 | <wartość> | UNLIMITED]; // ile dopuszczalnych błędów przy
wczytaniu pliku

Strona 35 z 51
6. Sprawdź, czy w schemacie użytkownika integracja znajdują się wcześniej utworzone tabele
zewnętrzne. W tym celu wykonaj zapytanie do perspektywy systemowej
USER_EXTERNAL_TABLES.
SELECT table_name, type_name, default_directory_name, reject_limit
FROM user_external_tables;
7. Zaprojektuj tabele zewnętrzną o nazwie OCENY_LEKTORAT_ZEW i następującym schemacie:
student_id – liczba całkowita o precyzji 6 (typ NUMBER(6)),
rok_semestr_akademicki – ciąg znaków o zmiennej długości, maks. 10 znaków (typ
VARCHAR2(10)),
semestr_studiow – liczba całkowita o precyzji 2 (typ NUMBER(2)),
przedmiot – ciąg znaków o zmiennej długości, maks. 60 znaków, (typ VARCHAR2(60))
ocena – ciąg znaków o zmiennej długości, maks. 20 znaków (typ VARCHAR2(20)).
Tabela będzie wypełniana danymi z pliku oceny_lektorat.txt z katalogu SJO. Jako
oprogramowanie wczytujące dane wybierz Oracle SQL*Loader. Dodatkowe pliki,
wykorzystywane podczas importu danych z pliku oceny_lektorat.txt, to:
plik z rekordami błędnymi – oceny_lektorat.txt.bad,
plik logu – oceny_lektorat.txt.log,
Oba pliki mają zostać umieszczone w katalogu SJO. Pobranie danych z pliku ma zostać
przerwane jeśli jakikolwiek rekord w pliku będzie błędny (reject limit 0).
CREATE TABLE oceny_lektorat_zew (...)
ORGANIZATION EXTERNAL(...);
8. Sprawdź działanie tabeli zewnętrznej. W tym celu wykonaj zapytanie, które odczyta wszystkie
rekordy z tabeli OCENY_LEKTORAT_ZEW. Następnie sprawdź plik logu operacji
(oceny_lektorat.txt.log w katalogu /home/oracle/SJO) – użyj edytora gedit do otwarcia pliku
(wykonaj w terminalu polecenie gedit
/home/oracle/SJO/oceny_lektorat.txt.log).
SELECT * FROM oceny_lektorat_zew;
9. Dodaj do pliku oceny_lektorat.txt nową linię, zawierającą poniższy tekst (użyj w terminalu
edytora gedit):
3347;2005/06 z;8i;J. niemiecki;dostateczny
Ponownie wykonaj zapytanie do tabeli OCENY_LEKTORAT_ZEW, wyszukując dane dodanej
oceny.
SELECT * FROM oceny_lektorat_zew WHERE student_id = 3347;
Co zaobserwowałaś/eś?
10. Odczytaj ponownie zawartość pliku logu a następnie zawartość pliku z błędnymi rekordami.

Strona 36 z 51
11. Zmień definicję tabeli OCENY_LEKTORAT_ZEW tak, aby zapytanie do niej dawało wynik
również wtedy, gdy w pliku znajdzie się co najwyżej 10 błędnych rekordów (podpowiedź:
najpierw usuń definicję tabeli poleceniem drop table <nazwa tabeli>, następnie
ponownie utwórz tabelę zewnętrzną z opcją REJECT LIMIT ustawioną na wartość 10).
Sprawdź działanie tabeli.
12. Część danych, które udostępnia tabela zewnętrzna OCENY_LEKTORAT_ZEW z pliku
oceny_lektorat.txt, nie zachowuje spójnego formatu. Chodzi o kolumny przedmiot oraz
ocena. Wykonaj poniższe zapytania, aby znaleźć wszystkie wartości tych kolumn.
SELECT distinct przedmiot
FROM oceny_lektorat_zew;
PRZEDMIOT
-----------------------
J. francuski
J. angielski
Język angielski
Język francuski
Język niemiecki
J. niemiecki
SELECT distinct ocena
FROM oceny_lektorat_zew;
OCENA
--------------------
niedostateczny
dobry
bardzo dobry
3
dostateczny
5
2
4
Chcemy doprowadzić dane do spójnego formatu: w nazwach przedmiotów skrót "J."
zastąpimy słowem "Język", natomiast oceny przetransformujemy do postaci liczbowej.
Dodatkowo atrybut rok_semestr_akademicki, definiujący semestr przyznania oceny (np.
"2005/06 z") zastąpimy parą atrybutów, jeden dla roku akademickiego ("2005/06"), drugi dla
rodzaju semestru ("zimowy"). Przy realizacji transformacji posłużymy się mechanizmem
funkcji tablicowych.
13. Funkcja tablicowa to składowana w bazie danych funkcja PL/SQL, zwracająca jako wynik
zbiór rekordów. Może być traktowana jak tabela – umieszczana w zapytaniu w klauzuli
FROM. Funkcja tablicowa służy najczęściej do realizacji złożonych transformacji danych.
Pierwszym krokiem przy definicji funkcji tablicowej będzie zdefiniowanie trwałego typu
rekordowego, określającego strukturę rekordu ze zbioru rekordów, jakie będzie zwracać
nasza funkcja tablicowa. Składnię polecenia tworzącego typ rekordowy przedstawiono
poniżej.
CREATE [OR REPLACE] TYPE <nazwa> AS OBJECT(<definicje atrybutów>);

Strona 37 z 51
W naszym przypadku rekord, zwracany przez funkcję tablicową, będzie miał następując
strukturę:
student_id, typ number(6),
rok_akademicki, typ varchar2(7),
rodzaj_semestru, typ varchar2(6),
semestr_studiow, typ number(2),
przedmiot, typ varchar2(60),
ocena, typ number(3,2).
Utwórz typ obiektowy o nazwie tOcena i strukturze jak powyżej. Strukturę utworzonego typu
możesz podejrzeć poleceniem describe <nazwa typu>.
CREATE TYPE tOcena AS OBJECT(…);
describe tOcena;
14. W drugim kroku musimy zdefiniować typ tablicowy, który będzie korzystał ze zdefiniowanego
w kroku poprzednim typu rekordowego. Składnia definicji typu tablicowego jest następująca:
CREATE [OR REPLACE] TYPE <nazwa> AS TABLE OF <typ bazowy>;
Typ tablicowy będzie nosił nazwę tTablicaOcen, polecenie go definiujące umieszczono
poniżej.
CREATE TYPE tTablicaOcen AS TABLE OF tOcena;
15. Przystąpimy teraz do definicji funkcji tablicowej. Schemat polecenia tworzącego funkcję
tablicową przedstawiono poniżej.
CREATE [OR REPLACE] FUNCTION <nazwa> RETURN <typ_tablicowy> PIPELINED IS
...
BEGIN
...
PIPE ROW(<rekord>);
...
END;
Polecenie PIPE ROW w ciele funkcji przesyła do tablicy, zwracanej przez funkcję, jeden
rekord.
16. Sygnatura naszej funkcji powinna być następująca:
CREATE FUNCTION OCENY_LEKTORAT_ZEW_TAB RETURN tTablicaOcen PIPELINED IS
Zadeklarujemy kursor, który będzie udostępniał wszystkie rekordy tabeli
OCENY_LEKTORAT_ZEW.
cursor cOceny is SELECT * FROM oceny_lektorat_zew ORDER BY student_id;

Strona 38 z 51
Następnie zaprojektuj pętlę FOR z kursorem, w której przeglądniesz wszystkie rekordy
pobrane przez kursor i skonstruujesz rekord o strukturze zdefiniowanej przez typ tOcena,
który następnie zwrócisz poleceniem PIPE ROW. Pamiętaj o ujednoliceniu formatu nazw
przedmiotów i ocen. Podpowiedź: konstrukcja rekordu to wywołanie konstruktora typu
tOcena z parametrami będącymi wartościami dla poszczególnych pól rekordu, np.:
PIPE ROW(tOcena(1234, '2005/06', 'zimowy', 5, 'Język angielski', 3.0));
Kod funkcji, realizujący powyższe zadania, może wyglądać np. tak:
CREATE FUNCTION oceny_lektorat_zew_tab
RETURN tTablicaOcen pipelined IS
CURSOR cOceny IS
SELECT * FROM oceny_lektorat_zew ORDER BY student_id;
vNazwaPrzedmiotu varchar2(60);
vOcena number(3,2);
vRok varchar2(7);
vRodzajSemestru varchar2(6);
BEGIN
FOR O IN cOceny LOOP
-- Konwersja nazwy przedmiotu
IF substr(O.przedmiot, 1, 2) = 'J.' THEN
vNazwaPrzedmiotu := replace(O.przedmiot, 'J.', 'Język');
ELSE
vNazwaPrzedmiotu := O.przedmiot;
END IF;
-- Konwersja oceny
CASE O.ocena
WHEN 'niedostateczny' THEN vOcena := 2;
WHEN 'dostateczny' THEN vOcena := 3;
WHEN 'dobry' THEN vOcena := 4;
WHEN 'bardzo dobry' THEN vOcena := 5;
ELSE vOcena := to_number(O.ocena);
END CASE;
-- Transformacja nazwy semestru
vRok := substr(O.rok_semestr_akademicki,1,7);
CASE substr(O.rok_semestr_akademicki,9,1)
WHEN 'z' THEN vRodzajSemestru := 'zimowy';
WHEN 'l' THEN vRodzajSemestru := 'letni';
END CASE;
-- Przesłanie rekordu do tablicy
PIPE ROW(tOcena(O.student_id, vRok, vRodzajSemestru,
O.semestr_studiow, vNazwaPrzedmiotu, vOcena));
END LOOP;
return;
END oceny_lektorat_zew_tab;

Strona 39 z 51
17. Wykorzystanie funkcji tablicowej w zapytaniach przedstawia poniższy schemat:
SELECT <lista kolumn> FROM TABLE(funkcja_tablicowa);
18. Wywołaj utworzoną przez siebie funkcję tablicową i sprawdź poprawność jej działania.
Zauważ, że dane w pliku tekstowym a także dane w tabeli zewnętrznej
OCENY_LEKTORAT_ZEW nie uległy zmianie.
19. Zamknij narzędzie Oracle SQL Developer.

Strona 40 z 51
Ć wićzenie 4.
W bieżącym ćwiczeniu spróbujemy zintegrować nasz Dział Kształcenia z Dziekanatem Wirtualnej
Uczelni. Naszym celem jest pobranie z Dziekanatu danych osobowych studentów oraz danych o
uzyskanych przez studentów ocenach. Dziekanat korzysta z tego samego systemu zarządzania bazą
danych co Dział Kształcenia, a więc Oracle 11g. Serwer dziekanatowy jest zainstalowany na innym
komputerze. Przeprowadzimy proces konfiguracji homogenicznego środowiska tzw. asynchronicznej
replikacji danych.
1. W pierwszym kroku dokonamy konfiguracji oprogramowania Oracle Net Services w celu
umożliwienia podłączenia z naszego lokalnego serwera bazodanowego danych Oracle do
zdalnego serwera bazodanowego Oracle o nazwie dblab01. Konfiguracja sprowadza się do
dodania odpowiedniego wpisu (patrz poniżej) w pliku
$ORACLE_HOME/network/admin/tnsnames.ora. (otwórz terminal jako użytkownik oracle,
przejdź do katalogu $ORACLE_HOME/network/admin, uruchom edycję pliku poleceniem
gedit tnsnames.ora).
DBLAB01 =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = admlab2-main.cs.put.poznan.pl)(PORT
= 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = dblab01.cs.put.poznan.pl)
)
)
Serwer działa na komputerze o adresie admlab2-main.cs.put.poznan.pl, proces nasłuchujący
żądań klientów zajmuje port 1521. Nazwa usługi bazodanowej na serwerze to
dblab01.cs.put.poznan.pl. Pod tą samą nazwą będziemy się odwoływać do tego serwera z
naszego komputera. Do konfiguracji Oracle Net Services możesz również użyć programu
netca.
2. Sprawdź poprawność dokonanej konfiguracji, wykonując w terminalu polecenie tnsping
dblab01.
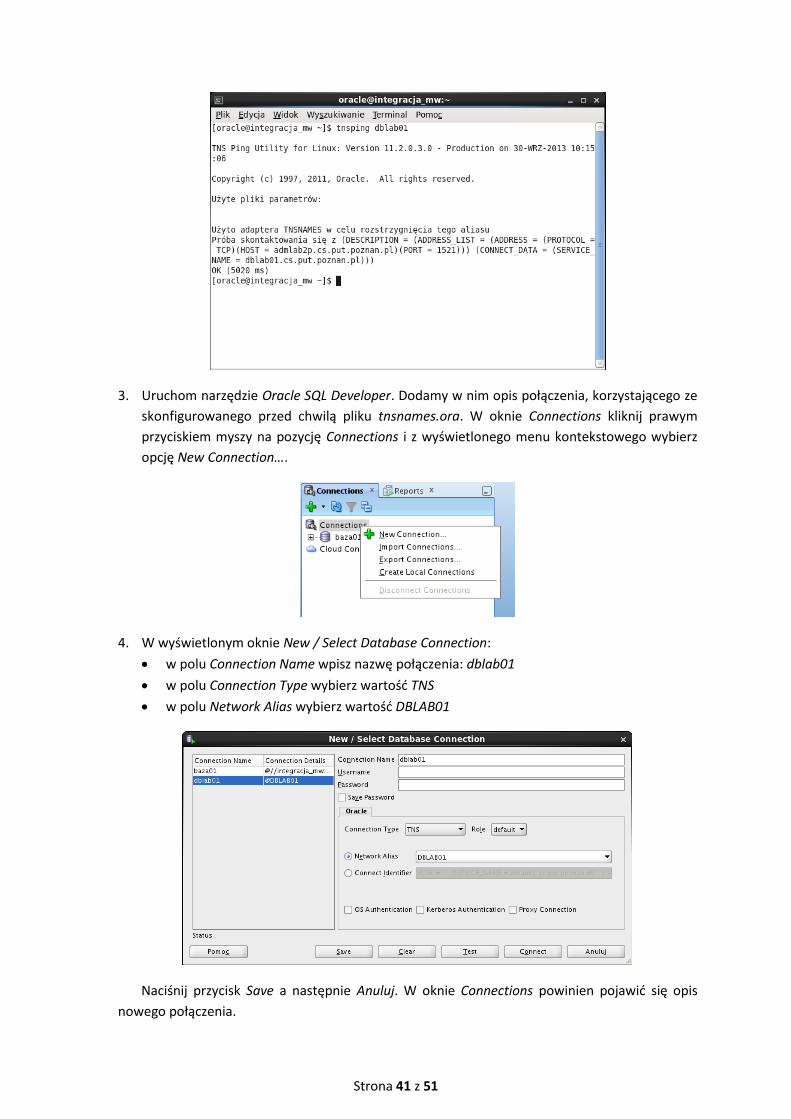
Strona 41 z 51
3. Uruchom narzędzie Oracle SQL Developer. Dodamy w nim opis połączenia, korzystającego ze
skonfigurowanego przed chwilą pliku tnsnames.ora. W oknie Connections kliknij prawym
przyciskiem myszy na pozycję Connections i z wyświetlonego menu kontekstowego wybierz
opcję New Connection….
4. W wyświetlonym oknie New / Select Database Connection:
w polu Connection Name wpisz nazwę połączenia: dblab01
w polu Connection Type wybierz wartość TNS
w polu Network Alias wybierz wartość DBLAB01
Naciśnij przycisk Save a następnie Anuluj. W oknie Connections powinien pojawić się opis
nowego połączenia.

Strona 42 z 51
5. W bazie dblab01 masz konto bazodanowe o nazwie utworzonej z dodania do Twojego
nazwiska przedrostka "sphd_" oraz dołączenia przyrostka w postaci pierwszej litery imienia
(np. sphd_kowalski_j dla Jana Kowalskiego) i haśle będącym Twoim imieniem (zarówno
nazwa jak i hasło składają się z małych liter bez polskich znaków diakrytycznych). Spróbuj
przyłączyć się do swojego konta na serwerze dblab01. Sprawdź, jakie tabele masz utworzone
w swoim schemacie.
SELECT table_name FROM user_tables ORDER BY table_name;
TABLE_NAME
------------------------------
KATEGORIE_STUDIOW
KIERUNKI_STUDIOW
MIASTA
OCENY
PRZEDMIOTY
RODZAJE_OCEN
RODZAJE_STUDIOW
RODZAJE_ZAJEC
RODZAJE_ZALICZEN
SEMESTRY_AKADEMICKIE
STUDENCI
Schemat zawiera główną część danych naszej wirtualnej uczelni, mianowicie dane osobowe
studentów wraz z przebiegiem studiów oraz uzyskanymi ocenami i zaliczeniami. Będziemy
chcieli pobrać te dane do bazy integrującej informacje różnych jednostek naszej wirtualnej
uczelni (czyli do danych użytkownika integracja w lokalnej bazie baza01).
6. Przyłącz się w narzędziu Oracle SQL Developer do użytkownika integracja w bazie baza01.
Połączenie z Twoim użytkownikiem w bazie dblab01 pozostaw aktywne (w tekście ćwiczenia
do nazwy Twojego użytkownika będziemy się odwoływać przez nazwę sphd_uzytkownik).
Przełączanie się między aktywnymi połączeniami jest możliwe za pośrednictwem zakładek.
7. Zdefiniujemy teraz łącze bazodanowe, pozwalające na dostęp z bazy danych baza01 do bazy
danych dblab01. Łącze o nazwie dblabdaneosobowe będzie własnością użytkownika
integracja i będzie wskazywać na schemat użytkownika sphd_uzytkownik w bazie dblab01.
Wykonaj odpowiednie polecenie w zakładce baza01, następnie przetestuj poprawność
działania łącza.
CREATE DATABASE LINK dblabdaneosobowe ...
SELECT count(*) FROM studenci@dblabdaneosobowe;
COUNT(*)
----------
12615

Strona 43 z 51
8. Do tej pory aby ukryć lokalizację zdalnego obiektu (czyli obiektu, do którego dostęp
umożliwia łącze bazodanowe) w poleceniu SQL, używaliśmy perspektywy. Innym
mechanizmem, często używanym w tym celu, jest synonim. Synonim jest alternatywną
nazwą dla obiektu. Schemat polecenia tworzącego synonim przedstawiono poniżej:
CREATE SYNONYM <synonim> FOR <nazwa obiektu oryginalnego>;
9. Utwórz synonim studencidblab, który ukryje nazwę studenci@dblabdaneosobowe. Następnie
użyj synonimu w zapytaniu.
CREATE SYNONYM ...
select count(*) from studencidblab;
10. Dane, które zintegrowaliśmy w poprzednich ćwiczeniach, nie były kopiowane do serwera
baza01 z miejsc ich oryginalnych lokalizacji, a jedynie do źródeł, gdzie dane są
przechowywane, były wysyłane odpowiednie polecenia SQL. Taki sposób integracji nie
zabezpiecza środowiska przed ewentualnymi awariami sieci komunikacyjnej, powodującej
niedostępność danych ze zdalnych źródeł. Tym razem chcemy, aby dane z serwera dblab01
były dostępne dla użytkownika integracja w baza01 nawet w sytuacji niedostępności serwera
dblab01. Zbudujemy środowisko replikacji danych.
Replikacja to proces kopiowania danych z jednego miejsca (źródła danych) do miejsca
docelowego. W relacyjnych bazach danych źródłem danych będzie tabela, nazywana tabelą
źródłową, natomiast obiekt docelowy, do którego trafią skopiowane dane, nosi nazwę
repliki. Kopiowanie danych powtarzane jest okresowo w celu uaktualnienia repliki danymi,
które zostały dodane/zmodyfikowane w tabeli źródłowej. Proces ten jest nazywany
odświeżaniem repliki.
11. Replika w bazach danych Oracle implementowana jest za pomocą tzw. perspektywy
materializowanej. Jest to tabela, składująca w lokalnej bazie danych dane, pobrane z tabel
źródłowych zdalnej bazy danych, do której dołączamy się przy pomocy łącznika
bazodanowego. Perspektywa materializowana definiowana jest przez zapytanie, w którym
umieszczone są odwołania do tabel źródłowych ze zdalnej bazy danych. Jedną z
charakterystycznych cech perspektywy materializowanej, odróżniających ją od zwykłej
perspektywy, jest to, że perspektywa materializowana posiada swoje własne dane oraz że te
dane mogą być odświeżane. Fakt, że perspektywa materializowana posiada własne dane,
powoduje, że połączenie ze zdalną bazą danych jest konieczne tylko w momencie
wypełnienia repliki danymi oraz podczas procesu odświeżania. Użytkownicy korzystają z
danych zdalnych wykonując dostęp do ich lokalnej kopii, a więc do repliki. Z kolei proces
odświeżania perspektywy materializowanej polega na uaktualnieniu jej zawartości danymi,
które uległy zmianie (np. zostały zmodyfikowane) w tabelach źródłowych repliki. Proces
odświeżania jest charakteryzowany dwoma podstawowymi parametrami: (1) w jaki sposób
odświeżyć replikę oraz (2) kiedy zrealizować proces odświeżania.

Strona 44 z 51
Jeśli chodzi o sposób odświeżenia, to perspektywa materializowana może być odświeżana:
całkowicie – bieżąca zawartość perspektywy zostaje usunięta, perspektywa zostaje
ponownie wypełniona danymi z tabel źródłowych,
przyrostowo – do bieżącej zawartości perspektywy materializowanej zostają
dodane/usunięte/ zmodyfikowane dane, które uległy zmianom w tabelach źródłowych
od momentu ostatniej realizacji procesu odświeżenia.
Z kolei z uwagi na moment odświeżenia perspektywy materializowane możemy podzielić na:
odświeżane okresowo – proces odświeżania jest realizowane co zadany okres czasu (np.
co 10 minut),
odświeżane na żądanie – odświeżanie jest uruchamiane ręcznie przez użytkownika,
nigdy nie odświeżane – perspektywa zostaje wypełniona danymi tylko raz, nie jest potem
nigdy odświeżana.
Składnię polecenia tworzącego perspektywę materializowaną przedstawiono poniżej.
CREATE MATERIALIZED VIEW <nazwa perspektywy>
<moment pierwszego wypełnienia danymi>
{never refresh | <sposób odświeżania> <moment odświeżania>}
WITH <sposób identyfikacji rekordów>
AS <zapytanie do tabel źródłowych>;
gdzie:
moment pierwszego wypełnienia danymi:
build immediate – wypełnij perspektywę danymi zaraz po utworzeniu,
build deferred – wypełnij perspektywę danymi przy pierwszym odświeżaniu,
never refresh – perspektywa nigdy nie będzie odświeżana,
sposób odświeżania:
refresh complete – odświeżanie całkowite,
refresh fast – odświeżanie przyrostowe,
refresh force – system sam wybierze rodzaj odświeżania,
moment odświeżania:
on demand – odświeżania na żądanie użytkownika,
start with – wyrażenie definiujące moment pierwszej realizacji procesu
odświeżenia, np.:
start with sysdate – pierwsze odświeżenie zaraz po utworzeniu repliki,
start with sysdate+1/24 – pierwsze odświeżenie po 1 godzinie od utworzenia
repliki,
next – wyrażenie definiujące moment kolejnej realizacji procesu odświeżenia, np.:
next sysdate+1/1440 – odświeżanie będzie realizowane co 1 minutę (1440 =
24h * 60 minut),
next sysdate+1/4320 – odświeżanie będzie realizowane co 20 sekund (4320 =
24h * 60 minut * 3),
sposób identyfikacji rekordów repliki:

Strona 45 z 51
with rowid – powiązanie między rekordami perspektywy i tabeli źródłowej
realizowane jest na podstawie adresu rekordu,
with primary key – powiązanie między rekordami perspektywy i tabeli źródłowej
realizowane jest na podstawie wartości klucza głównego tabeli źródłowej.
Informacje słownikowe dotyczące perspektyw materializowanych:
USER_MVIEWS – lista perspektyw materializowanych, będących własnością użytkownika:
NAME – nazwa perspektywy,
MASTER – nazwa tabeli źródłowej,
MASTER_LINK – nazwa łącznika bazodanowego do bazy danych tabeli źródłowej,
REFRESH_METHOD – sposób identyfikacji rekordów,
TYPE – sposób odświeżenia (FAST, FORCE, COMPLETE, NEVER),
NEXT – wyrażenie definiujące moment następnego odświeżenia,
START WITH – wyrażenie definiujące moment pierwszego wypełnienia,
QUERY – tekst zapytania.
USER_MVIEW_REFRESH_TIMES –informacje o momencie ostatniej realizacji odświeżenia
perspektywy:
NAME – nazwa perspektywy,
LAST_REFRESH – moment realizacji ostatniego procesu odświeżania.
Perspektywa odświeżana całkowicie
12. Jako użytkownik integracja utwórz, korzystając z Oracle SQL Developer, perspektywę
materializowaną STUDENCI_MV, która będzie pobierać dane z relacji STUDENCI z bazy
dblab01. Parametry perspektywy są następujące:
nazwa perspektywy: STUDENCI_MV,
pierwsze wypełnienie danymi po 1 minucie od utworzenia,
replika ma być odświeżana całkowicie,
odświeżanie ma być realizowane co 2 minuty,
sposób identyfikacji rekordów repliki: za pomocą klucza głównego,
zakres danych, pobieranych z tabeli źródłowej STUDENCI: wszystkie dane.
CREATE MATERIALIZED VIEW studenci_mv ...;
Zmaterializowana perspektywa została utworzona.
Następnie sprawdź, czy utworzona perspektywa zawiera dane – wykonaj do niej przykładowe
zapytanie.
SELECT * FROM studenci_mv
WHERE kierunek = 'NZK3' AND plec = 'kobieta' ORDER BY student_id;
nie wybrano żadnych wierszy
Po ok. 2 minutach ponownie sprawdź, czy perspektywa zawiera dane.
SELECT * FROM studenci_mv
WHERE kierunek = 'NZK3' AND plec = 'kobieta' ORDER BY student_id;

Strona 46 z 51
STUDENT_ID KIERUNEK MIASTO_ID DATA_UR PLEC
---------- -------- ---------- -------- ---------
771 NZK3 2320 82/09/13 kobieta
1745 NZK3 1583 78/02/07 kobieta
1949 NZK3 1593 71/06/15 kobieta
9424 NZK3 1703 84/06/12 kobieta
10665 NZK3 1816 86/05/24 kobieta
11010 NZK3 2309 86/10/21 kobieta
11036 NZK3 1593 83/01/01 kobieta
13058 NZK3 1569 82/05/09 kobieta
16380 NZK3 2382 88/01/30 kobieta
9 wierszy zostało wybranych.
13. W Oracle SQL Developer w zakładce użytkownika sphd_uzytkownik (baza dblab01) dodaj do
tabeli STUDENCI w bazie dblab01 nowy rekord opisujący studentkę o identyfikatorze 99999
na kierunku NZK3 z miasta o identyfikatorze 5377, urodzonej 1 stycznia 1994 r.. Pamiętaj o
zakończeniu transakcji poleceniem commit.
INSERT INTO studenci VALUES(99999, 'NZK3', 5377, DATE '1994-01-01',
'kobieta');
commit;
14. Przejdź do zakładki użytkownika integracja i ponownie wykonaj ostatnie zapytanie z punktu
12. Odczekaj ok. 2 minut i ponów zapytanie – czy w replice pojawił się rekord dodany w bazie
dblab01?
STUDENT_ID KIERUNEK MIASTO_ID DATA_UR PLEC
---------- -------- ---------- -------- ---------
771 NZK3 2320 82/09/13 kobieta
1745ZK NZK3 1583 78/02/07 kobieta
1949 NZK3 1593 71/06/15 kobieta
9424 NZK3 1703 84/06/12 kobieta
10665 NZK3 1816 86/05/24 kobieta
11010 NZK3 2309 86/10/21 kobieta
11036 NZK3 1593 83/01/01 kobieta
13058 NZK3 1569 82/05/09 kobieta
16380 NZK3 2382 88/01/30 kobieta
99999 NZK3 5377 94/01/01 kobieta
10 wierszy zostało wybranych.
15. Sprawdź w perspektywie systemowej USER_MVIEW_REFRESH_TIMES, kiedy została
odświeżona replika STUDENCI_MV. W tym celu wykonaj poniższe zapytanie:
SELECT to_char(last_refresh,'yyyy.mm.dd hh24:mi:ss') AS last_refresh
FROM user_mview_refresh_times WHERE name = 'STUDENCI_MV';

Strona 47 z 51
Informacje o momencie ostatniego odświeżenia oraz jego typie (całkowite czy przyrostowe)
możesz również uzyskać z perspektywy systemowej USER_MVIEWS:
SELECT last_refresh_type, to_char(last_refresh_date,'yyyy.mm.dd hh24:mi:ss')
AS last_refr_date
FROM user_mviews WHERE mview_name = 'STUDENCI_MV';
Perspektywa odświeżana przyrostowo
16. Utworzymy teraz perspektywę materializowana odświeżaną przyrostowo. Aby taki sposób
odświeżania mógł być realizowany, muszą być spełnione dwa warunki:
perspektywa materializowana musi być tzw. perspektywą prostą – zapytanie ją
definiujące nie może zawierać m.in. połączeń, grupowania, funkcji agregujących i
analitycznych, klauzuli DISTINCT,
dla tabeli źródłowej w zdalnej bazie danych musi zostać utworzony dziennik,
przechowujący informacje o zmianach, jakie zostały zrealizowane na danych tabeli – jest
to tzw. dziennik perspektywy materializowanej.
Składnię polecenia tworzącego dziennik przedstawiono poniżej.
CREATE MATERIALIZED VIEW LOG ON <nazwa tabeli źródłowej> WITH <sposób
identyfikacji rekordów>;
Dziennik implementowany jest w postaci tabeli o nazwie MLOG$_<nazwa tabeli źródłowej>.
Dziennik tworzymy oczywiście tam, gdzie zlokalizowana jest tabela źródłowa perspektywy, a
więc w bazie zdalnej!
Tym razem utworzymy replikę drugiej tabeli zdalnej, umieszczonej w schemacie użytkownika
sphd_uzytkownik w bazie dblab01. Tabela nosi nazwę OCENY i zawiera informacje o ocenach,
jakie uzyskali ci studenci. Replika ta będzie odświeżana w sposób przyrostowy.
17. Przejdź do zakładki dblab01 (użytkownik sphd_uzytkownik). Następnie utwórz dziennik
perspektywy materializowanej dla tabeli OCENY. Dziennik będzie wspierał identyfikację
rekordów przez adres rekordu (identyfikacja przez klucz główny nie jest możliwa – tabela nie
posiada klucza głównego).
CREATE MATERIALIZED VIEW LOG ...;
Sprawdź, jaka tabela implementuje utworzony dziennik. W tym celu wykonaj poniższe
zapytanie do słownika danych bazy dblab01. Zapisz uzyskaną nazwę (będzie potrzebna w
późniejszej części ćwiczenia).
SELECT log_table FROM user_mview_logs WHERE master = 'OCENY';
Obejrzyj strukturę dziennika (polecenie describe <nazwa>), możesz również odczytać
jego zawartość– jednak na razie powinien być pusty.
SELECT * FROM ...;
18. Przejdź do zakładki baza01 (użytkownik integracja). Następnie utwórz replikę tabeli OCENY z
bazy dblab01 o następujących parametrach:
a. nazwa repliki: OCENY_MV,

Strona 48 z 51
b. pierwsze wypełnienie natychmiast po utworzeniu,
c. odświeżanie przyrostowe,
d. odświeżanie okresowe z częstotliwością co 1 minutę,
e. sposób identyfikacji rekordów: adres rekordu,
f. zakres danych, pobieranych z tabeli źródłowej OCENY: wszystkie dane.
Po utworzeniu spróbuj odczytać dane z repliki.
SELECT count(*) FROM oceny_mv;
19. Jako użytkownik sphd_uzytkownik (zakładka dblab01) wykonaj kilka operacji modyfikacji
danych tabeli OCENY.
INSERT INTO oceny(student_id, rok_akademicki, rodzaj_semestru, przedmiot_id,
ocena)
VALUES(99999,'2006/07','letni',1701,5);
UPDATE oceny SET ocena = 4
WHERE student_id = 1618 AND przedmiot_id = 24 AND rodzaj_zajec = 'W';
DELETE oceny WHERE student_id = 1618 AND przedmiot_id = 24 AND rodzaj_zajec =
'C';
Po modyfikacjach zatwierdź transakcję poleceniem commit.
20. Spróbuj odczytać zawartość dziennika dla tabeli OCENY (nazwa dziennika: MLOG$_OCENY).
M_ROW$$ SNAPTIME DMLTYPE$$ OLD_NEW$$ CHANGE_VECTOR$$ XIDSS
------------------ -------- --------- --------- --------------- ----------------
AAAWD6AAEAABANTAAB 00/01/01 I N FEFF 1688927169729111
AAAWD6AAEAAAuWbAAc 00/01/01 U U 0001 1688927169729111
AAAWD6AAEAAAuWbAAe 00/01/01 D O 0000 1688927169729111
Zwróć uwagę na kolumnę DMLTYPE$$ – zawiera ona informacje o rodzaju operacji, która
zmodyfikowała dane tabeli, dla której utworzono dziennik. Pierwsza kolumna, M_ROW$$
zawiera adres zmodyfikowanego rekordu.
21. Poczekaj, aż nastąpi odświeżenie perspektywy OCENY_MV. Sprawdź, czy zmiany zostały
zreplikowane, następnie ponownie odczytaj zawartość dziennika dla tabeli OCENY.
22. Replika może zostać odświeżona poza ustalonym harmonogramem, na żądanie użytkownika.
Jest to tzw. odświeżanie ręczne. Aby ręcznie odświeżyć perspektywę materializowaną należy
wykonać procedurę REFRESH z pakietu DBMS_MVIEW. Parametry procedury to:
lista perspektyw do odświeżenia,
sposób realizacji procesu odświeżenia:
C – całkowicie,
F – przyrostowo,
? – system sam wybierze odpowiedni sposób odświeżenia (jeśli dostępny jest
dziennik, będzie realizowane odświeżenie przyrostowe; w przypadku braku dziennika
realizowane jest odświeżanie całkowite).
Np. aby ręcznie odświeżyć perspektywy materializowane P1 (przyrostowo) i P2 (całkowicie),
należy wykonać polecenie execute DBMS_MVIEW.REFRESH(’P1, P2’, ’CF’);.

Strona 49 z 51
23. Zażądaj ręcznego odświeżenia perspektyw STUDENCI_MV i OCENY_MV – wykonaj to przy
pomocy jednego polecenia (zakładka baza01).
execute DBMS_MVIEW.REFRESH...
24. Sprawdź w zbiorze perspektyw systemowych, czy i kiedy odświeżenie ręczne perspektyw
materializowanych zostało zrealizowane.
Grupy odświeżania
25. Utworzone przez nas perspektywy materializowane mają różne harmonogramy odświeżania
(STUDENCI_MV co 2 minuty, OCENY_MV co minutę). Może to powodować pewne problemy.
Przeprowadźmy następujący eksperyment:
a. jako użytkownik sphd_uzytkownik dodaj do tabel w bazie dblab01 dane jednego nowego
studenta z dwoma ocenami, np.:
INSERT INTO studenci(student_id, kierunek) VALUES(100000,'NZK3');
INSERT INTO oceny(student_id, przedmiot_id, ocena)
VALUES (100000, 1645, 5);
INSERT INTO oceny(student_id, przedmiot_id, ocena)
VALUES (100000, 1646, 3);
Zatwierdź transakcję poleceniem commit.
b. jako użytkownik integracja sprawdź, czy dane nowego studenta i jego ocen pojawiły się
w perspektywach STUDENCI_MV i OCENY_MV:
SELECT * FROM studenci_mv WHERE student_id = 100000;
SELECT * FROM oceny_mv WHERE student_id = 100000;
Co zaobserwowałaś/eś? (Podpowiedź: dane ocen studenta pojawiły się w bazie baza01 przed
danymi studenta).
Rozwiązaniem zaprezentowanego problem mogłoby być ujednolicenie harmonogramów
odświeżania obu perspektyw. Jednak takie rozwiązanie nie zapobiegnie sytuacji, w której
jedna z perspektyw zostanie odświeżona, natomiast odświeżenie drugiej nie powiedzie się
(np. z powodu awarii sieci). Stosowanym rozwiązaniem jest umieszczenie perspektyw
w jednej grupie odświeżania.
26. Grupa odświeżania pozwala na jednoczesne odświeżanie wielu perspektyw, zapewniając
spójność danych w ramach wszystkich perspektyw z grupy. Typowym zastosowaniem grup
odświeżania jest odświeżanie perspektyw, których tabele źródłowe są połączone kluczem
obcym. Każda grupa odświeżania posiada nazwę, listę perspektyw, oraz zdefiniowany
harmonogram odświeżania perspektyw w grupie (harmonogram odświeżania, ustalony dla
grupy, zastępuje indywidualne harmonogramy perspektyw w grupie).
27. Sprawdź, jakie aktualnie mamy utworzone grupy odświeżania. W tym celu wykonaj zapytanie
do perspektywy systemowej USER_REFRESH (nazwa grupy odświeżania znajduje się w
kolumnie RNAME, kolumna NEXT_DATE przechowuję moment kolejnego odświeżenia
perspektyw w grupie) .

Strona 50 z 51
SELECT rname, to_char(next_date,'yyyy.mm.dd hh24:mi:ss') AS next_date FROM
user_refresh;
Mimo tego, że nie tworzyliśmy dotąd jawnie grup odświeżania, powyższe zapytanie zwróciło
dwa rekordy. Powodem tego jest fakt, że każda perspektywa materializowana zostaje
domyślnie przydzielona do grupy o nazwie równej nazwie perspektywy. Aby sprawdzić, jakie
perspektywy należą do danej grupy odświeżania, wykonaj zapytanie do perspektywy
systemowej USER_REFRESH_CHILDREN.
SELECT name, type FROM user_refresh_children WHERE rname = 'STUDENCI_MV';
SELECT name, type FROM user_refresh_children WHERE rname = 'OCENY_MV';
Jak widać, w każdej grupie odświeżania znajduje się teraz jedna perspektywa
materializowana.
28. Utworzymy teraz nową grupę odświeżania i przydzielimy do niej obie perspektywy
materializowane. Do zdefiniowania grupy odświeżania używa się procedury MAKE z pakietu
DBMS_REFRESH. Parametry procedury są następujące:
name – nazwa grupy (RG_GRUPA_01),
list – lista perspektyw, które mają być odświeżane przez grupę (STUDENCI_MV
i OCENY_MV),
next_date – moment pierwszego odświeżenia perspektyw z grupy (natychmiast),
interval – wyrażenie określające częstotliwość odświeżania perspektyw z grupy (co
1,5 minuty)
implicit_destroy – czy po usunięciu ostatniej perspektywy z grupy ma ona zostać
automatycznie usunięta (domyślnie – TRUE) (nie),
lax – czy można dodać do grupy perspektywę, które jest już w innej grupie (czy można
przenieść perspektywę do grupy)(domyślnie FALSE)(TRUE),
begin
DBMS_REFRESH.MAKE(name => 'RG_GRUPA_01', list => 'studenci_mv, oceny_mv',
next_date => sysdate, interval => 'sysdate + 1/960',
implicit_destroy => FALSE, lax => TRUE);
end;
29. Sprawdź, jakie grupy odświeżania aktualnie istnieją w schemacie użytkownika integracja.
Następnie powtórz eksperyment z p. 25 (zmień identyfikator studenta na 10001).

Strona 51 z 51
Podsumowanie
Zakończyliśmy proces tworzenia i konfigurowania środowiska integracji danych. Udało nam się
połączyć ze sobą systemy zarządzania bazami danych DB2, MySQL i Oracle a także uzyskać dostęp z
SZBD Oracle do danych zgromadzonych w pliku tekstowym.
Jeśli masz jeszcze czas, spróbuj wykonać kilka prostych zestawień danych z wykorzystaniem
zintegrowanych w ćwiczeniu danych.
1. Dla każdego studenta podaj jego średnie ocen w poszczególnych semestrach akademickich
(przy wyliczaniu średniej weź pod uwagę zarówno oceny z przedmiotów jak i z języków
obcych). Jeśli studentowi w danym semestrze akademickim przyznano stypendium
dowolnego rodzaju, podaj informacje o uzyskanym stypendium. Dodatkowo, jeśli studentowi
w danym semestrze przyznano miejsce w akademiku, podaj odpowiednie informacje o jego
zakwaterowaniu.
2. Znajdź 10 najlepszych studentów. Ranking studentów będzie ustalony na podstawie
punktów, które przydzielisz poszczególnym studentom. Zasady przydzielania punktów są
następujące:
a. średnia ocen (z całych studiów):
<2,0; 3,5) – 0 punktów,
<3,5; 4,0) – 10 punktów,
<4,5; 4,5) – 15 punktów,
<4,5; 5,0> – 25 punktów.
b. przyznane stypendia:
c. stypendium za wyniki w nauce – 8 punktów (np. jeśli student uzyskał stypendium za
wyniki w nauce w 4 semestrach, uzyskuje 4*8 = 32 punkty),
d. stypendium sportowe – 10 punktów za każde.
Wyświetl numery albumów wraz z uzyskanymi punktami dla 10 najlepszych studentów.
3. Zbuduj listę przedmiotów, studiowanych przez studentów. Dla każdego przedmiotu podaj
liczbę studentów, którzy go studiowali oraz średnią uzyskanych z tego przedmiotu ocen.
Budując listę przedmiotów weź pod uwagę również oceny, uzyskane przez studentów z
lektoratów.





























