Embed Size (px)
DESCRIPTION
bab i
Citation preview
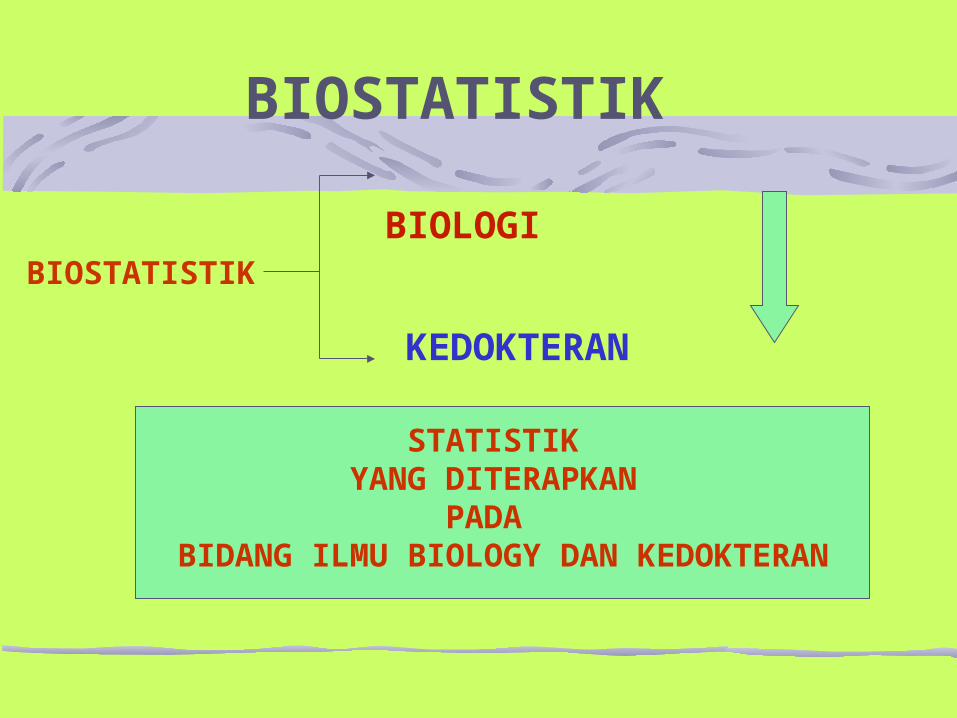
BIOSTATISTIK
BIOSTATISTIK
STATISTIK YANG DITERAPKAN
PADA BIDANG ILMU BIOLOGY DAN KEDOKTERAN
BIOLOGI
KEDOKTERAN

ARTI STATISTIK1. Adalah sekumpulan konsep & metode yang
digunakan untuk mengumpulkan dan menginterpretasikan data tentang bidang kegiatan tertentu dan mengambil kesimpulan dalam situasi dimana ada ketidakpastian dan variasi.
2 Adalah Kumpulan fakta umumnya berbentuk angka yang dapat disusun dalam bentuk tabel atau Diagram yang melukiskan atau menggambarkan suatu persoalan
3. Adalah pengetahuan yang berhubungan dengan cara cara Pengumpulan ,Pengolahan,Penyajian serta Analisa data yang dilanjutkan dengan penarikan kesimpulan serta pembuatan keputusan yang beralasan beredasarkan hasil analisa yang dilakukan.

Menurut sejarah “statistik” (bahasa Latin) “status” yang berarti “negara”.
Untuk beberapa dekade, statistik penyajian fakta-fakta dan angka-angka tentang situasi perekonomian, kependudukan dan politik yang terjadi di suatu negara.
Sebagai suatu disiplin ilmu saat ini statistik meliputi berbagai metode dan konsep yang sangat penting dalam semua penyelidikan yang melibatkan:
pengumpulan data dengan cara eksperimentasi dan observasi,
pengambilan inferensi atau kesimpulan dengan menganalisis data.

Contoh:
Pusdakes menaksir proporsi ibu hamil yang melakukan pemeriksaan K4 di Kabupaten MUBA
Seorang Ahli (Bakteriologi) ingin menaksir probabilitas (p) bahwa seekor anjing yang telah diberikan vaksin pada dosis tertentu akan mendapatkan kekebalan untuk penyakit tertentu tersebut.
Bagian pendidikan suatu fakultas ingin mempelajari hubungan indeks prestasi pada semester pertama dengan yang didapat pada waktu masuk fakultas tersebut.
Apoteker ingin mengetahui kebenaran kadar amoxicilin capsul yang beradaran dipasaran
Ahli Ekologi ingin mengetahui pengaruh toxic Plumbum pada kelompok beresiko ( Pekerja SPBU;Pabrik Baterei dll

. PEMBAGIAN STATISTIK I.BERDASARKAN CARA MEMPELAJARINYA:
1 STATISTIKA TEORITIS2. STATISTIKA MATEMATIS
II.BERDASARKAN TAHAPANYANG DILAKUKAN/PROSES
A. STATISTIK PARAMETRIK 1. STATISTIK DESKRIPTIF 2.STATISTIK INFERENSIAL B. STATISTIK NON PARAMETRIK.

B.NON PARAMETRIK STATISTIK
ADALAH UJI STATISTIK YANG TIDAK MEMERLUKAN ANGGAPAN ANGGAPAN TERTENTU DARI POPULASINYA
1.UJI NON PARAMETRIK :
UJI STATISTIK YANG HIPOTESA HIPOTESANYA TIDAKBERSANGKUT PAUT DENGAN PARAMETER TERT
2.UJI DISTRBUTION FREE /SEBARAN BEBAS
ADALAH METODA PENGUJIAN HIPOTESA ATAU PEMBENTUKAN INTERVAL KEPERCAYAAN TIDAK DIDASARKAN PADA BENTUK TERTENTU DARI POPULASINYA.

DESKRIPTIF BIOSTATISTIK SUATU PROSES YANG TERDIRI DARI
1. PENGUMPULAN DATA2. PENGOLAHAN DATA3. PENYAJIAN DATA4. ANALISA DATA MEMAKAI UKURAN UKURAN 5. DESKRIPTIF BIOSTATISTIK6. INTERPRETASI HASIL ANALISA DATA
HIPOTESA HIPOTESA

HIPOTESISHIPO : LEMAH, TESIS : PERNYATAAN
DUGAAN / JAWABAN SEMENTARA ATAS PERMASALAHAN YANG PALING MUNGKIN BERDASARKAN TEORI (YANG RELEVANT & RECENT)
CIRI-CIRI HIPOTESIS DEKLARATIF (PERNYATAAN) PROPOSISI (KOMPARASI/KORELASI) TENTATIF (TERGANTUNG BUKTI EMPIRIS) TESTABLE (OBSERVABLE &MEASURABLE)

DASAR PERUMUSAN HIPOTESIS
SATU TEORIPROPOSISI KONSEP BEBERAPA TEORIGENERALISASI FAKTA EMPIRISIMAJINASI / AKAL SEHAT/ DUGAAN LIAR PENELITI

KEGUNAAN HIPOTESISSEBAGAI PEDOMAN
MENYUSUN / MEMILIH RAGAM / DESAIN RISETMENENTUKAN / MEMILIH DATA YG AKAN DIGUNAKANMENENTUKAN / MEMILIH METODE / MODEL ANALISIS DATA YG AKAN DIPAKAI

PENULISAN HIPOTESAPENELITIAN
TIDAK DITULISKAN DALAM BENTUK H0 DAN H1HIPOTESA DITULISKAN DALAM BENTUK HIPOTESA MAYOR YANG MERUPAKAN HIPOTESA YANG AKAN DIBUKTIKAN KEBENARANNYABIASANYA ADALAH H1 DALAM HIPOTESA STATISTIIK

INFERENSIAL STATISTIK
SUATU PROSES YANG TERDIRI DARI
1. PENGUMPULAN DATA2. PENGOLAHAN DATA3. PENYAJIAN DATA4. ANALISA DATA MEMAKAI UJI HIPOTESA5. INTERPRETASI HASIL ANALISA DATA YANG 6. DILANJUTKAN DENGAN PENARIKAN KESIMPULAN7. ILMIAH
KESIMPULAN ILMIAH
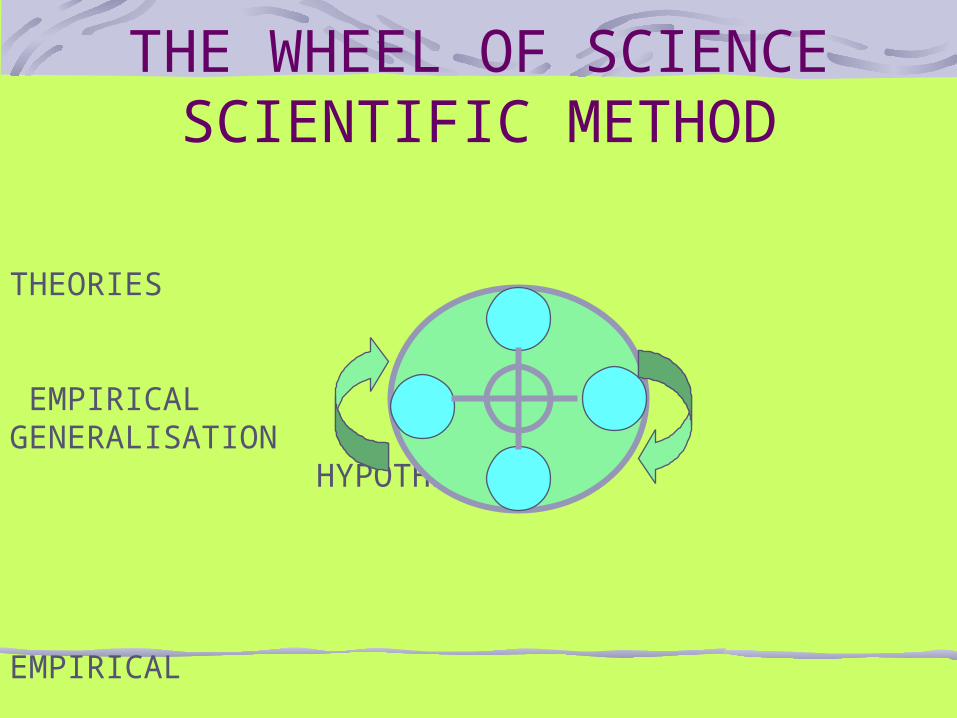
THE WHEEL OF SCIENCE SCIENTIFIC METHOD
THEORIES
EMPIRICALGENERALISATION HYPOTHESES
EMPIRICAL OBSERVATIONS
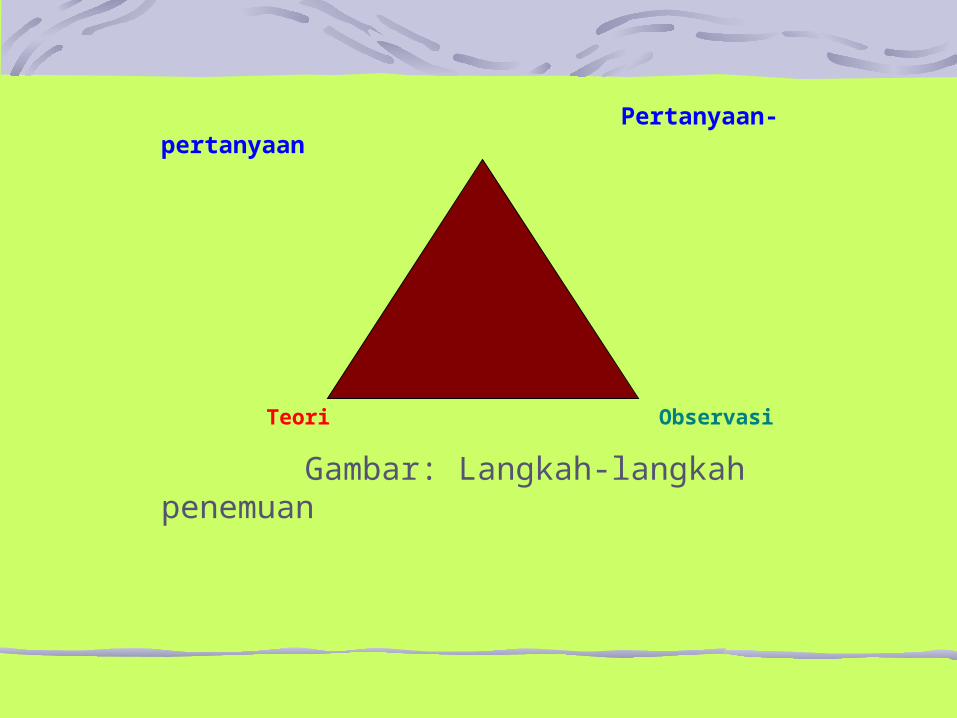
Pertanyaan-pertanyaan
Teori Observasi
Gambar: Langkah-langkah penemuan
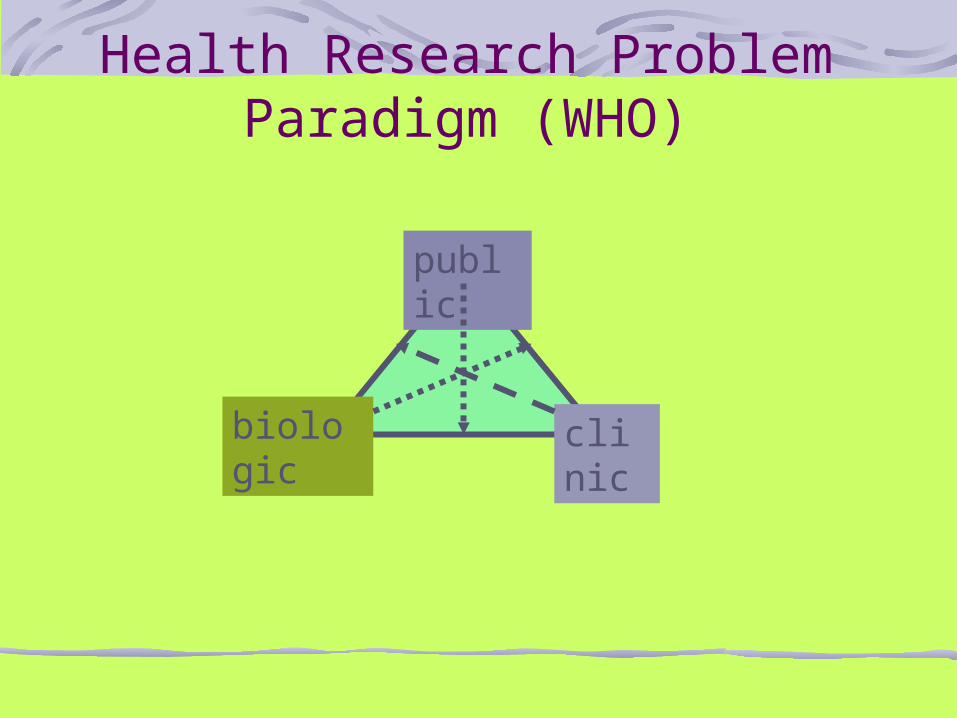
Health Research Problem Paradigm (WHO)
public
biologic clinic
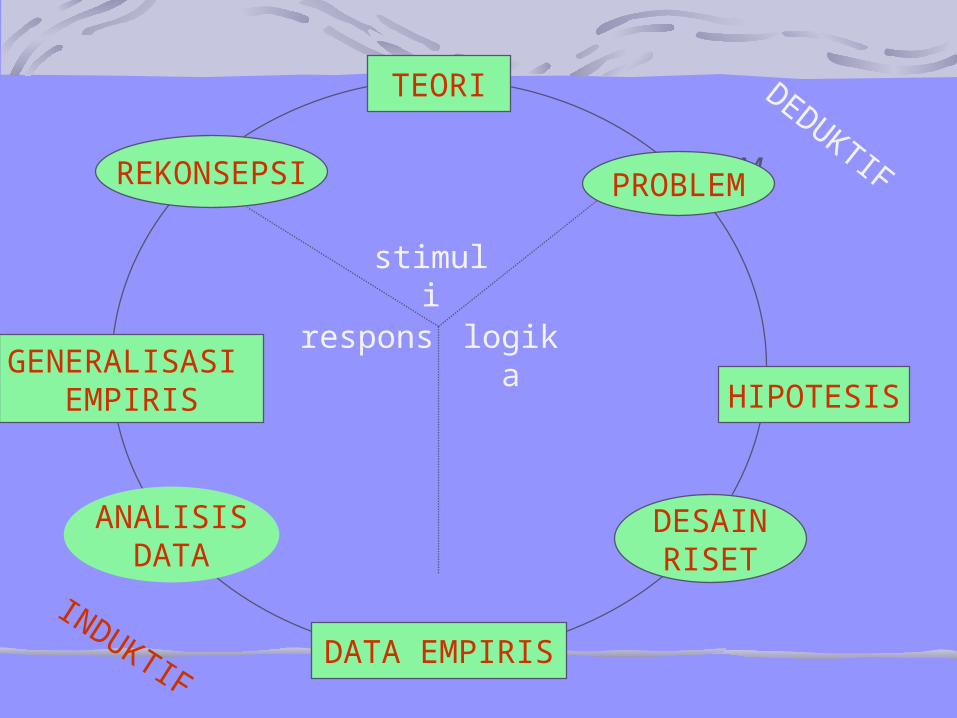
TEORI
stimuli
respons logika
HIPOTESIS
DATA EMPIRIS
GENERALISASI EMPIRIS
PROBLEM
DESAIN
DEDUKTIF
INDUKTIF
TEORI
HIPOTESIS
DATA EMPIRIS
GENERALISASI EMPIRIS
PROBLEM
DESAINRISET
ANALISISDATA
REKONSEPSI
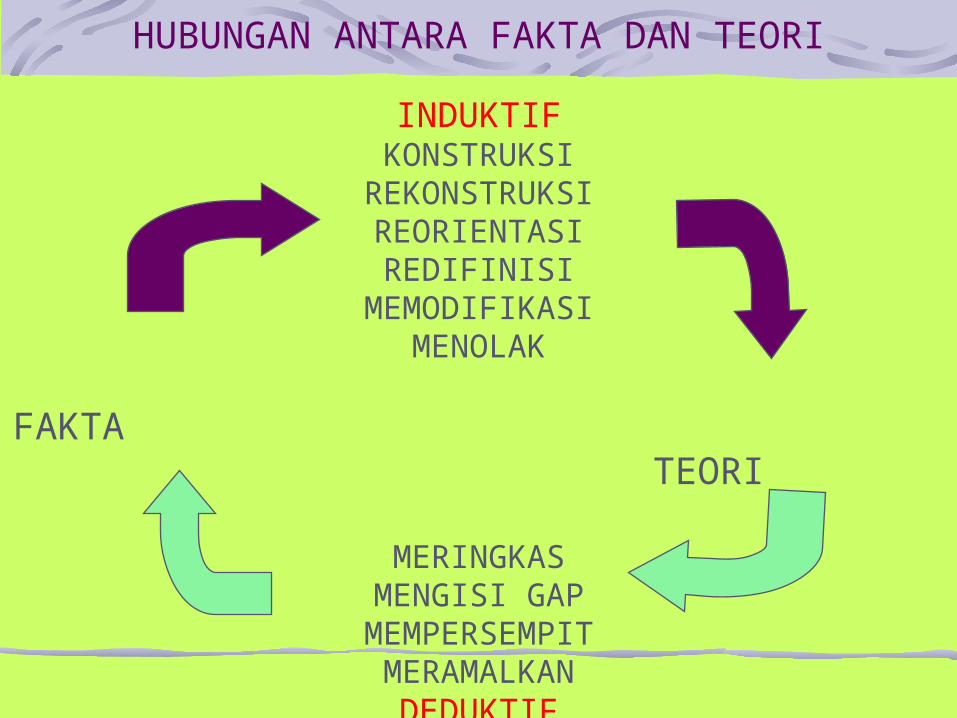
HUBUNGAN ANTARA FAKTA DAN TEORI
INDUKTIFKONSTRUKSI
REKONSTRUKSIREORIENTASI
REDIFINISIMEMODIFIKASI
MENOLAK
FAKTA TEORI
MERINGKASMENGISI GAP
MEMPERSEMPITMERAMALKAN
DEDUKTIF
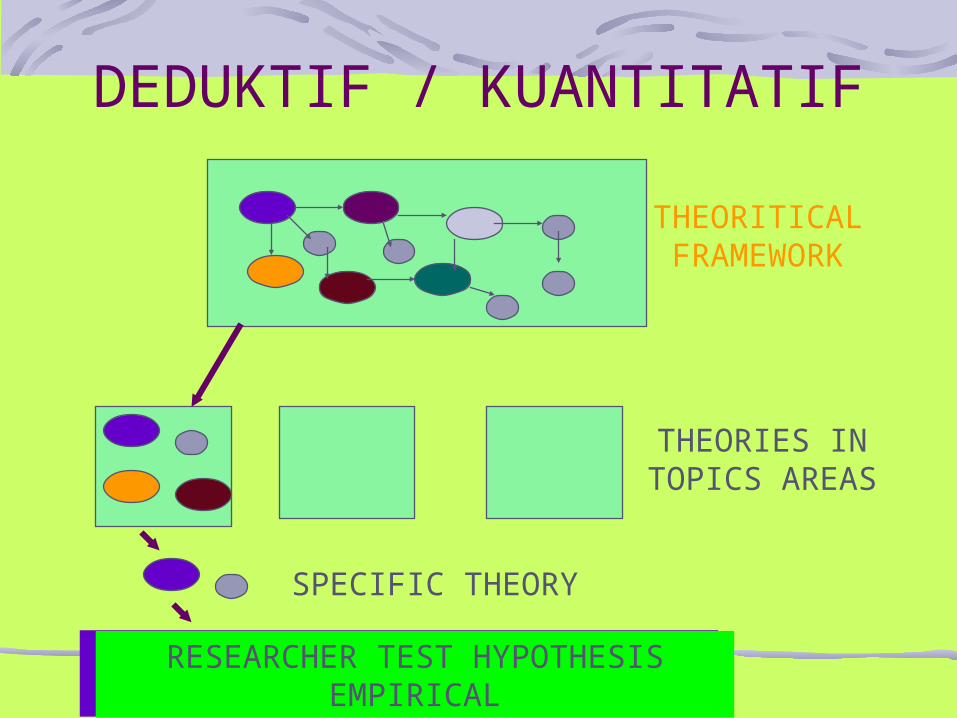
DEDUKTIF / KUANTITATIF
RESEARCHER TEST HYPOTHESIS EMPIRICAL
THEORITICAL FRAMEWORK
THEORIES IN TOPICS AREAS
SPECIFIC THEORY
RESEARCHER TEST HYPOTHESIS EMPIRICAL
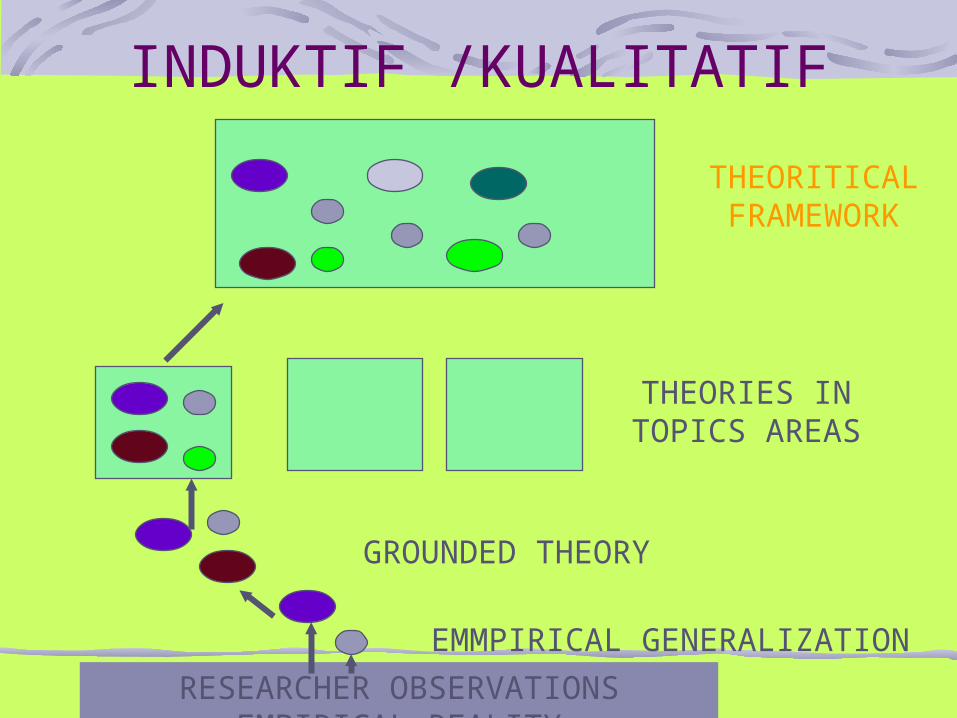
INDUKTIF /KUALITATIF
RESEARCHER OBSERVATIONS EMPIRICAL REALITY
EMMPIRICAL GENERALIZATION
GROUNDED THEORY
THEORIES IN TOPICS AREAS
THEORITICAL FRAMEWORK

KAJIAN TEORITIK / KONSEPTUAL
THE TRADITIONAL IMAGE OF SCIENCE
RESEARCH PROBLEM
THEORITICAL UNDERSTANDING
HYPOTHESES

Inti perbedaan metode ilmiah dan non-ilmiah adalah:
Metode Ilmiah Metode Non-Ilmiah
•Perumusan masalahn jelas dan spesifik •Masalah merupakan hal yang dapat diamati dan diukur secara empiris. •Jawaban permasalahan didasarkan pada data •Proses pengumpulan dan analisis data, serta pengambilan keputusan berdasarkan logika yang benar •Kesimpulan siap/terbuka untuk diuji oleh orang lain
•Perumusan masalah kabur atau abstrak •Masalah tidak selalu dapat diukur, dapat saja bersifat supernatural atau dogmatis •Jawaban tidak diperoleh dai hasil pengamatan data lapangan •Keputusan tidak didasarkan pada hasil pengumpulan dan analisis data yang logis •Kesimpulan tidak dibuat untuk diuji ulang oleh orang lain

UKURAN UKURAN DESKRIPTIF STATISTIK1. MEAN2. MEDIAN3. MODUS4. GEOMETRIC MEAN5. HARMONIC MEAN6. VARIANCE7. STANDARD DEVIASI8. STANDARD ERROR9. KOEFICIENT KORELASI = r MATERI DESKRIPTIF BIOSTATISTIK 1. PENGUMPULAN DATA2. PENGOLAHAN DATA3. PENYAJIAN DATA4. DISTRIUBSI FREKWENSI5. CENTRAL TENDENCY6. DISPERSI7. SKEWNESS DAN KURTOSIS8. DISTRIBUSI PROBABILITAS9. DISTRIBUSI SAMPLING

MATERI INFERENSIAL BIOSTATISTIK
1. TEORI ESTIMASI2. UJI KECOCOKAN/GOODNES OF FIT3. ANALISA KORELASI4. ANALISA REGRESI5. PENGUJIAN HIPOTESIS6. METODA SEKUENSIAL7. PENGONTROLAN KWALITAS

. UNTUK APA BIOSTATISTIK ???a. Health Science: - drug design, causes of diseases (many "causes" of cancers).b. Health Professional (nurses, physical therapists):- type of care and recovery period (importance of a persons mood on health).- exercise regime and recovery from injury.c. Nutrition:- vitamins and health- diet and healthd. Evolution & Ecology:- causes of changes in population sizes (conservation biology)- effects of pollution on organisms and ecosystems- evolution of traits in populations over time- Global environmental changes and changes in population sizes or species diversity.e. Genetics- identifying genes that influence traits. - genetics versus environmental effects.f. Agriculture- fertilizer effects on plant growth and productivity.- organic farming versus conventional farming.- productivity of different plant and animal varieties.

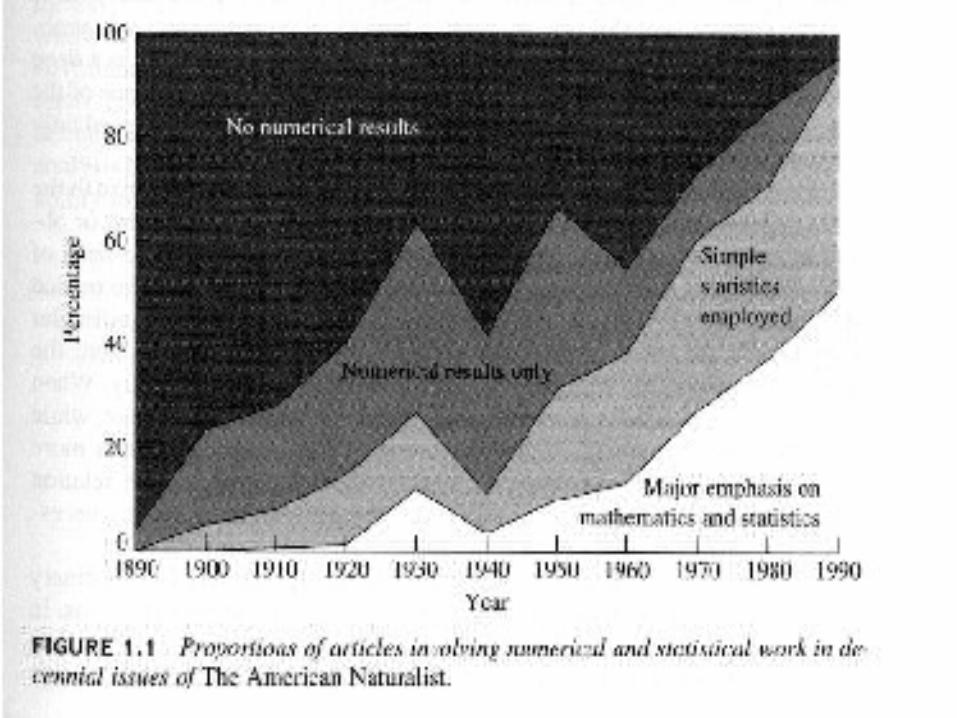
Scientific Method and Statistics
The Scientific Method can be characterized by the following steps.
1. Formulate a hypothesis.
2. State Predictions from the hypothesis.
3. Perform an experiment or observation.
4. Interpret the experiment or observation.
5. Evaluate the Predictions and Hypothesis.
6. Restate (refine) the Hypothesis and start again.
A Statistical Approach to the Scientific Method can be characterized by the following steps.
1. Formualte a Null & Alternative Hypotheses.
2. State Predictions from the Null & Alternative Hypotheses.
3. Design an experiment or observation.
4. Perform the experiment or observation.
5. Analyze the data from the experiment or observation.
6. Interpret the experiment or observation.
7. Evaluate the Predictions from the Null & Alternative Hypotheses.
8. Accept or Reject the Null Hypothesis.
9. Restate (refine) the Hypotheses and start again.
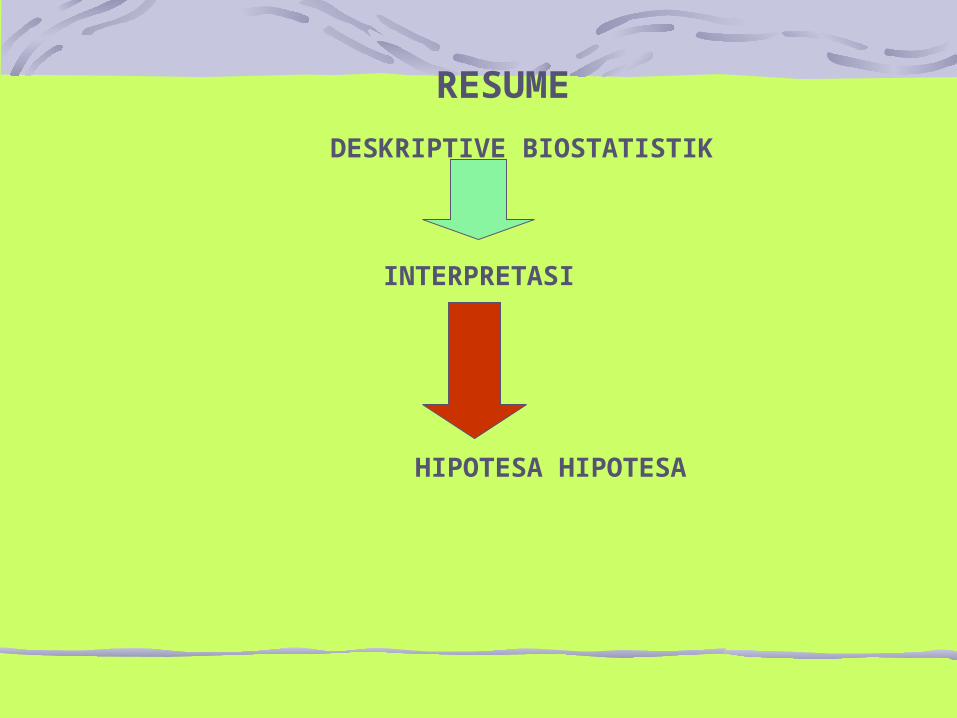
RESUME
DESKRIPTIVE BIOSTATISTIK
INTERPRETASI
HIPOTESA HIPOTESA
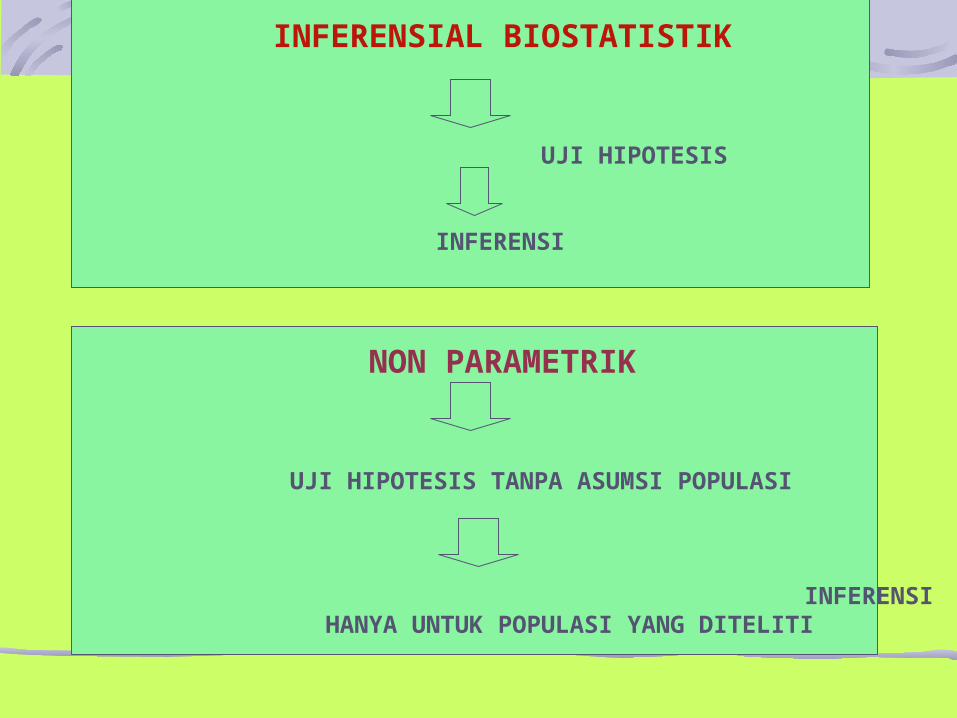
INFERENSIAL BIOSTATISTIK
UJI HIPOTESIS
INFERENSI
NON PARAMETRIK
UJI HIPOTESIS TANPA ASUMSI POPULASI
INFERENSI HANYA UNTUK POPULASI YANG DITELITI

.POPULASI DAN SAMPEL
Populasi adalah keseluruhan dari unit didalam pengamatan yang akan kita lakukan/TELITISemua nilai yang mungkin dari perhitungan,pengukuran baik kwantitatif ataupun kwalitatif dari karakteristik tertentu mengenai sekumpulan objek yang lengkap dan jelas yang akan diteliti sifat sifatnya Sampel adalah sebagian dari populasi yang nilai/karakteristiknya kita ukur dan yang nantinya kita pakai untuk menduga karakteristik dari populasi.

REPRESENTATIVE SAMPEL
Adalah sampel yang karakteristiknya mencerminkan populasi asalnya atau dengan kata lain ukuran ukuran statistik yang dihasilkan tidak berbeda secara bermakna dengan ukuran ukuran yang dihasilkan oleh populasi asalnya
Nilai nilai pada sampel representatif tidak berbeda secara bermaknaDengan nilai nilai yang ada populasi asalnya

Misal:Kita ingin mengetahui kadar hemoglobin ibu hamil di kotamadya Palembang
Populasi kita adalah keseluruhan ibu hamil di Palembang
Kita tidak mungkin mengukur Hb seluruh ibu hamil tersebut, untuk itu kita ambil saja sebagian dari ibu hamil (sampel) yang mewakili keseluruhan (Populasi) ibu hamil di Palembang.Kadar Hb ibu hamil yang menjadi sampel tersebut kita ukur. Hasilnya nanti dapat kita pakai untuk menduga nilai Hb ibu hamil di Palembang



.TAHAPAN KEGIATAN STATISTIK
Pengumpulan data
Penyajian data
Pengolahan data
Analisis/interpretasi data
Penarikan Kesimpulan Statistik

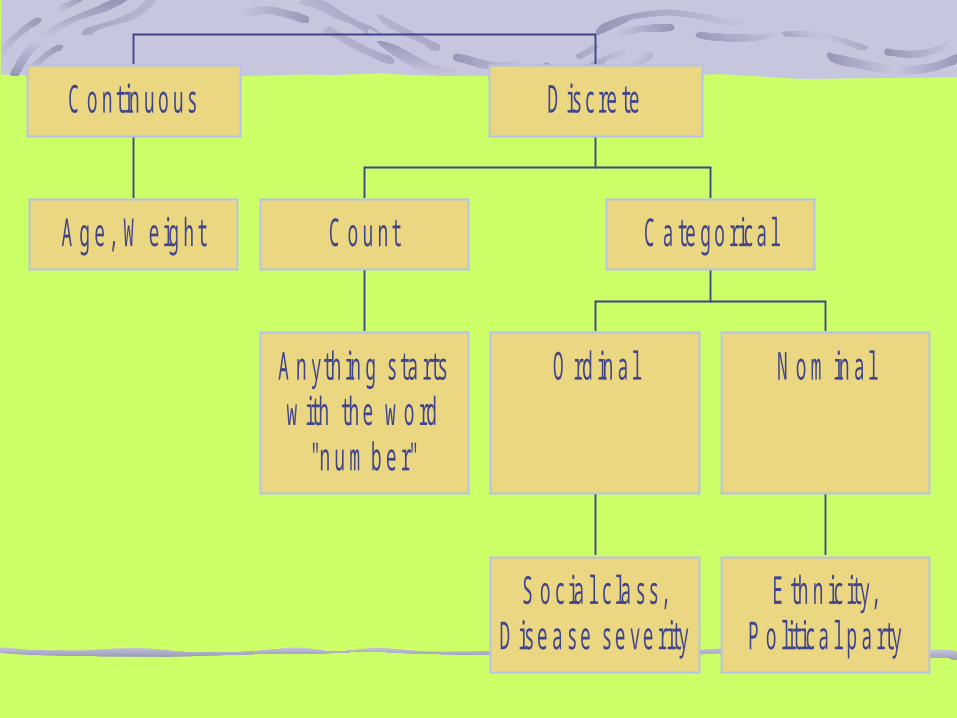
.DATA, PROSES PENGUKURAN DAN SKALAData adalah himpunan angka-angka yang merupakan nilai dari unit sampel sebagai hasil dari suatu pengamatan/pengukuran
Ditinjau dari jenis data dapat kita tentukan bermacam-macam data antara lain:
Data diskrit: data yang dalam bentuk bilangan bulat, misalnya jumlah anak dalam keluarga, jumlah penderita penyakit TBC, jumlah kecelakaan di jalan raya.(Unit Terkecilnya tidak dapat dibagi bagi lagi)

Data kontinu: data yang dapat merupakan rangkaian data, nilainya dapat dalam bentuk desimal; misalnya tinggi badan 162,5 cm; berat badan 63,8 Kg.(Unit terkecil masih dapat dibagi bagi lagi)
Data kualitatif: data yang dalam bentuk kualitas seperti pernyataan terhadap KB (keluarga berencana), setuju, kurang setuju, tidak setuju,Perlakuan diberi obat dan tidak diberi obat)
Data kuantitatif: data dalam bentuk bilangan (numerik) misal, jumlah balita yang telah mendapat imunisasi.

Ditinjau dari sumber data: data Primer
adalah data yang dikumpulkan oleh penelitinya sendiri,
data Sekunderadalah data yang diambil dari suatu sumber dan biasanya data itu sudah dikompilasi lebih dahulu oleh instasi atau yang punya data
Cara pengumpulan data observasi langsung terhadap objek
penelitiannya tanya jawab memakai kuesioner dengan
objek penelitian.

Dalam pengumpulan data dikenal juga beberapa istilah antara lain:
Variabel adalah suatu sifat yang akan diukur atau diamati yang nilainya bervariasi antara satu objek ke objek lainnya misal kita akan mengamati bayi baru lahir, variabel yang akan diamati atau yang akan diukur adalah: berat badan, panjang badan yang tentu saja nilai ini bervariasi antara satu bayi dengan bayi lainnya.Agregate adalah keseluruhan kumpulan nilai-nilai observasi yang merupakan suatu kesatuan dan setiap nilai observasi hanya mempunyai arti sebagai bagian dari keseluruhan tersebut.

Dalam mengumpulkan nilai dari variabel perlu juga diketahui skala pengukuran dari variabel tersebut. Skala ada 4 macam yaitu:
Nominal
Ordinal
Interval
Ratio.

Skala NominalPengukuran yang paling lemah tingkatannya terjadi apabila bilangan atau lambang-lambang lain digunakan untuk mengklasifikasikan obyek pengamatan. Setiap objek akan masuk salah satu lambang atau kelompok.Kelompok ini juga biasa disebut sebagai “kategori”, kalau hanya ada dua kategori seperti laki-laki dan perempuan disebut dikotomi.(Dichotomuous/Binary)Contoh: Tidak menderita MCI dan Menderita MCI.
Biasanya dilabel dengan 0 = Non MCI 1 = MCI

Skala OrdinalPengukuran ini tidak hanya membagi objek menjadi kelompok-kelompok yang tidak tumpang tindih, tetapi antara kelompok itu ada hubungan (rangking). Hubungan antara kelompok ini dapat ditulis sebagai lebih kecil (<) atau lebih besar (>). Jadi dari kelompok yang sudah ditentukan dapat diurutkan menurut besar kecilnya.
kolesterol < 200 mg% = 1 kolesterol > 200 mg% = 2Sebagai contoh lain ,Obesitas dapat dikelompokan menjadi obesitas ringan sedang,berat dan Morbid
Biasanya di label dengan
1.=obesitas ringan 3.= obesitas berat
2.= obesitas sedang 4.= obesitas Morbid

Skala IntervalDalam skala interval selain membagi objek menjadi kelompok tertentu dan dapat diurutkan juga dapat ditentukan jarak dari urutan kelompok tersebut dan skala interval ini tidak mempunyai nilai nol mutlak Contoh adalah pengukuran panas dengan termometer, katakanlah Celcius, temperatur 40 derajat lebih panas 15 derajat dari temperatur 25 derajat. Karena tidak mempunyai nilai nol mutlak dapat mempunyai nilai minus misalnya suhu – 200 C

Skala RatioData Dengan skala ratio Dapat dikelompokkan , Kelompok itupun dapat diurutkan dan jarak antara urutan dapat ditentukan. Datadengan skala ratio dapat diperbandingkan (ratio). Data dengan skala mempunyai titik “nol mutlak”.Biasanya bersifat Numerik
Contoh: Berat badan ;Tinggi badan Kadar Hb,Kadar kolesterol ,diameter katup jantung dll

Struktur tingkatan skala
Sifat Skala Nominal Ordinal Interval Ratio
1. Persamaan pengamatan
(pengelompokkan), klasifikasi pengamatan
dapat dilakukan.Ya Ya Ya Ya
2. Urutan tertentu, urutan pengamatan dapat dilakukan
Tidak Ya Ya Ya
3. Jarak antara kelompok dapat ditentukan
Tidak Tidak Ya Ya
4. Perbandingan antara kelompok (adanya titik
nol mutlak).Tidak Tidak Tidak Ya
A g e, W e ig h t
C o ntin uo us
A n yth in g s ta rtsw ith the w o rd
"n u m b e r"
C o u n t
S o c ia l c la ss,D ise a se se ve rity
O rd in a l
E th n ic ity,P o lit ica l p a rty
N o m in a l
C a te go rica l
D isc re te

SAJIAN STATISTIK/PENYAJIAN DATA
Secara umum sajian data dapat dibagi dalam tiga bentuk yaitu:A. Tulisan (textular)B. Tabel (tabular)C. Gambar/grafik (diagram)

A. Tulisan (textular)Hampir semua bentuk laporan dari pengumpulan data diberikan tertulis, mulai dari bagaimana proses pengambilan sampel, pelaksanaan pengumpulan data sampai hasil analisis yang berupa informasi dari pengumpulan data tersebut.
B. TabelPenyajian data dalam bentuk tabel adalah penyajian dengan memakai kolom dan baris.

JENIS TABEL1. Master tabel (tabel induk)
Tabel induk adalah tabel yang berisikan semua hasilpengumpulan data yang masih dalam bentuk datamentah, biasanya tabel ini disajikan dalam lampiran suatu laporan pengumpulan data.
2. Text tabel (tabel rincian) merupakan uraian dari data
yang diambil dari tabel induk.
Contoh:
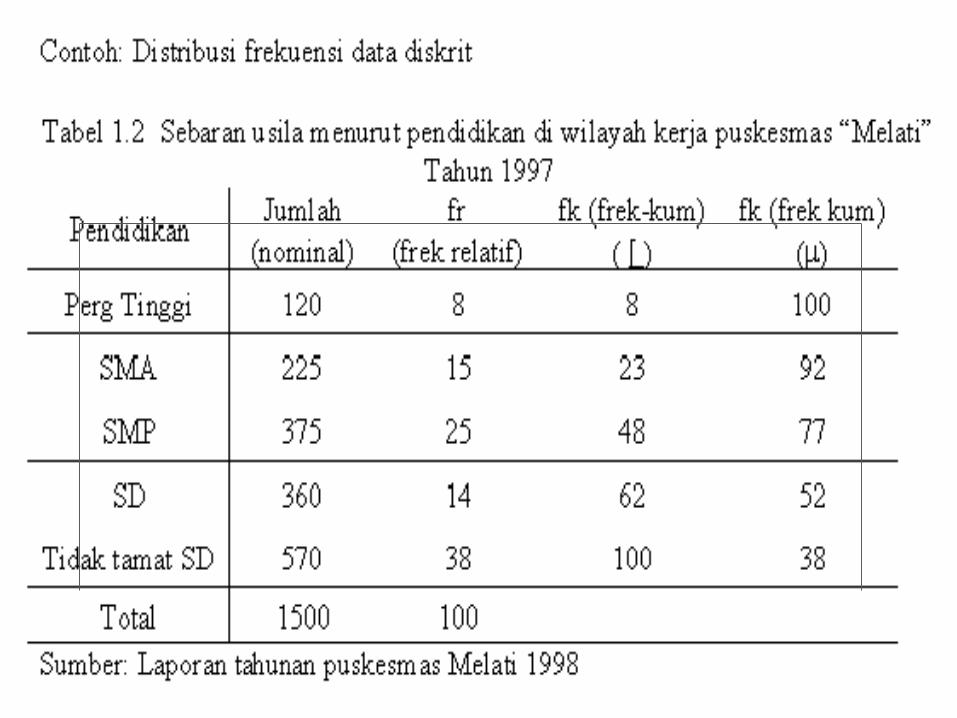
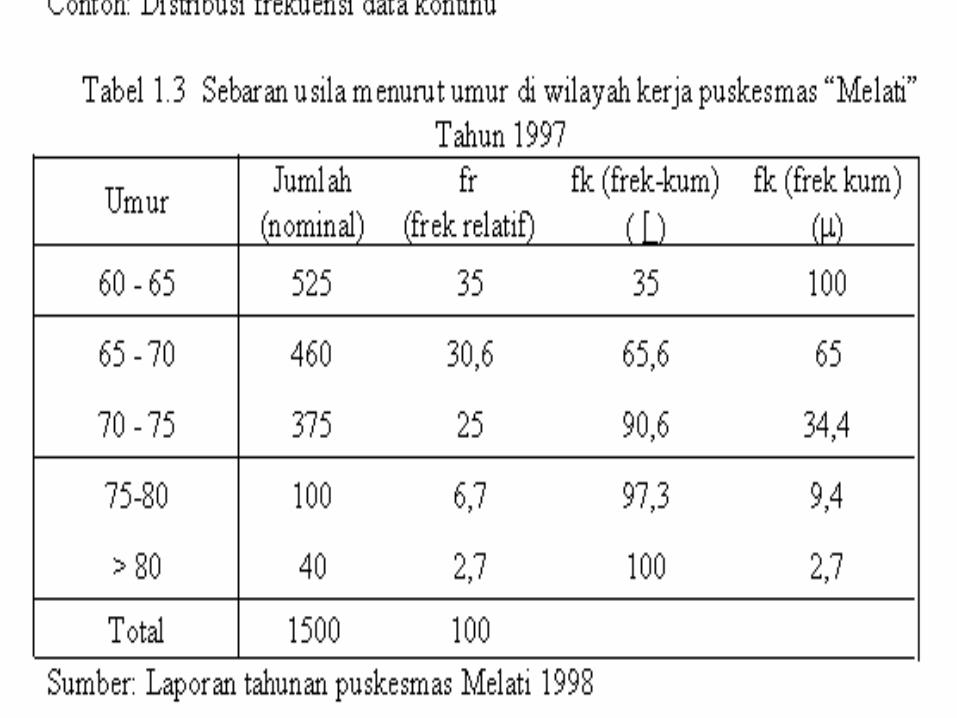
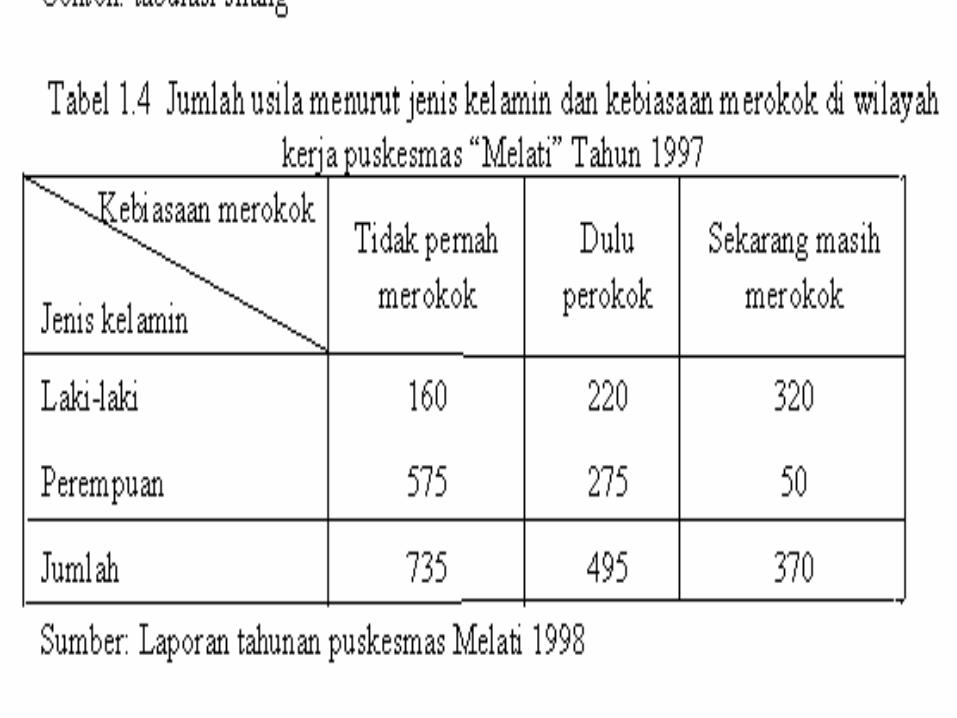
a) Distribusi frekuensib) Distribusi relatifc) Distribusi kumulatifd) Tabel silang (kontingensi tabel = cross tabulasi)

CARA MENYAJIKAN TABEL1. Judul tabel, judul tabel harus singkat, jelas dan
lengkap & dapat menjelaskan apa yang disajikan dimana kejadiannya dan kapan
terjadi.
2. Nomor tabel
3. Keterangan-keterangan (catatan kaki=foot note) yaitu keterangan yang diperlukan untuk menjelaskan mengenai hal-hal tertentu yang tidak bisa dituliskan di dalam badan tabel.
4. Sumber, bila mengutip tabel dari sumber

3. Grafik/diagram Cara menyajikan grafik
a. Judul yang singkat, jelas dan lengkapb. Dalam menggambar, kita memerlukan 2 sumbu sebagai ordinat dan aksis.c. Skala tertentud. Nomor gambare. Foot notef. Sumber

Jenis-jenis grafik/gambar:a. Histogramb. Frekuensi Poligonc. Ogived. Diagram garis (line diagram)e. Diagram batang (bar diagram)f. Diagram pinca (pie diagram)g. Diagram tebar (scatter diagram)h. Pictogrami. Mapgramj. Box Whisker Plotk. Stem and Leaf Plotl. Pareto
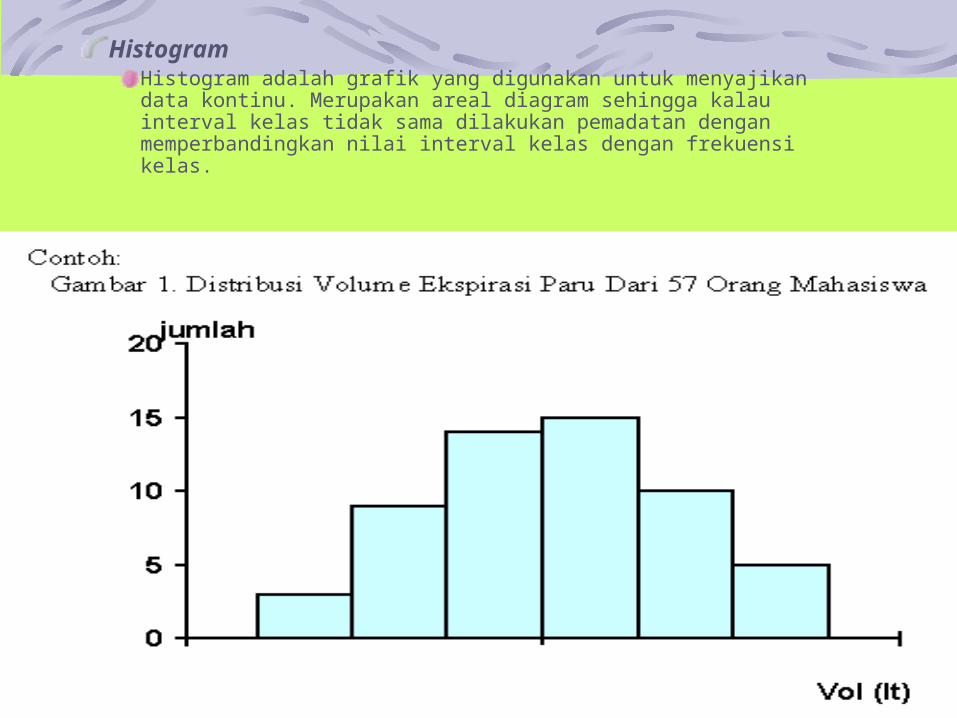
HistogramHistogram adalah grafik yang digunakan untuk menyajikan data kontinu. Merupakan areal diagram sehingga kalau interval kelas tidak sama dilakukan pemadatan dengan memperbandingkan nilai interval kelas dengan frekuensi kelas.
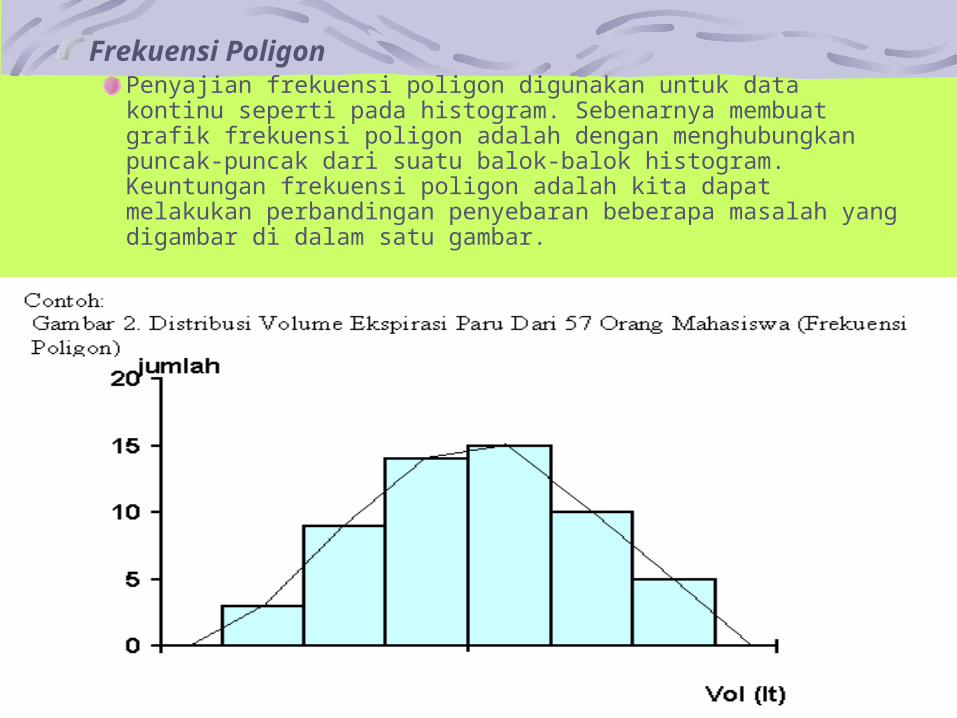
Frekuensi PoligonPenyajian frekuensi poligon digunakan untuk data kontinu seperti pada histogram. Sebenarnya membuat grafik frekuensi poligon adalah dengan menghubungkan puncak-puncak dari suatu balok-balok histogram. Keuntungan frekuensi poligon adalah kita dapat melakukan perbandingan penyebaran beberapa masalah yang digambar di dalam satu gambar.
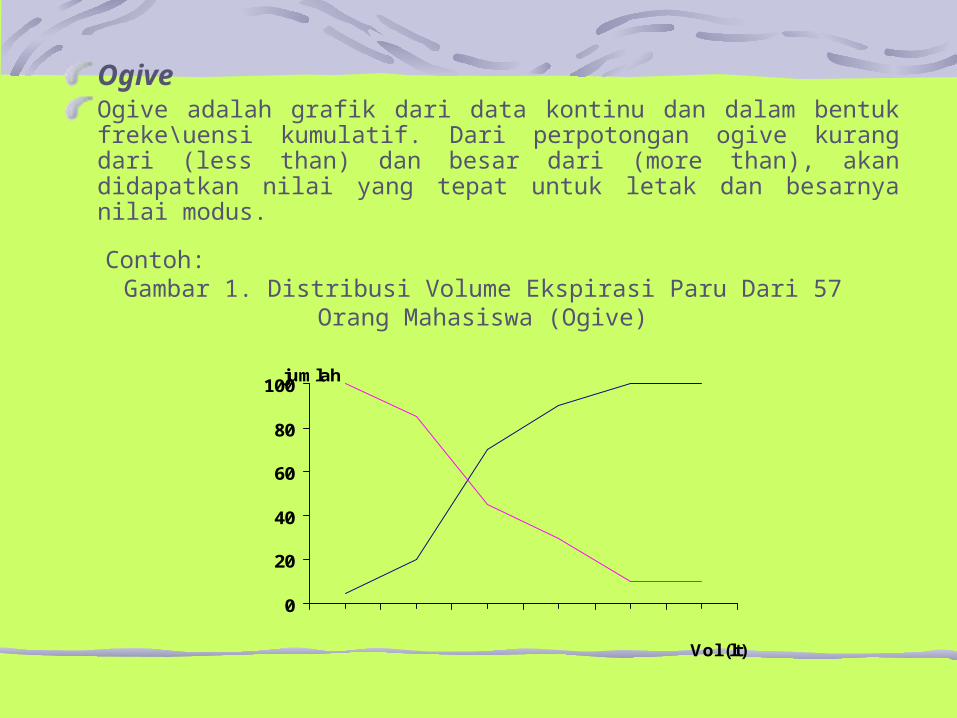
OgiveOgive adalah grafik dari data kontinu dan dalam bentuk freke\uensi kumulatif. Dari perpotongan ogive kurang dari (less than) dan besar dari (more than), akan didapatkan nilai yang tepat untuk letak dan besarnya nilai modus.
0
20
40
60
80
100
Vol (lt)
jumlah
Contoh:Gambar 1. Distribusi Volume Ekspirasi Paru Dari 57 Orang Mahasiswa
(Ogive)
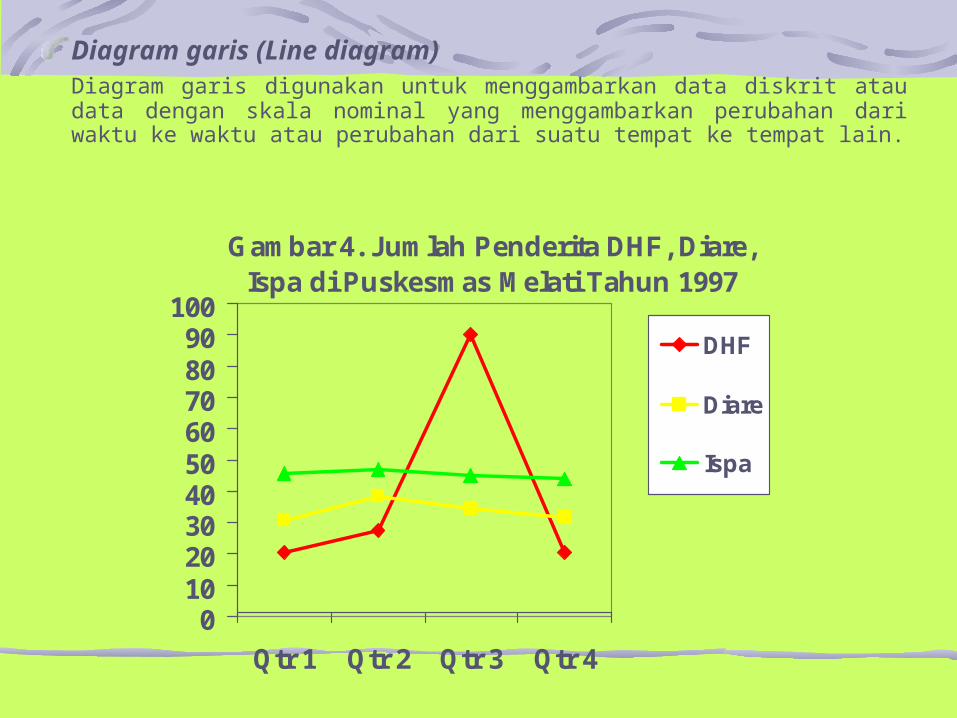
Diagram garis (Line diagram)Diagram garis digunakan untuk menggambarkan data diskrit atau data dengan skala nominal yang menggambarkan perubahan dari waktu ke waktu atau perubahan dari suatu tempat ke tempat lain.
Gambar 4. Jumlah Penderita DHF, Diare, Ispa di Puskesmas Melati Tahun 1997
0102030405060708090
100
Qtr 1 Qtr 2 Qtr 3 Qtr 4
DHF
Diare
Ispa

Diagram Batang (diagram balok = bar diagram)
Diagram batang digunakan untuk menyajikan data diskrit atau data dengan skala nominal maupun ordinal. Beda dengan balok-balok diagram batang dengan balok-balok histogram adalah, pada histogram balok-baloknya menyambung sebab histogram adalah menggambarkan data kontinu.Gambar balok dapat vertikal (berdiri) atau horizontal.Dari cara menampilkan balok-balok tersebut dapat dibagi menjadi:
.Single bar
.Multiple bar
.Subdivided bar

Gambar 5. Jumlah Akseptor KB Tahun 1998 (Single Bar)
0100200300400500600
Pil Suntikan IUD
1998
Jumlah
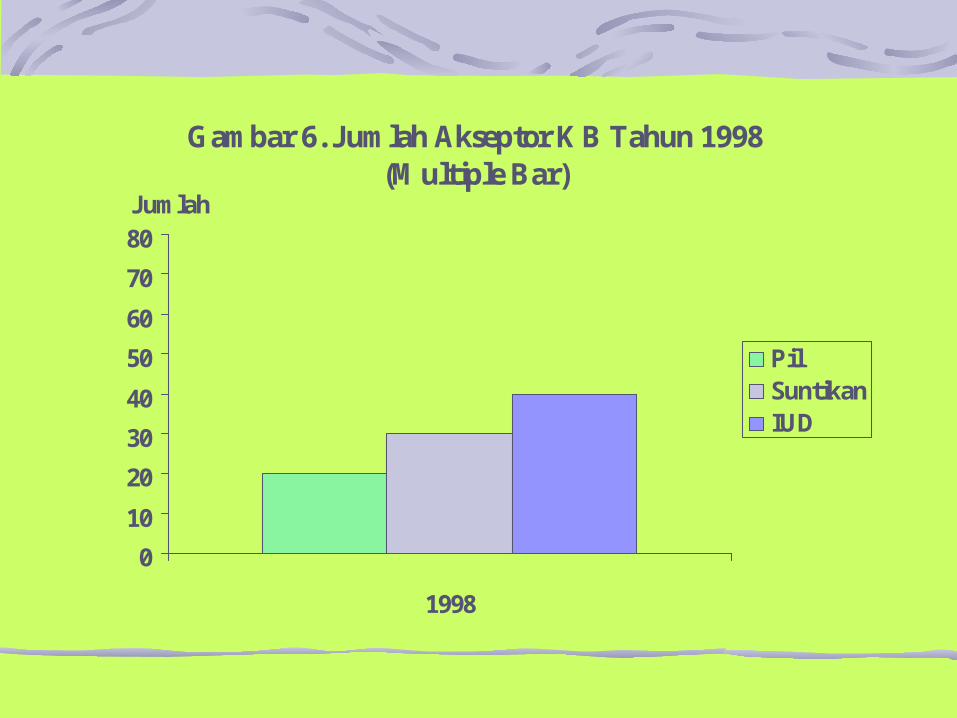
Gambar 6. Jumlah Akseptor KB Tahun 1998 (Multiple Bar)
0
10
20
30
40
50
60
70
80
1998
Jumlah
PilSuntikanIUD
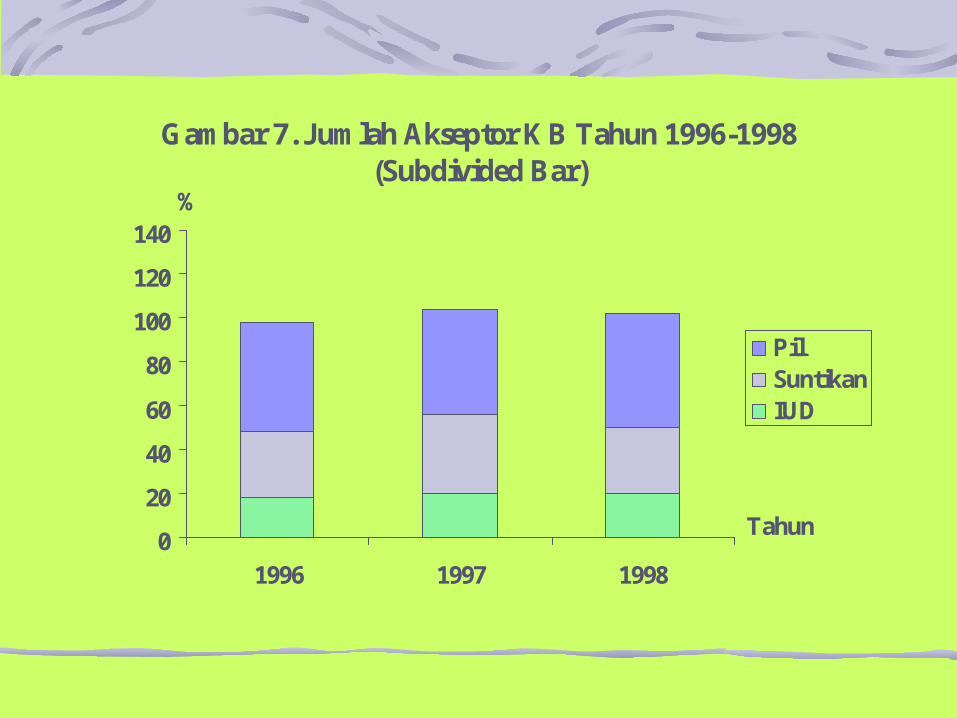
Gambar 7. Jumlah Akseptor KB Tahun 1996-1998 (Subdivided Bar)
0
20
40
60
80
100
120
140
1996 1997 1998
Tahun
%
PilSuntikanIUD

Diagram pinca (diagram lingkar = pie diagram)
Diagram pinca/lingkar digunakan untuk menyajikan data diskrit atau data dengan skala nominal dan ordinal atau disebut juga data kategori. Luas satu lingkaran adalah 360 derajat. Proporsi data yang akan disajikan dalam bentuk derajat.
Gambar 8. Jumlah Penderita DHF, Diare, ISPA pada Bulan Desember 1997
45
35
25DHF
Diare
ISPA

Diagram tebar (scatter diagram)
Diagram tebar adalah diagram yang digunakan untuk menggambarkan hubungan dua macam variabel yang diperkirakan ada hubungan. Sumbu Y menggambarkan variabel dependen sedang sumbu X menggambarkan variabel independen.
Gambar 9. Contoh Scatter Diagram
020406080
100120140160180
0 40 80
Berat Badan (kg)
Tin
ggi B
adan
(cm
)

Pictogram adalah diagram yang digambar sesuai dengan objeknya misalnya , menggambarkan penyakit jantung langsung menggambarkan jantung. Misalnya setiap penggambaran satu orang menunjukkan satu jantung menunjukkan 10 orang penderita.Gambar 10. Jumlah Penderita Penyakit Jantung Koroner yang Dirawat di Rumah Sakit Kabupaten “X” Tahun 1996-1998
1996 ♥ ♥1997 ♥ ♥ ♥1998 ♥ ♥ ♥ ♥ ♥ ♥
♥ = 10 Penderita
PICTOGRAM

MapgramDigunakan map atau peta dari suatu daerah. Permasalahan yang akan digambarkan ditunjukkan langsung di peta tersebut.Contoh, ingin menggambarkan prevalensi dari penderita penyakit gondok endemik prevalensi yang tinggi digambar lebih gelap dari prevalensi sedang.
Gambar . Daerah Kejadian Penyakit Gondok di Kabupaten “X” Tahun 1997
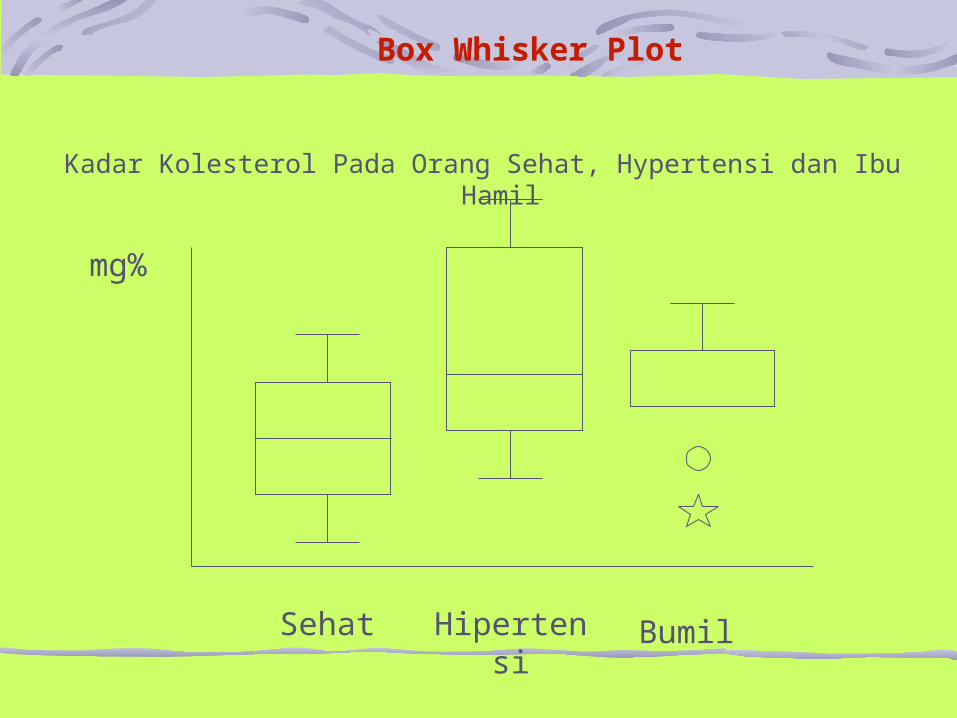
Kadar Kolesterol Pada Orang Sehat, Hypertensi dan Ibu Hamil
mg%
Sehat Hipertensi Bumil
Box Whisker Plot

Box & Whisker plot, digunakan untuk menyajikan data numerik.. dipakai juga untuk memperbandingkan beberapa pengamatan. Seperti gambar 12) adalah membandingkan sebaran kadar kolesterol antara orang normal hiperntensi dan ibu hamil (bumil).
Kotak (Box) terdiri dari:garis tengah adalah nilai Quartile dua (Q2) atau mediangaris bawah adalah nilai Quartile satu (Q1)
garis atas kotak adalah nilai Quartile tiga (Q3)

Tali (Whisker) batas bawah adalah nilai batas yang tidak lebih perbedaannya dengan Q1 sebanyak 1½ x (Q3-Q2) atau perbedan inter quartile, sedangkan batas atas adalah nilai yang paling jauh dan tidak lebih dari 1½ x (Q3-Q2). Tanda bintang adalah nilai yang menjadi nilai pencilan (outliner), selanjutnya adalanya lingkaran kecil adalah kandidat untuk outliner (pencilan).
Stem and Leaf PlotPenyajian data dalam bentuk distribusi frekuensi akan menghilangkan nilai aslinya dari data tersebut. Untuk menghilangkan kelemahan ini suatu penyajian yang disebut stem & leaves (batan dan daun) (gambar : 14).

Penyajian dalam bentuk Sten & Leaf (Batang dan Daun)Pada distribusi frekuensi kita telah mengelompokkan data di dalam kelas sehingga tidak dapat dilihat lagi nilai aslinya. Untuk kelemahan ini penyajian dalam bentuk stem & leaf dapat menghilangkan kelemahan tersebut.Contoh:Dari data di atas akan diambil sebanyak 25 akseptor, datanya dapat kita sajikan dalam bentuk batang dan daun
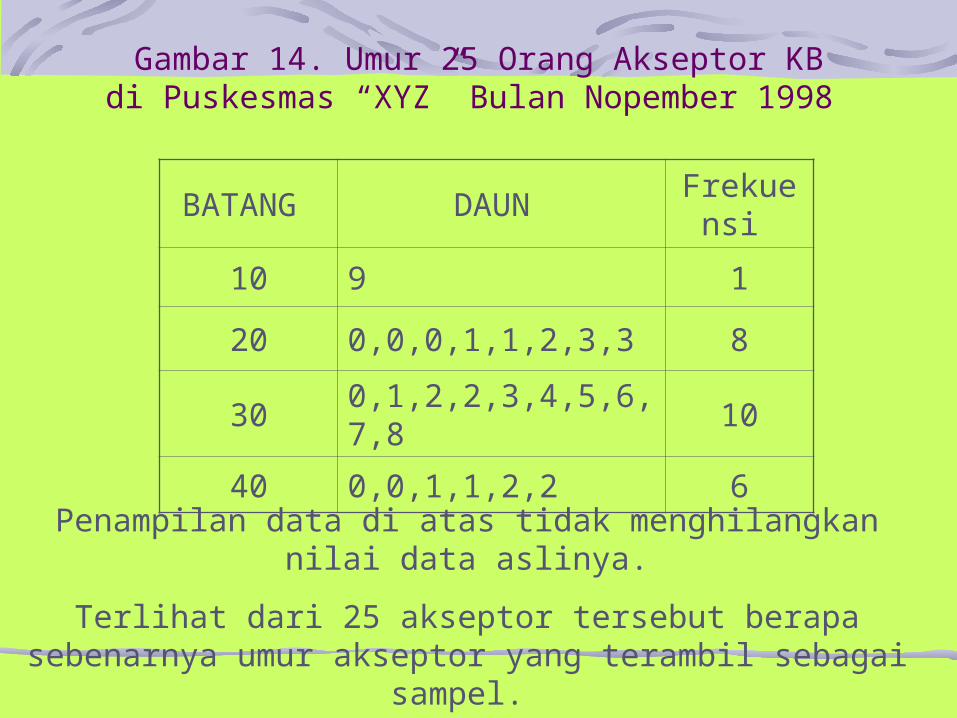
Gambar 14. Umur 25 Orang Akseptor KBdi Puskesmas “XYZ” Bulan Nopember 1998
BATANG DAUN Frekuen
si
10 9 1
20 0,0,0,1,1,2,3,3 8
30 0,1,2,2,3,4,5,6,7,8 10
40 0,0,1,1,2,2 6
Penampilan data di atas tidak menghilangkan nilai data aslinya.
Terlihat dari 25 akseptor tersebut berapa sebenarnya umur akseptor yang terambil sebagai sampel.
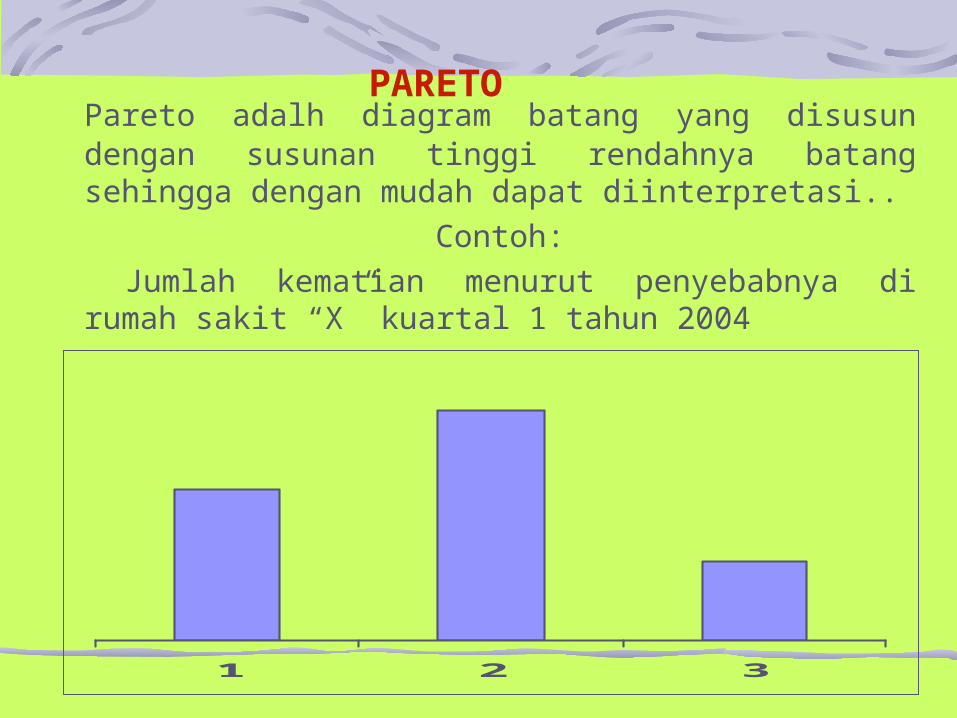
Pareto adalh diagram batang yang disusun dengan susunan tinggi rendahnya batang sehingga dengan mudah dapat diinterpretasi..
Contoh: Jumlah kematian menurut penyebabnya di rumah sakit “X” kuartal 1 tahun 2004
1 2 3
PARETO

SIMPULAN NUMERIK (INTERPRETASI)
Distribusi frekuensi Nilai Tengah Nilai Letak (POSISI) Nilai-nilai Variasi

Distribusi frekuensiDistribusi frekuensi adalah susunan
dataangka menurut besarnya (kuantitas)
atau menurut kategorinya (kualitas).
1. Distribusi frekuensi kuantitatif 2. Distribusi frekuensi kualitatif.

Penyusunan distribusi frekuensi data kuantitatif
Carilah harga maksimum dan minimum (selisih nilai maksimum dan minimum disebut Range = R).Tentukan jumlah kelas dan interval kelas (sebaiknya sama).Jumlah kelas : (rumus Sturgess)
M = 1 + 3,3 log NM = Jumlah kelasN = Jumlah data (observasi)
RInterval kelas: =-----
MHitung banyak observasi yang termasuk ke dalam
setiapkelas,disebut frekuensi dengan Tally Method
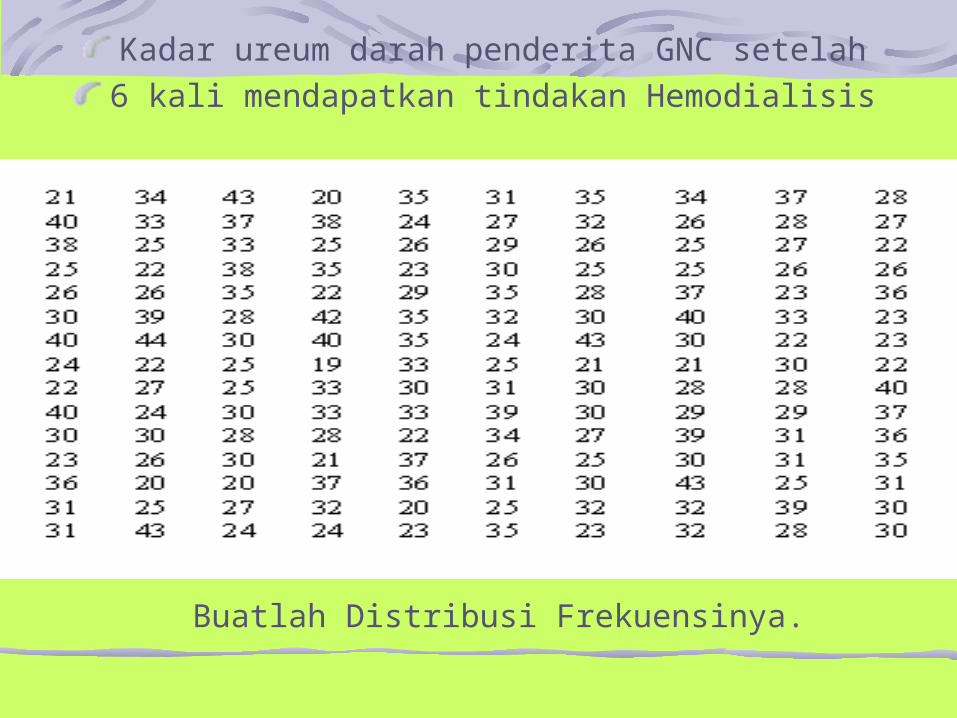
Kadar ureum darah penderita GNC setelah6 kali mendapatkan tindakan Hemodialisis
Buatlah Distribusi Frekuensinya.
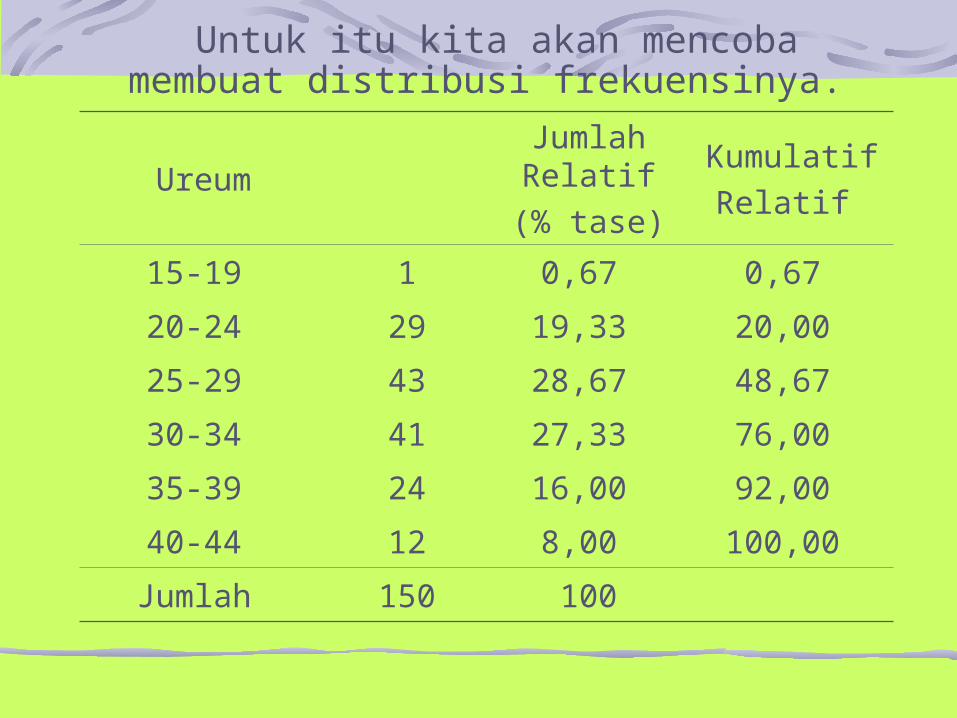
Untuk itu kita akan mencoba membuat distribusi frekuensinya.
UreumJumlah Relatif
(% tase)
KumulatifRelatif
15-19 1 0,67 0,67
20-24 29 19,33 20,00
25-29 43 28,67 48,67
30-34 41 27,33 76,00
35-39 24 16,00 92,00
40-44 12 8,00 100,00
Jumlah 150 100
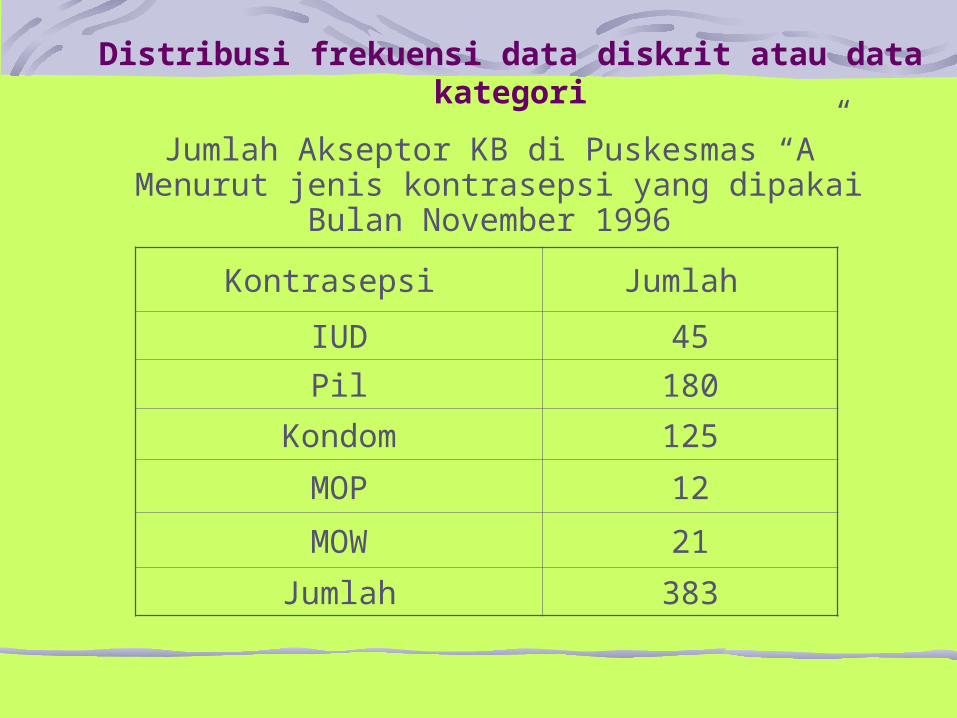
Distribusi frekuensi data diskrit atau data kategori
Kontrasepsi Jumlah
IUD 45
Pil 180
Kondom 125
MOP 12
MOW 21
Jumlah 383
Jumlah Akseptor KB di Puskesmas “A”Menurut jenis kontrasepsi yang dipakai
Bulan November 1996

Dari sekumpulan data (distribusi), ada beberapaharga/nilai yang dapat kita anggap sebaga wakildari kelompok data tersebut.
a. Mean (Arithmatic mean) = rata-rata hitungb. Medianc. Modus (Mode)d. Geometric Meane. Harmonic Meanf. Quadratic Mean
Nilai Tengah/central tendency

Rata-rata hitung (mean)Rata-rata Hitung atau arithmatic mean atau lebih dikenal dengan mean saja adalah nilai yang baik mewakili suatu data. Nilai ini sangat sering dipakai dan malah yang paling banyak
dikenal dalam menyimpulkan sekelompok data.
Misalnya kalau kita mempunyai n pengamatan yang terdiri dari x1, x2, x3,…….xn, maka nilai rata-rata adalah: jumlah harga x dibagi dengan frekuensinya

Ada data dari berat badan lima orang dewasa56, 62, 52, 48, 68 kg
Rata-rata berat badan lima orang ini adalah
56+62+52+48+67---------------------- = 57 kg
5
Sifat dari mean:1. Merupakan wakil dari keseluruhan nilai.2. Mean sangat dipengaruhi nilai ekstrim
baik ekstrim kecil maupun ekstrim besar.3. Nilai mean berasal dari semua nilai pengamatan.

b. MedianMedian adalah nilai yang terletak
pada observasi yang di tengah, kalau data
tersebut telah disusun (array).Nilai median disebut juga nilai letak.Posisi median adalah:
n + 1------- 2
Nilai median adalah nilai pada posisi tersebut

Berat lima orang dewasa di atas disusun menurut besar kecilnya nilai maka didapatkan susunan seperti berikut: 48, 52, 56, 62, 67 kg.Posisi median:
5 + 1-------- = 3 2
Nilai observasi ketiga adalah 56, maka dikatakan median adalah 56 kg. Kalau ditanya genap maka posisi median terletak antara dua nilai, maka nilai median adalah rata-rata dari kedua nilai tersebut.Bila data terdiri dari enam orang, 48, 52, 56, 62, 67, 70 kg. Posisi median adalah pengamatan ke-3 dan ke-4. Maka nilai median adalah jumlah pengamatan ketiga dan keempat dibagi dua. Dalam hal ini nilai median adalah:
56 kg – 62 kg------------------ = 54 kg 2
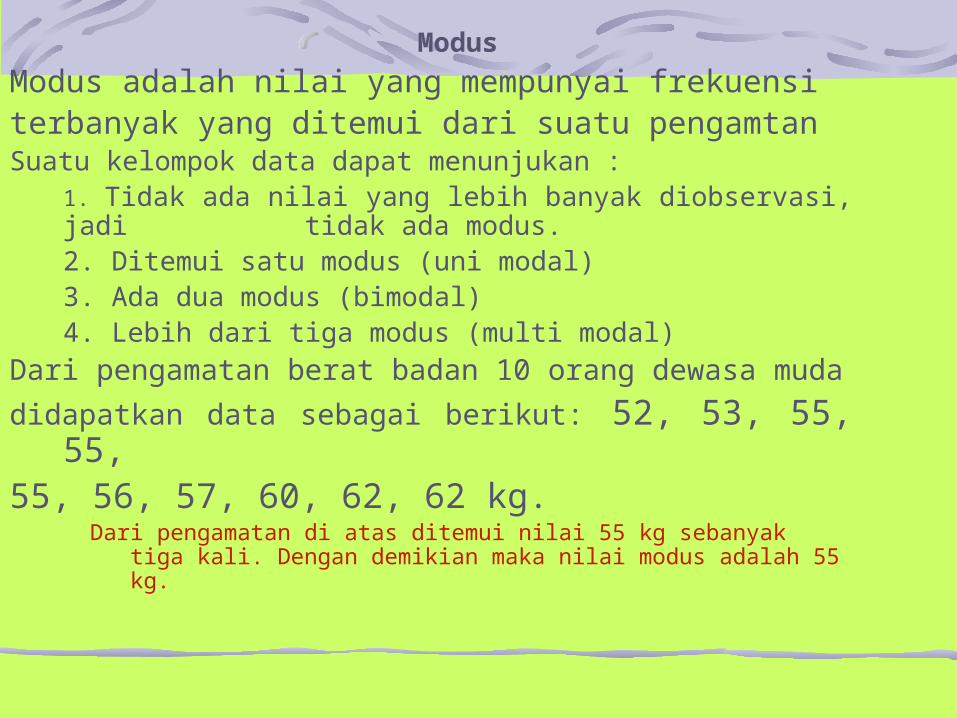
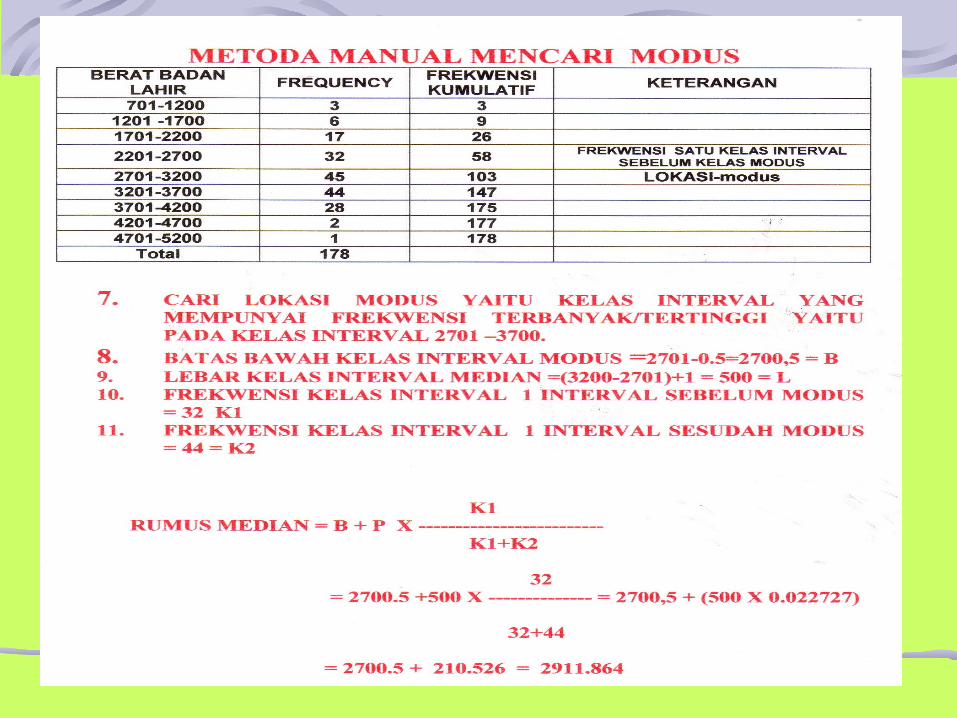
Modus
Modus adalah nilai yang mempunyai frekuensiterbanyak yang ditemui dari suatu pengamtanSuatu kelompok data dapat menunjukan :
1. Tidak ada nilai yang lebih banyak diobservasi, jadi tidak ada modus.
2. Ditemui satu modus (uni modal)3. Ada dua modus (bimodal)4. Lebih dari tiga modus (multi modal)
Dari pengamatan berat badan 10 orang dewasa muda
didapatkan data sebagai berikut: 52, 53, 55, 55, 55, 56, 57, 60, 62, 62 kg.
Dari pengamatan di atas ditemui nilai 55 kg sebanyak tiga kali. Dengan demikian maka nilai modus adalah 55 kg.

Hubungan antara nilai Mean, Median dan Modus:
Pada distribusi yang simetris ketiga nilai ini sama besarnya.Nilai Median selalu terletak antara nilai Modus dan Mean pada distribusi yang menceng.Apabila nilai Mean lebih besar dari nilai Median dan Modus maka dikatakan distribusi menceng ke kanan.Bila nilai Mean lebih kecil dari nilai Median dan Modus maka distribusi menceng ke kiri.

Nilai Letak (POSISI)Median adalah nilai pengamatan pada posisi paling tengah kalau data itu disusun (Array). Nilai-nilai posisi lainnya adalah:Kuartil, nilai yang membagi pengamatan menjadi empat. Karena itu ada tiga kuartil (kuartil I, kuartil II, kuartil III)Desil, nilai yang membagi pengamatan menjadi sepuluh, sehingga ada sembilan kuartil.Persentil, adalah nilai yang membagi data menjadi 100 bagian, sehingga ada 99 persentil.
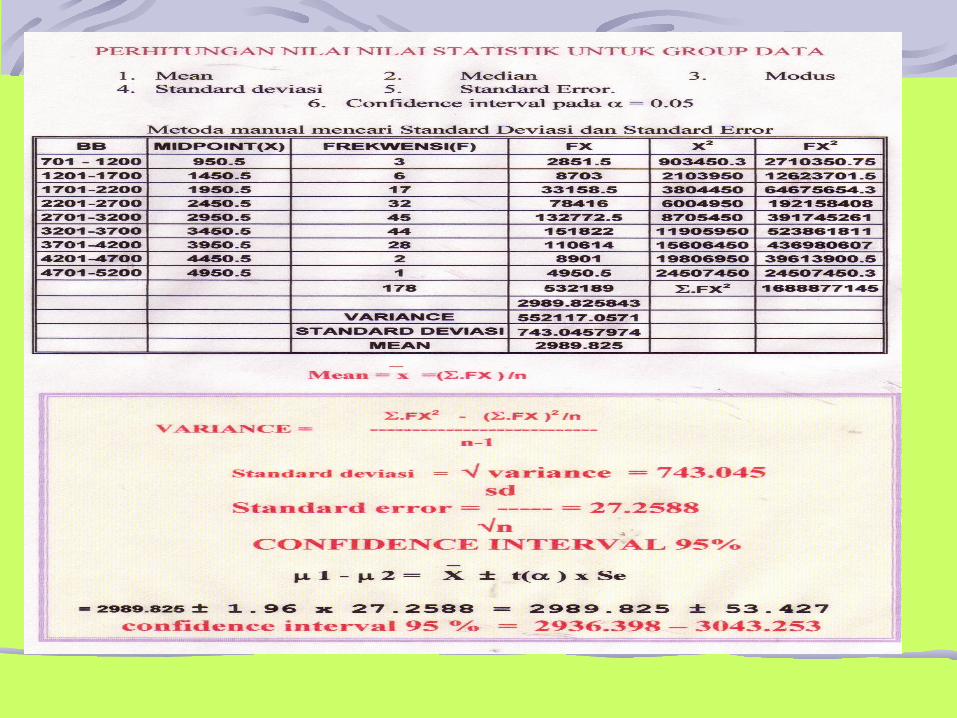


Nilai-nilai Variasi
Nilai variasi atau deviasi adalah nilai
yang menunjukkan bagaimana
bervariasinya data di dalam kelompok
data itu terhadap nilai rata-ratanya.
Sehingga makin besar nilai variasi maka
makin bervariasi pula data tersebut.

Ada bermacam-macam nilai variasi:
a) RangeRange adalah nilai yang menunjukkan perbedaan nilai pengamatan yang paling besar dengan nilai yang paling kecil.Contoh: 48, 52, 56, 62, 67 kg adalah berat badan dari pengamatan lima orang dewasa. Range adalah: 67 kg - 48kg = 17 kg

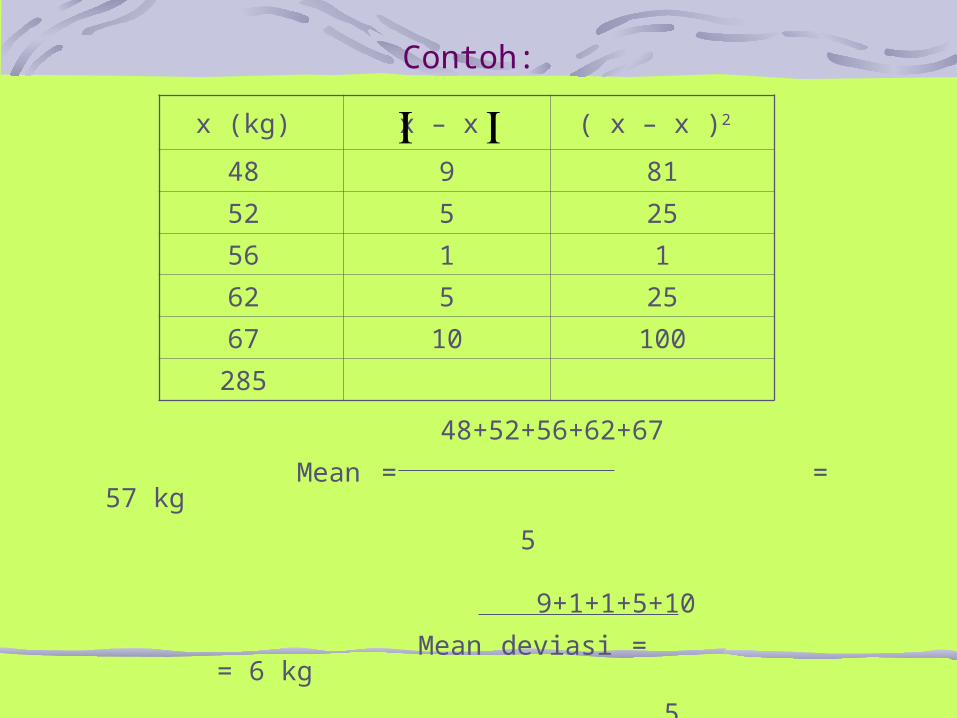
b) Rata-rata deviasi (Mean deviation)Rata-rata deviasi adalah rata-rata dan seluruh perbedaan pengamatan dibagi banyaknya pengamatan. Untuk ini diambil nilai mutlak.Rumus: ( x – xbar )
Md = ---------------- N
x (kg) x – x ( x – x )2
48 9 81
52 5 25
56 1 1
62 5 25
67 10 100
285
Contoh:
48+52+56+62+67
Mean = = 57 kg
5
9+1+1+5+10
Mean deviasi = = 6 kg
5

c) VarianVarian adalah rata-rata perbedaan antara mean dengan nilai masing-masing observasi.Rumus: ( x – x )2
V (S)2 = n-1
Contoh:Dari data di atas dapat dihitung Varian
81+25+1+25+100V = = 58
4

d) Standar deviasiStandar deviasi adalah akar dari varian.Nilai standar deviasi ini disebut juga sebagai “simpangan baku” karena merupakan patokan luas area di bawah kurva normal.
Rumus: S = varian = S2
Contoh: Standar deviasi dari data di atas adalah
S = 58 = 7,6 kg

e) Koefisien Variasi (Coeficient of Variation= COV)
SCOV = ----- x 100 %
X

Small Group Project 1. A study of possible correlations between water clarity and coliform bacteria
in PALEMBANG2. Age class distribution of four common reef fish species 3. Comparison of fungicides, Fungo-50 and Dithane in the colonal propagation of rainbow papaya (Carca papaya L.).4. Fecal coliform contamination along the MUSI river. 5. Creatine monohydrate: a comparitive study.6. Vegetation regeneration after broomsedege fire 2000.7. Change in heart rate and blood pressure after strenuous exercise. 8. Blood glucose levels and the factors that affect them.9. Impact of age and body mass index on blood pressure in persons over age
fifty. 11. Studies of smoking using the one-way Anova..

Small Group Project 1. A study of possible correlations between water clarity and coliform bacteria
in PALEMBANG2. Age class distribution of four common reef fish species 3. Comparison of fungicides, Fungo-50 and Dithane in the colonal propagation of rainbow papaya (Carca papaya L.).4. Fecal coliform contamination along the MUSI river. 5. Creatine monohydrate: a comparitive study.6. Vegetation regeneration after broomsedege fire 2000.7. Change in heart rate and blood pressure after strenuous exercise. 8. Blood glucose levels and the factors that affect them.9. Impact of age and body mass index on blood pressure in persons over age
fifty. 11. Studies of smoking using the one-way Anova..





























